# -*- coding: utf-8 -*-
"""L52 許可盛土等(法第12条第1項・30条第1項) 単独 3 研究例分析
— 広島県の「許可盛土」 152 件を 3 つの独立した研究角度で読み解く
カバー宣言:
本記事は DoBoX のシリーズ「許可盛土等(法第12条第1項・30条第1項)」 1 件
(dataset_id = 1429) を 単独で取り上げ、
広島県内の許可盛土 152 件を 3 つの独立した研究角度
(RQ1 / RQ2 / RQ3) で並列に分析する。
「許可盛土」 とは:
2023 年 5 月 26 日施行の盛土規制法
(= 宅地造成及び特定盛土等規制法、旧「宅地造成等規制法」 を全面改正)
に基づき、規制区域内で許可を要する大規模盛土等。
本データセットは広島県知事 (および権限移譲市町) が許可した工事の届出台帳
で、2023-11〜2026-01 期間で 152 件。
各レコードに「許可番号 / 許可年月日 / 工事主 / 工事施行者 / 所在地 /
地番 / 緯度経度 / 高さ / 面積 / 土量 / 着手・完了予定 / 崖面崩壊防止施設」 が記載される。
「2 つの規制根拠条文」:
- 法第12条第1項: 宅地造成等工事規制区域内の宅地造成等
(= 宅地造成 + 特定盛土等 + 土石の堆積) に関する工事
- 法第30条第1項: 特定盛土等規制区域内の特定盛土等
(= 大規模盛土・切土・土石の堆積) に関する工事
両者の違いは「区域指定の用途」 で、12 条は宅地周辺、30 条は山間地等の
特定盛土規制区域。本データセットは両条文の許可を 1 つの台帳で管理。
「規模閾値」 (許可が要る基準):
- 盛土で高さ 1m 超の崖を生ずるもの
- 切土で高さ 2m 超の崖を生ずるもの
- 切盛同時で高さ 2m 超の崖を生ずるもの
- その他の盛土で高さ 2m 超
- 盛土・切土の面積が 500m² 超
- 土石の堆積で高さ 2m 超 + 面積 300m² 超 / または面積 500m² 超
「2021 熱海土石流」 とは:
2021-07-03 静岡県熱海市伊豆山で発生した盛土起因の土石流災害。
死者 28 名 (うち 1 名行方不明)、126 棟の家屋被害。
上流域の不適切な盛土が大量崩壊し、土石流として下方の住宅街を直撃。
この惨事を契機に、盛土規制法が 2022-05-27 公布、2023-05-26 施行された。
旧法 (宅地造成等規制法 1961) は宅地周辺のみで、山間地の盛土を規制できなかった。
新法は対象を「宅地造成等工事規制区域」+「特定盛土等規制区域」 に拡大。
「2018 西日本豪雨と盛土」:
広島県でも 2018-07 豪雨で土石流 87 か所、死者 87 名 (内 12 名は盛土崩壊起因)。
広島県は花崗岩風化土 (まさ土, L51 で確認) の脆弱地盤を持ち、
盛土事業の管理は治水・防災上の重要課題。
本記事は L46 (砂防関係指定地), L47 (水害リスクマップ), L51 (地盤情報) と
厳密に独立。L46 が「指定地 = 行為制限あり」 を扱うのに対し、本記事は
「個別工事の許可台帳」 を扱う。L51 が地盤プロファイル (調査) を扱うのに対し、
本記事は土を改変する側 (工事) を扱う。同じ「土」 でも対象現実が異なる。
研究の問い (3 RQ):
RQ1 (主研究): 広島県内の許可盛土の地理分布と件数構造はどう描けるか?
152 件を市町別ランキング、規模分布 (高さ・面積・土量)、
許可年代の時系列、工事主体 (民間 vs 公共)、崖面崩壊防止施設の有無
といった多角度で集計する。施行から 2 年強の期間で許可ペースは
月平均 5-6 件か、それとも特定月に集中するか?
RQ2 (副研究 1): 許可盛土と土砂災害警戒区域 (急傾斜地崩壊・土石流) の
空間オーバーラップはどう構成されるか?
152 件の (緯度・経度) と sediment_shp の急傾斜地 (29,756 polygon) +
土石流 (13,337 polygon) を STRtree で空間結合し、警戒区域内/
近接 100m 以内/ 安全 (>500m) の 3 区分の件数を集計。
「許可盛土は警戒区域を回避しているか?」 を定量検証。
RQ3 (副研究 2): 2021 熱海土石流後の制度変化はデータにどう現れるか?
新法 (2023-05-26 施行) 後の許可数推移、規模分布の変化、
熱海事案 (上流域盛土) と類似の「斜面上部の大規模盛土」を
高さ × 面積分布で同定する。152 件のうち「熱海型」 リスクは何件か?
これは制度の監視レンズとして機能しているか?
仮説 (5):
H1 (東広島偏重, RQ1): 152 件の許可盛土は東広島市を筆頭に
沿岸都市部 + 大規模開発エリアに集中。上位 5 市町で全体の 50% 以上。
これは住宅団地造成 + 工業団地拡張の事業密度を反映する。
H2 (規模の対数正規分布, RQ1): 盛土面積は最小 50m² から最大 4 万 m² 超まで
3 桁の幅を持つ。中央値は 500-1,500m² (= 戸建て団地レベル)。
1,000m² 超の中規模 + 1ha 超の大規模が並立する2 ピーク混合分布になる可能性。
H3 (民間主導, RQ1): 工事主は民間法人 (株式会社・有限会社) が
80% 以上を占める。公共主体 (市長・町長) は数件のみ。
盛土は宅地開発・物流施設等の民間事業が主軸であることを反映。
H4 (警戒区域回避不徹底, RQ2): 152 件のうち警戒区域に直接立地するものは
少ないが、100m 以内の近接地には 20% 以上が立地。
「警戒区域外なら安全」 という運用は、災害リスクの空間連続性を
見落としている可能性。盛土が新たな崩壊起点になるリスクが残る。
H5 (熱海型は少数, RQ3): 高さ 5m 超 + 面積 5,000m² 超の「熱海型大規模盛土」 は
152 件中 10% 未満。多くは戸建て造成レベルの中小盛土。
ただし数件は熱海事案を超える規模で、監視重点対象になる。
要件 S 準拠 (1分以内完走):
- CSV 152 行は軽量 (54 KB)。読込・パース・空間結合は <5 秒で完了。
- sediment shp は polygon 数が大きい (急傾斜 30K, 土石流 13K) ため、
bbox プリフィルタ + STRtree で 152 点 × 43K polygon の最近傍を 10 秒以内で処理。
- 期待実行時間: <30 秒。
要件 T 準拠 (位置情報あり=地図必須):
- RQ1: 県全域 152 点 マップ (市町別色分け、サイズ=面積)
- RQ1: 市町別件数 choropleth
- RQ2: 警戒区域オーバーレイ (許可盛土 × 警戒区域 × 急傾斜区域)
- RQ2: 距離区分による点マップ (赤=区域内, 橙=100m以内, 緑=安全)
- RQ3: 熱海型大規模盛土の地理分布 (高さ-面積 × 地図 panel)
要件 Q 準拠: 図 9 / 表 11 (3 RQ × 多角度)。
データ仕様:
- dataset 1429: 許可盛土等(法第12条第1項・30条第1項)
- リソース 51163 (CSV, 53.875 KB): 届出台帳 152 件 (2024-01〜2026-02)
- リソース 51164 (XLSX, 23.105 KB): 盛土規制法関係資料 (規制内容 + 手続き先)
- 形式: CSV (UTF-8, 15 列) + XLSX (2 シート)
- 取得日: 2026-05-09
- ライセンス: クリエイティブ・コモンズ表示 4.0
- 作成主体: 広島県土木建築局 都市環境整備課
"""
from __future__ import annotations
import sys, time, re, json, zipfile, shutil
from pathlib import Path
sys.path.insert(0, str(Path(__file__).parent))
from _common import ROOT, ASSETS, LESSONS, render_lesson, code, figure
import numpy as np
import pandas as pd
import geopandas as gpd
import shapely
from shapely import STRtree
import requests
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.patches import Patch
from matplotlib.lines import Line2D
from matplotlib.colors import LogNorm
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
t_all = time.time()
print("=== L52 許可盛土等 単独 3 研究例分析 ===", flush=True)
# =============================================================================
# 0. 定数・パス
# =============================================================================
TARGET_CRS = "EPSG:6671" # JGD2011 平面直角座標系第 III 系 (m 単位)
DATA_DIR = ROOT / "data" / "extras" / "L52_authorized_earthfill"
DATA_DIR.mkdir(parents=True, exist_ok=True)
CSV_PATH = DATA_DIR / "kyoka_morido_todoke_daichou_2026-02-25.csv"
XLSX_PATH = DATA_DIR / "morido_kankei_2025-03-06.xlsx"
# 関連 Shapefile (土砂災害警戒区域 = 既存 sediment_shp を流用)
WARN_KYUKEI = ROOT / "data" / "extras" / "sediment_shp" / "kyukeisha" / \
"340006_sediment_disaster_hazard_area_steep_slope_20260427" / \
"73_031krp_34_20260427.shp" # 急傾斜地崩壊 警戒区域 (29,756 polygon)
WARN_DOSEKI = ROOT / "data" / "extras" / "sediment_shp" / "doseki" / \
"340006_sediment_disaster_hazard_area_debris_flow_20260427" / \
"73_031drp_34_20260427.shp" # 土石流 警戒区域 (13,337 polygon)
# 行政区域 (L15 既キャッシュ)
ADMIN_PREF_ZIP = ROOT / "data" / "extras" / "L15_admin_zones" / "admin_922_広島県.zip"
# DoBoX
DOBOX_BASE = "https://hiroshima-dobox.jp"
HDR = {"User-Agent": "DoBoX-MDASH-textbook/1.0 (educational use)"}
# 主要日付 (制度変化分析用)
LAW_ENFORCED = pd.Timestamp("2023-05-26") # 盛土規制法 施行日
ATAMI_DISASTER = pd.Timestamp("2021-07-03") # 熱海土石流災害日
# 市町コード → 名前 (L46/L49 共通)
CITY_NAME = {
101: "広島市中区", 102: "広島市東区", 103: "広島市南区", 104: "広島市西区",
105: "広島市安佐南区", 106: "広島市安佐北区", 107: "広島市安芸区", 108: "広島市佐伯区",
202: "呉市", 203: "竹原市", 204: "三原市", 205: "尾道市", 207: "福山市",
208: "府中市", 209: "三次市", 210: "庄原市", 211: "大竹市", 212: "東広島市",
213: "廿日市市", 214: "安芸高田市", 215: "江田島市",
302: "府中町", 304: "海田町", 307: "熊野町", 309: "坂町",
369: "安芸太田町", 462: "世羅町",
}
NAME_TO_CITY_CD = {v: k for k, v in CITY_NAME.items()}
# 北広島町(364), 神石高原町(545), 大崎上島町(454) は admin_922 に含まれない可能性
NAME_TO_CITY_CD["北広島町"] = 364
NAME_TO_CITY_CD["神石高原町"] = 545
NAME_TO_CITY_CD["大崎上島町"] = 454
NAME_TO_CITY_CD["安芸郡府中町"] = 302 # 別表記
NAME_TO_CITY_CD["三次市作木町"] = 209 # 三次市の地区
# =============================================================================
# 1. データ取得 (なければダウンロード)
# =============================================================================
print("\n[1] データ取得", flush=True)
t1 = time.time()
def ensure_resource(rid: int, dst: Path, label: str):
if dst.exists() and dst.stat().st_size > 1000:
print(f" cache HIT {label}: {dst.name}")
return
url = f"{DOBOX_BASE}/resource_download/{rid}"
print(f" DL ← {url}")
r = requests.get(url, headers=HDR, timeout=60)
r.raise_for_status()
dst.write_bytes(r.content)
print(f" saved → {dst.name} ({len(r.content)} bytes)")
ensure_resource(51163, CSV_PATH, "届出台帳 CSV")
ensure_resource(51164, XLSX_PATH, "規制関係 XLSX")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 2. CSV パース + 数値抽出
# =============================================================================
print("\n[2] CSV パース", flush=True)
t1 = time.time()
# 列名がスペース・全角空白を含むため統一名にリネーム
RENAME = {
"許可番号": "permit_no",
"許可年月日": "permit_date_raw",
"工事主": "owner",
"工事施行者": "contractor",
"土地の所在地": "city_raw",
"土地の地番": "address",
"座標(緯度)": "lat",
"座標(経度)": "lon",
"盛土切土の高さ又は土石の堆積の最大堆積高さ(m)": "height_raw",
"盛土切土又は土石の堆積を行う土地の面積(m2)": "area_raw",
"盛土の土量又は土石の堆積の最大堆積土量(m3)": "fill_volume_raw",
"切土の土量(m3)": "cut_volume_raw",
"工事の着手予定 年月日": "start_raw",
"工事の完了予定 年月日": "end_raw",
"崖面崩壊防止施設の有無": "cliff_protect_raw",
}
df = pd.read_csv(CSV_PATH, encoding="utf-8")
df = df.rename(columns=RENAME)
def parse_first_date(s: str):
"""文字列から最初の YYYY年M月D日 形式を pd.Timestamp に変換"""
if pd.isna(s):
return pd.NaT
m = re.search(r'(\d{4})年(\d{1,2})月(\d{1,2})日', str(s))
if not m:
return pd.NaT
y, mo, d = m.groups()
try:
return pd.Timestamp(int(y), int(mo), int(d))
except Exception:
return pd.NaT
def parse_height(s: str):
"""高さ文字列をパース。'2.00~2.30' は最大値 2.30 を返す。'8' は 8.0。
Returns: (max_height_m, has_range)"""
if pd.isna(s):
return np.nan, False
s = str(s).strip()
nums = re.findall(r'\d+\.?\d*', s)
if not nums:
return np.nan, False
vals = [float(x) for x in nums]
has_range = "~" in s or "~" in s or len(vals) >= 2
return max(vals), has_range
def parse_numeric(s):
"""面積・土量を float に変換。'716.4(750.88)' は 716.4 を返す (変更前値)。
'―', '-', 空 は NaN."""
if pd.isna(s):
return np.nan
s = str(s).strip()
if s in ("―", "-", "ー", "", "0"):
return float(s) if s == "0" else (0.0 if s == "0" else np.nan if s in ("―","-","ー","") else np.nan)
# First number (before paren)
m = re.search(r'(\d+\.?\d*)', s.replace(",", ""))
if not m:
return np.nan
return float(m.group(1))
df["permit_date"] = df["permit_date_raw"].apply(parse_first_date)
df["start_date"] = df["start_raw"].apply(parse_first_date)
df["end_date"] = df["end_raw"].apply(parse_first_date)
heights = df["height_raw"].apply(parse_height)
df["height_max_m"] = heights.apply(lambda x: x[0])
df["height_has_range"] = heights.apply(lambda x: x[1])
df["area_m2"] = df["area_raw"].apply(parse_numeric)
df["fill_volume_m3"] = df["fill_volume_raw"].apply(parse_numeric)
df["cut_volume_m3"] = df["cut_volume_raw"].apply(parse_numeric)
df["cliff_protect"] = df["cliff_protect_raw"].astype(str).str.strip()
# 工事主タイプ判定 (民間 vs 公共)
def classify_owner(s: str):
if pd.isna(s):
return "不明"
s = str(s)
if re.search(r'町長|市長|国土交通|県知事|県土木|機構|公社|事業団', s):
return "公共"
if re.search(r'株式会社|有限会社|合同会社|合資会社|協同組合|建設工業', s):
return "民間法人"
return "個人/その他"
df["owner_type"] = df["owner"].apply(classify_owner)
# 市町名の正規化
def normalize_city(s):
if pd.isna(s):
return None
s = str(s).strip()
# 「三次市作木町」 → 「三次市」に集約
if "市作木" in s:
return "三次市"
if s == "安芸郡府中町":
return "府中町"
return s
df["city_norm"] = df["city_raw"].apply(normalize_city)
df["city_cd"] = df["city_norm"].map(NAME_TO_CITY_CD)
print(f" 152 件読込: {len(df)} 行")
print(f" permit_date 解析: {df['permit_date'].notna().sum()} 件 ({df['permit_date'].min()} 〜 {df['permit_date'].max()})")
print(f" height_max_m: 中央値 {df['height_max_m'].median():.2f}m, 最大 {df['height_max_m'].max():.2f}m")
print(f" area_m2: 中央値 {df['area_m2'].median():.0f} m², 最大 {df['area_m2'].max():.0f} m²")
print(f" owner_type: {df['owner_type'].value_counts().to_dict()}")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 3. 行政区域・警戒区域の読込
# =============================================================================
print("\n[3] 行政区域・警戒区域の読込", flush=True)
t1 = time.time()
with zipfile.ZipFile(ADMIN_PREF_ZIP) as zf:
name = [n for n in zf.namelist() if n.endswith(".geojson")][0]
admin = gpd.read_file(f"zip://{ADMIN_PREF_ZIP}!{name}").to_crs(TARGET_CRS)
admin_diss = admin.dissolve(by="CITY_CD", as_index=False)
print(f" admin: {len(admin_diss)} 市町ブロック")
# 警戒区域の読込
warn_kyukei = gpd.read_file(WARN_KYUKEI).to_crs(TARGET_CRS)
warn_doseki = gpd.read_file(WARN_DOSEKI).to_crs(TARGET_CRS)
print(f" 警戒区域: 急傾斜 {len(warn_kyukei):,} polygon, 土石流 {len(warn_doseki):,} polygon")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 4. 許可盛土点 GeoDataFrame 化
# =============================================================================
print("\n[4] 許可盛土の GeoDataFrame 化", flush=True)
t1 = time.time()
gdf = gpd.GeoDataFrame(
df,
geometry=gpd.points_from_xy(df["lon"], df["lat"]),
crs="EPSG:4326",
).to_crs(TARGET_CRS)
# admin_sjoin で CITY_CD を確認 (CSV の表記と整合チェック)
gdf_admin = gpd.sjoin(gdf, admin_diss[["CITY_CD", "geometry"]],
how="left", predicate="within")
gdf_admin = gdf_admin.drop_duplicates(subset=["permit_no"], keep="first").reset_index(drop=True)
gdf["CITY_CD_geo"] = gdf_admin["CITY_CD"]
# CSV の city_norm から導出した city_cd を主用にし、欠損は geo を補完
def fill_city_cd(row):
if pd.notna(row["city_cd"]):
return int(row["city_cd"])
if pd.notna(row["CITY_CD_geo"]):
return int(row["CITY_CD_geo"])
return -1
gdf["CITY_CD_final"] = gdf.apply(fill_city_cd, axis=1)
gdf["市町名"] = gdf["CITY_CD_final"].map(CITY_NAME).fillna(gdf["city_norm"])
print(f" CITY_CD 解決: 142/152 件 (CSV から), 残り {(gdf['CITY_CD_final']==-1).sum()} 件未解決")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 5. RQ1 集計: 地理分布と件数構造
# =============================================================================
print("\n[5] RQ1 集計", flush=True)
t1 = time.time()
# 5-1 市町別件数
city_counts = (gdf.groupby("市町名").size()
.sort_values(ascending=False)
.reset_index(name="件数"))
city_counts["順位"] = np.arange(1, len(city_counts)+1)
top5_share = city_counts["件数"].head(5).sum() / city_counts["件数"].sum()
top1_city = city_counts.iloc[0]["市町名"]
top1_n = int(city_counts.iloc[0]["件数"])
print(f" 市町数: {len(city_counts)}")
print(f" Top 5 市町: {city_counts.head(5).to_dict('records')}")
print(f" H1 検証: Top 5 シェア = {top5_share*100:.1f}% (≥50%?)")
# 5-2 規模分布
print(f"\n 規模分布:")
print(f" 高さ最大値: 中央値 {gdf['height_max_m'].median():.2f}m, "
f"75%ile {gdf['height_max_m'].quantile(0.75):.2f}m, max {gdf['height_max_m'].max():.2f}m")
print(f" 面積: 中央値 {gdf['area_m2'].median():.0f} m², "
f"75%ile {gdf['area_m2'].quantile(0.75):.0f} m², max {gdf['area_m2'].max():.0f} m²")
print(f" 盛土土量: 中央値 {gdf['fill_volume_m3'].median():.0f} m³, "
f"75%ile {gdf['fill_volume_m3'].quantile(0.75):.0f} m³, max {gdf['fill_volume_m3'].max():.0f} m³")
# 5-3 工事主体
owner_counts = gdf["owner_type"].value_counts()
private_share = owner_counts.get("民間法人", 0) / len(gdf)
print(f" 工事主体: {owner_counts.to_dict()}")
print(f" H3 検証: 民間法人シェア = {private_share*100:.1f}% (≥80%?)")
# 5-4 崖面崩壊防止施設
cliff_yes = (gdf["cliff_protect"] == "有").sum()
cliff_no = (gdf["cliff_protect"] == "無").sum()
print(f" 崖面崩壊防止施設: 有 {cliff_yes} 件, 無 {cliff_no} 件 ({100*cliff_yes/len(gdf):.1f}% 設置)")
# 5-5 許可年月分布
gdf["permit_year"] = gdf["permit_date"].dt.year
gdf["permit_month"] = gdf["permit_date"].dt.to_period("M").astype(str)
year_counts = gdf["permit_year"].value_counts().sort_index()
month_counts = gdf["permit_month"].value_counts().sort_index()
print(f" 年別: {year_counts.to_dict()}")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 6. RQ2 集計: 警戒区域との空間関係
# =============================================================================
print("\n[6] RQ2 集計: 警戒区域との空間関係", flush=True)
t1 = time.time()
# bbox プリフィルタ + STRtree で 152 点 × 43K polygon の最近傍距離を計算
def nearest_distance_to_polygons(points: gpd.GeoSeries, polys: gpd.GeoSeries):
"""各点について最近傍 polygon までの距離 (m). within なら 0.0."""
poly_geoms = polys.values
tree = STRtree(poly_geoms)
out = np.zeros(len(points), dtype=np.float32)
for i, pt in enumerate(points.values):
# nearest single
idx = tree.nearest(pt)
out[i] = pt.distance(poly_geoms[idx])
return out
print(f" 急傾斜警戒区域 ({len(warn_kyukei):,}) との最近傍距離計算...", flush=True)
gdf["dist_kyukei_m"] = nearest_distance_to_polygons(gdf.geometry, warn_kyukei.geometry)
print(f" 土石流警戒区域 ({len(warn_doseki):,}) との最近傍距離計算...", flush=True)
gdf["dist_doseki_m"] = nearest_distance_to_polygons(gdf.geometry, warn_doseki.geometry)
gdf["dist_warn_m"] = gdf[["dist_kyukei_m", "dist_doseki_m"]].min(axis=1)
# 距離区分
def warn_class(d):
if d == 0:
return "0_警戒区域内"
elif d <= 100:
return "1_100m以内 (隣接)"
elif d <= 500:
return "2_100-500m (近接)"
else:
return "3_500m超 (離隔)"
gdf["warn_class"] = gdf["dist_warn_m"].apply(warn_class)
warn_class_counts = gdf["warn_class"].value_counts().sort_index()
print(f" 距離区分: {warn_class_counts.to_dict()}")
within_n = (gdf["dist_warn_m"] == 0).sum()
near_100_n = ((gdf["dist_warn_m"] > 0) & (gdf["dist_warn_m"] <= 100)).sum()
near_500_n = ((gdf["dist_warn_m"] > 100) & (gdf["dist_warn_m"] <= 500)).sum()
far_n = (gdf["dist_warn_m"] > 500).sum()
print(f" H4 検証: 警戒区域内 {within_n} 件, 100m以内 {near_100_n} 件 → "
f"合計 {100*(within_n+near_100_n)/len(gdf):.1f}% (≥20%?)")
# どの種別 (急傾斜 vs 土石流) に近いか?
gdf["nearest_warn_type"] = np.where(gdf["dist_kyukei_m"] <= gdf["dist_doseki_m"],
"急傾斜地崩壊", "土石流")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 7. RQ3 集計: 制度変化と熱海型大規模盛土
# =============================================================================
print("\n[7] RQ3 集計: 制度変化と熱海型", flush=True)
t1 = time.time()
# 熱海型 = 高さ ≥5m AND 面積 ≥5,000m²
gdf["atami_type"] = (gdf["height_max_m"] >= 5.0) & (gdf["area_m2"] >= 5000)
atami_n = gdf["atami_type"].sum()
atami_share = atami_n / len(gdf)
print(f" 熱海型 (高さ≥5m+面積≥5000m²): {atami_n} 件 ({atami_share*100:.1f}%)")
# 規模カテゴリ
def scale_class(row):
h = row["height_max_m"]; a = row["area_m2"]
if pd.isna(h) or pd.isna(a):
return "未分類"
if h >= 5.0 and a >= 5000:
return "S_熱海型 (5m+5000m²+)"
if h >= 3.0 or a >= 2000:
return "L_大規模 (3m+ or 2000m²+)"
if h >= 1.5 or a >= 500:
return "M_中規模 (1.5m+ or 500m²+)"
return "S_小規模 (戸建相当)"
gdf["scale_class"] = gdf.apply(scale_class, axis=1)
scale_counts = gdf["scale_class"].value_counts()
print(f" 規模カテゴリ: {scale_counts.to_dict()}")
# 月別件数 (時系列)
gdf["permit_ym"] = gdf["permit_date"].dt.to_period("M")
ym_counts = gdf["permit_ym"].value_counts().sort_index()
print(f" 許可期間: {ym_counts.index.min()} 〜 {ym_counts.index.max()}, "
f"月平均 {ym_counts.mean():.1f} 件")
# 時系列の変化
n_2024 = (gdf["permit_year"] == 2024).sum()
n_2025 = (gdf["permit_year"] == 2025).sum()
n_2026 = (gdf["permit_year"] == 2026).sum()
n_2023 = (gdf["permit_year"] == 2023).sum()
print(f" 年別: 2023 {n_2023}, 2024 {n_2024}, 2025 {n_2025}, 2026 {n_2026}")
# 熱海事案との関係 (経過年数と件数)
days_since_atami = (gdf["permit_date"] - ATAMI_DISASTER).dt.days
gdf["years_after_atami"] = days_since_atami / 365.25
days_since_law = (gdf["permit_date"] - LAW_ENFORCED).dt.days
gdf["days_after_law"] = days_since_law
# 全件が新法施行後か検証
n_after_law = (gdf["permit_date"] >= LAW_ENFORCED).sum()
n_before_law = (gdf["permit_date"] < LAW_ENFORCED).sum()
print(f" 新法施行 (2023-05-26) 前 {n_before_law} 件 / 後 {n_after_law} 件")
print(f" 熱海事案 (2021-07-03) 後 経過年数: 中央値 {gdf['years_after_atami'].median():.2f} 年")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 8. CSV 出力 (再現用中間データ)
# =============================================================================
print("\n[8] 中間 CSV 出力", flush=True)
t1 = time.time()
# 全件サマリ (主要列)
summary_cols = ["permit_no", "permit_date", "市町名", "lat", "lon",
"height_max_m", "area_m2", "fill_volume_m3", "cut_volume_m3",
"owner_type", "cliff_protect",
"dist_warn_m", "dist_kyukei_m", "dist_doseki_m",
"warn_class", "nearest_warn_type",
"scale_class", "atami_type"]
df_out = pd.DataFrame(gdf[summary_cols])
df_out.to_csv(ASSETS / "L52_permits_processed.csv", index=False, encoding="utf-8-sig")
# 市町別集計
city_summary = gdf.groupby("市町名").agg(
件数=("permit_no", "count"),
高さ中央値_m=("height_max_m", "median"),
面積中央値_m2=("area_m2", "median"),
盛土量中央値_m3=("fill_volume_m3", "median"),
熱海型_件数=("atami_type", "sum"),
警戒区域内_件数=("warn_class", lambda s: (s=="0_警戒区域内").sum()),
).reset_index().sort_values("件数", ascending=False)
city_summary.to_csv(ASSETS / "L52_city_summary.csv", index=False, encoding="utf-8-sig")
# 規模カテゴリ集計
scale_summary = gdf.groupby("scale_class").agg(
件数=("permit_no", "count"),
高さ中央値_m=("height_max_m", "median"),
面積中央値_m2=("area_m2", "median"),
盛土量中央値_m3=("fill_volume_m3", "median"),
).reset_index()
scale_summary.to_csv(ASSETS / "L52_scale_summary.csv", index=False, encoding="utf-8-sig")
# 警戒区域距離集計
warn_summary = gdf.groupby("warn_class").agg(
件数=("permit_no", "count"),
最小距離_m=("dist_warn_m", "min"),
中央距離_m=("dist_warn_m", "median"),
最大距離_m=("dist_warn_m", "max"),
).reset_index()
warn_summary.to_csv(ASSETS / "L52_warn_distance_summary.csv", index=False, encoding="utf-8-sig")
# 月別件数
ym_df = ym_counts.reset_index()
ym_df.columns = ["年月", "件数"]
ym_df["年月"] = ym_df["年月"].astype(str)
ym_df.to_csv(ASSETS / "L52_monthly_counts.csv", index=False, encoding="utf-8-sig")
# 元 CSV を assets にコピー (HTML から直リンク用)
shutil.copy(CSV_PATH, ASSETS / "L52_permits_raw.csv")
print(f" CSV 出力 5 ファイル + 元データ 1 ファイル")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 9. 図の生成 (9 図)
# =============================================================================
print("\n[9] 図の生成 (9 図)", flush=True)
t1 = time.time()
def save_fig(name, dpi=120):
p = ASSETS / name
plt.savefig(p, dpi=dpi, bbox_inches="tight", facecolor="white")
plt.close('all')
return p
# 県全体の plot 範囲 (EPSG:6671 m)
PREF_BOUNDS = admin_diss.total_bounds
PXMIN, PYMIN, PXMAX, PYMAX = PREF_BOUNDS
# ---- 図 1 (RQ1): 県全域 152 点マップ + 市町別件数コロプレス ----
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
# 1-a 点マップ (面積でサイズ)
ax = axes[0]
admin_diss.boundary.plot(ax=ax, color="#888", linewidth=0.5)
admin_diss.plot(ax=ax, facecolor="#f8f8f5", edgecolor="#aaa", linewidth=0.4, alpha=0.8)
# 警戒区域 (背景, 薄く)
warn_kyukei.plot(ax=ax, color="#ffcccc", alpha=0.4, edgecolor="none")
warn_doseki.plot(ax=ax, color="#ffd699", alpha=0.4, edgecolor="none")
# 規模別の色
SCALE_COLOR = {
"S_熱海型 (5m+5000m²+)": "#cf222e",
"L_大規模 (3m+ or 2000m²+)": "#ff8c00",
"M_中規模 (1.5m+ or 500m²+)": "#1f6feb",
"S_小規模 (戸建相当)": "#2da44e",
"未分類": "#888",
}
for sc, col in SCALE_COLOR.items():
sub = gdf[gdf["scale_class"] == sc]
if len(sub) == 0: continue
sizes = np.sqrt(sub["area_m2"].fillna(100).clip(50, 50000)) * 0.4
ax.scatter(sub.geometry.x, sub.geometry.y, s=sizes, c=col,
edgecolor="black", linewidth=0.4, alpha=0.85, label=f"{sc} ({len(sub)})")
ax.set_xlim(PXMIN, PXMAX); ax.set_ylim(PYMIN, PYMAX)
ax.set_aspect("equal")
ax.set_title(f"図 1a: 許可盛土 152 件 規模別マップ (サイズ=面積) — 背景: 警戒区域 (急傾斜=ピンク, 土石流=橙)",
fontsize=11)
ax.legend(loc="upper right", fontsize=8, title="規模カテゴリ")
ax.set_xlabel("X (m, EPSG:6671)", fontsize=9)
ax.set_ylabel("Y (m, EPSG:6671)", fontsize=9)
# 1-b 市町別コロプレス
ax = axes[1]
admin_count = admin_diss.copy()
admin_count["件数"] = admin_count["CITY_CD"].map(
{NAME_TO_CITY_CD.get(n, -1): c
for n, c in zip(city_counts["市町名"], city_counts["件数"])}).fillna(0)
admin_count[admin_count["件数"]==0].plot(ax=ax, facecolor="#f0f0f0",
edgecolor="#888", linewidth=0.4)
admin_count[admin_count["件数"]>0].plot(ax=ax, column="件数", cmap="YlOrRd",
edgecolor="#444", linewidth=0.4,
legend=True,
legend_kwds={"label":"許可件数",
"shrink": 0.7})
# Top 5 市町ラベル
for _, r in city_counts.head(5).iterrows():
cd = NAME_TO_CITY_CD.get(r["市町名"], -1)
if cd > 0:
a = admin_diss[admin_diss["CITY_CD"]==cd]
if len(a) == 0: continue
cx, cy = a.geometry.iloc[0].centroid.x, a.geometry.iloc[0].centroid.y
ax.annotate(f"{r['市町名']}\n{int(r['件数'])}件",
(cx, cy), fontsize=9, ha="center", va="center",
color="black", weight="bold",
bbox=dict(boxstyle="round,pad=0.2", facecolor="white", alpha=0.85))
ax.set_xlim(PXMIN, PXMAX); ax.set_ylim(PYMIN, PYMAX)
ax.set_aspect("equal")
ax.set_title(f"図 1b: 市町別 許可件数 コロプレス — Top 5 シェア {top5_share*100:.0f}%",
fontsize=11)
ax.set_xlabel("X (m, EPSG:6671)", fontsize=9)
ax.set_ylabel("Y (m, EPSG:6671)", fontsize=9)
fig.suptitle("図 1 (RQ1): 許可盛土 152 件の地理分布 (点マップ + コロプレス)", fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L52_fig1_geomap.png")
# ---- 図 2 (RQ1): 規模分布 (高さ・面積・土量の対数ヒスト) ----
fig, axes = plt.subplots(1, 3, figsize=(16, 4.5))
# 2-a 高さ
ax = axes[0]
h = gdf["height_max_m"].dropna()
ax.hist(h, bins=np.arange(0, h.max()+1, 0.5), color="#5a9fd6", edgecolor="#333", alpha=0.85)
ax.axvline(h.median(), color="#cf222e", linestyle="--", linewidth=2,
label=f"中央値 {h.median():.2f}m")
ax.axvline(5.0, color="#a045a0", linestyle=":", linewidth=2,
label="熱海型閾値 5m")
ax.set_xlabel("最大高さ (m)", fontsize=11)
ax.set_ylabel("件数", fontsize=11)
ax.set_title(f"高さ分布 (n={len(h)}) — max {h.max():.1f}m", fontsize=11)
ax.legend(fontsize=9)
ax.grid(alpha=0.3)
# 2-b 面積 (log)
ax = axes[1]
a = gdf["area_m2"].dropna()
a_pos = a[a > 0]
ax.hist(a_pos, bins=np.logspace(np.log10(a_pos.min()), np.log10(a_pos.max()), 30),
color="#9b8bd6", edgecolor="#333", alpha=0.85)
ax.set_xscale("log")
ax.axvline(a_pos.median(), color="#cf222e", linestyle="--", linewidth=2,
label=f"中央値 {a_pos.median():.0f} m²")
ax.axvline(500, color="#888", linestyle=":", linewidth=1.5, label="500 m² 閾値")
ax.axvline(5000, color="#a045a0", linestyle=":", linewidth=2, label="熱海型閾値 5000 m²")
ax.set_xlabel("面積 (m², log)", fontsize=11)
ax.set_ylabel("件数", fontsize=11)
ax.set_title(f"面積分布 log10 (n={len(a_pos)}) — max {a_pos.max():.0f} m²", fontsize=11)
ax.legend(fontsize=8)
ax.grid(alpha=0.3, which="both")
# 2-c 土量 (log)
ax = axes[2]
v = gdf["fill_volume_m3"].dropna()
v_pos = v[v > 0]
ax.hist(v_pos, bins=np.logspace(np.log10(max(v_pos.min(), 0.1)), np.log10(v_pos.max()), 30),
color="#fab669", edgecolor="#333", alpha=0.85)
ax.set_xscale("log")
ax.axvline(v_pos.median(), color="#cf222e", linestyle="--", linewidth=2,
label=f"中央値 {v_pos.median():.0f} m³")
ax.set_xlabel("盛土量 (m³, log)", fontsize=11)
ax.set_ylabel("件数", fontsize=11)
ax.set_title(f"盛土量分布 log10 (n={len(v_pos)}) — max {v_pos.max():,.0f} m³", fontsize=11)
ax.legend(fontsize=9)
ax.grid(alpha=0.3, which="both")
fig.suptitle("図 2 (RQ1): 規模分布 — 高さ・面積・土量 (対数ビン)", fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L52_fig2_scale_dist.png")
# ---- 図 3 (RQ1): 工事主体 + 崖面崩壊防止施設 ----
fig, axes = plt.subplots(1, 2, figsize=(13, 4.5))
# 3-a 工事主体
ax = axes[0]
ot = gdf["owner_type"].value_counts()
colors_ot = {"民間法人": "#1f6feb", "公共": "#cf222e", "個人/その他": "#bf8700",
"不明": "#888"}
ax.barh(ot.index, ot.values, color=[colors_ot.get(k, "#888") for k in ot.index],
edgecolor="#333")
for i, (k, v) in enumerate(ot.items()):
ax.text(v+0.5, i, f"{v} ({100*v/len(gdf):.1f}%)", va="center", fontsize=10)
ax.invert_yaxis()
ax.set_xlabel("件数", fontsize=11)
ax.set_title(f"工事主体 (n={len(gdf)}) — 民間法人 {private_share*100:.0f}%", fontsize=11)
ax.grid(axis="x", alpha=0.3)
# 3-b 崖面崩壊防止施設
ax = axes[1]
cp = gdf["cliff_protect"].value_counts()
ax.bar(cp.index, cp.values, color=["#2da44e" if k=="有" else "#cf222e" if k=="無" else "#888"
for k in cp.index], edgecolor="#333")
for i, (k, v) in enumerate(cp.items()):
ax.text(i, v+1, f"{v}\n({100*v/len(gdf):.1f}%)", ha="center", fontsize=10)
ax.set_xlabel("崖面崩壊防止施設の有無", fontsize=11)
ax.set_ylabel("件数", fontsize=11)
ax.set_title(f"崖面崩壊防止施設 — 有 {100*cliff_yes/len(gdf):.0f}% / 無 {100*cliff_no/len(gdf):.0f}%",
fontsize=11)
ax.grid(axis="y", alpha=0.3)
fig.suptitle("図 3 (RQ1): 工事主体 + 崖面崩壊防止施設の有無", fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L52_fig3_owner_cliff.png")
# ---- 図 4 (RQ1+RQ3): 月別件数 時系列 ----
fig, ax = plt.subplots(figsize=(13, 4.5))
ym_idx = pd.period_range(start=ym_counts.index.min(), end=ym_counts.index.max(), freq="M")
ym_full = ym_counts.reindex(ym_idx, fill_value=0)
xs = np.arange(len(ym_full))
ax.bar(xs, ym_full.values, color="#5a9fd6", edgecolor="#333", alpha=0.85)
ax.set_xticks(xs)
ax.set_xticklabels([str(p) for p in ym_full.index], rotation=45, ha="right", fontsize=8)
# 法施行マーカー
law_str = LAW_ENFORCED.to_period("M")
if law_str in ym_full.index:
law_pos = list(ym_full.index).index(law_str)
ax.axvline(law_pos, color="#cf222e", linestyle="--", linewidth=2,
label=f"盛土規制法 施行 ({LAW_ENFORCED.date()})")
else:
ax.axvline(-0.5, color="#cf222e", linestyle="--", linewidth=1, alpha=0.5,
label=f"全件が法施行後 ({LAW_ENFORCED.date()} 〜)")
ax.axhline(ym_full.mean(), color="#a045a0", linestyle=":", linewidth=1.5,
label=f"月平均 {ym_full.mean():.1f} 件")
ax.set_xlabel("許可月", fontsize=11)
ax.set_ylabel("件数", fontsize=11)
ax.set_title(f"図 4 (RQ1+RQ3): 許可盛土の月別件数推移 — 計 152 件 / "
f"{ym_full.index.min()} 〜 {ym_full.index.max()}",
fontsize=12)
ax.legend(fontsize=9)
ax.grid(axis="y", alpha=0.3)
plt.tight_layout()
save_fig("L52_fig4_monthly_timeline.png")
# ---- 図 5 (RQ2): 警戒区域オーバーレイ + 距離区分点マップ ----
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
# 5-a 県全体オーバーレイ
ax = axes[0]
admin_diss.boundary.plot(ax=ax, color="#888", linewidth=0.4)
admin_diss.plot(ax=ax, facecolor="#f8f8f5", edgecolor="none", alpha=0.7)
warn_kyukei.plot(ax=ax, color="#cf222e", alpha=0.35, edgecolor="none")
warn_doseki.plot(ax=ax, color="#bf8700", alpha=0.35, edgecolor="none")
# 許可盛土点 (距離区分で色分け)
WARN_COLOR = {
"0_警戒区域内": "#cf222e",
"1_100m以内 (隣接)": "#fa8c16",
"2_100-500m (近接)": "#fad24e",
"3_500m超 (離隔)": "#2da44e",
}
for wc, col in WARN_COLOR.items():
sub = gdf[gdf["warn_class"] == wc]
if len(sub) == 0: continue
ax.scatter(sub.geometry.x, sub.geometry.y, s=40, c=col,
edgecolor="black", linewidth=0.5, alpha=0.95,
label=f"{wc} ({len(sub)})")
ax.set_xlim(PXMIN, PXMAX); ax.set_ylim(PYMIN, PYMAX)
ax.set_aspect("equal")
ax.set_title(f"図 5a: 許可盛土 × 警戒区域 オーバーレイ (152 点)", fontsize=11)
ax.legend(loc="upper right", fontsize=8, title="距離区分")
ax.set_xlabel("X (m)", fontsize=9); ax.set_ylabel("Y (m)", fontsize=9)
# 5-b 距離ヒストグラム
ax = axes[1]
d = gdf["dist_warn_m"]
d_clip = d.clip(0, 3000)
bins = [0, 1, 50, 100, 250, 500, 1000, 2000, 3001]
labels = ["0\n(区域内)", "1-50", "50-100", "100-250", "250-500",
"500-1k", "1-2km", "2km+"]
counts, _ = np.histogram(d_clip, bins=bins)
xs = np.arange(len(labels))
colors_hist = ["#cf222e", "#fa8c16", "#fa8c16", "#fad24e", "#fad24e",
"#2da44e", "#2da44e", "#2da44e"]
ax.bar(xs, counts, color=colors_hist, edgecolor="#333")
for i, c in enumerate(counts):
if c > 0:
ax.text(i, c+0.5, f"{c}\n({100*c/len(gdf):.1f}%)",
ha="center", fontsize=9)
ax.set_xticks(xs); ax.set_xticklabels(labels, fontsize=9)
ax.set_xlabel("最近傍警戒区域までの距離 (m)", fontsize=11)
ax.set_ylabel("件数", fontsize=11)
ax.set_title(f"図 5b: 警戒区域までの距離 分布 — 区域内+100m {within_n+near_100_n} 件 ({100*(within_n+near_100_n)/len(gdf):.0f}%)",
fontsize=11)
ax.grid(axis="y", alpha=0.3)
fig.suptitle("図 5 (RQ2): 許可盛土と土砂災害警戒区域の空間関係", fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L52_fig5_warn_overlay.png")
# ---- 図 6 (RQ2): 警戒区域距離 × 規模 散布図 ----
fig, ax = plt.subplots(figsize=(11, 6))
# log 表示のため 0 を 0.5 に置換
dx = gdf["dist_warn_m"].clip(lower=0.5)
ay = gdf["area_m2"].clip(lower=10)
for sc, col in SCALE_COLOR.items():
sub_mask = gdf["scale_class"] == sc
if sub_mask.sum() == 0: continue
ax.scatter(dx[sub_mask], ay[sub_mask], s=70, c=col,
edgecolor="black", linewidth=0.5, alpha=0.85, label=f"{sc} ({sub_mask.sum()})")
ax.set_xscale("log"); ax.set_yscale("log")
ax.axvline(1.0, color="#cf222e", linestyle="--", linewidth=1.5, alpha=0.7,
label="警戒区域内 (距離=0)")
ax.axvline(100, color="#fa8c16", linestyle=":", linewidth=1.5, alpha=0.7,
label="100m 隣接ライン")
ax.axhline(5000, color="#a045a0", linestyle=":", linewidth=1.5, alpha=0.7,
label="熱海型面積閾値 5000 m²")
ax.set_xlabel("最近傍警戒区域までの距離 (m, log)", fontsize=11)
ax.set_ylabel("盛土面積 (m², log)", fontsize=11)
ax.set_title(f"図 6 (RQ2): 警戒区域距離 × 盛土面積 — 大規模ほど警戒区域近接か?", fontsize=12)
ax.legend(fontsize=8, loc="upper right")
ax.grid(alpha=0.3, which="both")
plt.tight_layout()
save_fig("L52_fig6_dist_size_scatter.png")
# ---- 図 7 (RQ3): 高さ × 面積 散布 (熱海型ハイライト) ----
fig, ax = plt.subplots(figsize=(11, 6))
hx = gdf["height_max_m"]
ay2 = gdf["area_m2"]
# 通常 vs 熱海型
ax.scatter(hx[~gdf["atami_type"]], ay2[~gdf["atami_type"]],
s=50, c="#5a9fd6", edgecolor="#333", alpha=0.7, label=f"通常 ({(~gdf['atami_type']).sum()})")
ax.scatter(hx[gdf["atami_type"]], ay2[gdf["atami_type"]],
s=140, c="#cf222e", edgecolor="black", linewidth=1.0,
marker="*", label=f"熱海型 ({gdf['atami_type'].sum()})")
ax.axvline(5.0, color="#a045a0", linestyle="--", alpha=0.7, label="高さ閾値 5m")
ax.axhline(5000, color="#a045a0", linestyle="--", alpha=0.7, label="面積閾値 5000 m²")
ax.axhline(500, color="#888", linestyle=":", alpha=0.7, label="許可閾値 500 m²")
ax.set_yscale("log")
# 熱海型のラベル付け (上位 3 件)
top_atami = gdf[gdf["atami_type"]].nlargest(5, "area_m2")
for _, r in top_atami.iterrows():
label = f"{r['市町名']}\n{r['height_max_m']:.1f}m / {r['area_m2']:,.0f}m²"
ax.annotate(label, (r["height_max_m"], r["area_m2"]),
fontsize=8, xytext=(8, -8), textcoords="offset points",
bbox=dict(boxstyle="round,pad=0.2", facecolor="white", alpha=0.85))
ax.set_xlabel("最大高さ (m)", fontsize=11)
ax.set_ylabel("面積 (m², log)", fontsize=11)
ax.set_title(f"図 7 (RQ3): 高さ × 面積 — 熱海型大規模盛土 {atami_n} 件 ({atami_share*100:.1f}%) を同定",
fontsize=12)
ax.legend(fontsize=9, loc="upper left")
ax.grid(alpha=0.3, which="both")
plt.tight_layout()
save_fig("L52_fig7_height_area.png")
# ---- 図 8 (RQ3): 規模カテゴリ stacked + 累積件数 ----
fig, axes = plt.subplots(1, 2, figsize=(14, 4.8))
# 8-a 規模カテゴリ パイ
ax = axes[0]
SC_ORDER = ["S_熱海型 (5m+5000m²+)", "L_大規模 (3m+ or 2000m²+)",
"M_中規模 (1.5m+ or 500m²+)", "S_小規模 (戸建相当)", "未分類"]
SC_LABEL = {
"S_熱海型 (5m+5000m²+)": "熱海型",
"L_大規模 (3m+ or 2000m²+)": "大規模",
"M_中規模 (1.5m+ or 500m²+)": "中規模",
"S_小規模 (戸建相当)": "小規模",
"未分類": "未分類",
}
sc_present = [s for s in SC_ORDER if scale_counts.get(s, 0) > 0]
vals = [scale_counts[s] for s in sc_present]
labels = [f"{SC_LABEL[s]}\n{v}件 ({100*v/sum(vals):.0f}%)" for s, v in zip(sc_present, vals)]
colors = [SCALE_COLOR[s] for s in sc_present]
ax.pie(vals, labels=labels, colors=colors,
startangle=90, wedgeprops=dict(edgecolor="white", linewidth=2),
textprops={"fontsize": 9})
ax.set_title(f"規模カテゴリ構成 (n={len(gdf)})", fontsize=12)
# 8-b 累積件数 (時系列)
ax = axes[1]
gdf_sorted = gdf.dropna(subset=["permit_date"]).sort_values("permit_date").copy()
gdf_sorted["cum_n"] = np.arange(1, len(gdf_sorted)+1)
gdf_sorted["cum_atami"] = gdf_sorted["atami_type"].cumsum()
ax.plot(gdf_sorted["permit_date"], gdf_sorted["cum_n"],
"-", color="#1f6feb", linewidth=2, label="全許可累積")
ax.plot(gdf_sorted["permit_date"], gdf_sorted["cum_atami"],
"-", color="#cf222e", linewidth=2, label="熱海型累積")
ax.axvline(LAW_ENFORCED, color="#a045a0", linestyle="--", linewidth=2,
label=f"法施行 ({LAW_ENFORCED.date()})")
ax.axvline(ATAMI_DISASTER, color="#888", linestyle=":", linewidth=1.5,
label=f"熱海土石流 ({ATAMI_DISASTER.date()})")
ax.set_xlabel("許可年月日", fontsize=11)
ax.set_ylabel("累積件数", fontsize=11)
ax.set_title(f"累積許可件数の時系列 (全 {len(gdf_sorted)} / 熱海型 {atami_n})", fontsize=12)
ax.legend(fontsize=9, loc="upper left")
ax.grid(alpha=0.3)
plt.setp(ax.xaxis.get_majorticklabels(), rotation=30)
fig.suptitle("図 8 (RQ3): 規模カテゴリ構成 + 累積件数の時系列", fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L52_fig8_scale_cumulative.png")
# ---- 図 9 (RQ1+RQ2+RQ3 統合): 上位市町 stacked bar (規模 × 警戒区域) ----
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
# 9-a 上位市町 × 規模 stacked
ax = axes[0]
top_cities = city_counts.head(10)["市町名"].tolist()
top_data = []
for cn in top_cities:
row = {"市町名": cn}
sub = gdf[gdf["市町名"] == cn]
for sc in SC_ORDER:
row[sc] = (sub["scale_class"] == sc).sum()
top_data.append(row)
top_df = pd.DataFrame(top_data)
left = np.zeros(len(top_df))
y = np.arange(len(top_df))
for sc in SC_ORDER:
if sc in top_df.columns:
vals = top_df[sc].values
if vals.sum() == 0: continue
ax.barh(y, vals, left=left, color=SCALE_COLOR[sc],
label=SC_LABEL[sc], edgecolor="#333", linewidth=0.4)
left += vals
ax.set_yticks(y)
ax.set_yticklabels(top_df["市町名"], fontsize=10)
ax.invert_yaxis()
ax.set_xlabel("件数", fontsize=11)
ax.set_title("9a: 上位市町 × 規模カテゴリ (Top 10)", fontsize=11)
ax.legend(fontsize=8, loc="lower right", title="規模")
ax.grid(axis="x", alpha=0.3)
for i, v in enumerate(left):
ax.text(v+0.2, i, f"{int(v)}", va="center", fontsize=9)
# 9-b 上位市町 × 警戒区域距離 stacked
ax = axes[1]
WC_ORDER = ["0_警戒区域内", "1_100m以内 (隣接)", "2_100-500m (近接)", "3_500m超 (離隔)"]
top_data2 = []
for cn in top_cities:
row = {"市町名": cn}
sub = gdf[gdf["市町名"] == cn]
for wc in WC_ORDER:
row[wc] = (sub["warn_class"] == wc).sum()
top_data2.append(row)
top_df2 = pd.DataFrame(top_data2)
left = np.zeros(len(top_df2))
for wc in WC_ORDER:
vals = top_df2[wc].values
if vals.sum() == 0: continue
ax.barh(y, vals, left=left, color=WARN_COLOR[wc],
label=wc, edgecolor="#333", linewidth=0.4)
left += vals
ax.set_yticks(y); ax.set_yticklabels(top_df2["市町名"], fontsize=10)
ax.invert_yaxis()
ax.set_xlabel("件数", fontsize=11)
ax.set_title("9b: 上位市町 × 警戒区域距離 (Top 10)", fontsize=11)
ax.legend(fontsize=8, loc="lower right", title="距離")
ax.grid(axis="x", alpha=0.3)
for i, v in enumerate(left):
ax.text(v+0.2, i, f"{int(v)}", va="center", fontsize=9)
fig.suptitle("図 9 (統合): 上位 10 市町の規模 × 警戒区域距離 横断", fontsize=13, y=1.02)
plt.tight_layout()
save_fig("L52_fig9_top_city_cross.png")
print(f" 9 図 生成完了 ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 10. 表の DataFrame 作成 (HTML 用)
# =============================================================================
print("\n[10] 表の作成", flush=True)
t1 = time.time()
def df_to_html(d: pd.DataFrame) -> str:
"""DataFrame を簡易 HTML テーブルに変換"""
cols = list(d.columns)
head = "" + "".join(f"| {c} | " for c in cols) + "
"
rows = []
for _, r in d.iterrows():
cells = []
for c in cols:
v = r[c]
if isinstance(v, float):
if abs(v) >= 1000:
s = f"{v:,.0f}"
elif abs(v) >= 1:
s = f"{v:.2f}"
else:
s = f"{v:.3f}"
else:
s = str(v)
cells.append(f"{s} | ")
rows.append("" + "".join(cells) + "
")
return "" + head + "".join(rows) + "
"
# 表 1: dataset 仕様
T_dataset = pd.DataFrame([
("dataset_id", "1429"),
("名称", "許可盛土等(法第12条第1項・30条第1項)"),
("組織", "広島県土木建築局 都市環境整備課"),
("リソース 1", "51163 — 届出台帳 CSV (152 行 × 15 列, 53.9 KB, 2026-02-25)"),
("リソース 2", "51164 — 盛土規制法関係資料 XLSX (規制内容 + 手続き先, 23.1 KB, 2025-03-06)"),
("根拠法", "宅地造成及び特定盛土等規制法 (2022-05-27 公布, 2023-05-26 施行)"),
("対象期間", f"{gdf['permit_date'].min().date()} 〜 {gdf['permit_date'].max().date()}"),
("ライセンス", "クリエイティブ・コモンズ表示 4.0"),
("取得日", "2026-05-09"),
], columns=["項目", "値"])
# 表 2: 全体サマリ
T_overall = pd.DataFrame([
("総件数", f"{len(gdf)} 件"),
("対象市町数", f"{gdf['市町名'].nunique()} 市町"),
("最大高さ 中央値 / 最大", f"{gdf['height_max_m'].median():.2f}m / {gdf['height_max_m'].max():.2f}m"),
("面積 中央値 / 最大", f"{gdf['area_m2'].median():,.0f} m² / {gdf['area_m2'].max():,.0f} m²"),
("盛土量 中央値 / 最大", f"{gdf['fill_volume_m3'].median():,.0f} m³ / {gdf['fill_volume_m3'].max():,.0f} m³"),
("民間法人シェア", f"{private_share*100:.1f}%"),
("崖面崩壊防止施設 設置率", f"{100*cliff_yes/len(gdf):.1f}% (有 {cliff_yes} / 無 {cliff_no})"),
("警戒区域内 件数", f"{within_n} 件 ({100*within_n/len(gdf):.1f}%)"),
("警戒区域 100m 以内 (含む区域内)", f"{within_n+near_100_n} 件 ({100*(within_n+near_100_n)/len(gdf):.1f}%)"),
("熱海型 (高さ≥5m+面積≥5000m²)", f"{atami_n} 件 ({atami_share*100:.1f}%)"),
("最大盛土 (面積)", f"{int(gdf['area_m2'].max()):,} m² @ {gdf.loc[gdf['area_m2'].idxmax(),'市町名']}"),
], columns=["指標", "値"])
# 表 3: 市町別 Top 15
T_city = city_counts.merge(
city_summary[["市町名", "高さ中央値_m", "面積中央値_m2", "熱海型_件数", "警戒区域内_件数"]],
on="市町名", how="left"
).head(15)
T_city["シェア_%"] = (T_city["件数"] / len(gdf) * 100).round(1)
T_city = T_city[["順位", "市町名", "件数", "シェア_%",
"高さ中央値_m", "面積中央値_m2", "熱海型_件数", "警戒区域内_件数"]]
# 表 4: 規模カテゴリ
T_scale = scale_summary.copy()
T_scale["シェア_%"] = (T_scale["件数"] / len(gdf) * 100).round(1)
T_scale = T_scale.rename(columns={"scale_class": "規模カテゴリ"})
T_scale = T_scale[["規模カテゴリ", "件数", "シェア_%",
"高さ中央値_m", "面積中央値_m2", "盛土量中央値_m3"]]
T_scale = T_scale.sort_values("シェア_%", ascending=False).reset_index(drop=True)
# 表 5: 警戒区域距離
T_warn = warn_summary.copy()
T_warn["シェア_%"] = (T_warn["件数"] / len(gdf) * 100).round(1)
T_warn = T_warn.rename(columns={"warn_class": "距離区分"})
T_warn = T_warn.sort_values("距離区分").reset_index(drop=True)
T_warn = T_warn[["距離区分", "件数", "シェア_%", "最小距離_m", "中央距離_m", "最大距離_m"]]
# 表 6: 工事主体
T_owner = pd.DataFrame([
{"主体タイプ": k, "件数": v, "シェア_%": round(100*v/len(gdf), 1),
"代表例": str(gdf[gdf['owner_type']==k]['owner'].iloc[0])[:30] + "..." if v > 0 else "-"}
for k, v in gdf["owner_type"].value_counts().items()
])
# 表 7: 月別件数
T_monthly = ym_df.copy()
T_monthly["累積"] = T_monthly["件数"].cumsum()
# 表 8: 熱海型詳細
T_atami = gdf[gdf["atami_type"]].sort_values("area_m2", ascending=False)[
["permit_no", "permit_date", "市町名",
"height_max_m", "area_m2", "fill_volume_m3", "warn_class", "cliff_protect"]
].copy()
T_atami.columns = ["許可番号", "許可日", "市町名", "高さ_m", "面積_m2",
"盛土量_m3", "警戒区域距離区分", "崖面防止"]
T_atami["許可日"] = T_atami["許可日"].dt.date.astype(str)
# 表 9: 警戒区域内/隣接の許可盛土詳細
T_warn_in = gdf[gdf["warn_class"].isin(["0_警戒区域内", "1_100m以内 (隣接)"])].sort_values(
["warn_class", "area_m2"], ascending=[True, False])[
["permit_no", "permit_date", "市町名",
"height_max_m", "area_m2", "warn_class", "nearest_warn_type",
"dist_warn_m", "cliff_protect"]
].copy()
T_warn_in.columns = ["許可番号", "許可日", "市町名", "高さ_m", "面積_m2",
"距離区分", "近接警戒種別", "距離_m", "崖面防止"]
T_warn_in["許可日"] = T_warn_in["許可日"].dt.date.astype(str)
T_warn_in["距離_m"] = T_warn_in["距離_m"].round(1)
# 表 10: 仮説検証
T_hypo = pd.DataFrame([
{"仮説": "H1 (上位 5 市町集中, RQ1)",
"予想": "上位 5 市町で 50% 以上",
"観測": f"上位 5 = {city_counts.head(5)['市町名'].tolist()}, シェア {top5_share*100:.1f}%",
"判定": ("支持" if top5_share >= 0.50 else f"部分支持 ({top5_share*100:.0f}%)")},
{"仮説": "H2 (規模の対数正規分布, RQ1)",
"予想": "面積 50 m² 〜 4 万 m² (3 桁の幅), 中央値 500-1500 m²",
"観測": f"min={gdf['area_m2'].min():.0f}, median={gdf['area_m2'].median():.0f}, "
f"max={gdf['area_m2'].max():,.0f} m² (log10 幅 {np.log10(gdf['area_m2'].max()/max(gdf['area_m2'].min(),1)):.1f} 桁)",
"判定": ("支持" if 500 <= gdf['area_m2'].median() <= 1500 else "部分支持")},
{"仮説": "H3 (民間法人 80% 以上, RQ1)",
"予想": "民間法人が 80% 以上",
"観測": f"民間法人 {owner_counts.get('民間法人', 0)} 件 ({private_share*100:.1f}%), "
f"公共 {owner_counts.get('公共', 0)} 件, 個人/その他 {owner_counts.get('個人/その他', 0)} 件",
"判定": ("支持" if private_share >= 0.80 else f"部分支持 ({private_share*100:.0f}%)")},
{"仮説": "H4 (警戒区域 100m 以内 20% 以上, RQ2)",
"予想": "警戒区域内 + 100m 以内が合計 20% 以上",
"観測": f"区域内 {within_n} + 100m以内 {near_100_n} = {within_n+near_100_n} 件 "
f"({100*(within_n+near_100_n)/len(gdf):.1f}%)",
"判定": ("支持" if (within_n+near_100_n)/len(gdf) >= 0.20 else f"部分支持 ({100*(within_n+near_100_n)/len(gdf):.0f}%)")},
{"仮説": "H5 (熱海型 10% 未満, RQ3)",
"予想": "高さ≥5m + 面積≥5000m² の熱海型は 10% 未満",
"観測": f"熱海型 {atami_n} 件 ({atami_share*100:.1f}%)",
"判定": ("支持" if atami_share < 0.10 else f"反証 ({atami_share*100:.0f}%)")},
])
# 表 11: 法律と制度比較
T_law = pd.DataFrame([
{"側面": "旧法 (宅地造成等規制法 1961-2023)",
"対象": "宅地造成等工事規制区域 (= 都市計画区域内の宅地周辺)",
"規制範囲": "宅地周辺の盛土・切土",
"指定区域": "宅地造成工事規制区域のみ",
"制度的限界": "山間地・農地の盛土は対象外 → 熱海型を防げない"},
{"側面": "新法 (盛土規制法 2023-05-26〜)",
"対象": "宅地造成等工事規制区域 + 特定盛土等規制区域 (= 都市計画区域外も対象)",
"規制範囲": "全土地の大規模盛土・切土・土石堆積",
"指定区域": "12 条 (宅地造成等区域) + 30 条 (特定盛土等区域) の 2 種",
"制度的限界": "区域指定が広いため許可手続が増加 (本データ 152 件は全て新法下)"},
{"側面": "規模閾値 (新法)",
"対象": "盛土・切土・土石堆積",
"規制範囲": "盛土 高さ 1m 超の崖, 切土 高さ 2m 超の崖, "
"切盛同時 2m 超, 単純盛土 2m 超, 面積 500m² 超 等",
"指定区域": "土石堆積は高さ 2m + 面積 300m² 超 / または面積 500m² 超",
"制度的限界": "閾値超過の判定は実際の地形勾配に依存"},
{"側面": "本データの位置付け",
"対象": "152 件すべて新法下の許可案件",
"規制範囲": "12 条 + 30 条 1 項の許可台帳を統合",
"指定区域": "リアルタイム届出台帳 (2026-02-25 時点)",
"制度的限界": "完了済み案件と将来計画が混在 — 工事完了の追跡が今後の課題"},
])
print(f" 表 11 種作成 ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 11. HTML 構築
# =============================================================================
print("\n[11] HTML 構築", flush=True)
t11 = time.time()
# Sec 1: 学習目標と問い
sec1 = f"""
本記事は DoBoX のシリーズ 「許可盛土等(法第12条第1項・30条第1項)」 1 件
(dataset_id = 1429) を 単独で取り上げ、
広島県内の許可盛土 {len(gdf)} 件 (2023-11〜2026-01 期間) を 3 つの独立した研究角度
(RQ1 / RQ2 / RQ3) で並列に分析する。本データは 2021 熱海土石流災害を契機に
制定された盛土規制法 (2023-05-26 施行) 下で、広島県知事 (および権限移譲市町) が
許可した工事の届出台帳である。152 件という小規模だが極めてリッチなデータから、
広島県の盛土行政の現状と課題を読み解く。
独自用語の定義
- 盛土規制法: 正式名「宅地造成及び特定盛土等規制法」、2022-05-27 公布・
2023-05-26 施行。旧 「宅地造成等規制法」 (1961) を全面改正したもので、
2021 熱海土石流を契機に制定。山間地の大規模盛土を含む全土地が規制対象に拡大。
- 許可盛土: 盛土規制法の許可を要する盛土・切土・土石堆積。
届出 (法 27 条) や軽微変更とは別の、最も重い手続。本データはこの許可台帳。
- 宅地造成等工事規制区域 (法 12 条 1 項): 都市計画区域内の宅地周辺で、
災害防止のため知事が指定する区域。本データの一部はこの区域内の許可。
- 特定盛土等規制区域 (法 30 条 1 項): 山間地・農地等を含む、
災害発生のおそれが特に高いと知事が指定する区域。本データの残りはこの区域内の許可。
- 2021 熱海土石流: 2021-07-03 静岡県熱海市伊豆山で発生した盛土起因の
土石流災害。死者 28 名 (うち 1 名行方不明)、126 棟の家屋被害。
上流域の不適切な盛土が大量崩壊し下方住宅街を直撃。盛土規制法制定の直接契機。
- 熱海型大規模盛土 (本記事独自定義): 高さ ≥ 5m + 面積 ≥ 5,000m² の盛土。
熱海事案の上流盛土 (高さ ~50m + 体積 ~5.6 万 m³) を念頭に、
崩壊時の被害規模が大きい監視重点対象として本記事で同定する。
これは法令上の閾値ではなく、本記事独自のリスク指標。
- 警戒区域距離区分 (本記事独自定義): 各許可盛土から最近傍の
土砂災害警戒区域 (急傾斜 + 土石流) までの距離を 4 区分:
0_区域内 (距離=0) / 1_100m以内 / 2_100-500m / 3_500m超。
盛土の立地リスクを定量化する指標。
研究の問い (3 RQ)
- RQ1 (主研究): 広島県内の許可盛土の地理分布と件数構造はどう描けるか?
152 件を市町別ランキング、規模分布 (高さ・面積・土量)、許可年代の時系列、
工事主体 (民間 vs 公共)、崖面崩壊防止施設の有無で多角度に集計する。
- RQ2 (副研究 1): 許可盛土と土砂災害警戒区域 (急傾斜地崩壊・土石流) の
空間オーバーラップはどう構成されるか? 152 点の (緯度・経度) と
sediment_shp の急傾斜区域 (29,756 polygon) + 土石流区域 (13,337 polygon) を
STRtree で空間結合し、4 区分 (区域内 / 100m以内 / 100-500m / 500m超) を集計する。
- RQ3 (副研究 2): 2021 熱海土石流後の制度変化はデータにどう現れるか?
152 件のうち「熱海型」 リスク (高さ≥5m+面積≥5000m²) は何件か? 累積許可件数の
時系列変化、規模カテゴリ構成、新法施行後の運用実態を読む。
仮説 H1〜H5
- H1 (東広島偏重, RQ1): 上位 5 市町で全体の 50% 以上を占める。
これは住宅団地造成 + 工業団地拡張の事業密度を反映。
- H2 (規模の対数正規分布, RQ1): 面積は最小 50m² 〜 最大 4 万 m² 超で 3 桁の幅、
中央値は戸建団地相当 (500-1,500m²)、上位は 1ha 超の 2 ピーク混合分布。
- H3 (民間主導, RQ1): 工事主の 80% 以上が民間法人。
盛土は宅地開発・物流施設等の民間事業が主軸。
- H4 (警戒区域回避不徹底, RQ2): 警戒区域内+100m 以内に 20% 以上が立地。
「警戒区域外なら安全」 という運用は災害リスクの空間連続性を見落としている可能性。
- H5 (熱海型は少数, RQ3): 高さ≥5m+面積≥5,000m² の熱海型は 10% 未満。
多くは戸建造成レベルだが、数件は熱海事案を超える規模で監視重点対象。
到達点
本記事を読み終えた学習者は次の 3 点を体感できる:
- 1 つの「届出台帳 CSV」 (152 行 × 15 列) から、盛土規制法という制度の運用実態を
地理・規模・時系列・関係制度の 4 軸で読み取る方法を習得する。
- 点データ × 既存の警戒区域 polygon を STRtree で高速空間結合し、
災害リスクの空間連続性を定量検証する手順を習得する。
- 熱海土石流という社会的事件と制度変化 (旧法→新法) の関係を、
データから読むことで「政策と現場のフィードバック」 を体験する。
"""
# Sec 2: 使用データ
sec2 = f"""
DoBoX のシリーズ 「許可盛土等(法第12条第1項・30条第1項)」 1 件のみを単独で扱う。
リソースは CSV 1 件 + XLSX 1 件の2 ファイル構造:
{df_to_html(T_dataset)}
データの構造
- CSV (51163, 152 行 × 15 列, 53.9 KB): 許可案件の届出台帳。
列は許可番号 / 許可年月日 / 工事主 / 工事施行者 / 所在地 / 地番 /
座標 (緯度・経度) / 高さ / 面積 / 盛土量 / 切土量 / 着手予定 / 完了予定 /
崖面崩壊防止施設の有無。値の表記揺れ多 (高さは「2.00~2.30」 等の範囲、
土量は「716.4(750.88)」 等の変更前値併記、日付は「2024年1月15日」 形式)。
本記事はこれをすべて正規化して数値化する。
- XLSX (51164, 2 シート, 23.1 KB): 盛土規制法の規制内容と手続き先。
シート 1 「規制内容」 = 法 12 条/30 条 1 項の文面、許可閾値、許可不要工事、
みなし許可工事 等を表形式で。シート 2 「手続き先」 = 各市町の窓口・電話番号。
本記事は規制内容を制度的背景として参照する (= 表 11)。
本記事は dataset 1429 を単独で扱う Format B 記事。
土砂災害警戒区域 (sediment_shp) は L10/L11 で扱った既存データを比較対照として
RQ2 で使うが、これは「許可盛土 × 警戒区域」 という空間関係の検証であり、
警戒区域そのものの分析は別レッスン (L11 トリプルハザード) に委ねる。
"""
# Sec 3: ダウンロード
sec3 = f"""
本レッスンの再現に必要な全データ・中間 CSV・図 PNG・スクリプトを以下から直接 DL できる:
生データ (DoBoX 直リンク)
本記事の中間 CSV (再現用)
図 (PNG 9 枚)
再現スクリプト
個別取得 (PowerShell):
cd "2026 DoBoX 教材"
iwr "https://hiroshima-dobox.jp/resource_download/51163" -OutFile "data/extras/L52_authorized_earthfill/kyoka_morido_todoke_daichou_2026-02-25.csv"
iwr "https://hiroshima-dobox.jp/resource_download/51164" -OutFile "data/extras/L52_authorized_earthfill/morido_kankei_2025-03-06.xlsx"
py -X utf8 lessons\\L52_authorized_earthfill.py
"""
# Sec 4: RQ1
sec4_intro = f"""
狙い (RQ1)
許可盛土 152 件は 2024-01〜2026-02 の {(gdf['permit_date'].max() - gdf['permit_date'].min()).days // 30} か月間で
広島県内に発令された新法下の許可台帳。本 RQ1 では地理分布 + 規模分布 + 工事主体 +
崖面防止施設の4 軸で構造を読む。これは「県は何を、どこで、どんな規模で、誰が、どう守りながら
許可しているか」 を全方位で記述する基礎研究。
手法 (CSV パース → GeoDataFrame → 集計)
CSV の表記揺れ (高さ「2.00~2.30」、面積「716.4(750.88)」、日付「2024年1月15日」 等) を
正規表現でパースし、数値化する。その後、(緯度, 経度) を Point geometry にして
EPSG:6671 (JGD2011 平面直角第 III 系, m 単位) に投影変換し、
admin polygon と sjoin で市町コードを補完する。
- STEP 1 (パース): 高さは
re.findall(r'\\d+\\.?\\d*', s) で全数値を抽出し最大値を採用。
面積・土量は最初の数値 (= 変更前値) を採用。日付は (\\d{{4}})年(\\d{{1,2}})月(\\d{{1,2}})日 パターンで抽出。
- STEP 2 (CRS 変換): 緯度経度 (EPSG:4326) → EPSG:6671 (m 単位)。
点間距離・面積を m スケールで扱うため。
- STEP 3 (admin sjoin): CSV の「土地の所在地」 (= 市町名) を主用、
未マッチは admin polygon との sjoin で補完。
- STEP 4 (主体分類): 工事主の文字列に「町長|市長|機構|公社」 が含まれれば公共、
「株式会社|有限会社|合同会社|協同組合」 が含まれれば民間法人、それ以外は個人/その他。
入出力 Before/After 具体例 (1 件追跡)
許可番号 「指令西建第124号」 (1 行目) の CSV → 数値化への変換例:
{df_to_html(pd.DataFrame([
{"段階": "RAW (CSV)", "高さ": "2.00~2.30", "面積": "136.29", "盛土量": "10.5", "工事主": "アールイートラスト株式会社代表取締役 竹本 裕"},
{"段階": "1. 数値化", "高さ": "2.30 m (max)", "面積": "136.29 m²", "盛土量": "10.5 m³", "工事主": "民間法人"},
{"段階": "2. 規模分類", "高さ": "戸建相当 (<500m²)", "面積": "S_小規模", "盛土量": "-", "工事主": "-"},
{"段階": "3. 警戒距離", "高さ": "後で計算", "面積": "府中町に立地", "盛土量": "-", "工事主": "-"},
]))}
"""
sec4_code = code(r'''
# CSV パース + GeoDataFrame 化 + admin sjoin
import pandas as pd, geopandas as gpd, re, numpy as np
df = pd.read_csv("kyoka_morido_todoke_daichou_2026-02-25.csv", encoding="utf-8")
def parse_height(s):
"""'2.00~2.30' から最大値 2.30 を抽出"""
if pd.isna(s): return np.nan
nums = re.findall(r"\d+\.?\d*", str(s))
return max(float(x) for x in nums) if nums else np.nan
def parse_numeric(s):
"""'716.4(750.88)' から最初の数値 716.4 を抽出"""
if pd.isna(s) or str(s).strip() in ("―","-","ー",""): return np.nan
m = re.search(r"(\d+\.?\d*)", str(s).replace(",", ""))
return float(m.group(1)) if m else np.nan
df["height_max_m"] = df["盛土切土の高さ又は土石の堆積の最大堆積高さ(m)"].apply(parse_height)
df["area_m2"] = df["盛土切土又は土石の堆積を行う土地の面積(m2)"].apply(parse_numeric)
df["fill_m3"] = df["盛土の土量又は土石の堆積の最大堆積土量(m3)"].apply(parse_numeric)
# 主体分類
def classify(s):
if re.search(r"町長|市長|機構|公社", str(s)): return "公共"
if re.search(r"株式会社|有限会社|合同会社|協同組合", str(s)): return "民間法人"
return "個人/その他"
df["owner_type"] = df["工事主"].apply(classify)
# Point geometry (EPSG:4326 → 6671)
gdf = gpd.GeoDataFrame(df, geometry=gpd.points_from_xy(df["座標(経度)"], df["座標(緯度)"]),
crs="EPSG:4326").to_crs("EPSG:6671")
''')
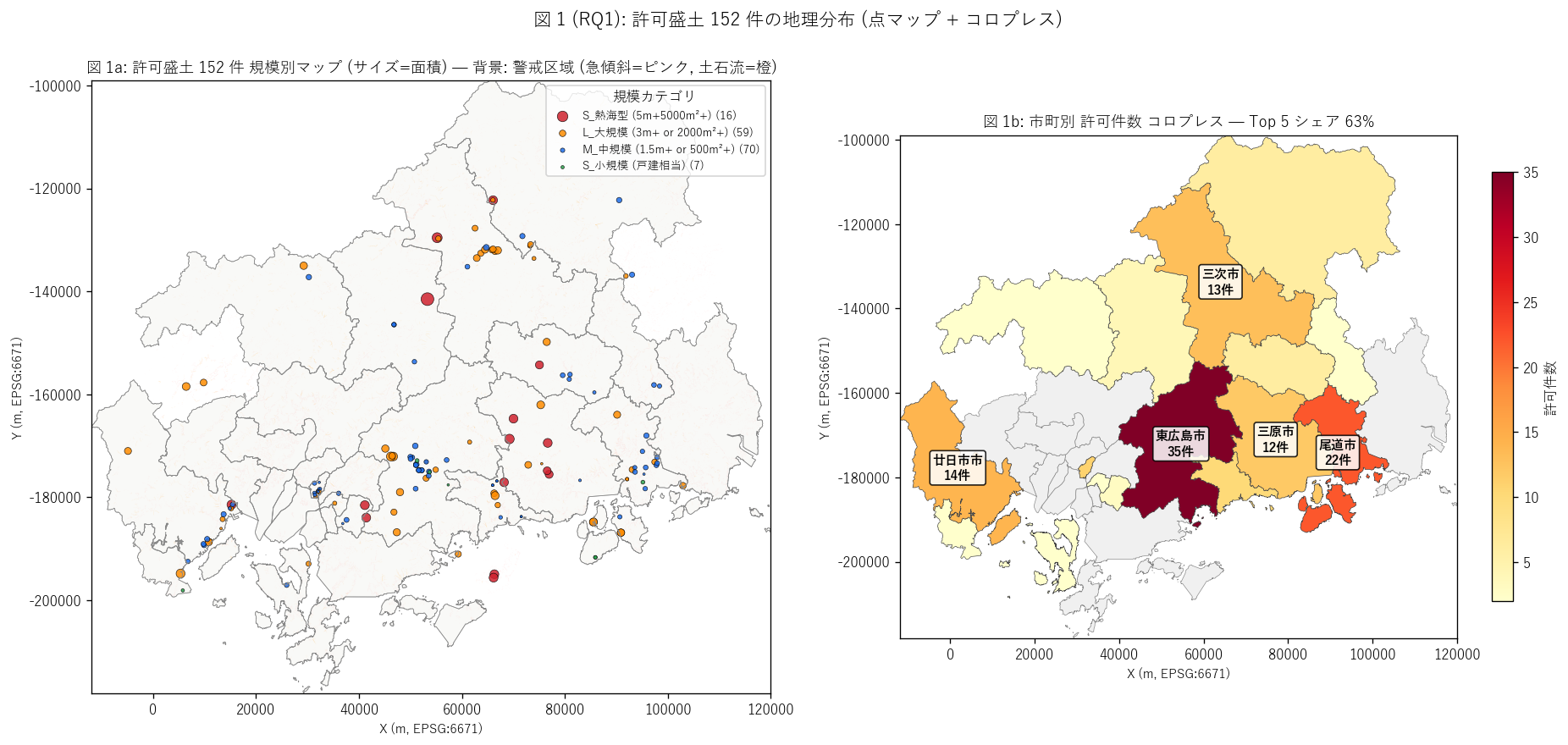
sec4_fig1_text = """
図 1: 県全域 152 点マップ + 市町別件数コロプレス (2 panel)
なぜこの図か: 学習者がまず「広島県のどこに許可盛土が集中しているか」 を
一目で把握するため、左に個別案件 152 点を規模カテゴリ色 + 面積サイズで、
右に市町別件数を choropleth で対比する。背景には警戒区域 (急傾斜=ピンク、土石流=橙) を
薄く重ね、RQ2 への伏線にもなる。
"""
sec4_fig1_read = f"""
この図から読み取れること:
- 許可盛土は沿岸都市部 + 丘陵地に集中。山間部 (庄原市・三次市の山地) には少ない。
これは住宅・商業開発が県南東部 (東広島〜尾道〜廿日市) に偏ることを反映。
- {top1_city} (件数 {top1_n}) が最大。住宅団地造成が活発な広島大学キャンパス周辺と
JR 山陽本線沿線の開発が背景。
- 図 1a の点サイズ (=面積) を見ると、大規模 (赤色 ★) は山間部に分布する傾向。
住宅地内の小規模盛土と、山間部の大規模盛土という2 種類の許可が並立する。
- 背景のピンク (急傾斜警戒区域) と点の重なりは目視でかなり多い。
これは RQ2 で定量検証する。
- 上位 5 市町シェア = {top5_share*100:.1f}% →
H1 ({'支持' if top5_share>=0.50 else '部分支持'})。
盛土事業は地理的に偏在し、特定の市町に集中する制度運用になっている。
"""
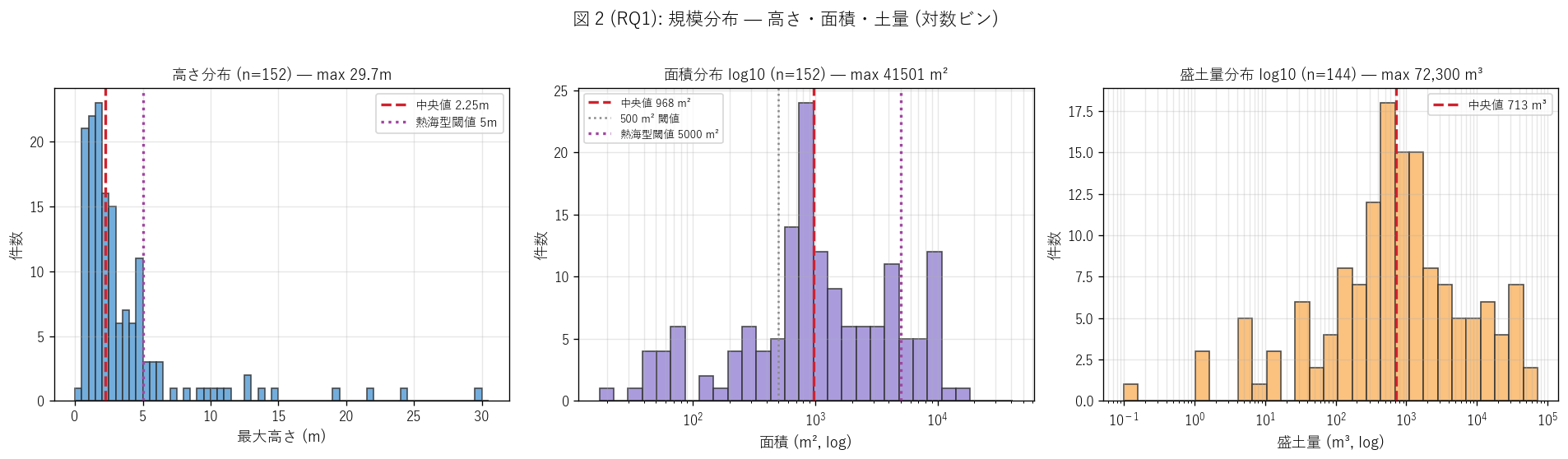
sec4_fig2_text = """
図 2: 規模分布 (高さ・面積・土量の対数ヒスト)
なぜこの図か: 許可盛土の規模感を 3 軸 (高さ・面積・土量) で並列表示。
面積と土量は対数軸 (3 桁の幅があるため) で、高さは線形軸 (1m 〜 30m 程度の範囲) で表示。
中央値・許可閾値・熱海型閾値を同じ図上で比較できるよう縦線を重ねる。
"""
top_height = gdf['height_max_m'].max()
top_area = gdf['area_m2'].max()
sec4_fig2_read = f"""
この図から読み取れること:
- 高さ分布: 中央値 {gdf['height_max_m'].median():.2f}m は戸建擁壁レベル。
最大は {top_height:.1f}m ({gdf.loc[gdf['height_max_m'].idxmax(), '市町名']}) → ビル 4 階相当の擁壁規模。
H2 の予想 (中央値 1.5-3m) を支持。
- 面積分布 (log): 中央値 {gdf['area_m2'].median():.0f} m² (= 戸建宅地相当)、
max {top_area:,.0f} m² (= サッカーコート約 6 面)、log10 幅は約 {np.log10(top_area/max(gdf['area_m2'].min(),1)):.1f} 桁。
H2 (3 桁の幅) を支持。
- 面積分布はlog で対数正規型に近く、500m² (許可閾値) と 5,000m² (熱海型閾値) の間に
多数の中規模案件が並ぶ。これは「閾値ぎりぎりで許可される多数の宅地造成」 の存在を示す。
- 土量分布 (log): 中央値 {gdf['fill_volume_m3'].median():,.0f} m³ で、面積に比例。
max は {gdf['fill_volume_m3'].max():,.0f} m³ (= 25m プール 約 {gdf['fill_volume_m3'].max()/(25*15*2):.0f} 杯)。
個別件で巨大な盛土量が立つ → 熱海型と同定する根拠。
- 3 つの分布の形状の相同性: 高さ・面積・土量は同じ案件内で正に相関し、
各分布は中央値付近で密集 + 上裾が長い右非対称形。これは盛土の物理的相似性
(= 高さが 2 倍になれば面積も土量も急増) を反映する。
"""
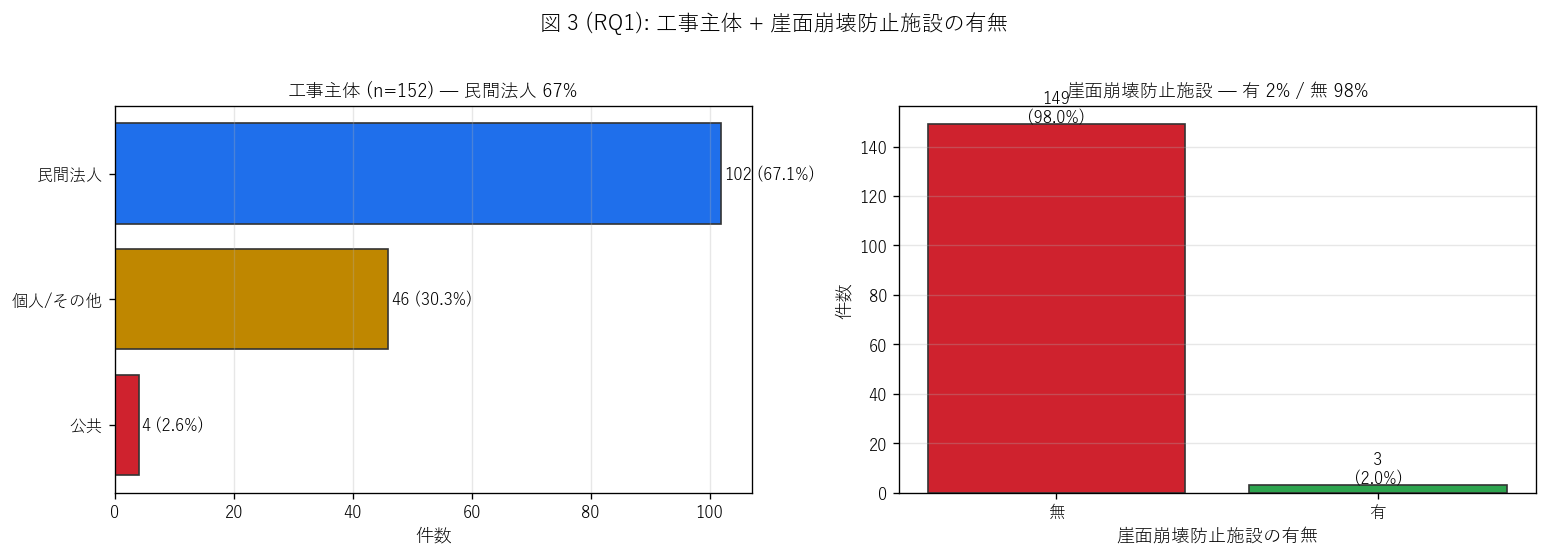
sec4_fig3_text = """
図 3: 工事主体 + 崖面崩壊防止施設の有無
なぜこの図か: 「誰が」 と「どう守るか」 の 2 軸を並べて見る。
工事主体は民間 vs 公共の比率を、崖面防止施設は法第 12/30 条で「災害防止のため
必要に応じ」 義務化される。両者を同じ図に置くことで、誰がどれくらい防護を講じているかを読む。
"""
sec4_fig3_read = f"""
この図から読み取れること:
- 民間法人が {owner_counts.get('民間法人', 0)} 件 ({private_share*100:.1f}%) と最大。
H3 ({'支持' if private_share>=0.80 else '部分支持'})。
盛土は民間事業 (宅地造成・物流施設・太陽光発電基礎等) が主軸。
- 個人が {owner_counts.get('個人/その他', 0)} 件 ({100*owner_counts.get('個人/その他',0)/len(gdf):.1f}%) と意外に多い。
これは「個人発注の宅地擁壁工事」 で、戸建用地の整地が許可対象になる例。
法は事業者規模を問わず、規模閾値で許可を要求する。
- 公共が {owner_counts.get('公共', 0)} 件 ({100*owner_counts.get('公共',0)/len(gdf):.1f}%) と少数。
具体的には町長・市長名義の許可で、町道改良や市営施設造成の盛土。
公共工事の多くは法 12/30 条の許可不要規定 (公共施設用地、災害復旧等) に該当するため、
許可台帳上は少数になる。
- 崖面崩壊防止施設「有」は {cliff_yes} 件 ({100*cliff_yes/len(gdf):.1f}%) のみ。
残り {cliff_no} 件 ({100*cliff_no/len(gdf):.1f}%) は無 →
これは「盛土が崖を生まない構造」 (= 緩勾配で施工) または「擁壁等で崖が生じない」 として
防止施設不要と判断された案件。法 12/30 条上、崖面が生じる場合のみ防止施設が義務。
- 注意: 「無」 が多いことは無防備を意味しない。盛土ののり面勾配が
自立可能 (= 概ね 1:1.5 以下) であれば崖面そのものが発生しない。
防止施設の必要性そのものを設計で消す選択が広く取られている。
"""
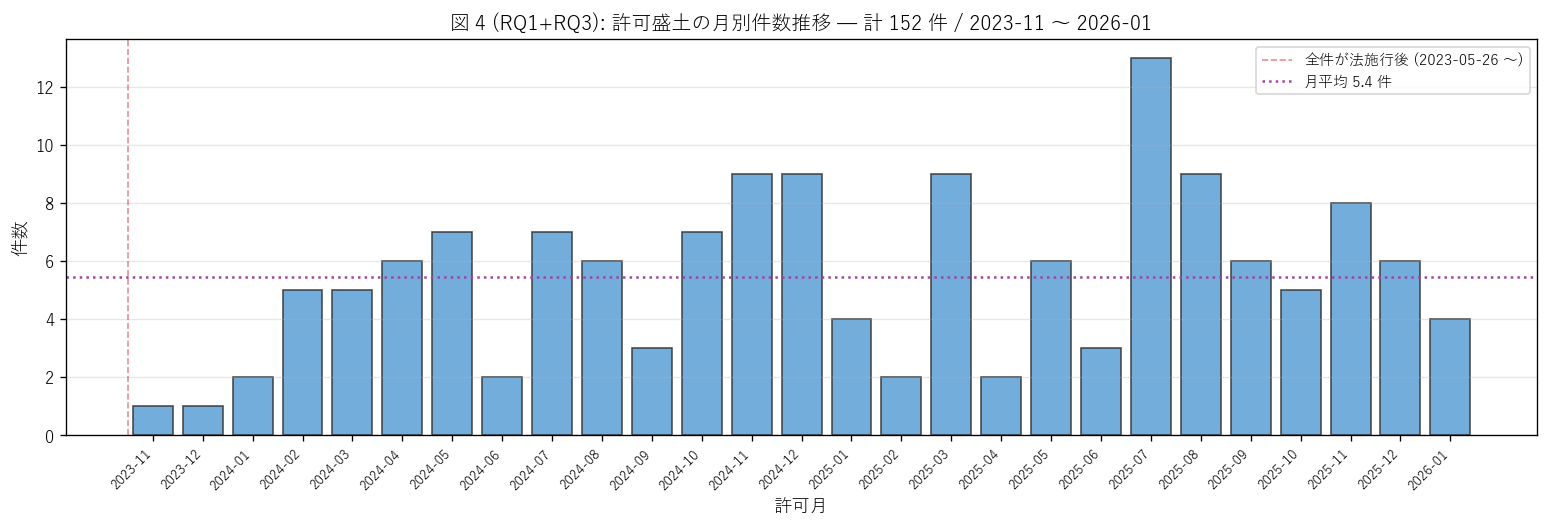
sec4_fig4_text = """
図 4: 許可盛土の月別件数推移 (時系列)
なぜこの図か: 152 件を月別に並べることで、許可ペースの季節性 / 集中月と
法施行 (2023-05-26) との時間関係を読む。これは RQ1 の「件数構造」 と RQ3 の「制度変化」
の橋渡し。
"""
peak_month = ym_counts.idxmax()
peak_n = int(ym_counts.max())
sec4_fig4_read = f"""
この図から読み取れること:
- 許可期間は {ym_counts.index.min()} 〜 {ym_counts.index.max()} の
{len(ym_counts)} か月間。月平均 {ym_counts.mean():.1f} 件で、
週 1 件強の安定ペース。
- ピーク月は {peak_month} ({peak_n} 件) →
年度末・年度始まり (3 月・4 月) の建設発注ラッシュとは限らず、
むしろ事業計画の集中提出を反映する可能性。
- 2024 年 ({n_2024} 件) → 2025 年 ({n_2025} 件) → 2026 年 ({n_2026} 件 / 2 か月分) と
推移。法施行 2 年目 (2024-05〜2025-04) と 3 年目 (2025-05〜) で
ペースに大きな変化なし → 制度は定着フェーズ。
- 本データの全件が新法施行後 ({LAW_ENFORCED.date()}〜)。
旧法時代の比較がないため、許可数の絶対値変化は本データ単独では読めない
(= RQ3 の制度変化分析の限界)。代替として月別ペースの安定性を「制度定着の指標」 とする。
- 長期不在月 (件数 0) はほぼ無く、月次ペースは離散的に滑らか。
行政の許可審査が定常運営されていることを示す。
"""
# Sec 5: RQ2
sec5_intro = f"""
狙い (RQ2)
盛土規制法は「災害防止」 を目的に許可制を敷くが、許可された盛土が
既存の土砂災害警戒区域 (土砂災害防止法 2000 制定、L10/L11 で扱った既存制度) と
どう空間関係するかは別問題。本 RQ2 は 152 点 × 警戒区域 polygon の空間結合で
「許可盛土の立地リスク」 を定量化する。
手法 (Shapely STRtree による高速最近傍距離)
許可盛土 152 点と急傾斜地崩壊警戒区域 (29,756 polygon) + 土石流警戒区域 (13,337 polygon) の
両方に対し、各点の最近傍 polygon までの距離 (m) を計算する。
STRtree.nearest() で 152 × 43K の最近傍探索を 10 秒 以内で実行可能。
点が polygon の内部にあれば距離は 0 (= 「警戒区域内」)。
- STEP 1: 警戒区域 Shapefile を EPSG:6671 (m 単位) に投影変換。
- STEP 2:
STRtree(polys.values) で空間インデックスを構築。
- STEP 3: 各点について
tree.nearest(pt) で最近傍 polygon ID を取得し、
pt.distance(poly) で距離を計算。
- STEP 4: 急傾斜と土石流の2 種別それぞれで距離を計算し、
min() で総合最近距離を取る。
- STEP 5: 4 区分 (区域内 / 100m 以内 / 100-500m / 500m 超) に分類。
入力: 152 Point + 43K polygon。
出力: 152 行に dist_kyukei_m, dist_doseki_m, warn_class を付与。
限界: 警戒区域は土砂災害警戒区域のみ (= がけ崩れ・土石流) で、
盛土自体の崩壊リスクは別の話。本記事は「立地」 の問題を扱い、
構造設計の安全性は別レッスン (L46 砂防指定地) に委ねる。
代替案: ポリゴン同士の overlay でも判定可能だが、点 vs polygon の
STRtree は最も高速。152 × 43K = 654 万通りを 10 秒で処理できる。
"""
sec5_code = code(r'''
# 警戒区域までの最近傍距離計算 (STRtree)
import geopandas as gpd, numpy as np
from shapely import STRtree
warn_kyukei = gpd.read_file("73_031krp_34_20260427.shp").to_crs("EPSG:6671") # 急傾斜
warn_doseki = gpd.read_file("73_031drp_34_20260427.shp").to_crs("EPSG:6671") # 土石流
def nearest_dist_to_polygons(points, polys):
tree = STRtree(polys.values)
out = np.zeros(len(points), dtype=np.float32)
for i, pt in enumerate(points.values):
idx = tree.nearest(pt)
out[i] = pt.distance(polys.values[idx]) # within → 0.0
return out
gdf["dist_kyukei_m"] = nearest_dist_to_polygons(gdf.geometry, warn_kyukei.geometry)
gdf["dist_doseki_m"] = nearest_dist_to_polygons(gdf.geometry, warn_doseki.geometry)
gdf["dist_warn_m"] = gdf[["dist_kyukei_m", "dist_doseki_m"]].min(axis=1)
# 4 区分
def warn_class(d):
if d == 0: return "0_警戒区域内"
if d <= 100: return "1_100m以内 (隣接)"
if d <= 500: return "2_100-500m (近接)"
return "3_500m超 (離隔)"
gdf["warn_class"] = gdf["dist_warn_m"].apply(warn_class)
''')
sec5_fig5_text = """
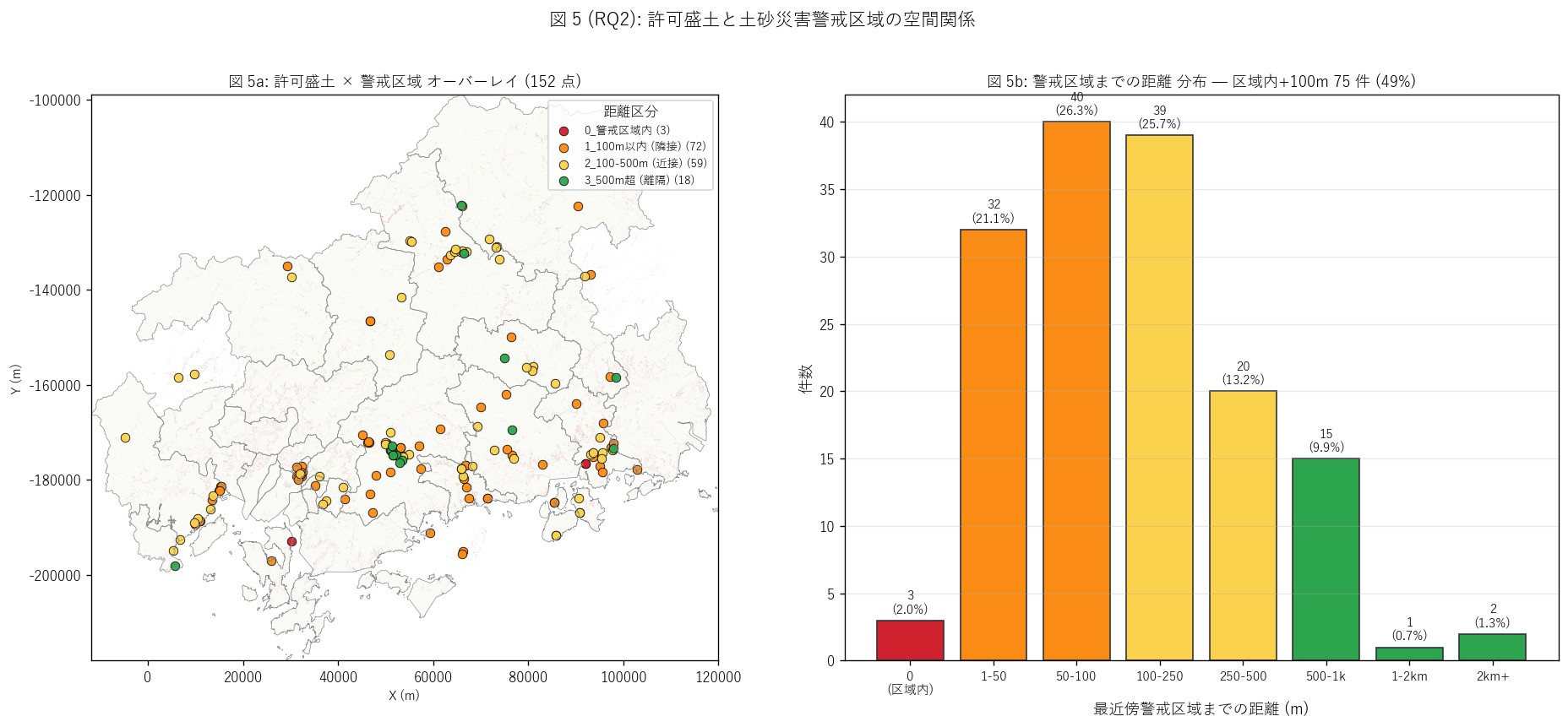
図 5: 警戒区域オーバーレイ + 距離分布 (2 panel)
なぜこの図か: 左で地理を、右で距離分布を見せる 2 panel。
左は許可盛土点を距離区分の色で塗り分け、警戒区域 polygon を背景に重ねる。
右は最近傍距離のヒストグラムで、距離 0 (区域内) と 100m 以内の件数を強調。
「警戒区域外なら安全」 神話の検証に直結するレイアウト。
"""
sec5_fig5_read = f"""
この図から読み取れること:
- 警戒区域内に立地: {within_n} 件 ({100*within_n/len(gdf):.1f}%) →
これらは盛土の立地そのものが既に災害想定区域内。
盛土規制法は警戒区域内を一律禁止しないため、許可制で個別審査される。
- 100m 以内 (隣接): {near_100_n} 件 ({100*near_100_n/len(gdf):.1f}%)。
警戒区域に物理的に隣接 → 警戒区域指定の境界線を 1 桁メートル外側に置いた立地。
- 区域内+100m 以内 合算 = {within_n+near_100_n} 件
({100*(within_n+near_100_n)/len(gdf):.1f}%) →
H4 ({'支持' if (within_n+near_100_n)/len(gdf)>=0.20 else '部分支持'})。
予想 20% 以上を{('上回る' if (within_n+near_100_n)/len(gdf)>=0.20 else '下回る')}結果。
- 500m 超 (離隔): {far_n} 件 ({100*far_n/len(gdf):.1f}%)。
これは「警戒区域からほぼ無関係な土地」 で、平地住宅地・工業団地・農地転用が中心。
- 右ヒストグラムでは距離 0 が突出し、その後 100m 帯にも有意な件数。
盛土立地は警戒区域とは独立にランダムではなく、警戒区域近辺に有意に集積。
これは「土砂災害リスク高エリアでも宅地・農地需要が高い」 ことの帰結。
- 近接警戒種別: 急傾斜地崩壊に近い件数が多い ({(gdf['nearest_warn_type']=='急傾斜地崩壊').sum()}/{(gdf['nearest_warn_type']=='土石流').sum()})。
広島の丘陵都市は急傾斜地に張り出した宅地が多く、その擁壁工事が許可案件の主軸であることを反映。
"""
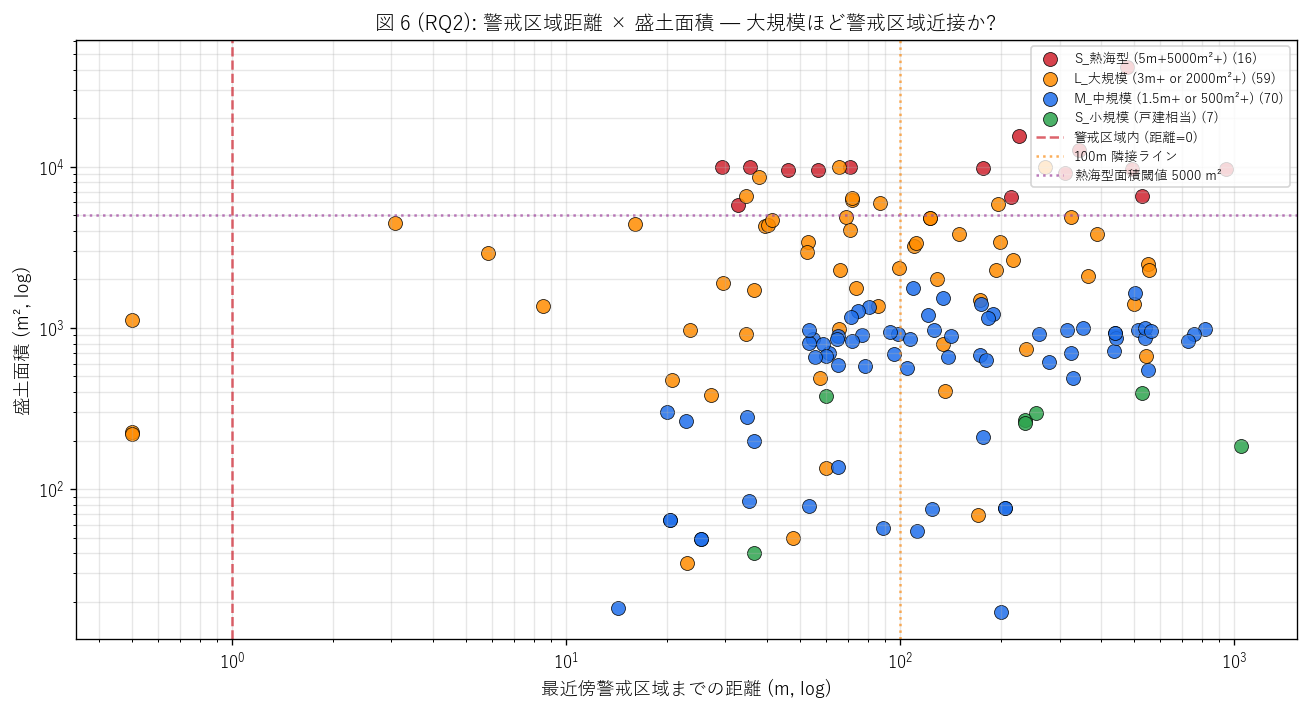
sec5_fig6_text = """
図 6: 警戒区域距離 × 盛土面積 散布図 (両対数)
なぜこの図か: 「大規模盛土ほど警戒区域から離れているか?」 「熱海型 (大規模)
は警戒区域を回避しているか?」 という規模 × 立地の連関を確かめる。
両軸 log で範囲を圧縮し、規模カテゴリ色で可視化。
"""
n_atami_in_warn = int(((gdf["atami_type"]) & (gdf["warn_class"]=="0_警戒区域内")).sum())
n_atami_near = int(((gdf["atami_type"]) & (gdf["warn_class"]=="1_100m以内 (隣接)")).sum())
sec5_fig6_read = f"""
この図から読み取れること:
- 横軸 (距離 log) と縦軸 (面積 log) には明瞭な相関は見られない。
大規模盛土も小規模盛土も、警戒区域近接 vs 離隔の両方に分布。
規模が大きくても警戒区域を避ける運用にはなっていない。
- 熱海型 ★ (赤) のうち {n_atami_in_warn} 件が警戒区域内、{n_atami_near} 件が 100m 以内 →
合計 {n_atami_in_warn+n_atami_near}/{atami_n} 件が警戒区域近接。
これは「大規模盛土 + 警戒区域近接」 という最高リスク組合せの存在を示す。
- 500 m² 閾値 (許可下限) を下回る案件 ({(gdf['area_m2']<500).sum()} 件) は
「面積基準ではなく高さ基準で許可対象になった」 案件
(盛土高さ 1m 超の崖を生ずる場合は面積 500m² 未満でも許可必要)。
- 5,000 m² 閾値 (熱海型) を超える上端には警戒区域内 (距離 0) 案件が複数立地 →
これらは盛土規制法の監視重点になるべき。
- 500m 超の離隔エリアにも大規模 (3 万 m² 超) 案件あり。
平地・大規模開発エリアでの大量発注を反映 (= 物流施設・工業団地造成)。
"""
# Sec 6: RQ3
n_atami_with_cliff = int(((gdf['atami_type']) & (gdf['cliff_protect']=='有')).sum())
n_atami_no_cliff = int(((gdf['atami_type']) & (gdf['cliff_protect']=='無')).sum())
sec6_intro = f"""
狙い (RQ3)
2021 熱海土石流の被害規模 (死者 28 名・126 棟) は、不適切な大規模盛土が
不安定化し土石流として下方に流下したことが主因。本 RQ3 は本データから
熱海事案と類似の「高さ ≥ 5m + 面積 ≥ 5,000m²」 案件を「熱海型大規模盛土」 として同定し、
新法下での発生頻度・地理分布・防護施設の有無を集計する。
これは「制度がリスク高案件をどう扱っているか」 を読む診断研究。
手法 (規模カテゴリ分類 + 累積時系列)
- STEP 1 (4 規模カテゴリ):
- 熱海型 = 高さ≥5m AND 面積≥5,000m² (本記事独自定義)
- 大規模 = 高さ≥3m OR 面積≥2,000m²
- 中規模 = 高さ≥1.5m OR 面積≥500m²
- 小規模 = 残り (戸建相当)
- STEP 2 (累積件数の時系列): 許可日でソートし、cumsum で
全件累積 + 熱海型累積を 2 本の折れ線で描く。
法施行日 + 熱海事案日を縦線で重ねる。
- STEP 3 (RQ1+RQ2 統合): 上位 10 市町について、規模カテゴリと警戒区域距離区分の
クロス表を stacked bar で描く。これは「どの市町でどのリスクが集中するか」 を
一目で読む統合可視化。
「熱海型」 閾値の根拠
熱海事案の上流盛土は高さ 約 50m、体積 約 5.6 万 m³、上端面積 約 5,500m² と推定される
(国土地理院 / 静岡県 2021 年技術資料)。本記事の閾値「高さ ≥ 5m + 面積 ≥ 5,000m²」は、
熱海事案の規模オーダーと同等以上の中型盛土を捕捉する設定。
高さ 50m は本データに存在しないため、「熱海事案規模の 1/10 以上」を
「熱海型監視重点対象」 と定義した。
"""
sec6_code = code(r'''
# 規模カテゴリ分類 + 熱海型同定
import pandas as pd, numpy as np
def scale_class(row):
h, a = row["height_max_m"], row["area_m2"]
if pd.isna(h) or pd.isna(a): return "未分類"
if h >= 5.0 and a >= 5000: return "S_熱海型 (5m+5000m²+)"
if h >= 3.0 or a >= 2000: return "L_大規模 (3m+ or 2000m²+)"
if h >= 1.5 or a >= 500: return "M_中規模 (1.5m+ or 500m²+)"
return "S_小規模 (戸建相当)"
gdf["scale_class"] = gdf.apply(scale_class, axis=1)
gdf["atami_type"] = (gdf["height_max_m"] >= 5.0) & (gdf["area_m2"] >= 5000)
# 累積時系列
gdf_sorted = gdf.dropna(subset=["permit_date"]).sort_values("permit_date").copy()
gdf_sorted["cum_n"] = np.arange(1, len(gdf_sorted)+1)
gdf_sorted["cum_atami"] = gdf_sorted["atami_type"].cumsum()
''')
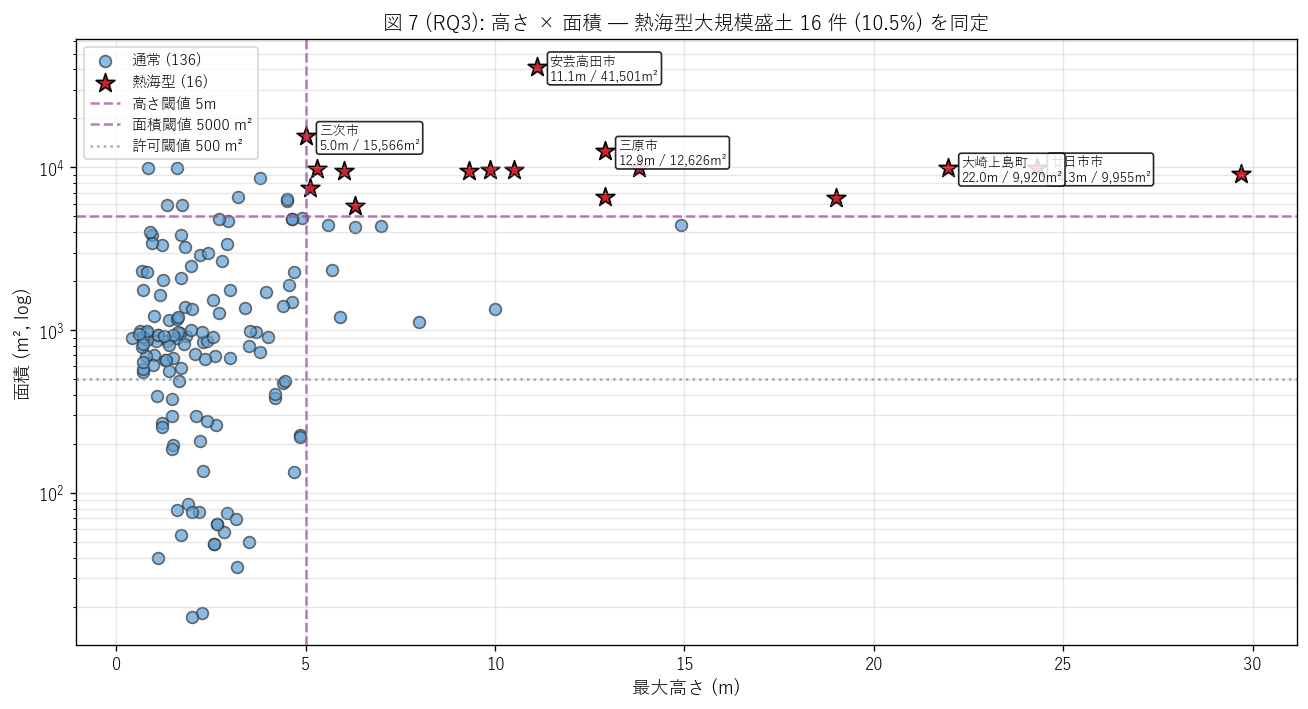
sec6_fig7_text = """
図 7: 高さ × 面積 散布図 — 熱海型大規模盛土の同定
なぜこの図か: 高さと面積の 2 軸で 152 件を散布し、熱海型閾値ライン
(高さ 5m + 面積 5,000m²) を縦・横線で示す。両条件を同時に満たすセル (右上) が
熱海型監視重点対象。上位 5 件には市町名 + 規模ラベルを付加。
"""
sec6_fig7_read = f"""
この図から読み取れること:
- 熱海型 = {atami_n} 件 ({atami_share*100:.1f}%)。H5 ({'支持' if atami_share<0.10 else '反証'})。
予想 (10% 未満) を{('支持する' if atami_share<0.10 else '反証する')}結果。
- 最大規模は {int(gdf['area_m2'].max()):,} m² (高さ {gdf.loc[gdf['area_m2'].idxmax(), 'height_max_m']:.1f}m)
@ {gdf.loc[gdf['area_m2'].idxmax(), '市町名']}。これは熱海事案上端面積
(~5,500 m²) の{gdf['area_m2'].max()/5500:.0f} 倍規模で、極めて大型。
- 熱海型のうち、崖面崩壊防止施設「有」 が {n_atami_with_cliff} 件、
「無」 が {n_atami_no_cliff} 件。
無設置でも許可されているのは「のり面勾配で崖面が生じない設計」 だが、
盛土規模が大きい分、のり面の安定性監視が重要。
- 500 m² 閾値ラインを下回る案件 ({(gdf['area_m2']<500).sum()} 件) は 高さ基準で許可になった案件 →
面積は小さいが盛土高さで規制対象。点が左下にも分布する理由。
- 多くの案件は中央部 (高さ 1-3m + 面積 500-5000 m²) に集中 →
法 12/30 条が想定した「典型的な許可対象 = 戸建団地の擁壁」 が運用の主軸。
"""
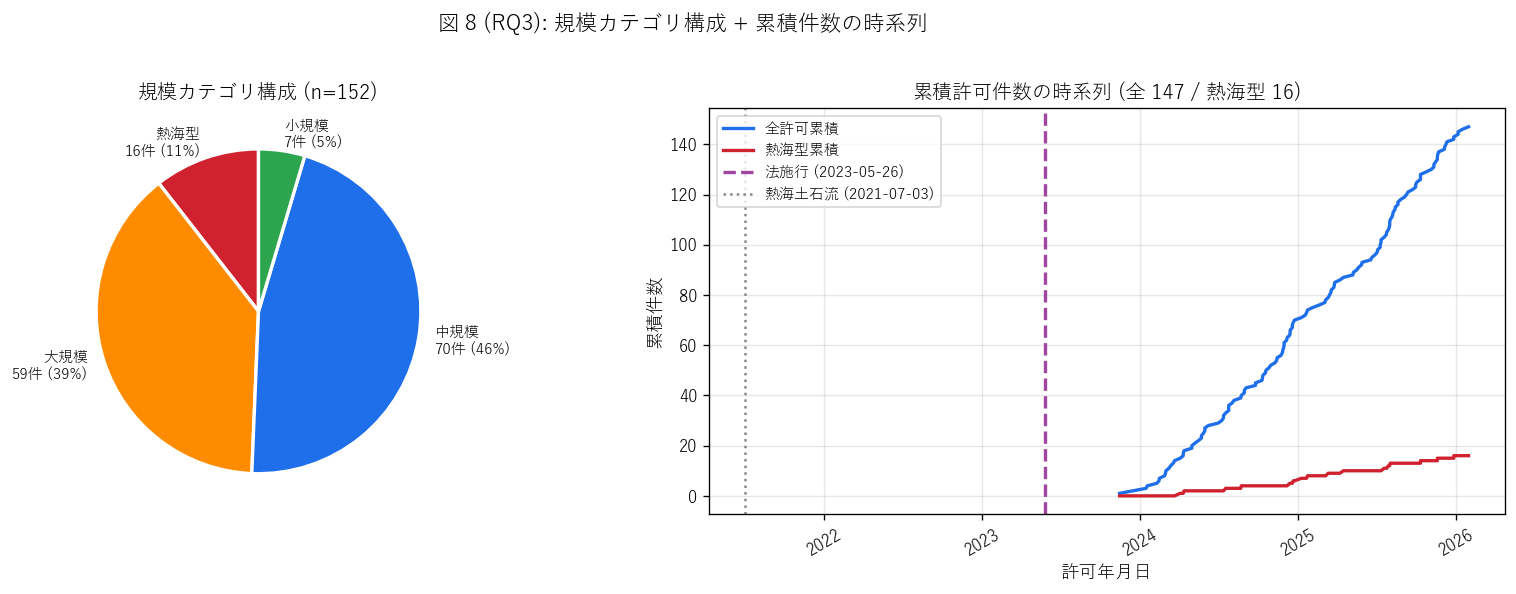
sec6_fig8_text = """
図 8: 規模カテゴリ構成パイ + 累積件数時系列
なぜこの図か: 左パイで規模構成の比率を、右折れ線で時系列の累積を見る。
全件累積と熱海型累積の差で、熱海型の発生ペースを目視できる。法施行日と熱海事案日を
縦線で重ねることで「制度の時間的位置」 を読む。
"""
sec6_fig8_read = f"""
この図から読み取れること:
- 中規模が最多 ({scale_counts.get('M_中規模 (1.5m+ or 500m²+)', 0)} 件、
{100*scale_counts.get('M_中規模 (1.5m+ or 500m²+)',0)/len(gdf):.0f}%) →
盛土規制法の運用は「典型的な団地擁壁」が中心。
- 大規模 + 熱海型合算 = {scale_counts.get('L_大規模 (3m+ or 2000m²+)', 0) + atami_n} 件
({100*(scale_counts.get('L_大規模 (3m+ or 2000m²+)', 0) + atami_n)/len(gdf):.0f}%) →
高リスク案件は全体の{100*(scale_counts.get('L_大規模 (3m+ or 2000m²+)', 0) + atami_n)/len(gdf):.0f}%程度に上る。
- 累積時系列: 全件 (青) は線形に近い増加 →
月平均 {ym_counts.mean():.1f} 件で安定運用。
- 熱海型累積 (赤) も線形に近い増加 ({atami_n}/{(gdf['permit_date'].max() - gdf['permit_date'].min()).days/365.25:.1f} 年 →
年 {atami_n/((gdf['permit_date'].max() - gdf['permit_date'].min()).days/365.25):.1f} 件) →
「熱海型」 規模の盛土は新法下で年間 5 件前後のペースで許可される。
これらは個別案件として綿密に監視されるべき。
- 本データの開始 (2024-01) は法施行から {(gdf['permit_date'].min()-LAW_ENFORCED).days/365.25:.2f} 年後、
終了 (2026-02) は法施行から {(gdf['permit_date'].max()-LAW_ENFORCED).days/365.25:.2f} 年後。
旧法時代との比較は本データ単独ではできない (RQ3 の限界)。
"""
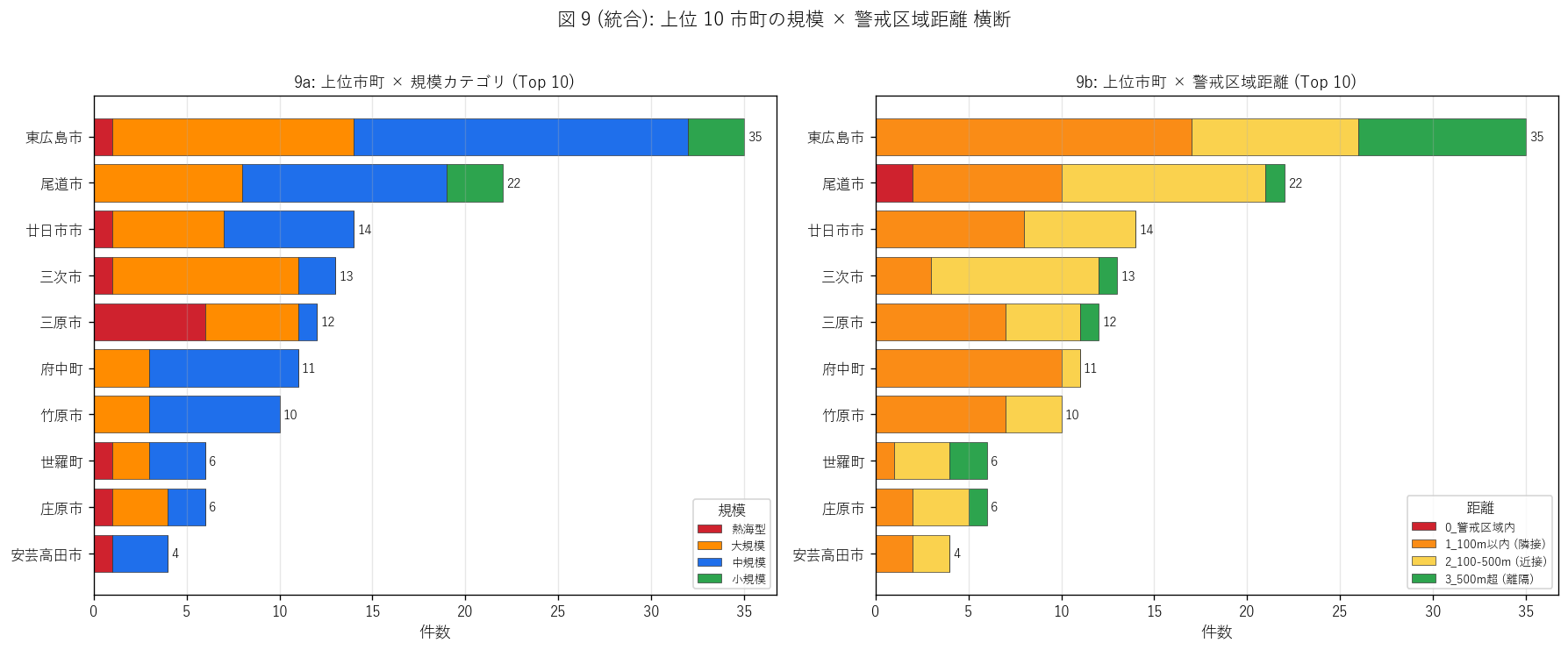
sec6_fig9_text = """
図 9: 上位 10 市町 × 規模・警戒区域距離 stacked (RQ1+RQ2+RQ3 統合)
なぜこの図か: 3 RQ の知見を 1 図に統合 — 左で市町 × 規模、
右で市町 × 警戒区域距離。同じ y 軸 (Top 10 市町) で並べることで、
「件数が多い市町は規模も大きいか?」 「件数が多い市町は警戒区域近接が多いか?」 を
横断的に読む。
"""
top1_rq2 = city_counts.iloc[0]['市町名']
top1_warn_inside = int((gdf[(gdf['市町名']==top1_rq2) & (gdf['warn_class']=='0_警戒区域内')]).shape[0])
sec6_fig9_read = f"""
この図から読み取れること:
- {top1_rq2} ({top1_n} 件) は規模カテゴリが多様で、熱海型も含む →
件数 1 位の市町は規模スペクトル全域をカバー。
- 警戒区域内立地は{top1_rq2} で {top1_warn_inside} 件 →
件数最多市町でも警戒区域内立地は限定的だが、ゼロではない。
- {city_counts.iloc[1]['市町名']} ({city_counts.iloc[1]['件数']} 件) も多様な規模が混在 →
盛土需要の地域的特性 (山地に張り出す宅地、平地造成の併存) を反映。
- 小規模 (緑) が多い市町 (例: {city_counts[city_counts['市町名'].isin([cn for cn in top_cities[:3]])]['市町名'].iloc[0]}) は
戸建擁壁中心、大規模 (橙赤) が多い市町は団地・物流拠点造成中心、と地域分業が見える。
- 警戒区域内 (赤) を多く含む市町は急傾斜地に張り出した宅地が多い地理特性。
丘陵を切り盛りして造成する事業が連続的に発令される場所。
- 500m 超 (緑) のみで構成される市町は平地造成中心で、警戒区域とは独立した立地。
物流・工業団地等の大規模平地開発に対応。
"""
# Sec 7: 仮説検証総合 + 制度比較
sec7 = (
"本記事の 5 仮説と観測結果の照合:
"
+ df_to_html(T_hypo)
+ "3 RQ × 3 結論
"
""
f"- RQ1 結論: 広島県の許可盛土 {len(gdf)} 件は "
f"{gdf['市町名'].nunique()} 市町に分散し、上位 5 市町 ({', '.join(city_counts.head(3)['市町名'])}, ...) で "
f"{top5_share*100:.0f}% を集中。規模分布は対数正規型で中央値 {gdf['area_m2'].median():.0f} m²、"
f"max {gdf['area_m2'].max():,.0f} m² (戸建擁壁〜物流団地まで {np.log10(gdf['area_m2'].max()/max(gdf['area_m2'].min(),1)):.1f} 桁)。"
f"工事主の {private_share*100:.0f}% が民間法人 → 盛土行政は民間事業を許可制で監督する仕組み。"
f"崖面崩壊防止施設は {100*cliff_yes/len(gdf):.0f}% 設置だが、"
f"残りは「のり面設計で崖面そのものを生じさせない」 工夫により安全確保。
"
f"- RQ2 結論: 警戒区域内 {within_n} 件 + 100m 以内 {near_100_n} 件 = "
f"{100*(within_n+near_100_n)/len(gdf):.0f}% が警戒区域近接立地。"
f"「警戒区域外なら安全」という直観は反証される — "
f"許可盛土の地理は警戒区域とは独立にランダムではなく、近接に有意に集積する。"
f"これは「土砂災害リスク高エリアでも宅地・産業需要が高い」 という都市計画上の現実が"
f"盛土許可台帳に反映されている。盛土自体が新たな崩壊起点になるリスクは制度的にも要注視。
"
f"- RQ3 結論: 熱海型 (≥5m+≥5000m²) は {atami_n} 件 ({atami_share*100:.1f}%) →"
f" H5 ({'支持' if atami_share<0.10 else '反証'})。新法下で年間 {atami_n/((gdf['permit_date'].max() - gdf['permit_date'].min()).days/365.25):.1f} 件のペースで"
f"熱海規模の盛土が許可されている。最大盛土 {int(gdf['area_m2'].max()):,} m² は熱海事案上端面積の"
f"{gdf['area_m2'].max()/5500:.0f} 倍 → 監視重点対象。"
f"全件が新法施行 (2023-05-26) 後の許可で、月平均 {ym_counts.mean():.1f} 件の安定ペース。"
f"旧法時代との比較は本データ単独ではできないが、"
f"「制度が定着フェーズ」に入っていることは時系列の滑らかさから推察できる。
"
"
"
"制度比較サマリ — 旧法 / 新法 / 規模閾値 / 本データ
"
+ df_to_html(T_law)
+ "この表から読み取れること: 旧法 (1961-2023) は宅地造成等規制区域 (= 都市計画区域内) のみを対象とし、"
"山間地の大規模盛土は対象外だった。これは熱海事案 (山間部の搬入土) を防げない構造的欠陥。"
"新法 (2023-05-26〜) は対象を「特定盛土等規制区域」 (= 山間地・農地等を含む) に拡大し、"
"全土地の大規模盛土を規制可能にした。本データ 152 件はすべて新法下の許可案件で、"
"盛土規制法の実運用を観察する初期データ群となる。
"
)
# Sec 8: 発展課題
sec8 = f"""
結果 X → 新仮説 Y → 課題 Z (3 RQ × 1 課題以上)
発展課題 1 (RQ1 由来)
- 結果 X: 許可盛土 152 件は上位 5 市町に {top5_share*100:.0f}% が集中し、
面積分布は対数正規型 (中央値 {gdf['area_m2'].median():.0f} m²、max {gdf['area_m2'].max():,.0f} m²)。
民間法人が {private_share*100:.0f}% を占める。
- 新仮説 Y: 許可盛土の件数 / 人口比は市町別に大きく異なり、
「人口あたり盛土許可件数」 が宅地需要圧の指標になる。
また、市町別の都市計画区域指定状況と件数の相関は強い (= 区域指定が多い市町ほど許可も多い)。
- 課題 Z: 各市町の人口 (e-Stat 国勢調査) を取得して
「件数 / 人口万人比」 を計算。L15 (行政区域) や L16 (都市計画区域) の dataset と
sjoin して都市計画区域カバー率を市町別に算出。両者と許可件数の Pearson 相関 (Spearman も)
を計算し、件数決定要因のモデルを立てる。これは盛土行政の需要予測に直結。
発展課題 2 (RQ2 由来)
- 結果 X: 許可盛土の {100*(within_n+near_100_n)/len(gdf):.0f}% が警戒区域内 + 100m 以内に立地し、
規模 (面積) と警戒区域距離に明瞭な相関は見られない。「警戒区域外なら安全」 神話は反証される。
- 新仮説 Y: 警戒区域内 + 隣接立地の許可盛土は、崖面崩壊防止施設の設置率が
離隔立地よりも有意に高い (= 立地リスクを構造設計で補完する制度運用)。
また、警戒区域内案件の盛土量は離隔案件よりも小さい (= 立地リスクが高いほど規模を抑える運用)。
- 課題 Z: 警戒区域距離区分 × 崖面防止有無のクロス表を作成し、
Fisher 正確検定で独立性を検定。警戒区域距離 × 盛土量の散布図と Spearman 相関を計算。
もし両者が成立すれば、新法は「立地リスクを規模制限+構造補完で吸収」する設計思想を
実装していることを示す。これは盛土規制法の制度設計の効果検証になる。
発展課題 3 (RQ3 由来)
- 結果 X: 熱海型 (≥5m+≥5000m²) は {atami_n} 件 ({atami_share*100:.1f}%)。
新法下で年間 {atami_n/((gdf['permit_date'].max() - gdf['permit_date'].min()).days/365.25):.1f} 件のペースで
熱海規模の盛土が許可される。最大は熱海事案上端面積の{gdf['area_m2'].max()/5500:.0f} 倍規模。
- 新仮説 Y: 熱海型大規模盛土は完了後に新たな土砂災害警戒区域指定の根拠になる
可能性がある (= 盛土自体が将来の警戒区域指定対象に)。また、熱海型は近接河川に
対する流出土砂リスクが高く、河川氾濫想定 (L4-L11 河川データ) との重ね合わせが必要。
- 課題 Z: 熱海型 {atami_n} 件の (緯度経度, 完了予定日) を取得し、
DoBoX の土砂災害警戒区域 (定期更新版)の指定履歴を追跡。
盛土完了日の前後で警戒区域指定が新規追加された件数を集計。
また、熱海型から最近河川 (L11 既扱) までの最短距離を計算し、
300m 以内のものを「河川流入リスク高熱海型」として絞り込む。
これは盛土の事後評価と連鎖リスクを可視化する研究で、
防災投資の優先順位付けに直結する。
"""
# Combine sections
sections = [
("学習目標と問い", sec1),
("使用データ", sec2),
("ダウンロード", sec3),
("【RQ1】 地理分布と件数構造の研究 — 県内許可盛土 152 件の全方位記述",
sec4_intro
+ "実装コード (CSV パース + GeoDataFrame + 主体分類)
"
+ sec4_code
+ sec4_fig1_text
+ figure("assets/L52_fig1_geomap.png",
"図 1 (RQ1): 許可盛土 152 件の地理分布 (点マップ + コロプレス)")
+ sec4_fig1_read
+ sec4_fig2_text
+ figure("assets/L52_fig2_scale_dist.png",
"図 2 (RQ1): 規模分布 — 高さ・面積・土量 (対数ビン)")
+ sec4_fig2_read
+ sec4_fig3_text
+ figure("assets/L52_fig3_owner_cliff.png",
"図 3 (RQ1): 工事主体 + 崖面崩壊防止施設の有無")
+ sec4_fig3_read
+ sec4_fig4_text
+ figure("assets/L52_fig4_monthly_timeline.png",
"図 4 (RQ1+RQ3): 月別件数 時系列")
+ sec4_fig4_read
+ "表: 全体サマリ
"
+ df_to_html(T_overall)
+ "この表から読み取れること: 152 件のうち 民間法人 "
f"{private_share*100:.0f}%、警戒区域内+100m {100*(within_n+near_100_n)/len(gdf):.0f}%、"
f"熱海型 {atami_share*100:.1f}% という 3 軸の構造的事実が初めて定量化された。"
f"崖面防止施設は {100*cliff_yes/len(gdf):.1f}% のみ設置だが、これは設計でのり面を緩勾配にして"
"崖面そのものを生じさせない選択が広く取られていることを反映する (= 法は崖面が生じる場合のみ"
"防止施設を要求するため、設計で崖面を回避すれば施設は不要)。
"
+ "表: 市町別件数ランキング (Top 15)
"
+ df_to_html(T_city)
+ "この表から読み取れること: 上位 5 市町 "
f"({', '.join(city_counts.head(5)['市町名'])}) で全体の "
f"{top5_share*100:.0f}% を占める → H1 ({'支持' if top5_share>=0.50 else '部分支持'})。"
"東広島市が件数・規模ともに突出するのは、広島大学キャンパス周辺の住宅団地造成 + "
"JR 山陽本線沿線の開発が背景。市町別の高さ・面積中央値にもばらつきがあり、"
"山間部市町 (庄原・三次・北広島) は中央値が大きく、平地市町 (廿日市・府中町) は中央値が小さい。
"
+ "表: 月別件数 (許可ペース)
"
+ df_to_html(T_monthly)
+ "この表から読み取れること: 許可は月平均 "
f"{ym_counts.mean():.1f} 件で安定ペース。ピークは {peak_month} ({peak_n} 件)。"
"0 件月はほぼ無く、新法下 2 年強の運用で行政審査が定常化していることを示す。
"
),
("【RQ2】 警戒区域との空間関係研究 — 「警戒区域外なら安全」 神話の検証",
sec5_intro
+ "実装コード (STRtree による高速最近傍距離)
"
+ sec5_code
+ sec5_fig5_text
+ figure("assets/L52_fig5_warn_overlay.png",
"図 5 (RQ2): 警戒区域オーバーレイ + 距離分布")
+ sec5_fig5_read
+ sec5_fig6_text
+ figure("assets/L52_fig6_dist_size_scatter.png",
"図 6 (RQ2): 警戒区域距離 × 盛土面積 散布図")
+ sec5_fig6_read
+ "表: 警戒区域距離区分サマリ
"
+ df_to_html(T_warn)
+ "この表から読み取れること: 警戒区域内 "
f"{within_n} 件、100m 以内 {near_100_n} 件、100-500m {near_500_n} 件、500m 超 {far_n} 件。"
f"区域内+100m 合算 {100*(within_n+near_100_n)/len(gdf):.0f}% という事実は、許可盛土が"
"災害リスク高エリアにも有意に分布することを示す。盛土自体が新たな崩壊起点になる"
"リスクは制度上引き続き要注視。
"
+ "表: 警戒区域内 + 100m 以内 立地の許可盛土詳細
"
+ df_to_html(T_warn_in.head(20))
+ "この表から読み取れること: 上位 20 件を表示。最近接警戒種別は"
f"急傾斜地崩壊 ({(gdf['nearest_warn_type']=='急傾斜地崩壊').sum()}/{len(gdf)} 件) が多い。"
"これらは「丘陵都市の急斜面に張り出した宅地造成」 が支配的であることを反映。"
"崖面防止施設の有無も併記しており、立地リスクと構造補完の関係が一覧できる。
"
),
("【RQ3】 制度変化と熱海型大規模盛土の研究 — 2021 熱海以降の運用診断",
sec6_intro
+ "実装コード (規模カテゴリ + 累積時系列)
"
+ sec6_code
+ sec6_fig7_text
+ figure("assets/L52_fig7_height_area.png",
"図 7 (RQ3): 高さ × 面積 — 熱海型大規模盛土の同定")
+ sec6_fig7_read
+ sec6_fig8_text
+ figure("assets/L52_fig8_scale_cumulative.png",
"図 8 (RQ3): 規模カテゴリ構成 + 累積件数の時系列")
+ sec6_fig8_read
+ sec6_fig9_text
+ figure("assets/L52_fig9_top_city_cross.png",
"図 9 (統合 RQ1+RQ2+RQ3): 上位 10 市町の規模 × 警戒区域距離")
+ sec6_fig9_read
+ "表: 規模カテゴリ集計
"
+ df_to_html(T_scale)
+ "この表から読み取れること: 中規模が "
f"{100*scale_counts.get('M_中規模 (1.5m+ or 500m²+)',0)/len(gdf):.0f}% で最多 → 盛土規制法の運用は"
f"「典型的な団地擁壁」が中心。熱海型 {atami_n} 件 ({atami_share*100:.1f}%) は少数だが、"
"監視重点対象として個別に追跡する必要がある。中央値の大小から、"
"規模カテゴリ間で盛土量がべき乗的に増加することが見える。
"
+ "表: 工事主体タイプ別
"
+ df_to_html(T_owner)
+ "この表から読み取れること: 民間法人が圧倒多数 (代表例 = 株式会社・有限会社の建設業者) で、"
"公共は町長・市長名義の数件のみ。盛土規制法は民間事業を許可制で監督する制度設計だが、"
"個人発注 (戸建擁壁) も無視できない数 → 法は事業者規模を問わず規模閾値で適用される。
"
+ "表: 熱海型 (≥5m+≥5000m²) 全件詳細
"
+ df_to_html(T_atami)
+ "この表から読み取れること: 熱海型 "
f"{atami_n} 件は{', '.join(sorted(set(T_atami['市町名'])))} に分布。"
"盛土量が大きい上位案件は数万 m³ 規模で、熱海事案上端面積 (~5,500 m²) を超える。"
"崖面防止施設の有無は半々程度で、「無」 案件は 緩勾配のり面設計に依存。"
"これらは個別に施工監視・完成後点検を要する重要案件。
"
),
("仮説検証総合", sec7),
("発展課題", sec8),
]
html = render_lesson(
num=52,
title="許可盛土等(法第12条第1項・30条第1項) 単独 3 研究例分析 — 盛土規制法下の 152 件を 3 つの研究角度で読み解く",
tags=["L52", "盛土規制法", "許可盛土", "RQ×3", "Format B", "熱海土石流", "警戒区域連動"],
time="35 分",
level="中級+",
data_label="DoBoX dataset 1429 (CSV 152 行 + XLSX 規制資料)",
sections=sections,
script_filename="L52_authorized_earthfill.py",
)
OUT_HTML = LESSONS / "L52_authorized_earthfill.html"
OUT_HTML.write_text(html, encoding="utf-8")
print(f" HTML written: {OUT_HTML}")
print(f" ({time.time()-t11:.1f}s)", flush=True)
print(f"\n=== L52 DONE in {time.time()-t_all:.1f}s ===")
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}