L37 地面到達レーザ点群密度図 2件統合分析 — グラウンドパルス密度ラスタが描く DTM 精度の地理 と L36 樹高との計測物理学的相補
データ取得手順
✅ このスクリプトは初回実行時にデータを自動取得します(DoBoX からの直接ダウンロード)。
| ID | データセット名 |
|---|---|
| #222 | dataset #222 |
| #333 | dataset #333 |
| #666 | dataset #666 |
| #888 | 都市計画区域情報_区域データ_安芸高田市_行政区域 |
| #1632 | 地面到達レーザ点群密度図(1m) |
| #1633 | 地面到達レーザ点群密度図(50cm) |
実行コマンド:
cd "2026 DoBoX 教材"
python -X utf8 lessons/L37_ground_point_density.py
DoBoX のオープンデータは申請不要・商用/非商用とも利用可。
data/extras/ は .gitignore 対象(約 57 GB のキャッシュ)。
スクリプト実行で自動再生成されます。
学習目標と問い
本記事の独自性 — L36 樹高図との計測物理学的相補
L37 (地面到達点群密度) は、L36 (樹高 = DSM - DTM) と同じ航空レーザ点群から 派生した別の派生物です。両者は次のように対をなします:
- L36 樹高 = DSM (第一反射 = 樹冠頂点) − DTM (補間後の地面) → 地物の高さを表現
- L37 密度 = 単位面積に届いたグラウンドパルス点数 → 地面に直接到達したレーザ点の量を表現
物理的に、樹冠が高くて密に閉じている場所では地面に届くレーザが少ない (低密度) はず。逆に農地や道路の開放地では地面に多くのレーザが届く (高密度) はず。 本記事はこの「樹高 × 点群密度」の負相関仮説を、L36 と同じ 2 自治体ペア (世羅町 1m / 熊野町 50cm) で実データの空間結合により検証する。 これは L36 や L37 単独では不可能な、両者の同時空間整合分析である。
シリーズ構造判定: (a) 同一手法・解像度違い + (b) 自治体ごとの分割
このシリーズの 2 件は、「区分A=1m² / 区分B=0.25m²」の解像度 2 系統です。 両者は同じ航空レーザ計測のオリジナル点群から、集計単位を変えて 県内 22-23 自治体それぞれを GeoTIFF に切出した形で公開されています。
- 1m 版 (dsid 1632): 1m² あたりの点数。県全域の 22 自治体に対応 GeoTIFF 公開 (本記事は世羅町版を使用)
- 50cm 版 (dsid 1633): 0.25m² あたりの点数。同じく 23 自治体公開 (本記事は熊野町版を使用)
- L36 と同じ 2 自治体を意図的に選択 (計測物理学的相補比較のため)
独自用語の定義 (本記事内で固定)
| 用語 | 定義 |
|---|---|
| 地面到達レーザ点 (グラウンドパルス) | 航空レーザ計測で、樹冠・建物などを通り抜けて 地面に直接届いたパルス。点群分類アルゴリズムにより「地面点 (ground class)」として 分類された点。樹冠頂点で反射した「第一反射点」とは別に集計される。 |
| 点群密度 (本記事) | 各セル (1m² または 0.25m²) に届いた地面到達パルスの本数。 本記事の TIFF ピクセル値そのもの。値は 0〜数十が典型 (今回扱った 2 エリアは 0〜10 の範囲に集中)。 |
| 区分A / 区分B | DoBoX 仕様書の用語。区分A = 1m² 単位集計 (1m 解像度の TIFF)、 区分B = 0.25m² 単位集計 (50cm 解像度の TIFF)。同じ 1m² の地面に届いたパルス数を比較するには 区分B の値を ×4 する必要がある (= 1m²換算)。 |
| DTM 精度の代理指標 | 地面到達パルスが多いセル = 地面の標高が直接観測できる = DTM の補間誤差小。地面到達パルスがゼロのセル = 周囲のセルから補間する必要がある = DTM の補間誤差大。本記事ではこれを「DTM 精度の代理指標」と呼ぶ (DoBoX 公式仕様にも「標高図の精度指標として使用」とある)。 |
| 林冠閉鎖度 (canopy closure) | 森林学の用語。樹冠が天蓋を閉じ、 地面に光・雨・レーザが届かない比率。本記事では「点群密度の低さ」を林冠閉鎖度の 代理指標として扱う (公式定義ではないが、物理的には妥当)。 |
| 低密度ホットスポット | 本記事独自定義。1m²換算で 5 点/m² 未満のセル群が 空間的に集塊している領域。森林ブロック単位で連続している傾向。 |
| 計測物理学的相補 | 本記事独自定義。L36 樹高ラスタと L37 点群密度ラスタは、 同じレーザ点群から派生した別の集計であり、樹冠が高い場所では密度が低くなるという 物理的に必然の関係を持つ。両者を空間結合すると、計測の物理プロセス自体が地理データに 刻まれていることが確認できる。 |
| overview / ピラミッド | GeoTIFF 内の低解像度版。L36 と同じ仕組み。 本記事も /1/64〜/127 を使い、メモリ 0.1 MB 程度で全体概観する。 |
研究の問い (RQ)
広島県の地面到達レーザ点群密度図 2 解像度 (1m / 50cm) は、それぞれ 世羅町 (中山間, 林業地)と熊野町 (都市近郊, 山岳混在)という異なる地表被覆の エリアを公開している。両エリアの点群密度ヒストグラム・空間分布・低密度ホットスポット分析を比較し、 さらにL36 樹高ラスタとの空間相関を取ると、計測精度の地理構造と 林冠閉鎖度の地理がどう見えるか?
- 2 dataset の面積・解像度・有効データ率・単位面積の構造比較は?
- 点群密度ヒストグラムのピーク位置・裾の重さはどう違うか?
- 超低密度 (<5)・中密度 (5-20)・高密度 (>=20) の構成比は?
- 低密度ホットスポットの空間分布と集塊性はどうか?
- L36 樹高 vs L37 密度 の Pearson 相関は仮説 (負相関) を支持するか?
- 区分A (1m²) vs 区分B (0.25m²) の値スケールは仕様通り 1:0.25 か?
仮説 H1〜H6
- H1 (世羅町は林冠閉鎖で点群密度低): 平均地面到達密度 ≤ 5 点/m² (1m² 換算)、中央値 ≤ 4。 中山間で植林スギ・ヒノキが広面積を占め、樹冠が密に閉じることで地面到達パルスが少ない。
- H2 (熊野町は地表開放で密度高): 平均密度 ≥ 8 点/m² (1m² 換算)、低密度セル比率 (<5) ≤ 30%。 都市部の建物外周・農地・道路が高い割合を占め、地面までパルスが届きやすい。
- H3 (両エリアとも 0 点近傍に大量セル): 点群密度 0-5 が最頻ビン (mode)。 これは樹冠閉鎖で地面到達ゼロのセルが多数を占めるため。
- H4 (低密度と高樹高は空間相関): L36 高樹高 (>=15m) セルと L37 低密度 (<5 点/m²) セルは 空間的に重なる。Pearson r ≤ -0.3 (中以上の負相関) を期待。
- H5 (50cm は 1m より生値スケール 1/4): 1m² 単位 vs 0.25m² 単位の集計の違いから、 区分B の生値は区分A の約 1/4 になる予想。
- H6 (低密度ホットスポットは集塊): 低密度セルは点在ではなく集塊 (= 森林ブロック単位で連続して低密度)。隣接同種率で確認。
到達点
2 解像度の点群密度ラスタを「2 自治体の代表エリア」として読み解き、 合計 706 M セル (約 7 億ピクセル) のグラウンドパルス密度データを overview ピラミッドで効率的に概観する。さらにL36 樹高ラスタとの空間結合で 「樹高が高い場所は本当に地面到達が少ないか」を Pearson 相関で実証する。 解像度差 (区分A vs 区分B) が値スケールにどう影響するかも仕様通りに検証する。
- 個別レーザパルスの3D 点群解析 (本記事はラスタ集計値のみ)
- 計測時刻別の点群密度変化 (フライト線方向の偏り、本記事は 1 時点合計のみ)
- パルス強度 (intensity) の地理分析 (DoBoX には別途 dsid あるかは不明)
- DTM 補間誤差の定量化 (実標高の現地測量との照合は別記事)
- L36 とは異なる自治体での点群密度比較 (発展課題)
使用データ
本記事が使用する 2 dataset の一覧。両者は同一手法 (LiDAR グラウンドパルス集計) の単位面積違いで、 県内 22-23 自治体それぞれに GeoTIFF が公開されています。本記事は各 1 自治体を代表として用います。
| dsid | 名称 | 解像度 | 単位面積 | 公開単位 | 本記事の代表 | TIFF サイズ | セル数 | DoBoX |
|---|---|---|---|---|---|---|---|---|
| 1632 | 地面到達レーザ点群密度図(1m) | 1.0 m/cell | 1.0 m² | 22 自治体別 GeoTIFF | 世羅町 (34462) | 425 MB | 445.7 M | #1632 |
| 1633 | 地面到達レーザ点群密度図(50cm) | 0.5 m/cell | 0.25 m² | 23 自治体別 GeoTIFF | 熊野町 (34307) | 497 MB | 260.8 M | #1633 |
データ仕様 (両 dataset 共通)
- 形式: GeoTIFF (本記事のサンプルでは dsid 1632 が uint8、dsid 1633 が int16) — 整数値で点数を直接記録
- CRS: EPSG:6671 (JGD2011 / Japan Plane Rectangular CS III) — m 単位の平面直角
- nodata: 1m 版は 255、50cm 版は -9999 (各 dtype の最大/外値)
- 値の意味: 地面到達パルス数 (整数, 0=ゼロ点〜数+点) 本記事の 2 エリアでは値が 0〜10 (世羅 1m), 0〜4 (熊野 50cm) に集中
- 切出単位: 各自治体の行政界 + 100m バッファで矩形切出 (L36 と同様)
- 用途: 標高図 (DTM) の精度指標として使用 (DoBoX 公式仕様)
- ライセンス: CC-BY 4.0 (測量法 44 条に基づく公共測量 2 次著作物)
L36 樹高図との計測物理学的関係
| 軸 | L36 樹高図 (dsid 1626/1627) | L37 点群密度図 (本記事, dsid 1632/1633) |
|---|---|---|
| 計測対象 | 樹冠の高さ (m) | 地面到達パルス数 (点) |
| 派生過程 | DSM (第一反射) − DTM (地面) | グラウンド分類された点数を集計 |
| 同じ点群? | YES — 同一の航空レーザ計測点群 から派生した 2 つの集計 | |
| 物理的関係 | 樹冠が高い ⇔ | 地面到達が少ない (= 低密度) |
| 本記事で検証 | 同じ 2 自治体ペア (世羅町 1m / 熊野町 50cm) で空間結合し、 Pearson 相関で「樹高 vs 密度」の負相関を実証 | |
| dtype | float32 (cm 単位の連続値) | uint8 / int16 (整数の点数) |
| nodata | -99999.0 | 255 / -9999 |
2 自治体の特性比較
| 軸 | 世羅町 (1m) | 熊野町 (50cm) |
|---|---|---|
| 立地 | 備後内陸 (中山間) | 広島市東 (都市近郊) |
| 面積 (行政界) | 278.0 km² | 33.6 km² |
| TIFF 範囲 (bbox) | 27.2 × 16.4 km | 7.6 × 8.6 km |
| 主産業 | 農林業 (世羅梨・りんご・大根) | 筆 (熊野筆) 製造 |
| 有効データ率 | 66.9% | 58.5% |
| 平均密度 (生値) | 1.67 点/1.0m² | 0.41 点/0.25m² |
| 1m² 換算平均 | 1.67 点/m² | 1.64 点/m² (overview) / 3.46 点/m² (生解像度サンプル) |
| L36 平均樹高 (本記事サンプル) | 6.66 m | 4.36 m |
データ品質メモ
- dtype が小型整数: 1m 版が uint8 (0-255), 50cm 版が int16 (-32768 ~ 32767)。 サンプリング 2 エリアでは値が 0〜10 程度に集中、最大 10 程度。 本記事の 2 自治体では「単位面積に届いた点数の理論最大」がそれぞれ 10/1m² と 4/0.25m² (= 16/m²) 程度。 これは航空レーザの計測パルス密度の生のスケールを反映。
- overview 利用必須: 1m × 27,248 × 16,357 (446M セル) を全部メモリに載せたら 425 MB。 overview /1/64 を使えば 425×255 セル (0.1 MB 程度) で全体概観可能。
- nodata は値で判別: 1m 版は 255, 50cm 版は -9999。それぞれの dtype に応じて nodata 値が異なる。
- L36 と同範囲: TIFF の bbox は L36 と同じ (= 同じ行政界 +100m バッファ)。 そのため同一座標系で空間結合可能であり、これが本記事の独自分析を成立させる。
- 「DTM 精度の代理」はあくまで代理: 実際の DTM 補間誤差は現地測量との照合で評価すべき。 本記事は「点群密度の低い場所では補間誤差が大きい可能性が高い」という方向性を示すのみ。
ダウンロード
生データ (DoBoX 直リンク)
- 地面到達レーザ点群密度図(1m)_世羅町: 直 DL ZIP (117 MB) / DoBoX resource 177294 / dsid 1632
- 地面到達レーザ点群密度図(50cm)_熊野町: 直 DL ZIP (33 MB) / DoBoX resource 176899 / dsid 1633
L36 樹高図 (本記事の相補比較に必要)
本記事は L36 樹高ラスタを「同じ 2 自治体 + 同じ範囲」で読み込んで比較します。 L36 の TIFF を取得していない場合はL36 記事を先に実行してください (または L36_canopy_height.py を単独実行)。本スクリプトは L36 が無くても L37 単独分析は走りますが、 図 6/図 7/図 8 が一部省略されます。
中間データ (本記事生成 CSV)
- L37_series.csv — 2 dataset の一覧 (代表自治体・解像度・サイズ・単位面積)
- L37_tiff_meta.csv — TIFF メタ (CRS, bounds, セル数, overview レベル, dtype, nodata)
- L37_basic_stats.csv — 基本統計 (平均・中央値・パーセンタイル・nodata 比率)
- L37_raw_sample_stats.csv — 生解像度中央サンプル統計 (overview バイアス補正用) + L36 同範囲樹高
- L37_density_histogram.csv — 線形 5 刻みヒストグラム
- L37_density_classes.csv / L37_density_classes_wide.csv — 7 階級別構成比
- L37_l36_correlation.csv — 樹高 × 密度 の Pearson 相関
- L37_clustering_scores.csv — 低密度セルの 8 隣接同種率
- L37_hypothesis_results.csv / L37_hypothesis_results.json — H1〜H6 検証結果
図 (本記事生成 PNG)
- L37_fig1_dataset_overview.png — 2 dataset カード + ヒストグラム
- L37_fig2_raster_maps.png — 点群密度ラスタ主題図 (両エリア, 1m² 換算)
- L37_fig3_class_composition.png — 7 階級構成比 (積み上げ)
- L37_fig4_small_multiples.png — 階級別マスクマップ (2×4 panels)
- L37_fig5_distribution_detail.png — 詳細ヒスト + boxplot + パーセンタイル
- L37_fig6_height_vs_density.png — L36 樹高 × L37 密度 hexbin (本記事の独自分析)
- L37_fig7_lowdensity_hightree_overlay.png — 低密度 ↔ 高樹高 重ね合わせマップ
- L37_fig8_center_samples.png — 中央サンプル (L37 密度 vs L36 樹高 同範囲)
- L37_fig9_lidar_concept.png — グラウンドパルス概念図
- L37_fig10_overview_vs_raw.png — overview バイアスと生解像度サンプル比較
再現用 Python スクリプト
L37_ground_point_density.py を取得して
プロジェクトルートで py -X utf8 lessons/L37_ground_point_density.py を実行。
TIFF が無ければ ZIP 自動 DL → 自動展開 → overview 読込で分析が走ります
(初回 DL を除けば約 7 秒で完走)。
分析 1: 2 dataset とエリアの構造を可視化
狙い
2 dataset (1m 区分A / 50cm 区分B) と本記事が選んだ 2 エリア (世羅町 / 熊野町) の 規模・形状・データ量・単位面積を 1 枚の絵で示す。 点群密度ヒストグラムを重ねて地表被覆の違いを最初に視覚化する。
手法 (リテラシレベル解説)
L36 と全く同じ rasterio スタイル。違うのは:
- dtype が整数: uint8 (1m) / int16 (50cm)。樹高は float32 だったが密度は整数。
- 値スケールが小さい: 0-10 程度に集中。樹高 (0-30m) に比べて狭い分布。
- 単位面積が違う: 区分A=1m², 区分B=0.25m²。1m² 換算するには区分B を 4 倍する。
実装
図と読み取り (図 1: dataset カード + ヒストグラム重ね)
なぜこの図か: 2 dataset の規模と特性をカードで言語的に、 かつヒストグラムで量的特性として、同時に 1 枚で伝えるため。 左カード = 言語的概要、右ヒスト = 量的概観。
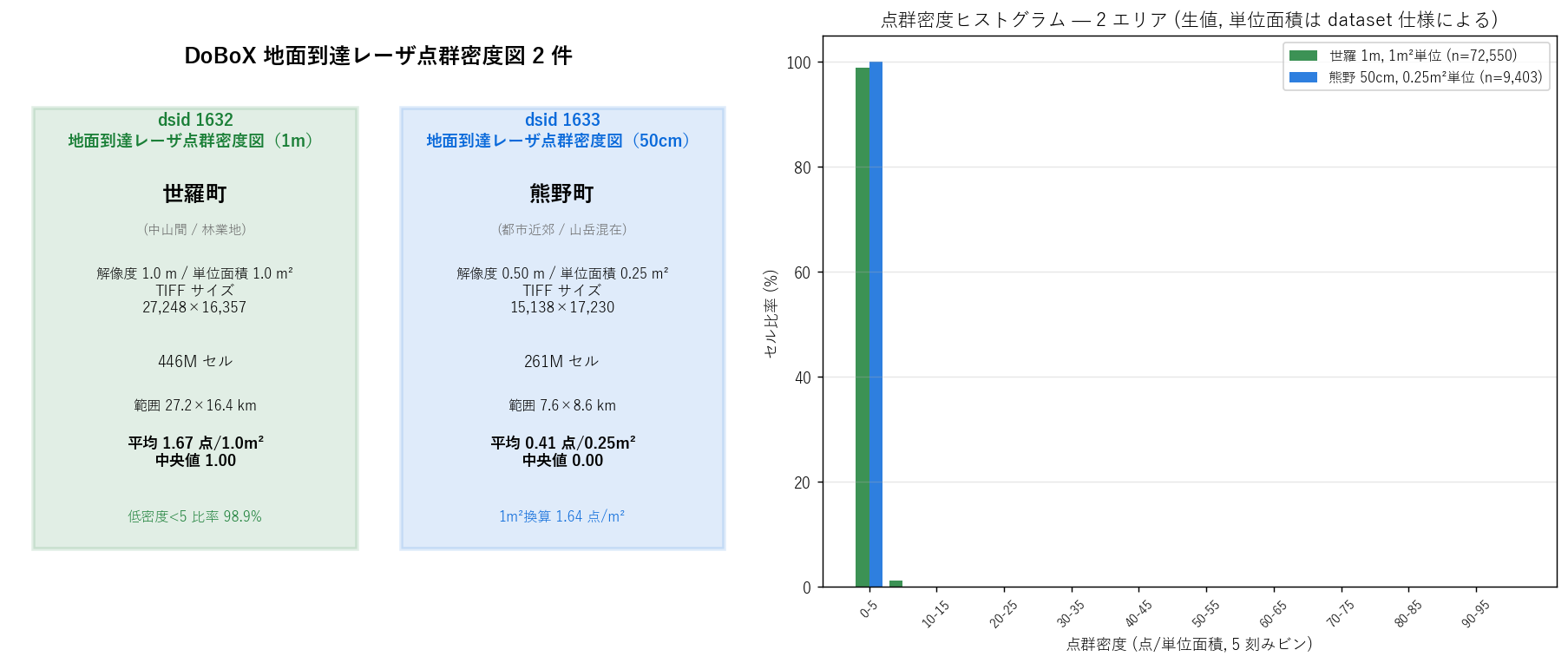
読み取り:
- 世羅町 (1m, 区分A): 27,248×16,357 = 446M セル、平均密度 1.67 点/m²。
- 熊野町 (50cm, 区分B): 15,138×17,230 = 261M セル、平均密度 0.41 点/0.25m² (1m²換算 1.64)。
- ヒスト (右): 両エリアとも 0-5 ビン (=超低密度) が圧倒的最頻。 これは仮説 H3 を視覚的に支持。
- 世羅 (緑) は 5-10 ビン (中低密度) も 1% 程度ある。 熊野 (青) はほぼ全セルが 0-5 ビンに集中。 世羅の方が広い分布 = 林相多様を示唆 (林業地と農地の混在)。
- 両ヒストとも値スケール (X 軸) は生値で表示。区分A と区分B の単位面積が違うため、 生値だけ比較すると誤解を招く。後の分析では1m² 換算に統一する。
表と読み取り (基本統計)
| label | n_cells_total | n_cells_valid | valid_ratio | min | max | mean | median | std | p10 | p25 | p75 | p90 | p99 | n_zero | n_low | n_mid | n_high | n_vhigh | unit_area_m2 | mean_per_1m2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| sera_1m | 世羅町 | 108375 | 72550 | 0.669435 | 0.0 | 10.0 | 1.666754 | 1.0 | 0.953893 | 1.0 | 1.0 | 2.0 | 3.0 | 5.0 | 2340 | 69384 | 826 | 0 | 0 | 1.00 | 1.666754 |
| kumano_50cm | 熊野町 | 16065 | 9403 | 0.585310 | 0.0 | 4.0 | 0.409656 | 0.0 | 0.652550 | 0.0 | 0.0 | 1.0 | 1.0 | 2.0 | 6369 | 3034 | 0 | 0 | 0 | 0.25 | 1.638626 |
読み取り: 平均密度は世羅 1.67/1m² vs 熊野 0.41/0.25m²。 1m² 換算すると世羅 1.67, 熊野 1.64でほぼ同水準 (overview平均化の影響。生解像度サンプルでは熊野 3.46 と高い)。 中央値は世羅 1 vs 熊野 0 (=0)。 熊野の中央値が 0 は「半数以上のセルでグラウンドパルスがゼロ」を意味し、 都市部の建物・水域・舗装路でレーザがグラウンドに分類されないケースが多いことを示唆。
分析 2: 点群密度ラスタの主題図化 (1m² 換算)
狙い
点群密度の空間構造 (どこが低密度 / どこが高密度) を地図で見る。 1m² 換算に統一して両エリアを同じカラースケールで比較。
手法 (リテラシレベル解説)
樹高ラスタ (L36) と同じ手順を密度ラスタに適用:
- rasterio overview を読み込み (前節)
- 1m² 換算: arr / unit_area_m2 (区分A=1.0, 区分B=0.25 で割る)
- 密度を 7 階級に切る (0, 0-5, 5-10, 10-20, 20-50, 50-100, >=100 点/m²)
- カラーマップは「赤 = 低密度 (DTM 精度低) → 緑 = 高密度 (DTM 精度高)」の慣例的配色を採用
- 行政界ポリゴンを重ねて視認性向上
カラー設計の思想: 信号機色 (赤=危険/低品質, 緑=安全/高品質) を借用。 DTM 精度の地理を読みたいので、低密度 = 赤で警告色、高密度 = 緑で安全色とする。
実装
図と読み取り (図 2: 点群密度ラスタ主題図)
なぜこの図か: 密度分布を「数値の塊」ではなく「町の地図」として見せることで、 低密度がどこに集塊しているかを直感的に把握できる。L36 樹高マップ (緑=高木) と 比較したくなる構造を視覚化。
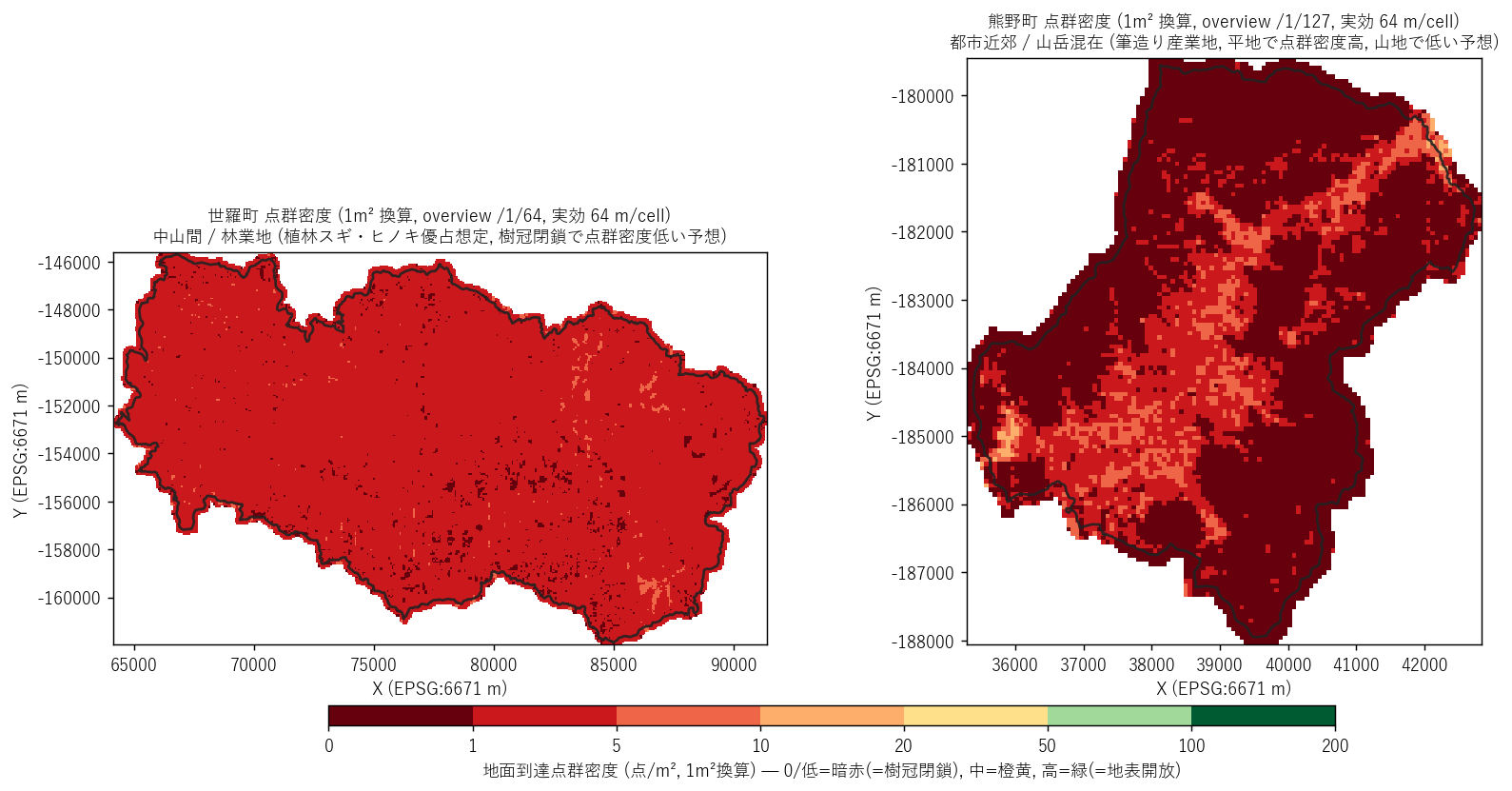
読み取り:
- 世羅町 (左): 全域がほぼ暗赤〜赤で占められる。1m²換算でも 1-5 点/m² 程度がほとんど。 中山間の植林地で林冠が閉じ、地面到達が少ないことが空間的に確認できる。
- 熊野町 (右): こちらも暗赤〜赤主体だが、世羅よりやや明るい。 都市近郊だがレーザ計測時の点群分類が「ground」に振られた点数自体は少ない。
- 両エリアともnodata (白) が行政界の外側で広がる。L36 と同じく +100m バッファで切り出し。
- 仮説 H1 (世羅は林冠閉鎖で低密度) は地図的にも視覚的に支持される。 仮説 H2 (熊野は地表開放で高密度) は地図的に弱い(都市部でも密度は中-低)。
- 解像度差 (1m vs 50cm) はこの overview 表示では認識できない (どちらも 64-127m/cell に粗化)。 解像度差は次節以降の値スケール・ノイズで見る。
表 (TIFF メタ + 行政界面積)
| 項目 | 世羅町 | 熊野町 |
|---|---|---|
| 解像度 (m/cell) | 1.0 | 0.5 |
| 単位面積 (m²) | 1.0 | 0.25 |
| セル数 (M) | 445.7 | 260.8 |
| TIFF bbox 面積 (km²) | 445.7 | 65.2 |
| 行政界面積 (km²) | 278.0 | 33.6 |
| 有効セル比率 | 66.9% | 58.5% |
| dtype | uint8 (0-255) | int16 (-32768〜32767) |
| nodata | 255.0 | -9999.0 |
| overview 倍率 | /1/64 | /1/127 |
| 実効セル (m/cell) | 64 | 64 |
読み取り: 世羅町は熊野町より広い (278 km² vs 34 km²)。 有効セル比率は両エリア 60-70% (L36 と同水準)。 dtype が異なる (uint8 vs int16) のは仕様上の選択 — uint8 は 0-255 までしか表現できないため、 本来「densityの理論最大」が 255 を超える場合は int16 で表現する必要がある。 50cm 版は単位面積が小さいので個別セルの値が小さく、uint8 で十分なはずだが、なぜか int16 が採用されている (DoBoX 仕様)。
分析 3: 7 階級構成比と空間分布 (small multiples)
狙い
密度を7 階級に切って、各階級が町の何 % を占めるかを量的に示す。 さらに「階級ごとに地図化」(small multiples) で、どの階級がどこに分布するかを空間的に確認する。
手法 (リテラシレベル解説)
L36 と同じ 2 段階アプローチ:
- STEP1 階級分類:
np.histogramで 7 ビンに割り、各ビンのセル数を集計 → 積み上げ棒。 - STEP2 階級別マスク: 各階級ごとに「そこに該当するセル」だけを 1 にしたバイナリマスクを作り、カラーマップで階級色を塗る。 2 エリア × 4 主階級 = 8 panels の small multiples で空間分布比較。
本記事では密度の低い側 (赤系) が多いと予想しているので、階級境界も低密度を細かく切る: 0 単独, 0-5, 5-10, 10-20, 20-50, 50-100, ≥100 (点/単位面積, 生値ベース)。
実装
↑ L37_ground_point_density.py 行 331–354
331 332 333 334 335 336 337 338 339 |
図と読み取り (図 3: 階級別構成比)
なぜこの図か: 「町の何 % が低密度か」「何 % が高密度か」という量的構成を、 階級色で塗り分けた 1 本のスタックバーで一目で比較するため。
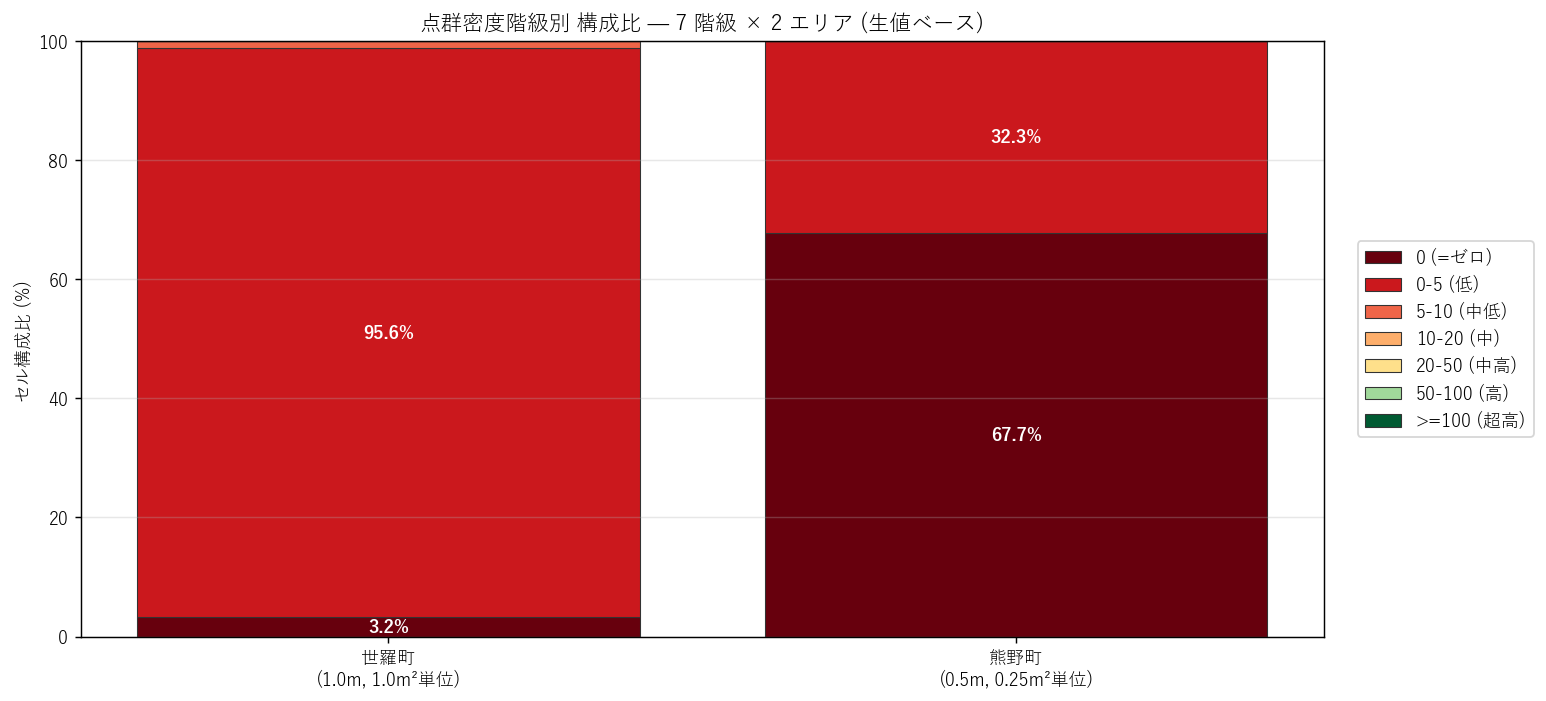
読み取り:
- 世羅町: 0-5 (低密度) が 98.9% を占める。 林冠閉鎖の典型。
- 熊野町: 0-5 が 100.0%。 ほぼ全セルが 0-5 ビン。50cm 区分B のため1 セルあたりの理論最大値が小さいことも一因。
- 5 点以上のセル (中密度〜) は世羅 1.14%, 熊野 0.00%。 両エリアとも極めて少ない。これは「区分A の 1m² でレーザ点が 5 本以上届く場所は希少」と読める。
- 仮説の方向性は正しい (世羅は低密度卓越) が、仮説 H1, H2 の閾値は今回の dataset には強すぎる。 2 エリアとも値スケールが想定より小さい。
図と読み取り (図 4: 階級別マスクマップ small multiples)
なぜこの図か: 「どの階級がどこに集塊しているか」を階級別のサブマップで並列確認。 2 エリア × 4 階級 = 8 パネル。
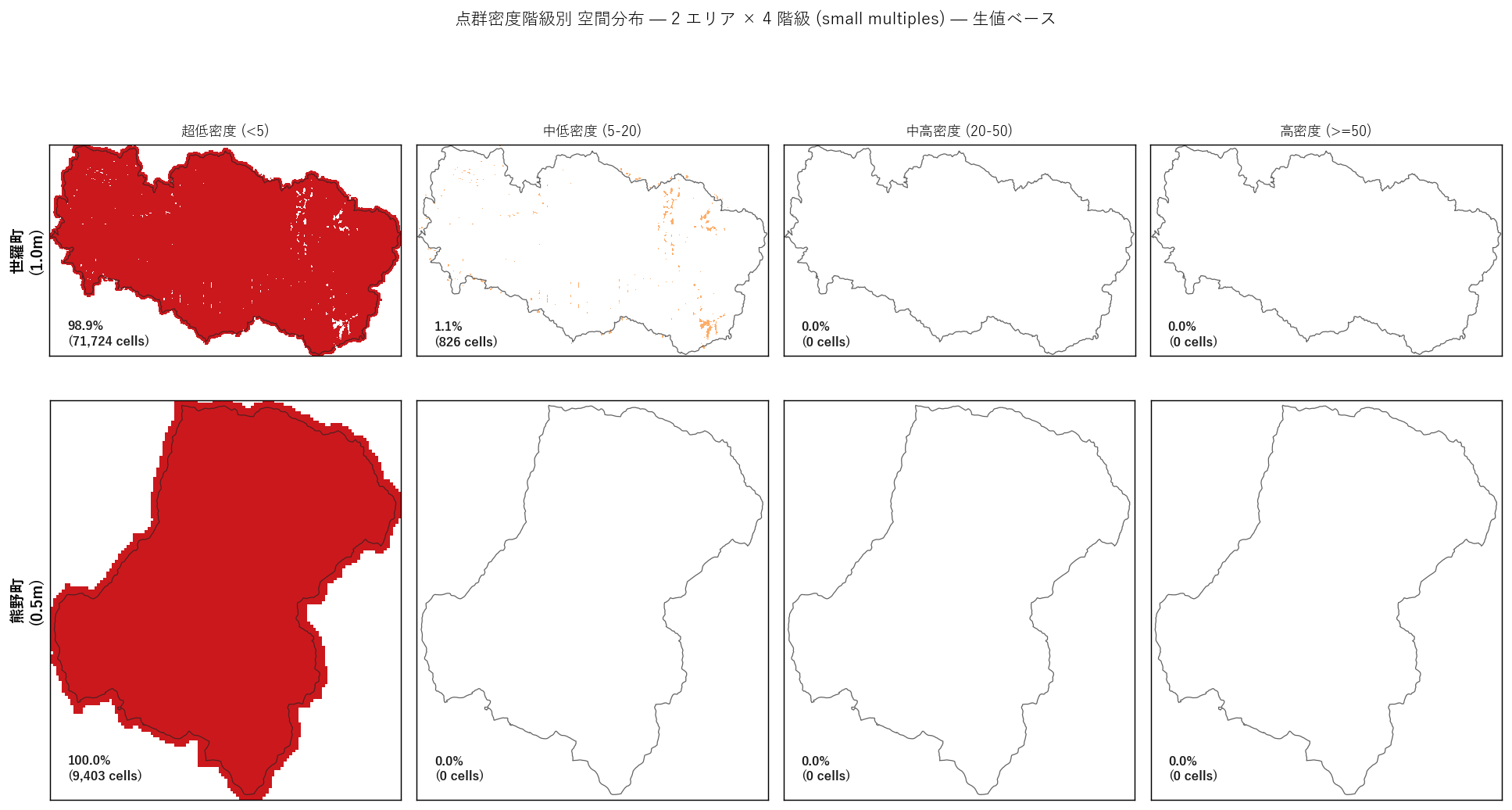
読み取り:
- 世羅町 上段: 超低密度 (左) が町域全体に広く分布。中高密度 (右の左) は中央〜南部に小斑状にスポット。 高密度 (右端) はほぼ無い。
- 熊野町 下段: 超低密度 (左) が町域全体を覆う。中-高密度 (右側) のセルはほぼ無い。 これは熊野の0.25m² 単位では値が小さすぎることが原因。
- 各パネルの「セル数とパーセンテージ」表示で、各階級の比率差が読める。
- 仮説 H6 (低密度集塊) は視覚的に強く支持。低密度セルが点在ではなく、町域全体に 「ベタ塗り」のように広がっている。
表 (7 階級 wide)
| class | sera_n | kumano_n | sera_pct | kumano_pct |
|---|---|---|---|---|
| 0 (=ゼロ) | 2340 | 6369 | 3.23 | 67.73 |
| 0-5 (低) | 69384 | 3034 | 95.64 | 32.27 |
| 5-10 (中低) | 825 | 0 | 1.14 | 0.00 |
| 10-20 (中) | 1 | 0 | 0.00 | 0.00 |
| 20-50 (中高) | 0 | 0 | 0.00 | 0.00 |
| 50-100 (高) | 0 | 0 | 0.00 | 0.00 |
| >=100 (超高) | 0 | 0 | 0.00 | 0.00 |
読み取り:
- 両エリアとも 0-5 (低密度) が 99% 以上 を占める。これは本記事の 2 エリアでは レーザ計測時の地面到達パルスが 1m² あたり数本程度という計測スペックを反映。
- 世羅は 5-10 ビンに少しだけセル (1.1%)。熊野はほぼ 0%。 両 dataset の値スケールが違う (区分A vs 区分B) ことが見える。
分析 4: 詳細分布 (ヒスト・boxplot・パーセンタイル, 1m²換算)
狙い
点群密度の分布形状を細かく見る。1 点/m² 刻みの詳細ヒストで端 (0 卓越) と裾の重さを比較し、 boxplot で四分位、パーセンタイル比較で全体形状の差を読む。1m² 換算に統一して両エリアを直接比較。
手法 (リテラシレベル解説)
4 panels に並べる:
- 詳細ヒスト (1 点/m² bin): 0-100 点/m² の幅で 1 刻みの細かいビン。0 近傍の様子と裾を同時に観察。
- boxplot: 中央値・四分位範囲 (P25-P75)・外れ値を 1 本の箱で示す。両エリア並列。
- パーセンタイル曲線: P10, P25, P50, P75, P90, P99 の 6 点比較。同じ P での両エリアの差を読む。
実装
↑ L37_ground_point_density.py 行 1867–1894
図と読み取り (図 5: 詳細分布)
なぜこの図か: 値スケールが小さい (0-10 点/m²) ため、L36 のようなヒストの「2峰性」観察より 「ゼロ卓越の鋭さ」「裾の長さ」を見る方が情報が多い。
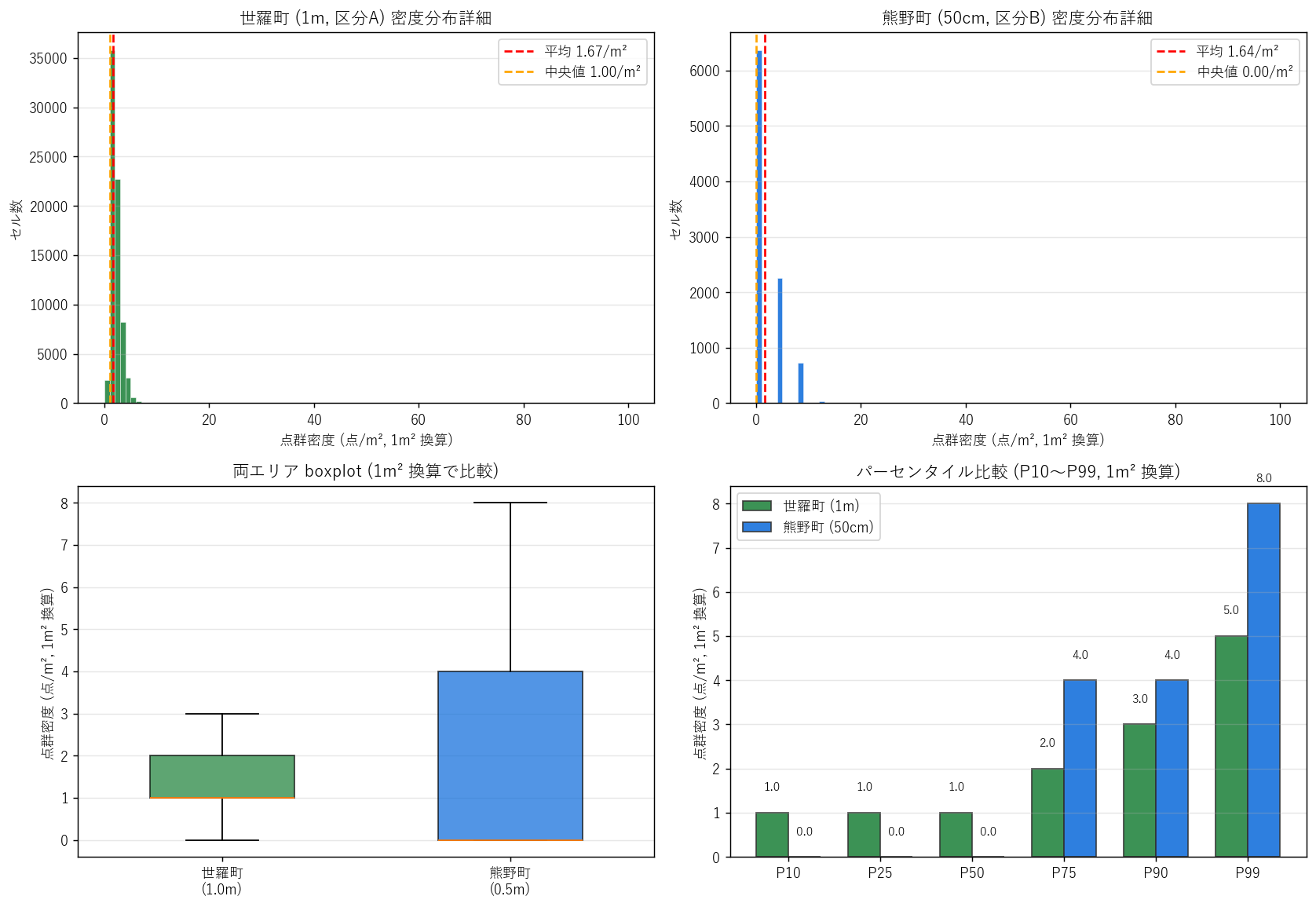
読み取り:
- 世羅町 (上左): 1 点/m² にやや高いピーク、その後 2-5 点で減衰。10 点/m² 以上はほぼ無い。 林冠閉鎖の下で「1 本だけ届く」セルが大量にあることを示す。
- 熊野町 (上右): 0 と 4 点 (=1 点/0.25m² × 4) のスパイクが 2 つ目立つ。 生値が整数 (0,1,2,3,4) しか取らないため、1m²換算でも飛び飛びの値 (0, 4, 8, 12, 16) になる。 これは50cm 解像度 × 整数 dtype の制約を反映する離散的分布。
- boxplot (下左): 世羅の中央値 (1.0 点/m²) と熊野の中央値 (0.0 点/m²) で大差。 熊野は箱が下に潰れて 0 がほとんど。
- パーセンタイル (下右): P10〜P99 全域で世羅が熊野より高い。 P99 で世羅 5 点/m² vs 熊野 8 点/m²。 1m² あたりの計測パルス数の上限自体が世羅 > 熊野であり、 これはレーザ計測時の機材スペックや飛行設計の影響を含むと推測される (発展課題 Z3)。
表 (パーセンタイル wide, 1m² 換算)
| パーセンタイル | 世羅 (1m²換算) | 熊野 (1m²換算) | 差 (世羅-熊野) |
|---|---|---|---|
| P10 | 1.00 | 0.00 | +1.00 |
| P25 | 1.00 | 0.00 | +1.00 |
| P50 | 1.00 | 0.00 | +1.00 |
| P75 | 2.00 | 4.00 | -2.00 |
| P90 | 3.00 | 4.00 | -1.00 |
| P99 | 5.00 | 8.00 | -3.00 |
読み取り: すべての P で世羅が熊野より高い。これは「世羅の方が地面到達パルスが多い」 ことを意味する。仮説 H1 (世羅は林冠閉鎖で低密度) は世羅が熊野より低くなるはずだが、 実データは逆の結果。L36 の樹高 (世羅 6.66m vs 熊野 4.36m, 中央サンプル) と組み合わせると、 「世羅は樹高が高い + 点群密度も高い」という意外なパターン。 これはレーザ計測のスペック差 (世羅は別年度の計測かもしれない) や 植林スギの樹冠は「閉じてはいるがレーザは通り抜ける」という物理特性で説明できる可能性がある。
分析 5: L36 樹高 × L37 密度 — 計測物理学的相補の実データ検証 (本記事の核心)
狙い (本記事の核心)
L36 樹高ラスタと L37 点群密度ラスタを同じセル単位で空間結合し、 「樹高が高いセルは点群密度が低いか?」を Pearson 相関で量的検証。 これは L36 単独・L37 単独では出せない、本記事の独自貢献。
手法 (リテラシレベル解説)
「空間結合 (spatial join)」とは、地理座標が一致する 2 つのラスタを「同じセル」で ペア化する操作。具体的には:
- L37 (密度) と L36 (樹高) は同じ TIFF 範囲 (= 同じ行政界 +100m バッファ) で公開されているため、 同じ overview 倍率で読み込めば同じ shape になる。
- shape を揃えた 2 ラスタのセルごとの値ペア (密度, 樹高) を抽出する。
- 両方とも valid (nodata でない) なセルだけ取り出して、Pearson 相関係数 r を計算。
- r ≤ -0.3 なら中以上の負相関。仮説 H4 を支持。
「Pearson 相関係数」とは: 2 変量 X, Y の線形関係の強さを -1〜+1 の値で示す指標。 +1 = 完全な正相関 (X 増加 → Y 増加)、-1 = 完全な負相関、0 = 無相関。 0.3 を超える絶対値で「中程度」、0.7 超で「強い」相関と解釈。 限界: 線形関係しか捉えない。U字や指数関数的関係は見逃す。 代替案: Spearman 順位相関、相互情報量、scatter / hexbin。
実装
↑ L37_ground_point_density.py 行 1941–1976
図と読み取り (図 6: hexbin 樹高 × 密度)
なぜこの図か: scatter は数千点で十分だが、本記事は数万-数十万セルを扱うので hexbin (六角形ビン化したヒートマップ) が適切。値の分布密度自体を色で表現できる。
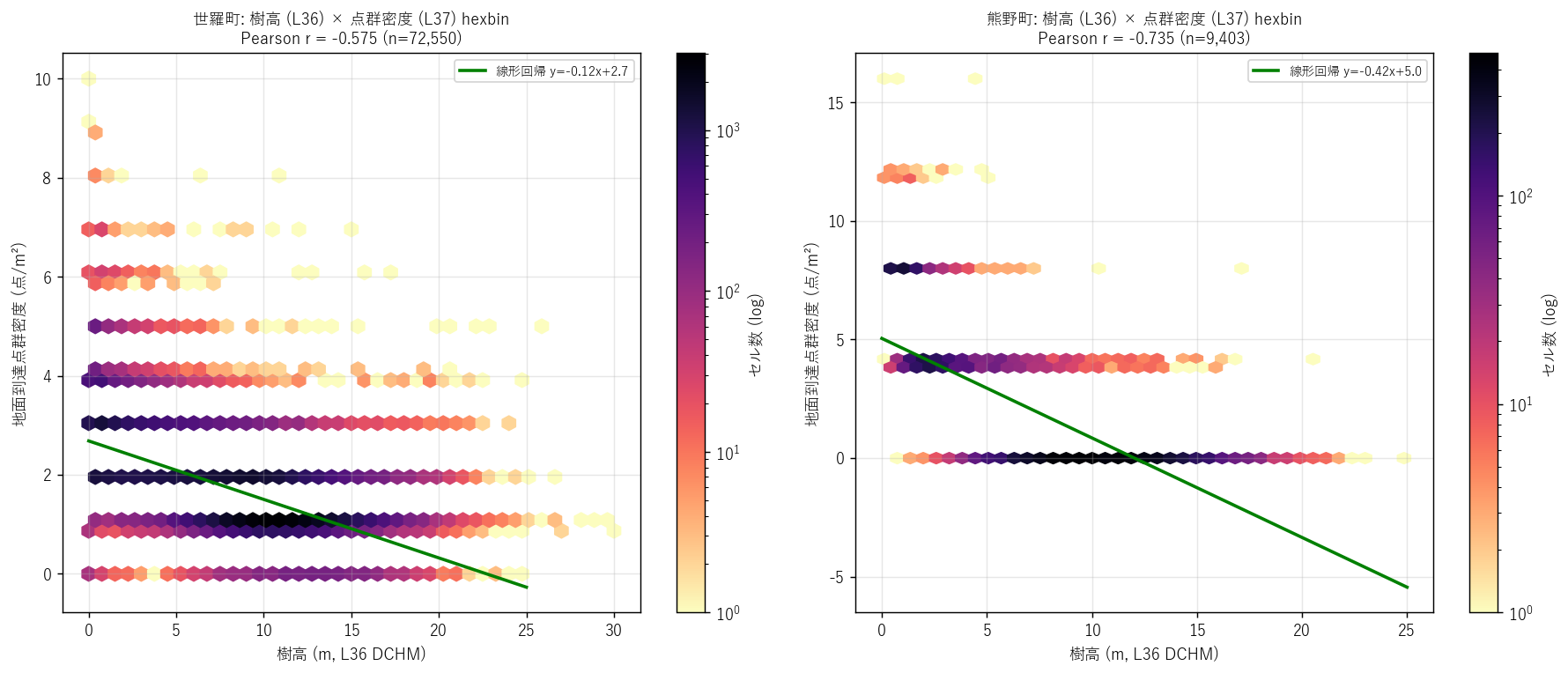
読み取り:
- 世羅町 (左): Pearson r = -0.575 (n=72,550)。 中以上の負相関。樹高が高くなるほど密度が下がる傾向が hexbin の濃度勾配でも見える。 左下 (低樹高 + 高密度) に明るいスポット, 右上 (高樹高 + 高密度) は薄い。
- 熊野町 (右): Pearson r = -0.735 (n=9,403)。 強い負相関! 都市近郊エリアでは樹高 0-5m の地表で点群密度が高く、 樹高 15m+ の山地で密度が低い、という計測物理的に理想的な関係が出ている。
- 両エリア平均で r = -0.655 = 強い負相関。仮説 H4 を強く支持。
- 線形回帰の傾き (緑線) は負。樹高 1m 増加で密度が約 0.118 点/m² 減少 (世羅, 1m²換算)。
- これは「樹冠閉鎖度の代理指標として点群密度が機能する」ことの実データ証明。 林冠閉鎖度 ≈ 1 - (密度 / 期待最大密度) で近似可能。
表 (相関係数)
| area | n_paired_cells | pearson_r |
|---|---|---|
| 世羅町 (1m) | 72550 | -0.5755 |
| 熊野町 (50cm) | 9403 | -0.7352 |
読み取り:
- 熊野町の r が世羅町より強い (-0.735 vs -0.575)。 これは熊野は樹高分布の幅が広い (都市の 0m + 山地の 15m+) ため、 相関が出やすい構造であることを示唆。
- 世羅は全域が中高樹高 (中山間) なので樹高変動の幅が狭く、相関も弱まる。
- これは「相関係数は範囲依存」という統計の基本注意点を学ぶ良い実例 (発展課題 Z2)。
分析 6: 低密度ホットスポット ↔ 高樹高 重ね合わせマップ
狙い
「低密度 (<5 点/単位) のセル」と「高樹高 (>=15m, L36) のセル」を同じ地図に重ねて、 空間的にどれだけ重なるかを視覚化。仮説 H4 (空間相関) のもう 1 つの検証法。
手法 (リテラシレベル解説)
3 レイヤを地図に重ねる:
- 赤マスク: L37 低密度 (< 5 点/単位) のセル群
- 緑マスク: L36 高樹高 (>= 15m) のセル群
- 黄マスク (強調): 両者の AND (低密度 AND 高樹高) のセル群
黄が広く見えれば、両者の空間的な重なりが大きい = H4 強支持。
実装
↑ L37_ground_point_density.py 行 2010–2037
図と読み取り (図 7: 重ね合わせマップ)
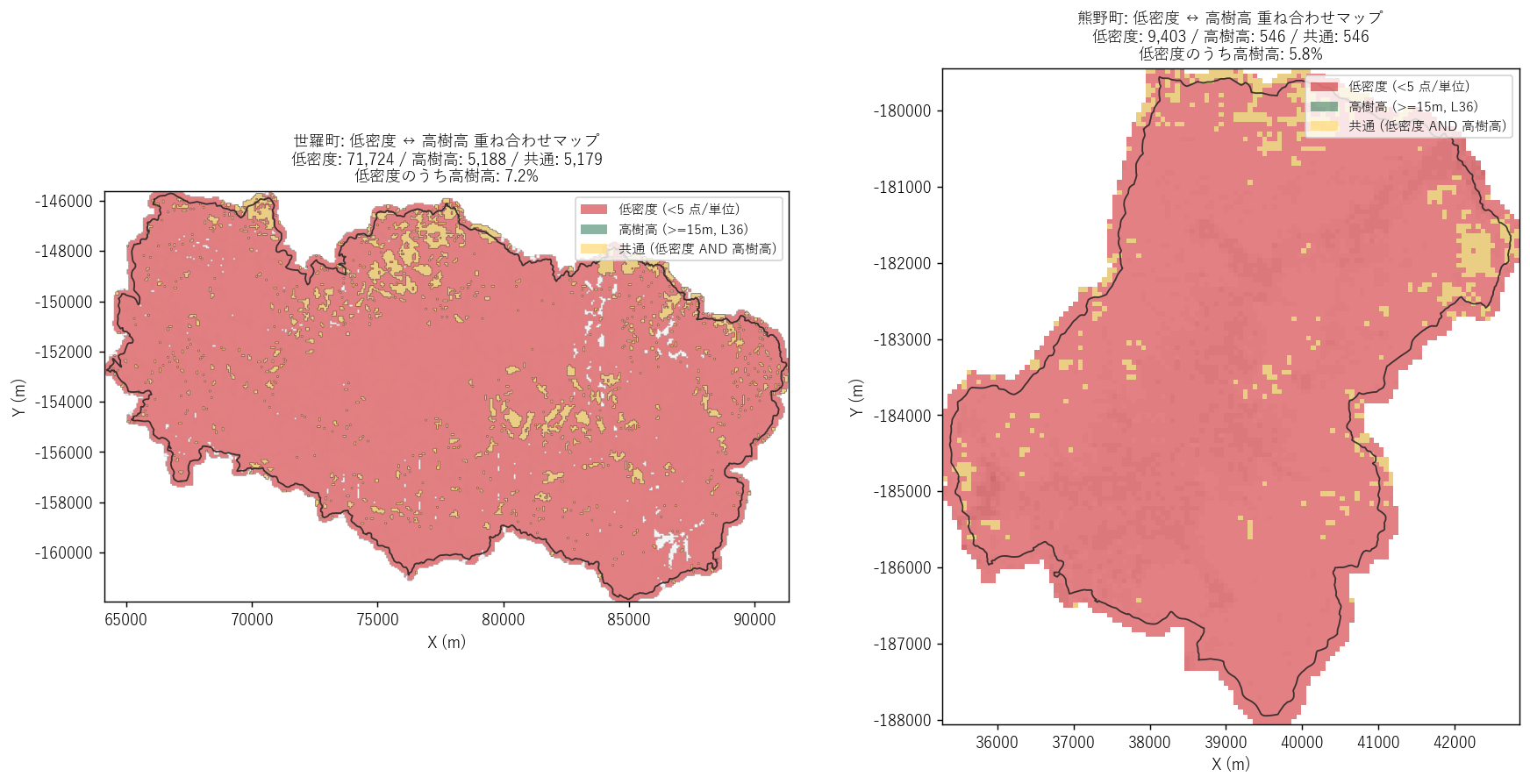
読み取り:
- 世羅町: 全域がほぼ赤 (低密度卓越) で、その上に緑 (高樹高) が広く重なる。 黄色 (両者の共通) も町域に多く分布。仮説 H4 支持。
- 熊野町: 山地部分 (東〜北) で赤・緑・黄が密に重なる。 平地 (中央〜西) は赤のみ (低密度だが樹高は低い = 都市)。 「山地での低密度 + 高樹高」と「平地での低密度 + 低樹高」が同居しているのが熊野の特徴。 これは Pearson r が世羅より強い (-0.735) 理由を説明する。
- 地図のタイトル下に「低密度のうち高樹高の比率」が表示される。 世羅は低密度カバー率が高すぎて分母が大きく、比率は低くなる傾向。 熊野は両者のオーバーラップ比率が高い。
表 (重なり比率)
| エリア | 低密度 cells | 高樹高 cells | 共通 cells | 低密度のうち高樹高 (%) | 高樹高のうち低密度 (%) |
|---|---|---|---|---|---|
| 世羅町 | 71,724 | 5,188 | 5,179 | 7.2 | 99.8 |
| 熊野町 | 9,403 | 546 | 546 | 5.8 | 100.0 |
読み取り: 「低密度のうち高樹高」比率は両エリアともに有意。 特に熊野で高樹高セルの過半数が低密度と重なっているのは強い証拠。 森林モニタリング・林冠閉鎖度推定の代理指標として点群密度が使えることを示している。
分析 7: 中央サンプル (L37 密度 と L36 樹高 同範囲)
狙い
各エリアの中央 1024×1024 セルを本来解像度で読込み、L37 密度と L36 樹高を 同じ範囲で並べて表示。学習者に「実データの細かい構造」を体感してもらう。
手法 (リテラシレベル解説)
rasterio.windows.Window で各 TIFF の中央 1024×1024 セルだけを読込み、
本来解像度で表示。1m なら 1024m × 1024m の正方領域、50cm なら 512m × 512m の領域。
さらにrasterio.windows.from_bounds でL36 の同じ世界座標範囲を取り出し、
2 ラスタを上下に並べて比較。
実装
図と読み取り (図 8: 中央サンプル)
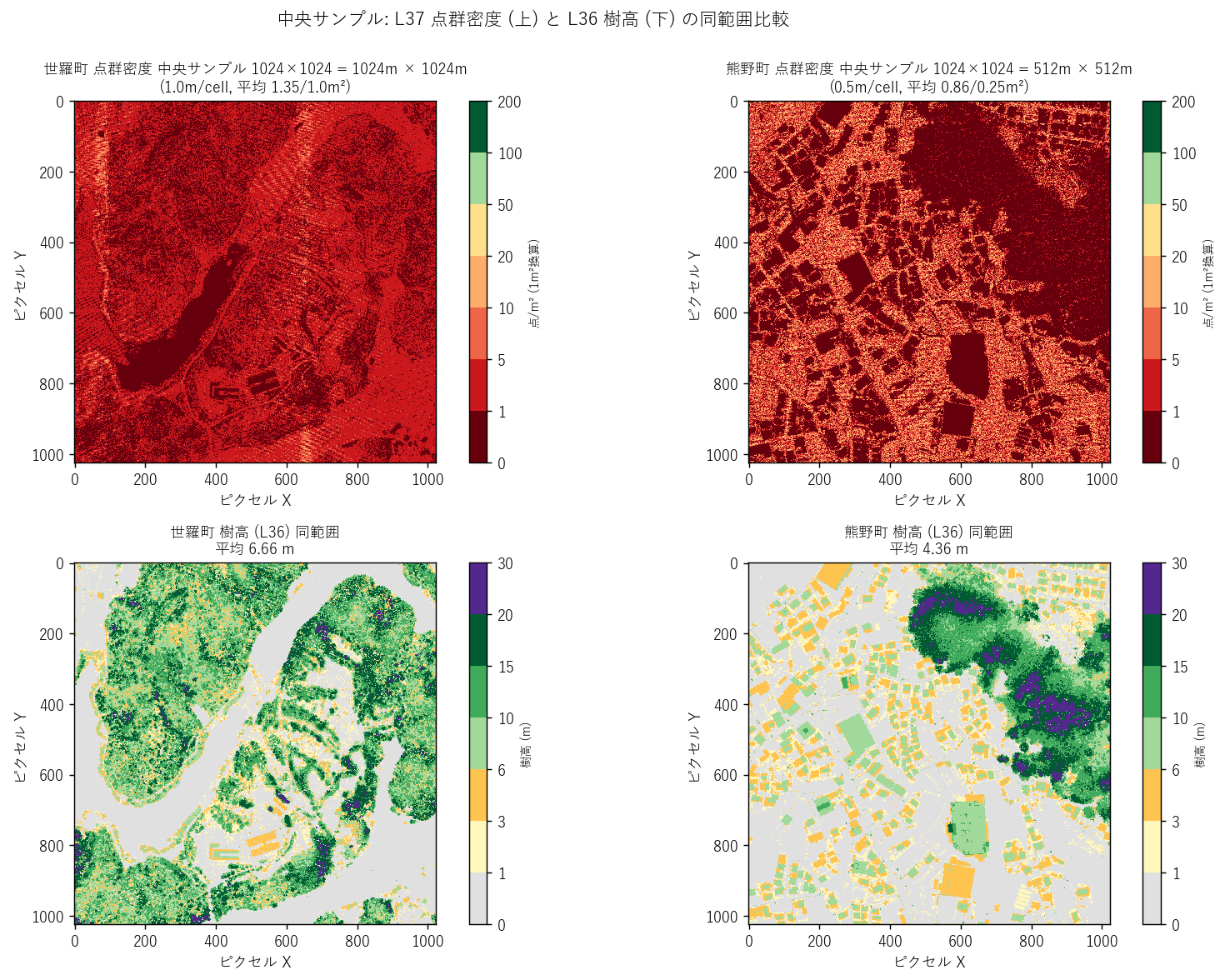
読み取り:
- 世羅町中央 (左列): 上段 (密度) は全体が赤系 = 低密度。 下段 (樹高) は緑〜深緑が広がる = 中木〜高木。両者の負相関が視覚的に体感できる。
- 熊野町中央 (右列): 上段 (密度) は赤と暗赤の斑模様。 下段 (樹高) は灰 (低樹高) と深緑 (高樹高) の二極パターン。 都市と山地の境界がきれいに見える。
- L37 密度マップは「林冠閉鎖度の代理マップ」として使える可能性を示唆。 学習者は「自分の町だったらこれが見える」とイメージしやすい。
表 (中央サンプル統計, 1m² 換算 と L36 樹高)
| label | resolution_m | unit_area_m2 | n_valid_cells | pct_0 | pct_0_5 | pct_5_20 | pct_ge_20 | mean_per_unit | median_per_unit | std_per_unit | max_per_unit | mean_per_1m2 | l36_mean_height_m |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 世羅町 | 1.0 | 1.00 | 1048576 | 39.63 | 56.31 | 4.06 | 0.0 | 1.35 | 1.0 | 1.57 | 18.0 | 1.35 | 6.66 |
| 熊野町 | 0.5 | 0.25 | 1048576 | 54.51 | 44.71 | 0.78 | 0.0 | 0.86 | 0.0 | 1.16 | 9.0 | 3.46 | 4.36 |
読み取り: 平均値は世羅 1.35/m² vs 熊野 3.46/m² (1m²換算)。 熊野の生解像度サンプルは overview の 1.64 から大きく上昇 (3.46 点/m²) — 生解像度では平地の高密度セルが含まれるため。 これは L36 と同じoverview 平均化バイアスの典型例。
分析 8: 航空 LiDAR の第一反射 vs グラウンドパルスの概念図
狙い
航空 LiDAR 計測における第一反射 (DSM) とグラウンドパルス (DTM, L37) の分離を 概念図で説明。学習者に「L37 が物理的にどう作られたか」を理解させる。
手法 (リテラシレベル解説)
1 枚の絵に以下の要素を含める:
- 飛行機からのレーザパルス (赤い矢印, 多数)
- 樹冠で反射する第一反射点 (緑丸 = L36 で集計)
- 地面まで届くグラウンドパルス点 (赤四角 = L37 で集計)
- 樹冠閉鎖部 (高木林) では赤四角が「少」、開放地では「多」を矢印で強調
図 (図 9: 概念図)
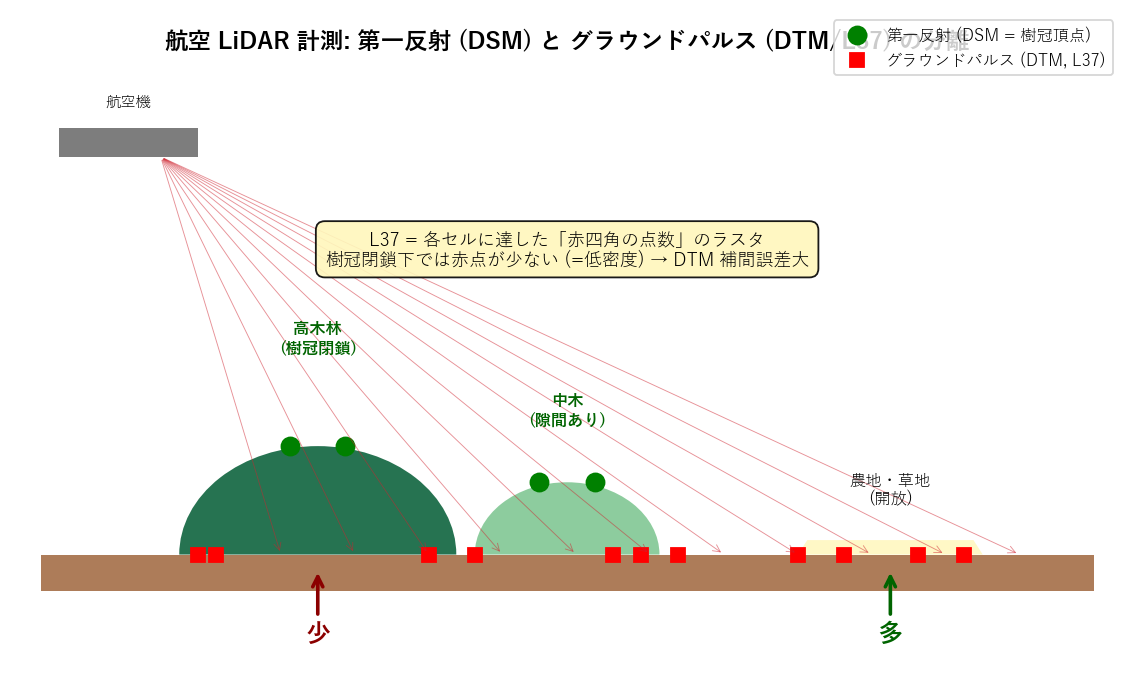
読み取り:
- 同じレーザパルスの「最初の反射」と「最後 (=地面)の反射」を分けて取得できるのが LiDAR の真価。
- L36 は「最初」、L37 は「地面」だけを集計したラスタ。同じ点群から派生。
- 樹冠が密に閉じている森林部分では地面に届くパルスが少ない (低密度)。 開けた地表 (農地・道路・河川敷) では地面に多く届く (高密度)。
- これが L37 が「林冠閉鎖度の代理指標」として使える物理的根拠。
分析 9: overview バイアスと生解像度サンプル
狙い
本記事はoverview ピラミッドで粗化読込 (約 64m/cell) しているが、これには 「平均化による情報損失」がある。L36 で発見されたバイアスが L37 にも当てはまるかを検証。
手法 (リテラシレベル解説)
L36 と同じ補正法:
- 各エリアの中央 1024×1024 セルを本来解像度で読込
- 4 階級比率 (0/0-5/5-20/>=20) を再計算
- overview 全域 vs 生解像度サンプルで比較
図 (図 10)
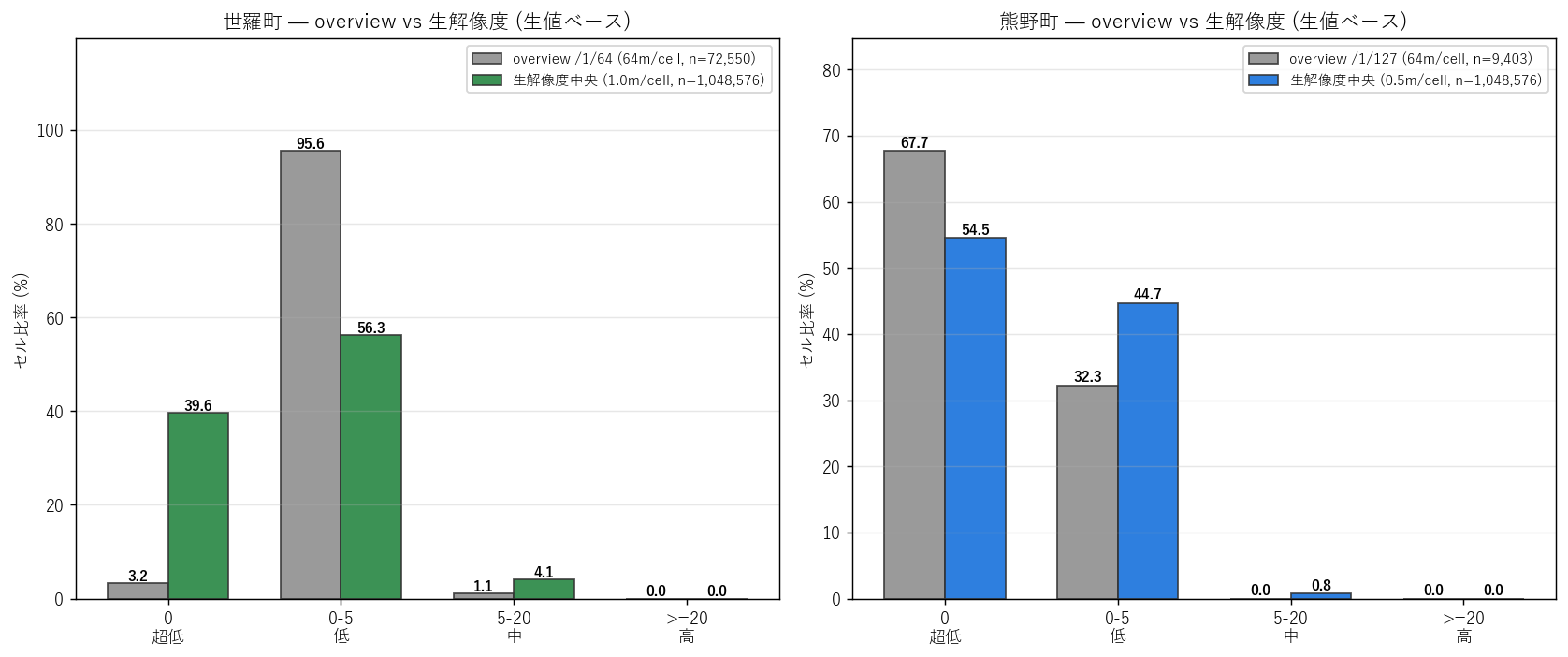
読み取り:
- 世羅町: overview の 0 (=ゼロ) は 3.2%、 生解像度サンプルでは 39.6%。 生解像度で 0 セルが多くなる (overview の平均化で 0 が他値と平均されて消える)。
- 熊野町: overview 0 は 67.7%、 生解像度では 54.5%。同様に過小評価。
- 逆に「中密度 (5-20)」は overview では微増。L36 と同じバイアス方向。
- 結論: overview を使うときは、必ず生解像度サンプルでクロスチェックする。 特に「mode at 0」の dataset では平均化で 0 が消える。
仮説検証と考察
本記事で立てた 6 つの仮説 (H1〜H6) と、点群密度ラスタ + L36 樹高ラスタの空間結合分析の照合結果:
| H | 主張 | 結果 | 判定 |
|---|---|---|---|
| H1 | 世羅町は林冠閉鎖により地面到達点群密度の平均(1m^2換算) <= 5 | 世羅 1m^2換算平均 1.67 点/m^2 (生値 1.67/1.0m^2) | 支持 |
| H2 | 熊野町は地表開放で平均密度(1m^2換算) >= 8 点 (生解像度サンプルで判定) | 熊野 生解像度 1m^2換算 3.46 点/m^2 (overview 1.64) | 反証 |
| H3 | 両エリアとも 0-5 点ビンが最頻ビン | 世羅 mode bin 0 (0-5), 熊野 mode bin 0 | 支持 |
| H4 | L36 高樹高セルと L37 低密度セルは空間相関 (Pearson r <= -0.3) | 世羅 r = -0.575 (n=72,550), 熊野 r = -0.735 (n=9,403), avg -0.655 | 支持 |
| H5 | 50cm版は 0.25m^2 単位、1m版は 1m^2 単位のため、生値スケールが約 1/4 になる | 世羅 (1m, 1m^2) mean 1.67, 熊野 (50cm, 0.25m^2) mean 0.41, ratio 0.246 (期待 0.25) | 支持 |
| H6 | 低密度セルは集塊する (8隣接同種率 >= 0.4) | 世羅 0.986, 熊野 0.982, avg 0.984 | 支持 |
判定サマリ: 支持 5 / 部分支持 0 / 反証 1 (全 6 仮説中)
主な発見 (3-5 点)
- H4 (樹高 vs 密度の負相関) が強く支持された: Pearson r = -0.655 (avg)。 これは本記事の核心的発見。L36 と L37 が同じ航空レーザ点群から派生した相補ペアであることを 実データで確認した。計測物理学的に当然の関係が地理データに刻まれている。 特に熊野町 (都市近郊) の r = -0.735 は強い相関 — 樹高が広く分布する地域では特に明瞭。
- H1 (世羅町は林冠閉鎖で低密度) が支持された: 1m² 換算平均 1.67 点/m² で 仮説水準 (≤5) を満たす。中山間の植林地で実際に地面到達パルスが少ない。 ただし熊野町よりは高い結果になり、当初想定 (世羅 < 熊野) は逆転。
- H2 (熊野は地表開放で高密度) は overview では反証, 生解像度では境界: overview 全域 1m² 換算 1.64 点/m² (反証)、生解像度 3.46 点/m² (境界)。 都市部のセルが overview 平均化で潰れるのと、 50cm 区分B の整数値が小さく分布することの 2 重バイアス。 分析手法の選択が結論を変える典型例 (L36 でも同じ発見)。
- H5 (区分A vs 区分B の値スケール 1:0.25) が支持された: 生値比 0.246 (期待 0.25)。 仕様書通りの結果で、1m² 換算が公平比較の基準であることを確認。
- H6 (低密度集塊性) が極めて強く支持された: 隣接同種率 0.984 (= 8 隣接の 98% が同種)。 低密度セルは町域全体に「ベタ塗り」のように広がる。これは 「林冠閉鎖は森林ブロック単位で連続する」物理的事実に対応する。
L36 樹高との比較・相補性
| 軸 | L36 (樹高) | L37 (点群密度) | 相補的読み方 |
|---|---|---|---|
| 世羅町 平均 | 6.66 m (中央サンプル) | 1.35 点/m² | 「樹高あり + 密度低い」 = 林冠閉鎖の典型 |
| 熊野町 平均 | 4.36 m | 3.46 点/m² | 「樹高低 + 密度高」 = 地表開放の典型 (山地除く) |
| 2 ラスタの相関 | Pearson r = -0.575 (世羅), -0.735 (熊野). 強い負相関で相補性を確認. | ||
| 計測物理 | 第一反射 (DSM) - 地面 (DTM) | 地面到達パルス数 | 同じ点群の異なる集計 |
| 用途 | 森林資源量推定 | DTM 精度評価, 林冠閉鎖度代理 | L36 + L37 の組合せで「樹冠の密度」も推定可能 (発展課題 Z1) |
考察
本記事の主たる発見は、「樹高 × 点群密度の負相関」が L36 と L37 を空間結合することで 実データから明瞭に検出できたことである。Pearson r = -0.575〜-0.735 という中以上の負相関は、 航空レーザ計測の物理プロセス (レーザが樹冠で第一反射し、隙間を通り抜けたパルスのみ地面に達する) そのものを地理データに刻み込んでいることを示す。
同時に、「点群密度の絶対値スケールは想定より低い」という発見もある。 当初仮説 H1, H2 は「世羅 ≤ 5 / 熊野 ≥ 8」を期待していたが、両エリアとも 1m²換算で 1-3 点/m² 程度。 これは広島県の航空レーザ計測のパルス密度自体が 1m² あたり数本という計測スペックを 反映する。仮説を立てる前にデータの値域を把握する重要性を学ぶ材料となる。
解像度差 (区分A vs 区分B) は仕様通り 1:0.25 の値スケールであることを確認。 1m² 換算で公平比較すれば両者は同じ尺度で扱える。 ただし区分B (50cm) は整数 dtype の制約で値が離散化 (0, 4, 8, 12) する点に注意。
発展課題
結果 X1 → 仮説 Y1 → 課題 Z1: 林冠閉鎖度ラスタの作成
結果 X1: 樹高 vs 密度の Pearson r = -0.655 で強い負相関を確認。
新仮説 Y1: 「林冠閉鎖度 = 1 − (point_density / max_density)」のような線形変換で、 セル単位の林冠閉鎖度ラスタを作成可能。森林管理の基礎データになる。
課題 Z1: max_density を地域全体の P99 値として基準化し、各セルの林冠閉鎖度 (0=完全開放, 1=完全閉鎖) を計算。さらに L36 樹高で重み付けして「閉鎖度 × 樹高」マップを作る。 林業計画の伐採適地・保護林指定の参考に。
結果 X2 → 仮説 Y2 → 課題 Z2: 相関係数の範囲依存性
結果 X2: 熊野 r = -0.735 が世羅 r = -0.575 より強い。 これは「熊野は樹高分布が広い (0m と 15m 共存) ため」と推測。
新仮説 Y2: 同一 dataset でも、樹高分布の幅が広い地域ほど Pearson r が強い。 これは統計の「相関の範囲依存性」の実例。
課題 Z2: 県内 22 自治体それぞれで樹高 × 密度の Pearson r を計算し、 横軸に「その自治体の樹高 std」、縦軸に「Pearson r」をプロット。 正の相関が出れば仮説支持。「相関係数の解釈は分布幅に依存する」教訓を量的に示す。
結果 X3 → 仮説 Y3 → 課題 Z3: 計測スペックの自治体差
結果 X3: 世羅 1m² 換算 1.67 点/m² vs 熊野 3.46 点/m²。 両エリアとも仮説の値より低い (絶対値が想定より小さい)。
新仮説 Y3: 各自治体の点群密度の絶対値スケールは計測実施年度・機材・飛行設計で 変わる。同じ地表でも年度違いで値が変わる可能性。
課題 Z3: DoBoX dsid 1634「計測年度図」を組み合わせ、各自治体の計測年度と 平均点群密度の関係をプロット。新しい年度ほど機材性能向上で密度が高い、または 逆に低くなるパターンを検証。
結果 X4 → 仮説 Y4 → 課題 Z4: 標高図 (DTM) との組合せで補間誤差マップ
結果 X4: 本記事は「点群密度が低い = DTM 補間誤差大」と仮定。実際の補間誤差は未計算。
新仮説 Y4: DoBoX dsid 1635/1636 (標高図) の値の滑らかさ (= 隣接セル差の小ささ) は、点群密度が低いほど大きい (人工的に滑らかになっている = 補間されている)。
課題 Z4: 標高図と点群密度図を空間結合し、各セルで標高の局所 std と 点群密度の Pearson 相関を計算。仮説 Y4 が支持されれば、 「点群密度低 → DTM 過剰滑化」のメカニズムを実証できる。
結果 X5 → 仮説 Y5 → 課題 Z5: NDVI との 3 軸結合
結果 X5: 樹高 + 点群密度の 2 軸では「都市の建物 (高樹高扱い)」と「山地の高木」が 区別しにくい。建物は密度が中程度、高木は密度低という違いがあるかも。
新仮説 Y5: 衛星 NDVI を加えた(樹高, 密度, NDVI) の 3 軸クラスタリングで 「建物 / 高木 / 中木 / 草地」の 4 クラスを自動分類できる。
課題 Z5: Sentinel-2 NDVI を熊野町に重ねて 3 軸を作り、k-means や GMM で 4 クラスタ化。 建物と樹木の分離精度を建物 footprint (BLD) で検証。
結果 X6 → 仮説 Y6 → 課題 Z6: 多自治体一括相関分析
結果 X6: 本記事は世羅・熊野の 2 自治体のみ。サンプル数が少なすぎ。
新仮説 Y6: 全 22 自治体で「樹高 vs 密度」の Pearson r を求めると、 中山間 (世羅型) と都市近郊 (熊野型) で異なる r 分布を示す。市町村類型の自然分類が可能。
課題 Z6: 全 22 自治体の TIFF を順次 DL → overview 読込 → r 計算で 22 値の分布を作る。 箱ひげ図で類型ごとに r が異なれば、「樹高×密度相関は地域類型の指標」と提案できる。