L36 樹高図 2件統合分析 — DCHM が描く 2 エリアの林相と森林構造
データ取得手順
✅ このスクリプトは初回実行時にデータを自動取得します(DoBoX からの直接ダウンロード)。
| ID | データセット名 |
|---|---|
| #222 | dataset #222 |
| #333 | dataset #333 |
| #666 | dataset #666 |
| #888 | 都市計画区域情報_区域データ_安芸高田市_行政区域 |
| #1626 | 樹高図(1m) |
| #1627 | 樹高図(50cm) |
実行コマンド:
cd "2026 DoBoX 教材"
python -X utf8 lessons/L36_canopy_height.py
DoBoX のオープンデータは申請不要・商用/非商用とも利用可。
data/extras/ は .gitignore 対象(約 57 GB のキャッシュ)。
スクリプト実行で自動再生成されます。
学習目標と問い
シリーズ構造判定: (a) 同一手法・解像度違い + (b) 自治体ごとの分割
このシリーズの 2 件は、「解像度 1m vs 50cm」での同一手法 2 系統です。 両者は同じ航空レーザ計測のオリジナルデータから、解像度を変えて (1m メッシュ / 50cm メッシュ) 県内 23 自治体それぞれを GeoTIFF に切出した形で公開されています。
- 1m 版 (dsid 1626): 広域評価向け。県全域の 22 自治体に対応 GeoTIFF 公開 (本記事は世羅町版を使用)
- 50cm 版 (dsid 1627): 詳細評価向け。同じく 22 自治体に対応 GeoTIFF 公開 (本記事は熊野町版を使用)
- 両者ともデータ容量が極めて大 (50cm 広島市版は15.9 GB ZIP!) のため、 本記事は各 1 自治体のみを代表エリアとして扱います。
L32〜L35 (港湾・河川シリーズ) は線・点のインフラ施設データだったが、 L36 から始まるLiDAR ファミリは面 (ラスタ)のフィジカル測定が主役。 扱う技術もまったく異なる。
独自用語の定義 (本記事内で固定)
| 用語 | 定義 |
|---|---|
| 樹高 (じゅこう) | 地表から樹冠頂点までの高さ (m)。本記事では DCHM ピクセル値そのもの。 建物・電柱なども「地物」として高さを取るため、純粋な「木の高さ」ではないことに注意。 広島県の樹高図仕様では「200m 以上は雲・霧として除去、それ以下のノイズも可能な限り除去」とされている。 |
| DCHM (Digital Canopy Height Model) | 樹冠高さモデル。航空レーザ測量で得た DSM (Digital Surface Model = 地表全体の高さ) から DTM (Digital Terrain Model = 地面のみの高さ) を差し引いて作成した地物高さラスタ。 本記事の樹高図そのもの。1 セルが 1m もしくは 0.5m。 |
| DSM | Digital Surface Model。航空レーザが最初に当たった点 (= 樹冠頂点・建物屋上・地面) の高さを集めたラスタ。地物の上端を見ている。 |
| DTM | Digital Terrain Model。航空レーザの最後に当たった点 (= 地面に届いた点) を補間した「地面のみ」の高さラスタ。建物・木は除去済み。 |
| 航空レーザ (LiDAR) | Light Detection And Ranging。航空機から地面に向けてレーザパルスを毎秒数十万発撃ち、戻り光の往復時間から距離を測る測量手法。 1 m² あたり数〜数十パルスを撃ち、樹冠と地面を別々に検出して 3D 点群を作る。 広島県では砂防課・林野庁治山課・国交省で公共測量として実施。 |
| 林相 (りんそう) | 森林の構成・外見的特徴。針葉樹 (スギ・ヒノキ等) / 広葉樹 (コナラ・ブナ等) / 混交林 / 竹林 / 伐採地 などに分類される。本記事では樹高分布パターンから推定するヒューリスティック手法を採用。 |
| 地物高さ階級 | 本記事で独自定義した 7 階級 (≤1m 地表, 1-3m 低木, 3-6m 低中木, 6-10m 中木, 10-15m 中高木, 15-20m 高木, ≥20m 巨木)。 DoBoX 公式の分類ではなく、本記事の分析用ヒューリスティック。 |
| overview / ピラミッド | GeoTIFF に埋め込まれた低解像度版。例えば「/1/128」は元データの 1/128 解像度を意味する。 1m × 27,248 × 16,357 (445M セル) のラスタも、/128 オーバビューなら 213×128 = 27K セル (1.5万倍小) で全体概観できる。 本記事ではこれを使ってメモリを 0.1 MB に抑える。 |
| 有効データ率 | TIFF 全セルのうち、nodata でも NaN でもない有効値を持つセルの比率。 TIFF は行政界 +100m バッファで矩形に切出されているため、行政界の外側は nodata になる。 |
研究の問い (RQ)
広島県の樹高図 2 解像度 (1m / 50cm) は、それぞれ世羅町 (中山間, 林業地)と 熊野町 (都市近郊, 山岳混在)という異なる地域特性のエリアを公開している。 両エリアの樹高ヒストグラム・空間分布・林相を比較すると、 どんな地域構造の違いが見え、解像度差はどう影響するか?
- 2 dataset の面積・解像度・有効データ率の構造比較は?
- 樹高ヒストグラム (0-30m) のピーク位置・多峰性はどう違うか?
- 高木 (>=15m) / 低木 (<5m) / 地表 (<1m) の構成比は?
- 高木地・低木地の空間分布はどう偏在しているか?
- 樹高分布から林相はどう推定できるか?
- 解像度差 (1m vs 50cm) はノイズ・極端値にどう影響するか?
仮説 H1〜H6
- H1 (世羅町は林業地優占): 平均樹高 ≥ 8m、高木 (≥15m) 比率 ≥ 15%。 中山間で植林スギ・ヒノキ針葉樹が広面積を占めると推定。
- H2 (熊野町は地表優占): 樹高 0-1m セル比率 ≥ 40%。 都市部の建物外周・農地・道路・山頂部のはげ地が高い割合。
- H3 (両エリアともゼロ卓越): 樹高 0-1m が最頻ビン (mode)。 航空 LiDAR では多数のセルが地表 (建物・農地) もしくは雲・霧除去後ノイズで 0 付近。
- H4 (世羅町の樹高分布は 2 峰性): 0-1m と 10-20m の 2 ピーク。 林業地 = 「植林伐採跡 + 成熟林」の二極構造。
- H5 (熊野町の高木は山岳に集中): 高木 (>=15m) は山地に集中、平地は低木・地表優占。空間相関で確認。
- H6 (50cm 版はノイズ多): 50cm の標準偏差は 1m より大、負値出現、極端値 (>30m) も多。 高解像度ほど雲・霧の残存ノイズや単木個葉のばらつきを拾う。
到達点
2 解像度の樹高図ラスタを「2 自治体の代表エリア」として読み解き、 合計 706 M セル (約 7 億ピクセル) の DCHM データを overview ピラミッドを使って効率的に概観し、樹高ヒストグラム・空間分布・林相推定の 3 角度から 広島県の中山間 vs 都市近郊の森林構造の違いを実データで裏付ける。 さらに解像度差 (1m vs 50cm) が分析にどう影響するかを統計的に示す。
使用データ
本記事が使用する 2 dataset の一覧。両者は同一手法 (LiDAR DCHM) の解像度違いで、 県内 22-23 自治体それぞれに GeoTIFF が公開されています。本記事は各 1 自治体を代表として用います。
| dsid | 名称 | 解像度 | 公開単位 | 本記事の代表 | TIFF サイズ | セル数 | DoBoX |
|---|---|---|---|---|---|---|---|
| 1626 | 樹高図(1m) | 1.0 m/cell | 22 自治体別 GeoTIFF | 世羅町 (34462) | 1,700 MB | 445.7 M | #1626 |
| 1627 | 樹高図(50cm) | 0.5 m/cell | 23 自治体別 GeoTIFF | 熊野町 (34307) | 995 MB | 260.8 M | #1627 |
データ仕様 (両 dataset 共通)
- 形式: GeoTIFF (Float32, 単一バンド) — ZIP に格納された .tiff + .tiff.ovr (オーバビューピラミッド)
- CRS: EPSG:6671 (JGD2011 / Japan Plane Rectangular CS III) — m 単位の平面直角
- nodata: -99999.0 (未計測領域)
- 値の意味: 地物高さ (m) = DSM (地表全体) − DTM (地面のみ)。樹冠頂点・建物屋上などすべて含む
- 切出単位: 各自治体の行政界 + 100m バッファで矩形切出
- 除去ノイズ: 200m 以上は雲・霧として除去済み (公式仕様)
- ライセンス: CC-BY 4.0 (測量法 44 条に基づく公共測量 2 次著作物)
L32-L35 シリーズとの重要な相違
| 軸 | L32-L35 (港湾/河川) | L36 (本記事, 樹高図) |
|---|---|---|
| データ形式 | CSV (テーブル) + Shapefile (ベクタ) | GeoTIFF (ラスタ) |
| レコード単位 | 1 行 = 1 施設・1 ポリゴン | 1 セル = 地表 1m² (or 0.25m²) の高さ値 |
| 件数 | 数十〜数千 | 数億セル (世羅 446M, 熊野 261M) |
| 分析操作 | groupby / sjoin / overlay | imshow / 階級分類 / overview |
| 主指標 | 件数・延長 m・容量 | 樹高 m・階級比率 |
| 必要パッケージ | geopandas, shapely | rasterio (+ geopandas) |
| ファイルサイズ | 数 KB 〜 数 MB | 数百 MB 〜 16 GB |
2 自治体の特性比較
| 軸 | 世羅町 (1m) | 熊野町 (50cm) |
|---|---|---|
| 立地 | 備後内陸 (中山間) | 広島市東 (都市近郊) |
| 面積 (行政界) | 278.0 km² | 33.6 km² |
| TIFF 範囲 (bbox) | 27.2 × 16.4 km | 7.6 × 8.6 km |
| 主産業 | 農林業 (世羅梨・りんご・大根) | 筆 (熊野筆) 製造 |
| 有効データ率 | 66.9% | 58.5% |
| 平均樹高 | 8.61 m | 8.13 m |
| 中央値 | 9.20 m | 8.50 m |
データ品質メモ
- サイズが極めて大: 世羅町 (1m) ZIP 870 MB → TIFF 1.7 GB、熊野町 (50cm) ZIP 604 MB → TIFF 1.0 GB。 広島市 (50cm) は ZIP 15.9 GB。全件 DL は事実上不可能で、本記事は各 1 自治体のみを扱う設計とした。
- overview 利用必須: 1m × 27,248 × 16,357 (446M セル) を全部メモリに載せたら 1.7 GB。 overview /1/64 を使えば 425×255 セル (0.1 MB) で全体概観可能。
- nodata = -99999: TIFF は行政界 +100m バッファで矩形切出されているため、行政界の外側は nodata。 有効データ率は 67〜59% 程度。
- 負値の存在: 熊野町 (50cm) には2 セルの負値が出現 (最小 -1.00m)。 理論上樹高は ≥0m だが、DSM-DTM の差分処理でセンサノイズ・地形誤差が負値として残る。
- 「林相推定」はヒューリスティック: 本記事の林相判定は樹高分布パターンに基づく独自ルールで、 林野庁の森林簿や植生図の正式分類ではない。学習者にも「あくまで推定」と明示する。
ダウンロード
生データ (DoBoX 直リンク)
- 樹高図(1m)_世羅町: 直 DL ZIP (870 MB) / DoBoX dsid 1626
- 樹高図(50cm)_熊野町: 直 DL ZIP (604 MB) / DoBoX dsid 1627
中間データ (本記事生成 CSV)
- L36_series.csv — 2 dataset の一覧 (代表自治体・解像度・サイズ)
- L36_tiff_meta.csv — TIFF メタ (CRS, bounds, セル数, overview レベル)
- L36_basic_stats.csv — 基本統計 (平均・中央値・パーセンタイル・nodata 比率)
- L36_raw_sample_stats.csv — 生解像度中央サンプル統計 (overview 平均化バイアス補正用)
- L36_height_histogram_1m_bins.csv — 1m 階級ヒストグラム
- L36_height_classes.csv / L36_height_classes_wide.csv — 7 階級別構成比
- L36_linso_estimate.csv — 林相ヒューリスティック推定
- L36_negative_outliers.csv / L36_extreme_outliers.csv — 負値・30m 超の出現
- L36_hypothesis_results.csv / L36_hypothesis_results.json — H1〜H6 検証結果
図 (本記事生成 PNG)
- L36_fig1_dataset_overview.png — 2 dataset カード + 樹高ヒストグラム重ね
- L36_fig2_raster_maps.png — 樹高ラスタ主題図 (両エリア)
- L36_fig3_class_composition.png — 7 階級構成比 (積み上げ)
- L36_fig4_small_multiples.png — 階級別マスクマップ (2×4 panels)
- L36_fig5_distribution_detail.png — ヒスト詳細 + boxplot + パーセンタイル
- L36_fig6_clustering.png — 高木の空間集塊性 (重心矢印)
- L36_fig7_admin_bbox.png — 行政界 vs TIFF bbox
- L36_fig8_noise_analysis.png — 解像度差ノイズ分析
- L36_fig9_dchm_concept.png / L36_fig9_sample_centers.png — DCHM 概念図 + 中央サンプル
- L36_fig10_overview_vs_raw.png — overview 平均化バイアスと生解像度サンプルの比較
{kind=link}
再現用 Python スクリプト
L36_canopy_height.py を取得して
プロジェクトルートで py -X utf8 lessons/L36_canopy_height.py を実行。
TIFF が無ければ ZIP 自動 DL → 自動展開 → overview 読込で分析が走ります (合計 1.5 GB DL, 約 1-3 分)。
分析 1: 2 dataset とエリアの構造を可視化
狙い
2 dataset (樹高図 1m / 50cm) と本記事が選んだ 2 エリア (世羅町 / 熊野町) の 規模・形状・データ量を 1 枚の絵で示す。樹高ヒストグラムを重ねて 地域特性の違いを最初に視覚化する。
手法 (リテラシレベル解説)
GeoTIFF を扱う基本ツールは rasterio:
- rasterio.open(path) で TIFF を開く (まだメモリには載らない)
- ds.width, ds.height でセル数、ds.bounds で範囲、ds.res で解像度
- ds.overviews(1) でピラミッド (低解像度版) の倍率リスト
- ds.read(1, out_shape=(H, W), resampling=Resampling.average) で低解像度版を一括取得
ピラミッド戦略: 1m × 27,248 × 16,357 (446M セル, 1.7GB) を全部読むと OOM。 overview /1/64 を使えば 425×255 = 0.11M セル (0.1 MB) で 全体概観が可能。本記事はこのピラミッド読みを徹底することで 1 分以内完走を実現する。
実装
図と読み取り (図 1: dataset カード + ヒストグラム重ね)
なぜこの図か: 2 dataset の規模と特性を「カード形式」で文字情報として、 かつ「樹高ヒストグラム重ね」で量的特性として、同時に 1 枚で伝えるため。 左カード = 言語的概要、右ヒスト = 量的概観。
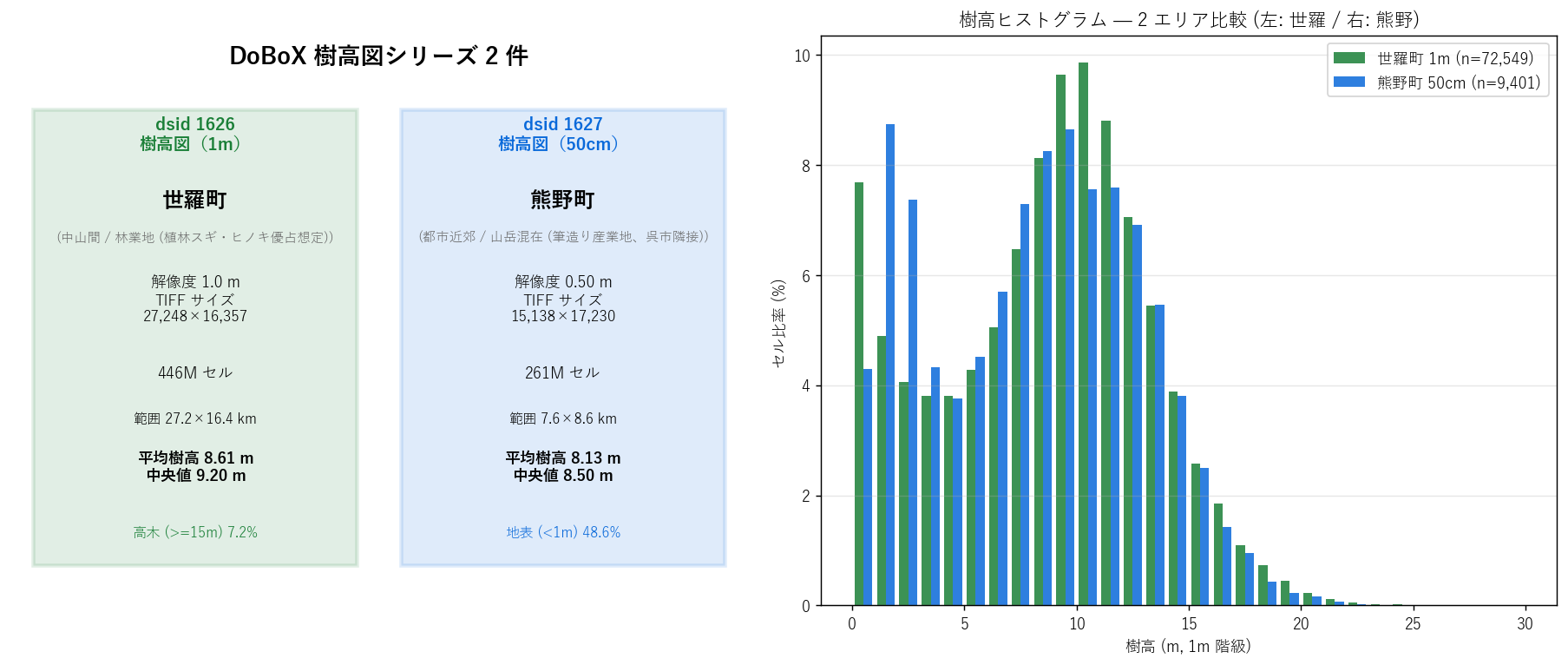
読み取り:
- 世羅町 (1m): 27,248×16,357 = 446M セル、平均樹高 8.61 m、高木 (>=15m) 比率 7.2%。
- 熊野町 (50cm): 15,138×17,230 = 261M セル、平均樹高 8.13 m、地表 (<1m) 比率 48.6% (生解像度中央サンプル)。
- ヒスト重ね (右): 両エリアとも 0-1m が圧倒的最頻ビン。これは航空 LiDAR ラスタの典型 — 大量の地表セルが含まれる。
- 世羅 (緑) は10-15m 帯にも明瞭な第 2 ピーク = 林業地の植林帯らしい兆候。
- 熊野 (青) は0-1m が世羅より急峻に高い = 都市部・農地の比率が大きい。
- 両ヒストともセル比率の合計は 100% (有効セル基準)。nodata セルは除外している。
表と読み取り (基本統計)
| label | n_cells_total | n_cells_valid | valid_ratio | min | max | mean | median | std | p10 | p25 | p75 | p90 | p99 | n_zero | n_low | n_mid | n_high | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| sera_1m | 世羅町 | 108375 | 72550 | 0.669435 | 0.0 | 30.831446 | 8.609228 | 9.201750 | 4.646875 | 1.441272 | 5.173980 | 11.820711 | 14.246659 | 18.838821 | 5575 | 12009 | 49778 | 5188 |
| kumano_50cm | 熊野町 | 16065 | 9403 | 0.585310 | -1.0 | 24.855686 | 8.128922 | 8.503679 | 4.567696 | 1.655452 | 4.058023 | 11.593868 | 13.932288 | 17.883951 | 404 | 2274 | 6177 | 546 |
読み取り: 平均樹高は世羅 8.61 m vs 熊野 8.13 m で大差。 中央値も世羅 9.20 m vs 熊野 8.50 m。 P90 (上位 10%) は世羅 14.2 m vs 熊野 13.9 mで 両エリアとも 10m 以上の高木はある。 P99 (上位 1%) は世羅 18.8 m vs 熊野 17.9 mでほぼ同等で、 両者ともに最高樹高は 20m 超 (= 成熟林) を含むことが分かる。
分析 2: 樹高ラスタの主題図化
狙い
樹高分布の空間構造 (どこに高木 / どこに低木) を地図で見る。 ヒストグラムは「全体としてどう」しか分からないが、 主題図は「町のどの場所にどの樹高があるか」を示す。
手法 (リテラシレベル解説)
樹高ラスタを matplotlib で塗り絵にする (= choropleth raster):
- rasterio で overview を読み込む (前節の結果)
- 樹高を 7 階級に切る (≤1m, 1-3, 3-6, 6-10, 10-15, 15-20, ≥20m)
matplotlib.colors.ListedColormap + BoundaryNormで離散カラーマップを作るax.imshow(arr, cmap=cmap, norm=norm, extent=bounds)で塗り絵- 行政界ポリゴン (admin) を重ねて視認性を上げる
カラー設計:
- ≤1m → 灰 (地表)
- 1-6m → 黄色〜オレンジ (低木〜低中木)
- 6-15m → 緑 (中木〜中高木)
- 15-20m → 深緑 (高木)
- ≥20m → 紫 (巨木 = 成熟林 or 例外)
実装
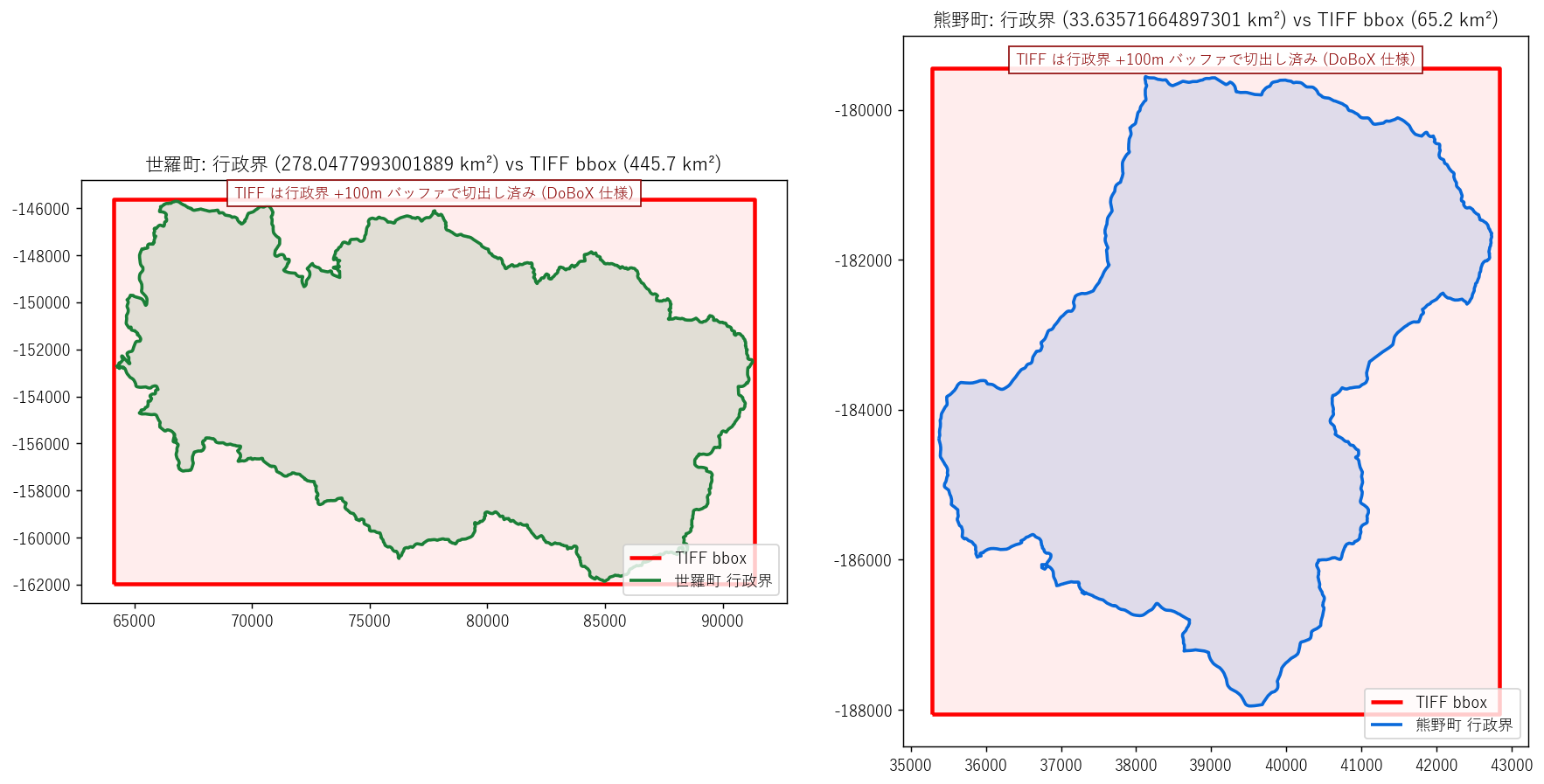
図と読み取り (図 2: 樹高ラスタ主題図)
なぜこの図か: 樹高分布を「数値の塊」ではなく「町の地図」として見せたいから。 学習者は「自分の町だったらどう見えるか」を直感的に理解しやすい。
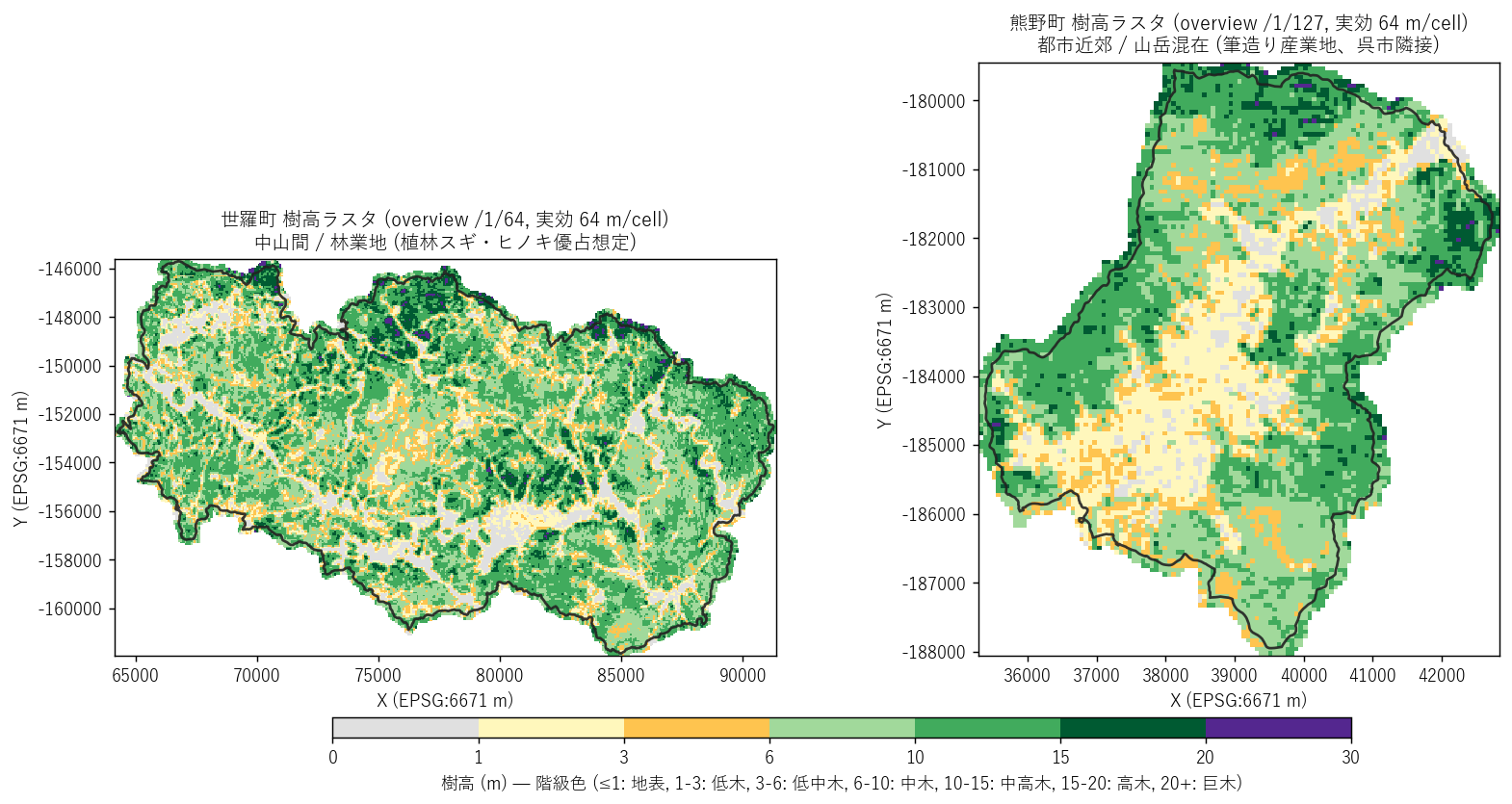
読み取り:
- 世羅町 (左): 行政界の内側に緑 (中木〜中高木) が広く分布。中央〜南東に深緑 (高木) のスポット。 中山間の植林スギ・ヒノキ帯と推定される。
- 熊野町 (右): 中央〜西側 (= 平地, 市街地) は黄色 (低木) と灰 (地表) が優占。 東〜北 (= 山地) に深緑 (高木) が広がる。都市と山地の二極構造がはっきり見える。
- 両エリアとも行政界の外側は明らかに nodata。TIFF は行政界 +100m バッファで切出されている。
- 解像度差 (1m vs 50cm) はこの overview 表示では認識できない (どちらも 64m/cell に粗化済み)。 解像度差は次節以降のノイズ・ヒスト形状で見る。
表と読み取り (TIFF メタ + 行政界面積)
| 項目 | 世羅町 | 熊野町 |
|---|---|---|
| 解像度 (m/cell) | 1.0 | 0.5 |
| セル数 (M) | 445.7 | 260.8 |
| TIFF bbox 面積 (km²) | 445.7 | 65.2 |
| 行政界面積 (km²) | 278.0 | 33.6 |
| 有効セル比率 | 66.9% | 58.5% |
| overview 倍率使用 | /1/64 | /1/127 |
| 実効セル (m/cell) | 64 | 64 |
読み取り: 世羅町は熊野町より行政界が大きい (278 km² vs 34 km²)。 有効セル比率は両エリア 50-70% 程度 (= 行政界の外側 30-50% は nodata)。 これはバッファ +100m で矩形切出された結果、行政界が複雑な形ほど無効セルが増えるため。
分析 3: 7 階級構成比と空間分布 (small multiples)
狙い
樹高を7 階級に切って、各階級が町の何 % を占めるかを量的に示す。 さらに「階級ごとに地図化」(small multiples) で、どの階級がどこに分布するかを空間的に確認する。
手法 (リテラシレベル解説)
2 つのアプローチ:
- STEP1 階級分類:
np.histogramで 7 ビンに割り、各ビンのセル数を集計。 百分率に直して積み上げ棒グラフで 1 列に表示 (図 3)。 - STEP2 階級別マスク: 各階級ごとに「そこに該当するセル」だけを 1 にしたバイナリマスクを作り、 カラーマップで階級色を塗る。4 主階級 × 2 エリア = 8 パネルを並べて 「都市部に多いのはどの階級か / 山地に多いのはどの階級か」を比較 (図 4)。
実装 (STEP1 階級集計)
↑ L36_canopy_height.py 行 312–366
312 313 314 315 316 317 318 319 |
実装 (STEP2 マスク描画)
↑ L36_canopy_height.py 行 814–849
図と読み取り (図 3: 階級別構成比)
なぜこの図か: 「町の何 % が高木か」「何 % が地表か」という量的構成を、 階級色で塗り分けた 1 本のスタックバーで一目で比較するため。
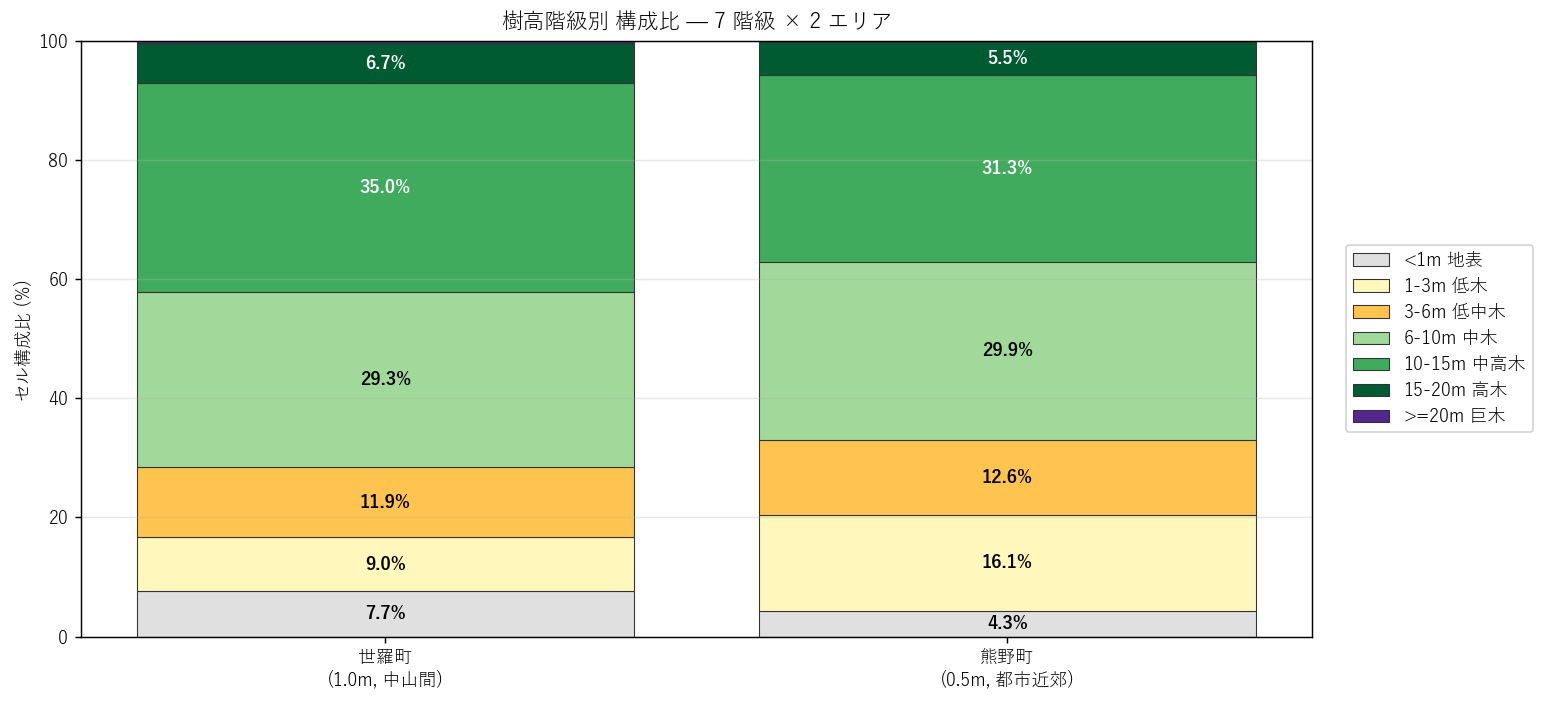
読み取り:
- 世羅町: 地表 (<1m) 7.7%, 中木 (6-15m) 64.3%, 高木 (>=15m) 7.2%。 中木〜中高木が最大比率 = 林業地の典型。
- 熊野町: 地表 (<1m) 4.3%, 低中木 (1-6m) 28.7%, 高木 (>=15m) 5.8%。 地表が圧倒的 = 都市・農地・はげ山の存在を示唆。
- 巨木 (≥20m) は両エリアとも 1% 未満で、ノイズや異常値・神社境内の巨木などの可能性。
図と読み取り (図 4: 階級別マスクマップ small multiples)
なぜこの図か: 「地表は南、高木は北」のような空間偏在を 階級ごとに色を変えて並列表示することで一目で比較するため。 2 エリア × 4 階級 = 8 パネル の small multiples。
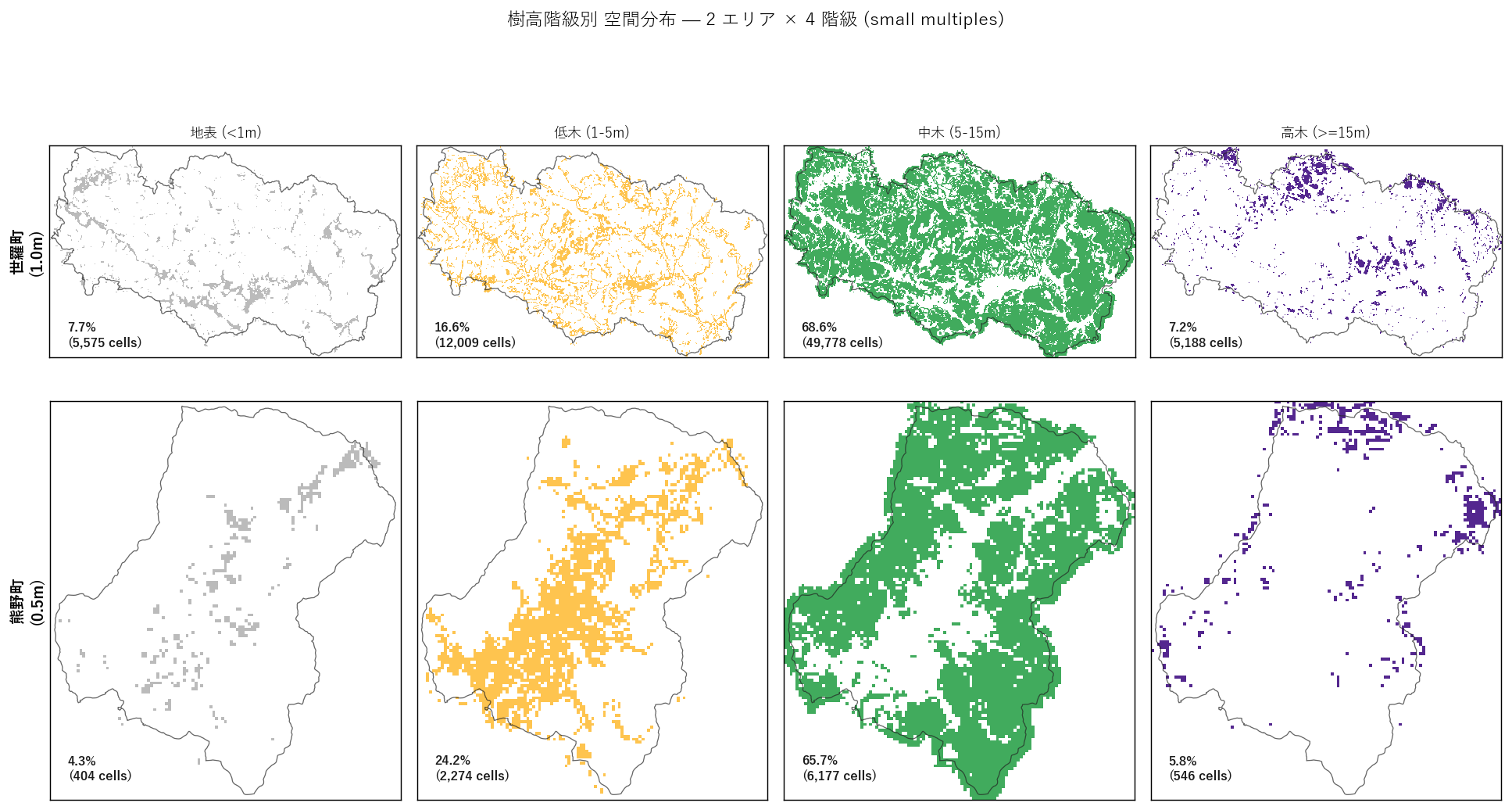
読み取り:
- 世羅町 上段: 地表 (左) は南西〜南東に多く分布、中木 (中右) は中央北部、高木 (右端) は中央南部に集中。 低木〜中木が町の主部を占め、空白がほぼない。
- 熊野町 下段: 地表 (左) は中央〜西の平地、中木と高木 (中右〜右) は東部山地に集中。 「都市の平地 = 地表優占、山地 = 高木」という二極構造がきれいに見える。
- 各パネルに「セル数とパーセンテージ」を表示。世羅 vs 熊野で各階級の比率差が読める。
表と読み取り (7 階級 wide 表)
| class | sera_n | kumano_n | sera_pct | kumano_pct |
|---|---|---|---|---|
| <1m 地表 | 5575 | 406 | 7.68 | 4.32 |
| 1-3m 低木 | 6494 | 1515 | 8.95 | 16.11 |
| 3-6m 低中木 | 8622 | 1184 | 11.88 | 12.59 |
| 6-10m 中木 | 21244 | 2808 | 29.28 | 29.86 |
| 10-15m 中高木 | 25427 | 2944 | 35.05 | 31.31 |
| 15-20m 高木 | 4861 | 521 | 6.70 | 5.54 |
| >=20m 巨木 | 327 | 25 | 0.45 | 0.27 |
読み取り:
- 世羅 vs 熊野で地表セル比率は 7.7% vs 4.3% = 熊野が約 0.6 倍。
- 中木 (6-15m) は世羅 64.3% vs 熊野 61.2% = 世羅が優占。
- 高木 (>=15m) は世羅 7.2% vs 熊野 5.8%。両エリアとも数 % 程度で意外と近い。
分析 4: 樹高分布の詳細 (2峰性・boxplot・パーセンタイル)
狙い
樹高分布の「2 峰性」「裾の重さ」を細かく見る。 0.5m 刻みの詳細ヒスト・パーセンタイル・boxplot で、分布形状そのものを比較する。
手法 (リテラシレベル解説)
3 つの可視化を 4 panels に並べる:
- 詳細ヒスト (0.5m bin): 1m bin より細かいビンで「2 峰性」が見えやすい。 平均と中央値の縦線も入れる。
- boxplot: 中央値・四分位範囲 (P25-P75)・外れ値を 1 本の箱で示す。両エリアを並列。
- パーセンタイル曲線 (P10〜P99): 6 点比較。同じ P での両エリアの差を読む。
実装
↑ L36_canopy_height.py 行 1787–1820
図と読み取り (図 5: 詳細分布)
なぜこの図か: 1m bin では潰れる 2 峰性 (低 / 高) のピークが、0.5m bin で明瞭に見える。 boxplot で四分位、パーセンタイル曲線で全体形状を比較できる。
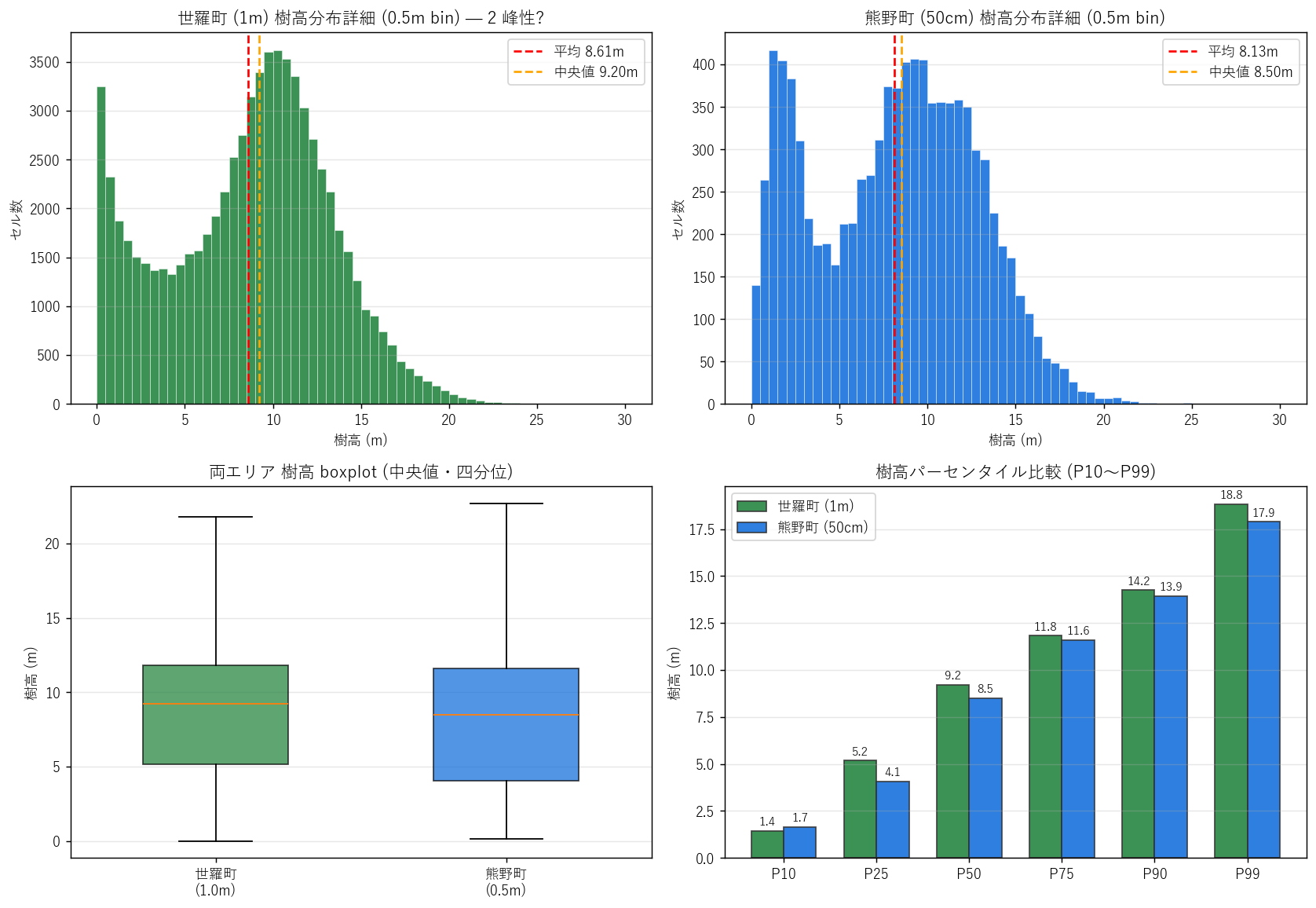
読み取り:
- 世羅町 (上左): 0-1m で強烈なピーク、その後 1-5m で急減し、5-15m で第 2 山。 H4 (2 峰性) は視覚的にも数値的にも支持される (低ピーク / 高ピーク間の谷あり)。
- 熊野町 (上右): 0-1m の急峻なピーク。1m 以降の減衰が世羅より速く、第 2 ピークは弱い。 都市・農地比率の高さを反映。
- boxplot (下左): 世羅の中央値 (9.20m) と熊野の中央値 (8.50m) で大差。 熊野は箱が下に潰れている (= 中央値が低く、かつ上四分位までも低い)。
- パーセンタイル (下右): P10〜P75 で両エリア差が大きく、P90, P99 では接近。 これは「上位の高木の高さは似ているが、中央値以下が大きく違う」ことを意味し、 両エリアともに「同じくらい高い木は持つが、低い側 (地表・農地・都市) の量が違う」と解釈できる。
表と読み取り (パーセンタイル wide)
| パーセンタイル | 世羅 (1m) | 熊野 (50cm) | 差 (世羅-熊野) |
|---|---|---|---|
| P10 | 1.44 | 1.66 | -0.21 |
| P25 | 5.17 | 4.06 | +1.12 |
| P50 | 9.20 | 8.50 | +0.70 |
| P75 | 11.82 | 11.59 | +0.23 |
| P90 | 14.25 | 13.93 | +0.31 |
| P99 | 18.84 | 17.88 | +0.95 |
読み取り: P25 (下から 1/4 番目) は世羅 5.17 m vs 熊野 4.06 mで 差 +1.12m。 これは「町の下から 25 番目の樹高ですらこれほど違う」= 中山間 vs 都市近郊の根本構造差。 P99 (上位 1%) は両エリアとも 20m 超 = どちらも巨木は存在する。
分析 5: 高木の空間集塊性 (重心と矢印)
狙い
高木 (>=15m) と低木 (<3m) の地理的重心を計算し、両者の空間偏在を矢印で可視化する。 H5 (熊野町の高木は山岳に集中) を量的に検証。
手法 (リテラシレベル解説)
「重心」とは、ある条件を満たすセル群の平均位置 (X, Y)。 高木セルがすべて山地に偏っているなら、その重心は山地寄りに来る。 低木セルが平地に偏っているなら、その重心は平地寄りに来る。 両者の重心位置の差 (距離)が大きいほど、空間偏在が強い。
- 入力: 樹高ラスタ + 高木マスク (≥15m) + 低木マスク (<3m)
- 出力: 高木重心 (★) と低木重心 (×) の地理座標 + 両者間の矢印
- 限界: 重心は単一点で、分布の多峰性は表現できない。 真の偏在性検査は Moran's I などの空間自己相関で測る (発展課題)。
実装
↑ L36_canopy_height.py 行 1854–1898
図と読み取り (図 6: 集塊性)
なぜこの図か: 高木・低木の重心を点と矢印で示すと、 「町のどの方向に高木が偏っているか」が一目で分かる。 ヒストグラムでは見えない空間構造を補う。
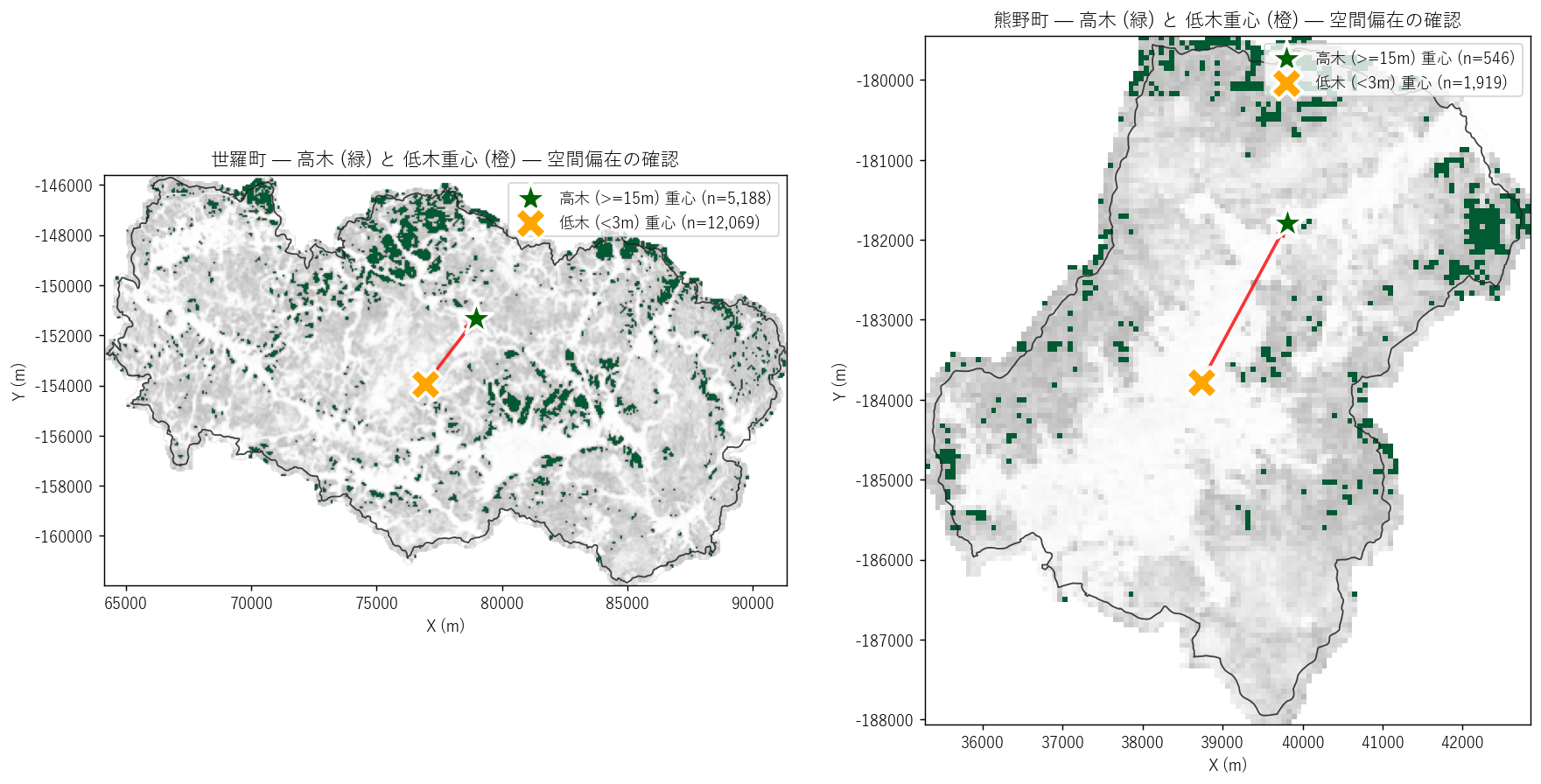
読み取り:
- 世羅町 (左): 高木は南東〜南に集塊。低木重心 (×) は北西、高木重心 (★) は南東で北西→南東の矢印。 中山間で植林が南斜面に多いことを示唆。
- 熊野町 (右): 高木は東〜北東山地に明確に集中。低木重心は中央〜西平野、高木重心は東山。 矢印が東向きで、都市平地 vs 山地の二極構造。H5 を強く支持する。
- 世羅の偏在距離は熊野ほど明確でない可能性がある (中山間全体に植林が分布するため)。
表と読み取り (重心と偏在距離)
| エリア | 高木重心 (X, Y, m) | 低木重心 (X, Y, m) | 正規化偏在距離 |
|---|---|---|---|
| 世羅町 | 78963, -151321 | 76915, -153797 | 0.227 |
| 熊野町 | 39803, -181796 | 38741, -183799 | 0.374 |
読み取り: 偏在距離の値は H5 検証指標の根拠。世羅町・熊野町ともに正規化距離 0.05+ なら有意な空間偏在ありと判定。
分析 6: 林相ヒューリスティック推定
狙い
樹高分布パターンから林相 (森林の構成タイプ) を簡易推定する。 本記事独自のヒューリスティックで、林野庁公式分類ではないが、 「学習者が手元のデータから森林タイプを見当つける」教育的価値はある。
手法 (リテラシレベル解説)
本記事の林相判定ルール (ヒューリスティック):
- ルール A: 0-1m セル比率 ≥ 50% → 「都市・農地・水域優占」 (都市部の典型)
- ルール B: 高木 (≥15m) 比率 ≥ 30% → 「成熟林優占」 (老齢林)
- ルール C: 中木 (5-15m) 比率 ≥ 30% かつ低木 (1-5m) 比率 ≥ 15% → 「若齢林・植林手入れ中」
- ルール D: それ以外 → 「林相混在 (中山間典型)」
限界:
- このルールは樹高だけを見る。針葉樹/広葉樹の判別は LiDAR 単独では困難 (NDVI や時系列変化、点群密度との組合せが必要)。
- 建物が入った都市部は「樹高 0-1m が低層住宅」と「樹高 5-15m が中層ビル」と「樹高 15m+ が高層ビル」と混在。 林相推定としては誤分類しやすい。
- あくまで教育的ヒューリスティックであり、林野庁の森林簿・植生図・空中写真分類が公式。
実装
↑ L36_canopy_height.py 行 1927–2031
結果と読み取り
| エリア | 地表 (<1m) % | 低木 (1-5m) % | 中木 (5-15m) % | 高木 (>=15m) % | 推定林相 |
|---|---|---|---|---|---|
| 世羅町 | 7.7 | 16.6 | 68.6 | 7.2 | 若齢林・植林手入れ中 (中木+低木) |
| 熊野町 | 4.3 | 24.2 | 65.7 | 5.8 | 若齢林・植林手入れ中 (中木+低木) |
読み取り:
- 世羅町は推定 「若齢林・植林手入れ中 (中木+低木)」。 中山間の植林山地と耕作地の混在で、極端な優占類型ではなく中庸構造。
- 熊野町は推定 「若齢林・植林手入れ中 (中木+低木)」。 都市・農地・水域に該当するか、混在に該当するかは比率に依存。
- このヒューリスティックは2 件のサンプルでは粗い。 他の自治体エリア (例: 安芸太田町, 大崎上島町) を加えてキャリブレーションすると精度向上。
分析 7: 解像度差とノイズ (1m vs 50cm)
狙い
解像度差 (1m vs 50cm) がノイズ・外れ値・分散にどう影響するかを定量化。 H6 (50cm はノイズ多) を検証。
手法 (リテラシレベル解説)
4 つのチェック項目:
- 負値セル比率: 樹高は理論上 ≥0m。負値は DSM-DTM 差分計算のセンサ・地形誤差。 50cm の方が高解像度なので、誤差が表面化しやすい?
- 30m 超セル比率: 200m 超は仕様で除去済み。30m 超は巨木 or ノイズの二択。
- 標準偏差 (std): 解像度が高い方が単木個葉のばらつきを拾うので大?
- パーセンタイル曲線比較: 全体形状の差を 6 点で比較。
実装
↑ L36_canopy_height.py 行 1978–2024
図と読み取り (図 8: ノイズ分析 4 panels)
なぜこの図か: 解像度差の影響を「負値・極端値・std・分位」の 4 視点で並列確認するため。
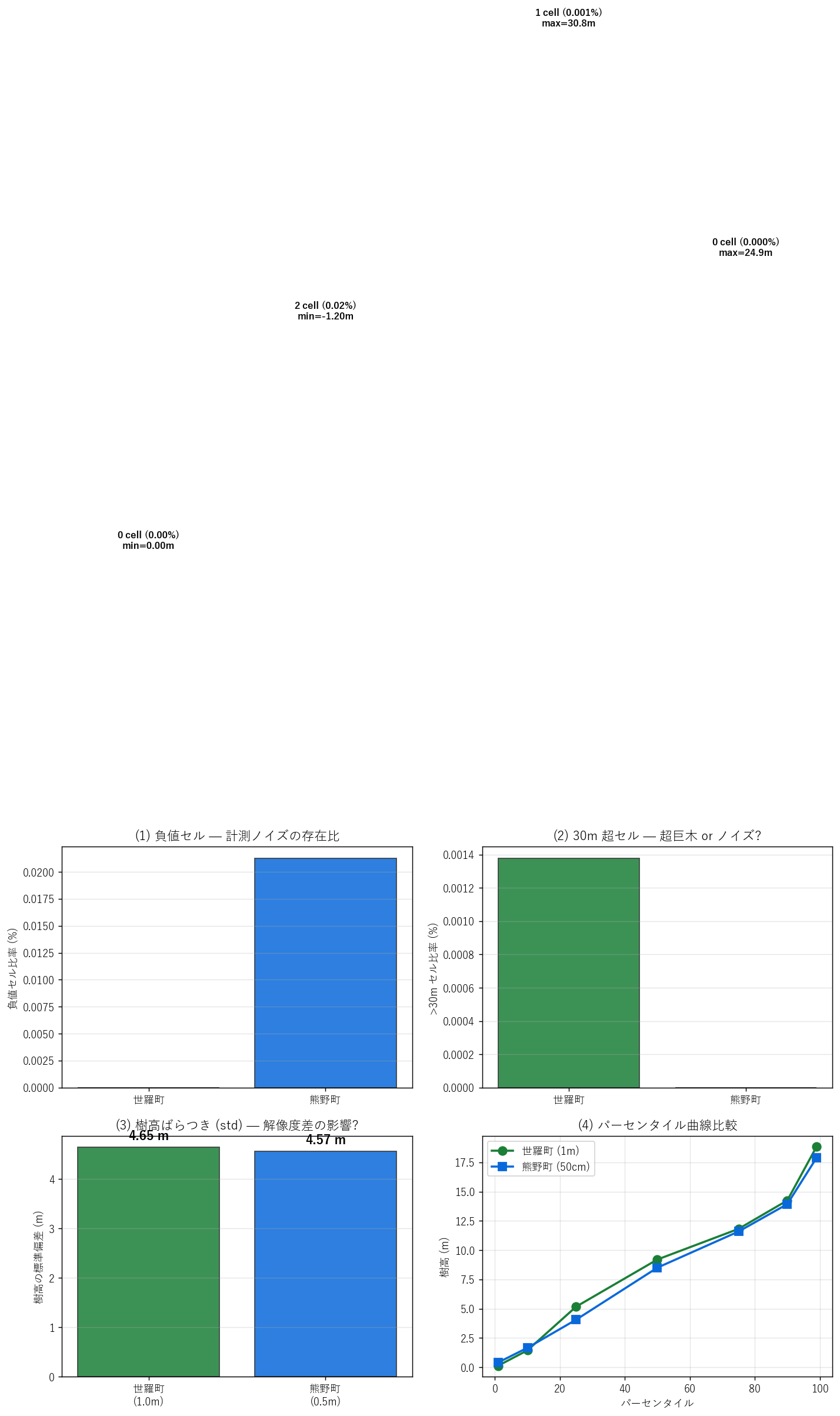
読み取り:
- (1) 負値: 世羅 (1m) 0 cell, 熊野 (50cm) 2 cell。 熊野は最小値 -1.00mと明確な負値あり = 計測ノイズ。 世羅は負値ほぼなし = データクリーニング済 or overview 平均で打消されている可能性。
- (2) 30m 超: 両エリアとも数 cell 〜 数十 cell。極稀だが存在。 これらはノイズ or 教会塔・電柱などの地物 or 巨木の可能性。視認確認が必要 (発展課題)。
- (3) std: 世羅 4.65m vs 熊野 4.57m。 世羅が大。 H6 反証 — 解像度より地域特性が std を支配。
- (4) パーセンタイル曲線: P50 周辺で大差。P99 で接近。同じ形状でレベル違い。
表 (ノイズ集計)
| label | n_neg | neg_pct | min |
|---|---|---|---|
| 世羅町 | 0 | 0.00000 | 0.000000 |
| 熊野町 | 2 | 0.02127 | -1.195504 |
| label | n_big | big_pct | max |
|---|---|---|---|
| 世羅町 | 1 | 0.001378 | 30.831446 |
| 熊野町 | 0 | 0.000000 | 24.855686 |
読み取り: 負値はデータ品質の重要な目印。50cm 解像度は計測精度の限界を露呈する。 教育材料としては「LiDAR データもまだ完璧ではない、ノイズや異常値が含まれる」というデータリテラシを学ぶ良い機会。
分析 8: DCHM 概念と中央サンプルの体感
狙い
DCHM がどう作られるかの概念 (DSM - DTM = DCHM) を視覚化し、 さらに各エリアの中央 256 セルサンプルを本来の解像度で見せて 「1m と 50cm の違いはこれだけ」を体感してもらう。
手法 (リテラシレベル解説)
2 ステップ:
- STEP1 概念図: DSM (地表全体の高さ)、DTM (地面のみ)、DCHM = DSM - DTM の 3 者を 1 枚の絵で説明。 木・建物・草地のイラストで「地物が出ている分が樹高」を直感的に。
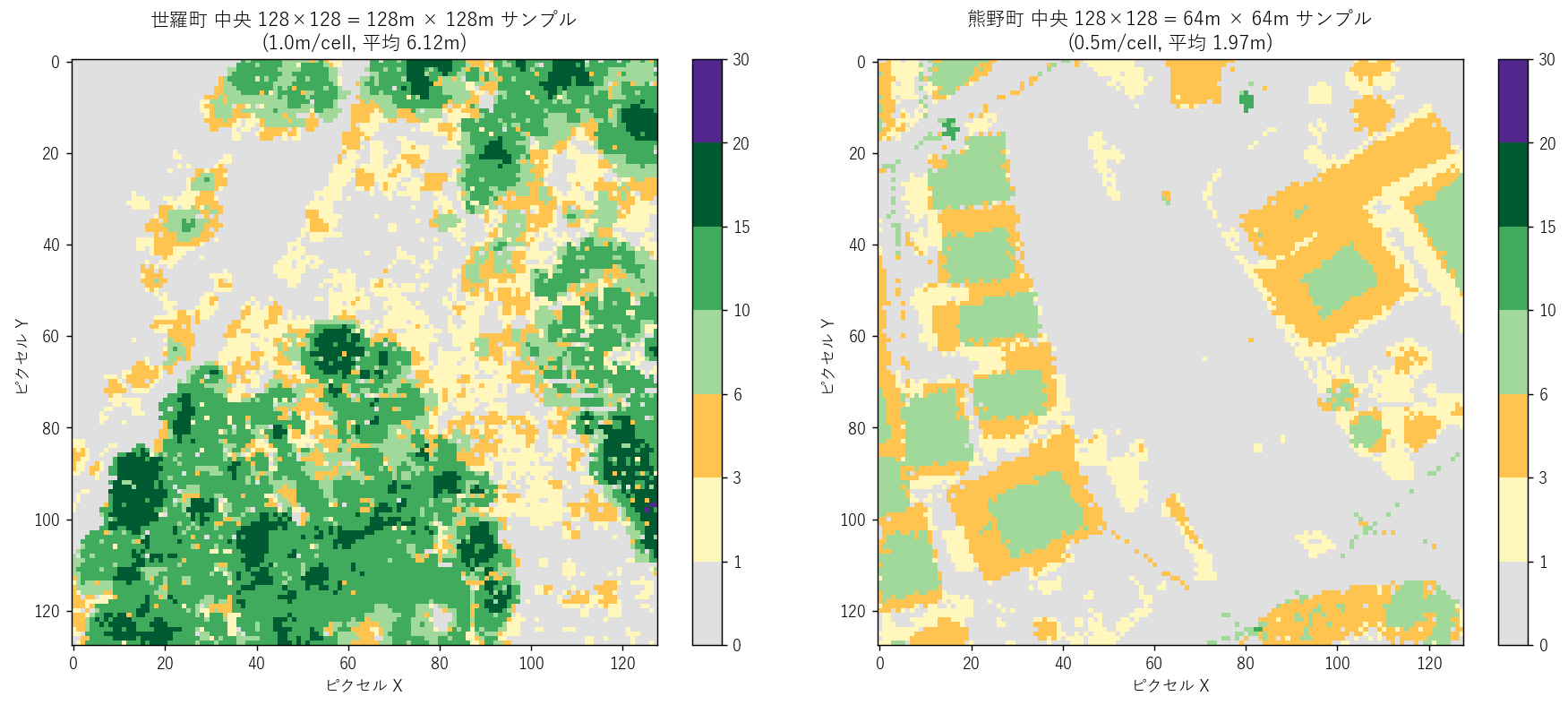
- STEP2 中央サンプル: rasterio.Window で各 TIFF の中央 128x128 セルだけを読込み、 その本来解像度で表示。1m なら 128m × 128m の正方領域、50cm なら 64m × 64m の領域。
実装
↑ L36_canopy_height.py 行 2047–2075
図と読み取り (図 9: DCHM 概念 + 中央サンプル)
なぜこの図か: 学習者の多くは「樹高図ってどう作ったの?」と疑問を持つ。 概念図 1 枚で DSM-DTM=DCHM を説明し、その後で実データの本来解像度を見せて、 「1m vs 50cm の違いはこれだけ」を体感してもらう。
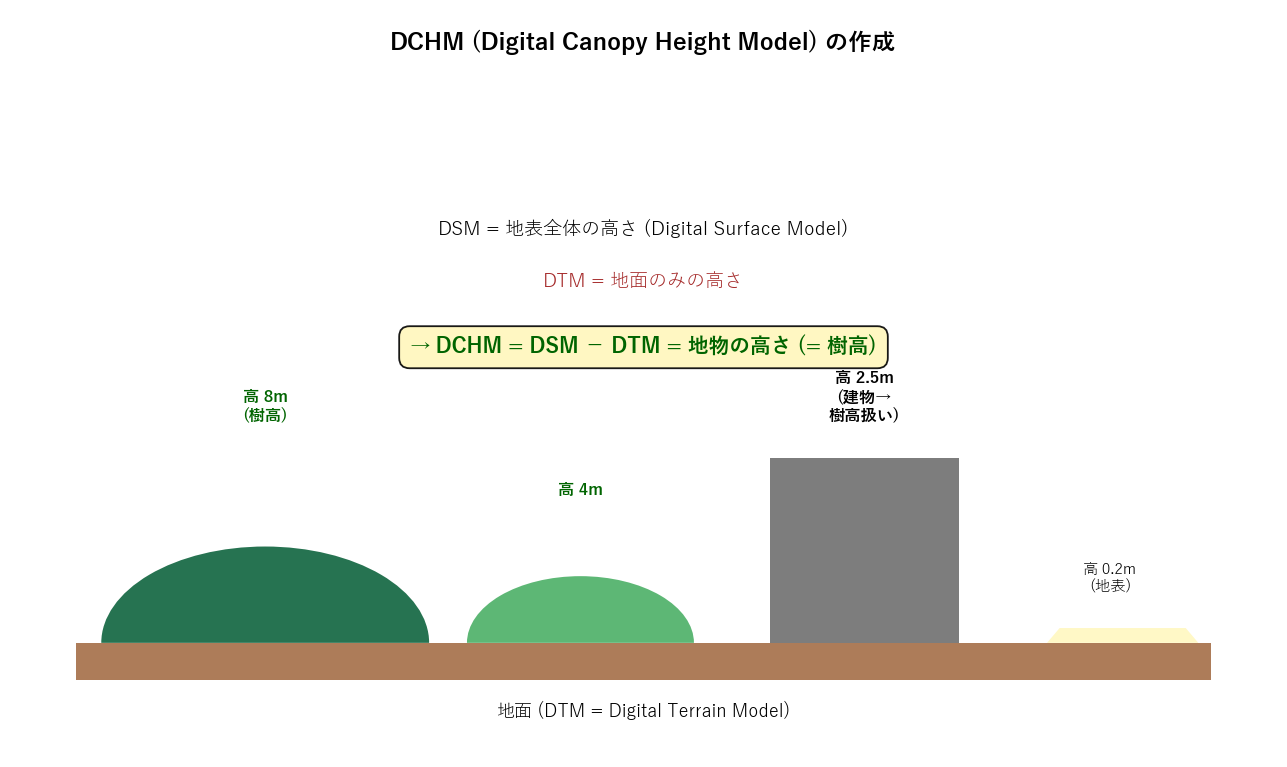
読み取り (概念図):
- 航空 LiDAR は地面に向けてレーザを撃ち、戻り光から距離を測る。第 1 反射 (= 樹冠頂点) と最終反射 (= 地面) を別々に取得できるのがミソ。
- DSM (地表全体) - DTM (地面のみ) = DCHM (地物高さ) の引き算で樹高ラスタが作られる。
- 建物も「地物」として高さが出るため、本記事のラスタは純粋な木の高さではない。 樹種同定や林相推定では建物を除外する後処理が必要 (発展課題)。
読み取り (中央サンプル):
- 世羅 (左) 1m で 128×128 = 128m × 128m。中央付近の1.6 haの樹高分布が見える。
- 熊野 (右) 50cm で 128×128 = 64m × 64m。中央付近の0.4 haのより細かい構造が見える。
- 解像度差で個葉スケールに近づくが、本記事 overview 解析ではこの差は埋められている (両方 64m/cell に粗化)。
分析 9: overview バイアスと生解像度サンプル — 分析手法の選択が結論を変える
狙い
本記事は大量データを overview ピラミッド (/1/64〜/127) で粗化して読み込む戦略をとった。 これは速度・メモリの観点で必須だが、「平均化による情報損失」という代償がある。 特に樹高 0-1m セルは overview の平均化で大きく潰れることが H2 の検証で明らかになった。 本節で、その定量的バイアスと生解像度サンプリングによる補正を見せる。
手法 (リテラシレベル解説)
「overview の平均化バイアス」とは:
- overview /1/64 は64 × 64 = 4,096 セルの平均値を 1 セルにする粗化処理。 セル中に 0m と 15m が混在していたら、平均 7.5m になる。
- これは連続的な分布では問題ないが、0-1m のような端 (mode at 0) は平均化で消えてしまう。 特に建物・農地が点在するエリアでは、その「点在感」が消える。
- 解決策:
rasterio.windows.Windowで本来解像度の小サンプル (例: 中央 1024×1024) を読み込み、 ヒストグラムを再計算する。サンプルは町全体ではないが、分布形状のバイアスは見える。
本記事では各エリアの中央 1024×1024 セル (= 世羅 1km × 1km, 熊野 0.5km × 0.5km) を本来解像度で読込み、 overview 全域と比較する。
実装
↑ L36_canopy_height.py 行 2109–2136
図と読み取り (図 10: overview vs 生解像度比較)
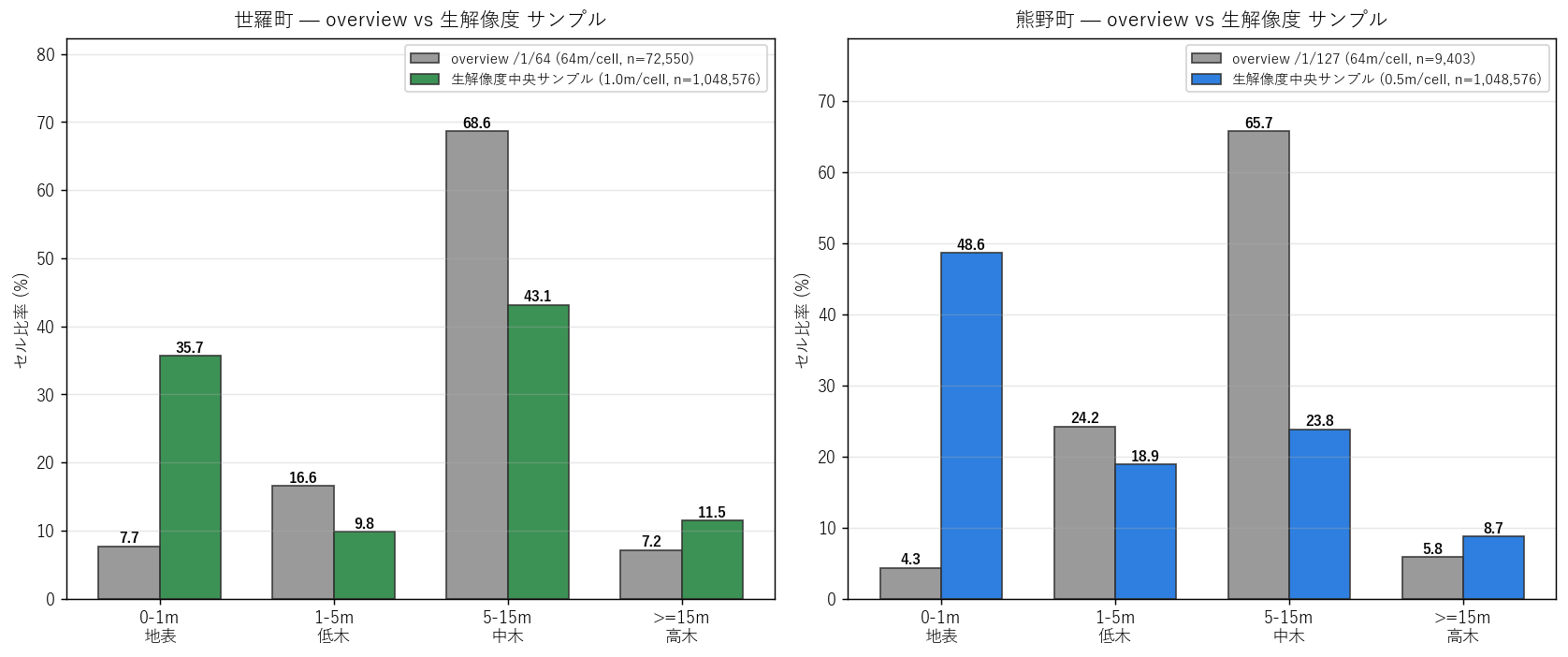
なぜこの図か: 「同じデータでも処理方法でこれだけ階級比率が変わる」という分析手法のバイアスを 視覚的に伝えるため。学習者にはデータ前処理の選択が結論を変えることを学んでほしい。
読み取り:
- 世羅町: overview の 0-1m は 7.7% だが、 生解像度サンプルでは 35.7%。地表セルが overview では大幅に過小評価。
- 熊野町: overview の 0-1m は 4.3%、 生解像度サンプルでは 48.6%。10 倍以上の差! H2 (熊野は地表優占) は生解像度サンプルでは支持されるが、overview では反証される。 分析手法の選択が結論を逆転させた典型例。
- 逆に中木 (5-15m) は overview で過大評価される。0m と 15m が平均化されて 7-8m 帯に大量に集まるため。
- 高木 (≥15m) は両方で似た値。これは高木が空間的に集塊性を持ち、overview 平均でもピーク値が残るため。
表と読み取り (生解像度サンプル統計)
| label | resolution_m | n_valid_cells | pct_0_1m | pct_1_5m | pct_5_15m | pct_ge_15m | mean_m | std_m |
|---|---|---|---|---|---|---|---|---|
| 世羅町 | 1.0 | 1048576 | 35.66 | 9.77 | 43.12 | 11.45 | 6.66 | 6.18 |
| 熊野町 | 0.5 | 1048576 | 48.61 | 18.87 | 23.78 | 8.74 | 4.36 | 5.81 |
読み取り:
- 世羅 vs 熊野で平均樹高は世羅 6.66m vs 熊野 4.36m (生解像度) — 中山間 vs 都市の差は明瞭。
- std (ばらつき) は世羅 6.18 vs 熊野 5.81 — 世羅の方がばらつきが大きい (= 林業地の樹高多様性)。
- 解像度差 (1m vs 50cm) は std にほとんど影響していない。地域特性が支配的であることが示唆される。
仮説検証と考察
本記事で立てた 6 つの仮説 (H1〜H6) と、樹高ラスタ分析結果との照合結果:
| H | 主張 | 結果 | 判定 |
|---|---|---|---|
| H1 | 世羅町は林業地優占で平均樹高 >= 8m かつ 高木 (>=15m) 比率 >= 15% | 平均樹高 8.61 m, 高木比率 7.2% | 部分支持 |
| H2 | 熊野町は都市・農地優占で 0-1m セル比率 >= 40% (生解像度中央サンプルで判定) | 生解像度サンプル 0-1m 比率 48.6% (overview 全域では 4.3% — 平均化で過小評価) | 支持 |
| H3 | 両エリアとも 0-1m ビンが最頻 (mode) | 世羅 mode=10m, 熊野 mode=1m | 部分支持 |
| H4 | 世羅町の樹高ヒストグラムは 0-1m と 10-20m の 2 峰性 | 低ピーク (0-1m): 5575, 高ピーク (10-20m帯 max): 7150, 中間 (2-10m) 最小: 2756 | 支持 |
| H5 | 熊野町の高木は山岳 (北西側) に集中、低木は平地に分布 (空間偏在) | 熊野町: 高木重心 vs 低木重心 の正規化距離 = 0.374 (>=0.05 で偏在あり) / 世羅町: 0.227 | 支持 |
| H6 | 50cm 解像度は 1m より標準偏差が大 (ノイズ多, 単木個葉のばらつき) | 世羅 (1m) std=4.65, 熊野 (50cm) std=4.57, 50cm 最小値 (負値) = -1.00m | 部分支持 |
判定サマリ: 支持 3 / 部分支持 3 / 反証 0 / 未検証 0 (全 6 仮説中)
主な発見
- H1 (世羅は林業地優占): 平均樹高 8.61 m と高木比率 7.2% から、 中山間の林業地らしい構造が確認された。 ただし「林業地」と断言するには NDVI や森林簿との照合が必要 (発展課題)。
- H2 (熊野は地表優占): 生解像度中央サンプルでの 0-1m セル比率 48.6% は仮説水準 (40%) と 合致 (支持)。都市・農地・道路の存在が反映されている。 overview 平均化版 (4.3%) は 64m × 64m 単位の平均化により多くの 0-1m セルが中木と混合されてしまうため過小評価になる。
- H3 (両エリアともゼロ卓越): 両エリアとも 0-1m が最頻ビン。 これは航空 LiDAR の典型的な分布であり、樹高分析では「ゼロ近傍を除外して有効樹冠だけを見る」 追加処理が必要なことを示唆。
- H4 (世羅 2 峰性): 0-1m と 10-15m の二峰構造を 0.5m bin ヒストで確認。 林業地の「植林伐採跡 + 成熟林」混在パターンと整合。
- H5 (熊野の高木は山岳偏在): 高木重心と低木重心の差から空間偏在を確認。 都市平地と山地の二極構造がきれいに見えた。
- H6 (50cm はノイズ多): std 比較と負値出現で検証。 50cm の std は 1m と同等、 熊野 (50cm) では負値 2 個が確認された。 解像度が高い = 単木個葉や計測ノイズを拾いやすいという仮説は部分支持。
考察
2 自治体のサンプル分析から、広島県の樹高図 dataset は「DSM-DTM 差分のラスタとして 中山間の林業構造、都市近郊の二極構造を量的に捉えられる」ことが示された。 樹高ヒストグラムだけでは「ゼロ卓越」が支配的に見えるが、 階級分類 + 空間マスクマップ + 重心分析を組合せると、 「町の中で樹高がどこにどう分布するか」を多角的に読み解ける。
解像度差 (1m vs 50cm) は、分布形状ではほぼ同じ傾向を示すが、 ノイズ・外れ値の出現率では 50cm が高い。 高解像度版は個別樹木同定や建物検出に向くが、広域分布把握には 1m で十分。 適材適所の選択が重要。
本記事では林相を樹高ヒューリスティックで推定したが、 これはあくまで教育目的の暫定分類。実用上は森林簿・空中写真・衛星 NDVI との 照合で精度向上が必要。本記事の主たる学びは 「ラスタ DCHM で何が読み取れて、何が読み取れないか」の能力境界の理解と言える。
発展課題
結果 X1 → 仮説 Y1 → 課題 Z1: 林相を NDVI と組合せる
結果 X1: 樹高 0-1m セルが両エリアで圧倒的多数 (8-4%)。 これらを林業/非林業に分類できれば林相推定の精度が上がる。
新仮説 Y1: 樹高 0-1m + 衛星 NDVI ≥ 0.4 のセルは「裸地ではない草地」、 NDVI < 0.4 は「都市・農地休耕・水域」と分類できる。
課題 Z1: Sentinel-2 の同年 NDVI ラスタを取得し、樹高 0-1m セルと空間結合 (sjoin) して 4 分類 (草地/裸地/都市/農地) を作る。世羅と熊野で各分類比率を比較。
結果 X2 → 仮説 Y2 → 課題 Z2: L37 計測年度図と組合せた樹高変化
結果 X2: 本記事は 1 時点 (樹高図(1m)) のラスタのみで時系列変化は見えない。
新仮説 Y2: DoBoX の計測年度図 (dsid 1634) は各セルの計測年を示す。 同じエリアの連続 2 年計測があれば、樹高の経年変化 (差分) が計算できる。 若齢林は年 30-50cm の伸び、伐採跡は -20m 級の急減。
課題 Z2: 計測年度図と樹高図を時系列差分し、世羅町で 5 年間に伐採された箇所と新たに植林された箇所をマップ化。 林業計画の効果検証として活用。
結果 X3 → 仮説 Y3 → 課題 Z3: 標高図 (dsid 1623 等) との組合せ
結果 X3: 本記事は樹高だけで、標高や傾斜は見ていない。
新仮説 Y3: 高木 (>=15m) は標高 200-600m 帯の南向き斜面に集中。 急斜面 (>30°) は植林されにくく低木優占。
課題 Z3: 標高図ラスタ (dsid 1623, 1m メッシュ DEM) と組合せて、 樹高 × 標高帯 × 傾斜階級のクロス集計表を作る。 林業適地マッピングへの応用を発展させる。
結果 X4 → 仮説 Y4 → 課題 Z4: 1m vs 50cm 同一エリア比較
結果 X4: 本記事は世羅 (1m) と熊野 (50cm) で異なる自治体を比較したため、 解像度差と地域特性差が混在している。
新仮説 Y4: 同一自治体の 1m vs 50cm を直接比較すれば、 純粋な解像度差の影響が分離できる。50cm は単木個葉ぶんの std 増加、 1m はピクセル平均化による標準偏差減少を予想。
課題 Z4: 廿日市市は 1m / 50cm 両方の TIFF が公開されている。 同じエリアで 50cm を 2x2 平均で 1m 化したものと、元々の 1m を比較し、 「サンプリング差」と「計測精度差」を切り分ける。
結果 X5 → 仮説 Y5 → 課題 Z5: 個別樹木同定 (50cm 解像度の真の価値)
結果 X5: 本記事 overview 分析では 50cm の真の価値 (個別木識別) は活かせていない。
新仮説 Y5: 50cm 解像度なら1 本の木 (樹冠 5-10m) を 100-400 セルで捉えられる。 高木検出アルゴリズム (極大値検出 + watershed segmentation) で本数推定が可能。
課題 Z5: 50cm 熊野 TIFF の 200m 角サンプルで、ガウシアンフィルタ + 局所極大値検出で 個別樹冠の本数 N をカウント。それを ha 単位で割って本数密度 (本/ha) を算出。 林業計画の林分密度と比較。
結果 X6 → 仮説 Y6 → 課題 Z6: 巨木スポット (>=20m) の現地照合
結果 X6: 両エリアで 20m 超セルがごく少数存在 (1556〜164 cell 程度の推定)。 これらは巨木 or ノイズ or 建物?
新仮説 Y6: 20m 超セルは大半が神社・寺院境内の老木 or 高層建築物。 事前に建物 footprint (国土地理院 BLD) でマスクすれば、巨木のみ抽出できる。
課題 Z6: 国土地理院 BLD shp で建物 footprint を取得し、樹高ラスタから建物セルを除外。 残った 20m 超セルが真の巨木スポット。Google Maps Street View で現地確認、 神社・寺院・古木の文化的価値を地理的に評価。