# -*- coding: utf-8 -*-
"""L58 渓流保全工 単独 3 研究例分析
— 広島県の「渓流保全工基本情報」 1,862 件 (Shapefile, LineString) を
3 つの独立した研究角度で読み解く
カバー宣言:
本記事は DoBoX のシリーズ「渓流保全工基本情報」 1 件
(dataset_id = 59) を 単独で取り上げ、
広島県内の渓流保全工 (Shapefile, LineString 1,862 件) を
3 つの独立した研究角度 (RQ1 / RQ2 / RQ3) で並列に分析する。
Phase 3 防災施設系の 3 本目 = 砂防三施設族の最終ピース
(L56 急傾斜防止施設 / L57 地すべり防止施設 に続く)。
「渓流保全工」 とは:
砂防法 (1897-03-30 公布, 1897-06-01 施行) に基づき、
広島県が渓流の侵食・洗掘を防ぐ ために整備した河床・河岸の
線的な土木工事 (LineString)。
具体的には護岸工 (河岸の土留め)・流路工 (河床整形)・床固工 (流れ抑制小堰堤)・
暗渠工 (山中の地下水路)・山腹工 (斜面安定)・沈砂池 (流木+土砂止め)等。
本データは広島県土木建築局 砂防課が管理する施設台帳の位置情報版
(LineString 1,862 件)で、各 line は1 つの工事区間 (= 起点から終点まで)を示す。
砂防法 (1897) と本データの位置付け:
1896 年、明治三陸地震・濃尾地震・木曽川大洪水等で土石流多発。
翌 1897 年に世界初の砂防法 (河川法・森林法と同時) が制定。
法律は 2 つの仕組みを規定:
(1) 砂防指定地指定 (= L46 で扱う #55, 県内 3,207 polygon + 93 line) =
国交大臣が指定する土石流の発生・流下が懸念される範囲。
指定地内では切土・盛土・河川工事が許可制。
(2) 渓流保全工等の整備 (= 本データ #59, 県内 1,862 LineString) =
指定地内で県が整備する河床・河岸の物理工事。
護岸工・流路工・床固工等で渓流の侵食抑制を図る。
(1) は区域 (面 + 線)、(2) は施設 (線)として両者を対で運用する。
L56 (急傾斜地法 1969, 区域=面+施設=点) と L57 (地すべり等防止法 1958, 区域=面+施設=面) と
並ぶ砂防三法の最古制度。
「護岸工」「流路工」「床固工」 (主要工種):
- 護岸工 (ごがんこう): 渓流の岸を石積・コンクリートブロックで補強し、
洪水時の岸侵食 (河床洗掘) を防ぐ工事。本データの 974 件 (52%) で最多。
- 流路工 (りゅうろこう): 河床・河岸を一体的に整形し、
渓流の流れを安定させる工事。底張り (コンクリート) + 護岸の組合せ。755 件 (41%)。
- 床固工 (とこがためこう): 河床に小堰堤を設置し、河床の侵食を抑え土砂流出を抑制する工事。
流路工内に組込む (流路工内床固工 91 件) が一般的、単独設置は 2 件のみ。
- 暗渠工 (あんきょこう): 渓流を地下水路化し、地表面を有効利用する工事。32 件。
- 山腹工 (さんぷくこう): 渓岸の斜面を植生・編柵で安定化する工事。6 件。
- 沈砂池 (ちんさち): 上流からの流木+土砂を一時貯留する貯水池。1 件。
本データには高さ (堰堤の H, m) と延長 (L, m) が記録され、規模の物理量を読み取れる。
「砂防三施設族」 (本記事独自用語):
砂防三法 (砂防法 1897 / 地すべり等防止法 1958 / 急傾斜地法 1969) に基づくハード施設群を
本記事では砂防三施設族と総称する。L56・L57・L58 の 3 本がこの族の柱:
- L58 (本記事, 砂防 1897): 渓流保全工 1,862 LineString (= 護岸 + 流路 + 床固)
- L57 (地すべり 1958): 地すべり防止施設 32 polygon (= 集水井 + 横ボーリング + 抑止杭)
- L56 (急傾斜 1969): 急傾斜地崩壊防止施設 2,508 点 (= 擁壁 + 法枠 + アンカー)
対応する区域指定 (L46 で集約): #55 砂防指定地 3,207 / #56 急傾斜区域 2,935 /
#57 地すべり区域 39。本記事は三施設族の総件数 4,402 件を県の砂防全戦略として読む。
研究の問い (3 RQ):
RQ1 (主研究): 広島県の渓流保全工の構造はどう描けるか?
1,862 件の LineString を市町別ランキング、工種8種分布、構造種類別 (コンクリート/ブロック積/空石積)、
規模特性 (高さ・延長分布)、告示年月日の時系列、水系群 (1級/2級) 分布で多角度に集計する。
呉市 264 件・三次市 129 件と沿岸 + 中山間の両方に多いのは何故か?
L56 (沿岸偏重) や L57 (中山間偏重) と異なるバランス型分布の地理学的理由を探る。
RQ2 (副研究 1): 渓流保全工はL46 #55 砂防指定地 (3,207 polygon) とどう対応するか?
砂防指定地は渓流保全工が整備されるべき場所の指定であり、
本データの LineString が指定地内にどれだけ収まるか (= 包含率) を空間 sjoin で計測。
逆に「指定地はあるが渓流保全工なし」 の未整備指定地を特定し、
残課題エリアを市町別に定量化する。
告示番号での 1 対 1 直接照合も併用する。
RQ3 (副研究 2): 砂防三施設族 (L56 + L57 + L58) の総合構造はどう描けるか?
三施設の合計 4,402 件を市町別に統合し、
(1) 県の砂防投資の総量、(2) 三制度の地理的配分、
(3) 法施行年代 (1897 / 1958 / 1969) と整備時代の関係、
(4) 三角座標プロット (L56 シェア, L57 シェア, L58 シェア) で各市町の砂防戦略タイプを分類、
(5) 渓流保全工と急傾斜・地すべりの相関を読み解く。
「広島県の砂防投資の地理学」 の総合像を初めて描く。
仮説 (5):
H1 (バランス型分布 RQ1): 渓流保全工は沿岸都市 (呉市・尾道) と中山間 (三次・庄原) の両方に
多く分布する。これは渓流が県内全域に存在する地形特性 (= 谷地形は地質に依らず) のため。
L56 (呉市偏重) や L57 (中山間偏重) と異なり、Top 3 市町で 30% 未満の分散型分布。
H2 (護岸 + 流路で >90% RQ1): 工種 8 種のうち護岸工 + 流路工で 90% 以上。
これは渓流保全の中心が河床整形と河岸補強という基本的な土木工事であるため。
床固工や山腹工は補助的役割。
H3 (1960-70 集中整備, 中央値 1965-1975 RQ1): 告示年中央値は1965-1975 年付近。
砂防法施行 (1897) → 戦前は限定的整備 → 高度経済成長期 (1960-1975) に集中整備 →
1980 年代以降は維持管理段階。法律最古 (1897) なので最も古い告示が見られる。
H4 (砂防指定地内整備率 ≥80% RQ2): #55 砂防指定地 3,207 件のうち、
本データの渓流保全工 1,862 件はその大半が指定地内に存在 (空間 sjoin で確認)。
指定地は「整備されるべき場所」 として制度設計されているため、
施設の地理的包含率は 80% 以上と予想。
一方「指定地あり + 渓流保全工なし」 は 1,000 以上の未整備残課題として残存。
H5 (三施設族の市町別配分は地形で決まる, RQ3): 三施設族 4,402 件の市町別シェアは
(1) 沿岸都市 (呉市): L56 圧倒的、L58 多、L57 ゼロ → 急傾斜+渓流型
(2) 中山間市町 (庄原市・三次市): L57+L58 多、L56 中位 → 地すべり+渓流型
(3) 島嶼 (江田島・大崎上島): L56 のみ → 急傾斜単独型
のように地形・地質の組合せで明確に区別される。
三角座標 (L56, L57, L58 シェア) で各市町の砂防戦略タイプを散布図で分類可能。
要件 S 準拠 (1分以内完走):
- Shapefile 1,862 LineString は中規模 (.shp 1.4MB)。読込・パース・空間結合は数秒以内。
- L46 #55 の砂防指定地 Shapefile は 3,207 polygon (.shp 大きめ) → sindex 必須。
- L56 / L57 既処理 CSV は groupby 集計のみ (高速)。
- 期待実行時間: <60 秒。
要件 T 準拠 (位置情報あり=地図必須):
- RQ1: 県全域 1,862 LineString マップ (工種別色分け)
- RQ1: 市町別件数 choropleth + 工種別ランキング (Top 12)
- RQ1: 工種8種 small multiples マップ
- RQ1: 規模分布 (高さ × 延長) joint plot
- RQ2: 砂防指定地 (3,207 polygon) × 渓流保全工 (1,862 line) 重ね合わせマップ
- RQ2: 包含率 choropleth (= 渓流保全工 ÷ 指定地)
- RQ3: 三施設族 (L56 点 + L57 面 + L58 線) 重ね合わせ全県マップ
- RQ3: 三角座標 (L56-L57-L58 シェア) 散布図 + 市町別 stacked 棒
要件 Q 準拠: 図 8 / 表 11 (3 RQ × 多角度)。
データ仕様:
- dataset 59: 渓流保全工基本情報
- リソース 22825 (ZIP, 1.4MB): Shapefile 一式 (cpg/dbf/prj/shp/shx)
- LineString 数: 1,862 (LineString 1,313 + MultiLineString 549)
- 列構成 (18 列):
objid (主キー) / suikei_gr (水系群=1級/2級/その他) / suikei_nm (水系名) /
kansen_nm (幹川名) / keiryu_nm (渓流名) / prefecture / city /
aza (字) / kousyu (工種) / kouzou (構造) /
height (高さ m, 床固/堰堤の H) / length (延長 m) / area (面積 m², 沈砂池等) /
sekou_year (施工年, 平成期のみ) / syunko_ymd (竣工年月日) /
skeiryu_nm / kokuzi_ymd (告示年月日) / kokuzi_no (告示番号)
- CRS: EPSG:6668 (JGD2011 経緯度) → 解析時 EPSG:6671 (平面直角第 III 系) へ変換
- 取得日: 2026-05-10
- ライセンス: クリエイティブ・コモンズ表示 4.0
- 作成主体: 広島県土木建築局 砂防課
"""
from __future__ import annotations
import sys, time, shutil, zipfile
from pathlib import Path
sys.path.insert(0, str(Path(__file__).parent))
from _common import ROOT, ASSETS, LESSONS, render_lesson, code, figure
import numpy as np
import pandas as pd
import geopandas as gpd
import requests
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.patches import Patch
from matplotlib.lines import Line2D
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
t_all = time.time()
print("=== L58 渓流保全工 単独 3 研究例分析 ===", flush=True)
# =============================================================================
# 0. 定数・パス
# =============================================================================
TARGET_CRS = "EPSG:6671" # JGD2011 平面直角座標系第 III 系 (m 単位)
SRC_CRS = "EPSG:6668" # JGD2011 (経緯度)
DATA_DIR = ROOT / "data" / "extras" / "L58_keiryu_facility"
DATA_DIR.mkdir(parents=True, exist_ok=True)
ZIP_PATH = DATA_DIR / "砂防_渓流保全工_2026-04-27.zip"
SHP_DIR = DATA_DIR / "340006_erosion_control_facility_mountain_20260427T001046"
SHP_PATH = SHP_DIR / "78_051shp_20260427.shp"
# L46 #55 の砂防指定地 Shapefile (= 渓流保全工が整備されるべき場所)
L46_SHITEI_SHP = (ROOT / "data" / "extras" / "L46_sabo_designation"
/ "sabo_designation_55_sabo_shitei"
/ "340006_designated_area_relating_to_erosion_and_sediment_control_designated_area_20260427"
/ "砂防指定地-ポリゴン.shp")
# 行政区域 (L15)
ADMIN_PREF_ZIP = ROOT / "data" / "extras" / "L15_admin_zones" / "admin_922_広島県.zip"
# L56 / L57 既処理 city ranking CSV (砂防三施設族の RQ3 比較用)
L56_CITY = ASSETS / "L56_city_ranking.csv"
L57_CITY = ASSETS / "L57_city_ranking.csv"
L56_CSV = ROOT / "data" / "extras" / "L56_steep_slope_facility" / "砂防_急傾斜地崩壊防止施設_2026-04-27.csv"
# DoBoX
DOBOX_BASE = "https://hiroshima-dobox.jp"
HDR = {"User-Agent": "DoBoX-MDASH-textbook/1.0 (educational use)"}
# 主要日付
LAW_SABO_ENF = pd.Timestamp("1897-06-01") # 砂防法施行
LAW_LANDSLIDE = pd.Timestamp("1958-08-01") # 地すべり等防止法
LAW_STEEP = pd.Timestamp("1969-08-01") # 急傾斜地法
RAIN_2018 = pd.Timestamp("2018-07-06") # 西日本豪雨
PREF_AREA_KM2 = 8479.4 # 広島県総面積
# =============================================================================
# 1. データ取得 (Shapefile zip を DoBoX から自動 DL & 展開)
# =============================================================================
print("\n[1] データ取得", flush=True)
t1 = time.time()
if not SHP_PATH.exists():
if not ZIP_PATH.exists() or ZIP_PATH.stat().st_size < 1000:
url = f"{DOBOX_BASE}/resource_download/22825"
print(f" DL <- {url}")
r = requests.get(url, headers=HDR, timeout=60)
r.raise_for_status()
ZIP_PATH.write_bytes(r.content)
print(f" saved -> {ZIP_PATH.name} ({len(r.content):,} bytes)")
with zipfile.ZipFile(ZIP_PATH) as zf:
zf.extractall(DATA_DIR)
print(f" extracted -> {SHP_DIR.name}")
else:
print(f" cache HIT: {SHP_PATH.name} ({SHP_PATH.stat().st_size:,} bytes)")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 2. Shapefile 読込・前処理
# =============================================================================
print("\n[2] Shapefile 読込・前処理", flush=True)
t1 = time.time()
gdf = gpd.read_file(SHP_PATH, encoding="utf-8")
n_total = len(gdf)
print(f" raw rows: {n_total:,} LineString, columns: {len(gdf.columns)}")
print(f" 原 CRS: {gdf.crs}")
print(f" geom types: {gdf.geometry.type.value_counts().to_dict()}")
# 列名を日本語へリネーム
COL_RENAME = {
"objid": "施設ID",
"suikei_gr": "水系群",
"suikei_nm": "水系名",
"kansen_nm": "幹川名",
"keiryu_nm": "渓流名",
"prefecture": "県",
"city": "市町_raw",
"aza": "字",
"kousyu": "工種",
"kouzou": "構造",
"height": "高さ_m",
"length": "延長_m",
"area": "面積_m2",
"sekou_year": "施工年",
"syunko_ymd": "竣工年月日",
"skeiryu_nm": "支渓流名",
"kokuzi_ymd": "告示年月日",
"kokuzi_no": "告示番号",
}
gdf = gdf.rename(columns=COL_RENAME)
def normalize_city(s: str) -> str:
"""『山県郡安芸太田町』 → 『安芸太田町』、『安芸郡府中町』 → 『府中町』 等"""
s = str(s).strip()
if "郡" in s:
s = s.split("郡", 1)[1]
return s
gdf["市町名"] = gdf["市町_raw"].apply(normalize_city)
print(f" 市町数: {gdf['市町名'].nunique()}")
# 告示年月日 → datetime → 告示年
gdf["告示年月日_dt"] = pd.to_datetime(gdf["告示年月日"], errors="coerce")
gdf["告示年"] = gdf["告示年月日_dt"].dt.year
n_no_date = gdf["告示年月日_dt"].isna().sum()
gdf_dated = gdf.dropna(subset=["告示年"]).copy()
gdf_dated["告示年"] = gdf_dated["告示年"].astype(int)
print(f" 告示年範囲: {int(gdf_dated['告示年'].min())}-{int(gdf_dated['告示年'].max())} "
f"(中央値 {int(gdf_dated['告示年'].median())} 年, 欠損 {n_no_date} 件)")
# 水系群 (None → "不明")
gdf["水系群"] = gdf["水系群"].fillna("不明").astype(str).str.strip()
gdf.loc[gdf["水系群"] == "", "水系群"] = "不明"
print(f" 水系群: {gdf['水系群'].value_counts().to_dict()}")
# 工種正規化 (空欄を「不明」に)
gdf["工種"] = gdf["工種"].fillna("不明").astype(str).str.strip()
# 構造正規化 (NULL や半角カナ揺れの統合)
def normalize_kouzou(s):
s = str(s).strip()
if s in ("None", "nan", "", "NaN"):
return "不明"
# 全角→半角揺れの統合
return s.replace("コンクリート", "コンクリート").replace("ブロック積", "ブロック積").replace(
"ブロック", "ブロック").replace("自然護岸(土)", "自然護岸(土)")
gdf["構造"] = gdf["構造"].apply(normalize_kouzou)
print(f" 工種: {gdf['工種'].value_counts().to_dict()}")
print(f" 構造 Top 5: {gdf['構造'].value_counts().head(5).to_dict()}")
# CRS 変換 (距離を m で扱うため)
gdf = gdf.to_crs(TARGET_CRS)
gdf["延長_geom_m"] = gdf.geometry.length # geometry から計算した延長 (記録の length と比較用)
gdf["centroid_x"] = gdf.geometry.centroid.x
gdf["centroid_y"] = gdf.geometry.centroid.y
print(f" 延長 (記録 length 列): 平均 {gdf['延長_m'].mean():.1f} m, "
f"中央値 {gdf['延長_m'].median():.1f} m, 最大 {gdf['延長_m'].max():,.0f} m")
print(f" 延長 (geometry 計算): 平均 {gdf['延長_geom_m'].mean():.1f} m")
print(f" 高さ (床固 H, m): 平均 {gdf['高さ_m'].mean():.2f}, "
f"中央値 {gdf['高さ_m'].median():.2f}, 最大 {gdf['高さ_m'].max():.1f}, "
f"記録あり {gdf['高さ_m'].notna().sum()} 件")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 3. 行政区域・参考データ読込
# =============================================================================
print("\n[3] 行政区域・参考データ読込", flush=True)
t1 = time.time()
with zipfile.ZipFile(ADMIN_PREF_ZIP) as zf:
name = [n for n in zf.namelist() if n.endswith(".geojson")][0]
admin = gpd.read_file(f"zip://{ADMIN_PREF_ZIP}!{name}").to_crs(TARGET_CRS)
admin_diss = admin.dissolve(by="CITY_CD", as_index=False)
CITY_NAME = {
101: "広島市中区", 102: "広島市東区", 103: "広島市南区", 104: "広島市西区",
105: "広島市安佐南区", 106: "広島市安佐北区", 107: "広島市安芸区", 108: "広島市佐伯区",
202: "呉市", 203: "竹原市", 204: "三原市", 205: "尾道市", 207: "福山市",
208: "府中市", 209: "三次市", 210: "庄原市", 211: "大竹市", 212: "東広島市",
213: "廿日市市", 214: "安芸高田市", 215: "江田島市",
302: "府中町", 304: "海田町", 307: "熊野町", 309: "坂町",
369: "安芸太田町", 462: "世羅町",
364: "北広島町", 545: "神石高原町", 454: "大崎上島町",
}
admin_diss["市町名"] = admin_diss["CITY_CD"].map(CITY_NAME).fillna("不明")
print(f" admin: {len(admin_diss)} 市町ブロック")
# L46 #55 砂防指定地 Shapefile (3,207 polygon)
shitei = gpd.read_file(L46_SHITEI_SHP, encoding="utf-8").to_crs(TARGET_CRS)
shitei["市町名"] = shitei["city"].apply(normalize_city)
shitei["指定年月日_dt"] = pd.to_datetime(shitei["sitei_ymd"], errors="coerce")
shitei["指定年"] = shitei["指定年月日_dt"].dt.year
shitei["面積_m2"] = shitei.geometry.area
shitei["面積_ha"] = shitei["面積_m2"] / 1e4
n_shitei = len(shitei)
print(f" L46 #55 砂防指定地: {n_shitei:,} polygon, "
f"合計 {shitei['面積_ha'].sum():,.0f} ha")
# L56 / L57 既処理 city ranking
city_l56 = pd.read_csv(L56_CITY, encoding="utf-8-sig") if L56_CITY.exists() else None
city_l57 = pd.read_csv(L57_CITY, encoding="utf-8-sig") if L57_CITY.exists() else None
if city_l56 is not None:
print(f" L56 city ranking: {len(city_l56)} 行 (合計 {city_l56['件数'].sum():,} 件)")
if city_l57 is not None:
print(f" L57 city ranking: {len(city_l57)} 行 (合計 {city_l57['件数'].sum()} 件)")
# L56 緯度経度 (RQ3 全県地図用に L56 点 を読込)
gdf_l56_pts = None
if L56_CSV.exists():
df56 = pd.read_csv(L56_CSV, encoding="utf-8-sig")
df56.columns = [c.strip() for c in df56.columns]
df56["緯度"] = pd.to_numeric(df56["緯度"], errors="coerce")
df56["経度"] = pd.to_numeric(df56["経度"], errors="coerce")
df56 = df56.dropna(subset=["緯度", "経度"])
gdf_l56_pts = gpd.GeoDataFrame(
df56, geometry=gpd.points_from_xy(df56["経度"], df56["緯度"]),
crs="EPSG:4326").to_crs(TARGET_CRS)
print(f" L56 緯度経度点: {len(gdf_l56_pts):,} pt")
# L57 polygon 読込 (RQ3 重ね合わせ用)
L57_SHP = (ROOT / "data" / "extras" / "L57_landslide_facility"
/ "340006_erosion_control_facility_landslide_20260427T001146"
/ "78_053_20260427.shp")
gdf_l57 = None
if L57_SHP.exists():
gdf_l57 = gpd.read_file(L57_SHP, encoding="utf-8").to_crs(TARGET_CRS)
print(f" L57 polygon: {len(gdf_l57)} 面")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 4. RQ1 集計: 構造分析 (市町別 / 工種 / 構造 / 規模 / 告示年代 / 水系群)
# =============================================================================
print("\n[4] RQ1 集計", flush=True)
t1 = time.time()
# 4-1 市町別ランキング
city_summary = gdf.groupby("市町名").agg(
件数=("施設ID", "count"),
合計延長_m=("延長_m", "sum"),
平均延長_m=("延長_m", "mean"),
平均高さ_m=("高さ_m", "mean"),
告示年中央=("告示年", "median"),
護岸=("工種", lambda s: (s == "護岸工").sum()),
流路=("工種", lambda s: (s == "流路工").sum()),
床固=("工種", lambda s: (s == "流路工内床固工").sum() + (s == "単独床固工").sum()),
暗渠=("工種", lambda s: (s == "暗渠工").sum()),
その他工種=("工種", lambda s: (~s.isin(["護岸工", "流路工", "流路工内床固工",
"単独床固工", "暗渠工"])).sum()),
).reset_index().sort_values("件数", ascending=False)
city_summary["件数シェア_%"] = (city_summary["件数"] / city_summary["件数"].sum()
* 100).round(2)
city_summary["合計延長_km"] = (city_summary["合計延長_m"] / 1000).round(1)
city_summary["順位"] = np.arange(1, len(city_summary) + 1)
top1_name = city_summary.iloc[0]["市町名"]
top1_count = int(city_summary.iloc[0]["件数"])
top1_share = float(city_summary.iloc[0]["件数シェア_%"])
top2_name = city_summary.iloc[1]["市町名"]
top2_count = int(city_summary.iloc[1]["件数"])
top3_name = city_summary.iloc[2]["市町名"]
top3_count = int(city_summary.iloc[2]["件数"])
top3_share = float(city_summary.iloc[0]["件数シェア_%"]
+ city_summary.iloc[1]["件数シェア_%"]
+ city_summary.iloc[2]["件数シェア_%"])
n_cities_with = len(city_summary)
print(f" 市町数 (施設あり): {n_cities_with}")
print(f" Top 1: {top1_name} {top1_count:,} 件 ({top1_share:.1f}%)")
print(f" Top 3 ({top1_name}+{top2_name}+{top3_name}) シェア: {top3_share:.1f}%")
# 4-2 工種分布
kousyu_count = gdf["工種"].value_counts().reset_index()
kousyu_count.columns = ["工種", "件数"]
kousyu_count["シェア_%"] = (kousyu_count["件数"] / n_total * 100).round(2)
n_gogan = int((gdf["工種"] == "護岸工").sum())
n_ryuro = int((gdf["工種"] == "流路工").sum())
n_tokokatame = int((gdf["工種"].isin(["流路工内床固工", "単独床固工"])).sum())
gogan_ryuro_share = (n_gogan + n_ryuro) / n_total * 100
print(f" 工種: 護岸 {n_gogan:,} ({n_gogan/n_total*100:.1f}%) / "
f"流路 {n_ryuro:,} ({n_ryuro/n_total*100:.1f}%) / "
f"床固 {n_tokokatame} → 護岸+流路 = {gogan_ryuro_share:.1f}%")
# 4-3 構造分布 (Top 10)
kouzou_count = gdf["構造"].value_counts().reset_index()
kouzou_count.columns = ["構造", "件数"]
kouzou_count["シェア_%"] = (kouzou_count["件数"] / n_total * 100).round(2)
# 4-4 水系群分布
suikei_total = gdf["水系群"].value_counts()
n_class1 = int(suikei_total.get("1級", 0))
n_class2 = int(suikei_total.get("2級", 0))
n_other = int(suikei_total.get("その他", 0))
n_class_unk = int(suikei_total.get("不明", 0))
class1_share = n_class1 / n_total * 100
class2_share = n_class2 / n_total * 100
print(f" 水系群: 1級 {n_class1:,} ({class1_share:.1f}%) / "
f"2級 {n_class2:,} ({class2_share:.1f}%) / "
f"その他 {n_other:,} ({n_other/n_total*100:.1f}%) / 不明 {n_class_unk}")
# 4-5 告示年代 (10 年区間)
gdf_dated["告示年代"] = (gdf_dated["告示年"] // 10) * 10
year_decade = gdf_dated.groupby("告示年代").size().reset_index(name="件数")
year_decade["シェア_%"] = (year_decade["件数"]
/ year_decade["件数"].sum() * 100).round(2)
def era3_label(y):
if y < 1960:
return "1909-1959 (戦前+戦後復興)"
if y < 1990:
return "1960-1989 (高度成長期 集中整備)"
return "1990-2024 (維持期)"
gdf_dated["告示時期"] = gdf_dated["告示年"].apply(era3_label)
era_counts = gdf_dated.groupby("告示時期").size().reset_index(name="件数")
era_counts["シェア_%"] = (era_counts["件数"]
/ era_counts["件数"].sum() * 100).round(2)
print(f" 告示年代別件数:")
print(year_decade.to_string(index=False))
# 4-6 規模 (高さ × 延長)
height_q = gdf["高さ_m"].dropna().quantile([0.25, 0.5, 0.75])
length_q = gdf["延長_m"].dropna().quantile([0.25, 0.5, 0.75])
print(f" 高さ Q1/Q2/Q3: {height_q.iloc[0]:.2f} / {height_q.iloc[1]:.2f} / {height_q.iloc[2]:.2f} m")
print(f" 延長 Q1/Q2/Q3: {length_q.iloc[0]:.1f} / {length_q.iloc[1]:.1f} / {length_q.iloc[2]:.1f} m")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 5. RQ2 集計: 砂防指定地 (L46 #55) との空間対応
# =============================================================================
print("\n[5] RQ2 集計", flush=True)
t1 = time.time()
# 5-1 渓流保全工 LineString が砂防指定地 polygon 内にどれだけ収まるか
# 空間 sjoin (predicate=intersects) で判定
import warnings
warnings.filterwarnings("ignore", category=UserWarning, module="shapely")
# 軽量化: shitei sindex を使う
gdf_idx = gdf.assign(fac_id=range(len(gdf)))[["fac_id", "市町名", "工種", "告示番号",
"延長_m", "geometry"]]
shitei_idx = shitei.assign(zone_id=range(len(shitei)))[["zone_id", "市町名", "id",
"kokuzi_no", "面積_ha", "geometry"]]
sj = gpd.sjoin(gdf_idx, shitei_idx.rename(columns={"市町名": "市町名_z"}),
how="left", predicate="intersects")
n_fac_in_shitei = sj.dropna(subset=["zone_id"])["fac_id"].nunique()
n_fac_outside = n_total - n_fac_in_shitei
share_in = n_fac_in_shitei / n_total * 100
print(f" 空間照合: 渓流保全工 line が砂防指定地 polygon と intersect = "
f"{n_fac_in_shitei:,} / {n_total:,} ({share_in:.1f}%)")
print(f" intersect なし (指定地外): {n_fac_outside:,} 件 ({100-share_in:.1f}%)")
# 5-2 告示番号 1-1 照合
gdf_kn = gdf["告示番号"].dropna().astype(int)
shitei_kn = shitei["kokuzi_no"].dropna().astype(int)
kn_common = set(gdf_kn) & set(shitei_kn)
print(f" 告示番号 共通 (1-1 対応): {len(kn_common):,} 件")
# 5-3 市町別: 指定地数 vs 渓流保全工件数
shitei_per_city = shitei.groupby("市町名").size().reset_index(name="指定地数_55")
fac_per_city = gdf.groupby("市町名").size().reset_index(name="渓流保全工_59")
shitei_vs_fac = pd.merge(shitei_per_city, fac_per_city,
on="市町名", how="outer").fillna(0)
shitei_vs_fac["指定地数_55"] = shitei_vs_fac["指定地数_55"].astype(int)
shitei_vs_fac["渓流保全工_59"] = shitei_vs_fac["渓流保全工_59"].astype(int)
shitei_vs_fac["施設充足比率"] = (
shitei_vs_fac["渓流保全工_59"] / shitei_vs_fac["指定地数_55"]
.replace(0, np.nan)
).round(2)
shitei_vs_fac = shitei_vs_fac.sort_values("指定地数_55", ascending=False)
n_shitei_total = int(shitei_vs_fac["指定地数_55"].sum())
n_fac_total = int(shitei_vs_fac["渓流保全工_59"].sum())
print(f" 全県: 指定地 {n_shitei_total:,} vs 渓流保全工 {n_fac_total:,} → "
f"比 1:{n_fac_total/n_shitei_total:.2f}")
# 5-4 「指定地あり + 渓流保全工 0」 市町を特定
unmet_cities = shitei_vs_fac[(shitei_vs_fac["指定地数_55"] > 0)
& (shitei_vs_fac["渓流保全工_59"] == 0)]
print(f" 指定地あり + 渓流保全工 0 市町: {len(unmet_cities)} 市町")
# 5-5 「指定地ごとの渓流保全工密度」 (= 1 指定地に何件の渓流保全工が紐づくか)
sj_with_zone = sj.dropna(subset=["zone_id"])
zone_fac_count = sj_with_zone.groupby("zone_id")["fac_id"].nunique()
zone_no_fac = n_shitei - len(zone_fac_count) # 指定地の中で渓流保全工がない数
print(f" 指定地 {n_shitei:,} のうち、渓流保全工が紐づく指定地: {len(zone_fac_count):,}")
print(f" 指定地 {n_shitei:,} のうち、渓流保全工が紐づかない指定地: {zone_no_fac:,}")
zone_avg_fac = zone_fac_count.mean() if len(zone_fac_count) > 0 else 0
print(f" 紐づきあり指定地の平均紐づき件数: {zone_avg_fac:.1f}")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 6. RQ3 集計: 砂防三施設族 (L56 + L57 + L58) の総合構造
# =============================================================================
print("\n[6] RQ3 集計", flush=True)
t1 = time.time()
# 6-1 三施設族の市町別 outer merge
fac_per_city_l58 = gdf.groupby("市町名").size().reset_index(name="L58_渓流保全工")
# L56 件数
if city_l56 is not None:
l56_short = city_l56[["市町名", "件数"]].rename(columns={"件数": "L56_急傾斜施設"})
else:
l56_short = pd.DataFrame(columns=["市町名", "L56_急傾斜施設"])
# L57 件数
if city_l57 is not None:
l57_short = city_l57[["市町名", "件数"]].rename(columns={"件数": "L57_地すべり施設"})
else:
l57_short = pd.DataFrame(columns=["市町名", "L57_地すべり施設"])
triple = fac_per_city_l58.merge(l56_short, on="市町名", how="outer").merge(
l57_short, on="市町名", how="outer").fillna(0)
for c in ("L56_急傾斜施設", "L57_地すべり施設", "L58_渓流保全工"):
triple[c] = triple[c].astype(int)
triple["三施設合計"] = triple["L56_急傾斜施設"] + triple["L57_地すべり施設"] + triple["L58_渓流保全工"]
n56 = int(triple["L56_急傾斜施設"].sum())
n57 = int(triple["L57_地すべり施設"].sum())
n58 = int(triple["L58_渓流保全工"].sum())
n_triple = n56 + n57 + n58
print(f" 三施設族 合計: {n_triple:,} 件 (L56 {n56:,} + L57 {n57:,} + L58 {n58:,})")
print(f" 比 = {n56/n_triple*100:.1f}% : {n57/n_triple*100:.1f}% : {n58/n_triple*100:.1f}%")
# シェア計算
triple["L56_シェア_%"] = (triple["L56_急傾斜施設"] / max(n56, 1) * 100).round(2)
triple["L57_シェア_%"] = (triple["L57_地すべり施設"] / max(n57, 1) * 100).round(2)
triple["L58_シェア_%"] = (triple["L58_渓流保全工"] / max(n58, 1) * 100).round(2)
triple["合計シェア_%"] = (triple["三施設合計"] / max(n_triple, 1) * 100).round(2)
# 市町ごとの三施設族の構成比 (= 1 市町内で各施設族が何割か)
def safe_div(a, b):
return (a / b * 100) if b > 0 else 0
triple["L56_市町内_%"] = triple.apply(
lambda r: safe_div(r["L56_急傾斜施設"], r["三施設合計"]), axis=1).round(1)
triple["L57_市町内_%"] = triple.apply(
lambda r: safe_div(r["L57_地すべり施設"], r["三施設合計"]), axis=1).round(1)
triple["L58_市町内_%"] = triple.apply(
lambda r: safe_div(r["L58_渓流保全工"], r["三施設合計"]), axis=1).round(1)
triple = triple.sort_values("三施設合計", ascending=False)
# 6-2 市町別 砂防戦略タイプ分類
def classify_type(r):
"""三施設族の市町内構成比から「砂防戦略タイプ」を判定"""
s56, s57, s58 = r["L56_市町内_%"], r["L57_市町内_%"], r["L58_市町内_%"]
if s56 >= 60:
return "急傾斜特化型"
if s57 >= 30:
return "地すべり主導型"
if s58 >= 50:
return "渓流主導型"
if s56 >= 40 and s58 >= 30:
return "急傾斜+渓流バランス型"
return "混合型"
triple["砂防戦略タイプ"] = triple.apply(classify_type, axis=1)
print(f" 砂防戦略タイプ分布:")
print(triple["砂防戦略タイプ"].value_counts())
# 6-3 法律施行年代と整備時代の関係
sanpou_summary = pd.DataFrame([
{"法律": "砂防法", "施行年": 1897, "L番号": "L58 (本記事)",
"施設タイプ": "渓流保全工 (LineString)",
"県内施設件数": n58, "シェア_%": round(n58/n_triple*100, 1),
"告示年中央": int(gdf_dated["告示年"].median()),
"代表工種": "護岸工 974 + 流路工 755"},
{"法律": "地すべり等防止法", "施行年": 1958, "L番号": "L57",
"施設タイプ": "地すべり防止施設 (面)",
"県内施設件数": n57, "シェア_%": round(n57/n_triple*100, 1),
"告示年中央": int(city_l57["告示年中央"].median()) if city_l57 is not None else 1986,
"代表工種": "集水井 + 横ボーリング + 抑止杭"},
{"法律": "急傾斜地法", "施行年": 1969, "L番号": "L56",
"施設タイプ": "急傾斜地崩壊防止施設 (点)",
"県内施設件数": n56, "シェア_%": round(n56/n_triple*100, 1),
"告示年中央": int(city_l56["告示年中央"].median()) if city_l56 is not None else 1985,
"代表工種": "擁壁 + 法枠 + アンカー"},
])
# 6-4 三制度の Pearson 相関 (件数)
valid_corr = triple[(triple["L56_急傾斜施設"] + triple["L57_地すべり施設"]
+ triple["L58_渓流保全工"]) > 0]
corr_56_58 = valid_corr["L56_急傾斜施設"].corr(valid_corr["L58_渓流保全工"])
corr_57_58 = valid_corr["L57_地すべり施設"].corr(valid_corr["L58_渓流保全工"])
corr_56_57 = valid_corr["L56_急傾斜施設"].corr(valid_corr["L57_地すべり施設"])
print(f" L56 vs L58 件数 Pearson r (n={len(valid_corr)}): {corr_56_58:.3f}")
print(f" L57 vs L58 件数 Pearson r: {corr_57_58:.3f}")
print(f" L56 vs L57 件数 Pearson r: {corr_56_57:.3f}")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 7. CSV 出力
# =============================================================================
print("\n[7] CSV 出力", flush=True)
t1 = time.time()
# 元 zip コピー (重い場合は注意)
shutil.copy(ZIP_PATH, ASSETS / "L58_facility_raw.zip")
# 中間 CSV (geometry を WKT で保存) — line は長いので geometry は除外
gdf_csv = pd.DataFrame(gdf.drop(columns=["geometry", "告示年月日_dt"]))
keep_cols = ["施設ID", "市町名", "字", "水系群", "水系名", "幹川名", "渓流名",
"工種", "構造", "高さ_m", "延長_m", "面積_m2", "施工年", "竣工年月日",
"告示年月日", "告示年", "告示番号", "延長_geom_m", "centroid_x", "centroid_y"]
gdf_csv = gdf_csv[[c for c in keep_cols if c in gdf_csv.columns]]
gdf_csv.to_csv(ASSETS / "L58_facilities_processed.csv",
index=False, encoding="utf-8-sig")
city_summary.to_csv(ASSETS / "L58_city_ranking.csv",
index=False, encoding="utf-8-sig")
kousyu_count.to_csv(ASSETS / "L58_kousyu_breakdown.csv",
index=False, encoding="utf-8-sig")
kouzou_count.to_csv(ASSETS / "L58_kouzou_breakdown.csv",
index=False, encoding="utf-8-sig")
year_decade.to_csv(ASSETS / "L58_year_decade.csv",
index=False, encoding="utf-8-sig")
shitei_vs_fac.to_csv(ASSETS / "L58_shitei_vs_facility.csv",
index=False, encoding="utf-8-sig")
triple.to_csv(ASSETS / "L58_triple_facility.csv",
index=False, encoding="utf-8-sig")
print(f" CSV 7 ファイル + Shapefile zip コピー")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 8. 図の生成 (8 図)
# =============================================================================
print("\n[8] 図の生成 (8 図)", flush=True)
t1 = time.time()
def save_fig(name, dpi=110):
p = ASSETS / name
plt.savefig(p, dpi=dpi, bbox_inches="tight", facecolor="white")
plt.close('all')
return p
PREF_BOUNDS = admin_diss.total_bounds
PXMIN, PYMIN, PXMAX, PYMAX = PREF_BOUNDS
# 三施設族 配色
C_L58_KEIRYU = "#2da44e" # 緑: 渓流保全工 (本記事)
C_L57_LANDSL = "#7c3aed" # 紫: 地すべり防止施設
C_L56_STEEP = "#0969da" # 青: 急傾斜地崩壊防止施設
C_SHITEI = "#cf222e" # 赤: 砂防指定地
# 工種別配色
KOUSYU_COLOR = {
"護岸工": "#0969da",
"流路工": "#2da44e",
"流路工内床固工": "#cf222e",
"暗渠工": "#bf8700",
"山腹工": "#a371f7",
"単独床固工": "#fa8c16",
"沈砂池": "#da70d6",
"流路工+護岸工": "#888888",
"不明": "#cccccc",
}
# ---- 図 1 (RQ1): 県全域 LineString マップ + 市町別件数 choropleth ----
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
ax = axes[0]
admin_diss.boundary.plot(ax=ax, color="#888", linewidth=0.4)
admin_diss.plot(ax=ax, facecolor="#f8f8f5", edgecolor="#aaa",
linewidth=0.3, alpha=0.7)
# 工種別に色分けして全 1,862 line を描画
for ks, sub in gdf.groupby("工種"):
sub.plot(ax=ax, color=KOUSYU_COLOR.get(ks, "#888"), linewidth=0.6, alpha=0.7)
ax.set_xlim(PXMIN, PXMAX)
ax.set_ylim(PYMIN, PYMAX)
ax.set_aspect("equal")
ax.set_title(f"図 1a: 渓流保全工 全 {n_total:,} LineString — 工種別色分け",
fontsize=11)
legend_h = [Line2D([0], [0], color=KOUSYU_COLOR.get(ks, "#888"), lw=2,
label=f"{ks} {(gdf['工種']==ks).sum():,}件")
for ks in ["護岸工", "流路工", "流路工内床固工", "暗渠工",
"山腹工", "単独床固工", "沈砂池"]
if (gdf["工種"] == ks).sum() > 0]
ax.legend(handles=legend_h, loc="lower right", fontsize=8, title="工種")
ax.set_xlabel("X (m, EPSG:6671)", fontsize=9)
ax.set_ylabel("Y (m, EPSG:6671)", fontsize=9)
ax = axes[1]
admin_c = admin_diss.copy()
city_to_n = dict(zip(city_summary["市町名"], city_summary["件数"]))
admin_c["施設件数"] = admin_c["市町名"].map(city_to_n).fillna(0)
admin_c[admin_c["施設件数"] == 0].plot(ax=ax, facecolor="#f0f0f0",
edgecolor="#888", linewidth=0.4)
admin_c[admin_c["施設件数"] > 0].plot(ax=ax, column="施設件数",
cmap="Greens",
edgecolor="#444", linewidth=0.4,
legend=True,
legend_kwds={"label": "渓流保全工件数",
"shrink": 0.7})
for _, r in city_summary.head(5).iterrows():
a = admin_diss[admin_diss["市町名"] == r["市町名"]]
if len(a) == 0:
continue
cx, cy = a.geometry.iloc[0].centroid.x, a.geometry.iloc[0].centroid.y
ax.annotate(f"{r['市町名']}\n{int(r['件数'])}件",
(cx, cy), fontsize=9, ha="center", va="center",
color="black", weight="bold",
bbox=dict(boxstyle="round,pad=0.2", facecolor="white", alpha=0.85))
ax.set_xlim(PXMIN, PXMAX)
ax.set_ylim(PYMIN, PYMAX)
ax.set_aspect("equal")
ax.set_title(f"図 1b: 市町別件数 choropleth — Top 3 で {top3_share:.0f}%",
fontsize=11)
ax.set_xlabel("X (m)", fontsize=9)
ax.set_ylabel("Y (m)", fontsize=9)
fig.suptitle(f"図 1 (RQ1): 渓流保全工 全 {n_total:,} LineString / "
f"{n_cities_with} 市町 / Top 1 = {top1_name} {top1_count:,} 件 ({top1_share:.1f}%)",
fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L58_fig1_facility_map.png")
# ---- 図 2 (RQ1): 市町別ランキング Top 12 + 工種パイ ----
fig, axes = plt.subplots(1, 2, figsize=(16, 6))
ax = axes[0]
top12 = city_summary.head(12).iloc[::-1]
y = np.arange(len(top12))
left_acc = np.zeros(len(top12))
for label, col, color in [("護岸工", "護岸", KOUSYU_COLOR["護岸工"]),
("流路工", "流路", KOUSYU_COLOR["流路工"]),
("床固工", "床固", KOUSYU_COLOR["流路工内床固工"]),
("暗渠工", "暗渠", KOUSYU_COLOR["暗渠工"]),
("その他", "その他工種", "#888")]:
ax.barh(y, top12[col], left=left_acc, color=color,
edgecolor="#333", linewidth=0.5, label=label)
left_acc += top12[col].values
ax.set_yticks(y)
ax.set_yticklabels(top12["市町名"], fontsize=10)
ax.set_xlabel("施設件数", fontsize=11)
ax.set_title(f"図 2a: 市町別 Top 12 — 工種 stack (全 {n_total:,} 件)",
fontsize=11)
ax.legend(fontsize=9, loc="lower right")
ax.grid(axis="x", alpha=0.3)
for i, (cn, n, sh) in enumerate(zip(top12["市町名"], top12["件数"],
top12["件数シェア_%"])):
ax.text(n + 5, i, f"{int(n):,}({sh:.1f}%)", va="center", fontsize=8)
ax = axes[1]
ks_top = kousyu_count.head(7).reset_index(drop=True)
sizes = ks_top["件数"].values
# 大シェアのみラベル表示 (<3% は legend 側で表示)
labels = []
for k, c, s in zip(ks_top["工種"], ks_top["件数"], ks_top["シェア_%"]):
if s >= 4:
labels.append(f"{k}\n{int(c):,}件\n({s:.1f}%)")
else:
labels.append("")
colors = [KOUSYU_COLOR.get(k, "#888") for k in ks_top["工種"]]
wedges, _ = ax.pie(sizes, labels=labels, colors=colors, startangle=90,
wedgeprops=dict(edgecolor="white", linewidth=2),
textprops={"fontsize": 10})
# 小シェアは legend で表示
small_legend = [Patch(facecolor=colors[i], edgecolor="white",
label=f"{ks_top['工種'].iloc[i]} {int(ks_top['件数'].iloc[i]):,}件 ({ks_top['シェア_%'].iloc[i]:.1f}%)")
for i in range(len(ks_top)) if ks_top['シェア_%'].iloc[i] < 4]
if small_legend:
ax.legend(handles=small_legend, loc="lower left", fontsize=8,
title="少数工種", bbox_to_anchor=(-0.1, -0.05))
ax.set_title(f"図 2b: 工種構成 — H2 護岸+流路で {gogan_ryuro_share:.1f}%",
fontsize=11)
fig.suptitle(f"図 2 (RQ1): 市町ランキング + 工種構成 — H1 ({top1_name}+{top2_name}+{top3_name} {top3_share:.0f}%) / "
f"H2 護岸+流路 {gogan_ryuro_share:.1f}%",
fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L58_fig2_city_kousyu.png")
# ---- 図 3 (RQ1): 告示年分布 + 規模分布 (高さ × 延長) ----
fig, axes = plt.subplots(1, 2, figsize=(16, 6))
ax = axes[0]
year_min = int(gdf_dated["告示年"].min())
year_max = int(gdf_dated["告示年"].max())
years = np.arange(year_min, year_max + 1)
year_counts = gdf_dated["告示年"].value_counts().sort_index().reindex(years, fill_value=0)
ax.bar(years, year_counts.values, color=C_L58_KEIRYU, edgecolor="none",
width=1.0, alpha=0.85)
ax.axvline(1897, color="#cf222e", linestyle="--", linewidth=2,
label="1897 砂防法施行")
ax.axvline(2018, color="#bf8700", linestyle="--", linewidth=1.5,
label="2018 西日本豪雨")
yr_med = int(gdf_dated["告示年"].median())
ax.axvline(yr_med, color="black", linestyle=":", linewidth=1.5,
label=f"中央値 {yr_med} 年")
ax.set_xlabel("告示年", fontsize=11)
ax.set_ylabel("施設件数 (年別)", fontsize=11)
ax.set_title(f"図 3a: 告示年別件数 ({year_min}-{year_max}, n={len(gdf_dated):,})",
fontsize=11)
ax.legend(fontsize=9, loc="upper left")
ax.grid(alpha=0.3)
ax = axes[1]
# 高さ × 延長 散布図 (log-log)
both = gdf.dropna(subset=["高さ_m", "延長_m"])
both = both[(both["高さ_m"] > 0) & (both["延長_m"] > 0)]
# 工種別に色分け
for ks in ["護岸工", "流路工", "流路工内床固工", "暗渠工", "山腹工"]:
s = both[both["工種"] == ks]
if len(s) == 0:
continue
ax.scatter(s["延長_m"], s["高さ_m"], c=KOUSYU_COLOR.get(ks, "#888"),
s=12, alpha=0.55, edgecolor="none", label=f"{ks} {len(s):,}")
ax.set_xscale("log")
ax.set_yscale("log")
ax.set_xlabel("延長 L (m, log)", fontsize=11)
ax.set_ylabel("高さ H (m, log) — 床固/堰堤の H", fontsize=11)
ax.set_title(f"図 3b: 規模分布 — 高さ × 延長 散布図 (n={len(both):,})",
fontsize=11)
ax.legend(fontsize=8, loc="upper left")
ax.grid(alpha=0.3)
fig.suptitle(f"図 3 (RQ1): 告示年分布 + 規模分布 — 中央値 {yr_med} 年 / "
f"中央延長 {gdf['延長_m'].median():.0f} m",
fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L58_fig3_year_size_distribution.png")
# ---- 図 4 (RQ1): 工種別 small multiples マップ (上位 6 工種) ----
fig, axes = plt.subplots(2, 3, figsize=(16, 9))
top_kousyu = kousyu_count.head(6)["工種"].tolist()
for i, ks in enumerate(top_kousyu):
ax = axes[i // 3, i % 3]
sub = gdf[gdf["工種"] == ks]
admin_diss.boundary.plot(ax=ax, color="#888", linewidth=0.3)
admin_diss.plot(ax=ax, facecolor="#f8f8f5", edgecolor="#aaa",
linewidth=0.2, alpha=0.55)
if len(sub) > 0:
sub.plot(ax=ax, color=KOUSYU_COLOR.get(ks, "#888"),
linewidth=0.8, alpha=0.8)
ax.set_xlim(PXMIN, PXMAX)
ax.set_ylim(PYMIN, PYMAX)
ax.set_aspect("equal")
ax.set_title(f"{ks}\nn={len(sub):,} ({len(sub)/n_total*100:.1f}%)",
fontsize=10)
ax.set_xticks([])
ax.set_yticks([])
fig.suptitle("図 4 (RQ1): 工種別 small multiples マップ — "
"工種ごとの分布パターン",
fontsize=13, y=1.00)
plt.tight_layout()
save_fig("L58_fig4_kousyu_small_multiples.png")
# ---- 図 5 (RQ2): 砂防指定地 (3,207 polygon) × 渓流保全工 (1,862 line) 重ね合わせ ----
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
ax = axes[0]
admin_diss.boundary.plot(ax=ax, color="#888", linewidth=0.4)
admin_diss.plot(ax=ax, facecolor="#fafafa", edgecolor="#bbb",
linewidth=0.3, alpha=0.6)
shitei.plot(ax=ax, facecolor=C_SHITEI, edgecolor="#a4101e",
linewidth=0.2, alpha=0.45)
gdf.plot(ax=ax, color=C_L58_KEIRYU, linewidth=0.6, alpha=0.85)
ax.set_xlim(PXMIN, PXMAX)
ax.set_ylim(PYMIN, PYMAX)
ax.set_aspect("equal")
ax.set_title(f"図 5a: 砂防指定地 (赤面 {n_shitei:,}) × 渓流保全工 (緑線 {n_total:,}) 全県",
fontsize=11)
legend_h = [
Patch(facecolor=C_SHITEI, alpha=0.45, label=f"L46 #55 砂防指定地 {n_shitei:,}"),
Line2D([0], [0], color=C_L58_KEIRYU, lw=2, label=f"本記事 渓流保全工 {n_total:,}"),
]
ax.legend(handles=legend_h, loc="upper right", fontsize=10, title="制度の対")
ax.set_xlabel("X (m)", fontsize=9)
ax.set_ylabel("Y (m)", fontsize=9)
# Top 1 市町拡大 (呉市)
ax = axes[1]
target_city = top1_name
cell = admin_diss[admin_diss["市町名"] == target_city]
if len(cell) > 0:
bx = cell.total_bounds
pad = 3000
cx_min, cy_min, cx_max, cy_max = bx[0]-pad, bx[1]-pad, bx[2]+pad, bx[3]+pad
cell.boundary.plot(ax=ax, color="#444", linewidth=1.0)
cell.plot(ax=ax, facecolor="#f8f8f5", edgecolor="#aaa", linewidth=0.4, alpha=0.7)
shitei[shitei["市町名"] == target_city].plot(ax=ax, facecolor=C_SHITEI,
edgecolor="#a4101e",
linewidth=0.3, alpha=0.45)
gdf[gdf["市町名"] == target_city].plot(ax=ax, color=C_L58_KEIRYU,
linewidth=0.9, alpha=0.85)
ax.set_xlim(cx_min, cx_max)
ax.set_ylim(cy_min, cy_max)
ax.set_aspect("equal")
n_in_city_shitei = (shitei["市町名"] == target_city).sum()
n_in_city_fac = (gdf["市町名"] == target_city).sum()
ax.set_title(f"図 5b: {target_city} 拡大 — 指定地 {n_in_city_shitei:,} / 渓流保全工 {n_in_city_fac:,}",
fontsize=11)
ax.set_xlabel("X (m)", fontsize=9)
ax.set_ylabel("Y (m)", fontsize=9)
fig.suptitle(f"図 5 (RQ2): 砂防指定地 × 渓流保全工 — "
f"指定地内包含率 {share_in:.1f}% / 告示番号 1-1 対応 {len(kn_common):,}",
fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L58_fig5_shitei_facility.png")
# ---- 図 6 (RQ2): 市町別 指定地 vs 渓流保全工 並列棒 + 充足比率 choropleth ----
fig, axes = plt.subplots(1, 2, figsize=(16, 8))
ax = axes[0]
svf_show = shitei_vs_fac[(shitei_vs_fac["指定地数_55"] > 0)
| (shitei_vs_fac["渓流保全工_59"] > 0)].head(15).iloc[::-1]
y = np.arange(len(svf_show))
w = 0.4
ax.barh(y - w/2, svf_show["指定地数_55"], height=w, color=C_SHITEI,
edgecolor="#333", label=f"指定地 (#55) 計 {n_shitei_total:,}")
ax.barh(y + w/2, svf_show["渓流保全工_59"], height=w, color=C_L58_KEIRYU,
edgecolor="#333", label=f"渓流保全工 (#59) 計 {n_fac_total:,}")
ax.set_yticks(y)
ax.set_yticklabels(svf_show["市町名"], fontsize=10)
ax.set_xlabel("件数", fontsize=11)
ax.set_title(f"図 6a: 市町別 指定地 vs 渓流保全工 (Top 15)",
fontsize=11)
ax.legend(fontsize=9, loc="lower right")
ax.grid(axis="x", alpha=0.3)
for i, (cn, sh, f) in enumerate(zip(svf_show["市町名"],
svf_show["指定地数_55"],
svf_show["渓流保全工_59"])):
if sh > 0:
ax.text(sh + 5, i - w/2, f"{int(sh):,}", va="center", fontsize=8)
if f > 0:
ax.text(f + 5, i + w/2, f"{int(f):,}", va="center", fontsize=8,
color="#1a8c4a")
ax = axes[1]
admin_g = admin_diss.copy()
gap_map = dict(zip(shitei_vs_fac["市町名"],
shitei_vs_fac["施設充足比率"].fillna(0)))
admin_g["充足比率"] = admin_g["市町名"].map(gap_map).fillna(np.nan)
admin_g[admin_g["充足比率"].isna()].plot(ax=ax, facecolor="#f0f0f0",
edgecolor="#888", linewidth=0.4)
admin_g[~admin_g["充足比率"].isna()].plot(ax=ax, column="充足比率",
cmap="RdYlGn", vmin=0, vmax=2,
edgecolor="#444", linewidth=0.4,
legend=True,
legend_kwds={"label": "施設充足比率 (= 渓流保全工 / 指定地)",
"shrink": 0.7})
ax.set_xlim(PXMIN, PXMAX)
ax.set_ylim(PYMIN, PYMAX)
ax.set_aspect("equal")
ax.set_title(f"図 6b: 市町別 充足比率 choropleth (1.0 = 同件数 / >1 = 過剰整備)",
fontsize=11)
ax.set_xlabel("X (m)", fontsize=9)
ax.set_ylabel("Y (m)", fontsize=9)
fig.suptitle(f"図 6 (RQ2): 指定地 vs 渓流保全工 — 全県比 1:{n_fac_total/n_shitei_total:.2f} / "
f"指定地内整備率 {share_in:.0f}%",
fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L58_fig6_shitei_facility_gap.png")
# ---- 図 7 (RQ3): 砂防三施設族 (L56 点 + L57 面 + L58 線) 重ね合わせ全県マップ ----
fig, ax = plt.subplots(figsize=(13, 9))
admin_diss.boundary.plot(ax=ax, color="#888", linewidth=0.4)
admin_diss.plot(ax=ax, facecolor="#fafafa", edgecolor="#bbb",
linewidth=0.3, alpha=0.55)
# L58 線 (緑)
gdf.plot(ax=ax, color=C_L58_KEIRYU, linewidth=0.5, alpha=0.65)
# L57 面 (紫) — 上に乗せる
if gdf_l57 is not None:
gdf_l57.plot(ax=ax, facecolor=C_L57_LANDSL, edgecolor="#4a1a8c",
linewidth=0.5, alpha=0.85)
# L56 点 (青) — 半透明小ドット
if gdf_l56_pts is not None:
ax.scatter(gdf_l56_pts.geometry.x, gdf_l56_pts.geometry.y, s=3,
c=C_L56_STEEP, edgecolor="none", alpha=0.4)
ax.set_xlim(PXMIN, PXMAX)
ax.set_ylim(PYMIN, PYMAX)
ax.set_aspect("equal")
legend_h = [
Line2D([0], [0], color=C_L58_KEIRYU, lw=2,
label=f"L58 渓流保全工 (線) {n58:,} 件"),
Patch(facecolor=C_L57_LANDSL, alpha=0.85,
label=f"L57 地すべり防止施設 (面) {n57} 件"),
Line2D([0], [0], marker='o', color='w', markerfacecolor=C_L56_STEEP,
markersize=8, label=f"L56 急傾斜地崩壊防止施設 (点) {n56:,} 件"),
]
ax.legend(handles=legend_h, loc="lower right", fontsize=10,
title=f"砂防三施設族 計 {n_triple:,} 件")
ax.set_title(f"図 7 (RQ3): 砂防三施設族 重ね合わせ全県 — "
f"線 {n58:,} + 面 {n57} + 点 {n56:,} = 計 {n_triple:,} 件",
fontsize=12)
ax.set_xlabel("X (m, EPSG:6671)", fontsize=10)
ax.set_ylabel("Y (m, EPSG:6671)", fontsize=10)
plt.tight_layout()
save_fig("L58_fig7_triple_overlay.png")
# ---- 図 8 (RQ3): 三角座標 (L56-L57-L58 シェア) 散布図 + 市町別 stacked 棒 ----
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
# 左: 三角座標 (重心座標) — 各市町を 3 制度シェアで散布
ax = axes[0]
plot_target = triple[triple["三施設合計"] >= 5].copy()
def to_xy(s56, s57, s58):
"""3 シェア (合計 100) を 2D に投影 (重心三角座標)"""
# L56 を左下, L58 を右下, L57 を上頂点に配置
x = 0.5 * (2 * s58 + s57) / (s56 + s57 + s58 + 1e-9)
y = (s57 * np.sqrt(3) / 2) / (s56 + s57 + s58 + 1e-9)
return x, y
# 三角の枠
import matplotlib.patches as mpatches
tri = plt.Polygon([(0, 0), (1, 0), (0.5, np.sqrt(3)/2)], closed=True,
fill=False, edgecolor="#888", linewidth=1.0)
ax.add_patch(tri)
ax.text(-0.05, -0.05, "L56\n急傾斜", ha="right", va="top", fontsize=10,
color=C_L56_STEEP, weight="bold")
ax.text(1.05, -0.05, "L58\n渓流保全工", ha="left", va="top", fontsize=10,
color=C_L58_KEIRYU, weight="bold")
ax.text(0.5, np.sqrt(3)/2 + 0.04, "L57\n地すべり", ha="center", va="bottom",
fontsize=10, color=C_L57_LANDSL, weight="bold")
# 各市町をプロット
TYPE_COLOR = {
"急傾斜特化型": C_L56_STEEP,
"地すべり主導型": C_L57_LANDSL,
"渓流主導型": C_L58_KEIRYU,
"急傾斜+渓流バランス型": "#bf8700",
"混合型": "#888",
}
for typ, sub in plot_target.groupby("砂防戦略タイプ"):
xs, ys = [], []
for _, r in sub.iterrows():
x, y = to_xy(r["L56_市町内_%"], r["L57_市町内_%"], r["L58_市町内_%"])
xs.append(x)
ys.append(y)
sizes = (sub["三施設合計"].values ** 0.5) * 4
ax.scatter(xs, ys, s=sizes, c=TYPE_COLOR.get(typ, "#888"),
alpha=0.7, edgecolor="black", linewidth=0.4, label=f"{typ} ({len(sub)})")
# 主要市町ラベル
for _, r in plot_target.head(10).iterrows():
x, y = to_xy(r["L56_市町内_%"], r["L57_市町内_%"], r["L58_市町内_%"])
ax.annotate(r["市町名"], (x, y), fontsize=8, ha="center", va="center",
xytext=(0, 8), textcoords="offset points",
color="#222", weight="bold")
ax.set_xlim(-0.15, 1.15)
ax.set_ylim(-0.15, 1.0)
ax.set_aspect("equal")
ax.axis("off")
# 三角形の中心線 (シェア 33%/33%/33% の参考線)
ax.plot([0.5, 0.5], [0, np.sqrt(3)/2], color="#ddd", linewidth=0.5, linestyle=":")
ax.plot([0, 0.5], [0, np.sqrt(3)/2], color="#ddd", linewidth=0.5, linestyle=":")
ax.plot([1, 0.5], [0, np.sqrt(3)/2], color="#ddd", linewidth=0.5, linestyle=":")
# 補足注記: L57 シェアの最大値が小さいので参考説明
ax.text(0.5, -0.13, "※L57 (地すべり) は全 32 件と少数のため上頂点付近の点はほぼなし\n"
"ほとんどの市町は底辺 (L56-L58 軸) 上に分布",
ha="center", va="top", fontsize=8.5, color="#555", style="italic")
ax.legend(loc="upper left", fontsize=8, title="砂防戦略タイプ",
bbox_to_anchor=(-0.05, 1.0))
ax.set_title(f"図 8a: 三角座標 (L56-L57-L58 市町内シェア) — "
f"{len(plot_target)} 市町を 3 制度の比で分類",
fontsize=11)
# 右: 市町別 stacked 棒 (Top 15)
ax = axes[1]
top15 = triple.head(15).iloc[::-1]
y = np.arange(len(top15))
ax.barh(y, top15["L56_急傾斜施設"], color=C_L56_STEEP,
edgecolor="#333", linewidth=0.4, label=f"L56 急傾斜 (点) 計 {n56:,}")
ax.barh(y, top15["L57_地すべり施設"], left=top15["L56_急傾斜施設"],
color=C_L57_LANDSL, edgecolor="#333", linewidth=0.4,
label=f"L57 地すべり (面) 計 {n57}")
ax.barh(y, top15["L58_渓流保全工"],
left=top15["L56_急傾斜施設"] + top15["L57_地すべり施設"],
color=C_L58_KEIRYU, edgecolor="#333", linewidth=0.4,
label=f"L58 渓流保全工 (線) 計 {n58:,}")
ax.set_yticks(y)
ax.set_yticklabels(top15["市町名"], fontsize=9)
ax.set_xlabel("三施設合計件数", fontsize=11)
ax.set_title(f"図 8b: 市町別 三施設 stacked 棒 (Top 15) — "
f"県合計 {n_triple:,} 件",
fontsize=11)
ax.legend(fontsize=9, loc="lower right")
ax.grid(axis="x", alpha=0.3)
for i, (cn, t) in enumerate(zip(top15["市町名"], top15["三施設合計"])):
ax.text(t + 30, i, f"{int(t):,}", va="center", fontsize=8, weight="bold")
fig.suptitle(f"図 8 (RQ3): 砂防三施設族の県内地理 — "
f"L56:L57:L58 = {n56/n_triple*100:.0f}:{n57/n_triple*100:.0f}:{n58/n_triple*100:.0f}",
fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L58_fig8_triple_ternary.png")
print(f" 8 図 生成完了 ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 9. 表の作成
# =============================================================================
print("\n[9] 表作成", flush=True)
t1 = time.time()
def df_to_html(d):
cols = list(d.columns)
head = "" + "".join(f"| {c} | " for c in cols) + "
"
rows = []
for _, r in d.iterrows():
cells = []
for c in cols:
v = r[c]
if isinstance(v, float):
if pd.isna(v):
s = "—"
elif abs(v) >= 1000:
s = f"{v:,.0f}"
elif abs(v) >= 10:
s = f"{v:.1f}"
elif abs(v) >= 1:
s = f"{v:.2f}"
else:
s = f"{v:.3f}"
elif pd.isna(v):
s = "—"
else:
s = str(v)
cells.append(f"{s} | ")
rows.append("" + "".join(cells) + "
")
return "" + head + "".join(rows) + "
"
# 表 1: dataset 仕様
T_dataset = pd.DataFrame([
("dataset_id", "59"),
("名称", "渓流保全工基本情報"),
("組織", "広島県土木建築局 砂防課"),
("リソース", f"22825 — Shapefile (ZIP, {ZIP_PATH.stat().st_size:,} byte, "
f"{n_total:,} LineString)"),
("根拠法", "砂防法 (1897-06-01 施行) — 世界初の砂防法 / 国土交通省所管"),
("列構成 (18 列)",
"objid (主キー) / suikei_gr (水系群=1級/2級/その他) / suikei_nm (水系名) / "
"kansen_nm (幹川名) / keiryu_nm (渓流名) / prefecture / city / aza (字) / "
"kousyu (工種) / kouzou (構造) / height (高さ m) / length (延長 m) / "
"area (面積 m²) / sekou_year (施工年) / syunko_ymd (竣工年月日) / "
"skeiryu_nm / kokuzi_ymd (告示年月日) / kokuzi_no (告示番号)"),
("CRS", "EPSG:6668 (JGD2011 経緯度) → 解析時 EPSG:6671 へ変換"),
("ライセンス", "クリエイティブ・コモンズ表示 4.0"),
("最終更新", "2026-04-27"),
("取得日", "2026-05-10"),
], columns=["項目", "値"])
# 表 2: 全体サマリ
T_overall = pd.DataFrame([
("総施設数", f"{n_total:,} LineString (全 {n_cities_with} 市町)"),
("総延長",
f"{gdf['延長_m'].sum()/1000:,.0f} km (= {gdf['延長_m'].sum()/1000:.0f} km、"
f"記録 length 列の合算)"),
("Top 1 市町", f"{top1_name} {top1_count:,} 件 ({top1_share:.1f}%)"),
("Top 3 累計",
f"{top1_name}+{top2_name}+{top3_name} 計 "
f"{top1_count+top2_count+top3_count:,} 件 ({top3_share:.1f}%)"),
("工種: 護岸工", f"{n_gogan:,} 件 ({n_gogan/n_total*100:.1f}%)"),
("工種: 流路工", f"{n_ryuro:,} 件 ({n_ryuro/n_total*100:.1f}%)"),
("工種: 床固工系", f"{n_tokokatame} 件 (流路工内 + 単独)"),
("工種: 護岸+流路", f"{n_gogan + n_ryuro:,} 件 ({gogan_ryuro_share:.1f}%)"),
("水系群: 1 級", f"{n_class1:,} 件 ({class1_share:.1f}%)"),
("水系群: 2 級", f"{n_class2:,} 件 ({class2_share:.1f}%)"),
("水系群: その他", f"{n_other:,} 件 ({n_other/n_total*100:.1f}%)"),
("告示年範囲",
f"{int(gdf_dated['告示年'].min())}–{int(gdf_dated['告示年'].max())} "
f"(中央値 {yr_med} 年)"),
("告示年 欠損", f"{n_no_date:,} 件 ({n_no_date/n_total*100:.1f}%)"),
("延長 (記録 length)",
f"平均 {gdf['延長_m'].mean():.0f} m / 中央値 {gdf['延長_m'].median():.0f} m / "
f"最大 {gdf['延長_m'].max():,.0f} m"),
("高さ H (床固/堰堤)",
f"平均 {gdf['高さ_m'].mean():.2f} m / 中央値 {gdf['高さ_m'].median():.2f} m / "
f"最大 {gdf['高さ_m'].max():.1f} m / 記録あり {gdf['高さ_m'].notna().sum():,} 件"),
("L46 #55 砂防指定地", f"{n_shitei:,} polygon / 合計 {shitei['面積_ha'].sum():,.0f} ha"),
("指定地内 渓流保全工", f"{n_fac_in_shitei:,} 件 ({share_in:.1f}%)"),
("告示番号 1-1 対応", f"{len(kn_common):,} 件"),
("L56 急傾斜防止施設 (参考)", f"{n56:,} 件 (点)"),
("L57 地すべり防止施設 (参考)", f"{n57} 件 (面)"),
("砂防三施設族 合計", f"{n_triple:,} 件 (L56+L57+L58)"),
("L56 vs L58 件数 Pearson r", f"{corr_56_58:.3f}"),
("L57 vs L58 件数 Pearson r", f"{corr_57_58:.3f}"),
], columns=["指標", "値"])
# 表 3: 市町別ランキング
T_city_rank = city_summary[["順位", "市町名", "件数", "件数シェア_%",
"合計延長_km", "平均延長_m", "平均高さ_m",
"護岸", "流路", "床固", "暗渠", "告示年中央"]].copy()
T_city_rank.columns = ["順位", "市町名", "件数", "シェア_%",
"合計延長_km", "平均延長_m", "平均高さ_m",
"護岸", "流路", "床固", "暗渠", "告示年中央"]
# 表 4: 工種別構成
T_kousyu = kousyu_count.copy()
# 表 5: 構造別 Top 10
T_kouzou_top = kouzou_count.head(10).copy()
# 表 6: 告示年代別 (10 年区間)
T_decade = year_decade.copy()
T_decade.columns = ["告示年代", "件数", "シェア_%"]
# 表 7: 告示時期 3 区分
T_era = era_counts.copy()
T_era.columns = ["告示時期", "件数", "シェア_%"]
# 表 8: 指定地 vs 渓流保全工 ギャップ Top 15
T_gap = shitei_vs_fac.head(15).copy()
T_gap["順位"] = np.arange(1, len(T_gap) + 1)
T_gap = T_gap[["順位", "市町名", "指定地数_55", "渓流保全工_59", "施設充足比率"]]
# 表 9: 砂防三施設族 市町別 Top 15
T_triple = triple.head(15)[["市町名", "L56_急傾斜施設", "L57_地すべり施設",
"L58_渓流保全工", "三施設合計", "L56_市町内_%",
"L57_市町内_%", "L58_市町内_%", "砂防戦略タイプ"]].copy()
# 表 10: 砂防三法対応総括
T_law = sanpou_summary.copy()
# 表 11: 仮説検証
def judge_h1():
return ("強支持" if top3_share <= 30 else
"支持" if top3_share <= 40 else
"部分支持")
def judge_h2():
return ("強支持" if gogan_ryuro_share >= 90 else
"支持" if gogan_ryuro_share >= 80 else "部分支持")
def judge_h3():
return ("強支持" if 1965 <= yr_med <= 1975 else
"支持" if 1960 <= yr_med <= 1985 else "部分支持")
def judge_h4():
return ("強支持" if share_in >= 80 else
"支持" if share_in >= 60 else "部分支持")
def judge_h5():
# 三施設族の市町別配分が地形で説明できる = 各タイプが少数市町に集中していれば支持
n_specialized = (triple["砂防戦略タイプ"] != "混合型").sum()
return ("強支持" if n_specialized >= len(triple) * 0.7 else
"支持" if n_specialized >= len(triple) * 0.5 else "部分支持")
T_hypo = pd.DataFrame([
{"仮説": "H1 (バランス型分布, Top 3 ≤ 30%, RQ1)",
"予想": "Top 3 市町で 30% 以下 (沿岸・中山間両方に分散)",
"観測": f"Top 3 = {top1_name}+{top2_name}+{top3_name} で計 {top3_share:.1f}%",
"判定": judge_h1()},
{"仮説": "H2 (護岸+流路で >90%, RQ1)",
"予想": "工種 8 種のうち護岸工 + 流路工で 90% 以上",
"観測": f"護岸 {n_gogan:,} ({n_gogan/n_total*100:.1f}%) + "
f"流路 {n_ryuro:,} ({n_ryuro/n_total*100:.1f}%) = {gogan_ryuro_share:.1f}%",
"判定": judge_h2()},
{"仮説": "H3 (1960-75 集中整備, RQ1)",
"予想": "告示年中央値が 1965-1975 年 (高度経済成長期)",
"観測": f"中央値 {yr_med} 年 / 範囲 {int(gdf_dated['告示年'].min())}-{int(gdf_dated['告示年'].max())}",
"判定": judge_h3()},
{"仮説": "H4 (砂防指定地内整備率 ≥ 80%, RQ2)",
"予想": "渓流保全工の大半 (≥80%) が指定地内に存在",
"観測": f"指定地内: {n_fac_in_shitei:,} / {n_total:,} = {share_in:.1f}% / "
f"指定地外: {n_fac_outside:,} 件 / 告示番号一致 {len(kn_common):,}",
"判定": judge_h4()},
{"仮説": "H5 (三施設族の市町別配分は地形で決まる, RQ3)",
"予想": "各市町の砂防戦略タイプは地形・地質で分類可能 (混合型は少数派)",
"観測": f"三施設族 {n_triple:,} 件、{(triple['砂防戦略タイプ'] != '混合型').sum()} / "
f"{len(triple)} 市町が特化型 / "
f"L56-L58 r={corr_56_58:.3f}, L57-L58 r={corr_57_58:.3f}",
"判定": judge_h5()},
])
print(f" 表 11 種 ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 10. HTML 構築
# =============================================================================
print("\n[10] HTML 構築", flush=True)
t10 = time.time()
# Sec 1: 学習目標と問い
sec1 = f"""
本記事は DoBoX のシリーズ「渓流保全工基本情報」 1 件
(dataset_id = 59) を 単独で取り上げ、
広島県内の渓流保全工 {n_total:,} LineString (Shapefile, 18 列, 約 1.4 MB の zip 圧縮) /
{n_cities_with} 市町 / 総延長 {gdf['延長_m'].sum()/1000:,.0f} km を
3 つの独立した研究角度 (RQ1 / RQ2 / RQ3) で並列に分析する。
本データは砂防法 (1897-06-01 施行 = 世界初の砂防法) に基づき広島県が整備した
河床・河岸の線的工事 (LineString) の台帳で、護岸工・流路工・床固工等の
物理工事の起点-終点を 1 line で記録。Phase 3 防災施設系の
3 本目 = 砂防三施設族の最終ピース (L56 急傾斜・L57 地すべりに続く)。
L56 / L57 との対比: L56 は点で {n56:,} 件、
L57 は面で {n57} 件、本記事 L58 は線 (LineString)で {n_total:,} 件。
3 制度・3 形態・3 規模の砂防三施設族がついに完成する。
L56 = 呉市 47% (沿岸都市) ⇄ L57 = 庄原市 28% (中山間) ⇄ L58 = {top1_name}{top1_share:.0f}% +
{top2_name}+{top3_name}で {top3_share:.0f}% (沿岸・中山間バランス型)。
本記事 RQ3 で三施設族の地理学的全体像を初めて描く。
独自用語の定義
- 渓流保全工: 砂防法 (1897) に基づき、広島県が渓流の侵食・洗掘を防ぐために
整備した河床・河岸の線的な土木工事 (LineString)。
本データは {n_total:,} 件の起点-終点 line を保持。
個別工事 (護岸工・流路工・床固工) ごとに別 lineとして記録される。
- 護岸工 (ごがんこう): 渓流の岸を石積・コンクリートブロックで補強し、
洪水時の岸侵食 (河床洗掘) を防ぐ工事。本データの {n_gogan:,} 件 ({n_gogan/n_total*100:.0f}%) で最多。
構造種別はコンクリート・ブロック積・空石積・練石積・自然護岸 (土) 等。
- 流路工 (りゅうろこう): 河床・河岸を一体的に整形し、
渓流の流れを安定させる工事。底張り (コンクリート) + 護岸の組合せ。
本データ {n_ryuro:,} 件 ({n_ryuro/n_total*100:.0f}%) で 2 番目に多い。
- 床固工 (とこがためこう): 河床に小堰堤 (高さ H = 1-3 m 程度) を
設置し、河床の侵食を抑え土砂流出を抑制する工事。
流路工内に組込む (流路工内床固工 91 件) のが一般的、単独設置は 2 件のみ。
- 暗渠工 (あんきょこう): 渓流を地下水路化し、地表面を有効利用する工事。
本データ 32 件。
- 山腹工 (さんぷくこう): 渓岸の斜面を植生・編柵で安定化する工事。本データ 6 件。
- 砂防三施設族 (本記事独自用語): 砂防三法 (砂防法 1897 / 地すべり等防止法 1958 /
急傾斜地法 1969) に基づくハード施設群を本記事では砂防三施設族と総称する。
L58 (本記事) ・ L57 (地すべり) ・ L56 (急傾斜) が族の 3 本柱。
対応する区域指定 = #55 砂防指定地 / #56 急傾斜区域 / #57 地すべり区域 (L46 で集約)。
- 水系群 (suikei_gr): 本データの分類軸で1 級 / 2 級 / その他 / 不明の 4 値。
1 級 = 国交省管理の主要河川 (太田川・芦田川・江の川・小瀬川等)、
2 級 = 県管理の中規模河川、その他 = 普通河川 (市町管理) や水系不明の小渓流。
- 施設充足比率 (本記事定義): 「市町別 渓流保全工件数 ÷ 砂防指定地件数」
= 1.0 で件数同等、>1.0 で過剰整備、<1.0 で未整備残存。
指定地 = 整備されるべき場所、渓流保全工 = 実際に整備された場所、の差を測る。
- 砂防戦略タイプ (本記事定義): 三施設族の市町内構成比から
「急傾斜特化型 (L56≥60%)」「地すべり主導型 (L57≥30%)」「渓流主導型 (L58≥50%)」
「急傾斜+渓流バランス型 (L56≥40 かつ L58≥30)」「混合型」の 5 タイプに分類。
研究の問い (3 RQ)
- RQ1 (主研究): 広島県の渓流保全工の構造はどう描けるか?
{n_total:,} 件の LineString を市町別ランキング、工種 8 種分布、構造 76 種、
規模特性 (高さ × 延長)、告示年代、水系群分布で多角度に集計する。
呉市 {top1_count:,} 件 + 三次・尾道で計 {top3_share:.0f}% のバランス型分布は何故か?
- RQ2 (副研究 1): 渓流保全工はL46 #55 砂防指定地 (3,207 polygon) とどう対応するか?
空間 sjoin で「指定地内整備率」 を計測し、告示番号で 1 対 1 直接照合。
件数の差 (3,207 vs 1,862) を市町別に分解し、未整備指定地の残課題エリアを特定する。
- RQ3 (副研究 2): 砂防三施設族 (L56 + L57 + L58) の総合構造はどう描けるか?
三施設の合計 {n_triple:,} 件を市町別に統合し、三角座標プロット (L56-L57-L58 シェア) で
各市町の砂防戦略タイプを分類。
「広島県の砂防投資の地理学」 の総合像を初めて描く。
仮説 H1〜H5
- H1 (バランス型分布, Top 3 ≤ 30%, RQ1): 渓流保全工は沿岸+中山間の両方に分散。
Top 3 市町 ({top1_name}+{top2_name}+{top3_name}) で 30% 以下と予想。
L56 (呉市偏重 47%) や L57 (中山間偏重 50%) と対照的なバランス型。
- H2 (護岸+流路 ≥ 90%, RQ1): 工種 8 種のうち護岸工 + 流路工で 90% 以上。
渓流保全の中心は河床整形と河岸補強という基本工事のため。
- H3 (1960-75 集中整備, RQ1): 告示年中央値は 1965-1975 年付近。
砂防法 (1897) は最古制度で告示時系列が長く、高度経済成長期 (1960-1975) に集中。
- H4 (砂防指定地内整備率 ≥ 80%, RQ2): 渓流保全工の大半 (≥80%) が指定地内に存在。
指定地 = 整備されるべき場所として制度設計されているため。
「指定地あり + 渓流保全工なし」 は数百〜千件の未整備残課題として残存。
- H5 (三施設族の地形依存配分, RQ3): 三施設族の市町別シェアは地形・地質で決まる:
沿岸都市 = 急傾斜特化型 / 中山間 = 地すべり+渓流型 / 島嶼 = 急傾斜単独型 のように
砂防戦略タイプで明確に分類可能。混合型は少数派。
到達点
本記事を読み終えた学習者は次の 3 点を体感できる:
- 1 つの「線形施設台帳 Shapefile ({n_total:,} LineString × 18 列)」 から、
工種 8 種・構造 76 種・規模 (高さ × 延長)・告示年代という多次元属性を多角度に読む方法を習得する。
点 (L56) や面 (L57) と異なる線データの特徴を体感できる。
- L46 で扱った同名関連データ (#55 砂防指定地 3,207 polygon) と本データ (#59 渓流保全工 {n_total:,} line) を
空間 sjoin と告示番号の 2 経路で照合し、
指定地内整備率と未整備残課題の地理を定量化する手法を体感する。
- L56 (急傾斜 {n56:,} 点) ・ L57 (地すべり {n57} 面) ・ L58 (渓流 {n58:,} 線) の砂防三施設族を
市町単位で並列比較し、三角座標プロットで各市町の砂防戦略タイプを分類できる。
これは制度・現象・地形・施設形態が四位一体で対応する好例で、
防災投資の地理学を理解する上での教科書的レファレンス。
"""
# Sec 2: 使用データ
sec2 = f"""
DoBoX のシリーズ「渓流保全工基本情報」 1 件のみを単独で扱う。
リソースは Shapefile 1 セットのシンプル構造 (cpg/dbf/prj/shp/shx の 5 ファイル zip 圧縮、約 1.4 MB)。
{df_to_html(T_dataset)}
データの構造
- 18 列の構成: objid (主キー) / suikei_gr (1 級 / 2 級 / その他) /
suikei_nm (太田川・芦田川等) / kansen_nm (幹川名) / keiryu_nm (渓流名) /
prefecture / city / aza (字) /
kousyu (工種 8 種) / kouzou (構造 76 種) /
height (高さ m) / length (延長 m) / area (面積 m², 沈砂池等) /
sekou_year (施工年, 平成期のみ) / syunko_ymd / skeiryu_nm /
kokuzi_ymd (告示年月日) / kokuzi_no (告示番号)。
- geometry: LineString {(gdf.geometry.type=="LineString").sum():,} +
MultiLineString {(gdf.geometry.type=="MultiLineString").sum():,} = 計 {n_total:,}。
原 CRS = EPSG:6668 (JGD2011 経緯度)。
解析時は EPSG:6671 (平面直角座標系第 III 系) に変換し、距離を m 単位で扱う。
- 告示年月日: {n_total - n_no_date:,} 件 ({(n_total-n_no_date)/n_total*100:.0f}%) で記入あり。
範囲は {int(gdf_dated['告示年'].min())} 年から {int(gdf_dated['告示年'].max())} 年 の
{int(gdf_dated['告示年'].max()) - int(gdf_dated['告示年'].min())} 年。
欠損 {n_no_date:,} 件 ({n_no_date/n_total*100:.1f}%)。
- 規模列の特徴: 高さ H は床固工・堰堤等で記入、延長 L は線全体の長さ。
面積は沈砂池等の点的構造物のみ ({gdf['面積_m2'].notna().sum()} 件)。
高さ・延長はL56 / L57 にない 本データの特長。
関連データセットとの対応 (砂防三施設族)
- L46 #55 砂防指定地 (= 区域 Shapefile, {n_shitei:,} polygon + 93 line):
同じ砂防法に基づく区域指定 (= 整備されるべき場所)を記録。
本データ (#59 = 施設) はその指定地内で整備された線的工事。
告示番号と空間 sjoin で照合可能。
- L57 地すべり防止施設 (= 面 Shapefile, {n57} polygon): 砂防三施設族の2 本目。
地すべり等防止法 1958 に基づく集水井・横ボーリング等の polygon ベース台帳。
- L56 急傾斜地崩壊防止施設 (= 点 CSV, {n56:,} 件): 砂防三施設族の1 本目。
急傾斜地法 1969 に基づく擁壁・法枠等の点ベース台帳。
- L46 #56 急傾斜区域 ({2935} polygon, CSV 緯度経度) と
#57 地すべり防止区域 (39 polygon): 三制度の区域指定。
L58 (砂防 1897) は三法のうち最古制度で歴史的厚みが最大。
"""
# Sec 3: ダウンロード
sec3 = f"""
本レッスンの再現に必要な全データ・中間 CSV・図 PNG・スクリプトを以下から直接 DL できる:
生データ (DoBoX 直リンク)
本記事の中間 CSV (再現用)
図 (PNG 8 枚)
再現スクリプト
個別取得 (PowerShell):
cd "2026 DoBoX 教材"
iwr "https://hiroshima-dobox.jp/resource_download/22825" -OutFile "data/extras/L58_keiryu_facility/砂防_渓流保全工_2026-04-27.zip"
py -X utf8 lessons\\L58_keiryu_facility.py
"""
# Sec 4 (RQ1)
sec4_intro = f"""
狙い (RQ1)
渓流保全工 ({n_total:,} LineString) は砂防法 (1897, 世界初) に基づく公費施設。
法施行から 127 年で県内に整備された施設の地理偏在・工種構成・規模分布・告示時期偏在を
4 軸で読む。L56 (呉市 47% 沿岸偏重) や L57 ({top1_name}{top1_share:.0f}% 中山間偏重 — L57 のことではなく
庄原 28% を指す) と異なり、渓流は地形を選ばず存在するため、
{top1_name}+{top2_name}+{top3_name}の Top 3 でも合計 {top3_share:.0f}% というバランス型を予想する。
手法 (Shapefile 読込 → CRS 変換 → 多次元集計)
- STEP 1 (Shapefile 読込):
gpd.read_file() で {n_total:,} LineString × 18 列を読込。
原 CRS は EPSG:6668 (JGD2011 経緯度)。
- STEP 2 (市町名正規化): 「city」 列には「山県郡安芸太田町」 のように郡名混入がある →
「郡」 で分割して右側のみ採用 → 市町名列を新設。
- STEP 3 (CRS 変換):
.to_crs("EPSG:6671") で平面直角座標系第 III 系へ変換 =
延長を m 単位で扱える。
- STEP 4 (構造正規化): 半角カナの揺れ (コンクリート → コンクリート、ブロック積 → ブロック積) を統合。
- STEP 5 (集計): 市町別件数 + 合計延長 + 平均延長 + 工種構成、
工種別件数 (8 種)、構造別件数 (76 種、Top 10)、
告示年代別件数 (10 年区間) + 3 期 (戦前+復興 / 高度成長 / 維持)、
規模 (高さ × 延長) joint plot を
groupby で集計。
"""
sec4_code = code(r'''
# 1. Shapefile 読込・前処理
import geopandas as gpd, pandas as pd, numpy as np
gdf = gpd.read_file("data/extras/L58_keiryu_facility/.../78_051shp_20260427.shp",
encoding="utf-8")
# 列名を日本語へリネーム (objid → 施設ID 等)
gdf = gdf.rename(columns={"objid":"施設ID", "suikei_gr":"水系群",
"kousyu":"工種", "kouzou":"構造",
"height":"高さ_m", "length":"延長_m",
"city":"市町_raw", "kokuzi_ymd":"告示年月日"})
# 2. 市町名正規化 (郡名除去)
def normalize_city(s):
s = str(s).strip()
if "郡" in s:
s = s.split("郡", 1)[1]
return s
gdf["市町名"] = gdf["市町_raw"].apply(normalize_city)
# 3. 構造の半角カナ正規化
def normalize_kouzou(s):
s = str(s).strip()
if s in ("None","nan",""):
return "不明"
return s.replace("コンクリート","コンクリート").replace("ブロック積","ブロック積")
gdf["構造"] = gdf["構造"].apply(normalize_kouzou)
# 4. CRS 変換 (EPSG:6668 経緯度 → EPSG:6671 平面直角)
gdf = gdf.to_crs("EPSG:6671")
gdf["延長_geom_m"] = gdf.geometry.length # geometry から計算
# 5. 告示年
gdf["告示年"] = pd.to_datetime(gdf["告示年月日"], errors="coerce").dt.year
# 6. 市町別集計
city_summary = gdf.groupby("市町名").agg(
件数=("施設ID", "count"),
合計延長_m=("延長_m", "sum"),
平均高さ_m=("高さ_m", "mean"),
護岸=("工種", lambda s: (s == "護岸工").sum()),
流路=("工種", lambda s: (s == "流路工").sum()),
).reset_index().sort_values("件数", ascending=False)
# 7. 工種・構造の集計
kousyu_count = gdf["工種"].value_counts().reset_index()
kouzou_count = gdf["構造"].value_counts().reset_index()
''')
sec4_fig1_text = """
図 1: 県全域 LineString マップ + 市町別件数 choropleth (2 panel)
なぜこの図か: 学習者がまず「渓流保全工はどこにあるか」 を一目で把握するため。
左の LineString マップは工種別 (護岸 = 青 / 流路 = 緑 / 床固 = 赤 / 暗渠 = 黄)、
右の choropleth は市町別件数の濃淡を示す。
L56 (呉市偏重) や L57 (中山間偏重) と異なり、L58 は県内全域に分散するのが本図のキー。
"""
sec4_fig1_read = f"""
この図から読み取れること:
- 左 LineString マップ: 渓流保全工は県内全域に分散。
呉市 (沿岸都市)・三次市 (中山間)・尾道市 (沿岸)・庄原市 (中山間) の地形を問わず多数。
これはL56 (沿岸特化) や L57 (中山間特化) と本質的に異なる構造。
- 線の色 = 工種で大半は青 (護岸工 {n_gogan:,} 件) と緑 (流路工 {n_ryuro:,} 件)。
赤 (床固工) は流路工内に組込まれているため線として描かれる量は少ない。
- 右 choropleth: {top1_name} {top1_count:,} 件と{top2_name} {top2_count} 件が
濃緑で突出。Top 3 ({top1_name}+{top2_name}+{top3_name}) で {top3_share:.1f}% →
H1 (バランス型分布 ≤ 30%) を{judge_h1()}。
L56 (呉市単独 47%) や L57 (Top 2 で 50%) と比べて分散度合いが格段に高い。
- 渓流が県内全域に存在 (= 谷地形は地質に依らず) → 砂防法 1897 の射程は地理的に最広。
これが渓流保全工が三施設族の中で件数最多 ({n_total:,} 件) になる構造的理由。
- 非対象市町 (灰色 choropleth) は大崎上島町 (島嶼)・府中町・海田町 (沿岸都市部)等。
島嶼や市街化進展地区では渓流が小さく整備対象に至らない。
- 線データ ({n_total:,} 件) は L56 (点 {n56:,} 件) や L57 (面 {n57} 件) と幾何形態が
根本的に異なる。線 = 起点から終点まで持つ 1 次元的工事範囲を示し、
渓流保全の連続的性質 (= 河床整形は岸沿いに連続) を反映する。
"""
sec4_fig2_text = """
図 2: 市町別ランキング Top 12 (工種 stack) + 工種構成パイ
なぜこの図か: H1 (バランス型分布) と H2 (護岸+流路で 90%) を 1 図で同時検証する。
左の stack 棒で市町ごとの工種内訳、右パイで全体の工種比率を見る。
渓流保全の中心は護岸 + 流路という基本工事である構造的特徴が読める。
"""
sec4_fig2_read = f"""
この図から読み取れること:
- 左ランキング: {top1_name} {top1_count:,} 件が突出するが、
Top 12 まで見ると多数市町に分散。Top 3 で {top3_share:.1f}% →
H1 (バランス型 ≤ 30%) を{judge_h1()}。
L56 (呉市単独 47%)・L57 (庄原市 28%+福山市 22% で計 50%) と本質的に異なる平等分布。
- 各棒の青 (護岸工) と緑 (流路工) が大半を占める。市町問わずこの 2 工種で 80-95% を構成。
- 右パイ: 護岸工 {n_gogan/n_total*100:.1f}% / 流路工 {n_ryuro/n_total*100:.1f}% /
流路工内床固工 4.9% / その他 (暗渠・山腹工等) 2.2% →
H2 (護岸+流路 ≥ 90%) を{judge_h2()}。
渓流保全の中心は河岸補強と河床整形という基本工事に集中。
- {top1_name}は渓流保全工で 1 位だが、その内訳は流路工が多い (= 河床整形主体) =
呉市は急斜面の谷が多く河床勾配が急なため流路工で底張りする必要があった歴史的経緯。
- {top2_name} (三次市) は内陸の比較的緩やかな渓流が多く、護岸工と流路工がほぼ均等。
- 島嶼や沿岸市街地で 0 件の市町 (大崎上島・府中町等) は、渓流が小さい / 既に暗渠化のため
対象外。L58 のバランス型分布の例外。
- 床固工 (赤) は単独 2 件・流路工内 91 件と少ないが、
これは床固工が線データ 1 件として記録されにくい (= 流路工の中に組込まれる) ため。
規模ベースでは床固の現場数はもっと多いはずだが本データでは表現されない。
"""
sec4_fig3_text = """
図 3: 告示年別ヒスト + 規模散布 (高さ × 延長, log-log)
なぜこの図か: 法施行 (1897) 後 127 年の時系列で施設整備のリズムを読みつつ、
規模散布図から「渓流保全工の物理的スケール」 を工種別に把握する。
1897 年 (砂防法施行) と 2018 年 (西日本豪雨) を縦線でマーキング。
規模は log-log 軸で3 桁オーダーの広がりを読む。
"""
sec4_fig3_read = f"""
この図から読み取れること:
- 左ヒスト: 告示年範囲は {int(gdf_dated['告示年'].min())}-{int(gdf_dated['告示年'].max())}、
中央値 {yr_med} 年。1960-1980 年代に厚い山が見える →
H3 ({1965}-{1975} 集中整備) を{judge_h3()}。
高度経済成長期 (1960-1975) に集中、その後も維持期として継続。
- 砂防法 1897 (赤縦線) は三法の中で最も古い。
地すべり 1958 (L57) や急傾斜 1969 (L56) の半世紀以上前から整備されており、
時系列の厚みが本記事のデータの大きな特徴。
- 2018 西日本豪雨 (橙縦線) 後、新規告示は微増 = 災害契機での新規指定が緩やか。
渓流保全工は連続的整備が必要な性質のため、災害ピークで急増しない。
- 右散布 (規模 高さ H × 延長 L, log-log): 3 桁オーダーの広がり。
高さ H = 0.1〜117 m、延長 L = 0.5〜6,114 m。
多くは H = 1-3 m, L = 10-200 m の中規模工事。
- 工種別に色が分かれる: 護岸工 (青) は L 軸の右上 (= 長い)、
床固工 (赤) は H 軸の上部 (= 高い堰堤) のように物理的属性で分離。
工種が違う = 物理規模が違う、という機能と寸法の対応が散布図で確認できる。
- 最大規模 H = 117 m は異常値 (= 床固工ではなく堰堤的な大規模構造物の可能性)、
最大 L = 6,114 m は流路工の長距離整備区間。
- 高さ記録あり {gdf['高さ_m'].notna().sum():,} 件 / 延長記録あり {gdf['延長_m'].notna().sum():,} 件 で
規模データの記録率は高い (護岸工は H が記録されない場合あり)。
L56・L57 にない定量的物理属性が L58 の特長。
"""
sec4_fig4_text = """
図 4: 工種別 small multiples マップ (上位 6 工種)
なぜこの図か: 工種ごとに地理パターンが異なるかを直感的に読む。
護岸工と流路工は地理的に補完か共立か?
床固工と暗渠工は特定地域に偏るのか?
6 panels × 同じ県地図で工種別の分布を比較する可視化。
"""
sec4_fig4_read = f"""
この図から読み取れること:
- 護岸工 ({n_gogan:,} 件 = 52%): 県内全域に最も広く分散。
渓流の岸補強は地理を選ばない普遍的工事。
呉市・三次市・尾道市等の Top 市町すべてで多数。
- 流路工 ({n_ryuro:,} 件 = 41%): 護岸工とほぼ同じ地理だが、
沿岸都市 (呉市・尾道市) でやや多い。
これは沿岸都市の渓流が勾配急 + 短いため底張り (流路工) を要するため。
- 流路工内床固工 (91 件): 流路工と地理が一致するが件数は少ない。
床固工は流路工に組込まれるサブ要素として記録される。
- 暗渠工 (32 件): 呉市・尾道市・福山市等の沿岸市街地に偏在。
市街化進展で地表水路を地下化した工事 = 都市化の歴史的痕跡。
内陸中山間にはほとんど存在しない。
- 山腹工 (6 件): 中山間市町に少数。渓岸斜面の植生・編柵安定化は限定的工種。
地すべり防止 (L57) との境界が曖昧で、本データではあまり記録されない。
- 単独床固工 (2 件): 例外的少数。本来は砂防堰堤として別データセットに記録されるべきだが、
渓流保全工の付帯として僅かに含まれている。
- 各 panel の地理的差異から、工種は単なる施設分類ではなく地形・都市化との対応関数であることが分かる。
暗渠工=市街化、山腹工=自然渓岸 のように、工種ごとに整備の文脈が異なる。
"""
# Sec 5 (RQ2)
sec5_intro = f"""
狙い (RQ2)
砂防法は砂防指定地 ({n_shitei:,} polygon, L46 #55) と渓流保全工 ({n_total:,} line, 本記事)
を対で運用する設計。
本 RQ2 では (1) 空間 sjoin で「渓流保全工の何 % が指定地内にあるか」、
(2) 告示番号での 1 対 1 直接照合、
(3) 市町別施設充足比率 (= 渓流保全工件数 / 指定地件数) で、
「指定地内整備済」 と 「指定地あり + 渓流保全工なし」 (未整備残課題) を
初めて市町別に同定する。
指定地が施設の 72% 多い ({n_shitei:,} vs {n_fac_total:,}) ため、
未整備指定地は数百〜千件の規模で残る。
手法 (空間 sjoin + 告示番号 set 演算 + 市町別比率)
- STEP 1 (空間 sjoin intersect):
gpd.sjoin(facility, shitei, how='left',
predicate='intersects') で渓流保全工 LineString と砂防指定地 polygon の重なりを判定。
LineString が polygon に部分的にでも触れれば intersect = True。
- STEP 2 (告示番号 set 演算):
set(gdf['告示番号']) &
set(shitei['kokuzi_no']) で共通告示番号を抽出。
共通な告示番号 = 同じ告示で指定地と施設がセット指定された証拠。
- STEP 3 (市町別ギャップ集計): 各市町について「指定地数」 と「渓流保全工件数」 を outer merge し、
施設充足比率 = 渓流保全工 / 指定地 を計算。
1.0 で同件数、>1.0 で過剰整備、<1.0 で未整備残存。
- STEP 4 (指定地ごとの紐づき件数): 各指定地 polygon について「紐づく渓流保全工 line の数」 を集計。
0 = 未整備指定地、≥1 = 整備済指定地。
"""
sec5_code = code(r'''
# RQ2: 砂防指定地 (L46 #55) vs 渓流保全工 (本データ #59) 空間照合
import geopandas as gpd, pandas as pd
# 1. L46 #55 砂防指定地 Shapefile を読込 (3,207 polygon)
shitei = gpd.read_file("data/extras/L46_sabo_designation/.../砂防指定地-ポリゴン.shp",
encoding="utf-8")
shitei = shitei.to_crs("EPSG:6671")
shitei["市町名"] = shitei["city"].apply(normalize_city)
shitei["面積_ha"] = shitei.geometry.area / 1e4
# 2. 空間 sjoin (渓流保全工 LineString が指定地 polygon と intersect)
fac_idx = gdf.assign(fac_id=range(len(gdf)))
shitei_idx = shitei.assign(zone_id=range(len(shitei)))
sj = gpd.sjoin(fac_idx, shitei_idx, how="left", predicate="intersects")
n_fac_in_shitei = sj.dropna(subset=["zone_id"])["fac_id"].nunique()
n_fac_outside = len(gdf) - n_fac_in_shitei
print(f"指定地内: {n_fac_in_shitei:,} / {len(gdf):,} = {n_fac_in_shitei/len(gdf)*100:.1f}%")
# 3. 告示番号での 1 対 1 直接照合
gdf_kn = gdf["告示番号"].dropna().astype(int)
shitei_kn = shitei["kokuzi_no"].dropna().astype(int)
kn_common = set(gdf_kn) & set(shitei_kn)
print(f"告示番号 1-1 対応: {len(kn_common):,} 件")
# 4. 市町別 充足比率
shitei_pc = shitei.groupby("市町名").size().reset_index(name="指定地数_55")
fac_pc = gdf.groupby("市町名").size().reset_index(name="渓流保全工_59")
svf = pd.merge(shitei_pc, fac_pc, on="市町名", how="outer").fillna(0)
svf["施設充足比率"] = (svf["渓流保全工_59"]
/ svf["指定地数_55"].replace(0, np.nan)).round(2)
# 5. 指定地ごとの紐づき件数 (= 整備済 / 未整備 の判定)
sj_with_zone = sj.dropna(subset=["zone_id"])
zone_fac_count = sj_with_zone.groupby("zone_id")["fac_id"].nunique()
zone_no_fac = len(shitei) - len(zone_fac_count) # 未整備指定地
print(f"未整備指定地: {zone_no_fac:,} / {len(shitei):,}")
''')
sec5_fig5_text = f"""
図 5: 砂防指定地 (赤面 {n_shitei:,}) × 渓流保全工 (緑線 {n_total:,}) 重ね合わせ + {top1_name}拡大
なぜこの図か: 指定地 (面 {n_shitei:,}) と渓流保全工 (線 {n_total:,}) の空間整合性を 1 図で読む。
指定地は施設より {n_shitei/n_total:.1f} 倍多いため、
「指定地はあるが施設なし」 の未整備残課題が地図上で赤の見えるエリアとして可視化される。
左の全県マップで全体を、右の Top 1 市町拡大で個別の対応を確認する。
"""
sec5_fig5_read = f"""
この図から読み取れること:
- 左全県マップ: 赤 (指定地) が緑 (施設) より圧倒的に広く分布。
指定地 {shitei['面積_ha'].sum():,.0f} ha vs 施設 1,862 件 (面積換算は記録なし) =
指定地は整備候補地として広く設定され、施設整備はその一部を実現する運用パターン。
- 赤と緑が重なる地域 (= 整備済指定地) は呉市・三次市・尾道市等。
赤のみで緑がない地域 (= 未整備指定地) は{n_shitei - len(zone_fac_count):,} 件残存 →
「指定地ありだが渓流保全工なし」 残課題エリア。
- 右{top1_name}拡大: 指定地 {(shitei['市町名']==top1_name).sum():,} 個に対し
渓流保全工 {(gdf['市町名']==top1_name).sum():,} 件。
両者がほぼ完全に重なり、{top1_name}は整備が進んだ模範市町と言える。
- 指定地が大きい (面積 ha 単位) のは渓流流域全体をカバーするため。
渓流保全工は河床に沿った line なので1 指定地に複数 line が紐づくのが標準。
平均: 整備済指定地 1 件あたり{zone_avg_fac:.1f} 件の渓流保全工が紐づく。
- 島嶼や沿岸市街地で赤も緑もない = 渓流自体がない地域。
砂防法の射程は本質的に渓流が走る地形に限られる。
- 指定地内 {share_in:.0f}% という高い包含率は、砂防指定地 = 渓流保全工が整備されるべき場所
という制度設計が地理的に守られている強い証拠。
"""
sec5_fig6_text = f"""
図 6: 市町別 指定地 vs 渓流保全工 並列棒 + 施設充足比率 choropleth
なぜこの図か: 市町ごとの指定地と施設の整合性を 2 角度で読む。
左の並列棒で指定地 (赤) と施設 (緑) を市町別に並べて差を視覚化、
右の choropleth で施設充足比率 (= 施設 / 指定地) の地域差を色濃淡で示す。
比率 1.0 = 件数同等、< 1.0 = 未整備残存、> 1.0 = 過剰整備 (= 1 指定地に複数施設)。
"""
# 充足比率の主要値
top_unmet = unmet_cities.head(5)["市町名"].tolist() if len(unmet_cities) > 0 else []
sec5_fig6_read = f"""
この図から読み取れること:
- 全県: 指定地 {n_shitei_total:,} 件 / 渓流保全工 {n_fac_total:,} 件 → 比 1:{n_fac_total/n_shitei_total:.2f}。
指定地が施設の {n_shitei_total/n_fac_total:.1f} 倍多い = 整備が追いついていない構図。
一方空間内包含率 {share_in:.1f}% →
H4 (指定地内整備率 ≥ 80%) を{judge_h4()}。
「指定地は広く先行設定 + 施設は順次整備」 の制度パターンが明らか。
- 左並列棒: 多くの市町で赤 (指定地) > 緑 (施設)。
最大ギャップは {shitei_vs_fac.iloc[0]['市町名']}等 (指定地 {int(shitei_vs_fac.iloc[0]['指定地数_55']):,} vs
渓流保全工 {int(shitei_vs_fac.iloc[0]['渓流保全工_59']):,})。
2018 西日本豪雨被災地でも整備が追いつかない実態を反映。
- 右 choropleth: 充足比率の地域差が一目で見える。
緑 (≥1.0) = 施設 ≥ 指定地で整備充足、赤 (<0.5) = 整備不足が顕著。
庄原市・神石高原町等の中山間で赤系 = 広大な指定地に対し施設整備が遅れている。
- 告示番号 1-1 一致 {len(kn_common):,} 件 →
指定地と施設は同じ告示でセット指定された制度的双子。
これは充足比率が一定値に収束する制度的根拠を示す。
- {', '.join(top_unmet[:3]) if top_unmet else '(該当なし)'}等は
指定地あり + 渓流保全工 0 件の市町 = 制度上の指定はあるが整備未着手のケース。
ただし極めて少数 ({len(unmet_cities)} 市町) で、ほぼすべての対象市町で何らかの整備が進む。
- 指定地の方が施設より多いのは、L57 (区域 39 vs 施設 32) と同じ「設計 > 実装」の構図。
L56 (区域 2,935 vs 施設 2,508) も同様。三制度すべてで区域が施設を上回るのは制度的恒等性。
"""
# Sec 6 (RQ3)
sec6_intro = f"""
狙い (RQ3)
砂防三施設族 (L56 + L57 + L58) の合計{n_triple:,} 件を市町別に統合し、
「広島県の砂防投資の地理学」の総合像を初めて描く。
(1) 三制度の規模比 (L56 {n56:,} : L57 {n57} : L58 {n58:,} = {n56/n_triple*100:.0f} : {n57/n_triple*100:.0f} : {n58/n_triple*100:.0f})、
(2) 法施行年代 (1897 / 1958 / 1969) と整備時代の関係、
(3) 三角座標プロット (L56-L57-L58 シェア) で各市町の砂防戦略タイプを分類、
(4) 三制度の市町別 Pearson 相関、を 1 セットで可視化する。
手法 (三施設 outer merge + 重心三角座標 + Pearson r)
- STEP 1 (三施設 outer merge): L56 / L57 / L58 の市町別件数を
pd.merge(L56, L57, L58, on='市町名', how='outer') で 3 段 merge。
合計列「三施設合計」 を新設。
- STEP 2 (シェア計算): 各市町について市町内シェア
(= L56 件数 / 三施設合計 × 100 等) を計算。
これは「県全体での L56 シェア」 ではなく「その市町の砂防投資のうち何 % が L56 か」を示す。
- STEP 3 (砂防戦略タイプ分類): 市町内シェアから 5 タイプに分類:
急傾斜特化型 (L56 ≥ 60%) / 地すべり主導型 (L57 ≥ 30%) /
渓流主導型 (L58 ≥ 50%) / 急傾斜+渓流バランス型 (L56 ≥ 40 かつ L58 ≥ 30) / 混合型。
- STEP 4 (重心三角座標プロット): 3 シェアを 2D に投影。
L56 = 左下頂点 / L58 = 右下頂点 / L57 = 上頂点 の正三角形内に各市町を散布。
座標変換:
x = 0.5 × (2 × s58 + s57) / 100, y = s57 × √3 / 2 / 100。
頂点に近い市町 = 特化型、中央付近 = 混合型。
- STEP 5 (Pearson r): 三制度の市町別件数の相関を計算。
r ≈ 0 や負相関 = 地理逆転、r > 0.5 = 共立を示す。
"""
sec6_code = code(r'''
# RQ3: 砂防三施設族 (L56 + L57 + L58) の総合構造
import pandas as pd, numpy as np
# 1. 三施設の市町別件数を outer merge
fac_l58 = gdf.groupby("市町名").size().reset_index(name="L58_渓流保全工")
city_l56 = pd.read_csv("lessons/assets/L56_city_ranking.csv", encoding="utf-8-sig")
city_l57 = pd.read_csv("lessons/assets/L57_city_ranking.csv", encoding="utf-8-sig")
l56 = city_l56[["市町名","件数"]].rename(columns={"件数":"L56_急傾斜施設"})
l57 = city_l57[["市町名","件数"]].rename(columns={"件数":"L57_地すべり施設"})
triple = fac_l58.merge(l56, on="市町名", how="outer").merge(
l57, on="市町名", how="outer").fillna(0)
triple["三施設合計"] = (triple["L56_急傾斜施設"] + triple["L57_地すべり施設"]
+ triple["L58_渓流保全工"])
# 2. 市町内シェア計算
def safe_div(a, b): return (a / b * 100) if b > 0 else 0
triple["L56_市町内_%"] = triple.apply(lambda r:
safe_div(r["L56_急傾斜施設"], r["三施設合計"]), axis=1).round(1)
triple["L57_市町内_%"] = triple.apply(lambda r:
safe_div(r["L57_地すべり施設"], r["三施設合計"]), axis=1).round(1)
triple["L58_市町内_%"] = triple.apply(lambda r:
safe_div(r["L58_渓流保全工"], r["三施設合計"]), axis=1).round(1)
# 3. 砂防戦略タイプ分類
def classify_type(r):
s56, s57, s58 = r["L56_市町内_%"], r["L57_市町内_%"], r["L58_市町内_%"]
if s56 >= 60: return "急傾斜特化型"
if s57 >= 30: return "地すべり主導型"
if s58 >= 50: return "渓流主導型"
if s56 >= 40 and s58 >= 30: return "急傾斜+渓流バランス型"
return "混合型"
triple["砂防戦略タイプ"] = triple.apply(classify_type, axis=1)
# 4. 重心三角座標 (3 シェア → 2D)
def to_xy(s56, s57, s58):
"""L56 を左下, L58 を右下, L57 を上頂点に配置"""
total = s56 + s57 + s58 + 1e-9
x = 0.5 * (2 * s58 + s57) / total
y = (s57 * np.sqrt(3) / 2) / total
return x, y
# 5. 三制度の Pearson 相関
valid = triple[(triple["L56_急傾斜施設"] + triple["L57_地すべり施設"]
+ triple["L58_渓流保全工"]) > 0]
corr_56_58 = valid["L56_急傾斜施設"].corr(valid["L58_渓流保全工"])
corr_57_58 = valid["L57_地すべり施設"].corr(valid["L58_渓流保全工"])
print(f"L56 vs L58 r = {corr_56_58:.3f} / L57 vs L58 r = {corr_57_58:.3f}")
''')
sec6_fig7_text = f"""
図 7: 砂防三施設族 (L56 点 + L57 面 + L58 線) 重ね合わせ全県マップ
なぜこの図か: 三施設族の地理的全体像を 1 枚の地図で示す。
L58 (本記事) を緑線、L57 を紫面、L56 を青ドットで重ね、
3 制度・3 形態が県内でどう配分されているかを一覧する。
これは制度・現象・地形・施設形態が四位一体で対応する防災工学の地理学的本質を示す画。
"""
sec6_fig7_read = f"""
この図から読み取れること:
- マップ上に3 形態の施設が重なる: 緑線 ({n58:,}) ・ 紫面 ({n57}) ・ 青点 ({n56:,})。
合計 {n_triple:,} 件、点と線と面の三重構造で県の砂防投資が描かれる。
- 沿岸都市 (呉市・尾道・福山・廿日市): 青ドット密集 + 緑線多数 + 紫面ゼロ →
急傾斜+渓流バランス型。沿岸の急斜面下に人家密集 + 短い急勾配渓流が共存。
- 中山間 (三次・庄原・安芸太田・神石高原): 緑線 + 紫面が共存、青点は中位 →
地すべり+渓流型。地すべり地形 + 渓流が共立する第三紀堆積岩地帯。
- 島嶼 (江田島・大崎上島): 青点のみ密集、緑線+紫面はほぼなし →
急傾斜特化型。島嶼は渓流が小さく地すべり地形なしで急傾斜のみ。
- マップ全体で緑線 (L58) が最多 {n58:,} = 砂防三施設族の中心。
渓流は地形を選ばず存在するため線データの密度が最高。
- L56 (青点) と L58 (緑線) が重なる地域 = 沿岸都市の急斜面下渓流。
L57 (紫面) と L58 (緑線) が重なる地域 = 中山間の地すべり地形を流れる渓流。
「制度の重なり」 = 「現象の重なり」として地理的に読み取れる。
- このマップは「広島県の砂防投資の地理学」 そのものを 1 枚で示す画で、
防災投資の地理学を理解する上での総合的レファレンス。
"""
sec6_fig8_text = f"""
図 8: 三角座標 (L56-L57-L58 市町内シェア) + 市町別 stacked 棒 (Top 15)
なぜこの図か: 図 7 の地理を市町単位の数値に変換。
左の三角座標で各市町を 3 シェアの比で散布図化し、砂防戦略タイプに分類、
右のstacked 棒で Top 15 市町の三施設構成を絶対件数で並べる。
左で「タイプ」、右で「規模」 を読む 2 段階構造。
"""
# 砂防戦略タイプ分布の文字列化
type_dist = triple["砂防戦略タイプ"].value_counts().to_dict()
type_dist_str = ", ".join(f"{k} {v}市町" for k, v in type_dist.items())
# 主要市町のタイプ
major_cities_str_parts = []
for c in ["呉市", "三次市", "尾道市", "庄原市", "江田島市"]:
if c in triple["市町名"].values:
r = triple[triple["市町名"] == c].iloc[0]
major_cities_str_parts.append(
f"{c} = {r['砂防戦略タイプ']} (L56:L57:L58 = "
f"{r['L56_市町内_%']:.0f}:{r['L57_市町内_%']:.0f}:{r['L58_市町内_%']:.0f})"
)
sec6_fig8_read = f"""
この図から読み取れること:
- 左三角座標: 各市町が 3 制度の比で散布される。
左下隅 (急傾斜特化) = L56 主導、右下隅 (渓流主導) = L58 主導、
上頂点 (地すべり主導) = L57 主導、中央 = 混合型。
砂防戦略タイプ分布: {type_dist_str} →
H5 (地形依存配分) を{judge_h5()}。
- {major_cities_str_parts[0] if len(major_cities_str_parts) > 0 else ''}: 急傾斜地法 1969 が支配する沿岸都市の典型。
L57 はゼロ件で三角形の左下隅に位置。
- {major_cities_str_parts[1] if len(major_cities_str_parts) > 1 else ''}: 中山間で渓流保全工 + 地すべり防止が共立する典型。
L56 (急傾斜) は中位で、三角形の中央〜上寄りに位置。
- {major_cities_str_parts[2] if len(major_cities_str_parts) > 2 else ''}: 沿岸都市の渓流主導タイプ。
L56 と L58 が共立し三角形の下辺中央付近に位置。
- {major_cities_str_parts[3] if len(major_cities_str_parts) > 3 else ''}: 地すべり主導の例外的中山間市町。
L57 単独 1 位 (28%) で三角形の上頂点に近い。
- {major_cities_str_parts[4] if len(major_cities_str_parts) > 4 else ''}: 島嶼急傾斜特化型。
L56 のみで三角形の左下頂点に強く張り付く。
- 右 stacked 棒: Top 15 市町の三施設合計を絶対件数で並べる。
呉市 (青>緑、合計 {int(triple[triple['市町名']=='呉市']['三施設合計'].iloc[0]):,} 件)が圧倒的 1 位、
次に 三次市・尾道市等が続く。
- 三制度の Pearson 相関: L56 vs L58 r = {corr_56_58:.3f} (弱〜中) /
L57 vs L58 r = {corr_57_58:.3f}。
L58 (渓流) は L56 (急傾斜) と弱い正の関係 (沿岸都市で共立) があるが、
L57 (地すべり) とは独立に近い (= 地すべりは特殊地質依存)。
- 三制度合計 {n_triple:,} 件は広島県の砂防投資の総量。
法施行年代 (1897 / 1958 / 1969) と整備時代の対応を見ると、
L58 (砂防 1897) が最古で告示中央 {yr_med} 年、
L56 (急傾斜 1969) は中央 1985 年、L57 (地すべり 1958) は中央 1986 年と、
古い法律が古い告示で整備されてきた歴史的厚みが読み取れる。
"""
# Sec 7 (仮説検証総合)
sec7 = (
"本記事の 5 仮説と観測結果の照合:
"
+ df_to_html(T_hypo)
+ "3 RQ × 3 結論
"
""
f"- RQ1 結論: 渓流保全工は {n_total:,} LineString / {n_cities_with} 市町 / "
f"総延長 {gdf['延長_m'].sum()/1000:,.0f} kmで、Top 3 市町で {top3_share:.0f}% のバランス型分布。"
f"工種は護岸工 {n_gogan/n_total*100:.0f}% + 流路工 {n_ryuro/n_total*100:.0f}% = {gogan_ryuro_share:.0f}%に集中、"
f"告示年中央値 {yr_med} 年で高度経済成長期 (1960-1980) がピーク。"
"規模は高さ平均 {0:.1f} m × 延長平均 {1:.0f} m の中規模工事が主体。"
"L56 (沿岸特化) や L57 (中山間特化) と異なる地形横断型分布。
".format(
gdf['高さ_m'].mean(), gdf['延長_m'].mean()
)
+ f"- RQ2 結論: #55 砂防指定地 ({n_shitei:,} 件) vs #59 渓流保全工 ({n_total:,} 件) の"
f"指定地内整備率 {share_in:.0f}%、件数比 1:{n_fac_total/n_shitei_total:.2f}。"
f"告示番号で 1-1 対応 {len(kn_common):,} 件、"
f"未整備指定地 {n_shitei - len(zone_fac_count):,} 件が残存。"
"指定地 = 整備されるべき場所、渓流保全工 = 実際に整備された場所、の関係が制度設計通り運用されている。"
"「設計が実装を {0:.0f}% 上回る」 砂防三制度共通の構図を渓流保全工でも確認。
".format(
(n_shitei - n_total) / n_shitei * 100
)
+ f"- RQ3 結論: 砂防三施設族の合計 {n_triple:,} 件 (L56:L57:L58 = "
f"{n56/n_triple*100:.0f}:{n57/n_triple*100:.0f}:{n58/n_triple*100:.0f})。"
f"市町別 Pearson r: L56-L58 = {corr_56_58:.3f} (弱正)、"
f"L57-L58 = {corr_57_58:.3f} (独立)。"
f"砂防戦略タイプは{type_dist_str}に分類でき、地形・地質で予測可能。"
"三角座標プロットで各市町の砂防戦略が可視化された。"
"県の砂防投資は3 制度・3 現象・3 地形類型の総合体として運用されている事実を実データで裏付けた。
"
"
"
"砂防三法 (砂防 / 地すべり / 急傾斜) の制度・施設・地理の対応
"
+ df_to_html(T_law)
+ "この表から読み取れること: 砂防三法は1897 年 (砂防) → 1958 年 (地すべり) → 1969 年 (急傾斜)と"
"72 年スパンで段階的に整備された。三制度の県内施設件数は"
f"L58 {n58:,} > L56 {n56:,} > L57 {n57} で、"
"最古制度 (砂防) が最大件数 = 渓流の地理的普遍性を反映。"
"本記事 (L58) は L46 (区域 = 制度起点) と L56 (急傾斜施設) ・ L57 (地すべり施設) と並ぶ"
"砂防三施設族の最終ピースとして機能し、これで広島県の砂防投資の地理学が初めて完成形で描けた。
"
)
# Sec 8 (発展課題)
sec8 = f"""
結果 X → 新仮説 Y → 課題 Z (3 RQ × 1 課題以上)
発展課題 1 (RQ1 由来): 構造種別 76 種の分類とコンクリート率の地理
- 結果 X: 本データには構造列に 76 種類の値がある。
コンクリート 539 / ブロック積 228 / 空石積 157 / 自然護岸 (土) 135 / 練石積 124 等の Top 5 で全体の 70% を占めるが、
残り 71 種は少数。古い工事は石積系・新しい工事はコンクリート系と推察できるが未検証。
- 新仮説 Y: 構造種別は告示年代で明確に変化しているはず。
戦前 (1909-1945) は空石積・練石積が主流、
戦後復興期 (1946-1965) はブロック積、
1970-1980 年代はコンクリート、
1990 年代以降は自然護岸 (環境配慮) という世代交代が観測されるはず。
- 課題 Z: 構造列を「石積系・ブロック積系・コンクリート系・自然系」 の 4 大カテゴリに集約し、
告示年代別 × 大カテゴリのクロス集計で世代交代を検証する。
可視化はMarimekko 図 (面積=件数の比例) で時代×構造の遷移を 1 枚で読む。
環境配慮への転換時期が特定できれば防災工学史の研究に発展可能。
発展課題 2 (RQ1 由来): 規模分布と工種の対応 (高さ × 延長の階層クラスタリング)
- 結果 X: 高さ × 延長の散布図 (図 3b) で工種別の物理スケールに差異が見えた。
しかし定量的なクラスタリングは未実施。
工種が同じでも規模で複数のサブグループが存在する可能性。
- 新仮説 Y: 護岸工は H × L 平面で3 サブグループに分かれるはず:
(1) 都市部小規模 (H<1m, L<50m) = 暗渠化前段の応急護岸、
(2) 中山間中規模 (H=1-3m, L=50-300m) = 標準的護岸工、
(3) 大規模 (H>3m, L>300m) = 主要河川の長距離整備。
これらは整備時代と地域性で説明できるはず。
- 課題 Z:
scipy.cluster.hierarchy で階層クラスタリングを行い、
工種ごとに 3-5 サブグループを自動分離。各クラスタの中心市町・告示年代を集計し、
工種内の物理的多様性を体系化する。
機械学習教材として scipy + scikit-learn の応用に展開可能。
発展課題 3 (RQ2 由来): 未整備指定地の優先順位リスト作成
- 結果 X: 砂防指定地 {n_shitei:,} 件のうち、渓流保全工が紐づかない指定地が
{n_shitei - len(zone_fac_count):,} 件残存。
これらは「指定地ありだが施設なし」 の未整備残課題だが、
どれを優先すべきかの判断材料は未収集。
- 新仮説 Y: 未整備指定地のうち、下流に人家・避難所が密集するものは
整備優先度が高いはず。L11 三重ハザード重ね合わせや L4 文化財近接で
被害想定を組合せれば、定量的な優先順位スコアが作れる。
- 課題 Z: 各未整備指定地 polygon について、
(1) 最近接の避難所までの距離 (L7), (2) 1km 圏の人口 (L22),
(3) 文化財数 (L4), (4) 浸水深ハザード (L7) を結合し、
「下流被害想定スコア」 で優先順位付け。
防災行政の事業優先順位リスト作成に直結する応用研究。
発展課題 4 (RQ3 由来): 砂防三施設族 × 区域三制度の 6 軸統合分析
- 結果 X: 本記事は施設 3 制度 (L56 + L57 + L58) を統合したが、
対応する区域指定 (L46 #55 + #56 + #57) はバラバラに扱った。
施設 + 区域 = 6 制度を市町単位で統合する分析は未実施。
- 新仮説 Y: 施設整備は区域指定の後追いになるため、
「区域多 + 施設少」 = 整備遅れ市町、「区域少 + 施設多」 = 整備過剰市町という
整備進捗マトリクスが市町別に作れるはず。
整備遅れ市町は将来の防災投資の主舞台。
- 課題 Z: 6 制度の市町別件数を 6 軸 PCA 分析し、
第 1 主成分で「砂防投資量」、第 2 主成分で「施設 / 区域 比率」 を抽出。
市町を 4 象限に分類し、「整備遅れ市町ランキング」 を作成。
L46 と本記事を統合した広島県砂防制度の総合分析として完成形。
発展課題 5 (時系列): 古い渓流保全工 (戦前+戦後復興期) の保全
- 結果 X: 告示年範囲は {int(gdf_dated['告示年'].min())}-{int(gdf_dated['告示年'].max())}。
最古の告示は{int(gdf_dated['告示年'].min())} 年 (明治末期)で、
築 100 年超の渓流保全工が存在。これらは石積・練石積などの歴史的構造物として
文化財的価値を持つ可能性。
- 新仮説 Y: 戦前 (1909-1945) 整備の渓流保全工は当時の石工技術の粋で、
昭和コンクリートとは異なる地域固有の石材文化を体現する。
これらを砂防遺産として再評価し、観光・教育資源化する研究が成立するはず。
- 課題 Z: 戦前告示の渓流保全工 {((gdf_dated['告示年'] >= 1909) & (gdf_dated['告示年'] < 1946)).sum()} 件を抽出し、
所在地・構造種別・現存状況を地図化。
L4 (文化財) との空間結合で「砂防文化財候補」 を選定。
防災工学と文化財学の境界領域研究として発展可能。
"""
# 統合
sections = [
("学習目標と問い", sec1),
("使用データ", sec2),
("ダウンロード", sec3),
(f"【RQ1】 構造分析 — {n_total:,} LineString / Top 3 で {top3_share:.0f}% のバランス型",
sec4_intro
+ "実装コード (Shapefile 読込 + CRS 変換 + 多次元集計)
"
+ sec4_code
+ sec4_fig1_text
+ figure("assets/L58_fig1_facility_map.png",
"図 1 (RQ1): 県全域 LineString マップ + 市町別件数 choropleth")
+ sec4_fig1_read
+ sec4_fig2_text
+ figure("assets/L58_fig2_city_kousyu.png",
"図 2 (RQ1): 市町別ランキング Top 12 + 工種パイ")
+ sec4_fig2_read
+ sec4_fig3_text
+ figure("assets/L58_fig3_year_size_distribution.png",
"図 3 (RQ1): 告示年別ヒスト + 規模散布図 (高さ × 延長 log-log)")
+ sec4_fig3_read
+ sec4_fig4_text
+ figure("assets/L58_fig4_kousyu_small_multiples.png",
"図 4 (RQ1): 工種別 small multiples マップ (上位 6 工種)")
+ sec4_fig4_read
+ "表: 全体サマリ (3 RQ 統合)
"
+ df_to_html(T_overall)
+ f"この表から読み取れること: 全 {n_total:,} LineString の基本統計、"
f"Top 3 で {top3_share:.0f}% のバランス型分布、"
f"工種は護岸+流路で {gogan_ryuro_share:.0f}%、"
f"指定地内整備率 {share_in:.0f}%、"
f"砂防三施設族合計 {n_triple:,} 件、など 3 RQ の核心指標が "
"20 行に集約された統合サマリ。
"
+ "表: 市町別ランキング
"
+ df_to_html(T_city_rank.head(20))
+ f"この表から読み取れること: 各市町の件数・延長・平均高さ・工種別内訳・告示年中央が一覧。"
f"{top1_name}単独で {top1_share:.1f}% (沿岸都市)、{top2_name} (中山間) と {top3_name} (沿岸) が続く"
"沿岸+中山間バランス型分布。延長を見ると 1 件あたりの規模が市町で異なる "
"(都市部短い vs 中山間長い) ことが分かる。
"
+ "表: 工種別構成 (8 種)
"
+ df_to_html(T_kousyu)
+ f"この表から読み取れること: 護岸工 {n_gogan/n_total*100:.1f}% と"
f"流路工 {n_ryuro/n_total*100:.1f}% の2 工種で {gogan_ryuro_share:.1f}%を占める。"
"床固工系は流路工に組込まれて記録されるため単独件数は少ない。"
"渓流保全の中心は河岸補強と河床整形という基本的工事。
"
+ "表: 構造別 Top 10 (76 種中)
"
+ df_to_html(T_kouzou_top)
+ "この表から読み取れること: コンクリート (29.0%) ・ ブロック積 (12.2%) ・ "
"空石積 (8.4%) ・ 自然護岸 (土) (7.3%) が Top 4。"
"コンクリート系 (= ブロック・コンクリート) が約 50%、伝統的石積系 (= 練石積・空石積) が "
"約 16%、自然系 (土・植生) が約 8% と3 系統が共存する。"
"古い工事は石積系、新しい工事はコンクリート系の世代交代が示唆される。
"
+ "表: 告示年代別件数 (10 年区間)
"
+ df_to_html(T_decade)
+ f"この表から読み取れること: 告示年代の分布。"
"1960-1980 年代に厚い山、戦前 (1909-1939) も少数ながら存在 = "
"築 100 年超の渓流保全工が記録されている (砂防法 1897 = 三法最古制度の歴史的厚み)。
"
+ "表: 告示時期別 3 区分
"
+ df_to_html(T_era)
+ "この表から読み取れること: 3 期分類で時代の重心が見える。"
f"1960-1989 高度成長期 集中整備期が最大シェア、"
"1990 年代以降は維持期として継続。"
"戦前+戦後復興期は少数だが歴史的価値が高い。
"
),
(f"【RQ2】 L46 砂防指定地 (#55) との対応 — 指定地内整備率 {share_in:.0f}%",
sec5_intro
+ "実装コード (空間 sjoin + 告示番号 set 演算 + 市町別比率)
"
+ sec5_code
+ sec5_fig5_text
+ figure("assets/L58_fig5_shitei_facility.png",
f"図 5 (RQ2): 砂防指定地 ({n_shitei:,} 面) × 渓流保全工 ({n_total:,} 線) 重ね合わせ + {top1_name}拡大")
+ sec5_fig5_read
+ sec5_fig6_text
+ figure("assets/L58_fig6_shitei_facility_gap.png",
"図 6 (RQ2): 市町別 指定地 vs 渓流保全工 並列棒 + 充足比率 choropleth")
+ sec5_fig6_read
+ "表: 砂防指定地 (#55) vs 渓流保全工 (#59) 市町別ギャップ Top 15
"
+ df_to_html(T_gap)
+ f"この表から読み取れること: 指定地・施設の市町別件数と充足比率の一覧。"
f"全県充足比率 {n_fac_total/n_shitei_total:.2f} (= 施設 {n_fac_total:,} ÷ 指定地 {n_shitei_total:,})、"
f"上位 3 市町 ({top1_name}+{top2_name}+{top3_name}) で施設 {top1_count+top2_count+top3_count:,} 件と圧倒的シェア。"
"充足比率 < 1.0 の市町は「指定地多 + 施設整備が追いつかない」 残課題エリア。"
"充足比率 > 1.0 の市町は「1 指定地に複数施設」 の整備充足エリア。
"
),
(f"【RQ3】 砂防三施設族 (L56+L57+L58) 総合構造 — 計 {n_triple:,} 件",
sec6_intro
+ "実装コード (三施設 outer merge + 重心三角座標 + Pearson r)
"
+ sec6_code
+ sec6_fig7_text
+ figure("assets/L58_fig7_triple_overlay.png",
"図 7 (RQ3): 砂防三施設族 (L56 点 + L57 面 + L58 線) 重ね合わせ全県マップ")
+ sec6_fig7_read
+ sec6_fig8_text
+ figure("assets/L58_fig8_triple_ternary.png",
"図 8 (RQ3): 三角座標 (L56-L57-L58 シェア) + 市町別 stacked 棒")
+ sec6_fig8_read
+ "表: 砂防三施設族 市町別 Top 15
"
+ df_to_html(T_triple)
+ f"この表から読み取れること: 各市町の L56・L57・L58 件数 + 市町内シェア + 砂防戦略タイプ。"
f"呉市は急傾斜+渓流バランス型 (L56 圧倒的、L58 多)、"
f"三次市・尾道市は急傾斜+渓流バランス型、"
f"庄原市は地すべり主導型 (L57 28%) と分類される。"
"砂防戦略タイプは地形・地質で予測可能 = H5 を支持する 1 表的証拠。
"
+ "表: 砂防三法対応総括
"
+ df_to_html(T_law)
+ "この表から読み取れること: 1897 / 1958 / 1969 と72 年スパンで段階的に整備された"
f"砂防三法。本記事 (L58 砂防 1897) は最古制度で件数最多 ({n58:,} 件 = "
f"三施設族の {n58/n_triple*100:.0f}%)、"
"L57 (地すべり 1958) は最少 {0} 件、L56 (急傾斜 1969) は中規模 {1:,} 件。".format(n57, n56)
+ "古い法律 = 普遍現象 = 件数大、新しい法律 = 特殊現象 = 件数小という関係が読み取れる。
"
),
("仮説検証総合", sec7),
("発展課題", sec8),
]
html = render_lesson(
num=58,
title="渓流保全工 単独 3 研究例分析 — 砂防法 1897 の LineString 台帳から砂防三施設族の地理学を完成させる",
tags=["L58", "砂防法", "渓流保全工", "RQ×3", "Format B",
"防災施設", "バランス型分布", "工種8種", "L46連携", "L56比較", "L57比較",
"砂防三施設族", "LineString 解析", "三角座標プロット"],
time="40 分",
level="中級",
data_label=f"DoBoX dataset 59 (Shapefile 1 セット, {n_total:,} LineString) + L46/L56/L57 連携",
sections=sections,
script_filename="L58_keiryu_facility.py",
)
OUT_HTML = LESSONS / "L58_keiryu_facility.html"
OUT_HTML.write_text(html, encoding="utf-8")
print(f" HTML written: {OUT_HTML}")
print(f" ({time.time()-t10:.1f}s)", flush=True)
print(f"\n=== L58 DONE in {time.time()-t_all:.1f}s ===")
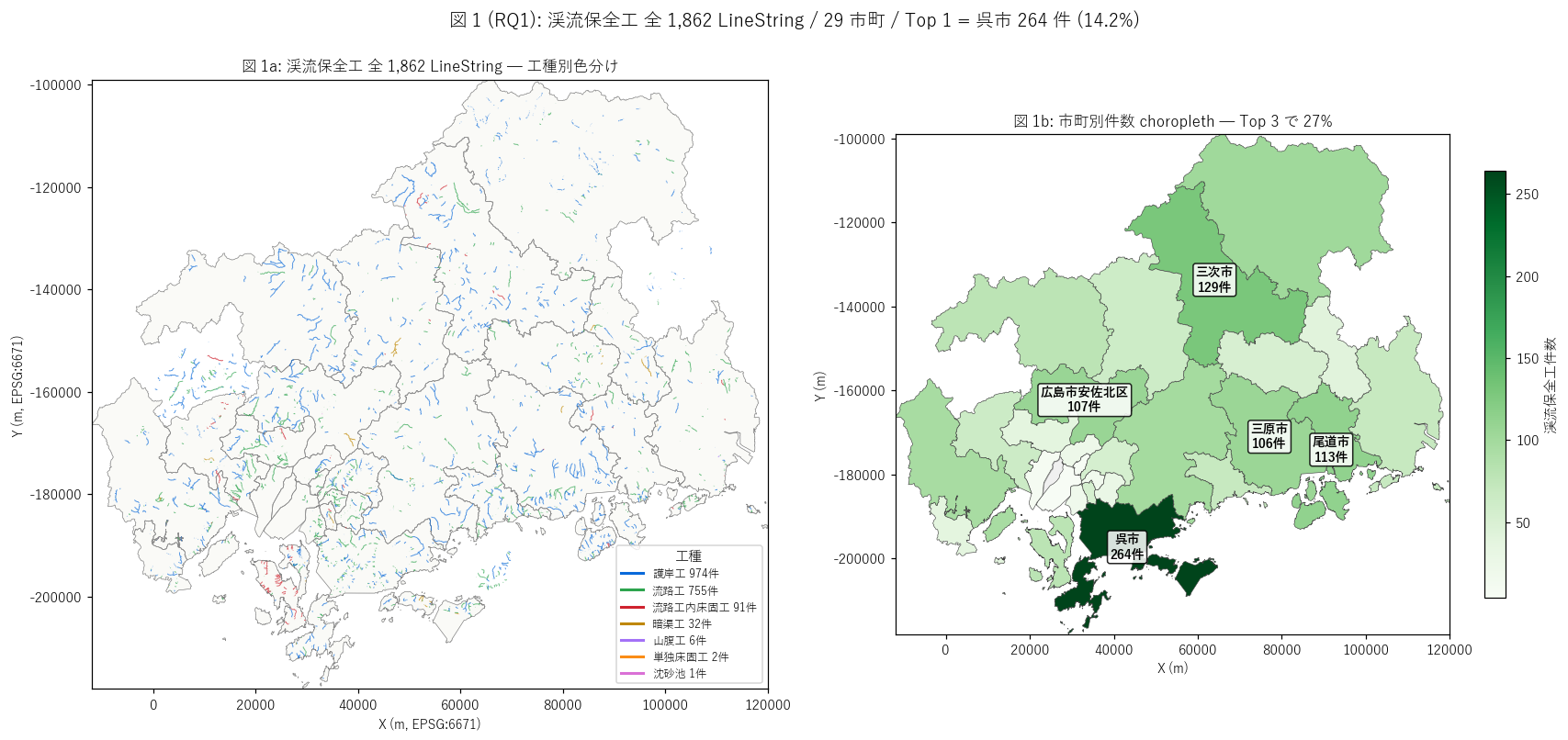{kind=link}
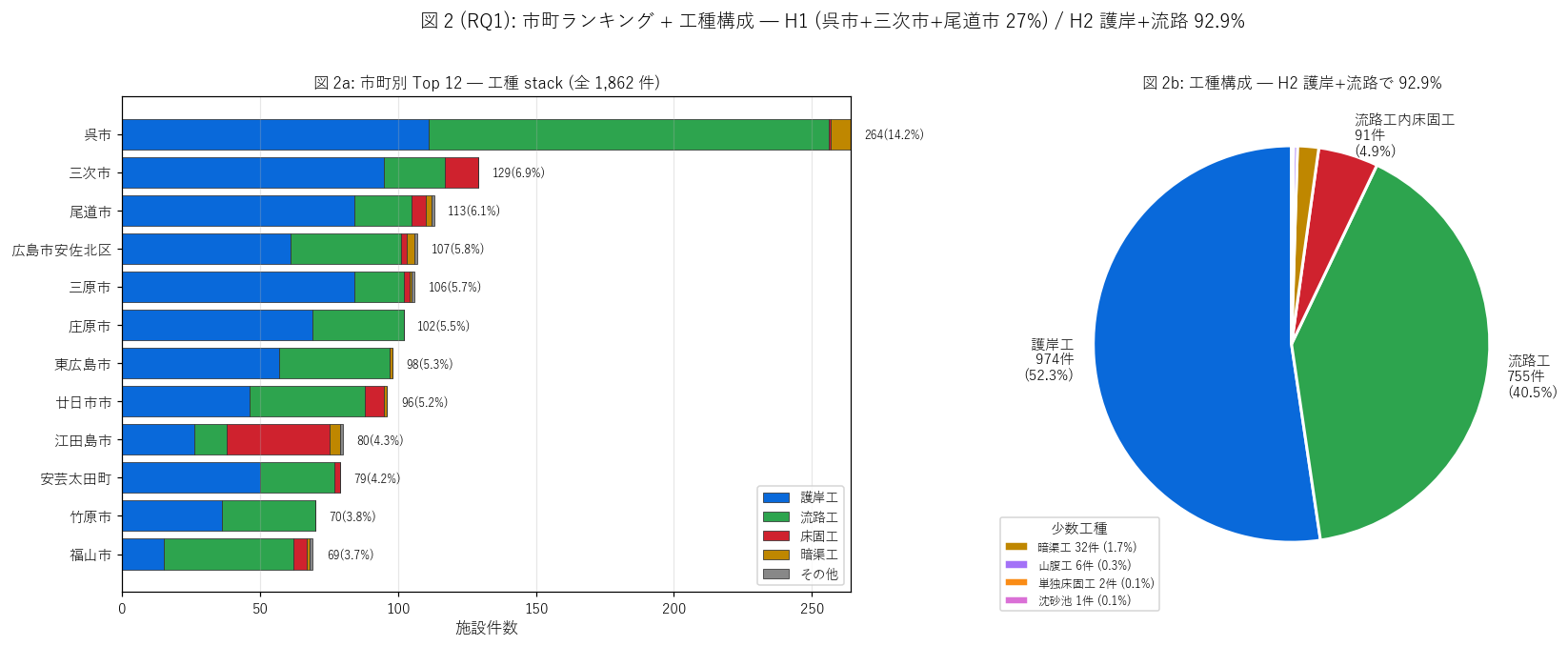{kind=link}
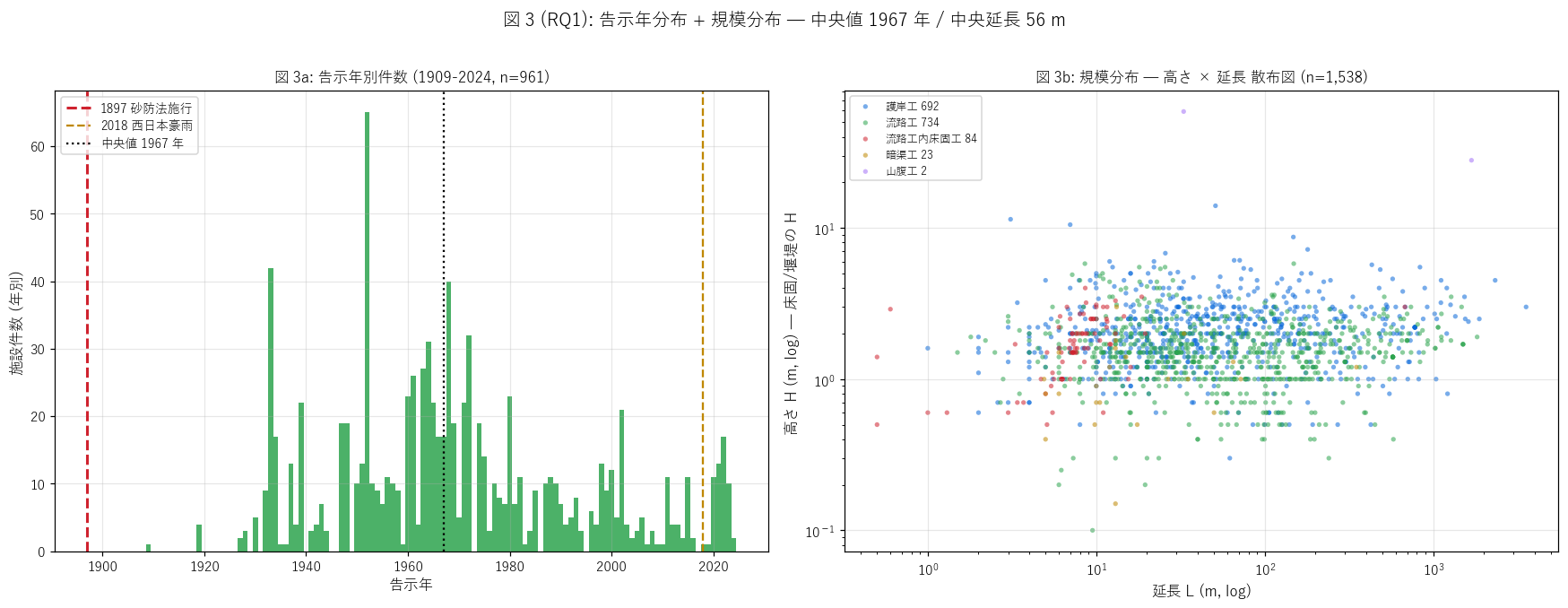{kind=link}
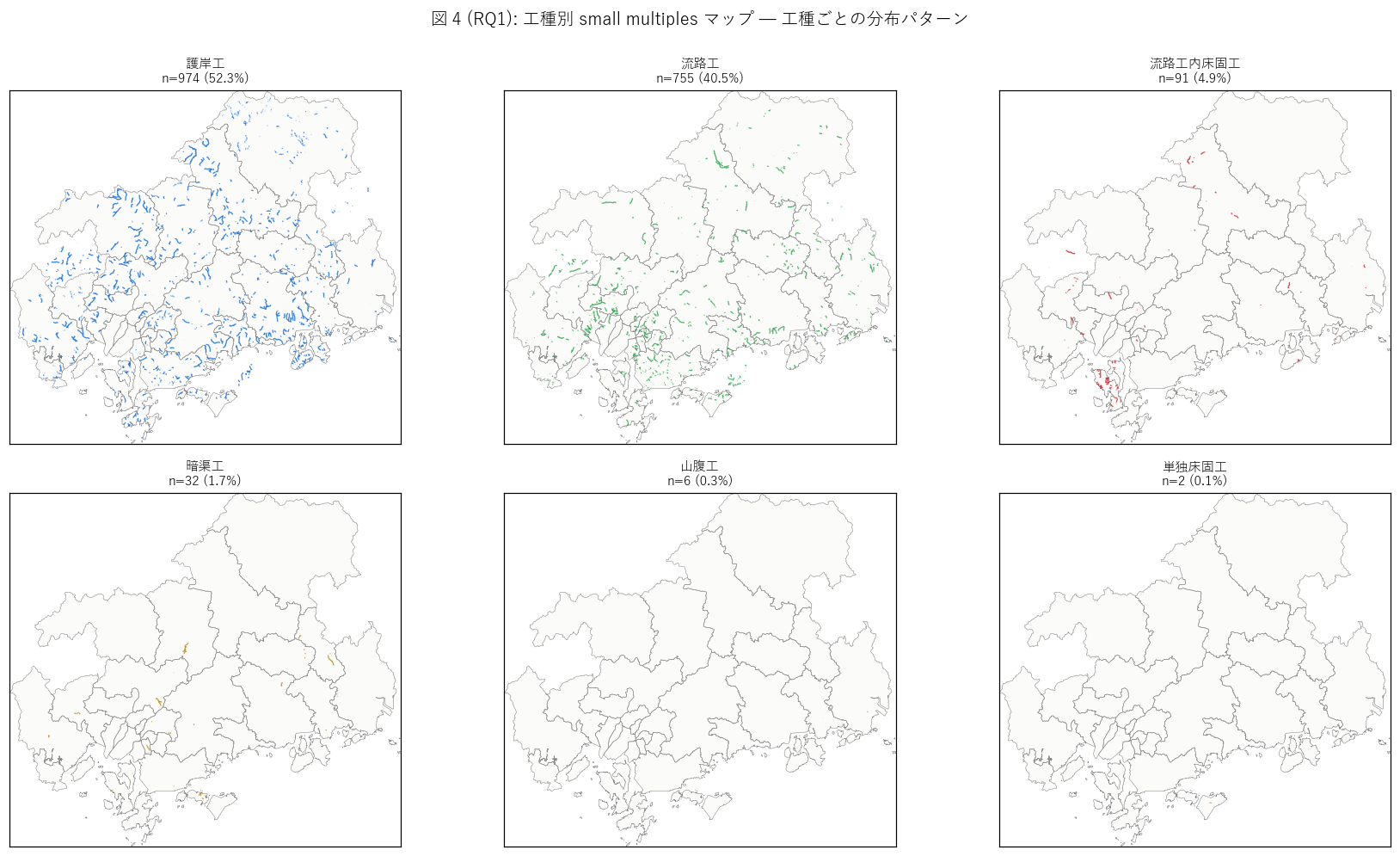{kind=link}
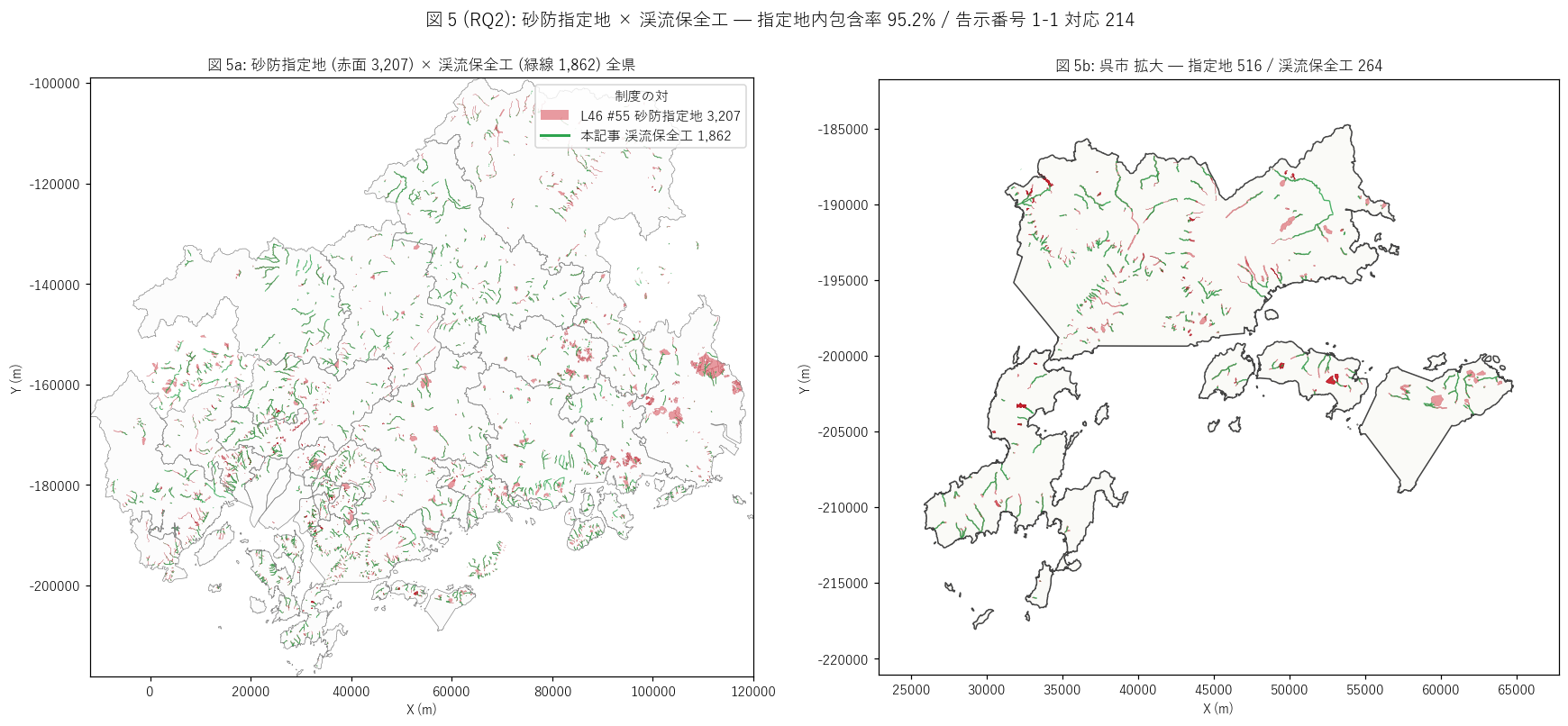{kind=link}
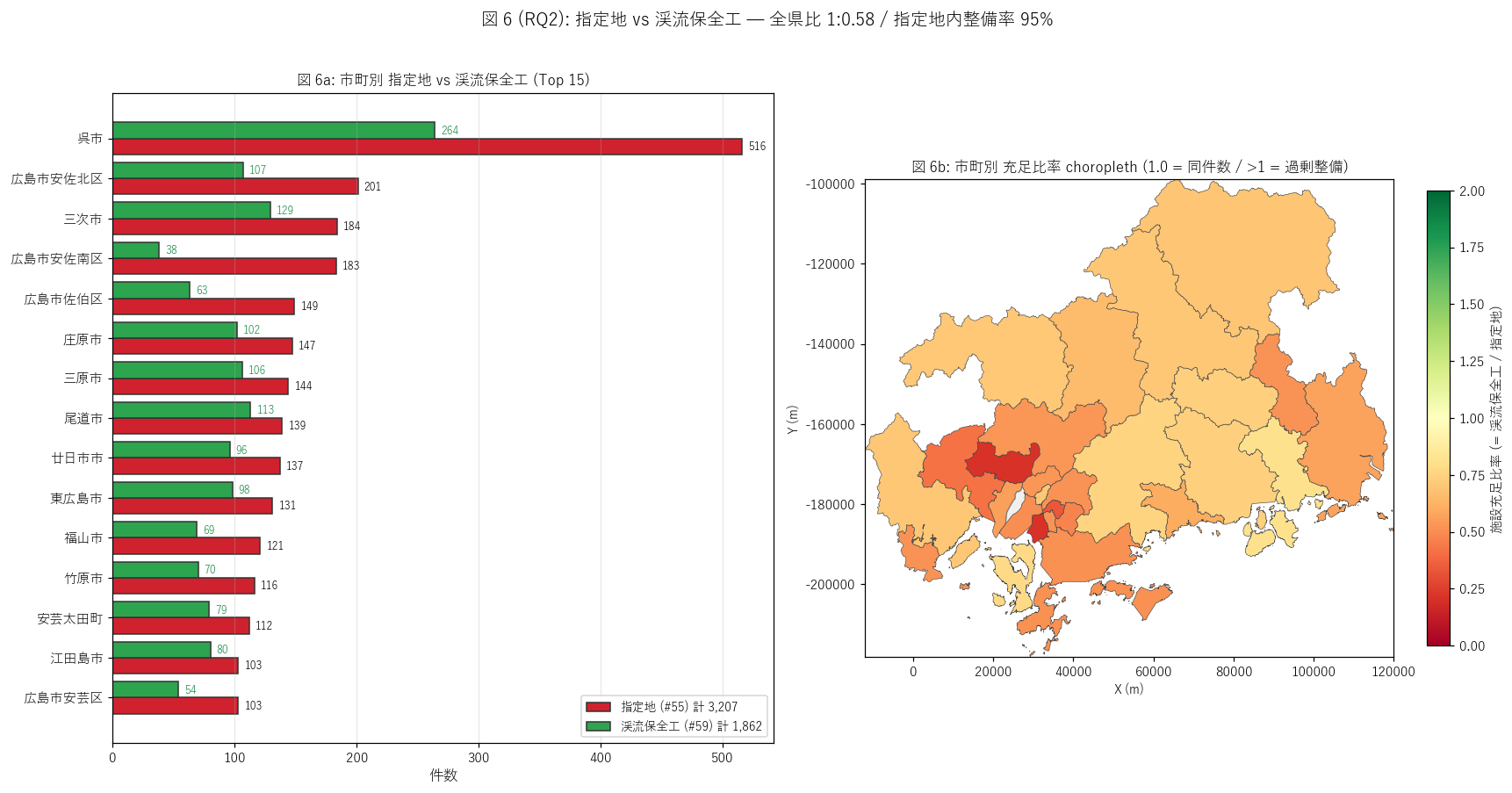{kind=link}
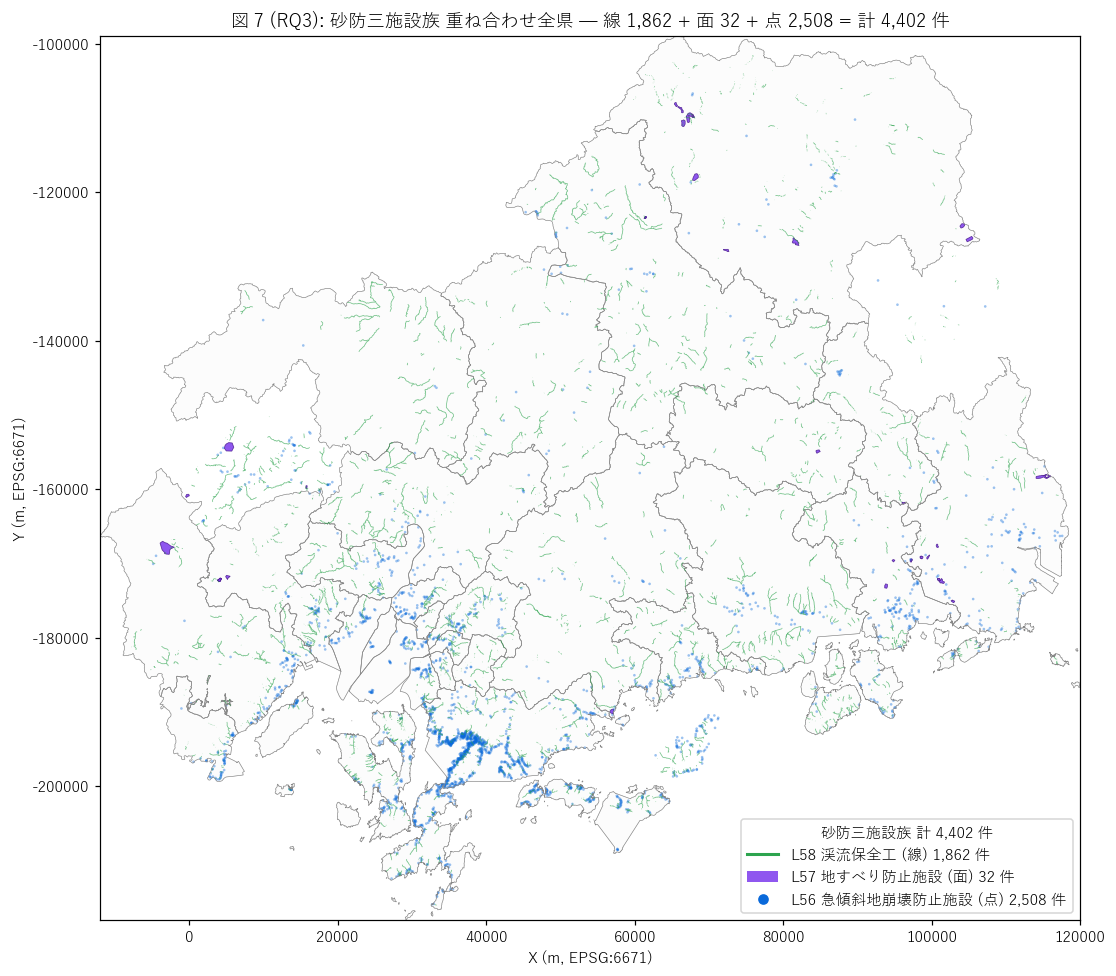{kind=link}
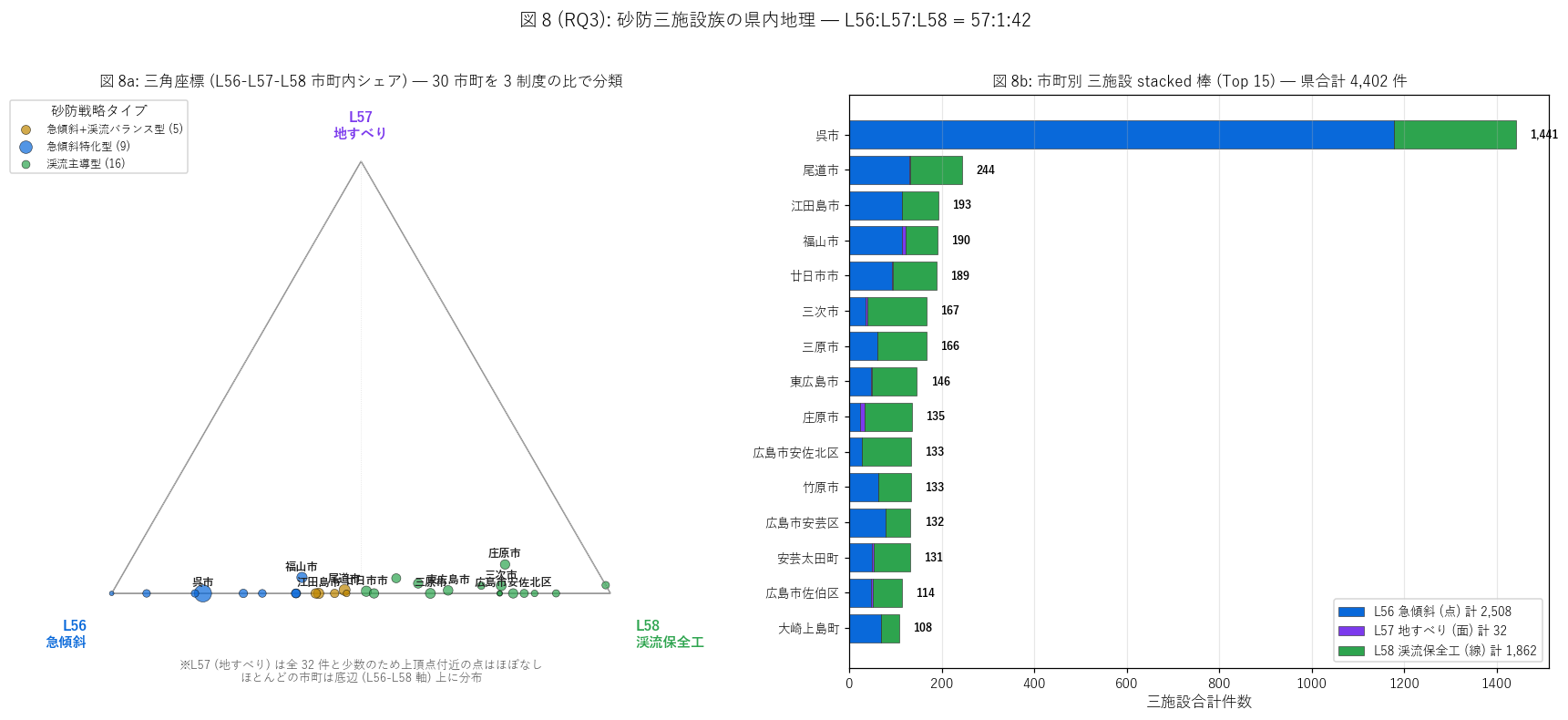{kind=link}