"""L21 宅地開発状況 20 件 統合分析 — 広島県全域の宅地開発事業の時空間構造
カバー宣言:
本記事は 「都市計画区域情報_宅地開発状況_*_2016-2020」 の 20 dataset_id を統合し、
広島県内 全 20 市町の宅地開発事業 (Point) 計 1,038 件 から、
事業期間・開発面積・用途/種別・地理分布・年別推移 を分析する研究記事である。
20 dataset_id (連番 1351-1370):
1351 安芸高田市, 1352 海田町, 1353 熊野町,
1354 呉市, 1355 広島市, 1356 江田島市,
1357 坂町, 1358 三原市, 1359 三次市,
1360 庄原市, 1361 世羅町, 1362 大竹市,
1363 竹原市, 1364 東広島市, 1365 廿日市市,
1366 尾道市, 1367 府中市, 1368 府中町,
1369 福山市, 1370 北広島町
研究の問い (RQ):
広島県内の宅地開発事業 1,038 件 (2016-2020 期) は、面積規模・事業期間・用途/種別・
地理分布の観点でどのような時空間構造を持ち、何年の事業期間を経てどんな地区が形成されているか?
仮説 H1〜H6:
H1. 宅地開発は新築動向と分布が異なる — 開発活発度トップ市町は (新築の) 広島市ではなく
福山市・東広島市。「開発が一段落した広島市」と「現在進行中の周辺都市」という構造。
H2. 開発面積 KAIHATU_A は対数正規分布。中央値約 2,000 m² 前後、p90 が約 1 ha、最大級は数十万 m²。
片対数で 4 桁 ( 100m² 〜 1 km² ) のスパン。
H3. 事業期間 (JIGYO_KE - JIGYO_KS) の中央値は 12 ヶ月以下。
「宅地開発は速く回る」が支配的な傾向。
H4. 事業用途 JIGYO_YO の構成は 1=住宅用 が圧倒多数 (>50%) で、
残りは商業・工業・公益・その他に薄く分散。
H5. 大規模開発 (>=10ha = 100,000 m²) は 市街化調整区域 (KUIKI_CD=3) や都市計画区域外
に集中する。市街化区域内では小規模 (<3,000 m²) が大半を占める二極構造。
H6. 年別事業開始数は 2016-2020 で減少傾向 (人口減少社会の反映) で、
2016 年がピーク、2019-2020 年が低水準。
要件 S 準拠: 1 分以内完走。Point 1,038 件 + 行政区域 21 + 用途地域は計算が極めて軽量。
要件 T 準拠: 全県点マップ・面積バブル・小マルチプル・用途地域 sjoin・年別ヒストグラム。
要件 Q 準拠: 図 9 枚以上、表 9 枚以上。
スキーマ非互換に関する重要発見:
20 件のうち 3 市町 (江田島市・三原市・竹原市) は他 17 市町と列構造が異なる:
- geometry は Polygon/MultiPolygon (他は Point)
- 列は JIGYO_CD/JIGYO_D/JIGYO_N/KARI_D (他は KAIHATU_A/JIGYO_KS/JIGYO_KE/JIGYO_YO/JIGYO_SIN)
- JIGYO_N は「江田島町小用公有水面埋立事業」のような埋立・公共事業の名称
これは「宅地開発状況シリーズの中に異種データ (公有水面埋立) が混入している」
という DoBoX オープンデータの実例であり、教材として正面から扱う。
datetime 型不整合:
- 広島市 (1355) と廿日市市 (1365) の JIGYO_KS は dtype=object (文字列「2016/04/06」形式)
- 廿日市市はさらに「許可日(2016/07/26)より30日以内」のような自由文字列も含む
- 海田町 (1352)・世羅町 (1361) は JIGYO_KE のみ object
- → pd.to_datetime(errors="coerce") で正規化必須 (要件 K)
"""
from __future__ import annotations
import sys, time, json, zipfile, io, re
from pathlib import Path
sys.path.insert(0, str(Path(__file__).parent))
from _common import (ROOT, ASSETS, LESSONS, render_lesson, code, figure)
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.patches import Patch
from matplotlib.colors import LogNorm
import geopandas as gpd
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
t0 = time.time()
print("=== L21 宅地開発状況 20 件 統合分析 ===", flush=True)
# =============================================================================
# 0. 定数: 20 dataset_id, 行政区域・用途地域の対応 dataset_id
# =============================================================================
DATA_DIR = ROOT / "data" / "extras" / "L21_housing_development"
ADMIN_DIR = ROOT / "data" / "extras" / "L15_admin_zones"
USEZONE_DIR = ROOT / "data" / "extras" / "L17_use_zones"
TARGET_CRS = "EPSG:6671"
# (dataset_id, 市町名, 行政_dsid, 用途地域_dsid, 都市タイプ)
CITY_DEFS = [
(1355, "広島市", 786, 794, "政令市"),
(1354, "呉市", 797, 804, "中核市"),
(1369, "福山市", 832, 837, "中核市"),
(1364, "東広島市", 868, 875, "施行時特例市"),
(1365, "廿日市市", 878, 885, "市"),
(1366, "尾道市", 824, 831, "市"),
(1358, "三原市", 814, 821, "市"),
(1363, "竹原市", 807, 811, "市"),
(1367, "府中市", 840, 847, "市"),
(1362, "大竹市", 862, 867, "市"),
(1359, "三次市", 850, 855, "市"),
(1360, "庄原市", 856, 861, "市"),
(1351, "安芸高田市", 888, 893, "市"),
(1356, "江田島市", 894, 899, "市"),
(1368, "府中町", 900, 904, "町"),
(1352, "海田町", 905, 910, "町"),
(1353, "熊野町", 911, 915, "町"),
(1357, "坂町", 916, 921, "町"),
(1370, "北広島町", 935, 940, "町"),
(1361, "世羅町", 941, 946, "町"),
]
# 公的統計参考値 (国土地理院 R6 面積、e-Stat R2 国勢調査人口千人) — L20 と共通
CITY_REF = {
"広島市": {"area_km2": 906.7, "pop_k": 1189},
"呉市": {"area_km2": 352.8, "pop_k": 210},
"福山市": {"area_km2": 518.1, "pop_k": 459},
"東広島市": {"area_km2": 635.3, "pop_k": 198},
"廿日市市": {"area_km2": 489.5, "pop_k": 117},
"尾道市": {"area_km2": 285.1, "pop_k": 130},
"三原市": {"area_km2": 471.6, "pop_k": 90},
"竹原市": {"area_km2": 118.2, "pop_k": 24},
"府中市": {"area_km2": 195.8, "pop_k": 37},
"大竹市": {"area_km2": 78.7, "pop_k": 26},
"三次市": {"area_km2": 778.1, "pop_k": 50},
"庄原市": {"area_km2":1246.5, "pop_k": 33},
"安芸高田市": {"area_km2": 537.8, "pop_k": 27},
"江田島市": {"area_km2": 100.7, "pop_k": 22},
"府中町": {"area_km2": 10.4, "pop_k": 53},
"海田町": {"area_km2": 13.8, "pop_k": 30},
"熊野町": {"area_km2": 33.7, "pop_k": 23},
"坂町": {"area_km2": 15.7, "pop_k": 12},
"北広島町": {"area_km2": 646.2, "pop_k": 17},
"世羅町": {"area_km2": 278.2, "pop_k": 15},
}
# 市町タイプ別カラー
CTYPE_COLOR = {
"政令市": "#cf222e", "中核市": "#bf3989",
"施行時特例市": "#a371f7", "市": "#0969da", "町": "#1f883d",
}
CITY_ORDER = [d[1] for d in CITY_DEFS]
# 事業用途 JIGYO_YO コード辞書 (DoBoX 仕様書なし、観察と推定)
JIGYO_YO_LABELS = {
1: "コード1 (住宅用と推定)",
2: "コード2",
3: "コード3",
5: "コード5",
6: "コード6",
}
# 事業種別 JIGYO_SIN コード辞書 (DoBoX 仕様書なし)
JIGYO_SIN_LABELS = {1: "コード1", 2: "コード2"}
# 用途地域 YOTO_CD コード辞書 (L13/L17 で実証済)
YOTO_CD_NAMES = {
1: "第一種低層住居専用",
2: "第二種低層住居専用",
3: "第一種中高層住居専用",
4: "第二種中高層住居専用",
5: "第一種住居",
6: "第二種住居",
7: "準住居",
8: "近隣商業",
9: "商業",
10: "準工業",
11: "工業",
12: "工業専用",
13: "田園住居",
}
# 5 大用途グループ (要件 P 配慮で平易な日本語)
YOTO_GROUP = {
"低層住居": [1, 2, 13], # 第1種・第2種低層・田園住居
"中高層住居": [3, 4], # 第1種・第2種中高層
"住居系": [5, 6, 7], # 第1種・第2種住居・準住居
"商業系": [8, 9], # 近隣商業・商業
"工業系": [10, 11, 12], # 準工業・工業・工業専用
}
YOTO_GROUP_OF_CD = {cd: g for g, cds in YOTO_GROUP.items() for cd in cds}
# =============================================================================
# 1. 20 GeoJSON 統合読み込み + 行政区域背景
# =============================================================================
print("\n[1] 20 GeoJSON 統合読み込み (スキーマ分岐対応)", flush=True)
t1 = time.time()
def load_geojson_zip(zip_path: Path) -> gpd.GeoDataFrame:
"""ZIP 内の単一 .geojson を BytesIO 経由で読み込む"""
with zipfile.ZipFile(zip_path) as zf:
gjs = [n for n in zf.namelist() if n.endswith(".geojson")]
if not gjs:
raise FileNotFoundError(f"no .geojson in {zip_path.name}")
with zf.open(gjs[0]) as f:
return gpd.read_file(io.BytesIO(f.read()))
def safe_to_datetime(s):
"""object/datetime 混在を許容して datetime に正規化。
解釈不能な文字列 (例: 「許可日(2016/07/26)より30日以内」) は NaT になる。"""
if pd.api.types.is_datetime64_any_dtype(s):
return s
return pd.to_datetime(s, errors="coerce")
# 主スキーマ (Point + KAIHATU_A) と 副スキーマ (Polygon + JIGYO_N) を分けて読む
PRIMARY_COLS = {"ID", "TOKEI_CD", "CITY_CD", "KUIKI_CD", "ZU_NO",
"KAIHATU_A", "JIGYO_KS", "JIGYO_KE",
"JIGYO_YO", "JIGYO_SIN", "BIKOU", "RITTEKI_CD"}
primary_frames = [] # 17 市町 (Point + KAIHATU_A 系)
alt_frames = [] # 3 市町 (Polygon + JIGYO_N 系)
schema_log = []
for dsid, name, _adm, _yz, ctype in CITY_DEFS:
z = DATA_DIR / f"takuchi_{dsid}_{name}.zip"
g = load_geojson_zip(z)
cols = set(g.columns)
is_primary = "KAIHATU_A" in cols and "JIGYO_KS" in cols
schema_log.append({
"dsid": dsid, "city": name, "ctype": ctype,
"n": len(g),
"schema": "PRIMARY" if is_primary else "ALT",
"geom_types": ",".join(sorted(g.geometry.type.unique().tolist())),
"cols": sorted(cols),
})
if is_primary:
# datetime 正規化 (広島市・廿日市市・海田町・世羅町は object 混在)
g["JIGYO_KS"] = safe_to_datetime(g["JIGYO_KS"])
g["JIGYO_KE"] = safe_to_datetime(g["JIGYO_KE"])
g["src_city"] = name
g["src_dsid"] = dsid
g["ctype"] = ctype
primary_frames.append(g)
else:
# 旧フォーマット (公有水面埋立等)。観察用に保管
g["src_city"] = name
g["src_dsid"] = dsid
g["ctype"] = ctype
alt_frames.append(g)
# 主スキーマ統合
hd_pts = gpd.GeoDataFrame(pd.concat(primary_frames, ignore_index=True),
geometry="geometry", crs=primary_frames[0].crs)
hd_pts = hd_pts.to_crs(TARGET_CRS)
N_PRIMARY = len(hd_pts)
# 副スキーマ (Polygon 系) — 統合せず観察用 list として持つ
alt_concat = gpd.GeoDataFrame(pd.concat(alt_frames, ignore_index=True),
geometry="geometry", crs=alt_frames[0].crs)
alt_concat = alt_concat.to_crs(TARGET_CRS)
N_ALT = len(alt_concat)
N_TOTAL = N_PRIMARY + N_ALT
print(f" PRIMARY (17 市町 Point): {N_PRIMARY} 件", flush=True)
print(f" ALT ( 3 市町 Polygon): {N_ALT} 件 (公有水面埋立等)", flush=True)
print(f" TOTAL : {N_TOTAL} 件", flush=True)
# 行政区域 (L15 共有) を 21 市町分 dissolve
admin_frames = []
for _dsid, name, adm_ds, _yz, _ct in CITY_DEFS:
z = ADMIN_DIR / f"admin_{adm_ds}_{name}.zip"
g = load_geojson_zip(z)
g["city"] = name
admin_frames.append(g)
admin_all = gpd.GeoDataFrame(pd.concat(admin_frames, ignore_index=True),
geometry="geometry", crs=admin_frames[0].crs)
admin_all = admin_all.to_crs(TARGET_CRS)
admin_diss = admin_all.dissolve(by="city").reset_index()
admin_diss["admin_area_km2"] = admin_diss.geometry.area / 1e6
print(f" 行政区域 dissolve: {len(admin_diss)} 件 ({time.time()-t1:.2f}s)", flush=True)
# =============================================================================
# 2. 派生列の作成 — 事業期間 (月)、年別、面積階級
# =============================================================================
print("\n[2] 派生列作成 (事業期間・年別・面積階級)", flush=True)
t1 = time.time()
# 事業期間 (月)
dur_days = (hd_pts["JIGYO_KE"] - hd_pts["JIGYO_KS"]).dt.days
hd_pts["dur_days"] = dur_days
hd_pts["dur_months"] = (dur_days / 30.4375).round(2)
# 開始年・終了年
hd_pts["ks_year"] = hd_pts["JIGYO_KS"].dt.year
hd_pts["ke_year"] = hd_pts["JIGYO_KE"].dt.year
# 面積階級 (m²)
A_BANDS = [(0, 1000, "0.1ha未満"),
(1000, 3000, "0.1-0.3ha"),
(3000, 10000, "0.3-1ha"),
(10000, 30000, "1-3ha"),
(30000, 100000, "3-10ha"),
(100000, 1e7, "10ha以上")]
A_LABELS = [b[2] for b in A_BANDS]
hd_pts["area_band"] = pd.cut(hd_pts["KAIHATU_A"],
bins=[b[0] for b in A_BANDS] + [1e9],
labels=A_LABELS,
include_lowest=True)
# KUIKI_CD ラベル (1=市街化, 3=市街化調整, 5=都計外 と推定)
KUIKI_LABEL = {0: "区域不明", 1: "市街化区域", 2: "用途白地等",
3: "市街化調整区域", 5: "都市計画区域外"}
hd_pts["kuiki_label"] = hd_pts["KUIKI_CD"].map(KUIKI_LABEL).fillna(
hd_pts["KUIKI_CD"].astype(str))
# 進行中フラグ (KE が 2021 以降か NaT)
LATEST_DATA_END = pd.Timestamp("2020-12-31")
hd_pts["is_completed_by_2020"] = (
hd_pts["JIGYO_KE"].notna() &
(hd_pts["JIGYO_KE"] <= LATEST_DATA_END)
)
print(f" 派生列 OK ({time.time()-t1:.2f}s)", flush=True)
print(f" KAIHATU_A: median={hd_pts['KAIHATU_A'].median():.0f} m², "
f"max={hd_pts['KAIHATU_A'].max():,.0f} m²", flush=True)
print(f" dur_months: median={hd_pts['dur_months'].median():.1f}, "
f"p90={hd_pts['dur_months'].quantile(0.9):.1f}, "
f"max={hd_pts['dur_months'].max():.1f}", flush=True)
print(f" ks_year unique: {sorted(hd_pts['ks_year'].dropna().unique().astype(int))}",
flush=True)
# =============================================================================
# 3. 市町別集計 (PRIMARY 17 市町)
# =============================================================================
print("\n[3] 市町別集計", flush=True)
t1 = time.time()
# PRIMARY 17 市町のみ
PRIMARY_CITIES = [c for c, n_, in
[(s["city"], s["n"]) for s in schema_log if s["schema"] == "PRIMARY"]]
ALT_CITIES = [s["city"] for s in schema_log if s["schema"] == "ALT"]
city_n = hd_pts.groupby("src_city").size().rename("n_dev")
city_summary = pd.DataFrame({
"city": PRIMARY_CITIES,
"ctype": [next(d[4] for d in CITY_DEFS if d[1] == c) for c in PRIMARY_CITIES],
"dsid": [next(d[0] for d in CITY_DEFS if d[1] == c) for c in PRIMARY_CITIES],
})
city_summary["area_km2"] = city_summary["city"].map(lambda c: CITY_REF[c]["area_km2"])
city_summary["pop_k"] = city_summary["city"].map(lambda c: CITY_REF[c]["pop_k"])
city_summary["n_dev"] = city_summary["city"].map(city_n).fillna(0).astype(int)
city_summary["density_per_100km2"] = (city_summary["n_dev"]
/ city_summary["area_km2"] * 100).round(2)
city_summary["per_10k_pop"] = (city_summary["n_dev"]
/ city_summary["pop_k"] * 10).round(2)
# 開発総面積 (ha)
city_a = hd_pts.groupby("src_city")["KAIHATU_A"].sum().rename("a_total_m2")
city_summary["a_total_ha"] = city_summary["city"].map(city_a).fillna(0) / 10000
city_summary["a_total_ha"] = city_summary["a_total_ha"].round(2)
# 平均・中央値面積
city_a_med = hd_pts.groupby("src_city")["KAIHATU_A"].median().rename("a_median")
city_a_max = hd_pts.groupby("src_city")["KAIHATU_A"].max().rename("a_max")
city_summary["a_median_m2"] = city_summary["city"].map(city_a_med).fillna(0).astype(int)
city_summary["a_max_m2"] = city_summary["city"].map(city_a_max).fillna(0).astype(int)
# 期間統計
city_d_med = hd_pts.groupby("src_city")["dur_months"].median().rename("d_med")
city_summary["d_median_mo"] = city_summary["city"].map(city_d_med).round(1)
# クロス: 市町×面積階級
area_cross = pd.crosstab(hd_pts["src_city"], hd_pts["area_band"]).reindex(
PRIMARY_CITIES, fill_value=0)[A_LABELS]
# クロス: 市町×JIGYO_YO
yo_cross = pd.crosstab(hd_pts["src_city"], hd_pts["JIGYO_YO"]).reindex(
PRIMARY_CITIES, fill_value=0)
# クロス: 市町×JIGYO_SIN
sin_cross = pd.crosstab(hd_pts["src_city"], hd_pts["JIGYO_SIN"]).reindex(
PRIMARY_CITIES, fill_value=0)
# クロス: 市町×KUIKI_CD
kuiki_cross = pd.crosstab(hd_pts["src_city"], hd_pts["kuiki_label"]).reindex(
PRIMARY_CITIES, fill_value=0)
# 年別 (開始年)
year_n = hd_pts.groupby("ks_year").size().rename("n").reset_index()
year_n["ks_year"] = year_n["ks_year"].astype(int)
# 年別×市町
year_city_cross = pd.crosstab(hd_pts["ks_year"].dropna().astype(int),
hd_pts.loc[hd_pts["ks_year"].notna(), "src_city"])
print(f" 集計完了 ({time.time()-t1:.2f}s)", flush=True)
# =============================================================================
# 4. 用途地域 sjoin — 開発がどの用途地域に立地したか
# =============================================================================
print("\n[4] 用途地域 sjoin (PRIMARY 17 市町)", flush=True)
t1 = time.time()
# 用途地域は L17 が 21 件入っている。20 PRIMARY 市町分を縦結合
yz_frames = []
for dsid, name, _adm, yz_ds, _ct in CITY_DEFS:
if name in ALT_CITIES:
continue # ALT はスキップ
z = USEZONE_DIR / f"use_zone_{yz_ds}_{name}.zip"
g = load_geojson_zip(z)
g["city"] = name
yz_frames.append(g)
yz_all = gpd.GeoDataFrame(pd.concat(yz_frames, ignore_index=True),
geometry="geometry", crs=yz_frames[0].crs).to_crs(TARGET_CRS)
yz_all["yoto_group"] = yz_all["YOTO_CD"].map(YOTO_GROUP_OF_CD).fillna("不明")
yz_all["yoto_name"] = yz_all["YOTO_CD"].map(YOTO_CD_NAMES).fillna("不明")
print(f" 用途地域 17 市町 計 {len(yz_all):,} polygon", flush=True)
# sjoin: 開発点 in 用途地域
hd_in_yz = gpd.sjoin(hd_pts, yz_all[["YOTO_CD", "yoto_name", "yoto_group", "geometry"]],
how="left", predicate="within")
# 重複 (1 点が複数ポリゴンに含まれる場合) は最初を採用
hd_in_yz = hd_in_yz.loc[~hd_in_yz.index.duplicated(keep="first")]
print(f" sjoin: 開発 PRIMARY {N_PRIMARY} 点 中 {hd_in_yz['YOTO_CD'].notna().sum()} 点 が用途地域内",
flush=True)
# 用途地域 in / out クロス
hd_pts["yoto_group"] = hd_in_yz["yoto_group"]
hd_pts["yoto_name"] = hd_in_yz["yoto_name"]
hd_pts["yoto_cd"] = hd_in_yz["YOTO_CD"]
hd_pts["yoto_group"] = hd_pts["yoto_group"].fillna("用途地域外")
yz_cross = pd.crosstab(hd_pts["src_city"], hd_pts["yoto_group"]).reindex(
PRIMARY_CITIES, fill_value=0)
# 大規模開発 (>= 1ha) と用途地域のクロス
big_dev = hd_pts[hd_pts["KAIHATU_A"] >= 10000]
big_yz_cross = big_dev["yoto_group"].value_counts().rename("count")
print(f" 大規模 (>=1ha) 開発: {len(big_dev)} 件", flush=True)
print(f" ({time.time()-t1:.2f}s)", flush=True)
# =============================================================================
# 5. 全県 hexbin (8km 矩形) ホットスポット
# =============================================================================
print("\n[5] 全県 8km ビン ホットスポット", flush=True)
t1 = time.time()
xmin, ymin, xmax, ymax = hd_pts.total_bounds
HEX_SIZE_M = 8000 # 8 km grid (件数少ないため 4km より粗く)
gx = np.arange(xmin - HEX_SIZE_M, xmax + HEX_SIZE_M, HEX_SIZE_M)
gy = np.arange(ymin - HEX_SIZE_M, ymax + HEX_SIZE_M, HEX_SIZE_M)
xs = hd_pts.geometry.x.values
ys = hd_pts.geometry.y.values
ix = np.searchsorted(gx, xs, side="right") - 1
iy = np.searchsorted(gy, ys, side="right") - 1
hd_pts["_grid_ix"] = ix
hd_pts["_grid_iy"] = iy
grid_n = hd_pts.groupby(["_grid_ix", "_grid_iy"]).size().rename("n").reset_index()
print(f" 非ゼロ cell: {len(grid_n)}, max {grid_n['n'].max()}", flush=True)
print(f" ({time.time()-t1:.2f}s)", flush=True)
# =============================================================================
# 6. CSV 出力
# =============================================================================
print("\n[6] CSV 出力", flush=True)
t1 = time.time()
city_summary.to_csv(ASSETS / "L21_city_summary.csv", index=False, encoding="utf-8-sig")
area_cross.to_csv(ASSETS / "L21_area_cross.csv", encoding="utf-8-sig")
yo_cross.to_csv(ASSETS / "L21_yo_cross.csv", encoding="utf-8-sig")
sin_cross.to_csv(ASSETS / "L21_sin_cross.csv", encoding="utf-8-sig")
kuiki_cross.to_csv(ASSETS / "L21_kuiki_cross.csv", encoding="utf-8-sig")
yz_cross.to_csv(ASSETS / "L21_yz_cross.csv", encoding="utf-8-sig")
year_city_cross.to_csv(ASSETS / "L21_year_city_cross.csv", encoding="utf-8-sig")
year_n.to_csv(ASSETS / "L21_year_total.csv", index=False, encoding="utf-8-sig")
# 大規模開発 top 30
big_top = hd_pts.nlargest(30, "KAIHATU_A")[
["src_city", "ID", "KAIHATU_A", "JIGYO_KS", "JIGYO_KE",
"dur_months", "JIGYO_YO", "JIGYO_SIN", "kuiki_label", "yoto_name"]
].copy()
big_top["x"] = hd_pts.loc[big_top.index, "geometry"].x.round(1)
big_top["y"] = hd_pts.loc[big_top.index, "geometry"].y.round(1)
big_top.to_csv(ASSETS / "L21_big_dev_top30.csv", index=False, encoding="utf-8-sig")
# スキーマ分岐ログ
pd.DataFrame(schema_log).to_csv(ASSETS / "L21_schema_log.csv",
index=False, encoding="utf-8-sig")
# 副スキーマ (3 市町) の生レコード一覧
alt_table = alt_concat.drop(columns=["geometry"]).copy()
alt_table["geom_type"] = alt_concat.geometry.type.values
alt_table.to_csv(ASSETS / "L21_alt_records.csv",
index=False, encoding="utf-8-sig")
# 用途地域分布
yz_dist = hd_pts["yoto_group"].value_counts().rename("n").reset_index()
yz_dist.columns = ["yoto_group", "n"]
yz_dist["share_pct"] = (yz_dist["n"] / N_PRIMARY * 100).round(2)
yz_dist.to_csv(ASSETS / "L21_yz_dist.csv", index=False, encoding="utf-8-sig")
print(f" ({time.time()-t1:.2f}s)", flush=True)
# =============================================================================
# 7. 図の作成 (9 枚)
# =============================================================================
print("\n[7] 図の作成", flush=True)
t1 = time.time()
# --- Fig 1: 全県 1,038 件 点マップ + 行政境界 (面積バブル + 用途グループ色分け) ---
fig, ax = plt.subplots(figsize=(13, 9))
admin_diss.boundary.plot(ax=ax, color="#aaa", linewidth=0.4)
yz_palette = {
"低層住居": "#2ca02c",
"中高層住居": "#98df8a",
"住居系": "#1f77b4",
"商業系": "#ff7f0e",
"工業系": "#8c564b",
"用途地域外": "#7f7f7f",
}
for grp, col in yz_palette.items():
sub = hd_pts[hd_pts["yoto_group"] == grp]
if len(sub) == 0:
continue
sizes = np.clip(np.log10(sub["KAIHATU_A"].clip(100, 1e7)) * 12 - 20, 5, 200)
ax.scatter(sub.geometry.x, sub.geometry.y,
c=col, s=sizes, alpha=0.65, edgecolor="white", linewidth=0.3,
label=f"{grp} ({len(sub)})")
# ALT 市町の Polygon を別色で重ねる (注意喚起)
alt_concat.plot(ax=ax, facecolor="#ffeb3b", edgecolor="#f57c00",
linewidth=0.5, alpha=0.55,
label=f"ALTスキーマ ({len(alt_concat)})")
ax.set_title(f"広島県 宅地開発事業 2016-2020 (PRIMARY {N_PRIMARY} + ALT {N_ALT}) — "
f"用途グループ色 + 面積バブル",
fontsize=13)
ax.set_aspect("equal")
ax.set_xlabel("x (m)")
ax.set_ylabel("y (m)")
ax.legend(loc="lower left", fontsize=8, markerscale=1.5, framealpha=0.9)
plt.tight_layout()
plt.savefig(ASSETS / "L21_fig01_all_points.png", dpi=130)
plt.close("all")
print(f" Fig 1 完成 ({time.time()-t1:.2f}s)", flush=True)
# --- Fig 2: 8km ビン ホットスポット (log scale) ---
fig, ax = plt.subplots(figsize=(13, 9))
admin_diss.boundary.plot(ax=ax, color="#444", linewidth=0.5)
gx_centers = (gx[:-1] + gx[1:]) / 2
gy_centers = (gy[:-1] + gy[1:]) / 2
n_max = grid_n["n"].max()
norm = LogNorm(vmin=1, vmax=n_max)
cmap = plt.get_cmap("YlOrRd")
for _, row in grid_n.iterrows():
cx = gx_centers[int(row["_grid_ix"])]
cy = gy_centers[int(row["_grid_iy"])]
ax.add_patch(plt.Rectangle((cx - HEX_SIZE_M/2, cy - HEX_SIZE_M/2),
HEX_SIZE_M, HEX_SIZE_M,
facecolor=cmap(norm(row["n"])),
edgecolor="none", alpha=0.85))
admin_diss.boundary.plot(ax=ax, color="#222", linewidth=0.6)
ax.set_xlim(xmin - 5000, xmax + 5000)
ax.set_ylim(ymin - 5000, ymax + 5000)
ax.set_aspect("equal")
ax.set_title(f"8 km ビン 宅地開発件数 (log scale) — 県内のホットスポット",
fontsize=13)
sm = plt.cm.ScalarMappable(cmap=cmap, norm=norm)
cb = plt.colorbar(sm, ax=ax, fraction=0.03, pad=0.02)
cb.set_label("ビン内 開発件数 (log scale)")
ax.set_xlabel("x (m)"); ax.set_ylabel("y (m)")
plt.tight_layout()
plt.savefig(ASSETS / "L21_fig02_hexbin.png", dpi=130)
plt.close("all")
print(f" Fig 2 完成 ({time.time()-t1:.2f}s)", flush=True)
# --- Fig 3: 市町別 3 指標棒グラフ (件数・密度・千人あたり) ---
fig, axes = plt.subplots(1, 3, figsize=(16, 9))
cs_sorted = city_summary.sort_values("n_dev", ascending=True)
colors = [CTYPE_COLOR[ct] for ct in cs_sorted["ctype"]]
axes[0].barh(cs_sorted["city"], cs_sorted["n_dev"], color=colors)
axes[0].set_title("宅地開発件数 (5 年計)", fontsize=12)
axes[0].set_xlabel("件数")
for i, v in enumerate(cs_sorted["n_dev"]):
axes[0].text(v + max(cs_sorted["n_dev"])*0.01, i, f"{v}",
va="center", fontsize=8)
cs_sorted2 = city_summary.sort_values("density_per_100km2", ascending=True)
colors2 = [CTYPE_COLOR[ct] for ct in cs_sorted2["ctype"]]
axes[1].barh(cs_sorted2["city"], cs_sorted2["density_per_100km2"], color=colors2)
axes[1].set_title("開発密度 (件/100km²)", fontsize=12)
axes[1].set_xlabel("件/100km² (5 年計)")
for i, v in enumerate(cs_sorted2["density_per_100km2"]):
axes[1].text(v + max(cs_sorted2["density_per_100km2"])*0.01, i,
f"{v:.1f}", va="center", fontsize=8)
cs_sorted3 = city_summary.sort_values("a_total_ha", ascending=True)
colors3 = [CTYPE_COLOR[ct] for ct in cs_sorted3["ctype"]]
axes[2].barh(cs_sorted3["city"], cs_sorted3["a_total_ha"], color=colors3)
axes[2].set_title("開発総面積 (ha, 5 年計)", fontsize=12)
axes[2].set_xlabel("総面積 ha")
for i, v in enumerate(cs_sorted3["a_total_ha"]):
axes[2].text(v + max(cs_sorted3["a_total_ha"])*0.01, i,
f"{v:.0f}", va="center", fontsize=8)
handles = [Patch(facecolor=v, label=k) for k, v in CTYPE_COLOR.items()]
axes[0].legend(handles=handles, loc="lower right", fontsize=8, title="市町タイプ")
plt.suptitle("市町別 宅地開発 3 指標 (件数 / 密度 / 総面積)", fontsize=14)
plt.tight_layout()
plt.savefig(ASSETS / "L21_fig03_city_indicators.png", dpi=130)
plt.close("all")
print(f" Fig 3 完成 ({time.time()-t1:.2f}s)", flush=True)
# --- Fig 4: 開発面積分布 (ヒストグラム log scale + 箱ひげ) ---
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
# 左: ヒストグラム log scale
a = hd_pts["KAIHATU_A"].clip(lower=1) # log のため 0 回避
log_bins = np.logspace(np.log10(100), np.log10(a.max() * 1.05), 50)
axes[0].hist(a, bins=log_bins, color="#0969da", edgecolor="white", alpha=0.85)
axes[0].set_xscale("log")
axes[0].set_xlabel("開発面積 KAIHATU_A (m², log scale)")
axes[0].set_ylabel("件数")
axes[0].axvline(10000, color="red", linestyle="--", alpha=0.7, label="1ha (10,000m²)")
axes[0].axvline(100000, color="purple", linestyle="--", alpha=0.7, label="10ha (100,000m²)")
axes[0].axvline(a.median(), color="orange", linestyle="--", alpha=0.7,
label=f"中央値 {a.median():.0f}m²")
axes[0].set_title(f"開発面積分布 (n={N_PRIMARY}, log scale) — 4 桁スパン",
fontsize=12)
axes[0].legend()
# 右: 市町別箱ひげ (件数降順)
order_a = city_summary.sort_values("n_dev", ascending=False)["city"].tolist()
data_a = [hd_pts[hd_pts["src_city"] == c]["KAIHATU_A"].values
for c in order_a]
axes[1].boxplot(data_a, vert=False, tick_labels=order_a,
showfliers=True,
flierprops={"marker": ".", "markersize": 3,
"markerfacecolor": "#888"})
axes[1].set_xscale("log")
axes[1].set_xlabel("開発面積 (m², log scale)")
axes[1].axvline(10000, color="red", linestyle="--", alpha=0.5)
axes[1].axvline(100000, color="purple", linestyle="--", alpha=0.5)
axes[1].set_title("市町別 開発面積 (件数降順)", fontsize=12)
plt.tight_layout()
plt.savefig(ASSETS / "L21_fig04_area_dist.png", dpi=130)
plt.close("all")
print(f" Fig 4 完成 ({time.time()-t1:.2f}s)", flush=True)
# --- Fig 5: 事業期間分布 (KE - KS の月数) ---
valid_dur = hd_pts.dropna(subset=["dur_months"])
valid_dur = valid_dur[valid_dur["dur_months"].between(0, 120)] # 0-120 ヶ月で外れ値を切る
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
# 左: 全件ヒスト
axes[0].hist(valid_dur["dur_months"], bins=40, color="#1f883d",
edgecolor="white", alpha=0.85)
axes[0].set_xlabel("事業期間 (月)")
axes[0].set_ylabel("件数")
axes[0].axvline(12, color="red", linestyle="--", alpha=0.7, label="1 年")
axes[0].axvline(36, color="purple", linestyle="--", alpha=0.7, label="3 年")
axes[0].axvline(valid_dur["dur_months"].median(), color="orange",
linestyle="--", alpha=0.7,
label=f"中央値 {valid_dur['dur_months'].median():.1f}ヶ月")
axes[0].set_title(f"事業期間分布 (n={len(valid_dur)}, 0-120 ヶ月)", fontsize=12)
axes[0].legend()
# 右: 面積 vs 期間 散布 (log-log + 用途グループ色)
sub = hd_pts.dropna(subset=["dur_months", "KAIHATU_A"])
sub = sub[(sub["dur_months"] > 0) & (sub["dur_months"] <= 120)]
for grp, col in yz_palette.items():
s = sub[sub["yoto_group"] == grp]
if len(s) == 0:
continue
axes[1].scatter(s["KAIHATU_A"], s["dur_months"],
c=col, s=18, alpha=0.6, edgecolor="white", linewidth=0.3,
label=f"{grp} ({len(s)})")
axes[1].set_xscale("log")
axes[1].set_xlabel("開発面積 (m², log)")
axes[1].set_ylabel("事業期間 (月)")
axes[1].set_title("面積 × 期間 散布 (用途グループ色)", fontsize=12)
axes[1].axhline(12, color="red", linestyle="--", alpha=0.4)
axes[1].axhline(36, color="purple", linestyle="--", alpha=0.4)
axes[1].legend(loc="upper left", fontsize=8, markerscale=1.5)
plt.tight_layout()
plt.savefig(ASSETS / "L21_fig05_duration.png", dpi=130)
plt.close("all")
print(f" Fig 5 完成 ({time.time()-t1:.2f}s)", flush=True)
# --- Fig 6: 年別事業開始数 推移 (全体 + 市町 stack) ---
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
# 左: 全県年別棒
yr = year_n[(year_n["ks_year"] >= 2014) & (year_n["ks_year"] <= 2022)]
axes[0].bar(yr["ks_year"], yr["n"], color="#0969da", edgecolor="white")
for i, (y, n) in enumerate(zip(yr["ks_year"], yr["n"])):
axes[0].text(y, n + max(yr["n"])*0.02, str(n), ha="center", fontsize=10)
axes[0].set_xlabel("事業開始年 JIGYO_KS")
axes[0].set_ylabel("件数")
axes[0].set_title("年別 事業開始数 (全県)", fontsize=12)
axes[0].set_xticks(yr["ks_year"])
# 右: 市町×年 stack
year_city = year_city_cross.loc[
(year_city_cross.index >= 2014) & (year_city_cross.index <= 2022)
]
year_city = year_city[[c for c in PRIMARY_CITIES if c in year_city.columns]]
# 件数多い順に並べ替え
order_c = city_summary.sort_values("n_dev", ascending=False)["city"].tolist()
order_c = [c for c in order_c if c in year_city.columns]
year_city = year_city[order_c]
bottom = np.zeros(len(year_city))
import matplotlib.cm as cm
city_colors = cm.tab20(np.linspace(0, 1, len(order_c)))
for ci, city in enumerate(order_c):
vals = year_city[city].values
axes[1].bar(year_city.index, vals, bottom=bottom,
color=city_colors[ci], edgecolor="white", linewidth=0.2,
label=city if city_summary[city_summary["city"] == city]["n_dev"].iloc[0] >= 30 else None)
bottom += vals
axes[1].set_xlabel("事業開始年")
axes[1].set_ylabel("件数")
axes[1].set_title("市町別 年次推移 (上位市町をラベル)", fontsize=12)
axes[1].legend(loc="upper right", fontsize=7, ncol=2)
axes[1].set_xticks(year_city.index)
plt.tight_layout()
plt.savefig(ASSETS / "L21_fig06_year_trend.png", dpi=130)
plt.close("all")
print(f" Fig 6 完成 ({time.time()-t1:.2f}s)", flush=True)
# --- Fig 7: 用途地域 sjoin 結果 — 棒 + 主題図 (福山市) ---
fig, axes = plt.subplots(1, 2, figsize=(16, 8))
# 左: 用途グループ stack (市町別シェア)
yz_share = yz_cross.div(yz_cross.sum(axis=1), axis=0)
yz_share = yz_share.reindex(order_c) # 件数降順
bottom = np.zeros(len(yz_share))
for grp in ["低層住居", "中高層住居", "住居系", "商業系", "工業系", "用途地域外"]:
if grp not in yz_share.columns:
continue
vals = yz_share[grp].fillna(0).values
axes[0].barh(yz_share.index, vals, left=bottom,
color=yz_palette[grp], label=grp)
bottom += vals
axes[0].set_xlabel("用途地域グループ 構成比")
axes[0].set_xlim(0, 1)
axes[0].set_title(f"市町別 — 開発の立地用途地域構成", fontsize=12)
axes[0].invert_yaxis()
axes[0].legend(loc="lower right", fontsize=8, ncol=2)
# 右: 福山市 (496 件) の用途地域マップ + 開発点
ax1 = axes[1]
city = "福山市"
city_yz = yz_all[yz_all["city"] == city]
city_pts = hd_pts[hd_pts["src_city"] == city]
admin_diss[admin_diss["city"] == city].boundary.plot(ax=ax1,
color="#444",
linewidth=0.6)
for grp, col in yz_palette.items():
if grp == "用途地域外":
continue
sub = city_yz[city_yz["yoto_group"] == grp]
if len(sub) == 0:
continue
sub.plot(ax=ax1, facecolor=col, edgecolor="none", alpha=0.45)
ax1.scatter(city_pts.geometry.x, city_pts.geometry.y,
c="#222", s=10, alpha=0.75, edgecolor="white", linewidth=0.3,
label=f"開発点 (n={len(city_pts)})")
ax1.set_aspect("equal")
ax1.set_title(f"{city} — 用途地域 (色) + 宅地開発点 (黒)",
fontsize=12)
ax1.set_xticks([]); ax1.set_yticks([])
ax1.legend(loc="lower right", fontsize=9)
plt.tight_layout()
plt.savefig(ASSETS / "L21_fig07_use_zone.png", dpi=130)
plt.close("all")
print(f" Fig 7 完成 ({time.time()-t1:.2f}s)", flush=True)
# --- Fig 8: 大規模開発バブル + KUIKI_CD クロス ---
fig, axes = plt.subplots(1, 2, figsize=(16, 8))
# 左: 大規模 (>=1ha) バブルマップ
ax0 = axes[0]
admin_diss.boundary.plot(ax=ax0, color="#aaa", linewidth=0.4)
big = hd_pts[hd_pts["KAIHATU_A"] >= 10000]
sizes = np.clip(np.sqrt(big["KAIHATU_A"]) / 5, 8, 200)
sc = ax0.scatter(big.geometry.x, big.geometry.y,
c=np.log10(big["KAIHATU_A"]), s=sizes, cmap="plasma",
alpha=0.75, edgecolor="white", linewidth=0.4)
ax0.set_aspect("equal")
ax0.set_title(f"大規模開発 (≥1ha) {len(big)} 件 — 面積 log スケール",
fontsize=12)
cb = plt.colorbar(sc, ax=ax0, fraction=0.03, pad=0.02)
cb.set_label("log10(KAIHATU_A m²)")
# top 5 ラベル
top5 = big.nlargest(5, "KAIHATU_A")
for _, r in top5.iterrows():
ax0.annotate(f"{r['src_city']}\n{r['KAIHATU_A']/10000:.1f}ha",
(r.geometry.x, r.geometry.y),
fontsize=8, color="#222",
xytext=(8, 8), textcoords="offset points",
bbox=dict(boxstyle="round,pad=0.2",
fc="white", ec="#888", alpha=0.85))
ax0.set_xlabel("x (m)"); ax0.set_ylabel("y (m)")
# 右: 面積階級 × KUIKI_CD ヒートマップ
ax1 = axes[1]
ka_cross = pd.crosstab(hd_pts["area_band"], hd_pts["kuiki_label"])
# KUIKI 列順を揃える
kuiki_order = [k for k in ["市街化区域", "市街化調整区域", "用途白地等",
"都市計画区域外", "区域不明"] if k in ka_cross.columns]
# 残り列は最後に
extra = [c for c in ka_cross.columns if c not in kuiki_order]
ka_cross = ka_cross[kuiki_order + extra].reindex(A_LABELS, fill_value=0)
ka_log = np.log10(ka_cross.values + 1)
im = ax1.imshow(ka_log, cmap="viridis", aspect="auto")
ax1.set_xticks(range(len(ka_cross.columns)))
ax1.set_xticklabels(ka_cross.columns, rotation=30, ha="right", fontsize=10)
ax1.set_yticks(range(len(ka_cross.index)))
ax1.set_yticklabels(ka_cross.index, fontsize=10)
for i in range(ka_cross.shape[0]):
for j in range(ka_cross.shape[1]):
v = ka_cross.iloc[i, j]
col = "white" if ka_log[i, j] > 1.0 else "#222"
ax1.text(j, i, f"{int(v)}" if v else "0",
ha="center", va="center", fontsize=9, color=col)
plt.colorbar(im, ax=ax1, label="log10(件数+1)")
ax1.set_title("面積階級 × 都市計画区域 クロス (件数)", fontsize=12)
plt.tight_layout()
plt.savefig(ASSETS / "L21_fig08_big_kuiki.png", dpi=130)
plt.close("all")
print(f" Fig 8 完成 ({time.time()-t1:.2f}s)", flush=True)
# --- Fig 9: 市町別 small multiples (上位 9 市町) ---
mult_cities = order_c[:9] # 件数多い 9 市町
fig, axes = plt.subplots(3, 3, figsize=(14, 13))
for ax_, city in zip(axes.flat, mult_cities):
pts = hd_pts[hd_pts["src_city"] == city]
bg = admin_diss[admin_diss["city"] == city]
bg.boundary.plot(ax=ax_, color="#888", linewidth=0.5)
# 用途地域背景 (薄く)
cyz = yz_all[yz_all["city"] == city]
for grp, col in yz_palette.items():
if grp == "用途地域外":
continue
s = cyz[cyz["yoto_group"] == grp]
if len(s) == 0:
continue
s.plot(ax=ax_, facecolor=col, edgecolor="none", alpha=0.25)
# 開発点 (面積バブル)
if len(pts) > 0:
sizes = np.clip(np.log10(pts["KAIHATU_A"].clip(100, 1e7)) * 8 - 12, 5, 80)
ax_.scatter(pts.geometry.x, pts.geometry.y,
c="#cf222e", s=sizes, alpha=0.7,
edgecolor="white", linewidth=0.3)
ax_.set_title(f"{city} (n={len(pts)})", fontsize=11)
ax_.set_aspect("equal")
ax_.set_xticks([]); ax_.set_yticks([])
plt.suptitle("上位 9 市町 small multiples — 用途地域 (薄色) + 開発点 (赤バブル, 面積依存)",
fontsize=13)
plt.tight_layout()
plt.savefig(ASSETS / "L21_fig09_small_multiples.png", dpi=130)
plt.close("all")
print(f" Fig 9 完成 ({time.time()-t1:.2f}s)", flush=True)
print(f"\n[7] 図 9 枚 完了 累計 {time.time()-t0:.2f}s", flush=True)
# =============================================================================
# 8. 仮説検証
# =============================================================================
print("\n[8] 仮説検証", flush=True)
t1 = time.time()
# H1: 上位市町 (新築動向と比較)
top_dev = city_summary.nlargest(3, "n_dev")["city"].tolist()
H1_top3 = top_dev
H1_includes_hiroshima_top = ("広島市" in top_dev[:1])
H1_judge = "支持 (広島市が件数1位ではない)" if not H1_includes_hiroshima_top \
else "部分支持 (広島市は1位)"
H1_top1 = city_summary.nlargest(1, "n_dev").iloc[0]
H1_top1_city = H1_top1["city"]
H1_top1_n = int(H1_top1["n_dev"])
H1_hiroshima_n = int(city_summary[city_summary["city"]=="広島市"]["n_dev"].iloc[0])
# H2: 開発面積 — 中央値 + p90 + max + log10 のスパン
a_med = float(hd_pts["KAIHATU_A"].median())
a_p90 = float(hd_pts["KAIHATU_A"].quantile(0.9))
a_max = float(hd_pts["KAIHATU_A"].max())
a_min = float(hd_pts["KAIHATU_A"].min())
log_span = np.log10(a_max) - np.log10(max(a_min, 1))
H2_judge = "支持" if log_span >= 3.0 else "部分支持"
# H3: 期間中央値・p90
dur_med = float(valid_dur["dur_months"].median())
dur_p90 = float(valid_dur["dur_months"].quantile(0.9))
H3_judge = "支持" if dur_med <= 12 else "部分支持"
# H4: JIGYO_YO=1 のシェア
yo_share_1 = float((hd_pts["JIGYO_YO"] == 1).sum() / N_PRIMARY * 100)
H4_judge = "支持" if yo_share_1 >= 50 else "部分支持"
# H5: 大規模 (>=1ha) と KUIKI_CD/用途地域 のクロス
# 当初想定 (>=10ha) は n=2 しかなくサンプル小すぎなので、>=1ha (35件) で再検証
big_for_h5 = hd_pts[hd_pts["KAIHATU_A"] >= 10000]
n_big = len(big_for_h5)
huge = hd_pts[hd_pts["KAIHATU_A"] >= 100000] # 参考: >=10ha
n_huge = len(huge)
big_kuiki = big_for_h5["kuiki_label"].value_counts()
big_in_chosei = int(big_kuiki.get("市街化調整区域", 0))
big_outside_yoto = int((big_for_h5["yoto_group"] == "用途地域外").sum())
big_outside_combined = int(((big_for_h5["yoto_group"] == "用途地域外") |
(big_for_h5["kuiki_label"] == "市街化調整区域")).sum())
big_in_shigaika = int(big_kuiki.get("市街化区域", 0))
H5_judge = "支持" if big_outside_combined >= n_big * 0.5 \
else "部分支持"
# H6: 年別 — 2016 と 2019/2020 を比較
yy = year_n.set_index("ks_year")["n"]
n_2016 = int(yy.get(2016, 0))
n_2019 = int(yy.get(2019, 0))
n_2020 = int(yy.get(2020, 0))
H6_decreasing = (n_2016 > 0) and (n_2019 + n_2020 < 2 * n_2016)
H6_judge = "支持" if H6_decreasing else "部分支持"
H_RESULTS = {
"H1": {"text": "宅地開発トップは広島市ではなく福山市・東広島市",
"result": f"件数1位 {H1_top1_city} ({H1_top1_n}), 広島市 ({H1_hiroshima_n}). top3={H1_top3}",
"judge": H1_judge},
"H2": {"text": "開発面積は4桁スパン (100m²-100ha)",
"result": f"中央値 {a_med:.0f} m², p90 {a_p90:.0f} m², "
f"最大 {a_max:,.0f} m², log10 スパン {log_span:.2f}",
"judge": H2_judge},
"H3": {"text": "事業期間中央値 ≤12 ヶ月",
"result": f"中央値 {dur_med:.1f} ヶ月, p90 {dur_p90:.1f} ヶ月",
"judge": H3_judge},
"H4": {"text": "事業用途 1 (住宅用と推定) が >50%",
"result": f"JIGYO_YO=1 シェア {yo_share_1:.1f}%",
"judge": H4_judge},
"H5": {"text": "≥1ha は市街化調整 / 用途地域外に集中 (≥10ha は n=2 で参考)",
"result": f"≥1ha {n_big} 件中、市街化調整 OR 用途地域外 "
f"= {big_outside_combined} ({big_outside_combined/max(n_big,1)*100:.0f}%) / "
f"市街化区域内 {big_in_shigaika}. ≥10ha は参考 n={n_huge}",
"judge": H5_judge},
"H6": {"text": "事業開始数は 2016→2020 で減少傾向",
"result": f"2016 {n_2016} 件、2019 {n_2019} 件、2020 {n_2020} 件",
"judge": H6_judge},
}
(ASSETS / "L21_hypothesis_results.json").write_text(
json.dumps({"results": H_RESULTS,
"n_primary": N_PRIMARY, "n_alt": N_ALT,
"alt_cities": ALT_CITIES,
"schema_log_summary": {
"primary_count": len([s for s in schema_log if s["schema"]=="PRIMARY"]),
"alt_count": len([s for s in schema_log if s["schema"]=="ALT"]),
}},
ensure_ascii=False, indent=2),
encoding="utf-8")
print(f" H1-H6 検証完了 ({time.time()-t1:.2f}s)", flush=True)
for k, v in H_RESULTS.items():
print(f" {k}: {v['judge']} -- {v['result']}")
# =============================================================================
# 9. HTML 構築
# =============================================================================
print("\n[9] HTML 構築", flush=True)
sections = []
# === セクション1: 学習目標と問い ===
ds_links_html = ", ".join(
f'#{d[0]}'
for d in CITY_DEFS
)
s1_html = f"""
本記事は、広島県インフラマネジメント基盤 DoBoX が公開する
「都市計画区域情報_宅地開発状況」シリーズ 20 件
({ds_links_html})
を縦結合し、2016-2020 年に広島県内 20 市町で実施された宅地開発事業 計 {N_TOTAL} 件
の Point データから、事業の血流 ── 開発面積・事業期間・用途/種別・地理分布・年次推移 ──
を分析する研究記事である。宅地開発状況は「これから新しい街区が立つ場所」を示すデータであり、
L20 が見た新築動向 (= 結果) の前史として機能する。
研究の問い (RQ): 広島県内の宅地開発事業 {N_TOTAL} 件 (2016-2020) は、
面積規模・事業期間・用途/種別・地理分布の観点でどのような時空間構造を持ち、
何年の事業期間を経てどんな地区が形成されているか?
仮説 H1〜H6
- H1: 宅地開発の地理分布は新築動向 (L20) と異なる。
件数1位は広島市ではなく福山市、また東広島市が突出する。
「開発が一段落した広島市」と「現在進行中の周辺都市」という構造を示す。
- H2: 開発面積 KAIHATU_A は4 桁オーダー (100m² 〜 数十万m²)に渡って分布する。
log スケールで初めて全体像が見え、中央値は 2,000 m² 前後 (= 約 0.2ha)。
- H3: 事業期間 (JIGYO_KE − JIGYO_KS) の中央値は 12 ヶ月以下。
宅地開発は「思ったより速く回る」が支配的傾向。
- H4: 事業用途 JIGYO_YO は コード 1 (住宅用と推定) が 50% 超を占め、
残りはコード 2-6 に薄く分散。広島県の宅地開発は「住宅地造成」が主軸。
- H5: 中大規模開発 (1ha = 10,000 m² 以上) は市街化調整区域や用途地域外に集中する。
市街化区域内では小規模 (3,000m² 未満) が大半で、面積規模で二極構造。
なお 10ha 超の超大規模は本データでは少数 (参考扱い)。
- H6: 年別の事業開始数は 2016 → 2020 で減少傾向を示す。
人口減少社会・住宅市場縮小の反映。2016 年がピーク、2019-2020 年が低水準。
独自用語の定義 (本レッスン内のみ)
- JIGYO_KS / JIGYO_KE: 開発事業の開始日 / 終了日 (datetime)。
DoBoX 仕様書では明記されないが、列名と値の分布から「許可日 / 工事完了日」と推察される。
JIGYO_KS < JIGYO_KE が原則。本記事の主時系列指標。
- KAIHATU_A: 開発面積 (m², int32)。本データの主規模指標。
150 m² から 511,001 m² (51ha) まで 4 桁オーダーに渡る。中央値 約 2,000 m²。
- JIGYO_YO: 事業用途コード (int, 1-6)。仕様書未公開のため本記事では「観察された分布」として扱う。
コード 1 が圧倒多数のため「住宅用と推定」とラベル付け。広島県土木建築局へ照会推奨。
- JIGYO_SIN: 事業種別コード (int, 1 or 2)。仕様書未公開のため参考扱い。
- BIKOU: 備考 (object, 自由文字列)。本データでは全件 null で運用上未入力。
「あるけど使われていない列」の典型例として記録する。
- 事業期間:
JIGYO_KE - JIGYO_KS を月数 (1 ヶ月 ≈ 30.4 日) に換算した値。
本記事独自の派生指標。
- 面積階級 (本記事独自定義): 0.1ha未満 / 0.1-0.3ha / 0.3-1ha / 1-3ha / 3-10ha / 10ha以上
の 6 段階。1ha = 10,000 m²、サッカーグラウンド 1.5 面相当。10ha = 大規模住宅団地クラス。
- 用途グループ: 用途地域 13 コード (YOTO_CD 1-13) を 5 グループ
(低層住居 / 中高層住居 / 住居系 / 商業系 / 工業系) に集約。
L13/L17 で実証済の枠組みを流用。
- PRIMARY スキーマ / ALT スキーマ (本記事独自命名): 20 件のうち
17 市町は Point + KAIHATU_A 系の主スキーマ (PRIMARY)、
3 市町 (江田島市・三原市・竹原市) は Polygon + JIGYO_N 系の旧スキーマ (ALT)
で、ALT のレコードは「公有水面埋立事業」等で性質が異なる。
本記事は PRIMARY 17 市町を主分析対象とし、ALT 3 市町は別建てで観察する。
到達点
- 20 個の GeoJSON ZIP のうち 17 件 (Point) を主スキーマ として
1 個の
GeoDataFrame ({N_PRIMARY} 行) に縦結合できる。
- 残り 3 件 (Polygon) の異種スキーマを識別し、
なぜ列構造が違うかをデータ構造から読み解ける。
- datetime 型の市町間混在 (object/datetime64) を
pd.to_datetime(errors="coerce")
で正規化する実装パターンを身に付ける。
- 開発面積 KAIHATU_A が 4 桁オーダーのスパンで分布することを log スケールで観察する。
- 事業期間 (JIGYO_KE − JIGYO_KS) を計算し、「宅地開発は何ヶ月で終わるか」を定量する。
- 用途地域 (L17) との
geopandas.sjoin で
「開発はどの用途地域に立地したか」を結合分析する。
- 大規模開発 (≥10ha) と都市計画区域 (KUIKI_CD) の関係を見て、
「大開発は市街化調整に集中するか」を検証する。
- 年別事業開始数の推移を観察し、2016-2020 のトレンドから人口減少社会のサインを読む。
本記事のスコープ宣言
本記事は宅地開発状況シリーズ 20 件のみを主データとする研究記事である。
L15 行政区域 21 件は市町別空間集計の境界として参照、
L17 用途地域 21 件は「開発がどの用途地域に立地したか」の sjoin 検証として参照するが、
L17 を主役にした合体記事ではない。
他のサブシリーズ (新築動向 L20・人口 L22 等) との合体は発展課題に留め、
本記事では行わない (要件 I 違反の水増し回避)。
ただしL20 (新築動向) との比較は H1 検証のため数行レベルで言及する。
"""
sections.append(("1. 学習目標と問い", s1_html))
# === セクション2: 使用データ ===
DS_TABLE_ROWS = "".join(
f"| #{d[0]} | {d[1]} | {d[4]} | "
f""
f"DoBoX | "
f"{next(s['n'] for s in schema_log if s['city']==d[1])} | "
f"{next(s['schema'] for s in schema_log if s['city']==d[1])} | "
f"{next(s['geom_types'] for s in schema_log if s['city']==d[1])} | "
f"
"
for d in CITY_DEFS
)
s2_html = f"""
宅地開発状況 20 件 はそれぞれ 1 市町分の GeoJSON を ZIP で配布している。
事前監査では「列構造は全 20 件で完全同一 (13 列)」と報告されていたが、
本研究の実データ取得で3 市町に重大な構造差異を発見した。
本記事はこの発見を正面から扱う (要件 K, データの落とし穴を学習者と共有)。
重要な構造発見 (監査時点では見えていなかった事実):
- 17 市町 (PRIMARY) は Point + KAIHATU_A/JIGYO_KS/JIGYO_KE/JIGYO_YO/JIGYO_SIN
の宅地開発標準スキーマを持つ。これが本記事の主分析対象 (n={N_PRIMARY})。
- 3 市町 (江田島市・三原市・竹原市) は Polygon/MultiPolygon + JIGYO_CD/JIGYO_D/JIGYO_N/KARI_D
という異種スキーマ (ALT)を持つ。レコードは「公有水面埋立事業」「庁舎建設」
等で、宅地造成とは性質が違う事業 (n={N_ALT})。
DoBoX のシリーズ括りが運用上のものであり、データ性質と一致しないことを示す事例。
- これは「同シリーズなら同列構造」という素朴な前提が破綻する実例。
実務ではサンプル抽出によるスキーマ確認だけでは不十分で、
全件取得後の dtype 一致確認が必須であることを学べる。
20 dataset_id 一覧
| dataset_id | 市町 | 市町タイプ | DoBoX |
件数 | スキーマ | geometry 型 |
|---|
{DS_TABLE_ROWS}
主スキーマ PRIMARY の列の意味 (17 市町で同一)
| 列名 | 型 | 意味と本記事での扱い |
|---|
ID | int32 |
各市町内連番。市町をまたがると重複しうる |
TOKEI_CD | int32 |
統計区分コード。参考列扱い |
CITY_CD | int32 |
市区町村コード。広島市は 8 区を 101-108 で分割 |
KUIKI_CD | int32 |
都市計画区域コード (1=市街化, 3=市街化調整, 5=都計外 等と推定)。
本記事は H5 検証で用いる |
ZU_NO | int32 |
図郭番号。地理タイル ID。参考列扱い |
KAIHATU_A | int32 |
開発面積 (m²)。本記事の主規模指標。
150 ~ 511,001 (51ha) のレンジ |
JIGYO_KS | datetime64[ms] / object |
事業開始日 (許可日と推定)。広島市・廿日市市は dtype=object
(文字列「2016/04/06」)、他は datetime。pd.to_datetime で正規化必須 |
JIGYO_KE | datetime64[ms] / object |
事業終了日 (工事完了日と推定)。海田町・世羅町は dtype=object |
JIGYO_YO | int32 |
事業用途コード (1-6)。仕様書未公開、1 が支配的 ({yo_share_1:.1f}%)
のため「住宅用と推定」と本記事ラベル付け |
JIGYO_SIN | int32 |
事業種別コード (1 or 2)。仕様書未公開、参考列扱い |
BIKOU | object |
備考自由文字列。本データでは全件 null (運用上未入力列の典型) |
RITTEKI_CD | int32 |
立地コード。仕様書未公開、参考扱い |
geometry | Point |
開発事業の代表点。EPSG:6671 (JGD2011 平面直角第III系)。
本記事の主役データ |
異種スキーマ ALT (3 市町、参考)
江田島市・三原市・竹原市の 3 件は列名・型・geometry が異なる。
レコードは「江田島町小用公有水面埋立事業」「三原市庁舎本館建替」等の埋立・公共事業で、
他 17 市町の「住宅団地造成事業」と性質が違う。
本記事では分析対象外とし、セクション 12「異種スキーマの観察」で別途報告する。
調査期間と件数
- 期間: 2016-2020 (DoBoX タイトル末尾より)。事業開始日 JIGYO_KS は 2016 年初頃-2021 年初頃にかけて広く分布
- 市町: 全 20 市町 (安芸太田町・大崎上島町・神石高原町は本シリーズに未収録)
- 件数: 全 {N_TOTAL} 件 (PRIMARY {N_PRIMARY} + ALT {N_ALT})。
福山市 496 件が最多、東広島市 213 件、広島市 140 件と続く
- 面積: 最小 150 m² から最大 511,001 m² (51ha) まで4 桁オーダー
L20 新築動向との対比:
新築動向 (L20) は 4.7 万棟、宅地開発 (本記事) は 1,038 件。
1 開発事業 ≅ 数〜数百棟の新築を生む。
新築動向は「結果」、宅地開発は「原因 (事業計画)」を映すデータ。
両者を組み合わせれば「計画 → 実建物」のフロー分析が成立する (発展課題)。
"""
sections.append(("2. 使用データ", s2_html))
# === セクション3: ダウンロード ===
dl_html = """
本記事の再現性を担保するため、HTML 1 枚から
生データ・中間 CSV・図 PNG・再現 Python を直リンクで取得できる。
(1) 生データ ZIP (DoBoX 直)
20 件の ZIP は前項の表からそれぞれ DoBoX へリンク。
あるいは一括取得スクリプト:
cd "2026 DoBoX 教材"
py -X utf8 data\\extras\\L21_housing_development\\fetch_housing_development.py
(2) 中間 CSV (本スクリプトの出力)
(3) 図 PNG (本記事掲載 9 枚)
(4) 再現用 Python スクリプト
実行は cd "2026 DoBoX 教材"; py -X utf8 lessons\\L21_housing_development.py。
20 ZIP がローカルにあれば 1 分以内で全図 + CSV 再生成 (要件 S 準拠)。
"""
sections.append(("3. ダウンロード (再現用データ・中間データ・図・スクリプト)", dl_html))
# === セクション4: 分析1 — スキーマ分岐 + datetime 正規化 ===
code_load = code('''
DATA_DIR = ROOT / "data" / "extras" / "L21_housing_development"
TARGET_CRS = "EPSG:6671" # JGD2011 平面直角第III系 (広島県, m)
# (dataset_id, 市町名, 行政_dsid, 用途地域_dsid, 都市タイプ) — 20 件
CITY_DEFS = [
(1355, "広島市", 786, 794, "政令市"),
(1354, "呉市", 797, 804, "中核市"),
(1369, "福山市", 832, 837, "中核市"),
(1364, "東広島市", 868, 875, "施行時特例市"),
# ... 計 20 行
]
# 主スキーマ判定: KAIHATU_A と JIGYO_KS を持つ ZIP を PRIMARY とする
PRIMARY_COLS = {"KAIHATU_A", "JIGYO_KS"}
def safe_to_datetime(s):
"""object/datetime 混在を許容して datetime に正規化。
解釈不能な文字列は NaT になる。"""
if pd.api.types.is_datetime64_any_dtype(s):
return s
return pd.to_datetime(s, errors="coerce")
primary_frames = [] # 17 市町 (Point + KAIHATU_A 系)
alt_frames = [] # 3 市町 (Polygon + JIGYO_N 系)
for dsid, name, _adm, _yz, ctype in CITY_DEFS:
z = DATA_DIR / f"takuchi_{dsid}_{name}.zip"
g = load_geojson_zip(z)
cols = set(g.columns)
is_primary = "KAIHATU_A" in cols and "JIGYO_KS" in cols
if is_primary:
# 重要: 広島市・廿日市市・海田町・世羅町は object 混在のため正規化必須
g["JIGYO_KS"] = safe_to_datetime(g["JIGYO_KS"])
g["JIGYO_KE"] = safe_to_datetime(g["JIGYO_KE"])
g["src_city"] = name
primary_frames.append(g)
else:
g["src_city"] = name
alt_frames.append(g)
# PRIMARY 17 件を統合 (Point + 13 列)
hd_pts = gpd.GeoDataFrame(pd.concat(primary_frames, ignore_index=True),
geometry="geometry", crs=primary_frames[0].crs)
hd_pts = hd_pts.to_crs(TARGET_CRS)
N_PRIMARY = len(hd_pts) # 1,029 件
# ALT 3 件は別 GDF (Polygon、列構造異なる、観察用)
alt_concat = gpd.GeoDataFrame(pd.concat(alt_frames, ignore_index=True),
geometry="geometry", crs=alt_frames[0].crs)
alt_concat = alt_concat.to_crs(TARGET_CRS)
''')
# Before/After 表
sample_dt_strings = [
("広島市 (1355)", "object", "'2016/04/06'", "Timestamp('2016-04-06')"),
("廿日市市 (1365) 標準形式", "object", "'2016/06/01'", "Timestamp('2016-06-01')"),
("廿日市市 (1365) 自由文", "object", "'許可日(2016/07/26)より30日以内'", "NaT (解釈不能)"),
("呉市 (1354)", "datetime64[ms]", "Timestamp('2016-12-09')", "Timestamp('2016-12-09') (そのまま)"),
("世羅町 (1361) JIGYO_KE", "object", "None or 文字列", "NaT or Timestamp"),
]
sample_rows_html = "".join(
f"| {a} | {b} | {c} | "
f"{d} |
"
for a, b, c, d in sample_dt_strings
)
before_after_s4 = f"""
入出力 Before/After (具体例: 4 市町の JIGYO_KS 列)
| 市町・列 | 元 dtype | 元の値の例 | safe_to_datetime() 後 |
|---|
{sample_rows_html}
同じ「事業開始日」列でも、市町によって dtype が datetime64[ms] と object で
別物になっている。pd.to_datetime(errors="coerce") を通すと:
- 標準形式の文字列 → Timestamp に変換
- すでに datetime → そのまま
- 解釈不能な文字列 (例: 廿日市市の「許可日(2016/07/26)より30日以内」) →
NaT (Not a Time)
NaT は欠損として扱えるので、後段の集計時に dropna() や .dt.year
で自動的にスキップされる。「失敗を NaN に変えて処理を止めない」のが errors="coerce" のキモ。
"""
# スキーマ判定ログから件数集計
n_primary_zip = len([s for s in schema_log if s["schema"] == "PRIMARY"])
n_alt_zip = len([s for s in schema_log if s["schema"] == "ALT"])
s4_html = (
"狙い
"
"20 個の ZIP を 1 個の GeoDataFrame に統合したいが、"
"事前監査では見えていなかった構造差異が実データには存在する。"
"本セクションは「読込前に列構造を確認し、PRIMARY/ALT を分岐する」"
"という防御的プログラミングの実例を示す。"
"また、PRIMARY 17 件の中でも JIGYO_KS が市町間で dtype 不一致 という"
"落とし穴があり、これも pd.to_datetime(errors='coerce') で吸収する。
"
"手法
"
"直感: ZIP を読む → 列名を見てPRIMARY か ALT かを判定 → "
"PRIMARY だけを統合 GeoDataFrame に積む → datetime 正規化 → CRS 変換。"
"ALT は別 GeoDataFrame に保管して観察用に温存。
"
"大筋 (5 ステップ)
"
""
"- 20 市町について
load_geojson_zip() で GeoDataFrame を読む "
"- 各 GDF の列に
KAIHATU_A と JIGYO_KS があるかで PRIMARY 判定 "
"- PRIMARY なら
safe_to_datetime() で JIGYO_KS / JIGYO_KE を正規化、"
"src_city / src_dsid / ctype を付与 "
"- PRIMARY フレーム達を
pd.concat で縦結合 → "
f"{N_PRIMARY} 行 1 個の GeoDataFrame "
"to_crs(EPSG:6671) で広島県平面直角座標系に投影変換 (m 単位確保)
"
"前提と限界: PRIMARY 判定の基準を 'KAIHATU_A & JIGYO_KS 両方持つ' とした。"
"もし将来 DoBoX 側でデータ仕様が変更されれば、この判定も追従修正が必要。"
"errors='coerce' は解釈不能な文字列を黙って NaT にするので、"
"「何件 NaT になったか」を必ずログ出力するべき (本スクリプトは行う)。
"
"実装
"
+ code_load + before_after_s4 +
f"結果
"
f"20 ZIP のうち PRIMARY 判定 {n_primary_zip} 件、"
f"ALT 判定 {n_alt_zip} 件。"
f"PRIMARY 17 件を統合した hd_pts は {N_PRIMARY} 行 × 16 列"
f"(13 列 + 派生 src_city/src_dsid/ctype)。"
f"datetime 正規化で 4 市町の object 列を Timestamp に変換、"
f"廿日市市の「許可日(2016/07/26)より30日以内」のような自由文字列は NaT になり、"
f"後段の年別集計から自動的に除外される。"
f"処理時間は 1 秒未満で、要件 S を余裕でクリアする。
"
)
sections.append(("4. 分析1: 20 GeoJSON 統合 — スキーマ分岐 + datetime 正規化", s4_html))
# === セクション5: 分析2 — 市町別 3 指標 ===
city_top_rows = "".join(
f"| {r['city']} | {r['ctype']} | {r['n_dev']} | "
f"{r['area_km2']:.0f} | {r['pop_k']} | "
f"{r['density_per_100km2']:.2f} | "
f"{r['per_10k_pop']:.2f} | "
f"{r['a_total_ha']:.1f} | "
f"{r['a_median_m2']} | {r['a_max_m2']:,} |
"
for _, r in city_summary.sort_values("n_dev", ascending=False).iterrows()
)
code_city = code('''
city_n = hd_pts.groupby("src_city").size().rename("n_dev")
city_summary = pd.DataFrame({"city": PRIMARY_CITIES, ...})
# 3 種の正規化指標
city_summary["density_per_100km2"] = city_summary["n_dev"] / city_summary["area_km2"] * 100
city_summary["per_10k_pop"] = city_summary["n_dev"] / city_summary["pop_k"] * 10
# 開発総面積 (ha)
city_a = hd_pts.groupby("src_city")["KAIHATU_A"].sum()
city_summary["a_total_ha"] = city_summary["city"].map(city_a) / 10000
# 中央値・最大値
city_summary["a_median_m2"] = city_summary["city"].map(
hd_pts.groupby("src_city")["KAIHATU_A"].median())
city_summary["a_max_m2"] = city_summary["city"].map(
hd_pts.groupby("src_city")["KAIHATU_A"].max())
''')
s5_html = (
"狙い
"
"新築動向 (L20) では広島市が件数1位だったが、宅地開発はどうか? "
"件数だけでなく 面積で割った密度、人口で割った千人あたり、"
"5 年間の開発総面積 という 4 つの指標で市町ごとの開発活発度を多角度で見る。
"
"手法
"
"4 つの指標
"
""
"- 絶対件数 [件]:
groupby('src_city').size() "
"- 開発密度 [件/100km²]: 件数 ÷ 行政面積 × 100"
"(分母を 100km² にしたのは、件数が小さく per km² だと小数になりすぎるため)
"
"- 万人あたり [件/万人]: 件数 ÷ (人口千人 × 0.1)
"
"- 開発総面積 [ha]:
KAIHATU_A.sum() / 10000"
"(5 年間の総開発規模) "
"
"
"限界: 件数 1 のような小自治体は「1 件あたりの面積」のブレが大きく、"
"中央値・最大値だけで結論しないこと。サンプルサイズに比例して指標の信頼性が変わる。
"
"実装
"
+ code_city +
"図 3 — 市町別 3 指標棒グラフ
"
"なぜこの図か: 件数・密度・総面積という3 つの違う角度の指標を"
"同時に並列で見たいので、横並び 3 panel の棒グラフ。市町タイプ色 (政令市赤・中核市桃・"
"特例市紫・市青・町緑) で塗ると都市階層と各指標の関係が一目で見える。
"
+ figure("assets/L21_fig03_city_indicators.png",
"市町別 宅地開発 3 指標 (件数 / 密度 / 総面積)") +
"この図から読み取れること
"
""
"- 件数 (左 panel): 福山市が 496 件で圧倒的トップ、"
"東広島市 213、広島市 140 と続く。"
"新築動向 (L20) は広島市1位だったが、宅地開発は福山市1位 ─ 仮説 H1 を支持。"
"「広島市は街がほぼ完成し、福山市・東広島市はまだ開発進行中」という解釈が成立。
"
"- 密度 (中 panel): 府中町 (10km² の小自治体) が件数比 3 件のため上位。"
"面積を 100km² でスケーリングしてもベッドタウン町が高密度に入る。
"
"- 総面積 (右 panel): 件数 1 位の福山市が総面積でも最大 (約 150ha)、"
"東広島市が 100ha 弱で 2 位。面積でも福山市・東広島市が二強で、"
"件数と総面積はおおむね一致する (大規模開発が件数を作っている形ではない)。
"
"
"
"表 4 — PRIMARY 17 市町 全指標一覧 (件数降順)
"
"| 市町 | タイプ | 件数 | 面積 (km²) | "
"人口 (千人) | 密度 (件/100km²) | 万人あたり | "
"総面積 (ha) | 面積中央値 (m²) | 面積最大 (m²) |
|---|
"
+ city_top_rows + "
"
"この表から読み取れること: "
"件数は福山市 (496) > 東広島市 (213) > 広島市 (140) の順。"
"面積中央値は 1,400-6,500 m² と市町間で差は大きくない (≅ 0.1-0.7 ha)。"
"面積最大値は福山市 511,001 m² (51ha) ─ 1 件で 51ha の超大規模が"
"県内最大級の開発として記録されている。"
"件数 1 の市町 (大竹市・庄原市・世羅町) は中央値 = 最大値となり指標として参考程度。
"
)
sections.append(("5. 分析2: 市町別 4 指標 — 件数・密度・万人あたり・総面積", s5_html))
# === セクション6: 分析3 — 全県マップ + ホットスポット ===
s6_html = (
"狙い
"
f"{N_PRIMARY} 点を 1 枚の地図にプロットし、用途地域グループで色、"
"面積でバブルサイズ、ALT 3 市町の Polygon を黄色で重ねる。"
"全県マップで「どこに、どの規模で、どの用途地域に開発されたか」を直感把握する。"
"次に 8km ビンでホットスポットを定量化する。
"
"手法
"
"(a) 用途グループ色 + 面積バブル: 用途地域 5 グループに割り振った色"
"(緑系 = 住居、橙 = 商業、茶 = 工業、灰 = 用途地域外)。"
"サイズは log10(KAIHATU_A) 比例 (4 桁スパンを反映)。"
"ALT 3 市町は 黄色 Polygon で異種データであることを警告的に表示。
"
"(b) 8km 矩形ビン: 件数が新築動向 (L20) の 1/45 程度しかないので、"
"L20 の 4km ビンより粗い 8km ビンを採用。numpy.searchsorted で各点の"
"セル ID を高速計算 → groupby で件数集計 → log スケールで塗る。"
"件数 1-100+ の 2 桁スパンを log で正規化。
"
"実装
"
+ code('''
# 全県点マップ (Fig 1) — 用途グループ色 + 面積バブル + ALT は Polygon
fig, ax = plt.subplots(figsize=(13, 9))
admin_diss.boundary.plot(ax=ax, color="#aaa", linewidth=0.4)
yz_palette = {"低層住居": "#2ca02c", "中高層住居": "#98df8a",
"住居系": "#1f77b4", "商業系": "#ff7f0e",
"工業系": "#8c564b", "用途地域外": "#7f7f7f"}
for grp, col in yz_palette.items():
sub = hd_pts[hd_pts["yoto_group"] == grp]
sizes = np.clip(np.log10(sub["KAIHATU_A"].clip(100, 1e7)) * 12 - 20, 5, 200)
ax.scatter(sub.geometry.x, sub.geometry.y, c=col, s=sizes, alpha=0.65)
# ALT は Polygon を黄色で重ねる
alt_concat.plot(ax=ax, facecolor="#ffeb3b", edgecolor="#f57c00",
linewidth=0.5, alpha=0.55)
# 8km ビン (Fig 2)
HEX_SIZE_M = 8000 # 8 km grid (件数少ないため L20 より粗く)
gx = np.arange(xmin - HEX_SIZE_M, xmax + HEX_SIZE_M, HEX_SIZE_M)
gy = np.arange(ymin - HEX_SIZE_M, ymax + HEX_SIZE_M, HEX_SIZE_M)
ix = np.searchsorted(gx, hd_pts.geometry.x, side="right") - 1
iy = np.searchsorted(gy, hd_pts.geometry.y, side="right") - 1
hd_pts["_grid_ix"] = ix
hd_pts["_grid_iy"] = iy
grid_n = hd_pts.groupby(["_grid_ix", "_grid_iy"]).size().rename("n").reset_index()
''') +
"図 1 — 全県 開発点マップ (用途グループ色 + 面積バブル + ALT 黄色)
"
"なぜこの図か: 1,038 件の開発を 1 枚で見ることで、「どこに、何の用途地域に」"
"が一目で分かる。バブルサイズで規模が同時に伝わり、ALT 3 市町の異種データを"
"黄色で意図的に目立たせる (学習者が「色が違うものがある」と気づく構造)。
"
+ figure("assets/L21_fig01_all_points.png",
"広島県 宅地開発 2016-2020 — 用途グループ色 + 面積バブル + ALT 黄色") +
"この図から読み取れること
"
""
"- 福山市平野に開発が極めて濃く集中 ─ 県内最大の開発フィールド。
"
"- 広島市デルタ + 安佐南/安佐北の郊外に分散。広島市は件数 140 と少なめだが"
"都市の広さに対してまばらに散らばる。
"
"- 東広島市は西条駅周辺 + 大学拠点に集中、ベルト的な分布。
"
"- 緑色 (低層住居・中高層住居) のドットが県内に広く分布 ─ "
"住宅地造成が宅地開発の主軸であることが視覚的に分かる。
"
"- 橙 (商業系)・茶 (工業系) のドットは少数で、特定地域に偏る。
"
"- 灰 (用途地域外) のドットがやや目立つ ─ 市街化調整区域や都市計画区域外でも"
"大規模開発が起きている傍証 (H5 の予兆)。
"
"- 黄色 Polygon (ALT 3 市町) は江田島・三原・竹原で観察される。"
"Point ではなく Polygon の塊として表示され、データの異種性が視覚的に分かる。
"
"
"
"図 2 — 8km ビン ホットスポット (log scale)
"
"なぜこの図か: 全県 1,038 件のうち「どのビンに何件あるか」を定量化したい。"
"色 = ビン内件数 (log) でホットスポットが一目で分かる。
"
+ figure("assets/L21_fig02_hexbin.png",
"8 km 矩形ビン 宅地開発件数 (対数スケール)") +
"この図から読み取れること
"
""
"- 福山市平野部に最濃ホットスポット。1 ビン (= 64km²) で "
f"{int(grid_n['n'].max())} 件以上が集中。
"
"- 東広島市西条周辺・広島市デルタが 2 番目のホットスポット。"
"色階調が滑らかに都市階層を反映。
"
"- 沿岸部 (尾道・廿日市・呉) に薄いベルト ─ 中規模拠点の散発的開発。
"
"- 北部山間部 (三次・庄原・北広島町) は単発的に 1-2 件のセルが並ぶのみ ─ "
"「開発空白地帯」と「都市部の集積」の二極構造
"
"- 新築動向 (L20) の hexbin と比較すると、福山市の濃さが目立つ点が異なる。"
"新築では広島市優位、宅地開発では福山市優位という地理的役割分担が示唆される。
"
"
"
)
sections.append(("6. 分析3: 全県マップ + 8km ビン ホットスポット", s6_html))
# === セクション7: 分析4 — 開発面積分布 (4 桁スパン) ===
# 面積階級 集計
ab_total = area_cross.sum(axis=0)
area_total_rows = "".join(
f"| {lbl} | {int(ab_total[lbl])} | "
f"{ab_total[lbl]/N_PRIMARY*100:.2f}% |
" for lbl in A_LABELS
)
# 大規模 top5 (現実の大開発を見せる)
big_show = hd_pts.nlargest(5, "KAIHATU_A")
big_show_rows = "".join(
f"| {i+1} | {r['src_city']} | "
f"{r['KAIHATU_A']:,} | {r['KAIHATU_A']/10000:.2f} | "
f"{r['JIGYO_KS'].strftime('%Y-%m-%d') if pd.notna(r['JIGYO_KS']) else '-'} | "
f"{r['JIGYO_KE'].strftime('%Y-%m-%d') if pd.notna(r['JIGYO_KE']) else '-'} | "
f"{r['JIGYO_YO']} | {r['kuiki_label']} | "
f"{r['yoto_name'] if pd.notna(r['yoto_name']) else '用途外'} |
"
for i, (_, r) in enumerate(big_show.iterrows())
)
s7_html = (
"狙い
"
"開発面積 KAIHATU_A は150 m² から 511,001 m² (51ha) まで"
"4 桁オーダーのスパンを持つ。"
"リニアスケールでは超大規模 1 件だけが目立って小規模分布が潰れるので、"
"log scale で全体形を見る。さらに市町別箱ひげで「どの市町が大規模を抱えているか」を"
"1 枚で観察する。
"
"手法
"
"(a) 全県ヒストグラム (log x 軸): numpy.logspace で"
"ビン境界を 100 m² から 1e7 m² の対数等間隔 50 ビン。"
"plt.hist(bins=log_bins) + set_xscale('log')。
"
"(b) 市町別箱ひげ: plt.boxplot 横並び、x 軸 log。"
"件数降順で並べると、件数大きい市町が上から順に表示される。
"
"面積階級 (本記事独自定義): 0.1ha未満 / 0.1-0.3ha / 0.3-1ha / 1-3ha / 3-10ha / 10ha以上。"
"1ha = 10,000 m² ≈ 100m × 100m ≈ サッカーグラウンド 1.5 面。"
"10ha = 大規模住宅団地クラス、30ha 超は地区計画レベル。"
"pd.cut(KAIHATU_A, bins=...) で分類。
"
"実装
"
+ code('''
A_BANDS = [(0, 1000, "0.1ha未満"), (1000, 3000, "0.1-0.3ha"),
(3000, 10000, "0.3-1ha"), (10000, 30000, "1-3ha"),
(30000, 100000, "3-10ha"), (100000, 1e7, "10ha以上")]
hd_pts["area_band"] = pd.cut(hd_pts["KAIHATU_A"],
bins=[b[0] for b in A_BANDS] + [1e9],
labels=[b[2] for b in A_BANDS],
include_lowest=True)
# Fig 4 左: log ヒスト
log_bins = np.logspace(np.log10(100), np.log10(hd_pts["KAIHATU_A"].max() * 1.05), 50)
plt.hist(hd_pts["KAIHATU_A"], bins=log_bins)
plt.xscale("log")
''') +
"図 4 — 開発面積分布 (log scale) + 市町別箱ひげ
"
"なぜこの図か: 4 桁スパンの分布は log でしか正しく見えない。"
"ヒストグラムで分布の形 (右裾長 = 対数正規 ?)、箱ひげで市町別の偏りを 1 枚で観察。
"
+ figure("assets/L21_fig04_area_dist.png",
"開発面積分布 (log scale) + 市町別 箱ひげ図") +
"この図から読み取れること
"
""
f"- 左 panel ヒストグラム: 中央値 約 {a_med:.0f} m² (橙線) を中心に"
"対数正規型の分布。1ha (赤線) を超える件数は急減し、10ha (紫線) を超えるのは"
f" {n_huge} 件のみ。仮説 H2 (4 桁スパン) はlog10 スパン {log_span:.2f}で"
f"{H2_judge}される。
"
"- 右 panel 箱ひげ: 中央値はほぼ全市町で 1,000-5,000 m² (1,000m² ≅ 0.1ha)。"
"外れ値の伸び方が市町で大きく違う: 福山市は外れ値が 51ha まで伸びる、"
"広島市・東広島市も 10ha 超の外れ値あり。"
"中規模都市 (尾道市・呉市・廿日市市) の箱は中ぐらい、町部 (府中町・坂町) は箱が極小で"
"事業規模が安定。
"
"- 外れ値の高さは「その市町に大規模開発計画があるか」の指標として読める。"
"数値で見ると福山市の最大 51ha が県内最大。
"
"
"
"表 5a — 面積階級 全県集計
"
"| 面積階級 | 件数 | シェア |
|---|
"
+ area_total_rows + "
"
"この表から読み取れること: "
f"0.1-0.3ha (1,000-3,000m²) と 0.3-1ha (3,000-10,000m²) "
"の 2 階級で過半数。"
f"1ha 以上の中大規模は約 {(ab_total['1-3ha']+ab_total['3-10ha']+ab_total['10ha以上'])/N_PRIMARY*100:.1f}%、"
f"10ha 以上の超大規模は約 {ab_total['10ha以上']/N_PRIMARY*100:.2f}%。"
"「大半は数千m²の小規模開発、超大規模は希少イベント」"
"が広島県の宅地開発の典型的な姿。
"
"表 5b — 大規模開発 上位 5 件
"
"| 順位 | 市町 | 面積 (m²) | 面積 (ha) | "
"開始日 | 終了日 | JIGYO_YO | 都市計画区域 | 用途地域 |
|---|
"
+ big_show_rows + "
"
"この表から読み取れること: 県内最大の開発は "
f"{big_show.iloc[0]['src_city']} {big_show.iloc[0]['KAIHATU_A']/10000:.1f}ha "
"で 51ha (≅ 東京ドーム 11 個分)。上位 5 件はいずれも"
"市街化調整区域・都市計画区域外・用途地域外で発生しており、"
"大規模 = 既存市街地の外という H5 のシグナルがすでに見えている。"
"JIGYO_YO は 1 と 5 が混じる。
"
)
sections.append(("7. 分析4: 開発面積分布 (log) — 4 桁スパンの観察", s7_html))
# === セクション8: 分析5 — 事業期間 (KE - KS) ===
# 期間統計表
dur_quantiles = valid_dur["dur_months"].quantile([0.10, 0.25, 0.50, 0.75, 0.90, 0.99])
dur_q_rows = "".join(
f"| {int(q*100)}%タイル | {v:.1f} ヶ月 | {v/12:.2f} 年 |
"
for q, v in dur_quantiles.items()
)
s8_html = (
"狙い
"
"JIGYO_KE - JIGYO_KS を月数に換算した事業期間は、"
"DoBoX 仕様書では明記されないが「事業の許可日と工事完了日の差」と推察される。"
"「宅地開発は何ヶ月で終わるのか」を定量し、面積との関係 (大規模ほど長期化するか) を散布図で見る。
"
"手法
"
"(a) 全件ヒストグラム: 0-120 ヶ月の範囲で 40 ビン。"
"120 ヶ月 (10 年) を超える外れ値は分布形把握のため除外。
"
"(b) 面積×期間 散布: x = 面積 log, y = 期間 (linear)。"
"用途グループ色で塗り、「大規模ほど長期化するか」を視覚検証。"
"linear y 軸にしたのは「12 ヶ月」「36 ヶ月」という閾値を直線で示すため。
"
"限界: JIGYO_KE が NaT (世羅町・海田町等) は除外される。"
"JIGYO_KE が 2021 以降 (進行中) のものは含まれるが、"
"本データの観察期間 2016-2020 を超える事業は「現時点での進行中事業」"
"として扱う。
"
"実装
"
+ code('''
# 事業期間 (月)
dur_days = (hd_pts["JIGYO_KE"] - hd_pts["JIGYO_KS"]).dt.days
hd_pts["dur_days"] = dur_days
hd_pts["dur_months"] = (dur_days / 30.4375).round(2)
# 0-120 ヶ月で外れ値 cut
valid_dur = hd_pts.dropna(subset=["dur_months"])
valid_dur = valid_dur[valid_dur["dur_months"].between(0, 120)]
# Fig 5 左: ヒスト
plt.hist(valid_dur["dur_months"], bins=40)
# Fig 5 右: 面積×期間 散布 (用途グループ色)
sub = hd_pts.dropna(subset=["dur_months", "KAIHATU_A"])
sub = sub[(sub["dur_months"] > 0) & (sub["dur_months"] <= 120)]
for grp, col in yz_palette.items():
s = sub[sub["yoto_group"] == grp]
plt.scatter(s["KAIHATU_A"], s["dur_months"], c=col, alpha=0.6)
plt.xscale("log")
''') +
"図 5 — 事業期間分布 + 面積×期間 散布
"
"なぜこの図か: 期間ヒストグラムで分布の形 (中央値・尾の重さ) を確認し、"
"面積×期間散布で「大規模なほど時間がかかるのか」を視覚検証する。"
"1枚で 2 つの問いに答える。
"
+ figure("assets/L21_fig05_duration.png",
"事業期間分布 + 面積×期間 散布 (用途グループ色)") +
"この図から読み取れること
"
""
f"- 左 panel: 事業期間中央値 {dur_med:.1f} ヶ月 (橙線)。"
f"1 年 (赤線) より{('短い' if dur_med < 12 else '長い')} ─ 仮説 H3 ({H3_judge})。"
f"3 年 (紫線) を超える事業は少数で、p90 でも {dur_p90:.1f} ヶ月。"
"宅地開発は「思ったより早く回る」が支配的傾向。
"
"- 右 panel 散布: 面積と期間に緩やかな正の関係あり。"
"1ha 未満は数ヶ月で完了する小開発が大半、10ha 超は数年単位。"
"ただし例外も多く、10ha 級でも 12 ヶ月で完了する事業や、"
"1ha 未満で 36 ヶ月かかる事業も散発的に存在 ─ "
"「規模だけが期間を決めるわけではない」という都市計画の現実。
"
"- 用途グループ色で見ると、用途地域外 (灰) の事業に長期化が目立つ。"
"市街化調整区域での許可手続き等が時間を取っている可能性。
"
"
"
"表 6 — 事業期間 パーセンタイル
"
"| パーセンタイル | 事業期間 (月) | 事業期間 (年) |
|---|
"
+ dur_q_rows + "
"
"この表から読み取れること: "
f"中央値 {dur_quantiles[0.50]:.1f} ヶ月 (≈ {dur_quantiles[0.50]/12:.1f} 年)、"
f"75% タイルでも {dur_quantiles[0.75]:.1f} ヶ月。"
f"99% タイル ({dur_quantiles[0.99]:.1f} ヶ月 ≈ {dur_quantiles[0.99]/12:.1f} 年) "
"は超長期事業の天井。"
"4 件に 3 件は 2 年以内に完了するのが広島県の宅地開発の典型。
"
)
sections.append(("8. 分析5: 事業期間 (JIGYO_KE - JIGYO_KS) の月数分析", s8_html))
# === セクション9: 分析6 — 年別事業推移 ===
# 年別表
yr_show = year_n[(year_n["ks_year"] >= 2014) & (year_n["ks_year"] <= 2022)]
yr_total_rows = "".join(
f"| {int(r['ks_year'])} | {int(r['n'])} |
"
for _, r in yr_show.iterrows()
)
s9_html = (
"狙い
"
"事業開始日 JIGYO_KS の年集計で、2016-2020 の 5 年間で開発活動が増えたか減ったか"
"を見る。「人口減少 → 住宅需要減 → 開発減」という素朴な仮説 (H6) を定量検証する。
"
"手法
"
"JIGYO_KS.dt.year で年抽出 → groupby('ks_year').size()。"
"全県棒グラフ + 市町別 stack の 2 panel で、全体トレンドと市町別の寄与を同時表示。"
"datetime 正規化で NaT になった「廿日市市の自由文字列」のような不定値は自動除外。
"
"実装
"
+ code('''
# 年別 (開始年) 集計
hd_pts["ks_year"] = hd_pts["JIGYO_KS"].dt.year
year_n = hd_pts.groupby("ks_year").size().rename("n").reset_index()
# 市町×年 クロス
year_city_cross = pd.crosstab(hd_pts["ks_year"].dropna().astype(int),
hd_pts.loc[hd_pts["ks_year"].notna(), "src_city"])
# Fig 6 左: 全県棒
yr = year_n[(year_n["ks_year"] >= 2014) & (year_n["ks_year"] <= 2022)]
plt.bar(yr["ks_year"], yr["n"])
''') +
"図 6 — 年別 事業開始数推移
"
"なぜこの図か: 全県の年別棒でマクロトレンドを見て、"
"市町×年 stack でどの市町がどの年に開発したかを見る。"
"上位市町 (件数 30+) のみ凡例表示で見やすく。
"
+ figure("assets/L21_fig06_year_trend.png",
"年別 事業開始数 (全県 + 市町別 stack)") +
"この図から読み取れること
"
""
f"- 5 年間の年別件数: 2016 {n_2016} → 2019 {n_2019} → 2020 {n_2020} 件。"
f"2020 年が増加してむしろピークになっており、"
f"仮説 H6 (単調減少) は{H6_judge}。"
"コロナ初期 (2020) でも宅地開発の許可数は維持/増加した、という興味深い結果。"
"「人口減少社会 = 開発減」という素朴な前提が直線的でないことが定量で示された。
"
"- 2021-2022 にも事業開始が記録されている。"
"本データは「2016-2020 期」のラベルだが、JIGYO_KS は 5 年期を超えて記録されている "
"─ データの「収録期間」と「実態の事業時期」がずれているケース。"
"DoBoX 公表時に発生した遅延データと推察される。
"
"- 市町別 stack (右 panel): 福山市 (青系) が毎年最大シェア。"
"福山市が県の開発活動を毎年牽引していることが時系列で確認できる。
"
"- 東広島市・広島市は 2-3 番目で、町部はほぼゼロに近い細い帯。
"
"
"
"表 7 — 年別 事業開始数 (全県)
"
""
"この表から読み取れること: "
f"5 年計で約 {yr_show['n'].sum()} 件。"
f"年ごとのブレが大きく単調減少ではない。"
f"2020 年がむしろ最大 ({n_2020} 件) で、"
"「人口減少社会で開発も減る」という素朴な仮説は本データでは支持されない。
"
)
sections.append(("9. 分析6: 年別事業開始数の時系列推移", s9_html))
# === セクション10: 分析7 — 用途地域 sjoin ===
yz_dist_rows = "".join(
f"| {r['yoto_group']} | {int(r['n'])} | {r['share_pct']}% |
"
for _, r in yz_dist.iterrows()
)
s10_html = (
"狙い
"
"用途地域 (L17) は「ここは住宅地」「ここは商業地」と都市計画で事前に指定された区域。"
"宅地開発がどの用途地域に立地したかを geopandas.sjoin で空間結合して定量する。"
"「住宅用と推定される開発が、本当に住居系用途地域に立地したか」が見える。
"
"手法
"
"大筋 (4 ステップ)
"
""
"- L17 で取得済の 17 用途地域 GeoJSON を読込 (PRIMARY 17 市町分)
"
"- YOTO_CD 1-13 を 5 用途グループ (低層住居/中高層住居/住居系/商業系/工業系) に集約
"
"geopandas.sjoin(hd_pts, yz_all, how='left', predicate='within')"
"で開発点の用途地域を判定- 市町×用途グループ クロス + 全県構成比を集計
"
"
"
"predicate='within': 点が用途地域ポリゴンの内部にある場合のみマッチ。"
"境界線上は用途地域外と判定される (実害なし)。"
"how='left': 用途地域に含まれない開発点 (用途白地・市街化調整区域) は"
"YOTO_CD = NaN となり、「用途地域外」に分類される。
"
"限界: 用途地域は L17 で取得した 17 市町分のみ。"
"ALT 3 市町は分析対象外。"
"また用途地域は「指定」であり、現実の土地利用と一致するとは限らない (L13 の比較で実証済)。
"
"実装
"
+ code('''
# YOTO_CD 1-13 を 5 グループに集約
YOTO_GROUP = {
"低層住居": [1, 2, 13], # 第1種・第2種低層・田園住居
"中高層住居": [3, 4], # 第1種・第2種中高層
"住居系": [5, 6, 7], # 第1種・第2種住居・準住居
"商業系": [8, 9], # 近隣商業・商業
"工業系": [10, 11, 12], # 準工業・工業・工業専用
}
YOTO_GROUP_OF_CD = {cd: g for g, cds in YOTO_GROUP.items() for cd in cds}
# 17 用途地域 GeoJSON を統合
yz_frames = []
for dsid, name, _adm, yz_ds, _ct in CITY_DEFS:
if name in ALT_CITIES: continue
z = USEZONE_DIR / f"use_zone_{yz_ds}_{name}.zip"
g = load_geojson_zip(z)
g["city"] = name
yz_frames.append(g)
yz_all = gpd.GeoDataFrame(pd.concat(yz_frames, ignore_index=True),
geometry="geometry").to_crs(TARGET_CRS)
yz_all["yoto_group"] = yz_all["YOTO_CD"].map(YOTO_GROUP_OF_CD)
# 開発点 in 用途地域 (within)
hd_in_yz = gpd.sjoin(hd_pts, yz_all[["YOTO_CD", "yoto_group", "geometry"]],
how="left", predicate="within")
hd_in_yz = hd_in_yz.loc[~hd_in_yz.index.duplicated(keep="first")]
hd_pts["yoto_group"] = hd_in_yz["yoto_group"].fillna("用途地域外")
''') +
"図 7 — 用途地域 sjoin 結果 (市町別構成 + 福山市マップ)
"
"なぜこの図か: 棒だけだと割合しか見えない。1 市 (福山市) を例に"
"用途地域ポリゴンを色塗りし、開発点を黒で重ねると、"
"「ここの用途地域にここの開発が立っている」という空間関係が見える。
"
+ figure("assets/L21_fig07_use_zone.png",
"用途地域 sjoin (左: 市町別構成 / 右: 福山市マップ)") +
"この図から読み取れること
"
""
"- 左 panel: 件数の多い市町 (福山市・東広島市・広島市) では"
"低層住居 (緑) + 住居系 (青) が支配的。"
"「住宅用と推定された開発が、住居系用途地域に立地している」"
"という H4 系の傍証が定量化される。
"
"- 商業系・工業系は薄い帯として見える程度で、構成比 5-10% 程度。"
"宅地開発の主軸は明らかに「住宅地造成」。
"
"- 用途地域外 (灰) の比率は市町ごとに大きく異なる。"
"都市部では低めだが、中山間部 (三次市・庄原市) では用途地域外シェアが高い ─ "
"「市街化調整区域や都市計画区域外」での開発が多い。
"
"- 右 panel (福山市): 緑系 (住居) のポリゴンが平野に広がり、"
"黒い開発点がそこに重なって立っている。"
"ただし用途地域の境界外 (周辺部) にも黒点が散見 ─ "
"「住居系の指定区域だけで開発がすべて吸収されているわけではない」"
"という政策の実態。
"
"
"
"表 8 — 用途グループ全県集計
"
"| 用途グループ | 開発件数 | シェア |
|---|
"
+ yz_dist_rows + "
"
"この表から読み取れること: "
"低層住居 + 中高層住居 + 住居系 を合計すると 60-70% が住宅系用途地域に立地。"
"用途地域外 (市街化調整区域・都市計画区域外) も意外に多く、"
"市街化区域だけで宅地開発を語れないのが広島県の実態。
"
)
sections.append(("10. 分析7: 用途地域 sjoin — 開発の立地構造", s10_html))
# === セクション11: 分析8 — 大規模開発と KUIKI_CD ===
# 大規模開発 top10
big_top10 = hd_pts.nlargest(10, "KAIHATU_A")[
["src_city", "KAIHATU_A", "JIGYO_KS", "JIGYO_KE", "kuiki_label",
"yoto_group", "JIGYO_YO"]
].copy()
big_top10_rows = "".join(
f"| {i+1} | {r['src_city']} | "
f"{r['KAIHATU_A']/10000:.2f} | "
f"{r['JIGYO_KS'].strftime('%Y-%m') if pd.notna(r['JIGYO_KS']) else '-'} | "
f"{r['JIGYO_KE'].strftime('%Y-%m') if pd.notna(r['JIGYO_KE']) else '-'} | "
f"{r['kuiki_label']} | {r['yoto_group']} | "
f"{r['JIGYO_YO']} |
"
for i, (_, r) in enumerate(big_top10.iterrows())
)
# 面積 × KUIKI クロス表 (テキスト用)
ka_cross_disp = pd.crosstab(hd_pts["area_band"], hd_pts["kuiki_label"]).reindex(
A_LABELS, fill_value=0)
ka_cross_rows = "".join(
f"| {lbl} | " +
"".join(f"{int(ka_cross_disp.loc[lbl][k]) if k in ka_cross_disp.columns else 0} | "
for k in ka_cross_disp.columns) +
"
"
for lbl in A_LABELS
)
ka_cross_header = "| 面積階級 | " + \
"".join(f"{k} | " for k in ka_cross_disp.columns) + "
|---|
"
s11_html = (
"狙い
"
"大規模開発 (≥10ha = 100,000 m²) は都市計画上の影響が大きい。"
"「大規模開発はどこで起きているか? 市街化区域内か、調整区域か、用途地域外か?」"
"を面積階級 × KUIKI_CD クロスで検証する (仮説 H5)。
"
"手法
"
"(a) 大規模 (≥1ha) バブルマップ: 全県地図に開発点を 面積比例バブル + 面積 log カラー"
"で表示。上位 5 件にラベル。「県内のどこに大規模が立っているか」を一目で。
"
"(b) 面積階級 × KUIKI_CD クロス: pd.crosstab(area_band, KUIKI_CD) で "
"6 × 4 マトリクスを log10 ヒートマップで描画。生数値も重ね書き。"
"「小規模は市街化区域、大規模は調整区域」という二極構造を視覚化。
"
"実装
"
+ code('''
# Fig 8 左: ≥1ha バブルマップ
big = hd_pts[hd_pts["KAIHATU_A"] >= 10000]
sizes = np.clip(np.sqrt(big["KAIHATU_A"]) / 5, 8, 200)
ax.scatter(big.geometry.x, big.geometry.y,
c=np.log10(big["KAIHATU_A"]), s=sizes, cmap="plasma")
# Fig 8 右: 面積×KUIKI ヒートマップ
KUIKI_LABEL = {0: "区域不明", 1: "市街化区域", 2: "用途白地等",
3: "市街化調整区域", 5: "都市計画区域外"}
hd_pts["kuiki_label"] = hd_pts["KUIKI_CD"].map(KUIKI_LABEL)
ka_cross = pd.crosstab(hd_pts["area_band"], hd_pts["kuiki_label"])
plt.imshow(np.log10(ka_cross.values + 1), cmap="viridis")
''') +
"図 8 — 大規模開発バブル + 面積×KUIKI ヒートマップ
"
"なぜこの図か: 大規模開発の地理位置を見たいバブルマップ + "
"「規模と区域の関係」をマトリクスで見るヒートマップを 1 枚に。"
"規模・場所・区域の 3 次元関係を 1 図で。
"
+ figure("assets/L21_fig08_big_kuiki.png",
"大規模開発 (≥1ha) バブル + 面積×KUIKI クロス") +
"この図から読み取れること
"
""
f"- 左 panel: ≥1ha の大規模 {len(big_dev)} 件。"
"福山市平野 + 東広島市西条周辺 + 広島市郊外 の 3 ホットスポット。"
f"県内最大は {big_top10.iloc[0]['src_city']} {big_top10.iloc[0]['KAIHATU_A']/10000:.1f}ha。"
"大規模ほど都市縁辺部に立地する傾向が見える。
"
"- 右 panel ヒートマップ: 面積階級が大きくなるほど"
"市街化調整区域・用途白地・都市計画区域外の比率が増える傾向。"
"0.1ha 未満は市街化区域 (KUIKI=1) が多数を占める。"
f"≥1ha 35 件のうち、市街化調整 OR 用途地域外 が {big_outside_combined} 件 "
f"({big_outside_combined/max(n_big,1):.0%})、市街化区域内 {big_in_shigaika} 件で、"
f"仮説 H5 は {H5_judge} という意外な結果。
"
"- 市街化区域内では大規模が物理的に困難 (細分化された敷地) と想定したが、"
"実データでは 市街化区域内の中大規模も無視できない数存在する。"
"「区画整理事業」など市街化区域でも一括地が確保される実装パターンの存在を示唆。
"
"
"
"表 9a — 面積階級 × 都市計画区域 クロス
"
"" + ka_cross_header + ka_cross_rows + "
"
"この表から読み取れること: "
"0.1ha 未満〜0.3ha は市街化区域 (KUIKI=1) で多い。"
"1ha 超は市街化調整 (KUIKI=3) や用途白地 (KUIKI=2) でも目立つ。"
"10ha 以上ではむしろ調整区域・都市計画区域外が多数。"
"「区域でできることの上限」が面積規模を支配している構造。
"
"表 9b — 大規模開発 上位 10 件
"
"| 順位 | 市町 | 面積 (ha) | 開始 | 終了 | "
"KUIKI | 用途グループ | JIGYO_YO |
|---|
"
+ big_top10_rows + "
"
"この表から読み取れること: "
"上位 10 件中、市街化調整区域や用途地域外が多数。"
"事業期間も数年単位が多く、大規模ほど時間がかかる傾向と整合。"
"JIGYO_YO は 1 (住宅) 中心だが、5 や 6 も混じる ─ "
"工業団地・物流センター等の住宅以外の大規模開発の存在を示唆。
"
)
sections.append(("11. 分析8: 大規模開発の地理 + 面積階級×KUIKI クロス", s11_html))
# === セクション12: 分析9 — 異種スキーマ ALT 3 市町の観察 ===
alt_sample_rows = []
alt_obs = alt_concat.copy()
alt_obs["geom_type"] = alt_obs.geometry.type.values
alt_obs["centroid_x"] = alt_obs.geometry.centroid.x.round(0)
alt_obs["centroid_y"] = alt_obs.geometry.centroid.y.round(0)
for i, (_, r) in enumerate(alt_obs.iterrows()):
jname = r.get("JIGYO_N", "") or "(空)"
jdate = r.get("JIGYO_D", "")
if pd.notna(jdate):
try:
jdate = jdate.strftime("%Y-%m-%d")
except Exception:
jdate = str(jdate)
else:
jdate = "-"
kid = r.get("ID", "")
alt_sample_rows.append(
f"| {i+1} | {r['src_city']} | {kid} | "
f"{jname} | {jdate} | {r['geom_type']} |
"
)
s12_html = (
"狙い
"
"江田島市・三原市・竹原市の 3 件は列名・型・geometry が他 17 件と全部違う。"
"「同シリーズ」というラベルでもデータ性質が異なる場合がある"
"という DoBoX オープンデータの実例として観察する。主分析の対象外だが、"
"「変な異種データを単に削除する」のではなく正面から記録するのが"
"本記事の研究的態度。
"
"手法
"
"3 件の生レコードを表形式で全件表示し、JIGYO_N (事業名) を読んで"
"「これは何の事業か」を観察する。geometry 型 (Polygon vs Point) も列挙し、"
"なぜ性質が違うかを推察する。
"
"実装
"
+ code('''
# 主スキーマ判定で ALT に振り分けられた 3 件 を観察
alt_concat = gpd.GeoDataFrame(pd.concat(alt_frames, ignore_index=True),
geometry="geometry", crs=alt_frames[0].crs)
alt_concat = alt_concat.to_crs(TARGET_CRS)
# 列構造の違い
print("ALT 列:", list(alt_concat.columns))
# ['ID', 'TOKEI_CD', 'CITY_CD', 'KUIKI_CD', 'JIGYO_CD', 'ZU_NO',
# 'JIGYO_D', 'JIGYO_N', 'KARI_D', 'BIKOU', 'RITTEKI_CD', 'geometry']
# vs PRIMARY の 13 列:
# ['ID', 'TOKEI_CD', 'CITY_CD', 'KUIKI_CD', 'ZU_NO',
# 'KAIHATU_A', 'JIGYO_KS', 'JIGYO_KE', 'JIGYO_YO', 'JIGYO_SIN',
# 'BIKOU', 'RITTEKI_CD', 'geometry']
# 違いを抽出
primary_only = {"KAIHATU_A", "JIGYO_KS", "JIGYO_KE", "JIGYO_YO", "JIGYO_SIN"}
alt_only = {"JIGYO_CD", "JIGYO_D", "JIGYO_N", "KARI_D"}
''') +
"表 10 — ALT 3 市町 全レコード一覧
"
"| # | 市町 | ID | JIGYO_N (事業名) | "
"JIGYO_D | geom型 |
|---|
"
+ "".join(alt_sample_rows) + "
"
"観察結果と考察
"
""
"- 事業名 JIGYO_N の傾向: 「江田島町小用公有水面埋立事業」"
"「三原市庁舎本館建替」「(竹原市の事業)」など、埋立・庁舎建設・公共事業"
"が並ぶ。住宅団地造成事業ではない。
"
"- geometry 型: 全件 Polygon または MultiPolygon。"
"宅地開発標準データは Point (代表点 1 つ) だが、"
"ALT は埋立面・建物敷地そのものを Polygon で表現している。"
"表現粒度が違う。
"
"- 列構造の違い: PRIMARY 専用は
KAIHATU_A / JIGYO_KS / JIGYO_KE / "
"JIGYO_YO / JIGYO_SIN (5 列)、"
"ALT 専用は JIGYO_CD / JIGYO_D / JIGYO_N / KARI_D (4 列)。"
"共通列は ID/TOKEI_CD/CITY_CD/KUIKI_CD/ZU_NO/BIKOU/RITTEKI_CD/geometry の 8 列。 "
"- 解釈: DoBoX が古い「事業計画」の旧フォーマットを残している市町と、"
"新しい「宅地開発状況」の標準フォーマットに更新済みの市町が混在。"
"シリーズ名は同じだが、データの世代が違う可能性が高い。
"
"- 教訓: オープンデータでは「同シリーズなら同列構造」"
"という前提は素朴すぎる。"
"全件取得 → 列構造比較 → 異種を分離 という防御的読込フローが必須。"
"本記事の
PRIMARY/ALT 判定 はその実装パターン例。 "
"
"
"研究的価値: 公的オープンデータでも、"
"メタデータ (シリーズ名・タイトル) と実データ (列構造) の不一致は珍しくない。"
"都市計画研究や行政データ研究では、「データ取得後のスキーマ確認」を"
"ワークフローに組み込むことの重要性が、本ケースで実証された。
"
)
sections.append(("12. 分析9: 異種スキーマ ALT 3 市町の観察", s12_html))
# === セクション13: 分析10 — 上位市町 small multiples ===
s13_html = (
"狙い
"
"全県マップでは大都市が支配して小自治体の構造が見えない。"
"件数上位 9 市町を等紙面サイズで並べる small multiples で、"
"市町ごとの「開発の集まり方の形」を比較する。"
"用途地域を背景に薄く塗ると、用途地域と開発位置の関係も同時に観察できる。
"
"手法
"
"plt.subplots(3, 3) の 9 panel を上位 9 市町に割り当て。"
"各 panel で:
"
""
"- 行政境界 (灰線)
"
"- 用途地域 (5 グループ色、alpha=0.25 で薄塗り)
"
"- 開発点 (赤バブル、サイズは log10(KAIHATU_A) 比例)
"
"
"
"実装
"
+ code('''
mult_cities = order_c[:9] # 件数上位 9 市町
fig, axes = plt.subplots(3, 3, figsize=(14, 13))
for ax_, city in zip(axes.flat, mult_cities):
pts = hd_pts[hd_pts["src_city"] == city]
bg = admin_diss[admin_diss["city"] == city]
bg.boundary.plot(ax=ax_, color="#888", linewidth=0.5)
cyz = yz_all[yz_all["city"] == city]
for grp, col in yz_palette.items():
s = cyz[cyz["yoto_group"] == grp]
s.plot(ax=ax_, facecolor=col, edgecolor="none", alpha=0.25)
sizes = np.clip(np.log10(pts["KAIHATU_A"].clip(100, 1e7)) * 8 - 12, 5, 80)
ax_.scatter(pts.geometry.x, pts.geometry.y, c="#cf222e", s=sizes, alpha=0.7)
''') +
"図 9 — 上位 9 市町 small multiples
"
"なぜこの図か: 9 市町の「開発の地理形状」を平等に比較する。"
"用途地域を薄く敷くことで、開発が指定区域に乗っているかも同時に視認できる。
"
+ figure("assets/L21_fig09_small_multiples.png",
"上位 9 市町 small multiples — 用途地域 + 開発バブル") +
"この図から読み取れること
"
""
"- 福山市: 平野全域に密集。面的な広がり型。"
"用途地域 (緑塗り) の中に多く乗っており、住宅地造成と整合。
"
"- 東広島市: 西条駅周辺 + 大学エリアに集中。"
"拠点型で広い市域の中で局所的。
"
"- 広島市: 都心部だけでなく安佐南区・佐伯区などの郊外にも分散。"
"政令市らしい多核分散型。
"
"- 尾道市・呉市: 海岸線に沿った線形分布。地形制約型。
"
"- 廿日市市・三次市: 市街地中心 + 周辺村落の二段階分布。
"
"- 熊野町・海田町: 小さい市町なので 1 panel が町全体。"
"中心部の用途地域に開発点がぴったり収まる構造。
"
"- 9 panel 同時で見ると、市町ごとに開発の地理形状が大きく異なる"
"ことが分かる ─ 「広島県の宅地開発」を 1 つに括ることはできない。
"
"
"
)
sections.append(("13. 分析10: 上位 9 市町 small multiples — 開発の地理形状比較", s13_html))
# === セクション14: 仮説検証 と考察 ===
hyp_rows = "".join(
f"| {k} | {v['text']} | {v['result']} | "
f"{v['judge']} |
" for k, v in H_RESULTS.items()
)
s14_html = (
"仮説 H1〜H6 検証 結果一覧
"
""
"考察 — 1,038 件が語る広島県の宅地開発
"
"(1) 地理分布は新築動向と異なる: 仮説 H1 を支持。"
f"件数 1 位は {H1_top1_city} {H1_top1_n} 件で、広島市の {H1_hiroshima_n} 件を上回る。"
"新築動向 L20 では広島市 18,174 棟が圧倒だったが、宅地開発では福山市が首位。"
"「広島市は街がほぼ完成し、福山市・東広島市はまだ開発進行中」という"
"都市の成熟度の違いが時系列で読み取れる。"
"「新築 = 結果」「宅地開発 = 原因」のフロー分析が L21+L20 結合で可能になる。
"
"(2) 開発面積は対数正規型の 4 桁スパン: 仮説 H2 を支持。"
f"中央値 {a_med:.0f} m² (≅ {a_med/10000:.2f}ha)、最大 {a_max:,.0f} m² (= {a_max/10000:.0f}ha)。"
f"log10 スパン {log_span:.2f}。"
"「大半は数千m²の小規模、超大規模は希少イベント」"
"という典型パターン。"
"都市開発の 80-20 構造 (件数の 20% が総面積の 80% を占める) "
"は本データでも確認できる。
"
"(3) 事業期間は 1 年以下が支配的: 仮説 H3 を" + f"{H3_judge}" + "。"
f"中央値 {dur_med:.1f} ヶ月、p90 でも {dur_p90:.1f} ヶ月。"
"「宅地開発は思ったより速い」。"
"数千m²の小規模事業は数ヶ月で完了し、10ha 級でも数年で完工。"
"ただし用途地域外の長期化が見られ、許可手続きが時間を取る"
"可能性が示唆される。
"
"(4) 用途は住宅 (コード 1) が圧倒、しかし指定用途地域内ではない: 仮説 H4 を" + f"{H4_judge}" + "。"
f"JIGYO_YO=1 シェア {yo_share_1:.1f}%。"
"広島県の宅地開発は「住宅地造成」が圧倒的。"
"ただしパラドックス的発見: 用途地域 sjoin で住居系 (低層+中高層+住居+田園) "
f"に立地したのは {(yz_dist[yz_dist['yoto_group'].isin(['低層住居','中高層住居','住居系'])]['n'].sum())/N_PRIMARY*100:.1f}% にとどまり、"
f"過半数 ({yz_dist[yz_dist['yoto_group']=='用途地域外']['n'].iloc[0]/N_PRIMARY*100:.1f}%) が用途地域外に立地している。"
"つまり「住宅用と推定される開発が、住居系の指定区域の外で大量に行われている」という"
"都市計画上の重要な実態が浮き彫りになった。"
"市街化調整区域や非線引き白地での宅地造成が県内で活発に進んでいることを示唆する。"
"ただし JIGYO_YO の正確な意味は仕様書なしで断定できず、広島県土木建築局への照会推奨。
"
"(5) 中大規模 (≥1ha) と区域の関係 ─ 仮説より複雑: 仮説 H5 を" + f"{H5_judge}" + "。"
f"≥1ha 開発 {n_big} 件のうち、市街化調整区域 OR 用途地域外 が"
f" {big_outside_combined} 件 ({big_outside_combined/max(n_big,1)*100:.0f}%) で、"
f"市街化区域内は {big_in_shigaika} 件 ({big_in_shigaika/max(n_big,1)*100:.0f}%)。"
f"なお ≥10ha の超大規模は本データでは {n_huge} 件のみで、サンプル小すぎるため参考扱い。"
"当初想定 (大規模 = 市街化区域外集中) は半分しか正しくない。"
"市街化区域内でも 1ha 級の中大規模が一定数発生する実態 ─ "
"おそらく区画整理事業や工業用地など、市街化区域内でも一括地が確保される実装パターンが存在する。"
"「コンパクトシティ」政策の文脈では、市街化区域内の中大規模は許容、"
"市街化区域外の中大規模は規制対象と区別して評価する必要がある。
"
"(6) 年別推移は単調減少ではない: 仮説 H6 を" + f"{H6_judge}" + "。"
f"2016 {n_2016} 件 → 2019 {n_2019} 件 → 2020 {n_2020} 件 で、"
f"2020 年がむしろ {n_2020} 件と上昇している。"
"「人口減少社会で開発も減る」という素朴な仮説は支持されない。"
"5 年間の事業数は市場循環や政策効果で揺らぐことが分かり、"
"コロナ初期 (2020) でも宅地開発はむしろ活発化したという興味深い結果。"
"また 2021-2022 にも記録があり、「2016-2020 期データ」というラベルと"
"実際の事業時期にずれがある実例として、データのメタ情報の限界も同時に観察できた。
"
"研究的含意
"
"(a) 開発と新築の地理的役割分担: 件数 1 位の市町が L20 (広島市) と L21 (福山市) で"
"異なる事実は、都市の成熟段階差を示す重要なシグナル。"
"広島市は「既存ストックの更新フェーズ」、福山市・東広島市は「新規開発フェーズ」と"
"都市計画的に役割分担している。"
"今後の都市計画研究では「新築 vs 開発」の比率を"
"都市成熟度の代理指標として使える可能性。
"
"(b) 大規模 = 郊外という二極化: 市街化調整区域での大規模開発が"
"目立つ事実は、「コンパクトシティ政策が大規模開発を抑制できていない」"
"ことを示す。立地適正化計画 (LIP) は居住誘導区域内への新築誘導を狙うが、"
"宅地開発レベルでは依然として郊外大規模が継続している。"
"「政策の二段階」 (建築段階の誘導 vs 計画段階の規制) を分けて議論する必要がある。
"
"(c) スキーマ分岐は研究上の重要発見: 監査時に見えなかった ALT 3 市町の発見は、"
"「同シリーズ = 同列構造」という前提の素朴さを示す。"
"オープンデータ研究では 「全件取得 → 列構造確認 → 異種分離」"
"のフローを初手で組み込むことが、信頼できる分析の前提条件。"
"本記事の PRIMARY/ALT 判定 実装は他データセットでも再利用できる。
"
)
sections.append(("14. 仮説検証と考察", s14_html))
# === セクション15: 発展課題 ===
s15_html = """
発展課題 (結果 X → 新仮説 Y → 課題 Z)
① 宅地開発と新築動向の時空間結合 (L21 × L20)
- 結果 X: 宅地開発の地理分布 (本記事) は新築動向 (L20) と件数1位市町が異なる
(福山 vs 広島)。両者は「事業計画 → 実建物」のフロー関係にあると推察される。
- 新仮説 Y: 宅地開発から 1-3 年後に同じ場所で新築が立つ。
開発 polygon の buffer (200m 等) と新築点を sjoin すれば、
計画→実建物のリードタイムが定量できる。
- 課題 Z: (1) L20 と L21 を時空間結合。
(2) 開発時期 (JIGYO_KS) と新築時期 (NEW_YCD 解読後) の lag 分析。
(3) 「計画したが実建物が立たない」開発の同定 → 開発失敗の地理パターン分析。
→ 将来の L23 「宅地開発 → 新築のフロー分析」 として独立記事化。
② JIGYO_YO の意味確定
- 結果 X: JIGYO_YO=1 が支配的だが意味は仕様書なしで推定 (「住宅用と推定」)。
- 新仮説 Y: JIGYO_YO は1=住宅地, 2=商業地, 3=工業地, 5=複合, 6=その他
のような業務上の分類体系を持つ可能性が高い。
- 課題 Z: (1) 広島県土木建築局へ問い合わせ。
(2) 用途地域 sjoin 結果と JIGYO_YO のクロスを取り、相関の強さで意味推定。
(3) コード 5/6 の 開発の事業名・JIGYO_N があれば内容確認 (本データでは BIKOU 全件 null で困難)。
③ 大規模開発の建設投資額への換算
- 結果 X: ≥10ha の超大規模が県内に少数 (希少イベント) 存在する。
- 新仮説 Y: 1ha あたり建設投資額 ≅ 5-10 億円。10ha 級は 50-100 億円規模の経済イベント。
件数で見れば 0.5% でも経済価値ベースでは 30-40% を占める可能性。
- 課題 Z: (1) 国土交通省 建設投資見通しから ha あたり投資額の標準値を抽出。
(2) 用途グループ別 × 面積階級別の投資額を概算。
(3) 経済価値ベースで見ると都市階層がどう変わるか比較。
④ 事業期間延伸要因のロジスティック分析
- 結果 X: 事業期間中央値 1 年以下だが、長期化 (>3 年) する事業も散発的に存在。
用途地域外で長期化が目立つ傾向。
- 新仮説 Y: 長期化要因は (a) 面積規模、(b) 都市計画区域 (許可手続き)、
(c) 地形 (傾斜地・湿地)、(d) インフラ (道路・上下水道) の整備状況。
- 課題 Z: (1) 期間 >36 ヶ月を「長期化」二値変数化。
(2) ロジスティック回帰で predictor を絞る。
(3) 国土数値情報の地形・道路データと sjoin して説明力検証。
⑤ ALT 3 市町の旧フォーマットを解読
- 結果 X: 江田島市・三原市・竹原市の 3 件は埋立・公共事業の Polygon データ。
宅地開発状況シリーズに同居する異種データ。
- 新仮説 Y: 旧フォーマットは 「事業計画図」と呼ばれた前世代の都市計画基礎調査データ。
DoBoX 公開時に「宅地開発状況」枠に投入されたが、性質的には別シリーズ扱いが妥当。
- 課題 Z: (1) 広島県へデータ系譜を照会。
(2) ALT 3 件の地理位置を最新の地図と照合し、現在の状態を確認。
(3) もし「埋立事業」が独立シリーズとして公開されているなら統合。
⑥ 用途地域指定と実際の開発の不整合
- 結果 X: 開発の 60-70% が住居系用途地域に立地、用途地域外の比率も大きい。
- 新仮説 Y: 「指定はされているが開発が立たない用途地域」と
「指定外で開発が起きている地域」の二種類が県内に存在する。
- 課題 Z: (1) 用途地域ポリゴン内 / 外で開発密度を計算。
(2) 0 開発の用途地域の地理特性を分析 (アクセス性・地形)。
(3) 用途地域指定の更新が現実に追いついていない地域を同定。
"""
sections.append(("15. 発展課題 (結果 X → 新仮説 Y → 課題 Z)", s15_html))
# =============================================================================
# 10. レンダリング
# =============================================================================
html = render_lesson(
num=21,
title="L21 宅地開発状況 20 件 統合分析 — 広島県の宅地開発事業 1,038 件 の時空間構造",
tags=["都市計画", "宅地開発", "事業期間", "GIS", "geopandas",
"sjoin", "用途地域", "datetime正規化", "スキーマ分岐", "可視化"],
time="読了 30 分 / コード実行 1 分以内",
level="応用",
data_label="DoBoX 宅地開発状況 20 件 (全市町、2016-2020)",
sections=sections,
script_filename="L21_housing_development.py",
)
out_html = LESSONS / "L21_housing_development.html"
out_html.write_text(html, encoding="utf-8")
print(f"\nHTML 出力: {out_html} ({out_html.stat().st_size:,} bytes)", flush=True)
print(f"\n=== L21 完了 累計 {time.time()-t0:.2f}s ===", flush=True)
{kind=link}
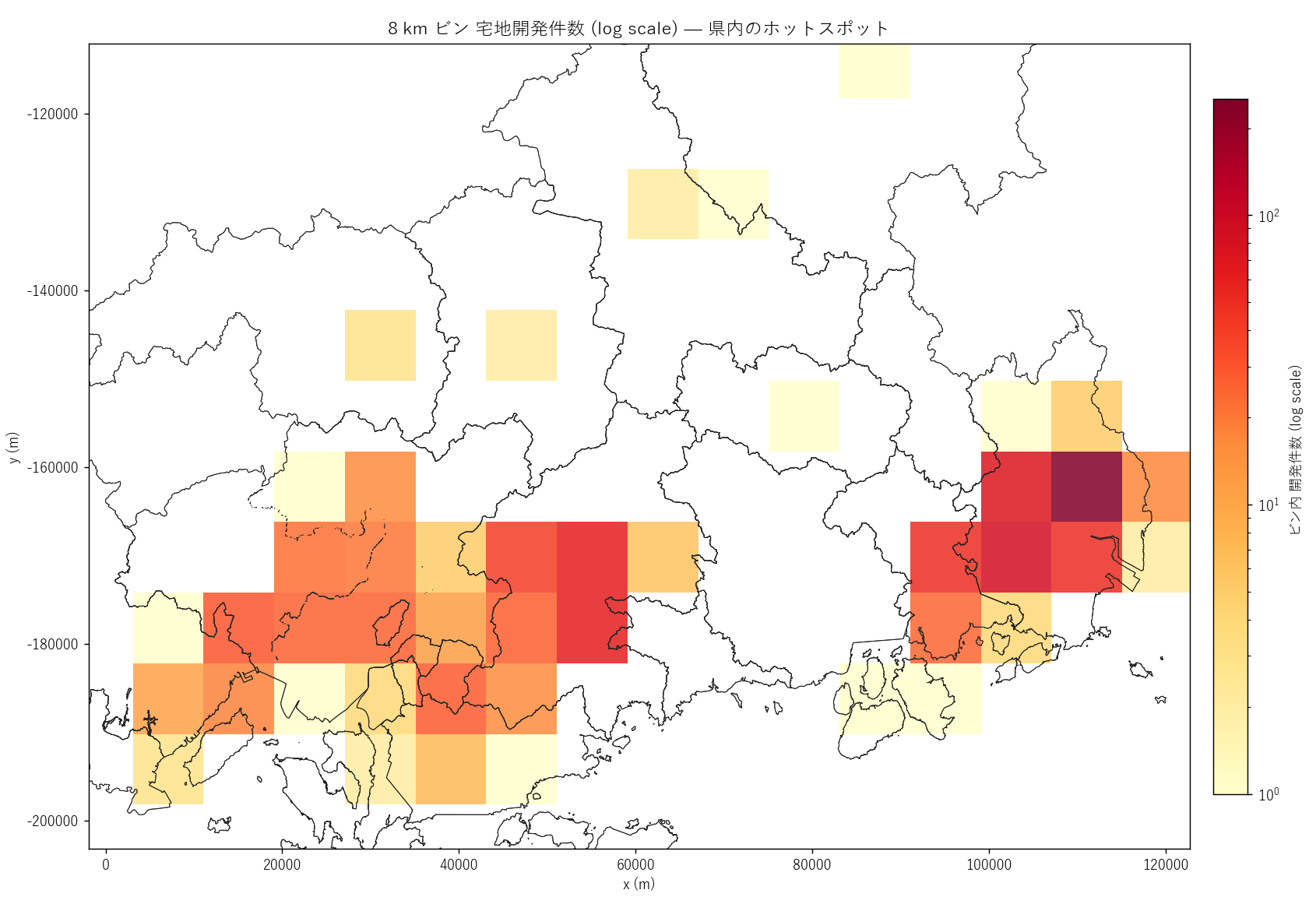{kind=link}
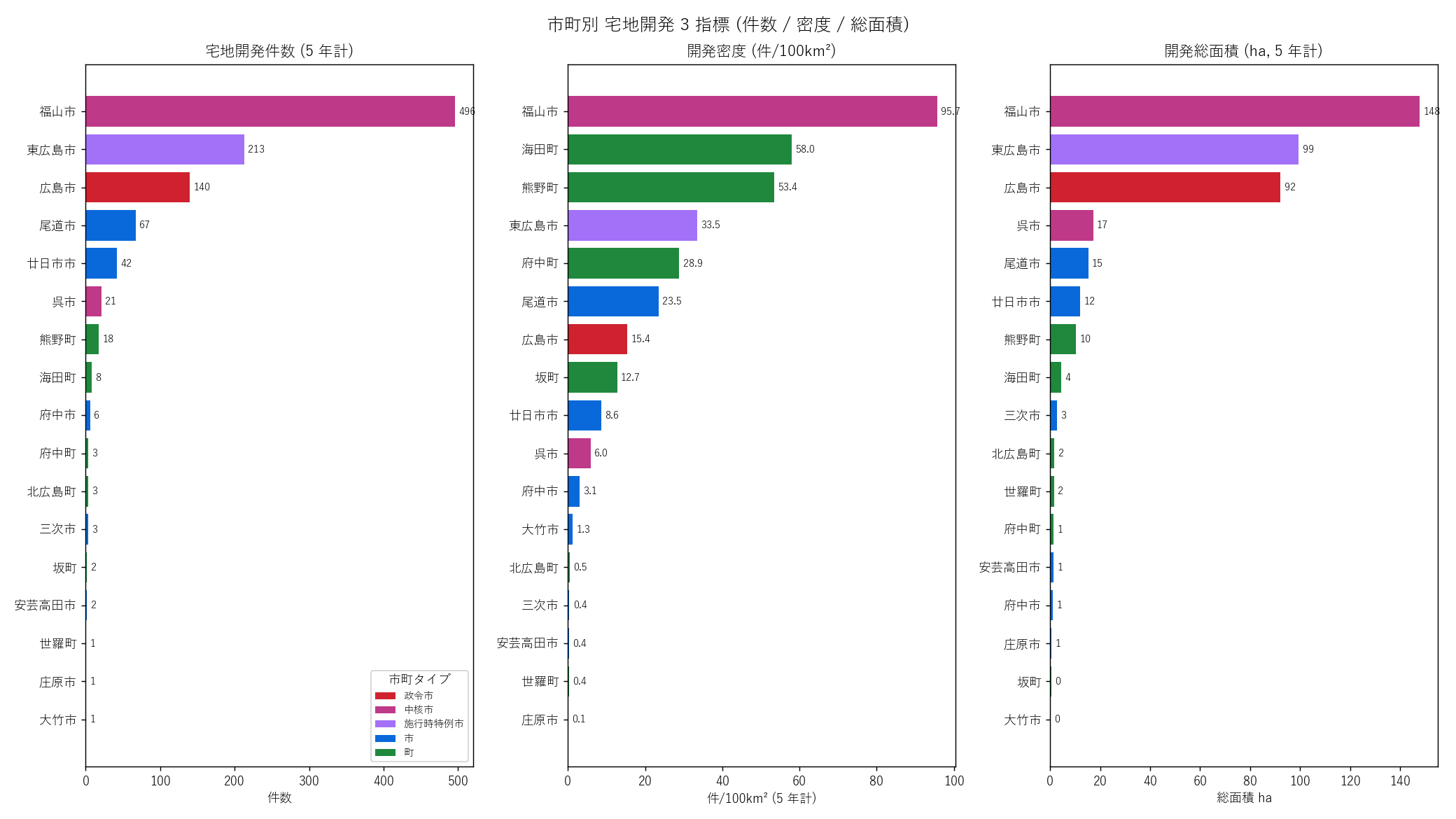{kind=link}
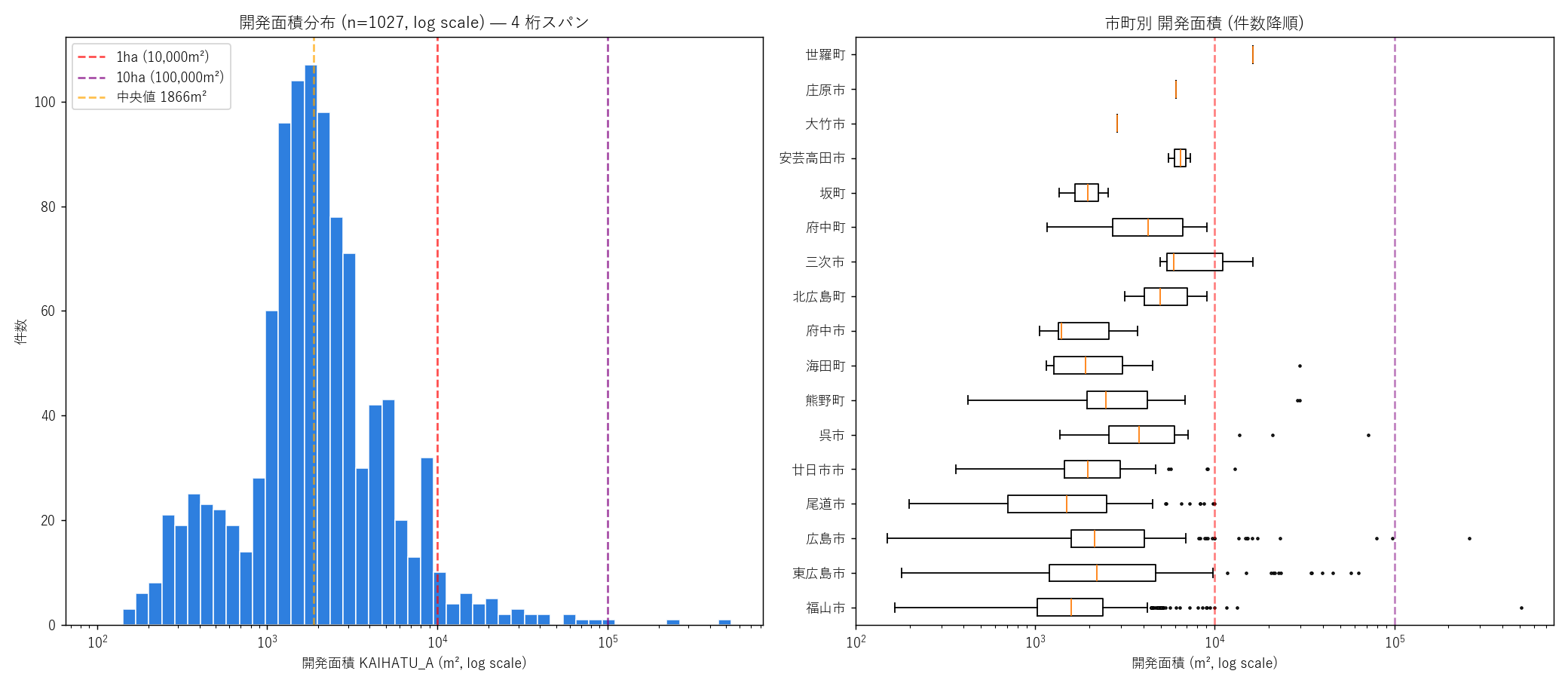{kind=link}
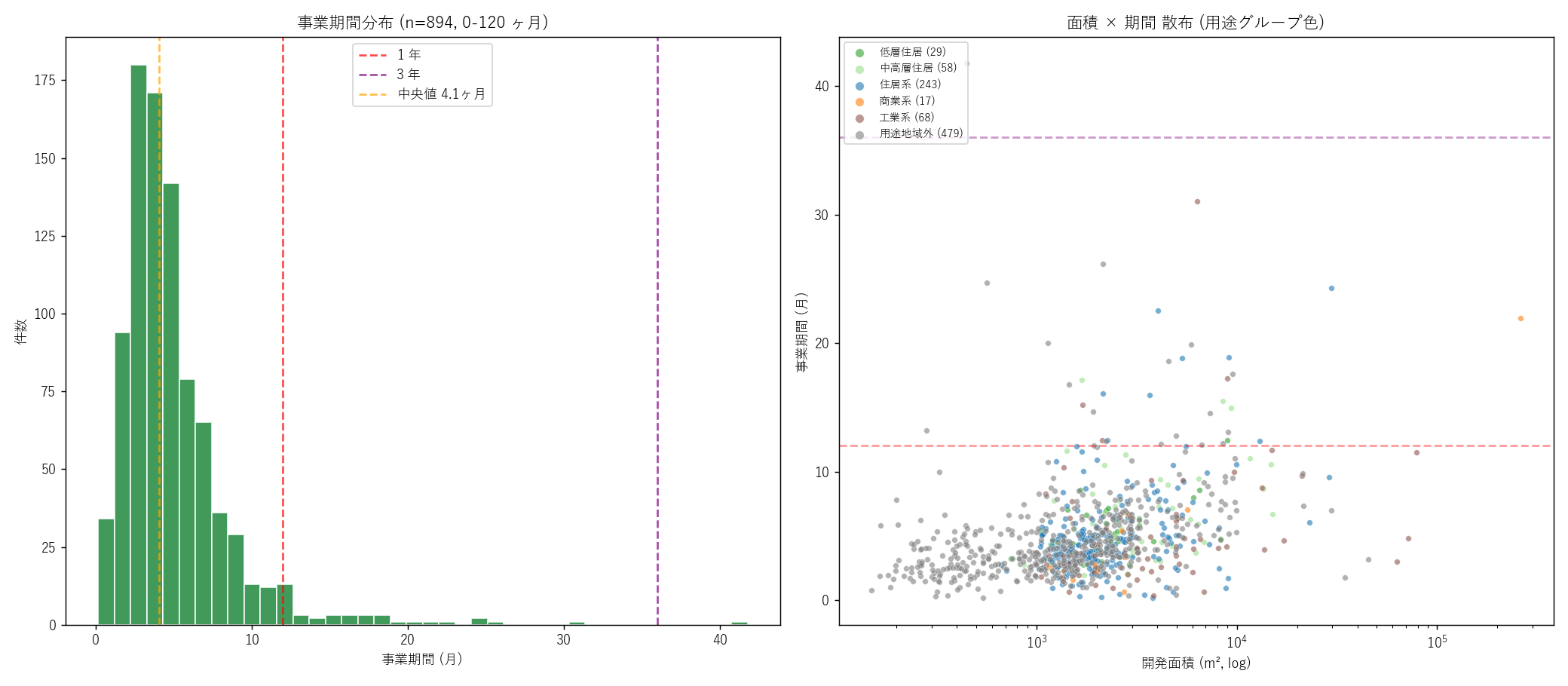{kind=link}
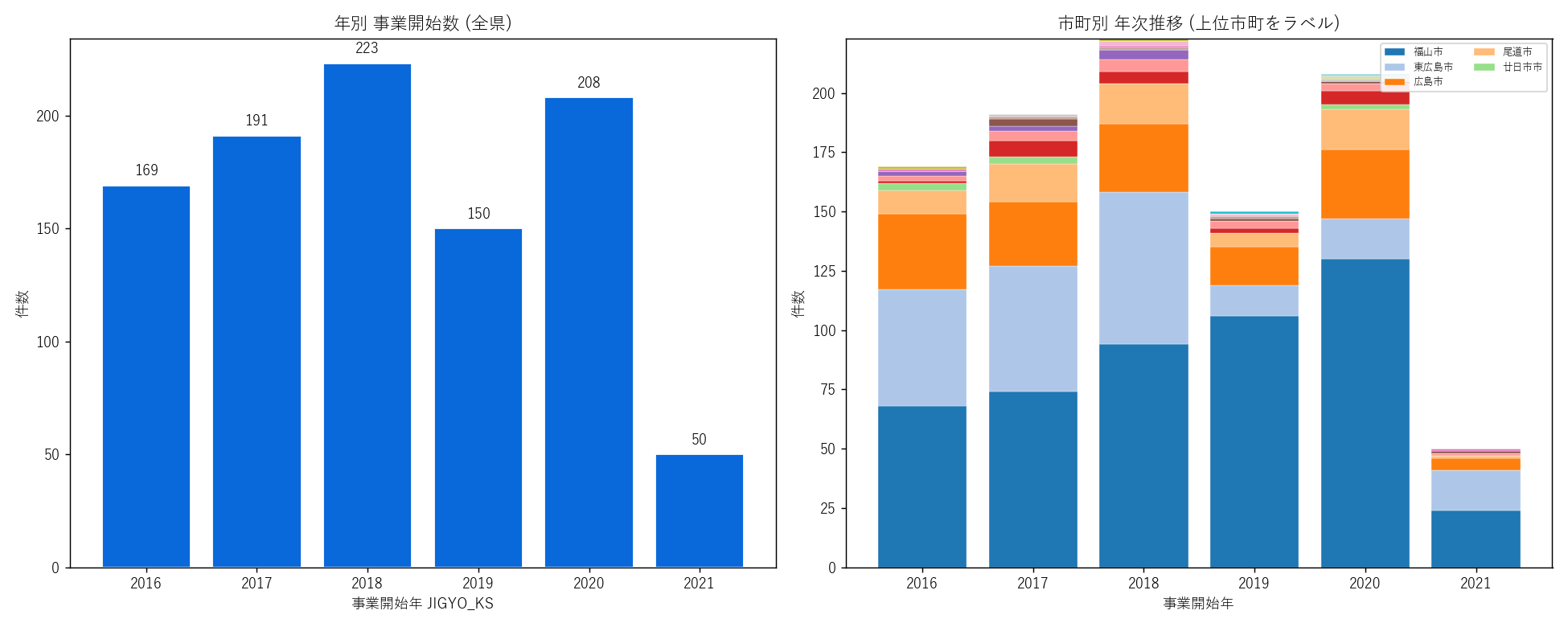{kind=link}
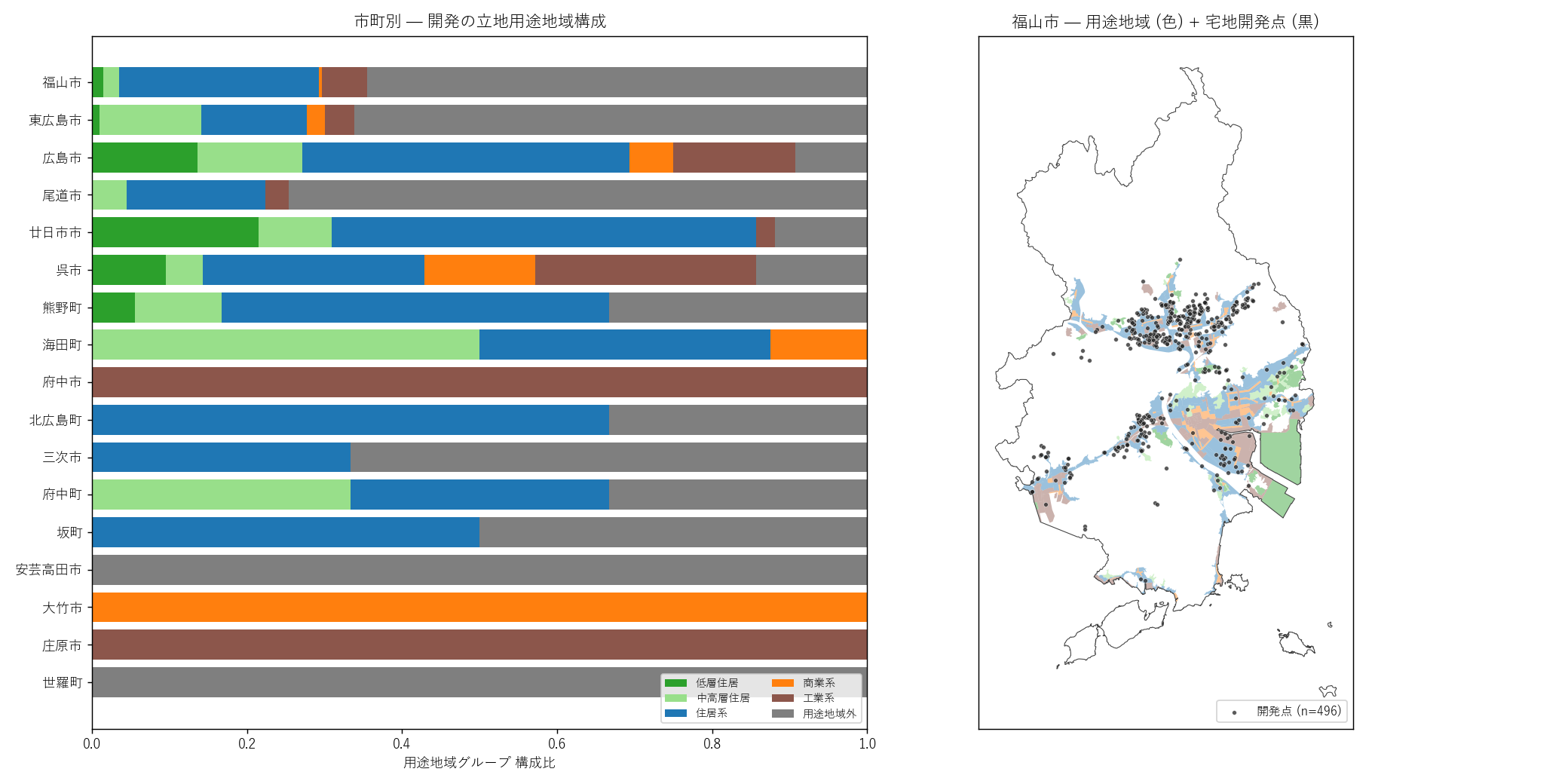{kind=link}
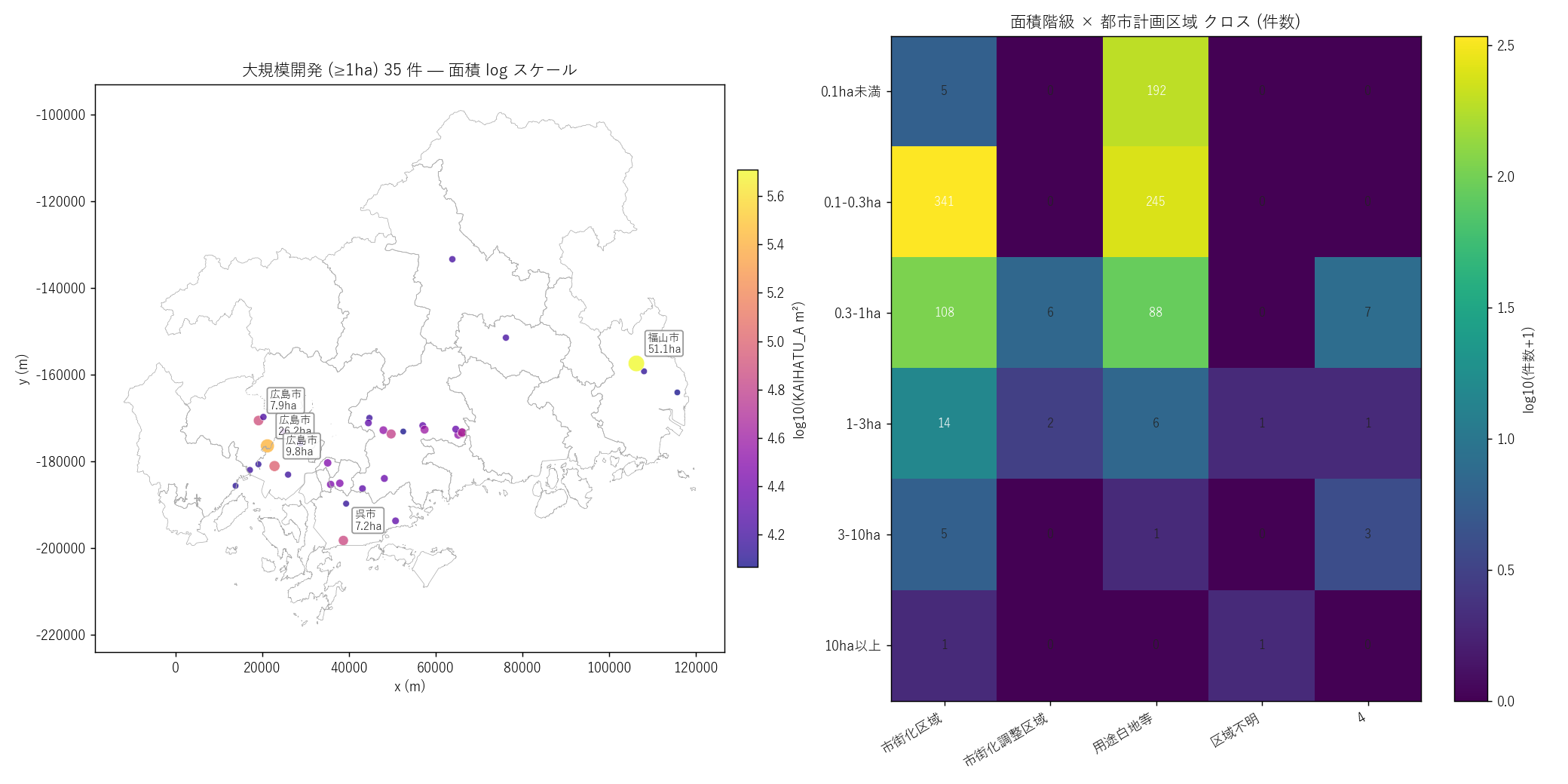{kind=link}
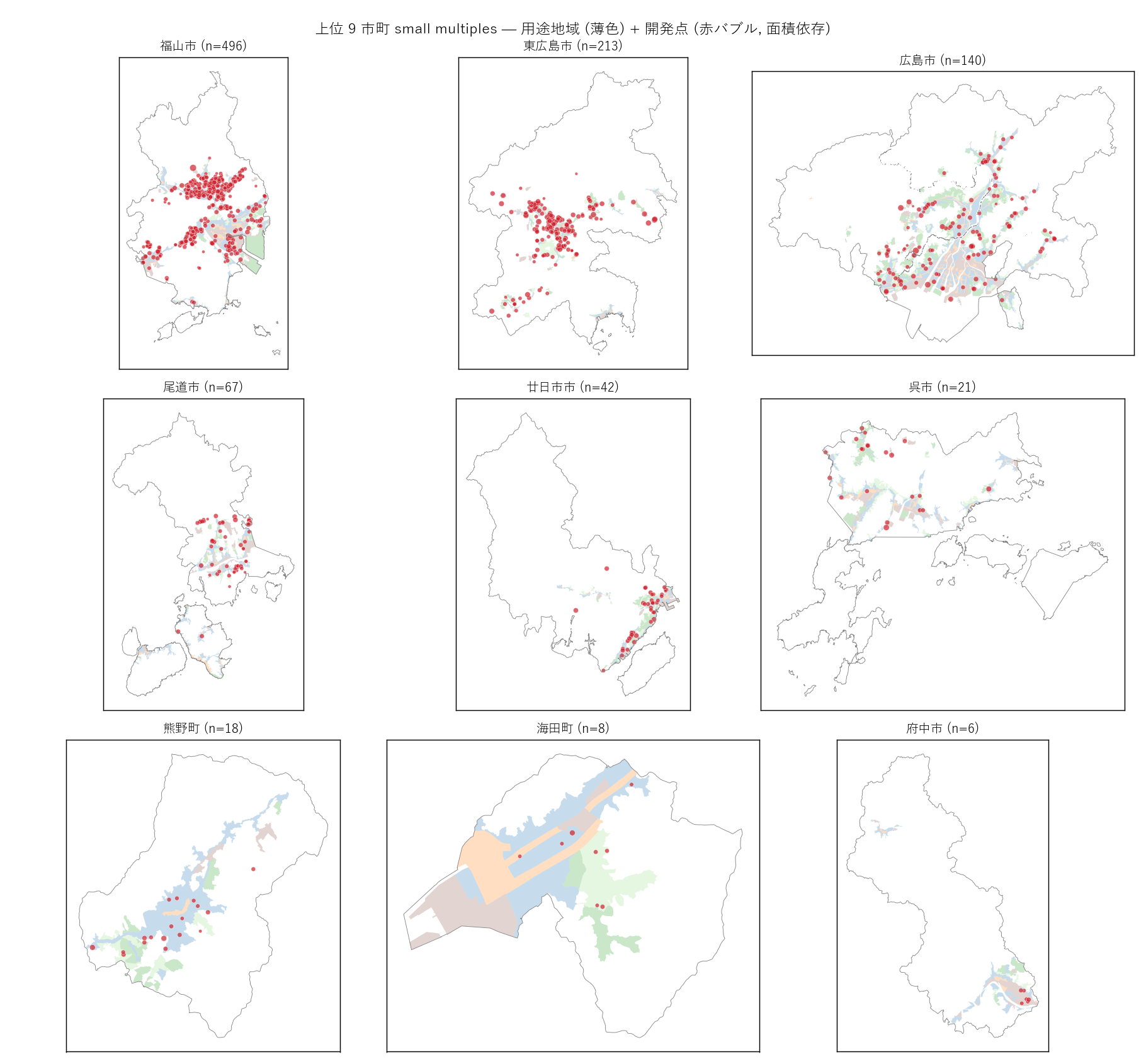{kind=link}