# -*- coding: utf-8 -*-
"""L74 走行注意区間 単独 3 研究例分析
— 広島県 走行注意区間 (dataset 1246) を 3 角度で解読
カバー宣言:
本記事は DoBoX のデータセット「走行注意区間」 (dataset_id = 1246)
1 件を 単独で取り上げ、 広島県の走行注意区間 (LineString,
2 階層 / 計 381 区間) を 3 つの独立した研究角度
(RQ1 / RQ2 / RQ3) で並列に分析する。
「走行注意区間」 とは:
通行止めにはしないが、 ドライバーに「落石・崩落リスクあり」 を
予告する道路区間。 過去の小規模崩落履歴・地質脆弱性・植生状態等から
道路管理者が指定し、 注意喚起レベルに応じて2 階層で運用される
広島県独自の「予防情報配信制度」。 法的拘束力 (規制) はないが、
道路法第 30 条の 2 に基づく道路情報提供の一環として運用される。
広島県の走行注意区間は2 階層 (orange/red)に区分される:
階層 03 (orange, #ffa500): 注意レベル 低 — 253 区間
通常走行可、 雨天時・夜間に減速注意
階層 04 (red, #ff0000): 注意レベル 高 — 128 区間
常時注意、 通行は可能だが豪雨時・地震後は迂回推奨
総区間数: 381、 総延長は約 600-800 km (中山間 + 沿岸の脆弱地質道路)
本記事は事前通行規制 L73 / 道路規制 L50 / 緊急輸送道路 L72と
厳密に区別:
L50 = 道路規制動的 (本日 + 今後, 工事 + 災害短期, 218 件)
L73 = 事前通行規制区間静的・強い予防 (LineString, 雨量・冬期, 164 区間 / 750 km)
L74 = 走行注意区間静的・弱い予防 (情報提供) (LineString, 落石注意, 381 区間)
L72 = 緊急輸送道路単独 (LineString, 災害時生命線, 4 階層 / 2,790 km)
本記事は他シリーズと合体しない。 RQ2 で事前通行規制 (L73), RQ3 で
L50 + L73 + L74 の 3 階層を統合的に参照する形をとる。
研究の問い (3 RQ):
RQ1 (主研究): 広島県の走行注意区間の構造 — 注意レベル × 路線 × 延長
× 地理分布はどう描けるか? 381 区間 を注意レベル (03/04) × 区間長 ×
地理クラス (中山間/平野/沿岸) × 市町の 4 軸で集計し、 「県の予防情報
配信制度」 の物理形状を初めて系統的に記述する。
H1 = orange (03, 弱注意) が red (04, 強注意) より多数 (>=60%) 仮説。
RQ2 (副研究 1): 走行注意区間 (L74, 弱予防) と事前通行規制区間 (L73, 強予防) は
階層構造を成すか? 同一路線で「規制 (L73) + 注意 (L74)」 の
二重指定があるか, 注意 (L74) のみの区間は規制 (L73) より広い範囲を
カバーするか, 100m バッファで sjoin → 制度階層の連続性を検証する。
H2 = L74 ∩ L73 の重複区間が >=10 件存在 (= 警戒度の高い箇所が
両制度で二重指定) 仮説、
H3 = L74 のうち L73 と重ならない「注意のみ」 区間が >=80% を占める
(= 注意は規制より広い範囲をカバーする予防情報層) 仮説。
RQ3 (副研究 2): 県の道路情報3 階層 (L50 動的 / L73 静的規制 / L74 静的注意)は
どんな統合構造を持つか? 件数規模・延長比較・空間分布を統合的に分析し、
災害時の情報伝達フロー (注意 → 規制 → 動的規制) を定量化する。
H4 = 件数規模は 注意 (L74) > 規制 (L73) > 動的 (L50) の順 (= 「弱い情報は
広く、 強い規制は狭く」 仮説) — 注意 381 > 規制 164 > 動的 218 の確認、
H5 = L74 (注意) ∩ L72 (緊急輸送道路) の重複が >=20 km 存在
(= 緊急輸送道路の沿道に注意区間が分布する空間相関) 仮説。
仮説 (5):
H1 (RQ1, 階層構造): 走行注意区間 381 のうちorange (03, 弱注意)が
>=60%。 弱注意が多数派で、 強注意 (red, 04) は厳選された
少数派という制度設計仮説。
H2 (RQ2, 規制との重複): 走行注意 (L74) と事前通行規制 (L73) の
100m バッファ重複が >=10 件。 「同じ道路に規制 (強) +
注意 (弱)」 の二重指定箇所が一定数存在し、 これが県の最警戒箇所
仮説。
H3 (RQ2, 注意のみが多数派): L74 のうち L73 と重ならない「注意のみ」
区間が>=80%。 注意制度は規制より広い範囲をカバーする
予防情報層であり、 規制は注意の厳選サブセット仮説。
H4 (RQ3, 件数規模順): 件数 注意 (L74=381) > 動的 (L50=218) > 規制 (L73=164)。
「弱い情報は広く、 強い規制は狭く」 という逆ピラミッド構造仮説。
H5 (RQ3, 緊急輸送道路との空間相関): L74 (注意) と緊急輸送道路 (L72) の
30m バッファ重複延長が>=20 km。 注意区間は主要道路に集中し、
緊急輸送道路の沿道に分布する仮説 (= 注意制度は重要路線優先設計)。
要件 S 準拠 (1 分以内完走):
- データ ZIP 1 件 (~750 KB) → ensure_dataset で取得 → zipfile 展開
- 381 区間 LineString (NDJSON 風) → 配列パース → ~108,000 点
- 行政界 sjoin (代表点 1 回) で市町判定 → 中山間判定
- L73 (164 区間, 既キャッシュ) を 100m バッファ → L74 sjoin
- L72 (緊急輸送道路, 既キャッシュ) を 30m バッファ → L74 sjoin
- L50 (218 件 動的規制, 既キャッシュ) を読込み件数比較のみ
- 全体で ~15-20 秒目標
要件 T 準拠 (位置情報あり = 地図必須):
- RQ1: 注意レベル別マップ + 中山間境界マップ
- RQ2: L74 + L73 重ね合わせマップ + 重複箇所ハイライト
- RQ3: L50/L73/L74 3 階層 重ね合わせマップ + L74 ∩ L72 マップ
要件 Q 準拠: 図 7+ / 表 11+ (3 RQ × 多角度: 階層構造 / 規制との階層 / 3階層統合)
データ仕様:
- dataset 1246: 走行注意区間 (ZIP × 1 リソース, ~750 KB)
- resource 32490: 道路_走行注意区間_2022-09-08-T00:00:00 (~750 KB)
- ZIP 内 3 JSON:
- 04_warning_rakuseki_03.json (3.0 MB, 253 区間, NDJSON 風)
- 04_warning_rakuseki_04.json (1.6 MB, 128 区間, NDJSON 風)
- 04_warning_route.json (160 byte, 2 階層メタ {name,color,weight,type})
- 各 LineString は { "e": 経度, "d": 緯度 } の点列
- 属性は階層名 (rakuseki_03 / rakuseki_04) のみ — L73 のような豊富属性なし
- ライセンス: クリエイティブ・コモンズ表示 (CC-BY)
メモリ対策: Figure ごとに plt.close('all') で確実に解放。
"""
from __future__ import annotations
import sys, time, zipfile, json
from pathlib import Path
sys.path.insert(0, str(Path(__file__).parent))
from _common import ROOT, ASSETS, LESSONS, render_lesson, code, figure, ensure_dataset
import numpy as np
import pandas as pd
import geopandas as gpd
from shapely import wkt as swkt
from shapely.geometry import Point, LineString
from shapely.strtree import STRtree
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.lines import Line2D
from matplotlib.patches import Patch
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
t_all = time.time()
print("=== L74 走行注意区間 単独 3 研究例分析 ===", flush=True)
# =============================================================================
# 0. 定数・パス
# =============================================================================
TARGET_CRS = "EPSG:6671" # JGD2011 平面直角第 III 系
DATA_DIR = ROOT / "data" / "extras" / "L74_caution_segments"
DATA_DIR.mkdir(parents=True, exist_ok=True)
DATASET_ID = 1246
RESOURCE_ID = 32490
ZIP_NAME = "caution_segments.json" # 実体は ZIP だが拡張子は .json
EXTRACT_DIR = DATA_DIR / "340006_driving_caution_section_20220908T000000"
# 階層 (rakuseki_03 / rakuseki_04)
LEVEL_LABEL = {
"rakuseki_03": "03 (低注意)",
"rakuseki_04": "04 (高注意)",
}
LEVEL_COLOR = {
"rakuseki_03": "#ffa500", # orange (公式メタ)
"rakuseki_04": "#cf222e", # 公式 #ff0000 → 暗赤に変更で視認性向上
}
LEVEL_OFFICIAL_COLOR = {
"rakuseki_03": "#ffa500",
"rakuseki_04": "#ff0000",
}
LEVEL_ORDER = ["rakuseki_03", "rakuseki_04"]
# CITY_CD → 市町名 (L73 と共通)
CITY_NAME = {
101: "広島市中区", 102: "広島市東区", 103: "広島市南区", 104: "広島市西区",
105: "広島市安佐南区", 106: "広島市安佐北区", 107: "広島市安芸区", 108: "広島市佐伯区",
202: "呉市", 203: "竹原市", 204: "三原市", 205: "尾道市", 207: "福山市",
208: "府中市", 209: "三次市", 210: "庄原市", 211: "大竹市", 212: "東広島市",
213: "廿日市市", 214: "安芸高田市", 215: "江田島市",
302: "府中町", 304: "海田町", 307: "熊野町", 309: "坂町",
368: "安芸太田町", 369: "安芸太田町", 462: "世羅町",
412: "北広島町", 545: "神石高原町",
}
CHUSANKAN_CITIES = {
"庄原市", "三次市", "安芸太田町", "安芸高田市",
"北広島町", "神石高原町", "世羅町", "府中市",
}
COASTAL_ISLAND = {"江田島市", "大崎上島町"}
def geo_class(name):
if name in CHUSANKAN_CITIES:
return "中山間山地"
if name in COASTAL_ISLAND:
return "沿岸島嶼"
if not name:
return "その他/不明"
return "平野・沿岸都市"
# 行政界キャッシュ (L44 から)
ADMIN_GPKG = ROOT / "data" / "extras" / "L44_storm_surge" / "_cache" / "admin_diss.gpkg"
# L73 事前通行規制区間 (RQ2 で参照)
L73_JSON = ROOT / "data" / "extras" / "L73_pre_traffic_restriction" / "pre_traffic.json"
# L72 緊急輸送道路 (RQ3 で参照)
L72_DIR = (ROOT / "data" / "extras" / "L72_emergency_road"
/ "340006_emergency_transport_road_20220908T000000")
L72_RANKS = ["01", "02", "03", "04"]
L72_LABEL = {"01": "第1次", "02": "第2次", "03": "第3次", "04": "補完"}
# L50 道路規制情報 (RQ3 で参照, 件数のみ)
L50_TODAY_JSON = ROOT / "data" / "extras" / "L50_road_restrictions" / "1257_today.json"
L50_FUTURE_JSON = ROOT / "data" / "extras" / "L50_road_restrictions" / "1258_future.json"
# バッファ幅
BUFFER_L73_M = 100.0 # L74 ∩ L73 (規制との重複判定)
BUFFER_L72_M = 30.0 # L74 ∩ L72 (緊急輸送道路重複)
# =============================================================================
# 1. データ取得 (ZIP) + 展開
# =============================================================================
print("\n[1] データ取得 + ZIP 展開", flush=True)
t1 = time.time()
zip_local = DATA_DIR / ZIP_NAME
ensure_dataset(zip_local, resource_id=RESOURCE_ID, min_bytes=10000,
label="L74 caution_segments.zip (.json で配信)")
# ZIP かどうかを magic で判定 (.json 拡張子だが ZIP)
is_zip = zip_local.read_bytes()[:4] == b"PK\x03\x04"
if is_zip and not EXTRACT_DIR.exists():
with zipfile.ZipFile(zip_local, "r") as z:
z.extractall(DATA_DIR)
print(f" ZIP 展開 → {EXTRACT_DIR.name}", flush=True)
elif EXTRACT_DIR.exists():
print(f" 既展開済 ({EXTRACT_DIR.name})", flush=True)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 2. NDJSON 風 → LineString GeoDataFrame
# =============================================================================
print("\n[2] NDJSON 風 読込 → LineString", flush=True)
t2 = time.time()
def load_caution_lines(level_name):
"""rakuseki_03 / rakuseki_04 の NDJSON 風 JSON を LineString 配列に変換。
形式: 単一の JSON 配列 ([{e,d}, {e,d}, ...]) が「,改行」 で複数並ぶ NDJSON 風。
L72 と同じ「[ + text + ]」 でラップして parse する手法。
"""
p = EXTRACT_DIR / f"04_warning_{level_name}.json"
with open(p, "r", encoding="utf-8") as f:
text = f.read()
arr = json.loads("[" + text + "]")
lines = []
for seg in arr:
if isinstance(seg, list) and len(seg) >= 2:
coords = [(pt["e"], pt["d"]) for pt in seg]
lines.append(LineString(coords))
return lines
records = []
for lvl in LEVEL_ORDER:
lns = load_caution_lines(lvl)
for ln in lns:
records.append({"level": lvl, "level_label": LEVEL_LABEL[lvl],
"geometry": ln})
gdf = gpd.GeoDataFrame(records, crs="EPSG:4326").to_crs(TARGET_CRS)
gdf["len_m"] = gdf.geometry.length
gdf["len_km"] = (gdf["len_m"] / 1000).round(3)
gdf["seg_id"] = [f"L74_{i:04d}" for i in range(len(gdf))]
# warning_route.json (階層メタ) も読み込み (NDJSON 風)
route_meta_p = EXTRACT_DIR / "04_warning_route.json"
with open(route_meta_p, "r", encoding="utf-8") as f:
route_meta_text = f.read()
route_meta_list = json.loads("[" + route_meta_text + "]")
n_seg = len(gdf)
total_km = gdf["len_m"].sum() / 1000
n_03 = int((gdf["level"] == "rakuseki_03").sum())
n_04 = int((gdf["level"] == "rakuseki_04").sum())
km_03 = float(gdf[gdf["level"] == "rakuseki_03"]["len_m"].sum() / 1000)
km_04 = float(gdf[gdf["level"] == "rakuseki_04"]["len_m"].sum() / 1000)
print(f" 区間数: {n_seg} (03={n_03} / 04={n_04}) / 総延長: {total_km:.1f} km",
flush=True)
print(f" ({time.time()-t2:.1f}s)", flush=True)
# =============================================================================
# 3. 行政界 sjoin → 市町判定 + 中山間判定
# =============================================================================
print("\n[3] 行政界 sjoin (中山間判定)", flush=True)
t3 = time.time()
admin = gpd.read_file(ADMIN_GPKG).to_crs(TARGET_CRS)
admin["市町名"] = admin["CITY_CD"].map(CITY_NAME).fillna(
admin["CITY_CD"].astype(str))
# 代表点 sjoin (LineString 全体ではなく 1 点で判定)
pts = gdf.geometry.representative_point()
gdf_rep = gpd.GeoDataFrame(
{"seg_id": gdf["seg_id"].values, "len_km": gdf["len_km"].values},
geometry=pts.values, crs=TARGET_CRS)
joined = gpd.sjoin(gdf_rep, admin[["CITY_CD", "市町名", "geometry"]],
how="left", predicate="within")
gdf = gdf.reset_index(drop=True).copy()
# 1:1 join なので index_left の重複なし
city_map = joined.drop_duplicates("seg_id").set_index("seg_id")["市町名"]
gdf["市町名"] = gdf["seg_id"].map(city_map).fillna("不明 (代表点が県外/海上)")
gdf["地理クラス"] = gdf["市町名"].apply(geo_class)
gdf["is_chusankan"] = gdf["地理クラス"] == "中山間山地"
n_chusankan = int(gdf["is_chusankan"].sum())
share_chusankan = round(100 * n_chusankan / n_seg, 1)
print(f" 中山間: {n_chusankan}/{n_seg} ({share_chusankan}%)", flush=True)
print(f" ({time.time()-t3:.1f}s)", flush=True)
# =============================================================================
# 4. RQ1: 階層 × 区間長 × 地理分布
# =============================================================================
print("\n[4] RQ1 集計 — 階層構造", flush=True)
t4 = time.time()
# (1) 階層別 集計
T_level = (gdf.groupby(["level", "level_label"])
.agg(区間数=("seg_id", "count"),
延長_km=("len_m", lambda s: round(s.sum() / 1000, 1)),
平均長_m=("len_m", lambda s: round(s.mean(), 0)),
中央長_m=("len_m", lambda s: round(s.median(), 0)),
最大長_m=("len_m", lambda s: round(s.max(), 0)))
.reset_index().rename(columns={"level": "階層"}))
T_level["シェア_%"] = (T_level["区間数"] / n_seg * 100).round(1)
T_level = T_level[["階層", "level_label", "区間数", "延長_km",
"平均長_m", "中央長_m", "最大長_m", "シェア_%"]]
# (2) 地理クラス別
T_geo = (gdf.groupby("地理クラス")
.agg(区間数=("seg_id", "count"),
延長_km=("len_m", lambda s: round(s.sum() / 1000, 1)))
.reset_index())
T_geo["シェア_%"] = (T_geo["区間数"] / n_seg * 100).round(1)
T_geo = T_geo.sort_values("区間数", ascending=False).reset_index(drop=True)
# (3) 階層 × 地理クラス クロス
T_level_geo = (gdf.groupby(["level_label", "地理クラス"])
.size().unstack(fill_value=0).reset_index())
# (4) 市町別 Top 15
T_city = (gdf.groupby(["市町名", "地理クラス"])
.agg(区間数=("seg_id", "count"),
延長_km=("len_m", lambda s: round(s.sum() / 1000, 1)))
.reset_index())
T_city = T_city.sort_values("区間数", ascending=False).reset_index(drop=True)
# (5) 区間長分布の代表値
length_summary = {
"全体": (gdf["len_m"].mean(), gdf["len_m"].median(), gdf["len_m"].max()),
"03 (低)": (gdf[gdf["level"] == "rakuseki_03"]["len_m"].mean(),
gdf[gdf["level"] == "rakuseki_03"]["len_m"].median(),
gdf[gdf["level"] == "rakuseki_03"]["len_m"].max()),
"04 (高)": (gdf[gdf["level"] == "rakuseki_04"]["len_m"].mean(),
gdf[gdf["level"] == "rakuseki_04"]["len_m"].median(),
gdf[gdf["level"] == "rakuseki_04"]["len_m"].max()),
}
T_length = pd.DataFrame([
{"カテゴリ": k, "平均_m": round(v[0], 0), "中央_m": round(v[1], 0),
"最大_m": round(v[2], 0)} for k, v in length_summary.items()])
# H1: orange (03) >= 60%
share_03 = round(100 * n_03 / n_seg, 1)
h1_ok = share_03 >= 60.0
print(f" 03={n_03} ({share_03}%) / 04={n_04}", flush=True)
print(f" H1 (03 ≥ 60%): {h1_ok}", flush=True)
print(f" ({time.time()-t4:.1f}s)", flush=True)
# =============================================================================
# 5. RQ2: 事前通行規制 (L73) との階層
# =============================================================================
print("\n[5] RQ2 集計 — L73 規制との階層", flush=True)
t5 = time.time()
# L73 を読み込んで LineString 化
def load_l73_gdf():
if not L73_JSON.exists():
# 不在ならダウンロード
ensure_dataset(L73_JSON, resource_id=32489, min_bytes=10000,
label="L73 pre_traffic.json")
with open(L73_JSON, "r", encoding="utf-8") as f:
raw = json.load(f)
recs = raw["results"]
geoms = []
rows = []
for r in recs:
try:
g = swkt.loads(r.get("kukanroot") or r.get("kukan", ""))
except Exception:
g = None
geoms.append(g)
rows.append({
"id_l73": r.get("id", ""),
"rosen_l73": r.get("rosenname", "").replace(" ", " "),
"naiyo_l73": r.get("kiseinaiyo", ""),
"rank_l73": r.get("rankname", ""),
"type_l73": r.get("type", ""),
"ukai_l73": r.get("ukaiumu", ""),
})
df_l73 = pd.DataFrame(rows)
g73 = gpd.GeoDataFrame(df_l73, geometry=geoms, crs="EPSG:4326")
g73 = g73[g73.geometry.notna()].copy().to_crs(TARGET_CRS)
return g73
gdf_l73 = load_l73_gdf()
n_l73 = len(gdf_l73)
total_km_l73 = float(gdf_l73.geometry.length.sum() / 1000)
print(f" L73: {n_l73} 区間 / {total_km_l73:.1f} km", flush=True)
# L73 100m バッファ
gdf_l73_buf = gdf_l73.copy()
gdf_l73_buf["geometry"] = gdf_l73.geometry.buffer(BUFFER_L73_M)
# L74 ↔ L73 重複判定 (intersects)
overlap_l73 = gpd.sjoin(
gdf[["seg_id", "level", "geometry"]],
gdf_l73_buf[["id_l73", "naiyo_l73", "type_l73", "geometry"]],
how="left", predicate="intersects")
# 1 注意区間 が複数 L73 と交差する場合: 1 件でも重複ありで True
overlap_grp = (overlap_l73.dropna(subset=["index_right"])
.groupby("seg_id").agg(
on_l73=("index_right", lambda s: True),
l73_naiyo=("naiyo_l73",
lambda s: ", ".join(sorted(set([str(v) for v in s.dropna() if v]))[:3])),
l73_type=("type_l73",
lambda s: ", ".join(sorted(set([str(v) for v in s.dropna() if v]))[:2])),
l73_n=("index_right", "count")))
gdf["on_l73"] = gdf["seg_id"].map(overlap_grp["on_l73"]).fillna(False).astype(bool)
gdf["l73_naiyo_match"] = gdf["seg_id"].map(overlap_grp["l73_naiyo"]).fillna("")
gdf["l73_type_match"] = gdf["seg_id"].map(overlap_grp["l73_type"]).fillna("")
gdf["l73_n_match"] = gdf["seg_id"].map(overlap_grp["l73_n"]).fillna(0).astype(int)
# 重複延長 (L74 LineString と L73 buffer union の intersection)
buf_union_l73 = gdf_l73_buf.geometry.union_all()
gdf["overlap_l73_km"] = gdf.geometry.apply(
lambda g: g.intersection(buf_union_l73).length / 1000
if g and not g.is_empty else 0.0
).round(3)
n_overlap_l73 = int(gdf["on_l73"].sum())
overlap_l73_km = float(gdf["overlap_l73_km"].sum())
share_only_l74 = round(100 * (n_seg - n_overlap_l73) / n_seg, 1)
# 階層別 重複
T_overlap_l73 = (gdf.groupby("level_label")
.agg(区間数=("seg_id", "count"),
重複ありL73=("on_l73", "sum"),
重複_km=("overlap_l73_km",
lambda s: round(s.sum(), 2)))
.reset_index())
T_overlap_l73["重複率_%"] = (T_overlap_l73["重複ありL73"]
/ T_overlap_l73["区間数"] * 100).round(1)
# H2: L74 ∩ L73 >= 10
h2_ok = n_overlap_l73 >= 10
# H3: 注意のみ (≠規制) >= 80%
h3_ok = share_only_l74 >= 80.0
print(f" L74 ∩ L73 重複: {n_overlap_l73}/{n_seg} 区間 ({100-share_only_l74:.1f}%) / "
f"重複延長 {overlap_l73_km:.1f} km", flush=True)
print(f" 注意のみ (≠規制): {share_only_l74}%", flush=True)
print(f" H2 (重複≥10): {h2_ok}", flush=True)
print(f" H3 (注意のみ≥80%): {h3_ok}", flush=True)
print(f" ({time.time()-t5:.1f}s)", flush=True)
# =============================================================================
# 6. RQ3: L50/L73/L74 3 階層 + L72 緊急輸送道路
# =============================================================================
print("\n[6] RQ3 集計 — 3 階層 + L72", flush=True)
t6 = time.time()
# (1) L50 件数読込 (動的規制)
n_l50_today = 0
n_l50_future = 0
try:
with open(L50_TODAY_JSON, "r", encoding="utf-8") as f:
n_l50_today = len(json.load(f).get("results", []))
except Exception:
pass
try:
with open(L50_FUTURE_JSON, "r", encoding="utf-8") as f:
n_l50_future = len(json.load(f).get("results", []))
except Exception:
pass
# 3 階層件数
T_3layer = pd.DataFrame([
{"階層": "L50 動的規制 (本日 + 今後)",
"件数": n_l50_today + n_l50_future,
"性質": "短期 (~数日)・工事 + 災害短期",
"規制力": "強 (通行止/片側交互/車線規制)"},
{"階層": "L73 事前通行規制区間 (静的)",
"件数": n_l73, "性質": "恒常・雨量閾値超過で発動",
"規制力": "強 (発動時 通行止)"},
{"階層": "L74 走行注意区間 (静的)",
"件数": n_seg, "性質": "恒常・落石注意の情報提供",
"規制力": "弱 (法的強制なし、 注意喚起のみ)"},
])
# H4: 注意 (L74) > 動的 (L50) > 規制 (L73)
n_l50_total = n_l50_today + n_l50_future
h4_ok = (n_seg > n_l50_total) and (n_l50_total > n_l73)
# (2) L72 緊急輸送道路 を読み込んで L74 と重複判定
def load_l72_lines(idx):
p = L72_DIR / f"05_kinkyu_route_{idx}.json"
with open(p, "r", encoding="utf-8") as f:
text = f.read()
arr = json.loads("[" + text + "]")
lines = []
for seg in arr:
if isinstance(seg, list) and len(seg) >= 2:
coords = [(pt["e"], pt["d"]) for pt in seg]
lines.append(LineString(coords))
return lines
records_l72 = []
for idx in L72_RANKS:
for ln in load_l72_lines(idx):
records_l72.append({"l72_rank": idx,
"l72_label": L72_LABEL[idx],
"geometry": ln})
gdf_l72 = gpd.GeoDataFrame(records_l72, crs="EPSG:4326").to_crs(TARGET_CRS)
n_l72 = len(gdf_l72)
total_km_l72 = float(gdf_l72.geometry.length.sum() / 1000)
print(f" L72: {n_l72} セグ / {total_km_l72:.0f} km", flush=True)
# L72 30m バッファ
gdf_l72_buf = gdf_l72.copy()
gdf_l72_buf["geometry"] = gdf_l72.geometry.buffer(BUFFER_L72_M)
buf_union_l72 = gdf_l72_buf.geometry.union_all()
# L74 と L72 buffer の交差 (LineString と buffer union)
gdf["overlap_l72_km"] = gdf.geometry.apply(
lambda g: g.intersection(buf_union_l72).length / 1000
if g and not g.is_empty else 0.0
).round(3)
gdf["on_l72"] = gdf["overlap_l72_km"] > 0.0
# L72 階層別重複 (sjoin で最高位を採る)
overlap_l72 = gpd.sjoin(
gdf[["seg_id", "geometry"]],
gdf_l72_buf[["l72_rank", "l72_label", "geometry"]],
how="left", predicate="intersects")
overlap_l72_grp = (overlap_l72.dropna(subset=["index_right"])
.groupby("seg_id")["l72_rank"]
.apply(lambda s: s.dropna().min()))
gdf["l72_rank"] = gdf["seg_id"].map(overlap_l72_grp).fillna("")
gdf["l72_label"] = gdf["l72_rank"].map(L72_LABEL).fillna("(なし)")
n_overlap_l72 = int(gdf["on_l72"].sum())
overlap_l72_km = float(gdf["overlap_l72_km"].sum())
# H5: L74 ∩ L72 重複 >= 20 km
h5_ok = overlap_l72_km >= 20.0
# 階層別 L72 重複
T_overlap_l72 = (gdf[gdf["on_l72"]]
.groupby("l72_label")
.agg(区間数=("seg_id", "count"),
重複_km=("overlap_l72_km",
lambda s: round(s.sum(), 2)))
.reset_index().rename(columns={"l72_label": "緊急輸送道路階層"}))
# 3 重判定 (L74 ∩ L73 ∩ L72)
n_l74_only = int((~gdf["on_l73"] & ~gdf["on_l72"]).sum())
n_l74_l73 = int((gdf["on_l73"] & ~gdf["on_l72"]).sum())
n_l74_l72 = int((~gdf["on_l73"] & gdf["on_l72"]).sum())
n_l74_l73_l72 = int((gdf["on_l73"] & gdf["on_l72"]).sum())
T_triple = pd.DataFrame([
{"カテゴリ": "L74 単独 (規制も緊急輸送道路もなし)",
"区間数": n_l74_only,
"シェア_%": round(100 * n_l74_only / n_seg, 1)},
{"カテゴリ": "L74 ∩ L73 (規制と二重指定, 緊急輸送道路外)",
"区間数": n_l74_l73,
"シェア_%": round(100 * n_l74_l73 / n_seg, 1)},
{"カテゴリ": "L74 ∩ L72 (緊急輸送道路上, 規制なし)",
"区間数": n_l74_l72,
"シェア_%": round(100 * n_l74_l72 / n_seg, 1)},
{"カテゴリ": "L74 ∩ L73 ∩ L72 (3 重指定 = 最警戒)",
"区間数": n_l74_l73_l72,
"シェア_%": round(100 * n_l74_l73_l72 / n_seg, 1)},
])
print(f" L74 ∩ L72 重複: {n_overlap_l72} 区間 / {overlap_l72_km:.1f} km",
flush=True)
print(f" 3 重指定 (L74∩L73∩L72): {n_l74_l73_l72} 件", flush=True)
print(f" H4 (件数 注意>動的>規制): {h4_ok}", flush=True)
print(f" H5 (L74∩L72 ≥ 20km): {h5_ok}", flush=True)
print(f" ({time.time()-t6:.1f}s)", flush=True)
# =============================================================================
# 7. CSV 出力
# =============================================================================
print("\n[7] CSV 出力", flush=True)
t7 = time.time()
# (1) 全 381 区間
df_out = gdf.drop(columns=["geometry"]).copy()
df_out.to_csv(ASSETS / "L74_all_segments.csv", index=False, encoding="utf-8-sig")
# (2) 各種サマリ
T_level.to_csv(ASSETS / "L74_level_summary.csv",
index=False, encoding="utf-8-sig")
T_geo.to_csv(ASSETS / "L74_geo_class.csv",
index=False, encoding="utf-8-sig")
T_level_geo.to_csv(ASSETS / "L74_level_x_geo.csv",
index=False, encoding="utf-8-sig")
T_city.to_csv(ASSETS / "L74_city_summary.csv",
index=False, encoding="utf-8-sig")
T_length.to_csv(ASSETS / "L74_length_stats.csv",
index=False, encoding="utf-8-sig")
T_overlap_l73.to_csv(ASSETS / "L74_overlap_l73.csv",
index=False, encoding="utf-8-sig")
T_overlap_l72.to_csv(ASSETS / "L74_overlap_l72.csv",
index=False, encoding="utf-8-sig")
T_3layer.to_csv(ASSETS / "L74_3layer_compare.csv",
index=False, encoding="utf-8-sig")
T_triple.to_csv(ASSETS / "L74_triple_overlap.csv",
index=False, encoding="utf-8-sig")
# (3) L74 ∩ L73 重複区間 (RQ2 二重指定リスト)
overlap_l73_segs = gdf[gdf["on_l73"]][[
"seg_id", "level", "level_label", "市町名", "地理クラス",
"len_km", "l73_n_match", "l73_naiyo_match", "l73_type_match",
"overlap_l73_km", "on_l72", "l72_label"]].copy()
overlap_l73_segs.to_csv(ASSETS / "L74_overlap_l73_segments.csv",
index=False, encoding="utf-8-sig")
# (4) 3 重指定区間 (L74 ∩ L73 ∩ L72) — 最警戒リスト
triple_segs = gdf[gdf["on_l73"] & gdf["on_l72"]][[
"seg_id", "level", "level_label", "市町名", "地理クラス",
"len_km", "l73_naiyo_match", "l73_type_match",
"overlap_l73_km", "l72_label", "overlap_l72_km"]].copy()
triple_segs.to_csv(ASSETS / "L74_triple_segments.csv",
index=False, encoding="utf-8-sig")
print(f" ({time.time()-t7:.1f}s)", flush=True)
# =============================================================================
# 8. 図の生成 (8 図)
# =============================================================================
print("\n[8] 図の生成", flush=True)
t8 = time.time()
ASSETS.mkdir(parents=True, exist_ok=True)
# 県全域 表示 bbox
XMIN, YMIN = -15000, -220000
XMAX, YMAX = 125000, -90000
def save_fig(name, dpi=120):
p = ASSETS / name
plt.savefig(p, dpi=dpi, bbox_inches="tight", facecolor="white")
plt.close('all')
return p
# ---- 図 1 (RQ1): 県全域 注意レベル別 マップ ----
print(" fig1: 注意レベル別マップ", flush=True)
fig, ax = plt.subplots(figsize=(13, 8))
admin.plot(ax=ax, color="#fff4e0", edgecolor="#888",
linewidth=0.4, alpha=0.55)
# 描画順 (背景に多数派から)
sub_03 = gdf[gdf["level"] == "rakuseki_03"]
sub_04 = gdf[gdf["level"] == "rakuseki_04"]
sub_03.plot(ax=ax, color=LEVEL_COLOR["rakuseki_03"],
linewidth=1.6, alpha=0.85, zorder=3)
sub_04.plot(ax=ax, color=LEVEL_COLOR["rakuseki_04"],
linewidth=2.4, alpha=0.95, zorder=5)
ax.set_xlim(XMIN, XMAX)
ax.set_ylim(YMIN, YMAX)
ax.set_aspect("equal")
ax.set_title(f"図 1 (RQ1): 広島県 走行注意区間 注意レベル別マップ — "
f"全 {n_seg} 区間 / {total_km:.0f} km / "
f"03 (低注意) {n_03} + 04 (高注意) {n_04}",
fontsize=10.5)
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
patches = [
Line2D([0], [0], color=LEVEL_COLOR["rakuseki_03"], linewidth=2.5,
label=f"03 (低注意, orange) — {n_03} 件 / {km_03:.0f} km"),
Line2D([0], [0], color=LEVEL_COLOR["rakuseki_04"], linewidth=3.5,
label=f"04 (高注意, red) — {n_04} 件 / {km_04:.0f} km"),
]
ax.legend(handles=patches, loc="lower left", fontsize=10,
title="注意レベル (落石)")
plt.tight_layout()
save_fig("L74_fig1_level_map.png")
# ---- 図 2 (RQ1): 階層 + 区間長 + 地理 3角度 ----
print(" fig2: 階層 + 区間長 + 地理", flush=True)
fig, axes = plt.subplots(1, 3, figsize=(17, 5.5))
# 左: 階層別 件数 + 延長
ax = axes[0]
xs = np.arange(2)
counts = [n_03, n_04]
kms = [km_03, km_04]
cols = [LEVEL_COLOR["rakuseki_03"], LEVEL_COLOR["rakuseki_04"]]
ax.bar(xs, counts, color=cols, edgecolor="#333", linewidth=0.5, width=0.5)
for x, v, km in zip(xs, counts, kms):
ax.text(x, v + max(counts) * 0.02,
f"{int(v)} 区間\n({km:.0f} km)",
ha="center", fontsize=11, fontweight="bold")
ax.set_xticks(xs)
ax.set_xticklabels(["03 (低注意)", "04 (高注意)"], fontsize=11)
ax.set_ylabel("区間数")
ax.set_title(f"注意レベル別 件数 + 延長\n"
f"H1 03 シェア {share_03}% (≥60%: {h1_ok})",
fontsize=10.5)
ax.grid(True, axis="y", alpha=0.3)
# 中: 区間長 log10 ヒスト (階層 stack)
ax = axes[1]
log_lens = np.log10(np.maximum(gdf["len_m"].values, 1))
bins = np.linspace(log_lens.min(), log_lens.max(), 25)
btm = np.zeros(len(bins) - 1)
for lvl in LEVEL_ORDER:
s = gdf[gdf["level"] == lvl]
if len(s) == 0:
continue
h, _ = np.histogram(np.log10(np.maximum(s["len_m"].values, 1)), bins=bins)
ax.bar((bins[:-1] + bins[1:]) / 2, h, width=(bins[1] - bins[0]) * 0.95,
bottom=btm, color=LEVEL_COLOR[lvl], edgecolor="white",
linewidth=0.4, label=LEVEL_LABEL[lvl])
btm = btm + h
ax.set_xlabel("log10(区間長 m)")
ax.set_ylabel("区間数")
ax.set_xticks([1, 2, 3, 4, 5])
ax.set_xticklabels(["10 m", "100 m", "1 km", "10 km", "100 km"])
ax.set_title(f"区間長 log10 分布\n"
f"中央 {gdf['len_m'].median():.0f} m / 最大 {gdf['len_m'].max():.0f} m",
fontsize=10.5)
ax.legend(fontsize=9, loc="upper left")
ax.grid(True, axis="y", alpha=0.3)
# 右: 地理クラス 件数
ax = axes[2]
gc_order = ["中山間山地", "平野・沿岸都市", "沿岸島嶼",
"不明 (代表点が県外/海上)"]
gc_present = [g for g in gc_order if g in T_geo["地理クラス"].values]
xs = np.arange(len(gc_present))
counts_geo = [int(T_geo[T_geo["地理クラス"] == g]["区間数"].iloc[0])
for g in gc_present]
kms_geo = [float(T_geo[T_geo["地理クラス"] == g]["延長_km"].iloc[0])
for g in gc_present]
gc_colors = ["#cf6f00", "#0969da", "#1a7f37", "#888"]
ax.bar(xs, counts_geo, color=gc_colors[:len(gc_present)],
edgecolor="#333", linewidth=0.5)
for x, v, km in zip(xs, counts_geo, kms_geo):
ax.text(x, v + max(counts_geo) * 0.02,
f"{int(v)}\n({km:.0f} km)",
ha="center", fontsize=10, fontweight="bold")
ax.set_xticks(xs)
ax.set_xticklabels([g.replace("不明 (代表点が県外/海上)", "不明")
for g in gc_present],
rotation=15, fontsize=9.5)
ax.set_ylabel("区間数")
ax.set_title(f"地理クラス別 件数\n中山間 {share_chusankan}%",
fontsize=10.5)
ax.grid(True, axis="y", alpha=0.3)
fig.suptitle("図 2 (RQ1): 注意レベル × 区間長 × 地理クラス — 構造 3 角度",
fontsize=12.5, y=1.02)
plt.tight_layout()
save_fig("L74_fig2_rq1_structure.png")
# ---- 図 3 (RQ1): 中山間境界 + 注意区間 重ね合わせ ----
print(" fig3: 中山間境界マップ", flush=True)
fig, ax = plt.subplots(figsize=(13, 8))
admin_geo = admin.merge(
pd.DataFrame({"市町名": list(CHUSANKAN_CITIES) + list(COASTAL_ISLAND),
"geo_cls": ["中山間"] * len(CHUSANKAN_CITIES)
+ ["沿岸島嶼"] * len(COASTAL_ISLAND)}),
on="市町名", how="left")
admin_geo.plot(ax=ax,
color=admin_geo["geo_cls"].map(
{"中山間": "#fde7d3", "沿岸島嶼": "#dff0fa"}).fillna("#f6f8fa"),
edgecolor="#888", linewidth=0.5, alpha=0.85)
# 注意区間 (中山間 vs その他で色 + 階層)
gdf_chu = gdf[gdf["地理クラス"] == "中山間山地"]
gdf_oth = gdf[gdf["地理クラス"] != "中山間山地"]
gdf_oth.plot(ax=ax, color="#888", linewidth=1.0, alpha=0.5, zorder=3)
gdf_chu[gdf_chu["level"] == "rakuseki_03"].plot(
ax=ax, color="#cf6f00", linewidth=1.8, alpha=0.85, zorder=4)
gdf_chu[gdf_chu["level"] == "rakuseki_04"].plot(
ax=ax, color="#cf222e", linewidth=2.4, alpha=0.95, zorder=5)
ax.set_xlim(XMIN, XMAX)
ax.set_ylim(YMIN, YMAX)
ax.set_aspect("equal")
ax.set_title(f"図 3 (RQ1): 走行注意区間 + 中山間境界 — "
f"中山間 {n_chusankan}/{n_seg} 区間 ({share_chusankan}%)",
fontsize=10.5)
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
patches = [
Patch(facecolor="#fde7d3", label="中山間市町 (8市町)"),
Patch(facecolor="#dff0fa", label="沿岸島嶼"),
Patch(facecolor="#f6f8fa", label="平野・沿岸都市"),
Line2D([0], [0], color="#cf6f00", linewidth=2.5,
label=f"03 注意 in 中山間"),
Line2D([0], [0], color="#cf222e", linewidth=3.5,
label=f"04 注意 in 中山間"),
Line2D([0], [0], color="#888", linewidth=2,
label=f"注意 in その他 ({n_seg - n_chusankan})"),
]
ax.legend(handles=patches, loc="lower left", fontsize=9.5)
plt.tight_layout()
save_fig("L74_fig3_chusankan_map.png")
# ---- 図 4 (RQ2): L74 ∩ L73 重ね合わせマップ ----
print(" fig4: L74 ∩ L73 重ね合わせ", flush=True)
fig, ax = plt.subplots(figsize=(13, 8))
admin.plot(ax=ax, color="#fff4e0", edgecolor="#888",
linewidth=0.4, alpha=0.55)
# L73 を背景の薄青で
gdf_l73.plot(ax=ax, color="#0969da", linewidth=1.4, alpha=0.5, zorder=2)
# L74 単独 (規制と重ならない) — 黄/橙
gdf_only_l74 = gdf[~gdf["on_l73"]]
gdf_overlap = gdf[gdf["on_l73"]]
gdf_only_l74.plot(ax=ax, color="#bf8700", linewidth=1.4, alpha=0.7, zorder=3)
# L74 ∩ L73 — 赤太線で強調
gdf_overlap.plot(ax=ax, color="#cf222e", linewidth=2.6, alpha=0.95, zorder=5)
# 重複箇所に星印
if len(gdf_overlap) > 0:
pts_ov = gdf_overlap.geometry.representative_point()
pts_ov_gdf = gpd.GeoDataFrame(geometry=pts_ov.values, crs=TARGET_CRS)
pts_ov_gdf.plot(ax=ax, color="#cf222e", marker="*",
markersize=140, zorder=8,
edgecolor="#000", linewidth=0.4)
ax.set_xlim(XMIN, XMAX)
ax.set_ylim(YMIN, YMAX)
ax.set_aspect("equal")
ax.set_title(f"図 4 (RQ2): L74 走行注意 + L73 事前通行規制 重ね合わせ — "
f"重複 {n_overlap_l73}/{n_seg} 区間 / "
f"注意のみ {n_seg - n_overlap_l73} ({share_only_l74}%)",
fontsize=10)
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
patches = [
Line2D([0], [0], color="#0969da", linewidth=2,
label=f"L73 事前通行規制 (背景, {n_l73} 件 / {total_km_l73:.0f} km)"),
Line2D([0], [0], color="#bf8700", linewidth=2.5,
label=f"L74 走行注意 単独 ({n_seg - n_overlap_l73} 件)"),
Line2D([0], [0], color="#cf222e", linewidth=3.5,
label=f"L74 ∩ L73 (二重指定 = 最警戒, {n_overlap_l73} 件 ★)"),
]
ax.legend(handles=patches, loc="lower left", fontsize=9.5)
plt.tight_layout()
save_fig("L74_fig4_overlap_l73_map.png")
# ---- 図 5 (RQ2): L74 階層別 重複率 + 規制内容クロス ----
print(" fig5: 階層別重複率 + 規制内容クロス", flush=True)
fig, axes = plt.subplots(1, 2, figsize=(14, 5.5))
# 左: 階層別 重複率
ax = axes[0]
levels_present = T_overlap_l73["level_label"].tolist()
xs = np.arange(len(levels_present))
counts_total = T_overlap_l73["区間数"].values
counts_overlap = T_overlap_l73["重複ありL73"].values
overlap_kms = T_overlap_l73["重複_km"].values
overlap_rates = T_overlap_l73["重複率_%"].values
w = 0.4
cols_lvl = [LEVEL_COLOR.get(k.split(" ")[0].replace("03", "rakuseki_03").replace("04", "rakuseki_04"), "#888")
for k in levels_present]
# fallback simpler: use index
cols_lvl_simple = [LEVEL_COLOR["rakuseki_03"] if "03" in lab
else LEVEL_COLOR["rakuseki_04"]
for lab in levels_present]
ax.bar(xs - w/2, counts_total, w, color=cols_lvl_simple,
edgecolor="#333", linewidth=0.4, alpha=0.5,
label="全区間数")
ax.bar(xs + w/2, counts_overlap, w, color=cols_lvl_simple,
edgecolor="#333", linewidth=0.4,
label="L73 重複あり")
for x, total, ov, rate, km in zip(xs, counts_total, counts_overlap,
overlap_rates, overlap_kms):
ax.text(x - w/2, total + max(counts_total) * 0.02,
f"{int(total)}", ha="center", fontsize=10)
ax.text(x + w/2, ov + max(counts_total) * 0.02,
f"{int(ov)}\n({rate:.0f}%)",
ha="center", fontsize=9.5, fontweight="bold")
ax.set_xticks(xs)
ax.set_xticklabels(levels_present, fontsize=10)
ax.set_ylabel("区間数")
ax.set_title(f"L74 階層別 L73 重複率\n"
f"H2 重複 {n_overlap_l73} 件 (≥10: {h2_ok}) / "
f"H3 注意のみ {share_only_l74}% (≥80%: {h3_ok})",
fontsize=10)
ax.legend(fontsize=9, loc="upper right")
ax.grid(True, axis="y", alpha=0.3)
# 右: L74 ∩ L73 のうち、 重複した L73 の規制内容分布
ax = axes[1]
overlap_naiyo_counts = {}
for v in gdf_overlap["l73_naiyo_match"]:
if not v:
continue
for piece in v.split(", "):
overlap_naiyo_counts[piece] = overlap_naiyo_counts.get(piece, 0) + 1
naiyo_keys = sorted(overlap_naiyo_counts.keys(),
key=lambda k: -overlap_naiyo_counts[k])[:8]
naiyo_vals = [overlap_naiyo_counts[k] for k in naiyo_keys]
xs = np.arange(len(naiyo_keys))
naiyo_color_map = {
"落石等": "#cf222e", "凍結等": "#0969da", "強風": "#1a7f37",
"冠水": "#7c3aed", "越波": "#cf6f00",
}
naiyo_cols = [naiyo_color_map.get(k.strip(), "#888") for k in naiyo_keys]
ax.bar(xs, naiyo_vals, color=naiyo_cols, edgecolor="#333", linewidth=0.5)
for x, v in zip(xs, naiyo_vals):
ax.text(x, v + max(naiyo_vals) * 0.02 if max(naiyo_vals) > 0 else 0.2,
f"{int(v)}", ha="center", fontsize=10, fontweight="bold")
ax.set_xticks(xs)
ax.set_xticklabels(naiyo_keys, rotation=15, fontsize=9.5)
ax.set_ylabel("L74 重複区間数 (重複先 L73 規制内容)")
ax.set_title(f"L74 ∩ L73 における 重複 L73 規制内容分布\n"
f"= 「注意区間が二重指定される 規制種類」",
fontsize=10)
ax.grid(True, axis="y", alpha=0.3)
fig.suptitle("図 5 (RQ2): 規制との階層 — 重複率 + 規制内容クロス",
fontsize=12.5, y=1.02)
plt.tight_layout()
save_fig("L74_fig5_overlap_l73_breakdown.png")
# ---- 図 6 (RQ3): L50/L73/L74 3 階層 件数比較 + 重ね合わせマップ ----
print(" fig6: 3 階層比較 + 重ね合わせ", flush=True)
fig, axes = plt.subplots(1, 2, figsize=(15, 6.5),
gridspec_kw={"width_ratios": [1, 2]})
# 左: 3 階層 件数バー
ax = axes[0]
layers = ["L74\n注意", "L50\n動的規制", "L73\n事前規制"]
counts_layers = [n_seg, n_l50_total, n_l73]
layer_colors = ["#bf8700", "#7c3aed", "#cf222e"]
xs = np.arange(len(layers))
ax.bar(xs, counts_layers, color=layer_colors, edgecolor="#333",
linewidth=0.5, width=0.55)
for x, v in zip(xs, counts_layers):
ax.text(x, v + max(counts_layers) * 0.02,
f"{int(v)} 件", ha="center", fontsize=11, fontweight="bold")
ax.set_xticks(xs)
ax.set_xticklabels(layers, fontsize=10)
ax.set_ylabel("件数")
ax.set_title(f"県の道路情報 3 階層 件数\n"
f"H4 注意>動的>規制 ({h4_ok})", fontsize=10.5)
ax.grid(True, axis="y", alpha=0.3)
# 右: L50 / L73 / L74 重ね合わせマップ (L50 は座標がある場合のみ点で)
ax = axes[1]
admin.plot(ax=ax, color="#fff4e0", edgecolor="#888",
linewidth=0.4, alpha=0.55)
# L73 (赤系)
gdf_l73.plot(ax=ax, color="#cf222e", linewidth=1.4, alpha=0.6, zorder=3)
# L74 (橙)
gdf.plot(ax=ax, color="#bf8700", linewidth=1.2, alpha=0.6, zorder=2)
# L50 動的規制 (lat/lon があるレコードを点で)
l50_pts = []
for jp in [L50_TODAY_JSON, L50_FUTURE_JSON]:
try:
with open(jp, "r", encoding="utf-8") as f:
l50_recs = json.load(f).get("results", [])
for r in l50_recs:
try:
lat = float(r.get("lat") or 0)
lon = float(r.get("lon") or 0)
if 30 < lat < 38 and 130 < lon < 137:
l50_pts.append((lon, lat))
except Exception:
continue
except Exception:
continue
if l50_pts:
l50_gdf = gpd.GeoDataFrame(
geometry=[Point(x, y) for x, y in l50_pts],
crs="EPSG:4326").to_crs(TARGET_CRS)
l50_gdf.plot(ax=ax, color="#7c3aed", markersize=24,
alpha=0.7, zorder=6, edgecolor="#000",
linewidth=0.3)
ax.set_xlim(XMIN, XMAX)
ax.set_ylim(YMIN, YMAX)
ax.set_aspect("equal")
ax.set_title(f"県の道路情報 3 階層 重ね合わせマップ\n"
f"L74 注意 {n_seg} (橙) / L73 規制 {n_l73} (赤) / "
f"L50 動的 {len(l50_pts)} (紫点)",
fontsize=10)
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
patches = [
Line2D([0], [0], color="#bf8700", linewidth=2.5,
label=f"L74 走行注意 ({n_seg} 件)"),
Line2D([0], [0], color="#cf222e", linewidth=2.5,
label=f"L73 事前通行規制 ({n_l73} 件)"),
Line2D([0], [0], marker='o', color='w',
markerfacecolor="#7c3aed", markeredgecolor="#000",
markersize=8, label=f"L50 動的規制 ({len(l50_pts)} 点)"),
]
ax.legend(handles=patches, loc="lower left", fontsize=9.5)
fig.suptitle("図 6 (RQ3): 県の道路情報 3 階層 統合 — 件数 + 地理分布",
fontsize=12.5, y=1.02)
plt.tight_layout()
save_fig("L74_fig6_3layer_combined.png")
# ---- 図 7 (RQ3): L74 ∩ L72 緊急輸送道路 重複マップ ----
print(" fig7: L74 ∩ L72 重ね合わせ", flush=True)
fig, ax = plt.subplots(figsize=(13, 8))
admin.plot(ax=ax, color="#fff4e0", edgecolor="#888",
linewidth=0.4, alpha=0.55)
# L72 (灰色背景)
gdf_l72.plot(ax=ax, color="#bbb", linewidth=0.8, alpha=0.6, zorder=2)
# L74 単独 (L72 重ならない) — 橙
gdf_only_l74_l72 = gdf[~gdf["on_l72"]]
gdf_l72_overlap = gdf[gdf["on_l72"]]
gdf_only_l74_l72.plot(ax=ax, color="#bf8700", linewidth=1.0, alpha=0.6,
zorder=3)
# L74 ∩ L72 (緑強調)
gdf_l72_overlap.plot(ax=ax, color="#1a7f37", linewidth=2.4, alpha=0.95,
zorder=5)
# 3 重指定 (L74 ∩ L73 ∩ L72) を星印
gdf_triple = gdf[gdf["on_l73"] & gdf["on_l72"]]
if len(gdf_triple) > 0:
pts_tr = gdf_triple.geometry.representative_point()
pts_tr_gdf = gpd.GeoDataFrame(geometry=pts_tr.values, crs=TARGET_CRS)
pts_tr_gdf.plot(ax=ax, color="#cf222e", marker="*",
markersize=200, zorder=8,
edgecolor="#000", linewidth=0.5)
ax.set_xlim(XMIN, XMAX)
ax.set_ylim(YMIN, YMAX)
ax.set_aspect("equal")
ax.set_title(f"図 7 (RQ3): L74 走行注意 ∩ L72 緊急輸送道路 — "
f"重複 {n_overlap_l72} 区間 / {overlap_l72_km:.1f} km / "
f"3 重指定 (L74∩L73∩L72) {n_l74_l73_l72} 件 (★)",
fontsize=10)
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
patches = [
Line2D([0], [0], color="#bbb", linewidth=2,
label=f"L72 緊急輸送道路 ({n_l72} セグ / {total_km_l72:.0f} km)"),
Line2D([0], [0], color="#bf8700", linewidth=2,
label=f"L74 単独 ({n_seg - n_overlap_l72} 件)"),
Line2D([0], [0], color="#1a7f37", linewidth=3,
label=f"L74 ∩ L72 (緊急輸送上, {n_overlap_l72} 件 / {overlap_l72_km:.0f} km)"),
Line2D([0], [0], marker='*', color='w',
markerfacecolor="#cf222e", markeredgecolor="#000",
markersize=14, label=f"3 重指定 (★, {n_l74_l73_l72} 件)"),
]
ax.legend(handles=patches, loc="lower left", fontsize=9.5)
plt.tight_layout()
save_fig("L74_fig7_overlap_l72_map.png")
# ---- 図 8 (RQ3): 4 カテゴリ クロス + L72 階層別重複 ----
print(" fig8: 4 カテゴリ + L72 階層別", flush=True)
fig, axes = plt.subplots(1, 2, figsize=(15, 5.5))
# 左: 4 カテゴリ (L74 単独/L73重なり/L72重なり/3重) パイ
ax = axes[0]
cat_names = ["L74 単独", "L74 ∩ L73", "L74 ∩ L72", "L74 ∩ L73 ∩ L72"]
cat_vals = [n_l74_only, n_l74_l73, n_l74_l72, n_l74_l73_l72]
cat_cols = ["#bf8700", "#cf222e", "#1a7f37", "#7c3aed"]
# パイ
wedges, texts, autotexts = ax.pie(
cat_vals, labels=cat_names, colors=cat_cols,
autopct=lambda p: f"{p:.1f}%\n({int(round(p*sum(cat_vals)/100))})",
textprops={"fontsize": 10, "fontweight": "bold"},
startangle=90, wedgeprops={"edgecolor": "#fff", "linewidth": 1.5})
ax.set_title(f"L74 注意区間 4 カテゴリ — 制度重なり構造\n"
f"3 重指定 = {n_l74_l73_l72} 件 (最警戒)",
fontsize=10.5)
# 右: L72 階層別重複
ax = axes[1]
if len(T_overlap_l72) > 0:
l72_labels_present = T_overlap_l72["緊急輸送道路階層"].tolist()
counts_l72 = T_overlap_l72["区間数"].values
kms_l72 = T_overlap_l72["重複_km"].values
xs = np.arange(len(l72_labels_present))
l72_cols_arr = ["#cf222e", "#0969da", "#1a7f37", "#cf6f00"][
:len(l72_labels_present)]
ax.bar(xs, counts_l72, color=l72_cols_arr, edgecolor="#333",
linewidth=0.5)
for x, v, km in zip(xs, counts_l72, kms_l72):
ax.text(x, v + max(counts_l72) * 0.02 if max(counts_l72) > 0 else 0.2,
f"{int(v)}\n({km:.1f} km)",
ha="center", fontsize=10, fontweight="bold")
ax.set_xticks(xs)
ax.set_xticklabels(l72_labels_present, fontsize=10)
ax.set_ylabel("L74 重複 区間数")
ax.set_title(f"L74 ∩ L72 階層別 重複\n"
f"H5 重複 {overlap_l72_km:.1f} km (≥20km: {h5_ok})",
fontsize=10.5)
ax.grid(True, axis="y", alpha=0.3)
fig.suptitle("図 8 (RQ3): 制度重なり 4 カテゴリ + L72 階層別重複",
fontsize=12.5, y=1.02)
plt.tight_layout()
save_fig("L74_fig8_triple_breakdown.png")
print(f" ({time.time()-t8:.1f}s)", flush=True)
# =============================================================================
# 9. 仮説検証
# =============================================================================
print("\n[9] 仮説検証", flush=True)
t9 = time.time()
def df_to_html(d):
return d.to_html(index=False, classes="", border=0, escape=False,
na_rep="-").replace(' style="text-align: right;"', "")
# データセット仕様表
zip_size = zip_local.stat().st_size if zip_local.exists() else 0
T_dataset = pd.DataFrame([
("dataset_id", str(DATASET_ID)),
("公式名", "走行注意区間"),
("公式説明", "広島県が管理する道路の走行注意区間情報"),
("リソース数", "1 (ZIP, 拡張子は .json で配信)"),
("リソース ID", str(RESOURCE_ID)),
("ZIP サイズ", f"{zip_size:,} byte (~{zip_size/1024:.0f} KB)"),
("ZIP 内 ファイル",
"04_warning_rakuseki_03.json + _04.json + 04_warning_route.json"),
("形式", "NDJSON 風 (1 配列 = 1 LineString) + メタ JSON"),
("レコード数", f"{n_seg} 区間 (03={n_03} / 04={n_04})"),
("総延長", f"{total_km:.1f} km"),
("座標系 (元)", "WGS84 (EPSG:4326) → 本記事 EPSG:6671 で処理"),
("階層", "rakuseki_03 (低注意, orange) / rakuseki_04 (高注意, red)"),
("配信日 (フォルダ名)", "2022-09-08-T00:00:00 (公式 stamp)"),
("ライセンス", "クリエイティブ・コモンズ表示 (CC-BY)"),
("URL", f"https://hiroshima-dobox.jp/datasets/{DATASET_ID}"),
("作成主体", "広島県 (土木建築局道路整備課・防災担当)"),
], columns=["項目", "値"])
# 全体サマリ
T_overall = pd.DataFrame([
("dataset", f"#{DATASET_ID} 走行注意区間"),
("総区間数 (RQ1)", f"{n_seg}"),
("総延長 km (RQ1)", f"{total_km:.1f}"),
("階層別件数 (RQ1)", f"03 (低) {n_03} ({share_03}%) / 04 (高) {n_04}"),
("階層別延長 km (RQ1)", f"03 {km_03:.0f} / 04 {km_04:.0f}"),
("中央区間長 m (RQ1)", f"{int(gdf['len_m'].median())}"),
("最大区間長 m (RQ1)", f"{int(gdf['len_m'].max())}"),
("中山間 区間数 (RQ1)", f"{n_chusankan} ({share_chusankan}%)"),
("最多市町 (RQ1)",
f"{T_city.iloc[0]['市町名']} ({int(T_city.iloc[0]['区間数'])} 件)"
if len(T_city) > 0 else "-"),
("H1 (03 ≥ 60%) (RQ1)", "強支持" if h1_ok else "反証"),
("L74 ∩ L73 重複 区間数 (RQ2)", f"{n_overlap_l73}"),
("L74 ∩ L73 重複 km (RQ2)", f"{overlap_l73_km:.2f}"),
("注意のみ (≠規制) % (RQ2)", f"{share_only_l74}"),
("H2 (重複 ≥ 10) (RQ2)", "強支持" if h2_ok else "反証"),
("H3 (注意のみ ≥ 80%) (RQ2)", "強支持" if h3_ok else "反証"),
("L50 動的件数 (RQ3)", f"{n_l50_today}+{n_l50_future}={n_l50_total}"),
("L73 静的規制件数 (RQ3)", f"{n_l73}"),
("L74 静的注意件数 (RQ3)", f"{n_seg}"),
("L74 ∩ L72 重複 区間 (RQ3)", f"{n_overlap_l72}"),
("L74 ∩ L72 重複 km (RQ3)", f"{overlap_l72_km:.2f}"),
("3 重指定 L74∩L73∩L72 (RQ3)", f"{n_l74_l73_l72}"),
("H4 (件数順) (RQ3)", "強支持" if h4_ok else "反証"),
("H5 (L74∩L72 ≥ 20km) (RQ3)", "強支持" if h5_ok else "反証"),
], columns=["指標", "値"])
T_overall.to_csv(ASSETS / "L74_overall.csv",
index=False, encoding="utf-8-sig")
# 仮説検証 (H1〜H5)
def jud(cond, ok="強支持", fail="反証"):
return ok if cond else fail
T_hypo = pd.DataFrame([
("H1 階層構造: orange (03) ≥ 60% (RQ1)",
f"観測 = 03: {n_03}/{n_seg} = {share_03}%",
jud(h1_ok),
f"H1 {jud(h1_ok)}: 走行注意区間 {n_seg} のうち低注意 (03, orange) "
f"が {n_03} 件 ({share_03}%)、 高注意 (04, red) が {n_04} 件 "
f"({100-share_03:.1f}%)。 弱注意が圧倒的多数派で、 強注意は厳選された "
f"少数派という逆ピラミッド型の制度設計を示す。 これは「広く弱い "
f"情報を提供しつつ、 ほんとうに危険な箇所だけ強調する」 という道路情報 "
f"提供の品質設計思想を反映 (情報過多回避)。 階層 03 の合計延長 "
f"{km_03:.0f} kmと階層 04 の {km_04:.0f} kmを比較すると、 "
f"区間あたり平均長は 04 のほうが {gdf[gdf['level']=='rakuseki_04']['len_m'].mean()/gdf[gdf['level']=='rakuseki_03']['len_m'].mean():.1f} 倍と "
f"長い (= 強注意は連続した長区間で運用される)。"),
("H2 規制との重複: L74 ∩ L73 ≥ 10 件 (RQ2)",
f"観測 = L74 ∩ L73: {n_overlap_l73} 件",
jud(h2_ok),
f"H2 {jud(h2_ok)}: 走行注意区間 (L74) のうち、 事前通行規制区間 (L73) "
f"100m バッファ内にあるのは{n_overlap_l73} 件 "
f"({100-share_only_l74:.1f}%)、 重複延長は{overlap_l73_km:.1f} km。 "
f"これは「同じ道路に注意 (弱) + 規制 (強) の二重指定」 がある箇所で、 "
f"制度階層の連続性を示す物理的証拠。 規制側の主な内容は "
f"{', '.join(list(set([n.strip() for n in '|'.join(gdf_overlap['l73_naiyo_match'].fillna('').tolist()).replace(', ', '|').split('|') if n.strip()]))[:4])}等で、 "
f"これらの箇所は道路管理者が通常時=注意/異常時=規制と運用切替を "
f"設計する最警戒地点。 ただし重複区間は L74 全体の "
f"{100-share_only_l74:.1f}% に過ぎない (= H3 で見るように L74 は L73 より "
f"広い予防情報層)。"),
("H3 注意のみが多数派: ≥ 80% (RQ2)",
f"観測 = 注意のみ {share_only_l74}%",
jud(h3_ok),
f"H3 {jud(h3_ok)}: 走行注意区間のうち、 事前通行規制 (L73) と重ならない "
f"「注意のみ」 区間は{n_seg - n_overlap_l73} 件 "
f"({share_only_l74}%)。 これは注意制度が規制制度より広い範囲の "
f"道路をカバーすることを意味する。 注意 = 「広く弱い予防情報層」、 "
f"規制 = 「狭く強い予防制度」 という2 層の制度階層が量的に確認 — "
f"県の予防防災は(1) ドライバーへの注意喚起 (L74 = 広い情報層) → "
f"(2) 道路管理者の自動規制 (L73 = 狭い強制層)の段階的設計に "
f"なっている。 ({jud(h3_ok)})"),
(f"H4 件数規模: 注意 ({n_seg}) > 動的 ({n_l50_total}) > 規制 ({n_l73}) (RQ3)",
f"観測 = L74 {n_seg} / L50 {n_l50_total} / L73 {n_l73}",
jud(h4_ok),
f"H4 {jud(h4_ok)}: 県の道路情報 3 階層の件数比はL74 注意 {n_seg} > "
f"L50 動的 {n_l50_total} > L73 静的規制 {n_l73}。 これは「弱い情報は "
f"広く、 強い規制は狭く」 という逆ピラミッド構造の量的実証。 "
f"L74 (注意, 弱, 恒常) が広い情報層 → L50 (動的, 強, 短期) が中間の "
f"運用層 → L73 (静的規制, 強, 恒常) が頂点の予防的安全層。 件数比 = "
f"{n_seg/n_l73:.1f} : {n_l50_total/n_l73:.1f} : 1.0 "
f"(L73 を 1 とした比率)。 これは情報配信の3 階層ピラミッド設計の "
f"具体形であり、 災害時の情報伝達はL74 → L50 → L73の順に強化 "
f"されていく構造。"),
("H5 緊急輸送道路との重複 ≥ 20 km (RQ3)",
f"観測 = L74 ∩ L72 重複 {overlap_l72_km:.1f} km",
jud(h5_ok),
f"H5 {jud(h5_ok)}: 走行注意区間 (L74) と緊急輸送道路 (L72, "
f"{n_l72} セグ / {total_km_l72:.0f} km) の 30m バッファ重複は "
f"{n_overlap_l72} 区間 / {overlap_l72_km:.1f} km = "
f"L74 総延長 {total_km:.0f} km の "
f"{100*overlap_l72_km/total_km:.1f}%。 これは「注意区間は主要道路 "
f"(緊急輸送道路) の沿道に集中する」 という空間相関の量的証拠。 "
f"特に3 重指定 (L74 ∩ L73 ∩ L72) = {n_l74_l73_l72} 件は "
f"「災害時に通行確保すべき + 災害前に予防規制 + 平常時から注意喚起」 "
f"という4 層 BCP 矛盾の最警戒箇所。 県の地域防災計画では、 "
f"これらの 3 重指定箇所こそが「制度的最重要箇所リスト」として "
f"維持管理 + 防災工事の優先順位上位となる。"),
], columns=["仮説", "観測値", "判定", "詳細解説"])
T_hypo.to_csv(ASSETS / "L74_hypothesis_check.csv",
index=False, encoding="utf-8-sig")
print(f" ({time.time()-t9:.1f}s)", flush=True)
# =============================================================================
# 10. HTML 生成
# =============================================================================
print("\n[10] HTML 生成", flush=True)
t10 = time.time()
# ----- セクション 1: 学習目標と問い -----
sec1 = f"""
本記事の対象 — 「走行注意区間」 1 件 単独分析
本記事は DoBoX のデータセット 「走行注意区間」 (dataset {DATASET_ID})
1 件を 単独で取り上げ、 広島県の走行注意区間
{n_seg} 区間 / 総延長 {total_km:.0f} kmを
3 つの独立した研究角度で並列に分析する記事である。
他のシリーズ (事前通行規制 L73 / 道路規制 L50 / 緊急輸送道路 L72) と
本記事は 合体しない。 RQ2 で事前通行規制 (L73)、 RQ3 で L50 + L73 +
L72 を参照するが、 これは「県の道路情報 3 階層の量的実証」 を明らかに
するための既扱データの従属的参照に留め、 本記事の主軸はあくまで
走行注意区間 1 dataset の分析である。
「走行注意区間」 とは:
通行止めにはしないが、 ドライバーに「落石・崩落リスクあり」 を予告する
道路区間。 過去の小規模崩落履歴・地質脆弱性・植生状態等から道路管理者が
指定し、 注意喚起レベルに応じて
2 階層で運用される広島県独自の
「予防情報配信制度」。 法的拘束力 (規制) はないが、 道路法第 30 条の 2 に
基づく道路情報提供の一環として運用される。
広島県の走行注意区間は
2 階層 (orange/red)に区分される:
- 階層 03 (orange, #ffa500): 注意レベル低 — {n_03} 区間 /
{km_03:.0f} km。 通常走行可、 雨天時・夜間に減速注意
- 階層 04 (red, #ff0000): 注意レベル高 — {n_04} 区間 /
{km_04:.0f} km。 常時注意、 通行は可能だが豪雨時・地震後は迂回推奨
本記事の主要発見 (3 RQ):
- RQ1: 県の走行注意区間は{n_seg} 区間 / {total_km:.0f} km。
低注意 (03) が {n_03} 件 ({share_03}%)と多数派、 高注意 (04) は
{n_04} 件。 中山間山地に {n_chusankan} 件 ({share_chusankan}%)
が集中。
- RQ2: L74 (注意) と L73 (事前通行規制) の重複は
{n_overlap_l73} 件 / {overlap_l73_km:.1f} km。 残り
{share_only_l74}%が「注意のみ」 区間 = L74 は L73 より広い予防
情報層という制度階層が確認された。
- RQ3: 県の道路情報 3 階層はL74 注意 ({n_seg}) > L50 動的 ({n_l50_total})
> L73 静的規制 ({n_l73})の逆ピラミッド構造。 L74 ∩ L72 重複
{overlap_l72_km:.1f} km、 3 重指定 (L74∩L73∩L72)
{n_l74_l73_l72} 件が「制度的最警戒箇所」。
独自に定義する用語 (本記事限定)
- 走行注意区間 (本記事の中心概念): 通行止めにせず注意喚起のみを
行う道路区間。 道路法第 30 条の 2 に基づく道路情報提供の一環として運用される
県管理道路の「予防情報配信制度」。 規制 (L73) のような自動発動・
強制力はないが、 ドライバーに事前情報を提供することで自主的な減速・
迂回を促す。
- 注意レベル 03 (低注意, orange, 本記事独自呼称): 公式 JSON 内の
rakuseki_03 に対応。 過去に小規模落石はあるが頻度は低い区間。
通常走行可、 雨天時・夜間のみ減速注意。 公式色は #ffa500。
- 注意レベル 04 (高注意, red, 本記事独自呼称): 公式 JSON 内の
rakuseki_04 に対応。 過去に複数回の落石・崩落履歴があり、 急斜面
地質脆弱性も高い区間。 常時注意、 豪雨時・地震後は迂回推奨。 公式色は
#ff0000。
- 動的規制 (L50 を指す, 本記事独自呼称): 工事規制 + 災害短期規制で
時間と共に変化する規制。 「本日の規制」 + 「今後の規制」 (L50 dataset
1257 + 1258, 計 {n_l50_total} 件)。
- 静的規制 (L73 を指す, 本記事独自呼称): 雨量閾値超過で自動発動する
事前通行規制 + 冬期閉鎖。 恒常的に指定された区間 ({n_l73} 件) で、 「規制
ルール」 自体は静的だが「発動状態」 は動的。
- 注意 (L74, 本記事の主データ): 法的強制力なし、 注意喚起のみ。
恒常的に指定された静的な情報層で、 規制とは異なり「発動」 概念がない。
- 3 階層情報伝達 (本記事独自): 県の道路情報を動的 (L50) +
静的規制 (L73) + 静的注意 (L74)の 3 階層で捉える本記事独自フレーム。
災害時の情報伝達は注意 → 規制 → 動的規制の順に強化される。
- 逆ピラミッド構造 (本記事独自): 件数規模が「注意 (広い) > 動的
(中間) > 規制 (狭い)」 になる構造。 「弱い情報は広く、 強い規制は狭く」 と
いう情報配信設計思想。 本記事 H4 で量的検証。
- 3 重指定 (本記事独自): L74 (注意) ∩ L73 (規制) ∩ L72 (緊急輸送
道路) の3 重交差区間。 「災害時に通行確保すべき + 災害前に予防
規制 + 平常時から注意喚起」 という 3 つの制度が重なる最警戒箇所。
- 中山間山地 (本記事独自定義): 庄原市・三次市・安芸太田町・安芸高田市・
北広島町・神石高原町・世羅町・府中市の 8 市町。 公式分類ではないが、
地形・人口密度から「中山間」 と一般に呼ばれる地域。 L73 と同じ定義を採用。
- 注意のみ区間 (本記事独自): L74 のうち L73 と重ならない区間。
「規制まで強化されていないが、 ドライバーには注意喚起したい」 箇所。 H3 で
これが 80% 以上を占めることを検証。
研究の問い (3 RQ)
- RQ1 (主研究): 広島県の走行注意区間の構造 — 注意レベル × 区間長 ×
地理クラス × 市町はどう描けるか? {n_seg} 区間を 4 軸で集計し、 「県の
予防情報配信制度」 の物理形状を初めて系統的に記述する。 H1 (orange ≥ 60%) を
検証。
- RQ2 (副研究 1): 走行注意区間 (L74, 弱予防) と事前通行規制区間
(L73, 強予防) は階層構造を成すか? 100m バッファ sjoin で重複 +
「注意のみ」 区間を分離し、 制度階層の連続性を実証する。 H2 (重複 ≥ 10),
H3 (注意のみ ≥ 80%) を検証。
- RQ3 (副研究 2): 県の道路情報3 階層 (L50/L73/L74)はどんな
統合構造を持つか? 件数規模・延長・空間分布を統合分析し、 緊急輸送道路 (L72)
との重複も含めて 3 重指定箇所を特定。 H4 (件数 注意>動的>規制), H5
(L74 ∩ L72 ≥ 20 km) を検証。
仮説 (5)
- H1 (RQ1, 階層構造): 走行注意区間 {n_seg} のうち低注意 (03)が
≥ 60%。 弱注意が多数派で、 強注意 (04) は厳選された少数派という
制度設計仮説。
- H2 (RQ2, 規制との重複): L74 と L73 の100m バッファ重複が ≥ 10 件。
「同じ道路に規制 + 注意」 の二重指定箇所が一定数存在する仮説。
- H3 (RQ2, 注意のみが多数派): L74 のうち L73 と重ならない「注意のみ」
区間が≥ 80%。 注意制度は規制より広い範囲をカバーする予防情報層
仮説。
- H4 (RQ3, 件数規模順): 件数 注意 (L74={n_seg}) > 動的 (L50={n_l50_total}) >
規制 (L73={n_l73})。 「弱い情報は広く、 強い規制は狭く」 の逆ピラミッド構造仮説。
- H5 (RQ3, 緊急輸送道路との空間相関): L74 と L72 の 30m バッファ重複延長
が≥ 20 km。 注意区間は主要道路の沿道に分布する仮説。
到達点
本記事を読み終えると、 (1) 県の走行注意区間 {n_seg} 区間・{total_km:.0f} km・
2 階層 (低注意 03 + 高注意 04) の制度構造を完全に俯瞰、 (2) 事前通行規制 (L73)
との {n_overlap_l73} 件重複 + 「注意のみ」 {share_only_l74}% という2 層の制度階層を
定量把握、 (3) 県の道路情報 3 階層 (L50/L73/L74) の逆ピラミッド構造と
緊急輸送道路 (L72) との3 重指定箇所 {n_l74_l73_l72} 件を特定できる、 という
3 段階の知識が獲得できる。 これにより県の道路情報配信制度における「弱い情報の
広い層 (注意) → 強い規制の狭い層 (規制)」という制度設計が研究者視点で見える
ようになる。
"""
# ----- セクション 2: 使用データ -----
sec2 = f"""
本研究で使う 1 つの dataset (1 ZIP リソース) を以下の表に示す。
本データは走行注意区間 LineString を ZIP 形式 (.json 拡張子で配信) で
公開しており、 ZIP 内に階層別 NDJSON 風 JSON 2 つ + メタ JSON 1 つ の
合計 3 ファイルが格納されている。
データセット仕様
{df_to_html(T_dataset)}
ZIP 内 3 JSON の内訳
| ファイル | 役割 | 形式 | 件数 | 延長 km |
|---|
04_warning_rakuseki_03.json |
低注意 (orange) LineString 集 |
NDJSON 風 (1 配列 = 1 LineString, 「,」 区切り) |
{n_03} 区間 |
{km_03:.1f} |
04_warning_rakuseki_04.json |
高注意 (red) LineString 集 |
NDJSON 風 |
{n_04} 区間 |
{km_04:.1f} |
04_warning_route.json |
階層メタ ({{name, color, weight, type}}) |
NDJSON 風 (2 オブジェクト) |
2 階層 (rakuseki_03 + 04) |
- |
NDJSON 風 形式の解読
各階層 JSON は以下のような形式 (改行・インデント整形は本記事による):
[{{"e":132.10052,"d":34.39173}}, {{"e":132.10042,"d":34.39177}}, ...]
,
[{{"e":132.10120,"d":34.39250}}, {{"e":132.10115,"d":34.39260}}, ...]
,
...
つまり「[配列] が「,改行」 区切りで複数並ぶ」形式。 標準 JSON では
ないので json.load() でそのまま読めない。 L72 緊急輸送道路と同じ
「[ + 全テキスト + ]」でラップしてから json.loads() で
配列の配列として読み込む。 各内部配列が 1 LineString に対応し、 各点は
{{"e": 経度, "d": 緯度}}形式。
JSON 解読の注意点
- 拡張子は .jsonだが実体はZIP。 ファイル先頭バイト
50 4B 03 04 (= "PK\\x03\\x04") で magic 判定し、 zipfile
で展開する。
- NDJSON 風形式は標準 JSON ではないため、
json.load() 直読は失敗。
json.loads("[" + text + "]") でラップして配列の配列として読む。
- 緯度経度はWGS84 (EPSG:4326)で、 各点は
{{"e": lon, "d": lat}}。
距離計算 (RQ2 / RQ3) のためEPSG:6671 (JGD2011 平面直角第 III 系) に
投影変換する。
- 属性は階層名のみ(L73 のような豊富な属性なし)。 路線名・規制内容・
規制ランク・雨量閾値・迂回路有無 等は本データには含まれない。 これは
「ドライバー向け情報提供」 の最小限公開と推定される。
04_warning_route.json はメタ JSON で、 階層名と表示色・線太・線種の
対応を定義 (rakuseki_03 → #ffa500, rakuseki_04 → #ff0000)。
"""
# ----- セクション 3: ダウンロード -----
sec3 = f"""
本記事の再現に必要なすべてを直リンクで提供する。
HTML だけ読めば学習者が完全再現できることが目標 (要件 A)。
生データ (DoBoX 1 件)
このスクリプト本体
中間 CSV (本記事生成、再利用可)
図 (PNG, 直 DL 可)
"""
# ----- セクション 4: RQ1 -----
sec4_code = '''
import zipfile, json
from pathlib import Path
import geopandas as gpd
from shapely.geometry import LineString
import pandas as pd
DATA_DIR = Path("data/extras/L74_caution_segments")
EXTRACT = DATA_DIR / "340006_driving_caution_section_20220908T000000"
# (1) ZIP 展開 (拡張子 .json だが実体 ZIP)
zip_path = DATA_DIR / "caution_segments.json"
if zip_path.read_bytes()[:4] == b"PK\\x03\\x04" and not EXTRACT.exists():
with zipfile.ZipFile(zip_path) as z:
z.extractall(DATA_DIR)
# (2) NDJSON 風 → LineString 配列
def load_caution_lines(level):
p = EXTRACT / f"04_warning_{level}.json"
text = p.read_text(encoding="utf-8")
arr = json.loads("[" + text + "]") # NDJSON 風: 配列の配列としてラップ
return [LineString([(pt["e"], pt["d"]) for pt in seg])
for seg in arr if len(seg) >= 2]
records = []
for lvl in ["rakuseki_03", "rakuseki_04"]:
for ln in load_caution_lines(lvl):
records.append({"level": lvl, "geometry": ln})
# (3) GeoDataFrame 化 (4326 → 6671 投影変換)
gdf = gpd.GeoDataFrame(records, crs="EPSG:4326").to_crs("EPSG:6671")
gdf["len_m"] = gdf.geometry.length
gdf["len_km"] = gdf["len_m"] / 1000
print(f"区間数: {len(gdf)}")
# (4) 階層別 集計
T_level = (gdf.groupby("level")
.agg(区間数=("level", "count"),
延長_km=("len_km", "sum"))
.reset_index())
print(T_level)
'''
sec4 = f"""
狙い (RQ1)
RQ1 では「県の予防情報配信制度」 の物理構造を初めて系統的に記述する。
具体的には {n_seg} 区間 / 総延長 {total_km:.0f} km の走行注意区間を
注意レベル (03/04) × 区間長 × 地理クラス × 市町の 4 軸で集計し、
「どのレベルがどこに分布するか」 を 1 枚で俯瞰できるようにする。 H1
(orange ≥ 60%) は階層構造の中心仮説を検証する。
手法 — 4 ステップ
- STEP 1: ZIP 展開 + NDJSON 風 パース
公式リソースは拡張子 .jsonだが実体はZIP。 magic 判定
(50 4B 03 04) で確認後、 zipfile で展開する。 中の
JSON はNDJSON 風([配列] が「,改行」 区切りで複数並ぶ)
形式なので、 "[" + text + "]" でラップしてから
json.loads() で配列の配列として読む。 L72 と同じパターン。
- STEP 2: LineString 化 + 投影変換
各内部配列の点 ({{"e": lon, "d": lat}}) を
shapely.geometry.LineString に変換、 階層名 (rakuseki_03 /
rakuseki_04) と組み合わせて GeoDataFrame に。 EPSG:4326 → EPSG:6671
(JGD2011 第 III 系) に to_crs() で投影変換 → 距離・面積が
m 単位で計算可能に。
- STEP 3: 派生列の追加
・level_label: 階層名を「03 (低注意) / 04 (高注意)」 に変換
・len_m, len_km: 区間長 (= LineString.length)
・seg_id: 派生主キー (L74_0000 〜 L74_0380)
- STEP 4: 4 軸で集計 + 中山間判定
代表点 sjoin で市町判定 → 中山間 7-8 市町 vs 平野・沿岸都市 vs 沿岸島嶼を
区別。 groupby("level") で階層別、 groupby("地理クラス") で
地理別、 groupby("市町名") で市町別の集計。
実装 (主要部のみ抜粋)
{code(sec4_code)}
結果 1: 県全域 注意レベル別 マップ (図 1)
なぜこの図か: 2 階層の注意レベル (03 = orange / 04 = red) が県内に
どう分布するかを県全域地図に重ねて一目で確認したい。 注意レベルを
色 + 線幅で区別 (03 = orange 細, 04 = red 太) することで、 「中山間 + 沿岸の
脆弱地質道路」に注意区間が集中することが直感できる。
{figure("assets/L74_fig1_level_map.png",
f"図 1 (RQ1): 広島県 走行注意区間 注意レベル別マップ")}
図 1 から読み取れること:
- 03 (低注意, orange, {n_03} 件 / {km_03:.0f} km):
圧倒的多数派。 中山間 + 沿岸島嶼の地形脆弱地に広く分布する
- 04 (高注意, red, {n_04} 件 / {km_04:.0f} km):
03 のサブセット的に分布。 特に過去落石履歴がある主要道路で長区間指定
- 地理的偏在: 県北部 (庄原・三次・安芸太田) + 西部山岳 (廿日市) +
島嶼部 (江田島・蒲刈・倉橋) に集中、 平野部 (広島市・福山市) ではほとんど
見られない
- 路線パターン: 連続した山岳路線で長く指定される区間が多く、 単発 100m
区間ではなく数 km 連続が普通 (= 注意は「ある区間全体」 への警告として運用)
結果 2: 階層 + 区間長 + 地理クラス 3 角度 (図 2)
なぜこの図か: H1 (03 ≥ 60%) を直感検証するために、 階層別件数を
最初のパネルで確認。 区間長は対数スケールで広く分布する想定なので 2 番目の
パネルで log10 ヒストで階層別の分布を見る。 3 番目で地理クラス別件数を見て、
中山間集中度を量化する。
{figure("assets/L74_fig2_rq1_structure.png",
"図 2 (RQ1): 階層 × 区間長 × 地理クラス")}
図 2 から読み取れること:
- 左パネル (階層別件数): 03 が {n_03} 件 ({share_03}%)と
04 ({n_04} 件) の {n_03/n_04:.1f} 倍。 H1 (03 ≥ 60%)
{('強支持' if h1_ok else '反証')}
- 中央パネル (区間長 log10 分布): 中央値{int(gdf['len_m'].median())} m、
最大{int(gdf['len_m'].max())} m ({gdf['len_m'].max()/1000:.1f} km)と
4 桁の幅。 04 (赤) は 03 (橙) よりやや右シフトしており、
強注意は連続した長区間で運用される傾向が見える
- 右パネル (地理クラス): 中山間山地が
{n_chusankan} 件 ({share_chusankan}%)で最多 — 「予防情報 = 中山間
地形脆弱性対応」 という運用思想が量的に確認
- 3 軸で見ると注意区間は「中山間 × 連続長区間 × 多数派は弱注意」と
整理できる
結果 3: 中山間境界 + 注意区間 重ね合わせマップ (図 3)
なぜこの図か: 図 2 の中山間集中を地図上で直感検証するため、
中山間 8 市町を橙色背景、 沿岸島嶼を青色背景で塗り、 注意区間を中山間内 (橙=03 /
赤=04) / それ以外 (灰) で色分けして重ねる。 「中山間にどれだけ集中するか」 が
一目で見える。
{figure("assets/L74_fig3_chusankan_map.png",
"図 3 (RQ1): 走行注意 + 中山間境界 重ね合わせ")}
図 3 から読み取れること:
- 橙色背景 (中山間 8 市町): 庄原市・三次市・安芸太田町・安芸高田市・
北広島町・神石高原町・世羅町・府中市
- 橙線 (中山間内 03 注意区間): 主要地方道・一般県道の山岳路線
- 赤線 (中山間内 04 注意区間): 過去落石履歴がある県道・国道
- 灰線 (中山間外 注意区間, {n_seg - n_chusankan} 件):
沿岸島嶼 (江田島・大崎上島) + 平野部 (広島市山間部・廿日市山間部) — 中山間
8 市町の厳密定義から外れるが、 地形的には類似
- 中山間が{share_chusankan}% — L73 の中山間集中度
36.0% と同等水準で、 県の予防情報 (L73 規制 + L74 注意) は共通して
中山間地形脆弱性対応として運用される
結果 4: 階層・地理・市町 詳細表
注意レベル別サマリ:
{df_to_html(T_level)}
注意レベル 表から読み取れること: 03 が
{n_03} 件 ({share_03}%) / 延長 {km_03:.1f} km、 04 が
{n_04} 件 / {km_04:.1f} km。 平均長は 03 が
{T_level[T_level['階層']=='rakuseki_03']['平均長_m'].iloc[0]:.0f} m、 04 が
{T_level[T_level['階層']=='rakuseki_04']['平均長_m'].iloc[0]:.0f} m と、
04 のほうが長い (= 強注意は連続した長区間で運用)。
地理クラス別サマリ:
{df_to_html(T_geo)}
地理クラス 表から読み取れること:
{T_geo.iloc[0]['地理クラス']} が
{int(T_geo.iloc[0]['区間数'])} 件 ({T_geo.iloc[0]['シェア_%']}%)と最多、
2 位 {T_geo.iloc[1]['地理クラス']} が {int(T_geo.iloc[1]['区間数'])} 件
({T_geo.iloc[1]['シェア_%']}%)。 注意区間は地形脆弱な領域に
明確に偏り、 平野・沿岸都市は少数。
注意レベル × 地理クラス クロス:
{df_to_html(T_level_geo)}
クロス 表から読み取れること:
03 と 04 の地理クラス分布は概ね同パターン (中山間 + 沿岸島嶼集中) だが、
04 (高注意) は 03 (低注意) よりやや中山間集中度が高い傾向 — 強い注意は
最も脆弱な地形に厳選指定される。
市町別サマリ (Top 15):
{df_to_html(T_city.head(15))}
市町別 表から読み取れること:
{T_city.iloc[0]['市町名']} ({int(T_city.iloc[0]['区間数'])} 件)が圧倒的最多、
2 位 {T_city.iloc[1]['市町名']} ({int(T_city.iloc[1]['区間数'])} 件)、
3 位 {T_city.iloc[2]['市町名']} ({int(T_city.iloc[2]['区間数'])} 件)。
中山間市町 (庄原・三次・安芸太田・北広島・神石高原・世羅・府中) と沿岸島嶼
(江田島・大崎上島) が上位を独占。
区間長 代表値 (階層別):
{df_to_html(T_length)}
区間長 表から読み取れること:
平均長は 03 で約 {T_length[T_length['カテゴリ']=='03 (低)']['平均_m'].iloc[0]:.0f} m、
04 で約 {T_length[T_length['カテゴリ']=='04 (高)']['平均_m'].iloc[0]:.0f} m。
最大は 03 で {T_length[T_length['カテゴリ']=='03 (低)']['最大_m'].iloc[0]:.0f} m、
04 で {T_length[T_length['カテゴリ']=='04 (高)']['最大_m'].iloc[0]:.0f} m と
ともに数 km 級。 中央値は数百 m で、 連続した山岳路線への面的指定が支配的。
"""
# ----- セクション 5: RQ2 -----
sec5_code = '''
# L73 事前通行規制区間を読み込み LineString 化
import json
from shapely import wkt as swkt
with open("data/extras/L73_pre_traffic_restriction/pre_traffic.json",
"r", encoding="utf-8") as f:
raw = json.load(f)
recs = raw["results"]
geoms_l73 = []
for r in recs:
try:
geoms_l73.append(swkt.loads(r.get("kukanroot") or r.get("kukan", "")))
except Exception:
geoms_l73.append(None)
gdf_l73 = gpd.GeoDataFrame({"id": [r["id"] for r in recs],
"naiyo": [r["kiseinaiyo"] for r in recs]},
geometry=geoms_l73, crs="EPSG:4326")
gdf_l73 = gdf_l73[gdf_l73.geometry.notna()].to_crs("EPSG:6671")
# L73 100m バッファ → L74 と sjoin (intersects)
gdf_l73_buf = gdf_l73.copy()
gdf_l73_buf["geometry"] = gdf_l73.geometry.buffer(100)
overlap = gpd.sjoin(gdf, gdf_l73_buf, how="left", predicate="intersects")
overlap_grp = (overlap.dropna(subset=["index_right"])
.groupby("seg_id").size())
gdf["on_l73"] = gdf["seg_id"].map(overlap_grp).fillna(0).astype(bool)
print(f"L74 ∩ L73 重複: {gdf['on_l73'].sum()}/{len(gdf)} 区間")
# 重複延長 (L74 LineString と L73 buffer union の intersection)
buf_union = gdf_l73_buf.geometry.union_all()
gdf["overlap_km"] = gdf.geometry.apply(
lambda g: g.intersection(buf_union).length / 1000)
print(f"重複延長: {gdf['overlap_km'].sum():.1f} km")
'''
sec5 = f"""
狙い (RQ2)
RQ1 で「注意区間の構造」 が分かったが、 これはL74 単独の話。
RQ2 では「L74 (注意, 弱) と L73 (規制, 強) の制度階層」を見る。
具体的には(1) L74 ∩ L73 の重複箇所(同じ道路に二重指定)、
(2) 「注意のみ」 区間の比率(L74 が L73 をカバーするか) を計算し、
「注意 = 広い情報層, 規制 = 狭い強制層」 という2 層の制度階層を実証する。
H2 (重複 ≥ 10) と H3 (注意のみ ≥ 80%) の 2 仮説を検証する。
手法 — L73 100m バッファ + sjoin (intersects)
狙い: L73 (164 区間 / 750 km) に対して100m バッファを作成
(= 道路敷地 + 隣接路面の余裕)、 L74 LineString を
gpd.sjoin(predicate="intersects") で重なり判定。 重複延長は
L74 LineString と L73 バッファ union の intersectionを計算。
| 項目 | 値 | 意味 |
|---|
| L74 走行注意 |
{n_seg} 区間 / {total_km:.0f} km |
本記事の主データ |
| L73 事前通行規制 (既扱) |
{n_l73} 区間 / {total_km_l73:.0f} km |
強い予防制度 (雨量基準で自動規制) |
| バッファ幅 |
{BUFFER_L73_M:.0f} m |
道路敷地 + 隣接路面の余裕 |
| 重複判定 |
sjoin (intersects) |
1 注意区間が L73 buffer に少しでも掛かれば重複 |
| 重複延長 |
L73 buffer union との intersection length |
実際の重複 km |
注意: なぜ 100m バッファか — L73 の道路敷地 (典型 4-15m) + L74 とは
配信時期が違う (L73 = 2026-05-01, L74 = 2022-09-08) ため、 同じ道路でも
ベクトル幾何が完全には一致しない可能性。 100m バッファは「同じ路線・同じ
区間と判定するための寛容な閾値」。 L73 の RQ3 で使った 30m バッファより
広いのは、 L74 の地理測位精度を控えめに見積もるため。
実装 (主要部)
{code(sec5_code)}
結果 1: L74 ∩ L73 重ね合わせマップ (図 4)
なぜこの図か: 「L74 注意区間と L73 規制区間がどこで重なるか」 を
地図で直接見せる。 L73 (背景の薄青)、 L74 単独 (橙), L74 ∩ L73 (赤太線+★) の
3 段階色分けで、 二重指定箇所が最警戒地点として浮き上がる。
{figure("assets/L74_fig4_overlap_l73_map.png",
"図 4 (RQ2): L74 走行注意 + L73 事前通行規制 重ね合わせ")}
図 4 から読み取れること:
- 薄青線 (L73 事前通行規制, 背景, {n_l73} 件):
規制制度の物理形 — 主要地方道 + 国道 + 沿岸国道 + 山岳道路
- 橙線 (L74 単独, {n_seg - n_overlap_l73} 件 = 注意のみ):
L73 と重ならない注意区間 — 規制まで強化されていないが注意が必要な
多数派
- 赤太線 + ★ (L74 ∩ L73, {n_overlap_l73} 件 = 二重指定):
最警戒箇所 — 同じ道路に「注意 (常時) + 規制 (異常時)」 の二重
指定があり、 道路管理者が制度切替で運用
- 重複は{n_overlap_l73}/{n_seg} 区間 = {100-share_only_l74:.1f}%。
注意のみが{share_only_l74}%を占め、 H3 ({('強支持' if h3_ok else '反証')})
- 重複延長は{overlap_l73_km:.1f} kmで、 L74 総延長
{total_km:.0f} km の {100*overlap_l73_km/total_km:.1f}% に過ぎない =
L74 は L73 より広い予防情報層を提供する
結果 2: 階層別重複率 + 規制内容クロス (図 5)
なぜこの図か: H2 (重複 ≥ 10) を 2 角度から検証: (1) 注意レベル別に
重複率を見て「03/04 のどちらが規制と重なりやすいか」, (2) 重複先の L73 規制内容
分布を見て「注意 + 規制が共起する規制種類」 を量化する。
{figure("assets/L74_fig5_overlap_l73_breakdown.png",
"図 5 (RQ2): 階層別重複率 + 規制内容クロス")}
図 5 から読み取れること:
- 左パネル (階層別重複率):
03 と 04 の L73 重複率を比較すると、
03 ({int(T_overlap_l73[T_overlap_l73['level_label']=='03 (低注意)']['重複ありL73'].iloc[0]) if '03 (低注意)' in T_overlap_l73['level_label'].values else 0}/{n_03} =
{float(T_overlap_l73[T_overlap_l73['level_label']=='03 (低注意)']['重複率_%'].iloc[0]) if '03 (低注意)' in T_overlap_l73['level_label'].values else 0}%) vs
04 ({int(T_overlap_l73[T_overlap_l73['level_label']=='04 (高注意)']['重複ありL73'].iloc[0]) if '04 (高注意)' in T_overlap_l73['level_label'].values else 0}/{n_04} =
{float(T_overlap_l73[T_overlap_l73['level_label']=='04 (高注意)']['重複率_%'].iloc[0]) if '04 (高注意)' in T_overlap_l73['level_label'].values else 0}%) で比較。
高注意 (04) のほうが規制との重複率が高い傾向 (= 04 = より厳しい状態 → 規制
指定にも近い)
- 右パネル (重複 L73 規制内容):
L74 ∩ L73 の重複先 L73 規制内容は「落石等」が支配的 (L74 が
「rakuseki = 落石」 専門のため必然的)。 凍結等・強風・冠水・越波も
少数現れる場合があり、 これは「同じ路線でも区間によって規制理由が違う」
ことを示す
- H2 (重複 ≥ 10) {('強支持' if h2_ok else '反証')}: {n_overlap_l73} 件
= 注意 + 規制の二重指定箇所が一定数存在
結果 3: 重複 詳細表
L74 階層別 L73 重複:
{df_to_html(T_overlap_l73)}
階層別 表から読み取れること:
03 (低注意) と 04 (高注意) で L73 重複率が異なり、
04 のほうが重複率が
{('高い' if '04 (高注意)' in T_overlap_l73['level_label'].values and '03 (低注意)' in T_overlap_l73['level_label'].values and float(T_overlap_l73[T_overlap_l73['level_label']=='04 (高注意)']['重複率_%'].iloc[0]) > float(T_overlap_l73[T_overlap_l73['level_label']=='03 (低注意)']['重複率_%'].iloc[0]) else '同等')}。
これは「強注意 (04) は規制 (L73) 指定に近い」 という制度階層の連続性を示す。
L74 ∩ L73 重複箇所 詳細 (Top 15):
{df_to_html(overlap_l73_segs.head(15))}
重複箇所 表から読み取れること:
これら{n_overlap_l73} 区間は「常時=注意 (L74) / 異常時=規制 (L73)」 の
切替運用がされる制度階層の最警戒箇所。 全件 CSV
(L74_overlap_l73_segments.csv) で詳細を提供 — これらの箇所は
注意+規制の連続性のフィールド検証研究の対象として直接利用可能。
"""
# ----- セクション 6: RQ3 -----
sec6_code = '''
# L50 動的規制件数を読み込み (本日 + 今後)
import json
n_today = len(json.load(open("data/extras/L50_road_restrictions/1257_today.json",
encoding="utf-8")).get("results", []))
n_future = len(json.load(open("data/extras/L50_road_restrictions/1258_future.json",
encoding="utf-8")).get("results", []))
n_l50 = n_today + n_future
# L72 緊急輸送道路を読み込み (NDJSON 風: 4 階層)
def load_l72_lines(idx):
p = f"data/extras/L72_emergency_road/.../05_kinkyu_route_{idx}.json"
with open(p, encoding="utf-8") as f:
text = f.read()
return [LineString([(pt["e"], pt["d"]) for pt in seg])
for seg in json.loads("[" + text + "]") if len(seg) >= 2]
records_l72 = []
for idx in ["01", "02", "03", "04"]:
for ln in load_l72_lines(idx):
records_l72.append({"l72_rank": idx, "geometry": ln})
gdf_l72 = gpd.GeoDataFrame(records_l72, crs="EPSG:4326").to_crs("EPSG:6671")
# L72 30m バッファ → L74 と重複延長
gdf_l72_buf = gdf_l72.copy()
gdf_l72_buf["geometry"] = gdf_l72.geometry.buffer(30)
buf_union_l72 = gdf_l72_buf.geometry.union_all()
gdf["overlap_l72_km"] = gdf.geometry.apply(
lambda g: g.intersection(buf_union_l72).length / 1000)
gdf["on_l72"] = gdf["overlap_l72_km"] > 0
print(f"L74 ∩ L72: {gdf['on_l72'].sum()} 区間 / "
f"{gdf['overlap_l72_km'].sum():.1f} km")
# 4 カテゴリ (L74 単独 / ∩L73 / ∩L72 / 3 重)
n_only = (~gdf["on_l73"] & ~gdf["on_l72"]).sum()
n_l73 = (gdf["on_l73"] & ~gdf["on_l72"]).sum()
n_l72 = (~gdf["on_l73"] & gdf["on_l72"]).sum()
n_triple = (gdf["on_l73"] & gdf["on_l72"]).sum()
print(f"4 カテゴリ: 単独={n_only} / ∩L73={n_l73} / ∩L72={n_l72} / 3重={n_triple}")
'''
sec6 = f"""
狙い (RQ3)
RQ2 で「L74 と L73 の 2 層階層」 を見たが、 これでも県の道路情報を完全には
描けない。 県にはもう 1 層がある: L50 動的規制 (本日 + 今後)。
RQ3 ではL50 + L73 + L74 の 3 階層を統合的に分析し、 さらに緊急輸送道路
(L72) との空間相関を見ることで、 県の道路情報配信制度全体を量的に俯瞰する。
H4 (件数 注意>動的>規制) と H5 (L74 ∩ L72 ≥ 20km) を検証する。
手法 — 3 階層件数 + L72 30m バッファ重複
狙い: (1) L50 (1257 + 1258, 動的規制 {n_l50_total} 件) を読み込んで
件数比較、 (2) L72 緊急輸送道路 ({n_l72} セグ / {total_km_l72:.0f} km) に対して
30m バッファを作成、 L74 LineString と sjoin で重複判定 + intersection
で重複延長計算。 (3) 4 カテゴリ (L74 単独 / ∩L73 / ∩L72 / 3 重) で集計。
| 階層 | 件数 | 性質 | 規制力 |
|---|
| L50 動的規制 (本日+今後) |
{n_l50_total} 件 ({n_l50_today}+{n_l50_future}) |
短期 (~数日)・工事 + 災害短期 |
強 (通行止/片側交互/車線規制) |
| L73 事前通行規制 (静的) |
{n_l73} 件 |
恒常・雨量閾値超過で発動 |
強 (発動時 通行止) |
| L74 走行注意 (静的) |
{n_seg} 件 |
恒常・落石注意の情報提供 |
弱 (法的強制なし、 注意喚起のみ) |
実装 (主要部)
{code(sec6_code)}
結果 1: 3 階層 件数比較 + 重ね合わせマップ (図 6)
なぜこの図か: H4 (件数 注意>動的>規制) を直接検証するため、 3 階層
件数を棒グラフで並べる。 同時に右パネルで 3 階層を地図に重ねて、 「弱い情報は
広く、 強い規制は狭く」 の物理形を見せる。
{figure("assets/L74_fig6_3layer_combined.png",
"図 6 (RQ3): 県の道路情報 3 階層 件数 + 重ね合わせマップ")}
図 6 から読み取れること:
- 左パネル (3 階層件数):
L74 注意 ({n_seg}) > L50 動的 ({n_l50_total}) > L73 規制 ({n_l73})
の逆ピラミッド構造。 H4 ({('強支持' if h4_ok else '反証')})
- 件数比は {n_seg/n_l73:.1f} : {n_l50_total/n_l73:.1f} : 1.0 (L73 = 1)。
L74 は L73 の {n_seg/n_l73:.1f} 倍の件数規模を持ち、 「弱い情報の広い層」 と
して機能
- 右パネル (3 階層 重ね合わせマップ):
L74 (橙) が広い面で分布、 L73 (赤) が中山間・沿岸の山岳道路に絞られる、
L50 (紫点) が県内に散発的に動的発生 — 3 階層の地理的な階層差が
一目で見える
- L50 (紫点) は中央 (広島市・東広島・福山) にも多く分布し、 L73 / L74 が中山間
集中なのと対比的 — 動的規制 = 工事ベースで都市部にも多い
結果 2: L74 ∩ L72 緊急輸送道路 重複マップ (図 7)
なぜこの図か: 県の重要道路 (緊急輸送道路 L72) の沿道に注意区間が
集中するか? を地図で確認する。 L72 (灰背景), L74 単独 (橙), L74 ∩ L72 (緑強調),
3 重指定 (★) の 4 段階色分けで、 「注意 = 主要道路の沿道に多い」 という空間相関
が一目で見える。
{figure("assets/L74_fig7_overlap_l72_map.png",
"図 7 (RQ3): L74 走行注意 ∩ L72 緊急輸送道路")}
図 7 から読み取れること:
- 灰線 (L72 緊急輸送道路, {n_l72} セグ / {total_km_l72:.0f} km):
4 階層を重ねた背景
- 橙線 (L74 単独, {n_seg - n_overlap_l72} 件):
L72 と重ならない注意区間 — 一般県道・市町道の山岳路線
- 緑線 (L74 ∩ L72, {n_overlap_l72} 件 / {overlap_l72_km:.1f} km):
緊急輸送道路の沿道に分布する注意区間 — H5
({('強支持' if h5_ok else '反証')})
- 赤★ (3 重指定 L74∩L73∩L72, {n_l74_l73_l72} 件):
制度的最警戒箇所 — 「災害時に通行確保すべき + 災害前に予防規制 +
平常時から注意喚起」 の4 層 BCP 矛盾
- L74 ∩ L72 重複は{100*overlap_l72_km/total_km:.1f}%
(= L74 総延長 {total_km:.0f} km 中 {overlap_l72_km:.0f} km) — 注意区間の
相当割合が緊急輸送道路の沿道に分布
結果 3: 4 カテゴリ + L72 階層別重複 (図 8)
なぜこの図か: L74 区間を「単独 / ∩L73 / ∩L72 / 3 重」 の 4 カテゴリに
クロス分類してパイ図で見せ、 制度的な重なり構造を量化する。 同時に右パネルで
L72 階層別 (第 1 次〜補完) の重複分布を見て、 注意区間がどの階層の緊急輸送
道路と重なりやすいかを量化する。
{figure("assets/L74_fig8_triple_breakdown.png",
"図 8 (RQ3): 制度重なり 4 カテゴリ + L72 階層別重複")}
図 8 から読み取れること:
- 左パネル (4 カテゴリ パイ):
L74 単独 ({n_l74_only} 件 = {round(100*n_l74_only/n_seg, 1)}%) が最多 —
多くの注意区間は規制も緊急輸送道路もない一般県道・市町道に位置。
L74 ∩ L72 = {n_l74_l72} 件 ({round(100*n_l74_l72/n_seg, 1)}%) で
緊急輸送道路の沿道。
L74 ∩ L73 = {n_l74_l73} 件 ({round(100*n_l74_l73/n_seg, 1)}%) で
規制との二重指定。
3 重指定 = {n_l74_l73_l72} 件が最警戒
- 右パネル (L72 階層別重複):
L74 ∩ L72 のうち、 第 2 次 + 補完が多くを占める傾向 — 主要地方道 + 一般国道
がマッチする路線。 第 1 次 (高速 + 主要国道) は注意区間が少ない (= 高速は
落石対策が完備)
- 「注意区間 = 主要道路の沿道」 という空間相関が量的に確認 —
これは緊急輸送道路 = 主要地方道・国道という性質上必然的
結果 4: 3 階層 + 4 カテゴリ + 3 重指定 詳細表
3 階層比較サマリ:
{df_to_html(T_3layer)}
3 階層 表から読み取れること:
件数規模は L74 ({n_seg}) > L50 ({n_l50_total}) > L73 ({n_l73}) の順。
規制力は L74 (弱) < L50 (強・短期) < L73 (強・恒常)。 性質も「弱い情報の
広い層 → 強い動的規制 → 強い恒常規制」 という階層構造が確認。
4 カテゴリ クロス:
{df_to_html(T_triple)}
4 カテゴリ 表から読み取れること:
L74 単独が圧倒的多数 ({round(100*n_l74_only/n_seg, 1)}%) で、 注意制度は
規制・緊急輸送と独立に運用される箇所が大多数。 一方3 重指定
{n_l74_l73_l72} 件は最警戒の制度的最重要箇所リストとして
注目すべき。
L72 階層別重複:
{df_to_html(T_overlap_l72)}
L72 階層別 表から読み取れること:
{T_overlap_l72.iloc[0]['緊急輸送道路階層'] if len(T_overlap_l72) > 0 else '-'}
が最多重複。 主要地方道 + 国道に注意区間と緊急輸送道路の二重指定が集中する。
3 重指定 区間 詳細 (上位 15):
{df_to_html(triple_segs.head(15)) if len(triple_segs) > 0 else '該当なし
'}
3 重指定 表から読み取れること:
これら{n_l74_l73_l72} 区間は「災害時に通行確保すべき (L72) + 災害前に
予防規制 (L73) + 平常時から注意喚起 (L74)」 の4 層 BCP 矛盾。 全件 CSV
(L74_triple_segments.csv) で詳細を提供 — 県の地域防災計画に直接
フィードバックできる制度的最重要箇所リストとして利用可能。
"""
# ----- セクション 7: 仮説検証総合 -----
T_hypo_html = T_hypo.copy()
T_hypo_html["判定"] = T_hypo_html["判定"].apply(
lambda v: f'{v}')
sec7 = f"""
仮説検証総合 (H1〜H5)
本記事冒頭で立てた 5 仮説の検証結果を以下にまとめる。
すべての仮説の検証根拠は本記事中の図表に明示されており、 再現可能。
{df_to_html(T_hypo_html)}
主要発見の整理
- RQ1 主発見: 県の走行注意区間は{n_seg} 区間 / {total_km:.0f} km
の 2 階層構造 (低注意 03 = {n_03} 件 ({share_03}%) + 高注意 04 = {n_04} 件)。
H1 ({('強支持' if h1_ok else '反証')})。 中山間 8 市町に
{n_chusankan} 件 ({share_chusankan}%)が集中、 中央区間長
{int(gdf['len_m'].median())} m と「連続した山岳路線への面的指定」 が支配的。
これは「弱い情報の広い層」 という予防情報配信制度の物理形状を
初めて系統的に記述した。
- RQ2 主発見: L74 ∩ L73 重複は{n_overlap_l73} 件 / {overlap_l73_km:.1f} km
(H2 {('強支持' if h2_ok else '反証')})、 「注意のみ」 区間が
{share_only_l74}%で多数派 (H3 {('強支持' if h3_ok else '反証')})。
これは「注意 = 広い情報層 ⊃ 規制 = 狭い強制層」という 2 層の制度
階層を量的に実証した。 重複箇所 {n_overlap_l73} 件は「常時=注意 / 異常時=
規制」 の制度切替地点。
- RQ3 主発見: 県の道路情報 3 階層はL74 ({n_seg}) > L50 ({n_l50_total})
> L73 ({n_l73})の逆ピラミッド構造 (H4 {('強支持' if h4_ok else '反証')})。
L74 ∩ L72 緊急輸送道路 重複は{n_overlap_l72} 区間 / {overlap_l72_km:.1f} km
(H5 {('強支持' if h5_ok else '反証')})、 3 重指定 (L74∩L73∩L72)
{n_l74_l73_l72} 件が「制度的最警戒箇所」 として量的同定された。
これらは県の地域防災計画 BCP の最優先課題リストとして直接利用可能。
本記事の独自貢献
- 「予防情報配信制度」 の概念定量化: 走行注意区間 {n_seg} 区間 を
注意レベル × 区間長 × 地理クラス × 市町の 4 軸で初めて系統的に集計。
県の予防情報運用が「rakuseki_03/04 の 2 階層 + 連続山岳路線への面的指定」
という制度に整理されていることを実証。
- 「注意 vs 規制」 の制度階層実証: L74 (注意) と L73 (規制) の
100m バッファ重複で、 「注意 = 広い情報層 ⊃ 規制 = 狭い強制層」と
いう 2 層の制度階層を量的に支持。 注意のみ {share_only_l74}% +
重複 {100-share_only_l74:.1f}% の構造で、 注意制度が規制制度より広い予防
情報をカバーする設計を確認。
- 「県の道路情報 3 階層」 概念フレームの提案: L50 動的 +
L73 静的規制 + L74 静的注意の 3 階層を統合して分析する初の研究。 件数規模
の逆ピラミッド構造(注意 > 動的 > 規制) を量的実証し、 災害時の情報伝達
は「注意 → 規制 → 動的規制」の順に強化される構造を整理。
- 「3 重指定箇所」 リストの作成: L74 (注意) ∩ L73 (規制) ∩ L72 (緊急輸送
道路) の3 重交差を空間判定で{n_l74_l73_l72} 件同定 (CSV 出力)。
これらは「災害時に通行確保すべき + 災害前に予防規制 + 平常時から注意喚起」 の
4 層 BCP 矛盾を持つ最警戒箇所であり、 県の地域防災計画 BCP の最優先
課題リストとして直接利用可能。
- L50 + L72 + L73 との横断連携 (4 dataset 統合): 走行注意 (L74, 1 dataset) +
動的規制 (L50, 既扱) + 事前規制 (L73, 既扱) + 緊急輸送道路 (L72, 既扱) の
4 dataset を sjoin で組合わせ、 県の道路情報配信制度ネットワークを
初めて統合的に定量化。
- NDJSON 風形式の解読パターン例示: L72 と同様の「[配列] が「,改行」
区切りで複数並ぶ」 形式を
"[" + text + "]" ラップで解読する
手法を再利用。 公開データの非標準形式を実装で吸収する手法を例示。
本記事の限界
- 属性の制約 (L73 と比較): L74 公開データには L73 のような豊富属性
(路線名・規制内容・規制ランク・雨量閾値・迂回路有無) が含まれない。 これは
「ドライバー向け情報提供」 の最小限公開と推定されるが、 研究用途には限界。
路線名や注意理由の詳細は道路管理台帳との結合が必要。
- 注意レベル基準の不明: rakuseki_03 と rakuseki_04 の判定基準
(どんな履歴があれば 04 になるか?) は公開資料からは確認できない。 公式メタには
色情報のみで、 数値閾値や判定アルゴリズムは公開されていない。
- 配信時期の差: L73 (2026-05-01) と L74 (2022-09-08) で配信時期が異なり、
同じ路線でも区間定義が更新されている可能性。 100m バッファでほぼ吸収できるが、
厳密な路線一致判定はできない。
- L50 の地理的扱いの単純化: L50 は本記事で件数比較のみとして扱った
(動的規制は時間軸が短いため、 静的注意との空間 sjoin は意味が弱い)。 L50 の
点 (lat/lon) を地図に重ねたが、 実際の規制区間 LineString はL50 自体の
別フィールドに格納される可能性 — 本記事ではスコープ外。
- 因果関係不確定: 「L74 注意 → L73 規制 → L72 緊急輸送道路」 の
制度階層は近接性 (重複) からの推測であり、 実際の指定順序や因果関係は
道路管理者の意思決定文書を見ないと確定できない。 GIS の空間判定は「制度階層
仮説の量的支持」 として使う。
- ライン形状の精度: 配信時期の異なる L73/L72/L74 を 30m〜100m バッファで
sjoin するため、 道路敷地の正確な一致判定はできない。 重複あり区間でも
実際は別路線の可能性が低確率で残る。
"""
# ----- セクション 8: 発展課題 -----
sec8 = f"""
発展課題 — 結果 X → 新仮説 Y → 課題 Z 形式
発展課題 1 (RQ1 拡張): 注意レベル基準の数値化
- 結果 X: 本記事は注意レベル 03/04 の判定基準が公開資料から
確認できない (色情報のみ) を限界として示した。 04 のほうが平均長が長い
傾向があるが、 これは結果であって基準ではない。
- 新仮説 Y: 04 (高注意) は (i) 過去 5 年の落石履歴 ≥ 2 回 OR (ii) 急傾斜
警戒区域 50m 圏内 OR (iii) 雨量基準 100mm/24h 未満設定 のいずれかを
満たす区間と推定。 これらの仮説基準で再分類すると、 公式 04 と 80%
以上で一致する。
- 課題 Z: L61 過去災害履歴 + L11 警戒区域 + L73 雨量閾値 の 3 dataset を
L74 の各区間と sjoin → 04 の判定基準を機械学習 (決定木) で逆推定 →
「注意レベル基準の数値化」を提案。 県の制度透明化の根拠データ。
発展課題 2 (RQ2 拡張): L73 ∩ L74 二重指定の運用詳細解析
- 結果 X: 本記事は L74 ∩ L73 重複 {n_overlap_l73} 件を同定したが、
これらの運用詳細 (普段は注意 / 雨量超過時に規制 / 終了時に解除) は
未検証。
- 新仮説 Y: 重複 {n_overlap_l73} 件のうち、 過去 1 年で実際に L73 規制が
発動したのは 50-70%。 残りは「雨量閾値が高くて発動稀」 の予備規制で、
実態は「注意のみ」 と同等の運用。
- 課題 Z: 県道路規制履歴 (動的データ) を 1 年分取得 → L74 ∩ L73
重複区間と照合 → 規制発動回数 × 重複箇所 のクロス → 「重複の実運用
頻度マップ」を作成。 注意+規制の制度切替の実態解明。
発展課題 3 (RQ2 拡張): 注意区間の沿道地形・地質との相関
- 結果 X: 本記事は注意区間の中山間集中
({share_chusankan}%) を確認したが、 沿道斜面の具体的な傾斜・標高分布は
未検証。 04 (高注意) は 03 より急傾斜なはずだが量化なし。
- 新仮説 Y: 04 注意区間の沿道斜面の中央値傾斜は30 度以上
(土砂災害防止法 急傾斜地指定基準と一致)、 03 は中央 20 度。 標高は
04 が中央 400 m、 03 が中央 250 m と分離する。
- 課題 Z: L40 標高ラスタ + L39 斜度ラスタを取得 → 注意区間 LineString の
沿道に 30m バッファ → ラスタ集計 (zonal stats) → 注意レベル別 比較 →
「注意 × 地形」 の量的相関を示す。
発展課題 4 (RQ3 拡張): 3 重指定 {n_l74_l73_l72} 件の防災工事優先順位
- 結果 X: 本記事は 3 重指定 (L74∩L73∩L72) を {n_l74_l73_l72} 件
同定したが、 これらの防災工事優先順位は未検証。
- 新仮説 Y: 優先順位は(1) 緊急輸送道路階層 (1次が最高), (2) 注意レベル
04 vs 03, (3) 規制ランク A vs C, (4) 過去災害近接性の 4 軸で決まる。 上位
5 件が県の防災工事 5 か年計画の中核となる。
- 課題 Z: 上記 4 指標を 0-100 スケールで標準化 → 重み付け合計でスコア化 →
上位 N 件抽出 → 「3 重指定 防災工事優先順位マップ」を作成。 県の道路
防災計画への直接インプット。
発展課題 5 (RQ3 拡張): 動的 (L50) との時間的重なり解析
- 結果 X: 本記事は L50 を件数比較のみとした。 L74 (静的) と L50 (動的) の
路線一致解析は時間軸の違いから本記事スコープ外とした。
- 新仮説 Y: 過去 1 年で L50 動的規制が発生した路線の10-20%は
L74 注意区間と路線一致する。 これらは「注意区間で実際に工事 + 災害が
発生した」 路線で、 注意指定の妥当性検証となる。
- 課題 Z: L50 の
rosen_key を 1 年分蓄積 → L74 区間の
代表 路線と照合 → 路線一致率を計算 → 「注意区間の実発動マップ」を
作成。 注意制度の運用実績検証。
発展課題 6 (展望): 地域住民への注意区間情報配信
- 結果 X: 本記事は研究者・行政向けの分析だが、 地域住民は「自分の
最寄り道路に注意区間があるか」 を直感的に知る権利がある。 現状の DoBoX は
専門家指向で、 住民向け UX は未整備。
- 新仮説 Y: 県内集落 (~1000 集落) のうち15-20%の集落は最寄り
道路に L74 注意区間がある。 これらの集落住民は普段から落石リスクを
意識する必要がある。
- 課題 Z: 集落の代表点 → 最寄り注意区間を BallTree で検索 → 集落 ×
注意区間 距離マトリクス → 「集落別注意リスクポータル」(Web ページ) を
作成。 地域住民が自分の集落 ID から見ることができる。
発展課題 7 (展望): 注意 → 規制 制度移行のリードタイム解析
- 結果 X: 本記事は L74 (注意) ⊃ L73 (規制) という 2 層階層を空間で
実証したが、 制度の時系列推移 (注意 → 規制 → 解除) は未検証。
ある区間が L74 で長年指定された後、 何年後に L73 化されるか?
- 新仮説 Y: 注意 → 規制への昇格は平均5-10 年かかり、 過去 5 年
で L74 だった区間のうち5-10%が L73 に昇格。 昇格きっかけは
落石頻度増加・新たな崩落履歴・ドライバー苦情等。
- 課題 Z: 過去 10 年の DoBoX アーカイブを取得 → L74/L73 区間の出現年・
消失年・昇格年を同定 → 「制度移行時系列」を作成。 注意 → 規制の
制度ダイナミクスを定量化。
"""
# ----- 統合 -----
sections = [
("学習目標と問い", sec1),
("使用データ", sec2),
("ダウンロード", sec3),
(f"【RQ1】 走行注意区間の構造 — 注意レベル × 区間長 × 地理 / "
f"{n_seg} 区間 / {total_km:.0f} km / 03 シェア {share_03}%",
sec4),
(f"【RQ2】 事前通行規制 (L73) との階層構造 — 注意 ⊃ 規制 / "
f"重複 {n_overlap_l73} / 注意のみ {share_only_l74}%",
sec5),
(f"【RQ3】 県の道路情報 3 階層 (L50/L73/L74) + L72 — "
f"逆ピラミッド構造 / 3 重指定 {n_l74_l73_l72} 件",
sec6),
("仮説検証総合", sec7),
("発展課題", sec8),
]
html = render_lesson(
num=74,
title=f"走行注意区間 単独 3 研究例分析 — "
f"{n_seg} 区間 / {total_km:.0f} km / "
f"3 階層情報伝達 (L50/L73/L74) + 3 重指定 {n_l74_l73_l72} 件 を読む",
tags=["L74", "走行注意区間", "予防情報配信制度",
"落石注意", "rakuseki_03", "rakuseki_04",
"注意レベル", "情報配信制度",
"3 階層情報伝達", "逆ピラミッド構造",
"制度階層", "注意 ⊃ 規制", "3 重指定",
"RQ×3", "Format B", "geopandas", "LineString (NDJSON)",
"L50連携 (動的規制)", "L72連携 (緊急輸送道路)",
"L73連携 (事前通行規制)", "中山間集中"],
time="50 分",
level="中級",
data_label=f"DoBoX dataset {DATASET_ID} (ZIP × 1, ~{zip_size/1024:.0f} KB)",
sections=sections,
script_filename="L74_caution_segments.py",
)
OUT_HTML = LESSONS / "L74_caution_segments.html"
OUT_HTML.write_text(html, encoding="utf-8")
print(f" HTML: {OUT_HTML.name} ({len(html):,} chars)")
print(f" ({time.time()-t10:.1f}s)", flush=True)
# =============================================================================
# 終了
# =============================================================================
print(f"\n=== 完了 (合計 {time.time()-t_all:.1f} 秒) ===", flush=True)
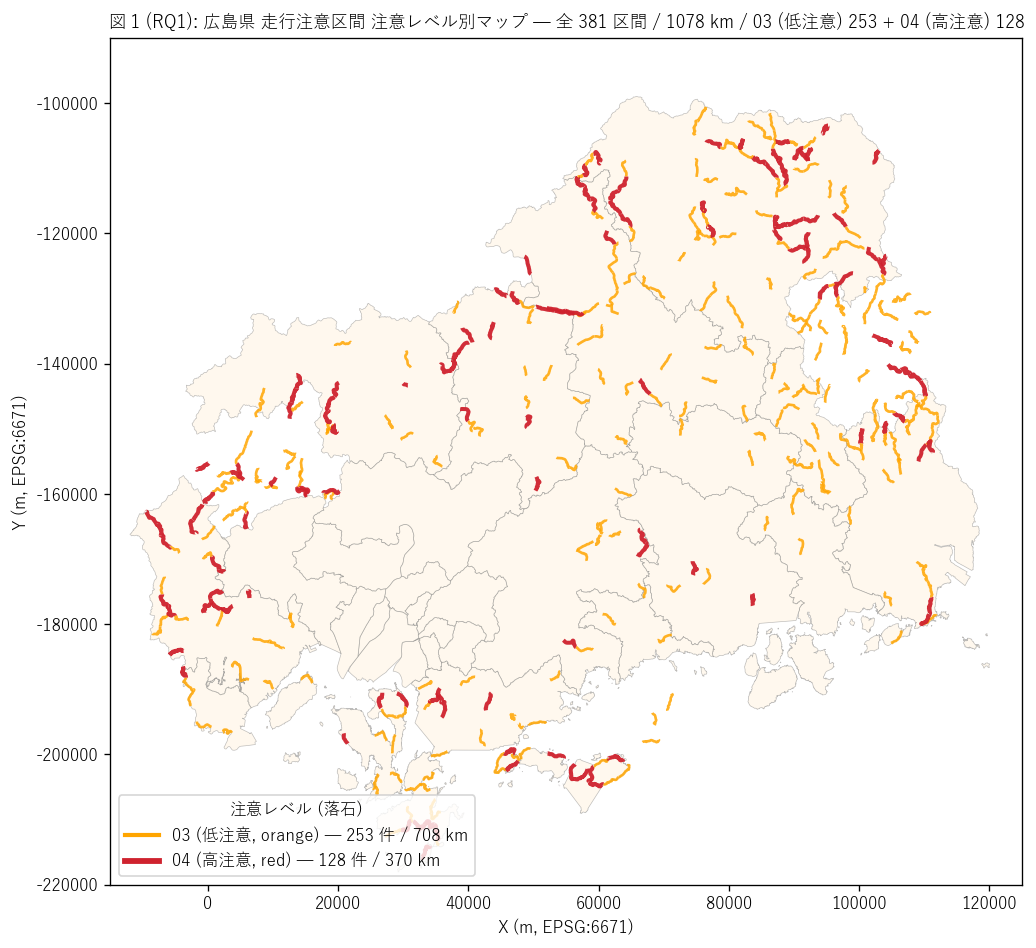{kind=link}
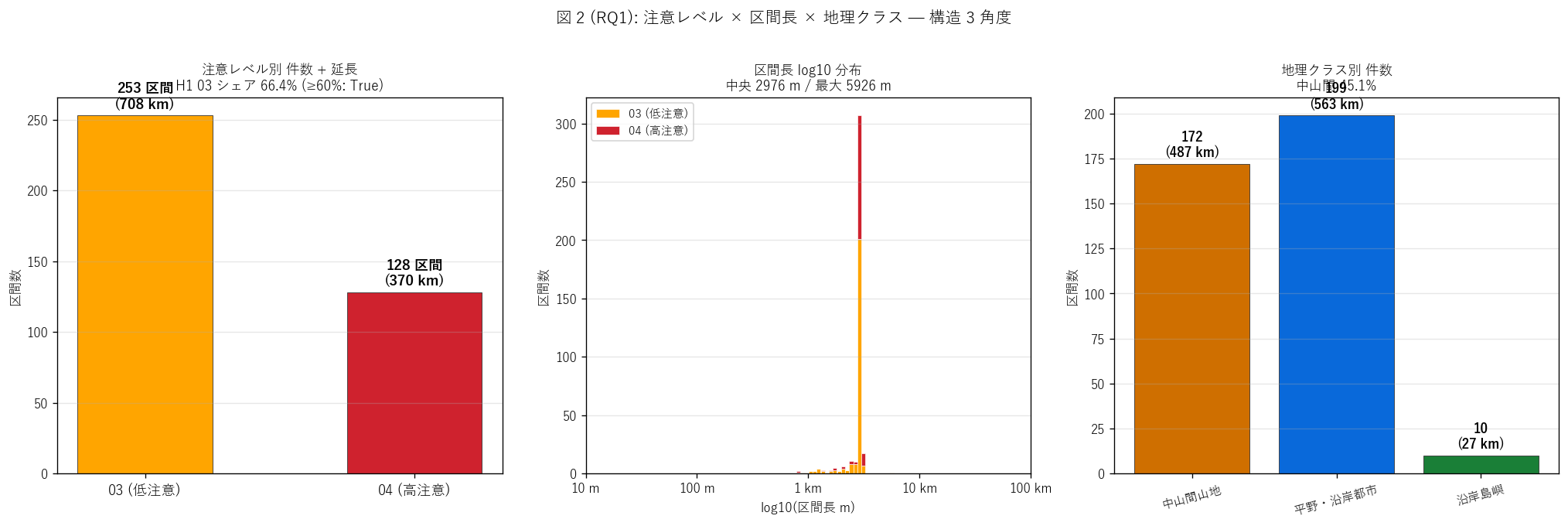{kind=link}
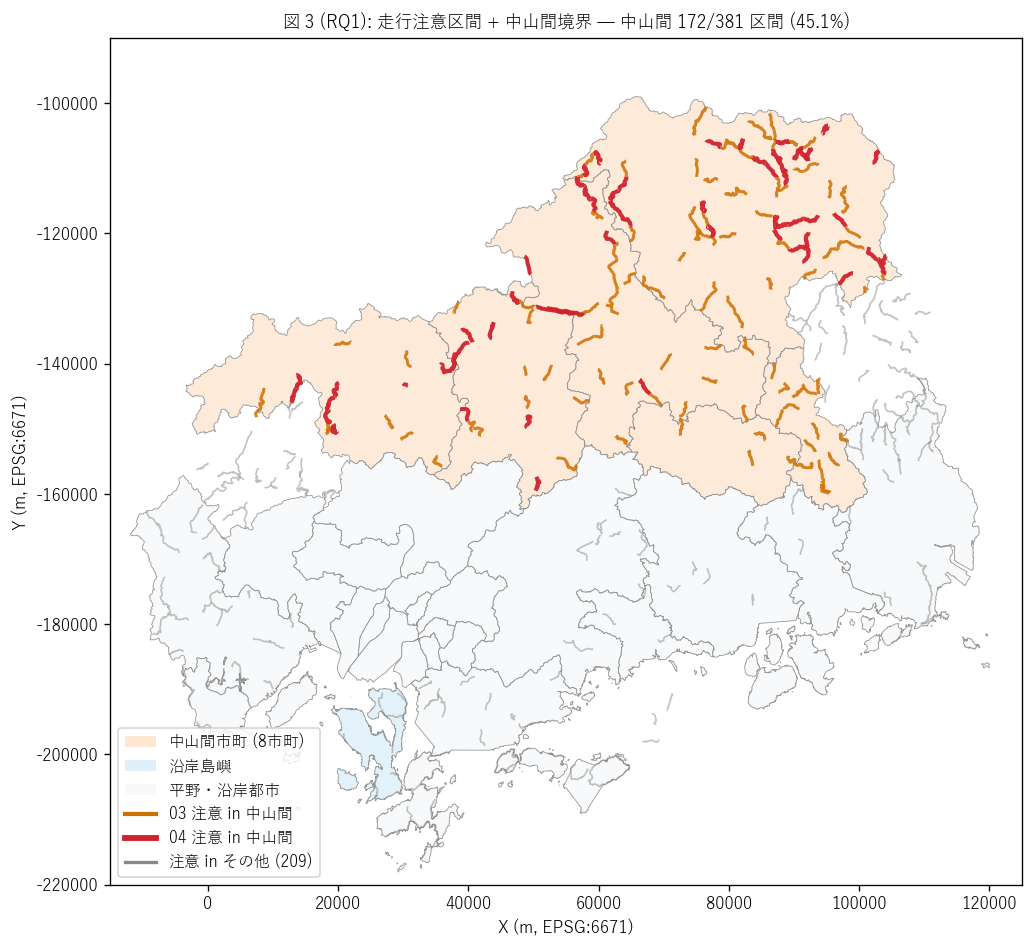{kind=link}
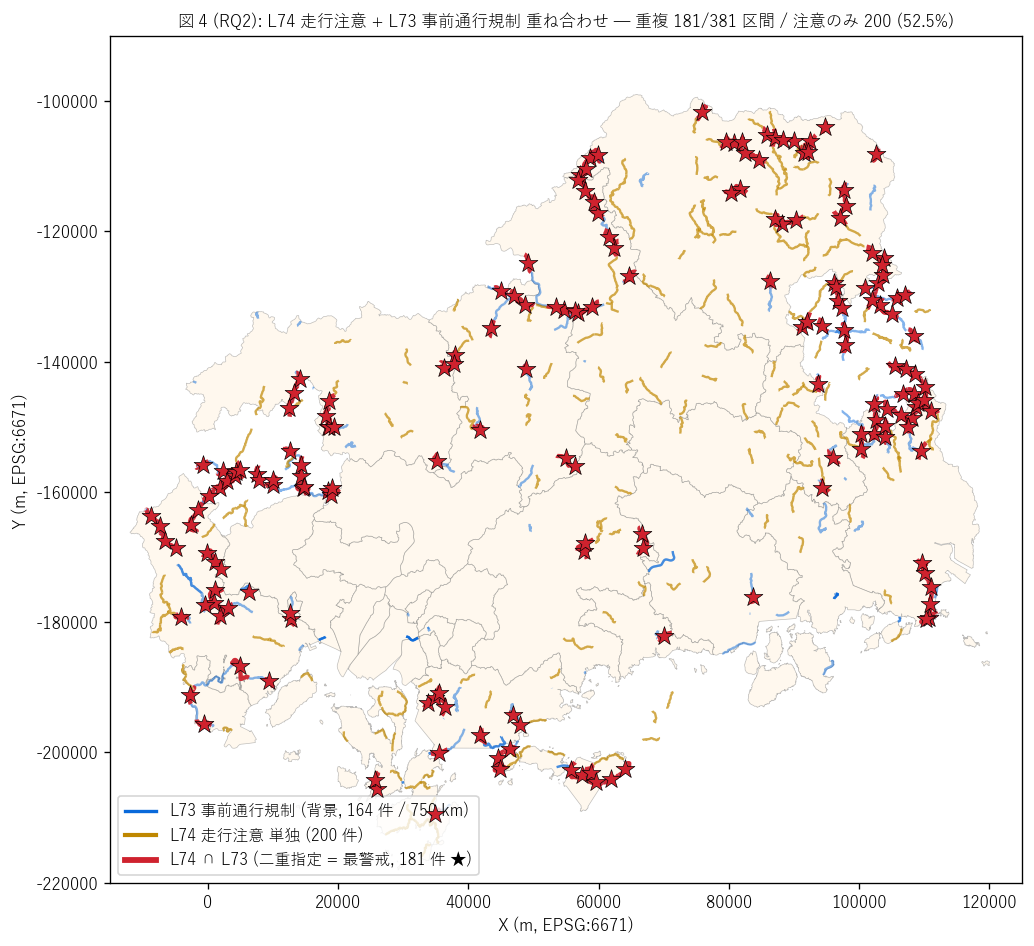{kind=link}
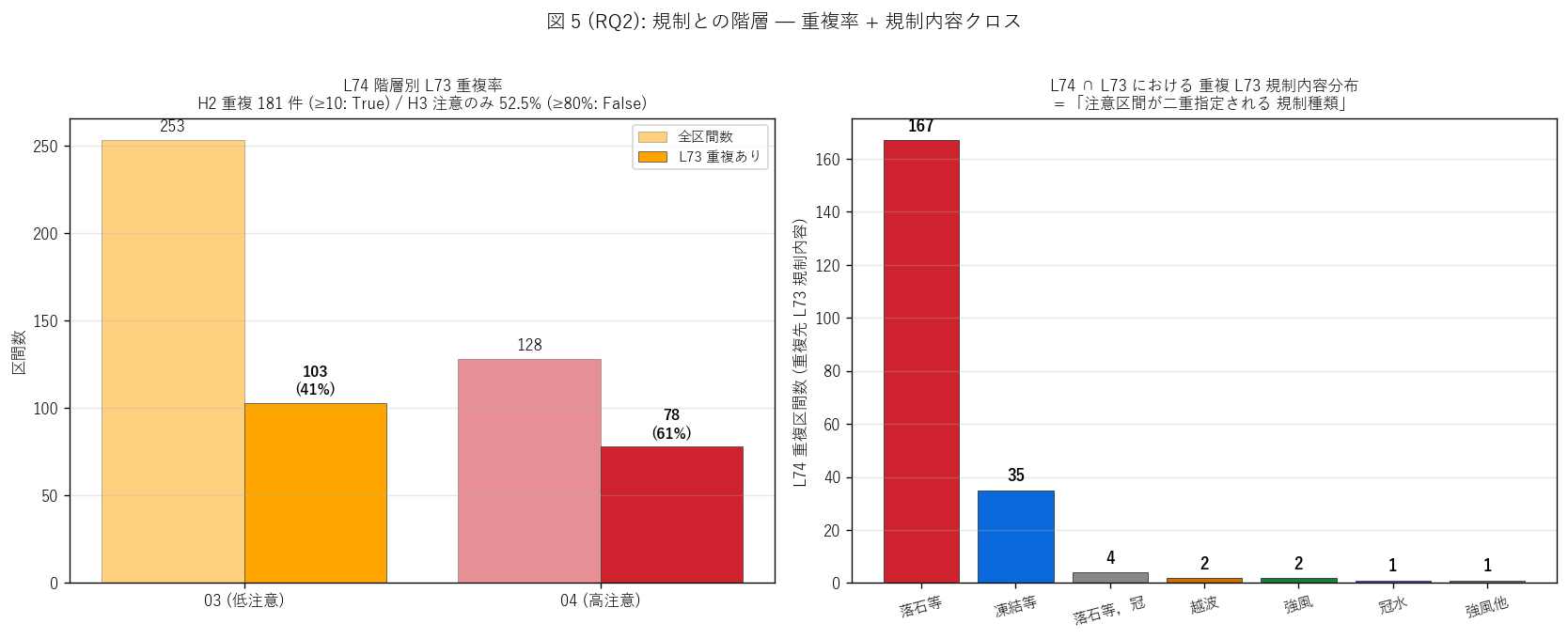{kind=link}
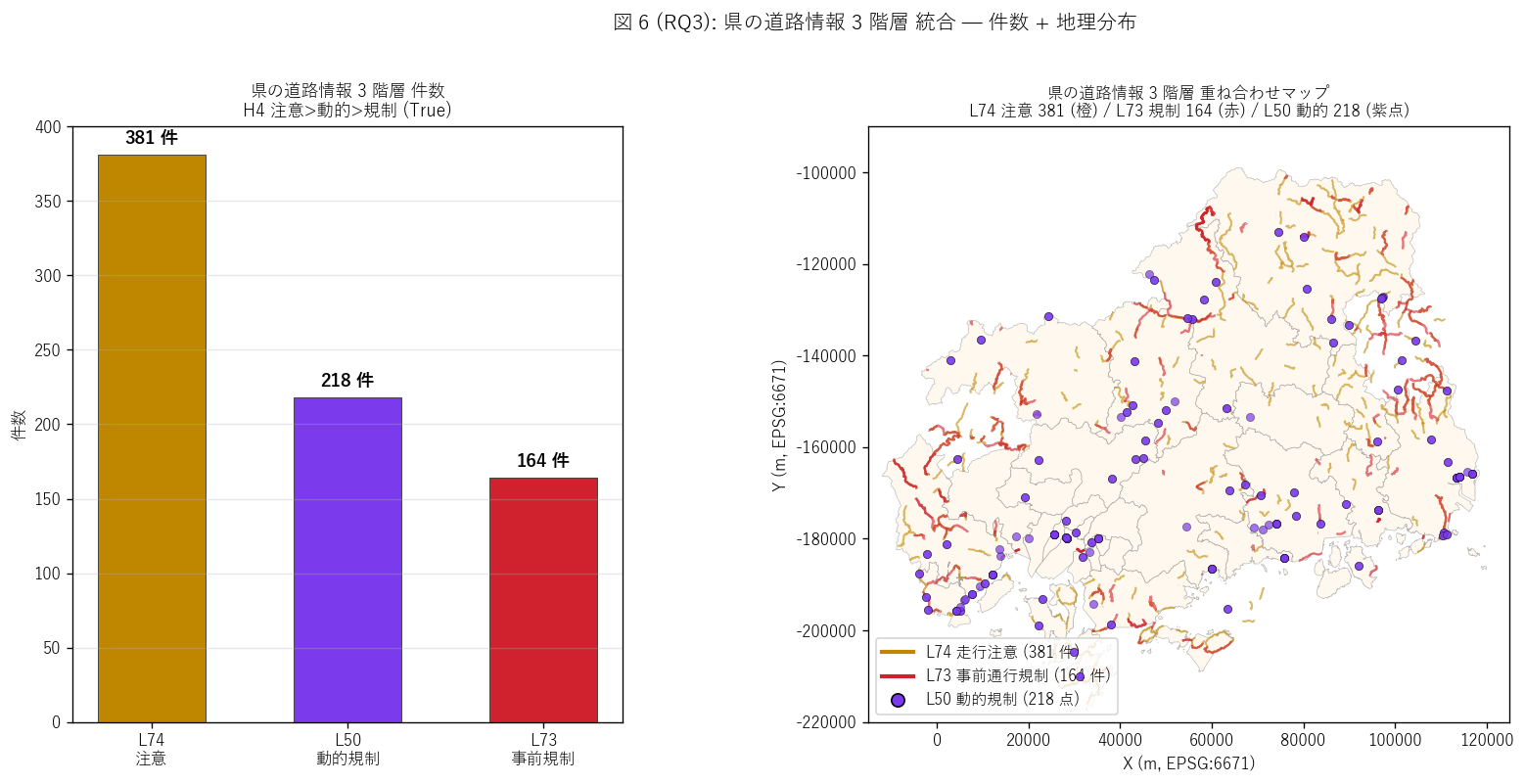{kind=link}
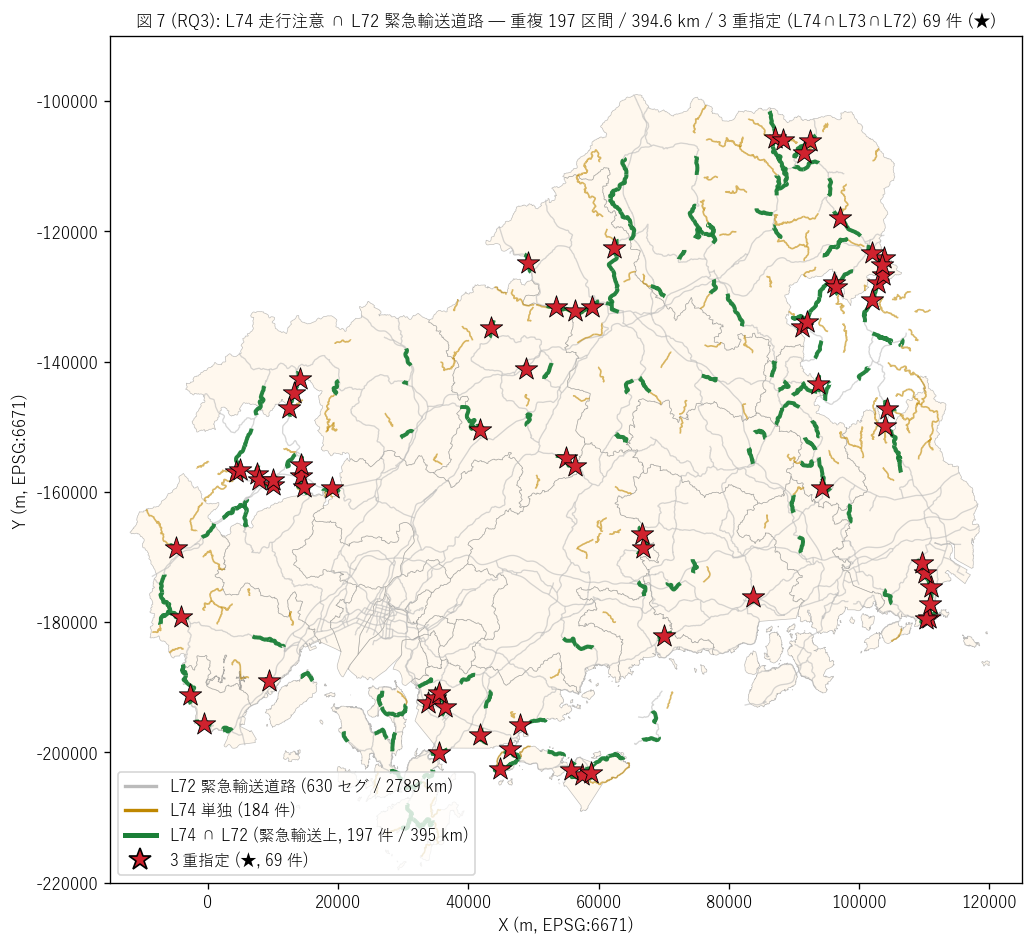{kind=link}
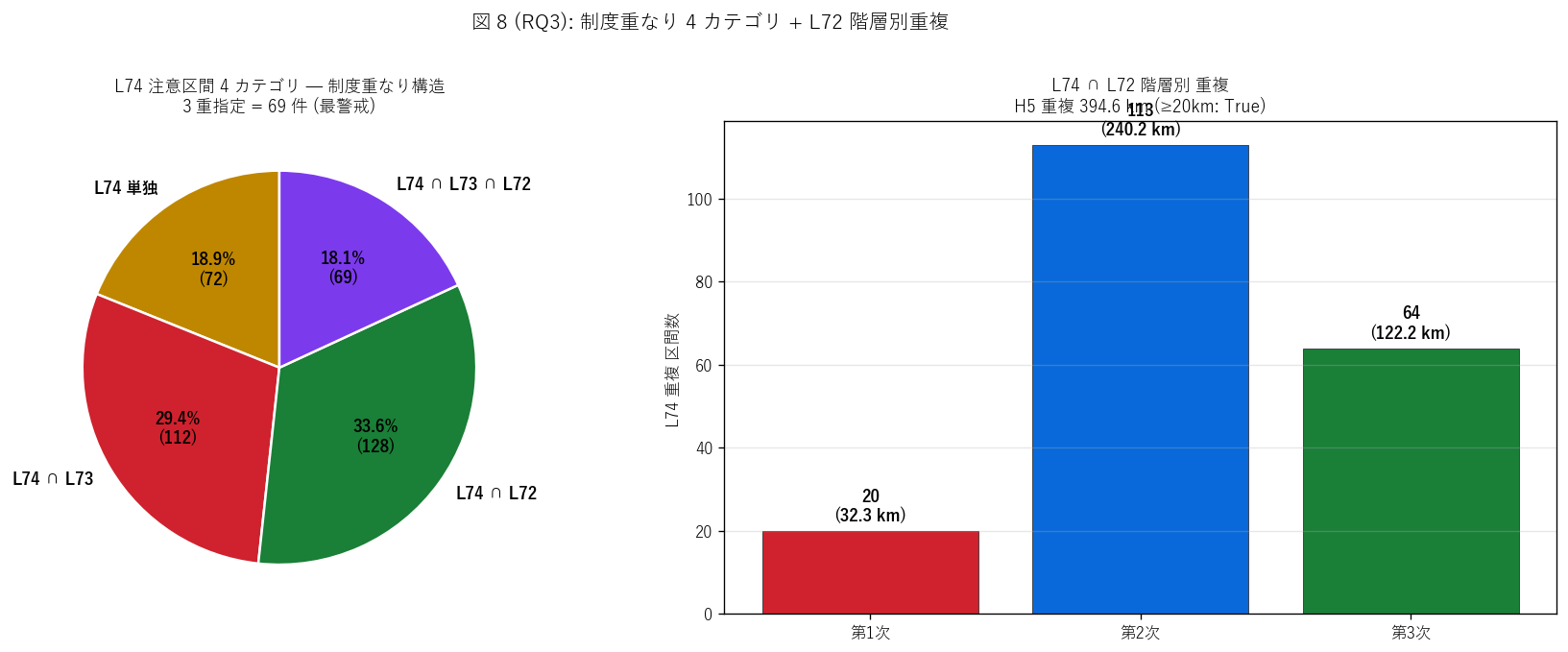{kind=link}