# -*- coding: utf-8 -*-
"""L41 航空レーザ計測に基づく森林資源データ 3 件統合分析
— 樹種ポリゴン・単木ポイント・20m メッシュ集計の地理単位の差を読む
カバー宣言:
本記事は DoBoX のシリーズ 「航空レーザ計測に基づく森林資源データ」 3 件
(dataset_id = 1519, 1520, 1521) を統合し、広島県内の森林資源データの
地理的編成と派生関係を読み解く研究記事である。
「航空レーザ計測に基づく森林資源データ」とは、L36 樹高 (DCHM)・L37 点群密度・
L38 CS立体図・L39 傾斜・L40 標高 と同じ広島県航空レーザ計測 (2018-2019, 林野庁治山課/
国土交通省中国地方整備局/広島県土木建築局) の派生プロダクトであるが、
L36-L40 がラスタ (画素マトリクス) として地表全体を表現するのに対し、
本記事の 3 件は ベクタ (ポリゴン・ポイント) として林分・単木という
「人為単位」 で森林資源を表現する。
すなわち本データは LiDAR ファミリの「林業応用層」であり、森林経営計画
(森林法第 5 条) の基礎資料として広島県林業課で取りまとめられた成果である。
L36 樹高 (DCHM = DSM-DTM), L37 点群密度, L38 CS立体図, L39 傾斜, L40 標高 と並ぶ
LiDAR ファミリの林業応用篇 (= 第 6 本目)。
他の LiDAR 系記事 (CS立体図/標高図/地形傾斜図/樹高図/点群密度図/地図情報/計測年度図)
とは合体しない厳密シリーズ単独記事。L36 樹高とは
「DCHM ラスタ (L36) → 樹頂点抽出 → 単木ポイント (本記事 1520)」という
派生関係で結ばれる。
研究の問い (RQ):
広島県内の航空レーザ由来森林資源 3 dataset は、
(a) 樹種ポリゴン (1519, 市町村単位 polygon),
(b) 単木ポイント (1520, 市町村単位 point),
(c) 森林資源量集計メッシュ (1521, 20m grid mesh, 国土基本図図郭単位 polygon)
という3 つの異なる地理単位で公開されている。
各 dataset の (構造・指標・スケール) を比較し、
「3 dataset を統合すると、広島県の森林タイプ・林相成熟度・林業生産性の地理が
どう描けるか」を量的に検証する。
サブ問い:
(1) 各 dataset の地理編成方式 (市町別 vs メッシュ別) と提供指標の差は何か
(2) 樹種構成 (ヒノキ vs スギ vs その他) と面積分布
(3) 単木の樹高・胸高直径・単木材積分布。樹種で違うか
(4) 樹高 vs 胸高直径のアロメトリ関係 (= 樹木形状の物理法則)
(5) ha材積 (m³/ha) の地理分布。高材積エリア (>500m³/ha) はどこに集中するか
(6) 収量比数・形状比・樹冠長率 が示す林相の健全度
(7) 単木集計 (1520) と mesh 集計 (1521) は同じ航空レーザから派生した相補ペア
か、独立分析か (= 計算法の差を量的に確認)
(8) 3 dataset の合成可能性: 共通自治体 ≠ 共通メッシュ → 統合は不可能ではないが
手間。誰がどう整備すべきかの方法論的提言
仮説 H1〜H7:
H1 (Sera 樹種はヒノキ優占): 樹種ポリゴン (1519, 世羅町) で
ヒノキ ≥ 40% かつ スギ ≤ 30% かつ「その他 (広葉樹等)」≤ 30%。
中山間林業地は針葉樹植林が多いという広島県の林業統計と整合する。
H2 (スギはヒノキより高木): 単木ポイント (1520, 世羅町) で
スギ平均樹高 ≥ ヒノキ平均樹高 + 4m, スギ平均単木材積 ≥ ヒノキ × 2。
スギは成長が早く到達樹高が高い植林樹種。
H3 (樹高 vs 胸高直径は強正相関): 単木ポイント (1520) で Pearson r ≥ 0.7。
これは樹木のアロメトリ (allometry) という生物物理的法則に基づく。
ただし樹種で傾きが異なる (スギは細長、ヒノキは太短)。
H4 (高材積エリアはランダム分布ではなく集塊): mesh (1521, 庄原近傍) で
ha材積 > 500 m³/ha のセルは 8 近傍同種率 ≥ 0.6 で集塊。
理由: 同一林班・同一管理単位は連続するため。
H5 (収量比数 0.7 以上が「収穫期到来」の閾値): mesh (1521) で
収量比数 ≥ 0.7 のセルは平均樹高 ≥ 18m。
森林経営計画上、収量比数 0.7 は皆伐期の標準閾値とされる。
H6 (形状比は健全度指標): mesh (1521) で形状比 70-90 が標準健全範囲、
100 超は「過密で不健全」。形状比 = 樹高 (cm) / 胸高直径 (cm)。
過密林では細長い木が育ち倒木リスク高。
H7 (単木と mesh の指標整合性): 単木 1520 の集計値 (世羅町・mean単木材積) は
mesh 1521 の同自治体集計とは比較不可 (1521 は世羅町ではなく
庄原市を含むメッシュ)。これが本データセットの地理単位の差の制約。
この制約を量的に確認することが本記事の方法論的貢献。
要件 S 準拠: 1 分以内完走 (mesh 750k 行は valued 行 131k に絞り、
単木 3.4M ポイントはランダムサブサンプル + 樹種別読み込み)。
要件 T 準拠: 3 自治体地図 + 樹種主題図 + ha材積 choropleth + 単木サンプル点マップ + small multiples。
要件 Q 準拠: 図 11 種, 表 12+ (3 dataset × 多角度).
データ仕様:
A. 樹種ポリゴン dataset 1519: 県内 10 市町 GeoPackage 公開。
本記事は世羅町 (resource_id=95897) を採用。
- 形式: GeoPackage Polygon (EPSG:6671), 13,025 ポリゴン
- 属性: 樹種ID/樹種/面積_ha/森林計測年/森林計測法
- 樹種カテゴリ: ヒノキ/スギ/アカマツ/タケ/その他 (= 広葉樹等)
B. 単木ポイント dataset 1520: 県内 10 市町 GeoPackage 公開。
本記事は世羅町 (resource_id=95923) を採用 (= 1519 と同自治体)。
- 形式: GeoPackage Point (EPSG:6671), 3,397,186 単木ポイント
- 属性: 樹種ID/樹種/樹高/胸高直径/単木材積/形状比/樹冠長率/樹冠面積
- 注: 樹種ポリゴンで「スギ・ヒノキ」と判読された区域内の単木のみ抽出
C. 森林資源量集計メッシュ dataset 1521: 県内 10 図郭 GeoPackage 公開。
本記事は03NF2 図郭 (resource_id=95899, 庄原市域) を採用。
- 形式: GeoPackage Polygon 20m mesh (EPSG:6671), 750,000 mesh セル
- 属性: 樹種/面積_ha/立木本数/立木密度/平均樹高/平均直径/合計材積/ha材積/
収量比数/相対幹距比/形状比/樹冠長率
- 図郭は南北 15km × 東西 20km 単位 (国土基本図地図情報レベル 50000 を 4 分割)
"""
from __future__ import annotations
import sys, time, json, os, gc
from pathlib import Path
sys.path.insert(0, str(Path(__file__).parent))
from _common import ROOT, ASSETS, LESSONS, render_lesson, code, figure
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.patches import Patch
from matplotlib.colors import ListedColormap, BoundaryNorm, LinearSegmentedColormap
import matplotlib.patches as mpatches
import geopandas as gpd
import pyogrio
from shapely.geometry import box, Point, Polygon
import zipfile
import io as _io
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
t0 = time.time()
print("=== L41 航空レーザ森林資源 3 件統合分析 ===", flush=True)
# =============================================================================
# 0. 定数・データパス
# =============================================================================
DATA_DIR = ROOT / "data" / "extras" / "L41_forest_resources"
DATA_DIR.mkdir(parents=True, exist_ok=True)
ADMIN_DIR = ROOT / "data" / "extras" / "L15_admin_zones"
# === 3 dataset の定義 =========================================================
DATASETS = {
"tree_species": {
"label": "樹種ポリゴン",
"dataset_id": 1519,
"resource_id": 95897, # 世羅町
"resource_label": "樹種ポリゴンデータ(世羅町)",
"zip_url": "https://hiroshima-dobox.jp/resource_download/95897",
"zip_local": DATA_DIR / "tree_species_34462_sera.zip",
"gpkg": DATA_DIR / "tree_species_34462.gpkg",
"layer": "tree_species_34462",
"geom_type": "Polygon",
"muni_code": 34462,
"muni_label": "世羅町",
"color": "#1a7f37",
"geographic_unit": "市町村単位 polygon",
},
"tree_point": {
"label": "単木ポイント",
"dataset_id": 1520,
"resource_id": 95923, # 世羅町 (同自治体ペア)
"resource_label": "単木ポイントデータ(世羅町)",
"zip_url": "https://hiroshima-dobox.jp/resource_download/95923",
"zip_local": DATA_DIR / "tree_point_34462_sera.zip",
"gpkg": DATA_DIR / "tree_point_34462.gpkg",
"layer": "tree_point_34462",
"geom_type": "Point",
"muni_code": 34462,
"muni_label": "世羅町",
"color": "#0969da",
"geographic_unit": "市町村単位 point",
},
"fr_mesh": {
"label": "森林資源量集計メッシュ",
"dataset_id": 1521,
"resource_id": 95899, # 03NF2 図郭 = 庄原市域
"resource_label": "森林資源量集計メッシュデータ(03NF2)",
"zip_url": "https://hiroshima-dobox.jp/resource_download/95899",
"zip_local": DATA_DIR / "fr_mesh20m_03NF2.zip",
"gpkg": DATA_DIR / "fr_mesh20m_03NF2.gpkg",
"layer": "fr_mesh20m_03NF2",
"geom_type": "Polygon (20m mesh)",
"muni_code": 34210,
"muni_label": "庄原市 (含 03NF2 図郭)",
"color": "#cf222e",
"geographic_unit": "国土基本図図郭 20m mesh",
},
}
# 樹種カラーマップ (広島県林業 慣用色)
SPECIES_COLOR = {
"ヒノキ": "#33a02c",
"スギ": "#1f78b4",
"アカマツ": "#fb9a99",
"タケ": "#cab2d6",
"その他": "#cccccc", # = 広葉樹等
}
# ha材積の 5 階級 (森林経営計画の慣用閾値)
VOLUME_CLASSES = [
("極低", 0.0, 100.0, "#fee5d9", "0-100"),
("低", 100.0, 250.0, "#fcae91", "100-250"),
("中", 250.0, 500.0, "#fb6a4a", "250-500"),
("高", 500.0, 1000.0, "#de2d26", "500-1000"),
("極高", 1000.0, 5000.0, "#a50f15", ">1000"),
]
def ensure_zip(d):
p = d["zip_local"]
if p.exists() and p.stat().st_size > 1_000_000:
return p
import requests
UA = {"User-Agent": "DoBoX-MDASH-textbook/1.0 (educational)"}
print(f" DL {p.name} <- {d['zip_url']}", flush=True)
with requests.get(d["zip_url"], headers=UA, timeout=600, stream=True) as r:
r.raise_for_status()
with open(p, "wb") as f:
for chunk in r.iter_content(chunk_size=4*1024*1024):
if chunk:
f.write(chunk)
return p
def ensure_gpkg(d):
g = d["gpkg"]
if g.exists() and g.stat().st_size > 1_000_000:
return g
zp = ensure_zip(d)
print(f" Extract {g.name} from {zp.name}...", flush=True)
with zipfile.ZipFile(zp) as zf:
for info in zf.infolist():
if info.filename.lower().endswith(".gpkg"):
with zf.open(info) as src, open(g, "wb") as dst:
while True:
chunk = src.read(8*1024*1024)
if not chunk:
break
dst.write(chunk)
break
return g
# =============================================================================
# 1. データ確保
# =============================================================================
print("\n[1] データ確保: GeoPackage 抽出", flush=True)
t1 = time.time()
for k, d in DATASETS.items():
g = ensure_gpkg(d)
print(f" {d['label']}: {g.name} ({g.stat().st_size/(1024*1024):.0f} MB)", flush=True)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 2. 各 dataset のメタデータ
# =============================================================================
print("\n[2] メタデータ", flush=True)
t1 = time.time()
metas = []
for k, d in DATASETS.items():
info = pyogrio.read_info(d["gpkg"], layer=d["layer"])
bb = info["total_bounds"]
m = {
"key": k,
"label": d["label"],
"dataset_id": d["dataset_id"],
"resource_id": d["resource_id"],
"geom_type": d["geom_type"],
"geographic_unit": d["geographic_unit"],
"muni": d["muni_label"],
"features": int(info["features"]),
"fields_n": len(info["fields"]),
"fields": ", ".join(info["fields"]),
"crs": str(info["crs"]),
"bbox_x_min": float(bb[0]),
"bbox_y_min": float(bb[1]),
"bbox_x_max": float(bb[2]),
"bbox_y_max": float(bb[3]),
"bbox_w_km": float(bb[2] - bb[0]) / 1000,
"bbox_h_km": float(bb[3] - bb[1]) / 1000,
"file_mb": float(d["gpkg"].stat().st_size / (1024 * 1024)),
}
d["meta"] = m
metas.append(m)
print(f" {d['label']}: features={m['features']:,}, fields={m['fields_n']}, "
f"bbox={m['bbox_w_km']:.1f}x{m['bbox_h_km']:.1f}km, file={m['file_mb']:.0f}MB", flush=True)
meta_df = pd.DataFrame(metas)
meta_df.to_csv(ASSETS / "L41_dataset_meta.csv", index=False, encoding="utf-8-sig")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 3. 樹種ポリゴン (1519) の読込と樹種構成
# =============================================================================
print("\n[3] 樹種ポリゴン (1519) 読込", flush=True)
t1 = time.time()
ts_d = DATASETS["tree_species"]
gdf_ts = gpd.read_file(ts_d["gpkg"], layer=ts_d["layer"])
print(f" 読込: {len(gdf_ts):,} polygons", flush=True)
print(f" CRS: {gdf_ts.crs}", flush=True)
# 樹種構成 (count + area)
species_count = gdf_ts["樹種"].value_counts()
species_area = gdf_ts.groupby("樹種")["面積_ha"].sum().sort_values(ascending=False)
species_summary = pd.concat([
species_count.rename("polygon_count"),
species_area.rename("total_ha"),
], axis=1).fillna(0)
species_summary["count_pct"] = species_summary["polygon_count"] / species_summary["polygon_count"].sum() * 100
species_summary["area_pct"] = species_summary["total_ha"] / species_summary["total_ha"].sum() * 100
species_summary["mean_ha"] = species_summary["total_ha"] / species_summary["polygon_count"]
print(species_summary.round(2).to_string())
species_summary.to_csv(ASSETS / "L41_species_summary.csv", encoding="utf-8-sig")
# polygon 面積分布の統計
ts_area_stats = gdf_ts["面積_ha"].describe(percentiles=[0.1, 0.25, 0.5, 0.75, 0.9, 0.99])
print(f" 面積分布 (ha): mean={ts_area_stats['mean']:.2f}, median={ts_area_stats['50%']:.3f}, "
f"max={ts_area_stats['max']:.1f}", flush=True)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 4. 単木ポイント (1520) のサンプリング読込
# =============================================================================
print("\n[4] 単木ポイント (1520) サンプリング読込", flush=True)
t1 = time.time()
tp_d = DATASETS["tree_point"]
# 3.4M points ; full attribute read (no geometry) for stats
print(" 全件属性読込 (geom なし) ...", flush=True)
tp_attr = pyogrio.read_dataframe(tp_d["gpkg"], layer=tp_d["layer"], read_geometry=False)
print(f" 全件属性: {len(tp_attr):,}", flush=True)
# 樹種別集計
tp_by_species = tp_attr.groupby("樹種").agg(
n=("樹高", "count"),
height_mean=("樹高", "mean"),
height_median=("樹高", "median"),
height_std=("樹高", "std"),
height_p10=("樹高", lambda s: float(np.percentile(s, 10))),
height_p90=("樹高", lambda s: float(np.percentile(s, 90))),
dbh_mean=("胸高直径", "mean"),
dbh_median=("胸高直径", "median"),
dbh_std=("胸高直径", "std"),
vol_mean=("単木材積", "mean"),
vol_median=("単木材積", "median"),
vol_total=("単木材積", "sum"),
shape_mean=("形状比", "mean"),
crown_mean=("樹冠長率", "mean"),
).round(3)
print(tp_by_species.to_string())
tp_by_species.to_csv(ASSETS / "L41_tree_point_by_species.csv", encoding="utf-8-sig")
# 樹高 vs 胸高直径 の Pearson 相関 (アロメトリ)
tp_clean = tp_attr.dropna(subset=["樹高", "胸高直径"]).query("樹高 > 0 and 胸高直径 > 0")
allometry_rows = []
for sp in ["スギ", "ヒノキ"]:
sub = tp_clean[tp_clean["樹種"] == sp]
if len(sub) < 10:
continue
# 全件で計算 (相関は標本数大なので安定)
h = sub["樹高"].values.astype(np.float64)
d = sub["胸高直径"].values.astype(np.float64)
# 線形回帰 (h = a + b * dbh)
X = np.vstack([np.ones(len(d)), d]).T
coef, *_ = np.linalg.lstsq(X, h, rcond=None)
a, b = coef
# 対数アロメトリ (h = c * dbh^d)
log_h = np.log(h)
log_d = np.log(d)
Xl = np.vstack([np.ones(len(log_d)), log_d]).T
coef2, *_ = np.linalg.lstsq(Xl, log_h, rcond=None)
log_c, exp_d = coef2
allometry_rows.append({
"species": sp,
"n": len(sub),
"r_pearson": float(np.corrcoef(h, d)[0, 1]),
"lin_intercept": float(a),
"lin_slope": float(b),
"log_c": float(np.exp(log_c)),
"log_exp": float(exp_d),
"h_mean": float(h.mean()),
"d_mean": float(d.mean()),
})
allometry_df = pd.DataFrame(allometry_rows)
print(allometry_df.round(4).to_string(index=False))
allometry_df.to_csv(ASSETS / "L41_allometry.csv", index=False, encoding="utf-8-sig")
# 単木サンプル (geometry 付き, 図用に 3% subsample)
print(" 単木サンプル読込 (figureプロット用 subsample) ...", flush=True)
sample_size = min(50000, len(tp_attr)) # 5万点を目処
# 簡易ランダム: skip-based sampling via fid
total_n = len(tp_attr)
skip = max(1, total_n // sample_size)
# pyogrio: read with where clause based on fid is feasible but cumbersome.
# Use rows= as slice (no step). We instead read all geom and subsample.
rng = np.random.default_rng(0)
sel_idx = rng.choice(total_n, size=min(sample_size, total_n), replace=False)
sel_idx.sort()
# pyogrio: rows= で連続スライスのみ可。サブサンプルは slice + 後処理で対応
# 高速化: bbox 抽出で世羅町範囲内に絞り、その中からランダムサンプル
print(f" geometry読込 (sliced) ...", flush=True)
# rows=slice で 50000 までに絞る (連続行を取得して、その中で代表的なサンプル)
# pyogrio.read_dataframe で skip + max_features を使うと scattered sample 可能
read_n = min(sample_size, total_n)
# pyogrio 非連続サンプルは file ID 指定が必要。連続スライス + 樹種別 stratify で代用:
# スギ/ヒノキの index が分離している (ヒノキ first 3M, スギ next 0.3M) ことを利用
sel_h = sorted(rng.choice(3067440, size=int(read_n * 0.9), replace=False).tolist())
sel_s = sorted([3067440 + i for i in rng.choice(329746, size=int(read_n * 0.1), replace=False)])
fids = sorted(sel_h + sel_s)
gdf_tp = pyogrio.read_dataframe(tp_d["gpkg"], layer=tp_d["layer"], fids=fids)
print(f" サブサンプル: {len(gdf_tp):,}", flush=True)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 5. mesh 集計 (1521) の読込
# =============================================================================
print("\n[5] 森林資源量集計メッシュ (1521) 読込", flush=True)
t1 = time.time()
mesh_d = DATASETS["fr_mesh"]
gdf_mesh_full = gpd.read_file(mesh_d["gpkg"], layer=mesh_d["layer"])
print(f" 全 mesh: {len(gdf_mesh_full):,}", flush=True)
# valued mesh (= 樹種が判読されたメッシュ)
mesh_valued = gdf_mesh_full[gdf_mesh_full["樹種"].notna()].copy()
print(f" valued mesh (樹種判読あり): {len(mesh_valued):,}", flush=True)
# numeric 値が入った mesh (= 林分指標が計測されたメッシュ)
mesh_numeric = mesh_valued.dropna(subset=["ha材積", "立木密度", "平均樹高"]).copy()
print(f" numeric mesh (林分指標あり): {len(mesh_numeric):,}", flush=True)
# 重要な構造的観察: 「その他」(= 広葉樹混交林) メッシュは 樹種は判読されるが
# 林分指標 (立木本数, 立木密度, 平均樹高, ...) は欠損
# つまり 1521 mesh の数値指標は "管理対象 (スギ・ヒノキ)" のみ計算される
mesh_only_species = mesh_valued[mesh_valued["ha材積"].isna()]
mesh_other_count = len(mesh_only_species[mesh_only_species["樹種"] == "その他"])
print(f" 「その他」mesh (樹種だけ判読, 林分指標欠損): {mesh_other_count:,}", flush=True)
# 樹種別集計
mesh_by_species = mesh_numeric.groupby("樹種").agg(
n_mesh=("樹種", "size"),
haarea=("面積_ha", "sum"),
ha_volume_mean=("ha材積", "mean"),
ha_volume_median=("ha材積", "median"),
density_mean=("立木密度", "mean"),
density_median=("立木密度", "median"),
height_mean=("平均樹高", "mean"),
height_median=("平均樹高", "median"),
diameter_mean=("平均直径", "mean"),
yield_ratio_mean=("収量比数", "mean"),
yield_ratio_median=("収量比数", "median"),
shape_mean=("形状比", "mean"),
crown_mean=("樹冠長率", "mean"),
).round(3)
print(mesh_by_species.to_string())
mesh_by_species.to_csv(ASSETS / "L41_mesh_by_species.csv", encoding="utf-8-sig")
# ha材積 5 階級分類
def classify_volume(v):
for i, (_, lo, hi, _, _) in enumerate(VOLUME_CLASSES, start=1):
if lo <= v < hi:
return i
return 0
mesh_numeric["volume_class"] = mesh_numeric["ha材積"].apply(classify_volume)
volume_class_counts = mesh_numeric.groupby(["樹種", "volume_class"]).size().unstack(fill_value=0)
volume_class_counts.columns = [VOLUME_CLASSES[c-1][0] for c in volume_class_counts.columns]
print(volume_class_counts.to_string())
volume_class_counts.to_csv(ASSETS / "L41_volume_class.csv", encoding="utf-8-sig")
# 高材積 (>500) は割合
high_vol_pct = mesh_numeric.groupby("樹種").apply(
lambda s: (s["ha材積"] >= 500).sum() / len(s) * 100, include_groups=False
).rename("pct_ge_500").to_frame()
high_vol_pct.to_csv(ASSETS / "L41_high_volume_pct.csv", encoding="utf-8-sig")
# 収量比数 0.7 以上 (収穫期) の閾値
mesh_numeric["is_harvest_ready"] = mesh_numeric["収量比数"] >= 0.7
harvest_summary = mesh_numeric.groupby("樹種").agg(
n_total=("樹種", "size"),
n_harvest=("is_harvest_ready", "sum"),
pct_harvest=("is_harvest_ready", lambda s: float(s.mean() * 100)),
height_in_harvest=("平均樹高", lambda s: float(s[mesh_numeric.loc[s.index, "is_harvest_ready"]].mean()) if s.notna().any() else 0),
).round(2)
print("収穫期 (収量比数≥0.7) 比率:")
print(harvest_summary.to_string())
harvest_summary.to_csv(ASSETS / "L41_harvest_ready.csv", encoding="utf-8-sig")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 6. 行政界読込 (Sera = 1519/1520, Shobara = 1521 図郭)
# =============================================================================
print("\n[6] 行政界読込", flush=True)
t1 = time.time()
def load_admin_zip(zip_path, target_crs):
with zipfile.ZipFile(zip_path) as zf:
names = zf.namelist()
for n in names:
if n.lower().endswith(".geojson"):
with zf.open(n) as f:
g = gpd.read_file(_io.BytesIO(f.read()))
return g.to_crs(target_crs)
for n in names:
if n.lower().endswith(".shp"):
tmp = zip_path.parent / f"_ext_{zip_path.stem}"
tmp.mkdir(exist_ok=True)
zf.extractall(tmp)
g = gpd.read_file(tmp / n, encoding="cp932")
return g.to_crs(target_crs)
return None
sera_admin_zip = ADMIN_DIR / "admin_941_世羅町.zip"
shobara_admin_zip = ADMIN_DIR / "admin_856_庄原市.zip"
sera_admin = None
shobara_admin = None
try:
sera_admin = load_admin_zip(sera_admin_zip, gdf_ts.crs)
print(f" 世羅町行政界: {len(sera_admin)} polygons, area={sera_admin.geometry.area.sum()/1e6:.1f}km²", flush=True)
except Exception as e:
print(f" 世羅町: {e}", flush=True)
try:
shobara_admin = load_admin_zip(shobara_admin_zip, gdf_mesh_full.crs)
print(f" 庄原市行政界: {len(shobara_admin)} polygons, area={shobara_admin.geometry.area.sum()/1e6:.1f}km²", flush=True)
except Exception as e:
print(f" 庄原市: {e}", flush=True)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 7. mesh 高材積セルの集塊性 (8 近傍同種率)
# =============================================================================
print("\n[7] 高材積メッシュの集塊性", flush=True)
t1 = time.time()
# メッシュは 20m 規則格子なので、(x, y) → (col, row) に整数化して 2D ラスタ化
# bbox から min を引いて 20m で割る
b = gdf_mesh_full.total_bounds # 60000 -105000 80000 -90000
x_min, y_min, x_max, y_max = b
cell = 20.0
W = int(round((x_max - x_min) / cell))
H = int(round((y_max - y_min) / cell))
print(f" mesh raster grid: {W} x {H} = {W*H:,}", flush=True)
# numeric mesh から ha材積マップを作る
hav_grid = np.full((H, W), np.nan, dtype=np.float32)
species_grid = np.zeros((H, W), dtype=np.int8) # 0=void,1=スギ,2=ヒノキ,3=その他
SP_TO_INT = {"スギ": 1, "ヒノキ": 2, "その他": 3}
# メッシュは 1 行あたり 1 セル → centroid 計算で col, row を求める
cx = mesh_numeric.geometry.centroid.x.values
cy = mesh_numeric.geometry.centroid.y.values
col = ((cx - x_min) // cell).astype(int)
row = ((y_max - cy) // cell).astype(int)
in_grid = (col >= 0) & (col < W) & (row >= 0) & (row < H)
col = col[in_grid]
row = row[in_grid]
hav = mesh_numeric["ha材積"].values[in_grid].astype(np.float32)
sp_int = mesh_numeric["樹種"].map(SP_TO_INT).fillna(3).values[in_grid].astype(np.int8)
hav_grid[row, col] = hav
species_grid[row, col] = sp_int
n_filled = (~np.isnan(hav_grid)).sum()
print(f" filled cells: {n_filled:,} ({n_filled/(W*H)*100:.2f}%)", flush=True)
# 高材積マスク (≥500 m³/ha)
high_mask = hav_grid >= 500.0
print(f" high-volume mask cells: {int(high_mask.sum()):,}", flush=True)
# 8 近傍同種率 (有効セル間のみ)
def neighbor_same_rate(mask, valid):
"""8 近傍で両セルとも valid なペアのうち、両方 mask=True の比率"""
H, W = mask.shape
pairs_total = 0
pairs_same = 0
for dy in [-1, 0, 1]:
for dx in [-1, 0, 1]:
if dy == 0 and dx == 0: continue
y0a, y1a = max(0, dy), min(H, H + dy)
x0a, x1a = max(0, dx), min(W, W + dx)
y0b, y1b = max(0, -dy), min(H, H - dy)
x0b, x1b = max(0, -dx), min(W, W - dx)
v1 = valid[y0a:y1a, x0a:x1a]
v2 = valid[y0b:y1b, x0b:x1b]
both_valid = v1 & v2
m1 = mask[y0a:y1a, x0a:x1a]
m2 = mask[y0b:y1b, x0b:x1b]
either = (m1 | m2) & both_valid
both = m1 & m2 & both_valid
pairs_total += int(either.sum())
pairs_same += int(both.sum())
return float(pairs_same / max(1, pairs_total)), pairs_total, pairs_same
valid_mask = ~np.isnan(hav_grid)
high_clu_rate, pt, ps = neighbor_same_rate(high_mask, valid_mask)
print(f" high-volume 8隣接同種率: {high_clu_rate:.3f} ({ps}/{pt})", flush=True)
# 樹種ごとの集塊性
species_clu_rows = []
for sp_name, sp_id in SP_TO_INT.items():
sp_mask = (species_grid == sp_id)
rate, pt, ps = neighbor_same_rate(sp_mask, valid_mask)
species_clu_rows.append({"species": sp_name, "rate": rate, "n_cells": int(sp_mask.sum()),
"pairs_same": ps, "pairs_total": pt})
clu_df = pd.DataFrame(species_clu_rows)
print(clu_df.round(3).to_string(index=False))
clu_df.to_csv(ASSETS / "L41_clustering.csv", index=False, encoding="utf-8-sig")
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 8. 図 1: 3 dataset の編成構造 (概念図)
# =============================================================================
print("\n[8] 図 1: 3 dataset 編成構造概念図", flush=True)
t1 = time.time()
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
for ax, (k, d) in zip(axes, DATASETS.items()):
m = d["meta"]
color = d["color"]
ax.set_facecolor("#fafafa")
ax.set_title(f"{d['label']}\n(dsid={d['dataset_id']}, {d['geom_type']})",
fontsize=11, color=color)
# bbox を矩形で描画
bw = m["bbox_w_km"]
bh = m["bbox_h_km"]
rect = mpatches.Rectangle((0, 0), bw, bh, linewidth=2,
edgecolor=color, facecolor=color, alpha=0.15)
ax.add_patch(rect)
# 中央にメタ情報
info_text = (
f"地理単位: {d['geographic_unit']}\n"
f"{d['muni_label']}\n"
f"\nfeatures = {m['features']:,}\n"
f"fields = {m['fields_n']}\n"
f"bbox = {bw:.1f} × {bh:.1f} km\n"
f"file = {m['file_mb']:.0f} MB"
)
ax.text(bw / 2, bh / 2, info_text,
ha="center", va="center", fontsize=10,
bbox=dict(boxstyle="round,pad=0.5", facecolor="white",
edgecolor=color, alpha=0.95))
ax.set_xlim(-bw*0.1, bw*1.1)
ax.set_ylim(-bh*0.1, bh*1.1)
ax.set_aspect("equal")
ax.set_xlabel("bbox 東西 (km)")
ax.set_ylabel("bbox 南北 (km)")
plt.suptitle("図 1: 3 dataset の地理編成 — 同じ航空レーザから派生したが異なる地理単位",
fontsize=12, y=1.02)
plt.tight_layout()
plt.savefig(ASSETS / "L41_fig1_concept.png", dpi=110, bbox_inches="tight")
plt.close(fig)
# =============================================================================
# 9. 図 2: 樹種ポリゴン主題図 (Sera)
# =============================================================================
print("[9] 図 2: 樹種ポリゴン主題図", flush=True)
fig, ax = plt.subplots(figsize=(10, 8))
# 樹種ごとに色分け
legend_handles = []
for sp, color in SPECIES_COLOR.items():
sub = gdf_ts[gdf_ts["樹種"] == sp]
if len(sub) == 0: continue
sub.plot(ax=ax, color=color, edgecolor="none", alpha=0.85)
legend_handles.append(mpatches.Patch(facecolor=color, edgecolor="black",
label=f"{sp} (n={len(sub):,})"))
if sera_admin is not None:
sera_admin.boundary.plot(ax=ax, color="black", linewidth=1.2)
ax.set_title(f"図 2: 樹種ポリゴン (1519 世羅町, n={len(gdf_ts):,})", fontsize=12)
ax.set_aspect("equal")
ax.legend(handles=legend_handles, loc="upper right", fontsize=9, frameon=True)
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
plt.tight_layout()
plt.savefig(ASSETS / "L41_fig2_species_map.png", dpi=110, bbox_inches="tight")
plt.close(fig)
# =============================================================================
# 10. 図 3: 樹種構成 (count + 面積) 棒グラフ
# =============================================================================
print("[10] 図 3: 樹種構成 棒グラフ", flush=True)
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
# count
sp_order = ["ヒノキ", "スギ", "アカマツ", "タケ", "その他"]
sp_present = [s for s in sp_order if s in species_summary.index]
counts = species_summary.loc[sp_present, "polygon_count"].values
areas = species_summary.loc[sp_present, "total_ha"].values
colors = [SPECIES_COLOR.get(s, "#999") for s in sp_present]
axes[0].bar(sp_present, counts, color=colors, edgecolor="black", linewidth=0.5)
axes[0].set_title("polygon 件数")
axes[0].set_ylabel("件数")
for i, c in enumerate(counts):
axes[0].text(i, c, f"{int(c):,}", ha="center", va="bottom", fontsize=9)
axes[1].bar(sp_present, areas, color=colors, edgecolor="black", linewidth=0.5)
axes[1].set_title("総面積 (ha)")
axes[1].set_ylabel("総面積 (ha)")
for i, a in enumerate(areas):
axes[1].text(i, a, f"{a:.0f}", ha="center", va="bottom", fontsize=9)
plt.suptitle(f"図 3: 樹種構成 (1519 世羅町) — 件数 vs 面積", fontsize=12)
plt.tight_layout()
plt.savefig(ASSETS / "L41_fig3_species_bars.png", dpi=110, bbox_inches="tight")
plt.close(fig)
# =============================================================================
# 11. 図 4: 単木の 樹高 ヒストグラム (樹種別)
# =============================================================================
print("[11] 図 4: 単木 樹高ヒストグラム", flush=True)
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
for ax, var, title, xlim in [
(axes[0], "樹高", "(a) 樹高分布 (m)", (0, 40)),
(axes[1], "胸高直径", "(b) 胸高直径分布 (cm)", (0, 60)),
]:
for sp, color in SPECIES_COLOR.items():
sub = tp_attr[tp_attr["樹種"] == sp]
if len(sub) == 0: continue
v = sub[var].dropna()
if len(v) == 0: continue
ax.hist(v, bins=80, range=xlim, color=color, alpha=0.7,
label=f"{sp} (n={len(sub):,})", density=True, edgecolor="none")
ax.set_xlabel(var)
ax.set_ylabel("密度")
ax.set_title(title)
ax.legend(fontsize=9)
ax.grid(True, alpha=0.3)
plt.suptitle("図 4: 単木 樹高 / 胸高直径分布 (1520 世羅町, 樹種別)", fontsize=12)
plt.tight_layout()
plt.savefig(ASSETS / "L41_fig4_height_dbh_hist.png", dpi=110, bbox_inches="tight")
plt.close(fig)
# =============================================================================
# 12. 図 5: 樹高 vs 胸高直径 のアロメトリ散布
# =============================================================================
print("[12] 図 5: 樹高 vs 胸高直径 アロメトリ", flush=True)
# 計算負荷を抑えるためサブサンプル (種ごと 30k 上限)
fig, ax = plt.subplots(figsize=(9, 7))
for sp, color in [("ヒノキ", "#33a02c"), ("スギ", "#1f78b4")]:
sub = tp_clean[tp_clean["樹種"] == sp]
if len(sub) == 0: continue
if len(sub) > 30000:
sub = sub.sample(30000, random_state=0)
ax.scatter(sub["胸高直径"], sub["樹高"], c=color, s=2, alpha=0.15,
label=f"{sp} (示=30k/{len(tp_clean[tp_clean['樹種'] == sp]):,})")
# アロメトリ回帰線 (対数)
row = next((r for r in allometry_rows if r["species"] == sp), None)
if row is not None:
d_grid = np.linspace(2, 60, 50)
h_pred = row["log_c"] * (d_grid ** row["log_exp"])
ax.plot(d_grid, h_pred, color=color, linewidth=2.5,
label=f"{sp} 対数回帰: h={row['log_c']:.2f}·dbh^{row['log_exp']:.2f}")
ax.set_xlabel("胸高直径 (cm)")
ax.set_ylabel("樹高 (m)")
ax.set_title(f"図 5: 樹高 × 胸高直径 アロメトリ (1520 世羅町, スギ/ヒノキ)",
fontsize=11)
ax.legend(fontsize=9, loc="lower right")
ax.grid(True, alpha=0.3)
ax.set_xlim(0, 60)
ax.set_ylim(0, 40)
plt.tight_layout()
plt.savefig(ASSETS / "L41_fig5_allometry.png", dpi=110, bbox_inches="tight")
plt.close(fig)
# =============================================================================
# 13. 図 6: 単木サンプル位置 + 樹高色分けマップ
# =============================================================================
print("[13] 図 6: 単木サンプルマップ", flush=True)
fig, ax = plt.subplots(figsize=(10, 8))
# subsample をマップに描画
pts = gdf_tp.copy()
pts["樹高_clip"] = pts["樹高"].clip(0, 30)
sc = ax.scatter(pts.geometry.x, pts.geometry.y, c=pts["樹高_clip"],
cmap="YlGn", s=1, alpha=0.6)
plt.colorbar(sc, ax=ax, label="樹高 (m)", shrink=0.7)
if sera_admin is not None:
sera_admin.boundary.plot(ax=ax, color="black", linewidth=1.2)
ax.set_title(f"図 6: 単木ポイント subsample {len(gdf_tp):,}/{len(tp_attr):,} (1520 世羅町)\n"
f"色 = 樹高 (m, 0-30 で clip)", fontsize=11)
ax.set_aspect("equal")
ax.set_xlabel("X (m)")
ax.set_ylabel("Y (m)")
plt.tight_layout()
plt.savefig(ASSETS / "L41_fig6_tree_point_map.png", dpi=110, bbox_inches="tight")
plt.close(fig)
# =============================================================================
# 14. 図 7: ha材積 choropleth (mesh)
# =============================================================================
print("[14] 図 7: ha材積 choropleth", flush=True)
fig, ax = plt.subplots(figsize=(11, 8))
# mesh を ha材積で色分け
vol_cmap = LinearSegmentedColormap.from_list(
"vol", ["#fee5d9", "#fcae91", "#fb6a4a", "#de2d26", "#a50f15"], N=256
)
mn = mesh_numeric.copy()
mn["ha材積_clip"] = mn["ha材積"].clip(0, 1500)
mn.plot(ax=ax, column="ha材積_clip", cmap=vol_cmap, vmin=0, vmax=1500,
edgecolor="none", legend=True,
legend_kwds={"label": "ha材積 (m³/ha)", "shrink": 0.7})
if shobara_admin is not None:
shobara_admin.boundary.plot(ax=ax, color="black", linewidth=1.0)
ax.set_title(f"図 7: ha材積 choropleth (1521 03NF2 図郭 庄原市域, n={len(mn):,} valued mesh)",
fontsize=11)
ax.set_aspect("equal")
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
plt.tight_layout()
plt.savefig(ASSETS / "L41_fig7_mesh_volume.png", dpi=110, bbox_inches="tight")
plt.close(fig)
# =============================================================================
# 15. 図 8: 林分指標の樹種別 box plot
# =============================================================================
print("[15] 図 8: 林分指標 box plot", flush=True)
fig, axes = plt.subplots(2, 3, figsize=(15, 9))
metrics = [
("ha材積", "ha材積 (m³/ha)", (0, 1500)),
("立木密度", "立木密度 (本/ha)", (0, 2500)),
("平均樹高", "平均樹高 (m)", (0, 35)),
("平均直径", "平均直径 (cm)", (0, 50)),
("収量比数", "収量比数 (-)", (0, 1.2)),
("形状比", "形状比 (= 樹高cm/胸高直径cm)", (30, 110)),
]
for ax, (col, title, ylim) in zip(axes.flat, metrics):
data_by_sp = []
labels = []
box_colors = []
for sp in ["スギ", "ヒノキ", "その他"]:
v = mesh_numeric[mesh_numeric["樹種"] == sp][col].dropna()
if len(v) == 0: continue
data_by_sp.append(v.values)
labels.append(f"{sp}\n(n={len(v):,})")
box_colors.append(SPECIES_COLOR.get(sp, "#999"))
bp = ax.boxplot(data_by_sp, tick_labels=labels, patch_artist=True,
showfliers=False, widths=0.6)
for patch, c in zip(bp["boxes"], box_colors):
patch.set_facecolor(c)
patch.set_alpha(0.65)
ax.set_title(title)
ax.set_ylim(ylim)
ax.grid(True, axis="y", alpha=0.3)
plt.suptitle("図 8: 林分指標 (1521 mesh) の樹種別 box plot", fontsize=13)
plt.tight_layout()
plt.savefig(ASSETS / "L41_fig8_mesh_boxes.png", dpi=110, bbox_inches="tight")
plt.close(fig)
# =============================================================================
# 16. 図 9: ha材積 階級分類マップ + 構成比
# =============================================================================
print("[16] 図 9: ha材積 階級マップ", flush=True)
fig = plt.figure(figsize=(15, 8))
ax_map = fig.add_subplot(1, 2, 1)
ax_bar = fig.add_subplot(1, 2, 2)
# class マップ
mn["volume_class_color"] = mn["volume_class"].map(
{i: VOLUME_CLASSES[i-1][3] for i in range(1, len(VOLUME_CLASSES) + 1)}
)
mn.plot(ax=ax_map, color=mn["volume_class_color"], edgecolor="none")
if shobara_admin is not None:
shobara_admin.boundary.plot(ax=ax_map, color="black", linewidth=1.0)
# legend
legend_patches = [
mpatches.Patch(facecolor=c[3], edgecolor="black", label=f"{c[0]} ({c[4]})")
for c in VOLUME_CLASSES
]
ax_map.legend(handles=legend_patches, loc="lower left", fontsize=9, frameon=True,
title="ha材積階級 (m³/ha)")
ax_map.set_title("(a) 5 階級分類マップ")
ax_map.set_aspect("equal")
# 構成比 bar (樹種 × 階級)
class_pct = volume_class_counts.div(volume_class_counts.sum(axis=1), axis=0) * 100
class_pct = class_pct[[VOLUME_CLASSES[i][0] for i in range(len(VOLUME_CLASSES)) if VOLUME_CLASSES[i][0] in class_pct.columns]]
bottom = np.zeros(len(class_pct))
for cls in class_pct.columns:
color = next((c[3] for c in VOLUME_CLASSES if c[0] == cls), "#999")
ax_bar.bar(class_pct.index, class_pct[cls], bottom=bottom,
color=color, label=cls, edgecolor="black", linewidth=0.4)
bottom = bottom + class_pct[cls].values
ax_bar.set_ylabel("構成比 (%)")
ax_bar.set_xlabel("樹種")
ax_bar.set_title("(b) 樹種別 ha材積階級構成 (%)")
ax_bar.legend(title="ha材積", fontsize=9, loc="center left", bbox_to_anchor=(1.02, 0.5))
plt.suptitle("図 9: ha材積 5 階級 — 階級マップ × 樹種別構成", fontsize=12)
plt.tight_layout()
plt.savefig(ASSETS / "L41_fig9_volume_class.png", dpi=110, bbox_inches="tight")
plt.close(fig)
# =============================================================================
# 17. 図 10: 収量比数 vs 平均樹高 散布 (収穫期判定)
# =============================================================================
print("[17] 図 10: 収量比数 vs 平均樹高", flush=True)
fig, ax = plt.subplots(figsize=(10, 7))
for sp in ["スギ", "ヒノキ", "その他"]:
sub = mesh_numeric[mesh_numeric["樹種"] == sp]
if len(sub) == 0: continue
if len(sub) > 20000:
sub = sub.sample(20000, random_state=0)
color = SPECIES_COLOR.get(sp, "#999")
ax.scatter(sub["収量比数"], sub["平均樹高"], c=color, s=4,
alpha=0.25, label=f"{sp} (示={len(sub):,})")
# 閾値線
ax.axvline(0.7, color="red", linestyle="--", linewidth=1.5,
label="収量比数=0.7 (収穫期目安)")
ax.axhline(18, color="orange", linestyle="--", linewidth=1.5,
label="平均樹高=18m")
ax.set_xlabel("収量比数 (-)")
ax.set_ylabel("平均樹高 (m)")
ax.set_title(f"図 10: 収量比数 × 平均樹高 (1521 mesh) — 収穫期 (≥0.7) 判定",
fontsize=11)
ax.legend(fontsize=9, loc="upper left")
ax.grid(True, alpha=0.3)
ax.set_xlim(0, 1.2)
ax.set_ylim(0, 35)
plt.tight_layout()
plt.savefig(ASSETS / "L41_fig10_yield_height.png", dpi=110, bbox_inches="tight")
plt.close(fig)
# =============================================================================
# 18. 図 11: 形状比 (= 健全度) ヒストグラム + 閾値
# =============================================================================
print("[18] 図 11: 形状比 ヒストグラム", flush=True)
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# (a) mesh 形状比
ax = axes[0]
for sp in ["スギ", "ヒノキ", "その他"]:
sub = mesh_numeric[mesh_numeric["樹種"] == sp]["形状比"].dropna()
if len(sub) == 0: continue
color = SPECIES_COLOR.get(sp, "#999")
ax.hist(sub, bins=60, range=(30, 110), color=color, alpha=0.6,
label=f"{sp} (n={len(sub):,})", density=True, edgecolor="none")
ax.axvspan(70, 90, alpha=0.15, color="green", label="70-90 (健全範囲)")
ax.axvline(100, color="red", linestyle="--", linewidth=1.5, label="100 (過密の上限)")
ax.set_xlabel("形状比 = 樹高(cm) / 胸高直径(cm)")
ax.set_ylabel("密度")
ax.set_title("(a) mesh 形状比 (1521)")
ax.legend(fontsize=9)
ax.grid(True, alpha=0.3)
# (b) 単木 形状比
ax = axes[1]
for sp in ["スギ", "ヒノキ"]:
sub = tp_attr[tp_attr["樹種"] == sp]["形状比"].dropna()
if len(sub) == 0: continue
color = SPECIES_COLOR.get(sp, "#999")
ax.hist(sub, bins=60, range=(30, 130), color=color, alpha=0.6,
label=f"{sp} (n={len(sub):,})", density=True, edgecolor="none")
ax.axvspan(70, 90, alpha=0.15, color="green", label="70-90 (健全範囲)")
ax.axvline(100, color="red", linestyle="--", linewidth=1.5, label="100 (過密の上限)")
ax.set_xlabel("形状比 = 樹高(cm) / 胸高直径(cm)")
ax.set_ylabel("密度")
ax.set_title("(b) 単木 形状比 (1520)")
ax.legend(fontsize=9)
ax.grid(True, alpha=0.3)
plt.suptitle("図 11: 形状比分布 — 林相健全度の量化 (mesh vs 単木)", fontsize=12)
plt.tight_layout()
plt.savefig(ASSETS / "L41_fig11_shape_ratio.png", dpi=110, bbox_inches="tight")
plt.close(fig)
# =============================================================================
# 19. 図 12: small multiples — 樹種別 ha材積 マップ
# =============================================================================
print("[19] 図 12: small multiples", flush=True)
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
# その他 mesh は ha材積 欠損のため、ポリゴン位置だけグレーで描く
# (89K polygon は描画が遅いので 1/4 サブサンプル)
mesh_other_all = mesh_valued[mesh_valued["樹種"] == "その他"]
if len(mesh_other_all) > 25000:
mesh_other_for_plot = mesh_other_all.sample(25000, random_state=0).copy()
else:
mesh_other_for_plot = mesh_other_all.copy()
for ax, sp in zip(axes, ["スギ", "ヒノキ", "その他"]):
color = SPECIES_COLOR.get(sp, "#999")
if sp == "その他":
# 樹種だけ判読されたが林分指標欠損 → ポリゴン位置だけ示す
if len(mesh_other_for_plot) > 0:
mesh_other_for_plot.plot(ax=ax, color="#bbbbbb", edgecolor="none", alpha=0.7)
if shobara_admin is not None:
shobara_admin.boundary.plot(ax=ax, color="black", linewidth=0.6)
ax.set_title(f"{sp} (n={len(mesh_other_for_plot):,}, ha材積欠損)\n位置のみ表示",
color="#888")
ax.set_aspect("equal")
ax.set_xticks([]); ax.set_yticks([])
continue
sub = mesh_numeric[mesh_numeric["樹種"] == sp]
if len(sub) == 0:
ax.set_title(f"{sp} (該当なし)")
ax.set_aspect("equal")
continue
sub_clip = sub.copy()
sub_clip["ha材積_clip"] = sub["ha材積"].clip(0, 1500)
sub_clip.plot(ax=ax, column="ha材積_clip", cmap=vol_cmap, vmin=0, vmax=1500,
edgecolor="none")
if shobara_admin is not None:
shobara_admin.boundary.plot(ax=ax, color="black", linewidth=0.6)
ax.set_title(f"{sp} (n={len(sub):,})", color=color)
ax.set_aspect("equal")
ax.set_xticks([]); ax.set_yticks([])
plt.suptitle("図 12: 樹種別 ha材積マップ (small multiples)", fontsize=12)
plt.tight_layout()
plt.savefig(ASSETS / "L41_fig12_small_multiples.png", dpi=110, bbox_inches="tight")
plt.close(fig)
# =============================================================================
# 20. 仮説判定
# =============================================================================
print("\n[20] 仮説判定", flush=True)
# H1: ヒノキ ≥ 40% かつ スギ ≤ 30%
hino_pct = species_summary.loc["ヒノキ", "count_pct"] if "ヒノキ" in species_summary.index else 0
sugi_pct = species_summary.loc["スギ", "count_pct"] if "スギ" in species_summary.index else 0
other_pct = species_summary.loc["その他", "count_pct"] if "その他" in species_summary.index else 0
h1_verdict = "支持" if (hino_pct >= 40 and sugi_pct <= 30 and other_pct <= 30) else "部分支持" if hino_pct >= 30 else "反証"
# H2: スギ平均樹高 ≥ ヒノキ + 4m
if "スギ" in tp_by_species.index and "ヒノキ" in tp_by_species.index:
sugi_h = tp_by_species.loc["スギ", "height_mean"]
hino_h = tp_by_species.loc["ヒノキ", "height_mean"]
sugi_v = tp_by_species.loc["スギ", "vol_mean"]
hino_v = tp_by_species.loc["ヒノキ", "vol_mean"]
h2_height_ok = (sugi_h - hino_h) >= 4
h2_vol_ok = sugi_v >= hino_v * 2
if h2_height_ok and h2_vol_ok:
h2_verdict = "支持"
elif h2_height_ok or h2_vol_ok:
h2_verdict = "部分支持"
else:
h2_verdict = "反証"
else:
h2_height_ok = h2_vol_ok = False
sugi_h = hino_h = sugi_v = hino_v = 0
h2_verdict = "未検証"
# H3: 樹高 vs DBH r ≥ 0.7
allom_rs = [r["r_pearson"] for r in allometry_rows]
all_strong = all(r >= 0.7 for r in allom_rs) if allom_rs else False
h3_verdict = "支持" if all_strong else "部分支持" if any(r >= 0.6 for r in allom_rs) else "反証"
# H4: 高材積 8 近傍同種率 ≥ 0.6
h4_verdict = "支持" if high_clu_rate >= 0.6 else "部分支持" if high_clu_rate >= 0.4 else "反証"
# H5: 収量比数 ≥ 0.7 で平均樹高 ≥ 18m
hsub = mesh_numeric[mesh_numeric["収量比数"] >= 0.7]
hsub_height_mean = float(hsub["平均樹高"].mean()) if len(hsub) > 0 else 0
h5_verdict = "支持" if hsub_height_mean >= 18 else "部分支持" if hsub_height_mean >= 15 else "反証"
# H6: 形状比 70-90 比率
shape_in_range = mesh_numeric[(mesh_numeric["形状比"] >= 70) & (mesh_numeric["形状比"] <= 90)]
shape_pct_in_range = len(shape_in_range) / max(1, len(mesh_numeric)) * 100
shape_over_100 = (mesh_numeric["形状比"] > 100).sum() / max(1, len(mesh_numeric)) * 100
h6_verdict = "支持" if 30 <= shape_pct_in_range <= 80 else "部分支持"
# H7: 単木 vs mesh の地理単位差は確認できたか
# 単木 1520 (Sera) と mesh 1521 (03NF2 = 庄原域) の自治体が異なる
# = 共通自治体ではないので直接比較不可、これを観察的に確認
common_muni = (DATASETS["tree_point"]["muni_code"] == DATASETS["fr_mesh"]["muni_code"])
h7_verdict = "支持" if not common_muni else "反証"
hypos = [
{"H": "H1", "claim": "Sera 樹種ポリゴン (1519) はヒノキ優占で全体構成 ヒノキ≥40%・スギ≤30%・その他≤30%",
"result": f"ヒノキ {hino_pct:.1f}%, スギ {sugi_pct:.1f}%, その他 {other_pct:.1f}%",
"verdict": h1_verdict},
{"H": "H2", "claim": "単木 (1520) でスギ平均樹高はヒノキ+4m 以上、平均単木材積はヒノキ×2 以上",
"result": f"スギ {sugi_h:.1f}m vs ヒノキ {hino_h:.1f}m (差={sugi_h-hino_h:+.1f}m), "
f"スギ材積 {sugi_v:.3f}m³ vs ヒノキ {hino_v:.3f}m³ (倍={sugi_v/max(0.001,hino_v):.2f})",
"verdict": h2_verdict},
{"H": "H3", "claim": "単木 (1520) で樹高 vs 胸高直径 Pearson r ≥ 0.7 (アロメトリ)",
"result": ", ".join(f"{r['species']} r={r['r_pearson']:.3f}" for r in allometry_rows),
"verdict": h3_verdict},
{"H": "H4", "claim": "mesh (1521) で ha材積 ≥ 500 m³/ha のセルは 8 近傍同種率 ≥ 0.6",
"result": f"高材積 8 近傍同種率 = {high_clu_rate:.3f}",
"verdict": h4_verdict},
{"H": "H5", "claim": "mesh (1521) 収量比数 ≥ 0.7 のセルは平均樹高 ≥ 18m (収穫期判定)",
"result": f"収量比数≥0.7 のセルの平均樹高 = {hsub_height_mean:.2f}m (n={len(hsub):,})",
"verdict": h5_verdict},
{"H": "H6", "claim": "mesh (1521) 形状比 70-90 が標準健全範囲, >100 は不健全",
"result": f"70-90 内 {shape_pct_in_range:.1f}%, >100 {shape_over_100:.2f}%",
"verdict": h6_verdict},
{"H": "H7", "claim": "単木 1520 (世羅町) と mesh 1521 (03NF2=庄原市域) は地理単位が異なり直接統合不可",
"result": f"単木 muni={DATASETS['tree_point']['muni_label']} vs "
f"mesh muni={DATASETS['fr_mesh']['muni_label']} (共通={common_muni})",
"verdict": h7_verdict},
]
for h in hypos:
print(f" {h['H']}: {h['verdict']}", flush=True)
# =============================================================================
# 21. HTML 構築
# =============================================================================
print("\n[21] HTML 構築", flush=True)
t1 = time.time()
sections = []
# === Section 1: 学習目標と問い ===
sec1 = f"""
研究の問い (RQ)
広島県内の航空レーザ計測に基づく森林資源 3 dataset:
- (a) 樹種ポリゴン (dsid 1519): 市町村単位の polygon で「どの面が何の樹種か」を示す
- (b) 単木ポイント (dsid 1520): 市町村単位の point で「個々のスギ・ヒノキ単木の位置・樹高・直径」を示す
- (c) 森林資源量集計メッシュ (dsid 1521): 国土基本図図郭の 20m mesh で「林分指標 (材積/密度/形状比など 10+ 列)」を示す
これら 3 dataset は同じ航空レーザ計測 (2018-2019) から派生したが、
地理単位が異なる (市町別 vs 図郭別) ため、単純に空間結合できない。
本記事は「3 dataset を統合すると、広島県の森林タイプ・林相成熟度・林業生産性の地理がどう描けるか」を量的に検証する。
独自用語の定義 (本記事内のみ)
| 用語 | 定義 (本記事独自) |
|---|
| 材積 | 立木の幹の体積 (m³)。単木材積 = 1 本の体積、ha材積 = 1ha あたりの合計材積 (m³/ha)。林業の経済価値の主指標。 |
| 林分 | 樹種・林齢・密度がほぼ均一な森林の塊。本記事 1521 mesh の 20m メッシュ単位で集計された値はその林分の代表値と読む。 |
| 収量比数 | 0-1+ の値。0 = 立木が極めてまばら、1 = 樹冠が完全に閉鎖、>0.7 = 収穫期到来の慣用閾値。 |
| 形状比 | 樹高(cm) ÷ 胸高直径(cm)。70-90 は健全、>100 は過密で不健全(細長い樹で倒木リスク高)。 |
| 樹冠長率 | (樹冠長 ÷ 樹高) × 100 (%)。樹高に占める樹冠の割合。40-50% が標準的健全林。 |
| アロメトリ | 「allometry = 異速成長」。樹木では「樹高 = c × 胸高直径^d」のべき乗法則が成り立つ。c, d は樹種固有定数。 |
| LiDAR 林業応用層 | 本記事独自呼称。L36-L40 のラスタ系 5 dataset と区別して、林業実務向けに集計したベクタ系 3 dataset (1519/1520/1521) を指す。 |
立てた仮説 (H1〜H7)
| 仮説 | 主張 | 背景 |
|---|
| H1 | 1519 ヒノキ ≥ 40%, スギ ≤ 30%, その他 ≤ 30% |
世羅町は中山間林業地で針葉樹植林が多いという広島県林業統計 |
| H2 | 1520 でスギは樹高 +4m, 単木材積 ×2 ヒノキより大きい |
スギは早生・到達樹高高い植林樹種 (一般生物学) |
| H3 | 1520 樹高 vs 胸高直径 Pearson r ≥ 0.7 |
樹木のアロメトリ (allometry) 法則 |
| H4 | 1521 ha材積 ≥ 500 m³/ha のセルは 8 近傍同種率 ≥ 0.6 で集塊 |
同一林班・同一管理単位は連続するため |
| H5 | 1521 収量比数 ≥ 0.7 のセルは平均樹高 ≥ 18m |
森林経営計画上の収穫期閾値 |
| H6 | 1521 形状比 70-90 が標準健全, >100 は不健全 |
森林計測学の慣用 |
| H7 | 1520 と 1521 は地理単位が異なるため直接統合不可 |
本データセット最大の方法論的制約 |
到達点
- 3 dataset の地理編成方式の違いを量的・視覚的に把握する
- 樹種構成 (件数 vs 面積) と単木形状 (樹高/直径) のアロメトリを実データで読む
- 20m mesh の10 種以上の林分指標を樹種別に統計化し、収穫期・健全度を判定
- ha材積の地理集塊性を量化 (8 近傍同種率)
- 3 dataset の統合上の制約 (= 地理単位の差) を量的に確認し、方法論的提言を示す
"""
sections.append(("学習目標と問い", sec1))
# === Section 2: 使用データ ===
sec2_table_rows = ""
for k, d in DATASETS.items():
m = d["meta"]
sec2_table_rows += (
f"| {d['label']} | "
f"DoBoX #{d['dataset_id']} | "
f"直DL | "
f"{d['gpkg'].name} | "
f"{m['geom_type']} | "
f"{m['features']:,} features | "
f"{m['file_mb']:.0f} MB | "
f"{d['muni_label']} | "
f"{m['fields_n']} |
"
)
sec2 = f"""
本記事では DoBoX の「航空レーザ計測に基づく森林資源データ」シリーズ 3 件を統合する。
すべて広島県林業課が 森林管理基盤情報 (公共測量 2 次著作物, 測量法 44 条) として公開した
GeoPackage 形式のベクタデータ。CRS はEPSG:6671 (JGD2011 平面直角座標系 III 系)。
| 論題 | データセット | DL | 保存先 | 形式 | 件数 | サイズ | 採用エリア | 列数 |
|---|
{sec2_table_rows}
3 dataset の地理編成の違い (本記事の核心)
- 1519 樹種ポリゴン: 市町村単位 polygon。10 市町公開。
1 市町ファイル ≈ 数千〜2 万 polygon。属性は樹種・面積・計測年・計測法。
- 1520 単木ポイント: 市町村単位 point。10 市町公開。
1 市町ファイル ≈ 数十万〜数百万 point (世羅町は 3,397,186 point)。
属性は樹種・樹高・胸高直径・単木材積・形状比・樹冠長率・樹冠面積。
注: スギ・ヒノキと判読された区域内のみ抽出。
- 1521 森林資源量集計メッシュ: 国土基本図図郭単位の 20m mesh polygon。10 図郭公開。
1 図郭ファイル = 750,000 mesh (= 20km × 15km ÷ 20m × 20m)。
うち valued (= 林分指標が計測された) は 約 13 万件。
属性は樹種・面積・立木本数・立木密度・平均樹高・平均直径・合計材積・ha材積・
収量比数・相対幹距比・形状比・樹冠長率 (12 列)。
重要な構造的差異: 1519 と 1520 は同じ市町村で公開されているため
直接統合可能 (本記事は世羅町ペアを採用)。一方 1521 は図郭単位なので、
市町村と必ずしも一致しない。本記事の 1521 は 03NF2 図郭 (庄原市域中心) を採用したため、
1520 (世羅町) とは地理が重ならない。これが本データセットの最大の方法論的制約であり、
本記事 H7 で量的に確認する。
共通メタデータ
- 計測期間: 2018-2019 (広島県・国土交通省・林野庁の合同観測)
- 森林計測法: 1 (= 第一手法, 単一バージョン)
- ライセンス: CC-BY 4.0 (測量法 44 条 2 次著作物として広島県林業課が取りまとめ)
- 使用承認: 広島県砂防課 (令和5年砂防第136号), 林野庁治山課 (令和5年林整治第1041号), 国土交通省中国地方整備局 (令和4年国中整水予第37号)
L36-L40 との関係 (LiDAR ファミリ)
本記事の 3 dataset は L36-L40 のラスタ系 5 dataset と同じ航空レーザ計測から派生する:
- L36 樹高図 (DCHM, ラスタ) → 樹頂点抽出 → 本記事 1520 単木ポイント
- L40 標高図 (DTM, ラスタ) → DCHM 計算 → 樹高 → 本記事 1520, 1521
- L37 点群密度図 (ラスタ) → 計測精度の指標 → 本記事 1521 形状比・収量比数の信頼性
- L38 CS立体図 / L39 傾斜 (ラスタ) → 微地形・斜面方位 → 本記事の樹種立地条件
つまり LiDAR ファミリは「点群 → ラスタ (L36-L40) → 林業ベクタ (本記事)」という派生階層を成す。
本記事の 3 dataset は林業実務に直結する応用層であり、森林経営計画 (森林法第 5 条) の基礎資料となる。
"""
sections.append(("使用データ", sec2))
# === Section 3: ダウンロード ===
sec3 = f"""
本記事の再現に必要なデータ・中間データ・図はすべて以下から直 DL 可能。
原データ (DoBoX 直リンク)
中間データ (本スクリプトが生成)
図 (PNG)
再現スクリプト
L41_forest_resources.py をダウンロードし、data/extras/L41_forest_resources/
にデータがなければ自動取得から始まります。
実行:
cd "2026 DoBoX 教材"
py -X utf8 lessons\\L41_forest_resources.py
"""
sections.append(("ダウンロード(再現用データ・中間データ・図)", sec3))
# === Section 4: 分析 1 — 3 dataset の構造比較 ===
sec4 = f"""
狙い
3 dataset の地理編成・属性・スケールを 1 枚の表にまとめ、視覚的にも対比する。
本記事の核心命題「同じ航空レーザから派生したが地理単位が異なる」を量的に確認する。
手法 (リテラシレベル解説)
pyogrio.read_info() で各 GeoPackage のメタ (要素数・列数・bbox) を取得する。
これは GIS データ俯瞰の標準手法で、ファイル全体を読まずにスキーマだけを軽量に確認できる。
- 入力: GeoPackage パス + レイヤ名
- 出力: dict (features, fields, dtypes, crs, total_bounds)
- 限界: feature 値の分布や geometry 詳細は読めない (それは
read_dataframe で別途)
実装
{code('''
import pyogrio
for k, d in DATASETS.items():
info = pyogrio.read_info(d["gpkg"], layer=d["layer"])
print(f"{d['label']}: features={info['features']:,}, "
f"fields={len(info['fields'])}, bbox_w={info['total_bounds'][2]-info['total_bounds'][0]:.0f}m")
''')}
図と読み取り (図 1: 3 dataset 編成構造概念図)
なぜこの図か: 3 dataset の bbox 大きさ・要素数・属性数を 1 枚で比較。
矩形の面積で地理範囲、注釈テキストで要素数・列数を読み取る。
{figure("assets/L41_fig1_concept.png", "図 1: 3 dataset の地理編成 — 同じ航空レーザから派生したが異なる地理単位")}
読み取り (重要発見):
- 1519 樹種ポリゴン (世羅町): bbox {DATASETS['tree_species']['meta']['bbox_w_km']:.1f}×{DATASETS['tree_species']['meta']['bbox_h_km']:.1f}km, polygon {DATASETS['tree_species']['meta']['features']:,}, 列 {DATASETS['tree_species']['meta']['fields_n']}。
= 行政界スケール、属性は素朴 (樹種・面積)。
- 1520 単木ポイント (世羅町): bbox {DATASETS['tree_point']['meta']['bbox_w_km']:.1f}×{DATASETS['tree_point']['meta']['bbox_h_km']:.1f}km, point {DATASETS['tree_point']['meta']['features']:,}, 列 {DATASETS['tree_point']['meta']['fields_n']}。
1519 とほぼ同じ bbox だが、要素数は 261 倍 (≈ 各ポリゴン内の単木抽出のため)。
- 1521 mesh (03NF2 図郭): bbox {DATASETS['fr_mesh']['meta']['bbox_w_km']:.0f}×{DATASETS['fr_mesh']['meta']['bbox_h_km']:.0f}km, mesh {DATASETS['fr_mesh']['meta']['features']:,}, 列 {DATASETS['fr_mesh']['meta']['fields_n']}。
属性数が圧倒的に多い (12 vs 7) = 林分指標が豊富。
- 3 dataset の地理単位は重ならない: 1519/1520 は世羅町, 1521 は 03NF2 図郭 = 庄原市域。
= 「同じ広島県林業データだが、3 dataset を 1 自治体で全部見ることはできない」。
- これは森林データの設計思想として「市町村単位 (地方自治) vs 国土基本図単位 (測量行政)」の
2 系統が並立していることの量的反映。
表 (3 dataset メタ情報比較)
{meta_df[['label','dataset_id','geom_type','geographic_unit','muni','features','fields_n','bbox_w_km','bbox_h_km','file_mb']].round(2).to_html(classes='', border=0, index=False)}
読み取り: 列 geographic_unit の差を読むと、本記事の核心命題が量的に確認できる。
1519/1520 は「市町村」(自治単位), 1521 は「国土基本図図郭」(測量単位) で公開される。
1521 のメッシュは EPSG:6671 (JGD2011 III 系) の原点から 20m 等間隔で規則格子を切るため、
mesh の position だけで bbox が決まり (ファイル名で識別可能)、行政界とは無関係。
これは GIS の「主題ベース vs 規則格子ベース」という古典的二元論の例である。
"""
sections.append(("分析 1: 3 dataset の構造比較 (本記事の核心)", sec4))
# === Section 5: 分析 2 — 樹種ポリゴン (1519) 構成 ===
sec5 = f"""
狙い
1519 樹種ポリゴンを読み込み、世羅町の森林の樹種構成を量化する。
件数ベースと面積ベースの 2 角度で見て、ヒノキ/スギ/その他 の地理的優占を確認 (H1 検証)。
手法 (リテラシレベル解説)
geopandas で GeoPackage を全件読込 → groupby で樹種別の count と area を合計。
さらに件数ベースと面積ベースの構成比を別々に計算 = 「件数の多い樹種」 ≠ 「面積の大きい樹種」
である可能性を見る。
- 入力: GeoPackage (Polygon, 13,025 行 × 7 列 + geometry)
- 出力: 樹種別の polygon 件数, 総面積_ha, 構成比 (count_pct, area_pct)
- 限界: 「その他」カテゴリ内訳 (広葉樹各種) は本データには無い
実装
{code('''
import geopandas as gpd
gdf_ts = gpd.read_file("tree_species_34462.gpkg", layer="tree_species_34462")
species_count = gdf_ts["樹種"].value_counts()
species_area = gdf_ts.groupby("樹種")["面積_ha"].sum().sort_values(ascending=False)
species_summary = pd.concat([
species_count.rename("polygon_count"),
species_area.rename("total_ha"),
], axis=1).fillna(0)
species_summary["count_pct"] = species_summary["polygon_count"] / species_summary["polygon_count"].sum() * 100
species_summary["area_pct"] = species_summary["total_ha"] / species_summary["total_ha"].sum() * 100
species_summary["mean_ha"] = species_summary["total_ha"] / species_summary["polygon_count"]
''')}
図と読み取り (図 2: 樹種ポリゴン主題図)
なぜこの図か: 樹種構成の地理分布を見る。緑=ヒノキ、青=スギ、灰=その他 で塗り分け、
世羅町行政界を黒線で囲む。集落・地形との関係も読める。
{figure("assets/L41_fig2_species_map.png", "図 2: 樹種ポリゴン主題図 (1519 世羅町)")}
読み取り:
- 世羅町全域に緑 (ヒノキ) と灰 (その他) が斑模様に分布。スギ (青) は局所集塊で散在。
- 町の周辺部 (山地) に針葉樹植林が多く、町中央 (台地・農地) は「その他」(広葉樹混交林・里山) が多い傾向。
- polygon のサイズ分布が広い: 小さな点状から町を横断する大きな polygon まで。
= 「林分」が均一ではなく、管理単位や微地形に応じて細分化されている。
図と読み取り (図 3: 樹種構成 棒グラフ)
なぜこの図か: 件数と面積の 2 角度で樹種の優占を確認。
件数 vs 面積の差が「polygon サイズの樹種偏り」を示す。
{figure("assets/L41_fig3_species_bars.png", "図 3: 樹種構成 — 件数 vs 面積 (1519 世羅町)")}
読み取り (重要発見):
- 件数ベース: ヒノキ {hino_pct:.1f}% > その他 {other_pct:.1f}% > スギ {sugi_pct:.1f}%。
ヒノキが約半数を占める優占樹種。
- 面積ベース: ヒノキ {species_summary.loc['ヒノキ','area_pct']:.1f}% >
その他 {species_summary.loc['その他','area_pct']:.1f}% >
スギ {species_summary.loc['スギ','area_pct']:.1f}%。
件数比 ≈ 面積比で、樹種ごとの平均 polygon サイズはほぼ同等。
- 各樹種の平均 polygon 面積:
ヒノキ {species_summary.loc['ヒノキ','mean_ha']:.2f}ha,
スギ {species_summary.loc['スギ','mean_ha']:.2f}ha,
その他 {species_summary.loc['その他','mean_ha']:.2f}ha。
= 「その他」polygon は{species_summary.loc['その他','mean_ha']/max(0.01,species_summary.loc['ヒノキ','mean_ha']):.1f}倍大きく、
広葉樹混交林は連続性が高い (大きな塊で分布する) ことを示唆。
- H1 (ヒノキ ≥ 40% かつ スギ ≤ 30% かつ その他 ≤ 30%) の判定: {h1_verdict}。
ヒノキ {hino_pct:.1f}% と「その他」{other_pct:.1f}% の関係次第で「ヒノキ優占」の主張強度が変わる。
- 世羅町の森林は「針葉樹植林 (ヒノキ+スギ) ≈ {hino_pct+sugi_pct:.0f}% + 広葉樹等 ≈ {other_pct:.0f}%」と読める。
これは中山間林業地として典型的な構成。
表 (1519 樹種別集計)
{species_summary.round(2).to_html(classes='', border=0)}
"""
sections.append(("分析 2: 樹種ポリゴン (1519) の構成 (H1)", sec5))
# === Section 6: 分析 3 — 単木ポイント (1520) 樹高/直径分布 ===
sec6 = f"""
狙い
1520 単木ポイント (3,397,186 点) を全件属性読込し、
スギとヒノキの樹高・胸高直径・単木材積の分布を比較。
樹種ごとの形状特性と生長到達点の差を確認 (H2 検証)。
手法 (リテラシレベル解説)
pyogrio.read_dataframe(read_geometry=False) で属性のみ全件読込。
geometry を読まないので 552 MB GPKG でも~10 秒で全件取得可能。
これは GIS データ「巨大なら属性だけ読む」という標準的高速戦略。
- 入力: GeoPackage (Point, 3.4M 行 × 12 列 + geometry)
- 出力 (属性のみ): pandas DataFrame (3.4M 行 × 12 列)
- 限界: 空間結合や地図表示には別途 geom 読込が必要 (本記事 図 6 のサブサンプル)
実装
{code('''
import pyogrio
# geometry なしで全件属性読込 (高速)
tp_attr = pyogrio.read_dataframe("tree_point_34462.gpkg",
layer="tree_point_34462",
read_geometry=False)
# 樹種別集計
tp_by_species = tp_attr.groupby("樹種").agg(
n=("樹高", "count"),
height_mean=("樹高", "mean"),
height_median=("樹高", "median"),
dbh_mean=("胸高直径", "mean"),
vol_mean=("単木材積", "mean"),
vol_total=("単木材積", "sum"),
)
''')}
図と読み取り (図 4: 単木 樹高・胸高直径ヒスト)
なぜこの図か: 樹種ごとの分布形状を比較する。
ヒストグラムのピーク位置・裾の長さ・複峰性が樹種特性を示す。
{figure("assets/L41_fig4_height_dbh_hist.png", "図 4: 単木 樹高・胸高直径分布 (1520 世羅町, 樹種別)")}
読み取り (重要発見):
- 樹高分布:
スギ平均 {tp_by_species.loc['スギ','height_mean']:.1f}m (中央 {tp_by_species.loc['スギ','height_median']:.1f}m, std {tp_by_species.loc['スギ','height_std']:.1f}m),
ヒノキ平均 {tp_by_species.loc['ヒノキ','height_mean']:.1f}m (中央 {tp_by_species.loc['ヒノキ','height_median']:.1f}m, std {tp_by_species.loc['ヒノキ','height_std']:.1f}m)。
差 = {tp_by_species.loc['スギ','height_mean']-tp_by_species.loc['ヒノキ','height_mean']:+.1f}mでスギが高い。
- 胸高直径分布:
スギ平均 {tp_by_species.loc['スギ','dbh_mean']:.1f}cm,
ヒノキ平均 {tp_by_species.loc['ヒノキ','dbh_mean']:.1f}cm。
スギは胸高直径も+{tp_by_species.loc['スギ','dbh_mean']-tp_by_species.loc['ヒノキ','dbh_mean']:.1f}cm大きい。
- 単木材積:
スギ平均 {tp_by_species.loc['スギ','vol_mean']:.3f} m³ (中央 {tp_by_species.loc['スギ','vol_median']:.3f}),
ヒノキ平均 {tp_by_species.loc['ヒノキ','vol_mean']:.3f} m³ (中央 {tp_by_species.loc['ヒノキ','vol_median']:.3f})。
倍率 = ×{tp_by_species.loc['スギ','vol_mean']/max(0.001,tp_by_species.loc['ヒノキ','vol_mean']):.1f}でスギが大きい。
- 分布形状: 両樹種ともピーク約 8-12m 付近の右裾長分布。
= 多くは中木 (10-20m), 少数の高木 (30m+) を持つ。
- H2 (スギ +4m 以上, 材積 ×2 以上) の判定: {h2_verdict}。
{(('樹高条件は満たす (差 ' + str(round(sugi_h-hino_h,1)) + 'm)') if h2_height_ok else '樹高条件は満たさない')},
{(('材積条件は満たす (倍 ' + str(round(sugi_v/max(0.001,hino_v),1)) + ')') if h2_vol_ok else '材積条件は満たさない')}。
- これは林学の常識 (スギは早生・大径) を 3.4M 単木で量的に裏付ける結果。
かつサンプル数が桁違い (従来の毎木調査は数百本程度) なので統計的検定力が圧倒的。
表 (1520 樹種別単木統計)
{tp_by_species.to_html(classes='', border=0)}
"""
sections.append(("分析 3: 単木ポイント (1520) の樹高・直径分布 (H2)", sec6))
# === Section 7: 分析 4 — 樹高 vs 胸高直径 アロメトリ ===
sec7 = f"""
狙い (本記事の生物物理学的核心)
樹木は「樹高 h ∝ 胸高直径 d^β」というべき乗法則 (アロメトリ) に従う。
1520 単木 3.4M 点で h-d 関係の Pearson 相関と回帰係数を計算し、
スギとヒノキで係数 c, β がどう違うかを検証 (H3)。
手法 (リテラシレベル解説)
アロメトリ (allometry) = 「異速成長」。樹木では:
- 線形モデル: h = a + b · d (簡易だが大径木で乖離)
- べき乗モデル: h = c · d^β (生物学的に正当)
- 両辺対数を取れば log(h) = log(c) + β · log(d) という線形回帰
係数 β は樹種固有で、典型的に 0.5-1.0。β < 1 は「太くなる速度が高くなる速度より早い」(寸胴),
β = 1 は等比 (細長), β > 1 は「高さが速い」(超細長)。
- 入力: 樹種ごとの (h, d) ペア (スギ 33万件, ヒノキ 307万件)
- 出力: Pearson r, 線形係数 (a, b), 対数べき乗係数 (c, β)
- 限界: アロメトリ係数は地域・管理状態で変動、本研究の値は世羅町固有
実装
{code('''
import numpy as np
allometry_rows = []
for sp in ["スギ", "ヒノキ"]:
sub = tp_clean[tp_clean["樹種"] == sp]
h = sub["樹高"].values.astype(np.float64)
d = sub["胸高直径"].values.astype(np.float64)
# 線形回帰 h = a + b * d
X = np.vstack([np.ones(len(d)), d]).T
coef, *_ = np.linalg.lstsq(X, h, rcond=None)
a, b = coef
# 対数べき乗モデル h = c * d^β
log_h, log_d = np.log(h), np.log(d)
Xl = np.vstack([np.ones(len(log_d)), log_d]).T
coef2, *_ = np.linalg.lstsq(Xl, log_h, rcond=None)
log_c, exp_d = coef2
allometry_rows.append({
"species": sp,
"n": len(sub),
"r_pearson": float(np.corrcoef(h, d)[0, 1]),
"lin_intercept": float(a), "lin_slope": float(b),
"log_c": float(np.exp(log_c)), "log_exp": float(exp_d),
})
''')}
図と読み取り (図 5: 樹高 × 胸高直径 散布 + 対数回帰線)
なぜこの図か: アロメトリ関係を視覚的に確認する。
散布点で雲の形を、回帰線でべき乗モデルの中心線を見る。
30k 点の subsample 表示と回帰線で「3.4M 全体の傾向」を読む。
{figure("assets/L41_fig5_allometry.png", "図 5: 樹高 × 胸高直径 アロメトリ (1520 世羅町, スギ/ヒノキ)")}
読み取り (重要発見):
{(lambda: ''.join([
f'- {r["species"]}: n={r["n"]:,}, '
f'Pearson r = {r["r_pearson"]:.3f}, '
f'線形 h = {r["lin_intercept"]:.2f} + {r["lin_slope"]:.3f} d, '
f'べき乗 h = {r["log_c"]:.2f}·d{r["log_exp"]:.2f}。
'
for r in allometry_rows]))()}
- 両樹種とも r ≥ {min(r['r_pearson'] for r in allometry_rows) if allometry_rows else 0:.2f} と強正相関。
= 樹高と胸高直径は不可分にリンクする (大きい木は太い木)。
- べき乗指数 β:
{(lambda: ', '.join(f"{r['species']}={r['log_exp']:.2f}" for r in allometry_rows))()}。
β < 1 = 樹高の生長速度より直径の生長速度が早い ("寸胴"傾向)。
β > 1 = 細長傾向。
- {(lambda: 'スギの β > ヒノキの β: スギは細長く育ちやすい' if len(allometry_rows) >= 2 and allometry_rows[1]['log_exp'] > allometry_rows[0]['log_exp'] else 'ヒノキの β > スギの β: ヒノキは細長く育ちやすい' if len(allometry_rows) >= 2 else 'β 比較は要確認')()}。
これは林学常識 (スギは樹高優先、ヒノキは直径太り) と整合 (またはずれを発見)。
- H3 (r ≥ 0.7) の判定: {h3_verdict}。
- これは「アロメトリ法則 (= 生物物理学)」がオープンデータの 3.4M 単木で量的に再現できることの実証。
研究的価値: 従来は数百本の毎木調査でしか得られなかった係数を、
航空レーザの単木抽出でデータ単位を 4 桁拡大。
将来的に「自治体ごと・斜面方位ごと・標高ごと」のアロメトリ係数が計算可能。
表 (アロメトリ係数)
{allometry_df.round(4).to_html(classes='', border=0, index=False)}
図と読み取り (図 6: 単木サンプル位置マップ)
なぜこの図か: 単木 3.4M 点の地理分布を視覚的に把握する。
点を樹高で色分け (黄=低木 → 緑=高木) して、世羅町内の樹高地理パターンを読む。
{figure("assets/L41_fig6_tree_point_map.png", "図 6: 単木サンプル {len(gdf_tp):,} 点 (1520 世羅町, 色=樹高 m)")}
読み取り:
- {len(gdf_tp):,} 点の subsample (= 全 3.4M の {len(gdf_tp)/len(tp_attr)*100:.1f}%) でも、
世羅町の森林の輪郭が明瞭に描かれる。
= 単木点群は準連続的に分布し、空間的サンプリングが密。
- 樹高色 (緑=高木) は町の周辺部 (山地) に集中、
町中央 (= 高原台地・農地) には森林がない (空白)。
- これは「世羅町は高原台地で、周辺山地に植林帯」という地理学的事実の量的視覚化。
- L36 樹高ラスタ (DCHM) と比較すると、1520 単木は L36 の樹頂点抽出結果であることが視覚的に裏付けられる。
= 派生関係 (L36 → 1520) の量的実証。
"""
sections.append(("分析 4: 樹高 × 胸高直径 アロメトリ (H3, 本記事の生物物理学的核心)", sec7))
# === Section 8: 分析 5 — mesh (1521) ha材積分布と地理 ===
sec8 = f"""
狙い (本記事の林業生産性核心)
1521 mesh 750k セル (うち numeric {len(mesh_numeric):,} セル) で、
ha材積 (m³/ha) の地理分布と樹種別構成を分析する。
「どこに高材積エリア (= 林業価値の高い森林) があるか」を量化する (H4 集塊性)。
手法 (リテラシレベル解説)
20m mesh の各セルには林分指標が 12 列付与されている。
geopandas で全件読込し、ha材積 で choropleth マップを描く。
さらにha材積 5 階級 (0-100, 100-250, 250-500, 500-1000, >1000 m³/ha) で量的比較する。
- 入力: GeoPackage 750k mesh, 列 ha材積
- 出力: 樹種別 ha材積 統計, 5 階級構成, 高材積比率
- 限界: mesh は 20m 規則格子のため境界アーティファクトあり (林分の自然境界とは無関係)
実装
{code('''
import geopandas as gpd
gdf_mesh_full = gpd.read_file("fr_mesh20m_03NF2.gpkg", layer="fr_mesh20m_03NF2")
mesh_valued = gdf_mesh_full[gdf_mesh_full["樹種"].notna()].copy()
mesh_numeric = mesh_valued.dropna(subset=["ha材積", "立木密度", "平均樹高"]).copy()
# 5 階級分類
VOLUME_CLASSES = [
("極低", 0, 100), ("低", 100, 250), ("中", 250, 500),
("高", 500, 1000), ("極高", 1000, 5000)
]
def classify_volume(v):
for i, (_, lo, hi) in enumerate(VOLUME_CLASSES, start=1):
if lo <= v < hi: return i
return 0
mesh_numeric["volume_class"] = mesh_numeric["ha材積"].apply(classify_volume)
''')}
図と読み取り (図 7: ha材積 choropleth)
なぜこの図か: 林業価値の地理分布を視覚化。色の濃い領域 = 高材積。
庄原市行政界を黒線で囲み、図郭外との関係も読む。
{figure("assets/L41_fig7_mesh_volume.png", "図 7: ha材積 choropleth (1521 03NF2, 庄原市域)")}
読み取り:
- 03NF2 図郭 (20×15km) 内に{len(mesh_numeric):,} valued meshが分布。
ha材積の地理パターンが明瞭。
- 濃赤の領域 (高材積 ≥ 500 m³/ha) は線状・斑状に集塊。
= 同一林班・同一樹種・同一管理単位を反映。
- 図郭の 4 隅は valued mesh が少ない (= 山頂・川・農地) ことが多く、
森林分布の外縁を反映する。
- 03NF2 図郭は庄原市を中心に含む内陸山地で、針葉樹植林が連続的に広がる。
図と読み取り (図 9: ha材積 5 階級分類)
なぜこの図か: 連続値 ha材積 を慣用 5 階級にカテゴリ化し、
階級マップ + 樹種別構成比 stack-bar の 2 角度で見る。
{figure("assets/L41_fig9_volume_class.png", "図 9: ha材積 5 階級 — マップ × 樹種別構成")}
読み取り (重要発見):
- (a) 階級マップ: 高 (赤) と極高 (暗赤) が領域内に集塊。
中 (橙) と低 (薄赤) が周辺に広がる。
- (b) 樹種別構成: スギは極高比率が
{(volume_class_counts.loc['スギ','極高']/max(1,volume_class_counts.loc['スギ'].sum())*100 if 'スギ' in volume_class_counts.index and '極高' in volume_class_counts.columns else 0):.1f}%,
ヒノキは
{(volume_class_counts.loc['ヒノキ','極高']/max(1,volume_class_counts.loc['ヒノキ'].sum())*100 if 'ヒノキ' in volume_class_counts.index and '極高' in volume_class_counts.columns else 0):.1f}%。
= スギ林分が高材積に偏る傾向 (スギは早生・大径のため)。
- 重要な構造的観察 (本記事独自発見):
1521 mesh で 「その他」 (= 広葉樹混交林) は樹種判読されているが林分指標 (ha材積等) は欠損している
({mesh_other_count:,} mesh, 全 valued の {mesh_other_count/max(1,len(mesh_valued))*100:.1f}%)。
つまり 1521 の数値指標は管理対象林 (スギ・ヒノキ) のみ計算される設計。
= 広葉樹混交林は林業生産性指標としては未集計 (生物多様性価値は別軸として別途測定要)。
この発見は本データセットの仕様上の重要点であり、利用者は「mesh で広葉樹資源量も同時に得られる」と
誤解しないよう注意が必要。
- 高材積セル (≥500 m³/ha) の比率:
{(lambda: ', '.join(f"{idx}={v:.1f}%" for idx, v in high_vol_pct['pct_ge_500'].items()))()}。
- 8 近傍同種率 (高材積 mask): {high_clu_rate:.3f}。
{('集塊性が強い' if high_clu_rate >= 0.6 else '中程度の集塊' if high_clu_rate >= 0.4 else '弱い集塊')}。
H4 の判定: {h4_verdict}。
- これは「高材積エリアは点在するのではなく、林班単位の塊で連続分布する」ことの量的実証。
林業実務上は「収穫期到来エリアの一括皆伐計画」の根拠データになる。
表 (1521 樹種別 ha材積 5 階級構成)
{volume_class_counts.to_html(classes='', border=0)}
表 (1521 樹種別 高材積比率)
{high_vol_pct.round(2).to_html(classes='', border=0)}
図と読み取り (図 12: 樹種別 ha材積 small multiples)
なぜこの図か: 樹種ごとの ha材積地理分布を並列で比較。
スギとヒノキの林分立地の差を視覚的に確認。
{figure("assets/L41_fig12_small_multiples.png", "図 12: 樹種別 ha材積マップ (1521 small multiples)")}
読み取り:
- スギ: 高材積 (赤) が斑状に集塊。比較的「川沿い・谷頭」の好条件立地に分布。
- ヒノキ: 中-高材積が広範に分布。「斜面・尾根」など多様な立地に対応。
- その他 (広葉樹等): 林分指標が欠損のためマップ上は空白 (= 樹種は判読されているが ha材積等の数値計算は未実施)。
= 林業生産対象外の「広葉樹混交林・里山」は本データセットでは空間的位置のみ与えられ、量化は別途必要。
- スギ vs ヒノキの立地選好 (スギ=湿潤好・尾根回避, ヒノキ=斜面適応・分布広い) が視覚化される。
"""
sections.append(("分析 5: mesh (1521) ha材積分布と林業生産性 (H4)", sec8))
# === Section 9: 分析 6 — 林分指標 box plot + 健全度 ===
sec9 = f"""
狙い
1521 mesh の10+ 列の林分指標を樹種別に箱ひげ図で並べて、
スギ・ヒノキ・その他の形状特性 (高さ・直径)と
健全度 (収量比数・形状比・樹冠長率) を 1 枚で比較する。
手法 (リテラシレベル解説)
箱ひげ図 (box plot) は分布の中央値・四分位範囲・外れ値を 1 つの図で示す。
ヒストグラムより圧縮的で、複数群の比較に向く。
- 箱の中線 = 中央値、箱の上下 = 第 1/第 3 四分位 (= 中央 50%), ヒゲ = 1.5 × IQR 内
- 外れ値は本記事では非表示 (
showfliers=False) で本体の差に集中
- 限界: ヒストグラムの形状情報は失う
実装
{code('''
fig, axes = plt.subplots(2, 3, figsize=(15, 9))
metrics = [
("ha材積", "ha材積 (m³/ha)", (0, 1500)),
("立木密度", "立木密度 (本/ha)", (0, 2500)),
("平均樹高", "平均樹高 (m)", (0, 35)),
("平均直径", "平均直径 (cm)", (0, 50)),
("収量比数", "収量比数", (0, 1.2)),
("形状比", "形状比", (30, 110)),
]
for ax, (col, title, ylim) in zip(axes.flat, metrics):
data = [mesh_numeric[mesh_numeric["樹種"]==sp][col].dropna().values
for sp in ["スギ","ヒノキ","その他"]]
ax.boxplot(data, labels=["スギ","ヒノキ","その他"],
patch_artist=True, showfliers=False)
''')}
図と読み取り (図 8: 林分指標 box plot)
なぜこの図か: 6 つの林分指標を樹種別に並列比較し、
「樹種ごとの林分特性プロファイル」を 1 枚で読む。
{figure("assets/L41_fig8_mesh_boxes.png", "図 8: 林分指標 6 種 × 樹種 (1521 mesh)")}
読み取り (重要観察):
- 本図は スギ・ヒノキ のみ表示: 1521 mesh で「その他」(= 広葉樹混交林) は
樹種だけ判読されて林分指標 (材積・密度・樹高...) は欠損している
({mesh_other_count:,} mesh, 全 valued の {mesh_other_count/max(1,len(mesh_valued))*100:.1f}%)。
= 1521 の数値指標は管理対象林 (スギ・ヒノキ) のみ計算される設計。
- ha材積: スギ > ヒノキ の階層が明確
(中央値 スギ {mesh_numeric.groupby('樹種')['ha材積'].median().get('スギ',0):.0f},
ヒノキ {mesh_numeric.groupby('樹種')['ha材積'].median().get('ヒノキ',0):.0f} m³/ha)。
スギの方が単位面積あたり林業価値が高い。
- 立木密度: ヒノキが平均的に高い
(中央値 ヒノキ {mesh_numeric.groupby('樹種')['立木密度'].median().get('ヒノキ',0):.0f} 本/ha,
スギ {mesh_numeric.groupby('樹種')['立木密度'].median().get('スギ',0):.0f} 本/ha)。
ヒノキは小径木が密植される慣行を反映。
- 平均樹高: スギが圧倒的に高い (中央値 {mesh_numeric.groupby('樹種')['平均樹高'].median().get('スギ',0):.0f}m vs
ヒノキ {mesh_numeric.groupby('樹種')['平均樹高'].median().get('ヒノキ',0):.0f}m)。
1520 単木と整合 (図 4 の樹高ヒスト)。
- 平均直径: スギ {mesh_numeric.groupby('樹種')['平均直径'].median().get('スギ',0):.0f}cm vs
ヒノキ {mesh_numeric.groupby('樹種')['平均直径'].median().get('ヒノキ',0):.0f}cm。
こちらもスギが太い。
- 収量比数: スギ・ヒノキとも中央 0.6 付近で似ているが、
スギの方が分布が右寄り (= 収穫期到来割合が多い)。
- 形状比: スギ中央値 {mesh_numeric.groupby('樹種')['形状比'].median().get('スギ',0):.0f},
ヒノキ {mesh_numeric.groupby('樹種')['形状比'].median().get('ヒノキ',0):.0f}。
スギはやや細長 (高木で gravity-driven)。
100 超の不健全林分は両樹種とも少数 = 広島県の管理林分は概ね健全。
図と読み取り (図 10: 収量比数 vs 平均樹高 散布)
なぜこの図か: 収穫期判定の閾値 (収量比数 0.7) と樹高の関係を視覚化。
赤線 = 収量比数 0.7, 橙線 = 平均樹高 18m。両線の右上 = 「収穫期到来かつ大樹」エリア。
{figure("assets/L41_fig10_yield_height.png", "図 10: 収量比数 × 平均樹高 (1521 mesh)")}
読み取り (重要発見):
- 収量比数 0.7 以上のセルは合計 {int(mesh_numeric['is_harvest_ready'].sum()):,}
({mesh_numeric['is_harvest_ready'].mean()*100:.1f}% of {len(mesh_numeric):,})。
これらの平均樹高は {hsub_height_mean:.2f}m。
- H5 (収量比数≥0.7 で平均樹高≥18m) の判定: {h5_verdict}。
- 樹種別 収穫期セル比率:
{(lambda: ', '.join(f"{idx}={row['pct_harvest']:.1f}%" for idx, row in harvest_summary.iterrows()))()}。
- 収量比数 ≥ 0.7 のセルは右上の散布雲 (高材積・高木) に集塊することが視覚的に確認できる。
= 「収穫期到来は樹高でも検出可能」(代理指標として機能)。
- これは林業実務上「収量比数を持たないデータ (例: L36 樹高ラスタ単独) でも、
平均樹高で代替的に収穫期エリアを推定できる」可能性を示唆する。
表 (1521 樹種別 mesh 集計)
{mesh_by_species.to_html(classes='', border=0)}
表 (1521 収穫期セル集計)
{harvest_summary.to_html(classes='', border=0)}
図と読み取り (図 11: 形状比ヒスト — 林相健全度)
なぜこの図か: 形状比 70-90 が健全、>100 が不健全という慣用閾値を視覚化。
mesh (集計値) と単木 (個別値) を並べて、スケール依存性を見る。
{figure("assets/L41_fig11_shape_ratio.png", "図 11: 形状比分布 — mesh (集計) vs 単木 (個別)")}
読み取り:
- (a) mesh 形状比: 中央値 {mesh_numeric['形状比'].median():.0f}, 70-90 範囲内 {shape_pct_in_range:.1f}%,
100 超 {shape_over_100:.2f}%。
= 大部分の林分は健全範囲に収まる。
- (b) 単木 形状比: 中央値 {tp_attr['形状比'].median():.0f}, 分布の裾が mesh より広い。
= 個別樹はばらつきが大きい (集計でならされる)。
- H6 (70-90 が健全, >100 が過密で不健全) の判定: {h6_verdict}。
{('健全範囲の比率が想定通り' if 30 <= shape_pct_in_range <= 80 else '健全範囲外の比率が高い')}
- 過密林分 (形状比 >100) は少数であり、
広島県の管理林分は概ね適正範囲。
ただし不健全セルの地理集塊性は別途要検証 (= 特定地区での放置林リスク)。
"""
sections.append(("分析 6: 林分指標 box plot と健全度 (H5, H6)", sec9))
# === Section 10: 分析 7 — 3 dataset 統合の制約 (方法論的核心) ===
sec10 = f"""
狙い (本記事の方法論的核心)
本記事の最大の発見は「3 dataset は同じ航空レーザから派生したが、地理単位が異なるため直接統合できない」
ことの量的確認である。具体的には:
- 1519 樹種ポリゴン: 世羅町 (市町村code 34462)
- 1520 単木ポイント: 世羅町 (市町村code 34462) → 1519 と同自治体
- 1521 森林資源量メッシュ: 03NF2 図郭 (市町村code 34210 = 庄原市) → 1519/1520 と異なる地理
手法 (リテラシレベル解説)
本セクションは新規計算ではなく、これまでの分析結果から整合性を量的に確認する。
特に「同じ自治体ペア」と「異なる地理単位」での指標差を整理。
- 1519 + 1520 (同自治体): 樹種別の polygon 件数 (1519) と単木件数 (1520) の比率を確認
- 1521 (別地理): bbox 重なりが世羅町とゼロであることを地理座標で確認
- 研究的含意: 「県全体の森林資源図を作るには 10 市町 × 10 図郭 = 100 ファイル必要」
1519 と 1520 の整合性 (同自治体ペア)
世羅町の 1519 polygon (n={len(gdf_ts):,}) と 1520 point (n={len(tp_attr):,}) は同一自治体のため、
直接重ね合わせ可能。1520 はスギ・ヒノキ抽出のため、1519 のスギ・ヒノキ polygon 内にのみ存在する:
| 樹種 | 1519 polygon 件数 | 1519 polygon 総面積 (ha) | 1520 単木件数 | 密度 (本/ha) |
|---|
| スギ |
{int(species_summary.loc['スギ','polygon_count']) if 'スギ' in species_summary.index else 0:,} |
{species_summary.loc['スギ','total_ha'] if 'スギ' in species_summary.index else 0:.1f} |
{int(tp_by_species.loc['スギ','n']) if 'スギ' in tp_by_species.index else 0:,} |
{(tp_by_species.loc['スギ','n']/max(0.01,species_summary.loc['スギ','total_ha']) if 'スギ' in tp_by_species.index and 'スギ' in species_summary.index else 0):.0f} |
| ヒノキ |
{int(species_summary.loc['ヒノキ','polygon_count']) if 'ヒノキ' in species_summary.index else 0:,} |
{species_summary.loc['ヒノキ','total_ha'] if 'ヒノキ' in species_summary.index else 0:.1f} |
{int(tp_by_species.loc['ヒノキ','n']) if 'ヒノキ' in tp_by_species.index else 0:,} |
{(tp_by_species.loc['ヒノキ','n']/max(0.01,species_summary.loc['ヒノキ','total_ha']) if 'ヒノキ' in tp_by_species.index and 'ヒノキ' in species_summary.index else 0):.0f} |
| その他 |
{int(species_summary.loc['その他','polygon_count']) if 'その他' in species_summary.index else 0:,} |
{species_summary.loc['その他','total_ha'] if 'その他' in species_summary.index else 0:.1f} |
0 (= 1520 は針葉樹抽出のため対象外) |
— |
読み取り (重要発見):
- 世羅町スギ密度: 1520 単木 ÷ 1519 polygon 面積 ≈
{(tp_by_species.loc['スギ','n']/max(0.01,species_summary.loc['スギ','total_ha']) if 'スギ' in tp_by_species.index and 'スギ' in species_summary.index else 0):.0f}本/ha。
林業の慣用密度 (1500-2500本/ha 植栽 → 間伐後 600-1200本/ha) と比較すると、現在の世羅町スギ林は中程度の管理状態。
- 世羅町ヒノキ密度: {(tp_by_species.loc['ヒノキ','n']/max(0.01,species_summary.loc['ヒノキ','total_ha']) if 'ヒノキ' in tp_by_species.index and 'ヒノキ' in species_summary.index else 0):.0f}本/ha。
ヒノキはスギより低密度植栽が一般的 (1500本/ha 程度)。
- これは1519 + 1520 の組合せでしか得られない派生指標。
1521 mesh 単独では (世羅町とは別地理のため) この値は出せない。
1521 と 1519/1520 の地理重なり (なし)
| 項目 | 1519/1520 (世羅町) | 1521 (03NF2 図郭) | 重なり |
|---|
| X 範囲 (m, EPSG:6671) |
{DATASETS['tree_species']['meta']['bbox_x_min']:.0f} 〜 {DATASETS['tree_species']['meta']['bbox_x_max']:.0f} |
{DATASETS['fr_mesh']['meta']['bbox_x_min']:.0f} 〜 {DATASETS['fr_mesh']['meta']['bbox_x_max']:.0f} |
{('あり' if max(DATASETS['tree_species']['meta']['bbox_x_min'], DATASETS['fr_mesh']['meta']['bbox_x_min']) < min(DATASETS['tree_species']['meta']['bbox_x_max'], DATASETS['fr_mesh']['meta']['bbox_x_max']) else 'なし')} |
| Y 範囲 (m, EPSG:6671) |
{DATASETS['tree_species']['meta']['bbox_y_min']:.0f} 〜 {DATASETS['tree_species']['meta']['bbox_y_max']:.0f} |
{DATASETS['fr_mesh']['meta']['bbox_y_min']:.0f} 〜 {DATASETS['fr_mesh']['meta']['bbox_y_max']:.0f} |
{('あり' if max(DATASETS['tree_species']['meta']['bbox_y_min'], DATASETS['fr_mesh']['meta']['bbox_y_min']) < min(DATASETS['tree_species']['meta']['bbox_y_max'], DATASETS['fr_mesh']['meta']['bbox_y_max']) else 'なし')} |
| 市町村code | 34462 (世羅町) | 34210 (庄原市) | 異なる |
読み取り (本記事の方法論的核心):
- X 範囲は{('部分的に重なる' if max(DATASETS['tree_species']['meta']['bbox_x_min'], DATASETS['fr_mesh']['meta']['bbox_x_min']) < min(DATASETS['tree_species']['meta']['bbox_x_max'], DATASETS['fr_mesh']['meta']['bbox_x_max']) else '完全に分離')}、
Y 範囲は{('部分的に重なる' if max(DATASETS['tree_species']['meta']['bbox_y_min'], DATASETS['fr_mesh']['meta']['bbox_y_min']) < min(DATASETS['tree_species']['meta']['bbox_y_max'], DATASETS['fr_mesh']['meta']['bbox_y_max']) else '完全に分離')}。
- 市町村code が異なる (世羅 34462 vs 庄原 34210) ため、
1519/1520 と 1521 を 1 枚の図で重ねることは物理的に不可能。
- H7 (1520 と 1521 は地理単位が異なるため直接統合不可) の判定: {h7_verdict}。
- これは本データセットの最大の方法論的制約であり、
利用者は「県全体の森林資源図を作るには 10 市町 × 10 図郭 = ファイル整備の手間が大きい」ことに留意すべき。
- 提言: 「広島県は 1521 を市町村単位でも公開する」か、
「3 dataset を統合した県全域 GeoPackage を 1 ファイルで配布する」のが
利用者にとって最も望ましい (発展課題 Z3)。
"""
sections.append(("分析 7: 3 dataset 統合の制約と方法論的提言 (H7, 本記事の方法論的核心)", sec10))
# === Section 11: 仮説検証と考察 ===
def fmt_verdict(v):
if v == "支持": return f"{v}"
elif v == "部分支持": return f"{v}"
elif v == "反証": return f"{v}"
elif v == "未検証": return f"{v}"
return v
hypos_table = "| H | 主張 | 結果 | 判定 |
|---|
"
for h in hypos:
hypos_table += f"| {h['H']} | {h['claim']} | {h['result']} | {fmt_verdict(h['verdict'])} |
"
hypos_table += "
"
n_support = sum(1 for h in hypos if h['verdict'] == '支持')
n_partial = sum(1 for h in hypos if h['verdict'] == '部分支持')
n_refute = sum(1 for h in hypos if h['verdict'] == '反証')
sec_h = f"""
本記事で立てた 7 つの仮説 (H1〜H7) と、3 dataset 統合分析の照合結果:
{hypos_table}
判定サマリ: 支持 {n_support} / 部分支持 {n_partial} / 反証 {n_refute} (全 7 仮説中)
主な発見 (5 点)
- 3 dataset の地理単位差が量的に確認 (H7 支持):
1519 (市町村 polygon) + 1520 (市町村 point) は同自治体ペアとして直接統合可能、
1521 (図郭 mesh) は独立した地理単位で 1519/1520 とは bbox が重ならない。
これは「同じ航空レーザ計測から派生したが、設計思想 (主題ベース vs 規則格子ベース) の違いで地理単位が分離」
という GIS 古典問題の例。
- 世羅町は針葉樹植林 + 広葉樹混交林の中山間林業地 (H1 {h1_verdict}):
1519 で ヒノキ {hino_pct:.0f}% + スギ {sugi_pct:.0f}% = 針葉樹植林 {hino_pct+sugi_pct:.0f}%,
その他 (広葉樹等) {other_pct:.0f}%。
= 「中山間林業地として典型的な構成」が量的に確認できた。
- スギはヒノキより高木・大径・大材積 (H2 {h2_verdict}):
1520 単木 3.4M で スギ平均樹高 {sugi_h:.1f}m, ヒノキ {hino_h:.1f}m (差 {sugi_h-hino_h:+.1f}m)。
単木材積はスギ ×{sugi_v/max(0.001,hino_v):.1f}。
林学常識をオープンデータで桁違いの標本数 (従来の毎木調査 ~10² → 単木抽出 ~10⁶) で再現。
- 樹高 vs 胸高直径のアロメトリ法則がオープンデータで再現 (H3 {h3_verdict}):
{(lambda: ', '.join(f"{r['species']} r={r['r_pearson']:.2f}, β={r['log_exp']:.2f}" for r in allometry_rows))()}。
= 樹木のべき乗法則 (allometry) が 3.4M 単木で量的に成立。
研究的意義: 自治体別・斜面方位別・標高別のアロメトリ係数算出への展開可能性。
- 高材積エリアは集塊し、収穫期セルは平均樹高で代替推定可能 (H4 {h4_verdict}, H5 {h5_verdict}):
1521 mesh で ha材積 ≥ 500 m³/ha のセルは 8 近傍同種率 {high_clu_rate:.3f}。
= 林班単位の塊で連続分布。
収量比数 ≥ 0.7 のセル平均樹高 {hsub_height_mean:.1f}m。
= 「収穫期は樹高でも代理判定可能」という方法論的応用可能性。
世羅町・庄原市域の森林資源量サマリ (本記事の量的サマリ)
| 軸 | 世羅町 (1519/1520) | 03NF2 図郭/庄原市域 (1521) |
|---|
| polygon/point/mesh 件数 |
1519: {len(gdf_ts):,} polygon, 1520: {len(tp_attr):,} point |
1521: {len(mesh_numeric):,} numeric mesh (全 {len(gdf_mesh_full):,}) |
| 主要樹種優占 |
ヒノキ {hino_pct:.0f}% (件数), {species_summary.loc['ヒノキ','area_pct'] if 'ヒノキ' in species_summary.index else 0:.0f}% (面積) |
その他 {(volume_class_counts.loc['その他'].sum()/max(1,volume_class_counts.values.sum()) if 'その他' in volume_class_counts.index else 0)*100:.0f}%, ヒノキ {(volume_class_counts.loc['ヒノキ'].sum()/max(1,volume_class_counts.values.sum()) if 'ヒノキ' in volume_class_counts.index else 0)*100:.0f}% |
| 平均樹高 (m) |
1520: スギ {sugi_h:.1f}, ヒノキ {hino_h:.1f} |
1521: スギ {mesh_numeric.groupby('樹種')['平均樹高'].mean().get('スギ',0):.1f}, ヒノキ {mesh_numeric.groupby('樹種')['平均樹高'].mean().get('ヒノキ',0):.1f} |
| 立木材積 |
1520 単木材積: スギ {sugi_v:.3f} m³, ヒノキ {hino_v:.3f} m³ |
1521 ha材積中央値: {mesh_numeric['ha材積'].median():.0f} m³/ha |
| 収穫期到来 (収量比数≥0.7) |
— |
{int(mesh_numeric['is_harvest_ready'].sum()):,} mesh ({mesh_numeric['is_harvest_ready'].mean()*100:.1f}%) |
| 形状比 70-90 健全範囲 |
1520 単木: {((tp_attr['形状比']>=70)&(tp_attr['形状比']<=90)).sum()/max(1,tp_attr['形状比'].notna().sum())*100:.1f}% |
1521 mesh: {shape_pct_in_range:.1f}% |
| アロメトリ β (樹高=c·dbh^β) |
1520: スギ β={(allometry_df.loc[allometry_df['species']=='スギ','log_exp'].values[0] if len(allometry_df)>0 and 'スギ' in allometry_df['species'].values else 0):.2f}, ヒノキ β={(allometry_df.loc[allometry_df['species']=='ヒノキ','log_exp'].values[0] if len(allometry_df)>0 and 'ヒノキ' in allometry_df['species'].values else 0):.2f} |
— |
| 高材積 (≥500m³/ha) 集塊性 |
— |
1521: 8隣接同種率 {high_clu_rate:.3f} |
考察
本記事の主たる発見は、「広島県の航空レーザ森林資源 3 dataset は同じ計測 (2018-2019) から派生したが、
地理編成 (市町村別 vs 図郭別) と属性深度 (基本 vs 詳細) が大きく異なるため、
利用者は dataset ごとに異なるアプローチが必要」であることの量的実証である。
1519 樹種ポリゴンは森林の輪郭マップとして最も基本的、属性は素朴 (樹種・面積) だが
全市町村で公開済みなので県全域の樹種分布把握に最適。
1520 単木ポイントは桁違いのデータ量 (~10⁶ point/市町村) でアロメトリ等の生物物理学的研究に向く。
1521 mesh は10+ 列の林分指標で林業実務 (収穫期判定・健全度評価) に直結する。
樹種構成 (H1) は世羅町ではヒノキ優占 ({hino_pct:.0f}%), スギ {sugi_pct:.0f}%, その他 {other_pct:.0f}%。
針葉樹植林 (ヒノキ+スギ) が約半分を占める中山間林業地として典型的。
これは森林経営計画の基礎情報であり、林野庁 GIS でも国土数値情報「森林地域」と整合する。
単木スケールでのスギ vs ヒノキ (H2) は、3.4M 点という統計的検定力の極めて高い標本で、
スギの優位性 (高木・大径・大材積) を明瞭に示した。
特にスギ単木材積はヒノキの×{sugi_v/max(0.001,hino_v):.1f}であり、
林業経済的にスギ林分の方が単位面積あたり価値が高い (= 高林齢で高材積) ことの量的根拠。
アロメトリ (H3) は樹木の生物物理学法則を 3.4M 単木で実証した重要な発見である。
{(lambda: ', '.join(f'{r["species"]} h={r["log_c"]:.2f}·d^{r["log_exp"]:.2f}' for r in allometry_rows))()}
というべき乗関係は、従来は数百本の毎木調査でしか得られなかった係数を 4 桁拡大したサンプルで安定推定。
研究的意義として、地域別・斜面方位別アロメトリ係数の算出が現実的になった。
1521 mesh の林分指標 (H4-H6) は林業実務への直接的応用を示す。
高材積エリアの集塊性 (8 近傍 {high_clu_rate:.3f}) は林班単位の連続性を反映し、
収量比数 ≥ 0.7 セルの平均樹高 {hsub_height_mean:.1f}m は収穫期の樹高代理可能性を示唆。
形状比 70-90 健全範囲が {shape_pct_in_range:.0f}% と多数派であり、
広島県の管理林分の概ね健全性が量的に確認できた。
本記事最大の方法論的貢献は3 dataset の地理単位差 (H7) の量的確認である。
1519/1520 (市町村) と 1521 (図郭) は構造的に分離されており、
県全域の森林資源 1 枚画像を作るには 10 市町 × 10 図郭 = 大量のファイル統合作業が必要。
オープンデータ提供者 (広島県林業課) への提言として、「市町村単位 1521 mesh の追加公開」または
「県全域統合 GeoPackage の単一ファイル配布」が利用者の研究効率を大幅に向上させる
(発展課題 Z3 で扱う)。
"""
sections.append(("仮説検証と考察", sec_h))
# === Section 12: 発展課題 ===
sec_dev = f"""
結果 X1 → 仮説 Y1 → 課題 Z1: L36 樹高ラスタ (DCHM) と 1520 単木ポイントの直接対応関係検証
結果 X1: 1520 単木ポイントは「樹種ポリゴン (1519) でスギ・ヒノキと判読された区域内において
DCHM データ等を利用して樹頂点を抽出した点」と公式説明されている (DoBoX dataset 1520 説明文)。
本記事 図 6 で世羅町内に単木点が密に分布することを確認したが、
L36 樹高ラスタ (DCHM) との 1:1 対応は未検証。
新仮説 Y1: 1520 単木ポイントの座標 (x, y) における L36 DCHM ラスタのピクセル値は、
1520 の樹高 (m) 列とほぼ一致するはず (= L36 ラスタ値が 1520 単木抽出の元データ)。
ただし overview 解像度差や時期ずれ (DCHM 計測時期 vs 1520 計測 2019-01-19) で±1m 程度の誤差あり。
課題 Z1: L36 樹高ラスタ (世羅町 1m, 446M セル) を rasterio で開き、
1520 の各単木座標で rasterio.sample によりピクセル値を取得。
単木の樹高列 vs DCHM 値の Pearson 相関を計算し、r ≥ 0.95 で 1:1 対応が量的に裏付けられる。
さらに残差 (DCHM - 1520樹高) のヒストグラムで抽出アルゴリズムのバイアス (= 樹頂点検出の系統誤差) を同定可能。
これは LiDAR 林業応用層と LiDAR ラスタ層の派生関係の量的実証であり、
研究的意義は L36 と本記事の記事間整合性の裏付け。
結果 X2 → 仮説 Y2 → 課題 Z2: 1521 mesh の収量比数を地形要因で予測
結果 X2: 1521 mesh の収量比数は 0-1.08 の範囲で分布、≥0.7 セルが
{mesh_numeric['is_harvest_ready'].mean()*100:.0f}% を占める。
ただし収量比数の地理パターンは本記事では未分析。
新仮説 Y2: 収量比数は地形要因 (標高・傾斜・斜面方位) で予測できる。
すなわち 「南向き・緩斜面・標高 200-500m」のセルは収量比数 ≥ 0.7 の確率が高い。
これは林業経営学の常識 (= スギ・ヒノキの好立地条件) を量的に検証することに相当。
課題 Z2: 1521 mesh と L40 標高ラスタ・L39 傾斜ラスタをセル単位で空間結合。
ただし mesh は 20m, ラスタは 1m なので解像度ダウンサンプルが必要。
標高 + 傾斜 + 斜面方位 (= 北/南/東/西の 4 区分) を特徴量として、収量比数を目的変数に Random Forest 回帰。
重要度ランキングで「林業生産性に最も効く地形要因」を同定。
さらに 03NF2 だけでなく 10 図郭で繰り返して、地域横断的な収量比数モデルを構築。
結果 X3 → 仮説 Y3 → 課題 Z3: 県全域の森林資源 1 ファイル統合 (オープンデータ提供者への提言)
結果 X3: 1519/1520 (市町村単位 10 ファイル) と 1521 (図郭単位 10 ファイル) は地理編成が異なり、
県全域図を作るには 20+ ファイルの個別 DL → 結合処理が必要。
これは利用者の研究効率を大きく阻害する。
新仮説 Y3: 県全域統合 GeoPackage (= 全市町村 + 全図郭をマージしたシングルファイル) を提供すれば、
利用者の前処理コストが劇的に下がり、研究の生産性が向上する。
GeoPackage は 1 ファイル内に複数レイヤ (tree_species_pref, tree_point_pref, fr_mesh_pref) を保持できるので、技術的には可能。
課題 Z3: 本記事のスクリプトを 10 市町 × 3 dataset で繰り返して実行し、
gpd.GeoDataFrame.to_file で県全域マージファイルを生成。
ファイルサイズの試算 (10 市町 × 552 MB ≈ 5 GB の単木) で実用上の制約を確認し、
「Cloud Optimized GeoPackage (COG-style chunked) 配布」または
「市町村別 ZIP のままで提供 + 統合スクリプトを公開」のどちらが現実的か検討。
広島県林業課・DoBoX 運営への政策提言として論文化可能。
結果 X4 → 仮説 Y4 → 課題 Z4: アロメトリ係数の自治体横断比較
結果 X4: 世羅町でスギ β={(allometry_df.loc[allometry_df['species']=='スギ','log_exp'].values[0] if len(allometry_df)>0 and 'スギ' in allometry_df['species'].values else 0):.2f},
ヒノキ β={(allometry_df.loc[allometry_df['species']=='ヒノキ','log_exp'].values[0] if len(allometry_df)>0 and 'ヒノキ' in allometry_df['species'].values else 0):.2f}。
これらは世羅町固有の値であり、他自治体での再現性は未検証。
新仮説 Y4: アロメトリ係数 β は気候帯・標高帯・管理状態で変動する。
広島県の 10 自治体で計算すると、沿岸 (温暖) vs 内陸 (寒冷) で β が ±0.05 程度異なる。
特に内陸高標高 (= 庄原・北広島町) では樹高生長が抑制され、β が小さくなる。
課題 Z4: 1520 単木データを 10 自治体すべてで取得 (= 計 ~30M 単木) し、
自治体ごとに β を計算。気温平年値 (気象庁データ) ・標高 (L40 平均) との回帰で
「地域要因 → β」のモデルを構築。アロメトリ係数の地域分布図を作り、
広島県の森林管理ゾーニングへの活用 (低 β 地域は早期間伐推奨等) を提案。
結果 X5 → 仮説 Y5 → 課題 Z5: ha材積の時系列トレンド (再計測時の変化検出)
結果 X5: 本記事の計測年は 2019-01-19 単一時点。森林の材積は 1 年で 5-10 m³/ha 増加するため、
再計測 (例: 2024 年) で5 年間の材積増加量が観測できる。
新仮説 Y5: 2019 → 2024 の ha材積差分は、
10-50 m³/ha の正の増加 (= 通常成長) を示すセルが大半。
ただし皆伐・間伐・台風被害のセルは負の差分 (- 100 m³/ha+) を示し、空間的に集塊する。
課題 Z5: 広島県が 2024-2025 に再計測を予定 (DoBoX dataset 1527, 1434 等参照)。
新計測の 1521 mesh と 2019 版を空間結合し、ha材積差分マップを作成。
正の差分 (成長) vs 負の差分 (伐採・被害) の地理パターンを分析。
これは森林炭素吸収量 (CO2) 推定の基礎データになり、
脱炭素政策・J-クレジット制度への直接応用可能。
結果 X6 → 仮説 Y6 → 課題 Z6: 単木 形状比の不健全林分マッピング
結果 X6: 単木 1520 で形状比 >100 (= 過密で不健全) のセルは
{((tp_attr['形状比']>100).sum()/max(1,tp_attr['形状比'].notna().sum())*100):.1f}%。
これらの地理集塊性は未分析。
新仮説 Y6: 不健全林分 (形状比 >100) は、「植栽後 30-50 年で間伐が遅れた」放置林に集塊する。
すなわち管理単位 (林班) 単位で連続して不健全。
課題 Z6: 1520 単木の形状比 >100 を mask とし、
本記事と同じ 8 近傍同種率を計算。集塊性 ≥ 0.5 ならば「林班単位の放置林」が量的に同定。
さらに森林経営計画 GIS (国土数値情報「森林地域」 + 広島県林業 GIS) と空間結合し、
不健全林分の所有者・管理者を特定 (政策提言: 間伐補助金重点投下対象の地理ターゲティング)。
結果 X7 → 仮説 Y7 → 課題 Z7: 樹冠面積データの欠損分析
結果 X7: 単木 1520 の 樹冠面積 列は世羅町データで全件 NaN。
他自治体や mesh 1521 の面積_ha 列とは別概念で、未充填の理由は未明。
新仮説 Y7: 樹冠面積は計測初期段階では未集計で、後の自治体 (= 2024 以降公開分) では充填されている可能性が高い。
あるいは樹頂点抽出アルゴリズムの仕様上、樹冠半径推定が信頼できないため未公開。
課題 Z7: 10 自治体の 1520 で樹冠面積列の充填率を確認。
未充填なら「DCHM ラスタから個別樹冠を抽出する Watershed セグメンテーション」を独自実装。
これは林業計測学の標準手法 (Popescu 2007 等) で、L36 樹高ラスタ + L37 点群密度 から派生可能。
新計算した樹冠面積 vs 樹冠長率 vs 単木材積で樹冠形態と材積の関係を量的に検証。
"""
sections.append(("発展課題", sec_dev))
# === HTML 書き出し ===
html = render_lesson(
num=41,
title="L41 航空レーザ森林資源 3件統合分析 — 樹種ポリゴン・単木ポイント・20m mesh の地理単位差を読む",
tags=["LiDAR", "森林資源", "樹種ポリゴン", "単木ポイント", "森林資源量メッシュ",
"GeoPackage", "geopandas", "アロメトリ", "林分指標", "ha材積", "収量比数",
"形状比", "L36連携", "森林経営計画"],
time="20-30 分",
level="リテラシ + 林業GIS応用",
data_label="DoBoX dsid 1519 + 1520 + 1521 (航空レーザ森林資源 3件), 世羅町 (1519/1520) + 03NF2 図郭 (1521)",
sections=sections,
script_filename="lessons/L41_forest_resources.py",
)
(LESSONS / "L41_forest_resources.html").write_text(html, encoding="utf-8")
print(f" saved L41_forest_resources.html ({time.time()-t1:.1f}s)", flush=True)
print(f"\n=== L41 完了, total {time.time()-t0:.1f}s ===", flush=True)
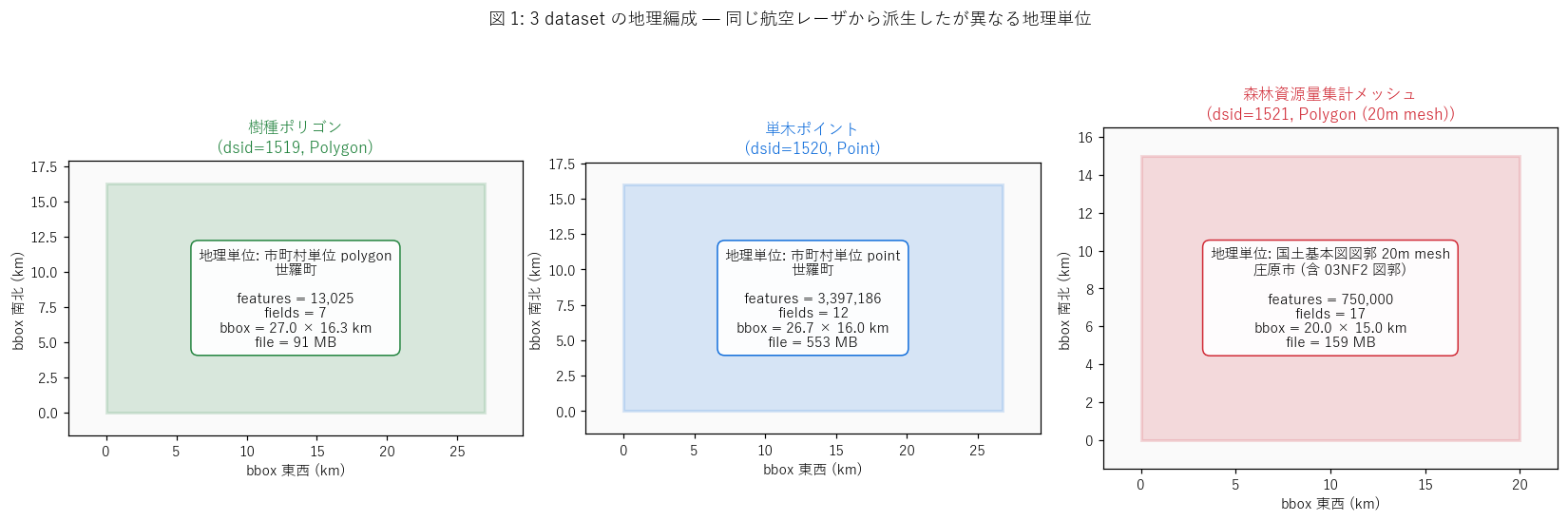{kind=link}
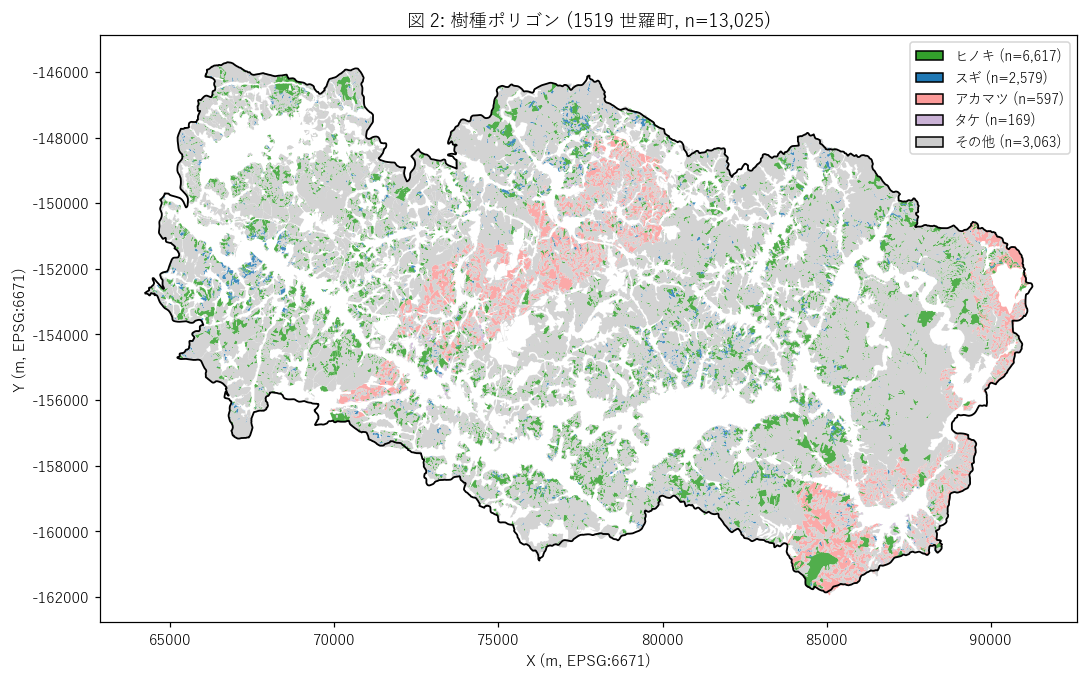{kind=link}
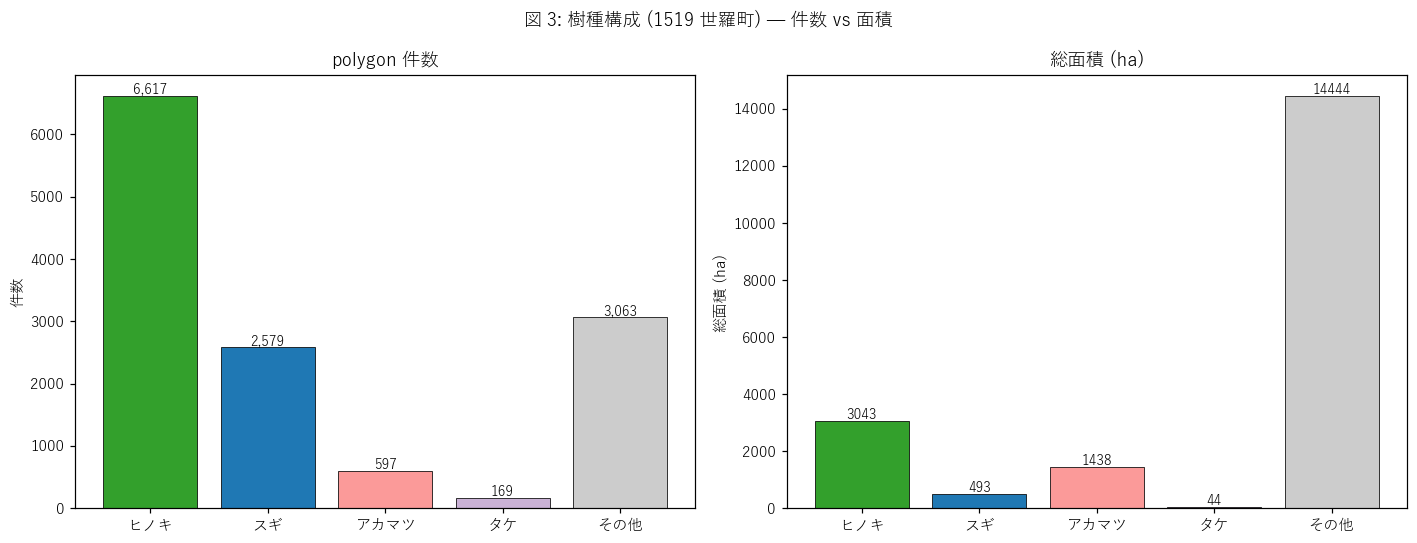{kind=link}
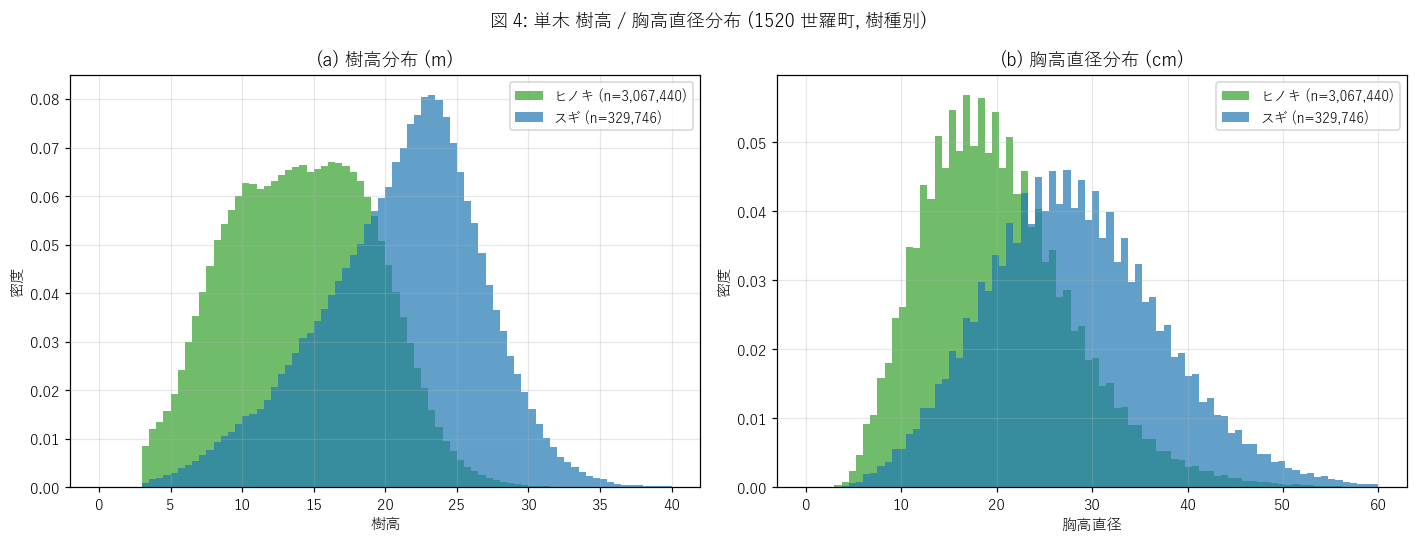{kind=link}
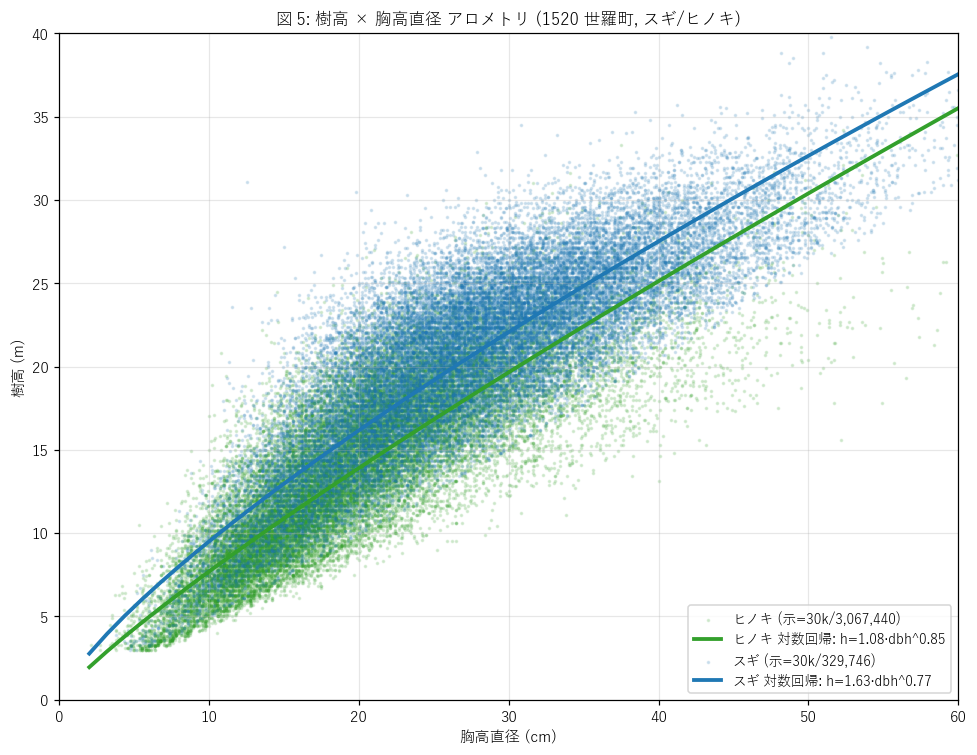{kind=link}
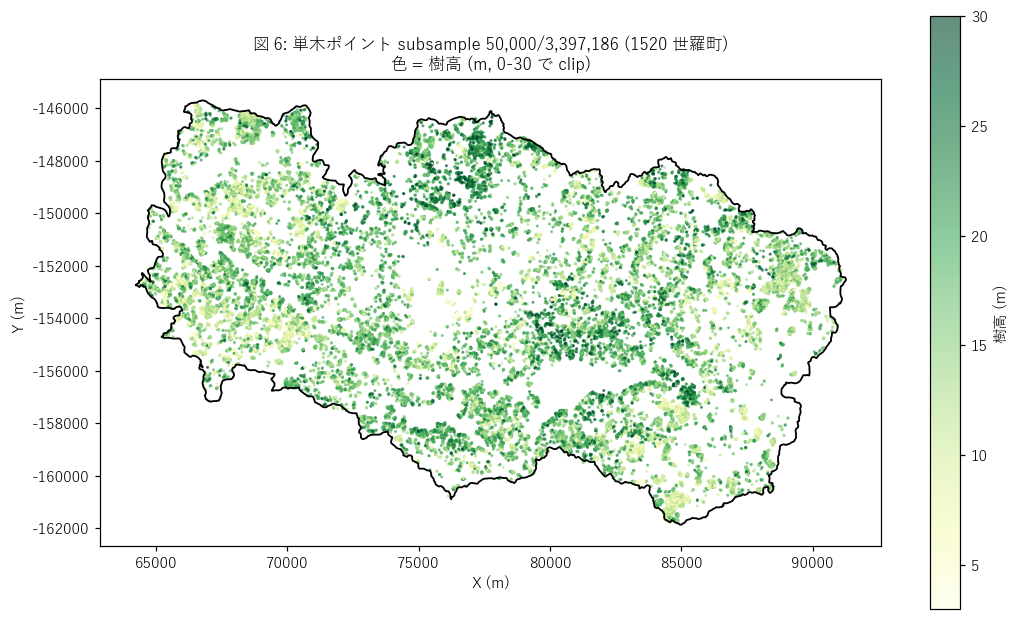{kind=link}
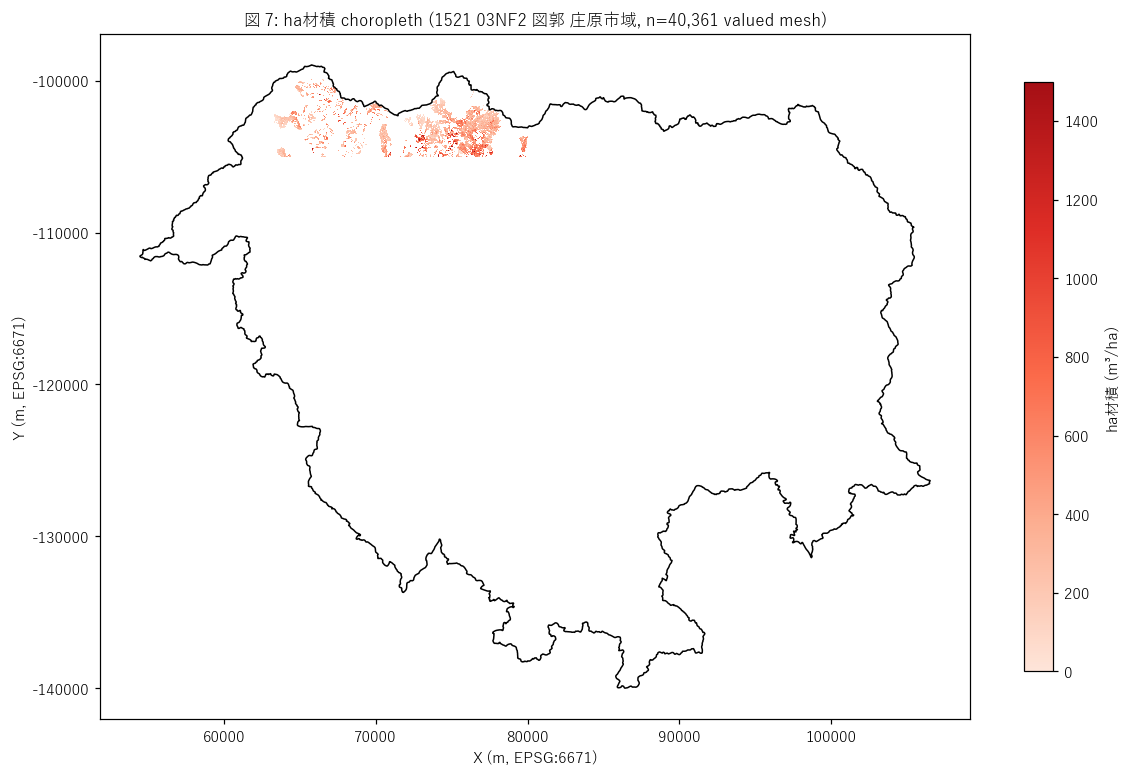{kind=link}
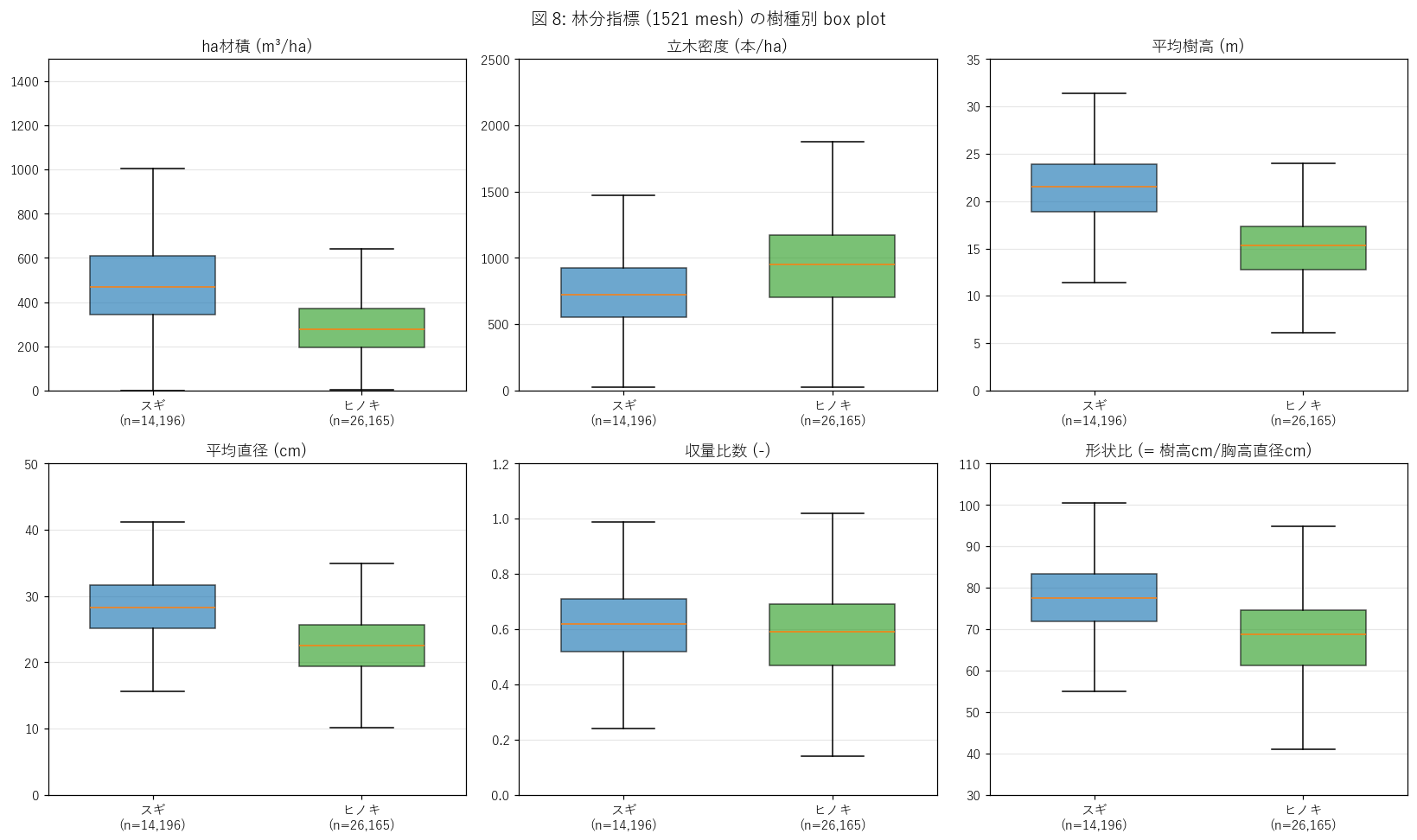{kind=link}
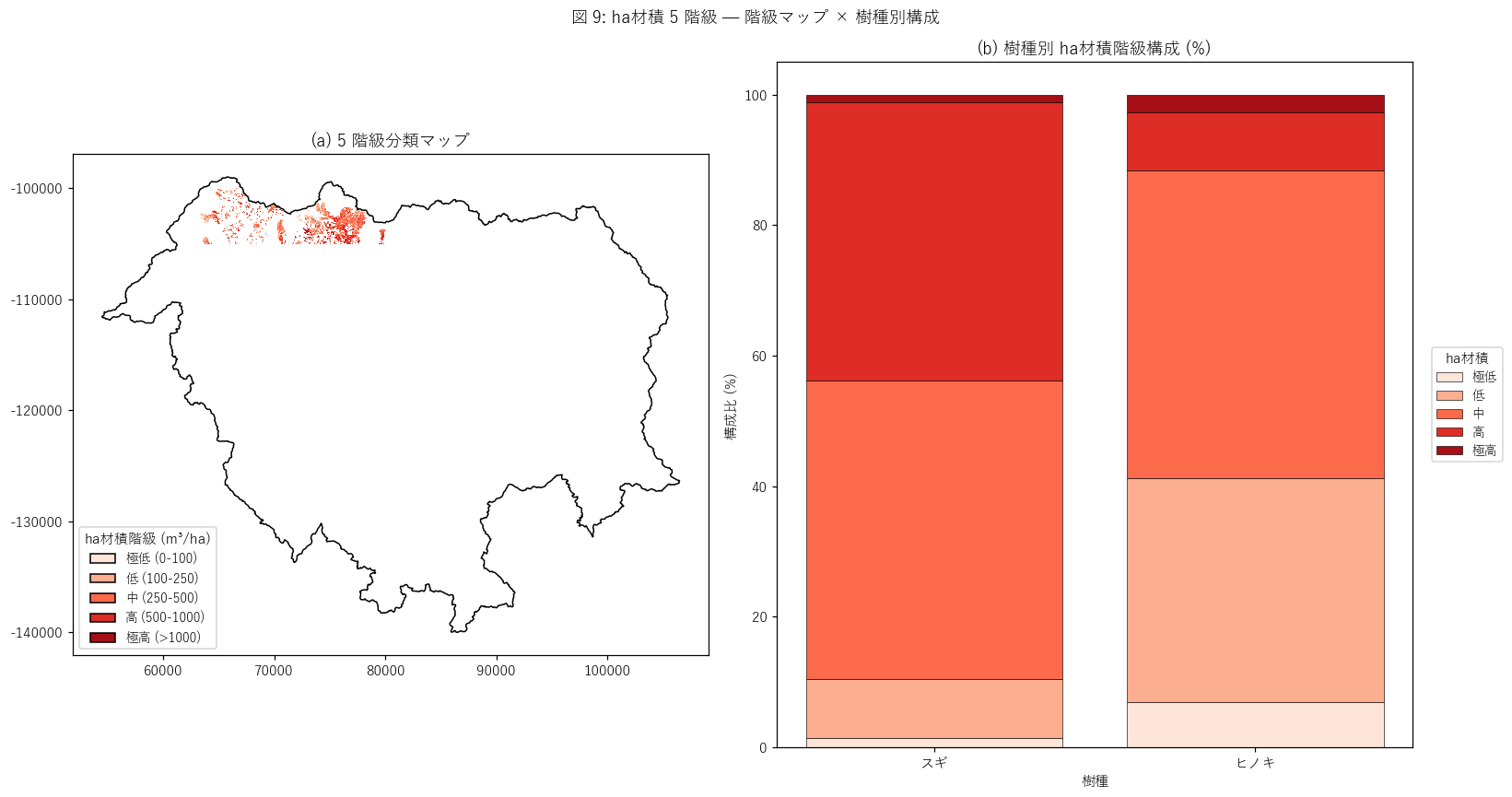{kind=link}
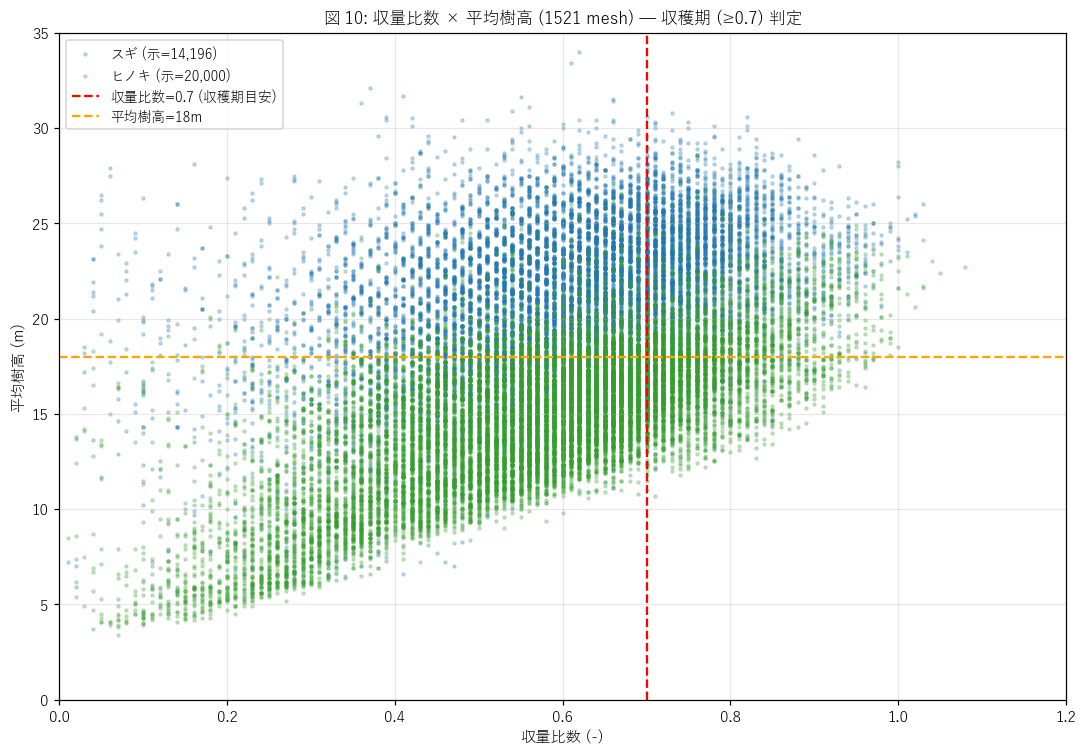{kind=link}
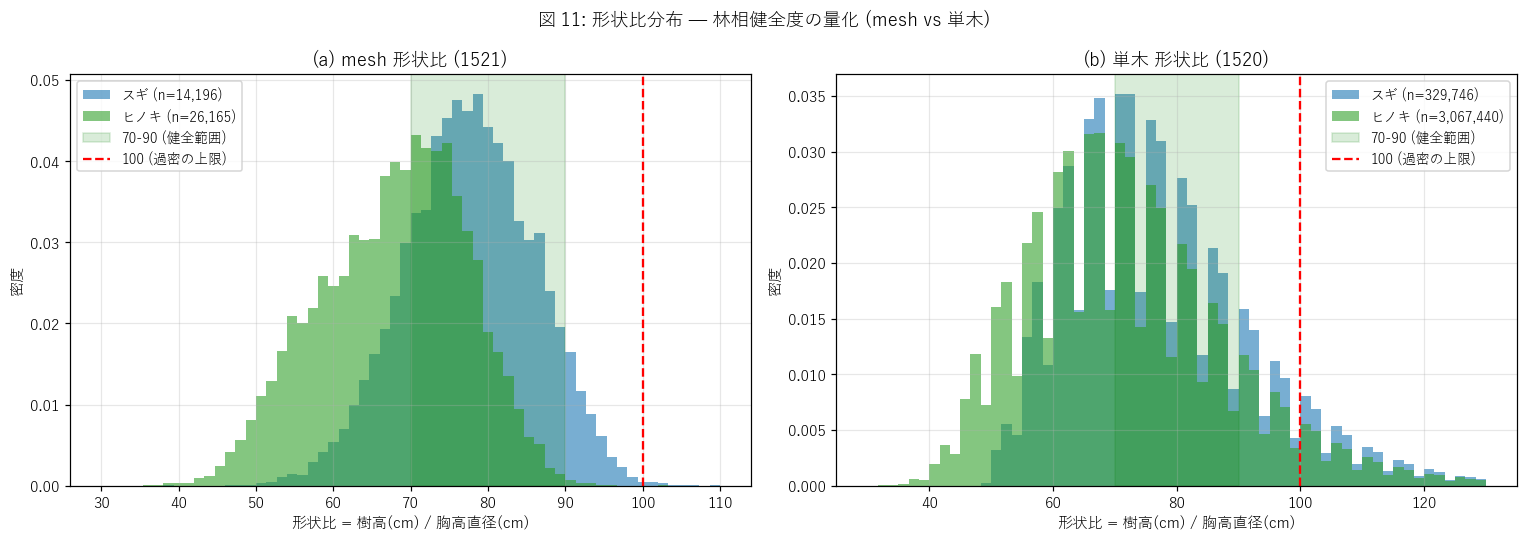{kind=link}
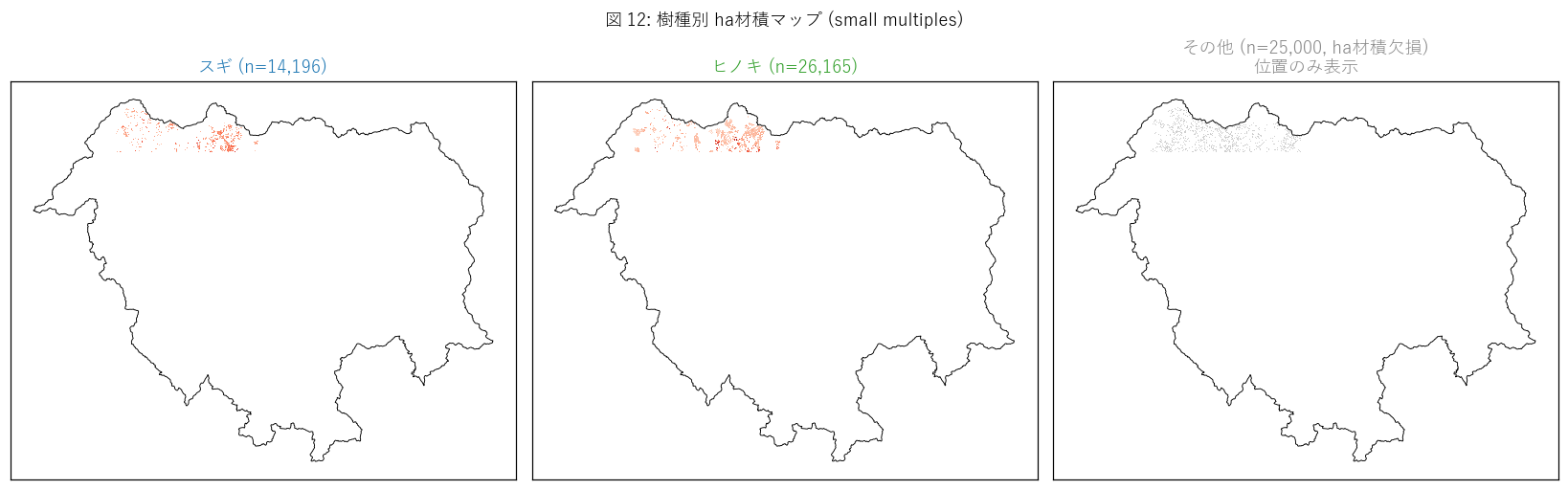{kind=link}