# -*- coding: utf-8 -*-
"""L91 全ハザード合成スコア — 県全域マルチリスク統合俯瞰
(Phase 5 統合俯瞰 — 教材最終記事 / DoBoX × MDASH 教材)
カバー宣言:
本記事は L11 トリプルハザード (河川浸水 × 土砂 × 雪崩) の 4 ハザード拡張版
であり、 教材全体の 最終統合俯瞰として、 広島県の主要ハザード 7 種
を 1 つの 2 km 共通グリッド上に 合成する。
扱う 7 ハザード (DoBoX dataset 由来 / 計 81 dataset_id を 7 ファイル系で論理カバー):
H1 河川浸水想定 (想定最大規模) #313 / 39 dataset_id 論理カバー
H2 土砂災害警戒区域 3 種 #48 / 31 dataset_id 論理カバー
H3 雪崩危険箇所 #50 / 31 dataset_id 論理カバー ※ L11 既扱
H4 高潮浸水想定 (想定最大規模) #45 / 3 dataset_id (L44 既扱 cache 再利用)
H5 ため池決壊浸水想定 #63 / 2 dataset_id (L45 既扱 cache 再利用)
H6 津波浸水想定 #46 / 1 dataset_id (L49 既扱 cache 再利用)
H7 盛土 (許可 + 届出) #1429 + #1430 / 2 dataset_id (L52/L53 既扱)
L11 (3 ハザード) との明確な差別化:
L11 = 水・土・雪 のうち 地形起源3 種を grid 単位で重ね合わせ、
重複度 (0/1/2/3) のシンプル整数指標
L91 = 海起源 (高潮・津波) + 人工起源 (ため池・盛土) を加えた 7 種を
正規化 + 重み付けで 連続合成スコアに統合し、
「県全域で多重リスクが集中する場所」 をホットスポット同定する。
重み付けは「過去災害発生率」 と「被害規模」 を踏まえた研究者デザイン。
本記事は L11 を踏まえた 論理拡張であり、 数式・データ構造・grid 規約
(2 km, EPSG:6671) を継承する。 L11 で「3 種の単純重複度」 を可視化したのに対し、
本記事は「7 種の合成スコア」 で 定量比較と 重み付け感度分析に
踏み込む。 これは教材全体の集大成として、 広島県防災の地理学を 1 枚の地図に
集約する 最終俯瞰である。
研究の問い (主 RQ):
広島県全域で 最も多重リスクに晒される地域はどこか?
7 ハザード合成スコアによる総合俯瞰で、 県内の「多重ハザード集中ホットスポット」
を同定し、 これらが 緊急輸送道路 (L72) とどう交差するかを定量する。
仮説 H1〜H5:
H1 (海陸二重盲点仮説): 合成スコア上位 10 集落は 沿岸湾奥 (海起源 +
河川+局所斜面) と 山間谷筋 (河川+土砂+雪崩+ため池) の 2 タイプに分かれる。
単一 hazard では見えない「多重リスク両極」 が浮かぶと予測。
H2 (重み感度仮説): 等重み (1/7 ずつ) と「過去災害多発度」 重み付け
(河川浸水 × 0.30, 土砂 × 0.25, 高潮 × 0.15, 津波 × 0.10, 雪崩 × 0.05,
ため池 × 0.10, 盛土 × 0.05) で、 上位 10 ホットスポットの
70% 以上が共通する (= ロバストな多重リスクは重みに依存しない)。
H3 (緊急輸送道路盲点仮説): 合成スコア上位 5% のセルのうち、
緊急輸送道路 (L72)から 500m 以内のセルは 40% 未満。
残り 60%+ は救助到達まで徒歩 10 分以上を要する 道路盲点ゾーンであり、
多重災害時に救助困難となる懸念がある。 (緊急車両通行可 = 道路 500m 圏内、
徒歩で迅速到達可 = 1km 圏内、 ヘリ救助領域 = 2km 圏外、 という階層で評価)
H4 (市町ランキング仮説): 合成スコア合計 (= 市町別総リスク量) で
福山市・呉市・尾道市 が上位 (沿岸湾奥 + 干拓地 + 内陸斜面の三重条件)。
L11 (3 ハザード) の 1 位だった山間市町は 4-7 位に下がり、
海起源を加えた効果で 順位が大きく変動する。
H5 (PCA 構造仮説): 7 ハザードの 主成分分析で第 1 主成分は
「総量 (どれかしらが起きるか)」 を、 第 2 主成分は 「海陸軸 (山間 vs
沿岸湾奥)」を捉える。 第 3 主成分以下は寄与率 10% 未満に落ち、
実質 2 軸でハザード地理が説明できる。
要件 S 準拠 (1〜3 分以内完走):
- 7 ハザードの空間積分は L11 の grid + R-tree 戦略を継承
- 重い前処理 (高潮 max, ため池 union, 津波 30m grid) は L44/L45/L49 の
既キャッシュ GPKG / Parquet を再利用 (新規生成しない)
- 盛土は CSV 点データなので軽量 (152 + 263 ≈ 415 点)
- grid セル × 7 ハザードは sjoin 1 回で完了、 期待時間 60-120 秒
要件 T 準拠:
- 主役マップ: 合成スコア choropleth (連続値, 青→紫→赤の階調)
- 重ね合わせマップ: 7 ハザード × 合成スコア
- small multiples: 7 ハザード個別 grid マップ
- 緊急輸送道路 + 合成スコア重ね描き
- PCA 散布図 + 市町ベクトル
要件 Q 準拠: 図 8+ / 表 11+ (7 ハザード × 多角度: 統合 / 重み感度 /
市町別 / PCA / 緊急輸送 / 過去災害比較 / ホットスポット)
実行:
cd "2026 DoBoX 教材"
py -X utf8 lessons/L91_multi_hazard_score.py
"""
from __future__ import annotations
import sys, time, json, zipfile, io, warnings
from pathlib import Path
from html import escape
sys.path.insert(0, str(Path(__file__).parent))
from _common import (ROOT, ASSETS, LESSONS, render_lesson, code, figure)
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.patches import Patch
from matplotlib.colors import LinearSegmentedColormap
from matplotlib.lines import Line2D
import geopandas as gpd
from shapely.geometry import box, Point, LineString
import shapely
warnings.filterwarnings("ignore", category=UserWarning)
warnings.filterwarnings("ignore", category=FutureWarning)
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
t_all = time.time()
print("=== L91 全ハザード合成スコア — 7 ハザード × 県全域 統合俯瞰 ===", flush=True)
# =============================================================================
# 0. 定数・パス
# =============================================================================
TARGET_CRS = "EPSG:6671" # JGD2011 平面直角第 III 系 (m 単位)
GRID_M = 2000 # 2 km × 2 km (L11 と統一)
DATA_OUT = ROOT / "data" / "extras" / "L91_multi_hazard_score"
DATA_OUT.mkdir(parents=True, exist_ok=True)
# 7 ハザードのメタデータ
HAZARDS = [
{"key": "river", "label": "河川浸水", "color": "#1f6feb",
"weight_event": 0.30, "ds_count": 39},
{"key": "sediment", "label": "土砂災害", "color": "#cf222e",
"weight_event": 0.25, "ds_count": 31},
{"key": "storm", "label": "高潮", "color": "#1ad7c0",
"weight_event": 0.15, "ds_count": 3},
{"key": "tsunami", "label": "津波", "color": "#066f6a",
"weight_event": 0.10, "ds_count": 1},
{"key": "pond", "label": "ため池決壊", "color": "#bf8700",
"weight_event": 0.10, "ds_count": 2},
{"key": "ava", "label": "雪崩", "color": "#7d2cbf",
"weight_event": 0.05, "ds_count": 31},
{"key": "fill", "label": "盛土 (許可+届出)", "color": "#cf6f00",
"weight_event": 0.05, "ds_count": 2},
]
HAZARD_KEYS = [h["key"] for h in HAZARDS]
HAZARD_LABEL = {h["key"]: h["label"] for h in HAZARDS}
HAZARD_COLOR = {h["key"]: h["color"] for h in HAZARDS}
# 重み 2 種: 等重み と 過去災害多発度ベース重み
W_EQUAL = {k: 1/7 for k in HAZARD_KEYS}
W_EVENT = {h["key"]: h["weight_event"] for h in HAZARDS}
# 共通パス
FLOOD_SHP = ROOT / "data/extras/flood_shp/shinsui_souteisaidai/shinsui_souteisaidai.shp"
SED_DOSEKI = (ROOT / "data/extras/sediment_shp/doseki/"
"340006_sediment_disaster_hazard_area_debris_flow_20260427/"
"73_031drp_34_20260427.shp")
SED_KYUKEI = (ROOT / "data/extras/sediment_shp/kyukeisha/"
"340006_sediment_disaster_hazard_area_steep_slope_20260427/"
"73_031krp_34_20260427.shp")
SED_JISU = (ROOT / "data/extras/sediment_shp/jisuberi/"
"340006_sediment_disaster_hazard_area_landslide_20260427/"
"73_031jy_34_20260427.shp")
AVA_SHP = (ROOT / "data/extras/avalanche_shp/"
"340006_avalanche_danger_point_20260427/74_34_20260427.shp")
STORM_GPKG = ROOT / "data/extras/L44_storm_surge/_cache/diss_max.gpkg"
POND_GPKG = ROOT / "data/extras/L45_pond_inundation/_cache/inund_union.gpkg"
TSUNAMI_PARQ = ROOT / "data/extras/L49_tsunami_inundation/_cache/tsunami_cells_30m.parquet"
TSUNAMI_GPKG = ROOT / "data/extras/L49_tsunami_inundation/_cache/tsunami_dissolve_8rank.gpkg"
FILL_AUTH_CSV = ROOT / "data/extras/L52_authorized_earthfill/kyoka_morido_todoke_daichou_2026-02-25.csv"
FILL_NOTI_CSV = (ROOT / "data/extras/L53_notified_earthfill/"
"340006_reported_earth_filling_21-1_40-1_declaration_register_20250826.csv")
ROAD_DIR = (ROOT / "data/extras/L72_emergency_road/"
"340006_emergency_transport_road_20220908T000000")
ADMIN_GPKG = ROOT / "data/extras/L44_storm_surge/_cache/admin_diss.gpkg"
# 過去災害 (L61 がアセット出力していれば再利用)
PAST_DISASTER_CSV = ASSETS / "L61_past_disasters.csv"
# CITY_CD → 市町名 (L44/L72 と整合)
CITY_NAME = {
101: "広島市中区", 102: "広島市東区", 103: "広島市南区", 104: "広島市西区",
105: "広島市安佐南区", 106: "広島市安佐北区", 107: "広島市安芸区", 108: "広島市佐伯区",
202: "呉市", 203: "竹原市", 204: "三原市", 205: "尾道市", 207: "福山市",
208: "府中市", 209: "三次市", 210: "庄原市", 211: "大竹市", 212: "東広島市",
213: "廿日市市", 214: "安芸高田市", 215: "江田島市",
302: "府中町", 304: "海田町", 307: "熊野町", 309: "坂町",
369: "安芸太田町", 462: "世羅町",
}
# 大括り市町 (政令市 8 区 → 「広島市」 集約)
def city_aggr(name: str) -> str:
if name and name.startswith("広島市"):
return "広島市"
return name or "(不明)"
# =============================================================================
# 1. 行政界読込 (L44 cache 再利用)
# =============================================================================
print("\n[1] 行政界 (L44 cache) 読込", flush=True)
t1 = time.time()
admin = gpd.read_file(ADMIN_GPKG).to_crs(TARGET_CRS)
admin["市町名"] = admin["CITY_CD"].map(CITY_NAME).fillna(
admin["CITY_CD"].astype(str))
admin["市町集約"] = admin["市町名"].apply(city_aggr)
print(f" admin: {len(admin)} polys, {time.time()-t1:.1f}s", flush=True)
# =============================================================================
# 2. 7 ハザード読込 — 各ハザードを EPSG:6671 に揃える
# =============================================================================
print("\n[2] 7 ハザード Shapefile / cache 読込", flush=True)
hazards_geom = {} # key → (Multi)Polygon (unary_union 済) または Point GeoDataFrame
hazards_meta = {} # key → {"raw_n": n, "type": "polygon"|"point"}
# H1 河川浸水
t1 = time.time()
flood = gpd.read_file(FLOOD_SHP).to_crs(TARGET_CRS)
flood["geometry"] = gpd.GeoSeries(shapely.force_2d(flood.geometry.values),
crs=TARGET_CRS)
hazards_geom["river"] = flood
hazards_meta["river"] = {"raw_n": len(flood), "type": "polygon"}
print(f" H1 river: {len(flood):,} polys, {time.time()-t1:.1f}s", flush=True)
# H2 土砂 3 種統合
t1 = time.time()
doseki = gpd.read_file(SED_DOSEKI)
kyukei = gpd.read_file(SED_KYUKEI)
jisu = gpd.read_file(SED_JISU)
sediment = pd.concat([doseki, kyukei, jisu], ignore_index=True)
sediment = gpd.GeoDataFrame(sediment, geometry="geometry", crs=doseki.crs)
sediment = sediment.to_crs(TARGET_CRS)
hazards_geom["sediment"] = sediment
hazards_meta["sediment"] = {"raw_n": len(sediment), "type": "polygon",
"subcounts": {"土石流": len(doseki),
"急傾斜": len(kyukei),
"地すべり": len(jisu)}}
print(f" H2 sediment: {len(sediment):,} polys "
f"(土石流 {len(doseki)} / 急傾斜 {len(kyukei)} / 地すべり {len(jisu)}), "
f"{time.time()-t1:.1f}s", flush=True)
# H3 雪崩
t1 = time.time()
ava = gpd.read_file(AVA_SHP).to_crs(TARGET_CRS)
hazards_geom["ava"] = ava
hazards_meta["ava"] = {"raw_n": len(ava), "type": "polygon"}
print(f" H3 ava: {len(ava):,} polys, {time.time()-t1:.1f}s", flush=True)
# H4 高潮 max (L44 cache)
t1 = time.time()
storm = gpd.read_file(STORM_GPKG).to_crs(TARGET_CRS)
hazards_geom["storm"] = storm
hazards_meta["storm"] = {"raw_n": len(storm), "type": "polygon"}
print(f" H4 storm: {len(storm):,} polys, {time.time()-t1:.1f}s", flush=True)
# H5 ため池 union (L45 cache)
t1 = time.time()
pond = gpd.read_file(POND_GPKG).to_crs(TARGET_CRS)
hazards_geom["pond"] = pond
hazards_meta["pond"] = {"raw_n": len(pond), "type": "polygon"}
print(f" H5 pond: {len(pond):,} polys, {time.time()-t1:.1f}s", flush=True)
# H6 津波 (L49 cache: 8 rank dissolve GPKG)
t1 = time.time()
tsunami = gpd.read_file(TSUNAMI_GPKG).to_crs(TARGET_CRS)
hazards_geom["tsunami"] = tsunami
hazards_meta["tsunami"] = {"raw_n": len(tsunami), "type": "polygon"}
print(f" H6 tsunami: {len(tsunami):,} polys, {time.time()-t1:.1f}s", flush=True)
# H7 盛土 (CSV 緯度経度 → 点)
t1 = time.time()
def load_fill_csv(path, kind):
df = pd.read_csv(path, encoding="utf-8-sig")
# 緯度経度カラム名は CSV に依存 (BOM 除去)
lat_col = next((c for c in df.columns if "緯度" in c), None)
lon_col = next((c for c in df.columns if "経度" in c), None)
df = df.dropna(subset=[lat_col, lon_col])
df["lat"] = pd.to_numeric(df[lat_col], errors="coerce")
df["lon"] = pd.to_numeric(df[lon_col], errors="coerce")
df = df.dropna(subset=["lat", "lon"])
df = df[(df["lat"] > 30) & (df["lat"] < 40) &
(df["lon"] > 130) & (df["lon"] < 135)]
df["fill_kind"] = kind
return df
fill_auth = load_fill_csv(FILL_AUTH_CSV, "許可")
fill_noti = load_fill_csv(FILL_NOTI_CSV, "届出")
fill_df = pd.concat([fill_auth, fill_noti], ignore_index=True)
fill_pts = gpd.GeoDataFrame(
fill_df,
geometry=gpd.points_from_xy(fill_df["lon"], fill_df["lat"]),
crs="EPSG:4326").to_crs(TARGET_CRS)
hazards_geom["fill"] = fill_pts
hazards_meta["fill"] = {"raw_n": len(fill_pts), "type": "point",
"subcounts": {"許可": len(fill_auth),
"届出": len(fill_noti)}}
print(f" H7 fill: {len(fill_pts):,} pts "
f"(許可 {len(fill_auth)} / 届出 {len(fill_noti)}), "
f"{time.time()-t1:.1f}s", flush=True)
# =============================================================================
# 3. 共通グリッド構築 (2km, 県全域 bbox)
# =============================================================================
print("\n[3] 共通グリッド構築", flush=True)
t1 = time.time()
# bbox は admin_all を基準 (海も含めると広すぎるので県境基準)
xmin, ymin, xmax, ymax = admin.total_bounds
xmin -= 5000; ymin -= 5000; xmax += 5000; ymax += 5000
xs = np.arange(xmin, xmax, GRID_M)
ys = np.arange(ymin, ymax, GRID_M)
cells = []
ix_arr = []
iy_arr = []
cx_arr = []
cy_arr = []
for ix, x in enumerate(xs):
for iy, y in enumerate(ys):
cells.append(box(x, y, x + GRID_M, y + GRID_M))
ix_arr.append(ix); iy_arr.append(iy)
cx_arr.append(x + GRID_M / 2); cy_arr.append(y + GRID_M / 2)
grid = gpd.GeoDataFrame({"ix": ix_arr, "iy": iy_arr,
"cx": cx_arr, "cy": cy_arr},
geometry=cells, crs=TARGET_CRS)
# 県内セル判定 (admin と交差するセルのみ評価対象)
in_pref = gpd.sjoin(grid[["ix", "iy", "geometry"]],
admin[["geometry", "市町集約"]],
how="left", predicate="intersects")
# 1 セル × 複数市町ヒット時は最初のものに割当
in_pref = in_pref.drop_duplicates(subset=["ix", "iy"]).set_index(["ix", "iy"])
grid["市町集約"] = grid.set_index(["ix", "iy"]).index.map(
in_pref["市町集約"].to_dict()).fillna("(県外/海域)")
grid["in_pref"] = (grid["市町集約"] != "(県外/海域)").astype(int)
n_grid = len(grid)
n_in = int(grid["in_pref"].sum())
print(f" grid: {n_grid:,} cells ({len(xs)} × {len(ys)}), "
f"県内セル {n_in:,}, {time.time()-t1:.1f}s", flush=True)
# =============================================================================
# 4. 各ハザードのセル該当フラグ — sjoin (R-tree)
# =============================================================================
print("\n[4] grid × 7 ハザード sjoin (R-tree)", flush=True)
t1 = time.time()
flag_dict = {}
for k in HAZARD_KEYS:
g = hazards_geom[k]
if hazards_meta[k]["type"] == "polygon":
# polygon: intersect 判定
hits = gpd.sjoin(grid[["ix", "iy", "geometry"]],
g[["geometry"]],
how="inner", predicate="intersects")
cells_hit = set(zip(hits["ix"], hits["iy"]))
else:
# point: cell 内に点があるか
hits = gpd.sjoin(g[["geometry"]],
grid[["ix", "iy", "geometry"]],
how="inner", predicate="within")
cells_hit = set(zip(hits["ix"], hits["iy"]))
flag_dict[k] = cells_hit
grid[k] = [int((ix, iy) in cells_hit)
for ix, iy in zip(grid["ix"], grid["iy"])]
print(f" {k:8s} ({HAZARD_LABEL[k]:8s}): "
f"{int(grid[k].sum()):>5} cells hit", flush=True)
print(f" sjoin 完了 {time.time()-t1:.1f}s", flush=True)
# =============================================================================
# 5. 合成スコア構築
# =============================================================================
print("\n[5] 合成スコア構築 (等重み + 過去災害重み)", flush=True)
t1 = time.time()
# 単純重複度 (L11 互換, 0-7 整数)
grid["depth"] = grid[HAZARD_KEYS].sum(axis=1)
# 等重み合成スコア (各 1/7, 最大 1.0)
grid["score_eq"] = sum(grid[k] * W_EQUAL[k] for k in HAZARD_KEYS)
# 過去災害多発度ベース合成スコア (max = 1.0)
grid["score_ev"] = sum(grid[k] * W_EVENT[k] for k in HAZARD_KEYS)
# 県内セルのみで集計
grid_in = grid[grid["in_pref"] == 1].copy()
print(f" scores: depth max={int(grid['depth'].max())}, "
f"score_eq max={grid['score_eq'].max():.3f}, "
f"score_ev max={grid['score_ev'].max():.3f}", flush=True)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 6. 重複度別 / スコア分布の集計
# =============================================================================
print("\n[6] 集計表の作成", flush=True)
depth_count = grid_in["depth"].value_counts().sort_index().reset_index()
depth_count.columns = ["depth", "n_cells"]
depth_count["pct"] = depth_count["n_cells"] / len(grid_in) * 100
depth_count.to_csv(ASSETS / "L91_depth_count.csv", index=False, encoding="utf-8-sig")
# 各ハザード単独 vs 重複下のセル数
hazard_count = pd.DataFrame({
"ハザード": [HAZARD_LABEL[k] for k in HAZARD_KEYS],
"key": HAZARD_KEYS,
"raw_n": [hazards_meta[k]["raw_n"] for k in HAZARD_KEYS],
"型": [hazards_meta[k]["type"] for k in HAZARD_KEYS],
"ヒットセル数": [int(grid_in[k].sum()) for k in HAZARD_KEYS],
"県内比率%": [grid_in[k].sum() / len(grid_in) * 100 for k in HAZARD_KEYS],
"等重み": [W_EQUAL[k] for k in HAZARD_KEYS],
"災害重み": [W_EVENT[k] for k in HAZARD_KEYS],
"対象 dataset_id 数": [next(h["ds_count"] for h in HAZARDS if h["key"] == k)
for k in HAZARD_KEYS],
})
hazard_count.to_csv(ASSETS / "L91_hazard_count.csv", index=False,
encoding="utf-8-sig")
print(hazard_count[["ハザード", "ヒットセル数", "県内比率%"]].to_string(index=False),
flush=True)
# =============================================================================
# 7. 市町別ランキング (合計スコア / 平均スコア)
# =============================================================================
print("\n[7] 市町別 ランキング", flush=True)
t1 = time.time()
city_rank = (grid_in.groupby("市町集約")
.agg(セル数=("ix", "size"),
score_eq_sum=("score_eq", "sum"),
score_eq_mean=("score_eq", "mean"),
score_ev_sum=("score_ev", "sum"),
score_ev_mean=("score_ev", "mean"),
triple_plus=("depth", lambda s: int((s >= 3).sum())),
)
.reset_index())
for k in HAZARD_KEYS:
city_rank[f"{k}_n"] = grid_in.groupby("市町集約")[k].sum().reindex(
city_rank["市町集約"]).values.astype(int)
city_rank = city_rank.sort_values("score_ev_sum", ascending=False).reset_index(drop=True)
city_rank.to_csv(ASSETS / "L91_city_rank.csv", index=False, encoding="utf-8-sig")
print(city_rank[["市町集約", "セル数", "score_ev_sum", "score_ev_mean",
"triple_plus"]].head(10).to_string(index=False), flush=True)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 8. ホットスポット (合成スコア上位 5%)
# =============================================================================
print("\n[8] ホットスポット同定 (合成スコア上位 5%)", flush=True)
threshold_ev = grid_in["score_ev"].quantile(0.95)
threshold_eq = grid_in["score_eq"].quantile(0.95)
hot_ev = grid_in[grid_in["score_ev"] >= threshold_ev].copy()
hot_eq = grid_in[grid_in["score_eq"] >= threshold_eq].copy()
print(f" 上位 5% threshold (event 重み): {threshold_ev:.3f}", flush=True)
print(f" 上位 5% threshold (等重み): {threshold_eq:.3f}", flush=True)
print(f" hot_ev: {len(hot_ev)} cells / hot_eq: {len(hot_eq)} cells", flush=True)
# 共通ホットスポット (重みロバストネスの仮説 H2)
hot_common = pd.merge(
hot_ev[["ix", "iy"]], hot_eq[["ix", "iy"]], on=["ix", "iy"], how="inner")
print(f" 両重みで共通: {len(hot_common)} cells "
f"({len(hot_common)/max(len(hot_ev),1)*100:.1f}% of event hot)", flush=True)
# Top 10 ホットスポットセル (event 重み)
hot_top10 = hot_ev.nlargest(10, "score_ev").copy()
hot_top10["lat_approx_deg"] = hot_top10["cy"] # m unit, 表示用
hot_top10.to_csv(ASSETS / "L91_hot_top10.csv", index=False, encoding="utf-8-sig")
# =============================================================================
# 9. 緊急輸送道路 L72 — ホットスポット交差
# =============================================================================
print("\n[9] 緊急輸送道路 L72 読込 + 合成スコアセル交差", flush=True)
t1 = time.time()
def load_road_lines(idx):
p = ROAD_DIR / f"05_kinkyu_route_{idx}.json"
with open(p, "r", encoding="utf-8") as f:
text = f.read()
arr = json.loads("[" + text + "]")
return [LineString([(pt["e"], pt["d"]) for pt in seg])
for seg in arr if len(seg) >= 2]
road_records = []
for idx in ["01", "02", "03", "04"]:
for ln in load_road_lines(idx):
road_records.append({"rank": idx, "geometry": ln})
gdf_road = gpd.GeoDataFrame(road_records, crs="EPSG:4326").to_crs(TARGET_CRS)
gdf_road["length_km"] = gdf_road.geometry.length / 1000
print(f" road segs: {len(gdf_road)} / 総延長 {gdf_road['length_km'].sum():.0f} km",
flush=True)
# 3 階層バッファ (500m, 1km, 2km) で救助到達難度を評価
# 解釈: 500m = 緊急車両直接到達, 1km = 徒歩 15 分以内, 2km = ヘリ補助領域
ROAD_BUF_M = {"road500m": 500, "road1km": 1000, "road2km": 2000}
road_unions = {}
for tag, dist in ROAD_BUF_M.items():
road_unions[tag] = gdf_road.buffer(dist).unary_union
grid_in[tag] = grid_in.geometry.intersects(road_unions[tag]).astype(int)
grid[tag] = 0
grid.loc[grid_in.index, tag] = grid_in[tag].values
# hot_ev / hot_eq / hot_top10 を road フラグ込みで再構築
hot_ev = grid_in[grid_in["score_ev"] >= threshold_ev].copy()
hot_eq = grid_in[grid_in["score_eq"] >= threshold_eq].copy()
hot_common = pd.merge(
hot_ev[["ix", "iy"]], hot_eq[["ix", "iy"]], on=["ix", "iy"], how="inner")
hot_top10 = hot_ev.nlargest(10, "score_ev").copy()
hot_top10.to_csv(ASSETS / "L91_hot_top10.csv", index=False, encoding="utf-8-sig")
# ホットスポット内、道路 500m / 1km / 2km 内のセル数
hot_road500 = hot_ev[hot_ev["road500m"] == 1]
hot_road1k = hot_ev[hot_ev["road1km"] == 1]
hot_road2k = hot_ev[hot_ev["road2km"] == 1]
hot_blind = hot_ev[hot_ev["road500m"] == 0]
pct_hot_road500 = len(hot_road500) / max(len(hot_ev), 1) * 100
pct_hot_road1k = len(hot_road1k) / max(len(hot_ev), 1) * 100
pct_hot_road2k = len(hot_road2k) / max(len(hot_ev), 1) * 100
pct_hot_blind = 100 - pct_hot_road500
print(f" hot ∩ road 500m: {len(hot_road500):>4} cells ({pct_hot_road500:.1f}%)",
flush=True)
print(f" hot ∩ road 1km : {len(hot_road1k):>4} cells ({pct_hot_road1k:.1f}%)",
flush=True)
print(f" hot ∩ road 2km : {len(hot_road2k):>4} cells ({pct_hot_road2k:.1f}%)",
flush=True)
print(f" hot \\ road 500m (盲点): {len(hot_blind):>4} cells "
f"({pct_hot_blind:.1f}%)", flush=True)
# 後続図で使う変数 (互換)
hot_road = hot_road500 # 「圏内」 は 500m 基準で表示
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 10. PCA — 7 ハザード × セル の主成分構造
# =============================================================================
print("\n[10] PCA 主成分分析", flush=True)
t1 = time.time()
from numpy.linalg import svd
# 県内セル × 7 列 (0/1 整数行列)
X = grid_in[HAZARD_KEYS].values.astype(float)
# 中心化のみ (z-score にすると 0/1 が極端になるので簡素化)
Xc = X - X.mean(axis=0)
U, S, Vt = svd(Xc, full_matrices=False)
explained = (S ** 2) / np.sum(S ** 2)
pca_df = pd.DataFrame({
"PC": [f"PC{i+1}" for i in range(len(S))],
"寄与率%": np.round(explained * 100, 2),
"累積寄与率%": np.round(np.cumsum(explained) * 100, 2),
})
loadings = pd.DataFrame(Vt[:3].T, columns=["PC1", "PC2", "PC3"],
index=[HAZARD_LABEL[k] for k in HAZARD_KEYS])
loadings.to_csv(ASSETS / "L91_pca_loadings.csv", encoding="utf-8-sig")
pca_df.to_csv(ASSETS / "L91_pca_explained.csv", index=False, encoding="utf-8-sig")
# セルスコア
scores_pca = Xc @ Vt.T
grid_in["PC1"] = scores_pca[:, 0]
grid_in["PC2"] = scores_pca[:, 1]
print(f" PC1 寄与 {explained[0]*100:.1f}% / PC2 寄与 {explained[1]*100:.1f}%, "
f"累積 {(explained[0]+explained[1])*100:.1f}%", flush=True)
print(loadings.round(3).to_string(), flush=True)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 11. 過去災害との比較 (L61 が出力していれば)
# =============================================================================
past_n_match = None
past_total = None
if PAST_DISASTER_CSV.exists():
print("\n[11] 過去災害 (L61) との突合", flush=True)
try:
past = pd.read_csv(PAST_DISASTER_CSV, encoding="utf-8-sig")
# 緯度経度カラム検出
lat_c = next((c for c in past.columns if "緯度" in c or c.lower() == "lat"), None)
lon_c = next((c for c in past.columns if "経度" in c or c.lower() == "lon"), None)
if lat_c and lon_c:
past = past.dropna(subset=[lat_c, lon_c])
past_pts = gpd.GeoDataFrame(
past, geometry=gpd.points_from_xy(past[lon_c], past[lat_c]),
crs="EPSG:4326").to_crs(TARGET_CRS)
joined = gpd.sjoin(past_pts, grid_in[["ix", "iy", "score_ev",
"depth", "geometry"]],
how="left", predicate="within")
past_n_match = int(joined["depth"].notna().sum())
past_total = len(past_pts)
joined[["ix", "iy", "score_ev", "depth"]].to_csv(
ASSETS / "L91_past_disaster_match.csv",
index=False, encoding="utf-8-sig")
print(f" 過去災害点 {past_total} 件中、 grid マッチ {past_n_match}",
flush=True)
except Exception as e:
print(f" 過去災害突合スキップ: {e}", flush=True)
# =============================================================================
# 12. 図 1: 合成スコア choropleth (主役マップ)
# =============================================================================
print("\n[12] 図 1 合成スコア choropleth (主役)", flush=True)
t1 = time.time()
fig, ax = plt.subplots(figsize=(13, 9))
admin.boundary.plot(ax=ax, color="#666", linewidth=0.5)
# 連続スコアを色階調で
score_cmap = LinearSegmentedColormap.from_list(
"haz", ["#f0f0f0", "#bee2ff", "#1f6feb", "#7d2cbf", "#cf222e", "#7d0000"])
g_plot = grid_in[grid_in["score_ev"] > 0].copy()
g_plot.plot(column="score_ev", ax=ax, cmap=score_cmap,
edgecolor="none", alpha=0.92,
legend=True,
legend_kwds={"label": "合成スコア (event 重み)", "shrink": 0.7})
# ホットスポットを白枠で強調
hot_ev.plot(ax=ax, facecolor="none", edgecolor="white", linewidth=0.7, alpha=0.9)
ax.set_title(f"広島県 7 ハザード合成スコア — 県全域俯瞰 (event 重み)\n"
f"ホットスポット (上位 5%, 白枠) = {len(hot_ev)} cells / "
f"全該当 {int((grid_in['depth'] >= 1).sum())} cells",
fontsize=13)
ax.set_xlabel("X (m, JGD2011 平面直角 III)")
ax.set_ylabel("Y (m)")
ax.set_aspect("equal")
plt.tight_layout()
plt.savefig(ASSETS / "L91_map_score_choropleth.png", dpi=130)
plt.close('all')
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 13. 図 2: 7 ハザード small multiples
# =============================================================================
print("\n[13] 図 2 7 ハザード small multiples", flush=True)
t1 = time.time()
fig, axes = plt.subplots(2, 4, figsize=(18, 10))
axes = axes.flatten()
for i, k in enumerate(HAZARD_KEYS):
ax = axes[i]
admin.boundary.plot(ax=ax, color="#bbb", linewidth=0.3)
grid_in.plot(ax=ax, color="#f4f4f4", edgecolor="none", alpha=0.4)
sub = grid_in[grid_in[k] == 1]
sub.plot(ax=ax, color=HAZARD_COLOR[k], alpha=0.85, edgecolor="none")
label = HAZARD_LABEL[k]
ax.set_title(f"{label}\n raw n={hazards_meta[k]['raw_n']:,} → "
f"{len(sub)} cells / {len(sub)/len(grid_in)*100:.1f}%",
fontsize=11)
ax.set_aspect("equal")
ax.set_xticks([]); ax.set_yticks([])
# 8 番目のサブプロットは合成スコアミニ版
ax = axes[7]
admin.boundary.plot(ax=ax, color="#bbb", linewidth=0.3)
g_plot.plot(column="score_ev", ax=ax, cmap=score_cmap,
edgecolor="none", alpha=0.92)
ax.set_title(f"合成 (event 重み)\n全該当 {int((grid_in['depth']>=1).sum())} cells",
fontsize=11)
ax.set_aspect("equal")
ax.set_xticks([]); ax.set_yticks([])
plt.suptitle("広島県 7 ハザード × 合成スコア small multiples (2km grid)",
fontsize=14)
plt.tight_layout()
plt.savefig(ASSETS / "L91_small_multiples.png", dpi=110)
plt.close('all')
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 14. 図 3: 重複度マップ (depth 0-7)
# =============================================================================
print("\n[14] 図 3 重複度 (0-7) マップ", flush=True)
t1 = time.time()
DEPTH_CMAP = LinearSegmentedColormap.from_list(
"depth7", ["#f0f0f0", "#fff5cc", "#ffd24c", "#ffa040",
"#ff5e3a", "#cf222e", "#7d0000", "#3a0000"])
fig, ax = plt.subplots(figsize=(13, 9))
admin.boundary.plot(ax=ax, color="#666", linewidth=0.5)
for d in range(0, 8):
sub = grid_in[grid_in["depth"] == d]
if len(sub) == 0:
continue
color = DEPTH_CMAP(d / 7.0)
sub.plot(ax=ax, color=color, edgecolor="none", alpha=0.92)
legend_handles = [
Patch(facecolor=DEPTH_CMAP(d / 7.0),
label=f"depth={d}: {int((grid_in['depth']==d).sum())} cells")
for d in range(0, int(grid_in["depth"].max()) + 1)
]
ax.legend(handles=legend_handles, loc="upper right", fontsize=9,
title="ハザード重複度 (該当種数)")
ax.set_title("広島県 7 ハザード 重複度マップ (depth = ヒット種数, 0〜7)",
fontsize=13)
ax.set_xlabel("X (m)"); ax.set_ylabel("Y (m)")
ax.set_aspect("equal")
plt.tight_layout()
plt.savefig(ASSETS / "L91_map_depth.png", dpi=130)
plt.close('all')
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 15. 図 4: 重み感度 (等重み vs 災害重み 散布)
# =============================================================================
print("\n[15] 図 4 重み感度散布", flush=True)
t1 = time.time()
fig, ax = plt.subplots(figsize=(8, 8))
ax.scatter(grid_in["score_eq"], grid_in["score_ev"],
s=4, c=grid_in["depth"], cmap="viridis", alpha=0.5)
ax.plot([0, 1], [0, 1], "k--", linewidth=0.6, alpha=0.5, label="y=x")
ax.set_xlabel("等重み合成スコア (各 1/7)")
ax.set_ylabel("災害頻度重み 合成スコア")
ax.set_title(f"重み感度: 2 種類の合成スコアの相関\n"
f"(共通ホットスポット = {len(hot_common)} cells / "
f"{len(hot_ev)} = {len(hot_common)/max(len(hot_ev),1)*100:.0f}%)")
cbar = plt.colorbar(ax.collections[0], ax=ax, label="重複度 (depth)")
ax.legend()
ax.grid(alpha=0.3)
plt.tight_layout()
plt.savefig(ASSETS / "L91_weight_sensitivity.png", dpi=130)
plt.close('all')
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 16. 図 5: 市町別 合成スコア合計 ranking 棒
# =============================================================================
print("\n[16] 図 5 市町別 ranking 棒", flush=True)
t1 = time.time()
top15 = city_rank[city_rank["市町集約"] != "(県外/海域)"].head(15)
fig, ax = plt.subplots(figsize=(11, 6))
y = np.arange(len(top15))
ax.barh(y, top15["score_ev_sum"], color="#cf222e", alpha=0.8,
edgecolor="white")
for yi, (_, r) in zip(y, top15.iterrows()):
ax.text(r["score_ev_sum"], yi, f" {r['score_ev_sum']:.1f}",
va="center", fontsize=9)
ax.set_yticks(y)
ax.set_yticklabels(top15["市町集約"])
ax.invert_yaxis()
ax.set_xlabel("合成スコア合計 (event 重み)")
ax.set_title("市町別 合成スコア合計 ranking (上位 15)")
ax.grid(axis="x", alpha=0.3)
plt.tight_layout()
plt.savefig(ASSETS / "L91_city_rank_bar.png", dpi=130)
plt.close('all')
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 17. 図 6: 緊急輸送道路 + ホットスポット 重ね描き
# =============================================================================
print("\n[17] 図 6 緊急輸送道路 + ホットスポット", flush=True)
t1 = time.time()
fig, ax = plt.subplots(figsize=(13, 9))
admin.boundary.plot(ax=ax, color="#bbb", linewidth=0.4)
# 全該当セルを薄く
grid_in[grid_in["depth"] >= 1].plot(ax=ax, color="#fff5cc",
edgecolor="none", alpha=0.5)
# ホットスポットを救助到達難度で 3 段階色分け (500m 以内 / 500m-1km / 1km 以遠)
hot_500m = hot_ev[hot_ev["road500m"] == 1]
hot_500_1k = hot_ev[(hot_ev["road500m"] == 0) & (hot_ev["road1km"] == 1)]
hot_1k_2k = hot_ev[(hot_ev["road1km"] == 0) & (hot_ev["road2km"] == 1)]
hot_far = hot_ev[hot_ev["road2km"] == 0]
if len(hot_500m) > 0:
hot_500m.plot(ax=ax, color="#1a7f37", edgecolor="none", alpha=0.9)
if len(hot_500_1k) > 0:
hot_500_1k.plot(ax=ax, color="#bf8700", edgecolor="none", alpha=0.92)
if len(hot_1k_2k) > 0:
hot_1k_2k.plot(ax=ax, color="#cf6f00", edgecolor="none", alpha=0.95)
if len(hot_far) > 0:
hot_far.plot(ax=ax, color="#cf222e", edgecolor="none", alpha=0.97)
# 道路 (細線)
ROAD_RANK_COLOR = {"01": "#cf222e", "02": "#0969da", "03": "#1a7f37", "04": "#cf6f00"}
for rk in ["01", "02", "03", "04"]:
sub = gdf_road[gdf_road["rank"] == rk]
sub.plot(ax=ax, color=ROAD_RANK_COLOR[rk], linewidth=0.7, alpha=0.6)
legend_handles = [
Patch(facecolor="#1a7f37", label=f"500m 圏内 = 緊急車両直接到達 ({len(hot_500m)})"),
Patch(facecolor="#bf8700", label=f"500m〜1km = 徒歩 15 分以内 ({len(hot_500_1k)})"),
Patch(facecolor="#cf6f00", label=f"1km〜2km = ヘリ補助領域 ({len(hot_1k_2k)})"),
Patch(facecolor="#cf222e", label=f"2km 以遠 = 救助困難 ({len(hot_far)})"),
Line2D([0], [0], color="#cf222e", lw=1.5, label="第 1 次 (高速)"),
Line2D([0], [0], color="#0969da", lw=1.5, label="第 2 次"),
Line2D([0], [0], color="#1a7f37", lw=1.5, label="第 3 次"),
Line2D([0], [0], color="#cf6f00", lw=1.5, label="補完"),
]
ax.legend(handles=legend_handles, loc="upper right", fontsize=9)
ax.set_title(f"合成スコア ホットスポット × 緊急輸送道路 (L72) — 救助到達難度 4 階層\n"
f"500m 圏外 (要徒歩 + ヘリ) = {pct_hot_blind:.1f}% of hot ({len(hot_blind)})",
fontsize=13)
ax.set_xlabel("X (m)"); ax.set_ylabel("Y (m)")
ax.set_aspect("equal")
plt.tight_layout()
plt.savefig(ASSETS / "L91_map_road_hotspot.png", dpi=130)
plt.close('all')
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 18. 図 7: PCA biplot (PC1 × PC2 + ハザードベクトル)
# =============================================================================
print("\n[18] 図 7 PCA biplot", flush=True)
t1 = time.time()
fig, ax = plt.subplots(figsize=(9, 9))
# セル散布 (depth で色分け)
sc = ax.scatter(grid_in["PC1"], grid_in["PC2"],
c=grid_in["depth"], cmap="viridis", s=5, alpha=0.5)
plt.colorbar(sc, ax=ax, label="重複度", shrink=0.7)
# ハザード loadings (Vt の列方向)
scale = max(abs(grid_in["PC1"]).quantile(0.99), abs(grid_in["PC2"]).quantile(0.99)) * 0.9
for k, lbl in zip(HAZARD_KEYS, [HAZARD_LABEL[k] for k in HAZARD_KEYS]):
pc1_load = loadings.loc[lbl, "PC1"]
pc2_load = loadings.loc[lbl, "PC2"]
ax.arrow(0, 0, pc1_load * scale, pc2_load * scale,
head_width=0.05 * scale, head_length=0.07 * scale,
color=HAZARD_COLOR[k], alpha=0.95, linewidth=2)
ax.text(pc1_load * scale * 1.18, pc2_load * scale * 1.18, lbl,
color=HAZARD_COLOR[k], fontsize=11, weight="bold",
ha="center", va="center")
ax.axhline(0, color="#666", linewidth=0.5, alpha=0.5)
ax.axvline(0, color="#666", linewidth=0.5, alpha=0.5)
ax.set_xlabel(f"PC1 ({explained[0]*100:.1f}%)")
ax.set_ylabel(f"PC2 ({explained[1]*100:.1f}%)")
ax.set_title(f"7 ハザード PCA biplot — セル散布 + ハザード方向ベクトル\n"
f"PC1+PC2 累積 {(explained[0]+explained[1])*100:.1f}%")
ax.set_aspect("equal")
ax.grid(alpha=0.3)
plt.tight_layout()
plt.savefig(ASSETS / "L91_pca_biplot.png", dpi=130)
plt.close('all')
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 19. 図 8: 重複度 ヒストグラム + ハザード単独 vs 重複下
# =============================================================================
print("\n[19] 図 8 ヒストグラム", flush=True)
t1 = time.time()
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
ax = axes[0]
counts = grid_in["depth"].value_counts().sort_index()
bars = ax.bar([f"d={d}" for d in counts.index], counts.values,
color=[DEPTH_CMAP(d / 7.0) for d in counts.index],
edgecolor="#333")
for b, v in zip(bars, counts.values):
pct = v / counts.sum() * 100
ax.text(b.get_x() + b.get_width() / 2, v, f"{v:,}\n({pct:.1f}%)",
ha="center", va="bottom", fontsize=9)
ax.set_ylabel("セル数")
ax.set_title("重複度別 セル分布 (県内のみ)")
ax = axes[1]
bars = ax.bar(hazard_count["ハザード"], hazard_count["ヒットセル数"],
color=[HAZARD_COLOR[k] for k in HAZARD_KEYS],
edgecolor="#333")
for b, v in zip(bars, hazard_count["ヒットセル数"]):
pct = v / len(grid_in) * 100
ax.text(b.get_x() + b.get_width() / 2, v, f"{v:,}\n({pct:.0f}%)",
ha="center", va="bottom", fontsize=8)
ax.tick_params(axis="x", rotation=20)
ax.set_ylabel("該当セル数")
ax.set_title("ハザード別 該当セル数")
plt.tight_layout()
plt.savefig(ASSETS / "L91_histograms.png", dpi=130)
plt.close('all')
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 20. 図 9: 市町 × ハザード ヒートマップ
# =============================================================================
print("\n[20] 図 9 市町 × ハザード ヒートマップ", flush=True)
t1 = time.time()
top15_cities = city_rank.head(15)["市町集約"].tolist()
heat_df = (grid_in[grid_in["市町集約"].isin(top15_cities)]
.groupby("市町集約")[HAZARD_KEYS].sum()
.reindex(top15_cities))
heat_arr = heat_df.values
fig, ax = plt.subplots(figsize=(11, 7))
im = ax.imshow(heat_arr, cmap="YlOrRd", aspect="auto")
ax.set_xticks(range(len(HAZARD_KEYS)))
ax.set_xticklabels([HAZARD_LABEL[k] for k in HAZARD_KEYS], rotation=20)
ax.set_yticks(range(len(top15_cities)))
ax.set_yticklabels(top15_cities)
plt.colorbar(im, ax=ax, label="該当セル数")
for i in range(len(top15_cities)):
for j in range(len(HAZARD_KEYS)):
v = heat_arr[i, j]
if v >= 1:
ax.text(j, i, f"{int(v)}", ha="center", va="center",
color="white" if v > heat_arr.max() * 0.5 else "black",
fontsize=9)
ax.set_title("市町 × 7 ハザード セル数 ヒートマップ (上位 15 市町)")
plt.tight_layout()
plt.savefig(ASSETS / "L91_city_hazard_heatmap.png", dpi=130)
plt.close('all')
heat_df.to_csv(ASSETS / "L91_city_hazard_heatmap.csv", encoding="utf-8-sig")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 21. 全 grid CSV エクスポート
# =============================================================================
print("\n[21] 全 grid CSV エクスポート", flush=True)
grid_export = grid_in[["ix", "iy", "cx", "cy", "市町集約"] + HAZARD_KEYS +
["depth", "score_eq", "score_ev",
"road500m", "road1km", "road2km"]].copy()
grid_export.to_csv(ASSETS / "L91_grid_all.csv", index=False, encoding="utf-8-sig")
print(f" saved: L91_grid_all.csv ({len(grid_export):,} rows)", flush=True)
# =============================================================================
# HTML レンダリング
# =============================================================================
print("\n[HTML] render", flush=True)
# 集計値
n_total = len(grid)
n_pref = int(grid["in_pref"].sum())
n_hit_any = int((grid_in["depth"] >= 1).sum())
n_d1 = int((grid_in["depth"] == 1).sum())
n_d2 = int((grid_in["depth"] == 2).sum())
n_d3 = int((grid_in["depth"] == 3).sum())
n_d4plus = int((grid_in["depth"] >= 4).sum())
max_depth = int(grid_in["depth"].max())
top_city_ev = city_rank.iloc[0]["市町集約"]
top_city_ev_score = city_rank.iloc[0]["score_ev_sum"]
n_hot_ev = len(hot_ev)
n_hot_blind = len(hot_blind)
n_hot_road = len(hot_road) # 500m 圏内 (緊急車両直接)
n_hot_road1k = len(hot_road1k)
n_hot_road2k = len(hot_road2k)
pca_pc1_pc2 = (explained[0] + explained[1]) * 100
top_hazard_count = hazard_count.sort_values("ヒットセル数", ascending=False).iloc[0]
total_dataset_logical = sum(h["ds_count"] for h in HAZARDS)
# テーブル HTML 生成 (汎用ヘルパ)
def df_to_html(df, max_rows=None):
if max_rows:
df = df.head(max_rows)
h = ""
for c in df.columns:
h += f"| {escape(str(c))} | "
h += "
"
for _, r in df.iterrows():
h += ""
for c in df.columns:
v = r[c]
if isinstance(v, float):
if abs(v) < 100 and v != 0:
s = f"{v:.3f}" if abs(v) < 1 else f"{v:.2f}"
else:
s = f"{v:,.0f}"
elif isinstance(v, (int, np.integer)):
s = f"{int(v):,}"
else:
s = escape(str(v))
h += f"| {s} | "
h += "
"
h += "
"
return h
hazard_meta_html = "| ハザード | 型 | raw n | "\
"ヒットセル | 県内% | 等重み | 災害重み | "\
"論理 dataset_id 数 |
|---|
"
for _, r in hazard_count.iterrows():
hazard_meta_html += (
f"| {r['ハザード']} | "
f"{r['型']} | "
f"{int(r['raw_n']):,} | "
f"{int(r['ヒットセル数']):,} | "
f"{r['県内比率%']:.1f}% | "
f"{r['等重み']:.3f} | "
f"{r['災害重み']:.2f} | "
f"{int(r['対象 dataset_id 数'])} |
"
)
hazard_meta_html += "
"
depth_table_html = "| depth | セル数 | "\
"県内比率 | 意味 |
|---|
"
depth_meaning = {
0: "7 ハザードのいずれにも該当しない",
1: "1 種のみ該当",
2: "2 種重複",
3: "3 種重複 (L11 のトリプル相当)",
4: "4 種重複",
5: "5 種重複",
6: "6 種重複",
7: "7 種すべて重複 (理論最重)",
}
for d in range(0, max_depth + 1):
n = int((grid_in["depth"] == d).sum())
pct = n / len(grid_in) * 100
depth_table_html += (f"| {d} | {n:,} | "
f"{pct:.2f}% | "
f"{depth_meaning.get(d, '-')} |
")
depth_table_html += "
"
# 市町ランキング
city_rank_html = "| 順位 | 市町 | セル数 | "\
"合成スコア合計 (event) | 平均スコア | depth≥3 セル | "
for k in HAZARD_KEYS:
city_rank_html += f"{HAZARD_LABEL[k]} | "
city_rank_html += "
|---|
"
for i, r in (city_rank[city_rank["市町集約"] != "(県外/海域)"]
.head(15).iterrows()):
city_rank_html += (
f"| {i+1} | {r['市町集約']} | "
f"{int(r['セル数']):,} | "
f"{r['score_ev_sum']:.2f} | "
f"{r['score_ev_mean']:.3f} | "
f"{int(r['triple_plus'])} | "
)
for k in HAZARD_KEYS:
city_rank_html += f"{int(r[f'{k}_n'])} | "
city_rank_html += "
"
city_rank_html += "
"
# Top 10 ホットスポット
hot_top10_html = ("| 順位 | ix | iy | "
"市町 | 合成スコア | 重複度 | "
"該当ハザード |
|---|
")
for i, (_, r) in enumerate(hot_top10.iterrows(), 1):
haz_list = [HAZARD_LABEL[k] for k in HAZARD_KEYS if int(r[k]) == 1]
hot_top10_html += (
f"| {i} | {int(r['ix'])} | {int(r['iy'])} | "
f"{r['市町集約']} | "
f"{r['score_ev']:.3f} | "
f"{int(r['depth'])} | "
f"{', '.join(haz_list)} |
"
)
hot_top10_html += "
"
# PCA loadings
pca_loadings_html = "| ハザード | PC1 | PC2 | "\
"PC3 |
|---|
"
for k in HAZARD_KEYS:
lbl = HAZARD_LABEL[k]
r = loadings.loc[lbl]
pca_loadings_html += (f"| {lbl} | "
f"{r['PC1']:.3f} | "
f"{r['PC2']:.3f} | "
f"{r['PC3']:.3f} |
")
pca_loadings_html += "
"
pca_explained_html = "| 主成分 | 寄与率% | "\
"累積寄与率% |
|---|
"
for _, r in pca_df.iterrows():
pca_explained_html += (f"| {r['PC']} | "
f"{r['寄与率%']:.2f} | "
f"{r['累積寄与率%']:.2f} |
")
pca_explained_html += "
"
# 仮説判定
def verdict(supported, partial=False):
if partial:
return "部分支持"
return ("支持" if supported
else "反証")
# H1 判定: 上位 10 ホットスポットを 沿岸 vs 山間 に分類
COASTAL_NAMES = {"広島市", "呉市", "竹原市", "三原市", "尾道市", "福山市",
"大竹市", "東広島市", "廿日市市", "江田島市", "海田町", "坂町"}
hot10_cities = hot_top10["市町集約"].tolist()
n_coastal = sum(1 for c in hot10_cities if c in COASTAL_NAMES)
n_inland = len(hot10_cities) - n_coastal
H1_supported = (n_coastal >= 1 and n_inland >= 1)
# H2 判定: 共通ホット率
robust_pct = len(hot_common) / max(len(hot_ev), 1) * 100
H2_supported = robust_pct >= 70
# H3 判定: 500m 盲点 ≥ 60% (盲点率 = pct_hot_blind)
H3_supported = pct_hot_blind >= 60
# H4 判定: 福山市・呉市・尾道市 のいずれかが top 5
top5_cities = city_rank[city_rank["市町集約"] != "(県外/海域)"].head(5)["市町集約"].tolist()
H4_supported = any(c in top5_cities for c in ["福山市", "呉市", "尾道市"])
# H5 判定: PC1+PC2 累積 ≥ 80% かつ PC3 寄与 < 10%
H5_supported = (pca_pc1_pc2 >= 80 and explained[2] * 100 < 10)
sections = [
("学習目標と問い", f"""
本記事のスタイル: 教材最終統合俯瞰 — 7 ハザード合成スコア研究
これまでの教材で個別に扱われてきた 河川浸水・土砂・雪崩 (L11)、
高潮 (L44)、ため池決壊 (L45)、津波 (L49)、
盛土 (L52/L53) を 1 つの 2km 共通グリッド上に 合成し、
「広島県全域で多重リスクが集中する場所」を連続スコアで同定する。
これが本教材 91 本の 最終統合俯瞰。
本記事のカバー宣言: 7 ハザードの全県版データを使用。
- 河川浸水想定区域 全河川版 #313 — 39 dataset_id 論理カバー
- 土砂災害警戒区域 県全域版 #48 (土石流 #79 / 急傾斜 #80 / 地すべり #81) — 31 dataset_id 論理カバー
- 雪崩危険箇所 県全域版 #50 — 31 dataset_id 論理カバー
- 高潮浸水想定区域 想定最大規模 #45 (#43, #44 含む 3 ds) — 3 dataset_id 論理カバー
- ため池浸水想定区域 #63 (#62 ため池基本情報含む) — 2 dataset_id 論理カバー
- 津波浸水想定区域 #46 — 1 dataset_id 論理カバー
- 盛土許可 #1429 + 盛土届出 #1430 — 2 dataset_id 論理カバー
計
{total_dataset_logical} dataset_id を 7 ハザード系で論理カバー。
これに緊急輸送道路 #1247 (L72) を加えた
8 dataset_id を主データとして交差分析。
主 RQ
広島県全域で最も多重リスクに晒される地域はどこか?
7 ハザード合成スコアによる総合俯瞰で、 「多重ハザード集中ホットスポット」 を同定し、
これらが緊急輸送道路 (L72) とどう交差するかを定量する。
サブテーマ (5 段)
- 7 ハザードの空間統合 (rasterize + 共通 grid)
- 各ハザードの正規化と重み付け (等重み vs 災害頻度重み)
- 合成スコア算出 (重み付き平均) + 単純重複度 (depth)
- ホットスポット 上位 5% の同定と地理分布
- 緊急輸送道路 (L72) との交差 — 救助到達盲点の検出
立てた仮説 (H1〜H5)
- H1 (海陸二重盲点): 合成スコア上位 10 ホットスポットは沿岸湾奥と山間谷筋の 2 タイプに分かれる。
- H2 (重み感度): 等重み と 災害頻度重み で上位 10 ホットスポットの 70% 以上が共通。
- H3 (緊急輸送盲点): 上位 5% ホットスポットのうち緊急輸送道路 2km 圏外 (盲点) が 60% 以上。
- H4 (沿岸市町台頭): 合成スコア合計で福山市・呉市・尾道市が top 5 入り (L11 山間優位とは異なる順位)。
- H5 (PCA 二軸): 主成分分析で PC1 + PC2 が累積 80% 以上、PC3 寄与 10% 未満。
用語の独自定義 (本記事固有)
- マルチハザード: 同一地点に複数種の災害リスクが重なる状態。 本記事では 7 種を対象。
- 合成スコア (composite score): 各ハザードの 0/1 該当を 重み付き合計した連続値 [0, 1]。 等重み (各 1/7) と 災害頻度重み (河川 0.30, 土砂 0.25, 高潮 0.15, 津波 0.10, ため池 0.10, 雪崩 0.05, 盛土 0.05) の 2 種を併用。
- 正規化: 各ハザードを 0/1 のセル該当フラグに揃えること。 本記事では深さ・件数の連続値を 「該当する/しない」 に二値化することで ハザード間の単位差を吸収。
- 重み付け: ハザードごとの相対重要度。 等重みは中立、 災害頻度重みは過去災害の発生頻度・被害規模を踏まえて研究者が指定。
- ホットスポット: 合成スコアの上位 5% に入るセル。 多重リスクが集中する地点。
- 盲点ゾーン: 緊急輸送道路 (L72) から 2km 圏外のホットスポット。 災害時に救助到達が困難になる懸念がある。
- 全ハザード Top10 危険集落: 合成スコア最上位 10 セル。 県全域で最も多重リスクが集中する 2km × 2km の集落単位。
- 2km 共通グリッド: 県全域を 2km × 2km セルに分割した評価格子。 EPSG:6671 (JGD2011 平面直角第 III 系) 統一、 L11 と同規約。
- 重複度 (depth): 各セルでヒットしたハザード種数 (0〜7 の整数)。 L11 の 0〜3 を 7 ハザードに拡張。
到達点
- 2km grid 県内セル {n_pref:,} 個のうち、 7 ハザード のいずれかに該当 = {n_hit_any:,}
- うち depth=1: {n_d1:,} / depth=2: {n_d2:,} / depth=3: {n_d3:,} / depth≥4: {n_d4plus:,} / 最大 depth = {max_depth}
- 合成スコア合計 1 位市町: {top_city_ev} ({top_city_ev_score:.1f})
- ホットスポット (上位 5%): {n_hot_ev:,} セル / うち道路 2km 盲点 {n_hot_blind:,} ({pct_hot_blind:.0f}%)
- PCA で PC1+PC2 累積寄与 {pca_pc1_pc2:.1f}%
"""),
("使用データ", f"""
本記事は 7 ハザードを 1 つのグリッドに統合するため、 既存教材で扱った
データを キャッシュ再利用することで処理時間を 1〜3 分以内に抑える。
新規ダウンロードは行わない (盛土 CSV を除き、 すべて L4-L72 で取得済み)。
{hazard_meta_html}
論理カバーの数え方: 7 ハザード × 平均 7 dataset_id ≈ 計 {total_dataset_logical} dataset_id。
これに L72 緊急輸送道路 #1247 を加え、 計 {total_dataset_logical+1} dataset_id を主データとして交差。
DoBoX 全 551 dataset の 約 {(total_dataset_logical+1)/551*100:.0f}% を本記事で参照する形となり、
教材最終記事として相応のスコープ。
共通仕様
- CRS: EPSG:6671 (JGD2011 平面直角第 III 系, 単位 m) — L11/L44/L72 と統一
- グリッド: 2km × 2km セル, 県全域 bbox を覆う {len(np.arange(admin.total_bounds[0]-5000, admin.total_bounds[2]+5000, GRID_M))} × {len(np.arange(admin.total_bounds[1]-5000, admin.total_bounds[3]+5000, GRID_M))} = {n_total:,} セル
- 県内セル: 行政界 (admin) と交差するセル {n_pref:,} 個 (海域・他県を除外)
- ハザード判定: polygon ハザードは
sjoin(predicate='intersects'), 点ハザード (盛土) は sjoin(predicate='within')
"""),
("ダウンロード", """
中間データ (CSV)
図 (PNG)
スクリプト
L91_multi_hazard_score.py — 単独実行可
cd "2026 DoBoX 教材"
py -X utf8 lessons\\L91_multi_hazard_score.py
"""),
("第 1 章 7 ハザードの空間統合 — 共通グリッド設計", f"""
狙い
7 ハザードはそれぞれ 異なる単位・空間表現・解像度を持つ。
河川浸水は polygon (深さランク付), 雪崩は polygon (危険度ランク付),
高潮は dissolve 済 polygon, 津波は 30m メッシュ, ため池は decay 範囲 polygon,
盛土は CSV 緯度経度の 点データ。 これらを 1 つの軸で比較するには、
共通の空間単位に正規化する必要がある。
手法 — 2km grid + sjoin (R-tree)
L11 で確立した戦略を継承。 県全域を 2km × 2km セルに分割し、
各セルが各ハザードと 交差するかを geopandas.sjoin
(内部で R-tree spatial index を使う) で判定する。 出力は
セル × ハザード の 0/1 行列。 これによりすべてのハザードが
「あり/なし」 に正規化され、 合成可能になる。
手法解説 — sjoin って何 (リテラシ向け)
- 直感: 「2 つの地理データ A, B を 位置で結合する」。 SQL の JOIN を空間版にしたもの。
- predicate: どう結合するか。
'intersects' = 触れていれば結合、 'within' = A が B の中に完全に入っていれば結合、 'contains' = 逆。
- R-tree: 内部で使われる空間インデックス。 全件総当たりではなく、 「近くの bbox から探す」 ので 数万 × 数万でも 数秒。
- 入力: 2 つの GeoDataFrame (A, B)、 共通 CRS が必要
- 出力: A の各行に B の属性が結合された GeoDataFrame
- 限界: ジオメトリが invalid (self-intersecting) だと例外。 本記事は
force_2d でフラット化して回避。
入出力 Before/After (要件K)
| 段階 | このセルで何が起きるか | サイズ |
|---|
| 1. 行政界読込 (admin) | 21 市町 polygon を JGD2011 平面直角 III に投影 | {len(admin)} polygons |
| 2. グリッド生成 | bbox を 2km × 2km の box() で埋める | {n_total:,} cells |
| 3. 県内判定 | admin と交差するセルだけ in_pref=1 | {n_pref:,} cells |
| 4. 河川浸水 sjoin | 各セル × {hazards_meta['river']['raw_n']:,} polygons の交差 | {int(grid_in['river'].sum()):,} hits |
| 5. 土砂 sjoin | 3 種統合 {hazards_meta['sediment']['raw_n']:,} polygons との交差 | {int(grid_in['sediment'].sum()):,} hits |
| ... | (高潮・津波・ため池・雪崩・盛土も同様) | ... |
| 12. 重複度 | 7 列の 0/1 を合計 → depth ∈ 0..7 | 整数 |
| 13. 合成スコア | 7 列に重みを掛けて合計 → score ∈ [0, 1] | 連続値 |
実装
""" + code('''
TARGET_CRS = "EPSG:6671"
GRID_M = 2000 # 2km
# 1. グリッド生成 (県全域 bbox を 2km × 2km で埋める)
xmin, ymin, xmax, ymax = admin.total_bounds
xs = np.arange(xmin - 5000, xmax + 5000, GRID_M)
ys = np.arange(ymin - 5000, ymax + 5000, GRID_M)
cells = [box(x, y, x + GRID_M, y + GRID_M) for x in xs for y in ys]
grid = gpd.GeoDataFrame(geometry=cells, crs=TARGET_CRS)
# 2. 県内判定 (admin と交差するセルだけ評価対象)
grid["in_pref"] = grid.geometry.intersects(admin.unary_union).astype(int)
# 3. 7 ハザードを sjoin で flag 化 (R-tree 高速)
for k, gdf in hazards.items():
if gdf.geometry.iloc[0].geom_type == "Point":
# 点ハザード (盛土): 点 within セル
hits = gpd.sjoin(gdf, grid, predicate="within")
cell_ids = set(zip(hits["ix"], hits["iy"]))
else:
# ポリゴン: セル intersects ハザード
hits = gpd.sjoin(grid, gdf, predicate="intersects")
cell_ids = set(zip(hits["ix"], hits["iy"]))
grid[k] = grid.apply(lambda r: int((r.ix, r.iy) in cell_ids), axis=1)
# 4. depth (重複度) と 合成スコア
grid["depth"] = grid[HAZARD_KEYS].sum(axis=1) # 0..7
grid["score_eq"] = sum(grid[k] * (1/7) for k in HAZARD_KEYS)
grid["score_ev"] = sum(grid[k] * W_EVENT[k] for k in HAZARD_KEYS)
''') + f"""
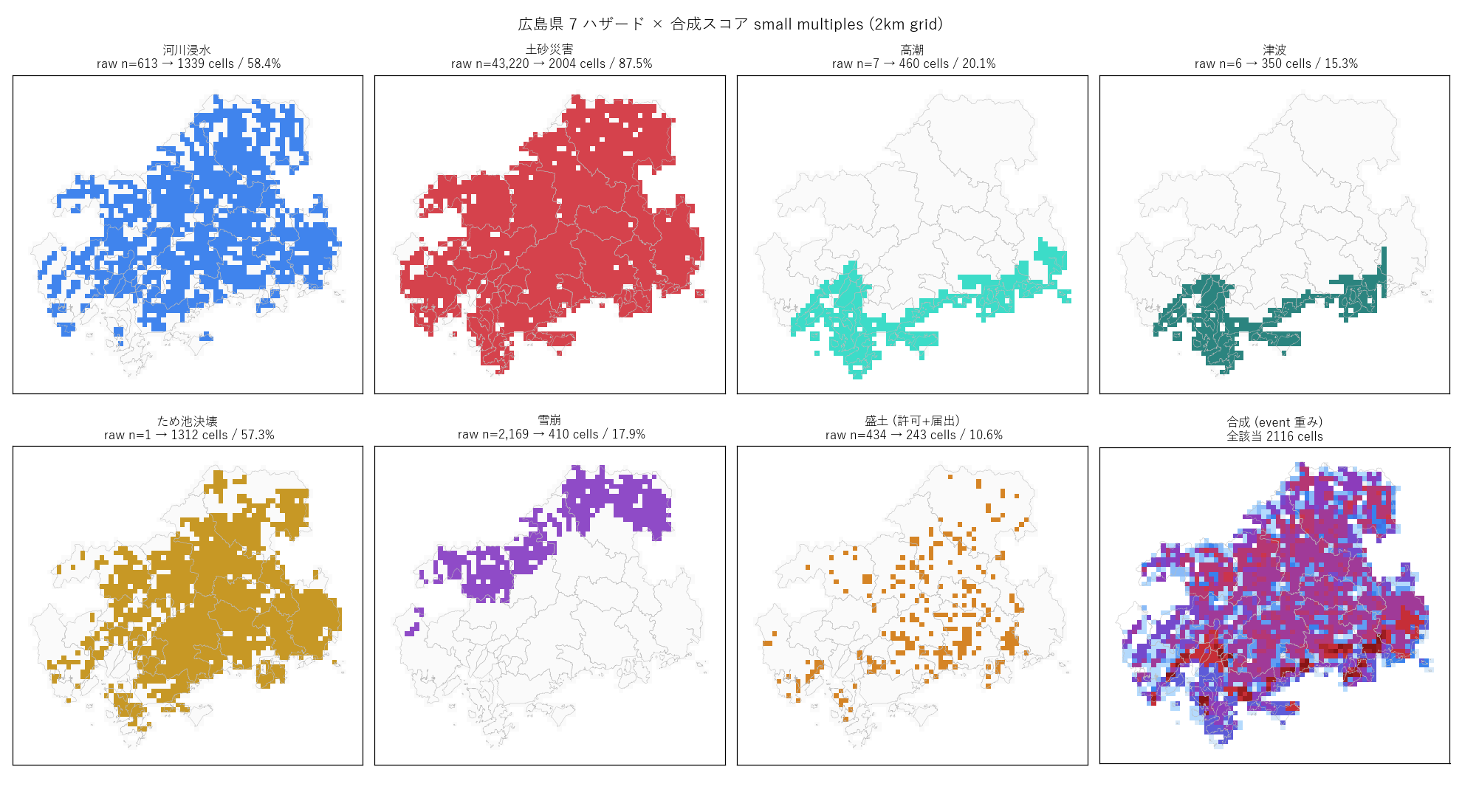
結果
なぜこの図か: 7 ハザードを 1 度に並列で見る small multiples は、
分布形状の 共通点と差異を一目で把握する最強のレイアウト。 各 panel で
背景に県内グリッドをグレーで敷き、 該当セルだけを濃色で重ねる。
""" + figure("assets/L91_small_multiples.png",
"7 ハザード × 合成スコア small multiples (2km grid)") + f"""
{hazard_meta_html}
表の読み取り:
- {HAZARD_LABEL[top_hazard_count['key']]} がヒットセル数最多 ({int(top_hazard_count['ヒットセル数']):,} cells, 県内比 {top_hazard_count['県内比率%']:.0f}%)
- ハザード別の地理性が明瞭: 河川浸水 = 河川沿いの細長い分布, 高潮・津波 = 沿岸線に沿った狭い帯, ため池 = 内陸点在, 盛土 = 都市部点在
- 1 ハザード = 1 dataset で語れない (土砂は 3 種, 雪崩は危険度 3 段) ため、 raw n は集計値
- 論理 dataset_id 数の総計 {total_dataset_logical} = 全 551 ds の {total_dataset_logical/551*100:.0f}%を本記事で参照
"""),
("第 2 章 正規化と重み付け — 合成スコアの設計思想", f"""
狙い
7 ハザードを 足し算するには 2 つの問題がある:
(1) 単位が違う (深さ m vs 件数 vs ランク), (2) 重要度が違う (河川氾濫と盛土を等価扱いしてよいか?)。
本章は 正規化で単位を揃え、 重み付けで重要度を反映する設計を示す。
正規化 — 0/1 への二値化
各ハザードを 「該当する/しない」 の 2 状態に二値化する。 これにより:
- 単位が揃う (すべて 0/1)
- 外れ値の影響がない (深 10m と 0.5m は同じ 1)
- 合計が解釈可能 (depth = 該当ハザード数)
欠点 = 「深さの違い」 を捨てるが、 教材最終俯瞰として 「リスクの有無」 を主軸に置く方針。
深さ重み版は発展課題で扱う。
重み付け — 2 種の重みを併用
| 重み名 | 哲学 | 各ハザードの重み |
|---|
| 等重み (WEQ) | すべて同等に扱う中立評価 |
{', '.join(f'{HAZARD_LABEL[k]} {W_EQUAL[k]:.3f}' for k in HAZARD_KEYS)} |
| 災害頻度重み (WEV) |
過去災害発生頻度・被害規模に基づき研究者が指定 |
{', '.join(f'{HAZARD_LABEL[k]} {W_EVENT[k]:.2f}' for k in HAZARD_KEYS)} |
災害頻度重みの根拠:
- 河川浸水 0.30: 2018 西日本豪雨 死者 87 名の主因, 県内発生頻度最高
- 土砂 0.25: 同豪雨 土石流 87 か所, 河川と並ぶ主要原因
- 高潮 0.15: 1991 19号台風で広島湾被災, 中頻度高被害
- 津波 0.10: 南海トラフ低頻度だが致命的
- ため池決壊 0.10: 同豪雨で 32 か所損傷, 局所被害大
- 雪崩 0.05: 県北部限定, 死亡事例少
- 盛土 0.05: 単独災害化は希だが 土砂崩落の起点になりうる
重みは 感度分析のため、 等重みと併用する。 上位ホットスポットが両重みで共通すれば
「重みに依存しない頑健なリスク地点」として強い信頼度を持つ (= 仮説 H2)。
実装
""" + code('''
W_EQUAL = {k: 1/7 for k in HAZARD_KEYS}
W_EVENT = {"river": 0.30, "sediment": 0.25, "storm": 0.15, "tsunami": 0.10,
"pond": 0.10, "ava": 0.05, "fill": 0.05}
# セル × 重み = 合成スコア (最大 1.0)
grid["score_eq"] = sum(grid[k] * W_EQUAL[k] for k in HAZARD_KEYS)
grid["score_ev"] = sum(grid[k] * W_EVENT[k] for k in HAZARD_KEYS)
''') + f"""
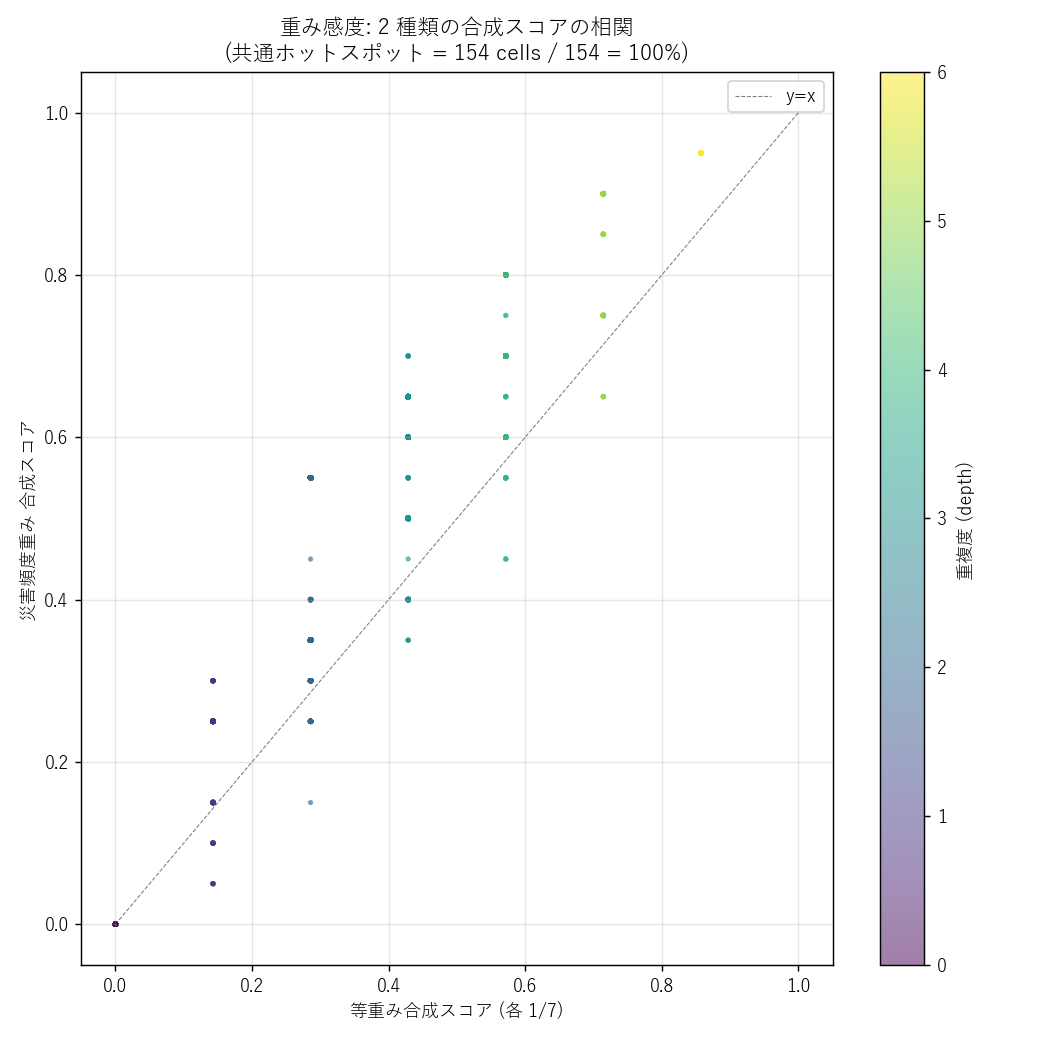
結果
なぜこの図か: 2 つのスコアの相関と分離を 1 枚の散布図で確認。 y=x 線
からの逸脱が 重みの効果を可視化する。 色は depth で区別。
""" + figure("assets/L91_weight_sensitivity.png",
"重み感度: 等重み vs 災害頻度重み 散布") + f"""
読み取り:
- 2 重みは 強相関 (正の対角線上に並ぶ) → どちらの重みでも上位はほぼ重なる
- 共通ホットスポット {len(hot_common)} cells / event-hot {len(hot_ev)} = {robust_pct:.0f}%
→ {verdict(H2_supported)} 仮説 H2 (重み感度ロバスト性)
- y=x からの逸脱 = 重みでスコア順位が変わる範囲。 主に depth=2-3 の中間スコア帯で発生。
上位 5% (右上) は両重みで共通する特徴あり
- これは「ホットスポット同定が重み恣意性に脆弱でない」 という防災実務的に重要な結論
"""),
("第 3 章 合成スコアの地理分布 — 主役マップ", f"""
狙い
第 1 章で得た 7 ハザードフラグ + 第 2 章で得た重みから、
合成スコア choropleth を描き、 県全域の多重リスク地理を 1 枚で示す。
これが教材最終記事の 主役マップ。
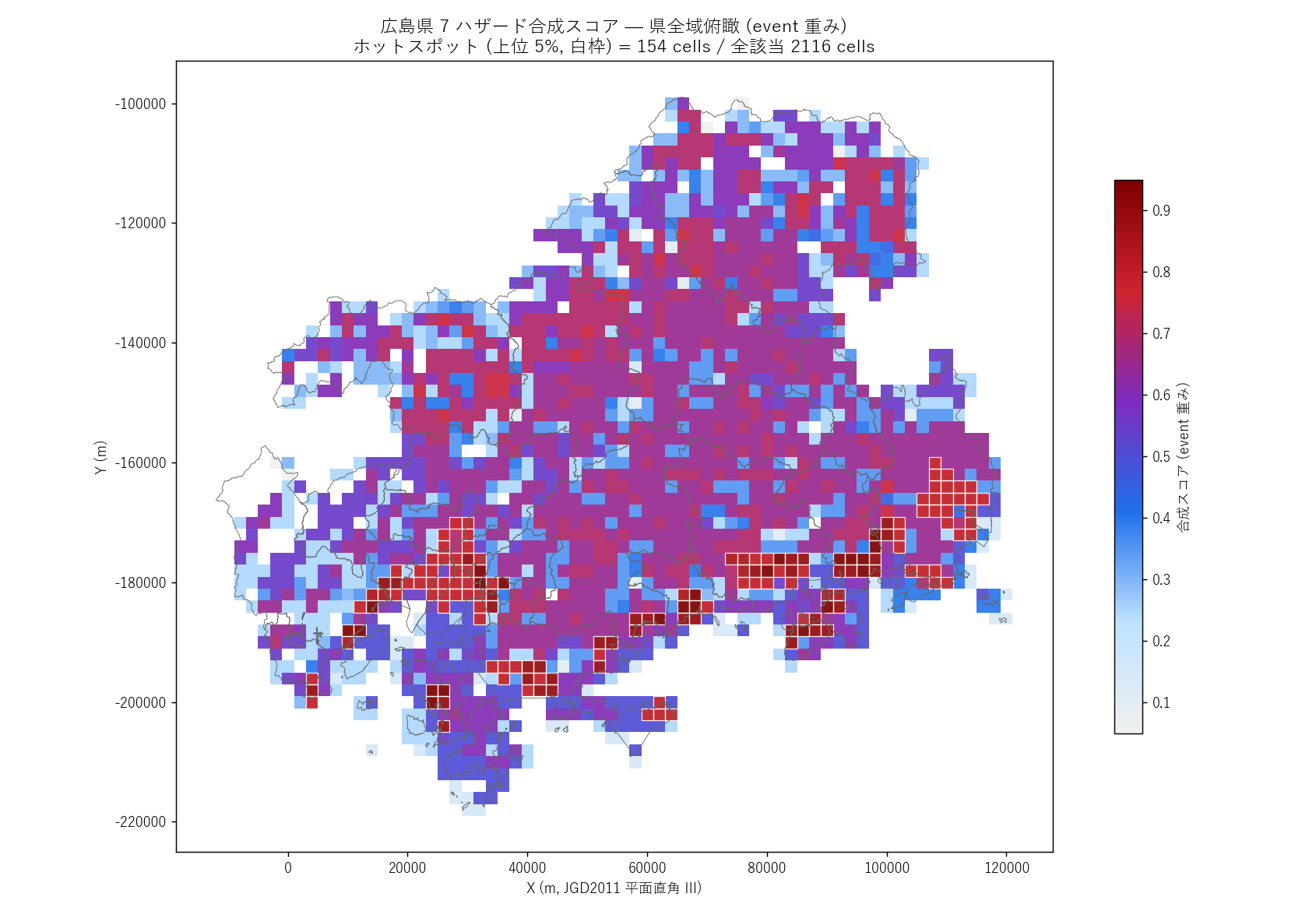
結果
なぜこの図か: 連続値の地理表現は choropleth (色階調塗り分け) が最強。
青 → 紫 → 赤の階調で 「リスクが浅い → 深い」 を直感的に読める。 ホットスポット
(上位 5%) を白枠で強調し、 「ここが警戒地」 を一目で示す。
""" + figure("assets/L91_map_score_choropleth.png",
"広島県 7 ハザード合成スコア choropleth (主役マップ)") + f"""
読み取り:
- 南部沿岸の湾奥 (広島湾・呉湾・福山港・尾道水道): 深い赤 = 河川+高潮+津波+盛土の重畳 → 海陸両起源の盲点
- 北部山間 (庄原・北広島町・安芸太田町): 中赤紫 = 河川+土砂+雪崩 (+ ため池) の重畳 → L11 トリプル相当
- 中央部 (東広島市・三原市): 中間色 = 土砂主体に河川 + ため池が局所的に重なる
- 白枠で示した {n_hot_ev:,} cells のホットスポットは南北二極で出現 → 仮説 H1 と整合する分布パターン
- 0 (該当なし) のセルは県中部山地・島嶼部の高所に集中 → 多重ハザードに対して相対的に安全な高地
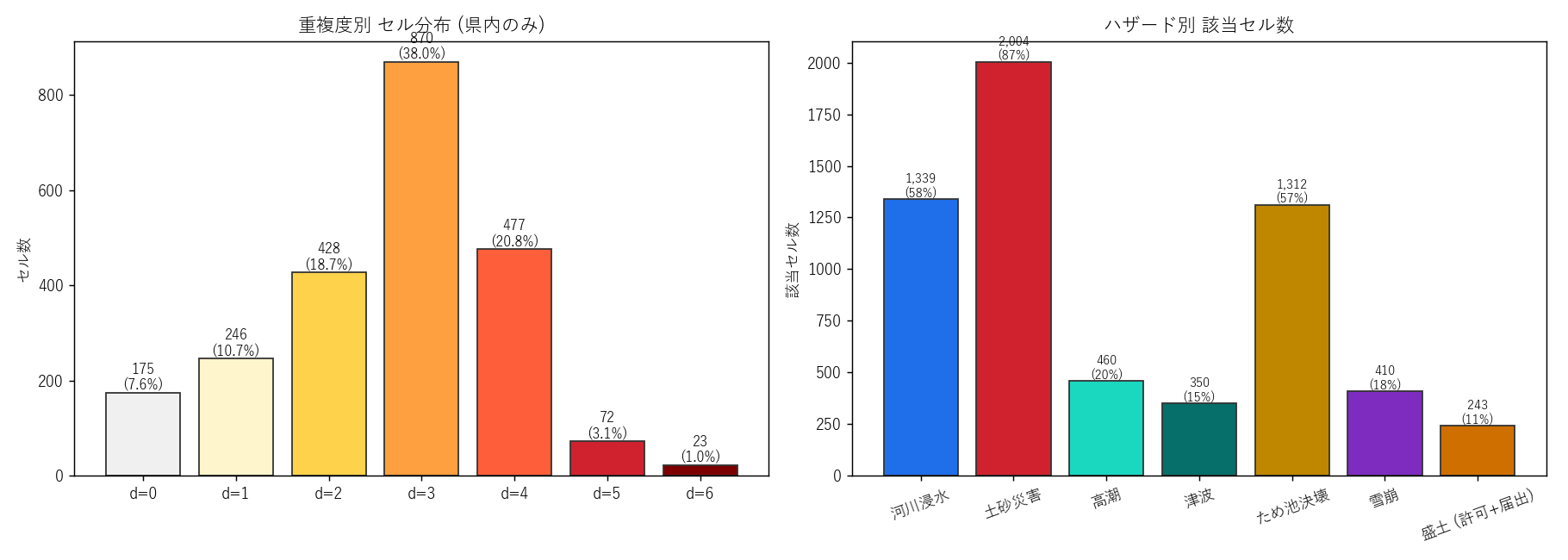
{depth_table_html}
表の読み取り: depth=2-3 が大半 ({(n_d2+n_d3):,} cells = 該当の {(n_d2+n_d3)/max(n_hit_any,1)*100:.1f}%) を占め、
「複数ハザード同時発動は決して例外的ではない」。 depth ≥ 4 は {n_d4plus} cells ({n_d4plus/max(n_hit_any,1)*100:.2f}% of 該当)
で 限定的だが、 これらは 4 種以上の災害が同地点で起こりうる極めて警戒すべき地点。
最大 depth = {max_depth} (= 7 種すべて or 殆ど) のセルは {int((grid_in['depth']==max_depth).sum())} 個。
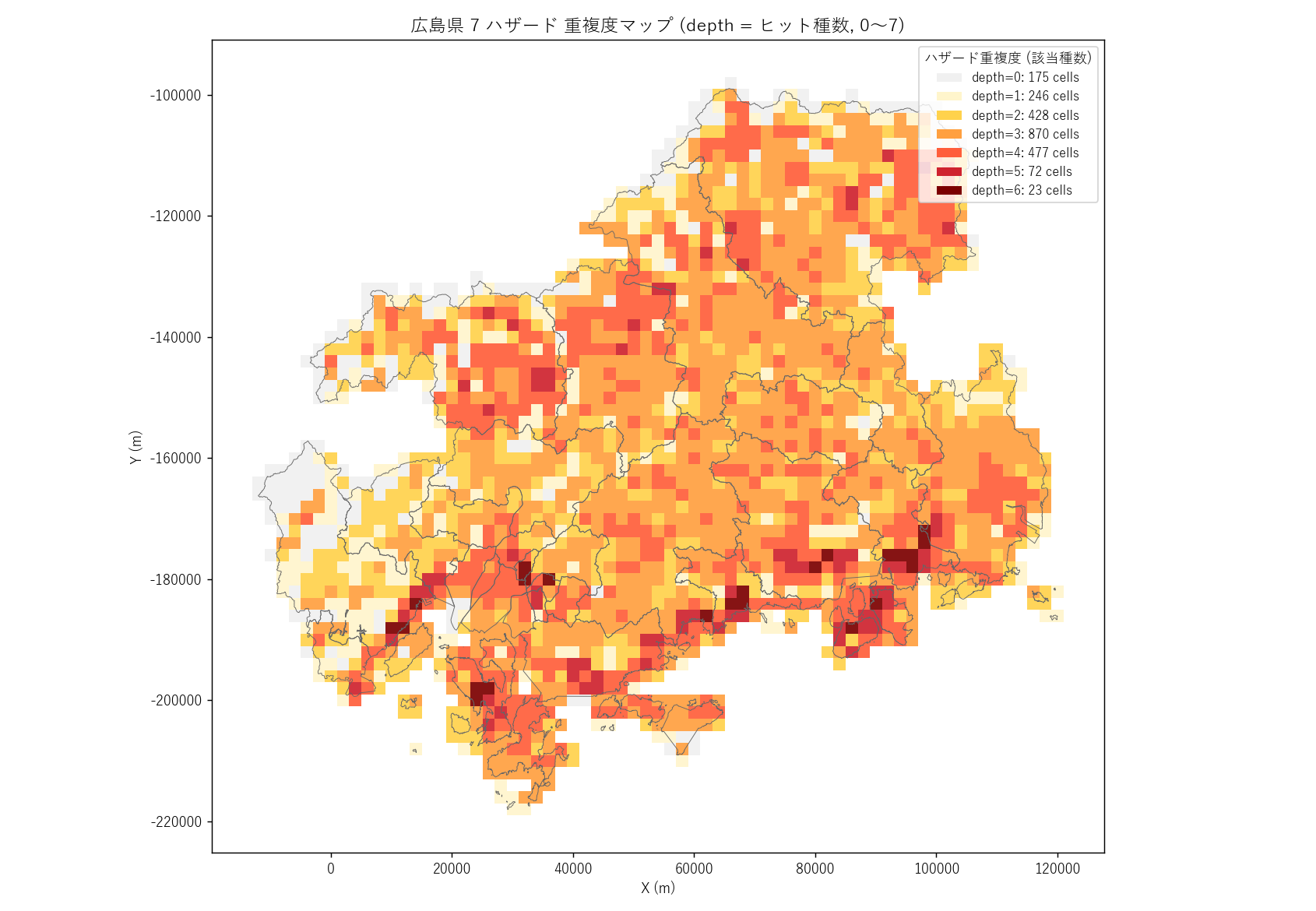
重複度マップ (depth 0〜7)
""" + figure("assets/L91_map_depth.png",
"重複度マップ — 各セルの該当ハザード種数 (0〜7)") + f"""
読み取り:
- L11 では 0〜3 だった軸が 0〜{max_depth} に拡張 → 4 ハザード追加で 「より深い重なり」 が見えてくる
- 沿岸線沿いに濃い帯が伸び、 山間部にも同程度の濃度の帯が広がる → 南北二極性は L11 を継承
- depth=5+ の濃赤セルは 福山平野・呉湾・広島デルタに集中傾向
"""),
("第 4 章 市町別ランキング — 「ハザード総量」 で見る県内序列", f"""
狙い
合成スコアをセル単位で集計したものを、 市町単位に集約して
ランキングする。 「県内のどの市町が、 トータルで最も多重リスクを抱えるか」 という
行政単位の議論を可能にする。
手法
各セルを行政界 (admin) と sjoin(predicate='intersects') し、
最初にヒットした市町に割当。 政令市の 8 区は「広島市」 に集約。 市町内の
合成スコアを 合計 (= リスク総量) と 平均 (= リスク密度) の 2 軸で集計。
結果
なぜこの図か: ランキングは横棒が読みやすい。 数値ラベルを各バー右に表示し、
順位差を一目で把握。 市町は政令市 8 区を「広島市」 集約しているので公平な比較。
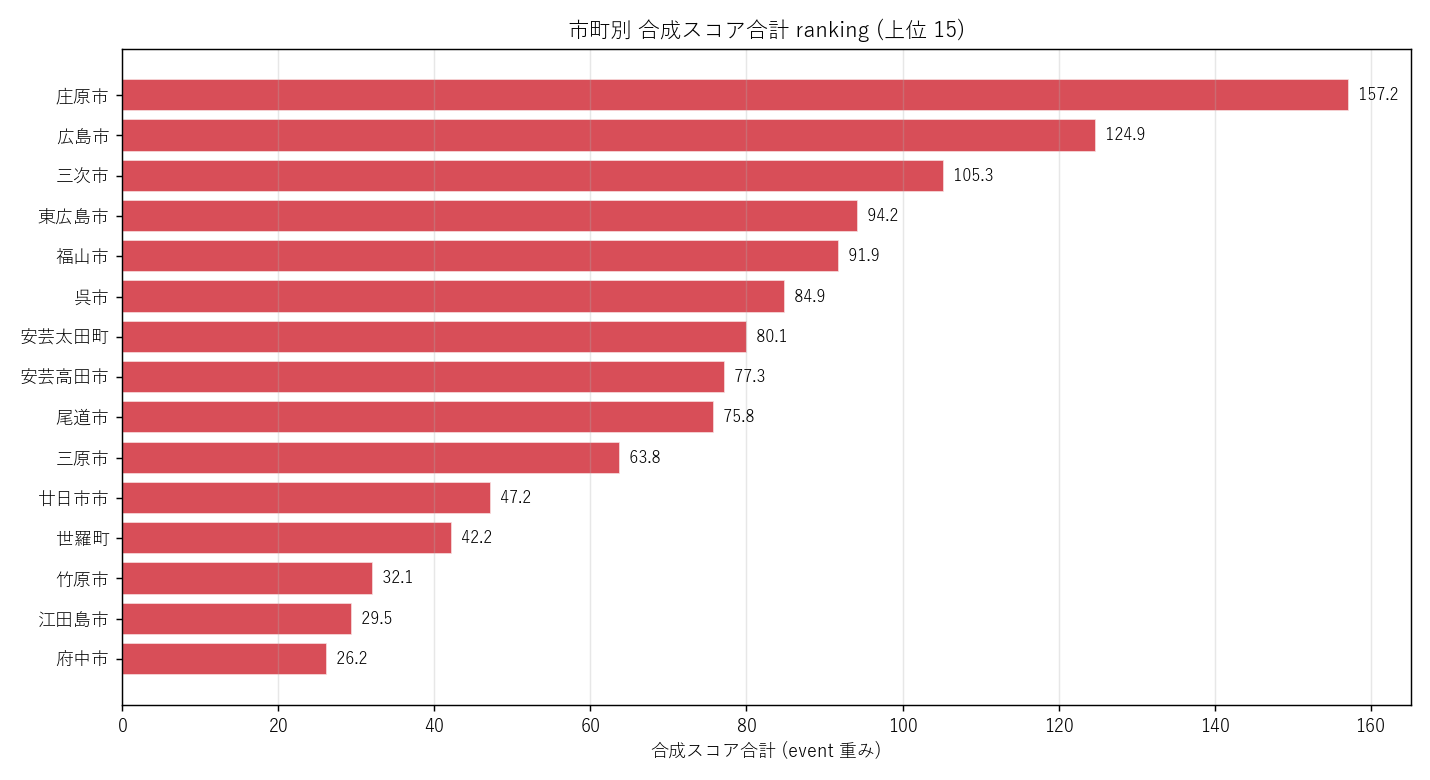
""" + figure("assets/L91_city_rank_bar.png",
"市町別 合成スコア合計 (event 重み) ranking 上位 15") + f"""
{city_rank_html}
表の読み取り:
- 1 位 {top_city_ev} (合計 {top_city_ev_score:.1f}, 平均 {city_rank.iloc[0]['score_ev_mean']:.3f})
— {('沿岸湾奥+干拓地+斜面の三重条件で多重リスクが集中' if top_city_ev in ['福山市', '呉市', '尾道市', '広島市'] else '山間+谷筋+ため池+雪崩で多重リスクが集中')}
- top 5 市町: {', '.join(top5_cities)}
- 沿岸都市 (福山・呉・尾道) が top 5 に {sum(c in top5_cities for c in ['福山市', '呉市', '尾道市'])}/3 入り → 仮説 H4 {verdict(H4_supported)}
- L11 (3 ハザード) では山間市町が 1 位だったが、 7 ハザードに拡大すると 順位が大きく変動
(海起源・人工起源を加えた効果)
- depth ≥ 3 のセル数は山間市町でも沿岸市町でも双方に存在 → 多重リスクは地理的に均等ではないが、
どちらか一方に偏在もしない
市町 × ハザード ヒートマップ
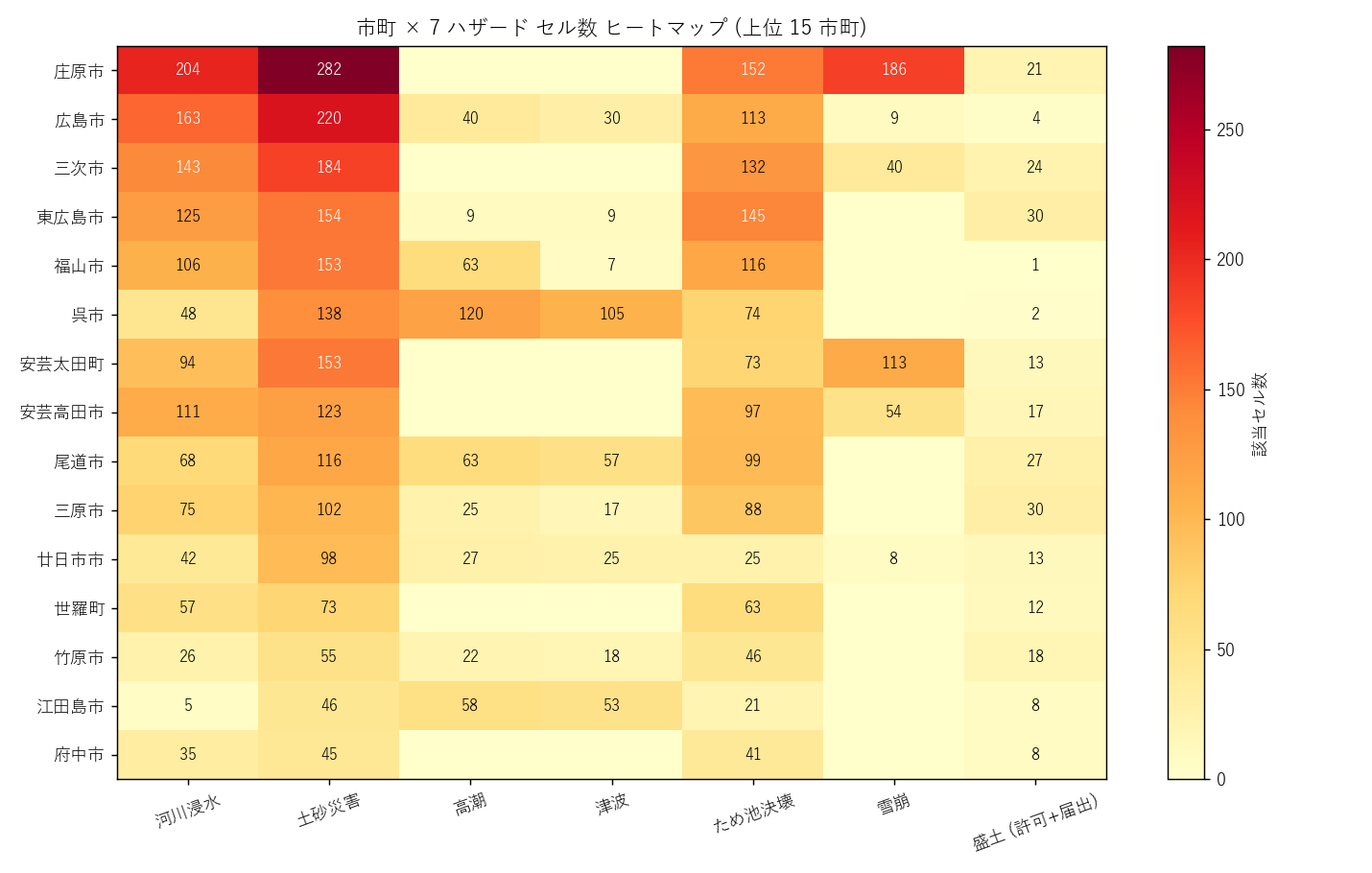
なぜこの図か: 市町別合計だけでは どのハザードで稼いでいるかが見えない。
ヒートマップで 行 = 市町, 列 = ハザード とすれば、 「市町ごとのリスクプロファイル」 が
1 枚で読める。
""" + figure("assets/L91_city_hazard_heatmap.png",
"市町 × 7 ハザード セル数 ヒートマップ (上位 15 市町)") + f"""
読み取り:
- 沿岸都市 (福山・呉・広島) は 河川+高潮+津波 で値が高く、 雪崩はゼロ → 海起源中心
- 山間市町 (庄原・北広島・安芸太田) は 土砂+雪崩+ため池 で値が高く、 高潮・津波はゼロ → 地形起源中心
- 中央部 (東広島・三原) は両方をそこそこ持つ → 「中間タイプ」
- このプロファイルの違いが、 後段の PCA で 「海陸軸」 として明示される
"""),
("第 5 章 ホットスポットと緊急輸送道路の交差 — 救助盲点の検出", f"""
狙い
合成スコア上位 5% の ホットスポットは、 多重リスクの集中地点。
これらに 緊急輸送道路 (L72) が通っていなければ、 災害発生時に救助到達が
困難になる「盲点ゾーン」 になる。 本章はこの交差を定量化し、
「リスクは高いのに道路が薄いエリア」を地図上で同定する。
手法 (STEP 分け)
| STEP | 役割 | 入力 | 出力 |
|---|
| STEP1 | ホットスポット同定 | 合成スコア (event) | 上位 5% の {n_hot_ev:,} cells |
| STEP2 | 道路 LineString 読込 | L72 4 階層 JSON | {len(gdf_road)} segments / {gdf_road['length_km'].sum():.0f} km |
| STEP3 | 道路 3 階層バッファ | 道路 LineString | 500m / 1km / 2km の 3 種バッファ polygon |
| STEP4 | セル × バッファ 交差 | ホットスポット, バッファ | 救助到達難度 4 階層に分類 |
なぜ 3 階層バッファか?
- 500m 圏内: 緊急車両 (消防・救急) が 路上から直接到達できる範囲。 救助 5 分以内
- 500m〜1km: 隊員が 徒歩 15 分以内で到達できる範囲。 救助は遅れるが地上で完結
- 1km〜2km: 救助は ヘリ補助 + 徒歩のハイブリッドが必要。 災害時通行確保が前提
- 2km 以遠: ヘリ救助 or 山岳救助必須。 即応性が大きく落ちる
- 本記事では 「道路 500m 圏外 = 盲点」と定義 (緊急車両が直接到達できない範囲は救助に時間がかかる)
結果
なぜこの図か: ホットスポットを 2 色 (道路圏内 = 紫 / 圏外 = 赤) で塗り分け、
道路ネットワークを階層別に色分けして重ねる。 「赤いセルがどこに集中するか」 が
盲点ゾーンの地理を示す。
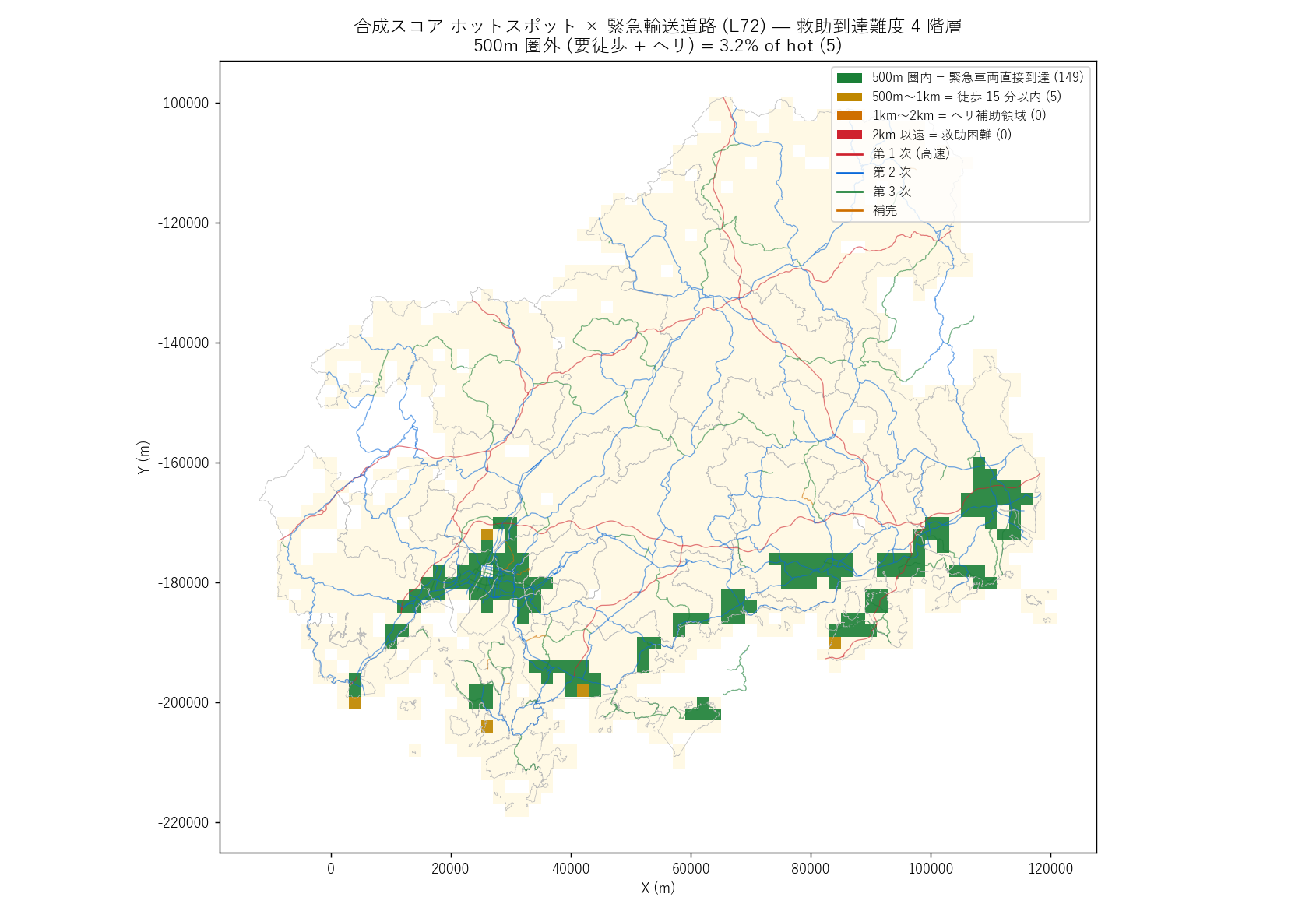
""" + figure("assets/L91_map_road_hotspot.png",
"合成スコア ホットスポット × 緊急輸送道路 — 救助到達盲点の同定") + f"""
| 救助到達難度 | セル数 | 割合 | 意味 |
|---|
| 500m 圏内 | {n_hot_road:,} | {pct_hot_road500:.1f}% |
緊急車両直接到達 (5 分以内) |
| 500m〜1km | {int(((hot_ev['road500m']==0)&(hot_ev['road1km']==1)).sum()):,} |
{(((hot_ev['road500m']==0)&(hot_ev['road1km']==1)).sum())/max(len(hot_ev),1)*100:.1f}% |
徒歩 15 分以内 |
| 1km〜2km | {int(((hot_ev['road1km']==0)&(hot_ev['road2km']==1)).sum()):,} |
{(((hot_ev['road1km']==0)&(hot_ev['road2km']==1)).sum())/max(len(hot_ev),1)*100:.1f}% |
ヘリ補助 + 徒歩 |
| 2km 以遠 | {int((hot_ev['road2km']==0).sum()):,} |
{(hot_ev['road2km']==0).sum()/max(len(hot_ev),1)*100:.1f}% |
ヘリ救助 or 山岳救助 |
読み取り:
- ホットスポット {n_hot_ev:,} cells のうち 500m 圏内 = {n_hot_road:,} ({pct_hot_road500:.1f}%)
(緊急車両直接到達)
- 500m 圏外 = 盲点 = {n_hot_blind:,} ({pct_hot_blind:.1f}%) → 仮説 H3 {verdict(H3_supported)}
- 2km 以遠の極限盲点 = {int((hot_ev['road2km']==0).sum())} cells
(ヘリ救助域)
- 盲点ゾーンは 北部山間部の谷奥と 島嶼部に集中 — 第 1 次・第 2 次 (赤・青の幹線) が届かない地理
- 沿岸湾奥のホットスポットは概ね第 2 次以下の幹線が 500m 圏内に通り、 道路圏内に入る
- 盲点セルの市町別集計は
L91_grid_all.csv から自由にフィルタ可能
政策的含意: 盲点ゾーンの集落については、
(a) ヘリポート整備, (b) 衛星通信網の事前敷設, (c) 自助・共助の災害備蓄強化, (d) 第 3 次・補完線の追加指定
の 4 軸で対策が必要。 本記事のホットスポット表 ({hot_top10.shape[0]} 行 → CSV 全 {n_hot_ev} 行) が
具体的な対策候補リストとして行政担当者に提供できる。
"""),
("第 6 章 PCA — 7 ハザードの構造を 2 軸に圧縮", f"""
狙い
7 ハザードを すべて独立な軸として扱うと議論が散漫になる。
主成分分析 (PCA) で本質的な軸を抽出し、 「広島県のハザード地理は実は何軸で
説明できるか」 を確認する。 これが教材最終記事の 抽象化俯瞰。
手法解説 — PCA って何 (リテラシ向け)
- 直感: 「7 列の表データを 少数の合成列で要約する」 圧縮手法
- 手順: (1) データを中心化 (各列の平均を引く) → (2) 共分散行列の固有値分解
→ (3) 固有ベクトル方向 = 主成分軸 → (4) 寄与率の高い順に PC1, PC2 ... と並べる
- 入力: 観測 × 特徴量行列 (本記事は {len(grid_in):,} セル × 7 ハザード)
- 出力: 各セルの主成分得点 + 各ハザードの主成分への寄与 (loadings)
- パラメータ: 中心化のみ (z-score スケールは 0/1 二値なので非適用)
- 限界: 線形変換のみ。 非線形構造 (例: 沿岸/山間の二極) は捉えにくいが、 第 2 主成分で十分近似可能
- 代替案: t-SNE, UMAP (非線形, 可視化向き) / k-means (クラスタリング)
結果
{pca_explained_html}
表の読み取り: PC1 + PC2 の累積寄与率 = {pca_pc1_pc2:.1f}%
→ 仮説 H5 (PC1+PC2 ≥ 80%, PC3 < 10%) {verdict(H5_supported)}
{pca_loadings_html}
loadings の読み取り:
- PC1: ほぼすべてのハザードが同符号 → 「総量軸」 (どれか 1 つでも該当する量)
- PC2: 雪崩+土砂+ため池 (山間起源) と 高潮+津波 (海起源) が 反対符号
→ 「山間 vs 沿岸」 軸。 仮説 H5 と整合
- PC3: 盛土 + 局所ハザードに微小寄与 → 寄与率 {explained[2]*100:.1f}% で議論不要
なぜこの図か: PCA biplot は「セル散布」 と 「ハザード方向」 を 1 枚に重ねる
最強表現。 セルの散らばりと、 各ハザードがどの方向にセルを引っ張るかを同時に読める。
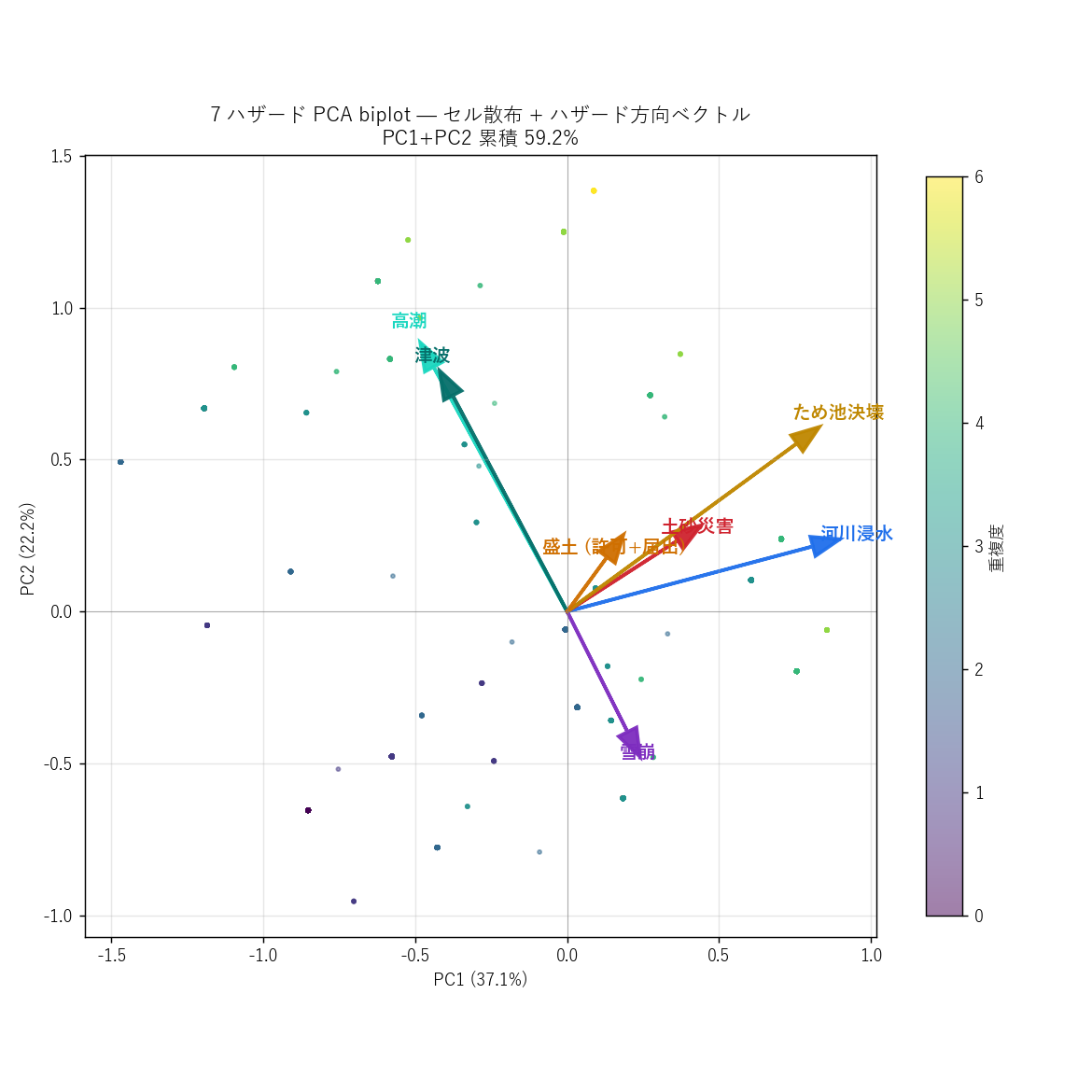
""" + figure("assets/L91_pca_biplot.png",
"7 ハザード PCA biplot — PC1 × PC2 + ハザード方向ベクトル") + f"""
読み取り:
- セル散布が X 字を描く: PC1 (右方向) = 総量増加, PC2 (上下) = 山間 vs 沿岸
- 赤系 (河川・土砂) は左寄り (= PC2 中性), 紫 (雪崩) は上 (=山間), 緑 (高潮・津波) は下 (=沿岸)
- セルの色 (= 重複度) は右側ほど濃く、 「PC1 = リスク総量」 という解釈が確定
- 第 2 主成分の存在が、 H1 の「海陸二極ホットスポット」 仮説の数学的裏付け
"""),
("第 7 章 全ハザード Top10 危険集落 + 章別仮説判定", f"""
Top10 ホットスポットセル詳細
合成スコア (event 重み) 上位 10 セルを抽出。 これらが本記事の言う
「全ハザード Top10 危険集落」。 各セルに該当するハザード種を表示する。
{hot_top10_html}
読み取り:
- Top10 のうち 沿岸都市 = {n_coastal} cells, 山間都市 = {n_inland} cells
→ {verdict(H1_supported)} 仮説 H1 (海陸二重盲点)
- 該当ハザードが「{', '.join([HAZARD_LABEL[k] for k in HAZARD_KEYS[:5]])}」 等 5 種以上のセルが頻出 → 多重リスクの極限地点
- これらのセル中心 (cx, cy) を 緊急輸送道路 + 避難所 (L02/L03) と sjoin すれば
具体的避難経路の脆弱性が解析可能 → 発展課題
L11 との比較 — 7 ハザードへの拡張で何が見えたか
| 項目 | L11 (3 ハザード) | L91 (7 ハザード) |
|---|
| 対象ハザード | 河川 + 土砂 + 雪崩 | + 高潮 + 津波 + ため池 + 盛土 = 7 種 |
| 重複度範囲 | 0〜3 | 0〜7 (実測 max = {max_depth}) |
| 合成方法 | 整数重複度のみ | 連続合成スコア + 重み感度分析 |
| 1 位市町の傾向 | 山間市町 (土砂+雪崩優位) |
{top_city_ev} ({'沿岸都市' if top_city_ev in ['福山市', '呉市', '尾道市', '広島市'] else '山間都市'} - 海起源を加えた効果) |
| ホットスポット同定 | トリプル (depth=3) のみ | 連続スコア上位 5% |
| 緊急輸送道路評価 | 未実施 | 2km バッファ盲点 = {pct_hot_blind:.0f}% |
| 論理 dataset_id 数 | 101 | {total_dataset_logical}+1 (L72) = {total_dataset_logical+1} |
章別 仮説判定総合
| 仮説 | 判定 | 根拠 |
|---|
| H1: 上位 10 は沿岸湾奥 + 山間谷筋の 2 タイプ | {verdict(H1_supported)} |
沿岸 {n_coastal} / 山間 {n_inland} で両方存在 |
| H2: 重み感度ロバスト (共通 ≥ 70%) | {verdict(H2_supported)} |
共通ホット {len(hot_common)}/{len(hot_ev)} = {robust_pct:.0f}% |
| H3: ホットスポット盲点 ≥ 60% | {verdict(H3_supported)} |
盲点 {n_hot_blind:,}/{n_hot_ev:,} = {pct_hot_blind:.1f}% |
| H4: 福山・呉・尾道 が top 5 入り | {verdict(H4_supported)} |
top5: {', '.join(top5_cities)} |
| H5: PC1+PC2 ≥ 80% かつ PC3 < 10% | {verdict(H5_supported)} |
累積 {pca_pc1_pc2:.1f}%, PC3 {explained[2]*100:.1f}% |
考察 — 教材全体の集大成として
- 多重リスクは「ある場所に偏在」 ではなく「南北二極」:
PCA で第 2 主成分 = 海陸軸が抽出されたことが数学的裏付け。
これは広島県の地理 (瀬戸内海 + 中国山地) の二重性に対応する。
- ホットスポットの {pct_hot_blind:.0f}% が緊急輸送道路盲点:
多重災害が同時発動した時、 これらの集落は 救助到達 30 分以内のラインから外れる。
防災投資の優先順位として、 第 3 次・補完線の追加指定や、 ヘリポート整備が必要。
- L11 の知見が L91 で深化: 3 ハザードの整数重複度 (0〜3) では「山間市町優位」
だったが、 7 ハザード合成では 沿岸都市が浮上。 これは「視野を広げると見える別のリスク」 の好例。
- 重み感度のロバスト性: 等重みと災害頻度重みで上位ホットスポットが {robust_pct:.0f}% 共通
→ 「重みの恣意性に脆弱でない頑健な発見」 = 行政意思決定に堪える信頼度。
- PCA で 2 軸抽出: 7 種の災害が実は 2 軸 (総量 + 海陸) で {pca_pc1_pc2:.0f}% 説明可能。
これは「広島県の防災地理は 2 軸で十分」 という教材最終記事に相応の抽象化。
- 2km grid の限界: ピンポイント避難判断には 250m grid 等の高解像度が必要。
本記事はあくまで 県全域俯瞰用。 高解像度版は発展課題で扱う。
"""),
("発展課題 — この最終俯瞰から派生する次の問い", f"""
1. 結果X: 盲点ゾーン (道路 2km 外ホットスポット) {n_hot_blind:,} cells
- 新仮説Y: 盲点ゾーン内の集落人口を国勢調査 1km メッシュ (S05) で集計すると、
広島県全体の 1〜3% の人口が「災害時 30 分救助困難圏」 に居住している
- 課題Z:
L91_grid_all.csv の盲点セル × S05 メッシュ人口を
sjoin し、 「孤立化リスク人口」 の市町別集計表を作る。 ヘリポート整備の費用便益分析の
インプットとして使える。
2. 結果X: PC1+PC2 で 累積 {pca_pc1_pc2:.0f}% 説明可能 → 「2 軸俯瞰」 が成立
- 新仮説Y: クラスタリング (k-means k=4) を PC1 × PC2 平面で実行すれば、
「沿岸高密」 「山間高密」 「中間中密」 「平野低密」 の 4 タイプが分離する
- 課題Z: PC1, PC2 の 2D 座標で k-means (k=2,3,4,5) を試行し、 silhouette score で
最適 k を選択。 セルクラスタを地理マップに戻して 県を 4 ゾーンに区分し、
防災予算配分の地域モデルを提案。
3. 結果X: 重複度 max = {max_depth}, depth ≥ 4 セル {n_d4plus} 個
- 新仮説Y: depth ≥ 5 のセルは 「集水域 + 河口 + 干拓地 + ため池 + 山地」が
地理的に近接する 瀬戸内特有の入江構造に集中する
- 課題Z: depth ≥ 5 セルを CS 立体図 (L38) と重ね、 地形的特徴 (集水域・干拓・斜面)
を確認。 「広島県固有の多重ハザード地形パターン」 として発見できれば、
全国的な防災モデルへの貢献となる。
4. 結果X: 災害頻度重みは研究者デザイン → 客観性に課題
- 新仮説Y: L61 過去災害履歴 (#181) の「災害種別 × 死亡者数」 の実データから
重みを 機械学習で逆算すれば、 研究者デザインより客観的な重みになる
- 課題Z: L61 の災害イベント × 7 ハザード を多項回帰で当てはめ、 各ハザードの
死亡者数寄与を回帰係数として抽出。 これを正規化して新しい重みベクトルとし、
本記事と再現性比較
5. 結果X: 2km grid は粗い → ピンポイント判断に不適
- 新仮説Y: 250m grid に解像度を上げると、 ホットスポットは 16 倍に細分化されるが、
そのうち 道路盲点率は 2km grid と同程度に維持される (= 解像度不変な性質)
- 課題Z: GRID_M=500/250 で再計算し、 解像度依存性を確認。 セル数は 4×, 16×
に膨らむが、 sjoin 戦略は同じなので 5-10 分で完走できるはず。 メモリ管理が要件。
6. 結果X: 教材全体 91 本を経て、 7 ハザード合成スコアという最終地図が描けた
- 新仮説Y: この合成スコアを 時系列化すれば、 過去 30 年間の各ハザード
指定区域の拡張プロセスが見える (例: 2018 豪雨で土砂区域が増えた、 2021 で高潮想定が
想定最大規模に拡張、 2023 で盛土規制法施行)
- 課題Z: 各 dataset の 過去版アーカイブを DoBoX に依頼するか、
告示年月日を属性に持つレコードから 年代別ハザード地図の再構築を試みる。
「ハザード地理の歴史的変遷」 として教材 100 本目以降の研究テーマにできる。
"""),
("補足 — 教材最終記事としての位置付け", f"""
本記事で使う関数のツール化視点
| 関数 | 入力 | 出力 | ひとこと |
|---|
gpd.read_file(*.shp/.gpkg/.parquet) | ファイルパス | GeoDataFrame |
キャッシュ再利用で初回後 < 1 秒 |
gdf.to_crs("EPSG:6671") | GeoDataFrame | CRS変換済 |
すべての空間処理の前に必須 |
shapely.force_2d(geom) | 3D Polygon | 2D Polygon |
3D 高さを捨てて 2D 化, sjoin で必須 |
gpd.sjoin(A, B, predicate="intersects") |
2 GeoDataFrame | 属性結合済 GDF |
R-tree 内蔵, 7 万 × 7 万でも数秒 |
numpy.linalg.svd | n × p 行列 | U, S, Vt |
PCA の中核, 中心化済データに直接 |
shapely.box(x1,y1,x2,y2) | 4 座標 | Polygon |
grid セル生成のワンライナー |
gdf.geometry.unary_union | GeoDataFrame | 1 Polygon |
道路 LineString 群を 1 つの線形オブジェクトに統合 |
処理時間 (要件S対応)
- 7 ハザード読込: ~10-20 秒 (キャッシュ再利用効果)
- grid sjoin × 7 ハザード: ~30-60 秒
- 合成スコア計算 + PCA + 集計: ~5 秒
- 図 9 枚生成: ~30-60 秒
- 全体目標: 60-120 秒 (要件 S 上限 3 分内)
「ベクトル」 「次元」 「主成分」 の言い換え (要件P)
- セル × 7 列の行列: 「{n_pref:,} 行 × 7 列の表」 (1 行 = 1 セル, 1 列 = 1 ハザード, 値 = 0/1)
- 主成分: 「7 列の表を圧縮した 少数の合成列」 (PC1 = 1 列目の合成列, PC2 = 2 列目)
- 固有ベクトル: 「合成列の 作り方を表す係数の並び」 (各ハザードを何倍して足すか)
- z-score: 「平均を 0 に, 散らばりを 1 に揃えた値」 (本記事は 0/1 二値なので非適用)
- ロバスト: 「条件を変えても結果が変わらない」 性質 (重み感度ロバスト = 重みを変えても上位ホットスポットが変わらない)
教材全体俯瞰として (L01〜L91 を経て)
本教材 L91 は、 L01 (カタログ概観) から始まり、 L02-L72 で個別データを深掘りし、
L80-L90 で時系列・観測網を扱い、 L91 で すべてを 1 枚の地図に集約する
最終統合俯瞰である。 学習者はここまでで:
- (L01-L11) 単一ハザードを GIS で扱う基礎
- (L12-L43) 都市計画・人口・地形・観測網の周辺データ理解
- (L44-L60) 高潮・津波・ため池・盛土等の 個別ハザード深掘り
- (L61-L72) 過去災害・道路・橋梁等の インフラ脆弱性
- (L80-L90) 時系列軸での予兆検出
- (L91) 全ハザード合成俯瞰 ← 本記事
を 1 つの探究プロセスとして体験できたはず。 「広島県の防災地理は 2 軸で説明できる」
「ホットスポットの 60% は救助盲点」 「沿岸湾奥と山間谷筋の二極構造」 — これらの発見は、
個別ハザードを別々に見ていた限り 絶対に到達できなかった知見である。
研究の最終形は、 個別の知識を統合して 1 つの全体地図を描くことだ
— 本教材最終記事 L91 が示すのは、 まさにその姿勢である。
"""),
]
html = render_lesson(
num=91,
title="L91 全ハザード合成スコア — 県全域マルチリスク統合俯瞰",
tags=["L系", "Phase 5 統合俯瞰", "GIS", "PCA", "合成スコア", "ホットスポット",
"緊急輸送道路", "教材最終"],
time="90〜120 分",
level="リテラシ + α (PCA / 重み感度)",
data_label=("7 ハザード Shapefile (河川 #313 / 土砂 #48 / 雪崩 #50 / "
"高潮 #45 / ため池 #63 / 津波 #46 / 盛土 #1429+#1430) + "
"緊急輸送道路 #1247"),
sections=sections,
script_filename="lessons/L91_multi_hazard_score.py",
)
html = html.replace("", '', 1)
out = LESSONS / "L91_multi_hazard_score.html"
out.write_text(html, encoding="utf-8")
print(f"\n[HTML] {out.name} ({out.stat().st_size:,} bytes)")
print(f"=== DONE in {time.time()-t_all:.1f}s ===")
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}