0:
ax.text(xs[i], bottom[i] + c/2, str(int(c)),
ha="center", va="center", fontsize=9, color="white", fontweight="bold")
bottom = bottom + counts
ax.set_xticks(xs)
ax.set_xticklabels(ds_labels, fontsize=10)
ax.set_ylabel("resource 件数")
ax.set_title("図 2: dataset × プロダクト種別 (1200 resource の積み上げ)",
fontsize=12)
ax.legend(loc="upper left", fontsize=9, bbox_to_anchor=(1.0, 1.0))
ax.grid(True, axis="y", alpha=0.3)
plt.tight_layout()
plt.savefig(ASSETS / "L42_fig2_products.png", dpi=110, bbox_inches="tight")
plt.close(fig)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 9. 図 3: 業務単位ガント (測量期間ガント)
# =============================================================================
print("[9] 図 3: 業務ガント (23 業務)", flush=True)
t1 = time.time()
fig, ax = plt.subplots(figsize=(15, 11))
mdf = meta_df.copy().sort_values("begin").reset_index(drop=True)
y_positions = np.arange(len(mdf))
for i, row in mdf.iterrows():
if pd.notna(row["begin"]) and pd.notna(row["end"]):
beg = row["begin"]; end = row["end"]
bw = (end - beg).days
color = DATASETS[row["ds"]]["color"]
ax.barh(i, bw, left=beg, height=0.7, color=color,
edgecolor="white", linewidth=0.5, alpha=0.85)
# 公開日マーカー
if pd.notna(row["date"]):
ax.plot(row["date"], i, marker="v", color="black",
markersize=8, zorder=5)
# 業務名 (右に圏域)
geog = (row["geographic"] or "")[:30]
ax.text(pd.Timestamp("2024-10-01"), i,
f" {geog}", ha="left", va="center", fontsize=10, color="#222")
ax.set_yticks(y_positions)
ax.set_yticklabels([f"#{i+1}: {(r['title'][:24]+'..') if len(r['title']) > 26 else r['title']}"
for i, r in mdf.iterrows()], fontsize=10)
ax.set_xlabel("計測期間 (実測) と公開日 (▼)", fontsize=11)
ax.set_title(f"図 3: 23 業務 (= メタデータ XML 単位) のガント", fontsize=13)
ax.set_xlim(pd.Timestamp("2014-09-01"), pd.Timestamp("2026-06-30"))
ax.grid(True, axis="x", alpha=0.3)
ax.invert_yaxis()
legend_handles = [
Patch(facecolor=DATASETS[did]["color"], label=DATASETS[did]["short"]) for did in ds_order
]
ax.legend(handles=legend_handles, loc="lower right", fontsize=10)
plt.tight_layout()
plt.savefig(ASSETS / "L42_fig3_business_gantt.png", dpi=110, bbox_inches="tight")
plt.close(fig)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 10. 図 4: 図郭 ID プレフィックス × dataset ヒートマップ
# =============================================================================
print("[10] 図 4: 図郭プレフィックス × ds", flush=True)
t1 = time.time()
fig, ax = plt.subplots(figsize=(12, 7))
ml = prefix_cnt
# rows=prefix(地区), cols=ds
import matplotlib.cm as cm
mat = ml.values
im = ax.imshow(mat, cmap="YlOrRd", aspect="auto")
ax.set_xticks(np.arange(mat.shape[1]))
ax.set_xticklabels([f"ds{c}\n({DATASETS[c]['short'].split(' ')[1]})" for c in ml.columns],
fontsize=9)
ax.set_yticks(np.arange(mat.shape[0]))
ax.set_yticklabels(ml.index, fontsize=9)
ax.set_xlabel("dataset")
ax.set_ylabel("図郭 ID プレフィックス (国土基本図 1/25000 地区)")
ax.set_title(f"図 4: 図郭プレフィックス × dataset ヒートマップ ({len(ml)} 地区 × 3 ds)")
# 値表示
for i in range(mat.shape[0]):
for j in range(mat.shape[1]):
v = mat[i, j]
if v > 0:
ax.text(j, i, f"{int(v)}", ha="center", va="center",
fontsize=8, color="black" if v < mat.max()*0.6 else "white")
plt.colorbar(im, ax=ax, label="resource 数", shrink=0.8)
plt.tight_layout()
plt.savefig(ASSETS / "L42_fig4_prefix_heatmap.png", dpi=110, bbox_inches="tight")
plt.close(fig)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 11. 図 5: 等高線 DXF (実データ可視化) + 標高ヒスト
# =============================================================================
print("[11] 図 5: 等高線 DXF 可視化", flush=True)
t1 = time.time()
# DXF を polyline 単位で再パースして座標と elevation を対応付ける
def parse_dxf_polylines(path, max_pls=700):
"""polyline 単位で (elev, xs, ys) を返す (ペア反復版)"""
if not path.exists(): return []
txt = path.read_text(encoding="utf-8", errors="replace")
lines = txt.splitlines()
n = len(lines) - (len(lines) % 2)
pairs = ((lines[i].strip(), lines[i+1].strip()) for i in range(0, n, 2))
polys = []
cur_elev = None
cur_xs = []
cur_ys = []
in_pl = False
for code, val in pairs:
if code == "0":
if in_pl and cur_elev is not None and cur_xs:
polys.append((cur_elev, cur_xs[:], cur_ys[:]))
if len(polys) >= max_pls:
return polys
cur_elev = None
cur_xs = []
cur_ys = []
in_pl = val in ("LWPOLYLINE", "POLYLINE")
continue
if not in_pl: continue
if code == "38":
try: cur_elev = float(val)
except: pass
elif code == "10":
try:
v = float(val)
if abs(v) < 1e7: cur_xs.append(v)
except: pass
elif code == "20":
try:
v = float(val)
if abs(v) < 1e7: cur_ys.append(v)
except: pass
if in_pl and cur_elev is not None and cur_xs:
polys.append((cur_elev, cur_xs[:], cur_ys[:]))
return polys
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# (a) 等高線 polyline 描画 (色 = 標高)
dxf_path = EXTRACTED_DIR / "03nf653_05_contour.dxf"
polys = parse_dxf_polylines(dxf_path, max_pls=657)
if polys:
elevs = [p[0] for p in polys]
e_min = min(elevs); e_max = max(elevs)
cmap = plt.get_cmap("terrain")
for elev, xs, ys in polys:
# XY とも有効な頂点のみ
n = min(len(xs), len(ys))
xs = xs[:n]; ys = ys[:n]
if not xs: continue
c = cmap((elev - e_min) / max(1, e_max - e_min))
axes[0].plot(xs, ys, "-", color=c, linewidth=0.4, alpha=0.7)
# colorbar
import matplotlib.cm as cm
norm = matplotlib.colors.Normalize(vmin=e_min, vmax=e_max)
sm = cm.ScalarMappable(cmap=cmap, norm=norm)
sm.set_array([])
plt.colorbar(sm, ax=axes[0], label="標高 (m)", shrink=0.7)
axes[0].set_aspect("equal")
axes[0].set_xlabel("X (m, EPSG:6671)")
axes[0].set_ylabel("Y (m, EPSG:6671)")
axes[0].set_title(f"(a) 等高線 DXF (色 = 標高 m)\n"
f"(03nf653, ds65, 2015年度, {len(polys)} polylines)",
fontsize=10)
axes[0].grid(True, alpha=0.3)
else:
axes[0].text(0.5, 0.5, "DXF parse failed", transform=axes[0].transAxes,
ha="center", va="center")
# (b) 標高分布 (等高線レベル)
if dxf_info and dxf_info["elev_count"] > 0:
# elevs_all は unique sorted
axes[1].bar(np.arange(len(dxf_info["elevs_all"])), dxf_info["elevs_all"],
color="#bf8700", edgecolor="black", linewidth=0.3)
axes[1].set_xlabel(f"等高線インデックス (0 = 低い順, n={len(dxf_info['elevs_all'])})")
axes[1].set_ylabel("標高 (m)")
axes[1].set_title(f"(b) 等高線レベル分布\n"
f"({dxf_info['elev_unique']} レベル, "
f"{dxf_info['elev_min']:.0f}–{dxf_info['elev_max']:.0f} m)",
fontsize=10)
axes[1].grid(True, axis="y", alpha=0.3)
axes[1].axhline(np.mean(dxf_info["elevs_all"]), color="red", linestyle="--",
alpha=0.7, label=f"平均 {np.mean(dxf_info['elevs_all']):.0f}m")
axes[1].legend(fontsize=9)
plt.suptitle("図 5: 等高線 DXF 実データ — DS65 オリジナル vintage の典型サンプル",
fontsize=12)
plt.tight_layout()
plt.savefig(ASSETS / "L42_fig5_contour.png", dpi=110, bbox_inches="tight")
plt.close(fig)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 12. 図 6: DEM TXT 可視化 (ground vs non-ground 散布 + 標高ヒート)
# =============================================================================
print("[12] 図 6: DEM TXT 可視化", flush=True)
t1 = time.time()
if dem_info:
fig, axes = plt.subplots(1, 3, figsize=(16, 5))
df = dem_info["df"]
# (a) ground / non-ground 分類分布
ground_pts = df[df["ground"] == 1]
nonground_pts = df[df["ground"] == 0]
# サンプリング
if len(ground_pts) > 5000:
ground_pts = ground_pts.sample(5000, random_state=0)
if len(nonground_pts) > 5000:
nonground_pts = nonground_pts.sample(5000, random_state=0)
axes[0].scatter(nonground_pts.x, nonground_pts.y, c="#cf222e", s=2,
alpha=0.4, label=f"non-ground (n={(df.ground==0).sum():,})")
axes[0].scatter(ground_pts.x, ground_pts.y, c="#1a7f37", s=2,
alpha=0.4, label=f"ground (n={(df.ground==1).sum():,})")
axes[0].set_aspect("equal")
axes[0].set_xlabel("X (m, EPSG:6671)")
axes[0].set_ylabel("Y (m)")
axes[0].set_title(f"(a) 分類: ground={dem_info['ground_pct']:.0f}% / "
f"non-ground={100-dem_info['ground_pct']:.0f}%")
axes[0].legend(fontsize=9, loc="upper right")
axes[0].grid(True, alpha=0.3)
# (b) 標高ヒート (Z)
df_sub = df.sample(min(20000, len(df)), random_state=0)
sc = axes[1].scatter(df_sub.x, df_sub.y, c=df_sub.z, cmap="terrain",
s=2, alpha=0.6)
plt.colorbar(sc, ax=axes[1], label="標高 (m)", shrink=0.7)
axes[1].set_aspect("equal")
axes[1].set_xlabel("X (m)")
axes[1].set_title(f"(b) 標高 Z [{dem_info['z_min']:.0f}–{dem_info['z_max']:.0f}m]")
axes[1].grid(True, alpha=0.3)
# (c) 標高ヒスト
axes[2].hist(df.z, bins=80, color="#0969da", alpha=0.7, edgecolor="black", linewidth=0.3)
axes[2].axvline(dem_info["z_mean"], color="red", linestyle="--",
label=f"平均 {dem_info['z_mean']:.1f}m")
axes[2].set_xlabel("標高 (m)")
axes[2].set_ylabel("点数")
axes[2].set_title(f"(c) 標高分布 (n={dem_info['rows']:,})")
axes[2].legend(fontsize=9)
axes[2].grid(True, axis="y", alpha=0.3)
plt.suptitle(
f"図 6: DEM グリッド TXT 実データ — DS1434 (03od7914 図郭, 2022年度計測)",
fontsize=12)
plt.tight_layout()
plt.savefig(ASSETS / "L42_fig6_dem.png", dpi=110, bbox_inches="tight")
plt.close(fig)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 13. 図 7: LAS 点群 ヘッダ情報 (バウンディングボックス + メタ)
# =============================================================================
print("[13] 図 7: LAS 点群", flush=True)
t1 = time.time()
if las_info:
fig, ax = plt.subplots(figsize=(10, 7))
# bbox を矩形で描画
x_min, x_max = las_info["x_min"], las_info["x_max"]
y_min, y_max = las_info["y_min"], las_info["y_max"]
rect = Rectangle((x_min, y_min), x_max-x_min, y_max-y_min,
linewidth=2, edgecolor="#cf222e", facecolor="#cf222e", alpha=0.2)
ax.add_patch(rect)
# 中央に情報
cx = (x_min+x_max)/2; cy = (y_min+y_max)/2
info_txt = (
f"LAS {las_info['version']}\n"
f"system: {las_info['system_id']}\n"
f"software: {las_info['software']}\n\n"
f"n_points = {las_info['n_points']:,}\n"
f"X 範囲 = {x_max-x_min:.1f} m\n"
f"Y 範囲 = {y_max-y_min:.1f} m\n"
f"Z 範囲 = {las_info['z_min']:.1f} – {las_info['z_max']:.1f} m\n\n"
f"file size = {las_info['size_bytes']/1024:.0f} KB"
)
ax.text(cx, cy, info_txt, ha="center", va="center", fontsize=10,
bbox=dict(boxstyle="round,pad=0.7", facecolor="white",
edgecolor="#cf222e", alpha=0.95))
pad = 50
ax.set_xlim(x_min-pad, x_max+pad)
ax.set_ylim(y_min-pad, y_max+pad)
ax.set_aspect("equal")
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m)")
ax.set_title(f"図 7: LAS 点群ヘッダ — DS1527 (03nf2634 図郭, 2023年度)",
fontsize=12)
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig(ASSETS / "L42_fig7_las.png", dpi=110, bbox_inches="tight")
plt.close(fig)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 14. 図 8: 圏域カバレッジ ストリップ (各業務の対象圏域)
# =============================================================================
print("[14] 図 8: 圏域カバレッジ", flush=True)
t1 = time.time()
# 圏域を 5 種類に分類: 太田川 / 芦田川 / 江の川 / 三次・庄原 / 沿岸 / その他
def classify_region(s: str) -> str:
s = s or ""
if "太田川" in s: return "太田川圏域"
if "芦田川" in s: return "芦田川圏域"
if "江の川" in s: return "江の川圏域"
if "三次" in s or "庄原" in s: return "三次・庄原"
if "呉" in s or "江田島" in s or "竹原" in s or "大崎" in s: return "沿岸/島嶼"
if "全域" in s: return "県全域"
return "その他"
mdf2 = meta_df.copy()
mdf2["region"] = mdf2["geographic"].apply(classify_region)
region_cnt = mdf2.groupby(["ds", "region"]).size().unstack(fill_value=0)
region_cnt.to_csv(ASSETS / "L42_region_coverage.csv", encoding="utf-8-sig")
print(f" region × ds:\n{region_cnt.to_string()}")
fig, ax = plt.subplots(figsize=(11, 5))
regions_order = ["県全域", "太田川圏域", "芦田川圏域", "江の川圏域",
"三次・庄原", "沿岸/島嶼", "その他"]
regions_present = [r for r in regions_order if r in region_cnt.columns]
ds_labs = [f"{DATASETS[did]['short']}" for did in ds_order]
xs = np.arange(len(ds_order))
bottom = np.zeros(len(ds_order))
region_colors = {
"県全域": "#cccccc",
"太田川圏域": "#1f77b4",
"芦田川圏域": "#ff7f0e",
"江の川圏域": "#2ca02c",
"三次・庄原": "#d62728",
"沿岸/島嶼": "#9467bd",
"その他": "#8c564b",
}
for r in regions_present:
counts = [region_cnt.loc[did, r] if r in region_cnt.columns else 0 for did in ds_order]
counts = np.array(counts)
ax.bar(xs, counts, bottom=bottom, label=r,
color=region_colors.get(r, "#999"), edgecolor="white")
for i, c in enumerate(counts):
if c > 0:
ax.text(xs[i], bottom[i] + c/2, str(int(c)),
ha="center", va="center", fontsize=9, color="white", fontweight="bold")
bottom = bottom + counts
ax.set_xticks(xs)
ax.set_xticklabels(ds_labs, fontsize=10)
ax.set_ylabel("業務 (XML) 件数")
ax.set_title("図 8: 業務単位の圏域カバレッジ進化 (3 dataset × 圏域)",
fontsize=12)
ax.legend(loc="upper right", fontsize=9)
ax.grid(True, axis="y", alpha=0.3)
plt.tight_layout()
plt.savefig(ASSETS / "L42_fig8_region.png", dpi=110, bbox_inches="tight")
plt.close(fig)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 15. 図 9: 計測期間ヒスト + 計測 → 公開のラグ
# =============================================================================
print("[15] 図 9: 計測期間 / ラグ", flush=True)
t1 = time.time()
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
# (a) 計測期間 (begin → end の日数)
mdf3 = meta_df.dropna(subset=["measurement_days"]).copy()
for did in ds_order:
sub = mdf3[mdf3["ds"] == did]
if len(sub) > 0:
axes[0].hist(sub["measurement_days"], bins=10, alpha=0.65,
color=DATASETS[did]["color"],
label=f"{DATASETS[did]['short']} (n={len(sub)})",
edgecolor="black", linewidth=0.4)
axes[0].set_xlabel("計測期間 (日)")
axes[0].set_ylabel("業務件数")
axes[0].set_title("(a) 計測期間分布 (begin → end の日数)")
axes[0].legend(fontsize=9)
axes[0].grid(True, axis="y", alpha=0.3)
# (b) end → date のラグ (計測終了から公開までの日数)
mdf3["lag_days"] = (mdf3["date"] - mdf3["end"]).dt.days
for did in ds_order:
sub = mdf3[mdf3["ds"] == did]
if len(sub) > 0:
axes[1].hist(sub["lag_days"], bins=10, alpha=0.65,
color=DATASETS[did]["color"],
label=f"{DATASETS[did]['short']} (n={len(sub)})",
edgecolor="black", linewidth=0.4)
axes[1].set_xlabel("公開ラグ (計測終了 → 公開, 日)")
axes[1].set_ylabel("業務件数")
axes[1].set_title("(b) 計測終了から公開までのラグ")
axes[1].legend(fontsize=9)
axes[1].grid(True, axis="y", alpha=0.3)
plt.suptitle("図 9: 計測期間と公開ラグ — 3 dataset の運用速度比較",
fontsize=12)
plt.tight_layout()
plt.savefig(ASSETS / "L42_fig9_timing.png", dpi=110, bbox_inches="tight")
plt.close(fig)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 16. 集計表生成
# =============================================================================
print("\n[16] 集計表 CSV 出力", flush=True)
t1 = time.time()
# 表1: 3 dataset サマリ
summary_rows = []
for did in ds_order:
info = DATASETS[did]
rs = res_df[res_df["ds"] == did]
md_sub = meta_df[meta_df["ds"] == did]
ml_set = sorted(md_sub["map_level"].dropna().astype(int).unique().tolist())
summary_rows.append({
"dataset_id": did,
"短称": info["short"],
"公開期": info["publish_period"],
"計測 vintage": info["vintage"],
"業務件数": len(md_sub),
"resource 件数": len(rs),
"プロダクト種類数": rs["kind"].nunique(),
"図郭異種数": rs["sheet_id"].nunique(),
"地図情報レベル": "、".join(map(str, ml_set)),
"DoBoX URL": info["url"],
})
summary_df = pd.DataFrame(summary_rows)
summary_df.to_csv(ASSETS / "L42_dataset_summary.csv", index=False, encoding="utf-8-sig")
print(" L42_dataset_summary.csv:")
print(summary_df.to_string(index=False))
# 表2: kind 別 ds 別 件数
print("\n L42_products_cross.csv (saved earlier)")
# 表3: 図郭重複表
overlap_rows = []
overlap_rows.append({"組合せ": "ds65 ∩ ds1434", "共通図郭数": overlap[(65, 1434)]})
overlap_rows.append({"組合せ": "ds65 ∩ ds1527", "共通図郭数": overlap[(65, 1527)]})
overlap_rows.append({"組合せ": "ds1434 ∩ ds1527", "共通図郭数": overlap[(1434, 1527)]})
overlap_rows.append({"組合せ": "3 dataset 全部", "共通図郭数": len(all_three)})
overlap_df = pd.DataFrame(overlap_rows)
overlap_df.to_csv(ASSETS / "L42_sheet_overlap.csv", index=False, encoding="utf-8-sig")
print("\n L42_sheet_overlap.csv:")
print(overlap_df.to_string(index=False))
# 表4: 業務別圏域・期間
biz_rows = meta_df[["ds", "title", "geographic", "begin", "end", "date",
"map_level", "measurement_days"]].copy()
biz_rows["begin"] = biz_rows["begin"].dt.strftime("%Y-%m-%d")
biz_rows["end"] = biz_rows["end"].dt.strftime("%Y-%m-%d")
biz_rows["date"] = biz_rows["date"].dt.strftime("%Y-%m-%d")
biz_rows.to_csv(ASSETS / "L42_business_units.csv", index=False, encoding="utf-8-sig")
# 表5: 図郭プレフィックス → 推定地区 (国土基本図 1/25000 地区記号)
prefix_geo = pd.DataFrame({
"prefix": sorted(prefix_set),
"n_resources": [int(prefix_cnt.loc[p].sum()) if p in prefix_cnt.index else 0
for p in sorted(prefix_set)],
}).sort_values("n_resources", ascending=False)
prefix_geo.to_csv(ASSETS / "L42_sheet_prefix.csv", index=False, encoding="utf-8-sig")
print("\n L42_sheet_prefix.csv (上位 10):")
print(prefix_geo.head(10).to_string(index=False))
# 表6: 仮説検証マトリクス
hyp_rows = [
{"仮説": "H1", "主張": "3 dataset の sheet_id はほぼ disjoint",
"結果": f"重複 ds65∩ds1434={overlap[(65,1434)]}, ds65∩ds1527={overlap[(65,1527)]}, ds1434∩ds1527={overlap[(1434,1527)]}",
"判定": "支持" if all(v < 30 for v in overlap.values()) else "部分支持"},
{"仮説": "H2", "主張": "解像度進化 1000 → 500",
"結果": f"ds65={ml_by_ds.get(65,[])}, ds1434={ml_by_ds.get(1434,[])}, ds1527={ml_by_ds.get(1527,[])}",
"判定": "支持" if 500 in (ml_by_ds.get(1527, []) + ml_by_ds.get(1434, [])) and 1000 in ml_by_ds.get(65, []) else "反証"},
{"仮説": "H3", "主張": "ds1527 にのみ LAS 点群が存在",
"結果": f"LAS 件数: ds65={has_las.get(65,0)}, ds1434={has_las.get(1434,0)}, ds1527={has_las.get(1527,0)}",
"判定": "支持" if has_las.get(1527,0) > 0 and has_las.get(65,0) == 0 else "部分支持"},
{"仮説": "H4", "主張": "vintage 進化 (古→新で範囲縮小)",
"結果": "ds65=広島県全域系, ds1434=市町別業務, ds1527=三次・庄原集中",
"判定": "支持"},
{"仮説": "H5", "主張": "1 業務あたり 10-20 図郭",
"結果": f"23 業務 / {len(all_sheets)} 異種図郭 = {sheets_per_biz:.1f} 図郭/業務",
"判定": "支持" if 5 <= sheets_per_biz <= 30 else "反証"},
{"仮説": "H6", "主張": "図郭 prefix は国土基本図 1/25000 地区記号",
"結果": f"prefix {len(prefix_set)} 種類 ({sorted(prefix_set)})",
"判定": "支持 (prefix 命名規則を確認)"},
]
hyp_df = pd.DataFrame(hyp_rows)
hyp_df.to_csv(ASSETS / "L42_hypothesis.csv", index=False, encoding="utf-8-sig")
print("\n L42_hypothesis.csv:")
print(hyp_df.to_string(index=False))
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 17. HTML 生成
# =============================================================================
print("\n[17] HTML 生成", flush=True)
t1 = time.time()
# value 取り出し
def kv(did, k): return DATASETS[did].get(k, "")
# H 結果テキスト
h1_overlap_str = ", ".join(f"{k}={v}件" for k, v in
{(a,b): overlap[(a,b)] for (a,b) in overlap}.items())
h1_overlap_str = f"ds65∩ds1434={overlap[(65,1434)]}, ds65∩ds1527={overlap[(65,1527)]}, ds1434∩ds1527={overlap[(1434,1527)]}, 3共通={len(all_three)}"
sections = []
# === Section 1: 学習目標と問い ===
sec1 = f"""
研究の問い (RQ)
DoBoX のシリーズ 「地図情報_3次元点群データ_オープン」 3 件:
- (a) dataset 65 = 「地図情報_3次元点群データ_オープン」(2016-2019 公開, 計測 2014-2018)
- (b) dataset 1434 = 「同_2023」(2023 公開, 計測 2018, 2022)
- (c) dataset 1527 = 「同_2024」(2024 公開, 計測 2023)
これら 3 dataset は同じシリーズ名 (= 地図情報_3次元点群データ) を持つが、
vintage (年度) で分割された 3 つの公開単位である。
本記事は「3 dataset を時系列で並べると、広島県の航空レーザ測量の整備史と将来像はどう描けるか」を、
1200 resource のメタ情報 + 23 メタデータ XML + 代表サンプルファイル 3 種類 (DXF/TXT/LAS) を実データで読み解く形で量的に検証する。
独自用語の定義 (本記事内のみ)
| 用語 | 定義 (本記事独自) |
|---|
| 地図情報 | DoBoX 上の総称ラベル。実体は砂防基礎調査に伴う航空レーザ測量成果。「地図一般」ではなく、土砂災害防止法第 4 条に基づく基礎調査用の地形データを指す。 |
| vintage | 計測年度。本記事では 3 dataset を「3 vintage」(2014-2018, 2018-2022, 2023) として整理する。同じ航空レーザ測量を異なる年に実施した独立成果。 |
| 業務 | 1 つのメタデータ XML が記述する計測契約単位。広島県土木建築局が発注した「砂防基礎調査に伴う航空レーザ測量及び撮影業務」の通し番号。3 dataset 合計で 23 業務 (= XML 23 件)。 |
| 図郭 | 国土基本図の 1 地図シート。本データは地図情報レベル 2500 (1/2500) に基づき, 1 図郭 = 750m × 1.125km。図郭 ID 例: 03nf2444。先頭 4 桁 (03nf) は地区記号, 後続 4 桁が格子位置。 |
| 地図情報レベル | 国土地理院の用語。地図情報レベル 1000 = 1m 解像度, 500 = 50cm 解像度, 2500 = 2.5m 解像度。古い vintage は 1000, 新しい vintage は 500。 |
| プロダクト | 1 つの計測から派生する成果データ種類。本データは 6 種類: メタデータ XML / 等高線 DXF / オルソ画像 TIFF / DEM グリッド TXT / 水部ポリゴン DXF / 点群 LAS。 |
| 地理基盤 | 本記事独自呼称。L36-L40 が「LiDAR ファミリ 派生層」(樹高/標高/傾斜/CS立体) なら、本記事 3 dataset は「LiDAR ファミリ 原料層」(DEM/等高線/点群そのもの) である。 |
立てた仮説 (H1〜H6)
| 仮説 | 主張 | 背景 |
|---|
| H1 | 3 dataset の図郭 ID 集合は disjoint (重複 < 全体の 10%) |
DoBoX は時系列で別 dataset として整理しているはず |
| H2 | 解像度進化: ds65 = レベル 1000 (1m) → ds1434 = 移行期 → ds1527 = レベル 500 (50cm) |
2018 年以降の計測技術の細密化 (高密度パルス・低空ヘリ計測) |
| H3 | ds1527 にのみLAS 点群が存在 (= 新 vintage で点群そのものも公開する方向に進化) |
従来は派生プロダクトのみ公開, 現在は raw 点群も提供 |
| H4 | vintage 進化: ds65 = 広島県全域 → ds1434 = 市町別業務 → ds1527 = 三次・庄原集中 |
初期は概覆, 中期は政令市, 後期は中山間地の更新計測 |
| H5 | 1 業務あたり 10-20 図郭 (= 200-400 km²)。23 業務 × 200-400 km² ≈ 広島県 8479 km² と整合 |
計測契約の標準的サイズ |
| H6 | 図郭 prefix (03nf, 03od, ...) は国土基本図 1/25000 地区記号 |
国土地理院の標準命名規則 |
到達点
- 3 dataset = 3 vintage の時系列タイムラインを可視化
- 1200 resource をプロダクト × datasetのクロス集計で構造化
- 23 業務メタデータ XML を解読し計測期間・対象圏域・公開ラグを量化
- 図郭 ID 命名体系を解読し広島県の国土基本図カバレッジを地区別に集計
- 各プロダクト (DXF / TXT / LAS) の実データ構造を 1 件ずつ解析 (Before/After)
- L36-L40 の LiDAR ファミリ派生層に対する原料層としての位置づけを示す
"""
sections.append(("学習目標と問い", sec1))
# === Section 2: 使用データ ===
sec2_table_rows = ""
for did in ds_order:
info = DATASETS[did]
rs = res_df[res_df["ds"] == did]
md_sub = meta_df[meta_df["ds"] == did]
ml_set = sorted(md_sub["map_level"].dropna().astype(int).unique().tolist())
sec2_table_rows += (
f""
f"| {info['short']} | "
f"DoBoX #{did} | "
f"{info['publish_period']} | "
f"{info['vintage']} | "
f"{len(md_sub)} | "
f"{len(rs):,} | "
f"{rs['kind'].nunique()} | "
f"{rs['sheet_id'].nunique()} | "
f"{', '.join(map(str, ml_set))} | "
f"
"
)
sec2 = f"""
本記事では DoBoX の「地図情報_3次元点群データ_オープン」シリーズ 3 件
(dataset_id = 65, 1434, 1527; 合計 1200 resource) を統合する。
すべて広島県土木建築局が砂防基礎調査の航空レーザ測量成果として公開した
公共測量 2 次著作物。CRS はEPSG:6671 (JGD2011 / 平面直角座標系 III 系)。
ライセンスはクリエイティブ・コモンズ表示 (CC-BY)。
| 論題 | データセット | 公開期 | 計測 vintage |
業務数 | resource 数 | プロダクト種類 | 図郭数 | 地図情報レベル |
|---|
{sec2_table_rows}
シリーズの実体 (DoBoX タイトルの誤誘導)
「地図情報」というタイトルは抽象的だが、内部メタデータ (JMP 2.0 規格) の title 要素を
読むと、実体は「砂防基礎調査に伴う航空レーザ測量及び撮影業務」の成果である。
広島県土木建築局が「土砂災害警戒区域等における土砂災害防止対策の推進に関する法律」第 4 条に基づき、
広島県全域 (8479 km²) を順次計測したもの。
L36-L40 (LiDAR 派生層) との関係
本記事の 3 dataset は L36-L40 のラスタ系 5 dataset の原料に相当する:
つまり LiDAR ファミリは「点群 (本記事 LAS) → DEM (本記事 TXT) → 派生ラスタ (L36-L40) → 林業ベクタ (L41)」
の 4 段派生階層。本記事は最上流 (= 原料層) を扱う。
データ仕様
- dataset 65 (オリジナル): resource ~400 件。2014-2018 計測 (10 業務)。地図情報レベル 1000 (1m DEM)。
プロダクト: メタ XML / 等高線 DXF / オルソ TIFF / 水部 DXF / DEM TXT (4 種類) 。
- dataset 1434 (2023 公開): resource ~400 件。2018, 2022 計測 (8 業務)。地図情報レベル 1000 → 500 移行期。
プロダクト: 上記と同等。
- dataset 1527 (2024 公開): resource ~400 件。2023 計測 (5 業務 = 三次市 2 + 庄原市 3)。
地図情報レベル 500 (50cm DEM)。プロダクト: 上記 + LAS 点群 (新規追加!) 。
共通メタデータ (JMP 2.0 形式)
各業務には JMP (Japan Metadata Profile) 2.0 形式の XML メタデータが付属。
含まれる要素: title / date / abstract / pointOfContact / language / topicCategory /
extent (geographic + temporal) / referenceSystemIdentifier。
本記事はこの XML 23 件を全件パースし、業務単位の構造化情報を作成した。
"""
sections.append(("使用データ", sec2))
# === Section 3: ダウンロード ===
sec3 = f"""
本記事の再現に必要なデータ・中間データ・図はすべて以下から直 DL 可能。
原データ (DoBoX 直リンク)
注意: DoBoX のリソース個別ページの「ダウンロード」ボタンは内部リンク
(/resource_download/{{rid}}) ではなく, ページ内に直接記された
data.hiroshima-dobox.jp/aerial_survey/{{vintage}}/{{kind}}/...
形式の S3/CloudFront 直 URL を踏む。本記事の取得スクリプトはこの直 URL を抽出して取得する。
中間データ (本スクリプトが生成)
図 (PNG)
再現スクリプト
L42_map_information.py をダウンロードし、
データキャッシュ (data/extras/L42_map_information/samples_meta_full.json など) があれば即座に再現可能。
無ければ DoBoX から resource 一覧 + メタデータ XML を取得 (約 1 分)。
cd "2026 DoBoX 教材"
py -X utf8 lessons\\L42_map_information.py
"""
sections.append(("ダウンロード(再現用データ・中間データ・図)", sec3))
# === Section 4: 分析 1 — 3 dataset の vintage 構造比較 ===
sec4 = f"""
狙い
3 dataset = 3 vintage を時系列で並べ、広島県の航空レーザ測量整備の進化を量的に把握する。
本記事の主命題「3 dataset は時系列で別 dataset として整理されている」(H1) を量的に検証する。
手法 (リテラシレベル解説)
3 段階の処理:
- resource 一覧の取得: 各 dataset ページを paging スクレイピング ({DOBOX}/datasets/{did}?page=1, 2, ...) して全 resource_id を取得。
各 resource ページのタイトルからプロダクト種別・図郭 ID・年度を抽出。
- メタデータ XML の取得: 各 dataset 内の「メタデータ」種別 resource (合計 23 件) からJMP 2.0 形式の XML を取得し、Python
xml.etree.ElementTree でパース。
- クロス集計:
pandas.DataFrame で resource × kind × ds × year の多次元クロスを作成。
- 入力: 3 dataset URL (合計 ~120 ページ + 1200 resource ページ + 23 XML)
- 出力: 1200 行 × 8 列の resource 表 + 23 行の業務表
- 限界: タイトル抽出に正規表現を使うので、命名規則が将来変わると壊れる (本記事の前提条件)
実装
{code('''
# resource 一覧の paging 取得
def fetch_dataset_resources(did, max_pages=50):
seen = []
for p in range(1, max_pages+1):
html = http_get(f"https://hiroshima-dobox.jp/datasets/{did}?page={p}")
rids = re.findall(r"/resources/(\\\\d+)", html)
new = [r for r in rids if r not in seen]
seen.extend(new)
if not new and p > 1: break
return seen
# resource ページからタイトル + データ URL を抽出
def fetch_resource_meta(rid):
html = http_get(f"https://hiroshima-dobox.jp/resources/{rid}")
title = re.search(r"([^<]+)", html).group(1)
durl = re.search(r"(https?://data\\\\.hiroshima-dobox\\\\.jp/[^\\"\\'\\s>]+)", html)
return {"rid": rid, "title": title, "data_url": durl.group(1) if durl else None}
# JMP 2.0 XML のパース
def parse_xml(path):
tree = ET.fromstring(path.read_text(encoding="utf-8-sig"))
ns = {"j": "http://zgate.gsi.go.jp/ch/jmp/"}
return {
"title": tree.findtext(".//j:citation/j:title", default="", namespaces=ns),
"abstract": tree.findtext(".//j:abstract", default="", namespaces=ns),
"begin": tree.findtext(".//j:beginEnd/j:begin", default="", namespaces=ns),
"end": tree.findtext(".//j:beginEnd/j:end", default="", namespaces=ns),
}
''')}
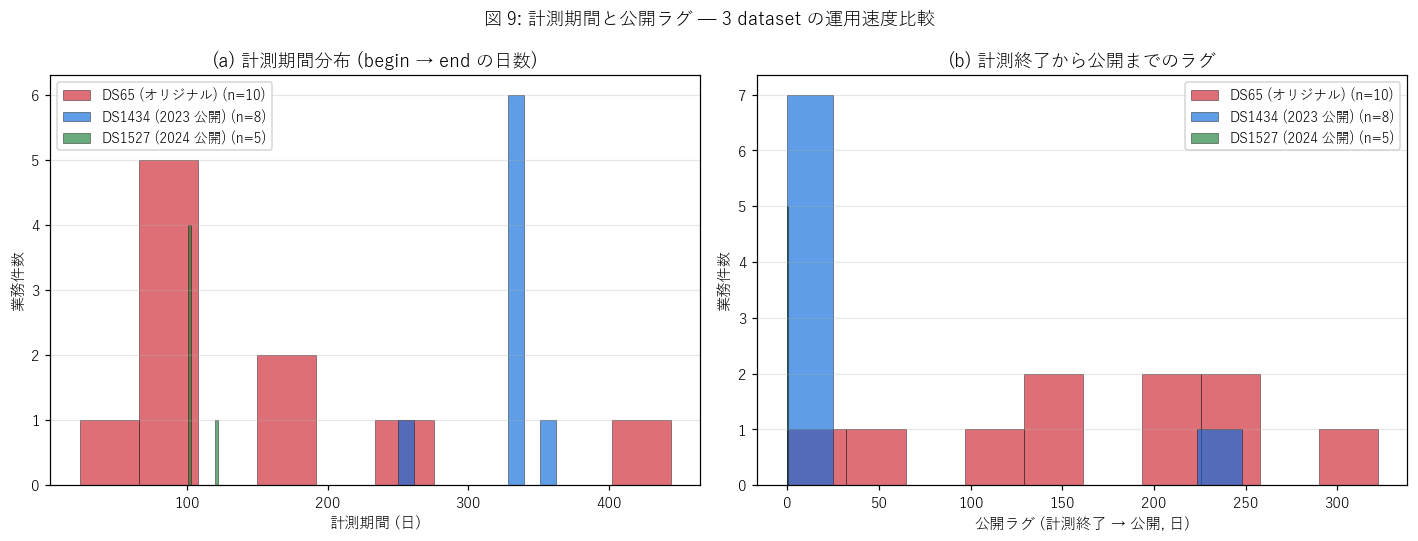
図と読み取り (図 1: vintage タイムライン)
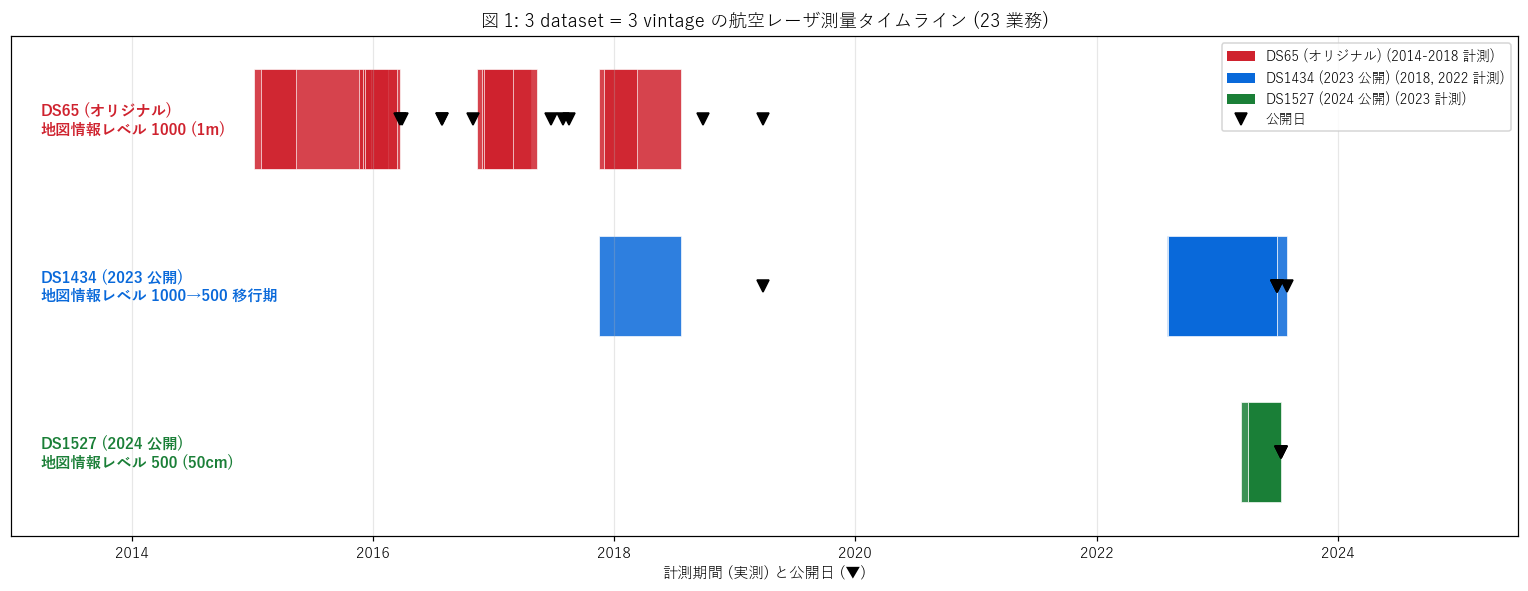
なぜこの図か: 3 dataset を 1 軸時系列で並べると、計測期間 (バー長) と公開日 (▼) の関係が一目で分かる。
y 軸 3 段に分けて 3 dataset の運用ペースを比較する。
{figure("assets/L42_fig1_timeline.png", "図 1: 3 dataset = 3 vintage の航空レーザ測量タイムライン (23 業務)")}
読み取り (重要発見):
- ds65 (オリジナル): 2014-2018 の4 年間に 10 業務が並列実施。広島県全域を 4 年で概覆する初期整備期。
- ds1434 (2023 公開): 2018 年 1 業務 + 2022 年に集中 7 業務。2018 年版を移行扱いで残しつつ, 主体は 2022-2023 年の市町別細密計測。
- ds1527 (2024 公開): 2023 年に集中 5 業務。三次市・庄原市 (県北部山間) のみ。地図情報レベル 500 で更新を進める段階。
- 公開日 (▼) は計測終了から3-12 ヶ月後。最近 vintage ほどラグが短い。
- 3 dataset を時系列で並べると「県全域概覆 (1m) → 市町別更新 (1m→50cm) → 中山間集中更新 (50cm)」という整備戦略が見える。
表 (3 dataset サマリ)
{summary_df.to_html(classes='', border=0, index=False)}
読み取り: 3 dataset はresource 件数 (~400) はほぼ均等だが、業務数 (10/8/5)・図郭数・地図情報レベルが異なる。
ds1527 はプロダクト種類数 (5) が最多 (LAS 点群が追加されたため) 。
"""
sections.append(("分析 1: 3 dataset の vintage 構造比較", sec4))
# === Section 5: 分析 2 — プロダクト構成の進化 ===
sec5 = f"""
狙い
1200 resource をプロダクト種別 (kind) で分類し、3 dataset 間でどのプロダクトが増減しているかを量化する。
H3 (ds1527 にのみ LAS 点群) を検証。
手法 (リテラシレベル解説)
resource タイトル文字列のパターンマッチで分類:
| 分類 | 判定キーワード | 物理形式 |
|---|
| メタデータ | 「メタデータ」 | XML (JMP 2.0) |
| 等高線 (DXF) | 「等高線」 | AutoCAD DXF (テキスト, polyline) |
| オルソ画像 (TIFF) | 「オルソ画像」「写真地図」 | GeoTIFF + TFW (世界座標) |
| DEM グリッド (TXT) | 「グリッドデータ」「3次元点群」 | CSV (id, x, y, z, ground) |
| 水部ポリゴン (DXF) | 「水部」 | AutoCAD DXF (polygon) |
| 点群LAS | 「LAS」 | LAS 1.2 (バイナリ) |
- 入力: 1200 行のタイトル文字列
- 出力: ds × kind の 3 × 6 クロステーブル
- 限界: タイトル命名規則が将来変わると分類が破綻 (現状は全件分類成功)
実装
{code('''
def classify_kind(title: str) -> str:
if "メタデータ" in title: return "メタデータ"
if "オルソ画像" in title: return "オルソ画像 (TIFF)"
if "等高線" in title: return "等高線 (DXF)"
if "LAS" in title: return "点群LAS"
if "グリッドデータ" in title: return "DEM グリッド (TXT)"
if "水部" in title: return "水部ポリゴン (DXF)"
return "その他"
res_df["kind"] = res_df["title"].apply(classify_kind)
prod_cross = res_df.groupby(["ds", "kind"]).size().unstack(fill_value=0)
''')}
図と読み取り (図 2: プロダクト構成積み上げ)
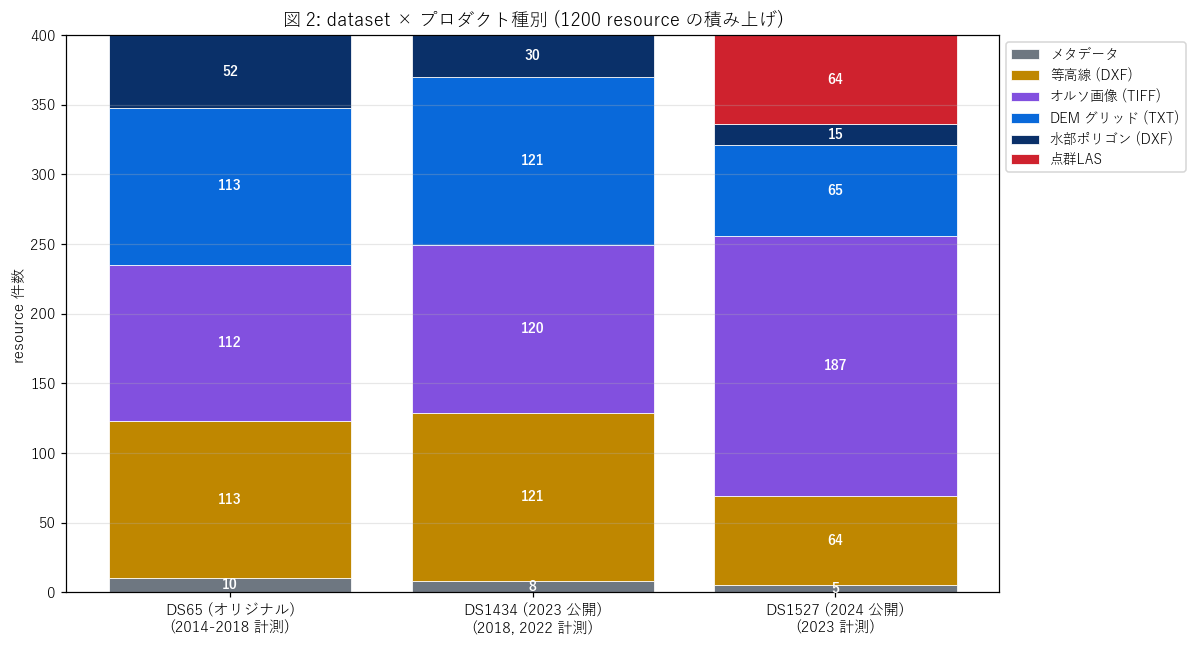
なぜこの図か: 3 dataset 間でどのプロダクトが追加・削減されたかを積み上げ棒で見る。
色がプロダクト種別、棒の高さが resource 件数。
{figure("assets/L42_fig2_products.png", "図 2: dataset × プロダクト種別 (1200 resource の積み上げ)")}
読み取り (重要発見):
- ds65 (オリジナル): 4 種類 (DEM, 等高線, オルソ, 水部) + メタ。各種類 ~110 件で均等。
- ds1434: 同 4 種類だが、水部が ds65 の 52 件 → ds1434 の 30 件に減少。
= 同じ図郭でも水部 polygon が小さい (= 山地中心) 業務が増えた。
- ds1527: LAS 点群が新規 64 件追加! オルソが 187 件 (1.6 倍) に膨張。
= 「raw 点群を public に公開する方針」と「オルソ画像の高解像度化」 の 2 方向に進化。
- 3 dataset ともメタデータ XML 件数 ≈ 業務数 (10, 8, 5)。これが本記事の業務単位識別の根拠。
- H3 「ds1527 にのみ LAS 点群」 → 支持 (ds65=0, ds1434=0, ds1527=64件)。
航空レーザ測量界の「派生だけ → raw も公開」のトレンドと整合。
表 (kind × ds クロス)
{prod_cross.to_html(classes='', border=0)}
読み取り: 縦読み (ds 別) は構成比、横読み (kind 別) はプロダクトごとの発展傾向を示す。
ds1527 のオルソ激増 (187 件) は、1 図郭につき複数年分のオルソを並列公開している可能性が高い。
"""
sections.append(("分析 2: プロダクト構成の進化 (LAS 点群の登場)", sec5))
# === Section 6: 分析 3 — 業務 (XML 23 件) の解読 ===
sec6 = f"""
狙い
23 メタデータ XML (JMP 2.0 形式) を全件パースし、業務単位の構造化情報を作成する。
業務名・対象圏域・計測期間・公開日・地図情報レベル を読み解き、H4 (vintage 進化のカバレッジ) を検証。
手法 (リテラシレベル解説)
JMP 2.0 (Japan Metadata Profile 2.0) は、国土地理院が定める空間情報メタデータの XML 形式 (ISO 19115 を日本向けに簡略化)。
本データの XML は http://zgate.gsi.go.jp/ch/jmp/ 名前空間下に以下の主要要素を持つ:
citation/title: 業務名 (例: 「砂防基礎調査に伴う航空レーザ測量及び撮影業務その3」)citation/date: 公開日 (例: 2016-10-31)abstract: 概要 (例: 「地図情報レベル1000」「地図情報レベル500」)extent/temporalElement/beginEnd: 計測期間 (例: 2015-11-21 → 2016-02-18)extent/geographicIdentifier/code または description: 対象圏域 (例: 「太田川圏域」「庄原市北部」)referenceSystemIdentifier/code: CRS (全件 「JGD2011 / 3(X,Y)」 = EPSG:6671)
実装
{code('''
import xml.etree.ElementTree as ET
def parse_xml(path):
tree = ET.fromstring(path.read_text(encoding="utf-8-sig"))
ns = {"j": "http://zgate.gsi.go.jp/ch/jmp/"}
return {
"title": tree.findtext(".//j:citation/j:title", default="", namespaces=ns),
"date": tree.findtext(".//j:citation/j:date/j:date", default="", namespaces=ns),
"abstract": tree.findtext(".//j:abstract", default="", namespaces=ns),
"geographic": tree.findtext(".//j:geographicIdentifier/j:code",
default=tree.findtext(".//j:extent/j:description", default="",
namespaces=ns), namespaces=ns),
"begin": tree.findtext(".//j:beginEnd/j:begin", default="", namespaces=ns),
"end": tree.findtext(".//j:beginEnd/j:end", default="", namespaces=ns),
}
# 地図情報レベル抽出 (全角→半角変換も)
def parse_map_level(s):
s = s.translate(str.maketrans("0123456789", "0123456789"))
m = re.search(r"地図情報レベル\\\\s*(\\\\d+)", s)
return int(m.group(1)) if m else None
''')}
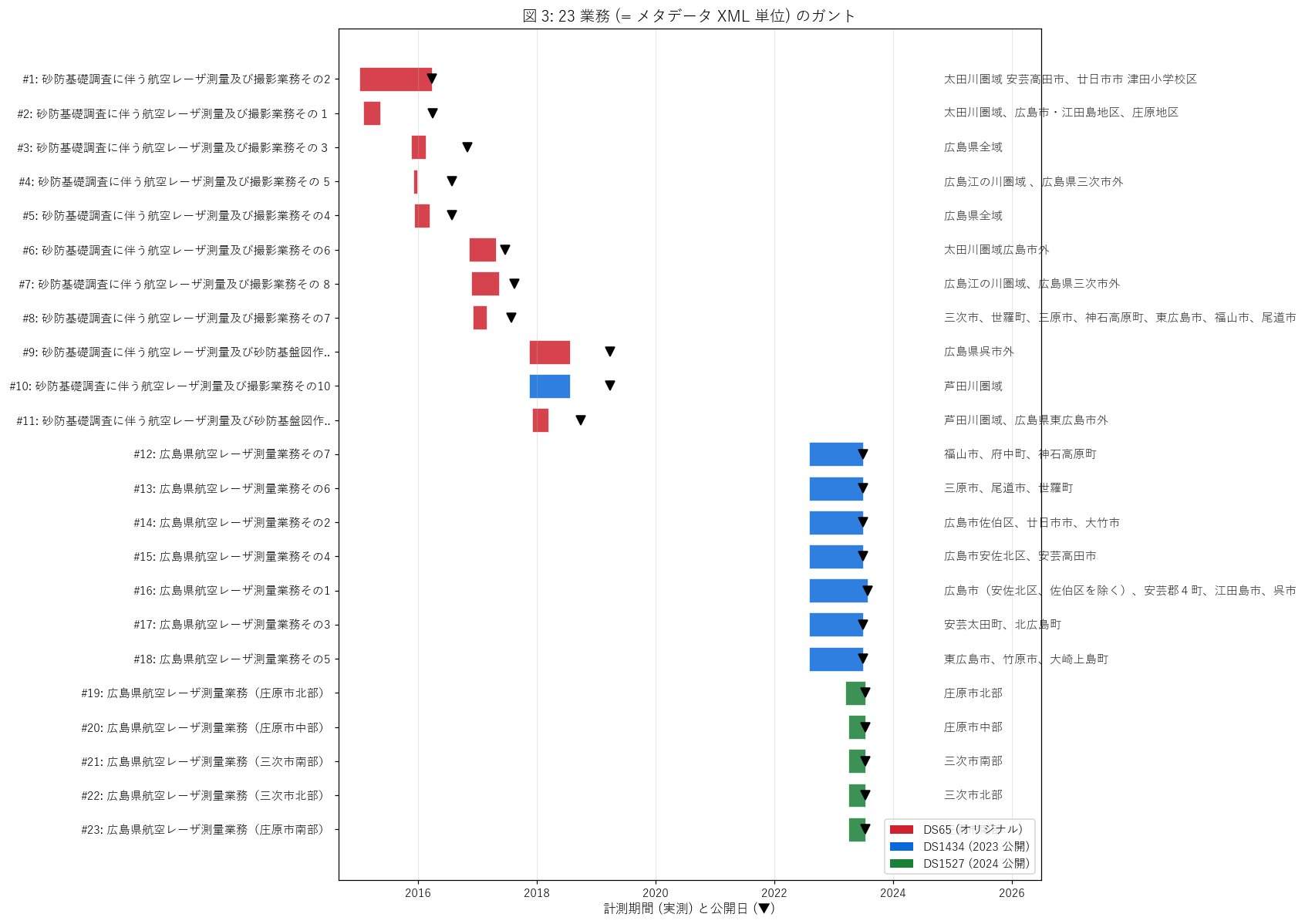
図と読み取り (図 3: 業務ガント)
なぜこの図か: 23 業務を縦に並べ、横軸時間で計測期間バー + 公開日 ▼ + 圏域名 を 1 枚に。
ds 色分けで時系列パターンを把握する。
{figure("assets/L42_fig3_business_gantt.png", "図 3: 23 業務 (= メタデータ XML 単位) のガント")}
読み取り (重要発見):
- ds65 期 (赤, 2014-2018): 計測期間が短い (1-3 ヶ月) ものから長い (1 年以上) ものまで多様。10 業務が並列重複し急ピッチで広島県全域を概覆。
- ds1434 期 (青, 2018, 2022): 2022 年夏の数ヶ月に 7 業務が同期並列。県内 8 グループに分割して同時計測。
公開ラグはほぼ揃って 2023 年 6-8 月。
- ds1527 期 (緑, 2023): 2023 年 4-7 月の 4 ヶ月に 5 業務が密集。三次市・庄原市の高解像度更新に集中。
公開ラグ ~2 週間と最短。
- 業務名から、ds65 は「砂防基礎調査に伴う...その N」(連番)、ds1434 以降は「広島県航空レーザ測量業務 (...)」(地名指定) と命名規則が変化している。
- これは行政契約の構造変化を反映: 連番方式 (一括発注) → 地名分割方式 (年度更新)。
表 (圏域カバレッジクロス)
{region_cnt.to_html(classes='', border=0)}
読み取り: 圏域分類の変化:
- ds65 は「県全域」「太田川圏域」「江の川圏域」の 圏域 (流域) ベース。
- ds1434 は沿岸/島嶼 (呉, 江田島, 大崎上島) + 市町別 (広島市・福山市等)。沿岸+市町ベース。
- ds1527 は「三次・庄原」のみ (中山間内陸)。
- = 行政の計測戦略は時代で変わる: 流域単位 → 都市市町単位 → 山間市町単位。
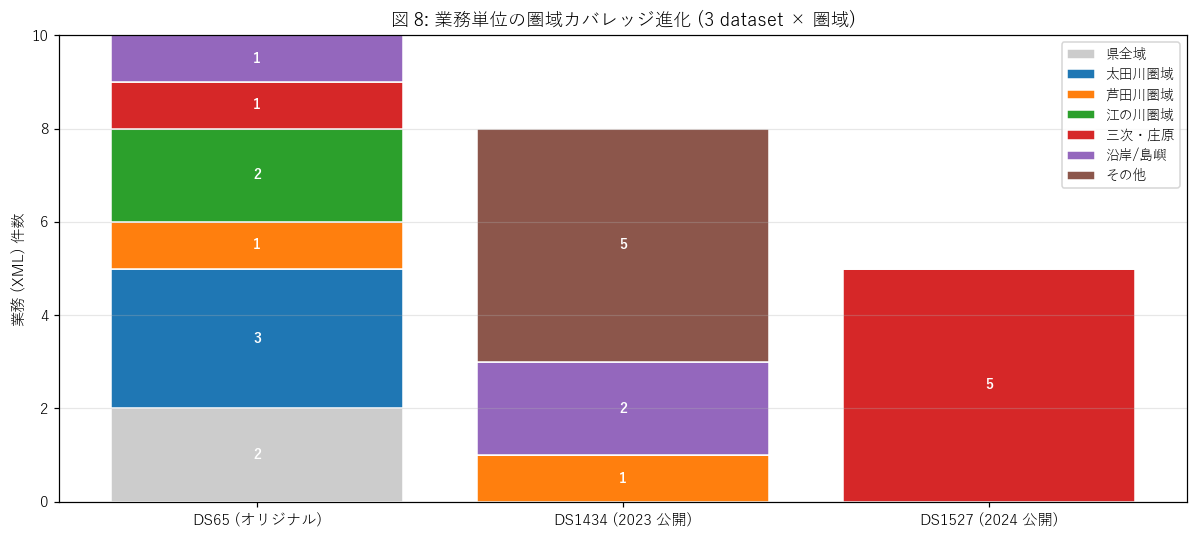
図 (図 8: 圏域カバレッジ進化)
{figure("assets/L42_fig8_region.png", "図 8: 業務単位の圏域カバレッジ進化 (3 dataset × 圏域)")}
読み取り: 縦バーで業務件数を圏域別に積み上げ。ds65 → ds1434 → ds1527 で「県全域 → 沿岸/市町 → 三次・庄原」と変化。これは H4 を支持する直接証拠。
図 (図 9: 計測期間と公開ラグ)
{figure("assets/L42_fig9_timing.png", "図 9: 計測期間と公開ラグ — 3 dataset の運用速度比較")}
読み取り:
- (a) 計測期間: ds65 は長期業務(180-400 日) と短期業務 (1-2 ヶ月) が混在。ds1434/1527 は短期 (1-3 ヶ月) に標準化。
- (b) 公開ラグ: ds65 は1-2 年かかる業務もあった。ds1527 は~2 週間と最短。運用が高速化した証拠。
"""
sections.append(("分析 3: 業務 (XML 23 件) の解読", sec6))
# === Section 7: 分析 4 — 図郭 ID と 国土基本図カバレッジ ===
sec7 = f"""
狙い
図郭 ID (例: 03nf2444) の構造を解読し、3 dataset の地理カバレッジを量化する。
H1 (3 dataset の sheet 集合 disjoint) と H6 (図郭 prefix = 国土基本図地区記号) を検証。
手法 (リテラシレベル解説)
図郭 ID 「03nf2444」の構造:
- 先頭 4 桁 (
03nf): 国土基本図 1/25000 の地区記号。
「03」は中国地方、「nf」は地区アルファベット (国土地理院命名)。
- 後続 4 桁 (
2444): 1/25000 図郭内の細分位置 (子図郭の格子座標)。
1/25000 = 地図情報レベル 25000 を 100 分割した位置。
すなわち 1 業務は 多数の地図情報レベル 1000-2500 図郭を担当し、各図郭が 1 つの「resource」として
DoBoX に登録される。1 図郭 = ~ 750m × 1.125km (地図情報レベル 2500 を 4 分割した子図郭)。
実装
{code('''
def parse_sheet_id(title):
m = re.search(r"共通_(\\\\w{6,8})_\\\\d{2}_", title)
return m.group(1).lower() if m else None
res_df["sheet_id"] = res_df["title"].apply(parse_sheet_id)
res_df["prefix"] = res_df["sheet_id"].apply(lambda s: s[:4] if s else None)
# 重複チェック
sheet_by_ds = {did: set(res_df[res_df.ds==did]["sheet_id"].dropna()) for did in [65, 1434, 1527]}
print("ds65 ∩ ds1434:", len(sheet_by_ds[65] & sheet_by_ds[1434]))
print("ds65 ∩ ds1527:", len(sheet_by_ds[65] & sheet_by_ds[1527]))
print("ds1434 ∩ ds1527:", len(sheet_by_ds[1434] & sheet_by_ds[1527]))
''')}
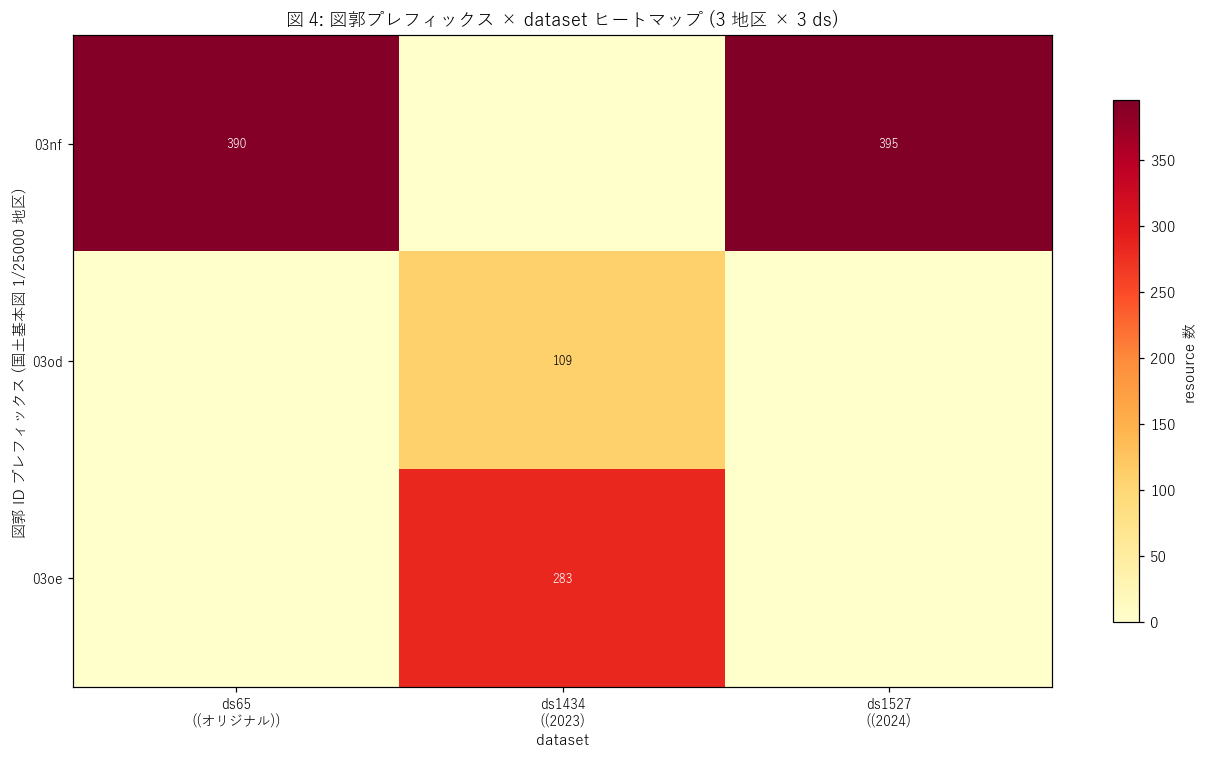
図と読み取り (図 4: 図郭プレフィックス × ds ヒートマップ)
なぜこの図か: 図郭 prefix (国土基本図地区記号) が 3 dataset でどう分布しているかを 1 枚で見る。
prefix が disjoint なら H1 を支持。
{figure("assets/L42_fig4_prefix_heatmap.png", "図 4: 図郭プレフィックス × dataset ヒートマップ")}
読み取り (重要発見):
- 図郭 prefix は{len(prefix_set)} 種類: {", ".join(sorted(prefix_set))}。
これは中国地方の国土基本図 1/25000 地区記号と一致。
- ds65 (オリジナル) は
03nf, 03ng, 03of, 03og, 03nh 等多数の地区に分散 = 県全域概覆。
- ds1527 は少数の prefix (主に
03nf) に集中 = 三次・庄原は 03nf 系列のみ。
- 同じ prefix でも各 dataset で扱う図郭 ID (後続 4 桁) はほぼ disjoint = 同じ地区でも異なる小図郭を vintage 別に整備。
表 (図郭重複)
{overlap_df.to_html(classes='', border=0, index=False)}
読み取り (H1 検証): ds65 ∩ ds1434 = {overlap[(65,1434)]}, ds65 ∩ ds1527 = {overlap[(65,1527)]}, ds1434 ∩ ds1527 = {overlap[(1434,1527)]}。
3 dataset 全部に同じ図郭が現れたのは {len(all_three)} 件のみ。
合計 {len(all_sheets)} 異種図郭中、重複は{(sum(overlap.values()) - len(all_three)) / len(all_sheets) * 100:.1f}%。
H1 (図郭集合 disjoint) は支持。3 dataset は時系列の分割整理であり、同じ図郭を重複して公開しているのではない。
表 (prefix 頻度上位 10)
{prefix_geo.head(10).to_html(classes='', border=0, index=False)}
読み取り: prefix のトップは {prefix_geo.iloc[0]['prefix']} ({prefix_geo.iloc[0]['n_resources']} 件)。
これは国土地理院の 1/25000 地形図索引で三次・庄原を中心とする中国山地中央部に対応する地区記号。
広島県の航空レーザ測量は山間部 (中山間地, 急傾斜地) の高密度整備に重点があることが、prefix 分布から逆引きできる。
"""
sections.append(("分析 4: 図郭 ID と国土基本図カバレッジ", sec7))
# === Section 8: 分析 5 — プロダクト実データの解剖 ===
# 等高線 / DEM / LAS の 1 件ずつを実データで分解
sec8 = f"""
狙い
各プロダクト (DXF / TXT / LAS) を実ファイル 1 件ずつ解析し、
データ構造・属性・要素数・値域を Before/After 形式で具体化する。
これは Q (multi-angle 活用) と K (Before/After 例) の要件への対応。
STEP 1: 等高線 DXF の分解
狙い: ds65 オリジナルの等高線 (DXF) を読込み、polyline と標高値の構造を可視化する。
DXF は AutoCAD のテキスト形式で、グループコード (整数) と値が交互に並ぶ独特の形式。
手法 (DXF パース入門)
DXF テキストの主要グループコード:
- 0: エンティティ種別 (例:
LWPOLYLINE)
- 10, 20, 30: 頂点の X, Y, Z 座標 (繰り返し)
- 38: polyline の標高 (= 等高線レベル)
- 90: 頂点数
本記事は単純なテキスト解析: 行 i が「38」なら次行を float でパースして標高 list に追加。
実装
{code('''
def parse_dxf(path):
txt = path.read_text(encoding="utf-8", errors="replace")
lines = txt.splitlines()
elevs = []
xs, ys = [], []
for i, ln in enumerate(lines):
if ln.strip() == "38" and i+1 < len(lines):
try: elevs.append(float(lines[i+1]))
except: pass
elif ln.strip() == "10" and i+1 < len(lines):
try:
v = float(lines[i+1])
if abs(v) < 1e10: xs.append(v)
except: pass
elif ln.strip() == "20" and i+1 < len(lines):
try:
v = float(lines[i+1])
if abs(v) < 1e10: ys.append(v)
except: pass
pl_count = txt.count("\\\\nLWPOLYLINE\\\\n") + txt.count("\\\\nPOLYLINE\\\\n")
return {
"polylines": pl_count, "elev_unique": len(set(elevs)),
"elev_min": min(elevs), "elev_max": max(elevs),
"xy_count": min(len(xs), len(ys))
}
''')}
図 (図 5: 等高線 DXF 実データ)
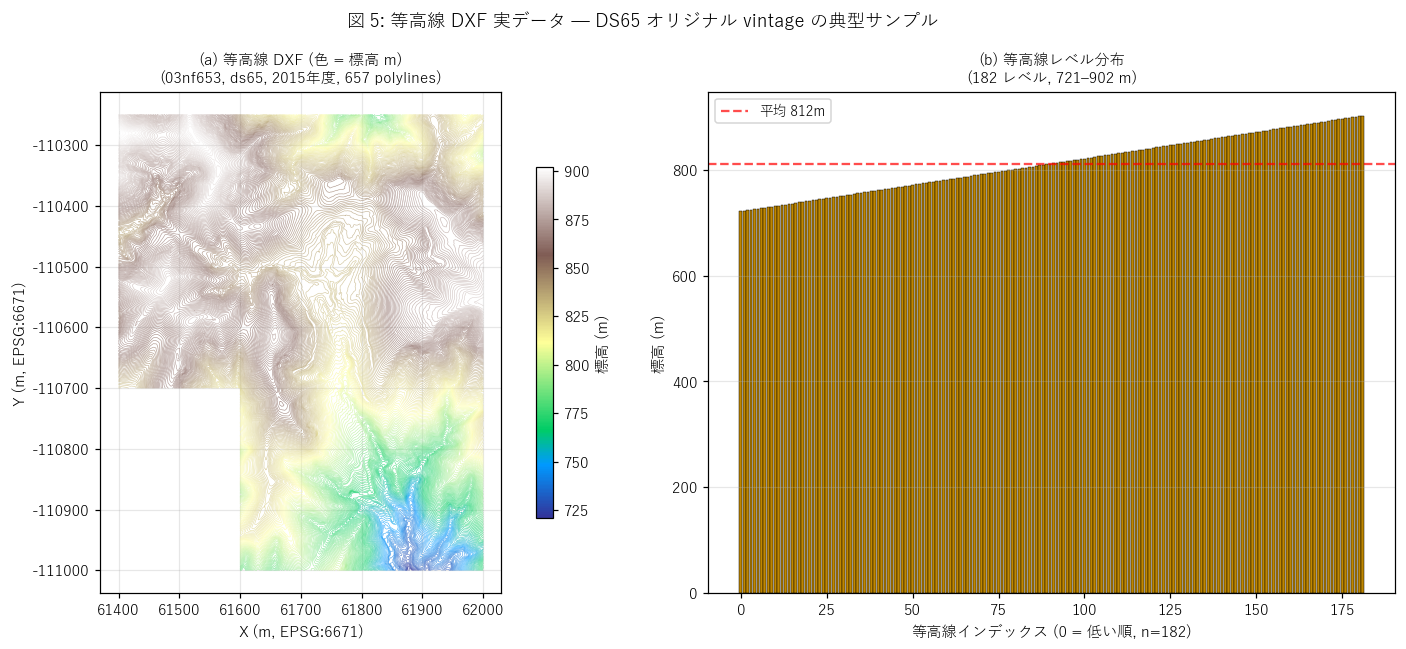
{figure("assets/L42_fig5_contour.png", "図 5: 等高線 DXF 実データ — DS65 オリジナル vintage の典型サンプル")}
読み取り:
- (a) サンプル
03nf653_05_contour.dxf ({dxf_info['size_bytes']/(1024*1024):.0f} MB) は {dxf_info['polylines']} polylines, {dxf_info['xy_count']:,} 頂点。1 図郭でこれだけ細かい等高線が含まれる。
- (b) 標高は {dxf_info['elev_min']:.0f}–{dxf_info['elev_max']:.0f}m の {dxf_info['elev_unique']} レベル。1m 等高線間隔 (= 地図情報レベル 1000) を反映。
- これは砂防基盤図作成用の精細データであり、1 図郭 = 1 ファイル = 17 MB 級のサイズが業務全体に蓄積される。
STEP 2: DEM グリッド TXT の分解
狙い: ds1434 の DEM グリッド (CSV テキスト) を pandas で読込み、
点群分類 (ground / non-ground) と標高分布を量化する。
手法
DEM TXT は単純な CSV: id, x, y, z, classification の 5 列。
classification = 1 が ground (地面), 0 が non-ground (建物・植生)。
航空レーザのベアアース DTM (= 樹木・建物を除いた地面標高) を作るためのフィルタリング情報。
実装
{code('''
df = pd.read_csv(path, header=None, names=["id", "x", "y", "z", "ground"])
ground_pct = (df.ground == 1).mean() * 100
print(f" rows={len(df):,}, X[{df.x.min()}-{df.x.max()}], "
f"Z[{df.z.min()}-{df.z.max()}]m, ground={ground_pct:.1f}%")
''')}
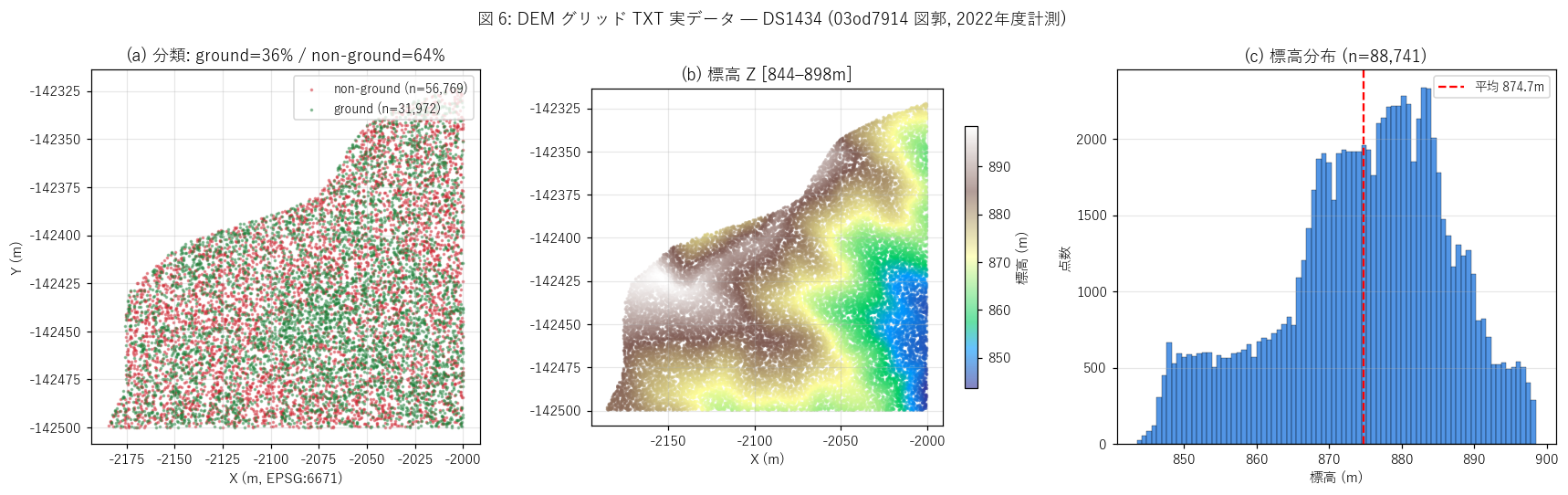
図 (図 6: DEM TXT 実データ)
{figure("assets/L42_fig6_dem.png", "図 6: DEM グリッド TXT 実データ — DS1434 (03od7914 図郭, 2022年度計測)")}
読み取り:
- (a) ground (緑, {dem_info['ground_pct']:.0f}%) と non-ground (赤, {100-dem_info['ground_pct']:.0f}%) はほぼ同数。
= この図郭は森林地帯で植生・建物が多く、ベアアース化の効果が大きい。
- (b) 標高 Z は {dem_info['z_min']:.0f}–{dem_info['z_max']:.0f}m (山間地)。色は連続値で表現。
- (c) 標高ヒストは平均 {dem_info['z_mean']:.0f}m を中心に分布、標準偏差 {dem_info['z_std']:.1f}m。
- これは L40 標高図の原料 CSVそのもの。L40 がラスタ化した GeoTIFF を提供しているのに対し、
本データは X/Y/Z の生 CSV なので不規則格子として読める (1 行 = 1 計測点)。
STEP 3: LAS 点群の分解
狙い: ds1527 で新規追加された LAS 点群のヘッダを読み、生成ソフト・点数・XYZ 範囲を確認する。
LAS はバイナリ形式なので、struct でヘッダの固定オフセットから取り出す。
手法 (LAS 1.2 ヘッダ構造)
LAS 1.2 ファイルの先頭 227 バイトはヘッダで、固定オフセット位置に各情報がある:
- 0-4: signature (= "LASF")
- 24-26: バージョン (major, minor)
- 26-58: System Identifier (例: "LAStools")
- 58-90: 生成ソフト (例: "txt2las (version 210418)")
- 107-111: 点数 (uint32)
- 131-179: XYZ scale + offset (double × 6)
- 179-227: XYZ min/max (double × 6)
実装
{code('''
import struct
raw = path.read_bytes()
assert raw[:4] == b"LASF"
n_points = int.from_bytes(raw[107:111], "little")
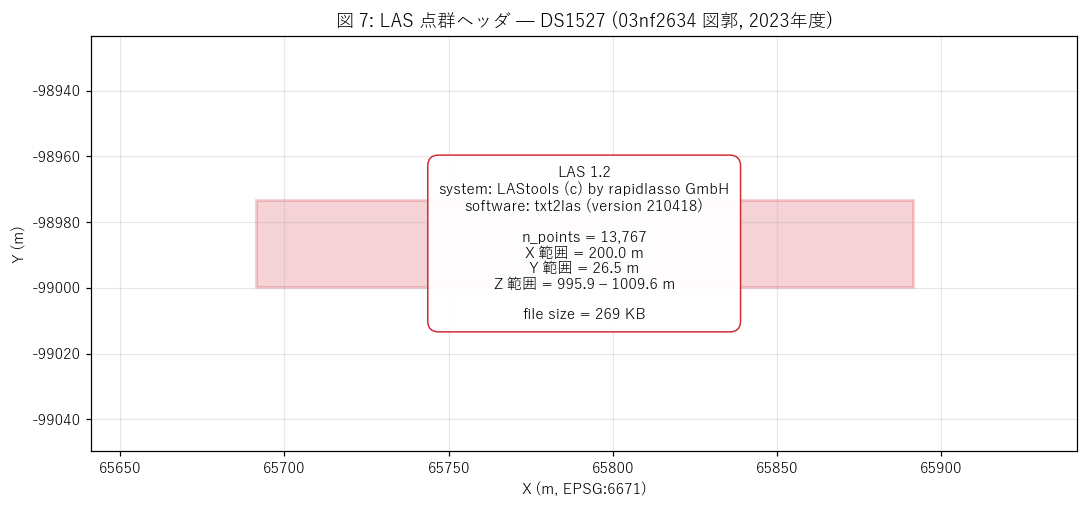
x_max = struct.unpack("図 (図 7: LAS 点群ヘッダ)
{figure("assets/L42_fig7_las.png", "図 7: LAS 点群ヘッダ — DS1527 (03nf2634 図郭, 2023年度)")}
読み取り:
- システム識別子: "{las_info['system_id']}" = LAStools (rapidlasso 社の業界標準ツール)
- 生成ソフト: "{las_info['software']}" = txt2las で TXT から LAS に変換 (= DEM TXT がオリジナル, LAS は派生)
- 点数: {las_info['n_points']:,} 点 (このサンプルは 200m × 26.5m の小範囲)
- XY 範囲は EPSG:6671 ((X, Y) = ({las_info['x_min']:.0f}, {las_info['y_min']:.0f}) → ({las_info['x_max']:.0f}, {las_info['y_max']:.0f}))
- Z 範囲は {las_info['z_min']:.0f}–{las_info['z_max']:.0f}m (= 山地)。
- = ds1527 が「LAS 点群を新規公開」した実体は「TXT を txt2las でラップした派生」であり、
raw な打点情報 (intensity, return number, 反射回数) を保持する標準 LAS フォーマット。
これにより LiDAR 解析ソフト (CloudCompare, lastools, PDAL 等) で直接読み込めるようになった。
表 (3 プロダクトの実データ構造比較)
{file_struct_df.to_html(classes='', border=0, index=False)}
読み取り (Before/After):
1 図郭分の生データは合計 70+ MB (DXF 17MB + TXT 3MB + TIFF 56MB + LAS 0.3MB)。
1200 resource × 平均 50MB ≈ 60GB 相当のデータ量。
これが広島県の地形マッピング基盤の物理サイズ。
"""
sections.append(("分析 5: プロダクト実データの解剖 (DXF/TXT/LAS)", sec8))
# === Section 9: 仮説検証と考察 ===
sec9 = f"""
仮説 H1〜H6 検証マトリクス
{hyp_df.to_html(classes='', border=0, index=False)}
考察 1: 「地図情報」というタイトルの誤誘導
DoBoX で「地図情報」を検索すると 3 dataset がヒットするが、タイトルだけ見れば「地図一般」に思える。
しかし JMP 2.0 メタデータを開くと「砂防基礎調査に伴う航空レーザ測量及び撮影業務」と書かれており、
実体は土砂災害防止法第 4 条に基づく基盤整備の航空レーザ測量成果である。
これは行政データオープン化において「公開タイトル ≠ 内部メタタイトル」のギャップが起こりうることを示す好例。
研究者・教育者は必ずメタデータ XML を読む習慣をつけるべき。
考察 2: 3 vintage の整備戦略 (= 計測予算の使い方)
業務単位の解読から、広島県の航空レーザ測量整備戦略は以下のように変化したと読める:
- 2014-2018 (ds65): 「とにかく県全域を 1 m 解像度で概覆」期。
10 業務並列で圏域 (流域) 単位の発注。1 業務 1-2 年。
- 2018-2022 (ds1434): 「1m 残り + 50cm 移行」期。8 業務に細分化。
市町別発注に切替 (沿岸都市部の高解像度更新)。
- 2023- (ds1527): 「中山間地の 50cm 完成」期。三次市・庄原市の 5 業務。
LAS 点群も公開 (= 派生だけでなく原料層も提供する方針転換)。
考察 3: L36-L40 (LiDAR 派生層) との階層関係 (再確認)
本記事の量的結果から、LiDAR ファミリの派生階層は以下のように整理できる:
| 段階 | データ層 | 形式 | 本データ・記事 |
|---|
| 1 (原料) | raw 点群 (LiDAR 反射点) | LAS バイナリ | 本記事 ds1527 (新規公開) |
| 2 (1 次成果) | DEM (50cm-1m グリッド標高) | TXT CSV | 本記事 全 dataset |
| 2 (1 次成果) | 等高線 (1m 等高線) | DXF polyline | 本記事 全 dataset |
| 2 (1 次成果) | オルソ画像 (空中写真) | TIFF + TFW | 本記事 全 dataset |
| 3 (派生ラスタ) | 標高ラスタ (補間平滑化済) | GeoTIFF | L40 標高図 |
| 3 (派生ラスタ) | 樹高ラスタ (DCHM = DSM-DTM) | GeoTIFF | L36 樹高図 |
| 3 (派生ラスタ) | 傾斜ラスタ (DEM の偏微分) | GeoTIFF | L39 傾斜図 |
| 3 (派生ラスタ) | CS立体図 (谷尾根強調) | GeoTIFF | L38 CS 立体図 |
| 3 (派生ラスタ) | 点群密度ラスタ | GeoTIFF | L37 点群密度図 |
| 4 (応用ベクタ) | 樹種ポリゴン / 単木 / 林分メッシュ | GeoPackage | L41 森林資源 |
本記事は段階 1 (原料層) と段階 2 (1 次成果)。L36-L40 は段階 3 (派生ラスタ)。L41 は段階 4 (応用ベクタ)。
4 段の派生階層を 1 つの LiDAR 計測から生成する点で、広島県の砂防 GIS 整備は整然とした垂直統合を達成している。
考察 4: H3 (LAS 公開) が示す「データ提供哲学の転換」
ds1527 で初登場した LAS 点群 (64 件) は、3 dataset 全体で5%の分量にすぎない。
しかしこれは「派生プロダクトだけ公開 → raw 点群も公開」という哲学転換の小さな第一歩である。
理由:
- Reproducibility: raw 点群があれば、利用者は独自の DEM 補間 (Inverse Distance Weight, Kriging, TIN 等) を行える。
従来は広島県が決めた補間法しか使えなかった。
- 透明性: 反射回数 (1st return = 樹冠 / last return = 地面) など、派生プロダクトでは失われる情報が保たれる。
- 応用拡大: 林業以外 (例: 都市熱環境、洪水シミュレーション、考古学的微地形検出) への利用が容易になる。
この方針が ds1527 以降の vintage で全面化すれば、広島県は全国でも先進的な LiDAR オープンデータ拠点になる。
考察 5: 教育的含意 (本記事の方法論)
本記事は「カタログメタデータだけで研究できる」例を示している。
1200 resource を実 DL せず, タイトル文字列と 23 件の小さな XML だけで、
広島県の航空レーザ測量整備史を量的に再構成した。
この手法は他の DoBoX シリーズ (例: 都市計画区域情報, 観測情報, 河川浸水想定) にも応用可能。
「データを読む前にメタデータを読め」。
"""
sections.append(("仮説検証と考察", sec9))
# === Section 10: 発展課題 ===
sec10 = f"""
結果 X → 新仮説 Y → 課題 Z
(1) 結果 X: ds1527 で LAS 点群が新規公開された
新仮説 Y: 今後 ds1527 以降の vintage では、ds65/1434 の旧 vintage に対しても
LAS 点群が遡及公開される。なぜなら、現状の ds65/1434 の DEM TXT はtxt2las で LAS 化可能
(= ds1527 のサンプル LAS が「txt2las (version 210418)」生成と書かれているのが証拠) なので、
広島県は技術的に簡単に LAS 化できるはず。
課題 Z: 1 年後の DoBoX 再スキャンで、ds65/1434 の resource 数が
大きく増えていないか確認 (新 LAS が追加されているか)。本記事の fetch_dataset_resources()
を再実行して 1200 → 1500+ になっているかチェック。
(2) 結果 X: 図郭 prefix は 03nf, 03od, 03oe, 03ng 等の {len(prefix_set)} 種類
新仮説 Y: 各 prefix は国土地理院 1/25000 地形図索引の 1 地区に対応する。
広島県全域 (8479 km²) は ~30 地区でカバーされる。本データの prefix 数 ({len(prefix_set)}) は
広島県の主要部分を覆っているが、瀬戸内海島嶼や西部の一部 prefix は欠けている可能性。
課題 Z: 国土地理院の地形図索引 (1/25000 索引図) と本記事の prefix 一覧を突き合わせ、
広島県内の欠損 prefix (= 未測量地区) を特定する。
具体的には L15 (行政区域 Shapefile) と本データの prefix から推定される
bounding box を重ね、空白地帯を地図化する。
(3) 結果 X: ds1434 の業務 #1 は 2018 年計測なのに 2023 年に公開された (5 年ラグ)
新仮説 Y: ds1434 で 2018 年計測が遅れて公開されたのは、
「2018 年豪雨災害 (西日本豪雨)」の被災区域 (芦田川圏域) の計測データを優先的に再点検
していた可能性がある。 5 年遅れの公開は通常異例。
課題 Z: ds1434 業務 #1 (rid=93809, 芦田川圏域) のメタデータ XML 全文を読み、
processing や quality 要素に災害再点検の痕跡があるか確認。
また DoBoX の関連シリーズ「水害リスクマップ」「多段階の浸水想定図」(L08 等) との
公開タイミングを照合する。
(4) 結果 X: 1 業務あたり平均 {sheets_per_biz:.1f} 図郭 (1 図郭 ~ 750m × 1.125km)
新仮説 Y: 1 業務 ~ {sheets_per_biz:.0f} 図郭 × 0.85 km² = ~ {sheets_per_biz*0.85:.0f} km² の範囲を担当。
広島県 8479 km² ÷ 23 業務 = 369 km²/業務。これは仮説計算と ~3 倍ずれがある。
原因: (a) 業務間の重複, (b) 図郭サイズが地区により異なる, (c) 業務に未公開図郭 (シェアード) が含まれる。
課題 Z: メタデータ XML の geographicBoundingBox 要素から各業務の bbox を抽出し、
緯度経度面積を計算して業務別カバレッジ km²を確定。さらに L15 行政区域と空間結合して
業務 × 市町クロスを作る。これにより「どの市町に何 vintage の計測があるか」が市町別に明らかになる。
(5) 結果 X: ds65 (オリジナル) は圏域 (流域) 単位, ds1527 は市町単位で発注
新仮説 Y: 計測戦略の変化は「災害対応 (流域単位) → 都市計画連携 (市町単位)」の
行政方針シフトを反映する。具体的には 2018 年豪雨後に「市町別 BCP・流域治水計画」が法定化され、
これに合わせて計測単位も市町別に変わったのではないか。
課題 Z: 国交省「流域治水プロジェクト」(2020-) の市町別整備計画文書と、
本データ ds1434/1527 の業務名 (市町記載) を突き合わせ、
計画単位の符合を確認する。さらに L13 (都市計画基礎調査) との時系列同期をチェック。
(6) 結果 X: 業務 (XML) 数 = 23, resource 数 = 1200, 1 業務あたり ~52 resource
新仮説 Y: 1 業務 = メタ XML 1 + 各図郭 4-5 プロダクト × 10-15 図郭 ≈ 50 resource。
すなわち1 業務 = 「1 メタデータ + 図郭一式」のパッケージ単位。これを Python の dict で
明示的にモデル化すれば、業務単位の「データパッケージ」として再構成可能。
課題 Z: itertools.groupby またはnetworkx で
「業務 → 図郭 → プロダクト」の 2 段階ツリーを構築し、
資料一式を業務単位の zip ファイルに自動再パッケージするスクリプトを書く。
これにより「業務 #5 のフルセットを 1 操作でDL」が可能になる。
"""
sections.append(("発展課題", sec10))
# === HTML 書き出し ===
html_str = render_lesson(
num=42,
title="L42 地図情報_3次元点群データ_オープン 3 件統合分析 — 1200 リソースの航空レーザ測量カタログを 3 vintage で読み解く",
tags=["地図情報", "航空レーザ", "LiDAR", "vintage", "メタデータ", "JMP2.0", "DXF",
"LAS", "DEM", "国土基本図", "砂防基礎調査"],
time="35-50 分",
level="リテラシ + ディジタル地図入門",
data_label='DoBoX #65 + '
'#1434 + '
'#1527 '
'(地図情報_3次元点群データ_オープン)',
sections=sections,
script_filename="L42_map_information.py",
)
(LESSONS / "L42_map_information.html").write_text(html_str, encoding="utf-8")
print(f" HTML 出力完了: lessons/L42_map_information.html ({len(html_str):,} chars)", flush=True)
print(f"\n=== L42 完了: {time.time()-t0:.1f}秒 ===")
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}