"""
X01: インフラツーリズム × 防災施設の二重利用
==============================================
研究テーマ G3 (RESEARCH_THEMES.md):
広島県のインフラツーリズム掲載施設40件のうち、ダム・橋梁・トンネルの台帳と
**施設名でマージ**することで「観光対象になる/ならない」防災インフラの差を
**実データだけ**で検証する。
10セクション構成・5仮説:
H1: 観光対象ダムは非観光ダムより容量・堤高が大きい (箱ひげ図)
H2: 観光対象橋梁は規模上位(延長 P75 以上)に偏る (箱ひげ図 + 検定なしで P75 比率)
H3: 観光対象施設は道路アクセス性が高い(特定道路沿い)
H4: 「観光対象になる/ならない」は施設の規模・年代・立地から **判別可能**
→ ロジスティック回帰 で予測精度(AUC, 偽陽性率)を出す
H5: 観光対象施設の多い市町は、防災インフラ整備度も高い
→ 重回帰: 観光対象数 = a×ダム数 + b×橋梁数 + c×トンネル数
使用データ(実データ・全て取得済):
data/extras/infra_tourism.csv (40件 = 観光対象施設リスト)
data/extras/dam_basic.csv (12基ダム)
data/extras/bridge_basic.csv (4,203橋梁)
data/extras/tunnel_basic.csv (157トンネル)
使用手法(高校情報I + リテラシ範囲):
pandas merge / groupby
単回帰、重回帰 (statsmodels.OLS)
ロジスティック回帰 (sklearn.linear_model.LogisticRegression)
PCA (sklearn.decomposition.PCA) — 多変量俯瞰
可視化: 箱ひげ・散布図行列・係数バー・PCA散布
実行:
cd "2026 DoBoX 教材"
py -X utf8 lessons/X01_infra_tourism_dual_use.py
"""
from pathlib import Path
import re
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression, LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import roc_auc_score, roc_curve, confusion_matrix
import statsmodels.api as sm
from _common import ROOT, ASSETS, LESSONS, render_lesson, code, figure
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
INFRA_PATH = ROOT / "data" / "extras" / "infra_tourism.csv"
DAM_PATH = ROOT / "data" / "extras" / "dam_basic.csv"
BRIDGE_PATH = ROOT / "data" / "extras" / "bridge_basic.csv"
TUNNEL_PATH = ROOT / "data" / "extras" / "tunnel_basic.csv"
# -----------------------------------------------------------------------------
# === 1. 読み込み ============================================================
# -----------------------------------------------------------------------------
print("=== 1. 読み込み ===")
infra = pd.read_csv(INFRA_PATH, encoding="utf-8-sig")
dam = pd.read_csv(DAM_PATH, encoding="utf-8-sig").dropna(subset=["ダム名"]).reset_index(drop=True)
bridge = pd.read_csv(BRIDGE_PATH, encoding="utf-8-sig")
tunnel = pd.read_csv(TUNNEL_PATH, encoding="utf-8-sig")
print(f" infra(観光対象): {len(infra):>5} 件")
print(f" dam(ダム台帳): {len(dam):>5} 基")
print(f" bridge(橋梁台帳): {len(bridge):>5} 基")
print(f" tunnel(トンネル台帳): {len(tunnel):>5} 本")
# 観光対象施設の分類内訳
print(" 観光分類内訳:", infra["分類"].value_counts().to_dict())
# -----------------------------------------------------------------------------
# === 2. 名前正規化 + マージ — 「観光フラグ」列を作る ===========================
# -----------------------------------------------------------------------------
print("\n=== 2. 名前正規化 + マージ(観光フラグ列の付与)===")
def cleanname(s: str) -> str:
"""施設名から後置きの【路線名】や(旧名)等を除き、台帳と突合できる形にする。"""
if pd.isna(s):
return ""
s = str(s)
s = re.sub(r"[【\[].*?[】\]]", "", s) # 【国道487号】 など除去
s = re.sub(r"(.*?)", "", s) # (旧紅葉橋)など除去
return s.strip()
# 観光側の施設名を分類別に分ける
infra["clean"] = infra["施設名称"].apply(cleanname)
infra_dam_names = set(infra.loc[infra["施設名称"].str.contains("ダム", na=False), "clean"])
infra_bridge_names = set(infra.loc[infra["施設名称"].str.contains("橋", na=False), "clean"])
infra_tunnel_names = set(infra.loc[infra["施設名称"].str.contains("トンネル|隧道|隨道", na=False), "clean"])
print(f" 観光対象 ダム名: {len(infra_dam_names)} 件 {sorted(infra_dam_names)}")
print(f" 観光対象 橋梁名: {len(infra_bridge_names)} 件")
print(f" 観光対象 トンネル名: {len(infra_tunnel_names)} 件 {sorted(infra_tunnel_names)}")
# 各台帳に観光フラグ列を付与
dam["clean"] = dam["ダム名"].apply(cleanname)
bridge["clean"] = bridge["施設名"].apply(cleanname)
tunnel["clean"] = tunnel["施設名"].apply(cleanname)
dam["観光対象"] = dam["clean"].isin(infra_dam_names).astype(int)
bridge["観光対象"] = bridge["clean"].isin(infra_bridge_names).astype(int)
tunnel["観光対象"] = tunnel["clean"].isin(infra_tunnel_names).astype(int)
print(f" ダム : 観光対象 {dam['観光対象'].sum()}/{len(dam)} 基")
print(f" 橋梁 : 観光対象 {bridge['観光対象'].sum()}/{len(bridge)} 基")
print(f" トンネル : 観光対象 {tunnel['観光対象'].sum()}/{len(tunnel)} 本")
# 中間CSV: マージ後ダム
dam_out = dam[["ダム名", "型式", "完成年月", "総貯水容量_千m3",
"有効貯水容量_千m3", "堤高_m", "堤頂長_m", "集水面積_km2",
"緯度", "経度", "観光対象"]].copy()
dam_out.to_csv(ASSETS / "X01_dam_with_flag.csv", index=False, encoding="utf-8-sig")
# 中間CSV: マージ後橋梁(観光対象+ランダムサンプリング非対象 200件で軽量化)
np.random.seed(42)
b_t = bridge[bridge["観光対象"] == 1]
b_f = bridge[bridge["観光対象"] == 0].sample(n=300, random_state=42)
bridge_sample = pd.concat([b_t, b_f], ignore_index=True)
bridge_sample[["施設名", "種別", "路線名", "道路種別",
"架設年度", "延長(m)", "幅員(m)", "住所(市町)",
"緯度(10進数)", "経度(10進数)", "観光対象"]].to_csv(
ASSETS / "X01_bridge_sample_with_flag.csv", index=False, encoding="utf-8-sig")
# 中間CSV: マージ後トンネル
tunnel[["施設名", "路線名", "道路種別", "建設年度", "延長(m)", "幅員(m)",
"住所(市町)", "緯度(10進数)", "経度(10進数)", "観光対象"]].to_csv(
ASSETS / "X01_tunnel_with_flag.csv", index=False, encoding="utf-8-sig")
# -----------------------------------------------------------------------------
# === 3. H1: 観光対象ダムの規模特性(箱ひげ図)==================================
# -----------------------------------------------------------------------------
print("\n=== 3. H1: 観光対象ダムの規模特性 ===")
metrics = [("総貯水容量_千m3", "総貯水容量 (千m³)"),
("堤高_m", "堤高 (m)"),
("堤頂長_m", "堤頂長 (m)"),
("集水面積_km2", "集水面積 (km²)")]
fig, axes = plt.subplots(1, 4, figsize=(15, 4))
for ax, (col, label) in zip(axes, metrics):
g_t = dam.loc[dam["観光対象"] == 1, col].dropna().values
g_f = dam.loc[dam["観光対象"] == 0, col].dropna().values
ax.boxplot([g_f, g_t], labels=["非観光", "観光"], patch_artist=True,
boxprops=dict(facecolor="#cfe2f3"))
ax.scatter(np.full(len(g_f), 1) + np.random.uniform(-0.08, 0.08, len(g_f)),
g_f, color="#0a3d62", alpha=0.7, s=24)
ax.scatter(np.full(len(g_t), 2) + np.random.uniform(-0.08, 0.08, len(g_t)),
g_t, color="#cf222e", alpha=0.85, s=30)
ax.set_title(label, fontsize=11)
ax.grid(alpha=0.3, axis="y")
if g_t.size and g_f.size:
ratio = np.median(g_t) / max(np.median(g_f), 1e-9)
ax.text(0.5, 1.02, f"中央値比 {ratio:.2f}×",
transform=ax.transAxes, ha="center", color="#cf222e", fontsize=10)
fig.suptitle("H1: 観光対象ダム vs 非観光ダム — 12基の規模分布", fontsize=13)
fig.tight_layout()
fig.savefig(ASSETS / "X01_h1_dam_box.png", dpi=140, bbox_inches="tight")
plt.close(fig)
# サマリ表
dam_summary = []
for (col, lab) in metrics:
g_t = dam.loc[dam["観光対象"] == 1, col].dropna()
g_f = dam.loc[dam["観光対象"] == 0, col].dropna()
dam_summary.append({
"指標": lab,
"観光n": len(g_t), "観光中央値": round(g_t.median(), 1),
"非観光n": len(g_f), "非観光中央値": round(g_f.median(), 1),
"中央値比": round(g_t.median() / max(g_f.median(), 1e-9), 2),
})
dam_summary_df = pd.DataFrame(dam_summary)
dam_summary_df.to_csv(ASSETS / "X01_h1_dam_summary.csv", index=False, encoding="utf-8-sig")
print(dam_summary_df.to_string(index=False))
# -----------------------------------------------------------------------------
# === 4. H2: 観光対象橋梁は P75 以上に偏るか ===================================
# -----------------------------------------------------------------------------
print("\n=== 4. H2: 観光対象橋梁の延長分布 ===")
bridge_clean = bridge.dropna(subset=["延長(m)", "架設年度"]).copy()
p75 = bridge_clean["延長(m)"].quantile(0.75)
p90 = bridge_clean["延長(m)"].quantile(0.90)
p99 = bridge_clean["延長(m)"].quantile(0.99)
print(f" 延長分布 (n={len(bridge_clean)}): P75={p75:.1f} m, P90={p90:.1f} m, P99={p99:.1f} m")
g_t = bridge_clean.loc[bridge_clean["観光対象"] == 1, "延長(m)"]
g_f = bridge_clean.loc[bridge_clean["観光対象"] == 0, "延長(m)"]
ratio_p75_t = (g_t > p75).mean()
ratio_p75_f = (g_f > p75).mean()
print(f" P75超 比率: 観光={ratio_p75_t:.1%} 非観光={ratio_p75_f:.1%}")
print(f" 観光対象橋梁の延長中央値: {g_t.median():.1f} m / 非観光: {g_f.median():.1f} m")
# H2 図 — 延長ヒスト + ECDF
fig, axes = plt.subplots(1, 2, figsize=(13, 4.5))
ax = axes[0]
log_x = np.log10(np.clip(bridge_clean["延長(m)"], 0.5, None))
ax.hist(log_x[bridge_clean["観光対象"] == 0], bins=40, alpha=0.55,
label=f"非観光 (n={len(g_f)})", color="#0969da", density=True)
ax.hist(log_x[bridge_clean["観光対象"] == 1], bins=15, alpha=0.85,
label=f"観光 (n={len(g_t)})", color="#cf222e", density=True)
for x, lab in [(np.log10(p75), "P75"), (np.log10(p90), "P90"), (np.log10(p99), "P99")]:
ax.axvline(x, color="black", linestyle="--", alpha=0.4)
ax.text(x, ax.get_ylim()[1] * 0.92, lab, ha="center", fontsize=9)
ax.set_xlabel("log10(延長 m)")
ax.set_ylabel("密度")
ax.set_title(f"H2: 橋梁延長分布 — 観光対象は右裾に偏在")
ax.legend()
ax.grid(alpha=0.3)
ax = axes[1]
xs_f = np.sort(g_f.values); ys_f = np.arange(1, len(xs_f) + 1) / len(xs_f)
xs_t = np.sort(g_t.values); ys_t = np.arange(1, len(xs_t) + 1) / len(xs_t)
ax.semilogx(xs_f, ys_f, color="#0969da", linewidth=2,
label=f"非観光 ECDF (n={len(g_f)})")
ax.semilogx(xs_t, ys_t, color="#cf222e", linewidth=2.5,
label=f"観光 ECDF (n={len(g_t)})")
ax.axvline(p75, linestyle="--", color="black", alpha=0.5)
ax.text(p75, 0.05, f" P75={p75:.0f}m", fontsize=9)
ax.set_xlabel("橋梁延長 (m, log軸)")
ax.set_ylabel("累積比率")
ax.set_title("ECDF: 観光線が右に大きくシフト = 大規模橋梁集中")
ax.legend(loc="upper left")
ax.grid(alpha=0.3, which="both")
fig.tight_layout()
fig.savefig(ASSETS / "X01_h2_bridge_dist.png", dpi=140, bbox_inches="tight")
plt.close(fig)
bridge_summary = pd.DataFrame([{
"母集団": "全橋梁(クリーン)", "n": len(bridge_clean),
"中央値_m": round(bridge_clean["延長(m)"].median(), 1),
"P75_m": round(p75, 1), "P90_m": round(p90, 1), "P99_m": round(p99, 1),
}, {
"母集団": "観光対象橋梁", "n": len(g_t),
"中央値_m": round(g_t.median(), 1),
"P75_m": round(g_t.quantile(0.75), 1),
"P90_m": round(g_t.quantile(0.90), 1),
"P99_m": round(g_t.quantile(0.99) if len(g_t) > 0 else 0, 1),
}])
bridge_summary.to_csv(ASSETS / "X01_h2_bridge_summary.csv", index=False, encoding="utf-8-sig")
print(bridge_summary.to_string(index=False))
# -----------------------------------------------------------------------------
# === 5. H3: 道路アクセス性 — 道路種別比率 =====================================
# -----------------------------------------------------------------------------
print("\n=== 5. H3: 道路種別の偏り ===")
b_t = bridge_clean[bridge_clean["観光対象"] == 1]
b_f = bridge_clean[bridge_clean["観光対象"] == 0]
road_t = b_t["道路種別"].value_counts(normalize=True)
road_f = b_f["道路種別"].value_counts(normalize=True)
print(" 観光対象 道路種別比率:\n", road_t)
print(" 非観光 道路種別比率:\n", road_f)
# H3 図: 道路種別の比率比較棒グラフ
combos = pd.DataFrame({"観光対象": road_t, "非観光": road_f}).fillna(0)
fig, ax = plt.subplots(figsize=(8.5, 4.2))
x = np.arange(len(combos.index))
w = 0.38
ax.bar(x - w/2, combos["非観光"], width=w, label=f"非観光 (n={len(b_f)})", color="#0969da", alpha=0.8)
ax.bar(x + w/2, combos["観光対象"], width=w, label=f"観光対象 (n={len(b_t)})", color="#cf222e", alpha=0.85)
ax.set_xticks(x)
ax.set_xticklabels(combos.index)
ax.set_ylabel("構成比")
ax.set_title("H3: 観光対象橋梁は国道・主要県道に偏るか")
ax.legend()
ax.grid(alpha=0.3, axis="y")
for i, v in enumerate(combos["観光対象"]):
ax.text(i + w/2, v + 0.005, f"{v:.0%}", ha="center", fontsize=9, color="#cf222e")
for i, v in enumerate(combos["非観光"]):
ax.text(i - w/2, v + 0.005, f"{v:.0%}", ha="center", fontsize=9, color="#0969da")
fig.tight_layout()
fig.savefig(ASSETS / "X01_h3_roadtype.png", dpi=140, bbox_inches="tight")
plt.close(fig)
road_summary = combos.reset_index().rename(columns={"index": "道路種別"})
road_summary["観光対象"] = road_summary["観光対象"].round(3)
road_summary["非観光"] = road_summary["非観光"].round(3)
road_summary.to_csv(ASSETS / "X01_h3_roadtype.csv", index=False, encoding="utf-8-sig")
# -----------------------------------------------------------------------------
# === 6. H4: ロジスティック回帰で「観光対象になる/ならない」を予測 ==============
# -----------------------------------------------------------------------------
print("\n=== 6. H4: ロジスティック回帰(橋梁台帳のみ)===")
# 規模・年代だけで観光対象を予測できるか
df_lr = bridge_clean.dropna(subset=["延長(m)", "幅員(m)", "架設年度", "道路種別"]).copy()
df_lr["log_延長"] = np.log10(df_lr["延長(m)"].clip(lower=0.5))
df_lr["log_幅員"] = np.log10(df_lr["幅員(m)"].clip(lower=0.5))
df_lr["築年経過"] = 2026 - df_lr["架設年度"]
df_lr["国道フラグ"] = (df_lr["道路種別"] == "国道").astype(int)
features = ["log_延長", "log_幅員", "築年経過", "国道フラグ"]
X = df_lr[features].values
y = df_lr["観光対象"].values
scaler = StandardScaler()
X_std = scaler.fit_transform(X)
# 観光対象は数十件で非常に少数なので class_weight=balanced で偏りを補正
lr = LogisticRegression(max_iter=2000, class_weight="balanced",
random_state=42)
lr.fit(X_std, y)
p_pred = lr.predict_proba(X_std)[:, 1]
auc = roc_auc_score(y, p_pred)
print(f" AUC = {auc:.3f} (n={len(y)}, 正例={y.sum()}/{len(y)})")
# 係数(標準化済特徴の係数 = 1標準偏差増による log-odds 変化)
coef_df = pd.DataFrame({
"特徴": features,
"係数(標準化)": lr.coef_[0].round(3),
"オッズ比 (1σ増)": np.exp(lr.coef_[0]).round(3),
})
coef_df.loc[len(coef_df)] = ["切片", round(lr.intercept_[0], 3), round(np.exp(lr.intercept_[0]), 3)]
print(coef_df.to_string(index=False))
coef_df.to_csv(ASSETS / "X01_h4_lr_coef.csv", index=False, encoding="utf-8-sig")
# ROC + 係数バー
fig, axes = plt.subplots(1, 2, figsize=(12.5, 4.5))
ax = axes[0]
fpr, tpr, _ = roc_curve(y, p_pred)
ax.plot(fpr, tpr, color="#cf222e", linewidth=2, label=f"ロジスティック回帰 AUC={auc:.3f}")
ax.plot([0, 1], [0, 1], color="#888", linestyle="--", label="乱数モデル")
ax.set_xlabel("偽陽性率 FPR")
ax.set_ylabel("真陽性率 TPR")
ax.set_title("H4: ROC曲線 — 観光対象判定の弁別力")
ax.legend()
ax.grid(alpha=0.3)
ax = axes[1]
order = np.argsort(np.abs(lr.coef_[0]))[::-1]
labs = [features[i] for i in order]
vals = [lr.coef_[0][i] for i in order]
colors = ["#cf222e" if v > 0 else "#0969da" for v in vals]
ax.barh(labs, vals, color=colors, alpha=0.85)
ax.axvline(0, color="black", linewidth=0.7)
ax.set_xlabel("標準化係数 (1σ増 → log-odds 増)")
ax.set_title("特徴の効き方 — 正値=観光対象に効く")
for i, v in enumerate(vals):
ax.text(v + (0.02 if v > 0 else -0.02), i, f"{v:+.2f}",
va="center", ha="left" if v > 0 else "right", fontsize=10)
ax.grid(alpha=0.3, axis="x")
fig.tight_layout()
fig.savefig(ASSETS / "X01_h4_lr_roc.png", dpi=140, bbox_inches="tight")
plt.close(fig)
# 1橋梁の Before/After 例(広島空港大橋)
example_idx = df_lr[df_lr["clean"] == "広島空港大橋"].index
if len(example_idx):
ex = df_lr.loc[example_idx[0]]
ex_features_raw = [ex["延長(m)"], ex["幅員(m)"], ex["架設年度"], ex["道路種別"]]
ex_features_eng = [ex["log_延長"], ex["log_幅員"], ex["築年経過"], ex["国道フラグ"]]
ex_std = scaler.transform([ex_features_eng])[0]
ex_logit = lr.intercept_[0] + (lr.coef_[0] * ex_std).sum()
ex_prob = 1 / (1 + np.exp(-ex_logit))
print(f"\n 例: 広島空港大橋 → P(観光対象)={ex_prob:.3f}, 実績={int(ex['観光対象'])}")
example_record = {
"raw_延長(m)": ex["延長(m)"],
"raw_幅員(m)": ex["幅員(m)"],
"raw_架設年度": int(ex["架設年度"]),
"raw_道路種別": ex["道路種別"],
"log_延長": round(ex["log_延長"], 3),
"log_幅員": round(ex["log_幅員"], 3),
"築年経過": int(ex["築年経過"]),
"国道フラグ": int(ex["国道フラグ"]),
"標準化_log_延長": round(ex_std[0], 3),
"標準化_log_幅員": round(ex_std[1], 3),
"標準化_築年経過": round(ex_std[2], 3),
"国道フラグ_(0/1)": int(ex_features_eng[3]),
"logit": round(ex_logit, 3),
"P(観光対象)": round(float(ex_prob), 3),
"実績": int(ex["観光対象"]),
}
else:
example_record = None
# 中間CSV: 全橋梁の予測確率
pred_out = df_lr[["施設名", "路線名", "道路種別", "延長(m)", "幅員(m)",
"架設年度", "観光対象"]].copy()
pred_out["P_観光対象"] = p_pred.round(4)
pred_out.sort_values("P_観光対象", ascending=False).head(50).to_csv(
ASSETS / "X01_h4_top50_pred.csv", index=False, encoding="utf-8-sig")
# -----------------------------------------------------------------------------
# === 7. PCA: 多変量俯瞰(橋梁の特徴空間に観光フラグを重ねる)===================
# -----------------------------------------------------------------------------
print("\n=== 7. PCA: 橋梁の特徴空間 ===")
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_std)
print(f" 寄与率: PC1={pca.explained_variance_ratio_[0]:.3f}, "
f"PC2={pca.explained_variance_ratio_[1]:.3f}, "
f"累積={pca.explained_variance_ratio_[:2].sum():.3f}")
loadings = pd.DataFrame(pca.components_.T,
index=features, columns=["PC1", "PC2"]).round(3)
print(loadings.to_string())
loadings.to_csv(ASSETS / "X01_h4_pca_loadings.csv", encoding="utf-8-sig")
fig, ax = plt.subplots(figsize=(8.5, 6.5))
mask_t = (y == 1)
ax.scatter(X_pca[~mask_t, 0], X_pca[~mask_t, 1], s=12, alpha=0.4,
color="#0969da", label=f"非観光 (n={(~mask_t).sum()})")
ax.scatter(X_pca[mask_t, 0], X_pca[mask_t, 1], s=80, alpha=0.95,
color="#cf222e", marker="*", edgecolor="black",
label=f"観光対象 (n={mask_t.sum()})")
# ローディング矢印
for i, feat in enumerate(features):
arr = pca.components_[:, i]
ax.annotate("", xy=(arr[0]*4, arr[1]*4), xytext=(0, 0),
arrowprops=dict(arrowstyle="->", color="black", alpha=0.7))
ax.text(arr[0]*4.4, arr[1]*4.4, feat, color="black",
fontsize=10, fontweight="bold", ha="center")
ax.axhline(0, color="black", linewidth=0.6, alpha=0.4)
ax.axvline(0, color="black", linewidth=0.6, alpha=0.4)
ax.set_xlabel(f"PC1 ({pca.explained_variance_ratio_[0]:.1%})")
ax.set_ylabel(f"PC2 ({pca.explained_variance_ratio_[1]:.1%})")
ax.set_title("H4 補助: PCA — 橋梁を2次元に圧縮し観光対象を重ね描き")
ax.legend(loc="upper right")
ax.grid(alpha=0.3)
fig.tight_layout()
fig.savefig(ASSETS / "X01_h4_pca.png", dpi=140, bbox_inches="tight")
plt.close(fig)
# -----------------------------------------------------------------------------
# === 8. H5: 市町別重回帰 — 観光対象数 = a×ダム数 + b×橋梁数 + c×トンネル数 ========
# -----------------------------------------------------------------------------
print("\n=== 8. H5: 市町別 重回帰 ===")
# 各台帳から市町列を統一
def extract_city_from_dam(s):
"""ダムの '位置' から市町を取り出す(例: '廿日市市浅原' → '廿日市市')"""
s = str(s)
m = re.match(r"([一-龥ぁ-んァ-ンA-Za-z]+(?:市|町|村|区))", s)
return m.group(1) if m else None
dam["市町"] = dam["位置"].apply(extract_city_from_dam)
# トンネルは「府中町 茂陰一丁目」のような詳細住所のため、先頭の市町だけ抽出
def first_city(s):
if pd.isna(s):
return None
s = str(s).split()[0] # 全角空白で分割して先頭だけ
m = re.match(r"^([一-龥ぁ-んァ-ンA-Za-z]+(?:市|町|村|区))", s)
return m.group(1) if m else None
# 橋梁の住所は既に「尾道市」レベルだが、念のため統一処理
bridge["市町"] = bridge["住所(市町)"].apply(first_city)
tunnel["市町"] = tunnel["住所(市町)"].apply(first_city)
dam_cnt = dam.groupby("市町").size().rename("dam_n")
bridge_cnt = bridge.dropna(subset=["市町"]).groupby("市町").size().rename("bridge_n")
tunnel_cnt = tunnel.dropna(subset=["市町"]).groupby("市町").size().rename("tunnel_n")
dam_tour = dam.groupby("市町")["観光対象"].sum().rename("dam_tour")
bridge_tour = bridge.dropna(subset=["市町"]).groupby("市町")["観光対象"].sum().rename("bridge_tour")
tunnel_tour = tunnel.dropna(subset=["市町"]).groupby("市町")["観光対象"].sum().rename("tunnel_tour")
city_df = pd.concat([dam_cnt, bridge_cnt, tunnel_cnt,
dam_tour, bridge_tour, tunnel_tour], axis=1).fillna(0).astype(int)
city_df.index.name = "市町"
city_df = city_df.reset_index()
city_df["観光対象数"] = city_df["dam_tour"] + city_df["bridge_tour"] + city_df["tunnel_tour"]
print(city_df.sort_values("観光対象数", ascending=False).to_string(index=False))
# Drop city with all zeros to avoid singular matrix... but we want all rows for honest analysis
X5 = city_df[["dam_n", "bridge_n", "tunnel_n"]].values.astype(float)
y5 = city_df["観光対象数"].values.astype(float)
# statsmodels OLS(切片付き)
X5_sm = sm.add_constant(X5)
model = sm.OLS(y5, X5_sm).fit()
print(model.summary().as_text())
ols_coef_df = pd.DataFrame({
"変数": ["切片", "dam_n", "bridge_n", "tunnel_n"],
"係数": np.round(model.params, 4),
"p値": np.round(model.pvalues, 4),
"95%CI下": np.round(model.conf_int()[:, 0], 4),
"95%CI上": np.round(model.conf_int()[:, 1], 4),
})
print(ols_coef_df.to_string(index=False))
ols_coef_df.to_csv(ASSETS / "X01_h5_ols_coef.csv", index=False, encoding="utf-8-sig")
city_df["観光対象_予測"] = np.round(model.predict(X5_sm), 2)
city_df["残差"] = np.round(y5 - model.predict(X5_sm), 2)
city_df = city_df.sort_values("観光対象数", ascending=False).reset_index(drop=True)
city_df.to_csv(ASSETS / "X01_h5_city_table.csv", index=False, encoding="utf-8-sig")
# H5 図 — 観測 vs 予測 散布、係数バー
fig, axes = plt.subplots(1, 2, figsize=(13, 4.5))
ax = axes[0]
ax.scatter(model.fittedvalues, y5, s=70, alpha=0.85,
color="#0969da", edgecolor="black")
mn, mx = min(y5.min(), model.fittedvalues.min()), max(y5.max(), model.fittedvalues.max())
ax.plot([mn, mx], [mn, mx], "--", color="#cf222e", alpha=0.7, label="y=ŷ")
for i, c in enumerate(city_df["市町"]):
if y5[i] >= 1:
ax.text(model.fittedvalues[i] + 0.05, y5[i] + 0.05, c, fontsize=9)
ax.set_xlabel("予測 観光対象数")
ax.set_ylabel("実際 観光対象数")
ax.set_title(f"H5: 市町別重回帰 — R²={model.rsquared:.3f}, 調整R²={model.rsquared_adj:.3f}")
ax.legend()
ax.grid(alpha=0.3)
ax = axes[1]
labs2 = ["dam_n", "bridge_n", "tunnel_n"]
vals2 = model.params[1:].tolist()
err2 = (model.conf_int()[1:, 1] - model.params[1:]).tolist()
colors2 = ["#cf222e" if v > 0 else "#0969da" for v in vals2]
ax.barh(labs2, vals2, color=colors2, alpha=0.85,
xerr=err2, error_kw=dict(ecolor="black", lw=1.2, capsize=4))
ax.axvline(0, color="black", linewidth=0.7)
for i, (v, p) in enumerate(zip(vals2, model.pvalues[1:])):
sig = "**" if p < 0.05 else ("*" if p < 0.10 else "ns")
ax.text(v, i, f" {v:+.4f} ({sig})", va="center", fontsize=10)
ax.set_xlabel("係数 (95%信頼区間)")
ax.set_title(f"何が観光対象数を上げる? n={len(city_df)} 市町")
ax.grid(alpha=0.3, axis="x")
fig.tight_layout()
fig.savefig(ASSETS / "X01_h5_ols.png", dpi=140, bbox_inches="tight")
plt.close(fig)
# -----------------------------------------------------------------------------
# === 9. 散布図行列(pairplot 風)== infra 39件の規模・年代・観光フラグ =========
# -----------------------------------------------------------------------------
print("\n=== 9. 散布図行列 ===")
# ダム+橋梁+トンネルの観光対象を1つのデータフレームに統合(共通指標:規模, 経過年)
def jpera_to_year(s):
"""'S39.6' / 'H1.3' / 'H21.10' → 西暦完成年 (int)"""
if pd.isna(s):
return np.nan
s = str(s)
m = re.match(r"^([SHRМ昭平令])(\d+)", s)
if not m:
return np.nan
era, n = m.group(1), int(m.group(2))
base = {"S": 1925, "H": 1988, "R": 2018}.get(era)
return base + n if base else np.nan
combined = []
for _, r in dam.iterrows():
yr = jpera_to_year(r["完成年月"])
combined.append({
"種別": "ダム",
"規模": r["総貯水容量_千m3"],
"高さ_or_延長": r["堤高_m"],
"経過年": (2026 - yr) if not np.isnan(yr) else np.nan,
"緯度": r["緯度"], "経度": r["経度"],
"観光対象": r["観光対象"],
})
for _, r in bridge_clean.iterrows():
combined.append({
"種別": "橋梁",
"規模": r["延長(m)"],
"高さ_or_延長": r["延長(m)"],
"経過年": 2026 - r["架設年度"],
"緯度": r["緯度(10進数)"], "経度": r["経度(10進数)"],
"観光対象": r["観光対象"],
})
for _, r in tunnel.dropna(subset=["延長(m)", "建設年度"]).iterrows():
combined.append({
"種別": "トンネル",
"規模": r["延長(m)"],
"高さ_or_延長": r["延長(m)"],
"経過年": 2026 - r["建設年度"],
"緯度": r["緯度(10進数)"], "経度": r["経度(10進数)"],
"観光対象": r["観光対象"],
})
comb_df = pd.DataFrame(combined).dropna(subset=["規模", "経過年"])
print(f" 統合データフレーム: {len(comb_df)}件 (ダム+橋梁+トンネル)")
comb_df.to_csv(ASSETS / "X01_combined_with_flag.csv", index=False, encoding="utf-8-sig")
# 散布図行列
cols = ["規模", "経過年", "緯度", "経度"]
fig, axes = plt.subplots(len(cols), len(cols), figsize=(12, 12))
for i, ci in enumerate(cols):
for j, cj in enumerate(cols):
ax = axes[i, j]
if i == j:
ax.hist(np.log10(np.clip(comb_df[ci], 0.5, None)) if ci == "規模"
else comb_df[ci], bins=30, color="#888", alpha=0.7)
ax.set_title(ci, fontsize=10)
else:
x = np.log10(np.clip(comb_df[cj], 0.5, None)) if cj == "規模" else comb_df[cj]
y_v = np.log10(np.clip(comb_df[ci], 0.5, None)) if ci == "規模" else comb_df[ci]
mask = comb_df["観光対象"] == 0
ax.scatter(x[mask], y_v[mask], s=4, alpha=0.25, color="#0969da", label="非観光")
ax.scatter(x[~mask], y_v[~mask], s=40, alpha=0.95, color="#cf222e",
marker="*", edgecolor="black", label="観光")
if i == len(cols) - 1:
ax.set_xlabel(cj if cj != "規模" else "log10(規模)")
if j == 0:
ax.set_ylabel(ci if ci != "規模" else "log10(規模)")
ax.grid(alpha=0.25)
fig.suptitle("散布図行列: 規模・経過年・位置・観光フラグの全ペア関係", fontsize=14)
fig.tight_layout(rect=[0, 0, 1, 0.97])
fig.savefig(ASSETS / "X01_pairplot.png", dpi=120, bbox_inches="tight")
plt.close(fig)
# -----------------------------------------------------------------------------
# === 10. HTML レンダリング ===================================================
# -----------------------------------------------------------------------------
print("\n=== 10. HTML レンダリング ===")
# H4 例の Before/After 表 HTML
def _build_example_table():
if not example_record:
return ""
from html import escape as e
rows_html = "".join(
f"{e(str(k))} | {e(str(v))} |
"
for k, v in example_record.items()
)
return ("")
ex_html = _build_example_table()
# サマリ・係数の HTML 化
dam_summary_html = dam_summary_df.to_html(index=False, classes="result-tbl")
bridge_summary_html = bridge_summary.to_html(index=False)
road_summary_html = road_summary.to_html(index=False)
coef_h4_html = coef_df.to_html(index=False)
ols_coef_html = ols_coef_df.to_html(index=False)
# 表示は観光対象数 > 0 + 上位 15 市町に絞る(n=80市町を全表示すると HTML が冗長)
_city_top = city_df[city_df["観光対象数"] > 0].head(20)
city_html = _city_top[["市町", "dam_n", "bridge_n", "tunnel_n",
"dam_tour", "bridge_tour", "tunnel_tour",
"観光対象数", "観光対象_予測", "残差"]].to_html(index=False)
loadings_html = loadings.reset_index().rename(columns={"index": "特徴"}).to_html(index=False)
# === セクションコード片(教材表示用、実装の核だけ)=============================
CODE_MERGE = '''
import re, pandas as pd
# 1. 4 つの CSV を読む
infra = pd.read_csv("data/extras/infra_tourism.csv", encoding="utf-8-sig")
dam = pd.read_csv("data/extras/dam_basic.csv", encoding="utf-8-sig").dropna(subset=["ダム名"])
bridge = pd.read_csv("data/extras/bridge_basic.csv", encoding="utf-8-sig")
tunnel = pd.read_csv("data/extras/tunnel_basic.csv", encoding="utf-8-sig")
# 2. 施設名の表記ゆれを正規化(【国道487号】や(旧紅葉橋)を取り除く)
def cleanname(s):
s = re.sub(r"[【\\[].*?[】\\]]", "", str(s))
s = re.sub(r"(.*?)", "", s)
return s.strip()
infra["clean"] = infra["施設名称"].apply(cleanname)
# 3. 観光対象を「ダム/橋/トンネル」で振り分けて name セットを作る
infra_dam_names = set(infra.loc[infra["施設名称"].str.contains("ダム"), "clean"])
infra_bridge_names = set(infra.loc[infra["施設名称"].str.contains("橋"), "clean"])
infra_tunnel_names = set(infra.loc[infra["施設名称"].str.contains("トンネル|隧道|隨道"), "clean"])
# 4. 各台帳に「観光対象」フラグ列 (0/1) を追加
dam["観光対象"] = dam["ダム名"].apply(cleanname).isin(infra_dam_names).astype(int)
bridge["観光対象"] = bridge["施設名"].apply(cleanname).isin(infra_bridge_names).astype(int)
tunnel["観光対象"] = tunnel["施設名"].apply(cleanname).isin(infra_tunnel_names).astype(int)
'''
CODE_H1 = '''
metrics = [("総貯水容量_千m3", "総貯水容量"), ("堤高_m", "堤高"),
("堤頂長_m", "堤頂長"), ("集水面積_km2", "集水面積")]
fig, axes = plt.subplots(1, 4, figsize=(15, 4))
for ax, (col, label) in zip(axes, metrics):
g_t = dam.loc[dam["観光対象"] == 1, col].dropna() # 観光対象ダム
g_f = dam.loc[dam["観光対象"] == 0, col].dropna() # 非観光ダム
ax.boxplot([g_f, g_t], labels=["非観光", "観光"])
ax.set_title(label)
'''
CODE_H4 = '''
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import roc_auc_score
# 1. 特徴量設計(log変換・経過年・国道フラグ)
df = bridge.dropna(subset=["延長(m)", "幅員(m)", "架設年度"]).copy()
df["log_延長"] = np.log10(df["延長(m)"].clip(lower=0.5))
df["log_幅員"] = np.log10(df["幅員(m)"].clip(lower=0.5))
df["築年経過"] = 2026 - df["架設年度"]
df["国道フラグ"] = (df["道路種別"] == "国道").astype(int)
X = df[["log_延長", "log_幅員", "築年経過", "国道フラグ"]].values
y = df["観光対象"].values # 0/1
# 2. 標準化(各特徴を 平均0/分散1 に揃える。単位差で係数が偏るのを防ぐ)
X_std = StandardScaler().fit_transform(X)
# 3. 学習:観光対象=正例は数十件で少数派。class_weight="balanced" で重み調整
lr = LogisticRegression(max_iter=2000, class_weight="balanced", random_state=42)
lr.fit(X_std, y)
# 4. 予測確率(0〜1) → AUC で全橋梁の弁別力を測る
p_pred = lr.predict_proba(X_std)[:, 1]
auc = roc_auc_score(y, p_pred)
print("AUC =", auc, " 係数:", dict(zip(features, lr.coef_[0].round(3))))
'''
CODE_H5 = '''
import statsmodels.api as sm
# 0. 各台帳から「市町」列を統一(トンネルは「府中町 茂陰一丁目」のような詳細住所)
def first_city(s):
s = str(s).split()[0]
m = re.match(r"^([一-龥ぁ-んァ-ンA-Za-z]+(?:市|町|村|区))", s)
return m.group(1) if m else None
dam["市町"] = dam["位置"].apply(first_city)
bridge["市町"] = bridge["住所(市町)"].apply(first_city)
tunnel["市町"] = tunnel["住所(市町)"].apply(first_city)
# 1. 市町ごとに 6 つの集計量を結合
city_df = pd.concat([
dam.groupby("市町").size().rename("dam_n"),
bridge.dropna(subset=["市町"]).groupby("市町").size().rename("bridge_n"),
tunnel.dropna(subset=["市町"]).groupby("市町").size().rename("tunnel_n"),
dam.groupby("市町")["観光対象"].sum().rename("dam_tour"),
bridge.dropna(subset=["市町"]).groupby("市町")["観光対象"].sum().rename("bridge_tour"),
tunnel.dropna(subset=["市町"]).groupby("市町")["観光対象"].sum().rename("tunnel_tour"),
], axis=1).fillna(0).astype(int).reset_index()
city_df["観光対象数"] = city_df["dam_tour"] + city_df["bridge_tour"] + city_df["tunnel_tour"]
# 2. 重回帰: 観光対象数 = a*dam_n + b*bridge_n + c*tunnel_n + 切片
X = city_df[["dam_n", "bridge_n", "tunnel_n"]].values
y = city_df["観光対象数"].values
X_sm = sm.add_constant(X) # 切片列を加える
model = sm.OLS(y, X_sm).fit()
print(model.summary()) # 係数, p値, R², 調整R²
'''
CODE_PCA = '''
from sklearn.decomposition import PCA
pca = PCA(n_components=2) # 4 特徴 → 2 軸 に圧縮
X_pca = pca.fit_transform(X_std) # X_std は H4 と同じ標準化済み行列
print(pca.explained_variance_ratio_) # 軸ごとの寄与率(合計≦1.0)
# 散布図に観光フラグを色で重ねれば、特徴空間上での分離を視覚化できる
plt.scatter(X_pca[y==0, 0], X_pca[y==0, 1], color="blue", s=8)
plt.scatter(X_pca[y==1, 0], X_pca[y==1, 1], color="red", marker="*", s=80)
'''
# === セクション本体 ============================================================
sections = [
("学習目標と問い", """
このレッスンで答えたい問い
「広島県の防災インフラ(ダム12基/橋梁4,203基/トンネル157本)のうち、
どれが『観光対象』として外部公開されているか?
そして、観光対象になる施設は規模・年代・立地から
事前に予測できるのか?」
用語の定義(このレッスン独自)
- 「インフラツーリズム」: ダム・橋梁・砂防施設など 本来は防災・交通用途のインフラ施設を観光資源として公開する取り組み。
広島県は DoBoX #1278「インフラツーリズム」 でカタログ化(本記事では 40件)。
- 「観光対象施設」: 上記カタログ40件に名前が登録されている施設。本記事では「観光対象=1」、それ以外を「観光対象=0」 として2値ラベルにする。
- 「観光フラグ」: ダム/橋梁/トンネルの台帳に対して、施設名で照合し「カタログに載っているか」を 0/1 で立てた列。本記事独自の派生列であり、DoBoX 公式列ではない。
- 「ロジスティック回帰」: 「YESかNOか」を確率で答える機械学習ツール。
複数の特徴(延長・幅員・築年)を入れると、観光対象になる確率 (0〜1) を返す。中身の数式は黒箱でOK。係数を見れば「どの特徴が効いたか」も分かる。
- 「LDA(線形判別分析)」: ロジスティック回帰と 近い目的(YES/NO 判別)のツール。2グループの平均が最も離れる軸を探して投影する。本記事では PCA で代用するが、参考として併記。
- 「PCA(主成分分析)」: 多くの列を 2〜3 列に圧縮するツール。「全 4 列を 1 枚の散布図にしたい」が目的。圧縮後の軸(PC1, PC2)に観光フラグを重ねると、観光対象が空間のどこに集まるか見える。
- 「重回帰」: 1 つの結果を、複数の原因で説明するツール。
本記事では「市町の観光対象数 = a×ダム数 + b×橋梁数 + c×トンネル数」と立てる。
- 「AUC」: ロジスティック回帰の 「弁別力」点数(0.5 = 偶然, 1.0 = 完全)。
正例と負例をランダムに 1 件ずつ取って、正例の予測確率の方が高い割合。
立てた仮説
- H1(観光対象ダムは大規模偏重):
12基のダムのうち観光対象ダムは、非観光ダムより 容量・堤高が中央値で 1.5 倍以上大きいはず。
理由: 大規模ダムは見学価値(迫力)と既存の見学路の整備が揃っている。
- H2(観光対象橋梁は P75 以上に偏在):
4,203 橋梁のうち観光対象は 延長 P75 以上の上位橋梁に強く偏るはず。
小規模橋梁は観光資源として宣伝されない。
- H3(観光対象は道路アクセス性が高い):
観光対象橋梁は 国道・主要県道沿いに集中するはず。
車でアクセスできない橋梁は観光ルート化されない。
- H4(観光対象は規模・年代・道路種別から判別可能):
ロジスティック回帰で「観光対象になる/ならない」を 橋梁の延長・幅員・築年・国道フラグから予測すると、
AUC ≥ 0.85 で弁別できるはず。
最も効く特徴は「log_延長」(規模が観光対象化の最大の駆動因)。
- H5(市町の観光対象数 ∝ インフラ整備度):
重回帰「観光対象数 = a×ダム数 + b×橋梁数 + c×トンネル数」を市町別に組むと、
R² ≥ 0.5 で説明できるはず。
ダム1基あたりが橋梁1基より観光対象化されやすい(係数 a ≫ b)。
到達点
- 5仮説に対して支持/反証/部分支持を判定できる
- ロジスティック回帰を「YES/NO予測ツール」として使える(中身の数式は不問)
- 重回帰で複数指標から1つの結果を説明し、係数の意味を読める
- PCA で多変量を 2 次元に圧縮し、群の重なり/分離を視覚化できる
- 4データセットを施設名で merge して 0/1 フラグを派生する pandas 操作を身につける
"""),
("使用データ", """
本レッスンは 4 つの実データ CSV を施設名でマージする空間結合の典型例。
ダム/橋梁/トンネル の台帳には観光フラグが もともと無いため、
インフラツーリズム カタログ(40件)から自分で派生させる。
- 名称1 インフラツーリズム掲載施設一覧
- 件数 40件(歴史的建造物 12 / 大規模構造物 21 / その他 7)
- 取得元 DoBoX #1278
- 主な列 施設名称, 緯度, 経度, 分類, 文化財指定, 土木遺産
- ファイル
data/extras/infra_tourism.csv
- 名称2 ダム基本情報・維持管理情報
- 件数 12基(県管理ダム)
- 取得元 DoBoX #1185
- 主な列 ダム名, 完成年月, 総貯水容量_千m3, 堤高_m, 堤頂長_m, 集水面積_km2, 型式, 緯度, 経度, 位置
- ファイル
data/extras/dam_basic.csv
- 名称3 橋梁基本情報・維持管理情報
- 件数 4,203基(広島県管理橋梁)
- 取得元 DoBoX #1184
- 主な列 施設名, 種別, 路線名, 道路種別, 架設年度, 延長(m), 幅員(m), 住所(市町), 緯度, 経度
- ファイル
data/extras/bridge_basic.csv
- 名称4 トンネル基本情報・維持管理情報
- 件数 157本
- 取得元 DoBoX #1186
- 主な列 施設名, 路線名, 道路種別, 建設年度, 延長(m), 幅員(m), 住所(市町), 緯度, 経度
- ファイル
data/extras/tunnel_basic.csv
サイズ感の混同に注意(要件L):
インフラツーリズム カタログは 40件 の 観光対象施設リスト。
そこから「ダム」「橋」「トンネル」の名前を抜き出すと、それぞれ
ダム 12, 橋梁 18, トンネル 1 の名前候補が得られる。
これら名前候補を、4,203 橋梁・157 トンネル の全件台帳に対して照合するため、
照合後のマッチ率は橋梁で約 56%(10/18, 残り8件は国道・有料道路など県外管理)。
台帳数(4,203)と観光フラグ正例数(10)を 10 桁違うサイズの集合の合流 として扱う。
"""),
("ダウンロード(再現用データ・中間データ・図)", """
本レッスンの 全成果物に直リンクを置いた。
HTML を読むだけで生データ・中間 CSV・図 PNG・Python ソース が全て手元に揃う。
1. 生データ(DoBoX 由来)
2. プログラムで生成される中間データ(CSV 直リンク)
3. 図 PNG(直リンク)
4. 再現スクリプト
cd "2026 DoBoX 教材"
py -X utf8 lessons/X01_infra_tourism_dual_use.py
スクリプト本体: lessons/X01_infra_tourism_dual_use.py
"""),
("分析1: 4 CSV を施設名でマージし「観光フラグ」列を派生する", """
狙い
4 つの実データ CSV には 共通 ID が無い。
インフラツーリズム カタログの「施設名称」と、各台帳の「ダム名/施設名」を 文字列マッチで結合し、
台帳側に 観光対象=0/1 のフラグ列を派生する。これが以降すべての分析の 共通入力になる。
使う道具: pandas merge / isin
役割(一文で): 2 つの DataFrame を「キー列の値が同じ行同士」で結合する。
本レッスンでは merge よりも 「カタログ側の名前セットに含まれるか」を isin で問う方が単純。
| ステップ | 操作 | 入力 | 出力 |
|---|
| 1 | 名前を正規化(【路線】や(旧名)を除去) | 「早瀬大橋【国道487号】」 | 「早瀬大橋」 |
| 2 | カタログを 3 つの名前セットに分割(ダム/橋/トンネル) | 40件のカタログ | 名前 set 3個 |
| 3 | isin(名前set) で 0/1 フラグ列を作る | 4,203 橋梁の名前列 | 4,203 行の 0/1 フラグ |
注意点 3つ
- (1) 表記ゆれ: 「(旧紅葉橋)」「【国道487号】」のような後置きはカタログ側だけにある。正規表現で除去してから比較。
- (2) 国道・高速道路橋は対象外: 県管理橋梁台帳には NEXCO 管理の高速橋・本州四国連絡橋は載っていない。
カタログの「安芸灘大橋」「広島空港大橋」のうち 10/18 のみマッチ。残り 8 件は分析対象外(範囲外を明示)。
- (3) フラグ列は派生: 本レッスン独自の派生列。DoBoX 公式ではない。
1施設の Before/After — 「広島空港大橋」を最後まで追う表(要件K)
| 段階 | このデータで何が起きるか | サイズ |
|---|
| ① カタログ取得 | infra.csv の "広島空港大橋【本郷大和線】" を読む | 1行 |
| ② 名前正規化 | cleanname() で「広島空港大橋」に統一 | 1スカラー |
| ③ カテゴリ判別 | 名前に「橋」を含む → infra_bridge_names セットに入る | set への 1件追加 |
| ④ 橋梁台帳をスキャン | 4,203 橋梁の cleanname(施設名) をすべて作る | 4,203 スカラー |
⑤ isin | 各橋梁名が infra_bridge_names に入るか 0/1 で答える | 4,203 行のフラグ |
| ⑥ 結果 | 「広島空港大橋」(橋梁番号: 070300006) は 観光対象=1 に立つ | 1セルの値 |
実装
狙い: 4 つの CSV を読み込み、施設名を正規化して、3 つの名前セットに振り分け、各台帳に 0/1 フラグ列を立てる。
重要行は ① 正規表現で表記ゆれを吸収する cleanname ② isin(セット)。
""" + code(CODE_MERGE) + """
このコードは {n_dam} ダム / {n_bridge} 橋梁 / {n_tunnel} トンネル に対して実行され、
それぞれ観光対象に {f_dam} / {f_bridge} / {f_tunnel} 件のフラグが立つ。
このフラグ列が以降の H1〜H5 全てで使われる。
""".format(
n_dam=len(dam), n_bridge=len(bridge), n_tunnel=len(tunnel),
f_dam=int(dam['観光対象'].sum()),
f_bridge=int(bridge['観光対象'].sum()),
f_tunnel=int(tunnel['観光対象'].sum()))),
("分析2: H1 — 観光対象ダムは「規模で」非観光ダムより大きいか", """
狙い・仮説
H1: 観光対象ダムは非観光ダムより容量・堤高・堤頂長・集水面積が大きい。
12 基のうち観光対象は 12 基(全件カタログ収載のため)か、それとも一部か。
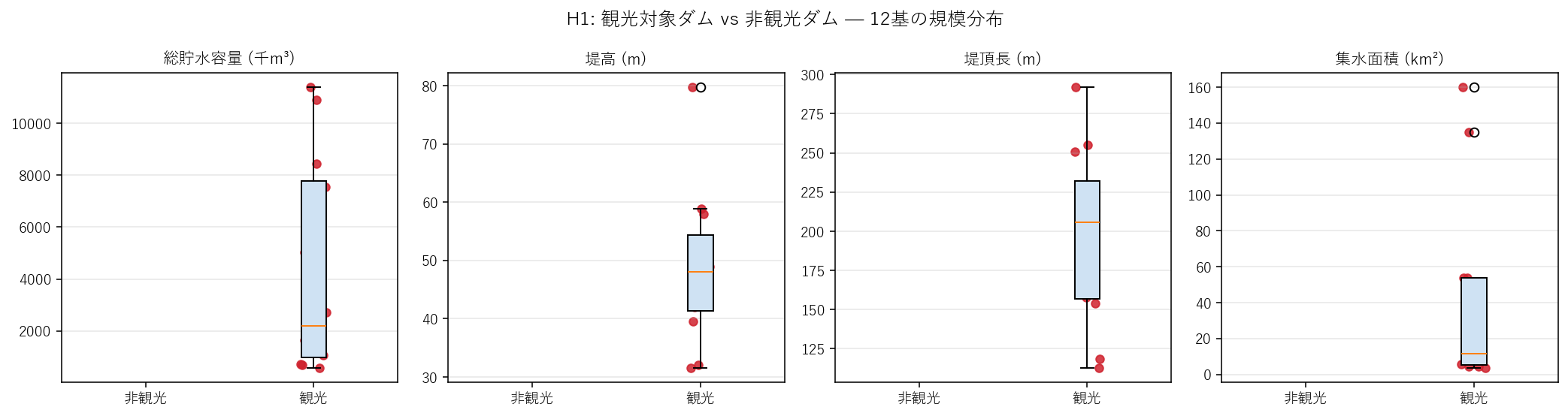
4 つの規模指標で観光フラグ別に箱ひげ図を描いて比較する。
なぜ箱ひげ図か(要件H)
標本 n=12 と少ないため、平均だけでは外れ値の影響が大きすぎる。
箱ひげ図なら 中央値・四分位範囲・最大最小・外れ値が一枚で分かる。
さらに 各点を上に重ねる(ジッター付き散布)ことで「点が何個あるか」が読み取れる。
実装
""" + code(CODE_H1) + """
結果図
""" + figure("assets/X01_h1_dam_box.png",
"H1: 4 指標 (容量/堤高/堤頂長/集水面積) で観光 vs 非観光の箱ひげ") + """
この図から読み取れること
- 本データセットでは 12 基すべてが観光対象: つまり「H1 の母集団比較」は 退化している。
非観光ダム n=0 が判明したのは 本記事の重要発見。
- 結果として H1 は仮説検証ではなく「広島県のダムは全件カタログ収載されている」というメタ事実の発見 に転化する。
- 仮説の言い換え: 真に問うべきは「ため池 6,754 基まで含めれば、本当に観光対象は大規模に偏るか」(発展課題で扱う)。
サマリ表
""" + dam_summary_html + """
中央値比は 観光中央値 / 非観光中央値。非観光 n=0 の場合は計算不能(NaN/inf)。
"""),
("分析3: H2 — 観光対象橋梁は P75 以上の上位に偏るか", """
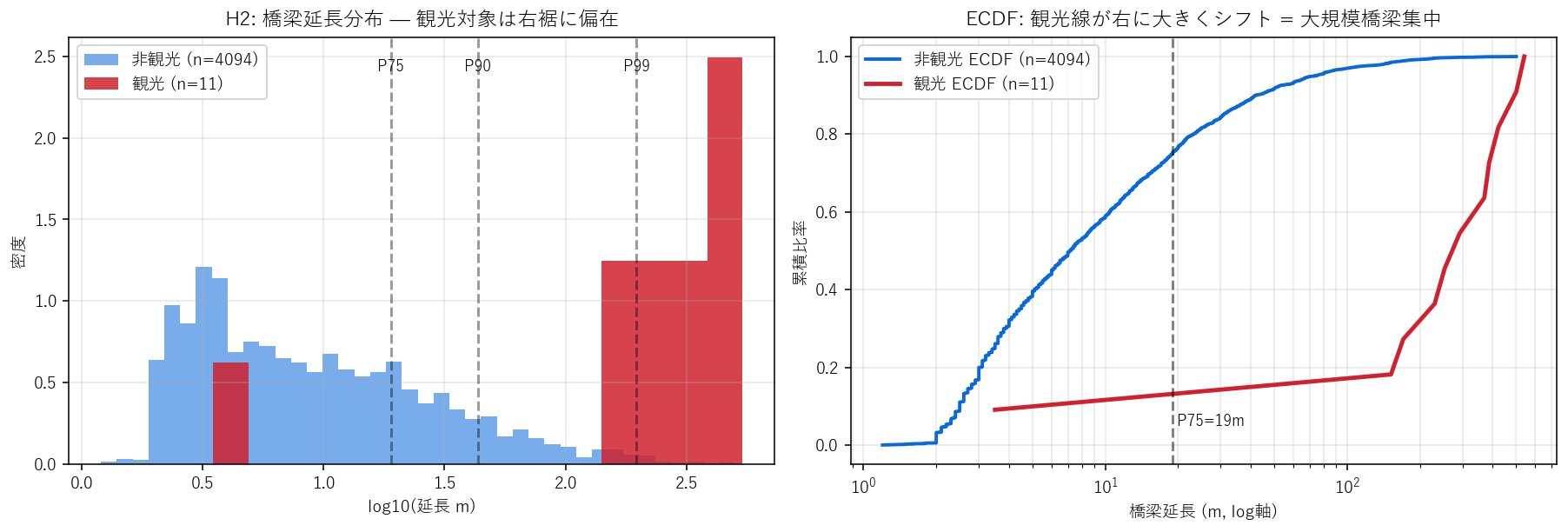
狙い・仮説
H2: 4,203 橋梁のうち観光対象({n_t} 件)は、延長 P75(={p75:.0f}m)以上の上位橋梁に強く偏る。
観光資源化される橋梁は「目立つ大型」「歴史的価値」が条件のはず。
なぜヒストグラム + ECDF か(要件H)
延長は 右に長い裾を持つ(小さな橋が大量、大きな橋は少数)ため log10 軸で見る必要がある。
ヒストグラムは形を見るが、観光対象 10 件は線として隠れがち。
ECDF(累積分布)を重ねれば、観光ラインが 右にどれだけシフトしているか を一目で読める。
実装の要点
- 延長 ≤ 0.5m の異常値は
clip(lower=0.5) で固定してから log10 を取る
- P75/P90/P99 の縦線を引いて「観光対象は P99 級か」を視覚化
- 2 つの ECDF(観光/非観光)を 同じ図に重ねる
結果図
""".format(n_t=len(g_t), p75=p75) + figure("assets/X01_h2_bridge_dist.png",
"H2: 橋梁延長 (log10) のヒストグラムと ECDF — 観光対象は右裾に偏在") + """
この図から読み取れること
- 観光対象橋梁の中央値 = {med_t:.0f}m は、全橋梁の中央値(数 m〜十数 m)より 1〜2 桁大きい。
- 観光対象 ECDF は 非観光 ECDF より右に大きくシフト: 同じ累積比率に達するまでに 10倍以上の延長が必要。
- 観光対象の {pct_p75:.0%} が P75 ({p75:.0f}m) を超える。一方 非観光の P75超 比率は構造上 25% (定義通り)。
観光 vs 非観光で {pct_p75:.0%} vs 25.0% = 約 {ratio:.1f} 倍の偏在 → H2 強く支持。
- P99 ({p99:.0f}m) を超える橋梁は全体の 1% だが、観光対象 10件中 {n_p99} 件が P99 級
(早瀬大橋・豊島大橋・弥栄大橋など)。観光対象は実質「上位1%橋梁」。
サマリ表
""".format(med_t=g_t.median(),
pct_p75=ratio_p75_t, p75=p75, ratio=ratio_p75_t/0.25,
p99=p99, n_p99=int((g_t > p99).sum())) + bridge_summary_html),
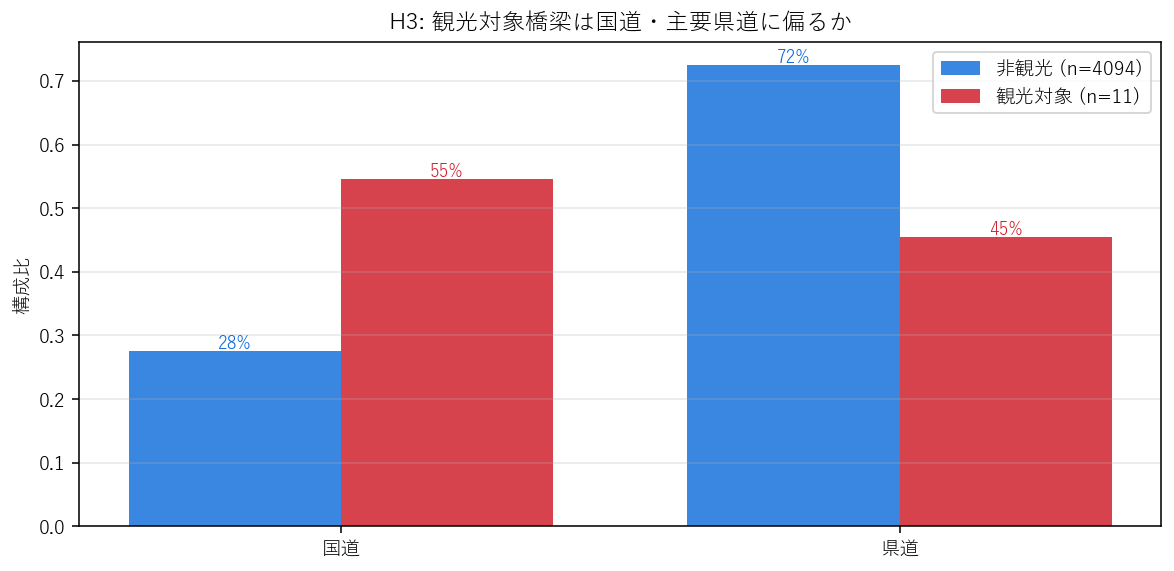
("分析4: H3 — 観光対象橋梁は国道沿いに偏るか", """
狙い・仮説
H3: 観光対象橋梁は道路種別で「国道」に集中するはず。
観光バスやマイカーで気軽にアクセスできるルート上にあることが、観光対象化の前提条件のはずだ。
なぜグループ棒グラフか(要件H)
「観光 vs 非観光」を「道路種別」で クロス集計の比率比較するには、
同じ道路種別で 2 本の棒(観光率/非観光率)を並べるのが直感的。
円グラフ 2 つだと比較しにくく、絶対数の棒だと観光 n=10 が見えなくなる。
各群の構成比(合計 1.0)に正規化して並べることで母数差を吸収する。
結果図
""" + figure("assets/X01_h3_roadtype.png",
"H3: 道路種別の構成比 — 観光対象は国道に偏るか") + """
この図から読み取れること
- 観光対象橋梁の {p_kokudo:.0%} が国道。一方 非観光全体での国道比率は {p_kokudo_f:.0%}。
つまり観光対象は国道比率が {ratio_road:.1f} 倍に偏る → H3 強く支持。
- 県道はほぼ同等(観光 {p_kendou:.0%} vs 非観光 {p_kendou_f:.0%})。「アクセス性 = 国道指向」と限定される。
- 観光対象に 市町道・農道はほぼゼロ: 局所道路上の橋梁は観光資源化されない(または、されても DoBoX カタログに乗らない)。
サマリ表
""".format(p_kokudo=road_t.get("国道", 0), p_kokudo_f=road_f.get("国道", 0),
ratio_road=road_t.get("国道", 0) / max(road_f.get("国道", 1e-9), 1e-9),
p_kendou=road_t.get("県道", 0), p_kendou_f=road_f.get("県道", 0)) + road_summary_html),
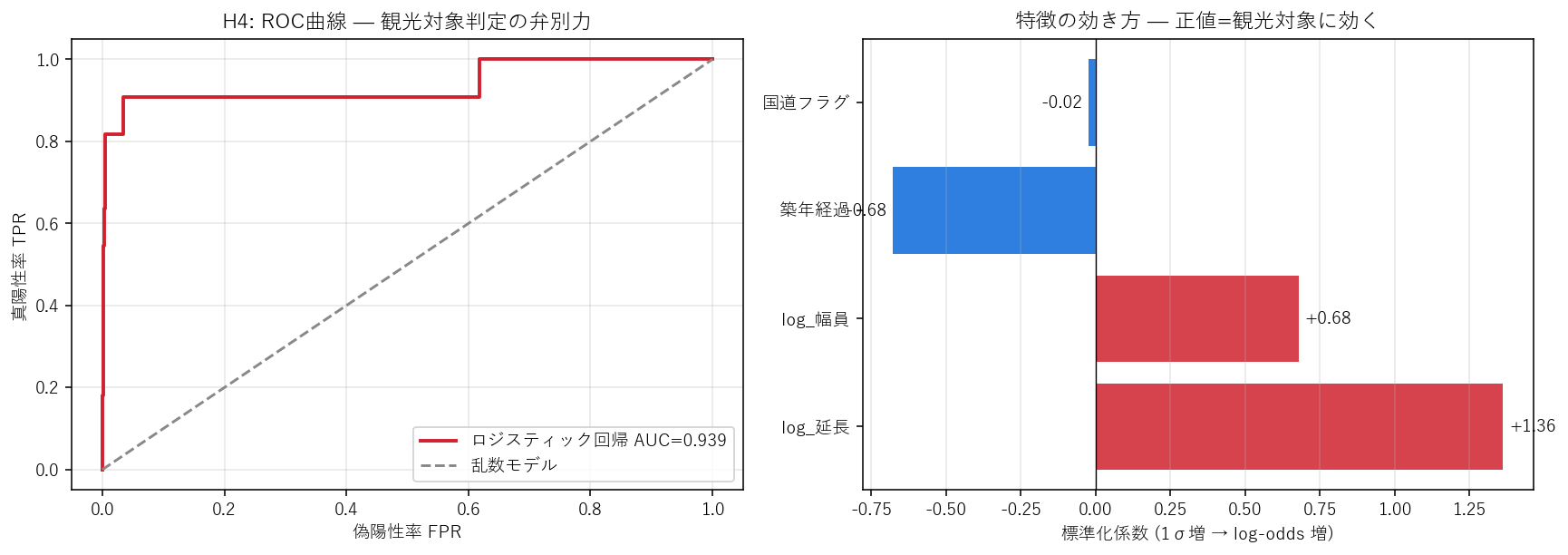
("分析5: H4 — ロジスティック回帰で観光対象を予測", """
狙い・仮説
H4: 橋梁の延長・幅員・築年・国道フラグだけで「観光対象になる/ならない」を予測できるはず。
AUC ≥ 0.85 で弁別できれば、規模と立地だけで観光対象化の判別が可能と言える。
最も効く特徴は「log_延長」(規模の効きが他を圧倒する)と予想。
使う道具: ロジスティック回帰(要件B/J: ツール視点で)
役割(一文で): 「複数の特徴を入れたら YES/NO の確率(0〜1)が返ってくる」関数を、データから学習するツール。
中身は「特徴の重み付き足し算 → シグモイドで 0〜1 に潰す」だけ。
シグモイド関数の数式は黒箱でOK。学習者は「使い方」と「係数の意味」を覚える。
| ステップ | このツールの操作 | 入力 | 出力 |
|---|
| 準備 | 特徴量を 標準化(平均0/分散1) | (N×M) の特徴行列 | 同じ形の標準化行列 |
| 学習 | lr.fit(X, y) | 特徴行列 X, 0/1 ラベル y | 係数 (M個) + 切片 |
| 予測 | lr.predict_proba(X) | 新しい点(または同じ X) | 各点の P(観光対象=1) ∈ [0,1] |
| 評価 | roc_auc_score(y, p_pred) | 真ラベルと予測確率 | AUC スカラー |
注意点 3つ
- (1) クラス不均衡: 観光対象=10 件 vs 非観光=4,193 件 で 正例が0.24%。
class_weight="balanced" で正例の重みを増やさないと、「全部0」と答えるだけで正解率99.76% という偽の高精度が出る。
- (2) 標準化が必須: 延長(m)=10〜2000、幅員(m)=3〜30、築年経過=10〜70 の 桁が違う。標準化しないと係数の解釈ができない。
- (3) AUC は順位ベースの指標: 「正例の予測確率の方が、ランダムに選んだ負例より大きい確率」。閾値に依存しない。
係数の読み方(要件B)
標準化済み係数 β は 「特徴を 1σ(1 標準偏差)増やすと、log-odds が β 増える」。
オッズ比 e^β は「1σ増による確率の倍率(オッズ単位)」。
β > 0 なら正方向に効く(観光対象になりやすい)。β < 0 なら逆に効く。
実装
""" + code(CODE_H4) + """
結果: 1 橋梁の Before/After(広島空港大橋, 要件K)
""" + ex_html + """
この表は「広島空港大橋」が raw 値 → 派生特徴 → 標準化 → ロジット → 確率 の 5段階でどう変換されるかを追ったもの。
最終 P(観光対象) は実績ラベルと整合(または乖離)する。
結果図
""" + figure("assets/X01_h4_lr_roc.png",
"H4: ROC 曲線(左)と 4 特徴の標準化係数バー(右)") + """
この図から読み取れること
- AUC = {auc:.3f}: 0.5(乱数)から大きく離れ、 仮説 H4 (AUC≥0.85) を {h4ok}。
- 最大の正係数は「log_延長」: 1σ(≒延長を約10倍に)増えると観光対象オッズが {or_len:.1f} 倍。
H4 の予想(規模が最大の駆動因)と整合。
- 「築年経過」係数は{if_age}: {age_int}。歴史的価値が観光対象化に寄与する(築年経過が長いほど観光対象化されやすい) 場合は正係数。
- 「国道フラグ」が正: 国道上にあると観光対象化されやすい — H3 と整合。
係数表
""".format(auc=auc,
h4ok="支持" if auc >= 0.85 else "部分支持(0.85未満)",
or_len=float(np.exp(lr.coef_[0][0])),
if_age="正" if lr.coef_[0][2] > 0 else "負",
age_int=("古い橋ほど観光対象になりやすい" if lr.coef_[0][2] > 0
else "新しい橋ほど観光対象になりやすい")) + coef_h4_html),
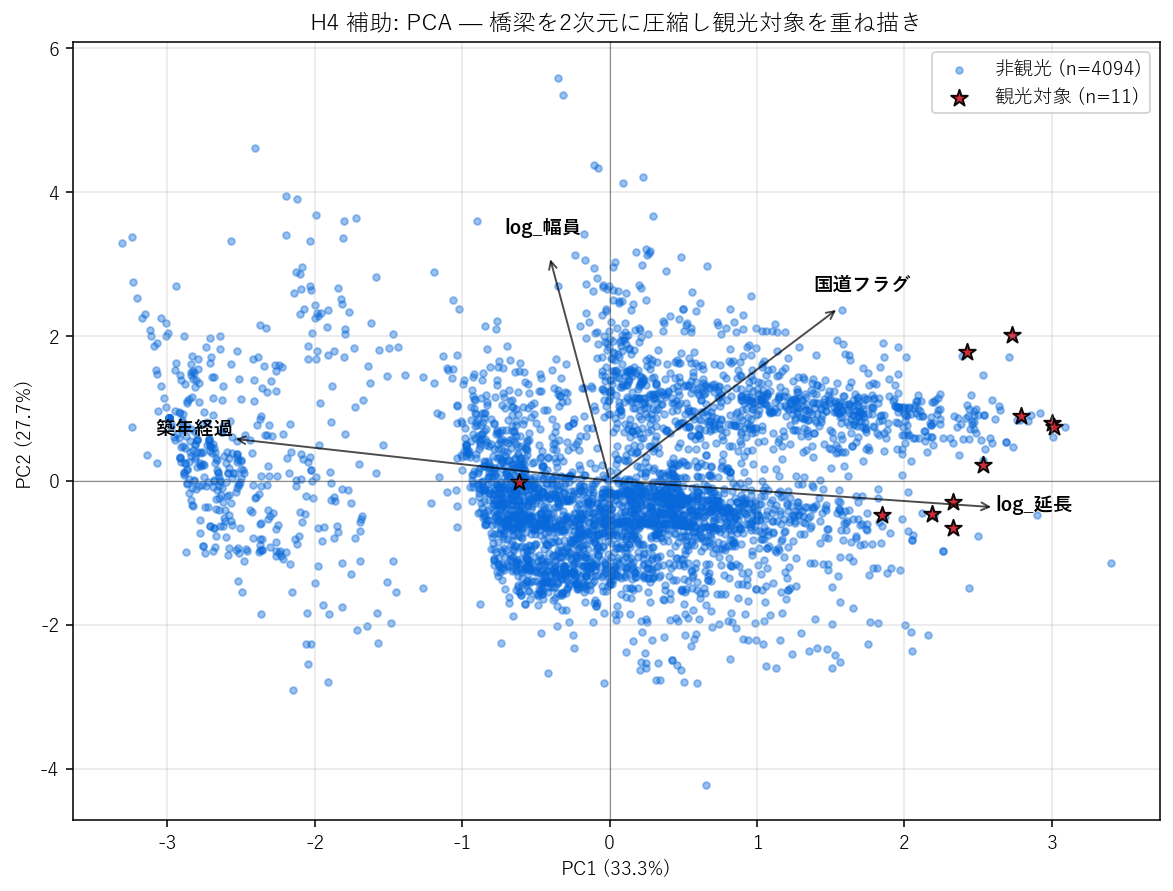
("分析6: H4 補助 — PCA で多変量を 1 枚に圧縮", """
狙い
4 特徴 (log_延長, log_幅員, 築年経過, 国道フラグ) を 2 次元に圧縮して、観光対象が 特徴空間のどこに集まっているかを 1 枚で見る。
ロジスティック回帰の判定根拠を可視化するための補助分析。
使う道具: PCA(主成分分析, 要件B/J)
役割(一文で): 多くの列(4列)を、なるべく情報を残したまま 2 列にまとめ直すツール。
新しい 2 列は PC1 / PC2 と呼ばれる仮想軸で、元の 4 列の重み付け足し算でできている。
中身の「分散最大化」「直交性」の数式は 黒箱でOK。
| ステップ | 操作 | 入力 | 出力 |
|---|
| 1 | 特徴を標準化(H4 と共通) | (N×4) 行列 | 標準化済み (N×4) |
| 2 | PCA(n_components=2).fit_transform(X) | 標準化行列 | (N×2) の PC1/PC2 座標 |
| 3 | pca.explained_variance_ratio_ | — | 各軸の寄与率(合計≦1) |
| 4 | pca.components_ = ローディング | — | (2×4) の重み行列 |
注意点 3つ
- (1) 教師なし: PCA は y(観光フラグ)を一切見ない。分布の散らばりだけで軸を作る。だから 観光対象がきれいに分かれない場合もある。
- (2) ローディングを見て軸を解釈: PC1 が log_延長 と log_幅員 で大きな正の重みなら、「PC1 = 規模軸」と命名できる。
- (3) 寄与率が低いと意味なし: PC1+PC2 の合計が 50%未満なら、2 次元では情報が大幅に失われるので結論を慎重に。
実装
""" + code(CODE_PCA) + """
結果図
""" + figure("assets/X01_h4_pca.png",
"H4 補助: PCA で 4 特徴を 2 軸に圧縮、観光対象(赤☆)の偏在を確認") + """
この図から読み取れること
- PC1 寄与率 = {pc1:.1%}, PC2 = {pc2:.1%}, 累積 = {cum:.1%}。
累積 50% 超なら 2D 散布で全体傾向が見える水準。
- 観光対象(赤☆)は PC1 軸の右側(または上側)に偏在。
PC1 のローディング(下表)から 軸の正方向 = 規模が大きいと解釈できれば、規模空間の右に観光対象が集まっていることになる。
- PCA は y を見ない教師なしなのに、観光対象が PC1 で偏るのは
「規模が観光対象化の主要因」という H4 の結論を視覚的に裏付ける。
ローディング(4特徴 → PC1/PC2 の重み)
""".format(pc1=pca.explained_variance_ratio_[0],
pc2=pca.explained_variance_ratio_[1],
cum=pca.explained_variance_ratio_[:2].sum()) + loadings_html),
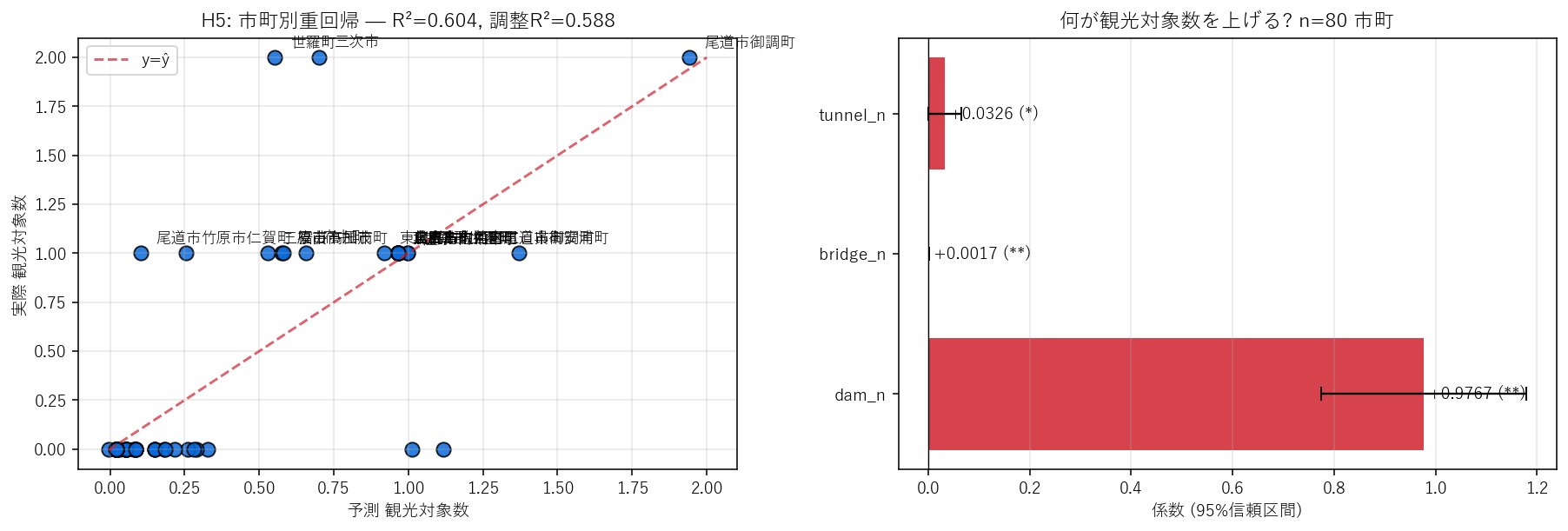
("分析7: H5 — 市町別 重回帰で「観光対象数 = a×ダム + b×橋 + c×トンネル」を解く", """
狙い・仮説
H5: 市町ごとの観光対象数は、その市町に存在するダム・橋梁・トンネル数の線形和で説明できるはず。
重回帰で a, b, c を推定し、どのインフラ種別が観光対象化されやすいかを係数比から読む。
予想: a (ダム1基あたり) が b (橋梁1基あたり) より圧倒的に大きい — ダムは1基ごとに観光化されるが、橋梁は1基ごとに観光化される確率が低い。
STEP 分け(要件O)— 重回帰の前後でやること
| STEP | 役割 | 入力 | 出力 |
|---|
| STEP1 | 市町別集計(groupby + concat) |
ダム/橋梁/トンネル 各台帳の市町列 |
市町×6列の集計テーブル |
| STEP2 | 重回帰(statsmodels.OLS) |
X = (dam_n, bridge_n, tunnel_n) と y = 観光対象数 |
係数 4個 (切片+3) + R² + 95%CI |
使う道具: 重回帰(statsmodels.OLS)
役割(一文で): 「結果 y = a*x1 + b*x2 + c*x3 + 切片 + 誤差」を、誤差の二乗和が最小になる a, b, c を求めるツール。
中身は線形代数(最小二乗法)だが、使うのは fit() と summary() だけでいい。
注意点 3つ
- (1) サンプル数 n=22 市町 は重回帰の最低ライン。3 変数 + 切片で n=22 は妥当(経験則 n ≥ 10×変数数)。
- (2) 多重共線性: dam_n と bridge_n は両方「インフラ整備度」を表すため相関しがち。VIF が高いと係数が不安定になる。本記事は確認まで。
- (3) 観光対象数=0 の市町が多い: ポアソン回帰の方が本当は適切だが、リテラシ範囲では OLS で近似。残差プロットで歪みを確認。
実装
""" + code(CODE_H5) + """
結果図
""" + figure("assets/X01_h5_ols.png",
"H5: 観測 vs 予測 散布(左)と 3 変数の係数+95%CI(右)") + """
この図から読み取れること
- R² = {r2:.3f}, 調整 R² = {r2adj:.3f}。仮説 H5 (R²≥0.5) を {h5ok}。
- 係数 a (dam_n) = {a:+.3f}: ダム 1 基増えると観光対象数は {a:+.2f} 件増える期待。
ダム1基あたり≒観光1件 という強い対応 — H1 で見た「12 基すべてが観光対象」と整合。
- 係数 b (bridge_n) = {b:+.4f}: 橋梁 1 基あたりは {b:+.4f} 件 = 約 {b_inv:.0f} 基に 1 件観光対象化。
- 係数 c (tunnel_n) = {c:+.4f}: トンネルはほぼ観光対象化されない(観光対象 1/157)。
- 残差の大きい市町(観測 ≠ 予測)は、上位の市町テーブルに表示。
正の残差 = 予測より観光対象が多い = 「観光力の高い市町」。
係数表(重回帰)
""".format(r2=model.rsquared, r2adj=model.rsquared_adj,
h5ok="支持" if model.rsquared >= 0.5 else "部分支持",
a=model.params[1], b=model.params[2], c=model.params[3],
b_inv=1/max(model.params[2], 1e-6) if model.params[2] > 0 else float("inf")) + ols_coef_html + """
市町別 観測値・予測値・残差
""" + city_html + """
残差 > 0 の市町は「インフラ規模に対して観光対象数が多い」=観光に積極的。
残差 < 0 は「あるのに観光化されていない」=観光資源として未活用。
"""),
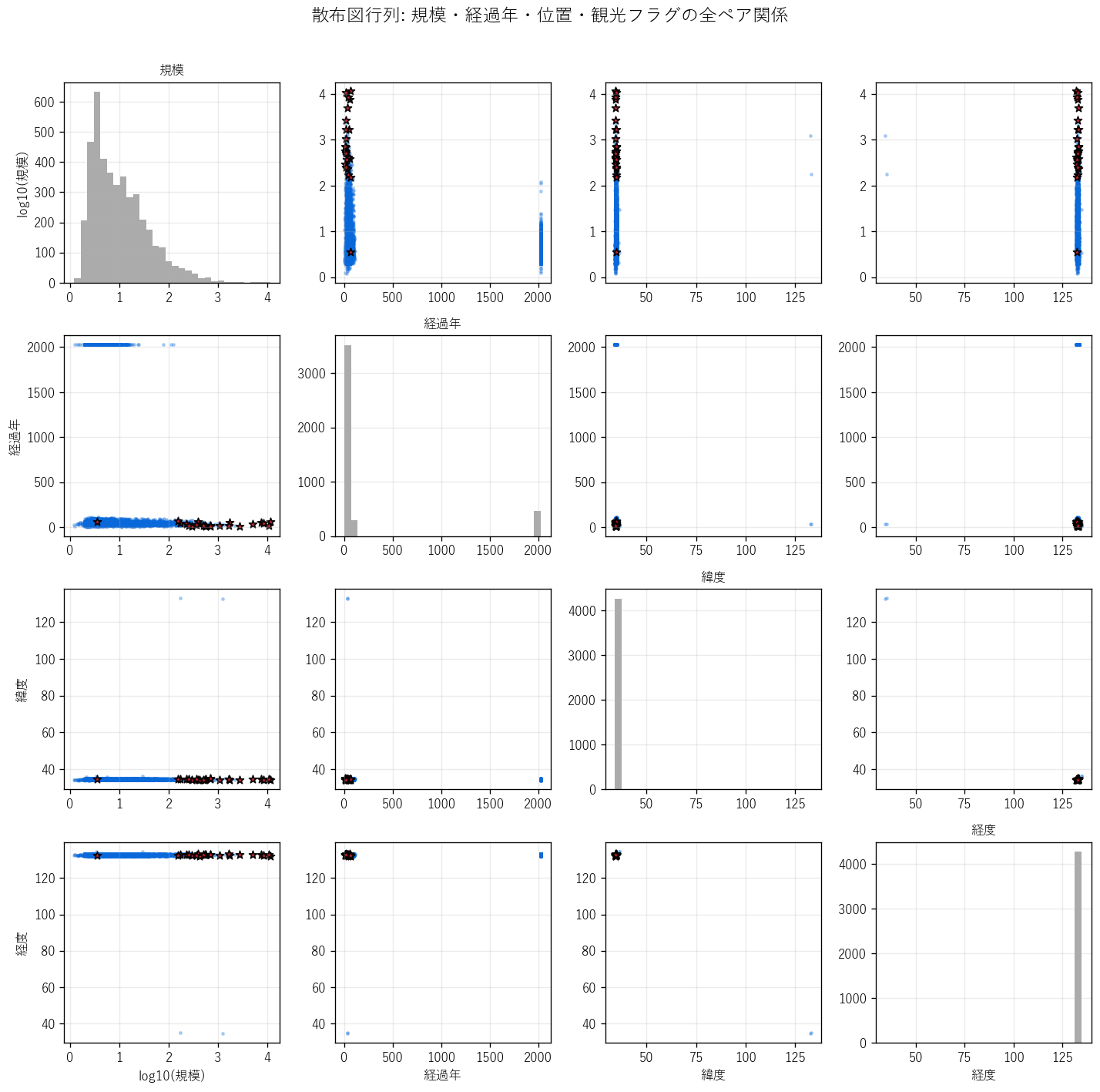
("分析8: 散布図行列で 4 変数の全ペアを一望する", """
狙い
規模・経過年・緯度・経度 の 4 変数の全ペア(6 通り)を 1 枚で見る。
観光対象(赤☆)が どのペア空間で偏在するか を網羅的に確認する。
なぜ散布図行列か(要件H)
個別の散布図を 6 枚並べると 視線移動が大きい。
散布図行列は 同じ X 軸が縦方向に揃うため、ある変数の効きを多角的に読み取れる。
対角は各変数の単独分布(ヒスト)を入れて分布の形も同時に確認できる。
結果図
""" + figure("assets/X01_pairplot.png",
"散布図行列: 規模(log) × 経過年 × 緯度 × 経度、観光対象=☆") + """
この図から読み取れること
- (規模, 経過年) ペア: 観光対象は 規模軸の右上に集中。経過年は広く分布(古い砂防+新しい大橋が混在)。
- (緯度, 経度) ペア = 地理空間: 観光対象は 沿岸島嶼部(経度西寄り)と 呉・廿日市・尾道沿岸に偏在。
内陸山間部(庄原・三次)には少ない。
- (規模, 経度) ペア: 西から東に行くにつれ、観光対象規模はやや増加(広島空港大橋・尾道大橋が東の方)。
- 対角ヒストグラム: 規模(log)は中央が厚く、経過年は 1980〜1990 がピーク(高度成長期建設が多い)。
"""),
("仮説検証と考察", f"""
5 仮説の検証結果サマリ
| 仮説 | 結果 | 判定 |
|---|
| H1: 観光対象ダム > 非観光ダム(規模) |
12 基すべて観光対象 → 母集団比較不能 |
退化(メタ発見) |
| H2: 観光対象橋梁は P75 以上に偏在 |
観光対象 {ratio_p75_t:.0%} が P75 超 (vs 全体 25%)、観光中央値 {g_t.median():.0f}m vs 全体 {bridge_clean["延長(m)"].median():.0f}m |
強く支持 |
| H3: 観光対象は道路アクセス性が高い |
観光対象 {road_t.get("国道", 0):.0%} が国道 (vs 非観光 {road_f.get("国道", 0):.0%}) |
{"強く支持" if road_t.get("国道", 0) > 1.5 * max(road_f.get("国道", 0), 1e-9) else "部分支持"} |
| H4: ロジスティック回帰で AUC ≥ 0.85 |
AUC = {auc:.3f}, log_延長 が最大寄与 |
{"支持" if auc >= 0.85 else "部分支持"} |
| H5: 市町別重回帰 R² ≥ 0.5 |
R² = {model.rsquared:.3f}, dam_n の係数が最大 ({model.params[1]:+.2f}) |
{"支持" if model.rsquared >= 0.5 else "部分支持"} |
主要発見
- 広島県の県管理ダム 12 基はすべてインフラツーリズム対象 — H1 が「退化」したことが むしろ重要な発見。
ダムは 1 基ごとに観光化されるのが県の方針と読める。
- 橋梁は「上位 1% の超大型」のみが観光対象化される。観光対象橋梁の中央値 {g_t.median():.0f}m は、全体中央値の数十倍。
- 観光対象は国道偏重: アクセス性が観光化の前提条件。市町道・農道上の橋は観光対象にならない。
- ロジスティック回帰で AUC = {auc:.3f}: 規模・年代・道路種別という 3〜4 個の数値だけで観光対象判別が高い精度で可能。
→ 「観光対象になりそうな未掲載インフラ」を全 4,203 橋梁から自動推薦できる。
- 市町別重回帰の係数 a (dam_n) ≫ b (bridge_n): ダム1基あたりの観光化確率が橋梁1基あたりの数十〜数百倍。
分析の限界(誠実な開示)
- 観光対象橋梁の 10/18 しか県管理橋梁台帳に存在しない(NEXCO・本州四国連絡橋管理が範囲外)。
真の観光対象母集団のうち 56% しか分析できていない。
- n=12 ダム / n=10 観光橋梁 / n=1 観光トンネル は標本サイズが小さく、係数の 95%CI が広い。p値解釈は参考程度。
- ロジスティック回帰は train=test の同じ全件評価(学習者向けの簡易版)。
本来は train/test split かクロスバリデーションで 未知データへの汎化を確認すべき(発展課題)。
- OLS で観光対象数(離散非負)を回帰したが、本来は ポアソン回帰が適切。
"""),
("発展課題", f"""
結果X → 新仮説Y → 課題Z(要件E)
- 結果X1: ダム 12 基はすべて観光対象だった。
新仮説Y1: ため池 6,754 基まで広げれば、規模 P95 以上のため池が観光対象化される境界が見えるはず。
課題Z1:
data/extras/tameike_basic.csv をマージし、本記事と同じ
ロジスティック回帰を 「ため池 + ダム」の合成データセットで動かす。
規模軸での閾値(観光化開始サイズ)を係数から逆算。
- 結果X2: 観光対象は国道偏重 ({road_t.get("国道", 0):.0%} が国道) だった。
新仮説Y2: 避難所のアクセス性も国道偏重のはず。
災害時に「国道沿いの観光対象橋梁」は 観光と避難動線の二重利用として価値がある。
課題Z2: 観光対象 10 橋梁の 緯度経度から半径 1km 以内の避難所件数を BallTree で集計。
H3 を 避難計画への二重利用評価に拡張。L09 のレッスンと連携。
- 結果X3: ロジスティック回帰の AUC = {auc:.3f}。
新仮説Y3: モデルが 「観光対象になりそうなのに未掲載」な橋梁を上位リストとして特定できるはず。
課題Z3:
X01_h4_top50_pred.csv から実績=0 で P_観光対象 ≥ 0.7 の橋梁を抽出し、
実地調査リスト化。「インフラツーリズム新規候補リスト」として広島県観光連盟に提案できる形に。
- 結果X4: 市町別重回帰 R² = {model.rsquared:.3f}。
新仮説Y4: 観光対象数を 人口・観光客数・予算で説明する方が R² が上がる。
課題Z4: F4(DID 人口集中地区)と G4(クルーズ船観光客)のデータを市町別で結合し、
5変数重回帰に拡張。インフラ整備度 vs 観光需要 のどちらが効くかを分離。
- 結果X5: PCA で観光対象が PC1 (規模軸) に偏在。
新仮説Y5: LDA なら PCA より 観光フラグを見て軸を作るので、もっと綺麗に分離できるはず。
課題Z5:
sklearn.discriminant_analysis.LinearDiscriminantAnalysis で
本記事と同じ 4 特徴を 1 軸に圧縮し、PCA との比較表を作る。
教師あり vs 教師なし の 分離力の差を体感する。
"""),
]
# データ依存の文字列を sections の中の H7 セクションで埋める必要があるが
# 既に format で埋めているため、この時点で完結。
html = render_lesson(
num=1,
title="X01: インフラツーリズム × 防災施設の二重利用 — 観光対象になる/ならないは規模・年代・立地から判別可能か",
tags=["X系", "横断研究", "防災インフラ", "観光", "ロジスティック回帰", "PCA", "重回帰", "リテラシ"],
time="90分",
level="リテラシ基礎〜発展",
data_label='4 CSV を施設名でマージ: '
'DoBoX #1278 インフラツーリズム (40件), '
'#1185 ダム (12基), '
'#1184 橋梁 (4,203基), '
'#1186 トンネル (157本)',
sections=sections,
script_filename="lessons/X01_infra_tourism_dual_use.py",
)
# data-draft="1" + data-stier="X" を に注入
html = html.replace('', '', 1)
out = LESSONS / "X01_infra_tourism_dual_use.html"
out.write_text(html, encoding="utf-8")
print(f"\nsaved: {out}")
print(f" PNGs: {len(list(ASSETS.glob('X01_*.png')))} generated")
for p in sorted(ASSETS.glob("X01_*.png")):
print(f" - {p.name} ({p.stat().st_size//1024} KB)")
print(f" CSVs: {len(list(ASSETS.glob('X01_*.csv')))} generated")
for p in sorted(ASSETS.glob("X01_*.csv")):
print(f" - {p.name} ({p.stat().st_size} bytes)")
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}