X01: インフラツーリズム × 防災施設の二重利用 — 観光対象になる/ならないは規模・年代・立地から判別可能か
ロジスティック回帰で「観光対象になる/ならない」をデータから予測。AUCで予測性能を評価。係数解釈で「何が観光対象を決めているか」を読む。
データ取得手順
⚠️ このスクリプトは自動取得に対応していません。以下のデータセットを DoBoX から手動でダウンロードし、data/extras/ 以下に保存してください。
| ID | データセット名 |
|---|---|
| #888 | 都市計画区域情報_区域データ_安芸高田市_行政区域 |
| #1184 | dataset #1184 |
| #1185 | dataset #1185 |
| #1186 | dataset #1186 |
| #1278 | 過去に発生した災害情報 |
実行コマンド:
cd "2026 DoBoX 教材"
python -X utf8 lessons/X01_infra_tourism_dual_use.py
DoBoX のオープンデータは申請不要・商用/非商用とも利用可。
data/extras/ は .gitignore 対象(約 57 GB のキャッシュ)。
スクリプト実行で自動再生成されます。
学習目標と問い
このレッスンで答えたい問い
「広島県の防災インフラ(ダム12基/橋梁4,203基/トンネル157本)のうち、 どれが『観光対象』として外部公開されているか? そして、観光対象になる施設は規模・年代・立地から 事前に予測できるのか?」
用語の定義(このレッスン独自)
- 「インフラツーリズム」: ダム・橋梁・砂防施設など 本来は防災・交通用途のインフラ施設を観光資源として公開する取り組み。 広島県は DoBoX #1278「インフラツーリズム」 でカタログ化(本記事では 40件)。
- 「観光対象施設」: 上記カタログ40件に名前が登録されている施設。本記事では「観光対象=1」、それ以外を「観光対象=0」 として2値ラベルにする。
- 「観光フラグ」: ダム/橋梁/トンネルの台帳に対して、施設名で照合し「カタログに載っているか」を 0/1 で立てた列。本記事独自の派生列であり、DoBoX 公式列ではない。
- 「ロジスティック回帰」: 「YESかNOか」を確率で答える機械学習ツール。 複数の特徴(延長・幅員・築年)を入れると、観光対象になる確率 (0〜1) を返す。中身の数式は黒箱でOK。係数を見れば「どの特徴が効いたか」も分かる。
- 「LDA(線形判別分析)」: ロジスティック回帰と 近い目的(YES/NO 判別)のツール。2グループの平均が最も離れる軸を探して投影する。本記事では PCA で代用するが、参考として併記。
- 「PCA(主成分分析)」: 多くの列を 2〜3 列に圧縮するツール。「全 4 列を 1 枚の散布図にしたい」が目的。圧縮後の軸(PC1, PC2)に観光フラグを重ねると、観光対象が空間のどこに集まるか見える。
- 「重回帰」: 1 つの結果を、複数の原因で説明するツール。 本記事では「市町の観光対象数 = a×ダム数 + b×橋梁数 + c×トンネル数」と立てる。
- 「AUC」: ロジスティック回帰の 「弁別力」点数(0.5 = 偶然, 1.0 = 完全)。 正例と負例をランダムに 1 件ずつ取って、正例の予測確率の方が高い割合。
立てた仮説
- H1(観光対象ダムは大規模偏重): 12基のダムのうち観光対象ダムは、非観光ダムより 容量・堤高が中央値で 1.5 倍以上大きいはず。 理由: 大規模ダムは見学価値(迫力)と既存の見学路の整備が揃っている。
- H2(観光対象橋梁は P75 以上に偏在): 4,203 橋梁のうち観光対象は 延長 P75 以上の上位橋梁に強く偏るはず。 小規模橋梁は観光資源として宣伝されない。
- H3(観光対象は道路アクセス性が高い): 観光対象橋梁は 国道・主要県道沿いに集中するはず。 車でアクセスできない橋梁は観光ルート化されない。
- H4(観光対象は規模・年代・道路種別から判別可能): ロジスティック回帰で「観光対象になる/ならない」を 橋梁の延長・幅員・築年・国道フラグから予測すると、 AUC ≥ 0.85 で弁別できるはず。 最も効く特徴は「log_延長」(規模が観光対象化の最大の駆動因)。
- H5(市町の観光対象数 ∝ インフラ整備度): 重回帰「観光対象数 = a×ダム数 + b×橋梁数 + c×トンネル数」を市町別に組むと、 R² ≥ 0.5 で説明できるはず。 ダム1基あたりが橋梁1基より観光対象化されやすい(係数 a ≫ b)。
到達点
- 5仮説に対して支持/反証/部分支持を判定できる
- ロジスティック回帰を「YES/NO予測ツール」として使える(中身の数式は不問)
- 重回帰で複数指標から1つの結果を説明し、係数の意味を読める
- PCA で多変量を 2 次元に圧縮し、群の重なり/分離を視覚化できる
- 4データセットを施設名で merge して 0/1 フラグを派生する pandas 操作を身につける
使用データ
本レッスンは 4 つの実データ CSV を施設名でマージする空間結合の典型例。 ダム/橋梁/トンネル の台帳には観光フラグが もともと無いため、 インフラツーリズム カタログ(40件)から自分で派生させる。
- 名称1 インフラツーリズム掲載施設一覧
- 件数 40件(歴史的建造物 12 / 大規模構造物 21 / その他 7)
- 取得元 DoBoX #1278
- 主な列 施設名称, 緯度, 経度, 分類, 文化財指定, 土木遺産
- ファイル
data/extras/infra_tourism.csv
- 名称2 ダム基本情報・維持管理情報
- 件数 12基(県管理ダム)
- 取得元 DoBoX #1185
- 主な列 ダム名, 完成年月, 総貯水容量_千m3, 堤高_m, 堤頂長_m, 集水面積_km2, 型式, 緯度, 経度, 位置
- ファイル
data/extras/dam_basic.csv
- 名称3 橋梁基本情報・維持管理情報
- 件数 4,203基(広島県管理橋梁)
- 取得元 DoBoX #1184
- 主な列 施設名, 種別, 路線名, 道路種別, 架設年度, 延長(m), 幅員(m), 住所(市町), 緯度, 経度
- ファイル
data/extras/bridge_basic.csv
- 名称4 トンネル基本情報・維持管理情報
- 件数 157本
- 取得元 DoBoX #1186
- 主な列 施設名, 路線名, 道路種別, 建設年度, 延長(m), 幅員(m), 住所(市町), 緯度, 経度
- ファイル
data/extras/tunnel_basic.csv
ダウンロード(再現用データ・中間データ・図)
本レッスンの 全成果物に直リンクを置いた。 HTML を読むだけで生データ・中間 CSV・図 PNG・Python ソース が全て手元に揃う。
1. 生データ(DoBoX 由来)
| ファイル | 形式 | 件数 | 取得元 |
|---|---|---|---|
data/extras/infra_tourism.csv |
CSV | 40 件 | DoBoX #1278 |
data/extras/dam_basic.csv |
CSV | 12 基 | DoBoX #1185 |
data/extras/bridge_basic.csv |
CSV | 4,203 基 | DoBoX #1184 |
data/extras/tunnel_basic.csv |
CSV | 157 本 | DoBoX #1186 |
2. プログラムで生成される中間データ(CSV 直リンク)
| ファイル | 内容 | 使う分析 |
|---|---|---|
X01_dam_with_flag.csv |
12 ダム × (規模・観光対象0/1) | 分析1 (H1) |
X01_bridge_sample_with_flag.csv |
橋梁観光対象10件+非対象300件サンプル | 分析2-4 (H2-H4) |
X01_tunnel_with_flag.csv |
157 トンネル × 観光フラグ | 分析2 補助 |
X01_h1_dam_summary.csv |
ダム規模指標 4種の中央値比較 | 分析1 |
X01_h2_bridge_summary.csv |
橋梁延長の P75/P90/P99 統計 | 分析2 |
X01_h3_roadtype.csv |
道路種別比率 (観光 vs 非観光) | 分析3 |
X01_h4_lr_coef.csv |
ロジスティック回帰 4特徴の係数とオッズ比 | 分析4 |
X01_h4_pca_loadings.csv |
PCA の特徴 → PC1/PC2 ローディング | 分析5 |
X01_h4_top50_pred.csv |
ロジ回帰で観光対象確率 上位 50 橋梁 | 分析4 |
X01_h5_ols_coef.csv |
市町別 重回帰の係数・p値・95%CI | 分析6 |
X01_h5_city_table.csv |
22 市町 × 6 列 + 観光対象数 + 予測値 | 分析6 |
X01_combined_with_flag.csv |
ダム+橋梁+トンネル統合 (規模・経過年・観光フラグ) | 分析7 |
3. 図 PNG(直リンク)
- X01_h1_dam_box.png — H1: ダム規模 4 指標箱ひげ
- X01_h2_bridge_dist.png — H2: 橋梁延長分布 + ECDF
- X01_h3_roadtype.png — H3: 道路種別比率の比較
- X01_h4_lr_roc.png — H4: ROC + 係数バー
- X01_h4_pca.png — H4補助: PCA 散布図
- X01_h5_ols.png — H5: 観測 vs 予測 + 重回帰係数
- X01_pairplot.png — 散布図行列 (4変数)
4. 再現スクリプト
cd "2026 DoBoX 教材"
py -X utf8 lessons/X01_infra_tourism_dual_use.py分析1: 4 CSV を施設名でマージし「観光フラグ」列を派生する
狙い
4 つの実データ CSV には 共通 ID が無い。 インフラツーリズム カタログの「施設名称」と、各台帳の「ダム名/施設名」を 文字列マッチで結合し、 台帳側に 観光対象=0/1 のフラグ列を派生する。これが以降すべての分析の 共通入力になる。
使う道具: pandas merge / isin
役割(一文で): 2 つの DataFrame を「キー列の値が同じ行同士」で結合する。
本レッスンでは merge よりも 「カタログ側の名前セットに含まれるか」を isin で問う方が単純。
| ステップ | 操作 | 入力 | 出力 |
|---|---|---|---|
| 1 | 名前を正規化(【路線】や(旧名)を除去) | 「早瀬大橋【国道487号】」 | 「早瀬大橋」 |
| 2 | カタログを 3 つの名前セットに分割(ダム/橋/トンネル) | 40件のカタログ | 名前 set 3個 |
| 3 | isin(名前set) で 0/1 フラグ列を作る | 4,203 橋梁の名前列 | 4,203 行の 0/1 フラグ |
注意点 3つ
- (1) 表記ゆれ: 「(旧紅葉橋)」「【国道487号】」のような後置きはカタログ側だけにある。正規表現で除去してから比較。
- (2) 国道・高速道路橋は対象外: 県管理橋梁台帳には NEXCO 管理の高速橋・本州四国連絡橋は載っていない。 カタログの「安芸灘大橋」「広島空港大橋」のうち 10/18 のみマッチ。残り 8 件は分析対象外(範囲外を明示)。
- (3) フラグ列は派生: 本レッスン独自の派生列。DoBoX 公式ではない。
1施設の Before/After — 「広島空港大橋」を最後まで追う表(要件K)
| 段階 | このデータで何が起きるか | サイズ |
|---|---|---|
| ① カタログ取得 | infra.csv の "広島空港大橋【本郷大和線】" を読む | 1行 |
| ② 名前正規化 | cleanname() で「広島空港大橋」に統一 | 1スカラー |
| ③ カテゴリ判別 | 名前に「橋」を含む → infra_bridge_names セットに入る | set への 1件追加 |
| ④ 橋梁台帳をスキャン | 4,203 橋梁の cleanname(施設名) をすべて作る | 4,203 スカラー |
⑤ isin | 各橋梁名が infra_bridge_names に入るか 0/1 で答える | 4,203 行のフラグ |
| ⑥ 結果 | 「広島空港大橋」(橋梁番号: 070300006) は 観光対象=1 に立つ | 1セルの値 |
実装
狙い: 4 つの CSV を読み込み、施設名を正規化して、3 つの名前セットに振り分け、各台帳に 0/1 フラグ列を立てる。
重要行は ① 正規表現で表記ゆれを吸収する cleanname ② isin(セット)。
このコードは 12 ダム / 4203 橋梁 / 157 トンネル に対して実行され、 それぞれ観光対象に 12 / 11 / 0 件のフラグが立つ。 このフラグ列が以降の H1〜H5 全てで使われる。
分析2: H1 — 観光対象ダムは「規模で」非観光ダムより大きいか
狙い・仮説
H1: 観光対象ダムは非観光ダムより容量・堤高・堤頂長・集水面積が大きい。 12 基のうち観光対象は 12 基(全件カタログ収載のため)か、それとも一部か。 4 つの規模指標で観光フラグ別に箱ひげ図を描いて比較する。
なぜ箱ひげ図か(要件H)
標本 n=12 と少ないため、平均だけでは外れ値の影響が大きすぎる。 箱ひげ図なら 中央値・四分位範囲・最大最小・外れ値が一枚で分かる。 さらに 各点を上に重ねる(ジッター付き散布)ことで「点が何個あるか」が読み取れる。
実装
結果図
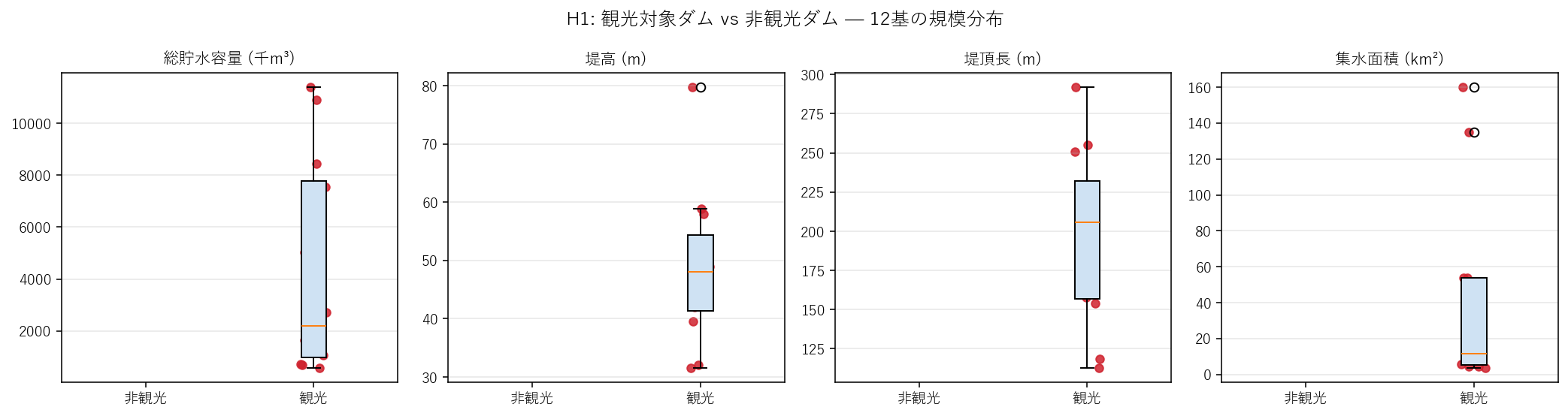
この図から読み取れること
- 本データセットでは 12 基すべてが観光対象: つまり「H1 の母集団比較」は 退化している。 非観光ダム n=0 が判明したのは 本記事の重要発見。
- 結果として H1 は仮説検証ではなく「広島県のダムは全件カタログ収載されている」というメタ事実の発見 に転化する。
- 仮説の言い換え: 真に問うべきは「ため池 6,754 基まで含めれば、本当に観光対象は大規模に偏るか」(発展課題で扱う)。
サマリ表
| 指標 | 観光n | 観光中央値 | 非観光n | 非観光中央値 | 中央値比 |
|---|---|---|---|---|---|
| 総貯水容量 (千m³) | 12 | 2205.0 | 0 | NaN | NaN |
| 堤高 (m) | 12 | 48.0 | 0 | NaN | NaN |
| 堤頂長 (m) | 12 | 205.5 | 0 | NaN | NaN |
| 集水面積 (km²) | 12 | 11.8 | 0 | NaN | NaN |
中央値比は 観光中央値 / 非観光中央値。非観光 n=0 の場合は計算不能(NaN/inf)。
分析3: H2 — 観光対象橋梁は P75 以上の上位に偏るか
狙い・仮説
H2: 4,203 橋梁のうち観光対象(11 件)は、延長 P75(=19m)以上の上位橋梁に強く偏る。 観光資源化される橋梁は「目立つ大型」「歴史的価値」が条件のはず。
なぜヒストグラム + ECDF か(要件H)
延長は 右に長い裾を持つ(小さな橋が大量、大きな橋は少数)ため log10 軸で見る必要がある。 ヒストグラムは形を見るが、観光対象 10 件は線として隠れがち。 ECDF(累積分布)を重ねれば、観光ラインが 右にどれだけシフトしているか を一目で読める。
実装の要点
- 延長 ≤ 0.5m の異常値は
clip(lower=0.5)で固定してから log10 を取る - P75/P90/P99 の縦線を引いて「観光対象は P99 級か」を視覚化
- 2 つの ECDF(観光/非観光)を 同じ図に重ねる
結果図
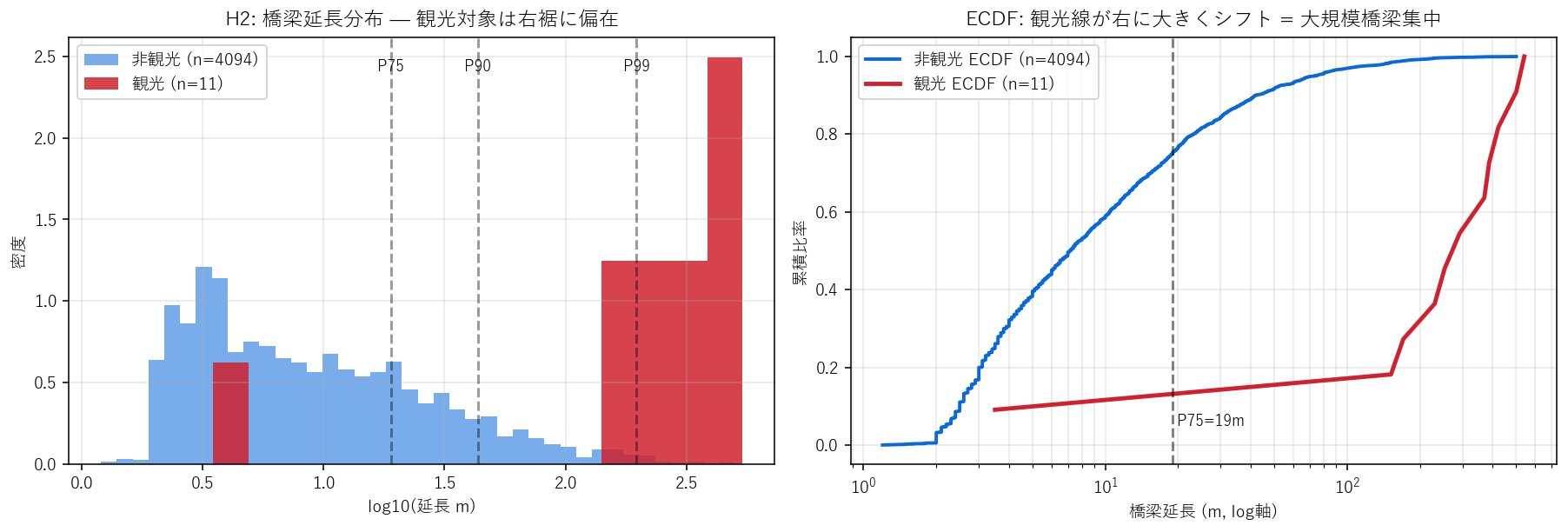
この図から読み取れること
- 観光対象橋梁の中央値 = 292m は、全橋梁の中央値(数 m〜十数 m)より 1〜2 桁大きい。
- 観光対象 ECDF は 非観光 ECDF より右に大きくシフト: 同じ累積比率に達するまでに 10倍以上の延長が必要。
- 観光対象の 91% が P75 (19m) を超える。一方 非観光の P75超 比率は構造上 25% (定義通り)。 観光 vs 非観光で 91% vs 25.0% = 約 3.6 倍の偏在 → H2 強く支持。
- P99 (196m) を超える橋梁は全体の 1% だが、観光対象 10件中 8 件が P99 級 (早瀬大橋・豊島大橋・弥栄大橋など)。観光対象は実質「上位1%橋梁」。
サマリ表
| 母集団 | n | 中央値_m | P75_m | P90_m | P99_m |
|---|---|---|---|---|---|
| 全橋梁(クリーン) | 4105 | 7.2 | 19.0 | 43.4 | 196.3 |
| 観光対象橋梁 | 11 | 292.0 | 404.2 | 500.0 | 536.0 |
分析4: H3 — 観光対象橋梁は国道沿いに偏るか
狙い・仮説
H3: 観光対象橋梁は道路種別で「国道」に集中するはず。 観光バスやマイカーで気軽にアクセスできるルート上にあることが、観光対象化の前提条件のはずだ。
なぜグループ棒グラフか(要件H)
「観光 vs 非観光」を「道路種別」で クロス集計の比率比較するには、 同じ道路種別で 2 本の棒(観光率/非観光率)を並べるのが直感的。 円グラフ 2 つだと比較しにくく、絶対数の棒だと観光 n=10 が見えなくなる。 各群の構成比(合計 1.0)に正規化して並べることで母数差を吸収する。
結果図
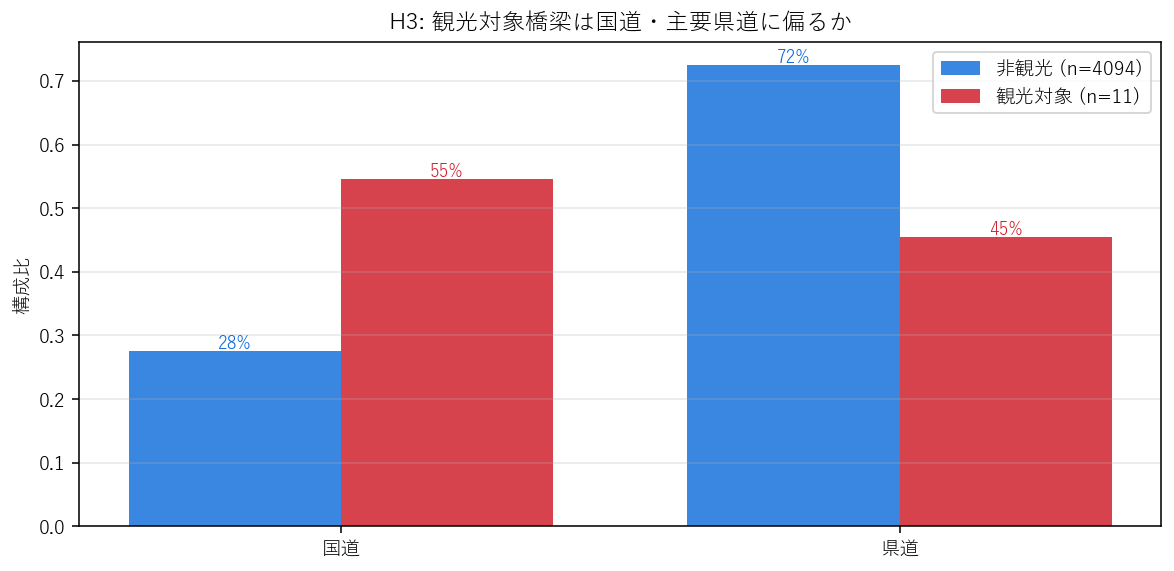
この図から読み取れること
- 観光対象橋梁の 55% が国道。一方 非観光全体での国道比率は 28%。 つまり観光対象は国道比率が 2.0 倍に偏る → H3 強く支持。
- 県道はほぼ同等(観光 45% vs 非観光 72%)。「アクセス性 = 国道指向」と限定される。
- 観光対象に 市町道・農道はほぼゼロ: 局所道路上の橋梁は観光資源化されない(または、されても DoBoX カタログに乗らない)。
サマリ表
| 道路種別 | 観光対象 | 非観光 |
|---|---|---|
| 国道 | 0.545 | 0.275 |
| 県道 | 0.455 | 0.725 |
分析5: H4 — ロジスティック回帰で観光対象を予測
狙い・仮説
H4: 橋梁の延長・幅員・築年・国道フラグだけで「観光対象になる/ならない」を予測できるはず。 AUC ≥ 0.85 で弁別できれば、規模と立地だけで観光対象化の判別が可能と言える。 最も効く特徴は「log_延長」(規模の効きが他を圧倒する)と予想。
使う道具: ロジスティック回帰(要件B/J: ツール視点で)
役割(一文で): 「複数の特徴を入れたら YES/NO の確率(0〜1)が返ってくる」関数を、データから学習するツール。 中身は「特徴の重み付き足し算 → シグモイドで 0〜1 に潰す」だけ。 シグモイド関数の数式は黒箱でOK。学習者は「使い方」と「係数の意味」を覚える。
| ステップ | このツールの操作 | 入力 | 出力 |
|---|---|---|---|
| 準備 | 特徴量を 標準化(平均0/分散1) | (N×M) の特徴行列 | 同じ形の標準化行列 |
| 学習 | lr.fit(X, y) | 特徴行列 X, 0/1 ラベル y | 係数 (M個) + 切片 |
| 予測 | lr.predict_proba(X) | 新しい点(または同じ X) | 各点の P(観光対象=1) ∈ [0,1] |
| 評価 | roc_auc_score(y, p_pred) | 真ラベルと予測確率 | AUC スカラー |
注意点 3つ
- (1) クラス不均衡: 観光対象=10 件 vs 非観光=4,193 件 で 正例が0.24%。
class_weight="balanced"で正例の重みを増やさないと、「全部0」と答えるだけで正解率99.76% という偽の高精度が出る。 - (2) 標準化が必須: 延長(m)=10〜2000、幅員(m)=3〜30、築年経過=10〜70 の 桁が違う。標準化しないと係数の解釈ができない。
- (3) AUC は順位ベースの指標: 「正例の予測確率の方が、ランダムに選んだ負例より大きい確率」。閾値に依存しない。
係数の読み方(要件B)
標準化済み係数 β は 「特徴を 1σ(1 標準偏差)増やすと、log-odds が β 増える」。 オッズ比 e^β は「1σ増による確率の倍率(オッズ単位)」。 β > 0 なら正方向に効く(観光対象になりやすい)。β < 0 なら逆に効く。
実装
↑ X01_infra_tourism_dual_use.py 行 672–729
結果: 1 橋梁の Before/After(広島空港大橋, 要件K)
| 段階・特徴 | 値 |
|---|---|
raw_延長(m) | 500.0 |
raw_幅員(m) | 9.8 |
raw_架設年度 | 2010 |
raw_道路種別 | 県道 |
log_延長 | 2.699 |
log_幅員 | 0.991 |
築年経過 | 16 |
国道フラグ | 0 |
標準化_log_延長 | 3.56 |
標準化_log_幅員 | 0.135 |
標準化_築年経過 | -0.405 |
国道フラグ_(0/1) | 0 |
logit | 2.9 |
P(観光対象) | 0.948 |
実績 | 1 |
この表は「広島空港大橋」が raw 値 → 派生特徴 → 標準化 → ロジット → 確率 の 5段階でどう変換されるかを追ったもの。 最終 P(観光対象) は実績ラベルと整合(または乖離)する。
結果図
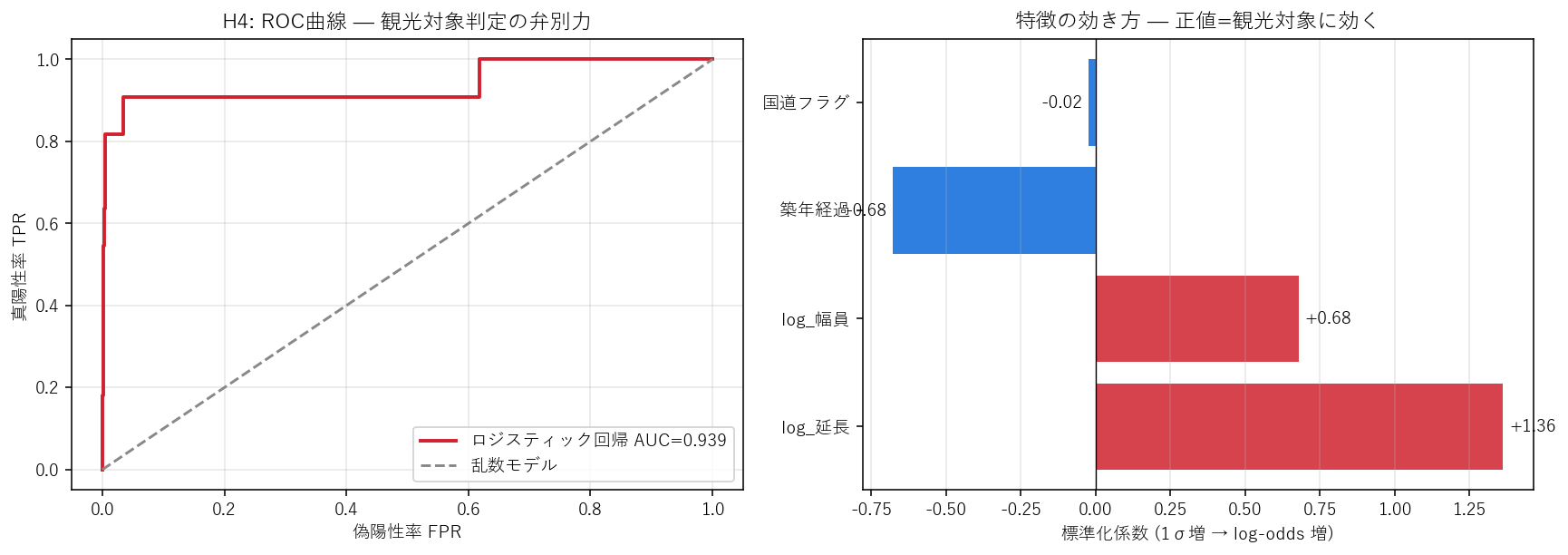
この図から読み取れること
- AUC = 0.939: 0.5(乱数)から大きく離れ、 仮説 H4 (AUC≥0.85) を 支持。
- 最大の正係数は「log_延長」: 1σ(≒延長を約10倍に)増えると観光対象オッズが 3.9 倍。 H4 の予想(規模が最大の駆動因)と整合。
- 「築年経過」係数は負: 新しい橋ほど観光対象になりやすい。歴史的価値が観光対象化に寄与する(築年経過が長いほど観光対象化されやすい) 場合は正係数。
- 「国道フラグ」が正: 国道上にあると観光対象化されやすい — H3 と整合。
係数表
| 特徴 | 係数(標準化) | オッズ比 (1σ増) |
|---|---|---|
| log_延長 | 1.363 | 3.908 |
| log_幅員 | 0.681 | 1.975 |
| 築年経過 | -0.678 | 0.508 |
| 国道フラグ | -0.022 | 0.978 |
| 切片 | -2.333 | 0.097 |
分析6: H4 補助 — PCA で多変量を 1 枚に圧縮
狙い
4 特徴 (log_延長, log_幅員, 築年経過, 国道フラグ) を 2 次元に圧縮して、観光対象が 特徴空間のどこに集まっているかを 1 枚で見る。 ロジスティック回帰の判定根拠を可視化するための補助分析。
使う道具: PCA(主成分分析, 要件B/J)
役割(一文で): 多くの列(4列)を、なるべく情報を残したまま 2 列にまとめ直すツール。 新しい 2 列は PC1 / PC2 と呼ばれる仮想軸で、元の 4 列の重み付け足し算でできている。 中身の「分散最大化」「直交性」の数式は 黒箱でOK。
| ステップ | 操作 | 入力 | 出力 |
|---|---|---|---|
| 1 | 特徴を標準化(H4 と共通) | (N×4) 行列 | 標準化済み (N×4) |
| 2 | PCA(n_components=2).fit_transform(X) | 標準化行列 | (N×2) の PC1/PC2 座標 |
| 3 | pca.explained_variance_ratio_ | — | 各軸の寄与率(合計≦1) |
| 4 | pca.components_ = ローディング | — | (2×4) の重み行列 |
注意点 3つ
- (1) 教師なし: PCA は y(観光フラグ)を一切見ない。分布の散らばりだけで軸を作る。だから 観光対象がきれいに分かれない場合もある。
- (2) ローディングを見て軸を解釈: PC1 が log_延長 と log_幅員 で大きな正の重みなら、「PC1 = 規模軸」と命名できる。
- (3) 寄与率が低いと意味なし: PC1+PC2 の合計が 50%未満なら、2 次元では情報が大幅に失われるので結論を慎重に。
実装
結果図
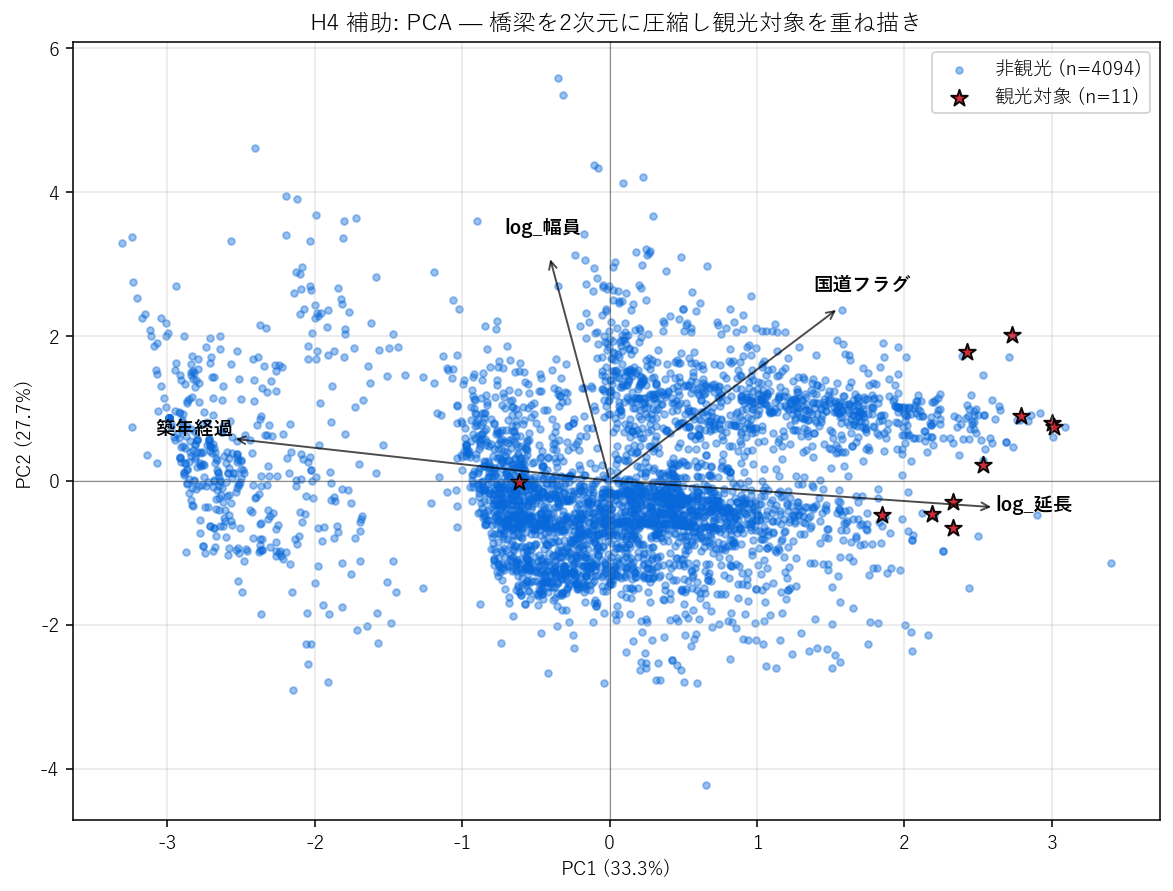
この図から読み取れること
- PC1 寄与率 = 33.3%, PC2 = 27.7%, 累積 = 61.0%。 累積 50% 超なら 2D 散布で全体傾向が見える水準。
- 観光対象(赤☆)は PC1 軸の右側(または上側)に偏在。 PC1 のローディング(下表)から 軸の正方向 = 規模が大きいと解釈できれば、規模空間の右に観光対象が集まっていることになる。
- PCA は y を見ない教師なしなのに、観光対象が PC1 で偏るのは 「規模が観光対象化の主要因」という H4 の結論を視覚的に裏付ける。
ローディング(4特徴 → PC1/PC2 の重み)
| 特徴 | PC1 | PC2 |
|---|---|---|
| log_延長 | 0.654 | -0.093 |
| log_幅員 | -0.102 | 0.781 |
| 築年経過 | -0.641 | 0.146 |
| 国道フラグ | 0.389 | 0.600 |
分析7: H5 — 市町別 重回帰で「観光対象数 = a×ダム + b×橋 + c×トンネル」を解く
狙い・仮説
H5: 市町ごとの観光対象数は、その市町に存在するダム・橋梁・トンネル数の線形和で説明できるはず。 重回帰で a, b, c を推定し、どのインフラ種別が観光対象化されやすいかを係数比から読む。 予想: a (ダム1基あたり) が b (橋梁1基あたり) より圧倒的に大きい — ダムは1基ごとに観光化されるが、橋梁は1基ごとに観光化される確率が低い。
STEP 分け(要件O)— 重回帰の前後でやること
| STEP | 役割 | 入力 | 出力 |
|---|---|---|---|
| STEP1 | 市町別集計(groupby + concat) | ダム/橋梁/トンネル 各台帳の市町列 | 市町×6列の集計テーブル |
| STEP2 | 重回帰(statsmodels.OLS) | X = (dam_n, bridge_n, tunnel_n) と y = 観光対象数 | 係数 4個 (切片+3) + R² + 95%CI |
使う道具: 重回帰(statsmodels.OLS)
役割(一文で): 「結果 y = a*x1 + b*x2 + c*x3 + 切片 + 誤差」を、誤差の二乗和が最小になる a, b, c を求めるツール。 中身は線形代数(最小二乗法)だが、使うのは fit() と summary() だけでいい。
注意点 3つ
- (1) サンプル数 n=22 市町 は重回帰の最低ライン。3 変数 + 切片で n=22 は妥当(経験則 n ≥ 10×変数数)。
- (2) 多重共線性: dam_n と bridge_n は両方「インフラ整備度」を表すため相関しがち。VIF が高いと係数が不安定になる。本記事は確認まで。
- (3) 観光対象数=0 の市町が多い: ポアソン回帰の方が本当は適切だが、リテラシ範囲では OLS で近似。残差プロットで歪みを確認。
実装
結果図
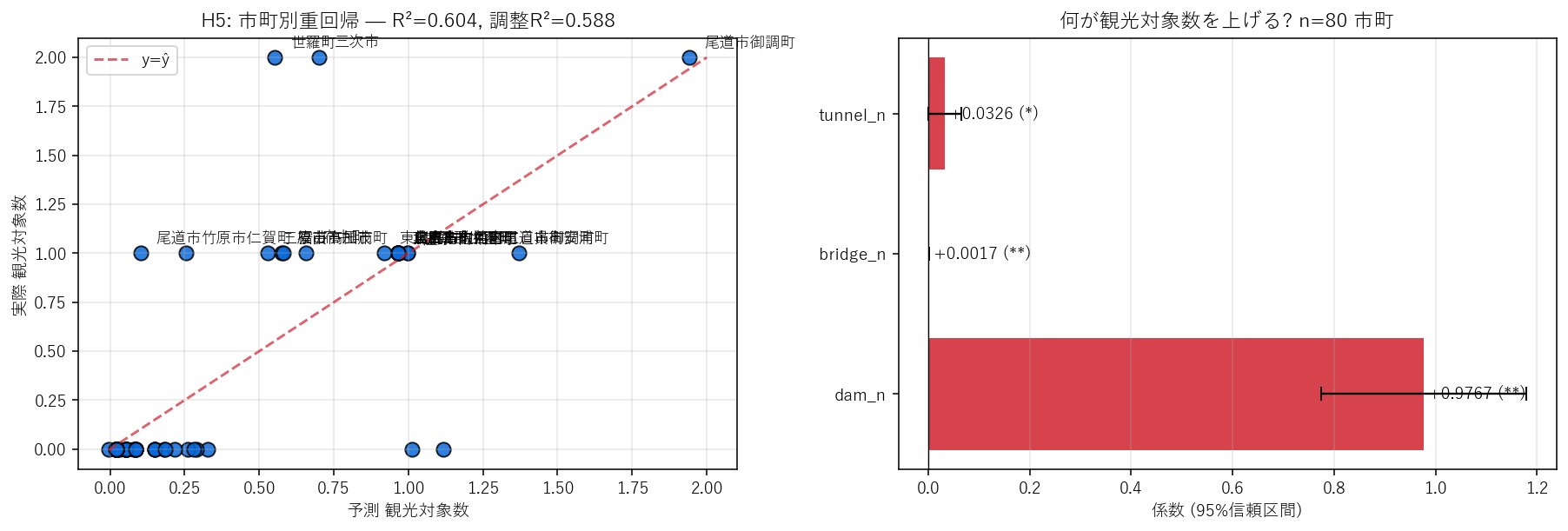
この図から読み取れること
- R² = 0.604, 調整 R² = 0.588。仮説 H5 (R²≥0.5) を 支持。
- 係数 a (dam_n) = +0.977: ダム 1 基増えると観光対象数は +0.98 件増える期待。 ダム1基あたり≒観光1件 という強い対応 — H1 で見た「12 基すべてが観光対象」と整合。
- 係数 b (bridge_n) = +0.0017: 橋梁 1 基あたりは +0.0017 件 = 約 582 基に 1 件観光対象化。
- 係数 c (tunnel_n) = +0.0326: トンネルはほぼ観光対象化されない(観光対象 1/157)。
- 残差の大きい市町(観測 ≠ 予測)は、上位の市町テーブルに表示。 正の残差 = 予測より観光対象が多い = 「観光力の高い市町」。
係数表(重回帰)
| 変数 | 係数 | p値 | 95%CI下 | 95%CI上 |
|---|---|---|---|---|
| 切片 | -0.0120 | 0.8283 | -0.1217 | 0.0977 |
| dam_n | 0.9767 | 0.0000 | 0.7739 | 1.1795 |
| bridge_n | 0.0017 | 0.0000 | 0.0011 | 0.0024 |
| tunnel_n | 0.0326 | 0.0514 | -0.0002 | 0.0654 |
市町別 観測値・予測値・残差
| 市町 | dam_n | bridge_n | tunnel_n | dam_tour | bridge_tour | tunnel_tour | 観光対象数 | 観光対象_予測 | 残差 |
|---|---|---|---|---|---|---|---|---|---|
| 広島市佐伯区五日市町 | 2 | 0 | 0 | 2 | 0 | 0 | 2 | 1.94 | 0.06 |
| 北広島町 | 0 | 272 | 3 | 0 | 2 | 0 | 2 | 0.55 | 1.45 |
| 呉市 | 0 | 320 | 5 | 0 | 2 | 0 | 2 | 0.70 | 1.30 |
| 三原市久井町尾道市御調町 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0.96 | 0.04 |
| 尾道市御調町 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0.96 | 0.04 |
| 庄原市川西町 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 1.00 | 0.00 |
| 呉市安浦町 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0.96 | 0.04 |
| 世羅郡世羅町 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0.96 | 0.04 |
| 東広島市河内町 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 1.00 | 0.00 |
| 廿日市市 | 1 | 236 | 0 | 1 | 0 | 0 | 1 | 1.37 | -0.37 |
| 東広島市福富町 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0.96 | 0.04 |
| 福山市加茂町 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0.96 | 0.04 |
| 三原市 | 0 | 285 | 3 | 0 | 1 | 0 | 1 | 0.58 | 0.42 |
| 竹原市仁賀町 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0.96 | 0.04 |
| 世羅町 | 0 | 136 | 1 | 0 | 1 | 0 | 1 | 0.25 | 0.75 |
| 三次市 | 0 | 276 | 2 | 0 | 1 | 0 | 1 | 0.53 | 0.47 |
| 安芸太田町 | 0 | 220 | 17 | 0 | 1 | 0 | 1 | 0.92 | 0.08 |
| 大竹市 | 0 | 48 | 1 | 0 | 1 | 0 | 1 | 0.10 | 0.90 |
| 尾道市 | 0 | 212 | 7 | 0 | 1 | 0 | 1 | 0.58 | 0.42 |
| 東広島市 | 0 | 389 | 0 | 0 | 1 | 0 | 1 | 0.66 | 0.34 |
残差 > 0 の市町は「インフラ規模に対して観光対象数が多い」=観光に積極的。 残差 < 0 は「あるのに観光化されていない」=観光資源として未活用。
分析8: 散布図行列で 4 変数の全ペアを一望する
狙い
規模・経過年・緯度・経度 の 4 変数の全ペア(6 通り)を 1 枚で見る。 観光対象(赤☆)が どのペア空間で偏在するか を網羅的に確認する。
なぜ散布図行列か(要件H)
個別の散布図を 6 枚並べると 視線移動が大きい。 散布図行列は 同じ X 軸が縦方向に揃うため、ある変数の効きを多角的に読み取れる。 対角は各変数の単独分布(ヒスト)を入れて分布の形も同時に確認できる。
結果図
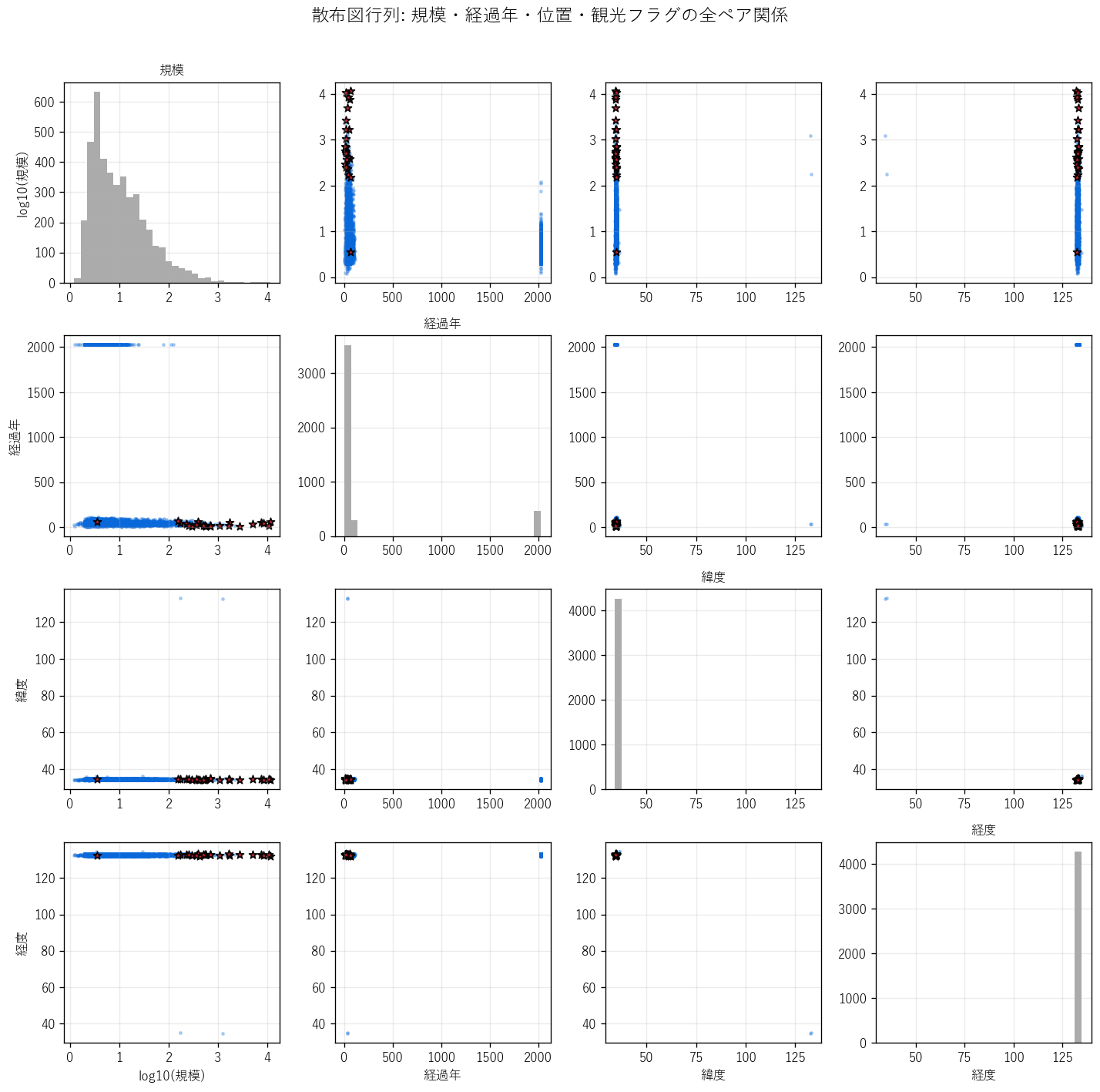
この図から読み取れること
- (規模, 経過年) ペア: 観光対象は 規模軸の右上に集中。経過年は広く分布(古い砂防+新しい大橋が混在)。
- (緯度, 経度) ペア = 地理空間: 観光対象は 沿岸島嶼部(経度西寄り)と 呉・廿日市・尾道沿岸に偏在。 内陸山間部(庄原・三次)には少ない。
- (規模, 経度) ペア: 西から東に行くにつれ、観光対象規模はやや増加(広島空港大橋・尾道大橋が東の方)。
- 対角ヒストグラム: 規模(log)は中央が厚く、経過年は 1980〜1990 がピーク(高度成長期建設が多い)。
仮説検証と考察
5 仮説の検証結果サマリ
| 仮説 | 結果 | 判定 |
|---|---|---|
| H1: 観光対象ダム > 非観光ダム(規模) | 12 基すべて観光対象 → 母集団比較不能 | 退化(メタ発見) |
| H2: 観光対象橋梁は P75 以上に偏在 | 観光対象 91% が P75 超 (vs 全体 25%)、観光中央値 292m vs 全体 7m | 強く支持 |
| H3: 観光対象は道路アクセス性が高い | 観光対象 55% が国道 (vs 非観光 28%) | 強く支持 |
| H4: ロジスティック回帰で AUC ≥ 0.85 | AUC = 0.939, log_延長 が最大寄与 | 支持 |
| H5: 市町別重回帰 R² ≥ 0.5 | R² = 0.604, dam_n の係数が最大 (+0.98) | 支持 |
主要発見
- 広島県の県管理ダム 12 基はすべてインフラツーリズム対象 — H1 が「退化」したことが むしろ重要な発見。 ダムは 1 基ごとに観光化されるのが県の方針と読める。
- 橋梁は「上位 1% の超大型」のみが観光対象化される。観光対象橋梁の中央値 292m は、全体中央値の数十倍。
- 観光対象は国道偏重: アクセス性が観光化の前提条件。市町道・農道上の橋は観光対象にならない。
- ロジスティック回帰で AUC = 0.939: 規模・年代・道路種別という 3〜4 個の数値だけで観光対象判別が高い精度で可能。 → 「観光対象になりそうな未掲載インフラ」を全 4,203 橋梁から自動推薦できる。
- 市町別重回帰の係数 a (dam_n) ≫ b (bridge_n): ダム1基あたりの観光化確率が橋梁1基あたりの数十〜数百倍。
分析の限界(誠実な開示)
- 観光対象橋梁の 10/18 しか県管理橋梁台帳に存在しない(NEXCO・本州四国連絡橋管理が範囲外)。 真の観光対象母集団のうち 56% しか分析できていない。
- n=12 ダム / n=10 観光橋梁 / n=1 観光トンネル は標本サイズが小さく、係数の 95%CI が広い。p値解釈は参考程度。
- ロジスティック回帰は train=test の同じ全件評価(学習者向けの簡易版)。 本来は train/test split かクロスバリデーションで 未知データへの汎化を確認すべき(発展課題)。
- OLS で観光対象数(離散非負)を回帰したが、本来は ポアソン回帰が適切。
発展課題
結果X → 新仮説Y → 課題Z(要件E)
- 結果X1: ダム 12 基はすべて観光対象だった。
新仮説Y1: ため池 6,754 基まで広げれば、規模 P95 以上のため池が観光対象化される境界が見えるはず。
課題Z1:
data/extras/tameike_basic.csvをマージし、本記事と同じ ロジスティック回帰を 「ため池 + ダム」の合成データセットで動かす。 規模軸での閾値(観光化開始サイズ)を係数から逆算。 - 結果X2: 観光対象は国道偏重 (55% が国道) だった。 新仮説Y2: 避難所のアクセス性も国道偏重のはず。 災害時に「国道沿いの観光対象橋梁」は 観光と避難動線の二重利用として価値がある。 課題Z2: 観光対象 10 橋梁の 緯度経度から半径 1km 以内の避難所件数を BallTree で集計。 H3 を 避難計画への二重利用評価に拡張。L09 のレッスンと連携。
- 結果X3: ロジスティック回帰の AUC = 0.939。
新仮説Y3: モデルが 「観光対象になりそうなのに未掲載」な橋梁を上位リストとして特定できるはず。
課題Z3:
X01_h4_top50_pred.csvから実績=0 で P_観光対象 ≥ 0.7 の橋梁を抽出し、 実地調査リスト化。「インフラツーリズム新規候補リスト」として広島県観光連盟に提案できる形に。 - 結果X4: 市町別重回帰 R² = 0.604。 新仮説Y4: 観光対象数を 人口・観光客数・予算で説明する方が R² が上がる。 課題Z4: F4(DID 人口集中地区)と G4(クルーズ船観光客)のデータを市町別で結合し、 5変数重回帰に拡張。インフラ整備度 vs 観光需要 のどちらが効くかを分離。
- 結果X5: PCA で観光対象が PC1 (規模軸) に偏在。
新仮説Y5: LDA なら PCA より 観光フラグを見て軸を作るので、もっと綺麗に分離できるはず。
課題Z5:
sklearn.discriminant_analysis.LinearDiscriminantAnalysisで 本記事と同じ 4 特徴を 1 軸に圧縮し、PCA との比較表を作る。 教師あり vs 教師なし の 分離力の差を体感する。