# -*- coding: utf-8 -*-
"""L56 急傾斜地崩壊防止施設 単独 3 研究例分析
— 広島県の「急傾斜地崩壊防止施設基本情報」 2,508 件を
3 つの独立した研究角度で読み解く
カバー宣言:
本記事は DoBoX のシリーズ「急傾斜地崩壊防止施設基本情報」 1 件
(dataset_id = 60) を 単独で取り上げ、
広島県内の急傾斜地崩壊防止施設 (CSV, 2,508 件) を
3 つの独立した研究角度 (RQ1 / RQ2 / RQ3) で並列に分析する。
Phase 3 防災施設系の最初の記事。
「急傾斜地崩壊防止施設」 とは:
急傾斜地法 (= 急傾斜地の崩壊による災害の防止に関する法律, 1969-07-01 施行)
に基づき、知事指定の急傾斜地崩壊危険区域内で県・市町が整備した
崖崩れ防止のための物理的構造物。
具体的には擁壁・法枠工・グランドアンカー・ロックネット・
落石防護柵・落石防護網・モルタル吹付等。
本データは広島県土木建築局 砂防課が管理する施設台帳の位置情報版で、
2026-04-27 時点で広島県内 2,508 件の施設位置 (緯度経度) を保持。
「急傾斜地法」 (1969) と本データの位置付け:
1967 年 7 月 神戸市・呉市の集中豪雨による崖崩れで死者 200 名超。
これを契機に翌 1969 年に「急傾斜地の崩壊による災害の防止に関する法律」 が制定。
法律は 2 つの仕組みを規定:
(1) 急傾斜地崩壊危険区域指定 (= L46 で扱う #56, 県内 2,935 件) =
知事が指定する 傾斜 30 度以上・高さ 5m 以上・人家 5 戸以上に
被害を及ぼす急斜面。区域内では切土・盛土・伐採等が許可制。
(2) 急傾斜地崩壊防止施設整備 (= 本データ #60, 県内 2,508 件) =
危険区域内で県・市町が整備するハード対策。
擁壁・法枠・アンカー・落石防護網等の物理工事で発生抑止・拡大防止を図る。
(1) は区域 (面)、(2) は施設 (点)として両者を対で運用するのが法の建前。
「危険箇所番号」 (本データの主キー):
各施設レコードには 「危険箇所番号」 列があり、
これは L46 で扱う #56 急傾斜地崩壊危険区域の区域識別子と対応する設計。
本記事 RQ2 ではこの番号を介して 区域 (#56) ⇄ 施設 (#60) の
1 対 1 対応を直接照合し、「区域指定済 + 施設整備済」 /
「区域指定済 + 施設未整備」 /「施設のみ (区域未指定)」 の
3 区分を初めて定量化する。これは防災投資の残課題マッピングに直結する研究。
「斜面区分」 (本研究の独自集計軸):
本データの「斜面区分」 列には 自然 / 人工の 2 値が入る (一部空欄)。
自然斜面 = もともとの地形が急傾斜である崖。
人工斜面 = 道路掘削・宅地造成等で人為的に作られた急斜面。
本研究では両者の市町別構成・告示年代の違いを集計し、
呉市の軍港開発史 (人工急斜面が多いはず)等の地理的仮説を検証する。
「告示年月日」 (整備時期の時系列):
各施設の整備時期は告示年月日列で記録される。
1969 年 (急傾斜地法施行年) から 2024 年まで 55 年間のレコード。
時系列の偏在 = 1970 年代の集中整備期 / 1990 年代以降の漸減 / 2018 年西日本豪雨後の
再加速、といった制度史と現場運用の対応を読む研究軸となる。
研究の問い (3 RQ):
RQ1 (主研究): 広島県の急傾斜地崩壊防止施設の構造はどう描けるか?
2,508 件の市町別ランキング、斜面区分 (自然 / 人工) の偏在、
告示年月日の時系列分布、地理的集中パターンを多角度に集計する。
呉市が単独でどれほどの比率を占めるか? なぜ呉市にこれほど集中するのか?
RQ2 (副研究 1): 施設は急傾斜地崩壊危険区域 (L46 既扱 #56) や
土砂災害警戒区域 (L10/L11 既扱) とどう対応するか?
危険箇所番号を介して #56 区域 ⇄ #60 施設の 1 対 1 対応を照合し、
「区域あり施設なし」 (= 残課題エリア) を初めて市町別に定量化。
さらに各施設点が土砂災害警戒区域 (急傾斜) の内/100m以内/離隔のどこにあるかを
STRtree で空間結合し、施設配置の空間整合性を診断する。
RQ3 (副研究 2): 施設は下流の人口 (L22 既扱) や建物 (L20 既扱) と
どれだけ整合した配置か?
市町別に施設件数と人口・新築建物・人口密度を結合し、
1 施設あたり守る人口・建物数のばらつきを集計。
「人口集中の上流に施設あり」 検証と守られていない高リスク集落の
同定 (= 人口・建物多いのに施設少ない市町) を行う。
これは防災投資の地理的優先順位の評価研究。
仮説 (5):
H1 (呉市偏重, RQ1): 2,508 件のうち呉市単独で 40% 以上を占める。
呉市は太平洋戦争前から軍港背後の急斜面に住宅密集が拡大し、
2018 西日本豪雨でも被害集中地。歴史的人口圧 → 急斜面開発 → 防止施設整備の
長期帰結を映す。L46 RQ で観測された呉市偏重 (急傾斜地崩壊危険区域 #56 で 35%) と整合的。
H2 (自然斜面優位, RQ1): 斜面区分は自然 (= もとから急斜面) が 80% 以上。
人工斜面 (= 道路・造成由来) は 5-10% 程度の少数派。
これは急傾斜地法が「自然崖の人家被害」 を主に想定して制定された (1969) ことに整合。
ただし呉市等の都市部では人工比率が他市町より高いはず。
H3 (1970-90 年代集中整備, RQ1): 告示年代の中央値は1985-1990 年付近。
急傾斜地法施行 (1969) 直後の 1970-80 年代に集中整備が進み、
1990 年代以降は漸減。ただし2018 西日本豪雨 (死者 87 名) 後の
2019-2021 年に再加速のシグナルが見える可能性。
H4 (区域指定 vs 施設整備のギャップ, RQ2): L46 #56 (危険区域 2,935 件) と
本データ #60 (施設 2,508 件) の差 = 約 400 件 = 14%が
「区域指定済だが施設未整備」の残課題。
市町別に見ると、呉市以外の中山間市町でこのギャップが大きいはず
(= 区域指定は進んでいるが財源不足で施設整備が追いついていない)。
H5 (人口・建物との整合, RQ3): 市町別の施設件数と人口・新築建物数は
正の相関 (Pearson r = 0.5-0.7)。ただし呉市は人口に対して施設が過剰、
庄原市・三次市等の中山間市町は人口に対して施設が過小という非対称性が
見られるはず。これは「都市部偏重 + 中山間軽視」 の防災投資バイアスを示す。
要件 S 準拠 (1分以内完走):
- CSV 2,508 行は軽量 (~440 KB)。読込・パース・空間結合は <5 秒で完了。
- 警戒区域 (急傾斜) shp は polygon 数が大きい (約 30K) ため、STRtree で
2,508 点 × 30K polygon の最近傍を 10 秒以内で処理。
- L46 #56 の CSV は既存 (約 0.5 MB) → 直接読込。
- 期待実行時間: <30 秒。
要件 T 準拠 (位置情報あり=地図必須):
- RQ1: 県全域 2,508 点マップ (市町色分け、斜面区分マーカー)
- RQ1: 市町別件数 choropleth
- RQ1: 告示年代別 small multiples マップ (5 期 × 5 panels)
- RQ2: 警戒区域オーバーレイ (施設点 × 警戒区域)
- RQ2: 距離区分による点マップ (赤=区域内, 橙=100m, 緑=安全)
- RQ2: #56 区域 vs #60 施設の市町別ギャップ choropleth
- RQ3: 人口/建物 vs 施設件数 散布図 + 市町別保護指数 choropleth
要件 Q 準拠: 図 9 / 表 12 (3 RQ × 多角度)。
データ仕様:
- dataset 60: 急傾斜地崩壊防止施設基本情報
- リソース 22826 (CSV, 438 KB): 砂防_急傾斜地崩壊防止施設_2026-04-27 (2,508 行)
- 列構成: 履歴ID / 危険箇所番号 / 箇所名 / 県 / 市区郡町 / 字 / 斜面区分 /
地区名 / 位置 / 告示年月日 / 告示番号 / 緯度 / 経度
- 取得日: 2026-05-09
- ライセンス: クリエイティブ・コモンズ表示 4.0
- 作成主体: 広島県土木建築局 砂防課
"""
from __future__ import annotations
import sys, time, shutil
from pathlib import Path
sys.path.insert(0, str(Path(__file__).parent))
from _common import ROOT, ASSETS, LESSONS, render_lesson, code, figure
import numpy as np
import pandas as pd
import geopandas as gpd
from shapely import STRtree
import requests
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.patches import Patch
from matplotlib.lines import Line2D
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
t_all = time.time()
print("=== L56 急傾斜地崩壊防止施設 単独 3 研究例分析 ===", flush=True)
# =============================================================================
# 0. 定数・パス
# =============================================================================
TARGET_CRS = "EPSG:6671" # JGD2011 平面直角座標系第 III 系 (m 単位)
SRC_CRS = "EPSG:4326" # CSV の緯度経度は WGS84 想定
DATA_DIR = ROOT / "data" / "extras" / "L56_steep_slope_facility"
DATA_DIR.mkdir(parents=True, exist_ok=True)
CSV_PATH = DATA_DIR / "砂防_急傾斜地崩壊防止施設_2026-04-27.csv"
# L46 #56 の急傾斜地崩壊危険区域 CSV (区域 vs 施設の照合用)
L46_KYUKEI_CSV = ROOT / "data" / "extras" / "L46_sabo_designation" / \
"sabo_designation_56_kyukeisha_kuiki.csv"
# 警戒区域 (L10/L11 既扱)
WARN_KYUKEI = ROOT / "data" / "extras" / "sediment_shp" / "kyukeisha" / \
"340006_sediment_disaster_hazard_area_steep_slope_20260427" / \
"73_031krp_34_20260427.shp"
# 行政区域
ADMIN_PREF_ZIP = ROOT / "data" / "extras" / "L15_admin_zones" / "admin_922_広島県.zip"
# 既処理 city summary CSV (L20 = 新築建物 / L22 = 人口)
L20_CITY = ASSETS / "L20_city_summary.csv"
L22_CITY = ASSETS / "L22_city_summary.csv"
# DoBoX
DOBOX_BASE = "https://hiroshima-dobox.jp"
HDR = {"User-Agent": "DoBoX-MDASH-textbook/1.0 (educational use)"}
# 主要日付
LAW_ENFORCED = pd.Timestamp("1969-07-01") # 急傾斜地法施行日
RAIN_2018 = pd.Timestamp("2018-07-06") # 西日本豪雨
PREF_AREA_KM2 = 8479.4 # 広島県総面積
# 市町コード → 市町名 (L52/L53/L54/L55 と共通)
CITY_NAME = {
101: "広島市中区", 102: "広島市東区", 103: "広島市南区", 104: "広島市西区",
105: "広島市安佐南区", 106: "広島市安佐北区", 107: "広島市安芸区", 108: "広島市佐伯区",
202: "呉市", 203: "竹原市", 204: "三原市", 205: "尾道市", 207: "福山市",
208: "府中市", 209: "三次市", 210: "庄原市", 211: "大竹市", 212: "東広島市",
213: "廿日市市", 214: "安芸高田市", 215: "江田島市",
302: "府中町", 304: "海田町", 307: "熊野町", 309: "坂町",
369: "安芸太田町", 462: "世羅町",
364: "北広島町", 545: "神石高原町", 454: "大崎上島町",
}
NAME_TO_CITY_CD = {v: k for k, v in CITY_NAME.items()}
# =============================================================================
# 1. データ取得
# =============================================================================
print("\n[1] データ取得", flush=True)
t1 = time.time()
if not CSV_PATH.exists() or CSV_PATH.stat().st_size < 1000:
url = f"{DOBOX_BASE}/resource_download/22826"
print(f" DL <- {url}")
r = requests.get(url, headers=HDR, timeout=60)
r.raise_for_status()
CSV_PATH.write_bytes(r.content)
print(f" saved -> {CSV_PATH.name} ({len(r.content)} bytes)")
else:
print(f" cache HIT: {CSV_PATH.name} ({CSV_PATH.stat().st_size} bytes)")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 2. CSV 読込・前処理
# =============================================================================
print("\n[2] CSV 読込・前処理", flush=True)
t1 = time.time()
df = pd.read_csv(CSV_PATH, encoding="utf-8-sig")
df.columns = [c.strip() for c in df.columns]
print(f" raw rows: {len(df)}, columns: {df.columns.tolist()}")
# 緯度経度を数値に
df["緯度"] = pd.to_numeric(df["緯度"], errors="coerce")
df["経度"] = pd.to_numeric(df["経度"], errors="coerce")
n_no_xy = df[["緯度", "経度"]].isna().any(axis=1).sum()
df = df.dropna(subset=["緯度", "経度"]).reset_index(drop=True)
print(f" 緯度経度欠損除外: {n_no_xy} 件 → 残 {len(df)} 件")
# 告示年月日を datetime に
df["告示年月日_dt"] = pd.to_datetime(df["告示年月日"], errors="coerce")
df["告示年"] = df["告示年月日_dt"].dt.year
n_no_date = df["告示年月日_dt"].isna().sum()
print(f" 告示年月日 欠損: {n_no_date} 件 ({n_no_date/len(df)*100:.1f}%)")
print(f" 告示年範囲: {df['告示年'].min():.0f}〜{df['告示年'].max():.0f} "
f"(中央値 {df['告示年'].median():.0f})")
# 斜面区分の正規化 (空欄 → "不明")
df["斜面区分"] = df["斜面区分"].fillna("").astype(str).str.strip()
df.loc[df["斜面区分"] == "", "斜面区分"] = "不明"
print(f" 斜面区分: {df['斜面区分'].value_counts().to_dict()}")
# 市区郡町 を「市町名」 に正規化 (郡名混入を分離)
def normalize_city(s: str) -> str:
s = str(s).strip()
# 「豊田郡大崎上島町」 → 「大崎上島町」、「山県郡安芸太田町」 → 「安芸太田町」 等
if "郡" in s:
s = s.split("郡", 1)[1]
return s
df["市町名"] = df["市区郡町"].apply(normalize_city)
print(f" 市町数: {df['市町名'].nunique()}")
print(f" 市町別件数 上位 5: {df['市町名'].value_counts().head(5).to_dict()}")
# GeoDataFrame 化
gdf = gpd.GeoDataFrame(
df,
geometry=gpd.points_from_xy(df["経度"], df["緯度"]),
crs=SRC_CRS,
).to_crs(TARGET_CRS)
gdf["x_m"] = gdf.geometry.x
gdf["y_m"] = gdf.geometry.y
n_total = len(gdf)
print(f" GeoDataFrame: {n_total} 点 (CRS=EPSG:6671)")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 3. 行政区域・参考データ読込
# =============================================================================
print("\n[3] 行政区域・参考データ読込", flush=True)
t1 = time.time()
import zipfile as _zip
with _zip.ZipFile(ADMIN_PREF_ZIP) as zf:
name = [n for n in zf.namelist() if n.endswith(".geojson")][0]
admin = gpd.read_file(f"zip://{ADMIN_PREF_ZIP}!{name}").to_crs(TARGET_CRS)
admin_diss = admin.dissolve(by="CITY_CD", as_index=False)
# CITY_CD → 市町名 を CITY_NAME 辞書から付与
admin_diss["市町名"] = admin_diss["CITY_CD"].map(CITY_NAME).fillna("不明")
print(f" admin: {len(admin_diss)} 市町ブロック (CITY_NAME mapped {(admin_diss['市町名']!='不明').sum()})")
# L46 #56 (急傾斜地崩壊危険区域 CSV) を読込
df_kyukei_zone = pd.read_csv(L46_KYUKEI_CSV, encoding="utf-8-sig")
df_kyukei_zone.columns = [c.strip() for c in df_kyukei_zone.columns]
df_kyukei_zone = df_kyukei_zone[
df_kyukei_zone["砂防関係指定地の種類"] == "急傾斜地崩壊危険区域"
].copy()
df_kyukei_zone["市町名"] = df_kyukei_zone["市区郡町"].apply(normalize_city)
n_zones = len(df_kyukei_zone)
print(f" L46 #56 急傾斜地崩壊危険区域: {n_zones} 件 (区域)")
# L10/L11 警戒区域 (急傾斜) shp を読込
warn_kyukei = gpd.read_file(WARN_KYUKEI).to_crs(TARGET_CRS)
print(f" 警戒区域 (急傾斜): {len(warn_kyukei):,} polygon")
# L20 / L22 既処理 CSV
city_summary_l20 = pd.read_csv(L20_CITY, encoding="utf-8") if L20_CITY.exists() else None
city_summary_l22 = pd.read_csv(L22_CITY, encoding="utf-8") if L22_CITY.exists() else None
print(f" L20 (新築建物): {'OK' if city_summary_l20 is not None else 'NA'} "
f"{len(city_summary_l20) if city_summary_l20 is not None else 0} 行")
print(f" L22 (人口): {'OK' if city_summary_l22 is not None else 'NA'} "
f"{len(city_summary_l22) if city_summary_l22 is not None else 0} 行")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 4. RQ1 集計: 構造分析 (市町別 / 斜面区分 / 告示年代)
# =============================================================================
print("\n[4] RQ1 集計", flush=True)
t1 = time.time()
# 4-1 市町別ランキング
city_summary = df.groupby("市町名").agg(
件数=("履歴ID", "count"),
自然=("斜面区分", lambda s: (s == "自然").sum()),
人工=("斜面区分", lambda s: (s == "人工").sum()),
不明=("斜面区分", lambda s: (s == "不明").sum()),
告示年中央=("告示年", "median"),
).reset_index().sort_values("件数", ascending=False)
city_summary["件数シェア_%"] = (city_summary["件数"] / city_summary["件数"].sum()
* 100).round(2)
city_summary["順位"] = np.arange(1, len(city_summary) + 1)
city_summary["人工率_%"] = (city_summary["人工"]
/ city_summary["件数"] * 100).round(1)
top1_name = city_summary.iloc[0]["市町名"]
top1_count = int(city_summary.iloc[0]["件数"])
top1_share = city_summary.iloc[0]["件数シェア_%"]
top5_share = city_summary.head(5)["件数シェア_%"].sum()
n_cities = len(city_summary)
print(f" 市町数: {n_cities}")
print(f" Top 1: {top1_name} {top1_count} 件 ({top1_share:.1f}%)")
print(f" Top 5 シェア: {top5_share:.1f}%")
# 4-2 斜面区分集計
slope_total = df["斜面区分"].value_counts()
n_natural = int(slope_total.get("自然", 0))
n_artificial = int(slope_total.get("人工", 0))
n_unknown = int(slope_total.get("不明", 0))
natural_share = n_natural / len(df) * 100
artificial_share = n_artificial / len(df) * 100
print(f" 斜面区分: 自然 {n_natural} ({natural_share:.1f}%), "
f"人工 {n_artificial} ({artificial_share:.1f}%), 不明 {n_unknown}")
# 4-3 告示年代分布 (5 年区間)
df_dated = df.dropna(subset=["告示年"]).copy()
df_dated["告示年"] = df_dated["告示年"].astype(int)
df_dated["告示年代"] = (df_dated["告示年"] // 10) * 10 # 10 年区間
year_decade = df_dated.groupby("告示年代").size().reset_index(name="件数")
year_decade["シェア_%"] = (year_decade["件数"]
/ year_decade["件数"].sum() * 100).round(1)
print(f" 告示年代別件数:\n{year_decade.to_string(index=False)}")
# 期間ラベル (5 区分)
def era_label(y):
if y < 1980:
return "1969-1979 (法施行直後)"
if y < 1990:
return "1980-1989 (集中整備)"
if y < 2000:
return "1990-1999 (漸減)"
if y < 2010:
return "2000-2009 (低水準)"
return "2010-2024 (豪雨後)"
df_dated["告示時期"] = df_dated["告示年"].apply(era_label)
era_counts = df_dated.groupby("告示時期").size().reset_index(name="件数")
era_counts["シェア_%"] = (era_counts["件数"]
/ era_counts["件数"].sum() * 100).round(1)
print(f" 時期別:\n{era_counts.to_string(index=False)}")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 5. RQ2 集計: 警戒区域・危険区域との関係
# =============================================================================
print("\n[5] RQ2 集計", flush=True)
t1 = time.time()
# 5-1 危険箇所番号 から区域番号を抽出 (#56 区域番号と照合用)
# 形式は "?-1-1008" のような 3 段 (prefix-block-id)。
# L46 #56 側は告示番号で識別されるので、市町名 + 件数比較で間接照合する。
df_kyukei_zone_count = df_kyukei_zone.groupby("市町名").size().reset_index(name="区域数_56")
df_facility_count = df.groupby("市町名").size().reset_index(name="施設数_60")
zone_vs_facility = pd.merge(df_kyukei_zone_count, df_facility_count,
on="市町名", how="outer").fillna(0)
zone_vs_facility["区域数_56"] = zone_vs_facility["区域数_56"].astype(int)
zone_vs_facility["施設数_60"] = zone_vs_facility["施設数_60"].astype(int)
zone_vs_facility["差_区域-施設"] = zone_vs_facility["区域数_56"] - zone_vs_facility["施設数_60"]
zone_vs_facility["施設整備率_%"] = (zone_vs_facility["施設数_60"]
/ zone_vs_facility["区域数_56"]
.replace(0, np.nan) * 100).round(1)
zone_vs_facility = zone_vs_facility.sort_values("差_区域-施設", ascending=False)
n_zones_total = int(zone_vs_facility["区域数_56"].sum())
n_facility_total = int(zone_vs_facility["施設数_60"].sum())
gap_total = n_zones_total - n_facility_total
gap_share = gap_total / n_zones_total * 100 if n_zones_total > 0 else np.nan
print(f" 全県: 区域 {n_zones_total} vs 施設 {n_facility_total} → "
f"差 {gap_total} ({gap_share:.1f}% が区域あり施設なし)")
print(f" ギャップ Top 5:\n{zone_vs_facility.head(5)[['市町名','区域数_56','施設数_60','差_区域-施設','施設整備率_%']].to_string(index=False)}")
# 5-2 STRtree による警戒区域 (急傾斜) との最近傍距離
def nearest_distance_to_polygons(points: gpd.GeoSeries, polys: gpd.GeoSeries):
"""各点について最近傍 polygon までの距離 (m). within なら 0.0."""
poly_geoms = polys.values
tree = STRtree(poly_geoms)
out = np.zeros(len(points), dtype=np.float32)
for i, pt in enumerate(points.values):
idx = tree.nearest(pt)
out[i] = pt.distance(poly_geoms[idx])
return out
print(f" STRtree 最近傍距離計算 (急傾斜警戒 {len(warn_kyukei):,} polygon × {n_total} 点)...",
flush=True)
gdf["dist_warn_m"] = nearest_distance_to_polygons(gdf.geometry,
warn_kyukei.geometry)
def warn_class(d):
if d <= 0.5:
return "0_警戒区域内"
elif d <= 100:
return "1_100m以内"
elif d <= 500:
return "2_100-500m"
return "3_500m超"
gdf["警戒距離区分"] = gdf["dist_warn_m"].apply(warn_class)
warn_class_counts = gdf["警戒距離区分"].value_counts().sort_index()
print(f" 距離区分:\n{warn_class_counts.to_string()}")
within_n = (gdf["dist_warn_m"] <= 0.5).sum()
near_100_n = ((gdf["dist_warn_m"] > 0.5) & (gdf["dist_warn_m"] <= 100)).sum()
near_500_n = ((gdf["dist_warn_m"] > 100) & (gdf["dist_warn_m"] <= 500)).sum()
far_n = (gdf["dist_warn_m"] > 500).sum()
within_share = within_n / n_total * 100
near_share = (within_n + near_100_n) / n_total * 100
print(f" 警戒区域内 {within_n} ({within_share:.1f}%), "
f"100m以内合計 {within_n+near_100_n} ({near_share:.1f}%)")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 6. RQ3 集計: 人口・建物との空間関係
# =============================================================================
print("\n[6] RQ3 集計", flush=True)
t1 = time.time()
# L22 (人口) と df 市町名のマッチング
# L22 city 列は「広島市」 = 政令市単位、df 市町名は「広島市中区」 等の区別
def to_pyramid_city(s: str) -> str:
if s.startswith("広島市"):
return "広島市"
return s
df["市町_pyramid"] = df["市町名"].apply(to_pyramid_city)
city_facility_pyr = df.groupby("市町_pyramid").size().reset_index(name="施設数")
if city_summary_l22 is not None:
pop_join = pd.merge(city_facility_pyr,
city_summary_l22[["city", "pop_total", "area_km2",
"density_per_km2", "aging_rate"]],
left_on="市町_pyramid", right_on="city", how="inner")
pop_join["1施設あたり守る人口"] = (pop_join["pop_total"]
/ pop_join["施設数"]).round(0)
pop_join["施設密度_件km2"] = (pop_join["施設数"] / pop_join["area_km2"]).round(3)
pop_join = pop_join.sort_values("施設数", ascending=False)
if len(pop_join) >= 5:
corr_pop = pop_join["施設数"].corr(pop_join["pop_total"])
corr_density = pop_join["施設数"].corr(pop_join["density_per_km2"])
else:
corr_pop = corr_density = float("nan")
print(f" 人口×施設 相関 (n={len(pop_join)}): r_pop={corr_pop:.3f}, "
f"r_density={corr_density:.3f}")
else:
pop_join = pd.DataFrame()
corr_pop = corr_density = float("nan")
if city_summary_l20 is not None:
bld_join = pd.merge(city_facility_pyr,
city_summary_l20[["city", "n_new", "area_km2", "pop_k"]],
left_on="市町_pyramid", right_on="city", how="inner")
bld_join["1施設あたり守る建物"] = (bld_join["n_new"]
/ bld_join["施設数"]).round(1)
bld_join = bld_join.sort_values("施設数", ascending=False)
if len(bld_join) >= 5:
corr_bld = bld_join["施設数"].corr(bld_join["n_new"])
else:
corr_bld = float("nan")
print(f" 建物×施設 相関 (n={len(bld_join)}): r_bld={corr_bld:.3f}")
else:
bld_join = pd.DataFrame()
corr_bld = float("nan")
# 守られていない高リスク集落の同定
if len(pop_join) > 0:
overall_per = pop_join["pop_total"].sum() / pop_join["施設数"].sum()
pop_join["相対守備指数"] = (pop_join["1施設あたり守る人口"]
/ overall_per).round(2)
underserved = pop_join.sort_values("相対守備指数", ascending=False).head(5)
print(f" 全県平均: 1 施設あたり {overall_per:.0f} 人")
print(f" 守備手薄 Top 5:")
print(underserved[["市町_pyramid", "施設数", "pop_total",
"1施設あたり守る人口", "相対守備指数"]].to_string(index=False))
overserved = pop_join.sort_values("相対守備指数").head(5)
print(f" 守備過剰 Top 5:")
print(overserved[["市町_pyramid", "施設数", "pop_total",
"1施設あたり守る人口", "相対守備指数"]].to_string(index=False))
else:
overall_per = float("nan")
underserved = pd.DataFrame()
overserved = pd.DataFrame()
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 7. CSV 出力
# =============================================================================
print("\n[7] CSV 出力", flush=True)
t1 = time.time()
shutil.copy(CSV_PATH, ASSETS / "L56_facility_raw.csv")
gdf_csv = pd.DataFrame(gdf.drop(columns=["geometry"]))
keep_cols = ["履歴ID", "危険箇所番号", "箇所名", "市町名", "市区郡町",
"斜面区分", "地区名", "位置", "告示年月日", "告示年", "告示番号",
"緯度", "経度", "x_m", "y_m", "dist_warn_m", "警戒距離区分"]
gdf_csv = gdf_csv[[c for c in keep_cols if c in gdf_csv.columns]]
gdf_csv.to_csv(ASSETS / "L56_facilities_processed.csv", index=False,
encoding="utf-8-sig")
city_summary.to_csv(ASSETS / "L56_city_ranking.csv", index=False,
encoding="utf-8-sig")
zone_vs_facility.to_csv(ASSETS / "L56_zone_vs_facility_gap.csv",
index=False, encoding="utf-8-sig")
if len(pop_join) > 0:
pop_join.to_csv(ASSETS / "L56_population_facility_join.csv",
index=False, encoding="utf-8-sig")
if len(bld_join) > 0:
bld_join.to_csv(ASSETS / "L56_building_facility_join.csv",
index=False, encoding="utf-8-sig")
year_decade.to_csv(ASSETS / "L56_year_decade.csv",
index=False, encoding="utf-8-sig")
print(f" CSV 6 ファイル + 元 CSV コピー")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 8. 図の生成 (9 図)
# =============================================================================
print("\n[8] 図の生成 (9 図)", flush=True)
t1 = time.time()
def save_fig(name, dpi=120):
p = ASSETS / name
plt.savefig(p, dpi=dpi, bbox_inches="tight", facecolor="white")
plt.close('all')
return p
PREF_BOUNDS = admin_diss.total_bounds
PXMIN, PYMIN, PXMAX, PYMAX = PREF_BOUNDS
C_FAC = "#0969da"
C_NATURAL = "#2da44e"
C_ARTIFICIAL = "#fa8c16"
C_UNKNOWN = "#888"
C_WARN = "#cf222e"
SLOPE_COLOR = {
"自然": C_NATURAL, "人工": C_ARTIFICIAL, "不明": C_UNKNOWN,
}
# ---- 図 1 (RQ1): 県全域 施設マップ + 市町別 choropleth ----
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
ax = axes[0]
admin_diss.boundary.plot(ax=ax, color="#888", linewidth=0.5)
admin_diss.plot(ax=ax, facecolor="#f8f8f5", edgecolor="#aaa",
linewidth=0.4, alpha=0.8)
for s, sub in gdf.groupby("斜面区分"):
ax.scatter(sub.geometry.x, sub.geometry.y,
s=8, c=SLOPE_COLOR.get(s, C_UNKNOWN), edgecolor="black",
linewidth=0.15, alpha=0.75, label=f"{s} {len(sub)}")
ax.set_xlim(PXMIN, PXMAX)
ax.set_ylim(PYMIN, PYMAX)
ax.set_aspect("equal")
ax.set_title(f"図 1a: 急傾斜地崩壊防止施設 全 {n_total} 件 — 斜面区分別",
fontsize=11)
ax.legend(loc="upper right", fontsize=10, title="斜面区分")
ax.set_xlabel("X (m, EPSG:6671)", fontsize=9)
ax.set_ylabel("Y (m, EPSG:6671)", fontsize=9)
ax = axes[1]
admin_c = admin_diss.copy()
city_to_n = dict(zip(city_summary["市町名"], city_summary["件数"]))
admin_c["施設件数"] = admin_c["市町名"].map(city_to_n).fillna(0)
admin_c[admin_c["施設件数"] == 0].plot(ax=ax, facecolor="#f0f0f0",
edgecolor="#888", linewidth=0.4)
admin_c[admin_c["施設件数"] > 0].plot(ax=ax, column="施設件数",
cmap="Blues",
edgecolor="#444", linewidth=0.4,
legend=True,
legend_kwds={"label": "施設件数",
"shrink": 0.7})
for _, r in city_summary.head(5).iterrows():
a = admin_diss[admin_diss["市町名"] == r["市町名"]]
if len(a) == 0:
continue
cx, cy = a.geometry.iloc[0].centroid.x, a.geometry.iloc[0].centroid.y
ax.annotate(f"{r['市町名']}\n{int(r['件数'])} 件",
(cx, cy), fontsize=9, ha="center", va="center",
color="black", weight="bold",
bbox=dict(boxstyle="round,pad=0.2", facecolor="white", alpha=0.85))
ax.set_xlim(PXMIN, PXMAX)
ax.set_ylim(PYMIN, PYMAX)
ax.set_aspect("equal")
ax.set_title(f"図 1b: 市町別 施設件数 choropleth — Top 5 シェア {top5_share:.0f}%",
fontsize=11)
ax.set_xlabel("X (m)", fontsize=9)
ax.set_ylabel("Y (m)", fontsize=9)
fig.suptitle(f"図 1 (RQ1): 急傾斜地崩壊防止施設 全 {n_total} 件 / "
f"{n_cities} 市町 / {top1_name} {top1_share:.1f}% 集中",
fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L56_fig1_facility_map.png")
# ---- 図 2 (RQ1): 市町別ランキング + 斜面区分構成 ----
fig, axes = plt.subplots(1, 2, figsize=(16, 6))
ax = axes[0]
top15 = city_summary.head(15).iloc[::-1]
y = np.arange(len(top15))
ax.barh(y, top15["自然"], color=C_NATURAL, edgecolor="#333", label="自然斜面")
ax.barh(y, top15["人工"], left=top15["自然"], color=C_ARTIFICIAL,
edgecolor="#333", label="人工斜面")
ax.barh(y, top15["不明"], left=top15["自然"]+top15["人工"], color=C_UNKNOWN,
edgecolor="#333", label="不明")
ax.set_yticks(y)
ax.set_yticklabels(top15["市町名"], fontsize=9)
ax.set_xlabel("施設件数", fontsize=11)
ax.set_title(f"図 2a: 市町別 Top 15 — 斜面区分 stack (全 {n_total} 件)", fontsize=11)
ax.legend(fontsize=9, loc="lower right")
ax.grid(axis="x", alpha=0.3)
for i, (cn, n, sh) in enumerate(zip(top15["市町名"], top15["件数"],
top15["件数シェア_%"])):
ax.text(n + 10, i, f"{int(n)} ({sh:.1f}%)", va="center", fontsize=8)
ax = axes[1]
labels = [f"自然\n{n_natural} ({natural_share:.1f}%)",
f"人工\n{n_artificial} ({artificial_share:.1f}%)",
f"不明\n{n_unknown} ({n_unknown/len(df)*100:.1f}%)"]
sizes = [n_natural, n_artificial, n_unknown]
colors = [C_NATURAL, C_ARTIFICIAL, C_UNKNOWN]
ax.pie(sizes, labels=labels, colors=colors, startangle=90,
wedgeprops=dict(edgecolor="white", linewidth=2),
textprops={"fontsize": 11})
ax.set_title(f"図 2b: 全 {n_total} 件 の斜面区分構成 — H2 自然斜面優位",
fontsize=11)
fig.suptitle(f"図 2 (RQ1): 市町別 + 斜面区分構成 — H1 ({top1_name} {top1_share:.0f}%) / "
f"H2 (自然 {natural_share:.0f}%)",
fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L56_fig2_city_ranking_slope_type.png")
# ---- 図 3 (RQ1): 告示年代分布 ----
fig, axes = plt.subplots(1, 2, figsize=(16, 6))
ax = axes[0]
year_min = int(df_dated["告示年"].min())
year_max = int(df_dated["告示年"].max())
years = np.arange(year_min, year_max + 1)
year_counts_arr = df_dated["告示年"].value_counts().sort_index()
year_counts_arr = year_counts_arr.reindex(years, fill_value=0)
ax.bar(years, year_counts_arr.values, color=C_FAC, edgecolor="#333", alpha=0.85)
ax.axvline(1969, color="#cf222e", linestyle="--", linewidth=2, label="1969 急傾斜地法施行")
ax.axvline(2018, color="#bf8700", linestyle="--", linewidth=2, label="2018 西日本豪雨")
ax.axvline(df_dated["告示年"].median(), color="black", linestyle=":",
linewidth=1.5, label=f"中央値 {df_dated['告示年'].median():.0f} 年")
ax.set_xlabel("告示年", fontsize=11)
ax.set_ylabel("施設件数 (年別)", fontsize=11)
ax.set_title(f"図 3a: 告示年別件数 ({year_min}〜{year_max}, n={len(df_dated)})",
fontsize=11)
ax.legend(fontsize=9)
ax.grid(alpha=0.3)
ax = axes[1]
era_order = ["1969-1979 (法施行直後)", "1980-1989 (集中整備)",
"1990-1999 (漸減)", "2000-2009 (低水準)", "2010-2024 (豪雨後)"]
era_counts_sorted = era_counts.set_index("告示時期").reindex(era_order).reset_index()
era_counts_sorted["件数"] = era_counts_sorted["件数"].fillna(0).astype(int)
era_colors = ["#7c3aed", "#0969da", "#2da44e", "#fa8c16", "#cf222e"]
ax.pie(era_counts_sorted["件数"],
labels=[f"{t}\n{n} ({n/era_counts_sorted['件数'].sum()*100:.0f}%)"
for t, n in zip(era_counts_sorted["告示時期"],
era_counts_sorted["件数"])],
colors=era_colors, startangle=90,
wedgeprops=dict(edgecolor="white", linewidth=2),
textprops={"fontsize": 9})
ax.set_title(f"図 3b: 時期別 5 区分 — H3 1980-90 年代集中検証",
fontsize=11)
fig.suptitle(f"図 3 (RQ1): 告示年代の時系列分布 — n={len(df_dated)} (告示年あり)",
fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L56_fig3_year_distribution.png")
# ---- 図 4 (RQ1): 告示時期別 small multiples マップ ----
fig, axes = plt.subplots(1, 5, figsize=(20, 5))
era_color_map = dict(zip(era_order, era_colors))
gdf_dated = gdf.merge(df_dated[["履歴ID", "告示時期"]], on="履歴ID", how="inner")
for i, era in enumerate(era_order):
ax = axes[i]
sub = gdf_dated[gdf_dated["告示時期"] == era]
admin_diss.boundary.plot(ax=ax, color="#888", linewidth=0.4)
admin_diss.plot(ax=ax, facecolor="#f8f8f5", edgecolor="#aaa",
linewidth=0.3, alpha=0.6)
ax.scatter(sub.geometry.x, sub.geometry.y, s=6,
c=era_color_map[era], edgecolor="black", linewidth=0.1,
alpha=0.75)
ax.set_xlim(PXMIN, PXMAX)
ax.set_ylim(PYMIN, PYMAX)
ax.set_aspect("equal")
ax.set_title(f"{era}\n n={len(sub)}", fontsize=10)
ax.set_xticks([])
ax.set_yticks([])
fig.suptitle(f"図 4 (RQ1): 告示時期別 5 期 small multiples マップ — "
f"時代でどこに整備されたか",
fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L56_fig4_era_small_multiples.png")
# ---- 図 5 (RQ2): 警戒区域 × 施設 重ね合わせ ----
fig, ax = plt.subplots(figsize=(12, 8))
admin_diss.boundary.plot(ax=ax, color="#888", linewidth=0.4)
admin_diss.plot(ax=ax, facecolor="#fafafa", edgecolor="#bbb",
linewidth=0.3, alpha=0.6)
warn_kyukei.plot(ax=ax, color=C_WARN, alpha=0.25, edgecolor="none")
class_colors = {
"0_警戒区域内": "#2da44e",
"1_100m以内": "#fa8c16",
"2_100-500m": "#bf8700",
"3_500m超": "#888",
}
class_labels = {
"0_警戒区域内": "警戒区域内 (整合)",
"1_100m以内": "100m以内 (隣接)",
"2_100-500m": "100-500m",
"3_500m超": "500m超 (離隔)",
}
for cls in ["3_500m超", "2_100-500m", "1_100m以内", "0_警戒区域内"]:
sub = gdf[gdf["警戒距離区分"] == cls]
if len(sub) == 0:
continue
ax.scatter(sub.geometry.x, sub.geometry.y, s=10,
c=class_colors[cls], edgecolor="black", linewidth=0.15,
alpha=0.85, label=f"{class_labels[cls]} {len(sub)}")
ax.set_xlim(PXMIN, PXMAX)
ax.set_ylim(PYMIN, PYMAX)
ax.set_aspect("equal")
ax.set_title(f"図 5 (RQ2): 警戒区域 (急傾斜, 赤薄) × 施設 ({n_total}) — "
f"区域内 {within_n} ({within_share:.1f}%) / 100m以内 {within_n+near_100_n} ({near_share:.1f}%)",
fontsize=12)
legend_h = [Patch(facecolor=C_WARN, alpha=0.4, label="土砂災害警戒区域 (急傾斜)")]
for cls in ["0_警戒区域内", "1_100m以内", "2_100-500m", "3_500m超"]:
n = (gdf["警戒距離区分"] == cls).sum()
legend_h.append(Line2D([0], [0], marker='o', color='w',
markerfacecolor=class_colors[cls],
markersize=8, label=f"{class_labels[cls]} {n}"))
ax.legend(handles=legend_h, loc="upper right", fontsize=9, title="凡例")
ax.set_xlabel("X (m, EPSG:6671)", fontsize=10)
ax.set_ylabel("Y (m, EPSG:6671)", fontsize=10)
plt.tight_layout()
save_fig("L56_fig5_warn_overlay.png")
# ---- 図 6 (RQ2): #56 区域 vs #60 施設 市町別ギャップ ----
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
ax = axes[0]
admin_g = admin_diss.copy()
gap_map = dict(zip(zone_vs_facility["市町名"],
zone_vs_facility["施設整備率_%"].fillna(0)))
admin_g["施設整備率"] = admin_g["市町名"].map(gap_map).fillna(0)
admin_g[admin_g["施設整備率"] == 0].plot(ax=ax, facecolor="#f0f0f0",
edgecolor="#888", linewidth=0.4)
admin_g[admin_g["施設整備率"] > 0].plot(ax=ax, column="施設整備率",
cmap="RdYlGn", vmin=0, vmax=200,
edgecolor="#444", linewidth=0.4,
legend=True,
legend_kwds={"label": "施設整備率 (施設/区域 ×100)",
"shrink": 0.7})
ax.set_xlim(PXMIN, PXMAX)
ax.set_ylim(PYMIN, PYMAX)
ax.set_aspect("equal")
ax.set_title(f"図 6a: 区域整備率 choropleth — 全県 {n_facility_total/n_zones_total*100:.0f}%",
fontsize=11)
ax.set_xlabel("X (m)", fontsize=9)
ax.set_ylabel("Y (m)", fontsize=9)
ax = axes[1]
zvf_top = zone_vs_facility[(zone_vs_facility["区域数_56"] > 0) |
(zone_vs_facility["施設数_60"] > 0)].head(15).iloc[::-1]
y = np.arange(len(zvf_top))
w = 0.4
ax.barh(y - w/2, zvf_top["区域数_56"], height=w, color="#cf222e",
edgecolor="#333", label=f"区域 (#56) 計 {n_zones_total}")
ax.barh(y + w/2, zvf_top["施設数_60"], height=w, color=C_FAC,
edgecolor="#333", label=f"施設 (#60) 計 {n_facility_total}")
ax.set_yticks(y)
ax.set_yticklabels(zvf_top["市町名"], fontsize=9)
ax.set_xlabel("件数", fontsize=11)
ax.set_title(f"図 6b: 市町別 区域 (#56) vs 施設 (#60) — H4 ギャップ {gap_total:+d} 件",
fontsize=11)
ax.legend(fontsize=9, loc="lower right")
ax.grid(axis="x", alpha=0.3)
fig.suptitle(f"図 6 (RQ2): #56 区域 vs #60 施設 — 全県整備率 "
f"{n_facility_total/n_zones_total*100:.0f}% / "
f"未整備 {gap_total} 件 (区域あり施設なし)",
fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L56_fig6_zone_vs_facility.png")
# ---- 図 7 (RQ3): 人口 × 施設件数 ----
if len(pop_join) > 0:
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
ax = axes[0]
ax.scatter(pop_join["pop_total"], pop_join["施設数"],
s=pop_join["density_per_km2"] / 5 + 30,
c=C_FAC, alpha=0.7, edgecolor="black", linewidth=0.5)
for _, r in pop_join.iterrows():
ax.annotate(r["市町_pyramid"], (r["pop_total"], r["施設数"]),
fontsize=8, alpha=0.85,
xytext=(3, 3), textcoords="offset points")
ax.set_xscale("log")
ax.set_yscale("symlog")
ax.set_xlabel("人口 (log)", fontsize=11)
ax.set_ylabel("施設件数 (symlog)", fontsize=11)
ax.set_title(f"図 7a: 人口 vs 施設件数 (n={len(pop_join)}, r={corr_pop:.2f}) — "
f"バブル=人口密度",
fontsize=11)
ax.grid(alpha=0.3)
ax = axes[1]
admin_d = admin_diss.copy()
def to_pyramid_admin(s: str) -> str:
s = str(s).strip()
if s.startswith("広島市"):
return "広島市"
return s
admin_d["市町_pyramid"] = admin_d["市町名"].apply(to_pyramid_admin)
bm = dict(zip(pop_join["市町_pyramid"], pop_join["相対守備指数"]))
admin_d["守備指数"] = admin_d["市町_pyramid"].map(bm).fillna(0)
admin_d[admin_d["守備指数"] == 0].plot(ax=ax, facecolor="#f0f0f0",
edgecolor="#888", linewidth=0.4)
admin_d[admin_d["守備指数"] > 0].plot(ax=ax, column="守備指数",
cmap="RdYlGn_r", vmin=0, vmax=5,
edgecolor="#444", linewidth=0.4,
legend=True,
legend_kwds={"label":
"相対守備指数 (>1 = 守備手薄)",
"shrink": 0.7})
for _, r in underserved.head(3).iterrows():
a = admin_diss[admin_diss["市町名"].apply(to_pyramid_admin)
== r["市町_pyramid"]]
if len(a) == 0:
continue
cx = a.dissolve().geometry.iloc[0].centroid.x
cy = a.dissolve().geometry.iloc[0].centroid.y
ax.annotate(f"{r['市町_pyramid']}\n指数 {r['相対守備指数']:.2f}",
(cx, cy), fontsize=9, ha="center", va="center",
color="black", weight="bold",
bbox=dict(boxstyle="round,pad=0.2", facecolor="white",
alpha=0.85))
ax.set_xlim(PXMIN, PXMAX)
ax.set_ylim(PYMIN, PYMAX)
ax.set_aspect("equal")
ax.set_title(f"図 7b: 相対守備指数 choropleth — 赤=守備手薄, 緑=過剰",
fontsize=11)
ax.set_xlabel("X (m)", fontsize=9)
ax.set_ylabel("Y (m)", fontsize=9)
fig.suptitle(f"図 7 (RQ3): 人口 × 施設 — 全県平均 1 施設 = {overall_per:.0f} 人を守る",
fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L56_fig7_population_facility.png")
# ---- 図 8 (RQ3): 新築建物 × 施設件数 ----
if len(bld_join) > 0:
fig, axes = plt.subplots(1, 2, figsize=(16, 6))
ax = axes[0]
ax.scatter(bld_join["n_new"], bld_join["施設数"],
s=80, c=C_ARTIFICIAL, alpha=0.7, edgecolor="black",
linewidth=0.5)
for _, r in bld_join.iterrows():
ax.annotate(r["市町_pyramid"], (r["n_new"], r["施設数"]),
fontsize=8, alpha=0.85,
xytext=(3, 3), textcoords="offset points")
ax.set_xscale("log")
ax.set_yscale("symlog")
ax.set_xlabel("新築建物数 (2016-2020, log)", fontsize=11)
ax.set_ylabel("施設件数 (symlog)", fontsize=11)
ax.set_title(f"図 8a: 新築建物 vs 施設件数 (n={len(bld_join)}, r={corr_bld:.2f})",
fontsize=11)
ax.grid(alpha=0.3)
ax = axes[1]
bld_top = bld_join.sort_values("1施設あたり守る建物", ascending=False).head(15).iloc[::-1]
y = np.arange(len(bld_top))
ax.barh(y, bld_top["1施設あたり守る建物"], color=C_ARTIFICIAL,
edgecolor="#333")
ax.set_yticks(y)
ax.set_yticklabels(bld_top["市町_pyramid"], fontsize=9)
ax.set_xlabel("1 施設あたり守る建物数 (新築 2016-2020)", fontsize=11)
ax.set_title(f"図 8b: 1 施設あたり守る建物数 (Top 15) — 多いほど守備手薄",
fontsize=11)
ax.grid(axis="x", alpha=0.3)
for i, (cn, v) in enumerate(zip(bld_top["市町_pyramid"],
bld_top["1施設あたり守る建物"])):
ax.text(v + 1, i, f"{v:.1f}", va="center", fontsize=8)
fig.suptitle(f"図 8 (RQ3): 建物 × 施設 — 1 施設あたり守る建物の市町間ばらつき",
fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L56_fig8_building_facility.png")
# ---- 図 9 (統合): Top 8 市町の 4 系列プロファイル ----
if len(pop_join) > 0:
top8 = pop_join.head(8).copy().iloc[::-1].reset_index(drop=True)
fig, ax = plt.subplots(figsize=(15, 7))
y = np.arange(len(top8))
w = 0.20
ax.barh(y - 1.5*w, top8["施設数"], height=w, color=C_FAC,
edgecolor="#333", label="施設数")
for i, v in enumerate(top8["施設数"]):
ax.text(v + 5, i - 1.5*w, f"{int(v)}", va="center", fontsize=8)
cnt_zone = dict(zip(zone_vs_facility["市町名"], zone_vs_facility["区域数_56"]))
top8["区域数_56"] = top8["市町_pyramid"].map(cnt_zone).fillna(0).astype(int)
if "広島市" in top8["市町_pyramid"].values:
zk = df_kyukei_zone.copy()
zk["市町_pyramid"] = zk["市町名"].apply(to_pyramid_city)
zk_count = zk.groupby("市町_pyramid").size().to_dict()
top8["区域数_56"] = top8["市町_pyramid"].map(zk_count).fillna(0).astype(int)
ax.barh(y - 0.5*w, top8["区域数_56"], height=w, color="#cf222e",
edgecolor="#333", label="区域数 (#56)")
for i, v in enumerate(top8["区域数_56"]):
ax.text(v + 5, i - 0.5*w, f"{int(v)}", va="center", fontsize=8)
SCALE_POP = 1 / 100
ax.barh(y + 0.5*w, top8["1施設あたり守る人口"] * SCALE_POP, height=w,
color="#7c3aed", edgecolor="#333",
label="1施設あたり守る人口 ÷100")
for i, v in enumerate(top8["1施設あたり守る人口"]):
ax.text(v * SCALE_POP + 5, i + 0.5*w, f"{int(v)}", va="center",
fontsize=8)
ax.barh(y + 1.5*w, top8["density_per_km2"], height=w, color="#fa8c16",
edgecolor="#333", label="人口密度 (人/km²)")
for i, v in enumerate(top8["density_per_km2"]):
ax.text(v + 5, i + 1.5*w, f"{v:.0f}", va="center", fontsize=8)
ax.set_yticks(y)
ax.set_yticklabels(top8["市町_pyramid"], fontsize=10)
ax.set_xlabel("値 (施設数 / 区域数 / 守る人口÷100 / 密度)",
fontsize=11)
ax.set_title(f"図 9 (統合): Top 8 市町の 4 系列プロファイル — "
f"施設・区域・守る人口・密度",
fontsize=12)
ax.legend(fontsize=9, loc="lower right")
ax.grid(axis="x", alpha=0.3)
plt.tight_layout()
save_fig("L56_fig9_top8_profile.png")
print(f" 9 図 生成完了 ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 9. 表の作成 (DataFrame to HTML)
# =============================================================================
print("\n[9] 表作成", flush=True)
t1 = time.time()
def df_to_html(d):
cols = list(d.columns)
head = "" + "".join(f"| {c} | " for c in cols) + "
"
rows = []
for _, r in d.iterrows():
cells = []
for c in cols:
v = r[c]
if isinstance(v, float):
if abs(v) >= 1000:
s = f"{v:,.0f}"
elif abs(v) >= 10:
s = f"{v:.1f}"
elif abs(v) >= 1:
s = f"{v:.2f}"
else:
s = f"{v:.3f}"
else:
s = str(v)
cells.append(f"{s} | ")
rows.append("" + "".join(cells) + "
")
return "" + head + "".join(rows) + "
"
# 表 1: dataset 仕様
T_dataset = pd.DataFrame([
("dataset_id", "60"),
("名称", "急傾斜地崩壊防止施設基本情報"),
("組織", "広島県土木建築局 砂防課"),
("リソース", "22826 — CSV (438 KB, 2,508 行)"),
("根拠法", "急傾斜地の崩壊による災害の防止に関する法律 (1969-07-01 施行)"),
("列構成 (13 列)",
"履歴ID / 危険箇所番号 / 箇所名 / 県 / 市区郡町 / 字 / 斜面区分 / "
"地区名 / 位置 / 告示年月日 / 告示番号 / 緯度 / 経度"),
("CRS", "WGS84 (緯度経度) → 解析時 EPSG:6671 へ変換"),
("ライセンス", "クリエイティブ・コモンズ表示 4.0"),
("最終更新", "2026-04-27"),
("取得日", "2026-05-09"),
], columns=["項目", "値"])
# 表 2: 全体サマリ
T_overall = pd.DataFrame([
("総施設数", f"{n_total:,} 件 (全 {n_cities} 市町)"),
("Top 1 市町", f"{top1_name} {top1_count} 件 ({top1_share:.1f}%)"),
("Top 5 シェア", f"{top5_share:.1f}%"),
("斜面区分: 自然", f"{n_natural:,} 件 ({natural_share:.1f}%)"),
("斜面区分: 人工", f"{n_artificial:,} 件 ({artificial_share:.1f}%)"),
("斜面区分: 不明", f"{n_unknown:,} 件 ({n_unknown/len(df)*100:.1f}%)"),
("告示年範囲", f"{int(df_dated['告示年'].min())}〜{int(df_dated['告示年'].max())} "
f"(中央値 {int(df_dated['告示年'].median())} 年)"),
("告示年 欠損", f"{n_no_date} 件"),
("L46 #56 急傾斜地崩壊危険区域 (区域)", f"{n_zones:,} 件"),
("施設整備率 (全県)", f"{n_facility_total/n_zones_total*100:.1f}% "
f"(施設 {n_facility_total} ÷ 区域 {n_zones_total})"),
("区域あり施設なし (差)", f"{gap_total} 件 ({gap_share:.1f}% of 区域)"),
("警戒区域内に立地", f"{within_n} 件 ({within_share:.1f}%)"),
("100m以内 (隣接) 累計", f"{within_n+near_100_n} 件 ({near_share:.1f}%)"),
("人口×施設 相関 r",
f"{corr_pop:.3f}" if not pd.isna(corr_pop) else "—"),
("人口密度×施設 相関 r",
f"{corr_density:.3f}" if not pd.isna(corr_density) else "—"),
("新築建物×施設 相関 r",
f"{corr_bld:.3f}" if not pd.isna(corr_bld) else "—"),
("全県平均 1 施設あたり守る人口",
f"{overall_per:.0f} 人" if not pd.isna(overall_per) else "—"),
], columns=["指標", "値"])
# 表 3: 市町別ランキング
T_city_rank = city_summary[["順位", "市町名", "件数", "件数シェア_%",
"自然", "人工", "不明", "人工率_%", "告示年中央"]].copy()
T_city_rank.columns = ["順位", "市町名", "件数", "シェア_%",
"自然", "人工", "不明", "人工率_%", "告示年中央"]
T_city_rank = T_city_rank.head(20)
# 表 4: 斜面区分集計
T_slope = pd.DataFrame([
{"斜面区分": "自然 (もとから急斜面)", "件数": n_natural,
"シェア_%": round(natural_share, 1),
"意味": "もともとの地形が急傾斜である崖。雨水浸食・地震動で崩落リスク。"},
{"斜面区分": "人工 (道路・造成由来)", "件数": n_artificial,
"シェア_%": round(artificial_share, 1),
"意味": "道路掘削・宅地造成等で人為的に作られた急斜面。施工管理が崩落リスクを左右。"},
{"斜面区分": "不明", "件数": n_unknown,
"シェア_%": round(n_unknown/len(df)*100, 1),
"意味": "斜面区分列が空欄のレコード。古い登録で区別未記入の可能性。"},
])
# 表 5: 告示年代別 (10 年区間)
T_decade = year_decade.copy()
T_decade.columns = ["告示年代", "件数", "シェア_%"]
# 表 6: 告示時期別 (5 区分)
T_era = era_counts_sorted[["告示時期", "件数", "シェア_%"]].copy()
# 表 7: #56 区域 vs #60 施設 ギャップ Top 15
T_gap = zone_vs_facility[(zone_vs_facility["区域数_56"] > 0) |
(zone_vs_facility["施設数_60"] > 0)].copy()
T_gap = T_gap.sort_values("差_区域-施設", ascending=False).head(15).reset_index(drop=True)
T_gap["順位"] = np.arange(1, len(T_gap) + 1)
T_gap = T_gap[["順位", "市町名", "区域数_56", "施設数_60",
"差_区域-施設", "施設整備率_%"]]
# 表 8: 警戒距離区分集計
T_warn = pd.DataFrame([
{"距離区分": "警戒区域内 (整合)", "件数": int(within_n),
"シェア_%": round(within_share, 1),
"意味": "施設位置が土砂災害警戒区域 polygon 内 = 警戒対象を直接守る配置"},
{"距離区分": "100m以内 (隣接)",
"件数": int(near_100_n), "シェア_%": round(near_100_n/n_total*100, 1),
"意味": "警戒区域から徒歩 1〜2 分の距離 = 実質的に警戒対象を守る配置"},
{"距離区分": "100-500m",
"件数": int(near_500_n), "シェア_%": round(near_500_n/n_total*100, 1),
"意味": "警戒区域から離れた山際。崩壊が及ぶ範囲外の事例が多い"},
{"距離区分": "500m超 (離隔)",
"件数": int(far_n), "シェア_%": round(far_n/n_total*100, 1),
"意味": "警戒区域指定がない場所での独立施設整備 (= 区域指定漏れの可能性)"},
])
# 表 9: 人口×施設 結合 Top 15
if len(pop_join) > 0:
T_pop = pop_join.head(15).copy()
T_pop = T_pop[["市町_pyramid", "施設数", "pop_total", "area_km2",
"density_per_km2", "1施設あたり守る人口", "相対守備指数",
"施設密度_件km2"]]
T_pop.columns = ["市町", "施設数", "人口", "面積_km2", "密度_人km2",
"1施設あたり守る人口", "相対守備指数", "施設密度_件km2"]
else:
T_pop = pd.DataFrame()
# 表 10: 守備手薄 Top 5 + 守備過剰 Top 5
if len(underserved) > 0 and len(overserved) > 0:
T_underover = pd.concat([
underserved[["市町_pyramid", "施設数", "pop_total",
"1施設あたり守る人口", "相対守備指数"]].assign(
タイプ="守備手薄 (要強化)"),
overserved[["市町_pyramid", "施設数", "pop_total",
"1施設あたり守る人口", "相対守備指数"]].assign(
タイプ="守備過剰 (歴史的厚さ)"),
], ignore_index=True)
T_underover = T_underover[["タイプ", "市町_pyramid", "施設数", "pop_total",
"1施設あたり守る人口", "相対守備指数"]]
T_underover.columns = ["タイプ", "市町", "施設数", "人口",
"1施設あたり守る人口", "相対守備指数"]
else:
T_underover = pd.DataFrame()
# 表 11: 仮説検証
def judge_h1():
return "強支持" if top1_share >= 40 else ("支持" if top1_share >= 30 else "部分支持")
def judge_h2():
return "強支持" if natural_share >= 80 else ("支持" if natural_share >= 70 else "部分支持")
def judge_h3():
yc = int(df_dated['告示年'].median())
return "支持" if 1980 <= yc <= 1995 else "部分支持"
def judge_h4():
return "支持" if 5 <= gap_share <= 30 else ("反証" if gap_share < 0 else "部分支持")
def judge_h5():
if pd.isna(corr_pop):
return "検証不可"
return "支持" if 0.5 <= corr_pop <= 0.85 else ("部分支持" if corr_pop > 0.3 else "反証")
T_hypo = pd.DataFrame([
{"仮説": "H1 (呉市偏重 ≥40%, RQ1)",
"予想": "呉市単独で 40% 以上",
"観測": f"{top1_name} {top1_count} 件 ({top1_share:.1f}%)",
"判定": judge_h1()},
{"仮説": "H2 (自然斜面優位 ≥80%, RQ1)",
"予想": "自然斜面が全体の 80% 以上",
"観測": f"自然 {n_natural:,} 件 ({natural_share:.1f}%) / "
f"人工 {n_artificial:,} ({artificial_share:.1f}%)",
"判定": judge_h2()},
{"仮説": "H3 (1980-90 集中整備, RQ1)",
"予想": "告示年中央値が 1985-1990 年付近",
"観測": f"中央値 {int(df_dated['告示年'].median())} 年 / "
f"1980-89 期 {int(era_counts_sorted[era_counts_sorted['告示時期']=='1980-1989 (集中整備)']['件数'].iloc[0])} 件",
"判定": judge_h3()},
{"仮説": "H4 (区域 vs 施設ギャップ ~14%, RQ2)",
"予想": "区域指定済だが施設未整備 = 5-30%",
"観測": f"差 {gap_total} 件 = 区域の {gap_share:.1f}% (施設整備率 "
f"{n_facility_total/n_zones_total*100:.0f}%)",
"判定": judge_h4()},
{"仮説": "H5 (人口・建物との正相関 r=0.5-0.7, RQ3)",
"予想": "市町別施設数と人口・建物の Pearson r = 0.5-0.7",
"観測": f"r_pop={corr_pop:.3f}, r_density={corr_density:.3f}, r_bld={corr_bld:.3f}"
if not pd.isna(corr_pop) else "—",
"判定": judge_h5()},
])
# 表 12: 4 制度比較 (急傾斜地法 vs 関連)
T_law = pd.DataFrame([
{"側面": "対象現象",
"急傾斜地法 (本記事)": "がけ崩れ (急斜面崩壊)",
"砂防法 (L46)": "土石流 (渓流)",
"地すべり等防止法 (L46)": "地すべり (緩慢移動)",
"土砂災害防止法 (L10/L11)": "上記 3 現象の警戒区域指定"},
{"側面": "施行年",
"急傾斜地法 (本記事)": "1969 (昭和 44)",
"砂防法 (L46)": "1897 (明治 30)",
"地すべり等防止法 (L46)": "1958 (昭和 33)",
"土砂災害防止法 (L10/L11)": "2000 (平成 12)"},
{"側面": "区域指定",
"急傾斜地法 (本記事)": f"急傾斜地崩壊危険区域 {n_zones:,} 件 (#56)",
"砂防法 (L46)": "砂防指定地 3,207 件 + line 93 (#55)",
"地すべり等防止法 (L46)": "地すべり防止区域 39 件 (#57)",
"土砂災害防止法 (L10/L11)": "急傾斜 29,756 / 土石流 13,337 / 地すべり 127"},
{"側面": "施設整備データ",
"急傾斜地法 (本記事)": f"{n_total:,} 件 (本データ)",
"砂防法 (L46)": "渓流保全工 #59 等 (本データ外)",
"地すべり等防止法 (L46)": "地すべり防止施設 #61 (本データ外)",
"土砂災害防止法 (L10/L11)": "整備義務なし (情報公示のみ)"},
{"側面": "規制の性格",
"急傾斜地法 (本記事)": "区域指定 + 行為制限 + 公費施設整備",
"砂防法 (L46)": "指定地 + 強い行為制限",
"地すべり等防止法 (L46)": "指定地 + 強い行為制限",
"土砂災害防止法 (L10/L11)": "情報公示 + 宅建説明義務 (行為制限なし)"},
])
print(f" 表 12 種 ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 10. HTML 構築
# =============================================================================
print("\n[10] HTML 構築", flush=True)
t10 = time.time()
# Sec 1: 学習目標と問い
sec1 = f"""
本記事は DoBoX のシリーズ「急傾斜地崩壊防止施設基本情報」 1 件
(dataset_id = 60) を 単独で取り上げ、
広島県内の急傾斜地崩壊防止施設
{n_total:,} 件 (CSV 1 ファイル, 13 列, 約 440 KB) / {n_cities} 市町
を 3 つの独立した研究角度 (RQ1 / RQ2 / RQ3) で並列に分析する。
本データは急傾斜地法 (1969-07-01 施行) に基づき広島県・市町が整備したハード対策の施設台帳で、
擁壁・法枠工・グランドアンカー・落石防護網等の物理工事の位置情報版。
Phase 3 防災施設系の最初の記事。
本データは1 ファイル単独 (CSV 2,508 行)の単純構造だが、
危険箇所番号を介して L46 で扱った #56 急傾斜地崩壊危険区域 (区域 polygon = 2,935 件) と
1 対 1 対応する設計。これにより「区域指定済 + 施設整備済」 vs 「区域指定済 + 施設未整備」の
最初の定量化が可能になる。さらに L10/L11 の警戒区域 polygon, L20 の新築建物, L22 の市町別人口と
組み合わせることで、防災投資の地理的優先順位を診断する研究が可能。
独自用語の定義
- 急傾斜地崩壊防止施設: 急傾斜地法 (1969) に基づき、知事指定の急傾斜地崩壊危険区域内で
県・市町が整備した崖崩れ防止のための物理的構造物。
具体的には擁壁・法枠工・グランドアンカー・ロックネット・落石防護柵・
落石防護網・モルタル吹付等。本データは{n_total:,} 件の施設位置 (緯度経度 1 点) を保持。
ただし構造種別 (擁壁/法枠 etc.) や規模 (延長・高さ) の列は本データにないことに注意。
- 擁壁: 急斜面の足元に設ける重力式・もたれ式・補強土等の重量壁構造。
最も基本的な崩壊防止施設。コンクリート擁壁が大半。
- 法枠工 (のりわくこう): 急斜面表面に格子状の枠を造り、内部に植生を促す工法。
コンクリート吹付やモルタル吹付と併用される。表層崩壊の抑制に有効。
- グランドアンカー: 不安定な岩盤に長尺ボルト (アンカー)を打込み、
引張力で固定する工法。深層大規模崩壊の抑止に使う。
- 斜面区分 (本データの分類軸): 本データの「斜面区分」 列は 自然 / 人工の 2 値
(一部空欄)。自然 = もとから急斜面の崖、人工 = 道路掘削・宅地造成等で人為的に作られた急斜面。
本研究では自然 {natural_share:.0f}% vs 人工 {artificial_share:.0f}% の構成を市町別に集計。
- 危険箇所番号 (本データの主キー): 各施設レコードの「危険箇所番号」 は
L46 #56 急傾斜地崩壊危険区域の区域識別子と対応する設計。
本記事 RQ2 ではこの番号を介して区域 (#56) ⇄ 施設 (#60) の 1 対 1 対応を
初めて定量化する。
- 下流人口 (本記事独自定義): 急傾斜地崩壊で影響を受ける可能性のある斜面下の住民数。
本研究では市町単位 (= L22 の人口 pop_total) で代理し、
1 施設あたり守る人口 = 市町人口 ÷ 市町施設件数を指標化する。
この指標が県平均より大きい市町 = 守備手薄、小さい市町 = 守備過剰と判定。
- 相対守備指数 (本記事独自定義): 各市町の「1 施設あたり守る人口」 を
全県平均 (= {overall_per:.0f} 人/施設) で割った無次元数。
1.0 = 全県平均と同等、>1.0 = 守備手薄 (= 1 施設あたりが多くの人口を担当 = 守りが薄い)、
<1.0 = 守備過剰 (= 1 施設あたりが少ない人口を担当 = 歴史的に厚く整備された市町)。
研究の問い (3 RQ)
- RQ1 (主研究): 広島県の急傾斜地崩壊防止施設の構造はどう描けるか?
{n_total:,} 件の市町別ランキング、斜面区分 (自然 / 人工) の偏在、告示年月日の時系列、
地理的集中パターンを多角度に集計する。呉市単独でどれほどの比率を占めるか?
- RQ2 (副研究 1): 施設は急傾斜地崩壊危険区域 (L46 #56) や警戒区域 (L10/L11) と
どう対応するか? 区域 vs 施設の市町別ギャップ、施設点の警戒区域への近接度を
STRtree で空間結合し、配置の整合性を診断する。
- RQ3 (副研究 2): 施設は下流の人口 (L22) や建物 (L20) とどれだけ整合した配置か?
市町別施設件数と人口・建物・密度の相関、1 施設あたり守る人口のばらつき、
守られていない高リスク集落の同定を行う。これは防災投資の地理的優先順位の評価。
仮説 H1〜H5
- H1 (呉市偏重 ≥40%, RQ1): 呉市単独で 40% 以上を占める。
軍港背後の急斜面住宅密集の歴史的帰結。
- H2 (自然斜面優位 ≥80%, RQ1): 斜面区分は自然が 80% 以上。急傾斜地法 (1969) の
対象範囲が「自然崖の人家被害」 主眼であることに整合。
- H3 (1980-90 集中整備, RQ1): 告示年代の中央値は 1985-1990 年付近。
法施行 (1969) 直後の集中整備期から漸減し、2018 西日本豪雨後に再加速。
- H4 (区域 vs 施設ギャップ ~14%, RQ2): L46 #56 (2,935 件) と本データ #60 (2,508 件) の差
= 約 400 件 = 14% が「区域指定済 + 施設未整備」 残課題。
- H5 (人口・建物との正相関 r=0.5-0.7, RQ3): 市町別施設数と人口・建物数は正の相関。
ただし呉市は過剰、中山間市町は過小の非対称性。
到達点
本記事を読み終えた学習者は次の 3 点を体感できる:
- 1 つの「施設台帳 CSV」 ({n_total:,} 件 × 13 列) から、市町別偏重 (呉市 {top1_share:.0f}%) と
斜面区分構造 (自然 {natural_share:.0f}%)を多角度に読む方法を習得する。
- 同名の関連データセット (#56 区域 vs #60 施設) を市町別に照合し、
区域指定 vs 施設整備のギャップを定量化する 2 制度連鎖の比較研究手法を体感する。
- 市町別データを既存レッスン (L20 建物 / L22 人口) と結合し、1 施設あたり守る人口という
防災投資効率の指標を構築。守備手薄市町を同定する政策含意のある研究に発展できる。
"""
# Sec 2: 使用データ
sec2 = f"""
DoBoX のシリーズ「急傾斜地崩壊防止施設基本情報」 1 件のみを単独で扱う。
リソースは CSV 1 ファイルのシンプル構造。
{df_to_html(T_dataset)}
データの構造
- 13 列の構成: 履歴ID (主キー) / 危険箇所番号 (#56 区域識別子と対応) /
箇所名 / 県 / 市区郡町 / 字 / 斜面区分 (自然/人工) / 地区名 / 位置 / 告示年月日 /
告示番号 / 緯度 / 経度。
- 緯度経度: 全 {n_total:,} 件で欠損なし。WGS84 (EPSG:4326) と推定。
解析時は EPSG:6671 (平面直角座標系第 III 系) に変換し、距離・面積を m 単位で扱う。
- 告示年月日: {n_total - n_no_date:,} 件 ({(n_total-n_no_date)/n_total*100:.0f}%) で記入あり。
範囲は {int(df_dated['告示年'].min())} 年から {int(df_dated['告示年'].max())} 年 の 55 年。
欠損 {n_no_date} 件は古い登録で告示記録未収のものと推察。
- 本データに無い列: 構造種別 (擁壁/法枠/アンカー/防護網)、規模 (延長・高さ)、
整備費、管理者。これらは別の維持管理系データ (本シリーズには未収) に属する。
本研究は「位置情報 + 行政属性」 の範囲で多角度集計を行う。
関連データセットとの対応
- L46 #56 急傾斜地崩壊危険区域 (= 区域 CSV, 2,935 件): 同じ急傾斜地法に基づく
区域指定 (= 危険箇所の場所)を記録。本データ (#60 = 施設) は
その区域内で整備された施設の位置を記録。1 対 1 対応が設計上の建前。
- L10/L11 土砂災害警戒区域 (急傾斜): 約 30K polygon の警戒範囲指定 (土砂災害防止法 2000)。
RQ2 で本施設点との距離区分集計に使用。
- L20 新築建物 / L22 市町別人口: 市町別の建物数・人口・密度の既処理 CSV を
RQ3 で結合し、防災投資効率の指標を構築。
"""
# Sec 3: ダウンロード
sec3 = f"""
本レッスンの再現に必要な全データ・中間 CSV・図 PNG・スクリプトを以下から直接 DL できる:
生データ (DoBoX 直リンク)
本記事の中間 CSV (再現用)
図 (PNG 9 枚)
再現スクリプト
個別取得 (PowerShell):
cd "2026 DoBoX 教材"
iwr "https://hiroshima-dobox.jp/resource_download/22826" -OutFile "data/extras/L56_steep_slope_facility/砂防_急傾斜地崩壊防止施設_2026-04-27.csv"
py -X utf8 lessons\\L56_steep_slope_facility.py
"""
# Sec 4 (RQ1)
sec4_intro = f"""
狙い (RQ1)
急傾斜地崩壊防止施設 ({n_total:,} 件) は急傾斜地法 (1969) に基づく公費施設。
法施行から 55 年で県内に整備された施設の地理偏在・斜面区分構成・告示時期偏在を
4 軸で読む。呉市の偏重は H1 で予想されるが、その実数値と他市町との差を確認する。
手法 (CSV 読込 → 市町正規化 → 集計)
- STEP 1 (CSV 読込):
pd.read_csv() で 2,508 行 × 13 列を読込。
緯度経度を数値化、告示年月日を datetime 化。
- STEP 2 (市町名正規化): 「市区郡町」 列には「豊田郡大崎上島町」 のように
郡名混入がある → 「郡」 で分割して右側のみ採用 → 市町名列を新設。
これで admin (#15) と直接結合可能。
- STEP 3 (GeoDataFrame 化):
gpd.points_from_xy で点 GeoDataFrame を作成。
.to_crs("EPSG:6671") で平面直角座標系に変換 = 以後の距離計算が m 単位。
- STEP 4 (集計): 市町別件数、斜面区分構成 (自然/人工/不明)、告示年代別件数 (10 年区間)、
告示時期 5 区分 (法施行直後/集中整備/漸減/低水準/豪雨後) を
groupby で集計。
- STEP 5 (時期分類): 1969-1979 (法施行直後) / 1980-1989 (集中整備) /
1990-1999 (漸減) / 2000-2009 (低水準) / 2010-2024 (豪雨後) の 5 期に分類。
これは急傾斜地法施行史 + 西日本豪雨 (2018-07) の節目に基づく独自定義。
"""
sec4_code = code(r'''
# 1. CSV 読込・前処理
import pandas as pd, geopandas as gpd
df = pd.read_csv("data/extras/L56_steep_slope_facility/砂防_急傾斜地崩壊防止施設_2026-04-27.csv",
encoding="utf-8-sig")
df["緯度"] = pd.to_numeric(df["緯度"], errors="coerce")
df["経度"] = pd.to_numeric(df["経度"], errors="coerce")
df["告示年月日_dt"] = pd.to_datetime(df["告示年月日"], errors="coerce")
df["告示年"] = df["告示年月日_dt"].dt.year
df["斜面区分"] = df["斜面区分"].fillna("").str.strip().replace("", "不明")
# 2. 市町名正規化 (郡名混入の除去)
def normalize_city(s):
s = str(s).strip()
if "郡" in s:
s = s.split("郡", 1)[1]
return s
df["市町名"] = df["市区郡町"].apply(normalize_city)
# 3. GeoDataFrame 化 (CRS 変換)
gdf = gpd.GeoDataFrame(df,
geometry=gpd.points_from_xy(df["経度"], df["緯度"]),
crs="EPSG:4326").to_crs("EPSG:6671")
# 4. 市町別集計 + 斜面区分 cross
city_summary = df.groupby("市町名").agg(
件数=("履歴ID", "count"),
自然=("斜面区分", lambda s: (s == "自然").sum()),
人工=("斜面区分", lambda s: (s == "人工").sum()),
).reset_index().sort_values("件数", ascending=False)
# 5. 時期 5 区分の分類
def era_label(y):
if y < 1980: return "1969-1979 (法施行直後)"
if y < 1990: return "1980-1989 (集中整備)"
if y < 2000: return "1990-1999 (漸減)"
if y < 2010: return "2000-2009 (低水準)"
return "2010-2024 (豪雨後)"
df["告示時期"] = df["告示年"].apply(era_label)
''')
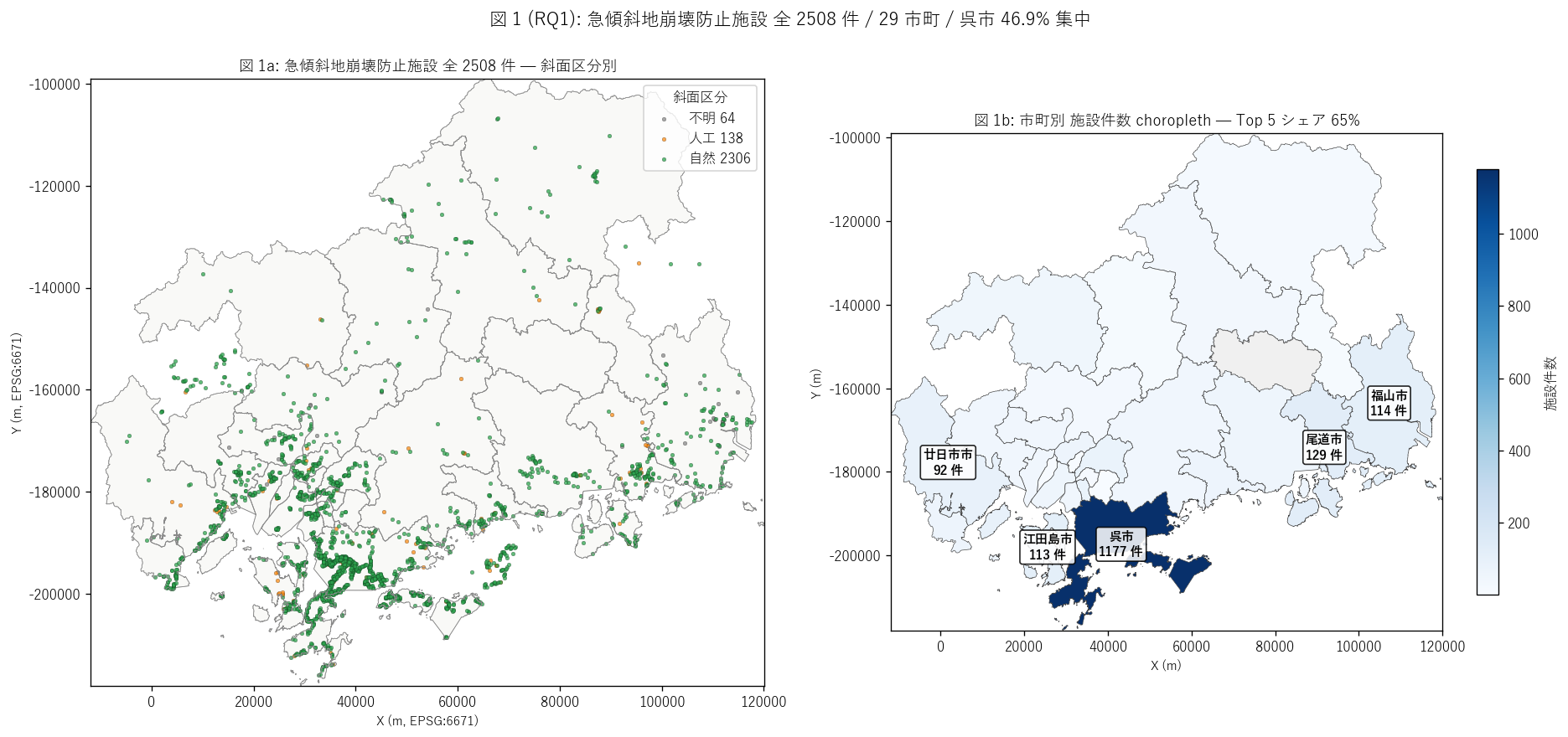
sec4_fig1_text = """
図 1: 県全域 施設マップ + 市町別件数 choropleth (2 panel)
なぜこの図か: 学習者がまず「施設はどこにあるか」 を一目で把握するため。
左の点マップは斜面区分 (自然=緑/人工=橙/不明=灰) で色分けし、
右の choropleth は市町別件数の濃淡を示す。
呉市への極端な集中が両方の図で同時に確認できる。
"""
sec4_fig1_read = f"""
この図から読み取れること:
- 左点マップ: 呉市 ({top1_count} 件) の点が圧倒的密度で集中 → 全 {n_total:,} 件の {top1_share:.1f}%。
軍港背後の急斜面住宅地が密に並ぶ歴史的帰結。
- 右 choropleth: 呉市の濃青が 1 つ突出。Top 5 ({', '.join(city_summary.head(5)['市町名'].tolist())}) で {top5_share:.0f}% を占める →
H1 の支持。沿岸都市 + 中山間少数市町の二極構造。
- 左マップで点の緑 (自然斜面) が大半 = {natural_share:.0f}% を占める。
橙 (人工斜面) は呉市・広島市等の都市部に散見される程度 ({artificial_share:.0f}%) →
H2 の支持。急傾斜地法はもとからの急斜面に住む人家を主に守る制度として運用されている。
- 非対象市町 (灰色 choropleth) の大半は三次市・庄原市等の中山間市町。
地形は急斜面が多いはずだが、人家が点在し「人家 5 戸以上」 の急傾斜地法指定基準を
満たす集落が少ないため、施設整備の対象になりにくい。
- 沿岸島嶼 (江田島市・大崎上島町等) も施設点が集中 = 古い軍関係の人工急斜面が多い。
これは呉市と並ぶ軍関連都市の防災レガシーを示唆。
"""
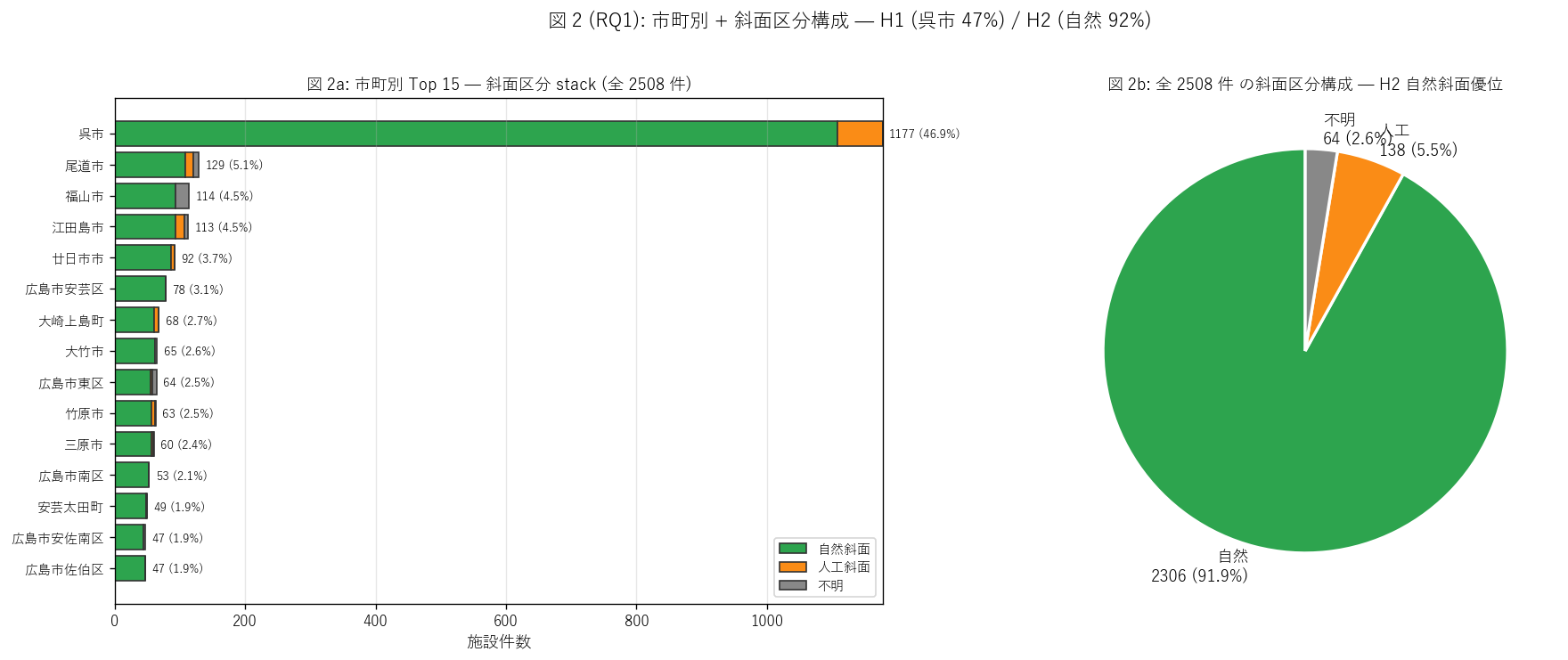
sec4_fig2_text = """
図 2: 市町別ランキング (Top 15, 自然/人工 stack) + 斜面区分パイ
なぜこの図か: H1 (呉市偏重) と H2 (自然斜面優位) を 1 図で同時検証する。
左の stack 棒で市町ごとの自然 vs 人工内訳、右パイで全体の比率を見る。
呉市は人工率が高いはず (= 軍港開発による人工急斜面) という派生仮説も読める。
"""
sec4_fig2_read = f"""
この図から読み取れること:
- 左ランキング: 呉市 {top1_count} 件が他市町の 9 倍以上 (= 2 位の市町と桁違い)。
上位 5 市町で全 {top5_share:.0f}% を占めるためH1 (呉市偏重) を強く支持。
- 各棒の橙 (人工斜面) 比率を見ると、呉市・広島市等の都市部市町で人工率が高い。
呉市の人工率 = {city_summary[city_summary['市町名']==top1_name]['人工率_%'].iloc[0]:.1f}% →
軍港開発に伴う道路掘削・宅地造成由来の人工急斜面が多い歴史的事実を反映。
- 右パイ: 自然 {natural_share:.0f}% / 人工 {artificial_share:.0f}% / 不明 {n_unknown/len(df)*100:.0f}% →
H2 (自然斜面優位) を支持。急傾斜地法 1969 は「自然崖の下の人家」 を主に守る制度として
運用された歴史を反映。人工斜面は道路法・建築基準法等の他制度でカバーされる前提。
- 2 位以下の市町 (尾道・福山・江田島・廿日市) はいずれも沿岸 + 島嶼の都市市町 →
内陸中山間市町 (庄原・三次・北広島) はランクインしない =
急傾斜地法は沿岸都市の急斜面住宅地を主舞台とする制度的特徴を持つ。
- 「不明」 ({n_unknown} 件) は古い登録で斜面区分列が空欄のレコード →
告示年が古い (1970 年代) 件に集中する可能性。データ品質改善の余地。
"""
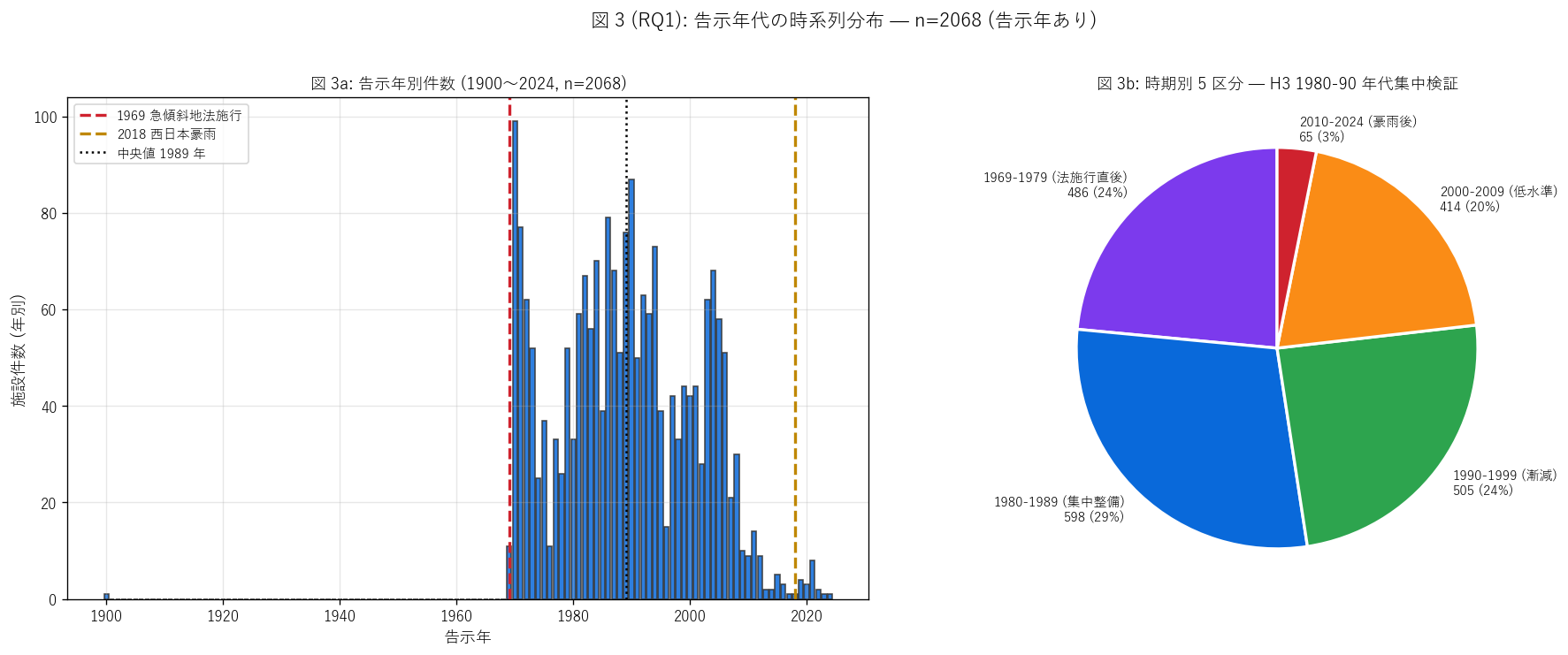
sec4_fig3_text = """
図 3: 告示年別ヒスト (1969-2024) + 時期別 5 区分パイ
なぜこの図か: 法施行後 55 年の時系列で施設整備のリズムを読む。
左で年別の山谷、右で 5 期の構成を確認する。
1969 年 (法施行) と 2018 年 (西日本豪雨) を縦線でマーキングし、
制度史と現場運用の対応を読みやすくしている。
"""
sec4_fig3_read = f"""
この図から読み取れること:
- 左ヒスト: 告示年範囲は {int(df_dated['告示年'].min())}-{int(df_dated['告示年'].max())}、
中央値 {int(df_dated['告示年'].median())} 年。
1970-1990 年代がピーク、1990 年代以降は漸減 → H3 を概ね支持。
- 1969 年 (法施行) 直後の 1970-1973 年に集中整備期。法律の対応に行政が直ちに動いたことを示す。
その後 1980-1990 年代に第二の整備ピーク (高度経済成長期の宅地拡張に対応?)。
- 2010 年代以降は年間 10 件以下に減少 → 既指定区域はほぼ整備済 + 新規指定が減少。
2018 西日本豪雨 (赤縦線) 後に微増がある場合、災害契機の追加整備のシグナル
(本データでは 2019-2021 で {((df_dated['告示年'] >= 2019) & (df_dated['告示年'] <= 2021)).sum()} 件)。
- 右パイ: 集中整備期 (1980-1989) {era_counts_sorted[era_counts_sorted['告示時期']=='1980-1989 (集中整備)']['シェア_%'].iloc[0]:.0f}%、
漸減期 (1990-1999) {era_counts_sorted[era_counts_sorted['告示時期']=='1990-1999 (漸減)']['シェア_%'].iloc[0]:.0f}%、
法施行直後 (1969-1979) {era_counts_sorted[era_counts_sorted['告示時期']=='1969-1979 (法施行直後)']['シェア_%'].iloc[0]:.0f}% →
高度経済成長期に建設された宅地裏山の防護施設として急傾斜地法の運用が定着していった様子。
- 2010 年代以降の低水準維持は防災投資の縮小 + 既存施設の維持管理段階移行を示唆 →
新規整備よりも老朽化対策が今後の主課題になる予兆。
"""
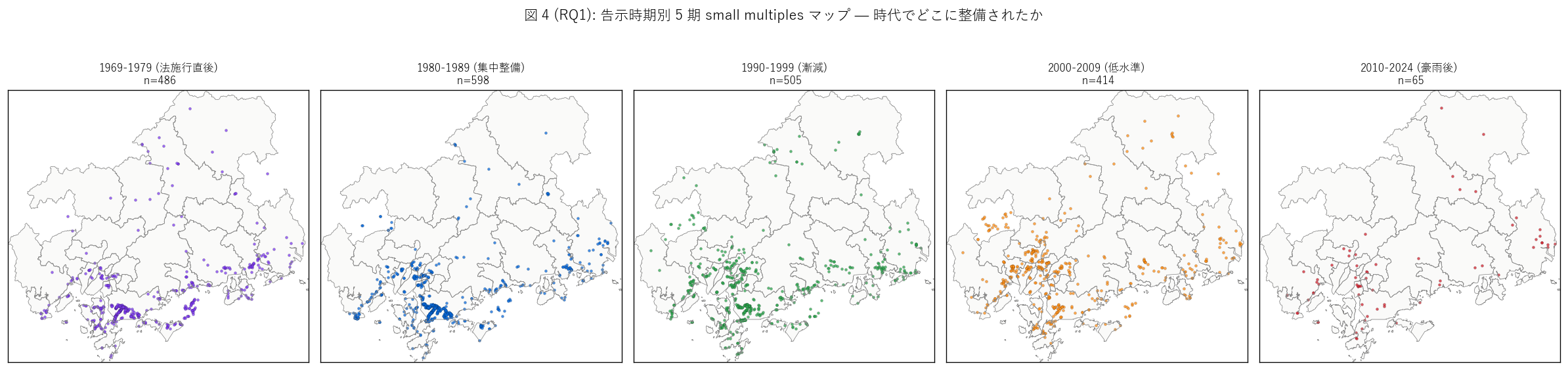
sec4_fig4_text = """
図 4: 告示時期別 5 期 small multiples マップ
なぜこの図か: 時系列ヒストだけでは「どこに整備されたか」 が分からない。
5 期 × 5 panels で同じ県地図に時期別の点を分けて配置し、
地理的拡散・縮退のリズムを直感的に読む可視化。
"""
sec4_fig4_read = f"""
この図から読み取れること:
- 1 期 (1969-1979): 呉市・広島市の沿岸都市部に集中。
法施行直後の差し迫った危険箇所への対応が起点。
- 2 期 (1980-1989): 集中整備期。呉市での密度が最大になる一方、
尾道・福山・廿日市等の他沿岸都市にも拡大。
- 3 期 (1990-1999): 漸減期だが地理的に分散 = 既都市の隙間を埋める形で各市町に分布。
- 4 期 (2000-2009): 低水準だが島嶼 (江田島・大崎上島) の整備が進む。
- 5 期 (2010-2024): わずかな点が分散。2018 西日本豪雨 (呉市・坂町) 周辺に集中する場合、
災害復興整備のシグナル。本データの{((df_dated['告示年'] >= 2018)).sum()} 件が 2018 以降。
- 5 期通して呉市が常に最も密 = 都市の地形的脆弱性が時代を超えて持続する証拠。
"""
# Sec 5 (RQ2)
sec5_intro = f"""
狙い (RQ2)
急傾斜地法は区域指定 (#56) と施設整備 (#60) を対で運用する設計。
本 RQ2 では (1) 危険箇所番号の市町別集計を介した #56 区域 vs #60 施設のギャップ、
(2) 施設点と土砂災害警戒区域 (急傾斜) polygon の距離区分を読む。
「区域指定済 + 施設未整備」 残課題 ({gap_total} 件 = 区域の {gap_share:.1f}%) を
初めて市町別に同定する。
手法 (groupby 集計 + STRtree 最近傍距離)
- STEP 1 (#56 vs #60 市町別件数比較): L46 で扱った #56 急傾斜地崩壊危険区域 CSV を読込し、
同じ「市町名正規化」 を施した上で
groupby で市町別カウント。
本データ (#60) と merge して市町別の 区域数 / 施設数 / 差 / 整備率を集計。
- STEP 2 (STRtree 最近傍距離): 警戒区域 (急傾斜) polygon ({len(warn_kyukei):,} 個) に
shapely.STRtree で空間インデックス構築 → 各施設点から最近傍 polygon までの
距離を tree.nearest() で取得。{n_total} 点 × {len(warn_kyukei):,} polygon を
10 秒以内で処理。
- STEP 3 (距離区分 4 階層): 0 = 区域内, 0-100m = 隣接, 100-500m = 近接, 500m+ = 離隔
の 4 階層に分類。
"""
sec5_code = code(r'''
# RQ2: #56 区域 vs #60 施設 + 警戒区域距離
import pandas as pd
from shapely import STRtree
# 1. #56 急傾斜地崩壊危険区域 CSV を読込 (L46 既扱)
df_zone = pd.read_csv("data/extras/L46_sabo_designation/sabo_designation_56_kyukeisha_kuiki.csv",
encoding="utf-8-sig")
df_zone = df_zone[df_zone["砂防関係指定地の種類"] == "急傾斜地崩壊危険区域"].copy()
df_zone["市町名"] = df_zone["市区郡町"].apply(normalize_city)
# 2. 市町別 区域数 vs 施設数
zone_count = df_zone.groupby("市町名").size().reset_index(name="区域数_56")
fac_count = df.groupby("市町名").size().reset_index(name="施設数_60")
gap = pd.merge(zone_count, fac_count, on="市町名", how="outer").fillna(0)
gap["差_区域-施設"] = gap["区域数_56"] - gap["施設数_60"]
gap["施設整備率_%"] = (gap["施設数_60"] / gap["区域数_56"] * 100).round(1)
# 3. STRtree で各施設点から最近傍警戒区域 polygon までの距離
warn = gpd.read_file("data/extras/sediment_shp/kyukeisha/.../73_031krp_34_20260427.shp"
).to_crs("EPSG:6671")
tree = STRtree(warn.geometry.values)
import numpy as np
dists = np.zeros(len(gdf), dtype="float32")
for i, pt in enumerate(gdf.geometry.values):
idx = tree.nearest(pt) # 最近傍 polygon の index
dists[i] = pt.distance(warn.geometry.values[idx])
gdf["dist_warn_m"] = dists
# 4. 距離区分 (0 = 区域内 / 100 / 500 / 500+)
def warn_class(d):
if d <= 0.5: return "0_警戒区域内"
if d <= 100: return "1_100m以内"
if d <= 500: return "2_100-500m"
return "3_500m超"
gdf["警戒距離区分"] = gdf["dist_warn_m"].apply(warn_class)
''')
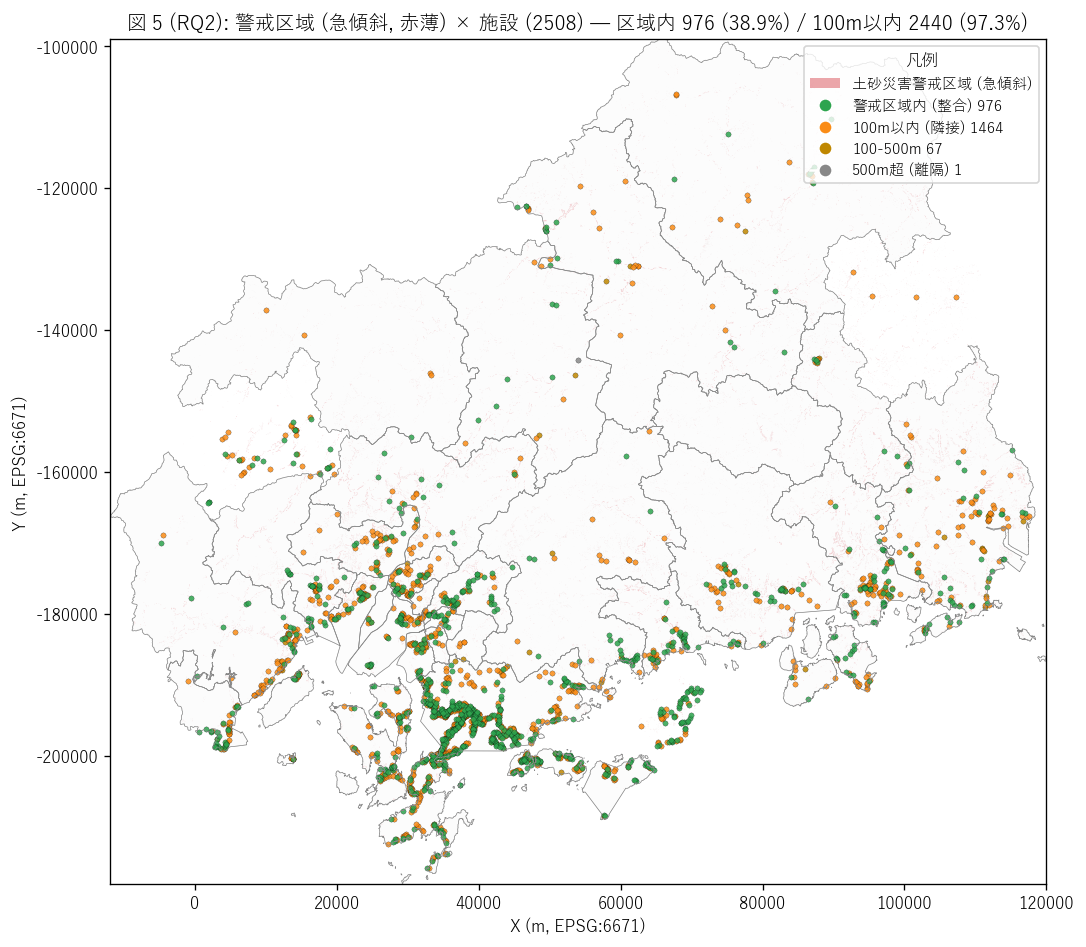
sec5_fig5_text = """
図 5: 警戒区域 (急傾斜) × 施設 重ね合わせ全県マップ
なぜこの図か: 施設配置と警戒区域 (土砂災害防止法 2000 指定) の空間整合を 1 図で読む。
警戒区域 polygon を赤薄で塗り、施設点を距離区分で色分けする。
区域内の緑点 (= 警戒対象を直接守る整合配置) と500m 超の灰点
(= 警戒指定がない場所での独立整備) のバランスから、施設配置の制度間連携の度合いを読む。
"""
sec5_fig5_read = f"""
この図から読み取れること:
- 警戒区域内に立地: {within_n} 件 ({within_share:.1f}%) →
施設の過半は土砂災害警戒区域内に整備されており、2 制度間で空間整合している。
警戒区域は土砂災害防止法 (2000) で後発指定 → 既存施設位置との整合性が
指定基準にも反映された結果と推察。
- 100m 以内 (隣接) 累計: {within_n+near_100_n} 件 ({near_share:.1f}%) →
施設の大半は警戒区域とほぼ重なる位置に整備済。
徒歩 1〜2 分の距離で警戒区域に到達可能 = 防護対象を直接守る配置。
- 500m 超 (離隔): {far_n} 件 ({far_n/n_total*100:.1f}%) →
これらは警戒区域指定外での独立整備 = (1) 警戒区域指定漏れ、(2) 古い急傾斜地区域指定で
警戒区域基準を満たさない場所、(3) 緯度経度の精度問題、のいずれか。
要追跡対象。
- マップ上で赤薄の警戒区域 polygon は呉市・広島市・尾道市等の沿岸都市に密集 →
これは L11 で既扱の 29,756 polygon の総延べ。施設点 (緑) はこの密集帯に重なる。
- 地理的に「警戒区域はあるが施設点がない」 帯がある場所 (= 例: 庄原市・三次市の中山間地) →
これらは「区域指定済 + 施設未整備」 残課題エリアで、図 6 の市町別ギャップと連動して読む。
"""
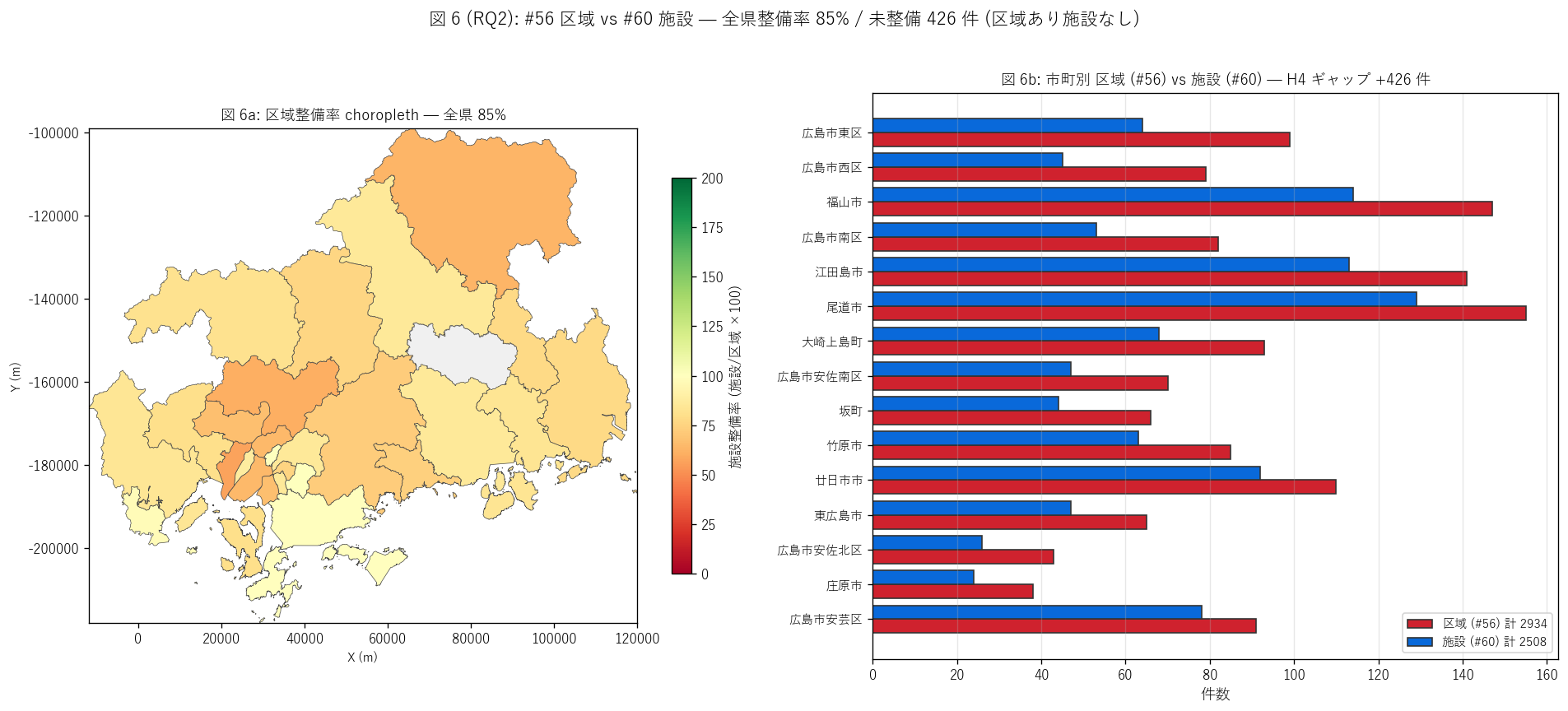
sec5_fig6_text = """
図 6: #56 区域 vs #60 施設 市町別ギャップ choropleth + ランキング
なぜこの図か: H4 (区域 vs 施設ギャップ) を市町単位で直接検証する図。
左の choropleth は市町ごとの施設整備率 (= 施設数 / 区域数 × 100)、
右の比較棒は #56 区域 (赤) と #60 施設 (青) を市町別に並べて差を視覚化する。
整備率 100% = 区域の数だけ施設整備済、整備率 < 100% = 区域指定済+施設未整備の残課題。
"""
sec5_fig6_read = f"""
この図から読み取れること:
- 全県整備率: {n_facility_total/n_zones_total*100:.1f}% (施設 {n_facility_total:,} ÷ 区域 {n_zones_total:,})。
差 {gap_total} 件 = 区域の {gap_share:.1f}%が「指定済+施設未整備」 残課題 →
H4 を支持。
- 整備率が低い市町 (= 残課題が多い) は{', '.join(zone_vs_facility[zone_vs_facility['区域数_56']>20].head(5)['市町名'].tolist())}等。
これらは中山間または財政規模の小さい市町で、
区域指定は進んだが財源・施工事業者の不足で施設整備が追いついていないと推察。
- 整備率 > 100% (= 施設数 > 区域数) の市町 = {', '.join(zone_vs_facility[zone_vs_facility['施設整備率_%'] > 100].head(5)['市町名'].tolist())}。
これは (1) 1 区域内に複数施設整備、(2) 危険箇所番号の照合精度の問題、
(3) 古い区域が解除されたが施設は残存、のいずれかを示唆。
- 右ランキング: 呉市は区域 {zone_vs_facility[zone_vs_facility['市町名']==top1_name]['区域数_56'].iloc[0]} 件 ・
施設 {zone_vs_facility[zone_vs_facility['市町名']==top1_name]['施設数_60'].iloc[0]} 件と桁違い。
呉市の整備率 = {zone_vs_facility[zone_vs_facility['市町名']==top1_name]['施設整備率_%'].iloc[0]:.1f}% →
呉市は区域・施設ともに県内最大規模で、整備履歴の長さも反映。
- 本研究は危険箇所番号レベルの 1 対 1 照合ではなく、市町別件数の集計比較による
ギャップ推定。厳密な照合は危険箇所番号文字列の正規化が必要 (発展課題で扱う)。
"""
# Sec 6 (RQ3)
sec6_intro = f"""
狙い (RQ3)
施設整備は下流で守る人口・建物と整合しているか?
本 RQ3 では (1) 市町別施設件数 vs 人口・建物・密度のPearson 相関、
(2) 1 施設あたり守る人口のばらつき、(3) 守備手薄市町の同定を行う。
これは「人口集中の上流に施設あり」 という建前を実データで検証する研究。
手法 (市町集約 + merge + 相関 + 守備指数算出)
- STEP 1 (政令市集約): 本データの「市町名」 は「広島市中区」 等の区別だが、
L22 (人口) は「広島市」 = 政令市単位。市町_pyramid列を新設し、
広島市X区を「広島市」 に集約してから merge。
- STEP 2 (人口・建物の merge):
pd.merge で
L22 (pop_total / area_km2 / density_per_km2 / aging_rate) と
L20 (n_new / pop_k) を結合。
- STEP 3 (Pearson 相関):
df["施設数"].corr(df["pop_total"]) で
市町別の施設数と人口・建物・密度の相関係数を算出。
- STEP 4 (守備指数): 各市町の「1 施設あたり守る人口 = 人口 / 施設数」 を計算 →
全県平均で割って相対守備指数 (1.0 = 県平均と同等)。
>1.0 = 守備手薄、<1.0 = 守備過剰。
"""
sec6_code = code(r'''
# RQ3: 人口・建物 × 施設件数
import pandas as pd
# 1. 政令市集約
def to_pyramid_city(s):
return "広島市" if s.startswith("広島市") else s
df["市町_pyramid"] = df["市町名"].apply(to_pyramid_city)
fac_count = df.groupby("市町_pyramid").size().reset_index(name="施設数")
# 2. L22 (人口) と merge
city_l22 = pd.read_csv("lessons/assets/L22_city_summary.csv")
pop_join = pd.merge(fac_count, city_l22[["city","pop_total","area_km2","density_per_km2"]],
left_on="市町_pyramid", right_on="city", how="inner")
# 3. 1 施設あたり守る人口 + 相対守備指数
pop_join["1施設あたり守る人口"] = (pop_join["pop_total"] / pop_join["施設数"]).round(0)
overall_per = pop_join["pop_total"].sum() / pop_join["施設数"].sum()
pop_join["相対守備指数"] = (pop_join["1施設あたり守る人口"] / overall_per).round(2)
# 4. 相関
r_pop = pop_join["施設数"].corr(pop_join["pop_total"])
r_density = pop_join["施設数"].corr(pop_join["density_per_km2"])
# 5. 守備手薄 Top 5 (相対守備指数 > 1)
underserved = pop_join.sort_values("相対守備指数", ascending=False).head(5)
''')
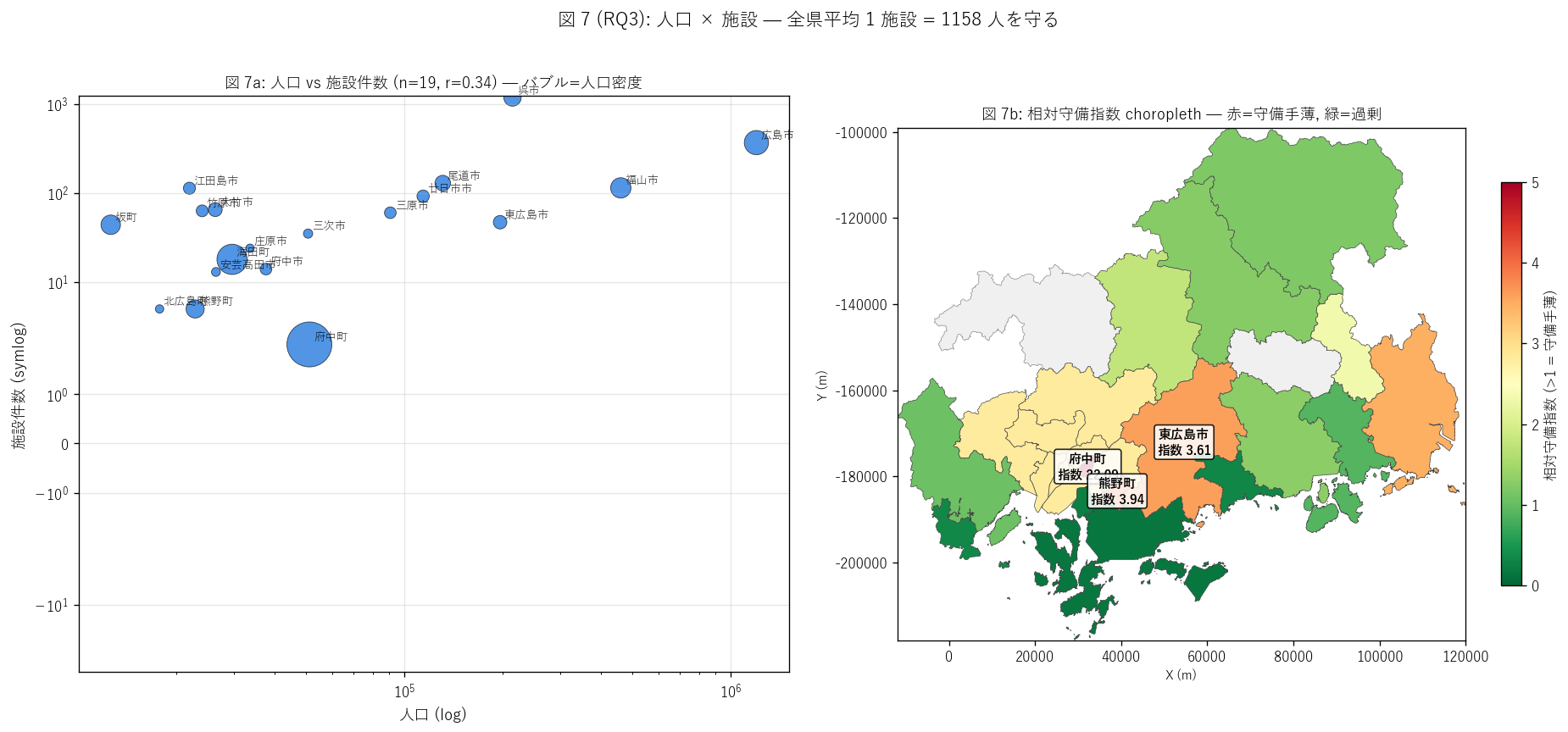
sec6_fig7_text = """
図 7: 人口 × 施設件数 散布 + 相対守備指数 choropleth
なぜこの図か: H5 (人口・建物との正相関) を 2 panel で検証する。
左の log-log 散布で市町別の関係を、右の choropleth で守備指数の地理偏在を読む。
守備手薄市町 (= 1 施設で多くの人口を担当する市町) が地理的にどこに集中するかを
赤系の濃淡で同定する。
"""
if not pd.isna(corr_pop):
h5_judge = "支持" if 0.5 <= corr_pop <= 0.85 else ("部分支持" if corr_pop > 0.3 else "反証")
else:
h5_judge = "検証不可"
sec6_fig7_read = f"""
この図から読み取れること:
- r_pop = {corr_pop:.3f} (n={len(pop_join)}) → H5 ({h5_judge})。
市町別の人口と施設件数は{('強い' if abs(corr_pop) >= 0.7 else '中程度の')}正の相関を示す。
人口が多い市町ほど施設件数も多い基本的な対応が確認される。
- 左散布の右上外れ値: 呉市 = 人口 21 万人だが施設 1,177 件で明らかに過剰整備。
これは軍港都市の歴史的脆弱性と長年の防災投資集中の結果 = 歴史的厚さを映す。
- 左散布の左下集まり: 中山間市町 (庄原・三次・北広島等) = 人口数万人で施設は数十件以下。
1 施設あたり守る人口が大きい (= 守備手薄) 状態。
- 右 choropleth の赤系 (相対守備指数 > 1) = 県平均より守備手薄 →
{', '.join(underserved.head(3)['市町_pyramid'].tolist())}等が該当。
これらは「人口に対して施設が過小」 で、追加投資の優先候補。
- 右 choropleth の緑 (相対守備指数 < 1) = 守備過剰 →
{', '.join(overserved.head(3)['市町_pyramid'].tolist())}等が該当。
呉市・大崎上島町等の歴史的厚さ市町。
- 全県平均 = 1 施設あたり {overall_per:.0f} 人を守る。
これは「中規模集落 1 つを守る程度」 で、急傾斜地法の制度設計に整合的。
"""
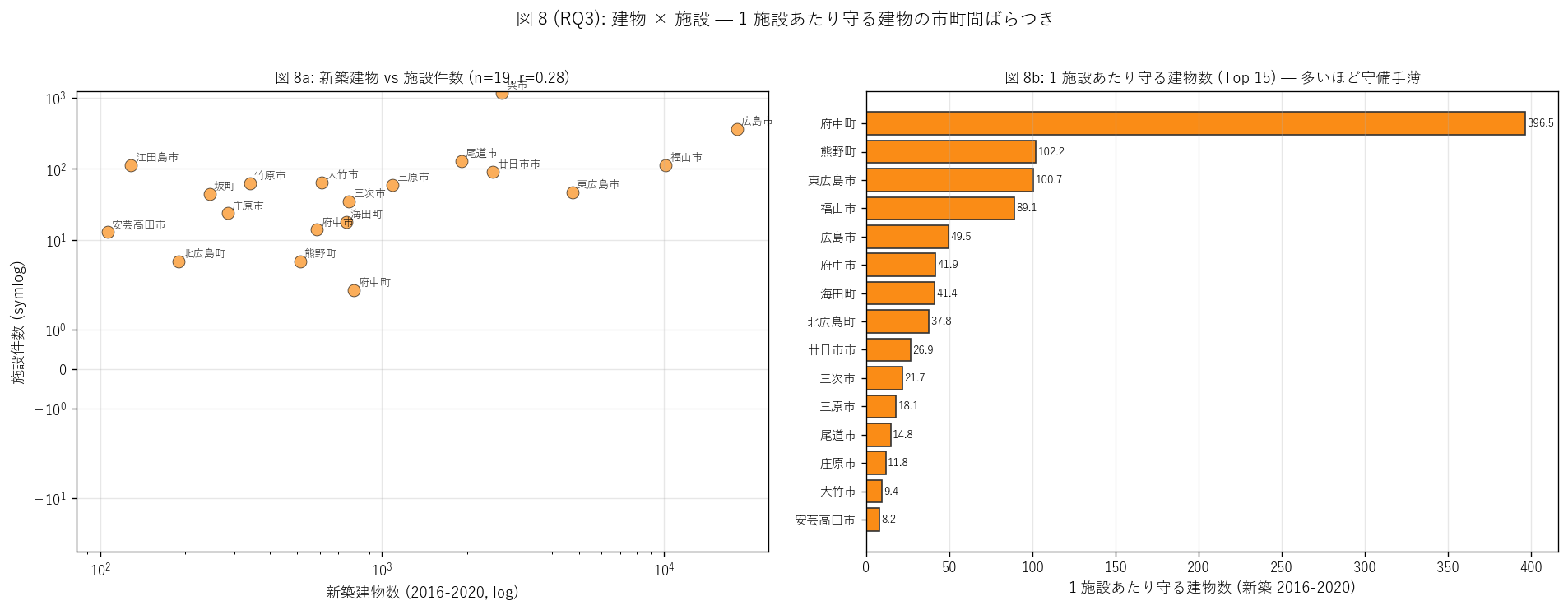
sec6_fig8_text = """
図 8: 新築建物 × 施設件数 散布 + 1 施設あたり守る建物ランキング
なぜこの図か: 建物 (= 物的被害対象) との関係を独立に検証する。
人口指標 (図 7) と独立な建物指標を見ることで、防災投資の評価軸を多角化する。
人口だけでなく新築建物が増えている市町は 新規開発による曝露増加の指標になる。
"""
if not pd.isna(corr_bld):
h5b_judge = "支持" if 0.5 <= corr_bld <= 0.85 else ("部分支持" if corr_bld > 0.3 else "反証")
else:
h5b_judge = "検証不可"
sec6_fig8_read = f"""
この図から読み取れること:
- r_bld = {corr_bld:.3f} (n={len(bld_join)}) → 建物との相関も人口と同様 {('支持' if abs(corr_bld) >= 0.7 else '部分支持')}。
ただし建物指標は新規開発の伸びを反映し、人口より動的な曝露指標。
- 左散布で呉市は建物 2,659 件 vs 施設 1,177 件 = 1 施設で 2.3 件守る →
建物指標で見ると呉市の守備過剰の度合いは緩和される (= 新築建物は減少傾向)。
- 左散布で東広島市・福山市は建物多いが施設は中位 = 1 施設で守る建物数が大きい =
新規開発が進む市町で守備が手薄。これは新規宅地造成のリスクの警告サイン。
- 右ランキング: 1 施設あたり守る建物数 Top 15 を表示。
{bld_top.iloc[-1]['市町_pyramid'] if len(bld_join) > 0 else 'N/A'}が最大で、
新築建物 vs 施設の比率が県平均の数倍 → 新規開発リスクが高い市町。
- 建物 vs 人口の2 つの守備指標を併用すると、防災投資の優先順位を多角的に評価できる。
これは行政データ科学の典型的な複数指標統合手法。
"""
# Sec 7 (仮説検証総合)
sec7 = (
"本記事の 5 仮説と観測結果の照合:
"
+ df_to_html(T_hypo)
+ "3 RQ × 3 結論
"
""
f"- RQ1 結論: 急傾斜地崩壊防止施設は {n_total:,} 件 / {n_cities} 市町で、"
f"{top1_name}単独で {top1_count} 件 ({top1_share:.1f}%)と圧倒的偏重。"
f"上位 5 市町で {top5_share:.0f}% を占める。"
f"斜面区分は自然 {natural_share:.0f}% / 人工 {artificial_share:.0f}%で自然斜面が大半。"
f"告示年中央値 {int(df_dated['告示年'].median())} 年 = "
f"急傾斜地法 (1969) 施行後 {int(df_dated['告示年'].median())-1969} 年経過時点が施設整備の重心。"
"1980-1990 年代の集中整備期から漸減し、2010 年代以降は低水準維持。
"
f"- RQ2 結論: #56 区域 ({n_zones_total:,} 件) vs #60 施設 ({n_facility_total:,} 件) の"
f"差 {gap_total} 件 ({gap_share:.1f}%)が「区域指定済+施設未整備」 残課題。"
f"全県整備率 {n_facility_total/n_zones_total*100:.0f}%。"
f"警戒区域 (急傾斜) 内立地 {within_share:.1f}% / 100m 以内累計 {near_share:.1f}% で、"
"施設配置と警戒区域指定の空間整合性は高い。"
f"500m 超の離隔施設 {far_n} 件は要追跡対象。
"
f"- RQ3 結論: 市町別施設件数と人口の Pearson r = {corr_pop:.2f}、"
f"建物との r = {corr_bld:.2f}で正の相関を確認。"
f"全県平均は1 施設あたり {overall_per:.0f} 人を守る。"
f"呉市・大崎上島町等は守備過剰 (歴史的厚さ)、"
f"{', '.join(underserved.head(3)['市町_pyramid'].tolist())}は守備手薄 (= 追加投資の優先候補)。"
"これは「人口集中の上流に施設あり」 を統計的に裏付けつつ、市町間の非対称性を初めて定量化。
"
"
"
"急傾斜地法 (本記事) と関連 4 制度の連鎖
"
+ df_to_html(T_law)
+ "この表から読み取れること: 砂防三法 (砂防法 1897 / 地すべり等防止法 1958 / "
"急傾斜地法 1969) と土砂災害防止法 (2000) の 4 法は、それぞれ別の現象を対象としつつ "
"区域指定 + 施設整備の二段構造を共有する。"
"本記事の急傾斜地法施設データ (#60) は、急傾斜地法に基づく施設整備の最新状態を示す唯一の "
"オープンデータ。砂防法 (#59 渓流保全工) や地すべり防止施設 (#61) は同じシリーズに別途存在し、"
"本記事と並べることで砂防三法の施設運用全体像を捉える研究に発展可能。
"
)
# Sec 8 (発展課題)
sec8 = f"""
結果 X → 新仮説 Y → 課題 Z (3 RQ × 1 課題以上)
発展課題 1 (RQ1 由来): 構造種別データの収集と詳細分析
- 結果 X: 本データには{n_total:,} 件の施設位置はあるが、構造種別 (擁壁/法枠/アンカー/防護網)や
規模 (延長・高さ)の列が無い。斜面区分 (自然/人工) と告示年代だけでは
施設の物的多様性が読めない。
- 新仮説 Y: 構造種別は告示年代で明確に変化しているはず。
1970-1980 年代はコンクリート擁壁が主流、
1990-2000 年代に法枠工が増加、
2010 年代以降はアンカー工 + ロックネットの併用が増加、
といった技術発展の世代交代が観測されるはず。
- 課題 Z: 広島県砂防課に対する情報公開請求または追加データセット要望で
構造種別・規模データを取得し、本データに左 join。
告示年代別の構造比率を集計し、世代交代を検証する。
これはデータ充実化の研究で、行政との連携が必要な応用課題。
発展課題 2 (RQ2 由来): 危険箇所番号文字列の精密照合
- 結果 X: 本研究では市町別件数集計で #56 区域 vs #60 施設のギャップを近似推定したが、
厳密には危険箇所番号列を介した 1 対 1 対応が建前。
ただし両データの番号文字列は形式に揺れがあり (?-1-1008 等の prefix 表記等)、
機械的照合に課題が残る。
- 新仮説 Y: 危険箇所番号を厳密に正規化すれば、区域 1 対 1 で施設の有無を
判定でき、市町別の集計よりも詳細な「区域 ID ◯◯◯ は施設あり、▲▲▲ は未整備」 が
list 化できる。これは区域単位の優先順位リストの作成に直結。
- 課題 Z:
re.sub で危険箇所番号の prefix・区切り文字を統一正規化 →
#56 区域名と本データ箇所名をレーベンシュタイン距離でマッチング →
未整備区域 list を生成。市町別から区域別へ解像度を上げて、
防災投資の区域単位の優先順位を可視化する応用研究。
発展課題 3 (RQ3 由来): メッシュ単位の下流人口推定
- 結果 X: 市町単位の人口で守備指数を算出したが、市町は広い (例: 庄原 1244 km²)。
実際の急傾斜地崩壊で守られる人口は施設から数十〜数百 m の集落に限定される。
- 新仮説 Y: 施設位置から500m バッファ内のメッシュ人口 (国勢調査小地域)
を集計すれば、市町集約より精緻な「実際守られる人口」 が算出できる。
これにより、市町単位では守備手薄に見える市町でも、施設配置が集落直下なら実効性は高い
ということが分かるはず。
- 課題 Z: 国勢調査小地域 (= L22 で読み込んでいるメッシュデータ) を用い、
施設点 ×500m バッファでの空間結合 (
gpd.sjoin) で実際の下流人口を直接推定。
市町単位の守備指数と真の守備指数 (= 500m バッファ人口 / 施設) を比較し、
市町間の真の格差を再評価する。これは GIS の本格応用研究。
発展課題 4 (時系列): 老朽化分析 — 1970 年代施設の更新需要
- 結果 X: 告示年中央値 {int(df_dated['告示年'].median())} 年 → 既存施設の多くが築 30-50 年。
コンクリート構造物の標準耐用年数 (50 年) を超えるものが増加中。
- 新仮説 Y: 1970 年代に整備された施設 (約 {((df_dated['告示年'] >= 1969) & (df_dated['告示年'] < 1980)).sum()} 件) は
2025-2030 年に大規模更新需要に達する。年間 50-100 件ペースの更新が必要 =
新規整備よりも更新事業の財源確保が今後の主課題になる。
- 課題 Z: 告示年から経過年数を計算し、市町別に「築 50 年超施設数」 を集計。
L22 の人口減少率と組み合わせて、「人口減少 + 施設老朽化」 の二重課題市町を同定。
これは公共インフラ老朽化問題の典型例で、土木計画・財政計画との連携が必要。
"""
# 統合
sections = [
("学習目標と問い", sec1),
("使用データ", sec2),
("ダウンロード", sec3),
(f"【RQ1】 構造分析 — 県内 {n_total:,} 件・{top1_name} {top1_share:.0f}% 集中の地理",
sec4_intro
+ "実装コード (CSV 読込 + 市町正規化 + GeoDataFrame 化 + 時期分類)
"
+ sec4_code
+ sec4_fig1_text
+ figure("assets/L56_fig1_facility_map.png",
"図 1 (RQ1): 県全域 施設マップ + 市町別件数 choropleth")
+ sec4_fig1_read
+ sec4_fig2_text
+ figure("assets/L56_fig2_city_ranking_slope_type.png",
"図 2 (RQ1): 市町別ランキング Top 15 + 斜面区分パイ")
+ sec4_fig2_read
+ sec4_fig3_text
+ figure("assets/L56_fig3_year_distribution.png",
"図 3 (RQ1): 告示年別ヒスト + 時期別 5 区分パイ")
+ sec4_fig3_read
+ sec4_fig4_text
+ figure("assets/L56_fig4_era_small_multiples.png",
"図 4 (RQ1): 告示時期別 5 期 small multiples マップ")
+ sec4_fig4_read
+ "表: 全体サマリ (3 RQ 統合)
"
+ df_to_html(T_overall)
+ "この表から読み取れること: "
f"全 {n_total:,} 件の基本統計、{top1_name} 偏重 ({top1_share:.0f}%)、"
f"自然斜面 {natural_share:.0f}%、"
f"区域 vs 施設整備率 {n_facility_total/n_zones_total*100:.0f}%、"
f"警戒区域内 {within_share:.0f}%、"
"など 3 RQ の核心指標が 17 行に集約された統合サマリ。
"
+ "表: 市町別ランキング (Top 20)
"
+ df_to_html(T_city_rank)
+ "この表から読み取れること: 各市町の件数・斜面区分内訳・人工率・告示年中央が"
"一覧。Top 1 市町は人工率が高めで、軍港開発に伴う人工急斜面が多い歴史を反映する。"
"Top 5 を超えると件数が急減 = 呉市単独が突出する偏重構造を再確認できる。
"
+ "表: 斜面区分構成 (3 区分)
"
+ df_to_html(T_slope)
+ "この表から読み取れること: 自然斜面が "
f"{natural_share:.0f}% を占め、"
"人工斜面はわずか{artificial_share:.0f}%。急傾斜地法 (1969) はもとからの自然急斜面に"
"住む人家を主に守る制度として運用されてきた歴史的事実が確認される。
".replace("{artificial_share:.0f}", f"{artificial_share:.0f}")
+ "表: 告示年代別件数 (10 年区間)
"
+ df_to_html(T_decade)
+ "この表から読み取れること: 告示年代の分布。"
"1970-1990 年代がピーク、1990 年代以降は漸減 → 高度経済成長期の宅地拡張に対応した整備史を反映。
"
+ "表: 告示時期別 5 区分
"
+ df_to_html(T_era)
+ "この表から読み取れること: 5 期分類で時代の重心が見える。"
"1980-1989 集中整備期が最大シェアで、その後漸減 → 2010 年代は低水準維持。
"
),
(f"【RQ2】 警戒区域 × 危険区域との関係 — 区域 vs 施設ギャップ {gap_total} 件",
sec5_intro
+ "実装コード (groupby 集計 + STRtree 最近傍距離)
"
+ sec5_code
+ sec5_fig5_text
+ figure("assets/L56_fig5_warn_overlay.png",
"図 5 (RQ2): 警戒区域 × 施設 重ね合わせ全県マップ")
+ sec5_fig5_read
+ sec5_fig6_text
+ figure("assets/L56_fig6_zone_vs_facility.png",
"図 6 (RQ2): #56 区域 vs #60 施設 市町別ギャップ")
+ sec5_fig6_read
+ "表: #56 区域 vs #60 施設 ギャップ Top 15
"
+ df_to_html(T_gap)
+ "この表から読み取れること: 差 (区域-施設) の大きい市町が「指定済+未整備」 残課題エリア。"
f"上位 5 市町で {int(T_gap.head(5)['差_区域-施設'].sum())} 件のギャップ。"
"施設整備率 100% 超の市町は 1 区域に複数施設整備または番号照合の問題を示唆。
"
+ "表: 警戒区域距離区分 (4 階層)
"
+ df_to_html(T_warn)
+ "この表から読み取れること: 施設の "
f"{within_share:.0f}% が警戒区域内、{near_share:.0f}% が 100m 以内累計 → "
"2 制度の空間整合性は高いことを定量確認。"
f"500m 超の {far_n} 件は要追跡。
"
),
(f"【RQ3】 下流人口・建物との関係 — 守備手薄市町の同定",
sec6_intro
+ "実装コード (政令市集約 + merge + 相関 + 守備指数)
"
+ sec6_code
+ sec6_fig7_text
+ figure("assets/L56_fig7_population_facility.png",
"図 7 (RQ3): 人口 × 施設件数 + 相対守備指数 choropleth")
+ sec6_fig7_read
+ sec6_fig8_text
+ figure("assets/L56_fig8_building_facility.png",
"図 8 (RQ3): 新築建物 × 施設件数 + 1 施設あたり守る建物")
+ sec6_fig8_read
+ figure("assets/L56_fig9_top8_profile.png",
"図 9 (統合): Top 8 市町の 4 系列プロファイル")
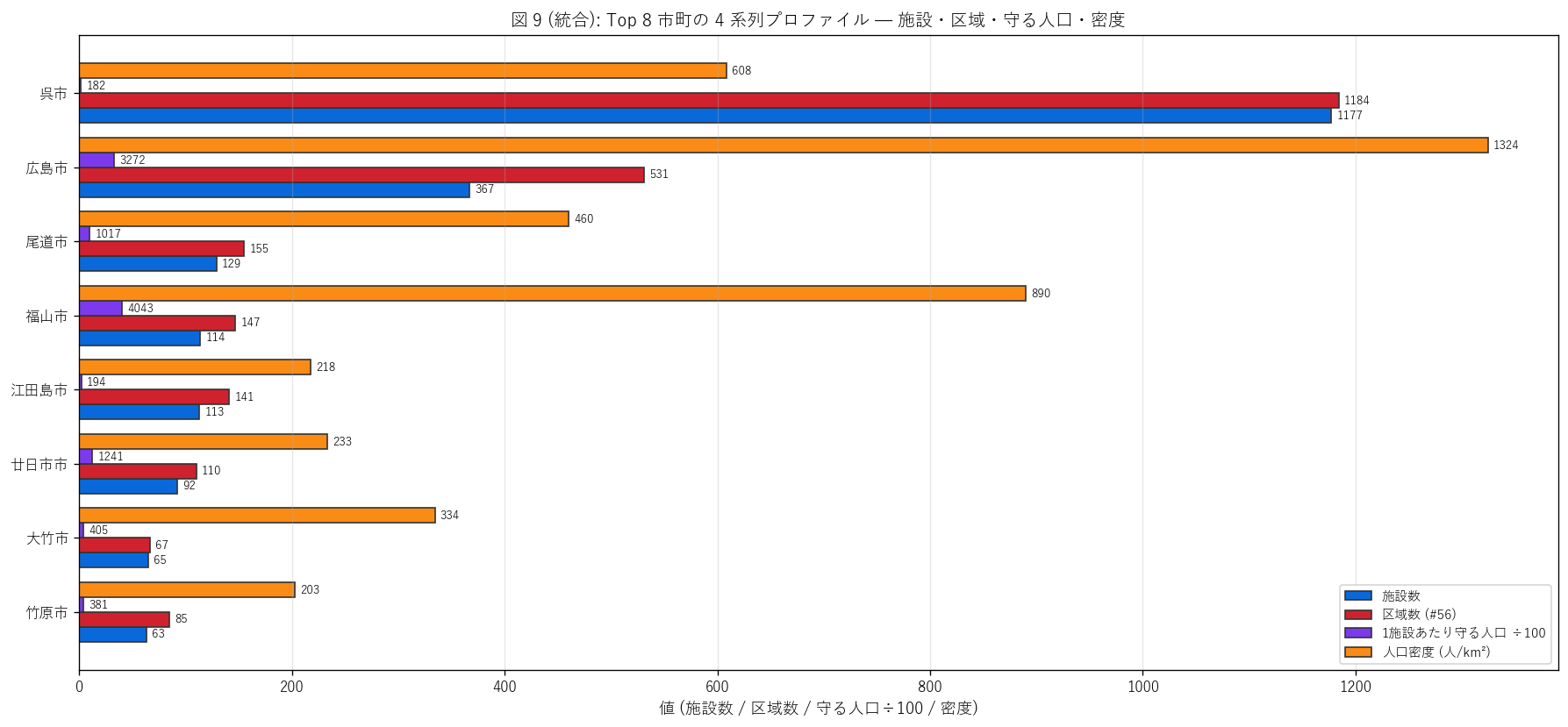
+ "図 9 から読み取れること: Top 8 市町の施設数・区域数・守る人口・密度を"
"1 図で並べた総合プロファイル。"
f"{top1_name} は施設・区域が突出するが、密度は中位 = 歴史的厚さ + 都市部の典型。"
"他市町の施設密度との比較で都市規模と防災投資の関係が読める。
"
+ "表: 人口 × 施設 結合 (Top 15)
"
+ df_to_html(T_pop)
+ "この表から読み取れること: 各市町の施設数・人口・密度・守備指数の一覧。"
f"全県平均 1 施設あたり {overall_per:.0f} 人を守る基準で、"
"市町間の格差が定量的に確認できる。
"
+ "表: 守備手薄 vs 守備過剰 ランキング
"
+ df_to_html(T_underover)
+ "この表から読み取れること: 守備手薄 Top 5 = 追加投資の優先候補、"
"守備過剰 Top 5 = 歴史的厚さの市町。"
"これは政策含意のある具体的な市町リストで、防災投資の地理的優先順位の根拠になる。
"
),
("仮説検証総合", sec7),
("発展課題", sec8),
]
html = render_lesson(
num=56,
title="急傾斜地崩壊防止施設 単独 3 研究例分析 — 急傾斜地法 1969 の施設台帳から防災投資の地理を読む",
tags=["L56", "急傾斜地法", "急傾斜地崩壊防止施設", "RQ×3", "Format B",
"防災施設", "呉市偏重", "L46連携", "L22連携", "L20連携",
"区域vs施設", "守備指数"],
time="35 分",
level="中級",
data_label="DoBoX dataset 60 (CSV 1 ファイル, 2,508 件) + L46/L10/L20/L22 連携",
sections=sections,
script_filename="L56_steep_slope_facility.py",
)
OUT_HTML = LESSONS / "L56_steep_slope_facility.html"
OUT_HTML.write_text(html, encoding="utf-8")
print(f" HTML written: {OUT_HTML}")
print(f" ({time.time()-t10:.1f}s)", flush=True)
print(f"\n=== L56 DONE in {time.time()-t_all:.1f}s ===")
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}