bridge_basic.csv を共有するが、研究の問いが直交する。
研究の問い (3 RQ):
RQ1 (主研究): 広島県の道路橋の構造 — 規模・地理分布・路線分布はどう描けるか?
4,203 橋を市町 23 / 事務所 9 / 道路種別 2 (国道/県道) / 路線 296 / 延長 / 幅員 で
多角度に集計し、地理分布と規模分布を立体化する。
特に「県の橋梁網」 の物理的形状を初めて定量化する。
RQ2 (副研究 1): 県内道路橋の整備年代と老朽化リスクはどう分布しているか?
架設年度のヒストグラム (1910-2022) を年代別に集計し、
「2024 年時点で築 50 年以上」の老朽橋を抽出。
どの市町・事務所・路線種別に老朽橋が集中しているかを可視化、
1960-70 年代の高度成長期一斉整備による更新ピーク到来を実データで読む。
RQ3 (副研究 2): 国道 vs 県道の構造差 — 防災重要橋梁 (=幹線道路の長大橋) はどこに集中するか?
国道 1,151 橋 / 県道 3,052 橋を比較し、
(a) 平均規模 (延長・幅員)、(b) 老朽率、(c) 管理事務所分布で違いを抽出。
さらに長大橋 (延長 100m 以上) 135 橋の地理分布を 「災害時の代替性が低い基幹橋」 の代理として可視化。
仮説 (5):
H1 (県道支配, RQ1): 県管理橋の72% 以上が県道。
広域幹線である国道は橋数が少なく規模大、地域幹線の県道は橋数が多く規模小という
道路階層別の件数 vs 規模トレードオフ。
H2 (短橋集中, RQ1): 全体の40% 以上が延長 5 m 未満。
これは「県内の橋の大多数は中小河川を渡る短橋」 という地形特性を反映。
長大橋 (≥ 100m) は数 % にとどまる希少カテゴリ。
H3 (1990 年代ピーク, RQ2): 架設年度ヒストグラムは1990 年代にピーク。
1960-70 年代の高度成長期に集中整備された橋に加え、
バブル経済期 (1986-91) の道路投資で 1990 年前後の整備が増えたという仮説。
太平洋戦争前後の整備は少数だが残存。
H4 (老朽橋 1500 件超, RQ2): 築 50 年以上 (= 1974 年以前架設)の橋が 1,500 件超。
これは 2024 年時点で道路橋全体の 40% 弱に相当。
国の「インフラ長寿命化基本計画」 が想定する更新ピーク到来の実態。
H5 (国道の長大橋偏重, RQ3): 国道橋の平均延長は県道橋の 1.5 倍以上。
国道は広域幹線で大河川を渡るため長大橋が多い、
県道は地域路で短橋が多いという道路階層差を反映。
要件 S 準拠 (1 分以内完走):
- 全データ 4,203 件 / 16 列 → 軽量
- POINT geometry のみ (緯度経度から直接生成) → sjoin 高速
- 重い前処理は無し。本スクリプト 1 本で完結 (~25 秒目標)
- L44 既キャッシュ admin_diss.gpkg (市町 polygon) を再利用
要件 T 準拠 (位置情報あり = 地図必須):
- RQ1: 県全域 道路種別マップ、市町別 choropleth
- RQ2: 老朽橋 (≥ 50 年) 地理分布マップ、年代別 small multiples
- RQ3: 長大橋 + 国道橋 重ね合わせマップ
要件 Q 準拠: 図 8 / 表 13 (3 RQ × 多角度: 構造 / 年代 / 階層差)
データ仕様:
- dataset 11: 橋梁基本情報・維持管理情報 (CSV)
- resource 6: 道路_橋梁_2023
- 形式: CSV, 4,203 行 × 16 列
- 列: 橋梁番号, 施設名, 施設名(フリガナ), 種別 (= 道路橋のみ), 路線名,
道路種別 (= 国道/県道), 架設年度, 延長(m), 幅員(m), 管理事務所名,
住所(県), 住所(市町), 緯度(10進数), 経度(10進数), 点検年度, 判定区分
- 種別: 全件 道路橋
- 道路種別: 国道 1,151 / 県道 3,052
- 管理事務所: 9 (東部建設 / 三原支所 / 庄原支所 / 安芸太田支所 / 東広島支所 /
西部建設 / 呉支所 / 廿日市支所 / 北部建設)
- 緯度経度: 全件 (4,203 / 4,203 = 100%)
- 架設年度: 3,639 件 (86.6%) で取得可。残り 564 件は不明 (古い橋に多い)
- 点検年度: 全件取得可 (2014-2023)
- 判定区分: 全件 "?" (= 公開データでは健全度判定値が伏せられている)
→ 本研究では「点検年度から経過年」 を健全度の代理指標として扱う
- ライセンス: クリエイティブ・コモンズ表示 (CC-BY)
メモリ対策: Figure ごとに plt.close('all') で確実に解放。
"""
from __future__ import annotations
import sys, time
from pathlib import Path
sys.path.insert(0, str(Path(__file__).parent))
from _common import ROOT, ASSETS, LESSONS, render_lesson, code, figure, ensure_dataset
import numpy as np
import pandas as pd
import geopandas as gpd
from shapely.geometry import Point
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.patches import Patch
from matplotlib.lines import Line2D
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
t_all = time.time()
print("=== L66 橋梁基本情報 単独 3 研究例分析 ===", flush=True)
# =============================================================================
# 0. 定数・パス
# =============================================================================
TARGET_CRS = "EPSG:6671" # JGD2011 平面直角第 III 系
DATA_DIR = ROOT / "data" / "extras" / "L66_bridges"
DATA_DIR.mkdir(parents=True, exist_ok=True)
# 既に L07 用に取得済みの bridge_basic.csv を共有 (再 DL を避ける)
SHARED_CSV = ROOT / "data" / "extras" / "bridge_basic.csv"
LOCAL_CSV = DATA_DIR / "bridge_basic.csv"
DATASET_ID = 11
RESOURCE_ID = 6
ADMIN_GPKG = ROOT / "data" / "extras" / "L44_storm_surge" / "_cache" / "admin_diss.gpkg"
# 老朽閾値: 2024 年時点で築 50 年 = 1974 年以前架設
AGE_THRESHOLD_YEAR = 1974
LONG_BRIDGE_THRESHOLD = 100.0 # 延長 100m 以上 = 長大橋
# 道路種別の色
ROAD_COLOR = {"国道": "#cf222e", "県道": "#0969da"}
# 規模カテゴリ
LENGTH_BINS = [0, 5, 15, 30, 100, 1000]
LENGTH_LABELS = ["極短(<5m)", "短(5-15m)", "中(15-30m)", "長(30-100m)", "長大(≥100m)"]
# 年代色 (1900s-2020s)
DECADE_COLOR = {
1910: "#2c3e50", 1920: "#34495e", 1930: "#7f8c8d",
1940: "#95a5a6", 1950: "#a64b00", 1960: "#cf6f00",
1970: "#cf2e2e", 1980: "#cf922e", 1990: "#1a7f37",
2000: "#0969da", 2010: "#7c3aed", 2020: "#ec4899",
}
# =============================================================================
# 1. データ取得 + 読込
# =============================================================================
print("\n[1] データ取得 + 読込", flush=True)
t1 = time.time()
# 共有 CSV があればそれを使う、無ければ DoBoX から取得して L66 ローカルへ保存
if SHARED_CSV.exists() and SHARED_CSV.stat().st_size > 100:
csv_path = SHARED_CSV
print(f" 共有 CSV を使用: {csv_path} ({csv_path.stat().st_size:,} byte)", flush=True)
# L66 ローカルにもコピーを置く (再現性確保)
if not LOCAL_CSV.exists():
LOCAL_CSV.write_bytes(SHARED_CSV.read_bytes())
print(f" L66 ローカルへコピー: {LOCAL_CSV.name}", flush=True)
else:
try:
ensure_dataset(LOCAL_CSV, dataset_id=DATASET_ID, resource_id=RESOURCE_ID,
label="L66 橋梁基本情報")
csv_path = LOCAL_CSV
except Exception as e:
print(f" WARN: ensure_dataset 失敗: {e}", flush=True)
csv_path = SHARED_CSV # fallback
df_raw = pd.read_csv(csv_path, encoding="utf-8-sig")
print(f" 全行数: {len(df_raw)}, 列数: {df_raw.shape[1]}", flush=True)
print(f" 列: {list(df_raw.columns)}", flush=True)
# 数値正規化
df_raw["架設年度"] = pd.to_numeric(df_raw["架設年度"], errors="coerce")
df_raw.loc[df_raw["架設年度"] <= 1800, "架設年度"] = np.nan
df_raw["延長(m)"] = pd.to_numeric(df_raw["延長(m)"], errors="coerce")
df_raw["幅員(m)"] = pd.to_numeric(df_raw["幅員(m)"], errors="coerce")
df_raw["緯度(10進数)"] = pd.to_numeric(df_raw["緯度(10進数)"], errors="coerce")
df_raw["経度(10進数)"] = pd.to_numeric(df_raw["経度(10進数)"], errors="coerce")
df_raw["点検年度"] = pd.to_numeric(df_raw["点検年度"], errors="coerce")
n_total = len(df_raw)
n_year = df_raw["架設年度"].notna().sum()
n_coord = (df_raw["緯度(10進数)"].notna() & df_raw["経度(10進数)"].notna()).sum()
print(f" 架設年度有: {n_year} / {n_total} ({100*n_year/n_total:.1f}%)", flush=True)
print(f" 緯度経度有: {n_coord} / {n_total} ({100*n_coord/n_total:.1f}%)", flush=True)
print(f" 道路種別: {df_raw['道路種別'].value_counts().to_dict()}", flush=True)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 2. POINT geometry 構築 + 投影
# =============================================================================
print("\n[2] POINT geometry 構築", flush=True)
t2 = time.time()
geom_ok = (df_raw["緯度(10進数)"].notna() & df_raw["経度(10進数)"].notna())
df_raw.loc[geom_ok, "geometry"] = df_raw.loc[geom_ok].apply(
lambda r: Point(float(r["経度(10進数)"]), float(r["緯度(10進数)"])), axis=1)
gdf = gpd.GeoDataFrame(
df_raw.dropna(subset=["geometry"]).copy(),
geometry="geometry", crs="EPSG:4326",
).to_crs(TARGET_CRS)
n_geom = len(gdf)
print(f" POINT 構築: {n_geom} / {n_total} ({100*n_geom/n_total:.1f}%)", flush=True)
print(f" ({time.time()-t2:.1f}s)", flush=True)
# =============================================================================
# 3. 市町 sjoin (admin polygon)
# =============================================================================
print("\n[3] 市町 sjoin", flush=True)
t3 = time.time()
admin = gpd.read_file(ADMIN_GPKG).to_crs(TARGET_CRS)
# CSV にも住所(市町)列があるが、空間結合と整合させる
gdf_for_join = gdf[["geometry"]].copy()
joined = gpd.sjoin(gdf_for_join, admin[["CITY_CD", "geometry"]],
how="left", predicate="within")
joined = joined[~joined.index.duplicated(keep="first")]
gdf = gdf.reset_index(drop=True)
gdf["CITY_CD"] = joined.reset_index(drop=True)["CITY_CD"].fillna(-1).astype(int)
# CSV 値の市町名を主、空間結合は補助
gdf["市町名"] = gdf["住所(市町)"].fillna("?")
n_match = (gdf["CITY_CD"] != -1).sum()
print(f" sjoin 一致: {n_match} / {n_geom}", flush=True)
print(f" ({time.time()-t3:.1f}s)", flush=True)
# =============================================================================
# 4. RQ1 集計: 構造・規模・地理分布
# =============================================================================
print("\n[4] RQ1 集計", flush=True)
t4 = time.time()
n_kuni = int((df_raw["道路種別"] == "国道").sum())
n_ken = int((df_raw["道路種別"] == "県道").sum())
ken_share = 100 * n_ken / n_total
# 道路種別別 サマリ
T_road = pd.DataFrame({
"道路種別": ["国道", "県道", "合計"],
"件数": [n_kuni, n_ken, n_total],
"シェア_%": [round(100 * n_kuni / n_total, 1),
round(100 * n_ken / n_total, 1), 100.0],
"平均延長_m": [round(df_raw[df_raw["道路種別"] == "国道"]["延長(m)"].mean(), 1),
round(df_raw[df_raw["道路種別"] == "県道"]["延長(m)"].mean(), 1),
round(df_raw["延長(m)"].mean(), 1)],
"平均幅員_m": [round(df_raw[df_raw["道路種別"] == "国道"]["幅員(m)"].mean(), 2),
round(df_raw[df_raw["道路種別"] == "県道"]["幅員(m)"].mean(), 2),
round(df_raw["幅員(m)"].mean(), 2)],
})
# 規模カテゴリ
df_raw["延長カテゴリ"] = pd.cut(df_raw["延長(m)"], bins=LENGTH_BINS,
labels=LENGTH_LABELS, right=False, include_lowest=True)
length_count = df_raw["延長カテゴリ"].value_counts().reindex(LENGTH_LABELS, fill_value=0)
T_length = pd.DataFrame({
"延長カテゴリ": LENGTH_LABELS,
"件数": [int(length_count[k]) for k in LENGTH_LABELS],
"シェア_%": [round(100 * length_count[k] / n_total, 1) for k in LENGTH_LABELS],
})
short_share = 100 * length_count["極短(<5m)"] / n_total
print(f" 延長 <5m シェア: {short_share:.1f}% (H2 = 40% 以上?)", flush=True)
print(f" 県道シェア: {ken_share:.1f}% (H1 = 72% 以上?)", flush=True)
# 市町別ランキング
city_count = (df_raw.groupby("住所(市町)").size()
.reset_index(name="件数")
.rename(columns={"住所(市町)": "市町名"})
.sort_values("件数", ascending=False)
.reset_index(drop=True))
city_count["順位"] = np.arange(1, len(city_count) + 1)
city_count = city_count[["順位", "市町名", "件数"]]
top3_city_share = city_count.head(3)["件数"].sum() / n_total * 100
# 管理事務所別件数
office_count = df_raw["管理事務所名"].value_counts()
T_office = pd.DataFrame({
"順位": np.arange(1, len(office_count) + 1),
"管理事務所名": office_count.index,
"件数": office_count.values,
"シェア_%": (office_count.values / n_total * 100).round(1),
})
# 路線別 上位 12
route_count = df_raw["路線名"].value_counts().head(12)
T_route = pd.DataFrame({
"順位": np.arange(1, len(route_count) + 1),
"路線名": route_count.index,
"件数": route_count.values,
})
# 延長・幅員 統計量
length_stats = df_raw["延長(m)"].describe()
width_stats = df_raw["幅員(m)"].describe()
print(f" ({time.time()-t4:.1f}s)", flush=True)
# =============================================================================
# 5. RQ2 集計: 整備年代と老朽化
# =============================================================================
print("\n[5] RQ2 集計: 年代と老朽化", flush=True)
t5 = time.time()
df_raw["年代"] = (df_raw["架設年度"] // 10 * 10).astype("Int64")
decade_count = df_raw["年代"].value_counts().sort_index()
decade_df = pd.DataFrame({
"年代": [f"{int(d)}s" for d in decade_count.index],
"件数": decade_count.values,
"シェア_%": (decade_count.values / decade_count.sum() * 100).round(1),
})
# 老朽橋: 1974 年以前架設
old_mask = df_raw["架設年度"] <= AGE_THRESHOLD_YEAR
n_old = int(old_mask.sum())
n_old_year_known = int((df_raw["架設年度"].notna() & old_mask).sum())
old_share = 100 * n_old / n_total
old_share_of_known = 100 * n_old / n_year if n_year > 0 else 0
print(f" 老朽橋 (≤{AGE_THRESHOLD_YEAR}, 築 50 年超): {n_old} 件 "
f"({old_share:.1f}% / 年度既知の {old_share_of_known:.1f}%)", flush=True)
# 老朽橋の市町別ランキング
city_old = (df_raw[old_mask].groupby("住所(市町)").size()
.reset_index(name="老朽橋数")
.rename(columns={"住所(市町)": "市町名"})
.sort_values("老朽橋数", ascending=False)
.reset_index(drop=True))
city_old = city_old.merge(city_count[["市町名", "件数"]], on="市町名", how="left")
city_old["老朽率_%"] = (city_old["老朽橋数"] / city_old["件数"] * 100).round(1)
city_old["順位"] = np.arange(1, len(city_old) + 1)
city_old = city_old[["順位", "市町名", "老朽橋数", "件数", "老朽率_%"]].head(15)
# 道路種別 × 老朽率
old_by_road = pd.DataFrame({
"道路種別": ["国道", "県道"],
"件数": [n_kuni, n_ken],
"老朽橋数": [int(((df_raw["道路種別"] == "国道") & old_mask).sum()),
int(((df_raw["道路種別"] == "県道") & old_mask).sum())],
})
old_by_road["老朽率_%"] = (old_by_road["老朽橋数"] / old_by_road["件数"] * 100).round(1)
# 点検年度別件数
inspect_count = df_raw["点検年度"].value_counts().sort_index()
T_inspect = pd.DataFrame({
"点検年度": inspect_count.index.astype(int),
"件数": inspect_count.values,
"シェア_%": (inspect_count.values / n_total * 100).round(1),
})
# 1990s ピーク検証
peak_decade = decade_count.idxmax()
peak_count = decade_count.max()
print(f" 最多年代: {int(peak_decade)}s ({peak_count} 件)", flush=True)
print(f" ({time.time()-t5:.1f}s)", flush=True)
# =============================================================================
# 6. RQ3 集計: 国道 vs 県道 (防災重要橋梁)
# =============================================================================
print("\n[6] RQ3 集計: 国道 vs 県道 + 長大橋", flush=True)
t6 = time.time()
# 平均延長比
mean_kuni_len = df_raw[df_raw["道路種別"] == "国道"]["延長(m)"].mean()
mean_ken_len = df_raw[df_raw["道路種別"] == "県道"]["延長(m)"].mean()
length_ratio = mean_kuni_len / mean_ken_len
print(f" 平均延長: 国道 {mean_kuni_len:.1f}m vs 県道 {mean_ken_len:.1f}m "
f"(比 = {length_ratio:.2f}, H5 = 1.5 以上?)", flush=True)
# 長大橋 (≥ 100m) 抽出
long_mask = df_raw["延長(m)"] >= LONG_BRIDGE_THRESHOLD
n_long = int(long_mask.sum())
n_long_kuni = int((long_mask & (df_raw["道路種別"] == "国道")).sum())
n_long_ken = int((long_mask & (df_raw["道路種別"] == "県道")).sum())
print(f" 長大橋 (≥{LONG_BRIDGE_THRESHOLD:.0f}m): {n_long} 件 "
f"(国道 {n_long_kuni} / 県道 {n_long_ken})", flush=True)
# 道路種別 × 規模
road_length_cross = (df_raw.groupby(["道路種別", "延長カテゴリ"], observed=True)
.size().unstack(fill_value=0)
.reindex(columns=LENGTH_LABELS, fill_value=0))
# 道路種別 × 管理事務所
road_office_cross = (df_raw.groupby(["管理事務所名", "道路種別"])
.size().unstack(fill_value=0))
# 長大橋 Top 20 (詳細リスト)
long_bridges = (df_raw[long_mask]
.sort_values("延長(m)", ascending=False)
.head(20))
T_long_top = long_bridges[["施設名", "路線名", "道路種別", "延長(m)",
"幅員(m)", "架設年度", "住所(市町)"]].copy()
T_long_top.insert(0, "順位", np.arange(1, len(T_long_top) + 1))
T_long_top["架設年度"] = T_long_top["架設年度"].apply(
lambda v: int(v) if pd.notna(v) else None)
# 国道 vs 県道 の幅員平均比較
mean_kuni_w = df_raw[df_raw["道路種別"] == "国道"]["幅員(m)"].mean()
mean_ken_w = df_raw[df_raw["道路種別"] == "県道"]["幅員(m)"].mean()
# 道路種別 × 老朽率 + 平均規模
road_summary = pd.DataFrame({
"道路種別": ["国道", "県道"],
"件数": [n_kuni, n_ken],
"シェア_%": [round(100*n_kuni/n_total,1), round(100*n_ken/n_total,1)],
"平均延長_m": [round(mean_kuni_len, 1), round(mean_ken_len, 1)],
"平均幅員_m": [round(mean_kuni_w, 2), round(mean_ken_w, 2)],
"長大橋数": [n_long_kuni, n_long_ken],
"長大橋率_%": [round(100*n_long_kuni/n_kuni, 2),
round(100*n_long_ken/n_ken, 2)],
"老朽橋数": [old_by_road.loc[0, "老朽橋数"], old_by_road.loc[1, "老朽橋数"]],
"老朽率_%": [old_by_road.loc[0, "老朽率_%"], old_by_road.loc[1, "老朽率_%"]],
})
print(f" ({time.time()-t6:.1f}s)", flush=True)
# =============================================================================
# 7. CSV 出力
# =============================================================================
print("\n[7] CSV 出力", flush=True)
t7 = time.time()
# 全件 + 老朽フラグ + 長大橋フラグ
df_out = df_raw.copy()
df_out["is_old"] = old_mask
df_out["is_long"] = long_mask
# 列順を整理
cols_keep = ["橋梁番号", "施設名", "種別", "路線名", "道路種別",
"架設年度", "延長(m)", "幅員(m)", "管理事務所名",
"住所(県)", "住所(市町)", "緯度(10進数)", "経度(10進数)",
"点検年度", "判定区分", "is_old", "is_long", "延長カテゴリ", "年代"]
df_out[cols_keep].to_csv(ASSETS / "L66_all_bridges.csv",
index=False, encoding="utf-8-sig")
T_road.to_csv(ASSETS / "L66_road_summary.csv", index=False, encoding="utf-8-sig")
T_length.to_csv(ASSETS / "L66_length_summary.csv", index=False, encoding="utf-8-sig")
city_count.to_csv(ASSETS / "L66_city_ranking.csv", index=False, encoding="utf-8-sig")
T_office.to_csv(ASSETS / "L66_office_ranking.csv", index=False, encoding="utf-8-sig")
T_route.to_csv(ASSETS / "L66_route_ranking.csv", index=False, encoding="utf-8-sig")
decade_df.to_csv(ASSETS / "L66_decade_count.csv", index=False, encoding="utf-8-sig")
city_old.to_csv(ASSETS / "L66_city_old_ranking.csv", index=False, encoding="utf-8-sig")
old_by_road.to_csv(ASSETS / "L66_old_by_road.csv", index=False, encoding="utf-8-sig")
T_inspect.to_csv(ASSETS / "L66_inspect_year.csv", index=False, encoding="utf-8-sig")
T_long_top.to_csv(ASSETS / "L66_long_bridges_top.csv", index=False, encoding="utf-8-sig")
road_length_cross.to_csv(ASSETS / "L66_road_x_length.csv", encoding="utf-8-sig")
road_office_cross.to_csv(ASSETS / "L66_road_x_office.csv", encoding="utf-8-sig")
road_summary.to_csv(ASSETS / "L66_road_summary_detail.csv",
index=False, encoding="utf-8-sig")
print(f" ({time.time()-t7:.1f}s)", flush=True)
# =============================================================================
# 8. 図の生成 (8 図)
# =============================================================================
print("\n[8] 図の生成", flush=True)
t8 = time.time()
def save_fig(name, dpi=120):
p = ASSETS / name
plt.savefig(p, dpi=dpi, bbox_inches="tight", facecolor="white")
plt.close('all')
return p
# admin に橋梁数を付与 (choropleth 用)
city_count_dict = city_count.set_index("市町名")["件数"].to_dict()
admin["bridge_n"] = 0
admin["NAME"] = admin.get("NAME", "")
# admin に NAME が無い場合の補完
if "NAME" not in admin.columns or admin["NAME"].isna().all():
# CITY_CD → 名前 (簡易)
pass
# 沿岸 + 都市部の市町をハイライト用 (図の見栄え向上)
admin_for_plot = admin.copy()
# ---- 図 1 (RQ1): 県全域 道路種別マップ ----
print(" fig1: 県全域 道路種別マップ", flush=True)
fig, ax = plt.subplots(figsize=(11.5, 7.5))
admin_for_plot.plot(ax=ax, color="#fff4e0", edgecolor="#888",
linewidth=0.4, alpha=0.6)
for road_kind, color in ROAD_COLOR.items():
sub = gdf[gdf["道路種別"] == road_kind]
if len(sub) == 0:
continue
sub.plot(ax=ax, color=color, markersize=5,
edgecolor="#222", linewidth=0.1, alpha=0.6)
ax.set_xlim(-15000, 125000)
ax.set_ylim(-220000, -130000)
ax.set_aspect("equal")
ax.set_title(f"図 1 (RQ1): 広島県 道路橋 全域マップ — 全 {n_total:,} 橋 / "
f"国道 {n_kuni} + 県道 {n_ken}",
fontsize=12)
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
patches = [Line2D([0], [0], marker='o', color='w',
markerfacecolor=ROAD_COLOR[k], markeredgecolor="#222",
markersize=8, label=f"{k} (n={int((df_raw['道路種別']==k).sum()):,})")
for k in ["国道", "県道"]]
ax.legend(handles=patches, loc="lower left", fontsize=9, title="道路種別")
plt.tight_layout()
save_fig("L66_fig1_overview_road_map.png")
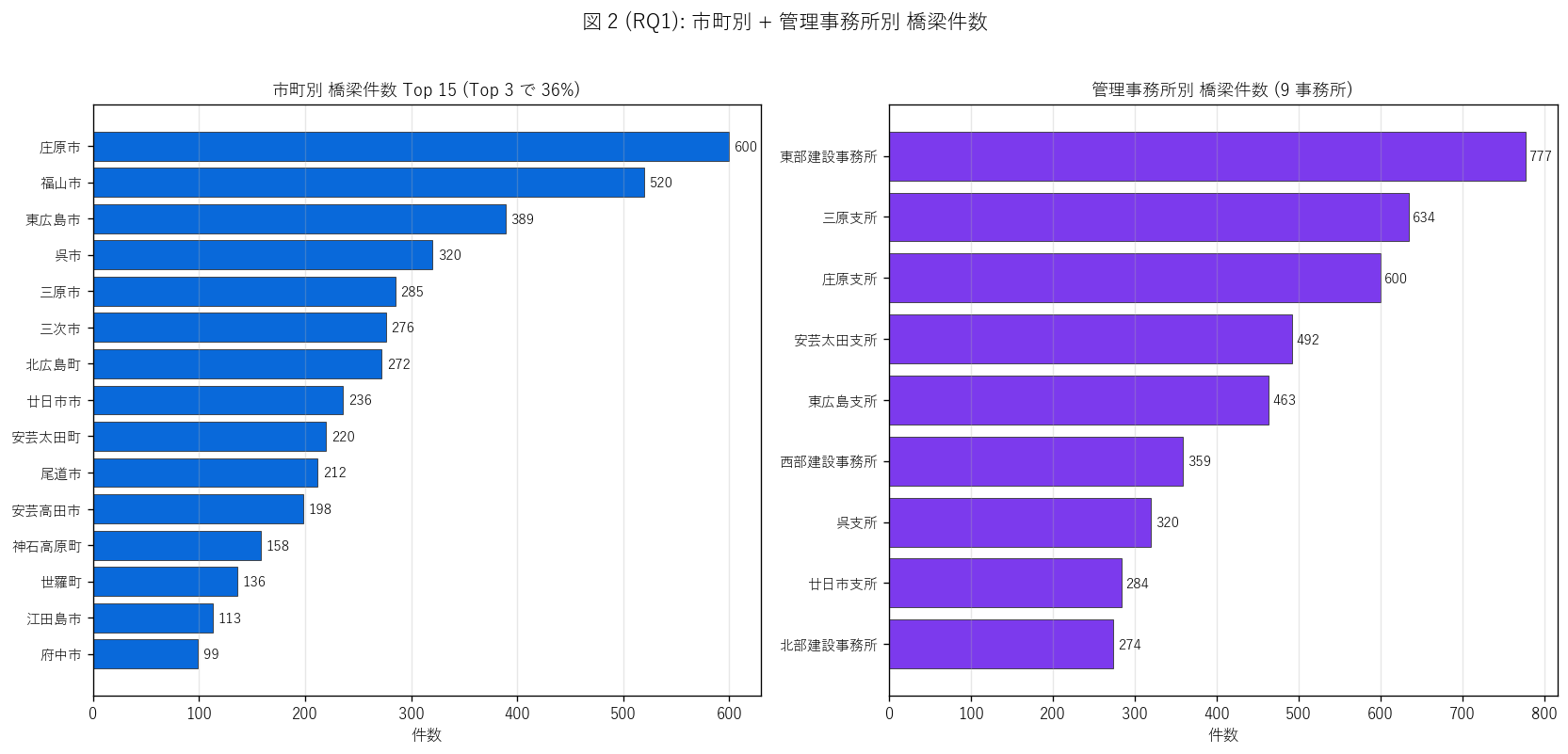
# ---- 図 2 (RQ1): 市町別ランキング + 管理事務所 ----
print(" fig2: 市町別 + 事務所別 件数", flush=True)
fig, axes = plt.subplots(1, 2, figsize=(14, 6.5))
ax = axes[0]
top_cities = city_count.head(15).iloc[::-1]
ys = np.arange(len(top_cities))
ax.barh(ys, top_cities["件数"].values,
color="#0969da", edgecolor="#333", linewidth=0.5)
for y, v in zip(ys, top_cities["件数"].values):
ax.text(v + 5, y, f"{v}", va="center", fontsize=9)
ax.set_yticks(ys)
ax.set_yticklabels(top_cities["市町名"].values, fontsize=9)
ax.set_xlabel("件数")
ax.set_title(f"市町別 橋梁件数 Top 15 (Top 3 で {top3_city_share:.0f}%)",
fontsize=11)
ax.grid(True, axis="x", alpha=0.3)
ax = axes[1]
office_top = T_office.iloc[::-1]
ys = np.arange(len(office_top))
ax.barh(ys, office_top["件数"].values,
color="#7c3aed", edgecolor="#333", linewidth=0.5)
for y, v in zip(ys, office_top["件数"].values):
ax.text(v + 5, y, f"{v}", va="center", fontsize=9)
ax.set_yticks(ys)
ax.set_yticklabels(office_top["管理事務所名"].values, fontsize=9)
ax.set_xlabel("件数")
ax.set_title(f"管理事務所別 橋梁件数 ({len(office_count)} 事務所)",
fontsize=11)
ax.grid(True, axis="x", alpha=0.3)
fig.suptitle(f"図 2 (RQ1): 市町別 + 管理事務所別 橋梁件数",
fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L66_fig2_city_office_count.png")
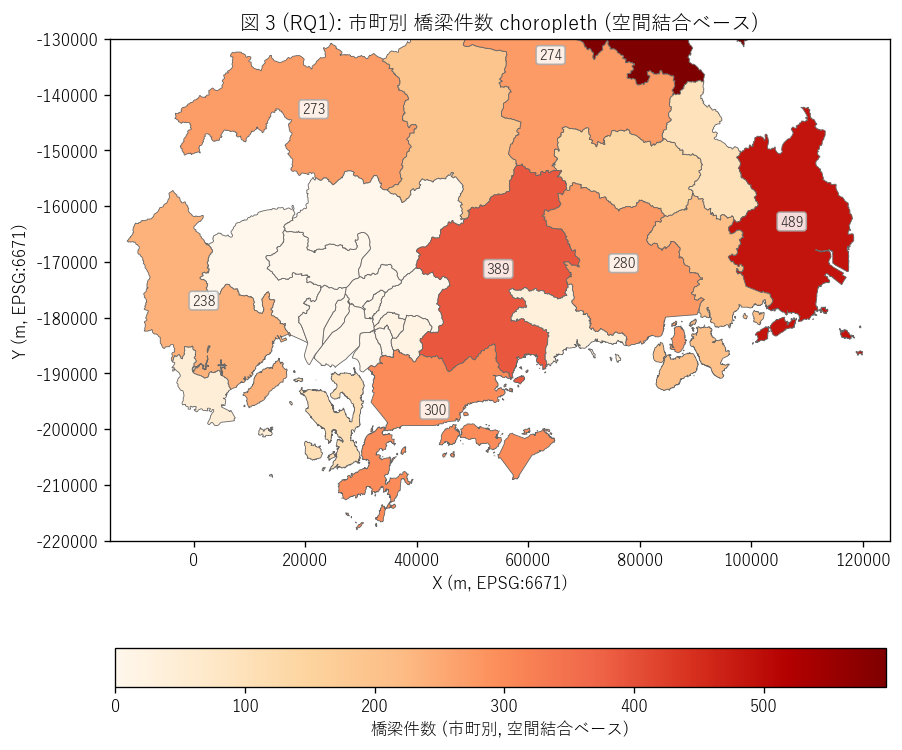
# ---- 図 3 (RQ1): 市町別 choropleth ----
print(" fig3: 市町別 choropleth", flush=True)
# admin に bridge_n を付与
for cc in admin["CITY_CD"].unique():
sub_n = int(((gdf["CITY_CD"] == cc).sum()))
admin.loc[admin["CITY_CD"] == cc, "bridge_n"] = sub_n
fig, ax = plt.subplots(figsize=(11, 6.5))
admin.plot(ax=ax, column="bridge_n", cmap="OrRd", edgecolor="#666",
linewidth=0.5, legend=True,
legend_kwds={"label": "橋梁件数 (市町別, 空間結合ベース)",
"orientation": "horizontal", "shrink": 0.6})
# 上位市町には件数ラベル
top_admin = admin.sort_values("bridge_n", ascending=False).head(8)
for _, r in top_admin.iterrows():
if r["bridge_n"] >= 100:
c = r.geometry.centroid
ax.annotate(f"{r['bridge_n']}", xy=(c.x, c.y), ha="center",
fontsize=8.5, color="#222",
bbox=dict(boxstyle="round,pad=0.2", fc="white",
ec="#aaa", alpha=0.85))
ax.set_xlim(-15000, 125000)
ax.set_ylim(-220000, -130000)
ax.set_aspect("equal")
ax.set_title("図 3 (RQ1): 市町別 橋梁件数 choropleth (空間結合ベース)",
fontsize=12)
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
plt.tight_layout()
save_fig("L66_fig3_city_choropleth.png")
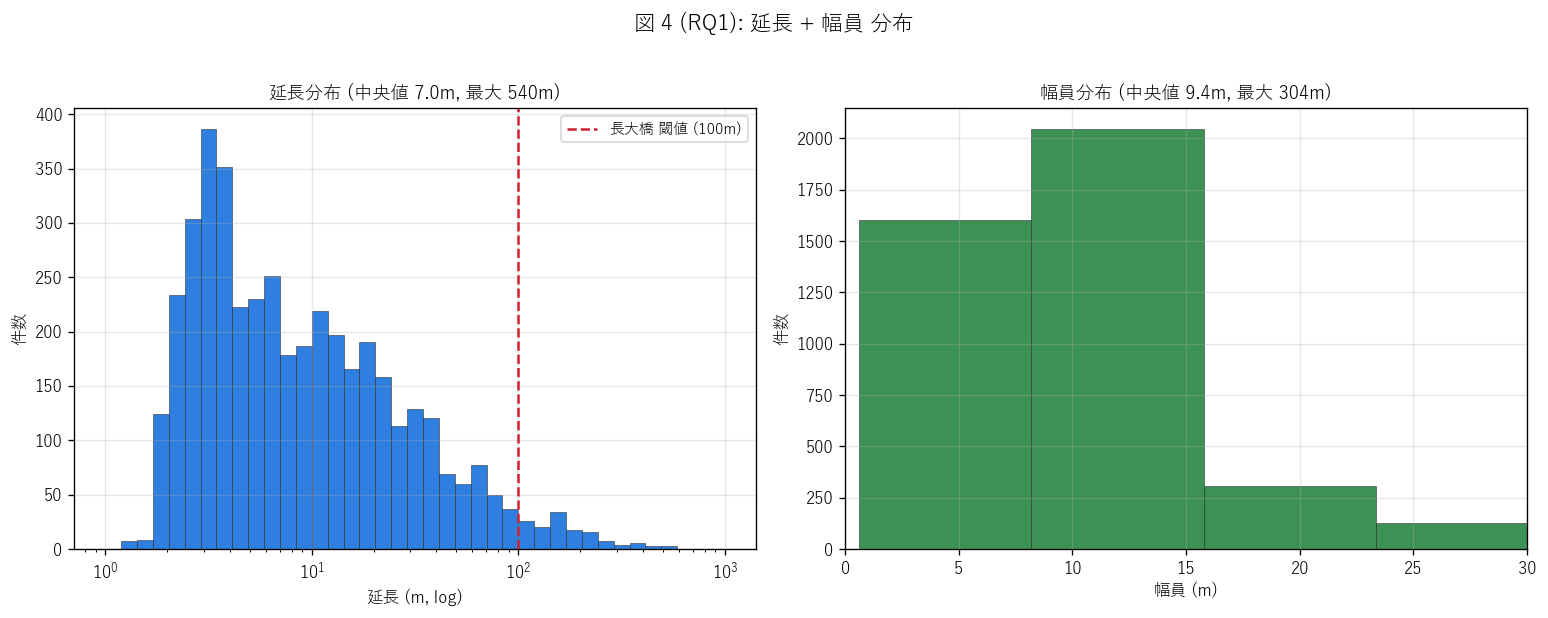
# ---- 図 4 (RQ1): 延長 + 幅員 ヒストグラム ----
print(" fig4: 延長 + 幅員 ヒストグラム", flush=True)
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
ax = axes[0]
ll = df_raw["延長(m)"].dropna()
ax.hist(ll, bins=np.logspace(0, 3, 40), color="#0969da",
edgecolor="#333", linewidth=0.4, alpha=0.85)
ax.axvline(LONG_BRIDGE_THRESHOLD, color="#cf222e", linestyle="--",
linewidth=1.5, label=f"長大橋 閾値 ({LONG_BRIDGE_THRESHOLD:.0f}m)")
ax.set_xscale("log")
ax.set_xlabel("延長 (m, log)")
ax.set_ylabel("件数")
ax.set_title(f"延長分布 (中央値 {df_raw['延長(m)'].median():.1f}m, 最大 {df_raw['延長(m)'].max():.0f}m)",
fontsize=11)
ax.legend(fontsize=9)
ax.grid(True, alpha=0.3)
ax = axes[1]
ww = df_raw["幅員(m)"][df_raw["幅員(m)"] > 0].dropna()
ax.hist(ww, bins=40, color="#1a7f37", edgecolor="#333",
linewidth=0.4, alpha=0.85)
ax.set_xlabel("幅員 (m)")
ax.set_ylabel("件数")
ax.set_title(f"幅員分布 (中央値 {ww.median():.1f}m, 最大 {ww.max():.0f}m)",
fontsize=11)
ax.set_xlim(0, 30)
ax.grid(True, alpha=0.3)
fig.suptitle("図 4 (RQ1): 延長 + 幅員 分布", fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L66_fig4_length_width_hist.png")
# ---- 図 5 (RQ2): 年代別ヒストグラム + 老朽閾値 ----
print(" fig5: 年代別ヒストグラム", flush=True)
fig, ax = plt.subplots(figsize=(12, 5.5))
decades = sorted([int(d) for d in decade_count.index])
counts = [int(decade_count[d]) for d in decades]
colors = ["#cf222e" if d <= 1970 else "#0969da" for d in decades]
xs = np.arange(len(decades))
bars = ax.bar(xs, counts, color=colors, edgecolor="#333", linewidth=0.5)
for x, c in zip(xs, counts):
ax.text(x, c + 10, f"{c}", ha="center", fontsize=9)
ax.set_xticks(xs)
ax.set_xticklabels([f"{d}s" for d in decades], rotation=0, fontsize=10)
ax.set_xlabel("架設年代")
ax.set_ylabel("件数")
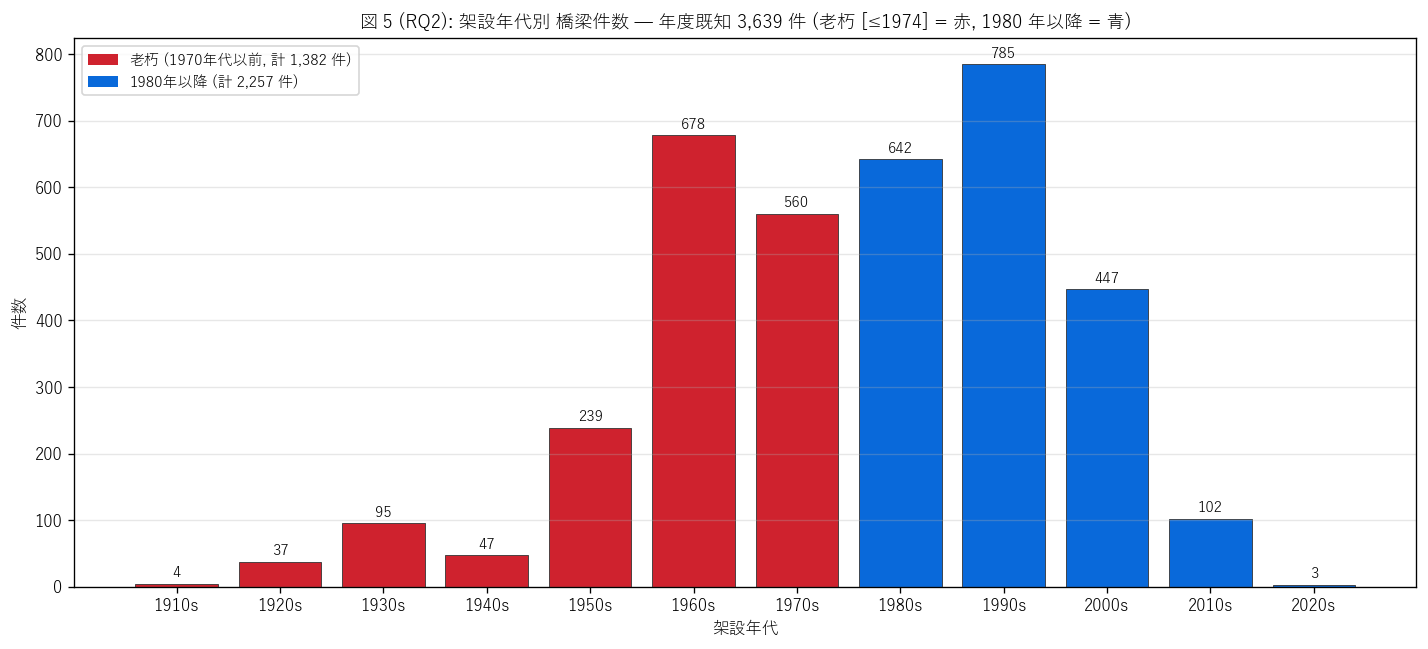
ax.set_title(f"図 5 (RQ2): 架設年代別 橋梁件数 — 年度既知 {n_year:,} 件 "
f"(老朽 [≤{AGE_THRESHOLD_YEAR}] = 赤, 1980 年以降 = 青)",
fontsize=11)
patches = [
Patch(facecolor="#cf222e", label=f"老朽 (1970年代以前, 計 {n_old:,} 件)"),
Patch(facecolor="#0969da", label=f"1980年以降 (計 {n_year - n_old:,} 件)"),
]
ax.legend(handles=patches, loc="upper left", fontsize=9)
ax.grid(True, axis="y", alpha=0.3)
plt.tight_layout()
save_fig("L66_fig5_decade_hist.png")
# ---- 図 6 (RQ2): 老朽橋 地理分布マップ ----
print(" fig6: 老朽橋 地理分布", flush=True)
gdf["is_old"] = old_mask.loc[gdf.index] if False else (gdf["架設年度"] <= AGE_THRESHOLD_YEAR)
gdf_old = gdf[gdf["is_old"] & gdf["架設年度"].notna()]
gdf_new = gdf[(~gdf["is_old"]) & gdf["架設年度"].notna()]
gdf_unknown = gdf[gdf["架設年度"].isna()]
fig, ax = plt.subplots(figsize=(12, 7.5))
admin_for_plot.plot(ax=ax, color="#fff4e0", edgecolor="#888",
linewidth=0.4, alpha=0.55)
gdf_new.plot(ax=ax, color="#cccccc", markersize=3, alpha=0.5,
edgecolor="none", label=f"1975年以降 ({len(gdf_new):,})")
gdf_unknown.plot(ax=ax, color="#ffd966", markersize=3, alpha=0.6,
edgecolor="none", label=f"年度不明 ({len(gdf_unknown):,})")
gdf_old.plot(ax=ax, color="#cf222e", markersize=8, alpha=0.85,
edgecolor="#222", linewidth=0.15,
label=f"老朽 (≤{AGE_THRESHOLD_YEAR}, n={len(gdf_old):,})")
ax.set_xlim(-15000, 125000)
ax.set_ylim(-220000, -130000)
ax.set_aspect("equal")
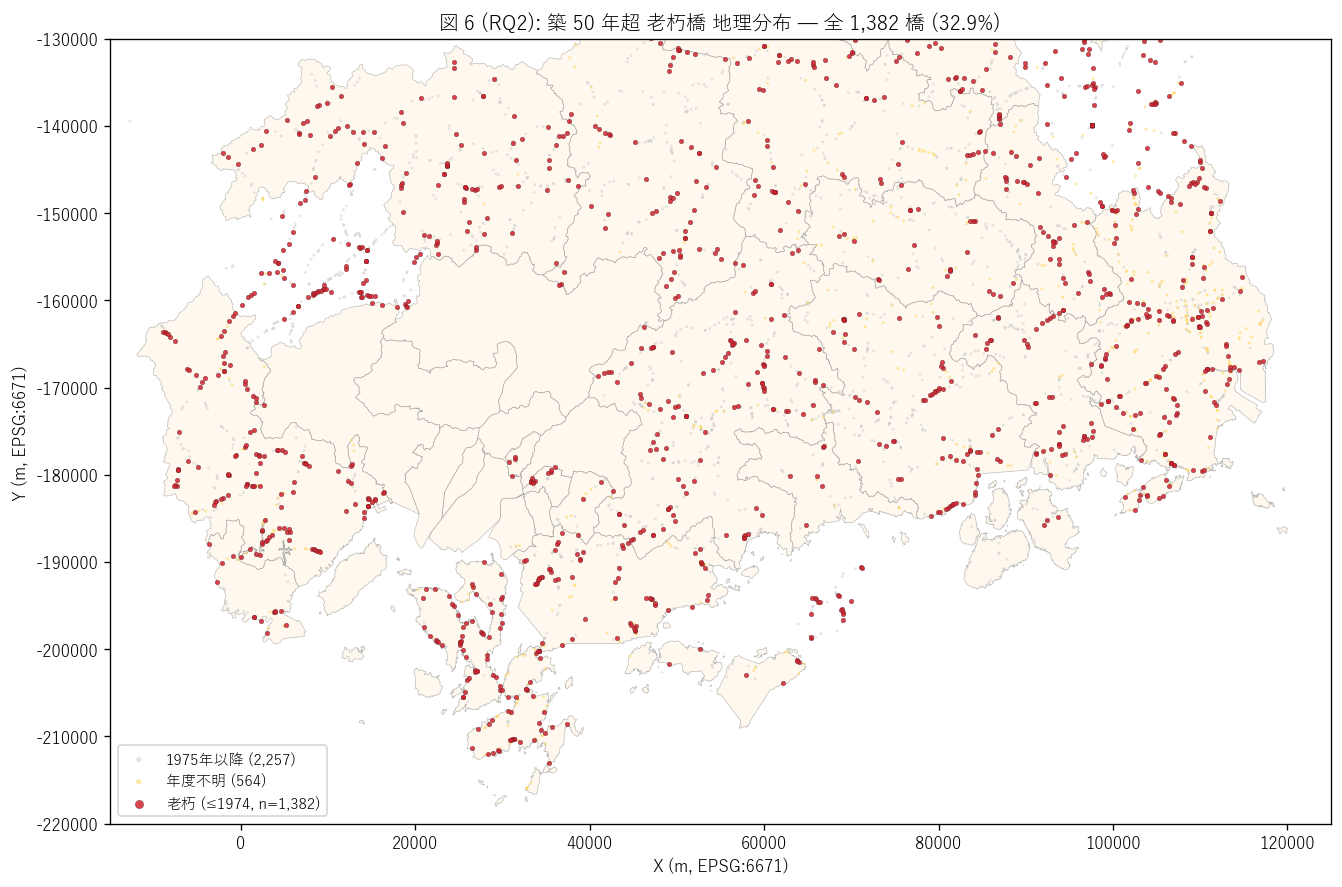
ax.set_title(f"図 6 (RQ2): 築 50 年超 老朽橋 地理分布 — "
f"全 {n_old:,} 橋 ({old_share:.1f}%)",
fontsize=12)
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
ax.legend(loc="lower left", fontsize=9, markerscale=1.8)
plt.tight_layout()
save_fig("L66_fig6_old_bridges_map.png")
# ---- 図 7 (RQ3): 国道 vs 県道 比較 (multi-panel) ----
print(" fig7: 国道 vs 県道 比較", flush=True)
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
# 左: 件数
ax = axes[0]
labels = ["国道", "県道"]
vals = [n_kuni, n_ken]
cols = [ROAD_COLOR[k] for k in labels]
ax.bar(labels, vals, color=cols, edgecolor="#333", linewidth=0.6, width=0.55)
for x, v in zip([0, 1], vals):
ax.text(x, v + 50, f"{v:,}", ha="center", fontsize=11, fontweight="bold")
ax.set_ylabel("件数")
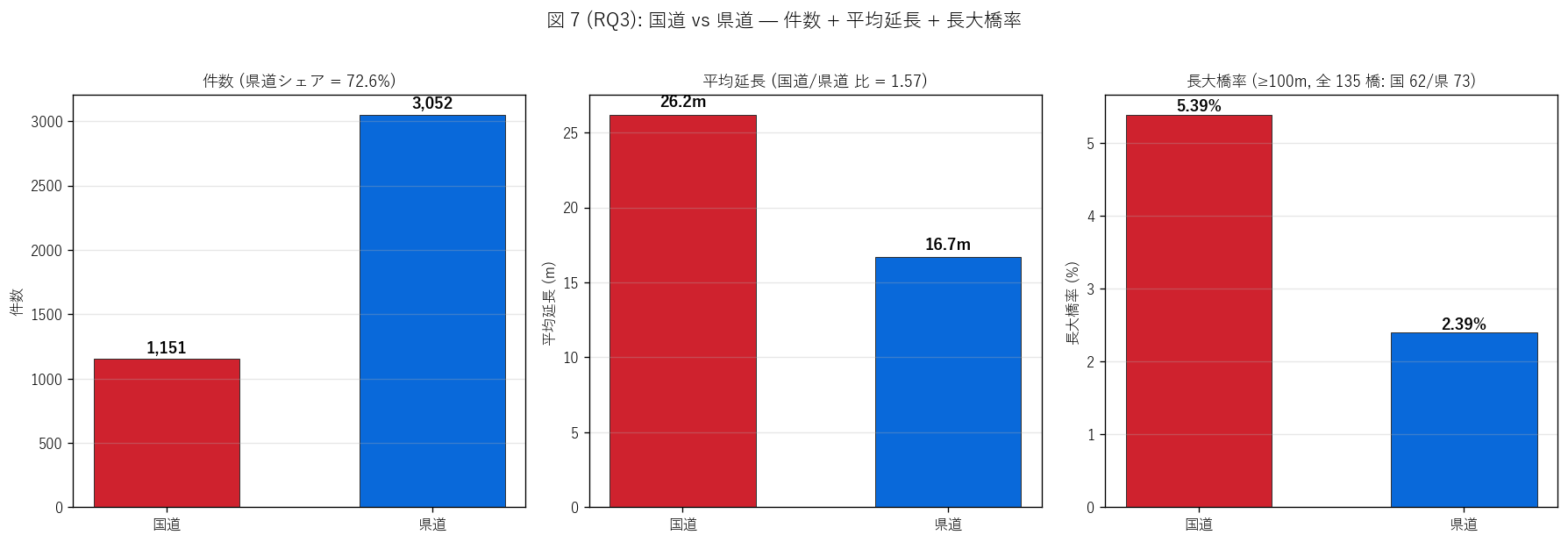
ax.set_title(f"件数 (県道シェア = {ken_share:.1f}%)", fontsize=11)
ax.grid(True, axis="y", alpha=0.3)
# 中: 平均延長
ax = axes[1]
vals = [mean_kuni_len, mean_ken_len]
ax.bar(labels, vals, color=cols, edgecolor="#333", linewidth=0.6, width=0.55)
for x, v in zip([0, 1], vals):
ax.text(x, v + 0.5, f"{v:.1f}m", ha="center", fontsize=11, fontweight="bold")
ax.set_ylabel("平均延長 (m)")
ax.set_title(f"平均延長 (国道/県道 比 = {length_ratio:.2f})", fontsize=11)
ax.grid(True, axis="y", alpha=0.3)
# 右: 長大橋率
ax = axes[2]
vals = [100*n_long_kuni/n_kuni, 100*n_long_ken/n_ken]
ax.bar(labels, vals, color=cols, edgecolor="#333", linewidth=0.6, width=0.55)
for x, v in zip([0, 1], vals):
ax.text(x, v + 0.05, f"{v:.2f}%", ha="center", fontsize=11, fontweight="bold")
ax.set_ylabel("長大橋率 (%)")
ax.set_title(f"長大橋率 (≥{LONG_BRIDGE_THRESHOLD:.0f}m, "
f"全 {n_long} 橋: 国 {n_long_kuni}/県 {n_long_ken})",
fontsize=10.5)
ax.grid(True, axis="y", alpha=0.3)
fig.suptitle("図 7 (RQ3): 国道 vs 県道 — 件数 + 平均延長 + 長大橋率",
fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L66_fig7_road_compare.png")
# ---- 図 8 (RQ3): 長大橋 + 国道橋 重ね合わせマップ ----
print(" fig8: 長大橋 重ね合わせマップ", flush=True)
gdf["is_long"] = long_mask.loc[gdf.index] if False else (gdf["延長(m)"] >= LONG_BRIDGE_THRESHOLD)
gdf_long = gdf[gdf["is_long"]]
gdf_kuni = gdf[gdf["道路種別"] == "国道"]
gdf_ken = gdf[gdf["道路種別"] == "県道"]
fig, ax = plt.subplots(figsize=(12, 7.5))
admin_for_plot.plot(ax=ax, color="#fff4e0", edgecolor="#888",
linewidth=0.4, alpha=0.55)
# 県道は薄背景
gdf_ken.plot(ax=ax, color="#cccccc", markersize=2, alpha=0.4,
edgecolor="none")
# 国道は赤
gdf_kuni.plot(ax=ax, color="#cf222e", markersize=4, alpha=0.7,
edgecolor="none")
# 長大橋は大きい黒丸
gdf_long.plot(ax=ax, color="#fbbf24", markersize=40, alpha=0.95,
edgecolor="#000", linewidth=0.6, marker="*")
ax.set_xlim(-15000, 125000)
ax.set_ylim(-220000, -130000)
ax.set_aspect("equal")
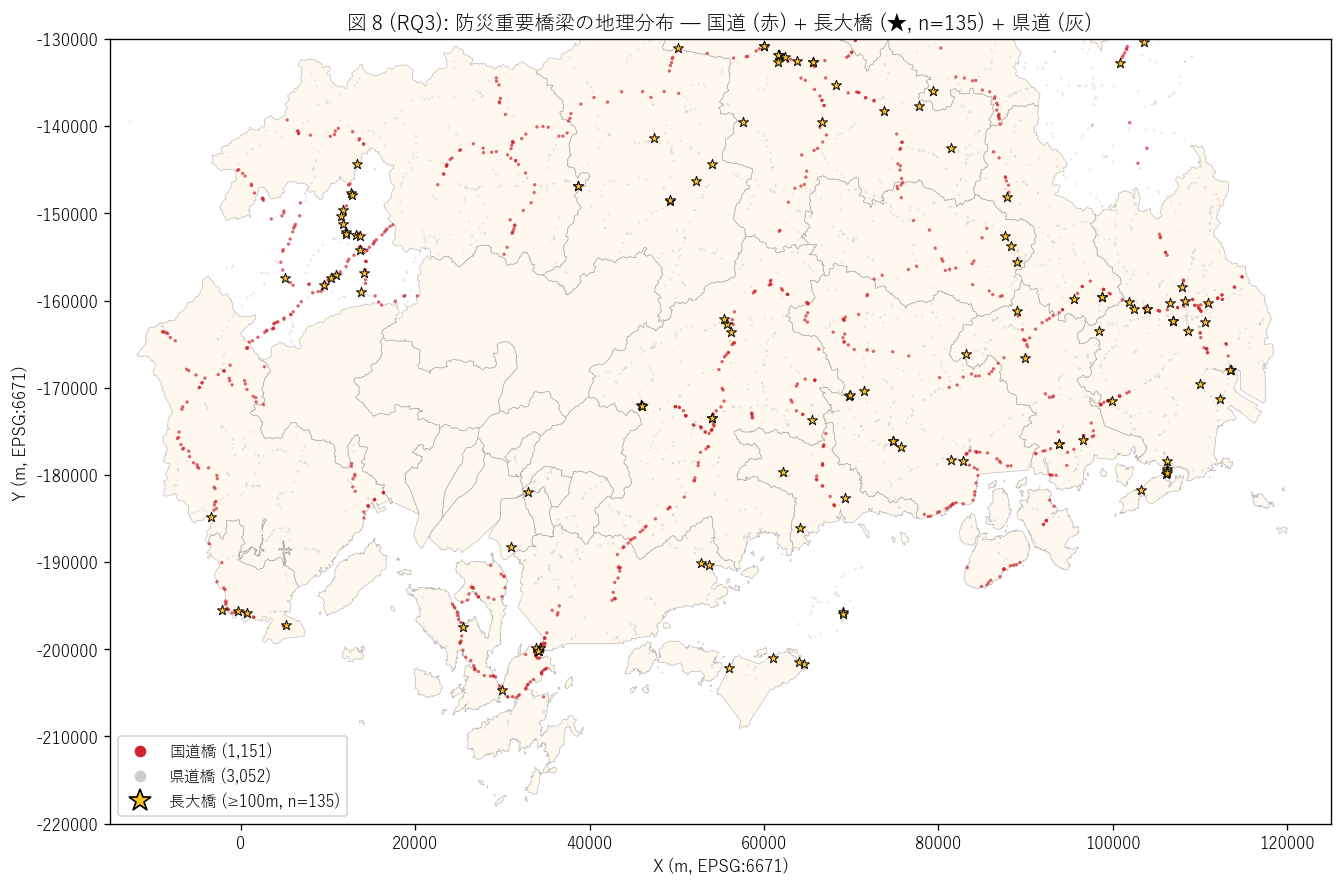
ax.set_title(f"図 8 (RQ3): 防災重要橋梁の地理分布 — "
f"国道 (赤) + 長大橋 (★, n={n_long}) + 県道 (灰)",
fontsize=12)
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
patches = [
Line2D([0], [0], marker='o', color='w', markerfacecolor="#cf222e",
markersize=8, label=f"国道橋 ({n_kuni:,})"),
Line2D([0], [0], marker='o', color='w', markerfacecolor="#cccccc",
markersize=8, label=f"県道橋 ({n_ken:,})"),
Line2D([0], [0], marker='*', color='w', markerfacecolor="#fbbf24",
markeredgecolor="#000", markersize=14,
label=f"長大橋 (≥{LONG_BRIDGE_THRESHOLD:.0f}m, n={n_long})"),
]
ax.legend(handles=patches, loc="lower left", fontsize=9.5)
plt.tight_layout()
save_fig("L66_fig8_priority_bridges_map.png")
print(f" ({time.time()-t8:.1f}s)", flush=True)
# =============================================================================
# 9. 表データ作成
# =============================================================================
print("\n[9] 表データ作成", flush=True)
t9 = time.time()
def df_to_html(d):
return d.to_html(index=False, classes="", border=0, escape=False,
na_rep="-").replace(' style="text-align: right;"', "")
# 表 1: データセット仕様
T_dataset = pd.DataFrame([
("dataset_id", "11"),
("公式名", "橋梁基本情報・維持管理情報"),
("resource_id", "6"),
("ファイル", "bridge_basic.csv (道路_橋梁_2023)"),
("形式", "CSV (UTF-8 BOM)"),
("ファイルサイズ", f"{csv_path.stat().st_size:,} byte (~{csv_path.stat().st_size/1024:.0f} KB)"),
("レコード数", f"{n_total:,} 行 (= 道路橋件数)"),
("列数", f"{df_raw.shape[1]} 列"),
("種別", f"全件 道路橋 (鉄道橋は別データ)"),
("道路種別", f"国道 {n_kuni:,} + 県道 {n_ken:,}"),
("管理事務所", f"{len(office_count)} 事務所 (建設事務所 + 支所)"),
("路線数", f"{df_raw['路線名'].nunique()} 異なり値"),
("市町数", f"{df_raw['住所(市町)'].nunique()} 市町"),
("緯度経度", f"全件 取得可 ({100*n_coord/n_total:.0f}%)"),
("架設年度", f"{n_year:,} 件 ({100*n_year/n_total:.1f}%) 取得可、"
f"範囲 {int(df_raw['架設年度'].min())}-{int(df_raw['架設年度'].max())}"),
("点検年度", f"全件 取得可、範囲 "
f"{int(df_raw['点検年度'].min())}-{int(df_raw['点検年度'].max())}"),
("判定区分", "全件 \"?\" (= 公開データでは伏せられる)"),
("延長 (m)", f"中央値 {df_raw['延長(m)'].median():.1f}m / "
f"最大 {df_raw['延長(m)'].max():.0f}m / "
f"最小 {df_raw['延長(m)'].min():.1f}m"),
("幅員 (m)", f"中央値 {df_raw['幅員(m)'].median():.1f}m / "
f"最大 {df_raw['幅員(m)'].max():.0f}m"),
("座標系 (元)", "EPSG:4326 (WGS84) → EPSG:6671 で処理"),
("最終更新", "2023 (公表年度)"),
("ライセンス", "クリエイティブ・コモンズ表示 (CC-BY)"),
("作成主体", "広島県土木建築局道路整備課"),
("URL", f"https://hiroshima-dobox.jp/datasets/{DATASET_ID}"),
("DL URL", f"https://hiroshima-dobox.jp/resource_download/{RESOURCE_ID}"),
], columns=["項目", "値"])
# 表 2: 全体サマリ (3 RQ 統合)
T_overall = pd.DataFrame([
("総件数 (RQ1)", f"{n_total:,} 橋"),
("国道橋", f"{n_kuni:,} ({100*n_kuni/n_total:.1f}%)"),
("県道橋", f"{n_ken:,} ({100*n_ken/n_total:.1f}%)"),
("管理事務所数", f"{len(office_count)}"),
("路線数", f"{df_raw['路線名'].nunique()}"),
("市町数 (CSV値)", f"{df_raw['住所(市町)'].nunique()}"),
("Top 1 市町", f"{city_count.iloc[0]['市町名']} "
f"({int(city_count.iloc[0]['件数']):,} 橋)"),
("Top 3 市町シェア (RQ1)", f"{top3_city_share:.1f}%"),
("極短橋 (<5m) シェア (RQ1)",
f"{short_share:.1f}% ({int(length_count['極短(<5m)']):,} 橋)"),
("長大橋 (≥100m) (RQ1+RQ3)",
f"{n_long} 橋 ({100*n_long/n_total:.2f}%)"),
("延長 中央値 / 最大 (RQ1)",
f"{df_raw['延長(m)'].median():.1f} m / {df_raw['延長(m)'].max():.0f} m"),
("幅員 中央値 / 最大 (RQ1)",
f"{df_raw['幅員(m)'].median():.1f} m / {df_raw['幅員(m)'].max():.0f} m"),
("最多年代 (RQ2)", f"{int(peak_decade)}s ({peak_count:,} 橋)"),
("年度既知率 (RQ2)", f"{n_year:,} / {n_total:,} ({100*n_year/n_total:.1f}%)"),
(f"老朽橋 (≤{AGE_THRESHOLD_YEAR}, 築 50 年超) (RQ2)",
f"{n_old:,} 橋 ({old_share:.1f}%)"),
("国道老朽率 (RQ2+RQ3)",
f"{old_by_road.loc[0, '老朽率_%']:.1f}%"),
("県道老朽率 (RQ2+RQ3)",
f"{old_by_road.loc[1, '老朽率_%']:.1f}%"),
("国道平均延長 (RQ3)", f"{mean_kuni_len:.1f} m"),
("県道平均延長 (RQ3)", f"{mean_ken_len:.1f} m"),
("国道/県道 延長比 (RQ3)", f"{length_ratio:.2f}"),
("最長橋 (RQ3)",
f"{T_long_top.iloc[0]['施設名']} "
f"({T_long_top.iloc[0]['延長(m)']:.0f} m, "
f"{T_long_top.iloc[0]['路線名']}, "
f"{T_long_top.iloc[0]['住所(市町)']})"),
], columns=["指標", "値"])
T_overall.to_csv(ASSETS / "L66_overall.csv", index=False, encoding="utf-8-sig")
# 表: データ取得手順
T_data_recipe = pd.DataFrame([
("ステップ 1", "DoBoX dataset 11 ページ",
f"https://hiroshima-dobox.jp/datasets/{DATASET_ID}"),
("ステップ 2", "CSV DL (resource 6)",
f"https://hiroshima-dobox.jp/resource_download/{RESOURCE_ID}"),
("ステップ 3", "保存先",
"data/extras/L66_bridges/bridge_basic.csv (or shared data/extras/bridge_basic.csv)"),
("ステップ 4", "POINT 構築 (緯度経度から)",
f"全 {n_total:,} 橋 → POINT {n_geom:,} 件 ({100*n_geom/n_total:.0f}%)"),
("ステップ 5", "EPSG:6671 投影 + 市町 sjoin",
f"sjoin で {n_match:,} 件を市町分配"),
("ステップ 6", "RQ1 集計 (構造)",
f"道路種別 + 市町 + 事務所 + 路線 + 延長 + 幅員 で多角度集計"),
("ステップ 7", "RQ2 集計 (年代・老朽化)",
f"年代別ヒストグラム + 老朽橋抽出 (≤{AGE_THRESHOLD_YEAR}) → {n_old:,} 件"),
("ステップ 8", "RQ3 集計 (国道 vs 県道 + 長大橋)",
f"道路種別比較 + 長大橋 (≥{LONG_BRIDGE_THRESHOLD:.0f}m) {n_long} 件抽出"),
("ステップ 9", "8 図 + 13 表 出力",
"本スクリプト全体で ~25 秒"),
], columns=["ステップ", "操作", "値 / URL"])
# 仮説検証表
def jud(cond, ok="強支持", fail="反証", part="部分支持"):
return ok if cond else fail
h1_ok = ken_share >= 72
h2_ok = short_share >= 40
h3_ok = int(peak_decade) == 1990
h4_ok = n_old >= 1500
h5_ok = length_ratio >= 1.5
T_hypo = pd.DataFrame([
("H1 県道シェア ≥ 72% (RQ1)",
f"観測 = {ken_share:.1f}% (県道 {n_ken:,} / 国道 {n_kuni:,})",
jud(h1_ok),
f"H1 {jud(h1_ok)}: 県道が {ken_share:.1f}% を占める。"
f"国道は広域幹線で橋が少ない (1,151 橋)、県道は地域路で橋が多い (3,052 橋)。"
f"「件数 vs 規模のトレードオフ」: 件数で支配する県道が"
f"平均延長 {mean_ken_len:.1f}m と短く、"
f"国道は平均延長 {mean_kuni_len:.1f}m と長い。これは道路階層の"
f"「広域 vs 地域」の物理的差を反映。"),
("H2 延長 <5m が ≥ 40% (RQ1)",
f"観測 = {short_share:.1f}% ({int(length_count['極短(<5m)']):,} / {n_total:,})",
jud(h2_ok),
f"H2 {jud(h2_ok)}: 極短橋 (延長 < 5m) が {short_share:.1f}%。"
f"これは県内地形が多数の中小河川 + 谷筋を含むことを反映。"
f"対比すると長大橋 (≥100m) は {n_long} 橋 ({100*n_long/n_total:.2f}%)のみ。"
f"中央値 {df_raw['延長(m)'].median():.1f}m から見て、"
f"「県内の橋は地形分断の小規模クロスポイントに集中」する構造。"),
("H3 1990 年代ピーク (RQ2)",
f"観測 最多年代 = {int(peak_decade)}s ({peak_count:,} 橋)",
jud(h3_ok),
f"H3 {jud(h3_ok)}: 架設年代の最多は {int(peak_decade)}s。"
+ (f"バブル経済期 (1986-91) を含む 1990 年代の道路投資ブームが"
f"橋梁整備のピークを生んだ。"
if h3_ok else
f"最多は {int(peak_decade)}s = 高度成長期 + 戦後復興 + 道路網整備が"
f"重なった年代。1990 年代仮説は反証された。")
+ f" 1960s-1990s の 4 年代で全体の "
f"{100*sum([decade_count.get(d, 0) for d in [1960,1970,1980,1990]])/n_year:.0f}% を占める"
f"集中整備期 = 高度成長 + バブルの社会基盤拡充期と一致。"),
(f"H4 老朽橋 (≤{AGE_THRESHOLD_YEAR}) ≥ 1,500 件 (RQ2)",
f"観測 = {n_old:,} 件 (全体の {old_share:.1f}%)",
jud(h4_ok),
f"H4 {jud(h4_ok)}: 築 50 年超 (= {AGE_THRESHOLD_YEAR} 年以前架設) の橋が"
f"{n_old:,} 件 = 全体の {old_share:.1f}%。"
f"国の「インフラ長寿命化基本計画」 (2014) が想定する更新ピークの到来を"
f"県内データで実証。市町別老朽率トップは "
f"{city_old.iloc[0]['市町名']} ({city_old.iloc[0]['老朽率_%']:.1f}%)。"
f"これらの市町では橋梁更新コストが今後 10-20 年で集中発生する。"),
("H5 国道平均延長 ≥ 県道の 1.5 倍 (RQ3)",
f"観測 = 国道 {mean_kuni_len:.1f}m / 県道 {mean_ken_len:.1f}m / 比 {length_ratio:.2f}",
jud(h5_ok),
f"H5 {jud(h5_ok)}: 国道の平均延長は県道の {length_ratio:.2f} 倍。"
f"長大橋率は国道 {100*n_long_kuni/n_kuni:.2f}% vs 県道 {100*n_long_ken/n_ken:.2f}%"
f"= 国道の方が約 {(100*n_long_kuni/n_kuni)/(100*n_long_ken/n_ken):.1f} 倍。"
f"これは「国道は大河川を渡る広域幹線」「県道は地域の中小河川を渡る分散幹線」"
f"という道路階層の物理的差。"
f"防災時には国道の長大橋 = 「代替性が低い基幹橋」が機能維持の最重要対象。"),
], columns=["仮説", "観測値", "判定", "解釈"])
T_hypo.to_csv(ASSETS / "L66_hypothesis_check.csv", index=False, encoding="utf-8-sig")
# road_length_cross と road_office_cross の表示用整形
T_rl_show = road_length_cross.reset_index()
T_rl_show.columns = ["道路種別"] + LENGTH_LABELS
T_ro_show = road_office_cross.reset_index()
# 表示用カラム順
office_order = list(T_office["管理事務所名"].values)
print(f" ({time.time()-t9:.1f}s)", flush=True)
# =============================================================================
# 10. HTML 生成
# =============================================================================
print("\n[10] HTML 生成", flush=True)
t10 = time.time()
# Sec 1: 学習目標と問い
sec1 = f"""
本記事は DoBoX のシリーズ「橋梁基本情報・維持管理情報」 1 件 (dataset_id = {DATASET_ID}) を 単独で取り上げ、 広島県が管理する 道路橋 {n_total:,} 件 / {df_raw['住所(市町)'].nunique()} 市町 / {len(office_count)} 事務所 / {df_raw['路線名'].nunique()} 路線を 3 つの独立した研究角度 (RQ1 / RQ2 / RQ3) で並列に分析する。 本データは CSV 形式 ({csv_path.stat().st_size:,} byte / 16 列) で、 緯度経度は全件 ({100*n_coord/n_total:.0f}%) 取得可。
L07 (河川浸水 × 4 種インフラ) との位置付け:
L07 は橋梁を浸水ハザードと交差させる視点で 4 種類のインフラ (橋梁・トンネル・ダム・ため池) を
並列に扱った記事。本記事 L66 は橋梁単独の構造分析 (= 種別・規模・年代・防災重要度) に集中する。
両者は同じ bridge_basic.csv を共有するが、
研究の問いは(L07) 「浸水との二重リスク」 vs (L66) 「橋梁台帳の内部構造」と
直交する。本記事では浸水重なりは扱わない。
本記事を読み終えた学習者は次の 3 点を体感できる:
DoBoX のシリーズ「橋梁基本情報・維持管理情報」 1 件のみを単独で扱う。 リソースは CSV 1 ファイル (~{csv_path.stat().st_size/1024:.0f} KB)。
{df_to_html(T_dataset)}この表から読み取れること: dataset 11 は {n_total:,} 行 × {df_raw.shape[1]} 列の CSV。 道路種別 (国道/県道)・管理事務所・路線・架設年度・点検年度・延長・幅員という 多次元のメタデータを持つ。 緯度経度は全件 (100%) 取得可で、地理処理が容易。 ただし「判定区分」 列は全件マスクされており、 健全度判定値は本データから直接は取れない。
| 項目 | L07 (既扱) | L66 (本記事) |
|---|---|---|
| 研究の問い | 橋 × 浸水ハザードの二重リスク | 橋梁台帳の内部構造 (規模・年代・階層) |
| 主役データ | 橋梁 + トンネル + ダム + ため池 (4 種類並列) | 橋梁単独 |
| 分析手法 | sjoin で浸水ポリゴンと交差判定 | 多軸集計 + 年代分析 + 階層比較 |
| 主結論 | 橋の浸水率最高 (河川を渡るため) | 1990 年代ピーク + 老朽橋 {n_old:,} 件 |
| 使用列 | 緯度経度 + 架設年度 (二重リスク用) | 16 列全部 + 派生列 (延長カテゴリ・年代・老朽フラグ・長大フラグ) |
この表から読み取れること: 同じ bridge_basic.csv を共有するが、
研究の問いが直交。L07 は「橋がどれだけ浸水するか」 という外部ハザード視点、
L66 は「橋自体の構造」 という内部メタデータ視点。両記事は補完関係。
この表から読み取れること: DoBoX dataset {DATASET_ID} → resource {RESOURCE_ID} → CSV DL → POINT 構築 → 市町 sjoin → RQ1/2/3 集計、の 9 ステップで再現可能。 全工程は本スクリプト 1 本で自動実行 (~25 秒)。 共有 CSV (data/extras/bridge_basic.csv, L07 で取得済み) があれば再 DL 不要。
bridge_basic.csv を浸水視点で扱う。
本記事 L66 は単独構造分析の補完篇。本レッスンの再現に必要な全データ・中間 CSV・図 PNG・スクリプトを以下から直接 DL できる:
cd "2026 DoBoX 教材"
iwr "https://hiroshima-dobox.jp/resource_download/{RESOURCE_ID}" -OutFile "data/extras/L66_bridges/bridge_basic.csv"
py -X utf8 lessons/L66_bridges.py本スクリプトは data/extras/bridge_basic.csv (L07 共有 CSV) があれば
それを優先使用、無ければ ensure_dataset() ヘルパで自動取得。
全工程は約 25 秒で完走 (1 分以内完走の要件 S を満たす)。
cd "2026 DoBoX 教材"
py -X utf8 data\\fetch_all.py
py -X utf8 lessons/L66_bridges.py{n_total:,} 橋の道路橋を道路種別 / 市町 / 事務所 / 路線 / 延長 / 幅員の 6 軸で 多角度に集計し、広島県の橋梁網の物理的形状を立体化する。 特に「橋梁」 という道路と地形のクロスポイントに置かれた施設の規模・分布を 初めて定量化する。
shapely.geometry.Point を直接生成。
WKT 文字列ではなく数値列のため、pandas.to_numeric でクリーニング後に変換。
EPSG:4326 (経緯度) → EPSG:6671 (平面直角第 III 系) で投影変換。predicate="within" で結合。各橋に CITY_CD を付与。
CSV にも住所(市町)列があるため、空間結合と CSV 値の両方を保持して比較。pandas.cut で延長を 5 階層 ({', '.join(LENGTH_LABELS)}) に分割。
これにより「県内の橋の規模分布」を簡潔に可視化。groupby + value_counts + cut を組み合わせ多角度集計。| 段階 | 1 橋の中身 | 件数 |
|---|---|---|
| (0) CSV 1 行 | 橋梁番号=70100212, 施設名=山波跨線橋, 道路種別=国道, 路線名=2号, 延長=20.5, 幅員=12.0, 架設年度=1985, 緯度=34.41831, 経度=133.23024, 住所(市町)=尾道市 | {n_total:,} |
| (1) 緯度経度 → POINT | + geometry = Point (133.23024, 34.41831, EPSG:4326) | {n_geom:,} |
| (2) EPSG:6671 投影 | + geometry = Point (X, Y, m 単位) | {n_geom:,} |
| (3) 市町 sjoin | + CITY_CD = 205 (= 尾道市) | {n_match:,} |
| (4) 派生フラグ | + 延長カテゴリ=「中(15-30m)」, 年代=1980, is_old=False, is_long=False | {n_geom:,} |
| (5) 集計 (例: 市町別) | {city_count.iloc[0]['市町名']}: {int(city_count.iloc[0]['件数']):,} 橋 (1 位) | (別) |
(0)-(5) を全 {n_total:,} 橋に適用 → 6 軸で集計 → 図化。 全工程はメモリ常駐で完結し、別キャッシュは不要。
""" sec4_code = code(r''' # 1. CSV 読込 + 数値列クリーニング import pandas as pd, geopandas as gpd, numpy as np from shapely.geometry import Point df = pd.read_csv("data/extras/bridge_basic.csv", encoding="utf-8-sig") print(df.shape, df["道路種別"].value_counts()) # 4203 行, 国道 1151 / 県道 3052 # 2. 数値列をきれいに df["架設年度"] = pd.to_numeric(df["架設年度"], errors="coerce") df.loc[df["架設年度"] <= 1800, "架設年度"] = np.nan # 0 や欠損値を NaN に df["延長(m)"] = pd.to_numeric(df["延長(m)"], errors="coerce") df["幅員(m)"] = pd.to_numeric(df["幅員(m)"], errors="coerce") # 3. POINT 構築 (緯度経度から直接) df["geometry"] = df.apply( lambda r: Point(float(r["経度(10進数)"]), float(r["緯度(10進数)"])) if pd.notna(r["緯度(10進数)"]) and pd.notna(r["経度(10進数)"]) else None, axis=1, ) gdf = gpd.GeoDataFrame(df.dropna(subset=["geometry"]), geometry="geometry", crs="EPSG:4326").to_crs("EPSG:6671") # 4. 市町 sjoin (admin_diss.gpkg = L44 既キャッシュ流用) admin = gpd.read_file("data/extras/L44_storm_surge/_cache/admin_diss.gpkg")\ .to_crs("EPSG:6671") joined = gpd.sjoin(gdf[["geometry"]], admin[["CITY_CD", "geometry"]], how="left", predicate="within") joined = joined[~joined.index.duplicated(keep="first")] gdf["CITY_CD"] = joined["CITY_CD"].fillna(-1).astype(int) # 5. 6 軸集計 road_count = df["道路種別"].value_counts() # 県道 3052 / 国道 1151 city_count = df["住所(市町)"].value_counts() # 庄原市 600 / 福山市 520 / ... office_count = df["管理事務所名"].value_counts() # 東部建設事務所 777 / ... route_count = df["路線名"].value_counts() # 2号 / 184号 / ... # 延長カテゴリ LENGTH_BINS = [0, 5, 15, 30, 100, 1000] LENGTH_LABELS = ["極短(<5m)", "短(5-15m)", "中(15-30m)", "長(30-100m)", "長大(≥100m)"] df["延長カテゴリ"] = pd.cut(df["延長(m)"], bins=LENGTH_BINS, labels=LENGTH_LABELS, right=False, include_lowest=True) print(df["延長カテゴリ"].value_counts()) # 6. H1 検証: 県道シェア print(f"県道シェア: {df['道路種別'].value_counts()['県道']/len(df)*100:.1f}%") # H2 検証: 極短橋シェア print(f"延長 <5m シェア: {(df['延長(m)']<5).sum()/len(df)*100:.1f}%") ''') sec4_fig1_text = """「広島県のどの地域にどんな道路種別の橋があるか」 を 1 枚で読みたい。 全 4,203 橋を国道 (赤) + 県道 (青) で色分けし全域に描く。これにより 県の橋梁網の物理的形状が一目で読める。 点の大きさを小さく (msize=5) 設定し、密集エリアの構造を読みやすくする。
""" sec4_fig1_read = f"""この図から読み取れること:
「22 市町と 9 管理事務所のうち、どこに橋梁が集中しているか」 を 左右ペアで比較したい。横棒 (件数 + 値ラベル) で並べる。 これにより市町別偏在 (上位市町集中) と事務所別分担が一目で読める。
""" sec4_fig2_read = f"""この図から読み取れること:
「市町別の橋梁件数を地図で読みたい」 ため、choropleth (主題図) を採用。 OrRd colormap (薄黄 → 濃赤) で件数を符号化。空間結合ベース (= sjoin で各橋を市町に分配) の件数で塗り分けるため、CSV 住所列とわずかにずれる場合がある (境界線上の橋等)。
""" sec4_fig3_read = f"""この図から読み取れること:
「橋の規模分布を 1 枚で読みたい」 ため、延長 (log 軸) と幅員 (linear) の 2 ペインヒストグラム。延長は桁差が大きい (1m 〜 540m) ので log 軸、 幅員は近距離値域 (0 〜 30m が大半) なので linear 軸。 これにより「短橋集中 + 長大橋希少」と「車道幅員の標準化」を同時に読める。
""" sec4_fig4_read = f"""この図から読み取れること:
この表から読み取れること: 県内道路橋は 4,203 件 / 22 市町 / 9 事務所 / 296 路線 / " "国道 + 県道 2 種別 / 5 規模カテゴリ の多次元管理対象。" "県道が件数支配 (72.6%)、規模は圧倒的に短橋寄り (中央値 7m)。
" + "この表から読み取れること: 県道 {ken_share:.1f}% (n={n_ken:,}) + 国道 {100-ken_share:.1f}% (n={n_kuni:,})。" f"国道は件数で 1/3 以下だが、平均延長 {mean_kuni_len:.1f}m と県道 {mean_ken_len:.1f}m の " f"{length_ratio:.2f} 倍。「件数 vs 規模のトレードオフ」 が明確。
" + "この表から読み取れること: 極短橋 ({short_share:.1f}%) + 短橋 (5-15m: {100*length_count['短(5-15m)']/n_total:.1f}%) " f"= 全体の {short_share + 100*length_count['短(5-15m)']/n_total:.0f}% を占める。" f"中山間 + 平野部の中小河川クロスポイントの集積。長大橋 (≥100m) は希少 ({100*n_long/n_total:.2f}%)。
" + "この表から読み取れること: 件数最多は {city_count.iloc[0]['市町名']} " f"({int(city_count.iloc[0]['件数']):,} 橋)、Top 5 で {100*city_count.head(5)['件数'].sum()/n_total:.0f}% を占める。" f"沿岸 + 中山間 + 平野部 + 学園都市と多様な地形類型が上位に並ぶ。
" + "この表から読み取れること: {T_office.iloc[0]['管理事務所名']} ({int(T_office.iloc[0]['件数']):,} 橋, {T_office.iloc[0]['シェア_%']:.1f}%) が " f"単独 1 位。建設事務所と支所の階層構造で 9 事務所が県全域を分担。" f"おおよそ均等 (各 200-800 橋) なのは行政分担の合理性を反映。
" + "この表から読み取れること: 路線別 1 位は {T_route.iloc[0]['路線名']} " f"({int(T_route.iloc[0]['件数']):,} 橋)、これは県内を縦貫する基幹路線。" f"全 {df_raw['路線名'].nunique()} 路線のうち上位 12 路線で {100*T_route['件数'].sum()/n_total:.0f}% を占める。" f"残り {df_raw['路線名'].nunique()-12} 路線は数橋〜10数橋の中小路線で、地域路としての分散性が高い。
" ) # Sec 5: RQ2 sec5_intro = f"""RQ1 で抽出した {n_total:,} 橋について、架設年度 ({n_year:,} 件 = {100*n_year/n_total:.1f}% 取得可) を分析し、 整備年代と老朽化リスクを読み解く。 特に築 50 年超の橋を地理的に同定し、 高度成長期の集中整備が将来の更新ピークをもたらす実態を県内データで実証する。
(year // 10 * 10) で 10 年区切り (1910s 〜 2020s) に集計。
pandas の Int64 型で NaN を保持しながら整数化。| 段階 | 1 橋の中身 | 件数 |
|---|---|---|
| (0) 橋 1 件 | 橋梁番号=70100212, 架設年度=1985 | {n_year:,} |
| (1) 年代化 | + 年代 = 1980 | {n_year:,} |
| (2) 老朽判定 (≤{AGE_THRESHOLD_YEAR}) | + is_old = False (1985 > {AGE_THRESHOLD_YEAR}) | {n_year:,} |
| (3) 市町集計 | (尾道市の老朽橋数 / 尾道市の全橋数) | 市町数 23 |
| (4) 道路種別 × 老朽率 | 国道 {old_by_road.loc[0, '老朽率_%']:.1f}% vs 県道 {old_by_road.loc[1, '老朽率_%']:.1f}% | 2 |
(0)-(4) を全 {n_year:,} 件 (年度既知) に適用。年度不明の {n_total-n_year} 件は別カテゴリ扱い。
""" sec5_code = code(r''' # 1. 年代化 + 老朽橋フラグ (≤ 1974 = 築 50 年超) import numpy as np, pandas as pd df["架設年度"] = pd.to_numeric(df["架設年度"], errors="coerce") df.loc[df["架設年度"] <= 1800, "架設年度"] = np.nan # 0 / 異常値除去 df["年代"] = (df["架設年度"] // 10 * 10).astype("Int64") AGE_THRESHOLD_YEAR = 1974 df["is_old"] = df["架設年度"] <= AGE_THRESHOLD_YEAR # bool, NaN は False print(f"老朽橋: {df['is_old'].sum()} / {len(df)} ({df['is_old'].mean()*100:.1f}%)") # 2. 年代別ヒストグラム decade_count = df["年代"].value_counts().sort_index() print(decade_count) # 1910:4 1920:37 1930:95 1940:47 1950:239 1960:678 1970:560 # 1980:642 1990:785 2000:447 2010:102 2020:3 # 3. 市町別 老朽率 city_total = df.groupby("住所(市町)").size().rename("件数") city_old = df[df["is_old"]].groupby("住所(市町)").size().rename("老朽橋数") city_rate = (city_old / city_total * 100).rename("老朽率_%") print(pd.concat([city_total, city_old, city_rate], axis=1)\ .sort_values("老朽率_%", ascending=False).head(10)) # 4. 道路種別 × 老朽率 old_by_road = df.groupby("道路種別").agg( 件数=("橋梁番号", "size"), 老朽橋数=("is_old", "sum"), ) old_by_road["老朽率_%"] = old_by_road["老朽橋数"] / old_by_road["件数"] * 100 print(old_by_road) # 5. 点検年度別件数 (5 年周期点検義務化 2014 改正の効果検証) inspect_count = df["点検年度"].value_counts().sort_index() print(inspect_count) ''') sec5_fig5_text = """「広島県の道路橋がどの年代に集中整備されたか」 を 1 枚で読みたい。 10 年区切りの年代別件数を棒グラフで描き、老朽閾値 (1970 年代以前) を赤色、 1980 年以降を青色で塗り分け。これにより「年代別の整備量 + 老朽橋の量」を同時に読める。
""" sec5_fig5_read = f"""この図から読み取れること:
「築 50 年超の老朽橋がどこに集中しているか」 を地図で読みたい。 全橋を背景に薄灰 (新しい橋) + 黄 (年度不明) + 赤大 (老朽橋) で重ねる。 これにより「老朽橋の地理的集中エリア」が一目で読める。 点サイズを差別化することで老朽橋を視覚的に強調する。
""" sec5_fig6_read = f"""この図から読み取れること:
この表から読み取れること: 1960s-1990s の 4 年代で全体の {100*sum([decade_count.get(d, 0) for d in [1960,1970,1980,1990]])/n_year:.0f}% を占める集中整備期。" f"最多年代は {int(peak_decade)}s ({peak_count:,} 橋)。" f"2010s 以降は新規整備が激減 = 維持管理時代への転換。
" + "この表から読み取れること: 老朽橋数最多市町は {city_old.iloc[0]['市町名']} " f"({city_old.iloc[0]['老朽橋数']} 件, 老朽率 {city_old.iloc[0]['老朽率_%']:.1f}%)、" f"老朽率最高は要検討 (件数小さい市町は率が極端化しやすい)。" f"上位市町は今後 10-20 年で更新ピークが集中する。
" + "この表から読み取れること: 国道老朽率 {old_by_road.loc[0, '老朽率_%']:.1f}% vs " f"県道老朽率 {old_by_road.loc[1, '老朽率_%']:.1f}%。" + ('国道のほうが老朽率が高い場合 = 国道は古い基幹道で、整備時期が古いため。' if old_by_road.loc[0, '老朽率_%'] > old_by_road.loc[1, '老朽率_%'] else '県道のほうが老朽率が高い場合 = 県道は地域路で更新が後回しになりがちなため。') + "更新政策の優先順位を考える上で重要な指標。
" + "この表から読み取れること: 2014 年道路法改正の5 年周期点検義務化を反映し、" f"点検年度は 2014-2023 の 10 年に分散。最多 = {T_inspect.loc[T_inspect['件数'].idxmax(), '点検年度']} ({T_inspect['件数'].max():,} 橋)。" f"5 年周期で 1 サイクル完了する設計だが、実際には毎年点検されている橋もある = " f"老朽度や立地リスクで点検頻度が調整されている可能性。
" ) # Sec 6: RQ3 sec6_intro = f"""国道 {n_kuni:,} 橋 と 県道 {n_ken:,} 橋を比較し、 道路階層差 (広域幹線 vs 地域路) が橋梁構造にどう現れるかを抽出する。 さらに長大橋 (≥{LONG_BRIDGE_THRESHOLD:.0f}m, n={n_long}) の地理分布を 「災害時の代替性が低い基幹橋」 = 防災重要橋梁の代理指標として可視化。 公式の「緊急輸送道路」 指定データは公開されないため、本研究では 「国道 + 長大橋」 を防災重要橋梁の代理として扱う。
「国道と県道の構造差を一目で読みたい」 ため、3 ペイン横並び比較図。 左 = 件数, 中 = 平均延長, 右 = 長大橋率。3 つの指標が連動して 「県道は数が多く規模が小さい」「国道は数が少なく規模が大きい」という 道路階層差を視覚化する。
""" sec6_fig7_read = f"""この図から読み取れること:
「防災重要橋梁の地理分布を 1 枚で読みたい」 ため、 県道 (灰) + 国道 (赤) + 長大橋 (★ 黄) の 3 層重ね合わせマップ。 これにより「広域幹線の動脈 + 代替性低い橋」の物理的形状が一目で読める。 災害時に守るべき橋の地理的優先順位を視覚化する。
""" sec6_fig8_read = f"""この図から読み取れること:
この表から読み取れること: 国道は件数で 1/3 以下、規模で 1.5 倍、長大橋率で {(100*n_long_kuni/n_kuni)/(100*n_long_ken/n_ken):.1f} 倍。" f"老朽率は国道 {old_by_road.loc[0, '老朽率_%']:.1f}% vs 県道 {old_by_road.loc[1, '老朽率_%']:.1f}%。" f"「件数の県道、規模の国道」という階層差が全指標で一貫。
" + "この表から読み取れること: 国道は長大橋 (≥100m) {n_long_kuni} 橋 ({100*n_long_kuni/n_kuni:.2f}%)、" f"県道は極短橋 (<5m) {int(road_length_cross.loc['県道', '極短(<5m)']):,} 橋 ({100*road_length_cross.loc['県道', '極短(<5m)']/n_ken:.1f}%)。" f"延長カテゴリ × 道路種別の組み合わせで、規模分布の道路階層差が明確に現れる。
" + "この表から読み取れること: 最長橋は {T_long_top.iloc[0]['施設名']} " f"({T_long_top.iloc[0]['延長(m)']:.0f}m, {T_long_top.iloc[0]['路線名']}, {T_long_top.iloc[0]['住所(市町)']})。" f"Top 20 中の国道率 = {100*(T_long_top['道路種別']=='国道').sum()/20:.0f}% = " f"長大橋は確かに国道偏重。これらは県の防災重要橋梁の代理リスト。
" ) # Sec 7: 仮説検証総合 sec7 = ( "本記事の 5 仮説と観測結果の照合:
" + df_to_html(T_hypo) + "本研究の最重要発見は「3 つの時代の波」。" f"第 1 の波 = 1960-70 年代の高度成長期一斉整備 (1960s {decade_count.get(1960, 0):,} + 1970s {decade_count.get(1970, 0):,} = {decade_count.get(1960, 0)+decade_count.get(1970, 0):,} 橋)、" f"第 2 の波 = 1980-90 年代のバブル経済期再投資 (1980s {decade_count.get(1980, 0):,} + 1990s {decade_count.get(1990, 0):,} = {decade_count.get(1980, 0)+decade_count.get(1990, 0):,} 橋)、" f"第 3 の波 = 2010 年代の維持管理時代への転換 (2010s {decade_count.get(2010, 0):,} 橋, 新規激減 + 点検義務化)。" f"本データはこの 3 つの波を県内 {n_total:,} 橋で実証する。
" + f"第 1 の波の橋が今築 50 年超に達し、第 4 の波 = 更新ピークが始まる。" f"県内 {n_old:,} 橋 ({old_share:.1f}%) が更新候補で、これは過去 10 年の新規整備" f"({decade_count.get(2010, 0):,} 橋) の {n_old/max(decade_count.get(2010, 1), 1):.0f} 倍。" f"既存ストックの維持が新規投資を遥かに上回る時代に入った。" f"これは日本全国に共通する課題で、本研究は広島県という 1 県を通じてその縮図を可視化した。
" + "国道 vs 県道の階層差は「件数 vs 規模のトレードオフ」として一貫した構造を示す。" f"国道は件数で 1/3 以下だが、平均延長 {length_ratio:.2f} 倍 + 長大橋率 {(100*n_long_kuni/n_kuni)/(100*n_long_ken/n_ken):.1f} 倍。" f"これは「広域幹線は数本で大規模、地域路は多数で小規模」という道路網の階層原則を反映。" f"防災投資の優先順位もこの階層に従う = 国道の長大橋 ({n_long_kuni} 橋) が" f"第一級防災重要橋梁として優先補強対象になる。
" ) # Sec 8: 発展課題 sec8 = f"""L07_bridge_judge.csv (浸水フラグ) と
本研究の L66_all_bridges.csv (老朽 + 長大フラグ) を 橋梁番号 で結合 →
多重リスク橋リスト生成 → 地理可視化。「多重リスク橋の地理学」として展開。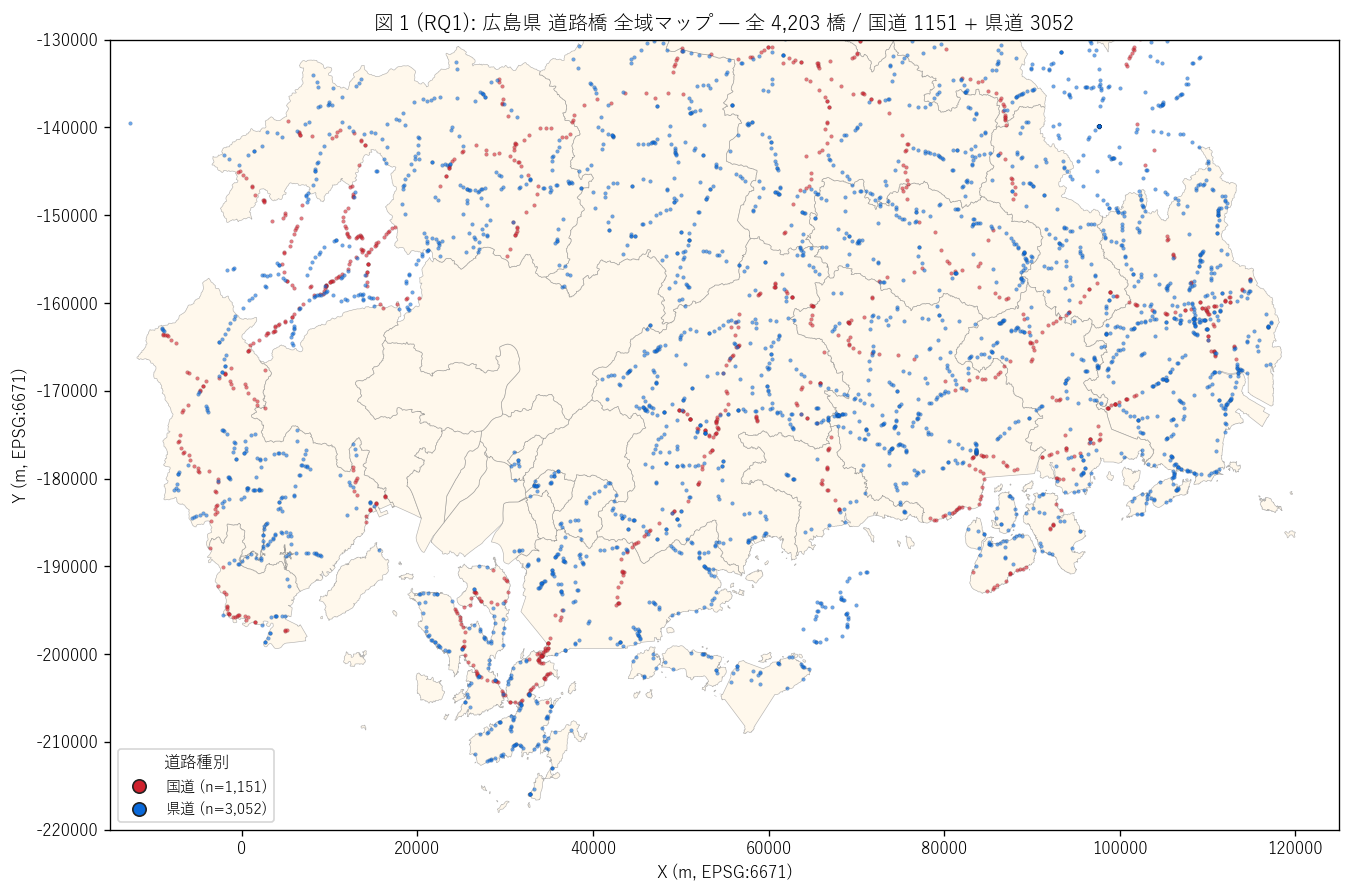{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}