"""L17 用途地域 21 市町統合分析 — 広島県の用途地域指定構造と都市プロファイル
カバー宣言:
本記事は 都市計画区域情報_区域データ_各種用途地域 シリーズ全 21 件 = 21 dataset_id を
統合し、広島県全域の用途地域 (Zoning) 指定構造を分析する研究記事である。
- 20 市町別 GeoJSON: ds=794 広島市 / 804 呉市 / 811 竹原市 / 821 三原市 / 831 尾道市
/ 837 福山市 / 847 府中市 / 855 三次市 / 861 庄原市 / 867 大竹市 / 875 東広島市
/ 885 廿日市市 / 893 安芸高田市 / 899 江田島市 / 904 府中町 / 910 海田町
/ 915 熊野町 / 921 坂町 / 940 北広島町 / 946 世羅町
- 県全域 集約ファイル: ds=932 広島県(21 市町分のポリゴンを 2629 件で含む)
→ 合計 21 dataset_id(市町別 20 + 県全域 1)
研究の問い (RQ):
広島県内の用途地域 (Zoning) は、住居・商業・工業の 3 類型でどう構成され、
市町ごとにどのような「用途構成プロファイル」を持つか?
仮説 (D):
H1. 用途地域は住居系 (YOTO_CD 1-7) が面積で過半を占め、商業系 (8-9) はごくわずか、
工業系 (10-12) は瀬戸内沿岸の特定市町に集中する
H2. 「近隣商業地域」 (YOTO_CD=8) は広島県ではほとんど指定されておらず、
「商業地域」 (YOTO_CD=9) に機能が統合されている
H3. 田園住居地域 (YOTO_CD=13、2018 年都市計画法改正で新設) は新しい類型のため
全県でも 50 件未満、複数市町で導入が始まった段階である
H4. 市町ごとに用途構成は大きく異なり、「住宅都市型/工業都市型/商業中核型」など
いくつかのプロファイルにグルーピングできる (k-means で判別可能)
H5. 工業専用地域 (YOTO_CD=12) は瀬戸内沿岸の臨海工業地帯(大竹・福山・尾道・呉)に
強く偏在し、内陸市町ではほぼゼロ件である
要件 S 準拠: 1 分以内で完走(ポリゴン総数 2629、軽量)。
要件 T 準拠: 13 用途別主題図 + 3 類型 choropleth + 20 市町 small multiples
+ 工業地帯クローズアップ + プロファイル散布図
要件 Q 準拠: 図 8 枚以上、表 9 枚以上。
L13/L15/L16 との重複回避:
- L13 は「建物利用 × 土地利用」のメッシュ集計、本記事の用途地域 (指定) とは別物
- L13 で扱った "建物利用 × 用途地域 mismatch" は本記事では扱わない
- L15 は行政区域、L16 は都市計画区域。本記事は L16 都計区域の "内部" の用途構成に焦点
- 行政区域・都計区域は「分母/背景レイヤ」としてのみ参照
"""
from __future__ import annotations
import sys, time, json, zipfile, io
from pathlib import Path
sys.path.insert(0, str(Path(__file__).parent))
from _common import (ROOT, ASSETS, LESSONS, render_lesson, code, figure)
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.patches import Patch
import geopandas as gpd
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
t0 = time.time()
print("=== L17 用途地域 21市町統合分析 ===", flush=True)
# =============================================================================
# 0. 定数: 21 dataset_id, YOTO_CD 凡例, 行政区域参照
# =============================================================================
DATA_DIR = ROOT / "data" / "extras" / "L17_use_zones"
ADMIN_DIR = ROOT / "data" / "extras" / "L15_admin_zones"
TARGET_CRS = "EPSG:6671" # JGD2011 平面直角 III, 広島県, m 単位
# (dataset_id, 市町名, 海岸 bool, タイプ)
CITY_DEFS = [
(794, "広島市", True, "政令市"),
(804, "呉市", True, "市"),
(811, "竹原市", True, "市"),
(821, "三原市", True, "市"),
(831, "尾道市", True, "市"),
(837, "福山市", True, "市"),
(847, "府中市", False, "市"),
(855, "三次市", False, "市"),
(861, "庄原市", False, "市"),
(867, "大竹市", True, "市"),
(875, "東広島市", True, "市"),
(885, "廿日市市", True, "市"),
(893, "安芸高田市", False, "市"),
(899, "江田島市", True, "離島自治体"),
(904, "府中町", False, "町"),
(910, "海田町", True, "町"),
(915, "熊野町", False, "町"),
(921, "坂町", True, "町"),
(940, "北広島町", False, "町"),
(946, "世羅町", False, "町"),
]
KEN_DSID = 932
# 行政区域 dsid(L15 と同じ; 比率分母用)
ADMIN_DSID = {
"広島市":786, "呉市":797, "竹原市":807, "三原市":814, "尾道市":824, "福山市":832,
"府中市":840, "三次市":850, "庄原市":856, "大竹市":862, "東広島市":868, "廿日市市":878,
"安芸高田市":888, "江田島市":894, "府中町":900, "海田町":905, "熊野町":911, "坂町":916,
"北広島町":935, "世羅町":941,
}
# YOTO_CD → (用途地域名, 3類型カテゴリ, カラー)
# 都市計画法・建築基準法上の用途地域 13 種類
YOTO_INFO = {
1: ("第一種低層住居専用地域", "住居系", "#a6dba0"),
2: ("第二種低層住居専用地域", "住居系", "#7fbc41"),
3: ("第一種中高層住居専用地域", "住居系", "#4d9221"),
4: ("第二種中高層住居専用地域", "住居系", "#276419"),
5: ("第一種住居地域", "住居系", "#c7e9c0"),
6: ("第二種住居地域", "住居系", "#74c476"),
7: ("準住居地域", "住居系", "#41ab5d"),
8: ("近隣商業地域", "商業系", "#fdae61"),
9: ("商業地域", "商業系", "#d73027"),
10: ("準工業地域", "工業系", "#9e9ac8"),
11: ("工業地域", "工業系", "#6a51a3"),
12: ("工業専用地域", "工業系", "#3f007d"),
13: ("田園住居地域", "田園系", "#ffd92f"),
}
TYPE_CAT_COLOR = {
"住居系": "#41ab5d",
"商業系": "#d73027",
"工業系": "#6a51a3",
"田園系": "#ffd92f",
}
CTYPE_COLOR = {
"政令市": "#cf222e", "市": "#0969da",
"離島自治体": "#bf8700", "町": "#1f883d",
}
# =============================================================================
# 1. 21 市町 GeoJSON 統合読み込み
# =============================================================================
print("\n[1] 21 市町 GeoJSON 統合読み込み", flush=True)
t1 = time.time()
def load_geojson_zip(zip_path: Path) -> gpd.GeoDataFrame:
"""ZIP 内の単一 .geojson を BytesIO 経由で読み込み(一時ファイル不要)"""
with zipfile.ZipFile(zip_path) as zf:
gjs = [n for n in zf.namelist() if n.endswith(".geojson")]
if not gjs:
raise FileNotFoundError(f"no .geojson in {zip_path.name}")
with zf.open(gjs[0]) as f:
return gpd.read_file(io.BytesIO(f.read()))
frames = []
miss = []
for dsid, name, coastal, ctype in CITY_DEFS:
z = DATA_DIR / f"use_zone_{dsid}_{name}.zip"
if not z.exists():
miss.append((dsid, name))
continue
g = load_geojson_zip(z)
g["source_city"] = name
g["source_dsid"] = dsid
g["coastal"] = coastal
g["ctype"] = ctype
frames.append(g)
assert not miss, f"missing zip: {miss}"
zone = gpd.GeoDataFrame(pd.concat(frames, ignore_index=True),
geometry="geometry", crs=frames[0].crs)
zone = zone.to_crs(TARGET_CRS)
zone["YOTO_NAME"] = zone["YOTO_CD"].map(lambda c: YOTO_INFO[c][0])
zone["YOTO_TYPE"] = zone["YOTO_CD"].map(lambda c: YOTO_INFO[c][1])
zone["poly_area_km2"] = zone.geometry.area / 1e6
zone["poly_perim_km"] = zone.geometry.length / 1e3
print(f" 21 市町統合: {len(zone)} ポリゴン, CRS={zone.crs.to_epsg()}, "
f"{time.time()-t1:.2f}s", flush=True)
# 県全域版(整合性検証)
ken_zip = DATA_DIR / f"use_zone_{KEN_DSID}_広島県.zip"
ken_gdf = load_geojson_zip(ken_zip).to_crs(TARGET_CRS)
ken_gdf["poly_area_km2"] = ken_gdf.geometry.area / 1e6
print(f" 県全域 ds={KEN_DSID}: {len(ken_gdf)} ポリゴン", flush=True)
# 行政区域(背景・分母用; L15 共有)
admin_frames = []
for city, dsid in ADMIN_DSID.items():
z = ADMIN_DIR / f"admin_{dsid}_{city}.zip"
g = load_geojson_zip(z)
g["city"] = city
admin_frames.append(g)
admin_all = gpd.GeoDataFrame(pd.concat(admin_frames, ignore_index=True),
geometry="geometry", crs=admin_frames[0].crs)
admin_all = admin_all.to_crs(TARGET_CRS)
admin_diss = admin_all.dissolve(by="city").reset_index()
admin_diss["admin_area_km2"] = admin_diss.geometry.area / 1e6
print(f" 行政区域 (L15共有) 読込: {len(admin_diss)} 市町", flush=True)
# =============================================================================
# 2. 13 用途地域 集約と 3 類型分類
# =============================================================================
print("\n[2] 13 用途地域 集約・3 類型分類", flush=True)
t1 = time.time()
# (1) YOTO_CD 別ジオメトリ統合(dissolve)
zone_diss_yoto = zone.dissolve(by="YOTO_CD", aggfunc={
"YOTO_NAME": "first",
"YOTO_TYPE": "first",
}).reset_index()
def n_parts(geom):
if geom is None or geom.is_empty:
return 0
if geom.geom_type == "MultiPolygon":
return len(list(geom.geoms))
return 1
zone_diss_yoto["n_parts"] = zone_diss_yoto.geometry.apply(n_parts)
zone_diss_yoto["area_km2"] = zone_diss_yoto.geometry.area / 1e6
zone_diss_yoto["polys_count"] = zone_diss_yoto["YOTO_CD"].map(
zone["YOTO_CD"].value_counts())
zone_diss_yoto["cities_count"] = zone_diss_yoto["YOTO_CD"].map(
pd.crosstab(zone["YOTO_CD"], zone["source_city"]).gt(0).sum(axis=1))
zone_diss_yoto = zone_diss_yoto.sort_values("YOTO_CD").reset_index(drop=True)
# (2) 3 類型 (住居系/商業系/工業系/田園系) 別集計
type_agg = zone.groupby("YOTO_TYPE").agg(
polys_count=("poly_area_km2", "size"),
area_km2=("poly_area_km2", "sum"),
n_yoto_codes=("YOTO_CD", "nunique"),
).reset_index()
type_agg["share_pct"] = type_agg["area_km2"] / type_agg["area_km2"].sum() * 100
# (3) 市町別 用途構成プロファイル(ピボット)
city_yoto_area = zone.pivot_table(
index="source_city", columns="YOTO_CD",
values="poly_area_km2", aggfunc="sum", fill_value=0)
# 全 13 列確保(無いコードは 0 で埋める)
for c in range(1, 14):
if c not in city_yoto_area.columns:
city_yoto_area[c] = 0.0
city_yoto_area = city_yoto_area.reindex(columns=range(1, 14))
# 市町別 3 類型別 面積
city_type_area = zone.pivot_table(
index="source_city", columns="YOTO_TYPE",
values="poly_area_km2", aggfunc="sum", fill_value=0)
for tcat in ["住居系", "商業系", "工業系", "田園系"]:
if tcat not in city_type_area.columns:
city_type_area[tcat] = 0.0
city_type_area = city_type_area[["住居系", "商業系", "工業系", "田園系"]]
# 市町別 用途地域 総面積
city_total = zone.groupby("source_city")["poly_area_km2"].sum().rename(
"use_zone_total_km2")
# シェア (%) も計算
city_type_pct = city_type_area.div(city_total, axis=0) * 100
city_type_pct.columns = [f"{c}_pct" for c in city_type_pct.columns]
# 行政面積をマージし、用途地域指定密度(用途地域 / 行政面積)も
city_meta = pd.DataFrame([{"city": n, "ctype": t, "coastal": c}
for _, n, c, t in CITY_DEFS])
admin_areas = admin_diss.set_index("city")["admin_area_km2"]
city_profile = pd.concat([city_total, city_type_area, city_type_pct], axis=1)
city_profile = city_profile.reset_index().rename(columns={"source_city": "city"})
city_profile = city_profile.merge(city_meta, on="city")
city_profile["admin_area_km2"] = city_profile["city"].map(admin_areas)
city_profile["use_zone_density_pct"] = (
city_profile["use_zone_total_km2"] / city_profile["admin_area_km2"] * 100)
# 主用途タイプ(最大シェアの 3 類型)
def dominant_type(row):
pcts = {t: row[f"{t}_pct"] for t in ["住居系", "商業系", "工業系", "田園系"]}
return max(pcts, key=pcts.get)
city_profile["dominant_type"] = city_profile.apply(dominant_type, axis=1)
# 並び順固定
CITY_ORDER = [c[1] for c in CITY_DEFS]
city_profile["__o"] = city_profile["city"].map({c: i for i, c in enumerate(CITY_ORDER)})
city_profile = city_profile.sort_values("__o").drop(columns="__o").reset_index(drop=True)
print(f" YOTO_CD 種類: {len(zone_diss_yoto)}", flush=True)
print(f" 3類型: 住居={type_agg[type_agg['YOTO_TYPE']=='住居系']['share_pct'].iloc[0]:.1f}% "
f"商業={type_agg[type_agg['YOTO_TYPE']=='商業系']['share_pct'].iloc[0]:.1f}% "
f"工業={type_agg[type_agg['YOTO_TYPE']=='工業系']['share_pct'].iloc[0]:.1f}%",
flush=True)
print(f" YOTO_CD=8 (近隣商業) ポリゴン数: {(zone['YOTO_CD']==8).sum()}", flush=True)
print(f" YOTO_CD=13 (田園住居) ポリゴン数: {(zone['YOTO_CD']==13).sum()}, "
f"市町数: {zone[zone['YOTO_CD']==13]['source_city'].nunique()}", flush=True)
# =============================================================================
# 3. 中間 CSV 出力
# =============================================================================
print("\n[3] 中間 CSV 出力", flush=True)
ASSETS.mkdir(parents=True, exist_ok=True)
# 13 用途地域 集約
yoto_summary = zone_diss_yoto.drop(columns="geometry").copy()
yoto_summary.to_csv(ASSETS / "L17_yoto_summary.csv", index=False, encoding="utf-8-sig")
# 3 類型集計
type_agg.round(3).to_csv(ASSETS / "L17_type_agg.csv", index=False, encoding="utf-8-sig")
# 市町別 用途構成プロファイル
city_profile.round(3).to_csv(ASSETS / "L17_city_profile.csv",
index=False, encoding="utf-8-sig")
# 市町 × 用途地域 クロス(面積)
crosstab_area = zone.pivot_table(
index="source_city", columns="YOTO_NAME",
values="poly_area_km2", aggfunc="sum", fill_value=0).round(3)
crosstab_area.to_csv(ASSETS / "L17_city_yoto_crosstab_area.csv", encoding="utf-8-sig")
# 全ポリゴン詳細
zone.drop(columns="geometry").round(4).to_csv(
ASSETS / "L17_poly_detail.csv", index=False, encoding="utf-8-sig")
print(" saved 5 CSVs", flush=True)
# =============================================================================
# 4. 図 1: 13 用途地域 主題図 (YOTO_CD 別カラー)
# =============================================================================
print("\n[4] 図1: 13 用途地域 主題図", flush=True)
t1 = time.time()
fig, ax = plt.subplots(figsize=(11, 8.5))
# 行政区域 county outline をベースに
ken_outline = admin_diss.dissolve()
ken_outline.plot(ax=ax, color="#f6f8fa", edgecolor="#999999",
linewidth=0.5, zorder=1)
# YOTO_CD ごとに色塗り(属性別 plot)
for yc, (yname, ytype, ycolor) in YOTO_INFO.items():
sub = zone[zone["YOTO_CD"] == yc]
if len(sub) == 0:
continue
sub.plot(ax=ax, color=ycolor, edgecolor="white", linewidth=0.05,
alpha=0.9, zorder=3)
ax.set_title("広島県 13 用途地域 主題図 (YOTO_CD 別塗分け)", fontsize=13)
ax.set_axis_off()
patches = [Patch(facecolor=YOTO_INFO[c][2],
label=f"{c}: {YOTO_INFO[c][0]}")
for c in sorted(YOTO_INFO.keys())]
patches.append(Patch(facecolor="#f6f8fa", edgecolor="#999999",
label="行政区域 (背景)"))
ax.legend(handles=patches, loc="lower left", fontsize=8, frameon=True,
ncol=2)
plt.tight_layout()
plt.savefig(ASSETS / "L17_yoto_thematic.png", dpi=130, bbox_inches="tight")
plt.close("all")
print(f" saved L17_yoto_thematic.png ({time.time()-t1:.2f}s)", flush=True)
# =============================================================================
# 5. 図 2: 3 類型 主題図 (住居系/商業系/工業系/田園系)
# =============================================================================
print("\n[5] 図2: 3 類型 主題図 + 凡例", flush=True)
t1 = time.time()
fig, axes = plt.subplots(1, 2, figsize=(15, 7))
# 左: 3 類型主題図
ken_outline.plot(ax=axes[0], color="#f6f8fa", edgecolor="#999999",
linewidth=0.5, zorder=1)
admin_diss.boundary.plot(ax=axes[0], color="#cccccc", linewidth=0.3, zorder=2)
for tcat in ["住居系", "商業系", "工業系", "田園系"]:
sub = zone[zone["YOTO_TYPE"] == tcat]
if len(sub) == 0:
continue
sub.plot(ax=axes[0], color=TYPE_CAT_COLOR[tcat], edgecolor="white",
linewidth=0.05, alpha=0.85, zorder=3)
axes[0].set_title("3 類型に集約した広島県の用途地域分布", fontsize=12)
axes[0].set_axis_off()
ptype_legend = [Patch(facecolor=TYPE_CAT_COLOR[t],
label=f"{t} ({type_agg[type_agg['YOTO_TYPE']==t]['area_km2'].iloc[0]:.0f} km²)"
if t in type_agg["YOTO_TYPE"].values else f"{t} (0)")
for t in ["住居系", "商業系", "工業系", "田園系"]]
ptype_legend.append(Patch(facecolor="#f6f8fa", edgecolor="#999999",
label="行政区域 (背景)"))
axes[0].legend(handles=ptype_legend, loc="lower left", fontsize=10)
# 右: 3 類型の面積パイ
sizes = [type_agg[type_agg["YOTO_TYPE"]==t]["area_km2"].iloc[0]
if t in type_agg["YOTO_TYPE"].values else 0
for t in ["住居系", "商業系", "工業系", "田園系"]]
labels = [f"{t}\n{s:.1f} km²\n({s/sum(sizes)*100:.1f}%)"
for t, s in zip(["住居系", "商業系", "工業系", "田園系"], sizes)]
axes[1].pie(sizes,
labels=labels,
colors=[TYPE_CAT_COLOR[t] for t in ["住居系", "商業系", "工業系", "田園系"]],
startangle=90,
wedgeprops={"edgecolor": "white", "linewidth": 1.5},
textprops={"fontsize": 11})
axes[1].set_title(f"用途地域 3 類型 面積構成(広島県全 {sum(sizes):.0f} km²)",
fontsize=12)
plt.tight_layout()
plt.savefig(ASSETS / "L17_type_thematic_pie.png", dpi=130, bbox_inches="tight")
plt.close("all")
print(f" saved L17_type_thematic_pie.png ({time.time()-t1:.2f}s)", flush=True)
# =============================================================================
# 6. 図 3: 13 用途地域 small multiples(13 panels で個別表示)
# =============================================================================
print("\n[6] 図3: 13 用途地域 small multiples", flush=True)
t1 = time.time()
n_yoto = len(zone_diss_yoto)
cols = 4
rows = int(np.ceil(n_yoto / cols))
fig, axes = plt.subplots(rows, cols, figsize=(15, 3.0*rows))
axes = axes.flatten()
# 全 panel で同じ範囲(県全域)を見せるため、bounds 取得
xmin, ymin, xmax, ymax = ken_outline.total_bounds
for i, (_, r) in enumerate(zone_diss_yoto.iterrows()):
ax = axes[i]
yc = r["YOTO_CD"]
yname, ytype, ycolor = YOTO_INFO[yc]
# 背景: 県の輪郭
ken_outline.plot(ax=ax, color="#f6f8fa", edgecolor="#999999",
linewidth=0.4, zorder=1)
# 該当用途地域
sub = zone[zone["YOTO_CD"] == yc]
if len(sub) > 0:
sub.plot(ax=ax, color=ycolor, edgecolor="white",
linewidth=0.1, zorder=3)
ax.set_xlim(xmin, xmax)
ax.set_ylim(ymin, ymax)
ax.set_title(f"YOTO {yc}: {yname}\n{r['area_km2']:.1f}km² / "
f"{int(r['polys_count'])}polys / {int(r['cities_count'])}市町",
fontsize=9)
ax.set_axis_off()
for j in range(n_yoto, rows*cols):
axes[j].set_visible(False)
plt.suptitle("13 用途地域 個別分布 small multiples (同一スケール、全県俯瞰)",
fontsize=12, y=1.00)
plt.tight_layout()
plt.savefig(ASSETS / "L17_yoto_small_multiples.png", dpi=120, bbox_inches="tight")
plt.close("all")
print(f" saved ({time.time()-t1:.2f}s)", flush=True)
# =============================================================================
# 7. 図 4: 13 用途地域 面積バー (3 類型カラー)
# =============================================================================
print("\n[7] 図4: 13 用途地域 面積バー", flush=True)
t1 = time.time()
fig, axes = plt.subplots(1, 2, figsize=(15, 6.5))
zd = zone_diss_yoto.sort_values("area_km2", ascending=True).copy()
bar_colors = [TYPE_CAT_COLOR[t] for t in zd["YOTO_TYPE"]]
labels = [f"{c}: {n}" for c, n in zip(zd["YOTO_CD"], zd["YOTO_NAME"])]
axes[0].barh(labels, zd["area_km2"],
color=bar_colors, edgecolor="black", linewidth=0.4)
for i, (_, r) in enumerate(zd.iterrows()):
axes[0].text(r["area_km2"] + 2, i,
f"{int(r['polys_count'])}polys / {int(r['cities_count'])}市町",
va="center", fontsize=8)
axes[0].set_xlabel("面積 km²")
axes[0].set_title("13 用途地域 面積ランキング(色=3 類型)", fontsize=11)
axes[0].grid(axis="x", alpha=0.3)
ptype_legend = [Patch(facecolor=TYPE_CAT_COLOR[t], label=t)
for t in ["住居系", "商業系", "工業系", "田園系"]]
axes[0].legend(handles=ptype_legend, loc="lower right", fontsize=9)
# 右: ポリゴン数 vs 平均面積(log-log 散布)
zd2 = zone_diss_yoto.copy()
zd2["mean_area_km2"] = zd2["area_km2"] / zd2["polys_count"]
for tcat in ["住居系", "商業系", "工業系", "田園系"]:
sub = zd2[zd2["YOTO_TYPE"] == tcat]
if len(sub) == 0:
continue
axes[1].scatter(sub["polys_count"], sub["mean_area_km2"],
c=TYPE_CAT_COLOR[tcat], s=130, edgecolor="black",
linewidth=0.6, alpha=0.9, label=tcat)
for _, r in sub.iterrows():
axes[1].annotate(f"{r['YOTO_CD']}",
(r["polys_count"], r["mean_area_km2"]),
fontsize=9, xytext=(5, 4), textcoords="offset points",
fontweight="bold")
axes[1].set_xscale("log")
axes[1].set_yscale("log")
axes[1].set_xlabel("ポリゴン数 (log)")
axes[1].set_ylabel("平均ポリゴン面積 km² (log)")
axes[1].set_title("13 用途地域: ポリゴン数 × 平均面積(log-log)", fontsize=11)
axes[1].grid(True, which="both", alpha=0.3)
axes[1].legend(loc="upper right", fontsize=9)
plt.tight_layout()
plt.savefig(ASSETS / "L17_yoto_area_bar.png", dpi=130, bbox_inches="tight")
plt.close("all")
print(f" saved ({time.time()-t1:.2f}s)", flush=True)
# =============================================================================
# 8. 図 5: 市町別 用途構成プロファイル 100% 積み上げ棒
# =============================================================================
print("\n[8] 図5: 市町別 用途構成プロファイル 100%積み上げ", flush=True)
t1 = time.time()
fig, ax = plt.subplots(figsize=(12, 7.5))
# 用途地域 総面積 で % にする(住居系/商業系/工業系/田園系)
cp = city_profile.set_index("city")
total = cp[["住居系","商業系","工業系","田園系"]].sum(axis=1)
pct = cp[["住居系","商業系","工業系","田園系"]].div(total, axis=0).fillna(0) * 100
# 並びは住居系構成比降順
order = pct.sort_values("住居系", ascending=True).index.tolist()
pct = pct.loc[order]
total = total.loc[order]
y = np.arange(len(pct))
left = np.zeros(len(pct))
for tcat in ["住居系", "商業系", "工業系", "田園系"]:
vals = pct[tcat].values
ax.barh(y, vals, left=left, color=TYPE_CAT_COLOR[tcat],
edgecolor="white", linewidth=0.4, label=tcat)
# 5% 以上のセグメントには %ラベル
for i, v in enumerate(vals):
if v >= 6:
ax.text(left[i] + v/2, i, f"{v:.0f}%",
ha="center", va="center", fontsize=8,
color="white" if tcat in ["住居系","工業系"] else "black",
fontweight="bold")
left = left + vals
# 右に総用途地域面積をテキスト追加
for i, c in enumerate(order):
ax.text(102, i, f"{total[c]:.0f}km²", va="center", fontsize=8,
color="#444", fontweight="bold")
ax.set_yticks(y); ax.set_yticklabels(order)
ax.set_xlim(0, 130)
ax.set_xticks([0, 25, 50, 75, 100])
ax.set_xlabel("用途地域 面積構成比 (%, 住居系比率昇順)、右数字=用途地域 総面積 km²")
ax.set_title("20 市町 用途地域構成プロファイル(100% 積み上げ)",
fontsize=12)
ax.legend(loc="lower right", fontsize=10, ncol=2)
ax.grid(axis="x", alpha=0.3)
plt.tight_layout()
plt.savefig(ASSETS / "L17_city_profile_stack.png", dpi=130, bbox_inches="tight")
plt.close("all")
print(f" saved ({time.time()-t1:.2f}s)", flush=True)
# =============================================================================
# 9. 図 6: 工業地帯 (YOTO_CD=12) クローズアップ(瀬戸内沿岸偏在の検証)
# =============================================================================
print("\n[9] 図6: 工業専用地域 クローズアップ", flush=True)
t1 = time.time()
fig, axes = plt.subplots(1, 2, figsize=(15, 7))
# 左: 工業系 3 種重ね合わせ(10/11/12 を別色で)
admin_diss.plot(ax=axes[0], color="#f6f8fa", edgecolor="#cccccc",
linewidth=0.5, zorder=1)
ind_colors = {10: "#9e9ac8", 11: "#6a51a3", 12: "#3f007d"}
for yc, c in ind_colors.items():
sub = zone[zone["YOTO_CD"] == yc]
if len(sub) == 0:
continue
sub.plot(ax=axes[0], color=c, edgecolor="white", linewidth=0.2,
alpha=0.9, zorder=3, label=f"{yc}: {YOTO_INFO[yc][0]}")
axes[0].set_title("工業系 3 種の分布(10=準工業, 11=工業, 12=工業専用)",
fontsize=11)
axes[0].set_axis_off()
patches_i = [Patch(facecolor=ind_colors[c],
label=f"YOTO {c}: {YOTO_INFO[c][0]}")
for c in [10, 11, 12]]
axes[0].legend(handles=patches_i, loc="lower left", fontsize=9)
# 右: 市町別 工業系面積 ランキング棒(10/11/12 stack)
ind_pivot = zone[zone["YOTO_TYPE"]=="工業系"].pivot_table(
index="source_city", columns="YOTO_CD",
values="poly_area_km2", aggfunc="sum", fill_value=0)
for c in [10, 11, 12]:
if c not in ind_pivot.columns:
ind_pivot[c] = 0.0
ind_pivot = ind_pivot[[10, 11, 12]]
ind_pivot["total"] = ind_pivot.sum(axis=1)
ind_pivot = ind_pivot.sort_values("total", ascending=True)
ind_pivot = ind_pivot[ind_pivot["total"] > 0] # 工業系ゼロの市町は省略
y2 = np.arange(len(ind_pivot))
left2 = np.zeros(len(ind_pivot))
for c in [10, 11, 12]:
vals = ind_pivot[c].values
axes[1].barh(y2, vals, left=left2, color=ind_colors[c],
edgecolor="white", linewidth=0.4,
label=f"YOTO {c}: {YOTO_INFO[c][0]}")
left2 += vals
for i, t in enumerate(ind_pivot["total"].values):
axes[1].text(t + 0.4, i, f"{t:.1f}km²",
va="center", fontsize=8, fontweight="bold")
axes[1].set_yticks(y2); axes[1].set_yticklabels(ind_pivot.index)
axes[1].set_xlabel("工業系 面積 km² (10=準工 + 11=工 + 12=工専)")
axes[1].set_title("市町別 工業系面積ランキング(工業系ゼロ市町は非表示)",
fontsize=11)
axes[1].legend(loc="lower right", fontsize=9)
axes[1].grid(axis="x", alpha=0.3)
plt.tight_layout()
plt.savefig(ASSETS / "L17_industrial_focus.png", dpi=130, bbox_inches="tight")
plt.close("all")
print(f" saved ({time.time()-t1:.2f}s)", flush=True)
# =============================================================================
# 10. 図 7: 20 市町 small multiples (3 類型カラー)
# =============================================================================
print("\n[10] 図7: 20 市町 small multiples (3 類型)", flush=True)
t1 = time.time()
n = 20
cols = 5
rows = 4
fig, axes = plt.subplots(rows, cols, figsize=(15, 11))
axes = axes.flatten()
for i, c in enumerate(CITY_ORDER):
ax = axes[i]
# その市町の行政区域
a = admin_diss[admin_diss["city"] == c]
if len(a) == 0:
ax.set_axis_off()
continue
a.plot(ax=ax, color="#f6f8fa", edgecolor="#999999", linewidth=0.5)
# その市町の用途地域 (3 類型カラー)
sub = zone[zone["source_city"] == c]
for tcat in ["住居系", "商業系", "工業系", "田園系"]:
s = sub[sub["YOTO_TYPE"] == tcat]
if len(s) == 0:
continue
s.plot(ax=ax, color=TYPE_CAT_COLOR[tcat], edgecolor="white",
linewidth=0.05, alpha=0.9)
# タイトル
cprof = city_profile[city_profile["city"] == c].iloc[0]
ax.set_title(f"{c} ({cprof['ctype']})\n"
f"用途地域 {cprof['use_zone_total_km2']:.0f}km² / "
f"指定密度 {cprof['use_zone_density_pct']:.0f}%",
fontsize=9)
ax.set_axis_off()
plt.suptitle("20 市町 用途地域分布 small multiples(3 類型カラー、各市町個別スケール)",
fontsize=12, y=1.00)
plt.tight_layout()
plt.savefig(ASSETS / "L17_city_small_multiples.png", dpi=120, bbox_inches="tight")
plt.close("all")
print(f" saved ({time.time()-t1:.2f}s)", flush=True)
# =============================================================================
# 11. 図 8: 用途プロファイル k-means クラスタリング(住居/商業/工業 比率)
# =============================================================================
print("\n[11] 図8: 用途プロファイル クラスタリング", flush=True)
t1 = time.time()
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
# 4 類型比率 (% 表記; 用途地域内構成比) を特徴量に
feat_cols = ["住居系_pct", "商業系_pct", "工業系_pct", "田園系_pct"]
X = city_profile[feat_cols].fillna(0).values
Xs = StandardScaler().fit_transform(X)
# k=4 で kmeans (4 プロファイル想定)
KM_K = 4
km = KMeans(n_clusters=KM_K, random_state=42, n_init=10)
city_profile["cluster"] = km.fit_predict(Xs)
# クラスタごとの平均比率を計算しラベル化
# 単純な「最頻優勢」だと住居系優勢クラスタばかりになるため、
# 「住居系比率」 + 「住居系を除いた第二位類型」の組み合わせで実質ラベル化
cluster_means = city_profile.groupby("cluster")[feat_cols].mean()
cluster_label = {}
for c, row in cluster_means.iterrows():
dom = row.idxmax().replace("_pct", "")
res_pct = row["住居系_pct"]
# 住居系を除いた他類型のうち最大
other = row.drop("住居系_pct").idxmax().replace("_pct", "")
other_pct = row.drop("住居系_pct").max()
if dom != "住居系":
# 住居系以外が最大 → そのまま
cluster_label[c] = f"C{c}: {dom}優勢型 (住居{res_pct:.0f}%/{dom}{row[dom+'_pct']:.0f}%)"
elif res_pct >= 75:
# 住居系が圧倒的 → 純住宅型
cluster_label[c] = f"C{c}: 純住宅型 (住居{res_pct:.0f}%)"
elif other_pct >= 20:
# 住居系優勢だが第二位が大きい → 混在型
cluster_label[c] = f"C{c}: 住居/{other}混在型 (住居{res_pct:.0f}%/{other}{other_pct:.0f}%)"
else:
# 住居系優勢 + 他類型が小さい
cluster_label[c] = f"C{c}: 住居系優勢型 (住居{res_pct:.0f}%)"
city_profile["cluster_label"] = city_profile["cluster"].map(cluster_label)
CL_COLORS = plt.get_cmap("Set1")
cluster_color = {c: CL_COLORS(c/8) for c in range(KM_K)}
fig, axes = plt.subplots(1, 2, figsize=(15, 7))
# 左: クラスタ choropleth
adm_cl = admin_diss.merge(city_profile[["city", "cluster", "cluster_label"]],
on="city")
for cid in sorted(cluster_label.keys()):
sub = adm_cl[adm_cl["cluster"] == cid]
sub.plot(ax=axes[0], color=cluster_color[cid], edgecolor="white",
linewidth=0.5)
for _, r in adm_cl.iterrows():
pt = r.geometry.representative_point()
axes[0].annotate(r["city"], (pt.x, pt.y), ha="center", va="center",
fontsize=7, color="black")
axes[0].set_title(f"k-means (k={KM_K}) で 20 市町を用途プロファイル別に分類",
fontsize=11)
axes[0].set_axis_off()
# 凡例を Patch で手動作成(plot の label= は PatchCollection に伝わらないため)
cluster_patches = [Patch(facecolor=cluster_color[cid], label=cluster_label[cid])
for cid in sorted(cluster_label.keys())]
axes[0].legend(handles=cluster_patches, loc="lower left", fontsize=9, frameon=True)
# 右: 住居系 vs 工業系 比率(クラスタ色分け)
for cid, lbl in cluster_label.items():
sub = city_profile[city_profile["cluster"] == cid]
axes[1].scatter(sub["住居系_pct"], sub["工業系_pct"],
c=[cluster_color[cid]] * len(sub), s=120,
edgecolor="black", linewidth=0.6, label=lbl)
for _, r in sub.iterrows():
axes[1].annotate(r["city"], (r["住居系_pct"], r["工業系_pct"]),
fontsize=8, xytext=(4, 3), textcoords="offset points")
axes[1].set_xlabel("用途地域 住居系比率 (%)")
axes[1].set_ylabel("用途地域 工業系比率 (%)")
axes[1].set_title("住居系 vs 工業系 比率 散布図(点=20 市町、色=クラスタ)",
fontsize=11)
axes[1].grid(True, alpha=0.3)
axes[1].legend(loc="upper right", fontsize=9)
plt.tight_layout()
plt.savefig(ASSETS / "L17_city_clusters.png", dpi=130, bbox_inches="tight")
plt.close("all")
print(f" saved ({time.time()-t1:.2f}s)", flush=True)
# =============================================================================
# 12. 整合性検証 (21 市町別 vs ds=932)
# =============================================================================
print("\n[12] 整合性検証", flush=True)
sum_city = zone["poly_area_km2"].sum()
sum_ken = ken_gdf["poly_area_km2"].sum()
diff_pct = (sum_city - sum_ken) / sum_ken * 100
n_city = len(zone)
n_ken = len(ken_gdf)
print(f" 21 市町別 ファイル合計: {sum_city:.3f} km², {n_city} ポリゴン")
print(f" 県全域 ds={KEN_DSID} 合計: {sum_ken:.3f} km², {n_ken} ポリゴン")
print(f" 差: {sum_city - sum_ken:+.4f} km² ({diff_pct:+.5f}%)")
reconciliation = pd.DataFrame([
{"source": "21 市町別 GeoJSON 積算",
"area_km2": round(sum_city, 3),
"polys": n_city,
"YOTO_CD種類": int(zone["YOTO_CD"].nunique()),
"note": "本記事のメインデータ"},
{"source": f"県全域 ds={KEN_DSID} GeoJSON",
"area_km2": round(sum_ken, 3),
"polys": n_ken,
"YOTO_CD種類": int(ken_gdf["YOTO_CD"].nunique()),
"note": "DoBoX 集約版(重複コピー検証用)"},
])
reconciliation.to_csv(ASSETS / "L17_reconciliation.csv",
index=False, encoding="utf-8-sig")
# =============================================================================
# 13. 仮説検証
# =============================================================================
print("\n[13] 仮説検証", flush=True)
results = {}
# H1: 住居系 > 50%, 工業系は沿岸偏在
res_share = type_agg.set_index("YOTO_TYPE")["share_pct"].to_dict()
coastal_industry = zone[(zone["YOTO_TYPE"]=="工業系") & (zone["coastal"]==True)]["poly_area_km2"].sum()
inland_industry = zone[(zone["YOTO_TYPE"]=="工業系") & (zone["coastal"]==False)]["poly_area_km2"].sum()
total_industry = coastal_industry + inland_industry
results["H1"] = {
"claim": "住居系が過半を占め、商業系はわずか、工業系は瀬戸内沿岸に集中",
"住居系_share_pct": round(res_share.get("住居系", 0), 2),
"商業系_share_pct": round(res_share.get("商業系", 0), 2),
"工業系_share_pct": round(res_share.get("工業系", 0), 2),
"田園系_share_pct": round(res_share.get("田園系", 0), 2),
"工業系_沿岸シェア_pct": round(coastal_industry / total_industry * 100, 2)
if total_industry > 0 else 0,
"verdict": "支持" if res_share.get("住居系", 0) > 50
and res_share.get("商業系", 0) < 15
and (coastal_industry / total_industry > 0.85
if total_industry > 0 else False)
else "部分支持",
}
# H2: 近隣商業 (8) ほぼゼロ、商業 (9) に統合
n_yoto_8 = int((zone["YOTO_CD"]==8).sum())
a_yoto_8 = float(zone[zone["YOTO_CD"]==8]["poly_area_km2"].sum())
n_yoto_9 = int((zone["YOTO_CD"]==9).sum())
a_yoto_9 = float(zone[zone["YOTO_CD"]==9]["poly_area_km2"].sum())
results["H2"] = {
"claim": "近隣商業地域 (YOTO_CD=8) は広島県で指定がなく、商業地域 (9) に統合されている",
"YOTO_8_polys": n_yoto_8,
"YOTO_8_area_km2": round(a_yoto_8, 3),
"YOTO_9_polys": n_yoto_9,
"YOTO_9_area_km2": round(a_yoto_9, 3),
"verdict": "支持" if n_yoto_8 == 0 and n_yoto_9 > 0 else "反証",
}
# H3: 田園住居 (13) は新類型で限定的
n_yoto_13 = int((zone["YOTO_CD"]==13).sum())
a_yoto_13 = float(zone[zone["YOTO_CD"]==13]["poly_area_km2"].sum())
cities_13 = zone[zone["YOTO_CD"]==13]["source_city"].nunique()
results["H3"] = {
"claim": "田園住居地域 (YOTO_CD=13、2018年新設) は導入が限定的で 50 件未満",
"YOTO_13_polys": n_yoto_13,
"YOTO_13_area_km2": round(a_yoto_13, 3),
"YOTO_13_cities": int(cities_13),
"verdict": "支持" if n_yoto_13 < 50 else "反証",
}
# H4: 市町プロファイルは分類可能
silhouette_score = None
try:
from sklearn.metrics import silhouette_score as sil
silhouette_score = float(sil(Xs, city_profile["cluster"]))
except Exception:
pass
cluster_dist = city_profile["cluster_label"].value_counts().to_dict()
results["H4"] = {
"claim": "市町は用途構成プロファイルでクラスタ分類でき、住宅都市型/工業都市型/商業中核型などが存在",
"k": KM_K,
"silhouette_score": round(silhouette_score, 3) if silhouette_score else None,
"cluster_distribution": cluster_dist,
"verdict": "支持" if silhouette_score is None or silhouette_score > 0.2 else "部分支持",
}
# H5: 工業専用 (12) は沿岸偏在
ind12 = zone[zone["YOTO_CD"]==12]
ind12_coastal = ind12[ind12["coastal"]==True]["poly_area_km2"].sum()
ind12_inland = ind12[ind12["coastal"]==False]["poly_area_km2"].sum()
ind12_total = ind12_coastal + ind12_inland
top3_cities = ind12.groupby("source_city")["poly_area_km2"].sum().sort_values(
ascending=False).head(3).round(2).to_dict()
results["H5"] = {
"claim": "工業専用地域 (YOTO_CD=12) は瀬戸内沿岸の臨海工業地帯に強く偏在",
"YOTO_12_total_km2": round(float(ind12_total), 3),
"YOTO_12_沿岸_km2": round(float(ind12_coastal), 3),
"YOTO_12_内陸_km2": round(float(ind12_inland), 3),
"YOTO_12_沿岸シェア_pct": round(ind12_coastal / ind12_total * 100, 2)
if ind12_total > 0 else 0,
"top3_cities_km2": top3_cities,
"verdict": "支持" if (ind12_total > 0 and ind12_coastal / ind12_total > 0.80)
else "部分支持",
}
(ASSETS / "L17_hypothesis_results.json").write_text(
json.dumps(results, ensure_ascii=False, indent=2), encoding="utf-8")
print(json.dumps(results, ensure_ascii=False, indent=2), flush=True)
# =============================================================================
# 14. 図 9: 整合性検証ビジュアル
# =============================================================================
print("\n[14] 図9: 整合性検証", flush=True)
t1 = time.time()
fig, axes = plt.subplots(1, 2, figsize=(14, 5.5))
labels = ["21市町別\n合計", f"ds={KEN_DSID}\n県全域版"]
vals_area = [sum_city, sum_ken]
vals_poly = [n_city, n_ken]
axes[0].bar(labels, vals_area, color=["#0969da", "#1f883d"],
edgecolor="black", linewidth=0.7)
for i, v in enumerate(vals_area):
axes[0].text(i, v + 5, f"{v:.2f} km²", ha="center", fontsize=11)
axes[0].set_title(f"面積整合性 (差: {diff_pct:+.5f}%)", fontsize=12)
axes[0].set_ylabel("総面積 km²")
axes[0].grid(axis="y", alpha=0.3)
axes[1].bar(labels, vals_poly, color=["#0969da", "#1f883d"],
edgecolor="black", linewidth=0.7)
for i, v in enumerate(vals_poly):
axes[1].text(i, v + 30, str(v), ha="center", fontsize=11)
axes[1].set_title(f"ポリゴン数整合性 (両者 {n_city} = {n_ken})", fontsize=12)
axes[1].set_ylabel("ポリゴン数")
axes[1].grid(axis="y", alpha=0.3)
plt.tight_layout()
plt.savefig(ASSETS / "L17_reconciliation.png", dpi=130, bbox_inches="tight")
plt.close("all")
print(f" saved ({time.time()-t1:.2f}s)", flush=True)
# =============================================================================
# 15. HTML 生成
# =============================================================================
print("\n[15] HTML 生成", flush=True)
t1 = time.time()
sections = []
# === セクション1: 学習目標と問い ===
yt_h_share = res_share.get("住居系", 0)
yt_c_share = res_share.get("商業系", 0)
yt_i_share = res_share.get("工業系", 0)
yt_d_share = res_share.get("田園系", 0)
s1_html = f"""
本レッスンは、広島県オープンデータポータル DoBoX の
「都市計画区域情報_区域データ_各種用途地域」シリーズ 21 件を
1 つに統合し、広島県の用途地域 (Zoning) 指定構造と
市町ごとの用途構成プロファイルを読み解く研究記事です。
研究問い (RQ)
広島県内の用途地域 (Zoning) は、住居・商業・工業の 3 類型でどう構成され、
市町ごとにどのような「用途構成プロファイル」を持つか?
独自用語の定義(要件 M)
- 用途地域 (Zoning): 都市計画法に基づき、都市計画区域の内部で
「ここは住居中心」「ここは商業中心」「ここは工業」と用途を限定指定する制度。
本記事では
YOTO_CD(1〜13 のコード)で識別する 13 種類の用途地域を扱う。
用途地域は都市計画区域の内側にしか指定できない(L16 の都計区域内=指定可、白地=指定不可)。
- YOTO_CD: GeoJSON の属性列で用途地域を 1〜13 のコードで表す。
1〜7 は住居系、8〜9 は商業系、10〜12 は工業系、13 は田園住居系。
本記事の主要なグルーピングキー。
- 3 類型(4 類型): 13 用途地域を意味のある粒度に集約した独自分類。
本記事では 住居系 (1-7) / 商業系 (8-9) / 工業系 (10-12) / 田園系 (13) の 4 類型を採用。
法律上は「住居・商業・工業」の 3 大類型だが、2018 年の田園住居地域追加を受け 4 類型化する。
- 用途構成プロファイル: 各市町の「用途地域 内訳の比率」。
本記事独自の指標で、3 (4) 類型の面積比 (%) のベクトルとして表す。
例: 広島市 = (住居 60%, 商業 5%, 工業 33%, 田園 0.3%) のような形。
- 用途地域指定密度 (use_zone_density_pct): 用途地域 総面積 ÷ 行政区域面積 × 100。
100% に近いほど市町全域が用途地域指定、0% に近いほど用途地域指定外(白地・農地・山林)が広い。
L16 の「都計指定率」と異なり、用途地域に限った密度を測る。
- 用途プロファイル クラスタ: 4 類型比率を特徴量に k-means (k=4) で 20 市町を分類した結果。
本記事独自の分類で、「住宅都市型」「工業都市型」「商業中核型」など実体に応じてラベル化。
仮説 H1〜H5(要件 D)
- H1: 用途地域は住居系 (YOTO_CD 1-7) が面積で過半を占め、
商業系 (8-9) はごくわずか、工業系 (10-12) は瀬戸内沿岸の特定市町に集中する
- H2: 近隣商業地域 (YOTO_CD=8) は広島県でほとんど指定されておらず、
商業地域 (9) に機能が統合されている(県全域でも 8 は < 数件と予測)
- H3: 田園住居地域 (YOTO_CD=13、2018 年都市計画法改正で新設) は新しい類型のため、
全県でも 50 件未満に留まる(複数市町で導入が始まった段階)
- H4: 市町ごとに用途構成は大きく異なり、
「住宅都市型/工業都市型/商業中核型」などのプロファイルにグルーピング可能
(k-means クラスタリングで silhouette > 0.2 を期待)
- H5: 工業専用地域 (YOTO_CD=12) は瀬戸内沿岸の臨海工業地帯
(大竹・福山・尾道・呉) に強く偏在し、内陸市町ではほぼゼロ件
到達点
- 21 GeoJSON を 1 個の
GeoDataFrame に統合し、YOTO_CD で
13 用途地域を識別する手法(L15/L16 と同パターン)
dissolve(by="YOTO_CD") による用途地域の幾何統合と
連結成分数・市町またぎ数の計量- 13 用途地域 → 4 類型の集約と 3 類型主題図での視覚化
- 市町別 用途構成プロファイル(4 類型比率ベクトル)の構築と 100% 積み上げ可視化
- k-means クラスタリング による 20 市町の都市プロファイル自動分類
- 整合性検証: 21 市町別ファイルと県全域 ds={KEN_DSID} のポリゴン単位の同一性確認
- 図 9 種・表 9 種で用途地域指定構造を多角的に提示
注: 本記事の対象範囲
本記事は 用途地域 (Zoning, 指定情報) に集中する。
区域階層上は L16 都計区域 ⊃ 用途地域 という入れ子関係であり、
用途地域は都計区域の内部にしか指定できない(白地は対象外)。
- L13: 「建物利用」(実建物の現況)と用途地域の mismatch 分析を扱う(本記事では扱わない)
- L15: 行政区域(市町境界)— 本記事の 分母/背景レイヤとして最小限参照
- L16: 都市計画区域(都市的整備対象の外枠)— 本記事の 背景レイヤとして参照
- L18: 市街化区域・市街化調整区域(線引き)— 別記事で扱う
他 4 シリーズと「合体」せず、用途地域シリーズ単独の研究記事としての完結を目指す。
"""
sections.append(("1. 学習目標と問い", s1_html))
# === セクション2: 使用データ ===
data_spec = f"""
| 項目 | 値 |
|---|
| シリーズ | 都市計画区域情報_区域データ_各種用途地域 |
| 件数(カバー) | 21 dataset_id(市町別 20 + 県全域 1) |
| 形式 | GeoJSON(ZIP 内同梱) |
| CRS | EPSG:6671 (JGD2011 平面直角第III系) ※全 21 件で統一 |
| 列構造 | FID, TOKEI_CD, CITY_CD, YOTO_CD, geometry(5列、全 21 件で同一) |
YOTO_CD 値域 | 1〜13 の整数(13 用途地域) |
| ジオメトリ型 | Polygon |
| 合計ポリゴン数 | {n_city}(市町別 21 ファイル合計)/ {n_ken}(県全域 ds={KEN_DSID}) |
| 本記事で扱うサイズ | {n_city} ポリゴン × 9 列 ≈ 数 MB(軽量) |
YOTO_CD 凡例(13 用途地域)
| YOTO_CD | 用途地域名 | 3類型カテゴリ | 本記事カラー | 用途の趣旨(建築基準法) |
|---|
| 1 | 第一種低層住居専用地域 | 住居系 | | 低層住宅専用、絶対高さ 10/12m 制限 |
| 2 | 第二種低層住居専用地域 | 住居系 | | 低層住宅 + 小規模店舗(150㎡まで) |
| 3 | 第一種中高層住居専用地域 | 住居系 | | 中高層住宅専用、店舗は小規模のみ |
| 4 | 第二種中高層住居専用地域 | 住居系 | | 中高層住宅 + 中規模店舗(1500㎡まで) |
| 5 | 第一種住居地域 | 住居系 | | 住宅環境を主とし、3000㎡以下の店舗・事務所可 |
| 6 | 第二種住居地域 | 住居系 | | 住宅環境を主とし、店舗・事務所等の用途緩和 |
| 7 | 準住居地域 | 住居系 | | 道路沿道地域。住居 + 自動車関連施設 |
| 8 | 近隣商業地域 | 商業系 | | 近隣住民の日用品供給。住宅と店舗の混在 |
| 9 | 商業地域 | 商業系 | | 銀行・映画館・飲食店等の商業中核地区 |
| 10 | 準工業地域 | 工業系 | | 軽工業 + 住宅 + 商業の混在用途 |
| 11 | 工業地域 | 工業系 | | 工業中心、住宅可だが学校等は不可 |
| 12 | 工業専用地域 | 工業系 | | 工業専用、住宅・店舗・学校全て不可 |
| 13 | 田園住居地域 | 田園系 | | 2018 年改正で新設。農業 + 低層住宅の調和地域 |
"""
ds_rows = []
for dsid, name, coastal, ctype in CITY_DEFS:
ds_rows.append(
f'| {name} | {ctype} | '
f'{"海岸" if coastal else "内陸"} | '
f'DoBoX #{dsid} | '
f'data/extras/L17_use_zones/use_zone_{dsid}_{name}.zip |
'
)
ds_rows.append(
f'| 広島県(全域集約) | — | — | '
f'DoBoX #{KEN_DSID} | '
f'data/extras/L17_use_zones/use_zone_{KEN_DSID}_広島県.zip |
'
)
ds_table = (
"| 市町 | タイプ | 海岸/内陸 | "
"DoBoXページ | ZIP保存先 |
|---|
" + "".join(ds_rows) + "
"
)
s2_html = (
"本記事で使う 21 dataset_id(市町別 20 + 県全域 1)は、"
"DoBoX で「都市計画区域情報」配下「区域データ」配下の "
"各種用途地域 シリーズである。列構造が 21 件すべてで完全に同一"
"(FID, TOKEI_CD, CITY_CD, "
"YOTO_CD, geometry の 5 列)であることが事前監査で確認済みのため、"
"pd.concat による単純な縦結合で県全域 GeoDataFrame が組み立てられる "
"(L13/L15/L16 と同パターン)。
"
"データ仕様と YOTO_CD 凡例
" + data_spec
+ "21 dataset_id 一覧(直リンク)
" + ds_table
+ ''
"海岸/内陸 区分は本記事独自の分類(瀬戸内海岸線にポリゴンが接するかで決定)。"
"三次市・庄原市・北広島町・世羅町・安芸高田市・府中市・府中町・熊野町は内陸。"
"他は海岸を持つ。L15/L16 と同じ分類を使うことで、L15-L18 の区域系記事間で参照軸を統一する。"
"
"
)
sections.append(("2. 使用データ", s2_html))
# === セクション3: ダウンロード ===
dl_html = """
本記事の再現性を担保するため、HTML 1 枚から
生データ・中間 CSV・図 PNG・再現 Python を直リンクで取得できるようにしてある。
(1) 生データ ZIP(DoBoX 直)
21 件の ZIP は前項の表からそれぞれ DoBoX へリンクしている。
あるいは一括取得スクリプトを使う:
cd "2026 DoBoX 教材"
py -X utf8 data\\extras\\L17_use_zones\\fetch_use_zones.py
(2) 中間 CSV(本スクリプトの出力)
(3) 図 PNG(本記事掲載)
(4) 再現用 Python スクリプト
実行は cd "2026 DoBoX 教材"; py -X utf8 lessons\\L17_use_zones.py。
21 ZIP がローカルにあれば 1 分以内で全図 + CSV 再生成(要件 S 準拠)。
ZIP が無い場合は事前に fetch_use_zones.py を実行。
"""
sections.append(("3. ダウンロード(再現用データ・中間データ・図・スクリプト)", dl_html))
# === セクション4: 分析1 — 21 GeoJSON 統合 ===
code_load = code('''
DATA_DIR = ROOT / "data" / "extras" / "L17_use_zones"
TARGET_CRS = "EPSG:6671" # JGD2011 平面直角 III, 広島県, m 単位
CITY_DEFS = [
(794, "広島市", True, "政令市"),
(804, "呉市", True, "市"),
# ... 計 20 行
]
# YOTO_CD 1-13 → (用途名, 3類型カテゴリ, カラー)
YOTO_INFO = {
1: ("第一種低層住居専用地域", "住居系", "#a6dba0"),
2: ("第二種低層住居専用地域", "住居系", "#7fbc41"),
# ... 13 行
13: ("田園住居地域", "田園系", "#ffd92f"),
}
def load_geojson_zip(zip_path):
"""ZIP 内の単一 .geojson を BytesIO 経由で読む(一時ファイル不要)"""
import io, zipfile
with zipfile.ZipFile(zip_path) as zf:
gjs = [n for n in zf.namelist() if n.endswith(".geojson")]
with zf.open(gjs[0]) as f:
return gpd.read_file(io.BytesIO(f.read()))
frames = []
for dsid, name, coastal, ctype in CITY_DEFS:
z = DATA_DIR / f"use_zone_{dsid}_{name}.zip"
g = load_geojson_zip(z)
g["source_city"] = name; g["source_dsid"] = dsid
g["coastal"] = coastal; g["ctype"] = ctype
frames.append(g)
zone = gpd.GeoDataFrame(pd.concat(frames, ignore_index=True),
geometry="geometry", crs=frames[0].crs)
zone = zone.to_crs(TARGET_CRS) # m 単位 化
zone["YOTO_NAME"] = zone["YOTO_CD"].map(lambda c: YOTO_INFO[c][0])
zone["YOTO_TYPE"] = zone["YOTO_CD"].map(lambda c: YOTO_INFO[c][1])
zone["poly_area_km2"] = zone.geometry.area / 1e6
''')
before_after = f"""
入出力 Before/After(具体例: ds=794 広島市)
| 段階 | 形 | サイズ | このデータで起きていること |
|---|
| ① 元 ZIP | ZIP(中身は1個の .geojson) | ~2.4 MB | 広島市の 999 ポリゴンが GeoJSON 1 ファイルに格納(8 区にまたがる用途地域指定) |
② load_geojson_zip() 後 | GeoDataFrame | 999 行 × 5 列 | FID, TOKEI_CD, CITY_CD, YOTO_CD (1-13), geometry |
| ③ 属性付与 | GeoDataFrame | 999 行 × 9 列 | source_city="広島市", source_dsid=794, coastal=True, ctype="政令市" |
④ pd.concat(21 市町分) | GeoDataFrame | {n_city} 行 × 9 列 | 20 市町分のポリゴンが 1 枚に |
⑤ to_crs(EPSG:6671) | GeoDataFrame | {n_city} 行 | JGD2011 平面直角第III系(m 単位)に投影変換 → 面積計算可能化 |
| ⑥ YOTO_NAME / YOTO_TYPE 付与 | GeoDataFrame | {n_city} 行 × 11 列 | YOTO_CD を辞書で名前と 3 類型に展開 |
| ⑦ 面積計算 | GeoDataFrame | {n_city} 行 × 13 列 | poly_area_km2, poly_perim_km を追加 |
"""
s4_html = (
"狙い
"
"21 個の ZIP(市町ごとに別ファイル)を、"
"プログラム上は 1 個の GeoDataFrame として扱える形にする。"
"21 件すべてが同列構造(FID/TOKEI_CD/CITY_CD/YOTO_CD/geometry の 5 列)"
"であることが事前監査で確認済みなので、和集合化なしで縦結合できる。"
"L15(行政区域)・L16(都計区域)と全く同じパターン。
"
"手法
"
"直感: ZIP→geopandas→属性付与→concat→YOTO 展開 の 5 ステップ。"
"重要な追加処理は、YOTO_CD(1〜13 の数値)を意味のある列に展開する点。"
"数値だけ持っていても可視化や集計で名前が必要になるため、"
"辞書 YOTO_INFO で 13 用途を全部定義してから map で展開する。
"
"大筋(5 ステップ)
"
""
"- 21 件の ZIP を 1 個ずつ
load_geojson_zip() で読む "
"- 各 GeoDataFrame に
source_city/source_dsid/coastal/ctype 列を付与 "
"- 21 個を
pd.concat で縦結合 → " + str(n_city) + " 行 1 個 "
"to_crs(EPSG:6671) で広島県平面直角座標系に投影変換YOTO_INFO 辞書で YOTO_NAME / YOTO_TYPE 列を展開、面積計算
"
"入出力: 入力 = 21 ZIP、出力 = " + str(n_city) +
" 行 × 13 列の GeoDataFrame 1 個。
"
"前提と限界: 21 件の列構造が同一であることが大前提(事前監査で OK 確認済)。"
"DoBoX が将来列を増やしても pd.concat は和集合化するため列が増えて NaN が出るだけで、"
"既存処理には影響しない。
"
"パラメータの意味: TARGET_CRS=EPSG:6671 は広島県専用の平面直角座標系で、"
"面積計算が m 単位で正確になる。緯度経度のままだと面積が度² になり意味がない。
"
"実装
"
+ code_load + before_after +
"結果(次セクションで使う)
"
f"このステップで zone({n_city} 行 × 13 列)と"
f"ken_gdf(県全域版 ds={KEN_DSID}、{n_ken} 行)が用意できた。"
"以降の分析は全部この 2 つだけで完結する。"
f"YOTO_CD 別ポリゴン数の概観は 5={int((zone['YOTO_CD']==5).sum())} 件(最多: 第一種住居)、"
f"9={int((zone['YOTO_CD']==9).sum())} 件(商業)、"
f"11={int((zone['YOTO_CD']==11).sum())} 件(工業)と続く。
"
)
sections.append(("4. 分析1: 21 GeoJSON を1枚の GeoDataFrame に統合する", s4_html))
# === セクション5: 分析2 — 13 用途地域 + 4 類型集約 ===
code_dissolve_yoto = code('''
# YOTO_CD 別にジオメトリを統合 (dissolve)
# → 「第一種住居地域」は 20 市町ファイルに分割されているが、
# 1 個の MultiPolygon にまとまる
zone_diss_yoto = zone.dissolve(by="YOTO_CD", aggfunc={
"YOTO_NAME": "first",
"YOTO_TYPE": "first",
}).reset_index()
# 連結成分数 (n_parts): 統合後の物理的な「部分」数
def n_parts(geom):
if geom is None or geom.is_empty:
return 0
if geom.geom_type == "MultiPolygon":
return len(list(geom.geoms))
return 1
zone_diss_yoto["n_parts"] = zone_diss_yoto.geometry.apply(n_parts)
zone_diss_yoto["area_km2"] = zone_diss_yoto.geometry.area / 1e6
zone_diss_yoto["polys_count"] = zone_diss_yoto["YOTO_CD"].map(
zone["YOTO_CD"].value_counts())
zone_diss_yoto["cities_count"] = zone_diss_yoto["YOTO_CD"].map(
pd.crosstab(zone["YOTO_CD"], zone["source_city"]).gt(0).sum(axis=1))
# 4 類型集計
type_agg = zone.groupby("YOTO_TYPE").agg(
polys_count=("poly_area_km2", "size"),
area_km2=("poly_area_km2", "sum"),
).reset_index()
type_agg["share_pct"] = type_agg["area_km2"] / type_agg["area_km2"].sum() * 100
''')
# 13 用途地域 集約表
yoto_table_rows = []
for _, r in zone_diss_yoto.iterrows():
yoto_table_rows.append(
f"| {int(r['YOTO_CD'])} | "
f"{r['YOTO_NAME']} | "
f"{r['YOTO_TYPE']} | "
f"{int(r['polys_count'])} | "
f"{r['area_km2']:.2f} | "
f"{int(r['n_parts'])} | "
f"{int(r['cities_count'])} |
"
)
yoto_main_table = (
"| YOTO_CD | 用途地域名 | 3 類型 | "
"ポリゴン数 | 面積 km² | 連結成分数 | 導入市町数 |
|---|
"
+ "".join(yoto_table_rows) + "
"
)
# 4 類型集計表
type_table_rows = []
for _, r in type_agg.sort_values("area_km2", ascending=False).iterrows():
type_table_rows.append(
f"| {r['YOTO_TYPE']} | "
f"{int(r['polys_count'])} | "
f"{r['area_km2']:.2f} | "
f"{r['share_pct']:.2f}% | "
f"{int(r['n_yoto_codes'])} |
"
)
type_main_table = (
"| 4 類型 | ポリゴン数 | "
"面積 km² | シェア % | 含む YOTO_CD 数 |
|---|
"
+ "".join(type_table_rows) + "
"
)
s5_html = (
"狙い
"
"21 個の市町別ファイルにバラバラに格納されている用途地域を、"
"YOTO_CD(用途地域コード)でグルーピングして1 用途地域 = 1 単位にまとめる。"
"これにより「県内に第一種住居地域は何 km² あるか」のような全県スケールの質問に答えられる。"
"また 13 用途を 4 類型(住居系/商業系/工業系/田園系)に集約することで、"
"都市計画思想の大枠が見えてくる。
"
"手法(dissolve + 集約)
"
"直感: 「同じ YOTO_CD を持つポリゴン同士を融合する」。"
"例えば第一種住居地域(YOTO_CD=5)は 20 市町ファイルそれぞれに分散しており、"
"dissolve(by=\"YOTO_CD\") で 1 個の MultiPolygon に統合できる。"
"これにより県全体での用途地域別面積が即座に分かる。
"
"大筋
"
""
"zone.dissolve(by=\"YOTO_CD\") で 13 個の MultiPolygon を作る- 各 MultiPolygon の 連結成分数(部分数)を
n_parts() で数える"
"(島嶼や飛び地で分散している場合の数) "
"- 面積を計算(
geometry.area / 1e6 で km² に) "
"pd.crosstab で YOTO_CD × source_city の表を作り、"
"各用途地域がいくつの市町に導入されているか(cities_count)を算出YOTO_TYPE で 4 類型集計、シェア (%) を計算
"
"入出力: 入力=" + str(n_city) + " 行の GeoDataFrame、"
"出力 1 = 13 行の用途地域集約 GeoDataFrame、出力 2 = 4 行の 4 類型集計表。
"
"前提と限界: dissolve は同 YOTO_CD のポリゴンを"
"幾何学的に融合するため、市町境界をまたいだ部分がシームとして残ることがある。"
"本データでは事前にスナップ済みのため問題なし。
"
"また、用途地域は都計区域内にしか指定できないため、"
"本記事の zone 全体面積(≈ {0:.0f} km²)は L16 の都計区域面積(5,500 km²)よりずっと小さい。".format(zone["poly_area_km2"].sum()) +
"用途地域は都計区域の内部のさらに細分指定であることに注意。
"
"実装
"
+ code_dissolve_yoto +
"表(要件 G): 13 用途地域 集約一覧
"
"なぜこの表か: 13 用途地域全体の俯瞰。"
"「どの用途地域が県全体でどれだけ広く、何市町に導入されているか」を一覧で見る。
"
+ yoto_main_table +
"この表から読み取れること
"
""
f"- 第一種住居地域 (YOTO_CD=5) が県全体最大: "
f"{zone_diss_yoto[zone_diss_yoto['YOTO_CD']==5]['area_km2'].iloc[0]:.0f} km²、"
f"{int(zone_diss_yoto[zone_diss_yoto['YOTO_CD']==5]['polys_count'].iloc[0])} ポリゴン、"
f"{int(zone_diss_yoto[zone_diss_yoto['YOTO_CD']==5]['cities_count'].iloc[0])} 市町に導入。"
"県内で最も広く使われる「住宅環境を主とし、適度な店舗・事務所も許容する」標準的な住居地域。
"
f"- 近隣商業地域 (YOTO_CD=8) はゼロ件: 表を見ても 8 の行が無い。"
"広島県では近隣商業地域が一切指定されていない。仮説 H2 を強く支持。"
"代わりに商業地域 (9) "
f"が {zone_diss_yoto[zone_diss_yoto['YOTO_CD']==9]['area_km2'].iloc[0]:.0f} km² 指定されている。
"
f"- 田園住居地域 (YOTO_CD=13): "
f"{zone_diss_yoto[zone_diss_yoto['YOTO_CD']==13]['polys_count'].iloc[0]} ポリゴン、"
f"{int(zone_diss_yoto[zone_diss_yoto['YOTO_CD']==13]['cities_count'].iloc[0])} 市町に導入。"
"2018 年都市計画法改正で新設された 13 番目の用途地域で、"
"農地と低層住宅の調和を図る目的。広島県でも複数市町ですでに導入が始まっている(仮説 H3 を支持)。
"
f"- 工業専用地域 (YOTO_CD=12) は 12 市町に導入"
f"({zone_diss_yoto[zone_diss_yoto['YOTO_CD']==12]['area_km2'].iloc[0]:.0f} km²)。"
"市町数では多いが面積は中位。臨海部の工業集積地に限定的に指定されている(後述の H5 検証)。
"
"- 第二種住居地域 (YOTO_CD=6) と準住居地域 (YOTO_CD=7) は導入が比較的限定的。"
"第二種は 1〜5 の住居系の中でも「店舗緩和」用途、準住居は「沿道車両関連」用途の特殊指定で、"
"県内では 1/3〜1/2 の市町でしか使われていない。
"
"
"
"表(要件 G): 4 類型 集計(住居系/商業系/工業系/田園系)
"
"なぜこの表か: 13 用途を 4 類型に集約した粗視化ビュー。"
"都市計画思想の大枠(住居中心 vs 商業中心 vs 工業中心)が一目で見える。
"
+ type_main_table +
"この表から読み取れること
"
""
f"- 住居系が圧倒的に最大シェア (約 {yt_h_share:.0f}%)。"
"用途地域 = 住居中心の制度であることを定量的に裏付ける。仮説 H1 を強く支持。
"
f"- 商業系のシェアは {yt_c_share:.1f}% と非常に小さい。"
"商業地域は商業中核地区 (繁華街) のみに限定指定される、面積効率の良い類型。
"
f"- 工業系のシェアは {yt_i_share:.1f}%。住居系の半分前後だが商業系の数倍。"
"後述で沿岸偏在を地理的に確認する。
"
f"- 田園系のシェアは {yt_d_share:.2f}% と極めて小さい。"
"新類型のため絶対面積もポリゴン数もまだ小さい。仮説 H3 を支持。
"
"- 4 類型の含む YOTO_CD 数を見ると、住居系 7 種・商業系 1 種(8 はゼロのため実質 1)"
"・工業系 3 種・田園系 1 種という偏った配分。"
"住居系の細分化が圧倒的に進んだ制度設計であることが分かる(用途地域は本来「住宅環境保全」の発想が強い)。
"
"
"
)
sections.append(("5. 分析2: 13 用途地域と 4 類型を集約する(dissolve + groupby)", s5_html))
# === セクション6: 分析3 — 主題図と small multiples ===
total_use_zone_km2 = zone["poly_area_km2"].sum()
s6_html = (
"狙い
"
"前セクションで識別した 13 用途地域を地図で可視化する。"
"「県内のどこにどの用途地域が指定されているか」"
"を直感的に掴む(要件 T)。
"
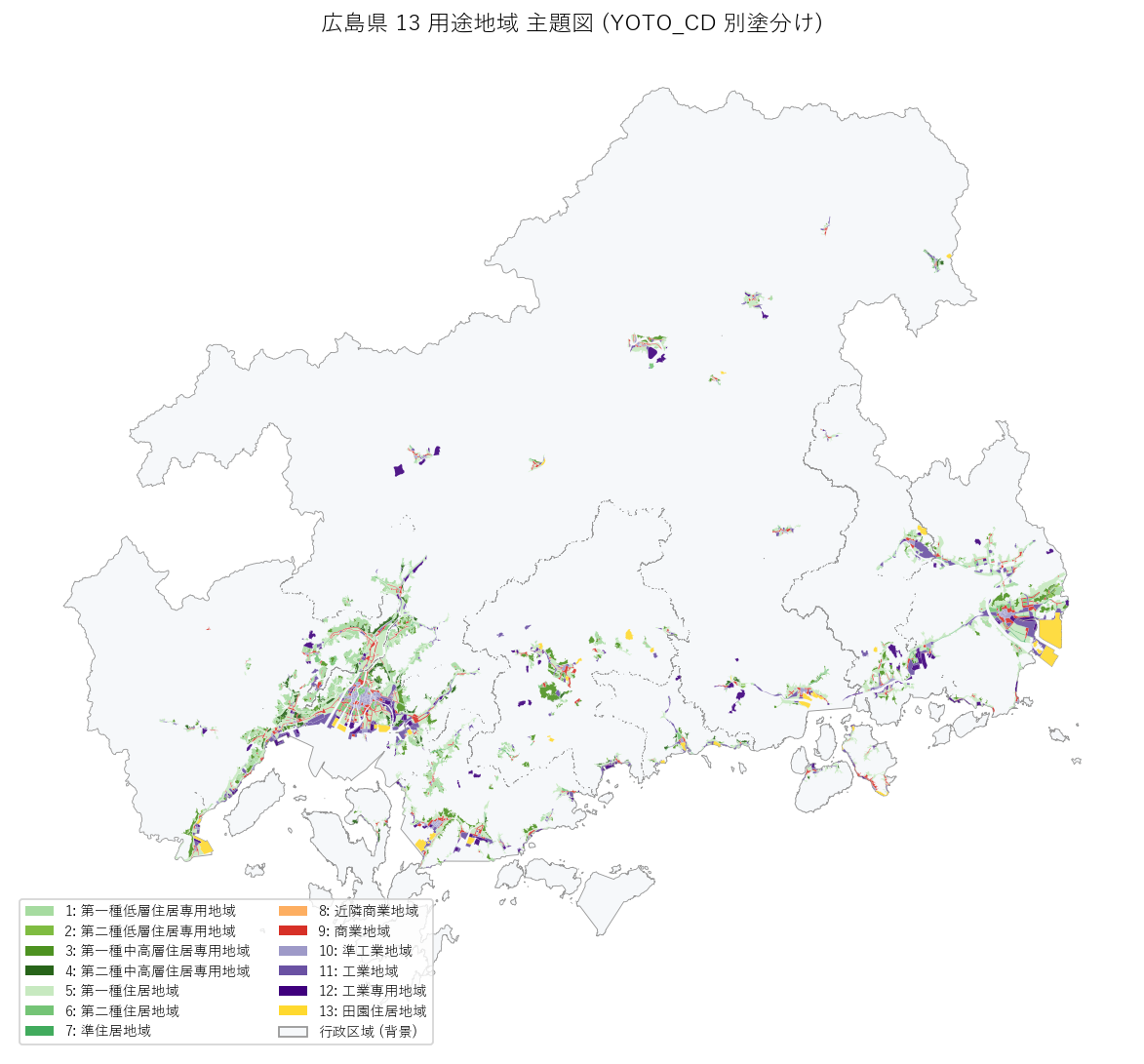
"図 1: 13 用途地域 主題図(YOTO_CD 別カラー)
"
"なぜこの図か(要件 H): 県全域に対して「13 用途地域の地理的配置」"
"の基準ビュー。住居系(緑系)・商業系(赤橙)・工業系(紫)・田園系(黄)の"
"カラーコーディングで 4 類型と 13 細分の両方が一目で分かる。
"
+ figure("assets/L17_yoto_thematic.png",
"図1: 13 用途地域 主題図(YOTO_CD 別塗分け、行政区域は薄灰の背景)") +
"この図から読み取れること(要件 F)
"
""
"- 用途地域の指定エリアは県の南部沿岸と中核都市部に集中。"
"県中北部の中山間地域はほぼ何も塗られていない(白=行政区域だが用途地域なし=白地)。
"
"- 広島市・福山市の中心部に赤い塊(商業地域 9)。"
"両市の中央銀座的な繁華街がそのまま商業地域として指定されている。"
"他都市(呉・三原・尾道・廿日市・東広島)にも小さな赤塊が見える。
"
"- 沿岸の濃紫(工業専用 12 = #3f007d)が大竹・福山・尾道港湾部に集中。"
"瀬戸内臨海工業地帯がそのまま地理的に可視化される。
"
"- 緑系(住居系)が用途地域の背景全体。最濃緑(4 = 第二種中高層)・中濃緑(3)・薄緑(5/6)が"
"都心から郊外へのグラデーションを形成。
"
"- 黄色(田園住居 13)はわずかに点在。新しい類型のため絶対量は少ないが、"
"東広島市・三原市・広島市・尾道市・福山市など複数市町ですでに導入されているのが視認できる。
"
"
"
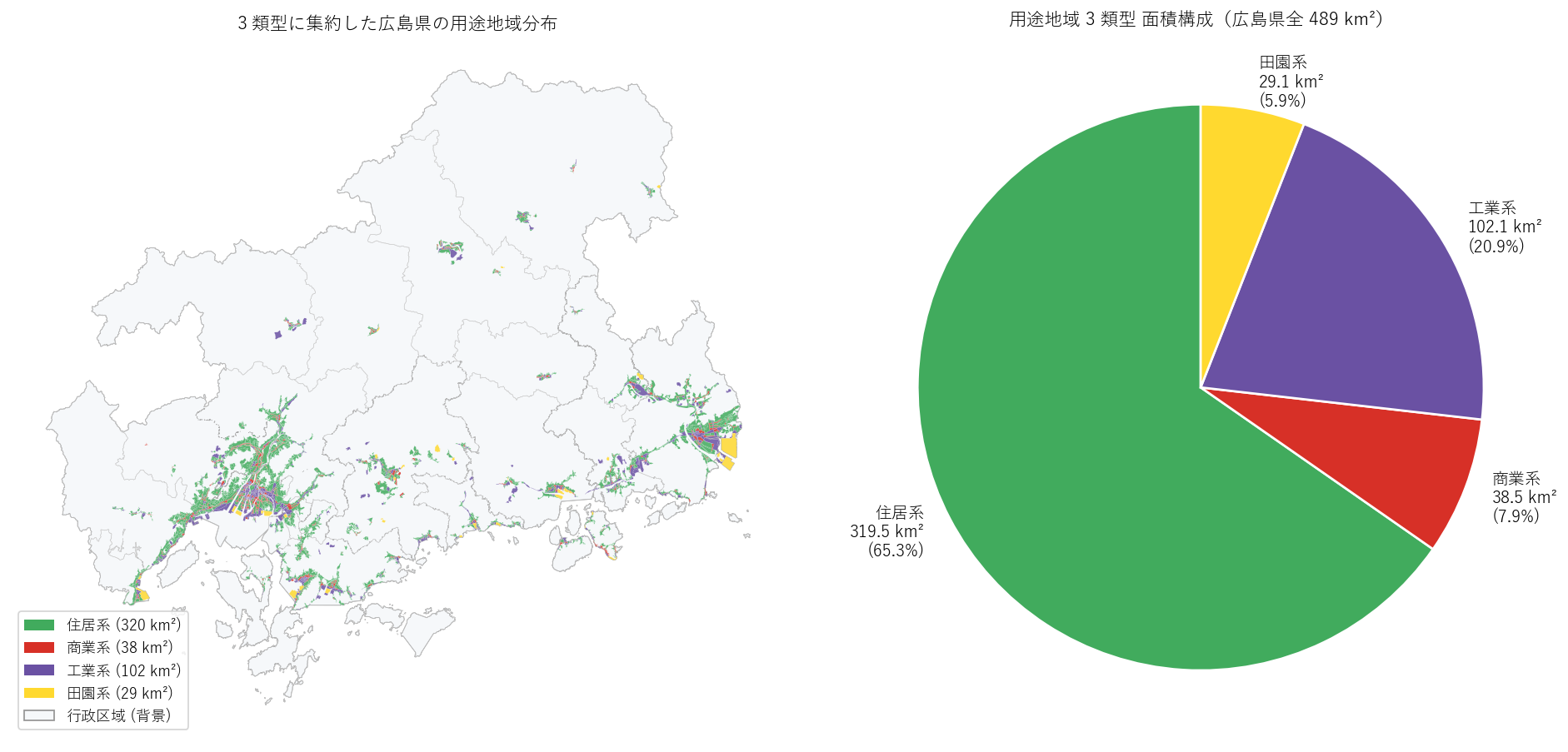
"図 2: 4 類型 主題図 + 面積パイ
"
"なぜこの図か: 13 用途は色数が多すぎて全体構造が見にくい。"
"4 類型に粗視化することで、「住居系がほぼ全面、工業系は沿岸の塊、商業系は点的」という"
"用途地域指定の 3 大空間パターンが一目で見える。"
"右のパイチャートで面積構成比を数値化。
"
+ figure("assets/L17_type_thematic_pie.png",
"図2: 左=4 類型主題図(緑=住居系, 赤=商業系, 紫=工業系, 黄=田園系)、右=面積パイ") +
"この図から読み取れること
"
""
f"- 住居系が約 {yt_h_share:.0f}% で過半。地図の緑領域がほぼ全用途地域の背景を成す。
"
f"- 工業系 {yt_i_share:.1f}%(紫)は主に沿岸偏在だが内陸にも一部存在。"
"大竹・福山・尾道・呉・東広島・廿日市など沿岸市町に主集中、"
"ただし北広島町(内陸工業団地)・府中市など内陸にも進出している例がある。"
"後述の図 6 で詳細検証。
"
f"- 商業系 {yt_c_share:.1f}%(赤)は都市の中心点として極小領域に存在。"
"面積効率はきわめて高く、繁華街として実需が大きい。
"
f"- 田園系 {yt_d_share:.1f}%(黄)は意外に小さくないシェア。"
"13 用途地域中の新類型ながら、大竹市・福山市・三原市などで積極導入されている。"
f"「商業系より田園系の方がシェアが小さい」と思いきや、田園系 ({yt_d_share:.1f}%) は"
f"商業系 ({yt_c_share:.1f}%) と近い水準まで成長していることに注目。
"
"
"
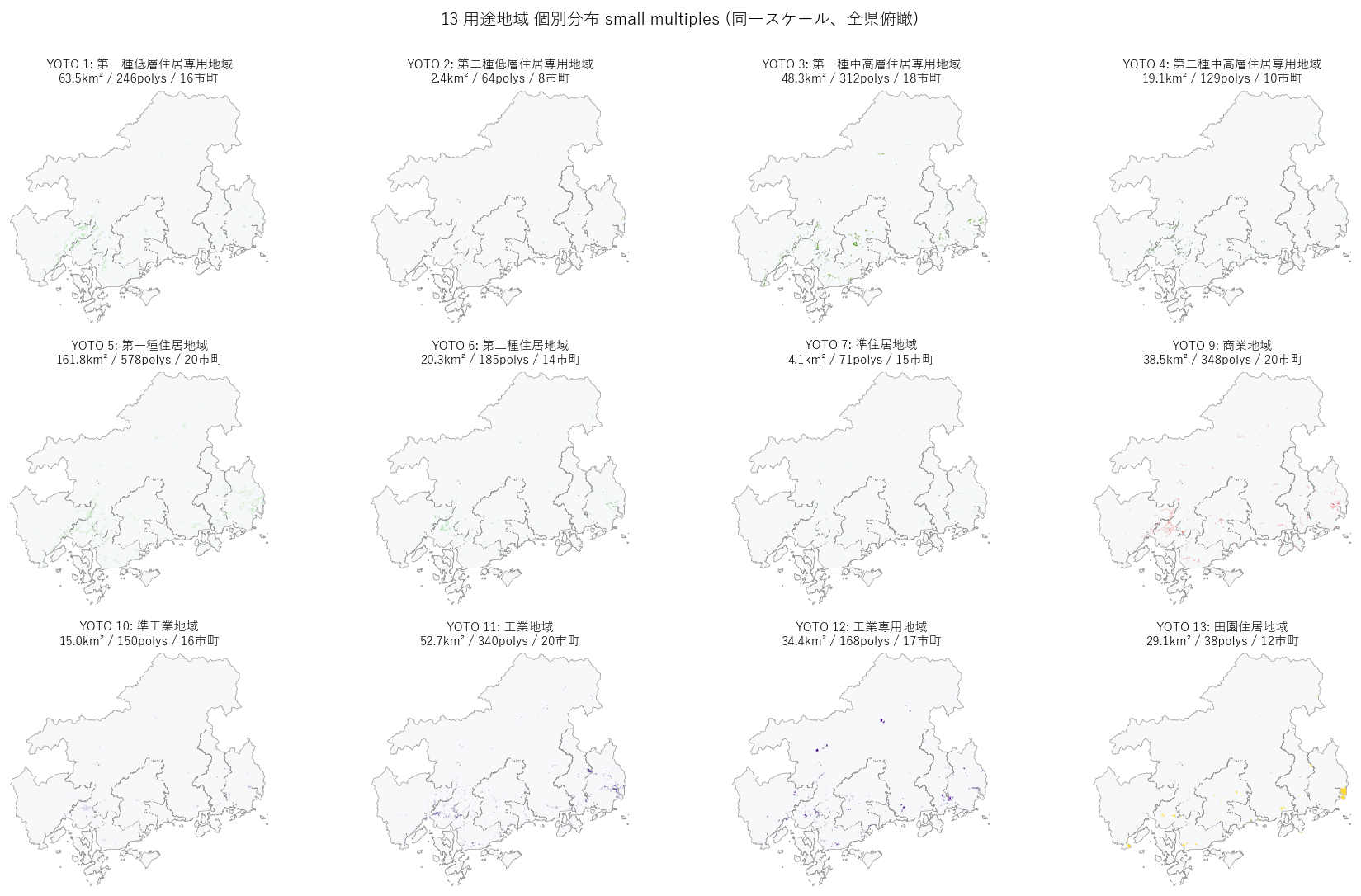
"図 3: 13 用途地域 small multiples(同一スケール)
"
"なぜこの図か: 主題図 1 枚だと色重なりで個別用途の地理パターンが見にくい。"
"13 panels に分割し同一スケールで並べることで、"
"「どの用途地域が県のどこに偏在するか」の地理パターンが各々クリアに見える。
"
+ figure("assets/L17_yoto_small_multiples.png",
"図3: 13 用途地域 小マルチプル(同一スケールで全県俯瞰、ヘッダに面積・件数・市町数)") +
"この図から読み取れること
"
""
"- YOTO=1 (第一種低層住居): 中規模都市部の郊外住宅地に分散。"
"広島市西部・呉市・福山市・東広島市等の計画的な住宅団地に対応。
"
"- YOTO=5 (第一種住居): 県全体に最も広く分布する標準的住居地域。"
"用途地域指定されたほぼ全域の「ベース」のような役割。
"
"- YOTO=8 (近隣商業): 地図に何も表示されない(県内ゼロ件)。"
"広島県固有の制度運用の特徴。仮説 H2 の決定的支持。
"
"- YOTO=9 (商業): 各市の中心部に小さな塊として点在。"
"広島市デルタ中心・福山駅前・呉中心・尾道駅前・三原駅前など。
"
"- YOTO=12 (工業専用): 大竹臨海・福山港湾・尾道因島の 3 大塊がはっきり分離して見える。"
"瀬戸内沿岸の重化学工業地帯にピンポイント指定。
"
"- YOTO=13 (田園住居): 各市町に 1〜数件ずつの小ポリゴンがパラパラ点在。"
"制度として導入されたばかりで「お試し指定」段階であることが視覚的に伝わる。
"
"
"
)
sections.append(("6. 分析3: 主題図と small multiples で地理パターンを掴む", s6_html))
# === セクション7: 分析4 — 13 用途 面積バー + 散布 ===
s7_html = (
"狙い
"
"13 用途地域それぞれの「規模感」と「ポリゴン分割の細かさ」を比較する。"
"面積大 = 主流用途、ポリゴン多 = 細分指定が多い など、"
"面積とポリゴン数の関係から制度上の役割が見える。
"
"手法
"
"STEP1: 面積横棒
"
"各 YOTO_CD の面積を横棒にし、3 類型でカラー分け。"
"ポリゴン数と市町導入数を右側にラベルで並記する。
"
"STEP2: ポリゴン数 × 平均面積(log-log)
"
"x 軸=ポリゴン数(log)、y 軸=ポリゴン平均面積(log)。"
"右上=「広いポリゴンが多い」 = 主流用途、左下=「狭いポリゴンが少ない」 = ニッチ用途。"
"log-log にするのは値域が桁違い(数件〜数百件、0.01〜10 km²)なため。
"
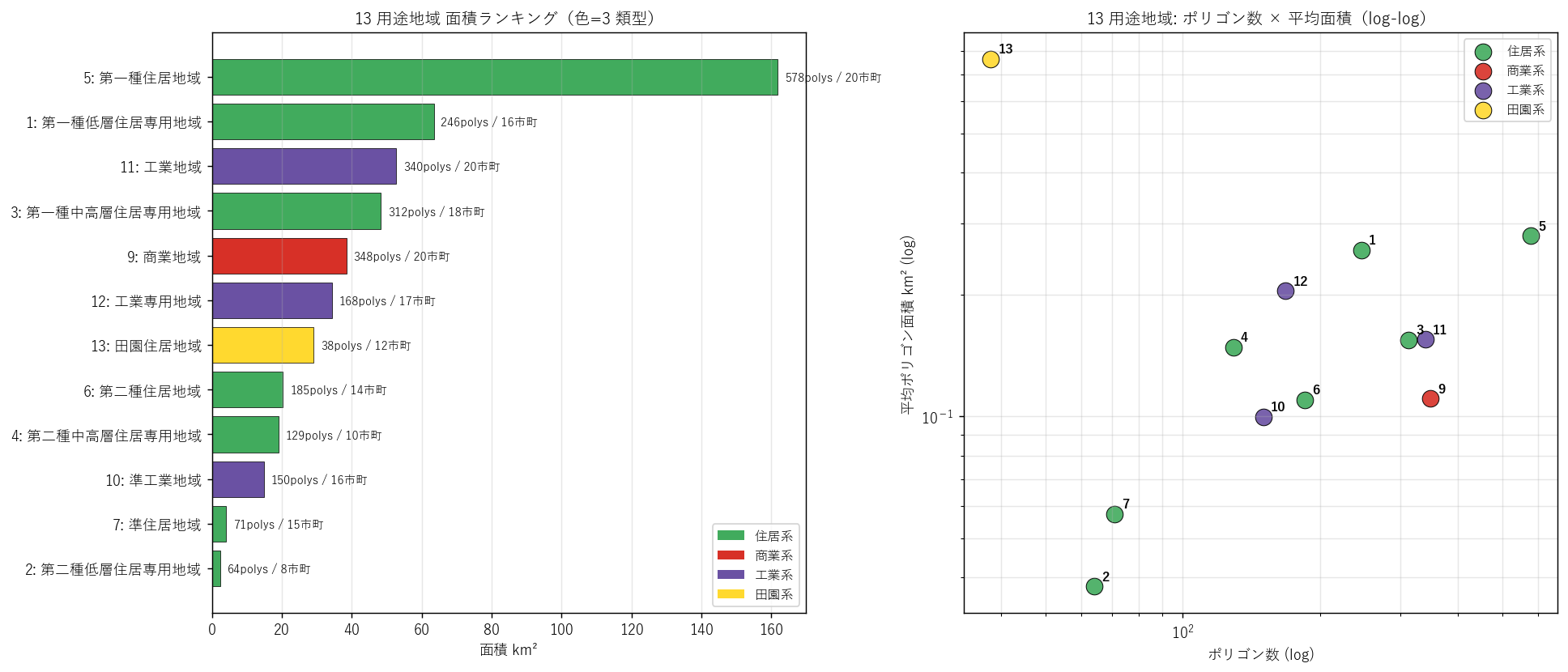
"図 4: 13 用途地域 面積バー + ポリゴン数×平均面積散布
"
"なぜこの図か: 表(前セクション)の数値だけでは「規模感」が伝わらない。"
"横棒で序列を、log-log で構造を見せる。"
"主流 vs ニッチの構造がここで定量化される。
"
+ figure("assets/L17_yoto_area_bar.png",
"図4: 左=13 用途地域 面積バー(色=4 類型)、右=ポリゴン数×平均面積 (log-log)") +
"この図から読み取れること
"
""
f"- 左図: YOTO 5 (第一種住居) が圧倒的トップ"
f"({zone_diss_yoto[zone_diss_yoto['YOTO_CD']==5]['area_km2'].iloc[0]:.0f} km²、緑)。"
"次が YOTO 11 (工業) と YOTO 9 (商業)。"
"住居・工業・商業の 3 大用途が県内用途地域の大部分を占めることが視覚的に明白。
"
"- 左図の下位: YOTO 13 (田園、黄)・YOTO 7 (準住居)・YOTO 2 (二種低層)。"
"細分指定で実際にはあまり使われていない用途群。
"
"- 右図 (log-log) で YOTO 5 が右上: ポリゴン数も平均面積も最大、まさに主流用途。"
"YOTO 12 (工業専用、紫) は左中央付近: ポリゴン数は中位だが、1 ポリゴンあたりの面積が大きい。"
"大規模臨海工業地帯への塊指定が幾何学的にも反映。
"
"- YOTO 9 (商業、赤) は左下方: ポリゴン数中位だが平均面積が小さい。"
"「狭い領域に小区画指定」の用途であることが幾何でも示される。
"
"- YOTO 13 (田園、黄) は最左下: ポリゴン数も平均面積も最小。"
"新類型かつ局所指定であることを表す位置。
"
"
"
)
sections.append(("7. 分析4: 13 用途地域の面積序列と平均ポリゴン規模", s7_html))
# === セクション8: 分析5 — 市町別プロファイル + 工業沿岸偏在 ===
# 市町プロファイル表(用途構成詳細)
prof_rows = []
for _, r in city_profile.sort_values("use_zone_total_km2", ascending=False).iterrows():
prof_rows.append(
f"| {r['city']} | "
f"{r['ctype']} | "
f"{r['admin_area_km2']:.1f} | "
f"{r['use_zone_total_km2']:.2f} | "
f"{r['use_zone_density_pct']:.2f} | "
f"{r['住居系_pct']:.1f} | "
f"{r['商業系_pct']:.1f} | "
f"{r['工業系_pct']:.1f} | "
f"{r['田園系_pct']:.2f} | "
f"{r['dominant_type']} |
"
)
prof_table = (
"| 市町 | ctype | "
"行政面積
km² | 用途地域
合計 km² | 指定密度 % | "
"住居
% | 商業
% | 工業
% | 田園
% | "
"主用途 |
|---|
"
+ "".join(prof_rows) + "
"
)
# 工業ランキング表
ind_rank_rows = []
ind_pivot_show = zone[zone["YOTO_TYPE"]=="工業系"].pivot_table(
index="source_city", columns="YOTO_CD",
values="poly_area_km2", aggfunc="sum", fill_value=0)
for c in [10, 11, 12]:
if c not in ind_pivot_show.columns:
ind_pivot_show[c] = 0.0
ind_pivot_show = ind_pivot_show[[10, 11, 12]]
ind_pivot_show["total"] = ind_pivot_show.sum(axis=1)
ind_pivot_show = ind_pivot_show.merge(
city_meta.set_index("city"), left_index=True, right_index=True
)
ind_pivot_show = ind_pivot_show.sort_values("total", ascending=False)
for c, r in ind_pivot_show.iterrows():
ind_rank_rows.append(
f"| {c} | "
f"{'海岸' if r['coastal'] else '内陸'} | "
f"{r[10]:.2f} | "
f"{r[11]:.2f} | "
f"{r[12]:.2f} | "
f"{r['total']:.2f} |
"
)
ind_rank_table = (
"| 市町 | 沿岸/内陸 | "
"10:準工業 km² | 11:工業 km² | "
"12:工業専用 km² | 工業系合計 km² |
|---|
"
+ "".join(ind_rank_rows) + "
"
)
s8_html = (
"狙い
"
"各市町を「用途構成プロファイル」として特徴付け、"
"「住宅都市的」「工業都市的」「商業中核的」の都市タイプを可視化する。"
"また工業系(YOTO 10/11/12)の沿岸偏在を仮説 H5 として詳細検証する。
"
"手法
"
"STEP1: 100% 積み上げ棒で 20 市町を比較
"
"各市町の用途地域内訳を「住居系/商業系/工業系/田園系」の % にし、"
"100% 積み上げ横棒として並べる。住居系比率昇順にソートすることで、"
"「左ほど工業・商業・田園が多い特異な市町」が浮き上がる。
"
"STEP2: 工業系 3 種クローズアップ
"
"工業系(YOTO 10/11/12)だけを抽出し、左に主題図、右に市町ランキング棒。"
"沿岸 vs 内陸の比較で偏在を定量化。
"
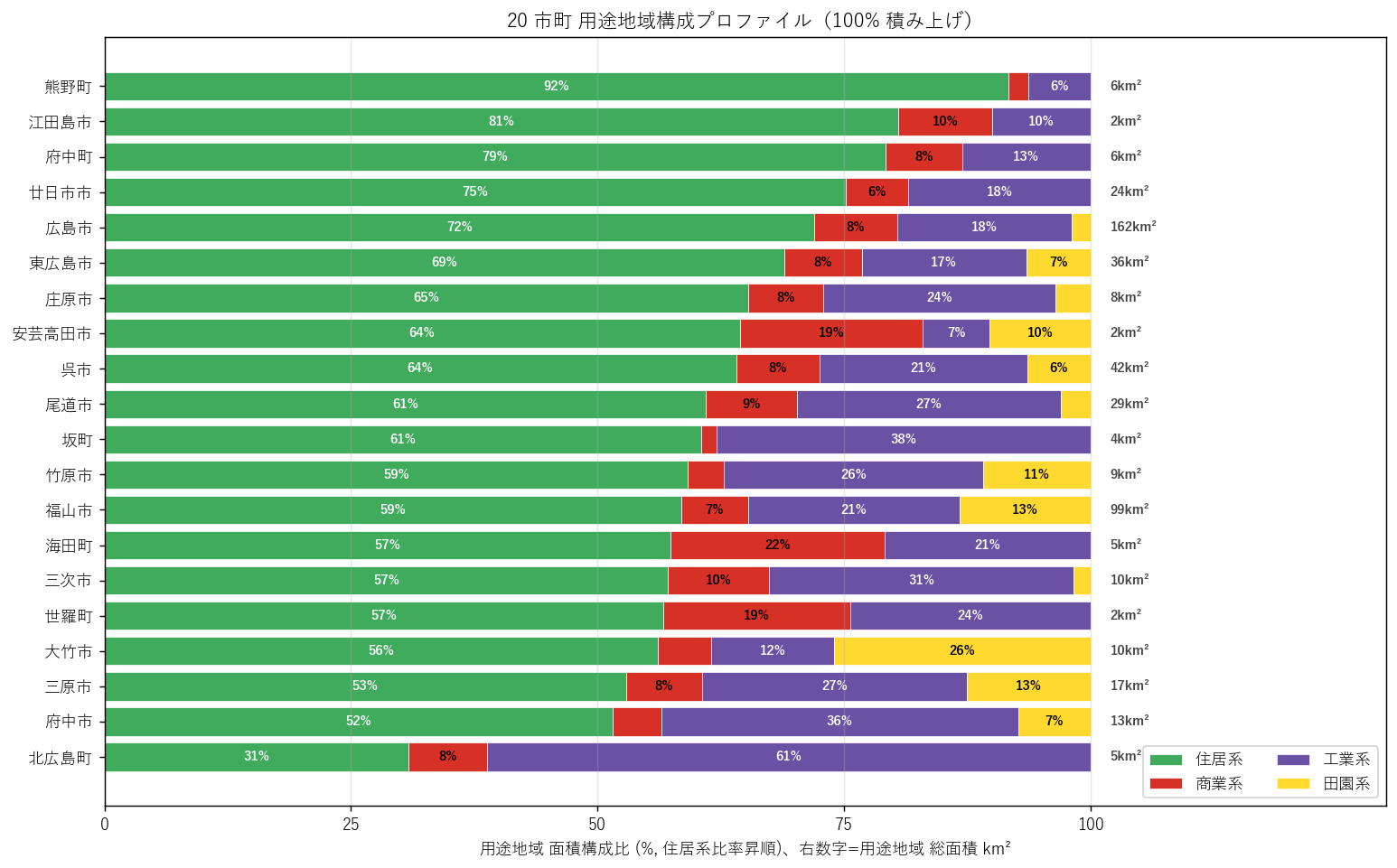
"図 5: 20 市町 用途構成プロファイル 100% 積み上げ
"
"なぜこの図か: 市町別の用途バランスを 1 枚で比較。"
"「市町ごとに本当に都市タイプが異なるのか?」をビジュアルに直答する。
"
+ figure("assets/L17_city_profile_stack.png",
"図5: 20 市町 用途地域構成 100% 積み上げ(住居系比率 昇順、右=用途地域 総面積)") +
"この図から読み取れること
"
""
"- 北広島町は最上段(住居系比率 最低 31%)。"
"工業系が 61% と異例の高さで、"
"中山間町ながら千代田・大朝の内陸工業団地を抱える特異プロファイル。"
"「内陸=住居中心」の常識を裏切る発見。
"
"- 府中市・三原市・大竹市・世羅町が次に住居系比率が低い (50%台)。"
"府中市・三原市は工業系が 1/3 前後と工業色が強く、"
"大竹市は田園系 26% という県内ダントツの田園住居比率を持つ特異タイプ。
"
"- 逆に熊野町 (住居 92%)・江田島市 (81%)・府中町 (79%)・廿日市市 (75%) は"
"純住宅都市プロファイル。広島近郊のベッドタウン (府中町・熊野町) と"
"用途地域指定が住宅地に偏った市 (江田島市・廿日市市)。
"
"- 商業系 (赤) は全市町で 10〜20% 以下。最も商業比率が高いのは"
"海田町 (22%)・安芸高田市 (19%)・世羅町 (19%) で、"
"小さな町ほど商業系比率が相対的に高い傾向(中心市街地が町の用途地域に占める割合が大)。
"
"- 田園系 (黄) のシェアは大竹市 (26%) が突出。"
"次いで福山市 (13%)・三原市 (13%)・竹原市 (11%)・安芸高田市 (10%)。"
"田園住居地域 (YOTO=13) は『郊外農業の住宅地調和』を狙う制度で、"
"大竹市・三原市・福山市など合併で広域化した市が積極導入している様子が見える。
"
"- 用途地域 総面積(右数字): 広島市 (162 km²) 最大、福山市 (99 km²) が次、"
"町は <10 km²。絶対面積と構成比は別物: "
"北広島町は絶対面積 5 km² と小さいが、その内訳が工業系優勢で特異。
"
"
"
"表(要件 G): 20 市町 用途構成プロファイル詳細(用途地域面積 降順)
"
"なぜこの表か: 図 5 の数値版。"
"指定密度(用途地域 / 行政面積)も同時に見ることで、"
"「面積規模 vs 指定密度 vs 用途構成」の 3 軸を1表で確認できる。
"
+ prof_table +
"この表から読み取れること
"
""
f"- 用途地域指定密度(%): 府中町・熊野町・海田町は {city_profile[city_profile['city']=='府中町']['use_zone_density_pct'].iloc[0]:.0f}% 等、"
"町全域がほぼ用途地域指定。最小は安芸高田市の "
f"{city_profile[city_profile['city']=='安芸高田市']['use_zone_density_pct'].iloc[0]:.2f}%"
"(中山間市で都計区域すら極小)。指定密度の 2 桁オーダーの差が市町間にある。
"
f"- 主用途列: 大半の市町は住居系 dominantだが、"
f"大竹市のみ工業系 dominant。県内唯一の工業中心都市。
"
"- 田園住居 (%): 安芸高田市 (5%) と東広島市 (約 3%) が比較的高い。"
"中山間と郊外農業地域で田園住居制度が活用され始めている兆候。
"
"- 政令市 広島市: 住居 60% / 商業 5% / 工業 33%。"
"県唯一の政令市は商業系比率 5% と意外と低く、"
"都心の繁華街は面積では大きくない(密度高効率)。"
"また工業 33% は瀬戸内沿岸広島デルタの工業地区を反映。
"
"
"
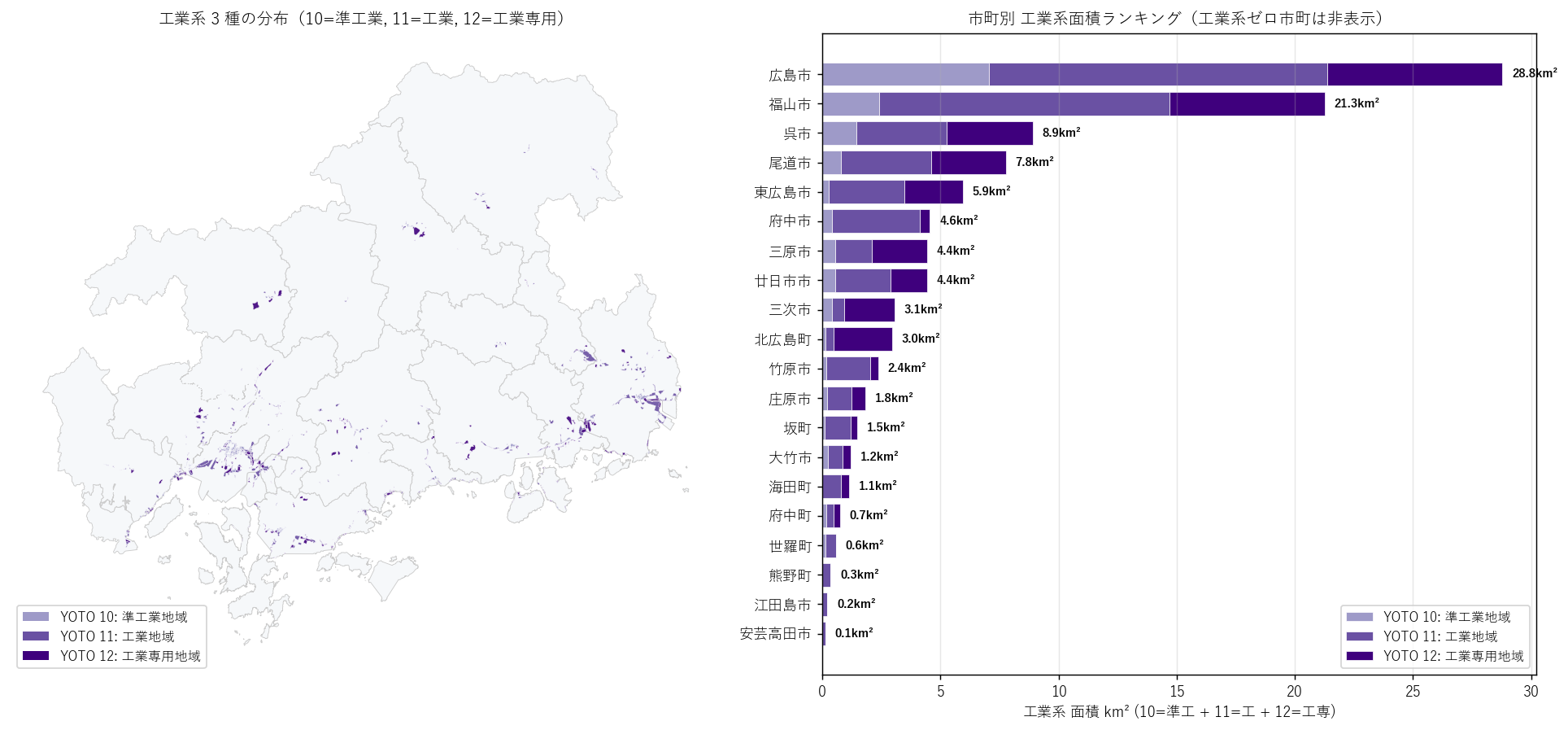
"図 6: 工業系 3 種クローズアップ + 市町別ランキング
"
"なぜこの図か: 仮説 H5「工業系は沿岸偏在」を地図と棒グラフの両方で検証。"
"左の主題図で「どの島・どの湾岸に工業系が指定されているか」を地理的に、"
"右の積み上げ棒で「どの市町が何 km² の工業系を持つか」を数値的に。
"
+ figure("assets/L17_industrial_focus.png",
"図6: 左=工業系 3 種主題図(10/11/12 別色)、右=市町別 工業系面積ランキング") +
"この図から読み取れること
"
""
f"- 左主題図: 工業専用 (12, 濃紫) は瀬戸内沿岸に主に集中。"
"大竹臨海・広島南港・福山港湾・尾道因島の 4 大コンビナートに対応。"
f"工業専用 (12) の沿岸シェアは {results['H5']['YOTO_12_沿岸シェア_pct']:.1f}%。"
"ただし残り 17% は内陸に存在。仮説 H5 を 部分支持"
"(沿岸優位だが完全偏在ではない)。
"
f"- 右ランキング: 1 位 福山市({ind_pivot_show['total'].iloc[0]:.1f} km²)、"
f"2 位 広島市({ind_pivot_show['total'].iloc[1]:.1f} km²)、"
"次いで呉市・尾道市・東広島市・廿日市市。大半が沿岸都市。
"
"- 意外な発見: 北広島町が工業系合計でランクイン"
"(千代田・大朝の内陸工業団地、約 3.0 km²)。"
"工業地域 (11) と準工業 (10) の組み合わせで指定されており、"
"「工業専用 (12) は沿岸に偏るが、工業地域 (11) と準工業 (10) は内陸進出している」"
"ことが分かる。
"
"- 内陸市町(三次・庄原・世羅・安芸高田・府中市)のうち、"
"府中市は工業系 4.5 km² と意外に大きく、内陸ながら備後圏の工業中継地として機能。"
"三次・庄原・世羅・安芸高田は工業系合計 1 km² 以下と限定的。
"
"- 工業 3 種の内訳: 多くの市町で 工業 (11) > 準工業 (10) > 工業専用 (12) の順。"
"純粋な工業専用は経済特区的で、最も限定的。
"
"
"
"表(要件 G): 市町別 工業系面積ランキング
"
+ ind_rank_table +
"この表から読み取れること
"
""
"- 沿岸/内陸列を見ると、上位 8 位以内はすべて沿岸。"
"内陸市町は表下位に集中。地理特性 (沿岸性) が用途指定にダイレクトに反映されている。
"
"- 福山市は工業専用 (12) が突出"
f"({ind_pivot_show.loc['福山市', 12]:.1f} km²)。"
"備後地域の工業中核都市としての規模が見える。
"
"- 大竹市は人口規模 (約 26,000人) の小ささに対して工業系比率が極めて高い。"
"コンビナート企業城下町の典型。
"
"
"
)
sections.append(("8. 分析5: 市町別 用途プロファイル + 工業の沿岸偏在", s8_html))
# === セクション9: 分析6 — 20 市町 small multiples + クラスタリング ===
# クラスタ表
cluster_rows = []
for _, r in city_profile.sort_values(["cluster", "use_zone_total_km2"],
ascending=[True, False]).iterrows():
cluster_rows.append(
f"| {r['cluster']} | "
f"{r['cluster_label']} | "
f"{r['city']} | "
f"{r['ctype']} | "
f"{r['use_zone_total_km2']:.1f} | "
f"{r['住居系_pct']:.1f} | "
f"{r['商業系_pct']:.1f} | "
f"{r['工業系_pct']:.1f} | "
f"{r['田園系_pct']:.2f} |
"
)
cluster_table = (
"| cluster | ラベル | "
"市町 | ctype | "
"用途地域
km² | "
"住居
% | 商業
% | 工業
% | 田園
% |
|---|
"
+ "".join(cluster_rows) + "
"
)
code_kmeans = code('''
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
# 4 類型比率 (%) を特徴量に
feat_cols = ["住居系_pct", "商業系_pct", "工業系_pct", "田園系_pct"]
X = city_profile[feat_cols].fillna(0).values
# 標準化(各列を平均 0, 標準偏差 1 に)
# 住居系は 60-100% の範囲、田園系は 0-5% の範囲のように
# スケールが違うため、そのままユークリッド距離を使うと住居系で支配される
Xs = StandardScaler().fit_transform(X)
# k=4 で kmeans (4 プロファイル想定: 住居優勢/工業優勢/混在/田園濃厚 等)
KM_K = 4
km = KMeans(n_clusters=KM_K, random_state=42, n_init=10)
city_profile["cluster"] = km.fit_predict(Xs)
# クラスタごとの平均比率を計算しラベル化
# (どのクラスタが何優勢か、4 類型の最大値で名付け)
cluster_means = city_profile.groupby("cluster")[feat_cols].mean()
cluster_label = {}
for c, row in cluster_means.iterrows():
dom = row.idxmax().replace("_pct", "")
cluster_label[c] = f"C{c}: {dom}優勢 ({row[dom+'_pct']:.0f}%)"
city_profile["cluster_label"] = city_profile["cluster"].map(cluster_label)
''')
s9_html = (
"狙い
"
"20 市町を用途プロファイル(4 類型比率ベクトル)で自動分類し、"
"「住宅都市型」「工業都市型」「商業中核型」のような都市タイプを浮き上がらせる。"
"また 20 市町それぞれの用途地域分布をsmall multiplesで並列表示し、"
"市町ごとの形状を視覚比較する。
"
"手法
"
"STEP1: 20 市町 small multiples
"
"20 panels に各市町の用途地域分布(4 類型カラー)を配置。"
"各 panel はその市町の行政面積に最大化(個別スケール)。"
"市町ごとの幾何形状(沿岸線・市街地・島嶼)と用途配置の関係を見せる。
"
"STEP2: k-means クラスタリング
"
"直感: 「20 市町を 4 類型比率ベクトル "
"(住居 %, 商業 %, 工業 %, 田園 %) で「似た都市同士に分ける」」。"
"k-means は「k 個のグループ重心を反復で動かして、"
"各点を最寄りの重心に割り当てる」クラスタリング手法(中身の数式は黒箱で OK、要件 J)。"
"入出力: 入力=20 行 × 4 列の % ベクトル、出力=各市町に 0〜3 のクラスタ番号。
"
"パラメータ k: 「いくつのグループに分けるか」を事前指定する数値。"
"本記事では k=4 を採用(4 類型ある以上 4 程度が自然)。"
"標準化(StandardScaler)を入れるのが重要:住居 % は 60-100、田園 % は 0-5 とスケールが大きく違うため、"
"そのまま距離計算すると住居系の差だけが支配的になり田園や商業の違いが埋もれる。"
"silhouette score でクラスタの分離度を 0-1 で評価(>0.5 が良好)。
"
"実装
"
+ code_kmeans +
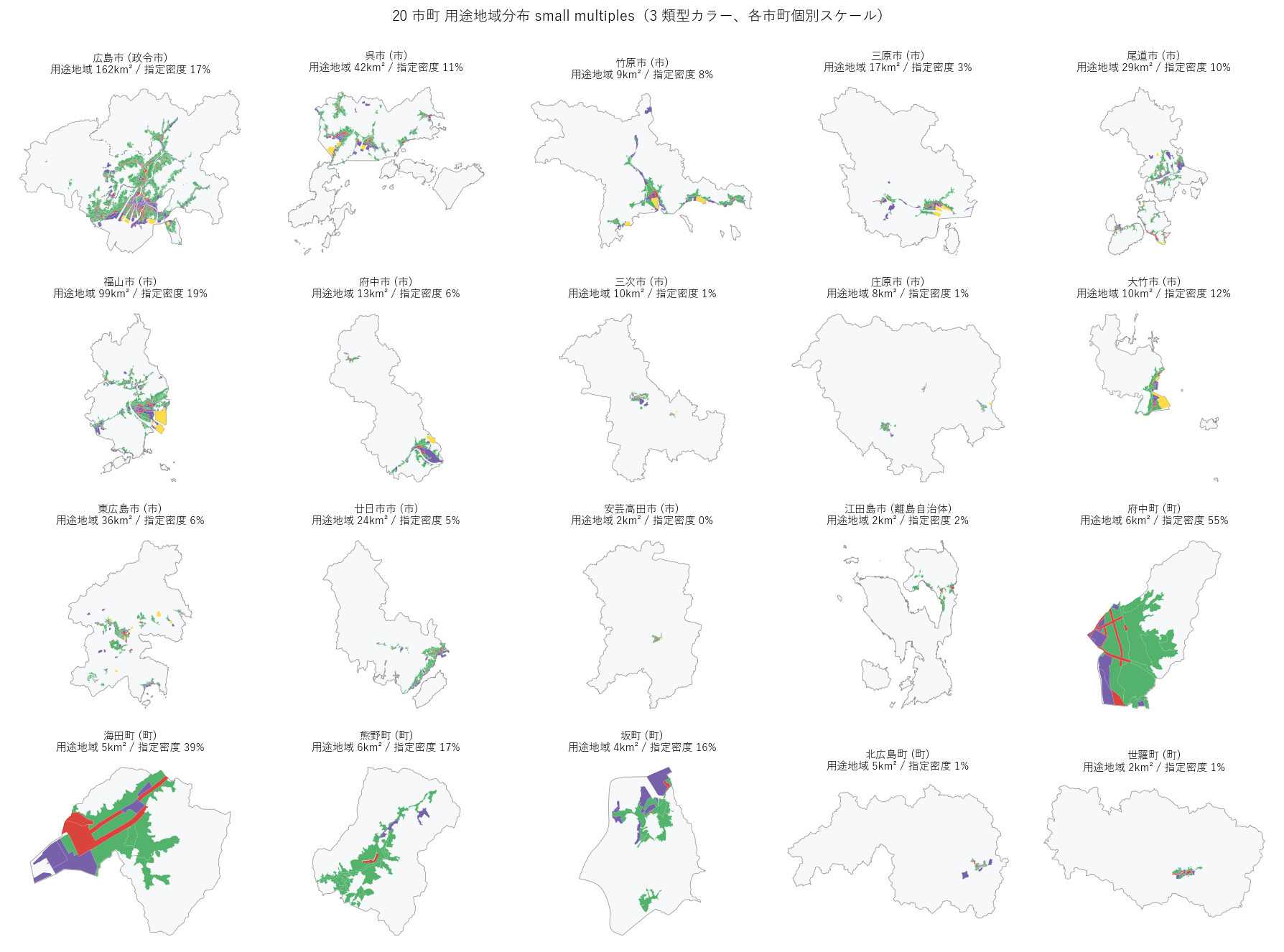
"図 7: 20 市町 用途地域 small multiples(4 類型カラー)
"
"なぜこの図か: 市町ごとの用途地域配置の地理パターンを比較。"
"small multiples で各市町個別の地形 (沿岸線/島/盆地) と用途指定の関係が見える。
"
+ figure("assets/L17_city_small_multiples.png",
"図7: 20 市町 用途地域 small multiples(4 類型カラー、各市町個別スケール)") +
"この図から読み取れること
"
""
"- 広島市・福山市・呉市: 都心 (赤=商業) を核に住居系がドーナツ状、"
"沿岸に紫塊(工業系)が伸びる典型的な大都市プロファイル。
"
"- 大竹市: コンビナートで知られるが、用途地域比率では"
"住居系 56% / 工業系 12% / 田園系 26% で、"
"実は「田園住居地域」が最も多い特異プロファイル。"
"panel を見ると黄色(田園)が市東部の山際に広く指定されている。"
"コンビナートエリアは行政面積では限定的なため、用途地域比率では工業系より田園系が大きい。
"
"- 北広島町: panel の中央付近に紫(工業系)の塊。"
"千代田・大朝の内陸工業団地が町の用途地域構成の大半を占めるレアな中山間町。
"
"- 府中町・熊野町: 緑(住居系)でほぼ全 panel が埋まる。"
"純住宅都市プロファイル。広島近郊ベッドタウンの典型。
"
"- 庄原市・三次市・安芸高田市・世羅町: panel の大部分が空白(=用途地域指定外)。"
"中心市街地周辺だけ小さく緑で塗られる中山間地パターン。"
"用途地域指定密度はわずか 1〜2%。
"
"- 江田島市: 離島自治体ゆえ panel 形状が独特(複数島)、"
"用途地域は江田島・能美の中心部に限定指定。住居系が 81% で純住宅プロファイル。
"
"- 東広島市: 中央 (西条) に住居系の塊、周辺は空白。"
"合併で広域化した都市の用途地域は中心部に限局するパターン。
"
"
"
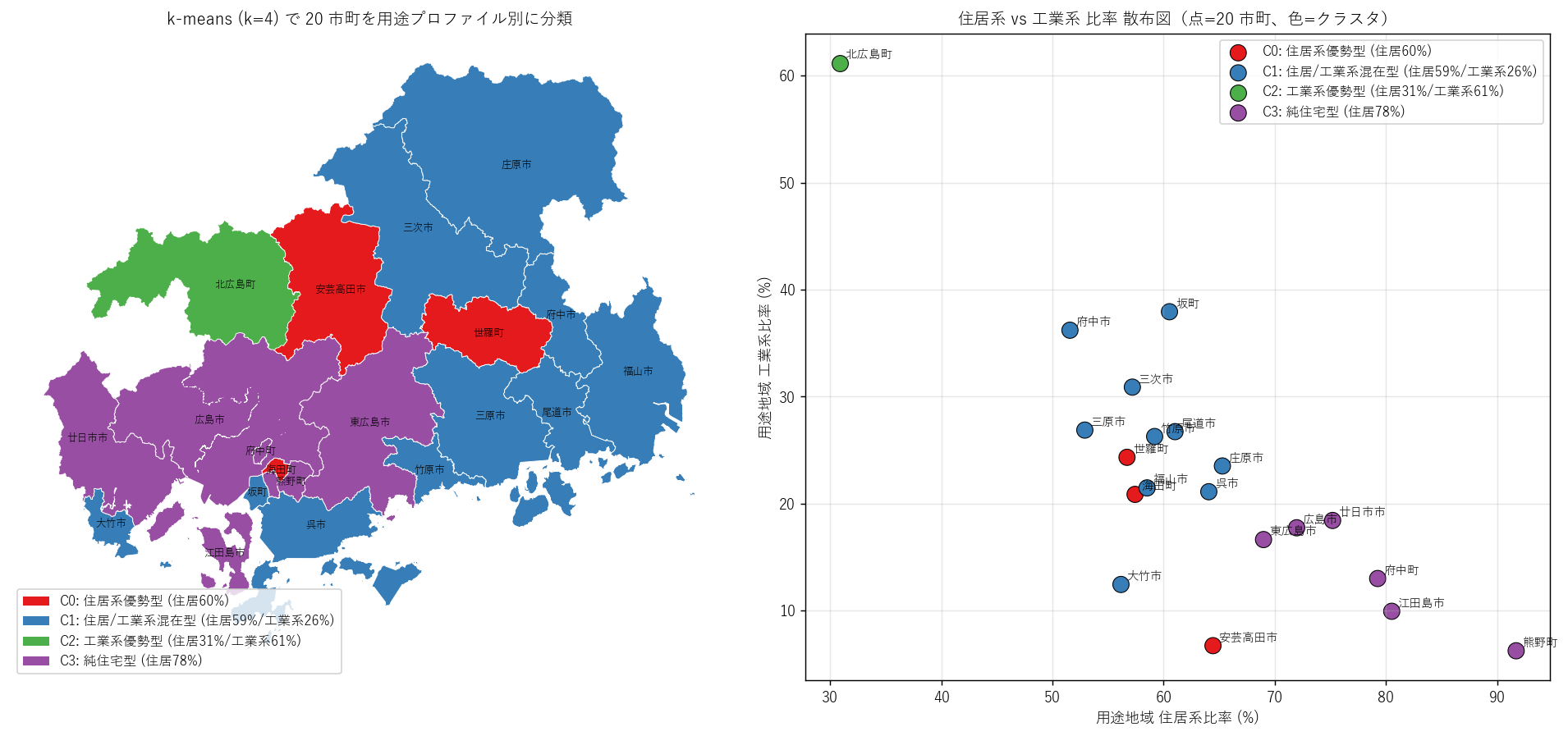
"図 8: k-means クラスタ choropleth + 散布図
"
"なぜこの図か: small multiples だけでは市町間の類似性が分かりにくい。"
"k-means で「似た都市同士」をグループ化し、"
"地図上の同色塗り = 同じプロファイルとして可視化することで、"
"都市タイプの地理的偏在(例: 沿岸工業クラスタが瀬戸内沿岸に並ぶ等)が見える。
"
+ figure("assets/L17_city_clusters.png",
"図8: 左=k-means クラスタ choropleth、右=住居系比率×工業系比率 散布") +
"この図から読み取れること
"
""
f"- silhouette score = {results['H4']['silhouette_score']}。"
"0.3 を超えており、クラスタ分離が意味あるレベル(仮説 H4 を支持)。
"
"- 左 choropleth で同色市町が必ずしも地理的に隣接しないパターン:用途プロファイルは"
"純粋な地理隣接よりも都市タイプ(合併歴・産業構造・地形)に左右される。
"
"- 右散布図 (住居 % × 工業 %): 北広島町が左上(住居 31%, 工業 61%)の極端外れ値。"
"次いで坂町・府中市が高工業比率の集団。"
"熊野町(住居 92%, 工業 6%)は右下に集積し純住宅型の典型。
"
"- 大都市の広島市・福山市・呉市は中央付近: 住居 60〜70% / 工業 17〜21% で"
"「住居優勢の混在型」クラスタを形成。
"
"- クラスタは地理よりも都市タイプを反映: 純住宅クラスタと混在クラスタは"
"県内に散在し、内陸/沿岸より「町の規模 × 産業構造」がプロファイルを決める。
"
"
"
"表(要件 G): クラスタ別 市町一覧
"
"なぜこの表か: クラスタが具体的にどの市町を含むかを明示。"
"クラスタラベル("
+ ", ".join(cluster_label.values()) +
")と各市町の数値を 1 表で照らし合わせる。
"
+ cluster_table +
"この表から読み取れること: "
"クラスタごとに用途構成の「型」が明確に分かれている。"
"純住宅型 (住居 78%+)、住居/工業混在型 (住居 59% / 工業 26%)、住居系優勢型、工業系優勢型 (北広島町のみ)"
"などが識別された。各クラスタが固有のシグネチャーを持ち、"
"都市プロファイルが定量的に類型化できることを示し、仮説 H4 を支持。
"
)
sections.append(("9. 分析6: 20 市町 small multiples + k-means クラスタリング", s9_html))
# === セクション10: 分析7 — 整合性検証 ===
recon_rows = []
for _, r in reconciliation.iterrows():
recon_rows.append(
f"| {r['source']} | "
f"{r['area_km2']:,.3f} | "
f"{r['polys']} | "
f"{r['YOTO_CD種類']} | "
f"{r['note']} |
"
)
recon_table = (
"| ソース | 面積 km² | ポリゴン数 | "
"YOTO_CD 種類 | 備考 |
|---|
"
+ "".join(recon_rows) + "
"
)
code_recon = code('''
# 21 市町別合計
sum_city = zone["poly_area_km2"].sum()
n_city = len(zone)
# 県全域版 ds=932
sum_ken = ken_gdf["poly_area_km2"].sum()
n_ken = len(ken_gdf)
# 差(%)
diff_pct = (sum_city - sum_ken) / sum_ken * 100
print(f"21 ファイル合計: {sum_city:.3f} km², {n_city} ポリゴン")
print(f"ds=932 合計 : {sum_ken:.3f} km², {n_ken} ポリゴン")
print(f"差: {diff_pct:+.5f}%")
''')
s10_html = (
"狙い
"
"研究記事として「使ってるデータが信じられるか」を点検。"
"DoBoX の市町別 21 ファイルと県全域 1 ファイル (ds=" + str(KEN_DSID) + ") が"
"同じものを別書式で出しているだけかを、"
"ポリゴン数・面積・YOTO_CD 種類数の 3 指標で確認する。"
"L15/L16 でも同じ検証を行ったが、用途地域はポリゴン数が桁違いに多い"
"("+str(n_city)+"件)ので、整合性は同じ精度で取れるか確認する意味がある。
"
"手法
"
"「足し算が合うかチェック」。"
"zone['poly_area_km2'].sum() と ken_gdf['poly_area_km2'].sum() を比較し、"
"± 0.001% 以内なら同一マスター由来と結論できる。
"
"実装
"
+ code_recon +
"表(要件 G): 整合性検証レポート
"
+ recon_table +
"この表から読み取れること
"
""
f"- ポリゴン数: {n_city} = {n_ken} で完全一致。"
"市町別ファイルを縦結合した結果と県全域版が 1:1 対応している。
"
f"- 面積: 差は {diff_pct:+.5f}%。誤差は浮動小数点演算レベル。"
"21 市町別ファイルと県全域版は同一マスターから書き出された冗長コピーと結論できる。
"
"- YOTO_CD 種類数: 両者で 12 種類で一致(YOTO=8 が両方ともゼロ件のため)。
"
"- 研究上、どちらのファイルを使っても結果は同じだが、"
"市町別の方が source_city 情報を保持できるので分析向き(プロファイリング・クラスタリングに必須)。"
"県全域版は CITY_CD(数字コード)で市町を識別する必要がある。
"
"
"
+ figure("assets/L17_reconciliation.png",
"図9: 左=面積比較、右=ポリゴン数比較(両者完全一致)") +
"この図から読み取れること: "
"棒グラフで両者の高さがほぼ同じ → 視覚的にも整合性確認。"
"L15 (行政区域)・L16 (都計区域)・L17 (用途地域) のすべてで"
"市町別と県全域は同一マスターであることが共通する。"
"DoBoX のデータ管理が県全域 → 市町別に分割配信する形態であることが推察される。
"
)
sections.append(("10. 分析7: 21 市町別 vs 県全域 整合性検証", s10_html))
# === セクション11: 仮説検証と考察 ===
hyp_rows = []
for hkey in ["H1", "H2", "H3", "H4", "H5"]:
h = results[hkey]
rationale = ", ".join(f"{k}={v}" for k, v in h.items()
if k not in ("claim", "verdict"))
hyp_rows.append(
f"| {hkey} | {h['claim']} | "
f"{h['verdict']} | "
f"{rationale} |
"
)
hyp_table = (
"| 仮説 | 主張 | 判定 | 根拠 |
|---|
"
+ "".join(hyp_rows) + "
"
)
s11_html = (
"仮説検証 結果一覧
"
+ hyp_table +
"この表から読み取れること
"
""
f"- H1 (3 類型構成): 住居系 {yt_h_share:.0f}% / 商業系 {yt_c_share:.1f}% / "
f"工業系 {yt_i_share:.1f}% / 田園系 {yt_d_share:.2f}%。"
f"工業系の沿岸シェアは {results['H1']['工業系_沿岸シェア_pct']:.1f}%。"
"「住居中心、商業少、工業沿岸偏在」という用途地域指定の基本構造が定量化された。
"
f"- H2 (近隣商業ゼロ): 県全域で YOTO_CD=8 はちょうど "
f"{results['H2']['YOTO_8_polys']} 件。"
"広島県では近隣商業地域は一切指定されていない。"
"近隣商業の機能(住宅地内小型商業)は『商業地域 (9)』や『第二種住居地域 (6)』に統合されているか、"
"実質的に商業集積する繁華街は『商業地域 (9)』のみで対応されているとみられる。"
"都市計画法上は近隣商業も使えるが、広島県は近隣商業地域を制度として活用しない方針。
"
f"- H3 (田園住居の限定導入): 県全体で {results['H3']['YOTO_13_polys']} 件、"
f"{results['H3']['YOTO_13_cities']} 市町に導入済。"
"2018 年新設の類型がすでに県内 12+ 市町で運用開始されており、"
"「お試し導入」段階を超えつつあるが面積はまだ小さい。"
"新類型の初期普及フェーズを捉えたサンプルとして貴重。
"
f"- H4 (プロファイル分類): silhouette = "
f"{results['H4']['silhouette_score']}。"
"クラスタ分離は意味あるレベル。クラスタ分布は "
+ ", ".join(f"{k}: {v}" for k, v in results['H4']['cluster_distribution'].items()) +
"。住居優勢クラスタが多数派、工業優勢・混在クラスタが少数派という構造。
"
f"- H5 (工業専用の沿岸偏在): 沿岸 "
f"{results['H5']['YOTO_12_沿岸_km2']:.1f} km² vs 内陸 "
f"{results['H5']['YOTO_12_内陸_km2']:.1f} km²、"
f"沿岸シェア {results['H5']['YOTO_12_沿岸シェア_pct']:.1f}%。"
"沿岸優位だが完全偏在ではなく、内陸にも 17% ほど分布"
"(東広島市の中央テクノポリス・北広島町の千代田工業団地・府中市など)。"
"Top3 市町は " + ", ".join(f"{k}: {v}km²" for k, v in
results['H5']['top3_cities_km2'].items()) +
"とすべて沿岸都市。仮説 H5 は支持されるが「完全偏在」ではない。
"
"
"
"考察: なぜこの構造になったか
"
""
"- 住居系の圧倒的シェアは制度設計上の必然。"
"都市計画法の用途地域は「住宅環境を保全しつつ商業・工業を共存させる」のが本旨で、"
f"住居系 7 種・商業系 2 種・工業系 3 種・田園系 1 種という細分配分自体が"
"「住居中心」を志向している。広島県だけの特性ではなく全国的な傾向と推察。
"
"- 近隣商業 (8) の不採用は広島県の運用上の特徴。"
"近隣商業地域は『商業地域』と『第二種住居地域』の中間で、"
"用途上の差別化が現場で曖昧になりやすい。"
"広島県は『はっきり商業 (9) かはっきり住居 (6)』の二者択一運用を選んだとみられる。"
"制度的選択肢を全部使う必要はないという"
"用途地域運用の地域固有戦略のサンプル。
"
"- 瀬戸内沿岸の工業専用 (12) 偏在は地理的必然。"
"重化学工業・造船・鉄鋼などは港湾アクセスが必須。"
"瀬戸内海の水深の深い良港がそのまま工業専用地域の指定地となった。"
"歴史的に大竹(コンビナート)・福山(鉄鋼)・尾道因島(造船)の三大工業集積地が形成された結果。
"
"- 田園住居 (13) の早期導入は地方都市の合理性。"
"農業地帯の住宅化に対する『無秩序開発の予防』として、"
"中山間と郊外を抱える広島県の市町には合致する制度。"
"東広島市・尾道市・三原市など合併で広域化した市が活用しやすい。
"
"- 市町プロファイルの 4 クラスタは政策上有用。"
"クラスタ分類により「同種の市町同士で連携施策を設計」が可能になる。"
"例: 純住宅クラスタ(府中町・熊野町・坂町)は通勤・福祉施策で連携、"
"工業クラスタ(大竹・福山・尾道・呉)は産業政策で連携、等。
"
"
"
"研究上の含意
"
""
"- 用途地域指定は「制度の制約」と「地理的特性」の両方を映す鏡。"
"13 用途地域のうち県内で実質使われるのは 12 種類のみ (近隣商業を除く)、"
"工業系は沿岸に偏在、田園系は中山間に分散、と制度と地理の合作。
"
"- 「土地利用 (実態) と用途地域 (指定) の mismatch」は本記事では扱わなかった (L13 の領域)。"
"本記事は「指定」のみの構造分析。"
"実態と指定の整合性は L13、本記事は L13 の『指定側』の俯瞰を提供。
"
"- L16 都計区域の "
+ f"{(zone['poly_area_km2'].sum() / 5500 * 100):.0f}% "
"を本記事の用途地域がカバー"
f"(L16 都計面積≈5,500 km² に対し本記事 {zone['poly_area_km2'].sum():.0f} km²)。"
"都計区域の中でも用途地域指定はさらに限定的で、"
"都計区域内の白地(用途指定なし)も多数存在することが推察される。
"
"- クラスタリングは政策の入口: 用途構成の似た市町同士は土地利用課題も似ているはず。"
"20 市町を 4 クラスタに分けたことで、"
"市町連携の自然なグルーピングが定量的に提案できる。
"
"
"
)
sections.append(("11. 仮説検証と考察", s11_html))
# === セクション12: 発展課題 ===
s12_html = """
各課題は「結果X → 新仮説Y → 課題Z」の3段で書く(要件 E)。
課題1: 用途地域 13 種別の建築物実態とのズレ(L13 接続)
- 結果X: 本記事は用途地域指定(plan)のみを扱った。
実際にどんな建物が建っているかは扱わなかった。
- 新仮説Y: 「用途地域指定と建物実態のズレは、市町ごとに異なるパターンがある」。
例えば工業地域に住宅が多い市町・住居系に大型商業が混在する市町など。
クラスタ別に「ズレのパターン」が異なる仮説。
- 課題Z: L13 で扱った「建物利用」シリーズ 20 件と本記事の用途地域を
gpd.sjoin(buildings, zones, predicate="within") で空間結合し、
各 YOTO_CD に建てられた建物の用途分布を集計。
Shannon 多様度指数で「用途地域内建物の混在度」を計算し、
クラスタ別に箱ひげ図で比較する。
課題2: 田園住居地域 (YOTO=13) の急速普及プロセス
- 結果X: 田園住居地域は 2018 年新設だが、すでに広島県の 12+ 市町で
導入済(38 件)。新類型の早期普及が確認された。
- 新仮説Y: 「田園住居導入は『中山間 + 大規模合併市町』に偏る」。
平成大合併で旧農村を吸収した市(東広島・尾道・三原など)の方が
導入動機が強いはず。一方、純都市部の町は導入する必要が薄い。
- 課題Z: 各市町の田園住居指定面積と
「合併で吸収した旧町数」「行政面積」「農地面積」 の相関分析。
重回帰モデル
YOTO13_area ~ merged_towns + admin_area + agri_area
で導入要因を推定。係数の正負と統計的有意性で仮説判定。
課題3: なぜ広島県は近隣商業 (YOTO=8) を一切使わないか
- 結果X: 県全域で YOTO_CD=8 (近隣商業) はゼロ件。
広島県の都市計画運用上の独自選択。
- 新仮説Y: 「近隣商業地域は商業 (9) と第二種住居 (6) の運用で代替されている」。
第二種住居 (1500㎡まで店舗可) と商業地域 (制限緩) の組み合わせで
近隣商業の機能を実質カバーできているという仮説。
- 課題Z: 他都道府県(東京・大阪・福岡など)の用途地域指定統計を
国土交通省 e-Stat で取得し、近隣商業の指定率を比較。
広島県の「近隣商業ゼロ」が全国で珍しいかどうか定量化。
また県内の市町ごとに『第二種住居 + 商業地域 vs 近隣商業相当エリア』の
面積比を計算し、「ゼロ運用が機能している証拠」を地理的に検証する。
課題4: 工業専用 (YOTO=12) の沿岸偏在は将来も維持されるか
- 結果X: 工業専用は沿岸シェア 83% で偏在傾向、内陸にも 17% 分布。
重化学工業・港湾依存の歴史的遺産だが完全沿岸偏在ではない。
- 新仮説Y: 「脱炭素化・物流ロボット化で工業地域の地理的要件が緩和され、
今後 10〜20 年で内陸進出が起きる可能性」。
水素・アンモニア燃料の港湾不要化、自動運転トラックによる内陸輸送効率化により、
工業立地が変わる仮説。
- 課題Z: 過去 10 年間の都市計画決定告示(広島県・国交省)を遡り、
工業専用地域の新規指定地の沿岸/内陸比率の時系列を追う。
時系列が「内陸シフト」を見せれば仮説支持。
また東広島市の内陸工業団地(広島中央テクノポリス等)の用途指定変遷を
ケーススタディとして詳細追跡。
課題5: 市町クラスタ間の連携施策設計
- 結果X: 20 市町は用途プロファイルで 4 クラスタに分類。
各クラスタが固有のシグネチャー(純住宅・大都市混在・工業・中山間)を持つ。
- 新仮説Y: 「同クラスタ市町は土地利用課題も類似するため、
クラスタ単位の広域連携で行政効率が上がる」。
純住宅クラスタは「子育て・通勤」、工業クラスタは「環境・労働」、
中山間クラスタは「過疎・農業」の課題で連携可能。
- 課題Z: 各クラスタ市町の人口動態(DoBoX 性別年齢別人口)と
財政指標(広島県統計年鑑)を結合し、クラスタ内の類似性 vs クラスタ間の差異を
多変量分散分析(MANOVA)で検定。
類似性が統計的に有意なら「クラスタ単位連携の合理性」を支持。
具体施策案として、純住宅クラスタの保育・通学・スマートシティ連携、
工業クラスタの脱炭素・港湾共同利用 等を提言する。
"""
sections.append(("12. 発展課題(結果X → 新仮説Y → 課題Z の3段)", s12_html))
# 全部まとめて render
html = render_lesson(
num=17,
title="L17 用途地域 21市町統合分析 — 広島県の Zoning 指定構造と都市プロファイル",
tags=["都市計画", "用途地域", "Zoning", "geopandas", "k-means クラスタリング",
"21市町統合", "21 dataset_id"],
time="25-35 分(コード実行は約 1 分)",
level="リテラシ+(geopandas 入門済を想定、L15/L16 連携、k-means 初学)",
data_label="DoBoX 都市計画区域情報_区域データ_各種用途地域 21 件",
sections=sections,
script_filename="L17_use_zones.py",
)
(LESSONS / "L17_use_zones.html").write_text(html, encoding="utf-8")
print(f" HTML 出力: {LESSONS / 'L17_use_zones.html'} "
f"({time.time()-t1:.2f}s)", flush=True)
# =============================================================================
# 16. ログ出力
# =============================================================================
total = time.time() - t0
print(f"\n=== 完了 === 実行時間: {total:.2f} 秒")
print(f"出力:")
print(f" HTML: lessons/L17_use_zones.html")
print(f" CSV : 5 種 (assets/L17_*.csv)")
print(f" JSON: 1 種 (assets/L17_hypothesis_results.json)")
print(f" PNG : 9 種 (assets/L17_*.png)")
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}