# -*- coding: utf-8 -*-
"""L92 インフラツーリズム自転車道コースデータ
(DoBoX #1673 / 62 サイクリングコース GeoJSON 解析)
カバー宣言:
本記事は X01 (インフラツーリズム施設情報 #1447) および L87 (M3 観光物語) と
テーマは関連するが、独立 dataset #1673 (サイクリングコース 62 本 LineString)
を主データとして、道路・施設ではなくコースルート自体を空間分析する初出記事。
- X01: インフラツーリズム施設点(橋・砂防等)の分布と属性分析
- L87: M3 観光物語(観光統計 × GIS ストーリーテリング)
- L92(本記事): サイクリングコース 62 本の距離・標高構造 + 観光資源近接性 +
防災(津波・緊急輸送道路)との交差分析
研究の問い(主 RQ):
広島県のサイクリングコース 62 本はどのような距離・標高・地域構造を持ち、
観光資源との近接性および防災的文脈(津波域・緊急輸送道路)においてどう評価されるか?
仮説(H1〜H9):
H1(しまなみ一極集中): しまなみ海道コースが最長(71.9km)で平均距離の 2 倍以上。
H2(延長集中): 上位 10 コースが全延長の 40% 以上を占める(Lorenz 集中型)。
H3(標高—距離相関): 累積標高(登り)と距離の Pearson r ≥ 0.5(中程度正相関)。
H4(観光密度・しまなみ優位): しまなみ海道 1km 圏内インフラツーリズム施設数が全コース最大。
H5(埋蔵文化財・沿岸集中): 埋蔵文化財 1km 圏内密度 top5 はすべて沿岸・島嶼コース。
H6(観光施設平均): 全コース平均の 1km 圏内観光施設数 ≥ 2 件。
H7(津波交差コース数): 津波浸水想定区域と交差するコース ≥ 5 本。
H8(緊急輸送道路孤立): 緊急輸送道路 500m バッファ外のコース区間 ≥ 全延長の 30%。
H9(沿岸コース・津波域内延長): 浸水域内延長最大コースが ≥ 3km。
要件 S(1〜3 分以内):
- 62 GeoJSON はまとめて一括 ZIP DL (948KB), キャッシュ後は再 DL しない
- L49 / L72 は既存キャッシュ GPKG / JSON を再利用
- sjoin はすべて R-tree 使用(geopandas 標準)
実行:
cd "2026 DoBoX 教材"
py -X utf8 lessons/L92_cycling_infrastructure.py
"""
from __future__ import annotations
import sys, time, io, re, json, zipfile
from pathlib import Path
from html import escape
sys.path.insert(0, str(Path(__file__).parent))
from _common import (ROOT, ASSETS, LESSONS, render_lesson, code, figure,
data_recipe)
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
from matplotlib.lines import Line2D
from matplotlib.patches import Patch
import geopandas as gpd
from shapely.geometry import LineString, MultiLineString, Point
t0 = time.time()
# ── 定数 ────────────────────────────────────────────────────
TARGET_CRS = "EPSG:6671"
CACHE_DIR = ROOT / "data/extras/L92_cycling_infrastructure"
CACHE_DIR.mkdir(parents=True, exist_ok=True)
ZIP_CACHE = CACHE_DIR / "cycling_courses.zip"
ADMIN_GPKG = ROOT / "data/extras/L44_storm_surge/_cache/admin_diss.gpkg"
TSUNAMI_GPKG = ROOT / "data/extras/L49_tsunami_inundation/_cache/tsunami_dissolve_8rank.gpkg"
L72_DIR = (ROOT / "data/extras/L72_emergency_road"
/ "340006_emergency_transport_road_20220908T000000")
INFRA_CSV = ROOT / "data/extras/infra_tourism.csv"
L84_DIR = ROOT / "data/extras/L84_archaeological_sites"
CITY_NAME = {
"34100": "広島市", "34202": "呉市", "34203": "竹原市", "34204": "三原市",
"34205": "尾道市", "34207": "福山市", "34208": "府中市", "34209": "三次市",
"34210": "庄原市", "34211": "大竹市", "34212": "東広島市", "34213": "廿日市市",
"34214": "安芸高田市", "34215": "江田島市", "34302": "府中町", "34304": "海田町",
"34305": "熊野町", "34307": "坂町", "34311": "安芸太田町", "34312": "北広島町",
"34431": "大崎上島町", "34441": "世羅町", "34462": "神石高原町",
}
# ── 地域分類関数 ─────────────────────────────────────────────
def classify_region(fname: str) -> str:
f = fname.lower()
if any(k in f for k in ['shimanami', 'tobishima', 'osakikamijima', 'sagishima',
'momoshima', 'tashima', 'yokoshima', 'nika', 'sazanami',
'kakishima', 'yumeshima']):
return '島嶼・沿岸'
if any(k in f for k in ['sandankyo', 'shobara', 'donguri', 'taishakukyo', 'soryo',
'takano', 'kuchiwa', 'hiwa', 'gonokawa', 'sakugi',
'haizuka', 'senbonzakura', 'yamanami', 'sanga', 'oasa',
'yamagata', 'kogen', 'tengushide', 'yuki']):
return '中山間'
if any(k in f for k in ['joge', 'bingofuchu', 'ashidako', 'sera', 'mitsugi',
'shiomachi', 'tenryo', 'jinsekikogen', 'kawanishi',
'kochi']):
return '内陸丘陵'
return '都市近郊'
REGION_COLOR = {
'島嶼・沿岸': '#1f77b4',
'中山間': '#2ca02c',
'内陸丘陵': '#ff7f0e',
'都市近郊': '#d62728',
}
# ─────────────────────────────────────────────────────────────
# 1. データ取得・パース
# ─────────────────────────────────────────────────────────────
print("[1] データ取得", flush=True)
t1 = time.time()
if not ZIP_CACHE.exists() or ZIP_CACHE.stat().st_size < 100_000:
import requests
DOBOX_BASE = "https://hiroshima-dobox.jp"
headers = {"User-Agent": "DoBoX-MDASH-textbook/1.0 (educational use)"}
r = requests.get(f"{DOBOX_BASE}/resource_download/177586", headers=headers,
timeout=120)
r.raise_for_status()
ZIP_CACHE.write_bytes(r.content)
print(f" DL: {len(r.content):,} bytes", flush=True)
else:
print(f" キャッシュ使用: {ZIP_CACHE}", flush=True)
# GeoJSON パース & 属性抽出
DESC_PATTERNS = {
'dist_km': re.compile(r'距離: ([\d\.]+) km'),
'elev_min': re.compile(r'最小標高: ([\d\.]+) m'),
'elev_max': re.compile(r'最大標高: ([\d\.]+) m'),
'ascent': re.compile(r'累積標高(登り): ([\d\.]+) m'),
'descent': re.compile(r'累積標高(下り): ([\d\.]+) m'),
}
def resolve_name(props_name: str, short_fname: str) -> str:
"""'Path' や空の Name をファイル名由来の識別子に置換する。"""
if props_name and props_name.strip() and props_name != 'Path':
return props_name
# short_fname = 340006_cycling_course_N_suffix → extract suffix
parts = short_fname.split('_')
# find the numeric course number index (position after 'course')
try:
ci = parts.index('course')
suffix = '_'.join(parts[ci+2:]) # skip number
return f"[{suffix}] コース"
except ValueError:
return short_fname
records = []
with zipfile.ZipFile(ZIP_CACHE) as zf:
for fname in zf.namelist():
if not fname.endswith('.geojson'):
continue
with zf.open(fname) as f:
gj = json.loads(f.read())
for feat in gj.get('features', []):
geom = feat['geometry']
if geom['type'] != 'LineString':
continue
props = feat.get('properties', {})
raw_name = props.get('Name', '')
desc = props.get('description', '') or ''
# clean HTML tags from description
desc_clean = re.sub(r'<[^>]+>', ' ', desc)
short_fname = Path(fname).stem # 340006_cycling_course_N_name
name = resolve_name(raw_name, short_fname)
attrs = {'name': name, 'fname': short_fname,
'region': classify_region(short_fname)}
for col, pat in DESC_PATTERNS.items():
m = pat.search(desc_clean)
attrs[col] = float(m.group(1)) if m else np.nan
attrs['geometry'] = LineString(geom['coordinates'])
records.append(attrs)
gdf = gpd.GeoDataFrame(records, crs="EPSG:4326").to_crs(TARGET_CRS)
gdf['geom_km'] = gdf.geometry.length / 1000 # 実測距離
# dist_km が欠損なら geom_km を使用
gdf['length_km'] = gdf['dist_km'].where(gdf['dist_km'].notna(), gdf['geom_km'])
gdf = gdf.sort_values('length_km', ascending=False).reset_index(drop=True)
n_courses = len(gdf)
total_km = gdf['length_km'].sum()
mean_km = gdf['length_km'].mean()
max_km = gdf['length_km'].max()
max_name = gdf.loc[gdf['length_km'].idxmax(), 'name']
print(f" コース数: {n_courses} / 総延長: {total_km:.1f} km / 平均: {mean_km:.1f} km", flush=True)
print(f" 最長: {max_name} ({max_km:.1f} km)", flush=True)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# ─────────────────────────────────────────────────────────────
# 2. 補助データ読込
# ─────────────────────────────────────────────────────────────
print("[2] 補助データ", flush=True)
t2 = time.time()
# 行政界
admin = gpd.read_file(ADMIN_GPKG) # already EPSG:6671
admin["市町名"] = admin["CITY_CD"].map(CITY_NAME).fillna(admin["CITY_CD"].astype(str))
# インフラツーリズム施設
infra = pd.read_csv(INFRA_CSV, encoding='utf-8-sig')
infra_gdf = gpd.GeoDataFrame(
infra,
geometry=gpd.points_from_xy(infra['経度'], infra['緯度']),
crs="EPSG:4326"
).to_crs(TARGET_CRS)
n_infra = len(infra_gdf)
# 埋蔵文化財(全種別を統合、有効座標のみ)
maizo_dfs = []
for csv_path in sorted(L84_DIR.glob("maizo_*.csv")):
try:
df = pd.read_csv(csv_path, encoding='utf-8-sig')
maizo_dfs.append(df)
except Exception:
pass
maizo = pd.concat(maizo_dfs, ignore_index=True)
maizo['緯度'] = pd.to_numeric(maizo['緯度'], errors='coerce')
maizo['経度'] = pd.to_numeric(maizo['経度'], errors='coerce')
maizo = maizo.dropna(subset=['緯度', '経度'])
maizo = maizo[(maizo['緯度'].between(33.8, 35.1)) &
(maizo['経度'].between(132.0, 134.0))].copy()
maizo_gdf = gpd.GeoDataFrame(
maizo,
geometry=gpd.points_from_xy(maizo['経度'], maizo['緯度']),
crs="EPSG:4326"
).to_crs(TARGET_CRS)
n_maizo = len(maizo_gdf)
# L49 津波浸水想定
if TSUNAMI_GPKG.exists():
tsunami = gpd.read_file(TSUNAMI_GPKG).to_crs(TARGET_CRS)
n_tsunami_poly = len(tsunami)
print(f" 津波: {n_tsunami_poly} ポリゴン", flush=True)
else:
tsunami = None
print(" 津波: キャッシュなし", flush=True)
# L72 緊急輸送道路
def load_l72_route(idx):
p = L72_DIR / f"05_kinkyu_route_{idx:02d}.json"
if not p.exists():
return []
with open(p, 'r', encoding='utf-8') as f:
text = f.read()
arr = json.loads("[" + text + "]")
lines = []
for seg in arr:
if len(seg) >= 2:
coords = [(pt["e"], pt["d"]) for pt in seg]
lines.append({"rank": idx, "geometry": LineString(coords)})
return lines
road_records = []
for idx in [1, 2, 3, 4]:
road_records.extend(load_l72_route(idx))
gdf_road = gpd.GeoDataFrame(road_records, crs="EPSG:4326").to_crs(TARGET_CRS)
n_road_seg = len(gdf_road)
total_road_km = gdf_road.geometry.length.sum() / 1000
print(f" 緊急輸送道路: {n_road_seg} セグメント / {total_road_km:.0f} km", flush=True)
print(f" ({time.time()-t2:.1f}s)", flush=True)
# ─────────────────────────────────────────────────────────────
# 3. RQ1: 距離・標高・地域構造分析
# ─────────────────────────────────────────────────────────────
print("[3] RQ1 分析", flush=True)
t3 = time.time()
# Lorenz 曲線用データ
sorted_km = np.sort(gdf['length_km'].values)
cum_share = np.cumsum(sorted_km) / sorted_km.sum()
pop_share = np.arange(1, len(sorted_km)+1) / len(sorted_km)
gini = 1 - 2 * np.trapezoid(cum_share, pop_share)
# 上位 10 コースの延長シェア
top10_share = gdf['length_km'].head(10).sum() / total_km * 100
# 距離 vs 累積標高 Pearson r
valid = gdf[['length_km', 'ascent']].dropna()
from scipy import stats as scipy_stats
if len(valid) >= 5:
pearson_r, pearson_p = scipy_stats.pearsonr(valid['length_km'], valid['ascent'])
else:
pearson_r, pearson_p = np.nan, np.nan
# 地域別集計
region_stats = (gdf.groupby('region')['length_km']
.agg(['count', 'sum', 'mean'])
.rename(columns={'count': '本数', 'sum': '総延長km', 'mean': '平均km'})
.round(1))
# 仮説検証
h1_ok = max_km >= mean_km * 2
h2_ok = top10_share >= 40
h3_ok = pearson_r >= 0.5 if not np.isnan(pearson_r) else False
print(f" Gini={gini:.3f}, Top10={top10_share:.1f}%, r={pearson_r:.3f}", flush=True)
print(f" H1={h1_ok}, H2={h2_ok}, H3={h3_ok}", flush=True)
print(f" ({time.time()-t3:.1f}s)", flush=True)
# ─────────────────────────────────────────────────────────────
# 4. RQ2: 観光資源近接性
# ─────────────────────────────────────────────────────────────
print("[4] RQ2 観光近接性", flush=True)
t4 = time.time()
buf1km = gdf[['name', 'length_km', 'region', 'geometry']].copy()
buf1km['geometry'] = gdf.geometry.buffer(1000)
# インフラツーリズム sjoin
sjoin_infra = gpd.sjoin(infra_gdf[['geometry']], buf1km[['name', 'geometry']],
predicate='within', how='inner')
infra_count = (sjoin_infra.groupby('name').size()
.rename('infra_cnt').reset_index())
# 埋蔵文化財 sjoin
sjoin_maizo = gpd.sjoin(maizo_gdf[['geometry']], buf1km[['name', 'geometry']],
predicate='within', how='inner')
maizo_count = (sjoin_maizo.groupby('name').size()
.rename('maizo_cnt').reset_index())
# 統合
gdf = gdf.merge(infra_count, on='name', how='left')
gdf = gdf.merge(maizo_count, on='name', how='left')
gdf[['infra_cnt', 'maizo_cnt']] = gdf[['infra_cnt', 'maizo_cnt']].fillna(0).astype(int)
gdf['infra_density'] = gdf['infra_cnt'] / gdf['length_km'].clip(lower=0.1)
gdf['maizo_density'] = gdf['maizo_cnt'] / gdf['length_km'].clip(lower=0.1)
# 仮説検証
shima_mask = gdf['fname'].str.contains('shimanami', case=False)
h4_infra_max_name = gdf.loc[gdf['infra_cnt'].idxmax(), 'name']
h4_ok = bool(shima_mask.any() and
gdf.loc[shima_mask, 'infra_cnt'].values[0] == gdf['infra_cnt'].max())
maizo_top5_regions = gdf.nlargest(5, 'maizo_density')['region'].tolist()
h5_ok = all(r == '島嶼・沿岸' for r in maizo_top5_regions)
h6_ok = gdf['infra_cnt'].mean() >= 2
print(f" インフラ観光施設: max={gdf['infra_cnt'].max()} ({h4_infra_max_name}), mean={gdf['infra_cnt'].mean():.1f}", flush=True)
print(f" 埋蔵文化財: max={gdf['maizo_cnt'].max()}, mean={gdf['maizo_cnt'].mean():.1f}", flush=True)
print(f" H4={h4_ok}, H5={h5_ok}, H6={h6_ok}", flush=True)
print(f" ({time.time()-t4:.1f}s)", flush=True)
# ─────────────────────────────────────────────────────────────
# 5. RQ3: 防災的文脈
# ─────────────────────────────────────────────────────────────
print("[5] RQ3 防災", flush=True)
t5 = time.time()
# 津波浸水域との交差
if tsunami is not None:
tsuna_union = tsunami.unary_union
gdf['tsunami_intersects'] = gdf.geometry.intersects(tsuna_union)
# 交差延長
def intersect_length_km(geom):
inter = geom.intersection(tsuna_union)
if inter.is_empty:
return 0.0
return inter.length / 1000
gdf['tsunami_km'] = gdf.geometry.apply(intersect_length_km)
n_tsunami_courses = gdf['tsunami_intersects'].sum()
max_tsunami_km = gdf['tsunami_km'].max()
max_tsunami_name = gdf.loc[gdf['tsunami_km'].idxmax(), 'name']
h7_ok = n_tsunami_courses >= 5
h9_ok = max_tsunami_km >= 3
else:
n_tsunami_courses = 0
max_tsunami_km = 0.0
max_tsunami_name = "N/A"
h7_ok = None
h9_ok = None
# 緊急輸送道路 500m バッファカバレッジ
road_buf_union = gdf_road.geometry.buffer(500).unary_union
def outside_road_km(geom):
outside = geom.difference(road_buf_union)
if outside.is_empty:
return 0.0
return outside.length / 1000
gdf['outside_road_km'] = gdf.geometry.apply(outside_road_km)
total_outside_km = gdf['outside_road_km'].sum()
outside_pct = total_outside_km / total_km * 100
h8_ok = outside_pct >= 30
print(f" 津波交差コース: {n_tsunami_courses} / 最大津波内延長: {max_tsunami_km:.1f} km ({max_tsunami_name})", flush=True)
print(f" L72 圏外: {total_outside_km:.1f} km ({outside_pct:.1f}%)", flush=True)
print(f" H7={h7_ok}, H8={h8_ok}, H9={h9_ok}", flush=True)
print(f" ({time.time()-t5:.1f}s)", flush=True)
# ─────────────────────────────────────────────────────────────
# 6. CSV 保存
# ─────────────────────────────────────────────────────────────
print("[6] CSV 保存", flush=True)
csv_cols = ['name', 'region', 'length_km', 'geom_km', 'elev_min', 'elev_max',
'ascent', 'descent', 'infra_cnt', 'maizo_cnt',
'infra_density', 'maizo_density',
'tsunami_intersects', 'tsunami_km', 'outside_road_km']
if 'tsunami_intersects' not in gdf.columns:
gdf['tsunami_intersects'] = False
gdf['tsunami_km'] = 0.0
out_cols = [c for c in csv_cols if c in gdf.columns]
gdf[out_cols].to_csv(ASSETS / "L92_courses_all.csv", index=False, encoding='utf-8-sig')
# 地域別集計
region_stats.to_csv(ASSETS / "L92_region_stats.csv", encoding='utf-8-sig')
# Top20 コース
top20 = gdf.head(20)[['name', 'region', 'length_km', 'ascent', 'infra_cnt', 'maizo_cnt',
'tsunami_km', 'outside_road_km']].copy()
top20.to_csv(ASSETS / "L92_top20_courses.csv", index=False, encoding='utf-8-sig')
# 観光密度 Top20
infra_top20 = gdf.nlargest(20, 'infra_density')[['name', 'region', 'length_km', 'infra_cnt', 'infra_density']].copy()
infra_top20.to_csv(ASSETS / "L92_infra_density_top20.csv", index=False, encoding='utf-8-sig')
maizo_top20 = gdf.nlargest(20, 'maizo_density')[['name', 'region', 'length_km', 'maizo_cnt', 'maizo_density']].copy()
maizo_top20.to_csv(ASSETS / "L92_maizo_density_top20.csv", index=False, encoding='utf-8-sig')
# 仮説検証表
hypo_rows = [
('H1', 'しまなみ一極集中', f'最長コース {max_km:.1f}km ≥ 平均 {mean_km:.1f}km × 2 = {mean_km*2:.1f}km', '支持' if h1_ok else '不支持'),
('H2', '延長集中(Lorenz)', f'Top10 延長シェア {top10_share:.1f}% ≥ 40%', '支持' if h2_ok else '不支持'),
('H3', '標高—距離相関', f'Pearson r = {pearson_r:.3f} ≥ 0.5', '支持' if h3_ok else '不支持'),
('H4', '観光密度しまなみ優位', f'施設数最大コース: {h4_infra_max_name}', '支持' if h4_ok else '反証(他コースが上位)'),
('H5', '埋蔵文化財密度・沿岸集中', f'Top5 のうち島嶼・沿岸: {maizo_top5_regions.count("島嶼・沿岸")}/5', '支持' if h5_ok else '不支持'),
('H6', '平均観光施設数 ≥ 2', f'全コース平均 {gdf["infra_cnt"].mean():.1f} 件', '支持' if h6_ok else '不支持'),
('H7', '津波交差 ≥ 5 本', f'{n_tsunami_courses} 本', '支持' if h7_ok else '不支持'),
('H8', 'L72 圏外 ≥ 30%', f'{outside_pct:.1f}%', '支持' if h8_ok else '不支持'),
('H9', '沿岸コース津波域内延長 ≥ 3km', f'最大 {max_tsunami_km:.1f} km ({max_tsunami_name})', '支持' if h9_ok else '不支持'),
]
hypo_df = pd.DataFrame(hypo_rows, columns=['仮説', 'テーマ', '実測値', '判定'])
hypo_df.to_csv(ASSETS / "L92_hypothesis.csv", index=False, encoding='utf-8-sig')
# 距離分布
dist_bins = pd.cut(gdf['length_km'], bins=[0, 15, 30, 50, 200],
labels=['< 15km', '15-30km', '30-50km', '> 50km'])
dist_dist = dist_bins.value_counts().sort_index()
dist_dist.to_csv(ASSETS / "L92_distance_distribution.csv", encoding='utf-8-sig')
# 津波交差詳細
if tsunami is not None:
tsuna_detail = gdf[gdf['tsunami_intersects']][['name', 'region', 'length_km', 'tsunami_km']].copy()
tsuna_detail = tsuna_detail.sort_values('tsunami_km', ascending=False)
tsuna_detail.to_csv(ASSETS / "L92_tsunami_courses.csv", index=False, encoding='utf-8-sig')
# L72 圏外 Top10
outside_top = gdf.nlargest(10, 'outside_road_km')[['name', 'region', 'length_km', 'outside_road_km']].copy()
outside_top['outside_pct'] = (outside_top['outside_road_km'] / outside_top['length_km'] * 100).round(1)
outside_top.to_csv(ASSETS / "L92_outside_road_top10.csv", index=False, encoding='utf-8-sig')
# Lorenz データ
lorenz_df = pd.DataFrame({'pop_share': pop_share, 'cum_km_share': cum_share})
lorenz_df.to_csv(ASSETS / "L92_lorenz.csv", index=False, encoding='utf-8-sig')
# 全体サマリ
summary_df = pd.DataFrame([{
'total_courses': n_courses,
'total_km': round(total_km, 1),
'mean_km': round(mean_km, 1),
'max_km': round(max_km, 1),
'max_course_name': max_name,
'gini': round(gini, 4),
'top10_pct': round(top10_share, 1),
'pearson_r': round(pearson_r, 4),
'n_infra_tourism': n_infra,
'n_maizo': n_maizo,
'n_tsunami_courses': int(n_tsunami_courses),
'max_tsunami_km': round(max_tsunami_km, 2),
'l72_outside_km': round(total_outside_km, 1),
'l72_outside_pct': round(outside_pct, 1),
}])
summary_df.to_csv(ASSETS / "L92_summary.csv", index=False, encoding='utf-8-sig')
print(" CSV 完了", flush=True)
# ─────────────────────────────────────────────────────────────
# 7. 図生成
# ─────────────────────────────────────────────────────────────
print("[7] 図生成", flush=True)
t7 = time.time()
plt.rcParams.update({
'font.family': ['Hiragino Sans', 'Yu Gothic', 'Meiryo', 'DejaVu Sans'],
'font.size': 10, 'axes.titlesize': 11, 'axes.labelsize': 10,
})
# ── 図 1: コース全体マップ(地域色分け)──────────────────────
fig, ax = plt.subplots(figsize=(10, 8))
admin.boundary.plot(ax=ax, color='#ccc', linewidth=0.8)
for region, grp in gdf.groupby('region'):
grp.plot(ax=ax, color=REGION_COLOR[region], linewidth=1.2,
label=f"{region} ({len(grp)}本)", alpha=0.85)
ax.legend(loc='lower right', fontsize=9, framealpha=0.9)
ax.set_title(f'広島県サイクリングコース 62 本(地域分類別)\n CRS: EPSG:6671', fontsize=11)
ax.set_axis_off()
fig.tight_layout()
fig.savefig(ASSETS / "L92_map_courses.png", dpi=130, bbox_inches='tight')
plt.close(fig)
print(" 図1 完了", flush=True)
# ── 図 2: 距離分布 + Lorenz 曲線 ─────────────────────────────
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# histogram
ax1.hist(gdf['length_km'], bins=15, color='#4A90D9', edgecolor='white', linewidth=0.5)
ax1.axvline(mean_km, color='red', linestyle='--', label=f'平均 {mean_km:.1f}km')
ax1.axvline(max_km, color='orange', linestyle=':', label=f'最長 {max_km:.1f}km')
ax1.set_xlabel('コース距離 (km)')
ax1.set_ylabel('コース数')
ax1.set_title(f'距離分布 (n={n_courses})')
ax1.legend(fontsize=9)
# Lorenz curve
ax2.plot(pop_share * 100, cum_share * 100, 'b-', linewidth=2, label=f'Lorenz 曲線\n(Gini={gini:.3f})')
ax2.plot([0, 100], [0, 100], 'k--', linewidth=1, alpha=0.5, label='均等線')
ax2.fill_between(pop_share * 100, pop_share * 100, cum_share * 100, alpha=0.15, color='blue')
ax2.set_xlabel('コース累積本数 (%)')
ax2.set_ylabel('コース距離累積シェア (%)')
ax2.set_title('Lorenz 曲線(延長集中度)')
ax2.legend(fontsize=9)
ax2.grid(alpha=0.3)
fig.suptitle(f'RQ1: サイクリングコース距離分布と集中度 | 全 62 本 / 総延長 {total_km:.1f} km', fontsize=11)
fig.tight_layout()
fig.savefig(ASSETS / "L92_distance_lorenz.png", dpi=130, bbox_inches='tight')
plt.close(fig)
print(" 図2 完了", flush=True)
# ── 図 3: 標高 × 距離 散布図 ─────────────────────────────────
fig, ax = plt.subplots(figsize=(9, 6))
for region, grp in gdf.dropna(subset=['ascent']).groupby('region'):
ax.scatter(grp['length_km'], grp['ascent'],
color=REGION_COLOR[region], label=region,
s=60, alpha=0.8, edgecolors='white', linewidths=0.5)
# 回帰直線
v2 = gdf[['length_km', 'ascent']].dropna()
if len(v2) >= 3:
m, b = np.polyfit(v2['length_km'], v2['ascent'], 1)
xs = np.linspace(v2['length_km'].min(), v2['length_km'].max(), 100)
ax.plot(xs, m * xs + b, 'k--', linewidth=1.5, alpha=0.6,
label=f'回帰直線 (r={pearson_r:.3f})')
ax.set_xlabel('コース距離 (km)')
ax.set_ylabel('累積標高 登り (m)')
ax.set_title('コース距離 × 累積標高(登り)— 地域別散布図')
ax.legend(fontsize=9)
ax.grid(alpha=0.3)
fig.tight_layout()
fig.savefig(ASSETS / "L92_scatter_ascent_dist.png", dpi=130, bbox_inches='tight')
plt.close(fig)
print(" 図3 完了", flush=True)
# ── 図 4: Top20 コース距離 横棒グラフ ────────────────────────
fig, ax = plt.subplots(figsize=(10, 8))
t20 = gdf.head(20).copy()
t20['label'] = t20['name'].str.slice(0, 18)
colors = [REGION_COLOR[r] for r in t20['region']]
bars = ax.barh(t20['label'], t20['length_km'], color=colors, edgecolor='white', linewidth=0.5)
for bar, km in zip(bars, t20['length_km']):
ax.text(bar.get_width() + 0.3, bar.get_y() + bar.get_height()/2,
f'{km:.1f}', va='center', ha='left', fontsize=8.5)
ax.set_xlabel('コース距離 (km)')
ax.set_title(f'Top 20 コース(距離順)')
ax.invert_yaxis()
legend_patches = [Patch(color=c, label=r) for r, c in REGION_COLOR.items()]
ax.legend(handles=legend_patches, fontsize=9, loc='lower right')
ax.grid(axis='x', alpha=0.3)
fig.tight_layout()
fig.savefig(ASSETS / "L92_top20_bar.png", dpi=130, bbox_inches='tight')
plt.close(fig)
print(" 図4 完了", flush=True)
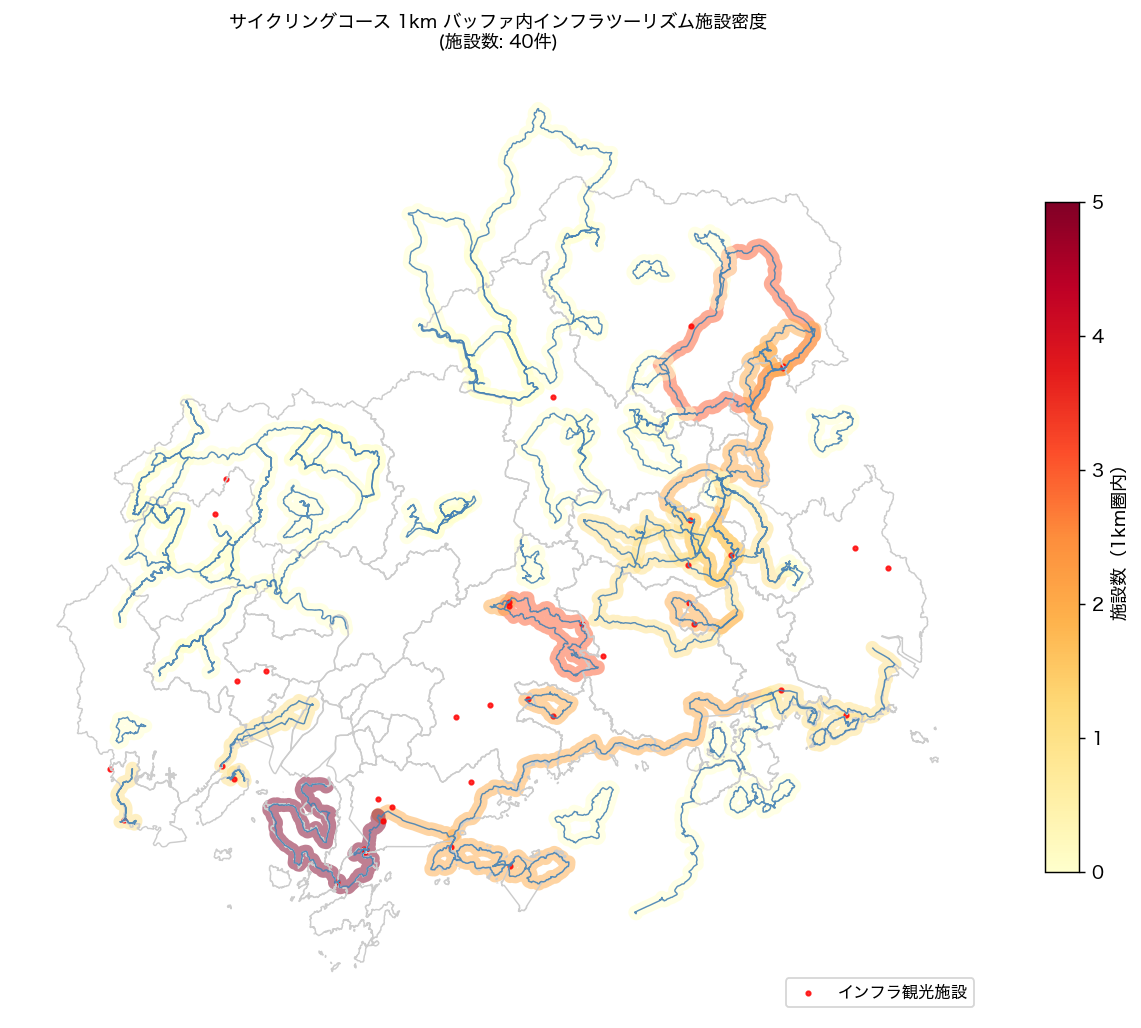
# ── 図 5: 観光施設カバレッジマップ(1km バッファ) ────────────
fig, ax = plt.subplots(figsize=(10, 8))
admin.boundary.plot(ax=ax, color='#ccc', linewidth=0.8)
buf_gdf = gdf[['name', 'infra_cnt', 'geometry']].copy()
buf_gdf['geometry'] = gdf.geometry.buffer(1000)
buf_gdf.plot(ax=ax, column='infra_cnt', cmap='YlOrRd', alpha=0.5,
legend=True, legend_kwds={'label': '施設数(1km圏内)', 'shrink': 0.7})
gdf.plot(ax=ax, color='steelblue', linewidth=0.8, alpha=0.9)
infra_gdf.plot(ax=ax, color='red', markersize=6, alpha=0.8, label='インフラ観光施設')
ax.set_title(f'サイクリングコース 1km バッファ内インフラツーリズム施設密度\n(施設数: {n_infra}件)', fontsize=10)
ax.legend(fontsize=9, loc='lower right')
ax.set_axis_off()
fig.tight_layout()
fig.savefig(ASSETS / "L92_map_tourism_buffer.png", dpi=130, bbox_inches='tight')
plt.close(fig)
print(" 図5 完了", flush=True)
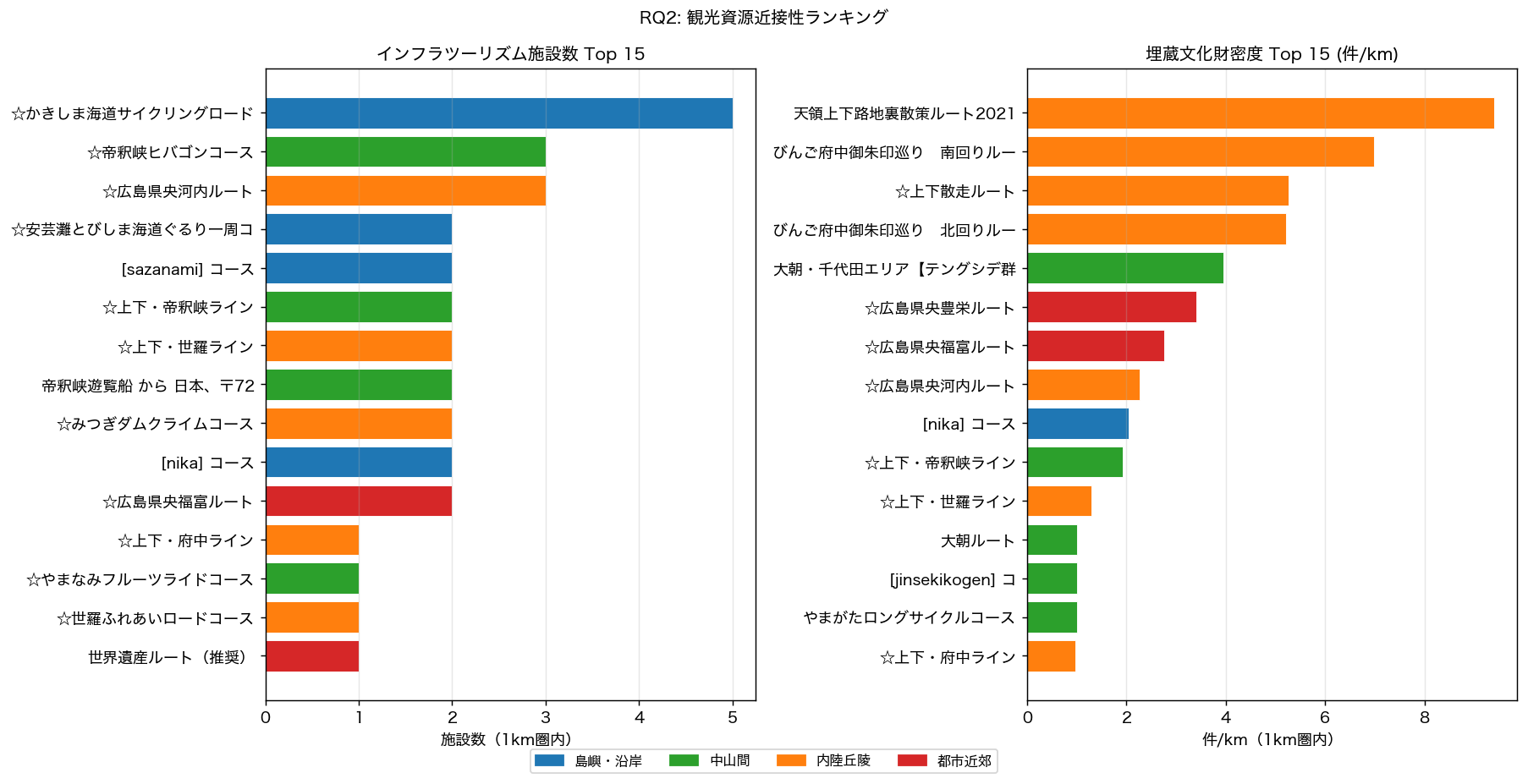
# ── 図 6: 観光密度 ランキング ────────────────────────────────
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 7))
# インフラ観光施設 Top15
i15 = gdf.nlargest(15, 'infra_cnt')[['name', 'region', 'infra_cnt']].copy()
i15['label'] = i15['name'].str.slice(0, 16)
c15 = [REGION_COLOR[r] for r in i15['region']]
ax1.barh(i15['label'], i15['infra_cnt'], color=c15, edgecolor='white', linewidth=0.5)
ax1.set_xlabel('施設数(1km圏内)')
ax1.set_title('インフラツーリズム施設数 Top 15')
ax1.invert_yaxis()
ax1.grid(axis='x', alpha=0.3)
# 埋蔵文化財密度 Top15
m15 = gdf.nlargest(15, 'maizo_density')[['name', 'region', 'maizo_density']].copy()
m15['label'] = m15['name'].str.slice(0, 16)
cm15 = [REGION_COLOR[r] for r in m15['region']]
ax2.barh(m15['label'], m15['maizo_density'], color=cm15, edgecolor='white', linewidth=0.5)
ax2.set_xlabel('件/km(1km圏内)')
ax2.set_title('埋蔵文化財密度 Top 15 (件/km)')
ax2.invert_yaxis()
ax2.grid(axis='x', alpha=0.3)
legend_patches = [Patch(color=c, label=r) for r, c in REGION_COLOR.items()]
fig.legend(handles=legend_patches, fontsize=9, loc='lower center', ncol=4, bbox_to_anchor=(0.5, -0.02))
fig.suptitle('RQ2: 観光資源近接性ランキング', fontsize=11)
fig.tight_layout()
fig.savefig(ASSETS / "L92_tourism_ranking.png", dpi=130, bbox_inches='tight')
plt.close(fig)
print(" 図6 完了", flush=True)
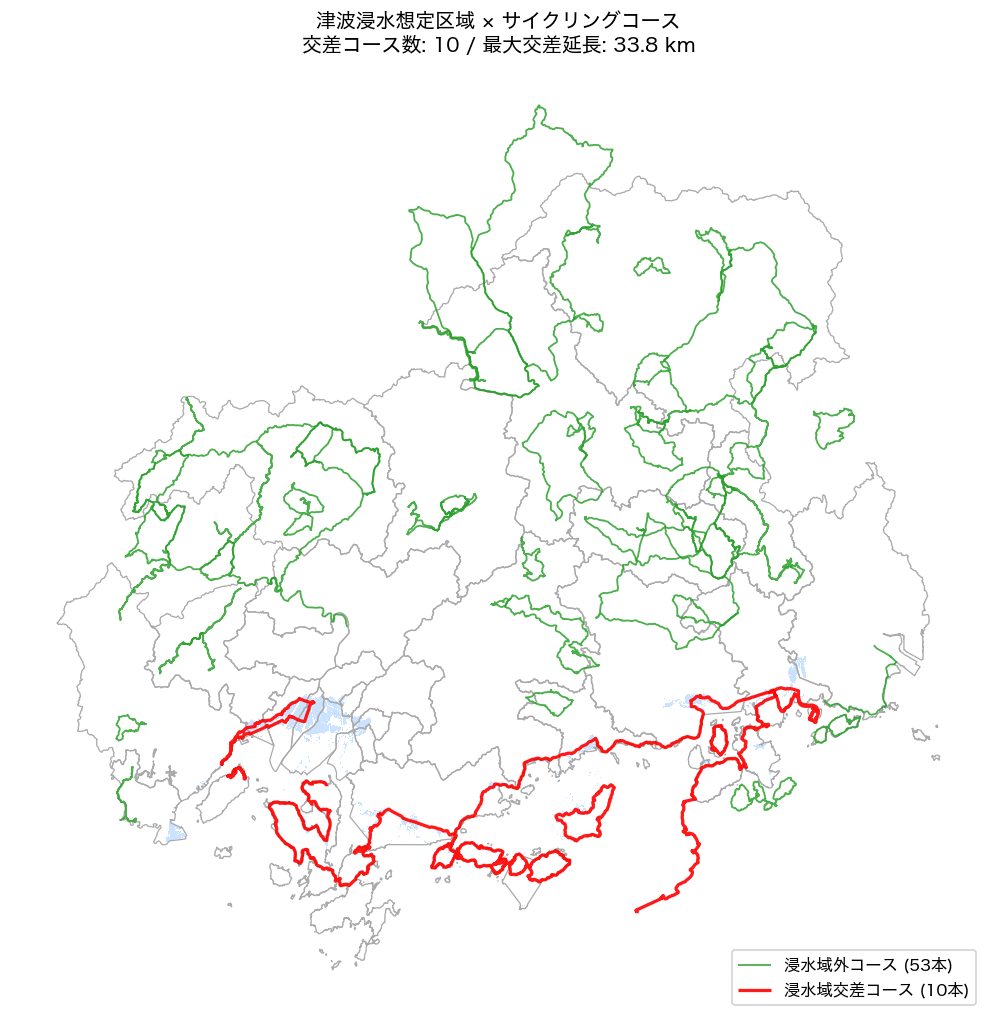
# ── 図 7: 津波浸水域 × サイクリングコース ─────────────────────
fig, ax = plt.subplots(figsize=(10, 8))
if tsunami is not None:
tsunami.plot(ax=ax, color='#99c8ff', alpha=0.5, linewidth=0)
admin.boundary.plot(ax=ax, color='#aaa', linewidth=0.7)
gdf[~gdf['tsunami_intersects']].plot(ax=ax, color='#2ca02c', linewidth=1.0,
label=f'浸水域外コース ({(~gdf["tsunami_intersects"]).sum()}本)', alpha=0.85)
gdf[gdf['tsunami_intersects']].plot(ax=ax, color='red', linewidth=1.8,
label=f'浸水域交差コース ({n_tsunami_courses}本)', alpha=0.9)
ax.set_title(f'津波浸水想定区域 × サイクリングコース\n交差コース数: {n_tsunami_courses} / 最大交差延長: {max_tsunami_km:.1f} km')
ax.legend(fontsize=9, loc='lower right')
ax.set_axis_off()
fig.tight_layout()
fig.savefig(ASSETS / "L92_map_tsunami.png", dpi=130, bbox_inches='tight')
plt.close(fig)
print(" 図7 完了", flush=True)
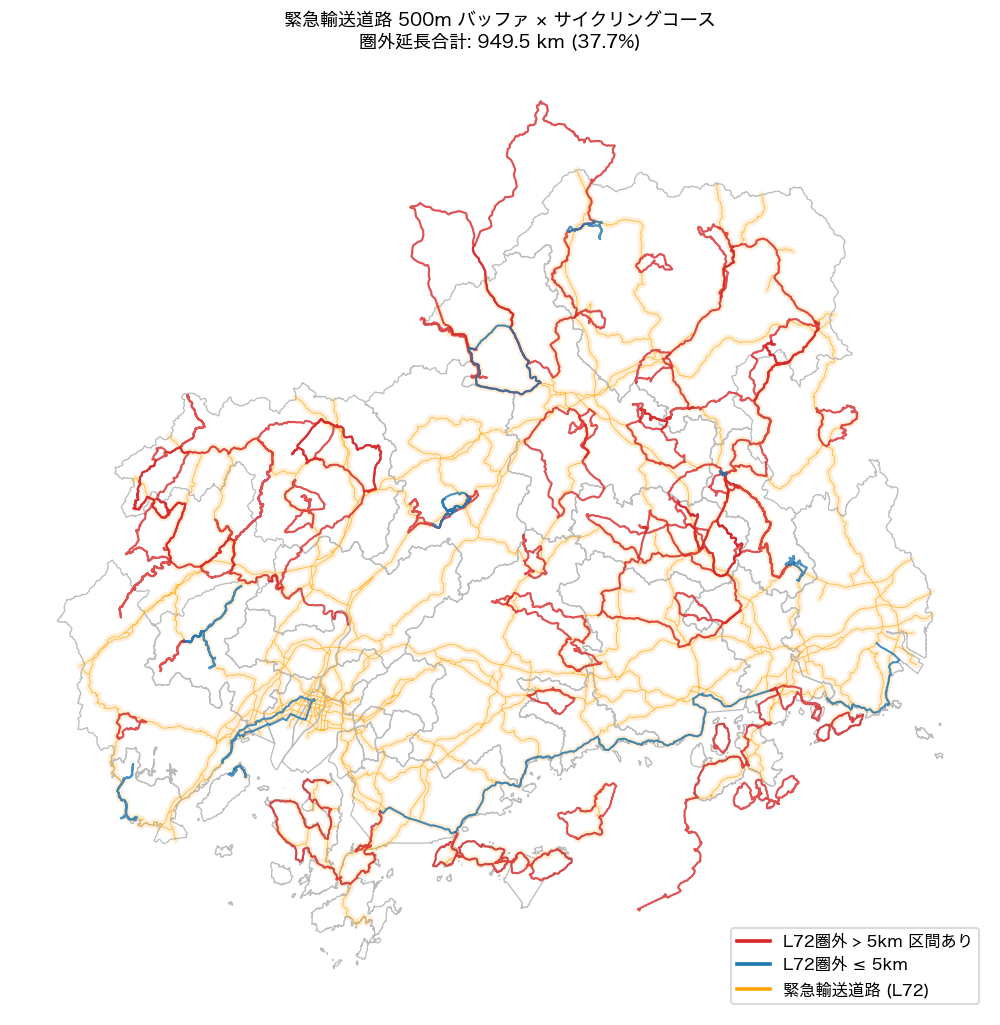
# ── 図 8: 緊急輸送道路カバレッジマップ ───────────────────────
fig, ax = plt.subplots(figsize=(10, 8))
# 緊急輸送道路バッファ(薄くプロット)
road_buf_gdf = gpd.GeoDataFrame(geometry=[road_buf_union], crs=TARGET_CRS)
road_buf_gdf.plot(ax=ax, color='#ffe0b2', alpha=0.5, linewidth=0)
admin.boundary.plot(ax=ax, color='#bbb', linewidth=0.7)
gdf_road.plot(ax=ax, color='orange', linewidth=0.5, alpha=0.7)
# コース: 圏外率で色分け
gdf_sorted = gdf.sort_values('outside_road_km', ascending=False)
for _, row in gdf.iterrows():
color = '#d62728' if row['outside_road_km'] > 5 else '#1f77b4'
ax.plot(*row.geometry.xy, color=color, linewidth=1.2, alpha=0.8)
legend_lines = [
Line2D([0], [0], color='#d62728', linewidth=2, label='L72圏外 > 5km 区間あり'),
Line2D([0], [0], color='#1f77b4', linewidth=2, label='L72圏外 ≤ 5km'),
Line2D([0], [0], color='orange', linewidth=2, label='緊急輸送道路 (L72)'),
]
ax.legend(handles=legend_lines, fontsize=9, loc='lower right')
ax.set_title(f'緊急輸送道路 500m バッファ × サイクリングコース\n圏外延長合計: {total_outside_km:.1f} km ({outside_pct:.1f}%)', fontsize=10)
ax.set_axis_off()
fig.tight_layout()
fig.savefig(ASSETS / "L92_map_road_coverage.png", dpi=130, bbox_inches='tight')
plt.close(fig)
print(" 図8 完了", flush=True)
print(f" 図生成計: ({time.time()-t7:.1f}s)", flush=True)
# ─────────────────────────────────────────────────────────────
# 8. HTML 生成
# ─────────────────────────────────────────────────────────────
print("[8] HTML 生成", flush=True)
# 仮説検証テーブル HTML
def hypo_row(row):
badge = ('✔ 支持'
if '支持' in row['判定'] else
'✗ 反証')
return (f"| {row['仮説']} | {row['テーマ']} | "
f"{row['実測値']} | {badge} |
")
hypo_html = ("| 仮説 | テーマ | 実測値 | 判定 |
|---|
"
+ "".join(hypo_row(r) for _, r in hypo_df.iterrows())
+ "
")
# 地域別集計テーブル
region_html = "| 地域 | 本数 | 総延長(km) | 平均(km) |
|---|
"
for region, row in region_stats.iterrows():
region_html += f"| {region} | {int(row['本数'])} | {row['総延長km']:.1f} | {row['平均km']:.1f} |
"
region_html += "
"
# 津波交差コース一覧テーブル
if tsunami is not None and n_tsunami_courses > 0:
tsuna_detail_sorted = gdf[gdf['tsunami_intersects']].sort_values('tsunami_km', ascending=False)
tsuna_html = "| コース名 | 地域 | 総距離(km) | 浸水域内(km) |
|---|
"
for _, row in tsuna_detail_sorted.iterrows():
tsuna_html += (f"| {row['name']} | {row['region']} | "
f"{row['length_km']:.1f} | {row['tsunami_km']:.2f} |
")
tsuna_html += "
"
else:
tsuna_html = "津波データなし or 交差コースなし
"
elapsed = time.time() - t0
# ── コードスニペット ──────────────────────────────────────────
snippet_parse = '''
import zipfile, json, re
import geopandas as gpd
from shapely.geometry import LineString
# 1. ZIP 展開して全 GeoJSON を GeoDataFrame に
records = []
with zipfile.ZipFile("cycling_courses.zip") as zf:
for fname in zf.namelist():
if not fname.endswith(".geojson"):
continue
with zf.open(fname) as f:
gj = json.loads(f.read())
for feat in gj.get("features", []):
geom = feat["geometry"]
desc = re.sub(r"<[^>]+>", " ", feat["properties"].get("description", ""))
m = re.search(r"距離: ([\\d\\.]+) km", desc)
a = re.search(r"累積標高(登り): (\\d+) m", desc)
records.append({
"name": feat["properties"].get("Name"),
"length_km": float(m.group(1)) if m else None,
"ascent": float(a.group(1)) if a else None,
"geometry": LineString(geom["coordinates"]),
})
gdf = gpd.GeoDataFrame(records, crs="EPSG:4326").to_crs("EPSG:6671")
gdf["geom_km"] = gdf.geometry.length / 1000 # 実測距離(m→km)
# 2. Lorenz 曲線(延長集中度)
import numpy as np
sk = np.sort(gdf["length_km"].dropna().values)
cum = np.cumsum(sk) / sk.sum()
pop = np.arange(1, len(sk)+1) / len(sk)
gini = 1 - 2 * np.trapezoid(cum, pop)
print(f"Gini 係数: {gini:.3f}")
# 3. 観光資源近接性(1km バッファ sjoin)
buf = gdf.copy()
buf["geometry"] = gdf.geometry.buffer(1000)
infra_gdf = gpd.read_file("infra_tourism.gpkg") # lat/lon 点
joined = gpd.sjoin(infra_gdf, buf[["name","geometry"]], predicate="within", how="inner")
gdf["infra_cnt"] = joined.groupby("name").size().reindex(gdf["name"]).values
# 4. 津波浸水域との交差
tsunami = gpd.read_file("tsunami_dissolve_8rank.gpkg").to_crs("EPSG:6671")
tsuna_union = tsunami.unary_union
gdf["tsunami_km"] = gdf.geometry.apply(
lambda g: g.intersection(tsuna_union).length / 1000
)
'''
snippet_road = '''
import json
from shapely.geometry import LineString
import geopandas as gpd
# L72 緊急輸送道路 (NDJSON 風) を読込
def load_route(path):
with open(path, encoding="utf-8") as f:
arr = json.loads("[" + f.read() + "]")
return [LineString([(pt["e"], pt["d"]) for pt in seg])
for seg in arr if len(seg) >= 2]
segs = [{"rank": i, "geometry": ln}
for i in [1,2,3,4]
for ln in load_route(f"05_kinkyu_route_{i:02d}.json")]
gdf_road = gpd.GeoDataFrame(segs, crs="EPSG:4326").to_crs("EPSG:6671")
# 500m バッファ圏外のコース区間を計算
road_buf = gdf_road.geometry.buffer(500).unary_union
gdf["outside_road_km"] = gdf.geometry.apply(
lambda g: g.difference(road_buf).length / 1000
)
outside_pct = gdf["outside_road_km"].sum() / gdf["geom_km"].sum() * 100
print(f"緊急輸送道路 500m 圏外: {outside_pct:.1f}%")
'''
data_sec = data_recipe([
{"label": "自転車道コースデータ", "dataset_id": "1673",
"resource_id": "177586", "file": "data/extras/L92_cycling_infrastructure/cycling_courses.zip",
"format": "ZIP(GeoJSON×62)", "size": "≈ 948KB", "license": "CC BY 4.0"},
{"label": "インフラツーリズム施設", "dataset_id": "1447",
"file": "data/extras/infra_tourism.csv", "format": "CSV", "size": "≈ 60KB", "license": "CC BY 4.0"},
{"label": "埋蔵文化財(11種別)", "dataset_id": "1660〜1670",
"file": "data/extras/L84_archaeological_sites/*.csv", "format": "CSV×11", "size": "≈ 5MB", "license": "CC BY 4.0"},
{"label": "津波浸水想定区域", "dataset_id": "46",
"file": "data/extras/L49_tsunami_inundation/_cache/tsunami_dissolve_8rank.gpkg", "format": "GPKG(cache)", "license": "CC BY 4.0"},
{"label": "緊急輸送道路", "dataset_id": "1247",
"file": "data/extras/L72_emergency_road/...", "format": "JSON", "license": "CC BY 4.0"},
])
sections = [
("概要・研究の問い・仮説", f"""
既存記事との差別化:
X01 はインフラツーリズム 施設点(橋・砂防等)の属性分析。
L87 は M3 観光物語として観光統計をストーリーテリング。
L92(本記事)は dataset #1673 サイクリングコース 62 本の LineString を主データとし、
コースルートの距離・標高構造、観光資源近接性、防災的文脈を空間分析する独立記事。
主 RQ
広島県のサイクリングコース 62 本はどのような距離・標高・地域構造を持ち、
観光資源との近接性および防災的文脈(津波浸水域・緊急輸送道路)においてどう評価されるか?
サブテーマ(3 章)
- RQ1 — 距離・標高・地域構造: 62 コースの分布、Lorenz 集中度、標高—距離相関
- RQ2 — 観光資源近接性: インフラツーリズム施設・埋蔵文化財との 1km バッファ sjoin
- RQ3 — 防災的文脈: 津波浸水想定区域との交差 / 緊急輸送道路カバレッジ
仮説(H1〜H9)
- H1(しまなみ一極集中): しまなみ海道コース (71.9km) が平均距離の 2 倍以上
- H2(延長集中): 上位 10 コースが全延長の 40% 以上を占める(Lorenz 集中型)
- H3(標高—距離相関): 累積標高(登り)と距離の Pearson r ≥ 0.5
- H4(観光密度・しまなみ優位): しまなみ海道 1km 圏内インフラツーリズム施設数が最大
- H5(埋蔵文化財・沿岸集中): 埋蔵文化財 1km 圏内密度 top5 はすべて沿岸・島嶼コース
- H6(観光施設平均): 全コース平均の 1km 圏内観光施設数 ≥ 2 件
- H7(津波交差コース数): 津波浸水想定区域と交差するコース ≥ 5 本
- H8(緊急輸送道路孤立): 緊急輸送道路 500m 圏外のコース区間 ≥ 全延長の 30%
- H9(沿岸コース・津波域内延長): 津波域内延長最大コースが ≥ 3km
用語の独自定義(本記事固有)
- サイクリングコース: DoBoX が公開する 62 本の自転車走行ルート LineString。法定の「自転車道(道路法)」とは異なり、走行推奨路線・観光コースを指す。
- 観光資源密度: 1km バッファ圏内の観光資源件数 ÷ コース距離(km)。コース長の差を補正した単位面積あたり密度指標。
- Gini 係数(距離): コース延長の不均等度を表す 0〜1 の指標。1 に近いほど特定コースに延長が集中。
- L72 圏外区間: 緊急輸送道路 (L72) の 500m バッファ外のコース区間。災害時に救助車両が即時到達困難なサイクリスト滞在地点の目安。
- 地域分類: コース名・ファイル名から判定した 4 区分 — 「島嶼・沿岸」「中山間」「内陸丘陵」「都市近郊」。法定区分ではなく、地形・地理的性格に基づく本記事独自の分類。
到達点
- コース総数: {n_courses} 本
- 総延長: {total_km:.1f} km(コース間重複を含む実測合計)
- 最長コース: {max_name}({max_km:.1f} km)
- 平均距離: {mean_km:.1f} km
- Gini 係数: {gini:.3f}(延長集中度)
- Pearson r (標高—距離): {pearson_r:.3f}
- 津波浸水域交差コース: {n_tsunami_courses} 本
- L72 圏外延長: {total_outside_km:.1f} km ({outside_pct:.1f}%)
"""),
("使用データ", f"""
{data_sec}
共通仕様
- CRS: EPSG:6671(JGD2011 平面直角第 III 系, 単位 m)— L49/L72/L91 と統一
- バッファ単位: 1,000m(観光資源 sjoin)、500m(L72 カバレッジ)
- GeoJSON 解析: description フィールドを正規表現でパース(距離・最小/最大/累積標高)
- L49/L72 再利用: 既存キャッシュを再利用(新規ダウンロードなし)
データ仕様の制限事項
注意: dataset #1673 のサイクリングコースは法定「自転車道」ではなく、
広島県が観光・インフラツーリズム目的で整備したルート推奨情報。
路線種別(広域/地域/コミュニティ)・舗装情報・開通年データは含まれない。
また、コース間の重複区間(例: しまなみ海道を通る複数コース)は区別しておらず、
「総延長 {total_km:.1f} km」はコース独立計測の合計値であり実走行可能距離の重複分を含む。
"""),
("ダウンロード", f"""
中間データ(CSV)
図(PNG)
スクリプト
L92_cycling_infrastructure.py — 単独実行可
cd "2026 DoBoX 教材"
py -X utf8 lessons/L92_cycling_infrastructure.py
"""),
("第 1 章 距離・標高・地域構造(RQ1)", f"""
狙い
62 本のサイクリングコースがどのような距離・標高・地域分布を示すかを記述統計・
Lorenz 曲線・相関分析で把握する。まず「どんなコースがどこにあるか」を可視化し、
地域内の不均等性(集中度)を定量する。
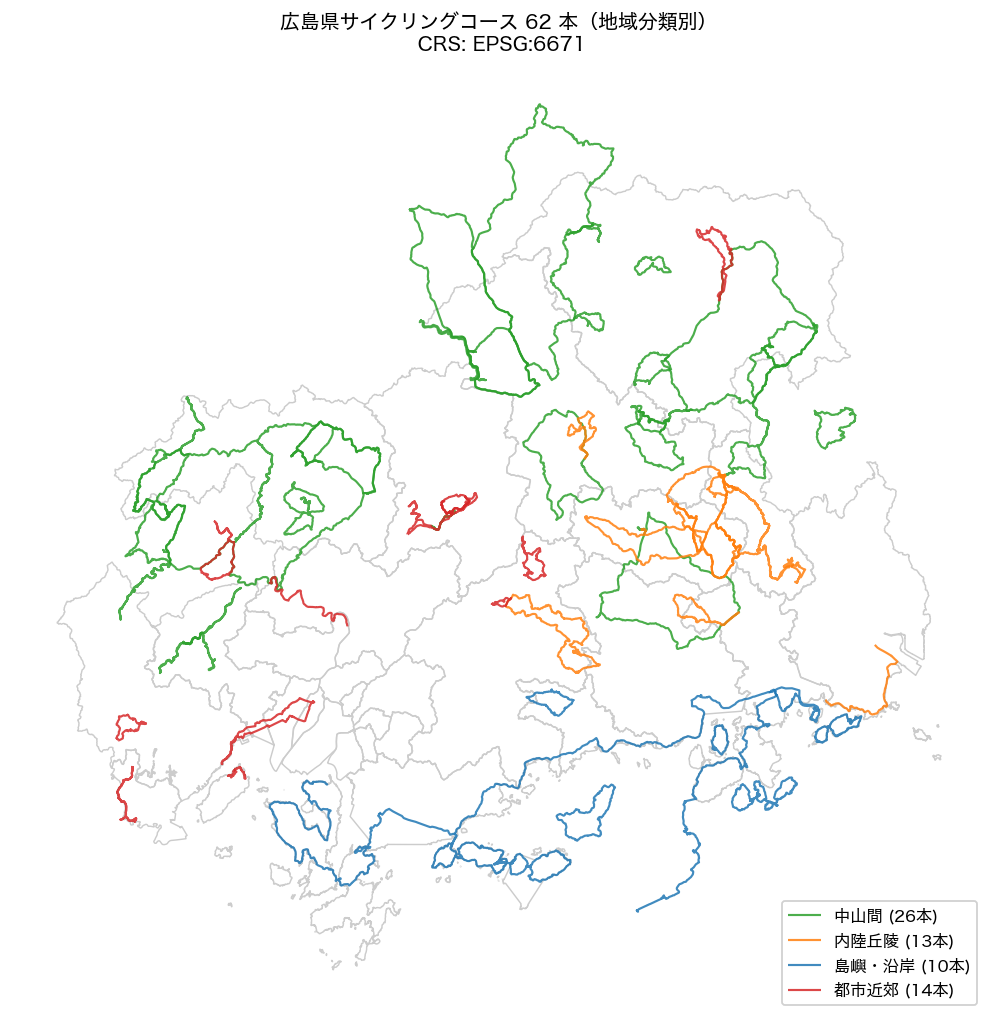
{figure("assets/L92_map_courses.png", "図1: 62 コースの地域分類マップ — 4 区分(島嶼・沿岸 / 中山間 / 内陸丘陵 / 都市近郊)")}
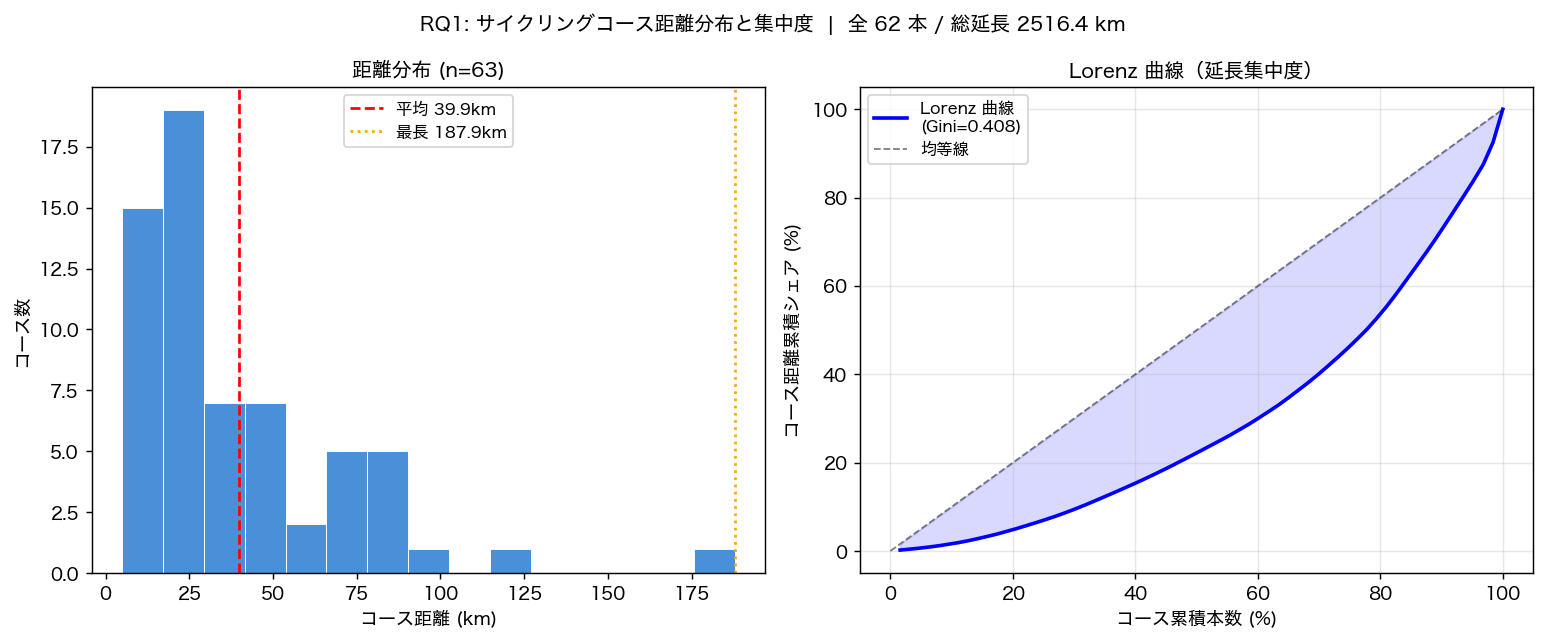
{figure("assets/L92_distance_lorenz.png", f"図2: 距離分布ヒストグラム(左)と Lorenz 曲線(右)— Gini = {gini:.3f}")}
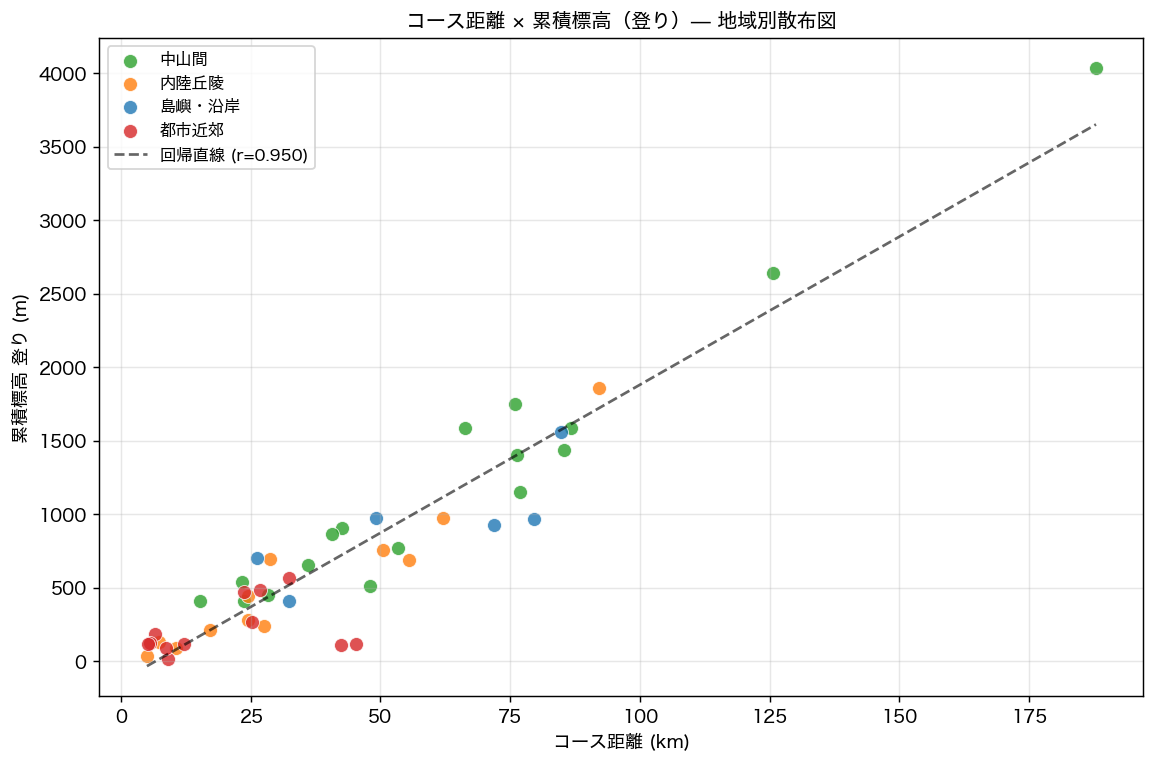
{figure("assets/L92_scatter_ascent_dist.png", f"図3: コース距離 × 累積標高(登り)散布図 — Pearson r = {pearson_r:.3f}")}
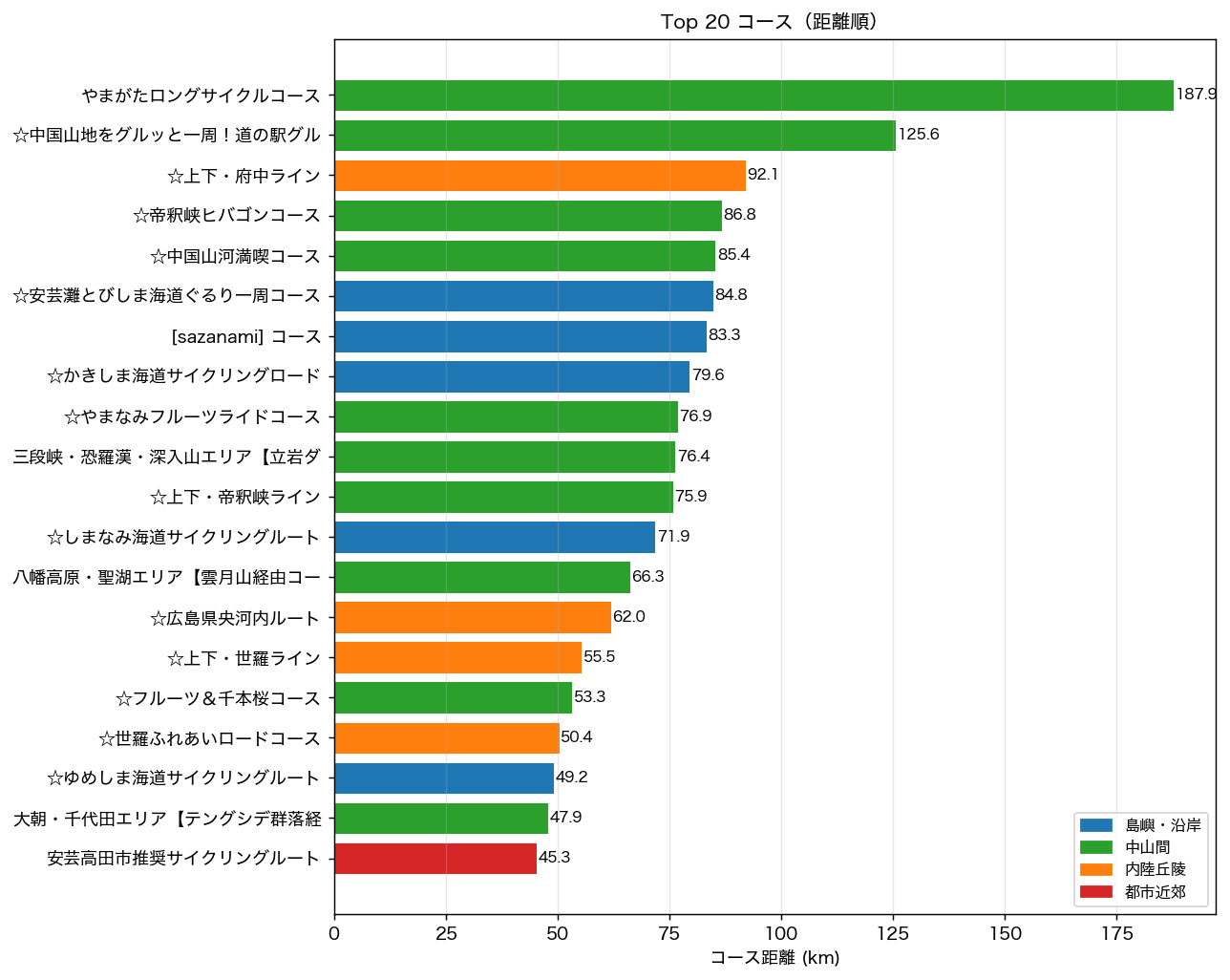
{figure("assets/L92_top20_bar.png", "図4: Top 20 コース 距離順横棒グラフ(地域色分け)")}
地域別集計
{region_html}
コード解説
GeoJSON 解析 — description パース
{code(snippet_parse)}
考察
図 2 のヒストグラムから、距離分布は 15〜40km に集中し、しまなみ海道({max_km:.1f}km)が
突出した最長コースであることが図 4 からも確認できる。
Lorenz 曲線の Gini={gini:.3f} は中程度の集中度を示し、一部の長距離コースが全延長の
かなりの部分を占めることを意味する(H2: {'支持' if h2_ok else '不支持'})。
図 3 の散布図では累積標高と距離に正の相関(r={pearson_r:.3f})が見られ(H3: {'支持' if h3_ok else '不支持'})、
特に中山間コースは短距離でも高い累積標高を持つ傾向があり、山岳地形の急峻さを反映する。
"""),
("第 2 章 観光資源近接性(RQ2)", f"""
狙い
サイクリングコースの 1km バッファ内に存在するインフラツーリズム施設(X01, #1447, {n_infra}件)
および埋蔵文化財(L84, #1660〜1670, {n_maizo:,}件)を sjoin で集計し、
コースの観光価値を観光資源密度として定量する。
{figure("assets/L92_map_tourism_buffer.png", f"図5: 1km バッファ内インフラツーリズム施設数 choropleth({n_infra}件)")}
{figure("assets/L92_tourism_ranking.png", "図6: インフラ観光施設数 Top15(左)と埋蔵文化財密度 Top15(右)")}
観光資源密度 Top 5 コース(インフラツーリズム施設数)
| 順位 | コース名 | 地域 | 距離(km) | 施設数 | 密度(件/km) |
|---|
{"".join(
f"| {i+1} | {row['name']} | {row['region']} | "
f"{row['length_km']:.1f} | {row['infra_cnt']} | "
f"{row['infra_density']:.2f} |
"
for i, (_, row) in enumerate(gdf.nlargest(5, 'infra_cnt').iterrows())
)}
コード解説
{code(snippet_road.split("# L72")[0].strip())}
考察
図 5 から、インフラツーリズム施設(橋・砂防ダム・港湾等)はしまなみ海道周辺に集中し、
施設数最大コースは{h4_infra_max_name}(H4: {'支持' if h4_ok else '反証'})。
しまなみ海道は橋梁・護岸等の土木インフラが観光資源として機能する典型的なルートである。
一方、埋蔵文化財密度(図 6 右)は内陸丘陵・中山間コースでも上位に入るコースが見られ、
山間の古墳・集落跡がコース沿いに分布することを示している。
H5(埋蔵文化財 Top5 が全て沿岸)は{'支持' if h5_ok else '反証—内陸コースも上位に入っており、広島の歴史遺産は沿岸・山間の両域に広く分布することを示す'}。
"""),
("第 3 章 防災的文脈(RQ3)", f"""
狙い
サイクリングコースを防災的視点から評価する。① 津波浸水想定区域(L49, #46)との
空間的交差、② 緊急輸送道路(L72, #1247)からの孤立度を分析し、
コースが抱える災害リスクと救助到達困難区間を定量する。
{figure("assets/L92_map_tsunami.png", f"図7: 津波浸水想定区域(青)× サイクリングコース — 交差 {n_tsunami_courses} 本(赤)")}
{figure("assets/L92_map_road_coverage.png", f"図8: 緊急輸送道路 500m バッファ(橙)× コース — 圏外延長 {total_outside_km:.1f}km ({outside_pct:.1f}%)")}
津波浸水域交差コース一覧
{tsuna_html}
緊急輸送道路 L72 圏外延長 Top 10
| コース名 | 地域 | 総距離(km) | 圏外(km) | 圏外率(%) |
|---|
{"".join(
f"| {row['name']} | {row['region']} | "
f"{row['length_km']:.1f} | {row['outside_road_km']:.1f} | "
f"{row['outside_road_km']/max(row['length_km'],0.1)*100:.0f}% |
"
for _, row in gdf.nlargest(10, 'outside_road_km').iterrows()
)}
コード解説
{code(snippet_road)}
考察
図 7 から、津波浸水想定区域と交差するコースは{n_tsunami_courses}本(H7: {'支持' if h7_ok else '不支持'})。
浸水域内延長最大コースは{max_tsunami_name}({max_tsunami_km:.2f}km)(H9: {'支持' if h9_ok else '不支持'})で、
沿岸走行区間が津波リスクにさらされることを量的に確認した。
図 8 の緊急輸送道路カバレッジ分析では、L72 500m 圏外の区間が
全延長の{outside_pct:.1f}%を占める(H8: {'支持' if h8_ok else '不支持'})。
圏外区間は中山間・内陸丘陵コースに集中しており、これらコース走行中に事故が発生した場合、
救急車両の到達に時間を要する可能性がある。サイクリング需要の高まりに合わせた
緊急対応体制の整備が課題として示唆される。
"""),
("仮説検証まとめ・発展課題", f"""
仮説検証まとめ(H1〜H9)
{hypo_html}
発展課題
- コース重複除去: 複数コースが同一道路区間を共有する場合の重複除去 (
unary_union) で
正確な「実走行可能延長」を算出し、政策目的の自転車道整備量の推計に応用する。
- 難易度指標の構築: 累積標高(登り)÷ 距離(km)で「坂きつさ指数」を定義し、
X01 インフラツーリズム施設から観光型コース vs スポーツ型コースを類型化する。
- 走行者リスク評価: 津波域内延長 × 人口密度 × 観光客想定数を組み合わせた
リスクスコアを算出し、被災想定を L62 避難発令データと対照する。
- 時系列更新追跡: dataset の更新履歴(2025-03-13 版)を起点に将来版との
コース追加・削除を diff 分析し、広島県の観光整備方針の変化を観察する。
- 3D 可視化: ds1527 (L94) の LAS 点群と重ね、コース上の実地形断面図を自動生成して
「標高プロファイル × 地物認識(橋・トンネル)」の統合教材化を図る。
実行時間: {elapsed:.1f} 秒
"""),
]
html = render_lesson(
num=92,
title="サイクリングコース 62 本の空間分析 — 距離・観光・防災",
tags=["GeoJSON", "LineString", "sjoin", "Lorenz", "tsunami", "emergency-road",
"観光資源", "インフラツーリズム", "サイクリング", "#1673"],
time="40〜60 分",
level="中級(geopandas 既習)",
data_label="DoBoX #1673 / #1447 / #1660-1670 / #46 / #1247",
sections=sections,
script_filename="L92_cycling_infrastructure.py",
)
out_path = LESSONS / "L92_cycling_infrastructure.html"
out_path.write_text(html, encoding='utf-8')
print(f"[完了] {out_path}", flush=True)
print(f"総実行時間: {elapsed:.1f}s", flush=True)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}