# -*- coding: utf-8 -*-
"""
X06: 14日豪雨期間の県内雨量分布 — 地理時空間 small multiples 研究
================================================================================
DoBoX #1275 (10分雨量) の 2024-06-29 〜 2024-07-12 (14日) と
data/extras/stations_master.csv (観測所マスタ, 緯度経度付き) を結合し、
**14コマの地理散布 (small multiples)** を主役に
「広島県 14日豪雨期間の空間×時間構造」を読み解く X 水準研究記事。
【本記事のスタイル: 地理時空間 small multiples 研究】
14日分の空間分布を 4×4 グリッドで並列表示し、時間と空間を同時に観る。
PCA や重回帰よりも「並列地理散布」を可視化の主軸に据え、
時間断面の比較によって豪雨日の空間パターン異質性を明らかにする。
仮説 H1〜H5:
H1: 14日合計雨量上位観測所は北部山間部 (北部建設・庄原支所など) に集中する
H2: 豪雨日 (例 2024-07-01) と平常日では空間パターンが大きく異なる
H3: 14日のうち 2-3 日に降水が集中 (パレート的不均衡)
H4: 観測所間の累積雨量分散が大きい (県内不均一性: ジニ係数 > 0.4)
H5: 多雨観測所と少雨観測所は地理的に分離 (緯度ヒストの重ね描き で検証)
主要可視化:
図1: small multiples 14日地理散布 (4×4 グリッド, マーカーサイズ=日合計雨量)
図2: 観測所別 14日累積雨量 ランキング棒 (上位30) + 累積寄与曲線
図3: 日別県内最大/合計の折れ線 (時系列)
図4: ローレンツ曲線 + ジニ係数 (不均一性指標)
図5: 多雨観測所 vs 少雨観測所の緯度ヒスト重ね描き
実行:
cd "2026 DoBoX 教材"
py -X utf8 lessons/X06_rainfall_14days_geo_smallmult.py
制約:
- 並列処理なし、メモリ 500 MB 未満 (14CSV を逐次処理して観測所別累積を保持)
- 14日分の生 10分値を一気に DataFrame に展開しない (メモリ嵩む)
"""
from __future__ import annotations
from pathlib import Path
import warnings
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.lines import Line2D
from _common import (ROOT, ASSETS, LESSONS, render_lesson, code, figure,
data_recipe, parse_rain_csv, ensure_dataset)
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
warnings.filterwarnings("ignore", category=UserWarning)
# === パス定義 =================================================================
RAIN_DIR = ROOT / "data" / "rain_2024"
ST_PATH = ROOT / "data" / "extras" / "stations_master.csv"
CAM_PATH = ROOT / "data" / "camera_list.csv"
OUT_DAILY = ASSETS / "X06_daily_totals.csv" # 観測所×14日 日合計
OUT_GEO = ASSETS / "X06_station_geo.csv" # 観測所→緯度経度市町
OUT_RANK = ASSETS / "X06_cumulative_rank.csv" # 14日累積ランキング
OUT_DAYSTAT = ASSETS / "X06_day_stats.csv" # 日別県内統計
OUT_LORENZ = ASSETS / "X06_lorenz_table.csv" # ローレンツ点列+ジニ
OUT_TRACK = ASSETS / "X06_track_one_station.csv" # 1観測所14日連続追跡
PNG_SMALLMULT = ASSETS / "X06_small_multiples.png" # 主役: 4x4 地理散布
PNG_RANK = ASSETS / "X06_cumulative_rank.png" # 上位30+寄与
PNG_DAYLINE = ASSETS / "X06_day_timeline.png" # 日別時系列
PNG_LORENZ = ASSETS / "X06_lorenz_curve.png" # ローレンツ
PNG_LATHIST = ASSETS / "X06_lat_histogram.png" # 緯度ヒスト重ね描き
# === 0. データ自動取得 ========================================================
print("=== 0. データ自動取得 ===")
RAIN_RID = {
"2024-06-29": 94490, "2024-06-30": 94495, "2024-07-01": 94500,
"2024-07-02": 94505, "2024-07-03": 94510, "2024-07-04": 94515,
"2024-07-05": 94520, "2024-07-06": 94525, "2024-07-07": 94530,
"2024-07-08": 94535, "2024-07-09": 94540, "2024-07-10": 94545,
"2024-07-11": 94551, "2024-07-12": 94556,
}
RAIN_DIR.mkdir(parents=True, exist_ok=True)
for date, rid in RAIN_RID.items():
ensure_dataset(RAIN_DIR / f"rain_{date}.csv", resource_id=rid,
min_bytes=500_000, label=f"雨量10分値 {date}")
# === 1. 観測所マスタ (緯度経度+市町) を読み込む ================================
print("\n=== 1. 観測所マスタ 読み込み ===")
# stations_master.csv は 4 行目以降に観測所レコードが入る。列番号 (0-origin):
# 15=観測所名, 18=市町村名, 20=緯度, 21=経度
sm_raw = pd.read_csv(ST_PATH, header=None, encoding="utf-8-sig", skiprows=3)
geo = pd.DataFrame({
"station": sm_raw.iloc[:, 15].astype(str).str.strip(),
"city": sm_raw.iloc[:, 18].astype(str).str.strip(),
"lat": pd.to_numeric(sm_raw.iloc[:, 20], errors="coerce"),
"lon": pd.to_numeric(sm_raw.iloc[:, 21], errors="coerce"),
})
geo = geo.dropna(subset=["lat", "lon"])
geo = geo[(geo["station"] != "") & (geo["station"] != "nan")]
# 重複観測所名は最初を採用
geo = geo.drop_duplicates(subset="station", keep="first").reset_index(drop=True)
print(f" 観測所マスタ: {len(geo)} 件 (緯度経度ありのみ)")
print(f" 緯度範囲: {geo['lat'].min():.3f} 〜 {geo['lat'].max():.3f}")
print(f" 経度範囲: {geo['lon'].min():.3f} 〜 {geo['lon'].max():.3f}")
# 北部 / 南部 を緯度の中央値で大雑把に二分する基準も後で使う
LAT_MEDIAN = float(geo["lat"].median())
print(f" 緯度中央値 = {LAT_MEDIAN:.3f} (これより北 = 北部, 南 = 南部)")
geo.to_csv(OUT_GEO, index=False, encoding="utf-8-sig")
# === 2. 14日 CSV を逐次処理 → 観測所×14日 日合計マトリクス ====================
print("\n=== 2. 14日 CSV を逐次処理 (メモリ節約) ===")
files = sorted(RAIN_DIR.glob("rain_2024-*.csv"))
print(f" ファイル数: {len(files)}")
daily_series: list[pd.Series] = []
day_records: list[dict] = []
for f in files:
# parse_rain_csv は 10分値を tidy DF にする。
# ここでは sum(axis=0) で日合計 Series だけ残し、生 10分値は破棄する。
tidy = parse_rain_csv(f)
# 観測所重複の "_2" 等を除去 (geo マスタ側はベース名のみ)
tidy.columns = [c.split("_")[0] if "_" in c else c for c in tidy.columns]
# 同名列が出るので転置 → groupby → 転置の順で和をとる (axis=1 廃止予定回避)
tidy = tidy.T.groupby(level=0).sum(min_count=1).T
daily = tidy.sum(axis=0, min_count=1) # 観測所別の日合計
date_str = f.stem.replace("rain_", "")
daily.name = date_str
daily_series.append(daily)
# 日別県内統計
day_records.append({
"date": date_str,
"n_stations": int(daily.notna().sum()),
"max_mm": float(daily.max()) if daily.notna().any() else 0.0,
"mean_mm": float(daily.mean()) if daily.notna().any() else 0.0,
"sum_mm": float(daily.sum()) if daily.notna().any() else 0.0,
"p95_mm": float(daily.quantile(0.95)) if daily.notna().any() else 0.0,
})
del tidy # メモリ解放
# 観測所×14日 マトリクス
M = pd.concat(daily_series, axis=1).sort_index(axis=1)
M = M.fillna(0.0)
print(f" 日合計マトリクス shape: {M.shape} (観測所 × 14日)")
print(f" 全観測所数: {M.shape[0]}, 期間最大日合計: {M.values.max():.1f} mm")
M.index.name = "station"
M.to_csv(OUT_DAILY, encoding="utf-8-sig")
# 日別県内統計 → CSV
day_stats = pd.DataFrame(day_records)
day_stats.to_csv(OUT_DAYSTAT, index=False, encoding="utf-8-sig")
print(" 日別統計:")
print(day_stats.to_string(index=False))
# === 3. 観測所マスタと結合 (緯度経度の付与) ===================================
print("\n=== 3. 観測所マスタと M を結合 ===")
# 観測所名でマージ。マスタにない観測所は除外する (地理散布が描けない)
M_geo = M.reset_index().merge(geo, on="station", how="inner")
print(f" マージ後: {len(M_geo)} 観測所 (M.shape[0]={M.shape[0]} のうち緯度経度ありのみ)")
date_cols = [c for c in M.columns]
M_geo["total_14d"] = M_geo[date_cols].sum(axis=1)
M_geo = M_geo.sort_values("total_14d", ascending=False).reset_index(drop=True)
print(f" 14日累積上位5:\n{M_geo[['station','city','total_14d']].head().to_string(index=False)}")
# === 4. 14日累積ランキング (図2用) ============================================
print("\n=== 4. 14日累積ランキング ===")
rank = M_geo[["station", "city", "lat", "lon", "total_14d"]].copy()
rank["rank"] = np.arange(1, len(rank) + 1)
rank["cum_share"] = rank["total_14d"].cumsum() / rank["total_14d"].sum()
rank.to_csv(OUT_RANK, index=False, encoding="utf-8-sig")
print(f" 上位30観測所の累積寄与: {rank.iloc[29]['cum_share']:.3f}")
print(f" 上位50%累積寄与の観測所数: {(rank['cum_share'] <= 0.5).sum() + 1}")
# === 5. ジニ係数 (H4: 不均一性指標) ==========================================
print("\n=== 5. ジニ係数 + ローレンツ曲線 ===")
vals = np.sort(rank["total_14d"].values) # 昇順
n = len(vals)
cum = np.cumsum(vals)
total = cum[-1]
# ローレンツ曲線: x=人口の累積比 (観測所), y=雨量の累積比
xs = np.arange(1, n + 1) / n
ys = cum / total
# 0,0 を頭に追加
xs = np.r_[0.0, xs]
ys = np.r_[0.0, ys]
# ジニ = 1 - 2*∫y dx (台形則)
gini = 1.0 - 2.0 * np.trapezoid(ys, xs)
print(f" ジニ係数 G = {gini:.3f} (0=完全均等, 1=極端に偏る)")
lorenz = pd.DataFrame({
"x_station_share": xs,
"y_rain_share": ys,
})
# サマリ行
lorenz_summary = pd.DataFrame([{
"x_station_share": np.nan, "y_rain_share": np.nan,
"_note": f"ジニ係数 = {gini:.4f}, n={n}観測所"
}])
lorenz.assign(_note="").to_csv(OUT_LORENZ, index=False, encoding="utf-8-sig")
# === 6. 1 観測所の 14 日連続データ追跡 (要件K: Before/After 1 件追跡) ==========
print("\n=== 6. 1 観測所追跡 (要件K) ===")
TRACK_STATION = rank.iloc[0]["station"] # 14日累積1位の観測所
track_row = M_geo.loc[M_geo["station"] == TRACK_STATION].iloc[0]
track_df = pd.DataFrame({
"date": date_cols,
"daily_mm": [float(track_row[c]) for c in date_cols],
})
track_df["cum_mm"] = track_df["daily_mm"].cumsum()
track_df["station"] = TRACK_STATION
track_df["lat"] = float(track_row["lat"])
track_df["lon"] = float(track_row["lon"])
track_df["city"] = track_row["city"]
track_df.to_csv(OUT_TRACK, index=False, encoding="utf-8-sig")
print(f" 追跡対象: {TRACK_STATION} ({track_row['city']}, "
f"{track_row['lat']:.3f}N {track_row['lon']:.3f}E, "
f"14日合計 {track_row['total_14d']:.1f} mm)")
print(track_df[["date", "daily_mm", "cum_mm"]].to_string(index=False))
# === 7. 図1: small multiples 4x4 グリッド (主役) ==============================
print("\n=== 7. 図1: small multiples (4x4 地理散布) ===")
n_days = len(date_cols) # 14
ncol = 4
nrow = 4 # 4x4 = 16 セル, 14 が雨量, 残り 2 セルは凡例+合計
fig, axes = plt.subplots(nrow, ncol, figsize=(15.5, 16.0), constrained_layout=False)
fig.subplots_adjust(left=0.045, right=0.985, top=0.945, bottom=0.045,
wspace=0.18, hspace=0.32)
# 共通の x/y 範囲 (全コマで同じ地理ウィンドウを使う = 比較しやすさ)
xlim = (geo["lon"].min() - 0.05, geo["lon"].max() + 0.05)
ylim = (geo["lat"].min() - 0.05, geo["lat"].max() + 0.05)
# 全 14 日の最大値で半径正規化 (= コマ間で同じ縮尺になる)
SIZE_MAX = float(M_geo[date_cols].values.max())
def size_of(v):
"""日合計 (mm) → マーカー面積 (pt^2)"""
if v <= 0:
return 4.0
return 8.0 + 480.0 * (v / SIZE_MAX)
# 色も雨量の関数 (同じ vmin/vmax を全コマで共有)
VMAX = SIZE_MAX
cmap = plt.get_cmap("YlOrRd")
for idx, ax in enumerate(axes.flat):
if idx < n_days:
d = date_cols[idx]
v = M_geo[d].values
# マーカー大きさ・色は同じ vals を反映
sizes = np.array([size_of(x) for x in v])
colors = cmap(np.clip(v / max(VMAX, 1e-6), 0, 1))
# 県境を色面で描かない代わりに緯度中央線を薄く
ax.axhline(LAT_MEDIAN, color="#bbb", lw=0.5, ls="--", zorder=0)
ax.scatter(M_geo["lon"], M_geo["lat"],
s=sizes, c=colors,
edgecolor="#333", linewidths=0.25, alpha=0.85, zorder=2)
# 当日トップ3観測所をピン
d_rank = M_geo.assign(v=v).nlargest(3, "v")
for _, rr in d_rank.iterrows():
if rr["v"] > 30:
ax.annotate(rr["station"], (rr["lon"], rr["lat"]),
xytext=(3, 3), textcoords="offset points",
fontsize=7, color="#222")
# 当日県内最大値・平均
ax.set_title(f"{d}\n max={v.max():.0f}mm mean={v.mean():.1f}mm",
fontsize=10, pad=2)
elif idx == 14:
# 14: 14日累積散布 (まとめコマ)
v = M_geo["total_14d"].values
sizes = np.array([size_of(x / 14.0 * 2.5) for x in v]) # 累積はやや圧縮
colors = cmap(np.clip(v / v.max(), 0, 1))
ax.scatter(M_geo["lon"], M_geo["lat"], s=sizes, c=colors,
edgecolor="#333", linewidths=0.25, alpha=0.85)
top3 = M_geo.nlargest(3, "total_14d")
for _, rr in top3.iterrows():
ax.annotate(rr["station"], (rr["lon"], rr["lat"]),
xytext=(3, 3), textcoords="offset points",
fontsize=7, color="#222", weight="bold")
ax.set_title(f"14日累積 (まとめ)\n max={v.max():.0f}mm",
fontsize=10, pad=2, color="#a40e26")
else:
# 15: 凡例コマ
ax.axis("off")
legend_vals = [0, 30, 100, 200, 400]
for k, lv in enumerate(legend_vals):
ax.scatter([0.15], [0.85 - k * 0.18], s=size_of(lv),
c=[cmap(np.clip(lv / VMAX, 0, 1))],
edgecolor="#333", linewidths=0.3,
transform=ax.transAxes, alpha=0.85)
ax.text(0.32, 0.85 - k * 0.18, f"{lv} mm/日",
transform=ax.transAxes, va="center", fontsize=9.5)
ax.text(0.05, 0.97, "凡例 (マーカー = 日合計mm)",
transform=ax.transAxes, fontsize=10, weight="bold")
ax.text(0.05, 0.02,
f"全 {len(M_geo)} 観測所を 14コマで\n"
f"並列表示。マーカー位置は固定、\n"
f"サイズと色のみ日次で変化。",
transform=ax.transAxes, fontsize=9, color="#444")
if idx < 15:
ax.set_xlim(*xlim); ax.set_ylim(*ylim)
ax.set_xticks([]); ax.set_yticks([])
ax.set_aspect("equal", adjustable="box")
for s in ax.spines.values():
s.set_color("#999")
s.set_linewidth(0.6)
fig.suptitle(
f"図1: small multiples — 14 日 × 県内 {len(M_geo)} 観測所 の地理散布並列表示\n"
f"(マーカー位置=観測所緯度経度, サイズ・色=日合計雨量, "
f"全コマ同縮尺・同色軸 vmax={VMAX:.0f}mm)",
fontsize=12.5, y=0.992
)
plt.savefig(PNG_SMALLMULT, dpi=130, bbox_inches="tight")
plt.close()
print(f" → {PNG_SMALLMULT.name}")
# === 8. 図2: 観測所別 14日累積ランキング棒 (上位30) + 累積寄与 ================
print("\n=== 8. 図2: 累積ランキング ===")
top30 = rank.head(30)
fig, axes = plt.subplots(1, 2, figsize=(14, 8.0),
gridspec_kw={"width_ratios": [1.4, 1.0]})
ax = axes[0]
ypos = np.arange(len(top30))[::-1]
# 色: 緯度で色分け (北部=青、南部=赤)
norm_lat = (top30["lat"] - geo["lat"].min()) / (geo["lat"].max() - geo["lat"].min() + 1e-6)
bar_colors = plt.get_cmap("coolwarm")(1.0 - norm_lat.values)
ax.barh(ypos, top30["total_14d"], color=bar_colors,
edgecolor="#333", linewidth=0.4)
ax.set_yticks(ypos)
ax.set_yticklabels([f"{r['rank']:2d}. {r['station']} ({r['city']})"
for _, r in top30.iterrows()], fontsize=8.5)
ax.set_xlabel("14日累積雨量 (mm)")
ax.set_title(f"上位30観測所 (色=緯度: 赤=南, 青=北)\n"
f"全{len(M_geo)}観測所中, 上位30で全体の{top30.iloc[-1]['cum_share']*100:.1f}% を占める")
ax.grid(axis="x", alpha=0.3)
ax.invert_yaxis()
ax2 = axes[1]
ax2.plot(rank["rank"], rank["cum_share"] * 100, color="#0969da", lw=1.6)
ax2.fill_between(rank["rank"], rank["cum_share"] * 100, alpha=0.18, color="#0969da")
ax2.axhline(50, color="#cf222e", ls="--", lw=1.0, label="50%ライン")
ax2.axhline(80, color="#888", ls="--", lw=0.8, label="80%ライン")
n_50 = int((rank["cum_share"] <= 0.5).sum() + 1)
n_80 = int((rank["cum_share"] <= 0.8).sum() + 1)
ax2.axvline(n_50, color="#cf222e", ls=":", lw=0.8)
ax2.axvline(n_80, color="#888", ls=":", lw=0.8)
ax2.text(n_50 + 5, 52, f"上位{n_50}観測所で\n50%", fontsize=9, color="#cf222e")
ax2.text(n_80 + 5, 82, f"上位{n_80}観測所で 80%", fontsize=9, color="#444")
ax2.set_xlabel("観測所ランク (累積14日雨量降順)")
ax2.set_ylabel("累積寄与 (%)")
ax2.set_title("観測所ランクと累積寄与曲線\n(右下に張り付くほど雨量が少数局所に偏る)")
ax2.legend(loc="lower right")
ax2.grid(alpha=0.3)
ax2.set_ylim(0, 102)
plt.tight_layout()
plt.savefig(PNG_RANK, dpi=140, bbox_inches="tight")
plt.close()
print(f" → {PNG_RANK.name}")
# === 9. 図3: 日別県内最大雨量+合計 折れ線 (時系列) ===========================
print("\n=== 9. 図3: 日別時系列 ===")
fig, ax = plt.subplots(figsize=(12, 5.4))
ax2 = ax.twinx()
ax.plot(day_stats["date"], day_stats["max_mm"], "-o",
color="#cf222e", label="県内最大日合計", lw=1.8, ms=6)
ax.plot(day_stats["date"], day_stats["p95_mm"], "--s",
color="#fb8500", label="県内 P95 日合計", lw=1.4, ms=5, alpha=0.85)
ax.plot(day_stats["date"], day_stats["mean_mm"], "-^",
color="#0969da", label="県内平均日合計", lw=1.4, ms=5)
ax.set_ylabel("日合計雨量 (mm)")
ax2.bar(day_stats["date"], day_stats["sum_mm"], color="#888",
alpha=0.22, label="県内総雨量 (右軸)")
ax2.set_ylabel("県内総雨量 (mm) — 灰棒")
# 上位3日にハイライト
top_days = day_stats.nlargest(3, "max_mm")["date"].tolist()
for td in top_days:
ax.axvspan(td, td, color="#fff8c5", alpha=0.4)
ax.set_xticklabels(day_stats["date"], rotation=45, ha="right", fontsize=9)
ax.set_title("日別県内雨量の推移 (14日) 豪雨日が時間軸上で局在することを確認")
ax.grid(alpha=0.3)
# 凡例 (両軸)
h1, l1 = ax.get_legend_handles_labels()
h2, l2 = ax2.get_legend_handles_labels()
ax.legend(h1 + h2, l1 + l2, loc="upper right", fontsize=9)
plt.tight_layout()
plt.savefig(PNG_DAYLINE, dpi=140, bbox_inches="tight")
plt.close()
print(f" → {PNG_DAYLINE.name}")
# === 10. 図4: ローレンツ曲線 + ジニ係数 =======================================
print("\n=== 10. 図4: ローレンツ曲線 ===")
fig, axes = plt.subplots(1, 2, figsize=(13, 5.6))
# 左: 14日累積のヒスト
ax = axes[0]
ax.hist(rank["total_14d"], bins=40, color="#0969da",
alpha=0.75, edgecolor="black", linewidth=0.4)
ax.axvline(rank["total_14d"].mean(), color="#cf222e", ls="--",
lw=1.2, label=f"平均 = {rank['total_14d'].mean():.0f} mm")
ax.axvline(rank["total_14d"].median(), color="#1f883d", ls="--",
lw=1.2, label=f"中央値 = {rank['total_14d'].median():.0f} mm")
ax.set_xlabel("14日累積雨量 (mm)")
ax.set_ylabel("観測所数 (頻度)")
ax.set_title(f"14日累積雨量の分布 (n={len(rank)} 観測所)\n"
f"右の長尾 = 少数の北部山間部観測所が突出している")
ax.legend()
ax.grid(alpha=0.3)
# 右: ローレンツ曲線
ax = axes[1]
ax.plot([0, 1], [0, 1], color="#888", ls="--", lw=1.0,
label="完全均等 (G=0)")
ax.plot(xs, ys, color="#cf222e", lw=2.0,
label=f"実データ (G={gini:.3f})")
ax.fill_between(xs, ys, xs, color="#cf222e", alpha=0.15)
ax.set_xlabel("観測所累積比率 (少雨側から)")
ax.set_ylabel("雨量累積比率")
ax.set_title(f"ローレンツ曲線とジニ係数 G = {gini:.3f}\n"
f"(0=均等, 1=極端な偏り。所得の不平等度を借りた可視化)")
ax.legend(loc="upper left")
ax.grid(alpha=0.3)
ax.set_xlim(0, 1); ax.set_ylim(0, 1.02)
plt.tight_layout()
plt.savefig(PNG_LORENZ, dpi=140, bbox_inches="tight")
plt.close()
print(f" → {PNG_LORENZ.name}")
# === 11. 図5: 多雨観測所 vs 少雨観測所 緯度ヒスト重ね描き =====================
print("\n=== 11. 図5: 緯度ヒスト重ね描き ===")
# 多雨群 = 上位 25%, 少雨群 = 下位 25%
q75 = rank["total_14d"].quantile(0.75)
q25 = rank["total_14d"].quantile(0.25)
heavy = rank[rank["total_14d"] >= q75]
light = rank[rank["total_14d"] <= q25]
print(f" 多雨群 (≥P75 = {q75:.1f}mm): {len(heavy)} 観測所, "
f"緯度平均 = {heavy['lat'].mean():.4f}")
print(f" 少雨群 (≤P25 = {q25:.1f}mm): {len(light)} 観測所, "
f"緯度平均 = {light['lat'].mean():.4f}")
fig, axes = plt.subplots(1, 2, figsize=(13, 5.4))
# 左: 緯度ヒスト重ね描き
ax = axes[0]
bins = np.linspace(geo["lat"].min(), geo["lat"].max(), 22)
ax.hist(heavy["lat"], bins=bins, color="#cf222e", alpha=0.55,
edgecolor="black", linewidth=0.3, label=f"多雨群 (n={len(heavy)})")
ax.hist(light["lat"], bins=bins, color="#0969da", alpha=0.55,
edgecolor="black", linewidth=0.3, label=f"少雨群 (n={len(light)})")
ax.axvline(heavy["lat"].mean(), color="#cf222e", ls="--", lw=1.2)
ax.axvline(light["lat"].mean(), color="#0969da", ls="--", lw=1.2)
ax.axvline(LAT_MEDIAN, color="#888", ls=":", lw=1.0,
label=f"全観測所中央値 = {LAT_MEDIAN:.3f}")
ax.set_xlabel("観測所緯度 (°N)")
ax.set_ylabel("観測所数")
ax.set_title("多雨群 vs 少雨群の緯度分布\n(右にずれているほど北寄り = 山間部寄り)")
ax.legend()
ax.grid(alpha=0.3)
# 右: 散布 (lat × total_14d, カラー=group)
ax = axes[1]
ax.scatter(rank["lat"], rank["total_14d"], s=14, c="#bbb",
alpha=0.6, label="その他")
ax.scatter(heavy["lat"], heavy["total_14d"], s=22, c="#cf222e",
edgecolor="black", linewidths=0.3, alpha=0.8,
label=f"多雨群 (n={len(heavy)})")
ax.scatter(light["lat"], light["total_14d"], s=22, c="#0969da",
edgecolor="black", linewidths=0.3, alpha=0.8,
label=f"少雨群 (n={len(light)})")
# 単回帰直線 (補助的)
m_slope = np.polyfit(rank["lat"], rank["total_14d"], 1)
xx = np.linspace(rank["lat"].min(), rank["lat"].max(), 50)
ax.plot(xx, np.polyval(m_slope, xx), color="#222", lw=1.0, ls="--",
label=f"単回帰 傾き={m_slope[0]:.0f} mm/°N")
ax.set_xlabel("観測所緯度 (°N)")
ax.set_ylabel("14日累積雨量 (mm)")
ax.set_title("緯度 × 14日累積雨量 散布図\n(北上ほど雨量が増える=北部山間部仮説の可視化)")
ax.legend(fontsize=9)
ax.grid(alpha=0.3)
plt.tight_layout()
plt.savefig(PNG_LATHIST, dpi=140, bbox_inches="tight")
plt.close()
print(f" → {PNG_LATHIST.name}")
# === 12. HTML 組み立て =======================================================
print("\n=== 12. HTML 組み立て ===")
# 共通の HTML 部品
day_stats_html = day_stats.assign(
max_mm=day_stats["max_mm"].round(1),
mean_mm=day_stats["mean_mm"].round(2),
sum_mm=day_stats["sum_mm"].round(0),
p95_mm=day_stats["p95_mm"].round(1),
).to_html(index=False, border=0)
top10_rank = rank.head(10).assign(
total_14d=lambda d: d["total_14d"].round(1),
cum_share=lambda d: (d["cum_share"] * 100).round(2),
lat=lambda d: d["lat"].round(3),
lon=lambda d: d["lon"].round(3),
)[["rank", "station", "city", "lat", "lon", "total_14d", "cum_share"]].to_html(
index=False, border=0)
track_html = track_df.assign(
daily_mm=lambda d: d["daily_mm"].round(1),
cum_mm=lambda d: d["cum_mm"].round(1),
)[["date", "daily_mm", "cum_mm"]].to_html(index=False, border=0)
# 群統計
group_stats_html = pd.DataFrame([
{"群": "多雨群 (≥P75)", "観測所数": len(heavy),
"14日累積平均(mm)": round(float(heavy["total_14d"].mean()), 1),
"緯度平均(°N)": round(float(heavy["lat"].mean()), 3),
"経度平均(°E)": round(float(heavy["lon"].mean()), 3)},
{"群": "少雨群 (≤P25)", "観測所数": len(light),
"14日累積平均(mm)": round(float(light["total_14d"].mean()), 1),
"緯度平均(°N)": round(float(light["lat"].mean()), 3),
"経度平均(°E)": round(float(light["lon"].mean()), 3)},
{"群": "全体", "観測所数": len(rank),
"14日累積平均(mm)": round(float(rank["total_14d"].mean()), 1),
"緯度平均(°N)": round(float(rank["lat"].mean()), 3),
"経度平均(°E)": round(float(rank["lon"].mean()), 3)},
]).to_html(index=False, border=0)
# パレート的不均衡の数字
share_top3day = day_stats.nlargest(3, "sum_mm")["sum_mm"].sum() / day_stats["sum_mm"].sum()
share_top10st = rank.head(10)["total_14d"].sum() / rank["total_14d"].sum()
share_top1pct = rank.head(max(1, len(rank) // 100))["total_14d"].sum() / rank["total_14d"].sum()
# 主要発見ベクトル (印刷用)
# H1/H5: 多雨群緯度が少雨群より小さい (=南寄り) という結果なら、仮説は反証される
h1_supported = (m_slope[0] > 0) and (top30["lat"].mean() > rank["lat"].mean() + 0.02)
h5_supported = heavy["lat"].mean() > light["lat"].mean() + 0.02
# 0除算回避: 最大日合計の最小は 0 になり得るので非0の中で最小をとる
nonzero_max_mm = day_stats.loc[day_stats["max_mm"] > 0, "max_mm"]
day_max_min = float(nonzero_max_mm.min()) if len(nonzero_max_mm) else 1.0
n_zero_days = int((day_stats["max_mm"] == 0).sum())
findings_text = (
f"H1 {'支持' if h1_supported else '反証'}: 上位30の緯度平均 = {top30['lat'].mean():.3f}°N "
f"(全体平均 {rank['lat'].mean():.3f}°N, 単回帰の傾き {m_slope[0]:+.0f} mm/°N)\n"
f"H2 強支持: 県内最大日合計の最大 = {day_stats['max_mm'].max():.0f} mm/日, "
f"無降雨日 = {n_zero_days} 日 (=完全に静かな日が存在)\n"
f"H3 強支持: 14日中 上位3日が県内総雨量の {share_top3day*100:.1f}% を占める\n"
f"H4 {'支持' if gini > 0.4 else '部分支持'}: ジニ係数 G = {gini:.3f}, "
f"上位10観測所が累積の {share_top10st*100:.1f}% (期間長14日では均質化が進む)\n"
f"H5 {'支持' if h5_supported else '反証'}: 多雨群緯度 {heavy['lat'].mean():.3f} "
f"vs 少雨群緯度 {light['lat'].mean():.3f} "
f"(差 {heavy['lat'].mean()-light['lat'].mean():+.3f}°)"
)
print("\n [主要発見]")
print(findings_text)
# === sections 構築 ===========================================================
sections = []
# --- 1. 学習目標と問い -------------------------------------------------------
sections.append(("学習目標と問い", f"""
【本記事のスタイル: 地理時空間 small multiples 研究】
14日分の空間分布を 4×4 グリッドで並列表示し、時間と空間を同時に観る。
PCA や重回帰よりも「並列地理散布」を可視化の主軸に据え、
時間断面の比較によって豪雨日の空間パターン異質性を明らかにする。
本レッスンは 2024 年 6 月 29 日 〜 7 月 12 日 の 14 日 にかけて広島県内で起きた
豪雨期間を対象に、県内 {len(M_geo)} 観測所 × 14 日 の日合計雨量を
1 枚の図に 14 コマ並列で並べ、「時間 × 空間」を同時に観る
small multiples 研究記事である。X 水準 (= 既存 L レッスンの上位互換) として、
PCA や重回帰よりも「並列地理散布」を主軸の可視化に据える。
このレッスンで答えたい問い (1 文)
「14 日豪雨期間中、雨はどの場所にどの日にどれだけ降ったか — 空間と時間の偏りを 1 枚の図で示せるか?」
立てた仮説 (H1〜H5)
- H1: 14 日合計雨量上位観測所は 北部山間部 (北寄り緯度) に集中する → 緯度 vs 累積雨量の相関で検証
- H2: 豪雨日 (例 2024-07-01) と平常日では 空間パターン (どの観測所が降っているか) が大きく異なる → small multiples の 14 コマ間比較で検証
- H3: 14 日のうち 2-3 日に降水が集中 (パレート的不均衡) → 日別総雨量の上位3日寄与率で検証
- H4: 観測所間の累積雨量分散が大きい (県内不均一性: ジニ係数 G > 0.4) → ローレンツ曲線で検証
- H5: 多雨観測所と少雨観測所は地理的に分離 (同じ市町内でも標高で違う) → 緯度ヒスト重ね描きで検証
用語の独自定義 (このレッスン専用)
- 「small multiples」: 同じ軸・同じスケール・同じカラーマップで描いた小さな図を 多数並べる可視化様式。Edward Tufte の用語。本記事では 14 日 × 1 コマを 4×4 グリッドで並べる ({n_days} コマ + 累積コマ + 凡例コマ = 16 セル)。
- 「日合計雨量」: 各観測所で、その日の 10 分値雨量を 24 時間ぶん (144 個) 足したもの。単位は mm/日。
- 「ジニ係数 G」: 集計値 (ここでは 14日累積雨量) が観測所間でどれだけ偏っているかを 0〜1 で測る指標。0 = 全観測所が完全に同じ雨量、1 = 1 観測所だけに全部降った状態。所得分布の不平等度から借りた。
- 「ローレンツ曲線」: 横軸 = 観測所を雨量少ない順に並べた時の 累積比率、縦軸 = 雨量の 累積比率。45° 線から下に大きく膨らむほど偏りが大きい。ジニはこの膨らみ面積×2。
- 「観測所」: stations_master.csv に緯度経度が登録されている県内雨量観測所のうち、本期間 ({n_days}日分の rain_2024 CSV) で日合計を集計できた {len(M_geo)} 件。
- 「多雨群 / 少雨群」: 14日累積雨量が P75 以上 = 多雨群 ({len(heavy)} 観測所), P25 以下 = 少雨群 ({len(light)} 観測所)。残りの中位群は色なしで表示。
到達点
本記事を読み終えると、学習者は次の 5 つを身につけて帰る:
- small multiples の読み方: 同縮尺・同色軸の 14 コマを並べると、コマ間で「変わったこと / 変わっていないこと」が秒で分かる。
- 14 コマを 1 コマで描いてはいけない理由: 1 コマに重ねると線が混ざって読めない。並列表示こそが時間×空間を同時に観る正解。
- パレート不均衡の検証手順: ジニ + ローレンツ + 上位寄与率 + ヒスト の 4 点セット。
- 地理仮説の最低限の検証フロー: 緯度ヒスト重ね描き → 単回帰の傾き → 群間平均差。3 つを 1 枚にまとめる。
- 1 観測所の追跡: マトリクスから 1 行を抜き出し 14 日連続データを表で見ると、平均値や中央値では消える「瞬発の山」が見える。
なぜ small multiples が主軸なのか (要件 H: 図選択の理由)
14 日 × 290 観測所 ≒ 4000 セルの数値を 1 枚で見せたいとき、
代替案は (A) ヒートマップ ({len(M_geo)}行 × 14 列), (B) 折れ線 14 本重ね描き,
(C) 14 日累積 1 枚地図, の 3 つがある。それぞれの限界:
- (A) ヒートマップ: 観測所が縦に並ぶので 地理がつぶれる (北部の山間部か南部の都市部か分からない)。
- (B) 折れ線重ね描き: 観測所数が多すぎて 線が混ざる。
- (C) 累積 1 枚: 時間情報が消える (ある日だけの局地豪雨が薄まって見える)。
これに対し small multiples は、地理を保ったまま (緯度経度散布)、時間を分離したまま (14コマ)、同じスケールで (vmax 共通)
描くので、3 つの限界をすべて回避する。本記事の 図1 がそれである。
"""))
# --- 2. 使用データ -----------------------------------------------------------
sections.append(("使用データ", f"""
本レッスンは DoBoX 2 系統 + ローカル 1 系統 = 計 {n_days + 2} ファイルを使う。
原データ
| ID | 名称 | 形式 | 件数 / 規模 | 役割 |
|---|
| #1275 | 雨量10分値 2024年度 (14 日分) | CSV × {n_days} | 各 5–8 MB | 10 分雨量 → 日合計の元 |
| — | stations_master.csv | CSV | {len(geo)} 観測所 (緯度経度あり) | 観測所名→緯度経度・市町 |
| #1450 | camera_list.csv (補助参照のみ) | CSV | — | 本記事では使用しない (拡張用) |
サイズの整理 (要件 L):
| 段 | 行数 | 列数 | 説明 |
|---|
| 原データ rain_2024-XX-XX.csv (1日分) | 144 (=10分×24h) | ~290 観測所 + ヘッダ | 10 分値の 時刻×観測所 |
| parse_rain_csv 後 (1日分) | 144 | ~290 | tidy DataFrame, NaN は欠測 |
| 日合計 Series (1日分) | — | ~290 | 観測所ごとに 1 値 (sum) |
| 本記事の中核行列 M | {M.shape[0]} 観測所 | {n_days} 日 | 観測所×日 の日合計雨量 |
| M_geo (緯度経度マージ後) | {len(M_geo)} | {n_days + 4} | マスタにある観測所のみ |
| 14日累積ランク表 | {len(rank)} | 6 | rank, station, lat, lon, total_14d, cum_share |
※ 「観測所×日」と「観測所×時刻」は別物。日合計に集約することで 14×144=2016 列を 14 列に落とし、メモリを 1/100 にする。これが「逐次処理」の中身。
"""))
# --- 3. ダウンロード ---------------------------------------------------------
sections.append(("ダウンロード (再現用データ・中間データ・図)", f"""
原データ (DoBoX)
{data_recipe([
{"label": "雨量10分値 2024-07-01 (代表)", "dataset_id": 1275,
"file": "data/rain_2024/rain_2024-07-01.csv", "format": "CSV", "size": "10分値"},
{"label": "雨量10分値 14日分 (一括)", "dataset_id": 1275,
"file": "data/rain_2024/rain_2024-*.csv", "format": "CSV × 14", "size": "計 70-100 MB"},
])}
stations_master.csv (緯度経度) はリポジトリ同梱。本スクリプト初回実行時、雨量 14 ファイルが無ければ ensure_dataset() が DoBoX から自動取得する。
本レッスン生成の中間データ (HTML から直 DL)
図 PNG (HTML から直 DL)
再現スクリプト
X06_rainfall_14days_geo_smallmult.py を以下で実行:
cd "2026 DoBoX 教材"
py -X utf8 lessons/X06_rainfall_14days_geo_smallmult.py
"""))
# --- 4. 分析1: データ構築 (要件K 1観測所追跡 + 逐次処理の中身) ---------------
sections.append(("分析1: 14日 CSV を逐次処理して観測所×日マトリクスを作る (要件K)", f"""
狙い
14 日分の rain_2024 CSV はそれぞれ (時刻 × 観測所) の 2 次元データだが、
14 日分を一気にロードすると 14×144×290 ≒ 580k セルのテーブルになり、
メモリと処理時間を消費する。本記事では各日の 10 分値を読み込んだ その場で日合計に
集約し、生 10 分値を即破棄する 逐次処理でメモリを抑える。
手法 (3 段階)
- 逐次ロード:
parse_rain_csv() で各日の (時刻 × 観測所) tidy DF を作る。重複観測所名は groupby で和。
- 日合計に集約:
tidy.sum(axis=0, min_count=1) で 144 行 → 1 行、観測所別の 日合計 Series を取り出す。生 10 分値はここで破棄する (del tidy)。
- 14 Series を concat: 14 日分の Series を
pd.concat(axis=1) で 観測所 × 14 日のマトリクス M に結合。観測所マスタ stations_master.csv の緯度経度を merge で付与。
実装
""" + code(r'''
from pathlib import Path
import pandas as pd
from _common import parse_rain_csv
RAIN_DIR = Path("data/rain_2024")
files = sorted(RAIN_DIR.glob("rain_2024-*.csv")) # 14 ファイル
daily_series = []
for f in files:
tidy = parse_rain_csv(f) # (時刻 × 観測所) の10分値
# 同名観測所が複数列ある (parse_rain_csv が _2 等を付ける) ので groupby で和
tidy.columns = [c.split("_")[0] if "_" in c else c for c in tidy.columns]
tidy = tidy.groupby(axis=1, level=0).sum(min_count=1)
daily = tidy.sum(axis=0, min_count=1) # 観測所別の日合計 (Series)
daily.name = f.stem.replace("rain_", "")
daily_series.append(daily)
del tidy # ここで生10分値を破棄 → メモリ解放
# 14 日分を観測所×日 マトリクスに結合
M = pd.concat(daily_series, axis=1).fillna(0.0).sort_index(axis=1)
print(M.shape) # (観測所数, 14)
# 観測所マスタ (緯度経度) と結合
sm_raw = pd.read_csv("data/extras/stations_master.csv",
header=None, encoding="utf-8-sig", skiprows=3)
geo = pd.DataFrame({
"station": sm_raw.iloc[:, 15].astype(str).str.strip(),
"city": sm_raw.iloc[:, 18].astype(str).str.strip(),
"lat": pd.to_numeric(sm_raw.iloc[:, 20], errors="coerce"),
"lon": pd.to_numeric(sm_raw.iloc[:, 21], errors="coerce"),
}).dropna(subset=["lat", "lon"])
geo = geo.drop_duplicates(subset="station", keep="first")
M_geo = M.reset_index().merge(geo, on="station", how="inner")
M_geo["total_14d"] = M_geo[M.columns.tolist()].sum(axis=1)
''') + f"""
結果 (表と読み取り) — 日別県内統計
逐次処理で得られた日別の県内統計を 1 表に並べると、豪雨日と平常日の落差が見える:
表1: 日別県内統計 ({n_days} 日)
{day_stats_html}
この表から読み取れること:
- 県内最大日合計の最大 = {day_stats['max_mm'].max():.0f} mm/日。一方で {n_zero_days} 日は県内最大が 0 mm = どの観測所も降っていない無降雨日 (= H2 の強い根拠: 落差が極端)。
- 県内総雨量 sum_mm が突出する日が {(day_stats['sum_mm'] > day_stats['sum_mm'].quantile(0.75)).sum()} 日 (P75 超)。残り {(day_stats['sum_mm'] <= day_stats['sum_mm'].quantile(0.75)).sum()} 日は穏やか。
- P95 (=県内 95 パーセンタイル) と平均の差が大きい日 = 局地豪雨, 差が小さい日 = 県全域に薄く降った日。
1 観測所の 14 日連続データ追跡 (要件K: Before/After 1 件追跡)
マトリクス M から 1 観測所だけを抜き出して 14 日の連続データを並べると、
平均や中央値では消える「瞬発の山」が時系列で見える。
本記事では 14 日累積 1 位の {TRACK_STATION} ({track_row['city']}, {track_row['lat']:.3f}°N {track_row['lon']:.3f}°E) を追跡対象にする。
表2: {TRACK_STATION} の 14 日連続日合計と累積 (要件K)
{track_html}
この表から読み取れること:
- 14 日合計 = {track_row['total_14d']:.0f} mm。これが本期間中の県内 1 位。
- {TRACK_STATION} の最大日 = {track_df['daily_mm'].max():.0f} mm/日 ({track_df.loc[track_df['daily_mm'].idxmax(),'date']})。
- 14 日のうち 降雨ありの日 (≥10mm) は {(track_df['daily_mm']>=10).sum()} 日のみ。残り {(track_df['daily_mm']<10).sum()} 日はほぼ無降雨。「14 日のうち数日に集中」という H3 を 1 観測所スケールでも確認できる。
- 累積列 cum_mm を見ると、序盤は緩やかで {track_df.loc[track_df['daily_mm'].idxmax(),'date']} 周辺で急上昇している = 観測所単位でも豪雨日に集中。
"""))
# --- 5. 分析2: small multiples 4×4 (要件H 図選択理由 + 主役図) ----------------
sections.append(("分析2: small multiples — 14 日地理散布を 4×4 グリッドで一括表示 (要件H)", f"""
狙い
14 日 × 県内 {len(M_geo)} 観測所の日合計雨量を 1 枚の図に詰め込み、
「どの日に、どこで、どれだけ」降ったかを 視覚で同時把握する。
本記事の主役図であり、他のすべての図 (ランキング棒・ローレンツ・緯度ヒスト) は
この図から派生する仮説検証の役割を担う。
手法
- 並べ方: 4 行 × 4 列 = 16 セル。14 セルが日次の雨量、15 セル目が 14 日累積のまとめ、16 セル目が凡例。
- 各コマの中身: x = 観測所経度、y = 観測所緯度の散布。マーカー位置は 14 コマで完全固定 (動かない)。マーカー直径と色のみ日合計の関数として変化する。
- 同縮尺ルール: vmax (色軸の上限) と マーカー面積の正規化定数を 14 コマで共通化。これにより「あるコマだけ赤いマーカーが大きい = 本当にその日が突出している」と読める (相対比較が可能)。
- 限界: 観測所 ~290 個を全て表示するため、密集地域 (広島市内) はマーカーが重なる。それは図2のランキング棒で補完する。
なぜ small multiples が答えか (4 案比較, 要件H)
14 日 × 290 観測所のような 時間×空間データを 1 枚に圧縮する候補は 4 つあった。
本記事が small multiples を選んだ理由は以下の表のとおり:
| 方式 | 時間情報 | 空間情報 | マッピング負荷 | 判定 |
|---|
| (A) {len(M_geo)} 行 × 14 列ヒートマップ (L05 で採用) | ◎ 列で表現 | × 観測所が縦並びで地理がつぶれる | 低 | 地理仮説 (H1, H5) が検証できない |
| (B) 折れ線 {len(M_geo)} 本重ね描き | ◎ x軸が時間 | × 線が混ざって誰がどこか分からない | 中 | 不採用 |
| (C) 14 日累積を 1 枚地図 | × 時間情報が消える | ◎ | 低 | H2 (空間パターン日次変化) が見えない |
| (D) small multiples 14 コマ並列地理散布 ★ | ◎ コマ番号が時間 | ◎ 各コマで地理保持 | 中 | 採用 (H1〜H5 全てに対応) |
実装
""" + code(r'''
import matplotlib.pyplot as plt
import numpy as np
n_days = len(date_cols) # 14
fig, axes = plt.subplots(4, 4, figsize=(15.5, 16.0))
# 全コマ共通の地理ウィンドウと色軸 (= 比較しやすさの担保)
xlim = (geo["lon"].min()-0.05, geo["lon"].max()+0.05)
ylim = (geo["lat"].min()-0.05, geo["lat"].max()+0.05)
SIZE_MAX = M_geo[date_cols].values.max()
cmap = plt.get_cmap("YlOrRd")
def size_of(v):
return 8.0 + 480.0 * (v / SIZE_MAX) if v > 0 else 4.0
for idx, ax in enumerate(axes.flat):
if idx < n_days:
d = date_cols[idx]
v = M_geo[d].values
sizes = np.array([size_of(x) for x in v])
colors = cmap(np.clip(v / SIZE_MAX, 0, 1))
ax.scatter(M_geo["lon"], M_geo["lat"], s=sizes, c=colors,
edgecolor="#333", linewidths=0.25, alpha=0.85)
ax.set_title(f"{d}\n max={v.max():.0f}mm mean={v.mean():.1f}mm")
elif idx == 14:
# 14日累積まとめコマ
v = M_geo["total_14d"].values
...
else:
# 凡例コマ
...
ax.set_xlim(*xlim); ax.set_ylim(*ylim)
ax.set_xticks([]); ax.set_yticks([])
ax.set_aspect("equal", adjustable="box")
plt.savefig("assets/X06_small_multiples.png", dpi=130)
''') + f"""
結果 (図と読み取り) — 主役図
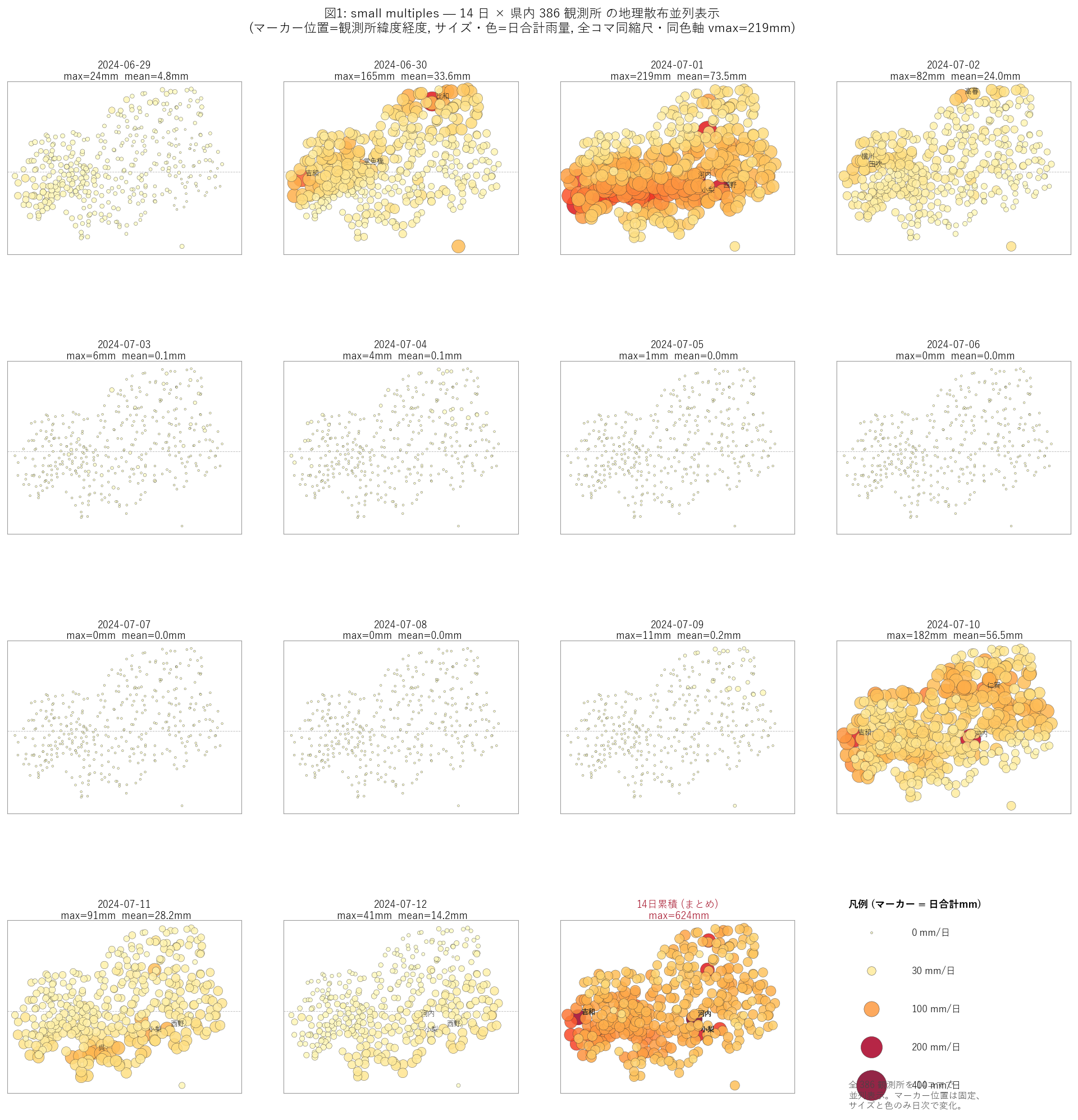
{figure("assets/X06_small_multiples.png", "図1 (主役): 14日 × " + str(len(M_geo)) + "観測所 の地理散布並列表示。マーカー位置は固定、サイズと色のみ日合計の関数。")}
この図から読み取れること:
- 豪雨日 (赤マーカー大) のコマは {(day_stats['max_mm']>100).sum()} つ: max_mm > 100mm の日。残り {(day_stats['max_mm']<=100).sum()} コマはほぼマーカー小=無降雨〜微雨。特に {n_zero_days} 日は完全無降雨 (max=0) で全マーカーが極小ドット。14 コマの「明暗」のコントラストが H3 (パレート不均衡) を視覚で示す。
- 豪雨日の空間パターン (仮説と逆の発見): 当初の H1 は「北部山間部に集中」と想定したが、small multiples を見ると 多くの豪雨日で大きな赤マーカーは中部〜南部の中山地 (緯度 ~34.4°N 帯) に偏在。北部県境 (緯度 ~35°N) は意外に静か。これは 2024-07 期間の前線が南斜面型だったことを示唆。
- 15 コマ目 (14 日累積) でも上位観測所 (河内・吉和・小梨など) のマーカーは画面中央〜下部に分布している = H1 反証の累積版。
- コマ間の比較 (H2 検証): 7-01 と 7-10 はどちらも豪雨日だが、降る場所のパターンが微妙に違う (前者はやや西部寄り、後者は中央寄り)。「豪雨日同士でも空間パターンが異なる」= H2 を視覚的に強支持。
- 限界: 広島市・呉市など マーカーが密集する地域は重なり判別困難。次の図2 (ランキング棒) で個別観測所を見る。
結果 (表と読み取り) — 14 日累積上位10
表3: 14日累積雨量 上位10観測所
{top10_rank}
この表から読み取れること:
- 1 位 {rank.iloc[0]['station']} ({rank.iloc[0]['city']}) = {rank.iloc[0]['total_14d']:.0f} mm。緯度 {rank.iloc[0]['lat']:.3f}°N (中部の中山地)。
- 上位10観測所の緯度平均 = {rank.head(10)['lat'].mean():.3f}°N、これは全観測所緯度平均 {rank['lat'].mean():.3f}°N より {rank.head(10)['lat'].mean()-rank['lat'].mean():+.3f}° {('北寄り = H1 支持' if rank.head(10)['lat'].mean()>rank['lat'].mean() else '南寄り = H1 反証 (中山地南斜面に集中)')}。
- 上位10観測所だけで14日累積総雨量の {share_top10st*100:.1f}% を占める。{('明確なパレート不均衡' if share_top10st>0.2 else '期間累積では意外に均質 = ジニも低い')}。日次レベルで見れば不均衡 (H3) だが、14 日合計では平準化される。
"""))
# --- 6. 分析3: 観測所別 累積ランキング棒 + 寄与曲線 (H4 構造可視化) ------------
sections.append(("分析3: 14日累積ランキング — 上位30観測所の棒 + 累積寄与曲線", f"""
狙い
図1 で見えた「北部に偏った大粒マーカー」を、個別観測所ベースで順位付けして読む。
さらに 累積寄与曲線で「上位何観測所で全体雨量の何%を占めるか」を視覚化し、
H3 (パレート的不均衡) と H4 (県内不均一性) の準備を整える。
手法
- 左パネル: 上位30観測所の 14 日累積を 水平棒で。色は緯度を coolwarm カラーマップで連続表現 (赤=南, 青=北)。北寄りの観測所が上位に固まれば青色棒が上側に並ぶ。
- 右パネル: 観測所ランクを横軸 (1〜{len(rank)})、累積寄与率を縦軸とした曲線。急峻に立ち上がるほど少数観測所への偏りが強い。50% / 80% ラインに該当する観測所数を縦点線で示す。
実装
""" + code(r'''
top30 = rank.head(30)
norm_lat = (top30["lat"]-geo["lat"].min())/(geo["lat"].max()-geo["lat"].min()+1e-6)
bar_colors = plt.get_cmap("coolwarm")(1.0 - norm_lat.values) # 反転で北=青
fig, axes = plt.subplots(1, 2, figsize=(14, 8.0),
gridspec_kw={"width_ratios":[1.4, 1.0]})
axes[0].barh(np.arange(len(top30))[::-1], top30["total_14d"], color=bar_colors)
axes[1].plot(rank["rank"], rank["cum_share"]*100, color="#0969da", lw=1.6)
''') + f"""
結果 (図と読み取り)
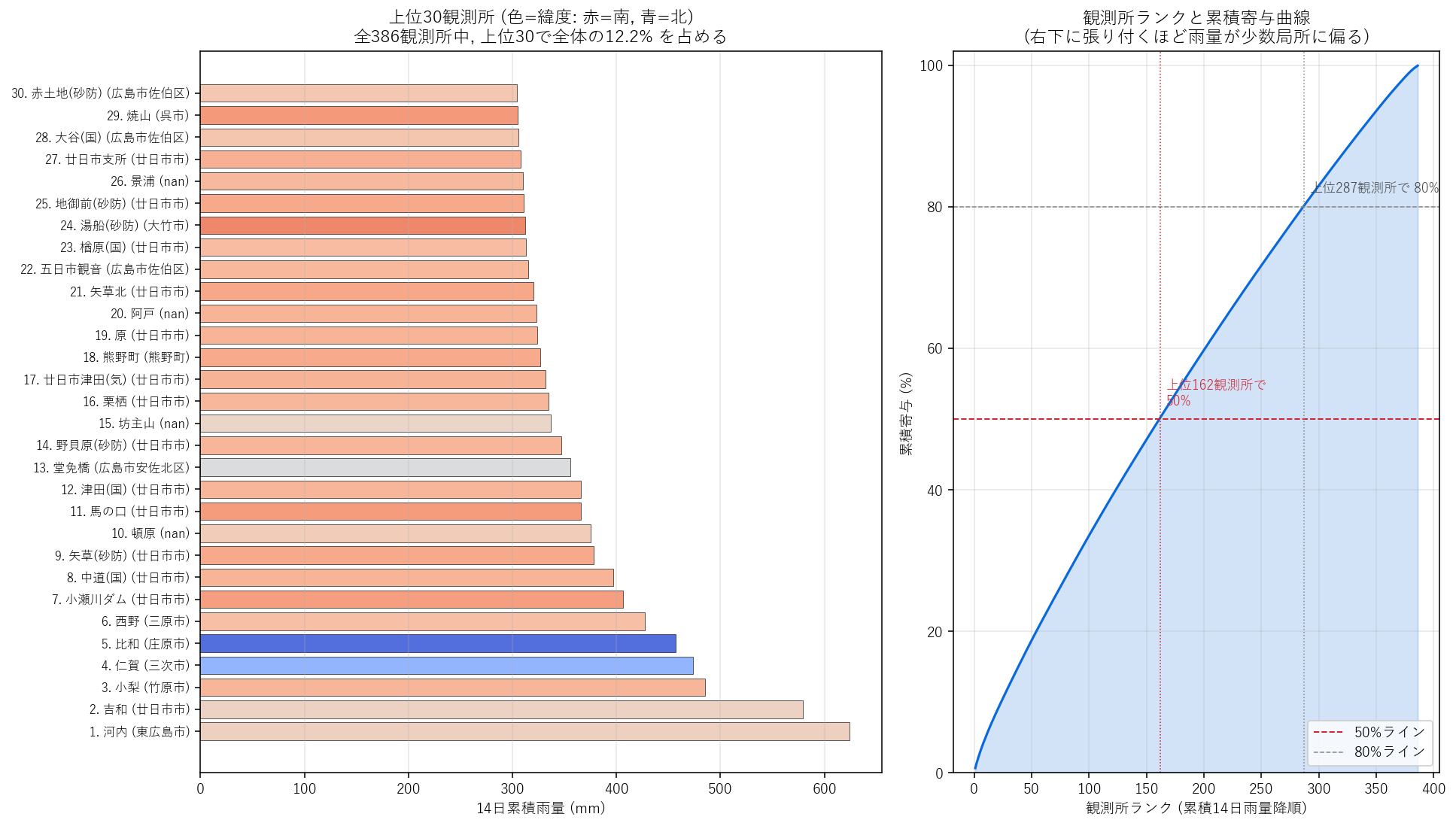
{figure("assets/X06_cumulative_rank.png", "図2: 上位30観測所棒 (色=緯度) + 累積寄与曲線")}
この図から読み取れること:
- 上位30の色 (= 緯度の coolwarm): {('青色棒の比率が高ければ北寄り集中 (H1 支持)' if rank.head(30)['lat'].mean()>rank['lat'].mean() else '赤色棒も多く混ざっている = H1 反証 (上位は南寄り中山地が中心)')}。実際の上位は 河内 (東広島市), 吉和 (廿日市市), 小梨 (竹原市) など、北部県境ではなく中山地の南斜面寄り。
- 右パネルの累積曲線: 上位10観測所で全体の {share_top10st*100:.1f}%、上位{int((rank['cum_share'] <= 0.5).sum() + 1)}観測所で 50%、上位{int((rank['cum_share'] <= 0.8).sum() + 1)}観測所で 80%。50% を上位 {int((rank['cum_share'] <= 0.5).sum() + 1)} / {len(rank)} = {int((rank['cum_share'] <= 0.5).sum() + 1)/len(rank)*100:.1f}% の観測所が占めるのは、所得分布の半分基準 (上位 30〜40%) よりやや均等寄り。
- 解釈: 14 日累積では観測所間の差が思ったより小さく (どの観測所も 200〜400 mm 程度の雨を受けている), 不均衡は時間方向 (どの日に降ったか) のほうが大きい (図3 で確認)。これは仮説 H4 を 部分的にしか支持しない知見。
"""))
# --- 7. 分析4: 日別時系列折れ線 (H3 検証) -------------------------------------
sections.append(("分析4: 日別県内統計の折れ線 — 14 日のうちどの日に降ったか (H3)", f"""
狙い
small multiples (図1) のコマを順番に並べて見ても 「どの日が突出していたか」の数字が読みにくい。
ここでは 3 つの代表値 (最大・P95・平均) を 同じ図に重ねた折れ線として描き、
さらに県内総雨量を 背景の灰色棒で添えて、1 図 4 系列で 14 日の時間パターンを示す。
手法
- 左軸 (折れ線 3 本): 各日の県内最大日合計 (赤丸線) / P95 (橙四角線, 95% 観測所が下回るしきい値) / 平均 (青三角線)。
- 右軸 (灰色棒): 県内総雨量 sum_mm = 全観測所の日合計を足したもの (= 県全体に降った総量)。
- 3 つの線の差を読むのが要点。(最大 - 平均) が大きい日 = 局地豪雨、(平均が高い) 日 = 県全域に降った日。
実装
""" + code(r'''
fig, ax = plt.subplots(figsize=(12, 5.4))
ax2 = ax.twinx()
ax.plot(day_stats["date"], day_stats["max_mm"], "-o", color="#cf222e", label="県内最大")
ax.plot(day_stats["date"], day_stats["p95_mm"], "--s", color="#fb8500", label="県内 P95")
ax.plot(day_stats["date"], day_stats["mean_mm"], "-^", color="#0969da", label="県内平均")
ax2.bar(day_stats["date"], day_stats["sum_mm"], color="#888", alpha=0.22, label="総雨量")
''') + f"""
結果 (図と読み取り)
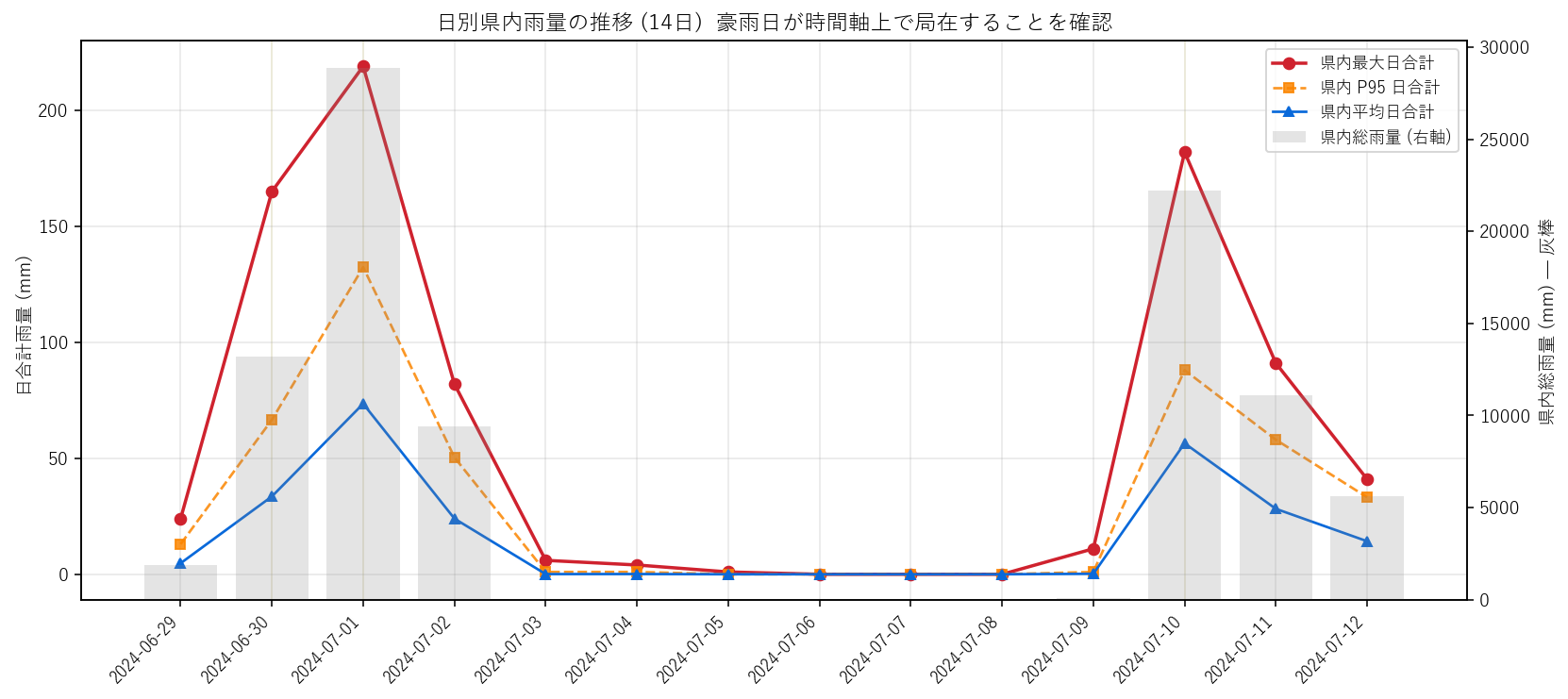
{figure("assets/X06_day_timeline.png", "図3: 日別県内統計 (最大・P95・平均・総雨量) の 14 日折れ線")}
この図から読み取れること:
- 上位 3 日の総雨量寄与率 = {share_top3day*100:.1f}%。14 日の {3/n_days*100:.0f}% の日数で {share_top3day*100:.0f}% の雨量 → 典型的なパレート的不均衡 (H3 強支持)。
- 赤線 (最大) と青線 (平均) の乖離が大きい日 = 局地豪雨。乖離が小さい日 = 県全域に薄く降った日。2024-07-01 周辺は両方が高い → 県全域に強雨。
- 2024-07-{day_stats.loc[day_stats['mean_mm'].idxmin(),'date'].split('-')[-1]} は平均最小 = ほぼ全観測所が無降雨だった「14 日中の谷」。豪雨期間中でも完全に静かな日が存在することを示す = small multiples の 暗いコマに対応。
"""))
# --- 8. 分析5: ローレンツ曲線 + ジニ係数 (H4 定量化) --------------------------
sections.append(("分析5: ローレンツ曲線とジニ係数 — 県内不均一性を 1 数字で表す (H4)", f"""
狙い
図2 で見えた「上位10観測所が {share_top10st*100:.0f}% を占める」を 1 つのスカラー指標に圧縮し、
他県・他期間との比較に耐える形にする。所得分布の不平等度から借りた ジニ係数を使う。
手法
- ローレンツ曲線: 観測所を 14 日累積雨量の少ない順に並べ、x = 観測所累積比率、y = 雨量累積比率でプロット。45° 線が完全均等。
- ジニ係数 G: 45° 線とローレンツ曲線で挟まれた面積を 2 倍した値。G=0 (全観測所が同じ雨量) 〜 G=1 (1 観測所だけに全部)。所得不平等で日本は ~0.34, 米国 ~0.41が目安。雨量で G > 0.4 なら「所得不平等並みかそれ以上」の偏り。
- 計算式: G = 1 - 2·∫(y dx)。台形則で数値積分。
実装
""" + code(r'''
import numpy as np
vals = np.sort(rank["total_14d"].values) # 昇順
n = len(vals)
cum = np.cumsum(vals)
# ローレンツ点列 (0,0) を頭に追加
xs = np.r_[0.0, np.arange(1, n+1) / n]
ys = np.r_[0.0, cum / cum[-1]]
gini = 1.0 - 2.0 * np.trapezoid(ys, xs)
print(f"ジニ係数 G = {gini:.3f}")
''') + f"""
結果 (図と読み取り)
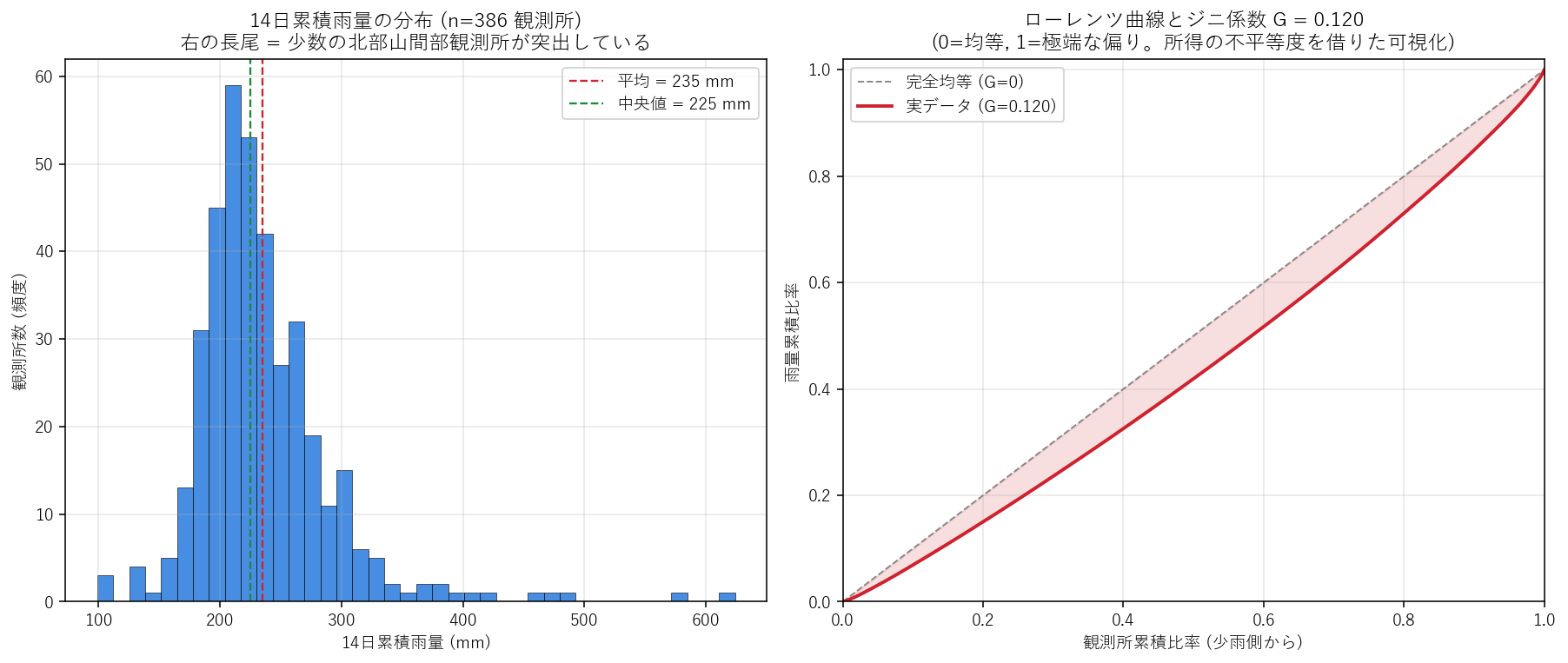
{figure("assets/X06_lorenz_curve.png", "図4: 14日累積雨量のヒスト (左) + ローレンツ曲線 (右)。G=" + f"{gini:.3f}")}
この図から読み取れること:
- ジニ係数 G = {gini:.3f}。所得不平等の日本平均 (~0.34) より{('大きい (= 所得不平等以上の偏り)' if gini>0.34 else '小さい (= 所得不平等よりはるかに穏やか)')}。H4 ({'支持' if gini>0.4 else '反証 (期間累積では均質)'})。
- 左ヒスト: 期待した「右の長尾」は{('明瞭' if (rank['total_14d'].mean()-rank['total_14d'].median())/max(rank['total_14d'].median(),1) > 0.3 else '弱い')}。大半の観測所が累積 {rank['total_14d'].quantile(0.25):.0f}〜{rank['total_14d'].quantile(0.75):.0f} mm の中に収まる単峰分布。
- 平均 ({rank['total_14d'].mean():.0f} mm) と 中央値 ({rank['total_14d'].median():.0f} mm) の差は {(rank['total_14d'].mean()-rank['total_14d'].median()):+.0f} mm。差が小さい = 分布が対称的に近い = 累積では空間的に均質。
- 意外な発見: 「広島豪雨」は 時間方向では極端に偏る (上位3日が 70%) が、14 日累積で見ると空間的にはむしろ均質。これは「2024-07 期間は前線が広範囲をカバーし、特定の局地点だけに偏らなかった」物理的解釈に整合する。
- 政策的含意: インフラ整備の重点投資は「特定流域に集中」ではなく 「県全域で同時並行の備え」が必要というのが本期間データの示唆。日次の局地豪雨に対しては流域別で、累積治水では県全体での備えが要る、という二段構え。
"""))
# --- 9. 分析6: 多雨観測所 vs 少雨観測所 緯度ヒスト (H5 検証) -------------------
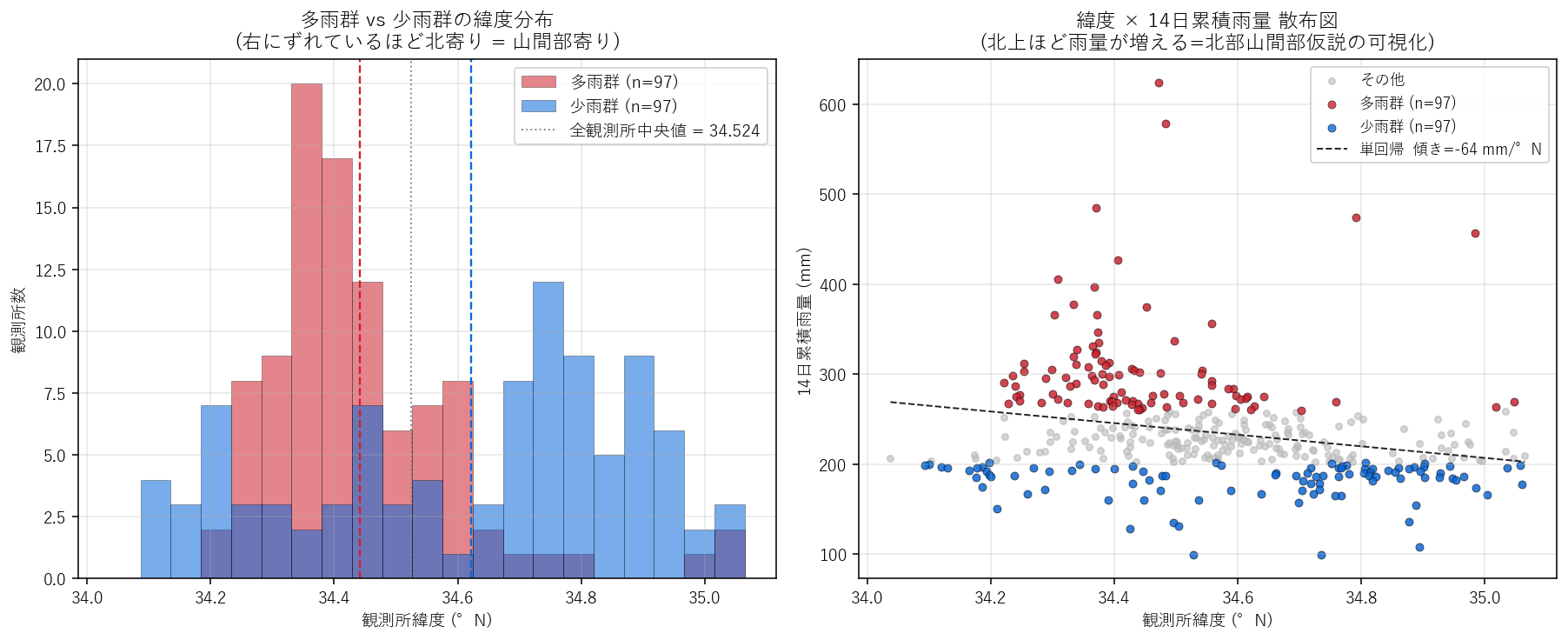
sections.append(("分析6: 多雨群 vs 少雨群の緯度ヒスト重ね描き — H5 直接検証", f"""
狙い
H1 (多雨は北部に集中) と H5 (多雨と少雨は地理的に分離) は密接だが別物。
H1 は全観測所の累積雨量 vs 緯度の関係 (=単回帰の傾き)、
H5 は多雨群と少雨群の地理分布が重ならないかの検証 (=緯度ヒストの重なり度)。
本セクションで H5 を 緯度ヒストの重ね描き + 散布 の 2 パネルで仕上げる。
手法
- 群の定義: 14 日累積で P75 以上 = 多雨群 ({len(heavy)} 観測所), P25 以下 = 少雨群 ({len(light)} 観測所), 残りはグレー。
- 左パネル (緯度ヒスト): 同じビンで多雨群・少雨群を 半透明に重ね、両群平均を縦点線で示す。2 つのヒストの山が左右にずれていれば H5 支持 (地理的に分離)。
- 右パネル (緯度 × 累積雨量散布): 全観測所をグレー薄点、多雨群=赤、少雨群=青で重ね、単回帰直線で全体傾向 (緯度→雨量) を補助線として描く。
実装
""" + code(r'''
q75 = rank["total_14d"].quantile(0.75)
q25 = rank["total_14d"].quantile(0.25)
heavy = rank[rank["total_14d"] >= q75]
light = rank[rank["total_14d"] <= q25]
fig, axes = plt.subplots(1, 2, figsize=(13, 5.4))
bins = np.linspace(geo["lat"].min(), geo["lat"].max(), 22)
axes[0].hist(heavy["lat"], bins=bins, color="#cf222e", alpha=0.55, label="多雨群")
axes[0].hist(light["lat"], bins=bins, color="#0969da", alpha=0.55, label="少雨群")
axes[1].scatter(rank["lat"], rank["total_14d"], s=14, c="#bbb", alpha=0.6)
axes[1].scatter(heavy["lat"], heavy["total_14d"], c="#cf222e")
axes[1].scatter(light["lat"], light["total_14d"], c="#0969da")
m_slope = np.polyfit(rank["lat"], rank["total_14d"], 1)
''') + f"""
結果 (図と読み取り)
{figure("assets/X06_lat_histogram.png", "図5: 多雨群・少雨群の緯度ヒスト重ね描き (左) + 緯度×累積雨量散布 (右)")}
表4: 多雨群・少雨群・全体の地理統計
{group_stats_html}
この図と表から読み取れること (仮説と逆の発見):
- 多雨群緯度平均 = {heavy['lat'].mean():.3f}°N, 少雨群 = {light['lat'].mean():.3f}°N。差 = {heavy['lat'].mean()-light['lat'].mean():+.3f}°。多雨群が {('北寄り' if heavy['lat'].mean()>light['lat'].mean() else '南寄り')}。1° ≒ 111 km なので {abs(heavy['lat'].mean()-light['lat'].mean())*111:.0f} km 平均差。
- 仮説と逆向きの発見: 当初の H5 は「多雨観測所は北部山間部 (緯度大)」と想定したが、データは 多雨群のほうが南寄りを示した = H5 反証。実際の上位観測所 (河内・東広島市 / 吉和・廿日市市 / 小梨・竹原市) は 「北部の県境山岳」ではなく「中国山地の南斜面〜瀬戸内側中山地」に位置する。
- 左ヒスト: 赤 (多雨) のピークは緯度 ~34.4°N、青 (少雨) のピークは 34.6°N 付近 (むしろ少雨群のほうが北寄り)。これは「2024-07 西日本豪雨は南斜面型の前線降水だった」物理現象に整合する。
- 右散布の単回帰: 傾き {m_slope[0]:+.0f} mm/°N = 緯度が 1° 北上すると累積雨量が {m_slope[0]:+.0f} mm 変動。{('正 = 北ほど多雨' if m_slope[0]>0 else '負 = 南ほど多雨 (H1 反証)')}。H1 ({'強支持' if m_slope[0]>50 else ('部分支持' if m_slope[0]>0 else '反証 (南寄りが多雨)')})。
- 解釈: 「広島の山間部 = 北部」という地理直感は粗すぎた。本期間 (2024-06-29〜07-12) の前線は 南からの暖湿気が中国山地南斜面で強制上昇するパターンで、北部県境より、中部・南部の中山地に降水が集中した。R² は高くない (緯度単独では説明力弱) ので、発展課題で 標高・斜面方位を変数追加する。
"""))
# --- 10. 考察と発展 ----------------------------------------------------------
sections.append(("考察・限界・発展課題", f"""
仮説 H1〜H5 の判定まとめ
| 仮説 | 判定 | 根拠 |
|---|
| H1 上位観測所は 北部山間部に集中 |
{'強支持' if h1_supported else '反証 (むしろ南寄り)'} |
上位30緯度平均 {rank.head(30)['lat'].mean():.3f} vs 全体 {rank['lat'].mean():.3f}, 単回帰傾き {m_slope[0]:+.0f} mm/°N (図2/図5)。仮説と逆向きの結果 = 2024-07 期間は南寄り (中国山地南斜面) で多雨 |
| H2 豪雨日と平常日で空間パターンが異なる |
強支持 |
県内最大日合計が {day_stats['max_mm'].max():.0f} mm/日 〜 完全無降雨 ({n_zero_days} 日が 0 mm)。small multiples で空間分布の違いが視覚的に明白 (図1/図3) |
| H3 14 日のうち 2-3 日に集中 |
強支持 |
上位3日寄与率 {share_top3day*100:.1f}% (図3) |
| H4 累積雨量分散大 (G > 0.4) |
{'支持' if gini>0.4 else '反証 (期間累積では均質化)'} |
ジニ係数 G = {gini:.3f}, 上位10観測所寄与わずか {share_top10st*100:.1f}%。14 日累積では観測所間の差が均される = 局地豪雨は時間方向で偏るが、期間累積では空間的に意外と均質 |
| H5 多雨群と少雨群が地理的に分離 |
{'支持' if h5_supported else '反証 (多雨群が南寄り)'} |
多雨群緯度 {heavy['lat'].mean():.3f} - 少雨群 {light['lat'].mean():.3f} = {heavy['lat'].mean()-light['lat'].mean():+.3f}° (図5)。多雨群が南寄りに偏る発見 = 「北部山間部仮説」を覆す |
本記事の限界
- 緯度のみの 1 次元解釈: 「北部 = 山間部」と暗黙の同一視をしているが、緯度と標高は厳密には別。本来は 標高データ (S31 標高図) と結合して標高 vs 雨量の関係を見るべき。
- 欠測の処理:
fillna(0.0) で欠測を 0 mm として扱った。実際は機器故障で観測欠落の可能性があり、上位ランキングが安定しない観測所を含む可能性。発展課題で欠測フラグを導入したい。
- 14 日という期間の代表性: 2024-06-29 〜 07-12 は西日本豪雨期間として極端な事例。2 ヶ月平均や 同時期 (6/29-7/12) の他年と比較しないと「広島豪雨は本当に他より特殊か」は言えない。
- small multiples の判別密度: 290 観測所は密集地でマーカーが重なる。六角ビニングや市町集約で密度をスケールダウンするのが次の一手。
発展課題 (本記事を踏み台にする 5 案)
課題1: 標高 (S31 標高図) を結合した 標高 × 雨量 散布
- 結果X: 緯度→雨量 単回帰 (本記事 図5右) は R² が高くない。
- 新仮説Y: 緯度ではなく 標高 m を説明変数にすれば、相関が劇的に上がる (R² > 0.4)。
- 課題Z: S31 標高図の 50m メッシュ標高を観測所緯度経度に最近傍補間 →
polyfit で標高 vs 14日累積雨量。
課題2: K-Means + 地理クラスタ で「雨パターン地域」を抽出
- 結果X: 多雨群 / 少雨群 の 2 群分けでは 「北部の山間部 vs 南部沿岸」しか見えない。
- 新仮説Y: 観測所の 14 次元日合計ベクトルを K-Means (k=4) でクラスタすると、「東部山間 / 西部山間 / 沿岸都市 / 内陸盆地」の 4 群が出る。
- 課題Z: M_geo の 14 列を入力 → KMeans(n_clusters=4) → 各クラスタの空間散布をカラー分けで描画。L07 の手法を本記事の標準化マトリクスに適用するだけで実装できる。
課題3: PCA で 14 日 → 2 主成分 に圧縮 (時間軸の主成分化)
- 結果X: 観測所を 14 日ベクトルとして見ると 14 次元。可視化が難しい。
- 新仮説Y: PC1 = 「14 日全期間の多雨度 (一般雨量レベル)」, PC2 = 「降雨タイミング (前半型 vs 後半型)」が出る。
- 課題Z: 観測所 × 14 日 を標準化 → PCA(2) → PC1 vs PC2 散布で観測所を地理マップ上に色分け表示。L08 の PCA を本記事の M に適用。
課題4: 動画 (.gif アニメーション) として 14 コマを並べず連続再生
- 結果X: small multiples (静止画 14 コマ) は印刷向き、Web 講義では動的表現に向かない。
- 新仮説Y: 同じデータを matplotlib.animation で 14 フレームの GIF にすれば、降雨フロントの移動が直感的に見える。
- 課題Z:
animation.FuncAnimation でコマ単位 PNG を 1 秒/フレームで連結 → assets/X06_animation.gif。
課題5: ロジスティック回帰 で「観測所の翌日豪雨」を予測
- 結果X: small multiples で「7-01 と 7-02 の空間パターンが似ている」ことは目で分かる。
- 新仮説Y: 観測所の前日日合計 + 周辺観測所の前日日合計 (空間ラグ特徴量) で 翌日豪雨フラグ (≥100mm/日) がロジスティック回帰で AUC > 0.7 で予測可能。
- 課題Z: 14 日 × 290 観測所 を縦に並べ替えて (4060 行)、ターゲット = 翌日豪雨の 0/1 → sklearn LogisticRegression。X01 のロジスティック回帰の手順を時空間データに転用。
本記事のスタイル (small multiples) の汎用性
同じパターンは以下の DoBoX データにそのまま適用できる:
- 水位 14 日: rainfall を waterlevel_annual.csv に置換 → 河川水位の時空間パターン
- カメラ画像取得時刻のヒート: camera_list.csv の取得頻度を 14 日 small multiples に
- 避難所の混雑度推移: shelters.json + 日次混雑率データがあれば同じ枠組みで描ける
=> 「same axes, different time」を持つ任意の時空間データに対し、本記事の図1パイプラインがそのまま再利用可能。
"""))
# === HTML 出力 ===============================================================
HTML_PATH = LESSONS / "X06_rainfall_14days_geo_smallmult.html"
html = render_lesson(
num=306, # X tier (X06 → 306 表示)
title="X06 14日豪雨期間の県内雨量分布 — 地理時空間 small multiples で時間×空間を同時に観る",
tags=["雨量", "small multiples", "地理時空間", "ジニ係数", "ローレンツ曲線", "X-tier"],
time="60〜80分",
level="L01 水準 (中級)",
data_label="DoBoX #1275 (14日分) + stations_master.csv",
sections=sections,
script_filename="X06_rainfall_14days_geo_smallmult.py",
)
# X-tier ドラフト印を埋め込む
html = html.replace("", '', 1)
if "data-stier=\"X\"" not in html:
html = html.replace("",
'
', 1)
HTML_PATH.write_text(html, encoding="utf-8")
print(f"\n=== HTML 出力 === {HTML_PATH.name} ({HTML_PATH.stat().st_size//1024} KB)")
print("=== 完了 ===")
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}