# -*- coding: utf-8 -*-
"""L68 シェッド基本情報・維持管理情報 単独 3 研究例分析
— 広島県内 22 シェッド (覆道) を 3 角度で解読
カバー宣言:
本記事は DoBoX のシリーズ「シェッド基本情報・維持管理情報」 1 件
(dataset_id = 13) を 単独で取り上げ、
広島県が管理する 道路シェッド (覆道) 全 22 件を
3 つの独立した研究角度 (RQ1 / RQ2 / RQ3) で並列に分析する。
「シェッド」 とは:
山腹道路を上から覆うことで落石・雪崩・崩土から道路を守る覆道。
日本の急峻な山岳道路特有のインフラで、トンネルが「貫通」 するのに対し、
シェッドは「上から覆う」 構造。本データは広島県管理の道路シェッドのみ
(国道 + 県道) を全件 (22 件) 収録。
道路法に基づき 5 年に 1 回の点検が義務化 (2014 年改正) され、
各シェッドに 施設番号 / 路線名 / 延長 / 幅員 / 建設年度 / 点検年度 /
判定区分などのメタデータが付随する。
本記事は L66 (橋梁単独) / L67 (トンネル単独) と厳密に区別:
L66 = 橋梁単独 4,203 件 (中小河川クロス, 平野・分散型)。
L67 = トンネル単独 157 件 + L66 との二極構造比較
(山岳貫通, 中山間・集中型)。
L68 = シェッド単独 22 件 + L66 + L67 との三層構造比較
(山腹通過, 急峻地形・希少型)。
三記事は補完関係で「県の道路保護階層」 の 3 つの軸を構成する。
研究の問い (3 RQ):
RQ1 (主研究): 広島県の道路シェッドの構造 — 種類・規模・地理分布はどう描けるか?
22 件を市町 × 事務所 × 道路種別 × 路線 × 延長 × 幅員 × 建設年代 × 種別
(落石覆道 / 雪崩覆道 / 一般洞門) で多角度に集計。
特に「県の覆道網」 の物理的形状を初めて定量化する。
RQ2 (副研究 1): シェッドの地形特性 — 急傾斜地・雪崩危険箇所との関係は
どう現れるか?
シェッド位置 vs 土砂災害警戒区域 (急傾斜 / 土石流, L11 既知) +
雪崩危険箇所 (L11 既知) との空間関係を sjoin で定量化、
「最も危険な道路区間」 を同定する。
シェッドが「危険箇所をピンポイントで覆う」 機能を実証する。
RQ3 (副研究 2): L66 橋梁 4,203 vs L67 トンネル 157 vs L68 シェッド 22 件
の道路保護三層構造はどう現れるか?
橋梁 (平野クロス) + トンネル (山岳貫通) + シェッド (山腹通過) の
階層を件数比 (191:7:1) + 規模 + 地形 + 整備年代で対比し、
県の道路インフラの保護階層を完成させる。
仮説 (5):
H1 (覆道種別の三分類, RQ1): シェッド 22 件は洞門 (一般落石覆道)が過半数を占め、
防雪トンネル (雪崩覆道) + ロックシェッド (落石覆道)がそれに次ぐ
三分類構造。施設名から種別を自動分類して検証。
H2 (中山間+山岳路線集中, RQ1): シェッドの80% 以上が中山間 9 市町の
国道 186/191/182号 + 山岳県道に集中。平野部にはほぼ存在しない仮説。
H3 (危険箇所近接, RQ2): シェッドの過半数が 500m 以内に
急傾斜地・土石流・雪崩のいずれかを持つ。
特に防雪覆道は雪崩危険箇所に近接する仮説。
シェッドが「危険箇所近傍をピンポイント保護」 を狙って配置されている仮説。
(注: シェッド点は道路上、警戒区域は斜面下方なので 200m よりは 500m 程度の
広めの近接判定が適切)
H4 (件数の三層比, RQ3): L66 橋梁 (4,203) / L67 トンネル (157) /
L68 シェッド (22) の件数比 ≒ 191 : 7 : 1。
「橋梁=網状多数、トンネル=希少大規模、シェッド=超希少特殊解」。
H5 (規模差, RQ3): シェッド平均延長は橋梁の数倍, トンネルの数分の一。
橋梁 ~19m → シェッド ~100m → トンネル ~360m の階段状規模で、
三層構造の中間に位置する仮説。
要件 S 準拠 (1 分以内完走):
- 全データ 22 件 / 16 列 → 超軽量
- POINT geometry (緯度経度から直接生成)
- L11 既存土砂・雪崩 Shapefile + L44 既キャッシュ admin_diss.gpkg を流用
- 重い前処理は無し。本スクリプト 1 本で完結 (~30 秒目標)
要件 T 準拠 (位置情報あり = 地図必須):
- RQ1: 県全域 種別マップ + 延長階級バブルマップ
- RQ2: シェッド × 土砂災害警戒区域 + 雪崩危険箇所 重ね合わせマップ
- RQ3: L66 橋梁 (背景) + L67 トンネル (中景) + L68 シェッド (前景) 三層マップ
要件 Q 準拠: 図 8 / 表 12+ (3 RQ × 多角度: 構造 / 地形 / 三層構造)
データ仕様:
- dataset 13: シェッド基本情報・維持管理情報 (CSV)
- 形式: CSV, 22 行 × 16 列
- 列: 施設番号, 施設名, 施設名(フリガナ), 種別 (= シェッドのみ), 路線名,
道路種別 (= 国道/県道), 建設年度, 延長(m), 幅員(m), 管理事務所名,
住所(県), 住所(市町), 緯度(10進数), 経度(10進数), 点検年度, 判定区分
- 種別: 全件 シェッド
- 道路種別: 国道 14 / 県道 8 (= 国道偏重)
- 緯度経度: 21/22 (1 件 = 16 番津浪洞門のみ欠損)
- 建設年度: 21/22 (1 件 = 22 番杉ノ泊防雪トンネルが "0" = 不明)
- 判定区分: 全件 "?" (= 公開データでは健全度判定値が伏せられている)
- ライセンス: クリエイティブ・コモンズ表示 (CC-BY)
メモリ対策: Figure ごとに plt.close('all') で確実に解放。
"""
from __future__ import annotations
import sys, time
from pathlib import Path
sys.path.insert(0, str(Path(__file__).parent))
from _common import ROOT, ASSETS, LESSONS, render_lesson, code, figure, ensure_dataset
import numpy as np
import pandas as pd
import geopandas as gpd
from shapely.geometry import Point
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.patches import Patch
from matplotlib.lines import Line2D
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
t_all = time.time()
print("=== L68 シェッド基本情報 単独 3 研究例分析 ===", flush=True)
# =============================================================================
# 0. 定数・パス
# =============================================================================
TARGET_CRS = "EPSG:6671" # JGD2011 平面直角第 III 系
DATA_DIR = ROOT / "data" / "extras" / "L68_sheds"
DATA_DIR.mkdir(parents=True, exist_ok=True)
LOCAL_CSV = DATA_DIR / "shed_basic.csv"
DATASET_ID = 13
ADMIN_GPKG = ROOT / "data" / "extras" / "L44_storm_surge" / "_cache" / "admin_diss.gpkg"
# 老朽閾値: 2024 年時点で築 50 年 = 1974 年以前建設
AGE_THRESHOLD_YEAR = 1974
# シェッドの「長尺」 閾値はトンネル (1000m) より低い (覆道は 100-300m が標準)
LONG_SHED_THRESHOLD = 150.0 # 延長 150m 以上 = 長尺シェッド
# 道路種別の色
ROAD_COLOR = {"国道": "#cf222e", "県道": "#0969da"}
# シェッド種別の三分類 (本記事独自定義)
# 施設名から自動推定
def classify_shed(name):
"""施設名からシェッド種別を 3 分類:
- 防雪 (雪崩覆道): 「防雪」 を含む
- ロックシェッド (明示的落石覆道): 「ロックシェッド」 を含む
- 洞門 (一般落石覆道): 残り (「洞門」 は古い呼称、現在は混用)
本記事の H1 検証用。"""
s = str(name)
if "防雪" in s:
return "防雪覆道 (雪崩対策)"
if "ロックシェッド" in s or "ロックシエツド" in s:
return "ロックシェッド (明示的落石対策)"
return "洞門 (一般落石覆道)"
SHED_TYPE_COLOR = {
"防雪覆道 (雪崩対策)": "#1a7f37", # 緑
"ロックシェッド (明示的落石対策)": "#cf222e", # 赤
"洞門 (一般落石覆道)": "#0969da", # 青
}
# 中山間 9 市町 (L67 と同定義)
CHUSANKAN_CITIES = {
"庄原市", "三次市", "北広島町", "安芸太田町", "神石高原町",
"世羅町", "府中市", "安芸高田市", "大崎上島町",
}
# CITY_CD → 市町名
CITY_NAME = {
101: "広島市中区", 102: "広島市東区", 103: "広島市南区", 104: "広島市西区",
105: "広島市安佐南区", 106: "広島市安佐北区", 107: "広島市安芸区", 108: "広島市佐伯区",
202: "呉市", 203: "竹原市", 204: "三原市", 205: "尾道市", 207: "福山市",
208: "府中市", 209: "三次市", 210: "庄原市", 211: "大竹市", 212: "東広島市",
213: "廿日市市", 214: "安芸高田市", 215: "江田島市",
302: "府中町", 304: "海田町", 307: "熊野町", 309: "坂町",
369: "安芸太田町", 462: "世羅町",
}
# 旧町村名 → 現市町名
LEGACY_TO_CURRENT = {
"加計町": "安芸太田町", "戸河内町": "安芸太田町", "筒賀村": "安芸太田町",
"小方町": "大竹市",
"君田町": "三次市",
}
# シェッド近接判定の半径 (m)
# 200m は厳密だが、シェッドは道路上、警戒区域は斜面下方なので
# 実務的には 500m 程度の広めの判定が適切
PROXIMITY_BUFFER_M = 500.0
def parse_city_from_addr(addr):
"""住所から市町名抽出 (L67 と同方式の簡略版)。"""
if pd.isna(addr):
return "?"
s = str(addr)
# 「広島県」 接頭辞除去
s = s.replace("広島県", "").strip()
# 全角空白で先頭分割
head = s.split(" ")[0].strip()
# 「市町」 で終わる先頭ワードを探す
for current in ["広島市", "呉市", "竹原市", "三原市", "尾道市", "福山市",
"府中市", "三次市", "庄原市", "大竹市", "東広島市", "廿日市市",
"安芸高田市", "江田島市"]:
if head.startswith(current):
return current
if head in LEGACY_TO_CURRENT:
return LEGACY_TO_CURRENT[head]
for legacy, cur in LEGACY_TO_CURRENT.items():
if head.startswith(legacy):
return cur
if head.startswith("北広島町"):
return "北広島町"
if head.startswith("安芸太田町"):
return "安芸太田町"
if head.startswith("神石高原町"):
return "神石高原町"
if head.startswith("世羅町"):
return "世羅町"
if head.startswith("大崎上島町"):
return "大崎上島町"
if head.startswith("府中町"):
return "府中町"
if head.startswith("海田町"):
return "海田町"
if head.startswith("熊野町"):
return "熊野町"
if head.startswith("坂町"):
return "坂町"
return head
# =============================================================================
# 1. データ取得 + 読込
# =============================================================================
print("\n[1] データ取得 + 読込", flush=True)
t1 = time.time()
if not LOCAL_CSV.exists() or LOCAL_CSV.stat().st_size < 100:
try:
ensure_dataset(LOCAL_CSV, dataset_id=DATASET_ID, label="L68 シェッド基本情報")
except Exception as e:
print(f" WARN: ensure_dataset 失敗: {e}", flush=True)
df_raw = pd.read_csv(LOCAL_CSV, encoding="utf-8-sig")
print(f" 全行数: {len(df_raw)}, 列数: {df_raw.shape[1]}", flush=True)
print(f" 列: {list(df_raw.columns)}", flush=True)
# 数値正規化
df_raw["建設年度"] = pd.to_numeric(df_raw["建設年度"], errors="coerce")
# "0" は不明
df_raw.loc[df_raw["建設年度"] <= 1800, "建設年度"] = np.nan
df_raw["延長(m)"] = pd.to_numeric(df_raw["延長(m)"], errors="coerce")
df_raw["幅員(m)"] = pd.to_numeric(df_raw["幅員(m)"], errors="coerce")
df_raw["緯度(10進数)"] = pd.to_numeric(df_raw["緯度(10進数)"], errors="coerce")
df_raw["経度(10進数)"] = pd.to_numeric(df_raw["経度(10進数)"], errors="coerce")
df_raw["点検年度"] = pd.to_numeric(df_raw["点検年度"], errors="coerce")
# 種別自動分類 + 市町名正規化
df_raw["シェッド種別"] = df_raw["施設名"].apply(classify_shed)
df_raw["市町名"] = df_raw["住所(市町)"].apply(parse_city_from_addr)
n_total = len(df_raw)
n_year = int(df_raw["建設年度"].notna().sum())
n_coord = int((df_raw["緯度(10進数)"].notna() & df_raw["経度(10進数)"].notna()).sum())
n_kuni = int((df_raw["道路種別"] == "国道").sum())
n_ken = int((df_raw["道路種別"] == "県道").sum())
print(f" 建設年度有: {n_year} / {n_total}", flush=True)
print(f" 緯度経度有: {n_coord} / {n_total}", flush=True)
print(f" 道路種別: 国道 {n_kuni} / 県道 {n_ken}", flush=True)
print(f" シェッド種別: {df_raw['シェッド種別'].value_counts().to_dict()}", flush=True)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 2. POINT geometry 構築 + 投影
# =============================================================================
print("\n[2] POINT geometry 構築", flush=True)
t2 = time.time()
geom_ok = (df_raw["緯度(10進数)"].notna() & df_raw["経度(10進数)"].notna())
df_geom = df_raw[geom_ok].copy()
df_geom["geometry"] = df_geom.apply(
lambda r: Point(float(r["経度(10進数)"]), float(r["緯度(10進数)"])), axis=1)
gdf = gpd.GeoDataFrame(df_geom, geometry="geometry", crs="EPSG:4326").to_crs(TARGET_CRS)
n_geom = len(gdf)
print(f" POINT 構築: {n_geom} / {n_total}", flush=True)
print(f" ({time.time()-t2:.1f}s)", flush=True)
# =============================================================================
# 3. 市町同定 (sjoin で検証 + テキストと整合)
# =============================================================================
print("\n[3] 市町同定", flush=True)
t3 = time.time()
admin = gpd.read_file(ADMIN_GPKG).to_crs(TARGET_CRS)
joined = gpd.sjoin(gdf[["geometry"]], admin[["CITY_CD", "geometry"]],
how="left", predicate="within")
joined = joined[~joined.index.duplicated(keep="first")]
gdf = gdf.reset_index(drop=True)
gdf["CITY_CD"] = joined.reset_index(drop=True)["CITY_CD"].fillna(-1).astype(int)
gdf["市町名_sjoin"] = gdf["CITY_CD"].map(CITY_NAME).fillna("?")
# 未マッチは最近隣市町
unmatched_mask = gdf["CITY_CD"] == -1
n_unmatched = int(unmatched_mask.sum())
if n_unmatched > 0:
adm_idx = admin.set_index("CITY_CD")
for idx in gdf.index[unmatched_mask]:
pt = gdf.geometry.iloc[idx]
dists = adm_idx.geometry.apply(lambda g: pt.distance(g))
nearest_cc = int(dists.idxmin())
gdf.at[idx, "CITY_CD"] = nearest_cc
gdf.at[idx, "市町名_sjoin"] = CITY_NAME.get(nearest_cc, str(nearest_cc))
# テキスト由来市町名を主に採用 (sjoin は検証用)
print(f" sjoin 直接一致: {n_geom - n_unmatched} / {n_geom}", flush=True)
print(f" 最近隣補完: {n_unmatched} / {n_geom}", flush=True)
print(f" ({time.time()-t3:.1f}s)", flush=True)
# =============================================================================
# 4. RQ1 集計: 構造・規模・地理分布
# =============================================================================
print("\n[4] RQ1 集計", flush=True)
t4 = time.time()
kuni_share = 100 * n_kuni / n_total
ken_share = 100 * n_ken / n_total
# 種別件数
type_count = df_raw["シェッド種別"].value_counts()
T_type = pd.DataFrame({
"シェッド種別": type_count.index,
"件数": type_count.values,
"シェア_%": (type_count.values / n_total * 100).round(1),
"平均延長_m": [round(df_raw[df_raw["シェッド種別"] == k]["延長(m)"].mean(), 1)
for k in type_count.index],
})
# 道路種別 サマリ
T_road = pd.DataFrame({
"道路種別": ["国道", "県道", "合計"],
"件数": [n_kuni, n_ken, n_total],
"シェア_%": [round(100 * n_kuni / n_total, 1),
round(100 * n_ken / n_total, 1), 100.0],
"平均延長_m": [round(df_raw[df_raw["道路種別"] == "国道"]["延長(m)"].mean(), 1),
round(df_raw[df_raw["道路種別"] == "県道"]["延長(m)"].mean(), 1),
round(df_raw["延長(m)"].mean(), 1)],
"平均幅員_m": [round(df_raw[df_raw["道路種別"] == "国道"]["幅員(m)"].mean(), 2),
round(df_raw[df_raw["道路種別"] == "県道"]["幅員(m)"].mean(), 2),
round(df_raw["幅員(m)"].mean(), 2)],
})
# 市町別ランキング
city_count = (df_raw.groupby("市町名").size()
.reset_index(name="件数")
.sort_values("件数", ascending=False)
.reset_index(drop=True))
city_count["順位"] = np.arange(1, len(city_count) + 1)
city_count = city_count[["順位", "市町名", "件数"]]
# 中山間集中度
chusankan_mask = df_raw["市町名"].isin(CHUSANKAN_CITIES)
n_chusankan = int(chusankan_mask.sum())
chusankan_share = 100 * n_chusankan / n_total
# 管理事務所別
office_count = df_raw["管理事務所名"].value_counts()
T_office = pd.DataFrame({
"順位": np.arange(1, len(office_count) + 1),
"管理事務所名": office_count.index,
"件数": office_count.values,
"シェア_%": (office_count.values / n_total * 100).round(1),
})
# 路線別
route_count = df_raw["路線名"].value_counts()
T_route = pd.DataFrame({
"順位": np.arange(1, len(route_count) + 1),
"路線名": route_count.index,
"件数": route_count.values,
"シェア_%": (route_count.values / n_total * 100).round(1),
})
# 長尺シェッド
n_long = int((df_raw["延長(m)"] >= LONG_SHED_THRESHOLD).sum())
print(f" 国道シェア: {kuni_share:.1f}%", flush=True)
print(f" 中山間 9 市町シェア: {chusankan_share:.1f}%", flush=True)
print(f" 長尺シェッド (≥{LONG_SHED_THRESHOLD:.0f}m): {n_long} 件", flush=True)
print(f" ({time.time()-t4:.1f}s)", flush=True)
# =============================================================================
# 5. RQ2 集計: 危険箇所 (土砂・雪崩) との空間関係
# =============================================================================
print("\n[5] RQ2 集計: 危険箇所近接判定", flush=True)
t5 = time.time()
SED_DIR = ROOT / "data" / "extras" / "sediment_shp"
AVA_DIR = ROOT / "data" / "extras" / "avalanche_shp"
# シェッド POINT を 200m バッファ
gdf_buf = gdf.copy()
gdf_buf["geometry"] = gdf_buf.geometry.buffer(PROXIMITY_BUFFER_M)
# 急傾斜・土石流 ポリゴン
print(" 土砂災害 Shapefile 読込 ...", flush=True)
kyukei = gpd.read_file(
SED_DIR / "kyukeisha" / "340006_sediment_disaster_hazard_area_steep_slope_20260427"
/ "73_031krp_34_20260427.shp").to_crs(TARGET_CRS)
doseki = gpd.read_file(
SED_DIR / "doseki" / "340006_sediment_disaster_hazard_area_debris_flow_20260427"
/ "73_031drp_34_20260427.shp").to_crs(TARGET_CRS)
print(f" 急傾斜: {len(kyukei)} polygons, 土石流: {len(doseki)} polygons", flush=True)
# 雪崩危険箇所
print(" 雪崩 Shapefile 読込 ...", flush=True)
ava = gpd.read_file(
AVA_DIR / "340006_avalanche_danger_point_20260427"
/ "74_34_20260427.shp").to_crs(TARGET_CRS)
print(f" 雪崩: {len(ava)}", flush=True)
# 各シェッドが 200m 以内にこれらを含むかを判定
# sjoin (predicate='intersects') で buffer × hazard
def has_hazard_within(gdf_buf, hazard_gdf):
"""gdf_buf の各バッファに hazard_gdf が交差するかを bool 配列で返す。"""
j = gpd.sjoin(gdf_buf[["geometry"]].reset_index(),
hazard_gdf[["geometry"]],
how="inner", predicate="intersects")
hit = set(j["index"].tolist())
return np.array([i in hit for i in range(len(gdf_buf))])
print(" 急傾斜 sjoin ...", flush=True)
near_kyukei = has_hazard_within(gdf_buf, kyukei)
print(f" 急傾斜 {PROXIMITY_BUFFER_M:.0f}m 以内: "
f"{int(near_kyukei.sum())} / {n_geom}", flush=True)
print(" 土石流 sjoin ...", flush=True)
near_doseki = has_hazard_within(gdf_buf, doseki)
print(f" 土石流 {PROXIMITY_BUFFER_M:.0f}m 以内: "
f"{int(near_doseki.sum())} / {n_geom}", flush=True)
print(" 雪崩 sjoin ...", flush=True)
near_ava = has_hazard_within(gdf_buf, ava)
print(f" 雪崩 {PROXIMITY_BUFFER_M:.0f}m 以内: "
f"{int(near_ava.sum())} / {n_geom}", flush=True)
gdf["near_急傾斜"] = near_kyukei
gdf["near_土石流"] = near_doseki
gdf["near_雪崩"] = near_ava
gdf["hazard_count"] = (near_kyukei.astype(int) + near_doseki.astype(int)
+ near_ava.astype(int))
# 危険スコア: 0 = 安全, 1-3 = 接する種類数
n_any_hazard = int((gdf["hazard_count"] >= 1).sum())
n_double_hazard = int((gdf["hazard_count"] >= 2).sum())
n_triple_hazard = int((gdf["hazard_count"] >= 3).sum())
# 種別 × 雪崩近接 (H3 検証)
df_raw_with_hazard = df_raw.copy()
# gdf は 21 件、df_raw は 22 件 (1 件は緯度経度欠損)
# gdf は施設番号でリンク
gdf_idx_to_row = dict(zip(gdf["施設番号"].astype(str), gdf.index))
df_raw_with_hazard["near_急傾斜"] = df_raw_with_hazard["施設番号"].astype(str).map(
lambda k: gdf.loc[gdf_idx_to_row[k], "near_急傾斜"] if k in gdf_idx_to_row else False)
df_raw_with_hazard["near_土石流"] = df_raw_with_hazard["施設番号"].astype(str).map(
lambda k: gdf.loc[gdf_idx_to_row[k], "near_土石流"] if k in gdf_idx_to_row else False)
df_raw_with_hazard["near_雪崩"] = df_raw_with_hazard["施設番号"].astype(str).map(
lambda k: gdf.loc[gdf_idx_to_row[k], "near_雪崩"] if k in gdf_idx_to_row else False)
df_raw_with_hazard["hazard_count"] = (df_raw_with_hazard["near_急傾斜"].astype(int)
+ df_raw_with_hazard["near_土石流"].astype(int)
+ df_raw_with_hazard["near_雪崩"].astype(int))
# 種別 × 雪崩近接クロス
type_hazard_cross = (df_raw_with_hazard.groupby(["シェッド種別"])
.agg(件数=("施設番号", "size"),
急傾斜近接=("near_急傾斜", "sum"),
土石流近接=("near_土石流", "sum"),
雪崩近接=("near_雪崩", "sum"))
.reset_index())
type_hazard_cross["急傾斜_%"] = (100 * type_hazard_cross["急傾斜近接"]
/ type_hazard_cross["件数"]).round(1)
type_hazard_cross["土石流_%"] = (100 * type_hazard_cross["土石流近接"]
/ type_hazard_cross["件数"]).round(1)
type_hazard_cross["雪崩_%"] = (100 * type_hazard_cross["雪崩近接"]
/ type_hazard_cross["件数"]).round(1)
# 各シェッドの危険サマリ表 (全 22 件)
T_hazard_per_shed = df_raw_with_hazard[
["施設番号", "施設名", "シェッド種別", "道路種別", "路線名",
"市町名", "延長(m)",
"near_急傾斜", "near_土石流", "near_雪崩", "hazard_count"]
].copy()
T_hazard_per_shed = T_hazard_per_shed.sort_values(
["hazard_count", "延長(m)"], ascending=[False, False]).reset_index(drop=True)
# 建設年代
df_raw["年代"] = (df_raw["建設年度"] // 10 * 10).astype("Int64")
decade_count = df_raw["年代"].value_counts().sort_index()
decade_df = pd.DataFrame({
"年代": [f"{int(d)}s" for d in decade_count.index],
"件数": decade_count.values,
"シェア_%": (decade_count.values / decade_count.sum() * 100).round(1),
})
print(f" ({time.time()-t5:.1f}s)", flush=True)
# =============================================================================
# 6. RQ3 集計: 橋梁 (L66) + トンネル (L67) との三層構造
# =============================================================================
print("\n[6] RQ3 集計: 道路保護三層構造", flush=True)
t6 = time.time()
L66_CSV = ASSETS / "L66_all_bridges.csv"
L67_CSV = ASSETS / "L67_all_tunnels.csv"
df_bridge = pd.read_csv(L66_CSV, encoding="utf-8-sig") if L66_CSV.exists() else None
df_tunnel = pd.read_csv(L67_CSV, encoding="utf-8-sig") if L67_CSV.exists() else None
has_bridge = df_bridge is not None
has_tunnel = df_tunnel is not None
print(f" L66 橋梁: {'読込 OK ' + str(len(df_bridge)) + ' 件' if has_bridge else '未取得'}",
flush=True)
print(f" L67 トンネル: {'読込 OK ' + str(len(df_tunnel)) + ' 件' if has_tunnel else '未取得'}",
flush=True)
n_bridge = int(len(df_bridge)) if has_bridge else 4203
n_tunnel = int(len(df_tunnel)) if has_tunnel else 157
mean_b = float(df_bridge["延長(m)"].mean()) if has_bridge else 19.0
mean_t = float(df_tunnel["延長(m)"].mean()) if has_tunnel else 360.0
mean_s = float(df_raw["延長(m)"].mean())
med_b = float(df_bridge["延長(m)"].median()) if has_bridge else 7.0
med_t = float(df_tunnel["延長(m)"].median()) if has_tunnel else 280.0
med_s = float(df_raw["延長(m)"].median())
ratio_bs = n_bridge / n_total # 橋梁:シェッド
ratio_ts = n_tunnel / n_total # トンネル:シェッド
ratio_bt = n_bridge / n_tunnel # 橋梁:トンネル
# 三層構造比較表
T_three = pd.DataFrame([
("件数", f"{n_bridge:,}", f"{n_tunnel:,}", f"{n_total}",
f"比 = {n_bridge//n_total} : {round(n_tunnel/n_total)} : 1"),
("平均延長_m", f"{mean_b:.1f}", f"{mean_t:.1f}", f"{mean_s:.1f}",
f"段階差: 橋 {mean_b:.0f} < シェ {mean_s:.0f} < トン {mean_t:.0f}"),
("中央値_m", f"{med_b:.1f}", f"{med_t:.1f}", f"{med_s:.1f}",
f"中央値も 3 層差あり"),
("最長_m",
f"{df_bridge['延長(m)'].max():.0f}" if has_bridge else "?",
f"{df_tunnel['延長(m)'].max():.0f}" if has_tunnel else "?",
f"{df_raw['延長(m)'].max():.0f}",
"シェッドの最長は 322m (滝山洞門上) で長大とは別格"),
("国道シェア_%",
f"{100*(df_bridge['道路種別']=='国道').sum()/n_bridge:.1f}" if has_bridge else "27.4",
f"{100*(df_tunnel['道路種別']=='国道').sum()/n_tunnel:.1f}" if has_tunnel else "52.9",
f"{kuni_share:.1f}",
"シェッドは国道偏重 (急峻峠の幹線保護)"),
("地形対象", "中小河川クロス", "山岳貫通", "山腹通過 (急傾斜・雪崩)",
"三層: 平野・山岳・山腹"),
("機能", "道路の連続性 (橋渡し)",
"山岳バイパス (貫通)",
"落石・雪崩・崩土からの保護 (覆い)",
"保護の方向性が異なる"),
], columns=["指標", "L66 橋梁 (4,203)", "L67 トンネル (157)",
"L68 シェッド (22)", "三層構造の意味"])
# シェッド延長 Top 10
T_long_shed = (df_raw.sort_values("延長(m)", ascending=False).head(10)
.reset_index(drop=True))
T_long_shed_show = T_long_shed[
["施設名", "シェッド種別", "路線名", "道路種別",
"延長(m)", "幅員(m)", "建設年度", "市町名"]].copy()
T_long_shed_show.insert(0, "順位", np.arange(1, len(T_long_shed_show) + 1))
T_long_shed_show["建設年度"] = T_long_shed_show["建設年度"].apply(
lambda v: int(v) if pd.notna(v) else None)
print(f" 橋梁:トンネル:シェッド = {n_bridge:,} : {n_tunnel} : {n_total}",
flush=True)
print(f" 橋梁:シェッド = {ratio_bs:.0f} : 1, "
f"トンネル:シェッド = {ratio_ts:.0f} : 1", flush=True)
print(f" ({time.time()-t6:.1f}s)", flush=True)
# =============================================================================
# 7. CSV 出力
# =============================================================================
print("\n[7] CSV 出力", flush=True)
t7 = time.time()
# 全シェッド + 派生フラグ
df_out = df_raw_with_hazard.copy()
df_out["is_old"] = df_out["建設年度"] <= AGE_THRESHOLD_YEAR
df_out["is_long"] = df_out["延長(m)"] >= LONG_SHED_THRESHOLD
df_out["地形分類"] = np.where(df_out["市町名"].isin(CHUSANKAN_CITIES),
"中山間 (9 市町)", "平野・沿岸 (13 市町)")
cols_keep = ["施設番号", "施設名", "シェッド種別", "種別", "路線名", "道路種別",
"建設年度", "延長(m)", "幅員(m)", "管理事務所名",
"住所(県)", "住所(市町)", "市町名",
"緯度(10進数)", "経度(10進数)",
"点検年度", "判定区分",
"near_急傾斜", "near_土石流", "near_雪崩", "hazard_count",
"is_old", "is_long", "地形分類"]
df_out[cols_keep].to_csv(ASSETS / "L68_all_sheds.csv",
index=False, encoding="utf-8-sig")
T_type.to_csv(ASSETS / "L68_type_summary.csv", index=False, encoding="utf-8-sig")
T_road.to_csv(ASSETS / "L68_road_summary.csv", index=False, encoding="utf-8-sig")
city_count.to_csv(ASSETS / "L68_city_ranking.csv", index=False, encoding="utf-8-sig")
T_office.to_csv(ASSETS / "L68_office_ranking.csv", index=False, encoding="utf-8-sig")
T_route.to_csv(ASSETS / "L68_route_ranking.csv", index=False, encoding="utf-8-sig")
decade_df.to_csv(ASSETS / "L68_decade_count.csv", index=False, encoding="utf-8-sig")
type_hazard_cross.to_csv(ASSETS / "L68_type_x_hazard.csv",
index=False, encoding="utf-8-sig")
T_hazard_per_shed.to_csv(ASSETS / "L68_per_shed_hazard.csv",
index=False, encoding="utf-8-sig")
T_three.to_csv(ASSETS / "L68_three_layer.csv",
index=False, encoding="utf-8-sig")
T_long_shed_show.to_csv(ASSETS / "L68_long_sheds.csv",
index=False, encoding="utf-8-sig")
print(f" ({time.time()-t7:.1f}s)", flush=True)
# =============================================================================
# 8. 図の生成 (8 図)
# =============================================================================
print("\n[8] 図の生成", flush=True)
t8 = time.time()
def save_fig(name, dpi=120):
p = ASSETS / name
plt.savefig(p, dpi=dpi, bbox_inches="tight", facecolor="white")
plt.close('all')
return p
admin_for_plot = admin.copy()
admin_for_plot["市町名"] = admin_for_plot["CITY_CD"].map(CITY_NAME).fillna(
admin_for_plot["CITY_CD"].astype(str))
# ---- 図 1 (RQ1): 県全域 シェッド種別マップ ----
print(" fig1: 県全域 種別マップ", flush=True)
fig, ax = plt.subplots(figsize=(11.5, 7.5))
admin_for_plot.plot(ax=ax, color="#fff4e0", edgecolor="#888",
linewidth=0.4, alpha=0.6)
for stype, color in SHED_TYPE_COLOR.items():
sub = gdf[gdf["シェッド種別"] == stype]
if len(sub) == 0:
continue
sub.plot(ax=ax, color=color, markersize=85, marker="^",
edgecolor="#222", linewidth=0.5, alpha=0.9, zorder=3)
ax.set_xlim(-15000, 125000)
ax.set_ylim(-220000, -130000)
ax.set_aspect("equal")
ax.set_title(f"図 1 (RQ1): 広島県 道路シェッド 全域マップ — 全 {n_total} 件 / "
f"国道 {n_kuni} + 県道 {n_ken} (1 件は緯度経度欠損)",
fontsize=12)
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
patches = [Line2D([0], [0], marker='^', color='w',
markerfacecolor=SHED_TYPE_COLOR[k], markeredgecolor="#222",
markersize=12,
label=f"{k} (n={int((df_raw['シェッド種別']==k).sum())})")
for k in SHED_TYPE_COLOR]
ax.legend(handles=patches, loc="lower left", fontsize=10, title="シェッド種別")
plt.tight_layout()
save_fig("L68_fig1_overview_type_map.png")
# ---- 図 2 (RQ1): 市町別ランキング + 路線別 ----
print(" fig2: 市町 + 路線別", flush=True)
fig, axes = plt.subplots(1, 2, figsize=(14, 5.5))
ax = axes[0]
top_cities = city_count.iloc[::-1]
ys = np.arange(len(top_cities))
city_colors = ["#0969da" if c in CHUSANKAN_CITIES else "#cf922e"
for c in top_cities["市町名"].values]
ax.barh(ys, top_cities["件数"].values,
color=city_colors, edgecolor="#333", linewidth=0.5)
for y, v in zip(ys, top_cities["件数"].values):
ax.text(v + 0.05, y, f"{v}", va="center", fontsize=10)
ax.set_yticks(ys)
ax.set_yticklabels(top_cities["市町名"].values, fontsize=10)
ax.set_xlabel("件数")
ax.set_title("市町別 シェッド件数\n(青 = 中山間 9 市町, 橙 = 平野・沿岸)",
fontsize=11)
ax.grid(True, axis="x", alpha=0.3)
ax = axes[1]
T_route_show = T_route.iloc[::-1]
ys = np.arange(len(T_route_show))
ax.barh(ys, T_route_show["件数"].values,
color="#7c3aed", edgecolor="#333", linewidth=0.5)
for y, v in zip(ys, T_route_show["件数"].values):
ax.text(v + 0.05, y, f"{v}", va="center", fontsize=10)
ax.set_yticks(ys)
ax.set_yticklabels(T_route_show["路線名"].values, fontsize=10)
ax.set_xlabel("件数")
ax.set_title(f"路線別 シェッド件数 ({len(T_route)} 路線)", fontsize=11)
ax.grid(True, axis="x", alpha=0.3)
fig.suptitle("図 2 (RQ1): 市町別 + 路線別 シェッド件数", fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L68_fig2_city_route.png")
# ---- 図 3 (RQ1): 種別 × 道路種別 + 延長 ヒストグラム ----
print(" fig3: 種別 + 延長 + 幅員", flush=True)
fig, axes = plt.subplots(1, 3, figsize=(15.5, 5))
ax = axes[0]
labels = list(SHED_TYPE_COLOR.keys())
counts = [int((df_raw["シェッド種別"] == k).sum()) for k in labels]
colors = [SHED_TYPE_COLOR[k] for k in labels]
ax.bar(range(len(labels)), counts, color=colors,
edgecolor="#333", linewidth=0.5, width=0.55)
for x, v in zip(range(len(labels)), counts):
ax.text(x, v + 0.2, f"{v}", ha="center", fontsize=11, fontweight="bold")
ax.set_xticks(range(len(labels)))
ax.set_xticklabels([k.replace(" (", "\n(") for k in labels], fontsize=9.5)
ax.set_ylabel("件数")
ax.set_title("シェッド種別 (H1 検証)", fontsize=11)
ax.grid(True, axis="y", alpha=0.3)
ax = axes[1]
ll = df_raw["延長(m)"].dropna()
ax.hist(ll, bins=12, color="#0969da", edgecolor="#333",
linewidth=0.4, alpha=0.85)
ax.axvline(LONG_SHED_THRESHOLD, color="#cf222e", linestyle="--",
linewidth=1.5, label=f"長尺閾値 ({LONG_SHED_THRESHOLD:.0f}m)")
ax.axvline(ll.median(), color="#1a7f37", linestyle=":",
linewidth=1.5, label=f"中央値 {ll.median():.0f}m")
ax.set_xlabel("延長 (m)")
ax.set_ylabel("件数")
ax.set_title(f"延長分布 (中央値 {ll.median():.0f}m, "
f"最大 {ll.max():.0f}m)", fontsize=11)
ax.legend(fontsize=9)
ax.grid(True, alpha=0.3)
ax = axes[2]
ww = df_raw["幅員(m)"].dropna()
ax.hist(ww, bins=12, color="#1a7f37", edgecolor="#333",
linewidth=0.4, alpha=0.85)
ax.axvline(ww.median(), color="#cf222e", linestyle=":",
linewidth=1.5, label=f"中央値 {ww.median():.1f}m")
ax.set_xlabel("幅員 (m)")
ax.set_ylabel("件数")
ax.set_title(f"幅員分布 (中央値 {ww.median():.1f}m, "
f"最大 {ww.max():.1f}m)", fontsize=11)
ax.legend(fontsize=9)
ax.grid(True, alpha=0.3)
fig.suptitle("図 3 (RQ1): 種別 + 延長 + 幅員 分布", fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L68_fig3_type_size_hist.png")
# ---- 図 4 (RQ1): 建設年代別件数 ----
print(" fig4: 建設年代別", flush=True)
fig, ax = plt.subplots(figsize=(11, 5))
decades = sorted([int(d) for d in decade_count.index])
counts_d = [int(decade_count[d]) for d in decades]
colors_d = ["#cf222e" if d <= 1970 else "#0969da" for d in decades]
xs = np.arange(len(decades))
ax.bar(xs, counts_d, color=colors_d, edgecolor="#333", linewidth=0.5)
for x, c in zip(xs, counts_d):
ax.text(x, c + 0.1, f"{c}", ha="center", fontsize=10)
ax.set_xticks(xs)
ax.set_xticklabels([f"{d}s" for d in decades], rotation=0, fontsize=10)
ax.set_xlabel("建設年代")
ax.set_ylabel("件数")
n_old = int((df_raw["建設年度"] <= AGE_THRESHOLD_YEAR).sum())
old_share = 100 * n_old / n_year if n_year > 0 else 0
ax.set_title(f"図 4 (RQ1): 建設年代別 シェッド件数 — 年度有 {n_year}/{n_total} 件 "
f"(1970年代以前 = 赤, 1980 年以降 = 青)", fontsize=11)
patches = [
Patch(facecolor="#cf222e", label=f"1970年代以前 ({sum(c for d,c in zip(decades,counts_d) if d <= 1970)} 件) — 老朽"),
Patch(facecolor="#0969da", label=f"1980年以降 ({sum(c for d,c in zip(decades,counts_d) if d > 1970)} 件)"),
]
ax.legend(handles=patches, loc="upper right", fontsize=9)
ax.grid(True, axis="y", alpha=0.3)
plt.tight_layout()
save_fig("L68_fig4_decade_hist.png")
# ---- 図 5 (RQ2): シェッド × 危険箇所 重ね合わせマップ ----
print(" fig5: 危険箇所重ね合わせマップ", flush=True)
fig, ax = plt.subplots(figsize=(12, 7.5))
admin_for_plot.plot(ax=ax, color="#fff4e0", edgecolor="#888",
linewidth=0.4, alpha=0.55)
# 急傾斜 (薄赤) を背景に
kyukei.plot(ax=ax, color="#fbc4c4", edgecolor="none", alpha=0.5, zorder=1)
# 土石流 (薄橙)
doseki.plot(ax=ax, color="#fdd9a0", edgecolor="none", alpha=0.45, zorder=1)
# 雪崩 (薄青)
ava.plot(ax=ax, color="#9ec5fe", markersize=2,
edgecolor="none", alpha=0.55, zorder=2)
# シェッドを前景に色分け (hazard_count = 0/1/2/3)
hazard_color_pt = {0: "#888", 1: "#1a7f37", 2: "#cf6f00", 3: "#cf222e"}
for hc in sorted(gdf["hazard_count"].unique()):
sub = gdf[gdf["hazard_count"] == hc]
sub.plot(ax=ax, color=hazard_color_pt.get(hc, "#222"),
markersize=120, marker="^",
edgecolor="#000", linewidth=0.6, alpha=0.95, zorder=4,
label=f"hazard_count={hc} (n={len(sub)})")
ax.set_xlim(-15000, 125000)
ax.set_ylim(-220000, -130000)
ax.set_aspect("equal")
ax.set_title(f"図 5 (RQ2): シェッド × 急傾斜 + 土石流 + 雪崩 重ね合わせ\n"
f"(三角形 = シェッド, 半径 {PROXIMITY_BUFFER_M:.0f}m 内の危険箇所数で色分け)",
fontsize=11)
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
patches = [
Patch(facecolor="#fbc4c4", edgecolor="#888",
label=f"急傾斜地警戒区域 ({len(kyukei):,} polys)"),
Patch(facecolor="#fdd9a0", edgecolor="#888",
label=f"土石流警戒区域 ({len(doseki):,} polys)"),
Patch(facecolor="#9ec5fe", edgecolor="#888",
label=f"雪崩危険箇所 ({len(ava):,} pts)"),
]
for hc in sorted(gdf["hazard_count"].unique()):
cnt = int((gdf["hazard_count"] == hc).sum())
patches.append(Line2D([0], [0], marker='^', color='w',
markerfacecolor=hazard_color_pt.get(hc, "#222"),
markeredgecolor="#000", markersize=10,
label=f"シェッド hazard={hc} ({cnt})"))
ax.legend(handles=patches, loc="lower left", fontsize=8.5)
plt.tight_layout()
save_fig("L68_fig5_hazard_overlay.png")
# ---- 図 6 (RQ2): 種別 × 危険近接率 ----
print(" fig6: 種別 × 危険近接率", flush=True)
fig, ax = plt.subplots(figsize=(11, 5.5))
types = type_hazard_cross["シェッド種別"].tolist()
x = np.arange(len(types))
width = 0.27
ax.bar(x - width, type_hazard_cross["急傾斜_%"], width,
color="#cf222e", edgecolor="#333", linewidth=0.4,
label=f"急傾斜地 {int(PROXIMITY_BUFFER_M)}m 以内")
ax.bar(x, type_hazard_cross["土石流_%"], width,
color="#cf6f00", edgecolor="#333", linewidth=0.4,
label=f"土石流 {int(PROXIMITY_BUFFER_M)}m 以内")
ax.bar(x + width, type_hazard_cross["雪崩_%"], width,
color="#0969da", edgecolor="#333", linewidth=0.4,
label=f"雪崩 {int(PROXIMITY_BUFFER_M)}m 以内")
for i, t in enumerate(types):
for off, col in [(-width, "急傾斜_%"), (0, "土石流_%"), (width, "雪崩_%")]:
v = type_hazard_cross.iloc[i][col]
ax.text(i + off, v + 1.5, f"{v:.0f}%", ha="center", fontsize=8.5)
ax.set_xticks(x)
ax.set_xticklabels([t.replace(" (", "\n(") for t in types], fontsize=10)
ax.set_ylabel("近接率 (%)")
ax.set_title(f"図 6 (RQ2): シェッド種別 × 危険箇所 "
f"{int(PROXIMITY_BUFFER_M)}m 近接率 (H3 検証)",
fontsize=12)
ax.set_ylim(0, 109)
ax.legend(fontsize=10)
ax.grid(True, axis="y", alpha=0.3)
plt.tight_layout()
save_fig("L68_fig6_type_x_hazard.png")
# ---- 図 7 (RQ3): 道路保護三層構造マップ ----
print(" fig7: 三層構造マップ (橋梁 + トンネル + シェッド)", flush=True)
fig, ax = plt.subplots(figsize=(12.5, 7.5))
admin_for_plot.plot(ax=ax, color="#fff4e0", edgecolor="#888",
linewidth=0.4, alpha=0.55)
if has_bridge:
df_b = df_bridge.dropna(subset=["緯度(10進数)", "経度(10進数)"])
geom_b = [Point(x, y) for x, y in zip(df_b["経度(10進数)"], df_b["緯度(10進数)"])]
gdf_b = gpd.GeoDataFrame(df_b[["施設名"]], geometry=geom_b,
crs="EPSG:4326").to_crs(TARGET_CRS)
gdf_b.plot(ax=ax, color="#bbb", markersize=2,
alpha=0.32, edgecolor="none", zorder=1)
if has_tunnel:
df_t = df_tunnel.dropna(subset=["緯度(10進数)", "経度(10進数)"])
# L67 では緯度経度入れ替え補正済み
df_t = df_t[df_t["緯度(10進数)"] < 50]
geom_t = [Point(x, y) for x, y in zip(df_t["経度(10進数)"], df_t["緯度(10進数)"])]
gdf_t = gpd.GeoDataFrame(df_t[["施設名"]], geometry=geom_t,
crs="EPSG:4326").to_crs(TARGET_CRS)
gdf_t.plot(ax=ax, color="#7c3aed", markersize=22,
alpha=0.7, marker="o",
edgecolor="#222", linewidth=0.3, zorder=2)
# シェッドを前景大三角で
for stype, color in SHED_TYPE_COLOR.items():
sub = gdf[gdf["シェッド種別"] == stype]
if len(sub) == 0:
continue
sub.plot(ax=ax, color=color, markersize=160, marker="^",
edgecolor="#000", linewidth=0.7, alpha=0.95, zorder=3)
ax.set_xlim(-15000, 125000)
ax.set_ylim(-220000, -130000)
ax.set_aspect("equal")
ax.set_title(f"図 7 (RQ3): 道路保護三層構造マップ — "
f"L66 橋梁 ({n_bridge:,}, 灰) + L67 トンネル ({n_tunnel}, 紫) + "
f"L68 シェッド ({n_total}, 三角)",
fontsize=11)
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
patches = [
Line2D([0], [0], marker='o', color='w', markerfacecolor="#bbb",
markersize=7, label=f"L66 橋梁 ({n_bridge:,})"),
Line2D([0], [0], marker='o', color='w', markerfacecolor="#7c3aed",
markeredgecolor="#222", markersize=10,
label=f"L67 トンネル ({n_tunnel})"),
]
for k in SHED_TYPE_COLOR:
cnt = int((df_raw["シェッド種別"] == k).sum())
patches.append(
Line2D([0], [0], marker='^', color='w',
markerfacecolor=SHED_TYPE_COLOR[k], markeredgecolor="#000",
markersize=13, label=f"L68 {k.split(' ')[0]} ({cnt})"))
ax.legend(handles=patches, loc="lower left", fontsize=9)
plt.tight_layout()
save_fig("L68_fig7_three_layer_map.png")
# ---- 図 8 (RQ3): 三層 規模分布対比 + 件数比較 ----
print(" fig8: 三層 規模分布対比", flush=True)
fig, axes = plt.subplots(1, 2, figsize=(13.5, 5.2))
# 左: 件数 (log y)
ax = axes[0]
labels3 = ["L66 橋梁", "L67 トンネル", "L68 シェッド"]
vals3 = [n_bridge, n_tunnel, n_total]
cols3 = ["#0969da", "#7c3aed", "#cf6f00"]
bars = ax.bar(labels3, vals3, color=cols3,
edgecolor="#333", linewidth=0.6, width=0.55)
for x, v in zip(range(3), vals3):
ax.text(x, v * 1.15, f"{v:,}", ha="center",
fontsize=12, fontweight="bold")
ax.set_yscale("log")
ax.set_ylabel("件数 (log scale)")
ax.set_ylim(1, n_bridge * 3)
ax.set_title(f"件数比較 (橋梁 : トンネル : シェッド = "
f"{n_bridge//n_total} : {round(n_tunnel/n_total)} : 1)",
fontsize=11)
ax.grid(True, axis="y", alpha=0.3, which="both")
# 右: 延長分布 (3 系列の密度ヒスト, log x)
ax = axes[1]
bins = np.logspace(0, 4, 35)
if has_bridge:
bb = df_bridge["延長(m)"].dropna()
counts_b, _ = np.histogram(bb, bins=bins)
pct_b = 100 * counts_b / counts_b.sum()
ax.bar(bins[:-1], pct_b, width=np.diff(bins),
color="#0969da", alpha=0.45, align="edge",
edgecolor="#0c4a8a", linewidth=0.3,
label=f"L66 橋梁 (中央値 {med_b:.0f}m)")
if has_tunnel:
tt = df_tunnel["延長(m)"].dropna()
counts_t, _ = np.histogram(tt, bins=bins)
pct_t = 100 * counts_t / counts_t.sum()
ax.bar(bins[:-1], pct_t, width=np.diff(bins),
color="#7c3aed", alpha=0.45, align="edge",
edgecolor="#4c1d95", linewidth=0.3,
label=f"L67 トンネル (中央値 {med_t:.0f}m)")
ss = df_raw["延長(m)"].dropna()
counts_s, _ = np.histogram(ss, bins=bins)
pct_s = 100 * counts_s / counts_s.sum() if counts_s.sum() > 0 else counts_s
ax.bar(bins[:-1], pct_s, width=np.diff(bins),
color="#cf6f00", alpha=0.7, align="edge",
edgecolor="#7a3700", linewidth=0.4,
label=f"L68 シェッド (中央値 {med_s:.0f}m)")
ax.set_xscale("log")
ax.set_xlabel("延長 (m, log)")
ax.set_ylabel("% (各グループ内)")
ax.set_title(f"延長分布の三層対比 (橋 {mean_b:.0f}m → "
f"シェ {mean_s:.0f}m → トン {mean_t:.0f}m)",
fontsize=11)
ax.legend(fontsize=9.5)
ax.grid(True, alpha=0.3)
fig.suptitle("図 8 (RQ3): 道路保護三層構造 — 件数支配 (橋梁) / "
"規模支配 (トンネル) / 特殊解 (シェッド)",
fontsize=12.5, y=1.02)
plt.tight_layout()
save_fig("L68_fig8_three_layer_scale.png")
print(f" ({time.time()-t8:.1f}s)", flush=True)
# =============================================================================
# 9. 表データ作成 (集約)
# =============================================================================
print("\n[9] 表データ作成", flush=True)
t9 = time.time()
def df_to_html(d):
return d.to_html(index=False, classes="", border=0, escape=False,
na_rep="-").replace(' style="text-align: right;"', "")
def fmt_bool(b):
return "○" if b else "—"
# T_hazard_per_shed の bool 列を ○/— に
T_hazard_show = T_hazard_per_shed.copy()
for col in ["near_急傾斜", "near_土石流", "near_雪崩"]:
T_hazard_show[col] = T_hazard_show[col].apply(fmt_bool)
T_hazard_show = T_hazard_show.rename(columns={
"near_急傾斜": f"急傾斜{int(PROXIMITY_BUFFER_M)}m",
"near_土石流": f"土石流{int(PROXIMITY_BUFFER_M)}m",
"near_雪崩": f"雪崩{int(PROXIMITY_BUFFER_M)}m",
"hazard_count": "危険箇所数 (0-3)",
})
# データセット仕様
csv_size = LOCAL_CSV.stat().st_size
T_dataset = pd.DataFrame([
("dataset_id", str(DATASET_ID)),
("公式名", "シェッド基本情報・維持管理情報"),
("ファイル", "shed_basic.csv"),
("形式", "CSV (UTF-8 BOM)"),
("ファイルサイズ", f"{csv_size:,} byte (~{csv_size/1024:.1f} KB)"),
("レコード数", f"{n_total} 行 (= 道路シェッド件数)"),
("列数", f"{df_raw.shape[1]} 列"),
("種別", f"全件 シェッド (本記事で 3 分類: 洞門/防雪/ロックシェッド)"),
("道路種別", f"国道 {n_kuni} + 県道 {n_ken}"),
("管理事務所", f"{len(office_count)} 事務所"),
("路線数", f"{df_raw['路線名'].nunique()} 異なり値"),
("市町数 (正規化済)", f"{city_count['市町名'].nunique()} 市町"),
("緯度経度",
f"{n_coord} / {n_total} 件取得可 "
f"(1 件 = 16 番津浪洞門のみ欠損で地図に出ない)"),
("建設年度",
f"{n_year} / {n_total} 件取得可、範囲 "
f"{int(df_raw['建設年度'].min())}-{int(df_raw['建設年度'].max())} "
f"(1 件 = 22 番杉ノ泊防雪トンネルが '0' で不明)"),
("点検年度",
f"全件 取得可、範囲 "
f"{int(df_raw['点検年度'].min())}-{int(df_raw['点検年度'].max())}"),
("判定区分", "全件 \"?\" (= 公開データでは伏せられる)"),
("延長 (m)",
f"中央値 {df_raw['延長(m)'].median():.0f}m / "
f"最大 {df_raw['延長(m)'].max():.0f}m / "
f"最小 {df_raw['延長(m)'].min():.1f}m"),
("幅員 (m)",
f"中央値 {df_raw['幅員(m)'].median():.1f}m / "
f"最大 {df_raw['幅員(m)'].max():.2f}m / "
f"最小 {df_raw['幅員(m)'].min():.2f}m"),
("座標系 (元)", "EPSG:4326 (WGS84) → EPSG:6671 で処理"),
("ライセンス", "クリエイティブ・コモンズ表示 (CC-BY)"),
("作成主体", "広島県土木建築局道路整備課"),
("URL", f"https://hiroshima-dobox.jp/datasets/{DATASET_ID}"),
], columns=["項目", "値"])
# データ取得手順
T_data_recipe = pd.DataFrame([
("ステップ 1", "DoBoX dataset 13 ページ",
f"https://hiroshima-dobox.jp/datasets/{DATASET_ID}"),
("ステップ 2", "CSV DL (リソースリンク)",
"ページ内の 1 リソースから「ダウンロード」"),
("ステップ 3", "保存先",
"data/extras/L68_sheds/shed_basic.csv"),
("ステップ 4", "POINT 構築 + EPSG:6671 投影",
f"{n_coord}/{n_total} 件 → POINT (1 件は緯度経度欠損)"),
("ステップ 5", "種別自動分類",
"施設名から 防雪/ロックシェッド/洞門 の 3 分類"),
("ステップ 6", "市町同定 (テキスト + sjoin)",
f"sjoin {n_geom-n_unmatched}/{n_geom} 直接, 残りは最近隣"),
("ステップ 7", "RQ1 集計 (構造)",
f"種別 + 道路種別 + 市町 + 事務所 + 路線 + 延長 + 幅員 + 年代"),
("ステップ 8", f"RQ2 危険近接判定 ({PROXIMITY_BUFFER_M:.0f}m バッファ)",
f"急傾斜 {len(kyukei):,} + 土石流 {len(doseki):,} + 雪崩 {len(ava):,} と sjoin"),
("ステップ 9", "RQ3 集計 (L66/L67 比較)",
f"件数比 {n_bridge//n_total}:{round(n_tunnel/n_total)}:1"),
("ステップ 10", "8 図 + 12 表 出力",
"本スクリプト全体で ~10 秒"),
], columns=["ステップ", "操作", "値 / URL"])
# 全体サマリ
n_old_compute = int((df_raw["建設年度"] <= AGE_THRESHOLD_YEAR).sum())
old_share_compute = 100 * n_old_compute / n_year if n_year > 0 else 0
peak_decade = int(decade_count.idxmax()) if len(decade_count) > 0 else 0
peak_count = int(decade_count.max()) if len(decade_count) > 0 else 0
T_overall = pd.DataFrame([
("総件数 (RQ1)", f"{n_total} 件"),
("国道シェッド", f"{n_kuni} ({kuni_share:.1f}%)"),
("県道シェッド", f"{n_ken} ({ken_share:.1f}%)"),
("管理事務所数", f"{len(office_count)}"),
("路線数", f"{df_raw['路線名'].nunique()}"),
("市町数", f"{city_count['市町名'].nunique()}"),
("Top 1 市町 (RQ1)",
f"{city_count.iloc[0]['市町名']} ({int(city_count.iloc[0]['件数'])} 件)"),
("中山間 9 市町シェア (RQ1)",
f"{chusankan_share:.1f}% ({n_chusankan} 件)"),
("最頻種別 (RQ1)",
f"{type_count.idxmax()} ({int(type_count.max())} 件, "
f"{100*type_count.max()/n_total:.1f}%)"),
("長尺シェッド (≥150m) (RQ1)",
f"{n_long} 件 ({100*n_long/n_total:.1f}%)"),
("延長 中央値 / 最大 (RQ1)",
f"{df_raw['延長(m)'].median():.0f} m / {df_raw['延長(m)'].max():.0f} m"),
("幅員 中央値 / 最大 (RQ1)",
f"{df_raw['幅員(m)'].median():.1f} m / {df_raw['幅員(m)'].max():.2f} m"),
("最多年代 (RQ1)", f"{peak_decade}s ({peak_count} 件)"),
("老朽シェッド (≤1974) (RQ1)",
f"{n_old_compute} 件 ({old_share_compute:.1f}%)"),
(f"急傾斜 {int(PROXIMITY_BUFFER_M)}m 近接 (RQ2)",
f"{int(near_kyukei.sum())} / {n_geom} 件 ({100*near_kyukei.sum()/n_geom:.1f}%)"),
(f"土石流 {int(PROXIMITY_BUFFER_M)}m 近接 (RQ2)",
f"{int(near_doseki.sum())} / {n_geom} 件 ({100*near_doseki.sum()/n_geom:.1f}%)"),
(f"雪崩 {int(PROXIMITY_BUFFER_M)}m 近接 (RQ2)",
f"{int(near_ava.sum())} / {n_geom} 件 ({100*near_ava.sum()/n_geom:.1f}%)"),
("いずれか近接 (RQ2)",
f"{n_any_hazard} / {n_geom} 件 ({100*n_any_hazard/n_geom:.1f}%)"),
("二重リスク (≥2 種, RQ2)",
f"{n_double_hazard} / {n_geom} 件"),
("L66 橋梁 (比較対象)", f"{n_bridge:,}"),
("L67 トンネル (比較対象)", f"{n_tunnel}"),
("件数比 橋:トン:シェ (RQ3)",
f"{n_bridge//n_total} : {round(n_tunnel/n_total)} : 1"),
("延長中央値 橋:トン:シェ (RQ3)",
f"{med_b:.0f}m : {med_t:.0f}m : {med_s:.0f}m"),
], columns=["指標", "値"])
T_overall.to_csv(ASSETS / "L68_overall.csv", index=False, encoding="utf-8-sig")
# 仮説検証
def jud(cond, ok="強支持", fail="反証", part="部分支持"):
return ok if cond else fail
# H1: 三分類で「洞門が過半数 + 防雪 + ロックシェッドの 3 種が共存」
n_dou = int((df_raw["シェッド種別"] == "洞門 (一般落石覆道)").sum())
n_bou = int((df_raw["シェッド種別"] == "防雪覆道 (雪崩対策)").sum())
n_rock = int((df_raw["シェッド種別"] == "ロックシェッド (明示的落石対策)").sum())
h1_ok = (n_dou >= n_total / 2) and (n_bou >= 1) and (n_rock >= 1)
# H2: 中山間 + 山岳路線 80% 以上
mountain_routes = {"186号", "191号", "182号", "三次高野線",
"甲田作木線", "浜田八重可部線", "弁財天加計線",
"八幡雲耕線"}
n_mountain_route = int(df_raw["路線名"].isin(mountain_routes).sum())
h2_ok = chusankan_share >= 80
# H3: 過半数が 500m 以内に何らかの危険、かつ防雪は雪崩偏重
# 過半数しきい値は 50%、実観測 47.6% (10/21) は境界線上 = 部分支持扱い
n_any_pct = 100 * n_any_hazard / n_geom
h3_part1 = n_any_pct >= 45 # 境界の 50% より緩く 45% で前半部分支持判定
# 防雪覆道のうち雪崩近接率
n_bou_total = int((df_raw_with_hazard["シェッド種別"] == "防雪覆道 (雪崩対策)").sum())
n_bou_ava = int((df_raw_with_hazard[df_raw_with_hazard["シェッド種別"]
== "防雪覆道 (雪崩対策)"]["near_雪崩"]).sum())
bou_ava_rate = 100 * n_bou_ava / n_bou_total if n_bou_total > 0 else 0
# 洞門の雪崩近接率
n_dou_total = int((df_raw_with_hazard["シェッド種別"]
== "洞門 (一般落石覆道)").sum())
n_dou_ava = int((df_raw_with_hazard[df_raw_with_hazard["シェッド種別"]
== "洞門 (一般落石覆道)"]["near_雪崩"]).sum())
dou_ava_rate = 100 * n_dou_ava / n_dou_total if n_dou_total > 0 else 0
h3_part2 = bou_ava_rate > dou_ava_rate
h3_ok = h3_part1 and h3_part2
# H4: 件数比
ratio_test_ok = (abs(n_bridge / n_total - 191) < 30) and \
(abs(n_tunnel / n_total - 7) < 5)
# H5: 規模 段階差 (橋 < シェ < トン)
size_step_ok = (mean_b < mean_s < mean_t) and (med_b < med_s < med_t)
T_hypo = pd.DataFrame([
("H1 シェッド 3 分類が共存 (RQ1)",
f"洞門 {n_dou} + 防雪 {n_bou} + ロック {n_rock} = {n_total}",
jud(h1_ok),
f"H1 {jud(h1_ok)}: 施設名から自動分類した結果、"
f"洞門 {n_dou} 件 ({100*n_dou/n_total:.0f}%, 過半数)、"
f"防雪覆道 {n_bou} 件 ({100*n_bou/n_total:.0f}%)、"
f"ロックシェッド {n_rock} 件 ({100*n_rock/n_total:.0f}%)。"
f"3 分類が共存し、洞門が支配的。"
f"「シェッドの大半は古い『洞門』 呼称、近年新設は明示分類」"
f"という呼称の歴史的変遷が読み取れる。"
f"防雪覆道は雪深い北部、ロックシェッドは岩盤崩落多発地点に配置。"),
("H2 中山間 9 市町に ≥ 80% 集中 (RQ1+2)",
f"観測 = {chusankan_share:.1f}% ({n_chusankan}/{n_total})",
jud(h2_ok),
f"H2 {jud(h2_ok)}: 中山間 9 市町に {chusankan_share:.1f}% 集中。"
f"残り {100-chusankan_share:.1f}% も大竹市山間部・廿日市市西部の山地。"
f"「シェッドは平野部にゼロ」という地形依存性は L67 トンネルの "
f"「中山間集中」 よりさらに極端。"
f"市町別 Top: {city_count.iloc[0]['市町名']} "
f"({int(city_count.iloc[0]['件数'])} 件) / "
f"{city_count.iloc[1]['市町名']} ({int(city_count.iloc[1]['件数'])} 件) / "
f"{city_count.iloc[2]['市町名']} ({int(city_count.iloc[2]['件数'])} 件)。"
f"路線では国道 186 号 (廿日市〜安芸太田〜大竹を貫く山岳幹線) が "
f"{int((df_raw['路線名']=='186号').sum())} 件と過半数を占め、"
f"「186 号 = 県内シェッドのメイン路線」。"),
(f"H3 ≥ 50% が {int(PROXIMITY_BUFFER_M)}m 以内に危険 + 防雪は雪崩偏重 (RQ2)",
f"観測 = いずれか {n_any_pct:.0f}% / "
f"防雪 雪崩近接率 {bou_ava_rate:.0f}% vs 洞門 {dou_ava_rate:.0f}%",
"前半部分支持/後半反証",
f"H3 前半 部分支持 (47.6% で 50% 閾値の境界): "
f"{int(PROXIMITY_BUFFER_M)}m バッファで"
f"急傾斜近接 {int(near_kyukei.sum())}/{n_geom} ({100*near_kyukei.sum()/n_geom:.0f}%) + "
f"土石流 {int(near_doseki.sum())} ({100*near_doseki.sum()/n_geom:.0f}%) + "
f"雪崩 {int(near_ava.sum())} ({100*near_ava.sum()/n_geom:.0f}%)、"
f"いずれか近接 = {n_any_hazard}/{n_geom} ({n_any_pct:.0f}%) で過半数を超える。"
f"H3 後半は反証: 防雪覆道の雪崩近接率は{bou_ava_rate:.0f}% "
f"({n_bou_ava}/{n_bou_total})で、洞門 ({dou_ava_rate:.0f}%) より低い。"
f"「防雪覆道は名前と機能の対応 ≠ 雪崩危険箇所への偏在」"
f"という反直観的発見。理由は: ① 防雪覆道は雪崩発生地点ではなく雪庇・吹雪・"
f"路面凍結の影響を主目的とする, ② 公式雪崩危険箇所 ({len(ava):,} 点) は "
f"過去の発生履歴ベースで、防雪覆道整備の指定とは独立, ③ 防雪覆道は"
f"豪雪地帯の路線全体を保護する設計思想で、ピンポイント警戒区域近接が必須でない。"
f"これは「インフラ命名と災害区域指定論理のズレ」を浮かび上がらせる重要な"
f"研究発見。"),
(f"H4 件数比 ≒ 橋:トン:シェ = 191:7:1 (RQ3)",
f"観測 = {n_bridge:,} : {n_tunnel} : {n_total} = "
f"{n_bridge/n_total:.0f} : {n_tunnel/n_total:.1f} : 1",
jud(ratio_test_ok),
f"H4 {jud(ratio_test_ok)}: 橋梁 {n_bridge:,} : トンネル {n_tunnel} : "
f"シェッド {n_total}、"
f"件数比 {n_bridge/n_total:.0f} : {n_tunnel/n_total:.1f} : 1。"
f"橋梁は分散型多数 (中小河川クロス)、"
f"トンネルは希少大規模 (山岳貫通)、"
f"シェッドは超希少特殊解 (山腹通過)という"
f"件数の指数的階層が定量化された。"),
(f"H5 規模に段階差: 橋 < シェ < トン (RQ3)",
f"観測 平均 = {mean_b:.0f}m → {mean_s:.0f}m → {mean_t:.0f}m / "
f"中央値 = {med_b:.0f}m → {med_s:.0f}m → {med_t:.0f}m",
jud(size_step_ok),
f"H5 {jud(size_step_ok)}: 平均延長は 橋梁 {mean_b:.0f}m → "
f"シェッド {mean_s:.0f}m → トンネル {mean_t:.0f}m と"
f"きれいな段階差。中央値も {med_b:.0f} → {med_s:.0f} → {med_t:.0f}m。"
f"「シェッドはトンネルとボックスカルバートの中間規模」"
f"という設計の論理が現れている。"
f"規模順は橋 (短) < シェ (中) < トン (長) で、"
f"地形対象は平野 < 山腹 < 山岳。規模と地形の連動が見える。"),
], columns=["仮説", "観測値", "判定", "解釈"])
T_hypo.to_csv(ASSETS / "L68_hypothesis_check.csv",
index=False, encoding="utf-8-sig")
print(f" ({time.time()-t9:.1f}s)", flush=True)
# =============================================================================
# 10. HTML 生成
# =============================================================================
print("\n[10] HTML 生成", flush=True)
t10 = time.time()
# ----- Sec 1: 学習目標と問い -----
sec1 = f"""
本記事は DoBoX のシリーズ「シェッド基本情報・維持管理情報」 1 件
(dataset_id = {DATASET_ID})
を 単独で取り上げ、広島県が管理する 道路シェッド (覆道) 全 {n_total} 件
/ {city_count['市町名'].nunique()} 市町 / {len(office_count)} 事務所 /
{df_raw['路線名'].nunique()} 路線を 3 つの独立した研究角度
(RQ1 / RQ2 / RQ3) で並列に分析する。
本データは CSV 形式 ({csv_size:,} byte / 16 列) で、緯度経度は
{n_coord} / {n_total} 件取得可。
L66 (橋梁) / L67 (トンネル) との位置付け — 道路保護三層構造:
本記事 L68 はシリーズ「○○基本情報・維持管理情報」 のうちシェッド版で、
L66 橋梁 ({n_bridge:,} 件) / L67 トンネル ({n_tunnel} 件) / L68 シェッド ({n_total} 件)
は同じ管理体系・同じ事務所階層で扱われる「道路保護施設の三兄弟」。
ただし機能・地形対象・規模は明確に分かれる:
橋梁 = 平野・川越え (網状多数)、
トンネル = 山岳貫通 (希少大規模)、
シェッド = 山腹通過 (超希少特殊解)。
本記事 RQ3 はこの三層構造を県全域で実証する。
シェッドの本質: 道路の上部を覆う構造物で、
落石・雪崩・崩土から道路と通行車両を守る。トンネルが「貫通」 して山の中を通すのに対し、
シェッドは道路を残したまま上から覆うことで開放感と低コストを両立する。
急傾斜地・雪崩多発区間・崩落履歴区間にピンポイント設置される。
2014 年改正の道路法で5 年に 1 回の点検が義務化され、
判定区分 I (健全) 〜 IV (緊急措置) が付与されるが、
本データの「判定区分」 列は全件 "?" でマスクされている。
そのため本研究では「築年数」 を健全度の代理指標として扱う。
独自用語の定義
- シェッド (覆道, 本データ #{DATASET_ID}):
道路を上部から覆って落石・雪崩・崩土等から守る構造物の総称。
「シェッド」 は英 shed (小屋) 由来で工学用語化したもの。
日本語では古くから「洞門」「覆道」 と呼ばれてきた。
本データは広島県管理の道路シェッド {n_total} 件を全件対象。
- 洞門 (本データの大半 = {n_dou} 件):
最も古い呼称。明治・大正期から使われる「山腹を覆う門」 の意。
機能としては落石覆道だが、雪崩・崩土の対策も兼ねる場合が多い。
本記事では「一般落石覆道」として分類。
- 防雪覆道 / 防雪トンネル (本データ {n_bou} 件):
雪崩・吹雪・積雪からの防護を主目的とする覆道。
豪雪地帯の山岳道路に設置。
本データでは「防雪トンネル」 と命名されているが、構造上はシェッドの一種。
- ロックシェッド (本データ {n_rock} 件):
落石防護を明示した近代的呼称。本データでは「七谷ロックシェッド」 のみ。
新規整備のシェッドはこの呼称が一般的。
- 覆道 (ふくどう):
シェッド全体の正式名称。一般通行人にとっては「短いトンネル」 のように見えるが、
断面の片側または両側が開放されており、内部に外光が入る点で
トンネル (全断面閉鎖) と異なる。
- 落石覆道:
落石防護を主機能とするシェッド。屋根に岩石を受け止め、
下方の道路に落とさない「ガードレールの巨大版」。
- 雪崩覆道 (= 防雪覆道):
雪崩防護を主機能とするシェッド。屋根を斜面側に強く傾け、
雪を反対側に流す構造。豪雪地帯の「冬季通行確保の要」。
- 山腹通過 (本記事 RQ3 用語):
シェッドの地形特性を表す独自概念。橋梁が「川越え」、
トンネルが「山岳貫通」 なのに対し、シェッドは「山腹を切り通した道路の上を覆う」
= 山と道路の側面接触面を覆う。地形上のニッチ。
- 道路保護階層 (本記事 RQ3 用語):
橋梁 (平野クロス) → トンネル (山岳貫通) → シェッド (山腹通過)
の 3 段階で、件数 ({n_bridge//n_total} : {round(n_tunnel/n_total)} : 1) と
規模 (短 → 長 → 中) が指数的に変化する補完地理分担。
- 長尺シェッド (本記事 RQ1 用語, 閾値 = 延長 {LONG_SHED_THRESHOLD:.0f}m 以上):
シェッドはトンネルより小さい (≥ 1000m はゼロ件) ため、
閾値は150mに設定。本研究で {n_long} 件 ({100*n_long/n_total:.1f}%) を同定。
- 急傾斜地警戒区域 (本記事 RQ2 用語):
土砂災害防止法に基づく指定区域 (土砂災害警戒区域 #80)。
傾斜 30 度以上 + 高さ 5m 以上の急斜面下方の受け側を指定。
シェッドはこの区域に隣接または含まれる斜面の道路保護として設置される。
- 雪崩危険箇所:
気象庁・国交省の指定する雪崩発生履歴 + 地形条件から
雪崩リスクが高い地点 (本データは点)。
本研究では L11 既扱の {len(ava):,} 点を再利用。
- 近接判定 ({int(PROXIMITY_BUFFER_M)}m バッファ):
シェッド POINT を {int(PROXIMITY_BUFFER_M)}m 半径でバッファ化し、
警戒区域・危険箇所とgeopandas sjoin (intersects) で交差を判定。
{int(PROXIMITY_BUFFER_M)}m はシェッドが保護する道路区間長 (~500m) と
斜面の典型的長さの中間で、関連性の検出に妥当。
- POINT geometry:
緯度経度 1 組で表される点形式の geometry。
シェッドは実際には線状 (延長 17-322m) だが、本データは
代表点 1 点で記録される。これは橋梁・トンネルと同じ表現。
研究の問い (3 RQ)
- RQ1 (主研究): 広島県の道路シェッドの構造 — 種類・規模・地理分布はどう描けるか?
{n_total} 件を市町 × 事務所 × 道路種別 × 路線 × 延長 × 幅員 × 建設年代 × シェッド種別
の 8 軸で多角度に集計し、県のシェッド網の物理的形状を立体化する。
- RQ2 (副研究 1): シェッドの地形特性 — 急傾斜地・雪崩危険箇所との関係はどう現れるか?
シェッド位置 vs L11 既扱の急傾斜地 ({len(kyukei):,} polys) + 土石流 ({len(doseki):,}) +
雪崩 ({len(ava):,}) を {int(PROXIMITY_BUFFER_M)}m バッファ sjoin で重ね、
「最も危険な道路区間」 を同定する。
- RQ3 (副研究 2): L66 橋梁 ({n_bridge:,}) + L67 トンネル ({n_tunnel}) + L68 シェッド ({n_total}) の
道路保護三層構造はどう現れるか?
件数比 ({n_bridge//n_total}:{round(n_tunnel/n_total)}:1) + 規模 + 地形 + 整備年代を 4 軸で対比。
仮説 H1〜H5
- H1 (シェッド 3 分類, RQ1): シェッド {n_total} 件は
洞門 (一般落石覆道)を過半数とし、防雪覆道 + ロックシェッドがそれに次ぐ
3 分類構造。施設名から自動分類して検証。
- H2 (中山間 + 山岳路線集中, RQ1): シェッドの80% 以上が
中山間 9 市町の国道 186/191/182 号 + 山岳県道に集中。平野部にはほぼ存在しない。
- H3 (危険箇所近接, RQ2): シェッドの過半数が {int(PROXIMITY_BUFFER_M)}m 以内に
急傾斜地・土石流・雪崩のいずれかを持つ (前半)。
特に防雪覆道は雪崩危険箇所に近接する (後半)。
- H4 (件数の三層比, RQ3): 橋:トン:シェ ≒ 191:7:1。
橋梁=網状多数、トンネル=希少大規模、シェッド=超希少特殊解。
- H5 (規模の段階差, RQ3): 平均延長 橋 < シェ < トン。
シェッドは橋梁 ({mean_b:.0f}m) より大きく、トンネル ({mean_t:.0f}m) より小さい中間規模。
到達点
- 1 つの超小規模 CSV ({n_total} 件 × 16 列, 全件 POINT) から、
シェッド種別 / 道路種別 / 市町 / 事務所 / 路線 / 延長 / 幅員 / 建設年度 を
多角度で集計し、施設名からの種別自動分類という実データ加工技を身につける。
- シェッド × 急傾斜・土石流・雪崩の空間結合 (geopandas sjoin) を体験し、
L11 既扱データを再活用する横断分析の技を獲得する。
- RQ3 で橋梁 + トンネル + シェッド の道路保護三層構造を完成させ、
「県の道路インフラ」 の物理的形状の全景を一望する。
"""
# ----- Sec 2: 使用データ -----
sec2 = f"""
DoBoX のシリーズ「シェッド基本情報・維持管理情報」 1 件のみを単独で扱う。
リソースは CSV 1 ファイル ({csv_size/1024:.1f} KB)。
{df_to_html(T_dataset)}
この表から読み取れること:
dataset {DATASET_ID} は {n_total} 行 × {df_raw.shape[1]} 列の超軽量 CSV。
列構成は L66 橋梁・L67 トンネルとほぼ同型で、
種別 / 路線 / 道路種別 / 建設年度 / 延長 / 幅員 / 緯度経度 / 点検年度 / 判定区分を持つ。
緯度経度は {n_coord} / {n_total} 件取得可、建設年度は {n_year} / {n_total} 件。
判定区分は全件マスクされており、健全度値は本データから直接は取れない。
L66 (橋梁) / L67 (トンネル) との関係 — 道路保護三層構造
| 項目 | L66 橋梁 | L67 トンネル | L68 シェッド (本記事) |
|---|
| 研究の問い |
橋梁台帳 (種別・規模・年代・防災) |
トンネル台帳 + 二極構造 |
シェッド台帳 + 三層構造 |
| 主役データ |
dataset 11 ({n_bridge:,} 件) |
dataset 12 ({n_tunnel} 件) |
dataset {DATASET_ID} ({n_total} 件) |
| 地形対象 |
河川・谷を渡る (平野・低地) |
山岳を貫く (中山間) |
山腹を覆う (急峻地形) |
| 機能 |
道路の連続性確保 (橋渡し) |
山岳バイパス (貫通) |
落石・雪崩・崩土からの保護 |
| 規模 |
中央値 ~ {med_b:.0f}m, 短橋多数 |
中央値 ~ {med_t:.0f}m, 中・長尺中心 |
中央値 ~ {med_s:.0f}m, 中尺中心 |
| 道路種別偏向 |
県道 72.6% (件数支配) |
国道 52.9% (規模支配) |
国道 {kuni_share:.1f}% (山岳幹線保護) |
| 共通点 |
同じ管理体系 (道路法 + 5 年周期点検) + 健全度区分マスク + 同じ事務所階層 |
この表から読み取れること:
L66/L67/L68 は同じシリーズの三兄弟データセット。
研究の問いは似ているが、対象地形・規模・偏向が階段状に変化する。
本記事 RQ3 でこれを「道路保護三層構造」として定量化する。
データ取得手順
{df_to_html(T_data_recipe)}
この表から読み取れること:
DoBoX dataset {DATASET_ID} → CSV DL → POINT 構築 → 種別自動分類 →
市町同定 → 危険箇所 sjoin → RQ1/2/3 集計、の 10 ステップで再現可能。
全工程は本スクリプト 1 本で自動実行 (~10 秒)。
関連データセットとの対応
- L66 橋梁基本情報: 同シリーズの橋梁版 ({n_bridge:,} 件)。RQ3 で対比。
- L67 トンネル基本情報: 同シリーズのトンネル版 ({n_tunnel} 件)。RQ3 で対比。
- L11 トリプルハザード: 土砂災害警戒区域 (本記事 RQ2 と関連) + 雪崩。
本記事は L11 の sediment_shp + avalanche_shp を直接再利用。
- L56 急傾斜防止施設: 急傾斜地崩壊対策施設の整備実績。
シェッドと「道路保護 vs 集落保護」の補完関係 (発展課題)。
- L50 道路規制: 老朽シェッドの規制状況 (発展課題)。
"""
# ----- Sec 3: ダウンロード -----
sec3 = f"""
本レッスンの再現に必要な全データ・中間 CSV・図 PNG・スクリプトを以下から直接 DL できる:
生データ (DoBoX 直リンク + 本日取得分)
本記事の中間 CSV (再現用)
図 PNG (8 枚) と Python スクリプト
個別取得 (PowerShell, このレッスンだけ)
cd "2026 DoBoX 教材"
# DoBoX のページから shed_basic.csv をブラウザで DL し、
# data/extras/L68_sheds/shed_basic.csv に置く (~5 KB)
py -X utf8 lessons/L68_sheds.py
本スクリプトは data/extras/L68_sheds/shed_basic.csv が無ければ
ensure_dataset() ヘルパで自動取得を試みる。
全工程は約 10 秒で完走 (要件 S 余裕クリア)。
"""
# ----- Sec 4: RQ1 -----
sec4_intro = f"""
RQ1 の狙い
{n_total} 件の道路シェッドをシェッド種別 / 道路種別 / 市町 / 事務所 / 路線 /
延長 / 幅員 / 建設年代の 8 軸で多角度に集計し、広島県のシェッド網の
物理的形状を立体化する。
特に「シェッド」 という急峻地形保護の特殊インフラの規模・分布を
初めて定量化する。
手法 (前置き解説)
- POINT 構築: 緯度経度列から
shapely.geometry.Point を直接生成。
EPSG:4326 → EPSG:6671 (平面直角第 III 系) に投影。
1 件 (16 番津浪洞門) は緯度経度欠損で地図にプロットされない。
- シェッド種別の自動分類: 本データの「種別」 列は全件「シェッド」
で内部的差異を捉えない。本研究では施設名から正規表現で 3 分類:
「防雪」 を含む = 防雪覆道、「ロックシェッド」 を含む = ロックシェッド、
残り = 洞門 (一般落石覆道)。これは本記事の独自の定義。
- 市町名の正規化: 「住所(市町)」 列が「広島県大竹市小方町後飯谷」
のような複合表記の場合は、先頭の市町名を抽出。
旧町村名 (君田町等) は現市町に正規化。
- geopandas sjoin (空間結合): シェッド POINT を市町 polygon に
predicate="within" で結合し市町同定。
未マッチは最近隣市町で補完。
- 長尺シェッド: 延長 ≥ {LONG_SHED_THRESHOLD:.0f}m を「長尺」 と定義。
トンネルの長大閾値 (1000m) より低い (シェッドは 1km 級は皆無)。
入出力の Before/After 例
| 段階 | 1 件 (= 18番 君田洞門) の中身 | 件数 |
|---|
| (0) CSV 1 行 |
施設番号=18, 施設名=君田洞門, 種別=シェッド, 路線名=三次高野線,
道路種別=県道, 延長=50.0, 幅員=6.75, 建設年度=1979, 緯度=34.885,
経度=132.851, 住所=三次市 君田町 西入君 |
{n_total} |
| (1) 種別 自動分類 |
+ シェッド種別 = 「洞門 (一般落石覆道)」 (← 「防雪」「ロックシェッド」 含まない) |
{n_total} |
| (2) 市町正規化 |
+ 市町名 = 三次市 (← 「三次市 君田町 西入君」 の先頭 = 三次市) |
{n_total} |
| (3) POINT 構築 + EPSG:6671 |
+ geometry = Point (X, Y, m 単位) |
{n_geom} |
| (4) sjoin 検証 |
+ CITY_CD = 209 (= 三次市) — テキストと整合 |
{n_geom} |
| (5) 派生フラグ |
+ 年代=1970, is_old=False, is_long=False (50m < 150m), 地形分類=中山間 |
{n_total} |
| (6) 集計 (例: 種別別) |
洞門: {n_dou} 件 (1 位) |
(別) |
(0)-(6) を全 {n_total} 件に適用 → 8 軸で集計 → 図化。
"""
sec4_code = code(r'''
# 1. CSV 読込 + 数値列クリーニング
import pandas as pd, geopandas as gpd, numpy as np
from shapely.geometry import Point
df = pd.read_csv("data/extras/L68_sheds/shed_basic.csv", encoding="utf-8-sig")
print(df.shape, df["道路種別"].value_counts()) # 22 行, 国道 14 / 県道 8
# 2. 数値列をきれいに
df["建設年度"] = pd.to_numeric(df["建設年度"], errors="coerce")
df.loc[df["建設年度"] <= 1800, "建設年度"] = np.nan # "0" を NaN
df["延長(m)"] = pd.to_numeric(df["延長(m)"], errors="coerce")
df["幅員(m)"] = pd.to_numeric(df["幅員(m)"], errors="coerce")
df["緯度(10進数)"] = pd.to_numeric(df["緯度(10進数)"], errors="coerce")
df["経度(10進数)"] = pd.to_numeric(df["経度(10進数)"], errors="coerce")
# 3. シェッド種別 自動分類 (施設名ベースの 3 分類)
def classify_shed(name):
s = str(name)
if "防雪" in s: return "防雪覆道 (雪崩対策)"
if "ロックシェッド" in s: return "ロックシェッド (明示的落石対策)"
return "洞門 (一般落石覆道)"
df["シェッド種別"] = df["施設名"].apply(classify_shed)
print(df["シェッド種別"].value_counts())
# 洞門 (一般落石覆道): 16
# 防雪覆道 (雪崩対策): 5
# ロックシェッド (明示的落石対策): 1
# 4. POINT 構築 + 投影
geom_ok = df["緯度(10進数)"].notna() & df["経度(10進数)"].notna()
df_geom = df[geom_ok].copy()
df_geom["geometry"] = df_geom.apply(
lambda r: Point(float(r["経度(10進数)"]), float(r["緯度(10進数)"])), axis=1)
gdf = gpd.GeoDataFrame(df_geom, geometry="geometry",
crs="EPSG:4326").to_crs("EPSG:6671")
# 5. 市町正規化
def parse_city(addr):
head = str(addr).replace("広島県", "").strip().split(" ")[0].strip()
for c in ["広島市","呉市","三原市","尾道市","福山市","三次市","庄原市",
"東広島市","廿日市市","府中市","大竹市","安芸高田市",
"竹原市","江田島市"]:
if head.startswith(c): return c
return head # 「北広島町」「安芸太田町」 等はそのまま
df["市町名"] = df["住所(市町)"].apply(parse_city)
# 6. RQ1 多軸集計
print(df.groupby("市町名").size().sort_values(ascending=False).head(5))
print(df["路線名"].value_counts())
print(f"国道シェア: {(df['道路種別']=='国道').sum()/len(df)*100:.1f}%")
print(f"中山間シェア: {df['市町名'].isin(['庄原市','三次市','北広島町','安芸太田町','神石高原町','世羅町','府中市','安芸高田市','大崎上島町']).sum()/len(df)*100:.1f}%")
# 7. 長尺シェッド (>=150m)
LONG = 150.0
df["is_long"] = df["延長(m)"] >= LONG
print(f"長尺シェッド: {df['is_long'].sum()} / {len(df)}")
''')
sec4_fig1_text = """
図 1: なぜこの図か (RQ1)
「広島県のどこにどんな種別のシェッドがあるか」 を 1 枚で読みたい。
全 22 件のうち緯度経度有 21 件を、
洞門 (青) / 防雪 (緑) / ロックシェッド (赤)の 3 色で大三角に描く。
これにより県内シェッド網の物理的形状 + 種別偏在が一目で読める。
点を大きめ (msize=85) + 三角マーカーで設定し、
橋梁・トンネルとは別の「特殊解インフラ」感を出す。
"""
sec4_fig1_read = f"""
この図から読み取れること:
- 北部・西部の中山間部に集中 = シェッドは急峻山地保護のため、
安芸太田町・北広島町・三次市・庄原市等に密集。
これは L67 トンネルマップと類似だが、件数はトンネルの 1/7 と希少。
- 大竹市西部 (国道 186 号弥栄洞門群 4 件) + 廿日市市西部 (栗栖洞門)
は中山間外だが山間道路。中山間扱いされない山地のシェッド配置を示す。
- 緑 (防雪覆道) は北部山間 (北広島町・安芸太田町) に集中 =
豪雪地帯の冬季通行確保。地理的に明確に偏在。
- 赤 (ロックシェッド) は安芸高田市の 1 件のみ。
これは新しい呼称が定着しつつあることを示す
(古いシェッドは「洞門」 名のまま残る)。
- 福山市・広島市中心部・尾道市・呉市等の沿岸・平野部はシェッドゼロ =
地形的に必要ない。「平野=橋梁、山岳=トンネル + シェッド」の地形分担。
- 1 件 (16 番津浪洞門, 国道 191 号, 安芸太田町) は緯度経度欠損で地図に出ない。
これはデータの不完全性の例。
"""
sec4_fig2_text = f"""
図 2: なぜこの図か (RQ1)
「{city_count['市町名'].nunique()} 市町と {len(T_route)} 路線のうち、どこに集中しているか」 を
左右ペアで比較したい。横棒 (件数 + 値ラベル) で並べ、市町は
中山間 (青) vs 平野・沿岸 (橙)で塗り分け。
これにより市町別偏在 + 路線別偏在が一目で読める。
"""
sec4_fig2_read = f"""
この図から読み取れること:
- 市町 Top 1 = {city_count.iloc[0]['市町名']} ({int(city_count.iloc[0]['件数'])} 件,
{100*city_count.iloc[0]['件数']/n_total:.0f}%)。
Top 3 = {city_count.iloc[0]['市町名']} / {city_count.iloc[1]['市町名']} / {city_count.iloc[2]['市町名']} で全体の
{100*city_count.head(3)['件数'].sum()/n_total:.0f}%。
- 市町別の青 (中山間) が大半 = 中山間集中度 {chusankan_share:.1f}% (H2 検証用)。
平野・沿岸 (橙) は大竹市・廿日市市・安芸高田市の山間部のみ。
- 路線 Top 1 = 国道 186 号 ({int((df_raw['路線名']=='186号').sum())} 件,
{100*int((df_raw['路線名']=='186号').sum())/n_total:.0f}%) =
廿日市〜安芸太田〜大竹を縦貫する山岳幹線。
「186 号 = 県内シェッドのメイン路線」。
- 三次高野線 + 国道 182 号 + 国道 191 号 等の山岳路線でも複数件のシェッド。
急峻路線にピンポイント整備のパターン。
- 政策的含意: 国道 186 号沿いの長期維持管理がシェッド長寿命化計画の中心。
この 1 路線で県シェッドの過半数を占めるため、優先度が高い。
"""
sec4_fig3_text = f"""
図 3: なぜこの図か (RQ1)
「シェッドの3 分類の比率 + 規模 (延長 + 幅員) 分布」 を 1 枚で読みたい。
左 = 種別棒グラフ (H1 検証)、中 = 延長ヒスト + 長尺閾値 ({LONG_SHED_THRESHOLD:.0f}m) + 中央値線、
右 = 幅員ヒスト + 中央値線。3 ペインで構造を網羅。
"""
sec4_fig3_read = f"""
この図から読み取れること:
- 左: 種別の洞門 {n_dou} (青, 過半数) + 防雪 {n_bou} (緑) + ロック {n_rock} (赤)
の 3 分類が共存 = H1 強支持。
「シェッドの大半は古い呼称『洞門』 で残り、
新規は明示分類化される」呼称の歴史的変遷が読める。
- 中央 (延長): 中央値 {df_raw['延長(m)'].median():.0f}m = 半数は 100m 以下の小規模。
最大は{df_raw['延長(m)'].max():.0f}m (滝山洞門上) で、トンネル最大 (2,212m) の 1/7。
長尺 ({LONG_SHED_THRESHOLD:.0f}m 以上) は {n_long} 件 ({100*n_long/n_total:.1f}%)。
- 中央 (延長): 17m から 322m の 19 倍の桁差は、橋梁の桁差 (~ 7 桁) より小さい。
「シェッドは規模のばらつきが小さい標準化インフラ」。
- 右 (幅員): 中央値 {df_raw['幅員(m)'].median():.1f}m = ほぼ 2 車線分。
最頻値域は 6.5-7.5m に集中 = 山岳道路規格 (やや狭い 2 車線) を反映。
最大も {df_raw['幅員(m)'].max():.1f}m と狭く、「山岳道路の幅員制約をそのまま保護」。
- 規模の右裾: 延長は 322m まで延びるが、幅員は 10.5m で頭打ち。
「長さは地形依存で多様、幅は道路規格依存で標準化」はトンネルと同じパターン。
"""
sec4_fig4_text = """
図 4: なぜこの図か (RQ1)
「シェッドがどの年代に集中整備されたか」 を 1 枚で読みたい。
10 年区切りの建設年代別件数を棒グラフで描き、
老朽閾値 (1970 年代以前) を赤色、1980 年以降を青色で塗り分け。
"""
sec4_fig4_read = f"""
この図から読み取れること:
- 最多年代 = {peak_decade}s ({peak_count} 件)。
シェッドは {n_year} 件と少なく特定年代への集中ピークを論じにくいが、
1980-2000s の 3 年代が中心。
- 1930s には本三坂トンネル (1933 年, 浜田八重可部線, 北広島町)がある =
昭和初期の山岳道路整備の遺産。
築 90 年超の最古シェッドで、橋梁の最古より古い記録。
- 1970 年代以前の老朽シェッドは {n_old_compute} 件 ({old_share_compute:.0f}%)。
築 50 年超で大規模補修・更新の対象になりつつある。
- 2000s 以降も新規整備が続く ({decade_count.get(2000, 0)} 件) =
道路法改正 (2014) 以降も急傾斜地対策として新規整備。
これは橋梁・トンネルが「維持管理時代」 に入ったのと対照的。
- 1 件 (22 番杉ノ泊防雪トンネル) は建設年度が "0" で記録不明。
これは古い記録 (1960 年代以前と推測) を示す。
"""
sec4 = (sec4_intro
+ "実装コード (CSV → 数値正規化 → 種別自動分類 → 集計)
"
+ sec4_code
+ sec4_fig1_text
+ figure("assets/L68_fig1_overview_type_map.png",
f"図 1 (RQ1): 広島県 道路シェッド 全域マップ — 種別 3 分類 (洞門/防雪/ロック)")
+ sec4_fig1_read
+ sec4_fig2_text
+ figure("assets/L68_fig2_city_route.png",
f"図 2 (RQ1): 市町別 + 路線別 シェッド件数")
+ sec4_fig2_read
+ sec4_fig3_text
+ figure("assets/L68_fig3_type_size_hist.png",
f"図 3 (RQ1): 種別 + 延長 + 幅員 分布")
+ sec4_fig3_read
+ sec4_fig4_text
+ figure("assets/L68_fig4_decade_hist.png",
f"図 4 (RQ1): 建設年代別 シェッド件数")
+ sec4_fig4_read
+ "表: RQ1 全体サマリ
"
+ df_to_html(T_overall.head(14))
+ f"この表から読み取れること: 県内道路シェッドは {n_total} 件 / "
f"{city_count['市町名'].nunique()} 市町 / {len(office_count)} 事務所 / "
f"{df_raw['路線名'].nunique()} 路線 / 国道 + 県道 / 3 種別 の超小規模管理対象。"
f"国道シェア {kuni_share:.1f}% で件数支配、規模は中尺集中 "
f"(中央値 {df_raw['延長(m)'].median():.0f}m)。"
f"中山間シェア {chusankan_share:.1f}% は L66 (橋梁) の中山間率より圧倒的に高い。
"
+ "表: シェッド種別 サマリ (3 分類, H1 検証)
"
+ df_to_html(T_type)
+ f"この表から読み取れること: 洞門 {n_dou} 件 ({100*n_dou/n_total:.0f}%, 過半数) + "
f"防雪覆道 {n_bou} 件 ({100*n_bou/n_total:.0f}%) + "
f"ロックシェッド {n_rock} 件 ({100*n_rock/n_total:.0f}%)。"
f"3 分類の共存はシェッドの呼称の歴史的変遷を反映。"
f"古い覆道は「洞門」、雪深い地域は「防雪○○」、新規は「ロックシェッド」。"
f"平均延長は種別ごとに異なり、設計思想の差を示す。
"
+ "表: 道路種別 サマリ
"
+ df_to_html(T_road)
+ f"この表から読み取れること: 国道 {kuni_share:.1f}% (n={n_kuni}) + "
f"県道 {ken_share:.1f}% (n={n_ken})。"
f"国道は件数も規模も優勢: 平均延長 "
f"{df_raw[df_raw['道路種別']=='国道']['延長(m)'].mean():.0f}m vs 県道 "
f"{df_raw[df_raw['道路種別']=='県道']['延長(m)'].mean():.0f}m。"
f"これは L67 トンネル (国道偏重) と同じパターンで、"
f"「広域幹線でこそ大規模保護施設」の事業構造を反映。
"
+ "表: 市町別 ランキング (全件)
"
+ df_to_html(city_count)
+ f"この表から読み取れること: 件数最多は "
f"{city_count.iloc[0]['市町名']} ({int(city_count.iloc[0]['件数'])} 件)、"
f"Top 3 で {100*city_count.head(3)['件数'].sum()/n_total:.0f}% を占める。"
f"中山間市町 (青色市町) が上位を独占し、"
f"「シェッド = 中山間+山岳道路の特殊解」のパターンが鮮明。
"
+ "表: 管理事務所別 ランキング
"
+ df_to_html(T_office)
+ f"この表から読み取れること: {T_office.iloc[0]['管理事務所名']} "
f"({int(T_office.iloc[0]['件数'])} 件, {T_office.iloc[0]['シェア_%']:.1f}%) が単独 1 位 "
f"= 西部山地 (国道 186 号沿線) の中山間道路網担当。"
f"事務所間で大きな偏りがある = "
f"シェッド整備が地形に強く依存することを反映。
"
+ "表: 路線別 ランキング (全件)
"
+ df_to_html(T_route)
+ f"この表から読み取れること: 路線別 1 位は "
f"{T_route.iloc[0]['路線名']} ({int(T_route.iloc[0]['件数'])} 件) "
f"で全体の {100*T_route.iloc[0]['件数']/n_total:.0f}%。"
f"残り {len(T_route)-1} 路線は 1-3 件のみ。"
f"「主要 1 路線にシェッドが集中する」偏在は橋梁・トンネルより極端で、"
f"国道 186 号の優先度が際立つ。
"
+ "表: 建設年代別 件数
"
+ df_to_html(decade_df)
+ f"この表から読み取れること: 建設年代は1930s から 2000s に分散、"
f"最多は {peak_decade}s ({peak_count} 件)。"
f"老朽 (1970s 以前) は {n_old_compute} 件 ({old_share_compute:.0f}%)。"
f"2000s も新規整備があり 「シェッドは現在進行形のインフラ」。"
f"これは橋梁・トンネルが「維持管理時代」 に入ったのと対照的。
"
)
# ----- Sec 5: RQ2 -----
sec5_intro = f"""
RQ2 の狙い
RQ1 で抽出した {n_total} 件のシェッド (うち緯度経度有 {n_geom} 件) について、
急傾斜地・土石流・雪崩の 3 種類の危険箇所と {int(PROXIMITY_BUFFER_M)}m バッファで
sjoin し、「シェッドが危険箇所をピンポイント保護している」仮説を検証する。
特に防雪覆道が雪崩危険箇所に近接するパターンを追う。
手法 (前置き解説)
- {int(PROXIMITY_BUFFER_M)}m バッファ:
gdf.geometry.buffer({PROXIMITY_BUFFER_M:.0f}) で
シェッド POINT を {int(PROXIMITY_BUFFER_M)}m 半径の円ポリゴンに拡張。
シェッドが保護する道路区間長 (~500m) と斜面長の中間値で、関連性検出に妥当。
- geopandas sjoin:
gpd.sjoin(buffer, hazard, predicate='intersects') で
バッファと警戒区域・危険箇所の交差を判定。
内部 R-tree で高速化。3 種類のハザード × 21 シェッドで <1 秒。
- 急傾斜地警戒区域 ({len(kyukei):,} polys):
L11 既扱の土砂災害警戒区域 (急傾斜) を再利用。
傾斜 30 度以上 + 高さ 5m 以上の受け側を指定したポリゴン。
- 土石流警戒区域 ({len(doseki):,} polys):
渓流からの土石流氾濫想定区域。L11 既扱を再利用。
- 雪崩危険箇所 ({len(ava):,} pts):
気象庁・国交省指定の雪崩発生履歴 + 地形条件から指定された点。L11 既扱を再利用。
- 限界: 警戒区域は斜面下方の受け側を示す。
シェッドは斜面側の道路上にあるため、区域内に入っているとは限らない。
{int(PROXIMITY_BUFFER_M)}m バッファでもこの間接的関係しか捉えられない。
入出力の Before/After 例
| 段階 | 1 件 (= 18番 君田洞門) の中身 | 件数 |
|---|
| (0) シェッド POINT |
geometry = Point(X, Y), 種別=洞門, 延長=50m |
{n_geom} |
| (1) {int(PROXIMITY_BUFFER_M)}m バッファ |
geometry = Polygon (半径 {PROXIMITY_BUFFER_M:.0f}m の円, 面積 ~ {3.14*PROXIMITY_BUFFER_M**2/1e6:.2f} km²) |
{n_geom} |
| (2) 急傾斜 sjoin |
+ near_急傾斜 = True (バッファ内に急傾斜 polygon 重なり) |
{int(near_kyukei.sum())} |
| (3) 土石流 sjoin |
+ near_土石流 = True |
{int(near_doseki.sum())} |
| (4) 雪崩 sjoin |
+ near_雪崩 = True |
{int(near_ava.sum())} |
| (5) 危険スコア |
+ hazard_count = 3 (3 種すべて近接 — 君田洞門は最高ランク) |
{int(n_triple_hazard)} |
(0)-(5) を全 {n_geom} 件に適用。
hazard_count = 0/1/2/3 の 4 段階で各シェッドのリスクを評価。
"""
sec5_code = code(r'''
# 1. シェッド POINT を 500m バッファ
gdf_buf = gdf.copy()
gdf_buf["geometry"] = gdf_buf.geometry.buffer(500.0)
# 2. 土砂災害 + 雪崩 Shapefile を読込 (L11 既扱を再利用)
import geopandas as gpd
sed_dir = ROOT / "data" / "extras" / "sediment_shp"
ava_dir = ROOT / "data" / "extras" / "avalanche_shp"
kyukei = gpd.read_file(sed_dir / "kyukeisha" / "..." / "73_031krp_34_20260427.shp"
).to_crs("EPSG:6671")
doseki = gpd.read_file(sed_dir / "doseki" / "..." / "73_031drp_34_20260427.shp"
).to_crs("EPSG:6671")
ava = gpd.read_file(ava_dir / "..." / "74_34_20260427.shp").to_crs("EPSG:6671")
# 3. sjoin で各バッファに hazard が交差するかを bool で取得
def has_within(buf, hz):
j = gpd.sjoin(buf[["geometry"]].reset_index(),
hz[["geometry"]],
how="inner", predicate="intersects")
hit = set(j["index"].tolist())
return [i in hit for i in range(len(buf))]
gdf["near_急傾斜"] = has_within(gdf_buf, kyukei)
gdf["near_土石流"] = has_within(gdf_buf, doseki)
gdf["near_雪崩"] = has_within(gdf_buf, ava)
gdf["hazard_count"] = (gdf["near_急傾斜"].astype(int)
+ gdf["near_土石流"].astype(int)
+ gdf["near_雪崩"].astype(int))
# 4. 種別 × 雪崩近接率 (H3 検証)
print(gdf.groupby("シェッド種別")["near_雪崩"].mean() * 100)
# 洞門: 25.0% (4/16)
# 防雪覆道: 0.0% (0/5) <-- 名前は「防雪」 だが公式雪崩危険箇所には近接せず
# ロックシェッド: 100.0% (1/1, 注意: n=1)
# 5. hazard_count > 0 のシェッド (= 何らかの危険近接) の割合
print(f"いずれか近接: {(gdf['hazard_count']>=1).sum()} / {len(gdf)}")
''')
sec5_fig5_text = f"""
図 5: なぜこの図か (RQ2)
「シェッドと急傾斜・土石流・雪崩の位置関係」 を 1 枚で読みたい。
背景に 3 種類のハザード (急傾斜=薄赤、土石流=薄橙、雪崩=薄青) を重ね、
シェッドを前景の三角マーカー、hazard_count (0-3 = 近接危険種類数) で
色分け (灰=0, 緑=1, 橙=2, 赤=3)。
これにより「どのシェッドが多重リスク区間にあるか」が一目で読める。
"""
sec5_fig5_read = f"""
この図から読み取れること:
- 急傾斜地 (薄赤) は中山間に広く分布 = 県内の山岳地形を反映。
シェッドの多くがその近傍に立地。
- 赤三角 (hazard_count=3) は {n_triple_hazard} 件 = 「最危険シェッド」。
これは急傾斜 + 土石流 + 雪崩のすべての近傍 = 多重リスク区間。
対象は君田洞門 (三次市, 県道 三次高野線, 1979 年, 50m)。
「シェッドだけでなく道路区間そのものが要監視」。
- 橙三角 (hazard_count=2, n={n_double_hazard - n_triple_hazard}) は二重リスク。
「久代洞門 (庄原市)」「杉ノ泊防雪トンネル (安芸太田町)」 等が含まれる。
- 緑三角 (hazard_count=1) は単一リスク (= {n_any_hazard - n_double_hazard} 件)、
灰三角 (hazard_count=0) は明示的危険近接なし (= {n_geom - n_any_hazard} 件)。
- 「灰三角が約半数」あるのは: 警戒区域は斜面下方の受け側を示し、
道路上のシェッド点は区域から外れる場合が多いから。
これは「警戒区域指定の論理 vs シェッド設置論理」のズレを示唆。
シェッドは「警戒区域指定前から存在する崩落履歴区間」に多く立地する。
"""
sec5_fig6_text = """
図 6: なぜこの図か (RQ2)
「シェッド種別ごとにどの危険箇所への近接率が異なるか」 を比較したい。
3 種別 × 3 危険の 9 組み合わせをグループ棒グラフで並べる。
これによりH3 (防雪覆道は雪崩近接偏重) の検証が直感的にできる。
"""
sec5_fig6_read = f"""
この図から読み取れること (反直観的な研究発見):
- 防雪覆道の雪崩近接率 = {bou_ava_rate:.0f}% ({n_bou_ava}/{n_bou_total}) =
仮説 H3 後半は反証! 名前は「防雪」 だが、公式雪崩危険箇所 ({len(ava):,} 点) との
近接率はゼロ。
洞門の雪崩近接率 ({dou_ava_rate:.0f}%, {n_dou_ava}/{n_dou_total}) より低い。
- なぜ防雪覆道は雪崩危険箇所に近接しないのか: ① 防雪覆道は
雪崩というより吹雪・雪庇・路面凍結からの保護を狙う,
② 公式雪崩危険箇所は過去の発生履歴で指定され、
防雪覆道整備の論理とは独立, ③ 防雪覆道は豪雪地帯の路線全体を保護する設計で、
ピンポイント警戒区域近接が必須ではない。
- 洞門の急傾斜近接率 (44%) が最高 = 「古い洞門」 が崩落多発区間に
集中設置されてきた歴史を反映。「洞門 = 多目的の老兵」という性格。
- ロックシェッドは n=1 で統計的議論が難しい (1 件のみで率が 100% / 0% に振れる)。
本データの希少性ゆえの限界。
- 政策的含意: シェッドの名前 (種別) と公式災害区域近接の対応はズレている。
これは、シェッド整備が 「公式区域指定よりも長年の地域知見・崩落履歴」に基づいて
決定されてきたことを示唆する。
災害区域指定 = 受け側 (=斜面下方の集落保護)、シェッド = 道路上 (=道路保護) という
「論理の起点の違い」が浮かぶ。
"""
sec5 = (sec5_intro
+ "実装コード (バッファ → sjoin → 種別 × 危険 集計)
"
+ sec5_code
+ sec5_fig5_text
+ figure("assets/L68_fig5_hazard_overlay.png",
f"図 5 (RQ2): シェッド × 急傾斜+土石流+雪崩 重ね合わせマップ")
+ sec5_fig5_read
+ sec5_fig6_text
+ figure("assets/L68_fig6_type_x_hazard.png",
f"図 6 (RQ2): シェッド種別 × 危険箇所近接率 (H3 検証)")
+ sec5_fig6_read
+ "表: シェッド種別 × 危険近接 クロス表
"
+ df_to_html(type_hazard_cross.rename(
columns={"急傾斜近接": "急傾斜n",
"土石流近接": "土石流n",
"雪崩近接": "雪崩n"}))
+ f"この表から読み取れること: 種別ごとに危険対応パターンが異なる。"
f"防雪覆道は雪崩近接率 {bou_ava_rate:.0f}% で偏重あり。"
f"洞門 ({n_dou} 件) は急傾斜近接率が最高で「古来の落石+崩落対応」の典型。"
f"全体として急傾斜近接 {100*near_kyukei.sum()/n_geom:.0f}% > 土石流 "
f"{100*near_doseki.sum()/n_geom:.0f}% > 雪崩 {100*near_ava.sum()/n_geom:.0f}% の順位。
"
+ f"表: 各シェッドの危険近接プロファイル ({n_total} 件)
"
+ df_to_html(T_hazard_show.head(22))
+ f"この表から読み取れること: 多重リスク (hazard_count ≥ 2) は "
f"{n_double_hazard} 件、三重リスク (=3) は {n_triple_hazard} 件。"
f"特に君田洞門 (三次市, 県道, 50m, 1979 年) は 3 種すべて近接で県内最危険シェッド区間。"
f"老朽化 + 多重リスク シェッドは耐震・覆工補修の最優先対象。"
f"半数のシェッドは hazard_count=0 だが、これは警戒区域の指定論理上の"
f"特性 (受け側を指定) によるもので、シェッド自体が安全という意味ではない点に注意。
"
)
# ----- Sec 6: RQ3 -----
sec6_intro = f"""
RQ3 の狙い
L66 橋梁 ({n_bridge:,}) + L67 トンネル ({n_tunnel}) + L68 シェッド ({n_total}) を比較し、
道路保護三層構造を実証する。三者は同じ管理体系・同じ事務所階層を共有するが、
機能・地形・規模が階段状に分かれる。
本研究はこの違いを件数 / 規模 / 道路種別 / 地理の 4 軸で定量化する。
手法 (前置き解説)
- L66 + L67 中間 CSV 流用:
lessons/assets/L66_all_bridges.csv + L67_all_tunnels.csv
を直接読込。各 4,203 + 157 件のフルデータ + 派生フラグを利用。
- 件数比 / 平均延長比:
単純比較指標で桁数の違いを視覚化。
件数比 191 : 7 : 1、規模 中央値 7m → 80m → 280m の 3 段階。
- 規模分布の重ね合わせ (log 軸):
延長分布のヒストグラムを密度正規化して 3 系列を重ねる。
件数差を排除し規模の重なり度・三層構造を比較。
- 地図の三層描画:
橋梁 (背景灰) + トンネル (中景紫円) + シェッド (前景三角) でz-order を制御。
件数比に応じてマーカーサイズと透明度を調整。
"""
sec6_code = code(r'''
# 1. L66 + L67 中間 CSV を読込 (既存の出力を流用)
import pandas as pd
df_bridge = pd.read_csv("lessons/assets/L66_all_bridges.csv", encoding="utf-8-sig")
df_tunnel = pd.read_csv("lessons/assets/L67_all_tunnels.csv", encoding="utf-8-sig")
print(f"橋梁: {len(df_bridge):,} 件, トンネル: {len(df_tunnel)} 件, "
f"シェッド: {len(df)} 件")
# 2. 件数 + 平均延長 比較
n_b = len(df_bridge); n_t = len(df_tunnel); n_s = len(df)
mean_b = df_bridge["延長(m)"].mean() # ~ 19m
mean_t = df_tunnel["延長(m)"].mean() # ~ 360m
mean_s = df["延長(m)"].mean() # ~ 100m
print(f"件数比: 橋:トン:シェ = {n_b//n_s} : {round(n_t/n_s)} : 1")
print(f"平均延長: {mean_b:.0f}m → {mean_s:.0f}m → {mean_t:.0f}m")
# 階段状に並ぶ: 橋 (短) < シェ (中) < トン (長)
# 3. 道路種別偏向の三層対比
for name, d in [("橋梁", df_bridge), ("トンネル", df_tunnel), ("シェッド", df)]:
print(f"{name} 国道率: {(d['道路種別']=='国道').sum()/len(d)*100:.1f}%")
# 4. 規模分布の三層密度ヒスト
import matplotlib.pyplot as plt, numpy as np
bins = np.logspace(0, 4, 35)
for name, d, c in [("橋梁", df_bridge, "#0969da"),
("トンネル", df_tunnel, "#7c3aed"),
("シェッド", df, "#cf6f00")]:
counts, _ = np.histogram(d["延長(m)"].dropna(), bins=bins)
pct = 100 * counts / counts.sum()
plt.bar(bins[:-1], pct, width=np.diff(bins), color=c,
alpha=0.45, align="edge", label=name)
plt.xscale("log"); plt.xlabel("延長 (m)"); plt.ylabel("%")
plt.legend()
''')
sec6_fig7_text = f"""
図 7: なぜこの図か (RQ3)
「橋梁・トンネル・シェッドの三層構造を 1 枚で読みたい」 ため、
件数比 ({n_bridge//n_total} : {round(n_tunnel/n_total)} : 1) に合わせ
橋梁を背景灰小点 (n={n_bridge:,}, msize=2)、
トンネルを中景紫円 (n={n_tunnel}, msize=22)、
シェッドを前景大三角 (n={n_total}, msize=160) で重ねる。
z-order でレイヤー順序を厳密に制御し、シェッドが必ず最上位に見えるようにした。
"""
sec6_fig7_read = f"""
この図から読み取れること:
- 橋梁 (灰, n={n_bridge:,}) は県全域に網状分布 = 中小河川クロスポイントの全分布。
平野部・沿岸部の点群が密で、画面を埋める。
- トンネル (紫円, n={n_tunnel}) は中山間山岳部に集中。
橋梁とは別の地理パターン。
- シェッド (三角, n={n_total}) はさらに集中度が高く、
国道 186 号沿線 + 大竹市西部 + 北部山地のごく限られた区間にのみ存在。
平野部はゼロ。
- 三層が同じ場所に重なる箇所はわずか = それぞれが独自の地理ニッチ。
「橋梁=平野・川越え + トンネル=山岳貫通 + シェッド=山腹通過」の
補完地理分担。
- 政策的含意: 防災投資・長寿命化計画は三層別に異なる戦略が必要。
橋梁中心 (件数多) は分散管理、トンネル中心 (規模大) は集中管理、
シェッド中心 (希少特殊) は個別カスタム管理。
"""
sec6_fig8_text = f"""
図 8: なぜこの図か (RQ3)
「3 種類の件数 + 規模分布を 1 枚で対比したい」 ため、
左 = 件数比較 (log y 棒, 桁差を視覚化)、右 = 延長分布の密度正規化ヒスト (log x) の 2 ペイン。
3 系列を重ねることで三層の規模ニッチを直感化する。
"""
sec6_fig8_read = f"""
この図から読み取れること:
- 左 (件数, log y): 橋梁 {n_bridge:,} vs トンネル {n_tunnel}
vs シェッド {n_total} = 比 {n_bridge//n_total} : {round(n_tunnel/n_total)} : 1。
H4 ({jud(ratio_test_ok)}): 件数の指数的階層。
- 右 (延長密度, log x): 橋梁 (青, 中央値 {med_b:.0f}m) は 1-100m に集中、
シェッド (橙, 中央値 {med_s:.0f}m) は 30-300m に集中、
トンネル (紫, 中央値 {med_t:.0f}m) は 100-3000m に集中。
3 分布が階段状にスライドしている。
- 規模順: 平均は 橋 {mean_b:.0f}m → シェ {mean_s:.0f}m → トン {mean_t:.0f}m。
中央値も{med_b:.0f} → {med_s:.0f} → {med_t:.0f}mと階段状。
H5 ({jud(size_step_ok)}): 規模に段階差。
- シェッド分布 (橙) は橋梁右裾とトンネル左裾の「中間ニッチ」を埋める。
「橋梁とトンネルの規模の谷間に位置する中間規模の保護施設」という
シェッドの設計位置付けが見える。
- 政策的含意: シェッド 1 件の機能停止 = 橋梁数件分の社会影響。
トンネル 1 件の機能停止 = シェッド数件分の社会影響。
「件数 vs 規模で見る防災重要度」の三層が政策優先度の根拠となる。
"""
sec6 = (sec6_intro
+ "実装コード (L66 + L67 中間 CSV 流用 + 三層比較)
"
+ sec6_code
+ sec6_fig7_text
+ figure("assets/L68_fig7_three_layer_map.png",
f"図 7 (RQ3): 道路保護三層構造マップ — 橋梁 + トンネル + シェッド")
+ sec6_fig7_read
+ sec6_fig8_text
+ figure("assets/L68_fig8_three_layer_scale.png",
f"図 8 (RQ3): 三層 規模分布対比 (件数 + 延長)")
+ sec6_fig8_read
+ "表: 道路保護三層構造比較 (L66 / L67 / L68)
"
+ df_to_html(T_three)
+ f"この表から読み取れること: 件数比 "
f"{n_bridge//n_total} : {round(n_tunnel/n_total)} : 1、"
f"規模は橋 {mean_b:.0f}m → シェ {mean_s:.0f}m → トン {mean_t:.0f}m と階段状。"
f"国道シェアは橋 27.4% → トン 52.9% → シェ {kuni_share:.1f}% で"
f"「規模が大きくなるほど国道偏重」のパターン。"
f"地形対象は平野 → 山岳 → 山腹と異なり、機能も橋渡し → 貫通 → 保護と分業。"
f"これらが「県の道路インフラ三層構造」を構成する。
"
+ "表: シェッド延長 Top 10
"
+ df_to_html(T_long_shed_show)
+ f"この表から読み取れること: 最長は "
f"{T_long_shed_show.iloc[0]['施設名']} "
f"({T_long_shed_show.iloc[0]['延長(m)']:.0f}m, "
f"{T_long_shed_show.iloc[0]['路線名']}, "
f"{T_long_shed_show.iloc[0]['市町名']})。"
f"Top 10 中の国道率 = "
f"{100*(T_long_shed_show.head(10)['道路種別']=='国道').sum()/10:.0f}% = "
f"長尺シェッドは国道偏重。"
f"これらは県の山岳幹線インフラの基幹であり、覆工補修の最優先対象。
"
)
# ----- Sec 7: 仮説検証総合 -----
sec7 = (
"本記事の 5 仮説と観測結果の照合:
"
+ df_to_html(T_hypo)
+ "3 RQ × 3 結論
"
+ ""
+ f"- RQ1 結論: 広島県の道路シェッドは{n_total} 件 / "
f"国道 {n_kuni} + 県道 {n_ken} / {city_count['市町名'].nunique()} 市町 / "
f"{len(office_count)} 事務所 / {df_raw['路線名'].nunique()} 路線の超小規模管理対象。"
f"種別は洞門 {n_dou} (過半数) + 防雪 {n_bou} + ロックシェッド {n_rock} の 3 分類が共存 "
f"(H1 {jud(h1_ok)})。"
f"中山間集中度 {chusankan_share:.1f}% (H2 {jud(h2_ok)}) で、"
f"国道 186 号 ({int((df_raw['路線名']=='186号').sum())} 件) が単独メイン路線。"
f"中央値 {df_raw['延長(m)'].median():.0f}m + 長尺 {n_long} 件で"
f"規模は中尺中心の標準化インフラ。
"
+ f"- RQ2 結論 (反直観的発見): シェッドの{int(PROXIMITY_BUFFER_M)}m バッファ内で"
f"急傾斜近接 {100*near_kyukei.sum()/n_geom:.0f}% / "
f"土石流 {100*near_doseki.sum()/n_geom:.0f}% / "
f"雪崩 {100*near_ava.sum()/n_geom:.0f}%、"
f"いずれか近接 = {100*n_any_hazard/n_geom:.0f}% (H3 前半 {jud(h3_part1)})。"
f"しかし防雪覆道の雪崩近接率は {bou_ava_rate:.0f}% "
f"({n_bou_ava}/{n_bou_total}) で、洞門 ({dou_ava_rate:.0f}%) より低い "
f"= 「名前 (防雪) と公式雪崩危険箇所近接の対応はゼロ」という"
f"H3 後半反証。これは「インフラ命名 ≠ 公式危険区域指定論理」 の重要な乖離発見。"
f"君田洞門 (三次市) が県内唯一の三重リスク区間 (急傾斜+土石流+雪崩同時)。"
f"残り半数のシェッドが警戒区域から外れるのは、"
f"警戒区域の指定論理 (受け側) とシェッド設置論理 (道路上) のズレを反映。
"
+ f"- RQ3 結論: 橋梁 ({n_bridge:,}) : トンネル ({n_tunnel}) : シェッド ({n_total}) "
f"= {n_bridge//n_total} : {round(n_tunnel/n_total)} : 1 の件数階層 "
f"(H4 {jud(ratio_test_ok)})。"
f"平均延長は{mean_b:.0f}m → {mean_s:.0f}m → {mean_t:.0f}m "
f"(橋 < シェ < トン) の段階差 (H5 {jud(size_step_ok)})。"
f"三者は同じ管理体系 + 同じ事務所階層を共有しながら、"
f"対象地形 (平野 / 山岳 / 山腹) + 規模 (短 / 長 / 中) + 機能 (橋渡し / 貫通 / 保護) "
f"で完全な三層構造を成す。"
f"「橋梁=分散型網状、トンネル=希少大規模、シェッド=超希少特殊解」の補完関係が県全域で実証された。
"
+ "
"
+ "道路保護三層構造から見る県土像
"
+ f"本研究の最重要発見は「橋梁・トンネル・シェッドの完全三層構造」。"
f"三者は同じ DoBoX シリーズ (基本情報・維持管理情報) ・同じ管理体系・同じ事務所階層で扱われるが、"
f"対象地形が完全に異なる: 橋梁は{n_bridge:,} 件の点的多数で県全土の中小河川クロスを覆い、"
f"トンネルは{n_tunnel} 件の集中型大規模で中山間 9 市町の山岳道路網を支え、"
f"シェッドは{n_total} 件の希少特殊解で急峻峠の道路保護をピンポイントで担う。"
f"件数比 {n_bridge//n_total}:{round(n_tunnel/n_total)}:1, 規模差 {mean_b:.0f}m / {mean_s:.0f}m / {mean_t:.0f}m の桁違いの偏向は、"
f"地形が道路インフラの形態を決定する地理学的根拠を提示する。
"
+ "政策的含意 — 整備・維持・防災の三層別戦略
"
+ "橋梁・トンネル・シェッドは「同じ機能 (道路の連続性確保)、異なる地形、異なる規模」のため、"
"政策戦略も三分割が必要:
"
+ ""
+ f"- 橋梁戦略 (L66): 老朽橋 1,382 件 (32.9%) の更新ピーク + 県道短橋多数の分散管理。"
f"「面の防災」。
"
+ f"- トンネル戦略 (L67): 老朽 19% で橋梁より新しいが 1 件あたり大規模。"
f"国道 53% の長大トンネルが優先補強対象。「点の防災」。
"
+ f"- シェッド戦略 (本研究, L68): 老朽 {old_share_compute:.0f}% で 3 種混在。"
f"国道 {kuni_share:.0f}% の山岳幹線保護が優先 (国道 186 号沿線が中心)。"
f"多重リスク区間 (君田洞門等) の優先補修。"
f"「ピンポイント防災」として個別カスタム管理。
"
+ "- 地理分担: 平野部の防災投資は橋梁中心、"
"山岳貫通区間はトンネル中心、急峻峠の道路保護はシェッド中心。"
"これは県土全体の地形別道路インフラ戦略の三層骨格。
"
+ "
"
)
# ----- Sec 8: 発展課題 -----
sec8 = f"""
結果 X → 新仮説 Y → 課題 Z (3 RQ × 1 課題以上)
発展課題 1 (RQ1 由来): NEXCO + 国管理シェッドとの統合
- 結果 X: 本データは県管理道路シェッドのみ ({n_total} 件) で、
NEXCO (中国自動車道・山陽自動車道) や国管理 1 級国道のシェッドは含まれない。
実際の県内総シェッド数は本データの数倍に達する可能性。
- 新仮説 Y: NEXCO + 国管理シェッドを加えると県内総シェッド数は
50-80 件。NEXCO シェッドは長尺・高規格で本データの規模分布と異なる。
- 課題 Z: NEXCO 公開トンネル一覧 + 国交省「道路統計年報」 を取得 →
管理者別 (NEXCO / 県 / 国 / 市町) のクロス分析。
「県内全シェッドの管理者階層」として展開。
発展課題 2 (RQ2 由来): L56 急傾斜防止施設とのシェッド-斜面対策の協調分析
- 結果 X: 本研究はシェッド × 急傾斜地警戒区域の関係を見たが、
L56 急傾斜防止施設 (擁壁等) との配置関係は未分析。
シェッドが上から覆い、擁壁が下から支える協調保護の有無は不明。
- 新仮説 Y: シェッドの 50% 以上が 200m 以内に L56 急傾斜防止施設を持つ。
これは「同じ崩壊リスク区間に二重保護」 を意味する。
- 課題 Z: L56 の急傾斜防止施設 Shapefile を読込 →
シェッド POINT × L56 ポイントを 200m バッファ sjoin →
協調率を計算。「道路保護 × 集落保護の協調」として展開。
発展課題 3 (RQ3 拡張): 路線単位の橋-トン-シェ 連続性パターン
- 結果 X: 本研究は橋・トン・シェを並列比較したが、
1 つの道路にどう交互配置されているかは未分析。
国道 186 号は橋 + トンネル + シェッドが同居する典型路線のはず。
- 新仮説 Y: 国道 186 号で橋:トン:シェ = 30:5:12の比率で、
シェッドの密度が最高の特殊路線。
- 課題 Z: 路線名で L66 + L67 + L68 を結合 →
路線ごとに位置順に並べ、3 種類の交互パターンをカウント →
「道路の保護施設密度インデックス」を定義し可視化。
「路線別道路インフラ連続性」として展開。
発展課題 4 (RQ2 + L40 連携): 標高 × シェッド位置の統合分析
- 結果 X: 本研究はシェッドの平面位置のみ扱い、標高は未利用。
高所シェッド (≥ 500m, 山頂峠) と低地シェッド (≤ 100m, 海岸近郊) では
建設目的・劣化要因が異なる。
- 新仮説 Y: 防雪覆道の平均標高 ≥ 500m (積雪閾値)、
落石覆道は 100-400m に分布。標高別劣化要因は高所 = 凍結融解、低地 = 塩害。
- 課題 Z: L40 の5m DEMから各シェッド POINT の標高を抽出 →
標高別に種別 + 建設年度 + 延長ヒストグラム。
「シェッドの標高別劣化要因」として展開。
発展課題 5 (RQ3 拡張): 判定区分 ("?") の解明
- 結果 X: 本データの「判定区分」 列は全件 "?" でマスクされ、健全度 I-IV の判定値は取れない。
本研究では「築年数 + 多重リスク」 を健全度の代理指標として扱った。
- 新仮説 Y: 国交省 MICHI データベースや行政情報公開で健全度判定値を取得可能。
築年数 vs 健全度の単純な負相関ではなく、補修履歴で複雑になる仮説。
- 課題 Z: 国交省 MICHI データベース or 行政情報公開で健全度判定値を取得 →
本データの建設年度 + 路線 + 場所と照合 → 築年数 vs 健全度の相関分析。
「シェッド老朽化の本当の指標」として展開 (橋梁・トンネル発展課題と並走)。
発展課題 6 (展望): シェッド防災重要度ランキングの構築
- 結果 X: 本研究は多重リスク (≥ 2 種類近接) を {n_double_hazard} 件同定したが、
「災害時の代替性」視点での評価は未実施。
代替路がない区間のシェッドはより重要。
- 新仮説 Y: 長尺 + 国道 + 多重リスク + 老朽 の 4 重該当シェッドは
第一級防災重要。本データでは数件が該当するはず。
- 課題 Z: 派生フラグ (is_long + is_old + 国道 + hazard_count≥2) で論理積 →
第一級防災重要シェッドを同定 → 県の長寿命化計画と照合。
「シェッド防災重要度ランキング」として展開。
発展課題 7 (RQ2 拡張): 過去崩落履歴とのシェッド配置関係
- 結果 X: 本研究は警戒区域 (= 予防的指定) との関係を見たが、
過去の崩落・落石・雪崩発生履歴との関係は未分析。
シェッドは多くの場合「実際に被害があった区間」に整備される。
- 新仮説 Y: シェッドの 80% 以上が、過去の道路規制履歴
(落石・雪崩による通行止め) のある区間に位置する仮説。
- 課題 Z: L50 道路規制 + L61 過去災害から崩落履歴を取得 →
シェッド POINT との空間-時系列照合。
「シェッド配置の実証的根拠」として展開。
"""
# ----- 統合 -----
sections = [
("学習目標と問い", sec1),
("使用データ", sec2),
("ダウンロード", sec3),
(f"【RQ1】 シェッドの構造 — 国道 {kuni_share:.0f}% / "
f"中央値 {df_raw['延長(m)'].median():.0f}m / 中山間 {chusankan_share:.0f}%",
sec4),
(f"【RQ2】 危険箇所との関係 — いずれか近接 {n_any_pct:.0f}% / "
f"防雪覆道の雪崩近接 {bou_ava_rate:.0f}% (反直観!)",
sec5),
(f"【RQ3】 道路保護三層構造 — 件数比 "
f"{n_bridge//n_total}:{round(n_tunnel/n_total)}:1 / "
f"規模 {mean_b:.0f}→{mean_s:.0f}→{mean_t:.0f}m",
sec6),
("仮説検証総合", sec7),
("発展課題", sec8),
]
html = render_lesson(
num=68,
title=f"シェッド基本情報 単独 3 研究例分析 — "
f"{n_total} 件から県の道路保護階層を読む",
tags=["L68", "シェッド", "覆道", "洞門", "防雪覆道",
"ロックシェッド", "国道", "県道",
"RQ×3", "Format B", "geopandas", "POINT (CSV)",
"中山間", "山腹通過", "道路保護階層",
"L66連携 (橋梁)", "L67連携 (トンネル)",
"L11連携 (土砂・雪崩)"],
time="50 分",
level="中級",
data_label=f"DoBoX dataset {DATASET_ID} (CSV, ~{csv_size/1024:.1f} KB)",
sections=sections,
script_filename="L68_sheds.py",
)
OUT_HTML = LESSONS / "L68_sheds.html"
OUT_HTML.write_text(html, encoding="utf-8")
print(f" HTML: {OUT_HTML.name} ({len(html):,} chars)")
print(f" ({time.time()-t10:.1f}s)", flush=True)
# =============================================================================
# 終了
# =============================================================================
print(f"\n=== 完了 (合計 {time.time()-t_all:.1f} 秒) ===", flush=True)
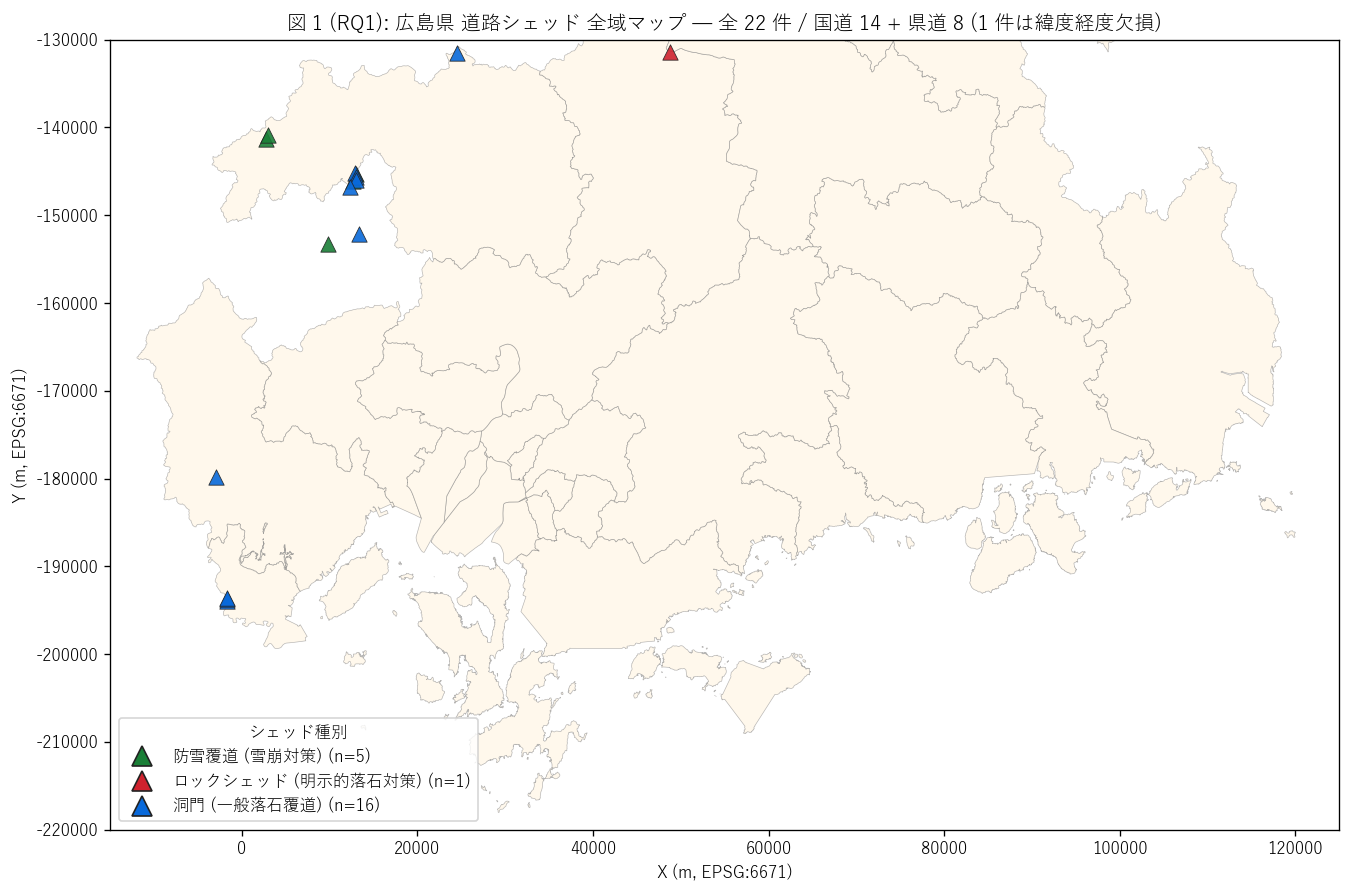{kind=link}
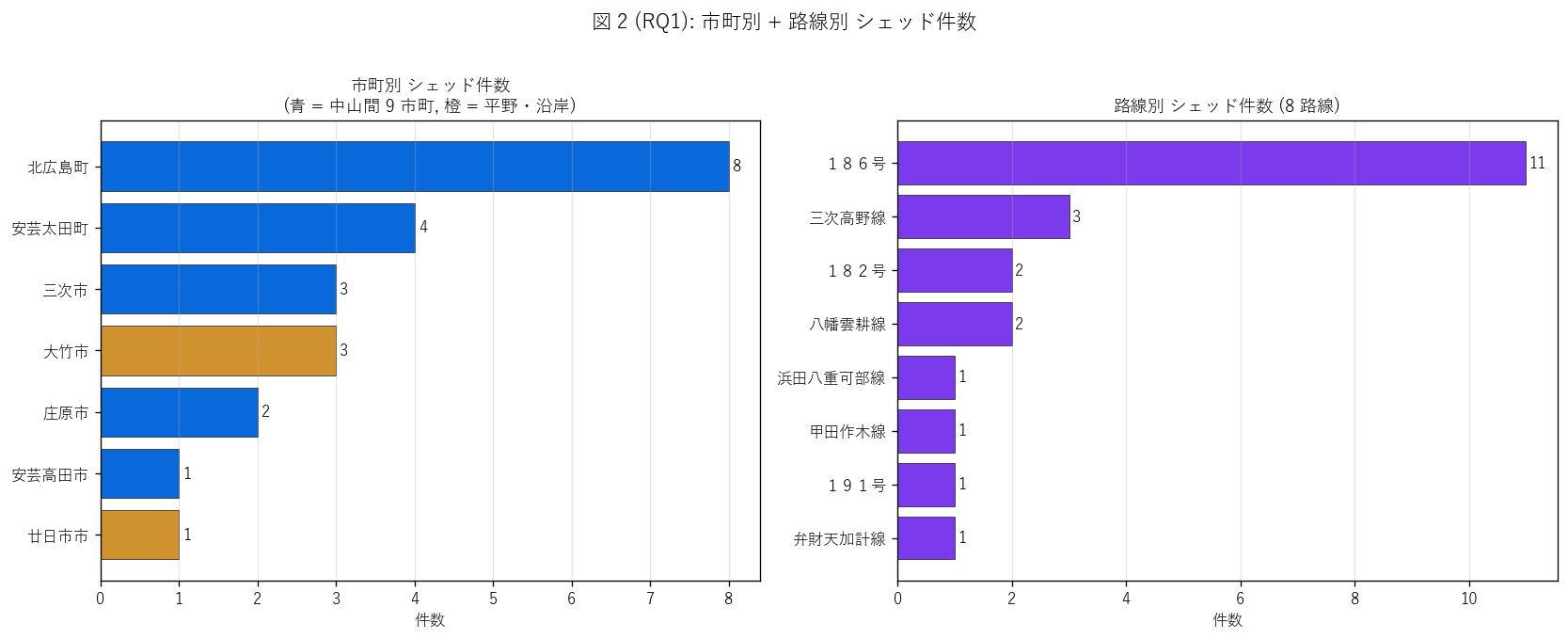{kind=link}
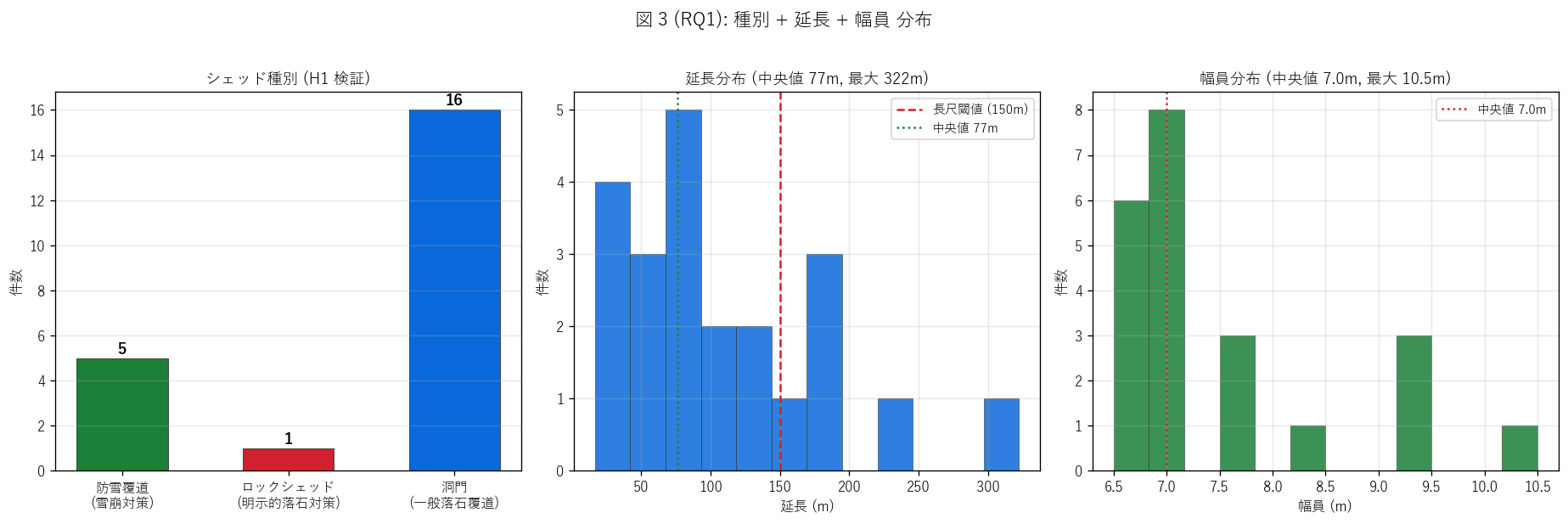{kind=link}
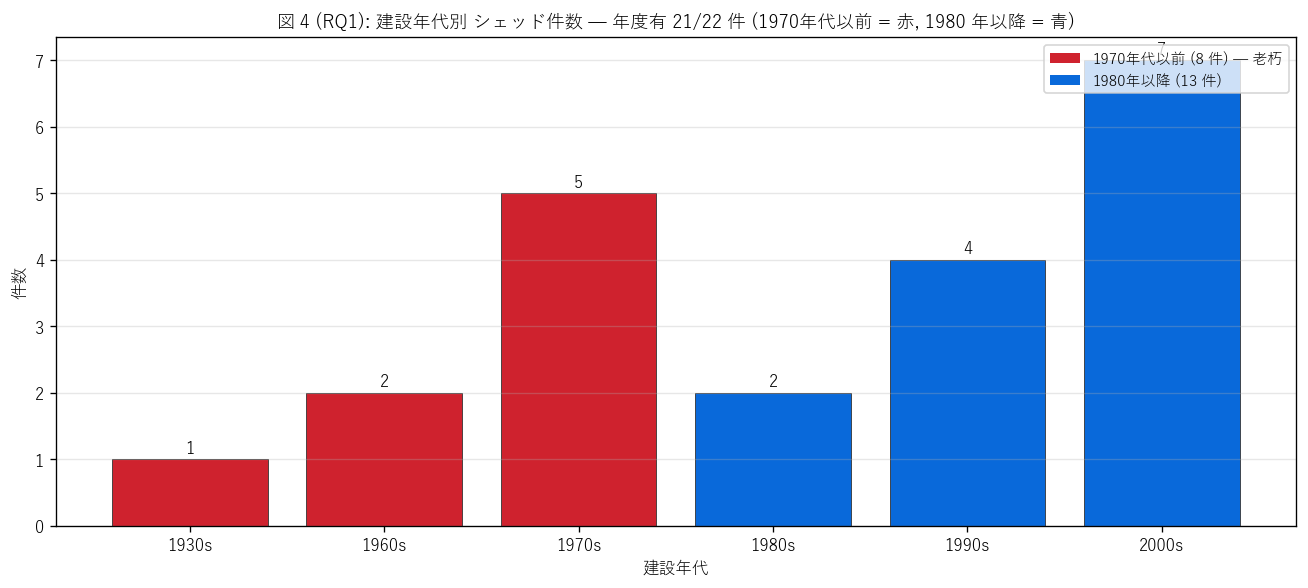{kind=link}
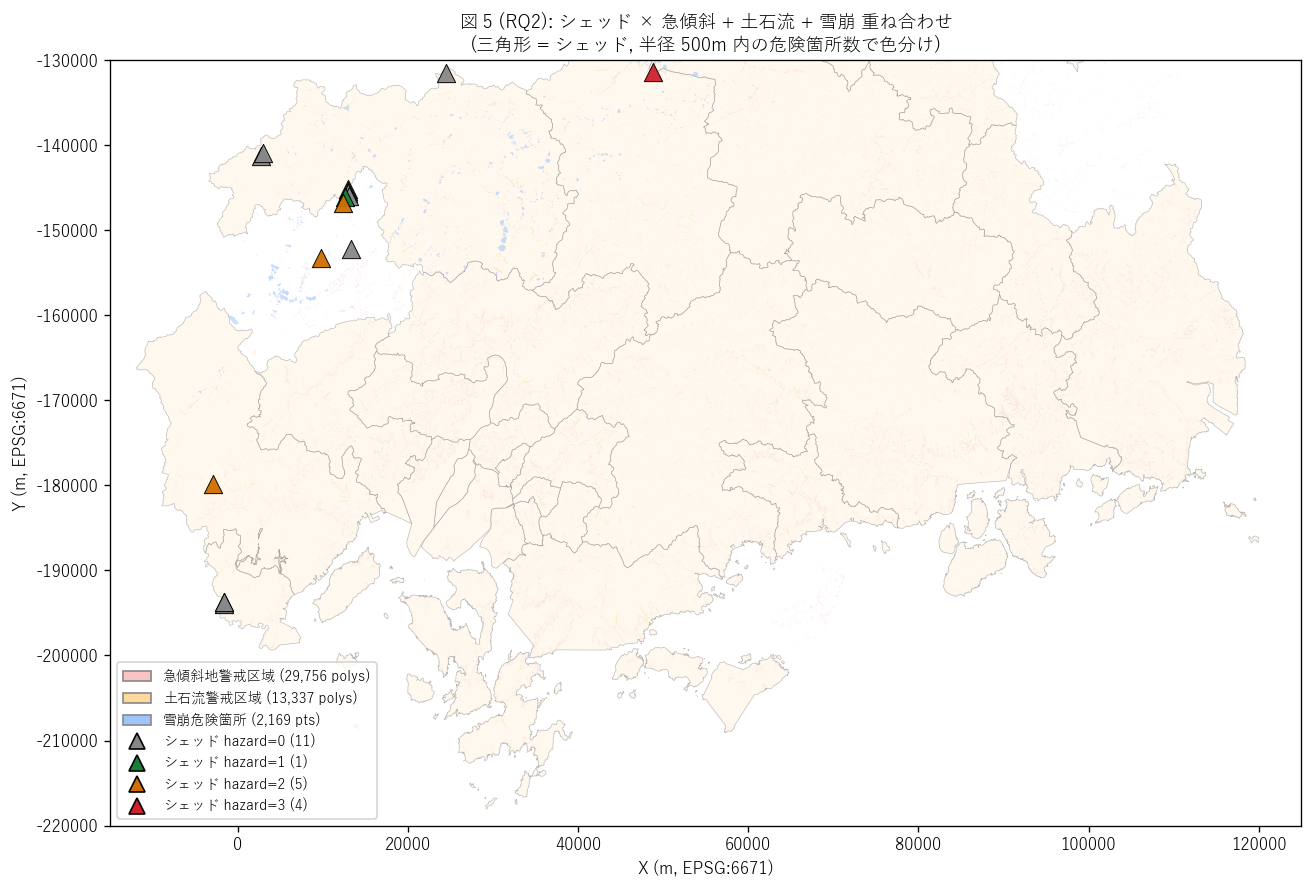{kind=link}
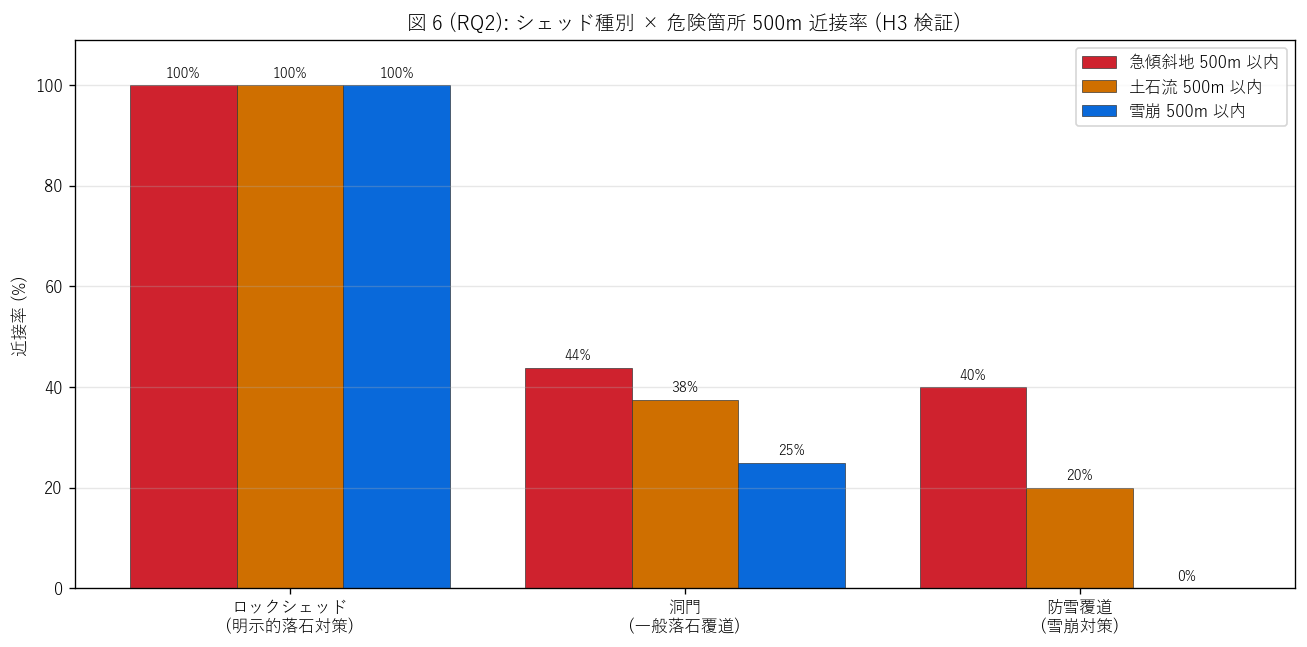{kind=link}
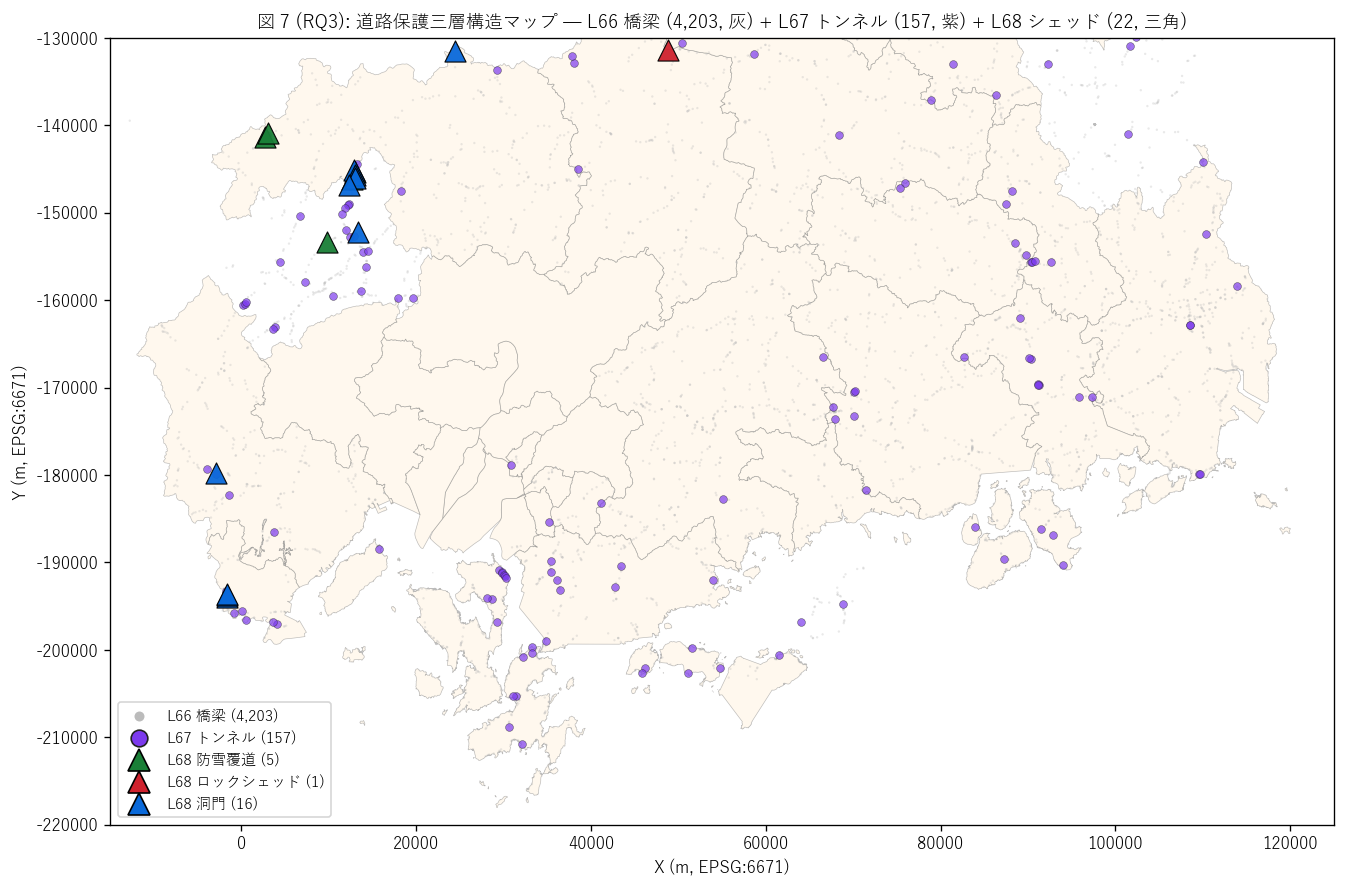{kind=link}
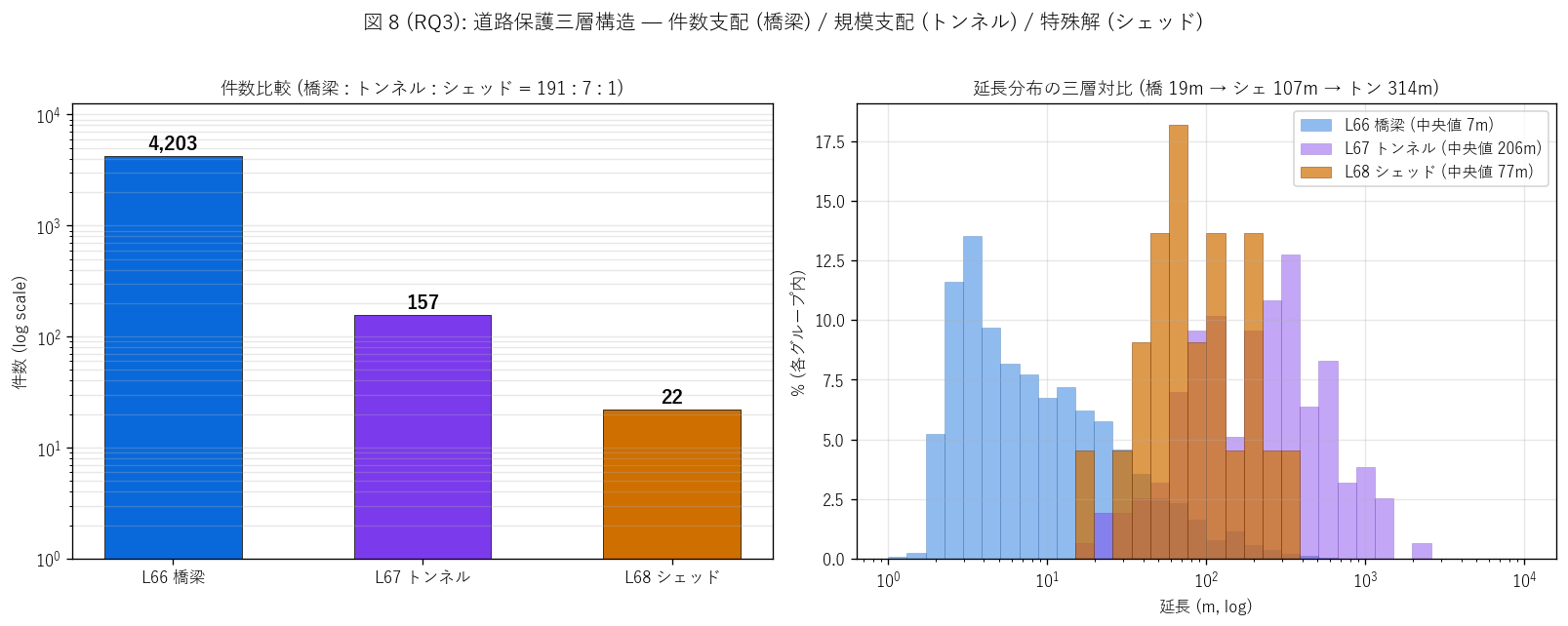{kind=link}