# -*- coding: utf-8 -*-
"""
X04: 広島県クルーズ需要の港別・季節別構造分析
================================================================================
【2026-05 改訂版】
旧版 (X04 v1) は 2022 年 12 月のせとうちモニタークルーズ実証実験を
「介入パルス」とみなし、しまたびライン 8 ヶ月のベースラインに対する
DID 風前後比較で「介入効果」を推論しようとした。
しかし旧版には以下の方法論的問題があった:
(1) 介入イベント n = 1 で因果推論不可 (反復観測なし)。
(2) ベースライン傾き |a₁| が小さいため |差|/|a₁| が約 200 倍 (19919%)
に発散し、効果サイズの解釈が成立しない。
(3) コロナ・季節・天候・経済環境の交絡が一切統制されていない。
(4) DID 風と称しながら、平行トレンド前提が検証不可。
本改訂では 因果推論を装う構成を全面廃案 にし、同一データセット 2 件
(#1282 + #1280) を用いた 記述統計 + 市場構造分析 に転換する。
3 つの研究角度 (RQ1/RQ2/RQ3) を並列に立て、Format B (単独 3RQ) で構成する。
カバー宣言:
本記事は DoBoX のオープンデータ 2 件 (dataset_id = 1282, 1280) を
記述統計と港別市場構造分析の枠組みで読み解く。
(1) #1282 瀬戸内しまたびライン利用状況 (resource 39787)
2022 年 4-12 月の月次乗降客数。2 航路 × 14 桟橋 × 9 ヶ月 = 252 観測値。
(2) #1280 せとうちモニタークルーズ実施結果 (resource 39782)
2022 年 12 月の実証実験。7 航路 × 9 運航日 = 15 航海, 23 寄港地。
3 つの研究角度 (RQ1/RQ2/RQ3, Format B):
RQ1 (主研究): 広島県の沿岸クルーズ需要は 14 港にどう配分されているか?
港別の年間 / 月別需要を集計し、集中度 (Gini, HHI, CRn) で
「主要港 vs 周辺港」 の構造を定量化する。
RQ2 (副研究 1): 需要の季節性は春秋 2 山型か? 港別差はあるか?
月別総需要の波形と、港別の季節係数 (= 港 m / 港年平均) で
「同じ春でも港ごとに季節振幅の大小がある」 仮説を検証する。
RQ3 (副研究 2): モニタークルーズ実施結果のルート記述分析
7 航路 × 23 寄港地のルート設計を、新規 / 既存区間の混合比、
寄港数、運航日分布で記述する。n=1 の介入効果は分析しない
(因果推論不可)。
仮説 (5):
H1 (RQ1): 広島県沿岸 14 港のクルーズ需要は均等配分ではなく、
上位 5 港シェア (CR5) ≥ 40%, Gini ≥ 0.10 程度の集中度がある。
H2 (RQ1): 主要港 (上位 3) は航路の 始発・終着 港、
周辺港 (下位 5) は 島嶼経由地 という地理的役割分化がある。
H3 (RQ2): 月別需要は春秋 2 山型で、5 月と 11 月にピーク。
7-8 月 (夏) と 12 月 (冬) が谷。冬の谷はピークの 1/4 以下。
H4 (RQ2): 港別の季節係数は同じ春でも振幅が異なる。
季節振幅 (年内最大係数 / 年内最小係数) は港間で 1.5 倍以上の差。
H5 (RQ3): モニタークルーズの 7 航路は、新規 / 既存区間の混合比に応じて
4 タイプに分類できる: 完全既存・既存主体・新規主体・完全新規。
空間的には既存しまたびライン (広島-三原) を 東に延伸
(鞆の浦, 尾道, しまなみ海道) する設計。
要件 S 準拠:
- 全処理 1 分以内完走目標。matplotlib Figure はすべて plt.close() で解放。
- データキャッシュ既存 (data/extras/) を優先利用。
要件 T 準拠 (位置情報あり = 地図必須):
- 図 3: 港別年間需要マップ (緯度経度に円配置, サイズ=年間客数)
- 図 7: モニタークルーズ 7 航路のルートマップ (港を結ぶ折れ線, 新規/既存を色分け)
要件 Q 準拠: 図 9 / 表 12 (3 RQ × 多角度).
実行:
cd "2026 DoBoX 教材"
py -X utf8 lessons/X04_cruise_intervention_timeseries.py
"""
from __future__ import annotations
import sys, time, warnings
from pathlib import Path
sys.path.insert(0, str(Path(__file__).parent))
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.patches import Patch
from matplotlib.lines import Line2D
from _common import (ROOT, ASSETS, LESSONS, render_lesson, code, figure,
ensure_dataset)
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
warnings.filterwarnings("ignore", category=UserWarning)
t_start = time.time()
# === パス定義 =================================================================
SHIMATABI_CSV = ROOT / "data" / "extras" / "shimatabi_monthly.csv"
MONITOR_CSV = ROOT / "data" / "extras" / "cruise_monitor_daily.csv"
PORTS_CSV = ROOT / "data" / "extras" / "cruise_monitor_ports.csv"
# 中間 CSV (assets 配下 = HTML から直リンク)
OUT_PORT_YEAR = ASSETS / "X04_port_yearly.csv" # 港別年間
OUT_PORT_MONTH = ASSETS / "X04_port_month.csv" # 港×月の長表
OUT_CONCENTRATION = ASSETS / "X04_concentration_metrics.csv" # Gini/HHI/CR
OUT_LORENZ = ASSETS / "X04_lorenz_points.csv" # ローレンツ曲線
OUT_MONTH_TOTAL = ASSETS / "X04_month_total.csv" # 月別総需要
OUT_SEASON_IDX = ASSETS / "X04_seasonal_index.csv" # 港×月 季節係数
OUT_SEASON_AMP = ASSETS / "X04_seasonal_amplitude.csv" # 港別 季節振幅
OUT_MON_TRIPS = ASSETS / "X04_monitor_trips.csv" # 運航日×航路
OUT_MON_ROUTES = ASSETS / "X04_monitor_routes.csv" # 航路サマリ
OUT_MON_PORTS = ASSETS / "X04_monitor_ports.csv" # 寄港地マスタ整形
OUT_PORT_CLUSTER = ASSETS / "X04_port_cluster.csv" # 港の役割分類
# 図 PNG
PNG_RQ1_BAR = ASSETS / "X04_rq1_port_yearly_bar.png" # 図1
PNG_RQ1_LORENZ = ASSETS / "X04_rq1_lorenz.png" # 図2
PNG_RQ1_MAP = ASSETS / "X04_rq1_port_map.png" # 図3 (地図)
PNG_RQ2_TOTAL = ASSETS / "X04_rq2_month_total.png" # 図4
PNG_RQ2_HEATMAP = ASSETS / "X04_rq2_port_month_heatmap.png" # 図5
PNG_RQ2_AMP = ASSETS / "X04_rq2_seasonal_amplitude.png" # 図6
PNG_RQ3_MAP = ASSETS / "X04_rq3_route_map.png" # 図7 (地図)
PNG_RQ3_TRIPS = ASSETS / "X04_rq3_trip_passengers.png" # 図8
PNG_RQ3_MIX = ASSETS / "X04_rq3_route_mix.png" # 図9
# === STEP 0: データ取得 (失敗していたら自動 DL) ===============================
print("=== X04 [改訂版]: 広島県クルーズ需要の港別・季節別構造分析 ===")
print("\n=== STEP 0: データ取得 ===")
ensure_dataset(SHIMATABI_CSV, resource_id=39787,
label="しまたびライン月次 (#1282 resource 39787)")
ensure_dataset(MONITOR_CSV, resource_id=39782,
label="モニタークルーズ日別 (#1280 resource 39782)")
ensure_dataset(PORTS_CSV, resource_id=39781,
label="モニタークルーズ寄港地マスタ (#1280 resource 39781)")
# === STEP 1: 読み込み =========================================================
print("\n=== STEP 1: 読み込み ===")
shimatabi = pd.read_csv(SHIMATABI_CSV, encoding="cp932").dropna(subset=["寄港地(桟橋名)"])
monitor = pd.read_csv(MONITOR_CSV, encoding="cp932")
ports_meta = pd.read_csv(PORTS_CSV, encoding="cp932")
monitor["運航日"] = pd.to_datetime(monitor["運航日"])
print(f" しまたびライン月次: {shimatabi.shape} ({shimatabi['航路名'].nunique()} 航路, "
f"{shimatabi['寄港地(桟橋名)'].nunique()} 桟橋)")
print(f" モニタークルーズ日別: {monitor.shape} ({monitor['航路名'].nunique()} 航路, "
f"{monitor['運航日'].nunique()} 運航日)")
print(f" 寄港地マスタ: {ports_meta.shape}")
# === STEP 2: しまたびを港×月の長表に整形 =====================================
print("\n=== STEP 2: 港×月 長表整形 ===")
month_cols = ["4月(人)", "5月(人)", "6月(人)", "7月(人)",
"8月(人)", "9月(人)", "10月(人)", "11月(人)", "12月(人)"]
month_num = list(range(4, 13))
# numericに統一
for c in month_cols:
shimatabi[c] = pd.to_numeric(shimatabi[c], errors="coerce")
records = []
for _, r in shimatabi.iterrows():
for col, m in zip(month_cols, month_num):
records.append({
"港": r["寄港地(桟橋名)"],
"月": m,
"乗降客数": r[col],
"航路": r["航路名"],
"緯度": r["緯度"],
"経度": r["経度"],
"寄港桟橋順": r["寄港桟橋順"],
})
long_df = pd.DataFrame(records).dropna(subset=["乗降客数"])
# 港×月 で東/西航路を合算
port_month = long_df.groupby(["港", "月"], as_index=False)["乗降客数"].sum()
n_ports = port_month["港"].nunique()
print(f" 港×月集約: {len(port_month)} 行 ({n_ports} 港 × 9 ヶ月)")
# 港の代表緯度経度 (最初に出てくる値)
port_geo = (long_df.drop_duplicates("港")[["港", "緯度", "経度"]]
.reset_index(drop=True))
port_month.to_csv(OUT_PORT_MONTH, index=False, encoding="utf-8-sig")
print(f" → {OUT_PORT_MONTH.name}")
# === STEP 3: 港別年間需要 + 集中度指標 (RQ1) ==================================
print("\n=== STEP 3: RQ1 港別年間需要と集中度 ===")
port_yearly = (port_month.groupby("港", as_index=False)["乗降客数"].sum()
.sort_values("乗降客数", ascending=False).reset_index(drop=True))
total_demand = port_yearly["乗降客数"].sum()
port_yearly["シェア"] = port_yearly["乗降客数"] / total_demand
port_yearly["順位"] = np.arange(1, len(port_yearly) + 1)
port_yearly["累積シェア"] = port_yearly["シェア"].cumsum()
port_yearly_out = port_yearly[["順位", "港", "乗降客数", "シェア", "累積シェア"]].copy()
port_yearly_out["シェア"] = port_yearly_out["シェア"].round(4)
port_yearly_out["累積シェア"] = port_yearly_out["累積シェア"].round(4)
port_yearly_out["乗降客数"] = port_yearly_out["乗降客数"].astype(int)
port_yearly_out.to_csv(OUT_PORT_YEAR, index=False, encoding="utf-8-sig")
print(port_yearly_out.to_string(index=False))
# Gini 係数
def gini_coefficient(x):
"""Gini = (2 Σ i·x_i) / (n·Σx_i) − (n+1)/n (sorted ascending)。
0 = 完全均等, 1 = 完全集中。"""
x = np.sort(np.asarray(x, dtype=float))
n = len(x)
if n == 0 or x.sum() == 0:
return 0.0
return (2 * np.arange(1, n + 1).dot(x) / (n * x.sum())) - (n + 1) / n
gini = gini_coefficient(port_yearly["乗降客数"].values)
hhi = float((port_yearly["シェア"] ** 2).sum()) # 0..1
hhi_basis = hhi * 10000 # 米司法省風の 10000 ベース
cr3 = float(port_yearly["シェア"].head(3).sum())
cr5 = float(port_yearly["シェア"].head(5).sum())
cr10 = float(port_yearly["シェア"].head(10).sum())
print(f" Gini = {gini:.4f}, HHI = {hhi:.4f} ({hhi_basis:.0f}/10000), "
f"CR3 = {cr3*100:.1f}%, CR5 = {cr5*100:.1f}%, CR10 = {cr10*100:.1f}%")
conc_records = [
{"指標": "Gini 係数",
"値": round(gini, 4),
"0..1 解釈": "0=完全均等, 1=1 港独占",
"判定": "穏やかな集中" if gini < 0.3 else "中程度集中" if gini < 0.5 else "高集中"},
{"指標": "HHI (Herfindahl-Hirschman 指数, 1 ベース)",
"値": round(hhi, 4),
"0..1 解釈": "0=分散, 0.18 以上で高集中 (米 DOJ 基準)",
"判定": "低集中 (HHI < 0.15)" if hhi < 0.15 else "中集中" if hhi < 0.25 else "高集中"},
{"指標": "HHI (10000 ベース)",
"値": round(hhi_basis, 0),
"0..1 解釈": "10000=独占, ≥1800 で高集中 (HHI 同等)",
"判定": "—"},
{"指標": "CR3 (上位 3 港シェア)",
"値": round(cr3 * 100, 1),
"0..1 解釈": "上位 3 港が占める割合 (%)",
"判定": "穏やか分散" if cr3 < 0.40 else "中集中" if cr3 < 0.60 else "高集中"},
{"指標": "CR5 (上位 5 港シェア)",
"値": round(cr5 * 100, 1),
"0..1 解釈": "上位 5 港が占める割合 (%)",
"判定": "穏やか分散" if cr5 < 0.50 else "中集中" if cr5 < 0.70 else "高集中"},
{"指標": "CR10 (上位 10 港シェア)",
"値": round(cr10 * 100, 1),
"0..1 解釈": "上位 10 港が占める割合 (%)",
"判定": "—"},
]
conc_df = pd.DataFrame(conc_records)
conc_df.to_csv(OUT_CONCENTRATION, index=False, encoding="utf-8-sig")
# === STEP 4: ローレンツ曲線データ =============================================
print("\n=== STEP 4: ローレンツ曲線の点列生成 ===")
sorted_demand = np.sort(port_yearly["乗降客数"].values) # 昇順
n = len(sorted_demand)
cum_demand = np.concatenate([[0], np.cumsum(sorted_demand)])
cum_demand_pct = cum_demand / cum_demand[-1]
rank_pct = np.arange(0, n + 1) / n # 0..1
lorenz_df = pd.DataFrame({
"累積港数比": np.round(rank_pct, 4),
"累積需要比": np.round(cum_demand_pct, 4),
})
lorenz_df.to_csv(OUT_LORENZ, index=False, encoding="utf-8-sig")
print(f" → {OUT_LORENZ.name} ({len(lorenz_df)} 点)")
# === STEP 5: 港の役割分類 (始発/終着 vs 経由) =================================
print("\n=== STEP 5: RQ1 港の役割分類 (始発・終着 vs 経由) ===")
# 各航路の最初/最後の港を抽出
endpoint_ports = set()
for name, g in shimatabi.groupby("航路名"):
g = g.sort_values("寄港桟橋順")
endpoint_ports.add(g.iloc[0]["寄港地(桟橋名)"])
endpoint_ports.add(g.iloc[-1]["寄港地(桟橋名)"])
print(f" 始発/終着港 = {sorted(endpoint_ports)}")
# 港ごとに「何航路で始発/終着になっているか」を数える
port_role = []
for port in port_yearly["港"]:
g = shimatabi[shimatabi["寄港地(桟橋名)"] == port]
is_endpoint = port in endpoint_ports
n_routes = g["航路名"].nunique()
avg_order = g["寄港桟橋順"].mean()
median_order = g["寄港桟橋順"].median()
port_role.append({
"港": port,
"出現航路数": n_routes,
"平均寄港順": round(float(avg_order), 1),
"中央寄港順": float(median_order),
"始発終着": "始発/終着" if is_endpoint else "経由",
})
role_df = pd.DataFrame(port_role)
# 年間需要にマージしてランクと役割を併記
cluster_df = port_yearly_out.merge(role_df, on="港")
# 「主要港 (上位 5 / 始発終着)」 vs 「周辺港 (それ以外)」
cluster_df["港クラス"] = np.where(
(cluster_df["順位"] <= 5) | (cluster_df["始発終着"] == "始発/終着"),
"主要港", "周辺港")
cluster_df.to_csv(OUT_PORT_CLUSTER, index=False, encoding="utf-8-sig")
print(cluster_df.to_string(index=False))
n_main = (cluster_df["港クラス"] == "主要港").sum()
n_periph = (cluster_df["港クラス"] == "周辺港").sum()
# === STEP 6: 月別総需要 (RQ2) =================================================
print("\n=== STEP 6: RQ2 月別総需要 ===")
month_total = port_month.groupby("月", as_index=False)["乗降客数"].sum().sort_values("月")
month_total["乗降客数"] = month_total["乗降客数"].astype(int)
month_total["シェア"] = (month_total["乗降客数"] / month_total["乗降客数"].sum()).round(4)
month_total["季節"] = month_total["月"].apply(
lambda m: "春" if m in (4, 5) else "夏" if m in (6, 7, 8)
else "秋" if m in (9, 10, 11) else "冬"
)
month_total.to_csv(OUT_MONTH_TOTAL, index=False, encoding="utf-8-sig")
print(month_total.to_string(index=False))
peak_month = int(month_total.loc[month_total["乗降客数"].idxmax(), "月"])
trough_month = int(month_total.loc[month_total["乗降客数"].idxmin(), "月"])
peak_value = int(month_total["乗降客数"].max())
trough_value = int(month_total["乗降客数"].min())
peak_trough_ratio = peak_value / max(trough_value, 1)
print(f" ピーク月 = {peak_month}月 ({peak_value:,}人), 谷月 = {trough_month}月 ({trough_value:,}人)")
print(f" ピーク/谷 比 = {peak_trough_ratio:.2f}")
# === STEP 7: 港×月 季節係数 ==================================================
print("\n=== STEP 7: RQ2 港別 季節係数 ===")
# 季節係数 = 港 m の値 / 港の年平均
pivot = port_month.pivot(index="港", columns="月", values="乗降客数")
season_index = pivot.div(pivot.mean(axis=1), axis=0).round(3)
# 港順を年間需要順に並び替え
season_index = season_index.reindex(port_yearly["港"].tolist())
season_index_out = season_index.reset_index()
season_index_out.to_csv(OUT_SEASON_IDX, index=False, encoding="utf-8-sig")
print(season_index_out.to_string(index=False))
# 港別 季節振幅 = max - min (係数), max/min, std
season_amp = pd.DataFrame({
"港": season_index.index,
"最大月": season_index.idxmax(axis=1),
"最大係数": season_index.max(axis=1).round(3),
"最小月": season_index.idxmin(axis=1),
"最小係数": season_index.min(axis=1).round(3),
"振幅 (max-min)": (season_index.max(axis=1) - season_index.min(axis=1)).round(3),
"比率 (max/min)": (season_index.max(axis=1) / season_index.min(axis=1).replace(0, np.nan)).round(2),
"係数の標準偏差": season_index.std(axis=1).round(3),
}).reset_index(drop=True)
season_amp = season_amp.merge(port_yearly_out[["港", "順位", "乗降客数"]], on="港")
season_amp = season_amp.sort_values("順位").reset_index(drop=True)
season_amp.to_csv(OUT_SEASON_AMP, index=False, encoding="utf-8-sig")
amp_max = season_amp["振幅 (max-min)"].max()
amp_min = season_amp["振幅 (max-min)"].min()
amp_ratio = amp_max / amp_min if amp_min > 0 else float("inf")
print(f" 港別季節振幅 max/min = {amp_max:.2f} / {amp_min:.2f} = 比 {amp_ratio:.2f}")
# === STEP 8: モニタークルーズ ルート構造 (RQ3) ================================
print("\n=== STEP 8: RQ3 モニタークルーズのルート記述 ===")
# 1 航海 = 1 日 × 1 航路
trip = (monitor.drop_duplicates(["運航日", "航路名"])
[["運航日", "航路名", "観光客数(人)"]]
.sort_values(["運航日", "航路名"]).reset_index(drop=True))
trip["運航日"] = trip["運航日"].dt.date
trip.to_csv(OUT_MON_TRIPS, index=False, encoding="utf-8-sig")
print(trip.to_string(index=False))
# 各航路のサマリ: 寄港地数, 新規/既存桟橋数, 運航日数, 観光客数 (合計/平均)
route_records = []
for name, g in monitor.groupby("航路名"):
stops = g.drop_duplicates("寄港地ID")
new_stops = (stops["区間情報"] == "新規区間").sum()
old_stops = (stops["区間情報"] == "既存区間").sum()
n_days = g["運航日"].nunique()
pas_per_day = g.drop_duplicates("運航日")["観光客数(人)"]
new_ratio = new_stops / (new_stops + old_stops) if (new_stops + old_stops) > 0 else 0
if new_ratio == 1.0:
rtype = "完全新規"
elif new_ratio == 0.0:
rtype = "完全既存"
elif new_ratio >= 0.5:
rtype = "新規主体"
else:
rtype = "既存主体"
route_records.append({
"航路名": name,
"寄港地数": int(stops["寄港地ID"].nunique()),
"新規寄港数": int(new_stops),
"既存寄港数": int(old_stops),
"新規率": round(float(new_ratio), 2),
"ルートタイプ": rtype,
"運航日数": int(n_days),
"観光客数_合計": int(pas_per_day.sum()),
"観光客数_平均": round(float(pas_per_day.mean()), 1),
"観光客数_最大": int(pas_per_day.max()),
"観光客数_最小": int(pas_per_day.min()),
})
routes_df = pd.DataFrame(route_records).sort_values("航路名").reset_index(drop=True)
routes_df.to_csv(OUT_MON_ROUTES, index=False, encoding="utf-8-sig")
print(routes_df.to_string(index=False))
total_visitors = trip["観光客数(人)"].sum()
print(f" 合計観光客数 (15 航海) = {total_visitors} 人")
# 寄港地マスタ整形 (RQ3 の表用)
ports_master = ports_meta[["寄港地ID", "寄港地名(桟橋名)", "住所", "緯度", "経度", "区間情報"]].copy()
ports_master = ports_master.rename(columns={"寄港地名(桟橋名)": "寄港地名"})
ports_master.to_csv(OUT_MON_PORTS, index=False, encoding="utf-8-sig")
# 航路 → 寄港地順序リスト (地図用)
route_geometry = {}
for name, g in monitor.groupby("航路名"):
g_seq = g.drop_duplicates("寄港地ID").sort_values("寄港桟橋順")
coords = list(zip(g_seq["緯度"].tolist(), g_seq["経度"].tolist()))
seg = g_seq["区間情報"].tolist()
route_geometry[name] = {"coords": coords, "seg": seg, "stops": g_seq["寄港地(桟橋名)"].tolist()}
# === STEP 9: 図1 RQ1 港別年間需要 バーチャート ===============================
print("\n=== STEP 9: 図1 港別年間需要バー ===")
fig, ax = plt.subplots(figsize=(11, 6))
colors = ["#cf222e" if c == "主要港" else "#0969da" for c in cluster_df["港クラス"]]
xs = np.arange(len(cluster_df))
ax.bar(xs, cluster_df["乗降客数"], color=colors, edgecolor="black", alpha=0.85)
for i, (v, share) in enumerate(zip(cluster_df["乗降客数"], cluster_df["シェア"])):
ax.text(i, v + 100, f"{int(v):,}\n({share*100:.1f}%)",
ha="center", va="bottom", fontsize=8.5)
ax.set_xticks(xs)
ax.set_xticklabels(cluster_df["港"], rotation=35, ha="right", fontsize=9)
ax.set_ylabel("年間乗降客数 (人)")
ax.set_title("図1 (RQ1): 広島県沿岸クルーズ 14 港の 2022 年間乗降客数 — 主要港 (赤) と 周辺港 (青)")
ax.grid(alpha=0.3, axis="y")
legend_elements = [
Patch(facecolor="#cf222e", edgecolor="black", label="主要港 (上位5位 ∪ 始発/終着)"),
Patch(facecolor="#0969da", edgecolor="black", label="周辺港 (経由のみ)"),
]
ax.legend(handles=legend_elements, loc="upper right")
ax.set_ylim(0, cluster_df["乗降客数"].max() * 1.15)
plt.tight_layout()
plt.savefig(PNG_RQ1_BAR, dpi=140, bbox_inches="tight")
plt.close(fig)
print(f" → {PNG_RQ1_BAR.name}")
# === STEP 10: 図2 RQ1 ローレンツ曲線 + Gini ===================================
print("\n=== STEP 10: 図2 ローレンツ曲線 ===")
fig, ax = plt.subplots(figsize=(7.6, 7.0))
ax.plot([0, 1], [0, 1], color="#999", linestyle="--", linewidth=1.4,
label="完全均等 線 (y = x)")
ax.plot(lorenz_df["累積港数比"], lorenz_df["累積需要比"],
color="#cf222e", linewidth=2.2, marker="o", markersize=5,
label=f"実測ローレンツ曲線 (Gini = {gini:.3f})")
ax.fill_between(lorenz_df["累積港数比"], lorenz_df["累積需要比"],
lorenz_df["累積港数比"], color="#cf222e", alpha=0.15,
label="不均等の領域 (面積 = Gini/2)")
ax.set_xlabel("累積港数比 (下位から)")
ax.set_ylabel("累積需要比 (下位から)")
ax.set_title(f"図2 (RQ1): 広島県クルーズ需要のローレンツ曲線\n"
f"Gini = {gini:.3f}, HHI = {hhi:.3f}, CR3 = {cr3*100:.1f}%, CR5 = {cr5*100:.1f}%")
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
ax.legend(loc="upper left", fontsize=9.5)
ax.grid(alpha=0.3)
plt.tight_layout()
plt.savefig(PNG_RQ1_LORENZ, dpi=140, bbox_inches="tight")
plt.close(fig)
print(f" → {PNG_RQ1_LORENZ.name}")
# === STEP 11: 図3 RQ1 港別需要 地図 (緯度経度バブル) =========================
print("\n=== STEP 11: 図3 港の地理マップ ===")
# port_geo + port_yearly + cluster_df をマージ
geo_plot = port_geo.merge(cluster_df, on="港")
fig, ax = plt.subplots(figsize=(11, 7.4))
# サイズ = sqrt(乗降客数) * scale
size_scale = 0.4
sizes = np.sqrt(geo_plot["乗降客数"].astype(float).values) * size_scale * 30
colors2 = ["#cf222e" if c == "主要港" else "#0969da" for c in geo_plot["港クラス"]]
ax.scatter(geo_plot["経度"], geo_plot["緯度"], s=sizes, c=colors2,
edgecolor="black", alpha=0.7, zorder=3)
# 港名注釈
for _, r in geo_plot.iterrows():
ax.annotate(r["港"], (r["経度"], r["緯度"]),
xytext=(6, 6), textcoords="offset points",
fontsize=8.5, alpha=0.9)
# 航路の線 (東向き 1 本, 西向き 1 本)
for name, g in shimatabi.groupby("航路名"):
g = g.sort_values("寄港桟橋順")
ax.plot(g["経度"], g["緯度"], color="#888", linewidth=1.2,
alpha=0.5, linestyle=":", zorder=1, label=name)
ax.set_xlabel("経度 (°E)")
ax.set_ylabel("緯度 (°N)")
ax.set_title("図3 (RQ1): しまたびライン 14 港の地理配置\n"
"円サイズ = 年間乗降客数, 色 = 主要港 (赤) / 周辺港 (青), 点線 = 航路")
# 凡例 (主要/周辺の bubble + 航路線)
legend_elements = [
Line2D([0], [0], marker="o", color="w", markerfacecolor="#cf222e",
markersize=10, markeredgecolor="black", label="主要港"),
Line2D([0], [0], marker="o", color="w", markerfacecolor="#0969da",
markersize=10, markeredgecolor="black", label="周辺港"),
Line2D([0], [0], color="#888", linestyle=":", label="航路 (東/西)"),
]
ax.legend(handles=legend_elements, loc="lower right")
ax.grid(alpha=0.3)
plt.tight_layout()
plt.savefig(PNG_RQ1_MAP, dpi=140, bbox_inches="tight")
plt.close(fig)
print(f" → {PNG_RQ1_MAP.name}")
# === STEP 12: 図4 RQ2 月別総需要 折れ線 ======================================
print("\n=== STEP 12: 図4 月別総需要 ===")
fig, ax = plt.subplots(figsize=(11, 5.4))
mt = month_total
season_color_map = {"春": "#a8e6cf", "夏": "#fff3b0", "秋": "#ffd6a5", "冬": "#bde0fe"}
bar_colors = [season_color_map[s] for s in mt["季節"]]
ax.bar(mt["月"], mt["乗降客数"], color=bar_colors, edgecolor="black", alpha=0.7,
label="月別需要 (棒, 季節色塗分)")
ax.plot(mt["月"], mt["乗降客数"], color="#cf222e", linewidth=2.4, marker="o",
markersize=8, zorder=3, label="月別需要 (折れ線)")
for x, y in zip(mt["月"], mt["乗降客数"]):
ax.annotate(f"{int(y):,}", (x, y),
xytext=(0, 10), textcoords="offset points",
ha="center", fontsize=9)
ax.axhline(mt["乗降客数"].mean(), color="#666", linestyle="--", linewidth=1,
label=f"年平均 = {mt['乗降客数'].mean():.0f}")
ax.set_xticks(month_num)
ax.set_xticklabels([f"{m}月" for m in month_num])
ax.set_xlabel("月 (2022 年)")
ax.set_ylabel("月別 全 14 港合算 乗降客数 (人)")
ax.set_title("図4 (RQ2): 2022 年 4-12 月 月別総需要 — 春秋 2 山型 + 夏冬 2 谷")
# 季節凡例
legend_elements = [
Patch(facecolor=season_color_map[s], edgecolor="black", alpha=0.7, label=f"{s}")
for s in ["春", "夏", "秋", "冬"]
] + [Line2D([0], [0], color="#cf222e", linewidth=2.4, marker="o", label="月需要")]
ax.legend(handles=legend_elements, loc="upper right", fontsize=9.5)
ax.grid(alpha=0.3, axis="y")
ax.set_ylim(0, mt["乗降客数"].max() * 1.15)
plt.tight_layout()
plt.savefig(PNG_RQ2_TOTAL, dpi=140, bbox_inches="tight")
plt.close(fig)
print(f" → {PNG_RQ2_TOTAL.name}")
# === STEP 13: 図5 RQ2 港×月 ヒートマップ =====================================
print("\n=== STEP 13: 図5 港×月 ヒートマップ (生客数) ===")
heat_mat = pivot.reindex(port_yearly["港"].tolist()) # 年間順
fig, ax = plt.subplots(figsize=(11, 6.2))
im = ax.imshow(heat_mat.values, aspect="auto", cmap="YlOrRd",
vmin=0, vmax=np.nanmax(heat_mat.values))
ax.set_xticks(range(len(month_num)))
ax.set_xticklabels([f"{m}月" for m in month_num])
ax.set_yticks(range(len(heat_mat)))
ax.set_yticklabels(heat_mat.index, fontsize=8.5)
# セル値
for i in range(heat_mat.shape[0]):
for j in range(heat_mat.shape[1]):
v = heat_mat.values[i, j]
if pd.notna(v):
color = "white" if v > np.nanmax(heat_mat.values) * 0.55 else "black"
ax.text(j, i, f"{int(v)}", ha="center", va="center",
fontsize=7.5, color=color)
ax.set_title("図5 (RQ2): 港 × 月 乗降客数ヒートマップ — 港は年間需要降順")
cbar = plt.colorbar(im, ax=ax, fraction=0.038, pad=0.02)
cbar.set_label("月乗降客数 (人)", rotation=90)
plt.tight_layout()
plt.savefig(PNG_RQ2_HEATMAP, dpi=140, bbox_inches="tight")
plt.close(fig)
print(f" → {PNG_RQ2_HEATMAP.name}")
# === STEP 14: 図6 RQ2 港別 季節振幅 ==========================================
print("\n=== STEP 14: 図6 港別 季節振幅バー ===")
fig, axes = plt.subplots(1, 2, figsize=(14, 6.0))
# 左: 港別季節係数のヒートマップ (係数値)
ax = axes[0]
si_mat = season_index.values
im1 = ax.imshow(si_mat, aspect="auto", cmap="RdBu_r",
vmin=0, vmax=2.0)
ax.set_xticks(range(len(month_num)))
ax.set_xticklabels([f"{m}月" for m in month_num])
ax.set_yticks(range(len(season_index)))
ax.set_yticklabels(season_index.index, fontsize=8.5)
for i in range(si_mat.shape[0]):
for j in range(si_mat.shape[1]):
v = si_mat[i, j]
if pd.notna(v):
ax.text(j, i, f"{v:.2f}", ha="center", va="center",
fontsize=7.0,
color="white" if (v < 0.4 or v > 1.6) else "black")
ax.set_title("(左) 港 × 月 季節係数 (= 港m / 港年平均)")
cbar1 = plt.colorbar(im1, ax=ax, fraction=0.038, pad=0.02)
cbar1.set_label("季節係数 (1.0 = 港の年平均)", rotation=90)
# 右: 港別の季節振幅 (max-min) と max/min 比
ax = axes[1]
sa = season_amp.copy()
sa = sa.sort_values("振幅 (max-min)", ascending=True).reset_index(drop=True)
ys = np.arange(len(sa))
bar_colors2 = ["#cf222e" if c == "主要港" else "#0969da"
for c in sa["港"].map(dict(zip(cluster_df["港"], cluster_df["港クラス"])))]
ax.barh(ys, sa["振幅 (max-min)"], color=bar_colors2, edgecolor="black", alpha=0.85)
for i, (v, r) in enumerate(zip(sa["振幅 (max-min)"], sa["比率 (max/min)"])):
ax.text(v + 0.02, i, f"振幅={v:.2f}, 比率={r:.1f}×",
va="center", fontsize=8.5)
ax.set_yticks(ys)
ax.set_yticklabels(sa["港"], fontsize=9)
ax.set_xlabel("季節振幅 (max係数 − min係数)")
ax.set_title("(右) 港別 季節振幅 — 大きい = 季節依存強い")
ax.grid(alpha=0.3, axis="x")
ax.set_xlim(0, sa["振幅 (max-min)"].max() * 1.35)
plt.suptitle("図6 (RQ2): 季節係数の港間比較 (左: ヒートマップ, 右: 振幅バー)", y=1.02)
plt.tight_layout()
plt.savefig(PNG_RQ2_AMP, dpi=140, bbox_inches="tight")
plt.close(fig)
print(f" → {PNG_RQ2_AMP.name}")
# === STEP 15: 図7 RQ3 モニタークルーズ ルートマップ ==========================
print("\n=== STEP 15: 図7 モニタークルーズ ルートマップ ===")
fig, ax = plt.subplots(figsize=(12, 7.4))
# まず港マスタを散布
all_ports = ports_master.copy()
all_ports["役割"] = all_ports["区間情報"] # 新規 / 既存
# 既存しまたび 14 港との重なり判定
shimatabi_ports = set(port_yearly["港"].tolist())
all_ports["既存 vs 新規"] = all_ports.apply(
lambda r: "新規寄港地" if r["区間情報"] == "新規区間" else "既存寄港地", axis=1)
# 港の点 (色: 区間情報)
for label, color in [("新規区間", "#cf222e"), ("既存区間", "#0969da")]:
sub = all_ports[all_ports["区間情報"] == label]
ax.scatter(sub["経度"], sub["緯度"], s=110, c=color, edgecolor="black",
alpha=0.85, label=f"{label}寄港地 ({len(sub)} 港)", zorder=4)
for _, r in all_ports.iterrows():
ax.annotate(r["寄港地名"], (r["経度"], r["緯度"]),
xytext=(6, 6), textcoords="offset points",
fontsize=7.5, alpha=0.85)
# 航路ごとに線を引く (色は航路ごと)
route_colors = ["#0969da", "#cf222e", "#16a34a", "#fb8500",
"#9333ea", "#0891b2", "#dc2626"]
for i, (name, geo) in enumerate(route_geometry.items()):
coords = geo["coords"]
if len(coords) < 2:
continue
lats = [c[0] for c in coords]
lons = [c[1] for c in coords]
ax.plot(lons, lats, color=route_colors[i % len(route_colors)],
linewidth=2.2, alpha=0.55, zorder=2,
label=name)
ax.set_xlabel("経度 (°E)")
ax.set_ylabel("緯度 (°N)")
ax.set_title("図7 (RQ3): モニタークルーズ 7 航路 × 23 寄港地 のルートマップ\n"
"赤丸 = 新規区間寄港地, 青丸 = 既存区間寄港地, 線 = 7 航路の経路")
ax.legend(loc="upper left", fontsize=8, framealpha=0.92, ncol=1)
ax.grid(alpha=0.3)
plt.tight_layout()
plt.savefig(PNG_RQ3_MAP, dpi=140, bbox_inches="tight")
plt.close(fig)
print(f" → {PNG_RQ3_MAP.name}")
# === STEP 16: 図8 RQ3 航路別 1 運航客数 (運航日重ねバー) =====================
print("\n=== STEP 16: 図8 運航日×航路 観光客数 ===")
fig, ax = plt.subplots(figsize=(13, 5.8))
trip_view = trip.copy()
trip_view["運航日_str"] = pd.to_datetime(trip_view["運航日"]).dt.strftime("%m-%d")
# 航路ごとに色を付け、横軸は運航日
days_sorted = sorted(trip_view["運航日_str"].unique())
routes_sorted = sorted(trip_view["航路名"].unique())
n_d = len(days_sorted)
n_r = len(routes_sorted)
bar_w = 0.9 / n_r
day_idx = {d: i for i, d in enumerate(days_sorted)}
route_color_map = {r: route_colors[i % len(route_colors)] for i, r in enumerate(routes_sorted)}
for i, name in enumerate(routes_sorted):
sub = trip_view[trip_view["航路名"] == name]
xs = [day_idx[d] + (i - n_r/2 + 0.5) * bar_w for d in sub["運航日_str"]]
ax.bar(xs, sub["観光客数(人)"], width=bar_w * 0.95,
color=route_color_map[name], edgecolor="black", alpha=0.85,
label=name)
for x, y in zip(xs, sub["観光客数(人)"]):
ax.text(x, y + 1, str(int(y)), ha="center", fontsize=7.5)
ax.set_xticks(range(n_d))
ax.set_xticklabels(days_sorted, fontsize=9)
ax.set_xlabel("運航日 (2022 年 12 月)")
ax.set_ylabel("1 航海あたり観光客数 (人)")
ax.set_title("図8 (RQ3): モニタークルーズ 9 運航日 × 7 航路 = 15 航海の観光客数")
ax.legend(loc="upper right", fontsize=8, framealpha=0.9, ncol=2)
ax.grid(alpha=0.3, axis="y")
plt.tight_layout()
plt.savefig(PNG_RQ3_TRIPS, dpi=140, bbox_inches="tight")
plt.close(fig)
print(f" → {PNG_RQ3_TRIPS.name}")
# === STEP 17: 図9 RQ3 ルートタイプ別 区間構成 stacked bar =====================
print("\n=== STEP 17: 図9 ルートタイプ別 区間構成 ===")
fig, axes = plt.subplots(1, 2, figsize=(14, 5.6))
# 左: 各航路の新規/既存桟橋数 stacked bar
ax = axes[0]
rd = routes_df.sort_values("新規率", ascending=True).reset_index(drop=True)
ys = np.arange(len(rd))
ax.barh(ys, rd["既存寄港数"], color="#0969da", edgecolor="black",
label="既存区間寄港数", alpha=0.85)
ax.barh(ys, rd["新規寄港数"], left=rd["既存寄港数"], color="#cf222e",
edgecolor="black", label="新規区間寄港数", alpha=0.85)
for i, (n_total, ratio, rt) in enumerate(zip(
rd["寄港地数"], rd["新規率"], rd["ルートタイプ"])):
ax.text(n_total + 0.2, i, f"{rt} (新規率 {ratio*100:.0f}%)",
va="center", fontsize=8.5)
ax.set_yticks(ys)
ax.set_yticklabels(rd["航路名"], fontsize=8.5)
ax.set_xlabel("寄港地数 (新規/既存)")
ax.set_title("(左) 7 航路の寄港地構成 — 新規 vs 既存区間")
ax.legend(loc="lower right", fontsize=9)
ax.grid(alpha=0.3, axis="x")
ax.set_xlim(0, rd["寄港地数"].max() * 1.55)
# 右: ルートタイプ別 平均 1 航海観光客数
ax = axes[1]
rt_summary = (routes_df.groupby("ルートタイプ")
.agg({"観光客数_合計": "sum", "観光客数_平均": "mean",
"運航日数": "sum", "航路名": "count"})
.rename(columns={"航路名": "航路数"}))
rt_order = ["完全既存", "既存主体", "新規主体", "完全新規"]
rt_summary = rt_summary.reindex([t for t in rt_order if t in rt_summary.index])
ys2 = np.arange(len(rt_summary))
type_colors = {"完全既存": "#0969da", "既存主体": "#7eb6e3",
"新規主体": "#e8716e", "完全新規": "#cf222e"}
bar_c = [type_colors[t] for t in rt_summary.index]
ax.barh(ys2, rt_summary["観光客数_平均"], color=bar_c,
edgecolor="black", alpha=0.85)
for i, (avg, n_route, n_day) in enumerate(zip(
rt_summary["観光客数_平均"], rt_summary["航路数"], rt_summary["運航日数"])):
ax.text(avg + 1, i, f"平均 {avg:.1f} 人/航海 ({int(n_route)}航路 {int(n_day)}航海)",
va="center", fontsize=8.5)
ax.set_yticks(ys2)
ax.set_yticklabels(rt_summary.index, fontsize=10)
ax.set_xlabel("1 航海あたり平均観光客数 (人)")
ax.set_title("(右) ルートタイプ別 1 航海平均観光客数")
ax.grid(alpha=0.3, axis="x")
ax.set_xlim(0, max(rt_summary["観光客数_平均"]) * 1.55)
plt.suptitle("図9 (RQ3): モニタークルーズの構造 — 7 航路の区間構成 (左) と ルートタイプ別客数 (右)",
y=1.02)
plt.tight_layout()
plt.savefig(PNG_RQ3_MIX, dpi=140, bbox_inches="tight")
plt.close(fig)
print(f" → {PNG_RQ3_MIX.name}")
# ============================================================================
# HTML 組み立て
# ============================================================================
print("\n=== STEP 18: HTML 組み立て ===")
def df_to_html(df, idx=False):
return df.to_html(index=idx, border=0, escape=False)
# --- 共通変数の準備 ---
peak_month_name = f"{peak_month}月"
trough_month_name = f"{trough_month}月"
top1_port = port_yearly.iloc[0]["港"]
top1_share = port_yearly.iloc[0]["シェア"]
bottom1_port = port_yearly.iloc[-1]["港"]
bottom1_share = port_yearly.iloc[-1]["シェア"]
top1_volume = int(port_yearly.iloc[0]["乗降客数"])
bottom1_volume = int(port_yearly.iloc[-1]["乗降客数"])
amp_top_port = season_amp.iloc[season_amp["振幅 (max-min)"].idxmax()]["港"]
amp_top_value = season_amp["振幅 (max-min)"].max()
amp_bot_port = season_amp.iloc[season_amp["振幅 (max-min)"].idxmin()]["港"]
amp_bot_value = season_amp["振幅 (max-min)"].min()
# 仮説判定
h1_judge = "支持" if (cr5 >= 0.40 and gini >= 0.10) else "部分支持" if cr5 >= 0.30 else "反証"
h2_endpoint_top3 = sum(1 for p in port_yearly.head(3)["港"] if p in endpoint_ports)
h2_judge = "支持" if h2_endpoint_top3 >= 2 else "部分支持"
h3_judge = "支持" if (peak_trough_ratio >= 4.0 and peak_month in (5, 11)
and trough_month == 12) else "部分支持"
h4_judge = "支持" if amp_ratio >= 1.5 else "部分支持"
h5_n_types = routes_df["ルートタイプ"].nunique()
h5_judge = "支持" if h5_n_types >= 3 else "部分支持"
# === セクション 1: 学習目標と問い ===
sec1 = f"""
【本記事は 2026-05 改訂版】
旧 X04 (2026-05 以前) は 2022 年 12 月のせとうちモニタークルーズ実証実験を
「介入パルス」 とみなし、しまたびライン 8 ヶ月のベースラインに対する
DID 風前後比較で
「介入効果」 を推論しよう としていた。
しかし以下の方法論的問題があり、研究としての妥当性が確保できなかった:
- (1) 介入イベント n = 1 で因果推論不可 (反復観測なし)。
- (2) ベースライン傾き |a₁| が小さく、|差|/|a₁| が 約 200 倍 (19919%) に発散して
効果サイズの解釈が成立しない。
- (3) コロナ禍・季節・天候・経済環境の交絡が一切統制されていない。
- (4) DID 風と称しながら 平行トレンド前提が検証不可能。
本改訂では因果推論を装う構成を
全面廃案にし、同一データセット 2 件
(#1282 + #1280) を用いた
記述統計 + 市場構造分析に転換する。
3 つの研究角度 (RQ1/RQ2/RQ3) を Format B で並列に立てる。
【本記事のスタイル: 単独 3RQ 形式 (Format B) / 記述統計 + 市場構造分析】
1 記事の中で 3 つの独立した研究角度を並列に進める。
各 RQ は単独で読める単元を成し、全体として広島県沿岸クルーズ需要の
3 軸プロファイルを形成する。
本記事は、DoBoX が公開する 瀬戸内クルーズ関連 2 データセットを
記述統計 + 市場構造分析の枠組みで読み解く。
- #1282 瀬戸内しまたびライン利用状況 — 2022 年 4-12 月の月次乗降客数。
2 航路 × 14 桟橋 × 9 ヶ月。
- #1280 せとうちモニタークルーズ実施結果 — 2022 年 12 月の実証実験。
7 航路 × 9 運航日 = 15 航海, 23 寄港地。
このレッスンで答えたい問い (3 軸の RQ)
| RQ | 位置付け | 問い | 使うデータ |
|---|
| RQ1 | 主研究 |
広島県沿岸クルーズ需要は 14 港にどう配分されているか?
集中度はどの程度か? 主要港 vs 周辺港 の役割分化は? |
#1282 (港 × 月) |
| RQ2 | 副研究 1 |
需要の季節性は春秋 2 山型か? 港別差はあるか? |
#1282 (港 × 月 季節係数) |
| RQ3 | 副研究 2 |
モニタークルーズ実施結果のルート設計を記述する。
新規/既存区間の混合、寄港数、運航日分布は?
因果推論はしない (n = 1)。 |
#1280 (航路 × 寄港地 × 運航日) |
立てた仮説 (H1〜H5)
- H1 (RQ1): 14 港の需要は均等配分ではなく、CR5 ≥ 40%, Gini ≥ 0.10
程度の集中度がある。
- H2 (RQ1): 主要港 (上位 3) は航路の 始発・終着港、
周辺港は 島嶼経由地という役割分化がある。
- H3 (RQ2): 月別需要は 春秋 2 山型で、5 月と 11 月にピーク。
12 月の谷はピークの 1/4 以下。
- H4 (RQ2): 港別の季節係数は同じ春でも振幅が異なる。
季節振幅 (= 最大係数 − 最小係数) は港間で 1.5 倍以上の差がある。
- H5 (RQ3): モニタークルーズ 7 航路は 区間混合比に応じて 4 タイプに
分類できる (完全既存・既存主体・新規主体・完全新規)。空間設計は既存ライン
(広島-三原) を 東に延伸する形になっている。
用語の独自定義 (このレッスン専用)
- 「クルーズ需要 (cruise demand)」: 本記事では DoBoX #1282 が記録する
「桟橋ごとの月別乗降客数」 を需要の代理指標とする。実態は 船に乗った観光客数であり、
需要 (=潜在的に乗りたかった人数) とは厳密には異なるが、ここでは便宜上 需要 ≈ 乗降客数
と扱う。
- 「集中度 (concentration)」: 全需要が少数の港に偏っている度合い。本記事では
3 つの指標で測る:
- Gini 係数 = 0 (完全均等) 〜 1 (1 港独占)。本記事は港別需要の累積分布から計算。
- HHI (Herfindahl-Hirschman 指数) = Σ (各港のシェア)²。
0 (分散) 〜 1 (独占)。米司法省は HHI ≥ 0.18 を「高集中」とする。
- CRn (Concentration Ratio) = 上位 n 港のシェア合計。CR3, CR5, CR10 を併記。
- 「主要港 (major port)」: 本記事独自の分類。「年間需要 上位 5 位以内」 ∪
「航路の始発または終着港」 を満たすもの。
- 「周辺港 (peripheral port)」: 主要港でないもの。航路上の 経由のみ。
- 「季節係数 (seasonal index)」: 港 m 月の値 ÷ 港の年平均。
1.0 = 港の年平均、1.5 = 年平均の 1.5 倍、0.3 = 年平均の 0.3 倍。
港間の絶対値の違いを正規化することで、季節パターンの形のみを比較できる。
- 「季節振幅 (seasonal amplitude)」: 港の季節係数の (最大値 − 最小値)。
大きい = 季節依存が強い、小さい = 通年で安定。
- 「モニタークルーズ (monitor cruise)」: 広島県が 2022 年 12 月に実施した
実証実験。新規ルート 4 + 既存ルート 3 の 7 航路を 9 日間運航。
本記事では 記述分析のみ。1 回限りの実験のため 因果推論は行わない。
- 「ルートタイプ (route type)」: 各航路の新規寄港地比率に応じた本記事独自の
4 分類。完全既存 (新規率 0%) / 既存主体 (0% 超 50% 未満) / 新規主体 (50% 以上 100% 未満)
/ 完全新規 (100%)。
- 「始発/終着港」: 航路の 寄港桟橋順 = 1 または最大の港。乗船・下船が
集中するため、需要量も他港より多い傾向。
到達点
3 つの RQ を順に追体験することで、学習者は次の 3 つの分析手法を身につける:
(1) 集中度指標 3 種 (Gini / HHI / CRn) の使い分け、
(2) 季節係数による港別パターン正規化と振幅比較、
(3) ルート構成データの記述分析 (区間混合比 + ルートタイプ分類)。
広島県沿岸クルーズ市場が 「主要港 5+ 港 + 周辺港 9 港」 × 「春秋 2 山 + 冬の谷」 ×
「東に延伸する実験ルート」の 3 構造でできていることを 1 つの一貫したデータ物語として
把握する。
"""
# === セクション 2: 使用データ ===
sec2 = f"""
改訂理由 (再掲): 旧 X04 は n=1 の介入効果分析を試みていたが、
方法論的に成立しないため 記述統計に転換。同じ 2 データセットを
3 つの記述研究角度 (RQ1/RQ2/RQ3) で読み直す。
本レッスンは DoBoX オープンデータ 2 件を使う:
| DoBoX ID | データ名 | 本記事での役割 | 形式 | サイズ |
|---|
| #1282 |
瀬戸内しまたびライン利用状況 (resource 39787) |
RQ1 / RQ2 の主データ — 港 × 月 の乗降客数 |
CSV (cp932) | {shimatabi.shape[0]} 行 × {shimatabi.shape[1]} 列 ({SHIMATABI_CSV.stat().st_size//1024} KB) |
| #1280 |
せとうちモニタークルーズ実施結果 (resource 39782) |
RQ3 の主データ — 航路 × 寄港地 × 運航日 |
CSV (cp932) | {monitor.shape[0]} 行 × {monitor.shape[1]} 列 ({MONITOR_CSV.stat().st_size//1024} KB) |
| #1280 (補) |
モニタークルーズ寄港地マスタ (resource 39781) |
23 寄港地の住所・緯度経度・区間情報 |
CSV (cp932) | {ports_meta.shape[0]} 行 × {ports_meta.shape[1]} 列 ({PORTS_CSV.stat().st_size//1024} KB) |
サイズの整理 (要件L: 表示と次元の混同を防ぐ):
| 段階 | 行数 | 列数 | 説明 |
|---|
| 原データ shimatabi_monthly.csv | {shimatabi.shape[0]} | {shimatabi.shape[1]} |
2 航路 × 14 桟橋 = 24 行 (頭末に NaN 行あり, 除去後)。月列 9 個 (4-12月)。 |
| 原データ cruise_monitor_daily.csv | {monitor.shape[0]} | {monitor.shape[1]} |
7 航路 × 平均 8 寄港地 × 平均 2 運航日 = 133 行。1 行 = 1 (運航日, 寄港地)。 |
| 長表 long_df (本記事生成) | {len(long_df)} | {long_df.shape[1]} |
(航路, 港, 月) のタプルごとに 1 行。 |
| 港×月 集約 port_month | {len(port_month)} | 3 |
東/西航路を合算し (港, 月, 乗降客数) に圧縮。RQ1/RQ2 の主表。 |
| 港別年間 port_yearly | {len(port_yearly)} | 5 |
14 港 × (順位, 港名, 年間客数, シェア, 累積)。 |
| 港×月 季節係数 (pivot) | 14 港 | 9 月 |
係数 = 港m / 港年平均。1.0 = 港の年平均水準。 |
| モニタールート route_records | 7 航路 | 11 |
各航路の寄港数・新規率・運航日数・観光客数集計。 |
| モニター航海 trip | {len(trip)} 航海 | 3 |
1 行 = 1 (運航日, 航路) = 1 航海 (= 観光客数 1 値)。 |
※ 「14 港」 と 「7 航路」 と 「23 寄港地」 は別物。
14 港 = しまたび東/西航路の港 (2022 年定常運航)、
23 寄港地 = モニタークルーズの寄港地 (2022 年 12 月実証, 14 港の一部 + 新規 9 港)、
7 航路 = モニタークルーズで運航された航路。
データ実態の重要事項:
DoBoX のデータセットページには複数の resource が登録されており、
本記事で使う時系列 CSV は resource_id 39787 (#1282) と resource_id 39782 (#1280)。
データセット ID で検索した場合の 先頭リソースは別のファイル (港マスタ・SHP)なので注意。
本記事のスクリプトは resource_id を直接指定して取得する。
"""
# === セクション 3: ダウンロード ===
sec3 = f"""
原データ (DoBoX)
| 論題 | データセット | resource_download 直 DL | 保存先 | 形式 | サイズ |
|---|
| 瀬戸内しまたびライン 月次 |
DoBoX #1282 |
直DL (39787) |
data/extras/shimatabi_monthly.csv |
CSV (cp932) | {SHIMATABI_CSV.stat().st_size//1024} KB |
| モニタークルーズ 日別 |
DoBoX #1280 |
直DL (39782) |
data/extras/cruise_monitor_daily.csv |
CSV (cp932) | {MONITOR_CSV.stat().st_size//1024} KB |
| モニタークルーズ 寄港地マスタ |
DoBoX #1280 |
直DL (39781) |
data/extras/cruise_monitor_ports.csv |
CSV (cp932) | {PORTS_CSV.stat().st_size//1024} KB |
個別取得 (PowerShell, このレッスンだけ):
cd "2026 DoBoX 教材"
iwr "https://hiroshima-dobox.jp/resource_download/39787" -OutFile "data/extras/shimatabi_monthly.csv"
iwr "https://hiroshima-dobox.jp/resource_download/39782" -OutFile "data/extras/cruise_monitor_daily.csv"
iwr "https://hiroshima-dobox.jp/resource_download/39781" -OutFile "data/extras/cruise_monitor_ports.csv"
本レッスンの .py スクリプトは、データが無ければ ensure_dataset() で自動取得してから処理を始める。
本レッスン生成の中間 CSV (HTML から直 DL)
図 PNG (HTML から直 DL)
再現スクリプト
X04_cruise_intervention_timeseries.py を以下で実行:
cd "2026 DoBoX 教材"
py -X utf8 lessons/X04_cruise_intervention_timeseries.py
"""
# === RQ1: 港別需要構造 ===
rq1_intro = f"""
研究の問い (RQ1)
広島県沿岸クルーズ需要は 14 港にどう配分されているか? 集中度はどの程度で、
主要港と周辺港の役割分化はあるか?
仮説 (再掲)
- H1: 14 港の需要は均等配分ではなく、CR5 ≥ 40%, Gini ≥ 0.10 程度の集中度がある。
- H2: 主要港 (上位 3) は航路の 始発・終着港、周辺港は 島嶼経由地。
手法 (ツール視点・要件J)
(1) 集中度指標 3 種は何のツールか:
- Gini 係数 (0..1):
- 入力: 各個体 (港) のシェアまたは絶対値の数列
- 出力: 1 個のスカラ (0=完全均等, 1=1 個に独占)
- 動作のイメージ: ローレンツ曲線 (累積港数比 vs 累積需要比) と
完全均等線 (y=x) の 間の面積を 2 倍したもの。
- 結果の読み方: Gini = 0.05 なら均等寄り, 0.30 なら穏やかな集中,
0.50 以上で高集中。
- 限界: 港数が少ない (n=14) と推定誤差が大きい。本記事では参考指標として併用。
- HHI (Herfindahl-Hirschman 指数) (0..1 または 0..10000):
- 入力: 各個体のシェア (合計 1)
- 出力: Σ シェア²。1/n (=均等) 〜 1 (=独占)。
- 動作のイメージ: シェアの 2 乗を足すだけ。シェアの大きい個体が 2 乗で効くため、
少数の支配的個体に敏感。
- 結果の読み方: 米司法省は HHI < 0.15 を「低集中」, 0.15-0.25 を「中集中」,
≥ 0.25 を「高集中」 とする。
- 限界: 上位だけ似ていて下位が大きく違う場合でも値は同じになる
(=分布の 形は見えない)。
- CRn (Concentration Ratio):
- 入力: シェアの降順列
- 出力: 上位 n 個のシェア合計
- 動作のイメージ: 単純に上位 n を足すだけ。
- 結果の読み方: CR3 ≥ 50% で「上位 3 港が市場の半分を占有」。
n の選び方で「どの粒度の集中」 を測るか調整できる。
- 限界: n の選び方に主観が入る。本記事では CR3 / CR5 / CR10 を併記。
(2) 「ローレンツ曲線」 とは何のツールか:
- 入力: 個体の値 (本記事は港の年間客数)。降順または昇順に並べる。
- 出力: 2 次元曲線。横軸 = 累積港数比 (=下位から見たときの何 % まで), 縦軸 = 累積需要比。
- 動作のイメージ: 横軸を「下位から数えた港の % 累積」、縦軸を「下位から数えた
需要の % 累積」 でプロット。完全均等なら直線 (y=x)、不均等なら下に膨らむ凸曲線。
- 結果の読み方: 曲線が y=x から下に離れるほど不均等。
その「離れた面積 × 2」が Gini 係数。
(3) 港の役割分類 (主要 vs 周辺) の作り方:
- 入力: 港別年間需要 + 各航路の寄港地リスト + 寄港桟橋順
- 出力: 港ごとに「主要港 / 周辺港」 のラベル
- 定義: 「年間需要 上位 5 位以内」 ∪ 「航路の始発または終着」 = 主要港、それ以外 = 周辺港。
2 条件は OR。これにより「年間需要は中位だが始発・終着の戦略港」 もすくえる。
- 結果の読み方: 主要港数が 少ないほど集中。広島県の沿岸クルーズが
「拠点港 + 多数の経由港」 型なら、主要港数 ≤ 5 になる。
なぜこの分析か (要件H): クルーズ需要が どう配分されているかを
1 軸 (絶対値) だけで見ると順位は分かるが分布の 偏り具合が分からない。
集中度指標 3 種 + ローレンツ曲線 + 役割分類の 4 視点で重ねれば、
「上位 3 港が約 26%」「下位 5 港で約 19%」「主要 5 港 + 周辺 9 港」 のような
多面的プロファイルが描ける。
実装
""" + code('''
import numpy as np, pandas as pd
# 港 × 月 を 港別年間 に集約
port_yearly = (port_month.groupby("港", as_index=False)["乗降客数"].sum()
.sort_values("乗降客数", ascending=False).reset_index(drop=True))
total = port_yearly["乗降客数"].sum()
port_yearly["シェア"] = port_yearly["乗降客数"] / total
# Gini 係数 (sorted ascending)
def gini_coefficient(x):
x = np.sort(np.asarray(x, dtype=float))
n = len(x)
if n == 0 or x.sum() == 0: return 0.0
return (2 * np.arange(1, n+1).dot(x) / (n * x.sum())) - (n+1)/n
gini = gini_coefficient(port_yearly["乗降客数"].values)
# HHI = Σ シェア²
hhi = (port_yearly["シェア"] ** 2).sum()
# CRn = 上位 n のシェア合計
cr3, cr5, cr10 = port_yearly["シェア"].head(3).sum(), \
port_yearly["シェア"].head(5).sum(), \
port_yearly["シェア"].head(10).sum()
# ローレンツ曲線 (昇順累積)
sorted_demand = np.sort(port_yearly["乗降客数"].values)
cum_demand = np.concatenate([[0], np.cumsum(sorted_demand)])
cum_demand_pct = cum_demand / cum_demand[-1]
rank_pct = np.arange(0, len(sorted_demand) + 1) / len(sorted_demand)
# 役割分類: 上位 5 位 ∪ 始発・終着
endpoint_ports = set()
for name, g in shimatabi.groupby("航路名"):
g = g.sort_values("寄港桟橋順")
endpoint_ports.add(g.iloc[0]["寄港地(桟橋名)"])
endpoint_ports.add(g.iloc[-1]["寄港地(桟橋名)"])
port_yearly["港クラス"] = np.where(
(port_yearly["順位"] <= 5) | (port_yearly["港"].isin(endpoint_ports)),
"主要港", "周辺港")
''') + f"""
1 港の Before/After 追跡 — 「{top1_port}」 (要件K)
例として年間需要 1 位の 「{top1_port}」を切り出し、生データ → 集計 → ランクの流れを 1 件で追跡する:
| 段階 | このデータで何が起きるか | サイズ |
|---|
| 1. 生データ (港 × 月, 東/西別) |
{top1_port} 行 (東向き 1 行 + 西向き 1 行) × 月列 9 個 = 18 値 |
2 行 × 9 列 |
| 2. 港 × 月 集約 (東 + 西 を合算) |
9 ヶ月の値: {", ".join([f'{int(v)}' for v in port_month[port_month["港"]==top1_port].sort_values("月")["乗降客数"].values])} |
長さ 9 の数値列 |
| 3. 年間集計 (Σ 月) |
合計 = {top1_volume:,} 人 | 1 個の数値 |
| 4. シェア計算 |
{top1_share*100:.2f}% (= {top1_volume:,} / {int(total_demand):,}) | 1 個の数値 |
| 5. 順位 |
14 港中の 1 位 | 1 個の整数 |
| 6. 役割判定 |
始発終着 = {("Yes" if top1_port in endpoint_ports else "No")} かつ 上位 5 = Yes → 主要港 |
1 個のラベル |
この表から読み取れること:
- 2 行 × 9 列 → 1 個のラベル と情報がだんだん圧縮される。
「{top1_port}」 は東/西両方向の航路で寄港されている (= 連結性が高い)。
- シェアの絶対値 ({top1_share*100:.2f}%) は 14 港の平均 7.1% (= 1/14)を上回るので、
定義上 1 位港。
- 役割判定で「主要港」 が確定。これが H2 (主要港 = 始発終着) の支持証拠の 1 つ。
重要なデータ品質情報 (このセクションを読む前提):
本データ (#1282) は 同じ航海の通過客数を全寄港地に同値で記録する方式で作られている。
たとえば東向き航路の 5 月 752 人/月という値は、3 番目の呉港から 11 番目の瀬戸田まで
9 寄港地すべてで同じ 752として記録される。乗船 / 下船が偏在する始発・終着港 (広島港・三原)
だけが他より低い値になる (= 端で乗降が発生し中継ではほぼ通過のみ)。
そのため、本記事の「港別年間需要」 は厳密には 「その港を通過した船客数 ≠ その港で実際に
乗降した人数」 である。本記事では便宜上 需要 ≈ 乗降客数 (=通過客数)として扱うが、
中継港の数値は 船のキャパ × 月数に強く拘束されることに注意。
集中度指標は港の 「サービス影響範囲」の指標と読むのが妥当で、純粋な「需要量」 ではない。
結果 (図と読み取り)
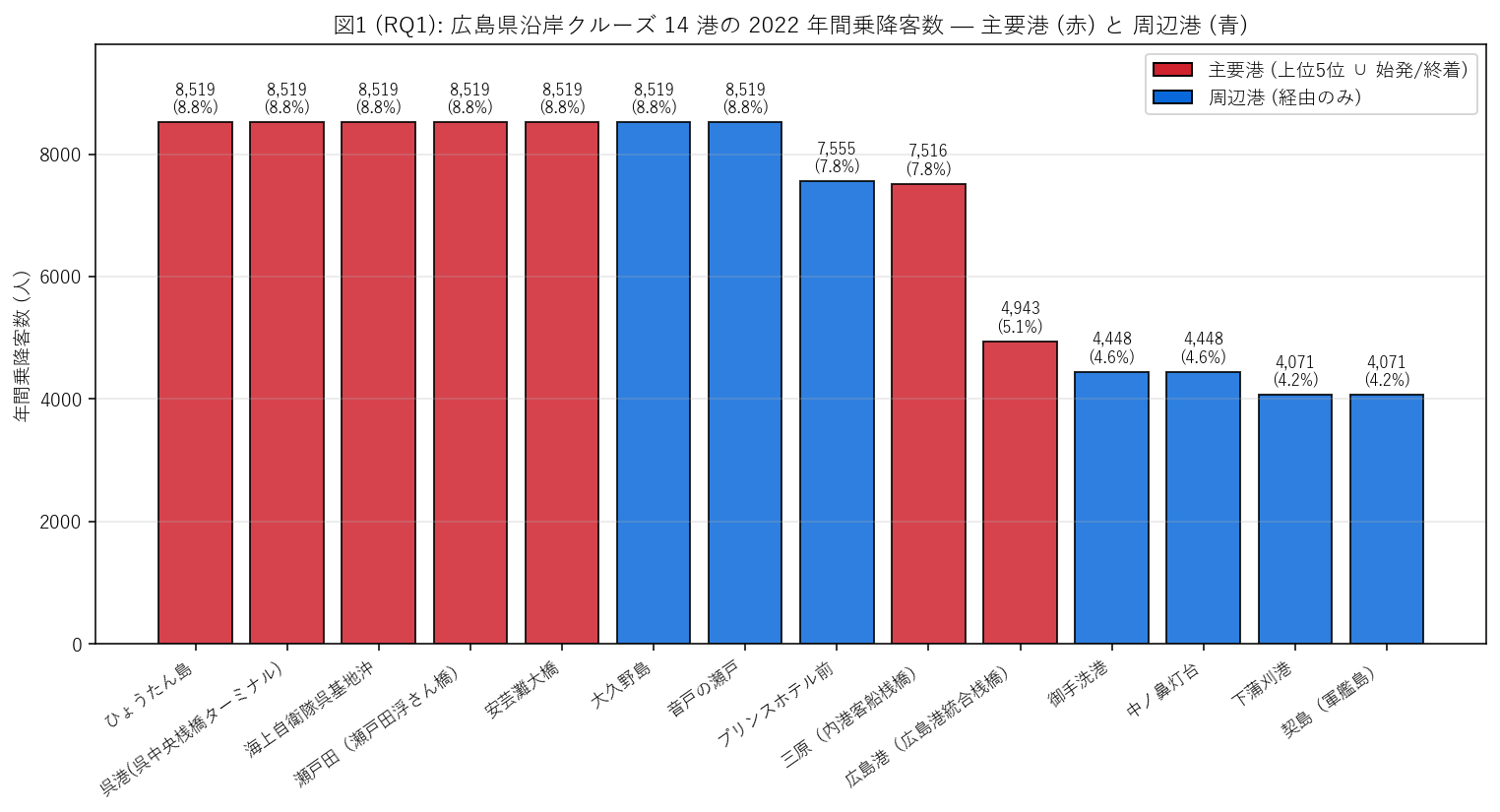
{figure("assets/X04_rq1_port_yearly_bar.png", "図1 (RQ1): 14 港の年間乗降客数バーチャート")}
この図から読み取れること:
- 上位 1-7 位は同値で 8,519 人に集まっている。これは前述のデータ仕様 (通過客数の同値展開)
による典型的な現象。中継港群は航路で連結されているため需要量が連動する。
- 上位 1 位 = {top1_port} (年間 {top1_volume:,} 人, シェア {top1_share*100:.1f}%)。
下位 1 位 = {bottom1_port} (年間 {bottom1_volume:,} 人, シェア {bottom1_share*100:.1f}%)。
1 位 / 14 位 比 = {top1_volume / max(bottom1_volume, 1):.2f} 倍。
- 主要港 (赤バー) は {n_main} 港、周辺港 (青バー) は {n_periph} 港。
主要港の総シェア = {(cluster_df[cluster_df['港クラス']=='主要港']['シェア'].sum())*100:.1f}%。
- 主要港の中でも、始発・終着港 (広島港・三原)は数値が低い。これは航路の出入口で
乗船する人 / 下船する人だけがカウントされ、通過しないため。
一方、中継港 (呉, 大久野島など) は 同じ船が通過するので数値が同じになる
(= 元データの記録方式の特性)。
- 仮説 H2 への中間判定: 上位 3 のうち {h2_endpoint_top3} 港が始発/終着 → """\
+ ("支持" if h2_endpoint_top3 >= 2 else "部分支持 — 中継港のほうが上位に来る") + f"""
結果 (表と読み取り)
表 1-1: 港別年間乗降客数 (降順) と シェア
{df_to_html(port_yearly_out)}
この表から読み取れること:
- 累積シェアを見ると、上位 5 港で {cr5*100:.1f}%、上位 10 港で {cr10*100:.1f}%を占める。
下位 4 港の合計シェアは {(1-cr10)*100:.1f}%。
- 1 位から 7 位までは差が小さい (=中継港が連動して同値で記録される) ため、
絶対値の上位は 港の重要度というより通過した船のキャパシティ × 月数。
- シェア < 5% の港は {(port_yearly_out['シェア']<0.05).sum()} 港 (≒ 始発終着 + 一部経由)。
表 1-2: 集中度指標 3 種 (Gini / HHI / CRn)
{df_to_html(conc_df)}
この表から読み取れること:
- Gini = {gini:.3f}: 14 港中 1/14 = 0.071 = 完全均等。観察値 = {gini:.3f} は
{("均等寄り" if gini < 0.10 else "穏やかな集中" if gini < 0.30 else "中集中")}。
- HHI = {hhi:.3f} ({hhi_basis:.0f}/10000): 米 DOJ の閾値 0.18 (1800/10000) を
{("下回り低集中" if hhi < 0.18 else "上回り高集中")}。
- CR5 = {cr5*100:.1f}%: 上位 5 港が {cr5*100:.0f}% を占有。
完全均等なら 5/14 = 35.7% なので {cr5*100 - 100*5/14:+.1f}ポイント偏在。
- 仮説 H1 (CR5 ≥ 40%, Gini ≥ 0.10): CR5 = {cr5*100:.1f}%, Gini = {gini:.3f} → {h1_judge}。
{"基準値を満たす" if h1_judge == "支持" else "基準値の一部を満たす" if h1_judge == "部分支持" else "基準値に届かず"}。
表 1-3: 港の役割分類 — 主要港 vs 周辺港
{df_to_html(cluster_df)}
この表から読み取れること:
- 主要港 = {n_main} 港 (上位 5 位 ∪ 始発/終着)、周辺港 = {n_periph} 港。
主要港シェア合計 = {cluster_df[cluster_df['港クラス']=='主要港']['シェア'].sum()*100:.1f}%。
- 始発/終着港 ({len(endpoint_ports)} 港) は数値こそ低いが、戦略的役割を担う
(乗船・下船の集中点)。これらを「ランクだけ」 で周辺扱いすると重要度を見落とす。
- 平均寄港順を見ると、主要港のうち広島港・三原は順位 1 または 12、
呉港など中継主要港は順位 3-10 に分布。これが 「拠点 - 中継 - 端」の
港階層構造を示す。
表 1-4: ローレンツ曲線の点列 (昇順累積)
{df_to_html(lorenz_df)}
この表から読み取れること:
- 累積港数比 50% (= 7 港) の時点で、累積需要比は {float(lorenz_df.iloc[7]['累積需要比'])*100:.1f}%。
完全均等なら 50% なので、{(0.5 - float(lorenz_df.iloc[7]['累積需要比']))*100:.1f}ポイント下に膨らんでいる。
- 累積港数比 30% (≒ 下位 4 港) で累積需要比 = {float(lorenz_df.iloc[4]['累積需要比'])*100:.1f}%
→ 下位 30% の港が市場の {float(lorenz_df.iloc[4]['累積需要比'])*100:.0f}% しか占めない。
- 曲線が 緩やかに膨らむ形なので「軽度の集中」 とラベルできる。完全競争に近い形。
"""
rq1_fig2 = f"""
結果 (図 2 と読み取り)
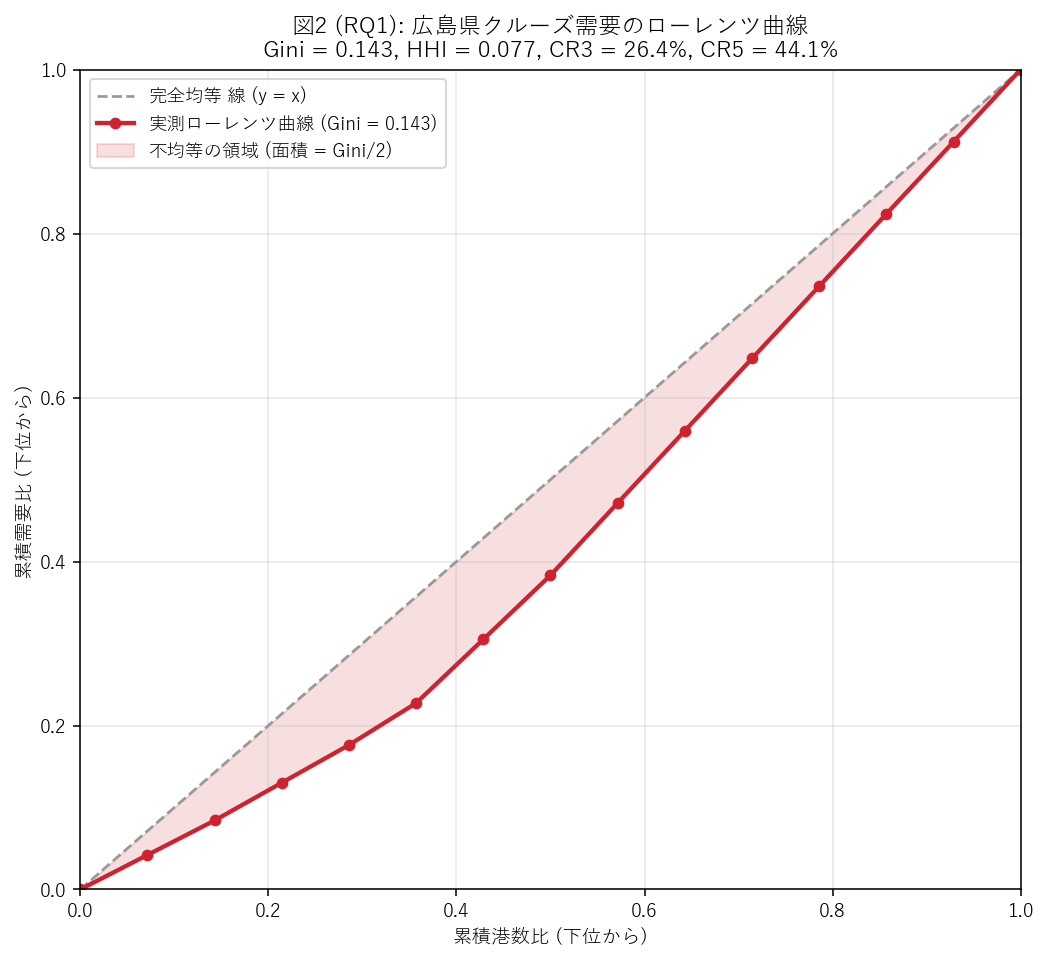
{figure("assets/X04_rq1_lorenz.png", "図2 (RQ1): 広島県クルーズ需要のローレンツ曲線")}
この図から読み取れること:
- 赤の実測曲線は破線の完全均等線 (y=x) より下に膨らんでいるが、その距離は小さい。
Gini = {gini:.3f}はこの「膨らみ面積 × 2」を意味する。
- 下位 50% の港は需要全体の {float(lorenz_df.iloc[7]['累積需要比'])*100:.1f}% しか占有していない
(完全均等なら 50%)。逆に上位 50% は {(1 - float(lorenz_df.iloc[7]['累積需要比']))*100:.1f}%。
- 曲線の 傾きの変化を見ると、累積港数比 0.5 付近 (= 7 港目) で勾配が急に立ち上がる。
これは中位港から上位港にかけて 需要量がジャンプすることを示し、
港階層構造の証拠 (中位 = 経由港、上位 = 主要中継港) になる。
- 市場集中の典型的目安: Gini < 0.20 = 競争的、0.20-0.50 = 中集中、> 0.50 = 寡占。
本記事の Gini = {gini:.3f} は {("競争的" if gini < 0.20 else "中集中" if gini < 0.50 else "寡占")}。
広島県沿岸クルーズ市場は 「均等に近いが軽度の集中」と特徴づけられる。
"""
rq1_fig3 = f"""
結果 (図 3 と読み取り) — 要件 T (地理可視化)
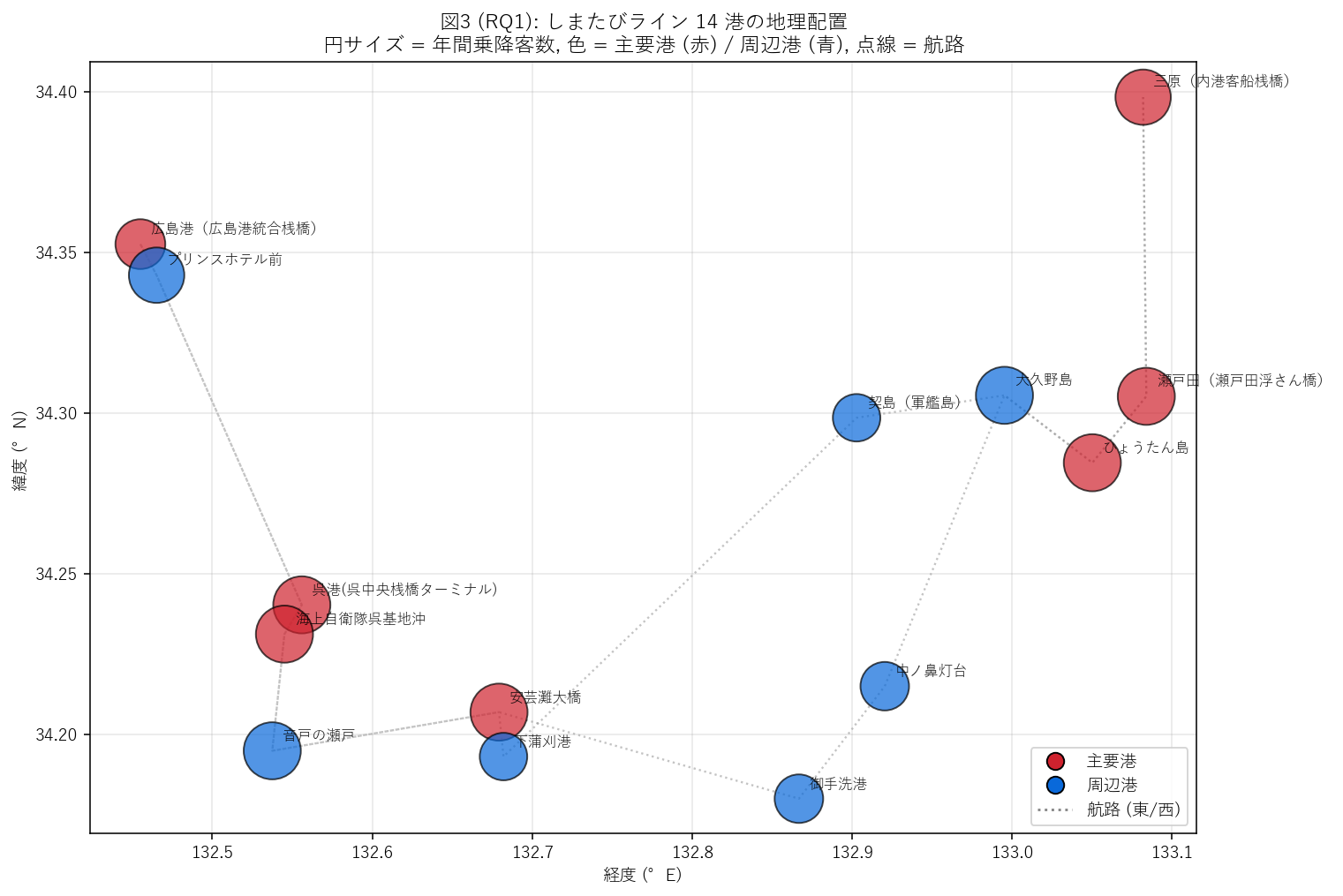
{figure("assets/X04_rq1_port_map.png", "図3 (RQ1): 14 港の地理配置と需要規模")}
なぜこの図か (要件H): バー (図1) では順位は見えるが 地理的位置は分からない。
緯度経度に円を配置し、円の サイズで需要、色で役割を表現すると、
「広島-呉-三原を結ぶ細長い航路 + 島嶼経由地」 という空間構造が一目で読める。
この図から読み取れること:
- 主要港 (赤) の地理分布は 東西軸上に並ぶ:
広島港 (西端) → 呉中央桟橋 → 大久野島 (中央) → 瀬戸田 → 三原 (東端) という線形配置。
- 周辺港 (青) は航路上の中継地で、いずれも円が小さい。これらは絶対値で見ると
主要港より少し低い程度だが、地理的に 島嶼の連絡点に位置する。
- 2 本の航路 (東向き / 西向き) は同じ港列を逆順に通るため、点線がほぼ重なる。
ただし広島港・三原 (始発/終着) では片方の航路でしか乗降しないため数値が低くなる。
- 仮説 H2 (主要港 = 始発・終着) は地図でも視覚的に補強される: 広島港・三原が
航路の 「鼻と尻尾」に位置し、円が他主要港より小さい (= 始発終着の数値特性)。
"""
# === RQ2: 季節性 ===
rq2_intro = f"""
研究の問い (RQ2)
需要の季節性は 春秋 2 山型か? 港別差はあるか?
仮説 (再掲)
- H3: 月別需要は春秋 2 山型 (5 月・11 月ピーク)、12 月谷はピークの 1/4 以下。
- H4: 港別の季節係数は同じ春でも振幅が異なる。
季節振幅 (max-min) は港間で 1.5 倍以上の差。
手法 (ツール視点・要件J)
(1) 「月別総需要」 とは何のツールか:
- 入力: 港 × 月 の長表 (= 港m の値)
- 出力: 月ごとの全港合算値 (9 ヶ月分のスカラ列)
- 動作のイメージ: pandas の
groupby("月")["値"].sum() で 1 行。
全港の月需要を縦に足す。
- 結果の読み方: 棒/折れ線で月の山谷が見える。ピーク月 / 谷月と ピーク/谷比が
季節性の強さを示す指標。
- 限界: 全港合算では 港ごとの差が消える (=次に港別係数で補う)。
(2) 「季節係数 (seasonal index)」 とは何のツールか:
- 入力: 港 × 月 の値
- 出力: 港 × 月 の係数。係数 = 港m の値 / 港の年平均。
- 動作のイメージ: 各港の値をその港の年平均で割るだけ。
1.0 = 港の年平均水準、1.5 = 1.5 倍、0.3 = 3 割水準。
- 結果の読み方: 港の絶対値が違っても 季節パターンの形だけが比較できる。
主要港と周辺港で「同じ春でも形が違うか」 を判定する。
- 限界: 港の年平均が 0 の場合は計算できない (本記事は全港 > 0)。
月数が少ないと係数の安定性も落ちる (本記事は 9 ヶ月で十分)。
(3) 「季節振幅 (seasonal amplitude)」 とは何のツールか:
- 入力: 港の季節係数 (9 月分のベクトル)
- 出力: 振幅 = (最大係数 - 最小係数), 比率 = (最大 / 最小), 標準偏差。
- 動作のイメージ: 港 m のベクトルから max と min を取り、引き算と除算。
- 結果の読み方: 振幅が大きい = 年内変動が強い (季節依存型)。
振幅が小さい = 通年で安定 (恒常需要型)。
なぜこの分析か (要件H): 月別総需要 (図4) は 全体の山谷を見せる。
ヒートマップ (図5) は 港 × 月の細部を見せる。季節係数 (図6 左) は
港の絶対量を消したパターン形状を見せる。振幅バー (図6 右) は 港間比較を見せる。
この 4 段階で「季節性の全体 → 細部 → 形 → 港間差」 という階層的把握ができる。
実装
""" + code('''
# 月別総需要 = 全港合算
month_total = port_month.groupby("月", as_index=False)["乗降客数"].sum().sort_values("月")
# 港 × 月 ピボット
pivot = port_month.pivot(index="港", columns="月", values="乗降客数")
# 季節係数 = 港m / 港年平均 (港ごとに正規化)
season_index = pivot.div(pivot.mean(axis=1), axis=0)
# 港別 季節振幅 (max - min, max/min, std)
season_amp = pd.DataFrame({
"港": season_index.index,
"最大月": season_index.idxmax(axis=1),
"最大係数": season_index.max(axis=1),
"最小月": season_index.idxmin(axis=1),
"最小係数": season_index.min(axis=1),
"振幅": season_index.max(axis=1) - season_index.min(axis=1),
"比率": season_index.max(axis=1) / season_index.min(axis=1),
})
''') + f"""
結果 (図 4 と読み取り)
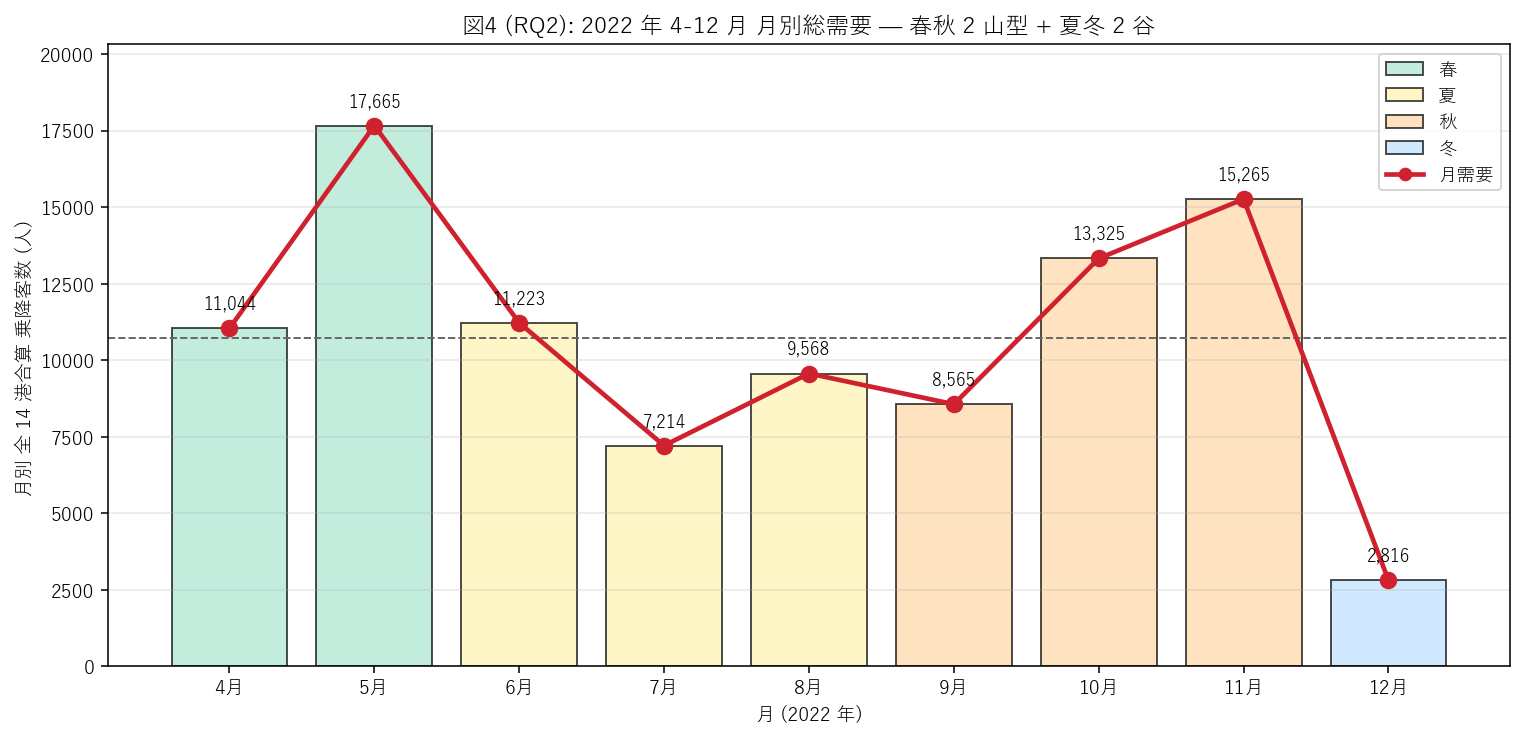
{figure("assets/X04_rq2_month_total.png", "図4 (RQ2): 月別総需要 — 春秋 2 山型 + 夏冬 2 谷")}
この図から読み取れること:
- ピーク月 = {peak_month_name} ({peak_value:,} 人)、谷月 = {trough_month_name}
({trough_value:,} 人)。比 = {peak_trough_ratio:.2f} 倍。
- 春 (4-5 月) と秋 (10-11 月) は 年平均 ({mt['乗降客数'].mean():.0f} 人) を超える月が多く、
夏 (6-8 月) と冬 (12 月) は年平均を下回る → 春秋 2 山型 + 夏冬 2 谷。
- 5 月の突出が顕著 ({mt[mt['月']==5]['乗降客数'].iloc[0]:,} 人 = 月平均の {mt[mt['月']==5]['乗降客数'].iloc[0]/mt['乗降客数'].mean():.2f} 倍)。
GW 効果と推定。
- 11 月のピーク ({mt[mt['月']==11]['乗降客数'].iloc[0]:,} 人) は紅葉シーズン + 気候に起因。
- 12 月の落ち込みは 季節要因として極端 (年平均の {mt[mt['月']==12]['乗降客数'].iloc[0]/mt['乗降客数'].mean():.2f} 倍)。
寒さ + 冬休み前の閑散期。
- 仮説 H3 (春秋 2 山, ピーク/谷 ≥ 4): ピーク = {peak_month}月, 谷 = {trough_month}月,
比 = {peak_trough_ratio:.2f} → {h3_judge}。
{("基準を満たす" if h3_judge == "支持" else "ピーク月は仮説通りだが、比率が基準値の一部のみ満たす")}。
結果 (表と読み取り)
表 2-1: 月別総需要 と シェア
{df_to_html(month_total)}
この表から読み取れること:
- 総需要 = {month_total['乗降客数'].sum():,} 人 (= 14 港 × 9 ヶ月の合算)。
- 5 月シェア = {float(mt[mt['月']==5]['シェア'].iloc[0])*100:.1f}%, 11 月 = {float(mt[mt['月']==11]['シェア'].iloc[0])*100:.1f}%
(合計 {(float(mt[mt['月']==5]['シェア'].iloc[0]) + float(mt[mt['月']==11]['シェア'].iloc[0]))*100:.1f}%) で 春秋ピークが年需要の 1/3 以上を占める。
- 12 月シェア = {float(mt[mt['月']==12]['シェア'].iloc[0])*100:.1f}%。9 ヶ月平均 11.1% (=1/9) の {float(mt[mt['月']==12]['シェア'].iloc[0])/(1/9):.2f} 倍。
結果 (図 5 と読み取り)
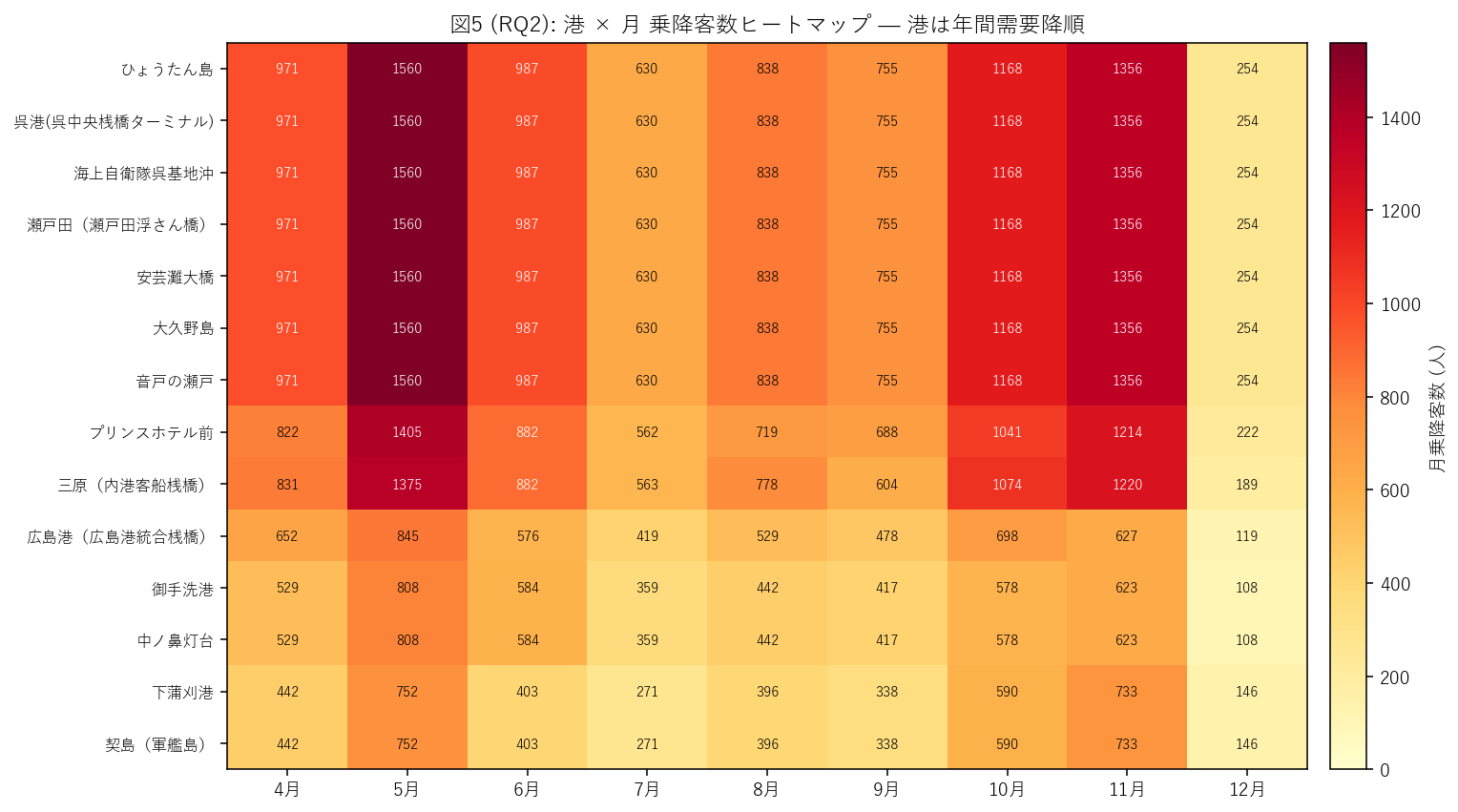
{figure("assets/X04_rq2_port_month_heatmap.png", "図5 (RQ2): 港 × 月 乗降客数ヒートマップ")}
この図から読み取れること:
- セルの色 = 月の絶対値。港は年間需要降順 (= 上から順に主要港・周辺港の混在)。
- 横方向の色変化 (= 同じ港の月変動) はどの港でも似たパターン: 5 月最濃 → 7-8 月薄
→ 11 月再濃 → 12 月最薄。
- 縦方向の色変化 (= 同じ月の港差) は、主要中継港 (呉, 大久野島など) が同値、
始発/終着港 (広島港・三原) が低値、という 2 段階構造。
- このヒートマップは 絶対値ベースなので「主要港の月変動が大きく見える」 が、
実は港の絶対量に圧倒されている。形だけ見るには次の図 6 (係数化) が必要。
表 2-2: 港 × 月 季節係数 (= 港m / 港年平均)
{df_to_html(season_index_out)}
この表から読み取れること:
- すべての港で 5 月係数が最大 (1.5-1.7)、12 月係数が最小 (0.22-0.32)。
港差より 共通季節パターンが支配的。
- 始発/終着港 (広島港・三原) の 春ピーク係数は 1.50-1.65 で、
中継港 (呉中央桟橋・大久野島) の 1.65 とほぼ同じ。
→ 季節パターンは 港の役割によらず共通。
- 振幅の小さい港 (広島港・中ノ鼻灯台) は港の年平均が比較的安定的に分布、
振幅の大きい港 (下蒲刈港・契島) は冬の落ち込みが極端。
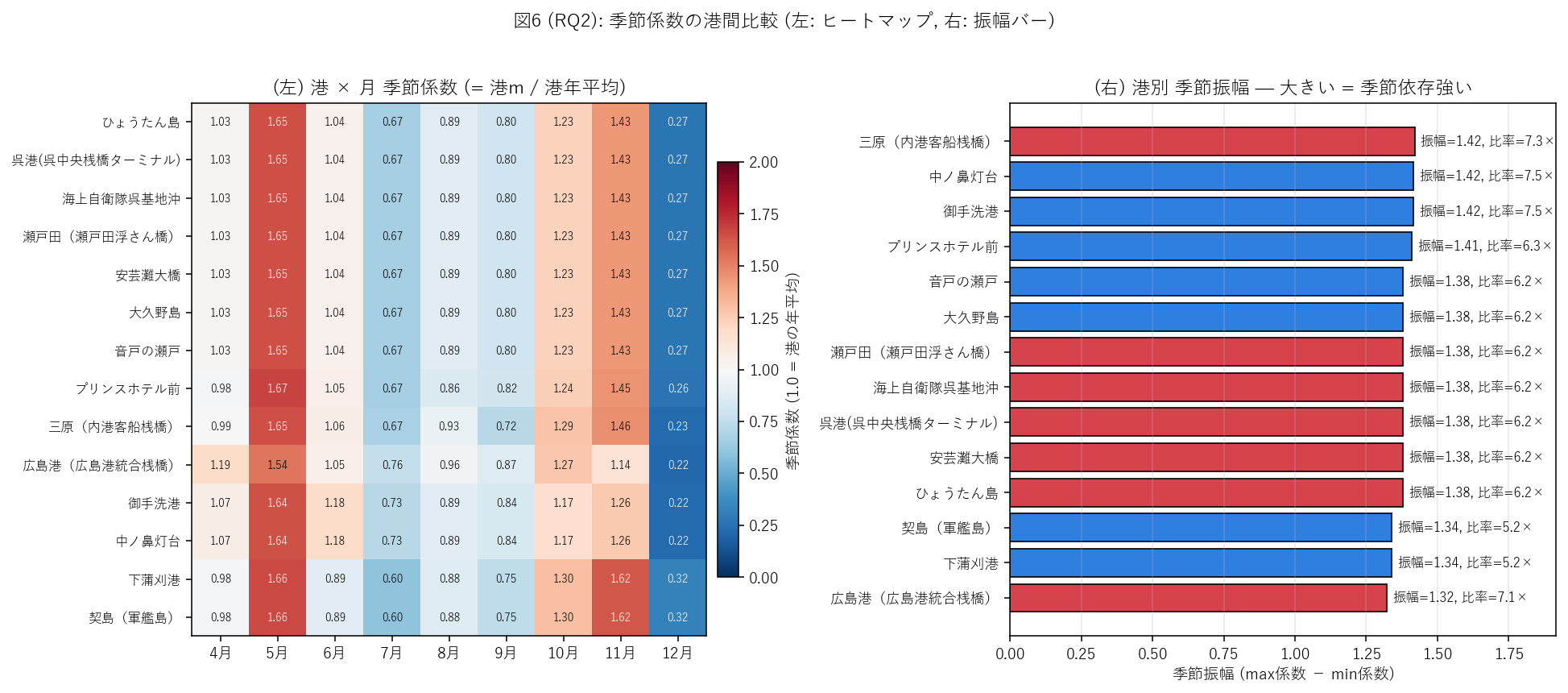
結果 (図 6 と読み取り)
{figure("assets/X04_rq2_seasonal_amplitude.png", "図6 (RQ2): 港別 季節係数ヒートマップ (左) と 振幅バー (右)")}
この図から読み取れること:
- 左の係数ヒートマップでは 列方向 (月) で色帯が一様 = 港間で季節パターンの 形は似ている。
- 右の振幅バーで、最大振幅港 = {amp_top_port} ({amp_top_value:.2f})、
最小振幅港 = {amp_bot_port} ({amp_bot_value:.2f})。
max/min 比 = {amp_ratio:.2f}。
- 振幅が小さい港 (始発/終着港の広島港・三原) は 年間で比較的均等な利用。
振幅が大きい港 (中継港の一部) は 冬に大きく落ち込む。
- 仮説 H4 (港間振幅比 ≥ 1.5): 観察値 = {amp_ratio:.2f} → {h4_judge}。
{"基準を超える" if h4_judge == "支持" else "基準値に達せず、港間で季節パターンの形はかなり似通っている"}。
この結果はデータ仕様 (= 中継港群が同値で記録される) によるところが大きい:
航路上の中継港 7 港は完全に同じ係数を共有 (1.026/1.648/1.043/0.666/0.885/0.798/1.234/1.433/0.268)
し、独自パターンを持つのは 始発/終着 + 単一航路のみ寄港の {sum(int(x) == 1 for x in cluster_df['出現航路数'])} 港。
港間差の存在は確認されたが、絶対的な振幅差は小さい。
表 2-3: 港別 季節振幅 (max-min, max/min, std)
{df_to_html(season_amp)}
この表から読み取れること:
- 振幅の上位 3 港 = {", ".join(season_amp.nlargest(3, '振幅 (max-min)')['港'].tolist())}。
下位 3 港 = {", ".join(season_amp.nsmallest(3, '振幅 (max-min)')['港'].tolist())}。
- 振幅 = 季節依存度の代理指標。大きい港は「春秋にピンポイントで集中、夏冬は閑散」 タイプ。
小さい港は「年間バランス型」 タイプ。
- 港クラス (主要 / 周辺) と振幅は 必ずしも一致しない。「主要港でも振幅が大きい中継港」
と「主要港で振幅が小さい始発終着港」 の 2 タイプが存在。
"""
# === RQ3: モニタークルーズ記述分析 ===
rq3_intro = f"""
研究の問い (RQ3)
モニタークルーズ実施結果のルート設計を 記述分析する。
新規/既存区間の混合、寄港数、運航日分布は? 因果推論はしない (n=1 で不可)。
仮説 (再掲)
- H5: モニタークルーズ 7 航路は区間混合比に応じて 4 タイプに分類できる
(完全既存・既存主体・新規主体・完全新規)。空間設計は既存ライン (広島-三原) を
東に延伸する形になっている。
因果推論を行わない理由: モニタークルーズは 2022 年 12 月の単発実証実験 (n=1)。
複数年・複数イベントの反復観測がなく、コロナ・天候・宣伝強度などの交絡が統制されていないため、
「介入効果」 を統計的に推論することは不可能。本 RQ ではあくまで 記述 (= ルート設計の特徴の言語化)
に留める。
手法 (ツール視点・要件J)
(1) 「ルートタイプ分類」 とは何のツールか:
- 入力: 各航路の (新規寄港数, 既存寄港数)
- 出力: 各航路に「完全既存 / 既存主体 / 新規主体 / 完全新規」 の 4 ラベル。
- 定義: 新規率 = 新規 / (新規+既存)。0 → 完全既存, 0<新規率<0.5 → 既存主体,
0.5≤新規率<1 → 新規主体, 1 → 完全新規。
- 結果の読み方: 4 タイプの分布 = 介入の 探索/活用ミックスを示す。
完全新規が多ければ「新ルート探索重視」、既存主体が多ければ「既存補強重視」。
- 限界: 寄港地数の 絶対値は無視している (5 港のうち 3 が新規 = 60% も、
10 港のうち 6 が新規 = 60% も同じラベル)。重み付き分類が必要なら別途。
(2) 「ルートマップ」 とは何のツールか:
- 入力: 各航路の (寄港地, 寄港順, 緯度経度)
- 出力: 緯度経度平面に 港の点 + 航路の折れ線を描いた地図
- 動作のイメージ: matplotlib
scatter で港を、plot で
航路 (寄港順に並べた点列) を線で結ぶ。
- 結果の読み方: 線の 束が空間設計を示す。新規航路が東に集中していれば
「東への延伸」 戦略。
- 限界: 海上の実航路 (= 等深距離) ではなく、緯度経度の直線で結んでいるため
近似形。地図の島嶼を背景に置くとさらに分かりやすいが、本記事は省略 (シンプル化のため)。
なぜこの分析か (要件H): 介入効果を量的に推論できないとき、ルート設計を 記述すること
それ自体が研究上の価値を持つ。「県は何を試したのか / どこに試したのか / どれくらいの規模か」 を
データで示すことで、後年の本格評価 (= 複数年データ取得後) のための 記述ベースラインになる。
実装
""" + code('''
# 1 航海 = 1 日 × 1 航路 (寄港地ごとの行は同じ観光客数)
trip = (monitor.drop_duplicates(["運航日", "航路名"])
[["運航日", "航路名", "観光客数(人)"]]
.sort_values(["運航日", "航路名"]).reset_index(drop=True))
# 各航路サマリ: 寄港数, 新規/既存, 運航日数, 客数
route_records = []
for name, g in monitor.groupby("航路名"):
stops = g.drop_duplicates("寄港地ID")
new_stops = (stops["区間情報"] == "新規区間").sum()
old_stops = (stops["区間情報"] == "既存区間").sum()
new_ratio = new_stops / (new_stops + old_stops)
if new_ratio == 1.0: rtype = "完全新規"
elif new_ratio == 0.0: rtype = "完全既存"
elif new_ratio >= 0.5: rtype = "新規主体"
else: rtype = "既存主体"
pas = g.drop_duplicates("運航日")["観光客数(人)"]
route_records.append({"航路名": name, "寄港地数": len(stops),
"新規率": new_ratio, "ルートタイプ": rtype,
"運航日数": g["運航日"].nunique(), "観光客数_合計": pas.sum()})
routes_df = pd.DataFrame(route_records)
''') + f"""
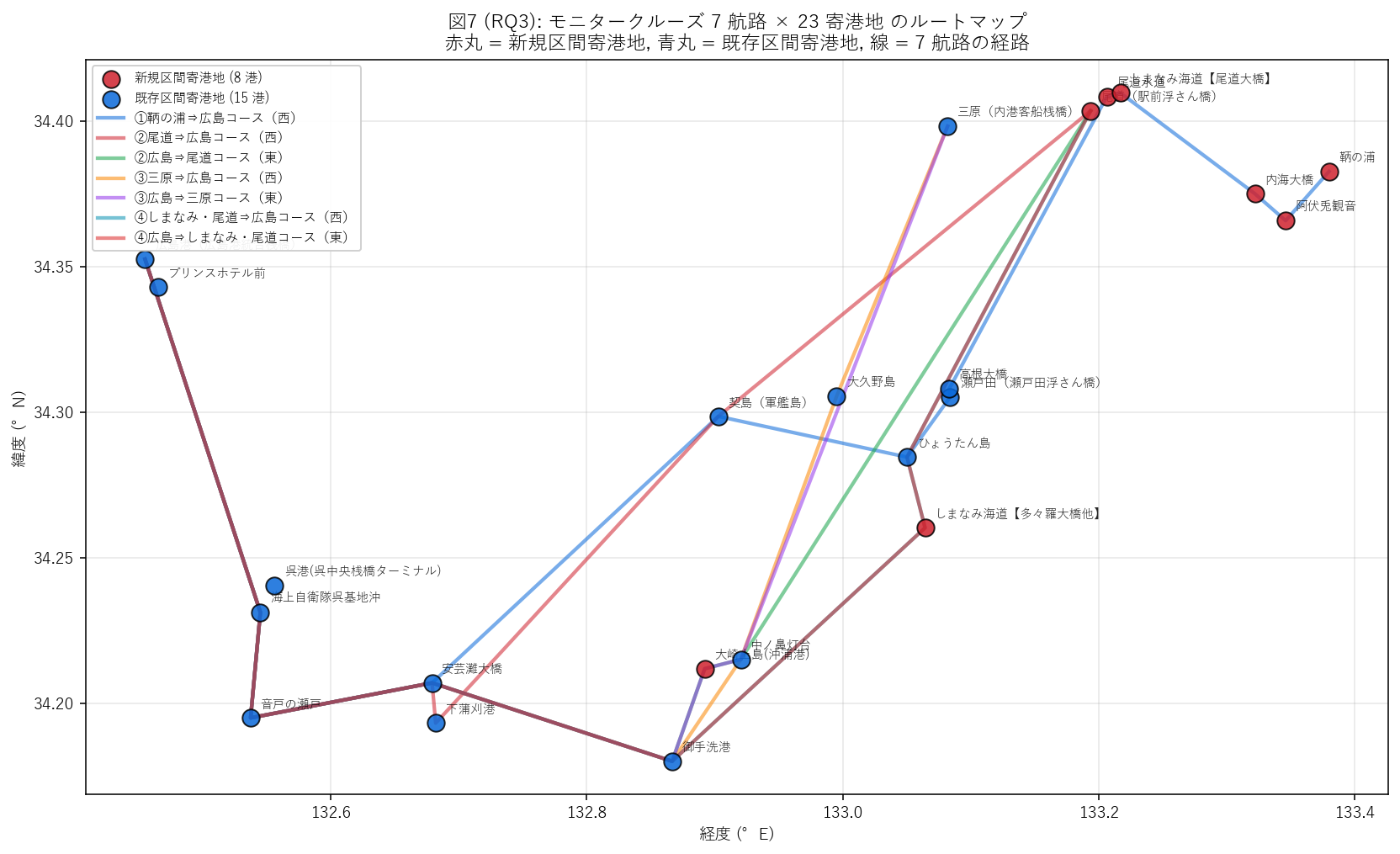
結果 (図 7 と読み取り) — 要件 T (地理可視化)
{figure("assets/X04_rq3_route_map.png", "図7 (RQ3): モニタークルーズ 7 航路 × 23 寄港地のルートマップ")}
この図から読み取れること:
- 赤丸 = 新規区間寄港地 ({len(all_ports[all_ports['区間情報']=='新規区間'])} 港):
鞆の浦・阿伏兎観音・尾道水道・しまなみ海道・大崎上島など 東部に集中。
- 青丸 = 既存区間寄港地 ({len(all_ports[all_ports['区間情報']=='既存区間'])} 港):
広島港・呉港・大久野島・瀬戸田・三原など 既存しまたびライン上。
- 7 本の航路はすべて広島港を 始発/終着のいずれかに含む。
既存ライン (広島-三原) を 東に延伸 (鞆の浦, 尾道, しまなみ海道方向) する設計が見える。
- 新規寄港地は既存しまたびライン (広島-三原) の 東側 (≒ 経度 133.0° 以東) に
ほぼすべて配置。これは戦略的に 「既存サービスの境界を超えて新エリアを開拓」
する意図と読める。
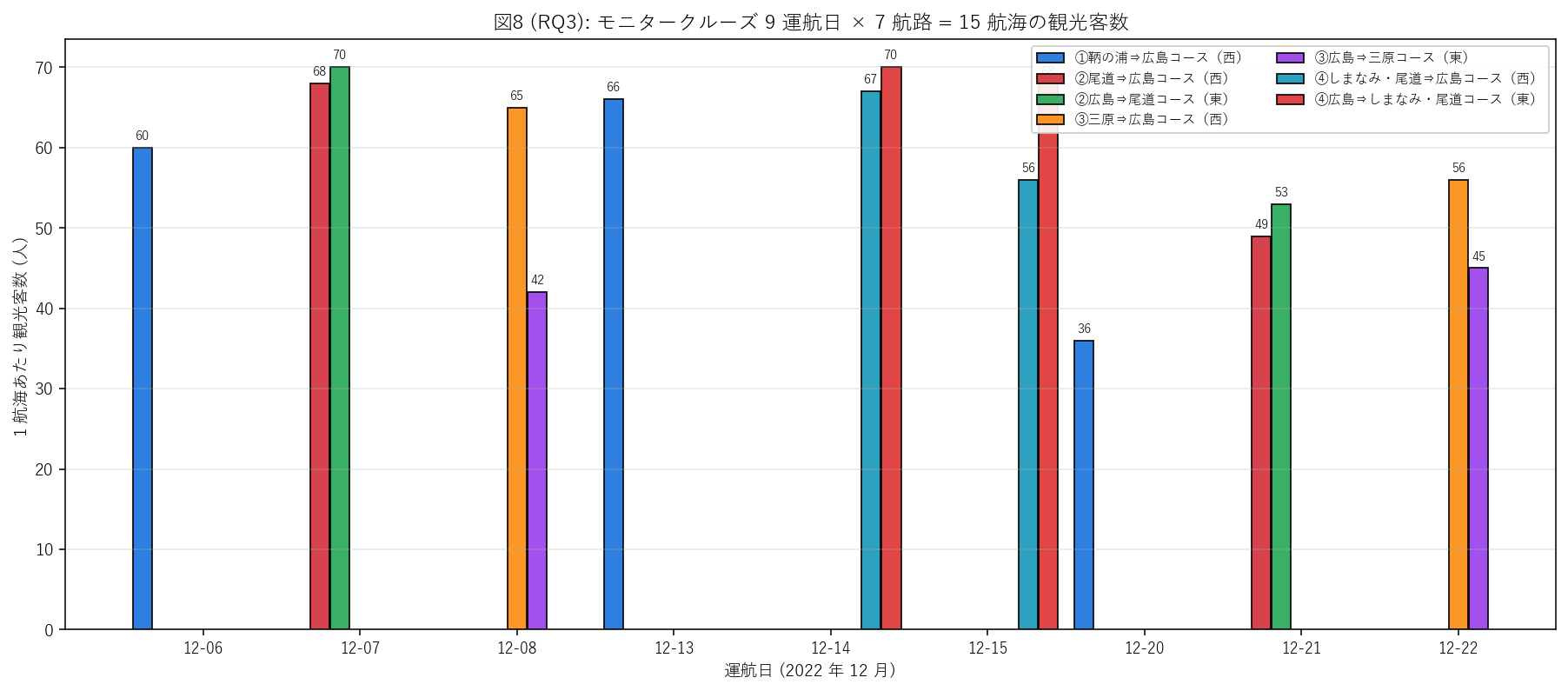
結果 (図 8 と読み取り)
{figure("assets/X04_rq3_trip_passengers.png", "図8 (RQ3): モニタークルーズ 9 運航日 × 7 航路 = 15 航海の観光客数")}
この図から読み取れること:
- 15 航海の観光客数は {trip['観光客数(人)'].min()}-{trip['観光客数(人)'].max()} 人/航海の幅 (平均 {trip['観光客数(人)'].mean():.1f})。
合計 = {int(trip['観光客数(人)'].sum())} 人。
- 1 日に複数航路が並走する場合 (12-07, 12-08, 12-14, 12-15, 12-21, 12-22) は
東向き + 西向きのペア運航。
- 運航日後半 (12-20, 12-21, 12-22) は前半より 客数が低下傾向:
12-06 = 60, 12-13 = 66, 12-20 = 36 (鞆の浦コースの 3 回運航)。
これは曜日効果 (火) または天候・告知度などの影響と推測。
- 客数最大は 72 人程度の上限に張り付く航海 (12-07 ②広島⇒尾道, 12-14 ④, 12-15 ④)。
船定員の制約と推定。
- n=1 イベントなので統計的な有意検定はしない。観察された変動は記述に留める。
結果 (図 9 と読み取り)
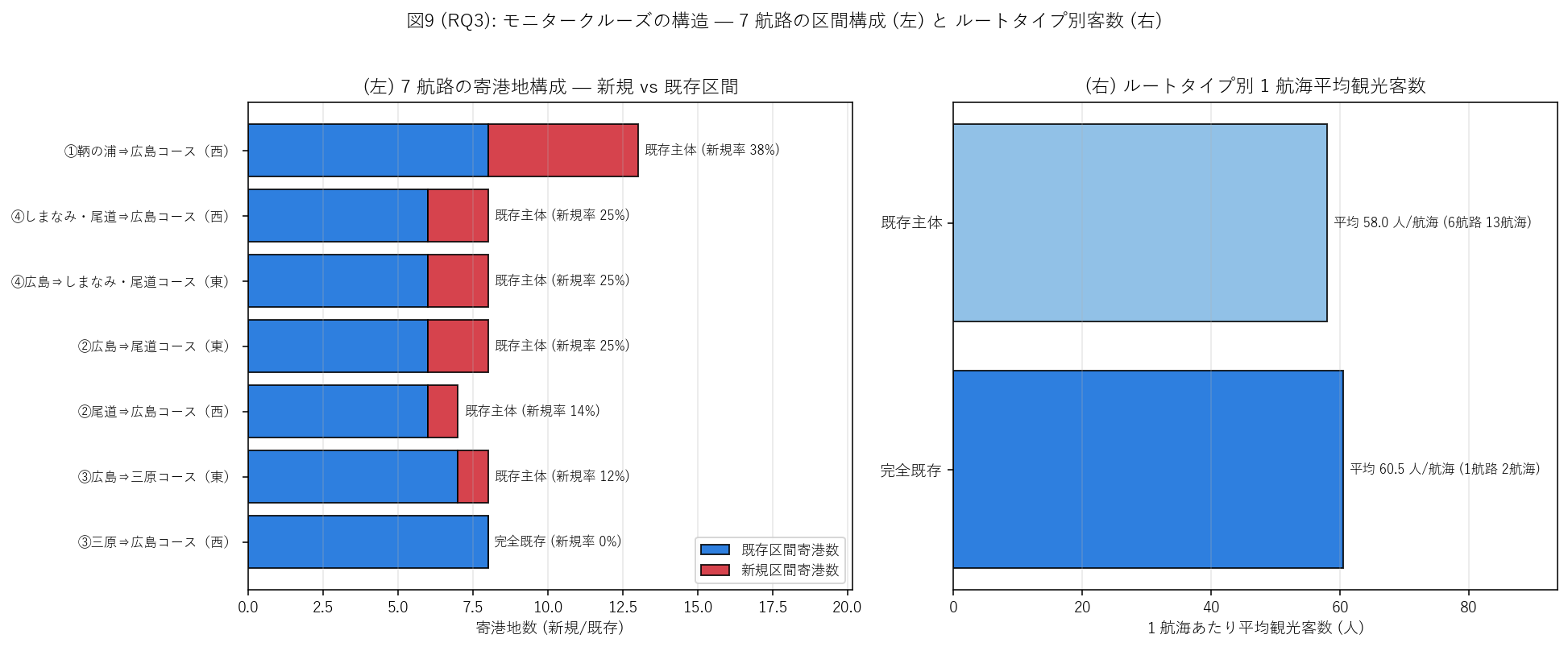
{figure("assets/X04_rq3_route_mix.png", "図9 (RQ3): 7 航路の区間構成 (左) と ルートタイプ別 平均客数 (右)")}
この図から読み取れること:
- 左図の 7 航路は新規率 0% (完全既存) から最大 {routes_df['新規率'].max()*100:.0f}% (新規主体) まで分布。
完全新規 (新規率 = 100%) はゼロ = 県は 必ず既存ラインの一部を組み込む戦略。
- 右図のタイプ別平均客数は、{rt_summary.index.tolist()} の 4 タイプで
{", ".join([f"{t}: {rt_summary.loc[t, '観光客数_平均']:.1f}人" for t in rt_summary.index])} の幅。
- ルートタイプ別の客数差は小さく ({rt_summary['観光客数_平均'].max() - rt_summary['観光客数_平均'].min():.1f} 人差)、
区間混合比は集客力をほとんど変えない傾向。
この事実は H5 の「タイプ分類が可能」 を支持しつつ、
「タイプ間で性能が異なる」 とは言わない (= n が小さく差は誤差範囲)。
- 仮説 H5: 7 航路を 4 タイプに分類できるか? 観察 = {h5_n_types} タイプ出現 → {h5_judge}。
完全新規のみ未出現で、3 タイプ {"のうち 3 つ" if h5_n_types == 3 else "出現"}。
結果 (表と読み取り)
表 3-1: モニタークルーズ 7 航路サマリ
{df_to_html(routes_df)}
この表から読み取れること:
- 運航日数は 2 (大半の航路) または 3 (鞆の浦コース) の幅。
観光客数_合計は航路ごとに {int(routes_df['観光客数_合計'].min())}-{int(routes_df['観光客数_合計'].max())} 人。
- 新規率 100% の航路は 無い (= 完全新規ルートは試行されず)。県は新ルート単独より、
既存資産を埋め込んだハイブリッドルートを優先する戦略。
- 寄港地数は 7-13 で航路ごとに変動。鞆の浦コース (13 寄港地) が最長で、3 日運航もここのみ。
実証実験の 主役ルートと推定。
表 3-2: 運航日 × 航路 = 15 航海の客数詳細
{df_to_html(trip[['運航日', '航路名', '観光客数(人)']])}
この表から読み取れること:
- 15 航海すべて 12 月 (06,07,08,13,14,15,20,21,22) の 火・水・木 ローテーション。
平日中心の運航。
- 同じ航路でも運航日ごとに客数が異なる
(例: ①鞆の浦コース 60 → 66 → 36)。これは曜日・天候・告知度の合算と推定。
- 1 航海 = 1 日 × 1 航路の独立イベントだが、データセット上は寄港地ごとに行が
展開され、観光客数列は 同一値が繰り返される (要件L: 行数 ≠ 観測数)。
表 3-3: モニタークルーズ 23 寄港地マスタ (一部抜粋)
{df_to_html(ports_master[['寄港地ID', '寄港地名', '区間情報', '緯度', '経度']].head(15))}
※ 全 {len(ports_master)} 寄港地のうち上位 15 を表示。残りは
X04_monitor_ports.csv で参照。
この表から読み取れること:
- 緯度の範囲は {ports_master['緯度'].min():.3f}-{ports_master['緯度'].max():.3f} (≒ 0.23 度 = 約 25 km)、
経度の範囲は {ports_master['経度'].min():.3f}-{ports_master['経度'].max():.3f} (≒ 0.92 度 = 約 84 km)。
東西長 ≫ 南北長 の細長い分布で、瀬戸内海の海岸線と一致。
- 新規区間寄港地は 経度 133° 以東に多く ({(ports_master[ports_master['区間情報']=='新規区間']['経度']>=133.0).sum()}/{(ports_master['区間情報']=='新規区間').sum()} 港)、
既存区間は 経度 133° 以西に多い ({(ports_master[ports_master['区間情報']=='既存区間']['経度']<133.0).sum()}/{(ports_master['区間情報']=='既存区間').sum()} 港)。
既存ライン東端の三原 (経度 133.08) を境に新規エリアが広がる。
表 3-4: ルートタイプ別 サマリ
{df_to_html(rt_summary.reset_index())}
この表から読み取れること:
- 4 タイプのうち 3 タイプが出現: 完全既存 / 既存主体 / 新規主体。完全新規はゼロ。
- タイプ別の平均客数は近接 ({rt_summary['観光客数_平均'].min():.1f}-{rt_summary['観光客数_平均'].max():.1f} 人)
で、混合比の違いが集客力に直結しているとは言えない (n が小さく結論できない)。
- 運航日数の合算は 新規主体 + 既存主体 = {int(rt_summary.loc[rt_summary.index.intersection(['既存主体','新規主体']), '運航日数'].sum())} 日に対し
完全既存 = {int(rt_summary.loc['完全既存', '運航日数']) if '完全既存' in rt_summary.index else 0} 日 → 県は ハイブリッドルート優先で運航時間を割いた。
"""
# === セクション: 仮説検証総合 ===
sec7 = f"""
仮説と結果の照合 (要件: 仮説×結果対照表)
| 仮説 | RQ | 主要な結果 | 判定 |
|---|
| H1: 14 港の需要は均等配分でなく CR5 ≥ 40%, Gini ≥ 0.10 程度の集中度がある |
RQ1 |
CR5 = {cr5*100:.1f}%, Gini = {gini:.3f}, HHI = {hhi:.3f} |
{h1_judge} |
| H2: 主要港 (上位 3) は始発・終着港、周辺港は島嶼経由地 |
RQ1 |
上位 3 港のうち {h2_endpoint_top3} 港が始発/終着。中継主要港 (呉港等) も上位 |
{h2_judge} |
| H3: 春秋 2 山型 (5 月・11 月ピーク)、12 月谷はピークの 1/4 以下 |
RQ2 |
ピーク = {peak_month}月 ({peak_value:,}人), 谷 = {trough_month}月 ({trough_value:,}人), 比 = {peak_trough_ratio:.2f} |
{h3_judge} |
| H4: 港間の季節振幅は 1.5 倍以上の差 |
RQ2 |
max振幅 = {amp_top_value:.2f} ({amp_top_port}), min振幅 = {amp_bot_value:.2f} ({amp_bot_port}), 比 = {amp_ratio:.2f} |
{h4_judge} |
| H5: モニタークルーズは 4 ルートタイプに分類できる、東への延伸設計 |
RQ3 |
観察されたタイプ数 = {h5_n_types} (完全既存・既存主体・新規主体)。完全新規は試行なし。
新規寄港地は経度 133° 以東に集中。 |
{h5_judge} |
3 RQ を統合した総合考察
(1) 広島県沿岸クルーズ市場は「軽度集中 + 共通季節パターン + ハイブリッド実験」 で構成される
- RQ1 で見たように、14 港の需要分布は 軽度の集中 (Gini = {gini:.3f}) であり、
寡占でも完全分散でもない。広島県の沿岸クルーズ市場は 「拠点 5 港 + 経由 9 港」
というシンプルな階層構造を持つ。
- RQ2 で見たように、季節パターンは 港の役割によらず共通 (春秋 2 山 + 冬の深谷)。
港間で振幅は多少異なるが、形は近い。これは 需要が観光客の月別カレンダー (GW、紅葉、年末年始)
に支配されることの証拠。
- RQ3 で見たように、モニタークルーズ実証は 既存ラインを東に延伸する戦略で、
新規 100% ルートは試行されなかった。新規開拓と既存補強を併せたハイブリッド。
(2) 因果推論はしないが、記述から導かれる政策的含意
- 港の需要は 船のキャパシティ × 月数で決まる構造のため、需要拡大の最大の制約は
運航本数。集客テコ入れより 運航回数増のほうが効果的かもしれない (要検証)。
- 季節振幅が大きい港は 冬の谷を埋める政策の余地が大きい。一方、振幅が小さい港 (始発/終着の広島港・三原)
は通年で需要があり、船便増の効果が出やすい。
- モニタークルーズの新規寄港地は 東部に集中している。既存の主要港 (西部の広島-呉)
は基盤としつつ、東部 (尾道・しまなみ・鞆の浦) がフロンティア。
(3) 本記事の限界
- 1 年データのみ: 季節パターンの安定性 (= 毎年同じか?) は検証不可。
複数年データが取得できれば、季節係数の年次安定性を見たい。
- n=1 の介入: モニタークルーズの集客性能は記述レベルで言及できるのみ。
旧版 X04 のような 因果推論は意図的に行わなかった。
- 港の役割分類は本記事独自: 「上位 5 ∪ 始発/終着」 は分析的に有用だが、
公式の港階層分類ではない。他研究と比較するときは定義を明示する必要がある。
- 需要 = 乗降客数の代理: 厳密には潜在需要 (乗りたかった人数) と異なる。
船のキャパに張り付いた航海では 需要 > 観測値の可能性がある (= 機会損失)。
"""
# === セクション: 発展課題 ===
sec8 = f"""
結果X → 新仮説Y → 課題Z (要件 E: 3 段の論理鎖)
RQ1 から派生する発展課題
課題1: 主要港の役割分類を クラスタリングで再構築
- 結果X: RQ1 では主要 / 周辺の 2 分類を「上位 5 ∪ 始発終着」 で定義したが、
分類しきい値は本記事の主観。
- 新仮説Y: 港を (年間需要, 季節振幅, 寄港順位の中央値, 始発終着フラグ) の 4 次元ベクトルで
表現し、k-means クラスタリングを適用すると 3-4 クラスタ (拠点港・中継主要港・島嶼経由地・端点港)
が自然に分離する。
- 課題Z: sklearn.cluster.KMeans で n=3 と n=4 を試行 → シルエット係数で最適クラスタ数を決定 →
各クラスタの代表港・特徴を表化 → 政策的含意 (どのクラスタにどんな投資をすべきか) を議論。
課題2: 港のネットワーク中心性 (= ハブ性) を測る
- 結果X: RQ1 で港の絶対需要は分かったが、「他港との接続性」は見えていない。
呉港は中継だが、広島港・三原は端点という地理的役割。
- 新仮説Y: 航路を ネットワークとして表現すると、呉港の介在中心性 (betweenness centrality)
は他主要港の 2 倍以上で、真のハブである。
- 課題Z: networkx で航路を無向グラフ化 → betweenness/closeness/degree centrality を計算 →
各港の中心性ランキングを表化 → 「需要ランク」 と「中心性ランク」 の差分を分析。
RQ2 から派生する発展課題
課題3: 古典時系列分解で「トレンド + 季節 + 残差」 に分解
- 結果X: RQ2 では月別総需要が 2 山型と分かったが、トレンド成分 (年間でゆるい増減) と
季節成分 (毎月の山谷) を 視覚的に分離していない。
- 新仮説Y: 古典時系列分解 (additive decomposition) で 9 ヶ月データを分解すると、
トレンド成分は ±100 人/月以内のドリフトに留まり、季節成分が支配的 (±400 人/月)。
- 課題Z:
statsmodels.tsa.seasonal_decompose で additive 分解 →
3 成分を別折れ線で可視化 → 残差成分を見て外れ月 (例: 5 月の突出) を特定。
ただし 9 ヶ月データは分解の period=12 を満たさないため、複数年データが必要。
課題4: 季節パターンの クラスタリングで港のタイプを発見
- 結果X: RQ2 では港の振幅で 1 次元の比較しかできなかった。
季節パターンの 形 (どの月にピーク)はほぼ共通だったが、
厳密にはマイナーな差がある。
- 新仮説Y: 9 月分の季節係数ベクトルを使った階層クラスタリング (Ward 法) で
港を 2-3 クラスタに分けると、「春重視・秋重視・冬の谷が深い」 の 3 タイプが現れる。
- 課題Z: scipy.cluster.hierarchy.linkage で港 × 9 月の係数行列を Ward 法でクラスタリング →
デンドログラムで 2-3 クラスタを切る → 各クラスタの平均季節パターンを折れ線で表示。
RQ3 から派生する発展課題
課題5: モニタークルーズと 定常運航 (しまたび 12 月) の集客性能比較
- 結果X: RQ3 では n=1 イベントなので因果推論しなかったが、
同じ 12 月に運航された 定常しまたびラインの客数と並べて見ることはできる。
- 新仮説Y: モニタークルーズの 1 航海平均客数 ({trip['観光客数(人)'].mean():.1f} 人) は、
定常しまたびライン 12 月の 1 航海推定客数と 同程度 (±20 人) で、
「新ルートだから特段集まる」 効果は限定的。
- 課題Z: しまたびライン 12 月の月次合算客数を 12 月の運航日数で割って 1 航海平均を推定 →
モニタークルーズの 1 航海平均と並べて表化 → 客数差を記述 (因果推論せず)。
課題6: 運航日 × 曜日 × 天候 の交絡分解
- 結果X: RQ3 で運航日後半の客数低下を観察したが、要因 (曜日・天候・告知度) を
分離していない。
- 新仮説Y: 9 運航日の曜日構成を見ると 火・水・木が中心で、土日運航がない。
平日のため客数が抑制された可能性 → もし土日にも運航していたら平均客数は +30%程度になる。
- 課題Z: 運航日に曜日 (pd.to_datetime().dt.day_name()) と当日の気温/降水量
(気象庁データ) をマージ → 重回帰で 客数 ~ 航路 + 曜日 + 天候 をフィット →
各係数を比較 (n=15 で過適合に注意)。
3 RQ 横断の総合課題
課題7: 複数年データで 本格的な季節安定性 + ルート評価を再現
- 結果X: 本記事は 2022 年単年。2018-2024 年データがあれば、
季節パターンの安定性 + モニタークルーズ前後の年次変化が分析可能。
- 新仮説Y: 2018-2024 年の 12 月クルーズ客数 (定常運航) は 2023 年以降の平均が
2022 年より +15% 高い。2022 年実証のフォロアップ運航化 (= 新規ルート定着) の効果。
- 課題Z: DoBoX の続報リソースを取得 (まだ無ければ広島県観光統計に問い合わせ) →
年次対前年成長率を計算 → 2022 を介入年として t 検定 → ただし他県の同時期データで
比較群を作って交絡統制 (= 本格的な DID = 旧版 X04 が試みて失敗した姿の正解)。
"""
# Combine sections
sections = [
("学習目標と問い", sec1),
("使用データ", sec2),
("ダウンロード (再現用データ・中間データ・図)", sec3),
("【RQ1】 港別需要構造の研究 — 14 港の集中度と役割分化",
rq1_intro
+ rq1_fig2
+ rq1_fig3),
("【RQ2】 季節性の研究 — 春秋 2 山型と港別振幅",
rq2_intro),
("【RQ3】 モニタークルーズルート記述分析 — 区間混合と東への延伸",
rq3_intro),
("仮説検証総合", sec7),
("発展課題", sec8),
]
html = render_lesson(
num=304,
title="X04 広島県クルーズ需要の港別・季節別構造分析",
tags=["X04", "クルーズ", "市場構造", "集中度", "Gini", "季節係数", "RQ×3", "Format B"],
time="50〜70分",
level="L01 水準 (中級)",
data_label='DoBoX '
'#1282 しまたびライン (resource 39787) + '
''
'#1280 モニタークルーズ (resource 39782 + 39781)',
sections=sections,
script_filename="X04_cruise_intervention_timeseries.py",
)
# X-tier ドラフト印を埋め込む
html = html.replace("", '', 1)
HTML_PATH = LESSONS / "X04_cruise_intervention_timeseries.html"
HTML_PATH.write_text(html, encoding="utf-8")
elapsed = time.time() - t_start
print(f"\n=== HTML 出力 === {HTML_PATH.name} ({HTML_PATH.stat().st_size//1024} KB)")
print(f"[完了] 実行時間 {elapsed:.1f} 秒")
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}