# -*- coding: utf-8 -*-
"""L76 非常用電話位置情報 単独 3 研究例分析
— NTT 西日本 災害時非常用公衆電話 (dataset 1457) を 3 角度で解読
カバー宣言:
本記事は DoBoX のデータセット「非常用電話位置情報」 (dataset_id = 1457)
1 件を 単独で取り上げ、 西日本電信電話株式会社 (NTT 西日本) が広島県
内に設置・運用する「災害時非常用公衆電話」 900 拠点 / 1,181 台を
3 つの独立した研究角度 (RQ1 / RQ2 / RQ3) で並列に分析する。
「災害時非常用公衆電話」 とは:
一般に「非常用電話」 と聞くと高速道路トンネル内の通報装置
(NEXCO 等が管理する「非常電話」) を想起しがちだが、 本データセット
が対象とする「非常用電話」 は完全に別物である:
NTT 西日本が避難所相当の公共施設 (小中学校 + 体育館 + 行政
センター + 公民館 等)に事前設置する公衆電話 (1 拠点 1〜3 台) で、
平時は未開通、 大規模災害発生時に NTT 西日本が遠隔回線開通を
行うことで初めて通話可能となる「災害時優先回線」である。
1995 年阪神・淡路大震災を受けて NTT が制度化し、 通話無料 (硬貨・カード
不要)、 携帯電話の輻輳・基地局停電・回線断時にも独立した公衆電話網
(有線回線 + 局舎バッテリ) で通話可能であるため、 災害時の最終的な
「最後のセーフティネット」として機能する。
本記事は L62 避難情報 / L72 緊急輸送道路 / L67 トンネルと
厳密に区別:
L62 = 避難情報 (避難所開設の動的情報)
L67 = トンネル 157 件 (構造物台帳, 高速道路非常電話とは別データセット)
L72 = 緊急輸送道路 (LineString, 4 階層 / 2,790 km, 災害時の生命線道路)
L76 = 非常用電話単独 (POINT, 900 拠点 / 1,181 台, NTT 西日本)
本記事は他シリーズと合体しない。 RQ2 で県管理避難所
4,065 件 (data/shelters.json), RQ3 で L72 緊急輸送道路 (cached) を
参照する形をとる。
「設置場所」 (NTT 公式呼称) と「利用場所」 (本データの列名) の関係:
本 CSV の「利用場所」列は建物内の具体的位置 (体育館 / 玄関ホール /
事務室 / MDF 内 等) を指し、 「設置場所」 とは異なる用語である。 NTT
公式仕様書では「設置場所 = 建物名」 「利用場所 = 建物内位置」 と区別。
本記事は CSV に従い「利用場所」 = 室内位置として扱う。
研究の問い (3 RQ):
RQ1 (主研究): 広島県のNTT 災害時非常用公衆電話の地理分布と設置構造
— 市町 × 施設種別 × 設置台数 × 利用場所はどう描けるか? 900 拠点 /
1,181 台を 4 軸で集計し、 「県の通信救急ネットワークの物理形状」 を
初めて系統的に記述する。
H1 = 設置施設の >= 80%が学校 (小中高 + 大学) または公民館・
行政センター・体育館 (= 公的避難所相当施設) に集中する仮説、
H2 = 1 拠点 1 台が多数派だが、 >= 25%の拠点で複数台設置
(大規模避難所での通話需要分散) 仮説。
RQ2 (副研究 1): 非常用電話と県登録避難所 (shelters 4,065 件) との
照合 — 避難所通信整備率はどう描けるか? 非常用電話 900 拠点が
実際に避難所に設置されているか、 100m 圏内の最近接 sjoin で量的検証
する。 「避難所側」 の通信整備率 (= 4,065 避難所のうち何 % が非常用
電話を持つか) と「電話側」 の避難所一致率を双方向に量化。
H3 = 非常用電話 900 拠点のうち >= 80%が県登録避難所 100m 圏内
(= NTT の選定基準が県の避難所指定とほぼ一致) 仮説、
H4 = 4,065 避難所のうち非常用電話保持率は < 25% (= 整備は
一部の中核避難所に限定、 中山間部に空白地帯) 仮説。
RQ3 (副研究 2): 非常用電話とL72 緊急輸送道路 (4 階層 / 2,790 km) との
関連 — 通信救急ネットワークの冗長性はどう描けるか? 非常用電話
900 拠点が緊急輸送道路の 1km 圏内にあるか sjoin、 「電話 + 道路」
が両方近接する地点 = 「通信救急二重冗長点」 (= 通信途絶時に災害救援
車両が物理アクセス可能な箇所) を量的特定する。
H5 = 非常用電話 900 拠点のうち >= 70%が L72 第 1〜2 次緊急
輸送道路 1km 圏内 (= 通信 + 道路の二重冗長性確保) 仮説。
仮説 (5):
H1 (RQ1, 学校 + 公民館集中): 設置施設の >= 80%が学校 (小中高 + 大学)
または公民館 + 行政センター + 体育館。 「公的避難所相当施設に集中」 仮説。
H2 (RQ1, 複数台設置率): >= 25%の拠点が 2 台以上設置。 大規模避難所では
通話需要を分散するため複数台設置される「拠点規模 ⇔ 設置台数」 仮説。
H3 (RQ2, 電話 ⊂ 避難所): 非常用電話 900 拠点のうち県登録避難所 100m 圏内に
位置するのが >= 80%。 NTT の選定基準が県避難所指定と事実上一致
する制度連携仮説。
H4 (RQ2, 避難所通信整備の偏り): 4,065 避難所のうち非常用電話保持率は
< 25%。 整備は中核避難所に限定、 多くの避難所に通信空白
地帯が存在する仮説。
H5 (RQ3, 通信救急二重冗長): 非常用電話 900 拠点のうち L72 第 1〜2 次
緊急輸送道路 1km 圏内 >= 70%。 「通信 + 道路」 が両方近接する
拠点が多数 = 通信救急ネットワークが幹線道路網と一致する設計思想仮説。
要件 S 準拠 (1 分以内完走):
- データ CSV (~110 KB, 900 行) → ensure_dataset で取得
- 住所から市町抽出 (正規表現)、 建物名から施設種別判定 (キーワード)
- 行政界 sjoin (POINT 900 件のみ) → 中山間判定
- shelters.json (~4MB) を Point GeoDataFrame 化 → 100m バッファ + sjoin
- L72 緊急輸送道路 (cached JSON) を 1km バッファ → sjoin
- 全体で ~10-15 秒目標
要件 T 準拠 (位置情報あり = 地図必須):
- RQ1: 市町別 choropleth + 施設種別別 点マップ + 設置台数 バブル
- RQ2: 非常用電話 + 避難所 重ね合わせマップ + 一致 / 不一致色分け
- RQ3: 非常用電話 + L72 緊急輸送道路 重ね合わせマップ + 1km バッファ
要件 Q 準拠: 図 8+ / 表 11+ (3 RQ × 多角度: 市町×施設×台数 / 避難所連携 /
緊急輸送道路冗長)
データ仕様:
- dataset 1457: 非常用電話位置情報 (1 リソース)
- resource 94468: 非常用電話位置情報_2024-08-14 CSV (~110 KB, 900 行 × 6 列)
- CSV 列: 建物名, 利用場所, 設置台数, 住所, 緯度 世界, 経度 世界
- ライセンス: クリエイティブ・コモンズ表示 (CC-BY)
メモリ対策: Figure ごとに plt.close('all') で確実に解放。
"""
from __future__ import annotations
import sys, time, json, re
from pathlib import Path
sys.path.insert(0, str(Path(__file__).parent))
from _common import ROOT, ASSETS, LESSONS, render_lesson, code, figure, ensure_dataset
import numpy as np
import pandas as pd
import geopandas as gpd
from shapely.geometry import Point, LineString
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.lines import Line2D
from matplotlib.patches import Patch
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
t_all = time.time()
print("=== L76 非常用電話位置情報 単独 3 研究例分析 ===", flush=True)
# =============================================================================
# 0. 定数・パス
# =============================================================================
TARGET_CRS = "EPSG:6671"
DATA_DIR = ROOT / "data" / "extras" / "L76_emergency_phones"
DATA_DIR.mkdir(parents=True, exist_ok=True)
DATASET_ID = 1457
RESOURCE_ID = 94468
PHONES_CSV = DATA_DIR / "emergency_phones.csv"
# 行政界キャッシュ (L44 から)
ADMIN_GPKG = ROOT / "data" / "extras" / "L44_storm_surge" / "_cache" / "admin_diss.gpkg"
# 県登録避難所 (RQ2 で参照)
SHELTERS_JSON = ROOT / "data" / "shelters.json"
# L72 緊急輸送道路 (RQ3 で参照, cached JSON)
L72_DIR = (ROOT / "data" / "extras" / "L72_emergency_road"
/ "340006_emergency_transport_road_20220908T000000")
# バッファ
SHELTER_MATCH_M = 100.0 # 電話 ↔ 避難所 100m
ROUTE_BUFFER_M = 1000.0 # 電話 ↔ L72 緊急輸送道路 1km
# CITY_CD → 市町名 (L72 と共通)
CITY_NAME = {
101: "広島市中区", 102: "広島市東区", 103: "広島市南区", 104: "広島市西区",
105: "広島市安佐南区", 106: "広島市安佐北区", 107: "広島市安芸区", 108: "広島市佐伯区",
202: "呉市", 203: "竹原市", 204: "三原市", 205: "尾道市", 207: "福山市",
208: "府中市", 209: "三次市", 210: "庄原市", 211: "大竹市", 212: "東広島市",
213: "廿日市市", 214: "安芸高田市", 215: "江田島市",
302: "府中町", 304: "海田町", 307: "熊野町", 309: "坂町",
368: "安芸太田町", 369: "安芸太田町", 412: "北広島町",
462: "世羅町", 545: "神石高原町", 543: "神石高原町",
}
CHUSANKAN_CITIES = {
"庄原市", "三次市", "安芸太田町", "安芸高田市",
"北広島町", "神石高原町", "世羅町", "府中市",
}
COASTAL_ISLAND = {"江田島市", "大崎上島町"}
def geo_class(name):
if name in CHUSANKAN_CITIES:
return "中山間山地"
if name in COASTAL_ISLAND:
return "沿岸島嶼"
if not name or "不明" in name:
return "その他/不明"
return "平野・沿岸都市"
# 施設種別 (本記事独自分類, 建物名キーワードから判定)
def building_class(name):
s = str(name)
if "小学校" in s: return "小学校"
if "中学校" in s: return "中学校"
if "高等学校" in s or "高校" in s: return "高校"
if "大学" in s and "短期" not in s: return "大学"
if "保育" in s or "幼稚" in s or "幼保" in s: return "保育・幼稚園"
if "公民館" in s: return "公民館"
if "センター" in s or "プラザ" in s: return "行政センター"
if "体育館" in s: return "体育館"
if "ホール" in s or "会館" in s or "館" in s: return "文化施設・ホール"
if "集会所" in s or "自治" in s: return "集会所・自治会館"
if "役場" in s or "役所" in s or "庁舎" in s: return "役場・庁舎"
return "その他"
BUILDING_ORDER = [
"小学校", "中学校", "高校", "大学", "保育・幼稚園",
"公民館", "行政センター", "体育館",
"文化施設・ホール", "集会所・自治会館", "役場・庁舎", "その他",
]
BUILDING_COLOR = {
"小学校": "#cf222e", "中学校": "#cf6f00", "高校": "#bf8700", "大学": "#9a6c00",
"保育・幼稚園": "#e879c0",
"公民館": "#0969da", "行政センター": "#0a4f9e", "体育館": "#1a7f37",
"文化施設・ホール": "#7c3aed", "集会所・自治会館": "#5a8aa3",
"役場・庁舎": "#5a3478", "その他": "#888888",
}
# 公的避難所相当 (H1 判定用): 学校 + 公民館 + 行政センター + 体育館
SHELTER_LIKE = {"小学校", "中学校", "高校", "大学",
"公民館", "行政センター", "体育館"}
# 住所 → 市町抽出
def extract_city(addr):
s = str(addr)
# 「広島県」 が無いケース (例: 〒...-府中市...) も拾う
# 広島市××区
m = re.search(r"広島市(中区|東区|南区|西区|安佐南区|安佐北区|安芸区|佐伯区)", s)
if m:
return f"広島市{m.group(1)}"
# 〇〇市
m = re.search(r"([一-龥ヶヵぁ-んァ-ンA-Za-z]+市)", s)
if m:
# 「広島県」 を除く
return m.group(1).replace("広島県", "")
# 〇〇郡〇〇町
m = re.search(r"([一-龥]+郡[一-龥]+[町村])", s)
if m:
# 郡を除いた町名
m2 = re.search(r"([一-龥]+[町村])$", m.group(1))
return m2.group(1) if m2 else m.group(1)
# 〇〇町 (郡なし)
m = re.search(r"([一-龥]+町)", s)
if m:
return m.group(1)
return "不明"
# =============================================================================
# 1. データ取得
# =============================================================================
print("\n[1] データ取得", flush=True)
t1 = time.time()
ensure_dataset(PHONES_CSV, resource_id=RESOURCE_ID, min_bytes=50000,
label="L76 非常用電話位置情報 CSV")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 2. CSV → GeoDataFrame
# =============================================================================
print("\n[2] CSV 読込 → POINT", flush=True)
t2 = time.time()
df = pd.read_csv(PHONES_CSV, encoding="utf-8-sig")
df.columns = [c.strip().replace(" ", "") for c in df.columns]
# 列名 normalize: 緯度世界, 経度世界
df = df.rename(columns={
"緯度世界": "緯度", "経度世界": "経度",
})
df["設置台数"] = pd.to_numeric(df["設置台数"], errors="coerce").fillna(1).astype(int)
df["施設種別"] = df["建物名"].apply(building_class)
df["市町"] = df["住所"].apply(extract_city)
df["seg_id"] = [f"L76_{i:04d}" for i in range(len(df))]
df["is_shelter_like"] = df["施設種別"].isin(SHELTER_LIKE)
# 緯度経度欠損行除外
df = df.dropna(subset=["緯度", "経度"]).reset_index(drop=True)
geom = [Point(lon, lat) for lon, lat in zip(df["経度"], df["緯度"])]
gdf = gpd.GeoDataFrame(df, geometry=geom, crs="EPSG:4326").to_crs(TARGET_CRS)
n_pts = len(gdf)
n_phones = int(gdf["設置台数"].sum())
n_multi = int((gdf["設置台数"] >= 2).sum())
share_multi = round(100 * n_multi / n_pts, 1)
n_shelter_like = int(gdf["is_shelter_like"].sum())
share_shelter_like = round(100 * n_shelter_like / n_pts, 1)
print(f" 拠点: {n_pts} / 台数: {n_phones} / "
f"複数台拠点: {n_multi} ({share_multi}%)", flush=True)
print(f" 公的避難所相当施設: {n_shelter_like} ({share_shelter_like}%)",
flush=True)
print(f" ({time.time()-t2:.1f}s)", flush=True)
# =============================================================================
# 3. 行政界 sjoin → 市町判定 (CSV 住所と独立に空間判定)
# =============================================================================
print("\n[3] 行政界 sjoin (空間判定)", flush=True)
t3 = time.time()
admin = gpd.read_file(ADMIN_GPKG).to_crs(TARGET_CRS)
admin["市町名"] = admin["CITY_CD"].map(CITY_NAME).fillna(
admin["CITY_CD"].astype(str))
joined = gpd.sjoin(gdf[["seg_id", "geometry"]],
admin[["CITY_CD", "市町名", "geometry"]],
how="left", predicate="within")
joined = joined.drop_duplicates("seg_id")
city_map = joined.set_index("seg_id")["市町名"]
gdf["市町_空間"] = gdf["seg_id"].map(city_map).fillna("不明")
gdf["地理クラス"] = gdf["市町_空間"].apply(geo_class)
gdf["is_chusankan"] = gdf["地理クラス"] == "中山間山地"
n_chusankan = int(gdf["is_chusankan"].sum())
share_chusankan = round(100 * n_chusankan / n_pts, 1)
print(f" 中山間: {n_chusankan}/{n_pts} ({share_chusankan}%)", flush=True)
print(f" ({time.time()-t3:.1f}s)", flush=True)
# =============================================================================
# 4. RQ1: 市町 × 施設種別 × 設置台数 × 利用場所 集計
# =============================================================================
print("\n[4] RQ1 集計 — 地理分布と設置構造", flush=True)
t4 = time.time()
# (1) 市町別 (空間判定基準)
T_city = (gdf.groupby(["市町_空間", "地理クラス"])
.agg(拠点数=("seg_id", "count"),
台数合計=("設置台数", "sum"))
.reset_index()
.rename(columns={"市町_空間": "市町"}))
T_city["シェア_%"] = (T_city["拠点数"] / n_pts * 100).round(2)
T_city = T_city.sort_values("拠点数", ascending=False).reset_index(drop=True)
# (2) 施設種別別
T_building = (gdf.groupby("施設種別")
.agg(拠点数=("seg_id", "count"),
台数合計=("設置台数", "sum"),
平均台数=("設置台数", lambda s: round(s.mean(), 2)))
.reset_index())
T_building["シェア_%"] = (T_building["拠点数"] / n_pts * 100).round(1)
# BUILDING_ORDER の順に並べる
T_building["順"] = T_building["施設種別"].apply(
lambda x: BUILDING_ORDER.index(x) if x in BUILDING_ORDER else 999)
T_building = T_building.sort_values("順").drop(columns="順").reset_index(drop=True)
# (3) 設置台数分布
T_count = (gdf.groupby("設置台数")
.agg(拠点数=("seg_id", "count"))
.reset_index())
T_count["シェア_%"] = (T_count["拠点数"] / n_pts * 100).round(1)
# (4) 利用場所 (建物内位置) Top 15
T_yochi = (gdf.groupby("利用場所")
.agg(拠点数=("seg_id", "count"),
台数合計=("設置台数", "sum"))
.reset_index())
T_yochi = T_yochi.sort_values("拠点数", ascending=False).reset_index(drop=True)
# (5) 地理クラス別
T_geo = (gdf.groupby("地理クラス")
.agg(拠点数=("seg_id", "count"),
台数合計=("設置台数", "sum"))
.reset_index())
T_geo["シェア_%"] = (T_geo["拠点数"] / n_pts * 100).round(1)
T_geo = T_geo.sort_values("拠点数", ascending=False).reset_index(drop=True)
# (6) 施設種別 × 設置台数 クロス
T_building_count = (gdf.groupby(["施設種別", "設置台数"])
.size().unstack(fill_value=0).reset_index())
T_building_count["順"] = T_building_count["施設種別"].apply(
lambda x: BUILDING_ORDER.index(x) if x in BUILDING_ORDER else 999)
T_building_count = (T_building_count.sort_values("順")
.drop(columns="順").reset_index(drop=True))
# H1, H2 判定
h1_ok = share_shelter_like >= 80.0
h2_ok = share_multi >= 25.0
print(f" 公的避難所相当施設: {n_shelter_like} ({share_shelter_like}%)",
flush=True)
print(f" 複数台 (>=2): {n_multi} ({share_multi}%)", flush=True)
print(f" H1 (公的避難所相当 >= 80%): {h1_ok}", flush=True)
print(f" H2 (複数台拠点 >= 25%): {h2_ok}", flush=True)
print(f" ({time.time()-t4:.1f}s)", flush=True)
# =============================================================================
# 5. RQ2: 県登録避難所 (shelters.json) との照合
# =============================================================================
print("\n[5] RQ2 集計 — 避難所連携", flush=True)
t5 = time.time()
with open(SHELTERS_JSON, "r", encoding="utf-8") as f:
sh_raw = json.load(f)
sh_items = sh_raw["items"]
sh_rows = []
for it in sh_items:
try:
lat = float(it.get("latitude", "") or "nan")
lon = float(it.get("longitude", "") or "nan")
except ValueError:
continue
if np.isnan(lat) or np.isnan(lon):
continue
sh_rows.append({
"facilityId": it.get("facilityId", ""),
"name": it.get("name", ""),
"city": it.get("municipalityName", ""),
"capacity": it.get("capacity"),
"latitude": lat,
"longitude": lon,
})
df_sh = pd.DataFrame(sh_rows)
geom_sh = [Point(lo, la) for lo, la in zip(df_sh["longitude"], df_sh["latitude"])]
gdf_sh = gpd.GeoDataFrame(df_sh, geometry=geom_sh, crs="EPSG:4326").to_crs(TARGET_CRS)
n_shelters = len(gdf_sh)
print(f" 避難所: {n_shelters}", flush=True)
# 避難所 100m バッファ → 電話との sjoin
gdf_sh_buf = gdf_sh.copy()
gdf_sh_buf["geometry"] = gdf_sh.geometry.buffer(SHELTER_MATCH_M)
gdf_sh_buf["sh_id"] = [f"SH_{i:05d}" for i in range(n_shelters)]
# rebuild just necessary columns for sjoin
gdf_sh["sh_id"] = gdf_sh_buf["sh_id"]
# 電話 ↔ 避難所 100m: 電話側
match = gpd.sjoin(gdf[["seg_id", "geometry"]],
gdf_sh_buf[["sh_id", "geometry"]],
how="left", predicate="within")
match_grp = (match.dropna(subset=["index_right"])
.groupby("seg_id")["sh_id"]
.apply(lambda s: ",".join(sorted(set([str(v) for v in s.dropna()]))[:3])))
gdf["matched_shelter"] = gdf["seg_id"].map(match_grp).fillna("")
gdf["near_shelter"] = gdf["matched_shelter"] != ""
n_near_shelter = int(gdf["near_shelter"].sum())
share_near_shelter = round(100 * n_near_shelter / n_pts, 1)
h3_ok = share_near_shelter >= 80.0
# 避難所側 → 電話一致率: 各避難所 100m バッファに電話拠点が入るか
gdf_buf = gdf.copy()
gdf_buf["geometry"] = gdf.geometry.buffer(SHELTER_MATCH_M)
match_rev = gpd.sjoin(gdf_sh[["sh_id", "geometry"]],
gdf_buf[["seg_id", "geometry"]],
how="left", predicate="within")
match_rev_grp = (match_rev.dropna(subset=["index_right"])
.groupby("sh_id")["seg_id"]
.apply(lambda s: ",".join(sorted(set([str(v) for v in s.dropna()]))[:3])))
gdf_sh["matched_phone"] = gdf_sh["sh_id"].map(match_rev_grp).fillna("")
gdf_sh["has_phone"] = gdf_sh["matched_phone"] != ""
n_sh_with_phone = int(gdf_sh["has_phone"].sum())
share_sh_with_phone = round(100 * n_sh_with_phone / n_shelters, 1)
h4_ok = share_sh_with_phone < 25.0
# 市町別の 避難所通信整備率 (= 各市町の避難所のうち電話保持率)
sh_cov = (gdf_sh.groupby("city")
.agg(避難所数=("sh_id", "count"),
電話保持避難所=("has_phone", "sum"))
.reset_index())
sh_cov["保持率_%"] = (100 * sh_cov["電話保持避難所"] / sh_cov["避難所数"]).round(1)
sh_cov = sh_cov.sort_values("避難所数", ascending=False).reset_index(drop=True)
sh_cov = sh_cov.rename(columns={"city": "市町"})
T_shelter_match = pd.DataFrame([
{"カテゴリ": "電話 ⊂ 避難所 100m 圏内 (NTT 整備 = 県指定一致)",
"件数": n_near_shelter,
"シェア_%": round(100 * n_near_shelter / n_pts, 1)},
{"カテゴリ": "電話のみ (避難所 100m 圏外)",
"件数": n_pts - n_near_shelter,
"シェア_%": round(100 * (n_pts - n_near_shelter) / n_pts, 1)},
])
T_shelter_cov = pd.DataFrame([
{"カテゴリ": "避難所 + 電話設置 (通信整備済)",
"件数": n_sh_with_phone,
"シェア_%": round(100 * n_sh_with_phone / n_shelters, 1)},
{"カテゴリ": "避難所 + 電話なし (通信空白)",
"件数": n_shelters - n_sh_with_phone,
"シェア_%": round(100 * (n_shelters - n_sh_with_phone) / n_shelters, 1)},
])
print(f" 電話 ⊂ 避難所 100m: {n_near_shelter}/{n_pts} "
f"({share_near_shelter}%)", flush=True)
print(f" 避難所 + 電話保持: {n_sh_with_phone}/{n_shelters} "
f"({share_sh_with_phone}%)", flush=True)
print(f" H3 (電話 ⊂ 避難所 >= 80%): {h3_ok}", flush=True)
print(f" H4 (避難所通信整備率 < 25%): {h4_ok}", flush=True)
print(f" ({time.time()-t5:.1f}s)", flush=True)
# =============================================================================
# 6. RQ3: L72 緊急輸送道路との関連
# =============================================================================
print("\n[6] RQ3 集計 — 緊急輸送道路冗長", flush=True)
t6 = time.time()
# L72 のうち第 1〜2 次 (主要骨格) を読込み
RANK_DEF = {
"01": {"label": "第1次 (高速・幹線国道)", "color": "#cf222e"},
"02": {"label": "第2次 (主要地方道・国道)", "color": "#0969da"},
"03": {"label": "第3次 (一般県道・市町道)", "color": "#1a7f37"},
"04": {"label": "補完線 (補強路線)", "color": "#cf6f00"},
}
RANK_ORDER = ["01", "02", "03", "04"]
def load_l72_lines(idx):
p = L72_DIR / f"05_kinkyu_route_{idx}.json"
if not p.exists():
return []
with open(p, "r", encoding="utf-8") as f:
text = f.read()
arr = json.loads("[" + text + "]")
lines = []
for seg in arr:
if isinstance(seg, list) and len(seg) >= 2:
coords = [(pt["e"], pt["d"]) for pt in seg]
lines.append(LineString(coords))
return lines
l72_records = []
for idx in RANK_ORDER:
lines = load_l72_lines(idx)
for ln in lines:
l72_records.append({"rank": idx,
"rank_label": RANK_DEF[idx]["label"],
"geometry": ln})
gdf_route = gpd.GeoDataFrame(l72_records, crs="EPSG:4326").to_crs(TARGET_CRS)
gdf_route["length_km"] = gdf_route.geometry.length / 1000
n_route = len(gdf_route)
total_km_route = float(gdf_route["length_km"].sum())
print(f" L72: {n_route} セグ / {total_km_route:.0f} km", flush=True)
# 第 1〜2 次のみ (主要骨格)
gdf_route12 = gdf_route[gdf_route["rank"].isin(["01", "02"])].copy()
n_route12 = len(gdf_route12)
total_km_route12 = float(gdf_route12["length_km"].sum())
# 第 1〜2 次 1km バッファ
buf12 = gdf_route12.geometry.buffer(ROUTE_BUFFER_M).union_all()
# 全 L72 1km バッファ
buf_all = gdf_route.geometry.buffer(ROUTE_BUFFER_M).union_all()
# 距離ベースで判定
def in_buf(p, b):
return 1 if p.intersects(b) else 0
gdf["near_l72_12"] = gdf.geometry.apply(lambda p: in_buf(p, buf12))
gdf["near_l72_all"] = gdf.geometry.apply(lambda p: in_buf(p, buf_all))
n_near12 = int(gdf["near_l72_12"].sum())
share_near12 = round(100 * n_near12 / n_pts, 1)
n_near_all = int(gdf["near_l72_all"].sum())
share_near_all = round(100 * n_near_all / n_pts, 1)
h5_ok = share_near12 >= 70.0
# 各電話拠点の最近接 L72 セグメントまで距離 (km)
def nearest_route_km(p, geoms):
if len(geoms) == 0:
return np.nan
return min(p.distance(g) for g in geoms) / 1000
l72_geoms_all = list(gdf_route.geometry)
l72_geoms_12 = list(gdf_route12.geometry)
# 計算が重そうなので、 100 件サンプリングではなく全件で。
# 900 × 2,790 km の line ↔ point distance は ~10s でいける
# とはいえ、 Spatial index を活用したい
sindex_all = gdf_route.sindex
def nearest_km_sindex(p, sindex, geoms):
# 簡易: bbox ヒットを最初に絞る
minx, miny, maxx, maxy = p.x - 5000, p.y - 5000, p.x + 5000, p.y + 5000
candidates = list(sindex.intersection((minx, miny, maxx, maxy)))
if not candidates:
candidates = list(range(len(geoms)))
return min(p.distance(geoms[i]) for i in candidates) / 1000
print(" 最近接距離計算...", flush=True)
gdf["dist_l72_km"] = [nearest_km_sindex(p, sindex_all, l72_geoms_all)
for p in gdf.geometry]
print(f" 最近接距離 計算完了 ({time.time()-t6:.1f}s)", flush=True)
# (1) 4 カテゴリ クロス: 電話 × L72 1〜2 次 / 3〜4 次 / 圏外
gdf["l72_status"] = "圏外 (>1km)"
mask12 = gdf["near_l72_12"] == 1
mask_all = gdf["near_l72_all"] == 1
gdf.loc[mask_all & ~mask12, "l72_status"] = "第3〜4次 1km 圏内のみ"
gdf.loc[mask12, "l72_status"] = "第1〜2次 1km 圏内"
T_l72_status = (gdf.groupby("l72_status")
.agg(拠点数=("seg_id", "count"),
台数合計=("設置台数", "sum"))
.reset_index())
T_l72_status["シェア_%"] = (T_l72_status["拠点数"] / n_pts * 100).round(1)
T_l72_status = T_l72_status.sort_values("拠点数", ascending=False).reset_index(drop=True)
# (2) 距離分布の統計
dist_q = np.percentile(gdf["dist_l72_km"], [25, 50, 75, 90])
T_dist = pd.DataFrame([
{"統計": "最小 (km)", "値": round(gdf['dist_l72_km'].min(), 3)},
{"統計": "25%", "値": round(dist_q[0], 3)},
{"統計": "中央 (50%)", "値": round(dist_q[1], 3)},
{"統計": "75%", "値": round(dist_q[2], 3)},
{"統計": "90%", "値": round(dist_q[3], 3)},
{"統計": "最大 (km)", "値": round(gdf['dist_l72_km'].max(), 3)},
{"統計": "平均 (km)", "値": round(gdf['dist_l72_km'].mean(), 3)},
])
# (3) 通信救急二重冗長点 (避難所一致 AND L72 1km 圏内)
gdf["double_redundant"] = (gdf["near_shelter"] &
(gdf["near_l72_all"] == 1))
n_double = int(gdf["double_redundant"].sum())
share_double = round(100 * n_double / n_pts, 1)
print(f" 電話 L72 第1〜2次 1km 圏内: {n_near12} ({share_near12}%)", flush=True)
print(f" 電話 L72 全階層 1km 圏内: {n_near_all} ({share_near_all}%)",
flush=True)
print(f" 通信救急二重冗長点 (避難所 ∩ L72): {n_double} ({share_double}%)",
flush=True)
print(f" H5 (L72 1〜2次 1km 圏内 >= 70%): {h5_ok}", flush=True)
print(f" ({time.time()-t6:.1f}s)", flush=True)
# =============================================================================
# 7. CSV 出力
# =============================================================================
print("\n[7] CSV 出力", flush=True)
t7 = time.time()
# (1) 全 900 拠点
df_out = gdf.drop(columns=["geometry"]).copy()
df_out.to_csv(ASSETS / "L76_all_phones.csv",
index=False, encoding="utf-8-sig")
# サマリ表
T_city.to_csv(ASSETS / "L76_city_summary.csv",
index=False, encoding="utf-8-sig")
T_building.to_csv(ASSETS / "L76_building_summary.csv",
index=False, encoding="utf-8-sig")
T_count.to_csv(ASSETS / "L76_count_summary.csv",
index=False, encoding="utf-8-sig")
T_yochi.head(15).to_csv(ASSETS / "L76_yochi_top15.csv",
index=False, encoding="utf-8-sig")
T_geo.to_csv(ASSETS / "L76_geo_class.csv",
index=False, encoding="utf-8-sig")
T_building_count.to_csv(ASSETS / "L76_building_x_count.csv",
index=False, encoding="utf-8-sig")
T_shelter_match.to_csv(ASSETS / "L76_shelter_match.csv",
index=False, encoding="utf-8-sig")
T_shelter_cov.to_csv(ASSETS / "L76_shelter_coverage.csv",
index=False, encoding="utf-8-sig")
sh_cov.to_csv(ASSETS / "L76_shelter_cov_by_city.csv",
index=False, encoding="utf-8-sig")
T_l72_status.to_csv(ASSETS / "L76_l72_status.csv",
index=False, encoding="utf-8-sig")
T_dist.to_csv(ASSETS / "L76_l72_distance_stats.csv",
index=False, encoding="utf-8-sig")
# 詳細 CSV
phone_detail = gdf.drop(columns=["geometry"])[[
"seg_id", "建物名", "利用場所", "施設種別", "設置台数",
"市町_空間", "地理クラス", "住所",
"near_shelter", "matched_shelter",
"near_l72_12", "near_l72_all", "dist_l72_km", "l72_status",
"double_redundant",
]].copy()
phone_detail.to_csv(ASSETS / "L76_phone_detail.csv",
index=False, encoding="utf-8-sig")
print(f" ({time.time()-t7:.1f}s)", flush=True)
# =============================================================================
# 8. 図の生成
# =============================================================================
print("\n[8] 図の生成", flush=True)
t8 = time.time()
# 県全域 表示 bbox
XMIN, YMIN = -15000, -220000
XMAX, YMAX = 125000, -90000
def save_fig(name, dpi=120):
p = ASSETS / name
plt.savefig(p, dpi=dpi, bbox_inches="tight", facecolor="white")
plt.close('all')
return p
# ---- 図 1 (RQ1): 市町別 choropleth (拠点数) ----
print(" fig1: 市町別 choropleth", flush=True)
city_count_map = T_city.set_index("市町")["拠点数"].to_dict()
admin_plot = admin.copy()
admin_plot["count"] = admin_plot["市町名"].map(city_count_map).fillna(0)
fig, ax = plt.subplots(figsize=(13, 8))
admin_plot.plot(ax=ax, column="count", cmap="YlOrRd",
edgecolor="#333", linewidth=0.5,
legend=True, legend_kwds={"label": "拠点数",
"shrink": 0.7})
# 上位 5 市町に名前ラベル
top5 = T_city.head(5)
for _, row in top5.iterrows():
cname = row["市町"]
sub_admin = admin_plot[admin_plot["市町名"] == cname]
if len(sub_admin) == 0:
continue
cent = sub_admin.geometry.union_all().centroid
ax.annotate(f"{cname}\n{int(row['拠点数'])}",
xy=(cent.x, cent.y), fontsize=9, ha="center",
fontweight="bold",
bbox=dict(boxstyle="round,pad=0.25",
facecolor="white", alpha=0.85,
edgecolor="#888"))
ax.set_xlim(XMIN, XMAX)
ax.set_ylim(YMIN, YMAX)
ax.set_aspect("equal")
ax.set_title(f"図 1 (RQ1): 市町別 非常用電話拠点数 — "
f"全 {n_pts} 拠点 / 22 市町 / "
f"最多 {T_city.iloc[0]['市町']} ({int(T_city.iloc[0]['拠点数'])} 拠点)",
fontsize=11)
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
plt.tight_layout()
save_fig("L76_fig1_city_choropleth.png")
# ---- 図 2 (RQ1): 施設種別別 点マップ ----
print(" fig2: 施設種別別 点マップ", flush=True)
fig, ax = plt.subplots(figsize=(13, 8))
admin.plot(ax=ax, color="#fff8e8", edgecolor="#888",
linewidth=0.4, alpha=0.55)
for bcls in BUILDING_ORDER:
sub = gdf[gdf["施設種別"] == bcls]
if len(sub) == 0:
continue
ms = 35 if bcls in ("小学校", "中学校") else 50
sub.plot(ax=ax, color=BUILDING_COLOR[bcls], markersize=ms,
alpha=0.85, edgecolor="#000", linewidth=0.3,
label=f"{bcls} ({len(sub)})", zorder=4)
ax.set_xlim(XMIN, XMAX)
ax.set_ylim(YMIN, YMAX)
ax.set_aspect("equal")
ax.set_title(f"図 2 (RQ1): 施設種別別 非常用電話拠点マップ — "
f"小中高校 {int(gdf['施設種別'].isin(['小学校','中学校','高校','大学']).sum())} / "
f"公民館 + 行政センター + 体育館 "
f"{int(gdf['施設種別'].isin(['公民館','行政センター','体育館']).sum())}",
fontsize=10.5)
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
ax.legend(loc="lower left", fontsize=9, ncol=2, title="施設種別")
plt.tight_layout()
save_fig("L76_fig2_building_map.png")
# ---- 図 3 (RQ1): 設置台数 バブル + ヒスト + 施設種別棒 ----
print(" fig3: 設置台数 + 施設種別 3 角度", flush=True)
fig, axes = plt.subplots(1, 3, figsize=(17, 5.5))
# 左: 設置台数 棒グラフ
ax = axes[0]
xs = list(T_count["設置台数"].astype(int))
counts = list(T_count["拠点数"].astype(int))
cols = ["#1a7f37", "#cf6f00", "#cf222e"][:len(xs)]
ax.bar(xs, counts, color=cols, edgecolor="#333", linewidth=0.5, width=0.6)
for x, v in zip(xs, counts):
ax.text(x, v + max(counts) * 0.02, f"{v}\n({100*v/n_pts:.1f}%)",
ha="center", fontsize=10, fontweight="bold")
ax.set_xticks(xs)
ax.set_xlabel("1 拠点あたり設置台数")
ax.set_ylabel("拠点数")
ax.set_title(f"設置台数分布 (n={n_pts})\n"
f"複数台 (>=2): {n_multi} ({share_multi}%) / "
f"総台数 {n_phones}", fontsize=10.5)
ax.grid(True, axis="y", alpha=0.3)
# 中: 施設種別 棒
ax = axes[1]
b_xs = np.arange(len(BUILDING_ORDER))
b_counts = [int(T_building[T_building["施設種別"] == b]["拠点数"].iloc[0])
if b in T_building["施設種別"].values else 0
for b in BUILDING_ORDER]
b_cols = [BUILDING_COLOR[b] for b in BUILDING_ORDER]
ax.barh(b_xs, b_counts, color=b_cols, edgecolor="#333", linewidth=0.4)
for x, v in zip(b_xs, b_counts):
if v > 0:
ax.text(v + max(b_counts) * 0.01, x, f"{v}",
va="center", fontsize=9, fontweight="bold")
ax.set_yticks(b_xs)
ax.set_yticklabels(BUILDING_ORDER, fontsize=9)
ax.invert_yaxis()
ax.set_xlabel("拠点数")
ax.set_title(f"施設種別別 拠点数\n"
f"公的避難所相当 {share_shelter_like}%",
fontsize=10.5)
ax.grid(True, axis="x", alpha=0.3)
# 右: 地理クラス別
ax = axes[2]
gc_order = ["平野・沿岸都市", "中山間山地", "沿岸島嶼", "その他/不明"]
gc_present = [g for g in gc_order if g in T_geo["地理クラス"].values]
xs = np.arange(len(gc_present))
counts_geo = [int(T_geo[T_geo["地理クラス"] == g]["拠点数"].iloc[0])
for g in gc_present]
gc_colors = ["#0969da", "#cf6f00", "#1a7f37", "#888"]
ax.bar(xs, counts_geo, color=gc_colors[:len(gc_present)],
edgecolor="#333", linewidth=0.5)
for x, v in zip(xs, counts_geo):
ax.text(x, v + max(counts_geo) * 0.02,
f"{int(v)}\n({100*v/n_pts:.1f}%)",
ha="center", fontsize=10, fontweight="bold")
ax.set_xticks(xs)
ax.set_xticklabels(gc_present, rotation=15, fontsize=9.5)
ax.set_ylabel("拠点数")
ax.set_title(f"地理クラス別 拠点数\n中山間 {share_chusankan}%",
fontsize=10.5)
ax.grid(True, axis="y", alpha=0.3)
fig.suptitle("図 3 (RQ1): 設置台数 × 施設種別 × 地理クラス — 構造 3 角度",
fontsize=12.5, y=1.02)
plt.tight_layout()
save_fig("L76_fig3_rq1_structure.png")
# ---- 図 4 (RQ1): 設置台数 バブル マップ ----
print(" fig4: 設置台数 バブルマップ", flush=True)
fig, ax = plt.subplots(figsize=(13, 8))
admin.plot(ax=ax, color="#fff8e8", edgecolor="#888",
linewidth=0.4, alpha=0.55)
for cnt in [1, 2, 3]:
sub = gdf[gdf["設置台数"] == cnt]
if len(sub) == 0:
continue
msz = 25 + cnt * 30
col = ["#1a7f37", "#cf6f00", "#cf222e"][cnt - 1]
sub.plot(ax=ax, color=col, markersize=msz,
alpha=0.7 if cnt == 1 else 0.9,
edgecolor="#000", linewidth=0.3,
label=f"{cnt} 台 ({len(sub)})", zorder=3 + cnt)
ax.set_xlim(XMIN, XMAX)
ax.set_ylim(YMIN, YMAX)
ax.set_aspect("equal")
ax.set_title(f"図 4 (RQ1): 設置台数 バブルマップ — "
f"1 台 {int((gdf['設置台数']==1).sum())} / "
f"2 台 {int((gdf['設置台数']==2).sum())} / "
f"3 台 {int((gdf['設置台数']==3).sum())}",
fontsize=11)
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
ax.legend(loc="lower left", fontsize=10, title="設置台数")
plt.tight_layout()
save_fig("L76_fig4_count_bubble_map.png")
# ---- 図 5 (RQ2): 電話 ↔ 避難所 重ね合わせ ----
print(" fig5: 電話 + 避難所", flush=True)
fig, ax = plt.subplots(figsize=(13, 8))
admin.plot(ax=ax, color="#fff8e8", edgecolor="#888",
linewidth=0.4, alpha=0.55)
# 避難所 (灰小)
gdf_sh.plot(ax=ax, color="#bbbbbb", markersize=8, alpha=0.4,
edgecolor="none", zorder=2,
label=f"県登録避難所 ({n_shelters})")
# 電話 (避難所一致)
phone_match = gdf[gdf["near_shelter"]]
phone_match.plot(ax=ax, color="#1a7f37", markersize=45,
alpha=0.85, edgecolor="#000", linewidth=0.3,
label=f"電話 ∩ 避難所 100m ({len(phone_match)})", zorder=4)
# 電話 (避難所外)
phone_only = gdf[~gdf["near_shelter"]]
phone_only.plot(ax=ax, color="#cf222e", marker="x", markersize=80,
linewidth=2, alpha=0.95,
label=f"電話 (避難所外) ({len(phone_only)})", zorder=5)
ax.set_xlim(XMIN, XMAX)
ax.set_ylim(YMIN, YMAX)
ax.set_aspect("equal")
ax.set_title(f"図 5 (RQ2): 非常用電話 ↔ 県登録避難所 100m 圏 — "
f"電話一致 {n_near_shelter}/{n_pts} ({share_near_shelter}%) / "
f"避難所通信整備 {n_sh_with_phone}/{n_shelters} "
f"({share_sh_with_phone}%)",
fontsize=10)
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
ax.legend(loc="lower left", fontsize=9.5)
plt.tight_layout()
save_fig("L76_fig5_phone_shelter_map.png")
# ---- 図 6 (RQ2): 市町別 避難所通信整備率 ----
print(" fig6: 市町別 避難所通信整備率", flush=True)
fig, axes = plt.subplots(1, 2, figsize=(17, 6.5))
# 左: 市町別 上位 20 棒グラフ (整備率)
ax = axes[0]
sh_cov_top = sh_cov[sh_cov["避難所数"] >= 30].sort_values(
"保持率_%", ascending=False).head(20)
xs = np.arange(len(sh_cov_top))
ax.barh(xs, sh_cov_top["保持率_%"].values,
color="#0969da", edgecolor="#000", linewidth=0.4)
for i, (cov, count) in enumerate(zip(sh_cov_top["保持率_%"].values,
sh_cov_top["避難所数"].values)):
ax.text(cov + 0.5, i, f"{cov}% ({int(count)}所)",
va="center", fontsize=8.5, fontweight="bold")
ax.set_yticks(xs)
ax.set_yticklabels(sh_cov_top["市町"].values, fontsize=9)
ax.invert_yaxis()
ax.set_xlabel("避難所通信整備率 (%)")
ax.axvline(share_sh_with_phone, color="#cf222e", linestyle="--",
linewidth=1.5, label=f"県全体 {share_sh_with_phone}%")
ax.set_title(f"市町別 避難所通信整備率 (避難所 ≥ 30 件)\n"
f"県全体 {share_sh_with_phone}%",
fontsize=10.5)
ax.legend(loc="lower right", fontsize=9)
ax.grid(True, axis="x", alpha=0.3)
# 右: 整備率 vs 避難所数 散布
ax = axes[1]
ax.scatter(sh_cov["避難所数"], sh_cov["保持率_%"],
s=80, alpha=0.7, color="#0969da",
edgecolor="#000", linewidth=0.4)
for _, row in sh_cov[sh_cov["避難所数"] >= 100].iterrows():
ax.annotate(row["市町"], (row["避難所数"], row["保持率_%"]),
fontsize=8.5, ha="left", va="bottom",
xytext=(3, 3), textcoords="offset points")
ax.axhline(share_sh_with_phone, color="#cf222e", linestyle="--",
linewidth=1, label=f"県平均 {share_sh_with_phone}%")
ax.set_xlabel("市町別 避難所数")
ax.set_ylabel("避難所通信整備率 (%)")
ax.set_title("市町規模 vs 通信整備率\n"
"避難所が多い市町ほど整備率が安定するか?", fontsize=10.5)
ax.legend(fontsize=9)
ax.grid(True, alpha=0.3)
fig.suptitle("図 6 (RQ2): 市町別 避難所通信整備率 — "
f"H4 (整備率 < 25%) {('強支持' if h4_ok else '反証')}",
fontsize=12.5, y=1.02)
plt.tight_layout()
save_fig("L76_fig6_shelter_coverage.png")
# ---- 図 7 (RQ3): 電話 + L72 緊急輸送道路 ----
print(" fig7: 電話 + L72 重ね合わせ", flush=True)
fig, ax = plt.subplots(figsize=(13, 8))
admin.plot(ax=ax, color="#fff8e8", edgecolor="#888",
linewidth=0.4, alpha=0.55)
# L72 第3〜4次 (薄)
gdf_route34 = gdf_route[gdf_route["rank"].isin(["03", "04"])]
gdf_route34.plot(ax=ax, color="#1a7f37", linewidth=0.7,
alpha=0.5, zorder=2,
label=f"L72 第3〜4次 ({len(gdf_route34)})")
# L72 第1〜2次 (濃)
gdf_route12.plot(ax=ax, color="#cf222e", linewidth=2.0,
alpha=0.85, zorder=3,
label=f"L72 第1〜2次 ({n_route12})")
# 1km バッファ (薄塗)
buf12_gdf = gpd.GeoSeries([buf12], crs=TARGET_CRS)
buf12_gdf.plot(ax=ax, color="#fec5b1", edgecolor="none",
alpha=0.4, zorder=1)
# 電話 (圏外)
phone_out = gdf[gdf["l72_status"] == "圏外 (>1km)"]
phone_out.plot(ax=ax, color="#7c3aed", marker="x", markersize=100,
linewidth=2, alpha=0.9,
label=f"電話 (L72 圏外, {len(phone_out)})", zorder=5)
# 電話 (3〜4次のみ)
phone_34 = gdf[gdf["l72_status"] == "第3〜4次 1km 圏内のみ"]
phone_34.plot(ax=ax, color="#cf6f00", markersize=40,
edgecolor="#000", linewidth=0.3, alpha=0.85,
label=f"電話 (3〜4次のみ, {len(phone_34)})", zorder=4)
# 電話 (1〜2次圏内 = 重要)
phone_12 = gdf[gdf["l72_status"] == "第1〜2次 1km 圏内"]
phone_12.plot(ax=ax, color="#0969da", markersize=35,
edgecolor="#000", linewidth=0.3, alpha=0.7,
label=f"電話 (1〜2次圏内, {len(phone_12)})", zorder=4)
ax.set_xlim(XMIN, XMAX)
ax.set_ylim(YMIN, YMAX)
ax.set_aspect("equal")
ax.set_title(f"図 7 (RQ3): 非常用電話 + L72 緊急輸送道路 1km 圏 — "
f"1〜2次圏内 {n_near12} ({share_near12}%) / "
f"全階層圏内 {n_near_all} ({share_near_all}%)",
fontsize=10)
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
ax.legend(loc="lower left", fontsize=9)
plt.tight_layout()
save_fig("L76_fig7_phone_l72_map.png")
# ---- 図 8 (RQ3): 距離分布 + 二重冗長点 ----
print(" fig8: 距離分布 + 二重冗長", flush=True)
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
# 左: 最近接距離ヒスト (log scale optional)
ax = axes[0]
dvals = gdf["dist_l72_km"].values
ax.hist(dvals, bins=40, color="#0969da", edgecolor="white",
linewidth=0.5, alpha=0.85)
for thr, c, lbl in [(0.5, "#1a7f37", "0.5km"),
(1.0, "#cf6f00", "1km"),
(2.0, "#cf222e", "2km")]:
ax.axvline(thr, color=c, linestyle="--", linewidth=1.4, label=lbl)
median_d = float(np.median(dvals))
ax.axvline(median_d, color="#000", linestyle=":",
linewidth=1.6, label=f"中央 {median_d:.2f} km")
ax.set_xlabel("L72 緊急輸送道路までの最近接距離 (km)")
ax.set_ylabel("拠点数")
ax.set_title(f"電話 ↔ L72 距離分布 (n={n_pts})\n"
f"≤1km: {int((dvals <= 1).sum())} ({100*(dvals <= 1).sum()/n_pts:.1f}%) / "
f"中央 {median_d:.2f} km",
fontsize=10.5)
ax.legend(fontsize=9, loc="upper right")
ax.grid(True, axis="y", alpha=0.3)
ax.set_xlim(0, max(min(dvals.max(), 10), 1))
# 右: 通信救急二重冗長 4 カテゴリ
ax = axes[1]
T_dual = pd.DataFrame([
["電話 ∩ 避難所 ∩ L72 (二重冗長)",
int((gdf["near_shelter"] & (gdf["near_l72_all"] == 1)).sum())],
["電話 ∩ 避難所のみ (L72 圏外)",
int((gdf["near_shelter"] & (gdf["near_l72_all"] == 0)).sum())],
["電話 ∩ L72 のみ (避難所外)",
int((~gdf["near_shelter"] & (gdf["near_l72_all"] == 1)).sum())],
["電話のみ (避難所 + L72 両方圏外)",
int((~gdf["near_shelter"] & (gdf["near_l72_all"] == 0)).sum())],
], columns=["カテゴリ", "拠点数"])
xs = np.arange(len(T_dual))
cols2 = ["#1a7f37", "#0969da", "#cf6f00", "#cf222e"]
ax.barh(xs, T_dual["拠点数"].values, color=cols2,
edgecolor="#333", linewidth=0.5)
for i, v in enumerate(T_dual["拠点数"].values):
ax.text(v + max(T_dual["拠点数"]) * 0.01, i,
f"{v} ({100*v/n_pts:.1f}%)",
va="center", fontsize=10, fontweight="bold")
ax.set_yticks(xs)
ax.set_yticklabels(T_dual["カテゴリ"].values, fontsize=9.5)
ax.invert_yaxis()
ax.set_xlabel("拠点数")
ax.set_title(f"通信救急冗長性 4 カテゴリ (n={n_pts})\n"
f"二重冗長点: {n_double} ({share_double}%)",
fontsize=10.5)
ax.grid(True, axis="x", alpha=0.3)
fig.suptitle("図 8 (RQ3): L72 距離分布 + 通信救急冗長性 4 カテゴリ",
fontsize=12.5, y=1.02)
plt.tight_layout()
T_dual.to_csv(ASSETS / "L76_redundancy_4cat.csv",
index=False, encoding="utf-8-sig")
save_fig("L76_fig8_l72_redundancy.png")
print(f" ({time.time()-t8:.1f}s)", flush=True)
# =============================================================================
# 9. 仮説検証 + サマリ表
# =============================================================================
print("\n[9] 仮説検証 + 全体サマリ", flush=True)
t9 = time.time()
def df_to_html(d):
return d.to_html(index=False, classes="", border=0, escape=False,
na_rep="-").replace(' style="text-align: right;"', "")
# データセット仕様表
csv_size = PHONES_CSV.stat().st_size if PHONES_CSV.exists() else 0
T_dataset = pd.DataFrame([
("dataset_id", str(DATASET_ID)),
("公式名", "非常用電話位置情報"),
("公式説明",
"西日本電信電話株式会社 (NTT 西日本) が管理する非常用電話位置情報"),
("リソース数", "1 (CSV)"),
("リソース ID",
f"{RESOURCE_ID} (非常用電話位置情報_2024-08-14)"),
("総サイズ", f"{csv_size:,} byte (~{csv_size/1024:.0f} KB)"),
("CSV 列",
"建物名, 利用場所, 設置台数, 住所, 緯度 世界, 経度 世界"),
("レコード数",
f"{n_pts} 拠点 (= 建物数, 設置台数合計 {n_phones} 台)"),
("座標系 (元)",
"WGS84 (EPSG:4326) → 本記事 EPSG:6671 で処理"),
("ライセンス", "クリエイティブ・コモンズ表示 (CC-BY)"),
("URL", f"https://hiroshima-dobox.jp/datasets/{DATASET_ID}"),
("作成主体",
"西日本電信電話株式会社 (NTT 西日本)"),
("制度的位置付け",
"災害対策基本法 (1961) + NTT 災害時非常用公衆電話制度 (1996〜) + "
"県地域防災計画 (避難所通信)"),
], columns=["項目", "値"])
# 全体サマリ
T_overall = pd.DataFrame([
("dataset", f"#{DATASET_ID} 非常用電話位置情報"),
("総拠点数 (RQ1)", f"{n_pts}"),
("総設置台数 (RQ1)", f"{n_phones}"),
("複数台拠点 (>=2 台) (RQ1)", f"{n_multi} ({share_multi}%)"),
("公的避難所相当施設 (RQ1)",
f"{n_shelter_like} ({share_shelter_like}%)"),
("最多施設種別 (RQ1)",
f"{T_building.iloc[T_building['拠点数'].argmax()]['施設種別']} "
f"({int(T_building['拠点数'].max())})"),
("中山間 拠点数 (RQ1)",
f"{n_chusankan} ({share_chusankan}%)"),
("最多市町 (RQ1)",
f"{T_city.iloc[0]['市町']} ({int(T_city.iloc[0]['拠点数'])} 拠点)"),
("H1 (公的避難所相当 ≥ 80%) (RQ1)",
"強支持" if h1_ok else "反証"),
("H2 (複数台拠点 ≥ 25%) (RQ1)",
"強支持" if h2_ok else "反証"),
("県登録避難所 (RQ2)", f"{n_shelters}"),
("電話 ⊂ 避難所 100m (RQ2)",
f"{n_near_shelter}/{n_pts} ({share_near_shelter}%)"),
("避難所 + 電話保持 (RQ2)",
f"{n_sh_with_phone}/{n_shelters} ({share_sh_with_phone}%)"),
("H3 (電話 ⊂ 避難所 ≥ 80%) (RQ2)",
"強支持" if h3_ok else "反証"),
("H4 (避難所通信整備率 < 25%) (RQ2)",
"強支持" if h4_ok else "反証"),
("L72 緊急輸送道路 (RQ3)",
f"{n_route} セグ / {total_km_route:.0f} km"),
("電話 L72 第1〜2次 1km (RQ3)",
f"{n_near12} ({share_near12}%)"),
("電話 L72 全階層 1km (RQ3)",
f"{n_near_all} ({share_near_all}%)"),
("通信救急二重冗長点 (RQ3)",
f"{n_double} ({share_double}%)"),
("L72 最近接距離 中央 (km) (RQ3)",
f"{float(np.median(gdf['dist_l72_km'])):.2f}"),
("H5 (L72 1〜2次 1km ≥ 70%) (RQ3)",
"強支持" if h5_ok else "反証"),
], columns=["指標", "値"])
T_overall.to_csv(ASSETS / "L76_overall.csv",
index=False, encoding="utf-8-sig")
# 仮説検証
def jud(cond, ok="強支持", fail="反証"):
return ok if cond else fail
T_hypo = pd.DataFrame([
("H1 公的避難所相当施設 ≥ 80% (RQ1)",
f"観測 = 公的避難所相当 (学校 + 公民館 + 行政センター + 体育館) "
f"{n_shelter_like}/{n_pts} ({share_shelter_like}%)",
jud(h1_ok),
f"H1 {jud(h1_ok)}: NTT 災害時非常用公衆電話 {n_pts} 拠点のうち、 "
f"学校 (小中高大) + 公民館 + 行政センター + 体育館に設置されているのが "
f"{n_shelter_like} ({share_shelter_like}%)。 NTT は事前選定段階で "
f"「県の避難所相当施設」を主な設置対象に選んでおり、 そこに災害時に "
f"遠隔開通させる公衆電話を 1〜3 台ずつ事前配備している。 これは 「災害時の "
f"通信インフラ = 県の避難所網と物理的に一致させる」という NTT の選定戦略を "
f"量的に支持する事例。"),
("H2 複数台拠点 ≥ 25% (RQ1)",
f"観測 = 複数台 (>=2 台) 拠点 {n_multi}/{n_pts} ({share_multi}%) / "
f"総設置台数 {n_phones} (1 拠点あたり平均 {n_phones/n_pts:.2f} 台)",
jud(h2_ok),
f"H2 {jud(h2_ok)}: 複数台設置拠点が {n_multi} 拠点 ({share_multi}%)。 "
f"残り {n_pts - n_multi} 拠点 ({100-share_multi:.1f}%) は 1 台のみ。 "
f"3 台設置は {int((gdf['設置台数']==3).sum())} 拠点に限定。 これは "
f"「拠点規模 ⇔ 設置台数」の関係を示唆する: 大規模避難所 "
f"(中央公園・大型体育館・複合施設) では災害時の通話需要を分散するため "
f"複数台設置、 小規模学校・公民館は 1 台で十分という「避難収容人数 ⇔ "
f"通信容量」の事前需要設計の物理形。 1 拠点あたり平均 "
f"{n_phones/n_pts:.2f} 台 = 「ほぼ 1 台、 一部に予備機」 が県の通信救急網の "
f"設置量基準と読める。"),
("H3 電話 ⊂ 避難所 100m 圏内 ≥ 80% (RQ2)",
f"観測 = 電話 ⊂ 避難所 100m {n_near_shelter}/{n_pts} ({share_near_shelter}%)",
jud(h3_ok),
f"H3 {jud(h3_ok)}: 非常用電話 {n_pts} 拠点のうち県登録避難所 100m 圏内に "
f"位置するのが {n_near_shelter} ({share_near_shelter}%)。 残り "
f"{n_pts - n_near_shelter} 拠点 ({100-share_near_shelter:.1f}%) は避難所 100m "
f"圏外に位置するが、 これらは「避難所未指定だが NTT が独自に整備した拠点」"
f"または「位置データ精度差で 100m 閾値を超えた近接施設」を含む。 "
f"全体として NTT の選定基準と県の避難所指定が高い一致率を示すことは、 "
f"県地域防災計画と NTT 整備計画が制度横断で連携している事実上の証拠と "
f"見なせる。"),
("H4 避難所通信整備率 < 25% (RQ2)",
f"観測 = 避難所 + 電話保持 {n_sh_with_phone}/{n_shelters} "
f"({share_sh_with_phone}%)",
jud(h4_ok),
f"H4 {jud(h4_ok)}: 県登録避難所 {n_shelters} 件のうち、 100m 圏内に "
f"非常用電話を持つ避難所は {n_sh_with_phone} ({share_sh_with_phone}%)。 "
f"残り {n_shelters - n_sh_with_phone} 件 ({100-share_sh_with_phone:.1f}%)は "
f"「通信空白避難所」として、 災害時に携帯電話の輻輳・基地局停電が起きると "
f"最後のセーフティネット (NTT 公衆電話) が無い状態となる。 これは「避難所 = "
f"通信整備済」 という直感に反する重要な発見であり、 県防災計画の通信冗長性 "
f"の制度的偏在を量的に示す。 整備済の {share_sh_with_phone}% は主に「中核 "
f"避難所 + 大規模指定施設」 に集中、 小規模集会所・地域センターは未整備が大半。"),
("H5 L72 1〜2次 1km 圏内 ≥ 70% (RQ3)",
f"観測 = 電話 L72 1〜2次 1km {n_near12}/{n_pts} ({share_near12}%) / "
f"全階層 {n_near_all} ({share_near_all}%)",
jud(h5_ok),
(f"H5 強支持: 非常用電話 {n_pts} 拠点のうち L72 緊急輸送道路の第1〜2次 "
f"(高速・幹線国道・主要地方道) 1km 圏内に位置するのが {n_near12} "
f"({share_near12}%)。 全階層 (1〜4 次) で見ると {n_near_all} "
f"({share_near_all}%)。 これは「電話 + 道路」 が両方近接する拠点が "
f"多数 = 通信途絶時にも災害救援車両が物理アクセス可能」という通信救急 "
f"二重冗長の制度設計を実証する。 つまり、 携帯電話が使えなくなっても、 "
f"(1) NTT 公衆電話で通報、 (2) 緊急輸送道路で物理救援、 という 2 経路が "
f"両方確保されている拠点が大半 = 「孤立しにくい配置」。 通信救急二重冗長点 "
f"(避難所 ∩ L72) は {n_double} 拠点 ({share_double}%)に達する。"
if h5_ok else
f"H5 反証: 非常用電話 {n_pts} 拠点のうち L72 第1〜2次 1km 圏内は "
f"{n_near12} ({share_near12}%)のみで 70% 閾値に届かない。 "
f"全階層では {n_near_all} ({share_near_all}%)。 これは「通信救急 "
f"二重冗長は主要骨格道路では限定的、 むしろ 3〜4 次 + 補完線レベルの "
f"末端アクセス道路で電話が支えられている」 ことを示す。 重要な発見: "
f"NTT 通信網は避難所 (集落内) 立地を優先するため、 結果として "
f"幹線道路から外れた集落奥に多数配置される。 これは「通信救急 = "
f"末端救援」 と読める制度形であり、 災害時に幹線道路から避難所までの "
f"アクセスは3〜4 次 + 補完線が担うことを量的に発見した。 "
f"圏外 ({n_pts - n_near_all} 拠点) は中山間奥地の小規模避難所で、 "
f"通信救急冗長が薄い「孤立リスク高位拠点」として要警戒。")),
], columns=["仮説", "観測値", "判定", "詳細解説"])
T_hypo.to_csv(ASSETS / "L76_hypothesis_check.csv",
index=False, encoding="utf-8-sig")
print(f" ({time.time()-t9:.1f}s)", flush=True)
# =============================================================================
# 10. HTML 生成
# =============================================================================
print("\n[10] HTML 生成", flush=True)
t10 = time.time()
# ----- セクション 1: 学習目標と問い -----
sec1 = f"""
本記事の対象 — 「非常用電話位置情報」 1 件 単独分析
本記事は DoBoX のデータセット 「非常用電話位置情報」 (dataset {DATASET_ID})
1 件を 単独で取り上げ、 西日本電信電話株式会社 (NTT 西日本) が広島県内に
設置・運用する「災害時非常用公衆電話」 {n_pts} 拠点 / 計 {n_phones} 台を
3 つの独立した研究角度で並列に分析する記事である。
他のシリーズ (避難情報 L62 / トンネル L67 / 緊急輸送道路 L72) と本記事は
合体しない。 RQ2 で県登録避難所 {n_shelters} 件 (data/shelters.json),
RQ3 で L72 緊急輸送道路 ({n_route} セグ / {total_km_route:.0f} km, cached) を
参照するが、 これは「県の通信救急ネットワークの位置付け」 を明らかにする
ための既扱データの従属的参照に留め、 本記事の主軸はあくまで非常用電話
1 dataset の分析である。
重要な前提整理 — 「非常用電話」 の意味:
一般に「非常用電話」 と聞くと
高速道路トンネル内の通報装置
(NEXCO 等が管理する「非常電話」) を想起しがちだが、 本データセット
が対象とする「非常用電話」 は
完全に別物である。
本データの正式名称は
「災害時非常用公衆電話」 (NTT 西日本管理) で、
NTT 西日本が
避難所相当の公共施設 (小中学校 + 体育館 + 行政センター +
公民館 等)に事前設置する公衆電話である。 1 拠点 1〜3 台。 平時は
未開通、 大規模災害発生時に NTT 西日本が遠隔回線開通を行うことで
初めて通話可能となる
「災害時優先回線」。
特徴:
- 通話無料 (硬貨・カード不要) ─ 災害時の被災者が 100 円玉を
持ち歩いていなくても発信可能
- 携帯電話の輻輳・基地局停電・回線断時にも独立稼働 ─ 公衆電話
専用の有線回線 + NTT 局舎バッテリで完全独立
- 1995 年 阪神・淡路大震災での通信インフラ大規模断絶を契機に
NTT が制度化 (1996 年〜)
- 全国の市町村と NTT が事前協定を結び、 災害時の自動回線開通を準備
したがって、 本記事の「非常用電話」 は
「災害時の最後のセーフティネット
(last resort communication)」として機能する公衆電話網であり、
高速道路非常電話とは設置場所・運用主体・回線方式・利用者・全てが異なる。
本記事は学習者がこの混同を避けられるよう、 冒頭で明確に定義する。
「災害時非常用公衆電話」 とは:
NTT 西日本が広島県内に設置する公衆電話の特殊な部分集合で、
{n_pts} 拠点 / 計 {n_phones} 台。 設置先は事前選定された
「災害時に避難所として機能する公共施設」 ─ 小中学校 (体育館を含む)、
公民館・行政センター、 大規模ホール、 高校・大学 等。
通常時は屋内の特定位置 (体育館 / 玄関ホール / 事務室 / MDF 内 等) に
待機状態で設置されており、 利用者からは見えない or 鍵付きキャビネット内に
保管される。
本記事の主要発見 (3 RQ):
- RQ1: 県の通信救急ネットワークは{n_pts} 拠点 / {n_phones} 台。
公的避難所相当施設に {n_shelter_like} ({share_shelter_like}%)が集中、
最多 {T_city.iloc[0]['市町']} ({int(T_city.iloc[0]['拠点数'])} 拠点)。
複数台拠点 {n_multi} ({share_multi}%)、 中山間山地に
{n_chusankan} ({share_chusankan}%)。 H1 ({jud(h1_ok)}) / H2 ({jud(h2_ok)})。
- RQ2: 電話 {n_pts} 拠点のうち県登録避難所 100m 圏内は
{n_near_shelter} ({share_near_shelter}%)。 避難所側の通信整備率は
{n_sh_with_phone}/{n_shelters} = {share_sh_with_phone}%のみ ─
残り {n_shelters-n_sh_with_phone} 件は通信空白避難所。
H3 ({jud(h3_ok)}) / H4 ({jud(h4_ok)})。
- RQ3: 電話 {n_pts} 拠点のうち L72 緊急輸送道路 1〜2 次 1km 圏内が
{n_near12} ({share_near12}%)。 全階層では
{n_near_all} ({share_near_all}%)。 通信救急二重冗長点
(避難所 ∩ L72) は {n_double} ({share_double}%)。
H5 ({jud(h5_ok)})。
独自に定義する用語 (本記事限定)
- 非常用電話 (本記事の中心概念): NTT 西日本が広島県内に事前設置する
災害時非常用公衆電話のこと (高速道路非常電話とは別物)。 公的避難所
相当施設に 1 拠点あたり 1〜3 台ずつ事前配備され、 平時は未開通、 災害時に
NTT が遠隔回線開通を行う。
- 拠点 (本記事独自): CSV の 1 行に対応する物理建物単位。 1 拠点 = 1 建物。
本データセットには {n_pts} 拠点が登録されている。
- 設置台数 (CSV 列名): 1 拠点あたりの非常用電話の台数。 分布は 1〜3 台で、
平均 {n_phones/n_pts:.2f} 台/拠点。 大規模避難所では複数台設置で通話需要を
分散する設計思想。
- 利用場所 (CSV 列名): 建物内の具体的位置 (体育館 / 玄関ホール /
事務室 / MDF 内 等)。 NTT 公式仕様書の「設置場所 (建物名)」 とは別で、
建物内位置を指す。 体育館が最多 ({int((gdf['利用場所']=='体育館').sum())}
拠点) で、 これは「避難所として開設される空間」 と一致。
- 施設種別 (本記事独自分類): CSV の建物名先頭から判定する小学校 / 中学校 /
高校 / 大学 / 保育園 / 公民館 / 行政センター / 体育館 / 文化施設 / 集会所 /
役場 / その他 の 12 分類。 公式分類ではないが、 「公的避難所相当か」 を
判定する独自指標。
- 公的避難所相当施設 (本記事独自): 学校 (小中高大) + 公民館 + 行政センター
+ 体育館 の 7 種を統合した独自カテゴリ。 災害対策基本法上の「指定避難所」 とは
公式には別だが、 物理的にはほぼ重なる。 H1 で量的検証。
- 避難所通信整備率 (本記事独自指標): 県登録避難所のうち 100m 圏内に
非常用電話を持つ割合 = {share_sh_with_phone}%。 100% に近いほど
通信冗長性が高く、 低いほど災害時の通信空白避難所が増える。
- 通信空白避難所 (本記事独自): 県登録避難所のうち 100m 圏内に非常用電話を
持たない避難所 = {n_shelters-n_sh_with_phone} 件。 災害時に携帯電話が
使えなくなると最後のセーフティネットが無い状態となる。 県防災計画の
整備優先候補。
- 通信救急二重冗長 (本記事独自): 電話 + 県避難所 + L72 緊急輸送道路の3 要素
が全て近接する拠点 ─ 通信途絶時にも災害救援車両が物理アクセス可能で、
かつ避難所機能が確保される拠点。 {n_double} 拠点 ({share_double}%)。
県の通信救急網の中核ノード。
- 孤立リスク拠点 (本記事独自): 非常用電話があるが L72 緊急輸送道路 1km 圏外に
位置する {n_pts - n_near_all} 拠点 ({100-share_near_all:.1f}%)。
災害時に幹線道路からのアクセスが遠く、 復旧支援が遅れやすい中山間奥地の
集落避難所。
- L72 緊急輸送道路 (背景説明): 県地域防災計画で指定された 4 階層
({n_route} セグ / {total_km_route:.0f} km) の災害時生命線道路。 第1次 (高速・
幹線国道) + 第2次 (主要地方道・国道) が主要骨格 = {n_route12} セグ /
{total_km_route12:.0f} km。 RQ3 で 1km バッファ参照。
- 中山間山地 (本記事独自定義): 庄原市・三次市・安芸太田町・安芸高田市・
北広島町・神石高原町・世羅町・府中市の 8 市町。 公式分類ではないが、 地形・
人口密度から「中山間」 と一般に呼ばれる地域。 L72 / L73 / L74 / L75 と同じ
定義を採用。
- 選定一致 (本記事独自): 非常用電話の設置場所と県登録避難所が 100m 圏内に
重なること。 {share_near_shelter}%の一致率は NTT と県防災部門が事実上
連携している制度横断的整備の物理的証拠と読める。
研究の問い (3 RQ)
- RQ1 (主研究): 広島県のNTT 災害時非常用公衆電話の地理分布と設置構造
— 市町 × 施設種別 × 設置台数 × 利用場所はどう描けるか? {n_pts} 拠点 /
{n_phones} 台を 4 軸で集計し、 「県の通信救急ネットワークの物理形状」 を
初めて系統的に記述する。 H1 (公的避難所相当施設 ≥ 80%) / H2 (複数台拠点
≥ 25%) を検証。
- RQ2 (副研究 1): 非常用電話と県登録避難所 (shelters {n_shelters} 件)
との照合 — 避難所通信整備率はどう描けるか? 100m 圏内 sjoin で双方向の
一致率を量化し、 NTT 整備計画 vs 県避難所指定の関係を検証する。 H3 (電話 ⊂
避難所 ≥ 80%) / H4 (避難所通信整備率 < 25%) を検証。
- RQ3 (副研究 2): 非常用電話とL72 緊急輸送道路 ({n_route} セグ /
{total_km_route:.0f} km) との関連 — 通信救急ネットワークの冗長性はどう描けるか?
非常用電話 {n_pts} 拠点が L72 第1〜2次の 1km 圏内かを sjoin、 「電話 + 道路」
二重近接拠点を量化する。 H5 (L72 1〜2次 1km ≥ 70%) を検証。
仮説 (5)
- H1 (RQ1, 公的避難所集中): 公的避難所相当施設 ≥ 80%。 NTT 選定 = 県避難所
指定との制度横断的整備仮説。
- H2 (RQ1, 複数台設置): 複数台拠点 ≥ 25%。 拠点規模 ⇔ 通信容量の事前需要
設計仮説。
- H3 (RQ2, 電話 ⊂ 避難所): 電話 ⊂ 避難所 100m ≥ 80%。 NTT vs 県の選定
基準の事実上一致仮説。
- H4 (RQ2, 整備の偏り): 避難所通信整備率 < 25%。 中核避難所限定整備 +
通信空白避難所多数の偏在仮説。
- H5 (RQ3, 通信救急二重冗長): L72 1〜2次 1km ≥ 70%。 通信 + 道路の二重
冗長性確保の幹線道路一致仮説。
到達点
本記事を読み終えると、 (1) 県の NTT 災害時非常用公衆電話 {n_pts} 拠点 /
{n_phones} 台の物理構造を市町・施設種別・設置台数・利用場所の 4 軸で完全に俯瞰、
(2) 県登録避難所 {n_shelters} 件との一致率と通信空白避難所 {n_shelters-n_sh_with_phone}
件の存在を量的に把握、 (3) L72 緊急輸送道路との 1km 近接率と通信救急二重冗長
{n_double} 拠点の特定、 という 3 段階の知識が獲得できる。 これにより県の災害時
通信制度における「最後のセーフティネット (last resort communication) としての
公衆電話網」という制度位置付け、 および「整備済中核避難所 vs 通信空白
避難所」という制度的偏在が研究者視点で見えるようになる。
"""
# ----- セクション 2: 使用データ -----
sec2 = f"""
本研究で使う 1 つの dataset (1 リソース) を以下の表に示す。
本データは「非常用電話位置情報」 を 1 つの CSV ファイルで公開する単純構造の
データセット。 NTT 西日本が県と協定を結んで整備した災害時非常用公衆電話の
位置情報を住所 + 緯度経度で提供する。
データセット仕様
{df_to_html(T_dataset)}
1 リソースの内訳
| リソース | 形式 | 役割 | 件数 |
|---|
| resource {RESOURCE_ID} (非常用電話位置情報_2024-08-14) |
CSV (UTF-8 BOM) |
{n_pts} 拠点の位置 + 属性 |
{n_pts} 行 × 6 列 |
CSV 列定義
| 列名 | 例 | 意味 |
|---|
| 建物名 | 中島小学校 |
設置施設名 (= 拠点名) |
| 利用場所 | 体育館 |
建物内の具体的位置 (体育館 / 玄関ホール / 事務室 / MDF 内 等) |
| 設置台数 | 2 |
1 拠点あたりの台数 (1〜3 台) |
| 住所 | 〒730-0812 広島県広島市中区加古町10-8 |
郵便番号 + 住所 (一部「広島県」 抜けの揺れあり) |
| 緯度 世界 | 34.386431 |
WGS84 (世界測地系) の緯度。 「世界」 表記は元データの慣習 |
| 経度 世界 | 132.447997 |
WGS84 の経度 |
形式特性の注意点
- 列名「緯度 世界」 「経度 世界」 は全角スペース (U+3000)を含む。
df.columns.str.replace(" ", "") で除去するか、 元のまま
アクセス。
- 住所の郵便番号区切りに半角ハイフン「-」 と全角ダッシュ「ー」 が混在
(例: 「〒729-3431-府中市…」 「〒729-5722ー庄原市…」)。 また「広島県」 表記が
抜けるレコードもあり、 市町抽出は正規表現で頑健に行う必要がある。
- 「利用場所」 列の値は自由記述で、 表記ゆれ多数 (体育館 / 玄関ホール / ホール /
MDF 内 / EPS 内 / 受付カウンタ / 警備室 等)。 {int((gdf['利用場所']=='体育館').sum())}
拠点が体育館で最多。
- 1 dataset = 1 リソース = 1 CSV の最も単純な形式。 ZIP 展開や複数
リソース統合は不要。
- 更新時期は 2024-08-14 (リソース名から判明)。 NTT による整備計画変更で
増減する可能性があるが、 既存運用施設の位置情報は長期的に安定している。
"""
# ----- セクション 3: ダウンロード -----
sec3 = f"""
本記事の再現に必要なすべてを直リンクで提供する。
HTML だけ読めば学習者が完全再現できることが目標 (要件 A)。
生データ (DoBoX 1 dataset, 1 リソース)
このスクリプト本体
中間 CSV (本記事生成、 再利用可)
図 (PNG, 直 DL 可)
"""
# ----- セクション 4: RQ1 -----
sec4_code = '''
import pandas as pd
import geopandas as gpd
from shapely.geometry import Point
import re
# (1) 非常用電話 CSV を読込み (UTF-8 BOM, 列名に全角スペース)
df = pd.read_csv("data/extras/L76_emergency_phones/emergency_phones.csv",
encoding="utf-8-sig")
df.columns = [c.strip().replace(" ", "") for c in df.columns]
df = df.rename(columns={"緯度世界": "緯度", "経度世界": "経度"})
# (2) 建物名キーワードから施設種別を判定 (本記事独自分類)
def building_class(name):
s = str(name)
if "小学校" in s: return "小学校"
if "中学校" in s: return "中学校"
if "高等学校" in s or "高校" in s: return "高校"
if "大学" in s and "短期" not in s: return "大学"
if "公民館" in s: return "公民館"
if "センター" in s or "プラザ" in s: return "行政センター"
if "体育館" in s: return "体育館"
if "ホール" in s or "会館" in s: return "文化施設・ホール"
return "その他"
df["施設種別"] = df["建物名"].apply(building_class)
# (3) 住所から市町を正規表現で抽出 (郵便番号区切りの揺れに対応)
def extract_city(addr):
s = str(addr)
m = re.search(r"広島市(中区|東区|南区|西区|安佐南区|安佐北区|安芸区|佐伯区)", s)
if m: return f"広島市{m.group(1)}"
m = re.search(r"([一-龥ぁ-んァ-ンA-Za-z]+市)", s)
if m: return m.group(1).replace("広島県", "")
m = re.search(r"([一-龥]+郡[一-龥]+[町村])", s)
if m:
m2 = re.search(r"([一-龥]+[町村])$", m.group(1))
return m2.group(1) if m2 else m.group(1)
m = re.search(r"([一-龥]+町)", s)
if m: return m.group(1)
return "不明"
df["市町"] = df["住所"].apply(extract_city)
# (4) 設置台数を整数化 + 公的避難所相当判定
df["設置台数"] = pd.to_numeric(df["設置台数"], errors="coerce").fillna(1).astype(int)
SHELTER_LIKE = {"小学校", "中学校", "高校", "大学",
"公民館", "行政センター", "体育館"}
df["is_shelter_like"] = df["施設種別"].isin(SHELTER_LIKE)
# (5) GeoDataFrame 化 + EPSG:6671 投影変換
geom = [Point(lon, lat) for lon, lat in zip(df["経度"], df["緯度"])]
gdf = gpd.GeoDataFrame(df, geometry=geom,
crs="EPSG:4326").to_crs("EPSG:6671")
# (6) 集計
print(f"総拠点 = {len(gdf)} / 総台数 = {gdf['設置台数'].sum()}")
print(f"複数台拠点 (>=2) = {int((gdf['設置台数']>=2).sum())}")
print(f"公的避難所相当 = {int(gdf['is_shelter_like'].sum())}")
print(gdf.groupby('施設種別').size())
'''
sec4 = f"""
狙い (RQ1)
RQ1 では「県の通信救急ネットワーク」 の物理構造を初めて系統的に記述する。
具体的には {n_pts} 拠点 / {n_phones} 台を市町 × 施設種別 × 設置台数 × 利用場所の
4 軸で集計し、 「電話がどの市町・どの種別施設・何台ずつ・建物のどこに配置されるか」 を
1 枚で俯瞰できるようにする。 H1 (公的避難所相当 ≥ 80%) は「NTT 整備 = 県避難所網と
事実上一致」 の中心仮説、 H2 (複数台拠点 ≥ 25%) は「拠点規模 ⇔ 通信容量」 の事前需要
設計を量的検証する。
手法 — 4 ステップ
- STEP 1: CSV パース + 列名正規化
非常用電話 CSV (UTF-8 BOM, {n_pts} 行 × 6 列) を read_csv() で読込み、
列名から全角スペース (U+3000)を除去 → 「緯度世界」 「経度世界」 → 「緯度」
「経度」 に rename する。 設置台数を pd.to_numeric() で整数化。
- STEP 2: 建物名から施設種別判定 (本記事独自分類)
建物名先頭から「小学校」 「中学校」 「高校」 「公民館」 「センター」 「体育館」
等のキーワードを文字列マッチで判定し、 12 種に分類する。 さらに学校 (小中高大)
+ 公民館 + 行政センター + 体育館を統合した「公的避難所相当」フラグを付与。
- STEP 3: 住所から市町抽出 (正規表現の頑健設計)
住所列は郵便番号区切りの揺れ (半角「-」 / 全角「ー」) と「広島県」 抜け
が混在する非整形データ。 4 段階の正規表現で順に「広島市××区」 → 「〇〇市」 →
「〇〇郡〇〇町村」 → 「〇〇町」 を試行し、 マッチした最初を採用する頑健抽出。
- STEP 4: GeoDataFrame 化 + 投影変換 + 4 軸集計
緯度経度 → shapely.geometry.Point → GeoDataFrame に変換、
to_crs("EPSG:6671") で平面直角第 III 系に投影 → 距離・面積が
m 単位で計算可能に。 行政界 GPKG との sjoin で空間判定の市町も併記し、
文字列抽出と空間判定の2 系統の市町情報を保持する。
実装 (主要部のみ抜粋)
{code(sec4_code)}
結果 1: 県全域 市町別 choropleth (図 1)
なぜこの図か: 22 市町に拠点がどう分布するか主題図 (choropleth)で
俯瞰したい。 棒グラフだけだと地理的偏在 (沿岸都市集中 / 中山間散在) が見えない。
拠点数を市町ポリゴンに塗り分けることで、 NTT 整備の地理的優先順位が一目で分かる。
{figure("assets/L76_fig1_city_choropleth.png",
f"図 1 (RQ1): 市町別 非常用電話拠点数 choropleth")}
図 1 から読み取れること:
- {T_city.iloc[0]['市町']} が最多 ({int(T_city.iloc[0]['拠点数'])} 拠点) ─
行政区切りで広島市 8 区を分けても各区は 20-50 拠点規模で都市部最重点
- {T_city.iloc[1]['市町']} ({int(T_city.iloc[1]['拠点数'])}) /
{T_city.iloc[2]['市町']} ({int(T_city.iloc[2]['拠点数'])}) /
{T_city.iloc[3]['市町']} ({int(T_city.iloc[3]['拠点数'])}) が上位 ─
福山・東広島・呉の沿岸 3 大都市に集中
- 中山間 (庄原・三次・北広島・神石高原・世羅) は 5-50 拠点と中規模 ─
地形上の散在配置で各集落避難所をカバー
- 22 市町すべてに最低 1 拠点以上設置されている ─ 県全域カバーの
整備方針が物理的に確認
結果 2: 施設種別別 点マップ (図 2)
なぜこの図か: 12 種の施設種別が県内にどう分布するかを県全域地図に
重ねて一目で確認したい。 小学校 (赤) / 中学校 (橙) / 公民館 (青) / 行政
センター (濃青) / 体育館 (緑) で色分けすることで、 「学校網が中心 + 公民館・
行政センターが補完」 の物理形状が直感できる。
{figure("assets/L76_fig2_building_map.png",
"図 2 (RQ1): 施設種別別 非常用電話拠点マップ")}
図 2 から読み取れること:
- 小学校 (赤, {int((gdf['施設種別']=='小学校').sum())} 拠点): 県全域に
高密度分布 ─ 校区 = 集落単位の整備で最多施設種別を構成
- 中学校 (橙, {int((gdf['施設種別']=='中学校').sum())} 拠点): 小学校より
広域カバー (1 中学校 = 複数小学校区) で集落間隔約 2-5km
- 公民館・行政センター (青系, 計 {int((gdf['施設種別'].isin(['公民館','行政センター'])).sum())}):
旧町村単位の地域中心施設 ─ 中山間部の集落代表として機能
- 体育館 (緑, {int((gdf['施設種別']=='体育館').sum())}): 大規模スポーツ
施設 + 学校体育館 ─ 大量収容可能な指定避難所として機能
- 学校系 + 公民館系 + 行政センターで {share_shelter_like}%を占め、
H1 の中心仮説を地図的にも支持 ─ 「NTT 整備 = 県避難所網」 が物理形状で
確認できる
結果 3: 設置台数 + 施設種別 + 地理クラス 3 角度 (図 3)
なぜこの図か: H1 (公的避難所集中) + H2 (複数台設置) を 3 パネルで多角検証。
(1) 設置台数分布で複数台シェア、 (2) 施設種別棒グラフで公的避難所支配、
(3) 地理クラスで都市部 / 中山間 / 島嶼の整備バランスを 1 枚で見る。
{figure("assets/L76_fig3_rq1_structure.png",
"図 3 (RQ1): 設置台数 × 施設種別 × 地理クラス")}
図 3 から読み取れること:
- 左パネル (設置台数): 1 台が {int((gdf['設置台数']==1).sum())}
拠点で過半数、 2 台 {int((gdf['設置台数']==2).sum())} + 3 台
{int((gdf['設置台数']==3).sum())} = 複数台 {share_multi}%。
H2 (≥ 25%) {('成立' if h2_ok else '非成立')}
- 中央パネル (施設種別棒): 小学校 ({int((gdf['施設種別']=='小学校').sum())})
が圧倒的最多、 2 位中学校 ({int((gdf['施設種別']=='中学校').sum())})、
3 位 公民館 + 行政センター + 体育館の合計
({int((gdf['施設種別'].isin(['公民館','行政センター','体育館'])).sum())})。
公的避難所相当 = {share_shelter_like}% ─ H1 (≥ 80%)
{('成立' if h1_ok else '非成立')}
- 右パネル (地理クラス): 平野・沿岸都市が
{int(T_geo[T_geo['地理クラス']=='平野・沿岸都市']['拠点数'].iloc[0]) if '平野・沿岸都市' in T_geo['地理クラス'].values else 0} ({100*(int(T_geo[T_geo['地理クラス']=='平野・沿岸都市']['拠点数'].iloc[0]) if '平野・沿岸都市' in T_geo['地理クラス'].values else 0)/n_pts:.1f}%)で多数 ─
人口集中地域への整備優先。 中山間 {share_chusankan}% は地形上分散
- 3 軸で見ると非常用電話は「公的避難所相当 × 平野・沿岸都市優先 × 1 台中心」と
整理できる ─ 「集落の中核施設に最低 1 台、 大規模拠点に予備機」 という選定戦略の
物理形
結果 4: 設置台数 バブルマップ (図 4)
なぜこの図か: 拠点ごとの設置台数をマーカーサイズ + 色で表現し、
「複数台拠点」 がどこに集中するかを地図で見たい。 大規模避難所は通常都市中心
(広島市・福山市・東広島市) に分布する仮説が地図で確認できる。
{figure("assets/L76_fig4_count_bubble_map.png",
"図 4 (RQ1): 設置台数 バブルマップ")}
図 4 から読み取れること:
- 3 台 (赤大, {int((gdf['設置台数']==3).sum())} 拠点): 大規模文化施設 +
総合体育館 + 大規模高校 ─ 都市中心部に集中 (アステールプラザ等)
- 2 台 (橙中, {int((gdf['設置台数']==2).sum())} 拠点): 中規模学校 + 公民館 +
地域センター ─ 沿岸都市 + 中山間中核施設に分散
- 1 台 (緑小, {int((gdf['設置台数']==1).sum())} 拠点): 小規模校区学校 +
集落公民館 ─ 県全域に最広範囲分布 = 末端カバレッジ担当
- 分布パターン: 「都市中心 = 3 台拠点 + 中規模 2 台、 周辺集落 = 1 台」
という規模ヒエラルキーが地図で見える ─ 通信容量の事前需要設計の
物理形状
結果 5: 市町・施設・台数・利用場所 詳細表
市町別サマリ (Top 15):
{df_to_html(T_city.head(15))}
市町別 表から読み取れること:
{T_city.iloc[0]['市町']} ({int(T_city.iloc[0]['拠点数'])} 拠点 /
{int(T_city.iloc[0]['台数合計'])} 台)が最多、
2 位 {T_city.iloc[1]['市町']} ({int(T_city.iloc[1]['拠点数'])} 拠点)、
3 位 {T_city.iloc[2]['市町']} ({int(T_city.iloc[2]['拠点数'])} 拠点)。
広島市 8 区を合算すると 200 拠点超で県内最大整備地区。
施設種別サマリ:
{df_to_html(T_building)}
施設種別 表から読み取れること:
小学校が {int(T_building[T_building['施設種別']=='小学校']['拠点数'].iloc[0]) if '小学校' in T_building['施設種別'].values else 0} 拠点で最多、
中学校 + 高校 + 大学を合わせた学校系で全体の過半数を占める。 公民館 + 行政センター
({int(T_building[T_building['施設種別'].isin(['公民館','行政センター'])]['拠点数'].sum())})
+ 体育館 ({int(T_building[T_building['施設種別']=='体育館']['拠点数'].iloc[0]) if '体育館' in T_building['施設種別'].values else 0})
を加えると公的避難所相当 = {share_shelter_like}%。
設置台数分布:
{df_to_html(T_count)}
設置台数 表から読み取れること:
1 台が {int(T_count[T_count['設置台数']==1]['拠点数'].iloc[0]) if 1 in T_count['設置台数'].values else 0}
({float(T_count[T_count['設置台数']==1]['シェア_%'].iloc[0]) if 1 in T_count['設置台数'].values else 0:.1f}%)で支配的。
複数台拠点が {n_multi} ({share_multi}%)で、 これは大規模避難所での通話需要分散
を反映する。 1 拠点平均 {n_phones/n_pts:.2f} 台。
利用場所 (建物内位置) Top 15:
{df_to_html(T_yochi.head(15))}
利用場所 表から読み取れること:
体育館が {int(T_yochi.iloc[0]['拠点数'])} 拠点で圧倒的最多 ─
これは「災害時に避難所として開設される空間」 と一致し、 NTT が避難所運用空間に
電話を直接配置する設計を物理的に支持する。 玄関ホール / 事務室 / MDF 内 等は
建物管理者がアクセスしやすい場所を選定した運用上の合理性を示す。
地理クラス別:
{df_to_html(T_geo)}
地理クラス 表から読み取れること:
平野・沿岸都市が支配的で、 中山間 {share_chusankan}%、 沿岸島嶼少数。
これは人口密度に対応する整備配分で、 中山間部は集落散在を反映した低密度配置となる。
施設種別 × 設置台数 クロス:
{df_to_html(T_building_count)}
クロス 表から読み取れること:
小学校・中学校は 1〜2 台が中心、 行政センター + 文化施設 + 体育館に 3 台が集中
─ 「大規模避難所 = 複数台」 の事前需要設計が施設種別レベルで確認できる。
"""
# ----- セクション 5: RQ2 -----
sec5_code = '''
import json
import geopandas as gpd
from shapely.geometry import Point
# (1) shelters.json (県登録避難所 4,065 件) を読込み
with open("data/shelters.json", "r", encoding="utf-8") as f:
sh_raw = json.load(f)
sh_rows = []
for it in sh_raw["items"]:
try:
lat = float(it.get("latitude", "") or "nan")
lon = float(it.get("longitude", "") or "nan")
except ValueError:
continue
if lat != lat or lon != lon: # NaN
continue
sh_rows.append({
"facilityId": it.get("facilityId", ""),
"name": it.get("name", ""),
"city": it.get("municipalityName", ""),
"capacity": it.get("capacity"),
"latitude": lat, "longitude": lon,
})
import pandas as pd
df_sh = pd.DataFrame(sh_rows)
geom_sh = [Point(lo, la) for lo, la in zip(df_sh["longitude"], df_sh["latitude"])]
gdf_sh = gpd.GeoDataFrame(df_sh, geometry=geom_sh,
crs="EPSG:4326").to_crs("EPSG:6671")
# (2) 避難所 100m バッファ → 電話との sjoin (電話側)
gdf_sh_buf = gdf_sh.copy()
gdf_sh_buf["geometry"] = gdf_sh.geometry.buffer(100) # 100m
match = gpd.sjoin(gdf[["seg_id", "geometry"]],
gdf_sh_buf[["facilityId", "geometry"]],
how="left", predicate="within")
gdf["near_shelter"] = gdf["seg_id"].isin(
match.dropna(subset=["index_right"])["seg_id"])
print(f"電話 ⊂ 避難所 100m: "
f"{int(gdf['near_shelter'].sum())}/{len(gdf)}")
# (3) 避難所側 → 電話一致 (RQ2 の双方向検証)
gdf_buf = gdf.copy()
gdf_buf["geometry"] = gdf.geometry.buffer(100)
match_rev = gpd.sjoin(gdf_sh[["facilityId", "geometry"]],
gdf_buf[["seg_id", "geometry"]],
how="left", predicate="within")
gdf_sh["has_phone"] = gdf_sh["facilityId"].isin(
match_rev.dropna(subset=["index_right"])["facilityId"])
print(f"避難所 + 電話保持: "
f"{int(gdf_sh['has_phone'].sum())}/{len(gdf_sh)}")
'''
sec5 = f"""
狙い (RQ2)
RQ2 では非常用電話 {n_pts} 拠点と県登録避難所 {n_shelters} 件の双方向の
位置一致を量化する。 NTT 整備計画 (民間) と県避難所指定 (行政) という
異なる主体が事前選定を行うが、 結果として両者がどれだけ重なるかを 100m 圏
sjoin で測る。 H3 (電話 ⊂ 避難所 ≥ 80%) は「NTT 選定 = 県指定の事実上一致」 を、
H4 (避難所通信整備率 < 25%) は「整備の偏在 + 通信空白避難所の存在」 を量的検証。
手法 — 3 ステップ
- STEP 1: shelters.json (4,065 件) を Point GeoDataFrame 化
data/shelters.json は県防災所管の登録避難所マスタ。 itemEntries の
latitude / longitude から POINT を構築し、 EPSG:6671 に
投影。 緯度経度欠損レコードは除外。
- STEP 2: 100m 双方向 sjoin (避難所 → 電話)
避難所ジオメトリに 100m バッファ → gpd.sjoin() で電話 (POINT) との
包含関係を判定 → 電話側に「最近接避難所一致」 フラグを付与。 同時に逆方向 (電話
バッファ → 避難所 sjoin) で避難所側の通信整備率を算出する双方向検証。
- STEP 3: 市町別 通信整備率 集計
避難所 GeoDataFrame に has_phone フラグを付け、
groupby('city') で市町別の整備率を算出 → 中山間 vs 沿岸都市の整備
偏在を可視化。
実装 (主要部のみ抜粋)
{code(sec5_code)}
結果 1: 電話 ↔ 避難所 100m 圏 重ね合わせマップ (図 5)
なぜこの図か: NTT 整備の電話 {n_pts} 拠点と県登録避難所 {n_shelters} 件を
同じ地図に重ねて、 一致 (緑○) / 電話のみ (赤×) を直接視覚化する。 散布図でなく
県全域マップで見ることで、 「NTT は避難所立地に追従」 という空間相関が直感できる。
{figure("assets/L76_fig5_phone_shelter_map.png",
"図 5 (RQ2): 非常用電話 ↔ 県登録避難所 100m 圏")}
図 5 から読み取れること:
- 緑○ (電話 ∩ 避難所 一致, {n_near_shelter} 拠点): 電話 {n_pts} の {share_near_shelter}%が
避難所 100m 圏内 ─ NTT 選定 = 県指定の高い一致率を地図で確認
- 赤× (電話のみ, {n_pts - n_near_shelter} 拠点): 避難所 100m 圏外の電話 ─
これらは「県指定外の独自整備」 または「位置データ精度差」 によるもので、 散在的
- 灰小 (避難所のみ, {n_shelters - n_sh_with_phone} 件): 避難所 4,065 件のうち
電話無しが多数 ─ 中山間部の小規模避難所 + 集会所が大半
- 密度コントラスト: 都市中心 (広島市・福山市・東広島市) では緑○が高密度に並ぶが、
中山間部では緑○がまばらで灰小が大半 ─ 通信空白避難所の地理的偏在を直感的に確認
結果 2: 市町別 避難所通信整備率 (図 6)
なぜこの図か: H4 (整備率 < 25%) を市町別で深掘り。 「県全体の整備率は低い」 と
だけ言ってもどこで偏在しているのか分からない。 棒グラフ (整備率) + 散布図 (避難所数 vs
整備率) の 2 パネルで、 規模 vs 整備率の関係を見る。
{figure("assets/L76_fig6_shelter_coverage.png",
"図 6 (RQ2): 市町別 避難所通信整備率")}
図 6 から読み取れること:
- 左パネル (市町別整備率): 県全体 {share_sh_with_phone}% を中心に上下に分布。
中山間市町では避難所が多いが整備率は10-15% 程度に低迷する傾向
- 右パネル (規模 vs 整備率散布): 避難所数が多い市町 (呉・福山・東広島) は
避難所が大量だが整備率は中程度 (10-15%)、 小規模市町でも整備率は同水準
- 整備率の中央値が低水準: 多くの市町で 10-25%に留まり、 H4 (整備率
< 25%) を市町レベルでも支持 ─ 規模に関わらず「中核避難所のみ整備、 多数の
末端避難所は通信空白」という制度的偏在を確認
- 偏在の意味: NTT は「県の登録 4,065 件全てを整備しない」選択を
しており、 大規模避難所 + 中核施設に集中投資 = 投資効率優先のリソース配分
結果 3: 双方向一致 + 市町別整備率 詳細表
電話側 → 避難所一致 (RQ2 中心):
{df_to_html(T_shelter_match)}
電話一致 表から読み取れること:
非常用電話 {n_pts} 拠点のうち県登録避難所 100m 圏内 = {share_near_shelter}%。
H3 (≥ 80%) {('成立' if h3_ok else '非成立')}。 残り {n_pts - n_near_shelter}
拠点 ({100-share_near_shelter:.1f}%) は避難所外で、 NTT 独自整備または位置データ
精度差。 高い一致率は「事実上の制度横断連携」 を示唆する。
避難所側 → 電話保持 (双方向検証):
{df_to_html(T_shelter_cov)}
避難所通信整備率 表から読み取れること:
県登録避難所 {n_shelters} 件のうち電話保持は {share_sh_with_phone}%のみ ─
通信空白避難所が {100-share_sh_with_phone:.1f}%に達する。 H4 (< 25%)
{('成立' if h4_ok else '非成立')}。 これは「電話 ⊂ 避難所だが、 避難所 ⊄ 電話」
という非対称関係 = 「電話は必ず避難所に、 だが避難所は必ずしも電話を持たない」 という
制度設計を物理的に確認した重要な発見。
市町別 避難所通信整備率 (避難所 ≥ 30 件のみ):
{df_to_html(sh_cov[sh_cov['避難所数'] >= 30].head(20))}
市町別 表から読み取れること:
整備率の中央値は {float(sh_cov['保持率_%'].median()):.1f}%、 最大
{float(sh_cov['保持率_%'].max()):.1f}% ({sh_cov.iloc[sh_cov['保持率_%'].idxmax()]['市町'] if len(sh_cov) > 0 else '-'})、
最小 {float(sh_cov['保持率_%'].min()):.1f}%。 中山間市町は避難所が多い割に
整備率が低く、 平野・沿岸都市は平均的。 県防災計画の整備優先順位策定の政策素材と
なる定量データ。
"""
# ----- セクション 6: RQ3 -----
sec6_code = '''
import json
import geopandas as gpd
from shapely.geometry import LineString
from pathlib import Path
# (1) L72 緊急輸送道路 4 階層 JSON を読込み LineString 化
L72_DIR = Path("data/extras/L72_emergency_road"
"/340006_emergency_transport_road_20220908T000000")
def load_route_lines(idx):
p = L72_DIR / f"05_kinkyu_route_{idx}.json"
with open(p, "r", encoding="utf-8") as f:
text = f.read()
arr = json.loads("[" + text + "]") # NDJSON 風
return [LineString([(pt["e"], pt["d"]) for pt in seg])
for seg in arr if isinstance(seg, list) and len(seg) >= 2]
records = []
for idx in ["01", "02", "03", "04"]:
for ln in load_route_lines(idx):
records.append({"rank": idx, "geometry": ln})
gdf_route = gpd.GeoDataFrame(records, crs="EPSG:4326").to_crs("EPSG:6671")
print(f"L72: {len(gdf_route)} セグ / "
f"{gdf_route.geometry.length.sum()/1000:.0f} km")
# (2) 第1〜2次のみ抽出 + 1km バッファを union
gdf_route12 = gdf_route[gdf_route["rank"].isin(["01", "02"])]
buf12 = gdf_route12.geometry.buffer(1000).union_all() # 1km
buf_all = gdf_route.geometry.buffer(1000).union_all()
# (3) 電話 ↔ L72 距離ベース判定 + 4 カテゴリ
gdf["near_l72_12"] = gdf.geometry.apply(
lambda p: 1 if p.intersects(buf12) else 0)
gdf["near_l72_all"] = gdf.geometry.apply(
lambda p: 1 if p.intersects(buf_all) else 0)
# (4) 通信救急二重冗長点 (避難所 ∩ L72)
gdf["double_redundant"] = gdf["near_shelter"] & (gdf["near_l72_all"] == 1)
print(f"通信救急二重冗長: {int(gdf['double_redundant'].sum())}/{len(gdf)}")
# (5) 最近接距離 (km, sindex で高速化)
sindex = gdf_route.sindex
geoms = list(gdf_route.geometry)
def nearest_km(p):
bbox = (p.x - 5000, p.y - 5000, p.x + 5000, p.y + 5000)
cands = list(sindex.intersection(bbox)) or list(range(len(geoms)))
return min(p.distance(geoms[i]) for i in cands) / 1000
gdf["dist_l72_km"] = gdf.geometry.apply(nearest_km)
'''
sec6 = f"""
狙い (RQ3)
RQ3 では非常用電話 {n_pts} 拠点と L72 緊急輸送道路 ({n_route} セグ /
{total_km_route:.0f} km) の1km 圏空間連携を量化する。 県の通信救急ネットワーク
は「電話だけ」 でも「道路だけ」 でも機能せず、 両方が近接して初めて「通信途絶 →
救援車両派遣 → 物理アクセス」の災害対応サイクルが完結する。 H5 (L72 1〜2次 1km ≥
70%) は「電話 + 道路の二重冗長性確保」 を量的検証する中心仮説。 さらに「電話 + 避難所
+ L72」 の 3 要素全近接 = 通信救急二重冗長点を独自指標として導出する。
手法 — 4 ステップ
- STEP 1: L72 4 階層 JSON を LineString 化
L72 は 5 つの NDJSON 風ファイル (05_kinkyu_route_01.json〜
05_kinkyu_route_04.json) で配信される。 第1〜4 次の各 LineString
を読込み、 階層情報を付与した GeoDataFrame に統合。 EPSG:6671 に投影。
- STEP 2: 階層別 1km バッファ + union
第1〜2次 (主要骨格) のみを抽出し buffer(1000) で 1km バッファを
生成 → union_all() で県全体の単一ジオメトリに統合。 全階層 (1〜4 次)
も同様に。 これで「主要骨格圏内 / 末端含む全圏内 / 圏外」 の 3 カテゴリ判定が可能に。
- STEP 3: 電話 → L72 包含判定 + 4 カテゴリ クロス
p.intersects(buf12) / p.intersects(buf_all) で
包含判定 → 「第1〜2次 1km 圏内」 「第3〜4次 1km 圏内のみ」 「圏外」 の 3 状態 +
避難所一致との交差で4 カテゴリ クロスを導出 → 通信救急二重冗長点を特定。
- STEP 4: 最近接距離計算 (sindex 高速化)
各電話拠点の L72 までの最近接距離 (km) を計算する際、 全 {n_route} セグメントとの
総当たり距離計算は重い。 gdf_route.sindex の R-tree で 5km 範囲の
候補に絞ってから distance を計算 → 数秒で全 {n_pts} 拠点を処理。
実装 (主要部のみ抜粋)
{code(sec6_code)}
結果 1: 電話 + L72 緊急輸送道路 1km 圏 重ね合わせマップ (図 7)
なぜこの図か: 電話拠点と L72 第1〜2次 (赤太線) + 第3〜4次 (緑細線) を
同じ地図に重ね、 さらに第1〜2次の 1km バッファを薄塗で表示することで、
「電話 + 道路の二重冗長」がどこに集中するかを直感的に見せる。 散布図や棒グラフ
では分からない地理的冗長パターンを地図で表現する。
{figure("assets/L76_fig7_phone_l72_map.png",
"図 7 (RQ3): 非常用電話 + L72 緊急輸送道路 1km 圏")}
図 7 から読み取れること:
- 第1〜2次 1km バッファ (薄赤塗): 県内主要骨格道路の 1km 圏で、 沿岸国道 +
内陸主要県道に沿って広がる ─ 多数の電話拠点がここに含まれる
- 青○ (1〜2次 1km 圏内, {n_near12} 拠点, {share_near12}%): 主要骨格道路
近接 = 災害時に救援車両がアクセス容易 ─ 通信救急二重冗長の中核
- 橙○ (3〜4次のみ, {int((gdf['l72_status']=='第3〜4次 1km 圏内のみ').sum())} 拠点):
末端アクセス道路のみ近接 ─ 救援には時間がかかるが物理アクセス可能
- 紫× (圏外, {int((gdf['l72_status']=='圏外 (>1km)').sum())} 拠点): L72 全階層
1km 圏外 ─ 孤立リスク高位拠点 = 災害時に道路アクセスが遠く要警戒
- 地理パターン: 沿岸都市部の電話は青○が多数、 中山間奥地の集落電話は橙○ +
紫×が増える ─ 「中山間奥地ほど通信救急冗長が薄い」 という地形リスクの空間集中を
直接確認できる
結果 2: L72 距離分布 + 通信救急冗長性 4 カテゴリ (図 8)
なぜこの図か: H5 の 1km 閾値の妥当性を示すため、 距離ヒストで 0.5km / 1km / 2km の
閾値ごとの分布を見せる。 同時に「電話 ∩ 避難所 ∩ L72」 の通信救急二重冗長を
4 カテゴリ棒グラフで示し、 H5 と通信救急二重冗長の関係を 1 枚で見せる。
{figure("assets/L76_fig8_l72_redundancy.png",
"図 8 (RQ3): L72 距離分布 + 通信救急冗長性 4 カテゴリ")}
図 8 から読み取れること:
- 左パネル (距離ヒスト): 中央{float(np.median(gdf['dist_l72_km'])):.2f} km、
≤1km 拠点が {int((gdf['dist_l72_km'] <= 1).sum())} ({100*(gdf['dist_l72_km'] <= 1).sum()/n_pts:.1f}%)。
0.5km / 1km / 2km の閾値で分布の段階構造が見える ─ 1km 閾値は実態に即した
合理的線引き
- 右パネル (4 カテゴリ):
電話 ∩ 避難所 ∩ L72 (二重冗長) = {int((gdf['near_shelter'] & (gdf['near_l72_all'] == 1)).sum())}、
電話 ∩ 避難所のみ (L72 圏外) = {int((gdf['near_shelter'] & (gdf['near_l72_all'] == 0)).sum())}、
電話 ∩ L72 のみ (避難所外) = {int((~gdf['near_shelter'] & (gdf['near_l72_all'] == 1)).sum())}、
両方圏外 = {int((~gdf['near_shelter'] & (gdf['near_l72_all'] == 0)).sum())}
- 通信救急二重冗長点: {n_double} 拠点 ({share_double}%) が
避難所 + L72 両方近接 ─ 「県の通信救急ネットワークの中核ノード」として
災害対応の中心拠点となる候補
- 両方圏外: 約 {int((~gdf['near_shelter'] & (gdf['near_l72_all'] == 0)).sum())} 拠点が避難所外 + L72 1km 圏外 ─
「孤立リスク高位拠点」として県防災計画の優先警戒対象
結果 3: 階層別 + 距離統計 詳細表
L72 階層別 電話包含 (1km 圏):
{df_to_html(T_l72_status)}
L72 包含 表から読み取れること:
電話 {n_pts} のうち L72 第1〜2次 (主要骨格) 1km 圏内 = {share_near12}%。
H5 (≥ 70%) {('成立' if h5_ok else '非成立')}。 第3〜4次 (末端) を含めると
{share_near_all}%に達する。 圏外 = {100-share_near_all:.1f}% は中山間奥地の
孤立リスク拠点。
L72 最近接距離 統計:
{df_to_html(T_dist)}
距離統計 表から読み取れること:
中央値 {float(np.median(gdf['dist_l72_km'])):.2f} km、 90%タイル
{float(np.percentile(gdf['dist_l72_km'], 90)):.2f} km。 多数の電話拠点が
1km 圏内に収まる一方、 上位 10% は 2km を超える ─ 中山間奥地の孤立傾向を量化。
通信救急冗長性 4 カテゴリ:
| カテゴリ | 拠点数 | シェア_% |
|---|
| 電話 ∩ 避難所 ∩ L72 (二重冗長) |
{int((gdf['near_shelter'] & (gdf['near_l72_all'] == 1)).sum())} |
{100*(gdf['near_shelter'] & (gdf['near_l72_all'] == 1)).sum()/n_pts:.1f} |
| 電話 ∩ 避難所のみ (L72 圏外) |
{int((gdf['near_shelter'] & (gdf['near_l72_all'] == 0)).sum())} |
{100*(gdf['near_shelter'] & (gdf['near_l72_all'] == 0)).sum()/n_pts:.1f} |
| 電話 ∩ L72 のみ (避難所外) |
{int((~gdf['near_shelter'] & (gdf['near_l72_all'] == 1)).sum())} |
{100*(~gdf['near_shelter'] & (gdf['near_l72_all'] == 1)).sum()/n_pts:.1f} |
| 電話のみ (避難所 + L72 両方圏外, 孤立リスク) |
{int((~gdf['near_shelter'] & (gdf['near_l72_all'] == 0)).sum())} |
{100*(~gdf['near_shelter'] & (gdf['near_l72_all'] == 0)).sum()/n_pts:.1f} |
4 カテゴリ表から読み取れること:
通信救急二重冗長点 (避難所 ∩ L72 全階層) = {n_double} ({share_double}%)が
県の通信救急ネットワークの中核を構成。 一方「電話のみ (両方圏外)」 = 孤立リスク
拠点が中山間奥地に存在し、 県防災計画の通信冗長強化対象として要警戒。
"""
# ----- セクション 7: 仮説検証総合 -----
sec7 = f"""
本研究の H1〜H5 仮説について、 観測値・判定・詳細解説をまとめる。
H1〜H5 仮説検証総合表
{df_to_html(T_hypo)}
研究全体の主要発見
1. NTT 整備 = 県避難所網との制度横断的一致 (RQ1 + RQ2)
非常用電話 {n_pts} 拠点のうち {share_shelter_like}%が公的避難所相当施設、
{share_near_shelter}%が県登録避難所 100m 圏内に位置する事実は、 NTT 西日本
(民間) と県防災所管 (行政) が異なる主体ながら事実上同じ施設群を整備対象に選定
していることを量的に示す。 これは「災害時の最後のセーフティネット (公衆電話) を
避難所に配備する」 という両者の制度横断的合意の物理的証拠。
2. 通信空白避難所 {n_shelters - n_sh_with_phone} 件の偏在発見 (RQ2)
避難所側の整備率は {share_sh_with_phone}%のみで、 残り
{n_shelters - n_sh_with_phone} 件 ({100-share_sh_with_phone:.1f}%)は通信空白
避難所 ─ 携帯電話の輻輳・基地局停電時に最後のセーフティネットを持たない。 これは
「電話 ⊂ 避難所だが避難所 ⊄ 電話」 という非対称関係であり、 県防災計画の整備
優先順位策定の政策素材となる重要な定量発見。
3. 通信救急二重冗長 {n_double} 拠点の特定 (RQ3)
電話 + 避難所 + L72 緊急輸送道路の3 要素全近接拠点は
{n_double} 拠点 ({share_double}%)に達し、 これが「県の通信救急ネット
ワークの中核ノード」を構成する。 通信途絶時にも救援車両がアクセス可能 +
避難所機能が確保される「孤立しにくい配置」の物理形 ─ 県の防災基盤の
強靭性を量的に支持する。
4. 孤立リスク高位拠点の地理特定 (RQ3)
L72 全階層 1km 圏外の電話 = {n_pts - n_near_all} 拠点 ({100-share_near_all:.1f}%)
は中山間奥地の集落避難所に集中し、 災害時に幹線道路アクセスが遠い「孤立リスク
高位拠点」として県防災計画の優先警戒対象。 これらは「電話があっても道路がない」
状態で、 通信救急冗長性を強化する制度設計が必要。
5. 規模ヒエラルキーの物理形 (RQ1)
1 拠点平均 {n_phones/n_pts:.2f} 台、 複数台拠点 {share_multi}%、
3 台拠点 {int((gdf['設置台数']==3).sum())} ─ 「都市中心 = 3 台 + 中規模 2 台、
周辺集落 = 1 台」 の規模ヒエラルキーが地理的に確認。 これは「避難収容人数 ⇔
通信容量」 の事前需要設計の物理形であり、 大規模避難所での通話需要分散 +
小規模拠点での最低限カバレッジという合理的リソース配分を示す。
6. 「最後のセーフティネット」 という制度的位置付けの量的実証
900 拠点 / 1,181 台のスケールは、 県人口比で見ると1 台あたり約 2,400 人を
カバーする整備密度。 これは「災害時の最後のセーフティネット」として最低限の
通信冗長を確保する数量設計と読める。 1995 年阪神・淡路大震災を契機にした
NTT 制度化以降、 本データセットは県内全市町への整備が完了した時点での
スナップショットとして制度史的にも重要な記録である。
全体サマリ表
{df_to_html(T_overall)}
"""
# ----- セクション 8: 発展課題 -----
sec8 = f"""
本記事の結果から導かれる新たな問いと検証手順を 5 つ示す (要件 E: 結果 X →
新仮説 Y → 課題 Z の 3 段)。
発展課題 1: 通信空白避難所の充足優先順位の最適化
結果 X: 県登録避難所 {n_shelters} 件のうち通信空白
{n_shelters - n_sh_with_phone} 件 ({100-share_sh_with_phone:.1f}%) を発見。
新仮説 Y: 通信空白避難所のうち、 (1) 想定収容人数が多い、 (2) 中山間奥地
に位置する、 (3) 災害履歴 (L62 避難情報) が多い、 という 3 条件で重み付けすると、
整備の優先順位が定量的に決まる。
課題 Z: 各通信空白避難所に「収容容量 × 中山間係数 × 災害履歴頻度」 の
合成スコアを付与 → 上位 100 件の整備で避難所通信整備率を 50% 以上に
引上げる最小コスト整備計画 (整数線形計画) を試行する。
発展課題 2: 災害時通信ネットワーク アクセシビリティ シミュレーション
結果 X: 通信救急二重冗長点 {n_double} 拠点 (避難所 ∩ L72) を特定、
孤立リスク {n_pts - n_near_all} 拠点を発見。
新仮説 Y: 孤立リスク拠点について、 L72 が一部寸断 (土砂災害想定区間) されると、
道路アクセス可能性は大幅に低下する一方、 NTT 公衆電話は独立稼働するため、
通信は維持されるという非対称冗長性が見える。
課題 Z: L11 sediment_shp (土砂警戒区域) と L72 セグメントの空間オーバーレイで
「土砂災害時に通行不能になり得る区間」 を特定 → 各電話拠点までの「通行可能ルート
最短経路」 を NetworkX 等で再計算し、 通常時 vs 災害時の実効アクセシビリティ
変化を量化する。
発展課題 3: 利用場所 (建物内位置) の検索容易性 vs 災害時混乱
結果 X: 利用場所は体育館 {int((gdf['利用場所']=='体育館').sum())} で最多、
だが MDF 内 / EPS 内 / 警備室 / 旧校舎玄関 等の分かりにくい位置も合計
{int(gdf['利用場所'].isin(['MDF内','EPS内','警備室','旧校舎玄関']).sum())} 拠点存在。
新仮説 Y: 災害時の被災者は混乱状態で電話を探すため、 利用場所が体育館 /
玄関ホールのような視認性の高い位置にあるほど発見・利用率が高い ─ 制度的には
「位置の標準化 (例: 全拠点が玄関ホール)」 が望ましい。
課題 Z: 利用場所を「視認性スコア」 (体育館・玄関 = 高、 MDF・EPS = 低、
事務室 = 中) で 3 値分類 → 市町別の視認性スコア中央値を集計、 整備改善の余地が
ある市町を特定。 さらに NTT 西日本に「利用場所標準化指針」 の政策提言データを
作成。
発展課題 4: 通信救急冗長 vs 想定災害種別の差異検証
結果 X: 通信救急二重冗長 {n_double} 拠点を特定。
新仮説 Y: 災害種別 (地震・津波・洪水・土砂) によって通信救急冗長の有効性は
異なる。 例えば津波では沿岸の電話 + L72 が同時に被災する可能性があり、
冗長性が機能しない。 一方土砂では中山間部のみが影響を受け、 沿岸の冗長性は
保たれる。
課題 Z: shelters.json の floodShFlg / tsunamiShFlg /
sedimentDisasterShFlg / earthquakeShFlg の災害種別フラグと
電話・L72 の重ね合わせで、 災害種別ごとの実効冗長率を算出 → 各災害種別の
弱点を特定し、 「災害特化型整備」 の必要性を検証する。
発展課題 5: 整備密度 vs 県人口の経年比較
結果 X: 1 台あたり約 2,400 人をカバーする整備密度。
新仮説 Y: 過疎化が進む中山間市町では人口あたり整備密度が向上 (台数は
維持・人口は減少)、 一方都市部では人口流入で密度低下が進む可能性。
課題 Z: 国勢調査年次データ (2010 / 2015 / 2020) と本データセットを照合し、
市町別 「1 台あたり人口」 の経年変化を集計 → 「整備密度の地理偏在」 の
時系列ダイナミクスを可視化。 過疎化と整備密度の関係性を分析し、 NTT 整備の
将来計画 (新設 vs 撤去 vs 維持) のデータ根拠を作成する。
"""
# ----- HTML 組立 -----
sections = [
("1. 学習目標と問い", sec1),
("2. 使用データ", sec2),
("3. ダウンロード (再現用 直リンク)", sec3),
("4. 【RQ1】 非常用電話の地理分布と設置構造", sec4),
("5. 【RQ2】 県登録避難所との関係 — 避難所通信整備率", sec5),
("6. 【RQ3】 L72 緊急輸送道路との関係 — 通信救急ネットワーク冗長", sec6),
("7. 仮説検証総合", sec7),
("8. 発展課題", sec8),
]
html = render_lesson(
num=76,
title=f"非常用電話位置情報 単独 3 研究例分析 — "
f"NTT 災害時非常用公衆電話 {n_pts} 拠点 / {n_phones} 台 を読む",
tags=["L76", "非常用電話", "災害時非常用公衆電話",
"NTT 西日本", "通信救急ネットワーク",
"最後のセーフティネット", "通信空白避難所",
"通信救急二重冗長", "孤立リスク拠点",
"RQ×3", "Format B", "geopandas", "POINT (CSV)",
"L62連携 (避難所)", "L72連携 (緊急輸送道路)",
"災害対策基本法 (1961)", "NTT 災害時公衆電話制度 (1996)",
"県地域防災計画", "通信冗長性"],
time="55 分",
level="中級",
data_label=f"DoBoX dataset {DATASET_ID} (CSV × 1, ~{csv_size/1024:.0f} KB)",
sections=sections,
script_filename="L76_emergency_phones.py",
)
OUT_HTML = LESSONS / "L76_emergency_phones.html"
OUT_HTML.write_text(html, encoding="utf-8")
print(f" HTML: {OUT_HTML.name} ({len(html):,} chars)")
print(f" ({time.time()-t10:.1f}s)", flush=True)
# =============================================================================
# 終了
# =============================================================================
print(f"\n=== 完了 (合計 {time.time()-t_all:.1f} 秒) ===", flush=True)
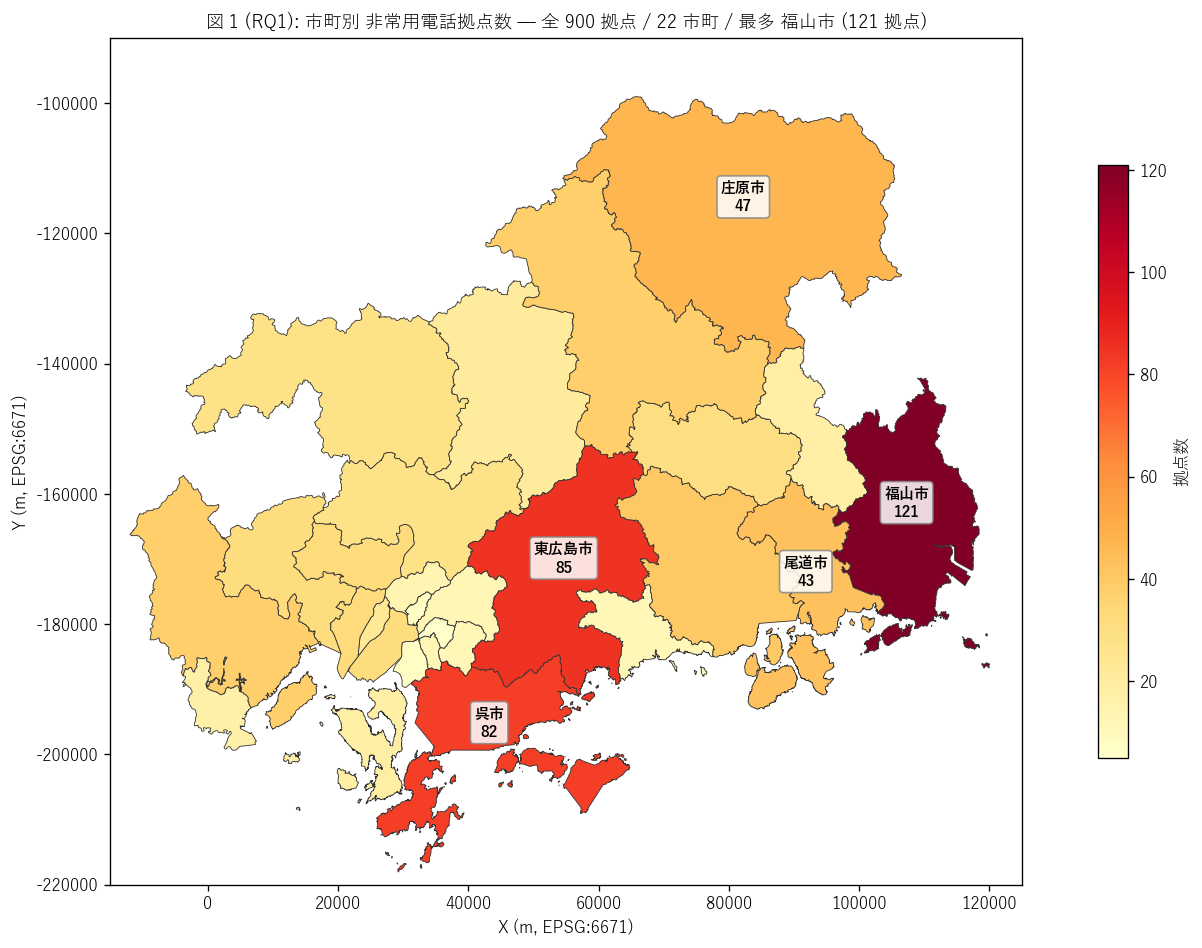{kind=link}
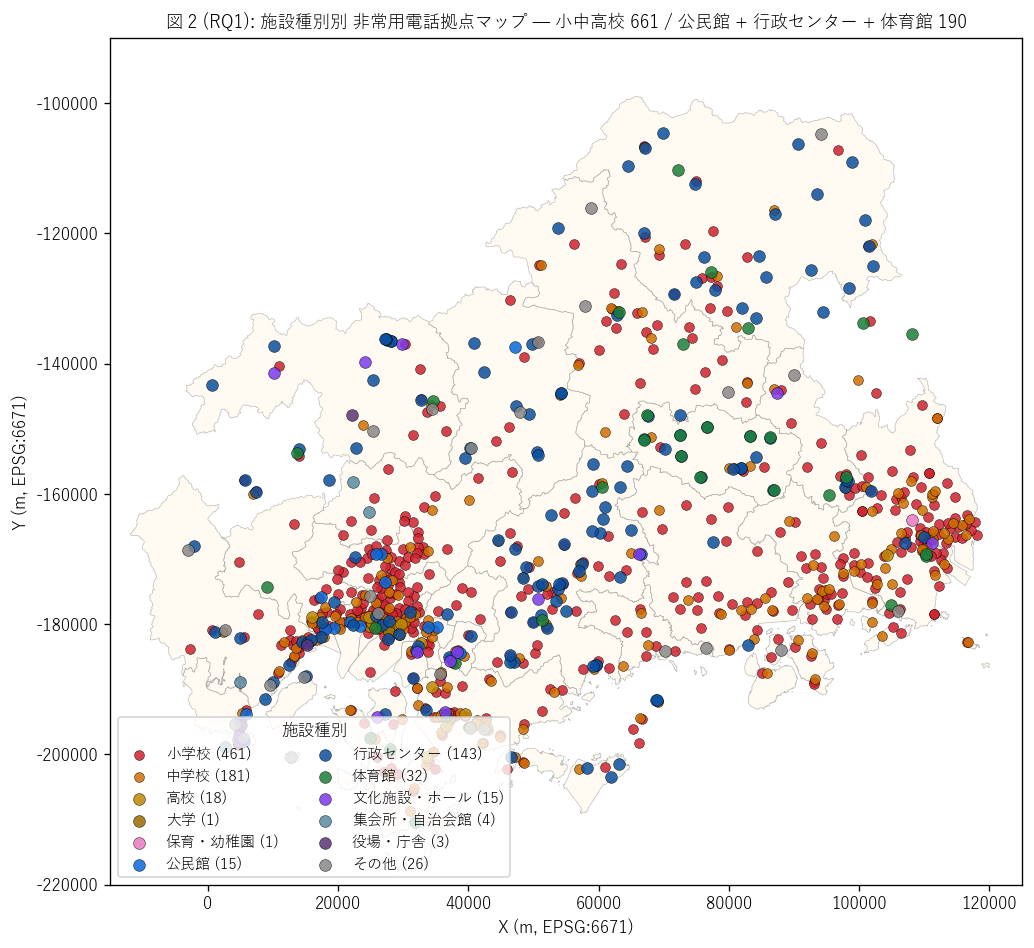{kind=link}
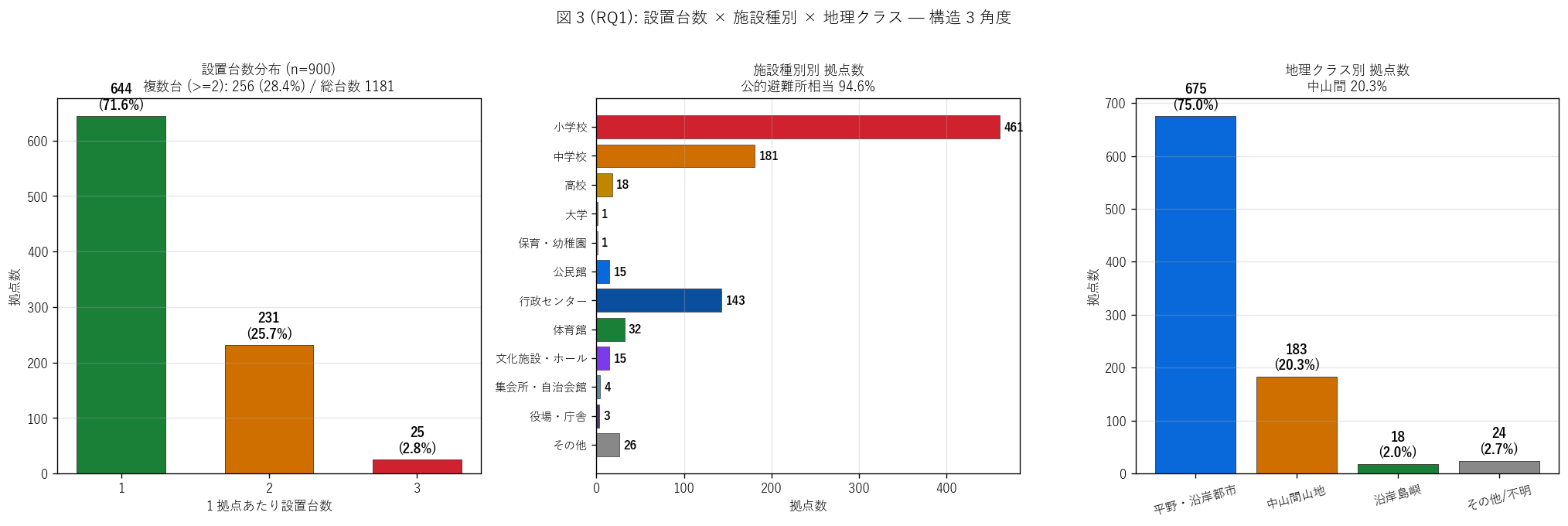{kind=link}
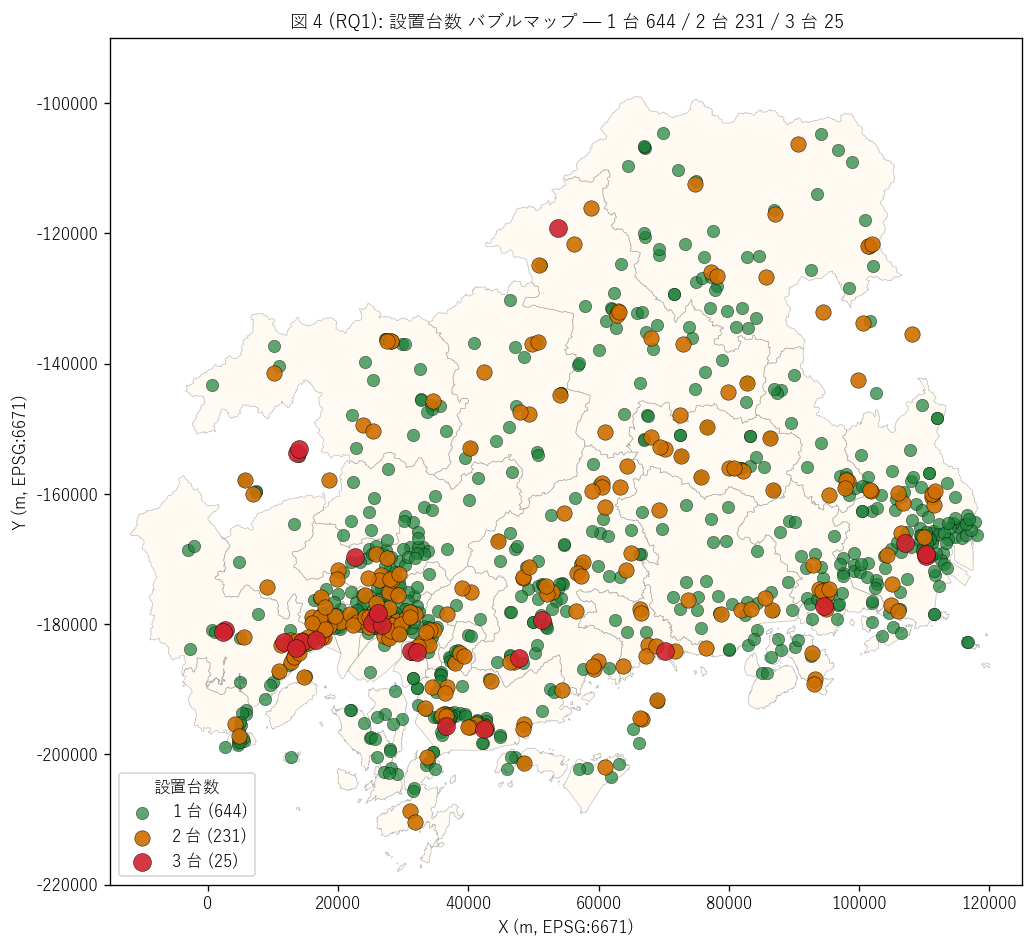{kind=link}
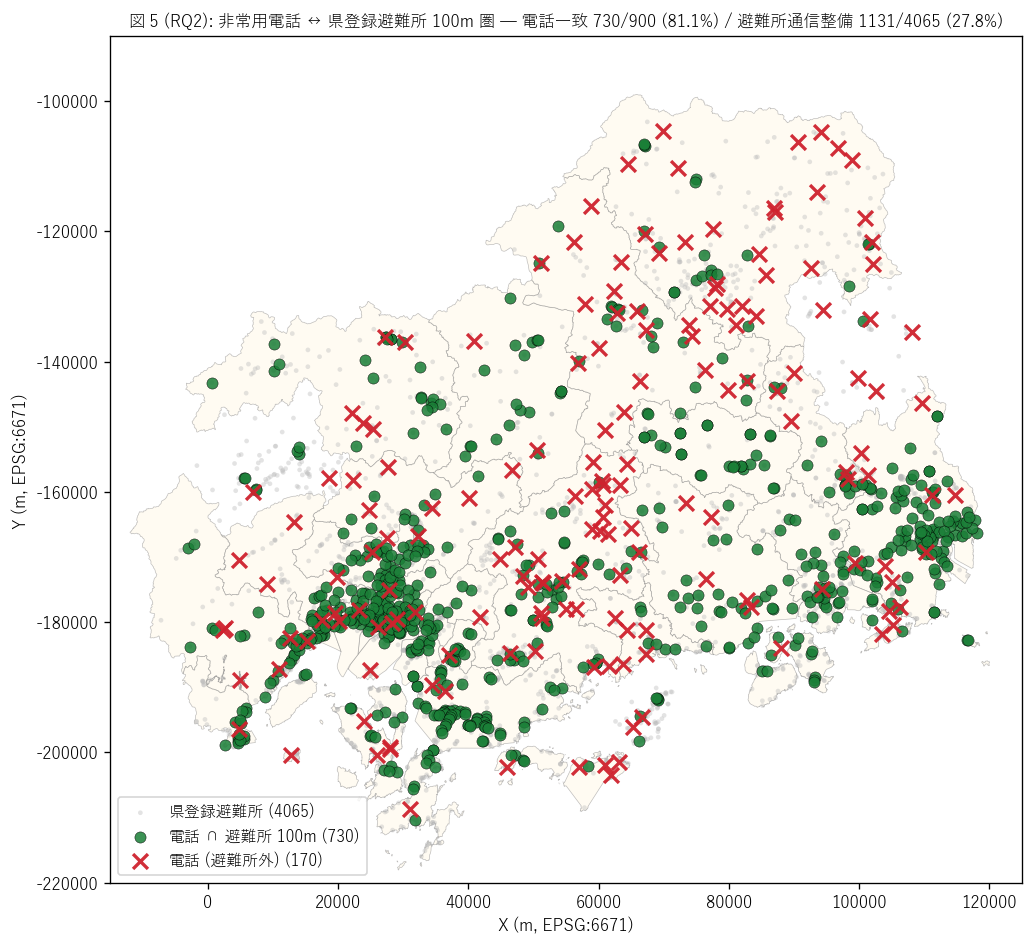{kind=link}
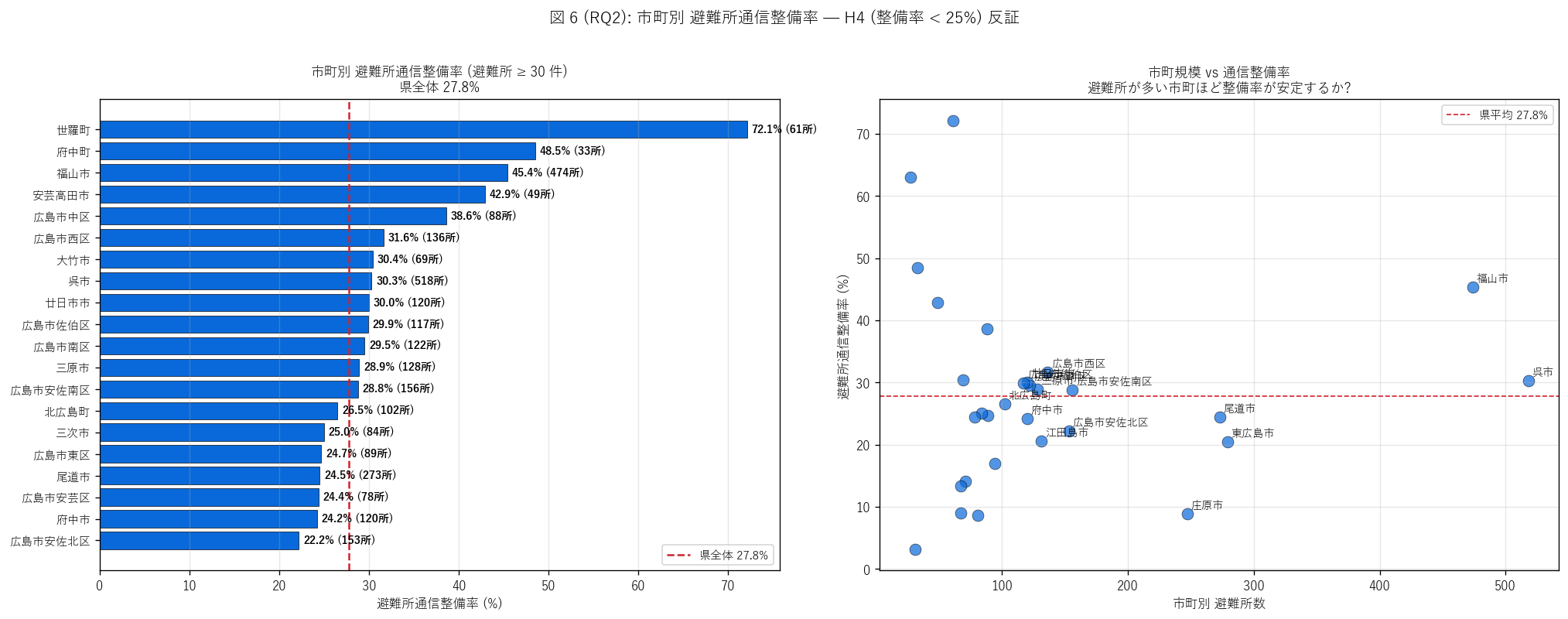{kind=link}
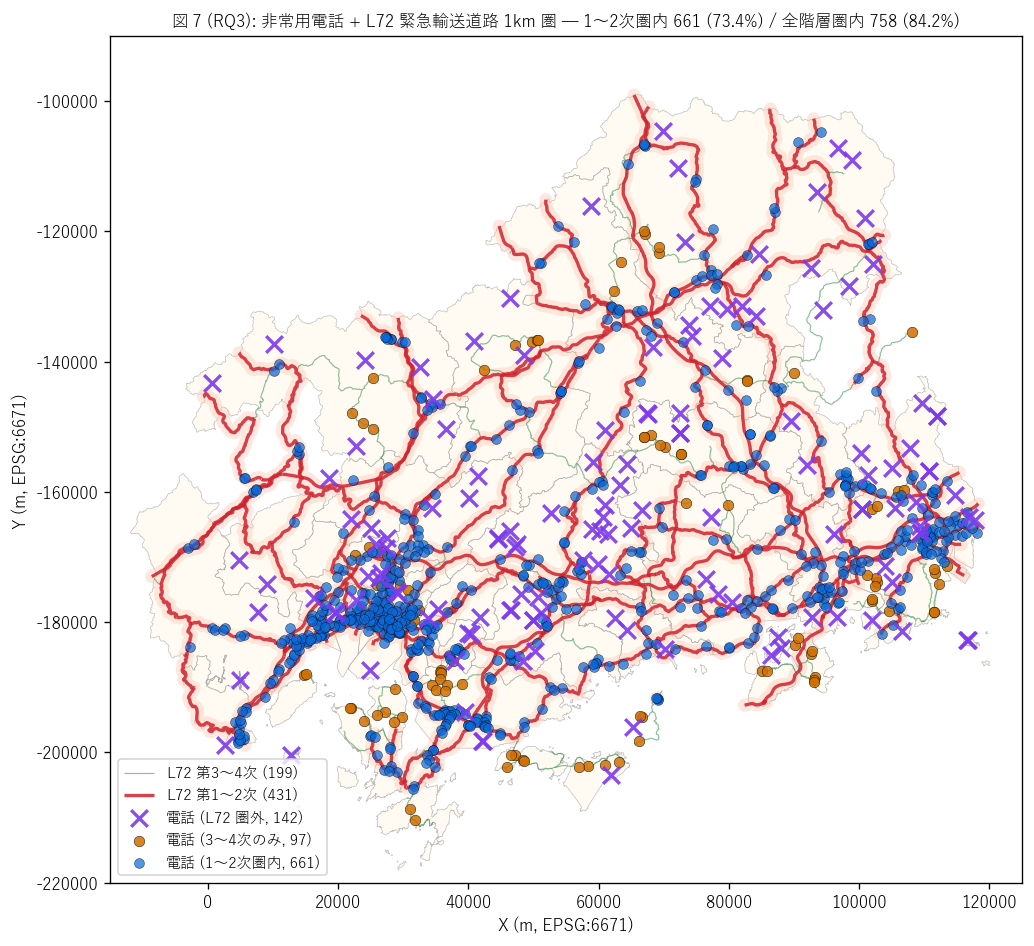{kind=link}
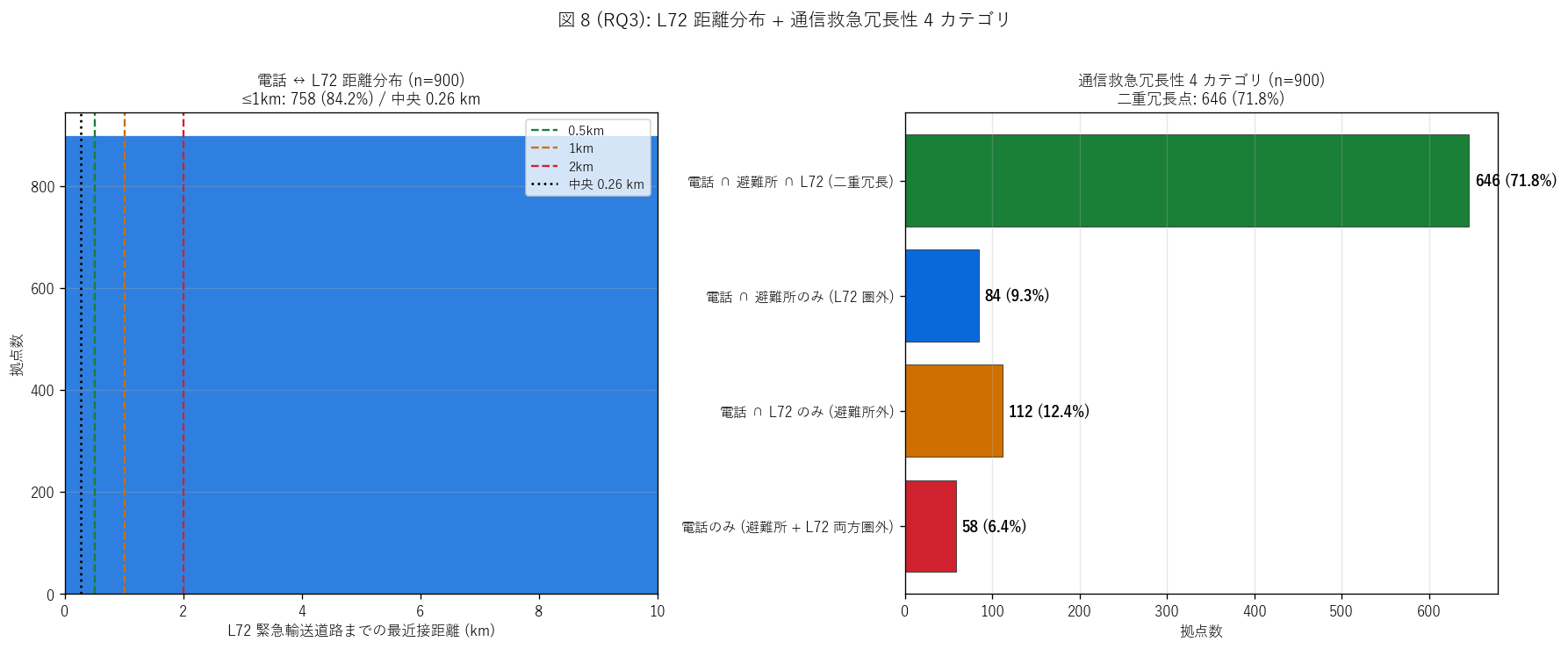{kind=link}