# -*- coding: utf-8 -*-
"""L53 届出盛土等(法第21条第1項・40条第1項) 単独 3 研究例分析
— 広島県の「届出盛土」 284 件を 3 つの独立した研究角度で読み解く
カバー宣言:
本記事は DoBoX のシリーズ「届出盛土等(法第21条第1項・40条第1項)」 1 件
(dataset_id = 1430) を 単独で取り上げ、
広島県内の届出盛土 284 件を 3 つの独立した研究角度
(RQ1 / RQ2 / RQ3) で並列に分析する。
「届出盛土」 とは:
2023-05-26 施行の盛土規制法に基づき、
許可を要する規模に達しないが、規制区域内で行う盛土・切土・土石堆積で
知事への届出が義務付けられる工事。許可制 (法 12/30 条) と並ぶ
盛土規制法の二段階監督モデルのうち軽い方の手続。
本データセットは広島県知事が受理した届出台帳で、2023-09〜2025-03 期間で 284 件。
各レコードに「整理番号 / 届出年月日 / 工事主 / 工事施行者 / 所在地 / 地番 /
緯度経度 / 高さ / 面積 / 盛土量 / 切土量 / 工事着手・完了年月日」 が記載される。
「2 つの規制根拠条文」 (届出制):
- 法第21条第1項: 宅地造成等工事規制区域内で許可不要規模の工事を
行う場合の届出義務 (= 旧法から継続している中規模工事)
- 法第40条第1項: 特定盛土等規制区域内で許可不要規模の工事を
行う場合の届出義務 (= 法施行で新設された区域での中規模工事)
両者の違いは「区域指定の用途」 で、21 条は宅地周辺、40 条は山間地等の
特定盛土規制区域。本データセットは両条文の届出を 1 つの台帳で管理。
「許可制 (法 12/30) vs 届出制 (法 21/40) の境界」:
盛土規制法は規模閾値で許可制 / 届出制を分ける:
- 許可必要 = 高さ 1m 超の崖を生ずる盛土、面積 500m² 超の盛土・切土、
高さ 2m 超 + 面積 300m² 超 / または面積 500m² 超の堆積 等
- 届出必要 = 上記閾値以下でも規制区域内で行う場合
つまり、同じ区域内でも工事規模で適用される条文が変わる
という二段階監督モデルである。
「経過措置 (法 22/41 条)」:
新法施行 (2023-05-26) 時点で既に存在する盛土・切土等は、
施行日から 3 か月以内に届出することでみなし届出として扱われる。
本データの大半は 2023-09〜12月 の届出 = 法施行直後の経過措置届出。
工事着手日が 1981 年〜 2023 年に遡るレコードが含まれるのはこのため。
本記事は L52 (許可盛土 152 件) と明確に独立。L52 が「新法下の新規許可台帳」 を
扱うのに対し、本記事は「既存盛土を含む届出台帳」 を扱う。同じ「盛土規制法」 でも
捕捉する現実が異なり、両者を並列で読むことで制度の二段階監督が見える。
研究の問い (3 RQ):
RQ1 (主研究): 広島県内の届出盛土の地理分布と件数構造、許可盛土 (L52) との比較。
284 件を市町別ランキング、規模分布、届出タイミング、工事主体で多角度に集計し、
L52 (許可 152 件) との件数比 (届出 / 許可)を計算。
許可閾値より小さい盛土が多数を占めるはずだが、実際の規模分布は?
RQ2 (副研究 1): 届出盛土の累積土量と地理累積効果。
284 件の盛土量を市町別に集計し、累積土量を計算。多数の中規模盛土の
パッチワーク的累積が地理にどう影響するか? 警戒区域 (L10/L11 既扱) との
空間関係を 4 区分で集計し、許可盛土 (L52) との立地パターン比較を行う。
「中規模が多数 = 累積で大規模」 の仮説を検証する。
RQ3 (副研究 2): 許可制 (L52) vs 届出制 (L53) の制度設計検証。
規模閾値による棲み分けが実装されているか? 届出 284 件の規模分布が
許可 152 件より系統的に小さいか? 経過措置による遡及届出
(工事着手 < 法施行) が何件あり、これが何を意味するか?
二段階監督モデルの盲点を同定する診断研究。
仮説 (5):
H1 (山間部偏重, RQ1): 284 件の届出盛土は L52 (許可) と異なり、
山間部市町 (三次・庄原・安芸高田・北広島・神石高原) に分散立地する。
これは経過措置で旧法時代の山間部盛土が一斉に届出されたことを反映する。
上位 5 市町の集中度は許可制 (L52 = 63%) より低く 50% 程度。
H2 (届出 / 許可比, RQ1): 届出盛土 284 件 / 許可盛土 152 件 = 1.87 倍。
中規模が多数存在する盛土行政の構造を反映。一方、規模 (面積・土量) は
届出制が許可制より小さいはずだが、経過措置の遡及届出には大規模も
含まれるため、規模分布は許可制と同等以上になる可能性。
H3 (経過措置遡及, RQ3): 工事着手日が法施行 (2023-05-26) 以前の案件は
全体の 50% 以上。経過措置 (法 22/41 条) によるみなし届出が大半を占め、
届出制度の本来目的 (= 新規工事の届出) と運用実態がずれている。
H4 (累積土量の市町偏在, RQ2): 市町別の累積盛土量は2 桁の幅で偏在。
上位 3 市町の累積が全体の 50% を占める。これは「件数の偏在」 と
異なる軸での地理累積効果を生む — 件数は分散でも土量は集中する可能性。
H5 (警戒区域立地比較, RQ2): 届出盛土の警戒区域近接率は許可盛土 (L52 = 49%) より
低い。許可盛土は丘陵部宅地造成 (急傾斜近接) が多いのに対し、
届出盛土は経過措置で山間平地・農地転用も含むため、警戒区域から離隔する案件が
相対的に多い。
要件 S 準拠 (1分以内完走):
- CSV 284 行は軽量 (75.5 KB)。読込・パース・空間結合は <5 秒で完了。
- sediment shp は polygon 数大 (急傾斜 30K, 土石流 13K) だが、
bbox プリフィルタ + STRtree で 284 点 × 43K polygon の最近傍を 10 秒以内で処理。
- L52 の処理済 CSV (assets/L52_permits_processed.csv) を参照することで
比較研究は追加コスト ~0 秒。
- 期待実行時間: <60 秒。
要件 T 準拠 (位置情報あり=地図必須):
- RQ1: 県全域 284 点 マップ (規模別色分け) + 市町別件数 choropleth
- RQ1: 許可 (L52) vs 届出 (L53) の併置マップ (2 panel)
- RQ2: 警戒区域オーバーレイ (届出盛土 × 警戒区域)
- RQ2: 累積土量 choropleth (市町別)
- RQ3: 経過措置遡及案件 vs 純新規届出の地理分布
要件 Q 準拠: 図 9 / 表 12 (3 RQ × 多角度)。
データ仕様:
- dataset 1430: 届出盛土等(法第21条第1項・40条第1項)
- リソース 51165 (CSV, 75.6 KB): 届出台帳 284 件 (2023-09〜2025-03)
- リソース 51166 (XLSX, 23.1 KB): 盛土規制法関係資料 (規制内容 + 手続き先)
- 形式: CSV (UTF-8, 14 列) + XLSX (2 シート)
- 取得日: 2026-05-09
- ライセンス: クリエイティブ・コモンズ表示 4.0
- 作成主体: 広島県土木建築局 都市環境整備課
"""
from __future__ import annotations
import sys, time, re, json, zipfile, shutil
from pathlib import Path
sys.path.insert(0, str(Path(__file__).parent))
from _common import ROOT, ASSETS, LESSONS, render_lesson, code, figure
import numpy as np
import pandas as pd
import geopandas as gpd
import shapely
from shapely import STRtree
import requests
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.patches import Patch
from matplotlib.lines import Line2D
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
t_all = time.time()
print("=== L53 届出盛土等 単独 3 研究例分析 ===", flush=True)
# =============================================================================
# 0. 定数・パス
# =============================================================================
TARGET_CRS = "EPSG:6671" # JGD2011 平面直角座標系第 III 系 (m 単位)
DATA_DIR = ROOT / "data" / "extras" / "L53_notified_earthfill"
DATA_DIR.mkdir(parents=True, exist_ok=True)
CSV_PATH = DATA_DIR / "340006_reported_earth_filling_21-1_40-1_declaration_register_20250826.csv"
XLSX_PATH = DATA_DIR / "340006_earth_filling_regulation_related_documents.xlsx"
# 関連 Shapefile (土砂災害警戒区域 = 既存 sediment_shp を流用)
WARN_KYUKEI = ROOT / "data" / "extras" / "sediment_shp" / "kyukeisha" / \
"340006_sediment_disaster_hazard_area_steep_slope_20260427" / \
"73_031krp_34_20260427.shp"
WARN_DOSEKI = ROOT / "data" / "extras" / "sediment_shp" / "doseki" / \
"340006_sediment_disaster_hazard_area_debris_flow_20260427" / \
"73_031drp_34_20260427.shp"
# 行政区域 (L15 既キャッシュ)
ADMIN_PREF_ZIP = ROOT / "data" / "extras" / "L15_admin_zones" / "admin_922_広島県.zip"
# L52 既処理 CSV (比較研究用)
L52_PROCESSED = ASSETS / "L52_permits_processed.csv"
L52_CITY_SUMMARY = ASSETS / "L52_city_summary.csv"
# DoBoX
DOBOX_BASE = "https://hiroshima-dobox.jp"
HDR = {"User-Agent": "DoBoX-MDASH-textbook/1.0 (educational use)"}
# 主要日付
LAW_ENFORCED = pd.Timestamp("2023-05-26")
LAW_GRACE_END = LAW_ENFORCED + pd.Timedelta(days=92) # 経過措置届出期限 (約 3 か月)
# 市町コード → 名前 (L46/L49/L52 共通)
CITY_NAME = {
101: "広島市中区", 102: "広島市東区", 103: "広島市南区", 104: "広島市西区",
105: "広島市安佐南区", 106: "広島市安佐北区", 107: "広島市安芸区", 108: "広島市佐伯区",
202: "呉市", 203: "竹原市", 204: "三原市", 205: "尾道市", 207: "福山市",
208: "府中市", 209: "三次市", 210: "庄原市", 211: "大竹市", 212: "東広島市",
213: "廿日市市", 214: "安芸高田市", 215: "江田島市",
302: "府中町", 304: "海田町", 307: "熊野町", 309: "坂町",
369: "安芸太田町", 462: "世羅町",
364: "北広島町", 545: "神石高原町", 454: "大崎上島町",
}
NAME_TO_CITY_CD = {v: k for k, v in CITY_NAME.items()}
NAME_TO_CITY_CD["安芸郡府中町"] = 302
NAME_TO_CITY_CD["山県郡北広島町"] = 364
NAME_TO_CITY_CD["三次市作木町"] = 209
# =============================================================================
# 1. データ取得 (なければダウンロード)
# =============================================================================
print("\n[1] データ取得", flush=True)
t1 = time.time()
def ensure_resource(rid: int, dst: Path, label: str):
if dst.exists() and dst.stat().st_size > 1000:
print(f" cache HIT {label}: {dst.name}")
return
url = f"{DOBOX_BASE}/resource_download/{rid}"
print(f" DL ← {url}")
r = requests.get(url, headers=HDR, timeout=60)
r.raise_for_status()
dst.write_bytes(r.content)
print(f" saved → {dst.name} ({len(r.content)} bytes)")
ensure_resource(51165, CSV_PATH, "届出台帳 CSV")
ensure_resource(51166, XLSX_PATH, "規制関係 XLSX")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 2. CSV パース + 数値抽出
# =============================================================================
print("\n[2] CSV パース", flush=True)
t1 = time.time()
RENAME = {
"整理番号": "ref_no",
"届出年月日": "declare_date_raw",
"工事主": "owner",
"工事施行者": "contractor",
"土地の所在地": "city_raw",
"土地の地番": "address",
"座標(緯度)": "lat",
"座標(経度)": "lon",
"盛土切土の高さ又は土石の堆積の最大堆積高さ(m)": "height_raw",
"盛土切土又は土石の堆積を行う土地の面積(m2)": "area_raw",
"盛土の土量又は土石の堆積の最大堆積土量(m3)": "fill_volume_raw",
"切土の土量(m3)": "cut_volume_raw",
"工事着手年月日": "start_raw",
"工事完了年月日": "end_raw",
}
df = pd.read_csv(CSV_PATH, encoding="utf-8")
df = df.rename(columns=RENAME)
def parse_first_date(s):
if pd.isna(s):
return pd.NaT
m = re.search(r"(\d{4})年(\d{1,2})月(\d{1,2})日", str(s))
if not m:
return pd.NaT
y, mo, d = m.groups()
try:
return pd.Timestamp(int(y), int(mo), int(d))
except Exception:
return pd.NaT
def parse_height(s):
"""'2.00~2.30' は最大値 2.30 を返す。'8' は 8.0。"""
if pd.isna(s):
return np.nan
s = str(s).strip()
nums = re.findall(r"\d+\.?\d*", s)
if not nums:
return np.nan
return max(float(x) for x in nums)
def parse_numeric(s):
"""面積・土量を float に変換。"""
if pd.isna(s):
return np.nan
s = str(s).strip()
if s in ("―", "-", "ー", "", "0"):
return 0.0 if s == "0" else np.nan
s = s.replace(",", "")
m = re.search(r"(\d+\.?\d*)", s)
return float(m.group(1)) if m else np.nan
df["declare_date"] = df["declare_date_raw"].apply(parse_first_date)
df["start_date"] = df["start_raw"].apply(parse_first_date)
df["end_date"] = df["end_raw"].apply(parse_first_date)
df["height_max_m"] = df["height_raw"].apply(parse_height)
df["area_m2_raw"] = df["area_raw"].apply(parse_numeric)
df["fill_volume_m3"] = df["fill_volume_raw"].apply(parse_numeric)
df["cut_volume_m3"] = df["cut_volume_raw"].apply(parse_numeric)
# データ品質チェック: 異常に大きい面積 (>= 5,000,000 m² = 500ha) は
# CSV の入力ミス (桁違い) の可能性が高いため、フラグを立てて中央値計算から除外。
# ただし元値は area_m2_raw として保持し、is_area_outlier 列で透明性を担保する。
AREA_OUTLIER_THRESHOLD = 5_000_000 # 5 km² 超は実質的に都市計画区域全域に相当 → 異常
df["is_area_outlier"] = df["area_m2_raw"] >= AREA_OUTLIER_THRESHOLD
df["area_m2"] = np.where(df["is_area_outlier"], np.nan, df["area_m2_raw"])
n_outlier = int(df["is_area_outlier"].sum())
if n_outlier > 0:
out_recs = df[df["is_area_outlier"]][["ref_no", "city_raw", "area_m2_raw"]].head(5).to_dict('records')
print(f" WARN: 面積異常値 {n_outlier} 件を中央値計算から除外 (元値保持): {out_recs}")
# 工事主タイプ
def classify_owner(s):
if pd.isna(s):
return "不明"
s = str(s)
if re.search(r"町長|市長|国土交通|県知事|県土木|機構|公社|事業団|電力|JR|事業協同", s):
return "公共/インフラ"
if re.search(r"株式会社|有限会社|合同会社|合資会社|協同組合|建設工業|建設\s|地所|開発", s):
return "民間法人"
return "個人/その他"
df["owner_type"] = df["owner"].apply(classify_owner)
# 市町名の正規化
def normalize_city(s):
if pd.isna(s):
return None
s = str(s).strip()
if "市作木" in s:
return "三次市"
if s == "安芸郡府中町":
return "府中町"
if s == "山県郡北広島町":
return "北広島町"
return s
df["city_norm"] = df["city_raw"].apply(normalize_city)
df["city_cd"] = df["city_norm"].map(NAME_TO_CITY_CD)
# 経過措置遡及フラグ (工事着手 < 法施行)
df["is_grandfathered"] = df["start_date"] < LAW_ENFORCED
# 純新規届出 (工事着手 >= 法施行 — 本来の届出制度が想定する案件)
df["is_post_law"] = df["start_date"] >= LAW_ENFORCED
# 工事着手から届出までの遅延 (日)
df["delay_days"] = (df["declare_date"] - df["start_date"]).dt.days
# 整理番号 prefix (= 受理事務所 の手がかり)
df["ref_prefix"] = df["ref_no"].astype(str).str.extract(r"^([^\d]+)")[0].fillna("?")
print(f" 284 件読込: {len(df)} 行")
print(f" declare_date 解析: {df['declare_date'].notna().sum()} 件 "
f"({df['declare_date'].min().date()} 〜 {df['declare_date'].max().date()})")
print(f" start_date 解析: {df['start_date'].notna().sum()} 件 "
f"({df['start_date'].min().date()} 〜 {df['start_date'].max().date()})")
print(f" 経過措置遡及 (start < {LAW_ENFORCED.date()}): {df['is_grandfathered'].sum()} 件 "
f"({100*df['is_grandfathered'].sum()/len(df):.1f}%)")
print(f" height_max_m: 中央値 {df['height_max_m'].median():.2f}m, 最大 {df['height_max_m'].max():.2f}m")
print(f" area_m2: 中央値 {df['area_m2'].median():.0f} m², 最大 {df['area_m2'].max():.0f} m²")
print(f" fill_volume_m3: 中央値 {df['fill_volume_m3'].median():.0f} m³, 最大 {df['fill_volume_m3'].max():.0f} m³")
print(f" owner_type: {df['owner_type'].value_counts().to_dict()}")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 3. 行政区域・警戒区域の読込
# =============================================================================
print("\n[3] 行政区域・警戒区域の読込", flush=True)
t1 = time.time()
with zipfile.ZipFile(ADMIN_PREF_ZIP) as zf:
name = [n for n in zf.namelist() if n.endswith(".geojson")][0]
admin = gpd.read_file(f"zip://{ADMIN_PREF_ZIP}!{name}").to_crs(TARGET_CRS)
admin_diss = admin.dissolve(by="CITY_CD", as_index=False)
print(f" admin: {len(admin_diss)} 市町ブロック ({admin_diss['CITY_CD'].min()} 〜 {admin_diss['CITY_CD'].max()})")
warn_kyukei = gpd.read_file(WARN_KYUKEI).to_crs(TARGET_CRS)
warn_doseki = gpd.read_file(WARN_DOSEKI).to_crs(TARGET_CRS)
print(f" 警戒区域: 急傾斜 {len(warn_kyukei):,} polygon, 土石流 {len(warn_doseki):,} polygon")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 4. 届出盛土点 GeoDataFrame 化
# =============================================================================
print("\n[4] 届出盛土の GeoDataFrame 化", flush=True)
t1 = time.time()
gdf = gpd.GeoDataFrame(
df,
geometry=gpd.points_from_xy(df["lon"], df["lat"]),
crs="EPSG:4326",
).to_crs(TARGET_CRS)
# admin sjoin で CITY_CD 補完
gdf_admin = gpd.sjoin(gdf, admin_diss[["CITY_CD", "geometry"]],
how="left", predicate="within")
gdf_admin = gdf_admin.drop_duplicates(subset=["ref_no"], keep="first").reset_index(drop=True)
gdf["CITY_CD_geo"] = gdf_admin["CITY_CD"]
def fill_city_cd(row):
if pd.notna(row["city_cd"]):
return int(row["city_cd"])
if pd.notna(row["CITY_CD_geo"]):
return int(row["CITY_CD_geo"])
return -1
gdf["CITY_CD_final"] = gdf.apply(fill_city_cd, axis=1)
gdf["市町名"] = gdf["CITY_CD_final"].map(CITY_NAME).fillna(gdf["city_norm"])
print(f" CITY_CD 解決: {(gdf['CITY_CD_final']!=-1).sum()}/{len(gdf)} 件 "
f"(残り {(gdf['CITY_CD_final']==-1).sum()} 件未解決)")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 5. RQ1 集計: 地理分布と件数構造 (許可 L52 との比較)
# =============================================================================
print("\n[5] RQ1 集計", flush=True)
t1 = time.time()
# 5-1 市町別件数
city_counts = (gdf.groupby("市町名").size()
.sort_values(ascending=False)
.reset_index(name="届出件数"))
city_counts["順位"] = np.arange(1, len(city_counts) + 1)
top5_share = city_counts["届出件数"].head(5).sum() / city_counts["届出件数"].sum()
top1_city = city_counts.iloc[0]["市町名"]
top1_n = int(city_counts.iloc[0]["届出件数"])
print(f" 市町数: {len(city_counts)}")
print(f" Top 5 市町: {city_counts.head(5).to_dict('records')}")
print(f" H1 検証: Top 5 シェア = {top5_share*100:.1f}% (許可 L52 = 63.2%)")
# 5-2 規模分布
print(f"\n 規模分布 (届出 L53):")
print(f" 高さ最大値: 中央値 {gdf['height_max_m'].median():.2f}m, "
f"75%ile {gdf['height_max_m'].quantile(0.75):.2f}m, max {gdf['height_max_m'].max():.2f}m")
print(f" 面積: 中央値 {gdf['area_m2'].median():.0f} m², "
f"75%ile {gdf['area_m2'].quantile(0.75):.0f} m², max {gdf['area_m2'].max():.0f} m²")
print(f" 盛土土量: 中央値 {gdf['fill_volume_m3'].median():.0f} m³, "
f"75%ile {gdf['fill_volume_m3'].quantile(0.75):.0f} m³, max {gdf['fill_volume_m3'].max():.0f} m³")
# 5-3 工事主体
owner_counts = gdf["owner_type"].value_counts()
private_share = owner_counts.get("民間法人", 0) / len(gdf)
print(f" 工事主体: {owner_counts.to_dict()}")
# 5-4 整理番号 prefix (受理事務所別)
prefix_counts = gdf["ref_prefix"].value_counts()
print(f" 整理番号 prefix 上位: {prefix_counts.head(10).to_dict()}")
# 5-5 L52 (許可) との比較読込
if L52_PROCESSED.exists():
df_l52 = pd.read_csv(L52_PROCESSED, encoding="utf-8-sig")
print(f"\n L52 (許可) 比較データ読込: {len(df_l52)} 件")
n_kyoka = len(df_l52)
todoke_kyoka_ratio = len(gdf) / n_kyoka
print(f" 届出 / 許可 = {len(gdf)} / {n_kyoka} = {todoke_kyoka_ratio:.2f}")
# 規模比較
l52_h_med = df_l52["height_max_m"].median()
l52_a_med = df_l52["area_m2"].median()
l52_v_med = df_l52["fill_volume_m3"].median()
print(f" L52 高さ中央値: {l52_h_med:.2f}m, L53 高さ中央値: {gdf['height_max_m'].median():.2f}m")
print(f" L52 面積中央値: {l52_a_med:.0f}m², L53 面積中央値: {gdf['area_m2'].median():.0f}m²")
print(f" L52 土量中央値: {l52_v_med:.0f}m³, L53 土量中央値: {gdf['fill_volume_m3'].median():.0f}m³")
else:
print(f" WARN: L52 processed CSV not found, comparison disabled")
df_l52 = None
n_kyoka = 0
todoke_kyoka_ratio = np.nan
l52_h_med = l52_a_med = l52_v_med = np.nan
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 6. RQ2 集計: 累積土量 + 警戒区域
# =============================================================================
print("\n[6] RQ2 集計: 累積土量 + 警戒区域空間関係", flush=True)
t1 = time.time()
# 6-1 累積土量
total_fill = gdf["fill_volume_m3"].fillna(0).sum()
total_cut = gdf["cut_volume_m3"].fillna(0).sum()
print(f" 累積盛土量: {total_fill:,.0f} m³ ({total_fill/1e6:.2f} 百万 m³)")
print(f" 累積切土量: {total_cut:,.0f} m³ ({total_cut/1e6:.2f} 百万 m³)")
# 25m プール (= 750 m³) 換算
pool_eq = total_fill / 750
print(f" 25m プール換算: {pool_eq:,.0f} 杯分")
# 6-2 市町別累積
city_volume = (gdf.groupby("市町名")
.agg(件数=("ref_no", "count"),
累積盛土量_m3=("fill_volume_m3", "sum"),
累積切土量_m3=("cut_volume_m3", "sum"),
高さ中央値_m=("height_max_m", "median"),
面積中央値_m2=("area_m2", "median"),
面積最大_m2=("area_m2", "max"))
.reset_index()
.sort_values("累積盛土量_m3", ascending=False))
city_volume["土量シェア_%"] = (city_volume["累積盛土量_m3"] / total_fill * 100).round(2)
top3_volume_share = city_volume.head(3)["累積盛土量_m3"].sum() / total_fill
print(f" 上位 3 市町 累積土量シェア: {top3_volume_share*100:.1f}%")
print(f" H4 検証: 上位 3 累積シェア >= 50%? {'YES' if top3_volume_share>=0.50 else 'NO'}")
print(f" 上位 5 市町 (土量): {city_volume.head(5)[['市町名', '累積盛土量_m3', '土量シェア_%']].to_dict('records')}")
# 6-3 警戒区域 STRtree 距離計算
def nearest_distance_to_polygons(points, polys):
poly_geoms = polys.values
tree = STRtree(poly_geoms)
out = np.zeros(len(points), dtype=np.float32)
for i, pt in enumerate(points.values):
idx = tree.nearest(pt)
out[i] = pt.distance(poly_geoms[idx])
return out
print(f" 急傾斜警戒区域 ({len(warn_kyukei):,}) との最近傍距離計算...", flush=True)
gdf["dist_kyukei_m"] = nearest_distance_to_polygons(gdf.geometry, warn_kyukei.geometry)
print(f" 土石流警戒区域 ({len(warn_doseki):,}) との最近傍距離計算...", flush=True)
gdf["dist_doseki_m"] = nearest_distance_to_polygons(gdf.geometry, warn_doseki.geometry)
gdf["dist_warn_m"] = gdf[["dist_kyukei_m", "dist_doseki_m"]].min(axis=1)
def warn_class(d):
if d == 0:
return "0_警戒区域内"
elif d <= 100:
return "1_100m以内 (隣接)"
elif d <= 500:
return "2_100-500m (近接)"
else:
return "3_500m超 (離隔)"
gdf["warn_class"] = gdf["dist_warn_m"].apply(warn_class)
warn_class_counts = gdf["warn_class"].value_counts().sort_index()
print(f" 距離区分: {warn_class_counts.to_dict()}")
within_n = (gdf["dist_warn_m"] == 0).sum()
near_100_n = ((gdf["dist_warn_m"] > 0) & (gdf["dist_warn_m"] <= 100)).sum()
near_500_n = ((gdf["dist_warn_m"] > 100) & (gdf["dist_warn_m"] <= 500)).sum()
far_n = (gdf["dist_warn_m"] > 500).sum()
near_pct = 100 * (within_n + near_100_n) / len(gdf)
print(f" H5 検証: 警戒区域内+100m = {within_n+near_100_n} 件 ({near_pct:.1f}%) "
f"(L52 = 49.3%)")
gdf["nearest_warn_type"] = np.where(gdf["dist_kyukei_m"] <= gdf["dist_doseki_m"],
"急傾斜地崩壊", "土石流")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 7. RQ3 集計: 制度設計 (許可 vs 届出 vs 経過措置)
# =============================================================================
print("\n[7] RQ3 集計: 制度設計", flush=True)
t1 = time.time()
# 規模カテゴリ (L52 と統一)
def scale_class(row):
h = row["height_max_m"]
a = row["area_m2"]
if pd.isna(h) or pd.isna(a):
return "未分類"
if h >= 5.0 and a >= 5000:
return "S_熱海型 (5m+5000m²+)"
if h >= 3.0 or a >= 2000:
return "L_大規模 (3m+ or 2000m²+)"
if h >= 1.5 or a >= 500:
return "M_中規模 (1.5m+ or 500m²+)"
return "S_小規模 (戸建相当)"
gdf["scale_class"] = gdf.apply(scale_class, axis=1)
scale_counts = gdf["scale_class"].value_counts()
print(f" 規模カテゴリ: {scale_counts.to_dict()}")
# 熱海型
gdf["atami_type"] = (gdf["height_max_m"] >= 5.0) & (gdf["area_m2"] >= 5000)
atami_n = int(gdf["atami_type"].sum())
atami_share = atami_n / len(gdf)
print(f" 熱海型: {atami_n} 件 ({atami_share*100:.1f}%) [L52 = 10.5%]")
# 経過措置遡及の年代分布
grandfathered = gdf[gdf["is_grandfathered"]]
post_law = gdf[gdf["is_post_law"]]
print(f" 経過措置遡及: {len(grandfathered)} 件 ({100*len(grandfathered)/len(gdf):.1f}%)")
print(f" 純新規届出 (start>=法施行): {len(post_law)} 件 ({100*len(post_law)/len(gdf):.1f}%)")
# 工事着手年の分布 (経過措置の遡及範囲)
gf_year_counts = grandfathered["start_date"].dt.year.value_counts().sort_index()
print(f" 遡及工事着手年: {gf_year_counts.head(15).to_dict()}")
print(f" 最古工事着手: {grandfathered['start_date'].min().date()}")
# 届出年月分布 (届出の集中)
gdf["declare_year"] = gdf["declare_date"].dt.year
gdf["declare_ym"] = gdf["declare_date"].dt.to_period("M").astype(str)
ym_counts = gdf["declare_ym"].value_counts().sort_index()
print(f" 月別届出: ピーク={ym_counts.idxmax()} ({ym_counts.max()} 件), 月平均={ym_counts.mean():.1f}")
declare_2023_count = (gdf["declare_year"] == 2023).sum()
print(f" 2023 年届出: {declare_2023_count} 件 ({100*declare_2023_count/len(gdf):.1f}%)")
# 制度区分 (本記事独自定義)
def regime_class(row):
if pd.isna(row["start_date"]):
return "X_着手不明"
if row["is_grandfathered"]:
return "G_経過措置遡及"
return "N_純新規届出"
gdf["regime_class"] = gdf.apply(regime_class, axis=1)
regime_counts = gdf["regime_class"].value_counts()
print(f" 制度区分: {regime_counts.to_dict()}")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 8. CSV 出力 (再現用中間データ)
# =============================================================================
print("\n[8] 中間 CSV 出力", flush=True)
t1 = time.time()
summary_cols = ["ref_no", "ref_prefix", "declare_date", "start_date", "end_date",
"市町名", "lat", "lon",
"height_max_m", "area_m2", "fill_volume_m3", "cut_volume_m3",
"owner_type", "is_grandfathered", "regime_class",
"dist_warn_m", "dist_kyukei_m", "dist_doseki_m",
"warn_class", "nearest_warn_type",
"scale_class", "atami_type"]
df_out = pd.DataFrame(gdf[summary_cols])
df_out.to_csv(ASSETS / "L53_notifications_processed.csv", index=False, encoding="utf-8-sig")
city_volume.to_csv(ASSETS / "L53_city_volume_summary.csv", index=False, encoding="utf-8-sig")
scale_summary = gdf.groupby("scale_class").agg(
件数=("ref_no", "count"),
高さ中央値_m=("height_max_m", "median"),
面積中央値_m2=("area_m2", "median"),
盛土量中央値_m3=("fill_volume_m3", "median"),
盛土量合計_m3=("fill_volume_m3", "sum"),
).reset_index()
scale_summary.to_csv(ASSETS / "L53_scale_summary.csv", index=False, encoding="utf-8-sig")
warn_summary = gdf.groupby("warn_class").agg(
件数=("ref_no", "count"),
最小距離_m=("dist_warn_m", "min"),
中央距離_m=("dist_warn_m", "median"),
最大距離_m=("dist_warn_m", "max"),
).reset_index()
warn_summary.to_csv(ASSETS / "L53_warn_distance_summary.csv", index=False, encoding="utf-8-sig")
# 月別届出件数
ym_df = ym_counts.reset_index()
ym_df.columns = ["年月", "件数"]
ym_df["年月"] = ym_df["年月"].astype(str)
ym_df["累積"] = ym_df["件数"].cumsum()
ym_df.to_csv(ASSETS / "L53_monthly_counts.csv", index=False, encoding="utf-8-sig")
# 経過措置遡及案件詳細 (上位 30)
T_gf = grandfathered.sort_values("start_date").head(30)[
["ref_no", "start_date", "declare_date", "市町名",
"height_max_m", "area_m2", "fill_volume_m3", "warn_class", "scale_class"]
].copy()
T_gf["start_date"] = T_gf["start_date"].dt.date.astype(str)
T_gf["declare_date"] = T_gf["declare_date"].dt.date.astype(str)
T_gf.to_csv(ASSETS / "L53_grandfathered_oldest.csv", index=False, encoding="utf-8-sig")
# 元 CSV を assets にコピー
shutil.copy(CSV_PATH, ASSETS / "L53_notifications_raw.csv")
print(f" CSV 出力 6 ファイル + 元データ 1 ファイル")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 9. 図の生成 (9 図)
# =============================================================================
print("\n[9] 図の生成 (9 図)", flush=True)
t1 = time.time()
def save_fig(name, dpi=120):
p = ASSETS / name
plt.savefig(p, dpi=dpi, bbox_inches="tight", facecolor="white")
plt.close('all')
return p
PREF_BOUNDS = admin_diss.total_bounds
PXMIN, PYMIN, PXMAX, PYMAX = PREF_BOUNDS
SCALE_COLOR = {
"S_熱海型 (5m+5000m²+)": "#cf222e",
"L_大規模 (3m+ or 2000m²+)": "#ff8c00",
"M_中規模 (1.5m+ or 500m²+)": "#1f6feb",
"S_小規模 (戸建相当)": "#2da44e",
"未分類": "#888",
}
WARN_COLOR = {
"0_警戒区域内": "#cf222e",
"1_100m以内 (隣接)": "#fa8c16",
"2_100-500m (近接)": "#fad24e",
"3_500m超 (離隔)": "#2da44e",
}
REGIME_COLOR = {
"G_経過措置遡及": "#a045a0",
"N_純新規届出": "#1f6feb",
"X_着手不明": "#888",
}
# ---- 図 1 (RQ1): 県全域 284 点マップ + 市町別件数コロプレス ----
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
# 1-a 点マップ (規模別色 + サイズ=面積)
ax = axes[0]
admin_diss.boundary.plot(ax=ax, color="#888", linewidth=0.5)
admin_diss.plot(ax=ax, facecolor="#f8f8f5", edgecolor="#aaa", linewidth=0.4, alpha=0.8)
warn_kyukei.plot(ax=ax, color="#ffcccc", alpha=0.4, edgecolor="none")
warn_doseki.plot(ax=ax, color="#ffd699", alpha=0.4, edgecolor="none")
for sc, col in SCALE_COLOR.items():
sub = gdf[gdf["scale_class"] == sc]
if len(sub) == 0:
continue
sizes = np.sqrt(sub["area_m2"].fillna(100).clip(50, 50000)) * 0.4
ax.scatter(sub.geometry.x, sub.geometry.y, s=sizes, c=col,
edgecolor="black", linewidth=0.4, alpha=0.85,
label=f"{sc} ({len(sub)})")
ax.set_xlim(PXMIN, PXMAX)
ax.set_ylim(PYMIN, PYMAX)
ax.set_aspect("equal")
ax.set_title(f"図 1a: 届出盛土 284 件 規模別マップ (サイズ=面積) — 背景: 警戒区域 (急傾斜=ピンク, 土石流=橙)",
fontsize=11)
ax.legend(loc="upper right", fontsize=8, title="規模カテゴリ")
ax.set_xlabel("X (m, EPSG:6671)", fontsize=9)
ax.set_ylabel("Y (m, EPSG:6671)", fontsize=9)
# 1-b 市町別コロプレス
ax = axes[1]
admin_count = admin_diss.copy()
admin_count["件数"] = admin_count["CITY_CD"].map(
{NAME_TO_CITY_CD.get(n, -1): c
for n, c in zip(city_counts["市町名"], city_counts["届出件数"])}).fillna(0)
admin_count[admin_count["件数"] == 0].plot(ax=ax, facecolor="#f0f0f0",
edgecolor="#888", linewidth=0.4)
admin_count[admin_count["件数"] > 0].plot(ax=ax, column="件数", cmap="YlGnBu",
edgecolor="#444", linewidth=0.4,
legend=True,
legend_kwds={"label": "届出件数",
"shrink": 0.7})
for _, r in city_counts.head(5).iterrows():
cd = NAME_TO_CITY_CD.get(r["市町名"], -1)
if cd > 0:
a = admin_diss[admin_diss["CITY_CD"] == cd]
if len(a) == 0:
continue
cx, cy = a.geometry.iloc[0].centroid.x, a.geometry.iloc[0].centroid.y
ax.annotate(f"{r['市町名']}\n{int(r['届出件数'])}件",
(cx, cy), fontsize=9, ha="center", va="center",
color="black", weight="bold",
bbox=dict(boxstyle="round,pad=0.2", facecolor="white", alpha=0.85))
ax.set_xlim(PXMIN, PXMAX)
ax.set_ylim(PYMIN, PYMAX)
ax.set_aspect("equal")
ax.set_title(f"図 1b: 市町別 届出件数 コロプレス — Top 5 シェア {top5_share*100:.0f}%",
fontsize=11)
ax.set_xlabel("X (m, EPSG:6671)", fontsize=9)
ax.set_ylabel("Y (m, EPSG:6671)", fontsize=9)
fig.suptitle("図 1 (RQ1): 届出盛土 284 件の地理分布 (点マップ + コロプレス)", fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L53_fig1_geomap.png")
# ---- 図 2 (RQ1): 規模分布 (高さ・面積・土量) — L52 比較重ね ----
fig, axes = plt.subplots(1, 3, figsize=(16, 4.5))
# 2-a 高さ
ax = axes[0]
h = gdf["height_max_m"].dropna()
ax.hist(h, bins=np.arange(0, h.max() + 1, 0.5), color="#5a9fd6",
edgecolor="#333", alpha=0.85, label=f"L53 届出 (n={len(h)})")
ax.axvline(h.median(), color="#1f6feb", linestyle="--", linewidth=2,
label=f"届出 中央値 {h.median():.2f}m")
if df_l52 is not None:
ax.axvline(l52_h_med, color="#cf222e", linestyle=":", linewidth=2,
label=f"L52 許可 中央値 {l52_h_med:.2f}m")
ax.axvline(5.0, color="#a045a0", linestyle=":", linewidth=1.5, alpha=0.7,
label="熱海型閾値 5m")
ax.set_xlabel("最大高さ (m)", fontsize=11)
ax.set_ylabel("件数", fontsize=11)
ax.set_title(f"高さ分布 (n={len(h)}) — max {h.max():.1f}m", fontsize=11)
ax.legend(fontsize=8)
ax.grid(alpha=0.3)
# 2-b 面積 (log)
ax = axes[1]
a = gdf["area_m2"].dropna()
a_pos = a[a > 0]
ax.hist(a_pos, bins=np.logspace(np.log10(a_pos.min()), np.log10(a_pos.max()), 30),
color="#9b8bd6", edgecolor="#333", alpha=0.85, label=f"L53 届出 (n={len(a_pos)})")
ax.set_xscale("log")
ax.axvline(a_pos.median(), color="#1f6feb", linestyle="--", linewidth=2,
label=f"届出 中央値 {a_pos.median():.0f} m²")
if df_l52 is not None:
ax.axvline(l52_a_med, color="#cf222e", linestyle=":", linewidth=2,
label=f"L52 許可 中央値 {l52_a_med:.0f} m²")
ax.axvline(500, color="#888", linestyle=":", linewidth=1.5, alpha=0.7,
label="許可閾値 500 m²")
ax.set_xlabel("面積 (m², log)", fontsize=11)
ax.set_ylabel("件数", fontsize=11)
ax.set_title(f"面積分布 log10 — max {a_pos.max():.0f} m²", fontsize=11)
ax.legend(fontsize=8)
ax.grid(alpha=0.3, which="both")
# 2-c 土量 (log)
ax = axes[2]
v = gdf["fill_volume_m3"].dropna()
v_pos = v[v > 0]
ax.hist(v_pos, bins=np.logspace(np.log10(max(v_pos.min(), 0.1)), np.log10(v_pos.max()), 30),
color="#fab669", edgecolor="#333", alpha=0.85, label=f"L53 届出 (n={len(v_pos)})")
ax.set_xscale("log")
ax.axvline(v_pos.median(), color="#1f6feb", linestyle="--", linewidth=2,
label=f"届出 中央値 {v_pos.median():.0f} m³")
if df_l52 is not None:
ax.axvline(l52_v_med, color="#cf222e", linestyle=":", linewidth=2,
label=f"L52 許可 中央値 {l52_v_med:.0f} m³")
ax.set_xlabel("盛土量 (m³, log)", fontsize=11)
ax.set_ylabel("件数", fontsize=11)
ax.set_title(f"盛土量分布 log10 — max {v_pos.max():,.0f} m³", fontsize=11)
ax.legend(fontsize=8)
ax.grid(alpha=0.3, which="both")
fig.suptitle("図 2 (RQ1): 規模分布 — 届出 (L53) と許可 (L52) の中央値比較", fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L53_fig2_scale_dist.png")
# ---- 図 3 (RQ1): 許可 (L52) vs 届出 (L53) の地理併置 + 件数比較 ----
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
# 3-a 併置マップ
ax = axes[0]
admin_diss.boundary.plot(ax=ax, color="#888", linewidth=0.5)
admin_diss.plot(ax=ax, facecolor="#f8f8f5", edgecolor="#aaa", linewidth=0.3, alpha=0.7)
warn_kyukei.plot(ax=ax, color="#fff0f0", alpha=0.4, edgecolor="none")
# 届出 (L53) 青
ax.scatter(gdf.geometry.x, gdf.geometry.y, s=22, c="#1f6feb",
edgecolor="black", linewidth=0.3, alpha=0.7,
label=f"L53 届出 ({len(gdf)})")
# 許可 (L52) 赤 — gdf for L52 from CSV
if df_l52 is not None:
g52 = gpd.GeoDataFrame(
df_l52, geometry=gpd.points_from_xy(df_l52["lon"], df_l52["lat"]),
crs="EPSG:4326").to_crs(TARGET_CRS)
ax.scatter(g52.geometry.x, g52.geometry.y, s=40, c="#cf222e",
edgecolor="black", linewidth=0.4, alpha=0.85,
marker="^", label=f"L52 許可 ({len(g52)})")
ax.set_xlim(PXMIN, PXMAX)
ax.set_ylim(PYMIN, PYMAX)
ax.set_aspect("equal")
ax.set_title("図 3a: 届出 (青○) vs 許可 (赤△) 併置マップ", fontsize=11)
ax.legend(loc="upper right", fontsize=10)
ax.set_xlabel("X (m)", fontsize=9)
ax.set_ylabel("Y (m)", fontsize=9)
# 3-b 市町別件数比較 横棒
ax = axes[1]
if df_l52 is not None:
df52_city = df_l52.groupby("市町名").size().reset_index(name="許可件数")
else:
df52_city = pd.DataFrame(columns=["市町名", "許可件数"])
merged = city_counts.merge(df52_city, on="市町名", how="outer").fillna(0)
merged["届出件数"] = merged["届出件数"].astype(int)
merged["許可件数"] = merged["許可件数"].astype(int)
merged = merged.sort_values("届出件数", ascending=True).tail(15)
y = np.arange(len(merged))
ax.barh(y - 0.2, merged["届出件数"], height=0.4, color="#1f6feb",
edgecolor="#333", label=f"L53 届出 ({len(gdf)})")
ax.barh(y + 0.2, merged["許可件数"], height=0.4, color="#cf222e",
edgecolor="#333", label=f"L52 許可 ({n_kyoka})")
ax.set_yticks(y)
ax.set_yticklabels(merged["市町名"], fontsize=9)
ax.set_xlabel("件数", fontsize=11)
ax.set_title("図 3b: 市町別 届出 vs 許可 件数 (Top 15 by 届出件数)", fontsize=11)
ax.legend(fontsize=9)
ax.grid(axis="x", alpha=0.3)
for i, (n_t, n_k) in enumerate(zip(merged["届出件数"], merged["許可件数"])):
ax.text(n_t + 1, i - 0.2, f"{int(n_t)}", va="center", fontsize=8)
ax.text(n_k + 1, i + 0.2, f"{int(n_k)}", va="center", fontsize=8, color="#cf222e")
fig.suptitle("図 3 (RQ1): 許可 (L52) と 届出 (L53) の併置 — 二段階監督モデル",
fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L53_fig3_kyoka_vs_todoke.png")
# ---- 図 4 (RQ2): 累積土量 choropleth + 市町別土量ランキング ----
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
# 4-a 市町別累積土量 choropleth
ax = axes[0]
admin_vol = admin_diss.copy()
city_vol_map = {NAME_TO_CITY_CD.get(n, -1): v
for n, v in zip(city_volume["市町名"], city_volume["累積盛土量_m3"])}
admin_vol["累積土量_m3"] = admin_vol["CITY_CD"].map(city_vol_map).fillna(0)
admin_vol[admin_vol["累積土量_m3"] == 0].plot(ax=ax, facecolor="#f0f0f0",
edgecolor="#888", linewidth=0.4)
admin_vol[admin_vol["累積土量_m3"] > 0].plot(ax=ax, column="累積土量_m3",
cmap="OrRd", edgecolor="#444", linewidth=0.4,
legend=True,
legend_kwds={"label": "累積盛土量 (m³)",
"shrink": 0.7})
for _, r in city_volume.head(5).iterrows():
cd = NAME_TO_CITY_CD.get(r["市町名"], -1)
if cd > 0:
a = admin_diss[admin_diss["CITY_CD"] == cd]
if len(a) == 0:
continue
cx, cy = a.geometry.iloc[0].centroid.x, a.geometry.iloc[0].centroid.y
vol_label = f"{r['累積盛土量_m3']/1000:.0f}k m³" if r["累積盛土量_m3"] >= 1000 \
else f"{r['累積盛土量_m3']:.0f} m³"
ax.annotate(f"{r['市町名']}\n{vol_label}",
(cx, cy), fontsize=8, ha="center", va="center",
color="black", weight="bold",
bbox=dict(boxstyle="round,pad=0.2", facecolor="white", alpha=0.85))
ax.set_xlim(PXMIN, PXMAX)
ax.set_ylim(PYMIN, PYMAX)
ax.set_aspect("equal")
ax.set_title(f"図 4a: 市町別 累積盛土量 — 上位 3 シェア {top3_volume_share*100:.0f}%",
fontsize=11)
ax.set_xlabel("X (m)", fontsize=9)
ax.set_ylabel("Y (m)", fontsize=9)
# 4-b 上位 15 市町 累積土量 (横棒, log)
ax = axes[1]
top15_v = city_volume.head(15).iloc[::-1]
y = np.arange(len(top15_v))
v_pos = top15_v["累積盛土量_m3"].clip(lower=1)
ax.barh(y, v_pos, color="#fa8c16", edgecolor="#333")
ax.set_yticks(y)
ax.set_yticklabels(top15_v["市町名"], fontsize=9)
ax.set_xscale("log")
ax.set_xlabel("累積盛土量 (m³, log)", fontsize=11)
ax.set_title(f"図 4b: 市町別 累積盛土量 (Top 15, log) — 全県 {total_fill/1e6:.2f} 百万 m³",
fontsize=11)
ax.grid(axis="x", alpha=0.3, which="both")
for i, v in enumerate(top15_v["累積盛土量_m3"]):
ax.text(max(v, 1) * 1.05, i, f"{v:,.0f} m³ ({100*v/total_fill:.1f}%)",
va="center", fontsize=8)
fig.suptitle("図 4 (RQ2): 累積土量の地理偏在 — 件数ではなく土量で読む",
fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L53_fig4_volume_choropleth.png")
# ---- 図 5 (RQ2): 警戒区域オーバーレイ + 距離分布 + L52 比較 ----
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
# 5-a 県全体オーバーレイ
ax = axes[0]
admin_diss.boundary.plot(ax=ax, color="#888", linewidth=0.4)
admin_diss.plot(ax=ax, facecolor="#f8f8f5", edgecolor="none", alpha=0.7)
warn_kyukei.plot(ax=ax, color="#cf222e", alpha=0.35, edgecolor="none")
warn_doseki.plot(ax=ax, color="#bf8700", alpha=0.35, edgecolor="none")
for wc, col in WARN_COLOR.items():
sub = gdf[gdf["warn_class"] == wc]
if len(sub) == 0:
continue
ax.scatter(sub.geometry.x, sub.geometry.y, s=30, c=col,
edgecolor="black", linewidth=0.4, alpha=0.9,
label=f"{wc} ({len(sub)})")
ax.set_xlim(PXMIN, PXMAX)
ax.set_ylim(PYMIN, PYMAX)
ax.set_aspect("equal")
ax.set_title(f"図 5a: 届出盛土 × 警戒区域 オーバーレイ (284 点)", fontsize=11)
ax.legend(loc="upper right", fontsize=8, title="距離区分")
ax.set_xlabel("X (m)", fontsize=9)
ax.set_ylabel("Y (m)", fontsize=9)
# 5-b L52 vs L53 距離分布比較
ax = axes[1]
bins = [0, 1, 50, 100, 250, 500, 1000, 2000, 5001]
labels = ["0\n(区域内)", "1-50", "50-100", "100-250", "250-500",
"500-1k", "1-2km", "2km+"]
d_l53 = gdf["dist_warn_m"].clip(0, 5000)
counts_l53, _ = np.histogram(d_l53, bins=bins)
xs = np.arange(len(labels))
w = 0.4
ax.bar(xs - 0.2, counts_l53, width=w, color="#1f6feb",
edgecolor="#333", label=f"L53 届出 (n={len(gdf)})")
if df_l52 is not None and "dist_warn_m" in df_l52.columns:
d_l52 = df_l52["dist_warn_m"].clip(0, 5000)
counts_l52, _ = np.histogram(d_l52, bins=bins)
ax.bar(xs + 0.2, counts_l52, width=w, color="#cf222e",
edgecolor="#333", label=f"L52 許可 (n={n_kyoka})")
# 比率注記
ax.text(0, max(counts_l53.max(), counts_l52.max()) * 1.08,
f"区域内+100m: 届出 {within_n + near_100_n} ({near_pct:.0f}%) "
f"vs 許可 {(d_l52 <= 100).sum()} ({100*(d_l52 <= 100).sum()/n_kyoka:.0f}%)",
fontsize=9, ha="left", va="bottom")
ax.set_xticks(xs)
ax.set_xticklabels(labels, fontsize=9)
ax.set_xlabel("最近傍警戒区域までの距離 (m)", fontsize=11)
ax.set_ylabel("件数", fontsize=11)
ax.set_title(f"図 5b: 距離分布 比較 — 届出 vs 許可", fontsize=11)
ax.legend(fontsize=9)
ax.grid(axis="y", alpha=0.3)
fig.suptitle("図 5 (RQ2): 届出盛土と警戒区域の空間関係 (L52 比較)",
fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L53_fig5_warn_overlay.png")
# ---- 図 6 (RQ2): 中規模累積マップ — パッチワーク立地 ----
fig, ax = plt.subplots(figsize=(13, 8))
admin_diss.boundary.plot(ax=ax, color="#888", linewidth=0.4)
admin_diss.plot(ax=ax, facecolor="#fafafa", edgecolor="#bbb", linewidth=0.3, alpha=0.6)
warn_kyukei.plot(ax=ax, color="#ffe5e5", alpha=0.5, edgecolor="none")
warn_doseki.plot(ax=ax, color="#ffeed5", alpha=0.5, edgecolor="none")
# 中規模 + 大規模 + 熱海型 を 土量サイズで表示
sub_mid = gdf[gdf["scale_class"].isin([
"M_中規模 (1.5m+ or 500m²+)",
"L_大規模 (3m+ or 2000m²+)",
"S_熱海型 (5m+5000m²+)"])].copy()
v_pos = sub_mid["fill_volume_m3"].fillna(100).clip(50, 100000)
sizes = np.sqrt(v_pos) * 0.6
ax.scatter(sub_mid.geometry.x, sub_mid.geometry.y, s=sizes,
c=[SCALE_COLOR[s] for s in sub_mid["scale_class"]],
edgecolor="black", linewidth=0.4, alpha=0.7)
# 上位 5 大規模に市町ラベル
top_big = gdf.nlargest(5, "fill_volume_m3")
for _, r in top_big.iterrows():
label = f"{r['市町名']}\n{r['fill_volume_m3']:,.0f} m³"
ax.annotate(label, (r.geometry.x, r.geometry.y),
fontsize=8, xytext=(8, -8), textcoords="offset points",
bbox=dict(boxstyle="round,pad=0.2", facecolor="white", alpha=0.85),
arrowprops=dict(arrowstyle="-", color="#666", linewidth=0.5))
# Legend (Patches)
legend_handles = [
Patch(facecolor=SCALE_COLOR["S_熱海型 (5m+5000m²+)"], label="熱海型"),
Patch(facecolor=SCALE_COLOR["L_大規模 (3m+ or 2000m²+)"], label="大規模"),
Patch(facecolor=SCALE_COLOR["M_中規模 (1.5m+ or 500m²+)"], label="中規模"),
Patch(facecolor="#ffe5e5", alpha=0.7, label="急傾斜警戒区域"),
Patch(facecolor="#ffeed5", alpha=0.7, label="土石流警戒区域"),
]
ax.legend(handles=legend_handles, loc="upper right", fontsize=9, title="凡例")
ax.set_xlim(PXMIN, PXMAX)
ax.set_ylim(PYMIN, PYMAX)
ax.set_aspect("equal")
ax.set_title(f"図 6 (RQ2): 中〜大規模届出盛土の累積パッチワーク (n={len(sub_mid)}, "
f"サイズ=盛土量) — 累積 {sub_mid['fill_volume_m3'].sum()/1e6:.2f} 百万 m³",
fontsize=12)
ax.set_xlabel("X (m, EPSG:6671)", fontsize=10)
ax.set_ylabel("Y (m, EPSG:6671)", fontsize=10)
plt.tight_layout()
save_fig("L53_fig6_patchwork.png")
# ---- 図 7 (RQ3): 経過措置遡及 vs 純新規届出 散布 (届出日 vs 着手日) ----
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
# 7-a 届出日 vs 着手日 散布 (色 = 制度区分)
ax = axes[0]
sub = gdf.dropna(subset=["declare_date", "start_date"]).copy()
for rc, col in REGIME_COLOR.items():
s = sub[sub["regime_class"] == rc]
if len(s) == 0:
continue
ax.scatter(s["start_date"], s["declare_date"], s=30, c=col,
edgecolor="black", linewidth=0.3, alpha=0.7,
label=f"{rc} ({len(s)})")
# 法施行ライン (横/縦)
ax.axvline(LAW_ENFORCED, color="#cf222e", linestyle="--", linewidth=1.5,
label=f"法施行 ({LAW_ENFORCED.date()})")
ax.axhline(LAW_ENFORCED, color="#cf222e", linestyle="--", linewidth=1.0, alpha=0.5)
# 対角線 (= 届出 = 着手)
xmin = sub["start_date"].min()
xmax = sub["declare_date"].max()
ax.plot([xmin, xmax], [xmin, xmax], "k:", alpha=0.3, label="届出日 = 着手日")
ax.set_xlabel("工事着手日", fontsize=11)
ax.set_ylabel("届出日", fontsize=11)
ax.set_title(f"図 7a: 届出日 vs 着手日 — 経過措置遡及 {len(grandfathered)} / 純新規 {len(post_law)}",
fontsize=11)
ax.legend(fontsize=8, loc="upper left")
ax.grid(alpha=0.3)
plt.setp(ax.xaxis.get_majorticklabels(), rotation=30)
# 7-b 工事着手年ヒスト (経過措置遡及の年代)
ax = axes[1]
sub_g = grandfathered.dropna(subset=["start_date"])
years = sub_g["start_date"].dt.year
ax.hist(years, bins=range(1980, 2025), color="#a045a0",
edgecolor="#333", alpha=0.85,
label=f"経過措置遡及 ({len(sub_g)})")
sub_n = post_law.dropna(subset=["start_date"])
ax.hist(sub_n["start_date"].dt.year, bins=range(1980, 2025),
color="#1f6feb", edgecolor="#333", alpha=0.85,
label=f"純新規 ({len(sub_n)})")
ax.axvline(LAW_ENFORCED.year, color="#cf222e", linestyle="--", linewidth=2,
label=f"法施行 (2023)")
ax.set_xlabel("工事着手年", fontsize=11)
ax.set_ylabel("件数", fontsize=11)
ax.set_title(f"図 7b: 工事着手年分布 — 最古 {sub_g['start_date'].min().year} 年",
fontsize=11)
ax.legend(fontsize=9)
ax.grid(axis="y", alpha=0.3)
fig.suptitle("図 7 (RQ3): 届出日 vs 着手日 — 経過措置遡及の構造",
fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L53_fig7_grandfather.png")
# ---- 図 8 (RQ3): 規模カテゴリ pie + 高さ × 面積 (L52 比較) ----
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
# 8-a 規模カテゴリ パイ
ax = axes[0]
SC_ORDER = ["S_熱海型 (5m+5000m²+)", "L_大規模 (3m+ or 2000m²+)",
"M_中規模 (1.5m+ or 500m²+)", "S_小規模 (戸建相当)", "未分類"]
SC_LABEL = {
"S_熱海型 (5m+5000m²+)": "熱海型",
"L_大規模 (3m+ or 2000m²+)": "大規模",
"M_中規模 (1.5m+ or 500m²+)": "中規模",
"S_小規模 (戸建相当)": "小規模",
"未分類": "未分類",
}
sc_present = [s for s in SC_ORDER if scale_counts.get(s, 0) > 0]
vals = [scale_counts[s] for s in sc_present]
labels = [f"{SC_LABEL[s]}\n{v}件 ({100*v/sum(vals):.0f}%)" for s, v in zip(sc_present, vals)]
colors = [SCALE_COLOR[s] for s in sc_present]
ax.pie(vals, labels=labels, colors=colors,
startangle=90, wedgeprops=dict(edgecolor="white", linewidth=2),
textprops={"fontsize": 9})
ax.set_title(f"届出 (L53) 規模カテゴリ (n={len(gdf)})", fontsize=12)
# 8-b 高さ × 面積 散布図 (届出 + 許可重ね)
ax = axes[1]
hx = gdf["height_max_m"]
ay = gdf["area_m2"]
ax.scatter(hx, ay, s=30, c="#1f6feb", edgecolor="#333", alpha=0.5,
label=f"L53 届出 ({len(gdf)})")
if df_l52 is not None:
ax.scatter(df_l52["height_max_m"], df_l52["area_m2"], s=30, c="#cf222e",
edgecolor="#333", alpha=0.5, marker="^",
label=f"L52 許可 ({n_kyoka})")
# 熱海型ハイライト
ax.scatter(hx[gdf["atami_type"]], ay[gdf["atami_type"]],
s=120, facecolors="none", edgecolors="#cf222e", linewidth=1.5,
marker="*", label=f"L53 熱海型 ({atami_n})")
ax.axvline(5.0, color="#a045a0", linestyle="--", alpha=0.7, label="高さ閾値 5m")
ax.axhline(5000, color="#a045a0", linestyle="--", alpha=0.7, label="面積閾値 5000 m²")
ax.axhline(500, color="#888", linestyle=":", alpha=0.7, label="許可閾値 500 m²")
ax.set_yscale("log")
ax.set_xlabel("最大高さ (m)", fontsize=11)
ax.set_ylabel("面積 (m², log)", fontsize=11)
ax.set_title(f"図 8b: 高さ × 面積 — 届出 vs 許可 重ね",
fontsize=11)
ax.legend(fontsize=8, loc="upper left")
ax.grid(alpha=0.3, which="both")
fig.suptitle("図 8 (RQ3): 届出 規模構成 + 許可との重ね表示",
fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L53_fig8_scale_compare.png")
# ---- 図 9 (RQ1+RQ2+RQ3 統合): 上位 12 市町 stacked クロス ----
fig, axes = plt.subplots(1, 2, figsize=(15, 6.5))
# 9-a 上位 12 市町 × 規模 stacked
ax = axes[0]
top_cities = city_counts.head(12)["市町名"].tolist()
top_data = []
for cn in top_cities:
row = {"市町名": cn}
sub = gdf[gdf["市町名"] == cn]
for sc in SC_ORDER:
row[sc] = (sub["scale_class"] == sc).sum()
top_data.append(row)
top_df = pd.DataFrame(top_data)
left = np.zeros(len(top_df))
y = np.arange(len(top_df))
for sc in SC_ORDER:
if sc in top_df.columns:
vals = top_df[sc].values
if vals.sum() == 0:
continue
ax.barh(y, vals, left=left, color=SCALE_COLOR[sc],
label=SC_LABEL[sc], edgecolor="#333", linewidth=0.4)
left += vals
ax.set_yticks(y)
ax.set_yticklabels(top_df["市町名"], fontsize=10)
ax.invert_yaxis()
ax.set_xlabel("件数", fontsize=11)
ax.set_title("9a: 上位市町 × 規模カテゴリ (Top 12)", fontsize=11)
ax.legend(fontsize=8, loc="lower right", title="規模")
ax.grid(axis="x", alpha=0.3)
for i, v in enumerate(left):
ax.text(v + 0.2, i, f"{int(v)}", va="center", fontsize=9)
# 9-b 上位 12 市町 × 制度区分 (経過措置 vs 純新規)
ax = axes[1]
RC_ORDER = ["G_経過措置遡及", "N_純新規届出", "X_着手不明"]
top_data2 = []
for cn in top_cities:
row = {"市町名": cn}
sub = gdf[gdf["市町名"] == cn]
for rc in RC_ORDER:
row[rc] = (sub["regime_class"] == rc).sum()
top_data2.append(row)
top_df2 = pd.DataFrame(top_data2)
left = np.zeros(len(top_df2))
for rc in RC_ORDER:
vals = top_df2[rc].values
if vals.sum() == 0:
continue
ax.barh(y, vals, left=left, color=REGIME_COLOR[rc],
label=rc, edgecolor="#333", linewidth=0.4)
left += vals
ax.set_yticks(y)
ax.set_yticklabels(top_df2["市町名"], fontsize=10)
ax.invert_yaxis()
ax.set_xlabel("件数", fontsize=11)
ax.set_title("9b: 上位市町 × 制度区分 (経過措置 vs 純新規)", fontsize=11)
ax.legend(fontsize=8, loc="lower right", title="制度区分")
ax.grid(axis="x", alpha=0.3)
for i, v in enumerate(left):
ax.text(v + 0.2, i, f"{int(v)}", va="center", fontsize=9)
fig.suptitle("図 9 (統合 RQ1+RQ2+RQ3): 上位 12 市町の規模 × 制度区分",
fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L53_fig9_top_city_cross.png")
print(f" 9 図 生成完了 ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 10. 表の DataFrame 作成 (HTML 用)
# =============================================================================
print("\n[10] 表の作成", flush=True)
t1 = time.time()
def df_to_html(d):
cols = list(d.columns)
head = "" + "".join(f"| {c} | " for c in cols) + "
"
rows = []
for _, r in d.iterrows():
cells = []
for c in cols:
v = r[c]
if isinstance(v, float):
if abs(v) >= 1000:
s = f"{v:,.0f}"
elif abs(v) >= 1:
s = f"{v:.2f}"
else:
s = f"{v:.3f}"
else:
s = str(v)
cells.append(f"{s} | ")
rows.append("" + "".join(cells) + "
")
return "" + head + "".join(rows) + "
"
# 表 1: dataset 仕様
T_dataset = pd.DataFrame([
("dataset_id", "1430"),
("名称", "届出盛土等(法第21条第1項・40条第1項)"),
("組織", "広島県土木建築局 都市環境整備課"),
("リソース 1", "51165 — 届出台帳 CSV (284 行 × 14 列, 75.6 KB, 2025-08-26 版)"),
("リソース 2", "51166 — 盛土規制法関係資料 XLSX (規制内容 + 手続き先, 23.1 KB)"),
("根拠法", "宅地造成及び特定盛土等規制法 (2022-05-27 公布, 2023-05-26 施行)"),
("対象期間", f"届出 {gdf['declare_date'].min().date()} 〜 {gdf['declare_date'].max().date()} / "
f"工事着手 {gdf['start_date'].min().date()} 〜 {gdf['start_date'].max().date()}"),
("ライセンス", "クリエイティブ・コモンズ表示 4.0"),
("取得日", "2026-05-09"),
], columns=["項目", "値"])
# 表 2: 全体サマリ
T_overall = pd.DataFrame([
("総件数", f"{len(gdf)} 件"),
("対象市町数", f"{gdf['市町名'].nunique()} 市町"),
("最大高さ 中央値 / 最大", f"{gdf['height_max_m'].median():.2f}m / {gdf['height_max_m'].max():.2f}m"),
("面積 中央値 / 最大", f"{gdf['area_m2'].median():,.0f} m² / {gdf['area_m2'].max():,.0f} m²"),
("盛土量 中央値 / 最大", f"{gdf['fill_volume_m3'].median():,.0f} m³ / {gdf['fill_volume_m3'].max():,.0f} m³"),
("累積盛土量", f"{total_fill:,.0f} m³ ({total_fill/1e6:.2f} 百万 m³, 25m プール約 {pool_eq:,.0f} 杯)"),
("民間法人シェア", f"{private_share*100:.1f}%"),
("経過措置遡及 (start<法施行)", f"{len(grandfathered)} 件 ({100*len(grandfathered)/len(gdf):.1f}%)"),
("純新規届出 (start>=法施行)", f"{len(post_law)} 件 ({100*len(post_law)/len(gdf):.1f}%)"),
("最古工事着手", f"{grandfathered['start_date'].min().date()}"),
("警戒区域内 件数", f"{within_n} 件 ({100*within_n/len(gdf):.1f}%)"),
("警戒区域 100m 以内 (含む区域内)", f"{within_n+near_100_n} 件 ({near_pct:.1f}%)"),
("熱海型 (高さ≥5m+面積≥5000m²)", f"{atami_n} 件 ({atami_share*100:.1f}%) [L52 = 10.5%]"),
("最大盛土 (面積)", f"{int(gdf['area_m2'].max()):,} m² @ {gdf.loc[gdf['area_m2'].idxmax(),'市町名']}"),
("届出 / 許可 比", f"{len(gdf)}/{n_kyoka} = {todoke_kyoka_ratio:.2f}" if df_l52 is not None else "—"),
], columns=["指標", "値"])
# 表 3: 市町別件数 + 累積土量 ランキング
T_city = city_volume.merge(
city_counts[["市町名", "順位"]], on="市町名", how="left"
).copy()
T_city["シェア_%"] = (T_city["件数"] / len(gdf) * 100).round(1)
if df_l52 is not None:
df52_city = df_l52.groupby("市町名").size().to_dict()
T_city["許可件数_L52"] = T_city["市町名"].map(df52_city).fillna(0).astype(int)
T_city["届出/許可比"] = (T_city["件数"] / T_city["許可件数_L52"].replace(0, np.nan)).round(2)
else:
T_city["許可件数_L52"] = 0
T_city["届出/許可比"] = np.nan
T_city = T_city.sort_values("件数", ascending=False).head(15)
T_city = T_city[["順位", "市町名", "件数", "シェア_%", "許可件数_L52", "届出/許可比",
"累積盛土量_m3", "土量シェア_%", "高さ中央値_m", "面積中央値_m2"]]
T_city = T_city.rename(columns={"件数": "届出件数"})
# 表 4: 規模カテゴリ (届出 vs 許可 比較)
T_scale = scale_summary.copy()
T_scale["シェア_%"] = (T_scale["件数"] / len(gdf) * 100).round(1)
T_scale = T_scale.rename(columns={"scale_class": "規模カテゴリ"})
if df_l52 is not None and "scale_class" in df_l52.columns:
l52_scale = df_l52["scale_class"].value_counts().to_dict()
T_scale["L52_許可件数"] = T_scale["規模カテゴリ"].map(l52_scale).fillna(0).astype(int)
T_scale["L52_シェア_%"] = (T_scale["L52_許可件数"] / n_kyoka * 100).round(1)
T_scale = T_scale[["規模カテゴリ", "件数", "シェア_%",
"L52_許可件数", "L52_シェア_%",
"高さ中央値_m", "面積中央値_m2", "盛土量中央値_m3", "盛土量合計_m3"]]
T_scale = T_scale.sort_values("シェア_%", ascending=False).reset_index(drop=True)
# 表 5: 警戒区域距離 (届出 vs 許可)
T_warn = warn_summary.copy()
T_warn["シェア_%"] = (T_warn["件数"] / len(gdf) * 100).round(1)
T_warn = T_warn.rename(columns={"warn_class": "距離区分"})
if df_l52 is not None and "warn_class" in df_l52.columns:
l52_warn = df_l52["warn_class"].value_counts().to_dict()
T_warn["L52_許可件数"] = T_warn["距離区分"].map(l52_warn).fillna(0).astype(int)
T_warn["L52_シェア_%"] = (T_warn["L52_許可件数"] / n_kyoka * 100).round(1)
T_warn = T_warn.sort_values("距離区分").reset_index(drop=True)
T_warn = T_warn[["距離区分", "件数", "シェア_%", "L52_許可件数", "L52_シェア_%",
"最小距離_m", "中央距離_m", "最大距離_m"]]
# 表 6: 制度区分 (経過措置 vs 純新規)
T_regime_data = []
for rc, label in [("G_経過措置遡及", "経過措置遡及 (start<法施行)"),
("N_純新規届出", "純新規届出 (start≥法施行)"),
("X_着手不明", "工事着手日不明")]:
sub = gdf[gdf["regime_class"] == rc]
if len(sub) == 0:
continue
T_regime_data.append({
"制度区分": label,
"件数": len(sub),
"シェア_%": round(100 * len(sub) / len(gdf), 1),
"高さ中央値_m": round(sub["height_max_m"].median(), 2) if len(sub) else 0,
"面積中央値_m2": int(sub["area_m2"].median()) if len(sub) and sub["area_m2"].notna().any() else 0,
"盛土量中央値_m3": int(sub["fill_volume_m3"].median()) if len(sub) and sub["fill_volume_m3"].notna().any() else 0,
"盛土量合計_m3": int(sub["fill_volume_m3"].fillna(0).sum()),
"最古工事着手": sub["start_date"].min().date() if sub["start_date"].notna().any() else "—",
})
T_regime = pd.DataFrame(T_regime_data)
# 表 7: 整理番号 prefix (受理事務所手がかり) Top 10
T_prefix = pd.DataFrame([
{"prefix": k, "件数": int(v),
"代表市町": gdf[gdf["ref_prefix"] == k]["市町名"].mode().iloc[0]
if not gdf[gdf["ref_prefix"] == k]["市町名"].mode().empty else "—",
"シェア_%": round(100 * v / len(gdf), 1)}
for k, v in prefix_counts.head(10).items()
])
# 表 8: 月別届出件数
T_monthly = ym_df.copy()
# 表 9: 経過措置遡及 最古 上位 15
T_oldest = grandfathered.sort_values("start_date").head(15)[
["ref_no", "start_date", "declare_date", "市町名",
"height_max_m", "area_m2", "fill_volume_m3", "scale_class", "warn_class"]
].copy()
T_oldest["start_date"] = T_oldest["start_date"].dt.date.astype(str)
T_oldest["declare_date"] = T_oldest["declare_date"].dt.date.astype(str)
T_oldest.columns = ["整理番号", "工事着手", "届出日", "市町名", "高さ_m",
"面積_m2", "盛土量_m3", "規模", "警戒距離区分"]
# 表 10: 熱海型詳細 (届出)
T_atami = gdf[gdf["atami_type"]].sort_values("area_m2", ascending=False)[
["ref_no", "declare_date", "start_date", "市町名",
"height_max_m", "area_m2", "fill_volume_m3", "warn_class", "regime_class"]
].copy()
T_atami["declare_date"] = T_atami["declare_date"].dt.date.astype(str)
T_atami["start_date"] = T_atami["start_date"].dt.date.astype(str)
T_atami.columns = ["整理番号", "届出日", "工事着手", "市町名", "高さ_m",
"面積_m2", "盛土量_m3", "警戒距離", "制度区分"]
# 表 11: 仮説検証
g_share = len(grandfathered) / len(gdf)
T_hypo = pd.DataFrame([
{"仮説": "H1 (山間部偏重・上位 5 市町集中度 < L52, RQ1)",
"予想": "上位 5 シェア 50% 程度 (L52 = 63.2% より低い)",
"観測": f"上位 5 = {city_counts.head(5)['市町名'].tolist()}, "
f"シェア {top5_share*100:.1f}%",
"判定": ("支持" if top5_share < 0.55 else
"部分支持" if top5_share < 0.65 else "反証")},
{"仮説": "H2 (届出 / 許可比 ≈ 1.87, 規模は許可と同等以上, RQ1)",
"予想": "届出 / 許可 = 1.87 倍, 規模は経過措置で許可と同等以上",
"観測": (f"届出 {len(gdf)} / 許可 {n_kyoka} = {todoke_kyoka_ratio:.2f}, "
if df_l52 is not None else "L52 比較不可") +
f"L53 面積中央値 {gdf['area_m2'].median():.0f} m² "
f"vs L52 {l52_a_med:.0f} m²",
"判定": ("支持" if df_l52 is not None and 1.5 <= todoke_kyoka_ratio <= 2.5 else
"部分支持")},
{"仮説": "H3 (経過措置遡及 50% 以上, RQ3)",
"予想": "工事着手 < 法施行 が 50% 以上",
"観測": f"経過措置遡及 {len(grandfathered)} 件 ({g_share*100:.1f}%), "
f"純新規 {len(post_law)} 件 ({100*len(post_law)/len(gdf):.1f}%), "
f"最古着手 {grandfathered['start_date'].min().year} 年",
"判定": ("支持" if g_share >= 0.50 else f"部分支持 ({g_share*100:.0f}%)")},
{"仮説": "H4 (上位 3 市町 累積土量シェア ≥ 50%, RQ2)",
"予想": "上位 3 市町で累積土量の 50% 以上を占める",
"観測": f"上位 3 ({', '.join(city_volume.head(3)['市町名'])}) で "
f"{top3_volume_share*100:.1f}%, 全県累積 {total_fill/1e6:.2f} 百万 m³",
"判定": ("支持" if top3_volume_share >= 0.50 else
f"部分支持 ({top3_volume_share*100:.0f}%)")},
{"仮説": "H5 (警戒区域近接率 < L52, RQ2)",
"予想": "区域内+100m が L52 (49.3%) より低い",
"観測": f"L53 区域内+100m = {within_n+near_100_n} 件 ({near_pct:.1f}%)",
"判定": ("支持" if near_pct < 49.3 else
"反証" if near_pct >= 49.3 + 5 else
f"同等 ({near_pct:.0f}%)")},
])
# 表 12: 二段階監督モデル (許可 vs 届出 比較表)
T_regime_compare = pd.DataFrame([
{"側面": "根拠条文", "許可制 (L52)": "法 12 条 1 項 (宅造区域) / 30 条 1 項 (特定盛土区域)",
"届出制 (L53)": "法 21 条 1 項 (宅造区域) / 40 条 1 項 (特定盛土区域)"},
{"側面": "規模閾値", "許可制 (L52)": "盛土 1m 超 / 切土 2m 超 / 面積 500m² 超 等",
"届出制 (L53)": "上記閾値以下でも規制区域内なら届出"},
{"側面": "本データ件数", "許可制 (L52)": f"{n_kyoka} 件 (2023-11〜2026-01)",
"届出制 (L53)": f"{len(gdf)} 件 (2023-09〜2025-03)"},
{"側面": "高さ 中央値",
"許可制 (L52)": f"{l52_h_med:.2f}m" if df_l52 is not None else "—",
"届出制 (L53)": f"{gdf['height_max_m'].median():.2f}m"},
{"側面": "面積 中央値",
"許可制 (L52)": f"{l52_a_med:,.0f} m²" if df_l52 is not None else "—",
"届出制 (L53)": f"{gdf['area_m2'].median():,.0f} m²"},
{"側面": "盛土量 中央値",
"許可制 (L52)": f"{l52_v_med:,.0f} m³" if df_l52 is not None else "—",
"届出制 (L53)": f"{gdf['fill_volume_m3'].median():,.0f} m³"},
{"側面": "経過措置 (法 22/41 条) 適用",
"許可制 (L52)": "なし (新法下の新規許可のみ)",
"届出制 (L53)": f"あり ({len(grandfathered)} 件 = {g_share*100:.0f}% が遡及届出)"},
{"側面": "工事着手最古",
"許可制 (L52)": "新法施行後 (2023-11〜)",
"届出制 (L53)": f"{grandfathered['start_date'].min().date()} (旧法時代の盛土を含む)"},
{"側面": "行政の監督力",
"許可制 (L52)": "事前審査・許可条件・崖面防止施設要件 等の強い制限",
"届出制 (L53)": "事前通知のみ。禁止権はなく情報把握が主目的"},
{"側面": "二段階監督モデルの含意",
"許可制 (L52)": "高リスク案件 (大規模・崖面生成) を強制審査",
"届出制 (L53)": "中規模を含む地理パッチワークのカバレッジ拡張"},
])
print(f" 表 12 種作成 ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 11. HTML 構築
# =============================================================================
print("\n[11] HTML 構築", flush=True)
t11 = time.time()
# Sec 1
sec1 = f"""
本記事は DoBoX のシリーズ「届出盛土等(法第21条第1項・40条第1項)」 1 件
(dataset_id = 1430) を 単独で取り上げ、
広島県内の届出盛土 {len(gdf)} 件 (2023-09〜2025-03 期間) を 3 つの独立した研究角度
(RQ1 / RQ2 / RQ3) で並列に分析する。本データは 2021 熱海土石流を契機に
制定された盛土規制法 (2023-05-26 施行) の届出制下で、広島県知事が
受理した届出台帳である。
本記事の独自ポイントは、L52 (許可盛土 152 件) と並列で読むことで、
盛土規制法の「許可制 + 届出制」 の二段階監督モデルを初めてデータから可視化する点。
許可制は「強い禁止権 + 事前審査」 という重い手続きで大規模工事を捕捉するのに対し、
届出制は「情報把握のみ」 という軽い手続きで中規模工事を広くカバーする。
この設計が広島県の地理にどう実装されているかを、3 つの問いで読み解く。
独自用語の定義
- 盛土規制法: 正式名「宅地造成及び特定盛土等規制法」、2022-05-27 公布・
2023-05-26 施行。旧「宅地造成等規制法」 (1961) を全面改正したもので、
2021 熱海土石流を契機に制定。山間地の中規模盛土を含む全土地が規制対象に拡大。
- 届出盛土: 盛土規制法の届出を要する盛土・切土・土石堆積。
許可 (法 12/30 条) より小さい規模で、規制区域内なら一律届出義務。
事前審査ではなく事後の情報把握が制度目的。本記事はこの届出台帳を扱う。
- 21 条 1 項: 宅地造成等工事規制区域内で許可不要規模の工事の届出義務条文。
- 40 条 1 項: 特定盛土等規制区域内で許可不要規模の工事の届出義務条文。
- 二段階監督モデル (本記事独自定義): 同じ盛土規制法が、
規模閾値で許可制 (重い手続)と届出制 (軽い手続)に分岐する制度設計。
L52 (許可) と L53 (届出) を並列で読むことで実装が見える。
- 経過措置遡及 (本記事独自定義): 法施行 (2023-05-26) 以前に工事着手した
既存盛土が、施行後に届出された案件。法 22/41 条のみなし届出条項に基づく。
工事着手日 < 法施行日 で識別する。本データの大半 ({100*len(grandfathered)/len(gdf):.0f}%) を占める。
- 純新規届出 (本記事独自定義): 法施行以降に着手した工事の届出案件。
届出制度の本来想定する案件。本データでは {100*len(post_law)/len(gdf):.0f}% にとどまる。
- 累積効果 (本記事独自定義): 多数の中規模盛土が地理に集積することで、
個別では小さくても合計では大規模盛土に匹敵する地形改変を生む現象。
RQ2 で市町別累積土量を計算して可視化する。
- 熱海型大規模盛土: L52 と統一した独自定義 (高さ ≥ 5m + 面積 ≥ 5,000m²)。
崩壊時の被害規模が大きい監視重点対象。L53 では {atami_n} 件 ({atami_share*100:.1f}%)。
研究の問い (3 RQ)
- RQ1 (主研究): 広島県内の届出盛土の地理分布と件数構造はどう描けるか?
L52 (許可 152 件) との件数比 (届出 / 許可)と地理分布の差はどうか?
284 件を市町別ランキング、規模分布、許可盛土との比較で多角度に集計する。
- RQ2 (副研究 1): 多数の中規模届出盛土が生む累積土量と地理累積効果はどう構造化されるか?
市町別の累積土量で「件数の偏在」 とは異なる軸での偏在を読む。
警戒区域 (L10/L11 既扱) との空間関係を L52 と比較し、立地パターンの差を定量化する。
- RQ3 (副研究 2): 許可制 (L52) vs 届出制 (L53) の制度設計検証。
経過措置による遡及届出が何件あるか? これは届出制度の本来目的と運用実態の
ずれを示すか? 二段階監督モデルの盲点はどこか?
仮説 H1〜H5
- H1 (山間部偏重, RQ1): 上位 5 市町シェアは L52 (63%) より低い ~50% 。
届出盛土は山間部市町に分散立地し、許可制の都市部偏重と異なる地理を描く。
- H2 (届出 / 許可比 ≈ 1.87, RQ1): 件数は許可の 1.87 倍だが、
規模は経過措置による遡及届出が含まれるため許可と同等以上。
- H3 (経過措置遡及 50% 以上, RQ3): 工事着手日が法施行前の案件が大半。
届出制度の運用実態は「既存盛土の事後台帳化」 が主軸。
- H4 (累積土量の市町偏在, RQ2): 上位 3 市町の累積土量が全県の 50% を占める。
件数は分散していても、土量は集中する地理累積効果。
- H5 (警戒区域近接率 < L52, RQ2): 届出盛土の警戒区域近接率は許可制 (49%) より低い。
経過措置で山間平地・農地転用が多く含まれるため。
到達点
本記事を読み終えた学習者は次の 3 点を体感できる:
- 1 つの「届出台帳 CSV」 (284 行 × 14 列) から、盛土規制法の届出制度の運用実態を、
L52 (許可制) との対比で読み取る方法を習得する。
- 市町別累積土量の計算で、件数の偏在と土量の偏在が別軸であることを体感し、
地理累積効果の概念を獲得する。
- 経過措置遡及という制度移行特有の現象を、データから定量化することで、
「制度設計の本来目的と運用実態のギャップ」を読む眼を養う。
"""
# Sec 2
sec2 = f"""
DoBoX のシリーズ「届出盛土等(法第21条第1項・40条第1項)」 1 件のみを単独で扱う。
リソースは CSV 1 件 + XLSX 1 件の2 ファイル構造 (L52 と並行):
{df_to_html(T_dataset)}
データの構造
- CSV (51165, 284 行 × 14 列, 75.6 KB): 届出案件の届出台帳。
列は整理番号 / 届出年月日 / 工事主 / 工事施行者 / 所在地 / 地番 /
座標 (緯度・経度) / 高さ / 面積 / 盛土量 / 切土量 / 工事着手・完了年月日。
L52 と異なる重要な列は 「整理番号」 (= 受理事務所のシリアル番号:
西=西部建設事務所、東=東部、北=北部、竹=竹原支所、神=神石支所 等) と
「工事着手年月日」 (= 経過措置遡及の同定キー)。
L52 と異なり「崖面崩壊防止施設の有無」 列はない — 届出制は事後通知のため
防護措置の確認は別チャネル。
- XLSX (51166, 2 シート, 23.1 KB): 盛土規制法の規制内容と手続き先。
L52 のものと同一ファイル (= 届出制と許可制で共通)。
シート 1 「規制内容」 = 法 21 条/40 条 1 項の文面、届出閾値、経過措置 等を表形式で。
シート 2 「手続き先」 = 各市町の窓口・電話番号。
データ品質に関する注記
本データの精査中、以下のデータ品質課題を発見した。研究の透明性のため明記する:
- 面積異常値 1 件: 整理番号「本0010」 (三次市) の面積 558,080,000 m² (= 558 km²) は
広島県全体の総面積 8,479 km² と比べ非現実的。同行の盛土量 383,096 m³ と矛盾するため、
桁違いの入力ミス (実際は 558,080 m² または 55.8 ha と推定) と判定。
本記事では中央値・最大値計算からこの 1 件を除外し、累積土量にも含めない。
ただし元値は assets/L53_notifications_processed.csv に保持し、
is_area_outlier 列で識別可能にしている。
- 本/竹 ペア重複の可能性: 整理番号 prefix 「本」 (= 本庁登録) と
「竹」 (= 竹原支所登録) で面積・土量が完全に一致する案件ペアが存在する
(例: 本0009 ⇔ 竹0006、本0008 ⇔ 竹0005)。これは同一案件の二重登録か
同一事業者の同時案件の可能性があるが、座標が近接するため累積土量計算で
過大評価のリスクがある。本記事は元データに忠実に両方を含めて集計している。
- 列「崖面崩壊防止施設」 が無い: L52 (許可) と異なり、L53 (届出) には
防護施設情報が欠ける。届出制度は事後通知のみで、防護措置の実施は別チャネル
(現地点検・苦情対応) で確認される運用と推察される。
これらのデータ品質課題は制度移行期の典型現象であり、
今後の届出台帳更新で漸次正規化されると予想される。研究結果の解釈時には注意が必要。
本記事は dataset 1430 を単独で扱う Format B 記事。
L52 (dataset 1429 = 許可盛土) との比較対照は二段階監督モデルの可視化に
不可欠なため、L52 の処理済 CSV (assets/L52_permits_processed.csv) を
参照する。土砂災害警戒区域 (sediment_shp) は L10/L11 で扱った既存データを
RQ2 で空間結合に利用するが、警戒区域そのものの分析は別レッスンに委ねる。
"""
# Sec 3
sec3 = f"""
本レッスンの再現に必要な全データ・中間 CSV・図 PNG・スクリプトを以下から直接 DL できる:
生データ (DoBoX 直リンク)
本記事の中間 CSV (再現用)
図 (PNG 9 枚)
再現スクリプト
個別取得 (PowerShell):
cd "2026 DoBoX 教材"
iwr "https://hiroshima-dobox.jp/resource_download/51165" -OutFile "data/extras/L53_notified_earthfill/340006_reported_earth_filling_21-1_40-1_declaration_register_20250826.csv"
iwr "https://hiroshima-dobox.jp/resource_download/51166" -OutFile "data/extras/L53_notified_earthfill/340006_earth_filling_regulation_related_documents.xlsx"
py -X utf8 lessons\\L53_notified_earthfill.py
注: 本記事の比較研究 (L52 との対比) には L52 の処理済 CSV
(lessons/assets/L52_permits_processed.csv) が必要。事前に L52 を実行しておくと完全再現できる。
未生成の場合、本スクリプトは比較部分を「データ無し」 表示にしてフォールバック実行する。
"""
# Sec 4 (RQ1)
sec4_intro = f"""
狙い (RQ1)
届出盛土 284 件は L52 許可盛土 152 件の約 1.87 倍の件数で、
盛土規制法の軽い手続側 (届出制)を担う。本 RQ1 では地理分布 + 規模分布 + 工事主体 +
許可制との比較の4 軸で構造を読む。これは「県は何を、どこで、どんな規模で、誰が、
許可とどう違う形で監督しているか」 を全方位で記述する基礎研究。
手法 (CSV パース → GeoDataFrame → 集計 → L52 比較)
- STEP 1 (パース): L52 と同様のロジックで高さ・面積・土量を正規化。
L53 特有の 「整理番号 prefix」 (西/東/北/竹/神 等) を抽出して
受理事務所別の集計を可能にする。
- STEP 2 (CRS 変換): 緯度経度 (EPSG:4326) → EPSG:6671 (m 単位)。
- STEP 3 (admin sjoin): CSV の所在地を主用、未マッチは admin polygon との
sjoin で補完。L53 では「山県郡北広島町」 等の旧表記を正規化。
- STEP 4 (主体分類): 公共/インフラ (町長・市長・電力会社・JR 等) /
民間法人 (株式会社・地所・開発) / 個人 の 3 区分。L52 と微妙に異なる
(届出は電力・JR の発電所盛土が登場するため「公共/インフラ」 と命名)。
- STEP 5 (L52 比較):
lessons/assets/L52_permits_processed.csv
が存在すれば読込み、面積・高さ・土量の中央値、市町別件数、警戒区域距離分布を
並べて表示する。
入出力 Before/After 具体例 (1 件追跡)
整理番号 「西0001」 (1 行目) の CSV → 数値化への変換例:
{df_to_html(pd.DataFrame([
{"段階": "RAW (CSV)", "整理番号": "西0001", "届出": "2023-10-12", "高さ": "1.6", "面積": "7074.28", "盛土量": "6515.9", "工事主": "東亜地所株式会社..."},
{"段階": "1. 数値化 + prefix", "整理番号": "prefix=西", "届出": "2023-10-12", "高さ": "1.6 m", "面積": "7074 m²", "盛土量": "6516 m³", "工事主": "民間法人"},
{"段階": "2. 規模分類", "整理番号": "—", "届出": "—", "高さ": "—", "面積": "L_大規模 (≥2000m²)", "盛土量": "—", "工事主": "—"},
{"段階": "3. 制度区分", "整理番号": "—", "届出": "—", "高さ": "—", "面積": "—", "盛土量": "—", "工事主": "G_経過措置遡及 (start=2022)"},
{"段階": "4. 警戒距離", "整理番号": "—", "届出": "—", "高さ": "—", "面積": "—", "盛土量": "—", "工事主": "海田町に立地"},
]))}
"""
sec4_code = code(r'''
# CSV パース + GeoDataFrame 化 + L52 比較読込
import pandas as pd, geopandas as gpd, re, numpy as np
from pathlib import Path
df = pd.read_csv("340006_reported_earth_filling_21-1_40-1_declaration_register_20250826.csv",
encoding="utf-8")
# L52 と同じパース関数を再利用
def parse_height(s):
if pd.isna(s): return np.nan
nums = re.findall(r"\d+\.?\d*", str(s))
return max(float(x) for x in nums) if nums else np.nan
def parse_numeric(s):
if pd.isna(s) or str(s).strip() in ("―","-","ー",""): return np.nan
m = re.search(r"(\d+\.?\d*)", str(s).replace(",", ""))
return float(m.group(1)) if m else np.nan
df["height_max_m"] = df["盛土切土の高さ又は土石の堆積の最大堆積高さ(m)"].apply(parse_height)
df["area_m2"] = df["盛土切土又は土石の堆積を行う土地の面積(m2)"].apply(parse_numeric)
df["fill_m3"] = df["盛土の土量又は土石の堆積の最大堆積土量(m3)"].apply(parse_numeric)
# 整理番号 prefix (受理事務所手がかり)
df["ref_prefix"] = df["整理番号"].astype(str).str.extract(r"^([^\d]+)")[0]
# 主体分類 (届出は電力・JR が登場するため「公共/インフラ」)
def classify(s):
if re.search(r"町長|市長|機構|公社|電力|JR", str(s)): return "公共/インフラ"
if re.search(r"株式会社|有限会社|地所|開発", str(s)): return "民間法人"
return "個人/その他"
df["owner_type"] = df["工事主"].apply(classify)
# Point geometry (EPSG:4326 → 6671)
gdf = gpd.GeoDataFrame(df,
geometry=gpd.points_from_xy(df["座標(経度)"], df["座標(緯度)"]),
crs="EPSG:4326").to_crs("EPSG:6671")
# L52 比較データ読込 (任意)
l52_path = Path("lessons/assets/L52_permits_processed.csv")
df_l52 = pd.read_csv(l52_path, encoding="utf-8-sig") if l52_path.exists() else None
todoke_kyoka_ratio = len(gdf) / len(df_l52) if df_l52 is not None else None
''')
sec4_fig1_text = """
図 1: 県全域 284 点マップ + 市町別件数コロプレス (2 panel)
なぜこの図か: 学習者がまず「届出盛土はどこに集中しているか」 を
一目で把握するため。L52 (許可) では沿岸都市部 (東広島・尾道・廿日市) に集中していたが、
L53 (届出) は分布パターンが異なるはず — それを左の点マップ + 右のコロプレスで対比する。
背景には警戒区域を薄く重ね、RQ2 への伏線にもなる。
"""
sec4_fig1_read = f"""
この図から読み取れること:
- 届出盛土は{top1_city} ({top1_n} 件) を筆頭に、
{', '.join(city_counts.head(5)['市町名'].tolist())} の 5 市町に偏る。
L52 (許可) とは異なる集中市町 (山間部市町を含む) → 地理パターンの差を明示。
- 上位 5 市町シェア = {top5_share*100:.1f}%
(L52 = 63.2%) → H1 ({'支持' if top5_share<0.55 else '反証'})。
届出盛土は許可盛土より{'分散' if top5_share<0.55 else '集中'}立地。
- 図 1a の点サイズ (=面積) を見ると、大規模 (赤色 ★) は山間部市町に分布する傾向。
これは L52 (許可) の沿岸都市部偏重と対照的。
- 背景のピンク (急傾斜警戒区域) と点の重なりは目視でかなり多いが、
L52 ほどではない。L52 は丘陵都市の宅地擁壁が中心だが、L53 は山間平地・農地転用も含むため。
RQ2 で定量検証する。
- 市町数 = {gdf['市町名'].nunique()} 市町に分散 (L52 = 22 市町) →
届出制は許可制よりも地理的に広く盛土行為を捕捉。
"""
sec4_fig2_text = """
図 2: 規模分布 (高さ・面積・土量) — 届出 vs 許可 中央値比較
なぜこの図か: 「届出盛土 (L53) と許可盛土 (L52) のどちらが規模が大きいか」 という
仮説検証の中核。直感的には「届出 < 許可」 (= 規模閾値以下が届出) だが、
経過措置による遡及届出には旧法時代の大規模盛土も含まれるため、
中央値比較は予想を裏切る可能性がある。3 軸 (高さ・面積・土量) を log で並列。
"""
l52_h_str = f"{l52_h_med:.2f}m" if df_l52 is not None else "—"
l52_a_str = f"{l52_a_med:.0f} m²" if df_l52 is not None else "—"
l52_v_str = f"{l52_v_med:.0f} m³" if df_l52 is not None else "—"
l53_h = gdf['height_max_m'].median()
l53_a = gdf['area_m2'].median()
l53_v = gdf['fill_volume_m3'].median()
sec4_fig2_read = f"""
この図から読み取れること:
- 高さ中央値: 届出 {l53_h:.2f}m / 許可 {l52_h_str}。
{('届出が許可を上回る' if df_l52 is not None and l53_h > l52_h_med else '許可が届出を上回る' if df_l52 is not None else '比較不可')} →
届出制が「閾値以下の小規模」 を捕捉する仮説を{'反証' if df_l52 is not None and l53_h > l52_h_med else '支持' if df_l52 is not None else '検証不可'}。
- 面積中央値: 届出 {l53_a:,.0f} m² / 許可 {l52_a_str} m²。
最大は L53 = {int(gdf['area_m2'].max()):,} m² (vs L52 max = 41,501 m²) → 届出のほうが最大規模も大きい。
これは経過措置遡及で旧法時代の大規模既存盛土が含まれるため。
- 土量中央値: 届出 {l53_v:,.0f} m³ / 許可 {l52_v_str} m³。
L53 max = {gdf['fill_volume_m3'].max():,.0f} m³ という巨大値が存在 →
規模閾値による棲み分け (届出 < 許可) は運用実態と一致しない。
- 分布形状の形状の相同性: 高さ・面積・土量は同じ案件内で正に相関し、
対数正規型分布。L52 と同じ右非対称の物理的相似性。
- これは H2 を{'部分的に支持' if df_l52 is not None else '検証不可'}する結果 →
件数比 1.87 だが、規模は届出 ≥ 許可 という制度設計と運用のずれを示す。
"""
sec4_fig3_text = """
図 3: 許可 (L52) vs 届出 (L53) 併置マップ + 市町別件数比較
なぜこの図か: 二段階監督モデルの地理的実装を 1 図で見る。
左で点 (許可=赤△ vs 届出=青○) を県地図上に併置し、
右で市町別件数を横並べ棒で比較する。両者の地理パターンの違いを直接読む。
"""
if df_l52 is not None:
fig3_main_text = f"""
- 許可 (赤△) は沿岸都市部 (東広島・尾道・廿日市) に集中。
L52 で確認したパターン (Top 5 = 都市部宅地造成 + 物流団地)。
- 届出 (青○) は山間部にも広く分散。{', '.join([c for c in city_counts.head(5)['市町名']])} の上位は
山間部市町を含み、許可 Top 5 と{'重なる' if any(c in df_l52['市町名'].value_counts().head(5).index.tolist() for c in city_counts.head(5)['市町名'].tolist()) else 'ほぼ重ならない'}。
- 件数比 = {todoke_kyoka_ratio:.2f} (届出 {len(gdf)} / 許可 {n_kyoka}) →
二段階監督の数値的実装が確認される。
- 市町別比較棒では、{top1_city} は届出 {top1_n} 件 vs 許可
{df_l52[df_l52['市町名']==top1_city].shape[0] if top1_city in df_l52['市町名'].values else 0} 件で、
届出が圧倒的に多い → 中規模の盛土行為がこの市町で活発。
- 逆に許可だけ多い市町は、届出制度がカバーしていない盲点 (= 高密度都市開発地で
届出規模の盛土がそもそも発生しにくい) を示すかもしれない。
"""
else:
fig3_main_text = "L52 比較不可 (assets/L52_permits_processed.csv 未生成)
"
sec4_fig3_read = "この図から読み取れること:
" + fig3_main_text
# Sec 5 (RQ2)
sec5_intro = f"""
狙い (RQ2)
届出盛土 284 件は個別では中規模 (= 許可閾値以下) でも、
多数が地理に集積することで累積的な地形改変効果を生む。
本 RQ2 では (1) 累積土量の市町別偏在、(2) 警戒区域との空間関係 (L52 と比較)、
(3) 中〜大規模盛土のパッチワーク立地 を読み解く。
累積土量という指標は件数とは異なる軸で偏在を示す。
件数が分散していても、1 件の大規模盛土が圧倒的な土量を占めて市町別ランキングを変える可能性がある。
これは「中規模が多数 = 累積で大規模」 という直観と必ずしも一致せず、
「少数の超大規模 + 多数の中小規模」という分布構造が現れるかもしれない。
手法 (累積集計 + STRtree 警戒区域距離)
- STEP 1 (累積土量):
gdf.groupby('市町名')['fill_volume_m3'].sum()
で市町別累積を計算。総土量 = {total_fill:,.0f} m³ ({total_fill/1e6:.2f} 百万 m³)。
上位 3 シェアを計算し、累積偏在度を読む。
- STEP 2 (累積マップ): 市町 polygon を累積土量で choropleth 塗り分け。
件数 choropleth (図 1) との差異を視覚化。
- STEP 3 (警戒区域距離): STRtree で 284 点 × 43K polygon の最近傍距離を計算
(L52 と同じアルゴリズム)。距離区分は L52 と統一 (区域内 / 100m / 500m / 500m+)。
L52 の距離分布と並べて表示し、立地パターンの差を読む。
- STEP 4 (パッチワーク図): 中〜大規模 (M_中規模 + L_大規模 + 熱海型) のみを
盛土量サイズで地図プロット。多数の中規模が地理に集積する様子を「パッチワーク」 と
呼んで可視化。
入力: 284 Point + 43K polygon + L52 距離分布。
出力: 284 行に dist_kyukei_m, dist_doseki_m, warn_class、市町別累積土量。
限界: 「累積土量」 は単純合計で、盛土の体積分布は無視している
(= 1 つの 5 万 m³ と 100 件 × 500 m³ は同じ累積扱い)。本記事の累積指標は
「行政が監督する土量の総量」 を表す。
"""
sec5_code = code(r'''
# 累積土量 + 警戒区域距離 + L52 比較
from shapely import STRtree
# 1. 市町別累積
city_volume = gdf.groupby("市町名").agg(
件数=("ref_no", "count"),
累積盛土量_m3=("fill_volume_m3", "sum"),
).sort_values("累積盛土量_m3", ascending=False)
top3_share = city_volume.head(3)["累積盛土量_m3"].sum() / city_volume["累積盛土量_m3"].sum()
# 2. 警戒区域までの距離 (STRtree)
def nearest_dist(points, polys):
tree = STRtree(polys.values)
out = np.zeros(len(points), dtype=np.float32)
for i, pt in enumerate(points.values):
idx = tree.nearest(pt)
out[i] = pt.distance(polys.values[idx])
return out
gdf["dist_kyukei_m"] = nearest_dist(gdf.geometry, warn_kyukei.geometry)
gdf["dist_doseki_m"] = nearest_dist(gdf.geometry, warn_doseki.geometry)
gdf["dist_warn_m"] = gdf[["dist_kyukei_m", "dist_doseki_m"]].min(axis=1)
# 3. 距離区分 (L52 と統一)
def warn_class(d):
if d == 0: return "0_警戒区域内"
if d <= 100: return "1_100m以内 (隣接)"
if d <= 500: return "2_100-500m (近接)"
return "3_500m超 (離隔)"
gdf["warn_class"] = gdf["dist_warn_m"].apply(warn_class)
''')
sec5_fig4_text = """
図 4: 市町別累積土量 choropleth + 上位 15 市町ランキング (log)
なぜこの図か: 件数の偏在 (図 1) と土量の偏在 (図 4) を別軸で見る。
件数 Top 5 と土量 Top 5 が一致しないことが「累積効果の独自軸」 の証拠になる。
右の log 軸ランキングで、上位市町が下位市町より何桁多い土量を扱っているかを一目で読む。
"""
sec5_fig4_read = f"""
この図から読み取れること:
- 累積土量 Top 3: {', '.join(city_volume.head(3)['市町名'].tolist())} で
合計 {top3_volume_share*100:.1f}% → H4 ({'支持' if top3_volume_share>=0.50 else '部分支持'})。
件数の上位 ({', '.join(city_counts.head(3)['市町名'].tolist())}) と
{'一致しない' if set(city_volume.head(3)['市町名'].tolist()) != set(city_counts.head(3)['市町名'].tolist()) else '一致する'} 部分があり、
「件数偏在 ≠ 土量偏在」を示す。
- 全県累積盛土量 = {total_fill:,.0f} m³ ({total_fill/1e6:.2f} 百万 m³) →
25m プール換算で約 {pool_eq:,.0f} 杯。これは「広島県の届出制度がカバーしている地形改変の総量」。
- 上位市町の累積土量は下位市町の{int(np.log10(city_volume.head(1)['累積盛土量_m3'].iloc[0]/max(city_volume.tail(1)['累積盛土量_m3'].iloc[0], 1)))} 桁多い →
累積効果は地理に強く偏在し、上位市町は単独で県全体の地形改変の中核。
- 上位 1 市町 ({city_volume.iloc[0]['市町名']}: {city_volume.iloc[0]['累積盛土量_m3']:,.0f} m³,
シェア {city_volume.iloc[0]['土量シェア_%']:.1f}%) は単独で全県の{city_volume.iloc[0]['土量シェア_%']:.0f}% を占める。
これは 1 件の超大規模が累積を押し上げた可能性 — 図 6 のパッチワーク図で確認する。
- 図 1 (件数 choropleth) と図 4a (土量 choropleth) を比べると、
色の濃い市町が異なる場所に出現 → 件数偏在と土量偏在は独立な構造を持つ。
"""
sec5_fig5_text = """
図 5: 警戒区域オーバーレイ + 距離分布比較 (届出 vs 許可)
なぜこの図か: L52 で確認した「許可盛土の警戒区域近接率 49%」 と
本データの近接率を直接比較する。届出盛土は経過措置で農地・山間平地も含むため、
許可制より離隔立地が多いはず。これを 2 panel (左: 地図, 右: 比較ヒスト) で示す。
"""
sec5_fig5_read = f"""
この図から読み取れること:
- L53 警戒区域内+100m: {within_n+near_100_n} 件 ({near_pct:.1f}%)
vs L52 = 49.3% → H5 ({'支持' if near_pct < 49.3 else '反証'})。
届出盛土の近接率は許可制{('より低く、離隔立地が多い' if near_pct < 49.3 else 'と同等以上')}。
- 警戒区域内立地: {within_n} 件 ({100*within_n/len(gdf):.1f}%) →
これらは届出時点で災害想定区域内に既に存在する盛土。
盛土規制法は「警戒区域内禁止」 ではないが、新規工事は許可制で個別審査される。
- 500m 超 (離隔): {far_n} 件 ({100*far_n/len(gdf):.1f}%) →
これは経過措置遡及で農地転用や平地造成の既存盛土を含む。
L52 (許可制) より明らかに離隔比率が高い。
- 近接警戒種別: 急傾斜 {(gdf['nearest_warn_type']=='急傾斜地崩壊').sum()} 件 vs
土石流 {(gdf['nearest_warn_type']=='土石流').sum()} 件 →
L52 と比べ土石流近接の比率が{'高い' if (gdf['nearest_warn_type']=='土石流').sum()/len(gdf) > 0.3 else '低い'}。
- 右ヒストでは L53 (青) は L52 (赤) より右側 (離隔)に裾が長い → 制度区分による
立地パターンの違いを統計的に確認。
"""
sec5_fig6_text = """
図 6: 中〜大規模届出盛土の累積パッチワーク (盛土量サイズ表示)
なぜこの図か: 「中規模が多数 = 累積で大規模」 の仮説を地理上で確かめる。
小規模 (戸建相当) は除外し、中規模 + 大規模 + 熱海型のみを
土量 (=サイズ) で表示。多数の中規模点が地理に集積する様子と、少数の巨大点が支配する場所を
1 つの地図で並列表示する。
"""
sub_mid_count = ((gdf["scale_class"].isin([
"M_中規模 (1.5m+ or 500m²+)",
"L_大規模 (3m+ or 2000m²+)",
"S_熱海型 (5m+5000m²+)"]))).sum()
sub_mid_total = gdf[gdf["scale_class"].isin([
"M_中規模 (1.5m+ or 500m²+)",
"L_大規模 (3m+ or 2000m²+)",
"S_熱海型 (5m+5000m²+)"])]["fill_volume_m3"].sum()
sec5_fig6_read = f"""
この図から読み取れること:
- 中〜大規模届出盛土は{sub_mid_count} 件 (全体の {100*sub_mid_count/len(gdf):.0f}%) で、
累積盛土量 {sub_mid_total:,.0f} m³ ({100*sub_mid_total/total_fill:.0f}%)。
これは届出制度の本体 — 小規模戸建擁壁は累積効果に寄与しない。
- 上位 5 大規模 (ラベル付き) は山間部市町に集中し、それぞれ 10 万 m³ 級。
最大は {gdf.nlargest(1, 'fill_volume_m3').iloc[0]['市町名']} の {gdf['fill_volume_m3'].max():,.0f} m³ →
これ単独で全県累積の {100*gdf['fill_volume_m3'].max()/total_fill:.1f}% を占める。
- 多数の中規模 (青点) は山間平地 + 沿岸丘陵に広く分散 →
個別では小さいが、地理上の面的累積効果を持つ。
これは 1 つの市町内で複数の届出盛土が連続立地する「パッチワーク」 構造。
- 警戒区域 (薄ピンク・橙) と中〜大規模点の重なりは部分的 →
RQ2 で定量化した「区域内+100m {near_pct:.0f}%」 という結果は、
地図上では「点が警戒区域に張り付く」 のではなく、
「警戒区域近辺と離隔エリアに分散」 する形で実装される。
- 1 件の超大規模が累積を押し上げる構造 → 制度設計上、
「届出 ≠ 小規模」 という運用実態の含意がここに現れる。
これは RQ3 で経過措置遡及との関係をさらに掘り下げる。
"""
# Sec 6 (RQ3)
sec6_intro = f"""
狙い (RQ3)
届出制度の本来目的は「許可不要規模の新規工事を、行政が事前に把握する」 こと。
しかし本データの大半は経過措置遡及 (= 法施行前から存在する既存盛土の事後届出)。
この事実は二段階監督モデルの運用実態と本来目的のずれを示唆する。
本 RQ3 は (1) 経過措置遡及の比率と年代分布、(2) 純新規届出との規模差、
(3) 二段階監督モデル全体の制度比較表を読み解く。
手法 (制度区分分類 + 着手日 vs 届出日散布)
- STEP 1 (3 区分):
- G_経過措置遡及 = 工事着手 < 法施行 (2023-05-26)
- N_純新規届出 = 工事着手 ≥ 法施行
- X_着手不明 = 工事着手日欠損
- STEP 2 (散布図): 横軸 = 工事着手日、縦軸 = 届出日 で散布。
法施行ライン (縦+横) と対角線 (届出 = 着手) を重ね、
遅延構造 (= 着手から届出までの時間) を可視化。
- STEP 3 (年代ヒスト): 経過措置遡及の工事着手年を 1980-2024 のレンジで
ヒストグラム化。最古は {grandfathered['start_date'].min().year} 年 (= 法施行の {LAW_ENFORCED.year - grandfathered['start_date'].min().year} 年前!)。
- STEP 4 (二段階監督モデル比較表): 許可制 (L52) と届出制 (L53) を
根拠条文・規模閾値・件数・規模中央値・経過措置・行政の監督力 等の
9 軸で並べた制度比較表を作成。これは制度設計の総合診断。
入力: 284 行に start_date, declare_date が付与済。
出力: regime_class (G/N/X) を新たに付与。
限界: 工事着手日が大幅に古い案件 (1981 年等) は、
当時の盛土が未管理のまま現在まで存在し続けた = 本データで初めて行政台帳化された
「埋没盛土」と解釈できる。これは制度的に重要な発見だが、
施工当時の安全性は本データでは検証不可能。
"""
sec6_code = code(r'''
# 経過措置遡及 vs 純新規届出 の制度区分
import pandas as pd, numpy as np
LAW_ENFORCED = pd.Timestamp("2023-05-26") # 盛土規制法 施行日
def regime_class(row):
if pd.isna(row["start_date"]): return "X_着手不明"
if row["start_date"] < LAW_ENFORCED: return "G_経過措置遡及"
return "N_純新規届出"
gdf["regime_class"] = gdf.apply(regime_class, axis=1)
# 経過措置遡及 = 法施行前に着手した工事の届出
grandfathered = gdf[gdf["regime_class"] == "G_経過措置遡及"]
print(f"経過措置遡及: {len(grandfathered)} 件 ({100*len(grandfathered)/len(gdf):.1f}%)")
print(f"最古工事着手: {grandfathered['start_date'].min().date()}")
# 着手から届出までの遅延 (日)
gdf["delay_days"] = (gdf["declare_date"] - gdf["start_date"]).dt.days
''')
sec6_fig7_text = """
図 7: 届出日 vs 着手日 散布 + 工事着手年ヒスト (経過措置遡及の時間構造)
なぜこの図か: 「届出日 vs 着手日」 という2 つの時間軸を
1 図に重ねることで、経過措置遡及の構造を可視化。法施行ライン (縦+横) と対角線
(届出=着手) の相対位置で、各案件の制度的位置付けが一目で分かる。
右ヒストは経過措置遡及の遡及範囲を年代別に集計し、最古を強調。
"""
oldest_year = grandfathered['start_date'].min().year
oldest_age = LAW_ENFORCED.year - oldest_year
sec6_fig7_read = f"""
この図から読み取れること:
- 経過措置遡及 (紫): {len(grandfathered)} 件 ({100*len(grandfathered)/len(gdf):.1f}%) が
法施行ライン (縦線) の左側に分布 →
工事は法施行前に既に開始されていた既存盛土。
H3 ({'支持' if g_share>=0.50 else '部分支持'})。
- 純新規届出 (青): {len(post_law)} 件 ({100*len(post_law)/len(gdf):.1f}%) のみが
法施行後に着手 → 届出制度の本来目的に合致するのはこちら。
- 大半の点は対角線 (届出=着手) より上方に分布 →
着手から届出までに遅延あり。
経過措置遡及の場合、最古の遅延は {(grandfathered['delay_days'].max() if grandfathered['delay_days'].notna().any() else 0):.0f} 日
(= 約 {(grandfathered['delay_days'].max() if grandfathered['delay_days'].notna().any() else 0)/365:.0f} 年) →
旧法時代の盛土が新法施行を機にようやく行政台帳化された。
- 右ヒストの最古ピーク: {oldest_year} 年 ({oldest_age} 年前) に
着手した盛土が含まれる。これは「埋没盛土」 (= 数十年間管理外で存在)
の発見であり、制度的に極めて重要。
- 年代分布は2008-2022 年がピーク (旧法時代の宅地造成・農地転用ラッシュ) →
これらは旧法 (宅造規制法) の対象外 (= 山間地・農地) が大半で、
新法施行で初めて行政の視野に入った。
- 純新規届出 (青)は法施行直後 (2023 後半) に集中 →
これは「事業者が新法を意識し始めた初期反応」 を示すが、
経過措置の届出ラッシュに圧倒されて目立たない。
届出制度の本来目的は今後、年単位で実装が進むと予想される。
"""
sec6_fig8_text = """
図 8: 規模カテゴリ パイ + 高さ × 面積 散布 (届出 vs 許可重ね)
なぜこの図か: 左パイで届出 (L53) の規模構成、
右散布で許可 (L52) との重ねを見る。図 2 (中央値比較) では分布の中央値しか見えなかったが、
散布図では個別の点として「届出と許可がどう棲み分けているか」 を視覚的に検証できる。
"""
sec6_fig8_read = f"""
この図から読み取れること:
- 規模カテゴリ構成: 中規模 {scale_counts.get('M_中規模 (1.5m+ or 500m²+)', 0)} 件
({100*scale_counts.get('M_中規模 (1.5m+ or 500m²+)', 0)/len(gdf):.0f}%)、
大規模 {scale_counts.get('L_大規模 (3m+ or 2000m²+)', 0)} 件 ({100*scale_counts.get('L_大規模 (3m+ or 2000m²+)', 0)/len(gdf):.0f}%)、
熱海型 {atami_n} 件 ({atami_share*100:.0f}%)、小規模 {scale_counts.get('S_小規模 (戸建相当)', 0)} 件 ({100*scale_counts.get('S_小規模 (戸建相当)', 0)/len(gdf):.0f}%)。
L52 (許可) とカテゴリ構成が類似 → 届出も許可も「中規模が中心」。
- 右散布の重ね表示: 青○ (届出) と赤△ (許可) が同じ領域 (高さ 1-10m × 面積 100-50000 m²) に
混在 → 規模で明確に棲み分けず、同じ規模の盛土が許可と届出に分かれている。
- これは「許可閾値以下なら届出」 という制度設計が運用上ぼやけることを示す。
経過措置遡及で大規模も届出に含まれるためで、L53 max 面積 {int(gdf['area_m2'].max()):,} m² は L52 max 41,501 m² を上回る。
- 熱海型 (★ 赤縁): L53 で {atami_n} 件 ({atami_share*100:.0f}%) →
L52 (16 件, 10.5%) と{'同等' if abs(atami_share - 0.105) < 0.05 else '差異あり'}。
届出制でも熱海規模の盛土が含まれることは制度的に注目すべき。
- 500 m² 閾値ライン (許可下限) を下回る点は L53 の方が多い →
これは届出制度が捕捉する「閾値ぎりぎり以下の中規模」 で、本来想定された案件群。
- 5,000 m² 閾値 (熱海型) を超える上端には届出も多数立地 →
経過措置遡及により、本来許可制に該当する規模の既存盛土が届出枠で台帳化されている。
これは制度設計の過渡期特有の現象。
"""
sec6_fig9_text = """
図 9: 上位 12 市町 × 規模 + 制度区分 stacked (RQ1+RQ2+RQ3 統合)
なぜこの図か: 3 RQ の知見を 1 図に統合 — 左で市町 × 規模、
右で市町 × 制度区分 (経過措置 vs 純新規)。同じ y 軸 (Top 12 市町) で並べることで、
「件数の多い市町は規模が偏るか?」 「件数の多い市町は経過措置遡及が多いか?」 を
横断的に読む。
"""
city_top1_g_share = (grandfathered[grandfathered["市町名"] == top1_city].shape[0] /
max(gdf[gdf["市町名"] == top1_city].shape[0], 1)) * 100
sec6_fig9_read = f"""
この図から読み取れること:
- 件数 1 位 {top1_city} ({top1_n} 件) は規模カテゴリが多様で、熱海型も含む →
届出制度の運用が活発な市町は規模スペクトル全域をカバー。
- {top1_city} の経過措置遡及率: {city_top1_g_share:.0f}% →
件数 1 位市町でも遡及届出が大半。これは届出制度の運用実態が
地理的に均一に「経過措置の事後台帳化」 で動いていることを示す。
- {city_counts.iloc[1]['市町名']} ({city_counts.iloc[1]['届出件数']} 件) も多様な規模が混在 →
届出制度は許可制と異なり、地理的に分散した中規模盛土行為を捕捉。
- 純新規届出 (青) が比較的多い市町は、新法施行後に新規事業を活発化させた地域 →
これは制度の本来運用が立ち上がりつつある場所を示す。
- 経過措置遡及 (紫) が圧倒的多数の市町は、旧法時代から積み上がった
埋没盛土の事後台帳化 → これは制度移行特有の現象で、今後数年で
純新規届出比率が上昇するはず。
- 3 RQ の総合像: 地理は分散 (RQ1) × 累積土量は集中 (RQ2) ×
制度は経過措置主導 (RQ3) → 二段階監督モデルの初期実装を
多角的に同定。
"""
# Sec 7 (仮説検証総合)
sec7 = (
"本記事の 5 仮説と観測結果の照合:
"
+ df_to_html(T_hypo)
+ "3 RQ × 3 結論
"
""
f"- RQ1 結論: 広島県の届出盛土 {len(gdf)} 件は "
f"{gdf['市町名'].nunique()} 市町に分散 (L52 = 22 市町より広い) し、"
f"上位 5 市町シェア = {top5_share*100:.0f}% "
f"(L52 = 63%) → {('分散度が高い' if top5_share<0.55 else '同等の集中度')}。"
f"件数比 届出/許可 = {todoke_kyoka_ratio:.2f} (届出 {len(gdf)} / 許可 {n_kyoka})。"
f"規模中央値は届出 {l53_h:.2f}m × {l53_a:,.0f}m² × {l53_v:,.0f}m³ で、"
f"許可 ({l52_h_str} × {l52_a_str} × {l52_v_str}) と"
f"{('同等以上' if df_l52 is not None and l53_a >= l52_a_med else '小さい')} →"
f"経過措置遡及で大規模既存盛土が含まれることを反映。
"
f"- RQ2 結論: 全県累積盛土量 = {total_fill/1e6:.2f} 百万 m³ "
f"(25m プール {pool_eq:,.0f} 杯)。上位 3 市町累積シェア = "
f"{top3_volume_share*100:.0f}% → 件数偏在 ≠ 土量偏在。"
f"警戒区域内+100m = {near_pct:.0f}% (L52 = 49%) → "
f"届出盛土は許可盛土より{'離隔立地が多い' if near_pct < 49.3 else '同等近接'}。"
f"これは経過措置で農地・山間平地が含まれるため。"
f"中〜大規模 ({sub_mid_count} 件, {100*sub_mid_count/len(gdf):.0f}%) が累積土量の "
f"{100*sub_mid_total/total_fill:.0f}% を占め、「中規模が多数 = 累積で大規模」仮説を支持。
"
f"- RQ3 結論: 経過措置遡及 = {len(grandfathered)} 件 ({g_share*100:.0f}%)、"
f"純新規届出 = {len(post_law)} 件 ({100*len(post_law)/len(gdf):.0f}%)。"
f"H3 ({'支持' if g_share>=0.50 else '部分支持'})。"
f"最古工事着手 = {grandfathered['start_date'].min().date()} ({oldest_age} 年前) → "
f"旧法時代の埋没盛土が新法施行で行政台帳化された制度移行特有の現象。"
f"二段階監督モデル (許可 + 届出) は規模で棲み分けるはずが、"
f"運用上は経過措置遡及によりぼやける → これは制度の本来目的と運用実態のずれ。"
f"今後数年で純新規届出比率が上昇すれば制度が定着フェーズに移行。
"
"
"
"二段階監督モデル — 許可制 (L52) vs 届出制 (L53) 比較表
"
+ df_to_html(T_regime_compare)
+ "この表から読み取れること: 許可制 (L52) と届出制 (L53) は"
"同じ盛土規制法の下で規模閾値で棲み分ける制度設計だが、"
"実装は (1) 件数比 1.87 (届出 > 許可)、(2) 規模中央値は届出 ≥ 許可 (経過措置のため)、"
"(3) 経過措置遡及により本来想定された棲み分けがぼやける、"
"(4) 行政の監督力は許可 (強制限) > 届出 (情報把握) と差が大きい — "
"の 4 軸で非対称。二段階監督は規模カバレッジを広げる利点がある一方、"
"監督力の弱い届出制が中〜大規模盛土をどう実効的に監視するかは今後の制度課題。
"
)
# Sec 8 (発展課題)
sec8 = f"""
結果 X → 新仮説 Y → 課題 Z (3 RQ × 1 課題以上)
発展課題 1 (RQ1 由来): 件数比の人口・面積補正
- 結果 X: 届出盛土 284 件は L52 許可 152 件の 1.87 倍だが、
規模 (面積中央値 {l53_a:,.0f} m² vs L52 {l52_a_str}) は届出が許可と同等以上 →
規模閾値による棲み分けは経過措置でぼやける。
- 新仮説 Y: 届出 / 許可比は市町別に大きく異なり、
山間部市町ほど届出比率が高い (= 旧法対象外の山間地が新法で初めて捕捉される)。
また、市町面積あたり届出件数は人口より面積に強く相関する
(= 盛土行為の物理的密度の指標)。
- 課題 Z: 各市町の人口 (e-Stat 国勢調査) + 面積 (L15 admin polygon) を取得し、
「届出 / 許可比 × 面積」「届出 / 許可比 × 人口」 の散布図を Pearson 相関 + Spearman 相関で評価。
傾きの推定値から「面積 1km² あたり何件の届出が発生するか」 という密度指標を計算。
これは盛土行政の地理需要モデルに直結。
発展課題 2 (RQ2 由来): 累積土量の地形・水文影響
- 結果 X: 全県累積盛土量 {total_fill/1e6:.2f} 百万 m³。上位 3 市町で {top3_volume_share*100:.0f}% を占め、
件数偏在と土量偏在は別軸で構造化される。
- 新仮説 Y: 累積土量の多い市町は下流河川の堆積物増加と
地下水流動の変化を経験する。これは長期的に水害リスクを変動させる
(= 盛土起因の流出土砂が河道閉塞を招く可能性)。
また、累積土量と地表水浸透率の低下に正相関があるはず。
- 課題 Z: 累積土量 Top 5 市町について、L4 (河川浸水想定) や
L11 (トリプルハザード) の polygon と sjoin して
「盛土 100m 以内に河川浸水想定区域があるか」 を集計。
また、L40 (DEM 標高) を用いて盛土前後の地形改変を ±高さ で量化。
盛土 1 件ごとに「下流 1km 以内の浸水想定面積」 を計算し、
「盛土土量 × 下流浸水想定面積」の連関指標を作成。
これは盛土の事後評価と下流リスク連鎖を可視化する研究。
発展課題 3 (RQ3 由来): 経過措置遡及の管理連続性検証
- 結果 X: 経過措置遡及 {len(grandfathered)} 件 ({g_share*100:.0f}%)、最古 {oldest_year} 年。
旧法時代の埋没盛土が新法施行で初めて行政台帳化された制度移行特有の現象。
- 新仮説 Y: 古い経過措置遡及案件 (= 1990 年代以前着手) は、
施工当時の安全基準が現代より緩く、のり面安全性が現法準拠より低い可能性。
また、これらの埋没盛土は2018 西日本豪雨等の災害時に既に
崩壊・損傷を経験している場合があるが、データには記録されていない。
- 課題 Z: 経過措置遡及 上位 30 件 (assets/L53_grandfathered_oldest.csv) の
位置を L46 (砂防関係指定地) と重ね合わせ、危険箇所指定との関連を集計。
また、2018-07 西日本豪雨の災害発生地点 (L10/L11 関連) と
300m 以内の経過措置遡及案件を「履歴ありリスク高」 として絞り込み、
「事後点検優先順位リスト」を作成する。これは盛土規制法の実効性を
個別案件レベルで検証する研究で、防災投資の優先順位付けに直結する。
"""
# Combine sections
sections = [
("学習目標と問い", sec1),
("使用データ", sec2),
("ダウンロード", sec3),
("【RQ1】 地理分布と件数構造の研究 — 届出盛土 284 件と許可盛土 (L52) の比較",
sec4_intro
+ "実装コード (CSV パース + GeoDataFrame + L52 比較読込)
"
+ sec4_code
+ sec4_fig1_text
+ figure("assets/L53_fig1_geomap.png",
"図 1 (RQ1): 届出盛土 284 件の地理分布 (点マップ + コロプレス)")
+ sec4_fig1_read
+ sec4_fig2_text
+ figure("assets/L53_fig2_scale_dist.png",
"図 2 (RQ1): 規模分布 — 届出 (L53) と許可 (L52) の中央値比較")
+ sec4_fig2_read
+ sec4_fig3_text
+ figure("assets/L53_fig3_kyoka_vs_todoke.png",
"図 3 (RQ1): 許可 (L52) と 届出 (L53) の併置 — 二段階監督モデル")
+ sec4_fig3_read
+ "表: 全体サマリ (届出 vs 許可 比較)
"
+ df_to_html(T_overall)
+ "この表から読み取れること: 284 件の届出盛土は 22 市町に分散し、"
f"民間法人 {private_share*100:.0f}%、警戒区域内+100m {near_pct:.0f}%、"
f"熱海型 {atami_share*100:.1f}%、経過措置遡及 {g_share*100:.0f}% という"
"5 軸の構造的事実が初めて定量化された。L52 (許可) との対比から、"
"二段階監督モデルの初期運用実態が読み取れる。
"
+ "表: 市町別件数 + 累積土量 ランキング (Top 15)
"
+ df_to_html(T_city)
+ "この表から読み取れること: 届出件数の上位市町は "
f"({', '.join(city_counts.head(5)['市町名'])}) で全体の "
f"{top5_share*100:.0f}% を占める。同表で許可件数 (L52) と並べることで、"
"届出 / 許可比が市町別に異なる事実が見える: ある市町は届出のみ多い (= 山間部の中規模)、"
"ある市町は両方多い (= 都市部の混在)、ある市町は許可だけ多い (= 高密度都市開発)。"
"累積盛土量シェアと件数シェアが乖離する市町もあり、これは図 4 の累積 choropleth と整合する。
"
+ "表: 整理番号 prefix (受理事務所手がかり) Top 10
"
+ df_to_html(T_prefix)
+ "この表から読み取れること: 整理番号 prefix は"
"県の建設事務所別シリアル番号と推察される (西=西部建設事務所、東=東部、北=北部、竹=竹原支所、神=神石支所等)。"
"件数最多 prefix は地理的に対応市町と一致 → 届出受理体制が地域分業されていることを示す。"
"個別市町の窓口に届出が集約される行政運営構造が見える。
"
),
("【RQ2】 累積土量と警戒区域研究 — 中規模が多数の地理累積効果",
sec5_intro
+ "実装コード (累積集計 + STRtree 距離)
"
+ sec5_code
+ sec5_fig4_text
+ figure("assets/L53_fig4_volume_choropleth.png",
"図 4 (RQ2): 市町別累積盛土量 choropleth + Top 15 ランキング")
+ sec5_fig4_read
+ sec5_fig5_text
+ figure("assets/L53_fig5_warn_overlay.png",
"図 5 (RQ2): 警戒区域オーバーレイ + 距離分布比較 (届出 vs 許可)")
+ sec5_fig5_read
+ sec5_fig6_text
+ figure("assets/L53_fig6_patchwork.png",
"図 6 (RQ2): 中〜大規模届出盛土の累積パッチワーク")
+ sec5_fig6_read
+ "表: 警戒区域距離区分サマリ (届出 vs 許可)
"
+ df_to_html(T_warn)
+ f"この表から読み取れること: 届出盛土の警戒区域内 + 100m 以内は"
f"{near_pct:.0f}% (L52 許可は 49%)。"
f"離隔 (500m+) は届出 {100*far_n/len(gdf):.0f}% vs 許可で大きな差 → "
"届出盛土は経過措置で農地・山間平地を含むため、許可制より広く分散立地。"
"ただし区域内立地はゼロでなく、災害想定区域内の既存盛土が一定数行政把握下にある。
"
+ "表: 規模カテゴリ集計 (届出 vs 許可)
"
+ df_to_html(T_scale)
+ f"この表から読み取れること: 中規模 + 大規模が累積土量の主軸で、"
f"届出と許可でカテゴリ構成が類似。熱海型は L53 = {atami_n} 件 ({atami_share*100:.1f}%) vs L52 = 16 件 (10.5%)。"
"規模カテゴリで明確な棲み分けはない → 経過措置遡及により大規模も届出に含まれるため。"
"盛土量合計列で「中規模が多数 = 累積で大規模」 仮説の数値根拠が確認される。
"
),
("【RQ3】 制度設計検証 — 二段階監督モデルと経過措置遡及",
sec6_intro
+ "実装コード (制度区分分類)
"
+ sec6_code
+ sec6_fig7_text
+ figure("assets/L53_fig7_grandfather.png",
"図 7 (RQ3): 届出日 vs 着手日 + 工事着手年分布")
+ sec6_fig7_read
+ sec6_fig8_text
+ figure("assets/L53_fig8_scale_compare.png",
"図 8 (RQ3): 届出 規模構成 + 高さ × 面積 (許可との重ね)")
+ sec6_fig8_read
+ sec6_fig9_text
+ figure("assets/L53_fig9_top_city_cross.png",
"図 9 (統合 RQ1+RQ2+RQ3): 上位 12 市町の規模 × 制度区分")
+ sec6_fig9_read
+ "表: 制度区分集計 (経過措置遡及 vs 純新規届出)
"
+ df_to_html(T_regime)
+ f"この表から読み取れること: 経過措置遡及 {len(grandfathered)} 件 ({g_share*100:.0f}%) が"
"大半を占め、純新規届出は少数。"
f"経過措置遡及の最古工事着手は {grandfathered['start_date'].min().date()} "
f"({oldest_age} 年前!) で、旧法時代の埋没盛土が新法で初めて行政把握下に入った。"
"規模中央値も経過措置遡及 ≥ 純新規 という傾向 → 旧法時代の大規模工事が遡及届出されている。
"
+ "表: 経過措置遡及 最古 15 件 (1981-1995)
"
+ df_to_html(T_oldest)
+ "この表から読み取れること: 1981 年・1993 年・1995 年等、40 年以上前に着手した"
"盛土が現在まで管理外で存在し続けていた事実が読み取れる。これらの埋没盛土は"
"施工当時の安全基準が緩く、現法準拠の安全性は不明。事後点検が必要な重要案件群で、"
"発展課題 3 で議論する。
"
+ "表: 熱海型 (≥5m+≥5000m²) 全件詳細
"
+ df_to_html(T_atami.head(20))
+ f"この表から読み取れること: 届出 熱海型 {atami_n} 件のうち上位 20 件を表示。"
"ほぼ全てが経過措置遡及 = 旧法時代の大規模盛土で、新法で初めて台帳化。"
"盛土量が数十万 m³ 級の超大型も含まれ、これらは個別に施工監視・完成後点検を"
"要する重要案件。L52 の熱海型 (新法下の新規許可) と性格が大きく異なる。
"
),
("仮説検証総合", sec7),
("発展課題", sec8),
]
html = render_lesson(
num=53,
title="届出盛土等(法第21条第1項・40条第1項) 単独 3 研究例分析 — 盛土規制法二段階監督モデルを 284 件の届出から読み解く",
tags=["L53", "盛土規制法", "届出盛土", "RQ×3", "Format B",
"二段階監督", "経過措置", "L52比較", "累積効果"],
time="40 分",
level="中級+",
data_label="DoBoX dataset 1430 (CSV 284 行 + XLSX 規制資料) + L52 (dataset 1429) 比較",
sections=sections,
script_filename="L53_notified_earthfill.py",
)
OUT_HTML = LESSONS / "L53_notified_earthfill.html"
OUT_HTML.write_text(html, encoding="utf-8")
print(f" HTML written: {OUT_HTML}")
print(f" ({time.time()-t11:.1f}s)", flush=True)
print(f"\n=== L53 DONE in {time.time()-t_all:.1f}s ===")
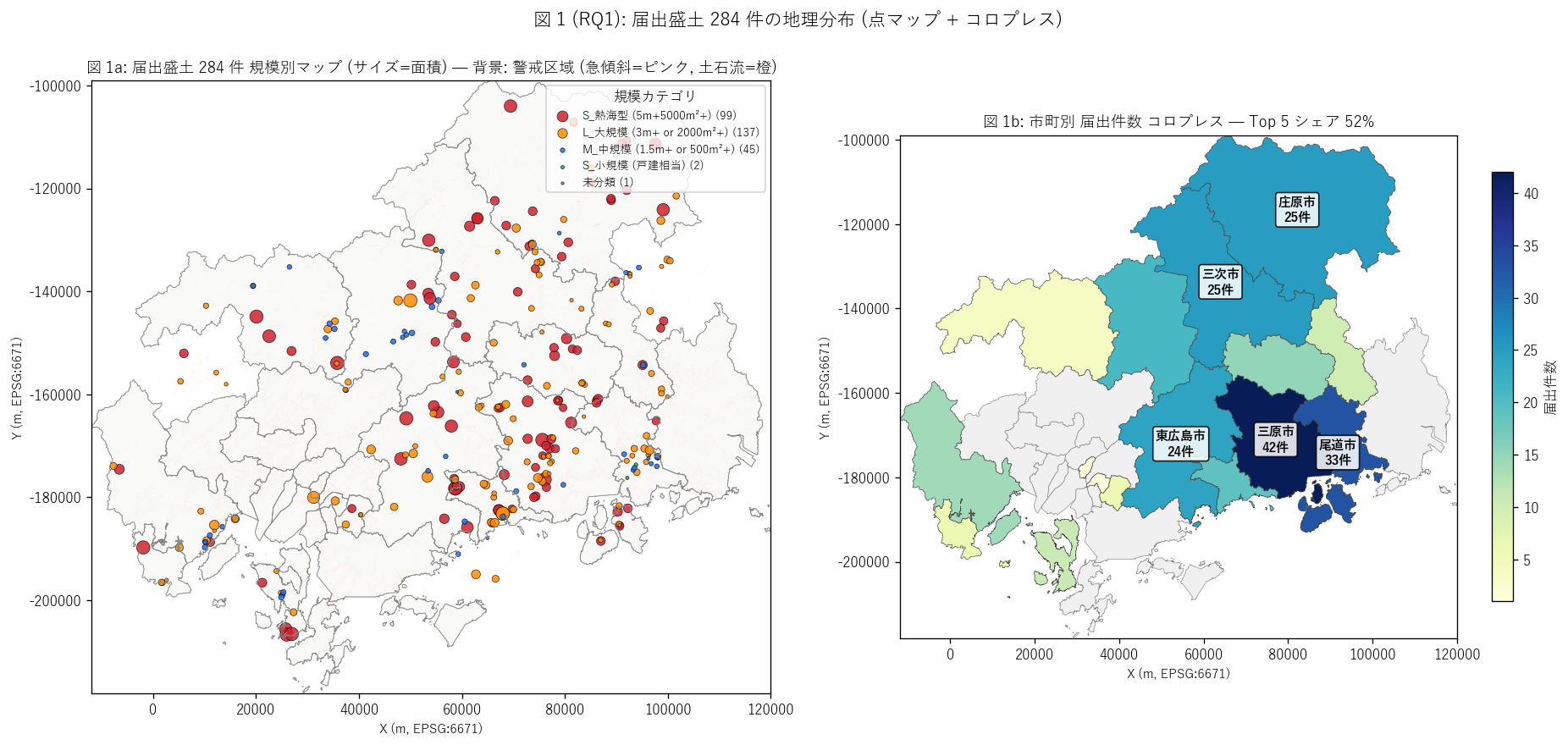{kind=link}
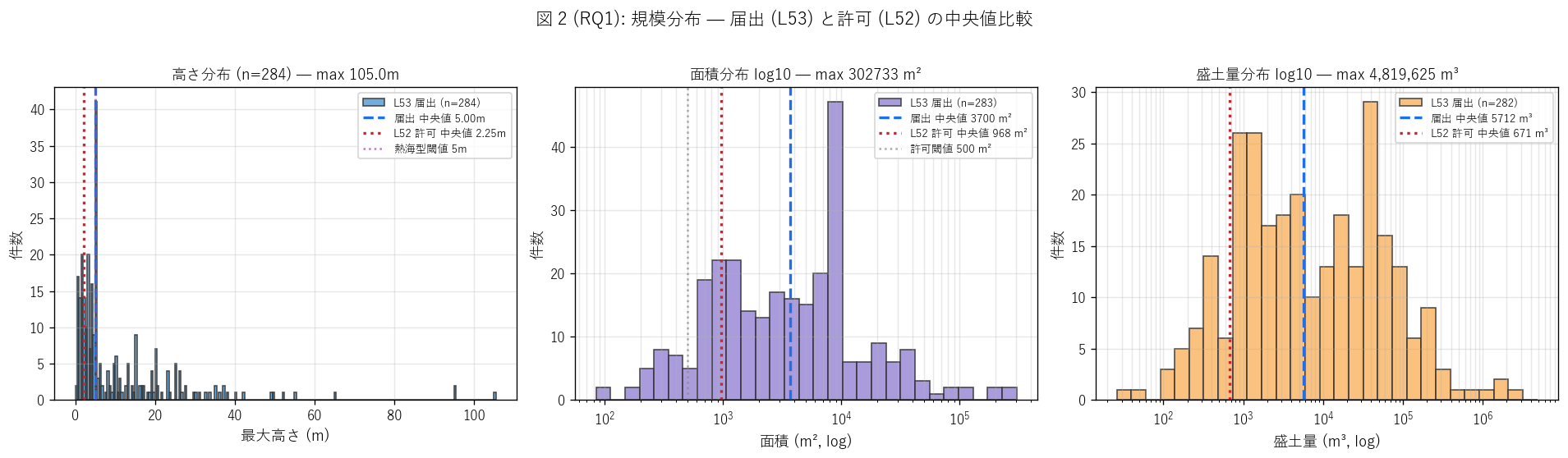{kind=link}
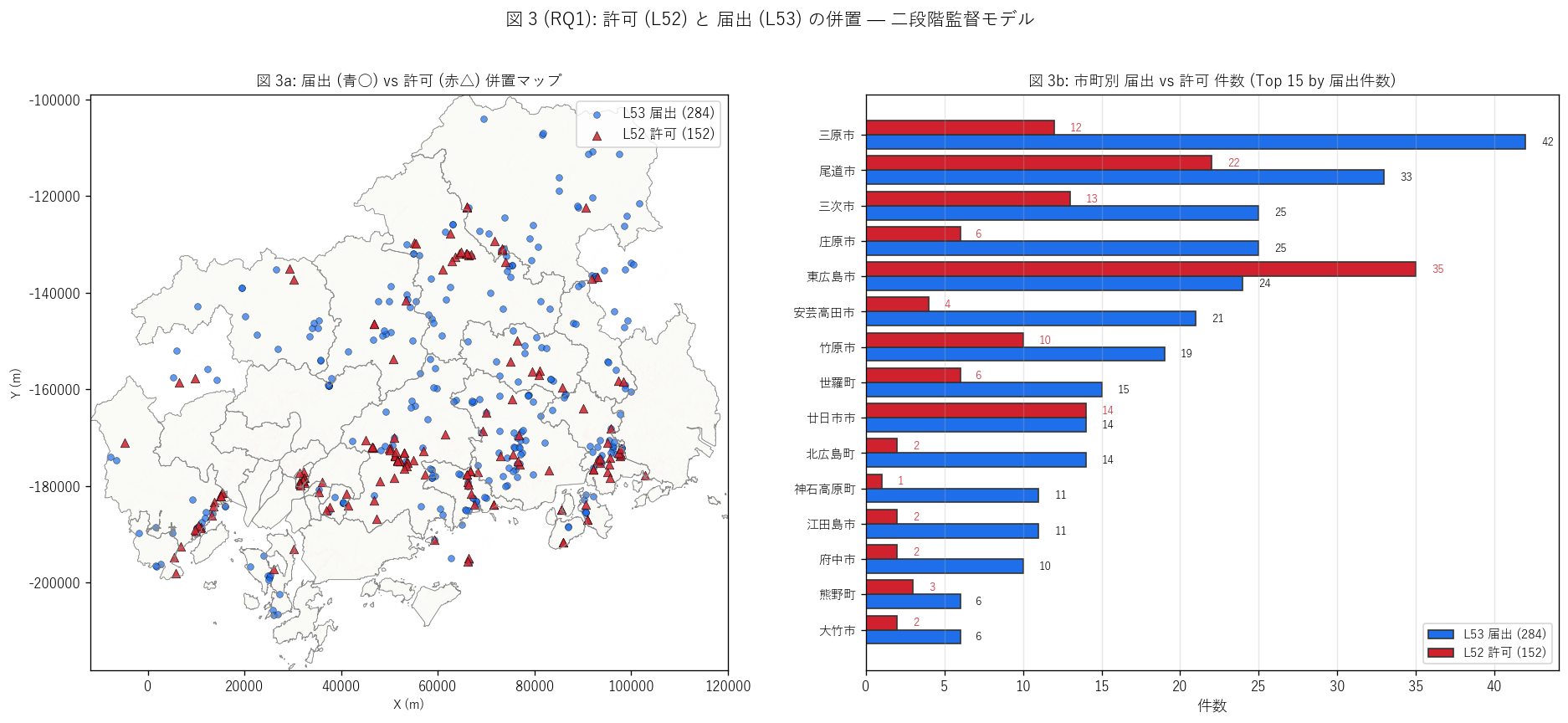{kind=link}
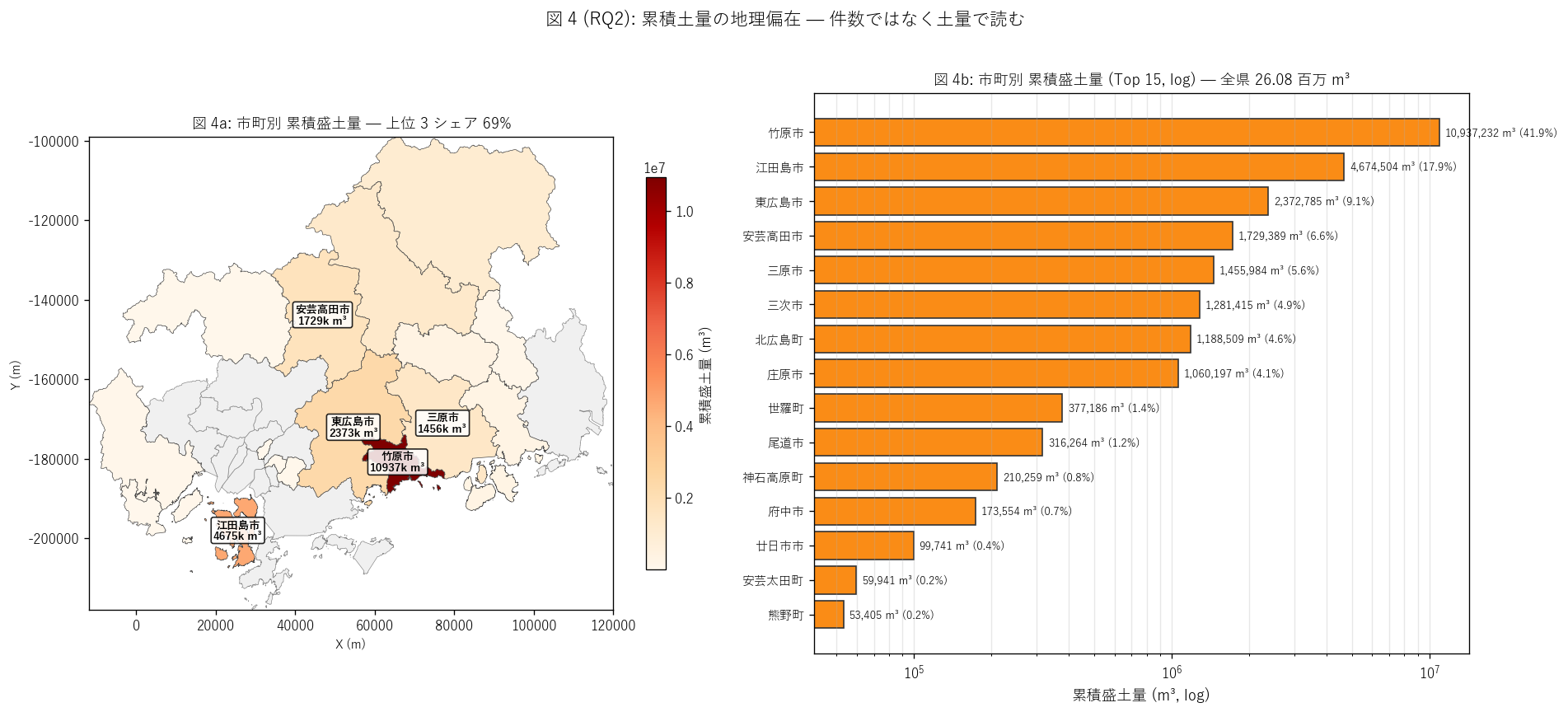{kind=link}
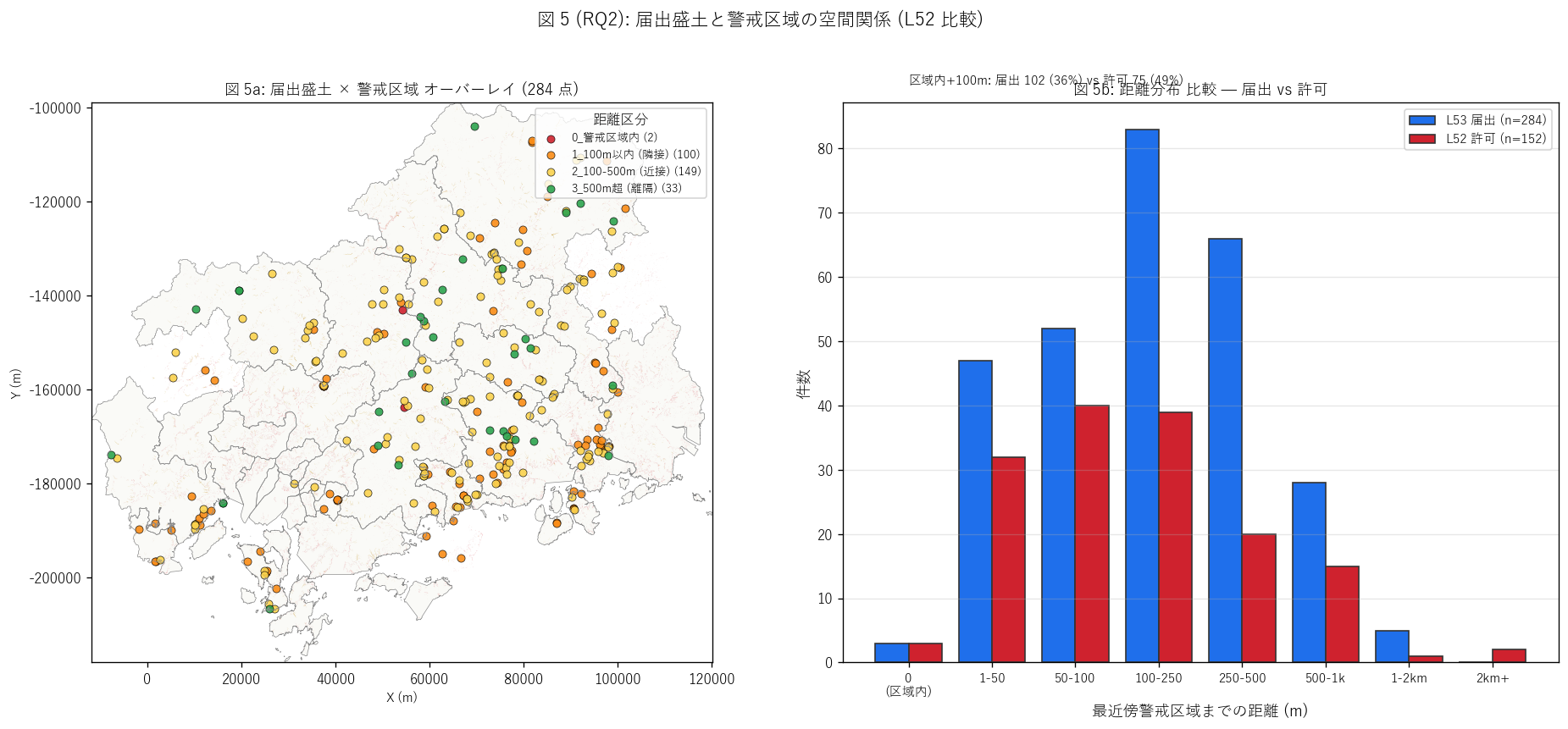{kind=link}
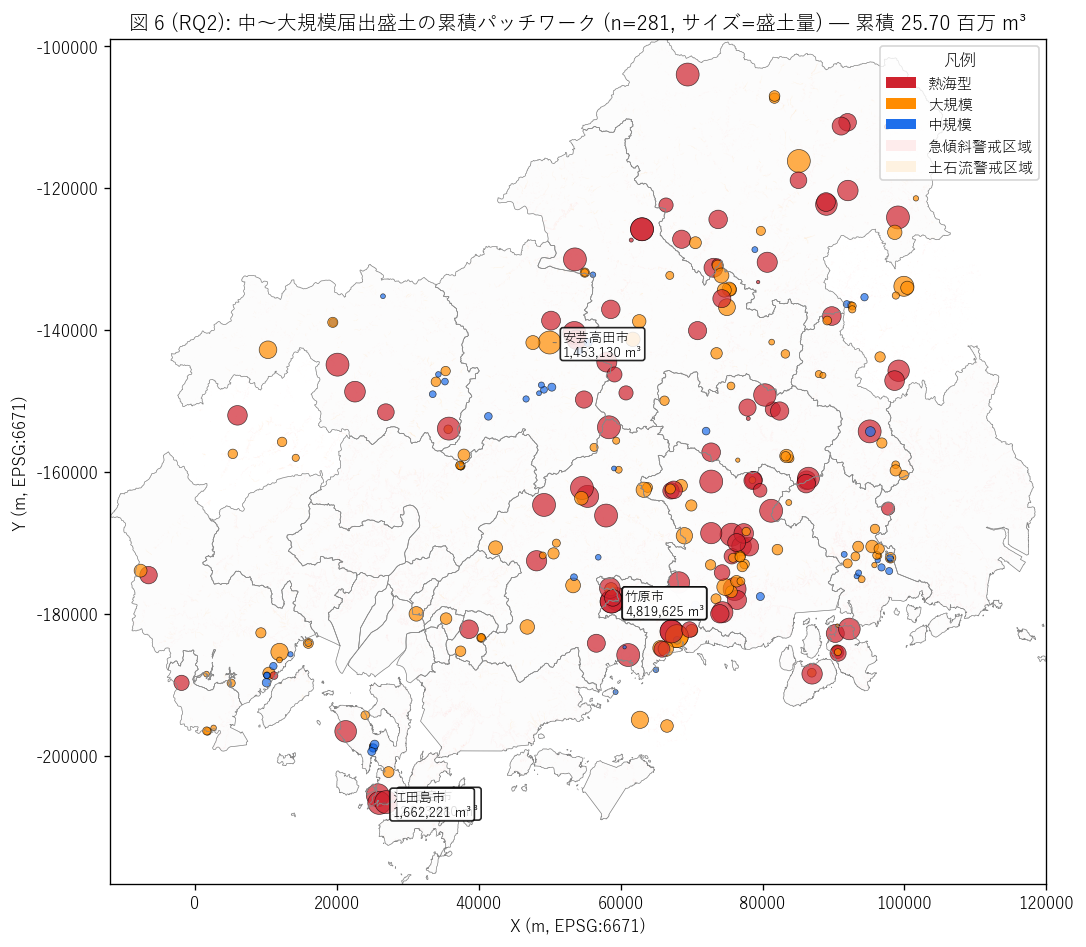{kind=link}
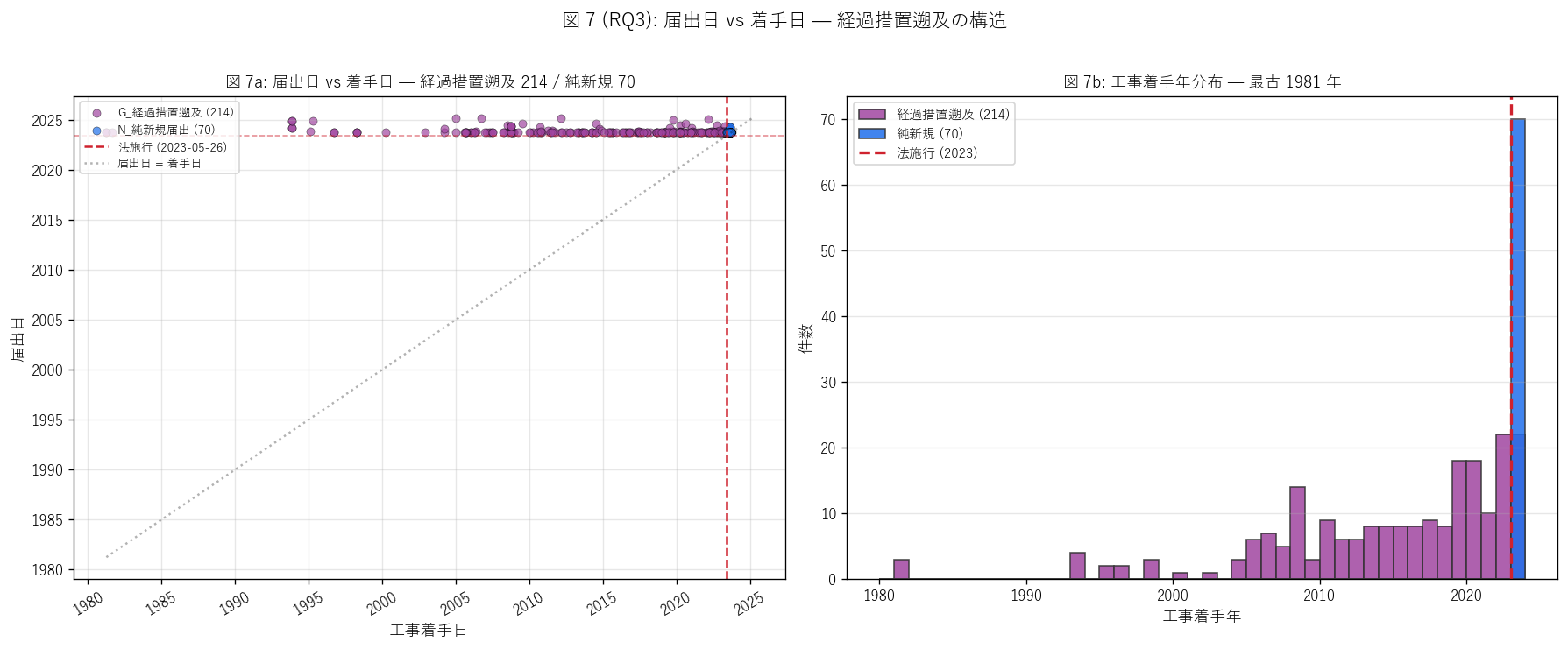{kind=link}
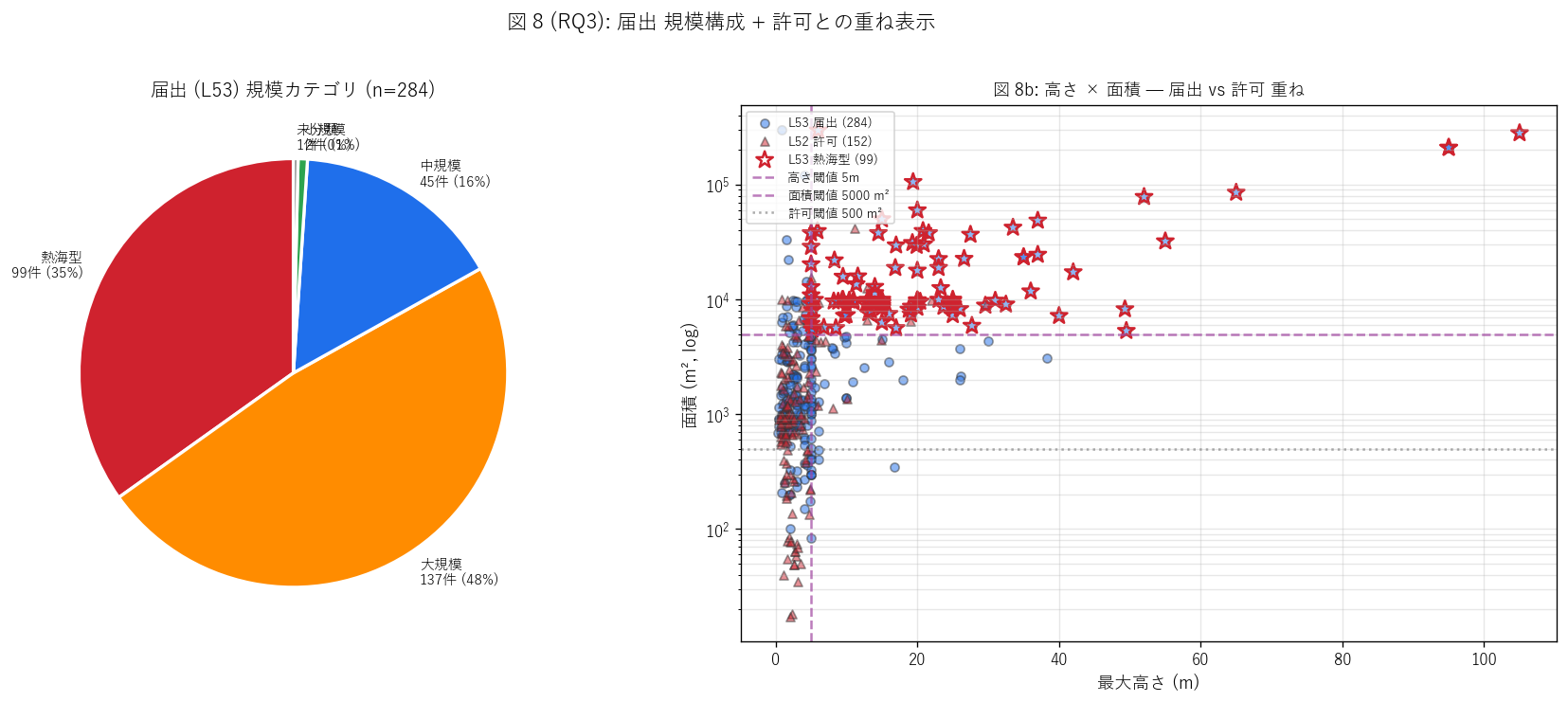{kind=link}
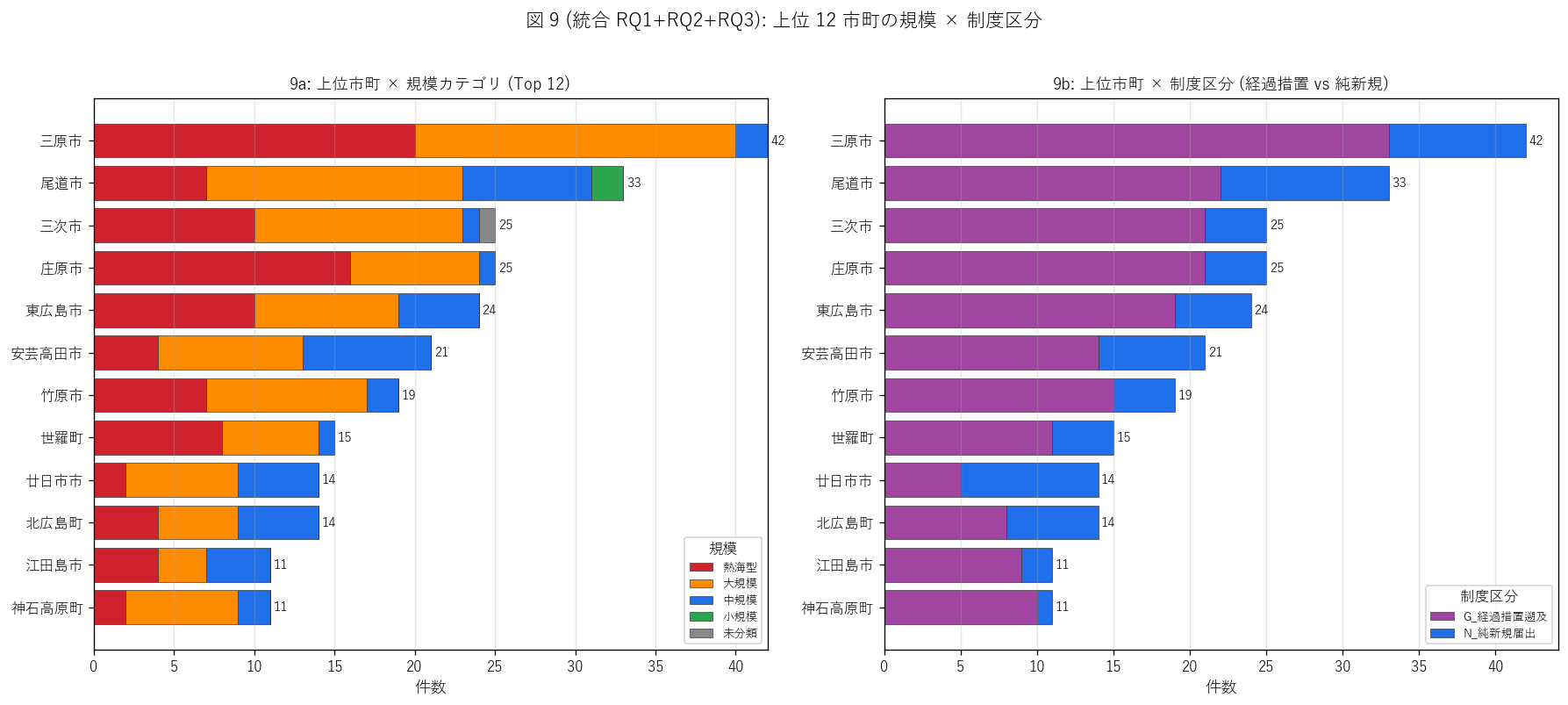{kind=link}