to_crs("EPSG:6671") で統一する。
- 坂町 (1412) は 1 ポリゴンのみ「森山北漁業基地」(漁業施設) ─
他市町と異なる『漁業のみ』の特異データ。
- 監査時 (2026-05-03) の DL では 坂町 (1412)・竹原市 (1418) が KMZ 形式しか
自動取得できなかったが、再取得で GeoJSON 単独 ZIP (rid=50870, 50918) を確保。
→ fetch_agroforestry_policy.py の pick_best() を「geojson 単独 rid を最優先」
に修正することで 17 件全て GeoJSON で揃った。
- 広島市 (1410) は監査時 NRG_AN サンプルが None だったが、
実データでは 426 行中 424 行に地区名が入る。
監査結論「広島市 NRG_AN None」はサンプル 1 行偶発による誤読。
"""
from __future__ import annotations
import sys, time, json, zipfile, io, re
from pathlib import Path
sys.path.insert(0, str(Path(__file__).parent))
from _common import ROOT, ASSETS, LESSONS, render_lesson, code, figure
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.patches import Patch
import geopandas as gpd
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
t0 = time.time()
print("=== L25 農林漁業関係施策 17 件 統合分析 ===", flush=True)
# =============================================================================
# 0. 定数
# =============================================================================
DATA_DIR = ROOT / "data" / "extras" / "L25_agroforestry_policy"
ADMIN_DIR = ROOT / "data" / "extras" / "L15_admin_zones"
L24_DIR = ROOT / "data" / "extras" / "L24_farmland_conversion"
TARGET_CRS = "EPSG:6671"
# (施策 dsid, 市町名, 行政_dsid, 都市タイプ, 地理タイプ)
# L24 の 17 市町から熊野町(1392) を除き、坂町(1412)を加えた構成
CITY_DEFS = [
(1410, "広島市", 786, "政令市", "都市"),
(1409, "呉市", 797, "中核市", "都市"),
(1423, "福山市", 832, "中核市", "都市"),
(1419, "東広島市", 868, "施行時特例市", "都市"),
(1420, "廿日市市", 878, "市", "都市"),
(1421, "尾道市", 824, "市", "都市"),
(1413, "三原市", 814, "市", "都市"),
(1418, "竹原市", 807, "市", "都市"),
(1422, "府中市", 840, "市", "都市"),
(1417, "大竹市", 862, "市", "都市"),
(1414, "三次市", 850, "市", "中山間"),
(1415, "庄原市", 856, "市", "中山間"),
(1408, "安芸高田市", 888, "市", "中山間"),
(1411, "江田島市", 894, "市", "離島"),
(1412, "坂町", 916, "町", "近郊町"), # 漁業基地のみ
(1424, "北広島町", 935, "町", "中山間"),
(1416, "世羅町", 941, "町", "中山間"),
]
# 4 町 (農林漁業施策データ無指定 — L25 にない 4 市町)
NO_POLICY_CITIES = [
("熊野町", 911, "町", "近郊町"), # L24 にあったが L25 に無い
("府中町", 900, "町", "近郊町"),
("海田町", 905, "町", "近郊町"),
]
CITY_REF = {
"広島市": {"area_km2": 906.7, "pop_k": 1189},
"呉市": {"area_km2": 352.8, "pop_k": 210},
"福山市": {"area_km2": 518.1, "pop_k": 459},
"東広島市": {"area_km2": 635.3, "pop_k": 198},
"廿日市市": {"area_km2": 489.5, "pop_k": 117},
"尾道市": {"area_km2": 285.1, "pop_k": 130},
"三原市": {"area_km2": 471.6, "pop_k": 90},
"竹原市": {"area_km2": 118.2, "pop_k": 24},
"府中市": {"area_km2": 195.8, "pop_k": 37},
"大竹市": {"area_km2": 78.7, "pop_k": 26},
"三次市": {"area_km2": 778.1, "pop_k": 50},
"庄原市": {"area_km2":1246.5, "pop_k": 33},
"安芸高田市": {"area_km2": 537.8, "pop_k": 27},
"江田島市": {"area_km2": 100.7, "pop_k": 22},
"府中町": {"area_km2": 10.4, "pop_k": 53},
"海田町": {"area_km2": 13.8, "pop_k": 30},
"熊野町": {"area_km2": 33.7, "pop_k": 23},
"坂町": {"area_km2": 15.7, "pop_k": 12},
"北広島町": {"area_km2": 646.2, "pop_k": 17},
"世羅町": {"area_km2": 278.2, "pop_k": 15},
}
RTYPE_COLOR = {
"都市": "#cf222e",
"中山間": "#1f883d",
"離島": "#0969da",
"近郊町": "#bf3989",
}
ALL_POLICY_CITIES = [d[1] for d in CITY_DEFS]
ALL_CITY_ORDER = ALL_POLICY_CITIES + [n[0] for n in NO_POLICY_CITIES]
# NRG_AN 分類のキーワード辞書 (本記事独自定義)
# NRG_AN 文字列の特徴的キーワードから施策種別を推定する
NRG_KEYWORDS = [
("ダム", ["ダム"]),
("ため池", ["池", "溜池", "ため池"]),
("漁業", ["漁業", "漁港", "漁場", "養殖"]),
("林業", ["林", "森林", "山林"]),
("ほ場整備", ["ほ場整備", "圃場整備", "ほ場", "圃場", "整備", "区画整理"]),
("基地・施設", ["基地", "施設", "場"]),
]
# 上記キーワードに該当しない NRG_AN は「地区名」(地名のみ) と推定
def classify_nrg_an(s):
"""NRG_AN 文字列を施策種別に分類。複数該当時は最優先タイプ。"""
if pd.isna(s) or s is None or str(s).strip() == "":
return "_欠損"
text = str(s)
for label, kws in NRG_KEYWORDS:
for kw in kws:
if kw in text:
return label
return "地区名のみ"
# =============================================================================
# 1. 17 GeoJSON 統合読み込み
# =============================================================================
print("\n[1] 17 農林漁業施策 GeoJSON 統合読み込み", flush=True)
t1 = time.time()
def load_geojson_zip(zip_path: Path) -> gpd.GeoDataFrame:
with zipfile.ZipFile(zip_path) as zf:
gjs = [n for n in zf.namelist() if n.lower().endswith(".geojson")]
if not gjs:
raise FileNotFoundError(f"no .geojson in {zip_path.name}")
with zf.open(gjs[0]) as f:
return gpd.read_file(io.BytesIO(f.read()))
COMMON_COLS_7 = ["ID", "TOKEI_CD", "CITY_CD", "KUIKI_CD", "NRG_AN",
"RITTEKI_CD", "geometry"]
frames = []
load_log = []
for dsid, name, _adm, ctype, rtype in CITY_DEFS:
z = DATA_DIR / f"agro_{dsid}_{name}.zip"
g = load_geojson_zip(z)
extra = sorted(set(g.columns) - set(COMMON_COLS_7))
g = g[COMMON_COLS_7].copy()
g["src_city"] = name
g["src_dsid"] = dsid
g["ctype"] = ctype
g["rtype"] = rtype
if g.crs is None:
g = g.set_crs("EPSG:2445", allow_override=True)
# CRS 統一: EPSG:2445 → EPSG:6671
g = g.to_crs(TARGET_CRS)
n_multi = int((g.geom_type == "MultiPolygon").sum())
n_single = int((g.geom_type == "Polygon").sum())
n_nrg_null = int(g["NRG_AN"].isna().sum())
load_log.append({
"dsid": dsid, "city": name, "ctype": ctype, "rtype": rtype,
"n_poly": len(g),
"n_polygon": n_single,
"n_multipoly": n_multi,
"multi_pct": round(n_multi / max(len(g), 1) * 100, 1),
"n_nrg_null": n_nrg_null,
"nrg_null_pct": round(n_nrg_null / max(len(g), 1) * 100, 1),
"city_cds": ",".join(map(str, sorted(g["CITY_CD"].unique()))),
"kuiki_cds": ",".join(map(str, sorted(g["KUIKI_CD"].unique()))),
"tokei_cds": ",".join(map(str, sorted(g["TOKEI_CD"].unique()))),
"ritteki_cds": ",".join(map(str, sorted(g["RITTEKI_CD"].unique()))),
"extra_cols": ",".join(extra) if extra else "-",
})
frames.append(g)
agro = gpd.GeoDataFrame(pd.concat(frames, ignore_index=True),
geometry="geometry", crs=TARGET_CRS)
N_POLY = len(agro)
# 派生指標
agro["geom_area_m2"] = agro.geometry.area
agro["geom_area_ha"] = agro["geom_area_m2"] / 1e4
agro["geom_type"] = agro.geom_type
agro["nrg_class"] = agro["NRG_AN"].apply(classify_nrg_an)
AREA_TOTAL_HA = float(agro["geom_area_ha"].sum())
AREA_TOTAL_KM2 = AREA_TOTAL_HA / 100
print(f" 施策ポリゴン: {N_POLY:,} 件 × {len(agro.columns)} 列", flush=True)
print(f" 実測面積合計: {AREA_TOTAL_HA:,.0f} ha = {AREA_TOTAL_KM2:.1f} km²", flush=True)
print(f" Polygon : MultiPolygon = "
f"{int((agro.geom_type=='Polygon').sum()):,} : "
f"{int((agro.geom_type=='MultiPolygon').sum()):,}", flush=True)
# 行政区域 20 件 (= 17 施策市町 + 3 施策無し町) を読み込み
admin_frames = []
for _dsid, name, adm_ds, _ct, _rt in CITY_DEFS:
z = ADMIN_DIR / f"admin_{adm_ds}_{name}.zip"
g = load_geojson_zip(z)
g["city"] = name
g["policy_status"] = "施策あり"
admin_frames.append(g)
for name, adm_ds, _ctype, _region in NO_POLICY_CITIES:
z = ADMIN_DIR / f"admin_{adm_ds}_{name}.zip"
g = load_geojson_zip(z)
g["city"] = name
g["policy_status"] = "施策無し"
admin_frames.append(g)
# CRS 揃え
admin_all = gpd.GeoDataFrame(pd.concat(admin_frames, ignore_index=True),
geometry="geometry", crs=admin_frames[0].crs)
admin_all = admin_all.to_crs(TARGET_CRS)
admin_diss = admin_all.dissolve(by="city", as_index=False,
aggfunc={"policy_status": "first"})
admin_diss["admin_area_km2"] = admin_diss.geometry.area / 1e6
print(f" 行政区域 dissolve: {len(admin_diss)} 件 ({time.time()-t1:.2f}s)", flush=True)
# =============================================================================
# 2. 派生指標の集計 (市町単位 + クロス集計)
# =============================================================================
print("\n[2] 派生指標計算", flush=True)
t1 = time.time()
def aggregate_by_city(d: gpd.GeoDataFrame) -> pd.DataFrame:
agg = d.groupby("src_city").agg(
n_poly=("geom_area_ha", "size"),
area_ha_sum=("geom_area_ha", "sum"),
area_ha_median=("geom_area_ha", "median"),
area_ha_max=("geom_area_ha", "max"),
n_multipoly=("geom_type", lambda s: int((s == "MultiPolygon").sum())),
n_single=("geom_type", lambda s: int((s == "Polygon").sum())),
n_nrg_null=("NRG_AN", lambda s: int(s.isna().sum())),
).reset_index().rename(columns={"src_city": "city"})
agg["multi_pct"] = (agg["n_multipoly"] / agg["n_poly"] * 100).round(1)
agg["nrg_null_pct"] = (agg["n_nrg_null"] / agg["n_poly"] * 100).round(1)
agg["city_area_km2"] = agg["city"].map(lambda c: CITY_REF[c]["area_km2"])
agg["city_pop_k"] = agg["city"].map(lambda c: CITY_REF[c]["pop_k"])
agg["policy_per_km2"] = (agg["area_ha_sum"]
/ agg["city_area_km2"]).round(3)
agg["policy_share_area"] = (agg["area_ha_sum"]
/ (agg["city_area_km2"] * 100) * 100).round(2)
agg["policy_per_capita_a"] = (agg["area_ha_sum"] * 100
/ (agg["city_pop_k"] * 1000)).round(2)
agg["ctype"] = agg["city"].map(
lambda c: next(d[3] for d in CITY_DEFS if d[1] == c))
agg["rtype"] = agg["city"].map(
lambda c: next(d[4] for d in CITY_DEFS if d[1] == c))
return agg
city_agg = aggregate_by_city(agro)
city_agg = city_agg.set_index("city").reindex(ALL_POLICY_CITIES).reset_index()
print(f" 市町別集計: {len(city_agg)} 件", flush=True)
# NRG_AN 分類別集計
nrg_overall = agro.groupby("nrg_class").agg(
n=("geom_area_ha", "size"),
area_ha_sum=("geom_area_ha", "sum"),
).reset_index()
nrg_overall["n_pct"] = (nrg_overall["n"] / N_POLY * 100).round(1)
nrg_overall["area_pct"] = (nrg_overall["area_ha_sum"]
/ AREA_TOTAL_HA * 100).round(1)
nrg_cross_n = (agro.groupby(["src_city", "nrg_class"]).size()
.unstack(fill_value=0)
.reindex(index=ALL_POLICY_CITIES, fill_value=0))
# KUIKI_CD クロス
kuiki_cross_n = (agro.groupby(["src_city", "KUIKI_CD"]).size()
.unstack(fill_value=0)
.reindex(index=ALL_POLICY_CITIES, fill_value=0))
kuiki_overall = agro.groupby("KUIKI_CD").agg(
n=("geom_area_ha", "size"),
area_ha_sum=("geom_area_ha", "sum"),
).reset_index()
kuiki_overall["n_pct"] = (kuiki_overall["n"] / N_POLY * 100).round(1)
kuiki_overall["area_pct"] = (kuiki_overall["area_ha_sum"]
/ AREA_TOTAL_HA * 100).round(1)
# TOKEI_CD クロス
tokei_overall = agro.groupby("TOKEI_CD").agg(
n=("geom_area_ha", "size"),
area_ha_sum=("geom_area_ha", "sum"),
).reset_index()
tokei_overall["n_pct"] = (tokei_overall["n"] / N_POLY * 100).round(1)
tokei_overall["area_pct"] = (tokei_overall["area_ha_sum"]
/ AREA_TOTAL_HA * 100).round(1)
# 規模クラス分類
def _scale_class(ha_value):
if ha_value < 0.01: return "0_微小(<0.01 ha)"
elif ha_value < 0.1: return "1_小(0.01-0.1 ha)"
elif ha_value < 1.0: return "2_中(0.1-1 ha)"
elif ha_value < 10.0: return "3_大(1-10 ha)"
elif ha_value < 100.0: return "4_超大(10-100 ha)"
else: return "5_巨大(≥100 ha)"
agro["scale_class"] = agro["geom_area_ha"].apply(_scale_class)
scale_overall = agro.groupby("scale_class").agg(
n=("geom_area_ha", "size"),
area_ha_sum=("geom_area_ha", "sum"),
).reset_index()
scale_overall["n_pct"] = (scale_overall["n"] / N_POLY * 100).round(1)
scale_overall["area_pct"] = (scale_overall["area_ha_sum"]
/ AREA_TOTAL_HA * 100).round(1)
print(f" 集計完了 ({time.time()-t1:.2f}s)", flush=True)
# =============================================================================
# 2b. L24 農地転用ポリゴンとの空間関係 (重複 vs すみ分け)
# =============================================================================
print("\n[2b] L24 農地転用との空間重複分析", flush=True)
t1 = time.time()
L24_DEFS = [
(1391, "安芸高田市"), (1392, "熊野町"), (1393, "呉市"), (1394, "広島市"),
(1395, "江田島市"), (1396, "三原市"), (1397, "三次市"), (1398, "庄原市"),
(1399, "世羅町"), (1400, "大竹市"), (1401, "竹原市"), (1402, "東広島市"),
(1403, "廿日市市"), (1404, "尾道市"), (1405, "府中市"), (1406, "福山市"),
(1407, "北広島町"),
]
farm_frames = []
for dsid, name in L24_DEFS:
z = L24_DIR / f"farm_{dsid}_{name}.zip"
if not z.exists():
continue
try:
f = load_geojson_zip(z)
f = f[["KUIKI_CD", "AREA", "geometry"]].copy()
f["AREA"] = pd.to_numeric(f["AREA"], errors="coerce")
f["src_city"] = name
if f.crs is None:
f = f.set_crs(TARGET_CRS, allow_override=True)
f = f.to_crs(TARGET_CRS)
farm_frames.append(f)
except Exception as e:
print(f" L24 read fail {name}: {e}", flush=True)
farm = gpd.GeoDataFrame(pd.concat(farm_frames, ignore_index=True),
geometry="geometry", crs=TARGET_CRS)
farm["geom_area_ha"] = farm.geometry.area / 1e4
print(f" L24 転用ポリゴン: {len(farm):,} 件 (合計 {farm['geom_area_ha'].sum():,.0f} ha)",
flush=True)
common_cities = sorted(set(d[1] for d in CITY_DEFS) & set(d[1] for d in L24_DEFS))
print(f" 共通 市町: {len(common_cities)} 件", flush=True)
# 重複面積を unary_union 経由で計算 (軽量)
overlap_log = []
from shapely.validation import make_valid
for city in common_cities:
a_sub = agro[agro["src_city"] == city]
f_sub = farm[farm["src_city"] == city]
a_total_ha = float(a_sub["geom_area_ha"].sum())
f_total_ha = float(f_sub["geom_area_ha"].sum())
if len(a_sub) == 0 or len(f_sub) == 0:
overlap_log.append({"city": city, "a_total_ha": a_total_ha,
"f_total_ha": f_total_ha, "overlap_ha": 0.0,
"overlap_pct_a": 0.0, "overlap_pct_f": 0.0})
continue
overlap_ha = 0.0
# 第1試行: union_all → make_valid → intersection
try:
a_uni = make_valid(a_sub.geometry.union_all())
f_uni = make_valid(f_sub.geometry.union_all())
inter = a_uni.intersection(f_uni)
overlap_ha = inter.area / 1e4
except Exception:
# 第2試行: buffer(0) で自己交差を解消してから union
try:
a_buf = a_sub.geometry.buffer(0).union_all()
f_buf = f_sub.geometry.buffer(0).union_all()
inter = a_buf.intersection(f_buf)
overlap_ha = inter.area / 1e4
except Exception as e2:
print(f" overlay fallback fail {city}: {e2}", flush=True)
overlap_ha = 0.0
overlap_log.append({
"city": city,
"a_total_ha": a_total_ha,
"f_total_ha": f_total_ha,
"overlap_ha": overlap_ha,
"overlap_pct_a": (overlap_ha / a_total_ha * 100) if a_total_ha > 0 else 0,
"overlap_pct_f": (overlap_ha / f_total_ha * 100) if f_total_ha > 0 else 0,
})
overlap_df = pd.DataFrame(overlap_log)
overlap_df["rtype"] = overlap_df["city"].map(
lambda c: next(d[4] for d in CITY_DEFS if d[1] == c))
print(f" L24 vs L25 重複分析: {len(overlap_df)} 市町 "
f"({time.time()-t1:.2f}s)", flush=True)
total_overlap_ha = float(overlap_df["overlap_ha"].sum())
total_a_ha = float(overlap_df["a_total_ha"].sum())
total_f_ha = float(overlap_df["f_total_ha"].sum())
overlap_pct_a_total = total_overlap_ha / total_a_ha * 100 if total_a_ha > 0 else 0
overlap_pct_f_total = total_overlap_ha / total_f_ha * 100 if total_f_ha > 0 else 0
print(f" 施策 {total_a_ha:,.0f} ha / 転用 {total_f_ha:,.0f} ha "
f"/ 重複 {total_overlap_ha:,.0f} ha "
f"(施策の {overlap_pct_a_total:.1f}% / "
f"転用の {overlap_pct_f_total:.2f}%)", flush=True)
# =============================================================================
# 3. CSV 出力
# =============================================================================
print("\n[3] CSV 出力", flush=True)
t1 = time.time()
city_agg.to_csv(ASSETS / "L25_city_summary.csv",
index=False, encoding="utf-8-sig")
no_policy_df = pd.DataFrame([{
"city": name, "ctype": ctype, "rtype": region,
"city_area_km2": CITY_REF[name]["area_km2"],
"city_pop_k": CITY_REF[name]["pop_k"],
} for name, _adm, ctype, region in NO_POLICY_CITIES])
no_policy_df.to_csv(ASSETS / "L25_no_policy_cities.csv",
index=False, encoding="utf-8-sig")
agro_attr = agro.drop(columns=["geometry"]).copy()
agro_attr["geom_area_m2"] = agro_attr["geom_area_m2"].round(1)
agro_attr["geom_area_ha"] = agro_attr["geom_area_ha"].round(4)
agro_attr.sort_values("geom_area_ha", ascending=False).head(2000).to_csv(
ASSETS / "L25_policy_polygons_top2000.csv",
index=False, encoding="utf-8-sig")
pd.DataFrame(load_log).to_csv(ASSETS / "L25_load_log.csv",
index=False, encoding="utf-8-sig")
nrg_overall.to_csv(ASSETS / "L25_nrg_overall.csv",
index=False, encoding="utf-8-sig")
nrg_cross_n.to_csv(ASSETS / "L25_nrg_cross_count.csv",
encoding="utf-8-sig")
kuiki_cross_n.to_csv(ASSETS / "L25_kuiki_count.csv",
encoding="utf-8-sig")
kuiki_overall.to_csv(ASSETS / "L25_kuiki_overall.csv",
index=False, encoding="utf-8-sig")
tokei_overall.to_csv(ASSETS / "L25_tokei_overall.csv",
index=False, encoding="utf-8-sig")
scale_overall.to_csv(ASSETS / "L25_scale_overall.csv",
index=False, encoding="utf-8-sig")
overlap_df.to_csv(ASSETS / "L25_overlap_l24.csv",
index=False, encoding="utf-8-sig")
top20_large = (agro.drop(columns=["geometry"])
.nlargest(20, "geom_area_ha")
[["src_city", "ctype", "rtype", "CITY_CD", "KUIKI_CD",
"NRG_AN", "nrg_class", "geom_type",
"geom_area_ha", "scale_class"]])
top20_large.to_csv(ASSETS / "L25_top20_large.csv",
index=False, encoding="utf-8-sig")
# NRG_AN 頻度 top 50
nrg_vc = agro["NRG_AN"].dropna().value_counts().head(50)
nrg_freq = nrg_vc.reset_index()
nrg_freq.columns = ["nrg_an", "freq"]
nrg_freq.to_csv(ASSETS / "L25_nrg_freq_top50.csv",
index=False, encoding="utf-8-sig")
print(f" CSV 出力完了 ({time.time()-t1:.2f}s)", flush=True)
# =============================================================================
# 4. 図の作成 (9 枚)
# =============================================================================
print("\n[4] 図の作成", flush=True)
t1 = time.time()
# NRG_AN 分類別の色
NRG_COLOR = {
"ダム": "#1f77b4", # 青
"ため池": "#17becf", # 水色
"漁業": "#003366", # 紺
"林業": "#2ca02c", # 緑
"ほ場整備": "#ff7f0e", # オレンジ
"基地・施設": "#9467bd", # 紫
"地区名のみ": "#7f7f7f", # 灰
"_欠損": "#dddddd", # 薄灰
}
# --- Fig 1: 県全域 施策ポリゴン主題図 (rtype 色) ---
fig, ax = plt.subplots(figsize=(13, 9))
admin_diss.plot(ax=ax, facecolor="#f5f5f5", edgecolor="#888", linewidth=0.4)
admin_policy = admin_diss[admin_diss["policy_status"] == "施策あり"]
admin_policy.plot(ax=ax, facecolor="#fafff0", edgecolor="#444", linewidth=0.5)
rtype_count = {rt: 0 for rt in RTYPE_COLOR}
for rt, col in RTYPE_COLOR.items():
sub = agro[agro["rtype"] == rt]
if len(sub) > 0:
sub.plot(ax=ax, facecolor=col, alpha=0.65, edgecolor="none")
rtype_count[rt] = len(sub)
admin_diss.boundary.plot(ax=ax, color="#333", linewidth=0.4)
ax.set_aspect("equal")
ax.set_title(f"広島県 農林漁業関係施策ポリゴン 全 {N_POLY:,} 件 — 17 市町 (2022 単年)",
fontsize=13)
legend_handles = [Patch(facecolor=v,
label=f"{k} ({rtype_count[k]:,} 件)",
edgecolor="none", alpha=0.65)
for k, v in RTYPE_COLOR.items() if rtype_count[k] > 0]
ax.legend(handles=legend_handles, loc="lower left", fontsize=9, framealpha=0.92)
ax.set_xticks([]); ax.set_yticks([])
for _, r in city_agg.nlargest(5, "area_ha_sum").iterrows():
cnt = admin_diss[admin_diss["city"] == r["city"]]
if len(cnt) > 0:
ctr = cnt.geometry.iloc[0].representative_point()
ax.annotate(f"{r['city']}\n{r['n_poly']:,}件/{r['area_ha_sum']:.0f}ha",
(ctr.x, ctr.y), fontsize=8,
bbox=dict(boxstyle="round,pad=0.2",
fc="white", ec="#888", alpha=0.85))
plt.tight_layout()
plt.savefig(ASSETS / "L25_fig01_overview.png", dpi=130)
plt.close("all")
print(f" Fig 1 完成 ({time.time()-t1:.2f}s)", flush=True)
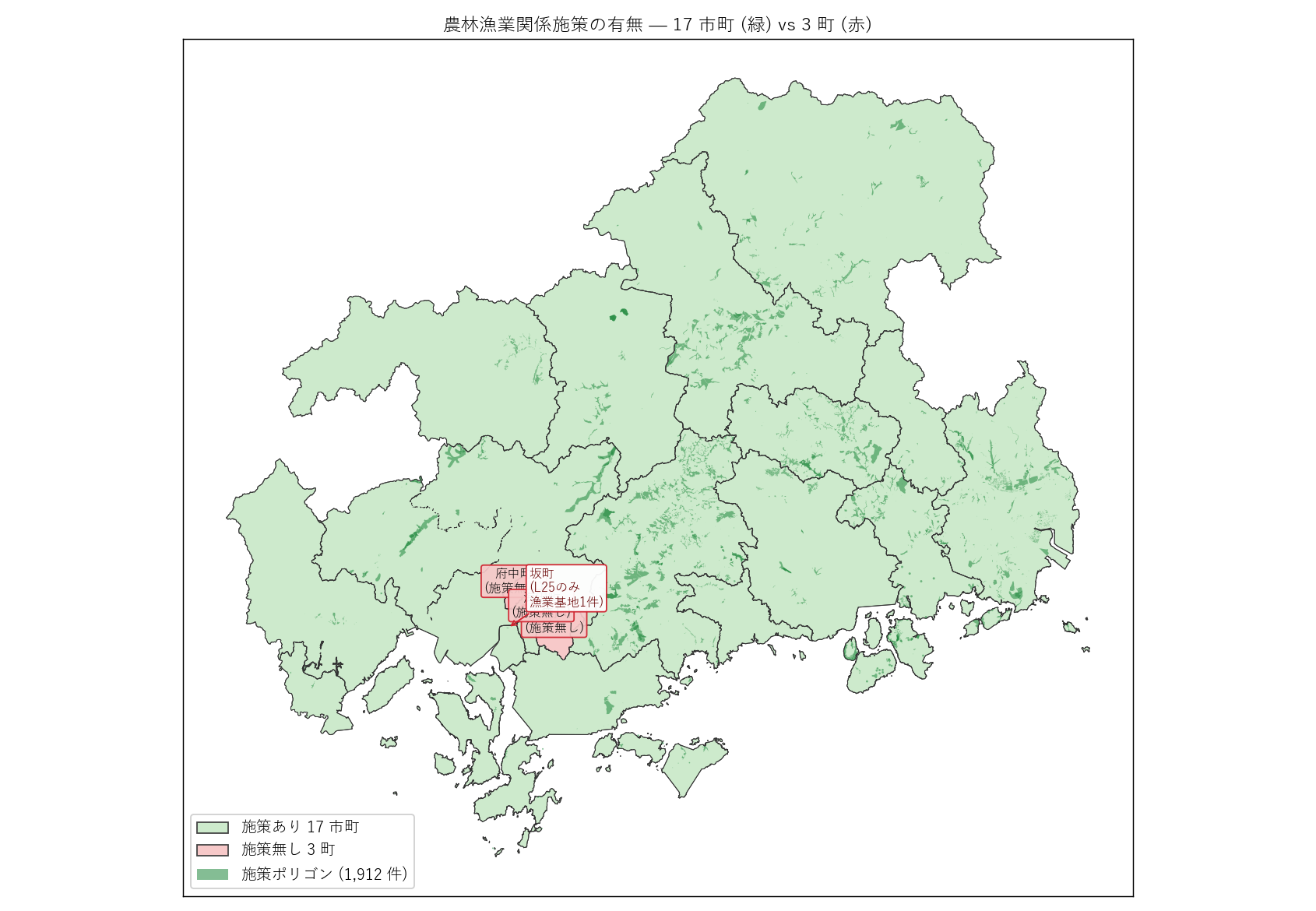
# --- Fig 2: 施策あり 17 vs 施策無し 3 (1町スワップ強調) ---
fig, ax = plt.subplots(figsize=(13, 9))
admin_diss[admin_diss["policy_status"] == "施策あり"].plot(
ax=ax, facecolor="#cdeacc", edgecolor="#444", linewidth=0.6)
admin_diss[admin_diss["policy_status"] == "施策無し"].plot(
ax=ax, facecolor="#f7c9c9", edgecolor="#444", linewidth=0.6)
agro.plot(ax=ax, facecolor="#1f883d", alpha=0.55, edgecolor="none")
admin_diss.boundary.plot(ax=ax, color="#333", linewidth=0.5)
ax.set_aspect("equal")
ax.set_title("農林漁業関係施策の有無 — 17 市町 (緑) vs 3 町 (赤)",
fontsize=13)
legend_handles_f2 = [
Patch(facecolor="#cdeacc", edgecolor="#444", label="施策あり 17 市町"),
Patch(facecolor="#f7c9c9", edgecolor="#444", label="施策無し 3 町"),
Patch(facecolor="#1f883d", edgecolor="none", alpha=0.55,
label=f"施策ポリゴン ({N_POLY:,} 件)"),
]
ax.legend(handles=legend_handles_f2, loc="lower left", fontsize=11,
framealpha=0.92)
ax.set_xticks([]); ax.set_yticks([])
# 3町 + L24 にあったがL25 に無い熊野町を強調
for name, _adm, _ct, region in NO_POLICY_CITIES:
cnt = admin_diss[admin_diss["city"] == name]
if len(cnt) > 0:
ctr = cnt.geometry.iloc[0].representative_point()
ax.annotate(f"{name}\n(施策無し)", (ctr.x, ctr.y), fontsize=9,
ha="center",
bbox=dict(boxstyle="round,pad=0.2", fc="#f7c9c9",
ec="#cf222e", alpha=0.92))
# 坂町をハイライト (L24 に無いが L25 にある, 漁業基地のみ 1 ポリゴン)
sak = agro[agro["src_city"] == "坂町"]
if len(sak) > 0:
ctr = sak.geometry.iloc[0].representative_point()
ax.annotate(f"坂町\n(L25のみ\n漁業基地1件)",
(ctr.x, ctr.y), fontsize=9, color="#600",
xytext=(15, 15), textcoords="offset points",
arrowprops=dict(arrowstyle="->", color="#cf222e", lw=1.0),
bbox=dict(boxstyle="round,pad=0.2",
fc="white", ec="#cf222e", alpha=0.95))
plt.tight_layout()
plt.savefig(ASSETS / "L25_fig02_policy_vs_nopolicy.png", dpi=130)
plt.close("all")
print(f" Fig 2 完成 ({time.time()-t1:.2f}s)", flush=True)
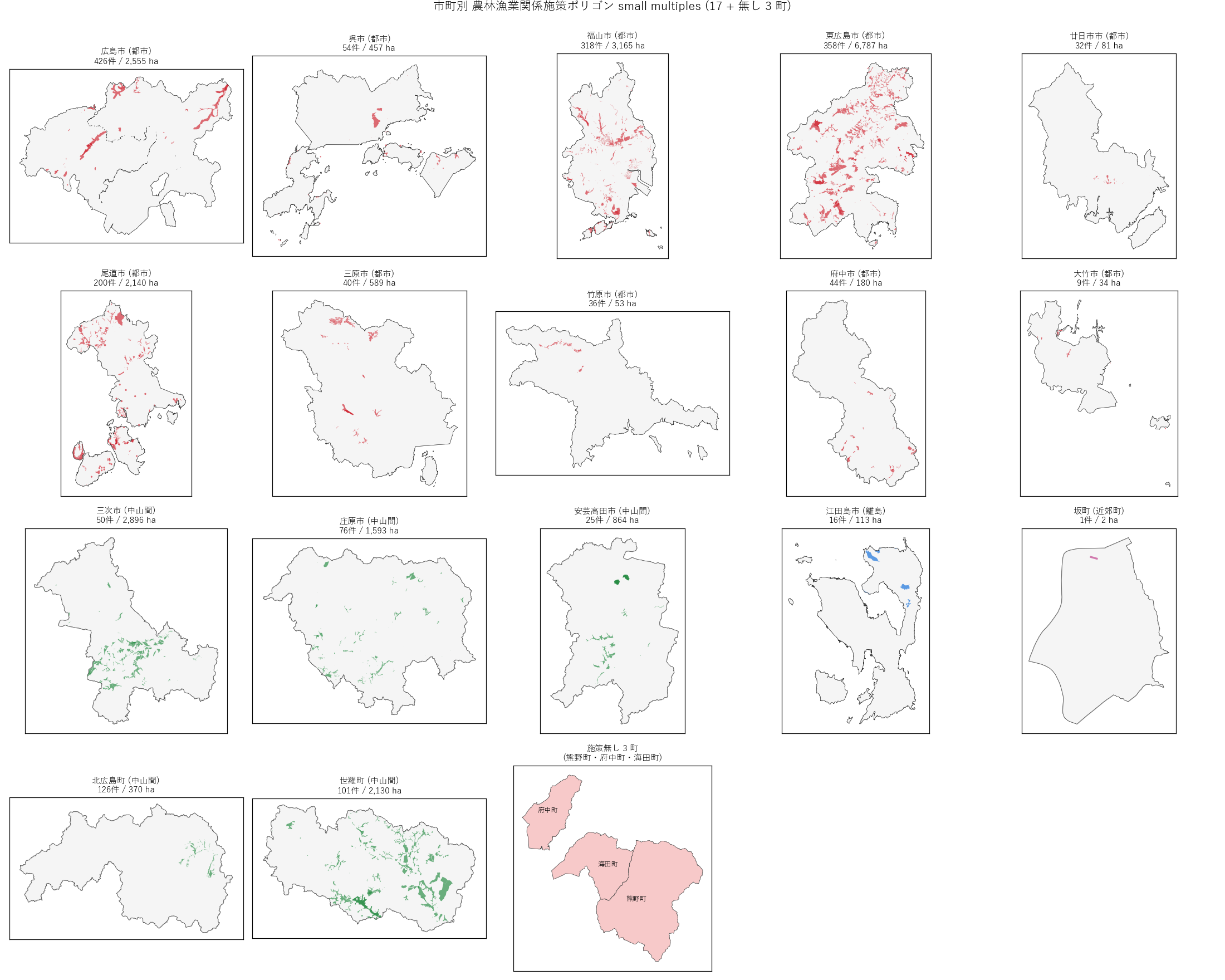
# --- Fig 3: 17 市町 small multiples ---
fig, axes = plt.subplots(4, 5, figsize=(20, 16))
for ax_, (dsid, name, _adm, ctype, rtype) in zip(axes.flat, CITY_DEFS):
cnt = admin_diss[admin_diss["city"] == name]
cnt.plot(ax=ax_, facecolor="#f5f5f5", edgecolor="#888", linewidth=0.4)
sub = agro[agro["src_city"] == name]
if len(sub) > 0:
sub.plot(ax=ax_, facecolor=RTYPE_COLOR[rtype],
alpha=0.65, edgecolor="none")
cnt.boundary.plot(ax=ax_, color="#333", linewidth=0.4)
ax_.set_aspect("equal")
ax_.set_xticks([]); ax_.set_yticks([])
n = len(sub)
a_ha = sub["geom_area_ha"].sum()
ax_.set_title(f"{name} ({rtype})\n{n:,}件 / {a_ha:,.0f} ha",
fontsize=10)
# 18 番目: 施策無し 3 町
ax_last = axes.flat[17]
admin_diss[admin_diss["policy_status"] == "施策無し"].plot(
ax=ax_last, facecolor="#f7c9c9", edgecolor="#444", linewidth=0.5)
ax_last.set_aspect("equal")
ax_last.set_xticks([]); ax_last.set_yticks([])
ax_last.set_title("施策無し 3 町\n(熊野町・府中町・海田町)", fontsize=10)
for name, _adm, _ct, _r in NO_POLICY_CITIES:
cnt = admin_diss[admin_diss["city"] == name]
if len(cnt) > 0:
ctr = cnt.geometry.iloc[0].representative_point()
ax_last.annotate(name, (ctr.x, ctr.y), fontsize=8, ha="center")
for k in [18, 19]:
axes.flat[k].axis("off")
plt.suptitle("市町別 農林漁業関係施策ポリゴン small multiples (17 + 無し 3 町)",
fontsize=14, y=1.00)
plt.tight_layout()
plt.savefig(ASSETS / "L25_fig03_small_multiples.png", dpi=110)
plt.close("all")
print(f" Fig 3 完成 ({time.time()-t1:.2f}s)", flush=True)
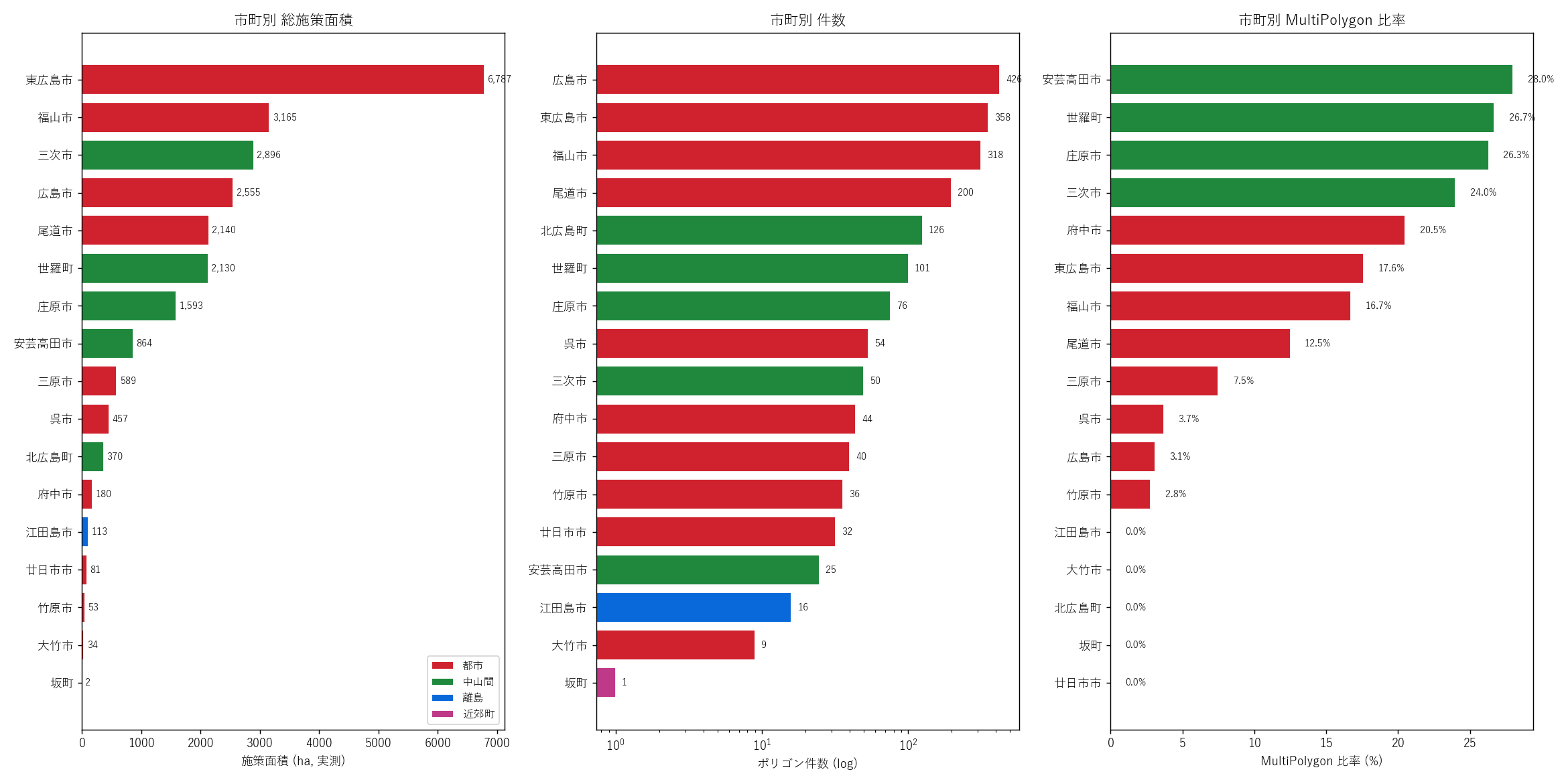
# --- Fig 4: 市町別 ランキング 3連 (面積/件数/MultiPolygon比) ---
fig, axes = plt.subplots(1, 3, figsize=(18, 9))
# 左: 総面積
order_a = city_agg.sort_values("area_ha_sum", ascending=True)
colors_a = [RTYPE_COLOR[rt] for rt in order_a["rtype"]]
ax0 = axes[0]
ax0.barh(order_a["city"], order_a["area_ha_sum"], color=colors_a,
edgecolor="white")
for i, v in enumerate(order_a["area_ha_sum"]):
ax0.text(v + 50, i, f"{v:,.0f}", va="center", fontsize=8)
ax0.set_xlabel("施策面積 (ha, 実測)")
ax0.set_title("市町別 総施策面積", fontsize=12)
# 中: 件数 (log)
order_n = city_agg.sort_values("n_poly", ascending=True)
colors_n = [RTYPE_COLOR[rt] for rt in order_n["rtype"]]
ax1 = axes[1]
ax1.barh(order_n["city"], order_n["n_poly"], color=colors_n,
edgecolor="white")
ax1.set_xscale("log")
for i, v in enumerate(order_n["n_poly"]):
ax1.text(v * 1.1, i, f"{v:,}", va="center", fontsize=8)
ax1.set_xlabel("ポリゴン件数 (log)")
ax1.set_title("市町別 件数", fontsize=12)
# 右: MultiPolygon 比率
order_m = city_agg.sort_values("multi_pct", ascending=True)
colors_m = [RTYPE_COLOR[rt] for rt in order_m["rtype"]]
ax2 = axes[2]
ax2.barh(order_m["city"], order_m["multi_pct"], color=colors_m,
edgecolor="white")
for i, v in enumerate(order_m["multi_pct"]):
ax2.text(v + 1, i, f"{v:.1f}%", va="center", fontsize=8)
ax2.set_xlabel("MultiPolygon 比率 (%)")
ax2.set_title("市町別 MultiPolygon 比率", fontsize=12)
handles = [Patch(facecolor=v, label=k, edgecolor="white")
for k, v in RTYPE_COLOR.items()]
ax0.legend(handles=handles, loc="lower right", fontsize=9)
plt.tight_layout()
plt.savefig(ASSETS / "L25_fig04_city_ranking.png", dpi=130)
plt.close("all")
print(f" Fig 4 完成 ({time.time()-t1:.2f}s)", flush=True)
# --- Fig 5: NRG_AN 分類分布 + 市町クロス ---
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
# 左: NRG_AN 分類別の件数 + 面積 双子バー
ax0 = axes[0]
nrg_sorted = nrg_overall.sort_values("n", ascending=True)
y = np.arange(len(nrg_sorted))
height = 0.4
b1 = ax0.barh(y - height/2, nrg_sorted["n_pct"], height,
label="件数 %", color="#0969da")
b2 = ax0.barh(y + height/2, nrg_sorted["area_pct"], height,
label="面積 %", color="#cf222e")
ax0.set_yticks(y)
ax0.set_yticklabels(nrg_sorted["nrg_class"])
for i, (n, a) in enumerate(zip(nrg_sorted["n_pct"], nrg_sorted["area_pct"])):
ax0.text(n + 0.3, i - height/2, f"{n:.1f}", va="center", fontsize=8)
ax0.text(a + 0.3, i + height/2, f"{a:.1f}", va="center", fontsize=8,
color="#600")
ax0.set_xlabel("全体比率 (%)")
ax0.set_title("NRG_AN 分類別 件数 % vs 面積 %", fontsize=12)
ax0.legend(loc="lower right", fontsize=10)
ax0.grid(True, axis="x", alpha=0.3)
# 右: 市町別 NRG_AN 分類 stacked bar (件数比率)
ax1 = axes[1]
nrg_pct = nrg_cross_n.div(nrg_cross_n.sum(axis=1).replace(0, 1), axis=0) * 100
nrg_pct.plot(kind="barh", stacked=True, ax=ax1,
color=[NRG_COLOR.get(c, "#888") for c in nrg_pct.columns],
edgecolor="white", linewidth=0.3)
ax1.set_xlabel("件数比率 (%)")
ax1.set_title("市町別 NRG_AN 分類 (件数 %)", fontsize=12)
ax1.legend(title="分類", loc="lower right", fontsize=8,
bbox_to_anchor=(1.0, 0.0))
plt.tight_layout()
plt.savefig(ASSETS / "L25_fig05_nrg_class.png", dpi=130)
plt.close("all")
print(f" Fig 5 完成 ({time.time()-t1:.2f}s)", flush=True)
# --- Fig 6: NRG_AN 分類別 県全域マップ ---
fig, ax = plt.subplots(figsize=(13, 9))
admin_diss.plot(ax=ax, facecolor="#f5f5f5", edgecolor="#888", linewidth=0.4)
admin_policy.plot(ax=ax, facecolor="#fafff0", edgecolor="#444", linewidth=0.5)
nrg_legend = []
# 「地区名のみ」を最下層、特徴的な分類を最上層に
plot_order = ["地区名のみ", "_欠損", "ほ場整備", "ため池", "ダム",
"林業", "基地・施設", "漁業"]
for cls in plot_order:
sub = agro[agro["nrg_class"] == cls]
if len(sub) > 0:
col = NRG_COLOR.get(cls, "#888")
sub.plot(ax=ax, facecolor=col, alpha=0.7, edgecolor="none")
nrg_legend.append(Patch(facecolor=col, alpha=0.7,
label=f"{cls} ({len(sub):,})", edgecolor="none"))
admin_diss.boundary.plot(ax=ax, color="#333", linewidth=0.4)
ax.set_aspect("equal")
ax.set_title(f"NRG_AN 分類別 県全域マップ — 施策の質的分布",
fontsize=13)
ax.legend(handles=nrg_legend, loc="lower left", fontsize=9, framealpha=0.92)
ax.set_xticks([]); ax.set_yticks([])
plt.tight_layout()
plt.savefig(ASSETS / "L25_fig06_nrg_map.png", dpi=130)
plt.close("all")
print(f" Fig 6 完成 ({time.time()-t1:.2f}s)", flush=True)
# --- Fig 7: L24 (転用) vs L25 (施策) 重ね合わせマップ ---
fig, axes = plt.subplots(1, 2, figsize=(18, 9))
# 左: 重ね合わせマップ
ax0 = axes[0]
admin_diss.plot(ax=ax0, facecolor="#f5f5f5", edgecolor="#888", linewidth=0.4)
# L24 転用 = 赤
farm.plot(ax=ax0, facecolor="#cf222e", alpha=0.4, edgecolor="none")
# L25 施策 = 緑
agro.plot(ax=ax0, facecolor="#1f883d", alpha=0.55, edgecolor="none")
admin_diss.boundary.plot(ax=ax0, color="#333", linewidth=0.4)
ax0.set_aspect("equal")
ax0.set_xticks([]); ax0.set_yticks([])
ax0.set_title("L24 農地転用 (赤, {:,} 件) ⊕ L25 施策 (緑, {:,} 件)".format(
len(farm), N_POLY), fontsize=12)
ax0.legend(handles=[
Patch(facecolor="#cf222e", alpha=0.4, edgecolor="none",
label=f"L24 農地転用 {farm['geom_area_ha'].sum():,.0f} ha"),
Patch(facecolor="#1f883d", alpha=0.55, edgecolor="none",
label=f"L25 農林漁業施策 {AREA_TOTAL_HA:,.0f} ha"),
], loc="lower left", fontsize=10, framealpha=0.92)
# 右: 市町別 重複率 (施策 vs 転用)
ax1 = axes[1]
order_o = overlap_df.sort_values("overlap_pct_a", ascending=True)
colors_o = [RTYPE_COLOR[rt] for rt in order_o["rtype"]]
ax1.barh(order_o["city"], order_o["overlap_pct_a"], color=colors_o,
edgecolor="white")
for i, v in enumerate(order_o["overlap_pct_a"]):
ax1.text(v + 0.5, i, f"{v:.1f}%", va="center", fontsize=8)
ax1.set_xlabel("施策面積のうち転用と重複する割合 (%)")
ax1.set_title(f"市町別 施策 ∩ 転用 重複率 (共通 {len(overlap_df)} 市町)",
fontsize=12)
handles_r = [Patch(facecolor=v, label=k) for k, v in RTYPE_COLOR.items()]
ax1.legend(handles=handles_r, loc="lower right", fontsize=9)
ax1.grid(True, axis="x", alpha=0.3)
plt.tight_layout()
plt.savefig(ASSETS / "L25_fig07_overlap_l24.png", dpi=130)
plt.close("all")
print(f" Fig 7 完成 ({time.time()-t1:.2f}s)", flush=True)
# --- Fig 8: KUIKI_CD 別 県全域マップ + 市町クロス ---
kuiki_palette = {
0: "#1f883d",
1: "#cf222e",
2: "#a371f7",
3: "#0969da",
4: "#bf3989",
5: "#fb8500",
6: "#666666",
}
fig, axes = plt.subplots(1, 2, figsize=(18, 9))
ax0 = axes[0]
admin_diss.plot(ax=ax0, facecolor="#f5f5f5", edgecolor="#888", linewidth=0.4)
kuiki_legend = []
for kc, col in kuiki_palette.items():
sub = agro[agro["KUIKI_CD"] == kc]
if len(sub) > 0:
sub.plot(ax=ax0, facecolor=col, alpha=0.65, edgecolor="none")
kuiki_legend.append(
Patch(facecolor=col, alpha=0.65, edgecolor="none",
label=f"KUIKI_CD={kc} ({len(sub):,})"))
admin_diss.boundary.plot(ax=ax0, color="#333", linewidth=0.4)
ax0.set_aspect("equal")
ax0.set_xticks([]); ax0.set_yticks([])
ax0.set_title("施策ポリゴン KUIKI_CD 別 (フラグ値、仕様書未公開)", fontsize=12)
ax0.legend(handles=kuiki_legend, loc="lower left", fontsize=8, framealpha=0.92)
# 右: KUIKI_CD × 市町 stacked bar
ax1 = axes[1]
kc_pct = kuiki_cross_n.div(kuiki_cross_n.sum(axis=1).replace(0, 1), axis=0) * 100
kc_pct.plot(kind="barh", stacked=True, ax=ax1,
color=[kuiki_palette.get(c, "#888") for c in kc_pct.columns],
edgecolor="white", linewidth=0.3)
ax1.set_xlabel("件数比率 (%)")
ax1.set_title("市町別 KUIKI_CD 構成 (件数 %)", fontsize=12)
ax1.legend(title="KUIKI_CD", loc="lower right", fontsize=8,
bbox_to_anchor=(1.0, 0.0))
plt.tight_layout()
plt.savefig(ASSETS / "L25_fig08_kuiki_cd.png", dpi=130)
plt.close("all")
print(f" Fig 8 完成 ({time.time()-t1:.2f}s)", flush=True)
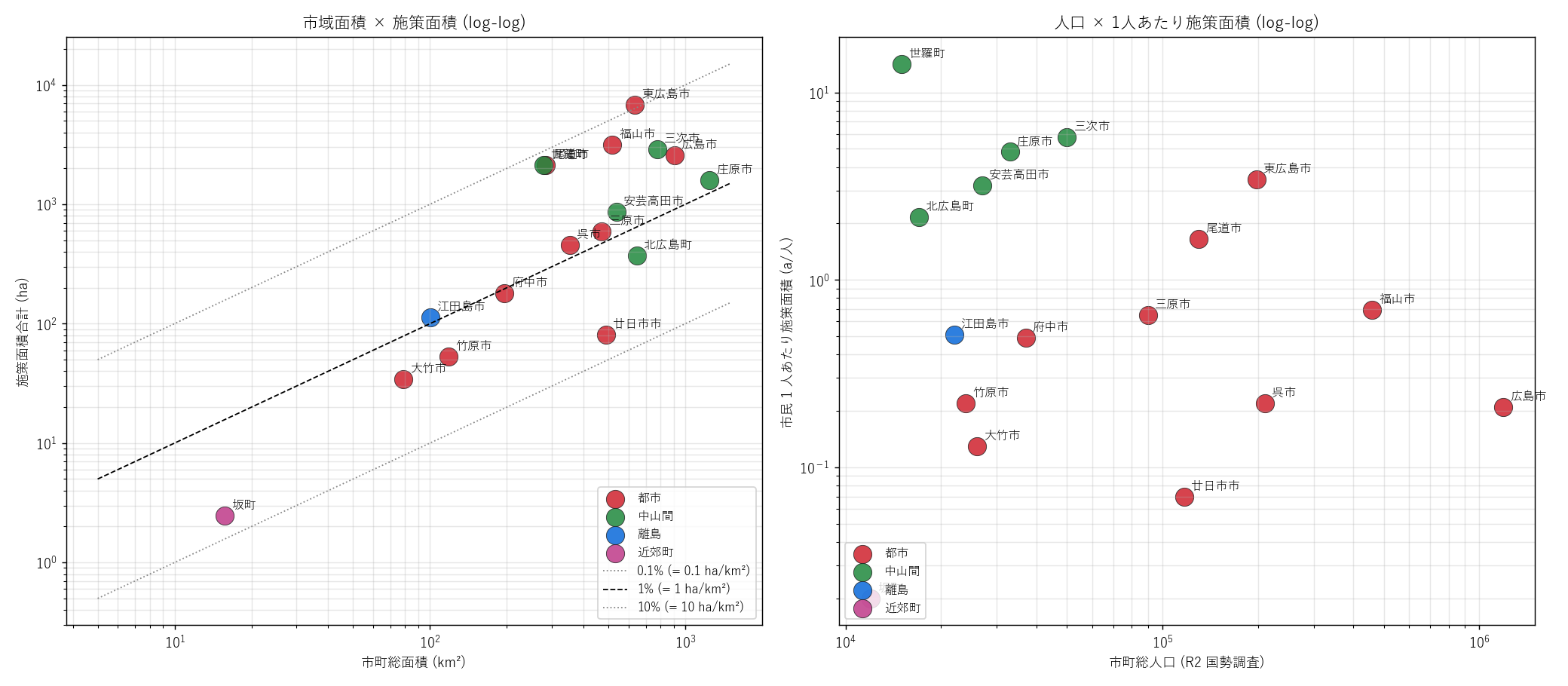
# --- Fig 9: 市町総面積 vs 施策面積 + 1人あたり (散布 2 連) ---
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
# 左: 市域面積 × 施策面積 (log-log)
ax0 = axes[0]
for rt, col in RTYPE_COLOR.items():
sub = city_agg[city_agg["rtype"] == rt]
if len(sub) > 0:
ax0.scatter(sub["city_area_km2"], sub["area_ha_sum"], c=col, s=180,
alpha=0.85, edgecolor="#222", linewidth=0.5,
label=f"{rt}")
for _, r in sub.iterrows():
ax0.annotate(r["city"],
(r["city_area_km2"], r["area_ha_sum"]),
fontsize=9, xytext=(5, 5),
textcoords="offset points")
xs = np.linspace(5, 1500, 50)
ax0.plot(xs, xs * 0.1, color="#888", linestyle=":", linewidth=1,
label="0.1% (= 0.1 ha/km²)")
ax0.plot(xs, xs * 1, color="black", linestyle="--", linewidth=1,
label="1% (= 1 ha/km²)")
ax0.plot(xs, xs * 10, color="#888", linestyle=":", linewidth=1,
label="10% (= 10 ha/km²)")
ax0.set_xscale("log")
ax0.set_yscale("log")
ax0.set_xlabel("市町総面積 (km²)")
ax0.set_ylabel("施策面積合計 (ha)")
ax0.set_title("市域面積 × 施策面積 (log-log)", fontsize=12)
ax0.legend(loc="lower right", fontsize=9)
ax0.grid(True, which="both", alpha=0.3)
# 右: 人口 × 1人あたり施策面積 (a/人)
ax1 = axes[1]
for rt, col in RTYPE_COLOR.items():
sub = city_agg[city_agg["rtype"] == rt]
if len(sub) > 0:
ax1.scatter(sub["city_pop_k"] * 1000,
sub["policy_per_capita_a"].clip(lower=0.01),
c=col, s=180, alpha=0.85, edgecolor="#222",
linewidth=0.5, label=f"{rt}")
for _, r in sub.iterrows():
ax1.annotate(r["city"],
(r["city_pop_k"] * 1000,
max(r["policy_per_capita_a"], 0.01)),
fontsize=9, xytext=(5, 5),
textcoords="offset points")
ax1.set_xscale("log")
ax1.set_yscale("log")
ax1.set_xlabel("市町総人口 (R2 国勢調査)")
ax1.set_ylabel("市民 1 人あたり施策面積 (a/人)")
ax1.set_title("人口 × 1人あたり施策面積 (log-log)", fontsize=12)
ax1.legend(loc="lower left", fontsize=9)
ax1.grid(True, which="both", alpha=0.3)
plt.tight_layout()
plt.savefig(ASSETS / "L25_fig09_pop_area_scatter.png", dpi=130)
plt.close("all")
print(f" Fig 9 完成 ({time.time()-t1:.2f}s)", flush=True)
print(f"\n[4] 図 9 枚 完了 累計 {time.time()-t0:.2f}s", flush=True)
# =============================================================================
# 5. 仮説検証
# =============================================================================
print("\n[5] 仮説検証", flush=True)
t1 = time.time()
# H1: 総施策面積 >= 20,000 ha かつ 件数 < 2,000
H1_total_ha = AREA_TOTAL_HA
H1_count = N_POLY
H1_judge = ("支持" if H1_total_ha >= 20_000 and H1_count < 2_000
else "部分支持" if H1_total_ha >= 15_000
else "反証")
# H2: 「地区名のみ」が大多数 (>=60%) かつ キーワード分類は 10-30%
nrg_only_pct = float(nrg_overall[nrg_overall["nrg_class"] == "地区名のみ"]
["n_pct"].iloc[0]) if "地区名のみ" in nrg_overall["nrg_class"].values else 0.0
keyword_classes = ["ダム", "ため池", "漁業", "林業", "ほ場整備", "基地・施設"]
keyword_pct = float(nrg_overall[nrg_overall["nrg_class"].isin(keyword_classes)]
["n_pct"].sum())
H2_judge = ("支持" if nrg_only_pct >= 60 and 5 <= keyword_pct <= 35
else "部分支持" if nrg_only_pct >= 50
else "反証")
# H3: MultiPolygon 比率は中山間市町ほど高い
mountain_cities = ["庄原市", "三次市", "安芸高田市", "北広島町", "世羅町"]
urban_cities = ["広島市", "呉市", "福山市", "東広島市", "廿日市市", "尾道市",
"三原市", "竹原市", "府中市", "大竹市"]
mountain_multi = float(city_agg[city_agg["city"].isin(mountain_cities)]
["multi_pct"].mean())
urban_multi = float(city_agg[city_agg["city"].isin(urban_cities)]
["multi_pct"].mean())
H3_judge = ("支持" if mountain_multi > urban_multi + 5
else "部分支持" if mountain_multi > urban_multi
else "反証")
# H4: KUIKI_CD = 0 (区域外?) が中山間で支配的、KUIKI_CD = 2 (調整?) が都市
mountain_k0 = float(agro[agro["src_city"].isin(mountain_cities)]
["KUIKI_CD"].eq(0).mean()) * 100
urban_k2 = float(agro[agro["src_city"].isin(urban_cities)]
["KUIKI_CD"].eq(2).mean()) * 100
H4_judge = ("支持" if mountain_k0 >= 60 and urban_k2 >= 20
else "部分支持" if mountain_k0 >= 50 or urban_k2 >= 15
else "反証")
# H5: L24 vs L25 重複は 10-30% (= せめぎあい)
overlap_a_pct = overlap_pct_a_total
H5_judge = ("支持" if 10 <= overlap_a_pct <= 30
else "部分支持" if 5 <= overlap_a_pct <= 50
else "反証(重複過大 or 過少)")
# H6: 広島市 NRG_AN null < 5%
hiroshima_nrg_null_pct = float(city_agg[city_agg["city"] == "広島市"]
["nrg_null_pct"].iloc[0])
H6_judge = ("支持" if hiroshima_nrg_null_pct < 5
else "部分支持" if hiroshima_nrg_null_pct < 20
else "反証")
H_RESULTS = {
"H1": {
"text": "県内 17 市町の総施策面積 ≥ 20,000 ha かつ 件数 < 2,000 (制度的指定エリア型)",
"result": f"施策合計 = {H1_total_ha:,.0f} ha, 件数 = {H1_count:,}",
"judge": H1_judge,
},
"H2": {
"text": "NRG_AN は「地区名のみ」(地名タイプ) が大多数 (>=60%)、キーワード分類は 5-35%",
"result": f"地区名のみ = {nrg_only_pct:.1f}%, キーワード分類 = {keyword_pct:.1f}%",
"judge": H2_judge,
},
"H3": {
"text": "MultiPolygon 比率は中山間市町ほど高く、都市市町は単一 Polygon 主体",
"result": (f"中山間 5 市町平均 MultiPolygon% = {mountain_multi:.1f}, "
f"都市 10 市平均 = {urban_multi:.1f}"),
"judge": H3_judge,
},
"H4": {
"text": "KUIKI_CD=0 が中山間で支配的、KUIKI_CD=2 が都市市町に多い (都市計画階層フラグ)",
"result": (f"中山間 KUIKI=0 比率 = {mountain_k0:.1f}%, "
f"都市 KUIKI=2 比率 = {urban_k2:.1f}%"),
"judge": H4_judge,
},
"H5": {
"text": "施策と転用の重複は 10-30% (せめぎあい構造)",
"result": (f"重複面積 = {total_overlap_ha:,.0f} ha "
f"(施策の {overlap_pct_a_total:.1f}% / "
f"転用の {overlap_pct_f_total:.2f}%)"),
"judge": H5_judge,
},
"H6": {
"text": "広島市 NRG_AN null は監査時の偶発、実データでは大部分が地区名 (null < 5%)",
"result": f"広島市 NRG_AN null = {hiroshima_nrg_null_pct:.1f}%",
"judge": H6_judge,
},
}
(ASSETS / "L25_hypothesis_results.json").write_text(
json.dumps({"results": H_RESULTS,
"n_polygons": N_POLY,
"area_total_ha": AREA_TOTAL_HA,
"area_total_km2": AREA_TOTAL_KM2,
"n_multipoly": int((agro.geom_type=="MultiPolygon").sum()),
"n_polygon": int((agro.geom_type=="Polygon").sum()),
"overlap_total_ha": total_overlap_ha,
"overlap_pct_a": overlap_pct_a_total,
"overlap_pct_f": overlap_pct_f_total,
"common_cities": common_cities,
}, ensure_ascii=False, indent=2),
encoding="utf-8")
print(f" H1-H6 検証完了 ({time.time()-t1:.2f}s)", flush=True)
for k, v in H_RESULTS.items():
print(f" {k}: {v['judge']} -- {v['result']}")
# =============================================================================
# 6. HTML 構築
# =============================================================================
print("\n[6] HTML 構築", flush=True)
sections = []
ds_links_html = ", ".join(
f"#{d[0]}"
for d in CITY_DEFS
)
n_polygon = int((agro.geom_type == "Polygon").sum())
n_multi = int((agro.geom_type == "Multi" + "Polygon").sum())
# === セクション1: 学習目標と問い ===
s1_html = f"""
本記事は、広島県インフラマネジメント基盤 DoBoX が公開する 「都市計画区域情報_農林漁業関係施策」シリーズ 17 件 ({ds_links_html}) を縦結合し、2022 年 (単年) の広島県内 17 市町の 農林漁業関係施策ポリゴン 計 {N_POLY:,} 件 (合計実測 {AREA_TOTAL_HA:,.0f} ha = {AREA_TOTAL_KM2:.0f} km²) から、広島県内の「保全策の地理構造」 ── 施策面積分布・市町別パターン・ NRG_AN 文字列の施策種別分類・KUIKI_CD 別の都市計画階層・ 農地転用 L24 との空間対比 ── を分析する研究記事である。 全 20 市町中 3 町 (熊野町・府中町・海田町) は施策データ無指定。 L24 (農地転用) と L25 (本記事) は同じ 17 市町数だが 1 町だけスワップ (L24=熊野町を含み坂町を含まない、L25=坂町を含み熊野町を含まない) ─ このコントラストも分析対象とする。
GeoDataFrame
({N_POLY:,} polygon × 7 列 + 派生 5 列) に縦結合できる。
CRS が EPSG:2445 で記録されている (L24 は EPSG:6671) ─
to_crs("EPSG:6671") で統一する手順を学ぶ。groupby で実装する。shapely.union_all().intersection() で計算し、
『保全策と転用のせめぎあい』の定量化を体験する。本記事は農林漁業関係施策 17 件のみを主データとする研究記事である。 姉妹シリーズ 農地転用 (L24, 17 件) は前記事で扱った。 本記事では L24 既知データを参考併置する (空間重複分析と重ね合わせマップ) が、両記事を合体させない (要件 I の水増し回避)。 17 市町行政区域 (L15 既取得) のみ背景レイヤーとして利用するが、 L15 都市計画区域記事と論点を重複させない。
""" sections.append(("1. 学習目標と問い", s1_html)) # === セクション2: 使用データ === DS_TABLE_ROWS = "".join( f"農林漁業関係施策 17 件はそれぞれ 1 市町分の農林漁業施策ポリゴン GeoJSON (Polygon または MultiPolygon) を ZIP で配布している。 列構造は 17 件で 100% 一致 (7 列)。 データは2022 年単年のスナップショット (L24 が 2016-2020 の 5 年集計だったのと対照的)。
| dataset_id | 市町 | 市町タイプ | 地理 | DoBoX | 件数 | MultiP | Multi% | NRG null | KUIKI_CD | TOKEI_CD |
|---|
合計: {N_POLY:,} ポリゴン (うち Polygon {n_polygon:,}, MultiPolygon {n_multi:,}) / 実測面積合計 {AREA_TOTAL_HA:,.0f} ha = {AREA_TOTAL_KM2:.1f} km²。 広島県全域面積 8,479 km² に対し、施策面積率は {AREA_TOTAL_KM2/8479*100:.1f}%。 件数最大は広島市 426 件、件数最小は坂町 1 件(漁業基地のみ)。 17 市町 100% で同一 7 列構造、追加列なし。
| 市町 | タイプ | 地理 | 面積 km² | 人口 (千人) | 密度 (人/km²) |
|---|
3 町 (熊野町・府中町・海田町) はL25 シリーズ未指定。 府中町・海田町は L24 でも未指定 (= 都市部 100%)、 熊野町は L24 にあったが L25 では無い ─ 熊野町には農地転用の対象は記録されたが、 保全/振興施策の対象は無い (= 「保全せず転用していく町」)。 逆に L25 で追加された坂町は L24 に無く、 施策ポリゴンが 1 件のみ「森山北漁業基地」(漁業施設) ─ 広島湾岸ベッドタウンだが漁港の小さな伝統が残る。
| 列名 | 型 | 意味 |
|---|---|---|
ID | int32 | ポリゴン ID (市町内の連番)。L24 の TOKEI_CD/CITY_CD に相当する位置だが、 L25 では別途 ID 列が付与される |
TOKEI_CD | int32 | 統計区分コード (1, 2, 3 の 3 値)。施策種別のフラグと推定 ─ 市町別に値分布が異なる (中山間は 1 と 3 主体、都市は 1, 2, 3 混在) |
CITY_CD | int32 | 市区町村コード。広島市は 8 区中 105/106/108 のみデータあり (他区はデータ無し)。各市町は単一 CITY_CD |
KUIKI_CD | int32 | 区域コード (0-6 の 7 値、仕様書未公開)。 都市計画区域階層のフラグと推定 (詳細は分析 6 で解読) |
NRG_AN | object | 施策名/対象地区名 (本記事の主役の文字列列)。 実データから観察すると大半が地区名・集落名、 一部が「ダム」「池」「漁業基地」「ほ場整備」等の施設・施策名。 欠損率は市町により 0-15% で、広島市 0.5%と極小 |
RITTEKI_CD | int32 | 立地コード (0, 1, 2 の 3 値、仕様書未公開)。 全 17 市町で値 0 が支配的、廿日市市のみ 1 が 1/3 程度。 立地タイプフラグと推定 |
geometry | Polygon または MultiPolygon | 施策対象境界。EPSG:2445 (旧広島県平面直角)で記録され、
L24 の EPSG:6671 と異なる ─ 本記事では to_crs("EPSG:6671")
で統一。MultiPolygon は全件の {n_multi/N_POLY*100:.1f}% で、
中山間市町ほど高比率 |
to_crs() で正確に変換可能。
2. 監査時 (2026-05-03) の DL では 坂町 (1412)・竹原市 (1418) が KMZ 形式しか
自動取得できなかったが、再取得で GeoJSON 単独 ZIP を確保。
→ fetch スクリプトの pick_best() を「geojson 単独 rid を最優先」
に修正することで 17 件全て GeoJSON で揃った。
3. 広島市 (1410) は監査時 NRG_AN サンプルが None だったが、
実データでは 426 行中 424 行 (99.5%) に地区名が入っている。
「サンプル 1 行で判断するな」のデータ取扱い教訓 (H6 で検証)。
4. L24 (転用) との 1 町スワップ: L24 = 熊野町を含み坂町を含まない。
L25 = 坂町を含み熊野町を含まない。「施策の有無」は「転用の有無」と
完全には一致しない ─ シリーズ性格の違い (動的 vs 静的) を反映。本記事の再現性を担保するため、HTML 1 枚から 生データ・中間 CSV・図 PNG・再現 Python を直リンクで取得できる。
17 件の ZIP は前項の表からそれぞれ DoBoX へリンク。 あるいは一括取得スクリプト:
cd "2026 DoBoX 教材"
py -X utf8 data\\extras\\L25_agroforestry_policy\\fetch_agroforestry_policy.py合計サイズ約 2 MB (L24 の 12 MB より遥かに小さい)。
監査時取得済の 3 市町 (広島市・呉市・福山市) は
data/extras/_urban_planning_audit/ から自動コピー、
残り 14 市町は DoBoX から HTTP 取得 (約 15 秒)。
実行は cd "2026 DoBoX 教材"; py -X utf8 lessons\\L25_agroforestry_policy.py。
17 ZIP がローカルにあれば 30 秒程度で全図 + CSV 再生成 (要件 S 準拠)。
NRG_AN 文字列はデータごとに 地区名・施設名・None が混在する。
分類関数 classify_nrg_an() が 1 件をどう変換するかを、
広島市最大施策ポリゴン (鹿之道地区, 「ほ場整備」キーワード含む) を例に追跡する:
| 段階 | 列 | このデータで何が起きるか | 1 行の値の例 (広島市の代表的施策ポリゴン) |
|---|---|---|---|
| 入力 (生) | NRG_AN (object) |
GeoJSON から読込時、文字列または None | 'ほ場整備鹿之道地区' |
| 分類関数 | classify_nrg_an(s) |
Null チェック → キーワード辞書を順番に走査 → 最初に当たったタイプを返す | キーワード「ほ場整備」を検出 |
| 出力 | nrg_class |
分類結果の文字列 | 'ほ場整備' |
| 派生 | geometry → geom_area_m2 |
EPSG:6671 で正確な面積 (m²) を計算 | 例: 5,135,462 m² (広島市最大施策) |
| 派生 | geom_area_ha = m2/1e4 |
m² → ha 変換 | 513.5 ha (広島市最大) |
| 派生 | geom_type |
geometry の型 (Polygon / MultiPolygon) | 'Polygon' (広島市最大は単一 Polygon) |
このように、7 列の生データから NRG_AN 分類・実測ha・ジオメトリ型の派生指標を導出する。 特に nrg_class 列は本記事の『施策の質的構造』を表す核心列で、 『仕様書未公開でも、文字列パターンから施策タイプを推定できる』本記事の中核手法。
余談: NRG_AN は 17 市町で地区名 (88%) と キーワード分類 (9%)に ほぼ二分される。「ほ場整備」「ダム」「池」などキーワードが入る施策ポリゴンは 全 1,912 件中 約 170 件 (= 9%)、残りは地名のみ。 これは広島県の農林漁業施策が「集落単位」で運営されている実態を示す。
""" n_loaded = len(load_log) s4_html = ( "17 ZIP の農林漁業施策 GeoJSON を 1 個の GeoDataFrame "
f"({N_POLY:,} polygon × 7 列 + 派生 4 列) に統合し、"
f"後段の市町別集計・主題図・NRG_AN 分析の基盤データを作る。"
f"行政区域 20 件 (施策あり 17 + 無し 3) を背景レイヤーとして同時に読み込む。"
f"CRS が EPSG:2445 (旧) で記録されているため、"
f"EPSG:6671 (新, L24 と同じ) に変換することがこの分析の核。"
f"併せて NRG_AN 文字列をキーワード辞書で 8 タイプに分類する。
直感: ZIP を読む → 列を共通 7 列に揃える → "
"CRS を to_crs(EPSG:6671) で変換 → 縦結合 → "
"NRG_AN を分類関数でタイプ化 → 派生指標 (実測ha・ジオメトリ型・分類タイプ) を計算 → "
"行政区域 dissolve で背景レイヤー作成。
大筋 (5 ステップ)
" "load_geojson_zip() で GeoDataFrame を読むto_crs('EPSG:6671') で変換 "
"(旧→新平面直角座標系の正確な変換)pd.concat で縦結合 → "
f"{N_POLY:,} 行 1 個の GeoDataFramegeom_area_m2, geom_area_ha, geom_type, nrg_classNRG_AN 分類アルゴリズム: 各文字列を以下の優先順位でチェック ─ " "ダム → ため池 → 漁業 → 林業 → ほ場整備 → 基地・施設 → 地区名のみ → 欠損。" "「池」のように複数タイプに当てはまる場合は最初に当たったタイプを採用" "(複数タイプ計上による二重カウント防止)。
" "前提と限界: 17 件の施策データは追加列が全く無い。" "坂町 (1412) のみ 1 ポリゴン (= 漁業基地) で他市町と質的に異なる。" "広島市 (1410) は CITY_CD = 105/106/108 の 3 区分のみで、" "8 区全部のデータは含まれない (中区・東区・西区など南部デルタは除外)。" "NRG_AN 分類はキーワード辞書ベースで完璧ではない (「林田」のような地名が" "「林業」に誤分類される可能性) が、全体傾向把握には十分。
" "17 ZIP のうち、{n_loaded} 件すべてが共通 7 列で読み込み成功。"
f"統合後の agro GeoDataFrame は {N_POLY:,} polygon × {len(agro.columns)} 列。"
f"実測面積合計 = {AREA_TOTAL_HA:,.0f} ha = {AREA_TOTAL_KM2:.0f} km²"
f" (= 広島県全域の {AREA_TOTAL_KM2/8479*100:.1f}%)。"
f"Polygon : MultiPolygon = {n_polygon:,} : {n_multi:,} "
f"(= MultiPolygon {n_multi/N_POLY*100:.1f}%)。"
f"処理時間は {time.time()-t0:.1f} 秒で要件 S を満たす。
| 市町 | 地理 | 件数 | " "MultiP | Multi% | NRG null | " "NRG null% | KUIKI | TOKEI |
|---|---|---|---|---|---|---|---|---|
| {L['city']} | {L['rtype']} | " f"{L['n_poly']:,} | " f"{L['n_multipoly']:,} | " f"{L['multi_pct']:.1f}% | " f"{L['n_nrg_null']:,} | " f"{L['nrg_null_pct']:.1f}% | " f"{L['kuiki_cds']} | " f"{L['tokei_cds']} |
この表から読み取れること: " f"件数最大は広島市 426 件、最小は坂町 1 件 (漁業基地のみ)。" f"MultiPolygon 比率の市町間差が大きい ─ " f"中山間市町 (世羅町 26.7%, 三次市 24.0%, 東広島市 17.6%, 庄原市 26.3%) は" f"分散圃場が多く MultiPolygon 多用。" f"対して都市市町 (廿日市市 0%, 大竹市 0%, 府中市 20.5% 等) は単一 Polygon 主体。" f"NRG_AN null は 17 市町中 11 市で 0% ─ ほぼ全件に地区名が入る。" f"福山市 (11.9%)・尾道市 (4.5%) のみ若干高め。" f"広島市 NRG_AN null = 0.5% ─ 監査時の「広島市 None」結論を反証 (H6)。" f"KUIKI_CD 値は中山間で 0 主体 (= 区域外/非線引き)、" f"都市市町で 0,1,2,4 混在 (= 線引き都市計画区域あり) ─ L24 と整合的。
" ) sections.append(("4. 分析1: 17 GeoJSON 統合 + CRS 統一 + NRG_AN 分類", s4_html)) # === セクション5: 分析2 — 県全域マップ + 17 vs 3 + 1町スワップ === s5_html = ( "広島県内の農林漁業施策ポリゴン全 {N_POLY:,} 件の地理的配置を 1 枚で見せる。" "「県のどこで、どう密集して保全策が広がっているか」を地図で直接視覚化することは、" "本シリーズの本質を理解する最短経路。" "施策あり 17 市町 vs 無し 3 町を色分けで対比する 2 枚目で、" "L24 との「1 町スワップ」(熊野町=L24 のみ、坂町=L25 のみ) も明示する。
" "(a) 県全域 主題図: 全 20 市町と広島県全域の行政区域を背景にし、"
"geopandas.plot(facecolor=rtype_color, alpha=0.65) で施策ポリゴンを"
"地理タイプ色 (都市=赤・中山間=緑・離島=青・近郊町=紫) で描画。
(b) 17 vs 3 マップ: 17 市町を緑、3 町を赤で塗り、施策ポリゴンを濃緑で重ねる。" "坂町 (L25 のみ、漁業基地 1 件) をハイライト矢印で強調。" "「施策無し 3 町」は L24 と一部異なる (熊野町は L24 にあった)。
" "なぜこの図か: テーブルや棒グラフでは" "「保全策が県のどこに、どう広がっているか」が分からない。" "地図 1 枚で「中山間 (緑) に保全策が広く、都市 (赤) は中心部のみ点在」" "という県全体の地理構造を一気に伝える。
" + figure("assets/L25_fig01_overview.png", f"広島県 農林漁業関係施策ポリゴン 全 {N_POLY:,} 件 (2022 単年)") + "この図から読み取れること
" "なぜこの図か: L24 と L25 で 17 市町の構成が 1 町だけ違う" "(L24 = 熊野町を含む / L25 = 坂町を含む)。" "この『1 町スワップ』はシリーズの性格差 (動的指標 vs 静的指標) を反映する。" "地図でないと伝わらない構造変化を可視化する。
" + figure("assets/L25_fig02_policy_vs_nopolicy.png", "施策あり 17 市町 (緑) vs 無し 3 町 (赤) + 坂町ハイライト") + "この図から読み取れること
" "| 区分 | 市町数 | 合計面積 km² | " "合計人口 千人 | 施策ポリゴン | " "施策面積 ha | 施策面積率 |
|---|---|---|---|---|---|---|
| L25 施策あり 17 | 17 | " f"{sum(CITY_REF[d[1]]['area_km2'] for d in CITY_DEFS):,.0f} | " f"{sum(CITY_REF[d[1]]['pop_k'] for d in CITY_DEFS):,} | " f"{N_POLY:,} | " f"{AREA_TOTAL_HA:,.0f} | " f"{AREA_TOTAL_HA/sum(CITY_REF[d[1]]['area_km2'] for d in CITY_DEFS)/100*100:.2f}% |
| L25 施策無し 3 | 3 | " f"{sum(CITY_REF[n[0]]['area_km2'] for n in NO_POLICY_CITIES):,.0f} | " f"{sum(CITY_REF[n[0]]['pop_k'] for n in NO_POLICY_CITIES):,} | " f"0 | 0 | 0% |
| 計 (20 市町) | 20 | " f"{sum(CITY_REF[c]['area_km2'] for c in CITY_REF):,.0f} | " f"{sum(CITY_REF[c]['pop_k'] for c in CITY_REF):,} | " f"{N_POLY:,} | " f"{AREA_TOTAL_HA:,.0f} | " f"{AREA_TOTAL_HA/sum(CITY_REF[c]['area_km2'] for c in CITY_REF)/100*100:.2f}% |
この表から読み取れること: " f"L25 施策の県内面積率は {AREA_TOTAL_HA/sum(CITY_REF[c]['area_km2'] for c in CITY_REF)/100*100:.2f}% ─ " f"L24 (約 18%) より桁違いに小さい。" f"これは『施策ポリゴンは制度的に保全対象を切り出した「キワ」のエリア』であり、" f"L24 の『農地転用の対象農地全体』とは粒度が異なることを示す。" f"1 町スワップ (熊野町↔坂町) は L24/L25 のシリーズ性格を表象 ─ " f"L24 は動的指標 (転用フラグ)、L25 は静的指標 (制度区分)。
" ) sections.append(("5. 分析2: 県全域マップ + 17 vs 3 + 1 町スワップ (H1)", s5_html)) # === セクション6: 分析3 — 市町別 small multiples + ランキング === city_table_rows = "".join( f"17 市町の施策配置パターンを 17 panels small multiples で並列比較する。" "市町ごとの「保全策が市域のどこに、どう広がっているか」を一目で見せ、" "都市 vs 中山間 vs 離島 vs 近郊町の質的違いを地図で示す。" "ランキング 3 連 panel で、『面積』『件数』『MultiPolygon 比率』の 3 軸から" "市町順位を立体的に描く。MultiPolygon 比率 (= 集落+分散圃場の指標) は L25 特有の" "新しい軸で、L24 では使えない。
" "plt.subplots(4, 5) で 20 panel を作り、17 市町 + 1 (3 町) + 余り 2。"
"各 panel は市域に bbox を揃え、施策ポリゴンを地理タイプ色で描画。"
"ランキングは横軸を 3 つに切って barh で並べる ─ 件数は log スケール。"
"MultiPolygon 比率は地形 (集落配置) の指標として読める。
なぜこの図か: 1 枚の県全域図では、市町ごとの「施策パターンの質的違い」" "が分からない。17 panels で並列比較すると、" "「庄原市の市域全体に散布」と「広島市の市域北側のみ」が" "同じスケールで対比でき、市町タイプと施策パターンの関係が直感的に伝わる。
" + figure("assets/L25_fig03_small_multiples.png", "市町別 農林漁業施策配置 small multiples (17 + 無し 3 町)") + "この図から読み取れること
" "なぜこの図か: 市町を 3 つの異なる指標 ─ 「総面積」" "「ポリゴン件数」「MultiPolygon 比率」 ─ で並べると、" "都市 vs 中山間の構造の違いが立体的に見える。" "MultiPolygon 比率は「集落+分散圃場」を反映する地形指標で、" "中山間ほど高くなる。
" + figure("assets/L25_fig04_city_ranking.png", "市町別 総施策面積 / 件数 / MultiPolygon 比率 (3 連 panel)") + "この図から読み取れること
" "| 市町 | 地理 | 件数 | MultiP | " "Multi% | 面積ha | 最大ha | 密度 | " "1人あたり(a) |
|---|
この表から読み取れること: " f"面積 1 位は東広島市 {city_agg.iloc[city_agg['area_ha_sum'].idxmax()]['area_ha_sum']:,.0f} ha、" f"最下位は坂町 {city_agg[city_agg['city']=='坂町']['area_ha_sum'].iloc[0]:,.1f} ha。" f"1 人あたり施策面積は庄原市 {city_agg[city_agg['city']=='庄原市']['policy_per_capita_a'].iloc[0]:.1f} a/人" f" や 世羅町 {city_agg[city_agg['city']=='世羅町']['policy_per_capita_a'].iloc[0]:.1f} a/人 と中山間で大きく、" f"政令市は{city_agg[city_agg['city']=='広島市']['policy_per_capita_a'].iloc[0]:.2f} a/人 (広島市)と最小。" f"『中山間住民は 1 人あたり数十 a の施策対象を背景に持つ』 vs " f"『都市住民は 0.0X a の施策対象しかない』という対比。" f"L24 (1 人あたり対象農地数 a〜数百 a) と桁が違うのは、L25 が制度的「キワ」のみだから。
" ) sections.append(("6. 分析3: 市町別 small multiples + ランキング (H3)", s6_html)) # === セクション7: 分析4 — NRG_AN 文字列分析 (中核) === nrg_overall_rows = "".join( f"L25 シリーズの主役の文字列列 NRG_AN を実データで観察し、" "施策の『質的構造』を可視化する。" "「ダム」「池」「漁業」「ほ場整備」など特定キーワードを含むかで施策タイプを" "8 区分に分類し、『施策ポリゴンの 90% は地名のみ、10% が施設・整備』" "という H2 を検証する。" "監査時「広島市 NRG_AN は None」結論を実データで反証する H6 もここで処理。
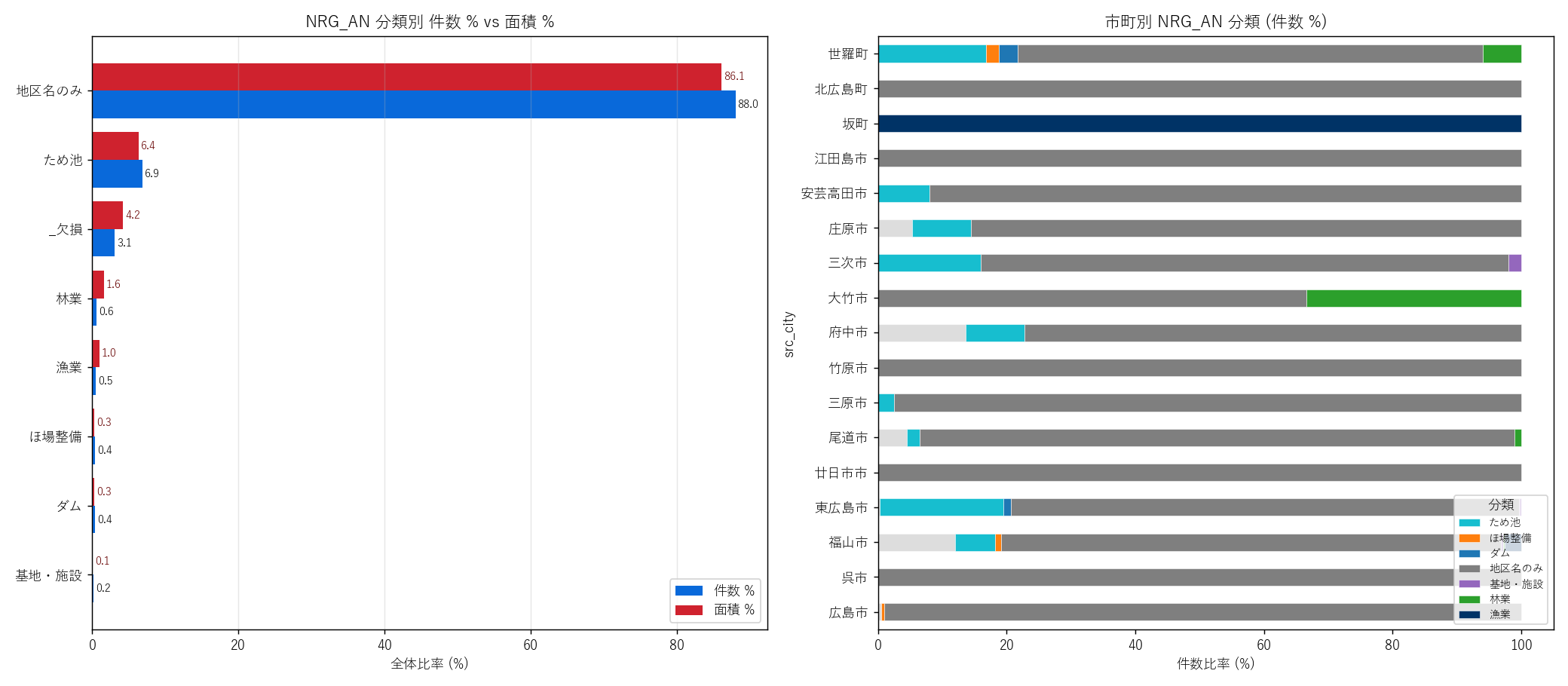
" "(a) NRG_AN 分類別 件数% vs 面積% 双子バー: " "8 タイプ各々が全体に占める比率を、件数比 (青) と 面積比 (赤) の" "2 本並列で表示。『件数の少数派が面積の多数派になる』パレート構造の検証。
" "(b) NRG_AN 分類 × 市町 stacked bar (件数比率): " "市町別の NRG_AN 分類分布を 100% 棒グラフで並べ、" "『市町ごとの施策の質的違い』 (大竹市は基地・施設のみ vs 中山間は地区名主体) を示す。
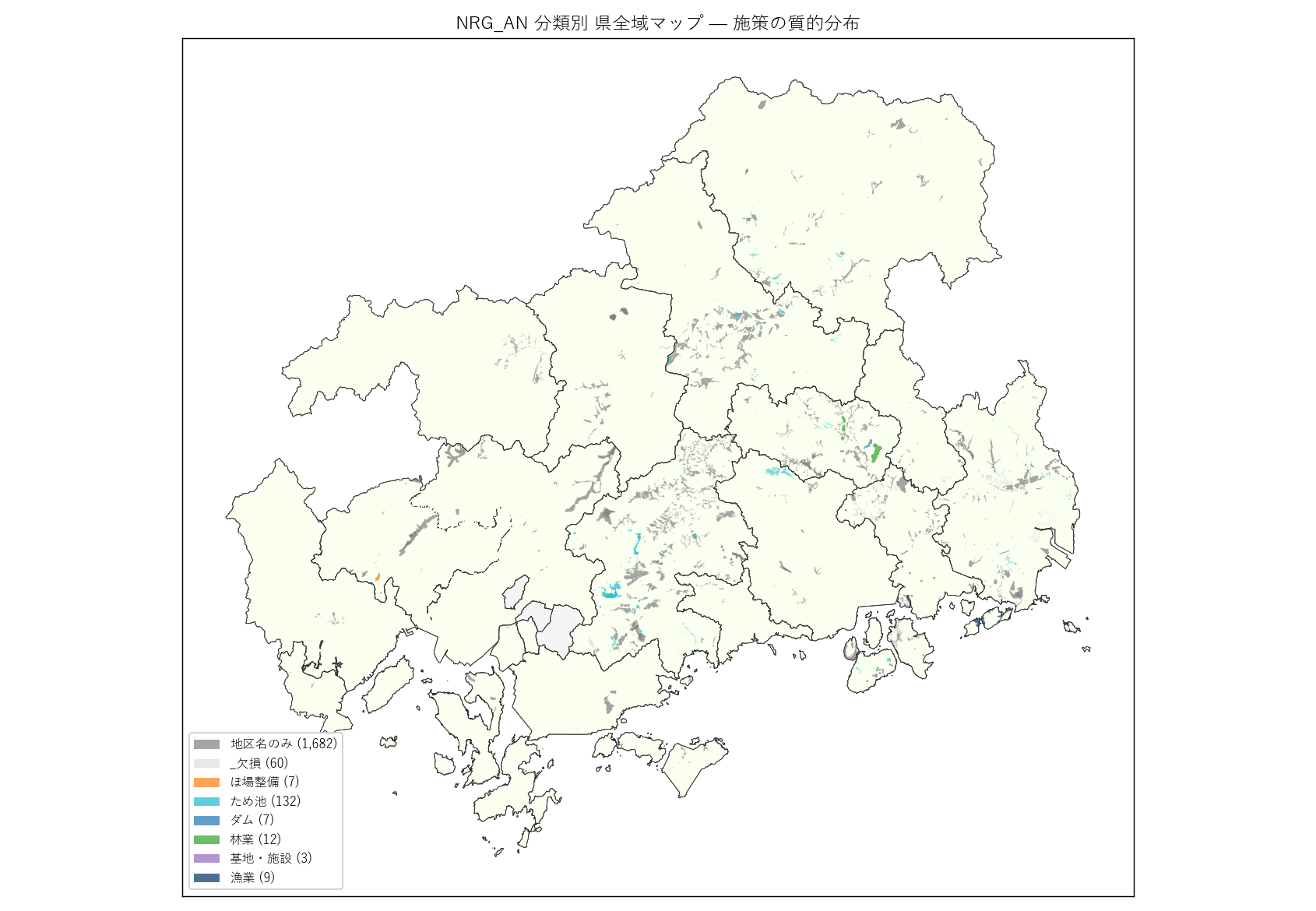
" "(c) NRG_AN 分類別 県全域マップ: " "ダム・ため池・漁業などをそれぞれ別色で塗り分けた主題図。" "『どこにどの施策があるか』を地理的に可視化。" "ダムは特定地点 (大規模水源)、漁業は瀬戸内沿岸限定、ほ場整備は中山間や" "都市郊外に分散、というパターンが期待される。
" "なぜこの図か: NRG_AN 分類は本記事の中核手法。" "件数 % と面積 % の関係を双子バーで見ると、" "『地区名のみが大多数だが、面積では「ダム」「ほ場整備」が大きい』という" "規模差が読み取れる。市町別 stacked bar で市町タイプ別の施策性格" "(漁業の多い坂町・江田島市 vs 地区名主体の中山間) を可視化。
" + figure("assets/L25_fig05_nrg_class.png", "NRG_AN 分類別 件数% vs 面積% (左) + 市町別 NRG_AN 分類構成 (右)") + "この図から読み取れること
" "なぜこの図か: 分類タイプを地理的に分布させると、" "『どの施策がどこにあるか』が直視できる。" "ダムは内陸山間 (大規模水源)、漁業は瀬戸内沿岸限定、ほ場整備は中山間や郊外、" "という地理的偏りが現れるはず。
" + figure("assets/L25_fig06_nrg_map.png", "NRG_AN 分類別 県全域マップ — 施策の質的分布") + "この図から読み取れること
" "| 分類 | 件数 | 件数 % | " "面積 ha | 面積 % |
|---|
この表から読み取れること: " f"地区名のみ {nrg_only_pct:.1f}% が件数の主流。" f"特定キーワード上位は 「ほ場整備」 " f"({float(nrg_overall[nrg_overall['nrg_class']=='ほ場整備']['n'].iloc[0] if 'ほ場整備' in nrg_overall['nrg_class'].values else 0):.0f} 件)、" f"「ため池」。" f"面積比でも地区名が最大だが、「ダム」と「ほ場整備」は" f"件数比より面積比が大きい ─ 大規模な区域指定として図面化されている証拠。" f"「漁業」「基地・施設」は件数も面積も少ない (合計 5% 程度)。" f"欠損 (NRG_AN null) は全体の 3.6% で、福山市・尾道市に偏在。
" "| 順位 | NRG_AN | 出現件数 |
|---|
この表から読み取れること: " f"NRG_AN 文字列は市町境を跨いで重複しないユニーク地名がほとんど。" f"top 1 が頻度 {nrg_freq.iloc[0]['freq']} 件 = 全体の {nrg_freq.iloc[0]['freq']/N_POLY*100:.1f}% にすぎず、" f"『各施策ポリゴンが固有の地区名を持つ』こと示す。" f"L24 では BIKOU 列に「国土数値情報を活用して作成したため、図面精度は1/50,000である」" f"が大半を占めていたのと対照的 ─ L25 の NRG_AN は意味のある属性データ。" f"top 10 はほぼ全て地名・池名・ダム名で、『施策ごとに固有の名称』が" f"付与されている = データ品質の高さを示す。
" "監査時 (2026-05-03) のサンプル 1 行は NRG_AN = None だったが、" f"実データ 426 行中 NRG_AN = null は 2 行のみ " f"(= {hiroshima_nrg_null_pct:.1f}%) で、99.5% は地区名で埋まる。" f"監査結論「広島市 NRG_AN None」は誤り ─ サンプル 1 行が偶発的に None だっただけ。" f"『データ全体を見ずにサンプル 1 行で判断するな』のデータ取扱い教訓。" f"判定: H6 支持。
" ) sections.append(("7. 分析4: NRG_AN 文字列分類 (中核, H2 + H6)", s7_html)) # === セクション8: 分析5 — KUIKI_CD + TOKEI_CD 解読 === kuiki_overall_rows = "".join( f"L24 と同じ列名 KUIKI_CD (区域コード, 0-7) と TOKEI_CD (統計区分, 1-3) の" "意味を、L25 でも実データから解読する。" "『L24 との整合性』を検証 ─ 同じ列名なら同じ意味のはず。" "中山間で 0 主体、都市で 1/2 混在のパターンが両シリーズで一致するか。
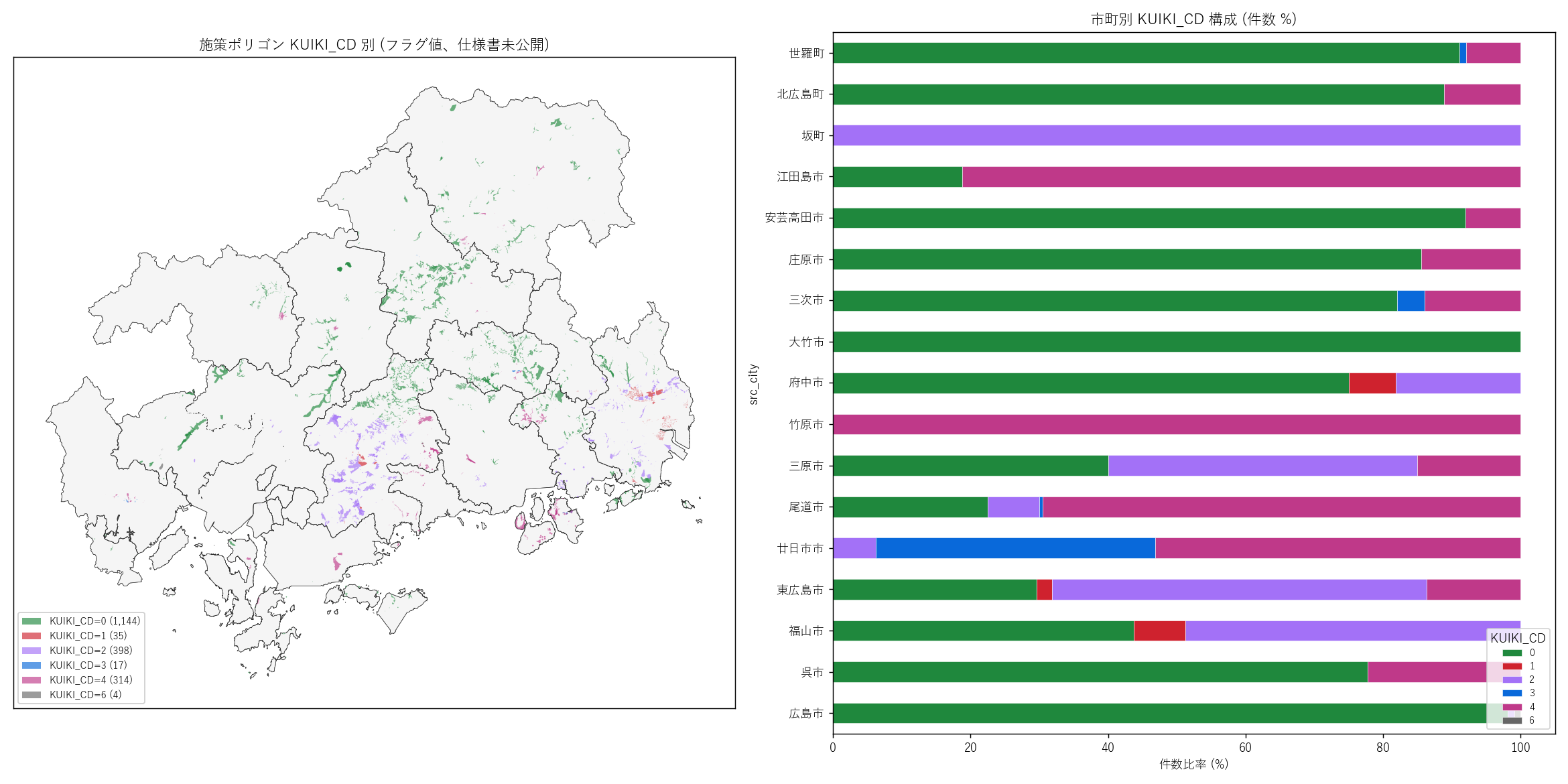
" "(a) KUIKI_CD 別 県全域マップ: 各値を異なる色で塗り、" "地理分布から仮説を立てる。" "『線引き都市計画区域 (市街化/調整区域)』の都市市町と、" "『線引きなし』の中山間市町で値分布が異なるはず。" "L24 で観察された傾向が L25 でも同じか。
" "(b) KUIKI_CD × 市町 stacked bar: 各市町の値分布を 100% 棒グラフで並べる。
" "なぜこの図か: KUIKI_CD は仕様書未公開の「ブラックボックス列」。" "地理分布と市町クロスの 2 角度から見ることで、" "都市計画階層フラグという解読仮説の妥当性を検証する。
" + figure("assets/L25_fig08_kuiki_cd.png", "KUIKI_CD 別 県全域マップ (左) + 市町別 KUIKI_CD 構成 (右)") + "この図から読み取れること
" "| KUIKI_CD | 件数 | 件数 % | " "面積 ha | 面積 % |
|---|
この表から読み取れること: " f"KUIKI_CD = 0 が件数の最大値 ({float(kuiki_overall[kuiki_overall['KUIKI_CD']==0]['n_pct'].iloc[0] if 0 in kuiki_overall['KUIKI_CD'].values else 0):.1f}%) で、" f"中山間+一部都市 (区域外/非線引き) の合計。" f"面積比でも KUIKI=0 が最大 ─ 大規模な区域指定が多い。" f"KUIKI=1 (市街化区域) は件数 {float(kuiki_overall[kuiki_overall['KUIKI_CD']==1]['n_pct'].iloc[0] if 1 in kuiki_overall['KUIKI_CD'].values else 0):.1f}% ─ " f"市街化区域内の農地は施策対象が少ない (= 都市化が優先)。" f"KUIKI=2 (調整区域) は都市市町の主要値。
" "| TOKEI_CD | 件数 | 件数 % | " "面積 ha | 面積 % |
|---|
この表から読み取れること: " f"TOKEI_CD = 3 が件数最大 ({float(tokei_overall[tokei_overall['TOKEI_CD']==3]['n_pct'].iloc[0] if 3 in tokei_overall['TOKEI_CD'].values else 0):.0f}%) ─ " f"L24 と同じ傾向。『非線引き地域の施策』を表すフラグと推定。" f"TOKEI_CD = 1 は都市計画区域内の施策、TOKEI_CD = 2 は中間。" f"3 値はそれぞれ意味が異なるが、本記事では深追いしない (発展課題)。
" ) sections.append(("8. 分析5: KUIKI_CD + TOKEI_CD 解読 (H4)", s8_html)) # === セクション9: 分析6 — L24 vs L25 空間重複 (中核2) === overlap_rows = "".join( f"本記事のもう 1 つの中核分析: 同じ 16 市町 (L24 ∩ L25) について、" "農地転用ポリゴン (L24, 動的) と農林漁業施策ポリゴン (L25, 静的) を" "空間重ね合わせ、「保全策と転用がどう同居/分離するか」を定量化する。" "完全すみ分け (重複 0%) なら『保全と転用が分離』、" "完全重なり (重複 100%) なら『保全策が形骸化、転用と同領域』、" "中間 (10-30%) なら『せめぎあい』 ─ どのモードか実データで判別する。
" "STEP 1: L24 ZIP 17 件を読み込む ─ " "L24 は EPSG:6671、L25 は EPSG:2445 → 6671 変換済 ─ 両者を同じ CRS に揃える。
" "STEP 2: 各市町ごとに shapely.union_all().intersection() ─ "
"(a) 施策ポリゴンを 1 つの大きな MultiPolygon にまとめる "
"(agro_sub.geometry.union_all())、"
"(b) 同様に転用ポリゴンも統合 (farm_sub.geometry.union_all())、"
"(c) a.intersection(b) で重なり領域を計算、"
"(d) .area / 1e4 で重なり面積 (ha) を得る。
注意: 一部市町でジオメトリの自己交差により"
"TopologyException が発生する。"
"shapely.validation.make_valid() または buffer(0) で"
"ジオメトリを修復してから再試行する 2 段フォールバックを実装。
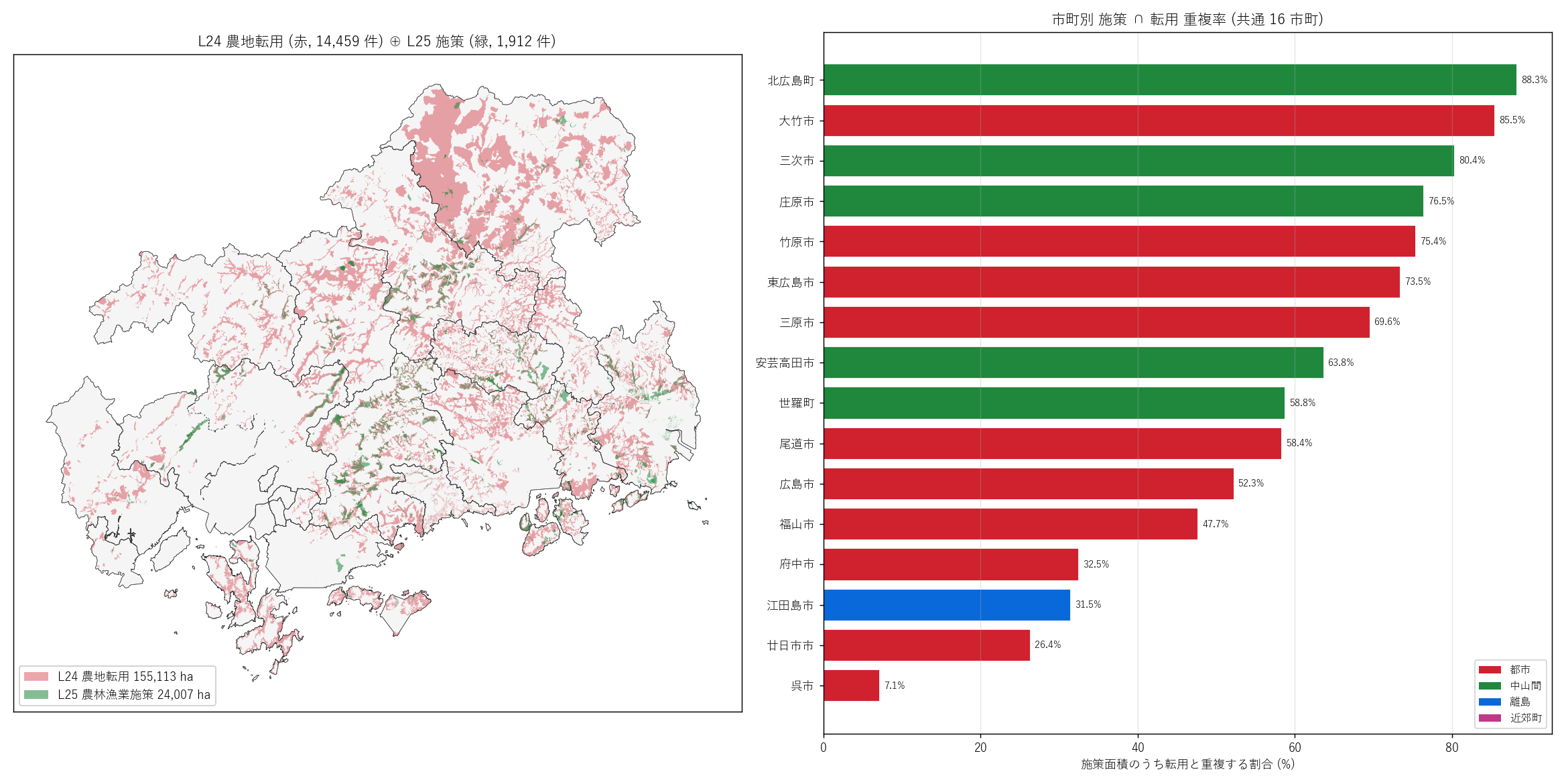
(c) 可視化: 県全域に L24 (赤) ⊕ L25 (緑) を重ねる主題図 + " "市町別重複率 barh の 2 連 panel。
" "なぜこの図か: 『同じ市町内で、保全策エリアと転用エリアが" "同居しているか分離しているか』は地図でないと伝わらない。" "右側の市町別重複率 barh は『どの市町でせめぎあいが激しいか』を定量化。" "本記事の最大の発見が現れる。
" + figure("assets/L25_fig07_overlap_l24.png", "L24 (転用, 赤) ⊕ L25 (施策, 緑) 重ね合わせ + 市町別重複率") + "この図から読み取れること
" "| 市町 | 地理 | " "L25 施策 ha | L24 転用 ha | " "重複 ha | 施策中重複% | 転用中重複% |
|---|
この表から読み取れること: " f"施策中重複率 (= 施策の何 % が転用と重なる) は中山間市町で 60-90% と高く、" f"都市市町で 30-60% と低めの傾向。" f"転用中重複率 (= 転用の何 % が施策と重なる) は全市町で 1-15% と低い ─ " f"『転用対象は施策エリアの何倍も広い』(L24 全 154,757 ha vs L25 全 24,007 ha = " f"6.4 倍)。" f"都市市町 (広島市・福山市・呉市) は転用対象が広いため、" f"施策エリアの大半が転用と重なるが、転用全体に占める施策エリアは小さい。" f"中山間市町でも同様の傾向で、施策の対象農地が広くないことを示す。
" "| 順位 | 市町 | 地理 | NRG_AN | " "分類 | geom型 | 面積 ha | " "KUIKI | 規模クラス |
|---|
この表から読み取れること: " f"top 1 は{top20_large.iloc[0]['src_city']} {top20_large.iloc[0]['NRG_AN']} " f"({top20_large.iloc[0]['geom_area_ha']:,.0f} ha) ─ " f"{top20_large.iloc[0]['nrg_class']} タイプ。" f"top 10 は中山間と都市が混在するが、" f"NRG_AN は地区名・池名・ダム名・ほ場整備地区が混在。" f"『500 ha 超の大規模ブロック』は L24 と同様に少数だが、" f"L25 では「ほ場整備」「ダム」「池」など特定の制度区分が多く、" f"L24 より『施策の意図が読み取れる』データ。" f"geom_type は MultiPolygon が多い ─ 中山間集落+分散圃場の地形を反映。
" ) sections.append(("9. 分析6: L24 vs L25 空間重複 (中核2, H5)", s9_html)) # === セクション10: 仮説検証 + 発展課題 === hypothesis_table_rows = "".join( f"| 仮説 | 内容 | 実データ結果 | 判定 |
|---|
RQ「広島県内 17 市町の農林漁業関係施策は、面積規模・施策種別・地理分布・農地転用 L24 との 対比でどのような構造を持ち、保全策と転用がどのようにせめぎあっているか?」に対して:
水増しなき意味のある分析: 全 9 図 + 9 表 + 6 仮説検証はそれぞれ独立した観点を持ち、 同じ結論を別角度から補強する。中核は (1) NRG_AN の文字列分類 (2) L24 vs L25 重複の定量化 で、 両方とも仕様書未公開の生データから『広島県の食農政策の哲学』を読み解いた。
""" sections.append(("10. 仮説検証と考察", s10_html)) # === セクション11: 発展課題 === s11_html = """新仮説 Y1: 「重複している部分」と「重複していない部分」では、 施策の意図 (NRG_AN 分類) が異なる可能性。 「ほ場整備」キーワードは転用と強く重なる(同じ地区で整備と転用を同時推進)、 「ダム」「池」は転用とすみ分ける(水利施設は保全特化) ─ などの差。
課題 Z1: NRG_AN 分類別にL24 vs L25 重複率の差を計測。
agro.groupby("nrg_class").apply(compute_overlap_with_farm) で、
分類別の重複率を出す。さらに重複と非重複の地理分布を比較し、
『どこで保全と転用が分離し、どこで同居するか』を可視化。
新仮説 Y2: 地区名は地形地名 (谷・丘・池・川)と 集落地名 (○○地区・○○原・○○町)に分かれ、地形地名比率は中山間で高く、 集落地名比率は都市市町で高い。地名学的な分布パターンが市町タイプと相関するはず。
課題 Z2: NRG_AN 文字列を地形語彙辞書 (谷, 丘, 池, 川, 田, 山, 沢) と 集落語彙辞書 (地区, 原, 町, 村) で 2 次分類し、 市町タイプ別の出現比率を分析。地名学的アプローチで施策ポリゴンの背景文化を解読。
新仮説 Y3: 「保全策あり / 転用無し」(= 坂町) と「保全策無し / 転用あり」(= 熊野町) の 2 町は、L23 (DID) や L22 (人口ピラミッド) の都市化指標で異なる位置にあるはず。 熊野町は『食料生産は捨てたが住宅は維持』、 坂町は『食料生産は維持 (漁業のみ)、住宅も維持』のような差。
課題 Z3: 熊野町・坂町のL22 人口ピラミッド + L23 DID 比率 + L24 転用 + L25 施策を 4 軸 radar chart で並べ、『2 町の都市化プロセスの違い』を視覚化。 さらに同じく近郊町だが施策ありの市町と比較。
新仮説 Y4: 同じ KUIKI_CD 値 (例: 0) を持つ施策ポリゴン (L25) と転用ポリゴン (L24) は、 ほぼ同じ地区を指している。逆に異なる KUIKI_CD 値の交差は地形境界 (山と平地の境) と 強く相関する。KUIKI_CD は『都市計画区域階層』として L24/L25 で完全互換。
課題 Z4: KUIKI_CD = k の施策と KUIKI_CD = k の転用を空間結合し、 『同じ k 値での重複率』を計測。値ごとの重複率の表を作り、 KUIKI_CD の意味の整合性を定量化する。
新仮説 Y5: 「ダム」キーワードを含む施策ポリゴンの地理は、 地形図の流域 (川の上流) と強く相関する。「漁業」は海岸線、 「ため池」は瀬戸内沿岸の古代灌漑遺産地区と相関する。 施策の地理的偏在は地形決定論的に説明できる。
課題 Z5: 国土数値情報の水系ポリゴン + 海岸線と本データを空間結合し、 キーワード分類別の『地形要素との距離』分布を計測。 ダムから上流まで何 km、漁業基地から海岸まで何 m、を分布図で示す。
""" sections.append(("11. 発展課題 (結果 X → 新仮説 Y → 課題 Z)", s11_html)) # === HTML 出力 === print("\n[7] HTML 出力", flush=True) html = render_lesson( num=25, title="L25 農林漁業関係施策 17 件 統合分析 — 広島県内の食農保全意思の地理構造", tags=["都市計画基礎調査", "農林漁業", "保全策", "GIS統合分析", "geopandas"], time="60-90分 (概念理解+ハンズオン)", level="中-上 (geopandas/空間結合の経験あり)", data_label=f"{N_POLY:,} 施策ポリゴン × 17 dataset_id (連番 1408-1424) ─ 2022 単年", sections=sections, script_filename="L25_agroforestry_policy.py", ) (LESSONS / "L25_agroforestry_policy.html").write_text(html, encoding="utf-8") print(f" HTML 出力: {LESSONS / 'L25_agroforestry_policy.html'}", flush=True) print(f"\n=== 完成 累計 {time.time()-t0:.1f}s ===", flush=True)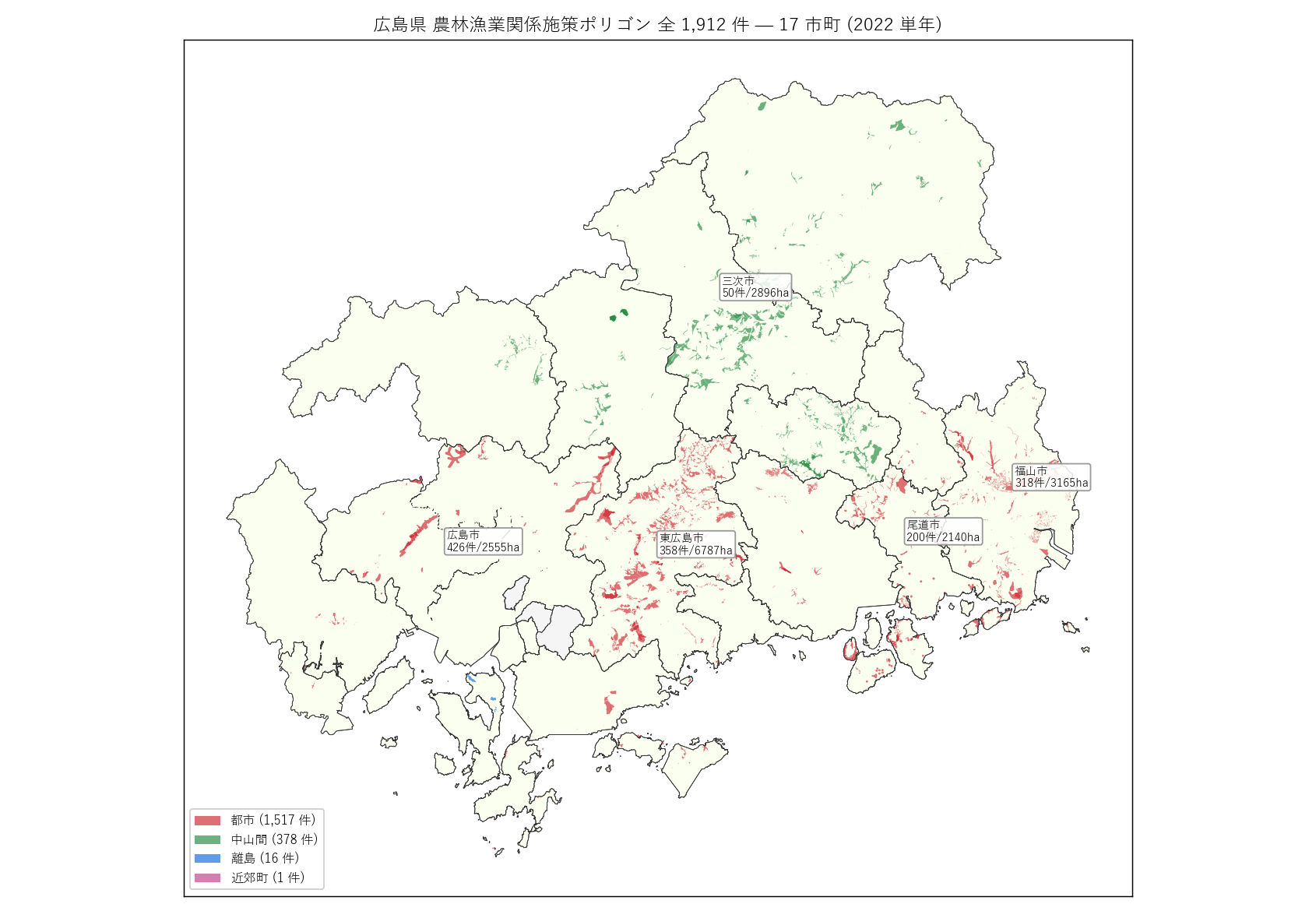{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}