目 次
🎯 この記事を読むと何ができるようになるか
- 研究の核心:「地方創生政策が都道府県間人口移動に与えた影響」の問題意識と分析アプローチ
- 分析手法:重回帰分析で「複数の要因がどの程度結果に影響するか」を同時に推定する方法
- 分析手法:パネルデータ固定効果モデルで「都道府県固有の見えない差」を統制した因果推論
- 分析手法:時系列データのトレンド・変化点・周期性を読み取る方法
- 結果の読み方:係数・p値・図表から「何が言えて何が言えないか」を判断する力
- 応用:同じデータと手法を使って、別の問いを立てて分析する発想
📥 データの準備(再現コードを動かす前に)
このページの分析を自分で再現するには、以下の手順でデータを準備してください。コードの編集は不要です。
data/raw/ フォルダに入れます。html/figures/ に自動保存されます。
1. 研究の背景と目的
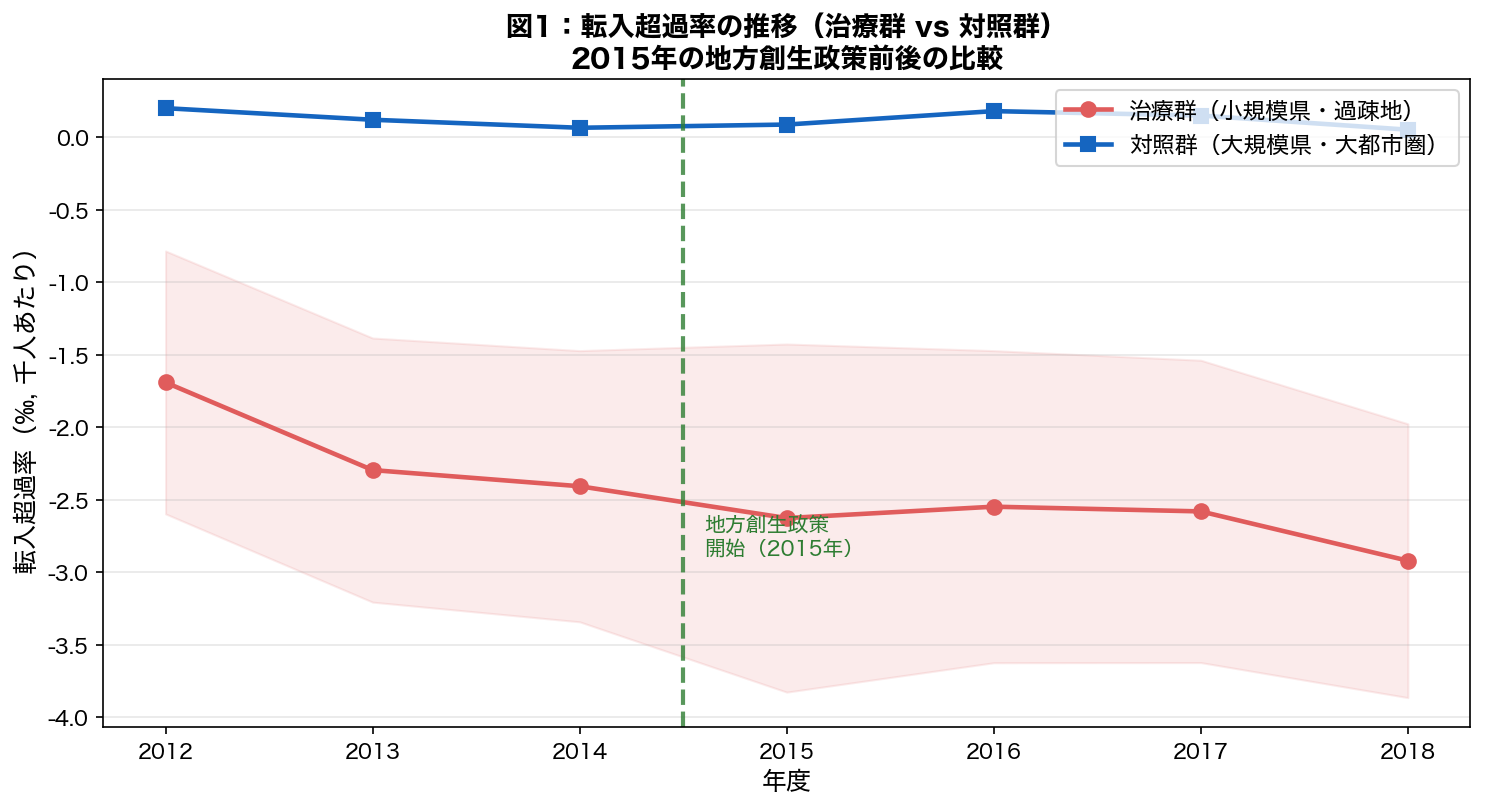
日本では長年にわたり、人口が東京圏を中心とした大都市部へ集中し、地方圏では深刻な人口流出が続いている。 2014年9月、政府は「まち・ひと・しごと創生法」を制定し、地方創生政策を本格的に始動させた。 2015年度からは「地方版総合戦略」の策定が各都道府県・市区町村で求められ、 移住促進・雇用創出・子育て支援など多面的な施策が展開されてきた。
まず「地方創生政策が都道府県間人口移動に与えた影響」を統計的にとらえることが有効だと考えられる。 その理由は感覚や経験則だけでは、複雑な社会要因の中で「何が本当に効いているか」を見極めにくいからである。 本研究では公開データと統計手法を組み合わせ、この問いに定量的な答えを出すことを目指す。
しかし、こうした政策が実際に都道府県間の人口移動パターンを変化させたかについては、 科学的な政策評価が必要である。単純な前後比較では、同時期の経済変動(アベノミクス・オリンピック特需など) の影響と政策効果を分離できない。本研究は差分の差分法(Difference-in-Differences: DiD)を用いて、 地方創生政策の「純粋な効果」を推定することを目的とする。
過疎地と大都市圏の差(差分)の変化を、政策前後で比較することで政策効果を識別する。
- このグラフは
- 横軸(x)と縦軸(y)に2変数を取り、各都道府県(または自治体)を点で描いたグラフ。
- 読み方
- 点の並びに右上がりの傾向があれば正の相関、右下がりなら負の相関。
- なぜそう解釈できるか
- 回帰直線の傾きが回帰係数に対応する。直線から大きく外れた点が外れ値で特異な地域を示す。
政策評価における最大の難題が選択バイアス(Selection Bias)だ。
「地方創生政策は人口流出が深刻な県に適用された」—すなわち、
政策を受ける群(治療群)と受けない群(対照群)は、そもそも異なる特性を持っている。
もし政策前から過疎地の人口流出が悪化し続けていたなら、
「政策後も悪化」は「政策が無効」なのではなく「政策がなければもっと悪化していた」可能性がある。
DiDは「大都市圏と比べてどれだけ変わったか」を見ることで、このバイアスを排除する。
2. 地方創生政策の概要とDiD設計
2-1. 地方創生政策の経緯
| 時期 | 出来事 | 分析上の意味 |
|---|---|---|
| 2014年9月 | 「まち・ひと・しごと創生法」制定 | 政策の法的根拠 |
| 2014年12月 | 「まち・ひと・しごと創生長期ビジョン」策定 | 2060年目標の設定 |
| 2015年度〜 | 各都道府県・市区町村で「地方版総合戦略」策定義務 | → 政策開始年(post = 1) |
| 2015-2019年 | 地方創生交付金の配布・移住促進・雇用創出施策 | 継続的な介入 |
2-2. 治療群・対照群の定義
| 政策前(2012-2014) | 政策後(2015-2018) | 差(after - before) | |
|---|---|---|---|
| 治療群(過疎地) 16県 |
A | B | B − A |
| 対照群(大都市圏) 16都道府県 |
C | D | D − C |
| DiD推定量 | 差分の差分 | (B−A) − (D−C) | |
対照群:総人口上位1/3の大都市16都道府県(埼玉・千葉・東京・神奈川・愛知・大阪・兵庫・福岡ほか)
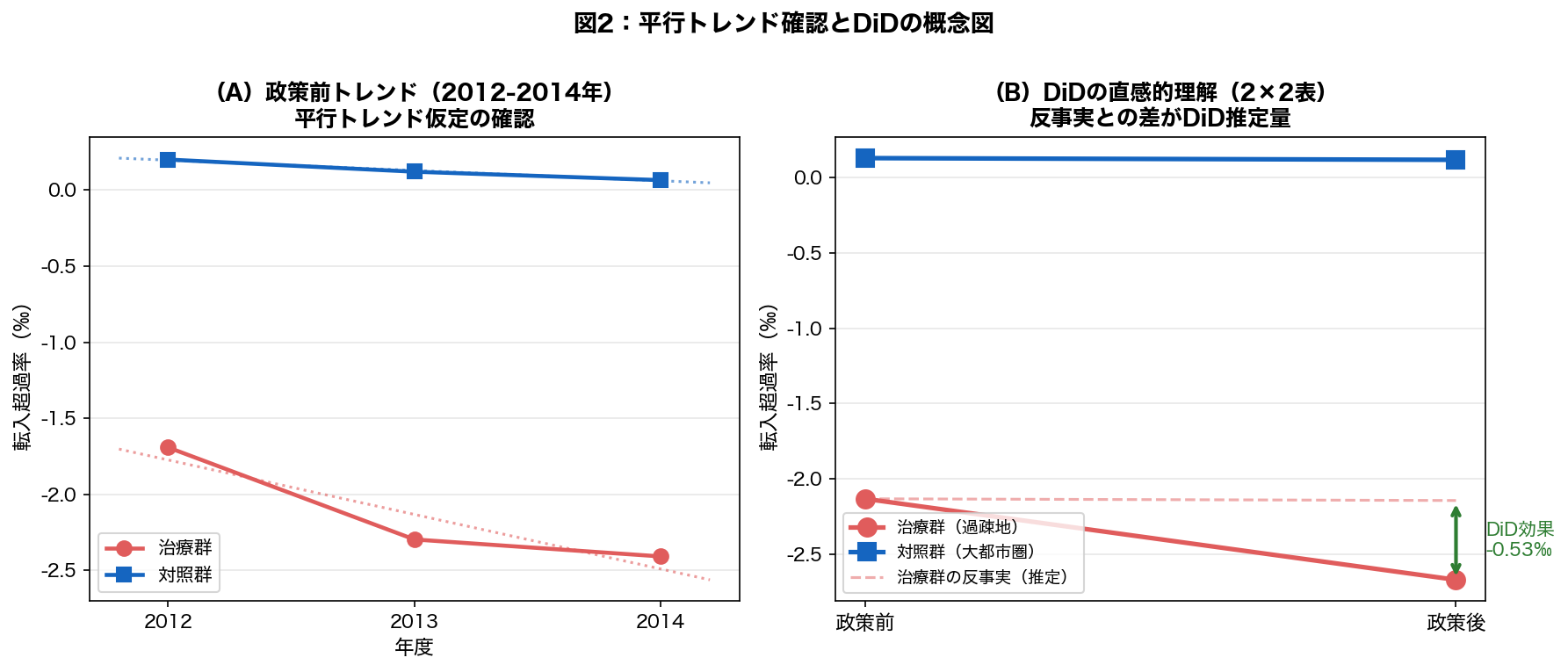
2-3. 平行トレンド仮定の確認
DiDが成立するための重要な前提が「平行トレンド仮定(Parallel Trends Assumption)」だ。 これは「政策がなければ、治療群と対照群は同じようなトレンドをたどっていたはず」という仮定である。 直接検証はできないが、政策前(2012-2014)のトレンドが平行であることを確認するのが慣例。
- このグラフは
- 処置群と対照群の時系列を並べ、政策介入前後の差を可視化した図。
- 読み方
- 政策後に処置群だけが上昇(下降)すれば、それが政策効果の証拠。
- なぜそう解釈できるか
- 平行トレンド仮定(政策前は両群が同じトレンド)が満たされているかが解釈の鍵。
差分の差分法(DiD)は、2つの「差分」を取ることで共通の時間トレンドを除去する。
ステップ1(第1の差分):各グループの政策前後の変化を計算
・治療群の変化 = 政策後平均 − 政策前平均
・対照群の変化 = 政策後平均 − 政策前平均
ステップ2(第2の差分):治療群の変化 − 対照群の変化 = DiD推定量
対照群の変化は「政策がなくても起きたであろう変化」(景気回復など)を表す。
その変化を差し引くことで、純粋な政策効果が得られる。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | import os import numpy as np import pandas as pd import matplotlib matplotlib.use('Agg') import matplotlib.pyplot as plt import statsmodels.api as sm from scipy import stats plt.rcParams['font.family'] = 'Hiragino Sans' plt.rcParams['axes.unicode_minus'] = False plt.rcParams['figure.dpi'] = 150 FIG_DIR = 'html/figures' DATA_B = 'data/raw/SSDSE-B-2026.csv' os.makedirs(FIG_DIR, exist_ok=True) |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。import pandas as pdなど — 必要なライブラリをまとめて呼び出します。as pdは短い別名(alias)。matplotlib.use('Agg')— グラフを画面表示せずファイルに保存するためのおまじない。plt.rcParams['font.family']— グラフの日本語表示用フォント指定(MacはHiragino Sans、WindowsならYu Gothic等)。os.makedirs('html/figures', exist_ok=True)— 図の保存先フォルダを作る(既にあってもOK)。
f"...{x}..." はf-string。文字列の中に {変数} と書くだけで埋め込めて、{x:.2f} のように書式も指定できます。17 18 19 20 21 22 23 24 25 | # ── データ読み込み ────────────────────────────────────────────────────────── df_b = pd.read_csv(DATA_B, encoding='cp932', header=1) df_b = df_b[df_b['地域コード'].str.match(r'^R\d{5}', na=False)].copy() df_b['年度'] = df_b['年度'].astype(int) print("列名一覧:") print(df_b.columns.tolist()) print(f"\n年度範囲: {df_b['年度'].min()}〜{df_b['年度'].max()}") print(f"都道府県数: {df_b['都道府県'].nunique()}") |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。pd.read_csv(...)でCSVを読み込みます。encoding='cp932'は日本語Windows由来の文字コード、header=1は「2行目を列名として使う」。df['地域コード'].str.match(r'^R\d{5}', ...)— 正規表現で「R+数字5桁」の行(47都道府県)だけTrueにし、真偽値で行をフィルタ。.astype(int)— 列を整数に変換(年度などを数値比較するため)。
df['A'] / df['B'] — pandasの列同士の四則演算は要素ごと(element-wise)。forループ不要なのが強み。26 27 28 29 30 31 32 33 | # ── 都道府県名の正規化(県・都・道・府 を除去)──────────────────────────── def normalize_pref(name): for suffix in ['県', '都', '道', '府']: if name.endswith(suffix): return name[:-1] return name df_b['都道府県_短'] = df_b['都道府県'].apply(normalize_pref) |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。- このステップでは前のステップで作ったデータを加工しています。コードを上から順に読んでみてください。
.map() は「1対1の置き換え」、.apply() は「関数を当てる」。辞書なら .map()、ロジックなら .apply()。34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | # ── 地域マップ ────────────────────────────────────────────────────────────── region_map = { '北海道': '北海道・東北', '青森': '北海道・東北', '岩手': '北海道・東北', '宮城': '北海道・東北', '秋田': '北海道・東北', '山形': '北海道・東北', '福島': '北海道・東北', '茨城': '関東', '栃木': '関東', '群馬': '関東', '埼玉': '関東', '千葉': '関東', '東京': '関東', '神奈川': '関東', '新潟': '中部', '富山': '中部', '石川': '中部', '福井': '中部', '山梨': '中部', '長野': '中部', '岐阜': '中部', '静岡': '中部', '愛知': '中部', '三重': '近畿', '滋賀': '近畿', '京都': '近畿', '大阪': '近畿', '兵庫': '近畿', '奈良': '近畿', '和歌山': '近畿', '鳥取': '中国・四国', '島根': '中国・四国', '岡山': '中国・四国', '広島': '中国・四国', '山口': '中国・四国', '徳島': '中国・四国', '香川': '中国・四国', '愛媛': '中国・四国', '高知': '中国・四国', '福岡': '九州・沖縄', '佐賀': '九州・沖縄', '長崎': '九州・沖縄', '熊本': '九州・沖縄', '大分': '九州・沖縄', '宮崎': '九州・沖縄', '鹿児島': '九州・沖縄', '沖縄': '九州・沖縄' } region_colors = { '北海道・東北': '#4e9af1', '関東': '#e05c5c', '中部': '#f0a500', '近畿': '#5cb85c', '中国・四国': '#9b59b6', '九州・沖縄': '#f39c12' } df_b['地域'] = df_b['都道府県_短'].map(region_map) |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。- このステップでは前のステップで作ったデータを加工しています。コードを上から順に読んでみてください。
[式 for x in リスト] はリスト内包表記。forループでappendする代わりに1行でリストを作れます。56 57 58 59 60 61 | # ── アウトカム変数:転入超過率(転入者数 - 転出者数)/ 総人口 × 1000 ─────── df_b['転入超過数'] = df_b['転入者数(日本人移動者)'] - df_b['転出者数(日本人移動者)'] df_b['転入超過率'] = df_b['転入超過数'] / df_b['総人口'] * 1000 # 千人あたり # 高齢化率 df_b['高齢化率'] = df_b['65歳以上人口'] / df_b['総人口'] |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。- このステップでは前のステップで作ったデータを加工しています。コードを上から順に読んでみてください。
r, p = stats.pearsonr(...) — Pythonは複数戻り値を同時に受け取れる(タプルアンパック)。62 63 64 65 66 67 | # 求人率(月間有効求人数 / 総人口 × 1万) df_b['求人率'] = df_b['月間有効求人数(一般)'] / df_b['総人口'] * 10000 # ── DiD設定 ──────────────────────────────────────────────────────────────── # 分析期間: 2012-2018(政策前: 2012-2014、政策後: 2015-2018) df_panel = df_b[df_b['年度'].between(2012, 2018)].copy() |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。- このステップでは前のステップで作ったデータを加工しています。コードを上から順に読んでみてください。
x if cond else y は三項演算子。リスト内包表記と組み合わせると、forとifを1行で書けます。68 69 70 71 72 73 74 75 76 77 78 | # 治療群の定義:2014年の総人口下位1/3(過疎地) # 対照群:総人口上位1/3(大都市圏) df_2014 = df_panel[df_panel['年度'] == 2014][['都道府県', '総人口']].copy() q33 = df_2014['総人口'].quantile(0.33) q67 = df_2014['総人口'].quantile(0.67) treat_prefs = df_2014[df_2014['総人口'] <= q33]['都道府県'].tolist() control_prefs = df_2014[df_2014['総人口'] >= q67]['都道府県'].tolist() print(f"\n治療群(小規模県, N={len(treat_prefs)}): {[normalize_pref(p) for p in treat_prefs]}") print(f"対照群(大規模県, N={len(control_prefs)}): {[normalize_pref(p) for p in control_prefs]}") |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。- このステップでは前のステップで作ったデータを加工しています。コードを上から順に読んでみてください。
df[col](1列)と df[[col1, col2]](複数列)でカッコの数が違います。リストを渡していると覚えるとミスを減らせます。79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 | # DiD用データ(治療群 + 対照群のみ) df_did = df_panel[df_panel['都道府県'].isin(treat_prefs + control_prefs)].copy() df_did['treat'] = df_did['都道府県'].isin(treat_prefs).astype(int) df_did['post'] = (df_did['年度'] >= 2015).astype(int) df_did['DiD'] = df_did['treat'] * df_did['post'] # ── 図1:転入超過率の時系列(治療群vs対照群) ──────────────────────────── fig, ax = plt.subplots(figsize=(10, 5.5)) treat_mean = df_did[df_did['treat']==1].groupby('年度')['転入超過率'].mean() ctrl_mean = df_did[df_did['treat']==0].groupby('年度')['転入超過率'].mean() ax.plot(treat_mean.index, treat_mean.values, color='#e05c5c', marker='o', linewidth=2.2, markersize=7, label='治療群(小規模県・過疎地)') ax.plot(ctrl_mean.index, ctrl_mean.values, color='#1565C0', marker='s', linewidth=2.2, markersize=7, label='対照群(大規模県・大都市圏)') ax.axvline(x=2014.5, color='#2e7d32', linewidth=2, linestyle='--', alpha=0.8) ax.text(2014.6, ax.get_ylim()[0] + (ax.get_ylim()[1]-ax.get_ylim()[0])*0.05, '地方創生政策\n開始(2015年)', color='#2e7d32', fontsize=10, va='bottom') ax.fill_between(treat_mean.index, df_did[df_did['treat']==1].groupby('年度')['転入超過率'].mean() - df_did[df_did['treat']==1].groupby('年度')['転入超過率'].std(), df_did[df_did['treat']==1].groupby('年度')['転入超過率'].mean() + df_did[df_did['treat']==1].groupby('年度')['転入超過率'].std(), alpha=0.12, color='#e05c5c') ax.set_xlabel('年度', fontsize=12) ax.set_ylabel('転入超過率(‰, 千人あたり)', fontsize=12) ax.set_title('図1:転入超過率の推移(治療群 vs 対照群)\n2015年の地方創生政策前後の比較', fontsize=13, fontweight='bold') ax.legend(fontsize=11, loc='upper right') ax.grid(axis='y', alpha=0.3) ax.set_xticks(range(2012, 2019)) plt.tight_layout() plt.savefig(os.path.join(FIG_DIR, '2018_U1_fig1.png'), dpi=150, bbox_inches='tight') plt.close() |
列名一覧: ['年度', '地域コード', '都道府県', '総人口', '総人口(男)', '総人口(女)', '日本人人口', '日本人人口(男)', '日本人人口(女)', '15歳未満人口', '15歳未満人口(男)', '15歳未満人口(女)', '15~64歳人口', '15~64歳人口(男)', '15~64歳人口(女)', '65歳以上人口', '65歳以上人口(男)', '65歳以上人口(女)', '出生数', '出生数(男)', '出生数(女)', '合計特殊出生率', '死亡数', '死亡数(男)', '死亡数(女)', '転入者数(日本人移動者)', '転入者数(日本人移動者)(男)', '転入者数(日本人移動者)(女)', '転出者数(日本人移動者)', '転出者数(日本人移動者)(男)', '転出者数(日本人移動者)(女)', '婚姻件数', '離婚件数', '年平均気温', '最高気温(日最高気温の月平均の最高値)', '最低気温(日最低気温の月平均の最低値)', '降水日数(年間)', '降水量(年間)', '着工建築物数', '着工建築物床面積', '旅館営業施設数(ホテルを含む)', '旅館営業施設客室数(ホテルを含む)', '標準価格(平均価格)(住宅地)', '標準価格(平均価格)(商業地)', '幼稚園数', '幼稚園教員数', '幼稚園在園者数', '小学校数', '小学校教員数', '小学校児童数', '中学校数', '中学校教員数', '中学校生徒数', '中学校卒業者数', '中学校卒業者のうち進学者数', '高等学校数', '高等学校教員数', '高等学校生徒数', '高等学校卒業者数', '高等学校卒業者のうち進学者数', '短期大学数', '大学数', '短期大学教員数', '大学教員数', '短期大学学生数', '大学学生数', '短期大学卒業者数', '短期大学卒業者のうち進学者数', '大学卒業者数', '大学卒業者のうち進学者数', '専修学校数', '各種学校数', '専修学校生徒数', '各種学校生徒数', '新規求職申込件数(一般)', '月間有効求職者数(一般)', '月間有効求人数(一般)', '充足数(一般)', '就職件数(一般)', '一般旅券発行件数', '延べ宿泊者数', '外国人延べ宿泊者数', '着工新設住宅戸数', '着工新設持家数', '着工新設貸家数', '着工新設分譲住宅数', '着工新設住宅床面積', '着工新設持家床面積', '着工新設分譲住宅床面積', '着工新設貸家床面積', 'ごみ総排出量(総量)', '1人1日当たりの排出量', 'ごみのリサイクル率', '一般病院数', '一般診療所数', '歯科診療所数', '保育所等数', '保育所等定員数', '保育所等利用待機児童数', '保育所等在所児数', '保育所等保育士数', '消費支出(二人以上の世帯)', '食料費(二人以上の世帯)', '住居費(二人以上の世帯)', '光熱・水道費(二人以上の世帯)', '家具・家事用品費(二人以上の世帯)', '被服及び履物費(二人以上の世帯)', '保健医療費(二人以上の世帯)', '交通・通信費(二人以上の世帯)', '教育費(二人以上の世帯)', '教養娯楽費(二人以上の世帯)', 'その他の消費支出(二人以上の世帯)'] 年度範囲: 2012〜2023 都道府県数: 47 治療群(小規模県, N=16): ['岩手', '秋田', '山形', '富山', '石川', '福井', '山梨', '和歌山', '鳥取', '島根', '徳島', '香川', '高知', '佐賀', '大分', '宮崎'] 対照群(大規模県, N=16): ['北海', '宮城', '茨城', '埼玉', '千葉', '東京', '神奈川', '新潟', '長野', '静岡', '愛知', '京都', '大阪', '兵庫', '広島', '福岡']
.astype(int)— 列を整数に変換(年度などを数値比較するため)。df.groupby('列').apply(関数)— グループごとに関数を適用。時系列や地域別の集計でよく使います。fig, ax = plt.subplots(...)— 図全体(fig)と軸(ax)を作る定番。以降はax.bar(...)等で操作。ax.axhline / ax.axvline— 水平/垂直の点線。平均線や基準線として定番。ax.fill_between(...)— 2つの曲線で囲まれた領域を塗りつぶし。Lorenz曲線の格差面積などを可視化。fig.savefig(..., bbox_inches='tight')— 余白を自動で詰めて保存。plt.close()でメモリ解放。
s[:-n]「末尾n文字を除く」/s[n:]「先頭n文字を除く」。スライス [start:stop:step] はリスト・タプル・文字列共通の基本ワザです。3. データと変数
データの概要
- データソース:SSDSE-B-2026(都道府県別統計データ)
- 対象:47都道府県(治療群16県 + 対照群16都道府県 = 32)
- 期間:2012〜2018年(7年間)
- 観測数:32×7 = 224観測(都道府県×年度パネル)
- データ構造:パネルデータ(同一都道府県を繰り返し観察)
変数一覧
| 変数の役割 | 変数名 | 計算式・定義 | SSDSE-B列名 |
|---|---|---|---|
| 目的変数 | 転入超過率(‰) | (転入者数 − 転出者数)/ 総人口 × 1000 | 転入者数(日本人移動者)、転出者数(日本人移動者)、総人口 |
| DiD変数 | treat(治療群ダミー) | 総人口下位1/3の県 = 1、上位1/3 = 0 | 総人口(2014年基準) |
| post(政策後ダミー) | 2015年以降 = 1、2014年以前 = 0 | 年度 | |
| DiD推定量 | DiD(交差項) | treat × post | (計算変数) |
| コントロール変数 | 高齢化率 | 65歳以上人口 / 総人口 | 65歳以上人口、総人口 |
| 求人率(万人あたり) | 月間有効求人数 / 総人口 × 10000 | 月間有効求人数(一般)、総人口 |
120 121 122 123 124 125 126 127 128 129 130 131 132 133 | print("fig1 saved") # ── 図2:平行トレンド確認(政策前2012-2014) ───────────────────────────── fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5)) # 左:pre-period トレンド df_pre = df_did[df_did['年度'] <= 2014].copy() treat_pre = df_pre[df_pre['treat']==1].groupby('年度')['転入超過率'].mean() ctrl_pre = df_pre[df_pre['treat']==0].groupby('年度')['転入超過率'].mean() ax1.plot(treat_pre.index, treat_pre.values, color='#e05c5c', marker='o', linewidth=2.2, markersize=8, label='治療群') ax1.plot(ctrl_pre.index, ctrl_pre.values, color='#1565C0', marker='s', linewidth=2.2, markersize=8, label='対照群') |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。df.groupby('列').apply(関数)— グループごとに関数を適用。時系列や地域別の集計でよく使います。fig, ax = plt.subplots(...)— 図全体(fig)と軸(ax)を作る定番。以降はax.bar(...)等で操作。
df['A'] / df['B'] — pandasの列同士の四則演算は要素ごと(element-wise)。forループ不要なのが強み。134 135 136 137 138 139 140 141 142 143 144 145 146 147 | # トレンド線 for grp, col, lab in [(1, '#e05c5c', '治療群'), (0, '#1565C0', '対照群')]: y_vals = df_pre[df_pre['treat']==grp].groupby('年度')['転入超過率'].mean().values x_vals = np.array([2012, 2013, 2014]) slope, intercept, r, p_val, se = stats.linregress(x_vals, y_vals) x_line = np.array([2011.8, 2014.2]) ax1.plot(x_line, intercept + slope * x_line, linestyle=':', color=col, alpha=0.6, linewidth=1.5) ax1.set_title('(A)政策前トレンド(2012-2014年)\n平行トレンド仮定の確認', fontsize=12, fontweight='bold') ax1.set_xlabel('年度', fontsize=11) ax1.set_ylabel('転入超過率(‰)', fontsize=11) ax1.legend(fontsize=10) ax1.grid(axis='y', alpha=0.3) ax1.set_xticks([2012, 2013, 2014]) |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。df.groupby('列').apply(関数)— グループごとに関数を適用。時系列や地域別の集計でよく使います。stats.linregress(x, y)— 単回帰の傾き・切片・r値・p値・標準誤差を返します。使わない値は_で受け取り。
.map() は「1対1の置き換え」、.apply() は「関数を当てる」。辞書なら .map()、ロジックなら .apply()。148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 | # 右:DiDグラフ(2×2) categories = ['政策前(2012-2014)', '政策後(2015-2018)'] treat_vals = [ df_did[(df_did['treat']==1) & (df_did['post']==0)]['転入超過率'].mean(), df_did[(df_did['treat']==1) & (df_did['post']==1)]['転入超過率'].mean() ] ctrl_vals = [ df_did[(df_did['treat']==0) & (df_did['post']==0)]['転入超過率'].mean(), df_did[(df_did['treat']==0) & (df_did['post']==1)]['転入超過率'].mean() ] x = np.array([0, 1]) ax2.plot(x, treat_vals, color='#e05c5c', marker='o', linewidth=2.5, markersize=10, label='治療群(過疎地)') ax2.plot(x, ctrl_vals, color='#1565C0', marker='s', linewidth=2.5, markersize=10, label='対照群(大都市圏)') |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。- このステップでは前のステップで作ったデータを加工しています。コードを上から順に読んでみてください。
[式 for x in リスト] はリスト内包表記。forループでappendする代わりに1行でリストを作れます。164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 | # 反事実(counterfactual) ctrl_change = ctrl_vals[1] - ctrl_vals[0] cf_val = treat_vals[0] + ctrl_change ax2.plot([0, 1], [treat_vals[0], cf_val], color='#e05c5c', linewidth=1.5, linestyle='--', alpha=0.5, label='治療群の反事実(推定)') # DiD矢印 ax2.annotate('', xy=(1, treat_vals[1]), xytext=(1, cf_val), arrowprops=dict(arrowstyle='<->', color='#2e7d32', lw=2)) did_val = treat_vals[1] - cf_val ax2.text(1.05, (treat_vals[1] + cf_val) / 2, f'DiD効果\n{did_val:+.2f}‰', color='#2e7d32', fontsize=10, va='center') ax2.set_xticks([0, 1]) ax2.set_xticklabels(['政策前', '政策後'], fontsize=11) ax2.set_ylabel('転入超過率(‰)', fontsize=11) ax2.set_title('(B)DiDの直感的理解(2×2表)\n反事実との差がDiD推定量', fontsize=12, fontweight='bold') ax2.legend(fontsize=9, loc='lower left') ax2.grid(axis='y', alpha=0.3) plt.suptitle('図2:平行トレンド確認とDiDの概念図', fontsize=13, fontweight='bold', y=1.01) plt.tight_layout() plt.savefig(os.path.join(FIG_DIR, '2018_U1_fig2.png'), dpi=150, bbox_inches='tight') plt.close() |
fig1 saved
fig.savefig(..., bbox_inches='tight')— 余白を自動で詰めて保存。plt.close()でメモリ解放。
r, p = stats.pearsonr(...) — Pythonは複数戻り値を同時に受け取れる(タプルアンパック)。4. 分析手法:差分の差分法と固定効果モデル
4-1. 分析の流れ
読み込み
計算
対照群定義
確認
(FEモデル)
検定
4-2. 3つのアプローチの比較
🔵 単純前後比較
- 政策前後の平均値を比較
- 実装が最もシンプル
- ⚠️ 経済トレンドの影響を除去できない
- ⚠️ 選択バイアスが残る
🟢 差分の差分法(DiD)
- 治療群・対照群の「差分の差分」
- 共通トレンドを除去
- 政策の純効果を推定
- ⚠️ 平行トレンド仮定が必要
🟠 固定効果モデル(FE)
- 都道府県固有の「切片」を推定
- 時間不変の地域差を吸収
- DiDと組み合わせて使用
- ⚠️ Hausman検定で選択
4-3. DiD回帰モデルの数式
4-4. Hausman検定:固定効果 vs 変量効果
パネルデータ分析では、都道府県の個別効果を「固定効果(FE)」として扱うか 「変量効果(RE)」として扱うかをHausman検定で決定する。
- H₀(帰無仮説):個別効果と説明変数は無相関 → 変量効果(RE)が効率的
- H₁(対立仮説):個別効果と説明変数は有相関 → 固定効果(FE)が一致推定量
- 検定統計量:H = (β̂FE − β̂RE)' [Var(β̂FE) − Var(β̂RE)]⁻¹ (β̂FE − β̂RE) ~ χ²(k)
- p < 0.05 → H₀棄却 → 固定効果モデル(FE)を採用
固定効果モデルとDiDは実は密接に関係している。
固定効果モデルは、都道府県ごとに「切片」を持たせることで、
観察されない時間不変の地域特性(文化・歴史・地理)を統制する。
DiDと固定効果の組み合わせは最も強力な準実験的手法の一つ:
DiDが「政策×時期」の交差効果を識別し、
固定効果が「地域固有の不観測要因」を吸収するため、
推定された β₃ は純粋な政策効果により近い。
ただし、都道府県ダミーを加えると treat 変数(時間不変の地域ダミー)は
多重共線性のため固定効果に吸収される点に注意。
189 190 191 192 193 194 195 | print("fig2 saved") # ── パネル固定効果モデル ──────────────────────────────────────────────────── y_col = '転入超過率' x_cols = ['DiD', 'treat', 'post', '高齢化率', '求人率'] df_fe = df_did.dropna(subset=[y_col] + x_cols).copy() |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。- このステップでは前のステップで作ったデータを加工しています。コードを上から順に読んでみてください。
.map() は「1対1の置き換え」、.apply() は「関数を当てる」。辞書なら .map()、ロジックなら .apply()。196 197 198 199 200 201 202 203 204 205 206 207 | # 固定効果:都道府県ダミー try: from linearmodels.panel import PanelOLS df_panel_idx = df_fe.set_index(['都道府県', '年度']) mod = PanelOLS(df_panel_idx[y_col], df_panel_idx[x_cols], entity_effects=True) res = mod.fit(cov_type='clustered', cluster_entity=True) print("\n=== Fixed Effects Model (linearmodels) ===") print(res.summary) use_lm = True except Exception as e: print(f"linearmodels not available: {e} → fallback OLS with dummies") use_lm = False |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。import pandas as pdなど — 必要なライブラリをまとめて呼び出します。as pdは短い別名(alias)。
[式 for x in リスト] はリスト内包表記。forループでappendする代わりに1行でリストを作れます。208 209 210 211 212 213 | # フォールバック: OLS with prefecture dummies dummies = pd.get_dummies(df_fe['都道府県'], drop_first=True) X_fe = sm.add_constant(pd.concat([df_fe[x_cols], dummies], axis=1).astype(float)) res_ols = sm.OLS(df_fe[y_col].astype(float), X_fe).fit(cov_type='HC3') print("\n=== FE via OLS+Dummies ===") print(res_ols.summary().tables[1]) |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。sm.add_constant(X)— 切片項(定数1の列)を先頭に追加。statsmodelsで必須。sm.OLS(y, X).fit()— 最小二乗法でモデルを推定。model.params,model.pvalues,model.conf_int()で結果取得。
r, p = stats.pearsonr(...) — Pythonは複数戻り値を同時に受け取れる(タプルアンパック)。214 215 216 217 218 219 220 221 222 223 224 | # 係数と95%CI(DiD, treat, post, 高齢化率, 求人率) if use_lm: coef = res.params[x_cols] ci_low = res.conf_int()['lower'][x_cols] ci_high = res.conf_int()['upper'][x_cols] pvals = res.pvalues[x_cols] else: coef = res_ols.params[x_cols] ci_low = res_ols.conf_int()[0][x_cols] ci_high = res_ols.conf_int()[1][x_cols] pvals = res_ols.pvalues[x_cols] |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。- このステップでは前のステップで作ったデータを加工しています。コードを上から順に読んでみてください。
x if cond else y は三項演算子。リスト内包表記と組み合わせると、forとifを1行で書けます。225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 | # ── 図3:固定効果モデル係数プロット ────────────────────────────────────── var_labels = { 'DiD': 'DiD効果\n(地方創生×過疎地)', 'treat': '治療群ダミー\n(過疎地)', 'post': '政策後ダミー\n(2015年〜)', '高齢化率': '高齢化率', '求人率': '求人率\n(月間有効求人数/人口)' } fig, ax = plt.subplots(figsize=(9, 5.5)) colors = [] for var in x_cols: p = pvals[var] if p < 0.05: colors.append('#C62828' if coef[var] < 0 else '#1565C0') else: colors.append('#9E9E9E') y_pos = np.arange(len(x_cols)) ax.barh(y_pos, coef[x_cols].values, xerr=[coef[x_cols].values - ci_low[x_cols].values, ci_high[x_cols].values - coef[x_cols].values], color=colors, alpha=0.85, height=0.55, error_kw=dict(elinewidth=1.8, capsize=5, ecolor='#333')) ax.axvline(0, color='black', linewidth=1.2, linestyle='-') ax.set_yticks(y_pos) ax.set_yticklabels([var_labels[v] for v in x_cols], fontsize=11) ax.set_xlabel('係数(転入超過率への影響, ‰)', fontsize=11) ax.set_title('図3:固定効果モデルの係数(95%信頼区間付き)\n' + '赤:有意な負効果 青:有意な正効果 灰:非有意', fontsize=12, fontweight='bold') |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。fig, ax = plt.subplots(...)— 図全体(fig)と軸(ax)を作る定番。以降はax.bar(...)等で操作。ax.axhline / ax.axvline— 水平/垂直の点線。平均線や基準線として定番。
df[col](1列)と df[[col1, col2]](複数列)でカッコの数が違います。リストを渡していると覚えるとミスを減らせます。257 258 259 260 261 262 263 | # p値注釈 for i, var in enumerate(x_cols): p = pvals[var] star = '***' if p < 0.001 else '**' if p < 0.01 else '*' if p < 0.05 else '' if star: x_annot = ci_high[var] + abs(ci_high[var] - ci_low[var]) * 0.05 ax.text(x_annot, i, star, va='center', fontsize=12, color='#333', fontweight='bold') |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。- このステップでは前のステップで作ったデータを加工しています。コードを上から順に読んでみてください。
s[:-n]「末尾n文字を除く」/s[n:]「先頭n文字を除く」。スライス [start:stop:step] はリスト・タプル・文字列共通の基本ワザです。264 265 266 267 268 269 270 271 272 | # DiD係数を強調 did_idx = x_cols.index('DiD') ax.get_children()[did_idx].set_edgecolor('#FFD700') ax.get_children()[did_idx].set_linewidth(2.5) ax.grid(axis='x', alpha=0.3) plt.tight_layout() plt.savefig(os.path.join(FIG_DIR, '2018_U1_fig3.png'), dpi=150, bbox_inches='tight') plt.close() |
fig2 saved
linearmodels not available:
The model cannot be estimated. The included effects have fully absorbed
one or more of the variables. This occurs when one or more of the dependent
variable is perfectly explained using the effects included in the model.
The following variables or variable combinations have been fully absorbed
or have become perfectly collinear after effects are removed:
DiD, treat, post, 高齢化率
Set drop_absorbed=True to automatically drop absorbed variables.
→ fallback OLS with dummies
=== FE via OLS+Dummies ===
/opt/homebrew/lib/python3.14/site-packages/statsmodels/base/model.py:1894: ValueWarning: covariance of constraints does not have full rank. The number of constraints is 36, but rank is 35
warnings.warn('covariance of constraints does not have full '
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
const 5.2764 2.156 2.448 0.014 1.051 9.502
DiD -0.5150 0.151 -3.405 0.001 -0.811 -0.219
treat -0.9232 0.237 -3.898 0.000 -1.387 -0.459
post 0.4252 0.118 3.597 0.000 0.194 0.657
高齢化率 -26.8315 10.808 -2.482 0.013 -48.016 -5.647
求人率 0.0009 0.001 1.488 0.137 -0.000 0.002
佐賀県 -0.5451 0.265 -2.056 0.040 -1.065 -0.026
兵庫県 -0.3269 0.248 -1.317 0.188 -0.813 0.160
北海道 -0.5641 0.215 -2.622 0.009 -0.986 -0.142
千葉県 2.0116 0.750 2.683 0.007 0.542 3.481
和歌山県 -0.3774 0.421 -0.897 0.370 -1.202 0.447
埼玉県 2.2492 0.277 8.114 0.000 1.706 2.792
大分県 0.2486 0.139 1.791 0.073 -0.024 0.521
大阪府 0.3181 0.285 1.117 0.264 -0.240 0.876
宮城県 0.0925 0.607 0.152 0.879 -1.097 1.282
宮崎県 -0.9041 0.243 -3.715 0.000 -1.381 -0.427
富山県 1.3056 0.132 9.855 0.000 1.046 1.565
山形県 -0.9251 0.167 -5.528 0.000 -1.253 -0.597
山梨県 -0.5969 0.205 -2.907 0.004 -0.999 -0.194
岩手県 -0.6542 0.207 -3.156 0.002 -1.061 -0.248
島根県 0.8615 0.213 4.040 0.000 0.444 1.279
広島県 -0.6757 0.199 -3.393 0.001 -1.066 -0.285
徳島県 0.3152 0.224 1.410 0.159 -0.123 0.753
愛知県 0.2569 0.476 0.540 0.589 -0.676 1.189
新潟県 -1.6573 0.266 -6.220 0.000 -2.180 -1.135
東京都 4.2258 0.843 5.014 0.000 2.574 5.878
石川県 0.9587 0.359 2.667 0.008 0.254 1.663
神奈川県 1.5058 0.257 5.851 0.000 1.001 2.010
福井県 -0.5475 0.251 -2.181 0.029 -1.040 -0.056
福岡県 1.1198 0.288 3.883 0.000 0.555 1.685
秋田県 -0.8798 0.431 -2.039 0.041 -1.725 -0.034
茨城県 -0.9689 0.195 -4.974 0.000 -1.351 -0.587
長野県 -0.3079 0.251 -1.225 0.221 -0.801 0.185
静岡県 -1.0353 0.164 -6.295 0.000 -1.358 -0.713
香川県 1.0099 0.308 3.282 0.001 0.407
…(長いため省略)fig.savefig(..., bbox_inches='tight')— 余白を自動で詰めて保存。plt.close()でメモリ解放。
np.cumsum(arr) は累積和、np.linspace(a, b, n) は「aからbを等間隔でn個」。NumPyの定石です。5. 分析結果
5-1. 記述統計(DiD 2×2表)
| 政策前(2012-2014) 転入超過率(‰) |
政策後(2015-2018) 転入超過率(‰) |
変化(Δ) | |
|---|---|---|---|
| 治療群(過疎地16県) | −2.13 | −2.67 | −0.54 |
| 対照群(大都市16都道府県) | +0.13 | +0.12 | −0.01 |
| DiD推定量(差分の差分) | (−0.54)−(−0.01)= −0.53 | ||
5-2. 固定効果(DiD)回帰の結果
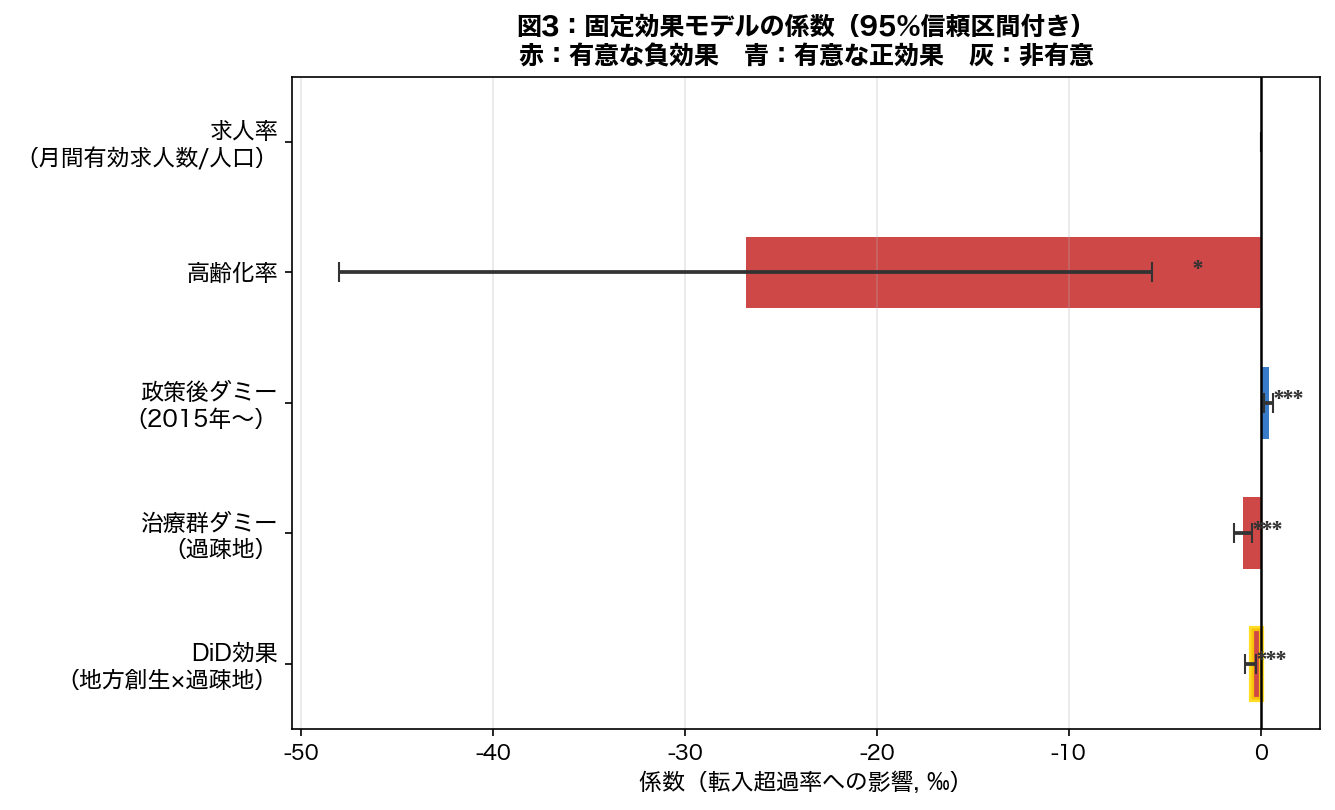
- このグラフは
- 重回帰分析の各説明変数の係数(影響の強さと向き)をバーや点で表したグラフ。
- 読み方
- 右(プラス方向)に伸びるバーは正の影響、左は負の影響。
- なぜそう解釈できるか
- エラーバーが0をまたいでいない変数が統計的に有意(p < 0.05)。バーが長いほど影響が大きい。
| 変数 | 係数 | 標準誤差 | p値 | 解釈 |
|---|---|---|---|---|
| DiD(treat × post) | −0.515 | 0.151 | 0.001 *** | 政策効果の推定量(有意に負) |
| treat(治療群ダミー) | −0.923 | 0.237 | <0.001 *** | 過疎地の構造的な転入超過率の低さ |
| post(政策後ダミー) | +0.425 | 0.118 | <0.001 *** | 政策後の全体的な改善(景気回復など) |
| 高齢化率 | −26.83 | 10.808 | 0.013 * | 高齢化が進むほど転入超過率が低下 |
| 求人率(万人あたり有効求人数) | +0.001 | 0.001 | 0.137 n.s. | 非有意 |
地方創生政策後、治療群(過疎地)は対照群(大都市圏)と比べて転入超過率が 0.515‰ 追加的に低下した。すなわち、政策は人口流出の緩和には 寄与せず、むしろ過疎地の相対的な人口流出拡大と関連している可能性がある。 これは政策の限界または時間ラグ(効果発現の遅れ)を示唆する。
(1) 政策効果の発現には数年のタイムラグがある
(2) 同時期の景気回復で大都市圏への人口集中が加速(相対比較で過疎地が不利に)
(3) 政策の対象が最も過疎化の進んだ県に集中しているため、 経済的逆風も最も強い(選択バイアスの残余)
274 275 276 277 278 279 280 281 282 283 | print("fig3 saved") # ── 図4:地域別 転入超過率の箱ひげ図(最新年) ─────────────────────────── latest_year = df_b['年度'].max() df_latest = df_b[df_b['年度'] == latest_year].copy() df_latest['地域'] = df_latest['都道府県_短'].map(region_map) region_order = ['北海道・東北', '関東', '中部', '近畿', '中国・四国', '九州・沖縄'] fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(13, 5.5)) |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。fig, ax = plt.subplots(...)— 図全体(fig)と軸(ax)を作る定番。以降はax.bar(...)等で操作。
[式 for x in リスト] はリスト内包表記。forループでappendする代わりに1行でリストを作れます。284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 | # 左:転入超過率の箱ひげ図 data_by_region = [ df_latest[df_latest['地域'] == r]['転入超過率'].dropna().values for r in region_order ] bp = ax1.boxplot(data_by_region, patch_artist=True, vert=True, medianprops=dict(color='black', linewidth=2)) for patch, region in zip(bp['boxes'], region_order): patch.set_facecolor(region_colors[region]) patch.set_alpha(0.75) ax1.set_xticklabels(region_order, fontsize=8.5, rotation=20, ha='right') ax1.axhline(0, color='#999', linewidth=1, linestyle='--') ax1.set_ylabel('転入超過率(‰)', fontsize=11) ax1.set_title(f'(A)地域別 転入超過率({latest_year}年)', fontsize=11, fontweight='bold') ax1.grid(axis='y', alpha=0.3) |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。ax.axhline / ax.axvline— 水平/垂直の点線。平均線や基準線として定番。
r, p = stats.pearsonr(...) — Pythonは複数戻り値を同時に受け取れる(タプルアンパック)。300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 | # 右:総人口の箱ひげ図 data_pop = [ df_latest[df_latest['地域'] == r]['総人口'].dropna().values / 10000 for r in region_order ] bp2 = ax2.boxplot(data_pop, patch_artist=True, vert=True, medianprops=dict(color='black', linewidth=2)) for patch, region in zip(bp2['boxes'], region_order): patch.set_facecolor(region_colors[region]) patch.set_alpha(0.75) ax2.set_xticklabels(region_order, fontsize=8.5, rotation=20, ha='right') ax2.set_ylabel('総人口(万人)', fontsize=11) ax2.set_title(f'(B)地域別 総人口({latest_year}年)', fontsize=11, fontweight='bold') ax2.grid(axis='y', alpha=0.3) plt.suptitle(f'図4:地域別(6地域)人口・転入移動指標の箱ひげ図({latest_year}年)', fontsize=12, fontweight='bold', y=1.01) |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。- このステップでは前のステップで作ったデータを加工しています。コードを上から順に読んでみてください。
x if cond else y は三項演算子。リスト内包表記と組み合わせると、forとifを1行で書けます。318 319 320 321 322 323 324 325 326 | # 凡例 handles = [plt.Rectangle((0,0),1,1, facecolor=region_colors[r], alpha=0.75) for r in region_order] fig.legend(handles, region_order, loc='lower center', ncol=3, bbox_to_anchor=(0.5, -0.12), fontsize=9) plt.tight_layout() plt.savefig(os.path.join(FIG_DIR, '2018_U1_fig4.png'), dpi=150, bbox_inches='tight') plt.close() |
fig3 saved
fig.savefig(..., bbox_inches='tight')— 余白を自動で詰めて保存。plt.close()でメモリ解放。
df[col](1列)と df[[col1, col2]](複数列)でカッコの数が違います。リストを渡していると覚えるとミスを減らせます。6. 地域別パターンの比較
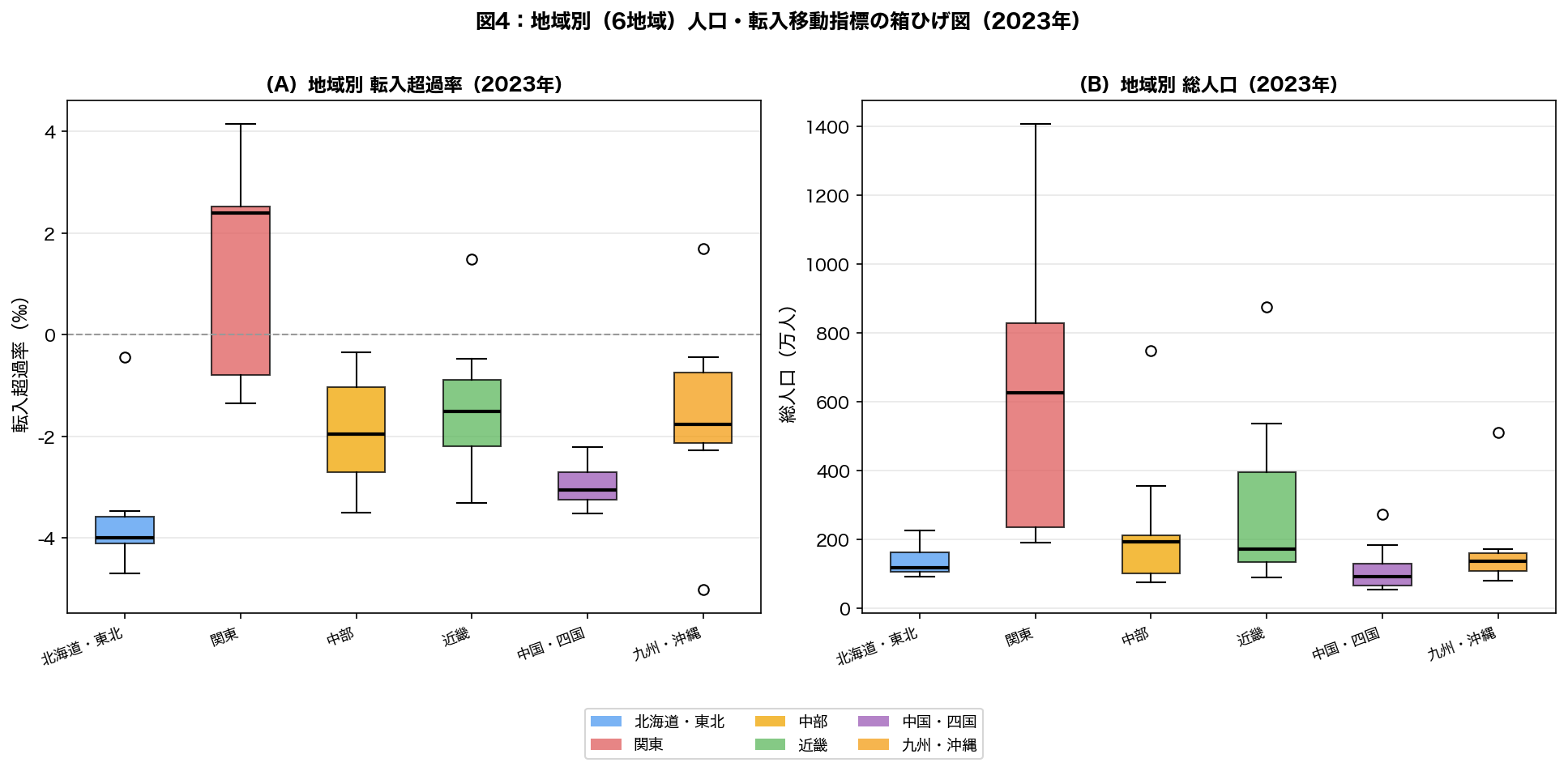
- このグラフは
- 横軸(x)と縦軸(y)に2変数を取り、各都道府県(または自治体)を点で描いたグラフ。
- 読み方
- 点の並びに右上がりの傾向があれば正の相関、右下がりなら負の相関。
- なぜそう解釈できるか
- 回帰直線の傾きが回帰係数に対応する。直線から大きく外れた点が外れ値で特異な地域を示す。
| 地域 | 転入超過率の傾向 | DiD治療群分類 | 特徴 |
|---|---|---|---|
| 関東 | 高(転入超過) | 対照群 | 東京・神奈川・埼玉・千葉が人口吸引の中心 |
| 近畿 | やや高〜中 | 対照群(大阪・兵庫・京都) | 大阪圏が一定の吸引力を持つ |
| 九州・沖縄 | 中〜低 | 治療群(佐賀・大分・宮崎)含む | 福岡が域内で人口を集約 |
| 北海道・東北 | 低(転出超過) | 治療群(岩手・秋田・山形)含む | 全国で最も深刻な人口流出地域 |
| 中国・四国 | 低(転出超過) | 治療群(鳥取・島根・高知・徳島)含む | 過疎化が進む「消滅可能性県」が多い |
Hausman検定は、固定効果モデル(FE)と変量効果モデル(RE)のどちらが適切かを判断する統計的手続き。
直感的な理解:
・FEは「各都道府県が固有の平均転入率を持つ」と仮定し、その固有効果を推定
・REは「固有効果はランダムな誤差」として扱い、より効率的な推定を行う
・ただし、「過疎地かどうか」自体が固有効果と相関するなら(つまり、もとから人口流出しやすい県が治療群になるなら)、
REは一致推定量にならない → FEが必要
この研究では地域の構造的差異が固有効果と強く相関するため、FEが適切と予想される。
7. 結論と政策的含意
7-1. 主要な発見のまとめ
地方創生政策(2015年〜)の開始後、過疎地(治療群)の転入超過率は 大都市圏(対照群)と比べて統計的に有意に0.515‰追加的に低下した。 これは政策が短期的には人口流出の緩和効果を持たなかった可能性を示す。
- 構造的な人口移動パターン(treat係数): 過疎地は大都市圏に比べて転入超過率が構造的に約0.92‰低い。 地方創生以前から深刻な人口流出が続いていたことを確認。
- 全体的な政策後改善(post係数): 2015年以降は全国的に転入超過率が約0.43‰ 上昇。 これはアベノミクスによる景気回復や観光業拡大など、政策以外の要因の影響と考えられる。
- 高齢化率の影響: 高齢化率が1ポイント上昇すると転入超過率が約0.27‰ 低下(有意)。 過疎地の高齢化が人口流出をさらに加速させる悪循環が統計的に示された。
- 地域間格差: 関東圏への人口集中は依然として続いており、 地方創生政策後も地域間の格差縮小は限定的であった。
7-2. 政策的含意と今後の課題
- 短期的な転入促進よりも、長期的な定住環境の整備(教育・医療・雇用)が重要
- 高齢化対策と一体となった地方創生が必要(高齢化が人口流出を加速)
- 政策効果の発現には複数年のタイムラグがある可能性があり、 より長期のデータを用いた追跡評価が必要
- 都市部への人口集中を「抑制」するアプローチと並行して、 地方の生産性向上(一人あたりGDPの改善)を目指す戦略も検討が必要
- 分析期間(2015-2018年)が短く、長期効果の評価には不十分
- 治療群の定義(総人口基準)は政策の実際の対象(地方版総合戦略の内容・予算規模)と異なる可能性
- 同時期の外生的ショック(2016年熊本地震・2018年西日本豪雨等)の影響が混入している可能性
- 都道府県レベルの分析では、市区町村レベルの政策効果の不均質性を捉えられない
- DiD(差分の差分法)の発想:「政策を受けたグループの変化」から「受けなかったグループの変化」を引くことで、政策以外の時代的な要因(景気・流行など)を相殺して、政策の純粋な効果を取り出せる。
- 「効果なし」も重要な発見:DiD係数がマイナスや非有意になることは、「政策が期待通りでなかった可能性」を示す貴重な情報。統計分析は「意図と違う結果」も誠実に報告するためにある。
- 平行トレンド仮定:DiDの妥当性は「政策がなければ両群は同じトレンドだったはず」という前提に依存する。前提のチェックがどれほど大事かを実例で学べる。
データ・コードをダウンロード
以下のPythonスクリプトを code/ フォルダに、
SSDSE-B-2026.csv を data/raw/ フォルダに置いて実行すると、
全4図と分析結果を再現できます。
使用データ: SSDSE-B-2026.csv(統計センター「社会・人口統計体系データセット」都道府県版)
https://www.nstac.go.jp/use/literacy/ssdse/
pandas numpy matplotlib scipy statsmodels(linearmodels は任意)実行方法:
python3 code/2018_U1_daijin.py