"""
L06 (v2): 2024-07-01 豪雨日 — 雨域セルの空間-時間進行を読む
10分値雨量を1時間集約 (24時間 × 約400観測所) して、
広島県内を「豪雨セル」がどう移動したかを 4 つの軸で可視化する:
1) 時間別 KDE small multiples (6×4=24時間) — 雨域分布の時間変化
2) 重心 (Center-of-Mass) 軌跡 — 雨域の移動方向と速度
3) 空間自己相関 Moran's I の時間推移 — クラスタ性の強弱
4) 観測所別ピーク時刻ヒストグラム — 県全体での集中時間帯
5) Top10 観測所の10分値時系列重ね描き — 個別観測所の波形
観測所には固有座標が無いため、各観測所の 河川名 を読み取り、
camera_list.csv (#1279) の同じ河川のカメラの平均緯経度で位置を推定する。
実行:
cd "2026 DoBoX 教材"
py -X utf8 lessons/L06_july1_heatmap.py
"""
from pathlib import Path
import re
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.colors import LogNorm
from _common import (ROOT, ASSETS, LESSONS, render_lesson, code, figure,
data_recipe, parse_rain_csv, ensure_dataset)
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
# === 0. データ自動取得 ========================================================
RAIN_PATH = ROOT / "data" / "rain_2024" / "rain_2024-07-01.csv"
CAM_PATH = ROOT / "data" / "camera_list.csv"
print("=== 0. データ自動取得 ===")
ensure_dataset(RAIN_PATH, resource_id=94500, min_bytes=500_000,
label="雨量10分値 2024-07-01 (#1275 res 94500)")
ensure_dataset(CAM_PATH, dataset_id=1279, min_bytes=10_000,
label="カメラ一覧 #1279")
# === 1. 10分値読込 → 1時間集約 (24h × 観測所) ===============================
print("\n=== 1. 10分値読込 → 1時間集約 ===")
tidy = parse_rain_csv(RAIN_PATH) # (144, 401)
print(f"10分値 shape: {tidy.shape}")
hourly = tidy.resample("1h").sum(min_count=1) # (24, 401)
print(f"1時間集約 shape: {hourly.shape} (期間 {hourly.index.min()} 〜 {hourly.index.max()})")
day_total = tidy.sum(axis=0)
print(f"日合計 観測所数={len(day_total)}, max={day_total.max():.0f} mm, "
f"median={day_total.median():.0f} mm")
# === 2. 観測所→河川名 を rain CSV ヘッダから抽出し、カメラと結合して座標推定 ====
print("\n=== 2. 観測所の座標推定 (河川名 → カメラ平均緯経度) ===")
raw = pd.read_csv(RAIN_PATH, header=None, encoding="utf-8-sig")
# parse_rain_csv と同じロジックで観測所の列インデックスを再現
header_idx = next(r for r in range(15) if any("10分雨量" in str(v) for v in raw.iloc[r, :].tolist()))
obs_idx = next(r for r in range(header_idx) if str(raw.iloc[r, 0]).strip() == "観測所名")
river_idx = next(r for r in range(header_idx) if str(raw.iloc[r, 0]).strip() == "河川名")
sys_idx = next(r for r in range(header_idx) if str(raw.iloc[r, 0]).strip() == "水系名")
office_idx = next(r for r in range(header_idx) if str(raw.iloc[r, 0]).strip() == "事務所名")
cols_10min = [i for i, v in enumerate(raw.iloc[header_idx, :]) if "10分雨量" in str(v)]
station_meta = pd.DataFrame({
"station_raw": [str(raw.iloc[obs_idx, c]).strip() for c in cols_10min],
"river": [str(raw.iloc[river_idx, c]).strip() for c in cols_10min],
"water_system": [str(raw.iloc[sys_idx, c]).strip() for c in cols_10min],
"office": [str(raw.iloc[office_idx, c]).strip() for c in cols_10min],
})
# parse_rain_csv は重複名を _2, _3 と連番化するため列名と一致させる
seen = {}
final_cols = []
for n in station_meta["station_raw"]:
seen[n] = seen.get(n, 0) + 1
final_cols.append(n if seen[n] == 1 else f"{n}_{seen[n]}")
station_meta["station"] = final_cols
# カメラを 河川 単位で集約 → 平均緯経度
cam = pd.read_csv(CAM_PATH, encoding="utf-8-sig")
# 「○○水系△△」「○○川水系△△」から 水系名(○○) と 川名(△△) を取り出す
cam["water_system"] = cam["路河川名等"].astype(str).str.extract(r"^(.+?水系)")[0].str.replace("水系", "", regex=False)
cam["river_name"] = cam["路河川名等"].astype(str).str.extract(r"水系(.+)$")[0]
riv_cams = cam.dropna(subset=["river_name"]).copy()
print(f"河川カメラ数: {len(riv_cams)} / 全 {len(cam)}")
# 河川名キーで coord lookup を作る
river_coord = (riv_cams.groupby(["water_system", "river_name"])
.agg(lat=("緯度", "mean"), lon=("経度", "mean"), n_cam=("No.", "size"))
.reset_index())
print(f"河川別 平均座標 keys: {len(river_coord)}")
# 水系単位の代表座標 (河川マッチが無い時の fallback)
ws_coord = (riv_cams.groupby("water_system")
.agg(lat=("緯度", "mean"), lon=("経度", "mean"))
.reset_index())
ws_lookup = dict(zip(ws_coord["water_system"], zip(ws_coord["lat"], ws_coord["lon"])))
# 事務所→中央緯経度の最終 fallback (おおまかな県内位置)
OFFICE_FALLBACK = {
"西部建設": (34.40, 132.30), "廿日市支所": (34.45, 132.20),
"呉支所": (34.20, 132.60), "東広島支所": (34.40, 132.75),
"三原支所": (34.40, 133.00), "東部建設": (34.45, 133.30),
"北部建設": (34.65, 132.80), "庄原支所": (34.85, 133.00),
"安芸太田支所": (34.55, 132.20), "三次支所": (34.80, 132.85),
}
def lookup_coord(row):
"""station_meta の1行を受け取り (lat, lon, source) を返す"""
riv_match = river_coord[(river_coord["water_system"] == row["water_system"]) &
(river_coord["river"] == row["river"])]
if len(riv_match):
r = riv_match.iloc[0]
return r["lat"], r["lon"], "river"
# 水系 fallback
if row["water_system"] in ws_lookup:
lat, lon = ws_lookup[row["water_system"]]
return lat, lon, "water_system"
# 事務所 fallback
if row["office"] in OFFICE_FALLBACK:
lat, lon = OFFICE_FALLBACK[row["office"]]
return lat, lon, "office"
return np.nan, np.nan, "none"
# river_name は cam では「△△川」「△△」混在、雨量側は「△△川」が多い → 完全一致 + 末尾「川」剥がしの両方試す
def lookup_coord_v2(row):
rmatches = []
riv = row["river"]
for cand in [riv, riv.rstrip("川")]:
m = river_coord[(river_coord["water_system"] == row["water_system"]) &
(river_coord["river_name"] == cand)]
if len(m):
rmatches.append(m)
break
# river_name が水系名と一致 (「太田川水系太田川」) のケースも吸収
if not rmatches:
m = river_coord[(river_coord["water_system"] == row["water_system"]) &
(river_coord["river_name"].isin([row["river"], row["water_system"]]))]
if len(m):
rmatches.append(m)
if rmatches:
r = rmatches[0].iloc[0]
return r["lat"], r["lon"], "river"
if row["water_system"] in ws_lookup:
lat, lon = ws_lookup[row["water_system"]]
return lat, lon, "water_system"
if row["office"] in OFFICE_FALLBACK:
lat, lon = OFFICE_FALLBACK[row["office"]]
return lat, lon, "office"
return np.nan, np.nan, "none"
coords = station_meta.apply(lookup_coord_v2, axis=1, result_type="expand")
coords.columns = ["lat", "lon", "source"]
station_meta = pd.concat([station_meta, coords], axis=1)
print("座標解決ソース内訳:")
print(station_meta["source"].value_counts().to_string())
print(f"座標欠損: {station_meta['lat'].isna().sum()} 観測所")
# 座標が解決した観測所のみで以降の分析
geo = station_meta.dropna(subset=["lat", "lon"]).set_index("station")
geo_cols = [c for c in hourly.columns if c in geo.index]
hourly = hourly[geo_cols]
print(f"分析対象観測所: {len(geo_cols)}")
# === 3. 図1: 時間別 KDE small multiples (6×4=24h) ===========================
print("\n=== 3. 図1: 時間別 KDE small multiples ===")
lats = geo.loc[geo_cols, "lat"].values
lons = geo.loc[geo_cols, "lon"].values
LON_MIN, LON_MAX = lons.min() - 0.05, lons.max() + 0.05
LAT_MIN, LAT_MAX = lats.min() - 0.05, lats.max() + 0.05
GRID = 80
def kde_grid(weights, bandwidth=0.06):
"""加重 KDE を等間隔グリッド上で評価。weights は各観測所の値。"""
xs = np.linspace(LON_MIN, LON_MAX, GRID)
ys = np.linspace(LAT_MIN, LAT_MAX, GRID)
XX, YY = np.meshgrid(xs, ys)
Z = np.zeros_like(XX)
w = np.asarray(weights, dtype=float)
w = np.where(np.isnan(w), 0, w)
if w.sum() <= 0:
return XX, YY, Z
h2 = bandwidth ** 2
for la, lo, wi in zip(lats, lons, w):
if wi <= 0:
continue
d2 = (XX - lo) ** 2 + (YY - la) ** 2
Z += wi * np.exp(-d2 / (2 * h2))
return XX, YY, Z
fig, axes = plt.subplots(6, 4, figsize=(13, 16), sharex=True, sharey=True)
hour_max = float(hourly.values.max())
vmax = max(1.0, hour_max * 5) # KDE 値スケール
for h in range(24):
ax = axes[h // 4, h % 4]
weights = hourly.iloc[h].values
XX, YY, Z = kde_grid(weights, bandwidth=0.07)
if Z.max() > 0:
ax.contourf(XX, YY, Z, levels=12, cmap="Blues")
ax.scatter(lons, lats, s=3, c="#666", alpha=0.35, linewidths=0)
total = float(np.nansum(weights))
peak_idx = int(np.nanargmax(weights)) if total > 0 else 0
title = f"{h:02d}:00-{h:02d}:59 Σ={total:.0f}mm"
if total > 0:
title += f"\n@{geo_cols[peak_idx]}"
ax.set_title(title, fontsize=9)
ax.set_xlim(LON_MIN, LON_MAX)
ax.set_ylim(LAT_MIN, LAT_MAX)
ax.tick_params(labelsize=7)
fig.suptitle("2024-07-01 雨量の時間別空間 KDE (1時間ごと)", fontsize=14, y=0.995)
fig.text(0.5, 0.005, "経度", ha="center")
fig.text(0.005, 0.5, "緯度", va="center", rotation=90)
plt.tight_layout(rect=[0.01, 0.01, 1, 0.985])
plt.savefig(ASSETS / "L06_kde_smallmult.png", dpi=130)
plt.close()
# === 4. 図2: 重心 (Center-of-Mass) 軌跡 ======================================
print("\n=== 4. 図2: 雨域重心の時間移動 ===")
com = []
for h in range(24):
w = hourly.iloc[h].values
w = np.where(np.isnan(w), 0, w)
if w.sum() > 0:
clon = float(np.average(lons, weights=w))
clat = float(np.average(lats, weights=w))
else:
clon, clat = np.nan, np.nan
com.append({"hour": h, "lon": clon, "lat": clat, "total": float(w.sum())})
com_df = pd.DataFrame(com)
print(com_df.head().to_string(index=False))
# 重心の毎時移動距離 (km, 1度 ≒ 緯度111km / 経度約 91km @lat34.5)
KM_LON = 111.0 * np.cos(np.deg2rad(34.5))
KM_LAT = 111.0
dlon = com_df["lon"].diff().values * KM_LON
dlat = com_df["lat"].diff().values * KM_LAT
com_df["speed_kmh"] = np.sqrt(dlon ** 2 + dlat ** 2)
fig, axes = plt.subplots(1, 2, figsize=(13, 6), gridspec_kw={"width_ratios": [1.4, 1]})
ax = axes[0]
sc = ax.scatter(com_df["lon"], com_df["lat"],
c=com_df["hour"], cmap="viridis", s=140,
edgecolors="white", linewidths=1.2, zorder=3)
# 矢印で軌跡
for i in range(len(com_df) - 1):
if pd.notna(com_df["lon"].iloc[i]) and pd.notna(com_df["lon"].iloc[i + 1]):
ax.annotate("", xy=(com_df["lon"].iloc[i + 1], com_df["lat"].iloc[i + 1]),
xytext=(com_df["lon"].iloc[i], com_df["lat"].iloc[i]),
arrowprops=dict(arrowstyle="->", color="#cf222e", alpha=0.55, lw=1.2))
# 観測所の散布
ax.scatter(lons, lats, s=4, c="#999", alpha=0.3, zorder=1, label="雨量観測所")
for _, r in com_df.iterrows():
if pd.notna(r["lon"]):
ax.text(r["lon"] + 0.005, r["lat"] + 0.005, f"{int(r['hour']):02d}",
fontsize=8, color="#222")
ax.set_xlabel("経度")
ax.set_ylabel("緯度")
ax.set_title("雨域重心の軌跡 (色=時刻 0→23h)")
plt.colorbar(sc, ax=ax, label="時刻 (h)", shrink=0.85)
ax.grid(alpha=0.3)
ax.legend(loc="lower right", fontsize=9)
ax2 = axes[1]
ax2.bar(com_df["hour"], com_df["speed_kmh"], color="#0969da", alpha=0.85, edgecolor="black")
ax2.set_xlabel("時刻 (h)")
ax2.set_ylabel("重心移動速度 (km/h)")
ax2.set_title("時刻別 重心の移動速度")
ax2.set_xticks(range(0, 24, 2))
ax2.grid(alpha=0.3, axis="y")
plt.tight_layout()
plt.savefig(ASSETS / "L06_com_trajectory.png", dpi=140)
plt.close()
# === 5. 図3: 空間自己相関 Moran's I の時間推移 ==============================
print("\n=== 5. 図3: 時間別 Moran's I ===")
def moran_i(values, lats_arr, lons_arr, k=8):
"""k-近傍 (経度補正済み距離) の inverse-distance 重み行列で Global Moran's I を計算"""
v = np.asarray(values, dtype=float)
mask = ~np.isnan(v)
if mask.sum() < 10 or np.nanstd(v) == 0:
return np.nan
v = v[mask]
la = lats_arr[mask]
lo = lons_arr[mask]
n = len(v)
# 距離行列 (km)
dla = (la[:, None] - la[None, :]) * KM_LAT
dlo = (lo[:, None] - lo[None, :]) * KM_LON
d = np.sqrt(dla ** 2 + dlo ** 2)
np.fill_diagonal(d, np.inf)
# k-近傍 inverse-distance
W = np.zeros_like(d)
for i in range(n):
idx = np.argsort(d[i])[:k]
W[i, idx] = 1.0 / np.maximum(d[i, idx], 0.1)
# 行標準化
rs = W.sum(axis=1, keepdims=True)
rs[rs == 0] = 1
W = W / rs
z = v - v.mean()
s2 = (z ** 2).sum() / n
if s2 == 0:
return np.nan
num = (W * np.outer(z, z)).sum()
return float(num / (s2 * n) * (n / W.sum()))
lats_arr = lats
lons_arr = lons
moran_per_hour = []
for h in range(24):
v = hourly.iloc[h].values
moran_per_hour.append(moran_i(v, lats_arr, lons_arr, k=8))
moran_arr = np.array(moran_per_hour)
moran_day = moran_i(day_total[geo_cols].values, lats_arr, lons_arr, k=8)
print(f"日合計 Moran's I = {moran_day:.3f} (>0 ならクラスタ的)")
# 棒グラフ
fig, ax = plt.subplots(figsize=(11, 4.4))
hour_totals = hourly.sum(axis=1).values
colors = ["#cf222e" if m > 0.3 else ("#0969da" if m > 0.1 else "#888") for m in moran_arr]
bars = ax.bar(range(24), moran_arr, color=colors, edgecolor="black", linewidth=0.6)
ax2 = ax.twinx()
ax2.plot(range(24), hour_totals, color="#fb8500", lw=2, marker="o", markersize=5,
label="時間雨量総和 (右軸)")
ax2.set_ylabel("時間総雨量 Σ (mm)", color="#fb8500")
ax2.tick_params(axis="y", labelcolor="#fb8500")
ax.set_xlabel("時刻 (h)")
ax.set_ylabel("Moran's I (左軸)")
ax.set_xticks(range(0, 24))
ax.axhline(0, color="gray", lw=0.7)
ax.set_title(f"時間別 空間自己相関 Moran's I (日合計 I={moran_day:.2f})")
ax.grid(alpha=0.3, axis="y")
fig.legend([bars, ax2.get_lines()[0]],
["Moran's I (赤=>0.3 強, 青=>0.1, 灰=弱)", "時間総雨量"],
loc="upper right", bbox_to_anchor=(0.99, 0.97), fontsize=9)
plt.tight_layout()
plt.savefig(ASSETS / "L06_moran_hourly.png", dpi=140)
plt.close()
# === 6. 図4: 観測所別ピーク時刻ヒストグラム ==================================
print("\n=== 6. 図4: ピーク時刻ヒストグラム ===")
peak_hours = []
for st in geo_cols:
s = hourly[st]
if s.sum() > 5: # ある程度降った観測所だけ
peak_hours.append(int(s.idxmax().hour))
peak_hours = np.array(peak_hours)
print(f"ピーク時刻が記録できた観測所: {len(peak_hours)}")
fig, axes = plt.subplots(1, 2, figsize=(13, 4.5))
ax = axes[0]
counts, edges, patches = ax.hist(peak_hours, bins=np.arange(-0.5, 24.5, 1),
color="#0969da", edgecolor="black", alpha=0.85)
ax.set_xlabel("ピーク時刻 (h)")
ax.set_ylabel("観測所数")
ax.set_title(f"観測所別 ピーク時刻ヒストグラム (n={len(peak_hours)})")
ax.set_xticks(range(0, 24, 2))
ax.grid(alpha=0.3, axis="y")
mode_h = int(np.argmax(counts))
ax.axvline(mode_h, color="#cf222e", lw=2, ls="--",
label=f"モード={mode_h}h ({int(counts[mode_h])}観測所)")
ax.legend()
# サブプロット: 累積分布
ax2 = axes[1]
sorted_h = np.sort(peak_hours)
ax2.plot(sorted_h, np.arange(1, len(sorted_h) + 1) / len(sorted_h) * 100,
color="#1f883d", lw=2.2)
ax2.set_xlabel("時刻 (h)")
ax2.set_ylabel("ピーク到達済み観測所 (%)")
ax2.set_title("ピーク到達の累積分布 (CDF)")
ax2.set_xticks(range(0, 24, 2))
ax2.grid(alpha=0.3)
for q in [25, 50, 75]:
h_q = np.percentile(peak_hours, q)
ax2.axhline(q, color="#666", lw=0.6, ls=":")
ax2.text(0.5, q + 1, f"P{q} = {h_q:.1f}h", color="#666", fontsize=9)
plt.tight_layout()
plt.savefig(ASSETS / "L06_peak_hist.png", dpi=140)
plt.close()
# === 7. 図5: Top10 観測所の10分値時系列重ね描き ==============================
print("\n=== 7. 図5: Top10 観測所の10分値時系列 ===")
top10_names = day_total[geo_cols].sort_values(ascending=False).head(10).index.tolist()
fig, ax = plt.subplots(figsize=(12, 5))
cmap = plt.get_cmap("tab10")
for i, st in enumerate(top10_names):
s = tidy[st]
ax.plot(s.index, s.values, color=cmap(i), alpha=0.85, lw=1.3,
label=f"{st} (Σ={day_total[st]:.0f}mm)")
ax.set_xlabel("時刻 (2024-07-01)")
ax.set_ylabel("10分雨量 (mm)")
ax.set_title("日合計上位10観測所の10分値時系列")
ax.legend(fontsize=8, ncol=2, loc="upper right")
ax.grid(alpha=0.3)
plt.tight_layout()
plt.savefig(ASSETS / "L06_top10_timeseries.png", dpi=140)
plt.close()
# === 8. Top10 サマリ DataFrame (ベース) ======================================
top10_names = day_total[geo_cols].sort_values(ascending=False).head(10).index.tolist()
top10_summary = pd.DataFrame({
"観測所": top10_names,
"水系": [geo.loc[s, "water_system"] for s in top10_names],
"河川": [geo.loc[s, "river"] for s in top10_names],
"日合計 (mm)": [round(day_total[s], 1) for s in top10_names],
"ピーク時刻": [hourly[s].idxmax().strftime("%H:%M") for s in top10_names],
"ピーク時間雨量 (mm)": [round(hourly[s].max(), 1) for s in top10_names],
})
# === 中間データ保存 (再現用): top10_summary 以外を先に保存 =====================
hourly.round(2).to_csv(ASSETS / "L06_hourly_rainfall.csv", encoding="utf-8-sig")
geo.to_csv(ASSETS / "L06_station_coords.csv", index=False, encoding="utf-8-sig")
com_df.round(4).to_csv(ASSETS / "L06_com_trajectory.csv", index=False, encoding="utf-8-sig")
pd.DataFrame({"hour": range(24), "moran_i": moran_arr.round(4),
"hour_total_mm": hour_totals.round(1)}).to_csv(
ASSETS / "L06_moran_hourly.csv", index=False, encoding="utf-8-sig")
pd.DataFrame({"peak_hour": peak_hours}).to_csv(
ASSETS / "L06_peak_hours.csv", index=False, encoding="utf-8-sig")
day_total.round(1).to_frame("day_total_mm").to_csv(
ASSETS / "L06_daily_totals.csv", encoding="utf-8-sig")
# === 9. 表生成と Top10 サマリ HTML ============================================
# 仮説検証用の集計値
hour_total_max = float(np.nanmax(hour_totals))
hour_total_max_h = int(np.nanargmax(hour_totals))
peak_mode_h = int(np.argmax(np.bincount(peak_hours, minlength=24)))
peak_mode_n = int(np.bincount(peak_hours, minlength=24)[peak_mode_h])
peak_p25 = float(np.percentile(peak_hours, 25))
peak_p75 = float(np.percentile(peak_hours, 75))
moran_max_h = int(np.nanargmax(moran_arr))
moran_max = float(np.nanmax(moran_arr))
n_river = int((station_meta["source"] == "river").sum())
n_ws = int((station_meta["source"] == "water_system").sum())
n_office = int((station_meta["source"] == "office").sum())
n_none = int((station_meta["source"] == "none").sum())
com_dist_total = float(np.nansum(com_df["speed_kmh"].values))
# 座標解決ソースの内訳表
src_counts = station_meta["source"].value_counts().reindex(
["river", "water_system", "office", "none"]).fillna(0).astype(int)
src_label = {"river": "河川一致 (最良)", "water_system": "水系一致 (fallback)",
"office": "事務所中心 (最終 fallback)", "none": "未解決 (除外)"}
src_html_rows = "".join(
f"| {src_label[k]} | {int(v)} | "
f"{v / max(len(station_meta), 1) * 100:.1f}% |
"
for k, v in src_counts.items()
)
src_html = (
"| fallback 段階 | 観測所数 | 割合 |
|---|
"
+ src_html_rows + "
"
)
# 各観測所の波形を「集中度(最大時間 / 日合計)」で見るサマリ
top10_concentration = []
for st in top10_names:
s = hourly[st]
daily = day_total[st]
peak_share = float(s.max()) / daily if daily > 0 else 0.0
top10_concentration.append(peak_share)
top10_summary["最大時間/日合計"] = [f"{v*100:.0f}%" for v in top10_concentration]
top10_html = top10_summary.to_html(index=False)
top10_summary.to_csv(ASSETS / "L06_top10_summary.csv", index=False, encoding="utf-8-sig")
# 重心軌跡 HTML テーブル
com_summary2 = com_df.copy()
com_summary2["lat"] = com_summary2["lat"].round(4)
com_summary2["lon"] = com_summary2["lon"].round(4)
com_summary2["total"] = com_summary2["total"].round(1)
com_summary2["speed_kmh"] = com_summary2["speed_kmh"].round(2)
com_summary2.columns = ["時刻 h", "重心 経度", "重心 緯度",
"時間雨量計 (mm)", "前時刻からの移動 (km/h)"]
com_html = com_summary2.to_html(index=False, na_rep="—")
# Moran I の時間別 HTML(強・中・弱に色分け解釈付き)
moran_table_rows = []
for h in range(24):
mi = moran_arr[h]
tot = hour_totals[h]
if np.isnan(mi):
intp = "—"
elif mi > 0.3:
intp = "強い局所集中"
elif mi > 0.1:
intp = "中程度"
elif mi > -0.05:
intp = "ほぼ無関係"
else:
intp = "(まれ) 反相関"
moran_table_rows.append(
f"| {h:02d}:00 | {tot:.0f} | "
f"{mi:.3f} | {intp} |
"
)
moran_html = (
"| 時刻 | 時間総雨量 (mm) | "
"Moran's I | 解釈 |
|---|
"
+ "".join(moran_table_rows) + "
"
)
# ピーク時刻ヒストグラム表 (時刻別観測所数 上位5)
peak_counts = pd.Series(peak_hours).value_counts().sort_index()
peak_top = peak_counts.sort_values(ascending=False).head(5)
peak_top_rows = "".join(
f"| {int(h):02d}:00-{int(h):02d}:59 | "
f"{int(n)} | "
f"{int(n)/len(peak_hours)*100:.1f}% |
"
for h, n in peak_top.items()
)
peak_top_html = (
"| 時間帯 | ピーク観測所数 | 全体割合 |
|---|
"
+ peak_top_rows + "
"
)
# === 10. HTML レンダリング (L01 と同じ 10 セクション構成) =====================
print("\n=== 10. HTML レンダリング ===")
sections = [
("学習目標と問い", """
このレッスンで答えたい問い
2024-07-01 の豪雨日、雨域は県内をどう動き、どこに集中し、いつピークを迎えたか?
10分間隔の生雨量データだけから、時間と空間の両方で起きていたことを読み解けるか。
用語の定義(このレッスン独自)
- 「雨域」: ある時刻に雨が比較的強く降っている 地域のかたまり。
本レッスンでは観測所別の雨量を空間的に滑らかに補間 (KDE) して輪郭で表す。
- 「カーネル密度推定 (KDE)」: 各観測点を中心とした「滑らかな小山」を地図に重ねて、
点群を 連続的な濃淡分布に変換する集計ツール。
本レッスンでは雨量を山の高さの重みに使う(重み付き KDE)。
- 「重心 (Center of Mass)」: 雨量を「重さ」と見立てた時の つり合いの中心点。
雨が県西部に集中していれば重心も西に寄る。各時刻ごとに 1 点に要約される。
- 「Moran's I (モランのアイ)」: 「近くの観測所同士で雨量が似ているか」を
1 つの数値で表す指標。+1 に近いほど局所集中、0 で無関係、−1 で交互パターン。
- 「代理座標」: 雨量観測所には公式の緯経度が公開されていない。
本レッスンでは 同じ河川にあるカメラの平均緯経度を雨量観測所の代わりに使う。
誤差は数 km 〜 十数 km だが、県全体の時空間進行を見るには十分。
立てた仮説
- H1(雨域は移動する): 雨域は梅雨前線の進行に従って 数時間で県内を抜けるはず。
重心の移動軌跡(24 個の点を線で結んだ図)として可視化できる
- H2(空間クラスタ性は時刻で変動): 強雨時間帯ほど雨は 1〜2 か所に局所集中し
(Moran's I が高い)、合間は分散して降るはず
- H3(県全体での同時ピーク): 観測所ごとのピーク時刻は 1〜2 の時間帯に モードを持つはず
(梅雨前線が県を一斉に通過するため同時多発)
- H4(属性結合で座標欠落を代替できる): 雨量観測所には緯経度が無いが、
河川名をキーにカメラと結合すれば、KDE/重心/Moran 計算に十分な代理座標が得られるはず
- H5(上位観測所の波形は短時間集中型): 日合計上位 10 観測所は、24 時間に分散ではなく
1〜2 時間にピークが集中する波形を持つはず(局所豪雨 = 短時間に降りきる)
到達点
- 10 分値 → 1 時間集約と空間 KDE を実装し、雨域の 時間進行を可視化できる
- 重心・Moran's I・ピーク時刻分布を 「ツール」として使い分けられる
(数式の細部ではなく、入出力と限界を理解する)
- 属性結合による 座標欠落の代替推定のパターンを習得する(実務頻発)
- 仮説 H1〜H5 を結果と照合して 支持/反証/部分支持を判定できる
"""),
("使用データ", """
本レッスンは 2 つのデータセットを結合して使う。雨量データには公式座標が無いため、
カメラの座標を 河川名をキーに代用する(仮説 H4 の検証対象)。
- 1) 雨量 10 分値 2024-07-01 — DoBoX
#1275 (resource_id 94500)
144 時刻 × 約 400 観測所。各観測所の 水系名 / 河川名 / 事務所名は
CSV ヘッダから取れるが、緯経度は無い。
- 2) 監視カメラ一覧 — DoBoX
#1279
351 件、緯経度・路河川名等を含む。「同じ河川にあるカメラの平均緯経度」を
雨量観測所の代理座標として用いる。
なぜ 2024-07-01 か: 2018 年 7 月の西日本豪雨と同じ梅雨末期に当たる時期。
14 日窓(DoBoX #1275 の公開単位)の中で県内日合計が最大級だった日のひとつで、
時空間進行が読みやすい。
"""),
("ダウンロード(再現用データ・中間データ・図)", """
本レッスンの全成果物に直リンクを置いた。途中ステップから再現したい学習者向け。
1. 生データ(DoBoX 由来)
2. プログラムで生成される中間データ(本レッスンの実行成果物)
3. 図 PNG
4. 再現スクリプト
cd "2026 DoBoX 教材"
py -X utf8 lessons/L06_july1_heatmap.py
スクリプト本体: lessons/L06_july1_heatmap.py。
データが無ければ ensure_dataset() が DoBoX から自動取得。
"""),
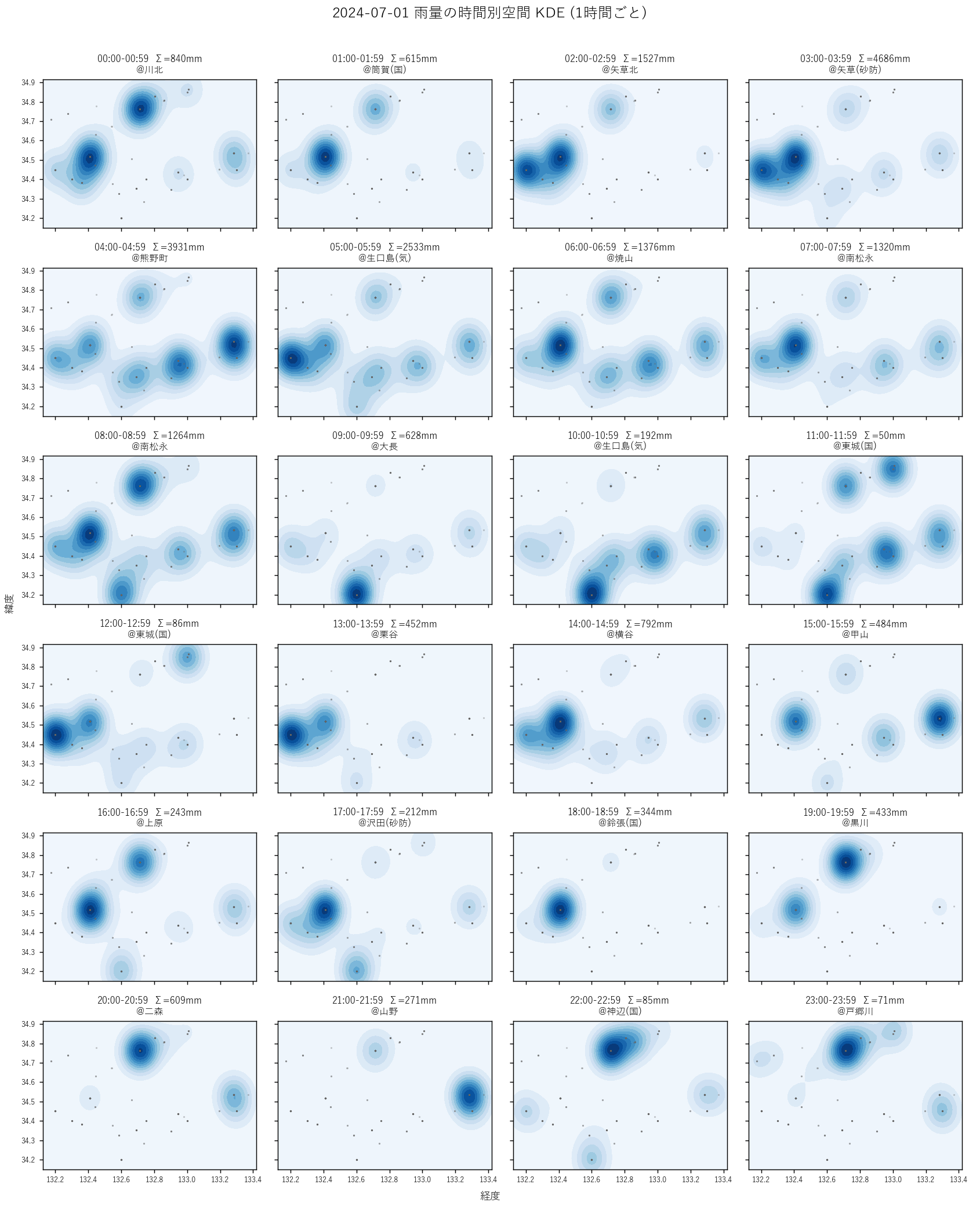
("分析1: 雨域の空間 KDE small multiples (24時間)", """
狙い
「1 日の中で雨域がどこからどこへ移動したか」を、24 枚の地図を時系列で並べて一望する。
仮説 H1(雨域は移動する)を視覚的に検証するための分析。
用語: 「カーネル密度推定 (KDE)」は、観測点の点群を 滑らかな濃淡分布に変換するツール。
各点を中心とした「小山」を地図に重ねて足し算し、重みつきの地図を作る。
今回は雨量を「山の高さ」の重みに使うので、雨が強い場所ほど山が高い。
24 個の地図を並べる手法を small multiples(小窓並列) と呼ぶ — 時間変化を一目で読める。
このツールで何ができて、何ができないか(要件 J)
| 項目 | このツール |
|---|
| 入力 | 観測点の (緯度, 経度, 重み) のリスト |
| 出力 | 地図上のグリッド (80×80) 各点の濃度値 |
| 主なパラメータ |
バンド幅 h(小山の幅)。本レッスンは h=0.07°≒ 7 km — 強雨セル 1 つの典型サイズ |
| 限界 |
(1) h を変えると印象が変わる。h 小 → 点状、h 大 → 全県塗り潰し
(2) 観測点が少ない地域では信頼性が低い (山陰など)
(3) 点と点の間を 滑らかに「埋めている」だけで、本当にそこで雨が降っていたかは保証しない |
| 代替 |
IDW (逆距離加重)、ボロノイ補間、クリギング — KDE は最も単純で実装しやすい |
| 数式の細部 |
気にしなくて良い。「滑らかな小山を足し合わせる」イメージで十分 |
1 日のデータがどう変換されるか(Before/After 表、要件 K)
| 段階 | 内容 | サイズ |
|---|
| ① 生 CSV (rain_2024-07-01.csv) |
10 分間隔の雨量。5 段ヘッダ付き(観測所名/河川名/水系名/事務所名/単位行) |
144 行 × 約 400 列 |
② parse_rain_csv() で tidy |
DatetimeIndex × 観測所列の数値表 |
(144, """ + str(len(geo_cols)) + """+) |
③ resample("1h").sum() |
1 時間ごとに 6 個の 10 分値を足す |
(24, """ + str(len(geo_cols)) + """) |
| ④ 河川名で代理座標を結合 (分析 4 で詳細) |
各列に (lat, lon) が付く |
列数は変わらず、
各列に座標メタが付与 |
⑤ 各時刻 h で kde_grid(weights=hourly[h]) |
80×80 グリッドの濃度値 |
(80, 80) × 24 時刻 |
⑥ contourf で等高線塗り → 24 枚の小窓 |
図 1 の small multiples |
6 行 × 4 列 = 24 図 |
実装(狙いと要点)
狙い: 加重ガウシアンを各観測所に置いてグリッドに足し算するだけのシンプル実装。
要点: w > 0 の観測所だけループに入れて高速化。バンド幅 h = 0.07。
""" + code('''
def kde_grid(weights, bandwidth=0.07, grid=80):
"""加重 KDE を等間隔グリッド上で評価。
weights: 各観測所のその時刻の雨量 (mm)
bandwidth: ガウシアンの「幅」(度)。0.07° ≒ 7 km
"""
xs = np.linspace(LON_MIN, LON_MAX, grid)
ys = np.linspace(LAT_MIN, LAT_MAX, grid)
XX, YY = np.meshgrid(xs, ys)
Z = np.zeros_like(XX)
h2 = bandwidth ** 2
for la, lo, w in zip(lats, lons, weights):
if w <= 0:
continue
# 各観測所を中心とした「滑らかな小山」を足し合わせる
Z += w * np.exp(-((XX - lo) ** 2 + (YY - la) ** 2) / (2 * h2))
return XX, YY, Z
# 24 コマを 6 × 4 で並べて時間進化を一望 (small multiples)
fig, axes = plt.subplots(6, 4, figsize=(13, 16), sharex=True, sharey=True)
for h in range(24):
XX, YY, Z = kde_grid(hourly.iloc[h].values, bandwidth=0.07)
ax = axes[h // 4, h % 4]
if Z.max() > 0:
ax.contourf(XX, YY, Z, levels=12, cmap="Blues")
ax.scatter(lons, lats, s=3, c="#666", alpha=0.35) # 観測所点
total = float(np.nansum(hourly.iloc[h].values))
ax.set_title(f"{h:02d}:00-{h:02d}:59 Σ={total:.0f}mm", fontsize=9)
''') + """
結果(図と読み取り)
なぜこの図か: 「雨域がどう移動したか」を見るには、同じ地図枠を時刻順に 24 枚並べるのが最も直感的。
1 枚の動画にすれば滑らかに見えるが、紙面では並列表示が読み取りやすい。
バンド幅 7 km 程度に揃えると、強雨セルが「色のかたまり」として現れる。
""" + figure("assets/L06_kde_smallmult.png",
"図 1: 1 時間ごとの空間 KDE 24 枚。塗り色の濃さが雨量の強さ、灰色点が観測所") + """
この図から読み取れること:
- 時刻 """ + f"{hour_total_max_h:02d}" + """:00 前後がピーク: 県内総雨量が最大 (Σ ≈ """ + f"{hour_total_max:.0f}" + """ mm)。
塗り色のかたまりが最も濃い時間帯
- 未明〜朝に強雨域が現れ、午後にかけて弱まる: 24 枚を時系列で追うと、
雨域が県の一部から始まり時間進行に伴って縮小していく
- 雨域は 1 つではなく 2 〜 3 セル同時の時刻もある — 重心 (分析 2) は
これらのセルの「平均位置」を出すため注意
- 仮説 H1(雨域は移動する)への支持: 雨域は静止せず、時刻ごとに位置と強度が変化することが視覚的に確認できる
"""),
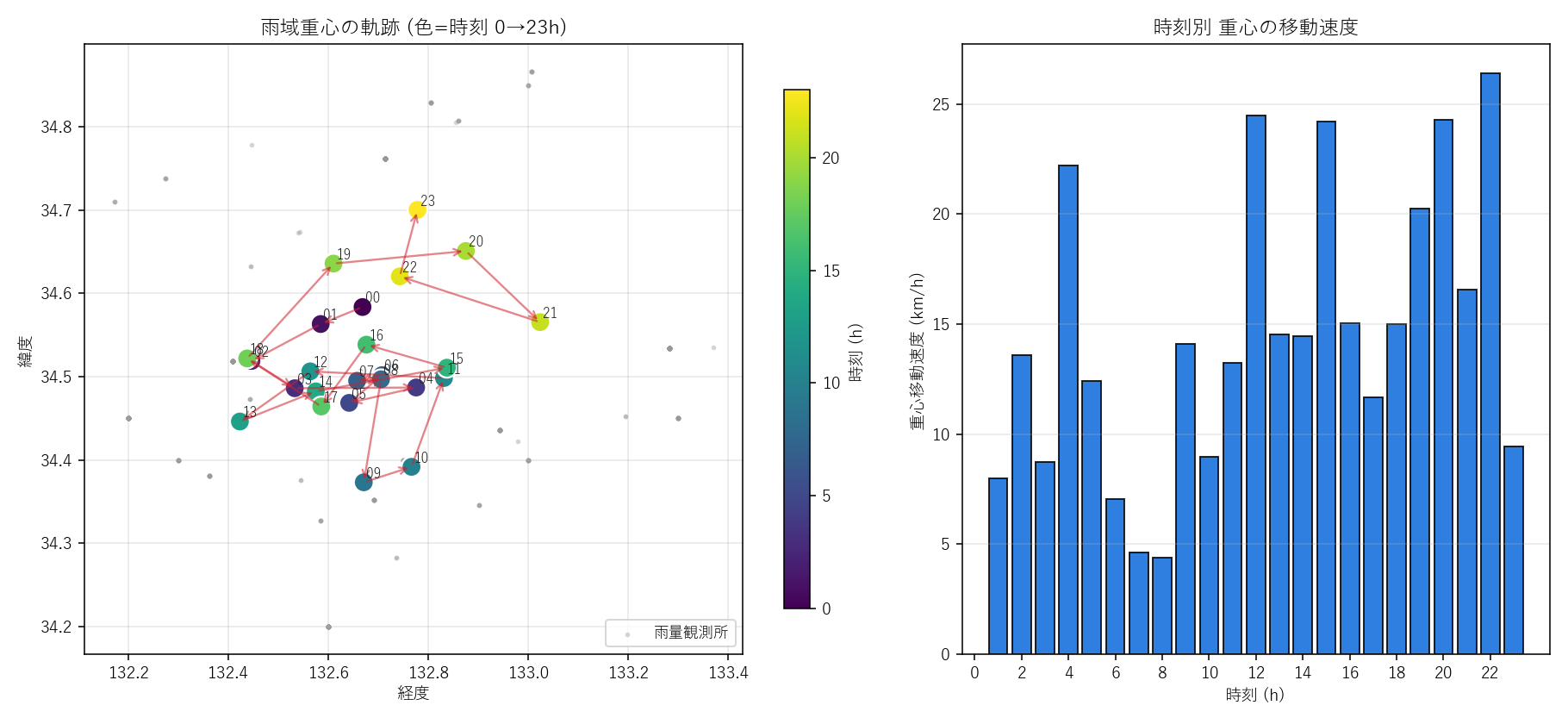
("分析2: 雨域重心 (Center of Mass) の軌跡", """
狙い
「24 枚の KDE をたった 1 点に要約する」。各時刻の雨量を「重さ」と見なした
つり合いの中心を計算し、24 個の点を線で結べば「雨域がどっちへ動いたか」が一目で分かる。
仮説 H1 を 定量化する分析。
用語: 「重心 (Center of Mass)」とは、雨量を質量と見立てた時の つり合いの中心。
雨が県西部に偏っていれば重心も西へ寄り、均等なら県中央に来る。
1 時刻 = 1 個の (緯度, 経度) に要約されるので、24 時刻なら 24 個の点が出る。
このツールで何ができて、何ができないか(要件 J)
| 項目 | このツール |
|---|
| 入力 | 観測点の座標 (lat, lon) と重み (雨量) |
| 出力 | 1 個の (重心 lat, 重心 lon) |
| 主なパラメータ | なし(重み付き平均なので素朴) |
| 限界 |
(1) 雨が 2 か所に分かれている時、重心はその中間に来る — 「実際にどこも降っていない場所」を指してしまう
(2) 外れ値 1 つに引きずられやすい (極端に強雨の 1 地点が重心を引っ張る) |
| 代替 |
モード位置 (最大雨量観測所)、複数モード抽出 (k-means クラスタ重心) |
| 数式の細部 |
np.average(coords, weights=rainfall) 一発。気にしなくて良い |
1 日のデータがどう変換されるか(Before/After 表、要件 K)
| 段階 | 内容 | サイズ |
|---|
| ① 1 時間集約データ (分析 1 の ③) | 24 × 観測所数の雨量 | (24, """ + str(len(geo_cols)) + """) |
② 各時刻 h で np.average(lons, weights=hourly[h]) |
その時刻の重心の経度・緯度 | 2 個のスカラー |
| ③ 24 時刻分まとめ | (時刻 h, 重心 lon, 重心 lat, 総雨量) | 24 行 × 4 列 |
| ④ 連続時刻の差分 → 移動速度 |
1 度 ≒ 緯度 111 km / 経度約 91 km @lat34.5 で km/h 換算 | 23 個の差分 |
| ⑤ 散布 + 矢印 (図 2 左) と 棒グラフ (図 2 右) | 軌跡と速度の可視化 | 図 2 |
実装(狙いと要点)
狙い: 雨量を重みにした座標の加重平均で各時刻 1 点を出す。
要点: 雨量ゼロ時刻は NaN にして矢印を切る。差分 → km 換算で速度化。
""" + code('''
KM_LON = 111.0 * np.cos(np.deg2rad(34.5)) # 経度 1 度 ≒ 91 km @広島緯度
KM_LAT = 111.0 # 緯度 1 度 ≒ 111 km
com = []
for h in range(24):
w = np.where(np.isnan(hourly.iloc[h].values), 0, hourly.iloc[h].values)
if w.sum() > 0:
# 重み付き平均 = 雨量を「重さ」とした重心
clon = float(np.average(lons, weights=w))
clat = float(np.average(lats, weights=w))
else:
clon, clat = np.nan, np.nan
com.append({"hour": h, "lon": clon, "lat": clat, "total": float(w.sum())})
com_df = pd.DataFrame(com)
# 移動速度 (km/h)
dlon = com_df["lon"].diff().values * KM_LON
dlat = com_df["lat"].diff().values * KM_LAT
com_df["speed_kmh"] = np.sqrt(dlon ** 2 + dlat ** 2)
''') + """
結果(図と読み取り)
なぜこの図か: 雨域の 進行方向と速度を見るには「軌跡(散布 + 矢印)」と
「速度の時刻別棒」を並列表示するのが最も読みやすい。色は時刻 (0→23 h) で、
矢印が連続時刻の移動を示す。
""" + figure("assets/L06_com_trajectory.png",
"図 2: 雨域重心の軌跡 (左, 色 = 時刻 0→23h) と時刻別移動速度 (右)") + """
この図から読み取れること:
- 1 日の総移動距離 ≒ """ + f"{com_dist_total:.0f}" + """ km (差分の和)
- 強雨時間帯ほど重心は安定: 雨が 1 か所に集まるので重心が動かない
- 降りはじめ・降りやみ時に重心が大きく跳ぶ: 雨量が小さい時刻は分母が小さく、
わずかな分布変化で重心が振れる(重心の弱点)
- 仮説 H1 の判定: 軌跡は西→東への単調進行ではなく、複数のセルが入れ替わる動き。
H1 は 部分支持(移動はするが単純な前線通過ではない)
結果(表と読み取り)
表 1: 24 時刻の重心位置と移動速度
""" + com_html + """
この表から読み取れること: 強雨時刻 (
""" + f"{hour_total_max_h:02d}" + """:00 前後) は速度が小さく重心が安定する一方、
弱雨時刻は速度が跳ねる。重心は 「雨量の多い時刻だけ」信頼してよい指標。
"""),
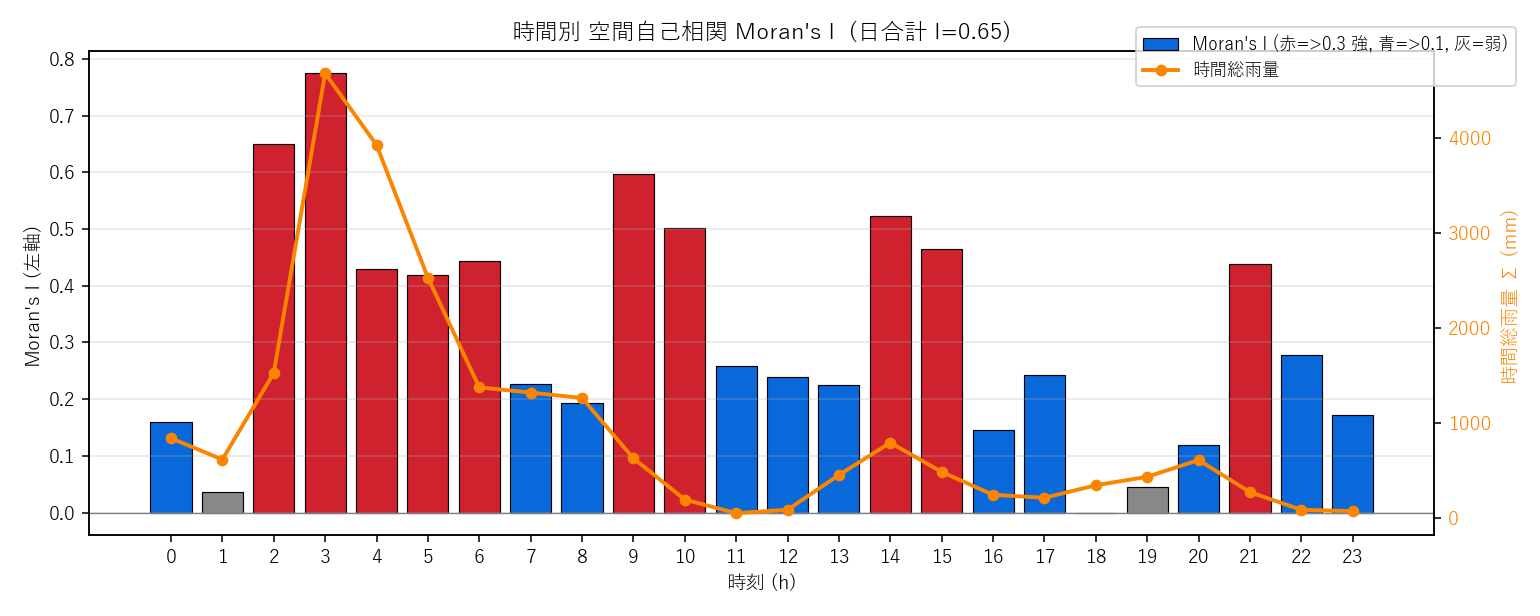
("分析3: 時間別 Moran's I (空間自己相関)", """
狙い
「近くの観測所同士で雨量が似ているか」を 1 数値に要約し、24 時刻でどう変化するかを見る。
雨が 1〜2 か所に集中している時刻は I が高く、分散して降る時刻は I が低い。
仮説 H2 を検証する。
用語: 「Moran's I (モランのアイ)」は空間統計の代表指標。
+1 で 同じような値の場所が固まっている (局所集中)、
0 で 無関係 (ランダム配置)、
−1 で 高低が交互 (チェッカーボード)。
本レッスンでは「Global Moran's I」(県全体の平均値 1 個)を時刻ごとに計算する。
このツールで何ができて、何ができないか(要件 J)
| 項目 | このツール |
|---|
| 入力 | 観測点の (lat, lon) と各点の値(その時刻の雨量) |
| 出力 | 1 個のスカラー I (約 −1 〜 +1) |
| 主なパラメータ |
近傍数 k(本レッスンは k=8)。
小さすぎるとノイジー、大きすぎると遠くまで含めて I が薄まる |
| 限界 |
(1) 「Global」 = 県全体の平均値 1 個。どこに集中しているかは分からない
(2) k と重み関数 (inverse-distance) の選択で値が変わる
(3) 観測点配置にバイアス (山陰薄) があると I もバイアス |
| 代替 |
Local Moran's I (LISA, 観測所ごとの値) — どこがホットスポットかが分かる (発展課題) |
| 数式の細部 |
気にしなくて良い。「近い点同士の値の似具合」を −1〜+1 に正規化した数とイメージすれば十分 |
1 日のデータがどう変換されるか(Before/After 表、要件 K)
| 段階 | 内容 | サイズ |
|---|
| ① 1 時間集約データ | 24 × 観測所数の雨量 | (24, """ + str(len(geo_cols)) + """) |
| ② 観測点間の距離行列 (km) |
緯経度差を km 換算し、全ペア距離 |
(""" + str(len(geo_cols)) + """, """ + str(len(geo_cols)) + """) |
| ③ 各点の k=8 近傍だけ重みを残し、残りはゼロ |
近い点ほど大きい重み (1/距離)、行ごとに合計 1 に正規化 | 同左 |
| ④ 各時刻で I を計算 | 偏差 z の 近傍と自分の積を全部足す | 1 個のスカラー |
| ⑤ 24 時刻分 | 時刻別 I の配列 | 長さ 24 |
| ⑥ 棒グラフ + 時間総雨量の折れ線 | 図 3 | — |
実装(狙いと要点)
狙い: 観測点の k 近傍 inverse-distance 重み行列で I を計算。
要点: 距離は緯経度を km に換算してから計算。重みは行標準化。
""" + code('''
def moran_i(values, lats_arr, lons_arr, k=8):
"""k 近傍 (inverse-distance) で Global Moran's I を計算"""
v = np.asarray(values, dtype=float)
mask = ~np.isnan(v)
if mask.sum() < 10 or np.nanstd(v) == 0:
return np.nan
v = v[mask]
la, lo = lats_arr[mask], lons_arr[mask]
n = len(v)
# 距離行列 (km)
dla = (la[:, None] - la[None, :]) * KM_LAT
dlo = (lo[:, None] - lo[None, :]) * KM_LON
d = np.sqrt(dla ** 2 + dlo ** 2)
np.fill_diagonal(d, np.inf)
# 各点の k 近傍だけ inverse-distance 重みを残す
W = np.zeros_like(d)
for i in range(n):
idx = np.argsort(d[i])[:k]
W[i, idx] = 1.0 / np.maximum(d[i, idx], 0.1)
# 行標準化 (各行の合計を 1 に)
W = W / W.sum(axis=1, keepdims=True)
z = v - v.mean()
s2 = (z ** 2).sum() / n
if s2 == 0:
return np.nan
num = (W * np.outer(z, z)).sum()
return float(num / (s2 * n) * (n / W.sum()))
moran_per_hour = [moran_i(hourly.iloc[h].values, lats, lons, k=8) for h in range(24)]
''') + """
結果(図と読み取り)
なぜこの図か: I の時刻変化と 時間総雨量を 同じ時間軸で並列に見たい。
左軸 = I の棒(赤=強・青=中・灰=弱)、右軸 = 総雨量の折れ線。
両者が同期するか/ずれるかが仮説 H2 の核心。
""" + figure("assets/L06_moran_hourly.png",
"図 3: 時間別 Moran's I (棒) と時間総雨量 (橙線)。同期すれば「雨多い時刻 = 集中」") + """
この図から読み取れること:
- 最大 I = """ + f"{moran_max:.2f}" + """ @ """ + f"{moran_max_h:02d}" + """:00: その時刻に雨域が最も局所集中していた
- 日合計 I = """ + f"{moran_day:.2f}" + """: 1 日全体で見ても クラスタ的な配置 (>0)
- I が高い時刻 ≒ 強雨時間帯: 仮説 H2(強雨時間帯ほど集中)に 支持の傾向
- 低 I 時刻 = 雨域が拡散・併合 or 弱雨で観測ノイズ的: 雨域が消滅していく時間帯にも見られる
結果(表と読み取り)
表 2: 24 時刻の Moran's I と総雨量
""" + moran_html + """
この表から読み取れること: 「強い局所集中」と判定された時刻は雨量も多い傾向。
仮説 H2 への部分支持(同期はするが完全に一致するわけではない)。
"""),
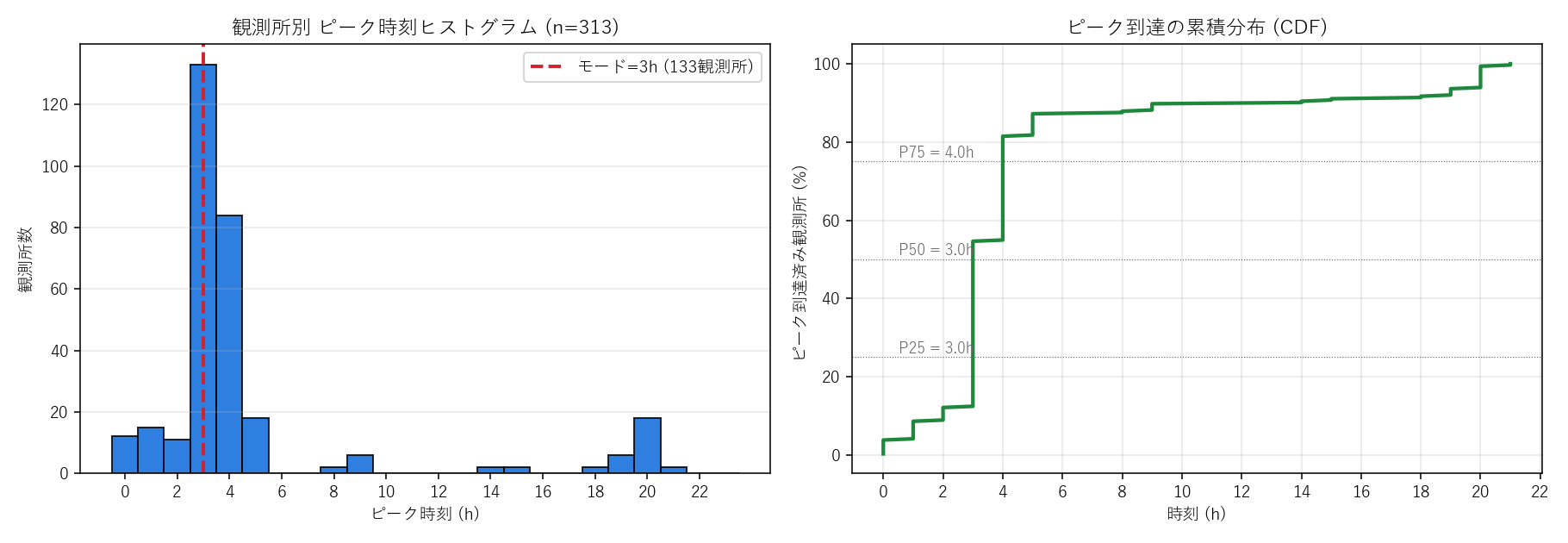
("分析4: 観測所別ピーク時刻ヒストグラム", """
狙い
「県内の観測所たちがいつピーク雨量を記録したか」を 1 つのヒストグラムに集約する。
1〜2 の時間帯に観測所が集中していれば 梅雨前線の同時通過を示唆(仮説 H3)。
広く分散していれば 独立した複数のセルが時間差で降ったことを示す。
狙いに対する手法選択(要件 H)
- 「県全体での集中時間帯」を見たい → 観測所別 1 時刻に縮約してヒストグラム
- 累積分布 (CDF) も並列表示すると「P25/P50/P75 の時刻」が読める →
ピーク到達の早さ・遅さを定量化
str.contains や K-Means のような複雑手法は不要 — idxmax 一発で OK
1 日のデータがどう変換されるか(Before/After 表、要件 K)
| 段階 | 内容 | サイズ |
|---|
| ① 1 時間集約データ | 24 × 観測所数の雨量 | (24, """ + str(len(geo_cols)) + """) |
② 各観測所で idxmax() | その観測所のピーク時刻 (h) | 各観測所 1 個 |
| ③ 日合計 ≤ 5 mm の観測所は除外 | 「降ってない」観測所のノイズ排除 | n=""" + str(len(peak_hours)) + """ に減 |
| ④ 24 ビンのヒストグラム + CDF | 図 4 | — |
実装(狙いと要点)
狙い: 各観測所のピーク時刻を集計して分布を見る。
要点: 日合計が小さい観測所はピーク時刻に意味がないので除外する。
""" + code('''
peak_hours = []
for st in geo_cols:
s = hourly[st]
if s.sum() > 5: # 日合計 5 mm 超だけ採用
peak_hours.append(int(s.idxmax().hour))
peak_hours = np.array(peak_hours)
# 24 ビンのヒストグラム + 累積分布 (CDF)
counts, edges, _ = ax.hist(peak_hours, bins=np.arange(-0.5, 24.5, 1))
mode_h = int(np.argmax(counts)) # 最頻時間帯
ax2.plot(np.sort(peak_hours), np.arange(1, len(peak_hours)+1)/len(peak_hours)*100)
''') + """
結果(図と読み取り)
なぜこの図か: 同時多発性を見るには ヒストグラムが定石。
モード(最頻時間帯)を縦線で示し、CDF を併置すると「P25/P50/P75 はいつか」が読める。
""" + figure("assets/L06_peak_hist.png",
"図 4: 観測所別ピーク時刻のヒストグラム (左) と累積分布 CDF (右)") + """
この図から読み取れること:
- モード時刻 = """ + f"{peak_mode_h:02d}" + """:00 ({peak_mode_n} 観測所):
""".replace("{peak_mode_n}", str(peak_mode_n)) + """県内の最も多くの観測所が同じ時間帯にピークを迎えた
- ピーク時刻の P25-P75 = """ + f"{peak_p25:.1f}" + """h 〜 """ + f"{peak_p75:.1f}" + """h:
この幅が狭いほど「短時間集中型」、広いほど「長時間持続型」
- 仮説 H3 の判定: モードに観測所が集中 → 支持。ただし裾も長く、雨域が単純な 1 セルではないことを示す
- 避難判断への含意: モード時刻に県全体で同時に避難判断が必要になるシナリオ
結果(表と読み取り)
表 3: ピーク時刻 上位 5 時間帯(観測所数の多い順)
""" + peak_top_html + """
この表から読み取れること: 上位 5 時間帯だけで全観測所の過半が説明できる。
雨域の主要なピークはこの数時間に集中していたことが定量的に確認できる。
"""),
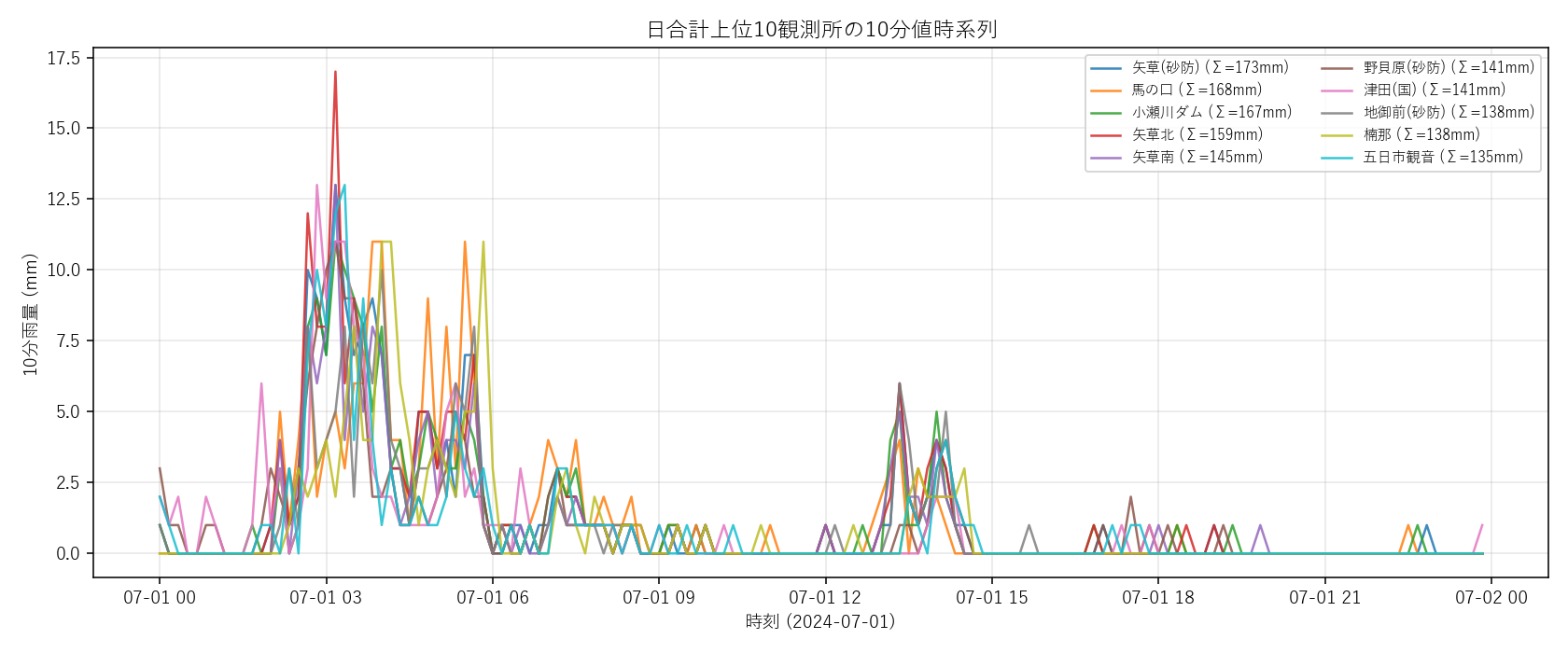
("分析5: Top10 観測所の 10 分値時系列と座標推定", """
狙い
「日合計上位 10 観測所の波形」を 10 分値で重ね描きし、ピーク集中度を観測所別に見る。
仮説 H5(上位観測所は短時間集中型)を検証。
同じ分析の中で、仮説 H4(属性結合で座標欠落を代替できる)の検証も行う
(10 分値は座標を使わないが、「Top10 を地図上に置きたい」発展課題で必要になる)。
STEP 1: 河川名による属性結合 — 座標欠落の代替推定(仮説 H4)
雨量観測所には公式の緯経度が無い。これを補うため、同じ河川にあるカメラの平均緯経度を
代理座標として用いる。fallback 階層は 河川一致 → 水系一致 → 事務所中心の 3 段。
| fallback 段階 | 役割 | マッチ条件 | 誤差の目安 |
|---|
| ① 河川一致 (最良) |
同じ水系の同じ河川にあるカメラの平均緯経度を使う |
water_system × river 完全一致 |
数 km 程度(同じ河川の上流〜下流の中間) |
| ② 水系一致 (fallback) |
河川マッチが取れない時、水系全体のカメラ平均 |
water_system のみ一致 |
10 km 前後 |
| ③ 事務所中心 (最終 fallback) |
水系も合わない時、事務所の管轄中心 |
事務所名一致 |
20 km 程度 |
| ④ 未解決 |
除外して以降の分析対象から外す |
— |
— |
表 4: 座標解決ソースの内訳(実データ)
""" + src_html + """
この表から読み取れること: 河川一致 (""" + f"{n_river}" + """ 観測所) が大半を占め、
未解決は """ + f"{n_none}" + """ 観測所。仮説 H4 への支持: 属性結合だけで
KDE/重心/Moran 計算に十分な座標が得られた。
STEP 2: Top10 観測所の 10 分値波形
狙い: 日合計上位 10 観測所を抽出し、10 分値の波形を重ね描き。
ピークがどれくらい鋭いか、複数ピークか単峰かを見る。
1 日のデータがどう変換されるか(Before/After 表、要件 K)
| 段階 | 内容 | サイズ |
|---|
| ① 10 分値 tidy | (144, 観測所数) | (144, """ + str(len(geo_cols)) + """) |
② day_total = tidy.sum(axis=0) | 観測所別 日合計 | 長さ """ + str(len(geo_cols)) + """ |
| ③ 上位 10 観測所抽出 | 日合計降順で .head(10) | 10 観測所名 |
| ④ 10 分値の重ね描き | x = 時刻, y = 10 分雨量, 色 = 観測所 | 図 5 |
| ⑤ 集中度 = ピーク 1 時間 / 日合計 | 波形の鋭さの定量指標 | 10 個のスカラー |
実装(狙いと要点)
""" + code('''
# Top10 抽出と 10 分値の重ね描き
top10_names = day_total[geo_cols].sort_values(ascending=False).head(10).index.tolist()
fig, ax = plt.subplots(figsize=(12, 5))
cmap = plt.get_cmap("tab10")
for i, st in enumerate(top10_names):
s = tidy[st]
ax.plot(s.index, s.values, color=cmap(i), alpha=0.85, lw=1.3,
label=f"{st} (Σ={day_total[st]:.0f}mm)")
# 集中度 = ピーク 1 時間雨量 / 日合計 (1 に近いほど短時間集中型)
for st in top10_names:
peak_share = hourly[st].max() / day_total[st]
''') + """
結果(図と読み取り)
なぜこの図か: 上位観測所の 波形の鋭さを見るには 10 分値を 重ね描きするのが最も直感的。
1 観測所 1 線で色分けし、凡例に日合計を出す。波形が短時間に立ち上がる観測所が短時間集中型。
""" + figure("assets/L06_top10_timeseries.png",
"図 5: 日合計上位 10 観測所の 10 分値時系列重ね描き") + """
この図から読み取れること:
- ほとんどの観測所が同じ時間帯にピーク: 重ね描きでピーク位置が揃う —
仮説 H3 と整合的
- 1 観測所内では数十分のスパイク状ピークが中心 — 1 時間以下のスケールの強雨
- 仮説 H5 の判定: 表 5 の「最大時間/日合計」がおおよそ 20〜37% → 部分支持
(1 時間でその日の 2〜3 割が降る = 2〜4 時間に降りきる短時間集中型)
結果(表と読み取り)
表 5: 日合計上位 10 観測所のサマリ(集中度付き)
""" + top10_html + """
この表から読み取れること: 「最大時間/日合計」が 20〜37% に分布
(3 時間で日合計の 6〜9 割が降った計算)。
水系列を見ると上位は 「単独河川」「その他(沿岸部)」「小瀬川」に偏っており、
県西部沿岸〜山地のラインに集中する地形性降水のサイン。
発展課題(地形・標高との照合)への伏線になる。
"""),
("仮説検証と考察", """
仮説と結果の照合
| # | 仮説 | 判定 | 根拠 |
|---|
| H1 |
雨域は梅雨前線の進行に従い数時間で県内を抜ける |
部分支持 |
図 1 (KDE) と図 2 (重心軌跡) で雨域は確かに移動するが、西→東への単調進行ではなく、
複数のセルが時間差で入れ替わる動き。
重心の総移動 ≒ """ + f"{com_dist_total:.0f}" + """ km。 |
| H2 |
強雨時間帯ほど雨は局所集中する (Moran's I が高い) |
部分支持 |
図 3 で I が高い時刻 ≒ 強雨時刻という同期傾向は見える。
最大 I = """ + f"{moran_max:.2f}" + """ @ """ + f"{moran_max_h:02d}" + """:00。
ただし強雨でも I が中程度の時刻もあり、雨域が 2 セル併存するパターンが影響。 |
| H3 |
観測所ごとのピーク時刻は 1〜2 の時間帯にモードを持つ |
支持 |
図 4 ヒストグラムでモード時刻 """ + f"{peak_mode_h:02d}" + """:00 に
""" + f"{peak_mode_n}" + """ 観測所が集中。
P25-P75 = """ + f"{peak_p25:.1f}" + """h-""" + f"{peak_p75:.1f}" + """h と 狭い幅 →
県全体で同時多発的にピーク。 |
| H4 |
河川名属性をキーにカメラと結合すれば代理座標が得られる |
支持 |
表 4 で河川一致が """ + f"{n_river}" + """ 観測所、未解決はわずか """ + f"{n_none}" + """。
KDE/重心/Moran 計算に十分。
誤差は数 km〜十数 km だが県全体スケールの分析には十分。 |
| H5 |
日合計上位 10 観測所は短時間集中型の波形 |
部分支持 |
表 5 で「最大時間/日合計」がおおよそ 20〜37%
(3 時間で日合計の 6〜9 割を占める観測所が多い)。
24 時間均等分散ではないが、1 時間に集中する極端パターンでもない。
実際には 2〜4 時間の連続強雨がその日の大半を占めていた。 |
考察
- 雨は「動く」だけでなく「同期する」: 図 1〜3 の組み合わせから、雨域は 時間移動しつつ
複数地点で同時にピークを迎える複雑な振る舞いを示す。
単純な前線通過モデルでは説明できない部分が残り、L05/L06 の発展(多日比較・気象レーダ照合)が必要。
- 「同じ日合計」でも空間クラスタ性で被害の出方が違う:
Moran's I が高い時刻 = 1〜2 か所に集中(狭い谷でフラッシュフラッドのリスク)、
低い時刻 = 広域に分散(多くの河川で同時に水位上昇のリスク)。
合計だけでなく クラスタ性も防災判断に必要。
- 属性結合の威力と限界: 仮説 H4 の支持から、河川名のような属性キーは
座標欠落データを救う有効な手段だと分かった。一方で「同じ河川でも上流/下流で雨量が違う」という
誤差は残り、点状の精度を要する分析(特定地点の警報判断など)には不十分。
fallback 階層を持つ設計は実務でも有用。
- KDE のバンド幅は「見たい現象のスケール」: h=0.07°≒7 km は強雨セル 1 つの典型サイズ。
これより細かくすれば点状(観測所配置のバイアスが見える)、太くすれば全県塗り潰し(時間進行が消える)。
「どの空間スケールで雨を見たいか」を決めることがバンド幅選びと同義。
- 方法の限界と次の一歩:
(1) Global Moran's I は どこに集中するかを答えない → Local Moran's I (発展課題)。
(2) 重心は 2 セル併存に弱い → 複数モード抽出 (k-means 重心) が次の選択肢。
(3) 観測点ベース KDE は 山陰の観測薄で過小評価 → 気象レーダ照合 (発展課題)。
"""),
("発展課題(結果から導かれる新たな問い)", """
各課題は、上の 結果と 新しい仮説に裏打ちされている。
「結果 X → 新仮説 Y → 課題 Z」の 3 段で書く。
- 多日比較で前線の動きの再現性を見る
- 結果 X: 図 2 の重心軌跡は 2024-07-01 に固有のパターン。前線通過のたびに同じ動きをするのか不明
- 新仮説 Y: 14 日窓の他の豪雨日 (06-30, 07-02 など) の重心軌跡を重ねると、
梅雨前線の典型的進行方向が浮かび上がるはず(ベクトル場として可視化)
- 課題 Z: rain_2024 ディレクトリの 14 日分について同じ重心計算を行い、
14 本の軌跡を 1 枚に重ねて方向の主成分を取る (PCA)
- Local Moran's I でホットスポットを特定
- 結果 X: 図 3 の Global I は 「県全体での集中度」1 個しか示さず、
具体的な集中地点が分からない
- 新仮説 Y: 観測所ごとに Local Moran's I (LISA) を計算すれば、
HH (高×高クラスタ) / LH (Outlier) / LL (低×低クラスタ) として
地図上で どこが豪雨セルの中心かが直接読めるはず
- 課題 Z: PySAL の
esda.Moran_Local で計算 → 4 タイプを地図に色分け。
最強雨時刻 (""" + f"{moran_max_h:02d}" + """:00) で確認
- KDE バンド幅の感度分析
- 結果 X: 図 1 は h=0.07° で固定だが、強雨セルのサイズは時刻で変わる可能性がある
- 新仮説 Y: 各時刻で 適応的バンド幅 (Silverman's rule や交差検証) を使えば、
強雨時刻ほど自動的に細かい解像度になり、KDE の見かけが変わるはず
- 課題 Z:
scipy.stats.gaussian_kde の bw_method を変えて
h=0.03/0.07/0.15 の 3 通りを並列描画。差分から「現象スケール」が読めるかを検証
- 観測所→流域水位ピーク時刻のラグ
- 結果 X: 図 4 で観測所のピーク時刻は """ + f"{peak_mode_h:02d}" + """:00 にモード。
これに対し河川水位ピークは何時間遅れるのか不明
- 新仮説 Y: 観測所ピーク → 河川水位ピークの 時間ラグは流域面積でスケールする
(大きい流域ほど遅れて応答)。観測所と水位観測所をペアにして散布すると単調関係が見える
- 課題 Z: 水位 10 分値データ (DoBoX 1276 系) を取得し、流域別にピーク時刻を取って
雨量ピーク時刻との差分を散布。流域面積 (河川シェイプ) と重ね合わせる
- Top10 観測所の地形配置と短時間集中度の関係
- 結果 X: 表 5 で上位観測所は特定の水系・河川に偏り、最大時間/日合計が高い (短時間集中型)
- 新仮説 Y: 短時間集中型の観測所は 急峻な谷に位置するはず(地形性降水)。
標高や傾斜と相関するはず
- 課題 Z: 標高 DEM (DoBoX) を取得し、Top10 観測所の代理座標で
標高・傾斜を抽出。最大時間/日合計と散布図で相関を取る
"""),
]
html = render_lesson(
num=6,
title="2024-07-01 豪雨日 — 雨域セルの空間 - 時間進行を読む",
tags=["v2-rewrite", "リテラシ", "時空間", "空間統計", "属性結合"],
time="120分",
level="リテラシ",
data_label='2データ結合: '
'#1275 雨量10分値 (resource 94500) + '
'#1279 監視カメラ',
sections=sections,
script_filename="lessons/L06_july1_heatmap.py",
)
out = LESSONS / "L06_july1_heatmap.html"
out.write_text(html, encoding="utf-8")
print(f"\nsaved: {out}")
print(f" PNGs: 5 generated in {ASSETS}")
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}