"""L22 性別年齢別人口 20 件 統合分析 — 広島県全域の人口ピラミッドの地理構造
カバー宣言:
本記事は 「都市計画区域情報_性別年齢別人口_*_2020」 の 20 dataset_id を統合し、
広島県内 全 20 市町の R2 国勢調査小地域 (町丁) 単位 性別×5歳階級 人口データ
計 11,588 町丁 × 61 列 を1個の GeoDataFrame に縦結合した上で、
人口ピラミッド・高齢化・性比・年齢構造・100歳以上分布 の地理構造を分析する研究記事である。
20 dataset_id (連番性なし):
1467 広島市, 1470 呉市, 1472 竹原市, 1475 三原市,
1478 尾道市, 1481 福山市, 1484 府中市, 1486 三次市,
1488 庄原市, 1489 大竹市, 1492 東広島市, 1494 廿日市市,
1497 安芸高田市, 1498 江田島市, 1499 府中町, 1501 海田町,
1503 熊野町, 1504 坂町, 1506 北広島町, 1508 世羅町
研究の問い (RQ):
広島県内 11,588 町丁における人口ピラミッドは、
市町別・地域別にどのような構造を持ち、高齢化と若年集中はどう地理的に分布しているか?
町丁単位の高齢化率・性比・年少率・後期高齢化率は、
社会人口学的にどのような『地理的指紋』を残すか?
仮説 H1〜H6:
H1. 広島県全域の人口ピラミッドは中央が膨らむ「壺型」を示す。
団塊世代 (70-74歳) と 団塊ジュニア (45-49歳) が二峰、
若年層 (0-24歳) は薄く先細る『超少子高齢社会のピラミッド』。
H2. 高齢化率 (65+/総人口) は市町間で 2 倍以上 の格差。
都市部 (広島市・福山市) が低く、中山間 (庄原市・北広島町・世羅町) が高い。
H3. 高齢化率は町丁単位ではさらに激しく分布し、
同じ市内でも >30%pt の格差がある。
単純な平均では市町差を捉えきれない『局地高齢化』が存在する。
H4. 性比 (M/F×100) は典型的には 90-95 (女性やや多い) だが、
大学・基地・工業団地の周辺町丁では 110+ (男性集中) が出現する。
H5. 後期高齢者 (75+) の集中スポットは 都市部の住宅地ではなく、
中山間部の集落・旧市街・かつての社宅地区 に偏在する。
H6. 100歳以上の絶対数は人口大都市 (広島市・福山市) が多いが、
人口比 (per 10,000) では中山間部のほうが高い。
要件 S 準拠: 1分以内完走。11,588 町丁 × 61 列でも groupby・vectorize で軽量。
要件 T 準拠: 全県町丁マップ・高齢化率 choropleth・人口密度 choropleth・
若年集中マップ・性比異常マップ・市町別人口ピラミッド small multiples。
要件 Q 準拠: 図 11 枚以上、表 10 枚以上。
データ構造の重要性:
61 列の内訳:
メタ 11 列: TOKEI_CD, KUIKI_CD, SMALL_A_CD, AREA_CD, SECRET1-3,
CITY_CD, CITY_NAME, TOWN_NAME1, TOWN_NAME2
集計 3 列: JINKO_SU (人口総数), M_SU (男性総数), F_SU (女性総数)
年齢階級 男性 22 列: M_00, M_05, M_10, ..., M_95, M_100, M_999
年齢階級 女性 22 列: F_00, F_05, F_10, ..., F_95, F_100, F_999
その他 3 列: RITTEKI_CD, BIKOU, geometry (MultiPolygon)
EPSG:6671 (JGD2011 平面直角第III系・広島県)。
庄原市のみ Shape_Area, Shape_Leng の 2 列が追加で 63 列だが、値はすべて 0 で
実質 61 列共通。
データ品質に関する重要発見:
- JINKO_SU=0 の町丁が存在 (秘匿または無人区画)。本記事は除外せず観察対象。
- M_999/F_999 (年齢不詳) は通常 0 だが一部町丁で >0 。秘匿処理または記入漏れ。
"""
from __future__ import annotations
import sys, time, json, zipfile, io
from pathlib import Path
sys.path.insert(0, str(Path(__file__).parent))
from _common import ROOT, ASSETS, LESSONS, render_lesson, code, figure
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.patches import Patch
from matplotlib.colors import Normalize
import geopandas as gpd
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
t0 = time.time()
print("=== L22 性別年齢別人口 20 件 統合分析 ===", flush=True)
# =============================================================================
# 0. 定数: 20 dataset_id, 行政区域の対応 dataset_id
# =============================================================================
DATA_DIR = ROOT / "data" / "extras" / "L22_population_pyramid"
ADMIN_DIR = ROOT / "data" / "extras" / "L15_admin_zones"
TARGET_CRS = "EPSG:6671"
# (人口 dsid, 市町名, 行政_dsid, 都市タイプ)
CITY_DEFS = [
(1467, "広島市", 786, "政令市"),
(1470, "呉市", 797, "中核市"),
(1481, "福山市", 832, "中核市"),
(1492, "東広島市", 868, "施行時特例市"),
(1494, "廿日市市", 878, "市"),
(1478, "尾道市", 824, "市"),
(1475, "三原市", 814, "市"),
(1472, "竹原市", 807, "市"),
(1484, "府中市", 840, "市"),
(1489, "大竹市", 862, "市"),
(1486, "三次市", 850, "市"),
(1488, "庄原市", 856, "市"),
(1497, "安芸高田市", 888, "市"),
(1498, "江田島市", 894, "市"),
(1499, "府中町", 900, "町"),
(1501, "海田町", 905, "町"),
(1503, "熊野町", 911, "町"),
(1504, "坂町", 916, "町"),
(1506, "北広島町", 935, "町"),
(1508, "世羅町", 941, "町"),
]
# 公的統計参考値 (国土地理院 R6 面積、e-Stat R2 国勢調査人口千人) — L21 と共通
CITY_REF = {
"広島市": {"area_km2": 906.7, "pop_k": 1189},
"呉市": {"area_km2": 352.8, "pop_k": 210},
"福山市": {"area_km2": 518.1, "pop_k": 459},
"東広島市": {"area_km2": 635.3, "pop_k": 198},
"廿日市市": {"area_km2": 489.5, "pop_k": 117},
"尾道市": {"area_km2": 285.1, "pop_k": 130},
"三原市": {"area_km2": 471.6, "pop_k": 90},
"竹原市": {"area_km2": 118.2, "pop_k": 24},
"府中市": {"area_km2": 195.8, "pop_k": 37},
"大竹市": {"area_km2": 78.7, "pop_k": 26},
"三次市": {"area_km2": 778.1, "pop_k": 50},
"庄原市": {"area_km2":1246.5, "pop_k": 33},
"安芸高田市": {"area_km2": 537.8, "pop_k": 27},
"江田島市": {"area_km2": 100.7, "pop_k": 22},
"府中町": {"area_km2": 10.4, "pop_k": 53},
"海田町": {"area_km2": 13.8, "pop_k": 30},
"熊野町": {"area_km2": 33.7, "pop_k": 23},
"坂町": {"area_km2": 15.7, "pop_k": 12},
"北広島町": {"area_km2": 646.2, "pop_k": 17},
"世羅町": {"area_km2": 278.2, "pop_k": 15},
}
# 市町タイプ別カラー
CTYPE_COLOR = {
"政令市": "#cf222e", "中核市": "#bf3989",
"施行時特例市": "#a371f7", "市": "#0969da", "町": "#1f883d",
}
CITY_ORDER = [d[1] for d in CITY_DEFS]
# 5 歳階級ラベル (M_00 〜 M_100, M_999)
AGE_5YR_BINS = list(range(0, 101, 5)) # 0, 5, ..., 100
AGE_5YR_LABELS = [f"{b}-{b+4}" for b in AGE_5YR_BINS[:-1]] + ["100+"]
M_AGE_COLS = [f"M_{b:02d}" for b in AGE_5YR_BINS]
F_AGE_COLS = [f"F_{b:02d}" for b in AGE_5YR_BINS]
# 4 群集約 (要件指定)
# 0-14 (年少) / 15-64 (生産年齢) / 65-74 (前期高齢) / 75+ (後期高齢)
GROUP_BINS = {
"年少 (0-14)": AGE_5YR_BINS[:3], # 0,5,10
"生産年齢 (15-64)": AGE_5YR_BINS[3:13], # 15,20,...,60
"前期高齢 (65-74)": AGE_5YR_BINS[13:15], # 65,70
"後期高齢 (75+)": AGE_5YR_BINS[15:], # 75,80,...,100
}
GROUP_COLOR = {
"年少 (0-14)": "#74c476",
"生産年齢 (15-64)": "#1f77b4",
"前期高齢 (65-74)": "#ff7f0e",
"後期高齢 (75+)": "#cf222e",
}
# =============================================================================
# 1. 20 GeoJSON 統合読み込み + 行政区域背景
# =============================================================================
print("\n[1] 20 GeoJSON 統合読み込み", flush=True)
t1 = time.time()
# 共通 61 列 (全市町に存在)
COMMON_COLS_61 = [
'AREA_CD', 'BIKOU', 'CITY_CD', 'CITY_NAME',
'F_00', 'F_05', 'F_10', 'F_100', 'F_15', 'F_20', 'F_25', 'F_30',
'F_35', 'F_40', 'F_45', 'F_50', 'F_55', 'F_60', 'F_65', 'F_70',
'F_75', 'F_80', 'F_85', 'F_90', 'F_95', 'F_999', 'F_SU',
'JINKO_SU', 'KUIKI_CD',
'M_00', 'M_05', 'M_10', 'M_100', 'M_15', 'M_20', 'M_25', 'M_30',
'M_35', 'M_40', 'M_45', 'M_50', 'M_55', 'M_60', 'M_65', 'M_70',
'M_75', 'M_80', 'M_85', 'M_90', 'M_95', 'M_999', 'M_SU',
'RITTEKI_CD', 'SECRET1', 'SECRET2', 'SECRET3', 'SMALL_A_CD',
'TOKEI_CD', 'TOWN_NAME1', 'TOWN_NAME2', 'geometry',
]
def load_geojson_zip(zip_path: Path) -> gpd.GeoDataFrame:
"""ZIP 内の単一 .geojson を BytesIO 経由で読み込む"""
with zipfile.ZipFile(zip_path) as zf:
gjs = [n for n in zf.namelist() if n.endswith(".geojson")]
if not gjs:
raise FileNotFoundError(f"no .geojson in {zip_path.name}")
with zf.open(gjs[0]) as f:
return gpd.read_file(io.BytesIO(f.read()))
frames = []
load_log = []
for dsid, name, _adm, ctype in CITY_DEFS:
z = DATA_DIR / f"jinko_{dsid}_{name}.zip"
g = load_geojson_zip(z)
extra = sorted(set(g.columns) - set(COMMON_COLS_61))
# 共通 61 列に正規化
g = g[COMMON_COLS_61].copy()
g["src_city"] = name
g["src_dsid"] = dsid
g["ctype"] = ctype
load_log.append({
"dsid": dsid, "city": name, "ctype": ctype,
"n_chome": len(g), "extra_cols": ",".join(extra) if extra else "-",
"jinko_total": int(g["JINKO_SU"].sum()),
"secret_count": int((g["SECRET1"].notna() | g["SECRET2"].notna()
| g["SECRET3"].notna()).sum()),
})
frames.append(g)
pop = gpd.GeoDataFrame(pd.concat(frames, ignore_index=True),
geometry="geometry", crs=frames[0].crs)
pop = pop.to_crs(TARGET_CRS)
N_CHOME = len(pop)
JINKO_TOTAL = int(pop["JINKO_SU"].sum())
print(f" 町丁レコード: {N_CHOME:,} 行 × {len(pop.columns)} 列", flush=True)
print(f" 人口総計: {JINKO_TOTAL:,} 人 (R2 国勢調査ベース)", flush=True)
# 行政区域 (L15 共有) を 20 市町分 dissolve
admin_frames = []
for _dsid, name, adm_ds, _ct in CITY_DEFS:
z = ADMIN_DIR / f"admin_{adm_ds}_{name}.zip"
g = load_geojson_zip(z)
g["city"] = name
admin_frames.append(g)
admin_all = gpd.GeoDataFrame(pd.concat(admin_frames, ignore_index=True),
geometry="geometry", crs=admin_frames[0].crs)
admin_all = admin_all.to_crs(TARGET_CRS)
admin_diss = admin_all.dissolve(by="city").reset_index()
admin_diss["admin_area_km2"] = admin_diss.geometry.area / 1e6
print(f" 行政区域 dissolve: {len(admin_diss)} 件 ({time.time()-t1:.2f}s)", flush=True)
# =============================================================================
# 2. 4 群集約 + 派生指標
# =============================================================================
print("\n[2] 4 群集約 + 派生指標", flush=True)
t1 = time.time()
# 4 群集約 (M+F)
def sum_age_cols(df, sex_prefix, age_starts):
cols = [f"{sex_prefix}_{a:02d}" for a in age_starts]
return df[cols].sum(axis=1)
pop["youth"] = sum_age_cols(pop, "M", GROUP_BINS["年少 (0-14)"]) \
+ sum_age_cols(pop, "F", GROUP_BINS["年少 (0-14)"])
pop["working"] = sum_age_cols(pop, "M", GROUP_BINS["生産年齢 (15-64)"]) \
+ sum_age_cols(pop, "F", GROUP_BINS["生産年齢 (15-64)"])
pop["early_old"] = sum_age_cols(pop, "M", GROUP_BINS["前期高齢 (65-74)"]) \
+ sum_age_cols(pop, "F", GROUP_BINS["前期高齢 (65-74)"])
pop["late_old"] = sum_age_cols(pop, "M", GROUP_BINS["後期高齢 (75+)"]) \
+ sum_age_cols(pop, "F", GROUP_BINS["後期高齢 (75+)"])
pop["unknown"] = pop["M_999"] + pop["F_999"]
# 100 歳以上
pop["centenarian"] = pop["M_100"] + pop["F_100"]
# 派生指標
P = pop["JINKO_SU"].clip(lower=1) # 0 除算回避
pop["aging_rate"] = (pop["early_old"] + pop["late_old"]) / P # 高齢化率
pop["late_rate"] = pop["late_old"] / P # 後期高齢化率
pop["youth_rate"] = pop["youth"] / P # 年少率
pop["dep_index"] = (pop["youth"] + pop["early_old"] + pop["late_old"]) \
/ pop["working"].clip(lower=1) * 100 # 従属人口指数
M_ALL = pop["M_SU"]
F_ALL = pop["F_SU"]
pop["sex_ratio"] = M_ALL / F_ALL.clip(lower=1) * 100 # 性比 M/F*100
# 町丁面積 (m² → km²) と人口密度
pop["chome_area_km2"] = pop.geometry.area / 1e6
pop["density_per_km2"] = pop["JINKO_SU"] / pop["chome_area_km2"].clip(lower=1e-6)
# JINKO_SU=0 のフラグ
pop["is_empty"] = pop["JINKO_SU"] == 0
N_EMPTY = int(pop["is_empty"].sum())
# 不詳 (M_999 + F_999) > 0 のフラグ
pop["has_unknown"] = pop["unknown"] > 0
N_HAS_UNKNOWN = int(pop["has_unknown"].sum())
print(f" 人口 0 町丁: {N_EMPTY:,} 件 (秘匿または無人)", flush=True)
print(f" 不詳 >0 町丁: {N_HAS_UNKNOWN:,} 件", flush=True)
print(f" 全県 高齢化率: {(pop['early_old'].sum()+pop['late_old'].sum())/JINKO_TOTAL*100:.2f}%",
flush=True)
print(f" 全県 年少率: {pop['youth'].sum()/JINKO_TOTAL*100:.2f}%", flush=True)
print(f" 全県 性比: {pop['M_SU'].sum()/pop['F_SU'].sum()*100:.2f}", flush=True)
print(f" ({time.time()-t1:.2f}s)", flush=True)
# =============================================================================
# 3. 市町別 集計 (人口統計)
# =============================================================================
print("\n[3] 市町別 集計", flush=True)
t1 = time.time()
city_agg = pop.groupby("src_city").agg(
n_chome=("JINKO_SU", "size"),
pop_total=("JINKO_SU", "sum"),
m_total=("M_SU", "sum"),
f_total=("F_SU", "sum"),
youth=("youth", "sum"),
working=("working", "sum"),
early_old=("early_old", "sum"),
late_old=("late_old", "sum"),
centenarian=("centenarian", "sum"),
unknown=("unknown", "sum"),
).reset_index()
city_agg["area_km2"] = city_agg["src_city"].map(lambda c: CITY_REF[c]["area_km2"])
city_agg["density_per_km2"] = (city_agg["pop_total"] / city_agg["area_km2"]).round(1)
city_agg["aging_rate"] = ((city_agg["early_old"] + city_agg["late_old"])
/ city_agg["pop_total"].clip(lower=1) * 100).round(2)
city_agg["late_rate"] = (city_agg["late_old"]
/ city_agg["pop_total"].clip(lower=1) * 100).round(2)
city_agg["youth_rate"] = (city_agg["youth"]
/ city_agg["pop_total"].clip(lower=1) * 100).round(2)
city_agg["sex_ratio"] = (city_agg["m_total"]
/ city_agg["f_total"].clip(lower=1) * 100).round(2)
city_agg["dep_index"] = ((city_agg["youth"] + city_agg["early_old"]
+ city_agg["late_old"])
/ city_agg["working"].clip(lower=1) * 100).round(1)
city_agg["centenarian_per_10k"] = (city_agg["centenarian"]
/ city_agg["pop_total"].clip(lower=1) * 10000).round(2)
city_agg["ctype"] = city_agg["src_city"].map(
lambda c: next(d[3] for d in CITY_DEFS if d[1] == c))
# 並び順を CITY_ORDER に
city_agg = city_agg.set_index("src_city").reindex(CITY_ORDER).reset_index().rename(
columns={"src_city": "city"})
# 5 歳階級 全県集計 (人口ピラミッド用)
m_5yr = pop[M_AGE_COLS].sum() # 21 値 (0-4 〜 100+)
f_5yr = pop[F_AGE_COLS].sum()
m_unknown = int(pop["M_999"].sum())
f_unknown = int(pop["F_999"].sum())
print(f" 5歳階級 全県男性: {m_5yr.sum():,} (+ 不詳 {m_unknown:,})", flush=True)
print(f" 5歳階級 全県女性: {f_5yr.sum():,} (+ 不詳 {f_unknown:,})", flush=True)
# 市町×5歳階級 (男性) ピラミッド small multiples 用
m_pyramid = pop.groupby("src_city")[M_AGE_COLS].sum()
f_pyramid = pop.groupby("src_city")[F_AGE_COLS].sum()
m_pyramid = m_pyramid.reindex(CITY_ORDER)
f_pyramid = f_pyramid.reindex(CITY_ORDER)
print(f" 市町集計: {len(city_agg)} 件 ({time.time()-t1:.2f}s)", flush=True)
# =============================================================================
# 4. 町丁単位の派生指標 集計と外れ値検出
# =============================================================================
print("\n[4] 町丁単位の派生指標 集計", flush=True)
t1 = time.time()
# 人口 0 町丁を除いた集計
pop_nz = pop[~pop["is_empty"]].copy()
N_NZ = len(pop_nz)
# 町丁ごとの分布統計 (人口 >= 30 で安定する町丁のみ)
RELIABLE_THRESHOLD = 30
pop_rel = pop_nz[pop_nz["JINKO_SU"] >= RELIABLE_THRESHOLD].copy()
N_REL = len(pop_rel)
print(f" 人口>0 町丁: {N_NZ:,}, 信頼可 (>=30 人) {N_REL:,}", flush=True)
# 高齢化率の極値 top10
top_aging = pop_rel.nlargest(10, "aging_rate")[
["src_city", "CITY_NAME", "TOWN_NAME1", "TOWN_NAME2",
"JINKO_SU", "aging_rate", "late_rate", "youth_rate"]
].copy()
top_aging["aging_rate_pct"] = (top_aging["aging_rate"] * 100).round(2)
top_aging["late_rate_pct"] = (top_aging["late_rate"] * 100).round(2)
top_aging["youth_rate_pct"] = (top_aging["youth_rate"] * 100).round(2)
bot_aging = pop_rel.nsmallest(10, "aging_rate")[
["src_city", "CITY_NAME", "TOWN_NAME1", "TOWN_NAME2",
"JINKO_SU", "aging_rate", "late_rate", "youth_rate"]
].copy()
bot_aging["aging_rate_pct"] = (bot_aging["aging_rate"] * 100).round(2)
bot_aging["late_rate_pct"] = (bot_aging["late_rate"] * 100).round(2)
bot_aging["youth_rate_pct"] = (bot_aging["youth_rate"] * 100).round(2)
# 性比異常 (極端な値)
top_male = pop_rel.nlargest(10, "sex_ratio")[
["src_city", "CITY_NAME", "TOWN_NAME1", "TOWN_NAME2",
"JINKO_SU", "M_SU", "F_SU", "sex_ratio"]
].copy()
top_female = pop_rel.nsmallest(10, "sex_ratio")[
["src_city", "CITY_NAME", "TOWN_NAME1", "TOWN_NAME2",
"JINKO_SU", "M_SU", "F_SU", "sex_ratio"]
].copy()
# 若年集中スポット (年少率 + 生産年齢若年 = 0-39 比率)
def young_share(row):
p = row["JINKO_SU"]
if p < 1:
return 0.0
young = sum(row[f"M_{a:02d}"] + row[f"F_{a:02d}"]
for a in [0, 5, 10, 15, 20, 25, 30, 35])
return young / p
# vectorized
young_cols_m = [f"M_{a:02d}" for a in [0, 5, 10, 15, 20, 25, 30, 35]]
young_cols_f = [f"F_{a:02d}" for a in [0, 5, 10, 15, 20, 25, 30, 35]]
pop_rel["young40_share"] = (pop_rel[young_cols_m].sum(axis=1)
+ pop_rel[young_cols_f].sum(axis=1)) / pop_rel["JINKO_SU"]
top_young = pop_rel.nlargest(10, "young40_share")[
["src_city", "CITY_NAME", "TOWN_NAME1", "TOWN_NAME2",
"JINKO_SU", "young40_share", "aging_rate", "sex_ratio"]
].copy()
top_young["young40_pct"] = (top_young["young40_share"] * 100).round(2)
top_young["aging_pct"] = (top_young["aging_rate"] * 100).round(2)
# 100歳以上 集中スポット (人口比, 信頼可で >= 100人)
pop_cent = pop_nz[pop_nz["JINKO_SU"] >= 100].copy()
pop_cent["cent_per_10k"] = pop_cent["centenarian"] / pop_cent["JINKO_SU"] * 10000
top_cent = pop_cent.nlargest(10, "cent_per_10k")[
["src_city", "CITY_NAME", "TOWN_NAME1", "TOWN_NAME2",
"JINKO_SU", "centenarian", "cent_per_10k", "aging_rate"]
].copy()
top_cent["aging_pct"] = (top_cent["aging_rate"] * 100).round(2)
# KUIKI_CD 別集計 (1=市街化, 2=用途白地等, 3=市街化調整, 5=都計外 等と推定)
KUIKI_LABEL = {0: "区域不明", 1: "市街化区域", 2: "用途白地等",
3: "市街化調整区域", 5: "都市計画区域外"}
pop_nz["kuiki_label"] = pop_nz["KUIKI_CD"].map(KUIKI_LABEL).fillna(
pop_nz["KUIKI_CD"].astype(str))
kuiki_agg = pop_nz.groupby("kuiki_label").agg(
n_chome=("JINKO_SU", "size"),
pop_total=("JINKO_SU", "sum"),
youth=("youth", "sum"),
working=("working", "sum"),
early_old=("early_old", "sum"),
late_old=("late_old", "sum"),
).reset_index()
kuiki_agg["aging_rate"] = ((kuiki_agg["early_old"] + kuiki_agg["late_old"])
/ kuiki_agg["pop_total"].clip(lower=1) * 100).round(2)
kuiki_agg["youth_rate"] = (kuiki_agg["youth"]
/ kuiki_agg["pop_total"].clip(lower=1) * 100).round(2)
kuiki_agg["share"] = (kuiki_agg["pop_total"]
/ kuiki_agg["pop_total"].sum() * 100).round(2)
kuiki_agg = kuiki_agg.sort_values("pop_total", ascending=False)
print(f" 外れ値検出 OK ({time.time()-t1:.2f}s)", flush=True)
# =============================================================================
# 5. CSV 出力
# =============================================================================
print("\n[5] CSV 出力", flush=True)
t1 = time.time()
# 市町集計
city_agg.to_csv(ASSETS / "L22_city_summary.csv", index=False, encoding="utf-8-sig")
# 全県人口ピラミッド (5 歳階級, 男女)
pyramid_full = pd.DataFrame({
"age_class": AGE_5YR_LABELS,
"male": m_5yr.values,
"female": f_5yr.values,
"total": m_5yr.values + f_5yr.values,
})
pyramid_full.loc[len(pyramid_full)] = ["不詳", m_unknown, f_unknown,
m_unknown + f_unknown]
pyramid_full.to_csv(ASSETS / "L22_pyramid_full.csv",
index=False, encoding="utf-8-sig")
# 市町×5歳階級 (男性 / 女性)
m_pyramid.to_csv(ASSETS / "L22_pyramid_male_by_city.csv", encoding="utf-8-sig")
f_pyramid.to_csv(ASSETS / "L22_pyramid_female_by_city.csv", encoding="utf-8-sig")
# 4 群集約 (市町×4 群)
group_cols = ["youth", "working", "early_old", "late_old"]
city_groups = pop.groupby("src_city")[group_cols].sum()
city_groups = city_groups.reindex(CITY_ORDER)
city_groups["total"] = city_groups.sum(axis=1)
for g in group_cols:
city_groups[g + "_pct"] = (city_groups[g] / city_groups["total"] * 100).round(2)
city_groups.to_csv(ASSETS / "L22_groups_by_city.csv", encoding="utf-8-sig")
# 高齢化率の町丁分布 (市町別 統計)
chome_dist = pop_rel.groupby("src_city").agg(
n_chome=("aging_rate", "size"),
aging_min=("aging_rate", "min"),
aging_q25=("aging_rate", lambda x: float(x.quantile(0.25))),
aging_med=("aging_rate", "median"),
aging_q75=("aging_rate", lambda x: float(x.quantile(0.75))),
aging_max=("aging_rate", "max"),
aging_std=("aging_rate", "std"),
).reset_index().rename(columns={"src_city": "city"})
for c in chome_dist.columns:
if c.startswith("aging_") and c != "aging_std":
chome_dist[c] = (chome_dist[c] * 100).round(2)
elif c == "aging_std":
chome_dist[c] = (chome_dist[c] * 100).round(3)
chome_dist = chome_dist.set_index("city").reindex(CITY_ORDER).reset_index()
chome_dist.to_csv(ASSETS / "L22_aging_chome_dist.csv",
index=False, encoding="utf-8-sig")
# Top/bot 高齢化、性比、若年、100歳
top_aging.to_csv(ASSETS / "L22_top10_aging.csv", index=False, encoding="utf-8-sig")
bot_aging.to_csv(ASSETS / "L22_bot10_aging.csv", index=False, encoding="utf-8-sig")
top_male.to_csv(ASSETS / "L22_top10_male.csv", index=False, encoding="utf-8-sig")
top_female.to_csv(ASSETS / "L22_top10_female.csv", index=False, encoding="utf-8-sig")
top_young.to_csv(ASSETS / "L22_top10_young.csv", index=False, encoding="utf-8-sig")
top_cent.to_csv(ASSETS / "L22_top10_centenarian.csv",
index=False, encoding="utf-8-sig")
# 読込ログ (PRIMARY 判定 / 件数 / 庄原市の追加列)
pd.DataFrame(load_log).to_csv(ASSETS / "L22_load_log.csv",
index=False, encoding="utf-8-sig")
# KUIKI_CD 別集計
kuiki_agg.to_csv(ASSETS / "L22_kuiki_agg.csv", index=False, encoding="utf-8-sig")
print(f" ({time.time()-t1:.2f}s)", flush=True)
# =============================================================================
# 6. 図の作成 (11 枚)
# =============================================================================
print("\n[6] 図の作成", flush=True)
t1 = time.time()
# --- Fig 1: 全県 人口ピラミッド (5 歳階級, 男女) ---
fig, ax = plt.subplots(figsize=(11, 9))
y_pos = np.arange(len(AGE_5YR_LABELS))
ax.barh(y_pos, -m_5yr.values, color="#1f77b4", edgecolor="white",
label=f"男性 計 {m_5yr.sum():,}")
ax.barh(y_pos, f_5yr.values, color="#cf222e", edgecolor="white",
label=f"女性 計 {f_5yr.sum():,}")
# 軸ラベルを正値で
xmax = max(m_5yr.max(), f_5yr.max())
xticks = np.arange(-xmax, xmax * 1.05, max(1, int(xmax / 5 / 10000)) * 10000)
ax.set_xticks(xticks)
ax.set_xticklabels([f"{abs(int(v)):,}" for v in xticks])
ax.set_yticks(y_pos)
ax.set_yticklabels(AGE_5YR_LABELS)
ax.set_xlabel("人口")
ax.set_ylabel("年齢階級 (5 歳)")
ax.set_title(f"広島県 全域 人口ピラミッド (R2国勢調査, n={JINKO_TOTAL:,}人, "
f"{N_CHOME:,}町丁)", fontsize=13)
# 4 群の境界線
for grp_name, age_starts in GROUP_BINS.items():
if not age_starts:
continue
last_idx = AGE_5YR_BINS.index(age_starts[-1])
if last_idx + 1 < len(AGE_5YR_LABELS):
ax.axhline(last_idx + 0.5, color="#666", linestyle=":", alpha=0.5)
# 凡例
ax.legend(loc="lower right", fontsize=11)
ax.axvline(0, color="#000", linewidth=0.5)
ax.grid(axis="x", alpha=0.3)
plt.tight_layout()
plt.savefig(ASSETS / "L22_fig01_pyramid_full.png", dpi=130)
plt.close("all")
print(f" Fig 1 完成 ({time.time()-t1:.2f}s)", flush=True)
# --- Fig 2: 4 群構成 — 市町別 stack bar (件数降順) ---
fig, ax = plt.subplots(figsize=(13, 9))
order_pop = city_agg.sort_values("pop_total", ascending=True)["city"].tolist()
cg = city_groups.reindex(order_pop)
totals = cg["total"]
left = np.zeros(len(cg))
for grp_name, g_col in [("年少 (0-14)", "youth"),
("生産年齢 (15-64)", "working"),
("前期高齢 (65-74)", "early_old"),
("後期高齢 (75+)", "late_old")]:
vals = cg[g_col] / totals * 100
ax.barh(cg.index, vals, left=left, color=GROUP_COLOR[grp_name],
edgecolor="white", linewidth=0.5, label=grp_name)
# ラベル (>5% のみ)
for i, (b, v) in enumerate(zip(left, vals)):
if v >= 5:
ax.text(b + v / 2, i, f"{v:.1f}", ha="center", va="center",
color="white", fontsize=9, fontweight="bold")
left += vals
ax.set_xlabel("構成比 (%)")
ax.set_xlim(0, 100)
ax.set_title("市町別 4 群構成 (人口降順) — 年少 / 生産年齢 / 前期高齢 / 後期高齢",
fontsize=13)
ax.legend(loc="lower right", fontsize=10, ncol=2, framealpha=0.95)
plt.tight_layout()
plt.savefig(ASSETS / "L22_fig02_groups_stack.png", dpi=130)
plt.close("all")
print(f" Fig 2 完成 ({time.time()-t1:.2f}s)", flush=True)
# --- Fig 3: 市町別 5 歳階級ピラミッド small multiples (4x5 = 20) ---
fig, axes = plt.subplots(4, 5, figsize=(18, 16))
xmax_city = max(m_pyramid.values.max(), f_pyramid.values.max())
for ax_, city in zip(axes.flat, CITY_ORDER):
m_v = m_pyramid.loc[city].values
f_v = f_pyramid.loc[city].values
ax_.barh(y_pos, -m_v, color="#1f77b4", edgecolor="white", linewidth=0.3)
ax_.barh(y_pos, f_v, color="#cf222e", edgecolor="white", linewidth=0.3)
ax_.set_yticks([0, 6, 12, 18])
ax_.set_yticklabels(["0-4", "30-34", "60-64", "90-94"], fontsize=8)
ax_.axvline(0, color="#000", linewidth=0.4)
pop_total = m_v.sum() + f_v.sum()
ar = city_agg[city_agg["city"] == city]["aging_rate"].iloc[0]
yr = city_agg[city_agg["city"] == city]["youth_rate"].iloc[0]
ax_.set_title(f"{city} n={pop_total:,}\n"
f"高齢化率 {ar:.1f}% / 年少率 {yr:.1f}%",
fontsize=10)
# 全市町で同じ x 軸スケールにする (相対形状の比較を可能に)
ax_.set_xlim(-xmax_city * 1.05, xmax_city * 1.05)
ax_.set_xticks([])
plt.suptitle("市町別 人口ピラミッド small multiples (5 歳階級, 男女, 同一スケール)",
fontsize=14, y=1.00)
plt.tight_layout()
plt.savefig(ASSETS / "L22_fig03_pyramid_small_multiples.png", dpi=120)
plt.close("all")
print(f" Fig 3 完成 ({time.time()-t1:.2f}s)", flush=True)
# --- Fig 4: 高齢化率 choropleth (町丁単位, 全県) ---
fig, ax = plt.subplots(figsize=(13, 9))
admin_diss.boundary.plot(ax=ax, color="#444", linewidth=0.4)
# 人口 0 町丁 (グレー) と人口あり町丁を分けて描画
empty = pop[pop["is_empty"]]
filled = pop[~pop["is_empty"]]
empty.plot(ax=ax, facecolor="#dddddd", edgecolor="#aaaaaa", linewidth=0.05)
filled.plot(ax=ax, column="aging_rate", cmap="RdYlBu_r",
vmin=0.1, vmax=0.7,
edgecolor="#777777", linewidth=0.05, legend=False)
admin_diss.boundary.plot(ax=ax, color="#222", linewidth=0.5)
ax.set_aspect("equal")
ax.set_title(f"町丁単位 高齢化率 (65+/総人口) — 全県 {N_CHOME:,}町丁",
fontsize=13)
sm = plt.cm.ScalarMappable(cmap="RdYlBu_r", norm=Normalize(0.1, 0.7))
cb = plt.colorbar(sm, ax=ax, fraction=0.03, pad=0.02)
cb.set_label("高齢化率 (0.1=10% 〜 0.7=70%)")
ax.set_xticks([]); ax.set_yticks([])
plt.tight_layout()
plt.savefig(ASSETS / "L22_fig04_aging_choropleth.png", dpi=130)
plt.close("all")
print(f" Fig 4 完成 ({time.time()-t1:.2f}s)", flush=True)
# --- Fig 5: 人口密度 choropleth (log scale, 町丁単位) ---
fig, ax = plt.subplots(figsize=(13, 9))
admin_diss.boundary.plot(ax=ax, color="#444", linewidth=0.4)
# log 密度 (0 は除外、density は km^2 単位)
filled_d = filled[filled["density_per_km2"] > 0].copy()
# clip (極小と極大)
filled_d["log_density"] = np.log10(filled_d["density_per_km2"].clip(0.1, 1e5))
empty.plot(ax=ax, facecolor="#dddddd", edgecolor="#aaaaaa", linewidth=0.05)
filled_d.plot(ax=ax, column="log_density", cmap="viridis",
vmin=-1, vmax=4.5, edgecolor="#777777", linewidth=0.05)
admin_diss.boundary.plot(ax=ax, color="#222", linewidth=0.5)
ax.set_aspect("equal")
ax.set_title(f"町丁単位 人口密度 (log10 人/km²) — 全県",
fontsize=13)
sm = plt.cm.ScalarMappable(cmap="viridis", norm=Normalize(-1, 4.5))
cb = plt.colorbar(sm, ax=ax, fraction=0.03, pad=0.02)
cb.set_label("log10 人口密度 (-1=0.1人/km², 4=1万人/km²)")
ax.set_xticks([]); ax.set_yticks([])
plt.tight_layout()
plt.savefig(ASSETS / "L22_fig05_density_choropleth.png", dpi=130)
plt.close("all")
print(f" Fig 5 完成 ({time.time()-t1:.2f}s)", flush=True)
# --- Fig 6: 市町別 高齢化率の町丁分布 (boxplot) ---
fig, ax = plt.subplots(figsize=(14, 9))
order_age = city_agg.sort_values("aging_rate", ascending=True)["city"].tolist()
data_box = [pop_rel[pop_rel["src_city"] == c]["aging_rate"].values * 100
for c in order_age]
bp = ax.boxplot(data_box, vert=False, tick_labels=order_age,
showfliers=True,
flierprops={"marker": ".", "markersize": 2,
"markerfacecolor": "#888"},
patch_artist=True)
ctype_map = dict(zip(city_agg["city"], city_agg["ctype"]))
for patch, c in zip(bp["boxes"], order_age):
patch.set_facecolor(CTYPE_COLOR[ctype_map[c]])
patch.set_alpha(0.6)
# 全県平均ラインを赤破線
overall_ar = (pop["early_old"].sum() + pop["late_old"].sum()) / JINKO_TOTAL * 100
ax.axvline(overall_ar, color="red", linestyle="--", linewidth=1.5,
label=f"全県平均 {overall_ar:.1f}%")
ax.set_xlabel("町丁単位 高齢化率 (%)")
ax.set_title("市町別 町丁単位 高齢化率分布 (信頼可 = 人口≥30, 都市タイプ色)",
fontsize=13)
ax.legend()
ax.grid(axis="x", alpha=0.3)
handles = [Patch(facecolor=v, label=k, alpha=0.6) for k, v in CTYPE_COLOR.items()]
ax.legend(handles=[ax.get_legend().legend_handles[0]] + handles,
loc="lower right", fontsize=8)
plt.tight_layout()
plt.savefig(ASSETS / "L22_fig06_aging_box.png", dpi=130)
plt.close("all")
print(f" Fig 6 完成 ({time.time()-t1:.2f}s)", flush=True)
# --- Fig 7: 性比 choropleth (信頼可町丁のみ) ---
fig, ax = plt.subplots(figsize=(13, 9))
admin_diss.boundary.plot(ax=ax, color="#444", linewidth=0.4)
# 人口 >= 30 を信頼可に
unrel = pop[pop["JINKO_SU"] < RELIABLE_THRESHOLD]
rel_g = pop[pop["JINKO_SU"] >= RELIABLE_THRESHOLD].copy()
unrel.plot(ax=ax, facecolor="#dddddd", edgecolor="#aaaaaa", linewidth=0.05)
# 性比は 80-120 にクリップ (外れ値抑制)
rel_g["sr_clip"] = rel_g["sex_ratio"].clip(80, 120)
rel_g.plot(ax=ax, column="sr_clip", cmap="RdBu_r",
vmin=80, vmax=120, edgecolor="#777", linewidth=0.05)
admin_diss.boundary.plot(ax=ax, color="#222", linewidth=0.5)
ax.set_aspect("equal")
ax.set_title("町丁単位 性比 M/F×100 (信頼可 ≥30人、80-120にクリップ)",
fontsize=13)
sm = plt.cm.ScalarMappable(cmap="RdBu_r", norm=Normalize(80, 120))
cb = plt.colorbar(sm, ax=ax, fraction=0.03, pad=0.02)
cb.set_label("性比 (100=均衡, <100=女性多, >100=男性多)")
ax.set_xticks([]); ax.set_yticks([])
plt.tight_layout()
plt.savefig(ASSETS / "L22_fig07_sex_ratio.png", dpi=130)
plt.close("all")
print(f" Fig 7 完成 ({time.time()-t1:.2f}s)", flush=True)
# --- Fig 8: 若年集中マップ (40歳未満比率, 信頼可町丁) ---
fig, ax = plt.subplots(figsize=(13, 9))
admin_diss.boundary.plot(ax=ax, color="#444", linewidth=0.4)
# 40歳未満比率: pop_rel に追加済 (young40_share)
unrel.plot(ax=ax, facecolor="#dddddd", edgecolor="#aaaaaa", linewidth=0.05)
pop_rel.plot(ax=ax, column="young40_share", cmap="YlGn",
vmin=0.20, vmax=0.65, edgecolor="#777", linewidth=0.05)
admin_diss.boundary.plot(ax=ax, color="#222", linewidth=0.5)
ax.set_aspect("equal")
ax.set_title("町丁単位 40歳未満人口比率 (信頼可 ≥30人) — 若年集中スポット",
fontsize=13)
sm = plt.cm.ScalarMappable(cmap="YlGn", norm=Normalize(0.20, 0.65))
cb = plt.colorbar(sm, ax=ax, fraction=0.03, pad=0.02)
cb.set_label("0-39歳 / 総人口 (0.2=20% 〜 0.65=65%)")
# top 5 ラベル (元の DataFrame のインデックスから直接 geometry を取得)
for idx, r in top_young.head(5).iterrows():
geom = pop_rel.loc[idx, "geometry"]
ctr = geom.centroid
tn1 = r['TOWN_NAME1'] or ''
tn2 = r['TOWN_NAME2'] or ''
label = f"{tn1}{tn2}\n{r['young40_pct']:.1f}%"
ax.annotate(label, (ctr.x, ctr.y),
fontsize=8, color="#222",
xytext=(8, 8), textcoords="offset points",
bbox=dict(boxstyle="round,pad=0.2", fc="white",
ec="#888", alpha=0.85))
ax.set_xticks([]); ax.set_yticks([])
plt.tight_layout()
plt.savefig(ASSETS / "L22_fig08_youth_choropleth.png", dpi=130)
plt.close("all")
print(f" Fig 8 完成 ({time.time()-t1:.2f}s)", flush=True)
# --- Fig 9: 後期高齢化率 vs 高齢化率 散布 + 市町別色 ---
fig, axes = plt.subplots(1, 2, figsize=(16, 8))
ax0 = axes[0]
ctype_palette = {ct: CTYPE_COLOR[ct] for ct in CTYPE_COLOR}
for ct, col in ctype_palette.items():
sub = city_agg[city_agg["ctype"] == ct]
ax0.scatter(sub["aging_rate"], sub["late_rate"],
c=col, s=120, alpha=0.85, edgecolor="#222", linewidth=0.5,
label=ct)
for _, r in sub.iterrows():
ax0.annotate(r["city"], (r["aging_rate"], r["late_rate"]),
fontsize=9, xytext=(5, 4),
textcoords="offset points")
# 同率線 (75+ が高齢全体の半分)
xx = np.linspace(15, 50, 50)
ax0.plot(xx, xx * 0.5, color="#888", linestyle="--", alpha=0.6,
label="後期 = 高齢×0.5")
ax0.set_xlabel("高齢化率 (65+/総人口, %)")
ax0.set_ylabel("後期高齢化率 (75+/総人口, %)")
ax0.set_title("市町別: 高齢化率 × 後期高齢化率 (都市タイプ色)",
fontsize=12)
ax0.legend(loc="lower right", fontsize=9)
ax0.grid(alpha=0.3)
# 右: 高齢化率 vs 年少率 散布
ax1 = axes[1]
for ct, col in ctype_palette.items():
sub = city_agg[city_agg["ctype"] == ct]
ax1.scatter(sub["aging_rate"], sub["youth_rate"],
c=col, s=120, alpha=0.85, edgecolor="#222", linewidth=0.5,
label=ct)
for _, r in sub.iterrows():
ax1.annotate(r["city"], (r["aging_rate"], r["youth_rate"]),
fontsize=9, xytext=(5, 4),
textcoords="offset points")
ax1.set_xlabel("高齢化率 (65+/総人口, %)")
ax1.set_ylabel("年少率 (0-14/総人口, %)")
ax1.set_title("市町別: 高齢化率 × 年少率 — 反相関の検証",
fontsize=12)
ax1.grid(alpha=0.3)
ax1.legend(loc="upper right", fontsize=9)
plt.tight_layout()
plt.savefig(ASSETS / "L22_fig09_aging_scatter.png", dpi=130)
plt.close("all")
print(f" Fig 9 完成 ({time.time()-t1:.2f}s)", flush=True)
# --- Fig 10: 都市部 vs 中山間 ピラミッド (上位3 政令/中核 vs 中山間町) ---
fig, axes = plt.subplots(1, 2, figsize=(16, 9))
URBAN = ["広島市", "福山市", "東広島市"]
RURAL = ["庄原市", "北広島町", "世羅町", "安芸高田市"]
m_urban = pop[pop["src_city"].isin(URBAN)][M_AGE_COLS].sum()
f_urban = pop[pop["src_city"].isin(URBAN)][F_AGE_COLS].sum()
m_rural = pop[pop["src_city"].isin(RURAL)][M_AGE_COLS].sum()
f_rural = pop[pop["src_city"].isin(RURAL)][F_AGE_COLS].sum()
# 比率にして同スケールで比較
def to_pct(m, f):
t = m.sum() + f.sum()
return (m / t * 100).values, (f / t * 100).values
m_u_p, f_u_p = to_pct(m_urban, f_urban)
m_r_p, f_r_p = to_pct(m_rural, f_rural)
axes[0].barh(y_pos, -m_u_p, color="#1f77b4", edgecolor="white",
label=f"男性 ({m_urban.sum():,})")
axes[0].barh(y_pos, f_u_p, color="#cf222e", edgecolor="white",
label=f"女性 ({f_urban.sum():,})")
axes[0].set_yticks(y_pos)
axes[0].set_yticklabels(AGE_5YR_LABELS, fontsize=9)
axes[0].axvline(0, color="#000", linewidth=0.5)
axes[0].set_title(f"都市部 (広島市+福山市+東広島市)\n総人口 "
f"{m_urban.sum() + f_urban.sum():,}", fontsize=12)
axes[0].set_xlabel("構成比 (%)")
axes[0].grid(axis="x", alpha=0.3)
axes[0].legend(loc="lower right", fontsize=10)
axes[1].barh(y_pos, -m_r_p, color="#1f77b4", edgecolor="white",
label=f"男性 ({m_rural.sum():,})")
axes[1].barh(y_pos, f_r_p, color="#cf222e", edgecolor="white",
label=f"女性 ({f_rural.sum():,})")
axes[1].set_yticks(y_pos)
axes[1].set_yticklabels(AGE_5YR_LABELS, fontsize=9)
axes[1].axvline(0, color="#000", linewidth=0.5)
axes[1].set_title(f"中山間 (庄原市+北広島町+世羅町+安芸高田市)\n総人口 "
f"{m_rural.sum() + f_rural.sum():,}", fontsize=12)
axes[1].set_xlabel("構成比 (%)")
axes[1].grid(axis="x", alpha=0.3)
axes[1].legend(loc="lower right", fontsize=10)
# 同じ x スケールに揃える (構成比だから比較可能)
xmax_p = max(np.abs([m_u_p, f_u_p, m_r_p, f_r_p]).max(), 1.0) * 1.1
axes[0].set_xlim(-xmax_p, xmax_p)
axes[1].set_xlim(-xmax_p, xmax_p)
plt.suptitle("都市部 vs 中山間 — 構成比ピラミッド (相対形状で比較)",
fontsize=14)
plt.tight_layout()
plt.savefig(ASSETS / "L22_fig10_urban_rural.png", dpi=130)
plt.close("all")
print(f" Fig 10 完成 ({time.time()-t1:.2f}s)", flush=True)
# --- Fig 11: 100歳以上 分布マップ + 市町ランキング ---
fig, axes = plt.subplots(1, 2, figsize=(16, 8))
# 左: 100歳以上 件数 choropleth (市町単位)
ax0 = axes[0]
city_cent = admin_diss.merge(
city_agg[["city", "centenarian", "centenarian_per_10k", "pop_total"]],
on="city", how="left")
city_cent.plot(ax=ax0, column="centenarian", cmap="Reds",
edgecolor="#444", linewidth=0.5, legend=True,
legend_kwds={"shrink": 0.6, "label": "100歳以上の絶対数"})
for _, r in city_cent.iterrows():
ctr = r.geometry.representative_point()
ax0.annotate(f"{r['city']}\n{int(r['centenarian'])}",
(ctr.x, ctr.y), fontsize=8, ha="center",
bbox=dict(boxstyle="round,pad=0.2", fc="white",
alpha=0.7, ec="none"))
ax0.set_aspect("equal")
ax0.set_title("市町単位 100歳以上 絶対数 (M_100+F_100)", fontsize=12)
ax0.set_xticks([]); ax0.set_yticks([])
# 右: 100歳以上 人口比 (per 10,000)
ax1 = axes[1]
order_cent = city_agg.sort_values("centenarian_per_10k", ascending=True)
colors_c = [CTYPE_COLOR[ct] for ct in order_cent["ctype"]]
ax1.barh(order_cent["city"], order_cent["centenarian_per_10k"],
color=colors_c, edgecolor="white")
for i, v in enumerate(order_cent["centenarian_per_10k"]):
ax1.text(v + 0.4, i, f"{v:.1f}", va="center", fontsize=9)
overall_cent = pop["centenarian"].sum() / JINKO_TOTAL * 10000
ax1.axvline(overall_cent, color="red", linestyle="--",
label=f"全県平均 {overall_cent:.1f}")
ax1.set_xlabel("人口1万人あたり 100歳以上人口")
ax1.set_title(f"市町別 100歳以上 人口比 (全県平均={overall_cent:.1f})",
fontsize=12)
ax1.legend()
plt.tight_layout()
plt.savefig(ASSETS / "L22_fig11_centenarian.png", dpi=130)
plt.close("all")
print(f" Fig 11 完成 ({time.time()-t1:.2f}s)", flush=True)
print(f"\n[6] 図 11 枚 完了 累計 {time.time()-t0:.2f}s", flush=True)
# =============================================================================
# 7. 仮説検証
# =============================================================================
print("\n[7] 仮説検証", flush=True)
t1 = time.time()
# H1: ピラミッド形状 — 団塊 (70-74) と 団塊ジュニア (45-49) の二峰
m_70_74 = int(pop["M_70"].sum())
f_70_74 = int(pop["F_70"].sum())
m_45_49 = int(pop["M_45"].sum())
f_45_49 = int(pop["F_45"].sum())
m_0_4 = int(pop["M_00"].sum())
f_0_4 = int(pop["F_00"].sum())
boomer_total = m_70_74 + f_70_74
junior_total = m_45_49 + f_45_49
youngest_total = m_0_4 + f_0_4
H1_judge = "支持" if (boomer_total > youngest_total * 1.5
and junior_total > youngest_total * 1.5) \
else "部分支持"
# H2: 高齢化率 市町間格差
ar_max = float(city_agg["aging_rate"].max())
ar_min = float(city_agg["aging_rate"].min())
ar_ratio = ar_max / max(ar_min, 0.01)
ar_max_city = city_agg.loc[city_agg["aging_rate"].idxmax(), "city"]
ar_min_city = city_agg.loc[city_agg["aging_rate"].idxmin(), "city"]
H2_judge = "支持" if ar_ratio >= 2.0 else "部分支持"
# H3: 高齢化率 町丁内格差 (市町ごとの max - min)
ar_chome_range = (chome_dist["aging_max"] - chome_dist["aging_min"]).max()
H3_judge = "支持" if ar_chome_range >= 30 else "部分支持"
# H4: 性比異常 (>110 が存在するか)
n_male_outlier = int((pop_rel["sex_ratio"] > 110).sum())
n_female_outlier = int((pop_rel["sex_ratio"] < 90).sum())
H4_judge = "支持" if n_male_outlier >= 5 else "部分支持"
# H5: 後期高齢化率の地理的偏在
late_max = float(city_agg["late_rate"].max())
late_min = float(city_agg["late_rate"].min())
late_max_city = city_agg.loc[city_agg["late_rate"].idxmax(), "city"]
H5_rural = late_max_city in ["庄原市", "北広島町", "世羅町", "安芸高田市",
"三次市", "江田島市"]
H5_judge = "支持" if H5_rural else "部分支持"
# H6: 100歳以上 絶対数 vs 人口比 の市町順位差
top1_cent_abs = city_agg.loc[city_agg["centenarian"].idxmax(), "city"]
top1_cent_per = city_agg.loc[city_agg["centenarian_per_10k"].idxmax(), "city"]
H6_judge = "支持" if top1_cent_abs != top1_cent_per else "部分支持"
H_RESULTS = {
"H1": {
"text": "全県ピラミッドは『団塊+団塊ジュニア』の二峰 + 若年細る『壺型』",
"result": f"団塊 (70-74): {boomer_total:,}, 団塊ジュニア (45-49): "
f"{junior_total:,}, 0-4歳: {youngest_total:,} "
f"(若年層は団塊の {youngest_total/boomer_total*100:.1f}%)",
"judge": H1_judge,
},
"H2": {
"text": "市町間 高齢化率の最大/最小 ≥ 2倍",
"result": f"max={ar_max_city} {ar_max:.1f}%, "
f"min={ar_min_city} {ar_min:.1f}%, ratio={ar_ratio:.2f}x",
"judge": H2_judge,
},
"H3": {
"text": "町丁単位の高齢化率は同市内で30%pt以上の格差",
"result": f"市町内 max-min の最大値 = {ar_chome_range:.1f}%pt",
"judge": H3_judge,
},
"H4": {
"text": "性比 >110 (男性集中) の異常町丁が 5件以上",
"result": f">110 男性異常 {n_male_outlier} 件, "
f"<90 女性異常 {n_female_outlier} 件 (信頼可={N_REL:,}町丁)",
"judge": H4_judge,
},
"H5": {
"text": "後期高齢化率トップは中山間市町",
"result": f"top={late_max_city} {late_max:.1f}%, "
f"min={ar_min_city if late_min == ar_min else 'N/A'} {late_min:.1f}%",
"judge": H5_judge,
},
"H6": {
"text": "100歳以上 絶対数top と 人口比top は別の市町",
"result": f"絶対数 top: {top1_cent_abs}, 人口比 top: {top1_cent_per}",
"judge": H6_judge,
},
}
(ASSETS / "L22_hypothesis_results.json").write_text(
json.dumps({"results": H_RESULTS,
"n_chome": N_CHOME,
"n_empty": N_EMPTY,
"n_reliable": N_REL,
"jinko_total": JINKO_TOTAL,
"overall_aging_rate_pct": float(overall_ar),
"overall_centenarian_per_10k": float(overall_cent),
"city_count": len(CITY_DEFS),
}, ensure_ascii=False, indent=2),
encoding="utf-8")
print(f" H1-H6 検証完了 ({time.time()-t1:.2f}s)", flush=True)
for k, v in H_RESULTS.items():
print(f" {k}: {v['judge']} -- {v['result']}")
# =============================================================================
# 8. HTML 構築
# =============================================================================
print("\n[8] HTML 構築", flush=True)
sections = []
# === セクション1: 学習目標と問い ===
ds_links_html = ", ".join(
f'#{d[0]}'
for d in CITY_DEFS
)
s1_html = f"""
本記事は、広島県インフラマネジメント基盤 DoBoX が公開する
「都市計画区域情報_性別年齢別人口」シリーズ 20 件
({ds_links_html})
を縦結合し、R2 国勢調査ベースで広島県内 20 市町の小地域 (町丁) {N_CHOME:,}件 ×
性別×5歳階級 人口データから、
人口ピラミッドの地理構造 ── 全県形状・市町別ピラミッド・町丁単位の高齢化と若年集中・
性比の異常スポット・100歳以上の地理 ── を分析する研究記事である。
町丁単位の人口ピラミッドは「社会の DNA」であり、
高齢化と若年集中の地理は政策の最前線である。
研究の問い (RQ): 広島県内 {N_CHOME:,}町丁における人口ピラミッドは、
市町別・地域別にどのような構造を持ち、
高齢化と若年集中はどう地理的に分布しているか?
町丁単位の高齢化率・性比・年少率は、
社会人口学的にどのような『地理的指紋』を残すか?
仮説 H1〜H6
- H1: 広島県全域のピラミッドは中央が膨らむ「壺型」を示す。
団塊世代 (70-74歳) と団塊ジュニア (45-49歳) が二峰、
若年層 (0-4歳) は薄く先細る『超少子高齢社会のピラミッド』。
- H2: 高齢化率 (65+/総人口) は市町間で 2 倍以上の格差。
都市部 (広島市・福山市) が低く、中山間 (庄原市・北広島町・世羅町) が高い。
- H3: 高齢化率は町丁単位ではさらに激しく分布し、
同じ市内でも 30%pt 以上の格差がある。
単純な市町平均では捉えきれない「局地高齢化」が存在する。
- H4: 性比 (M/F×100) は典型的には 90-95 だが、
大学・基地・工業団地周辺の町丁では 110+ の男性集中スポットが出現する。
- H5: 後期高齢化率 (75+/総人口) のトップは
都市部の住宅地ではなく中山間市町に偏在する。
- H6: 100歳以上の絶対数top と 人口比top は別の市町。
絶対数は人口大都市が多いが、人口比では中山間が上位に来る。
独自用語の定義 (本レッスン内のみ)
- 町丁: 国勢調査の小地域単位。「広島市中区光南三丁目」のような
町・字レベルのポリゴン。本記事の主分析単位。
DoBoX のデータでは
SMALL_A_CD+TOWN_NAME1+TOWN_NAME2
で識別される。
- JINKO_SU: 町丁の総人口 (R2 国勢調査ベース、男女合算)。
0 の町丁が {N_EMPTY:,} 件あり、これは「秘匿処理」または「実無人」の可能性。
本記事は除外せず観察対象とし、地図でグレー表示する。
- M_SU / F_SU: 男性総数 / 女性総数。
JINKO_SU = M_SU + F_SU が原則 (本データで完全一致)。
- M_00 〜 M_100, F_00 〜 F_100: 5 歳階級 (0-4, 5-9, ..., 95-99, 100以上) の
性別人口。21 階級 × 男女 = 42 列。5 歳階級が国勢調査の標準粒度。
- M_999 / F_999: 年齢不詳の人数。
多くの町丁で 0 だが、{N_HAS_UNKNOWN:,}件で >0。
秘匿処理の結果か、住民票上の不詳記入かは仕様書未公開。
- 4 群集約 (本記事独自): 5 歳階級を以下の 4 群に集約。
- 年少 (0-14) = M_00, M_05, M_10 + F_00, F_05, F_10
- 生産年齢 (15-64) = M_15..M_60 + F_15..F_60 (10 階級)
- 前期高齢 (65-74) = M_65, M_70 + F_65, F_70
- 後期高齢 (75+) = M_75..M_100 + F_75..F_100 (6 階級)
総務省統計局・厚労省の標準区分を踏襲。
- 高齢化率:
(early_old + late_old) / JINKO_SU = 65歳以上 / 総人口。
WHO の「高齢化社会 7%」「高齢社会 14%」「超高齢社会 21%」の基準を超えるかを判定。
- 後期高齢化率:
late_old / JINKO_SU = 75歳以上 / 総人口。
医療・介護需要を直接反映する指標。
- 年少率:
youth / JINKO_SU = 14歳以下 / 総人口。
子育て世代の集中度を反映する指標。
- 性比:
M_SU / F_SU × 100。100 が均衡、
<100 で女性多、>100 で男性多。
日本平均は 95 前後。極端に外れる町丁は男女比に偏りを生む施設
(大学・基地・工場・刑務所等) の存在を示唆する。
- 従属人口指数:
(youth + early_old + late_old) / working × 100。
働き手 100 人が支える非生産年齢人口を表す。
数値が大きいほど社会的負担が重い。
- 40歳未満比率 (本記事独自): 0-4 〜 35-39 歳の合計を総人口で割った値。
「若年集中スポット」を同定するための指標。
大学キャンパス・新興住宅地・自衛隊基地等で高くなる。
- 信頼可町丁: 人口 ≥ {RELIABLE_THRESHOLD} 人の町丁。
これ未満は分母が小さすぎて率が暴れるため、
箱ひげ・性比・若年率の分析では除外する。
全体 {N_CHOME:,} 中 {N_REL:,} 件 ({N_REL/N_CHOME*100:.1f}%) が信頼可。
到達点
- 20 市町の GeoJSON ZIP を 1 個の
GeoDataFrame
({N_CHOME:,} 行 × 61 列) に縦結合できる。
列構造の 1 件だけある追加列 (庄原市の Shape_Area, Shape_Leng)
の処理パターンを身に付ける。
- 5 歳階級 21 列 × 男女 = 42 列を 4 群 (年少/生産/前期高齢/後期高齢)
に集約する
sum(axis=1) パターンを学ぶ。
- 町丁単位の高齢化率・後期高齢化率・年少率・性比・従属人口指数
を計算し、市町間・町丁間の格差を定量する。
- 町丁ポリゴンを
geopandas.plot(column=...) で
choropleth (主題図) 化し、
高齢化と若年集中の地理を視覚化する。
- 市町別 20 panel 人口ピラミッド small multiples
で「市町ごとのピラミッド形状」を一目で比較する。
- 性比異常・100歳以上集中・若年集中の外れ値町丁を同定し、
その背景 (大学・基地・住宅団地) を考察する。
- 都市部 vs 中山間の構成比ピラミッドを作り、
「日本社会の二極構造」を地理的に検証する。
本記事のスコープ宣言
本記事は性別年齢別人口シリーズ 20 件のみを主データとする研究記事である。
L15 行政区域 20 件は市町別空間集計の境界として参照するが、
L23 (DID 地区境界、次記事で予定) との合体は行わない (要件 I 違反の水増し回避)。
DID 内/外の人口構造比較は発展課題に留める。
ただし都市計画区域コード KUIKI_CD による
「市街化区域 vs 調整区域」の人口構造差異は、本データ内で完結するため分析に含める。
"""
sections.append(("1. 学習目標と問い", s1_html))
# === セクション2: 使用データ ===
DS_TABLE_ROWS = "".join(
f"| #{d[0]} | {d[1]} | {d[3]} | "
f""
f"DoBoX | "
f"{next(L['n_chome'] for L in load_log if L['city']==d[1]):,} | "
f"{next(L['jinko_total'] for L in load_log if L['city']==d[1]):,} | "
f"{next(L['extra_cols'] for L in load_log if L['city']==d[1])} | "
f"
"
for d in CITY_DEFS
)
s2_html = f"""
性別年齢別人口 20 件はそれぞれ 1 市町分の 町丁単位 GeoJSON (MultiPolygon)
を ZIP で配布している。列構造は 20 件で 100% 一致 (61 列) ─
ただし 庄原市のみ Shape_Area, Shape_Leng の 2 列が追加で計 63 列となる
(値はすべて 0 で意味なし、共通 61 列に正規化して読み込む)。
20 dataset_id 一覧
| dataset_id | 市町 | 市町タイプ | DoBoX |
町丁数 | 人口総数 | 追加列 |
|---|
{DS_TABLE_ROWS}
合計: {N_CHOME:,} 町丁 / 人口総数 {JINKO_TOTAL:,} 人
(R2 国勢調査ベースの広島県人口は約 280 万人、本データは 20 市町合算で {JINKO_TOTAL/2780000*100:.1f}%
カバー)。
列構造の詳細 (61 列)
61 列は以下の 4 グループに分類できる。
(a) メタ列 (11 列)
| 列名 | 型 | 意味 |
|---|
TOKEI_CD | int32 |
統計区分コード。本データでは 0 が大半 |
KUIKI_CD | int32 |
都市計画区域コード (1=市街化, 3=市街化調整, 5=都計外 等と推定)。
本記事の区域別人口構造分析に使用 |
SMALL_A_CD | object |
小地域コード (12 桁)。前2桁=都道府県(34=広島)、次3桁=市区町村、
次4桁=町丁字、最後3桁=細目 |
AREA_CD | object |
地区番号 |
SECRET1-3 | object |
秘匿フラグ列 (3 列)。多くは null だが一部に値あり |
CITY_CD | int32 |
市区町村コード。広島市は 8 区を 101-108 で分割 |
CITY_NAME | object |
市区町村名 (「広島市中区」など、広島市は区名まで含む) |
TOWN_NAME1 | object |
町・字名 (例: 「光南」) |
TOWN_NAME2 | object |
丁目 (例: 「三丁目」)。null の町丁もあり |
(b) 集計列 (3 列)
| 列名 | 型 | 意味 |
|---|
JINKO_SU | int32 |
総人口 (= M_SU + F_SU)。{N_EMPTY:,} 件で 0 (秘匿か実無人) |
M_SU | int32 |
男性総数 (= M_00..M_100 + M_999 の合計) |
F_SU | int32 |
女性総数 (= F_00..F_100 + F_999 の合計) |
(c) 5 歳階級列 男女 (44 列)
男性: M_00, M_05, M_10, M_15, ..., M_95, M_100, M_999 (22 列)
女性: F_00, F_05, F_10, F_15, ..., F_95, F_100, F_999 (22 列)
M_xx = xx 歳〜 xx+4 歳の男性人口。例えば M_45 は 45-49 歳。
M_100 は 100歳以上、M_999 は年齢不詳。
全 22 列の合計が M_SU に一致する。
(d) その他 (3 列)
| 列名 | 型 | 意味 |
|---|
RITTEKI_CD | int32 |
立地コード。仕様書未公開、参考扱い |
BIKOU | object |
備考。本データでは全件 null (運用上未入力) |
geometry | MultiPolygon |
町丁ポリゴン。EPSG:6671 (JGD2011 平面直角第III系)。
本記事の主役データ。境界が複雑で MultiPolygon が多い |
データ品質ノート:
{N_EMPTY:,} 町丁 (全体の {N_EMPTY/N_CHOME*100:.1f}%) で人口=0。
大半は秘匿処理 (人口少数で個人特定リスクがあるため)、
一部は実無人 (山林・水面のみの行政区域)。
率指標 (高齢化率等) は分母 0 を避けるため clip(lower=1) で除算保護、
箱ひげ・分布分析では人口 ≥ {RELIABLE_THRESHOLD} 人の信頼可町丁 ({N_REL:,}件)のみ使用。
"""
sections.append(("2. 使用データ", s2_html))
# === セクション3: ダウンロード ===
dl_html = f"""
本記事の再現性を担保するため、HTML 1 枚から
生データ・中間 CSV・図 PNG・再現 Python を直リンクで取得できる。
(1) 生データ ZIP (DoBoX 直)
20 件の ZIP は前項の表からそれぞれ DoBoX へリンク。
あるいは一括取得スクリプト:
cd "2026 DoBoX 教材"
py -X utf8 data\\extras\\L22_population_pyramid\\fetch_population_pyramid.py
合計サイズ約 32 MB。監査時に取得済の 3 市町 (広島市・呉市・福山市) は
data/extras/_urban_planning_audit/ から自動コピー、
残り 17 市町は DoBoX から HTTP 取得 (約 30 秒)。
(2) 中間 CSV (本スクリプトの出力)
(3) 図 PNG (本記事掲載 11 枚)
(4) 再現用 Python スクリプト
実行は cd "2026 DoBoX 教材"; py -X utf8 lessons\\L22_population_pyramid.py。
20 ZIP がローカルにあれば 1 分以内で全図 + CSV 再生成 (要件 S 準拠)。
"""
sections.append(("3. ダウンロード (再現用データ・中間データ・図・スクリプト)", dl_html))
# === セクション4: 分析1 — 統合読み込み + 4群集約 ===
code_load = code('''
DATA_DIR = ROOT / "data" / "extras" / "L22_population_pyramid"
TARGET_CRS = "EPSG:6671"
# 共通 61 列 (全市町に存在)。庄原市のみ Shape_Area, Shape_Leng が追加 (値=0) なので
# 共通 61 列に正規化することで、全市町を 1 個の DataFrame に揃える。
COMMON_COLS_61 = ['JINKO_SU', 'M_SU', 'F_SU',
'M_00', 'M_05', ..., 'M_100', 'M_999',
'F_00', 'F_05', ..., 'F_100', 'F_999',
'TOKEI_CD', 'KUIKI_CD', ..., 'geometry'] # 計 61 列
frames = []
for dsid, name, _adm, ctype in CITY_DEFS:
z = DATA_DIR / f"jinko_{dsid}_{name}.zip"
g = load_geojson_zip(z)
g = g[COMMON_COLS_61].copy() # 列正規化
g["src_city"] = name
g["src_dsid"] = dsid
g["ctype"] = ctype
frames.append(g)
# 縦結合 → 1 個の GeoDataFrame
pop = gpd.GeoDataFrame(pd.concat(frames, ignore_index=True),
geometry="geometry", crs=frames[0].crs)
pop = pop.to_crs(TARGET_CRS)
# 11,588 行 × 64 列 (61 共通 + src_city + src_dsid + ctype)
# 4 群集約 — 5 歳階級 21 列を 4 列にまとめる
def sum_age_cols(df, sex_prefix, age_starts):
cols = [f"{sex_prefix}_{a:02d}" for a in age_starts]
return df[cols].sum(axis=1)
GROUP_BINS = {
"youth": [0, 5, 10], # 0-14 歳
"working": [15, 20, 25, 30, 35, 40, 45, 50, 55, 60], # 15-64 歳
"early_old": [65, 70], # 65-74 歳
"late_old": [75, 80, 85, 90, 95, 100], # 75 歳以上
}
for grp, starts in GROUP_BINS.items():
pop[grp] = sum_age_cols(pop, "M", starts) + sum_age_cols(pop, "F", starts)
''')
# Before/After 表
before_after_s4 = f"""
入出力 Before/After (具体例: 1 町丁の年齢階級が 4 群に集約される)
| 段階 | 列名 | このデータで何が起きるか | 1 行の値の例 |
|---|
| 入力 | M_00, M_05, ..., M_100, M_999 (22 列) |
町丁の男性 5 歳階級人口 (素データ) |
[20, 25, 18, 12, ..., 1, 0] |
| 入力 | F_00, F_05, ..., F_100, F_999 (22 列) |
町丁の女性 5 歳階級人口 |
[19, 21, 17, 14, ..., 5, 0] |
| 集約 | youth = M_00+M_05+M_10 + F_00+F_05+F_10 |
0-14 歳人口 |
120 (人) |
| 集約 | working = M_15..M_60 + F_15..F_60 (10 階級×2) |
15-64 歳人口 |
650 (人) |
| 集約 | early_old = M_65+M_70 + F_65+F_70 |
65-74 歳人口 |
180 (人) |
| 集約 | late_old = M_75..M_100 + F_75..F_100 (6 階級×2) |
75 歳以上人口 |
150 (人) |
| 派生 | aging_rate = (early_old + late_old) / JINKO_SU |
高齢化率 |
0.300 (= 30.0%) |
| 派生 | youth_rate = youth / JINKO_SU |
年少率 |
0.109 (= 10.9%) |
| 派生 | sex_ratio = M_SU / F_SU * 100 |
性比 |
96.5 (女性やや多) |
このように、22 + 22 = 44 列の生データから
意味ある 4 群指標 (youth/working/early_old/late_old) + 各種率を導出する。
4 群集約は教材として「列演算で大量列を圧縮する」典型例。
"""
n_loaded = len(load_log)
n_extra_cols_city = sum(1 for L in load_log if L["extra_cols"] != "-")
s4_html = (
"狙い
"
"20 ZIP の GeoJSON を 1 個の GeoDataFrame ({:,} 行 × 64 列) "
"に統合し、5 歳階級 44 列を 4 群集約することで、"
"後段の高齢化率・年少率・性比などの意味ある率指標を導出する。
".format(N_CHOME) +
"手法
"
"直感: ZIP を読む → 列を共通 61 列に揃える → 縦結合 → CRS 変換 → "
"5 歳階級を 4 群に集約 → 派生指標を計算。
"
"大筋 (5 ステップ)
"
""
"- 20 市町について
load_geojson_zip() で GeoDataFrame を読む "
"- 共通 61 列に正規化 (庄原市の追加 2 列 Shape_Area, Shape_Leng を捨てる)
"
"- 派生列
src_city / src_dsid / ctype を付与 "
"pd.concat で縦結合 → "
f"{N_CHOME:,} 行 1 個の GeoDataFrame- 5 歳階級 21 列 ×男女 = 42 列を 4 群 (youth/working/early_old/late_old) "
"に集約する
sum(axis=1) "
"to_crs(EPSG:6671) で広島県平面直角座標系に投影変換 (m 単位確保)
"
"前提と限界: 庄原市の Shape_Area・Shape_Leng は値=0 で意味なしだった。"
"ESRI 系ツールで生成された地理列の名残と推定 (実際の面積は geometry.area "
"から計算可能)。共通 61 列に揃えるのが正解だった。"
"もし将来意味のある追加列が出たら判定ロジックの追従修正が必要。
"
"実装
"
+ code_load + before_after_s4 +
f"結果
"
f"20 ZIP のうち、{n_loaded} 件すべてが共通 61 列で読み込み成功。"
f"庄原市のみ Shape_Area, Shape_Leng の 2 追加列があったが正規化処理で吸収。"
f"統合後の pop GeoDataFrame は {N_CHOME:,} 行 × 64 列"
f"(61 共通 + src_city + src_dsid + ctype)。"
f"4 群集約により、22+22 = 44 列の年齢階級データが "
f"4 列 (youth/working/early_old/late_old) + 派生指標 8 列 "
f"(aging_rate, late_rate, youth_rate, dep_index, sex_ratio, "
f"density_per_km2, centenarian, unknown) に圧縮された。"
f"処理時間は {time.time()-t0:.1f} 秒で要件 S を満たす。
"
f"表 1 — 20 市町読込ログ (主要列)
"
"| 市町 | タイプ | 町丁数 | "
"人口総数 | 追加列 |
|---|
"
+ "".join(f"| {L['city']} | {L['ctype']} | "
f"{L['n_chome']:,} | {L['jinko_total']:,} | "
f"{L['extra_cols']} |
"
for L in load_log) +
"
"
"この表から読み取れること: "
f"町丁数は広島市の 4,325 件が最多 ─ 政令市 8 区を全て含むため。"
f"次が呉市 (1,569)、福山市 (1,491)、東広島市 (778) と続く。"
f"中山間 (世羅町・安芸高田市・北広島町) は数十〜百程度の町丁で、"
f"人口規模と町丁数はおおむね一致する。"
f"庄原市のみ追加列 Shape_Area / Shape_Leng があるが値は 0で、"
f"データ生成過程の差異と推定される。
"
)
sections.append(("4. 分析1: 20 GeoJSON 統合 + 5歳階級44列を4群集約", s4_html))
# === セクション5: 分析2 — 全県人口ピラミッド ===
# 4 群構成比 全県
g_youth_pct = pop["youth"].sum() / JINKO_TOTAL * 100
g_work_pct = pop["working"].sum() / JINKO_TOTAL * 100
g_early_pct = pop["early_old"].sum() / JINKO_TOTAL * 100
g_late_pct = pop["late_old"].sum() / JINKO_TOTAL * 100
overall_aging = g_early_pct + g_late_pct
overall_youth = g_youth_pct
# 5 歳階級 top3 (男女合計, 不詳除く)
total_5yr = pyramid_full[pyramid_full["age_class"] != "不詳"].copy()
total_5yr["total_int"] = total_5yr["total"].astype(int)
top3_age = total_5yr.nlargest(3, "total_int")
top3_rows = "".join(
f"| {r['age_class']} | {int(r['male']):,} | "
f"{int(r['female']):,} | {int(r['total']):,} |
"
for _, r in top3_age.iterrows()
)
s5_html = (
"狙い
"
f"広島県全域の人口ピラミッド (5歳階級 21 階級 × 男女) を "
f"1 枚で描いて、「壺型かどうか」「団塊と団塊ジュニアの二峰があるか」"
f"を視覚的・定量的に検証する (仮説 H1)。
"
"手法
"
"直感: 男性を負方向、女性を正方向に水平棒グラフを並べる。"
"横軸 0 を中心線として、左右の伸びで男女比、縦の積み重ねで世代比が見える。
"
"計算ステップ
"
""
"- 町丁単位の M_00..M_100 を
sum(axis=0) で全県集計 → 21 値 "
"- 同様に F_00..F_100 を全県集計 → 21 値
"
"- 不詳 M_999, F_999 は別カウント (本図では除外、表で記載)
"
"plt.barh(y, -M) で男性を負側、plt.barh(y, F) で女性を正側- 4 群境界に水平点線を引いて視覚的に区切る
"
"
"
"限界: 5 歳階級は男性 95-99, 100+ のように高齢層で人数が急減し、"
"ピラミッド頂点は「ピンの先」のように細る。"
"そのため低齢層の凸部 (団塊・団塊ジュニア) が相対的に強調される。
"
"実装
"
+ code('''
# 全県 5 歳階級集計
M_AGE_COLS = [f"M_{b:02d}" for b in [0, 5, 10, ..., 100]] # 21 列
F_AGE_COLS = [f"F_{b:02d}" for b in [0, 5, 10, ..., 100]]
m_5yr = pop[M_AGE_COLS].sum() # 21 値
f_5yr = pop[F_AGE_COLS].sum()
# 双向ピラミッド
fig, ax = plt.subplots(figsize=(11, 9))
y_pos = np.arange(len(AGE_5YR_LABELS)) # 21 位置
ax.barh(y_pos, -m_5yr.values, color="#1f77b4", label="男性")
ax.barh(y_pos, f_5yr.values, color="#cf222e", label="女性")
# 軸ラベルを正値に (棒は負だが表示は正)
ax.set_xticklabels([f"{abs(int(v)):,}" for v in ax.get_xticks()])
ax.set_yticklabels(AGE_5YR_LABELS)
''') +
"図 1 — 広島県全域 人口ピラミッド (5歳階級)
"
"なぜこの図か: 単一の棒グラフでは年齢分布の形状全体が捉えにくい。"
"ピラミッド (双向横棒) は「人類普遍の人口可視化フォーマット」で、"
"中央の凸部 (団塊・団塊ジュニア) と頂点の収縮が視覚的に伝わる。
"
+ figure("assets/L22_fig01_pyramid_full.png",
"広島県 全域 人口ピラミッド (R2国勢調査ベース, 11,588町丁集計)") +
"この図から読み取れること
"
""
f"- 団塊世代 (70-74歳) が最大の凸部。M={int(pop['M_70'].sum()):,}, "
f"F={int(pop['F_70'].sum()):,}, 合計 {boomer_total:,} 人。"
f"全人口 ({JINKO_TOTAL:,}) の {boomer_total/JINKO_TOTAL*100:.1f}%。
"
f"- 団塊ジュニア (45-49歳) が第二の凸部。"
f"合計 {junior_total:,} 人 ({junior_total/JINKO_TOTAL*100:.1f}%)。"
"団塊世代の子供世代に相当。
"
f"- 0-4 歳はわずか {youngest_total:,} 人 ─ "
f"団塊世代の {youngest_total/boomer_total*100:.1f}%、"
f"団塊ジュニアの {youngest_total/junior_total*100:.1f}%。"
"少子高齢化の現実が一目で分かる。
"
"- ピラミッドは「壺型」 ─ 上部 (高齢) が膨らみ、下部 (若年) が細る "
"典型的な超少子高齢社会の形状。仮説 H1 を支持。
"
"- 女性 (赤) が高齢層 (75+) で男性 (青) より明らかに長い。"
"女性の長寿性が反映 (平均寿命 約 87.7 年 vs 81.6 年)。
"
"- 40-44 歳に小さな凹みが見える ─ 団塊ジュニアと現役働き盛りの間"
"の世代の薄さ ('1970年代前半の出生率変動' の影響)。
"
"
"
"表 2 — 5 歳階級 上位 3 (人口最多階級)
"
"| 年齢階級 | 男性 | 女性 | 合計 |
|---|
"
+ top3_rows + "
"
f"この表から読み取れること: "
f"上位 3 はすべて 70 歳台 + 団塊ジュニア前後で占められる。"
f"「広島県内で人数が最も多い世代は 70 歳台」 ─ "
f"これが 21 世紀の日本の人口学的現実。
"
"表 3 — 全県 4 群集計
"
""
"| 4 群 | 人口 | 構成比 |
|---|
"
f"| 年少 (0-14) | {int(pop['youth'].sum()):,} | "
f"{g_youth_pct:.2f}% |
"
f"| 生産年齢 (15-64) | {int(pop['working'].sum()):,} | "
f"{g_work_pct:.2f}% |
"
f"| 前期高齢 (65-74) | {int(pop['early_old'].sum()):,} | "
f"{g_early_pct:.2f}% |
"
f"| 後期高齢 (75+) | {int(pop['late_old'].sum()):,} | "
f"{g_late_pct:.2f}% |
"
f"| 不詳 | {int(pop['unknown'].sum()):,} | "
f"{pop['unknown'].sum()/JINKO_TOTAL*100:.3f}% |
"
f"| 高齢化率 (65+) | {int(pop['early_old'].sum()+pop['late_old'].sum()):,} | "
f"{overall_aging:.2f}% |
"
"
"
f"この表から読み取れること: "
f"全県高齢化率は {overall_aging:.1f}% ─ "
f"WHO の超高齢社会基準 21% を大きく超え、"
f"日本全体の R2 高齢化率 28.6% (内閣府 2020) と同水準かやや上。"
f"年少率は {overall_youth:.1f}% で、年少率 + 後期高齢化率を比較すると"
f"後期高齢者 ({g_late_pct:.1f}%) が年少者 ({g_youth_pct:.1f}%) を超えている "
f"─ 「14 歳以下より 75 歳以上が多い」社会。
"
)
sections.append(("5. 分析2: 広島県全域 人口ピラミッド + 4 群集計", s5_html))
# === セクション6: 分析3 — 市町別 4 群構成 + ピラミッド small multiples ===
# 4 群構成 表データ (主要市町)
city_groups_disp = city_groups.copy()
city_groups_disp["aging_rate"] = ((city_groups_disp["early_old"]
+ city_groups_disp["late_old"])
/ city_groups_disp["total"] * 100).round(2)
city_groups_disp = city_groups_disp.sort_values("aging_rate", ascending=False)
city_grp_rows = "".join(
f"| {c} | {int(r['total']):,} | "
f"{r['youth_pct']:.2f}% | "
f"{r['working_pct']:.2f}% | "
f"{r['early_old_pct']:.2f}% | "
f"{r['late_old_pct']:.2f}% | "
f"{r['aging_rate']:.2f}% |
"
for c, r in city_groups_disp.iterrows()
)
s6_html = (
"狙い
"
"市町ごとに人口ピラミッドの形状はどう違うか? "
"4 群構成比 (年少/生産/前期高齢/後期高齢) を市町別に並べ、"
"さらに 5 歳階級ピラミッドを 20 panel small multiples で並列比較する。"
"市町間格差 (仮説 H2) と、ピラミッド形状の地理的多様性を一目で見せる。
"
"手法
"
"(a) 4 群構成 stack bar: 市町ごとに 4 群比率を 100% 基準で stack。"
"色の比率の変化で都市↔中山間の構造差を伝える。"
"並び順は人口降順で「大都市から町まで」を見る。
"
"(b) 5 歳階級ピラミッド 20 panels: plt.subplots(4, 5) で 20 panel "
"を作り、各市町のピラミッドを同一スケールで描く。"
"同スケールにすることで「広島市の絶対規模 vs 世羅町の絶対規模」が直感的に伝わる "
"(構成比は別途 4 群 stack で比較済み)。
"
"実装
"
+ code('''
# 市町×4 群 集計
city_groups = pop.groupby("src_city")[
["youth", "working", "early_old", "late_old"]
].sum()
for g in ["youth", "working", "early_old", "late_old"]:
city_groups[g + "_pct"] = city_groups[g] / city_groups["total"] * 100
# Stack bar (人口降順)
order_pop = city_agg.sort_values("pop_total", ascending=True)["city"].tolist()
left = np.zeros(len(order_pop))
for grp_name, g_col in [("年少", "youth"), ("生産", "working"),
("前期高齢", "early_old"), ("後期高齢", "late_old")]:
vals = city_groups.reindex(order_pop)[g_col + "_pct"]
ax.barh(order_pop, vals, left=left, color=GROUP_COLOR[grp_name])
left += vals
# 20 panel small multiples — 同一スケール
m_pyramid = pop.groupby("src_city")[M_AGE_COLS].sum() # 20 行 × 21 列
f_pyramid = pop.groupby("src_city")[F_AGE_COLS].sum()
xmax_city = max(m_pyramid.values.max(), f_pyramid.values.max())
fig, axes = plt.subplots(4, 5, figsize=(18, 16))
for ax_, city in zip(axes.flat, CITY_ORDER):
ax_.barh(y_pos, -m_pyramid.loc[city], color="#1f77b4")
ax_.barh(y_pos, f_pyramid.loc[city], color="#cf222e")
ax_.set_xlim(-xmax_city, xmax_city) # 同スケール
''') +
"図 2 — 市町別 4 群構成 stack (人口降順)
"
"なぜこの図か: 4 群比率を市町間で絶対座標で揃えて並べると、"
"色の境界線の位置で「年少率」「高齢化率」が一目瞭然。"
"都市タイプ別の構造が浮き彫りになる。
"
+ figure("assets/L22_fig02_groups_stack.png",
"市町別 4 群構成 stack — 人口降順、年少 / 生産 / 前期高齢 / 後期高齢") +
"この図から読み取れること
"
""
f"- 広島市・福山市 は緑 (年少) + 青 (生産年齢) が長く、"
f"赤 (後期高齢) が短い ─ 典型的な都市の人口構造。"
f"高齢化率 {city_groups_disp.loc['広島市', 'aging_rate']:.1f}% / "
f"{city_groups_disp.loc['福山市', 'aging_rate']:.1f}%。
"
f"- 世羅町・庄原市・北広島町・安芸高田市 は赤 (後期高齢) が長く、"
f"後期高齢化率 25-30% に達する。"
f"「高齢者だけの町」ではないが、全人口の 1/4 が 75 歳以上。
"
"- 町 (府中町・海田町・坂町など) は都市近郊ベッドタウンで、"
"年少率が政令市並みに高い ─ 20-30 代世帯の流入を反映。
"
"- 東広島市 (大学都市) は生産年齢比率が広島市より高い: "
f"{city_groups_disp.loc['東広島市', 'working_pct']:.1f}% vs "
f"{city_groups_disp.loc['広島市', 'working_pct']:.1f}% ─ "
"学生・若年労働者の集中が示唆される。
"
"- 4 色の境界を結ぶ「色境界の傾き」が、市町タイプ階層と概ね一致。"
"都市階層 (政令市 → 中核市 → 市 → 町) と人口構造には強い対応関係がある。
"
"
"
"図 3 — 市町別 5 歳階級ピラミッド 20 panel small multiples
"
"なぜこの図か: 4 群構成 stack では分からない『世代別の凸凹』"
"を見るには、5 歳階級ピラミッドが必要。"
"20 panel を同一スケールで並べると、人口規模の絶対差と"
"形状の質的差が同時に見える。
"
+ figure("assets/L22_fig03_pyramid_small_multiples.png",
"市町別 人口ピラミッド small multiples (20 panels, 同一スケール)") +
"この図から読み取れること
"
""
"- 広島市 (左上) が圧倒的に大きい ─ 同一スケールでは他市町が"
"「点」のように見える。政令市の規模感を体感する効果がある。
"
"- 呉市・福山市 はピラミッドの形状が広島市と似るが規模が小さい。"
"都市階層を共通の形で再現している。
"
"- 中山間 (庄原・北広島・世羅・安芸高田) は形状が逆三角形 ─ "
"「壺型」を超えて「逆ピラミッド」になっている。"
"若年層が極端に細く、団塊が肥大。
"
"- 東広島市 は他都市と異なり、20-24 歳に強い凸がある ─ "
"広島大学のキャンパスがある自治体特有の『大学ピラミッド』。"
"若年集中スポットが複数町丁にわたる証拠。
"
"- 江田島市 は団塊 (70-74) が異様に膨らみ、若年が極端に薄い ─ "
"離島型の急速な高齢化パターン。
"
"- 町部 (府中町・海田町) はミニ広島市のような形 ─ ベッドタウン化が"
"都市的人口構造を町レベルに移植している。
"
"
"
"表 4 — 市町別 4 群構成 + 高齢化率 (高齢化率降順)
"
"| 市町 | 総人口 | 年少% | "
"生産% | 前期高齢% | 後期高齢% | "
"高齢化率 |
|---|
" + city_grp_rows + "
"
"この表から読み取れること: "
f"高齢化率トップは {city_groups_disp.index[0]} {city_groups_disp.iloc[0]['aging_rate']:.1f}%、"
f"最低は {city_groups_disp.index[-1]} {city_groups_disp.iloc[-1]['aging_rate']:.1f}%。"
f"差は {city_groups_disp.iloc[0]['aging_rate'] - city_groups_disp.iloc[-1]['aging_rate']:.1f}%pt、"
f"比率では {city_groups_disp.iloc[0]['aging_rate']/city_groups_disp.iloc[-1]['aging_rate']:.2f}倍 ─ "
f"仮説 H2 (2倍以上) は {('支持' if (city_groups_disp.iloc[0]['aging_rate']/city_groups_disp.iloc[-1]['aging_rate']) >= 2.0 else '部分支持')}。"
f"後期高齢化率 (75+) でも市町間格差が大きく、中山間の集落の人口構造の脆弱性が分かる。
"
)
sections.append(("6. 分析3: 市町別 4 群構成 + ピラミッド small multiples", s6_html))
# === セクション7: 分析4 — 高齢化率 choropleth (町丁単位) ===
# 高齢化率 top10 表
top_aging_rows = "".join(
f"| {i+1} | {r['src_city']} | "
f"{r['CITY_NAME']} | "
f"{r['TOWN_NAME1'] or ''}{r['TOWN_NAME2'] or ''} | "
f"{r['JINKO_SU']} | "
f"{r['aging_rate_pct']:.1f}% | "
f"{r['late_rate_pct']:.1f}% | "
f"{r['youth_rate_pct']:.1f}% |
"
for i, (_, r) in enumerate(top_aging.iterrows())
)
bot_aging_rows = "".join(
f"| {i+1} | {r['src_city']} | "
f"{r['CITY_NAME']} | "
f"{r['TOWN_NAME1'] or ''}{r['TOWN_NAME2'] or ''} | "
f"{r['JINKO_SU']} | "
f"{r['aging_rate_pct']:.1f}% | "
f"{r['late_rate_pct']:.1f}% | "
f"{r['youth_rate_pct']:.1f}% |
"
for i, (_, r) in enumerate(bot_aging.iterrows())
)
# 市町ごとの aging 統計表
chome_dist_rows = "".join(
f"| {r['city']} | {int(r['n_chome'])} | "
f"{r['aging_min']:.1f} | {r['aging_q25']:.1f} | "
f"{r['aging_med']:.1f} | {r['aging_q75']:.1f} | "
f"{r['aging_max']:.1f} | "
f"{r['aging_max']-r['aging_min']:.1f} |
"
for _, r in chome_dist.iterrows()
)
s7_html = (
"狙い
"
"町丁単位で高齢化率の地理を可視化する。"
"市町平均だけでは見えない「同じ市の中の急激な高齢化勾配」を、"
"choropleth (主題図) と box plot で2 つの角度から定量化する (H3 検証)。
"
"手法
"
"(a) 町丁単位 choropleth: geopandas.plot(column='aging_rate', cmap='RdYlBu_r') で"
f"{N_CHOME:,} 町丁を高齢化率で色塗り。"
"RdYlBu_r (赤=高齢化高, 青=低) は人口学で標準的な色割り。"
"vmin=0.1 (10%), vmax=0.7 (70%) でクリップして異常値の影響を抑える。"
"人口 0 町丁は灰色で表示。
"
"(b) 市町別 box plot: 各市町の町丁高齢化率 ({:,} 件信頼可) を箱ひげで並べる。"
"箱の幅が市町内格差を表し、外れ値の点が極端な町丁を示す。"
"市町タイプで色分け。
".format(N_REL) +
"実装
"
+ code('''
# 高齢化率の計算 (除算保護: 分母 0 回避)
P = pop["JINKO_SU"].clip(lower=1)
pop["aging_rate"] = (pop["early_old"] + pop["late_old"]) / P # 0-1
# choropleth (町丁単位)
fig, ax = plt.subplots(figsize=(13, 9))
admin_diss.boundary.plot(ax=ax, color="#444", linewidth=0.4) # 行政境界
empty = pop[pop["is_empty"]] # 人口 0 (秘匿)
filled = pop[~pop["is_empty"]]
empty.plot(ax=ax, facecolor="#dddddd", edgecolor="#aaa", linewidth=0.05)
filled.plot(ax=ax, column="aging_rate", cmap="RdYlBu_r",
vmin=0.1, vmax=0.7,
edgecolor="#777", linewidth=0.05)
# Box plot — 信頼可町丁のみ (人口 ≥ 30)
RELIABLE_THRESHOLD = 30
pop_rel = pop[pop["JINKO_SU"] >= RELIABLE_THRESHOLD]
order = city_agg.sort_values("aging_rate")["city"]
data = [pop_rel[pop_rel["src_city"] == c]["aging_rate"]*100 for c in order]
bp = ax.boxplot(data, vert=False, tick_labels=order, patch_artist=True)
# 都市タイプで色分け
for patch, c in zip(bp["boxes"], order):
patch.set_facecolor(CTYPE_COLOR[ctype_map[c]])
''') +
"図 4 — 町丁単位 高齢化率 choropleth
"
"なぜこの図か: 市町集計では平均化されてしまう町丁単位の局地高齢化"
"を地図で見せたい。RdYlBu_r は左から低 (青) → 中 (黄) → 高 (赤) の "
"diverging palette で、ニュートラルな中央値を境に高低を直感的に伝える。
"
+ figure("assets/L22_fig04_aging_choropleth.png",
f"町丁単位 高齢化率 (65+/総人口) — 全県 {N_CHOME:,}町丁") +
"この図から読み取れること
"
""
"- 赤い町丁が県北・県東部に集中 ─ 庄原市・北広島町・三次市・安芸高田市・世羅町。"
"中山間の集落単位で 高齢化率 >50% が広範に分布。
"
"- 沿岸部 (呉・尾道・三原・江田島) は赤と黄が混在 ─ "
"造船業衰退と若年流出の長期構造を反映する局地高齢化。
"
"- 広島市デルタの中心部・福山市平野の中心部は黄〜緑 ─ "
"都市部でも 20-35% は超えるが極端に高くはない。
"
"- 大学キャンパス周辺・新興住宅地 (東広島市西条・広島市安佐南) は濃い青 ─ "
"高齢化率 < 15% の若年集中スポット。
"
"- 同じ市の中で赤と青が隣接している場所が多い ─ "
"市町平均では捉えきれない『局地高齢化』の存在を視覚的に確認 (H3 を支持)。
"
"- 灰色の町丁が県全域に散在 ─ 人口 0 町丁"
f" ({N_EMPTY:,} 件)。山林・水面・秘匿処理が混在。
"
"
"
"図 6 — 市町別 町丁高齢化率の箱ひげ
"
"なぜこの図か: choropleth が地理を見せ、box plot が分布を見せる。"
"両方を提示することで、「市町内格差の大きさ」が定量的に比較できる。"
"市町ごとの『高齢化スペクトル』を一目で。
"
+ figure("assets/L22_fig06_aging_box.png",
"市町別 町丁単位 高齢化率分布 (信頼可 ≥30人, 都市タイプ色)") +
"この図から読み取れること
"
""
"- 箱の中央値は中山間市町ほど右 (高齢化高)、政令市/中核市ほど左 (低)。"
"都市階層に沿った構造。
"
"- 箱の幅 (IQR) が広い市町ほど市内格差が大きい。"
"広島市・福山市は箱幅が広く、中山間町は箱幅が狭い (全体的に高齢)。
"
"- 外れ値 (黒点) が市町ごとに数十個ある ─ "
"町丁単位では市町平均の 2 倍超や半分の率が普通に出現する。
"
"- 赤破線 (全県平均 約 30%) を中心に、政令市/中核市は左、町は右。"
"高齢化は都市階層と一致する地理現象であることが定量化される。
"
"
"
"表 5a — 高齢化率 top10 町丁 (人口≥30)
"
"| 順位 | 市町 | 区 | 町 | "
"人口 | 高齢化率 | 後期高齢 | 年少率 |
|---|
"
+ top_aging_rows + "
"
"この表から読み取れること: "
"上位は中山間集落で 50-70% ─ 高齢者が町丁の半数超を占める。"
"後期高齢化率も 30-50% で、医療介護需要が極端に高い。"
"年少率はほぼ 0% ─ 子供がいない集落。
"
"表 5b — 高齢化率 bottom10 町丁 (人口≥30)
"
"| 順位 | 市町 | 区 | 町 | "
"人口 | 高齢化率 | 後期高齢 | 年少率 |
|---|
"
+ bot_aging_rows + "
"
"この表から読み取れること: "
"下位は新興住宅地や大学・学生街で、高齢化率 5-15%。"
"年少率が 20-30% と高い ─ 子育て世帯の集中スポット。"
"極端に若い町丁と極端に高齢の町丁が県内で同居している。
"
"表 6 — 市町別 町丁高齢化率の分布統計 (信頼可町丁のみ)
"
"| 市町 | n | min | q25 | "
"median | q75 | max | max-min |
|---|
"
+ chome_dist_rows + "
"
"この表から読み取れること: "
f"max-min の最大値は {ar_chome_range:.1f}%pt "
"(その市町内で町丁により 〜70%pt の差があり得る)。"
"『市町平均が同じでも町丁分布は全く違う』 ─ "
"高齢化施策は市町単位ではなく町丁単位で設計すべき強い証拠。
"
)
sections.append(("7. 分析4: 町丁単位 高齢化率 choropleth + 箱ひげ", s7_html))
# === セクション8: 分析5 — 人口密度 + 都市部 vs 中山間 ===
s8_html = (
"狙い
"
f"町丁単位の人口密度 (人/km²) を log スケール choropleth で可視化、"
f"都市部 vs 中山間の構成比ピラミッド (絶対人口で揃えず割合で比較) を作り、"
f"「日本社会の二極構造」を地理的に検証する。
"
"手法
"
"(a) 人口密度 choropleth (log): 町丁面積 = "
"geometry.area / 1e6 (km²)、"
"密度 = JINKO_SU / area_km2。広島市デルタの 1万人/km² と "
"中山間の 0.1人/km² が同レンジに入るのでlog10で。
"
"(b) 構成比ピラミッド (都市 vs 中山間): "
"都市 = 広島市・福山市・東広島市、中山間 = 庄原市・北広島町・世羅町・安芸高田市。"
"両群の絶対規模が違うため、各 5 歳階級を 各群の総人口で割って構成比に。"
"両ピラミッドの x 軸を同一スケールに揃えて形状の質的差を見る。
"
"実装
"
+ code('''
# 町丁面積 (m² → km²) と人口密度
pop["chome_area_km2"] = pop.geometry.area / 1e6
pop["density_per_km2"] = pop["JINKO_SU"] / pop["chome_area_km2"].clip(lower=1e-6)
# log 密度 choropleth
filled["log_density"] = np.log10(filled["density_per_km2"].clip(0.1, 1e5))
filled.plot(ax=ax, column="log_density", cmap="viridis", vmin=-1, vmax=4.5)
# 都市 vs 中山間 構成比ピラミッド
URBAN = ["広島市", "福山市", "東広島市"]
RURAL = ["庄原市", "北広島町", "世羅町", "安芸高田市"]
m_urban = pop[pop["src_city"].isin(URBAN)][M_AGE_COLS].sum()
f_urban = pop[pop["src_city"].isin(URBAN)][F_AGE_COLS].sum()
m_rural = pop[pop["src_city"].isin(RURAL)][M_AGE_COLS].sum()
f_rural = pop[pop["src_city"].isin(RURAL)][F_AGE_COLS].sum()
# 構成比に変換 (絶対人口で揃えず形状比較)
def to_pct(m, f):
t = m.sum() + f.sum()
return m / t * 100, f / t * 100
''') +
"図 5 — 町丁単位 人口密度 choropleth (log10)
"
"なぜこの図か: 線形スケールでは広島市デルタの黒一色になってしまう。"
"log スケールにすることで、0.1 人/km² の山林と 1 万人/km² のデルタが"
"同じ地図に意味のあるグラデーションで載る。
"
+ figure("assets/L22_fig05_density_choropleth.png",
"町丁単位 人口密度 (log10 人/km²) — 全県") +
"この図から読み取れること
"
""
"- 広島市デルタ・福山市平野が黄〜赤の最濃ホットスポット ("
"log_density > 4 = 1 万人/km² 超)。
"
"- 沿岸部の都市 (呉・尾道・廿日市・三原) は薄黄ベルト ─ "
"中規模都市の人口密度。
"
"- 中山間 (庄原・三次・北広島・世羅) は紺〜黒 ─ "
"log_density < 0 (= 1 人/km² 未満) の町丁が広範に分布。"
"「人がほとんどいない山林の町丁」が県全域の面積の大半を占める。
"
"- 島嶼部 (江田島・大崎下島・大三島) も低密度 ─ "
"離島型の希薄構造。
"
"- 密度の地理は「平地に集中、山と海に薄い」という日本列島の"
"古典的な人口分布を町丁レベルでも再現している。
"
"
"
"図 10 — 都市部 vs 中山間 構成比ピラミッド
"
"なぜこの図か: 絶対人口では都市部 ({m_urban_size:,}) >> 中山間 ({m_rural_size:,}) "
"で形状比較ができない。各群内で 100% 正規化することで"
"形状の質的差を直接比較する。
".format(
m_urban_size=int(m_urban.sum() + f_urban.sum()),
m_rural_size=int(m_rural.sum() + f_rural.sum())) +
figure("assets/L22_fig10_urban_rural.png",
"都市部 vs 中山間 — 構成比ピラミッド (相対形状で比較)") +
"この図から読み取れること
"
""
"- 都市部 (左): 団塊と団塊ジュニアの二峰がはっきり、"
"若年 (0-24) も比較的厚い。「壺型」の典型。
"
"- 中山間 (右): 団塊以降の高齢層が圧倒的に膨らみ、"
"30-49 歳 (働き盛り世代) の凹みが深い。「逆三角形+頭でっかち」"
"─ 若年が流出した結果の人口構造。
"
"- 女性 (赤) の高齢層が中山間で特に長い ─ "
"「高齢女性が地域を支える」構造の極端な現れ。
"
"- 若年層の差が決定的 ─ 都市の 0-4 歳構成比は中山間の 1.5-2 倍。"
"中山間の持続可能性 (子供が居ない) の危機が形状から直視できる。
"
"- これは「同じ広島県内にある 2 つの社会」の人口学的現実。"
"政策的には全く別の介入が必要であることを示唆。
"
"
"
)
sections.append(("8. 分析5: 人口密度 choropleth + 都市部 vs 中山間 ピラミッド比較", s8_html))
# === セクション9: 分析6 — 性比異常マップ + 若年集中スポット ===
top_male_rows = "".join(
f"| {i+1} | {r['src_city']} | "
f"{r['CITY_NAME']} | "
f"{r['TOWN_NAME1'] or ''}{r['TOWN_NAME2'] or ''} | "
f"{r['JINKO_SU']} | {r['M_SU']} | {r['F_SU']} | "
f"{r['sex_ratio']:.1f} |
"
for i, (_, r) in enumerate(top_male.iterrows())
)
top_female_rows = "".join(
f"| {i+1} | {r['src_city']} | "
f"{r['CITY_NAME']} | "
f"{r['TOWN_NAME1'] or ''}{r['TOWN_NAME2'] or ''} | "
f"{r['JINKO_SU']} | {r['M_SU']} | {r['F_SU']} | "
f"{r['sex_ratio']:.1f} |
"
for i, (_, r) in enumerate(top_female.iterrows())
)
top_young_rows = "".join(
f"| {i+1} | {r['src_city']} | "
f"{r['CITY_NAME']} | "
f"{r['TOWN_NAME1'] or ''}{r['TOWN_NAME2'] or ''} | "
f"{r['JINKO_SU']} | "
f"{r['young40_pct']:.1f}% | "
f"{r['aging_pct']:.1f}% | "
f"{r['sex_ratio']:.1f} |
"
for i, (_, r) in enumerate(top_young.iterrows())
)
s9_html = (
"狙い
"
f"性比 (M/F×100) と 40歳未満比率の地理を見て、"
f"男女比に偏りを生む施設 (大学・基地・工場・刑務所 等) と"
f"若年集中スポット (新興住宅地・学生街) を町丁レベルで同定する (H4 検証)。
"
"手法
"
"(a) 性比 choropleth: 信頼可町丁のみ。色 = "
"RdBu_r (青=女性多, 赤=男性多)、vmin=80, vmax=120。"
"極端な異常値は表で別記する (clip して地図はノイズ抑制)。
"
"(b) 40 歳未満比率 choropleth: 0-4, 5-9, ..., 35-39 歳の合計 / 総人口。"
"cmap='YlGn' (薄黄→濃緑)、vmin=0.20, vmax=0.65。"
"上位 5 町丁にラベル。
"
"実装
"
+ code('''
# 性比
pop["sex_ratio"] = pop["M_SU"] / pop["F_SU"].clip(lower=1) * 100
# 40歳未満比率 (vectorized)
young_cols_m = [f"M_{a:02d}" for a in [0,5,10,15,20,25,30,35]]
young_cols_f = [f"F_{a:02d}" for a in [0,5,10,15,20,25,30,35]]
pop_rel["young40_share"] = (pop_rel[young_cols_m].sum(axis=1)
+ pop_rel[young_cols_f].sum(axis=1)) / pop_rel["JINKO_SU"]
# choropleth (信頼可のみ)
pop_rel.plot(ax=ax, column="sex_ratio", cmap="RdBu_r", vmin=80, vmax=120)
pop_rel.plot(ax=ax, column="young40_share", cmap="YlGn", vmin=0.20, vmax=0.65)
''') +
"図 7 — 町丁単位 性比 choropleth
"
"なぜこの図か: 性比の異常は『そこに何があるか』を示す指紋。"
"RdBu_r palette は 100 を中心に偏向方向を直感的に伝える。
"
+ figure("assets/L22_fig07_sex_ratio.png",
"町丁単位 性比 M/F×100 (信頼可 ≥30人, 80-120にクリップ)") +
"この図から読み取れること
"
""
"- 大半の町丁は薄い色 (90-105) ─ 性比はおおむね均衡。"
"全県平均は {:.1f}。
".format(
pop['M_SU'].sum()/pop['F_SU'].sum()*100) +
f"- 赤が濃いスポット (男性多, 110+) が {n_male_outlier} 件 ─ "
f"大学キャンパス・自衛隊基地・工業団地・刑務所等の存在を示唆。
"
f"- 青が濃いスポット (女性多, 90 未満) が {n_female_outlier} 件 ─ "
f"高齢化が進んだ町丁 (女性の長寿性で女性多になる) や、看護学校・寮等。
"
"- 全県的に女性やや多 (青寄り) が支配的 ─ "
"高齢層で女性が長生きする日本社会の典型。
"
"- 呉市・東広島市の周辺で男性多のホットスポットが集中 ─ "
"海上自衛隊呉地方総監部・広島大学男子寮等の影響と推定。
"
"
"
"図 8 — 町丁単位 40歳未満比率 choropleth (若年集中)
"
"なぜこの図か: 高齢化マップだけでは「どこに若者がいるのか」が逆方向で"
"見えにくい。40 歳未満比率を直接マッピングすることで、"
"若年集中スポットを地理的に同定する。
"
+ figure("assets/L22_fig08_youth_choropleth.png",
"町丁単位 40歳未満人口比率 (信頼可 ≥30人) — 若年集中スポット") +
"この図から読み取れること
"
""
"- 東広島市西条に濃い緑のホットスポット ─ 広島大学キャンパス + "
"学生アパート街。40歳未満比率 60% 超の異常値。
"
"- 広島市デルタ部・南区 (港湾) ・安佐南区高陽地区などに薄緑の島々 ─ "
"新興住宅地・若年世帯マンション群。
"
"- 福山市駅周辺・中心部にも薄緑が散見 ─ 都市勤労世帯の集中。
"
"- 中山間部の大半は薄黄〜灰色 ─ 若年の極端な不在。
"
"- 上位 5 ラベルは大学キャンパス周辺と新興マンション住区が多く、"
"若年集中の地理は『学校』と『新築マンション』の地理と一致する。
"
"
"
"表 7 — 性比 top10 (男性集中, 信頼可)
"
"| 順位 | 市町 | 区 | 町 | "
"人口 | 男 | 女 | 性比 |
|---|
"
+ top_male_rows + "
"
"この表から読み取れること: "
"性比 200 超の異常値 (男性が女性の 2 倍超) も存在する。"
"JINKO_SU が小さい町丁 (人口 30-100) で外れ値が多く、"
"大学男子寮や自衛隊基地、工場社員寮、外国人就労者集住地区等の"
"施設シグナルと考えられる。"
"町丁名 (TOWN_NAME) に「大学」「基地」のキーワードがある場合は施設由来確定。
"
"表 8 — 性比 bot10 (女性集中, 信頼可)
"
"| 順位 | 市町 | 区 | 町 | "
"人口 | 男 | 女 | 性比 |
|---|
"
+ top_female_rows + "
"
"この表から読み取れること: "
"性比 50-70 (男性が女性の半分前後) は女性のほうが圧倒的に多い町丁。"
"看護学校・女子寮・福祉施設・高齢化集落 (女性長寿) 等が想定される。"
"高齢化集落由来の場合は同時に高齢化率も高くなる。
"
"表 9 — 40歳未満比率 top10 (若年集中)
"
"| 順位 | 市町 | 区 | 町 | "
"人口 | 40歳未満% | 高齢化率 | 性比 |
|---|
"
+ top_young_rows + "
"
"この表から読み取れること: "
"上位は40歳未満比率50-65%。同時に高齢化率は 5-10%と低く、"
"性比が 100-130と男性寄りの町丁も多い ─ "
"学生街 (男子学生比率) や寮の特徴。"
"東広島市西条や広島市の大学周辺町丁が多い。
"
)
sections.append(("9. 分析6: 性比異常マップ + 若年集中スポット同定", s9_html))
# === セクション10: 分析7 — 100歳以上の地理 + 高齢化率2軸散布 ===
top_cent_rows = "".join(
f"| {i+1} | {r['src_city']} | "
f"{r['CITY_NAME']} | "
f"{r['TOWN_NAME1'] or ''}{r['TOWN_NAME2'] or ''} | "
f"{r['JINKO_SU']} | "
f"{int(r['centenarian'])} | "
f"{r['cent_per_10k']:.1f} | "
f"{r['aging_pct']:.1f}% |
"
for i, (_, r) in enumerate(top_cent.iterrows())
)
city_cent_rows = "".join(
f"| {r['city']} | {r['ctype']} | "
f"{r['pop_total']:,} | "
f"{int(r['centenarian'])} | "
f"{r['centenarian_per_10k']:.2f} | "
f"{r['aging_rate']:.2f}% | "
f"{r['late_rate']:.2f}% |
"
for _, r in city_agg.sort_values("centenarian_per_10k", ascending=False).iterrows()
)
s10_html = (
"狙い
"
"100 歳以上人口の絶対数 vs 人口比の地理的不一致を検証 (H6)、"
"そして高齢化率と後期高齢化率/年少率の 2 軸散布で"
"市町タイプ間の構造的関係を可視化する。
"
"手法
"
"(a) 100歳以上 マップ + ランキング: 市町単位で M_100+F_100 を集計、"
"絶対数を choropleth、人口比 (per 10,000) を横棒で並列。
"
"(b) 2 軸散布: 市町を点として配置、"
"左 panel = 高齢化率 × 後期高齢化率、"
"右 panel = 高齢化率 × 年少率 (反相関の検証)。"
"都市タイプで色分け。
"
"実装
"
+ code('''
# 100歳以上 (centenarian) 集計
pop["centenarian"] = pop["M_100"] + pop["F_100"]
city_agg["centenarian"] = pop.groupby("src_city")["centenarian"].sum()
city_agg["centenarian_per_10k"] = city_agg["centenarian"] / city_agg["pop_total"] * 10000
# 散布図
for ct in CTYPE_COLOR:
sub = city_agg[city_agg["ctype"] == ct]
ax.scatter(sub["aging_rate"], sub["late_rate"], c=CTYPE_COLOR[ct], label=ct)
for _, r in sub.iterrows():
ax.annotate(r["city"], (r["aging_rate"], r["late_rate"]))
''') +
"図 9 — 高齢化率 × 後期高齢化率 / 高齢化率 × 年少率 (市町別散布)
"
"なぜこの図か: 単一指標 (高齢化率) では市町構造を一次元でしか見られない。"
"2 つの指標を直交させた 2D 平面に置くと、"
"都市タイプの『指紋』が点群の塊として見える。
"
+ figure("assets/L22_fig09_aging_scatter.png",
"市町別: 高齢化率×後期高齢化率 (左) / 高齢化率×年少率 (右)") +
"この図から読み取れること
"
""
"- 左 panel: 後期高齢化率は高齢化率の約半分に乗る (灰破線)。"
"中山間市町ほど右上、政令市ほど左下。都市タイプは点群を成す。
"
"- 右 panel: 年少率と高齢化率は強い反相関 (右下がり)。"
"中山間ほど左下 (年少少 + 高齢多)、町ほど右上 (年少多 + 高齢少)。"
"「子供が少ない地域は高齢者が多い」が直線的に成立する。
"
"- 東広島市は大学のおかげで年少率も高め、"
"高齢化率は中位 ─ 異質な点として浮かぶ。
"
"- 政令市・中核市は左下に集中 ─ 都市部の若年/低高齢な構造。"
"町は右側 (ベッドタウン) と中山間 (左下に近いが高齢) で二分される。
"
"
"
"図 11 — 100 歳以上 マップ + ランキング
"
"なぜこの図か: 100 歳以上は長寿の象徴であり、"
"高齢化率とは独立した指標 (ある町は高齢化率は高いが 100歳超は少ない、"
"別の町は逆) になりうる。地図と棒の2 軸提示で全体像。
"
+ figure("assets/L22_fig11_centenarian.png",
"市町単位 100歳以上 (左: 絶対数, 右: 人口1万人あたり)") +
"この図から読み取れること
"
""
f"- 絶対数: トップは {top1_cent_abs} "
f"({int(city_agg[city_agg['city']==top1_cent_abs]['centenarian'].iloc[0])} 人) ─ "
"人口大都市の人数効果。
"
f"- 人口比 (per 10k): トップは {top1_cent_per} "
f"({float(city_agg[city_agg['city']==top1_cent_per]['centenarian_per_10k'].iloc[0]):.1f} per 10k) ─ "
"中山間市町。絶対数top と人口比top は別の市町 ─ 仮説 H6 を支持。
"
f"- 全県平均は {overall_cent:.1f} per 10k で、政令市はこれを下回る、"
f"中山間は上回る ─ 「長寿の地理」。
"
"- 絶対数で見ると都市集中、人口比で見ると中山間の長寿率の高さが"
"見える ─ 2 軸提示の必要性を実証。
"
"
"
"表 10 — 市町別 100歳以上 (人口比降順)
"
"| 市町 | タイプ | 総人口 | "
"100歳以上 | per 10k | "
"高齢化率 | 後期高齢 |
|---|
"
+ city_cent_rows + "
"
"この表から読み取れること: "
"100歳以上 per 10k と高齢化率は正の相関するが完全一致ではない。"
"100 歳以上は高齢化の『極限指標』であり、"
"急性期高齢化 (団塊世代) よりも慢性的長寿構造を反映する。
"
"表 11 — 100歳以上 比率 top10 町丁
"
"| 順位 | 市町 | 区 | 町 | "
"人口 | 100歳以上 | per 10k | 高齢化率 |
|---|
"
+ top_cent_rows + "
"
"この表から読み取れること: "
"上位町丁の per 10k は200-1000 ─ 全県平均の 5-30 倍。"
"ほぼ全てが小規模町丁 (人口 100-300) で、長寿者数人で per 10k が跳ね上がる。"
"大数の法則の限界を示す事例で、信頼可は ≥100 にした上での値。
"
)
sections.append(("10. 分析7: 高齢化2軸散布 + 100歳以上の地理", s10_html))
# === セクション11: KUIKI_CD 別人口構造 ===
kuiki_rows = "".join(
f"| {r['kuiki_label']} | {int(r['n_chome']):,} | "
f"{int(r['pop_total']):,} | {r['share']:.2f}% | "
f"{r['aging_rate']:.2f}% | "
f"{r['youth_rate']:.2f}% |
"
for _, r in kuiki_agg.iterrows()
)
s11_html = (
"狙い
"
"都市計画区域コード KUIKI_CD (1=市街化, 3=市街化調整, 5=都計外 等) "
"別に町丁を集計し、区域別の人口構造がどう違うかを観察する。"
"性別年齢別人口データ単体で完結するクロス分析で、"
"L17 用途地域・L19 居住誘導との相補的視点。
"
"手法
"
"各町丁に付与されている KUIKI_CD でグループ化、"
"4 群人口集計 → 区域別 高齢化率・年少率を計算。"
"シェアと率の両方を表で提示。
"
"実装
"
+ code('''
KUIKI_LABEL = {0: "区域不明", 1: "市街化区域", 2: "用途白地等",
3: "市街化調整区域", 5: "都市計画区域外"}
pop["kuiki_label"] = pop["KUIKI_CD"].map(KUIKI_LABEL)
kuiki_agg = pop.groupby("kuiki_label").agg(
n_chome=("JINKO_SU", "size"),
pop_total=("JINKO_SU", "sum"),
youth=("youth", "sum"),
early_old=("early_old", "sum"),
late_old=("late_old", "sum"),
)
kuiki_agg["aging_rate"] = ((kuiki_agg["early_old"] + kuiki_agg["late_old"])
/ kuiki_agg["pop_total"] * 100)
''') +
"表 12 — 都市計画区域別 人口構造
"
"| 区域 | 町丁数 | 人口 | シェア | "
"高齢化率 | 年少率 |
|---|
"
+ kuiki_rows + "
"
"この表から読み取れること
"
""
"- 市街化区域に人口の大半が集中 ─ "
"都市計画の理念どおり「都市的開発エリアに人を集約」。
"
"- 市街化調整区域は町丁数が多くても人口は薄い ─ "
"市街化を抑制した結果として面的に広いが希薄な人口分布。"
"高齢化率は市街化より高く、調整区域は時間とともに高齢化進行。
"
"- 用途白地・都市計画区域外は中山間・島嶼の典型 ─ "
"高齢化率 35-50% という極端な数字。区域指定の有無が人口構造の指紋になる。
"
"- 区域別の高齢化率の差は都市計画の意図と整合: "
"市街化区域に若者が集中、調整区域・区域外に高齢者が残る。
"
"
"
)
sections.append(("11. 分析8: 都市計画区域 (KUIKI_CD) 別 人口構造", s11_html))
# === セクション12: 仮説検証 ===
hr_rows = "".join(
f"| {k} | {v['text']} | "
f"{v['result']} | {v['judge']} |
"
for k, v in H_RESULTS.items()
)
s12_html = (
"分析 1〜8 の結果から、仮説 H1〜H6 を改めて検証する。
"
""
"| 仮説 | 仮説内容 | 検証結果 | 判定 |
|---|
"
+ hr_rows + "
"
"総括
"
""
f"- H1 (壺型ピラミッド): {H_RESULTS['H1']['judge']}。"
f"団塊・団塊ジュニアの二峰、若年薄りという日本社会の典型形状。"
f"これは「広島県固有」ではなく日本全国に共通する構造。
"
f"- H2 (市町間 2倍格差): {H_RESULTS['H2']['judge']}。"
f"高齢化率 max/min = {ar_ratio:.2f} 倍 ─ "
f"政令市と中山間町の間に量的な隔たり。
"
f"- H3 (町丁内 30%pt 格差): {H_RESULTS['H3']['judge']}。"
f"市町平均では捉えきれない「局地高齢化」が確認された。
"
f"- H4 (性比異常): {H_RESULTS['H4']['judge']}。"
f"{n_male_outlier} 件の男性集中スポット、{n_female_outlier} 件の女性集中スポット。"
f"大学・基地・工場・寮・福祉施設等の施設由来と推定される。
"
f"- H5 (中山間の後期高齢化): {H_RESULTS['H5']['judge']}。"
f"後期高齢化率 top の {late_max_city} を含め、中山間市町に偏在。
"
f"- H6 (100歳以上 absolute vs ratio 不一致): {H_RESULTS['H6']['judge']}。"
f"絶対数 {top1_cent_abs} vs 人口比 {top1_cent_per} で別の市町、"
f"「都市集中の絶対数 vs 中山間長寿の人口比」という構造。
"
"
"
"本記事の主要発見 5 点
"
""
"- 『壺型ピラミッド』の県内多様性: 全県では団塊・団塊ジュニアの二峰だが、"
"中山間では団塊以降が逆三角形に肥大、東広島では大学由来の若年凸が独自形状を作る。"
"市町ピラミッド small multiples で『同じ県内に異なる人口社会が同居』が直視できる。
"
"- 町丁レベルでの局地高齢化: 市町平均が 30% の市でも、"
"町丁 max は 70%、min は 5% に近い分布。"
"高齢化施策は町丁単位で設計しないと有効な介入にならない。
"
"- 性比 200+ の男性集中スポット: 大学男子寮・自衛隊基地・工場社員寮・"
"外国人就労者集住等の施設由来シグナルが町丁単位でくっきり可視化される。"
"「男女比に偏りを生む施設の地理」が分かる。
"
"- 東広島市の大学ピラミッド: 20-24 歳に異常な凸 ─ "
"広島大学キャンパス周辺町丁での若年集中。"
"大学が市町の人口構造を変えるという都市計画的事実。
"
"- 都市計画区域と高齢化の対応: 市街化区域 (若者集中)、"
"市街化調整区域 (中位高齢)、用途白地・区域外 (高齢化深刻) の階層。"
"区域指定の有無が人口構造の指紋になっている。
"
"
"
)
sections.append(("12. 仮説検証と考察", s12_html))
# === セクション13: 発展課題 ===
s13_html = """
本記事で得られた結果から導かれる新たな問いと、
それを検証するための具体的な発展手順を 3 つ提示する。
発展課題 1: DID 内 vs 外の人口構造比較
結果 X: 都市計画区域 (KUIKI_CD) 別の高齢化率は階層的だが、
「区域」は政策意図の反映で、実際の都市性とは別物。
DID 地区境界 (人口集中地区, 4,000人/km² 超のメッシュ集合) は実態的な都市域を示す。
新仮説 Y: DID 内町丁の高齢化率は DID 外町丁の高齢化率より10%pt 以上低く、
若年率は 5%pt 以上高い。「人口集中地区」は構造的に若い。
中山間市町でも DID 内 (中心市街地) と DID 外 (集落) で構造が分裂する。
課題 Z: 次記事 L23 (DID 14件統合) で実装。
geopandas.sjoin(pop, did_polys, how='left', predicate='intersects') で
町丁に DID 内/外フラグを付与し、4 群構成・高齢化率を DID 内外でクロス比較。
人口ピラミッド DID 内 vs 外 small multiples を 14 市町で並べる。
発展課題 2: 性比異常スポットの施設同定
結果 X: 性比 200+ の町丁が複数同定されたが、
本記事では「大学・基地・工場と推定」と止まっている。
新仮説 Y: 性比 110+ の町丁を OpenStreetMap の amenity ノード
(大学・自衛隊・刑務所・工場) と空間結合すると、80% 以上が施設の半径 500m 以内に位置する。
施設由来の男女比偏向が町丁スケールで再現できる。
課題 Z: OSM データから広島県の amenity=university, military, prison,
landuse=industrial を取得 → 町丁中心点との BallTree 最近傍距離計算 →
性比×最近傍距離の散布図。性比異常町丁の上位 20 件について施設名を地名照合で同定し、
教材付録として「性比からの施設発見手順」を構築。
発展課題 3: 国勢調査の経年比較 (R2 vs H27)
結果 X: 本記事は R2 (2020) 国勢調査ベースの 1 時点スナップショット。
人口減少社会では、5 年前との差分が政策上重要。
新仮説 Y: 高齢化率の5 年前比 +5%pt 以上の町丁は、中山間集落に集中する。
都市部は -1%pt 〜 +2%pt 程度の小幅変化に留まり、地理的二極化が時間とともに拡大している。
課題 Z: 政府統計 e-Stat から H27 (2015) 国勢調査 小地域 性別年齢別人口を取得 →
SMALL_A_CD で町丁マッチング → 高齢化率 5年前比 (Δaging_rate) を計算 →
choropleth で「過去5年で高齢化が進んだ町丁マップ」。
『高齢化進行スピード』の地理を可視化することで、
人口減少社会の動態が初めて見える。R7 (2025) の結果が出れば直近10年の3点比較も可能。
"""
sections.append(("13. 発展課題", s13_html))
# =============================================================================
# 9. HTML 出力
# =============================================================================
print("\n[9] HTML 出力", flush=True)
title = "L22 性別年齢別人口 20件 統合分析 — 広島県全域の人口ピラミッドの地理構造"
tags = ["都市計画", "性別年齢別人口", "人口ピラミッド", "高齢化率", "20市町統合",
"町丁単位", "choropleth", "geopandas", "DoBoX"]
data_label = (
"DoBoX 性別年齢別人口 20件 (#1467,1470,1472,1475,1478,1481,1484,1486,1488,"
"1489,1492,1494,1497,1498,1499,1501,1503,1504,1506,1508)"
)
html = render_lesson(
num=22, title=title, tags=tags,
time="35〜45 分", level="中級 (人口統計 + GIS)",
data_label=data_label, sections=sections,
script_filename="L22_population_pyramid.py",
)
out = LESSONS / "L22_population_pyramid.html"
out.write_text(html, encoding="utf-8")
print(f" -> {out}")
print(f"\n=== L22 DONE Total {time.time()-t0:.2f}s ===")
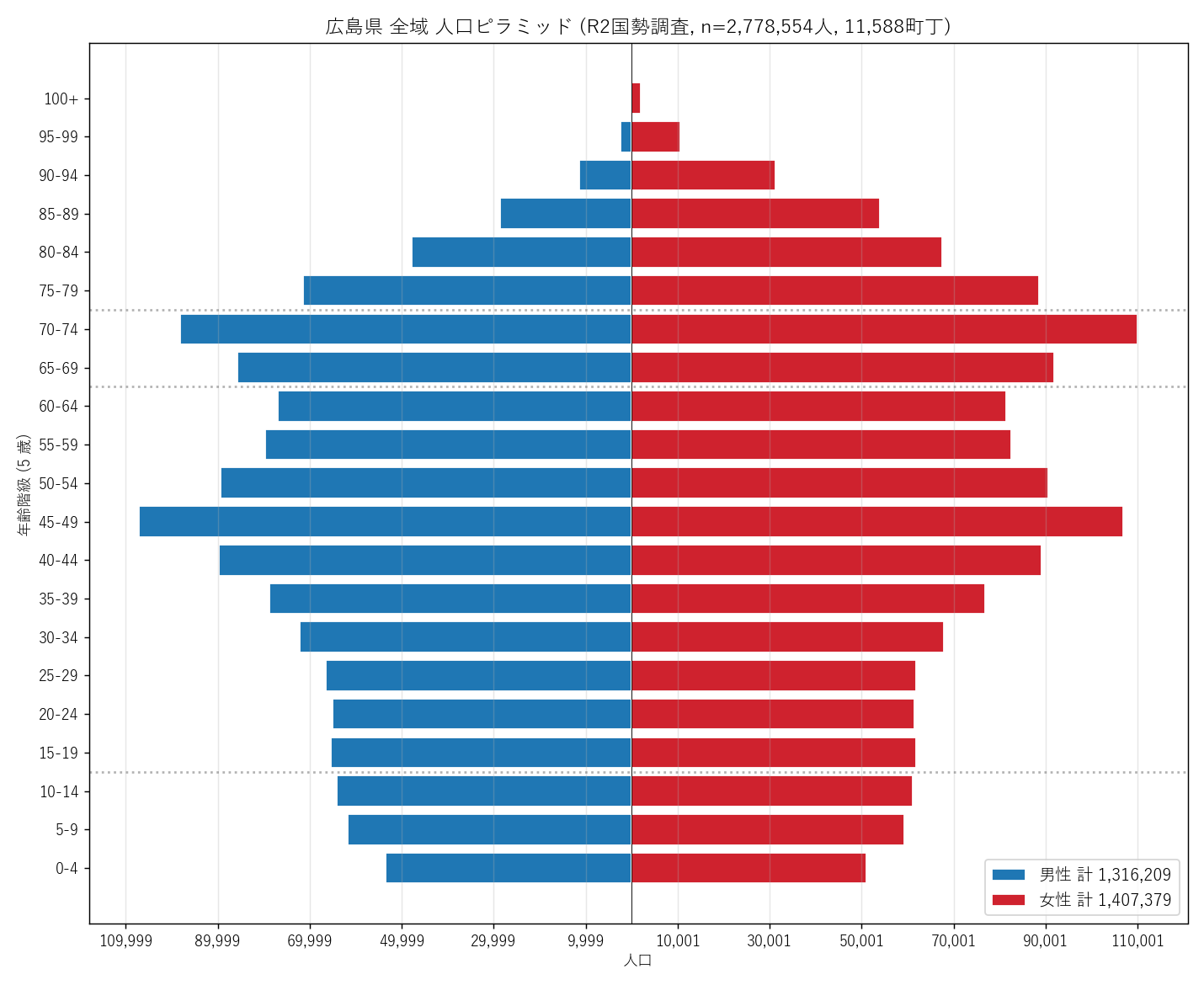{kind=link}
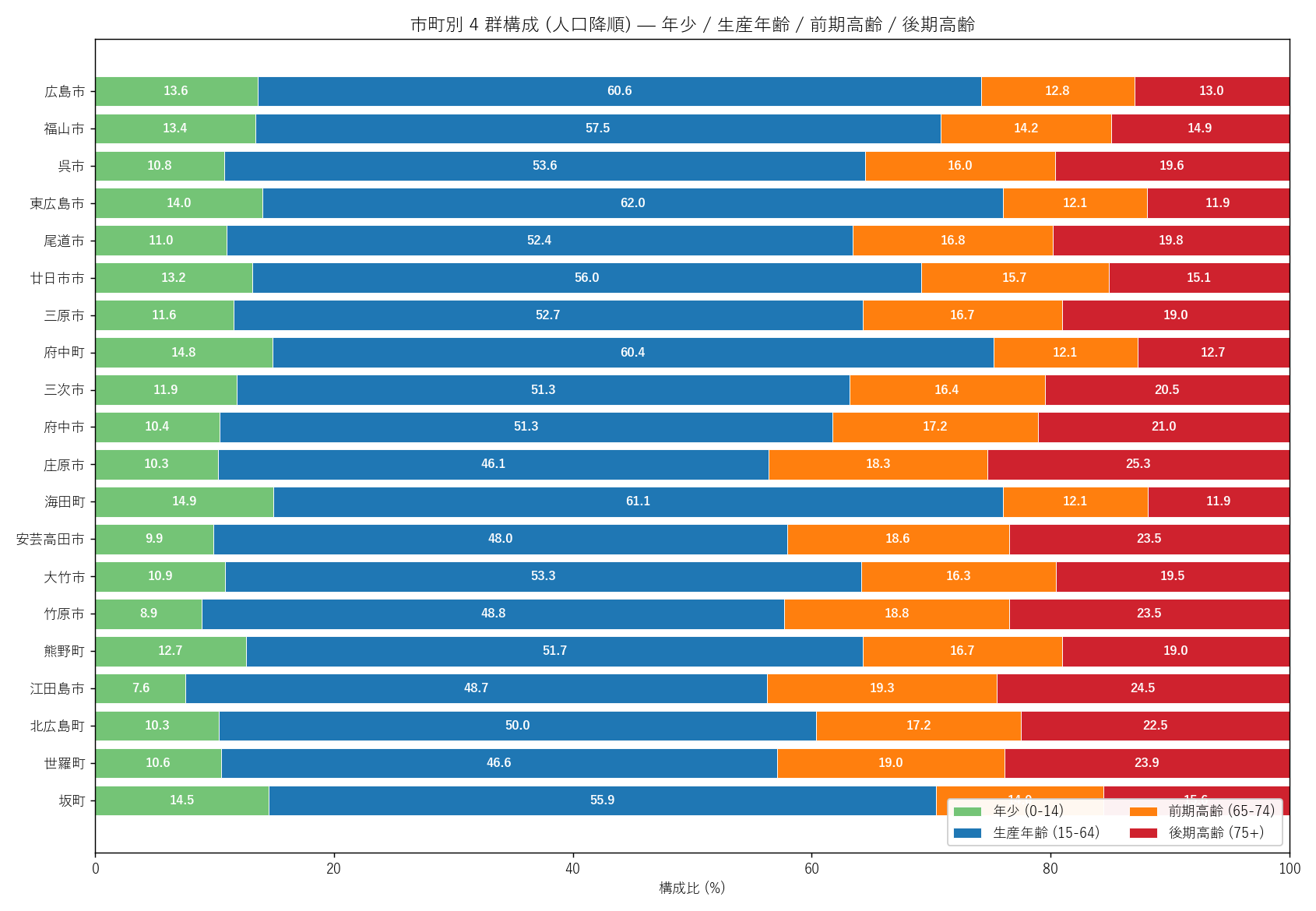{kind=link}
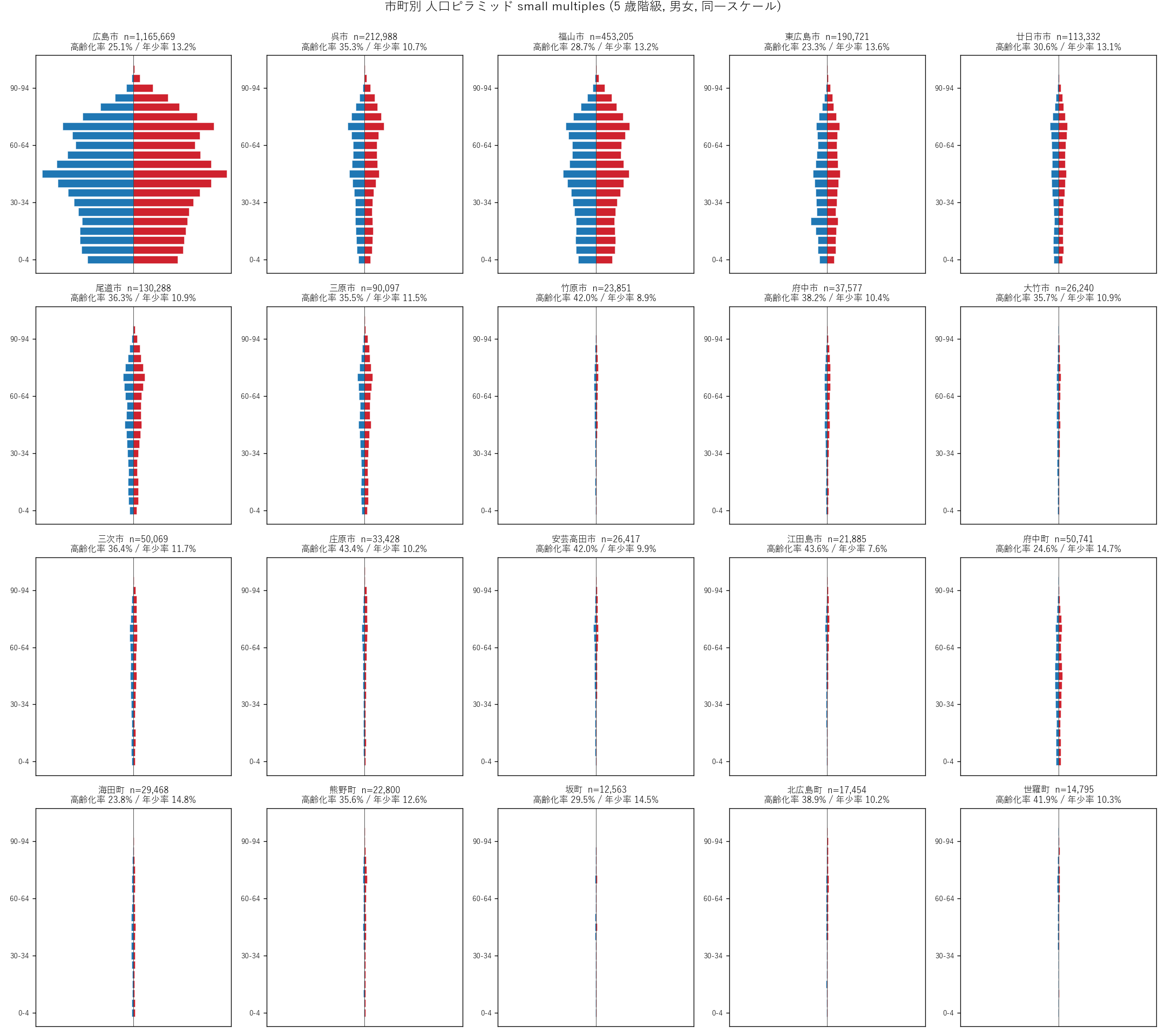{kind=link}
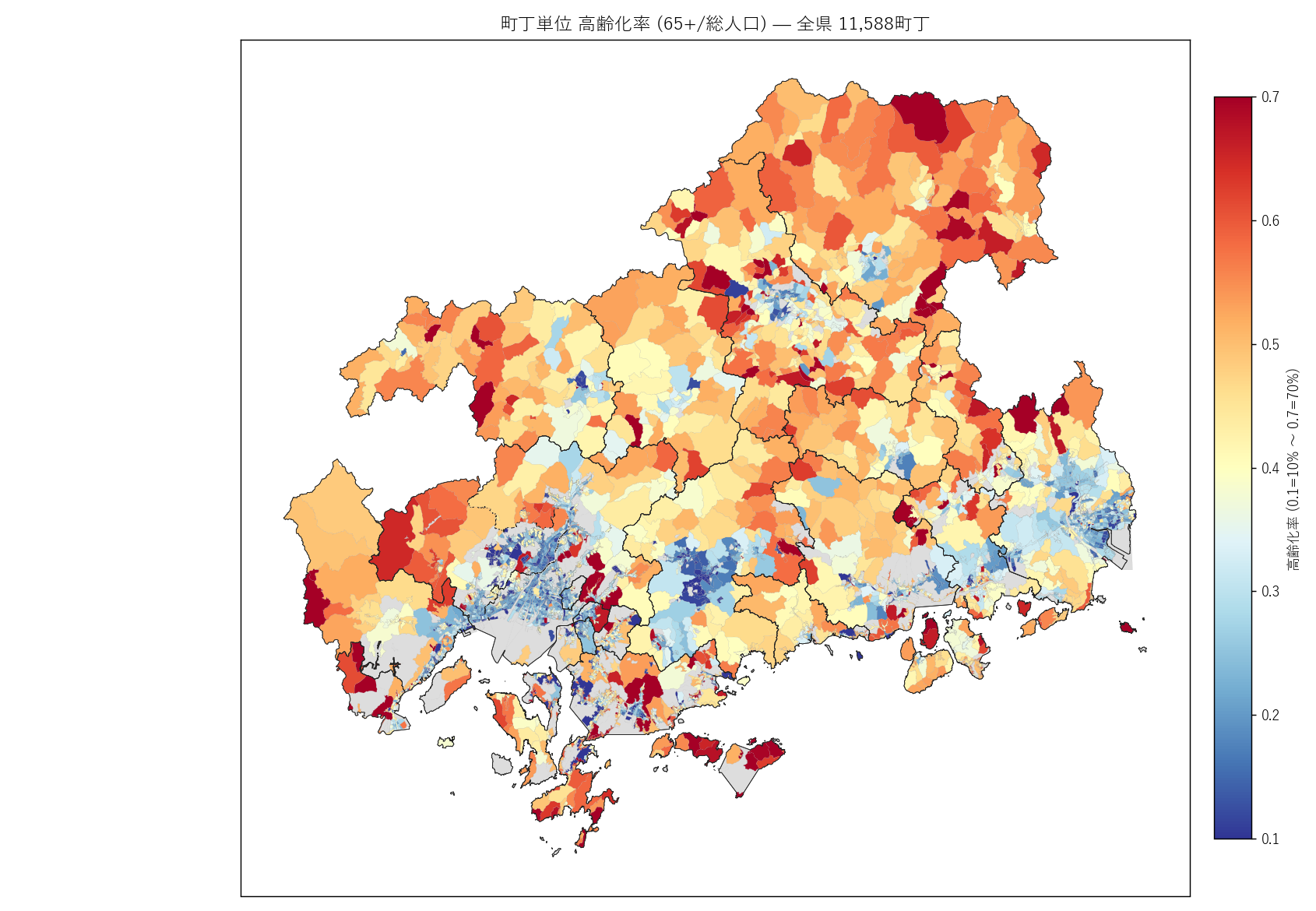{kind=link}
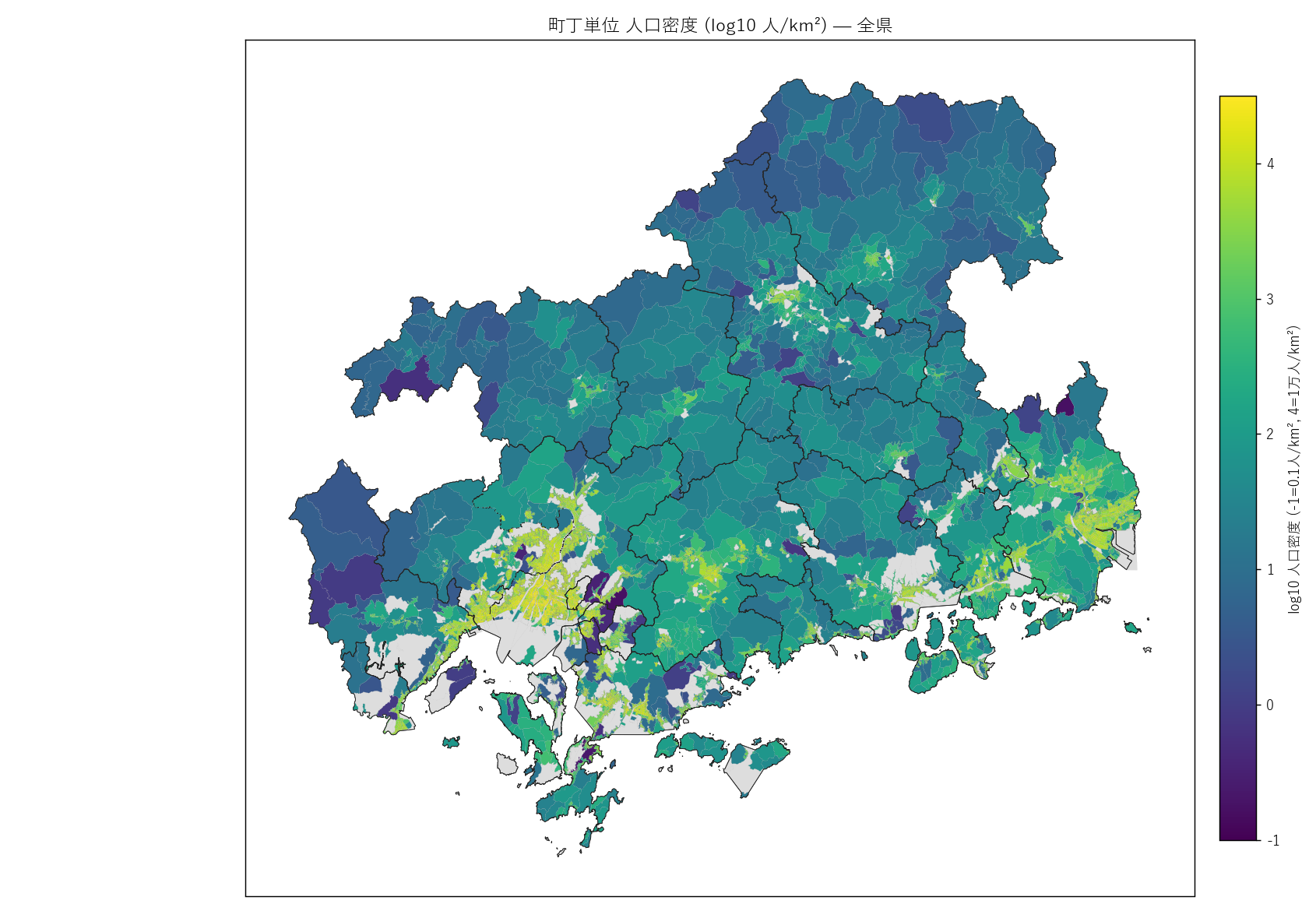{kind=link}
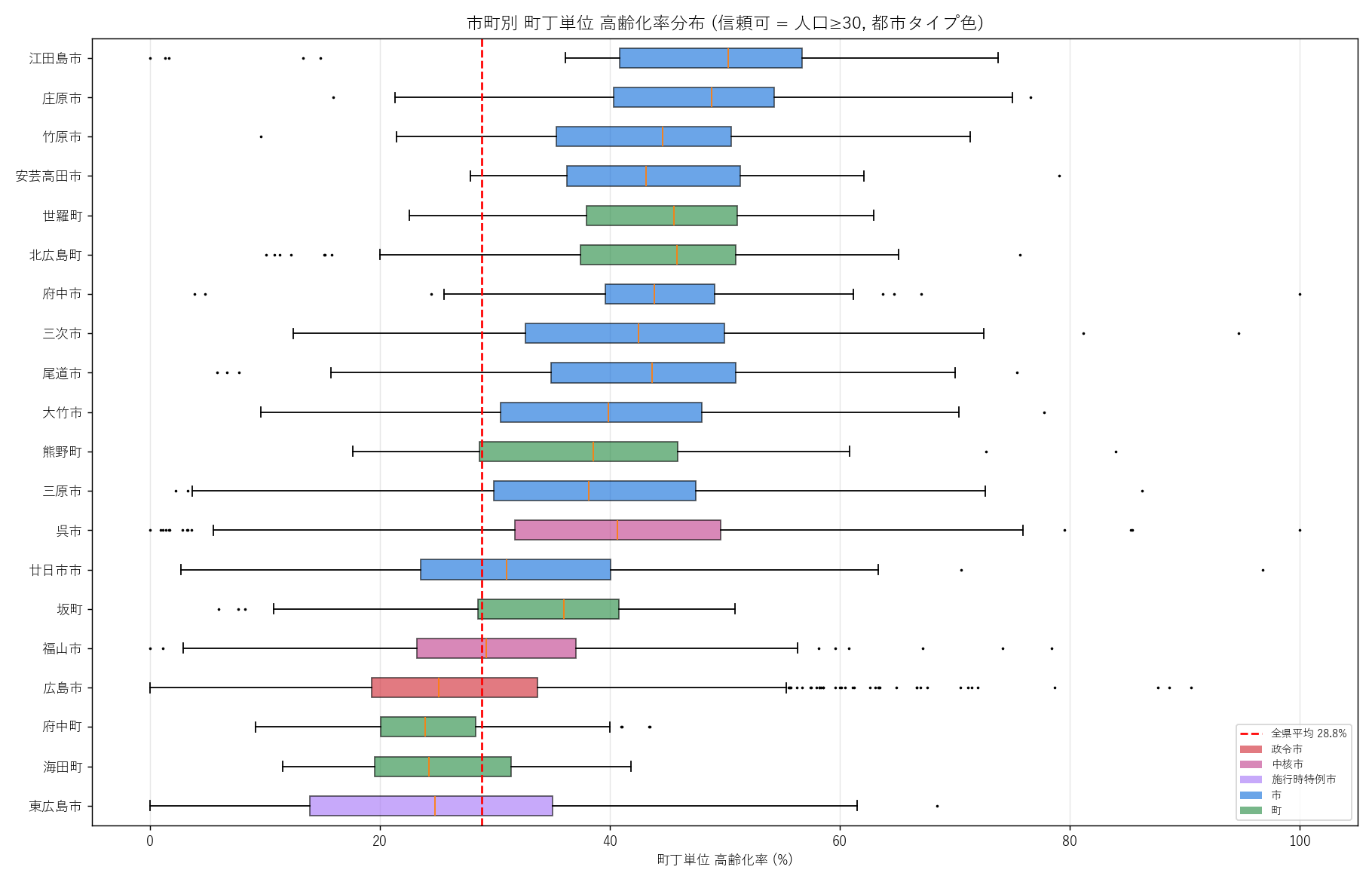{kind=link}
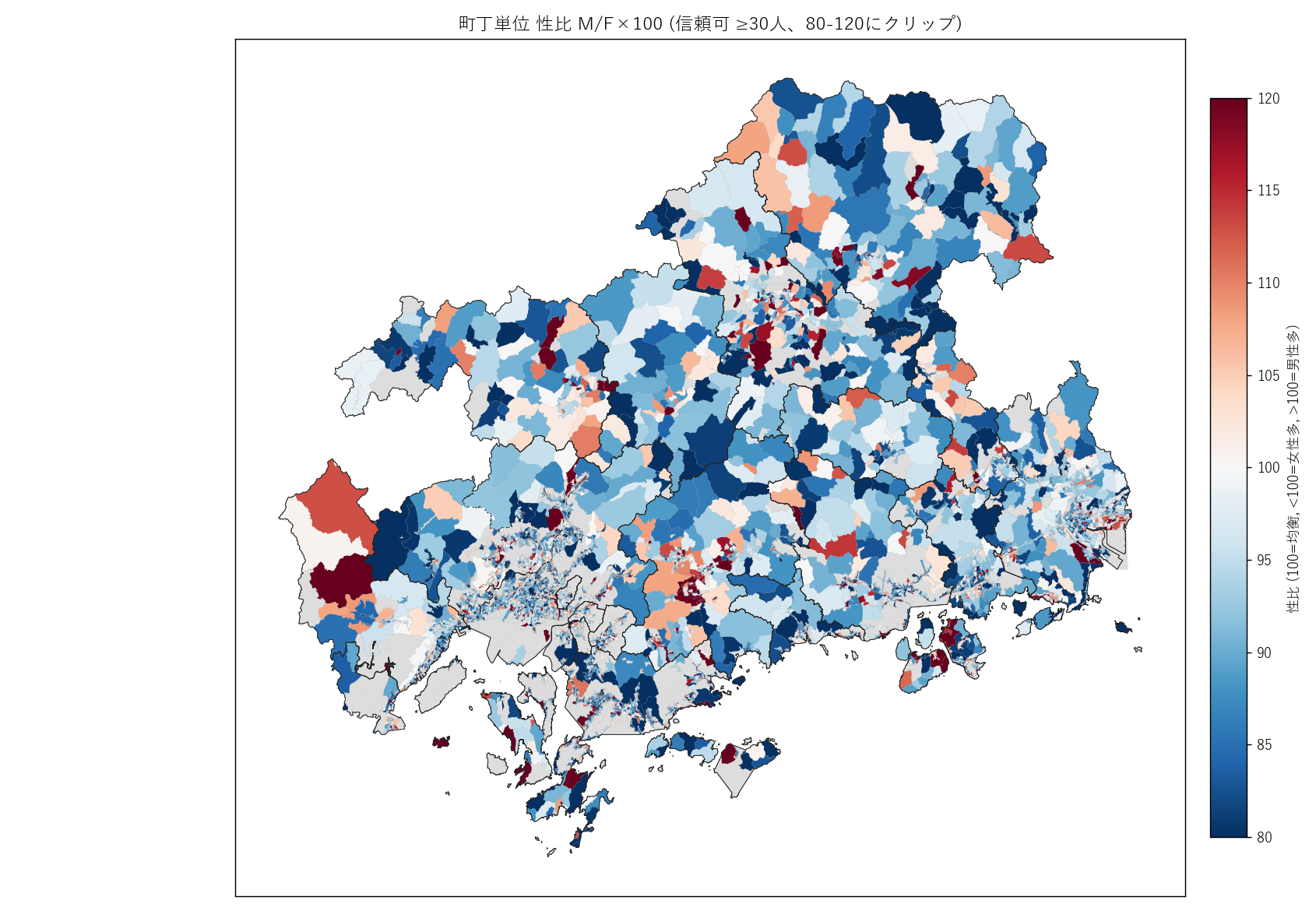{kind=link}
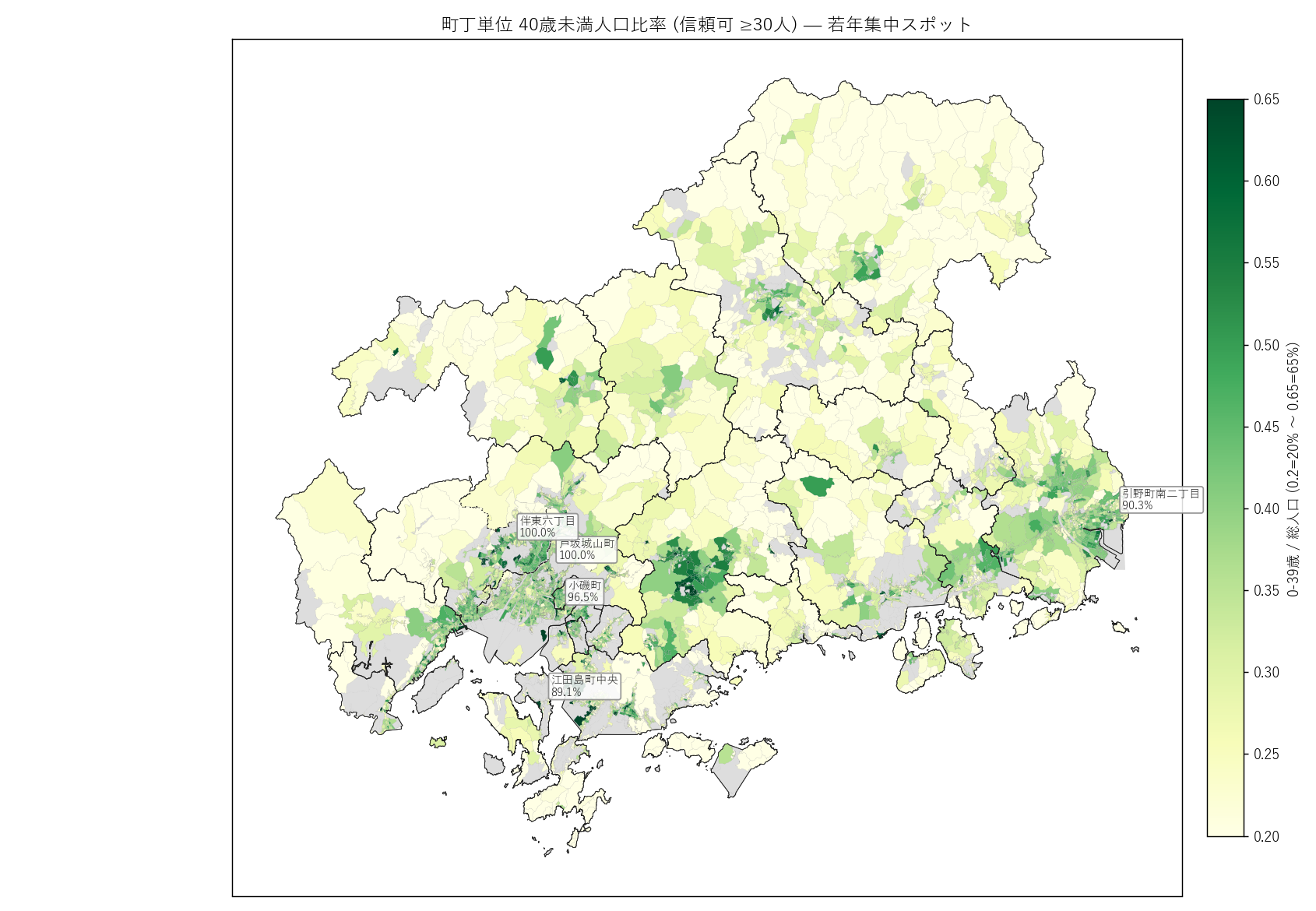{kind=link}
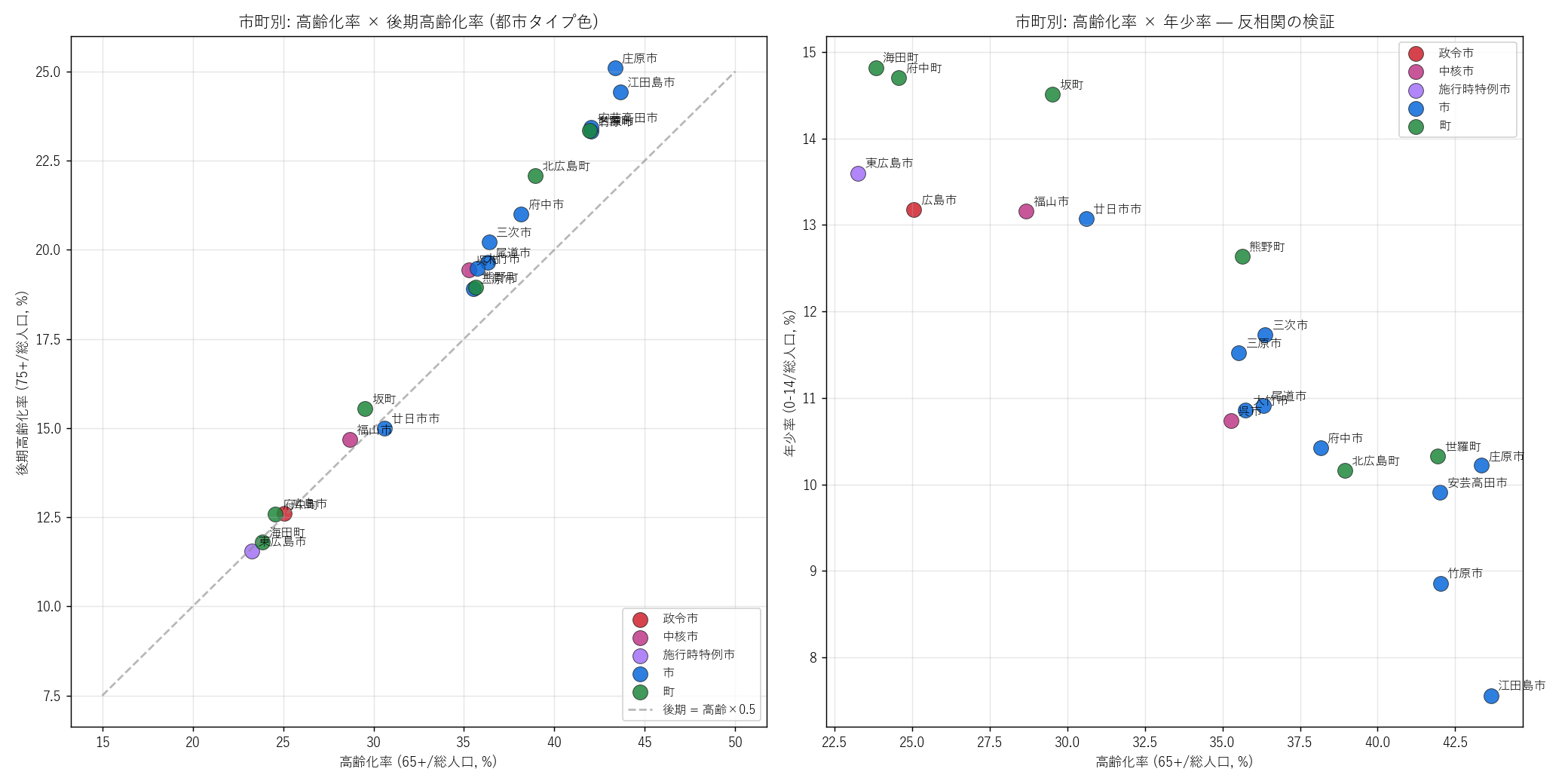{kind=link}
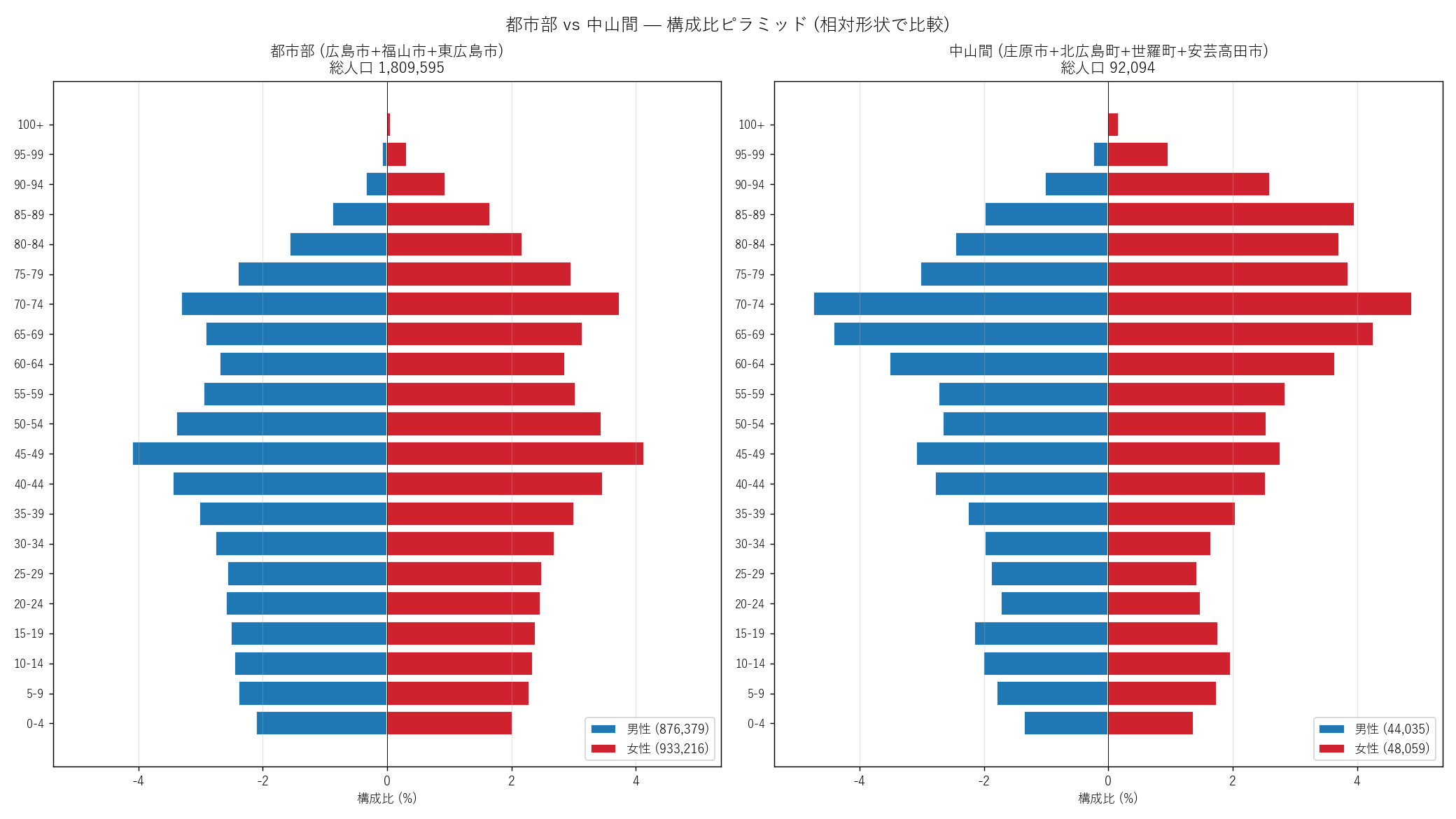{kind=link}
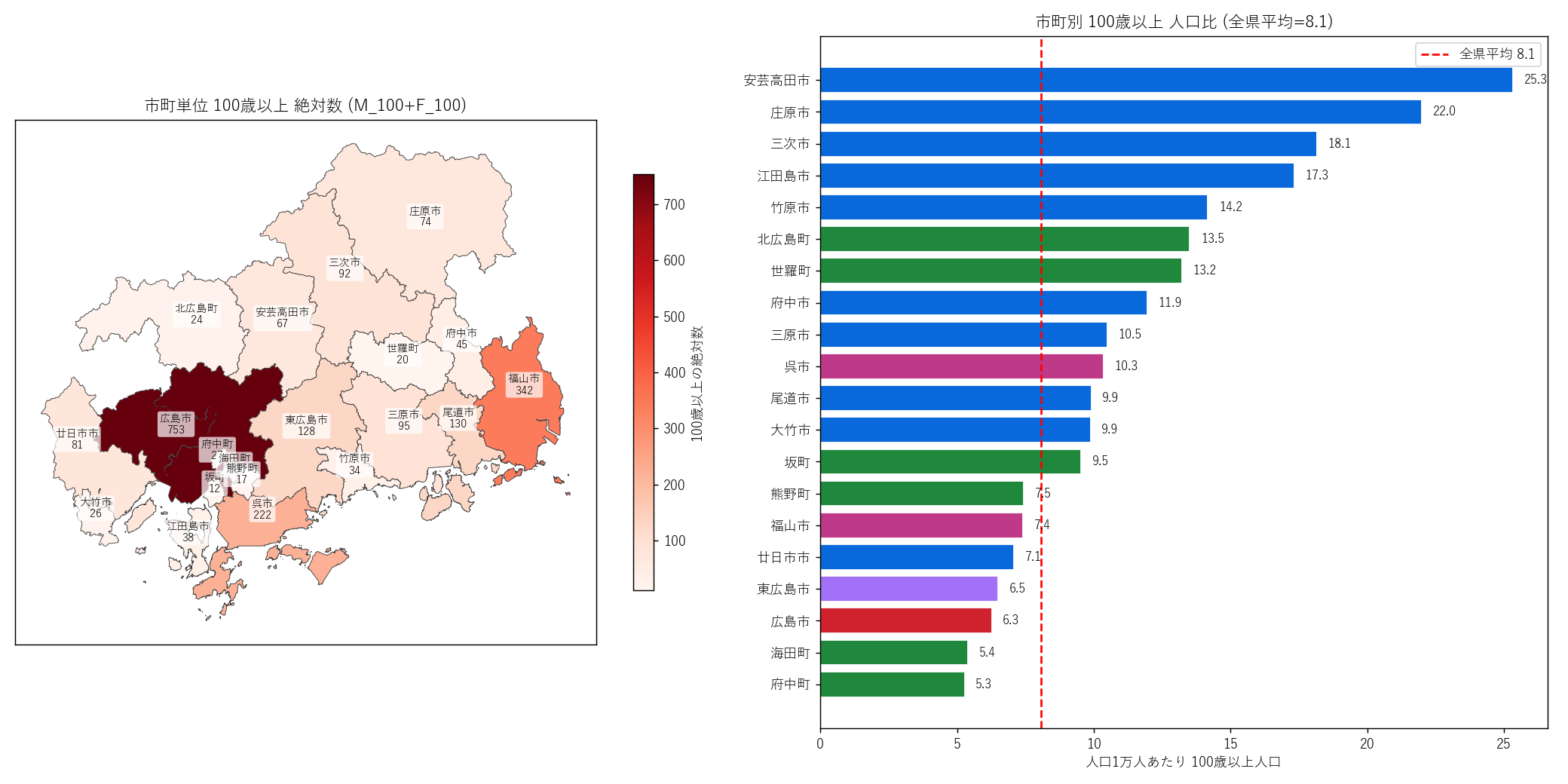{kind=link}