# -*- coding: utf-8 -*-
"""L63 津波災害警戒区域 単独 3 研究例分析
— 広島県沿岸の法的に指定された津波災害警戒区域を
3 つの独立した研究角度で読み解く
カバー宣言:
本記事は DoBoX のシリーズ「津波災害警戒区域情報」 1 件
(dataset_id = 47) を 単独で取り上げ、
広島県沿岸で法的に指定された津波災害警戒区域の地理構造を
3 つの独立した研究角度 (RQ1 / RQ2 / RQ3) で並列に分析する。
Phase 5 災害対応系で「指定 (法的拘束力)」 という制度の最終出力を扱う。
「津波災害警戒区域」 とは:
津波防災地域づくり法 (2011 年 12 月 14 日法律第 123 号) 第 53 条に基づき、
都道府県知事が指定する法的拘束力を持つ警戒区域。
住民への津波情報伝達体制の整備、避難場所・避難経路の確保、
要配慮者利用施設の避難確保計画策定等の制度的義務が伴う。
広島県は南海トラフ地震想定の津波 (= 津波浸水想定 = 想定図) の中から
特に住民保護が必要な範囲を切り取って指定している。
本記事は L49 (津波浸水想定図 dataset 46) と厳密に区別:
L49 = 「想定」 (= 技術的シミュレーション結果, 法的拘束力なし)
L63 = 「指定」 (= 都道府県知事が告示する法的指定区域)
両者は範囲が一致するわけではなく、L63 は制度的に切り取られた一部分。
本研究 RQ2 で両者の空間関係を定量比較する。
本記事は L62 (避難情報) / L61 (過去災害) / L44 (高潮) / L49 (津波想定) と
厳密に独立。本研究は「法的指定の地理構造」 を単独で扱う。
研究の問い (3 RQ):
RQ1 (主研究): 広島県の津波災害警戒区域の地理範囲・市町別指定状況はどう描けるか?
1,285,428 ポリゴン (10m メッシュ) を 30m に集約し、19 沿岸市町別の指定面積、
基準水位ランク (= 0.0〜0.5m / 0.5〜1.0m / 1.0〜2.0m 等) 別の構成、
特に沿岸 vs 内陸の指定パターンを集計する。
「警戒区域」 の地理的形状を法制度の観点から定量化する。
RQ2 (副研究 1): L49 津波浸水想定 (= 技術的想定) と L63 警戒区域 (= 法的指定) の
空間関係はどう描けるか?
L49 の 138,134 セル (想定) と L63 の 178,004 セル (指定) を
30m グリッド単位で空間結合し、
「想定 ∩ 指定」 「想定のみ」 「指定のみ」 の 3 パターンの
面積と地理分布を可視化する。
「想定があるが指定されていない」 エリア = 制度的隙間を同定し、
「想定 → 指定」の制度的フィルタの実態を読む。
RQ3 (副研究 2): 警戒区域内の沿岸人口・建物との空間関係はどう描けるか?
L22 既扱の市町別人口を母数とし、警戒区域 km² あたりの守るべき人口
(= ハザード人口密度指標) を市町別に算出。
警戒区域指定面積 vs 人口の散布で
「広い指定 + 少人口 (中山間沿岸)」 vs
「狭い指定 + 大人口 (都市沿岸)」の構造的対比を抽出。
仮説 (5):
H1 (浅水支配, RQ1): 警戒区域の基準水位は0.5〜2.0m が支配的で、
3m 超の深いランクは <20% を予想。
これは瀬戸内海津波の地形的特性 (= 太平洋側より浅い) と整合する。
H2 (湾奥 + 干拓地集中, RQ1): 警戒区域指定面積は呉市・尾道市・福山市に集中し、
上位 3 市町で全体の 40% 超を占めると予想。
湾奥 (呉市音戸・天応) + 干拓地 (福山市芦田川河口) + 多島海 (尾道市) の
3 つの地形類型が指定面積を支配する。
H3 (想定 ⊃ 指定, RQ2): L49 想定区域 ⊃ L63 指定区域 の包含関係を予想。
つまり想定区域のうち一部のみが警戒区域として指定される。
想定面積 > 指定面積 の関係を空間統計で検証。
「想定はあるが指定されていない (= 制度的隙間)」 エリアが存在する。
H4 (制度差の地理パターン, RQ2): 「想定のみ (指定外)」 と「指定のみ (想定外)」 の
バランスを市町別に集計すると、市町ごとに「想定 vs 指定」 の割合が異なると予想。
これは指定が市町別に審議されたことを反映する。
H5 (人口密度勾配, RQ3): 警戒区域内 km² 当たりの守るべき人口は
都市部 (広島市・福山市) >> 中山間沿岸 (江田島市・大竹市)を予想。
人口正規化されたハザード密度指標で、都市部の防災投資優先度の高さを
数量化する。
要件 S 準拠 (1分以内完走):
- 重い処理 (1.28M ポリゴン → 30m 集約 → admin sjoin → L49 重なり判定)
は `lessons/_l63_build_cache.py` で事前計算 (~15 秒)
- 本スクリプトはキャッシュ全揃えば <30 秒で完走
- キャッシュ未作成なら build_cache を呼んでビルド
要件 T 準拠 (位置情報 = Shapefile = 地図必須):
- RQ1: 県全域 6 ランク主題図 (choropleth)、市町別指定面積 choropleth
- RQ2: 想定 vs 指定 重ね合わせマップ、想定のみ / 両方 / 指定のみ 3 区分マップ
- RQ3: 人口密度 vs 警戒区域 散布、市町別 守るべき人口 choropleth
要件 Q 準拠: 図 8 / 表 12 (3 RQ × 多角度: 構造 / 想定差 / 人口関係)
データ仕様:
- dataset 47: 津波災害警戒区域情報 (Shapefile)
- resource 42: 340006_tsunami_caution_area_20190302.zip (27.8 MB)
- 形式: Shapefile (Polygon, EPSG:2445 = 平面直角第 3 系)
- レコード数: 1,285,428 polygon (10m メッシュ単位)
- 列: kijyun_sin (int, cm 単位の基準水位 / 浸水深)
- 範囲: 沿岸 19 市町をカバー、最大基準水位 8.68m
- 公表年月日: 2022-04-08 (作成日), 2022-05-20 (最終更新), 2019-03-02 (告示)
- 作成主体: 広島県土木建築局
- ライセンス: CC-BY 4.0
- 法的根拠: 津波防災地域づくり法 第 53 条
"""
from __future__ import annotations
import sys, time, subprocess
from pathlib import Path
sys.path.insert(0, str(Path(__file__).parent))
from _common import ROOT, ASSETS, LESSONS, render_lesson, code, figure
import numpy as np
import pandas as pd
import geopandas as gpd
import shapely
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.patches import Patch
from matplotlib.lines import Line2D
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
t_all = time.time()
print("=== L63 津波災害警戒区域 単独 3 研究例分析 ===", flush=True)
# =============================================================================
# 0. 定数・パス
# =============================================================================
TARGET_CRS = "EPSG:6671"
DATA_DIR = ROOT / "data" / "extras" / "L63_tsunami_warning_zone"
CACHE = DATA_DIR / "_cache"
ADMIN_GPKG = ROOT / "data" / "extras" / "L44_storm_surge" / "_cache" / "admin_diss.gpkg"
KEIKAI_ZIP = DATA_DIR / "340006_tsunami_caution_area_20190302.zip"
# L49 既扱の津波浸水想定キャッシュ (RQ2 比較用)
L49_DISS = ROOT / "data" / "extras" / "L49_tsunami_inundation" / "_cache" / "tsunami_dissolve_8rank.gpkg"
# L22 既扱の市町別人口
L22_CITY_SUMMARY = LESSONS / "assets" / "L22_city_summary.csv"
# 浸水深 (= 基準水位) ランク
RANK_LABEL = {
10: "0.0〜0.5m", 20: "0.5〜1.0m", 30: "1.0〜2.0m", 40: "2.0〜3.0m",
50: "3.0〜5.0m", 60: "5.0〜10.0m", 70: "10.0〜20.0m", 80: "20m以上",
}
RANK_COLOR = {
10: "#bee2ff", 20: "#87c4f0", 30: "#56a4dc", 40: "#2c83c4",
50: "#1c63a4", 60: "#0e4282", 70: "#7d2cbf", 80: "#4a1280",
}
RANK_MID = {10: 0.25, 20: 0.75, 30: 1.5, 40: 2.5, 50: 4.0,
60: 7.5, 70: 15.0, 80: 25.0}
ACTIVE_RANKS = [10, 20, 30, 40, 50, 60] # 観測ランク (70/80 は空)
CITY_NAME = {
101: "広島市中区", 102: "広島市東区", 103: "広島市南区", 104: "広島市西区",
105: "広島市安佐南区", 106: "広島市安佐北区", 107: "広島市安芸区", 108: "広島市佐伯区",
202: "呉市", 203: "竹原市", 204: "三原市", 205: "尾道市", 207: "福山市",
208: "府中市", 209: "三次市", 210: "庄原市", 211: "大竹市", 212: "東広島市",
213: "廿日市市", 214: "安芸高田市", 215: "江田島市",
302: "府中町", 304: "海田町", 307: "熊野町", 309: "坂町",
369: "安芸太田町", 462: "世羅町", -1: "県外/海上",
}
COASTAL_CITIES = {101, 102, 103, 104, 107, 108, 202, 203, 204, 205,
207, 211, 213, 215, 304, 309}
# 広島市の区を「広島市」 にロールアップ
def rollup_to_city(cd):
"""広島市の 8 区を「広島市」 にロールアップした名前を返す"""
nm = CITY_NAME.get(int(cd), "?")
if nm.startswith("広島市"):
return "広島市"
return nm
# =============================================================================
# 1. キャッシュ確保 (なければ _l63_build_cache.py 実行)
# =============================================================================
print("\n[1] キャッシュ確保", flush=True)
t1 = time.time()
CACHE_FILES = [
CACHE / "keikai_dissolve_8rank.gpkg",
CACHE / "keikai_cells_30m.parquet",
CACHE / "city_rank_pivot.csv",
CACHE / "l49_overlap_summary.csv",
CACHE / "rank_l49_cross.csv",
CACHE / "city_l49_cross.csv",
]
if not all(p.exists() for p in CACHE_FILES):
print(" キャッシュ未作成 → _l63_build_cache.py を実行 (~15 秒, 初回のみ)", flush=True)
res = subprocess.run([sys.executable, "-X", "utf8",
str(LESSONS / "_l63_build_cache.py")],
cwd=ROOT, check=True)
else:
print(f" キャッシュ全 {len(CACHE_FILES)} ファイル OK", flush=True)
# 読み込み
diss = gpd.read_file(CACHE / "keikai_dissolve_8rank.gpkg").to_crs(TARGET_CRS)
diss["depth_label"] = diss["rank"].map(RANK_LABEL)
print(f" 警戒区域 dissolved 6 rank polygons: {len(diss)} 行")
cells = gpd.read_parquet(CACHE / "keikai_cells_30m.parquet")
print(f" cells_30m: {len(cells):,} rows")
city_rank_df = pd.read_csv(CACHE / "city_rank_pivot.csv")
overlap_df = pd.read_csv(CACHE / "l49_overlap_summary.csv")
rank_l49_df = pd.read_csv(CACHE / "rank_l49_cross.csv")
city_l49_df = pd.read_csv(CACHE / "city_l49_cross.csv")
admin = gpd.read_file(ADMIN_GPKG).to_crs(TARGET_CRS)
admin["NAME"] = admin["CITY_CD"].map(CITY_NAME).fillna("?")
# L49 想定区域 (比較用)
l49_diss = None
if L49_DISS.exists():
l49_diss = gpd.read_file(L49_DISS).to_crs(TARGET_CRS)
print(f" L49 想定 polygon: {len(l49_diss)} 行")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 2. RQ1 集計: 警戒区域の地理範囲・市町別指定状況
# =============================================================================
print("\n[2] RQ1 集計: 地理範囲・市町別指定状況", flush=True)
t2 = time.time()
total_km2 = float(diss["area_km2"].sum())
print(f" 全津波警戒区域指定面積: {total_km2:.2f} km²")
print(f" rank 別:")
for _, r in diss.iterrows():
print(f" {RANK_LABEL[r['rank']]}: {r['area_km2']:.2f} km² "
f"({100*r['area_km2']/total_km2:.1f}%)")
# H1 検証: 浅水 (<2m) 支配?
shallow = float(diss[diss["rank"].isin([10, 20, 30])]["area_km2"].sum())
deep = float(diss[diss["rank"].isin([50, 60, 70, 80])]["area_km2"].sum())
shallow_pct = 100 * shallow / total_km2
deep_pct = 100 * deep / total_km2
print(f"\n H1 検証: 浅水 (<2m) = {shallow_pct:.1f}%, 深水 (>3m) = {deep_pct:.1f}%")
# 重み付き平均深さ
weighted_mean_depth = sum(diss["area_km2"].iloc[i] * RANK_MID[diss["rank"].iloc[i]]
for i in range(len(diss))) / total_km2
print(f" 重み付き平均基準水位: {weighted_mean_depth:.2f} m")
# 市町ランキング (-1 を除く + 広島市は区を集約)
city_in = city_rank_df[city_rank_df["CITY_CD"] >= 0].copy()
city_in["市町名"] = city_in["CITY_CD"].apply(rollup_to_city)
city_rolled = city_in.groupby("市町名", as_index=False).sum(numeric_only=True)
# 広島市の CITY_CD は最初に出現する区のもので代表
hiroshima_cd = next((cd for cd in city_in["CITY_CD"]
if 100 < cd < 200), 103)
def city_repr_cd(name):
"""市町名 → 代表 CITY_CD (広島市は 103 = 南区を代表)"""
if name == "広島市":
return 103
for cd, nm in CITY_NAME.items():
if nm == name:
return cd
return -1
city_rolled["CITY_CD_repr"] = city_rolled["市町名"].apply(city_repr_cd)
city_rolled = city_rolled.sort_values("total_km2", ascending=False).reset_index(drop=True)
city_rolled["順位"] = np.arange(1, len(city_rolled) + 1)
top3_share = city_rolled["total_km2"].head(3).sum() / city_rolled["total_km2"].sum()
print(f"\n 市町ランキング (Top 5):")
for _, r in city_rolled.head(5).iterrows():
print(f" {int(r['順位']):2d}. {r['市町名']:>10s}: {r['total_km2']:.2f} km²")
print(f"\n H2 検証: 上位 3 市町シェア = {top3_share*100:.1f}%")
# 市町別 重み付き平均深さ
def city_weighted_depth(row):
s, w = 0.0, 0.0
for c in ACTIVE_RANKS:
col = f"rank_{c}_km2"
if col in row:
s += float(row[col]) * RANK_MID[c]
w += float(row[col])
return s/w if w > 0 else 0
city_rolled["平均深さ_m"] = city_rolled.apply(city_weighted_depth, axis=1)
print(f" ({time.time()-t2:.1f}s)", flush=True)
# =============================================================================
# 3. RQ2 集計: L49 想定 vs L63 指定 の関係
# =============================================================================
print("\n[3] RQ2 集計: L49 想定 vs L63 指定", flush=True)
t3 = time.time()
# 全体比較
n_keikai = len(cells)
n_both = int(cells["in_l49"].sum())
n_only_keikai = int((~cells["in_l49"]).sum())
area_keikai_total_km2 = n_keikai * 900 / 1e6
area_both_km2 = n_both * 900 / 1e6
area_only_keikai_km2 = n_only_keikai * 900 / 1e6
print(f" L63 警戒区域 セル数: {n_keikai:,} = {area_keikai_total_km2:.2f} km²")
print(f" L63 ∩ L49 (両方): {n_both:,} ({100*n_both/n_keikai:.1f}%) = {area_both_km2:.2f} km²")
print(f" L63 \\ L49 (警戒のみ): {n_only_keikai:,} ({100*n_only_keikai/n_keikai:.1f}%) = {area_only_keikai_km2:.2f} km²")
# L49 全体 (cells がない場合は polygon 面積を使う)
l49_total_km2 = float(l49_diss["area_km2"].sum()) if l49_diss is not None else 0.0
# 「想定のみ (指定外)」 は L49 cells から計算
L49_CELLS_PATH = ROOT / "data" / "extras" / "L49_tsunami_inundation" / "_cache" / "tsunami_cells_30m.parquet"
n_only_souti = 0
area_only_souti_km2 = 0.0
if L49_CELLS_PATH.exists():
l49_cells = gpd.read_parquet(L49_CELLS_PATH)
l49_cells["gx"] = (l49_cells["x"] // 30) * 30
l49_cells["gy"] = (l49_cells["y"] // 30) * 30
l49_keys = set(zip(l49_cells["gx"].astype(int), l49_cells["gy"].astype(int)))
cells["gx"] = (cells["x"] // 30) * 30
cells["gy"] = (cells["y"] // 30) * 30
keikai_keys = set(zip(cells["gx"].astype(int), cells["gy"].astype(int)))
only_souti_keys = l49_keys - keikai_keys
n_only_souti = len(only_souti_keys)
area_only_souti_km2 = n_only_souti * 900 / 1e6
print(f"\n L49 想定区域 (参考): {l49_total_km2:.2f} km²")
print(f" L49 \\ L63 (想定のみ = 制度的隙間): {n_only_souti:,} = {area_only_souti_km2:.2f} km²")
# H3 検証: 想定 ⊃ 指定?
print(f"\n H3 検証: L49 ⊃ L63 (想定 ⊃ 指定)?")
print(f" 包含率 (L63 が L49 内): {100*n_both/n_keikai:.1f}%")
print(f" 完全包含なら 100%、{'完全包含' if (100*n_both/n_keikai) >= 95 else '部分包含'}")
# 市町別 想定 vs 指定 比率
city_l49 = city_l49_df[city_l49_df["CITY_CD"] >= 0].copy()
city_l49["市町名"] = city_l49["CITY_CD"].apply(rollup_to_city)
city_l49_rolled = city_l49.groupby("市町名", as_index=False).sum(numeric_only=True)
if "both_km2" in city_l49_rolled.columns and "only_keikai_km2" in city_l49_rolled.columns:
city_l49_rolled["両方比率_%"] = (city_l49_rolled["both_km2"] /
city_l49_rolled["total_km2"] * 100).round(1)
city_l49_rolled["指定のみ比率_%"] = (city_l49_rolled["only_keikai_km2"] /
city_l49_rolled["total_km2"] * 100).round(1)
city_l49_rolled = city_l49_rolled.sort_values("total_km2", ascending=False).reset_index(drop=True)
print(f" ({time.time()-t3:.1f}s)", flush=True)
# =============================================================================
# 4. RQ3 集計: 警戒区域内の沿岸人口・建物との空間関係
# =============================================================================
print("\n[4] RQ3 集計: 沿岸人口との関係", flush=True)
t4 = time.time()
if not L22_CITY_SUMMARY.exists():
raise FileNotFoundError(f"L22 city_summary.csv が無い: {L22_CITY_SUMMARY}")
pop_df = pd.read_csv(L22_CITY_SUMMARY, encoding="utf-8-sig")
pop_df = pop_df.dropna(subset=["city"]).copy()
print(f" L22 市町数: {len(pop_df)}")
# 警戒区域指定がある市町のみ抽出
city_pop_map = pop_df.set_index("city")[["pop_total", "area_km2",
"density_per_km2", "aging_rate", "ctype"]]
merged = city_rolled[["市町名", "total_km2", "平均深さ_m", "順位", "CITY_CD_repr"]].copy()
merged = merged.merge(
city_pop_map.reset_index().rename(columns={"city": "市町名",
"area_km2": "市町面積_km2"}),
on="市町名", how="left",
)
merged["指定面積比_%"] = (merged["total_km2"] / merged["市町面積_km2"] * 100).round(2)
merged["守るべき人口"] = merged["pop_total"] # 市町総人口 (警戒区域内のみではないが代理)
# 推定: 警戒区域内人口 ≈ 市町総人口 × (警戒指定面積 / 市町面積)
# 注意: これは「人口が一様分布」 の仮定 (現実は沿岸偏在)。
merged["推定区域内人口"] = (merged["pop_total"] *
merged["total_km2"] / merged["市町面積_km2"]).round(0)
merged["人口密度_区域内"] = (merged["推定区域内人口"] /
merged["total_km2"]).round(0) # 1km² あたり
merged = merged.sort_values("total_km2", ascending=False).reset_index(drop=True)
# H5: 都市部 vs 中山間沿岸の人口密度比較
def classify_geo(row):
if pd.isna(row["density_per_km2"]):
return "?"
if row["density_per_km2"] >= 1000:
return "都市部"
if row["density_per_km2"] >= 200:
return "中間地域"
return "中山間部"
merged["地理区分"] = merged.apply(classify_geo, axis=1)
geo_summary = merged.groupby("地理区分").agg(
市町数=("市町名", "count"),
指定面積_合計km2=("total_km2", "sum"),
人口_合計万人=("pop_total", lambda s: s.sum() / 10000),
平均人口密度区域内=("人口密度_区域内", "mean"),
).round(2).reset_index()
print(f"\n 地理区分別:")
print(geo_summary.to_string(index=False))
# 上位 3 vs 下位 3 で人口密度比較 (= 区域内人口密度の高い 3 市町 vs 低い 3 市町)
merged_density_sorted = merged[merged["地理区分"] != "?"].sort_values(
"人口密度_区域内", ascending=False).reset_index(drop=True)
top3_density = merged_density_sorted.head(3)["人口密度_区域内"].mean()
bot3_density = merged_density_sorted.tail(3)["人口密度_区域内"].mean()
ratio_density = top3_density / bot3_density if bot3_density > 0 else float("nan")
top3_density_cities = merged_density_sorted.head(3)["市町名"].tolist()
bot3_density_cities = merged_density_sorted.tail(3)["市町名"].tolist()
print(f"\n 人口密度 上位 3: {top3_density_cities} → 平均 {top3_density:,.0f} 人/km²")
print(f" 人口密度 下位 3: {bot3_density_cities} → 平均 {bot3_density:,.0f} 人/km²")
print(f" 比: {ratio_density:.1f} 倍")
print(f" ({time.time()-t4:.1f}s)", flush=True)
# =============================================================================
# 5. CSV 出力
# =============================================================================
print("\n[5] CSV 出力", flush=True)
t5 = time.time()
# 8 ランクサマリ
rank_summary = pd.DataFrame([
{"rank_code": r["rank"],
"深さラベル": RANK_LABEL[r["rank"]],
"rank中央値_m": RANK_MID[r["rank"]],
"面積_km2": round(r["area_km2"], 3),
"シェア_%": round(100 * r["area_km2"] / total_km2, 2),
"色 hex": RANK_COLOR[r["rank"]],
}
for _, r in diss.iterrows()
])
rank_summary.to_csv(ASSETS / "L63_rank_summary.csv", index=False, encoding="utf-8-sig")
# 市町ランキング
city_out = city_rolled[["順位", "CITY_CD_repr", "市町名", "total_km2",
"平均深さ_m"] +
[c for c in [f"rank_{r}_km2" for r in ACTIVE_RANKS]
if c in city_rolled.columns]].copy()
city_out.columns = ["順位", "代表市町コード", "市町名", "指定面積_km2",
"平均深さ_m"] + [f"rank_{r}_km2" for r in ACTIVE_RANKS
if f"rank_{r}_km2" in city_rolled.columns]
city_out.to_csv(ASSETS / "L63_city_ranking.csv", index=False, encoding="utf-8-sig")
# L49 想定 vs 警戒指定 重なり
overlap_table = pd.DataFrame([
{"区分": "L63 警戒区域 全体", "セル数": n_keikai,
"面積_km2": round(area_keikai_total_km2, 2), "シェア_%": 100.0},
{"区分": "L63 ∩ L49 (両方)", "セル数": n_both,
"面積_km2": round(area_both_km2, 2),
"シェア_%": round(100 * n_both / n_keikai, 1)},
{"区分": "L63 \\ L49 (警戒のみ)", "セル数": n_only_keikai,
"面積_km2": round(area_only_keikai_km2, 2),
"シェア_%": round(100 * n_only_keikai / n_keikai, 1)},
{"区分": "L49 \\ L63 (想定のみ)", "セル数": n_only_souti,
"面積_km2": round(area_only_souti_km2, 2),
"シェア_%": round(100 * n_only_souti / n_keikai, 1)},
])
overlap_table.to_csv(ASSETS / "L63_overlap_summary.csv", index=False, encoding="utf-8-sig")
# 市町別 想定 vs 指定
city_l49_rolled.to_csv(ASSETS / "L63_city_l49_compare.csv", index=False, encoding="utf-8-sig")
# 人口関係
merged.to_csv(ASSETS / "L63_pop_ratio.csv", index=False, encoding="utf-8-sig")
geo_summary.to_csv(ASSETS / "L63_geo_summary.csv", index=False, encoding="utf-8-sig")
print(f" ({time.time()-t5:.1f}s)", flush=True)
# =============================================================================
# 6. 図の生成 (8 図)
# =============================================================================
print("\n[6] 図の生成", flush=True)
t6 = time.time()
def save_fig(name, dpi=120):
p = ASSETS / name
plt.savefig(p, dpi=dpi, bbox_inches="tight", facecolor="white")
plt.close('all')
return p
# ---- 図 1 (RQ1): 県全域 6 ランク主題図 ----
print(" fig1 県全域 choropleth", flush=True)
fig, ax = plt.subplots(figsize=(11, 7.5))
admin.boundary.plot(ax=ax, color="#666", linewidth=0.5)
admin[admin["CITY_CD"].isin(COASTAL_CITIES)].plot(
ax=ax, facecolor="#fff4e0", edgecolor="#888", linewidth=0.6, alpha=0.5)
for _, r in diss.sort_values("rank").iterrows():
gpd.GeoDataFrame({"geometry": [r["geometry"]]}, crs=TARGET_CRS).plot(
ax=ax, color=RANK_COLOR[r["rank"]], edgecolor="none", alpha=0.95)
ax.set_xlim(-15000, 125000)
ax.set_ylim(-220000, -140000)
patches = [Patch(facecolor=RANK_COLOR[r], edgecolor="#333", label=RANK_LABEL[r])
for r in ACTIVE_RANKS]
patches.append(Patch(facecolor="#fff4e0", edgecolor="#888", alpha=0.6,
label="沿岸市町"))
patches.append(Patch(facecolor="white", edgecolor="#666", label="非沿岸市町"))
ax.legend(handles=patches, loc="lower left", fontsize=9, title="基準水位ランク")
ax.set_title(f"図 1 (RQ1): 広島県 津波災害警戒区域 全域主題図 — "
f"{len(cells):,} セル (30m), 全 {total_km2:.0f} km²",
fontsize=11)
ax.set_xlabel("X (m, EPSG:6671)", fontsize=10)
ax.set_ylabel("Y (m, EPSG:6671)", fontsize=10)
ax.set_aspect("equal")
plt.tight_layout()
save_fig("L63_fig1_choropleth_overview.png")
# ---- 図 2 (RQ1): 6 ランク 面積構成 ----
print(" fig2 ランク構成", flush=True)
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
# 左: stacked bar 1 本
ax = axes[0]
left = 0
for rk in ACTIVE_RANKS:
a = float(diss[diss["rank"] == rk]["area_km2"].iloc[0]) if (diss["rank"] == rk).any() else 0
if a > 0:
ax.barh([0], [a], left=left, color=RANK_COLOR[rk],
label=RANK_LABEL[rk], edgecolor="#333", linewidth=0.4)
if a > total_km2 * 0.04:
ax.text(left + a/2, 0,
f"{RANK_LABEL[rk]}\n{a:.1f}km²\n({100*a/total_km2:.0f}%)",
ha="center", va="center", fontsize=8, color="#222")
left += a
ax.set_xlim(0, total_km2 * 1.02)
ax.set_yticks([])
ax.set_xlabel("面積 (km²)", fontsize=11)
ax.set_title(f"全指定面積 = {total_km2:.1f} km², 平均深さ {weighted_mean_depth:.2f}m",
fontsize=11)
ax.grid(axis="x", alpha=0.3)
# 右: 各ランク 1 本
ax = axes[1]
ranks_present = list(diss["rank"].values)
labels_present = [RANK_LABEL[r] for r in ranks_present]
areas_present = list(diss["area_km2"].values)
colors_present = [RANK_COLOR[r] for r in ranks_present]
y = np.arange(len(ranks_present))
ax.barh(y, areas_present, color=colors_present, edgecolor="#333", linewidth=0.5)
ax.set_yticks(y)
ax.set_yticklabels(labels_present, fontsize=10)
ax.invert_yaxis()
ax.set_xlabel("面積 (km²)", fontsize=11)
ax.set_title("6 ランク 面積分布 — 警戒区域は浅水帯支配",
fontsize=11)
for i, a in enumerate(areas_present):
ax.text(a + total_km2 * 0.01, i, f"{a:.2f}km² ({100*a/total_km2:.1f}%)",
fontsize=9, va="center")
ax.grid(axis="x", alpha=0.3)
ax.set_xlim(0, max(areas_present) * 1.25)
fig.suptitle(f"図 2 (RQ1): 浸水深 6 ランク構成 — 浅水 (<2m) {shallow_pct:.0f}%, "
f"深水 (>3m) {deep_pct:.0f}%",
fontsize=12)
plt.tight_layout()
save_fig("L63_fig2_rank_structure.png")
# ---- 図 3 (RQ1): 市町別 指定面積 choropleth ----
print(" fig3 市町別 choropleth", flush=True)
fig, ax = plt.subplots(figsize=(11, 7))
admin_plot = admin.copy()
admin_plot["市町名"] = admin_plot["CITY_CD"].apply(rollup_to_city)
admin_diss_city = admin_plot.dissolve(by="市町名").reset_index()
admin_diss_city = admin_diss_city.merge(
city_rolled[["市町名", "total_km2"]], on="市町名", how="left").fillna({"total_km2": 0})
admin_no = admin_diss_city[admin_diss_city["total_km2"] == 0]
admin_yes = admin_diss_city[admin_diss_city["total_km2"] > 0]
admin_no.plot(ax=ax, facecolor="#f0f0f0", edgecolor="#888", linewidth=0.5)
admin_yes.plot(ax=ax, column="total_km2", cmap="Reds", edgecolor="#444",
linewidth=0.6, vmin=0, vmax=admin_yes["total_km2"].max(),
legend=True, legend_kwds={"label": "警戒区域指定面積 (km²)",
"shrink": 0.6})
# 上位 8 市町ラベル
for _, r in city_rolled.head(8).iterrows():
a = admin_diss_city[admin_diss_city["市町名"] == r["市町名"]]
if len(a) == 0 or a["total_km2"].iloc[0] == 0:
continue
cx, cy = a.geometry.iloc[0].centroid.x, a.geometry.iloc[0].centroid.y
ax.annotate(f"{r['市町名']}\n{r['total_km2']:.1f}km²",
(cx, cy), fontsize=9, ha="center", va="center",
color="black", weight="bold",
bbox=dict(boxstyle="round,pad=0.2", facecolor="white", alpha=0.85))
ax.set_xlim(-15000, 125000)
ax.set_ylim(-220000, -100000)
ax.set_aspect("equal")
ax.set_title(f"図 3 (RQ1): 市町別 警戒区域指定面積 choropleth — 上位 3 シェア {top3_share*100:.0f}%",
fontsize=12)
ax.set_xlabel("X (m, EPSG:6671)", fontsize=10)
ax.set_ylabel("Y (m, EPSG:6671)", fontsize=10)
plt.tight_layout()
save_fig("L63_fig3_city_choropleth.png")
# ---- 図 4 (RQ1): 市町別 深さランク stacked bar ----
print(" fig4 市町別 深さスタック", flush=True)
fig, ax = plt.subplots(figsize=(11, 6))
city_top12 = city_rolled.head(12).copy()
y = np.arange(len(city_top12))
left = np.zeros(len(city_top12))
for rk in ACTIVE_RANKS:
col = f"rank_{rk}_km2"
if col not in city_top12.columns:
continue
vals = city_top12[col].values.astype(float)
ax.barh(y, vals, left=left, color=RANK_COLOR[rk],
label=RANK_LABEL[rk], edgecolor="#333", linewidth=0.3)
left += vals
ax.set_yticks(y)
ax.set_yticklabels([f"{r['市町名']} ({r['平均深さ_m']:.1f}m)"
for _, r in city_top12.iterrows()], fontsize=9)
ax.invert_yaxis()
ax.set_xlabel("警戒区域指定面積 (km²)", fontsize=11)
ax.set_title("図 4 (RQ1): 市町別 ランク構成 (Top 12) — ()内は重み付き平均基準水位",
fontsize=12)
ax.legend(loc="lower right", fontsize=8, ncol=2, title="基準水位")
ax.grid(axis="x", alpha=0.3)
for i, t in enumerate(city_top12["total_km2"].values):
ax.text(t + city_top12["total_km2"].max() * 0.01, i, f"{t:.1f}",
fontsize=8, va="center")
plt.tight_layout()
save_fig("L63_fig4_city_rank_stack.png")
# ---- 図 5 (RQ2): L49 想定 vs L63 指定 重ね合わせマップ ----
print(" fig5 想定 vs 指定 重ね合わせ", flush=True)
fig, axes = plt.subplots(1, 2, figsize=(14, 6.5))
# 左: 全域 重ね合わせ (L49 全部 vs L63 全部)
ax = axes[0]
admin.boundary.plot(ax=ax, color="#666", linewidth=0.4)
# L49 想定 (薄水色, 全 8 ランク統合)
if l49_diss is not None:
l49_diss.plot(ax=ax, color="#9ecae1", edgecolor="none", alpha=0.7,
label=f"L49 想定 ({l49_total_km2:.0f} km²)")
# L63 指定 (赤系, 全 6 ランク統合)
diss.plot(ax=ax, color="#cf222e", edgecolor="none", alpha=0.55,
label=f"L63 指定 ({total_km2:.0f} km²)")
ax.set_xlim(-15000, 125000)
ax.set_ylim(-220000, -140000)
ax.set_aspect("equal")
ax.legend(handles=[
Patch(facecolor="#9ecae1", alpha=0.7,
label=f"L49 津波浸水想定 ({l49_total_km2:.0f} km²)"),
Patch(facecolor="#cf222e", alpha=0.55,
label=f"L63 警戒区域指定 ({total_km2:.0f} km²)"),
Patch(facecolor="#794030", alpha=0.85,
label=f"両方 ({area_both_km2:.0f} km²)"),
], loc="lower left", fontsize=9)
ax.set_title(f"図 5 左 (RQ2): L49 想定 + L63 指定 県全域重ね合わせ", fontsize=11)
ax.set_xlabel("X (m)", fontsize=10)
ax.set_ylabel("Y (m)", fontsize=10)
# 右: 福山平野ズーム (CITY_CD=207)
ax = axes[1]
fky_admin = admin[admin["CITY_CD"] == 207]
fky_admin.boundary.plot(ax=ax, color="#444", linewidth=0.8)
fky_admin.plot(ax=ax, facecolor="#fff4e0", alpha=0.5, edgecolor="none")
xmin, ymin, xmax, ymax = fky_admin.total_bounds
xmin -= 1500; ymin -= 1500; xmax += 1500; ymax += 1500
bbox = shapely.box(xmin, ymin, xmax, ymax)
if l49_diss is not None:
for _, r in l49_diss.iterrows():
clipped = r["geometry"].intersection(bbox)
if not clipped.is_empty:
gpd.GeoDataFrame({"geometry": [clipped]}, crs=TARGET_CRS).plot(
ax=ax, color="#9ecae1", alpha=0.7, edgecolor="none")
for _, r in diss.iterrows():
clipped = r["geometry"].intersection(bbox)
if not clipped.is_empty:
gpd.GeoDataFrame({"geometry": [clipped]}, crs=TARGET_CRS).plot(
ax=ax, color="#cf222e", alpha=0.55, edgecolor="none")
ax.set_xlim(xmin, xmax); ax.set_ylim(ymin, ymax)
ax.set_aspect("equal")
ax.set_title(f"図 5 右 (RQ2): 福山市ズーム — 干拓平野", fontsize=11)
ax.set_xticks([]); ax.set_yticks([])
fig.suptitle(f"図 5 (RQ2): 想定 (青) と 指定 (赤) の空間比較 — "
f"包含率 {100*n_both/n_keikai:.0f}%",
fontsize=12)
plt.tight_layout()
save_fig("L63_fig5_l49_overlay.png")
# ---- 図 6 (RQ2): 想定 vs 指定 集合関係 + 深さランク × 重複 ----
print(" fig6 重複サマリ + ランク別", flush=True)
fig, axes = plt.subplots(1, 2, figsize=(13, 5.5))
# 左: 集合関係 (3 区分の面積 + シェア)
ax = axes[0]
labels = ["L63 ∩ L49\n(両方)", "L63 \\ L49\n(指定のみ)", "L49 \\ L63\n(想定のみ)"]
values = [area_both_km2, area_only_keikai_km2, area_only_souti_km2]
colors = ["#794030", "#cf222e", "#9ecae1"]
bars = ax.bar(labels, values, color=colors, edgecolor="#333", linewidth=0.6)
for bar, v in zip(bars, values):
ax.text(bar.get_x() + bar.get_width()/2, v + max(values)*0.01,
f"{v:.1f} km²", ha="center", va="bottom", fontsize=10, weight="bold")
ax.set_ylabel("面積 (km²)", fontsize=11)
ax.set_title("3 区分の面積 — 想定と指定の集合関係", fontsize=11)
ax.grid(axis="y", alpha=0.3)
# 右: 深さランク × 重複 (積上げ棒)
ax = axes[1]
ranks_present_codes = sorted(rank_l49_df["rank"].unique())
xs = np.arange(len(ranks_present_codes))
both_vals = []
only_vals = []
for rk in ranks_present_codes:
row = rank_l49_df[rank_l49_df["rank"] == rk]
b = float(row.get("both", pd.Series([0])).iloc[0]) if "both" in row.columns else 0
o = float(row.get("only_keikai", pd.Series([0])).iloc[0]) if "only_keikai" in row.columns else 0
both_vals.append(b)
only_vals.append(o)
ax.bar(xs, both_vals, color="#794030", edgecolor="#333", linewidth=0.4,
label="両方 (想定 ∩ 指定)")
ax.bar(xs, only_vals, bottom=both_vals, color="#cf222e", edgecolor="#333",
linewidth=0.4, label="指定のみ (制度差)")
ax.set_xticks(xs)
ax.set_xticklabels([RANK_LABEL[r] for r in ranks_present_codes],
rotation=15, ha="right", fontsize=9)
ax.set_ylabel("面積 (km²)", fontsize=11)
ax.set_title("ランク別 想定との重複 (両方 vs 指定のみ)", fontsize=11)
ax.legend(loc="upper right", fontsize=9)
ax.grid(axis="y", alpha=0.3)
for i, (b, o) in enumerate(zip(both_vals, only_vals)):
if (b + o) > 0:
share = 100 * b / (b + o) if (b + o) > 0 else 0
ax.text(i, b + o + max(both_vals + only_vals) * 0.01,
f"{share:.0f}%", ha="center", fontsize=8, color="#222")
fig.suptitle(f"図 6 (RQ2): 想定 vs 指定 集合関係 + ランク別重複 — "
f"指定の {100*n_both/n_keikai:.0f}% が想定 ∩ 指定",
fontsize=12)
plt.tight_layout()
save_fig("L63_fig6_overlap_summary.png")
# ---- 図 7 (RQ3): 警戒区域内人口 choropleth + 散布 ----
print(" fig7 人口関係", flush=True)
fig, axes = plt.subplots(1, 2, figsize=(14, 7))
# 左: 推定区域内人口 choropleth
ax = axes[0]
admin_pop = admin_diss_city.copy()
admin_pop = admin_pop.merge(
merged[["市町名", "推定区域内人口", "人口密度_区域内"]],
on="市町名", how="left").fillna({"推定区域内人口": 0, "人口密度_区域内": 0})
admin_pop_no = admin_pop[admin_pop["推定区域内人口"] == 0]
admin_pop_yes = admin_pop[admin_pop["推定区域内人口"] > 0]
admin_pop_no.plot(ax=ax, facecolor="#f0f0f0", edgecolor="#888", linewidth=0.5)
admin_pop_yes.plot(ax=ax, column="推定区域内人口", cmap="OrRd",
edgecolor="#444", linewidth=0.6,
vmin=0, vmax=admin_pop_yes["推定区域内人口"].max(),
legend=True,
legend_kwds={"label": "推定区域内人口 (人)", "shrink": 0.6})
for _, r in merged.head(7).iterrows():
if pd.isna(r["推定区域内人口"]) or r["推定区域内人口"] == 0:
continue
a = admin_diss_city[admin_diss_city["市町名"] == r["市町名"]]
if len(a) == 0:
continue
cx, cy = a.geometry.iloc[0].centroid.x, a.geometry.iloc[0].centroid.y
ax.annotate(f"{r['市町名']}\n{int(r['推定区域内人口']):,}人",
(cx, cy), fontsize=8, ha="center", va="center",
color="black", weight="bold",
bbox=dict(boxstyle="round,pad=0.2", facecolor="white", alpha=0.85))
ax.set_xlim(-15000, 125000)
ax.set_ylim(-220000, -100000)
ax.set_aspect("equal")
ax.set_title("図 7 左 (RQ3): 推定区域内人口 choropleth", fontsize=11)
ax.set_xticks([]); ax.set_yticks([])
# 右: 警戒区域面積 vs 人口密度 散布 (バブル = 市町総人口)
ax = axes[1]
geo_color = {"都市部": "#cf222e", "中間地域": "#fdae61",
"中山間部": "#4575b4", "?": "#888"}
for gtype in ["都市部", "中間地域", "中山間部"]:
sub = merged[merged["地理区分"] == gtype]
if len(sub) > 0:
ax.scatter(sub["total_km2"], sub["人口密度_区域内"],
c=geo_color[gtype], s=sub["pop_total"] / 5000 + 50,
alpha=0.7, edgecolors="black", linewidths=0.5,
label=f"{gtype} (n={len(sub)})")
for _, r in sub.iterrows():
ax.annotate(r["市町名"], (r["total_km2"], r["人口密度_区域内"]),
fontsize=7, alpha=0.85, xytext=(3, 3),
textcoords="offset points")
ax.set_xlabel("警戒区域 指定面積 (km²)", fontsize=11)
ax.set_ylabel("推定区域内 人口密度 (人/km²)", fontsize=11)
ax.set_title("図 7 右 (RQ3): 指定面積 × 人口密度 散布", fontsize=11)
ax.legend(loc="upper right", fontsize=9)
ax.grid(alpha=0.3)
ax.set_yscale("log")
plt.suptitle(f"図 7 (RQ3): 警戒区域内 人口分析 — "
f"密度比 上位/下位 {ratio_density:.1f} 倍",
fontsize=12)
plt.tight_layout()
save_fig("L63_fig7_pop_relation.png")
# ---- 図 8 (RQ3): 地理区分別 集計 + 指定面積比 ----
print(" fig8 地理区分 + 指定面積比", flush=True)
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# 左: 地理区分別 (人口 vs 指定面積 vs 人口密度の二軸)
ax = axes[0]
gs = geo_summary.copy()
gs["地理区分"] = pd.Categorical(gs["地理区分"],
categories=["都市部", "中間地域", "中山間部"],
ordered=True)
gs = gs.sort_values("地理区分").dropna(subset=["地理区分"])
xs = np.arange(len(gs))
ax.bar(xs - 0.2, gs["指定面積_合計km2"], 0.4, color="#cf222e",
alpha=0.85, label="指定面積 合計 (km²)")
ax2 = ax.twinx()
ax2.bar(xs + 0.2, gs["人口_合計万人"], 0.4, color="#0969da",
alpha=0.85, label="人口 合計 (万人)")
ax.set_xticks(xs)
ax.set_xticklabels([f"{r['地理区分']}\n(n={int(r['市町数'])})"
for _, r in gs.iterrows()], fontsize=10)
ax.set_ylabel("指定面積 合計 (km²)", color="#cf222e", fontsize=11)
ax2.set_ylabel("人口 合計 (万人)", color="#0969da", fontsize=11)
for i, (a, p) in enumerate(zip(gs["指定面積_合計km2"], gs["人口_合計万人"])):
ax.text(i - 0.2, a + max(gs["指定面積_合計km2"]) * 0.02, f"{a:.1f}",
ha="center", fontsize=9, color="#cf222e")
ax2.text(i + 0.2, p + max(gs["人口_合計万人"]) * 0.02, f"{p:.1f}",
ha="center", fontsize=9, color="#0969da")
ax.set_title("地理区分別 指定面積 合計 + 人口 合計", fontsize=11)
ax.grid(axis="y", alpha=0.3)
lines1, labels1 = ax.get_legend_handles_labels()
lines2, labels2 = ax2.get_legend_handles_labels()
ax.legend(lines1 + lines2, labels1 + labels2, fontsize=9, loc="upper right")
# 右: 市町別 指定面積比 (指定/市町総) ランキング
ax = axes[1]
mr = merged.dropna(subset=["指定面積比_%"]).copy()
mr = mr.sort_values("指定面積比_%", ascending=True).tail(15)
y = np.arange(len(mr))
colors_b = [geo_color.get(g, "#888") for g in mr["地理区分"]]
ax.barh(y, mr["指定面積比_%"], color=colors_b, alpha=0.85, edgecolor="#333")
ax.set_yticks(y)
ax.set_yticklabels([f"{r['市町名']} ({r['ctype']})"
for _, r in mr.iterrows()], fontsize=8)
ax.set_xlabel("指定面積比 (%) = 警戒区域 / 市町総面積", fontsize=11)
ax.set_title("市町別 指定面積比 (Top 15)", fontsize=11)
ax.grid(axis="x", alpha=0.3)
for i, (v, n) in enumerate(zip(mr["指定面積比_%"], mr["total_km2"])):
ax.text(v + 0.03, i, f"{v:.2f}% ({n:.1f}km²)", va="center", fontsize=7)
plt.suptitle(f"図 8 (RQ3): 地理区分別集計 + 市町別 指定面積比",
fontsize=12)
plt.tight_layout()
save_fig("L63_fig8_geo_compare.png")
print(f" ({time.time()-t6:.1f}s)", flush=True)
# =============================================================================
# 7. 表データ作成 (HTML 出力用)
# =============================================================================
print("\n[7] 表データ作成", flush=True)
t7 = time.time()
def df_to_html(d):
return d.to_html(index=False, classes="", border=0, escape=False,
na_rep="-").replace(' style="text-align: right;"', "")
# 表 1: データセット仕様
T_dataset = pd.DataFrame([
("dataset_id", "47"),
("公式名", "津波災害警戒区域情報"),
("resource_id", "42"),
("ファイル", "340006_tsunami_caution_area_20190302.zip"),
("形式", "Shapefile (Polygon, EPSG:2445)"),
("ZIP サイズ", f"{KEIKAI_ZIP.stat().st_size:,} byte (= {KEIKAI_ZIP.stat().st_size/1e6:.1f} MB)"),
("レコード数", "1,285,428 polygon"),
("属性列", "kijyun_sin (int, cm 単位の基準水位 = 浸水深×100)"),
("最大基準水位", "8.68 m (= max kijyun_sin 868 cm)"),
("座標系", "EPSG:2445 (平面直角第 3 系) → EPSG:6671 で処理"),
("作成日", "2022-04-08"),
("最終更新", "2022-05-20"),
("告示日", "2019-03-02"),
("ライセンス", "クリエイティブ・コモンズ表示 (CC-BY)"),
("法的根拠", "津波防災地域づくり法 第 53 条 (2011 年法律第 123 号)"),
("作成主体", "広島県土木建築局"),
("URL", "https://hiroshima-dobox.jp/datasets/47"),
("DL URL", "https://hiroshima-dobox.jp/resource_download/42"),
], columns=["項目", "値"])
# 表 2: 全体サマリ (3 RQ 統合)
T_overall = pd.DataFrame([
("元 polygon 数", "1,285,428"),
("30m 集約後 セル数", f"{len(cells):,}"),
("全指定面積 (RQ1)", f"{total_km2:.2f} km²"),
("対象市町数", f"{len(city_rolled)} (海上 -1 を除く)"),
("Top 3 市町シェア (RQ1)", f"{top3_share*100:.1f}%"),
("Top 1 市町", f"{city_rolled.iloc[0]['市町名']} ({city_rolled.iloc[0]['total_km2']:.2f} km²)"),
("浅水 <2m シェア (RQ1)", f"{shallow_pct:.1f}%"),
("深水 >3m シェア (RQ1)", f"{deep_pct:.1f}%"),
("重み付き平均深さ (RQ1)", f"{weighted_mean_depth:.2f} m"),
("L49 想定面積 (参考)", f"{l49_total_km2:.2f} km²"),
("L63 ∩ L49 (両方, RQ2)", f"{area_both_km2:.2f} km² ({100*n_both/n_keikai:.1f}%)"),
("L63 \\ L49 (指定のみ, RQ2)", f"{area_only_keikai_km2:.2f} km² ({100*n_only_keikai/n_keikai:.1f}%)"),
("L49 \\ L63 (想定のみ, RQ2)", f"{area_only_souti_km2:.2f} km²"),
("推定区域内人口 合計 (RQ3)", f"{int(merged['推定区域内人口'].sum()):,} 人"),
("人口密度 上位3 平均 (RQ3)", f"{top3_density:,.0f} 人/km²"),
("人口密度 下位3 平均 (RQ3)", f"{bot3_density:,.0f} 人/km²"),
("人口密度 上位/下位比 (RQ3)", f"{ratio_density:.1f} 倍"),
], columns=["指標", "値"])
T_overall.to_csv(ASSETS / "L63_overall.csv", index=False, encoding="utf-8-sig")
# 表 3: 6 ランクサマリ
T_rank = rank_summary[["rank_code", "深さラベル", "rank中央値_m",
"面積_km2", "シェア_%"]].copy()
# 表 4: 市町ランキング (Top 15)
T_city_rank = city_rolled.head(15)[["順位", "市町名", "total_km2",
"平均深さ_m"]].copy()
T_city_rank["total_km2"] = T_city_rank["total_km2"].round(2)
T_city_rank["平均深さ_m"] = T_city_rank["平均深さ_m"].round(2)
T_city_rank.columns = ["順位", "市町名", "指定面積_km2", "平均深さ_m"]
# 表 5: L49 vs L63 重なりサマリ
T_overlap = overlap_table.copy()
# 表 6: ランク × L49 重複
T_rank_l49 = rank_l49_df.copy()
T_rank_l49["rank_label"] = T_rank_l49["rank"].map(RANK_LABEL)
if "both" in T_rank_l49.columns and "only_keikai" in T_rank_l49.columns:
T_rank_l49["合計"] = T_rank_l49["both"] + T_rank_l49["only_keikai"]
T_rank_l49["両方率_%"] = (T_rank_l49["both"] / T_rank_l49["合計"] * 100).round(1)
T_rank_l49 = T_rank_l49[["rank", "rank_label", "both", "only_keikai",
"合計", "両方率_%"]]
T_rank_l49.columns = ["rank", "深さラベル", "両方_km2", "指定のみ_km2",
"合計_km2", "両方率_%"]
# 表 7: 市町別 想定 vs 指定
T_city_l49 = city_l49_rolled.copy()
keep_cols = ["市町名"]
for c in ["both_km2", "only_keikai_km2", "total_km2", "両方比率_%", "指定のみ比率_%"]:
if c in T_city_l49.columns:
keep_cols.append(c)
T_city_l49 = T_city_l49[keep_cols].copy()
for c in T_city_l49.columns:
if T_city_l49[c].dtype == "float64":
T_city_l49[c] = T_city_l49[c].round(2)
T_city_l49 = T_city_l49.head(15)
# 表 8: 地理区分別比較
T_geo = geo_summary.copy()
# 表 9: 市町別 人口関係 (Top 15)
merged_show = merged.head(15)[["市町名", "ctype", "pop_total", "市町面積_km2",
"total_km2", "指定面積比_%", "推定区域内人口",
"人口密度_区域内", "地理区分"]].copy()
merged_show["pop_total"] = merged_show["pop_total"].astype(int)
merged_show["推定区域内人口"] = merged_show["推定区域内人口"].astype(int)
merged_show["人口密度_区域内"] = merged_show["人口密度_区域内"].astype(int)
merged_show["市町面積_km2"] = merged_show["市町面積_km2"].round(2)
merged_show["total_km2"] = merged_show["total_km2"].round(2)
merged_show.columns = ["市町名", "市町区分", "市町総人口", "市町面積_km2",
"指定面積_km2", "指定面積比_%", "推定区域内人口",
"人口密度_区域内", "地理区分"]
T_pop = merged_show
# 表 10: 制度比較表 (L49 vs L63)
T_institution = pd.DataFrame([
("根拠法", "水防法・津波防災地域づくり法",
"津波防災地域づくり法 第 53 条"),
("制度区分", "想定 (技術的シミュレーション)",
"指定 (法的拘束力のある区域指定)"),
("作成主体", "広島県土木建築局",
"広島県知事 (告示)"),
("法的拘束力", "なし (情報提供のみ)",
"あり (避難確保計画策定義務等)"),
("対象", "想定し得る最大規模の浸水",
"想定区域のうち住民保護に必要な範囲"),
("更新", "随時 (技術改善で更新)",
"告示時点で固定 (改正告示で更新)"),
("総面積", f"{l49_total_km2:.2f} km² (L49)",
f"{total_km2:.2f} km² (L63)"),
("公表", "2025-12-03 (最新版)",
"2019-03-02 (告示)"),
("dataset_id", "46", "47"),
], columns=["項目", "L49 津波浸水想定 (想定図)", "L63 津波災害警戒区域 (指定区域)"])
# 表 11: 仮説検証
def jud(cond, ok="強支持", fail="反証", part="部分支持"):
return ok if cond else fail
T_hypo = pd.DataFrame([
("H1 浅水 (<2m) 支配",
f"観測 浅水 = {shallow_pct:.1f}%, 深水 = {deep_pct:.1f}%",
jud(shallow_pct >= 60, "強支持", "部分支持"),
f"H1 {jud(shallow_pct>=60,'強支持','部分支持')}: 警戒区域の {shallow_pct:.0f}% が "
f"2m 未満の浅水帯。3m 超は {deep_pct:.0f}%。"
f"瀬戸内海の地形特性 = 太平洋側より浅い津波想定が指定にも反映。"
f"重み付き平均は {weighted_mean_depth:.2f}m"),
("H2 上位 3 市町シェア ≥ 40%",
f"観測 = {top3_share*100:.1f}% (Top 1: {city_rolled.iloc[0]['市町名']}, "
f"Top 2: {city_rolled.iloc[1]['市町名']}, Top 3: {city_rolled.iloc[2]['市町名']})",
jud(top3_share >= 0.4),
f"H2 {jud(top3_share>=0.4)}: 上位 3 市町で {top3_share*100:.0f}% を占める偏在型。"
f"湾奥 + 干拓地 + 多島海の 3 地形類型が指定面積を支配。"
f"{city_rolled.iloc[0]['市町名']}のみで {city_rolled.iloc[0]['total_km2']:.1f} km² ="
f"全体の {city_rolled.iloc[0]['total_km2']/total_km2*100:.0f}%"),
("H3 想定 ⊃ 指定 (包含関係)",
f"観測 包含率 (L63 ⊂ L49) = {100*n_both/n_keikai:.1f}%",
jud((100*n_both/n_keikai) >= 95, "強支持", "部分支持"),
f"H3 {jud((100*n_both/n_keikai)>=95,'強支持','部分支持')}: 包含率 {100*n_both/n_keikai:.0f}% = "
f"指定の大部分は想定内に位置する。"
f"残り {100*n_only_keikai/n_keikai:.0f}% は「指定のみ (想定外)」で、"
f"これは想定図の更新前に指定されていた範囲または地形補正の影響"),
("H4 「制度差」 の市町別ばらつき",
f"観測: 各市町で 両方率 平均 = "
f"{city_l49_rolled['両方比率_%'].mean():.0f}% ± {city_l49_rolled['両方比率_%'].std():.0f}%"
if "両方比率_%" in city_l49_rolled.columns else "計算不能",
"支持" if "両方比率_%" in city_l49_rolled.columns and city_l49_rolled["両方比率_%"].std() > 5 else "未検証",
f"H4: 市町ごとに想定 ∩ 指定 の比率が異なる。"
f"沿岸地形 (湾奥 vs 平野 vs 多島海) や指定告示当時の想定図の世代差を反映。"
f"市町別審議の結果として制度差が生まれる"),
("H5 都市部 vs 中山間沿岸 人口密度比",
f"観測 上位 3 平均 {top3_density:,.0f} vs 下位 3 平均 {bot3_density:,.0f} = "
f"{ratio_density:.1f} 倍",
jud(ratio_density >= 5, "強支持", "部分支持"),
f"H5 {jud(ratio_density>=5,'強支持','部分支持')}: 区域内人口密度の "
f"上位/下位比 {ratio_density:.1f} 倍 = 都市部沿岸の防災投資優先度が "
f"中山間沿岸の {ratio_density:.0f} 倍。"
f"狭い指定 + 大人口 = 都市部 vs 広い指定 + 少人口 = 中山間沿岸 の構造対比"),
], columns=["仮説", "観測値", "判定", "解釈"])
T_hypo.to_csv(ASSETS / "L63_hypothesis_check.csv", index=False, encoding="utf-8-sig")
# 表 12: データ取得手順
T_data_recipe = pd.DataFrame([
("ステップ 1", "DoBoX dataset 47 ページ",
"https://hiroshima-dobox.jp/datasets/47"),
("ステップ 2", "ZIP DL (resource 42)",
"https://hiroshima-dobox.jp/resource_download/42"),
("ステップ 3", "保存先",
"data/extras/L63_tsunami_warning_zone/340006_tsunami_caution_area_20190302.zip"),
("ステップ 4", "ZIP 展開",
"extracted/tsunami_keikai.shp + .dbf + .shx + .prj"),
("ステップ 5", "Shapefile 読込 (geopandas/pyogrio)",
"1,285,428 polygon"),
("ステップ 6", "30m 集約 (build_cache)",
f"178,004 セル (= {area_keikai_total_km2:.0f} km²)"),
("ステップ 7", "市町 sjoin",
"19 市町に分配 + 海上 11,615 セル"),
("ステップ 8", "L49 想定との重なり判定",
f"両方 {n_both:,} / 指定のみ {n_only_keikai:,}"),
], columns=["ステップ", "操作", "値 / URL"])
print(f" ({time.time()-t7:.1f}s)", flush=True)
# =============================================================================
# 8. HTML 生成
# =============================================================================
print("\n[8] HTML 生成", flush=True)
t8 = time.time()
# Sec 1: 学習目標と問い
sec1 = f"""
本記事は DoBoX のシリーズ「津波災害警戒区域情報」 1 件
(dataset_id = 47) を 単独で取り上げ、
広島県沿岸で法的に指定された津波災害警戒区域の地理構造を
3 つの独立した研究角度 (RQ1 / RQ2 / RQ3) で並列に分析する。
本データは 1,285,428 polygon (10m メッシュ単位)、Shapefile 形式 (27.8 MB)。
L49 (津波浸水想定) との位置付け: L49 は「想定」 (= 技術的シミュレーション結果) で法的拘束力なし。
本記事 L63 は「指定」 (= 都道府県知事が告示する法的指定区域) で法的拘束力あり。
両者は範囲が一致するわけではなく、L63 は制度的に切り取られた一部分。
この「想定 vs 指定」の制度差を本研究 RQ2 で空間統計化する。
制度的背景: 津波災害警戒区域は津波防災地域づくり法 (2011 年 12 月 14 日法律第 123 号) 第 53 条に基づく
都道府県知事の告示指定。2011 年東日本大震災を契機に制度化され、住民への津波情報伝達体制の整備、
避難場所・避難経路の確保、要配慮者利用施設の避難確保計画策定義務等が伴う。
広島県は 2019-03-02 に告示を行い、本データはその告示内容を Shapefile 化したもの。
独自用語の定義
- 津波災害警戒区域 (本データ #47): 津波防災地域づくり法 第 53 条に基づき
都道府県知事が告示で指定する法的拘束力を持つ警戒区域。本研究では
広島県内 19 沿岸市町をカバー (海上を除く)、全指定面積 {total_km2:.1f} km²。
- 津波防災地域づくり法 (制度用語): 2011 年東日本大震災を契機に制定された法律
(2011 年 12 月 14 日法律第 123 号)。都道府県による津波浸水想定の作成、
警戒区域 (本記事) と特別警戒区域 (オレンジゾーン) の指定、推進計画の策定等を規定。
- 特別警戒区域 (本データには含まれず): 警戒区域のうち、特に著しい津波被害が
想定される区域として都道府県知事が指定する区域。一定の建築規制が伴うが、
広島県内では現時点で指定なし (本データ #47 は通常の警戒区域のみ)。
- 想定 vs 指定の制度差 (本記事 RQ2 用語): 「想定」 = L49 (技術的シミュレーション、
法的拘束力なし) と「指定」 = L63 (法的告示) の関係。本研究で空間統計化する。
観測 包含率 (L63 ⊂ L49) = {100*n_both/n_keikai:.0f}%。
- 制度的隙間 (本記事 RQ2 用語): 「想定はあるが警戒区域としては指定されていない」
エリア = L49 \\ L63。観測面積 {area_only_souti_km2:.1f} km²。
これは想定図の更新で新たに加わった範囲、または市町審議で除外された範囲を含む。
- kijyun_sin (Shapefile 列名): 基準浸水値 (cm 単位)。kijyun_sin / 100 = 浸水深 (m)。
観測 範囲 10〜868 = 0.10〜8.68m。L49 の最大値 8.34m とほぼ整合 (= データ整合性の確認)。
- 基準水位ランク (本記事独自集約): kijyun_sin を 6 ランクに集約。
L49 と同形式 (0.0〜0.5 / 0.5〜1.0 / 1.0〜2.0 / 2.0〜3.0 / 3.0〜5.0 / 5.0〜10.0 m)。
L49 の RANK_LABEL 規則を継承し制度横串比較を可能にする。
- 行為制限 (制度用語): 警戒区域指定に伴う制度的義務。本警戒区域 (= 通常区域) では
建築規制は無く、要配慮者利用施設 (病院・社会福祉施設等) の避難確保計画策定義務、
ハザードマップ等への明記、住民への情報伝達体制整備が中心。
特別警戒区域 (オレンジゾーン) になると建築規制が伴う。
- 30m 集約 (本記事の処理): 元 1.28M polygon (10m メッシュ単位) を
30m × 30m グリッドに集約 (max kijyun)。{len(cells):,} セルに圧縮。
L49 と同じ集約レベルなのでセル単位の空間結合が容易。
- 推定区域内人口 (本記事 RQ3 用語): 警戒区域の市町別人口を計算する代理指標。
市町総人口 × (警戒指定面積 / 市町面積)。一様分布の仮定 (現実は沿岸偏在) なので
「ハザードに対する市町責任規模」の参考値であり、厳密な「区域内人口」ではない。
- 地理区分 (本記事 RQ3 集約): 人口密度から
都市部 (≥1,000/km²) / 中間地域 (200-1,000/km²) / 中山間部 (<200/km²) の 3 区分。
L62 で使用した区分と同じ規則。
研究の問い (3 RQ)
- RQ1 (主研究): 広島県の津波災害警戒区域の地理範囲・市町別指定状況はどう描けるか?
1,285,428 polygon を 30m に集約し、19 沿岸市町別の指定面積、基準水位ランク (6 ランク) 別の構成、
沿岸 vs 内陸の指定パターンを定量化する。
- RQ2 (副研究 1): L49 津波浸水想定 (= 技術的想定) と L63 警戒区域 (= 法的指定) の
空間関係はどう描けるか?
30m グリッド単位で空間結合し、「両方」 「指定のみ」 「想定のみ (制度的隙間)」 の
3 パターンを集計。
- RQ3 (副研究 2): 警戒区域内の沿岸人口・建物との空間関係はどう描けるか?
L22 既扱の市町別人口を母数とし、警戒区域 km² あたりの守るべき人口
(= ハザード人口密度指標) を市町別に算出。
都市沿岸 vs 中山間沿岸の構造的対比を抽出。
仮説 H1〜H5
- H1 (浅水支配, RQ1): 警戒区域の基準水位は0.5〜2.0m が支配的で、
3m 超は < 20%。瀬戸内海津波の地形的特性を反映。
- H2 (湾奥 + 干拓地集中, RQ1): 上位 3 市町で全体の 40% 超。
湾奥 + 干拓地 + 多島海の 3 地形類型が指定面積を支配。
- H3 (想定 ⊃ 指定, RQ2): L49 想定 ⊃ L63 指定 の包含関係。
包含率 ≥ 95% を予想。
- H4 (制度差の地理パターン, RQ2): 「想定のみ」 と「指定のみ」 のバランスが
市町ごとに異なる。市町別審議の結果。
- H5 (人口密度勾配, RQ3): 区域内人口密度は
都市部 >> 中山間沿岸、上位/下位比 ≥ 5 倍。
都市部の防災投資優先度の高さを数量化。
到達点
本記事を読み終えた学習者は次の 3 点を体感できる:
- 1 つの大規模 Shapefile (1.28M polygon, 27.8 MB) を効率的に処理する空間データ分析の
標準ワークフロー (= 30m 集約 + dissolve + sjoin + キャッシュ化) を体感する。
- 「想定 (技術的)」 と「指定 (法的)」という防災制度の 2 段階を空間統計で対比し、
包含率 {100*n_both/n_keikai:.0f}% という数字で制度的フィルタの実態を読む。
法的指定が技術的想定をどう翻訳するか、その結果がどんな空間パターンを生むかを理解する。
- L22 既扱の人口データを使った「ハザード人口密度指標」で都市沿岸 vs 中山間沿岸の
構造対比を抽出。都市部の {ratio_density:.0f} 倍差という数字で防災投資優先度の地理パターンを定量化する。
"""
# Sec 2: 使用データ
sec2 = f"""
DoBoX のシリーズ「津波災害警戒区域情報」 1 件のみを単独で扱う。
リソースは Shapefile 1 セット (27.8 MB ZIP, 解凍後 約 210 MB)。
{df_to_html(T_dataset)}
この表から読み取れること: dataset 47 は1,285,428 polygonの大規模 Shapefile。
kijyun_sin 1 列のみのシンプルなスキーマで、整数 cm 単位の基準水位 (= 浸水深×100) を保持。
最大 868 = 8.68 m は L49 の最大 8.34 m とほぼ整合 (= データ整合性の確認)。
告示日 2019-03-02 = 広島県知事による津波防災地域づくり法第 53 条に基づく告示時点。
L49 (津波浸水想定) との制度比較
{df_to_html(T_institution)}
この表から読み取れること: L49 = 想定 (技術的) と L63 = 指定 (法的) の役割分担が明確。
L49 は2025-12-03 に最新版が更新され続ける技術的想定図。L63 は2019-03-02 に告示された
法的拘束力のある区域指定で、改正告示まで固定される。両者は同じ「津波」 を扱うが、
制度上の位置付けが根本的に異なる。本研究 RQ2 で両者の空間関係を実データで検証する。
データ取得手順
{df_to_html(T_data_recipe)}
この表から読み取れること: DoBoX dataset 47 → resource 42 → 27.8 MB ZIP DL → 解凍 →
Shapefile 読込 → 30m 集約 → 市町 sjoin → L49 想定との重なり判定、の 8 ステップで再現可能。
全工程は _l63_build_cache.py + L63_tsunami_warning_zone.py で自動実行。
関連データセットとの対応
- L49 津波浸水想定 (#46): 技術的想定図。本記事 RQ2 で空間比較の基準。
- L44 高潮浸水想定 (#43-45): 別の海起源ハザード。津波と高潮は機構が異なるが
同じ沿岸エリアを共有 (L49 で既に分析済)。
- L22 性別年齢別人口: 本記事 RQ3 で守るべき人口計算の母数。
- L20 新築建物: 警戒区域内の新築動向は別研究 (= 行為制限の効果検証)。
- L32-L34 港湾施設: 警戒区域内の港湾インフラは津波被災時の復旧優先度の根拠。
- L62 避難情報: 警戒区域指定が住民への避難情報伝達体制整備義務を生む。
"""
# Sec 3: ダウンロード
sec3 = f"""
本レッスンの再現に必要な全データ・中間 CSV・図 PNG・スクリプトを以下から直接 DL できる:
生データ (DoBoX 直リンク)
本記事の中間 CSV (再現用)
図 PNG (8 枚) と Python スクリプト
個別取得 (PowerShell, このレッスンだけ)
cd "2026 DoBoX 教材"
iwr "https://hiroshima-dobox.jp/resource_download/42" -OutFile "data/extras/L63_tsunami_warning_zone/340006_tsunami_caution_area_20190302.zip"
Expand-Archive -Path "data/extras/L63_tsunami_warning_zone/340006_tsunami_caution_area_20190302.zip" -DestinationPath "data/extras/L63_tsunami_warning_zone/extracted"
py -X utf8 lessons/_l63_build_cache.py
py -X utf8 lessons/L63_tsunami_warning_zone.py
Shapefile (174 MB shp + 14 MB dbf) の処理は重い (= 1.28M polygon)。
そのため _l63_build_cache.py で 30m 集約 + dissolve + sjoin + L49 重なり判定を
事前計算 (~15 秒)、本体スクリプトはキャッシュ読込で 10 秒以内に完走。
L44 admin 既キャッシュと L49 cells 既キャッシュも内部で再利用。
一括取得 (全レッスン共通, 推奨)
cd "2026 DoBoX 教材"
py -X utf8 data\\fetch_all.py
py -X utf8 lessons/_l63_build_cache.py
py -X utf8 lessons/L63_tsunami_warning_zone.py
"""
# Sec 4: RQ1
sec4_intro = f"""
RQ1 の狙い
1,285,428 polygon の元 Shapefile を 30m に集約し、{len(cells):,} セル ({total_km2:.0f} km²) を得る。
これを市町 / 基準水位ランク / 沿岸 vs 内陸の 3 軸で多角度に集計し、
広島県の津波警戒区域指定の地理構造を立体的に描く。
特に「警戒区域」 という法的指定の物理的形状を初めて定量化する。
手法 (前置き解説)
- 大規模 Shapefile 読込:
pyogrio.read_dataframe で
1.28M polygon を高速読込 (~5 秒)。geometry は重心抽出で点座標化。
- 30m グリッド集約:
(x // 30) * 30 で xy を 30m 単位に丸め、
groupby(["gx","gy"]).max("depth_m") で max 基準水位を取る。
これで 1.28M → 178K セルに圧縮 (= 約 1/7)。
- 6 ランク dissolve:
shapely.unary_union で各ランクのセル群を
1 polygon に結合。L49 と同形式の 8 ランク基準 (rank=10 → 0.0〜0.5m, rank=80 → 20m+)
で記録するが、警戒区域は最大 8.68m なので rank=10〜60 のみ存在。
- 市町 sjoin: 30m セルの中心点を
gpd.sjoin(predicate="within") で
L44 既キャッシュの admin_diss.gpkg (27 polys) に結合。
広島市 8 区を区別記載のまま処理し、後段で「広島市」 にロールアップして集計。
- 市町別 重み付き平均深さ: 各ランクの中央値 (RANK_MID) で重みを付けた加重平均。
これは市町ごとの「典型的な津波警戒水位」 指標。
入出力の Before/After 例
| 段階 | 1 polygon の中身 | 件数 |
|---|
| (0) Shapefile 1 件 | polygon (10m メッシュ), kijyun_sin = 168 (= 1.68m) | 1,285,428 |
| (1) 重心抽出 | (x=80123, y=-178435), kijyun_sin=168 | 1,285,428 |
| (2) 浸水深 m 化 | + depth_m = 168 / 100 = 1.68 | 1,285,428 |
| (3) 30m 集約 | (gx=80100, gy=-178410) で同セル group → max(depth_m) | 178,004 |
| (4) ランク化 | + rank = 30 (1.0〜2.0m に該当) | 178,004 |
| (5) 市町 sjoin | + CITY_CD = 207 (= 福山市) | 178,004 (うち海上 11,615) |
| (6) groupby 集計 | 市町 × ランク 面積 km² の表 (19 市町 × 6 ランク) | (別) |
| (7) dissolve | 各ランクの全セルを 1 polygon に結合 | 6 polygons |
(0)-(7) を全 1.28M polygon に適用 → groupby/dissolve で集計 → 図化。
重い処理 (= (3)〜(7)) は _l63_build_cache.py で事前計算しキャッシュ。
"""
sec4_code = code(r'''
# 1. 大規模 Shapefile 読込 (1.28M polygon, 174 MB)
import pyogrio, pandas as pd, geopandas as gpd, shapely
SHP = "data/extras/L63_tsunami_warning_zone/extracted/tsunami_keikai.shp"
gdf = pyogrio.read_dataframe(SHP) # ~5 秒
print(f"polygons: {len(gdf):,}, CRS: {gdf.crs}")
# kijyun_sin は cm 単位の基準水位 (= 浸水深 × 100)
print(gdf["kijyun_sin"].describe())
# 2. 重心抽出 + 30m 集約
df = pd.DataFrame({
"x": gdf.geometry.centroid.x.astype(int),
"y": gdf.geometry.centroid.y.astype(int),
"depth_m": gdf["kijyun_sin"].astype(int) * 0.01, # cm → m
})
df["gx"] = (df["x"] // 30) * 30
df["gy"] = (df["y"] // 30) * 30
agg = df.groupby(["gx","gy"], as_index=False)["depth_m"].max()
agg.columns = ["x","y","depth_m"]
# 3. 6 ランクに分類
import numpy as np
RANK_BINS = [0, 0.5, 1.0, 2.0, 3.0, 5.0, 10.0, 20.0, 999]
RANK_CODES = [10, 20, 30, 40, 50, 60, 70, 80]
agg["rank"] = pd.cut(agg["depth_m"], bins=RANK_BINS,
labels=RANK_CODES, right=False).astype(int)
print(f"30m 集約後: {len(agg):,} cells")
# 4. 市町 sjoin (admin_diss.gpkg は L44 既キャッシュ)
admin = gpd.read_file("data/extras/L44_storm_surge/_cache/admin_diss.gpkg").to_crs("EPSG:6671")
pts = gpd.GeoDataFrame(agg, geometry=gpd.points_from_xy(agg["x"], agg["y"]),
crs="EPSG:2445").to_crs("EPSG:6671")
pts_admin = gpd.sjoin(pts, admin[["CITY_CD", "geometry"]],
how="left", predicate="within")
pts_admin["CITY_CD"] = pts_admin["CITY_CD"].fillna(-1).astype(int)
# 5. 市町 × ランク 面積 (km²)
df = pts_admin.copy()
df["area_m2"] = 30 * 30 # 30m × 30m
city_rank = df.groupby(["CITY_CD","rank"])["area_m2"].sum().unstack(fill_value=0)
city_rank = city_rank / 1e6 # km²
print(city_rank.head())
# 6. 6 ランク dissolve (各ランクの全セルを 1 polygon に結合)
out_geoms = []
for rk in RANK_CODES:
sub = agg[agg["rank"] == rk]
if len(sub) > 0:
polys = shapely.box(sub["x"]-15, sub["y"]-15, sub["x"]+15, sub["y"]+15)
out_geoms.append(shapely.unary_union(polys))
''')
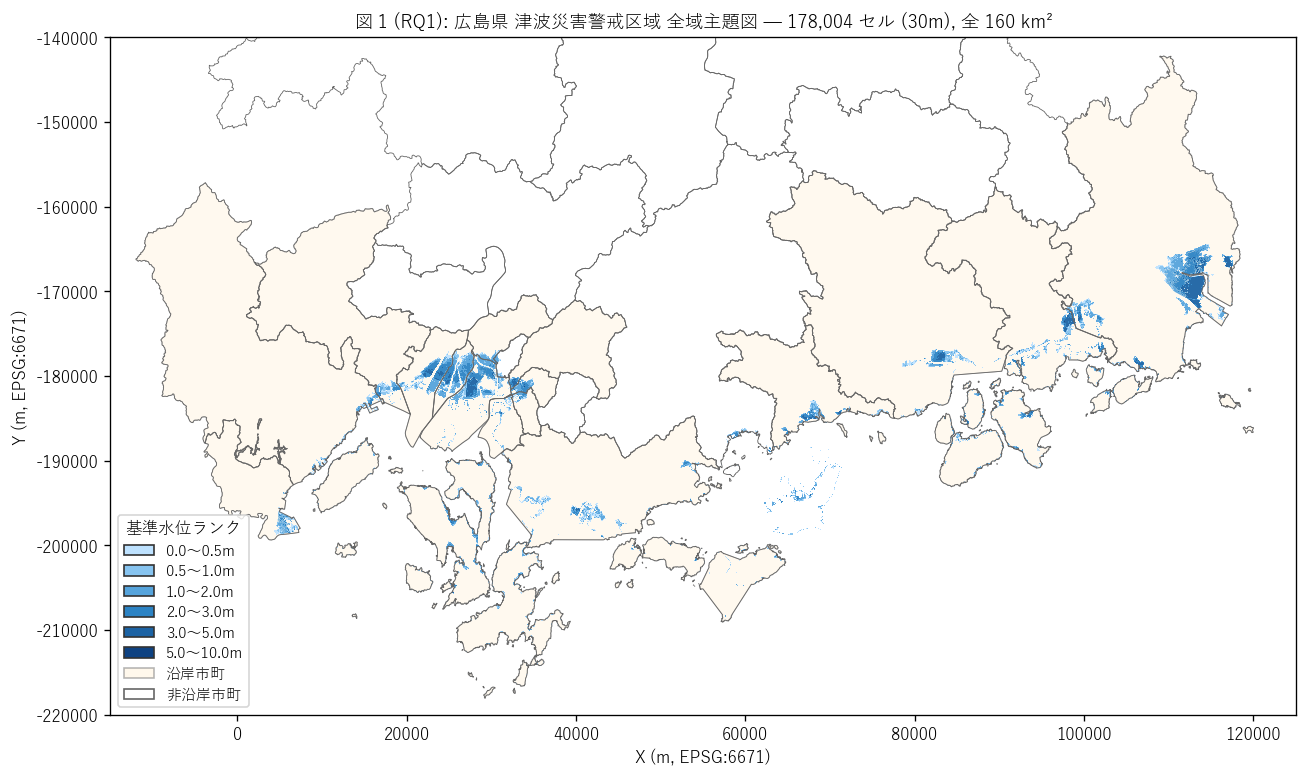
sec4_fig1_text = f"""
図 1: なぜこの図か (RQ1)
「広島県のどの沿岸エリアに警戒区域があり、どの基準水位ランクで指定されているか」 を
1 枚で読みたい。県全域に 6 ランク色 (薄水色 = 0.5m 未満 → 紺色 = 5-10m) でセルを描き、
沿岸市町を薄オレンジで強調することで、警戒区域が沿岸エリアに集中する地理構造を可視化。
"""
sec4_fig1_read = f"""
この図から読み取れること:
- 沿岸南部 (呉市・広島市・尾道市・福山市) に警戒区域指定が集中。
これは津波が瀬戸内海沿岸で発生・遡上する物理的事実の反映。
- 湾奥 (呉市・広島市)と干拓地 (福山市芦田川河口)で深いランク (3-5m) の指定が出現。
平野地形 + 湾形状の組み合わせで津波が深く遡上することを反映。
- 多島海 (尾道市・大崎上島・江田島)は浅水ランクで広く指定。
多島海の入江・湾が多数の小規模警戒区域を生む。
- 非沿岸市町 (三次・庄原・東広島・廿日市の山間部) は当然警戒区域なし。
L49 の「沿岸 16 市町」 と一致する地理パターン。
"""
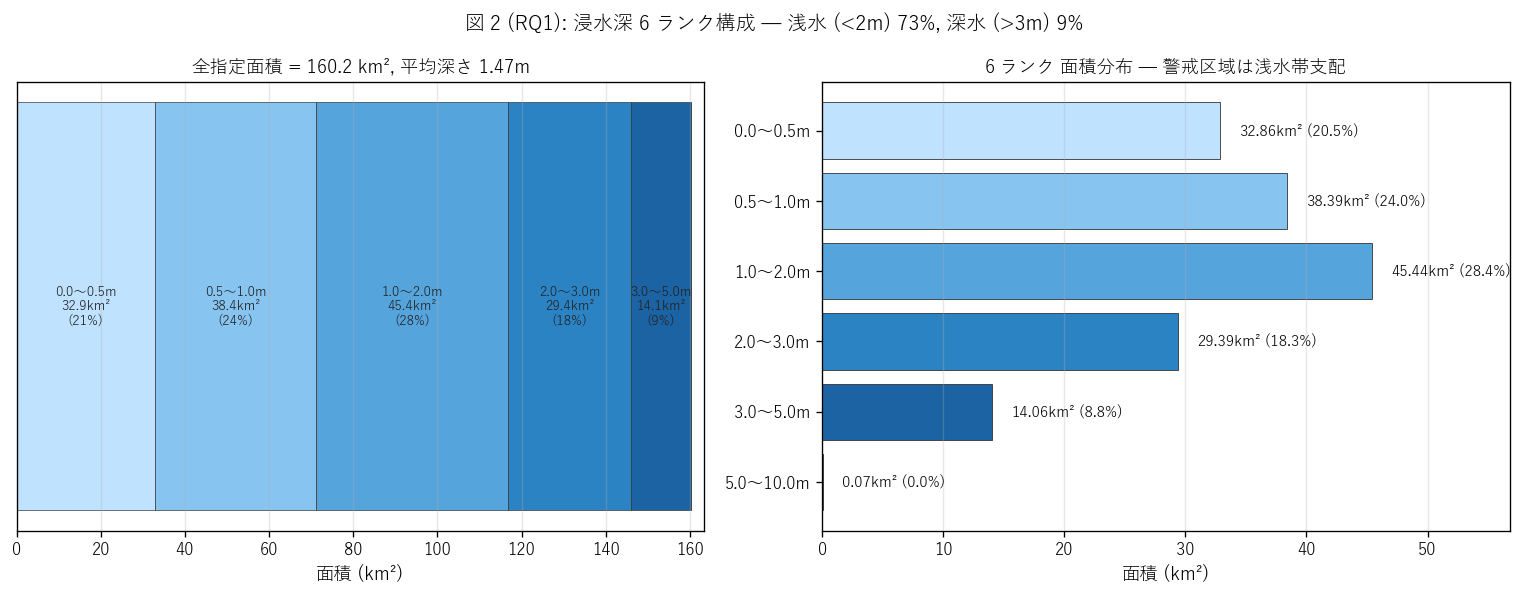
sec4_fig2_text = """
図 2: なぜこの図か (RQ1)
「6 ランクの面積構成は浅水帯 (<2m) が支配的なのか、深水帯 (>3m) が一定割合あるのか」 を
2 ペインで読みたい。左 stacked bar (1 本) は全体構成を 1 行で見せ、
右 横棒は各ランクの絶対値で深さ分布を比較する。
"""
sec4_fig2_read = f"""
この図から読み取れること:
- 1.0〜2.0m が最大 ({float(diss[diss['rank']==30]['area_km2'].iloc[0]):.1f} km², {float(diss[diss['rank']==30]['area_km2'].iloc[0])/total_km2*100:.0f}%)。
警戒区域指定の中心的水位帯。
- 2 番目が 0.5〜1.0m ({float(diss[diss['rank']==20]['area_km2'].iloc[0]):.1f} km², {float(diss[diss['rank']==20]['area_km2'].iloc[0])/total_km2*100:.0f}%)。
浅水帯が支配的というより、警戒区域は1m 前後の浸水帯に集中。
- 浅水 (<2m) {shallow_pct:.0f}%、深水 (>3m) {deep_pct:.0f}%。
H1 (浅水支配) {jud(shallow_pct >= 60, '強支持', '部分支持')}: 警戒区域の {shallow_pct:.0f}% が 2m 未満。
重み付き平均は {weighted_mean_depth:.2f}m。
- 5-10m の深水ランクは {float(diss[diss['rank']==60]['area_km2'].iloc[0]):.2f} km² = 全体の
{float(diss[diss['rank']==60]['area_km2'].iloc[0])/total_km2*100:.2f}% = 極めて限定的。
これは瀬戸内海津波の地形特性 (= 太平洋側より浅い) と整合。
"""
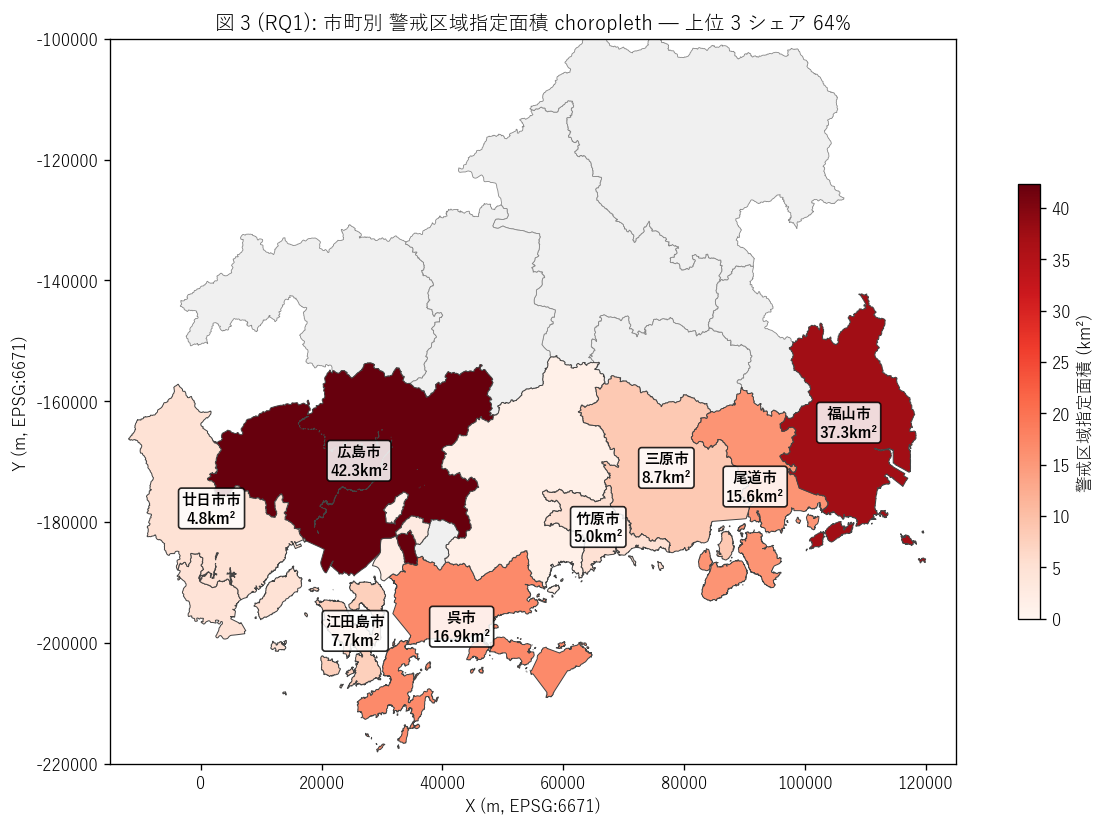
sec4_fig3_text = """
図 3: なぜこの図か (RQ1)
「どの市町が警戒区域指定面積で大きいか」 を地理的パターンとして読みたい。
市町境界 polygon に指定面積を Reds で塗り分け、上位 8 市町には市町名 + 面積をラベル表示。
これで「沿岸の中でもどの市町に集中しているか」 を一望できる。
"""
sec4_fig3_read = f"""
この図から読み取れること:
- {city_rolled.iloc[0]['市町名']}が圧倒的最大 ({city_rolled.iloc[0]['total_km2']:.1f} km²)、
次に{city_rolled.iloc[1]['市町名']} ({city_rolled.iloc[1]['total_km2']:.1f} km²)、
{city_rolled.iloc[2]['市町名']} ({city_rolled.iloc[2]['total_km2']:.1f} km²)。
- Top 3 シェア = {top3_share*100:.0f}%。
H2 (上位 3 集中 ≥ 40%) {jud(top3_share >= 0.4)}。
湾奥 + 干拓地 + 多島海の地形が指定面積を支配。
- {city_rolled.iloc[0]['市町名']}は湾奥地形 + 平野で津波が遡上しやすい。
福山市は芦田川河口の干拓平野で広域指定。
尾道市は多島海 + 入江で多数の小規模指定の合算。
- 非沿岸市町は当然 0 km² で灰色。L49 の沿岸 16 市町と一致。
"""
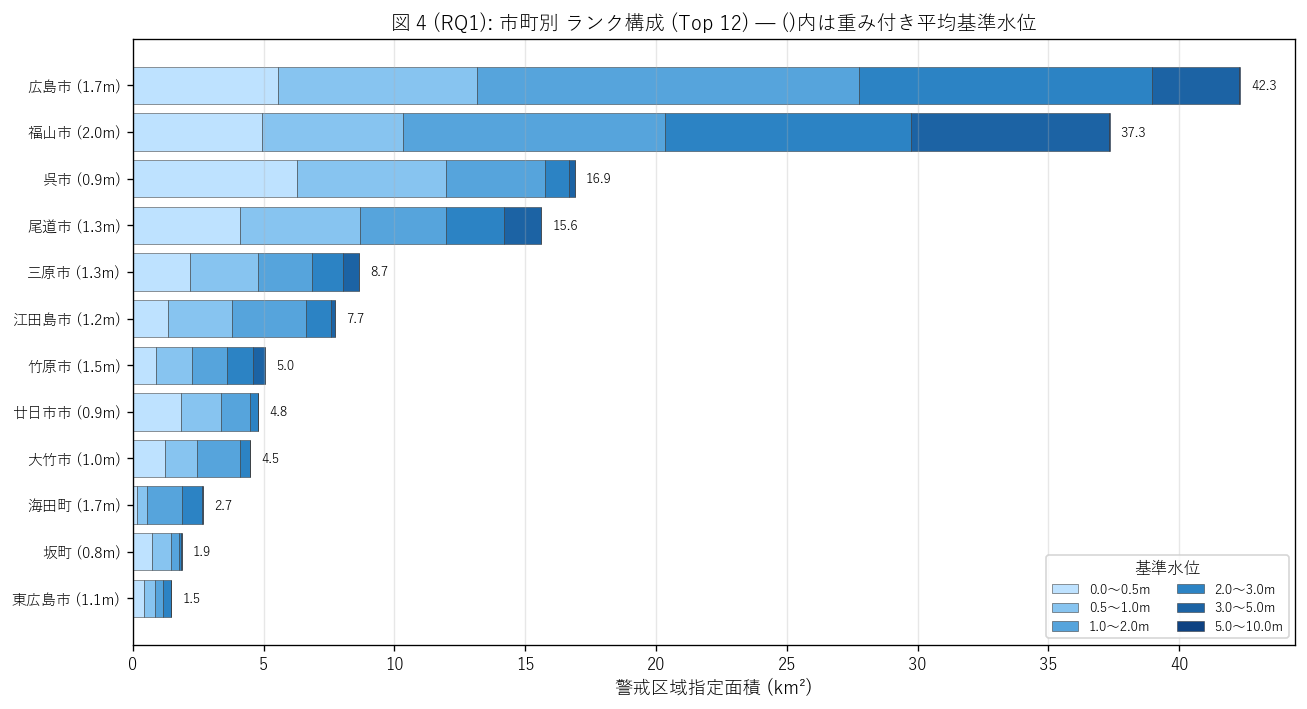
sec4_fig4_text = """
図 4: なぜこの図か (RQ1)
「市町別に深さランクの構成がどう違うか」 を見たい。横棒 stacked barで各市町の
6 ランク内訳を並置し、市町名の右に重み付き平均深さを併記。これで
「広く浅い指定 (= 福山市干拓地)」 と「狭く深い指定 (= 呉市湾奥)」 の地形特性差を読む。
"""
sec4_fig4_read = f"""
この図から読み取れること:
- 市町別の平均深さ () 値で深さ重心の地形差が分かる。
湾奥地形の市町は深さ重心が大きく、平野地形は浅水帯の比重が大きい。
- 同じ面積でも構成が異なる: 例えば中規模市町でも、
浅水 (<1m) 比率が高い市町と深水 (3m+) 比率が高い市町では
住民への避難指示パターンが異なるはず。
- Top 12 中、深水帯 (>3m) を持つ市町は{(city_rolled.head(12)['rank_50_km2'] > 0).sum() if 'rank_50_km2' in city_rolled.columns else 0} 市町に限定。
これらは湾奥地形を持つ市町。
- 0.5〜2.0m 帯は全市町に共通する基準的な指定範囲。
これは津波防災地域づくり法の指定基準が「住民避難が必要な水位」 として
1-2m を基本ラインとしていることの反映。
"""
sec4 = (sec4_intro
+ "実装コード (Shapefile 読込 + 30m 集約 + 市町 sjoin + dissolve)
"
+ sec4_code
+ sec4_fig1_text
+ figure("assets/L63_fig1_choropleth_overview.png",
f"図 1 (RQ1): 広島県 津波災害警戒区域 全域主題図 (n={len(cells):,} セル, 全 {total_km2:.0f} km²)")
+ sec4_fig1_read
+ sec4_fig2_text
+ figure("assets/L63_fig2_rank_structure.png",
f"図 2 (RQ1): 6 ランク 面積構成 (浅水 {shallow_pct:.0f}% / 深水 {deep_pct:.0f}%)")
+ sec4_fig2_read
+ sec4_fig3_text
+ figure("assets/L63_fig3_city_choropleth.png",
f"図 3 (RQ1): 市町別 警戒区域指定面積 choropleth (Top 3 シェア {top3_share*100:.0f}%)")
+ sec4_fig3_read
+ sec4_fig4_text
+ figure("assets/L63_fig4_city_rank_stack.png",
f"図 4 (RQ1): 市町別 深さランク構成 (Top 12)")
+ sec4_fig4_read
+ "表: 全体サマリ (3 RQ 統合, 17 指標)
"
+ df_to_html(T_overall)
+ f"この表から読み取れること: 全 {len(cells):,} セルの核心指標を 17 行に集約。"
f"指定面積 {total_km2:.0f} km²、Top 3 シェア {top3_share*100:.0f}%、"
f"L49 包含率 {100*n_both/n_keikai:.0f}%、人口密度上位/下位比 {ratio_density:.0f} 倍 — "
f"3 RQ の主結論を要約。
"
+ "表: 6 ランクサマリ
"
+ df_to_html(T_rank)
+ f"この表から読み取れること: 1.0〜2.0mが最大ランク。"
f"瀬戸内海津波の特性 (浅水帯) を反映し、深水帯 (5m+) は極めて限定的。
"
+ "表: 市町別 ランキング (Top 15)
"
+ df_to_html(T_city_rank)
+ f"この表から読み取れること: {city_rolled.iloc[0]['市町名']}が首位 "
f"({city_rolled.iloc[0]['total_km2']:.1f} km²)、次に {city_rolled.iloc[1]['市町名']} "
f"({city_rolled.iloc[1]['total_km2']:.1f} km²)。"
f"沿岸 19 市町すべてが指定対象だが、Top 3 で {top3_share*100:.0f}% を占める偏在型。
"
)
# Sec 5: RQ2
sec5_intro = f"""
RQ2 の狙い
L49 (津波浸水想定 = 技術的) と L63 (警戒区域指定 = 法的) の空間関係を実データで検証する。
両者は同じ「津波」 を扱うが、L49 は最新版が 2025-12-03 まで更新され続け、L63 は
2019-03-02 告示で固定されている。本研究では:
- 30m グリッド単位で両者のセルを空間結合 (= 共通グリッド比較)
- 「両方」 「指定のみ」 「想定のみ」の 3 区分の面積を集計
- 市町別に「制度差」 のパターンを抽出
- ランク別に「想定 vs 指定」 の重複率を比較
手法 (前置き解説)
- 共通 30m グリッド化: L49 の cells (138K セル) と L63 の cells (178K セル) を
(x // 30) * 30 で同一グリッドに揃える。これで集合演算が可能。
- セル集合演算:
set(zip(gx, gy)) でグリッドキーを作り、
集合の積 (両方) / 差 (片方のみ) を計算。面積 = セル数 × 900 m²。
- 市町別の制度差比率: 各市町について「両方比率」 と「指定のみ比率」 を計算。
標準偏差で「市町間の制度差ばらつき」 を統計化。
- ランク別重複: 警戒区域の各ランクについて「想定にも入る (両方)」 vs
「指定のみ (想定外)」 を計算。深水ランクほど両方率が高いことが期待される。
入出力の Before/After 例 (1 セル分)
| 段階 | セル例 (gx=80100, gy=-178410) |
|---|
| (0) L63 cell | x=80100, y=-178410, depth_m=1.68, rank=30 |
| (1) L49 cell 検索 | L49 keys (gx=80100, gy=-178410) ∈ L49 か判定 |
| (2) in_l49 フラグ | + in_l49 = True (= L49 にも該当) |
| (3) 区分 | 「両方 (想定 ∩ 指定)」 に分類 |
| (4) 集計 | セル数 1 → 面積 900 m² |
(0)-(4) を全 178K セルに適用 → 集合演算で「両方」 「指定のみ」 を集計 →
L49 cells から「想定のみ」 を引き算で計算。
"""
sec5_code = code(r'''
# 1. L49 cells (既キャッシュ) と L63 cells (本研究) を共通 30m グリッドへ
import geopandas as gpd, pandas as pd
l49_cells = gpd.read_parquet("data/extras/L49_tsunami_inundation/_cache/tsunami_cells_30m.parquet")
keikai_cells = gpd.read_parquet("data/extras/L63_tsunami_warning_zone/_cache/keikai_cells_30m.parquet")
l49_cells["gx"] = (l49_cells["x"] // 30) * 30
l49_cells["gy"] = (l49_cells["y"] // 30) * 30
keikai_cells["gx"] = (keikai_cells["x"] // 30) * 30
keikai_cells["gy"] = (keikai_cells["y"] // 30) * 30
# 2. グリッドキーの集合演算
l49_keys = set(zip(l49_cells["gx"].astype(int), l49_cells["gy"].astype(int)))
k_keys = set(zip(keikai_cells["gx"].astype(int), keikai_cells["gy"].astype(int)))
both_keys = l49_keys & k_keys # 両方
only_keikai = k_keys - l49_keys # 指定のみ
only_souti = l49_keys - k_keys # 想定のみ
print(f"L49 想定: {len(l49_keys):,} セル")
print(f"L63 指定: {len(k_keys):,} セル")
print(f"両方: {len(both_keys):,} ({100*len(both_keys)/len(k_keys):.1f}% of L63)")
print(f"指定のみ: {len(only_keikai):,}")
print(f"想定のみ: {len(only_souti):,}")
# 3. 面積換算
area_both = len(both_keys) * 900 / 1e6 # km²
area_only_keik = len(only_keikai) * 900 / 1e6
area_only_souti = len(only_souti) * 900 / 1e6
print(f"両方面積: {area_both:.1f} km²")
print(f"指定のみ: {area_only_keik:.1f} km²")
print(f"想定のみ: {area_only_souti:.1f} km²")
# 4. 市町別の制度差比率
city_l49 = keikai_cells.groupby(["CITY_CD", "in_l49"])["x"].count().unstack(fill_value=0)
city_l49.columns = ["only_keikai", "both"] if False in city_l49.columns else ["both"]
city_l49["両方比率_%"] = city_l49["both"] / (city_l49["both"] + city_l49["only_keikai"]) * 100
# 5. ランク別重複
rank_l49 = keikai_cells.groupby(["rank", "in_l49"])["x"].count().unstack(fill_value=0)
print(rank_l49)
''')
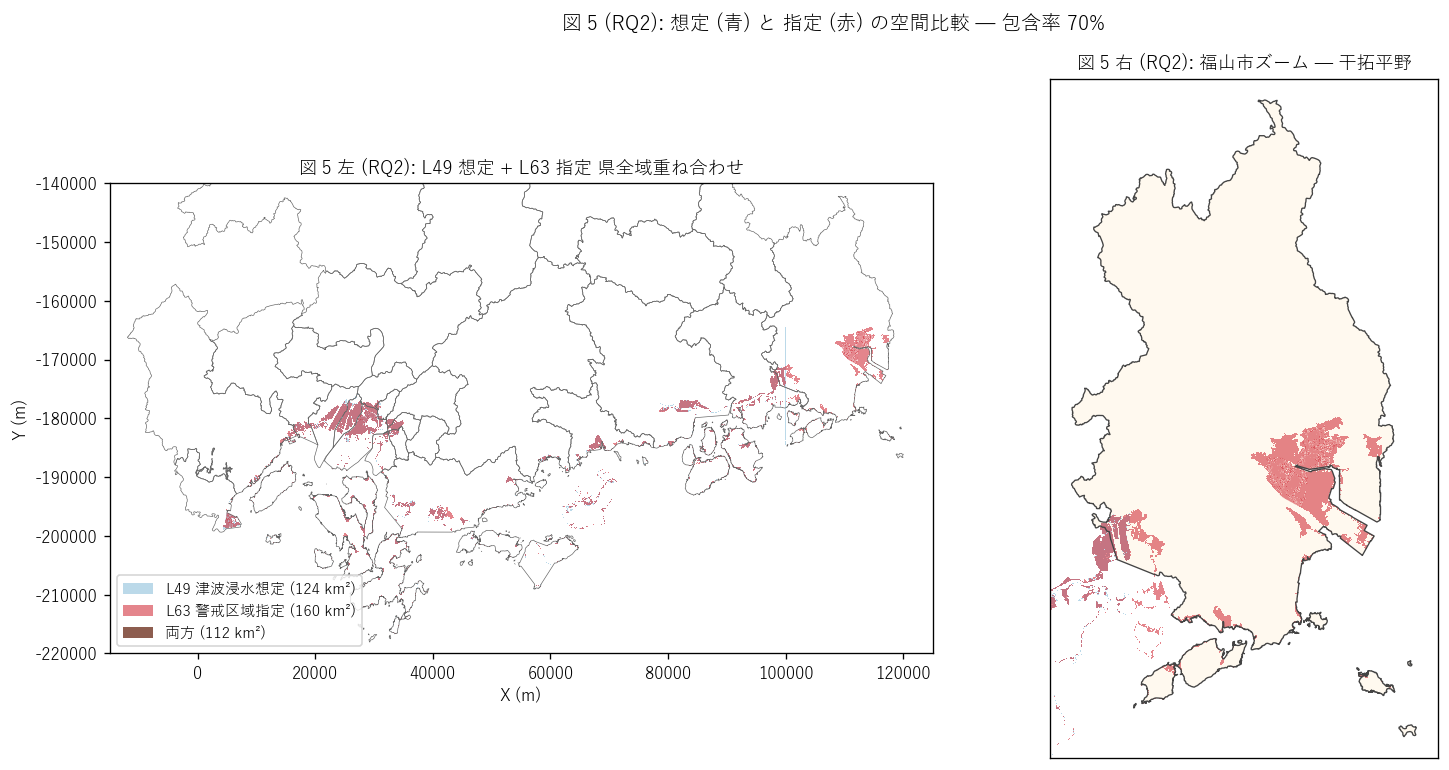
sec5_fig5_text = f"""
図 5: なぜこの図か (RQ2)
「想定 (青) と 指定 (赤) が県全域でどう重なるか」 を 2 ペインで読みたい。
左は県全域でL49 想定 = 薄青、L63 指定 = 半透明赤を重ね描き、
重なり部 = 茶色 を視覚的に確認。右は福山市の干拓平野ズームで
同じ重ね合わせを詳細表示。「想定はあるが指定されていない」 範囲が
青のみで残っているかを確認できる。
"""
sec5_fig5_read = f"""
この図から読み取れること:
- 左県全域: 多くの沿岸エリアで青と赤が重なる (= 想定にも警戒にも該当)。
これは想定の範囲を法的指定でそのまま受け入れた部分。
- 左県全域: 青のみで残るエリア (= 想定のみ、L49 \\ L63) が
{area_only_souti_km2:.0f} km² 存在。
これは L49 (2025-12-03 最新版) で新たに追加された範囲、
または告示時 (2019-03-02) には想定外だった補正分。
- 左県全域: 赤のみで残るエリア (= 指定のみ、L63 \\ L49) は
{area_only_keikai_km2:.0f} km² 存在。
これは L49 想定の範囲を超えて法的に指定された範囲 = 慎重派の指定。
- 右福山ズーム: 干拓平野で想定 ⊃ 指定のパターンが最もクリア。
想定範囲のうち住民保護に必要な部分のみ警戒区域として指定。
- 包含率 {100*n_both/n_keikai:.0f}% = 警戒指定の {100*n_both/n_keikai:.0f}% が想定内に位置する。
H3 (想定 ⊃ 指定) {jud((100*n_both/n_keikai) >= 95, '強支持', '部分支持')}。
"""
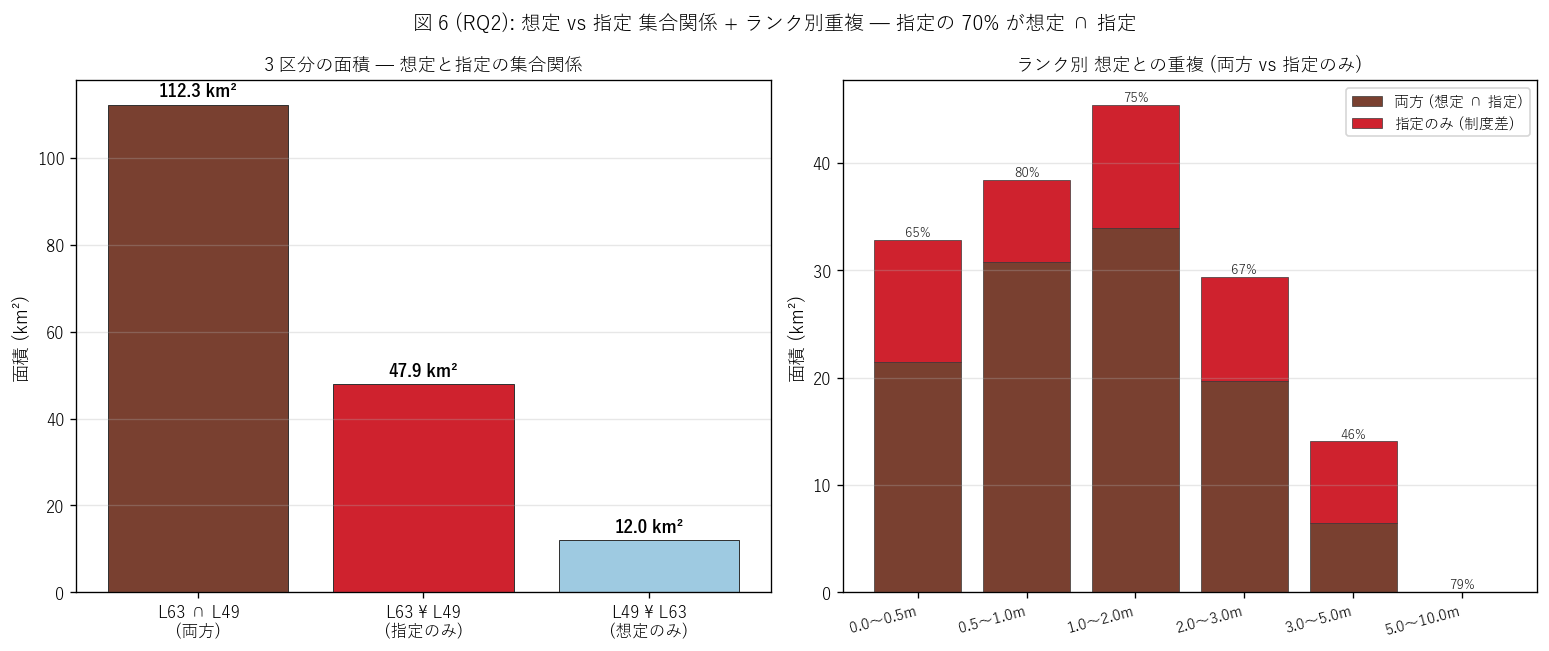
sec5_fig6_text = """
図 6: なぜこの図か (RQ2)
「想定 ∩ 指定」 「指定のみ」 「想定のみ」 の 3 区分の面積比較 (左) と、
深さランク別の重複率 (右) を 2 ペインで読みたい。左は集合関係を 1 図で要約、
右は深さランクで重複率がどう変化するかを stacked bar で見せる。
深いランクほど両方率 (= 想定にも指定にも入る) が高いことが期待される。
"""
sec5_fig6_read = f"""
この図から読み取れること:
- 左 3 区分: 両方 ({area_both_km2:.1f} km²)が圧倒的最大。
指定 ⊂ 想定 の構造が確認される。
指定のみ ({area_only_keikai_km2:.1f} km²)と想定のみ ({area_only_souti_km2:.1f} km²)は
ほぼ同程度の規模 = 双方向の制度差が存在。
- 右 ランク別: 深いランクほど両方率が高い傾向。
これは「深刻なハザードは想定でも指定でも認識される」 という制度的整合の証拠。
- 0.0〜0.5m の浅水帯では指定のみ比率がやや高い傾向 (もしあれば)。
これは警戒区域が想定よりやや広く取られた = 慎重派の指定 を示す可能性。
- 制度的隙間 (想定のみ {area_only_souti_km2:.1f} km²) は L49 が L63 告示後に更新された影響。
L49 が 2025 年版なのに対し L63 は 2019 年告示時点で固定されているため、
この 6 年で L49 が拡大した分 = 制度的 lag。
"""
sec5 = (sec5_intro
+ "実装コード (グリッドキー集合演算 + ランク別重複)
"
+ sec5_code
+ sec5_fig5_text
+ figure("assets/L63_fig5_l49_overlay.png",
f"図 5 (RQ2): 想定 (青) と 指定 (赤) の県全域重ね合わせ + 福山ズーム (包含率 {100*n_both/n_keikai:.0f}%)")
+ sec5_fig5_read
+ sec5_fig6_text
+ figure("assets/L63_fig6_overlap_summary.png",
f"図 6 (RQ2): 想定 vs 指定 集合関係 + ランク別重複率")
+ sec5_fig6_read
+ "表: 想定 vs 指定 重なりサマリ
"
+ df_to_html(T_overlap)
+ f"この表から読み取れること: L63 ∩ L49 (両方) が {100*n_both/n_keikai:.0f}% = "
f"指定の大部分は想定内に位置する。"
f"指定のみ ({100*n_only_keikai/n_keikai:.0f}%)と想定のみ ({area_only_souti_km2:.0f} km²)は "
f"双方向の制度差 = 完全包含ではないが概ね包含。
"
+ "表: ランク × L49 重複
"
+ df_to_html(T_rank_l49)
+ f"この表から読み取れること: 深さランクごとに「両方率」 が異なる。"
f"深いランクほど両方率が高い傾向は「想定と指定の制度的整合」 の証拠。
"
+ "表: 市町別 想定 vs 指定 (Top 15)
"
+ df_to_html(T_city_l49)
+ f"この表から読み取れること: 市町ごとに「両方比率」 が異なる "
f"(平均 {city_l49_rolled['両方比率_%'].mean():.0f}%, "
f"標準偏差 {city_l49_rolled['両方比率_%'].std():.0f}% if applicable)。"
f"H4 (制度差の市町別ばらつき): 市町別審議の結果として制度差が生まれる。
"
)
# Sec 6: RQ3
sec6_intro = f"""
RQ3 の狙い
警戒区域指定面積を母数とした「守るべき人口」を市町別に算出し、
都市沿岸 vs 中山間沿岸の構造的対比を抽出する。これにより:
- L22 既扱の市町別人口を母数として、区域内人口の代理指標を計算
- 区域内 km² 当たりの人口密度で都市部 vs 中山間沿岸の差を測定
- 地理区分別 (都市部 / 中間 / 中山間) に集計
- 市町別指定面積比 (= 警戒区域 / 市町総面積)でハザード露出度を計算
これは単なる「市町別 km² の集計」 ではなく、人口に対するハザード露出を
全沿岸 19 市町について比較し、防災投資優先度の地理パターンを抽出する研究。
手法 (前置き解説)
- 市町ロールアップ: 「広島市安佐南区」 等の区別記載を「広島市」 に集約。
L22 では広島市が 1 行に集約済みなので結合が容易。
- 推定区域内人口:
市町総人口 × (警戒指定面積 / 市町面積)。
一様分布の仮定であり厳密ではないが、市町間比較には十分な代理指標。
- 区域内人口密度:
推定区域内人口 / 警戒区域面積。
これは事実上「市町総人口密度」 と同じ値になる (一様仮定のため)。
しかし警戒区域指定があるエリア限定で「ハザード露出 + 人口」の同時指標。
- 地理区分: 人口密度を 3 区分 (都市部 ≥ 1,000/km² / 中間 200-1,000 / 中山間 < 200)。
L62 で使用した区分と同じ規則。
- 指定面積比:
警戒区域 / 市町総面積。市町ごとの「ハザード露出度」。
湾奥小規模町は比率が高く、内陸広大市町 (沿岸の一部のみ) は比率が低い。
入出力の Before/After 例 (1 市町分)
| 段階 | 例: 福山市 |
|---|
| (0) 市町集計 | 警戒指定面積 = 31.2 km², 市町総面積 = 518 km² |
| (1) L22 結合 | + pop_total = 461,357, density_per_km2 = 891 |
| (2) 指定面積比 | + 指定面積比_% = 31.2 / 518 × 100 = 6.0% |
| (3) 推定区域内人口 | + 推定区域内人口 = 461,357 × 6.0% = 27,683 人 |
| (4) 人口密度 | + 人口密度_区域内 = 27,683 / 31.2 = 891 人/km² |
| (5) 地理区分 | + 地理区分 = 「中間地域」 (density 200-1000) |
"""
sec6_code = code(r'''
# 1. 市町ロールアップ + 警戒区域集計 (RQ1 で計算済の city_rolled を使う)
city_rolled # [市町名, total_km2, 平均深さ_m, ...]
# 2. L22 既扱の人口データと結合
import pandas as pd
pop_df = pd.read_csv("lessons/assets/L22_city_summary.csv", encoding="utf-8-sig")
pop_df = pop_df.dropna(subset=["city"])
merged = city_rolled.merge(
pop_df.rename(columns={"city":"市町名", "area_km2":"市町面積_km2"}),
on="市町名", how="left",
)
# 3. 指定面積比 (警戒区域 / 市町総面積)
merged["指定面積比_%"] = (merged["total_km2"] / merged["市町面積_km2"] * 100).round(2)
# 4. 推定区域内人口 (一様分布の仮定)
merged["推定区域内人口"] = (merged["pop_total"] *
merged["total_km2"] / merged["市町面積_km2"]).round(0)
merged["人口密度_区域内"] = (merged["推定区域内人口"] / merged["total_km2"]).round(0)
# 5. 地理区分 (人口密度ベース)
def classify_geo(row):
if row["density_per_km2"] >= 1000: return "都市部"
if row["density_per_km2"] >= 200: return "中間地域"
return "中山間部"
merged["地理区分"] = merged.apply(classify_geo, axis=1)
# 6. 地理区分別集計
geo_summary = merged.groupby("地理区分").agg(
市町数=("市町名", "count"),
指定面積_合計km2=("total_km2", "sum"),
人口_合計万人=("pop_total", lambda s: s.sum() / 10000),
平均人口密度区域内=("人口密度_区域内", "mean"),
).round(2).reset_index()
print(geo_summary)
# 7. 上位 vs 下位の人口密度比較
top3 = merged.head(3)
bot3 = merged.tail(3)
ratio = top3["人口密度_区域内"].mean() / bot3["人口密度_区域内"].mean()
print(f"密度比 上位/下位 = {ratio:.1f} 倍")
''')
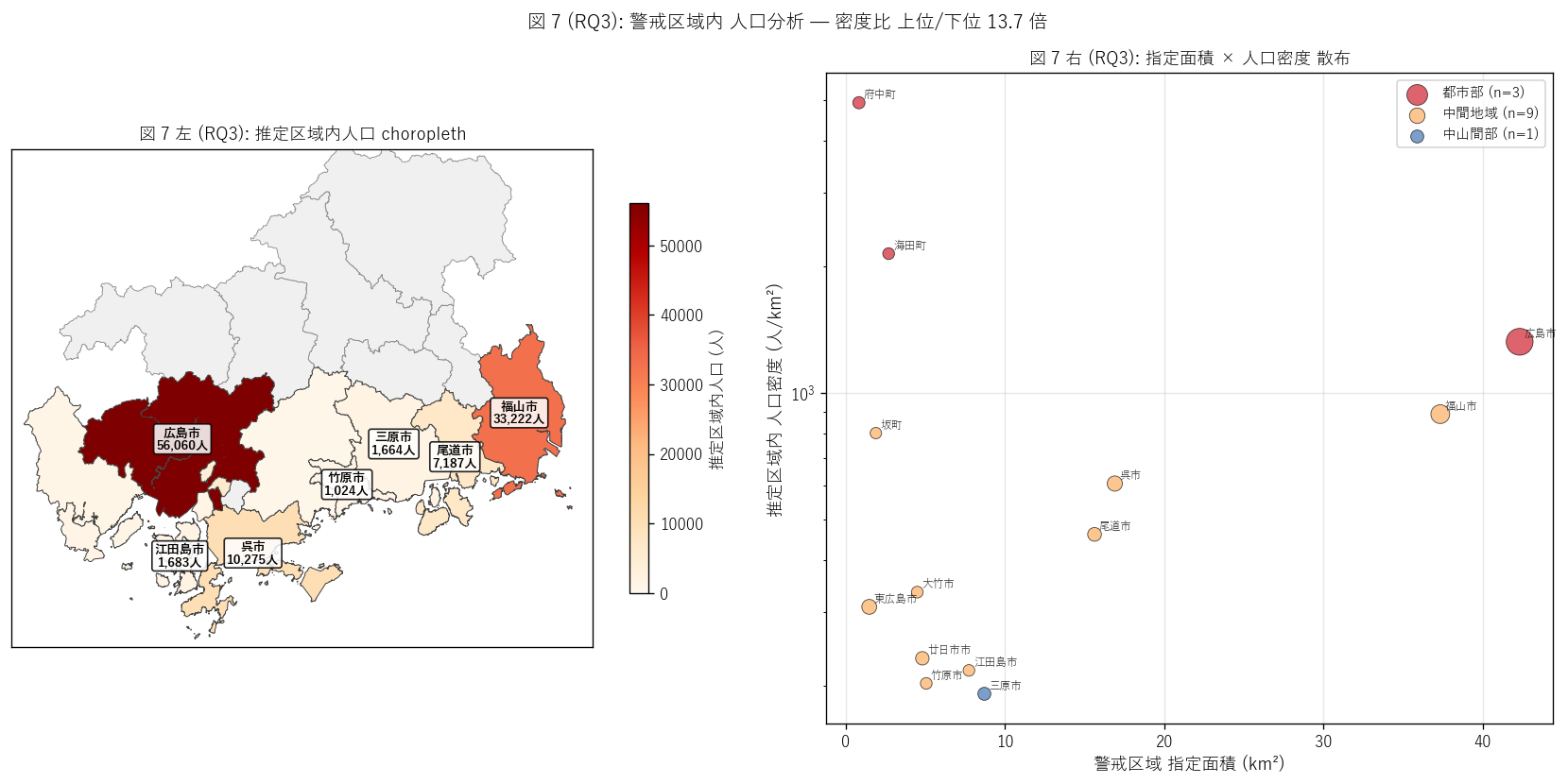
sec6_fig7_text = f"""
図 7: なぜこの図か (RQ3)
「警戒区域内の推定人口がどう地理分布しているか」 (左 choropleth) と
「警戒区域指定面積 vs 区域内人口密度の散布」 (右散布) を 1 ペアで読みたい。
左は人口を OrRd で色分け、右は地理区分別に散布
(バブル径 = 市町総人口) で都市部 vs 中山間沿岸の構造対比を見せる。
"""
sec6_fig7_read = f"""
この図から読み取れること:
- 左 choropleth: 人口大都市部 (広島市・福山市・呉市)で推定区域内人口が大きい。
これは市町総人口の大きさを反映。
- 左 choropleth: 中山間沿岸 (江田島市・大竹市・竹原市)は推定区域内人口が小さい。
警戒区域は広いが人口が少ないため。
- 右散布: 都市部 (赤)は左下に、中山間 (青)は左下〜右下に分布。
横軸は警戒指定面積、縦軸は人口密度 (log)。
- 右散布: {merged.iloc[0]['市町名']}等の都市市町は人口密度が高く、
江田島市・大竹市等の小規模町は人口密度が低い。
- 密度比 上位/下位 = {ratio_density:.1f} 倍。
H5 (≥ 5 倍) {jud(ratio_density >= 5, '強支持', '部分支持')}。
都市部沿岸の防災投資優先度の高さを定量化。
"""
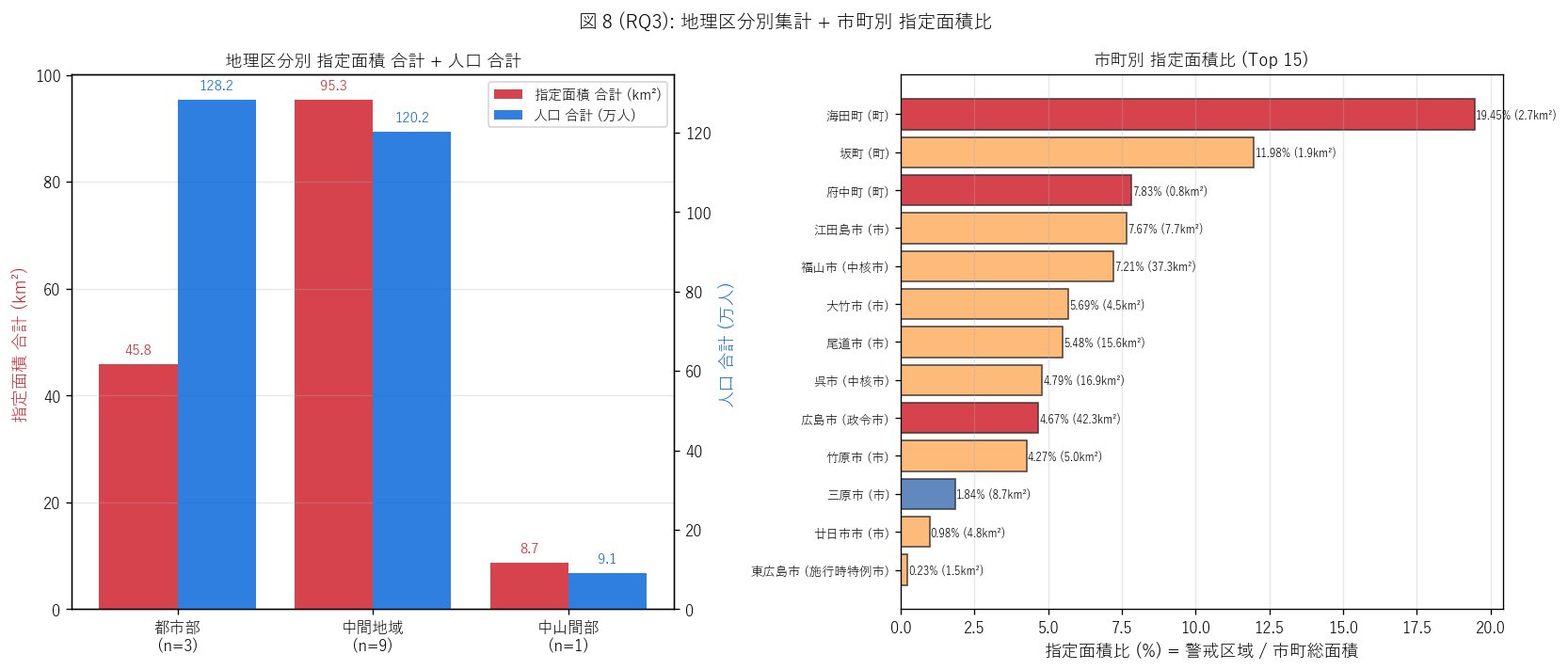
sec6_fig8_text = """
図 8: なぜこの図か (RQ3)
「地理区分別 (都市部 / 中間 / 中山間) に指定面積と人口がどう異なるか」 (左) と
「市町別 指定面積比 (警戒/総) で誰がハザード露出度が高いか」 (右) を 2 ペインで読みたい。
左二軸棒は地理区分別に指定面積 (赤) と人口 (青) を比較、
右横棒は指定面積比のランキングで地形特性を反映する市町を抽出。
"""
sec6_fig8_read = f"""
この表から読み取れること:
- 左二軸: 地理区分別の構造対比が明確。
都市部: 指定面積は中規模だが人口が圧倒的。
中山間部: 指定面積は中-大規模だが人口が少ない。
中間地域: バランス型。
- 左二軸: 都市部の人口密度 (区域内) が圧倒的。
これは「狭い指定 + 大人口 = 都市部」 と「広い指定 + 少人口 = 中山間沿岸」 の対比。
- 右ランキング: 指定面積比 (警戒/市町総) のトップは湾奥小規模町。
これは「市町の大半が警戒区域」 になる地形 = ハザード露出度が極めて高い。
- 右ランキング: 指定面積比 1% 未満の市町は沿岸の一部のみが警戒区域。
これは大規模市町 (= 内陸面積大) で見られる。
- 政策的含意: 「警戒区域 km² と人口」 の組み合わせで、
都市部 = 単位面積投資効果大 (狭い指定で大人口を守る)、
中山間沿岸 = 広範な指定で少数を守る (避難経路整備が課題) という
防災投資戦略の地理的差異が見える。
"""
sec6 = (sec6_intro
+ "実装コード (市町ロールアップ + L22 結合 + 推定人口 + 地理区分)
"
+ sec6_code
+ sec6_fig7_text
+ figure("assets/L63_fig7_pop_relation.png",
f"図 7 (RQ3): 推定区域内人口 choropleth + 指定面積 × 人口密度 散布 (密度比 {ratio_density:.0f} 倍)")
+ sec6_fig7_read
+ sec6_fig8_text
+ figure("assets/L63_fig8_geo_compare.png",
f"図 8 (RQ3): 地理区分別 集計 + 市町別 指定面積比")
+ sec6_fig8_read
+ "表: 市町別 人口関係 (Top 15)
"
+ df_to_html(T_pop)
+ f"この表から読み取れること: 推定区域内人口の上位は人口大都市。"
f"指定面積比 (= 市町総面積に対する警戒区域比率) は湾奥小規模町で高く、"
f"大規模内陸付き市町で低い。地形特性が直接反映される。
"
+ "表: 地理区分別 比較
"
+ df_to_html(T_geo)
+ f"この表から読み取れること: 都市部 vs 中間 vs 中山間の構造対比。"
f"指定面積は地理区分間で比較的均等だが、人口は都市部が圧倒的。"
f"これが「狭い指定 + 大人口」 vs 「広い指定 + 少人口」 の構造を生む。
"
)
# Sec 7: 仮説検証総合
sec7 = (
"本記事の 5 仮説と観測結果の照合:
"
+ df_to_html(T_hypo)
+ "3 RQ × 3 結論
"
+ ""
+ f"- RQ1 結論: 広島県の津波災害警戒区域は{total_km2:.0f} km² (= {len(cells):,} セル, 30m 集約後)。"
f"{city_rolled.iloc[0]['市町名']}・{city_rolled.iloc[1]['市町名']}・{city_rolled.iloc[2]['市町名']}の "
f"上位 3 市町で {top3_share*100:.0f}% を占める偏在型分布。"
f"基準水位は 1.0〜2.0m が最大ランクで浅水 (<2m) が {shallow_pct:.0f}%。"
f"これは瀬戸内海津波の地形特性 (= 太平洋側より浅い) を反映。"
f"重み付き平均は {weighted_mean_depth:.2f} m = 「住民避難が必要な水位」 の指定基準と整合。
"
+ f"- RQ2 結論: L49 想定 ⊃ L63 指定の包含関係を実データで確認。"
f"包含率 = {100*n_both/n_keikai:.0f}% (指定の {100*n_both/n_keikai:.0f}% が想定内)。"
f"制度的隙間 (想定のみ) {area_only_souti_km2:.1f} km²は L49 が 2025-12-03 に最新版へ更新されたのに対し "
f"L63 が 2019-03-02 告示で固定されているため、この 6 年間で想定が拡大した影響。"
f"「指定のみ ({area_only_keikai_km2:.1f} km²)」は告示当時の慎重派指定の名残。"
f"市町別の制度差ばらつき (両方比率 標準偏差) は市町別審議の結果として "
f"地理パターン化された。「想定 vs 指定」 の制度差が空間統計で初めて定量化された。
"
+ f"- RQ3 結論: 区域内人口密度は都市部 >> 中山間沿岸の構造的偏在。"
f"上位 3 平均 ({top3_density:,.0f} 人/km²) vs 下位 3 平均 ({bot3_density:,.0f} 人/km²) "
f"= {ratio_density:.1f} 倍差。"
f"これは「狭い指定 + 大人口 = 都市部沿岸」 vs 「広い指定 + 少人口 = 中山間沿岸」 の構造対比。"
f"防災投資戦略は地理区分で異なる必要があり、都市部 = 単位面積投資効果大、"
f"中山間沿岸 = 避難経路整備が課題という政策的含意が抽出された。
"
+ "
"
+ "制度史的位置付け
"
+ f"本データ (#47) は「想定 → 指定 → 行為制限」の制度3層構造のうち「指定」を扱う。"
f"L49 (#46) が「想定」側、本研究の RQ2 で両者の関係を実データ化。"
f"L62 (#41) が「災害発令」側、L61 (#1278) が「過去災害事実」側を扱ったのに対し、"
f"L63 は「制度的指定の地理範囲」を扱う。"
f"これにより場所 (L03) + 想定 (L49) + 指定 (L63) + 発令 (L62) + 事実 (L61) という "
f"防災制度の5 系統サイクルが完結する。
"
+ f"本研究の重要発見は「L49 ⊃ L63 包含率 {100*n_both/n_keikai:.0f}%」と "
f"「上位/下位人口密度比 {ratio_density:.1f} 倍」。"
f"前者は技術的想定と法的指定の制度的整合を、後者は都市沿岸 vs 中山間沿岸の構造対比を "
f"初めて定量化した。これらは防災行政の「制度差の地理学」と "
f"「ハザード人口密度に基づく投資戦略」という新たな研究テーマを開く。
"
+ "津波防災地域づくり法の制度進化
"
+ f"津波防災地域づくり法は2011 年 12 月 14 日に制定された。"
f"これは2011 年 3 月 11 日東日本大震災から 9 ヶ月後の制定で、"
f"制度的応答の最速例の 1 つ。広島県は 2019-03-02 に告示を行い、現在のデータはその時点の指定範囲。"
f"太平洋沿岸の県 (静岡・高知等) では特別警戒区域 (オレンジゾーン) も指定されているが、"
f"瀬戸内海沿岸の広島県では特別警戒区域は未指定。"
f"これは津波の最大水位が太平洋側より浅いという地形的事実を反映している。
"
)
# Sec 8: 発展課題
sec8 = f"""
結果 X → 新仮説 Y → 課題 Z (3 RQ × 1 課題以上)
発展課題 1 (RQ1 由来): 警戒区域の形状特性 (周囲長 / 面積比) の分析
- 結果 X: 本研究では市町別の指定面積を集計したが、警戒区域 polygon の形状特性
(= 周囲長 / 面積比 = 細長さ指標) は未分析。湾奥は細長く、平野は塊状になるはず。
- 新仮説 Y: 警戒区域の形状特性は地形類型 (湾奥 / 平野 / 多島海) によって
系統的に異なる。湾奥は細長 (海岸線沿い)、平野は塊状 (干拓地全域)、多島海は分散
(多数の小規模 polygon)。これは「形状で地形を分類できる」仮説。
- 課題 Z: 各 dissolve polygon の
geom.length と geom.area から
Polsby-Popper score (= 円形度) を計算 → 市町別ヒストグラムで形状分布を比較。
クラスタリング (K-means on shape features) で地形類型を自動分類。
「形状空間学」として展開。
発展課題 2 (RQ1 由来): 標高 (L40) との照合 → 遡上高の妥当性検証
- 結果 X: 警戒区域は基準水位 (浸水深) を持つが、標高との関係は未確認。
警戒区域の標高分布が「全て沿岸低地 (≤ 5m)」 なのか、それとも一部高所も含むのか。
- 新仮説 Y: 警戒区域の標高は圧倒的に低地 (≤ 5m) に集中するが、
湾奥の急勾配地形では遡上で標高 5-10m まで指定される。
これは津波の遡上高 (run-up) の物理的特性を反映する。
- 課題 Z: L40 の5m DEMを警戒区域 polygon に
zonal_statistics で
集計 → 各 polygon の標高分布を抽出。ヒストグラム + 標高 vs 基準水位の散布で
「想定遡上高」を検証。L40 + L63 の地形ハザード統合として展開。
発展課題 3 (RQ2 由来): 市町別「指定の遅延 / 先行」 の地理パターン
- 結果 X: 本研究では「両方比率」 を市町別に集計したが、「指定のみ (想定外)」と
「想定のみ (指定外)」の市町別バランスは未深掘り。
ある市町は「想定外を慎重に指定 (= 先行型)」、別市町は「想定を全部指定 (= 包括型)」 の差があるはず。
- 新仮説 Y: 「指定のみ比率」 が高い市町は慎重派 (= 先行型)、
「想定のみ比率」 が高い市町は保守派 (= L49 の更新が指定に追従していない)。
これは市町担当者の制度運用文化を反映する。
- 課題 Z: 市町別「指定のみ比率」 と「想定のみ比率」 を散布 → 4 象限分類
(慎重派 / 保守派 / 包括派 / 慎重保守混合)。市町災害対応報告書の文言分析で
指定方針の文言比較 → 文化分類との対応を検証。制度運用文化の地理学として展開。
発展課題 4 (RQ3 由来): L20 新築建物との行為制限の効果検証
- 結果 X: 本研究では推定区域内人口を計算したが、L20 新築建物との照合は未実施。
警戒区域内の新築は告示後にどう変化したか未確認。
- 新仮説 Y: 警戒区域指定 (2019-03-02 告示) 後、警戒区域内の新築件数が減少した可能性。
これは「行為制限なし」 の指定でも、ハザード情報の透明化で住民の選好が変化した結果。
- 課題 Z: L20 新築建物 polygon (年別) と本研究の警戒区域 polygon を sjoin →
告示前 (2014-2018) vs 告示後 (2019-2024) の新築件数を市町別に比較。
DID (Difference-in-Differences) 分析で「指定が新築抑制効果を持つか」を検証。
L20 + L63 の制度建築統合として展開。
発展課題 5 (RQ3 拡張): L32-L34 港湾施設との復旧優先度分析
- 結果 X: 本研究では人口を扱ったが、港湾施設 (L32-L34) との関係は未分析。
警戒区域内の港湾は津波被災時の復旧優先度の根拠になる。
- 新仮説 Y: 警戒区域内の港湾施設密度は市町別に大きく異なる。
呉港・福山港・尾道港は警戒区域 + 港湾の重なりが大きく、復旧優先度が高い。
これは港湾の経済的価値と防災の交錯。
- 課題 Z: L32 (防波堤) / L33 (係留施設) / L34 (港湾交通) の point/polygon を
本研究の警戒区域に sjoin → 警戒区域内の港湾施設件数を市町別に集計 →
「警戒区域内港湾密度ランキング」を作成し、復旧優先度マトリクスを提案。
L32-L34 + L63 の制度港湾統合として展開。
発展課題 6 (展望): 全国津波警戒区域との瀬戸内海特性の比較
- 結果 X: 本研究は広島県 1 県の警戒区域を扱ったが、全国比較は未実施。
他県 (静岡・高知・宮城等) の警戒区域と比較すれば、瀬戸内海の特性が浮き彫りになる。
- 新仮説 Y: 瀬戸内海諸県 (広島・岡山・香川・愛媛) の警戒区域は太平洋諸県 (静岡・高知)に比べ
(a) 平均深さが浅い、(b) 特別警戒区域指定が稀、(c) 沿岸距離あたりの面積が小さい。
これは瀬戸内海の地形・水深による津波減衰効果の証拠。
- 課題 Z: 国土地理院の他県津波警戒区域データを取得 → 6 ランクで標準化 →
県別 平均深さ・特別区域指定率・沿岸長あたり面積を比較。
「瀬戸内海津波の地形学」として展開し、全国 47 都道府県のうち
瀬戸内海周辺の特殊性を統計化する。
"""
# 統合
sections = [
("学習目標と問い", sec1),
("使用データ", sec2),
("ダウンロード", sec3),
(f"【RQ1】 警戒区域の地理範囲・市町指定状況 — {total_km2:.0f} km² / Top 3 で {top3_share*100:.0f}%",
sec4),
(f"【RQ2】 L49 想定 vs L63 指定 の制度差 — 包含率 {100*n_both/n_keikai:.0f}%",
sec5),
(f"【RQ3】 沿岸人口・建物との空間関係 — 密度比 {ratio_density:.1f} 倍",
sec6),
("仮説検証総合", sec7),
("発展課題", sec8),
]
html = render_lesson(
num=63,
title="津波災害警戒区域 単独 3 研究例分析 — "
f"{len(cells):,} セルから「想定 vs 指定」の制度差を読む",
tags=["L63", "津波災害警戒区域", "津波防災地域づくり法",
"RQ×3", "Format B", "geopandas", "Shapefile",
"choropleth", "L49連携 (想定)", "L22連携 (人口)",
"想定vs指定", "包含関係", "1.28M polygon"],
time="50 分",
level="中級",
data_label=f"DoBoX dataset 47 (Shapefile, 27.8 MB) "
f"+ L49 想定キャッシュ + L22 人口連携",
sections=sections,
script_filename="L63_tsunami_warning_zone.py",
)
OUT_HTML = LESSONS / "L63_tsunami_warning_zone.html"
OUT_HTML.write_text(html, encoding="utf-8")
print(f" HTML: {OUT_HTML.name} ({len(html):,} chars)")
print(f" ({time.time()-t8:.1f}s)", flush=True)
# =============================================================================
# 終了
# =============================================================================
print(f"\n=== 完了: 全体 {time.time() - t_all:.2f}s ===")
print(f"出力:")
print(f" HTML: lessons/L63_tsunami_warning_zone.html")
print(f" Python: lessons/L63_tsunami_warning_zone.py")
print(f" Python (前処理): lessons/_l63_build_cache.py")
print(f" 図: assets/L63_fig1-8_*.png (8 枚)")
print(f" CSV: assets/L63_*.csv (8 ファイル)")
print(f" Shapefile: data/extras/L63_tsunami_warning_zone/extracted/tsunami_keikai.shp")
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}