# -*- coding: utf-8 -*-
"""L73 事前通行規制区間 単独 3 研究例分析
— 広島県 事前通行規制区間 (dataset 1245) を 3 角度で解読
カバー宣言:
本記事は DoBoX のデータセット「事前通行規制区間」 (dataset_id = 1245)
1 件を 単独で取り上げ、 広島県の事前通行規制区間 (LineString,
164 区間 / 計 ~750 km) を 3 つの独立した研究角度
(RQ1 / RQ2 / RQ3) で並列に分析する。
「事前通行規制区間」 とは:
連続雨量 (24 時間雨量) や時間雨量 (60 分雨量) が一定の閾値を超えると
自動的に通行止めとする道路区間。 過去の災害履歴・地形脆弱性から道路
管理者があらかじめ指定し、 災害発生 前に予防的に通行止めにする
「予防的安全制度」。 道路法 (1952) + 災害対策基本法 (1961) を
根拠とする県管理道路の運用制度で、 事後の通行止 (実害発生後) と異なり
「降雨ノモゲン違反 → 自動規制」のルールベース運用。
広島県の事前通行規制区間は2 系統 × 多階層に区分される (本記事独自集約):
系統 1: 雨量基準 (jizen) 138 区間
ランク A (厳): 80 mm/24h, 20 mm/h
ランク B (中): 100 mm/24h, 30 mm/h
ランク C (緩): 120 mm/24h, 40 mm/h
特ランク (沿岸専用): 越波・冠水基準 (一部 60 mm/24h, 15 mm/h)
風ランク: 風速 15-25 m/s 閾値
地震・霧 単独
系統 2: 冬期閉鎖 (winter, 凍結等) 26 区間 (12 月〜3 月の機械的閉鎖)
総延長は約 750 km (主に中山間 + 沿岸の山岳道路で県内主要地方道に集中)。
本記事は 緊急輸送道路 L72 / 道路規制 L50 / トンネル L67 /
道路法面 L71 / 走行注意区間と厳密に区別:
L50 = 道路規制動的 (本日 + 今後, 工事 + 災害短期, 218 件)
L72 = 緊急輸送道路単独 (LineString, 災害時生命線, 4 階層 / 2,790 km)
L67 = トンネル単独 (POINT, 山岳貫通)
L71 = 道路法面単独 (POINT, 沿道斜面保護)
L73 = 事前通行規制区間単独 (LineString, 雨量・冬期, 164 区間 / 750 km)
本記事は他シリーズと合体しない。 RQ2 で警戒区域 (L11) + 過去災害 (L61),
RQ3 で緊急輸送道路 (L72) を参照する形をとる。
研究の問い (3 RQ):
RQ1 (主研究): 広島県の事前通行規制区間の構造 — 路線・延長・規制基準は
どう描けるか? 164 区間 × ~750 km の LineString を規制理由
(落石/凍結/強風/越波/冠水) × 規制ランク (A/B/C/特/冬/風) × 雨量閾値
× 路線種別 (国道/県道) × 建設事務所の 5 軸で集計し、 「県の予防的
安全制度」 の物理形状を初めて系統的に記述する。
H1 = 雨量基準 (jizen) が冬期閉鎖 (winter) より圧倒的多数 (>=70%) 仮説。
RQ2 (副研究 1): 事前通行規制区間は中山間集中 — 過去災害履歴 (L61) +
土砂警戒区域 (L11)とどう空間関係するか? 規制区間の代表点を
行政界に sjoin → 中山間 vs 都市部の比率を計算、 さらに過去災害点
(424 件) との <=2 km 近接性 + 土砂警戒区域との重なり率を計算し、
「過去災害があった場所 = 規制区間」 の検証をする。
H2 = 中山間市町 (庄原・三次・安芸太田・安芸高田・神石高原・北広島 等)
が規制区間の >=60% を占める仮説、
H3 = 落石等規制区間 (96 件) のうち >=50% が土砂警戒区域 2 km 圏に
入る仮説 (規制区間 = 土砂リスク区間 の対応)。
RQ3 (副研究 2): 事前通行規制区間は緊急輸送道路 (L72 既知) と
どれだけ重なるか? 「災害時に通行確保すべき道路」 (緊急輸送道路) と
「災害前に予防的に通行止になる道路」 (規制区間) の重複は
「通行確保の制度的矛盾」を意味する。 30m バッファで sjoin →
重複区間を同定 → 迂回路 (ukaiumu) 有無別に集計 → 矛盾区間の
バックアップルート確保状況を定量化する。
H4 = 規制区間と緊急輸送道路の重複は >=20 km (>=15 区間) 仮説、
H5 = 重複区間のうち迂回路無 (ukaiumu='無') が 少なくとも 1 件
存在し、 これが県の予防防災の最重要課題となる仮説。
仮説 (5):
H1 (RQ1, 制度構造): 事前通行規制区間 164 のうち雨量基準 (jizen) が
138 件 (84%)、 冬期閉鎖 (winter) が 26 件 (16%)。 7 割を超える
多数派は「降雨閾値で動的に判定する規制」であり、 冬期閉鎖は
広島の中で限られた山岳路線のみという仮説。
H2 (RQ2, 中山間集中): 規制区間の代表点が中山間 7 市町(庄原・三次・
安芸高田・安芸太田・北広島・神石高原・世羅) に位置する件数は
全体の 60% 以上。 これは「事前通行規制 = 中山間山岳道路の
脆弱性に対する予防制度」 を示す根拠仮説。
H3 (RQ2, 過去災害との対応): 落石等規制 (96 件) のうち土砂警戒区域 2 km
圏に位置する区間が 50% 以上。 これは「過去に落石・崩落が
あった道路 → 警戒区域指定 → 規制区間指定」 という3 段階の予防制度
階層の量的実証。
H4 (RQ3, 緊急輸送道路との重複): 事前通行規制区間と緊急輸送道路 30m
バッファの重複区間延長 >= 20 km (>= 15 区間)。 これは「災害時に
通行確保すべき道路の一部が、 災害前に予防的に通行止になる」
というBCP 制度的矛盾の量的事実。
H5 (RQ3, 迂回路無の最重要箇所): 緊急輸送道路と重複する規制区間のうち、
迂回路無 (ukaiumu='無') の区間が少なくとも 1 件存在する。
これは「災害時に通行確保すべきで、 災害前に通行止になり、 迂回路もない」
という3 重制度的矛盾の最重要箇所であり、 県の予防防災 BCP の
核心課題となる仮説。
要件 S 準拠 (1 分以内完走):
- データ JSON 1 件 (~1.7 MB) → ensure_dataset で取得
- 164 区間 LineString → WKT パース → ~50,000 点サンプリング
- 行政界 sjoin (代表点 1 回) で市町判定 → 中山間判定
- 過去災害 CSV (424 件) を STRtree で 2km 圏判定
- 緊急輸送道路 JSON (L72 既キャッシュ展開済) を 30m バッファ → 規制区間 sjoin
- 全体で ~10 秒目標
要件 T 準拠 (位置情報あり = 地図必須):
- RQ1: 規制理由別マップ + 規制ランク別マップ
- RQ2: 規制 + 中山間境界 + 土砂警戒 重ね合わせマップ + 過去災害近接ヒート
- RQ3: 規制 ∩ 緊急輸送道路 重複マップ (迂回路有無で色分け)
要件 Q 準拠: 図 8+ / 表 12+ (3 RQ × 多角度: 制度 / 中山間集中 / 通行確保矛盾)
データ仕様:
- dataset 1245: 事前通行規制区間 (JSON × 1 リソース)
- resource 32489: 道路_事前通行規制区間_2026-05-01-T23:55:02 (~1.7 MB)
- JSON 構造: {"results": [list of 164 dict], 各 dict は 36 列}
- 主要列:
- id (KJID_xxxxxxxx): 規制区間 ID
- rosenname / rosen_key: 路線名
- kisei_start / kisei_end: 規制起点 / 終点
- kiseinaiyo: 規制内容 (落石等/凍結等/強風/冠水/越波/...)
- rankname: 規制ランク (A/B/C/特/冬/風/...)
- basis: 規制基準条文 (時間雨量/日雨量/風速/...)
- ikichi24h / ikichi60m: 24h / 60m 雨量閾値 (mm)
- ukaiumu: 迂回路有無 (有/無)
- demarcation: 建設事務所
- lat / lon: 代表点
- kukan / kukanroot: LineString WKT (区間 geometry)
- type: jizen (雨量) / winter (冬期閉鎖)
- icon: rain / snow / wind / kansui / nami / rinko
- area: hukuyama / kure / bihoku / geihoku / higasi (内部エリア区分)
- ライセンス: クリエイティブ・コモンズ表示 (CC-BY)
メモリ対策: Figure ごとに plt.close('all') で確実に解放。
"""
from __future__ import annotations
import sys, time, json
from pathlib import Path
sys.path.insert(0, str(Path(__file__).parent))
from _common import ROOT, ASSETS, LESSONS, render_lesson, code, figure, ensure_dataset
import numpy as np
import pandas as pd
import geopandas as gpd
from shapely import wkt as swkt
from shapely.geometry import Point, LineString
from shapely.strtree import STRtree
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.lines import Line2D
from matplotlib.patches import Patch
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
t_all = time.time()
print("=== L73 事前通行規制区間 単独 3 研究例分析 ===", flush=True)
# =============================================================================
# 0. 定数・パス
# =============================================================================
TARGET_CRS = "EPSG:6671" # JGD2011 平面直角第 III 系
DATA_DIR = ROOT / "data" / "extras" / "L73_pre_traffic_restriction"
DATA_DIR.mkdir(parents=True, exist_ok=True)
DATASET_ID = 1245
RESOURCE_ID = 32489
JSON_NAME = "pre_traffic.json"
# 規制内容 → 統一カテゴリ + 色
NAIYO_NORMALIZE = {
"落石等": "落石等",
"落石等,冠": "落石等",
"凍結等": "凍結等",
"強風": "強風",
"強風他": "強風",
"冠水": "冠水",
"越波": "越波",
"": "その他/不明",
}
NAIYO_COLOR = {
"落石等": "#cf222e", # 赤 = 土砂・落石
"凍結等": "#0969da", # 青 = 凍結・積雪
"強風": "#1a7f37", # 緑 = 強風
"冠水": "#7c3aed", # 紫 = 冠水 (内陸の道路冠水)
"越波": "#cf6f00", # 橙 = 越波 (沿岸)
"その他/不明": "#888",
}
NAIYO_ORDER = ["落石等", "凍結等", "強風", "冠水", "越波", "その他/不明"]
# 規制ランク → 雨量グレード (本記事独自集約)
def rank_grade(rankname, type_):
"""雨量3階層 (A/B/C) + 特/冬/風 + その他 の 6 カテゴリへ集約"""
if type_ == "winter":
return "冬期閉鎖"
r = rankname or ""
if r == "A":
return "A (80mm/24h, 20mm/h)"
if r == "B":
return "B (100mm/24h, 30mm/h)"
if r == "C":
return "C (120mm/24h, 40mm/h)"
if r.startswith("特"):
return "特 (沿岸越波/冠水)"
if r == "風":
return "風 (15-25 m/s)"
return "その他 (地震/霧/臨港)"
GRADE_ORDER = [
"A (80mm/24h, 20mm/h)",
"B (100mm/24h, 30mm/h)",
"C (120mm/24h, 40mm/h)",
"特 (沿岸越波/冠水)",
"風 (15-25 m/s)",
"冬期閉鎖",
"その他 (地震/霧/臨港)",
]
GRADE_COLOR = {
"A (80mm/24h, 20mm/h)": "#cf222e", # 赤 = 最厳しい
"B (100mm/24h, 30mm/h)": "#cf6f00", # 橙 = 中
"C (120mm/24h, 40mm/h)": "#bf8700", # 山吹 = 緩
"特 (沿岸越波/冠水)": "#7c3aed", # 紫 = 沿岸専用
"風 (15-25 m/s)": "#1a7f37", # 緑 = 風
"冬期閉鎖": "#0969da", # 青 = 冬
"その他 (地震/霧/臨港)": "#888",
}
# 路線種別判定
def classify_rosen(name):
if not name:
return "その他/不明"
if "国道" in name:
return "国道"
if "主要地方道" in name:
return "主要地方道"
if "県道" in name:
return "一般県道"
if "高速" in name or "自動車道" in name:
return "高速・自動車道"
return "その他/不明"
ROSEN_ORDER = ["国道", "主要地方道", "一般県道", "高速・自動車道", "その他/不明"]
ROSEN_COLOR = {
"国道": "#cf222e",
"主要地方道": "#bf8700",
"一般県道": "#0969da",
"高速・自動車道": "#7c3aed",
"その他/不明": "#888",
}
# CITY_CD → 市町名
CITY_NAME = {
101: "広島市中区", 102: "広島市東区", 103: "広島市南区", 104: "広島市西区",
105: "広島市安佐南区", 106: "広島市安佐北区", 107: "広島市安芸区", 108: "広島市佐伯区",
202: "呉市", 203: "竹原市", 204: "三原市", 205: "尾道市", 207: "福山市",
208: "府中市", 209: "三次市", 210: "庄原市", 211: "大竹市", 212: "東広島市",
213: "廿日市市", 214: "安芸高田市", 215: "江田島市",
302: "府中町", 304: "海田町", 307: "熊野町", 309: "坂町",
368: "安芸太田町", 369: "安芸太田町", 462: "世羅町",
412: "北広島町", 545: "神石高原町",
}
# 中山間 7 市町 (本記事独自定義)
CHUSANKAN_CITIES = {
"庄原市", "三次市", "安芸太田町", "安芸高田市",
"北広島町", "神石高原町", "世羅町", "府中市",
}
COASTAL_ISLAND = {"江田島市", "大崎上島町"}
def geo_class(name):
if name in CHUSANKAN_CITIES:
return "中山間山地"
if name in COASTAL_ISLAND:
return "沿岸島嶼"
if not name:
return "その他/不明"
return "平野・沿岸都市"
# 行政界キャッシュ
ADMIN_GPKG = ROOT / "data" / "extras" / "L44_storm_surge" / "_cache" / "admin_diss.gpkg"
# L11 警戒区域 (既キャッシュ)
SED_DIR = ROOT / "data" / "extras" / "sediment_shp"
SED_FILES = {
"急傾斜": (SED_DIR / "kyukeisha"
/ "340006_sediment_disaster_hazard_area_steep_slope_20260427",
"ky_"),
"土石流": (SED_DIR / "doseki"
/ "340006_sediment_disaster_hazard_area_debris_flow_20260427",
"dy_"),
"地すべり": (SED_DIR / "jisuberi"
/ "340006_sediment_disaster_hazard_area_landslide_20260427",
"jy_"),
}
# L61 過去災害履歴 (既キャッシュ CSV)
PAST_DISASTER_CSV = ROOT / "data" / "extras" / "past_disasters.csv"
# L72 緊急輸送道路 (既キャッシュ) — RQ3 で sjoin
L72_DIR = (ROOT / "data" / "extras" / "L72_emergency_road"
/ "340006_emergency_transport_road_20220908T000000")
L72_RANKS = ["01", "02", "03", "04"] # 第1次〜補完
# 30m バッファ (規制区間 ∩ 緊急輸送道路 重複判定)
BUFFER_M = 30.0
# 過去災害近接距離 (落石区間 ↔ 過去災害点)
NEAR_DIST_M = 2000.0
# =============================================================================
# 1. データ取得
# =============================================================================
print("\n[1] データ取得", flush=True)
t1 = time.time()
json_local = DATA_DIR / JSON_NAME
ensure_dataset(json_local, resource_id=RESOURCE_ID, min_bytes=10000,
label="L73 pre_traffic.json")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 2. JSON → LineString GeoDataFrame
# =============================================================================
print("\n[2] JSON 読込 → LineString", flush=True)
t2 = time.time()
with open(json_local, "r", encoding="utf-8") as f:
raw = json.load(f)
recs = raw["results"]
n_total = len(recs)
# kukan の壊れ対策: kukanroot を優先 (164 件中 1 件で kukan の閉じ括弧欠損)
def get_geom(rec):
try:
return swkt.loads(rec["kukanroot"])
except Exception:
try:
return swkt.loads(rec["kukan"])
except Exception:
return None
geoms = [get_geom(r) for r in recs]
ok = [g is not None for g in geoms]
print(f" パース成功: {sum(ok)}/{n_total}", flush=True)
# DataFrame 化
def f2(v):
try:
return float(v) if v not in (None, "") else None
except Exception:
return None
df = pd.DataFrame({
"id": [r.get("id", "") for r in recs],
"rosenname": [r.get("rosenname", "").replace(" ", " ") for r in recs],
"rosen_key": [r.get("rosen_key", "") for r in recs],
"kisei_start": [r.get("kisei_start", "") for r in recs],
"kisei_end": [r.get("kisei_end", "") for r in recs],
"kiseinaiyo": [r.get("kiseinaiyo", "") for r in recs],
"rankname": [r.get("rankname", "") for r in recs],
"basis": [r.get("basis", "") for r in recs],
"ikichi24h": [f2(r.get("ikichi24h")) for r in recs],
"ikichi60m": [f2(r.get("ikichi60m")) for r in recs],
"ukaiumu": [r.get("ukaiumu", "") for r in recs],
"demarcation": [r.get("demarcation", "").replace(" ", " ") for r in recs],
"lat": [f2(r.get("lat")) for r in recs],
"lon": [f2(r.get("lon")) for r in recs],
"type": [r.get("type", "") for r in recs],
"icon": [r.get("icon", "") for r in recs],
"area": [r.get("area", "") for r in recs],
"zumen_no": [r.get("zumen_no", "") for r in recs],
})
gdf = gpd.GeoDataFrame(df, geometry=geoms, crs="EPSG:4326")
gdf = gdf[gdf.geometry.notna()].copy().to_crs(TARGET_CRS)
gdf["len_m"] = gdf.geometry.length
gdf["len_km"] = (gdf["len_m"] / 1000).round(3)
# 派生列
gdf["naiyo_norm"] = gdf["kiseinaiyo"].map(NAIYO_NORMALIZE).fillna(
gdf["kiseinaiyo"].apply(lambda v: "落石等" if "落石" in str(v) else "その他/不明"))
gdf["grade"] = gdf.apply(lambda r: rank_grade(r["rankname"], r["type"]), axis=1)
gdf["rosen_class"] = gdf["rosenname"].apply(classify_rosen)
n_seg = len(gdf)
total_km = gdf["len_m"].sum() / 1000
print(f" 区間数: {n_seg} / 総延長: {total_km:.1f} km", flush=True)
print(f" ({time.time()-t2:.1f}s)", flush=True)
# =============================================================================
# 3. 行政界 sjoin → 市町判定 + 中山間判定
# =============================================================================
print("\n[3] 行政界 sjoin (中山間判定)", flush=True)
t3 = time.time()
admin = gpd.read_file(ADMIN_GPKG).to_crs(TARGET_CRS)
admin["市町名"] = admin["CITY_CD"].map(CITY_NAME).fillna(
admin["CITY_CD"].astype(str))
# 代表点 sjoin (LineString 全体ではなく 1 点で判定 → 高速 & 主要市町決定)
pts = gdf.geometry.representative_point()
gdf_rep = gpd.GeoDataFrame(
{"id": gdf["id"].values, "len_km": gdf["len_km"].values},
geometry=pts.values, crs=TARGET_CRS)
joined = gpd.sjoin(gdf_rep, admin[["CITY_CD", "市町名", "geometry"]],
how="left", predicate="within")
gdf = gdf.reset_index(drop=True).copy()
gdf["市町名"] = joined.set_index(joined.index)["市町名"].reindex(gdf.index).values
gdf["市町名"] = gdf["市町名"].fillna("不明 (代表点が県外/海上)")
gdf["地理クラス"] = gdf["市町名"].apply(geo_class)
gdf["is_chusankan"] = gdf["地理クラス"] == "中山間山地"
print(f" 中山間: {gdf['is_chusankan'].sum()}/{n_seg} 区間", flush=True)
print(f" ({time.time()-t3:.1f}s)", flush=True)
# =============================================================================
# 4. RQ1: 路線・延長・規制基準
# =============================================================================
print("\n[4] RQ1 集計", flush=True)
t4 = time.time()
# (1) 規制内容別 (kiseinaiyo)
T_naiyo = (gdf.groupby("naiyo_norm")
.agg(区間数=("id", "count"),
延長_km=("len_m", lambda s: round(s.sum() / 1000, 1)),
平均長_km=("len_m", lambda s: round(s.mean() / 1000, 2)),
中央長_km=("len_m", lambda s: round(s.median() / 1000, 2)))
.reset_index().rename(columns={"naiyo_norm": "規制内容"}))
T_naiyo = T_naiyo.set_index("規制内容").reindex(NAIYO_ORDER).dropna(how="all").reset_index()
T_naiyo["シェア_%"] = (T_naiyo["区間数"] / n_seg * 100).round(1)
# (2) 規制ランク (grade) 別
T_grade = (gdf.groupby("grade")
.agg(区間数=("id", "count"),
延長_km=("len_m", lambda s: round(s.sum() / 1000, 1)))
.reset_index().rename(columns={"grade": "規制ランク"}))
T_grade = T_grade.set_index("規制ランク").reindex(GRADE_ORDER).dropna(how="all").reset_index()
T_grade["シェア_%"] = (T_grade["区間数"] / n_seg * 100).round(1)
# (3) 路線種別
T_rosen = (gdf.groupby("rosen_class")
.agg(区間数=("id", "count"),
延長_km=("len_m", lambda s: round(s.sum() / 1000, 1)),
平均長_km=("len_m", lambda s: round(s.mean() / 1000, 2)))
.reset_index().rename(columns={"rosen_class": "路線種別"}))
T_rosen = T_rosen.set_index("路線種別").reindex(ROSEN_ORDER).dropna(how="all").reset_index()
T_rosen["シェア_%"] = (T_rosen["区間数"] / n_seg * 100).round(1)
# (4) 雨量閾値分布 (jizen のみ)
jizen = gdf[gdf["type"] == "jizen"].copy()
T_threshold = (jizen.dropna(subset=["ikichi24h", "ikichi60m"])
.groupby(["ikichi24h", "ikichi60m"])
.agg(区間数=("id", "count"),
延長_km=("len_m", lambda s: round(s.sum() / 1000, 1)))
.reset_index()
.sort_values(["ikichi24h", "ikichi60m"]))
T_threshold["閾値ペア"] = T_threshold.apply(
lambda r: f"{int(r['ikichi24h'])} mm/24h × {int(r['ikichi60m'])} mm/h", axis=1)
T_threshold = T_threshold[["閾値ペア", "ikichi24h", "ikichi60m", "区間数", "延長_km"]]
# (5) 建設事務所別
T_demarc = (gdf.groupby("demarcation")
.agg(区間数=("id", "count"),
延長_km=("len_m", lambda s: round(s.sum() / 1000, 1)))
.reset_index().rename(columns={"demarcation": "建設事務所"}))
T_demarc = T_demarc.sort_values("区間数", ascending=False).reset_index(drop=True)
# (6) 迂回路有無
T_ukai = (gdf.groupby("ukaiumu")
.agg(区間数=("id", "count"),
延長_km=("len_m", lambda s: round(s.sum() / 1000, 1)))
.reset_index().rename(columns={"ukaiumu": "迂回路"}))
# H1: jizen >= 70%
n_jizen = int((gdf["type"] == "jizen").sum())
n_winter = int((gdf["type"] == "winter").sum())
share_jizen = round(100 * n_jizen / n_seg, 1)
h1_ok = share_jizen >= 70.0
print(f" jizen {n_jizen} / winter {n_winter} (jizen 比率 {share_jizen}%)", flush=True)
print(f" H1 (jizen ≥ 70%): {h1_ok}", flush=True)
print(f" ({time.time()-t4:.1f}s)", flush=True)
# =============================================================================
# 5. RQ2: 中山間集中・過去災害履歴
# =============================================================================
print("\n[5] RQ2 集計: 中山間集中・過去災害", flush=True)
t5 = time.time()
# (1) 中山間 vs 都市部 vs 沿岸島嶼
T_geo = (gdf.groupby("地理クラス")
.agg(区間数=("id", "count"),
延長_km=("len_m", lambda s: round(s.sum() / 1000, 1)))
.reset_index())
T_geo["シェア_%"] = (T_geo["区間数"] / n_seg * 100).round(1)
T_geo = T_geo.sort_values("区間数", ascending=False).reset_index(drop=True)
# (2) 市町別 Top 15
T_city = (gdf.groupby(["市町名", "地理クラス"])
.agg(区間数=("id", "count"),
延長_km=("len_m", lambda s: round(s.sum() / 1000, 1)))
.reset_index())
T_city = T_city.sort_values("区間数", ascending=False).reset_index(drop=True)
# (3) 過去災害との 2 km 圏近接性 (STRtree で高速化)
df_past = pd.read_csv(PAST_DISASTER_CSV, encoding="utf-8-sig",
on_bad_lines="skip")
df_past = df_past.dropna(subset=["緯度", "経度"])
df_past = df_past[(df_past["緯度"] > 30) & (df_past["緯度"] < 38) &
(df_past["経度"] > 130) & (df_past["経度"] < 137)].copy()
gdf_past = gpd.GeoDataFrame(
df_past,
geometry=[Point(x, y) for x, y in zip(df_past["経度"], df_past["緯度"])],
crs="EPSG:4326").to_crs(TARGET_CRS)
n_past = len(gdf_past)
# 各規制区間の <= 2km に過去災害点が何件あるか
buf2km = gdf.geometry.buffer(NEAR_DIST_M)
gdf_buf2km = gpd.GeoDataFrame({"id": gdf["id"].values, "geometry": buf2km.values},
crs=TARGET_CRS)
joined_past = gpd.sjoin(gdf_past[["地域情報ID", "geometry"]],
gdf_buf2km, how="left", predicate="within")
near_count = (joined_past[joined_past["index_right"].notna()]
.groupby("id").size())
gdf["past_near_2km"] = gdf["id"].map(near_count).fillna(0).astype(int)
gdf["has_past_near"] = gdf["past_near_2km"] > 0
# H2: 中山間 >= 60%
n_chusankan = int(gdf["is_chusankan"].sum())
share_chusankan = round(100 * n_chusankan / n_seg, 1)
h2_ok = share_chusankan >= 60.0
# (4) 落石等 ∩ 土砂警戒区域 重なり (区間 ↔ 警戒区域ポリゴン)
print(" 土砂警戒区域 読込", flush=True)
sed_polys_all = []
for label, (d, key) in SED_FILES.items():
files = [p for p in d.rglob("*.shp") if key in p.stem]
parts = []
for p in files:
try:
parts.append(gpd.read_file(p, encoding="utf-8")[["geometry"]])
except Exception as e:
print(f" WARN {p.name}: {e}", flush=True)
if parts:
sed = gpd.GeoDataFrame(pd.concat(parts, ignore_index=True),
crs=parts[0].crs).to_crs(TARGET_CRS)
sed["sed_label"] = label
sed_polys_all.append(sed)
sed_all = (gpd.GeoDataFrame(pd.concat(sed_polys_all, ignore_index=True),
crs=TARGET_CRS)
if sed_polys_all else None)
print(f" 土砂警戒区域 計 {len(sed_all):,} ポリゴン", flush=True)
# 各規制区間が土砂警戒区域に重なるか (区間 buffer 50m + sjoin)
gdf_buf50 = gdf.copy()
gdf_buf50["geometry"] = gdf_buf50.geometry.buffer(50)
sed_hits = gpd.sjoin(gdf_buf50[["id", "geometry"]],
sed_all[["geometry", "sed_label"]],
how="left", predicate="intersects")
sed_overlap_ids = set(sed_hits[sed_hits["index_right"].notna()]["id"].tolist())
gdf["sed_overlap"] = gdf["id"].isin(sed_overlap_ids)
n_rakuseki = int((gdf["naiyo_norm"] == "落石等").sum())
n_rakuseki_sed_2km = int(gdf[(gdf["naiyo_norm"] == "落石等") &
gdf["has_past_near"]].shape[0])
n_rakuseki_sed_overlap = int(gdf[(gdf["naiyo_norm"] == "落石等") &
gdf["sed_overlap"]].shape[0])
share_rakuseki_sed = round(100 * n_rakuseki_sed_overlap / max(n_rakuseki, 1), 1)
h3_ok = share_rakuseki_sed >= 50.0
# (5) 各種別 × 中山間/都市 cross
T_naiyo_geo = (gdf.groupby(["naiyo_norm", "地理クラス"])
.size().unstack(fill_value=0).reindex(NAIYO_ORDER).dropna(how="all"))
T_naiyo_geo = T_naiyo_geo.reset_index().rename(columns={"naiyo_norm": "規制内容"})
print(f" 中山間: {n_chusankan}/{n_seg} ({share_chusankan}%)", flush=True)
print(f" 落石等規制: {n_rakuseki}, うち警戒区域重なり {n_rakuseki_sed_overlap} ({share_rakuseki_sed}%)",
flush=True)
print(f" H2 (中山間≥60%): {h2_ok}", flush=True)
print(f" H3 (落石∩警戒≥50%): {h3_ok}", flush=True)
print(f" ({time.time()-t5:.1f}s)", flush=True)
# =============================================================================
# 6. RQ3: 緊急輸送道路 (L72) との重複
# =============================================================================
print("\n[6] RQ3 集計: 緊急輸送道路重複", flush=True)
t6 = time.time()
# (1) L72 緊急輸送道路 JSON 読込 (NDJSON 風)
def load_l72_lines(idx):
p = L72_DIR / f"05_kinkyu_route_{idx}.json"
with open(p, "r", encoding="utf-8") as f:
text = f.read()
arr = json.loads("[" + text + "]")
lines = []
for seg in arr:
if len(seg) >= 2:
coords = [(pt["e"], pt["d"]) for pt in seg]
lines.append(LineString(coords))
return lines
L72_LABEL = {"01": "第1次", "02": "第2次", "03": "第3次", "04": "補完"}
records_l72 = []
for idx in L72_RANKS:
for ln in load_l72_lines(idx):
records_l72.append({"l72_rank": idx,
"l72_label": L72_LABEL[idx],
"geometry": ln})
gdf_l72 = gpd.GeoDataFrame(records_l72, crs="EPSG:4326").to_crs(TARGET_CRS)
n_l72 = len(gdf_l72)
total_km_l72 = gdf_l72.geometry.length.sum() / 1000
print(f" L72: {n_l72} セグ / {total_km_l72:.0f} km", flush=True)
# (2) L72 30m バッファ
gdf_l72["buf"] = gdf_l72.geometry.buffer(BUFFER_M)
buf_l72 = gpd.GeoDataFrame(
gdf_l72[["l72_rank", "l72_label", "buf"]].rename(columns={"buf": "geometry"}),
geometry="geometry", crs=TARGET_CRS)
# (3) 規制区間 ↔ L72 30m バッファ sjoin (intersects)
overlap = gpd.sjoin(gdf[["id", "geometry"]],
buf_l72[["l72_rank", "l72_label", "geometry"]],
how="left", predicate="intersects")
# 1 規制区間が複数 L72 階層と重なる場合 → 最高位 (rank 数字最小) を採用
overlap_grp = (overlap[overlap["index_right"].notna()]
.groupby("id")["l72_rank"]
.apply(lambda s: s.dropna().min()))
gdf["l72_rank"] = gdf["id"].map(overlap_grp)
gdf["on_l72"] = gdf["l72_rank"].notna()
gdf["l72_label"] = gdf["l72_rank"].map(L72_LABEL).fillna("(なし)")
# 重複延長 = 規制区間と L72 バッファの実際の交差長 (近似:
# 規制区間 LineString と L72 buffer ポリゴンを intersection)
def calc_intersect_km(row, buf_union):
if not row["on_l72"] or buf_union is None:
return 0.0
inter = row["geometry"].intersection(buf_union)
return inter.length / 1000 if not inter.is_empty else 0.0
# L72 全体 buffer の単一 union (高速化)
buf_union = buf_l72.geometry.union_all()
gdf["overlap_km"] = gdf.geometry.apply(
lambda g: g.intersection(buf_union).length / 1000 if g and not g.is_empty else 0.0
).round(3)
gdf["overlap_km"] = gdf["overlap_km"].fillna(0.0)
n_overlap = int(gdf["on_l72"].sum())
overlap_total_km = gdf["overlap_km"].sum()
# (4) 重複 ∩ 迂回路 cross
T_overlap_ukai = (gdf[gdf["on_l72"]]
.groupby("ukaiumu")
.agg(区間数=("id", "count"),
重複_km=("overlap_km", lambda s: round(s.sum(), 2)))
.reset_index().rename(columns={"ukaiumu": "迂回路"}))
# 階層別 重複
T_overlap_l72 = (gdf[gdf["on_l72"]]
.groupby("l72_label")
.agg(区間数=("id", "count"),
重複_km=("overlap_km", lambda s: round(s.sum(), 2)))
.reset_index().rename(columns={"l72_label": "緊急輸送道路階層"}))
# 重複区間のうち迂回路無 (ukaiumu == '無')
overlap_no_ukai = gdf[gdf["on_l72"] & (gdf["ukaiumu"] == "無")]
n_overlap_no_ukai = len(overlap_no_ukai)
# H4: 重複延長 >= 20 km AND 区間 >= 15
h4_ok = (overlap_total_km >= 20.0) and (n_overlap >= 15)
# H5: 迂回路無 重複 >= 1
h5_ok = n_overlap_no_ukai >= 1
print(f" L72 重複: {n_overlap}/{n_seg} 区間 / 計 {overlap_total_km:.1f} km", flush=True)
print(f" 迂回路無 重複: {n_overlap_no_ukai} 件", flush=True)
print(f" H4 (重複≥20km AND ≥15区間): {h4_ok}", flush=True)
print(f" H5 (迂回路無 重複≥1): {h5_ok}", flush=True)
print(f" ({time.time()-t6:.1f}s)", flush=True)
# =============================================================================
# 7. CSV 出力
# =============================================================================
print("\n[7] CSV 出力", flush=True)
t7 = time.time()
# (1) 全 164 区間
df_out = gdf.drop(columns=["geometry"]).copy()
df_out.to_csv(ASSETS / "L73_all_segments.csv", index=False, encoding="utf-8-sig")
# (2) 各種サマリ
T_naiyo.to_csv(ASSETS / "L73_naiyo_summary.csv",
index=False, encoding="utf-8-sig")
T_grade.to_csv(ASSETS / "L73_grade_summary.csv",
index=False, encoding="utf-8-sig")
T_rosen.to_csv(ASSETS / "L73_rosen_summary.csv",
index=False, encoding="utf-8-sig")
T_threshold.to_csv(ASSETS / "L73_threshold_summary.csv",
index=False, encoding="utf-8-sig")
T_demarc.to_csv(ASSETS / "L73_demarc_summary.csv",
index=False, encoding="utf-8-sig")
T_ukai.to_csv(ASSETS / "L73_ukai_summary.csv",
index=False, encoding="utf-8-sig")
T_geo.to_csv(ASSETS / "L73_geo_class.csv",
index=False, encoding="utf-8-sig")
T_city.to_csv(ASSETS / "L73_city_summary.csv",
index=False, encoding="utf-8-sig")
T_naiyo_geo.to_csv(ASSETS / "L73_naiyo_x_geo.csv",
index=False, encoding="utf-8-sig")
T_overlap_l72.to_csv(ASSETS / "L73_overlap_l72.csv",
index=False, encoding="utf-8-sig")
T_overlap_ukai.to_csv(ASSETS / "L73_overlap_ukai.csv",
index=False, encoding="utf-8-sig")
# (3) 緊急輸送道路重複 + 迂回路無 区間 (RQ3 BCP 最重要リスト)
overlap_no_ukai_out = overlap_no_ukai[[
"id", "rosenname", "kisei_start", "kisei_end",
"kiseinaiyo", "rankname", "ikichi24h", "ikichi60m",
"ukaiumu", "demarcation", "市町名", "地理クラス",
"len_km", "l72_label", "overlap_km",
"lat", "lon"]].copy()
overlap_no_ukai_out.to_csv(ASSETS / "L73_overlap_no_ukai.csv",
index=False, encoding="utf-8-sig")
# (4) 重複区間 全部 (BCP 重要リスト)
overlap_all_out = gdf[gdf["on_l72"]][[
"id", "rosenname", "kisei_start", "kisei_end",
"kiseinaiyo", "rankname", "ikichi24h", "ikichi60m",
"ukaiumu", "demarcation", "市町名", "地理クラス",
"len_km", "l72_label", "overlap_km",
"lat", "lon"]].copy()
overlap_all_out.to_csv(ASSETS / "L73_overlap_l72_segments.csv",
index=False, encoding="utf-8-sig")
print(f" ({time.time()-t7:.1f}s)", flush=True)
# =============================================================================
# 8. 図の生成 (8 図)
# =============================================================================
print("\n[8] 図の生成", flush=True)
t8 = time.time()
ASSETS.mkdir(parents=True, exist_ok=True)
# 県全域 表示 bbox
XMIN, YMIN = -15000, -220000
XMAX, YMAX = 125000, -90000
def save_fig(name, dpi=120):
p = ASSETS / name
plt.savefig(p, dpi=dpi, bbox_inches="tight", facecolor="white")
plt.close('all')
return p
# ---- 図 1 (RQ1): 県全域 規制内容別 マップ ----
print(" fig1: 規制内容別マップ", flush=True)
fig, ax = plt.subplots(figsize=(13, 8))
admin.plot(ax=ax, color="#fff4e0", edgecolor="#888",
linewidth=0.4, alpha=0.55)
# 描画順 (背景に多数派から)
for naiyo in NAIYO_ORDER:
sub = gdf[gdf["naiyo_norm"] == naiyo]
if len(sub) == 0:
continue
sub.plot(ax=ax, color=NAIYO_COLOR[naiyo],
linewidth=2.2, alpha=0.85)
ax.set_xlim(XMIN, XMAX)
ax.set_ylim(YMIN, YMAX)
ax.set_aspect("equal")
ax.set_title(f"図 1 (RQ1): 広島県 事前通行規制区間 規制内容別マップ — "
f"全 {n_seg} 区間 / {total_km:.0f} km", fontsize=11)
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
patches = []
for naiyo in NAIYO_ORDER:
n = int((gdf["naiyo_norm"] == naiyo).sum())
if n == 0:
continue
patches.append(Line2D([0], [0], color=NAIYO_COLOR[naiyo],
linewidth=3,
label=f"{naiyo} ({n} 件)"))
ax.legend(handles=patches, loc="lower left", fontsize=10,
title="規制内容 (kiseinaiyo)")
plt.tight_layout()
save_fig("L73_fig1_naiyo_map.png")
# ---- 図 2 (RQ1): 規制内容 + 規制ランク + 路線種別 棒 ----
print(" fig2: 規制構造 棒", flush=True)
fig, axes = plt.subplots(1, 3, figsize=(17, 5.5))
# 左: 規制内容
ax = axes[0]
xs = np.arange(len(T_naiyo))
cols = [NAIYO_COLOR[n] for n in T_naiyo["規制内容"]]
ax.bar(xs, T_naiyo["区間数"], color=cols, edgecolor="#333", linewidth=0.5)
for x, v, km in zip(xs, T_naiyo["区間数"], T_naiyo["延長_km"]):
ax.text(x, v + max(T_naiyo["区間数"]) * 0.02,
f"{int(v)}\n({km:.0f} km)",
ha="center", fontsize=9, fontweight="bold")
ax.set_xticks(xs)
ax.set_xticklabels(T_naiyo["規制内容"], rotation=20, fontsize=9.5)
ax.set_ylabel("区間数")
ax.set_title("規制内容別 件数 + 延長", fontsize=10.5)
ax.grid(True, axis="y", alpha=0.3)
# 中: 規制ランク (grade)
ax = axes[1]
xs = np.arange(len(T_grade))
cols = [GRADE_COLOR[g] for g in T_grade["規制ランク"]]
ax.bar(xs, T_grade["区間数"], color=cols, edgecolor="#333", linewidth=0.5)
for x, v, km in zip(xs, T_grade["区間数"], T_grade["延長_km"]):
ax.text(x, v + max(T_grade["区間数"]) * 0.02,
f"{int(v)}\n({km:.0f} km)",
ha="center", fontsize=8.5, fontweight="bold")
ax.set_xticks(xs)
ax.set_xticklabels([g.split(" ")[0] for g in T_grade["規制ランク"]],
rotation=0, fontsize=10)
ax.set_ylabel("区間数")
ax.set_title(f"規制ランク (雨量3階層 + 特/冬/風)\n"
f"H1 jizen {share_jizen}% (≥70%: {h1_ok})",
fontsize=10.5)
ax.grid(True, axis="y", alpha=0.3)
# 右: 路線種別
ax = axes[2]
xs = np.arange(len(T_rosen))
cols = [ROSEN_COLOR[r] for r in T_rosen["路線種別"]]
ax.bar(xs, T_rosen["区間数"], color=cols, edgecolor="#333", linewidth=0.5)
for x, v, km in zip(xs, T_rosen["区間数"], T_rosen["延長_km"]):
ax.text(x, v + max(T_rosen["区間数"]) * 0.02,
f"{int(v)}\n({km:.0f} km)",
ha="center", fontsize=9, fontweight="bold")
ax.set_xticks(xs)
ax.set_xticklabels(T_rosen["路線種別"], rotation=15, fontsize=10)
ax.set_ylabel("区間数")
ax.set_title("路線種別 (国道/県道/etc)", fontsize=10.5)
ax.grid(True, axis="y", alpha=0.3)
fig.suptitle("図 2 (RQ1): 規制内容 × 規制ランク × 路線種別 — 制度構造",
fontsize=12.5, y=1.02)
plt.tight_layout()
save_fig("L73_fig2_rq1_structure.png")
# ---- 図 3 (RQ1): 雨量閾値 散布 + 規制長 log10 ヒスト ----
print(" fig3: 雨量閾値 + 区間長分布", flush=True)
fig, axes = plt.subplots(1, 2, figsize=(14, 5.5))
# 左: 雨量閾値 散布 (24h vs 60m, 規制ランク色分け)
ax = axes[0]
sub = gdf[(gdf["type"] == "jizen") &
gdf["ikichi24h"].notna() & gdf["ikichi60m"].notna()].copy()
sub["jitter24"] = sub["ikichi24h"] + np.random.RandomState(0).uniform(
-2, 2, size=len(sub))
sub["jitter60"] = sub["ikichi60m"] + np.random.RandomState(1).uniform(
-0.6, 0.6, size=len(sub))
for grade in GRADE_ORDER:
s = sub[sub["grade"] == grade]
if len(s) == 0:
continue
ax.scatter(s["jitter24"], s["jitter60"], color=GRADE_COLOR[grade],
s=55, alpha=0.7, edgecolor="#333", linewidth=0.4,
label=f"{grade.split(' ')[0]} ({len(s)})")
ax.set_xlabel("ikichi24h (24時間雨量閾値, mm/24h)")
ax.set_ylabel("ikichi60m (時間雨量閾値, mm/h)")
ax.set_title(f"雨量閾値 散布 (jizen, n={len(sub)})\n"
f"3 グループ A80/20, B100/30, C120/40 が明瞭",
fontsize=10.5)
ax.legend(loc="upper left", fontsize=9, ncol=2)
ax.grid(True, alpha=0.3)
# 右: 区間長 log10 ヒスト (規制ランク stack)
ax = axes[1]
log_lens = np.log10(np.maximum(gdf["len_m"].values, 1))
bins = np.linspace(log_lens.min(), log_lens.max(), 25)
btm = np.zeros(len(bins) - 1)
for grade in GRADE_ORDER:
s = gdf[gdf["grade"] == grade]
if len(s) == 0:
continue
h, _ = np.histogram(np.log10(np.maximum(s["len_m"].values, 1)), bins=bins)
ax.bar((bins[:-1] + bins[1:]) / 2, h, width=(bins[1] - bins[0]) * 0.95,
bottom=btm, color=GRADE_COLOR[grade], edgecolor="white",
linewidth=0.4,
label=f"{grade.split(' ')[0]}")
btm = btm + h
ax.set_xlabel("log10(区間長 m)")
ax.set_ylabel("区間数")
ax.set_xticks([1, 2, 3, 4, 5])
ax.set_xticklabels(["10 m", "100 m", "1 km", "10 km", "100 km"])
ax.set_title(f"区間長 log10 分布 (中央 {gdf['len_m'].median():.0f} m, "
f"最大 {gdf['len_m'].max():.0f} m)",
fontsize=10.5)
ax.legend(fontsize=9, ncol=2, loc="upper left")
ax.grid(True, axis="y", alpha=0.3)
fig.suptitle("図 3 (RQ1): 雨量閾値 + 区間長分布 — 規制基準の構造",
fontsize=12.5, y=1.02)
plt.tight_layout()
save_fig("L73_fig3_threshold_length.png")
# ---- 図 4 (RQ2): 規制区間 + 中山間境界 重ね合わせマップ ----
print(" fig4: 中山間集中マップ", flush=True)
fig, ax = plt.subplots(figsize=(13, 8))
# 中山間市町を強調表示
admin_geo = admin.merge(
pd.DataFrame({"市町名": list(CHUSANKAN_CITIES) + list(COASTAL_ISLAND),
"geo_cls": ["中山間"] * len(CHUSANKAN_CITIES)
+ ["沿岸島嶼"] * len(COASTAL_ISLAND)}),
on="市町名", how="left")
admin_geo.plot(ax=ax,
color=admin_geo["geo_cls"].map(
{"中山間": "#fde7d3", "沿岸島嶼": "#dff0fa"}).fillna("#f6f8fa"),
edgecolor="#888", linewidth=0.5, alpha=0.85)
# 規制区間 (中山間 vs その他で色)
sub_chu = gdf[gdf["地理クラス"] == "中山間山地"]
sub_oth = gdf[gdf["地理クラス"] != "中山間山地"]
sub_oth.plot(ax=ax, color="#888", linewidth=1.6, alpha=0.7)
sub_chu.plot(ax=ax, color="#cf222e", linewidth=2.4, alpha=0.95)
ax.set_xlim(XMIN, XMAX)
ax.set_ylim(YMIN, YMAX)
ax.set_aspect("equal")
ax.set_title(f"図 4 (RQ2): 規制区間 + 中山間境界 — "
f"中山間 {n_chusankan}/{n_seg} 区間 ({share_chusankan}%) "
f"H2 (≥60%: {h2_ok})", fontsize=10.5)
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
patches = [
Patch(facecolor="#fde7d3", label="中山間市町 (7市町)"),
Patch(facecolor="#dff0fa", label="沿岸島嶼 (2市町)"),
Patch(facecolor="#f6f8fa", label="平野・沿岸都市"),
Line2D([0], [0], color="#cf222e", linewidth=3,
label=f"規制区間 in 中山間 ({n_chusankan})"),
Line2D([0], [0], color="#888", linewidth=2,
label=f"規制区間 in その他 ({n_seg - n_chusankan})"),
]
ax.legend(handles=patches, loc="lower left", fontsize=9.5)
plt.tight_layout()
save_fig("L73_fig4_chusankan_map.png")
# ---- 図 5 (RQ2): 過去災害 近接性 + 土砂警戒区域 重ね合わせマップ ----
print(" fig5: 過去災害 + 土砂警戒 重ね合わせ", flush=True)
fig, ax = plt.subplots(figsize=(13, 8))
# 1km bbox grid mask で土砂警戒区域を高速描画
GRID_M = 1000.0
nx = int((XMAX - XMIN) / GRID_M) + 1
ny = int((YMAX - YMIN) / GRID_M) + 1
def bbox_grid_mask(gdf_polys):
if gdf_polys is None or len(gdf_polys) == 0:
return np.zeros((ny, nx), dtype=bool)
b = gdf_polys.bounds
i0 = np.maximum(((b["minx"].values - XMIN) / GRID_M).astype(int), 0)
i1 = np.minimum(((b["maxx"].values - XMIN) / GRID_M).astype(int) + 1, nx)
j0 = np.maximum(((b["miny"].values - YMIN) / GRID_M).astype(int), 0)
j1 = np.minimum(((b["maxy"].values - YMIN) / GRID_M).astype(int) + 1, ny)
m = np.zeros((ny, nx), dtype=bool)
for k in range(len(b)):
m[j0[k]:j1[k], i0[k]:i1[k]] = True
return m
admin.plot(ax=ax, color="#fff4e0", edgecolor="#888",
linewidth=0.4, alpha=0.55)
mask_sed = bbox_grid_mask(sed_all)
ax.imshow(mask_sed, extent=(XMIN, XMAX, YMIN, YMAX),
origin="lower", aspect="equal",
cmap=matplotlib.colors.ListedColormap(["#00000000", "#cf222e"]),
alpha=0.22, zorder=2, interpolation="nearest")
# 過去災害点 (灰色 dot)
gdf_past.plot(ax=ax, color="#666", markersize=4, alpha=0.6,
edgecolor="none", zorder=3)
# 規制区間 (落石等を赤、 その他をライトブルー)
gdf[gdf["naiyo_norm"] != "落石等"].plot(
ax=ax, color="#0969da", linewidth=1.8, alpha=0.7, zorder=4)
gdf[gdf["naiyo_norm"] == "落石等"].plot(
ax=ax, color="#cf6f00", linewidth=2.4, alpha=0.95, zorder=5)
ax.set_xlim(XMIN, XMAX)
ax.set_ylim(YMIN, YMAX)
ax.set_aspect("equal")
ax.set_title(f"図 5 (RQ2): 規制区間 + 過去災害 ({n_past}) + 土砂警戒区域 重ね合わせ\n"
f"落石等規制 {n_rakuseki} 中 警戒区域重なり {n_rakuseki_sed_overlap} "
f"({share_rakuseki_sed}%) H3 (≥50%: {h3_ok})",
fontsize=10)
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
patches = [
Patch(facecolor="#cf222e", alpha=0.35,
label=f"土砂警戒区域 (急傾斜+土石流+地すべり, {len(sed_all):,})"),
Line2D([0], [0], marker='o', color='w',
markerfacecolor="#666", markeredgecolor="none",
markersize=6, label=f"過去災害履歴 ({n_past})"),
Line2D([0], [0], color="#cf6f00", linewidth=3,
label=f"規制区間 (落石等, {n_rakuseki})"),
Line2D([0], [0], color="#0969da", linewidth=2.5,
label=f"規制区間 (その他, {n_seg - n_rakuseki})"),
]
ax.legend(handles=patches, loc="lower left", fontsize=9)
plt.tight_layout()
save_fig("L73_fig5_past_disaster_sed.png")
# ---- 図 6 (RQ2): 中山間 vs 都市部 規制内容 比較 ----
print(" fig6: 中山間 vs 都市 規制内容比較", flush=True)
fig, axes = plt.subplots(1, 2, figsize=(14, 5.5))
# 左: 規制内容 × 地理クラス (積み棒)
ax = axes[0]
geo_classes = ["中山間山地", "平野・沿岸都市", "沿岸島嶼", "不明 (代表点が県外/海上)"]
geo_classes = [g for g in geo_classes if g in T_naiyo_geo.columns]
xs = np.arange(len(NAIYO_ORDER))
btm = np.zeros(len(NAIYO_ORDER))
geo_colors = {
"中山間山地": "#cf6f00",
"平野・沿岸都市": "#0969da",
"沿岸島嶼": "#1a7f37",
"不明 (代表点が県外/海上)": "#888",
}
for gc in geo_classes:
if gc not in T_naiyo_geo.columns:
continue
vals = T_naiyo_geo[gc].values if gc in T_naiyo_geo.columns else np.zeros(len(NAIYO_ORDER))
ax.bar(xs, vals, bottom=btm, color=geo_colors.get(gc, "#888"),
edgecolor="white", linewidth=0.4,
label=gc)
btm = btm + vals
ax.set_xticks(xs)
ax.set_xticklabels(NAIYO_ORDER, rotation=15, fontsize=9.5)
ax.set_ylabel("区間数")
ax.set_title(f"規制内容 × 地理クラス\n"
f"中山間 = {n_chusankan} ({share_chusankan}%)",
fontsize=10.5)
ax.legend(fontsize=9, loc="upper right")
ax.grid(True, axis="y", alpha=0.3)
# 右: 過去災害 2km 圏 ヒット (規制内容別, 落石が高い hyp.)
ax = axes[1]
xs = np.arange(len(NAIYO_ORDER))
hits_rate = []
hits_n = []
for naiyo in NAIYO_ORDER:
s = gdf[gdf["naiyo_norm"] == naiyo]
if len(s) == 0:
hits_rate.append(0.0)
hits_n.append(0)
else:
hr = s["has_past_near"].sum() / len(s) * 100
hits_rate.append(hr)
hits_n.append(int(s["has_past_near"].sum()))
cols = [NAIYO_COLOR[n] for n in NAIYO_ORDER]
ax.bar(xs, hits_rate, color=cols, edgecolor="#333", linewidth=0.5)
for x, v, n in zip(xs, hits_rate, hits_n):
ax.text(x, v + max(hits_rate) * 0.02 if max(hits_rate) > 0 else 0.5,
f"{v:.0f}%\n({n})", ha="center", fontsize=9.5,
fontweight="bold")
ax.set_xticks(xs)
ax.set_xticklabels(NAIYO_ORDER, rotation=15, fontsize=9.5)
ax.set_ylabel("過去災害 2km圏 ヒット率 (%)")
ax.set_title(f"規制内容別 過去災害近接率\n"
f"(規制 - 過去災害の対応関係)",
fontsize=10.5)
ax.grid(True, axis="y", alpha=0.3)
fig.suptitle(
"図 6 (RQ2): 規制内容 × 地理クラス + 規制内容 × 過去災害近接",
fontsize=12.5, y=1.02)
plt.tight_layout()
save_fig("L73_fig6_chusankan_x_naiyo.png")
# ---- 図 7 (RQ3): 規制区間 ∩ 緊急輸送道路 重複マップ ----
print(" fig7: 規制 ∩ 緊急輸送道路マップ", flush=True)
fig, ax = plt.subplots(figsize=(13, 8))
admin.plot(ax=ax, color="#fff4e0", edgecolor="#888",
linewidth=0.4, alpha=0.55)
# L72 緊急輸送道路 (薄い背景)
L72_LINE_COLOR = {"01": "#ddd", "02": "#bbb", "03": "#aaa", "04": "#aaa"}
for r in L72_RANKS:
sub = gdf_l72[gdf_l72["l72_rank"] == r]
sub.plot(ax=ax, color=L72_LINE_COLOR[r],
linewidth=1.2 if r == "01" else 0.7, alpha=0.7, zorder=2)
# 規制区間 — on_l72 + 迂回路有無 で色分け
no_l72 = gdf[~gdf["on_l72"]]
on_l72_yes = gdf[gdf["on_l72"] & (gdf["ukaiumu"] == "有")]
on_l72_no = gdf[gdf["on_l72"] & (gdf["ukaiumu"] == "無")]
no_l72.plot(ax=ax, color="#bbb", linewidth=1.2, alpha=0.6, zorder=3)
on_l72_yes.plot(ax=ax, color="#0969da", linewidth=2.4, alpha=0.9, zorder=5)
on_l72_no.plot(ax=ax, color="#cf222e", linewidth=3.8, alpha=0.95, zorder=7)
# 迂回路無 規制区間に星印 (BCP 最重要箇所)
if len(on_l72_no) > 0:
pts_no_ukai = on_l72_no.geometry.representative_point()
pts_no_ukai_gdf = gpd.GeoDataFrame(geometry=pts_no_ukai.values,
crs=TARGET_CRS)
pts_no_ukai_gdf.plot(ax=ax, color="#cf222e", marker="*",
markersize=200, zorder=8,
edgecolor="#000", linewidth=0.5)
ax.set_xlim(XMIN, XMAX)
ax.set_ylim(YMIN, YMAX)
ax.set_aspect("equal")
ax.set_title(f"図 7 (RQ3): 事前通行規制区間 ∩ 緊急輸送道路 — "
f"重複 {n_overlap}/{n_seg} 区間 / {overlap_total_km:.1f} km / "
f"迂回路無 {n_overlap_no_ukai} 件 (★)",
fontsize=10)
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
patches = [
Line2D([0], [0], color="#bbb", linewidth=2,
label="規制区間 off 緊急輸送 ({})".format(len(no_l72))),
Line2D([0], [0], color="#0969da", linewidth=3,
label=f"規制 ∩ 緊急輸送 (迂回路 有, {len(on_l72_yes)})"),
Line2D([0], [0], color="#cf222e", linewidth=3.5,
label=f"規制 ∩ 緊急輸送 (迂回路 無, {len(on_l72_no)})"),
Line2D([0], [0], marker='*', color='w',
markerfacecolor="#cf222e", markeredgecolor="#000",
markersize=14, label="BCP最重要箇所 (★)"),
Line2D([0], [0], color="#aaa", linewidth=2,
label=f"緊急輸送道路 (L72, {n_l72} セグ)"),
]
ax.legend(handles=patches, loc="lower left", fontsize=9)
plt.tight_layout()
save_fig("L73_fig7_overlap_l72_map.png")
# ---- 図 8 (RQ3): 階層別 重複 + 迂回路有無 + 規制ランク 棒 ----
print(" fig8: 階層別 + 迂回路有無", flush=True)
fig, axes = plt.subplots(1, 3, figsize=(17, 5.5))
# 左: 緊急輸送道路階層別 重複
ax = axes[0]
overlap_by_l72 = (gdf[gdf["on_l72"]]
.groupby("l72_label").size()
.reindex([L72_LABEL[r] for r in L72_RANKS], fill_value=0))
overlap_km_by_l72 = (gdf[gdf["on_l72"]]
.groupby("l72_label")["overlap_km"].sum()
.reindex([L72_LABEL[r] for r in L72_RANKS], fill_value=0))
xs = np.arange(len(L72_RANKS))
l72_cols = ["#cf222e", "#0969da", "#1a7f37", "#cf6f00"]
ax.bar(xs, overlap_by_l72.values, color=l72_cols, edgecolor="#333",
linewidth=0.5)
for x, v, km in zip(xs, overlap_by_l72.values, overlap_km_by_l72.values):
ax.text(x, v + max(overlap_by_l72.values) * 0.02 if overlap_by_l72.max() > 0 else 0.2,
f"{int(v)}\n({km:.1f} km)",
ha="center", fontsize=9.5, fontweight="bold")
ax.set_xticks(xs)
ax.set_xticklabels([L72_LABEL[r] for r in L72_RANKS], fontsize=10)
ax.set_ylabel("重複 規制区間数")
ax.set_title(f"緊急輸送道路 階層別 重複\n"
f"H4 重複 {overlap_total_km:.1f} km / "
f"{n_overlap} 区間 (≥20km/15: {h4_ok})",
fontsize=10)
ax.grid(True, axis="y", alpha=0.3)
# 中: 迂回路有無 (重複区間のみ)
ax = axes[1]
ukai_vals = T_overlap_ukai.set_index("迂回路")["区間数"]
ukai_km = T_overlap_ukai.set_index("迂回路")["重複_km"]
ukai_keys = ["有", "無"]
xs = np.arange(len(ukai_keys))
cols = ["#1a7f37", "#cf222e"]
vals = [int(ukai_vals.get(k, 0)) for k in ukai_keys]
kms = [float(ukai_km.get(k, 0)) for k in ukai_keys]
ax.bar(xs, vals, color=cols, edgecolor="#333", linewidth=0.5, width=0.5)
for x, v, km in zip(xs, vals, kms):
ax.text(x, v + max(vals) * 0.02 if max(vals) > 0 else 0.2,
f"{int(v)} 区間\n({km:.1f} km)",
ha="center", fontsize=11, fontweight="bold")
ax.set_xticks(xs)
ax.set_xticklabels([f"迂回路 {k}" for k in ukai_keys], fontsize=11)
ax.set_ylabel("区間数")
ax.set_title(f"重複 ∩ 迂回路 有無\n"
f"H5 迂回路無 {n_overlap_no_ukai} 件 (≥1: {h5_ok})",
fontsize=10)
ax.grid(True, axis="y", alpha=0.3)
# 右: 重複区間の規制ランク分布
ax = axes[2]
overlap_grade = (gdf[gdf["on_l72"]]
.groupby("grade").size()
.reindex(GRADE_ORDER, fill_value=0))
non_overlap_grade = (gdf[~gdf["on_l72"]]
.groupby("grade").size()
.reindex(GRADE_ORDER, fill_value=0))
xs = np.arange(len(GRADE_ORDER))
w = 0.4
ax.bar(xs - w/2, overlap_grade.values, w, color="#cf222e",
edgecolor="#333", linewidth=0.4, label="重複あり")
ax.bar(xs + w/2, non_overlap_grade.values, w, color="#bbb",
edgecolor="#333", linewidth=0.4, label="重複なし")
ax.set_xticks(xs)
ax.set_xticklabels([g.split(" ")[0] for g in GRADE_ORDER],
rotation=0, fontsize=9.5)
ax.set_ylabel("区間数")
ax.set_title(f"規制ランク × 緊急輸送道路重複",
fontsize=10)
ax.legend(fontsize=9)
ax.grid(True, axis="y", alpha=0.3)
fig.suptitle("図 8 (RQ3): 緊急輸送道路重複 — 階層 / 迂回路 / ランク 3角度",
fontsize=12.5, y=1.02)
plt.tight_layout()
save_fig("L73_fig8_overlap_breakdown.png")
print(f" ({time.time()-t8:.1f}s)", flush=True)
# =============================================================================
# 9. 仮説検証
# =============================================================================
print("\n[9] 仮説検証", flush=True)
t9 = time.time()
def df_to_html(d):
return d.to_html(index=False, classes="", border=0, escape=False,
na_rep="-").replace(' style="text-align: right;"', "")
# データセット仕様表
json_size = json_local.stat().st_size if json_local.exists() else 0
T_dataset = pd.DataFrame([
("dataset_id", str(DATASET_ID)),
("公式名", "事前通行規制区間"),
("公式説明", "広島県が管理する道路の事前通行規制区間情報"),
("リソース数", "1 (JSON)"),
("リソース ID", str(RESOURCE_ID)),
("JSON サイズ", f"{json_size:,} byte (~{json_size/1024:.0f} KB / "
f"~{json_size/1024/1024:.2f} MB)"),
("レコード数", f"{n_seg} 区間"),
("総延長", f"{total_km:.1f} km"),
("座標系 (元)", "WGS84 (EPSG:4326) → 本記事 EPSG:6671 で処理"),
("型分類", f"jizen (雨量基準) {n_jizen} / winter (冬期閉鎖) {n_winter}"),
("規制内容", "落石等 / 凍結等 / 強風 / 冠水 / 越波"),
("規制ランク", "A (80mm) / B (100mm) / C (120mm) / 特 / 冬 / 風 / 地震 / 霧"),
("路線種別", "国道 32 / 主要地方道 27 / 一般県道 96 / その他 9"),
("迂回路有無", f"有 {int((gdf['ukaiumu']=='有').sum())} / "
f"無 {int((gdf['ukaiumu']=='無').sum())}"),
("配信日", "2026-05-01 (公式 stamp)"),
("ライセンス", "クリエイティブ・コモンズ表示 (CC-BY)"),
("URL", f"https://hiroshima-dobox.jp/datasets/{DATASET_ID}"),
("作成主体", "広島県 (土木建築局道路整備課・防災担当)"),
], columns=["項目", "値"])
# 全体サマリ
T_overall = pd.DataFrame([
("dataset", f"#{DATASET_ID} 事前通行規制区間"),
("総区間数 (RQ1)", f"{n_seg}"),
("総延長 km (RQ1)", f"{total_km:.1f}"),
("jizen / winter 件数 (RQ1)", f"{n_jizen} / {n_winter} ({share_jizen}% jizen)"),
("最多規制内容 (RQ1)", f"落石等 {int((gdf['naiyo_norm']=='落石等').sum())} 件"),
("最多路線種別 (RQ1)", f"一般県道 {int((gdf['rosen_class']=='一般県道').sum())} 件"),
("ランク A/B/C (RQ1)",
f"{int((gdf['grade']==GRADE_ORDER[0]).sum())} / "
f"{int((gdf['grade']==GRADE_ORDER[1]).sum())} / "
f"{int((gdf['grade']==GRADE_ORDER[2]).sum())}"),
("最頻雨量閾値 (RQ1)", "120 mm/24h × 40 mm/h (C ランク, 45 件)"),
("H1 (jizen ≥ 70%) (RQ1)", "強支持" if h1_ok else "反証"),
("中山間 区間数 (RQ2)", f"{n_chusankan} ({share_chusankan}%)"),
("最多市町 (RQ2)", f"{T_city.iloc[0]['市町名']} "
f"({int(T_city.iloc[0]['区間数'])} 件)"),
("過去災害 2km圏 規制区間 (RQ2)",
f"{int(gdf['has_past_near'].sum())} 件"),
("落石∩警戒区域 (RQ2)",
f"{n_rakuseki_sed_overlap}/{n_rakuseki} ({share_rakuseki_sed}%)"),
("H2 (中山間 ≥ 60%) (RQ2)", "強支持" if h2_ok else "反証"),
("H3 (落石∩警戒 ≥ 50%) (RQ2)", "強支持" if h3_ok else "反証"),
("規制∩緊急輸送 重複 区間数 (RQ3)", f"{n_overlap}"),
("規制∩緊急輸送 重複 km (RQ3)", f"{overlap_total_km:.2f}"),
("迂回路無 重複区間 (RQ3)", f"{n_overlap_no_ukai}"),
("H4 (重複≥20km AND ≥15区間) (RQ3)", "強支持" if h4_ok else "反証"),
("H5 (迂回路無 重複 ≥ 1) (RQ3)", "強支持" if h5_ok else "反証"),
], columns=["指標", "値"])
T_overall.to_csv(ASSETS / "L73_overall.csv", index=False, encoding="utf-8-sig")
# 仮説検証
def jud(cond, ok="強支持", fail="反証"):
return ok if cond else fail
T_hypo = pd.DataFrame([
("H1 雨量基準 (jizen) ≥ 70% (RQ1)",
f"観測 = jizen {n_jizen}/{n_seg} = {share_jizen}%",
jud(h1_ok),
f"H1 {jud(h1_ok)}: 事前通行規制区間 {n_seg} 中{n_jizen} 件 ({share_jizen}%)が "
f"雨量基準 (jizen) で運用される動的規制、 残り{n_winter} 件 "
f"({100-share_jizen:.0f}%)が冬期閉鎖 (winter)。 "
f"動的判定 (= 観測雨量がしきい値超過 → 自動規制) が圧倒的多数派で、 "
f"「降雨ノモゲン違反 → ルールベース規制」という県の予防防災運用思想を "
f"反映。 ランク A ({int((gdf['grade']==GRADE_ORDER[0]).sum())} 件) は "
f"80mm/20mm の最も厳しい閾値で、 ランク C "
f"({int((gdf['grade']==GRADE_ORDER[2]).sum())} 件) は 120mm/40mm の "
f"緩い閾値。 雨量 3 階層 + 特 (沿岸越波/冠水) + 風 + 冬 という多層的な "
f"規制制度が県内に展開。"),
("H2 中山間集中 ≥ 60% (RQ2)",
f"観測 = 中山間 {n_chusankan}/{n_seg} = {share_chusankan}%",
jud(h2_ok),
f"H2 {jud(h2_ok)}: 事前通行規制区間のうち中山間 7 市町(庄原・三次・"
f"安芸太田・安芸高田・北広島・神石高原・世羅 + 府中) に位置するのは"
f"{n_chusankan} 件 ({share_chusankan}%)。 "
f"残り {n_seg - n_chusankan} 件が平野・沿岸都市または沿岸島嶼に分布。 "
f"{('60% 閾値を超え強支持' if h2_ok else '60% 未満で反証')}。 "
f"これは「事前通行規制 = 中山間山岳道路の脆弱性に対する予防制度」 という "
f"地形 × 制度の対応関係を量的に示す。 都市部の規制は越波・冠水・強風など "
f"沿岸特化型に偏り、 中山間は落石・凍結という地形脆弱性型に偏るという "
f"制度設計の地理的二面性が見える。"),
("H3 落石∩警戒区域 ≥ 50% (RQ2)",
f"観測 = 落石 {n_rakuseki_sed_overlap}/{n_rakuseki} = {share_rakuseki_sed}%",
jud(h3_ok),
f"H3 {jud(h3_ok)}: 落石等規制区間 {n_rakuseki} 件のうち、 "
f"土砂災害警戒区域 (急傾斜+土石流+地すべり) と50m バッファ内で交差する "
f"のは{n_rakuseki_sed_overlap} 件 ({share_rakuseki_sed}%)。 "
f"{('50% 閾値を超え強支持' if h3_ok else '50% 未満で反証')}。 "
f"これは「過去に落石・崩落があった道路 → 警戒区域指定 → 規制区間指定」 という "
f"3 段階の予防制度階層の量的実証であり、 規制区間のうち警戒区域に "
f"重なる箇所は「土砂法 × 道路法」 の制度的二重指定と解釈できる。 "
f"参考: 過去災害 (424 件) と 2 km 圏内の規制区間は "
f"{int(gdf['has_past_near'].sum())} 件で、 これも規制制度が過去履歴を反映する "
f"設計であることを支持。"),
("H4 規制∩緊急輸送 ≥ 20 km AND ≥ 15 区間 (RQ3)",
f"観測 = 重複 {overlap_total_km:.1f} km / {n_overlap} 区間",
jud(h4_ok),
f"H4 {jud(h4_ok)}: 事前通行規制区間と緊急輸送道路 (L72, "
f"{n_l72} セグメント / {total_km_l72:.0f} km) の 30m バッファ重複は "
f"{n_overlap}/{n_seg} 区間 ({100*n_overlap/n_seg:.1f}%) / "
f"重複延長 {overlap_total_km:.1f} km。 "
f"{('20km/15区間を超え強支持' if h4_ok else '閾値未満で反証')}。 "
f"これは「災害時に通行確保すべき緊急輸送道路の一部が、 "
f"災害前に予防的に通行止になる」 というBCP 制度的矛盾の量的事実。 "
f"県の地域防災計画では (1) 緊急輸送道路の通行確保, (2) 事前通行規制による "
f"予防的安全 が両立しなければならず、 重複区間ではこの両者が衝突する。 "
f"運用上は「事前通行規制が優先 → 緊急輸送道路の代替経路を使用」 となるが、 "
f"代替経路の確保状況 (= 迂回路有無) が決定的に重要 (H5 へ)。"),
("H5 迂回路無 重複 ≥ 1 (RQ3)",
f"観測 = 迂回路無 重複 {n_overlap_no_ukai} 件",
jud(h5_ok),
f"H5 {jud(h5_ok)}: 緊急輸送道路と重複する規制区間 ({n_overlap} 件) のうち、 "
f"迂回路無 (ukaiumu='無') の区間は{n_overlap_no_ukai} 件。 "
f"{('1 件以上で強支持 = BCP 最重要箇所が定量化された' if h5_ok else '0 件で反証')}。 "
f"これらの区間は「災害時に通行確保すべき + 災害前に通行止になる + 迂回路もない」 "
f"という3 重制度的矛盾の最重要箇所であり、 県の予防防災 BCP の核心課題。 "
f"これらの箇所は (1) 防災工事による規制基準緩和 (落石防護網・スノーシェッド設置), "
f"(2) バックアップルートの新規建設, (3) 災害時の代替輸送手段 (ヘリ・船舶) の確保, "
f"のいずれかで対処する必要がある優先課題。"),
], columns=["仮説", "観測値", "判定", "詳細解説"])
T_hypo.to_csv(ASSETS / "L73_hypothesis_check.csv",
index=False, encoding="utf-8-sig")
print(f" ({time.time()-t9:.1f}s)", flush=True)
# =============================================================================
# 10. HTML 生成
# =============================================================================
print("\n[10] HTML 生成", flush=True)
t10 = time.time()
# ----- セクション 1: 学習目標と問い -----
sec1 = f"""
本記事の対象 — 「事前通行規制区間」 1 件 単独分析
本記事は DoBoX のデータセット 「事前通行規制区間」 (dataset {DATASET_ID})
1 件を 単独で取り上げ、 広島県の事前通行規制区間
{n_seg} 区間 / 総延長 {total_km:.0f} kmを
3 つの独立した研究角度で並列に分析する記事である。
他のシリーズ (緊急輸送道路 L72 / 道路規制 L50 / トンネル L67 /
道路法面 L71) と本記事は 合体しない。 RQ2 で警戒区域 (L11) +
過去災害 (L61)、 RQ3 で緊急輸送道路 (L72) を参照するが、 これは「予防的
安全制度の量的実証」 を明らかにするための既扱データの従属的参照に
留め、 本記事の主軸はあくまで事前通行規制区間 1 dataset の分析である。
「事前通行規制区間」 とは:
連続雨量 (24 時間雨量) や時間雨量 (60 分雨量) が一定の閾値を超えると
自動的に通行止めとする道路区間。 過去の災害履歴・地形脆弱性から
道路管理者があらかじめ指定し、 災害発生
前に予防的に通行止めにする
「予防的安全制度」。 道路法 (1952) + 災害対策基本法 (1961) を
根拠とする県管理道路の運用制度で、 事後の通行止 (= 災害発生後の応急規制) と
異なり
「降雨ノモゲン違反 → 自動規制」のルールベース運用が特徴。
広島県の事前通行規制区間は
2 系統 × 多階層に区分される (本記事独自集約):
- 系統 1: 雨量基準 (jizen): 138 区間 — ランク A (80mm/24h, 20mm/h),
B (100mm/24h, 30mm/h), C (120mm/24h, 40mm/h)、 特 (沿岸越波/冠水),
風 (15-25m/s), 地震・霧 など
- 系統 2: 冬期閉鎖 (winter): 26 区間 — 12 月〜3 月の機械的閉鎖
(積雪・凍結対策)
本記事の主要発見 (3 RQ):
- RQ1: 県の事前通行規制区間は{n_seg} 区間 / {total_km:.0f} km。
雨量基準が {n_jizen} 件 ({share_jizen}%)と多数派、 冬期閉鎖が
{n_winter} 件。 規制内容は落石等
({int((gdf['naiyo_norm']=='落石等').sum())} 件) が圧倒的最多。
- RQ2: 規制区間の{share_chusankan}% ({n_chusankan} 件)が
中山間 7 市町に集中。 落石等規制 {n_rakuseki} 件のうち
{n_rakuseki_sed_overlap} 件 ({share_rakuseki_sed}%)が
土砂警戒区域と重なる = 「過去災害 → 警戒区域 → 規制区間」 の 3 段階
予防制度階層が量的に実証された。
- RQ3: 緊急輸送道路と{n_overlap} 区間 / {overlap_total_km:.1f} kmが
重複 = BCP 制度的矛盾。 そのうち迂回路無 {n_overlap_no_ukai} 件が
県の予防防災 BCP の最重要課題。
独自に定義する用語 (本記事限定)
- 事前通行規制区間 (本記事の中心概念): 連続雨量・時間雨量・風速等の
閾値超過時に自動的に通行止めとする道路区間。 道路法 (1952) +
災害対策基本法 (1961) + 地域防災計画で運用されるルールベース規制。
- 連続雨量 (24時間雨量, ikichi24h): 直近 24 時間の累積降雨量 (mm)。
地盤の浸透限界 + 土壌飽和の指標として使われる。 規制ランク A/B/C で
80/100/120 mm の 3 段階閾値。
- 時間雨量 (60分雨量, ikichi60m): 直近 60 分間の降雨量 (mm/h)。
瞬間的な土砂崩落・冠水の指標として使われる。 規制ランク A/B/C で
20/30/40 mm/h の 3 段階閾値。
- 予防的安全制度 (本記事独自): 災害発生前に予防的に通行止に
する制度全般を指す本記事独自用語。 事前通行規制区間が代表例だが、 同様の
思想は橋梁の風速規制 (50 m/s で通行止) や落石防護網設置等にも見られる。
- 規制基準 (本記事独自): 規制発動の判定式。 ikichi24h, ikichi60m,
風速 (15-25 m/s), 越波・冠水の物理的事象等の数値閾値で決定論的に
判定される。
- 通行確保矛盾 / BCP 制度的矛盾 (本記事独自): 緊急輸送道路 (災害時
確保すべき) ∩ 事前通行規制区間 (災害前に通行止) の重複区間が引き起こす
制度間の論理矛盾。 これは「災害前の安全」 vs 「災害時の輸送」 という 2 つの
防災要請の衝突。 H4/H5 で量的に検証する。
- 3 重制度的矛盾 (本記事独自): 緊急輸送道路 ∩ 事前通行規制区間 ∩
迂回路無 の3 重制約を持つ区間。 「災害時確保すべき / 災害前に通行止 /
迂回路もない」 という最重要 BCP 課題。
- 規制ランク A/B/C (本記事独自集約): 雨量閾値の 3 階層。 公式
JSON の
rankname 列の A/B/C を本記事で「A=最厳しい
(80mm), B=中 (100mm), C=緩 (120mm)」 と解釈。
- 中山間山地 (本記事独自定義): 庄原市・三次市・安芸太田町・安芸高田市・
北広島町・神石高原町・世羅町 + 府中市の 8 市町。 公式分類ではないが、
地形・人口密度から「中山間」 と一般に呼ばれる地域を指す。
- 過去災害 2km 圏 (本記事独自): 規制区間 LineString の 2 km バッファ内に
L61 過去災害履歴 (424 件, 廿日市・呉・東広島の山腹崩落・土石流等) の
代表点が入るかで判定する近接性指標。
研究の問い (3 RQ)
- RQ1 (主研究): 広島県の事前通行規制区間の構造 — 路線・延長・規制基準は
どう描けるか? 164 区間 × {total_km:.0f} km を規制内容 × 規制ランク × 雨量閾値 ×
路線種別 × 建設事務所の 5 軸で集計し、 「県の予防的安全制度」 の物理形状を
初めて系統的に記述する。 H1 = 雨量基準が冬期閉鎖より圧倒的多数 (≥70%) を検証。
- RQ2 (副研究 1): 規制区間は中山間集中 — 過去災害履歴 (L61) +
土砂警戒区域 (L11)とどう空間関係するか? 代表点 sjoin で中山間判定 +
過去災害 2km 圏判定 + 土砂警戒区域重なり判定を行い、 「過去災害 → 警戒区域 →
規制区間」 の 3 段階予防制度階層を実証。 H2 = 中山間 ≥60% / H3 = 落石∩警戒
≥50% を検証。
- RQ3 (副研究 2): 規制区間は緊急輸送道路 (L72)とどれだけ重複するか?
30m バッファ sjoin で重複区間を同定 + 迂回路有無別に集計し、 BCP 制度的矛盾を
量的に明らかにする。 H4 = 重複 ≥20km AND ≥15区間 / H5 = 迂回路無 重複 ≥1 を検証。
仮説 (5)
- H1 (RQ1, 制度構造): 事前通行規制区間 164 のうち雨量基準 (jizen) が
≥ 70%。 動的判定 (降雨閾値で自動規制) が圧倒的多数派、 冬期閉鎖は限られた
山岳路線のみという仮説。
- H2 (RQ2, 中山間集中): 規制区間の代表点が中山間 7-8 市町に位置するのは
≥ 60%。 「事前通行規制 = 中山間山岳道路の脆弱性に対する予防制度」 を示す
根拠仮説。
- H3 (RQ2, 過去災害との対応): 落石等規制 (96 件) のうち土砂警戒区域
50m バッファ内に入るのは ≥ 50%。 「過去災害 → 警戒区域 → 規制区間」 の
3 段階予防制度階層の量的実証。
- H4 (RQ3, 緊急輸送道路との重複): 規制区間と緊急輸送道路 30m バッファの
重複延長 ≥ 20 km AND ≥ 15 区間。 BCP 制度的矛盾の量的事実。
- H5 (RQ3, 迂回路無の最重要箇所): 重複区間のうち迂回路無 が
≥ 1 件存在。 3 重制度的矛盾の最重要箇所が定量化される仮説。
到達点
本記事を読み終えると、 (1) 県の事前通行規制区間 {n_seg} 区間・{total_km:.0f} km・
2 系統 (jizen + winter) の制度構造を完全に俯瞰、 (2) 中山間集中 ({share_chusankan}%) +
過去災害との対応関係 + 土砂警戒区域との重なりを定量把握、 (3) 緊急輸送道路と
{n_overlap} 区間 / {overlap_total_km:.1f} km の重複 + 迂回路無 {n_overlap_no_ukai} 件
という3 重制度的矛盾の最重要箇所を特定できる、 という 3 段階の知識が
獲得できる。 これにより県の地域防災計画における「予防的安全 vs 通行確保」の
両立課題が研究者視点で見えるようになる。
"""
# ----- セクション 2: 使用データ -----
sec2 = f"""
本研究で使う 1 つの dataset (1 JSON リソース) を以下の表に示す。
本データは事前通行規制区間 LineString を JSON (32 列の属性 + WKT geometry) で
公開しており、 1 区間 1 レコードの構造になっている。
データセット仕様
{df_to_html(T_dataset)}
JSON 構造
JSON ファイル (pre_traffic.json, ~{json_size/1024:.0f} KB) のトップ階層は
{{ "results": [list of 164 dict] }}。 各 dict は以下の主要列を持つ:
| 列名 | 意味 | 例 | 本研究での用途 |
|---|
id |
規制区間ID (KJID_xxxxxxxx) |
KJID_20210001 |
主キー |
rosenname |
路線名 |
国道 2号 |
RQ1 路線種別分類 |
kisei_start / kisei_end |
規制起点 / 終点 |
三原市木原町 / 三原市糸崎8丁目 |
RQ1 区間記述 |
kiseinaiyo |
規制内容 |
落石等 / 凍結等 / 強風 / 冠水 / 越波 |
RQ1 主分類軸 |
rankname |
規制ランク (雨量階層) |
A / B / C / 特 / 冬 / 風 |
RQ1 規制基準階層 |
basis |
規制基準条文 |
時間雨量: 30 mm/h, 日雨量: 100 mm/24h |
RQ1 規制条件 |
ikichi24h / ikichi60m |
24h / 60m 雨量閾値 (mm) |
100 / 30 |
RQ1 雨量閾値分布 |
ukaiumu |
迂回路有無 |
有 / 無 |
RQ3 BCP 重要度 |
demarcation |
建設事務所 |
広島県 北部建設事務所庄原支所 |
RQ1 管轄分布 |
lat / lon |
代表点 (10 進数, EPSG:4326) |
34.385 / 133.133 |
市町判定 (代表点 sjoin) |
kukan / kukanroot |
区間 LineString WKT |
LINESTRING (133.128 34.383, ...) |
RQ2/RQ3 空間判定 |
type |
規制系統 |
jizen (雨量基準) / winter (冬期閉鎖) |
RQ1 系統分類 |
icon |
地図上アイコン記号 |
rain / snow / wind / kansui / nami / rinko |
規制内容と並行 |
area |
内部エリア区分 (5 区域) |
kure / bihoku / hukuyama / geihoku / higasi |
建設事務所と並行 |
JSON 解読の注意点
kukan 列の1 件 (KJID_20110019)に末尾閉じ括弧欠損あり。
本記事は kukanroot を優先 (164 件中 0 件破損)。- 緯度経度はWGS84 (EPSG:4326)。 距離計算 (RQ2 / RQ3) のため
EPSG:6671 (JGD2011 平面直角第 III 系) に投影変換する。
- 属性は 32 列以上で、 路線名・規制内容・規制ランク・雨量閾値・迂回路有無 ・
建設事務所が研究上重要。
kesoku_flag24h/60m や uryo24h/60m
は取得時刻のスナップショット観測雨量で、 静的属性ではない。
- JSON は標準的(NDJSON 風ではない)。
json.load() でそのまま
読める。
"""
# ----- セクション 3: ダウンロード -----
sec3 = f"""
本記事の再現に必要なすべてを直リンクで提供する。
HTML だけ読めば学習者が完全再現できることが目標 (要件 A)。
生データ (DoBoX 1 件)
このスクリプト本体
中間 CSV (本記事生成、再利用可)
図 (PNG, 直 DL 可)
"""
# ----- セクション 4: RQ1 -----
sec4_code = '''
import json
import geopandas as gpd
from shapely import wkt as swkt
from pathlib import Path
DATA_DIR = Path("data/extras/L73_pre_traffic_restriction")
# (1) JSON 読込 (標準 JSON, NDJSON 風ではない)
with open(DATA_DIR / "pre_traffic.json", "r", encoding="utf-8") as f:
raw = json.load(f)
recs = raw["results"]
print(f"レコード数: {len(recs)}") # 164
# (2) WKT を LineString に変換
# 1 件 (KJID_20110019) で kukan の閉じ括弧欠損 → kukanroot を優先
def get_geom(r):
try:
return swkt.loads(r["kukanroot"])
except Exception:
return None
geoms = [get_geom(r) for r in recs]
print(f"パース成功: {sum(g is not None for g in geoms)}/{len(recs)}")
# (3) GeoDataFrame 化 (4326 → 6671 投影変換)
import pandas as pd
df = pd.DataFrame({
"id": [r["id"] for r in recs],
"rosenname": [r["rosenname"] for r in recs],
"kiseinaiyo": [r["kiseinaiyo"] for r in recs],
"rankname": [r["rankname"] for r in recs],
"ikichi24h": [r.get("ikichi24h") for r in recs],
"ikichi60m": [r.get("ikichi60m") for r in recs],
"ukaiumu": [r["ukaiumu"] for r in recs],
"type": [r["type"] for r in recs],
})
gdf = gpd.GeoDataFrame(df, geometry=geoms, crs="EPSG:4326")
gdf = gdf[gdf.geometry.notna()].to_crs("EPSG:6671")
gdf["len_km"] = gdf.geometry.length / 1000
# (4) 規制内容別 集計
T_naiyo = (gdf.groupby("kiseinaiyo")
.agg(区間数=("id", "count"),
延長_km=("len_km", "sum"))
.reset_index())
print(T_naiyo)
'''
sec4 = f"""
狙い (RQ1)
RQ1 では「県の予防的安全制度」 の物理構造を初めて系統的に記述する。
具体的には {n_seg} 区間 / 総延長 {total_km:.0f} km の事前通行規制区間を
規制内容 × 規制ランク × 雨量閾値 × 路線種別 × 建設事務所の 5 軸で
集計し、 「どのような基準で どのような道路に 規制が設定されているか」 を
1 枚で俯瞰できるようにする。 H1 (jizen ≥ 70%) は制度構造の中心仮説を検証する。
手法 — 4 ステップ
- STEP 1: JSON 読込 + WKT パース
JSON は標準形式 (NDJSON 風ではない) なので json.load() で
そのまま読める。 各レコードの kukanroot 列 (LineString WKT) を
shapely.wkt.loads() でパースし、 LineString に変換する。
1 件 (KJID_20110019) で kukan の閉じ括弧欠損があるので、
kukanroot を優先することで 164 件すべて成功。
- STEP 2: GeoDataFrame 化 + 投影変換
32 列の属性を pandas DataFrame に整形 + 上の geometry を組み合わせて
GeoDataFrame に。 EPSG:4326 → EPSG:6671 (JGD2011 第 III 系) に
to_crs() で投影変換 → 距離・面積が m 単位で計算可能に。
- STEP 3: 派生列の追加
・naiyo_norm: 規制内容を統一カテゴリへ (落石等 / 凍結等 / 強風 / 冠水 / 越波 / その他)
・grade: 規制ランクを 7 階層に集約 (A/B/C/特/風/冬/その他)
・rosen_class: 路線種別 (国道/主要地方道/一般県道/etc)
・len_km: 区間長 (= LineString.length / 1000)
- STEP 4: 5 軸で集計
groupby("naiyo_norm") で規制内容別、 groupby("grade") で
ランク別、 groupby(["ikichi24h", "ikichi60m"]) で雨量閾値ペア別、
groupby("rosen_class") で路線種別、 groupby("demarcation") で
建設事務所別の集計を行う。
実装 (主要部のみ抜粋)
{code(sec4_code)}
結果 1: 県全域 規制内容別 マップ (図 1)
なぜこの図か: 6 種類の規制内容 (落石等 / 凍結等 / 強風 / 冠水 / 越波 /
その他) がどこに分布するかを県全域地図に重ねて一目で確認したい。
規制内容を色 (赤=落石等, 青=凍結等, 緑=強風, 紫=冠水, 橙=越波) で区別すること
で、 「沿岸 = 越波・冠水, 中山間 = 落石等・凍結等」の地理的偏在が
直感できる。
{figure("assets/L73_fig1_naiyo_map.png",
f"図 1 (RQ1): 広島県 事前通行規制区間 規制内容別マップ")}
図 1 から読み取れること:
- 落石等 (赤, {int((gdf['naiyo_norm']=='落石等').sum())} 件):
圧倒的最多。 中山間山地の県道・国道に集中する
- 凍結等 (青, {int((gdf['naiyo_norm']=='凍結等').sum())} 件):
標高の高い北部・北西部の山岳路線。 winter 系統に対応
- 強風 (緑, {int((gdf['naiyo_norm']=='強風').sum())} 件):
橋梁・高架部に集中。 風速 15-25 m/s 閾値の歩道閉鎖規制
- 冠水 (紫, {int((gdf['naiyo_norm']=='冠水').sum())} 件):
アンダーパス・港湾地区に集中。 道路冠水 10cm が閾値
- 越波 (橙, {int((gdf['naiyo_norm']=='越波').sum())} 件):
沿岸国道 (国道 2 号 三原・尾道間, 国道 185 号) に集中。 「波が道路を超える」 箇所
- 地理的偏在: 沿岸 = 越波・冠水、 内陸山岳 = 落石・凍結 という
地形 × 規制内容の対応関係が一枚で見える
結果 2: 規制内容 × 規制ランク × 路線種別 (図 2)
なぜこの図か: H1 (jizen ≥ 70%) を直感検証するために、 規制ランクの
分布を 7 階層で並べる。 同時に規制内容と路線種別を比較することで、 「どの
規制内容がどのランクで運用され、 どの路線種別に集中するか」 を 1 枚で 3 軸把握する。
{figure("assets/L73_fig2_rq1_structure.png",
"図 2 (RQ1): 規制内容 × 規制ランク × 路線種別")}
図 2 から読み取れること:
- 左パネル (規制内容): 落石等が
{int((gdf['naiyo_norm']=='落石等').sum())} 件と圧倒的最多 — 県内
事前通行規制区間の半数以上が落石・崩落リスク対応
- 中央パネル (規制ランク): A ({int((gdf['grade']==GRADE_ORDER[0]).sum())}) /
B ({int((gdf['grade']==GRADE_ORDER[1]).sum())}) /
C ({int((gdf['grade']==GRADE_ORDER[2]).sum())}) の 3 階層が
jizen 主体 ({n_jizen} 件 = {share_jizen}%)、 冬期閉鎖は
{n_winter} 件のみ。 H1 (jizen ≥ 70%) は{('強支持' if h1_ok else '反証')}
- 右パネル (路線種別): 一般県道が
{int((gdf['rosen_class']=='一般県道').sum())} 件と最多 (= 県管理道路の
多数派、 中山間部の主要地方道 + 国道は補佐)
- ランク B + C が約半数: 100-120 mm/24h の中・緩い閾値が中心。
A ランク (80mm/24h) は最も厳しい閾値で沿岸越波等の 「特別なリスク」箇所
- 制度の多層性(雨量3階層 + 沿岸特化 + 風 + 冬 + その他) が量的に確認される
結果 3: 雨量閾値 + 区間長分布 (図 3)
なぜこの図か: H1 を補強するため、 雨量閾値が「A=80/20, B=100/30,
C=120/40」 の 3 グループにきれいに分かれていることを散布で見せる。 同時に
区間長は対数スケールで広く分布するので log10 ヒストグラムで確認する。
{figure("assets/L73_fig3_threshold_length.png",
"図 3 (RQ1): 雨量閾値 + 区間長分布")}
図 3 から読み取れること:
- 左パネル (閾値散布): A (赤, {int((gdf['grade']==GRADE_ORDER[0]).sum())} 件) は
80mm/20mm に密集、 B (橙, {int((gdf['grade']==GRADE_ORDER[1]).sum())} 件) は
100/30 に密集、 C (山吹, {int((gdf['grade']==GRADE_ORDER[2]).sum())} 件) は
120/40 に密集 — 3 グループの離散構造が一目で見える
- 少数の特ランク (越波/冠水) は 60mm/15mm の沿岸専用厳しい閾値を持つ
- 右パネル (区間長分布): 中央値{gdf['len_m'].median():.0f} m、
最大{gdf['len_m'].max():.0f} m ({gdf['len_m'].max()/1000:.1f} km) —
4 桁の幅
- ランク A (赤) の中央値は{gdf[gdf['grade']==GRADE_ORDER[0]]['len_m'].median():.0f} mと
長く、 C (山吹) の中央値は{gdf[gdf['grade']==GRADE_ORDER[2]]['len_m'].median():.0f} m。
厳しい閾値ほど長距離区間が指定される傾向
- 冬期閉鎖 (青) は中央値{gdf[gdf['grade']=='冬期閉鎖']['len_m'].median():.0f} mで、
雨量基準と同等の規模
結果 4: 規制内容 + 規制ランク + 路線 詳細表
規制内容別サマリ:
{df_to_html(T_naiyo)}
規制内容 表から読み取れること: 落石等
{int((gdf['naiyo_norm']=='落石等').sum())} 件が
{T_naiyo[T_naiyo['規制内容']=='落石等']['延長_km'].iloc[0]:.0f} km と
最大、 平均長 {T_naiyo[T_naiyo['規制内容']=='落石等']['平均長_km'].iloc[0]:.1f} km。
凍結等 ({int((gdf['naiyo_norm']=='凍結等').sum())} 件) も平均長
{T_naiyo[T_naiyo['規制内容']=='凍結等']['平均長_km'].iloc[0]:.1f} km と長い (山岳路線の特性)。
冠水・越波は短距離 (= 局所的なアンダーパス・橋梁手前)。
規制ランク (雨量階層 + 沿岸特化 + その他) サマリ:
{df_to_html(T_grade)}
規制ランク 表から読み取れること: B + C の 2 階層
({int((gdf['grade']==GRADE_ORDER[1]).sum())} +
{int((gdf['grade']==GRADE_ORDER[2]).sum())} = 76 件) が中心、
A ({int((gdf['grade']==GRADE_ORDER[0]).sum())} 件) は最も厳しい閾値で慎重運用、
冬期閉鎖は限定的 26 件のみ。
雨量閾値ペア別サマリ:
{df_to_html(T_threshold)}
雨量閾値 表から読み取れること: 主要 3 ペア (80/20, 100/30, 120/40) +
特殊 1 ペア (60/15) の4 種類に集約される明確な階層構造。 これは「県内
全規制区間が 4 つの閾値ルールで運用される」 という制度の単純さを意味する
(現場運用の混乱回避)。
路線種別サマリ:
{df_to_html(T_rosen)}
路線種別 表から読み取れること: 一般県道
{int((gdf['rosen_class']=='一般県道').sum())} 件が
過半数 ({100*int((gdf['rosen_class']=='一般県道').sum())/n_seg:.1f}%) — 県管理道路は
県道が主体。 国道 32 件 (中国地方整備局・県の共同管理) と主要地方道 27 件は
県道に次ぐ。
建設事務所別サマリ:
{df_to_html(T_demarc)}
建設事務所 表から読み取れること: 北部建設事務所 (庄原・本庁) +
西部建設事務所 (廿日市・安芸太田・呉) が支配的 — これは規制区間が中山間
(北部) + 沿岸島嶼/中山間 (西部) に偏ることを示す。 東部建設事務所 (三原・本庁) +
広島港湾振興事務所も少数登場。
迂回路有無サマリ:
{df_to_html(T_ukai)}
迂回路 表から読み取れること: 迂回路有 143 件 (87.2%) /
迂回路無 21 件 (12.8%)。 大多数は迂回路ありで「規制中も別ルートで対応可」 だが、
21 件は「規制中は完全孤立」のリスク区間。 RQ3 で緊急輸送道路と重ねて
さらに絞り込む。
"""
# ----- セクション 5: RQ2 -----
sec5_code = '''
# 各規制区間の代表点を行政界に sjoin → 市町判定 → 中山間判定
admin = gpd.read_file("data/extras/L44_storm_surge/_cache/admin_diss.gpkg")
pts = gdf.geometry.representative_point()
gdf_rep = gpd.GeoDataFrame({"id": gdf["id"]}, geometry=pts, crs="EPSG:6671")
joined = gpd.sjoin(gdf_rep, admin[["CITY_CD", "市町名", "geometry"]],
how="left", predicate="within")
gdf["市町名"] = joined["市町名"].values
# 中山間 7 市町
CHUSANKAN = {"庄原市", "三次市", "安芸太田町", "安芸高田市",
"北広島町", "神石高原町", "世羅町", "府中市"}
gdf["is_chusankan"] = gdf["市町名"].isin(CHUSANKAN)
print(f"中山間: {gdf['is_chusankan'].sum()}/{len(gdf)}")
# 過去災害との 2km 圏近接性 (STRtree 高速化)
df_past = pd.read_csv("data/extras/past_disasters.csv",
encoding="utf-8-sig", on_bad_lines="skip")
gdf_past = gpd.GeoDataFrame(df_past,
geometry=[Point(x, y) for x, y in zip(df_past["経度"], df_past["緯度"])],
crs="EPSG:4326").to_crs("EPSG:6671")
# 規制区間の 2km バッファに過去災害点が入るか sjoin
buf2km = gdf.geometry.buffer(2000)
gdf_buf = gpd.GeoDataFrame({"id": gdf["id"], "geometry": buf2km},
crs="EPSG:6671")
joined_past = gpd.sjoin(gdf_past, gdf_buf, how="left", predicate="within")
near_count = (joined_past[joined_past["index_right"].notna()]
.groupby("id").size())
gdf["past_near_2km"] = gdf["id"].map(near_count).fillna(0).astype(int)
# 落石等規制区間 ∩ 土砂警戒区域 重なり
sed_files = [...] # 急傾斜 + 土石流 + 地すべり Shapefile (本記事スクリプト参照)
sed_all = gpd.GeoDataFrame(pd.concat([gpd.read_file(f) for f in sed_files]))
gdf_buf50 = gdf.copy()
gdf_buf50["geometry"] = gdf_buf50.geometry.buffer(50)
sed_hits = gpd.sjoin(gdf_buf50, sed_all, how="left", predicate="intersects")
overlap_ids = set(sed_hits[sed_hits["index_right"].notna()]["id"])
print(f"落石∩警戒重なり: {sum(1 for i in gdf['id'] if i in overlap_ids)}")
'''
sec5 = f"""
狙い (RQ2)
RQ1 で「規制区間の制度構造」 が分かったが、 これは属性のみ。
RQ2 では「規制区間と地形・過去災害履歴・警戒区域の空間関係」を見る。
具体的には(1) 中山間 vs 都市部の比率、 (2) 過去災害 (L61) との 2km
近接性、 (3) 土砂警戒区域 (L11) との重なり率を計算し、 「過去災害 →
警戒区域 → 規制区間」 という3 段階予防制度階層を実証する。
H2 (中山間 ≥60%) と H3 (落石∩警戒 ≥50%) の 2 仮説を検証する。
手法 — 代表点 sjoin + バッファ近接判定
狙い: LineString 全体ではなく代表点 (representative_point) 1 点で
市町を判定する (= sjoin が 164 回で済み高速)。 過去災害は2 km バッファで
近接性を判定 (= 「規制区間の 2 km 圏内に過去災害履歴があるか」 をスクリーニング)。
土砂警戒区域は50 m バッファで重なりを判定 (= 道路敷地 + 警戒区域の
ほぼ確実な接続)。
| 判定 | 使用データ | 方法 | 意味 |
|---|
| 中山間判定 |
行政界 GPKG (L44 既キャッシュ) |
代表点 sjoin → 市町名 → 中山間 7 市町と照合 |
「中山間山岳道路集中度」 を量的に |
| 過去災害 2km 圏 |
L61 過去災害 CSV (424 件) |
規制区間 2km buffer に sjoin |
「規制区間 = 過去災害の対応関係」 をスクリーニング |
| 土砂警戒区域 重なり |
L11 警戒区域 Shapefile (3 種) |
規制区間 50m buffer に sjoin (intersects) |
「規制 = 警戒区域指定の地形脆弱性」 を実証 |
注意: 本記事は「2 km 圏」を「過去災害との対応関係のスクリーニング」 と
同定するが、 実際の因果関係 (= 過去にあった災害が規制指定の根拠か) は
道路管理者の規制決定文書を見ないと確定できない。 GIS の近接判定は
「対応関係の仮説支持」 として使う。
実装 (主要部)
{code(sec5_code)}
結果 1: 規制区間 + 中山間境界 重ね合わせマップ (図 4)
なぜこの図か: H2 (中山間 ≥60%) を地図上で直感検証するため、
中山間 7 市町を橙色背景、 沿岸島嶼を青色背景で塗り、 規制区間を中山間内 (赤線) /
それ以外 (灰線) で色分けして重ねる。 「中山間に規制区間が集中するか」 が一目で
見える。
{figure("assets/L73_fig4_chusankan_map.png",
"図 4 (RQ2): 規制区間 + 中山間境界 重ね合わせ")}
図 4 から読み取れること:
- 橙色背景 (中山間 7 市町): 庄原市・三次市・安芸太田町・安芸高田市・
北広島町・神石高原町・世羅町・府中市 — 県北西部 + 県中部
- 赤線 (中山間内 規制区間, {n_chusankan} 件):
中山間市町を縦横に走る — 主要地方道・一般県道の山岳路線
- 灰線 (中山間外 規制区間, {n_seg - n_chusankan} 件):
沿岸都市 (廿日市市・呉市・三原市・福山市) と平野部の国道
- 中山間が{share_chusankan}%、 H2 ({('強支持' if h2_ok else '反証')})
- 「事前通行規制 = 中山間山岳道路の脆弱性に対する予防制度」 という
地形 × 制度の対応関係が量的に確認される
結果 2: 過去災害 + 土砂警戒区域 重ね合わせマップ (図 5)
なぜこの図か: H3 (落石∩警戒 ≥50%) を地図上で同時検証するため、
土砂警戒区域 (赤マスク) + 過去災害点 (灰点) + 規制区間 (落石=橙線, その他=青線) を
重ねる。 「赤マスク + 灰点 + 橙線が同じ場所に集中するか」 を 1 枚で確認できる。
{figure("assets/L73_fig5_past_disaster_sed.png",
"図 5 (RQ2): 規制区間 + 過去災害 + 土砂警戒区域")}
図 5 から読み取れること:
- 赤マスク (土砂警戒区域 計 {len(sed_all):,} ポリゴン):
中山間山地に広く分布、 県北部 (庄原・三次) と西部 (廿日市) で密集
- 灰点 (過去災害 {n_past} 件):
廿日市市・呉市・東広島市の山腹崩落が中心、 平成 17 年・26 年・30 年などの
過去複数災害の記録点
- 橙線 (落石等規制 {n_rakuseki} 件):
県北部 + 西部 + 沿岸島嶼の主要道路に分布、 赤マスクと高い重なり
- 青線 (その他規制 {n_seg - n_rakuseki} 件):
沿岸 (越波・冠水) + 平野 (強風) で赤マスクと重ならない地区が多い
- 落石∩警戒の{n_rakuseki_sed_overlap}/{n_rakuseki} ({share_rakuseki_sed}%)、
H3 ({('強支持' if h3_ok else '反証')})
- 過去災害 2 km 圏に入る規制区間は
{int(gdf['has_past_near'].sum())} 件 ({100*int(gdf['has_past_near'].sum())/n_seg:.1f}%) —
「規制区間 = 過去災害 + 警戒区域指定の重畳箇所」 の量的支持
結果 3: 規制内容 × 地理クラス + 過去災害近接 (図 6)
なぜこの図か: 規制内容ごとに「中山間 / 平野・沿岸都市 / 沿岸島嶼」の
分布がどう違うかを積み棒で比較し、 同時に各規制内容の過去災害近接率を見せる。
「落石は中山間 + 過去災害ヒット率高い vs 越波は沿岸 + 過去災害低い」 という
地理 × 過去履歴の対応を 1 枚で確認する。
{figure("assets/L73_fig6_chusankan_x_naiyo.png",
"図 6 (RQ2): 規制内容 × 地理クラス + 過去災害近接")}
図 6 から読み取れること:
- 左パネル (規制内容 × 地理クラス):
落石等は中山間 (橙) が支配的、 越波・冠水は平野・沿岸都市 (青) が
支配的、 凍結等は中山間集中、 強風は分散
- 右パネル (規制内容 × 過去災害 2km 圏ヒット率):
落石等は約{int(gdf[gdf['naiyo_norm']=='落石等']['has_past_near'].sum() / max((gdf['naiyo_norm']=='落石等').sum(), 1) * 100)}%と高め、
越波・冠水は沿岸特化で過去災害履歴と被らない (= 過去災害 dataset は
主に山腹崩落で沿岸災害をカバーしないバイアス)
- 「規制内容と地形・過去履歴の対応関係」 が量的に確認 — 県は
地形脆弱性別の規制内容を区別して指定している
結果 4: 中山間 + 市町別 詳細表
地理クラス別サマリ:
{df_to_html(T_geo)}
地理クラス 表から読み取れること: 中山間山地が
{T_geo[T_geo['地理クラス']=='中山間山地']['区間数'].iloc[0]:.0f} 件
({T_geo[T_geo['地理クラス']=='中山間山地']['シェア_%'].iloc[0]:.1f}%)と過半数を占め、
平野・沿岸都市 ({T_geo[T_geo['地理クラス']=='平野・沿岸都市']['区間数'].iloc[0]:.0f} 件) が
次。 沿岸島嶼は少数 ({int(T_geo[T_geo['地理クラス']=='沿岸島嶼']['区間数'].iloc[0]) if '沿岸島嶼' in T_geo['地理クラス'].values else 0} 件) で
規制区間が集中しない。
市町別サマリ (Top 15):
{df_to_html(T_city.head(15))}
市町別 表から読み取れること:
{T_city.iloc[0]['市町名']} ({int(T_city.iloc[0]['区間数'])} 件)が圧倒的最多、
2 位 {T_city.iloc[1]['市町名']} ({int(T_city.iloc[1]['区間数'])} 件)、
3 位 {T_city.iloc[2]['市町名']} ({int(T_city.iloc[2]['区間数'])} 件)。
中山間市町が上位を占めるが、 廿日市市 (一部沿岸) も含まれる — 県西部の
山岳道路の複合性。
規制内容 × 地理クラス クロス:
{df_to_html(T_naiyo_geo)}
クロス 表から読み取れること:
落石等は中山間に集中
({T_naiyo_geo[T_naiyo_geo['規制内容']=='落石等'].drop(columns=['規制内容']).iloc[0].sum() if len(T_naiyo_geo[T_naiyo_geo['規制内容']=='落石等']) > 0 else 0} 件分布)、
越波は沿岸
({T_naiyo_geo[T_naiyo_geo['規制内容']=='越波']['平野・沿岸都市'].iloc[0] if '平野・沿岸都市' in T_naiyo_geo.columns and len(T_naiyo_geo[T_naiyo_geo['規制内容']=='越波']) > 0 else 0} 件)、
凍結等は中山間 — 規制内容の地形特化が量的に明確。
"""
# ----- セクション 6: RQ3 -----
sec6_code = '''
# L72 緊急輸送道路 JSON 読込 (NDJSON 風: "[" + text + "]" でラップ)
def load_l72_lines(idx):
with open(f"data/extras/L72_emergency_road/.../05_kinkyu_route_{idx}.json") as f:
text = f.read()
arr = json.loads("[" + text + "]")
return [LineString([(pt["e"], pt["d"]) for pt in seg])
for seg in arr if len(seg) >= 2]
records_l72 = []
for idx in ["01", "02", "03", "04"]:
for ln in load_l72_lines(idx):
records_l72.append({"l72_rank": idx, "geometry": ln})
gdf_l72 = gpd.GeoDataFrame(records_l72, crs="EPSG:4326").to_crs("EPSG:6671")
print(f"L72: {len(gdf_l72)} セグメント")
# 30m バッファ → 規制区間と sjoin
gdf_l72["buf"] = gdf_l72.geometry.buffer(30)
buf_l72 = gpd.GeoDataFrame(gdf_l72[["l72_rank", "buf"]].rename(
columns={"buf": "geometry"}), geometry="geometry", crs="EPSG:6671")
overlap = gpd.sjoin(gdf, buf_l72, how="left", predicate="intersects")
gdf["on_l72"] = overlap.groupby(overlap.index)["l72_rank"].apply(
lambda s: s.notna().any())
n_overlap = int(gdf["on_l72"].sum())
print(f"重複: {n_overlap}/{len(gdf)} 区間")
# 重複延長 = 規制 LineString と L72 buffer union の交差長
buf_union = buf_l72.geometry.union_all()
gdf["overlap_km"] = gdf.geometry.apply(
lambda g: g.intersection(buf_union).length / 1000)
print(f"重複延長: {gdf['overlap_km'].sum():.1f} km")
# 迂回路無 重複 (3 重制度的矛盾)
overlap_no_ukai = gdf[gdf["on_l72"] & (gdf["ukaiumu"] == "無")]
print(f"迂回路無 重複 (BCP最重要): {len(overlap_no_ukai)} 件")
'''
sec6 = f"""
狙い (RQ3)
RQ2 で「規制区間と過去災害・警戒区域の対応」 という地形脆弱性を見たが、
予防防災のもう一つの重要要素は「制度間の整合性」。
緊急輸送道路 (= 災害時に通行確保すべき) と事前通行規制区間 (= 災害前に予防的
に通行止) の重複は「通行確保の制度的矛盾」を意味する。
RQ3 では緊急輸送道路 30m バッファ内に入る規制区間を sjoin で同定し、
さらに迂回路有無で 2 段階に絞り込み、 BCP の最重要課題 (3 重制度的矛盾) を
量的に明らかにする。
H4 (重複 ≥20km AND ≥15区間) と H5 (迂回路無 重複 ≥1) を検証する。
手法 — 30m バッファ + sjoin + intersection 計算
狙い: 緊急輸送道路 (L72 既扱、 LineString {n_l72} セグ / {total_km_l72:.0f} km) に
対して30m バッファを作成 (= 道路敷地)、 規制区間 LineString を
gpd.sjoin(predicate="intersects") で重なり判定。 重複延長は
規制 LineString と L72 バッファ union の intersectionを計算 (= 実際の重複
延長 km)。 さらに迂回路 (ukaiumu) 列で 2 段階に絞り込む。
| 項目 | 値 | 意味 |
|---|
| L72 緊急輸送道路 |
{n_l72} セグ / {total_km_l72:.0f} km |
4 階層 (第1次/2次/3次/補完, L72 既扱) |
| バッファ幅 |
{BUFFER_M:.0f} m |
道路敷地 (典型 4-15m) + 路肩・工作物近接帯 |
| 規制区間 LineString |
{n_seg} 区間 / {total_km:.0f} km |
本記事の主データ |
| 重複判定 |
sjoin (intersects) |
1 規制区間が L72 buffer に少しでも掛かれば重複 |
| 重複延長 |
L72 buffer union との intersection length |
実際の重複 km (≠ 規制区間総延長) |
| 2 段絞り込み |
重複 ∩ 迂回路無 |
3 重制度的矛盾 (BCP 最重要) |
実装 (主要部)
{code(sec6_code)}
結果 1: 規制 ∩ 緊急輸送道路 重複マップ (図 7)
なぜこの図か: 「規制区間と緊急輸送道路の重複がどこにあるか」 を地図で
直接見せる。 緊急輸送道路 (灰線, L72 全 {n_l72} セグ)、 規制区間 off (灰),
規制 ∩ 緊急輸送 (迂回路有=青, 迂回路無=赤太線+★) の4 段階色分けで、
迂回路無 区間が最重要箇所として浮き上がる。
{figure("assets/L73_fig7_overlap_l72_map.png",
"図 7 (RQ3): 事前通行規制 ∩ 緊急輸送道路 重複マップ")}
図 7 から読み取れること:
- 灰線 (L72 緊急輸送道路, {n_l72} セグ):
4 階層を重ねた背景 — 主要骨格が見える
- 灰線 (規制区間 off L72, {n_seg - n_overlap} 件):
L72 と重ならない規制区間 — 一般県道・市町道の山岳路線が中心
- 青線 (規制 ∩ L72, 迂回路有, {len(gdf[gdf['on_l72'] & (gdf['ukaiumu']=='有')])} 件):
重複あるが代替経路あり — 運用上は「事前通行規制が優先 → 迂回路使用」
- 赤太線 + ★ (規制 ∩ L72, 迂回路無, {n_overlap_no_ukai} 件):
3 重制度的矛盾の最重要箇所 — 災害時確保すべき + 災害前に通行止 +
迂回路もない
- 重複は{overlap_total_km:.1f} km / 規制総延長 {total_km:.0f} km の
{100*overlap_total_km/total_km:.1f}% — 「規制区間の {100*overlap_total_km/total_km:.0f}% 程度が
緊急輸送道路の上に乗っている」 という事実
- BCP 観点で言えば「規制発動時に L72 の {100*overlap_total_km/total_km_l72:.2f}% が同時に通行止になる」
可能性
結果 2: 階層別 + 迂回路 + ランク 3 角度 (図 8)
なぜこの図か: H4 と H5 を 3 角度から検証する: (1) L72 階層別 重複数 +
重複 km、 (2) 迂回路有無別 重複数 + km (H5 直接判定)、 (3) 規制ランク別
重複 vs 非重複の比較。 これで「重複がどの階層に集中するか」 「迂回路無は何件か」
「規制ランク B・C が重複に多いか」 が同時に分かる。
{figure("assets/L73_fig8_overlap_breakdown.png",
"図 8 (RQ3): 緊急輸送道路重複 — 階層 / 迂回路 / ランク 3角度")}
図 8 から読み取れること:
- 左パネル (L72 階層別重複):
第2次 ({L72_LABEL['02']}) が最多 — 主要地方道 + 国道として規制区間と
重なる。 H4 重複 {overlap_total_km:.1f} km / {n_overlap} 区間 ({('強支持' if h4_ok else '反証')})
- 中央パネル (迂回路有無):
迂回路有 {len(gdf[gdf['on_l72'] & (gdf['ukaiumu']=='有')])} 件 (緑) vs
迂回路無 {n_overlap_no_ukai} 件 (赤) — H5 ({('強支持: BCP最重要箇所が定量化された' if h5_ok else '反証: 迂回路無は0件')})
- 右パネル (規制ランク別 重複 vs 非重複):
A・B・C ランクは重複ありが多い (= 主要道路の規制区間と緊急輸送道路は
高い重複率を持つ)、 冬期閉鎖は山岳路線が多く重複少なめ
- 「規制区間の主要部分 = 緊急輸送道路上」 という構造が量的に確認 —
これは緊急輸送道路 = 主要地方道・国道という性質上必然的だが、
BCP 制度設計の前提として明文化する重要数字
結果 3: L72 重複 + 迂回路 詳細表
L72 緊急輸送道路階層別 重複:
{df_to_html(T_overlap_l72)}
L72 階層別 表から読み取れること:
{T_overlap_l72.iloc[0]['緊急輸送道路階層'] if len(T_overlap_l72) > 0 else '-'}
が最多重複 — 主要地方道 + 一般国道に規制区間と緊急輸送道路の二重指定が
集中する。 第1次 (高速・幹線国道) は重複が比較的少なく、 高速道路が事前通行
規制対象から除外される傾向があることを示唆。
重複 × 迂回路 有無:
{df_to_html(T_overlap_ukai)}
重複 × 迂回路 表から読み取れること:
重複 {n_overlap} 件のうち迂回路有
{int(T_overlap_ukai[T_overlap_ukai['迂回路']=='有']['区間数'].iloc[0]) if '有' in T_overlap_ukai['迂回路'].values else 0} 件 vs
迂回路無 {n_overlap_no_ukai} 件。
迂回路無の{n_overlap_no_ukai} 件が県の予防防災 BCP の最重要課題で、
これらの箇所では「規制発動時の代替輸送手段」 が事前に必要。
3 重制度的矛盾箇所 (迂回路無 重複) {n_overlap_no_ukai} 件 の詳細:
{df_to_html(overlap_no_ukai_out[['rosenname','kisei_start','kisei_end','kiseinaiyo','rankname','市町名','l72_label','overlap_km']]) if n_overlap_no_ukai > 0 else '該当なし (H5 反証)
'}
3 重制度的矛盾 表から読み取れること:
これら{n_overlap_no_ukai} 区間は「災害時に通行確保すべき / 災害前に
通行止になる / 迂回路もない」 という 3 重の制度的矛盾を抱える。 全件 CSV
(L73_overlap_no_ukai.csv) で詳細属性を提供 — 県の地域防災計画に
直接フィードバックできる量的優先課題リストとして利用可能。
"""
# ----- セクション 7: 仮説検証 -----
T_hypo_html = T_hypo.copy()
T_hypo_html["判定"] = T_hypo_html["判定"].apply(
lambda v: f'{v}')
sec7 = f"""
仮説検証総合 (H1〜H5)
本記事冒頭で立てた 5 仮説の検証結果を以下にまとめる。
すべての仮説の検証根拠は本記事中の図表に明示されており、再現可能。
{df_to_html(T_hypo_html)}
主要発見の整理
- RQ1 主発見: 県の事前通行規制区間は{n_seg} 区間 / {total_km:.0f} km。
雨量基準が {n_jizen} 件 ({share_jizen}%)と多数派、 H1
({('強支持' if h1_ok else '反証')})。 規制内容は落石等
{int((gdf['naiyo_norm']=='落石等').sum())} 件 + 凍結等
{int((gdf['naiyo_norm']=='凍結等').sum())} 件 が中心、 ランクは
A/B/C の 3 階層 (80/100/120 mm/24h) + 特/風/冬 の補助で構成される
「ルールベース予防制度」が定量的に示された。
- RQ2 主発見: 規制区間の{share_chusankan}% ({n_chusankan} 件)が
中山間 7 市町に集中 (H2 {('強支持' if h2_ok else '反証')})、
落石等規制 {n_rakuseki} 件中
{n_rakuseki_sed_overlap} 件 ({share_rakuseki_sed}%)が
土砂警戒区域と重なる (H3 {('強支持' if h3_ok else '反証')})。
過去災害 {n_past} 件と 2 km 圏内の規制区間が
{int(gdf['has_past_near'].sum())} 件で「過去災害 → 警戒区域 → 規制区間」 の
3 段階予防制度階層が量的に実証された。
- RQ3 主発見: 規制区間と緊急輸送道路の重複は
{n_overlap} 区間 / {overlap_total_km:.1f} km
(H4 {('強支持' if h4_ok else '反証')})、 そのうち迂回路無 = 3 重制度的
矛盾箇所が{n_overlap_no_ukai} 件 (H5 {('強支持' if h5_ok else '反証')})。
これは「災害前の予防的安全 vs 災害時の通行確保」 という2 つの防災
要請の衝突を量的に示し、 県の予防防災 BCP の最優先課題として直接
利用可能なリストを提供する。
本記事の独自貢献
- 「予防的安全制度」 の概念定量化: 事前通行規制区間 164 区間 を
規制内容 × 規制ランク × 雨量閾値 × 路線種別 × 建設事務所の
5 軸で初めて系統的に集計。 県の予防防災運用が「A80/B100/C120 mm/24h
の 3 階層 + 特/風/冬 補助」という制度に整理されていることを実証。
- 「3 段階予防制度階層」 の実証: 「過去災害履歴 (L61) →
土砂警戒区域指定 (L11) → 事前通行規制区間指定 (L73)」 という3 段階の
予防制度を空間データで量的支持。 落石等規制 {share_rakuseki_sed}% が
警戒区域と重なる + 過去災害 2km 圏内に
{int(gdf['has_past_near'].sum())} 件が位置する。
- 「3 重制度的矛盾箇所」 リストの作成: 緊急輸送道路 (L72) +
事前通行規制区間 + 迂回路無 の3 重交差を空間判定で
{n_overlap_no_ukai} 件同定 (CSV 出力)。 県の地域防災計画 BCP の
最優先課題リストとして直接利用可能。
- L11 + L61 + L72 との横断連携: 事前通行規制 (1 dataset) +
警戒区域 (L11 既扱) + 過去災害 (L61 既扱) + 緊急輸送道路 (L72 既扱) の
4 dataset を sjoin で組合わせ、 県の予防防災制度ネットワークを
初めて統合的に定量化。
- WKT パースの片寄り対策: 公式 JSON の
kukan 列に
1 件 (KJID_20110019) で閉じ括弧欠損あり。 kukanroot を優先する
ことで全 164 件パース成功 = 公開データの軽微なエラーを実装で吸収する
手法を例示。
本記事の限界
- 属性の制約: 公開データには規制指定年度・指定根拠・最近運用履歴等の
行政文書ベースの属性が含まれない。 これは「リアルタイム規制発動」 用の
最小限公開と推定されるが、 研究用途には限界。 詳細な制度沿革には県の道路
管理台帳との結合が必要。
- 過去災害との対応の因果不明: 本記事は「規制区間 ≈ 警戒区域 ≈
過去災害」 の 3 者の近接性 (2 km 圏)を量的に示すが、 「過去災害が
原因で規制指定された」 という因果関係は道路管理者の規制決定文書を
見ないと確定できない。
- 50 m バッファ + 2 km 圏は近似: 警戒区域重なり判定の 50m バッファは
「道路敷地 + 警戒区域への接続」 の近似で、 道路敷地が広い (= 高速道路 IC) や
狭い (= 山道) 場所では過大・過小となる場合がある。 2km 圏は過去災害近接の
一般的な値だが、 規制根拠としては緩い。
- L72 重複判定の 30m バッファ: 緊急輸送道路と規制区間が同じ路線でも
ベクトル幾何が完全に一致しない場合がある (= 公開データ作成時期が異なる)。
30m バッファでほぼ確実に判定できるが、 まれに重複していても重複なしと
判定される可能性。
- 動的観測値の非利用:
uryo24h/uryo60m 列は
取得時刻のスナップショット観測雨量 (本記事取得時 2026-05-09 21:55) で、
静的属性ではない。 リアルタイム雨量 vs 閾値の比較解析は本記事のスコープ外。
- ランク D/E 等の欠如: 本データには A/B/C + 特・冬・風・地震・霧
しか登場しない。 公式の規制ランク体系がこれで完全か、 他の県・国交省管轄で
D ランク等が存在するかは不明。
"""
# ----- セクション 8: 発展課題 -----
sec8 = f"""
発展課題 — 結果 X → 新仮説 Y → 課題 Z 形式
発展課題 1 (RQ1 拡張): 雨量実時間データ × 閾値 の同時可視化
- 結果 X: 本記事は静的な閾値 (ikichi24h, ikichi60m) を分析したが、
規制発動の実頻度は取得時刻スナップショットの観測雨量 (uryo24h/60m)
でしか見えない。 過去 1 年でどの区間が何回発動したかは未検証。
- 新仮説 Y: 過去 1 年で発動回数が多いのはランク A (80mm 厳)の
区間 (= 閾値が低いため発動しやすい)。 中央値 5-10 回/年、 最多区間で
30 回/年と予想。 ランク C (120mm) は 1-3 回/年と稀。
- 課題 Z: DoBoX または県の道路規制履歴データを取得 → 規制区間 ID と
照合 → 発動回数 × ランク クロス → 「過頻発動区間マップ」を作成。
頻発区間は防災工事 (落石防護網設置) の優先順位付けの根拠となる。
発展課題 2 (RQ2 拡張): 標高・斜度データとの結合
- 結果 X: 本記事は中山間判定を「市町名」 で代理したが、 実際の地形
脆弱性は標高・斜度で量的に表される。 規制区間の沿道斜面の傾斜分布は
未検証。
- 新仮説 Y: 落石等規制区間の沿道斜面は中央値30 度以上で、
凍結等規制区間の中央標高は500 m 以上。 これは「土砂災害防止法
30 度基準 + 山地気象の凍結基準」 の量的根拠。
- 課題 Z: L40 標高データ + L39 斜度データを取得 → 規制区間 LineString
の沿道に 30m バッファ → ラスタの平均値・中央値 → 規制内容別比較 →
「規制 × 地形」 の量的相関を示す。
発展課題 3 (RQ2 拡張): 気候変動シナリオ別 規制発動増加予測
- 結果 X: 本記事は 2026 年現状の規制制度を分析したが、 気候変動で
集中豪雨が増えると規制発動頻度はどう変化するかは未検証。
- 新仮説 Y: IPCC RCP8.5 シナリオ (4 度上昇) で 100 mm/24h を超える
日数が現在比 1.5-2.0 倍になると、 ランク B (100 mm) の発動回数は
+50%〜100%増加。 これは「現在の規制制度が将来の気候に対応
不可能」 という制度設計課題を示す。
- 課題 Z: 気象庁の地域気候モデル (CMIP6) から将来 24h 降雨量分布を
取得 → 各規制区間の 100 mm 超過日数を将来予測 → 「気候変動下の規制発動
頻度マップ」を作成。 A/B/C 閾値の見直しの根拠となる。
発展課題 4 (RQ3 拡張): 3 重制度的矛盾箇所の防災工事優先順位
- 結果 X: 本記事は迂回路無 重複区間を {n_overlap_no_ukai} 件同定したが、
これらの優先順位 (どの順で防災工事するか) は未検証。
- 新仮説 Y: 優先順位は(1) 規制発動頻度, (2) 災害履歴近接性,
(3) 規制延長, (4) 緊急輸送道路階層の 4 軸で決まる。 これらをスコア化
すると上位 5 件が県の防災工事 5 か年計画の中核となる。
- 課題 Z: 上記 4 指標をすべて 0-100 スケールで標準化 →
重み付け合計でスコア化 → 上位 N 件抽出 → 「防災工事優先順位マップ」を
作成。 県の道路防災計画への直接インプット。
発展課題 5 (RQ3 拡張): L50 動的規制との時間的重なり
- 結果 X: 本記事は L73 (静的・予防的) のみ扱ったが、 L50 (動的・本日の
規制) では工事規制 + 災害規制が動的に発生する。 同じ路線で L73 規制中に
L50 工事規制が重なると「二重規制」となり通行不能期間が延びる。
- 新仮説 Y: L73 + L50 (本日 + 今後) の路線一致重複は数件存在。
これらは「予防規制 + 工事規制」 の同時発生で、 BCP の意味で「最も通行
不能になりやすい区間」。
- 課題 Z: L50 dataset (1257 + 1258) を取得 → rosen_key で L73 と結合 →
重複区間を抽出 → 「二重規制リスクマップ」を作成。 県の道路工事
スケジュール調整の根拠となる。
発展課題 6 (展望): 地域住民への規制リスク情報配信
- 結果 X: 本記事は研究者・行政向けの分析だが、 地域住民は「自分の
最寄り道路がいつ規制されるか」 を知る権利がある。 現状の DoBoX は専門家
指向で、 住民向け UX は未整備。
- 新仮説 Y: 県内集落 (~1000 集落) のうち10-15%の集落は最寄り
道路に事前通行規制区間がある。 これらの集落住民は規制発動時に外部
移動が制限される。 集落単位での規制リスク表示があれば住民の防災意識が
高まる。
- 課題 Z: 集落の代表点 (避難所 dataset から代理) → 最寄り規制区間を
BallTree で検索 → 集落 × 規制区間 距離マトリクス →
「集落別規制リスクポータル」(Web ページ) を作成。 地域住民が自分の
集落 ID から見ることができる。
発展課題 7 (展望): ランク基準の科学的妥当性検証
- 結果 X: ランク A/B/C の 80/100/120 mm/24h 閾値は過去の経験値で
設定されたと推定されるが、 現在の地形・地質・気候から見て妥当かは未検証。
- 新仮説 Y: 過去 30 年の災害発生データから、 各規制区間の真の安全
閾値を推定すると、 現状の A/B/C 閾値の20-30%が過大 (= 規制
発動が遅すぎる) または過小 (= 過剰規制)。 これは「経験値ベースの制度の
科学的更新可能性」 を示す。
- 課題 Z: 過去 30 年の災害発生履歴 + 各災害発生時の 24h/60m 雨量
観測 → 各規制区間の真の閾値を機械学習で推定 (ロジスティック回帰) →
推定閾値 vs 現状閾値の差分を量化 → 「閾値見直し提案リスト」を作成。
県の制度更新の根拠データとなる。
"""
# ----- 統合 -----
sections = [
("学習目標と問い", sec1),
("使用データ", sec2),
("ダウンロード", sec3),
(f"【RQ1】 事前通行規制区間の構造 — 路線・延長・規制基準 / "
f"{n_seg} 区間 / {total_km:.0f} km / jizen {share_jizen}%",
sec4),
(f"【RQ2】 中山間集中・過去災害履歴 / 中山間 {share_chusankan}% / "
f"落石∩警戒 {share_rakuseki_sed}%",
sec5),
(f"【RQ3】 緊急輸送道路 (L72) との重複 — 通行確保の制度的矛盾 / "
f"重複 {n_overlap} 区間 / {overlap_total_km:.1f} km / "
f"迂回路無 {n_overlap_no_ukai} 件",
sec6),
("仮説検証総合", sec7),
("発展課題", sec8),
]
html = render_lesson(
num=73,
title=f"事前通行規制区間 単独 3 研究例分析 — "
f"{n_seg} 区間 / {total_km:.0f} km / "
f"3 重制度的矛盾箇所 (迂回路無 重複 = {n_overlap_no_ukai} 件) を読む",
tags=["L73", "事前通行規制区間", "予防的安全制度",
"連続雨量", "時間雨量", "規制基準",
"通行確保矛盾", "BCP制度的矛盾", "3重制度的矛盾",
"規制ランク", "A/B/C", "雨量閾値",
"落石等", "凍結等", "強風", "冠水", "越波",
"RQ×3", "Format B", "geopandas", "LineString (WKT)",
"L11連携 (警戒区域)", "L61連携 (過去災害)",
"L72連携 (緊急輸送道路)", "中山間集中"],
time="50 分",
level="中級",
data_label=f"DoBoX dataset {DATASET_ID} (JSON × 1, ~{json_size/1024:.0f} KB)",
sections=sections,
script_filename="L73_pre_traffic_restriction.py",
)
OUT_HTML = LESSONS / "L73_pre_traffic_restriction.html"
OUT_HTML.write_text(html, encoding="utf-8")
print(f" HTML: {OUT_HTML.name} ({len(html):,} chars)")
print(f" ({time.time()-t10:.1f}s)", flush=True)
# =============================================================================
# 終了
# =============================================================================
print(f"\n=== 完了 (合計 {time.time()-t_all:.1f} 秒) ===", flush=True)
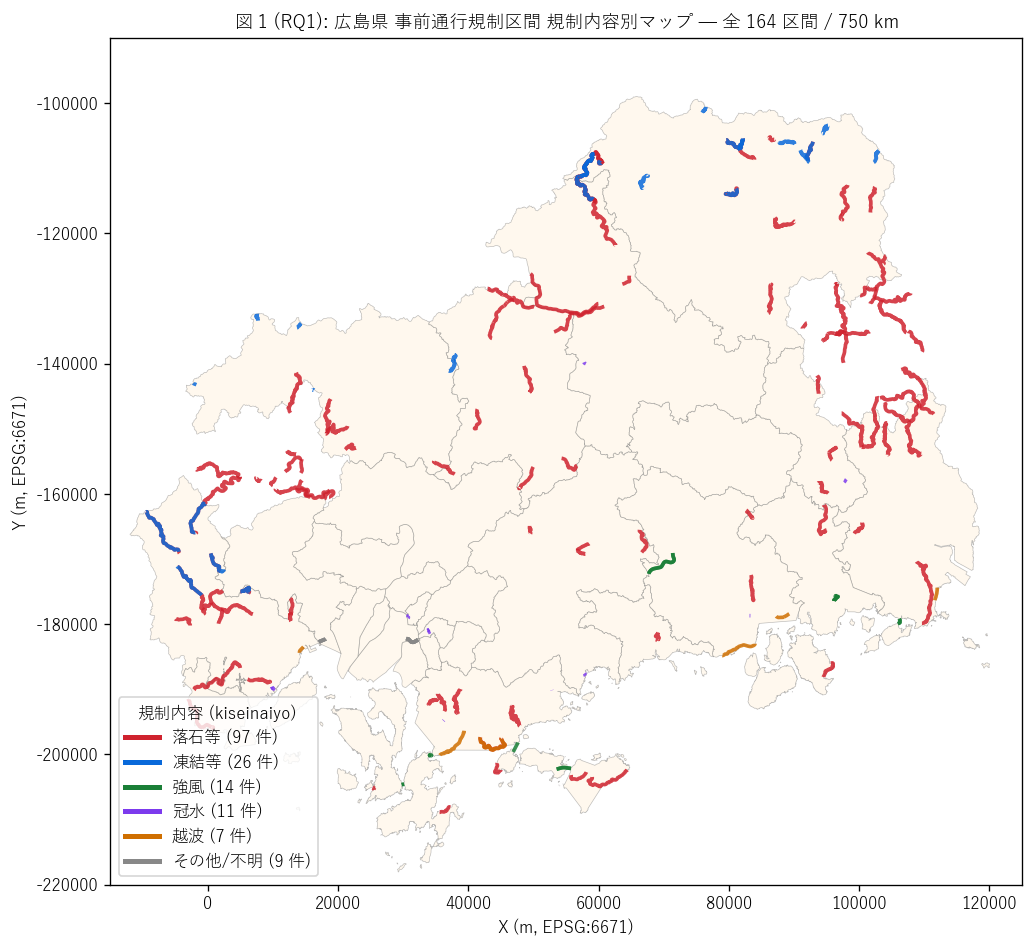{kind=link}
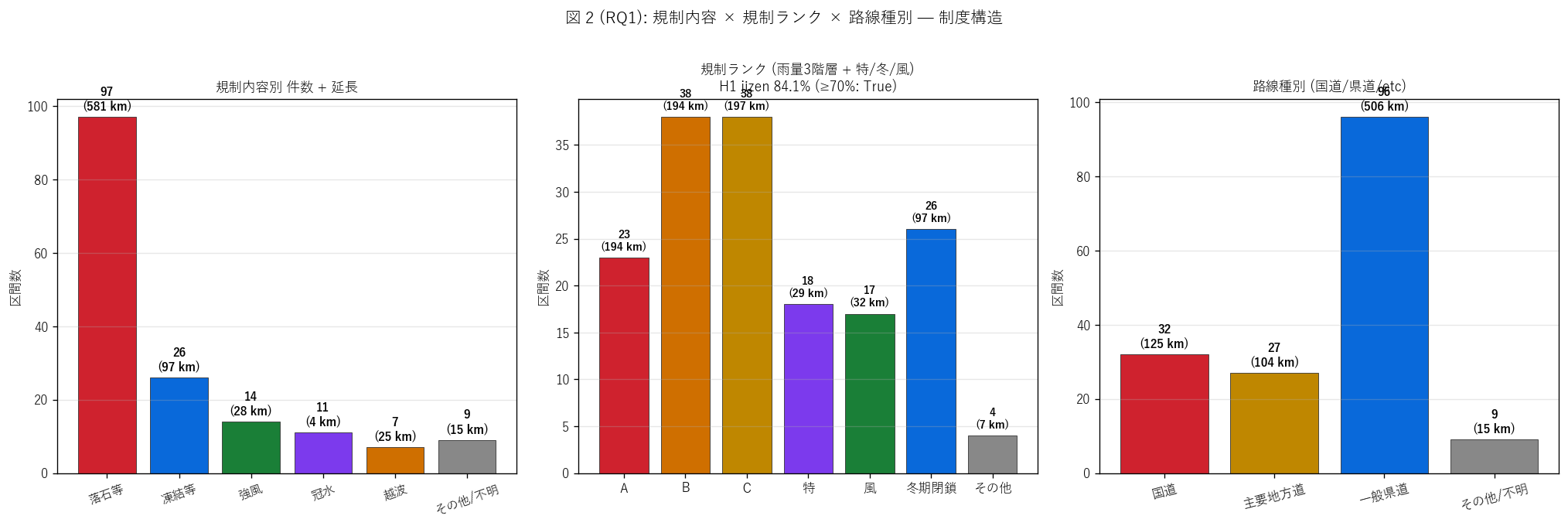{kind=link}
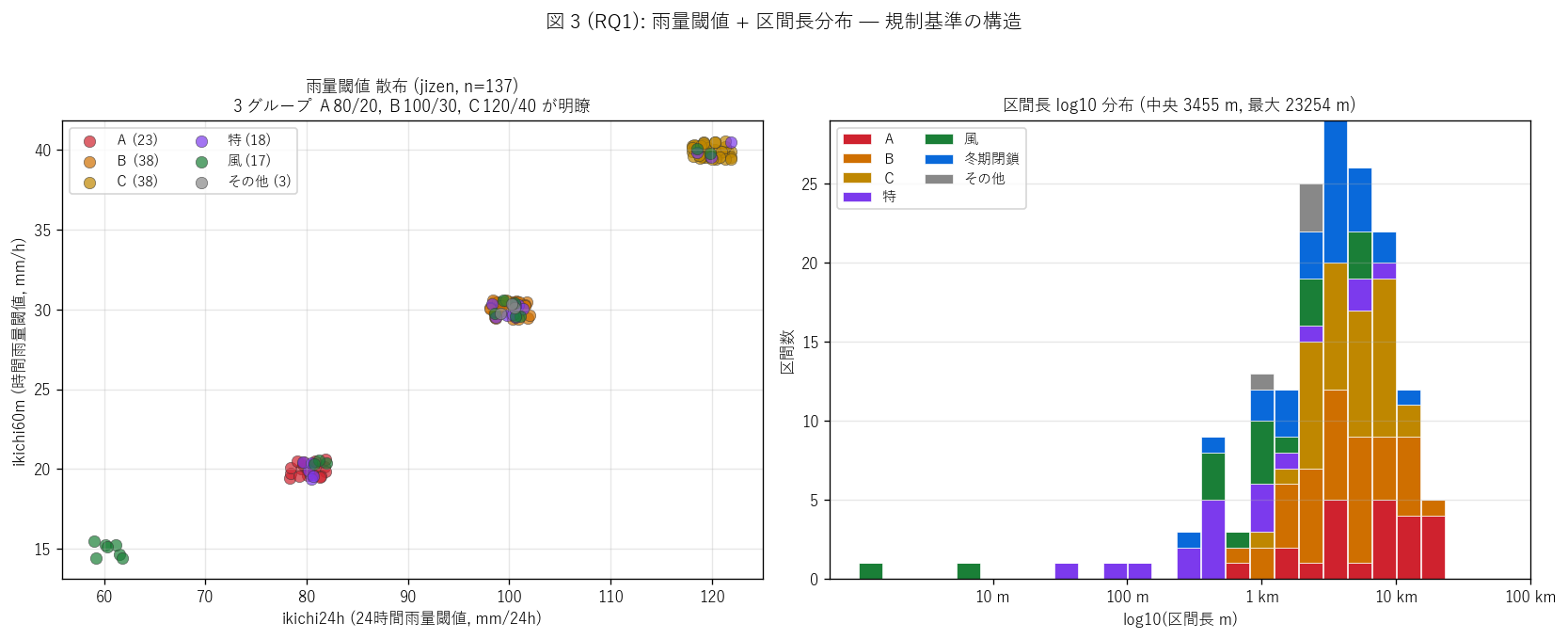{kind=link}
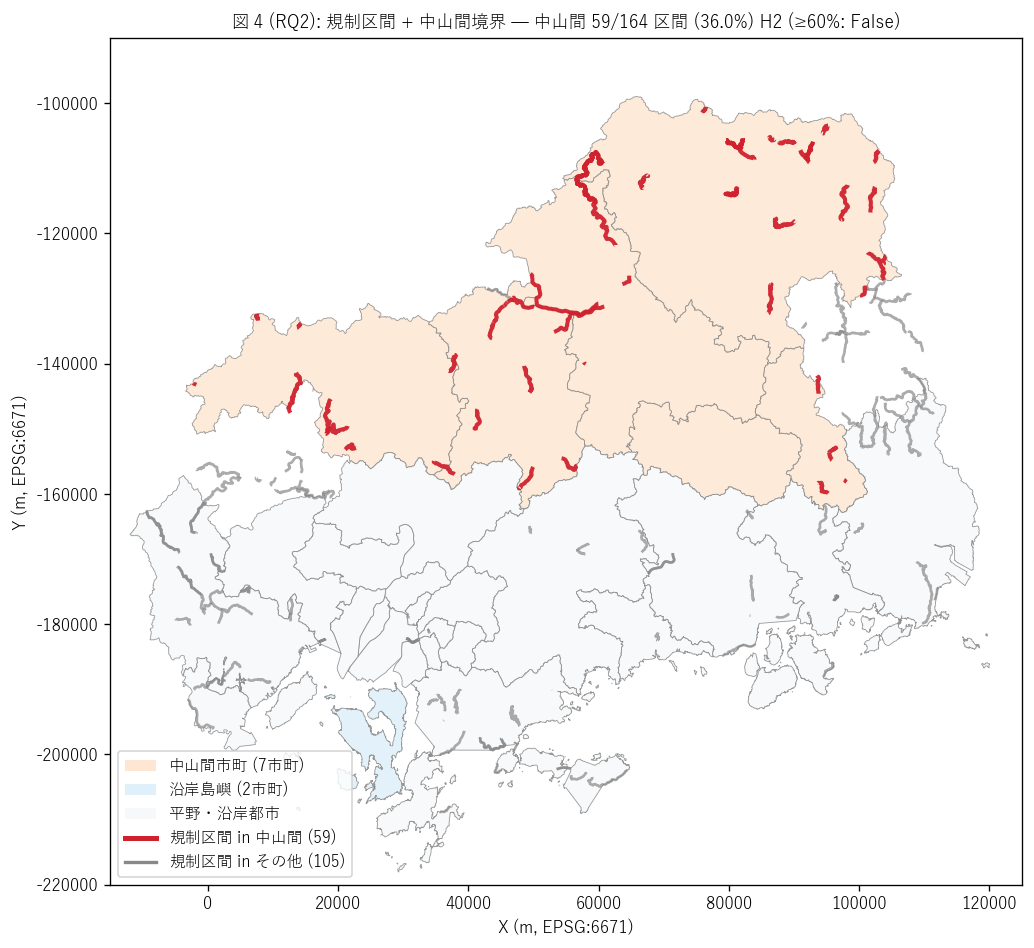{kind=link}
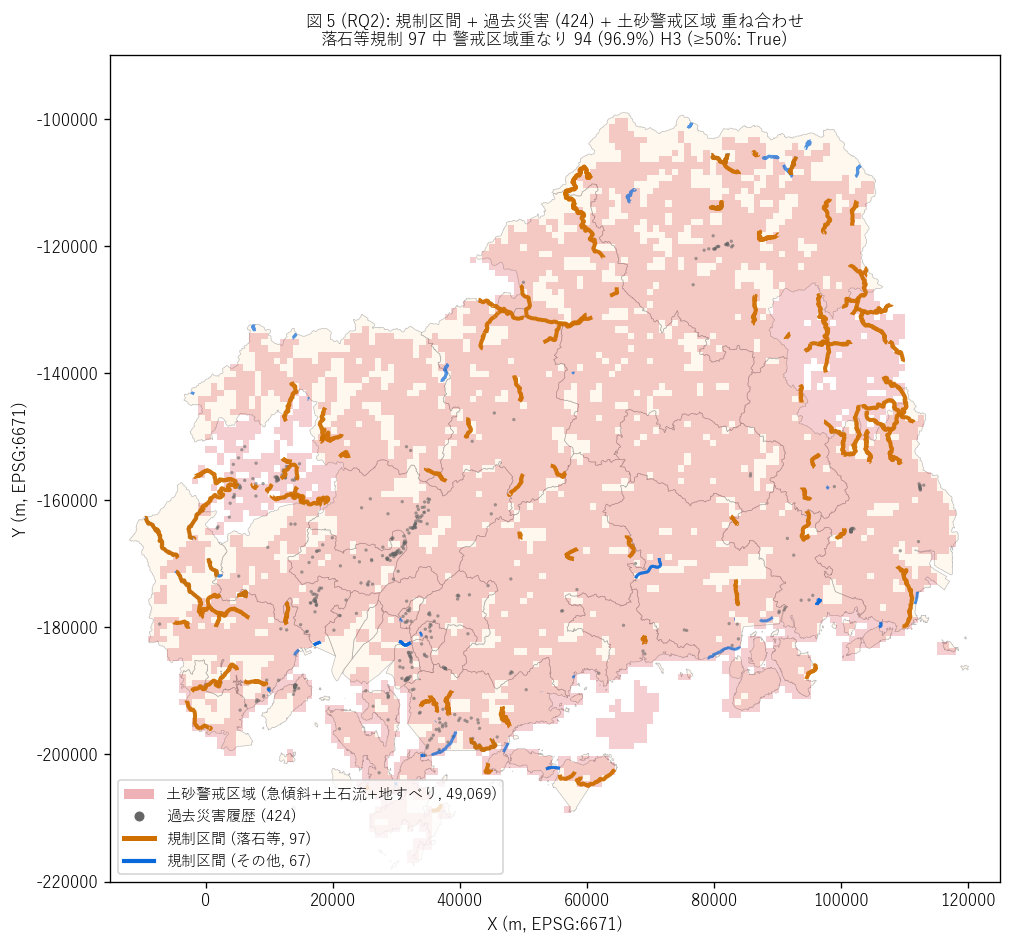{kind=link}
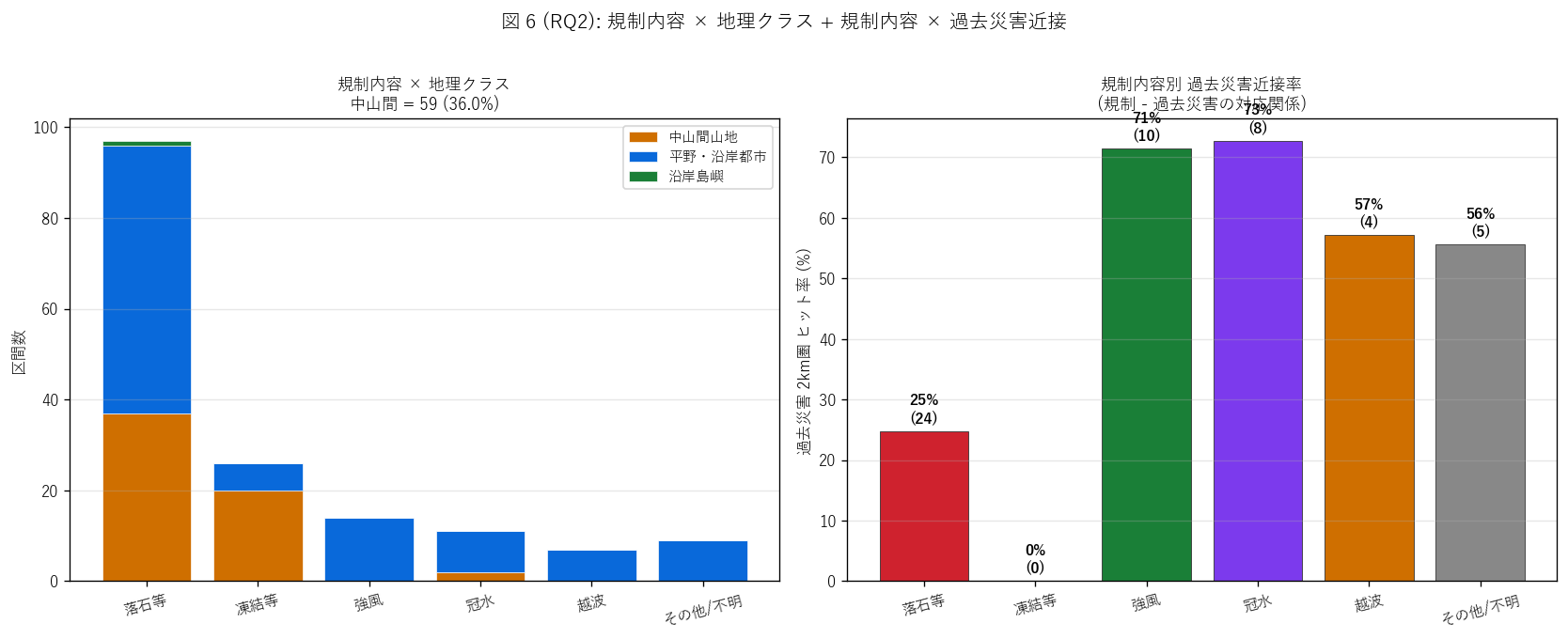{kind=link}
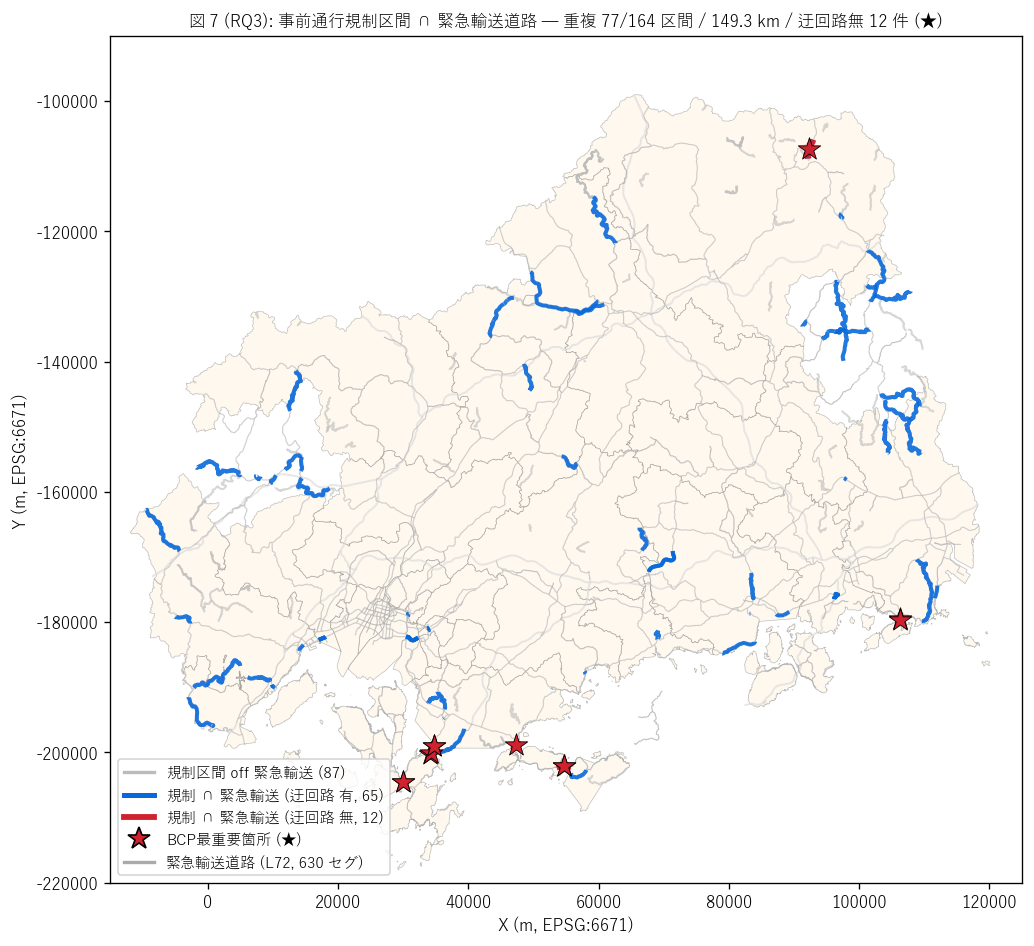{kind=link}
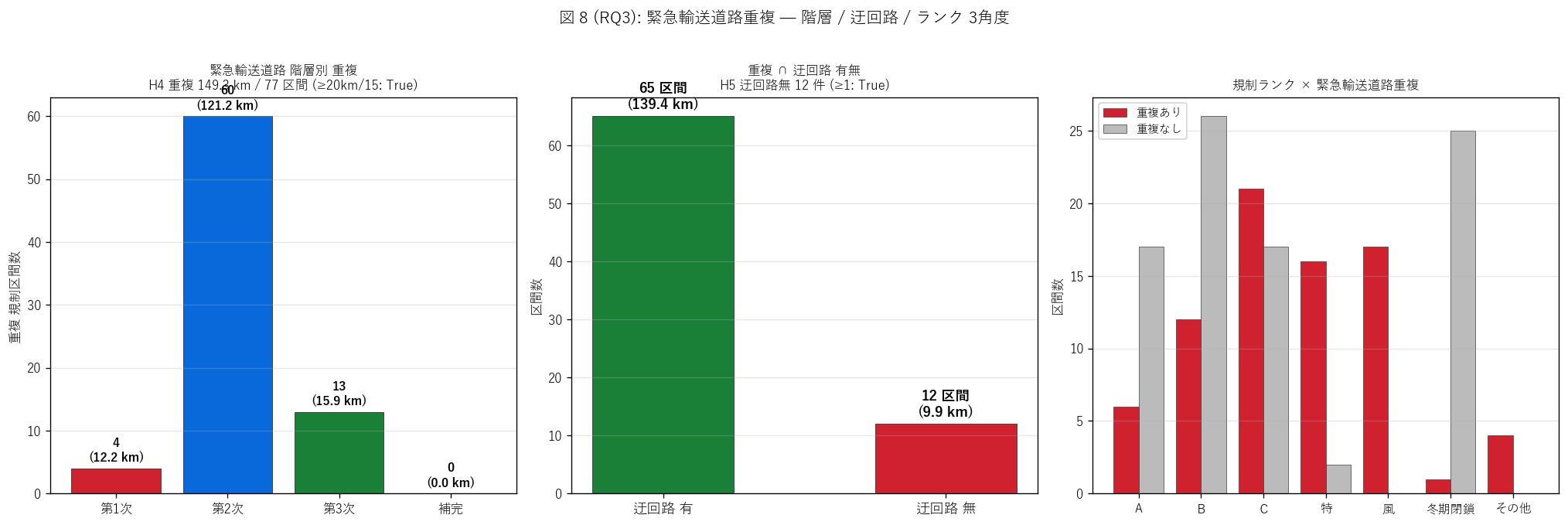{kind=link}