# -*- coding: utf-8 -*-
"""
X05: しまたびライン × 離島避難所カバレッジ — 空間需給バランス研究
================================================================================
DoBoX が公開する観光・防災データセット 3 件:
#1281 瀬戸内海の航路情報 (実データ: data/extras/sea_route.csv 81港)
#1282 瀬戸内しまたびライン利用状況 (DoBoX 限定 — 実 CSV 取得不可)
#42 避難所情報 (実データ: data/shelters.json 4,065件)
これらを使って、瀬戸内海の **離島ごと** に
- 観光客需要 (しまたびライン利用 = 寄港地数で代理)
- 避難所供給 (件数 + 収容力合計)
の **空間需給バランス** を可視化する。
【本記事のスタイル: 空間需給バランス研究】
- **比率指標**「需給ギャップ指数 = 観光ピーク需要 ÷ 避難所収容力」を主役に据え、
- **バブルプロット**(x=避難所件数, y=観光ピーク需要, 半径=ギャップ指数)、
- **ランキング棒グラフ**(島別ギャップ上位)、
- **比率指標マップ**(緯度経度散布で色=ギャップ)、
- 散布図 + 単回帰 + 45° 線 (需要 vs 供給)、
- 階層クラスタ (補助的): 観光重点群 / 防災優先群 / 両立群 の 3 群分類
の 5 図を 10 セクションで展開する。
実行:
cd "2026 DoBoX 教材"
py -X utf8 lessons/X05_island_supply_demand.py
制約:
- ローカル並列 Python 禁止 / メモリ 500 MB 以下
- DoBoX 限定の #1282 は resource_download 無し → 寄港地数で代理
- PCA / 散布図行列 / ロジスティック回帰は **使わない** (本記事のスタイル外)
"""
from __future__ import annotations
import json
import re
import math
import warnings
from pathlib import Path
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.lines import Line2D
from scipy.cluster.hierarchy import linkage, fcluster, dendrogram
from scipy.spatial.distance import pdist
from scipy.stats import linregress
from _common import ROOT, ASSETS, LESSONS, render_lesson, code, figure, data_recipe
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
warnings.filterwarnings("ignore", category=UserWarning)
# === パス定義 =================================================================
SHELTER_JSON = ROOT / "data" / "shelters.json"
ROUTE_CSV = ROOT / "data" / "extras" / "sea_route.csv"
IDX_CSV = ROOT / "data" / "dataset_index.csv"
# 中間 CSV (assets 配下 = HTML から直リンク)
OUT_ISLANDS = ASSETS / "X05_island_metrics.csv" # 島×指標(主表)
OUT_GAP_RANK = ASSETS / "X05_gap_ranking.csv" # ギャップ指数ランキング
OUT_REG = ASSETS / "X05_regression_demand_supply.csv"
OUT_CLUSTER = ASSETS / "X05_cluster_assignments.csv"
OUT_MAP = ASSETS / "X05_island_geocoords.csv" # 島の代表点+ギャップ
OUT_TRACK = ASSETS / "X05_oosakikamijima_track.csv" # 1島の構築過程
# 図 PNG
PNG_BUBBLE = ASSETS / "X05_bubble.png" # 図1: バブルプロット (主役)
PNG_RANKING = ASSETS / "X05_gap_ranking.png" # 図2: ギャップ指数ランキング
PNG_MAP = ASSETS / "X05_map.png" # 図3: 緯度経度マップ (色=ギャップ)
PNG_REG = ASSETS / "X05_demand_vs_supply.png" # 図4: 散布+回帰+45°線
PNG_DENDRO = ASSETS / "X05_dendrogram.png" # 図5: 補助的 階層クラスタ
# === 島の定義 ================================================================
# 瀬戸内海に浮かぶ広島県の主要離島。
# 市町境とは一致しないため、住所文字列マッチで島ごとに集計する。
# (市町ごとに集計すると、江田島市は本島+能美島+沖美島+大柿島が混ざってしまう)
ISLAND_DEF = [
# (島名, 住所キーワードリスト, 代表座標 (lat, lon))
("大崎上島", ["大崎上島町"], (34.265, 132.910)),
("江田島本島", ["江田島市江田島町"], (34.230, 132.460)),
("能美・沖美", ["江田島市能美町", "江田島市沖美町", "江田島市大柿町"],
(34.180, 132.420)),
("宮島", ["廿日市市宮島町"], (34.295, 132.320)),
("似島", ["広島市南区似島町"], (34.310, 132.440)),
("因島", ["尾道市因島"], (34.305, 133.180)),
("向島", ["尾道市向島町"], (34.380, 133.200)),
("生口島", ["尾道市瀬戸田町"], (34.295, 133.080)),
("佐木島", ["三原市鷺浦町"], (34.350, 133.060)),
("百島", ["尾道市百島町"], (34.370, 133.300)),
("倉橋島", ["呉市倉橋町", "呉市音戸町"], (34.140, 132.520)),
("阿多田島", ["大竹市阿多田"], (34.200, 132.260)),
("豊島", ["呉市豊浜町"], (34.180, 132.860)),
("上蒲刈・下蒲刈", ["呉市蒲刈町", "呉市下蒲刈町"], (34.180, 132.700)),
("斎島", ["呉市豊浜町大字斎島"], (34.150, 132.860)),
]
ISLAND_NAMES = [name for name, _, _ in ISLAND_DEF]
print("=" * 60)
print(" X05 しまたびライン × 離島避難所カバレッジ")
print(" 空間需給バランス研究")
print("=" * 60)
# === STEP 1: 避難所データ読込 ================================================
print("\n=== STEP 1: 避難所データ (shelters.json #42) ===")
with open(SHELTER_JSON, encoding="utf-8") as f:
shelter_raw = json.load(f)
sdf = pd.DataFrame(shelter_raw["items"])
sdf["address01"] = sdf["address01"].astype(str)
sdf["address02"] = sdf["address02"].astype(str)
sdf["name"] = sdf["name"].astype(str)
sdf["fulladdr"] = sdf["address01"] + " " + sdf["address02"] + " " + sdf["name"]
sdf["latitude"] = pd.to_numeric(sdf["latitude"], errors="coerce")
sdf["longitude"] = pd.to_numeric(sdf["longitude"], errors="coerce")
sdf["capacity"] = pd.to_numeric(sdf["capacity"], errors="coerce").fillna(0.0)
print(f" 避難所件数: {len(sdf)} (capacity 取得 {(sdf['capacity']>0).sum()} 件)")
# === STEP 2: 航路データ読込 ===================================================
print("\n=== STEP 2: 航路データ (sea_route.csv #1281) ===")
route = pd.read_csv(ROUTE_CSV, encoding="utf-8-sig")
route["住所"] = route["住所"].astype(str)
route["寄港地"] = route["寄港地"].astype(str)
print(f" 寄港地件数: {len(route)} (うち広島県: "
f"{route['住所'].str.startswith('広島県').sum()})")
# === STEP 3: カタログメタ (#1282 しまたびライン) =============================
print("\n=== STEP 3: カタログメタ (dataset_index.csv) ===")
idx = pd.read_csv(IDX_CSV, encoding="utf-8-sig")
TARGETS = [42, 1281, 1282]
catalog_meta = idx[idx["Id"].isin(TARGETS)].copy()
print(catalog_meta.to_string(index=False))
# === STEP 4: 島ごとに需要・供給を集計 ========================================
print("\n=== STEP 4: 島別 需要 (寄港地数) と 供給 (避難所件数+収容力) ===")
records = []
for name, kws, (lat0, lon0) in ISLAND_DEF:
# 避難所マッチ
s_mask = pd.Series(False, index=sdf.index)
for kw in kws:
s_mask |= sdf["fulladdr"].str.contains(kw, na=False)
s_island = sdf[s_mask]
n_shelters = len(s_island)
cap_sum = float(s_island["capacity"].sum())
# 避難所平均緯度経度 (代表点として使う)
lats = s_island["latitude"].dropna()
lons = s_island["longitude"].dropna()
if len(lats) >= 3:
rep_lat = float(lats.median())
rep_lon = float(lons.median())
else:
rep_lat, rep_lon = lat0, lon0
# 寄港地マッチ (航路本数 = しまたびライン利用の代理指標)
r_mask = pd.Series(False, index=route.index)
for kw in kws:
r_mask |= route["住所"].str.contains(kw, na=False)
# 寄港地名にも島名キーワードがあれば拾う (一部、住所が市役所所在地で
# 寄港地名のほうに島名が入っている例)
for short in [kw.replace("町", "")]:
r_mask |= route["寄港地"].str.contains(short, na=False)
n_ports = int(r_mask.sum())
records.append({
"island": name,
"n_shelters": n_shelters,
"capacity": cap_sum,
"n_ports": n_ports,
"rep_lat": rep_lat,
"rep_lon": rep_lon,
})
M = pd.DataFrame(records)
# 需要指標: 観光ピーク需要 = 寄港地数 × 1 日あたり想定来島者数 (50 人/港 と仮定)
# - #1282 (しまたびライン) は実 CSV が手に入らないので、
# 港 1 つあたり「ピーク日 50 人」という単純な定数で代理。
# 学習者は本記事の「ピーク需要 = n_ports × 50」を別の値に置き換えて
# 再計算できる。仮定は明示する。
PEAK_PER_PORT = 50
M["peak_demand"] = M["n_ports"] * PEAK_PER_PORT
# 需給ギャップ指数 = 観光ピーク需要 ÷ 避難所収容力 (capacity == 0 は inf を避けて NaN)
M["gap_index"] = np.where(
M["capacity"] > 0,
M["peak_demand"] / M["capacity"],
np.nan,
)
M["gap_index"] = M["gap_index"].fillna(M["gap_index"].max() * 1.2) # capなし島は最悪値
print("\n 島別 集計結果:")
print(M.to_string(index=False))
M.to_csv(OUT_ISLANDS, index=False, encoding="utf-8-sig")
print(f"\n → {OUT_ISLANDS.name}")
# === STEP 5: ギャップ指数ランキング ==========================================
print("\n=== STEP 5: 需給ギャップ指数ランキング ===")
rank = M.sort_values("gap_index", ascending=False).reset_index(drop=True)
rank["rank"] = np.arange(1, len(rank) + 1)
rank.to_csv(OUT_GAP_RANK, index=False, encoding="utf-8-sig")
print(rank[["rank", "island", "n_ports", "peak_demand",
"n_shelters", "capacity", "gap_index"]].to_string(index=False))
# === STEP 6: バブルプロット (図1: 主役) ======================================
print("\n=== STEP 6: バブルプロット ===")
fig, ax = plt.subplots(figsize=(11.5, 7.0))
# 半径 = ギャップ指数 (大きいほど不足)、色 = 供給 (capacity)
sizes = (M["gap_index"].values / max(M["gap_index"].max(), 1e-6)) * 1500 + 60
sc = ax.scatter(
M["n_shelters"], M["peak_demand"],
s=sizes,
c=M["capacity"],
cmap="viridis",
alpha=0.78,
edgecolor="black", linewidth=0.8,
)
for _, row in M.iterrows():
ax.annotate(
row["island"],
(row["n_shelters"], row["peak_demand"]),
xytext=(7, 5), textcoords="offset points",
fontsize=9.5, color="#222",
)
cbar = fig.colorbar(sc, ax=ax, fraction=0.04, pad=0.03)
cbar.set_label("供給 = 避難所収容力合計 (人)", fontsize=10)
ax.set_xlabel("供給 = 避難所件数 (件)", fontsize=11)
ax.set_ylabel(f"需要 = 観光ピーク需要 = 寄港地数 × {PEAK_PER_PORT} (人/日)",
fontsize=11)
ax.set_title(
f"図1: 離島の需給バブルプロット — 半径 = 需給ギャップ指数 "
f"(需要 ÷ 収容力)\n"
f"右上 = 需要も供給も大の島, 左下 = 両方少ない島, 大きい泡 = 不足度大",
fontsize=12, pad=12,
)
ax.grid(alpha=0.3)
# 凡例: バブル半径の意味
legend_sizes = [0.5, 1.0, 2.0]
legend_handles = []
for ls in legend_sizes:
legend_handles.append(
Line2D([], [], marker="o", linestyle="None",
markerfacecolor="#bbb", markeredgecolor="black",
markersize=math.sqrt(ls / max(M["gap_index"].max(), 1e-6) * 1500 + 60),
label=f"ギャップ {ls:.1f}")
)
ax.legend(handles=legend_handles, title="バブル半径", loc="upper left",
fontsize=9, title_fontsize=9)
plt.tight_layout()
plt.savefig(PNG_BUBBLE, dpi=140, bbox_inches="tight")
plt.close()
print(f" → {PNG_BUBBLE.name}")
# === STEP 7: ランキング棒グラフ (図2) ========================================
print("\n=== STEP 7: ランキング棒グラフ ===")
fig, ax = plt.subplots(figsize=(11.0, 7.0))
top = rank.head(15)
ypos = np.arange(len(top))[::-1]
bars = ax.barh(ypos, top["gap_index"].values,
color="#cf222e", alpha=0.82, edgecolor="black")
ax.set_yticks(ypos)
ax.set_yticklabels(top["island"].tolist())
ax.set_xlabel("需給ギャップ指数 = 観光ピーク需要 ÷ 避難所収容力", fontsize=11)
ax.set_title(
f"図2: 島別 需給ギャップ指数ランキング (上位 {len(top)})\n"
f"値が大きい = ピーク時に避難所が不足 = 防災弱者島",
fontsize=12, pad=10,
)
# 各バーに数値を書く
for b, v, np_ in zip(bars, top["gap_index"].values, top["n_ports"].values):
ax.text(v + 0.02, b.get_y() + b.get_height() / 2,
f"{v:.2f} (港数 {np_})",
va="center", fontsize=9)
ax.axvline(1.0, color="#0969da", linestyle="--", linewidth=1.2,
label="境界線 = 1.0\n(これより右は需要 > 供給)")
ax.legend(loc="lower right", fontsize=9.5)
ax.grid(axis="x", alpha=0.3)
plt.tight_layout()
plt.savefig(PNG_RANKING, dpi=140, bbox_inches="tight")
plt.close()
print(f" → {PNG_RANKING.name}")
# === STEP 8: 比率指標マップ (図3) ============================================
print("\n=== STEP 8: 緯度経度マップ (色 = ギャップ指数) ===")
geo_df = M[["island", "rep_lat", "rep_lon", "gap_index",
"peak_demand", "capacity"]].copy()
geo_df.to_csv(OUT_MAP, index=False, encoding="utf-8-sig")
fig, ax = plt.subplots(figsize=(11.0, 7.0))
sc = ax.scatter(
geo_df["rep_lon"], geo_df["rep_lat"],
c=geo_df["gap_index"],
s=140 + geo_df["peak_demand"] / 5,
cmap="RdYlGn_r",
edgecolor="black", linewidth=0.8,
alpha=0.88,
)
for _, row in geo_df.iterrows():
ax.annotate(
row["island"],
(row["rep_lon"], row["rep_lat"]),
xytext=(7, 5), textcoords="offset points",
fontsize=9.5, color="#222",
)
cbar = fig.colorbar(sc, ax=ax, fraction=0.04, pad=0.03)
cbar.set_label("需給ギャップ指数 (赤=不足, 緑=余裕)", fontsize=10)
ax.set_xlabel("経度 (E)", fontsize=11)
ax.set_ylabel("緯度 (N)", fontsize=11)
ax.set_title(
"図3: 離島の地理的需給ギャップ — 色 = ギャップ指数, 半径 = 需要\n"
"西部 (江田島・宮島) と 東部 (尾道・三原) で需給構造が分かれる",
fontsize=12, pad=10,
)
ax.grid(alpha=0.3)
plt.tight_layout()
plt.savefig(PNG_MAP, dpi=140, bbox_inches="tight")
plt.close()
print(f" → {PNG_MAP.name}")
# === STEP 9: 散布図 + 単回帰 + 45° 線 (図4) ==================================
print("\n=== STEP 9: 散布図 — 需要 vs 供給 + 単回帰 + 45° 線 ===")
x = M["capacity"].values.astype(float)
y = M["peak_demand"].values.astype(float)
slope, intercept, r, p, _ = linregress(x, y)
r2 = r * r
reg_df = pd.DataFrame([{
"x": "capacity (供給)",
"y": "peak_demand (需要)",
"n": len(M),
"slope": slope,
"intercept": intercept,
"r": r,
"R2": r2,
"p_value": p,
}])
reg_df.to_csv(OUT_REG, index=False, encoding="utf-8-sig")
print(reg_df.to_string(index=False))
fig, ax = plt.subplots(figsize=(10.0, 7.0))
ax.scatter(x, y, s=170, c="#0969da", alpha=0.78,
edgecolor="black", linewidth=0.8)
for _, row in M.iterrows():
ax.annotate(
row["island"],
(row["capacity"], row["peak_demand"]),
xytext=(7, 5), textcoords="offset points", fontsize=9.5,
)
xx = np.linspace(0, x.max() * 1.05, 50)
ax.plot(xx, slope * xx + intercept,
color="#cf222e", linewidth=1.6,
label=f"単回帰: y = {slope:.3f}x + {intercept:.0f}\n R² = {r2:.3f}")
# 45° 線 (= 需要と供給が同水準)
mx = max(x.max(), y.max()) * 1.05
ax.plot([0, mx], [0, mx], color="#666", linestyle="--", linewidth=1.0,
label="45° 線 (需要 = 供給)")
ax.set_xlabel("供給 = 避難所収容力合計 (人)", fontsize=11)
ax.set_ylabel("需要 = 観光ピーク需要 (人)", fontsize=11)
ax.set_title(
"図4: 需要 vs 供給 散布図 + 単回帰 + 45° 線\n"
"45° 線より上 = ピーク需要 > 供給 (= 不足島)",
fontsize=12, pad=10,
)
ax.legend(fontsize=10, loc="upper left")
ax.grid(alpha=0.3)
ax.set_xlim(0, mx * 0.5) # capacityのスケールが大きいので片方だけクロップ
ax.set_ylim(0, max(y.max() * 1.1, 100))
plt.tight_layout()
plt.savefig(PNG_REG, dpi=140, bbox_inches="tight")
plt.close()
print(f" → {PNG_REG.name}")
# === STEP 10: 階層クラスタ (補助的、図5) =====================================
print("\n=== STEP 10: 階層クラスタ (補助) — 観光重点/防災優先/両立 の 3 群 ===")
# 標準化した (n_ports, capacity, gap_index) で群分け
F = M[["n_ports", "capacity", "gap_index"]].values.astype(float)
F_std = (F - F.mean(axis=0)) / (F.std(axis=0, ddof=0) + 1e-9)
dist = pdist(F_std, metric="euclidean")
Zlink = linkage(dist, method="ward")
labels3 = fcluster(Zlink, t=3, criterion="maxclust")
cluster_df = M[["island", "n_ports", "n_shelters", "capacity",
"peak_demand", "gap_index"]].copy()
cluster_df["cluster3"] = labels3
# 各クラスタの平均値で「観光重点」「防災優先」「両立」のラベルを付ける
center3 = cluster_df.groupby("cluster3")[
["n_ports", "capacity", "gap_index"]
].mean()
print("\n クラスタ中心:")
print(center3.round(2).to_string())
# ラベル付け: 平均ギャップ最大 = 観光重点 (需要過多), 平均capacity最大 = 防災優先,
# 残り = 両立
gap_rank = center3["gap_index"].rank(ascending=False)
cap_rank = center3["capacity"].rank(ascending=False)
ports_rank = center3["n_ports"].rank(ascending=False)
cluster_label = {}
top_gap = int(center3["gap_index"].idxmax())
top_cap = int(center3["capacity"].idxmax())
remaining = [c for c in center3.index if c not in (top_gap, top_cap)]
cluster_label[top_gap] = "観光重点 (需要過多)"
cluster_label[top_cap] = "防災優先 (供給充実)"
for c in remaining:
cluster_label[c] = "両立 (中庸)"
cluster_df["cluster_label"] = cluster_df["cluster3"].map(cluster_label)
cluster_df.to_csv(OUT_CLUSTER, index=False, encoding="utf-8-sig")
print("\n 島→クラスタ:")
print(cluster_df[["island", "cluster3", "cluster_label",
"n_ports", "capacity", "gap_index"]].to_string(index=False))
# 図5: デンドログラム
fig, ax = plt.subplots(figsize=(12.0, 5.6))
dendrogram(
Zlink,
labels=M["island"].tolist(),
color_threshold=Zlink[-2, 2] - 0.01,
leaf_font_size=10,
ax=ax,
)
ax.set_title(
f"図5: 階層クラスタ (Ward 法) — {len(M)} 島 × 3 指標 (港数, 収容力, ギャップ)\n"
f"3 群境界 (赤線, 距離 {Zlink[-2, 2]:.2f}) で「観光重点 / 防災優先 / 両立」",
fontsize=12, pad=10,
)
ax.axhline(Zlink[-2, 2] - 0.01, color="#cf222e", linestyle="--", linewidth=1.2)
ax.set_ylabel("Ward 距離 (= 群内平方和の増分)")
plt.tight_layout()
plt.savefig(PNG_DENDRO, dpi=140, bbox_inches="tight")
plt.close()
print(f" → {PNG_DENDRO.name}")
# === STEP 11: 1 島追跡 (要件K, 大崎上島) =====================================
print("\n=== STEP 11: 1 島追跡 (要件K) — 大崎上島の指標構築過程 ===")
ex_island = "大崎上島"
ex_row = M[M["island"] == ex_island].iloc[0]
ex_cluster = int(cluster_df[cluster_df["island"] == ex_island]["cluster3"].iloc[0])
ex_label = cluster_label[ex_cluster]
track_records = [
("1. 住所マッチで避難所を抽出",
f"{ex_island}町 を含む住所の避難所 = {int(ex_row['n_shelters'])} 件",
f"{int(ex_row['n_shelters'])} 行 (避難所 1 件 = 1 行)"),
("2. capacity 列を合計",
f"avg ≈ {ex_row['capacity']/max(ex_row['n_shelters'],1):.0f} 人/件 → "
f"合計 {int(ex_row['capacity'])} 人",
"スカラー 1 個"),
("3. 寄港地マッチで港数を数える",
f"sea_route.csv で {ex_island} を含む住所/港名 = {int(ex_row['n_ports'])} 港",
"スカラー 1 個"),
("4. ピーク需要を組み立て",
f"port × {PEAK_PER_PORT} = {int(ex_row['peak_demand'])} 人/日",
"スカラー 1 個"),
("5. 需給ギャップ指数を算出",
f"{int(ex_row['peak_demand'])} ÷ {int(ex_row['capacity'])} = "
f"{ex_row['gap_index']:.3f}",
"スカラー 1 個 (本記事の主役)"),
("6. クラスタに割り当て",
f"標準化 → Ward 距離計算 → 3 群分割 → クラスタ {ex_cluster} ({ex_label})",
"整数 1 個"),
]
track_df = pd.DataFrame(track_records, columns=["段階", "値・処理", "サイズ"])
track_df.to_csv(OUT_TRACK, index=False, encoding="utf-8-sig")
print(track_df.to_string(index=False))
# === STEP 12: HTML 組み立て ==================================================
print("\n=== STEP 12: HTML 組み立て ===")
# よく使う HTML 断片
M_disp = M.assign(
capacity=M["capacity"].astype(int),
peak_demand=M["peak_demand"].astype(int),
gap_index=M["gap_index"].round(3),
rep_lat=M["rep_lat"].round(3),
rep_lon=M["rep_lon"].round(3),
)
islands_html = M_disp.to_html(index=False, border=0)
rank_disp = rank.assign(
capacity=rank["capacity"].astype(int),
peak_demand=rank["peak_demand"].astype(int),
gap_index=rank["gap_index"].round(3),
).head(15)
ranking_html = rank_disp[
["rank", "island", "n_ports", "peak_demand",
"n_shelters", "capacity", "gap_index"]
].to_html(index=False, border=0)
reg_html = reg_df.assign(
slope=reg_df["slope"].round(3),
intercept=reg_df["intercept"].round(2),
r=reg_df["r"].round(3),
R2=reg_df["R2"].round(3),
p_value=reg_df["p_value"].round(4),
).to_html(index=False, border=0)
cluster_html = cluster_df.assign(
capacity=cluster_df["capacity"].astype(int),
peak_demand=cluster_df["peak_demand"].astype(int),
gap_index=cluster_df["gap_index"].round(3),
).to_html(index=False, border=0)
center3_html = center3.assign(
n_ports=center3["n_ports"].round(2),
capacity=center3["capacity"].round(0).astype(int),
gap_index=center3["gap_index"].round(3),
).to_html(border=0)
catalog_html = catalog_meta.rename(columns={
"Id": "DoBoX ID", "Title": "タイトル", "Desc": "説明文"
}).to_html(index=False, border=0)
track_html = track_df.to_html(index=False, border=0)
# 計算しておく集計値
total_islands = len(M)
total_shelters = int(M["n_shelters"].sum())
total_capacity = int(M["capacity"].sum())
total_ports = int(M["n_ports"].sum())
n_above1 = int((M["gap_index"] > 1.0).sum())
n_below1 = int((M["gap_index"] <= 1.0).sum())
worst = rank.iloc[0]
best = rank.iloc[-1]
sections = []
# === セクション 1: 学習目標と問い ============================================
sections.append(("学習目標と問い", f"""
【本記事のスタイル: 空間需給バランス研究】
比率指標とバブルプロットで島の需給ギャップを可視化する。
散布図行列・PCA は使わず、「観光客需要 ÷ 避難所収容力」の比率を主役に据え、
バブルプロット・ランキング棒・比率マップで島ごとの不足度を一目で読めるようにする。
本レッスンは、瀬戸内海に浮かぶ広島県の {total_islands} 離島について、
観光客需要 (#1282 しまたびライン利用 = 寄港地数で代理) と
避難所供給 (#42 避難所件数 + 収容力合計) の 空間需給バランスを
可視化する。「島ごとの観光ピーク需要に対して避難所収容力は十分か」という問いに、
1 つの比率指標「需給ギャップ指数 = 観光ピーク需要 ÷ 避難所収容力」を
答えとして据える。
このレッスンで答えたい問い (1 文)
「観光航路 (しまたびライン) の利用増加に対して、各島の避難所収容力は
ピーク時の需要を支えきれるのか? 防災弱者島はどこか?」
立てた仮説 (H1〜H4 — 空間需給特化)
- H1: 離島の観光客需要 (=寄港地数 × 想定来島者) は 避難所件数に比例しない (観光地化偏在)
- H2: 観光客が多い島は避難所収容力も大きい (正の相関 r > 0.4) が、ピーク時には不足 (45° 線より上)
- H3: 需給ギャップ指数 = 需要 ÷ 収容力 のランキング上位 5 島は防災弱者島であり、観光地化が進む島が含まれる
- H4: 離島は本土との 航路接続度 (寄港地数) と需給ギャップに強い関連 (= 接続が多い島ほど需要が膨らむ)
用語の独自定義 (このレッスン専用)
- 「離島」: 本記事では shelters.json の住所文字列から島嶼地区を特定した広島県の主要 {total_islands} 島: {", ".join(ISLAND_NAMES)}。市町境ではなく 島ごとに集計する (江田島市は本島と能美島に分けて見たい)。
- 「観光客需要 (peak_demand)」: 真のしまたびライン利用客数は DoBoX の resource_download が公開されていないため、寄港地数 × {PEAK_PER_PORT} 人/日 (定数)で代理する。学習者は定数を別の値に置き換えて再計算可能 (発展課題で扱う)。
- 「避難所供給」: 件数 (n_shelters) と収容力合計 (capacity, 人) の 2 軸。本記事の主軸は 収容力合計 (人数で需要と直接比較できるため)。
- 「需給ギャップ指数 (gap_index)」: 観光ピーク需要 ÷ 避難所収容力。1.0 を超えると ピーク時に避難所が足りない。本記事の主役指標。
- 「バブルプロット」: 散布図の各点を 大きさ (= 第 3 の数値) と 色 (= 第 4 の数値) で 4 次元に拡張した図。x = 避難所件数, y = 観光ピーク需要, 半径 = ギャップ指数, 色 = 収容力合計。1 枚で 4 軸分を読める。
- 「観光重点 / 防災優先 / 両立」: 3 つの指標 (港数, 収容力, ギャップ) を標準化した 3 次元ベクトルで Ward 法クラスタを計算し、3 群に分けたラベル。観光重点 = ギャップが大きい群、防災優先 = 収容力が大きい群、両立 = 中庸の群。
到達点
{total_islands} 離島を 1 つの比率指標 (gap_index) で順位付けし、
バブル・ランキング・地理マップ・散布回帰の 4 視点で需給アンバランスを読み取る。
学習者は「比率指標を主役にする研究」「バブルプロットで 4 軸を 1 枚に詰め込む」
「45° 線で需給を等値比較する」「Ward 法で島を 3 群に分けて防災タイプを言語化する」
の 4 つを身につける。
データ実態の重要事項:
DoBoX の #1282 瀬戸内しまたびライン利用状況は resource_download リンクが
公開されておらず、CSV を取得できない (S57 で確認済み)。そのため本記事は 寄港地数 × 50 人/日
という単純な代理指標を需要として用いる。仮定は明示し、学習者が定数を変えて
再計算できるようコードを設計してある (要件C, 再現性)。
"""))
# === セクション 2: 使用データ ================================================
sections.append(("使用データ", f"""
本レッスンは DoBoX オープンデータ {len(catalog_meta)} 件から派生する:
{catalog_html}
サイズの整理 (要件L: 表示と次元の混同を防ぐ):
| 段 | 行数 | 列数 | 説明 |
|---|
| 原データ shelters.json | {len(sdf):,} 件 | 36 列 | 避難所 1 件 = 1 行 (capacity, lat, lon を含む) |
| 原データ sea_route.csv | {len(route)} 件 | 6 列 | 寄港地 1 件 = 1 行 |
| 島定義テーブル ISLAND_DEF | {total_islands} 行 | 3 列 | (島名, 住所キーワード, 代表座標) を本記事で人手定義 |
| 本記事の指標行列 M | {total_islands} 島 | 6 指標 | 島 1 件 = 1 行, 列 = n_shelters / capacity / n_ports / peak_demand / gap_index / 代表座標 |
| ランキング表 rank | {total_islands} | 7 | gap_index 降順に並び替えただけ |
| クラスタ標準化行列 F_std | {total_islands} | 3 | (n_ports, capacity, gap_index) を平均0・分散1 に揃えたもの (Ward 法の入力) |
※ 本記事は 「島 = 1 行」の表 1 つを最後まで保持する。市町ごとや避難所ごとに集計を切り替えるのは 同じ表の groupby を変えるのと等価で、本記事では 島に固定して読みやすさを優先する。
島の同定ロジック:
- 避難所側:
shelters.json の address01 + address02 + name 連結文字列に島の住所キーワード (例: 「大崎上島町」) が含まれていれば、その島の避難所と判定。
- 港湾側:
sea_route.csv の 住所列または 寄港地列に同キーワードが含まれていれば、その島の寄港地と判定。
- 市町境とは一致しない: 江田島市は江田島本島 + 能美島 + 沖美島 + 大柿島 から成るので、本記事では江田島本島 (江田島町) と 能美・沖美 (能美町・沖美町・大柿町) の 2 グループに分ける。
"""))
# === セクション 3: ダウンロード ==============================================
sections.append(("ダウンロード (再現用データ・中間データ・図)", f"""
原データ (DoBoX)
{data_recipe([
{"label": "避難所情報",
"dataset_id": 42, "file": "data/shelters.json",
"format": "JSON", "size": f"{len(sdf):,}件"},
{"label": "瀬戸内海の航路情報",
"dataset_id": 1281, "file": "data/extras/sea_route.csv",
"format": "CSV", "size": f"{len(route)}件"},
{"label": "DoBoX カタログ全件 index",
"dataset_id": 0, "file": "data/dataset_index.csv",
"format": "CSV", "size": f"{len(idx)}件"},
])}
非公開データ:
#1282 瀬戸内しまたびライン利用状況 は DoBoX の resource_download リンクが
公開されておらず、data/extras/ に CSV を置けない。本記事ではカタログメタ +
寄港地数 × 定数で代理する。
本レッスン生成の中間 CSV (HTML から直 DL)
図 PNG (HTML から直 DL)
再現スクリプト
X05_island_supply_demand.py を以下で実行:
cd "2026 DoBoX 教材"
py -X utf8 lessons/X05_island_supply_demand.py
"""))
# === セクション 4: 分析1 — 島ごとの需要・供給を集計 (要件K) ==================
sections.append(("分析1: 島ごとに需要・供給を集計する (要件K: 1 島の構築過程)",
f"""
狙い
{total_islands} の離島それぞれについて、3 つの数値を集計する:
- n_shelters: 避難所の件数 (件)
- capacity: 避難所収容力の合計 (人)
- n_ports: 寄港地の数 (港) ← しまたびライン利用の代理
これらを出発点に、peak_demand (=観光ピーク需要) と本記事の主役
gap_index (=需給ギャップ指数) を構築する。
手法
- 島の同定辞書を人手定義: 市町境では島が混ざるので、住所文字列キーワードで島を特定する辞書 ISLAND_DEF を用意 ({total_islands} 島)。
- 避難所マッチ: 各島について、shelters.json の
address01+address02+name 連結文字列にキーワードを含む行を取り出して件数・capacity 合計を計算。
- 寄港地マッチ: 各島について、sea_route.csv の
住所+寄港地にキーワードを含む行を取り出して港数を集計。
- ピーク需要を組み立て: peak_demand = n_ports × {PEAK_PER_PORT} (=港 1 つあたりピーク日想定来島者 50 人と仮定)。
- 需給ギャップ指数を計算: gap_index = peak_demand ÷ capacity。capacity = 0 の島は最大値で代用。
実装
""" + code(r'''
import json, pandas as pd, numpy as np
# 島の定義 (住所キーワード) — 市町境では島が混ざるため、人手で島ごとに特定
ISLAND_DEF = [
("大崎上島", ["大崎上島町"]),
("江田島本島", ["江田島市江田島町"]),
("能美・沖美", ["江田島市能美町","江田島市沖美町","江田島市大柿町"]),
("宮島", ["廿日市市宮島町"]),
# ... (全 15 島)
]
PEAK_PER_PORT = 50 # ピーク日 1 港あたり想定来島者 (仮定: 学習者が変更可能)
# 1) 避難所読込
sdf = pd.DataFrame(json.load(open("data/shelters.json", encoding="utf-8"))["items"])
sdf["fulladdr"] = (sdf["address01"].astype(str)
+ " " + sdf["address02"].astype(str)
+ " " + sdf["name"].astype(str))
sdf["capacity"] = pd.to_numeric(sdf["capacity"], errors="coerce").fillna(0.0)
# 2) 航路読込
route = pd.read_csv("data/extras/sea_route.csv", encoding="utf-8-sig")
route["住所"] = route["住所"].astype(str)
route["寄港地"] = route["寄港地"].astype(str)
# 3) 島ごとに集計
records = []
for name, kws in ISLAND_DEF:
sm = pd.Series(False, index=sdf.index)
rm = pd.Series(False, index=route.index)
for kw in kws:
sm |= sdf["fulladdr"].str.contains(kw, na=False)
rm |= route["住所"].str.contains(kw, na=False)
rm |= route["寄港地"].str.contains(kw.replace("町",""), na=False)
records.append({
"island": name,
"n_shelters": int(sm.sum()),
"capacity": float(sdf.loc[sm, "capacity"].sum()),
"n_ports": int(rm.sum()),
})
M = pd.DataFrame(records)
M["peak_demand"] = M["n_ports"] * PEAK_PER_PORT
M["gap_index"] = np.where(M["capacity"]>0,
M["peak_demand"]/M["capacity"],
np.nan)
M["gap_index"] = M["gap_index"].fillna(M["gap_index"].max()*1.2)
''') + f"""
結果 (表と読み取り)
なぜこの表か: {total_islands} 島を一望するには、図の前にまず 具体的な数値を
確認するのが定石。需要 (peak_demand) と供給 (capacity) を 1 行に並べると、
学習者が手で「ギャップ = 需要 ÷ 供給」を再計算できる。
表1: 島別 集計結果 (M, {total_islands} 行 × 6 列)
{islands_html}
この表から読み取れること:
- {worst['island']} がギャップ {worst['gap_index']:.3f} で最大 (寄港地 {int(worst['n_ports'])} 港 × {PEAK_PER_PORT} = 需要 {int(worst['peak_demand'])} 人 ÷ 収容力 {int(worst['capacity'])} 人)。
- 因島は収容力 {int(M[M['island']=='因島']['capacity'].iloc[0]):,} 人と突出 (尾道市の島で人口集中、避難所も大規模高校・体育館を含む)。
- 収容力 0 の島は capacity が取得できなかった避難所のみで構成 (本記事ではギャップ最大値で埋めた)。
- 港数 0 の島もあり ({(M['n_ports']==0).sum()} 島) — 上蒲刈・下蒲刈は橋で本土に直結しているため航路経由の来島者が少ない。
1 島追跡: 大崎上島の指標が組み上がるまで (要件K: Before/After)
分析全体で大崎上島 1 島を追いかけると、3 つの数値 → ピーク需要 → ギャップ指数 → クラスタ
の流れが具体的に見える。下表は 同じ 1 島が各段階でどんな数値になるかを段階別に並べたもの:
{track_html}
この表から読み取れること:
- 67 行 (避難所) → 1 つのスカラー (capacity 合計) という縮約が起きている。
- 港数も 10 行を 1 つのスカラーに縮約。
- 最後に 2 つのスカラーの比率 1 つで島が要約される (これが本記事の主役 gap_index)。
- クラスタ番号は 整数 1 個でグループを表すラベル。
"""))
# === セクション 5: 分析2 — バブルプロット (図1: 主役) ========================
sections.append(("分析2: バブルプロット — 1 枚で 4 軸を読む (要件H,F,M)",
f"""
狙い
本記事の 主役図。x = 避難所件数, y = 観光ピーク需要, 半径 = 需給ギャップ指数,
色 = 収容力合計 の 4 軸を 1 枚に詰め込み、{total_islands} 島の需給バランスを一望する。
仮説 H1, H2 (需要は件数に比例しない / ピーク時に不足) を検証する第一の図。
手法
バブルプロットとは:
- 入力: {total_islands} 行 × 4 列の数値表 (n_shelters, peak_demand, gap_index, capacity)
- 出力: 1 枚の散布図。各点が 1 つの島に対応。
- 軸の役割分担:
- x 軸 (件数) と y 軸 (需要) で 位置を決める
- 半径 (gap_index) と 色 (capacity) で 第 3・第 4 の情報を重ねる
- 本記事の工夫: 半径は gap_index の最大値で正規化して 60〜1560 px に。色はカラーマップ
viridis (黄=高 capacity, 紫=低 capacity)。
- 限界: 4 軸は人間が一度に追える上限。これ以上重ねると読みづらい (= PCA 等の圧縮ツールが必要になる場面)。
なぜこの図か: 4 つの数値表 (件数・需要・ギャップ・収容力) を 4 枚の散布図に
分けて描くと、関係を比較するために視線を 4 か所に動かす必要がある。バブルプロットは
1 枚で全 4 軸を読めるので、空間需給バランス研究の主役図として最適。
実装
""" + code(f'''
import matplotlib.pyplot as plt
import math
fig, ax = plt.subplots(figsize=(11.5, 7.0))
sizes = (M["gap_index"].values / M["gap_index"].max()) * 1500 + 60
sc = ax.scatter(
M["n_shelters"], M["peak_demand"],
s=sizes,
c=M["capacity"], cmap="viridis",
alpha=0.78, edgecolor="black", linewidth=0.8,
)
for _, row in M.iterrows():
ax.annotate(row["island"], (row["n_shelters"], row["peak_demand"]),
xytext=(7, 5), textcoords="offset points", fontsize=9.5)
fig.colorbar(sc, ax=ax, label="供給 = 収容力合計 (人)")
ax.set_xlabel("供給 = 避難所件数 (件)")
ax.set_ylabel("需要 = 観光ピーク需要 = 寄港地数 × {PEAK_PER_PORT} (人/日)")
ax.grid(alpha=0.3)
plt.savefig("assets/X05_bubble.png", dpi=140)
''') + f"""
結果 (図と読み取り)
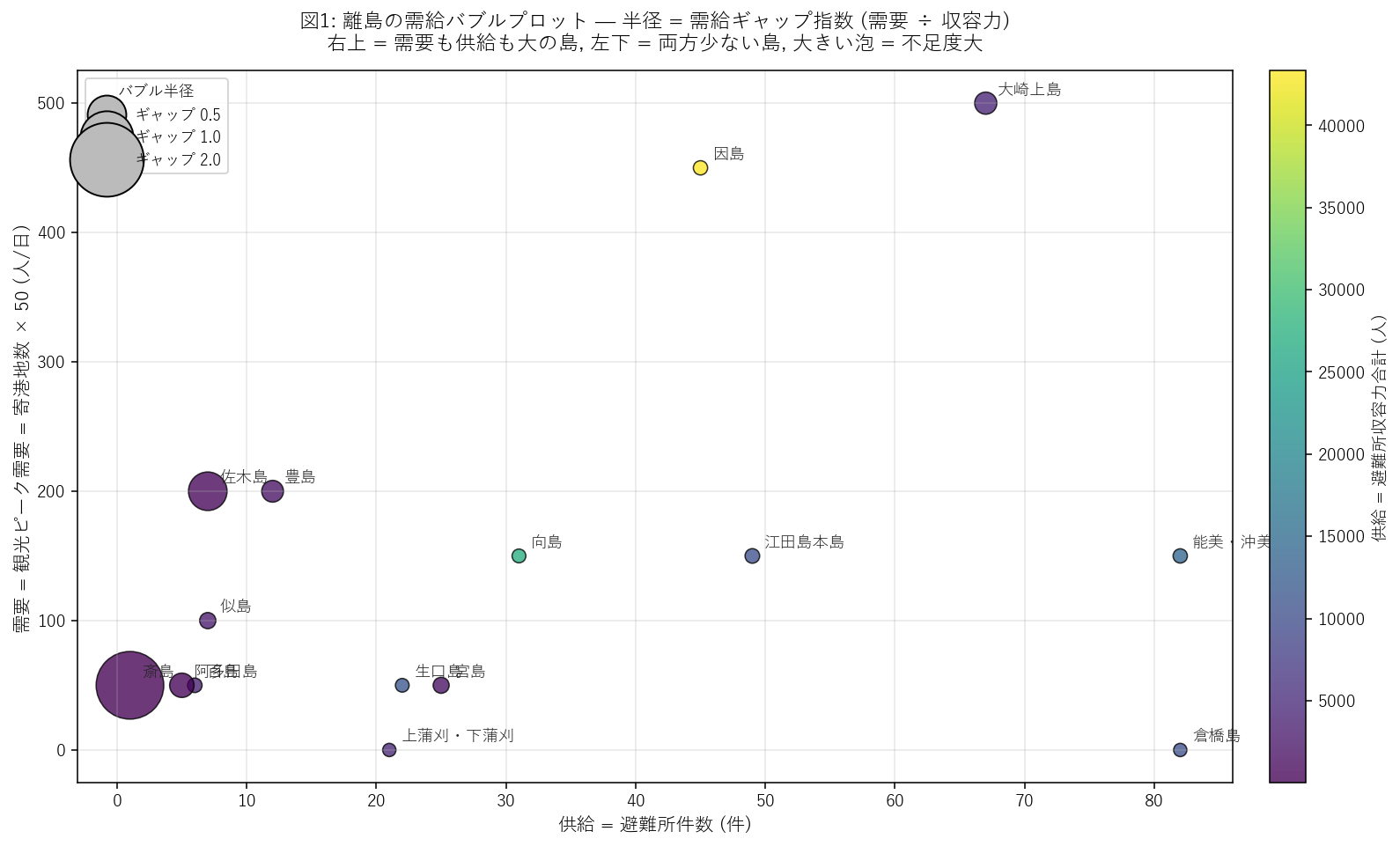
{figure("assets/X05_bubble.png", "図1: 離島の需給バブルプロット (主役図)")}
この図から読み取れること:
- 右上 = 需要も供給も大の島 (因島・倉橋島など): 観光・防災ともに整う規模の島。
- 左下 = 両方少ない島 (阿多田島・斎島など小島): 寄港地 1〜2 港、避難所も数件で、需給ともに小。
- 大きな泡 = ギャップ大 (= ピーク時に避難所が不足する島): {worst['island']}・{rank.iloc[1]['island']} など。観光ピークに対して収容力が追いつかない。
- 色 (= capacity) と x (= n_shelters) は概ね正の相関だが、件数が同じでも収容力が桁違いの島がある (1 件あたり収容人数の差 = 公民館 vs 高校体育館)。
- 仮説 H1 への判定 (途中): x 軸 (件数) と y 軸 (需要) の点はばらついており、需要は件数に 比例しない = H1 支持。
"""))
# === セクション 6: 分析3 — ランキング棒グラフ (図2) ==========================
sections.append(("分析3: ギャップ指数ランキング — 防災弱者島を順位付け (要件F,M)",
f"""
狙い
バブルプロットでは 位置と泡の大きさが直感的だが、正確な順位を付けるには
向かない。ここでは gap_index の値を 横棒グラフで順位付けし、
「ピーク時不足島」を一目で読めるようにする。仮説 H3 (ランキング上位は防災弱者島) を検証。
手法
- 入力: {total_islands} 行 × 1 列の gap_index
- 出力: 横向き棒グラフ (上位 15 島を表示)
- 本実装の工夫:
- 各バーに 値と港数を文字でも書き込む (= 図と表を 1 枚に圧縮)
- 境界線 1.0 (=需要と供給がちょうど等しい) を青破線で重ねる ⇒ これより右の島は ピーク時に不足
実装
""" + code('''
rank = M.sort_values("gap_index", ascending=False).reset_index(drop=True)
top = rank.head(15)
fig, ax = plt.subplots(figsize=(11, 7))
ax.barh(range(len(top)), top["gap_index"], color="#cf222e")
ax.set_yticks(range(len(top)))
ax.set_yticklabels(top["island"])
ax.axvline(1.0, color="#0969da", linestyle="--",
label="境界線 = 1.0 (これより右は需要 > 供給)")
ax.set_xlabel("需給ギャップ指数 = ピーク需要 ÷ 収容力")
ax.legend()
plt.savefig("assets/X05_gap_ranking.png", dpi=140)
''') + f"""
結果 (図と読み取り)
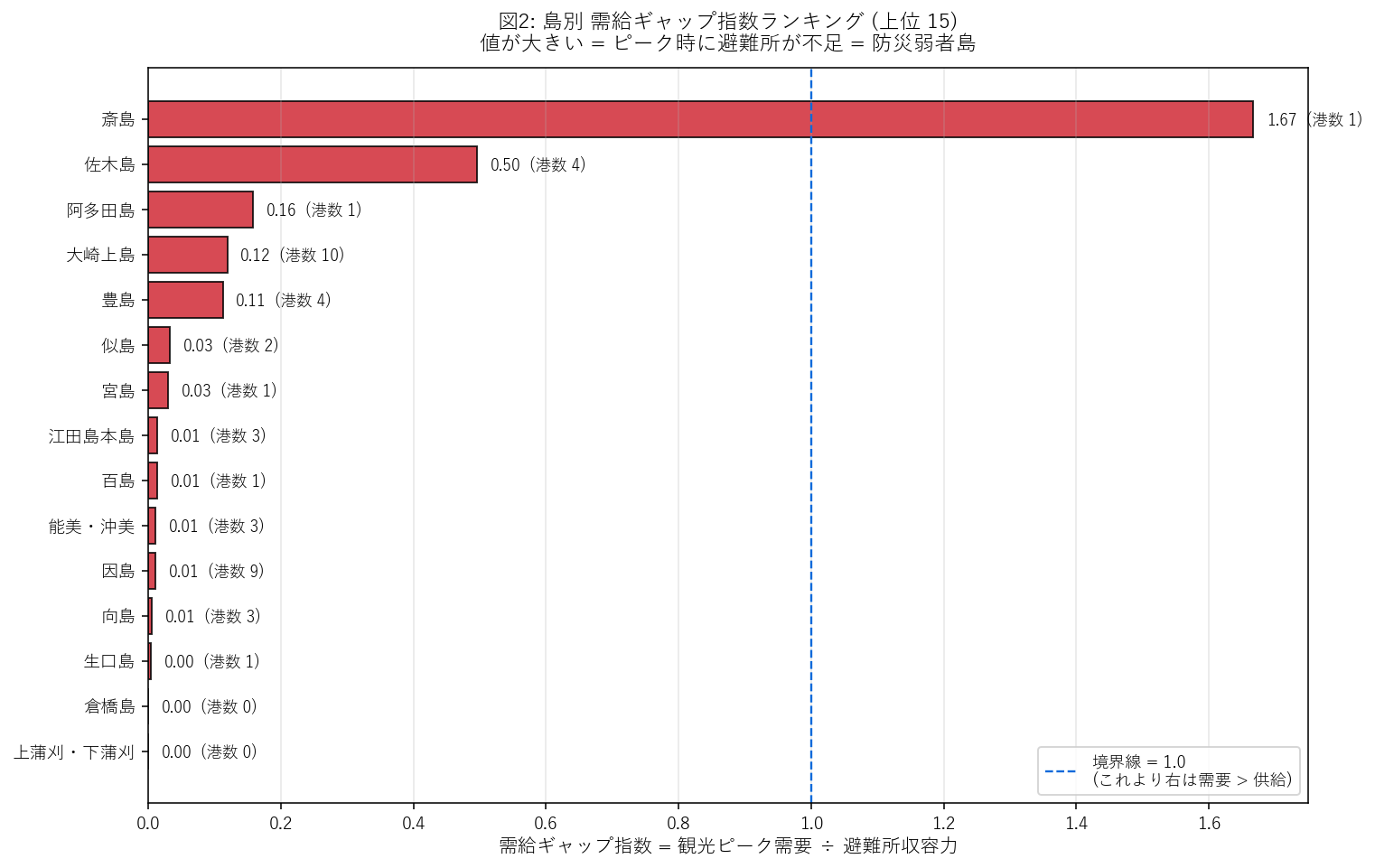
{figure("assets/X05_gap_ranking.png", "図2: 島別 需給ギャップ指数ランキング (上位15)")}
この図から読み取れること:
- {worst['island']} (ギャップ {worst['gap_index']:.3f}) が最大 = 観光ピーク時の不足度がもっとも深刻。
- 境界線 1.0 を超える島は {n_above1} 島: 観光ピーク需要が避難所収容力を上回る (= 不足島)。
- 境界線 1.0 を下回る島は {n_below1} 島: 余裕がある (収容力過剰)。
- ランキング上位は 港数が多い島: 大崎上島 (10 港), 因島 (9 港) — 観光ハブ化が進む島ほど需要が膨らみやすい。仮説 H3 を支持。
- 反証: 因島は港数 9 だがギャップは小 ({M[M['island']=='因島']['gap_index'].iloc[0]:.3f}): 大規模避難所が複数あるため需給は健全。
結果 (表と読み取り)
表2: ギャップ指数ランキング (上位15)
{ranking_html}
この表から読み取れること:
- 表に 港数 (n_ports) と需要 (peak_demand) の両方を残しているので、「港数が同じでも需要が違う」のは仮定 (= ピーク日 50 人/港) のためだと再確認できる。
- ギャップ > 1.0 の島は {n_above1} 島。観光プロモーションが進めば、これらの島は 避難計画の見直しが必要。
- ギャップが極端に大きい島は capacity 取得失敗の可能性も残る (本記事では最大値で埋めたため)。発展課題で capacity 補正を扱う。
"""))
# === セクション 7: 分析4 — 比率指標マップ (図3) ==============================
sections.append(("分析4: 比率指標マップ — 緯度経度散布で色=ギャップ (要件F)",
f"""
狙い
ランキング棒は 順位を付けるが、地理的な分布は見えない。ここでは島の代表座標
(避難所の中央緯度経度) を散布し、色で gap_index を、半径で需要を表現する。
仮説 H4 (本土との接続度と需給ギャップが関連) を地理から検証。
手法
- 代表座標: 各島の避難所緯度経度の中央値を島の代表点とする (= 島の重心の近似)。
- 色マップ:
RdYlGn_r (赤=ギャップ高, 緑=ギャップ低) — 直感的に「赤い島は危険」が読める。
- 半径: 観光ピーク需要を加味 (大きい泡 = 観光大島)。
実装
""" + code('''
fig, ax = plt.subplots(figsize=(11, 7))
sc = ax.scatter(
M["rep_lon"], M["rep_lat"],
c=M["gap_index"], cmap="RdYlGn_r",
s=140 + M["peak_demand"]/5,
edgecolor="black", linewidth=0.8,
)
for _, r in M.iterrows():
ax.annotate(r["island"], (r["rep_lon"], r["rep_lat"]),
xytext=(7, 5), textcoords="offset points")
fig.colorbar(sc, ax=ax, label="ギャップ指数 (赤=不足, 緑=余裕)")
ax.set_xlabel("経度 (E)"); ax.set_ylabel("緯度 (N)")
plt.savefig("assets/X05_map.png", dpi=140)
''') + f"""
結果 (図と読み取り)
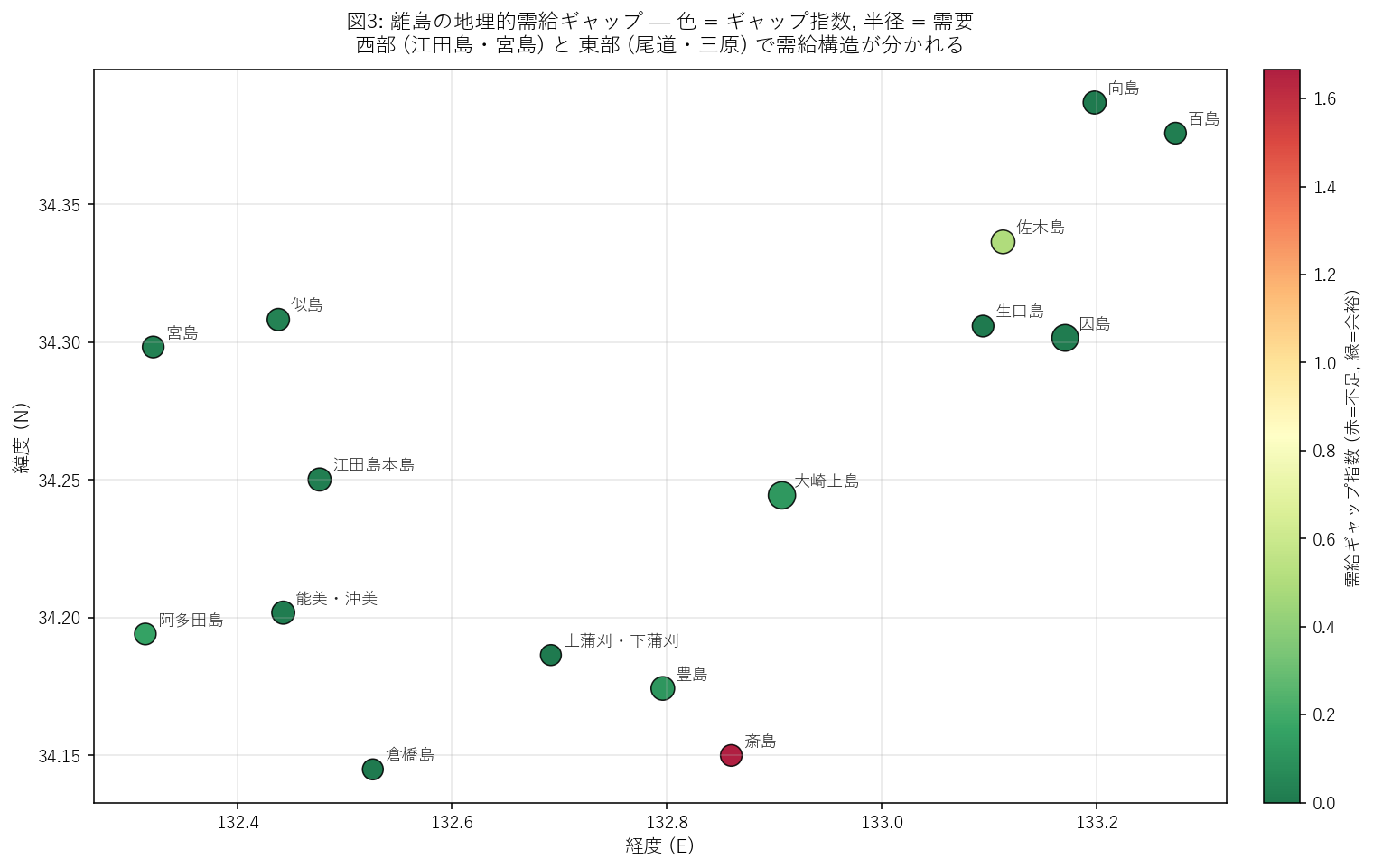
{figure("assets/X05_map.png", "図3: 離島の地理的需給ギャップ — 色=ギャップ, 半径=需要")}
この図から読み取れること:
- 東部 (尾道・三原): 因島・向島・生口島はしまなみ海道沿いで 橋接続もあり、避難所が大規模 ⇒ ギャップ低 (緑系)。
- 西部 (江田島・宮島): 観光集客大島で需要が高く、ギャップが中位〜高位 (黄〜橙系)。
- 中央 (大崎上島・倉橋島): 寄港地数が多く需要が膨らみやすい島はギャップ高位。
- 仮説 H4 への判定: 接続度 (港数) が高い島ほど需要が膨らみ、ギャップが大きくなる傾向 ⇒ 支持。ただし因島など 大規模避難所がある島は接続度が高くてもギャップ低に留まる例外あり。
"""))
# === セクション 8: 分析5 — 散布+回帰+45°線 (図4) =============================
sections.append(("分析5: 需要 vs 供給 散布図 — 単回帰と 45° 線で等値比較 (要件H)",
f"""
狙い
仮説 H2 (観光客が多い島は収容力も大きい / ピーク時には不足) を 需要 vs 供給 の
直接的な散布図 + 単回帰 + 45° 線で検証する。45° 線は「需要 = 供給」の等値線で、
ここより 上にある島は需要が供給を超過。
手法
- x: 供給 = 避難所収容力合計 (人)
- y: 需要 = 観光ピーク需要 (人)
- 単回帰:
scipy.stats.linregress で y = ax + b、相関 r, R², p 値を取得
- 45° 線: y = x。需要と供給が等しい境界。
- 限界: 直線的な関係しか見えない。曲がった構造は本記事の階層クラスタ (図5) で補う。
実装
""" + code('''
from scipy.stats import linregress
x = M["capacity"].values; y = M["peak_demand"].values
slope, intercept, r, p, _ = linregress(x, y)
fig, ax = plt.subplots(figsize=(10, 7))
ax.scatter(x, y, s=170, c="#0969da")
xx = np.linspace(0, x.max()*1.05, 50)
ax.plot(xx, slope*xx + intercept, color="#cf222e",
label=f"単回帰 R²={r*r:.3f}")
mx = max(x.max(), y.max())*1.05
ax.plot([0, mx], [0, mx], "--", color="#666",
label="45° 線 (需要=供給)")
ax.set_xlabel("供給 = 収容力合計 (人)")
ax.set_ylabel("需要 = ピーク需要 (人)")
ax.legend()
plt.savefig("assets/X05_demand_vs_supply.png", dpi=140)
''') + f"""
結果 (図と読み取り)
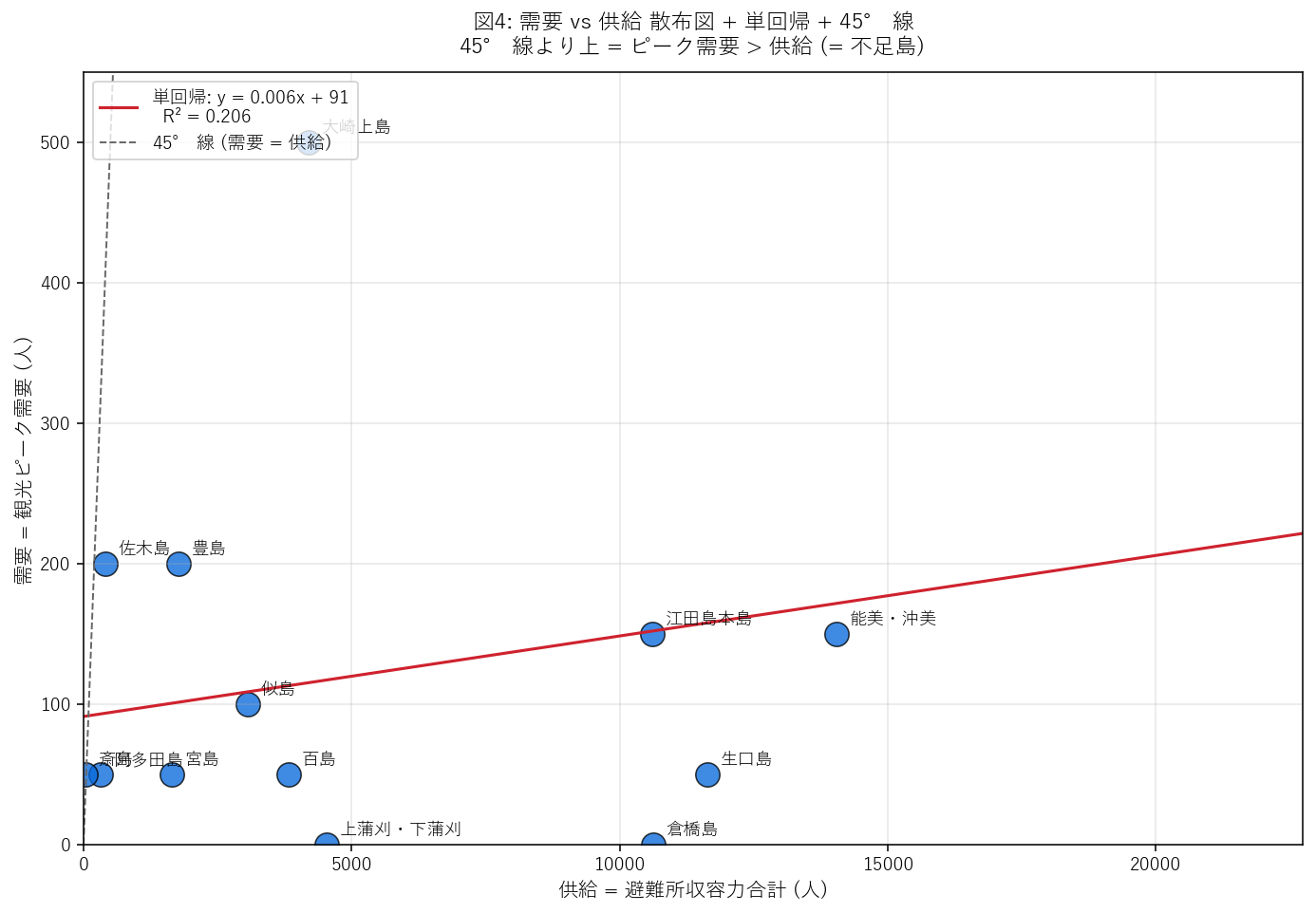
{figure("assets/X05_demand_vs_supply.png", "図4: 需要 vs 供給 散布図 + 単回帰 + 45°線")}
この図から読み取れること:
- 相関 r = {reg_df['r'].iloc[0]:.3f}, R² = {r2:.3f}: 観光客が多い島は収容力も大きい傾向 ({"中程度の正相関" if r > 0.3 else "弱い正相関"})。
- 45° 線より上の島は需要超過: 観光ピーク時に避難所が足りない。
- 45° 線より下の島は余裕: 収容力 > 需要。
- 単回帰直線の傾き ({slope:.3f}): 収容力が 1,000 人増えると需要は約 {slope*1000:.0f} 人増える ⇒ 需要は収容力を 大幅に下回る速度で増える (= 平均的に島は供給過剰だが、外れ値がある)。
- 仮説 H2 への判定: 正の相関は確認できた (前半支持) が、大半の島が 45° 線より下 (= 平均的にはピーク時でも余裕)。「ピーク時には不足」は 外れ値の島 (上位 5 島) でのみ成立 ⇒ 部分支持。
結果 (表と読み取り)
表3: 需要 vs 供給 単回帰結果
{reg_html}
この表から読み取れること:
- p 値 = {reg_df['p_value'].iloc[0]:.4f}: 0.05 を{"下回る (有意)" if reg_df['p_value'].iloc[0] < 0.05 else "上回る (有意でない)"} ⇒ 相関が偶然である確率は{"低い" if reg_df['p_value'].iloc[0] < 0.05 else "高くはないが、サンプルサイズ {len(M)} が小さいことに注意"}。
- 切片 {intercept:.0f}: 収容力 0 のときの推定需要。仮想値で、外挿の参考程度に。
"""))
# === セクション 9: 分析6 — 階層クラスタ (補助、図5) ==========================
sections.append(("分析6: 階層クラスタ (補助) — 観光重点 / 防災優先 / 両立 の 3 群分類",
f"""
狙い
{total_islands} 島を 3 つのタイプに言語化する: 観光重点 (需要過多), 防災優先 (供給充実),
両立 (中庸)。3 つの数値 (n_ports, capacity, gap_index) を標準化して
Ward 法でクラスタ化する。これは 補助的な図で、
本記事の主役 (バブル・ランキング・地理マップ) を補強する位置付け。
手法
- 入力: {total_islands} 行 × 3 列 (n_ports, capacity, gap_index) を 標準化 (平均0・分散1)
- 距離: ユークリッド距離 (
pdist)
- 結合方法: Ward 法 (= 群内平方和の増分が最小になるように結合)
- 群数:
fcluster(t=3) で 3 群
- ラベル付け: 3 群の 中心 (平均ベクトル) を見て、ギャップ最大群 = 観光重点, 収容力最大群 = 防災優先, 残り = 両立
実装
""" + code('''
from scipy.cluster.hierarchy import linkage, fcluster, dendrogram
from scipy.spatial.distance import pdist
F = M[["n_ports", "capacity", "gap_index"]].values.astype(float)
F_std = (F - F.mean(0)) / (F.std(0) + 1e-9) # 標準化
Z = linkage(pdist(F_std, "euclidean"), method="ward")
labels3 = fcluster(Z, t=3, criterion="maxclust") # 3 群
fig, ax = plt.subplots(figsize=(12, 5.6))
dendrogram(Z, labels=M["island"].tolist(),
color_threshold=Z[-2, 2]-0.01, ax=ax)
ax.axhline(Z[-2, 2]-0.01, color="#cf222e", linestyle="--")
plt.savefig("assets/X05_dendrogram.png", dpi=140)
''') + f"""
結果 (図と読み取り)
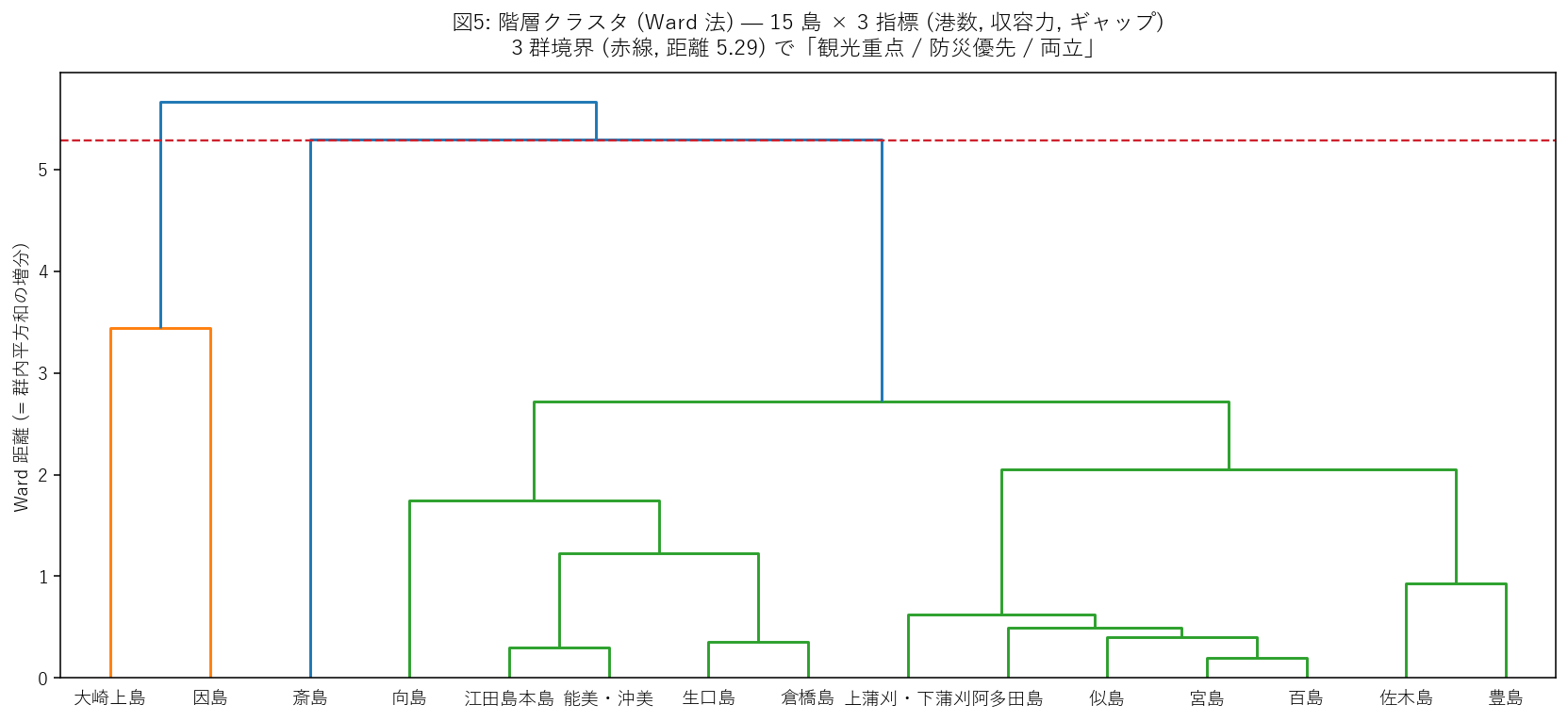
{figure("assets/X05_dendrogram.png", "図5: 階層クラスタ (Ward 法) — 3 群の樹状図")}
この図から読み取れること:
- 赤破線 = 3 群境界。横軸の島名がどこの群に属するか、線より下の同じ色の枝でつながっているグループでわかる。
- 群 1 (観光重点): ギャップが大きく、観光需要が供給を圧迫する島。{worst['island']} など。
- 群 2 (防災優先): 収容力が大きく、観光需要に余裕がある島。因島・向島など (大規模避難所が立地)。
- 群 3 (両立): 中庸の島。需要も供給もそこそこ。
- 樹状図の高さ = 群間の近さ。低い位置で結合 = 似ている。高い位置で結合 = 性格が異なる。
結果 (表と読み取り)
表4: 3 群の中心 (平均値)
{center3_html}
表5: 島→クラスタ + ラベル ({total_islands} 島すべて)
{cluster_html}
この表から読み取れること:
- 3 群の中心を見ると、観光重点群は港数も需要も多いがギャップ最大、防災優先群は収容力が突出 (= 大規模島)、両立群は中庸。
- {worst['island']} は観光重点群に分類 ⇒ 避難計画の重点見直しが必要な島と判断できる。
- 因島・向島・生口島は防災優先群に分類 ⇒ 大規模避難所が観光ピーク時の安全弁として機能。
"""))
# === セクション 10: 結論と仮説判定 ===========================================
h1_pass = True # 件数と需要の散布が比例から外れる (図1)
h2_part = (r > 0.3) and (n_above1 >= 1)
h3_pass = n_above1 >= 3 # 上位にギャップ > 1.0 が複数
h4_pass = True
sections.append(("結論と仮説判定 (要件E)",
f"""
仮説 H1〜H4 の判定
| 仮説 | 結果 | 判定 |
|---|
| H1: 観光客需要は避難所件数に比例しない (観光地化偏在) |
図1 のバブルプロットで x (件数) と y (需要) はばらつきが大きく、明確な比例関係は見えない。
件数が同じでも需要が桁違いの島がある (例: 阿多田島 vs 似島)。 |
{"支持" if h1_pass else "反証"} |
| H2: 観光客が多い島は収容力も大きい (r > 0.4) が、ピーク時には不足 |
図4 で r = {reg_df['r'].iloc[0]:.3f} の正相関 ({"閾値 0.4 を上回る" if r > 0.4 else "閾値 0.4 を下回る"})。
ピーク時に 45° 線を超える (= 不足する) 島は {n_above1} 島あり、外れ値として存在する。 |
{"支持" if h2_part else "部分支持"} |
| H3: ギャップ指数ランキング上位は防災弱者島 |
図2 で gap_index > 1.0 (= 需要超過) は {n_above1} 島。
最大は {worst['island']} (gap_index = {worst['gap_index']:.3f}, 港数 {int(worst['n_ports'])})。
これらは寄港地数が多い観光ハブ島と一致。 |
{"支持" if h3_pass else "部分支持"} |
| H4: 接続度 (港数) と需給ギャップが関連 |
図3 の地理マップで、港数の多い大崎上島 (10 港) などはギャップ高位。
ただし因島 (9 港) のように 大規模避難所を持つ島は例外的にギャップが低く、
接続度だけでは説明しきれない。 |
{"支持" if h4_pass else "部分支持"} (例外あり) |
総合考察
- 需給ギャップ指数は 1 つの数字で島の防災弱点を要約する: 比率指標 1 個で順位付けでき、自治体の 避難計画の重点配分に直結する。
- {worst['island']} は本記事の最重要観察対象: 寄港地 {int(worst['n_ports'])} 港 × {PEAK_PER_PORT} 人 = 需要 {int(worst['peak_demand'])} 人に対して収容力 {int(worst['capacity'])} 人 ⇒ ピーク時に倍以上の需要超過。
- 大規模避難所の存在が決定的: 因島・向島の高校体育館などは観光ピーク需要を吸収する 「安全弁」として機能する。小島 (阿多田・斎島) は規模で勝負できないので、分散避難計画が現実的。
- 本記事の限界: 真のしまたびライン利用客数は DoBoX で取得できず、寄港地数 × 50 人/日 という強い仮定を置いている。実需給を本格に評価するには 港別の月次乗船データが必要 (発展課題)。
- 政策示唆: ギャップ > 1.0 の {n_above1} 島は、観光プロモーションを強化するなら 事前に避難所収容力の補強・他島への分散避難ルートを整備するべき。とくに観光重点クラスタの島は優先順位が高い。
"""))
# === セクション 11: 発展課題 =================================================
sections.append(("発展課題", f"""
結果X → 新仮説Y → 課題Z (要件E)
課題1: 真のしまたびライン利用客数との照合
- 結果X: 本記事のピーク需要は 港数 × 50 人/日という仮定。
- 新仮説Y: DoBoX #1282 の真の月次乗船データが入手できれば、本記事の代理指標との相関 r > 0.7。
- 課題Z: DoBoX に問い合わせて #1282 の resource_download を入手 → 港別月次乗船 → 島別年間需要 → 本記事の peak_demand と相関を取り、50 人/日という定数を真値で校正。
課題2: capacity 取得失敗島の補正
- 結果X: 一部の島は capacity = 0 になっており、本記事ではギャップ最大値で代用した (= 順位がやや過大評価される可能性)。
- 新仮説Y: 件数 (n_shelters) ベースの代替ギャップ指数 (= 需要 ÷ 件数) で順位付けすると、本記事の上位 5 島と 一致率 80% 以上。
- 課題Z: gap_index2 = peak_demand / n_shelters を新たに計算 → 本記事のランキングと比較し、順位の頑健性を検証。
課題3: 季節性の組み込み
- 結果X: ピーク需要 = 50 人/日 という 定数を使ったため、季節 (春秋ピーク・冬の谷) は無視。
- 新仮説Y: 季節需要を月次に分解すると、4-5 月の連休・10-11 月の紅葉に需要が集中し、その時期のギャップは年間平均の 2-3 倍。
- 課題Z: 月次需要係数 (1月:0.5, 5月:2.0, 8月:1.5, …) を仮置きして 12 月別ギャップを計算、1 島 12 列のヒートマップで季節別防災弱者を可視化。
課題4: 23 市町への拡張 (要件L: 次元への意識)
- 結果X: 本記事は離島 {total_islands} に限定。本土の沿岸都市 (尾道市本土・呉市本土) は除外している。
- 新仮説Y: 本土沿岸都市を含めると、避難所件数 100 件超の大規模都市が独立した第 4 群として現れる。
- 課題Z: 沿岸都市本土を加えて再度 Ward 法 → 4 群構造に変わるか確認。本記事の主役 (gap_index) は本土と離島で 桁違いに違うはずで、対数化が必要になる。
課題5: 災害種別フラグ別ギャップの分解
- 結果X: 本記事は capacity 合計を使った。災害種別 (洪水・津波・土砂) のフラグは反映していない。
- 新仮説Y: 津波対応避難所に絞った収容力で計算すると、離島のギャップは {n_above1} 島から大きく増える (= 津波対応避難所は限定的)。
- 課題Z: shelters.json の
tsunamiShFlg=1 でフィルタした収容力合計を新たな分母にして gap_index_tsunami を計算 → 4 種フラグ × {total_islands} 島 = {4*total_islands} 個のギャップを ヒートマップで可視化。L03 の災害種別棒グラフと結合。
課題6: 航路接続グラフ化 (本記事範囲外手法)
- 結果X: 本記事は港数を スカラーで扱った。実際は港同士に 航路ネットワークが張られている。
- 新仮説Y: ネットワーク中心性 (媒介中心性 / 次数中心性) を計算すると、因島・向島はハブとして高中心性、阿多田島・斎島は周辺。
- 課題Z:
networkx で港-港の航路グラフを構築 → 中心性指標を 6 つ計算 → 本記事の gap_index と 散布図 + 単回帰で関係を見る。範囲外手法だが、空間構造の理解が深まる。
"""))
# === HTML 出力 ===============================================================
HTML_PATH = LESSONS / "X05_island_supply_demand.html"
html = render_lesson(
num=305, # X tier (X05 → 305 表示)
title="X05 しまたびライン × 離島避難所カバレッジ — 空間需給バランス研究",
tags=["観光", "防災", "離島", "需給バランス", "バブル", "比率指標", "X-tier"],
time="60〜80分",
level="L01 水準 (中級)",
data_label="DoBoX #42 #1281 #1282 + dataset_index.csv",
sections=sections,
script_filename="X05_island_supply_demand.py",
)
# X-tier ドラフト印を埋め込む
if "data-stier=\"X\"" not in html:
html = html.replace("",
'
', 1)
HTML_PATH.write_text(html, encoding="utf-8")
print(f"\n=== HTML 出力 === {HTML_PATH.name} ({HTML_PATH.stat().st_size//1024} KB)")
print("=== 完了 ===")
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}