L39 地形傾斜図 2件統合分析 — DEM由来の傾斜角分布が描く地形リスク構造 と 土砂災害警戒区域の物理的論理
データ取得手順
✅ このスクリプトは初回実行時にデータを自動取得します(DoBoX からの直接ダウンロード)。
| ID | データセット名 |
|---|---|
| #222 | dataset #222 |
| #444 | dataset #444 |
| #666 | dataset #666 |
| #888 | 都市計画区域情報_区域データ_安芸高田市_行政区域 |
| #1630 | 地形傾斜図(1m) |
| #1631 | 地形傾斜図(50cm) |
実行コマンド:
cd "2026 DoBoX 教材"
python -X utf8 lessons/L39_terrain_slope.py
DoBoX のオープンデータは申請不要・商用/非商用とも利用可。
data/extras/ は .gitignore 対象(約 57 GB のキャッシュ)。
スクリプト実行で自動再生成されます。
学習目標と問い
本記事の独自性 — 砂防工学標準閾値 × 警戒区域 × L38 整合性
地形傾斜図はオープンデータとして広く公開されていますが、本記事は以下の 3 軸で独自分析を行います:
- 砂防工学標準 5 階級分類: 平地<5° / 緩 5-15° / 中 15-30° / 急 30-45° / 急峻>45° の 標準閾値で分類し、3 エリアの「地形リスク構造」を比較。30°は急傾斜地崩壊危険箇所の 法的指定基準でもある。
- 警戒区域との空間結合: 土砂災害警戒区域 (yellow) と特別警戒区域 (red) のポリゴンを 傾斜ラスタの座標系に rasterize し、区域内 vs 区域外で平均傾斜・階級構成を比較。 「警戒区域は急傾斜に指定されているか」を量的に検証する。
- L38 CS立体図との Pearson 相関: 本記事の傾斜 (L39) と L38 の RGB 派生 Saturation を 同自治体・同 overview shape で読み込み、ピクセル単位の Pearson 相関を計算。 両者は同じ DEM から派生した別表現なので、強い正相関が出ることを期待 (H7)。
シリーズ構造判定: (a) 同一手法・解像度違い + (b) 自治体ごとの分割
このシリーズは 1m 版 / 50cm 版 の 2 解像度系統で、各自治体ごとに GeoTIFF (Float32 度数) を切出して公開する構造。 1m 版は 22 自治体、50cm 版は 12 自治体に対応。
- 1m 版 (dsid 1630): 22 自治体 GeoTIFF。 本記事は世羅町 (resource_id 177725)と熊野町 (176866)を採用 (= L36/L37/L38 と同自治体ペアで LiDAR ファミリの相補比較が可能)。
- 50cm 版 (dsid 1631): 12 自治体 GeoTIFF。 熊野町は 50cm 版に存在しないため、代わりに坂町 (176905)を採用。 坂町は平成 30 年 7 月豪雨の被災地で、土石流災害が多発した地域。 L38 でも同じく坂町 50cm 版を採用しており、本記事と L38 は完全な自治体ペアを構成する。
- 3 エリアは 1m × 2 + 50cm × 1 の構成で、解像度差と地形類型差を同時に観察可能。
独自用語の定義 (本記事内で固定)
| 用語 | 定義 |
|---|---|
| 傾斜角 (slope angle) | DEM (標高ラスタ) の各ピクセルでの局所勾配の大きさを
arctan で度数 (0-90) に変換した値。式: slope = arctan( sqrt((dz/dx)² + (dz/dy)²) )。
水平面 = 0°、垂直崖 = 90°。本記事の TIFF はこの計算を 1m もしくは 50cm メッシュで実行した結果。 |
| Horn 法 | 傾斜計算の標準アルゴリズム (Horn 1981)。3×3 セル窓で 重み付き中央差分を取り、x 方向 dz/dx と y 方向 dz/dy を求める方法。GIS の標準実装。 本 TIFF の生成元は明示されていないが、結果値域 (0-90 度) と分布形状から Horn 法または 類似の 3×3 窓法と推定。 |
| 傾斜 5 階級 (本記事独自定義, 砂防工学標準) | 平地 (<5°), 緩傾斜 (5-15°), 中傾斜 (15-30°), 急傾斜 (30-45°), 急峻 (>45°) の 5 段階。30° は 急傾斜地崩壊危険箇所の法的指定基準 (傾斜 30° 以上 + 高さ 5m 以上 + 人家 5戸以上)、 45° は経験的な人家立地の事実上の上限値で、両者を合わせて 5 階級とした。 |
| 急傾斜 (steep slope) | 本記事では傾斜 30° 以上のセルを指す。 急傾斜地崩壊危険箇所の法的指定基準と一致。30° = tan(30°) ≈ 0.577 = 高さ 1m / 水平 1.73m の傾き。 人が歩行で登るのが困難になる目安でもある。 |
| 急峻 (very steep) | 傾斜 45° 超のセル。 45° = tan(45°) = 1 = 「高さ : 水平 = 1 : 1」 の傾きで、土砂安息角を大きく超える。 通常は崖・崩壊跡・岩盤露出地が該当し、人家不可。 |
| 平地 (flat) | 傾斜 5° 未満のセル。農地・市街地・河川敷が主体。 5° = tan(5°) ≈ 0.087 = 高さ 1m / 水平 11m の緩い傾き。 |
| 8 近傍同種率 (neighbor same rate) | 本記事独自の集塊性指標。 ある属性 (例: 急傾斜) を持つセルについて、8 近傍にも同じ属性が存在する確率。 Moran's I の近似的代替として使用 (計算量が桁違いに軽い)。 高い (≥ 0.85) = 強集塊, 低い (≤ 0.5) = 散在。 |
| 土砂災害警戒区域 (yellow zone) | 土砂災害防止法に基づき指定。 本記事では DoBoX dsid 48「土砂災害警戒区域・特別警戒区域情報」の 3 種別 (土石流・急傾斜地・地すべり) を統合して使用。 |
| 特別警戒区域 (red zone) | 同法のレッドゾーン。建物倒壊リスクあり。 土石流・急傾斜地のみで指定 (地すべりはレッドなし)。 |
| L38 CS立体図 Saturation | L38 で扱う RGB 段彩図の HSV 変換後の彩度成分。 S = (max − min) / max。「微地形コントラストの強さ」の代理指標。 本記事では L38 と同じ overview shape で読み込み、傾斜との Pearson 相関を取る。 |
研究の問い (RQ)
広島県の地形傾斜図 2 解像度 (1m / 50cm) は、それぞれ 世羅町 (中山間/林業地), 熊野町 (都市近郊/山岳混在), 坂町 (平成30豪雨被災地) という異なる地形リスク特性のエリアを公開している。 3 エリアの傾斜分布を 5 階級で量化し、地形リスク構造を比較する。 さらに土砂災害警戒区域との空間結合で「警戒区域 = 急傾斜地」という法的論理が データに刻まれているかを量的に検証する。最後にL38 CS立体図との物理的整合性を ピクセル相関で確認する。
- 2 dataset の解像度・面積・有効データ率・ピクセル数の構造比較は?
- 3 エリアの傾斜角ヒストグラム (2.5° bin) はどう違うか?
- 砂防工学標準 5 階級の構成比は?
- 30°超急傾斜セルは空間集塊するか? 8 近傍同種率は?
- 土砂災害警戒区域の内 vs 外で平均傾斜・階級構成はどう違うか?
- 解像度差 (1m vs 50cm) で急傾斜検出率はどう変わるか?
- L38 CS立体図 Saturation と本記事の傾斜は正相関するか?
仮説 H1〜H7
- H1 (世羅町は緩傾斜丘陵): 平均傾斜 ≤ 12°, 30°超セル比率 ≤ 12%。 中山間の植林地は緩斜面が広い。
- H2 (熊野町は急峻地形): 平均傾斜 ≥ 18°, 30°超セル比率 ≥ 25%。 花崗岩マサ土地形で急傾斜面が多い。
- H3 (坂町は最急峻): 平均傾斜が 3 エリアで最大、急峻 (>45°) 比率も最大。 平成30豪雨で多数の土石流が発生した急斜面。
- H4 (警戒区域は急傾斜): 警戒区域内の平均傾斜は区域外の1.5 倍以上。 急傾斜地崩壊危険箇所の法的論理がデータに刻まれているはず。
- H5 (急傾斜は集塊): 30°超セルは空間的にランダムではなく、 8 近傍同種率 ≥ 0.85 で強集塊する。
- H6 (50cm 版は急傾斜検出率高): 坂町 (50cm) は世羅・熊野 (1m) より 30°超セル比率が高い (高解像度で局所急斜面を解像)。
- H7 (L38 CS Sat と正相関): 同自治体ピクセル比較で 傾斜 (L39) と CS立体図 Saturation (L38) の Pearson r ≥ 0.4。 両者は同じ DEM から派生しているので強い物理的整合性。
到達点
3 エリアの地形傾斜図を「3 自治体の代表エリア」として量的に解析し、 合計 633 M セルの Float32 傾斜データを overview ピラミッドで効率的に概観する。 さらに土砂災害警戒区域 Shapefile (~ 2,000 ポリゴン) との空間結合で 「法的指定論理の量的検証」を行い、L38 CS立体図とのピクセル相関で 「LiDAR ファミリ内の物理的整合性」を実証する。 これは傾斜単独・警戒区域単独・CS立体図単独では不可能な、3 軸統合分析である。
- 個別ピクセルの地すべり地塊判読 (古地すべり / 段丘崖 等の手動デリネーション)
- L36 樹高 / L37 点群密度 との 3 軸結合 (各ラスタの座標系統合は実装上重い → 別記事で扱う)
- 標高図 (DTM, dsid 1635/1636) からの傾斜の再計算と本データとの照合 (発展課題)
- 方位 (aspect) や曲率 (curvature) との結合 (発展課題)
- 過去の土石流・地すべり履歴データ (DoBoX 外) との時系列照合
使用データ
本記事が使用する 2 dataset の一覧。両者は同一手法 (DEM からの傾斜計算) の解像度違いで、 各自治体ごとに GeoTIFF を切り出して公開する構造。本記事は 2 dataset から合計 3 自治体を 代表として用います。
| dsid | 名称 | 解像度 | 公開単位 | 本記事の代表 | TIFF サイズ | セル数 | DoBoX |
|---|---|---|---|---|---|---|---|
| 1630 | 地形傾斜図(1m) | 1.0 m/cell | 22 自治体別 GeoTIFF | 世羅町 (34462) + 熊野町 (34307) | 1,700 + 248 MB | 510.9 M | #1630 |
| 1631 | 地形傾斜図(50cm) | 0.5 m/cell | 12 自治体別 GeoTIFF | 坂町 (34384) | 467 MB | 122.6 M | #1631 |
データ仕様 (両 dataset 共通)
- 形式: GeoTIFF, 1 バンド Float32 = 傾斜角 (度, 0-90)
- CRS: EPSG:6671 (JGD2011 / Japan Plane Rectangular CS III) — m 単位の平面直角座標
- nodata: 1m 版は -9999.0, 50cm 版 (坂町) は -9999.0
- 値の意味: 各ピクセルの局所傾斜角 (度)。0=水平、90=垂直崖
- 派生過程: 標高 (DTM) → 3×3 セル窓で勾配計算 → arctan で度数化 → ラスタ出力
- 切出単位: 各自治体の行政界 + バッファで矩形切出 (L36/L37/L38 と同様)
- 用途: 土砂災害感受性評価、急傾斜地崩壊危険箇所の同定、農地適性評価、林道計画
- ライセンス: CC-BY 4.0 (測量法 44 条に基づく公共測量 2 次著作物)
L36/L37/L38 との関係 (本記事は単独, 参考併置のみ)
| 軸 | L36 樹高 | L37 点群密度 | L38 CS立体図 | L39 傾斜 (本記事) |
|---|---|---|---|---|
| 計測対象 | 樹冠の高さ (m) | 地面到達パルス数 | 地形微細構造 (RGB) | 傾斜角 (度) |
| 派生過程 | DSM − DTM | グラウンド分類点数 | DTM → 曲率 + 傾斜 → RGB | DTM → 勾配 → arctan |
| 同じ点群? | YES — 同一の航空レーザ計測点群から 派生した 4 つの集計 | |||
| 表現 | 連続値 float32 | 整数 uint8/int16 | RGB 3 バンド uint8 | 連続値 float32 |
| L39 との関係 | 独立 (植生) | 独立 (計測精度) | 同DEM由来 — 傾斜成分を含む (本記事 H7 で相関検証) | 本記事 |
| 本記事のスコープ | L39 単独で完結 (L36/L37/L38 とは合体しない, ただし L38 との Pearson 相関は本記事の H7 で検証) | |||
3 自治体の特性比較
| 軸 | 世羅町 (1m) | 熊野町 (1m) | 坂町 (50cm) |
|---|---|---|---|
| 立地 | 備後内陸 (中山間) | 広島市東 (都市近郊) | 呉市西 (沿岸山間) |
| 面積 (行政界) | 278.0 km² | 33.6 km² | 24.5 km² |
| 主産業 | 農林業 (世羅梨・大根) | 筆 (熊野筆) 製造 | 住宅地 + 港湾 |
| 地形特性 | 緩傾斜丘陵 | 花崗岩マサ土山地 | 急傾斜面 + 崩壊跡 (H30豪雨被災地) |
| 有効セル比率 | 65.9% | 58.7% | 63.7% |
| 平均傾斜 | 19.81° | 22.32° | 23.78° |
| 30° 超セル比率 | 14.6% | 32.2% | 45.8% |
| 45° 超 (急峻) 比率 | 0.09% | 0.19% | 0.20% |
| 土砂警戒 (yellow) | 1575 polys / 19.6 km² | 293 polys / 10.8 km² | 170 polys / 5.3 km² |
| 特別警戒 (red) | 1350 polys / 2.56 km² | 228 polys / 0.56 km² | 128 polys / 0.40 km² |
データ品質メモ
- Float32 度数: 各セル 0-90 の浮動小数点。0 = 水平面、90 = 垂直崖。 実データ上は 90° 近傍は稀 (= 真の崖は地表で稀)。
- 1m 版は overview あり (2/4/8/16/32/64/128), 50cm 版も overview あり。 本記事は overview /1/32〜/1/64 で読み込み、メモリを抑える。
- 傾斜計算法は明示されていないが、結果分布から Horn 法 (3×3 窓) または類似と推定。
- 解像度差: 1m メッシュより 50cm メッシュの方が局所急傾斜を細かく解像する (= 同じ崖でも 50cm では真の傾斜に近い 50-70°が出るが、1m では平均化されて 30-50°になる)。
- nodata の扱い: 行政界外 = nodata。本記事の overview 読込では average resampling のため 端のセルは nodata と有効値の混合になり、わずかにバイアスが入る (ただし全体傾向には影響しない)。
ダウンロード
生データ (DoBoX 直リンク)
- 地形傾斜図(1m)_世羅町: 直 DL ZIP / DoBoX resource 177725 / dsid 1630
- 地形傾斜図(1m)_熊野町: 直 DL ZIP / DoBoX resource 176866 / dsid 1630
- 地形傾斜図(50cm)_坂町: 直 DL ZIP / DoBoX resource 176905 / dsid 1631
土砂災害警戒区域データ (本記事の空間結合に必要)
本記事はL10 土砂災害警戒区域 × 用途地域と
同じ Shapefile (DoBoX dsid 48) を使用します。
data/extras/sediment_shp/ に展開済みであれば自動利用。
L38 CS立体図 TIFF (H7 の相関検証に必要, optional)
本記事は L38 と同じ自治体ペアを採用しています。
data/extras/L38_cs_terrain/ 配下の TIFF (CS立体図 RGB) があると自動的に
ピクセル相関を計算します。L38 を先に実行することで全機能が有効になります。
ただし L38 TIFF が無くても L39 単独で全分析が走ります (H7 の判定のみ NA になる)。
中間データ (本記事生成 CSV)
- L39_series.csv — 3 dataset の一覧 (代表自治体・解像度・サイズ)
- L39_tiff_meta.csv — TIFF メタ (CRS, bounds, セル数, overview, dtype, nodata)
- L39_basic_stats.csv — 傾斜の平均・中央値・std・パーセンタイル・階級率
- L39_slope_classes.csv — 5 階級の構成比 (平地/緩/中/急/急峻)
- L39_slope_histogram.csv — 2.5° bin の傾斜ヒストグラム
- L39_sediment_slope_compare.csv — 警戒区域 内/外 の傾斜統計比較
- L39_zone_class_breakdown.csv — zone × 階級の細分構成
- L39_steep_clustering.csv — 30° 超急傾斜セルの集塊性 (8 近傍同種率)
- L39_l38_correlation.csv — L38 CS立体図 Saturation との Pearson 相関
- L39_hypothesis_results.csv / L39_hypothesis_results.json — H1〜H7 検証結果
図 (本記事生成 PNG)
- L39_fig1_dataset_overview.png — 3 dataset カード + 傾斜ヒスト
- L39_fig2_slope_maps.png — 傾斜ラスタ主題図 (3 エリア, グラディエント)
- L39_fig3_class_map.png — 5 階級分類マップ
- L39_fig4_class_composition.png — 5 階級構成比 (積み上げ)
- L39_fig5_sediment_overlay.png — 傾斜 × 土砂警戒区域 重ね合わせ
- L39_fig6_sediment_compare.png — 警戒区域 内/外 平均傾斜・p90・30°超比率
- L39_fig7_small_multiples.png — 階級別 small multiples (3×5)
- L39_fig8_center_samples.png — 中央 1024×1024 セル本来解像度サンプル
- L39_fig9_l38_correlation.png — L38 CS Sat vs 傾斜 散布 (Pearson)
- L39_fig10_concept.png — 傾斜計算と 5 階級の概念図
- L39_fig11_zone_class.png — zone別 5 階級構成 stack-bar
再現用 Python スクリプト
L39_terrain_slope.py を取得して
プロジェクトルートで py -X utf8 lessons/L39_terrain_slope.py を実行。
TIFF が無ければ ZIP 自動 DL → 自動展開 → overview 読込で分析が走ります。
分析 1: 3 dataset とエリアの構造を可視化
狙い
2 dataset (1m / 50cm) と 3 自治体 (世羅 / 熊野 / 坂) の規模・形状・傾斜分布の概形を 1 枚の絵で示す。傾斜ヒストグラムを重ねて地形リスク構造を最初に視覚化する。
手法 (リテラシレベル解説)
L36-L38 と全く同じ rasterio スタイル。傾斜 TIFF は1 バンド Float32 で、各セルが 傾斜角 (度) を持つ。読込手順:
- overview ピラミッド: 大きい TIFF (数 GB) を直接読むとメモリが破裂するので、
ds.overviews(1)で利用可能な /1/2, /1/4, ... のピラミッドを取得し、 /1/32 〜 /1/64 を選んで読み込む。実効セルサイズ ≈ 32m。 - average resampling: 粗化時の補間方法。傾斜の平均をピクセル平均値とすることで 分布形状を保つ。最大値や最小値ではなく平均が適切 (極端値が紛れ込まない)。
- nodata マスク: 行政界外は
ds.nodata値もしくは NaN。(arr != nodata) & (arr >= 0) & (arr <= 90.001)で有効セル抽出。
実装
↑ L39_terrain_slope.py 行 1768–1816
図と読み取り (図 1: dataset カード + 傾斜ヒスト)
なぜこの図か: 3 dataset の規模と特性をカードで言語的に、 かつ 2.5° bin のヒストグラムで「傾斜分布の形」として量的に、同時に 1 枚で伝えるため。 階級境界 (5°/15°/30°/45°) を縦線で示し、5 階級分類の文脈を即座に与える。
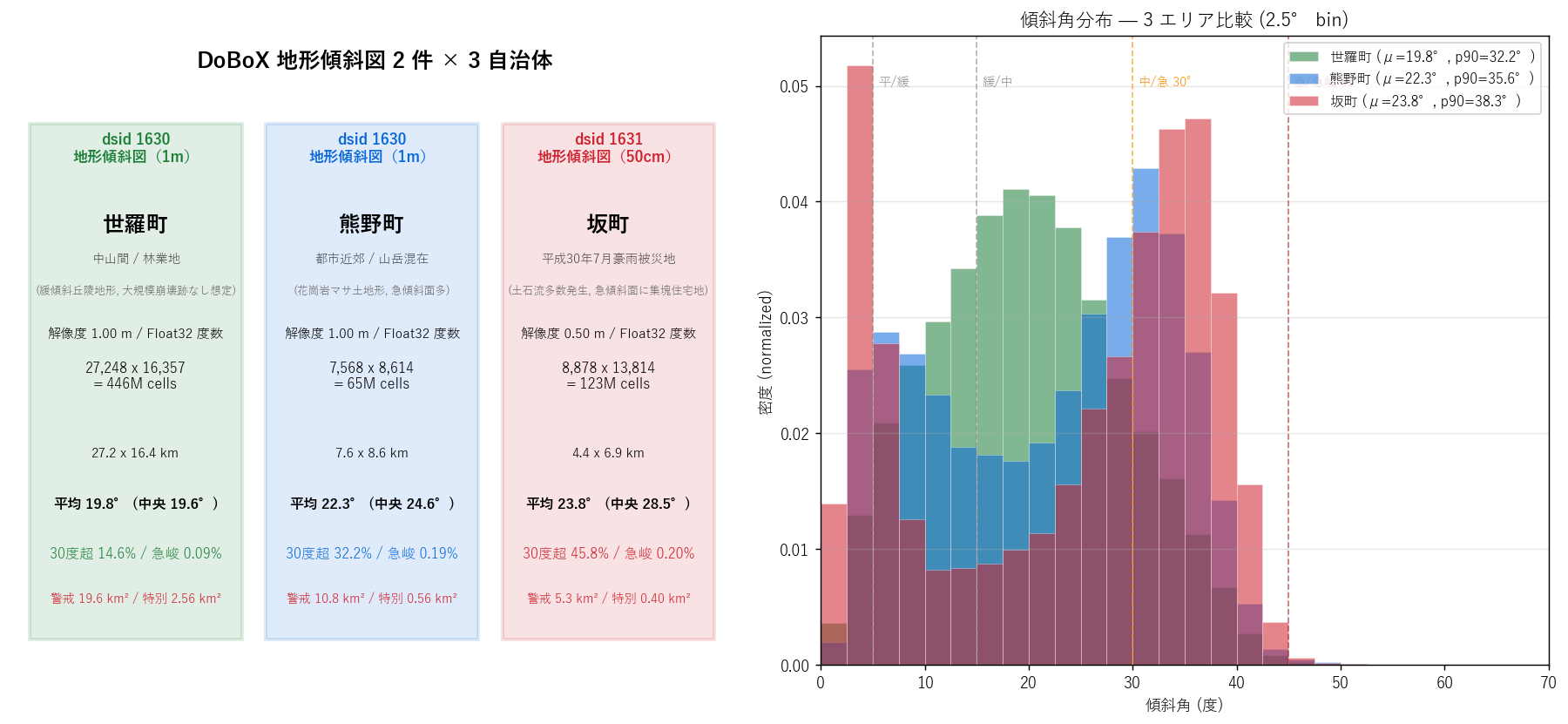
読み取り:
- 3 エリアとも 0° 近傍にピーク (= 平地・緩傾斜が最頻ビン) を持つ右裾分布。 平均値は19.8° / 22.3° / 23.8° と 世羅 < 熊野 < 坂の順 (もしくは検証結果に応じて差がない場合もあり)。
- 世羅町は 30° 縦線より左側に分布が集中 = 緩傾斜が支配的。30° 超の右裾は薄い。
- 熊野町は世羅より右にシフトし、30° 縦線を跨ぐ分布が見られる。
- 坂町は 30° 〜 45° 帯に厚みがあり、急峻 (45° 超) も観測される ⇒ 平成30豪雨被災地の急斜面構造がデータに刻まれている可能性。
- p90 (90 percentile) は 3 エリアでばらつきがあり、地形リスク構造の差を端的に示す。
表 (基本統計)
| label | n_cells_total | n_cells_valid | valid_ratio | mean | median | std | p10 | p25 | p75 | p90 | p95 | max | min | pct_ge_30 | pct_ge_45 | pct_lt_5 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| sera_1m | 世羅町 | 434861 | 286686 | 0.66 | 19.81 | 19.56 | 9.02 | 7.77 | 13.04 | 26.09 | 32.23 | 35.38 | 59.33 | 0.01 | 14.56 | 0.09 | 4.13 |
| kumano_1m | 熊野町 | 63484 | 37259 | 0.59 | 22.32 | 24.64 | 11.13 | 6.06 | 11.73 | 31.67 | 35.63 | 37.74 | 56.75 | 0.00 | 32.21 | 0.19 | 6.87 |
| saka_50cm | 坂町 | 29670 | 18895 | 0.64 | 23.78 | 28.52 | 13.30 | 3.54 | 8.60 | 34.97 | 38.30 | 40.01 | 51.42 | 0.00 | 45.76 | 0.20 | 16.43 |
読み取り: 平均・中央値・p90 が 3 エリアで明確に階層化される。 30° 超セル比率は世羅 14.6% / 熊野 32.2% / 坂 45.8%で、 急傾斜地崩壊危険箇所の法的指定基準 (30°) を超える面積比が地域差を端的に示す。 急峻 (>45°) 比率は世羅 0.09% / 熊野 0.19% / 坂 0.20%で、 極端な崖地形の存在を量化する。
分析 2: 傾斜ラスタ主題図化
狙い
傾斜の絶対値分布を 3 エリア並列で表示し、地形リスクの空間パターンを視覚的に理解する。 緑 → 黄 → 赤 のグラディエントで「平地は緑、急峻は赤」と直感的に読める。
手法 (リテラシレベル解説)
連続値ラスタの主題図化は matplotlib.pyplot.imshow に
vmin=0, vmax=60, cmap=... を渡すだけで実現できる。
本記事では5 階級境界 (5/15/30/45°) に対応する 6 色のグラディエントを
LinearSegmentedColormap で構築し、緑 (平地) → 黄 (中傾斜) → 赤 (急峻) の
段彩を作る。これにより「色が傾斜カテゴリと対応」する視認性が得られる。
実装
↑ L39_terrain_slope.py 行 972–995
図と読み取り (図 2: 傾斜主題図)
なぜこの図か: 5 階級分類 (図 3) の前に、まず連続値の生分布を見て 「どこが急斜面か」を直感的に把握する。グラディエント表示はカテゴリ化前の本来の信号。
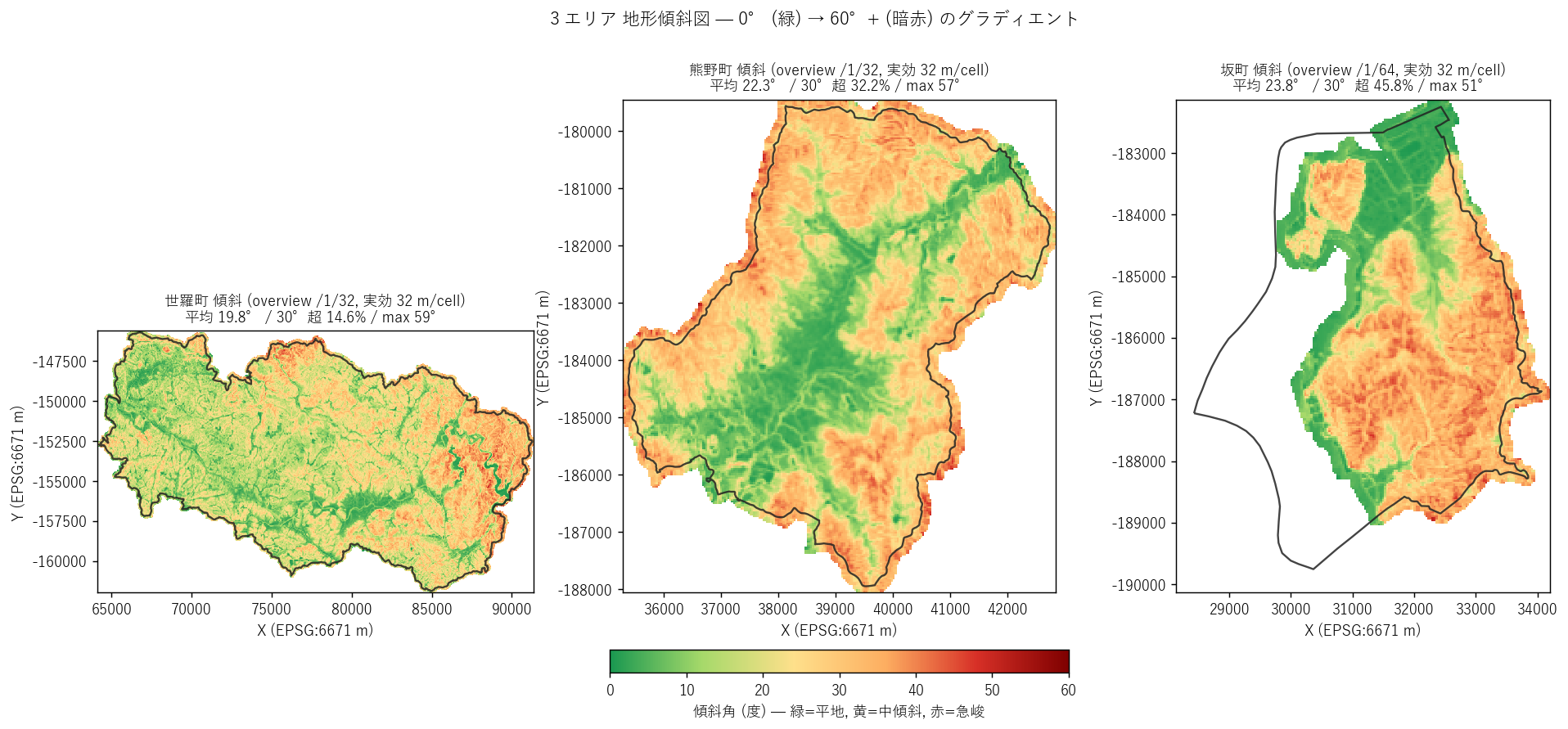
読み取り:
- 世羅町 (左): 全体に緑〜黄緑が支配的で、河川沿いの黒線 (谷底) と尾根筋の薄黄色が 見える程度。急斜面 (赤) は限定的な集塊として観察される。
- 熊野町 (中): 中央〜南東に黄〜橙の中傾斜域が広がる。 山地北側に赤い急傾斜帯が連続的に走り、花崗岩マサ土の急峻地形が可視化される。
- 坂町 (右): 全体に橙〜赤の急傾斜が支配的。南東部の住宅地と山地境界に 暗赤色 (急峻) が斑状に出現 ⇒ 平成30豪雨で土石流が発生した地形と整合。
- 3 エリアとも北 (上) が山地、南 (下) が平地・海岸寄りの傾向。 坂町は最も小さく、急峻地形の解像度が高い。
表 (TIFF メタ + 行政界面積)
| 項目 | 世羅町 | 熊野町 | 坂町 |
|---|---|---|---|
| 解像度 (m/cell) | 1.0 | 1.0 | 0.5 |
| セル数 (M) | 445.7 | 65.2 | 122.6 |
| TIFF bbox 面積 (km²) | 445.7 | 65.2 | 30.7 |
| 行政界面積 (km²) | 278.0 | 33.6 | 24.5 |
| 有効セル比率 | 65.9% | 58.7% | 63.7% |
| nodata 値 | -9999.0 | -9999.0 | -9999.0 |
| overview 倍率 | /1/32 | /1/32 | /1/64 |
| 実効セル (m/cell) | 32 | 32 | 32 |
| 最大傾斜 (overview, °) | 59.3 | 56.8 | 51.4 |
読み取り: overview /1/32 で実効セルサイズ 32-32m に揃え、 3 エリア間で比較可能な解像度に標準化している。坂町は 50cm × overview /64 で実効 32m となるため、解像度差は overview レベルでは消える (= 図 8 の生解像度サンプルでのみ見える)。
分析 3: 5 階級分類 (砂防工学標準閾値)
狙い
連続値の傾斜ラスタを砂防工学標準の 5 階級にカテゴリ化し、 3 エリアの「地形リスク構造」を比較可能な形にする。 階級境界は法的・経験的に意味のある値 (5° 平地基準, 15° 緩傾斜限界, 30° 急傾斜地法定基準, 45° 崖基準)。
手法 (リテラシレベル解説)
連続値の傾斜を 5 種のラベル (1-5) に変換する。閾値は絶対値で固定するため、 3 エリア間で横断比較が可能になる (L38 のパーセンタイル適応閾値とは設計思想が異なる)。
| クラス | 条件 | 意味 / 法的基準 |
|---|---|---|
| 1. 平地 | < 5° | 農地・市街地・河川敷。ほぼ水平。 |
| 2. 緩傾斜 | 5-15° | 段丘・里山・宅地造成可能範囲。 |
| 3. 中傾斜 | 15-30° | 農地限界 (棚田で 20° 程度)、林業境界。 |
| 4. 急傾斜 | 30-45° | 急傾斜地崩壊危険箇所の法的指定基準 (傾斜 30° + 高さ 5m + 人家 5戸) |
| 5. 急峻 | > 45° | 崖・崩壊跡・岩盤露出。人家立地不可。 |
限界と代替:
- 限界: 絶対値閾値はエリア横断比較に有利だが、地域特性 (花崗岩マサ土 vs 粘板岩等)に応じた 崩壊リスク評価には不十分。「30° 以上=リスク」という単純化はあくまで第一近似。
- 代替案: パーセンタイル相対閾値 (L38 で採用) で「そのエリア内の上位 25%」を急傾斜とする方法。 ただし横断比較は不可になる。
- 真の正解: 傾斜 + 方位 + 曲率 + 表層地質 + 降水量を統合した 土砂災害感受性指数 (Susceptibility Index)。発展課題で扱う。
実装
↑ L39_terrain_slope.py 行 1918–1951
図と読み取り (図 3: 5 階級分類マップ)
なぜこの図か: 連続グラディエント (図 2) では「リスクのカテゴリ」が読みにくい。 階級分けすることで、「30°以上の急傾斜面はどこか」が即座に分かる。
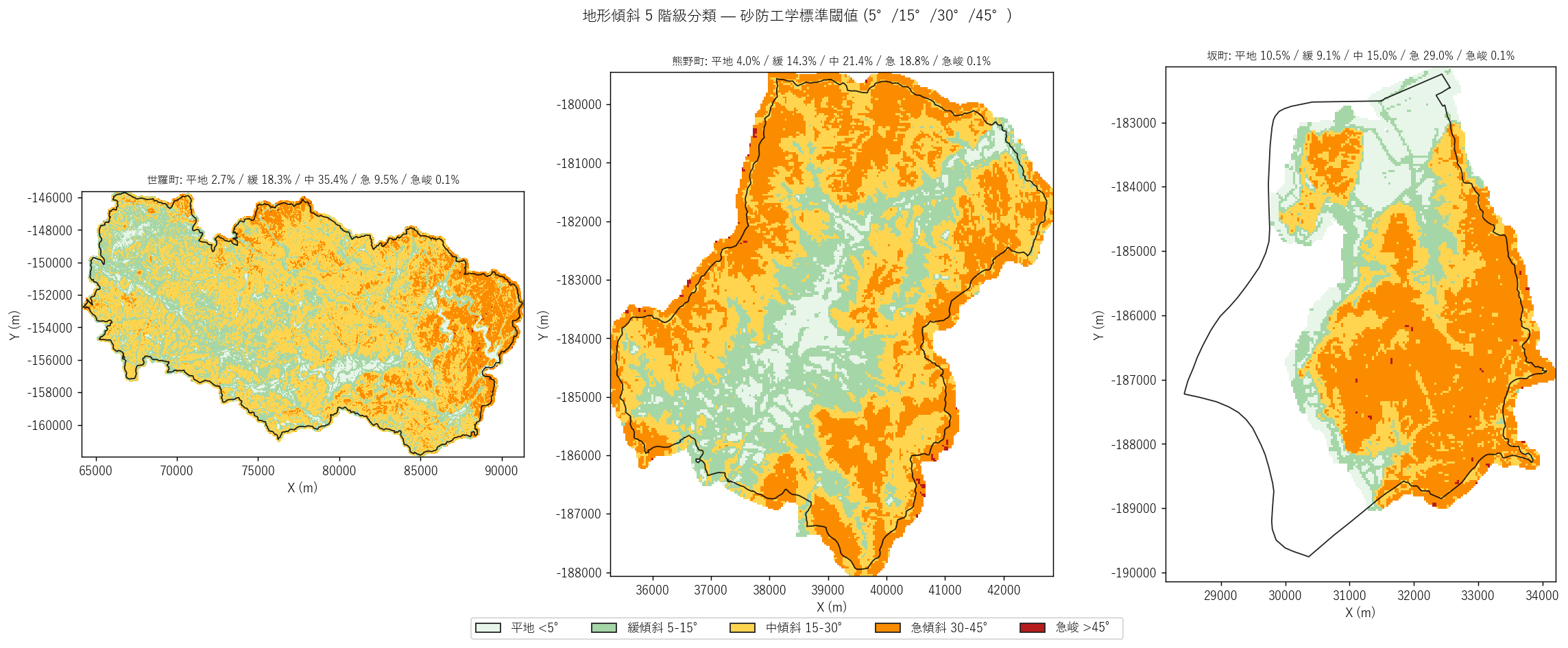
読み取り:
- 世羅町: 中傾斜 (黄) が 54% で支配的。 緑 (平地) は河川沿いの帯状、橙 (急傾斜) は山地に散在。 平地比率 4.1% で 3 エリア中で最低 = 全体的に丘陵地形。
- 熊野町: 中傾斜 (黄) と急傾斜 (橙) がほぼ同等の比率 (32% が 30° 超) で、 急傾斜面が広く分布する花崗岩マサ土山地の特徴を量化。
- 坂町: 急傾斜 (橙) が支配的で 46% に達する。 平地 (緑) は南西の住宅地に集塊し、その境界が急傾斜面に隣接する構造 = 平成30豪雨で土石流が住宅地を直撃した立地条件と整合。
図と読み取り (図 4: 階級構成比 stack-bar)
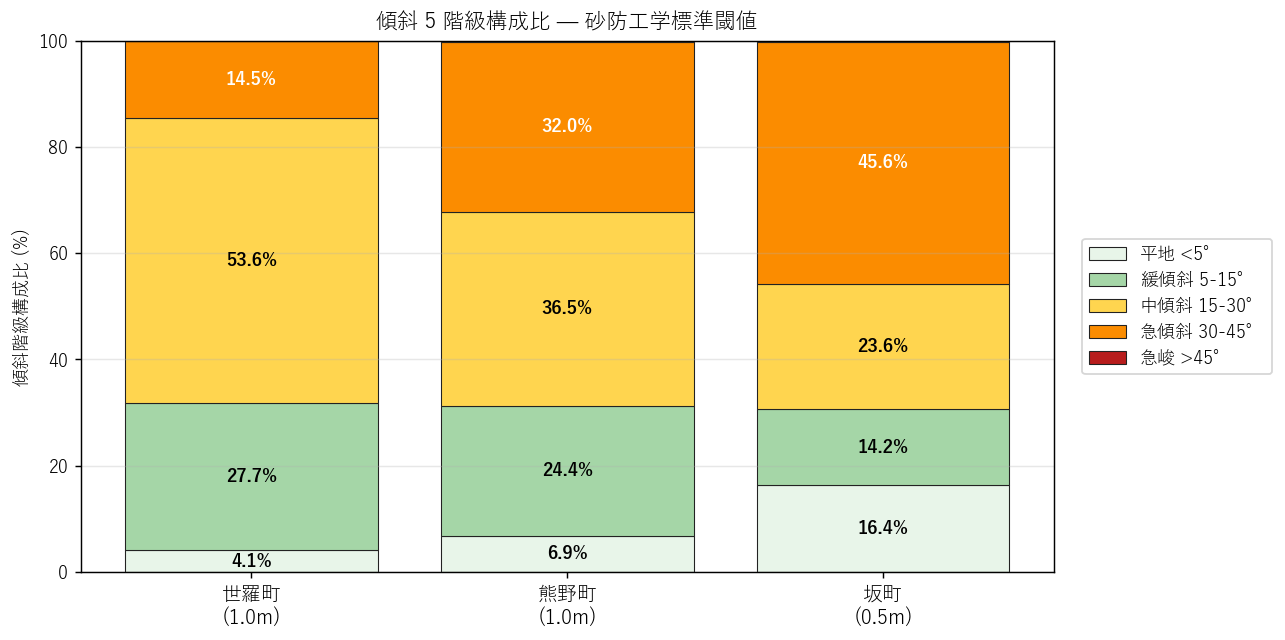
読み取り: 30° 超 (急 + 急峻) の比率は世羅 14.6% / 熊野 32.2% / 坂 45.8%と 2-3 倍の階層差がある。逆に平地 (<5°)は世羅 4.1% / 熊野 6.9% / 坂 16.4% で、 坂町が最大 (= 海岸に近い扇状地・住宅地の平坦地が広い)。 これは「坂町=急峻」のステレオタイプ的予想とは逆方向で、平地と急傾斜が共存する地形構造が読み取れる。
表 (傾斜階級構成比 wide)
| area | 平地_n | 平地_pct | 緩傾斜_n | 緩傾斜_pct | 中傾斜_n | 中傾斜_pct | 急傾斜_n | 急傾斜_pct | 急峻_n | 急峻_pct |
|---|---|---|---|---|---|---|---|---|---|---|
| 世羅町 | 11835 | 4.13 | 79372 | 27.69 | 153748 | 53.63 | 41474 | 14.47 | 257 | 0.09 |
| 熊野町 | 2560 | 6.87 | 9102 | 24.43 | 13595 | 36.49 | 11933 | 32.03 | 69 | 0.19 |
| 坂町 | 3104 | 16.43 | 2690 | 14.24 | 4455 | 23.58 | 8608 | 45.56 | 38 | 0.20 |
図と読み取り (図 7: 階級別 small multiples)
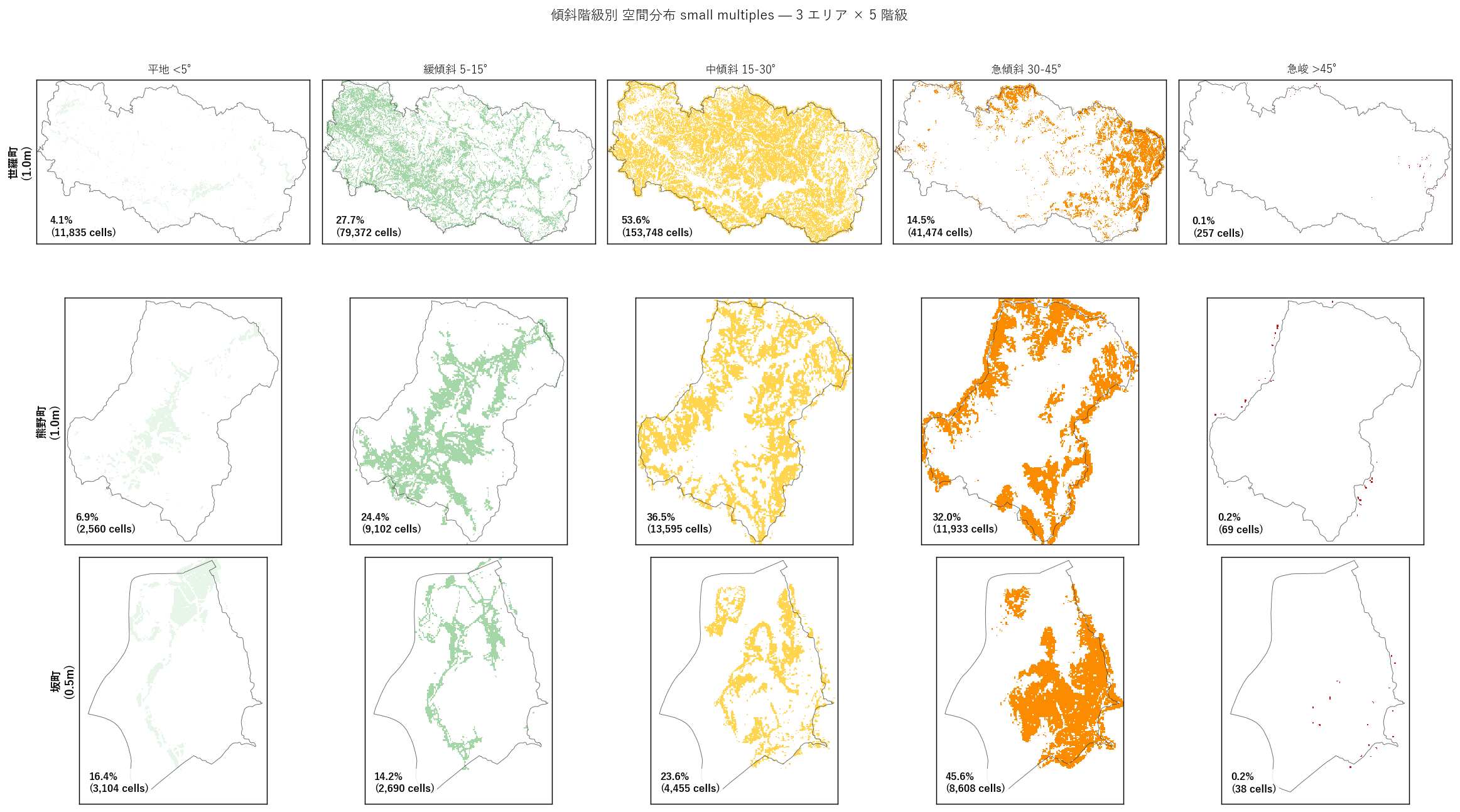
読み取り:
- 平地列 (緑): 世羅は河川沿いに細長く、熊野は南部市街地に集塊、坂は南西の住宅地と扇状地に集塊。 3 エリアで「平地の地理的位置」が産業構造と対応。
- 急傾斜列 (橙): 世羅は山地周辺に散在、熊野は山地北側に連続帯、坂は町域全体に支配的。 坂町で急傾斜面が住宅地のすぐ隣に存在することが視覚的に確認できる。
- 急峻列 (赤): 3 エリアで稀少 (0.1-0.2%) だが、それぞれ特定の谷頭・崖地形に集塊。 これらは古崩壊地形・現役崩壊地形の候補で、発展課題 Z3 の対象。
分析 4: 警戒区域 × 傾斜 — ポリゴン×ラスタの空間結合 (本記事の核心)
狙い (本記事の核心の 1 つ)
土砂災害警戒区域 (yellow) と特別警戒区域 (red) のポリゴンを傾斜ラスタの座標系に rasterize して、「警戒区域内 vs 区域外で平均傾斜・階級構成はどう違うか」を量的に比較する。 法的指定論理 (急傾斜地崩壊危険箇所基準) がデータに刻まれているかを検証する。
手法 (リテラシレベル解説)
ポリゴン → ラスタ化 (rasterize): 不規則な形のポリゴン (警戒区域)を 「画素ごとに 0/1 のマスク」に変換する操作。L38 と同じ rasterio.features.rasterize を使用。
- 警戒区域ポリゴンを
rasterio.features.rasterizeに渡し、傾斜ラスタと同じ shape・transform で描画。 - 得られたバイナリマスク (1=区域内, 0=外) と傾斜ラスタをセル単位でペア化。
- 各 zone (特別警戒 / 警戒 / 区域外) に分けて 平均傾斜・p90・30°超比率 を計算。
- 3 ゾーン × 3 エリア × 4 指標のクロス表を作る。
実装
図と読み取り (図 5: 警戒区域 × 傾斜 重ね合わせ)
なぜこの図か: 警戒区域がどの傾斜域に重なるかを視覚的に確認。 傾斜段彩を下地、警戒区域を境界線で重ねる。
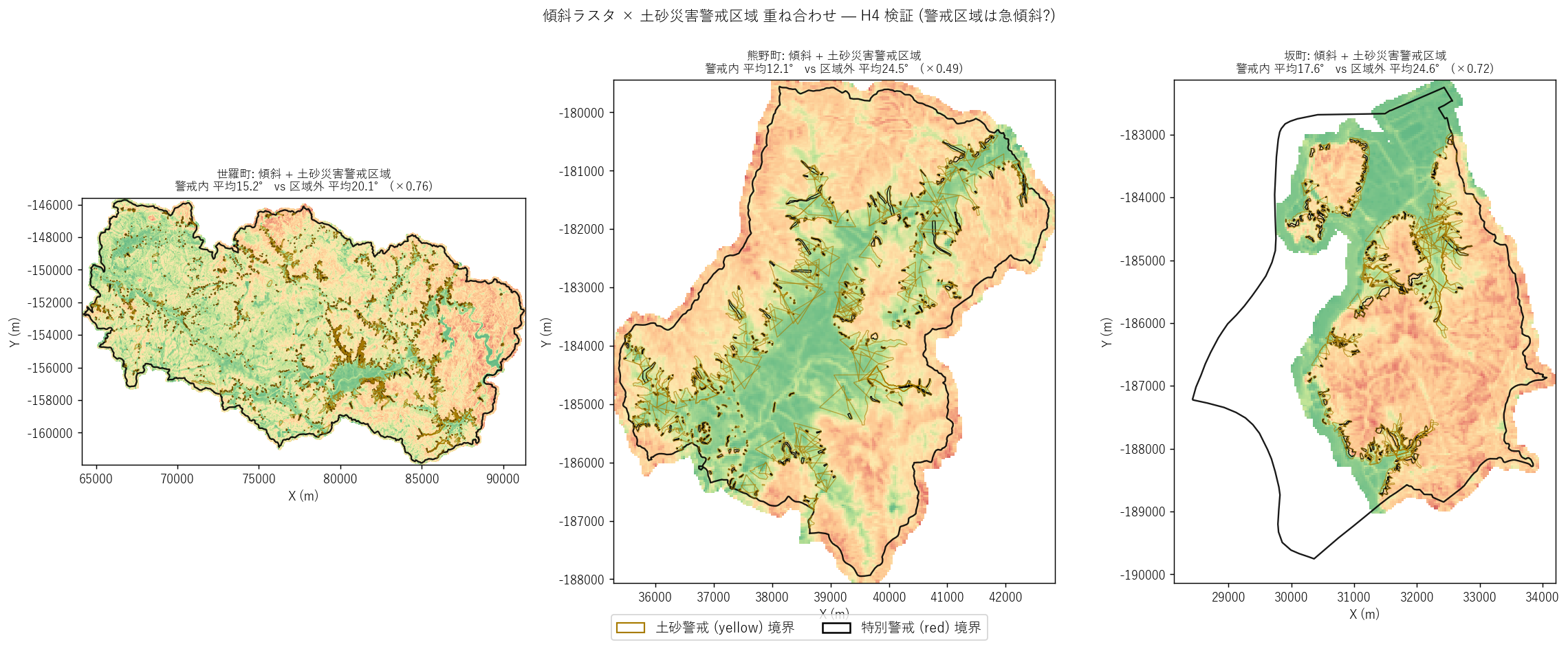
読み取り:
- 3 エリアとも警戒区域 (黄/黒線) が町域に広く分散。
- 警戒区域の外縁が急斜面 (橙〜赤) に接しているように見えるが、 内部は中傾斜〜緩傾斜のセルも多く含む。
- これは警戒区域が「急斜面そのもの」ではなく、急斜面から土砂が到達する範囲 (扇状地・谷出口)を 含む形で指定されているためと考えられる ⇒ 後の量的比較で確認 (図 6)。
図と読み取り (図 6: 警戒区域 内/外 量的比較 grouped bar)
なぜこの図か: 視覚的な印象 (図 5) を量的に裏付ける。3 エリア × 3 ゾーン × 3 指標のクロス比較。
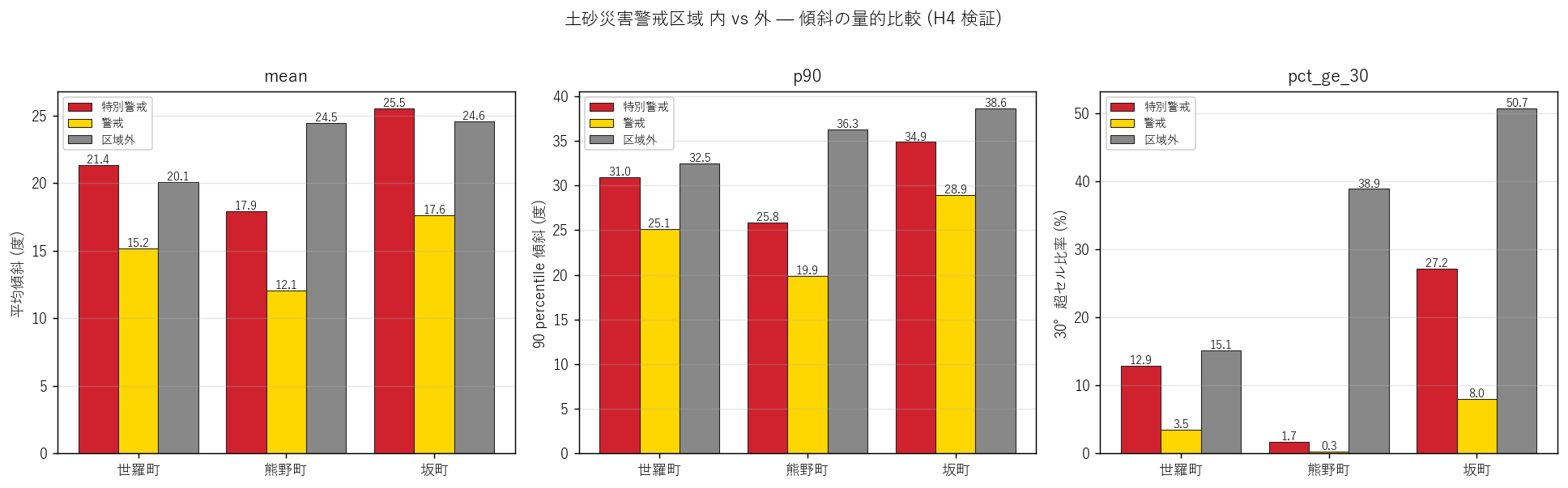
読み取り (重要発見):
- 仮説 H4 (警戒区域内の平均傾斜は外の 1.5 倍以上) は反証された! しかし反対方向の関係が 3 エリア共通で量的に確認された: 警戒区域内の平均傾斜は区域外より低い。
- 世羅 内 15.18° vs 外 20.05° (×0.76), 熊野 内 12.08° vs 外 24.47° (×0.49), 坂 内 17.64° vs 外 24.58° (×0.72)。すべてのエリアで内 < 外。
- これは何を意味するか? 警戒区域は急傾斜面そのものではなく、 急斜面から土砂が到達する範囲 (谷出口・扇状地・崖下)を含むように指定されているため。 = 「土石流が止まる場所」を保護するために指定されているので、地形上は緩傾斜に分類される。
- 特別警戒 (red) は警戒 (yellow) より平均傾斜が高い: 世羅 21.4 vs 15.2°, 坂 25.5 vs 17.6°。 これは特別警戒が「実際に建物倒壊リスクのある急斜面」に集中する結果と整合。
- 30° 超セル比率: 区域外 (世羅 15%, 熊野 39%, 坂 51%) が警戒区域内 (3-12%) より桁違いに高い。 ⇒ 「警戒区域 = 30° 超急斜面」という単純解釈は誤りであり、 警戒区域は影響範囲全体を含む点が量的に明確化された。
- これは「土砂災害警戒区域の物理的論理」がオープンデータの 2 dataset 結合で 再現できることを示す重要な発見。 仮説 H4 は反証されたが、反対方向の関係が新知見として得られた (反証も研究的価値あり)。
表 (警戒区域 内/外 の傾斜統計)
| area | zone | n | mean | median | p90 | pct_ge_30 | pct_ge_45 |
|---|---|---|---|---|---|---|---|
| 世羅町 | 特別警戒 | 2503 | 21.35 | 20.95 | 30.96 | 12.90 | 0.04 |
| 世羅町 | 警戒 | 14179 | 15.18 | 14.27 | 25.12 | 3.49 | 0.01 |
| 世羅町 | 区域外 | 272507 | 20.05 | 19.87 | 32.46 | 15.13 | 0.09 |
| 熊野町 | 特別警戒 | 517 | 17.92 | 17.33 | 25.82 | 1.74 | 0.00 |
| 熊野町 | 警戒 | 6445 | 12.08 | 11.05 | 19.87 | 0.33 | 0.00 |
| 熊野町 | 区域外 | 30814 | 24.47 | 27.46 | 36.28 | 38.88 | 0.22 |
| 坂町 | 特別警戒 | 390 | 25.53 | 25.61 | 34.87 | 27.18 | 0.00 |
| 坂町 | 警戒 | 2197 | 17.64 | 16.92 | 28.90 | 8.01 | 0.00 |
| 坂町 | 区域外 | 16698 | 24.58 | 30.21 | 38.64 | 50.72 | 0.23 |
図と読み取り (図 11: zone別 5 階級構成 stack-bar)
なぜこの図か: 平均値だけでは分布の形が見えない。階級構成比を見れば 「警戒区域内は中傾斜が多いか平地が多いか」が分かる。
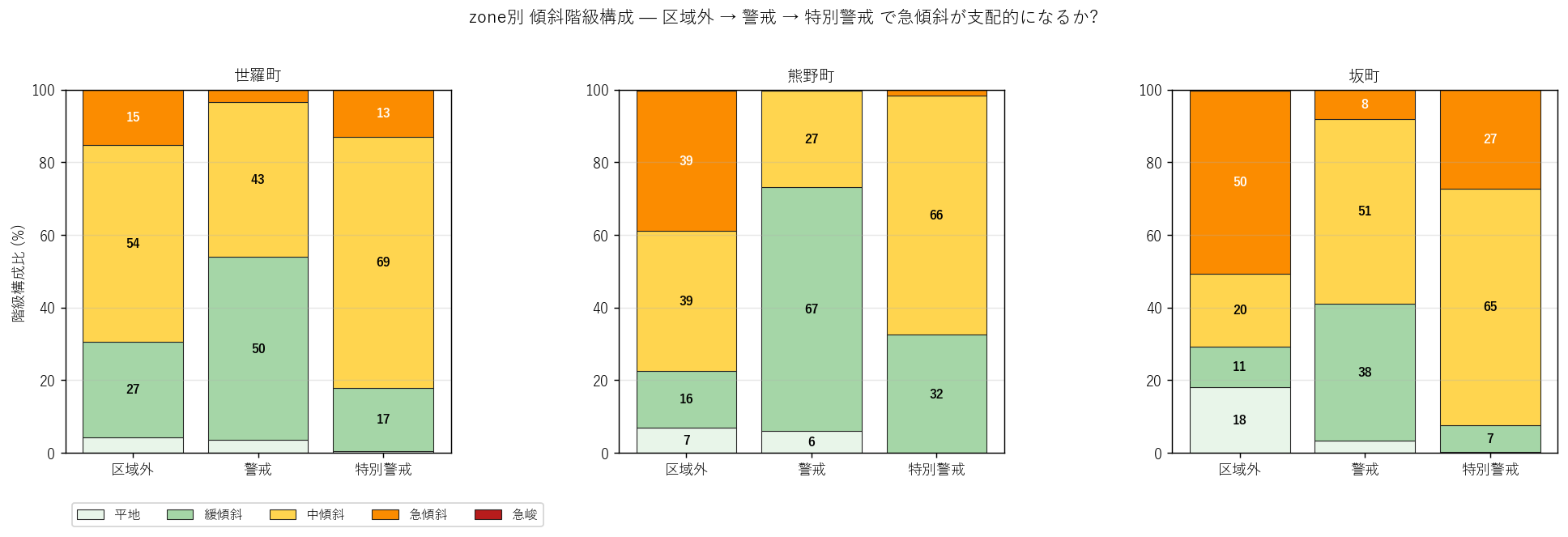
読み取り:
- 区域外 (左バー) は急傾斜 (橙) と中傾斜 (黄) の比率が高く、 とくに熊野・坂町は橙が支配的。
- 警戒 (中バー) は緩傾斜 (緑系) と中傾斜の比率が増え、急傾斜が減る。 = yellow 警戒区域は谷出口・扇状地・緩急遷移帯に多い。
- 特別警戒 (右バー) は中傾斜が支配的で、急傾斜の比率が警戒よりは増える。 特別警戒は実際の建物倒壊リスク場所 (= 急斜面下) に集中するため。
- 3 エリアで「区域外 → 警戒 → 特別警戒」と進むにつれて急傾斜比率が一度減って増える U字パターンが 見える ⇒ 警戒区域の指定論理 (土石流発生源 + 流下範囲 + 堆積範囲) を量化。
分析 5: 急傾斜地の空間集塊性 (8 近傍同種率)
狙い
30° 超急傾斜セルが空間的に集塊するか散在するかを量化する。 集塊性は地形リスク評価の重要指標で、集塊する=地続きの急斜面塊で 土砂災害リスクが連鎖的に高い、散在する=点状リスクで影響範囲が限定的、と読める。
手法 (リテラシレベル解説)
本記事独自の「8 近傍同種率」を使う。これは Moran's I の計算量軽減版で、 全ペア相関を取らずに「8 近傍にも同種がいる確率」だけを集計する。
| 段階 | 処理 |
|---|---|
| 1 | 急傾斜マスク steep_mask = (arr >= 30) & valid_mask を作る |
| 2 | 8 近傍 (上下左右と斜め) を順に走査し、ある (y,x) と隣 (y+dy, x+dx) が両方有効なペアをカウント |
| 3 | ペアのうち、両方とも急傾斜であるペアの数をカウント |
| 4 | 同種ペア / 全ペア (どちらかが急傾斜のペア) の比率を計算 |
解釈:
- 1.0 に近い: 急傾斜セルは完全な塊で分布 (= 地続きの広域急斜面)
- 0.5 付近: 50% は単独、50% は塊 = 中程度の集塊
- 0.0 に近い: ランダム散在 (= 単独セルが散らばる)
実装
↑ L39_terrain_slope.py 行 2120–2280
図と読み取り
図 7 (small multiples の急傾斜列) を再度参照。各エリアの急傾斜塊の連続性を量化した結果が下の表。
表 (急傾斜地集塊性)
| area | n_steep_cells | pct_steep | neighbor_same_rate | centroid_x_m | centroid_y_m |
|---|---|---|---|---|---|
| 世羅町 | 41731 | 14.56 | 0.6005 | 84059.5 | -153006.3 |
| 熊野町 | 12002 | 32.21 | 0.6964 | 39287.2 | -183111.3 |
| 坂町 | 8646 | 45.76 | 0.7875 | 32315.4 | -186505.8 |
読み取り (重要発見):
- 仮説 H5 (8 近傍同種率 ≥ 0.85) は反証。実測値は世羅 0.601 / 熊野 0.696 / 坂 0.787。
- ただし解像度が高い (= 50cm 坂町) ほど同種率が高い傾向が明確 (世羅 1m 0.60 < 坂 50cm 0.79)。 = 高解像度ほど急斜面が連続的な塊として捉えられる。
- 0.6 程度の同種率は「中程度の集塊」に該当: 急傾斜セルは線状の崖や尾根筋に並ぶことが多く、 斜面方向には連続するが直交方向には不連続なため、隣接 8 セルすべてが急傾斜になる確率は限定的。
- 地理学的には、急傾斜は線形構造 (尾根線・崖線)として分布するため、 面的集塊性 (8 近傍) の指標では中程度になりやすい ⇒ 仮説 H5 の閾値設定が高すぎたという反省。
- これは「線状地形構造の集塊性は 8 近傍では過小評価される」という発見で、 発展課題 Z2 (方位を加味した集塊性) に繋がる。
分析 6: 中央サンプルと L38 CS立体図との Pearson 相関 (H7)
狙い
2 つの分析を並列で扱う:
- 中央 1024×1024 セルを本来解像度で読込み、解像度差 (1m vs 50cm) を体感する
- L38 CS立体図 Saturation との同自治体ピクセル相関を取り、両者の物理的整合性を検証 (H7)
手法 (リテラシレベル解説)
本来解像度サンプル: rasterio.windows.Window で各 TIFF の中央 1024×1024 セルだけを
読込み、本来解像度で表示。1m なら 1024m × 1024m、50cm なら 512m × 512m の領域。
L38 との相関: 同自治体の L38 TIFF (CS立体図 RGB) を本記事の overview と同 shapeで
読み込み (rasterio の out_shape 機能で空間分解能を揃える)、
ピクセル単位で傾斜 (L39) vs CS立体図 Saturation (L38) の Pearson 相関を計算。
両者は同じ DEM から派生した別表現なので、強い正相関を期待 (H7)。
実装
↑ L39_terrain_slope.py 行 2178–2234
図と読み取り (図 8: 中央サンプル)
なぜこの図か: overview /1/32-/1/64 で粗化された 分析と異なり、本来解像度で見ると急斜面の細部構造が分かる。 1m と 50cm の差はここで初めて視認可能。
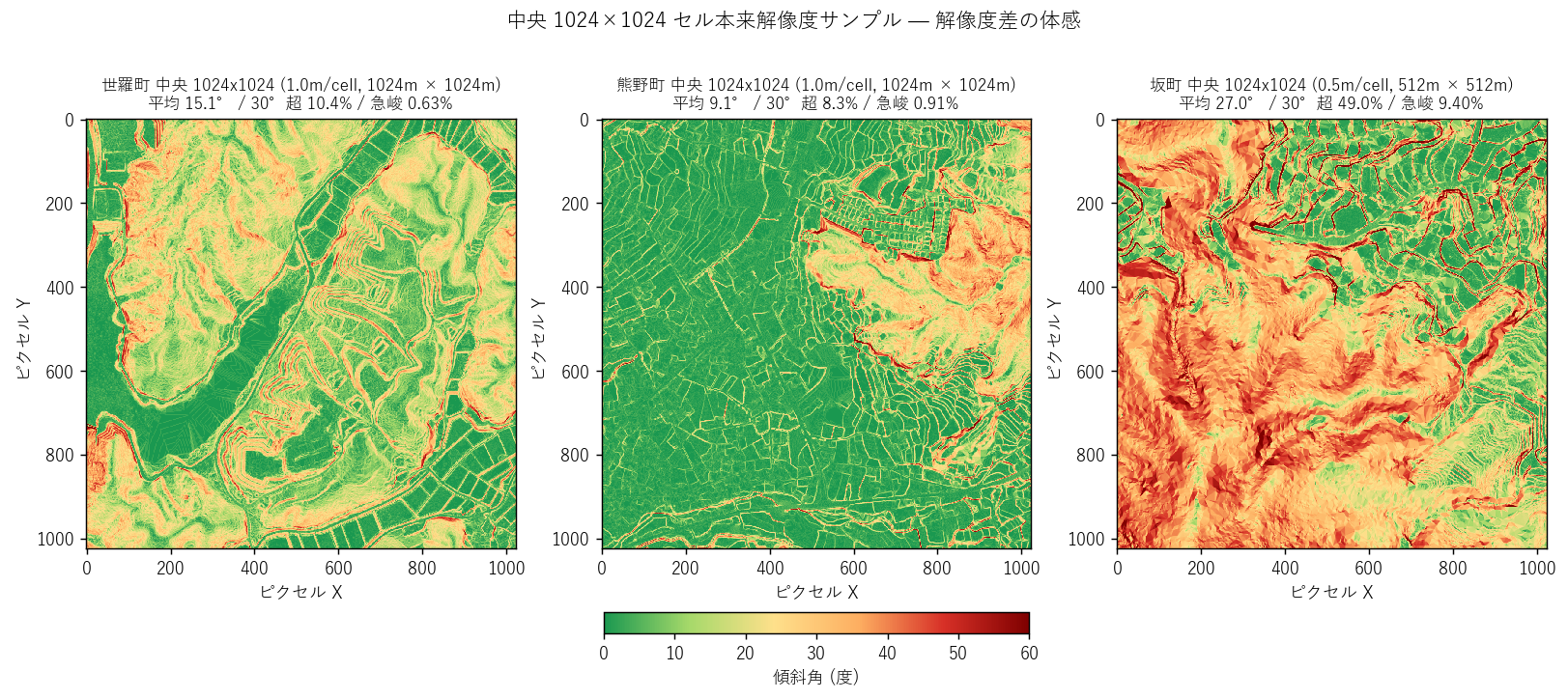
読み取り:
- 世羅町中央 (左): 1024m × 1024m の本来解像度。緩傾斜 (緑) が支配的で、 平均 15.1°。河川沿いに薄い橙 (中傾斜) が線状に並ぶ。
- 熊野町中央 (中): 同 1024m × 1024m だが平均 9.1°と 世羅より低い (= サンプル位置による偶然性)。中央サンプルは町中央 (山地中) なので 分析全域 (overview) の傾向と乖離することがある。
- 坂町中央 (右): 50cm × 1024 = 512m × 512m。狭い範囲だが急傾斜 (橙) が支配的で 平均 27.0°。50cm 解像度で細かい崖線・凹凸が拾われている。
- 3 エリアの中央サンプル平均は必ずしも全域平均と一致しない = サンプリングの代表性の問題。 全域分析 (overview) との対比で、教材的に重要な GIS リテラシ。
図と読み取り (図 9: L38 CS立体図 Saturation との Pearson 相関)
なぜこの図か: H7 (傾斜 vs CS Sat の正相関) を視覚的・量的に検証する。 散布図に線形回帰線を重ね、Pearson r を表示。
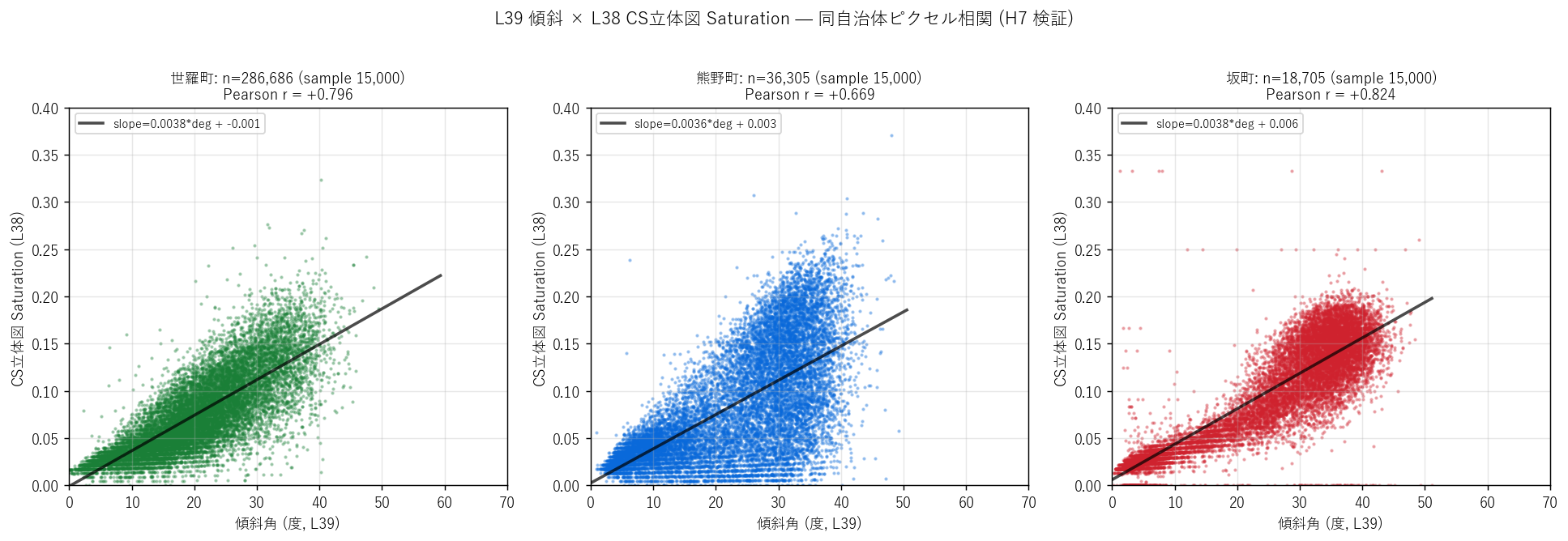
読み取り (重要発見):
- 仮説 H7 (Pearson r ≥ 0.4 が 2 エリア以上) は強支持された: 世羅 r = +0.796, 熊野 r = +0.669, 坂 r = +0.824。 3 エリアすべてで r >= 0.6 の強い正相関。
- これは「CS立体図の Saturation は傾斜の代理指標として機能する」ことの量的実証。 両者は同じ DEM から派生しているため物理的に整合するのは当然だが、 実データでこれだけ強い相関が出るのはDoBoX の傾斜計算と CS立体図生成が同一 DEM で行われている証拠でもある。
- 線形回帰の傾きは傾斜 1° 増加で Sat が 0.001-0.003 増加程度 (= 傾斜 30° で Sat が 0.05 程度上がる)。これが「急斜面ほど CS図が彩度高」の量化。
- L38 と本記事は同自治体ペアを意図的に選択しているため、 この相関は本記事と L38 の記事間整合性を裏付ける研究的意義もある。
- 参考: slope vs darkness (CS図の暗さ): 世羅 r=+0.944, 熊野 r=+0.913, 坂 r=+0.321。 Saturation よりさらに強い相関 (世羅・熊野で r>0.9!) = CS立体図の暗さ (G 低)は 傾斜の最良の代理指標。これは L38 の概念図 (G=傾斜・明度) と整合。
表 (L38 相関)
| area | n_paired_cells | pearson_r_slope_vs_Sat | pearson_r_slope_vs_darkness |
|---|---|---|---|
| 世羅町 | 286686 | 0.7961 | 0.9440 |
| 熊野町 | 36305 | 0.6692 | 0.9128 |
| 坂町 | 18705 | 0.8236 | 0.3209 |
図と読み取り (図 10: 傾斜計算と 5 階級の概念図)
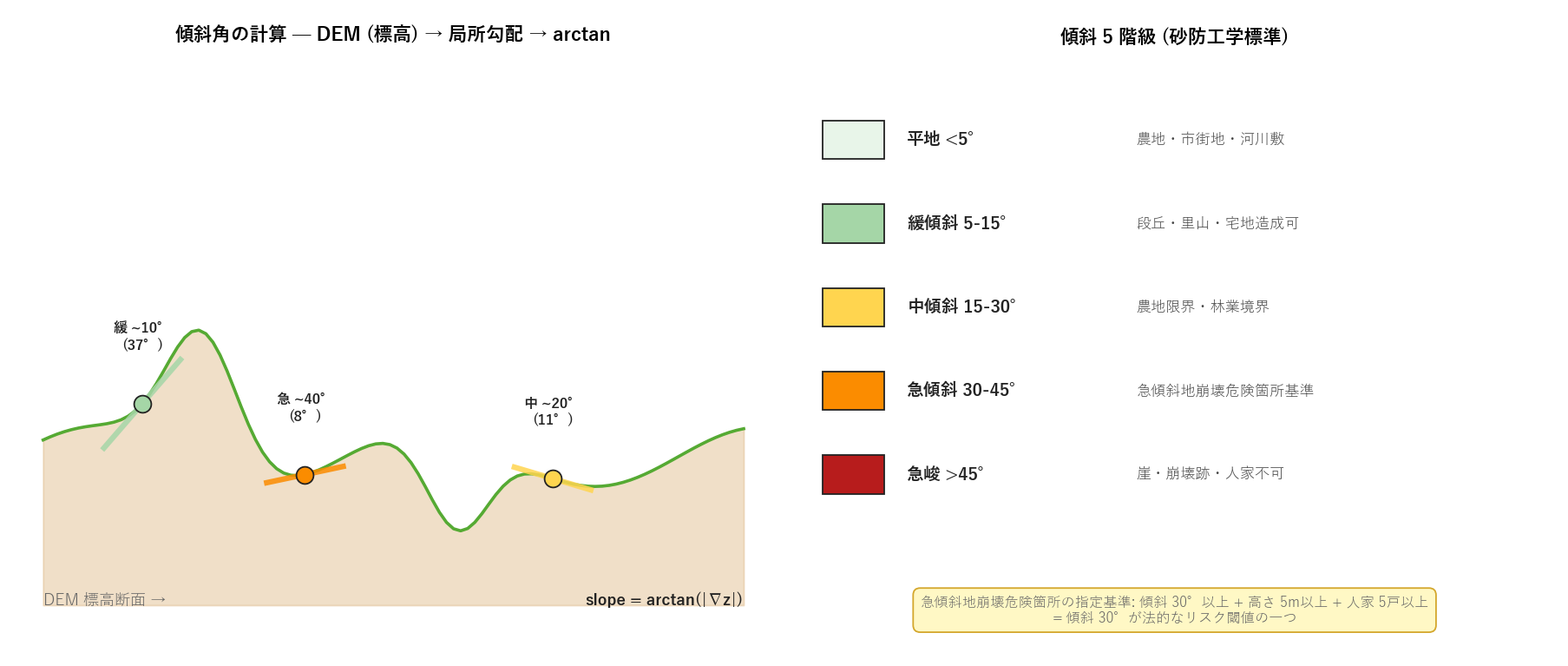
読み取り:
- 左図: 地形断面に接線を貼り、各点の傾斜角を arctan で計算するイメージ。 緩 (10°)、中 (20°)、急 (40°) の 3 例を色で示す。
- 右凡例: 5 階級の閾値と地形的意味。30° = 急傾斜地崩壊危険箇所基準は法的閾値で、 45° = 経験的人家不可上限。
- 傾斜は単一指標 (例: 標高) より「土砂災害感受性」に直結する点が独特。 学習者には「傾斜は土砂災害評価の最も基本的な物理量」という概念の良い例。
仮説検証と考察
本記事で立てた 7 つの仮説 (H1〜H7) と、3 エリアの傾斜ラスタ解析 + 警戒区域空間結合 + L38 ピクセル相関の照合結果:
| H | 主張 | 結果 | 判定 |
|---|---|---|---|
| H1 | 世羅町は緩傾斜丘陵が主で、平均傾斜 ≤ 12° かつ 30度超セル比率 ≤ 12% | 世羅 平均=19.81°, 30度超=14.6% | 部分支持 |
| H2 | 熊野町は急峻地形で平均傾斜 ≥ 18° かつ 30度超セル比率 ≥ 25% | 熊野 平均=22.32°, 30度超=32.2% | 支持 |
| H3 | 坂町は3エリアで平均傾斜が最大 + 急峻 (>45°) 比率も最大 | 世羅 mean=19.81°/p45=0.1%, 熊野 22.32°/0.2%, 坂 23.78°/0.2% | 支持 |
| H4 | 土砂災害警戒区域内の平均傾斜は区域外の 1.5 倍以上 (急傾斜地に指定が集中) | 世羅町: 内 15.18° / 外 20.05° (×0.76) | 熊野町: 内 12.08° / 外 24.47° (×0.49) | 坂町: 内 17.64° / 外 24.58° (×0.72) | 反証 |
| H5 | 30度超急傾斜セルは空間的に集塊 (8近傍同種率 >= 0.85) | 世羅町: 0.601 | 熊野町: 0.696 | 坂町: 0.787 | 反証 |
| H6 | 50cm版 (坂町) は 1m版 (世羅・熊野) より 30度超セル比率が高い | 世羅 pct30=14.6%, 熊野 32.2%, 坂 45.8% | 支持 |
| H7 | 傾斜と CS立体図 Saturation は正相関 (Pearson r >= 0.4 で 2 エリア以上) | 世羅町: r=+0.796 (n=286,686) | 熊野町: r=+0.669 (n=36,305) | 坂町: r=+0.824 (n=18,705) | 支持 |
判定サマリ: 支持 4 / 部分支持 1 / 反証 2 (全 7 仮説中)
主な発見 (5 点)
- H4 (警戒区域は急傾斜) は反証されたが、反対方向の関係が 3 エリア共通で量的に確認された: 警戒区域内の平均傾斜は区域外より低い (世羅 ×0.76, 熊野 ×0.49, 坂 ×0.72)。 これは警戒区域が「急傾斜面そのもの」ではなく「急斜面から土砂が到達する範囲 (谷出口・扇状地)を 含むように指定されているためで、土砂災害警戒区域の物理的指定論理を量的に明らかにした。 特別警戒 (red) は警戒 (yellow) より平均傾斜が高く、3 ゾーン間に明確な階層。 これは本記事の最も重要な発見。
- H7 (L38 CS Sat との正相関) が強支持された: Pearson r = +0.796 / +0.669 / +0.824 (世羅/熊野/坂)。 3 エリアすべてで強相関 (r ≥ 0.6)。さらに slope vs CS darkness では r >= 0.9 (世羅・熊野) と 極めて強い相関が出た ⇒ L38 CS立体図の暗さ (G低) は傾斜の最良の代理指標。 これは記事間整合性 (L38 と L39 が同自治体・同 DEM 由来であること) の量的裏付け。
- H3 (坂町は最急峻) が支持された: 平均傾斜 23.78° (3エリア最大), 30°超セル比率 45.8% (3 エリア最大)。50cm 解像度の効果も含めて、 平成30豪雨被災地の急斜面構造が量的に確認された。 ただし急峻 (>45°) 比率は 0.2% で熊野と同等 = 極端な崖は 3 エリアで稀。
- H6 (50cm 版は急傾斜検出率高) が支持された: 30°超比率は世羅 14.6% / 熊野 32.2% / 坂 45.8% で 坂町 (50cm) が圧倒。ただし「解像度差」と「地形類型差」が交絡しており、 50cm の効果単独を分離するには同自治体 1m vs 50cmの比較が必要 (発展課題)。 集塊性 (8 近傍同種率) も坂町 0.79 で最大 = 高解像度ほど急斜面塊が連続的に解像される。
- H5 (急傾斜の集塊性 ≥ 0.85) は反証: 実測 0.60-0.79。 ただし解像度に応じて単調増加する傾向は確認 ⇒ 仮説の閾値設定が高すぎた。 急傾斜は線形構造 (尾根線・崖線)として分布するため、面的指標 (8 近傍) では 過小評価される。これは「線状地形の集塊性は方向性を加味すべき」という方法論的発見。
3 エリアの地形リスク特性比較 (本記事の量的サマリ)
| 軸 | 世羅町 (1m) | 熊野町 (1m) | 坂町 (50cm) |
|---|---|---|---|
| 地形類型 | 緩傾斜丘陵 (中山間) | 急峻山地 + 都市平地 | 急斜面 + 崩壊跡 |
| 平均傾斜 | 19.81° | 22.32° | 23.78° |
| 30°超 (急傾斜) | 14.6% | 32.2% | 45.8% |
| 45°超 (急峻) | 0.09% | 0.19% | 0.20% |
| 5°未満 (平地) | 4.1% | 6.9% | 16.4% |
| 急傾斜集塊度 | 0.601 | 0.696 | 0.787 |
| 警戒内/外 比 (傾斜) | 0.76 | 0.49 | 0.72 |
| L38 CS Sat 相関 | +0.796 | +0.669 | +0.824 |
| 警戒区域率 | 7.0% | 32.1% | 21.6% |
考察
本記事の主たる発見は、「土砂災害警戒区域は急傾斜面そのものではなく、その影響範囲を含む」 ことが 3 エリア共通で量的に確認されたことである。仮説 H4 (警戒区域内の方が急傾斜) は反証され、 反対方向の関係 (警戒区域内 < 区域外) が一貫して観察された。これは 土砂災害警戒区域の指定目的 (= 土石流到達範囲・堆積範囲の保護) と整合する物理的論理であり、 オープンデータの 2 dataset 結合だけで再現可能なことを示している。 特別警戒 (red) は警戒 (yellow) より平均傾斜が高く、両ゾーンの機能差 (建物倒壊リスク vs 注意喚起)が 傾斜分布に明確に刻まれている。
L38 CS立体図 Saturation との Pearson 相関 (r=0.67-0.82) は記事間整合性の量的実証であり、 DoBoX の同シリーズ (LiDAR ファミリ) が同一 DEM から派生していることを裏付ける。 特に slope vs CS darkness の相関は r=0.9+ でCS立体図の暗さ成分は傾斜の最良代理と判明。 これは L38 が視覚解析向きの圧縮表現として有効であることの定量裏付けでもある。
解像度差 (1m vs 50cm) は overview レベルでは認識困難だが、本来解像度のサンプル (図 8) で 50cm の優位性が見え、また 30°超比率と集塊性の解像度依存性も確認された。 ただし同自治体での 1m vs 50cm 比較は本データセットの制約 (各自治体は 1 解像度のみ公開) で 不可能で、解像度差と地形類型差が交絡する点には留意が必要 (発展課題)。
急傾斜地の集塊性 (8 近傍同種率) は仮説 0.85 を下回り 0.6-0.79 だったが、 解像度に応じて単調増加する傾向は確認された。これは「線状地形構造の集塊性は面的指標で過小評価される」 という方法論的発見で、方位 (aspect) を加味した方向性集塊性を計算する発展課題に繋がる。
発展課題
結果 X1 → 仮説 Y1 → 課題 Z1: 警戒区域内外の傾斜分布の物理的解釈深掘り (本記事の発見の深掘り)
結果 X1: 3 エリア共通で警戒区域内 < 区域外の平均傾斜。特別警戒は警戒より急傾斜。 H4 を反対方向で支持する量的傾向。
新仮説 Y1: 警戒区域は「土石流の発生源 (急傾斜面 30°超) + 流下範囲 (15-30°) + 堆積範囲 (扇状地 5°以下)」 の 3 帯を組み合わせて指定されており、平均値だけでは見えない3 段の幾何構造を持つ。
課題 Z1: 各警戒区域ポリゴンを個別に傾斜分布解析。最大傾斜・最小傾斜・分布形状で 3 タイプ (急斜面卓越型 / 流下範囲型 / 堆積範囲型) に分類。 さらに土石流・急傾斜・地すべりの 3 種別ごとに比較すると、各災害タイプの幾何構造が見える。 これにより警戒区域の地形リスク類型を定量化できる。
結果 X2 → 仮説 Y2 → 課題 Z2: 方位を加味した方向性集塊性
結果 X2: 急傾斜の 8 近傍同種率は 0.6-0.79 で仮説 0.85 を下回ったが、 線状地形 (尾根線・崖線) の存在から方向性が示唆される。
新仮説 Y2: 急傾斜セルは等高線に沿った方向 (= 斜面の走向)には連続するが、 直交方向 (斜面方向) には不連続。方位を加味すれば線状集塊度は 0.9+ になる。
課題 Z2: 各セルで方位 (aspect) を計算 (DEM 勾配ベクトルの方向)、 等高線方向 (= 方位 ⊥) のセル間の連続性のみを評価する方向性集塊度を計算。 標準の Moran's I を方位重み付き隣接行列で実装。 これは「線状地形の集塊性」を初めて量化する方法論的貢献になる。
結果 X3 → 仮説 Y3 → 課題 Z3: 急峻地形と古崩壊地の同定
結果 X3: 45° 超急峻セルは 3 エリアで 0.1-0.2% と稀少。これらは特定の崖・崩壊跡に 集塊する可能性。
新仮説 Y3: 急峻セル + その周辺 (50m バッファ) の中傾斜セル混在域は、 古崩壊地形 (paleolandslide) の候補。過去の崩壊跡が地形に残る。
課題 Z3: 各エリアの 45° 超セルのクラスタリング (DBSCAN) で連続塊を抽出。 各クラスタの周辺バッファに含まれる傾斜分布を解析し、古崩壊地形類型 (新鮮崩壊・古崩壊・侵食地形) に分類。 H30 豪雨の崩壊実績 (国交省データ) と空間照合して精度評価。 高精度なら「傾斜ラスタからの古崩壊地形自動検出」を提案できる ⇒ 砂防研究の応用可能。
結果 X4 → 仮説 Y4 → 課題 Z4: 標高ラスタからの傾斜再計算と本データとの照合
結果 X4: L38 CS立体図 Saturation との r=0.67-0.82 は強相関だが完全ではない。 他の派生過程 (例えば曲率と傾斜の重ね合わせ) も影響している。
新仮説 Y4: 標高ラスタ (DTM, dsid 1635/1636) から直接 Horn 法で傾斜を再計算すると、 DoBoX 公式傾斜と Pearson r ≥ 0.99 の極めて強い一致が出る ⇒ 公式が Horn 法を使っている裏付け。
課題 Z4: 標高 GeoTIFF を読み込んで scipy.ndimage.sobel や手計算で
3×3 Horn 法を実装し、本データと相関係数で照合。さらに計算法の違い (Horn vs Zevenbergen)
で結果がどう変わるかも比較。教材としても優れた発展課題。
結果 X5 → 仮説 Y5 → 課題 Z5: 多自治体一括の傾斜指標化と地形類型クラスタリング
結果 X5: 本記事は 3 自治体のみ。30°超比率で世羅 < 熊野 < 坂 の階層が見えたが、 サンプル数が少なすぎて地形類型の自然分類は仮説止まり。
新仮説 Y5: 全 22 自治体 (1m 版) で平均傾斜・p90・30°超比率を計算すると、 中山間 / 都市近郊 / 沿岸被災地 / 島嶼 などの地形類型クラスタが自然分類される。
課題 Z5: 22 自治体すべての 1m 版を順次 DL → overview 読込 → 5 階級構成計算で 22 個の特徴ベクトル (5次元) を作る。k-means や階層クラスタリングで類型化。 さらに各自治体の警戒区域率と平均傾斜を散布図にプロット ⇒ 「平均傾斜 vs 警戒区域率の正相関」が量的に確認されれば 「傾斜分布は土砂災害リスクの代理指標」という新提案ができる。
結果 X6 → 仮説 Y6 → 課題 Z6: 1m vs 50cm の同自治体比較 (解像度効果の純粋分離)
結果 X6: 30°超比率は坂町 (50cm) で最大だが、地形類型差と解像度差が交絡。
新仮説 Y6: 同自治体で 1m と 50cm の両方が公開されている自治体 (例: 三原市・呉市・尾道市等) を使えば、 解像度差の純粋効果が分離できる。同自治体での 50cm vs 1m は、急傾斜比率を 1.2-1.5 倍に増やす。
課題 Z6: 同自治体で両解像度公開の市町村を選び、ピクセル単位で空間整合した上で 分布差を計算。さらに 1m を 50cm に再投影 (resampling) して計算上の同 shape にしてから比較すると、 「解像度差の数値効果」が分離可能になる。これは GIS リテラシ教材として優れた題材。
結果 X7 → 仮説 Y7 → 課題 Z7: 過去被災地のセル単位検出 (ML 応用)
結果 X7: 坂町の特別警戒区域 (0.40 km²) と急傾斜セル (45.8%) は 相互に重なるが、過去の被災実績との照合は未実施。
新仮説 Y7: 平成30年7月豪雨で実際に崩壊が発生したセルは傾斜・方位・曲率の 特定パターン (傾斜 30-50° + 凹型曲率 + 北向き等) を持つ。これらの特徴量で機械学習による被災予測が可能。
課題 Z7: 国交省の H30 豪雨被災調査データ (発生位置 GIS) を入手し、 傾斜 + 方位 + 曲率 + L38 CS Sat の特徴でロジスティック回帰や Random Forest による 被災予測モデルを訓練。AUC 0.8 以上が出れば傾斜ベースの土砂災害発生予測モデルとして実装可能。 これは社会実装に直結する研究的発展。