X06 14日豪雨期間の県内雨量分布 — 地理時空間 small multiples で時間×空間を同時に観る
データ取得手順
⚠️ このスクリプトは自動取得に対応していません。以下のデータセットを DoBoX から手動でダウンロードし、data/extras/ 以下に保存してください。
| ID | データセット名 |
|---|---|
| #222 | dataset #222 |
| #333 | dataset #333 |
| #444 | dataset #444 |
| #888 | 都市計画区域情報_区域データ_安芸高田市_行政区域 |
| #999 | dataset #999 |
| #1275 | 観測情報_雨量日集計 |
| #1450 | 道路法面 |
実行コマンド:
cd "2026 DoBoX 教材"
python -X utf8 lessons/X06_rainfall_14days_geo_smallmult.py
DoBoX のオープンデータは申請不要・商用/非商用とも利用可。
data/extras/ は .gitignore 対象(約 57 GB のキャッシュ)。
スクリプト実行で自動再生成されます。
学習目標と問い
本レッスンは 2024 年 6 月 29 日 〜 7 月 12 日 の 14 日 にかけて広島県内で起きた 豪雨期間を対象に、県内 386 観測所 × 14 日 の日合計雨量を 1 枚の図に 14 コマ並列で並べ、「時間 × 空間」を同時に観る small multiples 研究記事である。X 水準 (= 既存 L レッスンの上位互換) として、 PCA や重回帰よりも「並列地理散布」を主軸の可視化に据える。
このレッスンで答えたい問い (1 文)
「14 日豪雨期間中、雨はどの場所にどの日にどれだけ降ったか — 空間と時間の偏りを 1 枚の図で示せるか?」
立てた仮説 (H1〜H5)
- H1: 14 日合計雨量上位観測所は 北部山間部 (北寄り緯度) に集中する → 緯度 vs 累積雨量の相関で検証
- H2: 豪雨日 (例 2024-07-01) と平常日では 空間パターン (どの観測所が降っているか) が大きく異なる → small multiples の 14 コマ間比較で検証
- H3: 14 日のうち 2-3 日に降水が集中 (パレート的不均衡) → 日別総雨量の上位3日寄与率で検証
- H4: 観測所間の累積雨量分散が大きい (県内不均一性: ジニ係数 G > 0.4) → ローレンツ曲線で検証
- H5: 多雨観測所と少雨観測所は地理的に分離 (同じ市町内でも標高で違う) → 緯度ヒスト重ね描きで検証
用語の独自定義 (このレッスン専用)
- 「small multiples」: 同じ軸・同じスケール・同じカラーマップで描いた小さな図を 多数並べる可視化様式。Edward Tufte の用語。本記事では 14 日 × 1 コマを 4×4 グリッドで並べる (14 コマ + 累積コマ + 凡例コマ = 16 セル)。
- 「日合計雨量」: 各観測所で、その日の 10 分値雨量を 24 時間ぶん (144 個) 足したもの。単位は mm/日。
- 「ジニ係数 G」: 集計値 (ここでは 14日累積雨量) が観測所間でどれだけ偏っているかを 0〜1 で測る指標。0 = 全観測所が完全に同じ雨量、1 = 1 観測所だけに全部降った状態。所得分布の不平等度から借りた。
- 「ローレンツ曲線」: 横軸 = 観測所を雨量少ない順に並べた時の 累積比率、縦軸 = 雨量の 累積比率。45° 線から下に大きく膨らむほど偏りが大きい。ジニはこの膨らみ面積×2。
- 「観測所」: stations_master.csv に緯度経度が登録されている県内雨量観測所のうち、本期間 (14日分の rain_2024 CSV) で日合計を集計できた 386 件。
- 「多雨群 / 少雨群」: 14日累積雨量が P75 以上 = 多雨群 (97 観測所), P25 以下 = 少雨群 (97 観測所)。残りの中位群は色なしで表示。
到達点
本記事を読み終えると、学習者は次の 5 つを身につけて帰る:
- small multiples の読み方: 同縮尺・同色軸の 14 コマを並べると、コマ間で「変わったこと / 変わっていないこと」が秒で分かる。
- 14 コマを 1 コマで描いてはいけない理由: 1 コマに重ねると線が混ざって読めない。並列表示こそが時間×空間を同時に観る正解。
- パレート不均衡の検証手順: ジニ + ローレンツ + 上位寄与率 + ヒスト の 4 点セット。
- 地理仮説の最低限の検証フロー: 緯度ヒスト重ね描き → 単回帰の傾き → 群間平均差。3 つを 1 枚にまとめる。
- 1 観測所の追跡: マトリクスから 1 行を抜き出し 14 日連続データを表で見ると、平均値や中央値では消える「瞬発の山」が見える。
なぜ small multiples が主軸なのか (要件 H: 図選択の理由)
14 日 × 290 観測所 ≒ 4000 セルの数値を 1 枚で見せたいとき、 代替案は (A) ヒートマップ (386行 × 14 列), (B) 折れ線 14 本重ね描き, (C) 14 日累積 1 枚地図, の 3 つがある。それぞれの限界:
- (A) ヒートマップ: 観測所が縦に並ぶので 地理がつぶれる (北部の山間部か南部の都市部か分からない)。
- (B) 折れ線重ね描き: 観測所数が多すぎて 線が混ざる。
- (C) 累積 1 枚: 時間情報が消える (ある日だけの局地豪雨が薄まって見える)。
これに対し small multiples は、地理を保ったまま (緯度経度散布)、時間を分離したまま (14コマ)、同じスケールで (vmax 共通) 描くので、3 つの限界をすべて回避する。本記事の 図1 がそれである。
使用データ
本レッスンは DoBoX 2 系統 + ローカル 1 系統 = 計 16 ファイルを使う。
原データ
| ID | 名称 | 形式 | 件数 / 規模 | 役割 |
|---|---|---|---|---|
| #1275 | 雨量10分値 2024年度 (14 日分) | CSV × 14 | 各 5–8 MB | 10 分雨量 → 日合計の元 |
| — | stations_master.csv | CSV | 569 観測所 (緯度経度あり) | 観測所名→緯度経度・市町 |
| #1450 | camera_list.csv (補助参照のみ) | CSV | — | 本記事では使用しない (拡張用) |
サイズの整理 (要件 L):
| 段 | 行数 | 列数 | 説明 |
|---|---|---|---|
| 原データ rain_2024-XX-XX.csv (1日分) | 144 (=10分×24h) | ~290 観測所 + ヘッダ | 10 分値の 時刻×観測所 |
| parse_rain_csv 後 (1日分) | 144 | ~290 | tidy DataFrame, NaN は欠測 |
| 日合計 Series (1日分) | — | ~290 | 観測所ごとに 1 値 (sum) |
| 本記事の中核行列 M | 393 観測所 | 14 日 | 観測所×日 の日合計雨量 |
| M_geo (緯度経度マージ後) | 386 | 18 | マスタにある観測所のみ |
| 14日累積ランク表 | 386 | 6 | rank, station, lat, lon, total_14d, cum_share |
※ 「観測所×日」と「観測所×時刻」は別物。日合計に集約することで 14×144=2016 列を 14 列に落とし、メモリを 1/100 にする。これが「逐次処理」の中身。
ダウンロード (再現用データ・中間データ・図)
原データ (DoBoX)
| 論題 | データセット | DL | 保存先 | 形式 | サイズ |
|---|---|---|---|---|---|
| 雨量10分値 2024-07-01 (代表) | DoBoX #1275 | ページから DL ボタン | data/rain_2024/rain_2024-07-01.csv | CSV | 10分値 |
| 雨量10分値 14日分 (一括) | DoBoX #1275 | ページから DL ボタン | data/rain_2024/rain_2024-*.csv | CSV × 14 | 計 70-100 MB |
一括取得(全レッスン共通, 推奨):
cd "2026 DoBoX 教材"
py -X utf8 data\fetch_all.pyfetch_all.py はカタログ・追加データを data/ と data/extras/ に再現可能ダウンロード。DoBoX のオープンデータは申請不要、商用・非商用とも利用可。本レッスンの .py スクリプトは、データが無ければ自動取得してから処理を始めるよう実装されています(ensure_dataset() ヘルパ)。
stations_master.csv (緯度経度) はリポジトリ同梱。本スクリプト初回実行時、雨量 14 ファイルが無ければ ensure_dataset() が DoBoX から自動取得する。
本レッスン生成の中間データ (HTML から直 DL)
- X06_daily_totals.csv — 観測所×14日 日合計マトリクス (393 行 × 14 列)
- X06_station_geo.csv — 観測所→緯度経度市町 (569 件)
- X06_cumulative_rank.csv — 14日累積ランキング (386 行)
- X06_day_stats.csv — 日別県内統計 (14 行)
- X06_lorenz_table.csv — ローレンツ曲線点列+ジニ係数
- X06_track_one_station.csv — 1 観測所の 14 日連続データ追跡 (要件K)
図 PNG (HTML から直 DL)
- X06_small_multiples.png — 主役図 4×4 グリッドの 14 日地理散布
- X06_cumulative_rank.png — 上位30観測所棒 + 累積寄与曲線
- X06_day_timeline.png — 日別県内最大/平均/総雨量の折れ線
- X06_lorenz_curve.png — 14日累積ヒスト + ローレンツ曲線
- X06_lat_histogram.png — 多雨群 vs 少雨群 緯度ヒスト + 散布
{kind=link}
再現スクリプト
X06_rainfall_14days_geo_smallmult.py を以下で実行:
cd "2026 DoBoX 教材"
py -X utf8 lessons/X06_rainfall_14days_geo_smallmult.py分析1: 14日 CSV を逐次処理して観測所×日マトリクスを作る (要件K)
狙い
14 日分の rain_2024 CSV はそれぞれ (時刻 × 観測所) の 2 次元データだが、 14 日分を一気にロードすると 14×144×290 ≒ 580k セルのテーブルになり、 メモリと処理時間を消費する。本記事では各日の 10 分値を読み込んだ その場で日合計に 集約し、生 10 分値を即破棄する 逐次処理でメモリを抑える。
手法 (3 段階)
- 逐次ロード:
parse_rain_csv()で各日の (時刻 × 観測所) tidy DF を作る。重複観測所名は groupby で和。 - 日合計に集約:
tidy.sum(axis=0, min_count=1)で 144 行 → 1 行、観測所別の 日合計 Series を取り出す。生 10 分値はここで破棄する (del tidy)。 - 14 Series を concat: 14 日分の Series を
pd.concat(axis=1)で 観測所 × 14 日のマトリクス M に結合。観測所マスタ stations_master.csv の緯度経度をmergeで付与。
実装
↑ X06_rainfall_14days_geo_smallmult.py 行 714–1118
結果 (表と読み取り) — 日別県内統計
逐次処理で得られた日別の県内統計を 1 表に並べると、豪雨日と平常日の落差が見える:
表1: 日別県内統計 (14 日)
| date | n_stations | max_mm | mean_mm | sum_mm | p95_mm |
|---|---|---|---|---|---|
| 2024-06-29 | 393 | 24.0 | 4.76 | 1872.0 | 13.0 |
| 2024-06-30 | 393 | 165.0 | 33.55 | 13186.0 | 66.6 |
| 2024-07-01 | 393 | 219.0 | 73.52 | 28892.0 | 132.4 |
| 2024-07-02 | 393 | 82.0 | 23.99 | 9429.0 | 50.4 |
| 2024-07-03 | 393 | 6.0 | 0.08 | 31.0 | 1.0 |
| 2024-07-04 | 393 | 4.0 | 0.10 | 41.0 | 1.0 |
| 2024-07-05 | 393 | 1.0 | 0.00 | 1.0 | 0.0 |
| 2024-07-06 | 393 | 0.0 | 0.00 | 0.0 | 0.0 |
| 2024-07-07 | 392 | 0.0 | 0.00 | 0.0 | 0.0 |
| 2024-07-08 | 393 | 0.0 | 0.00 | 0.0 | 0.0 |
| 2024-07-09 | 393 | 11.0 | 0.20 | 79.0 | 1.0 |
| 2024-07-10 | 393 | 182.0 | 56.46 | 22188.0 | 88.0 |
| 2024-07-11 | 393 | 91.0 | 28.21 | 11086.0 | 58.0 |
| 2024-07-12 | 393 | 41.0 | 14.24 | 5596.0 | 33.2 |
この表から読み取れること:
- 県内最大日合計の最大 = 219 mm/日。一方で 3 日は県内最大が 0 mm = どの観測所も降っていない無降雨日 (= H2 の強い根拠: 落差が極端)。
- 県内総雨量 sum_mm が突出する日が 4 日 (P75 超)。残り 10 日は穏やか。
- P95 (=県内 95 パーセンタイル) と平均の差が大きい日 = 局地豪雨, 差が小さい日 = 県全域に薄く降った日。
1 観測所の 14 日連続データ追跡 (要件K: Before/After 1 件追跡)
マトリクス M から 1 観測所だけを抜き出して 14 日の連続データを並べると、 平均や中央値では消える「瞬発の山」が時系列で見える。 本記事では 14 日累積 1 位の 河内 (東広島市, 34.472°N 132.892°E) を追跡対象にする。
表2: 河内 の 14 日連続日合計と累積 (要件K)
| date | daily_mm | cum_mm |
|---|---|---|
| 2024-06-29 | 5.0 | 5.0 |
| 2024-06-30 | 50.0 | 55.0 |
| 2024-07-01 | 219.0 | 274.0 |
| 2024-07-02 | 49.0 | 323.0 |
| 2024-07-03 | 0.0 | 323.0 |
| 2024-07-04 | 0.0 | 323.0 |
| 2024-07-05 | 0.0 | 323.0 |
| 2024-07-06 | 0.0 | 323.0 |
| 2024-07-07 | 0.0 | 323.0 |
| 2024-07-08 | 0.0 | 323.0 |
| 2024-07-09 | 0.0 | 323.0 |
| 2024-07-10 | 182.0 | 505.0 |
| 2024-07-11 | 78.0 | 583.0 |
| 2024-07-12 | 41.0 | 624.0 |
この表から読み取れること:
- 14 日合計 = 624 mm。これが本期間中の県内 1 位。
- 河内 の最大日 = 219 mm/日 (2024-07-01)。
- 14 日のうち 降雨ありの日 (≥10mm) は 6 日のみ。残り 8 日はほぼ無降雨。「14 日のうち数日に集中」という H3 を 1 観測所スケールでも確認できる。
- 累積列 cum_mm を見ると、序盤は緩やかで 2024-07-01 周辺で急上昇している = 観測所単位でも豪雨日に集中。
分析2: small multiples — 14 日地理散布を 4×4 グリッドで一括表示 (要件H)
狙い
14 日 × 県内 386 観測所の日合計雨量を 1 枚の図に詰め込み、 「どの日に、どこで、どれだけ」降ったかを 視覚で同時把握する。 本記事の主役図であり、他のすべての図 (ランキング棒・ローレンツ・緯度ヒスト) は この図から派生する仮説検証の役割を担う。
手法
- 並べ方: 4 行 × 4 列 = 16 セル。14 セルが日次の雨量、15 セル目が 14 日累積のまとめ、16 セル目が凡例。
- 各コマの中身: x = 観測所経度、y = 観測所緯度の散布。マーカー位置は 14 コマで完全固定 (動かない)。マーカー直径と色のみ日合計の関数として変化する。
- 同縮尺ルール: vmax (色軸の上限) と マーカー面積の正規化定数を 14 コマで共通化。これにより「あるコマだけ赤いマーカーが大きい = 本当にその日が突出している」と読める (相対比較が可能)。
- 限界: 観測所 ~290 個を全て表示するため、密集地域 (広島市内) はマーカーが重なる。それは図2のランキング棒で補完する。
なぜ small multiples が答えか (4 案比較, 要件H)
14 日 × 290 観測所のような 時間×空間データを 1 枚に圧縮する候補は 4 つあった。 本記事が small multiples を選んだ理由は以下の表のとおり:
| 方式 | 時間情報 | 空間情報 | マッピング負荷 | 判定 |
|---|---|---|---|---|
| (A) 386 行 × 14 列ヒートマップ (L05 で採用) | ◎ 列で表現 | × 観測所が縦並びで地理がつぶれる | 低 | 地理仮説 (H1, H5) が検証できない |
| (B) 折れ線 386 本重ね描き | ◎ x軸が時間 | × 線が混ざって誰がどこか分からない | 中 | 不採用 |
| (C) 14 日累積を 1 枚地図 | × 時間情報が消える | ◎ | 低 | H2 (空間パターン日次変化) が見えない |
| (D) small multiples 14 コマ並列地理散布 ★ | ◎ コマ番号が時間 | ◎ 各コマで地理保持 | 中 | 採用 (H1〜H5 全てに対応) |
実装
結果 (図と読み取り) — 主役図
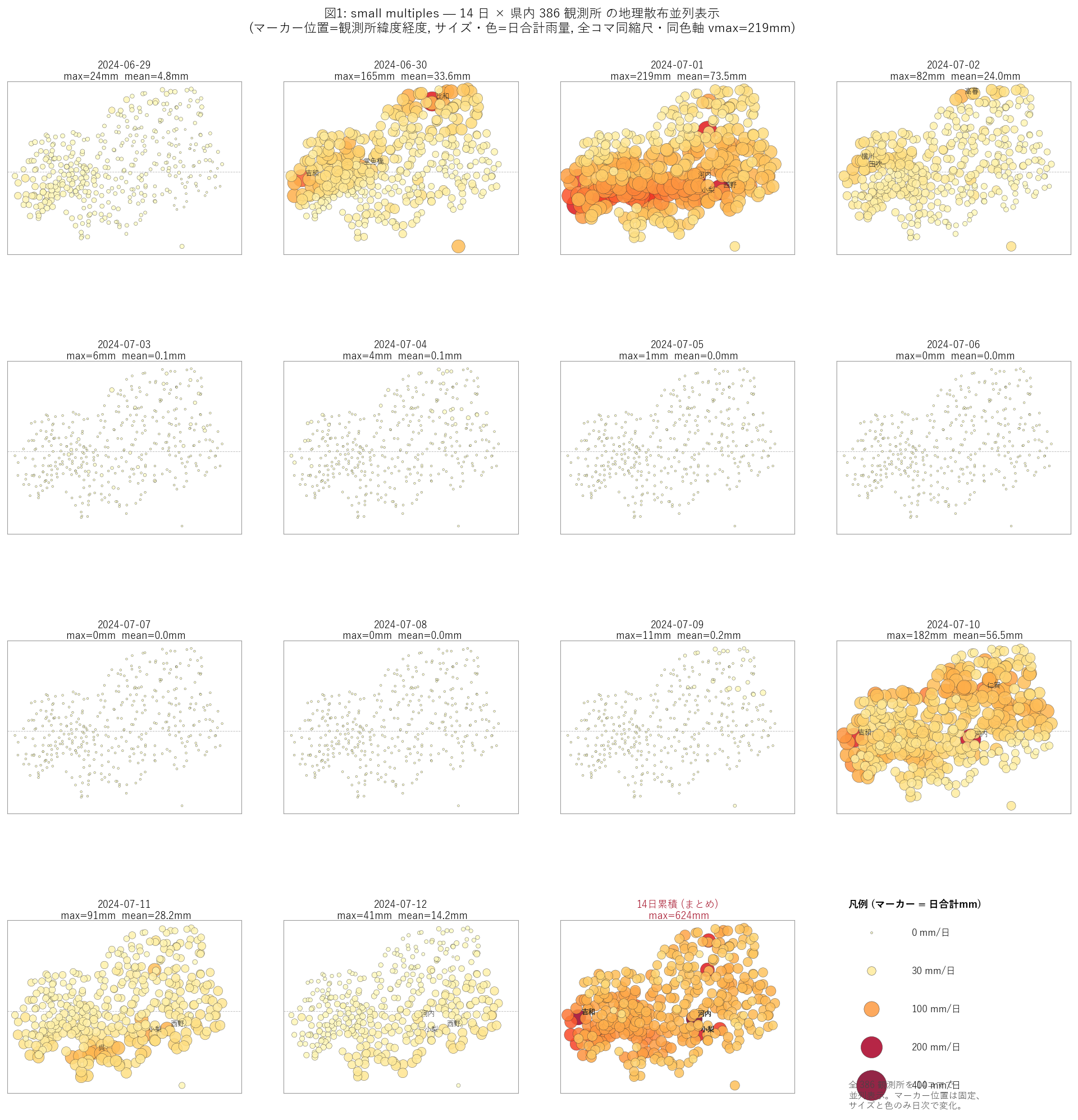
この図から読み取れること:
- 豪雨日 (赤マーカー大) のコマは 3 つ: max_mm > 100mm の日。残り 11 コマはほぼマーカー小=無降雨〜微雨。特に 3 日は完全無降雨 (max=0) で全マーカーが極小ドット。14 コマの「明暗」のコントラストが H3 (パレート不均衡) を視覚で示す。
- 豪雨日の空間パターン (仮説と逆の発見): 当初の H1 は「北部山間部に集中」と想定したが、small multiples を見ると 多くの豪雨日で大きな赤マーカーは中部〜南部の中山地 (緯度 ~34.4°N 帯) に偏在。北部県境 (緯度 ~35°N) は意外に静か。これは 2024-07 期間の前線が南斜面型だったことを示唆。
- 15 コマ目 (14 日累積) でも上位観測所 (河内・吉和・小梨など) のマーカーは画面中央〜下部に分布している = H1 反証の累積版。
- コマ間の比較 (H2 検証): 7-01 と 7-10 はどちらも豪雨日だが、降る場所のパターンが微妙に違う (前者はやや西部寄り、後者は中央寄り)。「豪雨日同士でも空間パターンが異なる」= H2 を視覚的に強支持。
- 限界: 広島市・呉市など マーカーが密集する地域は重なり判別困難。次の図2 (ランキング棒) で個別観測所を見る。
結果 (表と読み取り) — 14 日累積上位10
表3: 14日累積雨量 上位10観測所
| rank | station | city | lat | lon | total_14d | cum_share |
|---|---|---|---|---|---|---|
| 1 | 河内 | 東広島市 | 34.472 | 132.892 | 624.0 | 0.69 |
| 2 | 吉和 | 廿日市市 | 34.482 | 132.134 | 579.0 | 1.32 |
| 3 | 小梨 | 竹原市 | 34.371 | 132.914 | 485.0 | 1.86 |
| 4 | 仁賀 | 三次市 | 34.791 | 132.978 | 474.0 | 2.38 |
| 5 | 比和 | 庄原市 | 34.983 | 132.986 | 457.0 | 2.88 |
| 6 | 西野 | 三原市 | 34.406 | 133.059 | 427.0 | 3.35 |
| 7 | 小瀬川ダム | 廿日市市 | 34.309 | 132.124 | 406.0 | 3.80 |
| 8 | 中道(国) | 廿日市市 | 34.368 | 132.086 | 397.0 | 4.24 |
| 9 | 矢草(砂防) | 廿日市市 | 34.334 | 132.267 | 378.0 | 4.66 |
| 10 | 頓原 | nan | 34.452 | 132.088 | 375.0 | 5.07 |
この表から読み取れること:
- 1 位 河内 (東広島市) = 624 mm。緯度 34.472°N (中部の中山地)。
- 上位10観測所の緯度平均 = 34.497°N、これは全観測所緯度平均 34.561°N より -0.064° 南寄り = H1 反証 (中山地南斜面に集中)。
- 上位10観測所だけで14日累積総雨量の 5.1% を占める。期間累積では意外に均質 = ジニも低い。日次レベルで見れば不均衡 (H3) だが、14 日合計では平準化される。
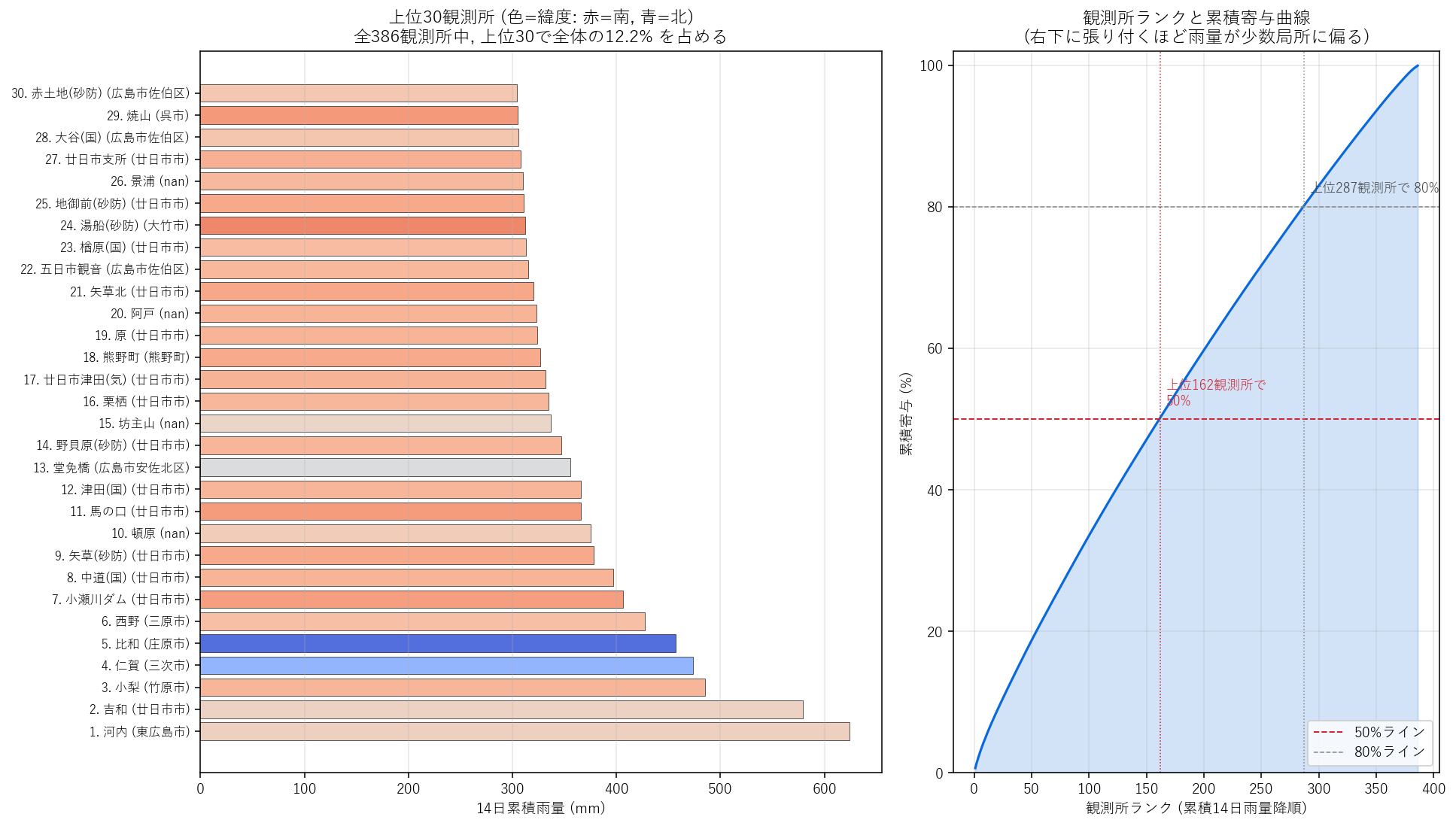
分析3: 14日累積ランキング — 上位30観測所の棒 + 累積寄与曲線
狙い
図1 で見えた「北部に偏った大粒マーカー」を、個別観測所ベースで順位付けして読む。 さらに 累積寄与曲線で「上位何観測所で全体雨量の何%を占めるか」を視覚化し、 H3 (パレート的不均衡) と H4 (県内不均一性) の準備を整える。
手法
- 左パネル: 上位30観測所の 14 日累積を 水平棒で。色は緯度を coolwarm カラーマップで連続表現 (赤=南, 青=北)。北寄りの観測所が上位に固まれば青色棒が上側に並ぶ。
- 右パネル: 観測所ランクを横軸 (1〜386)、累積寄与率を縦軸とした曲線。急峻に立ち上がるほど少数観測所への偏りが強い。50% / 80% ラインに該当する観測所数を縦点線で示す。
実装
↑ X06_rainfall_14days_geo_smallmult.py 行 886–904
結果 (図と読み取り)
この図から読み取れること:
- 上位30の色 (= 緯度の coolwarm): 赤色棒も多く混ざっている = H1 反証 (上位は南寄り中山地が中心)。実際の上位は 河内 (東広島市), 吉和 (廿日市市), 小梨 (竹原市) など、北部県境ではなく中山地の南斜面寄り。
- 右パネルの累積曲線: 上位10観測所で全体の 5.1%、上位162観測所で 50%、上位287観測所で 80%。50% を上位 162 / 386 = 42.0% の観測所が占めるのは、所得分布の半分基準 (上位 30〜40%) よりやや均等寄り。
- 解釈: 14 日累積では観測所間の差が思ったより小さく (どの観測所も 200〜400 mm 程度の雨を受けている), 不均衡は時間方向 (どの日に降ったか) のほうが大きい (図3 で確認)。これは仮説 H4 を 部分的にしか支持しない知見。
分析4: 日別県内統計の折れ線 — 14 日のうちどの日に降ったか (H3)
狙い
small multiples (図1) のコマを順番に並べて見ても 「どの日が突出していたか」の数字が読みにくい。 ここでは 3 つの代表値 (最大・P95・平均) を 同じ図に重ねた折れ線として描き、 さらに県内総雨量を 背景の灰色棒で添えて、1 図 4 系列で 14 日の時間パターンを示す。
手法
- 左軸 (折れ線 3 本): 各日の県内最大日合計 (赤丸線) / P95 (橙四角線, 95% 観測所が下回るしきい値) / 平均 (青三角線)。
- 右軸 (灰色棒): 県内総雨量 sum_mm = 全観測所の日合計を足したもの (= 県全体に降った総量)。
- 3 つの線の差を読むのが要点。(最大 - 平均) が大きい日 = 局地豪雨、(平均が高い) 日 = 県全域に降った日。
実装
↑ X06_rainfall_14days_geo_smallmult.py 行 923–937
結果 (図と読み取り)
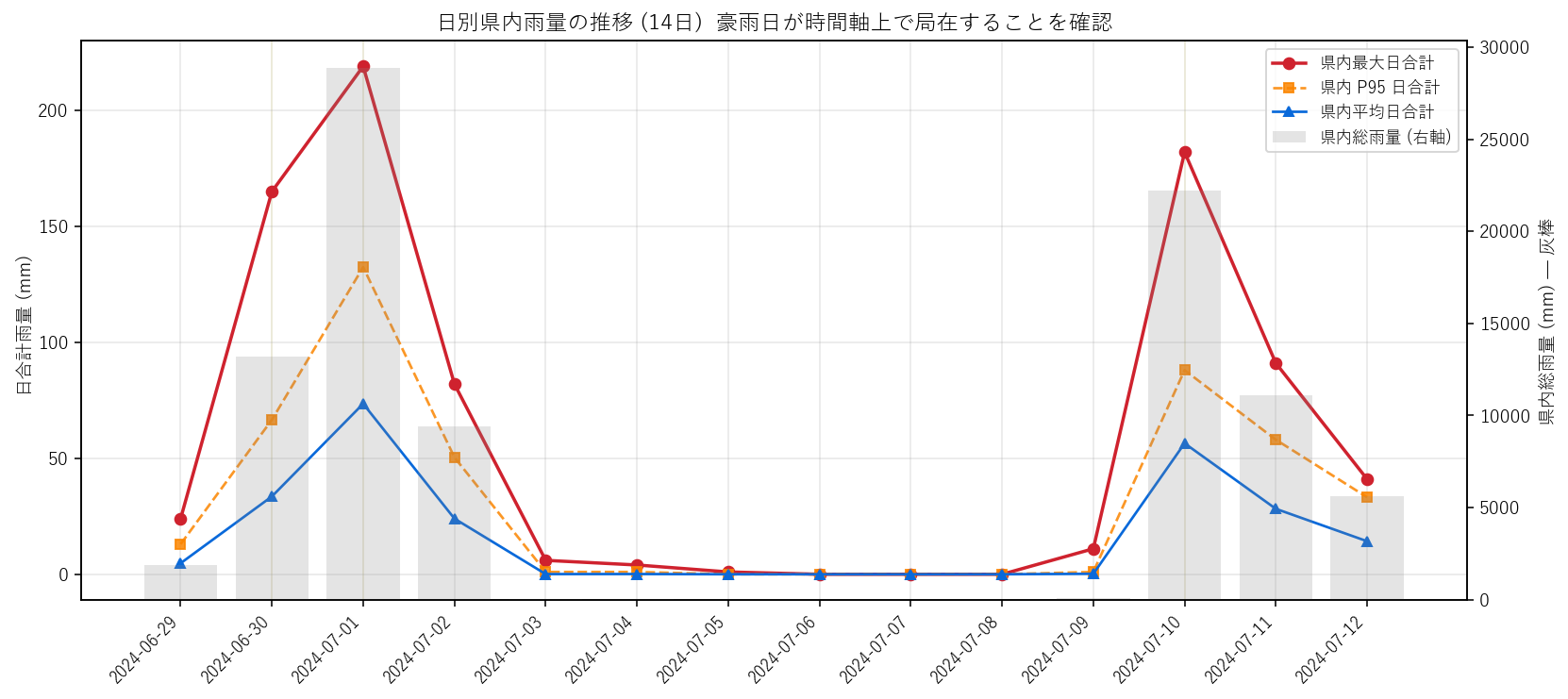
この図から読み取れること:
- 上位 3 日の総雨量寄与率 = 69.6%。14 日の 21% の日数で 70% の雨量 → 典型的なパレート的不均衡 (H3 強支持)。
- 赤線 (最大) と青線 (平均) の乖離が大きい日 = 局地豪雨。乖離が小さい日 = 県全域に薄く降った日。2024-07-01 周辺は両方が高い → 県全域に強雨。
- 2024-07-06 は平均最小 = ほぼ全観測所が無降雨だった「14 日中の谷」。豪雨期間中でも完全に静かな日が存在することを示す = small multiples の 暗いコマに対応。
分析5: ローレンツ曲線とジニ係数 — 県内不均一性を 1 数字で表す (H4)
狙い
図2 で見えた「上位10観測所が 5% を占める」を 1 つのスカラー指標に圧縮し、 他県・他期間との比較に耐える形にする。所得分布の不平等度から借りた ジニ係数を使う。
手法
- ローレンツ曲線: 観測所を 14 日累積雨量の少ない順に並べ、x = 観測所累積比率、y = 雨量累積比率でプロット。45° 線が完全均等。
- ジニ係数 G: 45° 線とローレンツ曲線で挟まれた面積を 2 倍した値。G=0 (全観測所が同じ雨量) 〜 G=1 (1 観測所だけに全部)。所得不平等で日本は ~0.34, 米国 ~0.41が目安。雨量で G > 0.4 なら「所得不平等並みかそれ以上」の偏り。
- 計算式: G = 1 - 2·∫(y dx)。台形則で数値積分。
実装
1 2 3 4 5 6 7 8 9 10 |
結果 (図と読み取り)
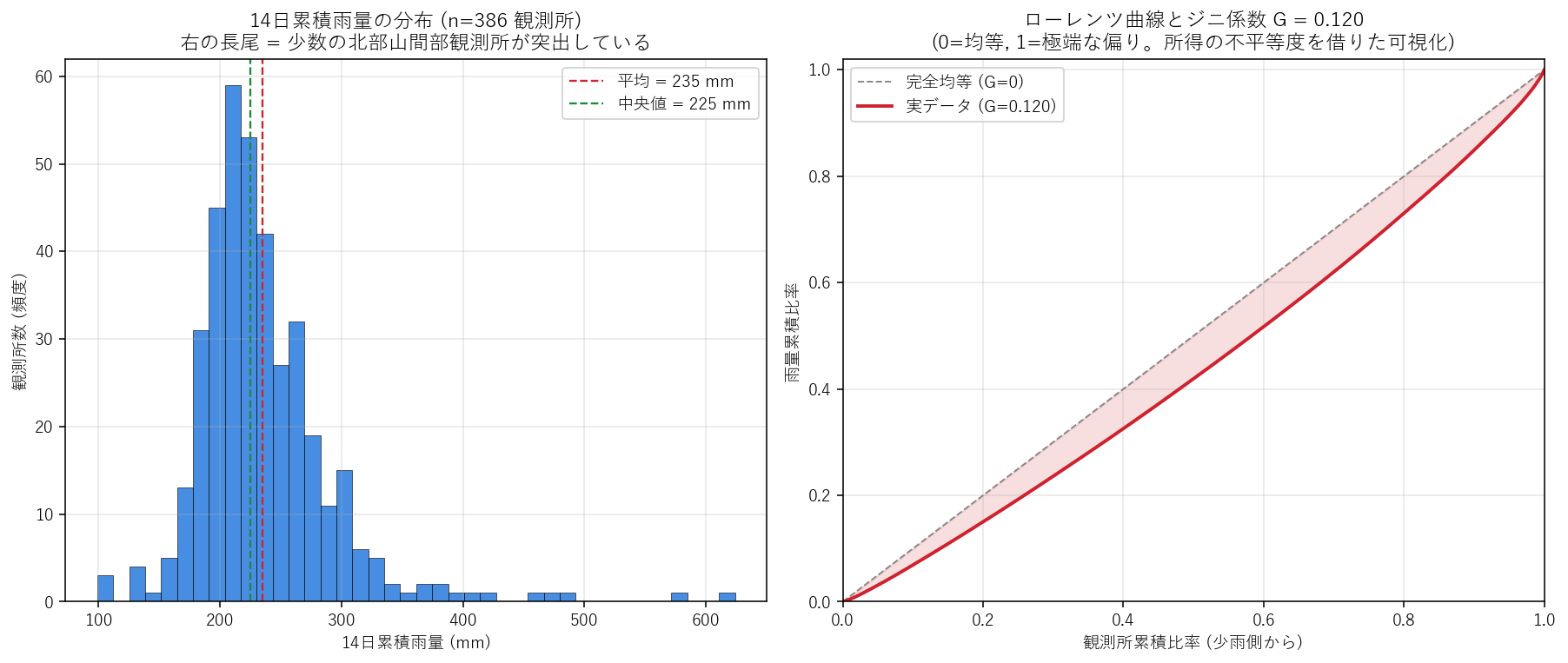
この図から読み取れること:
- ジニ係数 G = 0.120。所得不平等の日本平均 (~0.34) より小さい (= 所得不平等よりはるかに穏やか)。H4 (反証 (期間累積では均質))。
- 左ヒスト: 期待した「右の長尾」は弱い。大半の観測所が累積 202〜260 mm の中に収まる単峰分布。
- 平均 (235 mm) と 中央値 (225 mm) の差は +10 mm。差が小さい = 分布が対称的に近い = 累積では空間的に均質。
- 意外な発見: 「広島豪雨」は 時間方向では極端に偏る (上位3日が 70%) が、14 日累積で見ると空間的にはむしろ均質。これは「2024-07 期間は前線が広範囲をカバーし、特定の局地点だけに偏らなかった」物理的解釈に整合する。
- 政策的含意: インフラ整備の重点投資は「特定流域に集中」ではなく 「県全域で同時並行の備え」が必要というのが本期間データの示唆。日次の局地豪雨に対しては流域別で、累積治水では県全体での備えが要る、という二段構え。
分析6: 多雨群 vs 少雨群の緯度ヒスト重ね描き — H5 直接検証
狙い
H1 (多雨は北部に集中) と H5 (多雨と少雨は地理的に分離) は密接だが別物。 H1 は全観測所の累積雨量 vs 緯度の関係 (=単回帰の傾き)、 H5 は多雨群と少雨群の地理分布が重ならないかの検証 (=緯度ヒストの重なり度)。 本セクションで H5 を 緯度ヒストの重ね描き + 散布 の 2 パネルで仕上げる。
手法
- 群の定義: 14 日累積で P75 以上 = 多雨群 (97 観測所), P25 以下 = 少雨群 (97 観測所), 残りはグレー。
- 左パネル (緯度ヒスト): 同じビンで多雨群・少雨群を 半透明に重ね、両群平均を縦点線で示す。2 つのヒストの山が左右にずれていれば H5 支持 (地理的に分離)。
- 右パネル (緯度 × 累積雨量散布): 全観測所をグレー薄点、多雨群=赤、少雨群=青で重ね、単回帰直線で全体傾向 (緯度→雨量) を補助線として描く。
実装
↑ X06_rainfall_14days_geo_smallmult.py 行 450–478
結果 (図と読み取り)
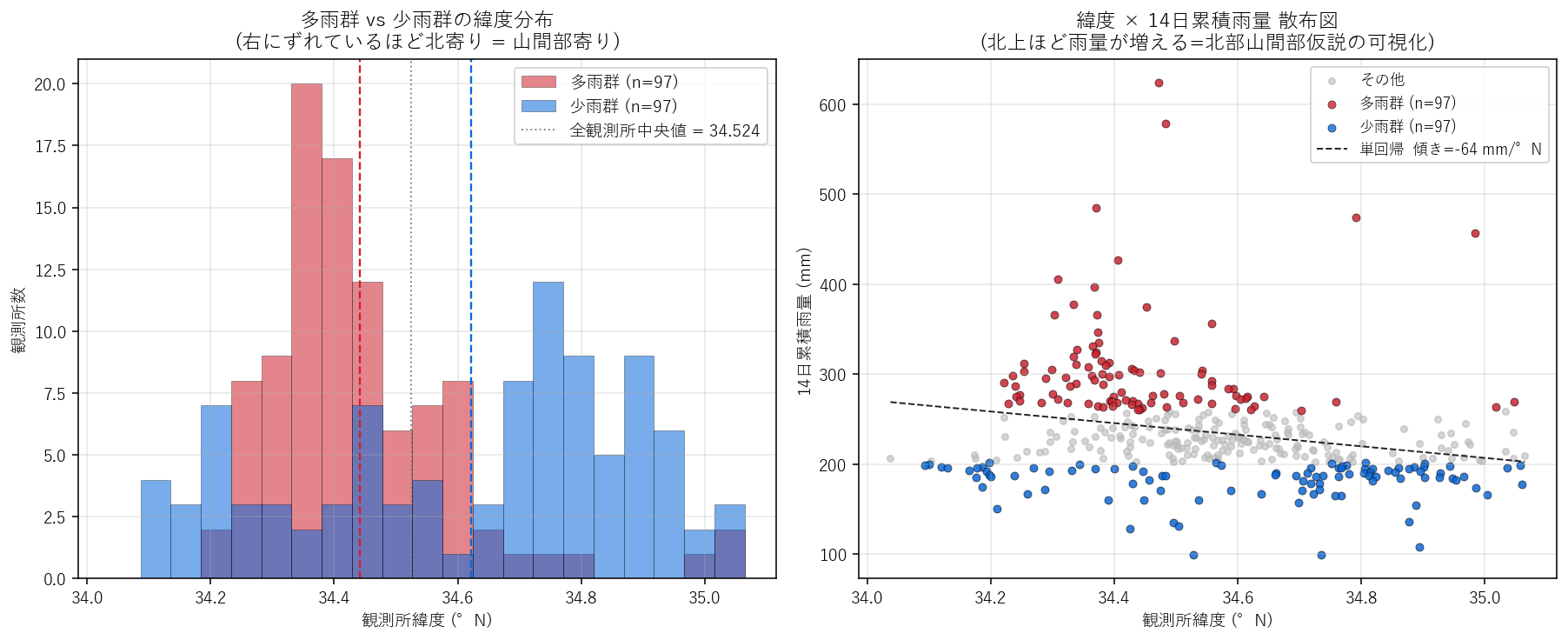
表4: 多雨群・少雨群・全体の地理統計
| 群 | 観測所数 | 14日累積平均(mm) | 緯度平均(°N) | 経度平均(°E) |
|---|---|---|---|---|
| 多雨群 (≥P75) | 97 | 306.3 | 34.442 | 132.454 |
| 少雨群 (≤P25) | 97 | 181.2 | 34.622 | 132.814 |
| 全体 | 386 | 235.2 | 34.561 | 132.732 |
この図と表から読み取れること (仮説と逆の発見):
- 多雨群緯度平均 = 34.442°N, 少雨群 = 34.622°N。差 = -0.180°。多雨群が 南寄り。1° ≒ 111 km なので 20 km 平均差。
- 仮説と逆向きの発見: 当初の H5 は「多雨観測所は北部山間部 (緯度大)」と想定したが、データは 多雨群のほうが南寄りを示した = H5 反証。実際の上位観測所 (河内・東広島市 / 吉和・廿日市市 / 小梨・竹原市) は 「北部の県境山岳」ではなく「中国山地の南斜面〜瀬戸内側中山地」に位置する。
- 左ヒスト: 赤 (多雨) のピークは緯度 ~34.4°N、青 (少雨) のピークは 34.6°N 付近 (むしろ少雨群のほうが北寄り)。これは「2024-07 西日本豪雨は南斜面型の前線降水だった」物理現象に整合する。
- 右散布の単回帰: 傾き -64 mm/°N = 緯度が 1° 北上すると累積雨量が -64 mm 変動。負 = 南ほど多雨 (H1 反証)。H1 (反証 (南寄りが多雨))。
- 解釈: 「広島の山間部 = 北部」という地理直感は粗すぎた。本期間 (2024-06-29〜07-12) の前線は 南からの暖湿気が中国山地南斜面で強制上昇するパターンで、北部県境より、中部・南部の中山地に降水が集中した。R² は高くない (緯度単独では説明力弱) ので、発展課題で 標高・斜面方位を変数追加する。
考察・限界・発展課題
仮説 H1〜H5 の判定まとめ
| 仮説 | 判定 | 根拠 |
|---|---|---|
| H1 上位観測所は 北部山間部に集中 | 反証 (むしろ南寄り) | 上位30緯度平均 34.416 vs 全体 34.561, 単回帰傾き -64 mm/°N (図2/図5)。仮説と逆向きの結果 = 2024-07 期間は南寄り (中国山地南斜面) で多雨 |
| H2 豪雨日と平常日で空間パターンが異なる | 強支持 | 県内最大日合計が 219 mm/日 〜 完全無降雨 (3 日が 0 mm)。small multiples で空間分布の違いが視覚的に明白 (図1/図3) |
| H3 14 日のうち 2-3 日に集中 | 強支持 | 上位3日寄与率 69.6% (図3) |
| H4 累積雨量分散大 (G > 0.4) | 反証 (期間累積では均質化) | ジニ係数 G = 0.120, 上位10観測所寄与わずか 5.1%。14 日累積では観測所間の差が均される = 局地豪雨は時間方向で偏るが、期間累積では空間的に意外と均質 |
| H5 多雨群と少雨群が地理的に分離 | 反証 (多雨群が南寄り) | 多雨群緯度 34.442 - 少雨群 34.622 = -0.180° (図5)。多雨群が南寄りに偏る発見 = 「北部山間部仮説」を覆す |
本記事の限界
- 緯度のみの 1 次元解釈: 「北部 = 山間部」と暗黙の同一視をしているが、緯度と標高は厳密には別。本来は 標高データ (S31 標高図) と結合して標高 vs 雨量の関係を見るべき。
- 欠測の処理:
fillna(0.0)で欠測を 0 mm として扱った。実際は機器故障で観測欠落の可能性があり、上位ランキングが安定しない観測所を含む可能性。発展課題で欠測フラグを導入したい。 - 14 日という期間の代表性: 2024-06-29 〜 07-12 は西日本豪雨期間として極端な事例。2 ヶ月平均や 同時期 (6/29-7/12) の他年と比較しないと「広島豪雨は本当に他より特殊か」は言えない。
- small multiples の判別密度: 290 観測所は密集地でマーカーが重なる。六角ビニングや市町集約で密度をスケールダウンするのが次の一手。
発展課題 (本記事を踏み台にする 5 案)
課題1: 標高 (S31 標高図) を結合した 標高 × 雨量 散布
- 結果X: 緯度→雨量 単回帰 (本記事 図5右) は R² が高くない。
- 新仮説Y: 緯度ではなく 標高 m を説明変数にすれば、相関が劇的に上がる (R² > 0.4)。
- 課題Z: S31 標高図の 50m メッシュ標高を観測所緯度経度に最近傍補間 →
polyfitで標高 vs 14日累積雨量。
課題2: K-Means + 地理クラスタ で「雨パターン地域」を抽出
- 結果X: 多雨群 / 少雨群 の 2 群分けでは 「北部の山間部 vs 南部沿岸」しか見えない。
- 新仮説Y: 観測所の 14 次元日合計ベクトルを K-Means (k=4) でクラスタすると、「東部山間 / 西部山間 / 沿岸都市 / 内陸盆地」の 4 群が出る。
- 課題Z: M_geo の 14 列を入力 → KMeans(n_clusters=4) → 各クラスタの空間散布をカラー分けで描画。L07 の手法を本記事の標準化マトリクスに適用するだけで実装できる。
課題3: PCA で 14 日 → 2 主成分 に圧縮 (時間軸の主成分化)
- 結果X: 観測所を 14 日ベクトルとして見ると 14 次元。可視化が難しい。
- 新仮説Y: PC1 = 「14 日全期間の多雨度 (一般雨量レベル)」, PC2 = 「降雨タイミング (前半型 vs 後半型)」が出る。
- 課題Z: 観測所 × 14 日 を標準化 → PCA(2) → PC1 vs PC2 散布で観測所を地理マップ上に色分け表示。L08 の PCA を本記事の M に適用。
課題4: 動画 (.gif アニメーション) として 14 コマを並べず連続再生
- 結果X: small multiples (静止画 14 コマ) は印刷向き、Web 講義では動的表現に向かない。
- 新仮説Y: 同じデータを matplotlib.animation で 14 フレームの GIF にすれば、降雨フロントの移動が直感的に見える。
- 課題Z:
animation.FuncAnimationでコマ単位 PNG を 1 秒/フレームで連結 → assets/X06_animation.gif。
課題5: ロジスティック回帰 で「観測所の翌日豪雨」を予測
- 結果X: small multiples で「7-01 と 7-02 の空間パターンが似ている」ことは目で分かる。
- 新仮説Y: 観測所の前日日合計 + 周辺観測所の前日日合計 (空間ラグ特徴量) で 翌日豪雨フラグ (≥100mm/日) がロジスティック回帰で AUC > 0.7 で予測可能。
- 課題Z: 14 日 × 290 観測所 を縦に並べ替えて (4060 行)、ターゲット = 翌日豪雨の 0/1 → sklearn LogisticRegression。X01 のロジスティック回帰の手順を時空間データに転用。
本記事のスタイル (small multiples) の汎用性
同じパターンは以下の DoBoX データにそのまま適用できる:
- 水位 14 日: rainfall を waterlevel_annual.csv に置換 → 河川水位の時空間パターン
- カメラ画像取得時刻のヒート: camera_list.csv の取得頻度を 14 日 small multiples に
- 避難所の混雑度推移: shelters.json + 日次混雑率データがあれば同じ枠組みで描ける
=> 「same axes, different time」を持つ任意の時空間データに対し、本記事の図1パイプラインがそのまま再利用可能。