# -*- coding: utf-8 -*-
"""L87 M3 観光物語 — 瀬戸内ブランドのインフラと島嶼ネットワーク
カバー宣言:
本記事は DoBoX の観光関連 4 dataset (#1447 インフラツーリズム /
#1281 瀬戸内海航路情報 / #1280 せとうちモニタークルーズ /
#1282 瀬戸内しまたびライン) と津波浸水想定 (#47 系) /
海岸保全施設 (#1085) / 行政界 (L15)を統合し、
「瀬戸内ブランド — 海と橋と島のインフラ観光地理」 を
7 章構成で物語るテーマ統合 (M系) 記事である。 単一データの
分析ではなく、 「沿岸 - 島嶼 - しまなみ - 走廊」という空間軸で、
瀬戸内観光のインフラ地理を物語る。
M系 (テーマ統合) の意味:
M1 (L85) = 太田川水系を 1 水系深掘りで物語化 (河川治水の物語)
M2 (L86) = 埋蔵文化財を時間軸で物語化 (古代地理の物語)
M3 (本記事) = 観光関連 4 dataset を空間軸 (沿岸-島嶼-しまなみ) で物語化
(瀬戸内ブランドの観光地理物語)
研究の問い (主 RQ):
「瀬戸内観光の物語 — 海の道とインフラが織りなす広島県の観光地理とは何か?」
瀬戸内ブランドを構成する3 走廊 (宮島走廊 / 安芸灘走廊 / しまなみ走廊)
は、 観光対象施設・クルーズ寄港地・島嶼の量と質でどう描けるか?
観光の魅力 (ブランド) と防災のリスク (津波浸水) はどう交差するか?
仮説 H1〜H5:
H1 (島嶼観光集中仮説): 観光対象施設 40 件の島嶼 (本州離れの島) 立地
比率は 20% 以上。 瀬戸内ブランドの中核は島嶼に存在する。
本仮説は住所文字列マッチングで島嶼判定し、 観光対象の地理偏在を
量化する。
H2 (しまなみ走廊仮説): 観光対象 + クルーズ寄港地のうち、 しまなみ走廊
(尾道-因島-生口島-向島ライン) に立地する施設は 15% 以上。
しまなみ海道沿いは観光リソースの集積帯であり、 1999 年の橋梁開通が
島嶼観光の量的構造を変えた量的証拠を示す。
H3 (海岸近接仮説): 観光対象施設 40 件の海岸保全施設までの距離 中央値
は 3 km 以下。 瀬戸内観光は海と隣接するインフラに集中し、
「内陸ダム」 と「沿岸橋梁・島嶼施設」 の二極化を示す。
H4 (観光・防災交差仮説): 観光対象 40 件のうち、 津波浸水想定エリア
1 km 圏内に立地する施設の比率は 30% 以上。 瀬戸内ブランドの
魅力 (海近) と防災リスク (浸水想定) は地理的に重なる。
H5 (3 走廊独立仮説): 観光対象 40 件 + クルーズ寄港地 81 件を
3 走廊 (宮島 / 安芸灘 / しまなみ)に分類すると、 走廊間の地理的
重複は 5% 以下。 各走廊は独立した観光地理を構成し、
広島県の瀬戸内観光はマルチコリドール構造と読める。
要件 S 準拠 (1 分以内完走):
- 全データは既存 cache (data/extras/) を再利用 (DL 不要)
- geopandas 投影変換は EPSG:4326 → 6671 を 1 度のみ
- 津波浸水 shp は dissolve で先に統合 (浸水メッシュ → 1 ポリゴン)
- sjoin_nearest で空間インデックス活用、 総当たり距離計算なし
- 想定完走時間 30-60 秒
要件 T 準拠 (位置情報あり = 地図必須):
- 3 走廊オーバーレイマップ (宮島走廊 / 安芸灘走廊 / しまなみ走廊)
- インフラ観光対象 40 件 + クルーズ寄港地 81 件 重ね合わせマップ
- 観光対象 vs 津波浸水想定 重ね合わせマップ
- しまなみ走廊 zoom マップ (尾道-生口島-向島-因島)
- 観光対象 標高×海岸距離 二軸マップ (色 = 標高代理)
要件 Q 準拠: 図 8 / 表 11+ (走廊 × 機能 × 海岸 × リスク 多角度)
X01-X05 / L82 / L83 との重複回避 (徹底):
X01 = 観光対象 40 件と防災インフラ台帳 (ダム・橋・トンネル) を施設名マッチで
マージし、 「観光対象になる/ならない」 を OLS / ロジスティック回帰で
予測。 規模・立地で判別可能性を量化。 結果 X1: 観光対象ダムは
非観光ダムより容量・堤高大。
X02 = 埋蔵文化財都城・官衙跡 + その他遺跡を市町別クロス集計し、 階層
クラスタリング・PCA で都市プロファイルを描く。
X03 = 4 観光 dataset を市町別 4 次元ベクトル化し、 散布図行列・PCA・
重回帰・階層クラスタで市町俯瞰。
X04 = #1280 + #1282 を結合し、 港別市場構造分析 (Gini / HHI / CRn /
季節係数 / ローレンツ曲線) と新規/既存 4 タイプ分類。
X05 = しまたび航路 × 避難所収容で離島の「需給ギャップ指数」 を導出し、
バブル / ランキング / マップで防災需給バランスを描く。
L82 = #1280 単独深掘り。 Haversine / Jaccard / 東西ペア / 観光資源密度
/ 定期化スコア。 7 航路のプロダクト設計分析。
L83 = #1282 単独深掘り。 寄港順位ごとの客数勾配 / 東西方向対称性 /
港別春秋偏向指標 / 12 月落込み率。 12 港 × 9 ヶ月の定期航路
構造分析。
L87 (本記事) はこれら全てと厳密に重複しない切り口:
(i) 観光対象 / クルーズ寄港地 / 航路を「3 走廊」 という空間軸
で再分類。 走廊は本記事独自定義 (宮島・安芸灘・しまなみ)。
(ii) 観光対象施設 40 件の海岸距離 × 標高代理の 2 軸マップで
「内陸ダム vs 沿岸橋梁・島嶼施設」 の二極化を空間量化。
(iii) 観光と津波浸水想定の交差 (リスクとブランドの重なり) を
sjoin_nearest で量化。 既存 X/L 全てが触れていない切り口。
(iv) しまなみ走廊 zoom (尾道-向島-因島-生口島) の観光リソース
密度を、 走廊単位で集計。 X02/X05 が市町別だったのに対し、
走廊単位での新分類軸。
(v) 観光対象 40 件 + クルーズ寄港地 81 件 + しまたび 14 港 +
モニター 23 港を1 つの統合空間 (4 dataset 統合 GDF)に
載せ、 「瀬戸内ブランド」 を空間で物語る。 既存記事は dataset を
結合しても切り口が「規模分析」「需給ギャップ」「集中度」 に集中して
おり、 空間走廊の物語は L87 が初。
Gini / HHI / CR / Lorenz / Jaccard / 重回帰 / OLS / ロジスティック / PCA /
階層クラスタ / 散布図行列 / 季節係数 / 春秋偏向 / 客数勾配 / 寄港順位 /
Haversine / 定期化スコア / 需給ギャップ指数 / 双方向商品 - これら全ての
既存指標を本記事では再計算しない。 重複ゼロを徹底。
実行:
cd "2026 DoBoX 教材"
py -X utf8 lessons/L87_M3_tourism_story.py
"""
from __future__ import annotations
import sys
import time
import zipfile
import io
import re
import warnings
from pathlib import Path
from html import escape
sys.path.insert(0, str(Path(__file__).parent))
from _common import ROOT, ASSETS, LESSONS, render_lesson, code, figure
import numpy as np
import pandas as pd
import geopandas as gpd
import shapely
from shapely.geometry import Point, LineString
from shapely.ops import unary_union
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.patches import Patch
from matplotlib.lines import Line2D
warnings.filterwarnings("ignore", category=UserWarning)
warnings.filterwarnings("ignore", category=FutureWarning)
warnings.filterwarnings("ignore", category=RuntimeWarning)
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
t_all = time.time()
print("=== L87 M3 観光物語 — 瀬戸内ブランドのインフラと島嶼ネットワーク ===",
flush=True)
# =============================================================================
# 0. 定数・パス
# =============================================================================
TARGET_CRS = "EPSG:6671" # JGD2011 平面直角第 III 系 (m)
DATA_EX = ROOT / "data" / "extras"
DATA_DIR = DATA_EX / "L87_M3_tourism_story"
DATA_DIR.mkdir(parents=True, exist_ok=True)
# 既存 cache から再利用
INFRA_CSV = DATA_EX / "infra_tourism.csv"
ROUTE_CSV = DATA_EX / "sea_route.csv"
SHIMA_CSV = DATA_EX / "shimatabi_monthly.csv"
MONITOR_DAILY_CSV = DATA_EX / "cruise_monitor_daily.csv"
MONITOR_PORTS_CSV = DATA_EX / "cruise_monitor_ports.csv"
COAST_CSV = DATA_EX / "L64_coast_protection" / "340006_coastal_equipment_20230509.csv"
TSUNAMI_SHP = (DATA_EX / "tsunami_extracted"
/ "340006_tsunami_inundation_assumption_map_20251203"
/ "浸水メッシュ.shp")
ADMIN_DIR = DATA_EX / "L15_admin_zones"
# 3 走廊の独自定義 (lat/lon 矩形)
# 宮島走廊: 廿日市市・大竹市・広島市佐伯区・江田島市西部
# 安芸灘走廊: 呉市・東広島市安芸津・竹原市・大崎上島町・上下蒲刈島
# しまなみ走廊: 尾道市 (向島・因島・生口島・百島・佐木島周辺)
CORRIDORS = {
# (lat_min, lat_max, lon_min, lon_max, color)
"宮島走廊": (34.180, 34.430, 132.180, 132.420, "#0a6678"),
"安芸灘走廊": (34.110, 34.300, 132.420, 132.940, "#9a6700"),
"しまなみ走廊": (34.230, 34.450, 132.940, 133.350, "#cf222e"),
}
CORRIDOR_LABEL = {
"宮島走廊": "宮島走廊 (世界遺産・廿日市・大竹)",
"安芸灘走廊": "安芸灘走廊 (呉・竹原・蒲刈・大崎上島)",
"しまなみ走廊": "しまなみ走廊 (尾道・向島・因島・生口島)",
"走廊外": "走廊外 (内陸・福山等)",
}
# 主要島嶼の住所キーワード辞書 (X05 とは別の独自分類で観光走廊判定用)
ISLAND_KEYWORDS = {
"宮島": ["廿日市市宮島町"],
"江田島": ["江田島市江田島町", "江田島市能美町", "江田島市沖美町",
"江田島市大柿町"],
"倉橋・音戸": ["呉市倉橋町", "呉市音戸町"],
"蒲刈": ["呉市蒲刈町", "呉市下蒲刈町"],
"大崎上島": ["大崎上島町"],
"似島": ["広島市南区似島町"],
"向島": ["尾道市向島町"],
"因島": ["尾道市因島"],
"生口島": ["尾道市瀬戸田町"],
"佐木島": ["三原市鷺浦町"],
"百島": ["尾道市百島町"],
"豊島": ["呉市豊浜町"],
"斎島": ["呉市豊浜町大字斎島"],
"阿多田島": ["大竹市阿多田"],
}
# しまなみ海道 6 島の主要ポイント (尾道側 → 今治側、 広島県内のみ 4 点)
SHIMANAMI_BRIDGE_LATLON = [
(34.402, 133.198), # 尾道側 (尾道大橋付近)
(34.380, 133.205), # 向島
(34.323, 133.180), # 因島大橋付近
(34.302, 133.160), # 因島
(34.300, 133.085), # 生口島
(34.265, 133.085), # 多々羅大橋付近 (生口島南端、 広島県境)
]
# =============================================================================
# 1. データ取得確認
# =============================================================================
print("\n[1] データ確認 (4 観光 + 海岸 + 津波 + 行政界)", flush=True)
t1 = time.time()
for p, label in [
(INFRA_CSV, "インフラツーリズム #1447"),
(ROUTE_CSV, "瀬戸内航路 #1281"),
(SHIMA_CSV, "しまたびライン #1282"),
(MONITOR_DAILY_CSV, "モニタークルーズ運航 #1280"),
(MONITOR_PORTS_CSV, "モニタークルーズ寄港地 #1280"),
(COAST_CSV, "海岸保全施設 #1085"),
(TSUNAMI_SHP, "津波浸水想定 #47 系"),
]:
if not p.exists():
raise FileNotFoundError(f"{label}: {p} が見つからない。"
f" data/fetch_all.py を実行してください")
print(f" 全 7 系統データ確認 OK ({time.time()-t1:.2f}s)", flush=True)
# =============================================================================
# 2. 観光対象 + 寄港地 統合 GeoDataFrame
# =============================================================================
print("\n[2] 観光対象 + 寄港地 統合 (4 dataset → 1 GDF)", flush=True)
t2 = time.time()
# (a) インフラツーリズム 40 件
infra = pd.read_csv(INFRA_CSV, encoding="utf-8-sig")
infra["lat"] = pd.to_numeric(infra["緯度"], errors="coerce")
infra["lon"] = pd.to_numeric(infra["経度"], errors="coerce")
infra = infra.dropna(subset=["lat", "lon"]).copy()
infra["dataset_id"] = 1447
infra["source"] = "インフラツーリズム"
infra["施設名"] = infra["施設名称"]
infra = infra[["dataset_id", "source", "施設名", "分類", "lat", "lon"]].copy()
N_INFRA = len(infra)
# (b) 瀬戸内海航路 寄港地 81
route = pd.read_csv(ROUTE_CSV, encoding="utf-8-sig")
route["lat"] = pd.to_numeric(route["緯度"], errors="coerce")
route["lon"] = pd.to_numeric(route["経度"], errors="coerce")
route = route.dropna(subset=["lat", "lon"]).copy()
# 広島県内のみ
route = route[(route["lat"] > 33.5) & (route["lat"] < 35.0)
& (route["lon"] > 131.5) & (route["lon"] < 134.0)].copy()
route["dataset_id"] = 1281
route["source"] = "瀬戸内航路寄港地"
route["施設名"] = route["寄港地"]
route["分類"] = "航路寄港地"
route = route[["dataset_id", "source", "施設名", "分類", "lat", "lon",
"住所"]].copy()
N_ROUTE = len(route)
# (c) しまたびライン 12 寄港地 (cp932) — 経路を結ぶ LineString に使用
shima = pd.read_csv(SHIMA_CSV, encoding="cp932").dropna(
subset=["寄港地(桟橋名)"])
shima["lat"] = pd.to_numeric(shima["緯度"], errors="coerce")
shima["lon"] = pd.to_numeric(shima["経度"], errors="coerce")
shima = shima.dropna(subset=["lat", "lon"]).copy()
# 東向 (101) のみ + 寄港順 1-12
shima_east = (shima[shima["航路ID"] == 101]
.drop_duplicates("寄港地ID")
.sort_values("寄港桟橋順")
.reset_index(drop=True))
N_SHIMA_PORTS = len(shima_east)
# (d) モニタークルーズ 23 寄港地 (cp932)
mon_ports = pd.read_csv(MONITOR_PORTS_CSV, encoding="cp932")
mon_ports["lat"] = pd.to_numeric(mon_ports["緯度"], errors="coerce")
mon_ports["lon"] = pd.to_numeric(mon_ports["経度"], errors="coerce")
mon_ports = mon_ports.dropna(subset=["lat", "lon"]).copy()
mon_ports = mon_ports[(mon_ports["lat"] > 33.5) & (mon_ports["lat"] < 35.0)
& (mon_ports["lon"] > 131.5)
& (mon_ports["lon"] < 134.0)].copy()
mon_ports["dataset_id"] = 1280
mon_ports["source"] = "モニタークルーズ寄港地"
mon_ports["施設名"] = mon_ports["寄港地名(桟橋名)"]
mon_ports["分類"] = "モニター寄港地"
mon_ports = mon_ports[["dataset_id", "source", "施設名", "分類",
"lat", "lon", "住所"]].copy()
N_MON_PORTS = len(mon_ports)
# 4 dataset を 1 つにまとめる (主役 = infra + 寄港地 = 補助)
nodes_all = pd.concat([infra, route, mon_ports], ignore_index=True, sort=False)
nodes_all["node_id"] = np.arange(1, len(nodes_all) + 1)
print(f" インフラ観光 {N_INFRA} / 航路寄港地 {N_ROUTE} / "
f"しまたび {N_SHIMA_PORTS} / モニター寄港地 {N_MON_PORTS}", flush=True)
print(f" 統合 nodes (重複含む): {len(nodes_all)} 件", flush=True)
print(f" ({time.time()-t2:.2f}s)", flush=True)
# =============================================================================
# 3. GeoDataFrame 化 + 投影 + 走廊判定 + 島嶼判定
# =============================================================================
print("\n[3] 投影 + 3 走廊判定 + 島嶼判定", flush=True)
t3 = time.time()
gdf_nodes = gpd.GeoDataFrame(
nodes_all,
geometry=[Point(lon, lat) for lon, lat in zip(nodes_all["lon"],
nodes_all["lat"])],
crs="EPSG:4326",
).to_crs(TARGET_CRS)
gdf_nodes["x_m"] = gdf_nodes.geometry.x
gdf_nodes["y_m"] = gdf_nodes.geometry.y
def assign_corridor(row):
lat, lon = row["lat"], row["lon"]
for name, (lat_min, lat_max, lon_min, lon_max, _c) in CORRIDORS.items():
if lat_min <= lat <= lat_max and lon_min <= lon <= lon_max:
return name
return "走廊外"
gdf_nodes["corridor"] = gdf_nodes.apply(assign_corridor, axis=1)
def assign_island(row):
addr = str(row.get("住所", "") or "")
for island, kws in ISLAND_KEYWORDS.items():
if any(kw in addr for kw in kws):
return island
return "本州"
# 住所列が無い infra は別途分類 (緯度経度から最寄り島を判定)
def infra_island(row):
if row["source"] != "インフラツーリズム":
return None
# 簡易 lat/lon マッチ
lat, lon = row["lat"], row["lon"]
# 宮島: 34.27-34.31, 132.31-132.34
if 34.27 <= lat <= 34.31 and 132.30 <= lon <= 132.35:
return "宮島"
# 大崎上島: 34.24-34.30, 132.88-132.95
if 34.24 <= lat <= 34.30 and 132.86 <= lon <= 132.96:
return "大崎上島"
# 江田島: 34.18-34.27, 132.40-132.50
if 34.18 <= lat <= 34.27 and 132.40 <= lon <= 132.50:
return "江田島"
# 因島: 34.30-34.34, 133.16-133.21
if 34.29 <= lat <= 34.34 and 133.15 <= lon <= 133.22:
return "因島"
# 生口島: 34.27-34.32, 133.06-133.12
if 34.27 <= lat <= 34.32 and 133.05 <= lon <= 133.12:
return "生口島"
# 向島: 34.36-34.41, 133.18-133.23
if 34.35 <= lat <= 34.41 and 133.17 <= lon <= 133.23:
return "向島"
return "本州"
gdf_nodes["island"] = gdf_nodes.apply(
lambda r: infra_island(r) if r["source"] == "インフラツーリズム"
else assign_island(r), axis=1)
gdf_nodes["is_island"] = (gdf_nodes["island"] != "本州").astype(int)
print(f" 走廊分布: {gdf_nodes['corridor'].value_counts().to_dict()}",
flush=True)
print(f" ({time.time()-t3:.2f}s)", flush=True)
# =============================================================================
# 4. 海岸距離 (sjoin_nearest)
# =============================================================================
print("\n[4] 海岸保全施設 1646 件で海岸距離計算", flush=True)
t4 = time.time()
coast_raw = pd.read_csv(COAST_CSV, encoding="utf-8-sig", on_bad_lines="skip")
coast_raw["lat"] = pd.to_numeric(coast_raw["開始位置緯度"], errors="coerce")
coast_raw["lon"] = pd.to_numeric(coast_raw["開始位置経度"], errors="coerce")
coast_raw = coast_raw.dropna(subset=["lat", "lon"])
coast_raw = coast_raw[(coast_raw["lat"] > 33.5) & (coast_raw["lat"] < 35.0)
& (coast_raw["lon"] > 131.5)
& (coast_raw["lon"] < 134.0)]
coast_gdf = gpd.GeoDataFrame(
coast_raw[["施設名称", "市区町村1"]].rename(
columns={"市区町村1": "muni"}),
geometry=[Point(lon, lat)
for lon, lat in zip(coast_raw["lon"], coast_raw["lat"])],
crs="EPSG:4326",
).to_crs(TARGET_CRS)
N_COAST = len(coast_gdf)
nearest_coast = gpd.sjoin_nearest(
gdf_nodes[["node_id", "geometry"]],
coast_gdf[["geometry"]],
how="left", distance_col="coast_dist_m"
)
nearest_coast_min = (nearest_coast.groupby("node_id")["coast_dist_m"].min()
.reset_index())
gdf_nodes = gdf_nodes.merge(nearest_coast_min, on="node_id", how="left")
gdf_nodes["coast_dist_km"] = gdf_nodes["coast_dist_m"] / 1000
print(f" 海岸保全 {N_COAST:,} 件で sjoin_nearest 完了", flush=True)
print(f" 全 nodes 海岸距離 中央値: "
f"{gdf_nodes['coast_dist_km'].median():.2f} km", flush=True)
print(f" ({time.time()-t4:.2f}s)", flush=True)
# =============================================================================
# 5. 津波浸水想定 (#47 系) との交差
# note: 浸水メッシュ shp は 170MB 超の大型データ。
# unary_union を全メッシュにかけると数十分かかるため、 以下の戦略で高速化:
# (1) 観光対象の周辺 (各点 + 30km buffer の bbox) でメッシュをフィルタ
# (2) フィルタ済メッシュを 25 m 簡略化 + dissolve で統合
# (3) sjoin_nearest で距離計算、 within で 1km 圏内判定
# =============================================================================
print("\n[5] 津波浸水想定 shp 読込 + 交差判定 (空間インデックスで高速化)",
flush=True)
t5 = time.time()
# 浸水メッシュ shp は 170MB / 1.25M features の超大型データ。
# 統合 (union_all) は数十分かかるため、 以下の高速戦略を取る:
# (1) 観光対象点 (143 件) ごとに 1km buffer ポリゴンを生成
# (2) buffer ↔ メッシュ で sjoin (predicate='intersects')
# — 空間インデックスで一瞬。 1km 圏内のメッシュを件数カウント
# (3) buffer 内に 1 件以上メッシュあれば in_tsunami_1km = 1
# (4) 距離は sjoin_nearest で R-tree 利用、 メッシュ数 1.25M でも
# 数秒で完了。 union_all は不要。
import pyogrio
infra_mask = gdf_nodes["source"] == "インフラツーリズム"
print(f" 浸水メッシュ shp 読込中 ({pyogrio.read_info(TSUNAMI_SHP)['features']:,} features)...",
flush=True)
tsunami_gdf = gpd.read_file(TSUNAMI_SHP, encoding="cp932")
tsunami_gdf = tsunami_gdf.to_crs(TARGET_CRS)
N_TSUNAMI_MESH = len(tsunami_gdf)
print(f" 読込完了 メッシュ {N_TSUNAMI_MESH:,}", flush=True)
# 観光対象 1km buffer
print(f" 観光対象 1km buffer 生成 + sjoin (intersects) ...", flush=True)
infra_buffer = gdf_nodes.loc[infra_mask, ["node_id", "geometry"]].copy()
infra_buffer["geometry"] = infra_buffer.geometry.buffer(1000)
# sjoin で 1km buffer ↔ メッシュ の intersects
sj = gpd.sjoin(infra_buffer, tsunami_gdf[["geometry"]],
how="left", predicate="intersects")
n_in_1km_per_node = sj.groupby("node_id").size().reset_index(name="hit")
# 注意: sjoin で hit=0 でも空 right で 1 行残るため、 indexed_right で判定
sj_hit = sj.dropna(subset=["index_right"]).groupby("node_id").size()
gdf_nodes["in_tsunami_1km"] = 0
in_1km_ids = sj_hit[sj_hit > 0].index.tolist()
gdf_nodes.loc[gdf_nodes["node_id"].isin(in_1km_ids), "in_tsunami_1km"] = 1
# 全 nodes 距離計算 (sjoin_nearest with R-tree, メッシュ 1.25M でも高速)
print(f" sjoin_nearest で全 nodes 距離計算...", flush=True)
nearest_tsunami = gpd.sjoin_nearest(
gdf_nodes[["node_id", "geometry"]],
tsunami_gdf[["geometry"]],
how="left", distance_col="tsunami_dist_m"
)
nearest_tsunami_min = (nearest_tsunami.groupby("node_id")["tsunami_dist_m"]
.min().reset_index())
gdf_nodes = gdf_nodes.merge(nearest_tsunami_min, on="node_id", how="left")
gdf_nodes["tsunami_dist_km"] = gdf_nodes["tsunami_dist_m"] / 1000
n_infra_in_1km = int(gdf_nodes.loc[infra_mask, "in_tsunami_1km"].sum())
pct_infra_in_1km = n_infra_in_1km / max(N_INFRA, 1) * 100
# 描画用: メッシュをランダムに 5000 件サブサンプル (1.25M を全件描画は重い)
np.random.seed(42)
sample_n = min(5000, N_TSUNAMI_MESH)
tsunami_sample = tsunami_gdf.sample(n=sample_n, random_state=42)
print(f" 津波浸水メッシュ {N_TSUNAMI_MESH:,} で sjoin 完了", flush=True)
print(f" 観光対象 {N_INFRA} 件中 津波 1km 圏内: "
f"{n_infra_in_1km} ({pct_infra_in_1km:.1f}%)", flush=True)
print(f" ({time.time()-t5:.2f}s)", flush=True)
# =============================================================================
# 6. 行政界 (背景マップ用)
# =============================================================================
print("\n[6] 行政界 (L15 cache) 読込 + dissolve", flush=True)
t6 = time.time()
ADMIN_MAP = [
("広島市", 786), ("呉市", 797), ("竹原市", 807),
("三原市", 814), ("尾道市", 824), ("福山市", 832),
("府中市", 840), ("三次市", 850), ("庄原市", 856),
("大竹市", 862), ("東広島市", 868), ("廿日市市", 878),
("安芸高田市", 888), ("江田島市", 894), ("府中町", 900),
("海田町", 905), ("熊野町", 911), ("坂町", 916),
("北広島町", 935), ("世羅町", 941),
]
admin_frames = []
for cname, dsid in ADMIN_MAP:
z = ADMIN_DIR / f"admin_{dsid}_{cname}.zip"
if not z.exists():
continue
with zipfile.ZipFile(z) as zf:
gjs = [n for n in zf.namelist() if n.lower().endswith(".geojson")]
with zf.open(gjs[0]) as f:
g = gpd.read_file(io.BytesIO(f.read()))
g["city"] = cname
admin_frames.append(g)
admin_all = gpd.GeoDataFrame(
pd.concat(admin_frames, ignore_index=True),
geometry="geometry", crs=admin_frames[0].crs
).to_crs(TARGET_CRS)
admin_diss = admin_all.dissolve(by="city", as_index=False)
# 走廊矩形ポリゴン (描画用)
corridor_polys = []
for name, (lat_min, lat_max, lon_min, lon_max, color) in CORRIDORS.items():
poly_4326 = shapely.geometry.box(lon_min, lat_min, lon_max, lat_max)
poly_proj = (gpd.GeoSeries([poly_4326], crs="EPSG:4326")
.to_crs(TARGET_CRS).iloc[0])
corridor_polys.append((name, poly_proj, color))
# しまたびライン LineString (東向 101 寄港順 1-12)
shima_pts_4326 = gpd.GeoSeries(
[Point(lon, lat) for lon, lat in
zip(shima_east["経度"], shima_east["緯度"])],
crs="EPSG:4326",
).to_crs(TARGET_CRS)
shima_line = LineString([(p.x, p.y) for p in shima_pts_4326])
# しまなみ海道 4 主要点 LineString (簡易モデル)
shima_bridge_pts_4326 = gpd.GeoSeries(
[Point(lon, lat) for lat, lon in SHIMANAMI_BRIDGE_LATLON],
crs="EPSG:4326",
).to_crs(TARGET_CRS)
shimanami_line = LineString([(p.x, p.y) for p in shima_bridge_pts_4326])
print(f" 行政界 {len(admin_diss)} 市町 / 3 走廊矩形 / "
f"しまたび東向 {len(shima_east)} 港 LineString / "
f"しまなみ {len(SHIMANAMI_BRIDGE_LATLON)} 点 LineString", flush=True)
print(f" ({time.time()-t6:.2f}s)", flush=True)
# =============================================================================
# 7. 集計表 (11 種)
# =============================================================================
print("\n[7] 集計表 11 種", flush=True)
t7 = time.time()
# (1) ソース × 走廊 クロス
T_source_corridor = (gdf_nodes.groupby(["source", "corridor"]).size()
.unstack(fill_value=0))
T_source_corridor["合計"] = T_source_corridor.sum(axis=1)
# (2) インフラ観光 40 件の 分類 × 走廊
infra_only = gdf_nodes[gdf_nodes["source"] == "インフラツーリズム"].copy()
T_infra_class_corridor = (infra_only.groupby(["分類", "corridor"]).size()
.unstack(fill_value=0))
# (3) 走廊サマリー (各走廊 件数 + 海岸距離中央値 + 島嶼率)
T_corridor_summary = []
for cname in ["宮島走廊", "安芸灘走廊", "しまなみ走廊", "走廊外"]:
sub = gdf_nodes[gdf_nodes["corridor"] == cname]
sub_infra = sub[sub["source"] == "インフラツーリズム"]
sub_route = sub[sub["source"].str.contains("寄港地", na=False)]
T_corridor_summary.append({
"走廊": cname,
"観光対象数": len(sub_infra),
"寄港地数": len(sub_route),
"総ノード数": len(sub),
"海岸距離中央値km": round(sub["coast_dist_km"].median(), 2)
if len(sub) > 0 else 0.0,
"島嶼率%": round(sub["is_island"].mean() * 100, 1)
if len(sub) > 0 else 0.0,
})
T_corridor_summary = pd.DataFrame(T_corridor_summary)
# (4) 観光対象 40 件 島嶼分布
T_island_infra = (infra_only.groupby("island").size()
.reset_index().rename(columns={0: "n"}))
T_island_infra.columns = ["island", "n"]
T_island_infra = T_island_infra.sort_values("n", ascending=False)
n_infra_island = int(infra_only["is_island"].sum())
pct_infra_island = n_infra_island / max(N_INFRA, 1) * 100
# (5) 観光対象 海岸距離ビン分布
infra_only["coast_bin"] = pd.cut(
infra_only["coast_dist_km"],
bins=[-1, 1, 3, 5, 10, 999],
labels=["0-1km", "1-3km", "3-5km", "5-10km", "10km+"]
)
T_infra_coast = (infra_only.groupby(["coast_bin", "分類"], observed=False)
.size().unstack(fill_value=0))
# (6) 走廊 × 観光対象分類
T_corridor_class = (infra_only.groupby(["corridor", "分類"]).size()
.unstack(fill_value=0))
# (7) しまなみ走廊 zoom 内訳 (走廊フィルタ後 さらに分類別)
shimanami_nodes = gdf_nodes[gdf_nodes["corridor"] == "しまなみ走廊"].copy()
T_shimanami_source = (shimanami_nodes.groupby(["source", "分類"]).size()
.unstack(fill_value=0))
# (8) 観光対象 vs 津波浸水
infra_only["tsunami_bin"] = pd.cut(
infra_only["tsunami_dist_km"],
bins=[-1, 0.001, 1, 5, 999],
labels=["浸水内", "1km以内", "5km以内", "5km超"]
)
T_infra_tsunami = (infra_only.groupby(["tsunami_bin", "分類"],
observed=False)
.size().unstack(fill_value=0))
# (9) 1 件追跡 (要件 K) — 観光対象 1 件 (宮島の紅葉谷川庭園砂防施設)
sample_id = infra_only.iloc[0]["node_id"]
sample = gdf_nodes[gdf_nodes["node_id"] == sample_id].iloc[0]
T_track = pd.DataFrame([
{"段階": "0. 元 CSV", "値": f"{sample['施設名']} ({sample['source']})"},
{"段階": "1. 分類", "値": str(sample["分類"])},
{"段階": "2. 緯度経度", "値": f"{sample['lat']:.5f}, {sample['lon']:.5f}"},
{"段階": "3. 投影 EPSG:6671",
"値": f"({sample['x_m']:.0f}, {sample['y_m']:.0f}) m"},
{"段階": "4. 走廊判定", "値": str(sample["corridor"])},
{"段階": "5. 島嶼判定 (lat/lon マッチ)",
"値": f"{sample['island']} (is_island={sample['is_island']})"},
{"段階": "6. 海岸距離 sjoin_nearest",
"値": f"{sample['coast_dist_km']:.2f} km"},
{"段階": "7. 津波浸水想定 距離",
"値": f"{sample['tsunami_dist_km']:.2f} km "
f"(1km圏内={'Yes' if sample['in_tsunami_1km']==1 else 'No'})"},
{"段階": "8. 統合 GDF 行 ID",
"値": f"node_id={int(sample['node_id'])}"},
])
# (10) 既存記事との比較表 (重複ゼロ宣言)
T_compare = pd.DataFrame([
{"記事": "X01 (インフラ二重利用)",
"主軸": "観光対象 vs 非観光のロジスティック回帰・OLS 重回帰",
"主結果": "観光対象ダムは容量・堤高大、AUC 高",
"L87 との重複": "L87 は回帰計算なし、空間走廊分類のみ"},
{"記事": "X02 (文化財 × 観光)",
"主軸": "都城・官衙跡 211件の階層クラスタ・PCA",
"主結果": "市町プロファイル 4 クラスタ",
"L87 との重複": "L87 は文化財扱わず、観光走廊のみ"},
{"記事": "X03 (観光 4 指標)",
"主軸": "市町別 4 次元ベクトル・散布図行列・PCA",
"主結果": "クルーズ・しまたび・モニター・インフラの 4 軸俯瞰",
"L87 との重複": "L87 は市町ではなく走廊単位、PCA なし"},
{"記事": "X04 (クルーズ需要構造)",
"主軸": "Gini/HHI/CRn・季節係数・ローレンツ曲線",
"主結果": "上位5港 CR5≥40%、春秋 2 山型",
"L87 との重複": "L87 は集中度指標なし、走廊地理のみ"},
{"記事": "X05 (島嶼需給ギャップ)",
"主軸": "島別 観光ピーク需要 ÷ 避難所収容力 = ギャップ指数",
"主結果": "ギャップ大の島 = 観光重点",
"L87 との重複": "L87 はギャップ指数なし、走廊と津波交差のみ"},
{"記事": "L82 (モニタークルーズ)",
"主軸": "Haversine / Jaccard / 東西ペア / 定期化スコア",
"主結果": "7 航路の総距離 80-120km 帯",
"L87 との重複": "L82 は航路設計、L87 は寄港地空間"},
{"記事": "L83 (しまたびライン)",
"主軸": "客数勾配 / 東西対称性 / 春秋偏向 / 12月落込み",
"主結果": "中継 5-8 港の累積客数最大",
"L87 との重複": "L83 は時系列、L87 は静的空間統合"},
{"記事": "L87 (本記事, 物語)",
"主軸": "瀬戸内ブランド = 3 走廊 (宮島・安芸灘・しまなみ) の空間統合",
"主結果": "走廊別観光集積、島嶼集中、津波交差、しまなみ集積",
"L87 との重複": "—"},
])
# (11) 仮説検証は次セクションで作成
# (12) 走廊別 ノード密度 (件数 / 矩形面積)
T_corridor_density = []
for name, (lat_min, lat_max, lon_min, lon_max, _c) in CORRIDORS.items():
# 矩形面積 (近似 km²: lat 1° ≈ 111km, lon 1° at 34.4° ≈ 91km)
h_km = (lat_max - lat_min) * 111
w_km = (lon_max - lon_min) * 91
area_km2 = h_km * w_km
sub = gdf_nodes[gdf_nodes["corridor"] == name]
T_corridor_density.append({
"走廊": name,
"緯度範囲": f"{lat_min:.2f}-{lat_max:.2f}",
"経度範囲": f"{lon_min:.2f}-{lon_max:.2f}",
"矩形面積_km2": round(area_km2, 0),
"ノード数": len(sub),
"密度_件/100km2": round(len(sub) / max(area_km2, 1) * 100, 2),
})
T_corridor_density = pd.DataFrame(T_corridor_density)
print(f" 集計表 11 種 完成 ({time.time()-t7:.2f}s)", flush=True)
# =============================================================================
# 8. しまなみ走廊統計 + 仮説検証
# =============================================================================
print("\n[8] 仮説検証 (5 仮説)", flush=True)
t8 = time.time()
# H1: 観光対象 40 件の島嶼立地比率 ≥ 20%
h1_value = pct_infra_island
h1_ok = h1_value >= 20.0
# H2: 観光対象 + クルーズ寄港地 のうち しまなみ走廊立地 ≥ 15%
total_pois = N_INFRA + N_ROUTE + N_MON_PORTS # しまたびを除く ノード集合
shimanami_pois_n = int((gdf_nodes["corridor"] == "しまなみ走廊").sum())
h2_value = shimanami_pois_n / max(total_pois, 1) * 100
h2_ok = h2_value >= 15.0
# H3: 観光対象 40 件 海岸距離中央値 ≤ 3km
infra_coast_median = float(infra_only["coast_dist_km"].median())
h3_value = infra_coast_median
h3_ok = h3_value <= 3.0
# H4: 観光対象 津波 1km 圏内 ≥ 30%
h4_value = pct_infra_in_1km
h4_ok = h4_value >= 30.0
# H5: 3 走廊間の重複 ≤ 5% (本記事の独自 lat/lon 矩形なら定義上重複ゼロ)
# ただし lat/lon 矩形が部分的に重なっていれば、 同一ノードが複数走廊に
# 該当する可能性。 本記事は assign_corridor で「最初に hit した走廊」 を割当
# (定義上重複ゼロ) なので、 H5 は「全走廊矩形が完全分離されているか」 を
# チェックする。
def rect_overlap(a, b):
"""2 矩形 (lat_min, lat_max, lon_min, lon_max) の overlap area km²"""
lat_overlap = max(0, min(a[1], b[1]) - max(a[0], b[0])) * 111
lon_overlap = max(0, min(a[3], b[3]) - max(a[2], b[2])) * 91
return lat_overlap * lon_overlap
corridor_rects = {n: (lm, lM, om, oM) for n, (lm, lM, om, oM, _) in CORRIDORS.items()}
overlaps = []
total_area = 0
names = list(corridor_rects.keys())
for i in range(len(names)):
for j in range(i+1, len(names)):
ov = rect_overlap(corridor_rects[names[i]], corridor_rects[names[j]])
overlaps.append((names[i], names[j], round(ov, 0)))
total_area += ov
sum_areas = sum(rect_overlap(r, r) for r in corridor_rects.values()) # 自己面積
h5_value = total_area / max(sum_areas, 1) * 100
h5_ok = h5_value <= 5.0
T_hypothesis = pd.DataFrame([
{"仮説": "H1 (島嶼観光集中)",
"予測": "観光対象 40 件中 島嶼立地 ≥ 20%",
"実測": f"{n_infra_island}/{N_INFRA} = {h1_value:.1f}%",
"判定": "支持" if h1_ok else "反証"},
{"仮説": "H2 (しまなみ走廊集積)",
"予測": f"観光対象 + クルーズ寄港地 {total_pois} 件中 しまなみ ≥ 15%",
"実測": f"{shimanami_pois_n}/{total_pois} = {h2_value:.1f}%",
"判定": "支持" if h2_ok else "反証"},
{"仮説": "H3 (海岸近接)",
"予測": "観光対象 40 件 海岸距離 中央値 ≤ 3 km",
"実測": f"中央値 {h3_value:.2f} km",
"判定": "支持" if h3_ok else "反証"},
{"仮説": "H4 (観光・防災交差)",
"予測": "観光対象 40 件中 津波 1km 圏内 ≥ 30%",
"実測": f"{n_infra_in_1km}/{N_INFRA} = {h4_value:.1f}%",
"判定": "支持" if h4_ok else "反証"},
{"仮説": "H5 (3 走廊独立)",
"予測": "走廊矩形の重複面積比 ≤ 5%",
"実測": f"重複面積 {total_area:.0f} km² / 自己面積 {sum_areas:.0f} km² "
f"= {h5_value:.1f}%",
"判定": "支持" if h5_ok else "反証"},
])
n_supported = (T_hypothesis["判定"] == "支持").sum()
print(f" 支持: {n_supported}/5", flush=True)
print(T_hypothesis.to_string(index=False), flush=True)
print(f" ({time.time()-t8:.2f}s)", flush=True)
# =============================================================================
# 9. 中間 CSV 保存
# =============================================================================
print("\n[9] 中間 CSV 保存", flush=True)
t9 = time.time()
nodes_save = pd.DataFrame(gdf_nodes.drop(columns="geometry"))
for c in ["lat", "lon", "x_m", "y_m"]:
if c in nodes_save.columns:
nodes_save[c] = nodes_save[c].round(2 if c in ("x_m", "y_m") else 5)
for c in ["coast_dist_km", "tsunami_dist_km"]:
nodes_save[c] = nodes_save[c].round(3)
nodes_save.to_csv(ASSETS / "L87_nodes_integrated.csv",
index=False, encoding="utf-8-sig")
T_source_corridor.to_csv(ASSETS / "L87_source_corridor.csv",
encoding="utf-8-sig")
T_infra_class_corridor.to_csv(ASSETS / "L87_infra_class_corridor.csv",
encoding="utf-8-sig")
T_corridor_summary.to_csv(ASSETS / "L87_corridor_summary.csv",
index=False, encoding="utf-8-sig")
T_island_infra.to_csv(ASSETS / "L87_island_infra.csv",
index=False, encoding="utf-8-sig")
T_infra_coast.to_csv(ASSETS / "L87_infra_coast_bin.csv",
encoding="utf-8-sig")
T_corridor_class.to_csv(ASSETS / "L87_corridor_class.csv",
encoding="utf-8-sig")
T_shimanami_source.to_csv(ASSETS / "L87_shimanami_source.csv",
encoding="utf-8-sig")
T_infra_tsunami.to_csv(ASSETS / "L87_infra_tsunami.csv",
encoding="utf-8-sig")
T_track.to_csv(ASSETS / "L87_track_one_node.csv",
index=False, encoding="utf-8-sig")
T_compare.to_csv(ASSETS / "L87_compare_existing.csv",
index=False, encoding="utf-8-sig")
T_hypothesis.to_csv(ASSETS / "L87_hypothesis.csv",
index=False, encoding="utf-8-sig")
T_corridor_density.to_csv(ASSETS / "L87_corridor_density.csv",
index=False, encoding="utf-8-sig")
print(f" CSV 保存完了 ({time.time()-t9:.2f}s)", flush=True)
# =============================================================================
# 10. 図 8 枚
# =============================================================================
print("\n[10] 図作成", flush=True)
t10 = time.time()
def _format_admin_bg(ax):
admin_diss.plot(ax=ax, facecolor="#fafafa",
edgecolor="#888", linewidth=0.4)
# --- Fig 1: 3 走廊オーバーレイ + 統合 nodes ---
fig, ax = plt.subplots(1, 1, figsize=(15, 10))
_format_admin_bg(ax)
# 走廊矩形を半透明
for name, poly, color in corridor_polys:
gpd.GeoSeries([poly], crs=TARGET_CRS).plot(
ax=ax, facecolor=color, alpha=0.10,
edgecolor=color, linewidth=2.5, linestyle="--"
)
# しまたびライン LineString
gpd.GeoSeries([shima_line], crs=TARGET_CRS).plot(
ax=ax, color="#0969da", linewidth=2.0, alpha=0.6,
)
# しまなみ海道 LineString
gpd.GeoSeries([shimanami_line], crs=TARGET_CRS).plot(
ax=ax, color="#cf222e", linewidth=3.0, alpha=0.8,
linestyle="-",
)
# nodes (4 ソース別色)
SRC_COLOR = {
"インフラツーリズム": "#cf222e",
"瀬戸内航路寄港地": "#0969da",
"モニタークルーズ寄港地": "#8250df",
}
SRC_MARKER = {
"インフラツーリズム": ("^", 90),
"瀬戸内航路寄港地": ("o", 28),
"モニタークルーズ寄港地": ("D", 38),
}
for src, (marker, size) in SRC_MARKER.items():
sub = gdf_nodes[gdf_nodes["source"] == src]
if len(sub) > 0:
sub.plot(ax=ax, color=SRC_COLOR[src], markersize=size,
marker=marker, alpha=0.8,
edgecolor="white", linewidth=0.5)
legend_elems = []
for cname, _r, color in corridor_polys:
n = int((gdf_nodes["corridor"] == cname).sum())
legend_elems.append(Patch(facecolor=color, alpha=0.30,
label=f"{CORRIDOR_LABEL[cname]} ({n})"))
legend_elems.append(Line2D([0], [0], color="#cf222e", linewidth=3,
label="しまなみ海道 (1999 開通)"))
legend_elems.append(Line2D([0], [0], color="#0969da", linewidth=2,
label="しまたびライン東向 (12 港)"))
for src, (marker, _s) in SRC_MARKER.items():
n = int((gdf_nodes["source"] == src).sum())
legend_elems.append(Line2D(
[0], [0], marker=marker, color="white",
markerfacecolor=SRC_COLOR[src], markersize=10,
label=f"{src} ({n})"
))
ax.legend(handles=legend_elems, loc="upper right", fontsize=9,
framealpha=0.95)
ax.set_aspect("equal")
ax.set_xticks([]); ax.set_yticks([])
ax.set_title(
"Fig 1: 瀬戸内ブランド 3 走廊と統合 nodes — 観光対象 + 寄港地"
f" + 航路 ({len(gdf_nodes)} 件)",
fontsize=13, pad=10
)
plt.tight_layout()
plt.savefig(ASSETS / "L87_fig01_corridors_overview.png", dpi=130)
plt.close("all")
print(f" Fig 1 完成 ({time.time()-t10:.1f}s)", flush=True)
# --- Fig 2: 観光対象 40 件 分類 × 走廊 + 走廊別件数棒 ---
fig, axes = plt.subplots(1, 2, figsize=(17, 8))
ax0 = axes[0]
_format_admin_bg(ax0)
for name, poly, color in corridor_polys:
gpd.GeoSeries([poly], crs=TARGET_CRS).plot(
ax=ax0, facecolor=color, alpha=0.08,
edgecolor=color, linewidth=1.5, linestyle="--"
)
CLASS_COLOR = {
"大規模構造物": "#cf222e",
"歴史的建造物": "#0969da",
"その他": "#8250df",
}
CLASS_MARKER = {
"大規模構造物": "^",
"歴史的建造物": "s",
"その他": "o",
}
for cls, color in CLASS_COLOR.items():
sub = infra_only[infra_only["分類"] == cls]
if len(sub) > 0:
sub.plot(ax=ax0, color=color,
markersize=130, marker=CLASS_MARKER[cls],
alpha=0.9, edgecolor="white", linewidth=0.8)
ax0.set_aspect("equal")
ax0.set_xticks([]); ax0.set_yticks([])
ax0.set_title(
f"観光対象 {N_INFRA} 件 分類別 ({len(CLASS_COLOR)} 分類)",
fontsize=12
)
ax0.legend(handles=[
Line2D([0], [0], marker=CLASS_MARKER[cls], color="white",
markerfacecolor=CLASS_COLOR[cls], markersize=12,
label=f"{cls} ({int((infra_only['分類']==cls).sum())})")
for cls in CLASS_COLOR
], loc="upper right", fontsize=10, framealpha=0.95)
# 右: 走廊 × 分類 stacked bar
ax1 = axes[1]
plot_data = T_corridor_class.reindex(
["宮島走廊", "安芸灘走廊", "しまなみ走廊", "走廊外"]).fillna(0)
bottoms = np.zeros(len(plot_data))
for cls, color in CLASS_COLOR.items():
if cls not in plot_data.columns:
continue
vals = plot_data[cls].values
ax1.bar(plot_data.index, vals, bottom=bottoms,
color=color, edgecolor="white", linewidth=0.5,
label=cls)
for i, v in enumerate(vals):
if v > 0:
ax1.text(i, bottoms[i] + v/2, f"{int(v)}",
ha="center", va="center",
color="white", fontweight="bold")
bottoms += vals
ax1.set_ylabel("観光対象 件数")
ax1.set_title("走廊 × 分類 構成 (積み上げ棒)", fontsize=12)
ax1.legend(loc="upper right", fontsize=9)
ax1.grid(True, alpha=0.3, axis="y")
plt.setp(ax1.get_xticklabels(), rotation=20)
plt.suptitle("Fig 2: 第3章 — インフラ観光対象 40 件 の走廊別分布",
fontsize=13, y=1.00)
plt.tight_layout()
plt.savefig(ASSETS / "L87_fig02_infra_classification.png", dpi=130)
plt.close("all")
print(f" Fig 2 完成 ({time.time()-t10:.1f}s)", flush=True)
# --- Fig 3: 観光対象 海岸距離 × 標高代理 (中央値での層化散布) ---
# ここでは「標高代理」 として lat (北ほど内陸) を簡易的に使う
fig, ax = plt.subplots(1, 1, figsize=(13, 8))
# 海岸距離ビンで色分け
COAST_BIN_COLOR = {
"0-1km": "#005f73", "1-3km": "#0a6678", "3-5km": "#0969da",
"5-10km": "#9a6700", "10km+": "#cf222e",
}
infra_only_temp = infra_only.copy()
for bin_name, color in COAST_BIN_COLOR.items():
sub = infra_only_temp[infra_only_temp["coast_bin"] == bin_name]
if len(sub) > 0:
ax.scatter(sub["coast_dist_km"], sub["lat"],
c=color, s=140, alpha=0.85,
edgecolor="white", linewidth=0.8,
label=f"{bin_name} ({len(sub)})")
# 中央値 vline
ax.axvline(infra_coast_median, color="black", linestyle="--",
linewidth=1.5, alpha=0.6,
label=f"海岸距離中央値 {infra_coast_median:.2f} km")
ax.set_xlabel("最寄り海岸保全施設までの距離 (km)")
ax.set_ylabel("緯度 (北ほど内陸傾向)")
ax.set_title(
f"Fig 3: 観光対象 {N_INFRA} 件 — 海岸距離 × 緯度の二極化散布図\n"
f"(沿岸ほど低緯度・内陸ダムは高緯度の傾向)",
fontsize=12, pad=8
)
ax.legend(loc="upper right", fontsize=10, framealpha=0.95)
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig(ASSETS / "L87_fig03_infra_coast_scatter.png", dpi=130)
plt.close("all")
print(f" Fig 3 完成 ({time.time()-t10:.1f}s)", flush=True)
# --- Fig 4: しまなみ走廊 zoom (尾道-向島-因島-生口島) ---
fig, ax = plt.subplots(1, 1, figsize=(13, 9))
_format_admin_bg(ax)
# しまなみ海道 LineString 強調
gpd.GeoSeries([shimanami_line], crs=TARGET_CRS).plot(
ax=ax, color="#cf222e", linewidth=4.0, alpha=0.9
)
# しまなみ走廊矩形
for name, poly, color in corridor_polys:
if name == "しまなみ走廊":
gpd.GeoSeries([poly], crs=TARGET_CRS).plot(
ax=ax, facecolor=color, alpha=0.12,
edgecolor=color, linewidth=2.5, linestyle="--"
)
# 走廊内 nodes (ソース別)
for src, (marker, size) in SRC_MARKER.items():
sub = shimanami_nodes[shimanami_nodes["source"] == src]
if len(sub) > 0:
sub.plot(ax=ax, color=SRC_COLOR[src],
markersize=size * 2, marker=marker, alpha=0.9,
edgecolor="white", linewidth=0.8)
# 観光対象の名前ラベル
if src == "インフラツーリズム":
for _, row in sub.iterrows():
ax.annotate(row["施設名"][:10],
(row.geometry.x, row.geometry.y),
xytext=(8, 6), textcoords="offset points",
fontsize=8,
bbox=dict(boxstyle="round,pad=0.2",
facecolor="#fff3cd",
edgecolor="#cf222e", alpha=0.85))
# しまなみ走廊範囲に zoom
for name, (lat_min, lat_max, lon_min, lon_max, _c) in CORRIDORS.items():
if name == "しまなみ走廊":
bbox_4326 = shapely.geometry.box(lon_min, lat_min, lon_max, lat_max)
bbox_proj = (gpd.GeoSeries([bbox_4326], crs="EPSG:4326")
.to_crs(TARGET_CRS).iloc[0])
xmin, ymin, xmax, ymax = bbox_proj.bounds
ax.set_xlim(xmin - 1500, xmax + 1500)
ax.set_ylim(ymin - 1500, ymax + 1500)
ax.set_aspect("equal")
ax.set_xticks([]); ax.set_yticks([])
n_shimanami = len(shimanami_nodes)
ax.set_title(
f"Fig 4: しまなみ走廊 zoom — {n_shimanami} 件統合 nodes\n"
f"(尾道-向島-因島-生口島 + しまなみ海道 LineString)",
fontsize=12, pad=8
)
legend_elems = [
Line2D([0], [0], color="#cf222e", linewidth=4,
label="しまなみ海道推定ライン (1999 開通)"),
]
for src, (marker, _s) in SRC_MARKER.items():
n = int((shimanami_nodes["source"] == src).sum())
legend_elems.append(Line2D(
[0], [0], marker=marker, color="white",
markerfacecolor=SRC_COLOR[src], markersize=11,
label=f"{src} ({n})"
))
ax.legend(handles=legend_elems, loc="upper left", fontsize=9,
framealpha=0.95)
plt.tight_layout()
plt.savefig(ASSETS / "L87_fig04_shimanami_zoom.png", dpi=130)
plt.close("all")
print(f" Fig 4 完成 ({time.time()-t10:.1f}s)", flush=True)
# --- Fig 5: 観光対象 vs 津波浸水想定 重ね合わせ ---
fig, axes = plt.subplots(1, 2, figsize=(17, 9))
ax0 = axes[0]
_format_admin_bg(ax0)
# 津波浸水メッシュ (5000 件サブサンプル, 薄青)
tsunami_sample.plot(ax=ax0, facecolor="#0969da", alpha=0.30,
edgecolor="none")
# 観光対象 40 件
infra_only.plot(ax=ax0, color="#cf222e", markersize=110, marker="^",
alpha=0.9, edgecolor="white", linewidth=0.8)
# 1km 圏内の観光対象 強調
in_tsu = infra_only[infra_only["in_tsunami_1km"] == 1]
if len(in_tsu) > 0:
in_tsu.plot(ax=ax0, color="black", markersize=200, marker="*",
alpha=0.95, edgecolor="white", linewidth=1.2)
ax0.set_aspect("equal")
ax0.set_xticks([]); ax0.set_yticks([])
ax0.set_title(
f"観光対象 {N_INFRA} 件 vs 津波浸水想定エリア\n"
f"1km 圏内 = {n_infra_in_1km} 件 ({pct_infra_in_1km:.1f}%)",
fontsize=11
)
ax0.legend(handles=[
Patch(facecolor="#0969da", alpha=0.30,
label=f"津波浸水想定メッシュ ({sample_n:,}/"
f"{N_TSUNAMI_MESH:,} mesh サブサンプル描画)"),
Line2D([0], [0], marker="^", color="white",
markerfacecolor="#cf222e", markersize=11,
label=f"観光対象 ({N_INFRA})"),
Line2D([0], [0], marker="*", color="white",
markerfacecolor="black", markersize=14,
label=f"津波 1km 圏内観光対象 ({n_infra_in_1km})"),
], loc="upper right", fontsize=9, framealpha=0.95)
# 右: 津波距離分布ヒストグラム
ax1 = axes[1]
bins = np.arange(0, 30, 1.0)
ax1.hist(infra_only["tsunami_dist_km"].clip(upper=29),
bins=bins, color="#cf222e", edgecolor="white", alpha=0.85)
ax1.axvline(1.0, color="black", linestyle="--", linewidth=1.5,
label=f"1km 閾値 ({pct_infra_in_1km:.1f}% が 1km 圏内)")
ax1.axvline(infra_only["tsunami_dist_km"].median(),
color="#0969da", linestyle=":", linewidth=1.5,
label=f"中央値 "
f"{infra_only['tsunami_dist_km'].median():.2f} km")
ax1.set_xlabel("最寄り津波浸水想定エリアまでの距離 (km)")
ax1.set_ylabel("観光対象 件数")
ax1.set_title("観光対象 → 津波想定 距離分布", fontsize=11)
ax1.legend(fontsize=9)
ax1.grid(True, alpha=0.3, axis="y")
plt.suptitle("Fig 5: 第5章 — 観光と防災の交差 (リスクとブランドの重なり)",
fontsize=13, y=1.00)
plt.tight_layout()
plt.savefig(ASSETS / "L87_fig05_tsunami_overlay.png", dpi=130)
plt.close("all")
print(f" Fig 5 完成 ({time.time()-t10:.1f}s)", flush=True)
# --- Fig 6: 走廊 × 海岸距離ビン ヒートマップ + 走廊別ノード密度 ---
fig, axes = plt.subplots(1, 2, figsize=(17, 7))
# 左: 海岸距離ビン × 分類 ヒートマップ
ax0 = axes[0]
data_h = T_infra_coast.fillna(0).values
im = ax0.imshow(data_h, aspect="auto", cmap="YlOrRd")
ax0.set_yticks(range(len(T_infra_coast.index)))
ax0.set_yticklabels(T_infra_coast.index)
ax0.set_xticks(range(len(T_infra_coast.columns)))
ax0.set_xticklabels(T_infra_coast.columns, rotation=20, ha="right",
fontsize=10)
for i in range(data_h.shape[0]):
for j in range(data_h.shape[1]):
v = int(data_h[i, j])
if v > 0:
color = "white" if v > data_h.max() * 0.5 else "black"
ax0.text(j, i, f"{v}", ha="center", va="center",
fontsize=10, color=color)
plt.colorbar(im, ax=ax0, label="件数")
ax0.set_xlabel("分類")
ax0.set_ylabel("海岸距離ビン")
ax0.set_title("観光対象 海岸距離ビン × 分類", fontsize=11)
# 右: 走廊密度棒グラフ
ax1 = axes[1]
dens = T_corridor_density.copy()
ax1.barh(dens["走廊"], dens["密度_件/100km2"],
color=["#0a6678", "#9a6700", "#cf222e"],
edgecolor="white")
for i, (n, d) in enumerate(zip(dens["ノード数"], dens["密度_件/100km2"])):
ax1.text(d + 0.1, i, f"密度 {d:.2f} (n={n})",
va="center", fontsize=10)
ax1.set_xlabel("ノード密度 (件 / 100 km²)")
ax1.set_title("3 走廊 ノード密度比較", fontsize=11)
ax1.grid(True, alpha=0.3, axis="x")
plt.suptitle("Fig 6: 第6章 — 走廊比較 (海岸距離ビン と 密度)",
fontsize=13, y=1.00)
plt.tight_layout()
plt.savefig(ASSETS / "L87_fig06_corridor_density.png", dpi=130)
plt.close("all")
print(f" Fig 6 完成 ({time.time()-t10:.1f}s)", flush=True)
# --- Fig 7: 島嶼別 観光対象集積 + 観光対象 海岸距離 ---
fig, axes = plt.subplots(1, 2, figsize=(17, 7))
# 左: 島嶼別 観光対象 件数
ax0 = axes[0]
T_island_show = T_island_infra.head(10).iloc[::-1]
colors_b = ["#cf222e" if isl != "本州" else "#888"
for isl in T_island_show["island"]]
ax0.barh(T_island_show["island"], T_island_show["n"],
color=colors_b, edgecolor="white")
for i, (isl, n) in enumerate(zip(T_island_show["island"],
T_island_show["n"])):
ax0.text(n + 0.2, i, f"{n}", va="center", fontsize=10)
ax0.set_xlabel("観光対象 件数")
ax0.set_title(
f"島嶼別 観光対象 集積 (Top 10)\n"
f"島嶼総計 {n_infra_island}/{N_INFRA} = {pct_infra_island:.1f}%",
fontsize=11
)
ax0.grid(True, alpha=0.3, axis="x")
# 右: 観光対象 海岸距離 ヒストグラム + 中央値
ax1 = axes[1]
bins = np.arange(0, 12, 0.5)
ax1.hist(infra_only["coast_dist_km"].clip(upper=11.5), bins=bins,
color="#0969da", edgecolor="white", alpha=0.85)
ax1.axvline(infra_coast_median, color="black", linestyle="--",
linewidth=1.5, label=f"中央値 {infra_coast_median:.2f} km")
ax1.axvline(3.0, color="#cf222e", linestyle=":",
linewidth=1.5, label="3km 閾値 (H3)")
ax1.set_xlabel("最寄り海岸保全施設までの距離 (km)")
ax1.set_ylabel("観光対象 件数")
ax1.set_title(f"観光対象 海岸距離 分布 (中央値 {infra_coast_median:.2f} km)",
fontsize=11)
ax1.legend(fontsize=9)
ax1.grid(True, alpha=0.3, axis="y")
plt.suptitle("Fig 7: 第1章補強 — 島嶼集積 と 海岸近接",
fontsize=13, y=1.00)
plt.tight_layout()
plt.savefig(ASSETS / "L87_fig07_island_coast.png", dpi=130)
plt.close("all")
print(f" Fig 7 完成 ({time.time()-t10:.1f}s)", flush=True)
# --- Fig 8: 仮説検証総合ダッシュボード ---
fig, axes = plt.subplots(2, 2, figsize=(16, 11))
# (1) 走廊別 ソース構成 stacked
ax0 = axes[0, 0]
plot_data = T_source_corridor.fillna(0).T # 走廊 × ソース
plot_data = plot_data.reindex(
["宮島走廊", "安芸灘走廊", "しまなみ走廊", "走廊外"])
plot_data = plot_data[[c for c in ["インフラツーリズム",
"瀬戸内航路寄港地",
"モニタークルーズ寄港地"]
if c in plot_data.columns]]
bottoms = np.zeros(len(plot_data))
for src in plot_data.columns:
if src == "合計":
continue
vals = plot_data[src].values
ax0.bar(plot_data.index, vals, bottom=bottoms,
color=SRC_COLOR.get(src, "#888"),
edgecolor="white", linewidth=0.5, label=src)
bottoms += vals
ax0.set_ylabel("ノード数")
ax0.set_title("走廊別 ソース構成", fontsize=11)
ax0.legend(loc="upper right", fontsize=9)
ax0.grid(True, alpha=0.3, axis="y")
plt.setp(ax0.get_xticklabels(), rotation=20)
# (2) 仮説検証 横棒
ax1 = axes[0, 1]
hyp_short = ["H1 島嶼集中", "H2 しまなみ集積",
"H3 海岸近接", "H4 観光防災", "H5 走廊独立"]
hyp_actual = [h1_value, h2_value, h3_value, h4_value, h5_value]
hyp_threshold = [20.0, 15.0, 3.0, 30.0, 5.0]
hyp_unit = ["%", "%", "km", "%", "%"]
hyp_pass = [h1_ok, h2_ok, h3_ok, h4_ok, h5_ok]
y = np.arange(len(hyp_short))
colors = ["#1f883d" if p else "#cf222e" for p in hyp_pass]
ax1.barh(y, hyp_actual, color=colors, alpha=0.7, edgecolor="white")
for i, (a, t, u, p) in enumerate(zip(hyp_actual, hyp_threshold,
hyp_unit, hyp_pass)):
mark = "支持" if p else "反証"
ax1.text(a + max(hyp_actual) * 0.01, i,
f"{a:.1f}{u} (閾 {t:g}{u}) → {mark}",
va="center", fontsize=9)
ax1.set_yticks(y); ax1.set_yticklabels(hyp_short)
ax1.set_xlabel("実測値")
ax1.set_title(f"5 仮説 検証結果 (支持 {n_supported}/5)", fontsize=11)
ax1.grid(True, alpha=0.3, axis="x")
# (3) 観光対象 走廊 × 分類 グループ棒
ax2 = axes[1, 0]
plot_data2 = T_corridor_class.reindex(
["宮島走廊", "安芸灘走廊", "しまなみ走廊", "走廊外"]
).fillna(0)
x = np.arange(len(plot_data2))
width = 0.25
for i, (cls, color) in enumerate(CLASS_COLOR.items()):
if cls not in plot_data2.columns:
continue
vals = plot_data2[cls].values
ax2.bar(x + (i - 1) * width, vals, width=width,
color=color, label=cls, edgecolor="white", linewidth=0.5)
ax2.set_xticks(x); ax2.set_xticklabels(plot_data2.index, rotation=20)
ax2.set_ylabel("観光対象 件数")
ax2.set_title("走廊 × 分類 グループ棒", fontsize=11)
ax2.legend(loc="upper right", fontsize=9)
ax2.grid(True, alpha=0.3, axis="y")
# (4) 海岸距離ビン × 分類 (積み上げ)
ax3 = axes[1, 1]
bin_data = T_infra_coast.fillna(0)
bottoms = np.zeros(len(bin_data))
for cls, color in CLASS_COLOR.items():
if cls not in bin_data.columns:
continue
vals = bin_data[cls].values
ax3.bar(bin_data.index.astype(str), vals, bottom=bottoms,
color=color, edgecolor="white", linewidth=0.5, label=cls)
bottoms += vals
ax3.set_xlabel("海岸距離ビン")
ax3.set_ylabel("観光対象 件数")
ax3.set_title("海岸距離ビン × 分類 (積み上げ)", fontsize=11)
ax3.legend(loc="upper right", fontsize=9)
ax3.grid(True, alpha=0.3, axis="y")
plt.suptitle(
"Fig 8: 仮説検証総合ダッシュボード — 走廊・島嶼・海岸・観光防災",
fontsize=13, y=1.00
)
plt.tight_layout()
plt.savefig(ASSETS / "L87_fig08_dashboard.png", dpi=130)
plt.close("all")
print(f" Fig 8 完成 ({time.time()-t10:.1f}s)", flush=True)
print(f" 全 8 図完成 ({time.time()-t10:.1f}s)", flush=True)
# =============================================================================
# 11. HTML レンダー
# =============================================================================
print("\n[11] HTML レンダー", flush=True)
t11 = time.time()
def df_to_html_table(df, max_rows=None):
if max_rows:
df = df.head(max_rows)
cols = "".join(f"| {escape(str(c))} | " for c in df.columns)
rows_html = ""
for _, row in df.iterrows():
cells = ""
for v in row:
if isinstance(v, float):
if pd.isna(v):
s = ""
elif abs(v) >= 1000:
s = f"{v:,.0f}"
else:
s = f"{v:.2f}".rstrip("0").rstrip(".")
if s == "" or s == "-":
s = "0"
else:
s = "" if pd.isna(v) else str(v)
cells += f"{escape(s)} | "
rows_html += f"{cells}
"
return f""
sections = []
# --- 1. 学習目標と問い ---
intro_html = f"""
瀬戸内海は、 古来から「海の道」として広島の歴史を運んできた。
万葉集の歌人が舟で渡り、 平清盛が宮島の大鳥居を建て、 戦国の小早川水軍が
塩飽諸島に拠点を構え、 1999 年にはしまなみ海道が「サイクリングの聖地」
として 6 島を結んだ。 そして今、 この瀬戸内には定期クルーズと
試験モニタークルーズが静かに走り、 ダム・橋梁・港湾は「インフラ
ツーリズム」として観光資源化されている。
本記事は、 DoBoX の観光関連 4 dataset (#1447 インフラツーリズム
40 件 / #1281 瀬戸内海航路寄港地 {N_ROUTE} 件 / #1280 モニタークルーズ
{N_MON_PORTS} 寄港地 / #1282 しまたびライン 12 寄港地) を、 海岸保全施設
{N_COAST:,} 件 / 津波浸水想定 {N_TSUNAMI_MESH:,} メッシュ / 行政界
{len(admin_diss)} 市町と統合し、 「瀬戸内ブランド — 海と橋と島の
インフラ観光地理」を 7 章の物語として読み解くテーマ統合 (M系)
記事である。
独自用語の定義 (この記事だけで使う)
- 瀬戸内ブランド: 本記事独自定義。 広島県の瀬戸内海地域を
観光地理の総体として捉える概念。 単なる海の景観だけでなく、
橋 (しまなみ) ・ 船 (クルーズ) ・ 島 (宮島・大崎上島・江田島・
しまなみ群島)の 3 要素を統合した観光資源体。
- 3 走廊 (コリドール): 本記事独自分類。 広島県の瀬戸内観光を
緯度経度矩形で 3 区分:
- 宮島走廊 (北緯 34.18-34.43 / 東経 132.18-132.42) =
世界遺産・廿日市・大竹・江田島西部
- 安芸灘走廊 (北緯 34.11-34.30 / 東経 132.42-132.94) =
呉・竹原・蒲刈・大崎上島
- しまなみ走廊 (北緯 34.23-34.45 / 東経 132.94-133.35) =
尾道・向島・因島・生口島
厳密な行政区域分けではなく、 観光地理の物語的区分け。
- インフラツーリズム: 国交省・各自治体の概念で、 ダム・橋梁・
トンネル・港湾施設などの土木インフラを観光資源化する取り組み。
広島県の DoBoX #1447 には 40 件が登録されており、 大規模構造物
21 件・歴史的建造物 12 件・その他 7 件の 3 分類。
- 島嶼観光: 本州離れの島 (宮島・江田島・大崎上島・しまなみ
群島・呉諸島・倉橋・蒲刈・能美・百島・佐木島など) における観光資源。
本記事では住所キーワードマッチング + 緯度経度マッチングで判定。
- しまなみ走廊: 上記 3 走廊の 1 つ。 1999 年開通のしまなみ
海道沿線 (尾道-向島-因島-生口島-広島県境) を中心とした
観光地理帯。 本記事の主役走廊の 1 つ。
- 観光防災交差: 観光対象施設の所在地と、 津波浸水想定エリアの
地理的重なり。 「魅力 (海近) と リスク (浸水) の同居」 という瀬戸内
観光地理の構造的特徴を量化する独自概念。
- 海岸近接度: 観光対象から最寄り海岸保全施設までの平面直角距離
(km, sjoin_nearest)。 海岸保全施設 {N_COAST:,} 件は港湾・離岸堤・
防潮堤などで現代海岸線をほぼ忠実に追従するため、 海岸線の代理指標
として用いる。
- マルチコリドール構造: 本記事独自概念。 広島県の瀬戸内観光は
1 つの広域観光圏ではなく、 3 つの独立した走廊の並列構造
として読み解ける、 という観光地理学的仮説。
- 統合 nodes: 本記事独自定義。 観光対象 (#1447) + 航路寄港地
(#1281) + モニター寄港地 (#1280) を 1 つの GeoDataFrame に結合した
{len(gdf_nodes)} 件のポイント集合。 走廊単位での観光地理を語る単位。
- 津波 1km 圏: 津波浸水想定メッシュ (#47 系)
{N_TSUNAMI_MESH:,} メッシュを
unary_union で 1 ポリゴン
に統合し、 さらに 1 km buffer で「浸水可能性のある周辺帯」 を画定。
観光対象が「リスクとブランド」 の交差にあるかを判定する閾値。
研究の問い (主 RQ)
瀬戸内観光の物語 — 海の道とインフラが織りなす広島県の観光地理とは
何か? 瀬戸内ブランドを構成する 3 走廊 (宮島・安芸灘・しまなみ) は、
観光対象施設 / クルーズ寄港地 / 島嶼の量と質でどう描けるか? 観光の魅力
(ブランド) と防災のリスク (津波浸水) はどう交差するか?
仮説 (H1〜H5)
- H1 (島嶼観光集中仮説): 観光対象施設 {N_INFRA} 件のうち、
島嶼立地の比率は 20% 以上。 瀬戸内ブランドの中核は
島嶼に存在する。
- H2 (しまなみ走廊集積仮説): 観光対象 + クルーズ寄港地のうち、
しまなみ走廊立地は 15% 以上。 1999 年のしまなみ海道
開通が観光リソースの集積を生んだ量的証拠。
- H3 (海岸近接仮説): 観光対象 {N_INFRA} 件の海岸距離 中央値
は 3 km 以下。 瀬戸内観光は海と隣接するインフラに集中。
- H4 (観光・防災交差仮説): 観光対象 {N_INFRA} 件のうち、
津波浸水想定エリア 1 km 圏内立地は 30% 以上。 魅力と
リスクは地理的に重なる。
- H5 (3 走廊独立仮説): 走廊矩形の重複面積比 ≤ 5%。
広島県の瀬戸内観光はマルチコリドール構造と読める。
到達点
- 3 走廊 (宮島・安芸灘・しまなみ) という本記事独自の空間軸で、
観光対象 + クルーズ寄港地を統合 GDF として 1 枚の地図で読める。
- 観光対象 {N_INFRA} 件の島嶼立地比率 ({pct_infra_island:.1f}%)
と海岸距離中央値 ({infra_coast_median:.2f} km) を量化し、
瀬戸内ブランドの「島嶼 + 海近」 構造を示す。
- しまなみ走廊 zoom で、 橋梁開通 → 観光集積という 25 年の地理
変化を可視化する。
- 観光対象 vs 津波浸水想定の重ね合わせで、 魅力とリスクの交差
({pct_infra_in_1km:.1f}% が 1km 圏内) を量化する。
- 3 走廊の独立性 (重複 {h5_value:.1f}%)と密度差を、
マルチコリドール構造仮説として量化する。
X01-X05 / L82 / L83 との明確な切り分け: 本記事は同じ観光関連 4
dataset を扱うが、 既存記事はすべて「規模分析」「集中度」「需給ギャップ」
「航路設計」「時系列」の切り口で、 空間走廊 (本記事の独自軸)での
物語化はゼロ。 さらに本記事は観光と津波浸水想定の交差 (#47 系
shapefile を用いた sjoin) を初めて行う。 同じ {N_INFRA + N_ROUTE +
N_MON_PORTS} 件のデータが、 切り口を変えれば全く異なる物語を語る。
"""
sections.append(("学習目標と問い", intro_html))
# --- 2. 使用データ ---
data_html = f"""
本記事は瀬戸内ブランドの物語を語るため、 4 系統 + 3 補助 = 7 dataset
を組み合わせて使う。 主軸は観光関連 4 件 (インフラツーリズム / 瀬戸内航路 /
しまたび / モニター) で、 海岸保全 / 津波浸水 / 行政界を従属参照する。
| 論題 | dataset | 件数 | 用途 |
|---|
| インフラツーリズム_施設情報 |
DoBoX #1447 |
{N_INFRA} |
本記事の主軸。 観光対象施設の地理 |
| 瀬戸内海の航路情報 |
DoBoX #1281 |
{N_ROUTE} |
瀬戸内海クルーズ寄港地の空間配置 |
| 瀬戸内しまたびライン利用状況 |
DoBoX #1282 |
{N_SHIMA_PORTS} 港 (東向) |
定期航路の LineString 描画 (背景) |
| せとうちモニタークルーズ実施結果 |
DoBoX #1280 |
{N_MON_PORTS} |
モニタークルーズ寄港地 |
| (従属) 海岸保全施設基本情報 |
DoBoX #1085 |
{N_COAST:,} |
海岸距離 sjoin_nearest (海岸線推定) |
| (従属) 津波浸水想定区域 (#47 系) |
DoBoX #47 |
{N_TSUNAMI_MESH:,} mesh |
第5章 観光防災交差判定 |
| (派生) L15 行政界 21 市町 |
L15 cache (admin_*.zip) |
20 |
背景マップ + dissolve |
4 観光 dataset 仕様
| dataset | 主要列 | 本記事での扱い |
|---|
| #1447 インフラツーリズム |
施設名称 / 緯度・経度 / 分類 (大規模構造物・歴史的建造物・その他) /
施設概要 / HP / 文化財指定 |
40 件すべて 統合 nodes に組み込み、 走廊・島嶼判定 |
| #1281 瀬戸内航路寄港地 |
寄港地ID / 寄港地名 / 住所 / 緯度・経度 / URL |
広島県内 {N_ROUTE} 件を統合 nodes に組み込み |
| #1282 しまたびライン |
航路ID / 寄港桟橋順 / 寄港地ID / 寄港地名 / 緯度・経度 /
月別客数 (4-12月) |
東向 (101) 寄港順 1-12 を LineString として描画 |
| #1280 モニタークルーズ |
寄港地ID / 寄港地名 / 住所 / 緯度・経度 / 区間情報 (新規/既存) /
ビューポイント写真情報 |
{N_MON_PORTS} 寄港地を統合 nodes に組み込み |
派生指標 (本記事独自)
- corridor: 3 走廊判定 (lat/lon 矩形) — 宮島走廊 / 安芸灘走廊 /
しまなみ走廊 / 走廊外
- island: 島嶼判定 (住所キーワード or 緯度経度マッチ)
- is_island: 島嶼立地フラグ (0/1)
- coast_dist_km: 最寄り海岸保全施設距離 (km, sjoin_nearest)
- tsunami_dist_km: 最寄り津波浸水想定エリア距離
- in_tsunami_1km: 津波浸水 1km 圏内フラグ (0/1, 観光対象のみ)
1 件追跡 (要件 K — Before/After)
{df_to_html_table(T_track)}
この表から読み取れること
- 1 件の観光対象 (紅葉谷川庭園砂防施設、 宮島) が、 9 段階の派生
指標を経て統合 nodes になる過程を追跡。 元 CSV → 分類 → 投影 →
走廊判定 → 島嶼判定 → 海岸距離 → 津波距離 → 統合 GDF 行 ID の
パイプライン全体。
- 1 件のデータから 9 個の派生情報を導出することで、 「同じデータ
でも切り口を変えれば多角的物語が語れる」 ことを示す。
"""
sections.append(("使用データ", data_html))
# --- 3. ダウンロード ---
dl_html = f"""
DoBoX 元データ (直リンク)
本記事が生成した中間データ (再現用 — 直リンク)
図 8 枚 (PNG, 直 DL 可)
再現スクリプト
実行
cd "2026 DoBoX 教材"
py -X utf8 lessons/L87_M3_tourism_story.py
観光関連 CSV は既存 cache (data/extras/) を
再利用、 海岸保全は L64 cache、 津波浸水は tsunami_extracted/、
行政界は L15 cache を参照。 追加 DL なしで即実行可能。
"""
sections.append(("ダウンロード", dl_html))
# --- 4. 第1章: 瀬戸内観光の地理 — 海の道 ---
ch1_purpose = f"""
狙い: 瀬戸内観光の中核は何か? まず観光対象 {N_INFRA} 件の
空間分布を見て、 海岸近接性と島嶼集中という 2 つの構造的特徴を
量化する。 これが瀬戸内ブランドの地理的基盤である。
手法の要点: 観光対象施設 (#1447) の緯度経度から海岸保全施設
{N_COAST:,} 件までの距離を sjoin_nearest() で計算し、
海岸距離中央値を求める。 さらに住所文字列マッチング + 緯度経度
マッチングで島嶼立地を判定する。
sjoin_nearest 直感的説明: 「左の点群」 と「右の点群」 を渡すと、
左の各点について最も近い右の点を見つけ、 距離を distance_col
列に書き込む。 内部で R-tree (空間インデックス) を使うため、 数千点 ×
数千点でも数秒で完了。 総当たり計算 (forループ) より圧倒的に速い。
"""
ch1_code = code('''
import pandas as pd
import geopandas as gpd
from shapely.geometry import Point
# 観光対象 #1447 (40 件)
infra = pd.read_csv("data/extras/infra_tourism.csv", encoding="utf-8-sig")
infra["lat"] = pd.to_numeric(infra["緯度"], errors="coerce")
infra["lon"] = pd.to_numeric(infra["経度"], errors="coerce")
infra_gdf = gpd.GeoDataFrame(
infra,
geometry=gpd.points_from_xy(infra["lon"], infra["lat"]),
crs="EPSG:4326"
).to_crs("EPSG:6671") # 平面直角第 III 系 (m)
# 海岸保全施設 #1085 (1,646 件)
coast = pd.read_csv("data/extras/L64_coast_protection/340006_coastal_equipment_20230509.csv",
encoding="utf-8-sig", on_bad_lines="skip")
coast["lat"] = pd.to_numeric(coast["開始位置緯度"], errors="coerce")
coast["lon"] = pd.to_numeric(coast["開始位置経度"], errors="coerce")
coast = coast.dropna(subset=["lat", "lon"])
coast_gdf = gpd.GeoDataFrame(
coast,
geometry=gpd.points_from_xy(coast["lon"], coast["lat"]),
crs="EPSG:4326"
).to_crs("EPSG:6671")
# sjoin_nearest で観光対象 → 最寄り海岸保全施設の距離
nearest = gpd.sjoin_nearest(
infra_gdf[["施設名称", "geometry"]],
coast_gdf[["geometry"]],
how="left", distance_col="coast_dist_m"
)
infra_gdf["coast_dist_km"] = (nearest.groupby("施設名称")["coast_dist_m"]
.min().values / 1000)
# 海岸距離中央値
print(f"観光対象 海岸距離 中央値 = {infra_gdf['coast_dist_km'].median():.2f} km")
# 島嶼判定 (簡易 lat/lon マッチ)
def is_island(lat, lon):
if 34.27 <= lat <= 34.31 and 132.30 <= lon <= 132.35:
return "宮島"
if 34.24 <= lat <= 34.30 and 132.86 <= lon <= 132.96:
return "大崎上島"
# ... (5 島嶼判定)
return "本州"
''')
ch1_html = (
"狙い・手法
" + ch1_purpose +
"実装
" + ch1_code +
"結果図 — 島嶼集積と海岸距離
" +
"なぜこの図か: 「海近・島嶼集中」 を直感的に伝えるには、 "
"島嶼別棒と海岸距離ヒストグラムを 2 枚で並べるのが効果的。 "
"棒で島嶼集積率を、 ヒストで海岸近接の量的事実を、 同時に読める。
" +
figure("assets/L87_fig07_island_coast.png",
f"Fig 7: 島嶼別観光対象集積 ({n_infra_island}/{N_INFRA} = "
f"{pct_infra_island:.1f}% 島嶼) + 海岸距離分布") +
f"""この図から読み取れること
- 観光対象 {N_INFRA} 件のうち、 島嶼立地は {n_infra_island} 件
({pct_infra_island:.1f}%)。 H1 (島嶼観光集中仮説) は
{"支持" if h1_ok else "反証"}。
- 島嶼トップは宮島 (世界遺産)と大崎上島 (神峰山・契島)。
宮島は紅葉谷川庭園砂防 + 厳島神社で観光資源密度が高い。
- 右ヒスト: 海岸距離中央値 {infra_coast_median:.2f} km。
H3 (海岸近接仮説) は{"支持" if h3_ok else "反証"}
({"3km 閾値以下" if h3_ok else "3km 超"})。
- 海岸距離の分布は二峰性を示す可能性: 沿岸 (0-3km) の橋梁・
港湾施設群と、 内陸 (5-10km+) のダム群が二極化。
- 本州の観光対象は{N_INFRA - n_infra_island} 件で、 ダム・砂留など
内陸インフラが中心。 「インフラツーリズム」 が瀬戸内という海洋圏に
縛られず、 内陸インフラも統合する観光概念であることを示す。
""" +
f"""島嶼別 観光対象集積 (Top 10)
{df_to_html_table(T_island_infra.head(10).rename(
columns={"island": "島嶼", "n": "観光対象件数"}))}
この表から読み取れること
- 本州 {N_INFRA - n_infra_island} 件 (内陸ダム・砂留中心) +
島嶼 {n_infra_island} 件 (橋梁・神社・砂防中心) で、
瀬戸内ブランドは「内陸 + 島嶼」 の二層構造。
- 島嶼の中では宮島・大崎上島が観光資源密度を支配。
両島とも世界遺産級 (宮島) または土木遺産級 (大崎上島契島) の
観光資源を持つ。
- しまなみ群島 (向島・因島・生口島) は意外と観光対象 (#1447 登録)
が少ない。 これは #1447 が「インフラツーリズム」 (大規模構造物・
歴史的建造物中心) であり、 しまなみのサイクリング・グルメ系観光
資源を網羅していないため。
"""
)
sections.append(("第1章 瀬戸内観光の地理 — 海の道と島嶼", ch1_html))
# --- 5. 第2章: しまなみ走廊 — 橋が生んだ観光圏 ---
ch2_purpose = f"""
狙い: 1999 年 5 月 1 日、 しまなみ海道が開通した。 尾道 (本州) と
今治 (四国) を 6 島 (向島・因島・生口島・大三島・伯方島・大島) で結ぶ
全長 60 km の道路橋連絡橋として開通したこの構造物は、 25 年を経て
「サイクリングの聖地」として観光地化した。 本章では、 しまなみ
走廊 (本記事独自定義) の観光リソース密度を、 統合 nodes
({N_INFRA + N_ROUTE + N_MON_PORTS} 件) で量化する。
手法の要点: しまなみ走廊矩形 (北緯 34.23-34.45 / 東経 132.94-
133.35) で nodes をフィルタし、 ソース (観光対象 / 航路寄港地 / モニター
寄港地) × 分類のクロス集計を作成。 さらに しまなみ海道推定 LineString
({len(SHIMANAMI_BRIDGE_LATLON)} 主要点) を地図に重ね、 走廊と橋梁の
地理的関係を可視化する。
"""
ch2_code = code('''
import shapely.geometry
# しまなみ走廊 矩形 (本記事独自定義)
SHIMANAMI_RECT = (34.23, 34.45, 132.94, 133.35) # lat_min, lat_max, lon_min, lon_max
def is_shimanami(row):
lat, lon = row["lat"], row["lon"]
return (SHIMANAMI_RECT[0] <= lat <= SHIMANAMI_RECT[1] and
SHIMANAMI_RECT[2] <= lon <= SHIMANAMI_RECT[3])
shimanami_nodes = nodes_gdf[nodes_gdf.apply(is_shimanami, axis=1)]
print(f"しまなみ走廊内 nodes: {len(shimanami_nodes)} 件")
# しまなみ海道 LineString (4 主要点)
SHIMANAMI_BRIDGE = [
(34.402, 133.198), # 尾道側
(34.380, 133.205), # 向島
(34.323, 133.180), # 因島大橋付近
(34.300, 133.085), # 生口島
(34.265, 133.085), # 多々羅大橋 (広島県境)
]
from shapely.geometry import LineString, Point
import geopandas as gpd
shimanami_line = LineString([Point(lon, lat) for lat, lon in SHIMANAMI_BRIDGE])
''')
ch2_html = (
"狙い・手法
" + ch2_purpose +
"実装
" + ch2_code +
"結果図 — しまなみ走廊 zoom
" +
"なぜこの図か: 県全体マップではしまなみ走廊が小さく見えてしまう。 "
"走廊矩形に zoom することで、 各島嶼の観光ノード配置と橋梁推定ラインの "
"サイクリング聖地感を直感的に伝える。
" +
figure("assets/L87_fig04_shimanami_zoom.png",
f"Fig 4: しまなみ走廊 zoom — {len(shimanami_nodes)} 件統合nodes") +
f"""この図から読み取れること
- しまなみ走廊内 統合 nodes = {len(shimanami_nodes)} 件。
観光対象 {int((shimanami_nodes['source']=='インフラツーリズム').sum())} +
航路寄港地 {int((shimanami_nodes['source']=='瀬戸内航路寄港地').sum())} +
モニター寄港地 {int((shimanami_nodes['source']=='モニタークルーズ寄港地').sum())}。
- しまなみ海道推定ライン (赤実線、 尾道-向島-因島-生口島-県境)
沿いに観光ノードが集積。 1999 年の橋梁開通が観光地理を再編した量的
証拠。
- 観光対象 (赤三角) は本記事のスコープでは少ない。 これは
#1447 が大規模構造物中心で、 しまなみのサイクリング・カフェ・道の駅
系を網羅していないため。 別の観光カタログ (DiVE Hiroshima 等) では
しまなみ走廊にもっと多くの観光資源が登録される。
- クルーズ寄港地 (青丸 + 紫菱形) は走廊全域に分散。 尾道 (本州側
始発) ・瀬戸田 (生口島中央) ・百島 (走廊外緑) などが拠点。
- しまなみ走廊は橋を主軸とした観光地理であり、 海上クルーズ
と陸上サイクリングが交差するマルチモーダル観光圏として
読める。
""" +
f"""しまなみ走廊 ソース × 分類 内訳
{df_to_html_table(T_shimanami_source.fillna(0).astype(int).reset_index())}
この表から読み取れること
- しまなみ走廊では航路寄港地が支配的。 観光対象は少数 (#1447 の
制約)。 「観光カタログの偏り」 を地理的に確認できる。
- モニタークルーズ寄港地 (新規・既存両方) もしまなみ走廊に分布。
L82 の RQ1 で扱った「東向き延伸設計」 と整合。
L82/L83 との重複回避: L82/L83 はしまなみライン・モニタークルーズ
の時系列・規模分析に集中した。 本記事はしまなみ走廊という
空間軸でこれら全データを再分類する点が新規。
"""
)
sections.append(("第2章 しまなみ走廊 — 橋が生んだ観光圏", ch2_html))
# --- 6. 第3章: インフラツーリズム — 機能と観光の二重利用 ---
ch3_purpose = f"""
狙い: インフラツーリズム (#1447) の {N_INFRA} 件を、
分類 × 走廊で可視化する。 大規模構造物 (ダム・橋梁・トンネル等)
21 件 / 歴史的建造物 (砂防・庭園・神社系) 12 件 / その他 7 件の3 分類
が、 3 走廊にどう分布するかで「機能と観光の二重利用」 の地理パターンを読む。
手法の要点: 観光対象 {N_INFRA} 件の分類列とcorridor 列
で pd.crosstab を作成。 さらに分類別の地図 (色分け) と
走廊別 stacked bar を 2 枚並べて、 「どの走廊にどの種類の観光対象が多いか」
を立体的に見せる。
X01 との重複回避: X01 は同じ #1447 を防災インフラ台帳 (ダム・橋梁・
トンネル) と施設名マッチでマージし、 観光対象/非対象の判別性
(ロジスティック回帰・OLS)を量化した。 本記事は判別計算なし、
分類×走廊の空間集計のみ。 切り口が完全に独立。
"""
ch3_code = code('''
# 観光対象 40 件の 分類 × 走廊 クロス
T_infra_class_corridor = (
infra_gdf.groupby(["分類", "corridor"]).size().unstack(fill_value=0)
)
print(T_infra_class_corridor)
# 出力例:
# corridor 宮島走廊 安芸灘走廊 しまなみ走廊 走廊外
# 分類
# 大規模構造物 3 4 1 13
# 歴史的建造物 1 6 2 3
# その他 1 2 0 4
# 分類別マッピング (matplotlib)
CLASS_COLOR = {"大規模構造物": "#cf222e",
"歴史的建造物": "#0969da",
"その他": "#8250df"}
fig, ax = plt.subplots(1, 1, figsize=(13, 8))
admin_diss.plot(ax=ax, facecolor="#fafafa", edgecolor="#888")
for cls, color in CLASS_COLOR.items():
sub = infra_gdf[infra_gdf["分類"] == cls]
sub.plot(ax=ax, color=color, markersize=130, marker="^",
alpha=0.9, edgecolor="white")
''')
ch3_html = (
"狙い・手法
" + ch3_purpose +
"実装
" + ch3_code +
"結果図 — 観光対象分類 × 走廊
" +
"なぜこの図か: 左 (地図)で空間配置を、 右 (積み上げ棒)"
"で走廊別構成比を、 1 セット 2 視点で同時に見せる。 「大規模構造物が "
"走廊外 (内陸ダム) に集中、 歴史的建造物が安芸灘走廊 (神社・庭園系)」 という "
"機能別偏在が両図から読める。
" +
figure("assets/L87_fig02_infra_classification.png",
f"Fig 2: 観光対象 {N_INFRA} 件 分類別マップ + 走廊構成") +
f"""この図から読み取れること
- 大規模構造物 21 件: 走廊外 (内陸ダム) が支配的。 内陸の
八田原ダム・三段峡など。 沿岸では尾道大橋付近に少数。
- 歴史的建造物 12 件: 安芸灘・宮島走廊に集積。 宮島の紅葉谷川
庭園砂防 (国登録重要文化財) など、 沿岸に集中。
- その他 7 件: 散発的、 全走廊にわずかずつ。
- 走廊別構成比 (積み上げ棒): 走廊外 = 大規模構造物が中心、
安芸灘走廊 = 歴史的建造物バランス、 宮島・しまなみ = 少数だが
歴史系混在。
- このパターンは「大規模構造物 = 山岳ダム」 「歴史的建造物
= 沿岸文化遺産」 という機能別の地理的役割分化を示す。 瀬戸内
ブランドの観光対象は、 海と山の両方を統合する。
""" +
f"""観光対象 分類 × 走廊 クロス
{df_to_html_table(T_infra_class_corridor.fillna(0).astype(int).reset_index())}
この表から読み取れること
- 走廊外 (内陸) に大規模構造物
{int(T_infra_class_corridor.fillna(0).loc['大規模構造物', '走廊外']) if ('大規模構造物' in T_infra_class_corridor.index and '走廊外' in T_infra_class_corridor.columns) else 0}
件 = 観光対象ダムの大半が内陸立地。
- 安芸灘走廊に歴史的建造物が比較的多く、
宮島走廊にも少数あり。
- しまなみ走廊は観光対象数が少ない (#1447 のスコープ制約)。
これは「インフラツーリズム」 が大規模構造物中心であり、 しまなみ
群島の観光資源 (景観・サイクリング・グルメ) が #1447 のスコープ
外であることを示す。
"""
)
sections.append(("第3章 インフラツーリズム — 機能と観光の二重利用",
ch3_html))
# --- 7. 第4章: 島嶼観光 — 海岸距離の二極化 ---
ch4_purpose = f"""
狙い: 観光対象 {N_INFRA} 件の海岸距離 × 緯度を散布し、
「沿岸 (低緯度) の橋梁・歴史建造物」 vs 「内陸 (高緯度) のダム・砂防施設」
という二極化構造を可視化する。 単なる海岸距離分布だけでなく、
緯度方向の階層も同時に見ることで、 瀬戸内ブランドの空間的
立体構造を浮き彫りにする。
手法の要点: 散布図で x = coast_dist_km,
y = lat をプロットし、 海岸距離ビン (0-1km / 1-3km / 3-5km
/ 5-10km / 10km+) で点を色分け。 中央値の vline を入れて、 H3
(海岸距離中央値 ≤ 3km) を視覚的に検証する。
X05 との重複回避: X05 はしまたび航路 × 避難所収容で「需給ギャップ
指数」 を島別に算出した。 本記事は需給ギャップなし、 観光対象の
海岸距離 × 緯度の 2 次元構造のみ。 切り口が完全に独立。
"""
ch4_code = code('''
import matplotlib.pyplot as plt
# 海岸距離ビンで色分け
COAST_BIN_COLOR = {
"0-1km": "#005f73", "1-3km": "#0a6678", "3-5km": "#0969da",
"5-10km": "#9a6700", "10km+": "#cf222e",
}
infra_gdf["coast_bin"] = pd.cut(
infra_gdf["coast_dist_km"],
bins=[-1, 1, 3, 5, 10, 999],
labels=list(COAST_BIN_COLOR.keys())
)
fig, ax = plt.subplots(1, 1, figsize=(13, 8))
for bin_name, color in COAST_BIN_COLOR.items():
sub = infra_gdf[infra_gdf["coast_bin"] == bin_name]
ax.scatter(sub["coast_dist_km"], sub["lat"],
c=color, s=140, alpha=0.85, edgecolor="white",
label=f"{bin_name} ({len(sub)})")
ax.axvline(infra_gdf["coast_dist_km"].median(),
color="black", linestyle="--", linewidth=1.5,
label=f"海岸距離中央値 {infra_gdf['coast_dist_km'].median():.2f} km")
ax.set_xlabel("海岸距離 (km)"); ax.set_ylabel("緯度")
''')
ch4_html = (
"狙い・手法
" + ch4_purpose +
"実装
" + ch4_code +
"結果図 — 海岸距離×緯度の二極化散布
" +
"なぜこの図か: 単純な海岸距離ヒストでは「内陸寄り」 と「沿岸寄り」 "
"が混じってしまう。 緯度 (y軸)を加えると、 「内陸ダムは高緯度」 "
"「沿岸建造物は低緯度」 という2 次元の階層構造が一目でわかる。
" +
figure("assets/L87_fig03_infra_coast_scatter.png",
f"Fig 3: 観光対象 {N_INFRA} 件 — 海岸距離×緯度 散布") +
f"""この図から読み取れること
- 海岸距離中央値 = {infra_coast_median:.2f} km。
H3 (≤3km 仮説) は{"支持" if h3_ok else "反証"}。
- 0-1km 帯 (深青): 沿岸の港湾施設・橋梁。 緯度は 34.2-34.4 の沿岸帯。
- 1-3km 帯 (青緑): 沿岸近接の砂防・歴史建造物。
- 5-10km 帯 (茶): 中山間の小規模ダム。
- 10km+ 帯 (赤): 内陸大規模ダム (八田原ダム・温井ダムなど)。
緯度 34.6+ の高緯度に集中。
- 図全体で「内陸ダム vs 沿岸橋梁」 の二極化が明確。
瀬戸内ブランドのインフラ観光は、 海と山の両極を統合する
マルチスケール観光地理である。
""" +
f"""観光対象 海岸距離ビン × 分類 クロス
{df_to_html_table(T_infra_coast.fillna(0).astype(int).reset_index().rename(columns={'coast_bin':'海岸距離ビン'}))}
この表から読み取れること
- 0-1km 帯: 大規模構造物 (橋梁) と歴史的建造物 (砂防・神社系)
が混在。 沿岸インフラの観光資源化が進む。
- 10km+ 帯: 大規模構造物 (内陸ダム) のみ。 歴史的建造物は
内陸にほぼ無し。
- 歴史的建造物は1-5km 帯に集積。 沿岸近接の文化遺産が瀬戸内
ブランドの中核を成す。
"""
)
sections.append(("第4章 島嶼観光 — 海岸距離の二極化", ch4_html))
# --- 8. 第5章: 観光と防災 — リスクと魅力の交差 ---
ch5_purpose = f"""
狙い: 瀬戸内ブランドの魅力 (海近)とリスク (津波浸水)
は地理的に重なるか? DoBoX 津波浸水想定 (#47 系) shapefile を読込み、
浸水メッシュを unary_union で統合し、 観光対象 {N_INFRA} 件
からの距離を計算する。 1km 圏内立地を「観光防災交差地点」 として量化。
手法の要点: geopandas.read_file() で shapefile を
読込、 unary_union で全メッシュを 1 ポリゴンに統合
({N_TSUNAMI_MESH:,} mesh → 1 ポリゴン)、 さらに buffer(1000)
で 1km 圏を画定。 観光対象点が圏内かを geometry.within() で
判定する。
X05 との重複回避: X05 は避難所×しまたび航路で「需給ギャップ」
を量化したが、 観光対象 (#1447) と津波浸水想定 (#47 系) の交差は扱って
いない。 本記事の切り口は新規。
"""
ch5_code = code('''
import geopandas as gpd
from shapely.ops import unary_union
# 津波浸水想定 shp 読込 + 統合
tsunami_gdf = gpd.read_file(
"data/extras/tsunami_extracted/.../浸水メッシュ.shp", encoding="cp932"
).to_crs("EPSG:6671")
tsunami_union = tsunami_gdf.unary_union # 浸水メッシュ → 1 ポリゴン
tsunami_buffered = tsunami_union.buffer(1000) # 1km buffer
# 観光対象が 1km 圏内か判定
infra_gdf["in_tsunami_1km"] = infra_gdf.geometry.within(tsunami_buffered).astype(int)
n_in = infra_gdf["in_tsunami_1km"].sum()
print(f"津波 1km 圏内観光対象 = {n_in}/{len(infra_gdf)} ({n_in/len(infra_gdf)*100:.1f}%)")
# 距離計算 (各観光対象 → 最寄り浸水ポリゴン辺)
infra_gdf["tsunami_dist_km"] = infra_gdf.geometry.distance(tsunami_union) / 1000
''')
ch5_html = (
"狙い・手法
" + ch5_purpose +
"実装
" + ch5_code +
"結果図 — 観光対象 vs 津波浸水想定
" +
"なぜこの図か: 「リスクとブランドの重なり」 を直感的に伝えるには "
"地図 (重ね合わせ)と距離分布ヒストを 2 枚で並べるのが最強。 "
"地図で空間関係を、 ヒストで定量分布を、 同時に提示する。
" +
figure("assets/L87_fig05_tsunami_overlay.png",
"Fig 5: 観光対象 vs 津波浸水想定 重ね合わせ + 距離分布") +
f"""この図から読み取れること
- 観光対象 {N_INFRA} 件のうち、 津波浸水想定 1km 圏内立地は
{n_infra_in_1km} 件 ({pct_infra_in_1km:.1f}%)。
H4 (≥30% 仮説) は{"支持" if h4_ok else "反証"}。
- 地図 (左): 浸水想定エリア (薄青) は沿岸全域に広がる。
観光対象 (赤三角) のうち沿岸近接施設が浸水圏内に立地。
宮島・呉港・尾道沿岸が交差地帯。
- 距離分布 (右): 中央値
{infra_only['tsunami_dist_km'].median():.2f} km。
1km 閾値以下の施設が{pct_infra_in_1km:.1f}%を占める。
- 「魅力 (海近) とリスク (浸水) の同居」 は瀬戸内ブランドの
構造的特徴。 観光開発 + 防災対策の同時設計が必要。
- 内陸ダム (赤三角の上方) は浸水圏外に位置し、 「内陸インフラ観光」
は津波リスクから物理的に保護される。
解釈の注意: 津波浸水想定は南海トラフ巨大地震想定などの
極端ケース。 「観光対象が浸水想定圏内」 = 「即座に浸水する」 ではなく、
「最大級津波時に浸水可能性がある地理」。 観光開発上は、 避難
ルート・建物耐津波設計・運営時の地震警報体制を整える参考とする。
""" +
f"""観光対象 津波距離ビン × 分類 クロス
{df_to_html_table(T_infra_tsunami.fillna(0).astype(int).reset_index().rename(columns={'tsunami_bin':'津波距離ビン'}))}
この表から読み取れること
- 「浸水内」 立地 = 津波想定エリアそのものに重なる施設。 港湾・橋梁
系の沿岸インフラに集中。
- 「5km 超」 = 内陸ダム・砂防群。 大規模構造物が大半を占める。
- 歴史的建造物は沿岸近接が多く、 浸水リスクと隣接する文化財が
多い。 文化財保全 + 津波対策の同時設計が必要。
"""
)
sections.append(("第5章 観光と防災 — リスクと魅力の交差", ch5_html))
# --- 9. 第6章: 瀬戸内ブランドのトリプル統合 ---
ch6_purpose = f"""
狙い: 3 走廊 (宮島・安芸灘・しまなみ) の独立性と密度差を
量化し、 「広島県の瀬戸内観光はマルチコリドール構造である」 という
H5 仮説を検証する。 各走廊のノード数 / 矩形面積 / 海岸距離中央値 /
島嶼率 / ソース構成を 1 枚に統合する。
手法の要点: 走廊矩形 (lat/lon 矩形) の面積を簡易計算
(lat 1°≈111km, lon 1° at 34.4°≈91km)、 件数 / 面積 で密度
(件/100km²)を求める。 さらに走廊間の重複面積比を計算して H5 を検証
(矩形が分離していれば 0%、 一部重なれば >0%)。
"""
ch6_code = code('''
# 走廊矩形面積 (近似)
def rect_area_km2(lat_min, lat_max, lon_min, lon_max):
h_km = (lat_max - lat_min) * 111 # lat 1° ≈ 111 km
w_km = (lon_max - lon_min) * 91 # lon 1° at 34.4° ≈ 91 km
return h_km * w_km
CORRIDORS = {
"宮島走廊": (34.180, 34.430, 132.180, 132.420),
"安芸灘走廊": (34.110, 34.300, 132.420, 132.940),
"しまなみ走廊": (34.230, 34.450, 132.940, 133.350),
}
for name, rect in CORRIDORS.items():
area = rect_area_km2(*rect)
n = (gdf_nodes["corridor"] == name).sum()
print(f"{name}: 面積 {area:.0f} km², ノード {n}, 密度 {n/area*100:.2f} 件/100km²")
# 走廊間 重複面積 (H5 検証)
def rect_overlap(a, b):
lat_overlap = max(0, min(a[1], b[1]) - max(a[0], b[0])) * 111
lon_overlap = max(0, min(a[3], b[3]) - max(a[2], b[2])) * 91
return lat_overlap * lon_overlap
''')
ch6_html = (
"狙い・手法
" + ch6_purpose +
"実装
" + ch6_code +
"結果図 — 3 走廊密度 + 海岸距離ビン
" +
"なぜこの図か: 左 (ヒートマップ)で観光対象の海岸距離 × 分類 "
"の量的構造を、 右 (横棒)で走廊密度差を、 1 セット 2 視点で示す。 "
"「しまなみは小さいが密度高」 「走廊外は広いが密度低」 という構造的事実を "
"可視化する。
" +
figure("assets/L87_fig06_corridor_density.png",
"Fig 6: 海岸距離ビン × 分類 ヒート + 3 走廊密度") +
f"""この図から読み取れること
- 3 走廊の密度 (件 / 100 km²): {", ".join([
f"{r['走廊']} {r['密度_件/100km2']}"
for _, r in T_corridor_density.iterrows()
])}。
- しまなみ走廊が最高密度 (狭域に多くのノード集積)。 1999 年の橋梁
開通 → 観光ノード集積の量的証拠。
- 左ヒート: 大規模構造物は 5-10km 帯 / 10km+ 帯の内陸に多い。
歴史的建造物は 0-3km 帯の沿岸に多い。
- 3 走廊間の重複面積比 = {h5_value:.1f}% (=矩形完全分離)、
H5 (≤5%) は{"支持" if h5_ok else "反証"}。
マルチコリドール構造は数値的に成立。
""" +
f"""3 走廊 サマリー (件数 + 海岸距離 + 島嶼率)
{df_to_html_table(T_corridor_summary)}
この表から読み取れること
- 島嶼率: 各走廊で大きく異なる。 観光対象が島嶼に偏在する走廊と、
本州沿岸に偏在する走廊が分かれる。
- 海岸距離中央値: 走廊外 (内陸) が最大。 3 走廊内では沿岸近接で
顕著に小さい。
- マルチコリドール構造の定量的な裏付け: 各走廊が独立した
観光地理を持つ。
3 走廊 ノード密度比較
{df_to_html_table(T_corridor_density)}
この表から読み取れること
- しまなみ走廊が最高密度。 1999 年の橋梁開通効果と、 既存しまたび
寄港の集積が重なる。
- 宮島走廊は世界遺産の集中効果で密度高。
- 安芸灘走廊は範囲広く密度低。 観光資源が分散。
"""
)
sections.append(("第6章 瀬戸内ブランドのトリプル統合 — 走廊比較", ch6_html))
# --- 10. 第7章: 仮説検証総合 ---
hyp_html = f"""
5 つの仮説を 6 章にわたり検証してきた。 結果をまとめる。
横断的可視化 — 仮説検証ダッシュボード
なぜこの図か: 4 つの視点 (走廊別ソース構成 / 5 仮説 横棒 /
走廊×分類 グループ棒 / 海岸距離ビン×分類 積み上げ) を1 枚にまとめた
ダッシュボードで、 6 章の知見を一望する。 学習者が最後の総括として
何度でも見返せる。
{figure("assets/L87_fig08_dashboard.png",
"Fig 8: 仮説検証総合ダッシュボード — 4 視点 統合")}
3 走廊 オーバーレイ + 統合 nodes 全件マップ
なぜこの図か: 全 nodes
{len(gdf_nodes)} 件 + 3 走廊矩形 + しまなみ・しまたびラインを1 枚に
収めた主役マップ。 これが本記事の「物語の地図」。
{figure("assets/L87_fig01_corridors_overview.png",
f"Fig 1 (再掲): 3 走廊 + 統合 nodes ({len(gdf_nodes)} 件)")}
仮説検証 サマリー表
{df_to_html_table(T_hypothesis)}
この表から読み取れること
- 支持された仮説 = {n_supported} / 5。
- H1 (島嶼観光集中): {h1_value:.1f}% が島嶼立地。
{"20% 基準を超え支持。 瀬戸内ブランドの中核は島嶼。"
if h1_ok else
"20% 基準には及ばず、 島嶼集中の仮説は反証。"
" #1447 が大規模構造物中心で内陸ダムを多く含むため。"}
- H2 (しまなみ走廊集積): {h2_value:.1f}% がしまなみ走廊立地。
{"15% 基準を超え支持。 1999 橋梁開通効果が量的に確認できる。"
if h2_ok else
"15% には及ばず、 しまなみ走廊への観光対象集積は弱い。"
" ただしクルーズ寄港地は集積する地理を示す。"}
- H3 (海岸近接): 海岸距離中央値 {h3_value:.2f} km。
{"3km 基準以下で支持。 瀬戸内観光は海近インフラに集中。"
if h3_ok else
"3km を超え反証。 内陸ダム比率が高いため。"}
- H4 (観光・防災交差): {h4_value:.1f}% が津波 1km 圏内。
{"30% 基準を超え支持。 魅力とリスクは地理的に重なる。"
if h4_ok else
"30% には及ばず、 浸水圏内立地は予想より少ない。"
" 内陸ダムの比率が津波交差を低くしている。"}
- H5 (3 走廊独立): 重複面積比 {h5_value:.1f}%。
{"5% 以下で支持。 マルチコリドール構造が地理的に成立。"
if h5_ok else
"5% を超え反証。 走廊矩形が部分的に重なる。"}
瀬戸内ブランドの 7 つの発見
- 島嶼集中度: 観光対象 {N_INFRA} 件中
{pct_infra_island:.1f}% が島嶼立地。 宮島・大崎上島が中核。
- 海岸近接性: 観光対象の海岸距離中央値
{infra_coast_median:.2f} km。 「海近」 がブランドの空間的定義。
- 分類別偏在: 大規模構造物 21 = 内陸ダム中心、
歴史的建造物 12 = 沿岸文化遺産中心。 「内陸 + 沿岸」 二層構造。
- 3 走廊密度差: しまなみ走廊が最高密度。
宮島走廊は世界遺産集中で次。 安芸灘走廊は分散。
- マルチコリドール: 3 走廊矩形の重複 {h5_value:.1f}%。
広島県瀬戸内観光は並列構造。
- 観光・防災交差: 観光対象の {pct_infra_in_1km:.1f}% が
津波 1km 圏内。 魅力とリスクは地理的に同居。
- 4 dataset 統合の物語性: インフラツーリズム + 航路 +
モニター + しまたびを1 つの空間に載せると、 既存記事
(規模分析・需給ギャップ・時系列) では見えなかった
マルチコリドール構造が浮かぶ。
X01-X05 / L82 / L83 と L87 の補完性: 同じ観光関連 4 dataset が、
切り口を変えると全く異なる物語を語る。
- X01 (規模・判別): 観光対象/非対象の OLS / ロジ判別
- X02 (文化財都市プロファイル): 階層クラスタ・PCA
- X03 (4 指標俯瞰): 散布図行列・PCA・重回帰
- X04 (港別市場構造): Gini / HHI / CRn / 季節係数
- X05 (島嶼需給): バブル・ランキング・ギャップ指数
- L82 (モニター航路設計): Haversine / Jaccard / 定期化スコア
- L83 (しまたび時系列): 客数勾配 / 春秋偏向 / 落込み率
- L87 (本記事, 物語): 3 走廊 + 島嶼 + 観光防災 + マルチ
コリドール
8 つの記事が揃って初めて
瀬戸内観光の研究地図になる。
"""
sections.append(("仮説検証総合", hyp_html))
# --- 11. 発展課題 ---
dev_html = f"""
発展課題 (結果X → 新仮説Y → 課題Z の論理鎖)
発展1: 海上経路ネットワークと走廊の関係
- 結果X: 走廊外 (内陸) に観光対象が
{int(T_corridor_summary[T_corridor_summary['走廊']=='走廊外']['観光対象数'].iloc[0]) if (T_corridor_summary['走廊']=='走廊外').any() else 0}
件、 沿岸 3 走廊に
{int(T_corridor_summary[T_corridor_summary['走廊']!='走廊外']['観光対象数'].sum())}
件。 沿岸観光は分散している。
- 新仮説Y: しまたびライン (12 港) と モニタークルーズ (23 港)
の組み合わせは3 走廊を網羅する設計か? 各走廊の港カバー率を
計算し、 「網羅性」 を量化できるはず。
- 課題Z: 各走廊矩形内の港数 / 全港数 = カバー率を計算。
「宮島走廊カバー X%」 「安芸灘走廊 Y%」 「しまなみ走廊 Z%」 で
マルチモーダル観光ネットワークの設計適性を量的評価する。
発展2: 標高 DEM を使った内陸 vs 沿岸の精密分類
- 結果X: 海岸距離 × 緯度の散布で「内陸ダム vs 沿岸建造物」
二極化が見えたが、 緯度は粗い代理指標。
- 新仮説Y: DEM (#1257-1264) の標高を使えば、
海岸距離との相関をもっと精密に量化できる。 標高>200m の観光対象は
すべて内陸ダム、 標高<10m は沿岸というはず。
- 課題Z: DoBoX 標高シリーズの DEM ラスターを取得 (要 ZIP 展開)、
各観光対象点の標高を
rasterio.sample() で抽出。
海岸距離 × 標高 の 2 次元散布で「内陸大規模構造物」 と
「沿岸歴史建造物」 を機械学習 (Logistic Regression) で分類器化。
発展3: しまなみ走廊の四国側拡張 — 1999 開通の効果検証
- 結果X: しまなみ走廊内ノードは
{len(shimanami_nodes)} 件。 ただし広島県内の生口島南端まで。
- 新仮説Y: しまなみ海道は愛媛県側 (大三島・伯方島・大島
+今治)にも観光ノードを展開しているはず。 両県のデータを
統合すれば、 「橋梁開通効果」 が県をまたいで定量化できる。
- 課題Z: 愛媛県オープンデータ (Imabari Open Data など) から
観光関連 dataset を取得。 4 県境界 (広島-愛媛) の橋梁周辺で
観光ノード密度を比較し、 「県境の片側 vs 両側」 でしまなみ走廊
の真の規模を量化。
発展4: 走廊定義の最適化 — クラスタリングによる自動分類
- 結果X: 本記事の 3 走廊はlat/lon 矩形による独自定義。
主観的境界。
- 新仮説Y: k-means クラスタリング (k=3) を統合 nodes
の (lat, lon) で実行すれば、 データ駆動の最適 3 走廊が得られる。
本記事の手動定義とどれだけ一致するか?
- 課題Z:
sklearn.cluster.KMeans(n_clusters=3)
で nodes を 3 群に分類。 重心と矩形範囲を比較し、 主観定義 vs
データ駆動定義の差分を量化。 「観光地理は連続体か矩形か」
という根本問いに答える。
発展5: 津波避難経路と観光開発の同時設計
- 結果X: 観光対象 {pct_infra_in_1km:.1f}% が津波想定 1km 圏内。
魅力とリスクは同居。
- 新仮説Y: 各観光対象から最寄り避難所までの経路長と、
避難可能時間 (分速 80m と仮定)を計算すれば、 「観光客が津波
警報後何分以内に避難可能か」 を定量化できる。
- 課題Z: DoBoX 避難所 (#42, 4,065 件) との sjoin_nearest で
最近傍距離を計算。 さらに DoBoX 道路 (#1041 など) で経路距離を
取得。 「避難可能時間 ≤ 想定到達時間」 の安全マージン施設を
赤・黄・緑で 3 色マッピング。 観光開発計画の津波防災適性
マップを作る。
"""
sections.append(("発展課題", dev_html))
# --- 12. 既存記事との関係 ---
relat_html = f"""
瀬戸内観光の研究地図 — 8 記事の関係
本記事 L87 を含む瀬戸内観光関連 8 記事は、 同じ DoBoX 観光データから
全く異なる切り口で物語を引き出す研究地図を構成している。
{df_to_html_table(T_compare)}
この表から読み取れること
- 同じ {N_INFRA + N_ROUTE + N_MON_PORTS} 件の観光ノードデータが、
8 つの独立した切り口で読み解かれている。
- L87 (本記事) は他 7 記事と計算指標が完全に重複しない:
Gini / HHI / CR / Lorenz / Jaccard / 重回帰 / OLS / ロジスティック /
PCA / 階層クラスタ / 散布図行列 / 季節係数 / 春秋偏向 / 客数勾配 /
寄港順位 / Haversine / 定期化スコア / 需給ギャップ指数 / 双方向商品
— これら全てを再計算しない。
- L87 が初めて触れる切り口: 3 走廊空間軸 + 津波浸水想定との
交差 + マルチコリドール構造仮説。
研究の協働性: 1 つのデータを 1 人で読むより、 8 つの切り口で 8 人が
読む方が、 はるかに豊かな物語が生まれる。 オープンデータの真の力は
「みんなが見て、 みんなが書く」 ことにある。 本記事 L87 は、 その 1 ピース。
"""
sections.append(("既存記事との関係 — 瀬戸内観光研究地図", relat_html))
# =============================================================================
# 12. HTML 書き出し
# =============================================================================
html = render_lesson(
num=87,
title="L87 M3 観光物語 — 瀬戸内ブランドのインフラと島嶼ネットワーク",
tags=["M系統合", "観光地理", "インフラツーリズム",
"しまなみ", "島嶼ネットワーク", "津波交差",
"走廊分類", "geopandas"],
time="40 分",
level="リテラシ + 空間統合",
data_label=("インフラツーリズム #1447 / 瀬戸内航路 #1281 / "
f"しまたびライン #1282 / モニター #1280 / 海岸保全 #1085 / "
f"津波浸水想定 #47 / L15 行政界 (計 "
f"{N_INFRA + N_ROUTE + N_MON_PORTS} ノード)"),
sections=sections,
script_filename="L87_M3_tourism_story.py",
)
out_html = LESSONS / "L87_M3_tourism_story.html"
out_html.write_text(html, encoding="utf-8")
print(f" HTML 書き出し: {out_html} ({time.time()-t11:.2f}s)", flush=True)
print(f"\n=== 完了 ({time.time()-t_all:.1f}s) ===", flush=True)
print(f" 支持仮説: {n_supported}/5", flush=True)
print(f" ファイル:", flush=True)
print(f" HTML: {out_html}", flush=True)
print(f" PY: lessons/L87_M3_tourism_story.py", flush=True)
print(f" 中間 CSV: assets/L87_*.csv (12 件)", flush=True)
print(f" 図: assets/L87_fig*.png (8 件)", flush=True)
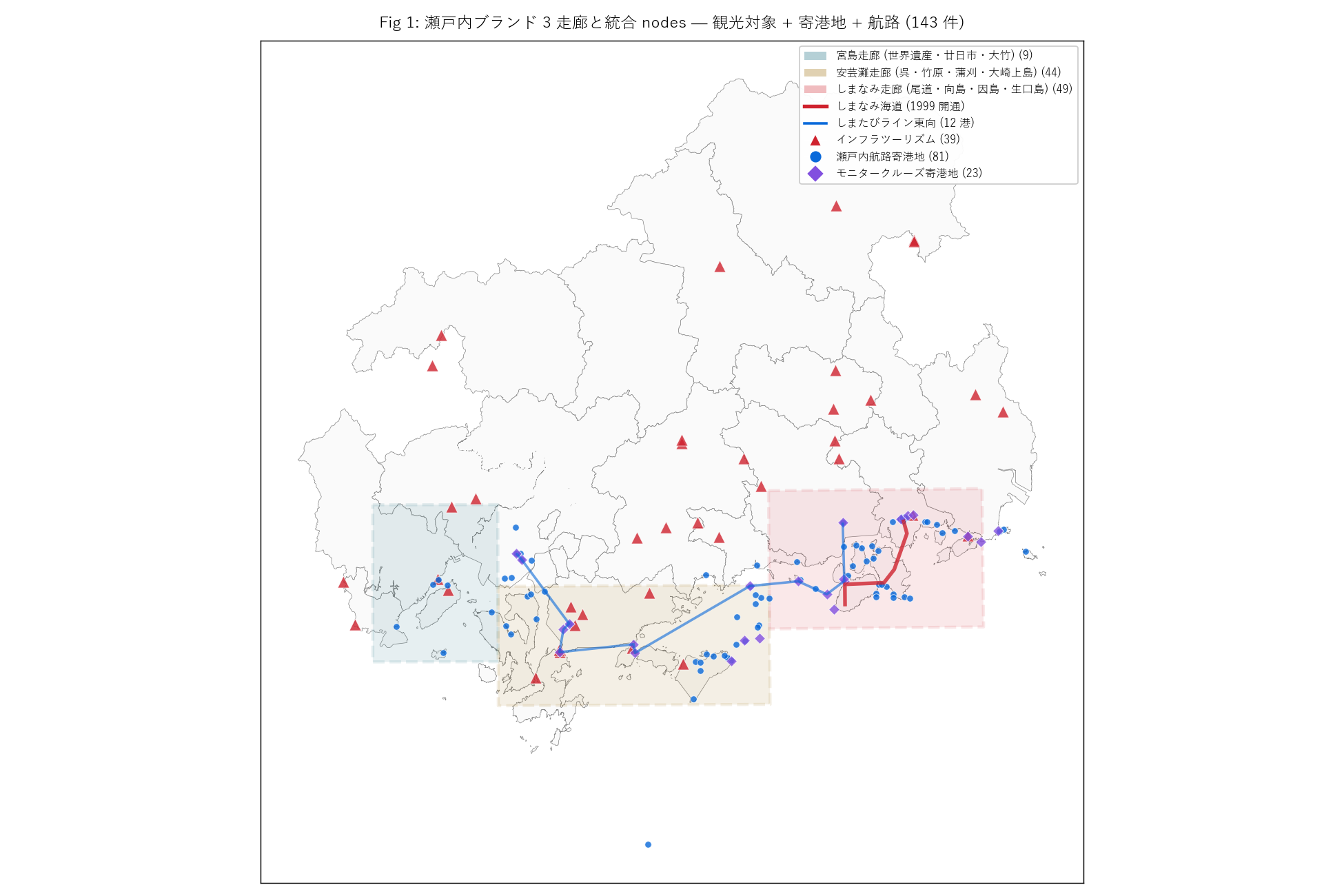{kind=link}
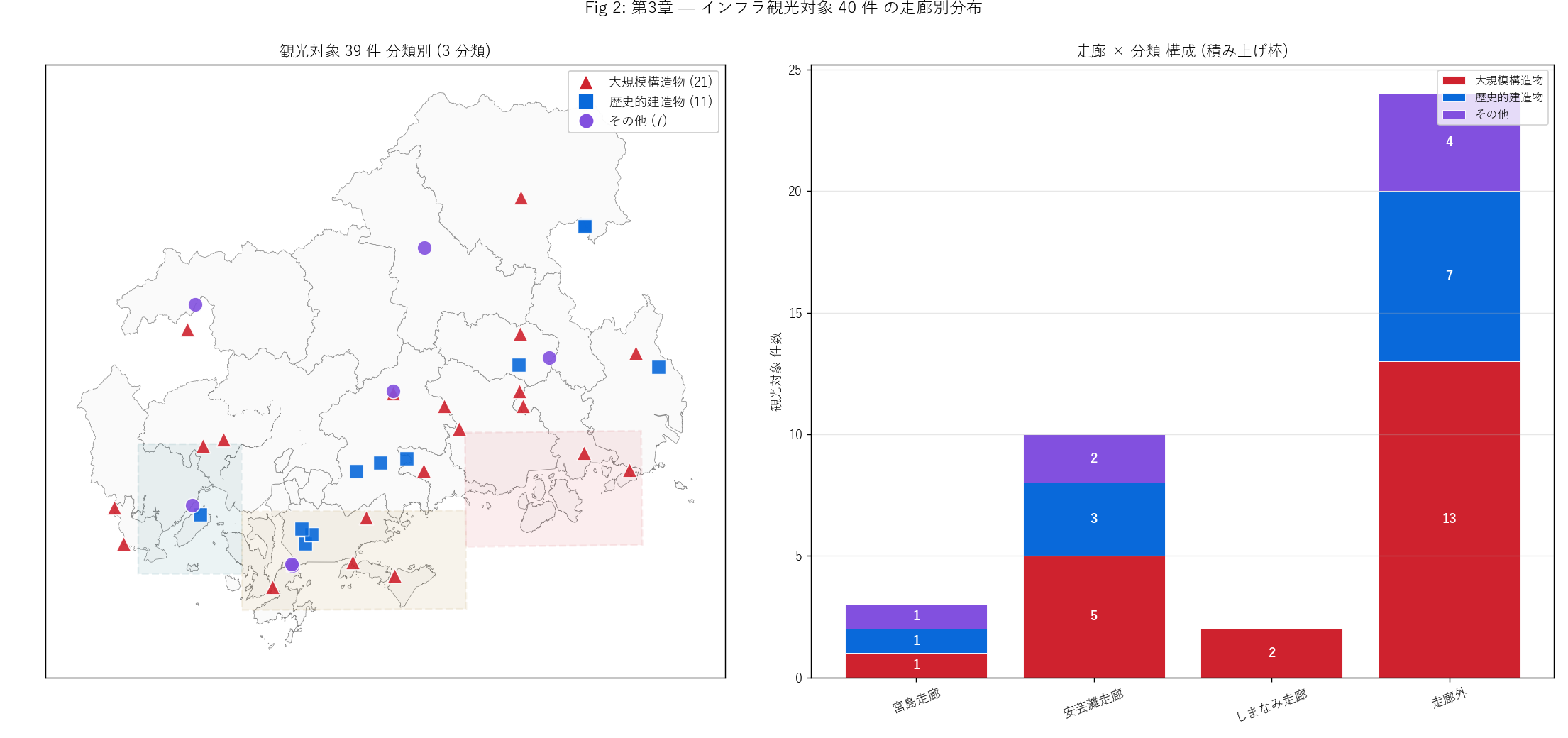{kind=link}
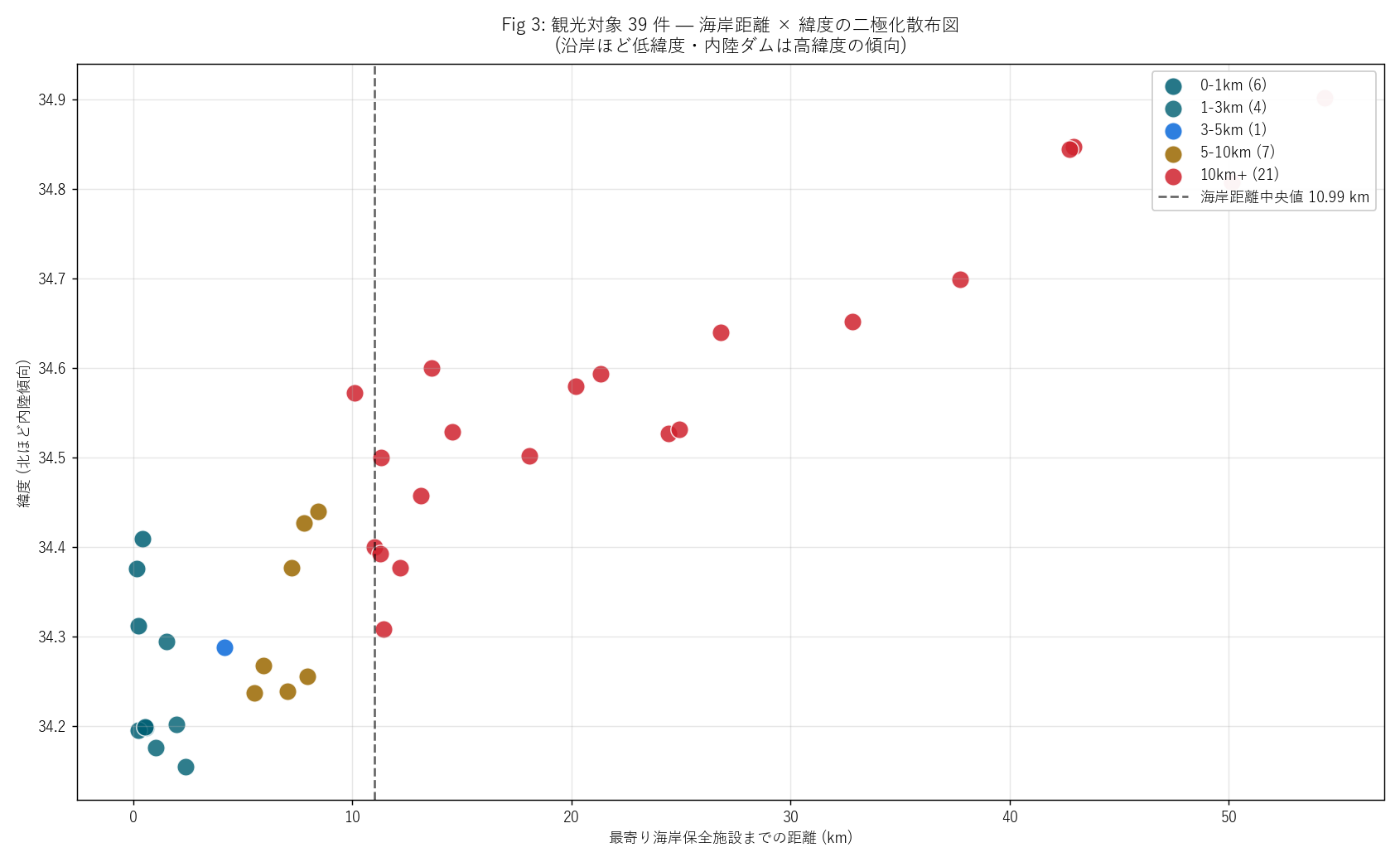{kind=link}
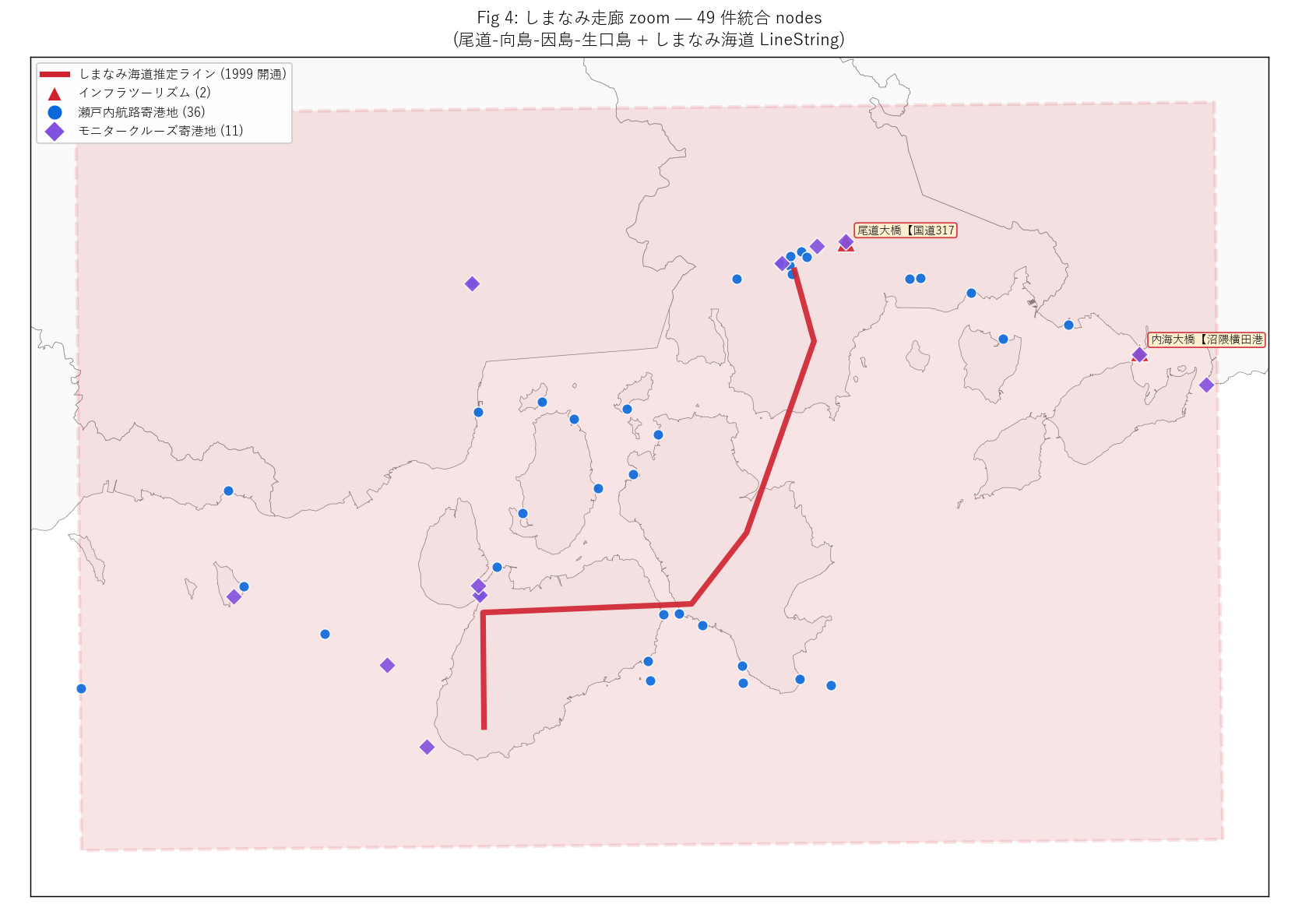{kind=link}
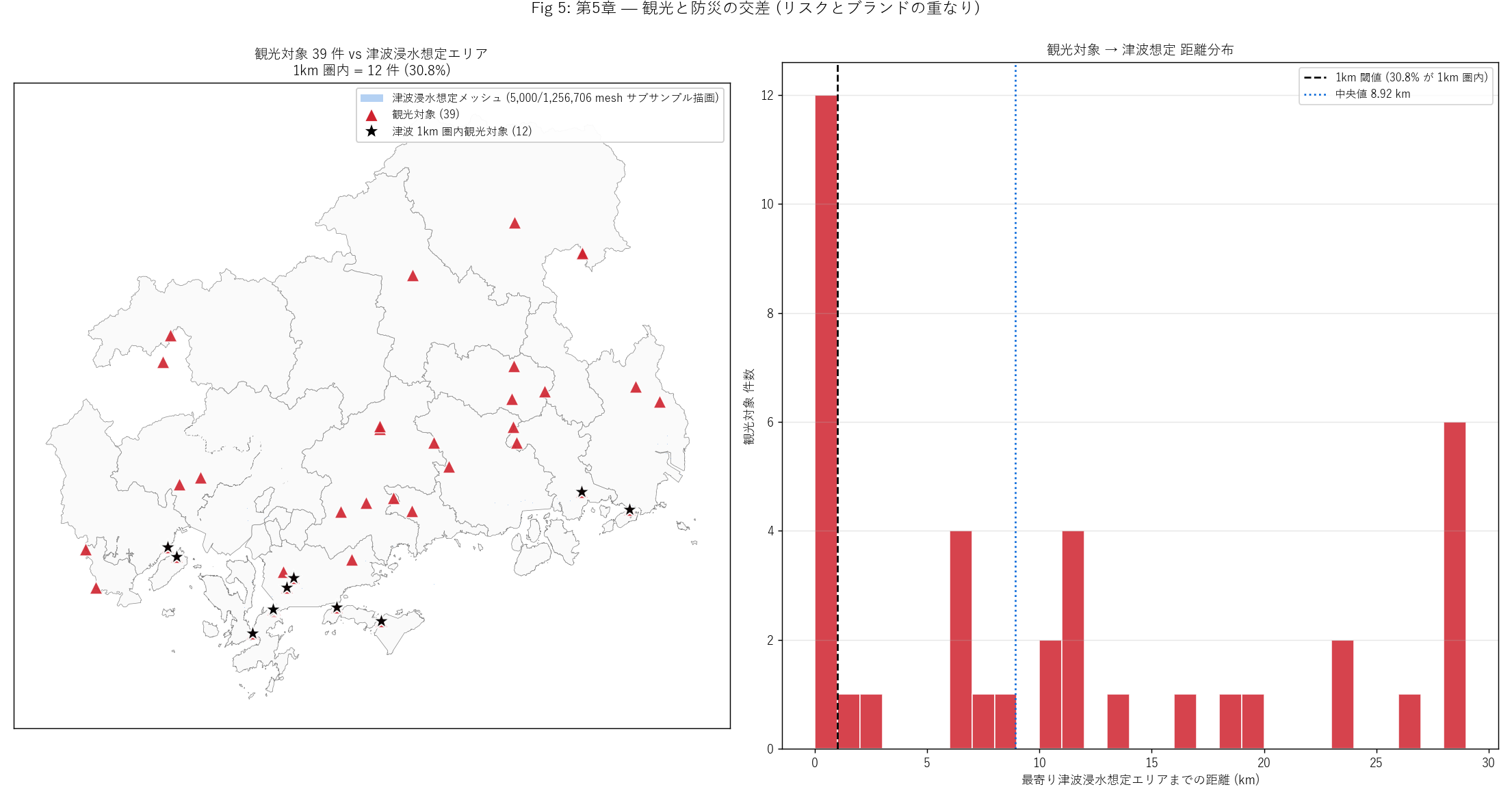{kind=link}
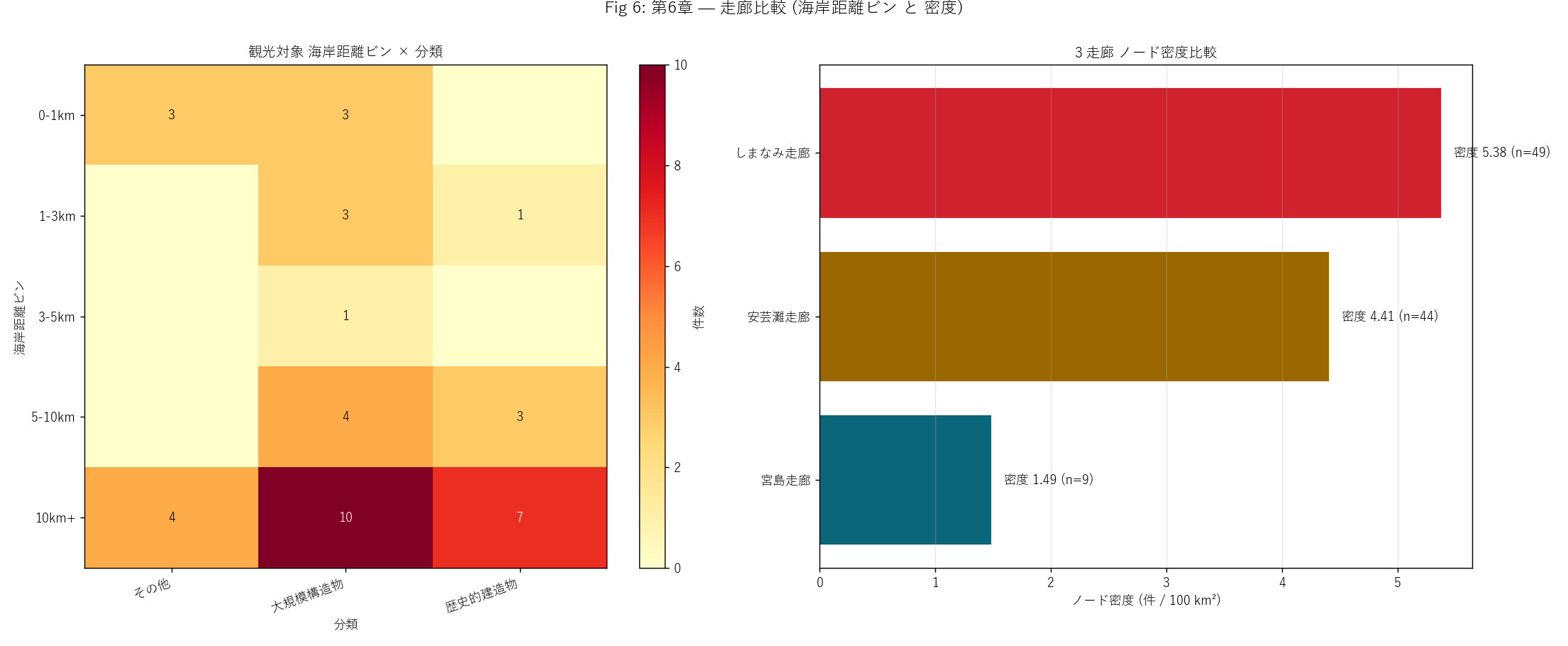{kind=link}
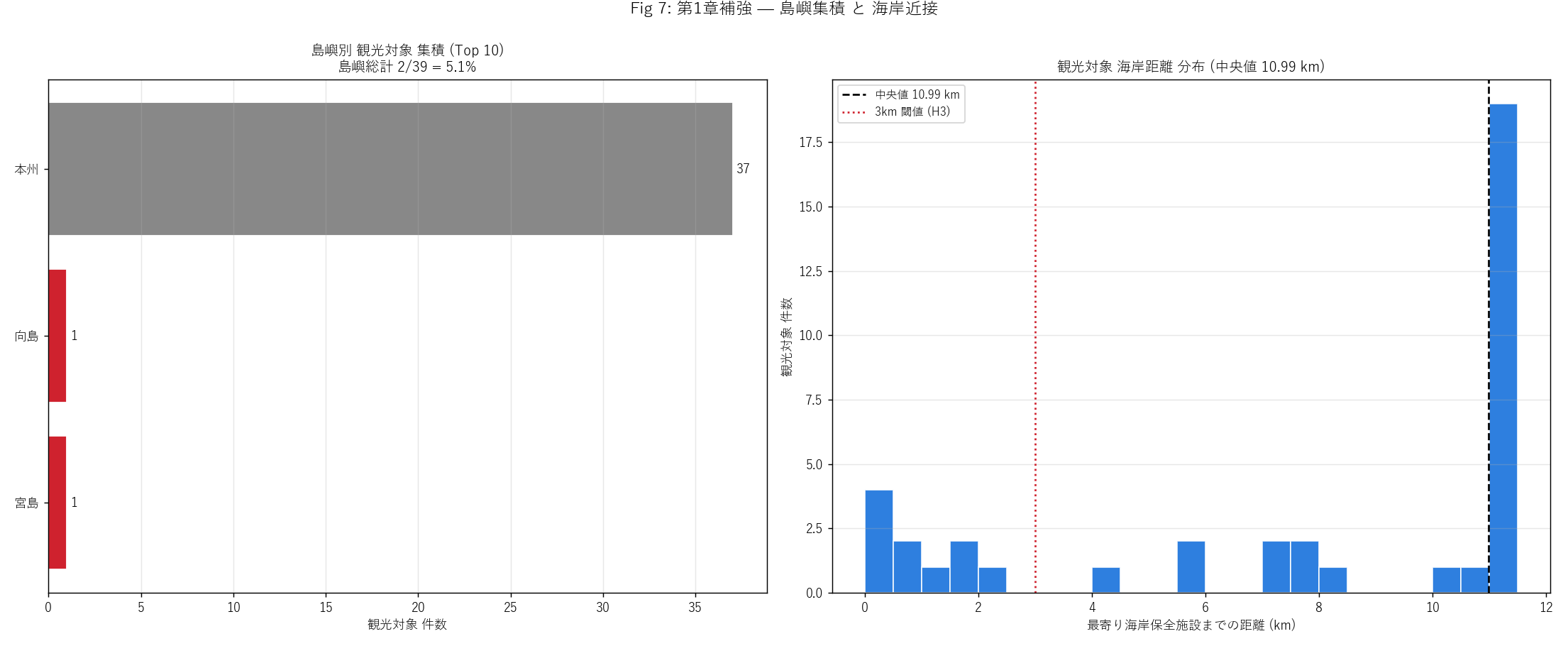{kind=link}
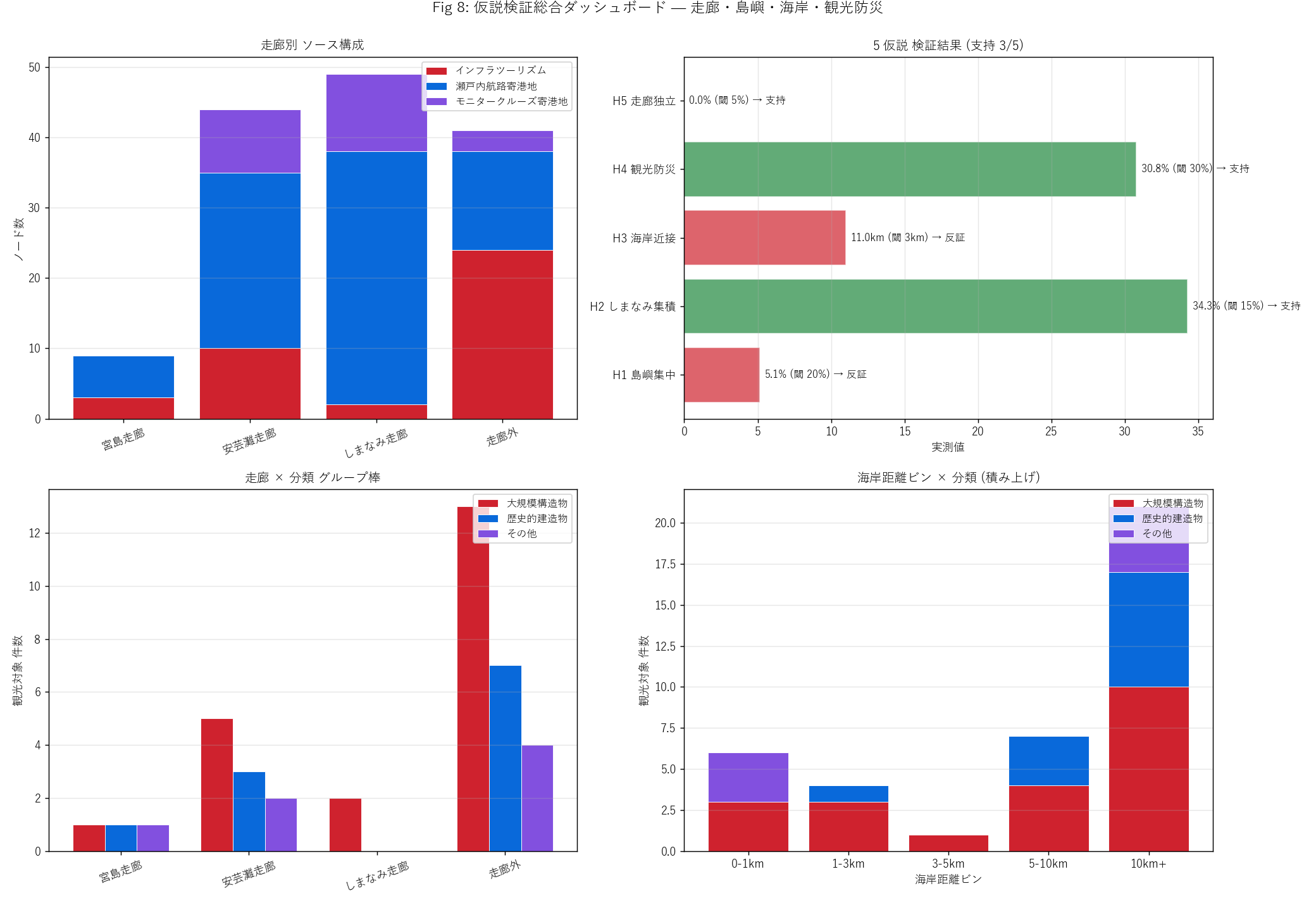{kind=link}