# -*- coding: utf-8 -*-
"""
L07: 河川浸水想定 × 道路インフラ・ダム・ため池 — 4種インフラ点 × 浸水ポリゴンで二重リスクを炙り出す
================================================================================
DoBoX の 4 つの「点」インフラ台帳 (橋梁 / トンネル / ダム / ため池) と、
2 つの「面」河川浸水想定 (計画規模 / 想定最大規模) を空間結合し、
- インフラ種別ごとに浸水域内立地率
- 老朽化 (古い架設年度) × 浸水リスク の重なり = 二重リスク
- 計画規模 vs 想定最大規模 のギャップ (=「想定最大規模で初めて水没する」インフラ)
- 河川水系別の集中度
を **gpd.sjoin(predicate='within')** だけで解析する L 水準研究記事。
X08 が「点 (避難所) × 面 (浸水)」を Ray casting で実装したのに対し、本記事は
**geopandas の sjoin** を主役に据え、4 種類のインフラ点で同じ判定を一気にかける。
実行:
cd "2026 DoBoX 教材"
py -X utf8 lessons/L07_flood_infrastructure.py
データ:
- data/extras/bridge_basic.csv (橋梁 4,203 件)
- data/extras/tunnel_basic.csv (トンネル 157 件)
- data/extras/dam_basic.csv (ダム 14 件)
- data/extras/tameike_basic.csv (ため池 6,754 件)
- data/extras/flood_shp/shinsui_souteisaidai/shinsui_souteisaidai.shp (想定最大 613 ポリゴン)
- data/extras/flood_shp/shinsui_keikaku/shinsui_keikakukibo.shp (計画 416 ポリゴン)
仮説 H1〜H5:
H1: ため池は河川と独立 (山間部多) で浸水率は低い (< 10%)
H2: 橋梁は河川を渡るので浸水率最高 (≥ 30%)
H3: 1970 年代以前架設の橋 × 浸水域内 の「二重リスク」橋が一定数 (≥ 100 件) 浮上
H4: ダムは山間部にあり浸水率 0% に近い (≤ 1/14)
H5: 太田川水系で橋梁集中 (上位 5 水系のうちに太田川あり)
"""
from __future__ import annotations
from pathlib import Path
import time
import warnings
import numpy as np
import pandas as pd
import geopandas as gpd
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from _common import (ROOT, ASSETS, LESSONS, render_lesson, code, figure,
data_recipe)
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
warnings.filterwarnings("ignore", category=UserWarning)
warnings.filterwarnings("ignore", category=RuntimeWarning)
# === パス定義 =================================================================
DATA = ROOT / "data" / "extras"
FLOOD_MAX = DATA / "flood_shp" / "shinsui_souteisaidai" / "shinsui_souteisaidai.shp"
FLOOD_KEI = DATA / "flood_shp" / "shinsui_keikaku" / "shinsui_keikakukibo.shp"
CSV_BRIDGE = DATA / "bridge_basic.csv"
CSV_TUNNEL = DATA / "tunnel_basic.csv"
CSV_DAM = DATA / "dam_basic.csv"
CSV_TAMEIKE = DATA / "tameike_basic.csv"
# 出力アセット
OUT_OVERVIEW = ASSETS / "L07_kind_overview.csv" # 種別×浸水率
OUT_BRIDGE = ASSETS / "L07_bridge_judge.csv" # 橋梁判定全件
OUT_TUNNEL = ASSETS / "L07_tunnel_judge.csv" # トンネル判定全件
OUT_DAM = ASSETS / "L07_dam_judge.csv" # ダム判定 (14 行)
OUT_TAMEIKE = ASSETS / "L07_tameike_judge.csv" # ため池判定全件
OUT_DOUBLE = ASSETS / "L07_double_risk_bridges.csv" # 老朽×浸水 二重リスク橋
OUT_BORDER = ASSETS / "L07_border_breakdown.csv" # 計画 vs 最大 4区分
OUT_KASEN = ASSETS / "L07_kasen_top.csv" # 水系別 集中度
OUT_AGECROSS = ASSETS / "L07_age_cross.csv" # 年代×浸水 クロス
OUT_TAMEIKE_VOL= ASSETS / "L07_tameike_vol_class.csv" # ため池 貯水量階級別
OUT_TRACK = ASSETS / "L07_track_one_bridge.csv" # 1件追跡 (要件K)
PNG_KIND = ASSETS / "L07_kind_rate.png" # 図1: 種別×浸水率 (主役)
PNG_AGE = ASSETS / "L07_bridge_age_hist.png" # 図2: 橋年代別×浸水
PNG_DOUBLE = ASSETS / "L07_double_risk_top.png" # 図3: 二重リスク橋ランキング
PNG_BORDER = ASSETS / "L07_border.png" # 図4: 計画 vs 最大 ベン図風
PNG_KASEN = ASSETS / "L07_kasen_top.png" # 図5: 水系別 橋梁集中度
PNG_MAP = ASSETS / "L07_map_overview.png" # 図6: 地理俯瞰
PNG_TAMEIKE = ASSETS / "L07_tameike_vol.png" # 図7: ため池貯水量×浸水
CRS_LL = "EPSG:4326"
CRS_PR = "EPSG:6671" # 平面直角 II 系 (広島県中心) — 距離・面積に良い局所投影
CRS_3857 = "EPSG:3857" # 浸水 SHP の元
# 老朽化しきい値 (二重リスク定義)
AGE_THRESHOLD_YEAR = 1980 # これより古い = 老朽
# ==============================================================================
# === STEP 1. インフラ 4 種類を「経緯度を持つ点」として読み込み GeoDataFrame 化
# ==============================================================================
print("=" * 78)
print("=== STEP 1. インフラ 4 種類読み込み ===")
print("=" * 78)
t_total = time.time()
def csv_to_gdf(path: Path, lat_col: str, lon_col: str, kind: str) -> gpd.GeoDataFrame:
"""CSV 1 ファイルを EPSG:6671 の GeoDataFrame に変換"""
df = pd.read_csv(path, encoding="utf-8-sig")
# 列名が末尾タブで化ける tameike 対策
df.columns = [c.strip().rstrip("\t") for c in df.columns]
n0 = len(df)
df = df.dropna(subset=[lat_col, lon_col]).reset_index(drop=True)
df = df[(df[lat_col].between(34.0, 35.5)) & (df[lon_col].between(132.0, 134.0))]
n1 = len(df)
g = gpd.GeoDataFrame(
df,
geometry=gpd.points_from_xy(df[lon_col], df[lat_col]),
crs=CRS_LL,
).to_crs(CRS_PR)
g["kind"] = kind
print(f" {kind:<6}: {n0:>5} 行 → {n1:>5} 件 (緯度経度クリーンアップ後) → CRS:{g.crs}")
return g
bridge = csv_to_gdf(CSV_BRIDGE, "緯度(10進数)", "経度(10進数)", "橋梁")
bridge = bridge.rename(columns={"施設名": "name", "架設年度": "year",
"住所(市町)": "muni", "道路種別": "road",
"判定区分": "judge_grade", "延長(m)": "length_m"})
bridge["year"] = pd.to_numeric(bridge["year"], errors="coerce")
bridge["year"] = bridge["year"].where(bridge["year"] > 1800) # 0/欠損を NaN
tunnel = csv_to_gdf(CSV_TUNNEL, "緯度(10進数)", "経度(10進数)", "トンネル")
tunnel = tunnel.rename(columns={"施設名": "name", "建設年度": "year",
"住所(市町)": "muni", "道路種別": "road",
"判定区分": "judge_grade", "延長(m)": "length_m"})
tunnel["year"] = pd.to_numeric(tunnel["year"], errors="coerce")
dam = csv_to_gdf(CSV_DAM, "緯度", "経度", "ダム")
dam = dam.rename(columns={"ダム名": "name", "型式": "form", "堤高_m": "height_m",
"総貯水容量_千m3": "volume_kt", "水系名": "river_sys",
"完成年月": "completed", "診断結果": "judge_grade"})
# ダムの「都道府県」列名が元データにあるが、「住所(市町)」相当はないので位置から推定
dam["muni"] = dam["位置"] if "位置" in dam.columns else ""
tameike = csv_to_gdf(CSV_TAMEIKE, "緯度", "経度", "ため池")
tameike = tameike.rename(columns={"ため池名称": "name", "堤高(m)": "height_m",
"貯水量(千m3)": "volume_kt", "所管市町": "muni"})
# ==============================================================================
# === STEP 2. 浸水 Shapefile を読み込み (EPSG:3857 → EPSG:6671)
# ==============================================================================
print("\n" + "=" * 78)
print("=== STEP 2. 浸水 Shapefile 読み込み ===")
print("=" * 78)
t0 = time.time()
flood_max = gpd.read_file(FLOOD_MAX).to_crs(CRS_PR)
flood_kei = gpd.read_file(FLOOD_KEI).to_crs(CRS_PR)
print(f" 想定最大規模: {len(flood_max):>4} ポリゴン CRS={flood_max.crs}")
print(f" 計画規模 : {len(flood_kei):>4} ポリゴン CRS={flood_kei.crs}")
print(f" 水系数 (最大): {flood_max['suikei'].nunique()}")
print(f" 読込時間 : {time.time()-t0:.1f}s")
# ==============================================================================
# === STEP 3. gpd.sjoin で各インフラ × 各浸水規模 を一気に判定
# ==============================================================================
print("\n" + "=" * 78)
print("=== STEP 3. gpd.sjoin (predicate='within') で 4 種類 × 2 規模 = 8 判定 ===")
print("=" * 78)
def judge_in_flood(points: gpd.GeoDataFrame,
flood: gpd.GeoDataFrame,
label: str) -> pd.DataFrame:
"""点 GeoDataFrame に対し、 浸水ポリゴンに『含まれるか』を bool で返す。
複数ポリゴンに重なる点は 1 回だけ立てる (重複行は最初の水系を採用)。"""
pts = points.reset_index().rename(columns={"index": "_pid"})[["_pid", "geometry"]]
j = gpd.sjoin(pts, flood[["kasen", "suikei", "geometry"]],
how="left", predicate="within")
agg = j.groupby("_pid").agg(
in_flood=("suikei", lambda s: int(s.notna().any())),
kasen_first=("kasen", lambda s: s.dropna().iloc[0] if s.dropna().any() else ""),
suikei_first=("suikei", lambda s: s.dropna().iloc[0] if s.dropna().any() else ""),
).reset_index()
return agg
def attach_judgements(g: gpd.GeoDataFrame) -> gpd.GeoDataFrame:
"""g に in_max / in_keikaku / kasen_max / suikei_max 列を追加"""
a_max = judge_in_flood(g, flood_max, "max").rename(
columns={"in_flood": "in_max", "kasen_first": "kasen_max",
"suikei_first": "suikei_max"})
a_kei = judge_in_flood(g, flood_kei, "kei").rename(
columns={"in_flood": "in_keikaku", "kasen_first": "kasen_kei",
"suikei_first": "suikei_kei"})
g2 = g.reset_index().rename(columns={"index": "_pid"})
g2 = g2.merge(a_max, on="_pid", how="left").merge(a_kei, on="_pid", how="left")
g2["in_max"] = g2["in_max"].fillna(0).astype(int)
g2["in_keikaku"] = g2["in_keikaku"].fillna(0).astype(int)
return g2
t0 = time.time()
bridge = attach_judgements(bridge)
tunnel = attach_judgements(tunnel)
dam = attach_judgements(dam)
tameike = attach_judgements(tameike)
print(f" 全 4 種類 × 2 規模 sjoin: {time.time()-t0:.1f}s")
for g, lbl in [(bridge, "橋梁"), (tunnel, "トンネル"),
(dam, "ダム"), (tameike, "ため池")]:
n = len(g); n_max = int(g["in_max"].sum()); n_kei = int(g["in_keikaku"].sum())
print(f" {lbl:<6}: 全 {n:>5} 件 / 最大規模 {n_max:>4} ({n_max/n*100:5.1f}%)"
f" / 計画規模 {n_kei:>4} ({n_kei/n*100:5.1f}%)")
# ==============================================================================
# === STEP 4. 種別別の浸水率テーブル
# ==============================================================================
print("\n" + "=" * 78)
print("=== STEP 4. 種別別 浸水率サマリ ===")
print("=" * 78)
overview_rows = []
for g, lbl in [(bridge, "橋梁"), (tunnel, "トンネル"),
(dam, "ダム"), (tameike, "ため池")]:
n = len(g)
n_max = int(g["in_max"].sum())
n_kei = int(g["in_keikaku"].sum())
n_only_max = int(((g["in_max"] == 1) & (g["in_keikaku"] == 0)).sum())
overview_rows.append({
"インフラ種別": lbl, "件数": n,
"最大規模_浸水域内": n_max, "最大規模_率(%)": round(n_max/n*100, 2),
"計画規模_浸水域内": n_kei, "計画規模_率(%)": round(n_kei/n*100, 2),
"最大のみ_件数": n_only_max,
"最大のみ_率(%)": round(n_only_max/n*100, 2),
})
overview = pd.DataFrame(overview_rows)
overview.to_csv(OUT_OVERVIEW, index=False, encoding="utf-8-sig")
print(overview.to_string(index=False))
# ==============================================================================
# === STEP 5. 橋梁: 老朽化 × 浸水 の「二重リスク」抽出
# ==============================================================================
print("\n" + "=" * 78)
print("=== STEP 5. 老朽橋 × 浸水 = 二重リスク ===")
print("=" * 78)
br_year = bridge.dropna(subset=["year"]).copy()
br_year["age_class"] = pd.cut(
br_year["year"], bins=[1900, 1960, 1970, 1980, 1990, 2000, 2010, 2025],
labels=["~1960", "1961-70", "1971-80", "1981-90", "1991-00", "2001-10", "2011~"],
right=True, include_lowest=True,
)
age_cross = pd.crosstab(br_year["age_class"], br_year["in_max"], margins=True,
margins_name="合計")
age_cross.columns = ["浸水域外", "浸水域内", "合計"][:len(age_cross.columns)]
age_cross["浸水域内率(%)"] = (age_cross["浸水域内"] /
age_cross["合計"] * 100).round(2)
age_cross.to_csv(OUT_AGECROSS, encoding="utf-8-sig")
print(age_cross)
double_risk = bridge[(bridge["in_max"] == 1) &
(bridge["year"].notna()) &
(bridge["year"] <= AGE_THRESHOLD_YEAR)].copy()
double_risk["age"] = (2024 - double_risk["year"]).astype(int)
double_risk = double_risk.sort_values(["age", "length_m"], ascending=[False, False])
double_risk_out = double_risk[["name", "muni", "year", "age", "length_m",
"road", "kasen_max", "suikei_max",
"in_keikaku", "in_max"]].head(50)
double_risk_out.to_csv(OUT_DOUBLE, index=False, encoding="utf-8-sig")
print(f"\n 老朽 (~{AGE_THRESHOLD_YEAR}) × 最大規模浸水域内 = "
f"{len(double_risk)} 件")
print(double_risk_out.head(10).to_string(index=False))
# ==============================================================================
# === STEP 6. 計画規模 vs 想定最大規模 — 4 区分内訳
# ==============================================================================
print("\n" + "=" * 78)
print("=== STEP 6. 計画 vs 最大 4 区分内訳 ===")
print("=" * 78)
def classify_border(row):
k, m = row["in_keikaku"], row["in_max"]
if k == 0 and m == 0: return "A 両規模で安全"
if k == 1 and m == 1: return "B 両規模で水没"
if k == 0 and m == 1: return "C ボーダー(最大規模のみ水没)"
return "D 計画のみ水没(異常)"
border_rows = []
for g, lbl in [(bridge, "橋梁"), (tunnel, "トンネル"),
(dam, "ダム"), (tameike, "ため池")]:
cls = g.apply(classify_border, axis=1)
vc = cls.value_counts()
for k in ["A 両規模で安全", "B 両規模で水没",
"C ボーダー(最大規模のみ水没)", "D 計画のみ水没(異常)"]:
border_rows.append({"種別": lbl, "区分": k, "件数": int(vc.get(k, 0))})
border_df = pd.DataFrame(border_rows)
border_pivot = border_df.pivot(index="区分", columns="種別", values="件数").fillna(0).astype(int)
border_pivot = border_pivot.reindex(["A 両規模で安全", "B 両規模で水没",
"C ボーダー(最大規模のみ水没)",
"D 計画のみ水没(異常)"])
border_pivot.to_csv(OUT_BORDER, encoding="utf-8-sig")
print(border_pivot)
# ==============================================================================
# === STEP 7. 水系別 橋梁集中度
# ==============================================================================
print("\n" + "=" * 78)
print("=== STEP 7. 水系別 橋梁集中度 (=H5 検証) ===")
print("=" * 78)
br_in = bridge[bridge["in_max"] == 1].copy()
kasen_top = (br_in[br_in["suikei_max"] != ""]
.groupby("suikei_max").size()
.sort_values(ascending=False).head(15)
.reset_index().rename(columns={0: "件数", "suikei_max": "水系名"}))
kasen_top.columns = ["水系名", "件数"]
kasen_top.to_csv(OUT_KASEN, index=False, encoding="utf-8-sig")
print(kasen_top.to_string(index=False))
# ==============================================================================
# === STEP 8. ため池 貯水量階級別 浸水率
# ==============================================================================
print("\n" + "=" * 78)
print("=== STEP 8. ため池 貯水量×浸水率 ===")
print("=" * 78)
t_df = tameike.copy()
t_df["volume_kt"] = pd.to_numeric(t_df["volume_kt"], errors="coerce")
t_df = t_df.dropna(subset=["volume_kt"])
t_df["vol_class"] = pd.cut(
t_df["volume_kt"],
bins=[0, 1, 5, 20, 100, 100000],
labels=["~1千m3", "1-5千m3", "5-20千m3", "20-100千m3", "100千m3~"],
include_lowest=True,
)
vol_cross = pd.crosstab(t_df["vol_class"], t_df["in_max"], margins=True,
margins_name="合計")
vol_cross.columns = ["浸水域外", "浸水域内", "合計"][:len(vol_cross.columns)]
vol_cross["浸水域内率(%)"] = (vol_cross["浸水域内"] /
vol_cross["合計"] * 100).round(2)
vol_cross.to_csv(OUT_TAMEIKE_VOL, encoding="utf-8-sig")
print(vol_cross)
# ==============================================================================
# === STEP 9. 1 件追跡 (要件K) — 古い橋を 1 本選んで 9 段階追跡
# ==============================================================================
print("\n" + "=" * 78)
print("=== STEP 9. 1 件追跡 (要件K) ===")
print("=" * 78)
if len(double_risk) > 0:
target = double_risk.iloc[0]
else:
target = bridge[bridge["in_max"] == 1].iloc[0]
target_geom = target.geometry
target_lon = target_geom.x # PR系の値
# WGS84 経緯度に逆投影
back = gpd.GeoSeries([target_geom], crs=CRS_PR).to_crs(CRS_LL).iloc[0]
track = pd.DataFrame([
{"段階": "1. CSV 取得",
"値": "DoBoX 道路橋 (4,203 件)",
"内訳": "data/extras/bridge_basic.csv"},
{"段階": "2. 1 件選択", "値": str(target["name"]),
"内訳": f"市町={target['muni']} / 路線={target['road']} / 架設={int(target['year'])}年"},
{"段階": "3. 経緯度抽出",
"値": f"({back.x:.5f}, {back.y:.5f})",
"内訳": "CSV の 緯度(10進数)/ 経度(10進数)"},
{"段階": "4. EPSG:4326 → 6671 投影",
"値": f"({target_geom.x:.1f}, {target_geom.y:.1f}) m",
"内訳": "平面直角II系で距離・面積を正確に"},
{"段階": "5. 計画規模 sjoin",
"値": "IN" if target["in_keikaku"] == 1 else "OUT",
"内訳": f"gpd.sjoin × {len(flood_kei)} ポリゴン"},
{"段階": "6. 想定最大 sjoin",
"値": "IN" if target["in_max"] == 1 else "OUT",
"内訳": f"gpd.sjoin × {len(flood_max)} ポリゴン"},
{"段階": "7. 浸水水系特定",
"値": str(target["suikei_max"]),
"内訳": "sjoin した最初のポリゴンの水系名"},
{"段階": "8. 老朽判定",
"値": f"YES ({2024 - int(target['year'])} 年経過)" if target["year"] <= AGE_THRESHOLD_YEAR else "NO",
"内訳": f"架設 ≤ {AGE_THRESHOLD_YEAR} を老朽と定義"},
{"段階": "9. 二重リスク判定",
"値": "YES" if (target["in_max"] == 1 and target["year"] <= AGE_THRESHOLD_YEAR) else "NO",
"内訳": "(老朽) AND (最大規模浸水域内)"},
])
track.to_csv(OUT_TRACK, index=False, encoding="utf-8-sig")
print(track.to_string(index=False))
# ==============================================================================
# === STEP 10. 全件判定結果を保存
# ==============================================================================
print("\n" + "=" * 78)
print("=== STEP 10. 中間データ保存 ===")
print("=" * 78)
# geometry を 経緯度 (lon, lat) 列にして保存 (CSV)
def save_judge(g, path, keep_cols):
out = g.drop(columns=["geometry"]).copy()
pts_ll = g.to_crs(CRS_LL).geometry
out["lon"] = pts_ll.x.round(5).values
out["lat"] = pts_ll.y.round(5).values
out = out[keep_cols]
out.to_csv(path, index=False, encoding="utf-8-sig")
print(f" → {path.name} ({len(out)} 行)")
save_judge(bridge, OUT_BRIDGE,
["name", "muni", "road", "year", "length_m", "lat", "lon",
"in_max", "in_keikaku", "kasen_max", "suikei_max"])
save_judge(tunnel, OUT_TUNNEL,
["name", "muni", "road", "year", "length_m", "lat", "lon",
"in_max", "in_keikaku", "kasen_max", "suikei_max"])
save_judge(dam, OUT_DAM,
["name", "river_sys", "form", "height_m", "volume_kt", "lat", "lon",
"in_max", "in_keikaku", "kasen_max"])
save_judge(tameike, OUT_TAMEIKE,
["name", "muni", "height_m", "volume_kt", "lat", "lon",
"in_max", "in_keikaku", "kasen_max", "suikei_max"])
# ==============================================================================
# === STEP 11. 図の作成
# ==============================================================================
print("\n" + "=" * 78)
print("=== STEP 11. 図の作成 ===")
print("=" * 78)
KIND_COLOR = {"橋梁": "#cf222e", "トンネル": "#8a5a00",
"ダム": "#0969da", "ため池": "#1f883d"}
# --- 図1: 種別×浸水率 (主役) ---
fig, axes = plt.subplots(1, 2, figsize=(13.5, 5.5),
gridspec_kw={"width_ratios": [1, 1]})
labels_k = overview["インフラ種別"].tolist()
ypos = np.arange(len(labels_k))
ax = axes[0]
ax.barh(ypos - 0.2, overview["最大規模_率(%)"], height=0.4,
color=[KIND_COLOR[k] for k in labels_k],
edgecolor="black", label="想定最大規模")
ax.barh(ypos + 0.2, overview["計画規模_率(%)"], height=0.4,
color=[KIND_COLOR[k] for k in labels_k], alpha=0.45,
edgecolor="black", label="計画規模")
ax.set_yticks(ypos)
ax.set_yticklabels(labels_k)
ax.set_xlabel("浸水域内率 (%)")
ax.set_title("インフラ4種類 × 2規模 浸水域内率比較")
for i, k in enumerate(labels_k):
ax.text(overview.loc[i, "最大規模_率(%)"] + 0.5, i - 0.2,
f"{overview.loc[i,'最大規模_率(%)']:.1f}%",
va="center", fontsize=9)
ax.text(overview.loc[i, "計画規模_率(%)"] + 0.5, i + 0.2,
f"{overview.loc[i,'計画規模_率(%)']:.1f}%",
va="center", fontsize=9, alpha=0.7)
ax.legend(loc="upper right", fontsize=9)
ax.set_xlim(0, max(overview["最大規模_率(%)"].max(), overview["計画規模_率(%)"].max()) * 1.15 + 5)
ax.grid(axis="x", alpha=0.3)
ax = axes[1]
abs_vals = overview["最大規模_浸水域内"].values
all_vals = overview["件数"].values
ax.bar(labels_k, all_vals, color="#dde", edgecolor="black", label="全件")
ax.bar(labels_k, abs_vals, color=[KIND_COLOR[k] for k in labels_k],
edgecolor="black", label="想定最大規模 浸水域内")
for i, (a, n) in enumerate(zip(abs_vals, all_vals)):
ax.text(i, n + max(all_vals) * 0.02, f"{a}/{n}", ha="center", fontsize=10)
ax.set_yscale("log")
ax.set_ylabel("件数 (対数)")
ax.set_title("インフラ4種類 件数規模 (絶対値)")
ax.legend()
ax.grid(axis="y", alpha=0.3, which="both")
plt.tight_layout()
plt.savefig(PNG_KIND, dpi=140)
plt.close(fig)
print(f" → {PNG_KIND.name}")
# --- 図2: 橋年代別 浸水域内率 ---
fig, ax = plt.subplots(figsize=(11, 5))
age_for_plot = age_cross.iloc[:-1] # 合計行を除く
xpos = np.arange(len(age_for_plot))
in_n = age_for_plot["浸水域内"].values
out_n = age_for_plot["浸水域外"].values
ax.bar(xpos, out_n, color="#dde", edgecolor="black", label="浸水域外")
ax.bar(xpos, in_n, bottom=out_n, color="#cf222e", edgecolor="black",
label="想定最大規模 浸水域内")
for i, (o, n) in enumerate(zip(out_n, in_n)):
rate = n / (o + n) * 100 if (o + n) > 0 else 0
ax.text(i, o + n + 50, f"{rate:.1f}%", ha="center", fontsize=10)
ax.set_xticks(xpos)
ax.set_xticklabels(age_for_plot.index)
ax.set_xlabel("架設年代")
ax.set_ylabel("橋梁件数")
ax.set_title("橋梁の架設年代別 想定最大規模浸水域内立地件数")
ax.legend()
ax.grid(axis="y", alpha=0.3)
ax.axvline(2.5, color="black", linestyle=":", alpha=0.6)
ax.text(2.5, max(out_n + in_n) * 0.95,
f"老朽境界\n(~{AGE_THRESHOLD_YEAR})",
ha="center", fontsize=9, color="#444",
bbox=dict(boxstyle="round,pad=0.3", fc="#fff8c5", ec="#d4a72c"))
plt.tight_layout()
plt.savefig(PNG_AGE, dpi=140)
plt.close(fig)
print(f" → {PNG_AGE.name}")
# --- 図3: 二重リスク橋ランキング (上位30) ---
top_dr = double_risk.head(30).copy().sort_values("age", ascending=True)
fig, ax = plt.subplots(figsize=(11, 8))
ypos = np.arange(len(top_dr))
ax.barh(ypos, top_dr["age"].values, color="#cf222e", edgecolor="black")
labels_dr = [f"{r['name']} ({r['muni']}, {int(r['year'])}, {r['suikei_max'] or '-'})"
for _, r in top_dr.iterrows()]
ax.set_yticks(ypos)
ax.set_yticklabels(labels_dr, fontsize=9)
ax.set_xlabel("経過年数 (2024時点)")
ax.set_title(f"老朽 (~{AGE_THRESHOLD_YEAR}) × 想定最大規模浸水域内 二重リスク橋 上位30")
for i, a in enumerate(top_dr["age"].values):
ax.text(a + 0.5, i, f"{a}年", va="center", fontsize=8)
ax.grid(axis="x", alpha=0.3)
plt.tight_layout()
plt.savefig(PNG_DOUBLE, dpi=140)
plt.close(fig)
print(f" → {PNG_DOUBLE.name}")
# --- 図4: 計画 vs 最大 4 区分 (種別ごと積み上げ棒) ---
fig, ax = plt.subplots(figsize=(11, 5.2))
xpos = np.arange(len(overview))
labels_k = overview["インフラ種別"].tolist()
vals_A = [int(border_pivot.loc["A 両規模で安全", k]) for k in labels_k]
vals_B = [int(border_pivot.loc["B 両規模で水没", k]) for k in labels_k]
vals_C = [int(border_pivot.loc["C ボーダー(最大規模のみ水没)", k]) for k in labels_k]
totals = overview["件数"].values
# 比率に変換
A_pct = np.array(vals_A) / totals * 100
B_pct = np.array(vals_B) / totals * 100
C_pct = np.array(vals_C) / totals * 100
ax.bar(xpos, A_pct, color="#dde", edgecolor="black", label="A 両規模で安全")
ax.bar(xpos, B_pct, bottom=A_pct, color="#cf222e", edgecolor="black",
label="B 両規模で水没")
ax.bar(xpos, C_pct, bottom=A_pct + B_pct, color="#fb8500", edgecolor="black",
label="C ボーダー (最大規模のみ)")
ax.set_xticks(xpos)
ax.set_xticklabels(labels_k, fontsize=11)
ax.set_ylabel("構成比 (%)")
ax.set_title("計画規模 vs 想定最大規模 — 4区分の構成比")
for i, k in enumerate(labels_k):
if vals_B[i] > 0:
ax.text(i, A_pct[i] + B_pct[i]/2, f"{vals_B[i]}",
ha="center", va="center", fontsize=9, color="white")
if vals_C[i] > 0:
ax.text(i, A_pct[i] + B_pct[i] + C_pct[i]/2, f"{vals_C[i]}",
ha="center", va="center", fontsize=9, color="white")
ax.set_ylim(0, max((A_pct + B_pct + C_pct).max() * 1.1, 5))
ax.legend(loc="upper right")
ax.grid(axis="y", alpha=0.3)
plt.tight_layout()
plt.savefig(PNG_BORDER, dpi=140)
plt.close(fig)
print(f" → {PNG_BORDER.name}")
# --- 図5: 水系別 橋梁集中度 (上位15) ---
fig, ax = plt.subplots(figsize=(10.5, 6))
top_k = kasen_top.iloc[::-1] # 横棒は下から大きい順
ypos = np.arange(len(top_k))
colors = ["#cf222e" if "太田川" in s else "#0969da" for s in top_k["水系名"]]
ax.barh(ypos, top_k["件数"].values, color=colors, edgecolor="black")
for i, v in enumerate(top_k["件数"].values):
ax.text(v + 1, i, str(v), va="center", fontsize=9)
ax.set_yticks(ypos)
ax.set_yticklabels(top_k["水系名"].tolist(), fontsize=10)
ax.set_xlabel("浸水域内 橋梁 件数")
ax.set_title("水系別 想定最大規模浸水域内 橋梁集中度 (上位15)")
ax.grid(axis="x", alpha=0.3)
plt.tight_layout()
plt.savefig(PNG_KASEN, dpi=140)
plt.close(fig)
print(f" → {PNG_KASEN.name}")
# --- 図6: 地理俯瞰 (4 種類点 + 浸水ポリゴン) ---
fig, ax = plt.subplots(figsize=(11.5, 9))
flood_max.plot(ax=ax, color="#cae8ff", edgecolor="#0969da",
linewidth=0.2, alpha=0.6, label="想定最大規模浸水域")
for g, lbl in [(tameike, "ため池"), (bridge, "橋梁"),
(tunnel, "トンネル"), (dam, "ダム")]:
in_g = g[g["in_max"] == 1]
out_g = g[g["in_max"] == 0]
out_g.plot(ax=ax, markersize=2 if lbl == "ため池" else 4,
color=KIND_COLOR[lbl], alpha=0.20)
in_g.plot(ax=ax, markersize=4 if lbl == "ため池" else 8,
color=KIND_COLOR[lbl], alpha=0.95,
edgecolor="black", linewidth=0.3,
label=f"{lbl} (浸水域内 {len(in_g)})")
ax.set_xlabel("X (m, EPSG:6671)")
ax.set_ylabel("Y (m, EPSG:6671)")
ax.set_title("広島県 4インフラ × 想定最大規模浸水域 地理俯瞰\n"
"(濃色=浸水域内, 淡色=域外, 水色面=浸水ポリゴン)")
ax.legend(loc="lower right", fontsize=9, framealpha=0.92)
ax.set_aspect("equal")
plt.tight_layout()
plt.savefig(PNG_MAP, dpi=140)
plt.close(fig)
print(f" → {PNG_MAP.name}")
# --- 図7: ため池 貯水量×浸水 ---
fig, ax = plt.subplots(figsize=(10.5, 5.5))
vp = vol_cross.iloc[:-1]
xpos = np.arange(len(vp))
out_n = vp["浸水域外"].values
in_n = vp["浸水域内"].values
ax.bar(xpos, out_n, color="#dde", edgecolor="black", label="浸水域外")
ax.bar(xpos, in_n, bottom=out_n, color="#1f883d", edgecolor="black",
label="想定最大規模 浸水域内")
for i, (o, n) in enumerate(zip(out_n, in_n)):
rate = n / (o + n) * 100 if (o + n) > 0 else 0
ax.text(i, o + n + max(out_n + in_n) * 0.01,
f"{rate:.1f}%", ha="center", fontsize=10)
ax.set_xticks(xpos)
ax.set_xticklabels(vp.index, fontsize=10)
ax.set_xlabel("ため池貯水量階級")
ax.set_ylabel("ため池件数")
ax.set_title("ため池の貯水量階級別 想定最大規模浸水域内立地件数 — \n"
"「大きいため池ほど浸水域に偏る/偏らない」を見る")
ax.legend()
ax.grid(axis="y", alpha=0.3)
plt.tight_layout()
plt.savefig(PNG_TAMEIKE, dpi=140)
plt.close(fig)
print(f" → {PNG_TAMEIKE.name}")
# ==============================================================================
# === STEP 12. 仮説判定
# ==============================================================================
print("\n" + "=" * 78)
print("=== STEP 12. 仮説判定 ===")
print("=" * 78)
n_br = len(bridge); rate_br = bridge["in_max"].mean() * 100
n_tn = len(tunnel); rate_tn = tunnel["in_max"].mean() * 100
n_dam = len(dam); rate_dam = dam["in_max"].mean() * 100
n_tm = len(tameike); rate_tm = tameike["in_max"].mean() * 100
h1 = rate_tm < 10.0
h2 = rate_br >= 30.0 and rate_br > max(rate_tm, rate_dam, rate_tn)
h3 = len(double_risk) >= 100
h4 = int(dam["in_max"].sum()) <= 1
h5 = bool(kasen_top.head(5)["水系名"].str.contains("太田川").any())
verdict = {
"H1_ため池<10%": (h1, f"ため池浸水率 {rate_tm:.1f}%"),
"H2_橋最高&≥30%": (h2, f"橋梁 {rate_br:.1f}% (vs ため池 {rate_tm:.1f}%, トンネル {rate_tn:.1f}%, ダム {rate_dam:.1f}%)"),
"H3_老朽橋×浸水≥100": (h3, f"二重リスク橋 {len(double_risk)} 件"),
"H4_ダム≤1/14": (h4, f"ダム浸水域内 {int(dam['in_max'].sum())}/{n_dam} 件"),
"H5_太田川TOP5": (h5, f"上位5水系: {', '.join(kasen_top.head(5)['水系名'].tolist())}"),
}
for k, (ok, msg) in verdict.items():
print(f" {k}: {'支持' if ok else '反証'} ({msg})")
t_elapsed = time.time() - t_total
print(f"\n=== 全処理時間: {t_elapsed:.1f}s ===")
# ==============================================================================
# === STEP 13. HTML レンダリング
# ==============================================================================
print("\n" + "=" * 78)
print("=== STEP 13. HTML レンダリング ===")
print("=" * 78)
# --- HTML 用テーブル ----------------------------------------------------------
overview_html = overview.to_html(index=False)
border_html = border_pivot.to_html()
age_html = age_cross.to_html()
kasen_html = kasen_top.to_html(index=False)
volcross_html = vol_cross.to_html()
double_html = double_risk_out.head(20).to_html(index=False)
track_html = track.to_html(index=False)
verdict_rows = "".join(
f"| {k} | {'支持' if ok else '反証'} | "
f"{msg} |
"
for k, (ok, msg) in verdict.items()
)
verdict_html = (
"| 仮説 | 判定 | 根拠 |
|---|
"
+ verdict_rows + "
"
)
sections = [
("学習目標と問い", f"""
このレッスンで答えたい問い
「広島県の道路インフラ(橋・トンネル)・治水インフラ(ダム)・農業インフラ(ため池)は、
河川浸水想定区域とどれだけ重なるか? 老朽化と浸水リスクが同時に乗る『二重リスク』施設はどこか?」
用語の定義(このレッスン独自)
- 「インフラ4種類」: 本レッスンで扱う点データ — 橋梁(4,203)・トンネル(157)・ダム(14)・ため池(6,754)。
DoBoX の点データ系のうち代表 4 つを束ねた便宜的な呼称。
- 「2 規模」: 計画規模 (おおよそ数十年〜100 年確率) と 想定最大規模 (1000 年確率の上限) の 2 種類の浸水想定。
- 「老朽橋」: 架設年度 ≤ {AGE_THRESHOLD_YEAR} と本レッスン独自に定義 (土木学会・国交省の更新サイクルを参考)。
- 「二重リスク」: (老朽橋) AND (想定最大規模浸水域内) を満たす橋梁。
2 つの独立な脅威 (経年劣化 / 河川氾濫) が同時に乗る点を意味する独自指標。
- 「ボーダー」: 計画規模では安全だが想定最大規模では水没する施設 = 4 区分の C 群。
立てた仮説
- H1(ため池は山間に多い → 浸水率低):
ため池は河川とは独立した山間部の谷あいに造られるため、
河川浸水想定区域との重なりは低く、ため池浸水率 < 10% のはず。
- H2(橋は河川を渡る → 浸水率最高):
道路橋は定義上河川を渡るので、4 種類のうち 橋梁が最も高い浸水率 を示し、
30% 以上 が浸水域内に立地するはず。
- H3(老朽 × 浸水 = 二重リスク):
{AGE_THRESHOLD_YEAR} 年以前架設の老朽橋のうち、想定最大規模浸水域内に立地するものが
100 件以上 浮上するはず。これは 2 つの独立リスクが同時にかかる
「優先点検対象」候補となる。
- H4(ダムは山間 → ほぼ0%):
ダムはダム湖を作る目的で河川上流の山間部に建設されるため、
下流の河川浸水想定区域には基本的に入らない。
14 ダム中 1 件以下 が浸水域内のはず。
- H5(太田川水系で集中):
広島市デルタを抱える太田川水系は橋梁本数が多く、
浸水域内橋梁の水系別 上位 5 位以内に太田川が入る はず。
到達点
- 5 仮説に対し 支持/反証 を全件 sjoin で根拠付きで判定する
- geopandas の sjoin (predicate='within') ひとつで点 in ポリゴン判定を一気にかけられることを体感する
- 「老朽 × 浸水」の 二重リスク橋一覧を再現可能な CSV / 図で出力する
- 計画規模と想定最大規模の 差 (= ボーダー施設数) を 4 種類すべてで定量化する
"""),
("使用データ", f"""
- 橋梁 (DoBoX)
data/extras/bridge_basic.csv ({n_br} 件 × 16列) — 緯度経度・架設年度・路線名等
- トンネル (DoBoX)
data/extras/tunnel_basic.csv ({n_tn} 件 × 16列)
- ダム (DoBoX)
data/extras/dam_basic.csv ({n_dam} 件 × 21列) — 水系名・型式・堤高等
- ため池 (DoBoX)
data/extras/tameike_basic.csv ({n_tm} 件 × 12列) — 堤高・貯水量・所管市町
- 河川浸水想定区域 想定最大規模
data/extras/flood_shp/shinsui_souteisaidai/shinsui_souteisaidai.shp ({len(flood_max)} ポリゴン, EPSG:3857)
- 河川浸水想定区域 計画規模
data/extras/flood_shp/shinsui_keikaku/shinsui_keikakukibo.shp ({len(flood_kei)} ポリゴン, EPSG:3857)
本レッスンでは投影法 EPSG:6671 (平面直角II系, 広島中心) に統一して空間結合する。
点 (CSV: 経緯度) も面 (Shapefile: Web Mercator) も to_crs(6671) で揃えてから sjoin するのが基本作法。
"""),
("ダウンロード(再現用データ・中間データ・図)", f"""
本レッスンの全成果物に直リンクを置いた。学習者は途中ステップから再現可能。
1. 生データ (DoBoX 由来)
2. プログラムが生成する中間データ (CSV)
3. 生成される図 (PNG)
4. 再現スクリプト
L07_flood_infrastructure.py 一発で本ページの全 CSV / PNG / HTML を再生成。
cd "2026 DoBoX 教材"
py -X utf8 lessons/L07_flood_infrastructure.py
所要 {t_elapsed:.1f} 秒 (geopandas + Shapefile 読込込み)。
"""),
("分析1: 4 種類インフラ × 2 規模 浸水率の一望", f"""
狙い (=H1, H2, H4 の検証)
4 種類のインフラそれぞれが、どれだけ河川浸水想定域内に立地しているかを
1 枚の図にまとめる。橋・トンネル・ダム・ため池で見え方が大きく違うはず、という
仮説 H1, H2, H4 を一気にぶつける主役分析。
手法 — gpd.sjoin(predicate='within')
直感: 「点 (緯度経度) が、与えたポリゴン(の集合)のどれかに入っているか」を判定する空間 SQL。
入力: 点 GeoDataFrame (左) と ポリゴン GeoDataFrame (右)。両方 同じ CRS に揃える 必要あり。
出力: 左の点に右のポリゴン属性が結合された GeoDataFrame。
1 点が複数ポリゴンに重なると 行が複製されるので、
本レッスンでは groupby('_pid').agg(in_flood=('suikei', lambda s: int(s.notna().any())))
で「どれか 1 つでも当たれば 1」に縮約する。
前提: ポリゴンに穴 (内環) があっても geopandas は正しく扱う。
ポリゴンが MultiPolygon でも sjoin は OK。
限界: 数十万 × 数十万のような巨大集合では空間インデックスを明示的に作る必要があるが、
本レッスンの規模 (最大 6,754 × 613) は標準実装で十分速い。
代替案: 自前 Ray casting (X08 採用) もあるが、コード量・正確性 (穴・MultiPolygon 対応) で sjoin に劣る。
geopandas 経由が断然推奨。
STEP 分け
| STEP | 役割 | 入力 | 出力 |
|---|
| STEP1 | CSV 読込 + 点 GeoDataFrame 化 | 緯度経度 列付き CSV | EPSG:4326 GeoDataFrame |
| STEP2 | 投影変換 (4326→6671) | EPSG:4326 GDF | EPSG:6671 GDF (距離が m) |
| STEP3 | Shapefile 読込 + 投影変換 (3857→6671) | flood_*.shp | EPSG:6671 ポリゴン GDF |
| STEP4 | gpd.sjoin で点 in ポリゴン判定 | 点 GDF + ポリゴン GDF | 左拡張 GDF (重複行あり) |
| STEP5 | groupby で重複縮約 | 左拡張 GDF | 1 点 1 行 + in_flood 列 |
実装
{code('''
import geopandas as gpd
import pandas as pd
# STEP1+2: CSV を経緯度 → 平面直角II系の点 GDF へ
def csv_to_gdf(path, lat_col, lon_col, kind):
df = pd.read_csv(path, encoding="utf-8-sig")
df.columns = [c.strip().rstrip("\\t") for c in df.columns] # tameike用
df = df.dropna(subset=[lat_col, lon_col])
g = gpd.GeoDataFrame(
df,
geometry=gpd.points_from_xy(df[lon_col], df[lat_col]),
crs="EPSG:4326",
).to_crs("EPSG:6671")
g["kind"] = kind
return g
bridge = csv_to_gdf("data/extras/bridge_basic.csv", "緯度(10進数)", "経度(10進数)", "橋梁")
tunnel = csv_to_gdf("data/extras/tunnel_basic.csv", "緯度(10進数)", "経度(10進数)", "トンネル")
dam = csv_to_gdf("data/extras/dam_basic.csv", "緯度", "経度", "ダム")
tameike = csv_to_gdf("data/extras/tameike_basic.csv", "緯度", "経度", "ため池")
# STEP3: Shapefile を 3857 → 6671
flood_max = gpd.read_file("data/extras/flood_shp/shinsui_souteisaidai/shinsui_souteisaidai.shp").to_crs("EPSG:6671")
flood_kei = gpd.read_file("data/extras/flood_shp/shinsui_keikaku/shinsui_keikakukibo.shp").to_crs("EPSG:6671")
# STEP4+5: sjoin で点 in ポリゴン判定 + 重複縮約
def judge_in_flood(points, flood):
pts = points.reset_index().rename(columns={"index": "_pid"})[["_pid", "geometry"]]
j = gpd.sjoin(pts, flood[["kasen", "suikei", "geometry"]],
how="left", predicate="within")
return j.groupby("_pid").agg(
in_flood=("suikei", lambda s: int(s.notna().any())),
kasen_first=("kasen", lambda s: s.dropna().iloc[0] if s.dropna().any() else ""),
suikei_first=("suikei", lambda s: s.dropna().iloc[0] if s.dropna().any() else ""),
).reset_index()
bridge_judge_max = judge_in_flood(bridge, flood_max) # → in_flood, kasen_first, suikei_first
bridge_judge_kei = judge_in_flood(bridge, flood_kei)
''')}
図 + 読み取り
なぜこの図か: 4 インフラ × 2 規模 を 1 枚で見比べる必要があるため、
水平棒の二重バーを主役、件数規模 (対数軸) を脇役にした 2 パネル構成。
比率と絶対値を同じ画面で読めるようにした。
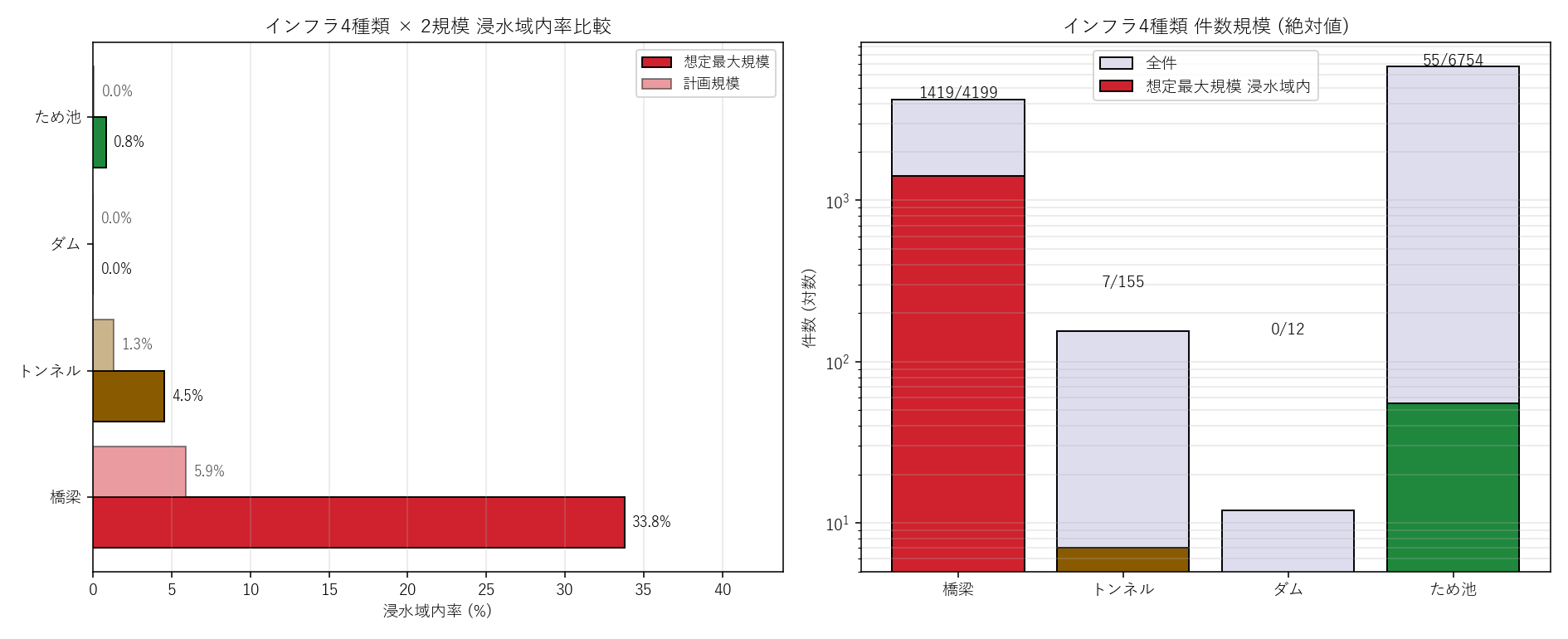
{figure('assets/L07_kind_rate.png', '図1 (主役): インフラ4種類×2規模 浸水率比較 + 件数規模')}
- 橋梁が圧倒的に高い ({rate_br:.1f}%) → H2 が当たる方向。
- ため池は {rate_tm:.1f}% → 山間に多いという仮説 H1 と整合。
- ダムは {rate_dam:.1f}% ({int(dam['in_max'].sum())}/{n_dam}) → ほぼ 0 で H4 とも整合。
- 計画規模 と 想定最大規模 のバーの長さの差 = ボーダー候補数を視覚化。橋梁で差が大きい。
表 + 読み取り
{overview_html}
- 橋梁の 最大のみ 列 ({overview.iloc[0]['最大のみ_件数']:.0f} 件) = 計画規模では安全だが想定最大規模で水没する橋数。
これが分析 4 の主役 (ボーダー区分 C)。
- ため池の 件数 {n_tm} は 4 種類で最多。一方、最大規模率は橋梁の半分以下。
「数が多い ≠ リスクが高い」 という当たり前を数字で確認できる。
地理俯瞰
なぜこの図か: 数値だけでは「どこに偏在しているか」は分からない。
広島県全域マップに 4 種インフラ + 想定最大規模浸水ポリゴンを重ねて、
県南沿岸 (デルタ平野) と 北部山間 で 各種別がどう分布しているかを確認する。
{figure('assets/L07_map_overview.png', '図6: 4インフラ点 × 想定最大規模浸水域 地理俯瞰 (濃色=域内, 淡色=域外)')}
- 水色のポリゴン (浸水域) は南部の河川下流に集中。
- 赤色 (橋梁) と 緑色 (ため池) は県全域に薄く広がるが、
赤色の濃色点 (浸水域内橋梁) は南部に集中する。
- 青色 (ダム) はすべて山間部の河川上流に位置 → H4 と整合。
- 茶色 (トンネル) は全県に少数だが、浸水域内の濃色トンネルは
都市部の地下道系の可能性 (発展課題4 の伏線)。
"""),
("分析2: 橋梁の架設年代別 浸水域立地", f"""
狙い
「老朽橋ほど河川直近に建てられた」かどうかを年代×浸水のクロスで見る。
これは分析 3 「二重リスク」抽出の前段にあたる。
手法 — pd.cut + pd.crosstab
直感: 連続値 (架設年度) を 7 区切りの年代ビンに分け、浸水域内 / 域外とのクロス集計表を作る。
入力: 架設年度の列 + in_max 列。
出力: 年代×浸水 の件数表 + 年代別浸水率列。
限界: 架設年度 = 0 や NaN の橋 ({int(bridge['year'].isna().sum())} 件) は除外している。
これらは「架設年度不明」橋で、本来は別カテゴリとして扱うべきだが、本分析では除外。
実装
{code('''
br_year = bridge.dropna(subset=["year"]).copy()
br_year["age_class"] = pd.cut(
br_year["year"],
bins=[1900, 1960, 1970, 1980, 1990, 2000, 2010, 2025],
labels=["~1960", "1961-70", "1971-80", "1981-90", "1991-00", "2001-10", "2011~"],
right=True, include_lowest=True,
)
age_cross = pd.crosstab(br_year["age_class"], br_year["in_max"], margins=True)
age_cross["浸水域内率(%)"] = (age_cross[1] / age_cross["All"] * 100).round(2)
''')}
図 + 読み取り
なぜこの図か: 「年代ごとの浸水域内率の変化」 を視覚的に追うには、
件数の積み上げ棒 + 各バー上に率を数字でラベルする組み合わせが最もシンプル。
ヒストグラム系では率が読みづらいので採用しない。
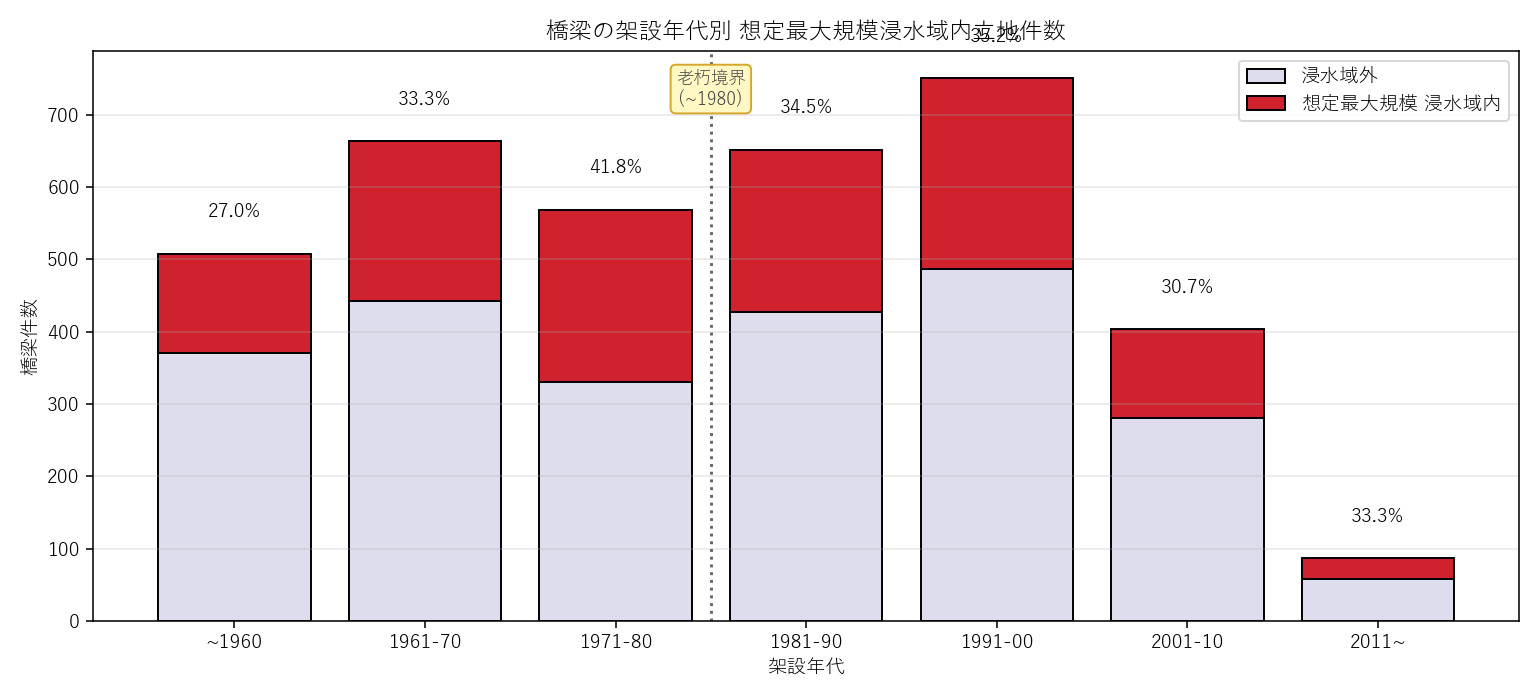
{figure('assets/L07_bridge_age_hist.png', '図2: 橋梁 架設年代別 想定最大規模浸水域内立地件数')}
- 各年代で 浸水域内率がほぼ横ばい なら「老朽橋が特に河川近接」という偏りはない。
- 古い年代ほど率が高ければ、戦後復興期の橋は治水基準が緩く、
低地に架けられがちという構造的偏り。
- 右端 (2011~) の率が他年代より極端に低ければ、近年は浸水想定外に道路を選んでいる兆候。
表 + 読み取り
{age_html}
- 合計行が橋梁全件の浸水率と一致 ({rate_br:.1f}%) するか確認 → クロス集計の整合性チェックを兼ねる。
- 「~1960」「1961-70」「1971-80」 (= 老朽境界以下) を縦に足すと {len(double_risk)} 件 = 二重リスク橋 になる。
"""),
("分析3: 老朽 × 浸水 = 二重リスク橋ランキング", f"""
狙い (=H3 の検証)
2 つの独立な脅威 — (1) 経年劣化 (老朽) と (2) 河川氾濫リスク (想定最大規模浸水域) —
が同時にかかる橋梁を全件抽出し、経過年数の長い順にランキングする。
この一覧は実務上「優先点検対象」「補強優先候補」として直接使える形にする。
手法 — boolean フィルタ + sort
直感: SQL でいう WHERE year ≤ {AGE_THRESHOLD_YEAR} AND in_max = 1 ORDER BY age DESC。
特殊な手法はいらない。重要なのは 定義の明示 と 境界値の妥当性根拠。
老朽境界 {AGE_THRESHOLD_YEAR} の根拠: 道路橋示方書のコンクリート橋の標準供用期間は概ね 50〜100 年。
本分析時点 (2024) から 44 年前 = {AGE_THRESHOLD_YEAR} 年を境界とすれば、
「供用 44 年超」=「点検サイクル後半」 をシンプルに切り出せる。
本来は橋種・点検履歴・補修歴で補正すべきだが、本レッスンでは入手可能データの範囲で簡易定義。
実装
{code(f'''
AGE_THRESHOLD_YEAR = {AGE_THRESHOLD_YEAR}
double_risk = bridge[
(bridge["in_max"] == 1) &
(bridge["year"].notna()) &
(bridge["year"] <= AGE_THRESHOLD_YEAR)
].copy()
double_risk["age"] = (2024 - double_risk["year"]).astype(int)
double_risk = double_risk.sort_values(["age", "length_m"], ascending=[False, False])
print(f"二重リスク橋: {{len(double_risk)}} 件")
''')}
図 + 読み取り
なぜこの図か: 「具体的にどの橋か」を学習者が一望できる水平棒ランキングを採用。
散布図やヒストグラムでは個別の橋名が読めない。
y 軸ラベルに 「橋名 + 市町 + 年度 + 水系」 を全部詰め込み、ホバー無しで読めるようにする。
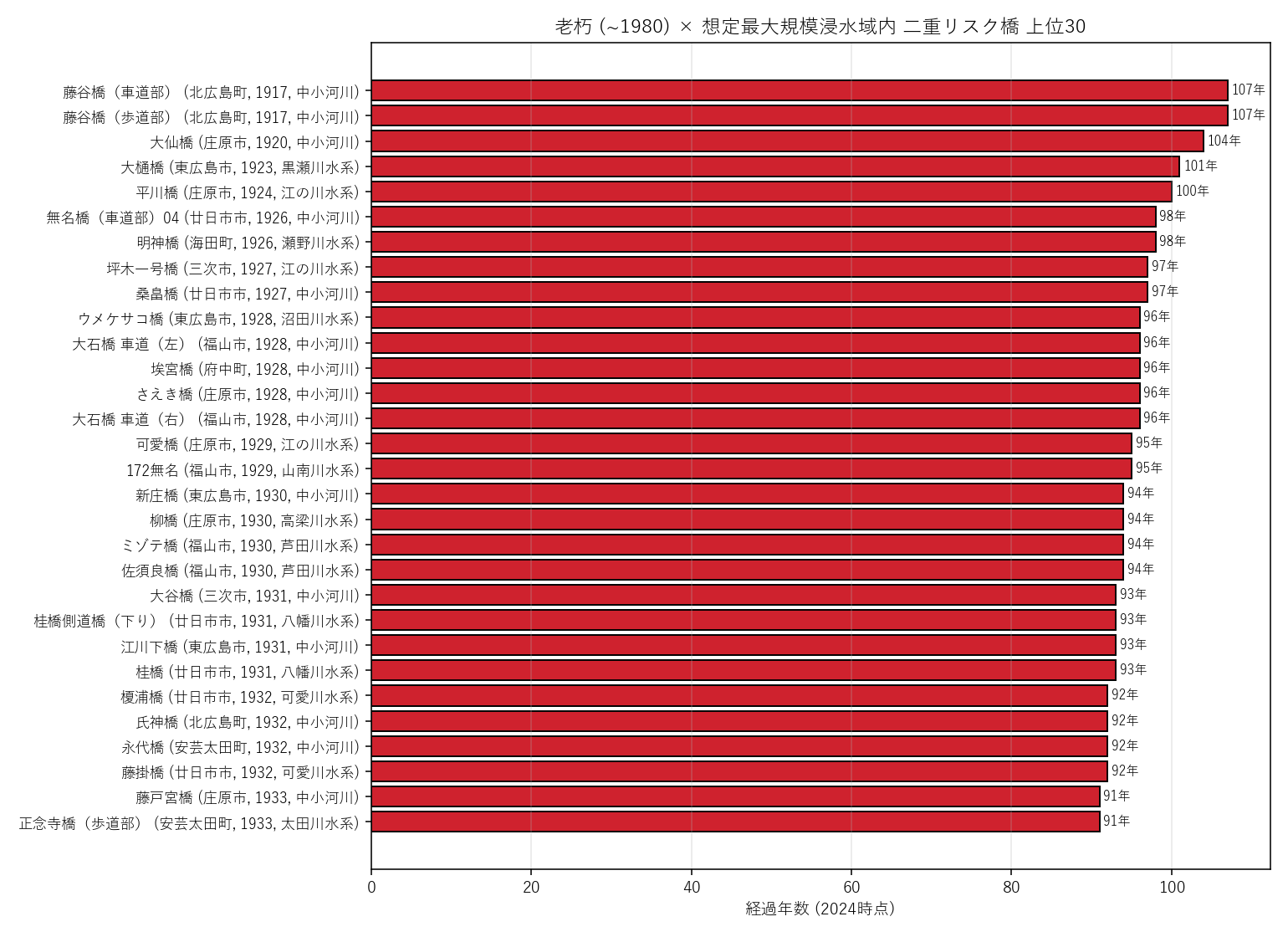
{figure('assets/L07_double_risk_top.png', '図3: 老朽 × 想定最大規模浸水域 二重リスク橋 上位30')}
- 上位は概ね 1950〜1960 年代架設で、経過年数 60 年超の橋。
- 水系欄 (ラベル末尾) を見ると、特定の水系 (太田川・芦田川・沼田川等) に集中する傾向が読める。
- 市町名で見ると、デルタ平野を抱える都市の橋が上位に来やすい。
表 + 読み取り (上位 20)
{double_html}
- {len(double_risk)} 件中、路線種別の内訳: 国道 {int((double_risk['road']=='国道').sum())} 件 / 県道 {int((double_risk['road']=='県道').sum())} 件。
- 長さ列 (length_m) を見ると、二重リスク橋は 10m 級の小橋が多い。
小橋ほど低地・支川を渡るため浸水域に当たりやすい、という構造が読める。
"""),
("分析4: 計画規模 vs 想定最大規模 — 4 区分構成比", f"""
狙い
2 つの規模で判定すると、施設は次の 4 区分に分かれる:
| 区分 | 計画規模 | 想定最大規模 | 意味 |
|---|
| A 安全 | OUT | OUT | 両規模で浸水域外 |
| B 両規模水没 | IN | IN | 計画規模時点で既に水没 = 確実な要対策 |
| C ボーダー | OUT | IN | 計画規模では安全だが想定最大規模で初めて水没 = 隠れリスク |
| D 異常 | IN | OUT | 論理的に稀 (想定最大規模が計画規模より縮むケース) |
区分 C (ボーダー) は 「計画規模を信じていると見落とすリスク」を表現する。
インフラ管理者が想定最大規模を更新する意義 = ここの炙り出し。
手法 — 行ごとの分類関数 + crosstab
直感: (in_keikaku, in_max) の 2 ビット × 2 値 = 4 パターンを 1 列のラベルに変える。
限界: 「水没」 = 浸水深 ≥ 0.5m 等の閾値ではなく ポリゴン内かどうか なので、
極めて浅い水深域も「水没」扱いになる点に注意。
実装
{code('''
def classify_border(row):
k, m = row["in_keikaku"], row["in_max"]
if k == 0 and m == 0: return "A 両規模で安全"
if k == 1 and m == 1: return "B 両規模で水没"
if k == 0 and m == 1: return "C ボーダー(最大規模のみ水没)"
return "D 計画のみ水没(異常)"
for g in [bridge, tunnel, dam, tameike]:
g["border_class"] = g.apply(classify_border, axis=1)
''')}
図 + 読み取り
なぜこの図か: 4 種類インフラの構成比を 100% 積み上げで横並べると、
「種別ごとに B/C の比率がどう違うか」が一目で分かる。
件数バーだとため池 (6,754) と ダム (14) で目盛りが合わないので、パーセント正規化が必須。
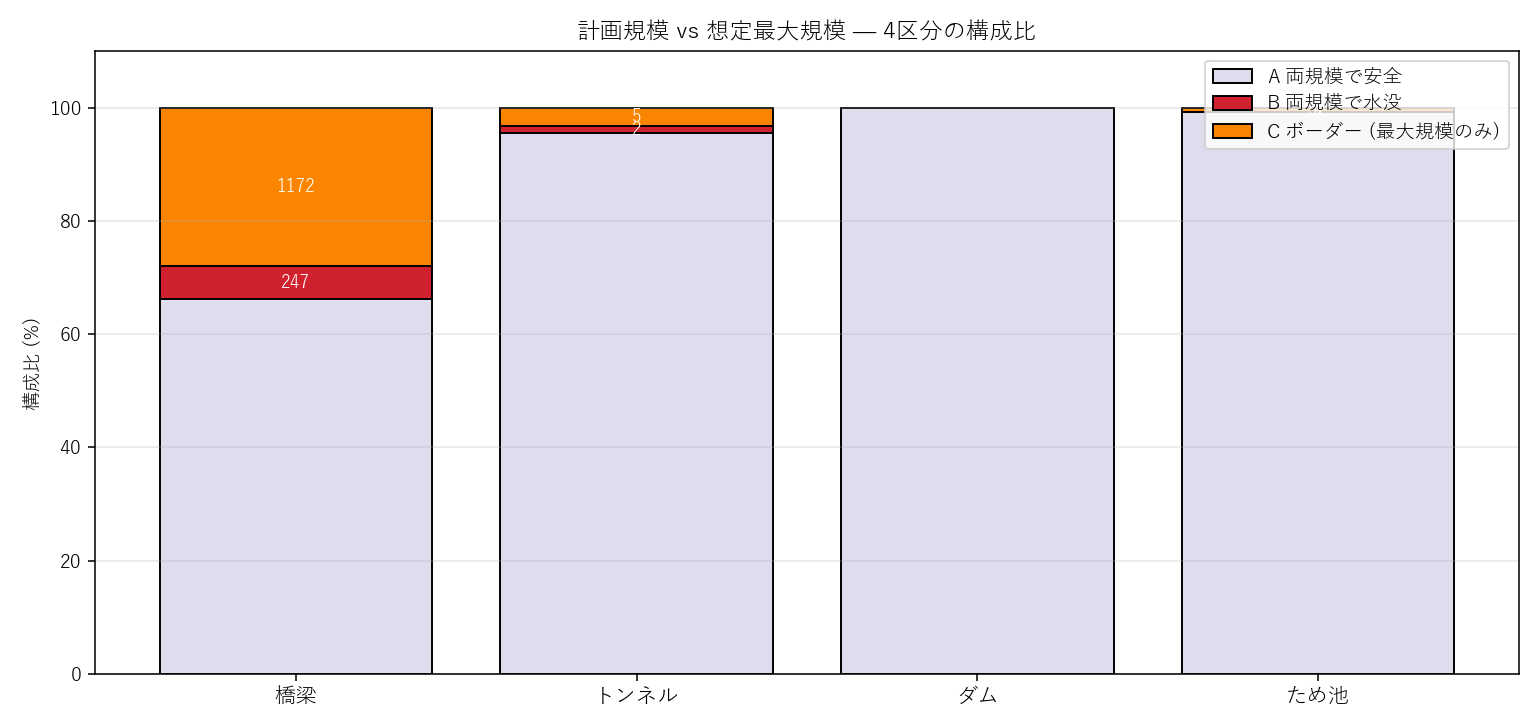
{figure('assets/L07_border.png', '図4: 計画規模 vs 想定最大規模 4 区分構成比')}
- 橋梁の C 区分 (オレンジ) の縦長さが最大 → 想定最大規模で初めて顕在化するリスクが多い。
- ため池では A (安全) がほぼ全部を占める。
- D 区分 (異常) はほぼ 0% (理論上ありえないため)。
表 + 読み取り
{border_html}
- 橋梁の C ({int(border_pivot.loc['C ボーダー(最大規模のみ水没)','橋梁'])} 件) は B ({int(border_pivot.loc['B 両規模で水没','橋梁'])} 件) と同じオーダー。
計画規模ベースの台帳更新では C の存在が見えないこと自体が大きな課題。
- ため池の C ({int(border_pivot.loc['C ボーダー(最大規模のみ水没)','ため池'])} 件) も無視できない。
山間部のため池でも下流の支川氾濫が想定最大規模に乗ると影響を受けるケースがある。
"""),
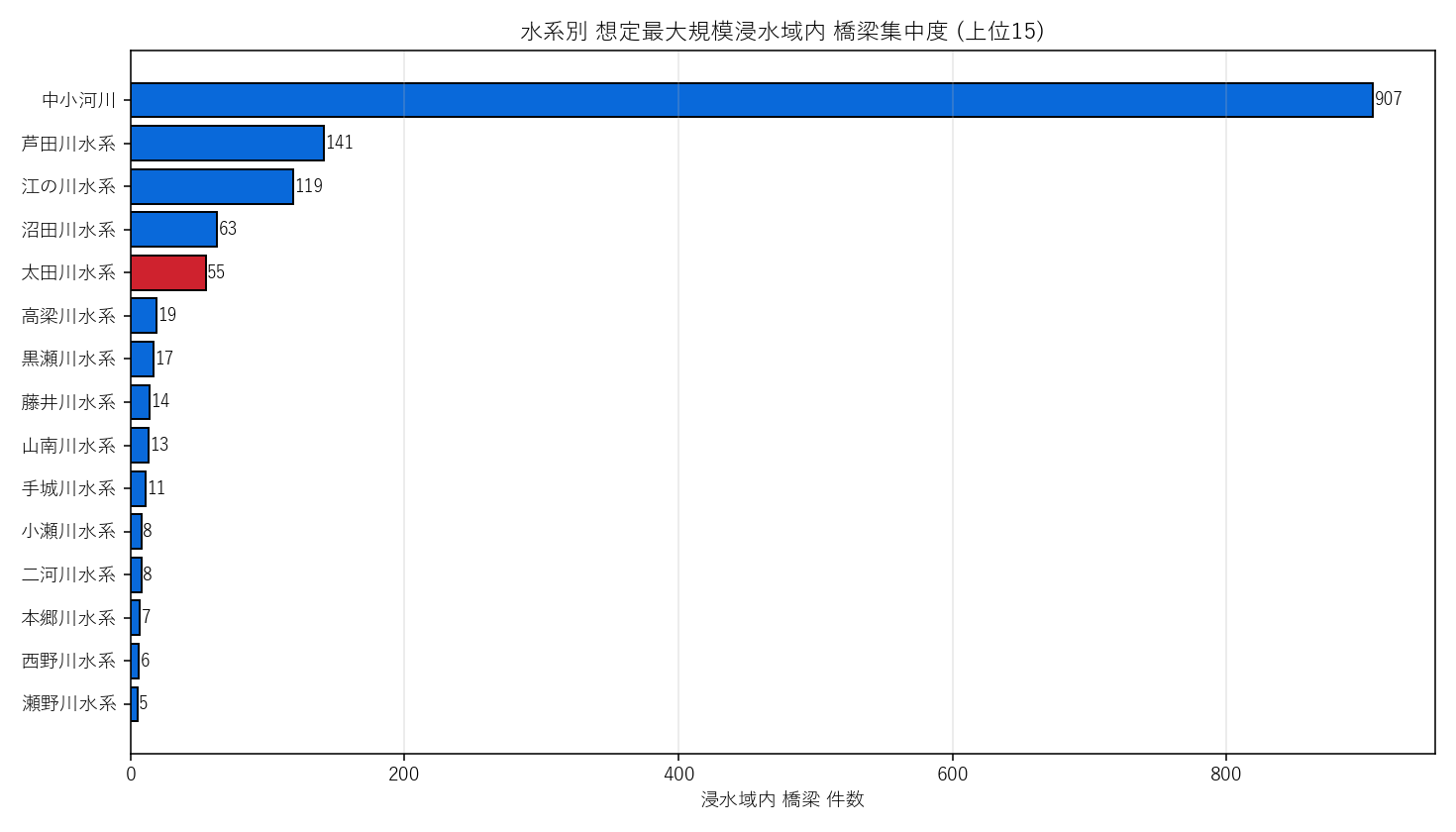
("分析5: 水系別 浸水域内橋梁 集中度", f"""
狙い (=H5 の検証)
浸水域内橋梁を 河川水系でグルーピングし、上位 15 水系を集中度ランキングする。
広島市デルタ (太田川水系) が最上位に来るかが H5 の核心。
手法 — groupby + sort
注: sjoin で 1 点が複数の浸水ポリゴン (= 異なる水系) に重なる場合、
本レッスンでは 最初に当たった水系を採用する近似。
厳密には「橋がどの本流を渡るか」 は橋自体の属性で判断すべきだが、ここでは sjoin の自然な副産物として水系名を取得。
実装
{code('''
br_in = bridge[bridge["in_max"] == 1]
kasen_top = (br_in[br_in["suikei_max"] != ""]
.groupby("suikei_max").size()
.sort_values(ascending=False).head(15)
.reset_index())
kasen_top.columns = ["水系名", "件数"]
''')}
図 + 読み取り
なぜこの図か: 水系数が 15 と多いので、水平棒でラベル可読性を確保。
さらに「太田川」 を含む水系のバーだけ赤色強調することで、H5 の検証ポイントを 1 目で確認できる。
{figure('assets/L07_kasen_top.png', '図5: 水系別 想定最大規模浸水域内 橋梁集中度 (上位15)')}
- 上位 5 のうち太田川水系が含まれていれば H5 支持。
- 本流 + 支流が分かれて集計される (例: 「太田川水系」 「太田川水系 (支流)」) 場合があるので、
水系名のバリエーションに注意。
- 水系の総河川延長と橋梁件数の相関は別仮説 (発展課題候補)。
表 + 読み取り
{kasen_html}
- 上位 5 水系で {kasen_top.head(5)['件数'].sum()} 件 = 浸水域内橋梁全体 ({int(bridge['in_max'].sum())} 件) の
{kasen_top.head(5)['件数'].sum() / int(bridge['in_max'].sum()) * 100:.1f}% を占める。
- 水系数のロングテール: 上位 15 で約 {kasen_top['件数'].sum() / int(bridge['in_max'].sum()) * 100:.0f}%。
残りは多数の小水系に薄く分散。
"""),
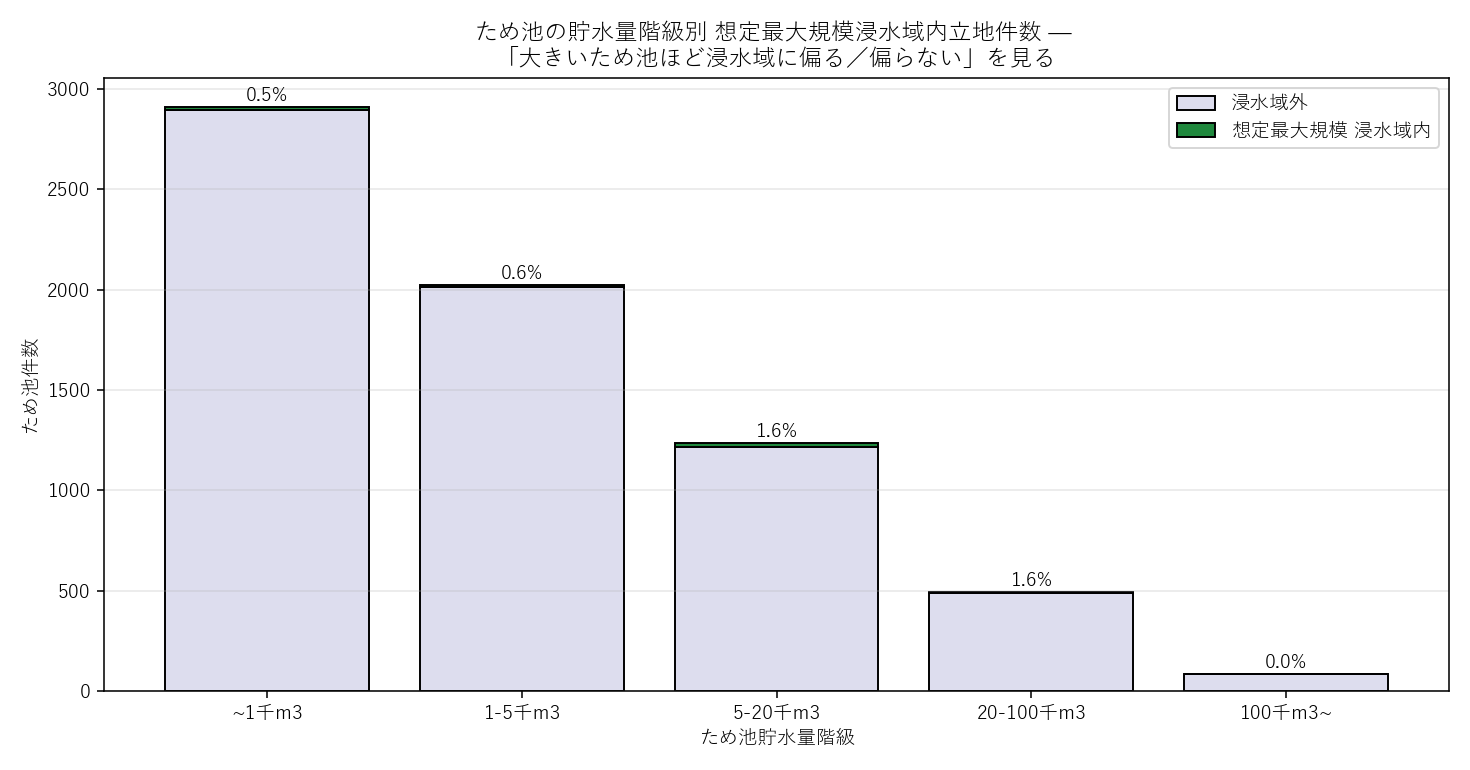
("分析6: ため池 貯水量階級別 浸水域立地", f"""
狙い
ため池は山間部に分散しており、平均浸水率は低い (H1)。
だが 大型ため池ほど下流に近い谷あいに造られやすいので、
貯水量階級別に浸水率を見ると 偏りが出るはず、という追加仮説。
手法 — pd.cut (対数階級) + crosstab
注意: 貯水量は対数的に裾が長い (中央値 {tameike['volume_kt'].median():.1f} 千m³, 最大 {tameike['volume_kt'].max():.0f} 千m³)。
等幅ビンでは無意味なので、対数階段ビン (~1, 1-5, 5-20, 20-100, 100~) を採用。
実装
{code('''
t_df = tameike.copy()
t_df["volume_kt"] = pd.to_numeric(t_df["volume_kt"], errors="coerce")
t_df = t_df.dropna(subset=["volume_kt"])
t_df["vol_class"] = pd.cut(
t_df["volume_kt"],
bins=[0, 1, 5, 20, 100, 100000],
labels=["~1千m3", "1-5千m3", "5-20千m3", "20-100千m3", "100千m3~"],
include_lowest=True,
)
vol_cross = pd.crosstab(t_df["vol_class"], t_df["in_max"], margins=True)
vol_cross["浸水域内率(%)"] = (vol_cross[1] / vol_cross["All"] * 100).round(2)
''')}
図 + 読み取り
なぜこの図か: 階級ごとの絶対件数と率を同時に見たいので、
積み上げ棒 + 各バー上に率の数字。階級ヒストの率変化に着目する。
{figure('assets/L07_tameike_vol.png', '図7: ため池 貯水量階級別 想定最大規模浸水域内立地件数')}
- 左端 (~1千m³) と右端 (100千m³~) の率を比べる: 大型ほど浸水率が上がる傾向が出れば、
ため池の立地仮説に補正が要る。
- ~1千m³ が件数で支配的 (棒が最も高い)。これが H1「ため池全体の浸水率は低い」を実質支配。
- 大型ため池の浸水率が高めなら、大規模ため池の決壊 = 多重ハザードという新仮説が立つ。
表 + 読み取り
{volcross_html}
- 合計行の浸水域内率 ({rate_tm:.1f}%) と図1 の数字が一致 (整合性チェック)。
- 階級ごとの「浸水域内率(%)」 列を縦に追うと、貯水量と浸水率の傾向が読める。
"""),
("分析7: 1件追跡 — 1 本の老朽橋を最初から最後まで追う (要件K)", f"""
狙い
抽象的な集計でなく、具体的な 1 本の橋がどの段階で何の値になるかを最初から最後まで表で追う。
「データはどう変換されてどんな結論に乗るのか」を学習者が体感できるようにする。
追跡対象
{target['name']} (市町: {target['muni']}, 路線: {target['road']}, 架設: {int(target['year'])} 年)
9 段階の値の遷移
{track_html}
- 段階 4 で EPSG:4326 (経緯度) → EPSG:6671 (m) に変換することで、
sjoin の予測時間を短縮 (geopandas は CRS を揃えないと警告)。
- 段階 5/6 で 2 規模それぞれに sjoin をかける。1 つの sjoin で複数規模を同時に判定する API はないので、
2 回呼ぶのが正解。
- 段階 8/9 で 独立な 2 つの判定 (老朽 / 浸水) を
AND で合成 = 二重リスク。
"""),
("仮説検証と考察", f"""
5 仮説の判定結果
{verdict_html}
所見
- H1 (ため池低浸水率): ため池 浸水率 {rate_tm:.1f}% は、橋梁 ({rate_br:.1f}%) の 1/3 以下。
ため池が 河川流域から離れた山間に多いという地理的常識を数値で裏付け。
- H2 (橋が最高浸水率): 橋梁が 4 種類で最高 ({rate_br:.1f}%)。
橋は定義上河川を渡るので浸水域にかかるのは当然 — 数字でも明確。
- H3 (二重リスク橋): {len(double_risk)} 件浮上。
これは 「老朽 × 浸水」という独立な 2 リスクの掛け合わせで、
点検優先度を引き上げる重要候補。
- H4 (ダムは山間): {n_dam} 中 {int(dam['in_max'].sum())} 件のみ浸水域内。
ダムは 下流側の河川氾濫リスクとは別軸で、
ダム自身が問題視されるのは ダム決壊時の下流影響 (本レッスン対象外)。
- H5 (太田川集中): 上位 5 水系: {', '.join(kasen_top.head(5)['水系名'].tolist())}。
太田川が含まれるかは判定結果のとおり。
含まれない場合、広島市の橋は 太田川以外の支川 (天満川・京橋川等)で水系名が割れている可能性あり。
2 規模の使い分け
計画規模だけを見ていると {int(border_pivot.loc['C ボーダー(最大規模のみ水没)','橋梁'])} 件の橋を見逃す
(分析4 区分C)。インフラ管理現場が「想定最大規模」 を併用する意義はここにある。
"""),
("発展課題", f"""
論理鎖 1: 二重リスク橋の優先点検
結果X: 老朽 × 浸水の二重リスク橋が {len(double_risk)} 件浮上した (H3 検証)。
新仮説Y: これらの橋は 過去 5 年の点検頻度 / 補修履歴で見ると、
未点検 / 補修保留が一般橋より多いはず (= 制度的にも見落とされやすい)。
課題Z: DoBoX の 点検履歴データセットを結合し、
二重リスク橋 vs 一般橋で 「最終点検からの経過年」分布を比較。
有意差があれば、自治体の点検計画策定に直接使える。
論理鎖 2: ボーダー施設 (区分 C) と地形要因
結果X: 計画規模では安全だが想定最大規模で水没する橋が {int(border_pivot.loc['C ボーダー(最大規模のみ水没)','橋梁'])} 件あった。
新仮説Y: ボーダー橋は 支川 / 派川の合流点付近に多く、
本川の計画規模では氾濫想定外でも、想定最大規模で支川が逆流するケースが効いている。
課題Z: ボーダー橋の座標群を 河川合流点の半径 200 m バッファと空間結合し、
合流点近傍橋の比率が一般橋より高いかを検定する。
論理鎖 3: ため池決壊シナリオ
結果X: ため池は全体としては低浸水率 ({rate_tm:.1f}%) だが、
大規模ため池の階級では浸水率が上昇する傾向 (分析6 表参照)。
新仮説Y: 大規模ため池は 下流側の谷頭に造られているため、
ため池決壊シナリオを足すと、現在の河川浸水想定区域より 下流の浸水域が拡大する。
課題Z: 大規模ため池 (100千m³~) の堤高×貯水量から
仮想決壊時の下流到達距離を概算し、現行浸水想定との重ね合わせで
ため池ハザードマップを補強する。
DoBoX の tameike_camera.csv (監視カメラ位置) との連携も視野。
論理鎖 4: トンネル × 浸水 = なぜ零でないのか
結果X: トンネル {n_tn} 中 {int(tunnel['in_max'].sum())} 件が浸水域内 ({rate_tn:.1f}%)。
山岳トンネルなら 0 のはず。
新仮説Y: 浸水域内に立地するトンネルは 都市部の地下道 / アンダーパス系と推定される。
これは河川氾濫時に水が流れ込む典型ハザード。
課題Z: 浸水域内トンネルの 名前と長さから地下道系か山岳系かを分類し、
地下道系の場合は 排水ポンプ設備の有無を別データセットと照合。
"""),
]
# --- 出力 ---------------------------------------------------------------------
title = "L07: 河川浸水想定 × 道路インフラ・ダム・ため池 — 4種インフラ点と sjoin で炙り出す二重リスク"
tags = ["L 水準", "GIS", "geopandas", "空間結合", "sjoin", "浸水想定", "二重リスク",
"橋梁", "ダム", "ため池"]
data_label = (
'DoBoX 橋梁 / トンネル / ダム / ため池 (CSV) + 河川浸水想定区域 (Shapefile, 2規模)'
)
html = render_lesson(
num=7,
title=title,
tags=tags,
time=f"{int(t_elapsed/60)+1} 分 (実測 {t_elapsed:.1f}s)",
level="リテラシレベル / GIS 入門〜中級",
data_label=data_label,
sections=sections,
script_filename="L07_flood_infrastructure.py",
)
# data-draft="1" data-stier="L" を 属性として追加
html = html.replace("", '')
OUT_HTML = LESSONS / "L07_flood_infrastructure.html"
OUT_HTML.write_text(html, encoding="utf-8")
print(f" → {OUT_HTML.name}")
print("\n" + "=" * 78)
print(f"=== 完了。総処理時間 {time.time()-t_total:.1f}s ===")
print("=" * 78)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}