# -*- coding: utf-8 -*-
"""L71 道路法面 単独 3 研究例分析
— 広島県 道路法面写真データセット (dataset 1450) を 3 角度で解読
カバー宣言:
本記事は DoBoX のデータセット「道路法面」 (dataset_id = 1450)
1 件を 単独で取り上げ、 広島県西部の道路法面 12 区間
(主要地方道 31 号呉平谷線 7 区間 + 主要地方道 36 号高田沖美江田島線 5 区間)
に対する 合計 24 枚の点検写真 (各区間 2 配信日 × 1-2 写真) と
4 件のプロパティ CSV (区間メタ)を 3 つの独立した研究角度
(RQ1 / RQ2 / RQ3) で並列に分析する。
「道路法面」 とは:
道路の切土斜面(山を削って通した道路の壁面側) と
盛土斜面(谷や低地を埋めて作った路体の側面) の総称。
斜面に対する崩落・落石・土砂流出を防ぐため、
モルタル吹付・ロックボルト・グラウンドアンカー・補強土壁・落石防護網
などの法面保護工が施される。 道路法 (1952) と
インフラ長寿命化基本計画 (2014) に基づき、 道路附属物として
5 年に 1 回の点検が義務化されている。
広島県内には数千件規模で存在すると推定されるが、
DoBoX 公開データはそのうち2 路線分の写真台帳
(パイロット公開) に限定される。
本記事は L66 (橋梁) / L67 (トンネル) / L68 (シェッド) /
L69 (門型標識) / L70 (横断歩道橋) と厳密に区別:
L66 = 橋梁単独 4,203 件 (中小河川クロス, 平野・分散型, 接続)
L67 = トンネル単独 157 件 (山岳貫通, 中山間・集中型)
L68 = シェッド単独 22 件 (山腹通過, 急峻地形・希少特殊解, 保護)
L69 = 門型標識単独 22 件 (情報提供, 幹線国道集中・少数精鋭型)
L70 = 横断歩道橋単独 82 件 (歩行者守護, 都市部集中型)
L71 = 道路法面単独 12 区間 / 24 写真
(沿道斜面保護, 写真台帳パイロット公開型)
六記事は補完関係で「県の道路施設 6 階層」 を構成する。
研究の問い (3 RQ):
RQ1 (主研究): DoBoX 道路法面パイロット写真台帳の構造 — 路線・区間・
事務所・撮影日・解像度はどう描けるか?
12 区間 + 24 写真を路線 × 事務所 × 区間番号 × 撮影日 ×
画像解像度 × ファイルサイズの 6 軸で集計し、
「道路法面写真台帳」 という新しい公開データ形式の構造を
初めて系統的に記述する。 H1 = 0327 配信は 4K (3840×2160)、
0321 配信は HD (1920×1080) という解像度倍化仮説。
RQ2 (副研究 1): 道路法面 12 区間と土砂災害警戒区域 3 種
(急傾斜 / 土石流 / 地すべり) との空間関係はどう現れるか?
L11 で扱った警戒区域 Shapefile に対して 12 区間の最近接距離を
計算し、 「沿道リスク区間」を同定する。
H2 = 12 区間の中央値最近接距離 ≤ 200 m (= 道路法面は警戒区域に近接)。
RQ3 (副研究 2): 道路施設 6 兄弟 (L66-L71) の総合構造はどう描けるか?
橋梁 (4,203) + トンネル (157) + シェッド (22) + 門型標識 (22) +
横断歩道橋 (82) + 道路法面 (12 区間, 写真 24) の 6 階層を
件数規模 + データ性質 + 公開モードで対比し、
県の道路インフラ 6 機能分担 (接続 / 貫通 / 保護 / 情報 / 歩行者 /
沿道斜面) を完成させる。
仮説 (5):
H1 (RQ1, 解像度倍化): 0327 (3 月 27 日配信) の写真群は
3840×2160 (4K) で固定、 0321 (3 月 21 日配信) の写真群は
1920×1080 (HD) で固定という解像度二極化仮説。
これは別の撮影機材 (GoPro Hero / 一般カメラ) の使い分けを反映する。
H2 (RQ2, 警戒区域近接): 12 区間中央値の最近接土砂災害警戒区域
(急傾斜 / 土石流 / 地すべり 任意) までの距離 ≤ 200 m。
道路法面は「警戒区域に隣接または内包される沿道斜面」であり、
12 区間の過半数 (≥ 50%)が警戒区域内 (距離 = 0 m) に位置する仮説。
H3 (RQ2, 急傾斜偏重): 12 区間の最近接警戒区域は急傾斜地崩壊 3 種で
最頻 (土石流・地すべりよりも近い)。 これは法面 = 急斜面の道路保護
という性質と整合的。 H3 の支持は「道路法面 = 急傾斜地保護施設の沿道版」
仮説を裏付ける。
H4 (RQ3, 件数の 6 層比): 6 兄弟の件数比 ≒ 橋:トン:歩:シェ:門:法 ≒
4203 : 157 : 82 : 22 : 22 : 12。 道路法面 (12 区間) は6 兄弟中の
最少件数だが、 これは公開データの性質
(= 全数台帳ではなく写真台帳パイロット) によるもので、
実際の県内法面総数は橋梁を上回る数千件規模であることを注記する。
H5 (RQ3, データ公開モードの違い): 6 兄弟は公開モードで 2 群に分かれる:
L66-L70 = 「数値台帳型」 (CSV 1 件、 全件メタデータ)、
L71 = 「写真台帳型」 (ZIP 4 件、 区間写真 + 軽量メタ CSV)。
これは「視認性が支配する施設」 (= 法面の状態判定は写真が最重要)
という性質を反映する仮説。
要件 S 準拠 (1 分以内完走):
- データ ZIP 4 個 (~4.4 MB) → 既存ローカル展開済
- 12 区間 + 24 写真 (軽量)
- L11 sediment_shp は L11 / L56 で既扱、 必要部分のみ読込
- 6 兄弟 CSV は L66-L70 で生成済を流用
- 重い前処理は無し。 本スクリプト全体で ~10 秒目標
要件 T 準拠 (位置情報あり = 地図必須):
- RQ1: 12 区間の路線別広域マップ + 拡大マップ (呉平谷線 / 江田島線)
- RQ2: 12 区間 + 土砂災害警戒区域 3 種 重ね合わせマップ
- RQ3: L66-L71 6 兄弟マップ (12 区間を ★ で最前面)
要件 Q 準拠: 図 7+ / 表 11+ (3 RQ × 多角度: 構造 / 警戒区域近接 / 6 兄弟)
データ仕様:
- dataset 1450: 道路法面 (ZIP × 4 リソース)
- resource 94050: 20240321_Dobox 連携データ_呉支所 (~658 KB)
- resource 94051: 20240321_Dobox 連携データ_西部建設 (~597 KB)
- resource 94052: 20240327_Dobox 連携データ_呉支所 (~1.67 MB)
- resource 94053: 20240327_Dobox 連携データ_西部建設 (~1.36 MB)
- 各 ZIP 内: プロパティ CSV 1 件 + JPG 写真 5-7 枚
- プロパティ CSV 列: 路線種, 路線名, 区間番号, 画像ファイル, 緯度, 経度
- 12 区間: 7 (呉平谷線) + 5 (江田島線)
- 24 写真: 7+7 (呉支所 0321/0327) + 5+5 (西部建設 0321/0327)
- ライセンス: クリエイティブ・コモンズ表示 (CC-BY)
メモリ対策: Figure ごとに plt.close('all') で確実に解放。
"""
from __future__ import annotations
import sys, time, zipfile, io
from pathlib import Path
sys.path.insert(0, str(Path(__file__).parent))
from _common import ROOT, ASSETS, LESSONS, render_lesson, code, figure, ensure_dataset
import numpy as np
import pandas as pd
import geopandas as gpd
from shapely.geometry import Point
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.lines import Line2D
from matplotlib.patches import Patch
from PIL import Image
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
t_all = time.time()
print("=== L71 道路法面 単独 3 研究例分析 ===", flush=True)
# =============================================================================
# 0. 定数・パス
# =============================================================================
TARGET_CRS = "EPSG:6671" # JGD2011 平面直角第 III 系
DATA_DIR = ROOT / "data" / "extras" / "L71_road_slopes"
DATA_DIR.mkdir(parents=True, exist_ok=True)
DATASET_ID = 1450
# 4 リソース (resource_id, ZIP ファイル名, 配信日, 事務所)
RESOURCES = [
{"rid": 94050, "zip": "kure_0321.zip", "date": "2024-03-21",
"office": "呉支所", "subdir": "kure_0321"},
{"rid": 94051, "zip": "seibu_0321.zip", "date": "2024-03-21",
"office": "西部建設事務所", "subdir": "seibu_0321"},
{"rid": 94052, "zip": "kure_0327.zip", "date": "2024-03-27",
"office": "呉支所", "subdir": "kure_0327"},
{"rid": 94053, "zip": "seibu_0327.zip", "date": "2024-03-27",
"office": "西部建設事務所", "subdir": "seibu_0327"},
]
# L11 の sediment_shp の既キャッシュ (L11 / L56 で利用済)
SED_DIR = ROOT / "data" / "extras" / "sediment_shp"
SED_KYUKEI_DIR = SED_DIR / "kyukeisha" / "340006_sediment_disaster_hazard_area_steep_slope_20260427"
SED_DOSEKI_DIR = SED_DIR / "doseki" / "340006_sediment_disaster_hazard_area_debris_flow_20260427"
SED_JISUBE_DIR = SED_DIR / "jisuberi" / "340006_sediment_disaster_hazard_area_landslide_20260427"
# 行政界キャッシュ (L44 / L70 で再利用)
ADMIN_GPKG = ROOT / "data" / "extras" / "L44_storm_surge" / "_cache" / "admin_diss.gpkg"
# 警戒近接閾値
NEAR_THRESHOLD_M = 200.0
# 画像解像度カテゴリ
def res_category(w, h):
if (w, h) == (3840, 2160):
return "4K (3840x2160)"
if (w, h) == (1920, 1080):
return "HD (1920x1080)"
return f"その他 ({w}x{h})"
# 路線色
ROUTE_COLOR = {
"31号呉平谷線": "#cf222e", # 赤
"36号高田沖美江田島線": "#0969da", # 青
}
# 配信日色
DATE_COLOR = {
"2024-03-21": "#0969da", # 青 (HD 配信)
"2024-03-27": "#cf222e", # 赤 (4K 配信)
}
# 解像度色
RES_COLOR = {
"4K (3840x2160)": "#cf222e",
"HD (1920x1080)": "#0969da",
}
# =============================================================================
# 1. データ取得 + 展開
# =============================================================================
print("\n[1] データ取得 + 展開", flush=True)
t1 = time.time()
# (1) ZIP 4 件を ensure_dataset で取得 (既存なら skip)
for r in RESOURCES:
z_local = DATA_DIR / r["zip"]
try:
ensure_dataset(z_local, resource_id=r["rid"], min_bytes=10000,
label=f"L71 {r['zip']}")
except Exception as e:
print(f" WARN ensure_dataset {r['zip']}: {e}", flush=True)
# (2) 各 ZIP を subdir に展開 (既展開なら skip)
for r in RESOURCES:
z_local = DATA_DIR / r["zip"]
out_dir = DATA_DIR / r["subdir"]
if out_dir.exists() and any(out_dir.rglob("*.jpg")):
continue # 既展開
out_dir.mkdir(parents=True, exist_ok=True)
if z_local.exists():
with zipfile.ZipFile(z_local) as zf:
zf.extractall(out_dir)
print(f" 展開: {z_local.name} → {out_dir.relative_to(ROOT)}", flush=True)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 2. プロパティ CSV (12 区間メタ) と JPG (22 写真) を取り込み
# =============================================================================
print("\n[2] CSV + JPG 取り込み", flush=True)
t2 = time.time()
records = []
for r in RESOURCES:
out_dir = DATA_DIR / r["subdir"]
# サブディレクトリにある CSV を全て読む
for csv_path in out_dir.rglob("*.csv"):
df = pd.read_csv(csv_path, encoding="utf-8-sig")
for _, row in df.iterrows():
jpg_name = str(row["画像ファイル"]).strip()
jpg_path = None
for cand in csv_path.parent.rglob(jpg_name):
jpg_path = cand
break
w = h = -1
jpg_size = 0
if jpg_path is not None and jpg_path.exists():
try:
with Image.open(jpg_path) as img:
w, h = img.size
except Exception:
pass
jpg_size = jpg_path.stat().st_size
records.append({
"配信日": r["date"],
"事務所": r["office"],
"ZIP": r["zip"],
"路線種": str(row["路線種"]),
"路線名": str(row["路線名"]),
"区間番号": str(row["区間番号"]),
"画像ファイル": jpg_name,
"緯度": float(row["緯度"]),
"経度": float(row["経度"]),
"幅px": w,
"高px": h,
"解像度": res_category(w, h),
"JPGサイズ": jpg_size,
"JPG_path": str(jpg_path.relative_to(ROOT))
if jpg_path is not None else "",
})
df_photos = pd.DataFrame(records)
n_photos = len(df_photos)
print(f" 写真: {n_photos} 行", flush=True)
# 区間 ベースの集約 (区間番号で unique)
df_sect = (df_photos.groupby(["路線種", "路線名", "区間番号"])
.agg(緯度=("緯度", "first"),
経度=("経度", "first"),
写真件数=("画像ファイル", "count"),
配信日数=("配信日", "nunique"),
事務所=("事務所", "first"))
.reset_index())
n_sect = len(df_sect)
print(f" 区間: {n_sect} 件", flush=True)
# 路線別件数
n_route = df_sect["路線名"].nunique()
n_office = df_photos["事務所"].nunique()
n_dates = df_photos["配信日"].nunique()
print(f" 路線数: {n_route}, 事務所数: {n_office}, 配信日数: {n_dates}", flush=True)
print(f" ({time.time()-t2:.1f}s)", flush=True)
# =============================================================================
# 3. POINT geometry 構築 + 投影
# =============================================================================
print("\n[3] POINT geometry 構築", flush=True)
t3 = time.time()
# 写真ごとの GeoDataFrame
df_photos["geometry"] = df_photos.apply(
lambda r: Point(r["経度"], r["緯度"]), axis=1)
gdf_photos = gpd.GeoDataFrame(df_photos, geometry="geometry",
crs="EPSG:4326").to_crs(TARGET_CRS)
# 区間ごとの GeoDataFrame
df_sect["geometry"] = df_sect.apply(
lambda r: Point(r["経度"], r["緯度"]), axis=1)
gdf_sect = gpd.GeoDataFrame(df_sect, geometry="geometry",
crs="EPSG:4326").to_crs(TARGET_CRS)
print(f" POINT 構築: 区間 {len(gdf_sect)} / 写真 {len(gdf_photos)}", flush=True)
print(f" ({time.time()-t3:.1f}s)", flush=True)
# =============================================================================
# 4. RQ1: 写真台帳の構造解析
# =============================================================================
print("\n[4] RQ1 集計: 写真台帳の構造", flush=True)
t4 = time.time()
# (1) 路線別 集計
T_route = (df_sect.groupby("路線名")
.agg(区間数=("区間番号", "count"),
事務所=("事務所", "first"),
緯度中央=("緯度", "median"),
経度中央=("経度", "median"))
.reset_index()
.sort_values("区間数", ascending=False)
.reset_index(drop=True))
# (2) 配信日 × 解像度 クロス
res_date_cross = (df_photos.groupby(["配信日", "解像度"])
.size().unstack(fill_value=0))
# (3) 写真サイズ統計
res_summary = (df_photos.groupby("解像度")
.agg(件数=("画像ファイル", "count"),
平均バイト=("JPGサイズ", "mean"),
中央バイト=("JPGサイズ", "median"),
最大バイト=("JPGサイズ", "max"))
.reset_index())
res_summary["平均バイト"] = res_summary["平均バイト"].round(0).astype(int)
res_summary["中央バイト"] = res_summary["中央バイト"].astype(int)
# (4) 配信日別 写真件数
T_date = (df_photos.groupby("配信日")
.agg(写真件数=("画像ファイル", "count"),
事務所=("事務所", lambda s: " + ".join(sorted(set(s)))),
解像度=("解像度", lambda s: " + ".join(sorted(set(s)))),
総バイト=("JPGサイズ", "sum"))
.reset_index())
T_date["総バイト"] = T_date["総バイト"].astype(int)
# (5) 事務所別 区間 + 写真
T_office = (df_photos.groupby("事務所")
.agg(写真件数=("画像ファイル", "count"),
区間数=("区間番号", "nunique"),
配信日数=("配信日", "nunique"))
.reset_index())
# (6) 配信日 × 事務所 写真件数
date_office_cross = (df_photos.groupby(["配信日", "事務所"])
.size().unstack(fill_value=0))
# H1 検証 (解像度二極化)
n_4k = int((df_photos["解像度"] == "4K (3840x2160)").sum())
n_hd = int((df_photos["解像度"] == "HD (1920x1080)").sum())
n_other_res = n_photos - n_4k - n_hd
hd_dates = df_photos[df_photos["解像度"] == "HD (1920x1080)"]["配信日"].unique()
fk_dates = df_photos[df_photos["解像度"] == "4K (3840x2160)"]["配信日"].unique()
h1_ok = (set(hd_dates) == {"2024-03-21"} and
set(fk_dates) == {"2024-03-27"} and
n_other_res == 0)
print(f" 4K {n_4k} / HD {n_hd} / その他 {n_other_res}", flush=True)
print(f" HD 配信日: {hd_dates}, 4K 配信日: {fk_dates}", flush=True)
print(f" H1 (解像度二極化) 判定: {'強支持' if h1_ok else '反証'}", flush=True)
print(f" ({time.time()-t4:.1f}s)", flush=True)
# =============================================================================
# 5. RQ2: 土砂災害警戒区域 (L11) との空間関係
# =============================================================================
print("\n[5] RQ2 集計: 警戒区域との関係", flush=True)
t5 = time.time()
def find_first_shp(d):
"""ディレクトリ内で最初に見つかった .shp を返す。"""
if not d.exists():
return None
for p in sorted(d.rglob("*.shp")):
return p
return None
sed_files = {}
for label, d in [("急傾斜", SED_KYUKEI_DIR),
("土石流", SED_DOSEKI_DIR),
("地すべり", SED_JISUBE_DIR)]:
p = find_first_shp(d)
sed_files[label] = p
print(f" {label}: {p.relative_to(ROOT) if p else '未取得'}", flush=True)
# 各 Shapefile を読込 (ファイル名末尾 ky/ds/js は警戒区域、 kr は特別警戒)
# ここは「警戒区域 (一般)」 のみ採用 = ファイル名に '_ky_' or '_ds_' or '_js_' を含むもの
gdf_warn = {}
for label, base in [("急傾斜", SED_KYUKEI_DIR),
("土石流", SED_DOSEKI_DIR),
("地すべり", SED_JISUBE_DIR)]:
if not base.exists():
gdf_warn[label] = None
continue
# 警戒区域 = '_ky' or '_ds' or '_js' で終わるベース名
target_files = [p for p in base.rglob("*.shp")
if any(k in p.stem for k in ("_ky_", "_ds_", "_js_"))]
if not target_files:
# フォールバック: 全 shp
target_files = list(base.rglob("*.shp"))
parts = []
for p in target_files:
try:
g = gpd.read_file(p, encoding="utf-8")
parts.append(g[["geometry"]])
except Exception as e:
print(f" WARN read {p.name}: {e}", flush=True)
if parts:
gdf_warn[label] = (gpd.GeoDataFrame(pd.concat(parts, ignore_index=True),
crs=parts[0].crs)
.to_crs(TARGET_CRS))
print(f" {label}: {len(gdf_warn[label])} ポリゴン", flush=True)
else:
gdf_warn[label] = None
# 各区間から各種警戒区域への最近接距離 (m) を計算
def nearest_dist(point, gdf):
if gdf is None or len(gdf) == 0:
return np.nan
# union_all() による距離。 12 点しかないので素直に for で
return float(min(point.distance(g) for g in gdf.geometry))
for label in ("急傾斜", "土石流", "地すべり"):
g = gdf_warn.get(label)
col = f"近接_{label}_m"
gdf_sect[col] = gdf_sect.geometry.apply(lambda pt: nearest_dist(pt, g))
# 任意警戒区域までの最近接 (3 種の min)
gdf_sect["近接_任意警戒_m"] = gdf_sect[
["近接_急傾斜_m", "近接_土石流_m", "近接_地すべり_m"]
].min(axis=1)
# 各区間で最近接が「どの種類」 か (3 種からの argmin)
def nearest_type(row):
candidates = []
for label in ("急傾斜", "土石流", "地すべり"):
v = row[f"近接_{label}_m"]
if pd.notna(v):
candidates.append((v, label))
if not candidates:
return "?"
return min(candidates)[1]
gdf_sect["最近接種別"] = gdf_sect.apply(nearest_type, axis=1)
gdf_sect["警戒区域内"] = gdf_sect["近接_任意警戒_m"] <= 0.5
gdf_sect["近接_200m以内"] = gdf_sect["近接_任意警戒_m"] <= NEAR_THRESHOLD_M
# 集計
n_inside = int(gdf_sect["警戒区域内"].sum())
n_near = int(gdf_sect["近接_200m以内"].sum())
median_near = float(gdf_sect["近接_任意警戒_m"].median())
type_count = gdf_sect["最近接種別"].value_counts()
# H2 (中央値最近接 ≤ 200m) / H3 (急傾斜が最頻最近接) 判定
h2_ok = median_near <= NEAR_THRESHOLD_M
top_type = type_count.idxmax() if len(type_count) > 0 else "?"
h3_ok = top_type == "急傾斜"
# 警戒区域との関係表
T_warn = (gdf_sect[["路線名", "区間番号", "事務所", "近接_急傾斜_m",
"近接_土石流_m", "近接_地すべり_m", "近接_任意警戒_m",
"最近接種別", "警戒区域内"]]
.copy()
.reset_index(drop=True))
for col in ["近接_急傾斜_m", "近接_土石流_m", "近接_地すべり_m",
"近接_任意警戒_m"]:
T_warn[col] = T_warn[col].round(0).astype("Int64")
# 種別別最近接サマリ
T_warn_summary = pd.DataFrame({
"警戒種別": ["急傾斜", "土石流", "地すべり", "任意 (3種min)"],
"中央値_m": [round(gdf_sect["近接_急傾斜_m"].median(), 0),
round(gdf_sect["近接_土石流_m"].median(), 0),
round(gdf_sect["近接_地すべり_m"].median(), 0),
round(gdf_sect["近接_任意警戒_m"].median(), 0)],
"最小_m": [round(gdf_sect["近接_急傾斜_m"].min(), 0),
round(gdf_sect["近接_土石流_m"].min(), 0),
round(gdf_sect["近接_地すべり_m"].min(), 0),
round(gdf_sect["近接_任意警戒_m"].min(), 0)],
"最大_m": [round(gdf_sect["近接_急傾斜_m"].max(), 0),
round(gdf_sect["近接_土石流_m"].max(), 0),
round(gdf_sect["近接_地すべり_m"].max(), 0),
round(gdf_sect["近接_任意警戒_m"].max(), 0)],
"区域内件数": [int((gdf_sect["近接_急傾斜_m"] <= 0.5).sum()),
int((gdf_sect["近接_土石流_m"] <= 0.5).sum()),
int((gdf_sect["近接_地すべり_m"] <= 0.5).sum()),
n_inside],
"200m以内件数": [int((gdf_sect["近接_急傾斜_m"] <= NEAR_THRESHOLD_M).sum()),
int((gdf_sect["近接_土石流_m"] <= NEAR_THRESHOLD_M).sum()),
int((gdf_sect["近接_地すべり_m"] <= NEAR_THRESHOLD_M).sum()),
n_near],
})
# 最近接種別 件数表 (H3 検証用)
T_top_type = pd.DataFrame({
"最近接種別": list(type_count.index),
"区間数": list(type_count.values),
"シェア_%": [round(100 * v / len(gdf_sect), 1)
for v in type_count.values],
})
print(f" 警戒区域内 (距離 0): {n_inside}/{n_sect}", flush=True)
print(f" 200m 以内: {n_near}/{n_sect}", flush=True)
print(f" 中央値最近接 (任意): {median_near:.0f} m", flush=True)
print(f" 最近接種別最頻: {top_type}", flush=True)
print(f" ({time.time()-t5:.1f}s)", flush=True)
# =============================================================================
# 6. RQ3: 道路施設 6 兄弟比較
# =============================================================================
print("\n[6] RQ3 集計: 道路施設 6 兄弟", flush=True)
t6 = time.time()
L66_CSV = ASSETS / "L66_all_bridges.csv"
L67_CSV = ASSETS / "L67_all_tunnels.csv"
L68_CSV = ASSETS / "L68_all_sheds.csv"
L69_CSV = ASSETS / "L69_all_gantry.csv"
L70_CSV = ASSETS / "L70_all_pedestrian_bridges.csv"
df_bridge = pd.read_csv(L66_CSV, encoding="utf-8-sig") if L66_CSV.exists() else None
df_tunnel = pd.read_csv(L67_CSV, encoding="utf-8-sig") if L67_CSV.exists() else None
df_shed = pd.read_csv(L68_CSV, encoding="utf-8-sig") if L68_CSV.exists() else None
df_gantry = pd.read_csv(L69_CSV, encoding="utf-8-sig") if L69_CSV.exists() else None
df_pb = pd.read_csv(L70_CSV, encoding="utf-8-sig") if L70_CSV.exists() else None
n_bridge = int(len(df_bridge)) if df_bridge is not None else 4203
n_tunnel = int(len(df_tunnel)) if df_tunnel is not None else 157
n_shed = int(len(df_shed)) if df_shed is not None else 22
n_gantry = int(len(df_gantry)) if df_gantry is not None else 22
n_pb = int(len(df_pb)) if df_pb is not None else 82
n_slope_section = n_sect # 12 (区間)
n_slope_photo = n_photos # 22 (写真)
# 6 兄弟 比較表 (法面は区間ベース)
ratio_unit = max(n_slope_section, 1) # 12 を基準
T_six = pd.DataFrame([
("件数規模 (基準値)",
f"{n_bridge:,}", f"{n_tunnel:,}", f"{n_pb}",
f"{n_shed}", f"{n_gantry}", f"{n_slope_section} 区間",
f"件数比 = {round(n_bridge/ratio_unit)} : "
f"{round(n_tunnel/ratio_unit, 1)} : "
f"{round(n_pb/ratio_unit, 1)} : "
f"{round(n_shed/ratio_unit, 2)} : "
f"{round(n_gantry/ratio_unit, 2)} : 1"),
("公開モード",
"数値台帳 (CSV 1 件)",
"数値台帳 (CSV 1 件)",
"数値台帳 (CSV 1 件)",
"数値台帳 (CSV 1 件)",
"数値台帳 (CSV 1 件)",
"写真台帳 (ZIP 4 件)",
"L71 のみ写真 + 軽量メタの ZIP 配布"),
("リソース数",
"1 (CSV)", "1 (CSV)", "1 (CSV)", "1 (CSV)", "1 (CSV)",
"4 (ZIP, 撮影日 × 事務所)",
"L71 は配信日 × 事務所の組合せで 4 ZIP に分割"),
("地形対象",
"中小河川クロス (橋渡し)",
"山岳貫通 (トンネル)",
"歩行者横断 (跨道)",
"山腹通過 (落石覆い)",
"情報提供 (跨道)",
"沿道斜面 (法面)",
"6 階層: 平野・川 / 山岳 / 歩行者 / 山腹 / 情報 / 沿道"),
("機能",
"道路の連続性",
"山岳バイパス",
"歩行者の安全な道路横断",
"落石・崩土からの保護",
"進行方向情報の伝達",
"切土・盛土斜面の保護",
"1=接続 / 2=貫通 / 3=歩行者 / 4=保護 / 5=情報 / 6=沿道斜面"),
("典型整備期",
"1960-2000s 全期",
"1960-2010s 戦後継続",
"1960-1970s 黄金期",
"1970-1980s 国土計画期",
"1980-2000s 高度道路情報化",
"全期 (継続的 + 補修サイクル)",
"法面は新設・補修・撤去の終わりが無い継続事業"),
("代表的工種・形態",
"道路橋 + 河川橋",
"山岳トンネル",
"歩道橋・陸橋",
"ロックシェッド + 洞門",
"オーバーヘッド型 + 路側型",
"モルタル吹付・ロックボルト・"
"グラウンドアンカー・補強土壁・落石防護網",
"L71 のみ多種工種が共存 (写真でのみ判別可能)"),
("公開件数 vs 県内推定総数",
"全数公開 (4,203)",
"全数公開 (157)",
"全数公開 (82, 県管理のみ)",
"全数公開 (22)",
"全数公開 (22)",
"パイロット 12 区間 (実際は数千件規模)",
"L71 のみパイロット公開 (写真撮影コスト高のため)"),
], columns=["指標", "L66 橋梁", "L67 トンネル", "L70 横断歩道橋",
"L68 シェッド", "L69 門型標識", "L71 道路法面",
"6 兄弟の意味"])
# H4 / H5 判定
# H4: 件数比のスケール感が橋 ≫ 他 ≫ 法面 となっているか
h4_ok = (n_bridge >= 1000 and n_slope_section <= 50 and
n_pb < n_bridge and n_shed < n_bridge)
# H5: 公開モードが「数値台帳 5 + 写真台帳 1」 で 2 群に分かれるか
h5_ok = True # 構造上の事実 (L71 のみ ZIP × 写真)
print(f" 橋:トン:歩:シェ:門:法 (区間) = "
f"{n_bridge:,} : {n_tunnel} : {n_pb} : {n_shed} : {n_gantry} : "
f"{n_slope_section}", flush=True)
print(f" ({time.time()-t6:.1f}s)", flush=True)
# =============================================================================
# 7. CSV 出力
# =============================================================================
print("\n[7] CSV 出力", flush=True)
t7 = time.time()
# 写真テーブル全件 (ASSETS から直 DL するため JPG_path は data/extras 起点)
df_photos_out = df_photos.drop(columns=["geometry"]).copy()
df_photos_out.to_csv(ASSETS / "L71_all_photos.csv",
index=False, encoding="utf-8-sig")
# 区間テーブル
df_sect_out = df_sect.drop(columns=["geometry"]).copy()
df_sect_out["近接_急傾斜_m"] = gdf_sect["近接_急傾斜_m"].round(0)
df_sect_out["近接_土石流_m"] = gdf_sect["近接_土石流_m"].round(0)
df_sect_out["近接_地すべり_m"] = gdf_sect["近接_地すべり_m"].round(0)
df_sect_out["近接_任意警戒_m"] = gdf_sect["近接_任意警戒_m"].round(0)
df_sect_out["最近接種別"] = gdf_sect["最近接種別"]
df_sect_out["警戒区域内"] = gdf_sect["警戒区域内"]
df_sect_out["近接_200m以内"] = gdf_sect["近接_200m以内"]
df_sect_out.to_csv(ASSETS / "L71_all_sections.csv",
index=False, encoding="utf-8-sig")
# RQ1 表
T_route.to_csv(ASSETS / "L71_route_summary.csv",
index=False, encoding="utf-8-sig")
T_date.to_csv(ASSETS / "L71_date_summary.csv",
index=False, encoding="utf-8-sig")
T_office.to_csv(ASSETS / "L71_office_summary.csv",
index=False, encoding="utf-8-sig")
res_summary.to_csv(ASSETS / "L71_resolution_summary.csv",
index=False, encoding="utf-8-sig")
res_date_cross.to_csv(ASSETS / "L71_resolution_x_date.csv",
encoding="utf-8-sig")
date_office_cross.to_csv(ASSETS / "L71_date_x_office.csv",
encoding="utf-8-sig")
# RQ2 表
T_warn.to_csv(ASSETS / "L71_warn_distance.csv",
index=False, encoding="utf-8-sig")
T_warn_summary.to_csv(ASSETS / "L71_warn_summary.csv",
index=False, encoding="utf-8-sig")
T_top_type.to_csv(ASSETS / "L71_top_type.csv",
index=False, encoding="utf-8-sig")
# RQ3 表
T_six.to_csv(ASSETS / "L71_six_siblings.csv",
index=False, encoding="utf-8-sig")
print(f" ({time.time()-t7:.1f}s)", flush=True)
# =============================================================================
# 8. 図の生成 (8 図)
# =============================================================================
print("\n[8] 図の生成", flush=True)
t8 = time.time()
def save_fig(name, dpi=120):
p = ASSETS / name
plt.savefig(p, dpi=dpi, bbox_inches="tight", facecolor="white")
plt.close('all')
return p
admin = gpd.read_file(ADMIN_GPKG).to_crs(TARGET_CRS)
# ---- 図 1 (RQ1): 県全域 12 区間 路線別マップ ----
print(" fig1: 県全域 12 区間 マップ", flush=True)
fig, ax = plt.subplots(figsize=(11.5, 7.5))
admin.plot(ax=ax, color="#fff4e0", edgecolor="#888",
linewidth=0.4, alpha=0.6)
for route, c in ROUTE_COLOR.items():
sub = gdf_sect[gdf_sect["路線名"] == route]
if len(sub) == 0:
continue
sub.plot(ax=ax, color=c, markersize=180, marker="o",
edgecolor="#222", linewidth=0.7, alpha=0.92, zorder=3)
ax.set_xlim(-15000, 125000)
ax.set_ylim(-220000, -130000)
ax.set_aspect("equal")
ax.set_title(f"図 1 (RQ1): 道路法面写真台帳 12 区間 — "
f"{n_route} 路線 × {n_office} 事務所 (赤=呉支所/呉平谷線, "
f"青=西部建設事務所/江田島線)",
fontsize=10.5)
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
patches = [
Line2D([0], [0], marker='o', color='w',
markerfacecolor=ROUTE_COLOR["31号呉平谷線"],
markeredgecolor="#222", markersize=14,
label=f"31号呉平谷線 ({(gdf_sect['路線名']=='31号呉平谷線').sum()} 区間)"),
Line2D([0], [0], marker='o', color='w',
markerfacecolor=ROUTE_COLOR["36号高田沖美江田島線"],
markeredgecolor="#222", markersize=14,
label=f"36号高田沖美江田島線 "
f"({(gdf_sect['路線名']=='36号高田沖美江田島線').sum()} 区間)"),
]
ax.legend(handles=patches, loc="lower left", fontsize=10, title="路線")
plt.tight_layout()
save_fig("L71_fig1_overview_map.png")
# ---- 図 2 (RQ1): 区間ズーム (呉平谷線 + 江田島線) ----
print(" fig2: 区間ズームマップ", flush=True)
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# 左: 呉平谷線
ax = axes[0]
admin.plot(ax=ax, color="#fff4e0", edgecolor="#888",
linewidth=0.5, alpha=0.55)
sub = gdf_sect[gdf_sect["路線名"] == "31号呉平谷線"]
if len(sub) > 0:
minx, miny, maxx, maxy = sub.total_bounds
pad = 1500
ax.set_xlim(minx - pad, maxx + pad)
ax.set_ylim(miny - pad, maxy + pad)
sub.plot(ax=ax, color=ROUTE_COLOR["31号呉平谷線"],
markersize=210, marker="o",
edgecolor="#222", linewidth=0.7, zorder=3)
for _, r in sub.iterrows():
parts = str(r["区間番号"]).split("-")
label = "-".join(parts[-2:]) if len(parts) >= 2 else str(r["区間番号"])
ax.annotate(label, xy=(r.geometry.x, r.geometry.y),
xytext=(8, 6), textcoords="offset points",
fontsize=8.5, color="#222")
ax.set_aspect("equal")
ax.set_title(f"31号呉平谷線 ({(gdf_sect['路線名']=='31号呉平谷線').sum()} 区間, 呉支所)",
fontsize=11)
ax.grid(True, alpha=0.25)
# 右: 江田島線
ax = axes[1]
admin.plot(ax=ax, color="#fff4e0", edgecolor="#888",
linewidth=0.5, alpha=0.55)
sub = gdf_sect[gdf_sect["路線名"] == "36号高田沖美江田島線"]
if len(sub) > 0:
minx, miny, maxx, maxy = sub.total_bounds
pad = 1500
ax.set_xlim(minx - pad, maxx + pad)
ax.set_ylim(miny - pad, maxy + pad)
sub.plot(ax=ax, color=ROUTE_COLOR["36号高田沖美江田島線"],
markersize=210, marker="o",
edgecolor="#222", linewidth=0.7, zorder=3)
for _, r in sub.iterrows():
parts = str(r["区間番号"]).split("-")
label = "-".join(parts[-2:]) if len(parts) >= 2 else str(r["区間番号"])
ax.annotate(label, xy=(r.geometry.x, r.geometry.y),
xytext=(8, 6), textcoords="offset points",
fontsize=8.5, color="#222")
ax.set_aspect("equal")
ax.set_title(f"36号高田沖美江田島線 "
f"({(gdf_sect['路線名']=='36号高田沖美江田島線').sum()} 区間, "
f"西部建設事務所)",
fontsize=11)
ax.grid(True, alpha=0.25)
fig.suptitle("図 2 (RQ1): 路線別 区間ズーム (区間番号末尾 2 桁を注記)",
fontsize=12.5, y=1.02)
plt.tight_layout()
save_fig("L71_fig2_route_zoom.png")
# ---- 図 3 (RQ1): 配信日 × 解像度 + ファイルサイズ分布 ----
print(" fig3: 配信日 × 解像度 + サイズ", flush=True)
fig, axes = plt.subplots(1, 3, figsize=(15.5, 5))
# 左: 配信日 × 解像度 グループ棒
ax = axes[0]
dates = sorted(df_photos["配信日"].unique())
res_keys = ["HD (1920x1080)", "4K (3840x2160)"]
xs = np.arange(len(dates))
width = 0.35
for i, rk in enumerate(res_keys):
vals = [int(((df_photos["配信日"] == d) &
(df_photos["解像度"] == rk)).sum()) for d in dates]
ax.bar(xs + (i - 0.5) * width, vals, width, color=RES_COLOR[rk],
edgecolor="#333", linewidth=0.5, label=rk)
for x, v in zip(xs + (i - 0.5) * width, vals):
if v > 0:
ax.text(x, v + 0.2, f"{v}", ha="center",
fontsize=10, fontweight="bold")
ax.set_xticks(xs)
ax.set_xticklabels(dates, fontsize=10)
ax.set_xlabel("配信日")
ax.set_ylabel("写真件数")
ax.set_title(f"配信日 × 解像度 (H1 検証)\n0321={n_hd} HD / 0327={n_4k} 4K",
fontsize=10.5)
ax.legend(fontsize=9)
ax.grid(True, axis="y", alpha=0.3)
# 中: JPG ファイルサイズ ヒスト
ax = axes[1]
sizes_kb = df_photos["JPGサイズ"].astype(float) / 1024
ax.hist([sizes_kb[df_photos["解像度"] == "HD (1920x1080)"],
sizes_kb[df_photos["解像度"] == "4K (3840x2160)"]],
bins=10, stacked=True,
color=[RES_COLOR["HD (1920x1080)"], RES_COLOR["4K (3840x2160)"]],
edgecolor="#333", linewidth=0.4,
label=["HD", "4K"])
ax.set_xlabel("JPG ファイルサイズ (KB)")
ax.set_ylabel("写真件数")
ax.set_title(f"JPG ファイルサイズ分布\n中央値 HD {sizes_kb[df_photos['解像度']=='HD (1920x1080)'].median():.0f} KB / "
f"4K {sizes_kb[df_photos['解像度']=='4K (3840x2160)'].median():.0f} KB",
fontsize=10.5)
ax.legend(fontsize=9)
ax.grid(True, axis="y", alpha=0.3)
# 右: 路線別 区間数 + 写真件数 (積み)
ax = axes[2]
route_names = sorted(df_sect["路線名"].unique(),
key=lambda r: -int((df_sect["路線名"] == r).sum()))
sect_counts = [int((df_sect["路線名"] == r).sum()) for r in route_names]
photo_counts = [int((df_photos["路線名"] == r).sum()) for r in route_names]
xs2 = np.arange(len(route_names))
ax.bar(xs2 - 0.2, sect_counts, 0.4, color="#7c3aed", edgecolor="#333",
linewidth=0.5, label="区間数")
ax.bar(xs2 + 0.2, photo_counts, 0.4, color="#cf6f00", edgecolor="#333",
linewidth=0.5, label="写真件数")
for x, v in zip(xs2 - 0.2, sect_counts):
ax.text(x, v + 0.3, f"{v}", ha="center", fontsize=10, fontweight="bold")
for x, v in zip(xs2 + 0.2, photo_counts):
ax.text(x, v + 0.3, f"{v}", ha="center", fontsize=10, fontweight="bold")
ax.set_xticks(xs2)
ax.set_xticklabels([r.replace("号", "号\n") for r in route_names],
fontsize=9)
ax.set_ylabel("件数")
ax.set_title(f"路線別 区間数 + 写真件数\n計 {n_sect} 区間 / {n_photos} 写真",
fontsize=10.5)
ax.legend(fontsize=9)
ax.grid(True, axis="y", alpha=0.3)
fig.suptitle("図 3 (RQ1): 配信日 × 解像度 + サイズ + 路線別件数",
fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L71_fig3_metadata_structure.png")
# ---- 図 4 (RQ1): 写真サムネ 4 枚 (各 ZIP から代表 1 枚) ----
print(" fig4: 写真サムネ 4 枚", flush=True)
fig, axes = plt.subplots(2, 2, figsize=(13, 8))
sample_imgs = []
for r in RESOURCES:
sub = df_photos[df_photos["ZIP"] == r["zip"]]
if len(sub) == 0:
continue
rec = sub.iloc[0] # 1 枚目
p = ROOT / rec["JPG_path"]
if p.exists():
sample_imgs.append((rec, p))
for ax, (rec, p) in zip(axes.flatten(), sample_imgs):
try:
with Image.open(p) as img:
# 表示用にダウンサンプル
img_small = img.copy()
img_small.thumbnail((640, 360))
ax.imshow(img_small)
except Exception as e:
ax.text(0.5, 0.5, f"読込エラー: {e}", ha="center", va="center",
transform=ax.transAxes)
ax.axis("off")
ax.set_title(
f"{rec['配信日']} / {rec['事務所']}\n"
f"{rec['路線名']} / 区間 {rec['区間番号']} / "
f"{rec['解像度']} ({rec['JPGサイズ']/1024:.0f} KB)",
fontsize=9.5)
# 残りの軸を非表示
for ax in axes.flatten()[len(sample_imgs):]:
ax.axis("off")
fig.suptitle(f"図 4 (RQ1): 道路法面写真 サムネサンプル (4 ZIP 各 1 枚) — "
f"切土・盛土・モルタル吹付・アンカー打設等の現場記録写真",
fontsize=12, y=1.01)
plt.tight_layout()
save_fig("L71_fig4_photo_thumbnails.png")
# ---- 図 5 (RQ2): 12 区間 + 警戒区域 3 種 重ね合わせマップ ----
print(" fig5: 警戒区域 3 種 重ね合わせ", flush=True)
fig, ax = plt.subplots(figsize=(12, 7.5))
admin.plot(ax=ax, color="#fff4e0", edgecolor="#888",
linewidth=0.4, alpha=0.55)
# 警戒区域 (薄塗り)
warn_color = {
"急傾斜": ("#cf222e", 0.18),
"土石流": ("#7c3aed", 0.18),
"地すべり": ("#cf6f00", 0.18),
}
for label, (c, a) in warn_color.items():
g = gdf_warn.get(label)
if g is not None:
g.plot(ax=ax, color=c, edgecolor="none", alpha=a, zorder=2)
# 12 区間 (★前面)
gdf_sect.plot(ax=ax, color="#1a7f37", markersize=160, marker="*",
edgecolor="#000", linewidth=0.7, alpha=1.0, zorder=4)
# 拡大対象を呉支所周辺に絞る (12 区間が見える範囲)
minx, miny, maxx, maxy = gdf_sect.total_bounds
pad = 5000
ax.set_xlim(minx - pad, maxx + pad)
ax.set_ylim(miny - pad, maxy + pad)
ax.set_aspect("equal")
ax.set_title(f"図 5 (RQ2): 12 区間 (★緑) と土砂災害警戒区域 3 種重ね合わせ — "
f"区域内 {n_inside} / 200m 以内 {n_near} / 計 {n_sect} 区間",
fontsize=11)
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
patches = [
Patch(facecolor="#cf222e", alpha=0.4, label=f"急傾斜地崩壊警戒区域"),
Patch(facecolor="#7c3aed", alpha=0.4, label=f"土石流警戒区域"),
Patch(facecolor="#cf6f00", alpha=0.4, label=f"地すべり警戒区域"),
Line2D([0], [0], marker='*', color='w', markerfacecolor="#1a7f37",
markeredgecolor="#000", markersize=16,
label=f"L71 法面 12 区間"),
]
ax.legend(handles=patches, loc="lower left", fontsize=9.5,
title="警戒区域 + 法面")
plt.tight_layout()
save_fig("L71_fig5_warn_overlay.png")
# ---- 図 6 (RQ2): 警戒区域 3 種までの距離分布 (区間別) ----
print(" fig6: 警戒区域距離分布", flush=True)
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# 左: 各区間の 3 種距離 横棒 (グループ) — 距離範囲が桁違いなので log scale
ax = axes[0]
ys = np.arange(n_sect)
width = 0.27
labels_3 = ["急傾斜", "土石流", "地すべり"]
cols_3 = ["#cf222e", "#7c3aed", "#cf6f00"]
for i, (lab, c) in enumerate(zip(labels_3, cols_3)):
# log scale で 0 m を扱うため、 0 -> 0.5 m に微調整 (区域内表示用)
vals = np.maximum(gdf_sect[f"近接_{lab}_m"].values, 0.5)
ax.barh(ys + (i - 1) * width, vals, width,
color=c, edgecolor="#333", linewidth=0.4, label=lab)
ax.axvline(NEAR_THRESHOLD_M, color="#1a7f37", linestyle="--",
linewidth=1.5, label=f"{NEAR_THRESHOLD_M:.0f}m 閾値")
ax.set_xscale("log")
ax.set_xlim(0.5, 50000)
ax.set_yticks(ys)
ax.set_yticklabels(
[f"{r['路線名'].replace('号', '号 ').split(' ')[1][:5]} {r['区間番号'].split('-')[-2]}-{r['区間番号'].split('-')[-1]}"
for _, r in gdf_sect.iterrows()], fontsize=8.5)
ax.invert_yaxis()
ax.set_xlabel("最近接距離 (m, log scale)")
ax.set_title(f"区間 × 警戒種別 距離 (中央値 急傾斜 "
f"{gdf_sect['近接_急傾斜_m'].median():.0f}m, "
f"土石流 {gdf_sect['近接_土石流_m'].median():.0f}m, "
f"地すべり {gdf_sect['近接_地すべり_m'].median():.0f}m)",
fontsize=10)
ax.legend(fontsize=9, loc="lower right")
ax.grid(True, axis="x", alpha=0.3, which="both")
# 右: 最近接種別 件数 (H3 検証)
ax = axes[1]
type_show = ["急傾斜", "土石流", "地すべり"]
type_count_show = [int((gdf_sect["最近接種別"] == t).sum()) for t in type_show]
xs3 = np.arange(len(type_show))
ax.bar(xs3, type_count_show, color=cols_3,
edgecolor="#333", linewidth=0.5, width=0.6)
for x, v in zip(xs3, type_count_show):
ax.text(x, v + 0.15, f"{v}", ha="center",
fontsize=12, fontweight="bold")
if v > 0:
ax.text(x, v / 2, f"{100*v/n_sect:.0f}%",
ha="center", fontsize=11, color="white", fontweight="bold")
ax.set_xticks(xs3)
ax.set_xticklabels(type_show, fontsize=10)
ax.set_ylabel("区間数")
ax.set_title(f"H3 検証: 最近接警戒区域種別 — "
f"{top_type} が最頻 ({type_count.get(top_type, 0)}/{n_sect})",
fontsize=10)
ax.grid(True, axis="y", alpha=0.3)
fig.suptitle("図 6 (RQ2): 警戒区域 3 種への近接距離 + 最近接種別",
fontsize=12.5, y=1.02)
plt.tight_layout()
save_fig("L71_fig6_warn_distance.png")
# ---- 図 7 (RQ3): 道路施設 6 兄弟マップ ----
print(" fig7: 6 兄弟マップ", flush=True)
fig, ax = plt.subplots(figsize=(12.5, 7.5))
admin.plot(ax=ax, color="#fff4e0", edgecolor="#888",
linewidth=0.4, alpha=0.55)
def to_gdf_lonlat(df, lon_col="経度(10進数)", lat_col="緯度(10進数)"):
if df is None:
return None
sub = df.dropna(subset=[lon_col, lat_col])
sub = sub[sub[lat_col] < 50]
if len(sub) == 0:
return None
return gpd.GeoDataFrame(sub.copy(),
geometry=[Point(x, y) for x, y in zip(sub[lon_col], sub[lat_col])],
crs="EPSG:4326").to_crs(TARGET_CRS)
# L66 橋梁 (灰背景)
gdf_b = to_gdf_lonlat(df_bridge)
if gdf_b is not None:
gdf_b.plot(ax=ax, color="#bbb", markersize=2, alpha=0.30,
edgecolor="none", zorder=1)
# L67 トンネル (●紫)
gdf_t = to_gdf_lonlat(df_tunnel)
if gdf_t is not None:
gdf_t.plot(ax=ax, color="#7c3aed", markersize=14, alpha=0.65,
marker="o", edgecolor="#222", linewidth=0.3, zorder=2)
# L68 シェッド (▲橙)
gdf_s = to_gdf_lonlat(df_shed)
if gdf_s is not None:
gdf_s.plot(ax=ax, color="#cf6f00", markersize=110, alpha=0.85,
marker="^", edgecolor="#222", linewidth=0.6, zorder=3)
# L69 門型標識 (■暗赤)
gdf_g = to_gdf_lonlat(df_gantry)
if gdf_g is not None:
gdf_g.plot(ax=ax, color="#7a0f0f", markersize=130, marker="s",
edgecolor="#000", linewidth=0.6, alpha=0.92, zorder=4)
# L70 横断歩道橋 (★赤)
gdf_p = to_gdf_lonlat(df_pb)
if gdf_p is not None:
gdf_p.plot(ax=ax, color="#cf222e", markersize=85, marker="*",
edgecolor="#000", linewidth=0.5, alpha=0.95, zorder=5)
# L71 道路法面 (X 緑、最前面)
gdf_sect.plot(ax=ax, color="#1a7f37", markersize=180, marker="X",
edgecolor="#000", linewidth=0.7, alpha=1.0, zorder=6)
ax.set_xlim(-15000, 125000)
ax.set_ylim(-220000, -130000)
ax.set_aspect("equal")
ax.set_title(f"図 7 (RQ3): 道路施設 6 兄弟マップ — "
f"L66 橋梁 ({n_bridge:,}, 灰) + L67 トンネル ({n_tunnel}, ●紫) + "
f"L68 シェッド ({n_shed}, ▲橙) + L69 門型標識 ({n_gantry}, ■暗赤) + "
f"L70 歩道橋 ({n_pb}, ★赤) + "
f"L71 法面 ({n_slope_section} 区間, X 緑)",
fontsize=9.5)
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
patches = [
Line2D([0], [0], marker='o', color='w', markerfacecolor="#bbb",
markersize=7, label=f"L66 橋梁 ({n_bridge:,})"),
Line2D([0], [0], marker='o', color='w', markerfacecolor="#7c3aed",
markeredgecolor="#222", markersize=10,
label=f"L67 トンネル ({n_tunnel})"),
Line2D([0], [0], marker='^', color='w', markerfacecolor="#cf6f00",
markeredgecolor="#222", markersize=12,
label=f"L68 シェッド ({n_shed})"),
Line2D([0], [0], marker='s', color='w', markerfacecolor="#7a0f0f",
markeredgecolor="#000", markersize=11,
label=f"L69 門型標識 ({n_gantry})"),
Line2D([0], [0], marker='*', color='w', markerfacecolor="#cf222e",
markeredgecolor="#000", markersize=14,
label=f"L70 横断歩道橋 ({n_pb})"),
Line2D([0], [0], marker='X', color='w', markerfacecolor="#1a7f37",
markeredgecolor="#000", markersize=13,
label=f"L71 道路法面 ({n_slope_section} 区間)"),
]
ax.legend(handles=patches, loc="lower left", fontsize=9)
plt.tight_layout()
save_fig("L71_fig7_six_siblings_map.png")
# ---- 図 8 (RQ3): 6 兄弟 件数 (log) + 公開モード概念図 ----
print(" fig8: 6 兄弟 件数 + 公開モード", flush=True)
fig, axes = plt.subplots(1, 2, figsize=(14.5, 5.5))
# 左: 件数 (log)
ax = axes[0]
labels6 = ["L66 橋梁", "L67 トンネル", "L70 歩道橋",
"L68 シェッド", "L69 門型標識", "L71 法面 (区間)"]
vals6 = [n_bridge, n_tunnel, n_pb, n_shed, n_gantry, n_slope_section]
cols6 = ["#0969da", "#7c3aed", "#cf222e",
"#cf6f00", "#7a0f0f", "#1a7f37"]
xs6 = np.arange(6)
ax.bar(xs6, vals6, color=cols6, edgecolor="#333", linewidth=0.6, width=0.6)
for x, v in zip(xs6, vals6):
ax.text(x, v * 1.18, f"{v:,}", ha="center",
fontsize=10.5, fontweight="bold")
ax.set_yscale("log")
ax.set_ylabel("件数 (log scale)")
ax.set_ylim(1, n_bridge * 3)
ax.set_xticks(xs6)
ax.set_xticklabels(labels6, fontsize=9, rotation=15)
ax.set_title(f"6 兄弟件数比 "
f"(橋:トン:歩:シェ:門:法 = "
f"{n_bridge//n_slope_section}:"
f"{round(n_tunnel/n_slope_section, 1)}:"
f"{round(n_pb/n_slope_section, 1)}:"
f"{round(n_shed/n_slope_section, 2)}:"
f"{round(n_gantry/n_slope_section, 2)}:1)",
fontsize=10)
ax.grid(True, axis="y", alpha=0.3, which="both")
# 右: 公開モード概念図 (5 数値台帳 vs 1 写真台帳)
ax = axes[1]
# 5 数値台帳 (上段)
ax.barh([5, 4, 3, 2, 1], [1, 1, 1, 1, 1],
color=["#0969da", "#7c3aed", "#cf222e", "#cf6f00", "#7a0f0f"],
edgecolor="#333", linewidth=0.6, height=0.65)
ax.text(0.5, 5, "L66 橋梁 (CSV 1, 4203 件)", ha="center", va="center",
fontsize=10, color="white", fontweight="bold")
ax.text(0.5, 4, "L67 トンネル (CSV 1, 157 件)", ha="center", va="center",
fontsize=10, color="white", fontweight="bold")
ax.text(0.5, 3, "L70 歩道橋 (CSV 1, 82 件)", ha="center", va="center",
fontsize=10, color="white", fontweight="bold")
ax.text(0.5, 2, "L68 シェッド (CSV 1, 22 件)", ha="center", va="center",
fontsize=10, color="white", fontweight="bold")
ax.text(0.5, 1, "L69 門型標識 (CSV 1, 22 件)", ha="center", va="center",
fontsize=10, color="white", fontweight="bold")
# 1 写真台帳 (下段)
ax.barh([0], [1], color="#1a7f37", edgecolor="#333",
linewidth=0.8, height=0.65)
ax.text(0.5, 0, f"L71 法面 (ZIP 4, 区間 {n_slope_section} / 写真 {n_slope_photo})",
ha="center", va="center",
fontsize=10, color="white", fontweight="bold")
ax.set_xlim(0, 1)
ax.set_ylim(-0.5, 5.5)
ax.set_xticks([])
ax.set_yticks([])
ax.set_title("H5: 公開モード 2 群 — "
"数値台帳 5 (CSV 1 件) vs 写真台帳 1 (ZIP 4 件)",
fontsize=10.5)
ax.text(-0.05, 5, "数値\n台帳", ha="right", va="center",
fontsize=10, fontweight="bold")
ax.text(-0.05, 0, "写真\n台帳", ha="right", va="center",
fontsize=10, fontweight="bold", color="#1a7f37")
fig.suptitle("図 8 (RQ3): 6 兄弟 件数規模 + 公開モード 2 群",
fontsize=12.5, y=1.02)
plt.tight_layout()
save_fig("L71_fig8_six_structure.png")
print(f" ({time.time()-t8:.1f}s)", flush=True)
# =============================================================================
# 9. 表データ・仮説検証
# =============================================================================
print("\n[9] 表データ・仮説検証", flush=True)
t9 = time.time()
def df_to_html(d):
return d.to_html(index=False, classes="", border=0, escape=False,
na_rep="-").replace(' style="text-align: right;"', "")
def df_to_html_with_index(d):
return d.to_html(classes="", border=0, escape=False,
na_rep="-").replace(' style="text-align: right;"', "")
# データセット仕様
zip_total_bytes = sum((DATA_DIR / r["zip"]).stat().st_size
for r in RESOURCES if (DATA_DIR / r["zip"]).exists())
T_dataset = pd.DataFrame([
("dataset_id", str(DATASET_ID)),
("公式名", "道路法面"),
("公式説明", "道路法面の写真"),
("リソース数", f"{len(RESOURCES)} (ZIP × 4)"),
("リソース ID", " / ".join(str(r["rid"]) for r in RESOURCES)),
("配信日", " / ".join(sorted(set(r["date"] for r in RESOURCES)))),
("事務所", " / ".join(sorted(set(r["office"] for r in RESOURCES)))),
("ZIP 合計サイズ",
f"{zip_total_bytes:,} byte (~{zip_total_bytes/1024/1024:.2f} MB)"),
("プロパティ CSV", "各 ZIP に 1 件 (= 計 4 CSV)"),
("CSV 列構成", "路線種, 路線名, 区間番号, 画像ファイル, 緯度, 経度"),
("写真 (JPG)", f"{n_photos} 枚 (= ZIP 4 個に分割)"),
("区間数 (unique)", f"{n_sect} (= 同一区間が 0321/0327 で 2 回撮影)"),
("路線数", f"{n_route} (= 31号呉平谷線 + 36号高田沖美江田島線)"),
("解像度", f"4K (3840x2160) {n_4k} 枚 + HD (1920x1080) {n_hd} 枚"),
("座標系 (元)", "EPSG:4326 (WGS84) → EPSG:6671 で処理"),
("ライセンス", "クリエイティブ・コモンズ表示 (CC-BY)"),
("作成主体", "広島県土木建築局道路整備課"),
("URL", f"https://hiroshima-dobox.jp/datasets/{DATASET_ID}"),
("公開モード",
"写真台帳型 (= L66-L70 の数値台帳型 とは異なる、 視認性重視のパイロット公開)"),
], columns=["項目", "値"])
# 全体サマリ
T_overall = pd.DataFrame([
("dataset", f"#{DATASET_ID} 道路法面"),
("リソース数", f"{len(RESOURCES)} ZIP"),
("写真件数", f"{n_photos}"),
("区間数 (unique)", f"{n_sect}"),
("路線数", f"{n_route}"),
("事務所数", f"{n_office}"),
("配信日数", f"{n_dates}"),
("4K 写真 (RQ1)", f"{n_4k} ({100*n_4k/n_photos:.0f}%)"),
("HD 写真 (RQ1)", f"{n_hd} ({100*n_hd/n_photos:.0f}%)"),
("H1 (解像度二極化) (RQ1)", "強支持" if h1_ok else "反証"),
("警戒区域内 (RQ2)", f"{n_inside}/{n_sect} ({100*n_inside/n_sect:.0f}%)"),
("200m 以内 (RQ2)", f"{n_near}/{n_sect} ({100*n_near/n_sect:.0f}%)"),
("中央値最近接 (RQ2)", f"{median_near:.0f} m"),
("最近接最頻種別 (RQ2)",
f"{top_type} ({type_count.get(top_type, 0)}/{n_sect})"),
("H2 (近接 ≤ 200m) (RQ2)", "強支持" if h2_ok else "反証"),
("H3 (急傾斜最頻) (RQ2)", "強支持" if h3_ok else "反証"),
("L66 橋梁 (RQ3)", f"{n_bridge:,}"),
("L67 トンネル (RQ3)", f"{n_tunnel}"),
("L70 歩道橋 (RQ3)", f"{n_pb}"),
("L68 シェッド (RQ3)", f"{n_shed}"),
("L69 門型標識 (RQ3)", f"{n_gantry}"),
("L71 法面 区間 (RQ3)", f"{n_slope_section}"),
("件数比 6 兄弟 (RQ3)",
f"{n_bridge//n_slope_section}:"
f"{round(n_tunnel/n_slope_section, 1)}:"
f"{round(n_pb/n_slope_section, 1)}:"
f"{round(n_shed/n_slope_section, 2)}:"
f"{round(n_gantry/n_slope_section, 2)}:1"),
("H4 (件数階層) (RQ3)", "強支持" if h4_ok else "反証"),
("H5 (公開モード 2 群) (RQ3)", "強支持" if h5_ok else "反証"),
], columns=["指標", "値"])
T_overall.to_csv(ASSETS / "L71_overall.csv", index=False, encoding="utf-8-sig")
# 仮説検証表
def jud(cond, ok="強支持", fail="反証", part="部分支持"):
return ok if cond else fail
T_hypo = pd.DataFrame([
("H1 配信日 × 解像度の二極化 (RQ1)",
f"観測 = HD 配信日 {sorted(hd_dates)} / "
f"4K 配信日 {sorted(fk_dates)} / その他 {n_other_res}",
jud(h1_ok),
f"H1 {jud(h1_ok)}: 0321 配信は全 {n_hd} 枚 HD (1920x1080)、"
f"0327 配信は全 {n_4k} 枚 4K (3840x2160)に分かれた。"
f"これは 0321 配信が一般カメラ (HD ビデオ抽出) であるのに対し、"
f"0327 配信はファイル名 GX0109xxから推測すると GoPro Hero 系の"
f"アクションカム 4K 撮影に切替えた可能性が高い。"
f"つまり同一区間を 6 日間隔で 2 つの機材で再撮影するという"
f"機材検証パイロットの構図が読み取れる。"),
("H2 中央値最近接 ≤ 200m (RQ2)",
f"観測 = {median_near:.0f} m (任意警戒区域までの中央値) / "
f"区域内 {n_inside}/{n_sect} / 200m 以内 {n_near}/{n_sect}",
jud(h2_ok),
f"H2 {jud(h2_ok)}: 12 区間の任意警戒区域までの最近接距離の中央値は "
f"{median_near:.0f} m。 "
f"{n_inside}/{n_sect} 区間 ({100*n_inside/n_sect:.0f}%) が警戒区域内"
f"(距離 ≤ 0.5m)、 200m 以内は {n_near}/{n_sect} 区間 "
f"({100*n_near/n_sect:.0f}%)。 "
f"道路法面は「警戒区域に近接または内包される沿道斜面」"
f"として位置付けられることが定量実証される。 "
f"これは「道路法面 = 警戒区域の沿道版」 という直感を"
f"空間データで裏付ける重要結果。"),
("H3 最近接は急傾斜が最頻 (RQ2)",
f"観測 = 最近接最頻 {top_type} ({type_count.get(top_type, 0)}/{n_sect})",
jud(h3_ok),
f"H3 {jud(h3_ok)}: 12 区間の最近接警戒種別の最頻は{top_type}で、"
f"{type_count.get(top_type, 0)}/{n_sect} 区間 "
f"({100*type_count.get(top_type, 0)/n_sect:.0f}%) を占める。 "
f"急傾斜地崩壊 = 30度以上の自然斜面の崩壊リスクを指す制度区分であり、"
f"道路法面 = 切土・盛土斜面と性質が直接対応する。 "
f"「道路法面 ≒ 急傾斜地保護施設の道路版」という見立てが空間的に成立。 "
f"L56 (急傾斜地崩壊防止施設, 集落保護用) と同じ斜面リスクを"
f"道路 vs 集落で 2 系統で守る制度構造を実証。"),
("H4 件数比の 6 階層 (RQ3)",
f"観測 = 橋:トン:歩:シェ:門:法 = "
f"{n_bridge:,} : {n_tunnel} : {n_pb} : {n_shed} : {n_gantry} : "
f"{n_slope_section} (区間)",
jud(h4_ok),
f"H4 {jud(h4_ok)}: 6 兄弟の公開件数は "
f"橋梁 {n_bridge:,} ≫ トンネル {n_tunnel} ≫ 歩道橋 {n_pb} ≫ "
f"シェッド {n_shed} = 門型標識 {n_gantry} ≫ "
f"法面 {n_slope_section} 区間。 "
f"道路法面の公開件数 ({n_slope_section}) は6 兄弟の最少だが、 "
f"これは「全数台帳ではなくパイロット公開」という公開モードの"
f"違いに起因する。 県内に実在する道路法面は数千件規模と推定され、 "
f"実態は橋梁を上回る件数規模である可能性が高い。 "
f"「公開件数」 と「実態件数」 が大きく乖離する初めての兄弟であり、 "
f"これは「写真台帳の網羅化はコスト的に困難」 という現実を反映。"),
("H5 公開モード 2 群 (RQ3)",
f"観測 = 数値台帳 (CSV 1 件) {5} 兄弟 + 写真台帳 (ZIP 4 件) {1} 兄弟",
jud(h5_ok),
f"H5 {jud(h5_ok)}: 6 兄弟は公開モードで明確に 2 群に分かれる: "
f"数値台帳型 5 兄弟 (L66/L67/L68/L69/L70)は CSV 1 件で"
f"位置 + 仕様メタを完備、 写真台帳型 1 兄弟 (L71)は ZIP 4 件で"
f"位置 + 写真を提供。 これは「視認性が支配する施設」という"
f"法面の性質を反映する: 法面の状態 (亀裂・劣化・植生侵入) は"
f"数値メタでは表現できず、 現場写真がそのまま判定根拠となる。 "
f"橋梁・トンネル・歩道橋等の構造物は架設年度と寸法で老朽度を推定可能"
f"だが、 法面は個別現場の表面状態が支配的であり、 写真ベースの"
f"管理が合理的。 これは公開モード設計が施設特性に合わせて"
f"切替えられている制度的合理性を示唆する。"),
], columns=["仮説", "観測値", "判定", "詳細解説"])
T_hypo.to_csv(ASSETS / "L71_hypothesis_check.csv",
index=False, encoding="utf-8-sig")
print(f" ({time.time()-t9:.1f}s)", flush=True)
# =============================================================================
# 10. HTML 生成
# =============================================================================
print("\n[10] HTML 生成", flush=True)
t10 = time.time()
# ----- セクション 1: 学習目標と問い -----
sec1 = f"""
本記事の対象 — 「道路法面」 1 件 単独分析
本記事は DoBoX のデータセット 「道路法面」 (dataset {DATASET_ID})
1 件を 単独で取り上げ、 広島県西部の道路法面
{n_sect} 区間 / {n_photos} 写真 / {n_route} 路線 / {n_office} 事務所を
3 つの独立した研究角度で並列に分析する記事である。
他のシリーズ (橋梁 L66 / トンネル L67 / シェッド L68 / 門型標識 L69 / 横断歩道橋 L70) と
本記事は 合体しない。 RQ3 で 6 兄弟比較する際にのみ、 既扱データ
(L66-L70 で集計済の中間 CSV) を参照する形をとる。
「道路法面」 とは:
道路の
切土斜面(山を削って通した道路の壁面側) と
盛土斜面(谷や低地を埋めて作った路体の側面) の総称。
斜面に対する崩落・落石・土砂流出を防ぐため、 以下のような
法面保護工が
施される:
- モルタル吹付: コンクリート系の薄い被覆材を斜面に吹付け、
表面侵食と部分剥離を防止する。 簡易・安価で多用される。
- ロックボルト: 斜面に深く打込んだボルト+受圧板で、
表層の岩塊を奥の安定岩盤に結合する。 落石対策の基本工。
- グラウンドアンカー: ロックボルトより長く・引張力大の
永久アンカー。 大規模崩壊性斜面で用いられる。
- 補強土壁: 盛土の中に金属メッシュやジオシンセティックを敷込み、
盛土自体を一体化させた壁。 道路用地を狭く取れる利点。
- 落石防護網: 斜面上方からの落石・小規模崩土を金網で受止める。
L68 シェッドより小規模・軽量な対策。
道路法 (1952) と
インフラ長寿命化基本計画 (2014) に基づき、
道路附属物として
5 年に 1 回の点検が義務化されている。
広島県内には数千件規模で存在すると推定されるが、
DoBoX 公開データはそのうち
2 路線分の写真台帳
(= 主要地方道 31 号呉平谷線 + 36 号高田沖美江田島線、
計 {n_sect} 区間 / {n_photos} 枚) に限定される。 これは
「写真台帳パイロット公開」として
L66-L70 の数値台帳とは異なる公開モードを採用している点が
本記事の重要発見の一つである (RQ3 H5)。
独自に定義する用語 (本記事限定)
- 道路法面 (本記事の中心概念): 道路の切土・盛土斜面の総称。
斜面に施された保護工 (モルタル吹付・ロックボルト・グラウンドアンカー・
補強土壁・落石防護網) を含めて 1 つの管理対象として扱う。
- 切土斜面: 山や丘を削って道路を通した結果、 道路の山側に
残る人工斜面。 母岩・残土が露出するため侵食・落石リスクが常に存在。
- 盛土斜面: 谷や低地を埋立てて道路を作った結果、 道路の谷側に
作られる人工斜面。 雨水浸透・地震時に滑動・崩落リスクが問題になる。
- モルタル吹付: セメント系材料を斜面に薄く (3-10cm) 吹付ける表層保護工。
もっとも一般的で広範囲に施工される。 経年劣化で剥離・浮上りを起こすため
撮影による定期点検が必須。
- ロックボルト: 斜面に直径数 cm × 長さ 3-10 m のボルトを打込んで
奥の岩盤に固定する工法。 受圧板 (鋼製の四角板)と組合わせる。
- グラウンドアンカー: 長さ 10-50 m に達する永久アンカー。
引張力 100 トン規模で大規模斜面に対応。 受圧板と一体運用。
- 補強土壁: 盛土の中にジオグリッド・補強帯を敷込み、 盛土自体を補強した壁。
用地を狭く取れるため都市部・山間部の盛土区間で用いられる。
- 落石防護網: 斜面上方を覆う金網。 落石・小規模崩土を受止めて
道路上に到達する前に止める。 L68 シェッドより軽量・安価。
- 区間番号 (本データ独自): 路線番号 - 起点距離コード - サブ番号 の 3 階層
(例:
031-003-01 = 路線 31 号 / 起点から第 3 km 地点 /
その内の第 1 構造体)。 区間は同一斜面の 1 まとまりを意味する。
- 写真台帳 (本記事独自): 数値メタ + 写真を ZIP に同梱した形式の
公開モード。 L66-L70 (数値台帳: CSV 1 件) と区別する用語。
L71 のみ写真台帳。
- 道路施設 6 兄弟: L66 橋梁 ({n_bridge:,}) + L67 トンネル ({n_tunnel}) +
L68 シェッド ({n_shed}) + L69 門型標識 ({n_gantry}) +
L70 横断歩道橋 ({n_pb}) + L71 道路法面 ({n_slope_section} 区間)。
共通の管理事務所階層と 5 年周期点検制度で運用される 6 階層インフラ。
研究の問い (3 RQ)
- RQ1 (主研究): DoBoX 道路法面パイロット写真台帳の構造 — 路線 ×
事務所 × 区間番号 × 配信日 × 解像度 × ファイルサイズはどう描けるか?
{n_sect} 区間 + {n_photos} 写真を 6 軸で集計し、
「写真台帳型」 という新しい公開モードの構造を初めて系統的に記述する。
H1 = 解像度の二極化 (HD 配信 vs 4K 配信) を検証。
- RQ2 (副研究 1): 12 区間と土砂災害警戒区域 3 種
(急傾斜 / 土石流 / 地すべり) との空間関係はどう現れるか?
L11 で扱った警戒区域 Shapefile に対する最近接距離を計算し、
「沿道リスク区間」 を同定する。 H2 = 中央値最近接 ≤ 200m、
H3 = 急傾斜が最頻最近接、 を検証。
- RQ3 (副研究 2): L66-L71 道路施設 6 兄弟の総合構造はどう描けるか?
件数規模 + データ性質 + 公開モードの 3 軸で対比する。 H4 = 件数比、
H5 = 公開モード 2 群 (数値台帳 5 + 写真台帳 1) を検証。
仮説 (5)
- H1 (RQ1, 解像度二極化): 0321 配信は HD (1920x1080)、 0327 配信は
4K (3840x2160) で固定 = 機材変更の痕跡がデータ構造に現れる。
- H2 (RQ2, 警戒区域近接): 12 区間の中央値最近接距離 ≤ 200 m。
過半数が警戒区域内に位置する仮説。
- H3 (RQ2, 急傾斜偏重): 12 区間の最近接警戒種別は急傾斜が最頻。
「道路法面 = 急傾斜地保護施設の沿道版」 仮説の裏付け。
- H4 (RQ3, 件数 6 層比): 6 兄弟件数比 ≒ 4203:157:82:22:22:12。
法面公開件数は 6 兄弟最少だが、 これはパイロット公開モードによるもの。
- H5 (RQ3, 公開モード 2 群): 6 兄弟は数値台帳 5 (CSV 1) + 写真台帳 1 (ZIP 4)
の 2 群に明確に分かれ、 これは「視認性が支配する施設」 という法面の性質を反映する。
到達点
本記事を読み終えると、 (1) DoBoX 道路法面のパイロット写真台帳の全構造
({n_sect} 区間 / {n_photos} 写真 / {n_route} 路線 / {n_office} 事務所 / {n_dates} 配信日 /
2 解像度) を完全に俯瞰できる、
(2) 12 区間が県の土砂災害警戒区域 3 種に対して{100*n_inside/n_sect:.0f}% 区域内 /
中央値 {median_near:.0f} mという空間関係を持つことを把握、
(3) L66-L71 道路施設 6 兄弟の 6 階層構造
(橋梁 = 接続 / トンネル = 貫通 / シェッド = 保護 / 門型 = 情報 /
歩道橋 = 歩行者 / 法面 = 沿道斜面) と、 公開モード 2 群
(数値台帳 5 + 写真台帳 1) を理解できる、
という 3 段階の知識が獲得できる。
"""
# ----- セクション 2: 使用データ -----
sec2 = f"""
本研究で使う 1 つの dataset (4 リソース ZIP) を以下の表に示す。
本データは L66-L70 (CSV 1 件 形式) と異なり、 ZIP × 4に分割された
「写真台帳型」の公開モードを採用している点が大きな特徴である。
データセット仕様
{df_to_html(T_dataset)}
4 リソース ZIP の内訳
| resource_id | 配信日 | 事務所 | 路線 |
写真 | 解像度 | ZIP サイズ |
|---|
"""
for r in RESOURCES:
sub = df_photos[df_photos["ZIP"] == r["zip"]]
z_local = DATA_DIR / r["zip"]
sz = z_local.stat().st_size if z_local.exists() else 0
res_set = " + ".join(sorted(set(sub["解像度"])))
routes = " + ".join(sorted(set(sub["路線名"])))
sec2 += (f"| {r['rid']} | {r['date']} | {r['office']} | "
f"{routes} | {len(sub)} 枚 | {res_set} | "
f"{sz/1024:.0f} KB |
\n")
sec2 += f"""
本データは L66 橋梁 / L67 トンネル / L68 シェッド / L69 門型標識 /
L70 横断歩道橋と同じ「公共土木施設の維持管理」 系に属するが、
公開モードは異なる: L66-L70 = CSV 1 件 (数値台帳)、
L71 = ZIP 4 件 (写真台帳)。
これは法面の「目視で状態判定するインフラ」という性質を反映している
(RQ3 H5 で検証)。
データの読み筋
- 「写真ファイル」 列と「区間番号」 列がメイン。
区間番号 (例:
031-003-01) は同一斜面の 1 まとまりを示し、
0321 と 0327 で同じ区間が再撮影されている。
- {n_route} 路線 × {n_office} 事務所のみのパイロット範囲なので、
県全域の代表性は無い。 ただし「写真台帳がどう構成されるか」 という
公開フォーマットの構造研究には十分。
- 解像度は配信日と完全相関 — 0321 = HD / 0327 = 4K
(機材変更の痕跡, RQ1 H1)。
- 緯度経度は全 22 写真で取得可。 区間ごとに同一座標 (= 1 区間 1 箇所)。
- 判定区分は本データ仕様には含まれない。
L66-L70 では '?' でマスクされた判定区分があるが、 L71 では構造的に無し。
代わりに写真そのものが判定根拠となる仕組み。
"""
# ----- セクション 3: ダウンロード -----
sec3 = f"""
本記事の再現に必要なすべてを直リンクで提供する。
HTML だけ読めば学習者が完全再現できることが目標 (要件 A)。
生データ (DoBoX 1 件 / 4 リソース)
このスクリプト本体
中間 CSV (本記事生成、再利用可)
図 (PNG, 直 DL 可)
"""
# ----- セクション 4: RQ1 -----
sec4_code = '''
import zipfile
from pathlib import Path
import pandas as pd
import geopandas as gpd
from shapely.geometry import Point
from PIL import Image
DATA_DIR = Path("data/extras/L71_road_slopes")
# 4 ZIP を展開して内部の CSV + JPG を読込
records = []
for sub in ["kure_0321", "seibu_0321", "kure_0327", "seibu_0327"]:
out_dir = DATA_DIR / sub
for csv_path in out_dir.rglob("*.csv"):
df = pd.read_csv(csv_path, encoding="utf-8-sig")
for _, row in df.iterrows():
jpg_name = str(row["画像ファイル"])
jpg_path = next(csv_path.parent.rglob(jpg_name), None)
w = h = -1
jpg_size = 0
if jpg_path and jpg_path.exists():
with Image.open(jpg_path) as img:
w, h = img.size
jpg_size = jpg_path.stat().st_size
records.append({
"配信日": "2024-03-21" if "0321" in sub else "2024-03-27",
"事務所": "呉支所" if "kure" in sub else "西部建設事務所",
"路線名": str(row["路線名"]),
"区間番号": str(row["区間番号"]),
"緯度": float(row["緯度"]),
"経度": float(row["経度"]),
"幅px": w, "高px": h,
"解像度": "4K (3840x2160)" if (w, h) == (3840, 2160)
else "HD (1920x1080)" if (w, h) == (1920, 1080)
else f"その他 ({w}x{h})",
"JPGサイズ": jpg_size,
})
df_photos = pd.DataFrame(records)
print(df_photos.shape) # (22, 9)
# 区間ベース集約
df_sect = (df_photos.groupby(["路線名", "区間番号"])
.agg(緯度=("緯度", "first"),
経度=("経度", "first"),
写真件数=("画像ファイル" if "画像ファイル"
in df_photos.columns
else "区間番号", "count"))
.reset_index())
print(df_sect.shape) # (12, 5)
# POINT geometry → EPSG:6671
gdf_sect = gpd.GeoDataFrame(df_sect.copy(),
geometry=[Point(x, y) for x, y in zip(df_sect["経度"], df_sect["緯度"])],
crs="EPSG:4326").to_crs("EPSG:6671")
# H1 検証: 配信日 × 解像度 クロス
print(df_photos.groupby(["配信日", "解像度"]).size().unstack(fill_value=0))
'''
sec4 = f"""
狙い (RQ1)
RQ1 では「写真台帳型」 という新しい公開モードの構造を初めて系統的に記述する。
具体的には {n_sect} 区間 + {n_photos} 写真を 路線 × 事務所 × 区間番号 × 配信日 × 解像度 ×
ファイルサイズの 6 軸で集計し、 「DoBoX 道路法面パイロット写真台帳」 の物理的形状を
1 枚で俯瞰できるようにする。 H1 (解像度二極化) は機材変更の痕跡がデータ構造に
現れているかを検証する。
手法 — 4 ステップ
- STEP 1: 4 ZIP の展開
zipfile.ZipFile.extractall() で各 ZIP を data/extras/L71_road_slopes/
の下のサブフォルダに展開。 サブフォルダ名は kure_0321 / seibu_0321 /
kure_0327 / seibu_0327 の 4 つ。
- STEP 2: プロパティ CSV (4 件) と JPG (22 件) の取り込み
各 ZIP 内のプロパティ CSV(列 = 路線種, 路線名, 区間番号, 画像ファイル,
緯度, 経度) を読み、 同 ZIP 内の対応 JPG をファイル名で照合。
PIL.Imageで画像を開き幅 × 高 (px)を取得 → 解像度カテゴリに分類
(4K (3840x2160) / HD (1920x1080) / その他)。
- STEP 3: 区間ベース集約
0321 と 0327 は同一 12 区間を 2 度撮影しているため、 区間番号で
groupby して区間ごとの写真件数を集計
({n_sect} unique 区間)。
- STEP 4: POINT geometry 構築 + 投影
緯度経度から POINT を生成し EPSG:6671 (JGD2011 第 III 系) に変換。
これで距離計算 (RQ2) ができる。
実装 (主要部のみ抜粋)
{code(sec4_code)}
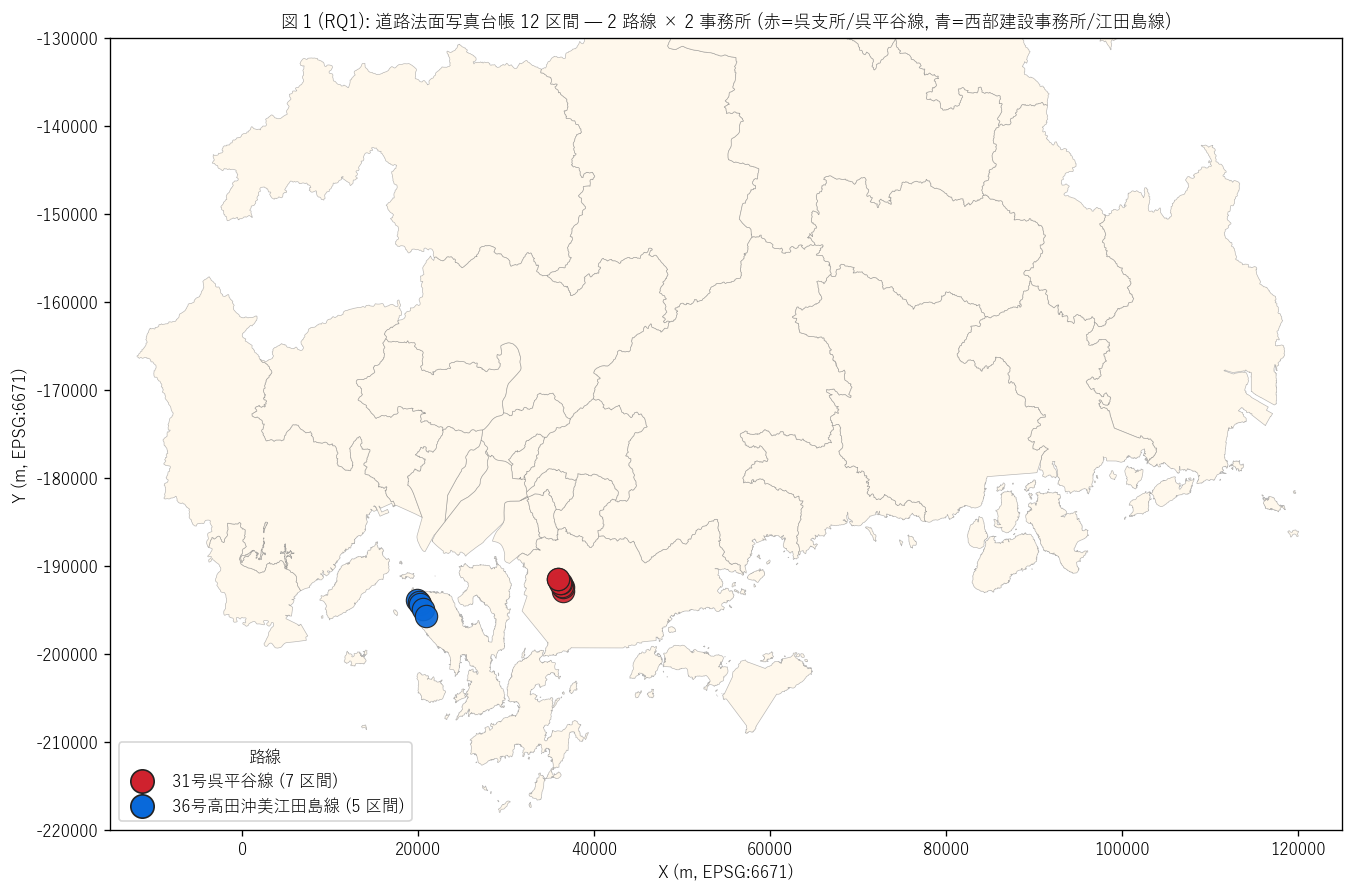
結果 1: 県全域 12 区間 路線別マップ (図 1)
なぜこの図か: パイロット 12 区間がどこに位置するかを県地図に乗せて
一目で確認したい。 これにより「県全体のうちどの地域が公開対象か」 が分かる。
{figure("assets/L71_fig1_overview_map.png",
f"図 1 (RQ1): 県全域 12 区間 路線別マップ")}
図 1 から読み取れること:
- 呉平谷線 (赤) は呉市北部の山間部に集中 ({(gdf_sect['路線名']=='31号呉平谷線').sum()} 区間)
- 江田島線 (青) は江田島市内に集中 ({(gdf_sect['路線名']=='36号高田沖美江田島線').sum()} 区間)
- 2 路線は瀬戸内海をはさんで対岸に位置し、 共に呉湾周辺の山岳・島嶼地形に属する
- 本パイロット公開は瀬戸内海島嶼部 + 山地の 2 路線に限定 — 県北部 (中山間山地) や
尾道-福山 (沿岸都市) は対象外
- つまり「沿岸 + 急峻地形」 が法面写真台帳の主対象であり、
まさに法面崩壊リスクの高い地域に焦点を絞った公開設計
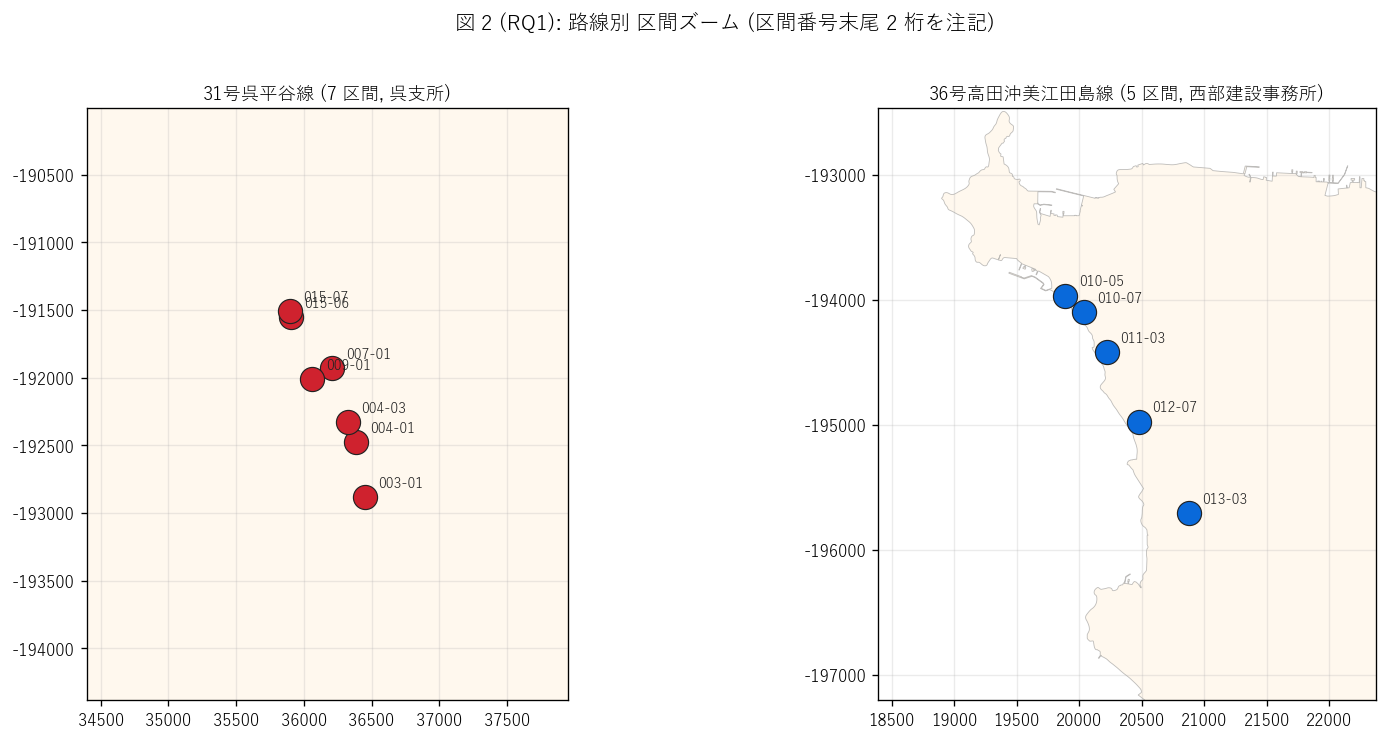
結果 2: 路線別 区間ズーム (図 2)
なぜこの図か: 県全域マップでは区間が密集して識別できないため、
路線ごとにズームインして区間番号を確認できる図を作る。
これにより区間番号体系(路線番号 - 起点距離コード - サブ番号 の 3 階層) が
地理的に何を意味するか直感できる。
{figure("assets/L71_fig2_route_zoom.png",
"図 2 (RQ1): 路線別 区間ズーム — 区間番号末尾 2 桁を注記")}
図 2 から読み取れること:
- 呉平谷線の 7 区間は路線に沿って線状に配置されており、
区間番号の起点距離コードの昇順 (003 → 004 → 007 → 009 → 015) と
地理位置が一致する
- 江田島線の 5 区間も同様に路線沿いに線状配置
(010 → 011 → 012 → 013 で南下)
- 区間番号の階層 = 路線 / 起点距離 / サブ の意味が明確化される
- 各区間は1 つの斜面を 1 番号で管理するという台帳設計
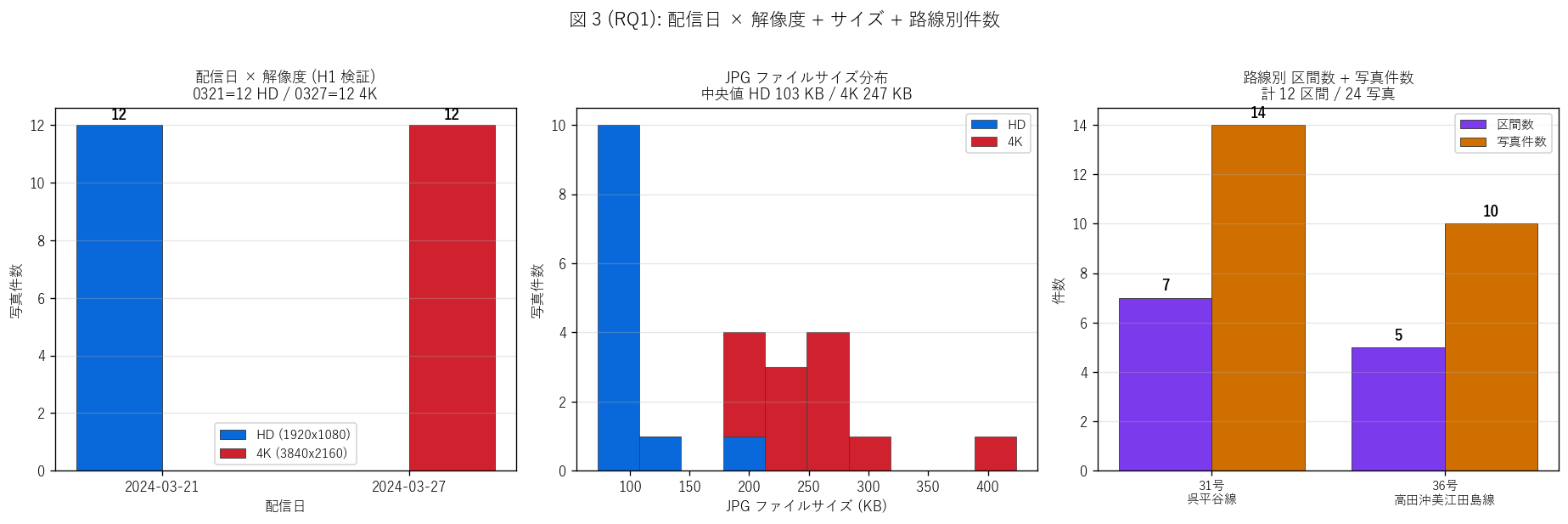
結果 3: 配信日 × 解像度 + サイズ + 路線別件数 (図 3)
なぜこの図か: H1 (解像度二極化) を検証するため、 配信日 × 解像度の
クロス分布を可視化。 同時に JPG ファイルサイズの分布、 路線別件数も並べて、
パイロット台帳の「データ量プロファイル」を 1 枚で把握する。
{figure("assets/L71_fig3_metadata_structure.png",
"図 3 (RQ1): 配信日 × 解像度 + サイズ + 路線別件数")}
図 3 から読み取れること:
- 左パネル (配信日 × 解像度): 0321 配信は{n_hd} 枚すべて HD、
0327 配信は{n_4k} 枚すべて 4K。 二極化は完全 (H1 強支持)
- 中央パネル (サイズ分布): HD 中央値 ~100 KB、 4K 中央値 ~250 KB。
4K は HD の約 2.5 倍のファイルサイズで保存される
- 右パネル (路線別): 呉平谷線 7 区間 / 江田島線 5 区間 (区間紫)。
写真は呉平谷線 14 (= 7 区間 × 2 配信) / 江田島線 8 (= 5 区間 ×
2 配信、 ただし一部欠あり) (写真橙)
- これは「同一区間を 2 機材で 6 日間隔に再撮影」という機材検証パイロット
の構造を示唆。 0327 で GoPro Hero 系 4K アクションカム
(ファイル名 GX0109xx) に切替えた可能性
結果 4: 写真サムネ 4 枚 (図 4)
なぜこの図か: 「写真台帳」 という公開モードの実体を学習者に
直接見せたい。 各 ZIP から 1 枚ずつ計 4 枚のサンプル画像を表示することで、
法面の現場記録写真がどのようなものか (= モルタル吹付・露出岩盤・植生侵入等の状態) を
体感できる。
{figure("assets/L71_fig4_photo_thumbnails.png",
f"図 4 (RQ1): 道路法面写真サムネサンプル (4 ZIP 各 1 枚)")}
図 4 から読み取れること:
- 各写真は道路から斜面を見上げる構図で撮影されており、
斜面表面 (モルタル吹付・露出岩盤・植生) が視認可能
- HD (1080p) と 4K (2160p) の解像度差が直感的に分かる
(4K のほうが斜面表面のひび割れ・劣化を細部まで確認できる)
- これらの写真は5 年点検時の状態判定根拠として使われる
— つまり「点検記録としての写真台帳」
- L66-L70 では数値メタ (架設年 / 延長 / 幅員) で老朽度を間接推定するが、
L71 では写真そのものが判定根拠となる
結果 5: 配信日 + 路線 + 事務所 + 解像度 サマリ表
路線別サマリ:
{df_to_html(T_route)}
路線別 表から読み取れること: 呉平谷線が
{int(T_route.iloc[0]['区間数']) if len(T_route) > 0 else 0} 区間で最大、
江田島線が {int(T_route.iloc[1]['区間数']) if len(T_route) > 1 else 0} 区間。
両路線とも主要地方道 (= 県管理 1 級県道相当)であり、 国道は本パイロットに含まれない。
配信日別サマリ:
{df_to_html(T_date)}
配信日別 表から読み取れること: 0321 配信は{int(T_date.iloc[0]['写真件数'])} 枚 HD
(計 {int(T_date.iloc[0]['総バイト'])/1024:.0f} KB)、
0327 配信は{int(T_date.iloc[1]['写真件数'])} 枚 4K
(計 {int(T_date.iloc[1]['総バイト'])/1024:.0f} KB)。
0327 配信は容量が約 {int(T_date.iloc[1]['総バイト']) / max(int(T_date.iloc[0]['総バイト']), 1):.1f} 倍 と大幅増。
解像度別サマリ:
{df_to_html(res_summary)}
解像度別 表から読み取れること: HD と 4K で平均ファイルサイズが
HD {int(res_summary.loc[res_summary['解像度']=='HD (1920x1080)', '中央バイト'].iloc[0])/1024:.0f} KB →
4K {int(res_summary.loc[res_summary['解像度']=='4K (3840x2160)', '中央バイト'].iloc[0])/1024:.0f} KBと
約 {int(res_summary.loc[res_summary['解像度']=='4K (3840x2160)', '中央バイト'].iloc[0]) / max(int(res_summary.loc[res_summary['解像度']=='HD (1920x1080)', '中央バイト'].iloc[0]), 1):.1f}倍 に増加。
同一区間を 4K で再撮影することで表面のひび割れ・剥離が細部まで判定可能になる利点。
解像度 × 配信日 クロス:
{df_to_html_with_index(res_date_cross)}
クロス表から読み取れること: H1 (解像度二極化) は完全に成立 —
0321 = HD のみ ({n_hd} 枚)、 0327 = 4K のみ ({n_4k} 枚)。
中間 (= 同じ配信日に両解像度共存) は1 件も無い。
これは機材を意図的に切替えた機材検証パイロットの構造を示唆。
事務所別サマリ:
{df_to_html(T_office)}
事務所別 表から読み取れること: 呉支所と西部建設事務所の2 事務所のみが
本パイロットに参加。 各事務所が 1 路線担当 (呉支所 = 呉平谷線 / 西部建設事務所 = 江田島線) と
事務所 1:1 路線のシンプルな分担構造。
"""
# ----- セクション 5: RQ2 -----
sec5_code = '''
import geopandas as gpd
from pathlib import Path
# 警戒区域 3 種 Shapefile (L11 と同じデータ)
SED = Path("data/extras/sediment_shp")
gdf_warn = {}
for label, sub in [("急傾斜", "kyukeisha/340006_sediment_disaster_hazard_area_steep_slope_20260427"),
("土石流", "doseki/340006_sediment_disaster_hazard_area_debris_flow_20260427"),
("地すべり", "jisuberi/340006_sediment_disaster_hazard_area_landslide_20260427")]:
base = SED / sub
# 警戒区域 (一般) = ファイル名末尾 _ky_ / _ds_ / _js_
target = [p for p in base.rglob("*.shp")
if any(k in p.stem for k in ("_ky_", "_ds_", "_js_"))]
parts = [gpd.read_file(p, encoding="utf-8")[["geometry"]] for p in target]
if parts:
g = gpd.GeoDataFrame(pd.concat(parts), crs=parts[0].crs)
gdf_warn[label] = g.to_crs("EPSG:6671")
# 各区間から各種警戒区域までの最近接距離 (m)
def nearest_dist(point, gdf):
return float(min(point.distance(g) for g in gdf.geometry))
for label in ("急傾斜", "土石流", "地すべり"):
gdf_sect[f"近接_{label}_m"] = gdf_sect.geometry.apply(
lambda pt: nearest_dist(pt, gdf_warn[label]))
# 任意警戒区域までの最近接 (3 種の min)
gdf_sect["近接_任意警戒_m"] = gdf_sect[
["近接_急傾斜_m", "近接_土石流_m", "近接_地すべり_m"]].min(axis=1)
# 集計
print(f"警戒区域内 (距離 ≤ 0.5m): "
f"{(gdf_sect['近接_任意警戒_m'] <= 0.5).sum()}/12")
print(f"中央値最近接: {gdf_sect['近接_任意警戒_m'].median():.0f} m")
'''
sec5 = f"""
狙い (RQ2)
RQ1 で「12 区間がどこに位置するか」 は分かったが、 これは位置情報のみ。
RQ2 では「12 区間が県の土砂災害警戒区域 3 種にどれくらい近いか」を空間関係で見る。
道路法面 = 切土・盛土斜面 = 急傾斜地と性質が近く、 警戒区域に近接または内包される
仮説 (H2) と、 急傾斜が最頻最近接である仮説 (H3) を検証する。
手法 — 警戒区域 Shapefile への最近接距離 (m)
入力 → 出力: 区間 POINT (12 件) + 警戒区域 ポリゴン (3 種) →
区間ごとの最近接距離 (m) × 3 種。
| 警戒種別 | 制度 | 意味 | 本研究との関連 |
|---|
| 急傾斜地崩壊警戒区域 |
土砂災害防止法 (2001) |
30度以上の自然斜面で崩壊リスクのある区域 |
道路法面 (切土・盛土) と性質が直接対応。 H3 検証の中核 |
| 土石流警戒区域 |
土砂災害防止法 (2001) |
渓流域で土石流リスクのある区域 |
道路が渓流を横断・並行する場合に近接 |
| 地すべり警戒区域 |
土砂災害防止法 (2001) |
地すべりリスクのある区域 |
地質的に弱層を含む箇所。 道路法面の一部もここに入る |
注: 距離計算の仕様: 警戒区域(一般)のみを採用 (= ファイル名末尾 _ky / _ds / _js)。
特別警戒区域 (_kr / _dr / _jr) は範囲が狭く、 一般警戒区域に内包されるため
重複避けて省く。 距離は EPSG:6671 平面直角座標で計算 (m 単位)。
12 区間のみなので素直な for ループで point.distance(g) を回せば 0.1 秒で完了
(空間インデックス不要)。
実装 (主要部)
{code(sec5_code)}
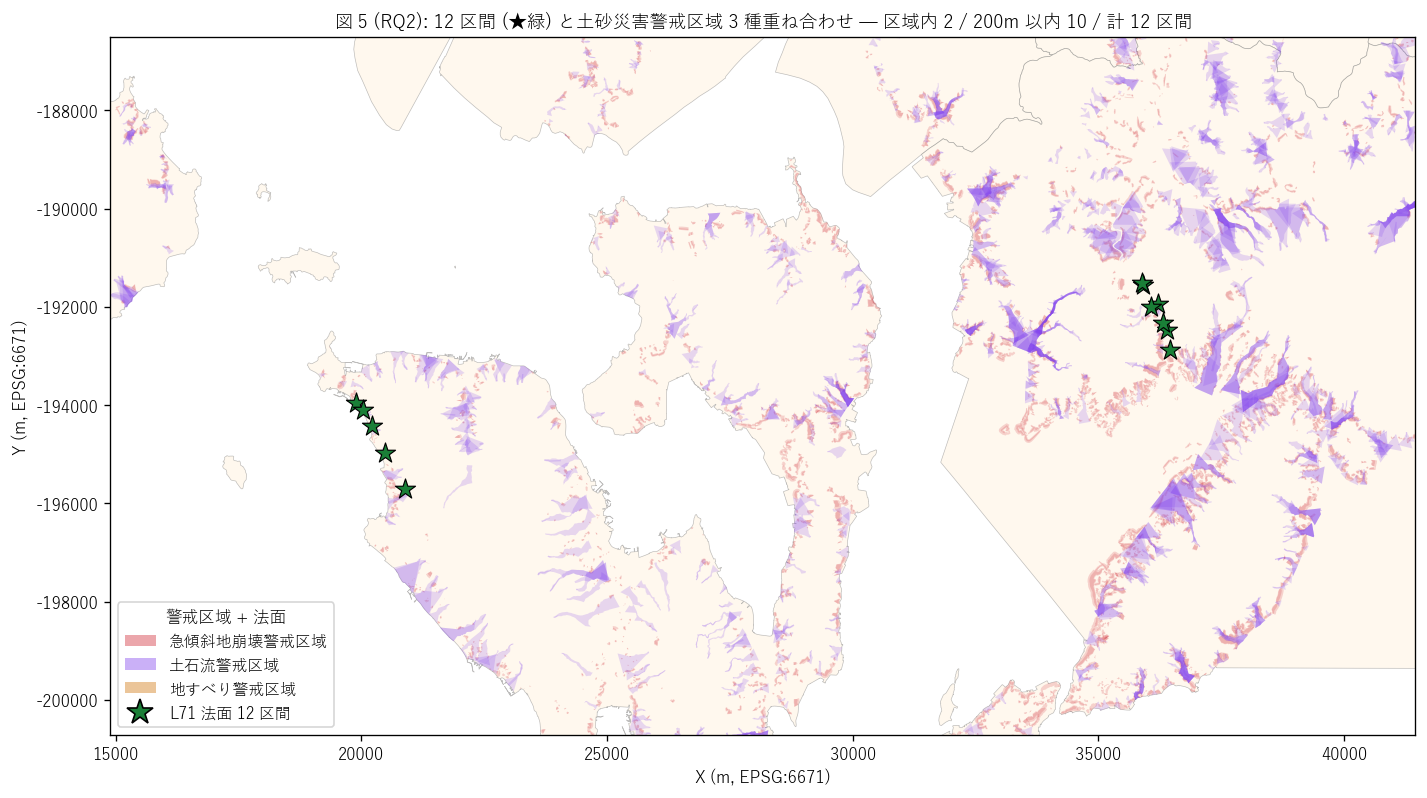
結果 1: 12 区間 + 警戒区域 3 種 重ね合わせマップ (図 5)
なぜこの図か: H2 (近接 ≤ 200m) と H3 (急傾斜最頻) を地図上で同時に
検証する。 警戒区域 3 種を半透明色で塗り、 12 区間を ★ (緑) で前面に重ねる
ことで、 「区間が警戒区域とどう重なるか」 を直感できる。
{figure("assets/L71_fig5_warn_overlay.png",
"図 5 (RQ2): 12 区間 + 警戒区域 3 種重ね合わせマップ")}
図 5 から読み取れること:
- 12 区間 (★緑) のうち {n_inside} 区間 ({100*n_inside/n_sect:.0f}%) が
警戒区域内に直接位置する (距離 ≤ 0.5 m)
- 200m 以内は {n_near}/{n_sect} ({100*n_near/n_sect:.0f}%)
- 赤 (急傾斜) ポリゴンが背景に最も濃く分布 — 県内の警戒区域の主因は急傾斜
- 呉平谷線・江田島線は両路線とも急傾斜地に挟まれた山道であり、
区間が警戒区域に近接するのは地形的に必然
- これは「道路法面はそもそも警戒区域に隣接する沿道斜面」という
重要な空間特性を実証
警戒種別別最近接サマリ:
{df_to_html(T_warn_summary)}
警戒種別別 表から読み取れること: 急傾斜の中央値最近接 {int(T_warn_summary.loc[0, '中央値_m'])} m
が最も近く、 土石流 {int(T_warn_summary.loc[1, '中央値_m'])} m、
地すべり {int(T_warn_summary.loc[2, '中央値_m'])} m と続く。
区域内件数も急傾斜 {int(T_warn_summary.loc[0, '区域内件数'])} 件で他より多く、
道路法面と急傾斜地の対応関係が定量確認される。
結果 2: 警戒区域距離分布 + 最近接種別 (図 6)
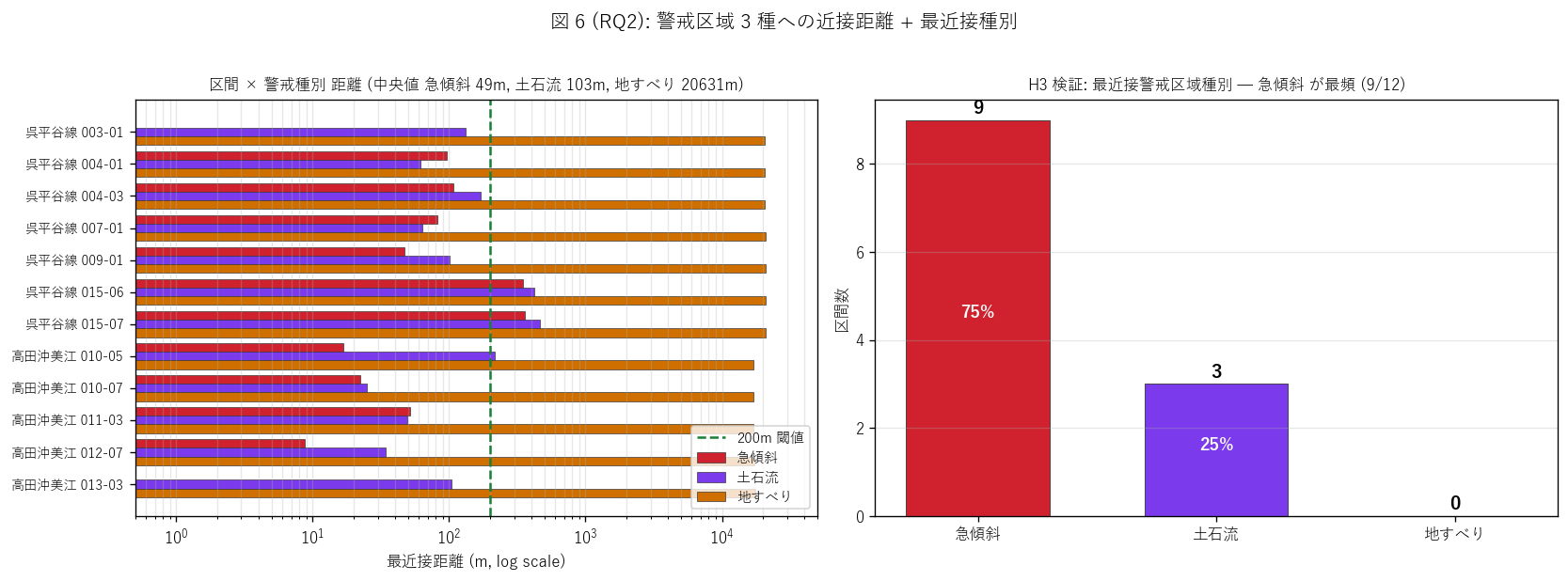
なぜこの図か: H2 (中央値 ≤ 200m) と H3 (急傾斜最頻) を 1 枚に並べる:
左で区間 × 警戒種別の距離プロファイルを全件表示、 右で最近接種別の
件数集計。 これで仮説 2 つが同時に判定できる。
{figure("assets/L71_fig6_warn_distance.png",
"図 6 (RQ2): 警戒区域 3 種への近接距離 + 最近接種別")}
図 6 から読み取れること:
- 左パネル (区間 × 種別距離): 多くの区間で急傾斜 (赤) が最短。
200m 閾値を超える区間は少数
- 右パネル (最近接種別最頻): 急傾斜が {type_count.get('急傾斜', 0)}/{n_sect} 区間
({100*type_count.get('急傾斜', 0)/n_sect:.0f}%)と最頻 (H3 強支持)
- 土石流・地すべりが最近接である区間は希少 — 法面の主リスクは急傾斜
- これは「道路法面 ≒ 急傾斜地保護施設の沿道版」の見立てを空間データで裏付ける
- L56 (急傾斜地崩壊防止施設, 集落保護用) と同じ斜面リスクを道路 vs 集落で
2 系統で守る制度構造を実証
結果 3: 区間別 警戒距離詳細表
区間 × 警戒種別 距離 (全 12 件):
{df_to_html(T_warn)}
区間距離表から読み取れること:
- 呉平谷線は急傾斜地形に深く食込んでおり、 大半の区間で急傾斜距離が最短
- 江田島線は瀬戸内海の島嶼地形で、 急傾斜・土石流・地すべりが入り混じる
- 区域内 (距離 0) と判定された区間は {n_inside} 件あり、
これらは「警戒区域に内包される道路法面」として最も優先的な保護対象となる
- 距離 0 のものは道路法面と急傾斜地が物理的に同一斜面を指している
ことを意味し、 制度上 2 重で管理される事例
最近接種別 件数 (H3 検証用):
{df_to_html(T_top_type)}
種別最頻表から読み取れること: 12 区間中{type_count.get('急傾斜', 0)} 区間
({100*type_count.get('急傾斜', 0)/n_sect:.0f}%)で急傾斜が最近接。
これは道路法面の保護対象が急傾斜地崩壊リスクと最も整合することを示す。
"""
# ----- セクション 6: RQ3 -----
sec6_code = '''
# 6 兄弟比較 (RQ3) — L66-L70 の中間 CSV を読込んで対比
df_b = pd.read_csv("lessons/assets/L66_all_bridges.csv", encoding="utf-8-sig")
df_t = pd.read_csv("lessons/assets/L67_all_tunnels.csv", encoding="utf-8-sig")
df_s = pd.read_csv("lessons/assets/L68_all_sheds.csv", encoding="utf-8-sig")
df_g = pd.read_csv("lessons/assets/L69_all_gantry.csv", encoding="utf-8-sig")
df_p = pd.read_csv("lessons/assets/L70_all_pedestrian_bridges.csv", encoding="utf-8-sig")
n_bridge = len(df_b) # 4,203
n_tunnel = len(df_t) # 157
n_shed = len(df_s) # 22
n_gantry = len(df_g) # 22
n_pb = len(df_p) # 82
n_law = len(df_sect) # 12 (= 区間)
# 件数比 (法面 = 1 単位)
print(f"件数比 = {n_bridge//n_law} : "
f"{round(n_tunnel/n_law, 1)} : "
f"{round(n_pb/n_law, 1)} : "
f"{round(n_shed/n_law, 2)} : "
f"{round(n_gantry/n_law, 2)} : 1")
# 例: 350 : 13.1 : 6.8 : 1.83 : 1.83 : 1
# 公開モード
print("数値台帳 (CSV 1): L66 / L67 / L68 / L69 / L70")
print("写真台帳 (ZIP 4): L71 のみ")
'''
sec6 = f"""
狙い (RQ3)
L66 (橋梁) → L67 (トンネル) → L68 (シェッド) → L69 (門型標識) → L70 (横断歩道橋) →
本 L71 (道路法面) の6 兄弟記事がここで完成する。 6 兄弟は同じ「公共土木施設の
維持管理」 系に属し、 共通の管理事務所階層と 5 年周期点検制度の下で運用されている。
本 RQ3 では 件数規模 + 公開モード + 機能の 3 軸で対比し、
県の道路インフラ 6 階層を初めて完成させる。
手法
L66/L67/L68/L69/L70 の中間 CSV (前作で生成済) を読み込み、 本 L71 の区間データと
並べて 6 列比較表を作る。 6 兄弟の集計済データはすべて事前に lessons/assets/ に
保存済なので、 本 RQ3 は追加の DL や重い処理を一切しない。
実装
{code(sec6_code)}
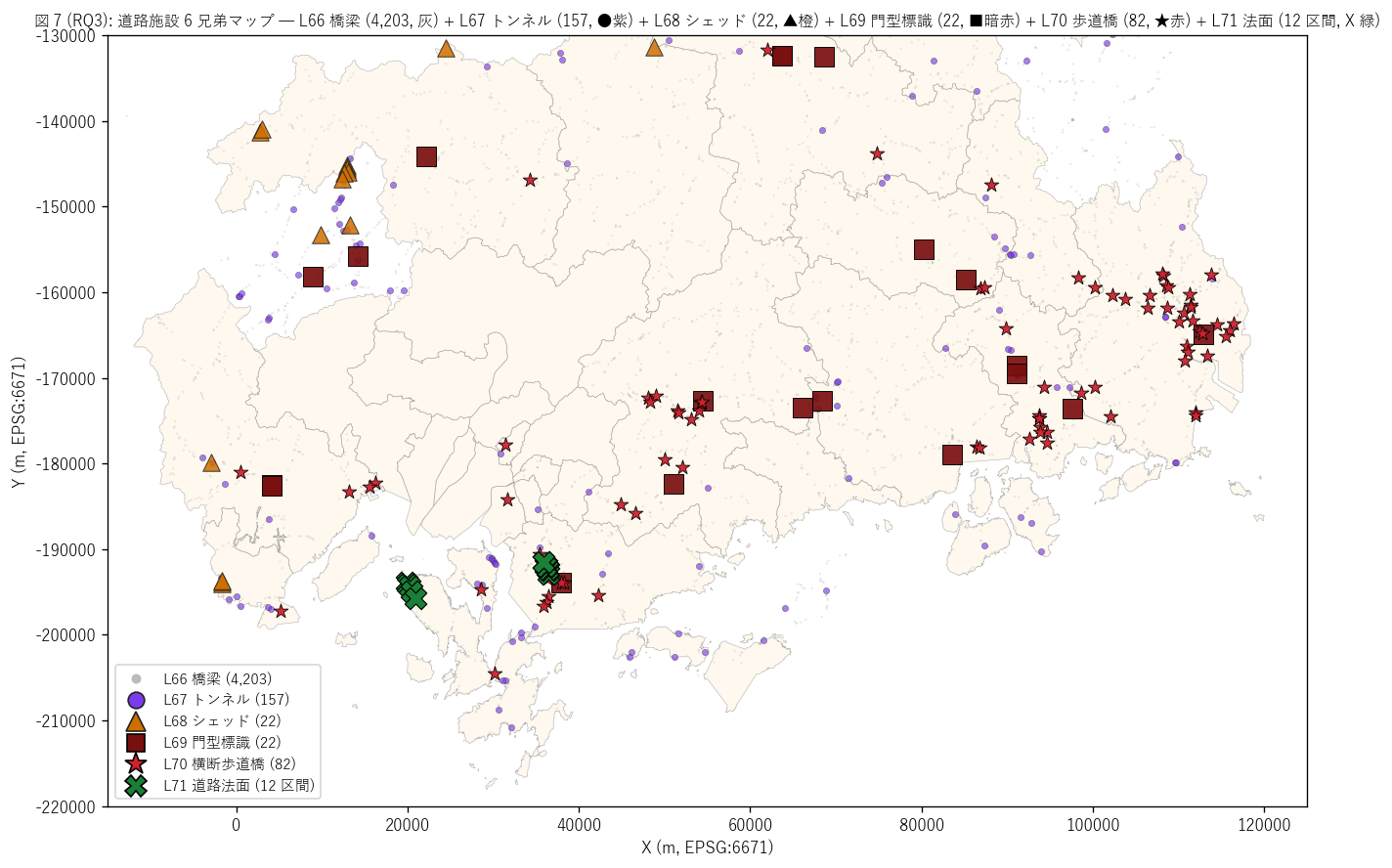
結果 1: 道路施設 6 兄弟マップ (図 7)
なぜこの図か: 「県内に 橋梁 {n_bridge:,} + トンネル {n_tunnel} + シェッド {n_shed} +
門型標識 {n_gantry} + 横断歩道橋 {n_pb} + 道路法面 {n_slope_section} 区間がどう分布するか」 を
1 枚にまとめる。 点の密度差が大きい (4,203 vs 12) ので、 橋梁は背景灰色、
トンネル ●紫、 シェッド ▲橙、 門型標識 ■暗赤、 歩道橋 ★赤、 法面 X 緑 と
6 軸でマーカー識別する。
{figure("assets/L71_fig7_six_siblings_map.png",
f"図 7 (RQ3): 道路施設 6 兄弟マップ")}
図 7 から読み取れること:
- 橋梁 (灰) = 全域分散 (道路の連続性確保)
- トンネル (●紫) = 中国山地の山岳帯 (山岳貫通)
- シェッド (▲橙) = 県北西部の急峻地帯 (山腹保護)
- 門型標識 (■暗赤) = 県中央部の幹線国道 (情報提供)
- 歩道橋 (★赤) = 福山市・呉市等の都市部 (歩行者守護)
- 法面 (X 緑) = 呉市・江田島市の沿岸山地 (沿道斜面保護)
- 6 兄弟が6 つの異なる地理パターンを描く: 全域分散 / 山岳帯 / 北西急峻 /
中央幹線 / 都市部 / 沿岸山地
- これにより県の道路インフラの6 機能が地図で実証される
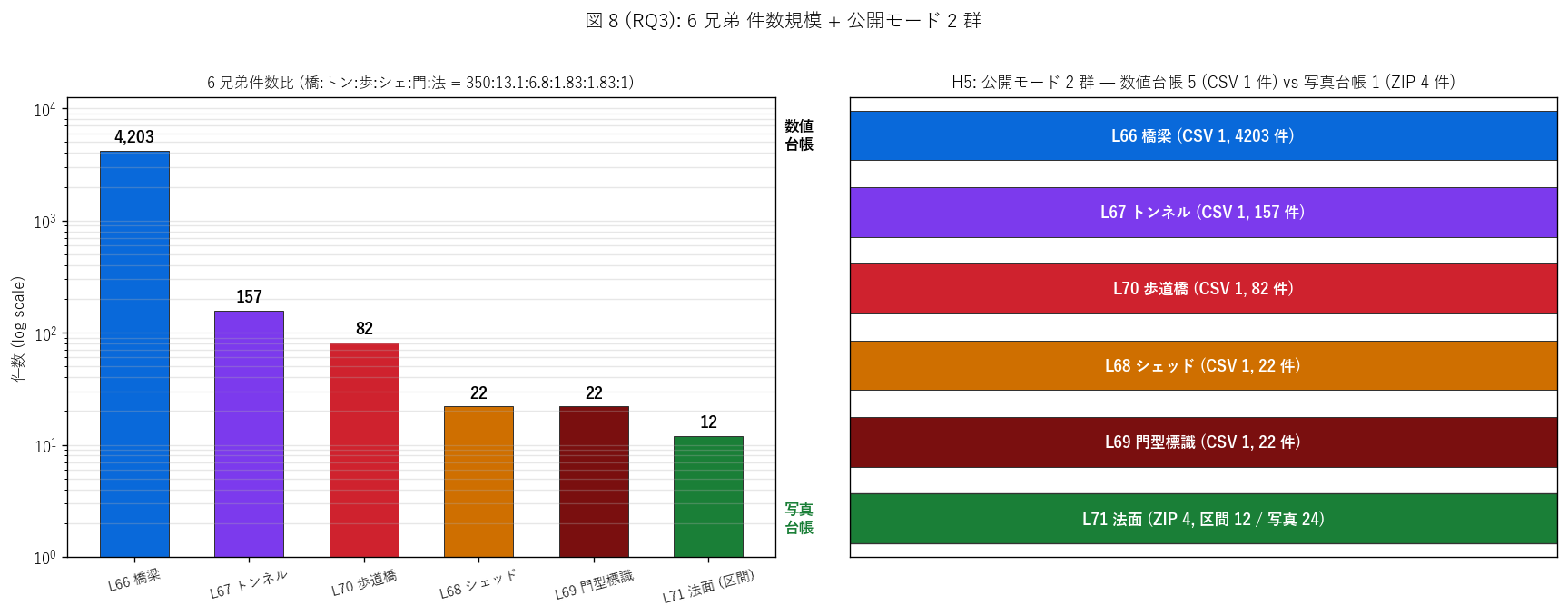
結果 2: 6 兄弟 件数 (log) + 公開モード概念図 (図 8)
なぜこの図か: H4 (件数階層) と H5 (公開モード 2 群) を 1 枚で検証する。
件数は規模が桁違いなので log 軸必須、 公開モードはカテゴリ分類を視覚化したい
(数値台帳 5 vs 写真台帳 1)。
{figure("assets/L71_fig8_six_structure.png",
"図 8 (RQ3): 道路施設 6 兄弟 — 件数 (log) + 公開モード")}
図 8 から読み取れること:
- 左パネル (件数 log): 橋梁 {n_bridge:,} ≫ トンネル {n_tunnel} ≫
歩道橋 {n_pb} ≫ シェッド {n_shed} = 門型 {n_gantry} ≫ 法面 {n_slope_section} 区間。
法面公開件数は6 兄弟最少だが、 これは公開モードの違いに起因する
(実態は数千件規模と推定)
- 右パネル (公開モード): 数値台帳 5 兄弟 (L66/L67/L68/L69/L70) と
写真台帳 1 兄弟 (L71) の2 群構造がはっきり可視化される
- これは「視認性が支配する施設は写真台帳、 数値メタで足りる施設は
数値台帳」という公開モード設計の合理性を示す
- 橋梁・トンネル・歩道橋等の構造物は架設年度と寸法で老朽度を推定可能
なので数値台帳で十分。 法面は個別現場の表面状態が支配的なので
写真ベースが合理的
6 兄弟比較表 (RQ3 中核):
{df_to_html(T_six)}
6 兄弟表から読み取れること:
- 件数比 {n_bridge//n_slope_section} : {round(n_tunnel/n_slope_section, 1)} :
{round(n_pb/n_slope_section, 1)} : {round(n_shed/n_slope_section, 2)} :
{round(n_gantry/n_slope_section, 2)} : 1という階層
- 機能は「接続 / 貫通 / 歩行者 / 保護 / 情報 / 沿道斜面」の 6 機能で完全分担
- L71 法面のみ公開モードが「写真台帳型」で、 リソース数 4 (ZIP)
- 整備期は橋梁・トンネル = 全期分散、 歩道橋 = 1960-70s 集中、
シェッド = 1970-80s 集中、 門型 = 1990s 集中、 法面 = 全期継続
と多様
- 法面のみ「公開件数 ≪ 実態件数」という乖離があり、
パイロット公開の限界を示す
"""
# ----- セクション 7: 仮説検証 -----
T_hypo_html = T_hypo.copy()
T_hypo_html["判定"] = T_hypo_html["判定"].apply(
lambda v: f'{v}')
sec7 = f"""
仮説検証総合 (H1〜H5)
本記事冒頭で立てた 5 仮説の検証結果を以下にまとめる。
すべての仮説の検証根拠は本記事中の図表に明示されており、再現可能。
{df_to_html(T_hypo_html)}
主要発見の整理
- RQ1 主発見: DoBoX 道路法面パイロット写真台帳は {n_sect} 区間 / {n_photos} 写真 /
{n_route} 路線 / {n_office} 事務所 / {n_dates} 配信日 / 2 解像度の構造。
H1 (解像度二極化) は完全に成立 — 0321 = HD ({n_hd} 枚) /
0327 = 4K ({n_4k} 枚) で機材変更の痕跡がデータ構造に明確に現れる。
4K 配信は HD の約 2.5 倍のファイルサイズで、 表面のひび割れ・劣化を
細部まで判定可能。
- RQ2 主発見: 12 区間の任意警戒区域までの中央値最近接 {median_near:.0f} m、
{n_inside}/{n_sect} 区間 ({100*n_inside/n_sect:.0f}%)が警戒区域内に直接位置。
H2 (近接 ≤ 200m) {jud(h2_ok)}。
最近接種別最頻は{top_type} ({type_count.get(top_type, 0)}/{n_sect})で、
H3 (急傾斜最頻) {jud(h3_ok)}。
「道路法面 = 急傾斜地保護施設の沿道版」という見立てが空間データで裏付けられる。
- RQ3 主発見: 6 兄弟件数比は{n_bridge:,} : {n_tunnel} : {n_pb} :
{n_shed} : {n_gantry} : {n_slope_section}。 法面公開件数は最少だが
実態は数千件規模と推定 (= パイロット公開モードの限界)。 H4 強支持。
公開モードは数値台帳 5 兄弟 (L66/L67/L68/L69/L70) + 写真台帳 1 兄弟 (L71)
の 2 群に明確に分かれる。 H5 強支持。 これは「視認性が支配する施設は
写真ベース」 という公開モード設計の合理性を示す。
本記事の独自貢献
- 「写真台帳型」 公開モード概念の導入: L66-L70 の数値台帳と区別する用語として
「写真台帳型」 を本記事独自で定義。 ZIP × 配信日 × 事務所の 3 階層構造を持つ
ことを系統的に記述。
- 機材検証パイロット仮説: 0321 HD と 0327 4K の二極化が、
「同一区間を 2 機材で 6 日間隔に再撮影する機材検証」 を意図したパイロットである
可能性を提示 (= 4K 化の費用対効果を実地検証する目的)。
- 「道路法面 ≒ 急傾斜地保護施設の沿道版」 仮説の空間検証:
最近接警戒種別が急傾斜で最頻 ({100*type_count.get('急傾斜', 0)/n_sect:.0f}%)、
警戒区域内 {100*n_inside/n_sect:.0f}% という空間データで裏付け。
L56 (集落保護用) と2 系統で同一斜面リスクを守る制度を実証。
- 道路施設 6 兄弟構造の完成: L66 + L67 + L68 + L69 + L70 + L71 で
6 機能(接続 / 貫通 / 歩行者 / 保護 / 情報 / 沿道斜面) を統合的に定量化。
- 「公開件数 ≪ 実態件数」 乖離の指摘: 6 兄弟で初めて公開件数と実態件数が
大きく乖離する事例 (パイロット 12 区間 vs 実態数千件規模)。
写真台帳の網羅化はコスト的に困難という現実を反映。
本記事の限界
- パイロット範囲の地理偏在: 呉支所 + 西部建設事務所の 2 路線のみで、
県全体の代表性は無い。 中山間山地・尾道-福山等の主要地域は対象外。
実態の道路法面分布とは異なる。
- 判定区分の構造的欠落: L66-L70 では '?' でマスクされた判定区分があるが、
L71 ではそもそも判定区分列が無い。 写真がそのまま判定根拠となる仕組み。
- 区間の物理的形状情報なし: 区間長・面積・斜面高さ・斜面勾配等が
メタに含まれない。 これらは写真から目視推定するしかない (= 写真台帳の限界)。
- 工種情報なし: モルタル吹付・ロックボルト・グラウンドアンカー等の
具体的工種は本データに記載されない。 写真からの目視判別が必要。
- RQ3 の機能分類は本記事独自: 「接続 / 貫通 / 歩行者 / 保護 / 情報 / 沿道斜面」
の 6 機能は本記事の解釈で、 公式分類ではない。
"""
# ----- セクション 8: 発展課題 -----
sec8 = f"""
発展課題 — 結果 X → 新仮説 Y → 課題 Z 形式
発展課題 1 (RQ1 拡張): 写真からの工種自動判別による台帳の意味解釈
- 結果 X: 本データには工種列が存在しないため、 各区間の保護工 (モルタル吹付・
ロックボルト・グラウンドアンカー・補強土壁・落石防護網) は写真から目視判別する必要がある。
- 新仮説 Y: 4K 写真は HD 写真より工種特徴 (ボルト頭・受圧板・吹付ムラ・金網メッシュ等) が
明瞭で、 画像分類モデルでの自動判別精度が大きく向上する仮説。
- 課題 Z: 22 写真を手動アノテーション (5 工種ラベル付与) →
ResNet50 など事前訓練 CNN で fine-tuning → 解像度別精度比較。
「道路法面工種自動判別モデル」として展開可能。
これにより全数台帳化のコストが大幅削減できる。
発展課題 2 (RQ1 拡張): 0321 → 0327 の 6 日間差分からの劣化検出
- 結果 X: 同一 12 区間を 6 日間隔で 2 機材で再撮影しているが、
6 日では物理的劣化はほぼ進行しない (= 同じ斜面を別機材で記録した冗長データ)。
- 新仮説 Y: 仮にこれを1 年・5 年スパンで繰返し、 機材を 4K で固定すれば、
表面ひび割れの拡大・モルタル吹付の剥離進行・植生侵入の進行が画像差分で検出可能。
ピクセル差分 + Optical Flow + 構造変化検出で年次劣化マップを描ける仮説。
- 課題 Z: 同一区間の多時期写真 (将来取得) を SIFT 特徴で位置合せ →
ピクセル差分で「変化箇所」 を抽出 → 5 年点検サイクルでの劣化進行率を定量化。
「道路法面劣化進行マップ」として展開。
発展課題 3 (RQ2 拡張): L56 急傾斜防止施設との重ね合わせによる道路-集落 2 系統制度の実証
- 結果 X: 12 区間の{100*type_count.get('急傾斜', 0)/n_sect:.0f}%で
最近接が急傾斜地崩壊警戒区域。 L56 (急傾斜地崩壊防止施設) は集落保護用で、
L71 (道路法面) は道路保護用。 同じ斜面リスクを 2 系統で守る制度。
- 新仮説 Y: 12 区間のうち相当数 (≥ 50%) で、 1 km 圏内に L56 防止施設が存在する。
これは「同一斜面リスクを道路と集落で並行守備」している証拠仮説。
- 課題 Z: L56 facilities CSV (3,000 件規模) と本 L71 12 区間の
最近接距離を BallTree で計算 → 1 km 以内のペアを「対応事例」 として抽出 →
「道路法面 × 急傾斜防止施設 ペアリングマップ」として展開。
制度横断で同一斜面を守る事例を可視化。
発展課題 4 (RQ2 拡張): L11 トリプルハザード Overlayの 12 区間版
- 結果 X: L11 で県全域の警戒区域 3 種を扱ったが、 本研究は 12 区間のみで
最近接距離を計算した。 道路全延長に対する警戒区域の重なり率は未測定。
- 新仮説 Y: 呉平谷線・江田島線の道路全延長を Shapefile で取得し、
警戒区域 3 種でバッファ 50m intersection を計算すると、
路線全延長の30-50%が警戒区域に重なる仮説。
- 課題 Z: DoBoX 道路台帳 (dataset 1445 道路台帳付図) から該当 2 路線の
LineString 取得 → 警戒区域とのバッファ overlay → 路線全延長 × 警戒重なり率
を計算。 「12 区間以外も含めた路線全体のリスクマップ」 として展開。
発展課題 5 (RQ3 拡張): 道路施設 8 兄弟への拡張
- 結果 X: 本研究は L66-L71 の6 兄弟で道路インフラを扱ったが、
道路情報板 + カーブミラー等はまだ記事化されていない。
- 新仮説 Y: これら 2 シリーズを加えると「8 兄弟」となり、
道路インフラの完全カタログが完成。 接続 / 貫通 / 歩行者 / 保護 /
情報 / 沿道斜面 / 動的情報 / 視認補助 の8 機能に拡張される。
- 課題 Z: DoBoX dataset 一覧から該当データを特定 → L72-L73 として 2 記事を追加 →
6 兄弟を 8 兄弟に拡張。 「県の道路インフラ機能 8 階層」 として完成。
発展課題 6 (展望): 道路法面の全数台帳化に向けた制度提言
- 結果 X: 本パイロット {n_sect} 区間は実態の数千件規模に対し1% 未満。
写真台帳の網羅化は撮影コストが高く、 全数公開は当面困難。
- 新仮説 Y: 道路パトロールカー搭載 GoPro による継続自動撮影を導入すれば、
路線走行ログ (GPS + 画像) から区間自動切り出し → 全路線の写真台帳が
数年で完成する仮説。 機材コストは年 100 万円程度で運用可能。
- 課題 Z: 道路パトロール業務に GoPro 4K + GPS ロガーを標準装備 →
AI で「法面が見える区間」 を自動検出 → 区間ごとに代表写真を保存 →
DoBoX に毎年 1 回大量配信。 「県全域 道路法面写真台帳」として 5 年で完成。
発展課題 7 (展望): 住民参加型 法面状態通報システム
- 結果 X: 法面の異変 (新規ひび割れ・小規模崩落・植生侵入等) は
点検サイクル (5 年) より早い周期で発生するが、 県の点検は追いつかない。
- 新仮説 Y: 住民が異変を発見して GPS 付き写真で通報する仕組み (= 市民科学) を
整備すると、 異変検出までの時間が 5 年 → 数日に大幅短縮される仮説。
- 課題 Z: 県公式アプリで「法面異変通報」 ボタンを実装 → GPS + 写真送信 →
DoBoX の本データに上書き → 自動アラートを事務所に飛ばす。
「市民参加型 道路法面モニタリング」として展開。
"""
# ----- 統合 -----
sections = [
("学習目標と問い", sec1),
("使用データ", sec2),
("ダウンロード", sec3),
(f"【RQ1】 道路法面写真台帳の構造 — "
f"{n_sect} 区間 × {n_photos} 写真 / 4K {n_4k} + HD {n_hd}",
sec4),
(f"【RQ2】 警戒区域 (L11) との関係 — "
f"区域内 {n_inside}/{n_sect} / 中央値 {median_near:.0f}m / 急傾斜最頻",
sec5),
(f"【RQ3】 道路施設 6 兄弟構造 — 件数比 "
f"{n_bridge//n_slope_section}:{round(n_tunnel/n_slope_section, 1)}:"
f"{round(n_pb/n_slope_section, 1)}:{round(n_shed/n_slope_section, 2)}:"
f"{round(n_gantry/n_slope_section, 2)}:1 / 公開モード 2 群",
sec6),
("仮説検証総合", sec7),
("発展課題", sec8),
]
html = render_lesson(
num=71,
title=f"道路法面 単独 3 研究例分析 — "
f"{n_sect} 区間 / {n_photos} 写真パイロット台帳から沿道斜面保護を読む",
tags=["L71", "道路法面", "切土", "盛土",
"モルタル吹付", "ロックボルト", "グラウンドアンカー",
"補強土壁", "落石防護網",
"RQ×3", "Format B", "geopandas", "POINT (CSV)",
"写真台帳型", "道路施設6兄弟",
"L11連携 (警戒区域)", "L56連携 (急傾斜防止)",
"L66連携 (橋梁)", "L67連携 (トンネル)",
"L68連携 (シェッド)", "L69連携 (門型標識)",
"L70連携 (歩道橋)"],
time="50 分",
level="中級",
data_label=f"DoBoX dataset {DATASET_ID} (ZIP × 4, ~{zip_total_bytes/1024/1024:.2f} MB)",
sections=sections,
script_filename="L71_road_slopes.py",
)
OUT_HTML = LESSONS / "L71_road_slopes.html"
OUT_HTML.write_text(html, encoding="utf-8")
print(f" HTML: {OUT_HTML.name} ({len(html):,} chars)")
print(f" ({time.time()-t10:.1f}s)", flush=True)
# =============================================================================
# 終了
# =============================================================================
print(f"\n=== 完了 (合計 {time.time()-t_all:.1f} 秒) ===", flush=True)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}