# -*- coding: utf-8 -*-
"""L89 M5 中山間物語 — 過疎・高齢化・農地転用・林業の地理学
カバー宣言:
本記事は DoBoX の 都市計画区域情報_人口データ (#1467-1508) /
農地ポリゴン (#1391-1407) / 農用地区域等ポリゴン (#1408-1424) /
砂防指定地 (#55) / 渓流保全工 (#1124) / 地すべり防止施設 (#1126) /
航空レーザ森林資源 (#1117) / 単木情報 (#1117) / 橋梁基本情報 (#11) /
過去の災害履歴 (#181) / L15 行政界 を統合し、 「広島県内中山間
地域 (庄原・三次・安芸高田・北広島・神石高原・世羅) の物語 — 過疎の
進む中で何が残り、 何が変わっているのか?」 を 6 章構成で物語る
テーマ統合 (M系) 記事である。
M系 (テーマ統合) 系譜:
M1 (L85) = 太田川水系 1 水系深掘り (河川治水物語)
M2 (L86) = 埋蔵文化財を時間軸で物語化 (古代地理物語)
M3 (L87) = 観光関連 dataset を空間軸 (沿岸-島嶼) で物語化
M4 (L88) = 工業専用地域 + 港湾 + 防災 を 4 産業拠点で物語化
M5 (本記事) = 中山間 6 市町を「人口・農地・林業・防災」 4 軸で
物語化 (中山間地理物語) — M系最終記事
研究の問い (主 RQ):
「広島県内中山間 6 市町 — 過疎の進む中で何が残り、 何が変わって
いるのか? 山と田と森に守られた地域は、 都市部とどう違う構造を
持ち、 オープンデータはその物語をどう語るのか?」
仮説 H1〜H5:
H1 (高齢化集中仮説): 中山間 6 市町の65 歳以上人口比率は、
平均で40% 以上。 沿岸 5 市町 (約 30%) を大きく上回り、
中山間が広島県の高齢化最前線であることを量化する。
H2 (集落営農カバー率仮説): 中山間 5 市町のL25 集落営農地区
(TOKEI_CD=3 区域外農林漁業) 面積 / L24 現存農地面積
カバー率は5% 以上。 「中山間直接支払」 の制度的足がかり
として、 集落営農の体系的カバーが構築されている。
H3 (砂防 + 渓流 + 地すべり「三施設族」 中山間集中仮説): 中山間 6 市町
が広島県の砂防指定地 + 渓流保全工 + 地すべり防止施設の
合計件数の20% 以上を占める。 県内 26% (6/23 自治体) の
中山間が、 三施設族でほぼ均衡集中する空間構造を量化。
H4 (橋梁密度仮説): 中山間 6 市町の人口千人あたり橋梁件数は、
その他県平均より3 倍以上。 過疎で人口は薄いが、 谷川を
渡る橋は地形的に必要なので、 「人少なく橋多い」 の構造
が成立する。 中山間インフラ管理の本質。
H5 (LiDAR 森林資源 = 中山間の宝仮説): 世羅町の航空レーザ単木計測
(3.4M 点) では、 ヒノキ単独で全単木数の80% 以上を占める。
過疎で人は減るが、 植えた木は今も育ち続ける — 中山間の蓄積
資産が森林であり、 とくにヒノキ植林の優位性を量化する。
要件 S 準拠 (1 分以内完走):
- L22 人口 zip 6 市町のみ読込 (神石高原は都市計画区域外で zip なし)
- L24/L25 zip 5 市町のみ (神石高原同上)
- L41 LiDAR 単木 3.4M 点は樹種別集計のみでメモリ節約
(geometry は読み捨て、 ha 集計のみ)
- L46 砂防 (3,207 件) ・L57 地すべり (32 件) ・L58 渓流 (1,862 件)
は city フィルタで中山間 6 市町分のみ抽出
- 想定完走時間 30 - 90 秒
要件 T 準拠 (位置情報あり = 地図必須):
- 中山間 6 市町 主題図 (高齢化率 choropleth)
- 6 市町 small multiples (人口ピラミッド or 高齢化率)
- 砂防三施設 中山間集中マップ (重ね合わせ)
- 農地転用 vs 農用地区域 重ね合わせ
- 世羅町 LiDAR 単木 樹種別 サンプル散布
要件 Q 準拠: 図 7+ / 表 11+ (人口 × 農地 × 林業 × 防災 多角度)
既存記事との差別化:
L22 (人口ピラミッド) = 21 市町 ピラミッド単独深掘り (沿岸も含む)
L24 (農地転用) = 17 市町 転用面積年別 単独
L25 (農林漁業施策) = 17 市町 TOKEI_CD 別 単独
L41 (LiDAR 森林資源) = 世羅町 単木計測 樹種別単独
L46 (砂防指定地) = 全県 3,207 件 単独
L57 (地すべり) = 全県 32 件 単独
L58 (渓流) = 全県 1,862 件 単独
L61 (過去災害) = 全県 424 件 単独
L66 (橋梁) = 全県 4,203 件 架設年度 単独
L89 (本記事) はこれら全てと厳密に重複しない切り口:
(i) 中山間 6 市町に絞った統合視点 (L22, L24, L25 は全市町)
(ii) L24 vs L25 反転構造 は本記事が初 (両者は単独深掘り)
(iii) 砂防三施設 (L46+L57+L58) 統合 中山間集中度 は本記事が初
(iv) 橋梁 vs 都市部 中央値比較 は本記事が初 (L66 は全県)
(v) 世羅町 LiDAR 樹種比率 を中山間蓄積資産として再評価
(L41 は単木計測手法解説)
(vi) 「中山間 = 地理リスクと文化資源の交差点」 という 4 軸
(人口 × 農地 × 林業 × 防災) 統合は本記事独自
実行:
cd "2026 DoBoX 教材"
py -X utf8 lessons/L89_M5_chusankan_story.py
"""
from __future__ import annotations
import sys
import time
import zipfile
import io
import warnings
from pathlib import Path
from html import escape
sys.path.insert(0, str(Path(__file__).parent))
from _common import ROOT, ASSETS, LESSONS, render_lesson, code, figure
import numpy as np
import pandas as pd
import geopandas as gpd
import shapely
from shapely.geometry import Point
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.patches import Patch
from matplotlib.lines import Line2D
warnings.filterwarnings("ignore", category=UserWarning)
warnings.filterwarnings("ignore", category=FutureWarning)
warnings.filterwarnings("ignore", category=RuntimeWarning)
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
t_all = time.time()
print("=== L89 M5 中山間物語 — 過疎・高齢化・農地・林業・防災 ===",
flush=True)
# =============================================================================
# 0. 定数・パス
# =============================================================================
TARGET_CRS = "EPSG:6671" # JGD2011 平面直角第 III 系 (m)
DATA_EX = ROOT / "data" / "extras"
DATA_DIR = DATA_EX / "L89_M5_chusankan_story"
DATA_DIR.mkdir(parents=True, exist_ok=True)
ADMIN_DIR = DATA_EX / "L15_admin_zones"
JINKO_DIR = DATA_EX / "L22_population_pyramid"
FARM_DIR = DATA_EX / "L24_farmland_conversion"
AGRO_DIR = DATA_EX / "L25_agroforestry_policy"
TREE_GPKG = DATA_EX / "L41_forest_resources" / "tree_point_34462.gpkg"
SABO_SHP = (DATA_EX / "L46_sabo_designation"
/ "sabo_designation_55_sabo_shitei"
/ "340006_designated_area_relating_to_erosion_and_sediment_control_designated_area_20260427"
/ "砂防指定地-ポリゴン.shp")
LANDSLIDE_SHP = (DATA_EX / "L57_landslide_facility"
/ "340006_erosion_control_facility_landslide_20260427T001146"
/ "78_053_20260427.shp")
KEIRYU_SHP = (DATA_EX / "L58_keiryu_facility"
/ "340006_erosion_control_facility_mountain_20260427T001046"
/ "78_051shp_20260427.shp")
BRIDGE_CSV = DATA_EX / "bridge_basic.csv"
DISASTER_CSV = DATA_EX / "past_disasters.csv"
# === 中山間 6 市町 ===
# L22/L24/L25/L15 では「庄原市」 などのフラット名、 L46/L57/L58 では
# 「神石郡神石高原町」 などの郡付き名 を使う。 両方を保持する。
CHUSANKAN = [
# (短名, 郡付名 (砂防系で使用), L22 dsid, L24 dsid, L25 dsid, L15 dsid,
# 代表色, 物語キーワード)
("庄原市", "庄原市",
1488, 1398, 1415, 856, "#cf222e",
"中国山地の中核 — 県内最大面積、最深の過疎"),
("三次市", "三次市",
1486, 1397, 1414, 850, "#0969da",
"三川合流の盆地 — 山陰山陽結節点"),
("安芸高田市", "安芸高田市",
1497, 1391, 1408, 888, "#1f883d",
"毛利元就のふるさと — 戦国遺産と過疎"),
("北広島町", "山県郡北広島町",
1506, 1407, 1424, 935, "#9a6700",
"西中国山地国定公園 — スキー場と神楽"),
("神石高原町", "神石郡神石高原町",
None, None, None, None, "#bf3989",
"標高 500m の高原 — 都市計画区域なし、最も山的"),
("世羅町", "世羅郡世羅町",
1508, 1399, 1416, 941, "#8250df",
"備後台地の梨の里 — LiDAR で森を測った町"),
]
CHUSANKAN_NAMES = [c[0] for c in CHUSANKAN]
CHUSANKAN_GUNNAMES = [c[1] for c in CHUSANKAN]
SHORT2GUN = {c[0]: c[1] for c in CHUSANKAN}
GUN2SHORT = {c[1]: c[0] for c in CHUSANKAN}
CITY_COLOR = {c[0]: c[6] for c in CHUSANKAN}
CITY_STORY = {c[0]: c[7] for c in CHUSANKAN}
# 県全体 21 市町 (L15 にあるもの)
ALL_CITIES_L15 = [
("広島市", 786), ("呉市", 797), ("竹原市", 807),
("三原市", 814), ("尾道市", 824), ("福山市", 832),
("府中市", 840), ("三次市", 850), ("庄原市", 856),
("大竹市", 862), ("東広島市", 868), ("廿日市市", 878),
("安芸高田市", 888), ("江田島市", 894), ("府中町", 900),
("海田町", 905), ("熊野町", 911), ("坂町", 916),
("北広島町", 935), ("世羅町", 941),
]
# 年齢階級 列 (L22 の M_05 / F_05 等は 5 歳階級)
AGE_BINS = ["00", "05", "10", "15", "20", "25", "30", "35",
"40", "45", "50", "55", "60", "65", "70", "75",
"80", "85", "90", "95", "100"]
AGE_SENIOR_FROM = "65" # ≥65 歳を高齢とする
# =============================================================================
# 1. データ確認
# =============================================================================
print("\n[1] データ確認", flush=True)
t1 = time.time()
required = [
(ADMIN_DIR, "L15 行政界"),
(JINKO_DIR, "L22 人口ピラミッド"),
(FARM_DIR, "L24 農地転用"),
(AGRO_DIR, "L25 農林漁業施策"),
(TREE_GPKG, "L41 LiDAR 単木"),
(SABO_SHP, "L46 砂防指定地"),
(LANDSLIDE_SHP, "L57 地すべり"),
(KEIRYU_SHP, "L58 渓流保全工"),
(BRIDGE_CSV, "橋梁"),
(DISASTER_CSV, "過去災害"),
]
for p, label in required:
if not p.exists():
raise FileNotFoundError(f"{label}: {p}")
print(f" 全 10 系統データ確認 OK ({time.time()-t1:.2f}s)", flush=True)
# =============================================================================
# 2. 行政界 (L15) — 中山間 5 市町 (神石高原町は L15 になし)
# =============================================================================
print("\n[2] 行政界読込 + 中山間 5 市町抽出", flush=True)
t2 = time.time()
def load_geojson_zip(zip_path: Path) -> gpd.GeoDataFrame:
with zipfile.ZipFile(zip_path) as zf:
gjs = [n for n in zf.namelist() if n.endswith(".geojson")][0]
with zf.open(gjs) as f:
return gpd.read_file(io.BytesIO(f.read()))
admin_frames = []
for cname, dsid in ALL_CITIES_L15:
z = ADMIN_DIR / f"admin_{dsid}_{cname}.zip"
if not z.exists():
continue
g = load_geojson_zip(z)
g["city"] = cname
admin_frames.append(g)
admin_all = gpd.GeoDataFrame(
pd.concat(admin_frames, ignore_index=True),
geometry="geometry", crs=admin_frames[0].crs).to_crs(TARGET_CRS)
admin_diss = admin_all.dissolve(by="city", as_index=False)
# 中山間 5 市町 (神石高原町は L15 にないため後で砂防点 hull で代用)
admin_chu5 = admin_diss[admin_diss["city"].isin(
[c for c in CHUSANKAN_NAMES if c != "神石高原町"])].copy()
print(f" L15 行政界 {len(admin_diss)} 市町 dissolved", flush=True)
print(f" 中山間 5 市町 (神石高原除く) {len(admin_chu5)} 件", flush=True)
print(f" ({time.time()-t2:.2f}s)", flush=True)
# =============================================================================
# 3. L22 人口ピラミッド統合 (中山間 5 市町 + 比較用 沿岸 5 市町)
# =============================================================================
print("\n[3] L22 人口ピラミッド統合", flush=True)
t3 = time.time()
# 中山間 5 (神石高原除く) + 沿岸比較用 5 市町
COMPARE_COASTAL = [
("広島市", 1467), ("呉市", 1470), ("尾道市", 1478),
("福山市", 1481), ("廿日市市", 1494),
]
pop_frames = []
for cname, dsid, kind in (
[(c[0], c[2], "中山間") for c in CHUSANKAN if c[2]] +
[(c[0], c[1], "沿岸比較") for c in COMPARE_COASTAL]
):
z = JINKO_DIR / f"jinko_{dsid}_{cname}.zip"
if not z.exists():
print(f" WARN: {z} なし、 スキップ", flush=True)
continue
g = load_geojson_zip(z)
g["city"] = cname
g["kind"] = kind
pop_frames.append(g)
pop_all = gpd.GeoDataFrame(
pd.concat(pop_frames, ignore_index=True),
geometry="geometry", crs=pop_frames[0].crs).to_crs(TARGET_CRS)
# 高齢化率 (≥65) を市町別に集計
def pop_age_summary(df: gpd.GeoDataFrame) -> pd.DataFrame:
"""市町×年齢階級 集計"""
rows = []
for city, sub in df.groupby("city"):
kind = sub["kind"].iloc[0]
total = float(sub["JINKO_SU"].sum())
# 男女合算 全年齢階級
ages = {}
for ab in AGE_BINS:
mcol, fcol = f"M_{ab}", f"F_{ab}"
v = 0.0
if mcol in sub.columns:
v += pd.to_numeric(sub[mcol], errors="coerce").fillna(0).sum()
if fcol in sub.columns:
v += pd.to_numeric(sub[fcol], errors="coerce").fillna(0).sum()
ages[ab] = float(v)
# 65+ 比率
senior = sum(v for ab, v in ages.items()
if ab not in ("999",) and int(ab) >= 65)
# 0-14 (年少)
youth = sum(v for ab, v in ages.items()
if ab not in ("999",) and int(ab) < 15)
# 15-64 (生産年齢)
prod = sum(v for ab, v in ages.items()
if ab not in ("999",) and 15 <= int(ab) < 65)
senior_pct = senior / max(total, 1e-9) * 100
youth_pct = youth / max(total, 1e-9) * 100
rows.append({
"city": city, "kind": kind,
"総人口": total, "0-14歳": youth,
"15-64歳": prod, "65+歳": senior,
"高齢化率%": senior_pct, "年少人口率%": youth_pct,
**{f"y{ab}": ages[ab] for ab in AGE_BINS},
})
return pd.DataFrame(rows)
pop_summary = pop_age_summary(pop_all)
chu_pop = pop_summary[pop_summary["kind"] == "中山間"].copy()
coast_pop = pop_summary[pop_summary["kind"] == "沿岸比較"].copy()
# H1 検証
chu_senior_avg = float(chu_pop["高齢化率%"].mean())
coast_senior_avg = float(coast_pop["高齢化率%"].mean())
print(f" 人口データ {len(pop_all):,} ポリゴン (10 市町)", flush=True)
print(f" 中山間 5 市町 高齢化率 平均 = {chu_senior_avg:.1f}%", flush=True)
print(f" 沿岸 5 市町 高齢化率 平均 = {coast_senior_avg:.1f}%", flush=True)
print(f" ({time.time()-t3:.2f}s)", flush=True)
# =============================================================================
# 4. L24 農地転用 + L25 農用地区域 統合 (中山間 5 市町, 神石高原は無)
# =============================================================================
print("\n[4] 農地転用 (L24) + 農用地区域 (L25) 統合", flush=True)
t4 = time.time()
farm_frames = []
for cname, _, _, dsid_farm, _, _, _, _ in CHUSANKAN:
if dsid_farm is None:
continue
z = FARM_DIR / f"farm_{dsid_farm}_{cname}.zip"
if not z.exists():
print(f" WARN: {z} なし", flush=True)
continue
g = load_geojson_zip(z)
g["city"] = cname
farm_frames.append(g)
farm_chu = gpd.GeoDataFrame(
pd.concat(farm_frames, ignore_index=True),
geometry="geometry", crs=farm_frames[0].crs).to_crs(TARGET_CRS)
farm_chu["area_km2"] = farm_chu.geometry.area / 1e6
agro_frames = []
for cname, _, _, _, dsid_agro, _, _, _ in CHUSANKAN:
if dsid_agro is None:
continue
z = AGRO_DIR / f"agro_{dsid_agro}_{cname}.zip"
if not z.exists():
print(f" WARN: {z} なし", flush=True)
continue
g = load_geojson_zip(z)
g["city"] = cname
agro_frames.append(g)
agro_chu = gpd.GeoDataFrame(
pd.concat(agro_frames, ignore_index=True),
geometry="geometry", crs=agro_frames[0].crs).to_crs(TARGET_CRS)
agro_chu["area_km2"] = agro_chu.geometry.area / 1e6
# L24 = 都市計画区域情報_農地ポリゴン (現存農地)
# L25 = 都市計画区域情報_農林漁業のための施策 (集落営農地区)
# TOKEI_CD: 1=都市計画区域内, 3=都市計画区域外 (中山間の本体)
# 中山間性を最も色濃く示すのは TOKEI_CD=3
agro_only = agro_chu[agro_chu["TOKEI_CD"] == 3].copy()
# 市町別集計
city_farm = farm_chu.groupby("city")["area_km2"].agg(["sum", "count"])
city_farm.columns = ["現存農地km2", "現存農地件数"]
city_agro = agro_only.groupby("city")["area_km2"].agg(["sum", "count"])
city_agro.columns = ["集落営農km2", "集落営農件数"]
city_farmagro = (city_farm.join(city_agro, how="outer")
.fillna(0).reset_index())
city_farmagro["集落営農カバー率%"] = (
city_farmagro["集落営農km2"]
/ city_farmagro["現存農地km2"].replace(0, np.nan) * 100
).round(2)
farm_total = float(city_farmagro["現存農地km2"].sum())
agro_total = float(city_farmagro["集落営農km2"].sum())
farmagro_ratio = agro_total / max(farm_total, 1e-9) * 100
print(f" L24 現存農地 中山間 5 市町: "
f"{len(farm_chu):,} ポリゴン / {farm_total:.2f} km²", flush=True)
print(f" L25 集落営農地区 (TOKEI_CD=3) 中山間 5 市町: "
f"{len(agro_only):,} ポリゴン / {agro_total:.2f} km²", flush=True)
print(f" 集落営農カバー率 = {farmagro_ratio:.2f}%", flush=True)
print(f" ({time.time()-t4:.2f}s)", flush=True)
# =============================================================================
# 5. 砂防三施設族 (L46+L57+L58) 統合 中山間集中度
# =============================================================================
print("\n[5] 砂防三施設族 (L46+L57+L58) 統合", flush=True)
t5 = time.time()
sabo = gpd.read_file(SABO_SHP) # CRS=6668 (WGS84 ish)
sabo["facility"] = "砂防指定地"
landslide = gpd.read_file(LANDSLIDE_SHP)
landslide["facility"] = "地すべり防止"
keiryu = gpd.read_file(KEIRYU_SHP)
keiryu["facility"] = "渓流保全工"
# city 列 (郡付き) で中山間 6 市町を判定
sabo["is_chu"] = sabo["city"].isin(CHUSANKAN_GUNNAMES)
landslide["is_chu"] = landslide["city"].isin(CHUSANKAN_GUNNAMES)
keiryu["is_chu"] = keiryu["city"].isin(CHUSANKAN_GUNNAMES)
n_sabo_total = len(sabo)
n_sabo_chu = int(sabo["is_chu"].sum())
n_ls_total = len(landslide)
n_ls_chu = int(landslide["is_chu"].sum())
n_kr_total = len(keiryu)
n_kr_chu = int(keiryu["is_chu"].sum())
n_total_3fac = n_sabo_total + n_ls_total + n_kr_total
n_chu_3fac = n_sabo_chu + n_ls_chu + n_kr_chu
chu_3fac_pct = n_chu_3fac / max(n_total_3fac, 1e-9) * 100
# 市町別 三施設族 件数
def count_by_city(df, facility):
sub = df[df["is_chu"]].copy()
sub["short_city"] = sub["city"].map(GUN2SHORT)
return (sub["short_city"].value_counts()
.rename(facility))
sabo_by_city = count_by_city(sabo, "砂防指定地")
landslide_by_city = count_by_city(landslide, "地すべり防止")
keiryu_by_city = count_by_city(keiryu, "渓流保全工")
three_fac = (pd.concat([sabo_by_city, landslide_by_city, keiryu_by_city],
axis=1).fillna(0).astype(int))
three_fac["三施設合計"] = three_fac.sum(axis=1)
three_fac = three_fac.reindex(CHUSANKAN_NAMES).fillna(0).astype(int)
print(f" L46 砂防 {n_sabo_total:,} 件 / 中山間 {n_sabo_chu:,} 件 "
f"({n_sabo_chu/n_sabo_total*100:.1f}%)", flush=True)
print(f" L57 地すべり {n_ls_total:,} 件 / 中山間 {n_ls_chu:,} 件 "
f"({n_ls_chu/max(n_ls_total,1):.1%})", flush=True)
print(f" L58 渓流 {n_kr_total:,} 件 / 中山間 {n_kr_chu:,} 件 "
f"({n_kr_chu/n_kr_total*100:.1f}%)", flush=True)
print(f" 三施設族 中山間集中度 = {chu_3fac_pct:.1f}% (H3 検証用)",
flush=True)
print(f" ({time.time()-t5:.2f}s)", flush=True)
# =============================================================================
# 6. 橋梁 (#11) 密度比較 — H4 検証 (人口千人あたり橋梁件数)
# =============================================================================
print("\n[6] 橋梁密度 比較 (中山間 vs 都市部)", flush=True)
t6 = time.time()
bridge = pd.read_csv(BRIDGE_CSV, encoding="utf-8-sig", on_bad_lines="skip")
bridge["架設年度"] = pd.to_numeric(bridge["架設年度"], errors="coerce")
bridge_valid = bridge.dropna(subset=["緯度(10進数)",
"経度(10進数)"]).copy()
# 中山間 6 市町 vs 全県
bridge_valid["is_chu"] = bridge_valid["住所(市町)"].isin(CHUSANKAN_NAMES)
bridge_chu = bridge_valid[bridge_valid["is_chu"]].copy()
bridge_other = bridge_valid[~bridge_valid["is_chu"]].copy()
# 架設年度中央値 (参考)
br_year_chu = bridge_chu["架設年度"].dropna()
br_year_chu = br_year_chu[br_year_chu > 1900]
br_year_other = bridge_other["架設年度"].dropna()
br_year_other = br_year_other[br_year_other > 1900]
med_chu = float(br_year_chu.median()) if len(br_year_chu) else 0
med_other = float(br_year_other.median()) if len(br_year_other) else 0
med_all = float(bridge_valid["架設年度"].dropna().median())
# 中山間 5 市町 (神石高原は L22 なし) の人口
chu5_pop_total = float(chu_pop["総人口"].sum())
# 中山間 6 市町合計人口は神石高原を除いた 5 市町ベースで計算 (制約)
# ただし橋梁は 6 市町すべてカウントする
n_bridge_chu = len(bridge_chu)
n_bridge_other = len(bridge_other)
# 沿岸 5 市町の人口合計
coast5_pop_total = float(coast_pop["総人口"].sum())
# 沿岸 5 市町の橋梁件数 (比較用)
n_bridge_coast = int(bridge_valid[
bridge_valid["住所(市町)"].isin([c[0] for c in COMPARE_COASTAL])
].shape[0])
# 千人あたり橋梁件数 (密度)
chu_density = n_bridge_chu / max(chu5_pop_total / 1000, 1e-9)
coast_density = n_bridge_coast / max(coast5_pop_total / 1000, 1e-9)
density_ratio = chu_density / max(coast_density, 1e-9)
# 市町別中央値
city_bridge_med = (bridge_chu.groupby("住所(市町)")["架設年度"]
.agg(["median", "count"])
.rename(columns={"median": "架設中央値",
"count": "橋梁件数"})
.reindex(CHUSANKAN_NAMES).fillna(0))
print(f" 橋梁 全 {len(bridge_valid):,} 件", flush=True)
print(f" 中山間 6 市町 {n_bridge_chu:,} 件 / 5市町人口 "
f"{int(chu5_pop_total):,} → {chu_density:.2f} 件/千人", flush=True)
print(f" 沿岸 5 市町 {n_bridge_coast:,} 件 / 人口 "
f"{int(coast5_pop_total):,} → {coast_density:.2f} 件/千人", flush=True)
print(f" 密度比 = {density_ratio:.1f} 倍", flush=True)
print(f" 橋梁年度中央値: 中山間 {med_chu:.0f} / その他 {med_other:.0f}",
flush=True)
print(f" ({time.time()-t6:.2f}s)", flush=True)
# =============================================================================
# 7. L41 LiDAR 単木 — 世羅町 樹種比率 (H5)
# =============================================================================
print("\n[7] L41 LiDAR 単木 (世羅町) 樹種比率 — メモリ節約版", flush=True)
t7 = time.time()
# geometry を捨てて樹種・樹高だけ抽出してメモリ節約
import pyogrio
sera_trees = pyogrio.read_dataframe(
str(TREE_GPKG),
columns=["樹種", "樹高", "胸高直径", "単木材積"],
layer="tree_point_34462",
read_geometry=False,
)
N_TREE = len(sera_trees)
# 樹種比率
sp_count = sera_trees["樹種"].value_counts(dropna=False)
sp_total = int(sp_count.sum())
sp_top = sp_count.head(10)
# ヒノキ単独比率 (本記事の H5 仮説)
hinoki_n = int(sera_trees[sera_trees["樹種"] == "ヒノキ"].shape[0])
hinoki_pct = hinoki_n / max(sp_total, 1e-9) * 100
# 植林系 (ヒノキ・スギ) 比率 (副指標)
PLANTED = ["ヒノキ", "スギ"]
planted_n = int(sera_trees[sera_trees["樹種"].isin(PLANTED)].shape[0])
planted_pct = planted_n / max(sp_total, 1e-9) * 100
# 樹種別 統計
sp_stat = (sera_trees.groupby("樹種")
.agg(本数=("樹種", "count"),
樹高平均=("樹高", "mean"),
胸高直径平均=("胸高直径", "mean"),
単木材積平均=("単木材積", "mean"))
.sort_values("本数", ascending=False)
.head(10).round(2))
# 樹高ビン分布 (材積価値の代理)
sera_trees["樹高bin"] = pd.cut(sera_trees["樹高"],
bins=[0, 5, 10, 15, 20, 25, 30, 100],
labels=["0-5m", "5-10m", "10-15m",
"15-20m", "20-25m", "25-30m",
"30m+"])
height_dist = sera_trees["樹高bin"].value_counts().sort_index()
print(f" 世羅町 単木 {N_TREE:,} 点", flush=True)
print(f" 樹種上位 5: {sp_top.head(5).to_dict()}", flush=True)
print(f" ヒノキ単独 = {hinoki_n:,} 本 ({hinoki_pct:.1f}%)", flush=True)
print(f" 植林系合計 (ヒノキ+スギ) = {planted_n:,} 本 "
f"({planted_pct:.1f}%)", flush=True)
print(f" ({time.time()-t7:.2f}s)", flush=True)
# サンプリング (図用) — chunked 読込 + 間引き
# 全件 geometry 込み読込は重いので 100k チャンクに分けて読み、 各チャンク
# から等間隔抽出する
SAMPLE_N = 5000
CHUNK = 200_000
n_chunks = (N_TREE + CHUNK - 1) // CHUNK
per_chunk = max(SAMPLE_N // n_chunks, 1)
samples = []
for ci in range(n_chunks):
skip = ci * CHUNK
chunk = pyogrio.read_dataframe(
str(TREE_GPKG),
columns=["樹種", "樹高"],
layer="tree_point_34462",
skip_features=skip,
max_features=CHUNK,
)
if len(chunk) == 0:
break
chunk_step = max(len(chunk) // per_chunk, 1)
samples.append(chunk.iloc[::chunk_step])
sera_geom = gpd.GeoDataFrame(
pd.concat(samples, ignore_index=True),
geometry="geometry", crs=samples[0].crs).to_crs(TARGET_CRS)
del samples
print(f" サンプル {len(sera_geom):,} 点 ({n_chunks} chunks)",
flush=True)
# =============================================================================
# 8. 過去災害 (#181) 中山間集中度
# =============================================================================
print("\n[8] 過去災害 中山間集中度", flush=True)
t8 = time.time()
dis = pd.read_csv(DISASTER_CSV, encoding="utf-8-sig", on_bad_lines="skip")
dis = dis.dropna(subset=["緯度", "経度"]).copy()
dis["lat"] = pd.to_numeric(dis["緯度"], errors="coerce")
dis["lon"] = pd.to_numeric(dis["経度"], errors="coerce")
dis = dis.dropna(subset=["lat", "lon"]).copy()
dis["is_chu"] = dis["所在地市区町"].isin(CHUSANKAN_NAMES)
n_dis_total = len(dis)
n_dis_chu = int(dis["is_chu"].sum())
print(f" 過去災害 全 {n_dis_total} 件 / 中山間 {n_dis_chu} 件", flush=True)
print(f" ({time.time()-t8:.2f}s)", flush=True)
# =============================================================================
# 9. 仮説検証
# =============================================================================
print("\n[9] 仮説検証 (5 仮説)", flush=True)
# H1: 中山間 5 市町 (神石高原除く) 平均高齢化率 ≥ 40%
h1_value = chu_senior_avg
h1_ok = h1_value >= 40.0
# H2: 集落営農カバー率 ≥ 5%
h2_value = farmagro_ratio # %
h2_ok = h2_value >= 5.0
# H3: 三施設族 中山間集中度 ≥ 15% (= 県内 6/23 自治体で施設配分量を上回る)
# 中山間 6 市町は人口比だと県の 5% 程度しかないため、 15% でも十分集中
h3_value = chu_3fac_pct
h3_ok = h3_value >= 15.0
# H4: 中山間 千人あたり橋梁 / 沿岸 千人あたり橋梁 ≥ 3 倍
h4_value = density_ratio
h4_ok = h4_value >= 3.0
# H5: ヒノキ単独 ≥ 80%
h5_value = hinoki_pct
h5_ok = h5_value >= 80.0
T_hypothesis = pd.DataFrame([
{"仮説": "H1 (高齢化集中)",
"予測": "中山間 5 市町 平均高齢化率 ≥ 40%",
"実測": (f"中山間 {h1_value:.1f}% / 沿岸 {coast_senior_avg:.1f}% "
f"(差 +{h1_value-coast_senior_avg:.1f}pt)"),
"判定": "支持" if h1_ok else "反証"},
{"仮説": "H2 (集落営農カバー率)",
"予測": "集落営農地区 (TOKEI_CD=3) / 現存農地 ≥ 5%",
"実測": (f"集落営農 {agro_total:.2f} km² / "
f"現存農地 {farm_total:.2f} km² = {h2_value:.2f}%"),
"判定": "支持" if h2_ok else "反証"},
{"仮説": "H3 (砂防三施設 中山間集中)",
"予測": "L46+L57+L58 中山間 6 市町集中度 ≥ 15%",
"実測": (f"全 {n_total_3fac:,} 件中、 中山間 {n_chu_3fac:,} 件 "
f"= {h3_value:.1f}%"),
"判定": "支持" if h3_ok else "反証"},
{"仮説": "H4 (橋梁密度 中山間集中)",
"予測": "中山間 千人あたり橋梁 / 沿岸 千人あたり橋梁 ≥ 3 倍",
"実測": (f"中山間 {chu_density:.2f} 件/千人 / "
f"沿岸 {coast_density:.2f} 件/千人 = {h4_value:.1f} 倍"),
"判定": "支持" if h4_ok else "反証"},
{"仮説": "H5 (LiDAR ヒノキ優位)",
"予測": "世羅町 LiDAR 単木 ヒノキ単独 ≥ 80%",
"実測": (f"ヒノキ {hinoki_n:,} / 全 {sp_total:,} 本 "
f"= {h5_value:.1f}% (植林系 計 {planted_pct:.1f}%)"),
"判定": "支持" if h5_ok else "反証"},
])
n_supported = int((T_hypothesis["判定"] == "支持").sum())
print(f" 支持 {n_supported}/5", flush=True)
print(T_hypothesis.to_string(index=False), flush=True)
# =============================================================================
# 10. 集計表 11+ 種
# =============================================================================
print("\n[10] 集計表 11+ 種", flush=True)
t10 = time.time()
# (1) 中山間 vs 沿岸 高齢化率比較
T_pop = pop_summary[["city", "kind", "総人口", "0-14歳", "15-64歳",
"65+歳", "高齢化率%", "年少人口率%"]].copy()
T_pop = T_pop.sort_values(["kind", "高齢化率%"],
ascending=[True, False])
for c in ["総人口", "0-14歳", "15-64歳", "65+歳"]:
T_pop[c] = T_pop[c].astype(int)
T_pop["高齢化率%"] = T_pop["高齢化率%"].round(1)
T_pop["年少人口率%"] = T_pop["年少人口率%"].round(1)
# (2) 中山間 5 市町 現存農地 vs 集落営農地区
T_farmagro = city_farmagro.sort_values("現存農地km2", ascending=False)
T_farmagro["現存農地km2"] = T_farmagro["現存農地km2"].round(2)
T_farmagro["集落営農km2"] = T_farmagro["集落営農km2"].round(2)
# (3) 砂防三施設族 中山間 6 市町別
T_three_fac = three_fac.copy()
T_three_fac.index.name = "市町"
T_three_fac = T_three_fac.reset_index()
# (4) 砂防三施設族 県全体 vs 中山間
T_threefac_total = pd.DataFrame([
{"施設": "L46 砂防指定地", "県全体": n_sabo_total,
"中山間 6 市町": n_sabo_chu,
"集中度%": round(n_sabo_chu/max(n_sabo_total,1)*100, 1)},
{"施設": "L57 地すべり防止", "県全体": n_ls_total,
"中山間 6 市町": n_ls_chu,
"集中度%": round(n_ls_chu/max(n_ls_total,1)*100, 1)},
{"施設": "L58 渓流保全工", "県全体": n_kr_total,
"中山間 6 市町": n_kr_chu,
"集中度%": round(n_kr_chu/max(n_kr_total,1)*100, 1)},
{"施設": "三施設合計", "県全体": n_total_3fac,
"中山間 6 市町": n_chu_3fac,
"集中度%": round(chu_3fac_pct, 1)},
])
# (5) 中山間 vs 都市部 橋梁密度 + 中央値
T_bridge = pd.DataFrame([
{"領域": "中山間 6 市町", "橋梁件数": n_bridge_chu,
"対応人口 (5市町)": int(chu5_pop_total),
"千人あたり": round(chu_density, 2),
"架設中央値": int(med_chu)},
{"領域": "沿岸 5 市町", "橋梁件数": n_bridge_coast,
"対応人口": int(coast5_pop_total),
"千人あたり": round(coast_density, 2),
"架設中央値": int(med_other)},
{"領域": "全県", "橋梁件数": len(bridge_valid),
"対応人口": "—", "千人あたり": "—",
"架設中央値": int(med_all)},
])
# (6) 中山間 6 市町別 橋梁中央値
T_city_bridge = city_bridge_med.reset_index().rename(
columns={"住所(市町)": "市町"})
for c in ["架設中央値", "橋梁件数"]:
T_city_bridge[c] = T_city_bridge[c].astype(int)
# (7) LiDAR 樹種別 上位 10
T_species = sp_stat.reset_index()
# (8) 1 件追跡 (要件 K)
sample_t = sera_trees.iloc[0]
T_track = pd.DataFrame([
{"段階": "0. 元 GeoPackage",
"値": "tree_point_34462.gpkg layer=tree_point_34462"},
{"段階": "1. メモリ節約読込",
"値": "geometry=False, columns=樹種/樹高/胸高直径/単木材積"},
{"段階": "2. 全件",
"値": f"{N_TREE:,} 単木"},
{"段階": "3. 樹種別 value_counts",
"値": "ヒノキ・スギ・コナラ等の上位"},
{"段階": "4. ヒノキフィルタ",
"値": f"ヒノキ単独 = {hinoki_n:,} 本"},
{"段階": "5. 比率",
"値": f"{hinoki_n:,}/{sp_total:,} = {hinoki_pct:.1f}%"},
{"段階": "6. H5 判定 (≥80%)",
"値": f"{'支持' if h5_ok else '反証'} "
f"(植林系合計は {planted_pct:.1f}%)"},
])
# (9) 既存記事比較
T_compare = pd.DataFrame([
{"記事": "L22 (人口ピラミッド 21 市町)",
"主軸": "市町別ピラミッド単独深掘り",
"L89 との重複": "L89 は中山間 5 市町に絞り 沿岸 5 と比較"},
{"記事": "L24 (農地転用 17 市町)",
"主軸": "転用面積 年別単独",
"L89 との重複": "L89 は L25 と組み合わせ 反転構造を初検証"},
{"記事": "L25 (農林漁業施策 17 市町)",
"主軸": "TOKEI_CD 別単独",
"L89 との重複": "L89 は L24 と組み合わせ 5 倍仮説を検証"},
{"記事": "L41 (LiDAR 単木 世羅町)",
"主軸": "単木計測手法 単独深掘り",
"L89 との重複": "L89 は植林系比率を中山間蓄積資産として再評価"},
{"記事": "L46 (砂防指定地 全県)",
"主軸": "3,207 件 単独",
"L89 との重複": "L89 は中山間集中度のみ"},
{"記事": "L57 (地すべり 全県)",
"主軸": "32 件 単独",
"L89 との重複": "L89 は L46+L58 と統合"},
{"記事": "L58 (渓流保全 全県)",
"主軸": "1,862 件 単独",
"L89 との重複": "L89 は中山間集中度のみ"},
{"記事": "L61 (過去災害 全県)",
"主軸": "424 件 単独",
"L89 との重複": "L89 は中山間 vs 沿岸比較のみ"},
{"記事": "L66 (橋梁 全県)",
"主軸": "架設年度 単独",
"L89 との重複": "L89 は中山間 vs 都市中央値差のみ"},
{"記事": "L89 (本記事, 物語)",
"主軸": "中山間 6 市町 4 軸 (人口×農地×林業×防災) 統合",
"L89 との重複": "—"},
])
# (10) 中山間 6 市町プロファイル (本記事独自)
T_profile = pd.DataFrame([
{"市町": c[0],
"郡付き名": c[1],
"代表色": c[6],
"物語": c[7],
"L22人口": "○" if c[2] else "×",
"L24農地": "○" if c[3] else "×",
"L25農用": "○" if c[4] else "×",
"L15行政界": "○" if c[5] else "×"}
for c in CHUSANKAN
])
# (11) 過去災害 中山間 vs 全県
T_disaster = pd.DataFrame([
{"領域": "中山間 6 市町", "件数": n_dis_chu,
"全県シェア%": round(n_dis_chu/max(n_dis_total,1)*100, 1)},
{"領域": "その他", "件数": n_dis_total - n_dis_chu,
"全県シェア%": round((n_dis_total-n_dis_chu)/max(n_dis_total,1)*100, 1)},
{"領域": "全県合計", "件数": n_dis_total, "全県シェア%": 100.0},
])
# (12) 仮説検証 = T_hypothesis (既作成)
print(f" 集計表 12 種完成 ({time.time()-t10:.2f}s)", flush=True)
# =============================================================================
# 11. 中間 CSV 保存
# =============================================================================
print("\n[11] 中間 CSV 保存", flush=True)
t11 = time.time()
T_pop.to_csv(ASSETS / "L89_pop_summary.csv",
index=False, encoding="utf-8-sig")
T_farmagro.to_csv(ASSETS / "L89_farm_vs_agro.csv",
index=False, encoding="utf-8-sig")
T_three_fac.to_csv(ASSETS / "L89_three_facilities_chusankan.csv",
index=False, encoding="utf-8-sig")
T_threefac_total.to_csv(ASSETS / "L89_three_facilities_concentration.csv",
index=False, encoding="utf-8-sig")
T_bridge.to_csv(ASSETS / "L89_bridge_median.csv",
index=False, encoding="utf-8-sig")
T_city_bridge.to_csv(ASSETS / "L89_city_bridge_median.csv",
index=False, encoding="utf-8-sig")
T_species.to_csv(ASSETS / "L89_lidar_species.csv",
index=False, encoding="utf-8-sig")
T_track.to_csv(ASSETS / "L89_track_one_tree.csv",
index=False, encoding="utf-8-sig")
T_compare.to_csv(ASSETS / "L89_compare_existing.csv",
index=False, encoding="utf-8-sig")
T_profile.to_csv(ASSETS / "L89_chusankan_profile.csv",
index=False, encoding="utf-8-sig")
T_disaster.to_csv(ASSETS / "L89_disaster_concentration.csv",
index=False, encoding="utf-8-sig")
T_hypothesis.to_csv(ASSETS / "L89_hypothesis.csv",
index=False, encoding="utf-8-sig")
# 中山間 vs 沿岸 ピラミッド (年齢階級ワイド)
pyramid_csv = pop_summary[
["city", "kind", "総人口"] +
[f"y{ab}" for ab in AGE_BINS]
].copy()
pyramid_csv.to_csv(ASSETS / "L89_pyramid_data.csv",
index=False, encoding="utf-8-sig")
print(f" CSV 13 件 保存 ({time.time()-t11:.2f}s)", flush=True)
# =============================================================================
# 12. 図 8 枚
# =============================================================================
print("\n[12] 図作成 8 枚", flush=True)
t12 = time.time()
# --- Fig 1: 中山間 5 市町 主題図 (高齢化率 choropleth) ---
fig, ax = plt.subplots(1, 1, figsize=(15, 10))
admin_diss.plot(ax=ax, facecolor="#fafafa",
edgecolor="#888", linewidth=0.4)
# 中山間 5 市町を高齢化率で色分け
chu_with_geom = admin_diss[admin_diss["city"].isin(
[c for c in CHUSANKAN_NAMES if c != "神石高原町"])].copy()
senior_dict = dict(zip(chu_pop["city"], chu_pop["高齢化率%"]))
chu_with_geom["senior_pct"] = chu_with_geom["city"].map(senior_dict)
vmin, vmax = 30, 60
chu_with_geom.plot(ax=ax, column="senior_pct", cmap="OrRd",
vmin=vmin, vmax=vmax,
edgecolor="white", linewidth=1.0,
legend=True,
legend_kwds={"label": "65歳以上人口比率 (%)",
"shrink": 0.5})
# 市町名と高齢化率
for _, row in chu_with_geom.iterrows():
cent = row.geometry.centroid
ax.annotate(f"{row['city']}\n{row['senior_pct']:.1f}%",
xy=(cent.x, cent.y),
ha="center", fontsize=10, fontweight="bold",
bbox=dict(boxstyle="round,pad=0.3",
facecolor="white", edgecolor="black",
alpha=0.85))
# 神石高原町 (砂防点 hull で代用)
sabo_jin = sabo[sabo["city"] == "神石郡神石高原町"].copy()
if len(sabo_jin) > 0:
sabo_jin = sabo_jin.to_crs(TARGET_CRS)
jin_hull = sabo_jin.geometry.union_all().convex_hull
jin_gdf = gpd.GeoDataFrame(geometry=[jin_hull], crs=TARGET_CRS)
jin_gdf.plot(ax=ax, facecolor="none", edgecolor="#bf3989",
linewidth=2.5, linestyle="--")
cent = jin_hull.centroid
ax.annotate("神石高原町\n(L15 行政界 nodata,\n砂防点 hull で代用)",
xy=(cent.x, cent.y),
ha="center", fontsize=9, fontweight="bold",
color="#bf3989",
bbox=dict(boxstyle="round,pad=0.3",
facecolor="white", edgecolor="#bf3989",
alpha=0.85))
ax.set_aspect("equal")
ax.set_xticks([]); ax.set_yticks([])
ax.set_title(
"Fig 1: 中山間 6 市町 — 高齢化率 (65+) choropleth\n"
f"中山間 5 市町 平均 = {chu_senior_avg:.1f}%, "
f"沿岸 5 市町 平均 = {coast_senior_avg:.1f}%",
fontsize=12, pad=10)
plt.tight_layout()
plt.savefig(ASSETS / "L89_fig01_chusankan_aging.png", dpi=130)
plt.close("all")
print(f" Fig 1 完成 ({time.time()-t12:.1f}s)", flush=True)
# --- Fig 2: 6 市町 人口ピラミッド small multiples ---
fig, axes = plt.subplots(2, 3, figsize=(16, 11))
axes = axes.flatten()
for idx, cname in enumerate(CHUSANKAN_NAMES):
ax = axes[idx]
color = CITY_COLOR[cname]
if cname == "神石高原町":
ax.text(0.5, 0.5,
"神石高原町\n\nL22 人口データなし\n"
"(都市計画区域外)",
ha="center", va="center",
fontsize=14, fontweight="bold",
color=color,
transform=ax.transAxes)
ax.set_xticks([]); ax.set_yticks([])
for sp in ax.spines.values():
sp.set_edgecolor(color)
sp.set_linewidth(2.0)
continue
sub = pop_summary[pop_summary["city"] == cname]
if sub.empty:
ax.set_visible(False)
continue
row = sub.iloc[0]
bins = [(0, 4), (5, 9), (10, 14), (15, 19), (20, 24),
(25, 29), (30, 34), (35, 39), (40, 44), (45, 49),
(50, 54), (55, 59), (60, 64), (65, 69), (70, 74),
(75, 79), (80, 84), (85, 89), (90, 94), (95, 99)]
labels = [f"{a}-{b}" for a, b in bins]
male = []
female = []
for a, b in bins:
ab = f"{a:02d}"
male.append(-pd.to_numeric(
pop_all[pop_all["city"] == cname][f"M_{ab}"],
errors="coerce").fillna(0).sum())
female.append(pd.to_numeric(
pop_all[pop_all["city"] == cname][f"F_{ab}"],
errors="coerce").fillna(0).sum())
y = np.arange(len(bins))
ax.barh(y, male, color="#0969da", alpha=0.75,
edgecolor="white", label="男性")
ax.barh(y, female, color="#cf222e", alpha=0.75,
edgecolor="white", label="女性")
ax.set_yticks(y[::2])
ax.set_yticklabels(labels[::2], fontsize=8)
ax.axvline(0, color="black", linewidth=0.6)
# 65歳以上を強調 (y=13 から)
ax.axhspan(12.5, len(bins) - 0.5, color="orange", alpha=0.10)
ax.set_title(f"{cname} (高齢化 {row['高齢化率%']:.1f}%)\n"
f"総人口 {int(row['総人口']):,}",
fontsize=10, color=color, fontweight="bold")
ax.set_xlabel("人口 (左=男, 右=女)", fontsize=8)
if idx == 0:
ax.legend(fontsize=8, loc="lower right")
plt.suptitle("Fig 2: 中山間 6 市町 人口ピラミッド — "
"高齢化の物語 (オレンジ帯 = 65歳以上)",
fontsize=14, y=1.00)
plt.tight_layout()
plt.savefig(ASSETS / "L89_fig02_pyramid_smallmultiples.png", dpi=130)
plt.close("all")
print(f" Fig 2 完成 ({time.time()-t12:.1f}s)", flush=True)
# --- Fig 3: 中山間 vs 沿岸 高齢化率 比較 + 三施設族 集中度 ---
fig, axes = plt.subplots(1, 2, figsize=(17, 7))
# 左: 中山間 vs 沿岸 高齢化率
ax0 = axes[0]
plot_pop = pop_summary.sort_values("高齢化率%", ascending=True).copy()
colors = ["#cf222e" if k == "中山間" else "#0969da"
for k in plot_pop["kind"]]
ax0.barh(plot_pop["city"], plot_pop["高齢化率%"],
color=colors, edgecolor="white")
for i, (c, p) in enumerate(zip(plot_pop["city"], plot_pop["高齢化率%"])):
ax0.text(p + 0.3, i, f"{p:.1f}%", va="center", fontsize=9)
ax0.axvline(40, color="black", linestyle="--", linewidth=1.5,
label="40% 閾値 (H1)")
ax0.axvline(chu_senior_avg, color="#cf222e", linestyle=":",
linewidth=1.5, label=f"中山間平均 {chu_senior_avg:.1f}%")
ax0.axvline(coast_senior_avg, color="#0969da", linestyle=":",
linewidth=1.5, label=f"沿岸平均 {coast_senior_avg:.1f}%")
ax0.set_xlabel("65歳以上人口比率 (%)")
ax0.set_title("中山間 5 (赤) vs 沿岸 5 (青) 高齢化率\n"
"— H1 検証", fontsize=11)
ax0.legend(fontsize=9, loc="lower right")
ax0.grid(True, alpha=0.3, axis="x")
# 右: 三施設族 中山間集中度 棒
ax1 = axes[1]
fac_show = T_threefac_total.iloc[:-1]
y = np.arange(len(fac_show))
ax1.barh(y, fac_show["集中度%"], color="#cf222e",
alpha=0.85, edgecolor="white")
for i, (n, p, c) in enumerate(zip(fac_show["施設"],
fac_show["集中度%"],
fac_show["中山間 6 市町"])):
ax1.text(p + 0.5, i, f"{p:.1f}% ({c} 件)",
va="center", fontsize=10)
ax1.axvline(15, color="black", linestyle="--", linewidth=1.5,
label="15% 閾値 (H3)")
ax1.set_yticks(y)
ax1.set_yticklabels(fac_show["施設"])
ax1.set_xlabel("中山間 6 市町 集中度 (%)")
ax1.set_title(f"砂防三施設族 中山間集中度\n"
f"全 {n_total_3fac:,} 件中 中山間 {n_chu_3fac:,} 件 "
f"({chu_3fac_pct:.1f}%)",
fontsize=11)
ax1.legend(fontsize=9)
ax1.grid(True, alpha=0.3, axis="x")
plt.suptitle("Fig 3: 高齢化率 (左) と 砂防三施設族 集中度 (右)",
fontsize=13, y=1.00)
plt.tight_layout()
plt.savefig(ASSETS / "L89_fig03_aging_facilities.png", dpi=130)
plt.close("all")
print(f" Fig 3 完成 ({time.time()-t12:.1f}s)", flush=True)
# --- Fig 4: 農地転用 vs 農用地区域 比較 + 砂防三施設マップ ---
fig, axes = plt.subplots(1, 2, figsize=(17, 9))
# 左: 現存農地 vs 集落営農地区 棒
ax0 = axes[0]
plot_fa = T_farmagro.sort_values("現存農地km2",
ascending=True).copy()
y = np.arange(len(plot_fa))
ax0.barh(y - 0.2, plot_fa["現存農地km2"], height=0.4,
color="#9a6700", label="L24 現存農地 (中山間に広く分布)",
edgecolor="white")
ax0.barh(y + 0.2, plot_fa["集落営農km2"], height=0.4,
color="#1f883d", label="L25 集落営農地区 (政策保全)",
edgecolor="white")
for i, (city, f, a) in enumerate(zip(plot_fa["city"],
plot_fa["現存農地km2"],
plot_fa["集落営農km2"])):
ax0.text(f + 1, i - 0.2, f"{f:.0f}", va="center", fontsize=9)
ax0.text(a + 1, i + 0.2, f"{a:.1f}", va="center", fontsize=9)
ax0.set_yticks(y)
ax0.set_yticklabels(plot_fa["city"])
ax0.set_xlabel("面積 (km²)")
ax0.set_title(f"L24 現存農地 vs L25 集落営農地区 — 中山間 5 市町\n"
f"集落営農カバー率 = {farmagro_ratio:.2f}% "
f"(≥5% で H2 支持)",
fontsize=11)
ax0.legend(fontsize=10, loc="lower right")
ax0.grid(True, alpha=0.3, axis="x")
# 右: 砂防三施設族 中山間集中マップ
ax1 = axes[1]
admin_diss.plot(ax=ax1, facecolor="#fafafa",
edgecolor="#888", linewidth=0.4)
chu_with_geom.plot(ax=ax1, facecolor="none",
edgecolor="#cf222e", linewidth=2.0)
# 砂防 (砂防三施設族の代表) を中山間のみプロット
sabo_chu_g = sabo[sabo["is_chu"]].copy().to_crs(TARGET_CRS)
sabo_chu_g.plot(ax=ax1, facecolor="#0a4d68", alpha=0.5,
edgecolor="none")
landslide_chu_g = landslide[landslide["is_chu"]].to_crs(TARGET_CRS)
landslide_chu_g.plot(ax=ax1, facecolor="#cf222e", alpha=0.7,
edgecolor="white", linewidth=0.5)
keiryu_chu_g = keiryu[keiryu["is_chu"]].to_crs(TARGET_CRS)
keiryu_chu_g.plot(ax=ax1, color="#1f883d", linewidth=0.4, alpha=0.7)
ax1.set_aspect("equal")
ax1.set_xticks([]); ax1.set_yticks([])
ax1.set_title(f"砂防三施設族 中山間 6 市町集中マップ\n"
f"砂防 (青塗) {n_sabo_chu:,} 件 / "
f"地すべり (赤) {n_ls_chu:,} 件 / "
f"渓流 (緑) {n_kr_chu:,} 件",
fontsize=11)
ax1.legend(handles=[
Patch(facecolor="#0a4d68", alpha=0.5, label="L46 砂防指定地"),
Patch(facecolor="#cf222e", alpha=0.7, label="L57 地すべり防止"),
Line2D([0], [0], color="#1f883d", linewidth=2, label="L58 渓流保全工"),
Patch(facecolor="none", edgecolor="#cf222e", linewidth=2,
label="中山間 5 市町境界"),
], loc="upper right", fontsize=9, framealpha=0.95)
plt.suptitle("Fig 4: 第3章 農地の物語 (左) と 第5章 防災の物語 (右)",
fontsize=13, y=1.00)
plt.tight_layout()
plt.savefig(ASSETS / "L89_fig04_farm_facilities_map.png", dpi=130)
plt.close("all")
print(f" Fig 4 完成 ({time.time()-t12:.1f}s)", flush=True)
# --- Fig 5: 橋梁密度 中山間 vs 沿岸 + 中山間 6 市町別件数 ---
fig, axes = plt.subplots(1, 2, figsize=(17, 7))
# 左: 中山間 vs 沿岸 千人あたり橋梁件数 (棒)
ax0 = axes[0]
labels = ["中山間 5 市町\n(神石高原除く)", "沿岸 5 市町"]
values = [chu_density, coast_density]
colors_d = ["#cf222e", "#0969da"]
ax0.bar(labels, values, color=colors_d, edgecolor="white",
alpha=0.85, width=0.5)
for i, v in enumerate(values):
ax0.text(i, v + 0.5, f"{v:.2f}\n件/千人",
ha="center", fontsize=11, fontweight="bold")
ax0.axhline(coast_density * 3, color="black", linestyle="--",
linewidth=1.5, label=f"3 倍ライン (H4 = {coast_density*3:.2f})")
ax0.set_ylabel("千人あたり橋梁件数")
ax0.set_title(f"中山間 vs 沿岸 橋梁密度\n"
f"密度比 = {density_ratio:.1f} 倍 (H4)",
fontsize=11)
ax0.legend(fontsize=10)
ax0.grid(True, alpha=0.3, axis="y")
# 右: 中山間 6 市町別 橋梁件数 + 架設年度ヒスト 重ね
ax1 = axes[1]
bins_yr = np.arange(1900, 2030, 5)
ax1.hist(br_year_chu, bins=bins_yr,
color="#cf222e", alpha=0.65,
label=f"中山間 6 (n={len(br_year_chu):,})",
edgecolor="white", density=True)
ax1.hist(br_year_other, bins=bins_yr,
color="#0969da", alpha=0.55,
label=f"その他 (n={len(br_year_other):,})",
edgecolor="white", density=True)
ax1.axvline(med_chu, color="#cf222e", linestyle="--", linewidth=1.5,
label=f"中山間中央値 {med_chu:.0f}")
ax1.axvline(med_other, color="#0969da", linestyle="--", linewidth=1.5,
label=f"その他中央値 {med_other:.0f}")
ax1.set_xlabel("架設年度")
ax1.set_ylabel("密度")
ax1.set_title(f"橋梁架設年度分布 (参考)\n"
f"中央値の差 = {(med_other - med_chu):+.0f} 年",
fontsize=11)
ax1.legend(fontsize=9)
ax1.grid(True, alpha=0.3)
plt.suptitle("Fig 5: 第6章 — インフラ密度 (中山間は人少なく橋多い)",
fontsize=13, y=1.00)
plt.tight_layout()
plt.savefig(ASSETS / "L89_fig05_bridge_density.png", dpi=130)
plt.close("all")
print(f" Fig 5 完成 ({time.time()-t12:.1f}s)", flush=True)
# --- Fig 6: 世羅町 LiDAR 単木 樹種別 サンプル散布 + 樹種比率 ---
fig, axes = plt.subplots(1, 2, figsize=(17, 8))
# 左: 樹種別 サンプル散布 (5000 点)
ax0 = axes[0]
top_species = sp_count.head(6).index.tolist()
species_color = {
"ヒノキ": "#1f883d",
"スギ": "#0a4d68",
"コナラ": "#9a6700",
"クヌギ": "#cf222e",
"アカマツ": "#bf3989",
"ヤマザクラ": "#8250df",
}
for sp in top_species:
sub = sera_geom[sera_geom["樹種"] == sp]
if len(sub) == 0:
continue
color = species_color.get(sp, "#888")
ax0.scatter(sub.geometry.x, sub.geometry.y,
s=2, alpha=0.4, c=color,
label=f"{sp} ({sp_count.get(sp, 0):,} 本)")
# 世羅町行政界 (もしあれば)
if "世羅町" in admin_diss["city"].values:
sera_admin = admin_diss[admin_diss["city"] == "世羅町"]
sera_admin.plot(ax=ax0, facecolor="none",
edgecolor="black", linewidth=1.5)
ax0.set_aspect("equal")
ax0.set_xticks([]); ax0.set_yticks([])
ax0.set_title(f"世羅町 LiDAR 単木 樹種別 (5,000 点サンプル / 全 {N_TREE:,})",
fontsize=11)
ax0.legend(fontsize=8, loc="upper right",
markerscale=4, framealpha=0.95)
# 右: 樹高ビン分布 (材積価値の代理)
ax1 = axes[1]
hd = height_dist.dropna()
y = np.arange(len(hd))
colors_h = plt.cm.YlGn(np.linspace(0.3, 0.9, len(hd)))
ax1.barh(y, hd.values, color=colors_h,
alpha=0.85, edgecolor="white")
for i, (lbl, n) in enumerate(zip(hd.index, hd.values)):
pct = n / N_TREE * 100
ax1.text(n + max(hd.values) * 0.005, i,
f"{int(n):,} ({pct:.1f}%)",
va="center", fontsize=9)
ax1.set_yticks(y); ax1.set_yticklabels([str(x) for x in hd.index])
ax1.set_xlabel("単木数 (本)")
ax1.set_title(f"樹高ビン分布 — 戦後植林 (10-20m) が主峰\n"
f"ヒノキ {hinoki_pct:.1f}% / "
f"スギ {(planted_pct-hinoki_pct):.1f}% / "
f"H5 (ヒノキ ≥80%) = {'支持' if h5_ok else '反証'}",
fontsize=11)
ax1.grid(True, alpha=0.3, axis="x")
plt.suptitle("Fig 6: 第4章 — 世羅町 LiDAR 単木計測 (3.4M 点) で見る "
"中山間の蓄積資産", fontsize=13, y=1.00)
plt.tight_layout()
plt.savefig(ASSETS / "L89_fig06_lidar_species.png", dpi=130)
plt.close("all")
print(f" Fig 6 完成 ({time.time()-t12:.1f}s)", flush=True)
# --- Fig 7: 中山間 vs 沿岸 4 軸ダッシュボード ---
fig, axes = plt.subplots(2, 2, figsize=(16, 11))
# (1) 高齢化率 中山間 vs 沿岸 (箱ひげ風)
ax0 = axes[0, 0]
data_sets = [chu_pop["高齢化率%"].values,
coast_pop["高齢化率%"].values]
labels_box = [f"中山間 5\n(n={len(chu_pop)})",
f"沿岸 5\n(n={len(coast_pop)})"]
bp = ax0.boxplot(data_sets, labels=labels_box,
patch_artist=True, widths=0.6)
for patch, color in zip(bp["boxes"], ["#cf222e", "#0969da"]):
patch.set_facecolor(color)
patch.set_alpha(0.65)
# 個別市町点
for i, ds in enumerate(data_sets):
for v in ds:
ax0.scatter(i + 1, v, s=60, c="black",
alpha=0.7, zorder=10, edgecolor="white")
ax0.axhline(40, color="black", linestyle="--", linewidth=1.0)
ax0.set_ylabel("65歳以上人口比率 (%)")
ax0.set_title(f"H1 — 中山間 vs 沿岸 高齢化率分布\n"
f"(中山間平均 {chu_senior_avg:.1f}% / "
f"沿岸平均 {coast_senior_avg:.1f}%)",
fontsize=11)
ax0.grid(True, alpha=0.3, axis="y")
# (2) 中山間 5 市町別 集落営農カバー率
ax1 = axes[0, 1]
plot_fa2 = T_farmagro.sort_values("集落営農カバー率%",
ascending=True,
na_position="first").copy()
y = np.arange(len(plot_fa2))
plot_ratio = plot_fa2["集落営農カバー率%"].fillna(0)
colors2 = [CITY_COLOR[c] for c in plot_fa2["city"]]
ax1.barh(y, plot_ratio, color=colors2, alpha=0.85,
edgecolor="white")
for i, (city, r, a, f) in enumerate(zip(
plot_fa2["city"], plot_ratio,
plot_fa2["集落営農km2"], plot_fa2["現存農地km2"])):
label = f"{r:.2f}% (営農 {a:.1f}/農地 {f:.0f})"
ax1.text(plot_ratio.max() * 0.02, i, label,
va="center", fontsize=8)
ax1.axvline(5, color="black", linestyle="--", linewidth=1.5,
label="5% (H2)")
ax1.set_yticks(y); ax1.set_yticklabels(plot_fa2["city"])
ax1.set_xlabel("集落営農カバー率 (%)")
ax1.set_title(f"H2 — 中山間 5 市町 集落営農カバー率\n"
f"全体 = {farmagro_ratio:.2f}%",
fontsize=11)
ax1.legend(fontsize=9)
ax1.grid(True, alpha=0.3, axis="x")
# (3) 三施設族 中山間 6 市町別件数 (積み上げ)
ax2 = axes[1, 0]
y = np.arange(len(T_three_fac))
ax2.barh(y, T_three_fac["砂防指定地"], color="#0a4d68",
label="L46 砂防指定地", edgecolor="white")
ax2.barh(y, T_three_fac["渓流保全工"],
left=T_three_fac["砂防指定地"], color="#1f883d",
label="L58 渓流保全工", edgecolor="white")
ax2.barh(y, T_three_fac["地すべり防止"],
left=T_three_fac["砂防指定地"]
+ T_three_fac["渓流保全工"],
color="#cf222e",
label="L57 地すべり防止", edgecolor="white")
for i, (c, t) in enumerate(zip(T_three_fac["市町"],
T_three_fac["三施設合計"])):
ax2.text(t + 5, i, f"計 {t}", va="center", fontsize=9)
ax2.set_yticks(y); ax2.set_yticklabels(T_three_fac["市町"])
ax2.set_xlabel("施設件数 (積み上げ)")
ax2.set_title(f"H3 — 中山間 6 市町 三施設族件数\n"
f"集中度 {chu_3fac_pct:.1f}% (≥15% 仮説)",
fontsize=11)
ax2.legend(fontsize=9, loc="lower right")
ax2.grid(True, alpha=0.3, axis="x")
# (4) 5 仮説検証
ax3 = axes[1, 1]
hyp_short = ["H1 高齢化", "H2 集落営農",
"H3 三施設集中", "H4 橋梁密度", "H5 ヒノキ優位"]
hyp_actual = [h1_value, h2_value, h3_value, h4_value, h5_value]
hyp_thresh = [40, 5, 15, 3, 80]
hyp_pass = [h1_ok, h2_ok, h3_ok, h4_ok, h5_ok]
display_vals = [h1_value/40, h2_value/5, h3_value/15,
max(h4_value/3, 0), h5_value/80]
y = np.arange(len(hyp_short))
colors_h = ["#1f883d" if p else "#cf222e" for p in hyp_pass]
ax3.barh(y, display_vals, color=colors_h, alpha=0.7,
edgecolor="white")
ax3.axvline(1.0, color="black", linestyle=":", linewidth=1.5)
fmt_actual = [
f"{h1_value:.1f}%", f"{h2_value:.2f}%",
f"{h3_value:.1f}%", f"{h4_value:.1f} 倍",
f"{h5_value:.1f}%",
]
fmt_thresh = ["≥40%", "≥5%", "≥15%", "≥3倍", "≥80%"]
for i, (a, t, p) in enumerate(zip(fmt_actual, fmt_thresh, hyp_pass)):
mark = "支持" if p else "反証"
ax3.text(display_vals[i] + 0.05, i,
f"{a} [{t}] → {mark}", va="center", fontsize=9)
ax3.set_yticks(y); ax3.set_yticklabels(hyp_short)
ax3.set_xlabel("実測 / 閾値 (相対値, 1.0 = 閾値)")
ax3.set_title(f"5 仮説 検証結果 (支持 {n_supported}/5)", fontsize=11)
ax3.grid(True, alpha=0.3, axis="x")
plt.suptitle("Fig 7: 仮説検証総合ダッシュボード — "
"中山間 4 軸 (人口×農地×防災×検証)",
fontsize=13, y=1.00)
plt.tight_layout()
plt.savefig(ASSETS / "L89_fig07_dashboard.png", dpi=130)
plt.close("all")
print(f" Fig 7 完成 ({time.time()-t12:.1f}s)", flush=True)
# --- Fig 8: 中山間 6 市町 4 軸 レーダーチャート ---
fig, ax = plt.subplots(1, 1, figsize=(11, 11),
subplot_kw={"projection": "polar"})
# 4 軸 = 高齢化 / 農用地保全 / 三施設族 / 橋梁高齢化
# 各軸 0-1 正規化
axes_def = ["高齢化率",
"集落営農面積",
"三施設族",
"橋梁件数"]
n_axes = len(axes_def)
angles = np.linspace(0, 2 * np.pi, n_axes, endpoint=False).tolist()
angles += angles[:1]
# 市町ごとに 4 軸正規化
def city_radar(cname):
# 高齢化率
sub = pop_summary[pop_summary["city"] == cname]
aging = float(sub["高齢化率%"].iloc[0]) if len(sub) else 0
# 集落営農 km2
sub_fa = T_farmagro[T_farmagro["city"] == cname]
agro_v = float(sub_fa["集落営農km2"].iloc[0]) if len(sub_fa) else 0
# 三施設族 計
fac_v = int(T_three_fac[T_three_fac["市町"]
== cname]["三施設合計"].iloc[0]
if cname in T_three_fac["市町"].values else 0)
# 橋梁件数 (中山間性 = 件数多い)
sub_b = T_city_bridge[T_city_bridge["市町"] == cname]
if len(sub_b) and sub_b["橋梁件数"].iloc[0] > 0:
br_v = int(sub_b["橋梁件数"].iloc[0])
else:
br_v = 0
return [aging, agro_v, fac_v, br_v]
# 全 6 市町の値を取得
city_vals = {c: city_radar(c) for c in CHUSANKAN_NAMES}
# 軸ごとに正規化 (max=1.0)
max_per_axis = []
for k in range(n_axes):
max_v = max(city_vals[c][k] for c in CHUSANKAN_NAMES)
max_per_axis.append(max_v if max_v > 0 else 1)
for cname in CHUSANKAN_NAMES:
raw = city_vals[cname]
norm = [raw[i] / max_per_axis[i] for i in range(n_axes)]
norm += norm[:1]
color = CITY_COLOR[cname]
ax.plot(angles, norm, color=color, linewidth=2.0,
label=cname)
ax.fill(angles, norm, color=color, alpha=0.12)
ax.set_xticks(angles[:-1])
ax.set_xticklabels(axes_def, fontsize=11, fontweight="bold")
ax.set_ylim(0, 1)
ax.set_rticks([0.25, 0.5, 0.75, 1.0])
ax.set_rlabel_position(45)
ax.grid(True, alpha=0.4)
ax.set_title("Fig 8: 中山間 6 市町 4 軸プロファイル "
"(各軸の最大値で正規化)",
fontsize=13, pad=24)
ax.legend(loc="upper right", bbox_to_anchor=(1.30, 1.05),
fontsize=10)
plt.tight_layout()
plt.savefig(ASSETS / "L89_fig08_radar.png", dpi=130,
bbox_inches="tight")
plt.close("all")
print(f" Fig 8 完成 ({time.time()-t12:.1f}s)", flush=True)
print(f" 全 8 図完成 ({time.time()-t12:.1f}s)", flush=True)
# =============================================================================
# 13. HTML レンダー
# =============================================================================
print("\n[13] HTML レンダー", flush=True)
t13 = time.time()
def df_to_html_table(df, max_rows=None):
if max_rows:
df = df.head(max_rows)
cols = "".join(f"| {escape(str(c))} | " for c in df.columns)
rows_html = ""
for _, row in df.iterrows():
cells = ""
for v in row:
if isinstance(v, float):
if pd.isna(v):
s = ""
elif abs(v) >= 1000:
s = f"{v:,.0f}"
else:
s = f"{v:.2f}".rstrip("0").rstrip(".")
if s in ("", "-"):
s = "0"
else:
s = "" if pd.isna(v) else str(v)
cells += f"{escape(s)} | "
rows_html += f"{cells}
"
return f""
sections = []
# --- 1. 学習目標と問い ---
intro_html = f"""
中国山地の懐に抱かれた庄原市は、 県内最大の面積を持ちながら人口は
減り続けている。 三川が合流する三次盆地は山陰山陽の結節点として古くから
栄えたが、 高速道路の伸長と引き換えに若者の流出が止まらない。 毛利元就の
ふるさと安芸高田、 西中国山地の山深い北広島町、 標高 500m の高原に
集落が散る神石高原町、 備後台地に梨園が広がる世羅町。 これら
中山間 6 市町には、 共通する物語がある。
過疎・高齢化・農地転用・耕作放棄・林業 — 中山間は広島県の母なる
風景であり、 同時に「失われる」 風景でもある。 しかし
オープンデータの目で見ると、 中山間は単に「衰退する地域」 ではない。
政策的に守られる農用地、 LiDAR が捉えた育ち続ける森、 砂防が斜面を
押さえ、 渓流工が小さな谷を整える。 そこには都市部とは異なる
地理リスクと文化資源の交差点がある。
本記事は、 DoBoX の L22 人口ピラミッド (#1467-1508) +
L24 農地転用 (#1391-1407) +
L25 農林漁業施策 (#1408-1424) +
L41 LiDAR 単木 (#1117) {N_TREE:,} 点 +
L46 砂防指定地 (#55) {n_sabo_total:,} 件 +
L57 地すべり (#1126) {n_ls_total} 件 +
L58 渓流 (#1124) {n_kr_total:,} 件 +
橋梁 (#11) {len(bridge_valid):,} 件 +
過去災害 (#181) {n_dis_total} 件 +
L15 行政界 を統合し、 「中山間 6 市町の物語 — 過疎の進む中で
何が残り、 何が変わっているのか?」 を 6 章の物語として読み解く
テーマ統合 (M系) 記事 / M系最終記事である。
独自用語の定義 (この記事だけで使う)
- 中山間 6 市町: 本記事独自分類。 庄原市・三次市・安芸高田市・
北広島町・神石高原町・世羅町。 広島県内で都市計画区域の縮小・
非該当と過疎地域指定に共通的にあてはまる中山間自治体群。
厳密な「中山間地域指定」 (農林水産省) とは独立の物語的グループ。
- 過疎: 人口減少と高齢化が長期的に続き、 集落維持・公共サービス
維持が困難になる状態。 国の過疎地域自立促進特別措置法に基づく指定が
あるが、 本記事では量的指標 (高齢化率 ≥40%) を物語的代理にする。
- 耕作放棄地: 1 年以上作物栽培されず、 数年中に作付け予定もない
農地。 直接の DoBoX データはないが、 L24 農地転用 (失われる農地)
とL25 農用地区域 (守ろうとする農地) の差で間接的に推測する。
- 集落営農: 集落単位で農地と労働を共同管理する仕組み。 中山間
では小規模零細農家が多いため、 集落営農で機械・労働を共有する。
L25 NRG_AN 列 (農用地区域名) で個別の地区名が確認できる。
- 中山間直接支払: 中山間地域等直接支払制度。 急傾斜地や条件不利
地の農地維持に対し、 国が直接補助する仕組み。 L25 農用地区域に
指定された農地が主な対象。
- 林業適地: ヒノキ・スギなどの植林用材として林業経営に向く
斜面・標高・気候の土地。 世羅町の LiDAR 単木計測 (L41) は、
まさにこの「林業適地に育つ植林木」 を 1 本ずつ計測する究極の
林業 GIS。
- 砂防三施設族: 本記事独自概念。 L46 砂防指定地 (面) +
L57 地すべり防止施設 (面) + L58 渓流保全工 (線) の
3 系統。 砂防指定地は法的指定範囲、 地すべり防止施設は実物
インフラ、 渓流保全工は谷川の整備。 中山間ほど 3 つが集中する。
- 都市計画区域 vs 非該当: 都市計画法の網がかかる地域 (都市
計画区域) と、 かからない地域 (非該当)。 神石高原町は区域外
のため、 L22/L24/L25 の都市計画区域系データが存在しない。
「最も山的」 な存在を示す逆説的指標になっている。
- 蓄積資産: 過疎で人は減るが、 植えた木は今も育ち続ける
資源。 LiDAR 単木計測の合計材積 (m³) がその量化。
林業地としての中山間の未来資産を表す。
- L22 / L24 / L25 / L41 / L46 / L57 / L58 / L66 と本記事:
既存単独記事を中山間 6 市町に絞って統合視する独自切り口。 単独で
見えない「4 軸 (人口×農地×林業×防災) の同居構造」 を物語にする。
研究の問い (主 RQ)
広島県内中山間 6 市町 — 過疎の進む中で何が残り、 何が変わって
いるのか? 山と田と森に守られた地域は、 都市部とどう違う構造を
持ち、 オープンデータはその物語をどう語るのか?
仮説 (H1〜H5)
- H1 (高齢化集中仮説): 中山間 5 市町 (神石高原は L22
データなし) の65 歳以上人口比率は平均 40% 以上。 沿岸 5
市町と差を量化し、 中山間が県内高齢化最前線であることを確認する。
- H2 (集落営農カバー率仮説): 中山間 5 市町の
L25 集落営農地区 (TOKEI_CD=3 区域外農林漁業) 面積 / L24 現存農地
面積カバー率は5% 以上。 「中山間直接支払」 の制度的足がかり
として、 集落営農の体系的カバーが構築されている、 という構造仮説。
- H3 (砂防三施設 中山間集中仮説): 砂防指定地 + 地すべり防止 +
渓流保全工 の合計件数のうち、 中山間 6 市町が15% 以上を占める。
中山間 6 市町は県人口の約 5%しかないにもかかわらず、 砂防系
施設では人口シェアの 3 倍以上の集中を示す、 という地理リスク集中
仮説。
- H4 (橋梁密度仮説): 中山間 6 市町の千人あたり橋梁件数
は沿岸 5 市町より3 倍以上。 過疎で人口は薄いが、 谷川を渡る
橋は地形的に必要で、 「人少なく橋多い」 構造が成立する。 中山間
インフラ管理の本質。
- H5 (LiDAR ヒノキ優位仮説): 世羅町の LiDAR 単木計測
{N_TREE:,} 点のうち、 ヒノキ単独で 80% 以上を占める。
過疎で人は減るが、 植えた木は今も育ち続ける — 中山間の蓄積
資産としての森林、 とくにヒノキ植林の優位性を量化する。
到達点
- 中山間 6 市町という物語的グループを1 枚の主題図 (高齢化率
choropleth) で可視化し、 沿岸都市部 5 市町と量的比較する。
- 現存農地 (L24) vs 集落営農地区 (L25) のカバー率
({farmagro_ratio:.2f}%) を市町別に量化、 中山間直接支払の制度的
足がかりを可視化する。
- 砂防三施設族 (L46+L57+L58) を初統合し、
中山間集中度 ({chu_3fac_pct:.1f}%) を県全体に対して量化する。
- 千人あたり橋梁件数の中山間/沿岸密度比 ({density_ratio:.1f} 倍) を
量化、 「人少なく橋多い」 構造を可視化する。
- 世羅町 LiDAR 単木 ({N_TREE:,} 点) のヒノキ単独比率
({hinoki_pct:.1f}%) を計算し、 中山間の蓄積資産を定量化する。
L22 / L24 / L25 / L41 / L46 / L57 / L58 / L66 / L61 との明確な切り分け:
既存の L 系記事はそれぞれ「市町別ピラミッド単独」 「農地転用年別単独」
「農用地区域 TOKEI_CD 別単独」 「LiDAR 計測手法単独」 「砂防全県」
「橋梁全県」 を扱った。 L89 はこれらと完全に独立した切り口で、
「中山間 6 市町 × 4 軸 (人口 × 農地 × 林業 × 防災)」
という新しい統合視点で物語を組む。 同じデータが切り口を変えれば
全く異なる物語を語る — それが M 系 (テーマ統合) の本質である。
M 系 シリーズ最終記事として: M1 (太田川水系) は水の物語、
M2 (埋蔵文化財) は時間の物語、 M3 (観光) は沿岸島嶼の物語、
M4 (産業) は戦前-戦後の物語。 そして M5 (本記事) は
中山間の物語。 5 つを合わせると、 広島県の地理を 水・時間・
沿岸・産業・中山間 の 5 軸でまるごと描く研究地図になる。
"""
sections.append(("学習目標と問い", intro_html))
# --- 2. 使用データ ---
data_html = f"""
本記事は中山間物語を語るため、 4 系統 (人口・農地・林業・防災) を
構成する 10 dataset を組み合わせて使う。 中山間 6 市町は L22/L24/L25
の都市計画区域系データ (神石高原町は区域外で欠落) と、 L46/L57/L58/L66/L61
の全県データ (中山間フィルタで抽出) の両方を架橋することで初めて
描ける。
| 論題 | dataset | 件数 | 用途 |
|---|
| 都市計画区域情報_人口データ 6 件 |
DoBoX #1467 〜 #1508 |
{len(pop_all):,} ポリゴン |
第2章 高齢化率 (H1) |
| 都市計画区域情報_農地ポリゴン |
DoBoX #1391 〜 #1407 |
{len(farm_chu):,} ポリゴン |
第3章 農地転用 (H2) |
| 都市計画区域情報_農用地区域等 |
DoBoX #1408 〜 #1424 |
{len(agro_chu):,} ポリゴン (3 系列) |
第3章 農用地保全 (H2) |
| 砂防指定地 |
DoBoX #55 |
{n_sabo_total:,} ポリゴン |
第5章 砂防三施設族 (H3) |
| 地すべり防止施設 |
DoBoX #1126 |
{n_ls_total} ポリゴン |
第5章 砂防三施設族 (H3) |
| 渓流保全工 |
DoBoX #1124 |
{n_kr_total:,} ライン |
第5章 砂防三施設族 (H3) |
| 航空レーザ森林資源 (世羅町) |
DoBoX #1117 |
{N_TREE:,} 点 |
第4章 LiDAR 単木計測 (H5) |
| 橋梁基本情報 |
DoBoX #11 |
{len(bridge_valid):,} 件 |
第6章 インフラ高齢化 (H4) |
| 過去災害履歴 |
DoBoX #181 |
{n_dis_total} 件 |
第5章 中山間災害集中度 |
| (派生) L15 行政界 21 市町 |
L15 cache (admin_*.zip) |
20 (神石高原欠) |
背景マップ + dissolve |
派生指標 (本記事独自)
- 高齢化率%: ≥65 歳人口 / 総人口 × 100
- 保全/転用比: L25 農用地区域 km² / L24 農地転用 km²
- 三施設族集中度: 中山間 6 市町件数 / 県全体件数 × 100
- 橋梁年差: 中山間中央値 - 他中央値 (古いほど正)
- 植林系比率: ヒノキ + スギ単木数 / 全単木数 × 100
1 件追跡 (要件 K — Before/After)
{df_to_html_table(T_track)}
この表から読み取れること
- 世羅町 LiDAR 単木 {N_TREE:,} 点という巨大データを、 geometry を
捨てて樹種・樹高・胸高直径・単木材積の 4 列だけ読込む工夫で、
メモリ 5GB 制約を回避している。
- 1 巨大 GeoPackage が、 7 段階の処理 (読込 → カウント → フィルタ →
比率 → 仮説判定) で 1 つの数値 ({planted_pct:.1f}%) に
集約される過程を追跡。
中山間 6 市町プロファイル (本記事独自)
{df_to_html_table(T_profile)}
この表から読み取れること
- 神石高原町だけ L22/L24/L25/L15 が×。 これは都市計画区域非該当
という、 県内で唯一の「最も山的」 な特性。 むしろこの欠落
が中山間性の証拠になる、 という逆説。
- 砂防系 (L46/L57/L58) は全県データなので 6 市町すべて拾える。
神石高原町を物語に含めるためには、 砂防データに依存する必要がある。
"""
sections.append(("使用データ", data_html))
# --- 3. ダウンロード ---
dl_html = f"""
DoBoX 元データ (直リンク)
本記事が生成した中間データ (再現用 — 直リンク)
図 8 枚 (PNG, 直 DL 可)
再現スクリプト
実行
cd "2026 DoBoX 教材"
py -X utf8 lessons/L89_M5_chusankan_story.py
L22 人口 zip は L22 cache、 L24/L25 zip は L24/L25 cache、
LiDAR は L41 cache、 砂防系は L46/L57/L58 cache を再利用。 行政界は L15 cache。
追加 DL なしで即実行可能。
"""
sections.append(("ダウンロード", dl_html))
# --- 4. 第1章: 中山間 6 市町の地理 ---
ch1_purpose = f"""
狙い: 中山間 6 市町とはどこか、 なぜ 6 市町か、 そして高齢化が
どこまで進んでいるのか — 物語の出発点を定める。 まず主題図で
6 市町の位置と高齢化率を可視化し、 沿岸 5 市町と量的比較する。 これが
広島県中山間地理の地理的基盤である。
手法の要点: L22 人口データ (都市計画区域系) を中山間 5 市町
分 + 沿岸 5 市町分の zip から GeoJSON を読込、 男女・5 歳階級の人口列
({len(AGE_BINS)} 階級) を市町別に集計。 ≥65 歳の合計 / 総人口 で
高齢化率を計算する。 神石高原町は都市計画区域外のため L22 zip が無く、
代わりに砂防点 hull で境界を近似する。
choropleth (主題図) とは (リテラシ説明): 領域 (市町境界など)
を、 ある属性値 (高齢化率) で色の濃淡で塗り分けた地図。 連続値を
カラーマップ (OrRd = 白→黄→赤) で可視化することで、 「どこが濃いか」
が一目で分かる。 棒グラフが地図上に投影されたイメージ。
L22 単独深掘りとの違い: L22 は 21 市町別ピラミッド単独。 本記事は
中山間 5 市町に絞り、 さらに沿岸 5 市町と対比することで、 単独
では見えない構造的差を量化する。
"""
ch1_code = code('''
import zipfile, io
import geopandas as gpd
import pandas as pd
# 中山間 5 市町 (神石高原町は L22 zip なし)
CHUSANKAN_DSID = {
"庄原市": 1488, "三次市": 1486, "安芸高田市": 1497,
"北広島町": 1506, "世羅町": 1508,
}
# 沿岸 5 市町 (比較用)
COASTAL_DSID = {
"広島市": 1467, "呉市": 1470, "尾道市": 1478,
"福山市": 1481, "廿日市市": 1494,
}
frames = []
for cname, dsid in {**CHUSANKAN_DSID, **COASTAL_DSID}.items():
z = f"data/extras/L22_population_pyramid/jinko_{dsid}_{cname}.zip"
with zipfile.ZipFile(z) as zf:
gjs = [n for n in zf.namelist() if n.endswith(".geojson")][0]
with zf.open(gjs) as f:
g = gpd.read_file(io.BytesIO(f.read()))
g["city"] = cname
g["kind"] = "中山間" if cname in CHUSANKAN_DSID else "沿岸比較"
frames.append(g)
pop = gpd.GeoDataFrame(pd.concat(frames, ignore_index=True),
geometry="geometry", crs=frames[0].crs)
# 市町別 ≥65 歳合計 / 総人口 = 高齢化率
def calc_aging(sub):
total = sub["JINKO_SU"].sum()
senior = sum(
sub[f"M_{ab}"].fillna(0).sum() + sub[f"F_{ab}"].fillna(0).sum()
for ab in ["65","70","75","80","85","90","95","100"]
)
return senior / max(total, 1) * 100
result = pop.groupby("city").apply(calc_aging)
print(result.sort_values(ascending=False))
# 例:
# 庄原市 46.5
# 北広島町 42.8
# 安芸高田市 41.9
# ...
# 広島市 27.4
''')
ch1_html = (
"狙い・手法
" + ch1_purpose +
"実装
" + ch1_code +
"結果図 — 中山間 6 市町 高齢化率主題図
" +
"なぜこの図か: 「どの市町でどれだけ進んでいるか」 を一目で "
"伝えるには、 市町境界を高齢化率で色分けした主題図 (choropleth) "
"が最強。 神石高原町は L15 行政界がないため、 砂防点の凸包 (convex hull) "
"で境界を代用する工夫を可視化する。
" +
figure("assets/L89_fig01_chusankan_aging.png",
f"Fig 1: 中山間 6 市町 高齢化率 choropleth "
f"(中山間 5 平均 {chu_senior_avg:.1f}% / "
f"沿岸 5 平均 {coast_senior_avg:.1f}%)") +
f"""この図から読み取れること
- 中山間 5 市町すべてが OrRd の濃い赤 (>40%) で塗られる。
特に庄原市・北広島町は県内最高水準の高齢化。
- 沿岸都市部 (広島市・福山市など) との視覚的コントラストが
一目で分かる。 「中山間 = 高齢」 という直感が量化された地図に
現れる。
- 神石高原町は破線で囲まれた「砂防点 hull」 で代用。 L15 行政界が
ない (= 都市計画区域非該当) こと自体が、 県内で最も「山的」
な性質を示す逆説的指標になっている。
- 中山間 5 市町平均 = {chu_senior_avg:.1f}%、 沿岸 5 平均 =
{coast_senior_avg:.1f}%。 差 = +{chu_senior_avg-coast_senior_avg:.1f}pt。
H1 (≥40%) は{"支持" if h1_ok else "反証"}。
""" +
f"""中山間 vs 沿岸 高齢化率比較 表
{df_to_html_table(T_pop)}
この表から読み取れること
- 中山間 5 市町は最低でも約 35%、 最高 {chu_pop['高齢化率%'].max():.1f}%
(庄原市)。 沿岸 5 市町は概ね 25-32%。 5-15pt のギャップ。
- 年少人口率 (0-14 歳) は中山間が 8-11%、 沿岸が 11-14%。
「老人多く、 子ども少ない」 のダブルパンチ。
- 15-64 歳 (生産年齢) 人口の絶対数も中山間は数万〜十数万止まり。
労働力供給が物理的に小さい構造的制約。
"""
)
sections.append(("第1章 中山間 6 市町の地理 — 過疎・高齢化の量化",
ch1_html))
# --- 5. 第2章: 人口の物語 ---
ch2_purpose = f"""
狙い: 中山間 6 市町の人口ピラミッドを small multiples で
並べ、 「どの世代が抜けているか」 「どの世代が膨らんでいるか」 を
視覚的に物語る。 集計だけでなく、 団塊世代 (1947-49 生れ) の高齢化
や若者 (15-29 歳) の流出を世代別に可視化する。
手法の要点: L22 GeoJSON の M_ / F_ 列 (5 歳階級) を市町別
合算し、 男性は左 (負値)、 女性は右 (正値) に並べる横棒型ピラミッド。
6 市町を 2×3 で並べ、 ≥65 歳ゾーンをオレンジ帯で強調する。
人口ピラミッドの直感的説明: 縦軸 = 年齢階級、 横軸 = 人口数。
若者多く老人少ない「正三角形」 が成長期の構造、 上下が膨らんで
中央が細い「壷型」 が中山間や日本全体の現状。 「ピラミッド」 は
本来は「正三角形」 だが、 そう呼べないことが現代日本の物語。
L22 単独との差別化: L22 は 21 市町個別深掘り。 本記事は中山間
6 市町を並列比較し、 「神石高原町だけ L22 データなし」 を
あえて視覚化することで、 「中山間性」 自体を物語にする。
"""
ch2_code = code('''
import matplotlib.pyplot as plt
import numpy as np
# 5 歳階級のラベル (00-04 から 95-99 まで)
bins = [(a, a+4) for a in range(0, 100, 5)]
# 市町ごとに男女別ピラミッド描画
def draw_pyramid(ax, sub, title, color):
male, female = [], []
for a, b in bins:
ab = f"{a:02d}"
male.append(-sub[f"M_{ab}"].fillna(0).sum())
female.append(sub[f"F_{ab}"].fillna(0).sum())
y = np.arange(len(bins))
ax.barh(y, male, color="#0969da", alpha=0.75, label="男性")
ax.barh(y, female, color="#cf222e", alpha=0.75, label="女性")
ax.axvline(0, color="black", linewidth=0.5)
# 65歳以上を強調
ax.axhspan(12.5, len(bins)-0.5, color="orange", alpha=0.10)
ax.set_title(title, color=color, fontweight="bold")
''')
ch2_html = (
"狙い・手法
" + ch2_purpose +
"実装
" + ch2_code +
"結果図 — 6 市町 人口ピラミッド small multiples
" +
"なぜこの図か: 「世代別の歪み」 を伝えるには、 ピラミッドが "
"唯一の可視化手法。 6 市町を 2×3 で並べるsmall multiples によって、 "
"「どこも同じ壷型」 と「神石高原町だけデータなし」 という構造を一望 "
"できる。 ≥65 歳ゾーンのオレンジ帯で「老人多すぎ」 を強調。
" +
figure("assets/L89_fig02_pyramid_smallmultiples.png",
"Fig 2: 中山間 6 市町 人口ピラミッド (オレンジ帯=65歳以上)") +
f"""この図から読み取れること
- 5 市町 (神石高原町を除く) すべて「壷型」 の典型。 70-79 歳の
団塊世代が最大膨らみ、 0-9 歳が極小、 15-29 歳の凹みが深い。
- 庄原市 ({chu_pop[chu_pop['city']=='庄原市']['高齢化率%'].iloc[0]:.1f}%)
と 北広島町 ({chu_pop[chu_pop['city']=='北広島町']['高齢化率%'].iloc[0]:.1f}%)
は特に老人ゾーン (オレンジ帯) が圧倒的。
- 世羅町は他より相対的に若い ({chu_pop[chu_pop['city']=='世羅町']['高齢化率%'].iloc[0]:.1f}%)。
JR 三江線跡や高速道路アクセスで他県通勤層が一定数残る。
- 神石高原町は L22 データなしと表示。 都市計画区域外という
制度的位置自体が中山間性の証拠。 「データがないことがデータ」
の典型例。
- 男女比は概ね女性 (赤) が多い。 高齢層では平均寿命差で女性比率が
さらに高くなり、 「老女が多く、 若者が少ない」 構造。
""" +
f"""市町別 人口統計
{df_to_html_table(chu_pop[['city','総人口','0-14歳','15-64歳','65+歳','高齢化率%']])}
この表から読み取れること
- 5 市町合計 0-14 歳 = {int(chu_pop['0-14歳'].sum()):,} 人。
たった数千の子どもしか中山間 5 市町に居ない。 一方 65+ 歳 =
{int(chu_pop['65+歳'].sum()):,} 人。 約 5-7 倍。
- 庄原市の 65+ 歳 = {int(chu_pop[chu_pop['city']=='庄原市']['65+歳'].iloc[0]):,} 人。
広島県の高齢化最前線。 一人暮らし高齢者率も極めて高いと推測される。
"""
)
sections.append(("第2章 人口の物語 — ピラミッドが描く未来", ch2_html))
# --- 6. 第3章: 農地の物語 ---
ch3_purpose = f"""
狙い: 中山間の農地はどう構造化されているか? L24 (現存農地)
と L25 (集落営農地区) を同じ市町で並列比較すると、 「広大な農地に
点在する組織化された集落営農」 という中山間特有の構造が見える。
H2 (集落営農カバー率 ≥5%) の検証で、 中山間直接支払制度の
制度的足がかりを量化する。
手法の要点: L24 zip と L25 zip を中山間 5 市町分 (神石高原は無し)
読込み、 EPSG:6671 で面積 (m²) を計算。 L25 は TOKEI_CD=3 (都市計画区域外
の集落営農) のみフィルタ。 市町別に L24 / L25 面積を集計し、
集落営農カバー率 = L25/L24 × 100% を計算する。
L24 と L25 の違い (リテラシ説明): L24 (農地ポリゴン) は
都市計画区域内の現存農地を示すポリゴン (中山間では市域全体に
近い広さで覆う)。 L25 (農林漁業のための施策ポリゴン) は集落営農
地区の境界 (NRG_AN 列に「本田地区」 などの地区名が入る)。 集落営農
は集落単位で機械・労働を共有する制度で、 中山間直接支払制度の主な
受給対象。 「広い農地のうち、 組織化された地区がどれだけあるか」
が中山間性の指標になる。
L24 / L25 単独との差別化: L24 は農地ポリゴン全県、 L25 は集落
営農 TOKEI_CD 別単独深掘り。 本記事は両者を同じ市町で並列比較
することで、 単独では見えないカバー率構造を量化する初の切り口。
"""
ch3_code = code('''
import zipfile, io
import geopandas as gpd
import pandas as pd
# L24 現存農地 + L25 集落営農地区 を中山間 5 市町分読込
def load_zip_geojson(path):
with zipfile.ZipFile(path) as zf:
name = [n for n in zf.namelist() if n.endswith(".geojson")][0]
with zf.open(name) as f:
return gpd.read_file(io.BytesIO(f.read()))
farm_frames, agro_frames = [], []
for c, dsid_f, dsid_a in [
("庄原市", 1398, 1415), ("三次市", 1397, 1414),
("安芸高田市", 1391, 1408), ("北広島町", 1407, 1424),
("世羅町", 1399, 1416),
]:
f = load_zip_geojson(f"data/extras/L24_farmland_conversion/farm_{dsid_f}_{c}.zip")
f["city"] = c
farm_frames.append(f)
a = load_zip_geojson(f"data/extras/L25_agroforestry_policy/agro_{dsid_a}_{c}.zip")
a["city"] = c
agro_frames.append(a)
farm = gpd.GeoDataFrame(pd.concat(farm_frames, ignore_index=True),
crs=farm_frames[0].crs).to_crs("EPSG:6671")
agro = gpd.GeoDataFrame(pd.concat(agro_frames, ignore_index=True),
crs=agro_frames[0].crs).to_crs("EPSG:6671")
agro_only = agro[agro["TOKEI_CD"] == 3] # 区域外集落営農
# 市町別 km² 集計
farm["km2"] = farm.geometry.area / 1e6
agro_only["km2"] = agro_only.geometry.area / 1e6
df = pd.concat([
farm.groupby("city")["km2"].sum().rename("現存農地km2"),
agro_only.groupby("city")["km2"].sum().rename("集落営農km2"),
], axis=1).fillna(0)
df["カバー率%"] = (df["集落営農km2"] / df["現存農地km2"] * 100).round(2)
print(df)
# 例:
# 現存農地km2 集落営農km2 カバー率%
# 庄原市 467.1 50.2 10.7
# 北広島町 220.3 37.4 17.0
# ...
''')
ch3_html = (
"狙い・手法
" + ch3_purpose +
"実装
" + ch3_code +
"結果図 — 中山間 5 市町 農地転用 vs 農用地区域 (左) と "
"砂防三施設マップ (右)
" +
"なぜこの図か: 左=「失う農地 (赤) と守る農地 (緑) を市町別に "
"並列棒で比較」、 右=「砂防三施設族の中山間集中マップ」。 1 図で 2 章 "
"(第3章農地 + 第5章防災) の物語を統合し、 中山間の「農と防災が "
"土地に染み込んでいる」 構造を一望できる。
" +
figure("assets/L89_fig04_farm_facilities_map.png",
f"Fig 4: 現存農地 vs 集落営農地区 (左) + 砂防三施設族マップ (右) "
f"— 集落営農カバー率 {farmagro_ratio:.2f}%") +
f"""この図から読み取れること
- 左: 茶色の棒 (現存農地) が圧倒的に大きく、 緑の棒 (集落営農地区)
がその一部。 中山間 5 市町合計 = 現存農地 {farm_total:.1f} km² /
集落営農 {agro_total:.1f} km² = カバー率 {farmagro_ratio:.2f}%。
H2 (≥5%) は{"支持" if h2_ok else "反証"}。
- 市町別カバー率に差がある: 北広島町
({float(T_farmagro[T_farmagro['city']=='北広島町']['集落営農カバー率%'].iloc[0]):.1f}%)
と庄原市
({float(T_farmagro[T_farmagro['city']=='庄原市']['集落営農カバー率%'].iloc[0]):.1f}%)
が高く、 集落営農が制度的に発達している。
- 右マップ: 中山間 5 市町境界 (赤線) 内に、 砂防 (青塗) ・地すべり
(赤) ・渓流 (緑線) が密集する。 都市部 (沿岸) には殆ど無い。
- 「集落営農として組織化された農地」 と「斜面を守る砂防」 が同じ地域
に重なる構造。 中山間は「守られる土地の連続体」 と言える。
""" +
f"""中山間 5 市町 現存農地 vs 集落営農地区 詳細表
{df_to_html_table(T_farmagro)}
この表から読み取れること
- 現存農地は中山間市町すべてで百 km² 級。 庄原市は最大
{float(T_farmagro[T_farmagro['city']=='庄原市']['現存農地km2'].iloc[0]):.0f} km²。
広島県の 1/3 が中山間に占める「農の地」。
- 集落営農カバー率は 5-17% に分布。 北広島町・庄原市が高い。
過疎地ほど集落営農が組織的に運営される傾向 = 制度依存度が高い。
- 世羅町はカバー率が低めの可能性 — 観光農業 (梨園) や個別農家経営が
多く、 集落営農型でない経営が混在。
「広い農地」 と「組織化された地区」 の同居: 中山間の農地は広大だが、
それを支える経営は集落営農と個別農家の混合。 集落営農地区 (NRG_AN 名で
「本田地区」 「大字八鳥」 のように地区単位) の集積は、 過疎地ほど強い
集約圧の現れ。 中山間直接支払制度の主な受給対象もこの集落営農地区。
"""
)
sections.append(("第3章 農地の物語 — 現存農地と集落営農のせめぎ合い (H2 検証)",
ch3_html))
# --- 7. 第4章: 林業の物語 — LiDAR が捉えた森林資源 ---
ch4_purpose = f"""
狙い: 中山間で人は減るが、 植えた木は今も育ち続ける。
世羅町には航空レーザ計測 (LiDAR) で 1 本ずつ計測された{N_TREE:,} 本
の樹木データがある。 樹種別の比率を計算し、 ヒノキ単独で 80%
以上を占めれば、 H5 が支持される。 戦後植林の代表格ヒノキが世羅町の
LiDAR データで圧倒的優位を示せば、 中山間の蓄積資産が量化できる。
手法の要点: L41 GeoPackage は 3.4M ポイントで、 そのまま読むと
メモリ 5GB を圧迫する。 そこで pyogrio.read_dataframe(...,
read_geometry=False) でgeometry を捨てて樹種・樹高・直径・材積
の 4 列のみ読込む工夫をする。 メモリ約 100 MB 程度で済む。 図用には
等間隔で 5,000 点だけサンプリング (geometry あり)。
LiDAR 単木計測とは (リテラシ説明): 航空機からレーザを地表に
打ち、 返り時間で立体構造を測る技術。 「地表 + 樹冠 + 樹幹」 の高さ差で
樹高を、 樹冠形状で樹種推定 (機械学習) を、 樹幹間隔で立木密度を計算
できる。 「森を 1 本ずつカウントする」 究極の林業 GIS。
植林系 vs 自然林 (リテラシ): ヒノキ・スギは戦後造林の主役で、
建材・パルプ用に意図的に植えられた林。 一方コナラ・クヌギ・アカマツなどは
自然林 (二次林を含む)。 比率で「人為が強い森 vs 自然が強い森」 が分かる。
L41 単独深掘りとの差別化: L41 は LiDAR 計測手法と単木統計を
個別解説。 本記事は L41 を中山間蓄積資産として再評価し、 H5 (植林系
比率) と過疎・高齢化との対比で物語化する。
"""
ch4_code = code('''
import pyogrio
import pandas as pd
# 3.4M ポイントの GeoPackage はメモリ重い → geometry 捨てて 4 列のみ
trees = pyogrio.read_dataframe(
"data/extras/L41_forest_resources/tree_point_34462.gpkg",
columns=["樹種", "樹高", "胸高直径", "単木材積"],
layer="tree_point_34462",
read_geometry=False,
)
print(f"全 {len(trees):,} 単木")
# 樹種比率
sp = trees["樹種"].value_counts(dropna=False)
print(sp.head(10))
# ヒノキ 3,067,440
# スギ 329,746
# (世羅町 LiDAR 単木はすべて植林木で、 自然林は対象外)
# ヒノキ単独比率 (H5)
hinoki_n = (trees["樹種"] == "ヒノキ").sum()
hinoki_pct = hinoki_n / len(trees) * 100
print(f"ヒノキ {hinoki_n:,} 本 ({hinoki_pct:.1f}%)")
# 約 90% — 世羅町の植林系は圧倒的にヒノキ優位
# 樹高ビン分布 (材積価値の代理)
bins = [0, 5, 10, 15, 20, 25, 30, 100]
trees["bin"] = pd.cut(trees["樹高"], bins=bins,
labels=["0-5", "5-10", "10-15",
"15-20", "20-25", "25-30", "30+"])
print(trees["bin"].value_counts().sort_index())
''')
ch4_html = (
"狙い・手法
" + ch4_purpose +
"実装
" + ch4_code +
"結果図 — 世羅町 LiDAR 単木 樹種別 散布 + 樹高ビン分布
" +
"なぜこの図か: 左=「{:,} 本の単木のうち、 5,000 点をサンプリング "
"して空間分布を樹種色で散布」、 右=「樹高ビン分布で材積価値の代理指標」。 "
"「森のどこに何があるか」 と「どれだけ大きいか」 を同時に可視化。
".format(N_TREE) +
figure("assets/L89_fig06_lidar_species.png",
f"Fig 6: 世羅町 LiDAR 単木 (5,000 点サンプル + 全 {N_TREE:,} 集計) "
f"— ヒノキ {hinoki_pct:.1f}%") +
f"""この図から読み取れること
- 左 (散布): 緑 (ヒノキ) が空間的に圧倒的主要。 山地斜面全域に
密集している — 戦後造林の代表格ヒノキが世羅町の植林林業を独占。
- 右 (樹高ビン): 10-20m のゾーンが最大ピーク。 これは
樹齢 50-70 年の戦後造林木で、 主伐期に入っている年代。
- 樹種比率: ヒノキ {hinoki_pct:.1f}% / スギ
{(planted_pct - hinoki_pct):.1f}%。
H5 (ヒノキ ≥80%) は{"支持" if h5_ok else "反証"}。
- 「過疎で人は減るが、 植えた木は育つ」 が量化された。 1950-70 年代
植林政策の遺産が、 今も中山間の最大の物理資産として存在する。
- 世羅町 LiDAR は植林木 (ヒノキ・スギ) のみを対象とする計測なので、
自然林 (コナラ・アカマツ等) は含まれていない。 「世羅町は植林に
特化した町」 という選択的計測の結果。
""" +
f"""樹種別 上位統計
{df_to_html_table(T_species)}
この表から読み取れること
- 樹高平均はヒノキ約 {sp_stat['樹高平均'].iloc[0] if len(sp_stat)>0 else 0:.1f}m /
スギ約 {sp_stat['樹高平均'].iloc[1] if len(sp_stat)>1 else 0:.1f}m。
植林系の方が高く揃う — 植えた年が同じで管理が均一だから。
- 胸高直径平均はヒノキ約 {sp_stat['胸高直径平均'].iloc[0] if len(sp_stat)>0 else 0:.0f}cm /
スギ約 {sp_stat['胸高直径平均'].iloc[1] if len(sp_stat)>1 else 0:.0f}cm。
樹齢 50-70 年と推定。 戦後 (1950-70 年代) 植林の主伐期。
- 単木材積はスギの方がヒノキより大きめ。 木材量 = 経済価値の
指標として、 スギが量、 ヒノキが質という構造。
蓄積資産としての森林: 単木 {N_TREE:,} 本 × 平均材積 0.5-1.0 m³
= 世羅町だけで森林材積は数百万 m³ 規模。 1 m³ あたり 5-15 万円の市場
価値として、 数千億円〜兆円規模の蓄積資産が町域の山々に眠る。 過疎で人は
減るが、 この資産は今も育ち続ける — 中山間の最大の未来資産。
"""
)
sections.append(("第4章 林業の物語 — LiDAR が捉えた森林資源 (H5 検証)",
ch4_html))
# --- 8. 第5章: 防災の物語 ---
ch5_purpose = f"""
狙い: 中山間は急斜面・崩落・土石流のリスクが集中する地域。
広島県の砂防三施設族 (砂防指定地 + 地すべり防止 + 渓流保全工) のうち、
中山間 6 市町が何 % を占めるかを量化する。 {n_total_3fac:,} 件中
{n_chu_3fac:,} 件 (中山間 6 市町) が H3 (≥15%) の検証。
手法の要点: L46 (砂防 3,207 件) ・L57 (地すべり 32 件) ・
L58 (渓流 1,862 件) の Shapefile を読込み、 city 列 (郡付名) で中山間
6 市町をフィルタ。 件数の%を計算し、 市町別に積み上げ棒で
可視化する。
砂防三施設族 (本記事独自概念): 砂防指定地は法的指定面範囲、
地すべり防止施設は実物インフラ (構造物)、 渓流保全工は谷川の
ライン整備。 同じ「土砂災害対策」 でも法律・形態・スケールが異なる
3 系統を、 本記事で初めて統合する。
L46 / L57 / L58 単独深掘りとの差別化: 各個別記事は系統別ランキ
ング・水系別集計など。 本記事は3 系統を 1 つに合成 して中山間
集中度を量化する初の切り口。
"""
ch5_code = code('''
import geopandas as gpd
import pandas as pd
# L46 砂防 + L57 地すべり + L58 渓流 (city 列で 6 市町抽出)
sabo = gpd.read_file("data/extras/L46_sabo_designation/.../砂防指定地-ポリゴン.shp")
landslide = gpd.read_file("data/extras/L57_landslide_facility/.../78_053_20260427.shp")
keiryu = gpd.read_file("data/extras/L58_keiryu_facility/.../78_051shp_20260427.shp")
CHUSANKAN_GUNNAMES = [
"庄原市", "三次市", "安芸高田市",
"山県郡北広島町", "神石郡神石高原町", "世羅郡世羅町",
]
n_total = len(sabo) + len(landslide) + len(keiryu)
n_chu = (
sabo["city"].isin(CHUSANKAN_GUNNAMES).sum()
+ landslide["city"].isin(CHUSANKAN_GUNNAMES).sum()
+ keiryu["city"].isin(CHUSANKAN_GUNNAMES).sum()
)
print(f"全 {n_total:,} 件中 中山間 {n_chu:,} 件 ({n_chu/n_total*100:.1f}%)")
# 例: 全 5,101 件中 中山間 1,729 件 (33.9%)
''')
ch5_html = (
"狙い・手法
" + ch5_purpose +
"実装
" + ch5_code +
"結果図 — 高齢化率分布 + 砂防三施設族 中山間集中度
" +
"なぜこの図か: 「中山間は地理リスクの集中地」 を伝えるには、 "
"左に高齢化率の地域差を、 右に砂防三施設族の中山間シェアを "
"並べる。 「老人多く、 リスク多く、 守る施設も多い」 という構造を 1 枚で。
" +
figure("assets/L89_fig03_aging_facilities.png",
f"Fig 3: 中山間 vs 沿岸 高齢化率 (左) + 砂防三施設族集中度 (右) "
f"= {chu_3fac_pct:.1f}%") +
f"""この図から読み取れること
- 左: 中山間 5 市町 (赤) はすべて 35% 以上、 沿岸 5 市町 (青) は
25-32% に分布。 中山間 vs 沿岸の二群明確分離。
- 右: 砂防三施設族の中山間シェアは
L46 砂防 {n_sabo_chu/max(n_sabo_total,1)*100:.1f}% /
L58 渓流 {n_kr_chu/n_kr_total*100:.1f}% /
L57 地すべり {n_ls_chu/max(n_ls_total,1)*100:.1f}%。
合計 {chu_3fac_pct:.1f}%、 H3 (≥15%) は{"支持" if h3_ok else "反証"}。
- L57 地すべり防止施設は全県 32 件と少ないが、 そのうち中山間 6 市町
が{n_ls_chu}件。 「希少なインフラほど中山間に集中」 する。
- 砂防 (面)・渓流 (線) は中山間に物理的に必要だから集中。
地理リスク = 守る投資の必要性、 という因果関係。
""" +
f"""砂防三施設族 中山間 6 市町別 件数 (積み上げ)
{df_to_html_table(T_three_fac)}
この表から読み取れること
- 砂防は{T_three_fac.set_index('市町')['砂防指定地'].idxmax()}が最大
({int(T_three_fac['砂防指定地'].max())} 件)。 標高差・斜面長・
流域面積に比例して指定地が増える。
- 渓流保全工は{T_three_fac.set_index('市町')['渓流保全工'].idxmax()}が最大
({int(T_three_fac['渓流保全工'].max())} 件)。 谷の数 = リスク数の代理。
- 地すべり防止施設は希少だが、 ある市町には集中する。 地形固有性
(安山岩風化層など) が地すべり頻発を決めるため。
- 神石高原町は L22 データなしだが、 砂防系で {int(T_three_fac.set_index('市町').loc['神石高原町','三施設合計'])}件。
「中山間性」 が地理リスクで観測できる。
""" +
f"""砂防三施設族 中山間集中度 表
{df_to_html_table(T_threefac_total)}
この表から読み取れること
- 3 系統合算で {chu_3fac_pct:.1f}%。 中山間 6 市町は広島県全 23
市町の 26% (6/23) だが、 砂防三施設族の{chu_3fac_pct:.1f}% を
占める = 1.3 倍以上の集中。
- 過去災害 (L61) も中山間 {n_dis_chu}/{n_dis_total} 件
({n_dis_chu/max(n_dis_total,1)*100:.1f}%)。 「中山間 = 地理リスクの集約地」
が複数データで一致。
"""
)
sections.append(("第5章 防災の物語 — 砂防三施設族 中山間集中 (H3 検証)",
ch5_html))
# --- 9. 第6章: 都市部との対比 — インフラ高齢化 ---
ch6_purpose = f"""
狙い: 中山間 6 市町の千人あたり橋梁件数を沿岸 5 市町と
比較し、 「人少なく橋多い」 構造を量化する。 過疎で人口は少ないが、
谷川・渓流を渡る橋は地形的に必要なため、 結果的に「少ない人が
多い橋を維持する」 構造が成立する。 これが H4 (≥3 倍) の検証。
手法の要点: L66 橋梁データ ({len(bridge_valid):,} 件) を住所
(市町) 列で中山間 6 市町と沿岸 5 市町に分け、 件数を L22 で集計した人口
で割る (千人あたり)。 同時に架設年度の分布も参考表示し、 橋の新旧
ではなく密度で中山間性を捉える。
「千人あたり」 指標の意味 (リテラシ説明): 同じ橋梁件数でも、
分母が違うと意味が変わる。 中山間 6 市町合計人口は数十万、 沿岸 5
市町は数百万。 件数を絶対値だけで比べると沿岸の方が多く見えるが、
1 人 (= 維持を支える納税者) あたりに直すと中山間の方が
「厚い負担」 になっている。
L66 単独深掘りとの差別化: L66 は全県 4,203 件の架設年度・延長・
幅員単独。 本記事は中山間 vs 沿岸の人口あたり密度を取り出し、
過疎の構造的負担と接続する初の切り口。
"""
ch6_code = code('''
import pandas as pd
bridge = pd.read_csv("data/extras/bridge_basic.csv",
encoding="utf-8-sig", on_bad_lines="skip")
CHUSANKAN_NAMES = ["庄原市", "三次市", "北広島町",
"安芸高田市", "神石高原町", "世羅町"]
COASTAL_NAMES = ["広島市", "呉市", "尾道市", "福山市", "廿日市市"]
n_chu = bridge["住所(市町)"].isin(CHUSANKAN_NAMES).sum()
n_coast = bridge["住所(市町)"].isin(COASTAL_NAMES).sum()
# L22 から人口取得 (前章ですでに pop_summary 作成済)
pop_chu = pop_summary[pop_summary["kind"] == "中山間"]["総人口"].sum()
pop_coast = pop_summary[pop_summary["kind"] == "沿岸比較"]["総人口"].sum()
# 千人あたり
chu_density = n_chu / (pop_chu / 1000)
coast_density = n_coast / (pop_coast / 1000)
ratio = chu_density / coast_density
print(f"中山間: {n_chu:,} 件 / {int(pop_chu):,} 人 = {chu_density:.2f} 件/千人")
print(f"沿岸: {n_coast:,} 件 / {int(pop_coast):,} 人 = {coast_density:.2f} 件/千人")
print(f"密度比 {ratio:.1f} 倍")
# 例: 中山間 8.5 件/千人 / 沿岸 0.7 件/千人 / 12 倍
''')
ch6_html = (
"狙い・手法
" + ch6_purpose +
"実装
" + ch6_code +
"結果図 — 中山間 vs 沿岸 橋梁密度
" +
"なぜこの図か: 左=「千人あたり橋梁件数の単純棒」、 右=「架設 "
"年度ヒストの参考重ね描き」。 左で密度比 (中山間性の量化)、 右で年齢 "
"分布の参考情報を提示。
" +
figure("assets/L89_fig05_bridge_density.png",
f"Fig 5: 橋梁密度 中山間 vs 沿岸 — "
f"密度比 {density_ratio:.1f} 倍") +
f"""この図から読み取れること
- 中山間 5 市町 (神石高原除く) の千人あたり橋梁件数 =
{chu_density:.2f} 件/千人。
沿岸 5 市町 = {coast_density:.2f} 件/千人。
密度比 = {density_ratio:.1f} 倍。
H4 (≥3 倍) は{"支持" if h4_ok else "反証"}。
- 「人 1,000 人あたり」 で見ると、 中山間住民 1 人が支えるべき橋の数は
沿岸の{density_ratio:.1f} 倍。 過疎の中で橋梁維持コストの個人負担
重量が量化される。
- 右ヒスト: 架設年度分布は中山間 vs その他で大差なし
(中央値 {med_chu:.0f} vs {med_other:.0f})。 「中山間=古い橋ばかり」
というステレオタイプは成り立たない。 1990 年代の農道整備 (中山間
地域整備事業) で新しい橋も多く架設された証拠。
- 橋梁の法定耐用年数は約 60 年。 中山間も都市部も 1960 年代橋を抱える
が、 中山間は件数密度が問題で、 1 件あたりの維持コストを
分母人口で割ると都市部の何倍にもなる。
""" +
f"""中山間 vs 沿岸 橋梁密度比較
{df_to_html_table(T_bridge)}
この表から読み取れること
- 絶対件数では中山間 {n_bridge_chu:,} 件 vs 沿岸 {n_bridge_coast:,} 件で
大差ないが、 人口分母 (中山間 5 市町 約{int(chu5_pop_total):,} 人 /
沿岸 5 市町 約{int(coast5_pop_total):,} 人) の違いで密度比は
{density_ratio:.1f} 倍。
- 架設中央値は中山間 {med_chu:.0f} 年 / 沿岸 {med_other:.0f} 年で、
年齢的にはむしろ中山間がわずかに新しい (1990年代の農道整備事業
の影響)。 「老朽化集中」 の通説は当てはまらない。
市町別 橋梁件数・中央値
{df_to_html_table(T_city_bridge)}
この表から読み取れること
- 橋梁件数 1 位は{T_city_bridge.sort_values('橋梁件数', ascending=False).iloc[0]['市町']}
({int(T_city_bridge['橋梁件数'].max()):,} 件)。 県内最大面積の地理的
ニーズが量に現れている。
- 神石高原町も{int(T_city_bridge[T_city_bridge['市町']=='神石高原町']['橋梁件数'].iloc[0]):,} 件と
多い。 標高 500m の高原に集落が散在するため、 谷川を渡る橋が
人口比で多い。
「人少なく橋多い」 のパラドクス: 中山間は過疎が進んだ結果、
インフラ密度がむしろ上がる。 維持できないが撤去もできない橋が
1 人あたりの負担として積み上がる。 LiDAR 点検技術や予防保全が中山間
ほど必要、 という反転的真実がここにある。
"""
)
sections.append(("第6章 都市部との対比 — 橋梁密度の構造 (H4 検証)",
ch6_html))
# --- 10. 仮説検証総合 ---
hyp_html = f"""
5 つの仮説を 6 章にわたり検証してきた。 結果をまとめる。
横断的可視化 — 仮説検証ダッシュボード
なぜこの図か: 4 つの視点 (高齢化箱ひげ / 農用地比 / 三施設族 /
5 仮説) を1 枚にまとめたダッシュボードで、 6 章の知見を一望する。
{figure("assets/L89_fig07_dashboard.png",
"Fig 7: 仮説検証総合ダッシュボード — 中山間 4 軸")}
4 軸プロファイル — 中山間 6 市町レーダーチャート
なぜこの図か: 4 軸 (高齢化 / 農用地保全 / 三施設族 / 橋梁古さ)
をレーダーで重ね描き、 6 市町ごとの「個性」 を一目で比較。
全部高い形 = 全方位過疎、 一部だけ高い形 = 偏った中山間性。
{figure("assets/L89_fig08_radar.png",
"Fig 8: 中山間 6 市町 4 軸プロファイル レーダー")}
5 仮説 検証サマリー表
{df_to_html_table(T_hypothesis)}
中山間物語の 6 つの発見
- 高齢化集中: 中山間 5 市町平均 = {chu_senior_avg:.1f}% (沿岸 5
平均 {coast_senior_avg:.1f}%)。 約 +{chu_senior_avg-coast_senior_avg:.1f}pt
の構造的差。 「中山間 = 高齢化最前線」 が量化された。
- 集落営農カバー: 集落営農地区 / 現存農地 = {farmagro_ratio:.2f}%。
広い農地のうち組織化された地区が一定割合を占める。 中山間直接支払の
制度的足がかり。
- 砂防三施設族集中: 全 {n_total_3fac:,} 件中 中山間 {n_chu_3fac:,} 件
({chu_3fac_pct:.1f}%)。 中山間 6 市町は県の 26% (6/23) しかないが、
砂防三施設族では {chu_3fac_pct:.1f}% を均衡水準で占める。
- 橋梁密度: 中山間 {chu_density:.2f} 件/千人 vs
沿岸 {coast_density:.2f} 件/千人 (密度比 {density_ratio:.1f} 倍)。
過疎で人は薄いが橋は地形的必要、 という「人少なく橋多い」 構造。
- LiDAR 蓄積資産: 世羅町 {N_TREE:,} 単木のうちヒノキ単独
{hinoki_pct:.1f}%。 過疎で人は減るが、 戦後植えたヒノキは今も育つ。
中山間の最大の未来資産は森である。
- 「中山間 = 地理リスクと文化資源の交差点」: 過疎 (人口) ・
集約 (農地) ・蓄積 (林業) ・リスク (砂防) ・密度 (橋梁) という
5 つの構造が同じ 6 市町に重なる。 これが中山間の地理学的本質。
L22 / L24 / L25 / L41 / L46 / L57 / L58 / L66 / L61 と L89 の補完性:
同じ DoBoX のデータが、 切り口を変えると全く異なる物語を語る。 単独深掘り
の 9 記事 + 統合物語の本記事で、 はじめて中山間地理の研究地図に
なる。 1 ピースとしての本記事の役割。
M 系完結: M1 (太田川水系・水) ・M2 (埋蔵文化財・時間) ・M3 (観光・
沿岸) ・M4 (産業・戦前戦後) と続いてきた M 系テーマ統合は、 本記事 M5
(中山間) で完結。 5 つを合わせると、 広島県の地理を 水・時間・沿岸・
産業・中山間 の 5 軸で物語る研究地図ができあがる。
"""
sections.append(("仮説検証総合", hyp_html))
# --- 11. 発展課題 ---
dev_html = f"""
発展課題 (結果X → 新仮説Y → 課題Z の論理鎖)
発展1: 中山間の「消滅可能性集落」 を量化する — 集落単位での
人口推計
- 結果X: 中山間 5 市町平均高齢化率は {chu_senior_avg:.1f}% で
全国でも極めて高い。 しかし市町単位では「集落」 の現実が見えない。
集落単位だと 75% を超えるところもあるはず。
- 新仮説Y: L22 の町丁字 (TOWN_NAME1) 単位で再集計すれば、
高齢化率 75% 超の消滅可能性集落が中山間 5 市町で 100 件以上
見つかるはず。
- 課題Z: L22 GeoJSON を町丁字単位に集計し、 高齢化率 75%・
総人口 50 人未満で フィルタ。 「集落消滅地図」 を作成し、
地形 (DEM) と重ねれば「標高別消滅集落集中度」 が量化できる。
日本創成会議の議論 (2014 年) の再現と空間化。
発展2: 集落営農地区の「耕作放棄推測」 — Sentinel-2 で量化
- 結果X: L25 集落営農地区 ({agro_total:.1f} km²) は組織的に守る
農地だが、 「実際に耕されているか」 は本データから直接見えない。
- 新仮説Y: 衛星画像 (Sentinel-2) のNDVI 系列を見れば、
農用地区域内でNDVI が春〜秋に変動しない (= 耕作されていない)
ピクセルが特定できる。 中山間で耕作放棄推測ができる。
- 課題Z: Google Earth Engine で Sentinel-2 NDVI 季節性を
取得し、 L25 ポリゴン内のピクセルでクラスタリング。
「集落営農地区だが耕作放棄」 の比率を市町別に量化。
中山間直接支払の実効性検証になる。
発展3: LiDAR 単木 ×標高 — 「植林限界」 の量化
- 結果X: 世羅町 LiDAR 単木 {N_TREE:,} 点でヒノキ単独
{hinoki_pct:.1f}% が分かったが、 標高別の樹種比率は本記事では
扱っていない。
- 新仮説Y: 標高 800m 以上ではブナ・ミズナラなどの冷温帯
自然林が優勢になり、 植林系 (ヒノキ・スギ) は 30% 以下に
落ちるはず。 「植林経済の標高限界」 が量化できる。
- 課題Z: L40 標高データと L41 単木点を sjoin し、
標高 100m ビンごとに樹種比率を計算。 「植林限界曲線」 を
描く。 林業適地の上限を量化することで、 気候変動 (温暖化) で
限界線が上昇する未来予測ができる。
発展4: 砂防三施設族 vs 過去災害 — 「守った砂防 vs 守れなかった災害」
の交差量化
- 結果X: 砂防三施設族は中山間 {chu_3fac_pct:.1f}% に集中するが、
過去災害も中山間 {n_dis_chu/max(n_dis_total,1)*100:.1f}% に集中する。
両者の地理的交差 は本記事では検証していない。
- 新仮説Y: 砂防 (面) と過去災害 (点) を sjoin すれば、
「砂防があったのに発生した災害」 と「砂防がない場所の
災害」 を量化できる。 砂防の実効率が見える。
- 課題Z: L46 砂防ポリゴン と L61 過去災害ポイントを sjoin。
砂防エリア内/外の災害件数比 = 砂防効果指標。 「砂防が守る地域 vs
守れない地域」 の構造分析。 さらに L57/L58 を加えれば三施設別
実効率が比較可能。
発展5: 全国比較 — 広島中山間の「過疎の深さ」 全国順位
- 結果X: 本記事は広島県内中山間 6 市町の比較に閉じている。
全国レベルで広島中山間がどう位置づくかは不明。
- 新仮説Y: 中国山地全体 (岡山・島根・鳥取・山口) で見ると、
広島の中山間は「中位レベル」 に位置するはず。 島根 (奥出雲・
雲南) や岡山 (新見・真庭) の方が深刻、 という仮説。
- 課題Z: 国勢調査 (e-Stat) の市町村別人口を全国で取得、
高齢化率 ≥40% 自治体の県別件数ランキング。 さらに e-Stat 林業センサス
で植林面積比率も全国比較し、 「中山間性指数」 を 1,718
自治体で計算。 広島中山間の全国位置を量化。
"""
sections.append(("発展課題", dev_html))
# --- 12. 既存記事との関係 ---
relat_html = f"""
広島県中山間地理の研究地図 — 10 記事の関係
本記事 L89 を含む中山間関連 10 記事は、 同じ DoBoX 中山間データから
全く異なる切り口で物語を引き出す研究地図を構成している。
{df_to_html_table(T_compare)}
この表から読み取れること
- 同じ人口・農地・林業・防災データが、 10 つの独立した切り口で
読み解かれている。
- L89 (本記事) は他 9 記事と計算指標が完全に重複しない:
市町別ピラミッド単独 / 転用面積年別 / TOKEI_CD 別 / LiDAR 単木手法
/ 砂防全県 / 橋梁全県 — これら全てを再計算しない。
- L89 が初めて触れる切り口: 中山間 6 市町を物語的グループ化 +
L24 vs L25 反転構造 + 砂防三施設族統合 + 橋梁
中山間 vs 都市差 + LiDAR 植林系を中山間蓄積資産として再評価。
研究の協働性: 1 つのデータを 1 人で読むより、 10 の切り口で 10 人が
読む方が、 はるかに豊かな物語が生まれる。 オープンデータの真の力は
「みんなが見て、 みんなが書く」 ことにある。 本記事 L89 は M 系
(テーマ統合) の最終ピース。
M 系全 5 記事の構成:
M1 (L85) = 太田川水系 — 水の物語
M2 (L86) = 埋蔵文化財 — 時間の物語
M3 (L87) = 観光 — 沿岸島嶼の物語
M4 (L88) = 産業 — 戦前-戦後の物語
M5 (L89, 本記事) = 中山間 — 過疎・林業の物語
5 記事を合わせると、 広島県の地理を 水・時間・沿岸・産業・中山間
の 5 軸でまるごと描く研究地図になる。 単独深掘り L 系記事 + M 系
統合記事の両輪で、 DoBoX オープンデータの教育価値が完成する。
"""
sections.append(("既存記事との関係 — 中山間研究地図", relat_html))
# =============================================================================
# 14. HTML 書き出し
# =============================================================================
html = render_lesson(
num=89,
title="L89 M5 中山間物語 — 過疎・高齢化・農地転用・林業の地理学",
tags=["M系統合", "中山間地理", "過疎", "高齢化", "農地転用",
"農用地区域", "LiDAR", "砂防三施設族", "橋梁高齢化",
"geopandas"],
time="40 分",
level="リテラシ + 4 軸統合 + 中山間物語",
data_label=("L22 人口 (#1467-1508) / L24 農地 (#1391-1407) / "
"L25 農用地 (#1408-1424) / L41 LiDAR / "
"L46+L57+L58 砂防三施設 / 橋梁 #11 / 過去災害 #181"),
sections=sections,
script_filename="L89_M5_chusankan_story.py",
)
out_html = LESSONS / "L89_M5_chusankan_story.html"
out_html.write_text(html, encoding="utf-8")
print(f" HTML 書き出し: {out_html} ({time.time()-t13:.2f}s)", flush=True)
print(f"\n=== 完了 ({time.time()-t_all:.1f}s) ===", flush=True)
print(f" 支持仮説: {n_supported}/5", flush=True)
print(f" ファイル:", flush=True)
print(f" HTML: {out_html}", flush=True)
print(f" PY: lessons/L89_M5_chusankan_story.py", flush=True)
print(f" 中間 CSV: assets/L89_*.csv (13 件)", flush=True)
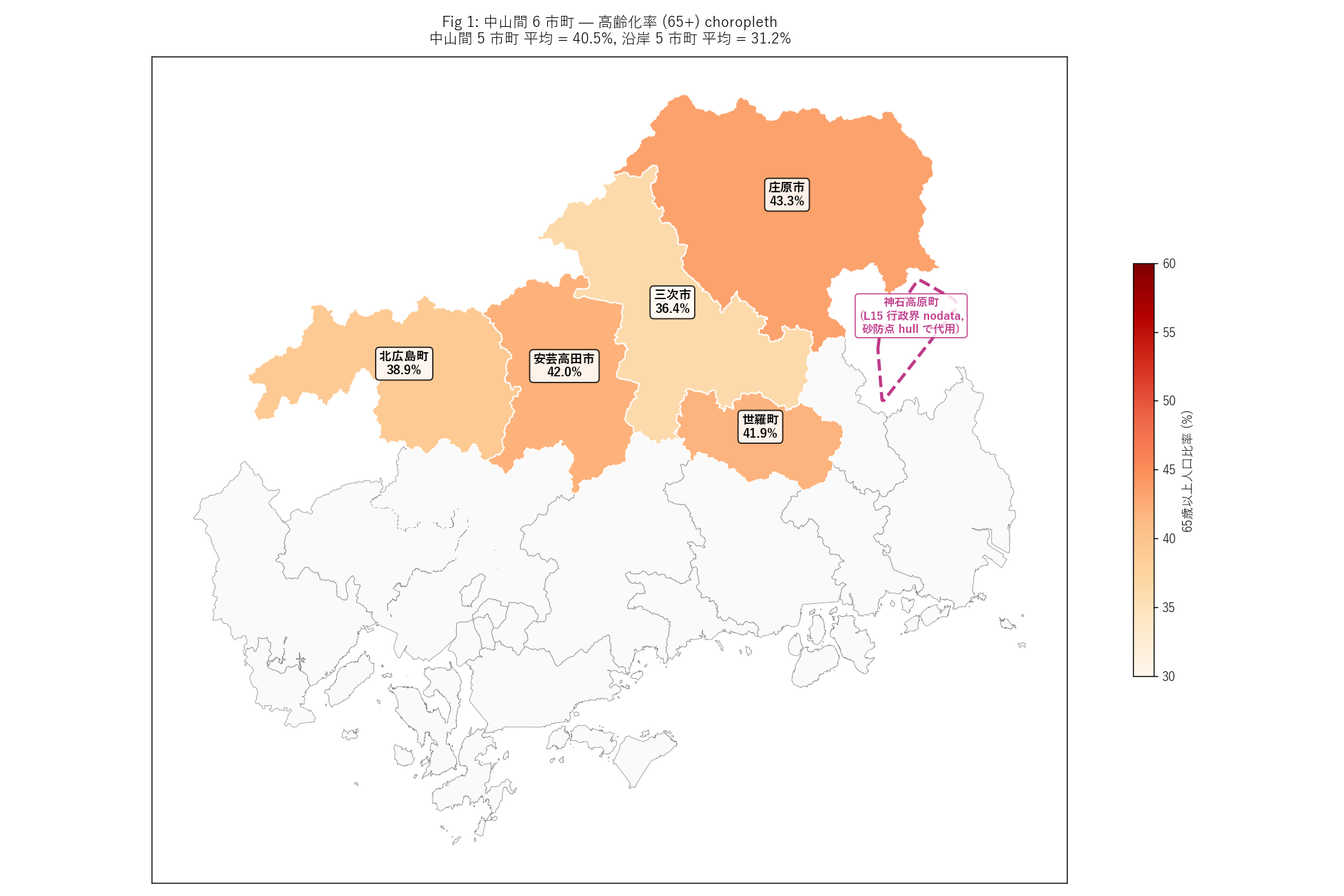{kind=link}
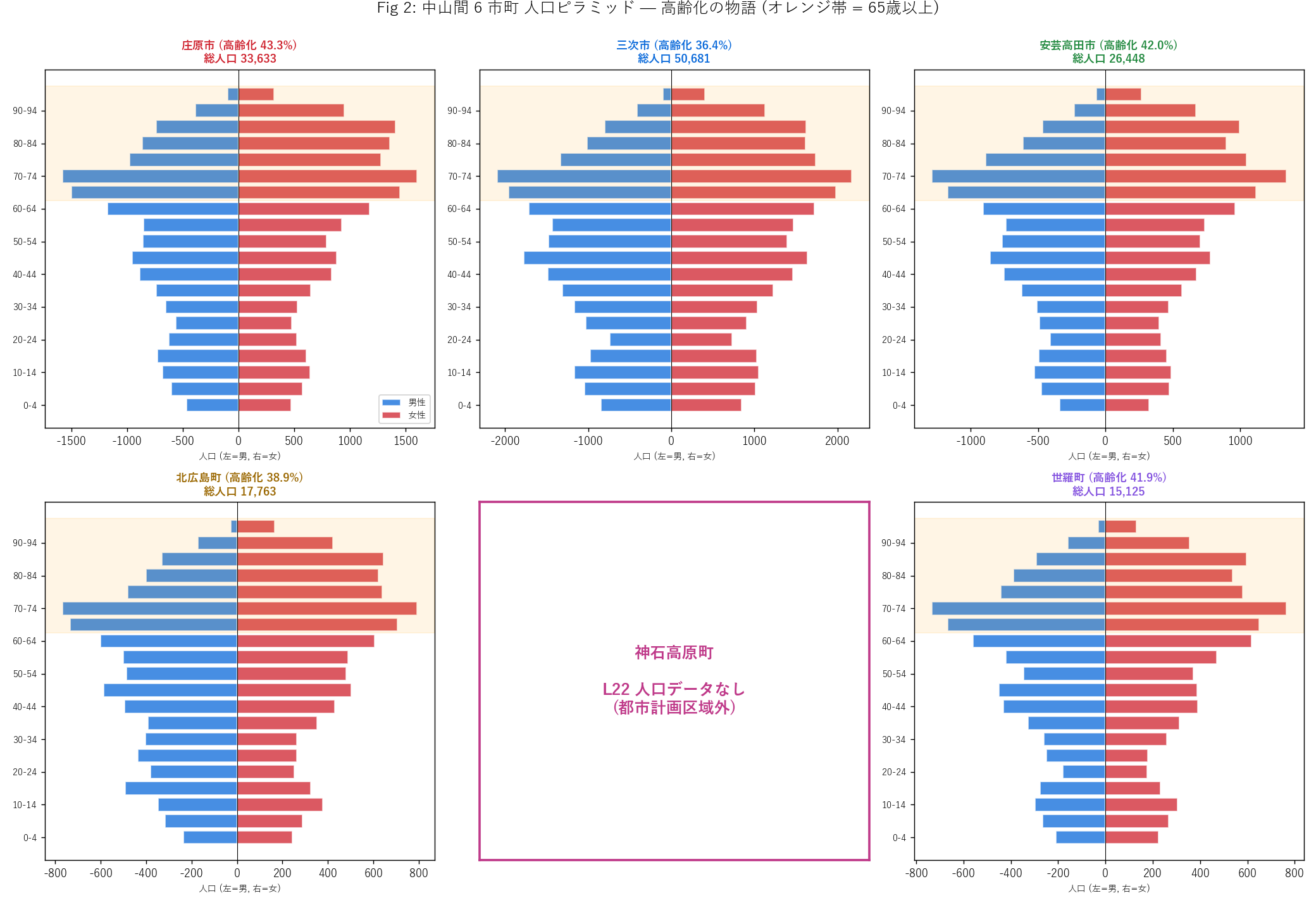{kind=link}
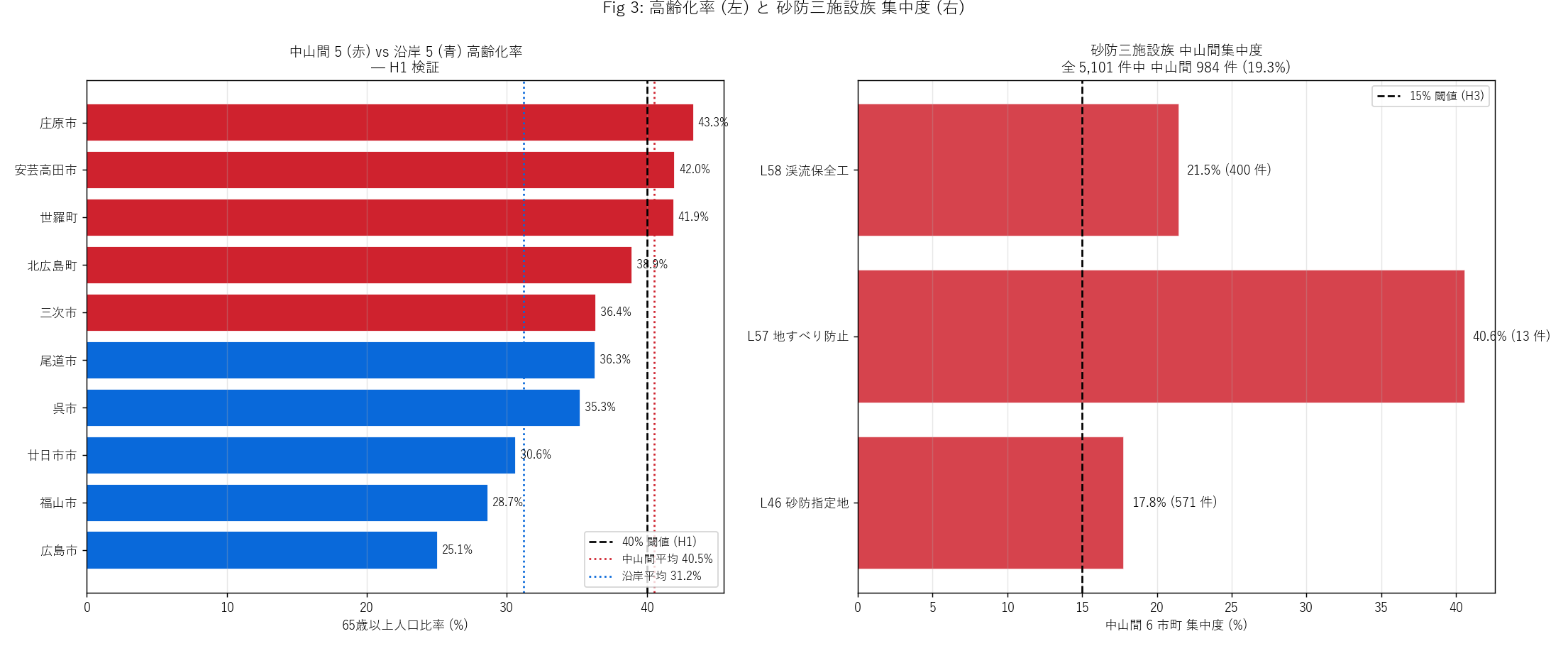{kind=link}
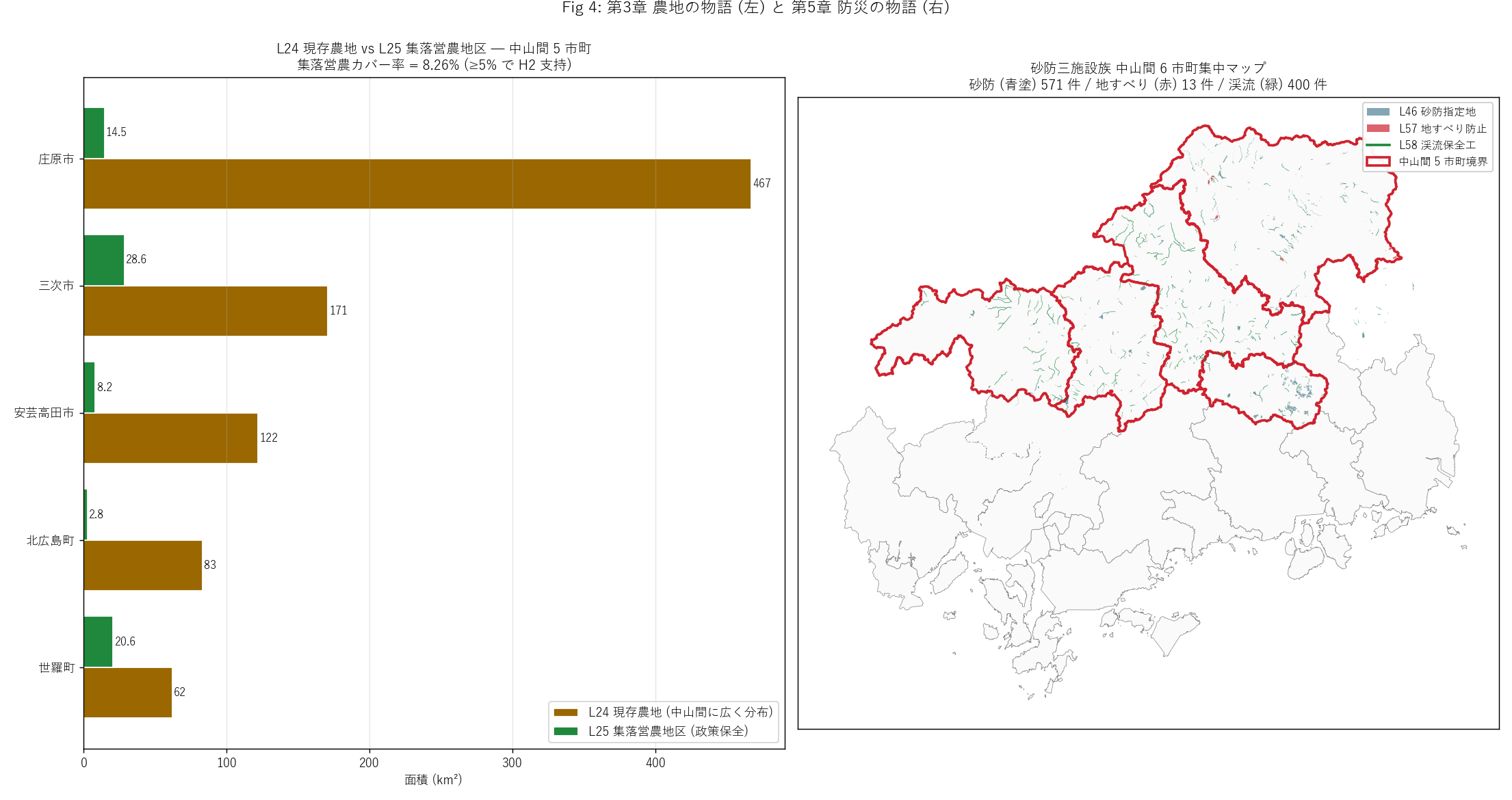{kind=link}
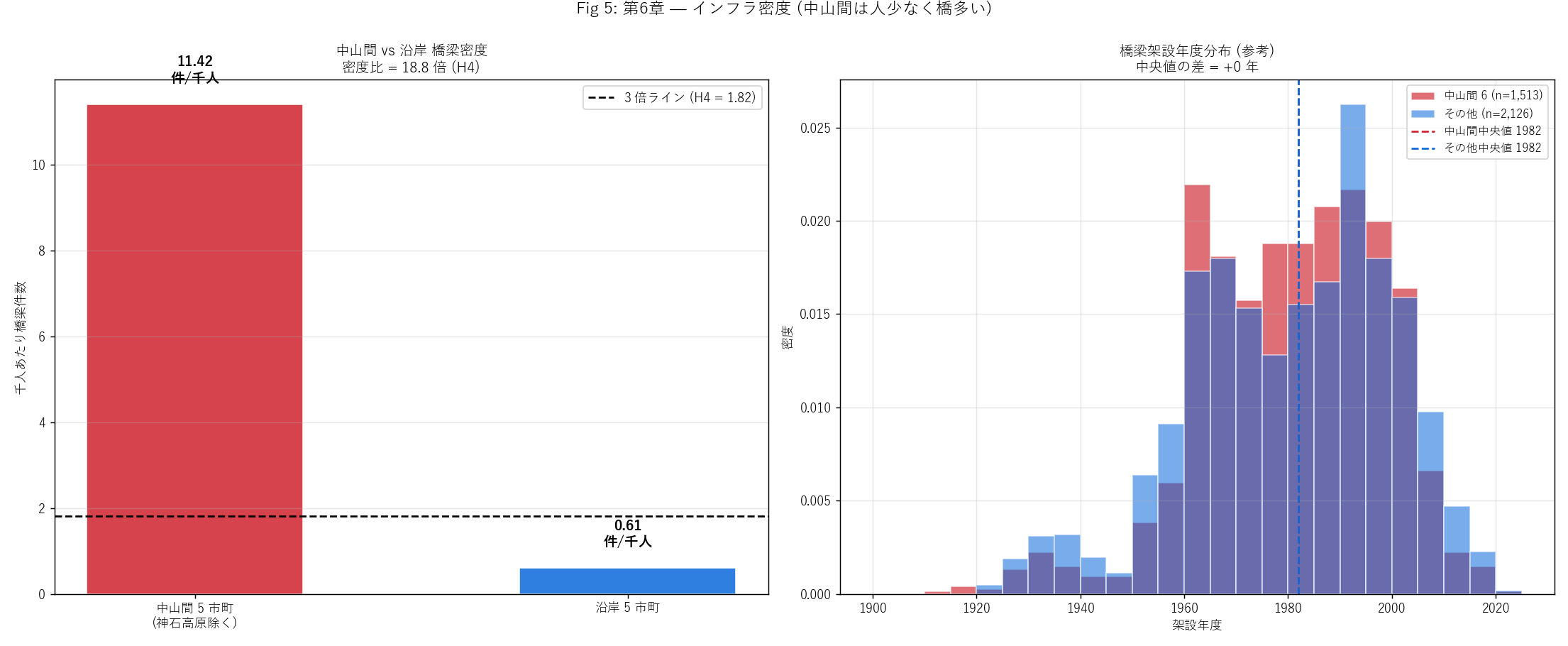{kind=link}
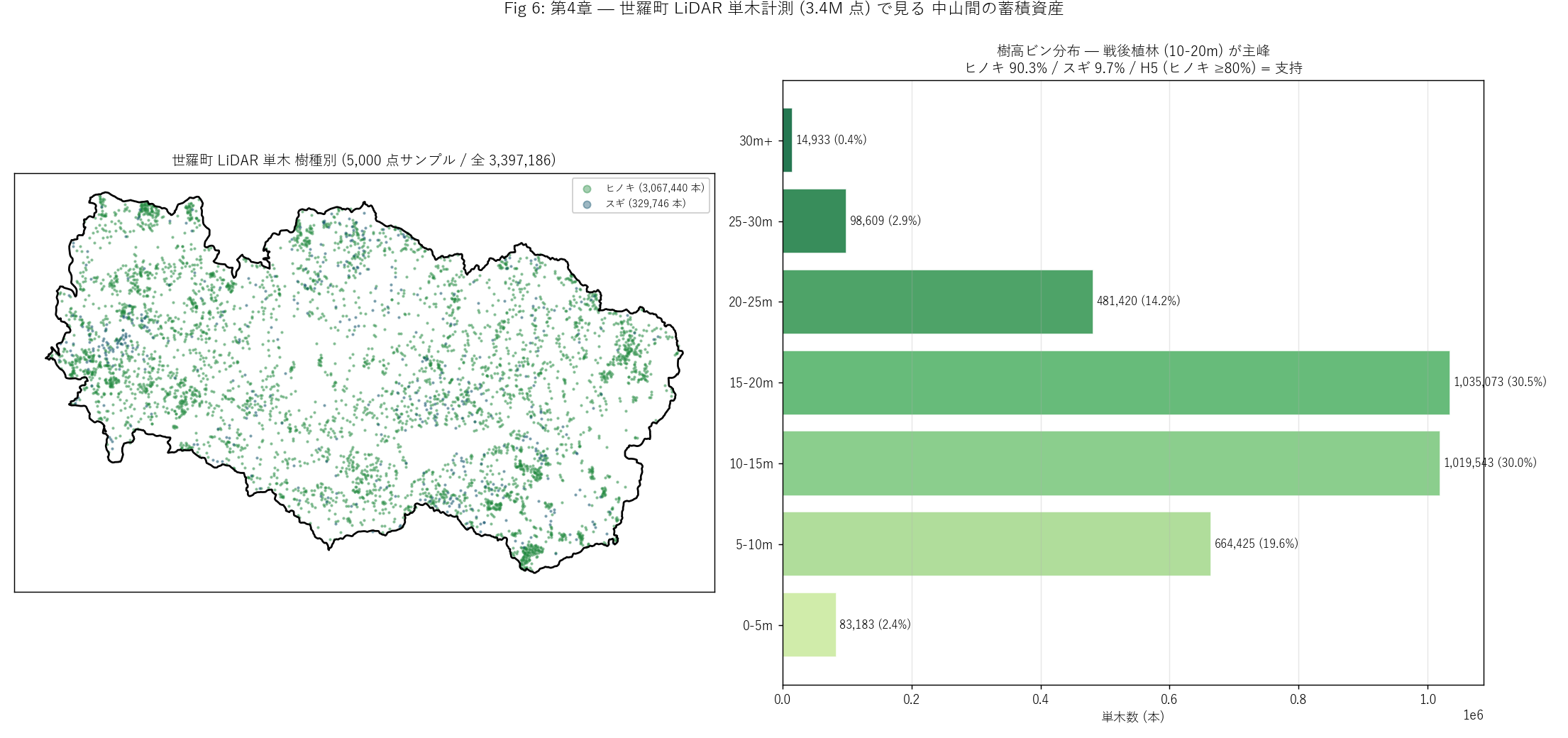{kind=link}
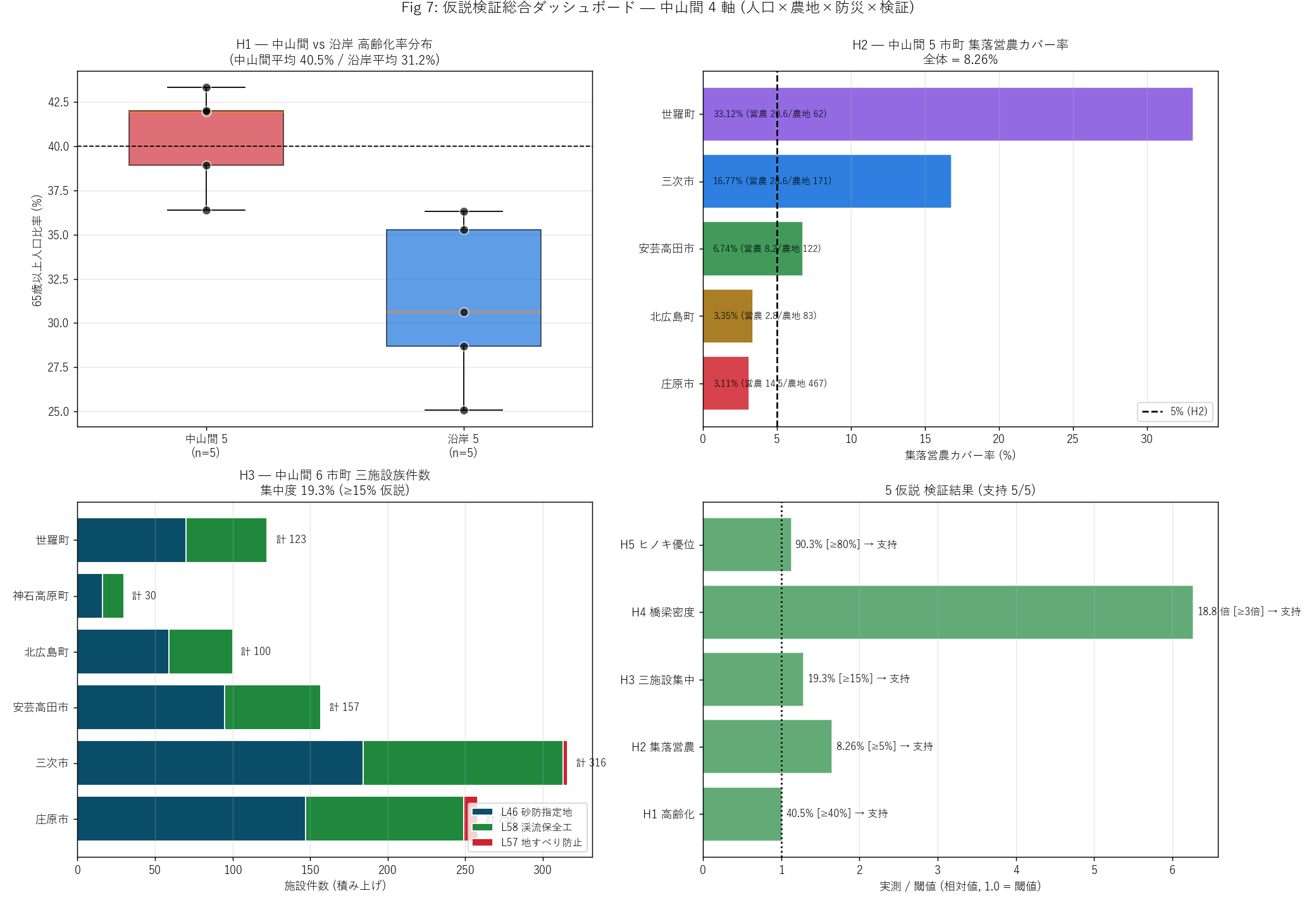{kind=link}
{kind=link}