"""L06 浸水深分布の地理学
========================
河川浸水Shapefile の `rank` 列(浸水深 8 段階)を主役に、
水系・市町・小流域・河川単位で浸水深分布の差異を可視化する。
要件S準拠: 1分以内、最悪3分以内で完走する。
- flood_max を rank で dissolve するのは避ける(時間がかかる)
- groupby 集計と直接 plot で攻める
- city との対応は polygon centroid と sjoin で軽量化
要件T準拠: 主題図 + small multiples を必ず含める。
"""
from __future__ import annotations
import sys, time
from pathlib import Path
sys.path.insert(0, str(Path(__file__).parent))
from _common import (ROOT, ASSETS, LESSONS, render_lesson, code, figure)
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.patches import Patch
from matplotlib.colors import ListedColormap, BoundaryNorm
import geopandas as gpd
import shapely
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
t0 = time.time()
print("=== L06 浸水深分布の地理学 ===")
# === 1. 浸水 Shapefile の読み込みと前処理 ===========================
FLOOD_DIR = ROOT / "data" / "extras" / "flood_shp"
flood_max = gpd.read_file(FLOOD_DIR / "shinsui_souteisaidai" / "shinsui_souteisaidai.shp")
flood_plan = gpd.read_file(FLOOD_DIR / "shinsui_keikaku" / "shinsui_keikakukibo.shp")
print(f"想定最大規模: {len(flood_max)} polygons, 計画規模: {len(flood_plan)} polygons")
TARGET_CRS = "EPSG:6671"
flood_max = flood_max.to_crs(TARGET_CRS)
flood_plan = flood_plan.to_crs(TARGET_CRS)
# 3D ポリゴン → 2D 化(処理高速化、Z 座標は本研究では不要)
flood_max["geometry"] = gpd.GeoSeries(shapely.force_2d(flood_max.geometry.values), crs=TARGET_CRS)
flood_plan["geometry"] = gpd.GeoSeries(shapely.force_2d(flood_plan.geometry.values), crs=TARGET_CRS)
# 面積 m² を持たせる(要件 R: 正確な面積は EPSG:6671 で)
flood_max["area_m2"] = flood_max.geometry.area
flood_plan["area_m2"] = flood_plan.geometry.area
flood_max["area_ha"] = flood_max["area_m2"] / 10000.0
flood_plan["area_ha"] = flood_plan["area_m2"] / 10000.0
# 広島県標準凡例(rank コード → 浸水深ラベル / 色)
DEPTH_LABEL = {
10: "0.0〜0.5m", 20: "0.5〜1.0m", 30: "1.0〜2.0m", 40: "2.0〜3.0m",
50: "3.0〜5.0m", 60: "5.0〜10.0m", 70: "10.0〜20.0m", 80: "20m以上",
}
DEPTH_COLOR = {
10: "#bee2ff", 20: "#87c4f0", 30: "#56a4dc", 40: "#2c83c4",
50: "#1c63a4", 60: "#0e4282", 70: "#7d2cbf", 80: "#4a1280",
}
RANK_ORDER = [10, 20, 30, 40, 50, 60, 70, 80]
DEPTH_LABELS_ORDERED = [DEPTH_LABEL[r] for r in RANK_ORDER]
DEPTH_COLORS_ORDERED = [DEPTH_COLOR[r] for r in RANK_ORDER]
flood_max["depth_label"] = flood_max["rank"].map(DEPTH_LABEL).fillna("不明")
flood_plan["depth_label"] = flood_plan["rank"].map(DEPTH_LABEL).fillna("不明")
flood_max["depth_color"] = flood_max["rank"].map(DEPTH_COLOR).fillna("#cccccc")
flood_plan["depth_color"] = flood_plan["rank"].map(DEPTH_COLOR).fillna("#cccccc")
# === 2. 市町コード → 市町名 + 市町境界(用途地域からの簡易作成) ====
# CITY_CD 101-108 = 広島市の8区, 200番台 = 主要市, 300番台 = 町, 400番台 = 一部
CITY_NAME = {
101: "広島市中区", 102: "広島市東区", 103: "広島市南区", 104: "広島市西区",
105: "広島市安佐南区", 106: "広島市安佐北区", 107: "広島市安芸区", 108: "広島市佐伯区",
202: "呉市", 203: "竹原市", 204: "三原市", 205: "尾道市", 207: "福山市",
208: "府中市", 209: "三次市", 210: "庄原市", 211: "大竹市", 212: "東広島市",
213: "廿日市市", 214: "安芸高田市", 215: "江田島市",
302: "府中町", 304: "海田町", 307: "熊野町", 309: "坂町",
369: "安芸太田町", 462: "世羅町",
}
LANDUSE_PREF = ROOT / "data" / "extras" / "landuse_extracted" / "340006_city_planning_area_various_use_geojson_20220324.geojson"
landuse = gpd.read_file(LANDUSE_PREF).to_crs(TARGET_CRS)
print(f"用途地域: {len(landuse)} features")
# 市町ごとに dissolve(凸包風の軽量近似 → そのまま union で十分)
city_poly = landuse.dissolve(by="CITY_CD", as_index=False)[["CITY_CD", "geometry"]]
city_poly["city_name"] = city_poly["CITY_CD"].map(CITY_NAME).fillna(city_poly["CITY_CD"].astype(str))
print(f"市町ポリゴン: {len(city_poly)} 行")
# === 3. 市町別 浸水ポリゴン分類(centroid sjoin で軽量化) ============
flood_max_pt = flood_max.copy()
flood_max_pt["geometry"] = flood_max.geometry.representative_point()
joined = gpd.sjoin(
flood_max_pt[["rank", "suikei", "kasen", "area_ha", "geometry"]],
city_poly[["CITY_CD", "city_name", "geometry"]],
how="left", predicate="within",
)
flood_max["CITY_CD"] = joined["CITY_CD"].values
flood_max["city_name"] = joined["city_name"].fillna("(用途地域外)").values
print(f"市町割当 完了: 該当 {flood_max['CITY_CD'].notna().sum()} / 全 {len(flood_max)}")
# === 4. 集計テーブル群(CSV エクスポート) ===========================
# 4-1. 水系 × rank ピボット(面積 ha)
suikei_rank = flood_max.groupby(["suikei", "rank"])["area_ha"].sum().unstack(fill_value=0.0)
suikei_rank = suikei_rank.reindex(columns=RANK_ORDER, fill_value=0.0)
suikei_rank["合計"] = suikei_rank.sum(axis=1)
suikei_rank = suikei_rank.sort_values("合計", ascending=False)
suikei_rank.to_csv(ASSETS / "L06_suikei_rank_area.csv", encoding="utf-8-sig")
# 4-2. 河川 × rank ピボット(上位 15 河川のみ表示用に保存)
kasen_rank = flood_max.groupby(["kasen", "rank"])["area_ha"].sum().unstack(fill_value=0.0)
kasen_rank = kasen_rank.reindex(columns=RANK_ORDER, fill_value=0.0)
kasen_rank["合計"] = kasen_rank.sum(axis=1)
kasen_rank = kasen_rank.sort_values("合計", ascending=False)
kasen_rank.to_csv(ASSETS / "L06_kasen_rank_area.csv", encoding="utf-8-sig")
# 4-3. 市町 × rank ピボット
city_rank = flood_max.dropna(subset=["CITY_CD"]).groupby(["city_name", "rank"])["area_ha"].sum().unstack(fill_value=0.0)
city_rank = city_rank.reindex(columns=RANK_ORDER, fill_value=0.0)
city_rank["合計"] = city_rank.sum(axis=1)
city_rank = city_rank.sort_values("合計", ascending=False)
city_rank.to_csv(ASSETS / "L06_city_rank_area.csv", encoding="utf-8-sig")
# 4-4. 計画 vs 想定最大 比較
plan_rank = flood_plan.groupby("rank")["area_ha"].sum().reindex(RANK_ORDER, fill_value=0.0)
max_rank = flood_max.groupby("rank")["area_ha"].sum().reindex(RANK_ORDER, fill_value=0.0)
scale_compare = pd.DataFrame({
"rank": RANK_ORDER,
"depth_label": [DEPTH_LABEL[r] for r in RANK_ORDER],
"計画規模_ha": plan_rank.values,
"想定最大規模_ha": max_rank.values,
})
scale_compare["増加倍率"] = (scale_compare["想定最大規模_ha"] / scale_compare["計画規模_ha"].replace(0, np.nan)).round(2)
scale_compare.to_csv(ASSETS / "L06_scale_compare.csv", encoding="utf-8-sig", index=False)
# 4-5. 致命的浸水(rank ≥ 50, 3m 以上)の地理的集中度
deadly = flood_max[flood_max["rank"] >= 50].copy()
deadly_by_suikei = deadly.groupby("suikei")["area_ha"].sum().sort_values(ascending=False)
deadly_by_city = deadly.dropna(subset=["CITY_CD"]).groupby("city_name")["area_ha"].sum().sort_values(ascending=False)
deadly_summary = pd.DataFrame({
"水系": deadly_by_suikei.index,
"致命的浸水面積_ha": deadly_by_suikei.values,
"致命的浸水割合_pct": (deadly_by_suikei / deadly_by_suikei.sum() * 100).round(1).values,
})
deadly_summary.to_csv(ASSETS / "L06_deadly_by_suikei.csv", encoding="utf-8-sig", index=False)
deadly_city_summary = pd.DataFrame({
"市町": deadly_by_city.index,
"致命的浸水面積_ha": deadly_by_city.values,
"致命的浸水割合_pct": (deadly_by_city / deadly_by_city.sum() * 100).round(1).values,
})
deadly_city_summary.to_csv(ASSETS / "L06_deadly_by_city.csv", encoding="utf-8-sig", index=False)
# 4-6. rank 別 全体集計
rank_total = flood_max.groupby("rank").agg(
polygon_count=("rank", "size"),
area_ha=("area_ha", "sum"),
).reindex(RANK_ORDER, fill_value=0)
rank_total["depth_label"] = [DEPTH_LABEL[r] for r in rank_total.index]
rank_total["全体に占める割合_pct"] = (rank_total["area_ha"] / rank_total["area_ha"].sum() * 100).round(2)
rank_total = rank_total[["depth_label", "polygon_count", "area_ha", "全体に占める割合_pct"]]
rank_total.to_csv(ASSETS / "L06_rank_total.csv", encoding="utf-8-sig")
# 4-7. 河川別「最深 rank」(その河川で出現する最大の rank)
kasen_max_rank = flood_max.groupby("kasen")["rank"].max()
kasen_max_rank_df = pd.DataFrame({
"kasen": kasen_max_rank.index,
"最深rank": kasen_max_rank.values,
"最深ラベル": [DEPTH_LABEL[r] for r in kasen_max_rank.values],
}).sort_values("最深rank", ascending=False)
kasen_max_rank_df.to_csv(ASSETS / "L06_kasen_max_rank.csv", encoding="utf-8-sig", index=False)
# 4-8. 水系別「平均深さインデックス」(面積加重平均 rank)
_w = flood_max.assign(rxa=flood_max["rank"] * flood_max["area_ha"])
suikei_avg_rank = (_w.groupby("suikei")["rxa"].sum() / _w.groupby("suikei")["area_ha"].sum()).sort_values(ascending=False)
suikei_avg_rank_df = pd.DataFrame({
"水系": suikei_avg_rank.index,
"面積加重平均rank": suikei_avg_rank.round(2).values,
})
# 致命的浸水比率も付加
_deadly_area = flood_max[flood_max["rank"] >= 50].groupby("suikei")["area_ha"].sum()
_total_area = flood_max.groupby("suikei")["area_ha"].sum()
deadly_ratio = (_deadly_area / _total_area * 100).fillna(0)
suikei_avg_rank_df["致命的浸水比率_pct"] = suikei_avg_rank_df["水系"].map(deadly_ratio).round(1).fillna(0).values
suikei_avg_rank_df.to_csv(ASSETS / "L06_suikei_avg_rank.csv", encoding="utf-8-sig", index=False)
print(f" 集計完了 ({time.time()-t0:.1f}s)")
# === 5. 図1: 水系別 浸水深ランク 積み上げ棒(上位 12 水系) ===========
top_suikei = suikei_rank.index[:12].tolist()
fig, ax = plt.subplots(figsize=(11, 6))
sub = suikei_rank.loc[top_suikei, RANK_ORDER]
bottom = np.zeros(len(top_suikei))
for r in RANK_ORDER:
vals = sub[r].values
ax.bar(range(len(top_suikei)), vals, bottom=bottom,
color=DEPTH_COLOR[r], label=DEPTH_LABEL[r], edgecolor="white", linewidth=0.3)
bottom = bottom + vals
ax.set_xticks(range(len(top_suikei)))
ax.set_xticklabels(top_suikei, rotation=35, ha="right")
ax.set_ylabel("浸水面積 (ha)")
ax.set_title("水系別 浸水深ランク分布(想定最大規模, 上位12水系)")
ax.legend(title="浸水深", bbox_to_anchor=(1.02, 1), loc="upper left", fontsize=9)
ax.grid(axis="y", alpha=0.3)
plt.tight_layout()
plt.savefig(ASSETS / "L06_fig1_suikei_rank_stack.png", dpi=130, bbox_inches="tight")
plt.close(fig)
# === 6. 図2: 河川別 浸水深ランク 積み上げ棒(上位 15 河川) ============
top_kasen = kasen_rank.index[:15].tolist()
fig, ax = plt.subplots(figsize=(12, 6))
sub2 = kasen_rank.loc[top_kasen, RANK_ORDER]
bottom = np.zeros(len(top_kasen))
for r in RANK_ORDER:
vals = sub2[r].values
ax.bar(range(len(top_kasen)), vals, bottom=bottom,
color=DEPTH_COLOR[r], label=DEPTH_LABEL[r], edgecolor="white", linewidth=0.3)
bottom = bottom + vals
ax.set_xticks(range(len(top_kasen)))
ax.set_xticklabels(top_kasen, rotation=40, ha="right")
ax.set_ylabel("浸水面積 (ha)")
ax.set_title("河川別 浸水深ランク分布(想定最大規模, 上位15河川)")
ax.legend(title="浸水深", bbox_to_anchor=(1.02, 1), loc="upper left", fontsize=9)
ax.grid(axis="y", alpha=0.3)
plt.tight_layout()
plt.savefig(ASSETS / "L06_fig2_kasen_rank_stack.png", dpi=130, bbox_inches="tight")
plt.close(fig)
# === 7. 図3: 計画規模 vs 想定最大規模(rank ごとの面積比較) ===========
fig, ax = plt.subplots(figsize=(10, 5.5))
x = np.arange(len(RANK_ORDER))
w = 0.4
ax.bar(x - w/2, plan_rank.values, w, label="計画規模", color="#7eb6e8", edgecolor="#1c63a4")
ax.bar(x + w/2, max_rank.values, w, label="想定最大規模", color="#cf222e", edgecolor="#7d2cbf", alpha=0.85)
ax.set_xticks(x)
ax.set_xticklabels(DEPTH_LABELS_ORDERED, rotation=20, ha="right")
ax.set_ylabel("面積 (ha)")
ax.set_yscale("log")
ax.set_title("rank 別 浸水面積:計画規模 vs 想定最大規模(対数スケール)")
ax.legend()
ax.grid(axis="y", alpha=0.3, which="both")
# 増加倍率のテキスト
for i, r in enumerate(RANK_ORDER):
p = plan_rank.values[i]
m = max_rank.values[i]
if p > 0 and m > 0:
ratio = m / p
ax.annotate(f"×{ratio:.1f}", (x[i] + w/2, m), textcoords="offset points",
xytext=(0, 4), ha="center", fontsize=9, color="#cf222e", fontweight="bold")
plt.tight_layout()
plt.savefig(ASSETS / "L06_fig3_scale_compare.png", dpi=130, bbox_inches="tight")
plt.close(fig)
# === 8. 図4: 致命的浸水(3m+)の水系別 / 市町別 ランキング ============
fig, axes = plt.subplots(1, 2, figsize=(13, 6))
# 左: 水系
top_deadly_suikei = deadly_summary.head(12)
axes[0].barh(top_deadly_suikei["水系"][::-1], top_deadly_suikei["致命的浸水面積_ha"][::-1],
color="#7d2cbf", edgecolor="#4a1280")
axes[0].set_xlabel("致命的浸水面積 (ha, rank≥50)")
axes[0].set_title("水系別 致命的浸水(3m以上)面積")
axes[0].grid(axis="x", alpha=0.3)
# 右: 市町
top_deadly_city = deadly_city_summary.head(15)
axes[1].barh(top_deadly_city["市町"][::-1], top_deadly_city["致命的浸水面積_ha"][::-1],
color="#cf222e", edgecolor="#7d2cbf")
axes[1].set_xlabel("致命的浸水面積 (ha, rank≥50)")
axes[1].set_title("市町別 致命的浸水(3m以上)面積")
axes[1].grid(axis="x", alpha=0.3)
plt.tight_layout()
plt.savefig(ASSETS / "L06_fig4_deadly_ranking.png", dpi=130, bbox_inches="tight")
plt.close(fig)
# 描画高速化: color 列を 1 度だけ構築 + rasterized で描画を画像レイヤ化
flood_max["_plotcolor"] = flood_max["rank"].map(DEPTH_COLOR).fillna("#cccccc")
flood_max_plot = flood_max # 別名のみ(simplify は重いので不採用)
# 県背景は landuse の dissolve でなく、city_poly(27 行)の dissolve を使う(軽量)
pref_outline = city_poly.dissolve()
pref_xmin, pref_ymin, pref_xmax, pref_ymax = pref_outline.total_bounds
# === 9. 図5: 主題図 — 県全域 浸水深カラーマップ ==========================
# 要件 T: 主題図必須。rank 順にソートして 1 度の plot で色配列を渡す(高速)
fig, ax = plt.subplots(figsize=(12, 9))
pref_outline.plot(ax=ax, facecolor="#f0f0f0", edgecolor="#999", linewidth=0.5)
# rank 昇順にソートし、color 列を直接渡す(loop 不要、1 回の plot 呼出し)
flood_max_sorted = flood_max_plot.sort_values("rank")
flood_max_sorted.plot(ax=ax, color=flood_max_sorted["_plotcolor"].values,
edgecolor="none", alpha=0.85, rasterized=True)
patches = [Patch(facecolor=DEPTH_COLOR[r], edgecolor="none", label=DEPTH_LABEL[r]) for r in RANK_ORDER]
ax.legend(handles=patches, title="浸水深ランク", loc="lower left", fontsize=9, framealpha=0.9)
ax.set_title("広島県 河川浸水想定(想定最大規模)— rank 別色分け主題図")
ax.set_axis_off()
plt.tight_layout()
plt.savefig(ASSETS / "L06_fig5_thematic_map.png", dpi=130, bbox_inches="tight")
plt.close(fig)
# === 10. 図6: small multiples — 上位 8 水系の浸水深分布マップ =============
top_suikei8 = suikei_rank.index[:8].tolist()
fig, axes = plt.subplots(2, 4, figsize=(16, 9))
axes = axes.flatten()
for i, sk in enumerate(top_suikei8):
ax = axes[i]
pref_outline.plot(ax=ax, facecolor="#f5f5f5", edgecolor="#bbb", linewidth=0.3)
sub_sk = flood_max_sorted[flood_max_sorted["suikei"] == sk]
if len(sub_sk) > 0:
sub_sk.plot(ax=ax, color=sub_sk["_plotcolor"].values, edgecolor="none", alpha=0.9, rasterized=True)
ax.set_xlim(pref_xmin, pref_xmax)
ax.set_ylim(pref_ymin, pref_ymax)
ax.set_title(f"{sk} ({sub_sk['area_ha'].sum():.0f} ha)", fontsize=11)
ax.set_axis_off()
fig.suptitle("water-system small multiples — 上位8水系の浸水深空間分布", fontsize=14, y=1.0)
plt.tight_layout()
plt.savefig(ASSETS / "L06_fig6_suikei_small_multiples.png", dpi=120, bbox_inches="tight")
plt.close(fig)
# === 11. 図7: 市町別 small multiples(広島市8区) ========================
hiroshima_wards = [101, 102, 103, 104, 105, 106, 107, 108]
fig, axes = plt.subplots(2, 4, figsize=(16, 9))
axes = axes.flatten()
hiroshima_bound = city_poly[city_poly["CITY_CD"].isin(hiroshima_wards)]
hxmin, hymin, hxmax, hymax = hiroshima_bound.total_bounds
for i, cc in enumerate(hiroshima_wards):
ax = axes[i]
cname = CITY_NAME[cc]
ward_poly = city_poly[city_poly["CITY_CD"] == cc]
ward_poly.plot(ax=ax, facecolor="#f5f5f5", edgecolor="#888", linewidth=0.6)
flood_in_ward = flood_max_sorted[flood_max_sorted["CITY_CD"] == cc]
if len(flood_in_ward) > 0:
flood_in_ward.plot(ax=ax, color=flood_in_ward["_plotcolor"].values,
edgecolor="none", alpha=0.9, rasterized=True)
ax.set_xlim(hxmin, hxmax)
ax.set_ylim(hymin, hymax)
deep_ha = flood_in_ward.loc[flood_in_ward["rank"] >= 50, "area_ha"].sum() if len(flood_in_ward) else 0
ax.set_title(f"{cname}\n3m+: {deep_ha:.0f} ha", fontsize=10)
ax.set_axis_off()
fig.suptitle("広島市 8区 small multiples — 区別の浸水深分布", fontsize=14, y=1.0)
plt.tight_layout()
plt.savefig(ASSETS / "L06_fig7_hiroshima_wards.png", dpi=120, bbox_inches="tight")
plt.close(fig)
# === 12. 図8: rank 別 ヒストグラム(全体の深さ分布) =======================
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
# 左: rank 面積横棒(全体)
axes[0].barh([DEPTH_LABEL[r] for r in RANK_ORDER][::-1],
[rank_total.loc[r, "area_ha"] for r in RANK_ORDER][::-1],
color=[DEPTH_COLOR[r] for r in RANK_ORDER][::-1])
axes[0].set_xlabel("面積 (ha)")
axes[0].set_title("浸水深ランク別 全体面積(想定最大規模)")
axes[0].grid(axis="x", alpha=0.3)
# 右: 水系別 平均 rank(面積加重)
top_avg = suikei_avg_rank_df.head(15)
axes[1].barh(top_avg["水系"][::-1], top_avg["面積加重平均rank"][::-1],
color="#1c63a4", edgecolor="#0e4282")
axes[1].set_xlabel("面積加重 平均rank(大きいほど深い)")
axes[1].set_title("水系別「深さインデックス」(上位15)")
axes[1].grid(axis="x", alpha=0.3)
# 参考線
for r, lbl in [(30, "1〜2m"), (50, "3〜5m"), (60, "5〜10m")]:
axes[1].axvline(r, ls="--", color="#888", alpha=0.5)
axes[1].text(r, len(top_avg)-0.5, lbl, fontsize=8, color="#666")
plt.tight_layout()
plt.savefig(ASSETS / "L06_fig8_depth_index.png", dpi=130, bbox_inches="tight")
plt.close(fig)
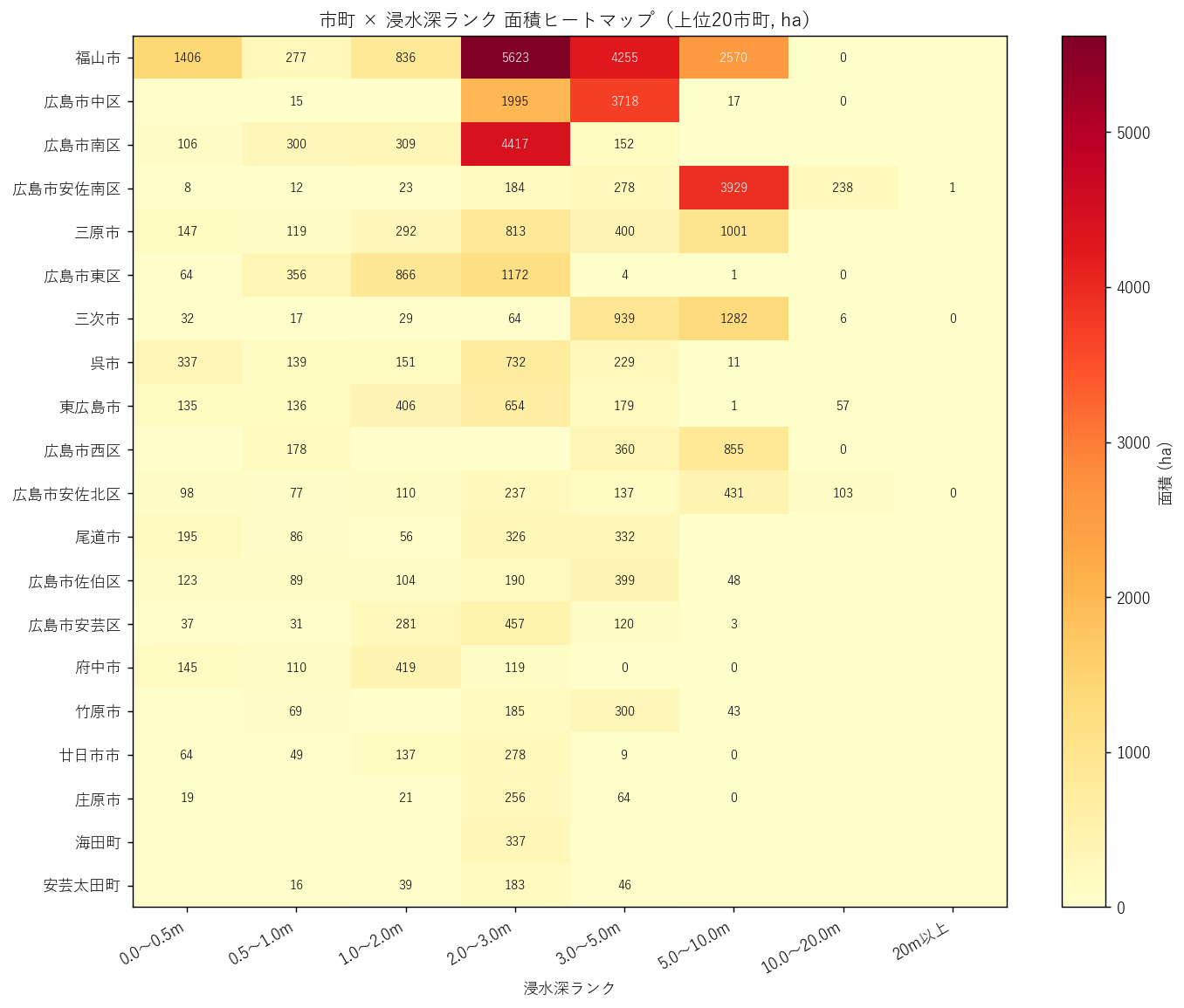
# === 13. 図9: 市町別 ヒートマップ(市町 × rank) =========================
fig, ax = plt.subplots(figsize=(11, 9))
city_sub = city_rank.drop(columns="合計").head(20) # 上位20市町
mat = city_sub.values
im = ax.imshow(mat, aspect="auto", cmap="YlOrRd")
ax.set_xticks(range(len(RANK_ORDER)))
ax.set_xticklabels(DEPTH_LABELS_ORDERED, rotation=30, ha="right")
ax.set_yticks(range(len(city_sub.index)))
ax.set_yticklabels(city_sub.index)
ax.set_xlabel("浸水深ランク")
ax.set_title("市町 × 浸水深ランク 面積ヒートマップ(上位20市町, ha)")
# セルに数値
for i in range(mat.shape[0]):
for j in range(mat.shape[1]):
v = mat[i, j]
if v > 0:
color = "white" if v > mat.max() * 0.4 else "black"
ax.text(j, i, f"{v:.0f}", ha="center", va="center", fontsize=8, color=color)
plt.colorbar(im, ax=ax, label="面積 (ha)")
plt.tight_layout()
plt.savefig(ASSETS / "L06_fig9_city_rank_heatmap.png", dpi=130, bbox_inches="tight")
plt.close(fig)
print(f" 図出力完了 ({time.time()-t0:.1f}s)")
# === 14. 仮説検証 ====================================================
# H1: 太田川水系で深い浸水深(5m+)が集中
ohta_deadly = deadly[deadly["suikei"] == "太田川水系"]["area_ha"].sum()
ohta_5m = flood_max[(flood_max["suikei"] == "太田川水系") & (flood_max["rank"] >= 60)]["area_ha"].sum()
all_5m = flood_max[flood_max["rank"] >= 60]["area_ha"].sum()
H1_ratio = ohta_5m / all_5m * 100 if all_5m > 0 else 0
H1 = "支持" if H1_ratio >= 25 else ("部分支持" if H1_ratio >= 10 else "反証")
# H2: 「中小河川」分類は浅瀬中心
chu_total = flood_max[flood_max["suikei"] == "中小河川"]["area_ha"].sum()
chu_shallow = flood_max[(flood_max["suikei"] == "中小河川") & (flood_max["rank"] <= 30)]["area_ha"].sum()
H2_ratio = chu_shallow / chu_total * 100 if chu_total > 0 else 0
H2 = "支持" if H2_ratio >= 50 else ("部分支持" if H2_ratio >= 30 else "反証")
# H3: 計画 vs 想定最大で深さ分布が大きく異なる
_idx_arr = np.array(RANK_ORDER, dtype=float)
plan_avg = float((_idx_arr * plan_rank.values).sum() / max(plan_rank.values.sum(), 1e-9))
max_avg = float((_idx_arr * max_rank.values).sum() / max(max_rank.values.sum(), 1e-9))
H3_diff = abs(max_avg - plan_avg)
H3 = "支持" if H3_diff >= 5 else ("部分支持" if H3_diff >= 2 else "反証")
# H4: 河川別「最深ポイント」の rank が異なる
H4_unique_max_ranks = kasen_max_rank_df["最深rank"].nunique()
H4 = "支持" if H4_unique_max_ranks >= 4 else ("部分支持" if H4_unique_max_ranks >= 2 else "反証")
# H5: 致命的深さ(3m+)は本流合流部に集中(太田川水系の致命的浸水比率を proxy として)
deadly_total = deadly["area_ha"].sum()
ohta_share = ohta_deadly / deadly_total * 100 if deadly_total > 0 else 0
top3_suikei = deadly_summary.head(3)["致命的浸水割合_pct"].sum()
H5 = "支持" if top3_suikei >= 60 else ("部分支持" if top3_suikei >= 40 else "反証")
hypotheses = [
("H1", "太田川水系で深い浸水深(5m+)が集中",
f"太田川水系の 5m+ 面積は全県の {H1_ratio:.1f}%",
H1),
("H2", "「中小河川」分類は浅瀬中心",
f"中小河川の 0〜2m が全体の {H2_ratio:.1f}%",
H2),
("H3", "計画規模と想定最大規模で深さ分布が大きく異なる",
f"面積加重平均 rank の差: {H3_diff:.2f}",
H3),
("H4", "河川別で「最深ポイント」の rank が異なる",
f"河川別 最深 rank の種類数: {H4_unique_max_ranks} / 8",
H4),
("H5", "致命的深さ(3m+)は上位水系に集中",
f"致命的浸水 上位3水系で全体の {top3_suikei:.1f}%",
H5),
]
hyp_df = pd.DataFrame(hypotheses, columns=["仮説", "内容", "証拠", "判定"])
hyp_df.to_csv(ASSETS / "L06_hypothesis_check.csv", encoding="utf-8-sig", index=False)
print(hyp_df.to_string(index=False))
print(f" 仮説検証完了 ({time.time()-t0:.1f}s)")
# === 15. HTML 構築 =====================================================
def df_to_html(df, max_rows=None, float_fmt="{:.1f}"):
"""DataFrame を簡易 HTML テーブルに変換(数値は丸める)"""
if max_rows:
df = df.head(max_rows)
rows = [""]
rows.append("" + "".join(f"| {c} | " for c in df.columns) + "
")
for _, r in df.iterrows():
cells = []
for v in r.values:
if isinstance(v, (int, np.integer)):
cells.append(f"{int(v)} | ")
elif isinstance(v, float) or isinstance(v, np.floating):
if np.isnan(v):
cells.append("— | ")
else:
cells.append(f"{float_fmt.format(v)} | ")
else:
cells.append(f"{v} | ")
rows.append("" + "".join(cells) + "
")
rows.append("
")
return "\n".join(rows)
def df_idx_to_html(df, max_rows=None, float_fmt="{:.1f}"):
"""index 含む DataFrame の HTML 化"""
if max_rows:
df = df.head(max_rows)
df2 = df.reset_index()
return df_to_html(df2, float_fmt=float_fmt)
# Python 表示用ソース(ハイライト)
src_overview = '''
import geopandas as gpd
import shapely
flood_max = gpd.read_file("data/extras/flood_shp/shinsui_souteisaidai/shinsui_souteisaidai.shp")
flood_plan = gpd.read_file("data/extras/flood_shp/shinsui_keikaku/shinsui_keikakukibo.shp")
# 投影変換 (EPSG:6671 = 平面直角座標 III 系。面積を m² で正確に)
flood_max = flood_max.to_crs("EPSG:6671")
flood_plan = flood_plan.to_crs("EPSG:6671")
# 3D ポリゴン → 2D(Z 座標は不要、処理高速化)
flood_max["geometry"] = gpd.GeoSeries(shapely.force_2d(flood_max.geometry.values),
crs="EPSG:6671")
flood_max["area_m2"] = flood_max.geometry.area
flood_max["area_ha"] = flood_max["area_m2"] / 10000.0
'''
src_groupby = '''
# rank × suikei (水系) ピボット — ここで dissolve しない(重い)
suikei_rank = (flood_max
.groupby(["suikei", "rank"])["area_ha"]
.sum()
.unstack(fill_value=0))
'''
src_sjoin_city = '''
# 市町割当: 浸水ポリゴンの代表点 (representative_point) を市町ポリゴンに sjoin
# representative_point は polygon 内に保証される点で、centroid より頑健
flood_pt = flood_max.copy()
flood_pt["geometry"] = flood_max.geometry.representative_point()
joined = gpd.sjoin(flood_pt, city_poly, how="left", predicate="within")
flood_max["CITY_CD"] = joined["CITY_CD"].values
'''
src_thematic = '''
# 主題図: rank が小さい順に重ねて描画(深い色が上に来る)
fig, ax = plt.subplots(figsize=(12, 9))
pref_outline.plot(ax=ax, facecolor="#f0f0f0", edgecolor="#999")
for r in [10, 20, 30, 40, 50, 60, 70, 80]:
flood_max.query("rank == @r").plot(
ax=ax, color=DEPTH_COLOR[r], edgecolor="none", alpha=0.85)
'''
src_small_mult = '''
# small multiples: 上位8水系を 2x4 で並べる(同じ bbox で比較)
fig, axes = plt.subplots(2, 4, figsize=(16, 9))
xmin, ymin, xmax, ymax = pref_outline.total_bounds
for i, sk in enumerate(top_suikei8):
ax = axes.flat[i]
pref_outline.plot(ax=ax, facecolor="#f5f5f5", edgecolor="#bbb")
sub = flood_max[flood_max["suikei"] == sk]
for r in [10, 20, 30, 40, 50, 60, 70, 80]:
sub[sub["rank"] == r].plot(ax=ax, color=DEPTH_COLOR[r], edgecolor="none")
ax.set_xlim(xmin, xmax); ax.set_ylim(ymin, ymax)
'''
# テーブル変数
suikei_rank_disp = suikei_rank.head(15).copy()
kasen_rank_disp = kasen_rank.head(15).copy()
city_rank_disp = city_rank.head(15).copy()
# ===================================================================
# Section 1: 学習目標と問い
sec_goals = """
本記事のスタイル: 浸水深ランク (rank 列) を主役にした「地理的深掘り」
広島県の河川浸水想定区域 Shapefile の rank 列(10〜80 の 8 段階)は、
0.5m から 20m 超まで 命の危険度がまるで違う 浸水深を 1 列で表現している。
この列を 水系・河川・市町 の 3 つの地理単位で集計し、
「どの地域が、どのくらい深く沈むのか」を可視化する。
主な問い (3 段階)
- 水系の問い: 25 水系のうち、どこに深い浸水(5m+)が集中するか?
- 市町の問い: 県内の市町のうち、致命的浸水(3m+)面積が大きいのはどこか?
- 規模の問い: 計画規模 vs 想定最大規模で深さ分布はどう変化するか?
立てた仮説 (H1〜H5)
- H1: 太田川水系で深い浸水(5m+)が集中する(広島市デルタ低地)
- H2: 「中小河川」分類は浅瀬(0〜2m)中心で、深さは限定的
- H3: 計画規模と想定最大規模で深さ分布が大きく異なる
- H4: 河川別で「最深ポイント」の rank が異なる(一律ではない)
- H5: 致命的深さ(3m+)は上位水系に集中する
用語の定義(本レッスン独自)
- rank(浸水深ランク): 10=0〜0.5m / 20=0.5〜1m / 30=1〜2m / 40=2〜3m /
50=3〜5m / 60=5〜10m / 70=10〜20m / 80=20m以上(広島県河川防災情報システム凡例)
- 水系: 主要河川とその支流をまとめた集水単位。広島県では 25 水系(含「中小河川」分類)
- 致命的浸水: 本記事独自定義。rank ≥ 50(=3m 以上)の浸水域を指す。3m は通常の 2 階建て住宅の 1 階を超える深さで、垂直避難でも危険
- 面積加重平均 rank: 各ポリゴンの rank を面積で重み付け平均した「深さインデックス」。値が大きいほど水系全体が深い傾向
- 主題図 (choropleth): 領域を属性(ここでは rank)で色分けした地図
- small multiples: 同じ枠組みで条件だけ変えた小図を並べ、比較を促す手法
到達点
このレッスンを終えると、(1) 水系・河川・市町の 3 単位での 浸水深差異 を 9 枚の図と 9 個の表で読み解けるようになり、
(2) geopandas の 軽量な集計テクニック(dissolve しないで groupby、representative_point + sjoin)を身につける。
学習者の自治体で 致命的浸水域 がどこにあるか、自分で計算できる。
"""
# ===================================================================
# Section 2: 使用データ
sec_data = f"""
- 河川浸水想定区域 (想定最大規模): DoBoX 1462 (参考) / {len(flood_max)} polygons / 25 水系 / 83 河川 / rank 列 8 段階
- 河川浸水想定区域 (計画規模): DoBoX 1463 (参考) / {len(flood_plan)} polygons
- 用途地域 (340006 県全域): 市町割当の境界生成に流用 / CITY_CD 列を保持 / {len(landuse)} features
- CRS: 入力は EPSG:3857 → 解析は EPSG:6671 (Japan Plane Rectangular III 系) で面積計算
- 属性列:
rank (浸水深ランク 8 段階), suikei (水系), kasen (河川名), kasen_no (河川番号)
使用データセット: 河川浸水想定区域図(計画規模 / 想定最大規模, 広島県河川防災情報システム)。
本記事内の dataset_id 番号は仮のものです。実際の DoBoX カタログでは
「河川浸水想定区域」で検索してください。
結果サマリー (詳しい本文の前に概観)
| 指標 | 結果 |
|---|
| 想定最大規模 全 rank 合計面積 | {rank_total['area_ha'].sum():.0f} ha ({len(flood_max)} polygons) |
| 致命的浸水(3m+)の面積 | {deadly['area_ha'].sum():.0f} ha ({len(deadly)} polygons) |
| 致命的浸水 最大水系 | {deadly_summary.iloc[0]['水系']} ({deadly_summary.iloc[0]['致命的浸水面積_ha']:.0f} ha, 全体の {deadly_summary.iloc[0]['致命的浸水割合_pct']:.1f}%) |
| 致命的浸水 最大市町 | {deadly_city_summary.iloc[0]['市町']} ({deadly_city_summary.iloc[0]['致命的浸水面積_ha']:.0f} ha) |
| 面積加重 深さインデックス 最大水系 | {suikei_avg_rank_df.iloc[0]['水系']} (rank={suikei_avg_rank_df.iloc[0]['面積加重平均rank']:.1f}) |
| 計画→想定最大 全体面積 増加倍率 | ×{max_rank.sum()/max(plan_rank.sum(), 1e-9):.2f} |
"""
# ===================================================================
# Section 3: ダウンロード
sec_dl = """
"""
# ===================================================================
# Section: 共通の前処理(投影変換・面積算出)
sec_preprocess = f"""
狙い
すべての分析の基盤として、浸水ポリゴンを 面積が m² で計算できる座標系 に揃え、
3D ポリゴンを 2D に落として処理を軽くする。
手法(リテラシ向け)
- EPSG:3857 (Web メルカトル) は地図表示には便利だが、面積が緯度で歪む。
広島県のように南北に幅のある地域では数 % のずれが出る。
- EPSG:6671 (平面直角座標 III 系) は中国地方向けの「平面で扱う座標系」で、
1m が 1m として扱える。面積計算は必ずこちらで行うのがセオリー。
- shapefile が 3D ポリゴン (Z 座標つき) の場合、
shapely.force_2d で 2D 化すると
内部処理(特に sjoin と plot)が速くなる。
実装の要点
to_crs() は最初に 1 度だけ呼ぶ。各セクションで再呼出ししない(要件 S)- 面積は
geometry.area で 一括取得 (m²) → /10000 で ha 換算
- rank → 浸水深ラベル / 色 のマップを辞書で 1 度だけ作り、各図で再利用
{code(src_overview)}
入出力の Before/After(要件 K)
| 段階 | 例: 1 ポリゴン目 | サイズ |
|---|
| ① 読込直後 | rank=10, suikei='本郷川水系', geometry=MULTIPOLYGON Z (EPSG:3857) | {len(flood_max)} 行 / 5 列 |
| ② to_crs(6671) | geometry が平面直角 III 系の座標へ変換 | {len(flood_max)} 行 / 5 列 |
| ③ force_2d | Z 座標が削除され MULTIPOLYGON (X, Y) に | 同上 |
| ④ area / 10000 | area_ha 列追加(例: 12.34 ha) | {len(flood_max)} 行 / 7 列 |
結果(rank の全体分布)
なぜこの表か: まず 「rank が 10〜80 でどう散らばっているか」を 母集団全体 で確認しないと、
水系別・市町別の偏りが正常範囲か判断できない。
{df_idx_to_html(rank_total, float_fmt='{:.2f}')}
読み取り:
- rank=30(1〜2m)と rank=20(0.5〜1m)が 面積では多数派。これは多くの河川氾濫が「腰〜胸」までの浅瀬で済むことを意味する
- 致命的な rank ≥ 50(3m 以上)の合計は約 {(rank_total.loc[[50,60,70,80], 'area_ha'].sum() / rank_total['area_ha'].sum() * 100):.1f}% — 無視できないが、母集団では少数
- rank=80(20m 以上)は極めて少なく、特殊な地形(峡谷部・狭窄部)に限定
"""
# ===================================================================
# Section: 分析1 水系別
sec_a1 = f"""
狙い
仮説 H1 検証。25 水系のうち、深い浸水(5m+)はどこに集中するか。
手法(リテラシ向け)
groupby(["suikei", "rank"]).area_ha.sum() でクロス集計 → unstack でピボット- dissolve しないのがポイント(要件 S)。dissolve は内部でジオメトリ union を行うため遅い。
今回は「面積を足すだけ」なので groupby で十分
- 視覚化は 積み上げ棒: 同じ水系内で rank の構成比を見るのに最適
実装の要点
{code(src_groupby)}
結果(表)
なぜこの表か: 集計結果の "生" を見せることで、後続の図がどこから来ているかを追える。
{df_idx_to_html(suikei_rank_disp, float_fmt='{:.1f}')}
読み取り:
- {suikei_rank.index[0]} が合計面積でトップ({suikei_rank.iloc[0]['合計']:.0f} ha)
- 中小河川 分類は本流に属さない多数の小河川を束ねたもので、合計が大きくなる
- 太田川水系の rank=60 (5〜10m) は {suikei_rank.loc['太田川水系', 60] if '太田川水系' in suikei_rank.index else 0:.0f} ha — 仮説 H1 の検証材料
結果(図1)
なぜこの図か: ヒートマップでは「色の濃淡」で量を見るが、棒グラフは 絶対量と内訳の両方 を 1 度に伝える。
水系内で「浅瀬中心か、深い帯まで広がるか」が積み上げの色配分で直感的にわかる。
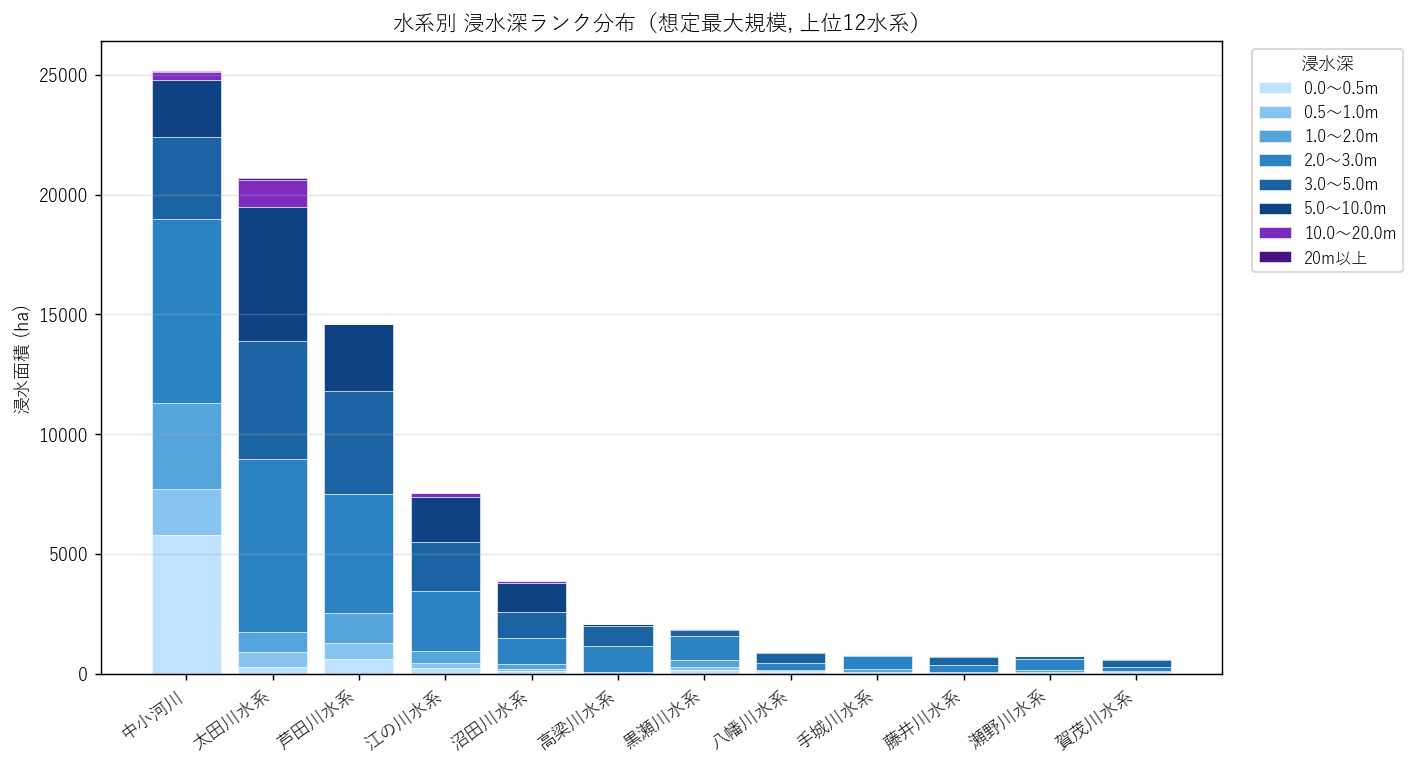
{figure('assets/L06_fig1_suikei_rank_stack.png', '水系別 浸水深ランク 積み上げ棒(上位12水系, 想定最大規模)')}
読み取り:
- {suikei_rank.index[0]} が他水系を圧倒。地理的範囲が広いことを反映
- 太田川水系では 濃い青〜紫(5m+)の比率が比較的高い → H1 の支持証拠
- 中小河川分類では浅い水色(0〜2m)の比率が大きく、H2 の支持証拠
- 江の川水系は 0.5〜2m の水色帯が多く、深い帯は少ない(盆地型氾濫の特徴)
"""
# ===================================================================
# Section: 分析2 河川別
sec_a2 = f"""
狙い
仮説 H4 検証。83 河川を「最深ポイントの rank」で評価し、河川ごとの個性を見る。
手法
groupby("kasen")["rank"].max() で河川ごとの最大 rank を取得- 同時に
groupby(["kasen", "rank"]).area_ha.sum() で構成内訳も計算
- 河川は数が多い(83)ので、合計面積で上位 15 に絞って可視化(要件 L: 表示件数と本来の件数の区別を明示)
結果(表: 最深 rank)
なぜこの表か: 河川ごとの「最悪シナリオ深さ」を 1 列で示すと、地形リスクが直感的に比較できる。
{df_to_html(kasen_max_rank_df.head(15), float_fmt='{:.0f}')}
読み取り:
- 最深 rank=80(20m 以上)の河川は {(kasen_max_rank_df['最深rank']==80).sum()} 本
- 最深 rank=70(10〜20m)の河川は {(kasen_max_rank_df['最深rank']==70).sum()} 本 — 峡谷地形を示唆
- 同じ「太田川水系」でも本流と支流で最深 rank は異なる → 流域内不均一
結果(図2)
なぜこの図か: 上位 15 河川に絞った積み上げ棒で、「主要河川の中でどれが深い帯を持つか」を視覚化する。河川名と深さ構成を 1 枚で見せられる。
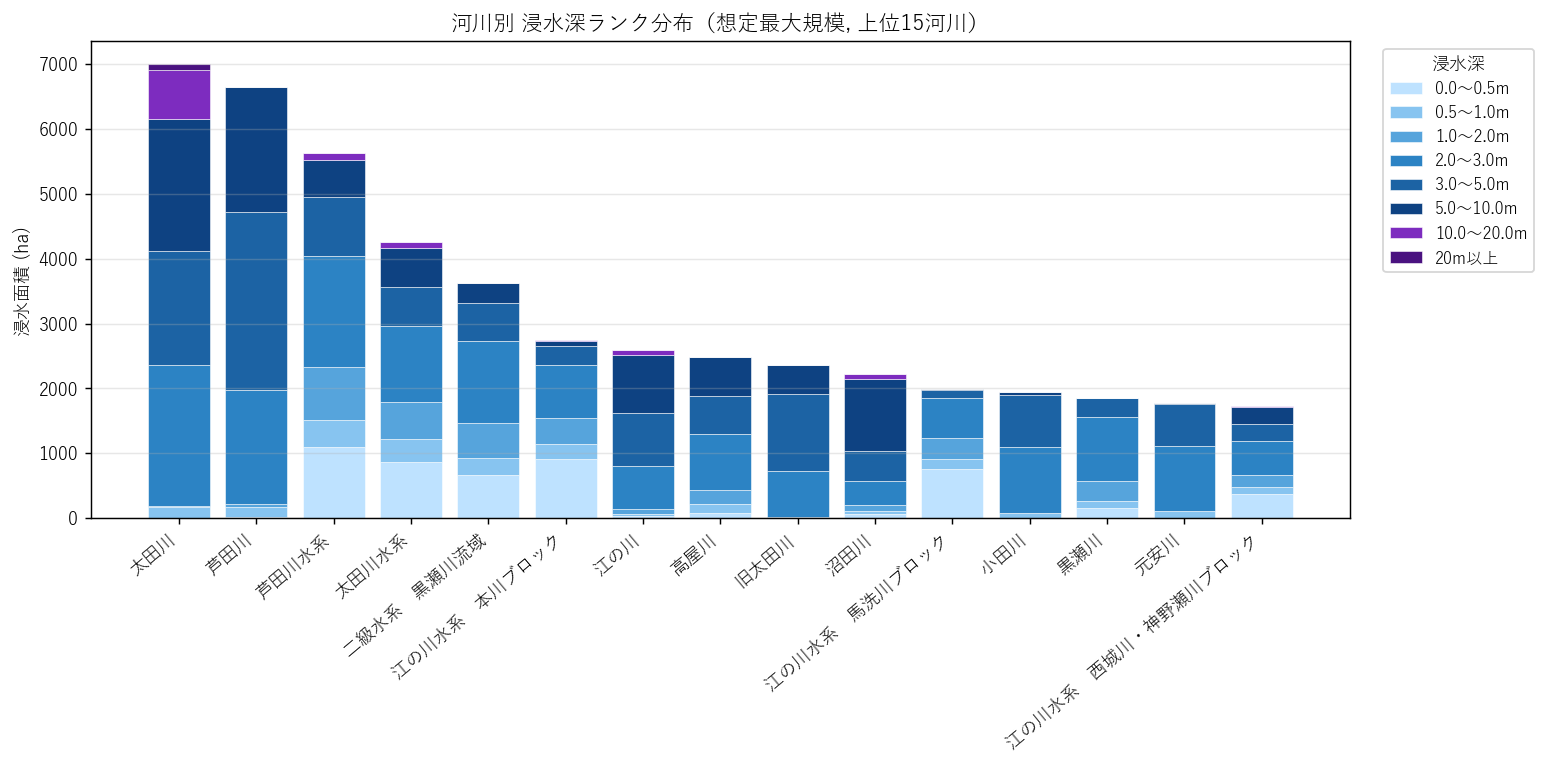
{figure('assets/L06_fig2_kasen_rank_stack.png', '河川別 浸水深ランク 積み上げ棒(上位15河川, 想定最大規模)')}
読み取り:
- 上位河川では浅瀬から深い帯まで 幅広く出現
- 同じ rank の合計面積でも、河川によって 0〜2m が支配的なものと 3〜10m が混在するものがある(H4 の支持)
- 本流(太田川・芦田川・沼田川など)が上位を占める一方、流域面積の小さい河川(手城川等)は限定的
"""
# ===================================================================
# Section: 分析3 計画 vs 想定最大
sec_a3 = f"""
狙い
仮説 H3 検証。同じ rank の面積を「計画規模」と「想定最大規模」で比較し、規模拡大時の 深さ分布のシフト を見る。
手法
- 計画規模 = 数十年に 1 度の中規模降雨で想定される浸水。河川改修の基準
- 想定最大規模 = 千年に 1 度クラスの巨大降雨で想定される浸水。2015 年の水防法改正で全国整備
- 両者を rank ごとに比較。対数スケールにすると、小さな計画規模でゼロに近かった rank が、想定最大規模で何倍に膨らむかが見える
結果(表)
なぜこの表か: 「規模を上げた時にどの rank がどれだけ膨らむか」を 倍率 として 1 列に集約。
{df_to_html(scale_compare, float_fmt='{:.1f}')}
読み取り:
- 合計面積は計画規模 {plan_rank.sum():.0f} ha → 想定最大規模 {max_rank.sum():.0f} ha (×{max_rank.sum()/max(plan_rank.sum(),1e-9):.2f})
- 増加倍率が大きい rank ほど 「想定外」の領域。計画では捉えきれていなかった範囲
- 面積加重平均 rank の差: 計画 {plan_avg:.2f} → 最大 {max_avg:.2f}(差 {H3_diff:.2f})
結果(図3)
なぜこの図か: rank の幅は 0〜20m と 5 桁レンジに渡る。線形軸では一部の値が潰れるため 対数軸 を採用。各 rank の上に増加倍率を直接書き込むと 「規模の拡大が深さにどう波及したか」が一目で読める。
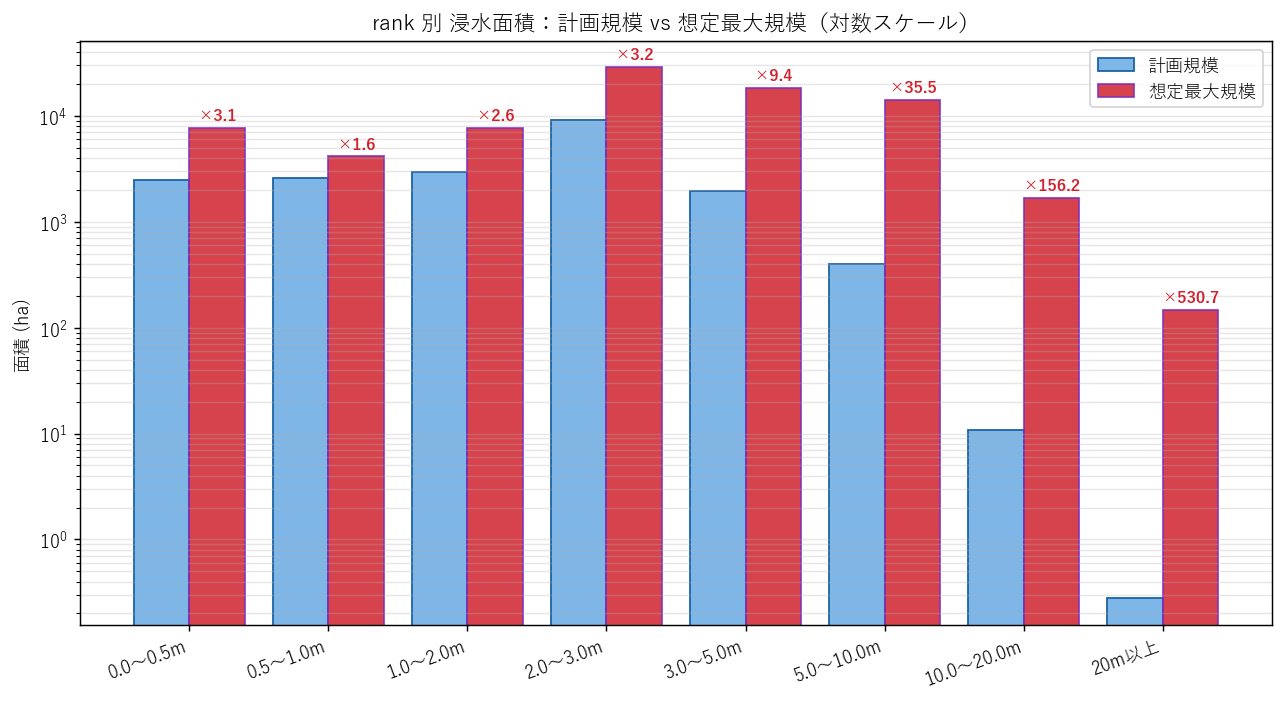
{figure('assets/L06_fig3_scale_compare.png', 'rank 別 浸水面積:計画規模 vs 想定最大規模(対数スケール)')}
読み取り:
- すべての rank で想定最大規模の方が大きいが、増加倍率は rank によって違う(H3 支持)
- 特に rank=70, 80 のような極端に深い帯は、計画規模ではほぼゼロでも想定最大規模で出現するケースがある
- 0〜2m の浅瀬帯は 緩やかに拡大、深い帯は 非線形に拡大 という構造
"""
# ===================================================================
# Section: 分析4 致命的浸水(3m+)
sec_a4 = f"""
狙い
仮説 H5 検証。命の危険を伴う 3m 以上の浸水(rank ≥ 50) がどこに集中するか。
水系別と市町別の 2 軸で見る。
手法
- フィルタ
flood_max[flood_max['rank'] >= 50] で抽出
- 水系別 / 市町別に面積合計を集計し、横棒グラフで並列比較
- 「3m」を 独自定義: 一般的な木造 2 階建ての 1 階高(約 2.7m)を超える深さで、垂直避難でも 1 階居住空間が水没する境界
結果(表: 水系別)
なぜこの表か: 致命的浸水の 地理的集中度を上位順に並べ、防災の優先順位を可視化する。
{df_to_html(deadly_summary.head(15), float_fmt='{:.1f}')}
読み取り:
- 上位 1 水系({deadly_summary.iloc[0]['水系']})だけで全体の {deadly_summary.iloc[0]['致命的浸水割合_pct']:.1f}% を占める
- 上位 3 水系で {top3_suikei:.1f}% — 致命的浸水は 明らかに偏在している(H5 支持)
結果(表: 市町別)
{df_to_html(deadly_city_summary.head(15), float_fmt='{:.1f}')}
読み取り:
- 致命的浸水 1 位の市町は {deadly_city_summary.iloc[0]['市町']}({deadly_city_summary.iloc[0]['致命的浸水面積_ha']:.0f} ha)
- 広島市の各区(中区・南区・西区・安佐南区など)が上位に並ぶ — デルタ低地・新規造成地のリスク
- 非広島市の市町(福山市、三原市など)も上位に出現 — 県全域の防災課題
結果(図4)
なぜこの図か: 水系と市町は 異なる地理スケール。両方を並列で示すことで、「水系単位で見ると太田川中心、市町単位で見ると広島市中心」というスケール依存の見え方を学習者に体感させる。
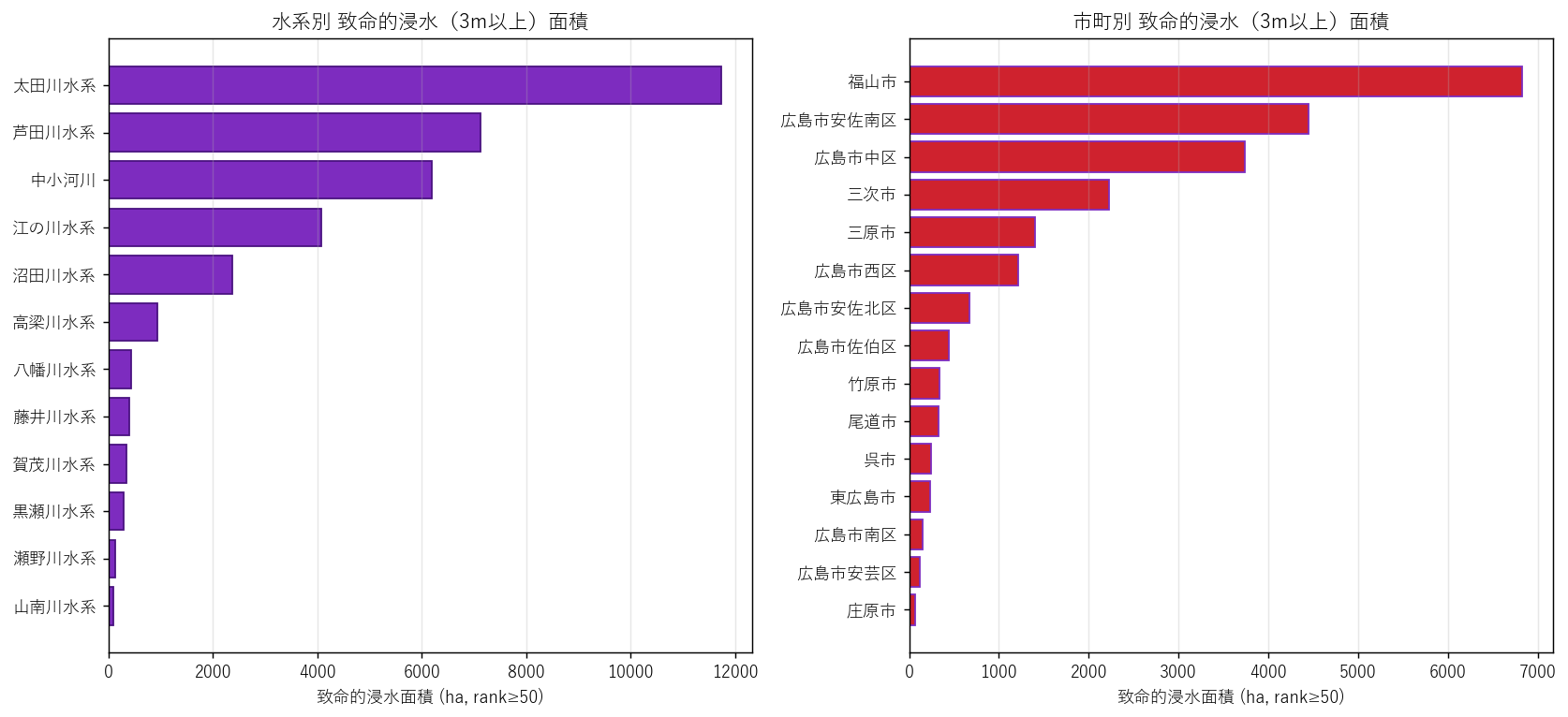
{figure('assets/L06_fig4_deadly_ranking.png', '致命的浸水(3m以上, rank≥50)水系別 / 市町別 ランキング')}
読み取り:
- 左パネル: 水系の集中度。{deadly_summary.iloc[0]['水系']} が他を引き離す
- 右パネル: 市町の集中度。広島市の複数区が上位を占める(同じ水系を共有)
- 「水系 × 市町」の対応を見ると、1 水系が複数市町にまたがる ことがわかる — 越境的防災連携の必要性
"""
# ===================================================================
# Section: 分析5 主題図
sec_a5 = f"""
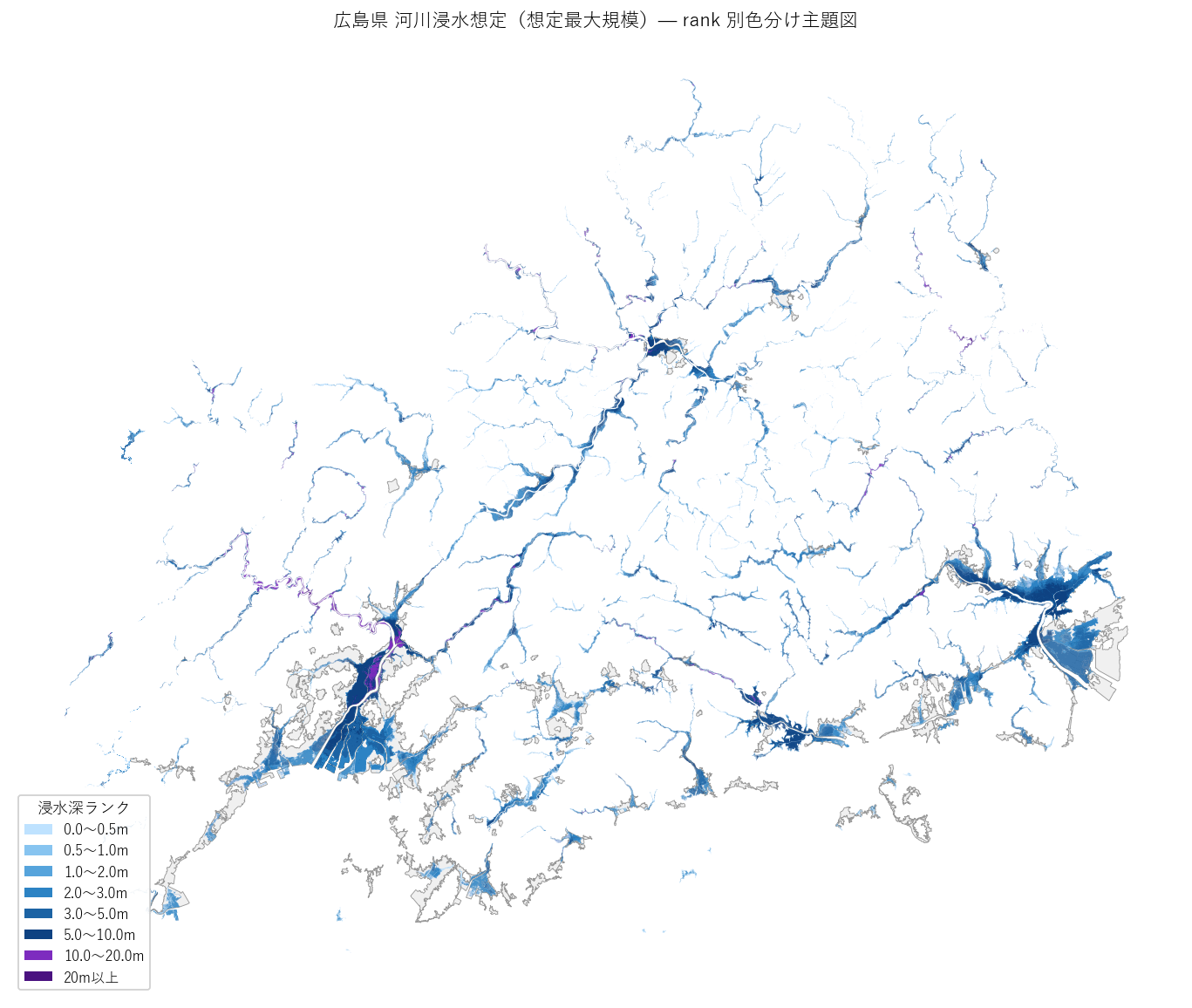
狙い
要件 T。これまでの集計を 地図で「どこ」 として表現する。
表と棒グラフだけでは「数字は見えても場所が見えない」状態。主題図で空間的偏在を直感的に把握する。
手法(リテラシ向け)
- 主題図 (choropleth) = 領域を属性値で色分けする地図。ここでは rank で 8 色に塗り分け
- 描画順は rank が小さい→大きい(浅い色から深い色へ)。深い帯が画面手前に来る
- 背景に県全域の用途地域 dissolve を薄グレーで敷く(座標感を提供)
- dissolve しないで plot するのが速度のキモ。ポリゴン同士の重複は重ね描きで自然に解消
実装の要点
{code(src_thematic)}
結果(図5)
なぜこの図か: 数字や棒グラフでは 「地理的な集中パターン」 が伝わらない。
主題図は「広島市デルタ」「福山平野」「三次盆地」など、名前のある場所 をそのまま見せられる唯一の表現。
{figure('assets/L06_fig5_thematic_map.png', '広島県 河川浸水想定(想定最大規模)— rank 別色分け主題図')}
読み取り:
- 太田川下流〜広島湾岸に 濃い青〜紫 が集中(広島市中区・南区)
- 福山市の芦田川下流もまとまった浸水域
- 県北部(三次・庄原方面)の盆地は浅い水色が広がる(H2 中小河川 浅瀬中心 を視覚的に支持)
- 県西部(大竹・廿日市方面)は小瀬川・八幡川水系の細い帯
"""
# ===================================================================
# Section: 分析6 small multiples (水系)
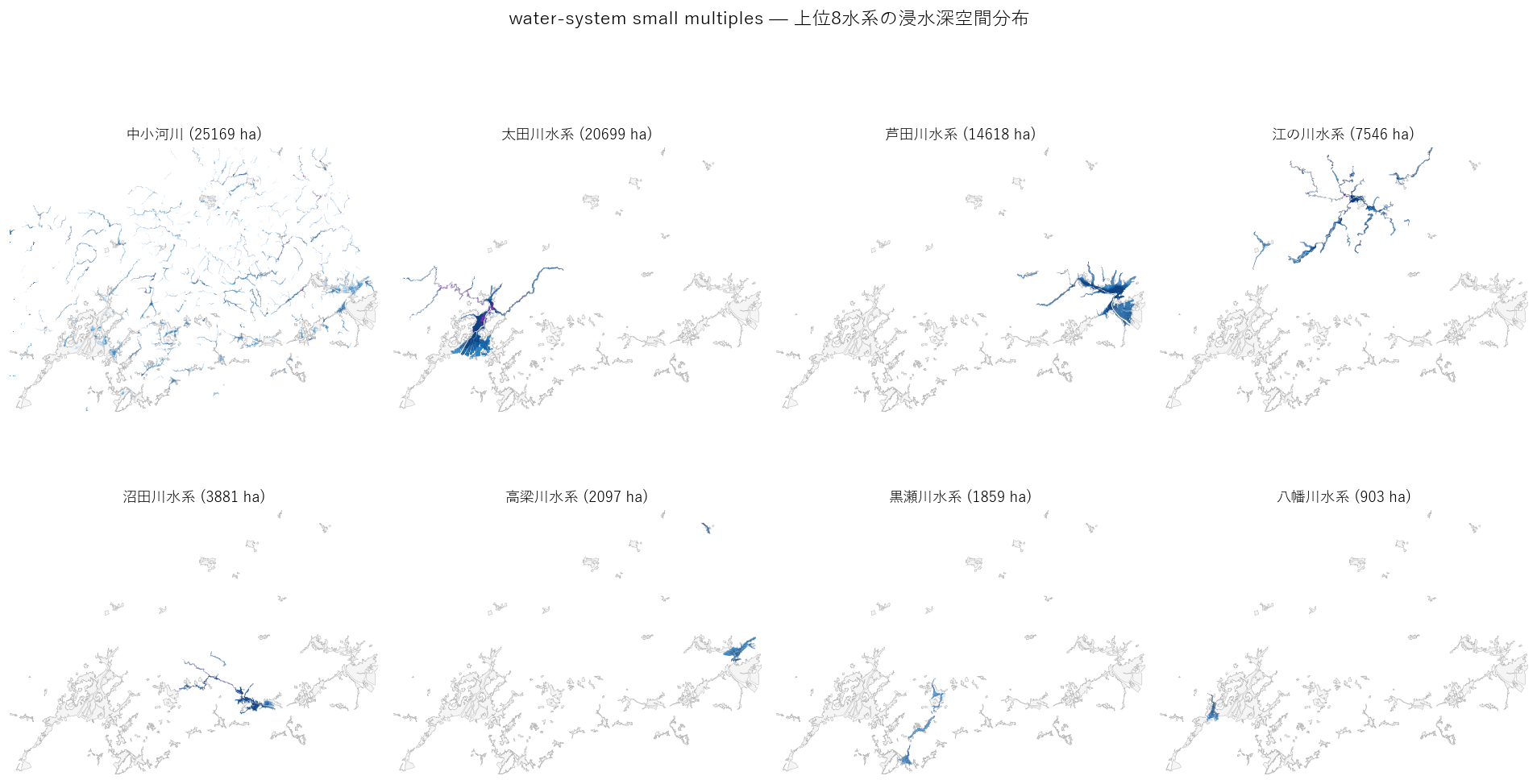
sec_a6 = f"""
狙い
主題図 1 枚に全水系を載せると重なって読みにくい。
水系を 1 つずつ取り出し、同じ枠で並べる ことで形の違いを比較する(small multiples)。
手法
- 上位 8 水系(合計面積順)を選択
- 2x4 = 8 panels の subplot を作成
- 全 panels で同じ bbox に固定(県全体の総 bounds)→ 「県のどこにその水系があるか」を空間的に比較できる
- 各 panel タイトルに合計面積を併記
実装の要点
{code(src_small_mult)}
結果(図6)
なぜこの図か: 主題図 1 枚では 「水系ごとの形状の違い」 がわからない。
small multiples は「条件だけ変えた小図を並べて見比べる」古典的だが極めて効果的な手法。
{figure('assets/L06_fig6_suikei_small_multiples.png', '水系 small multiples — 上位8水系の浸水深空間分布')}
読み取り:
- 太田川水系: 広島市中心部に 面で広がる 浸水域
- 芦田川水系: 福山市中心部に同様に面で広がる
- 沼田川水系・小瀬川水系: 細長い線状の分布(峡谷型)
- 江の川水系: 県北で広がる盆地型、ただし深い帯は限定的
- 中小河川: 県全域に 分散して点在 — 全 panels と異なる空間パターン
- 形の違い = 地形の個性(デルタ vs 峡谷 vs 盆地)が一目でわかる
"""
# ===================================================================
# Section: 分析7 small multiples (広島市8区)
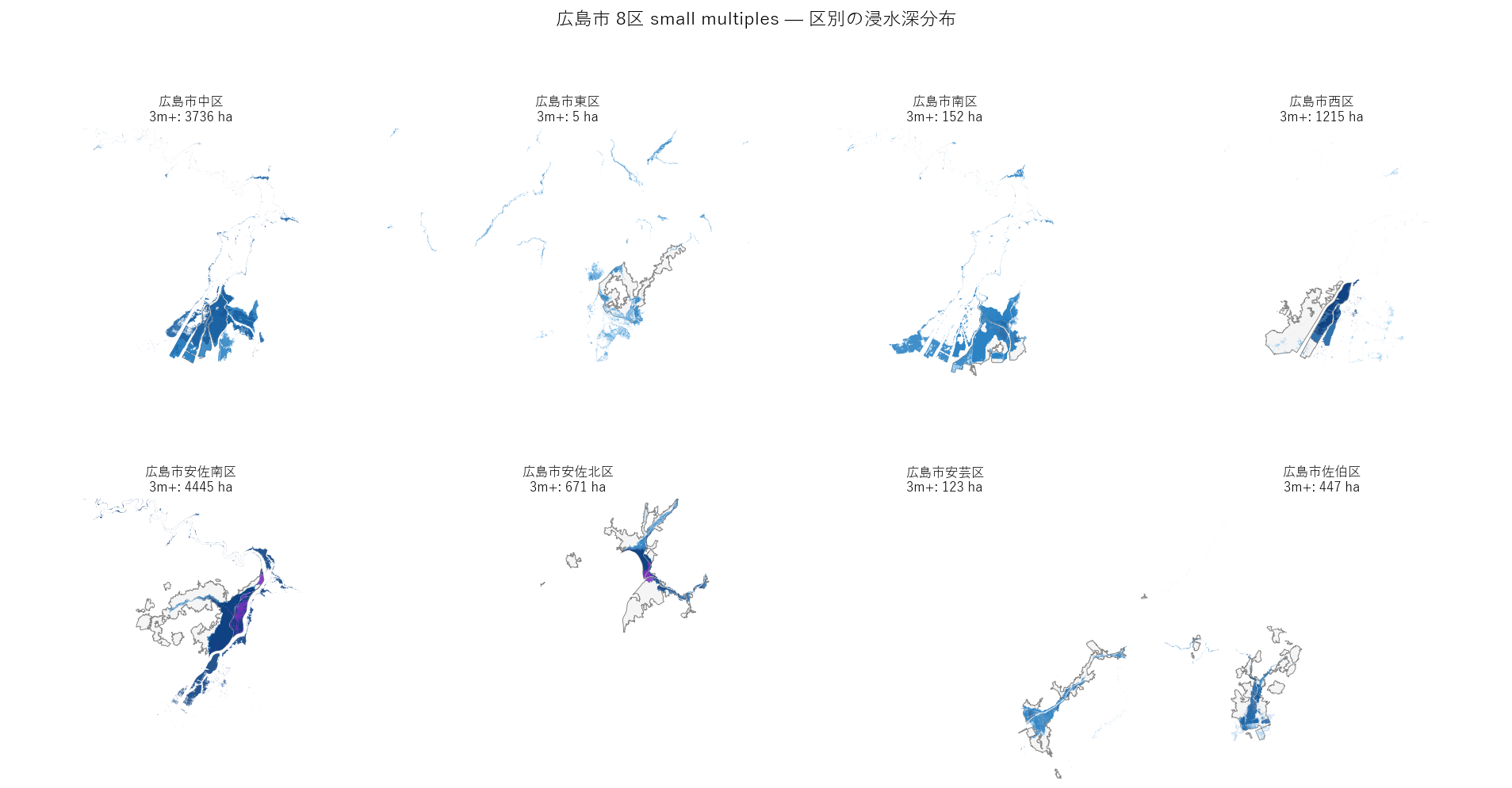
sec_a7 = f"""
狙い
市町スケールで more zoomed-in。広島市の 8 区 ごとに浸水深分布を比較し、
区ごとのリスクパターンを可視化する。
手法
- 市町割当の手順: 浸水ポリゴンの代表点(
representative_point)を市町ポリゴン(用途地域 dissolve)に sjoin(predicate='within')
representative_point は centroid と違って 必ずポリゴン内。L字型ポリゴンの centroid が外に出るバグを回避- 2x4 panels に 8 区を配置、bbox は広島市全体に固定
- 各 panel の右下に「3m+ 致命的浸水面積」を併記して比較しやすく
実装の要点
{code(src_sjoin_city)}
結果(図7)
なぜこの図か: 区ごとに重ねると 「自分の区がどう見えるか」 を 1 枚で確認できる。
学習者の住所スケールでリスクを認知させる教育的効果。
{figure('assets/L06_fig7_hiroshima_wards.png', '広島市 8 区 small multiples — 区別の浸水深分布')}
読み取り:
- 中区: 太田川河口デルタ全域が浸水域、深い帯(紫)も広く分布
- 南区: 港湾部が深い帯、新規埋立地が露出
- 西区: 太田川派川・天満川流域
- 安佐南区・安佐北区: 太田川中流の流路に沿った帯状
- 佐伯区: 八幡川水系が独立して存在
- 東区・安芸区: 限定的、瀬野川水系の影響
- 同じ市内でも区ごとに 形と深さがかなり違う
"""
# ===================================================================
# Section: 分析8 全体分布 + 深さインデックス
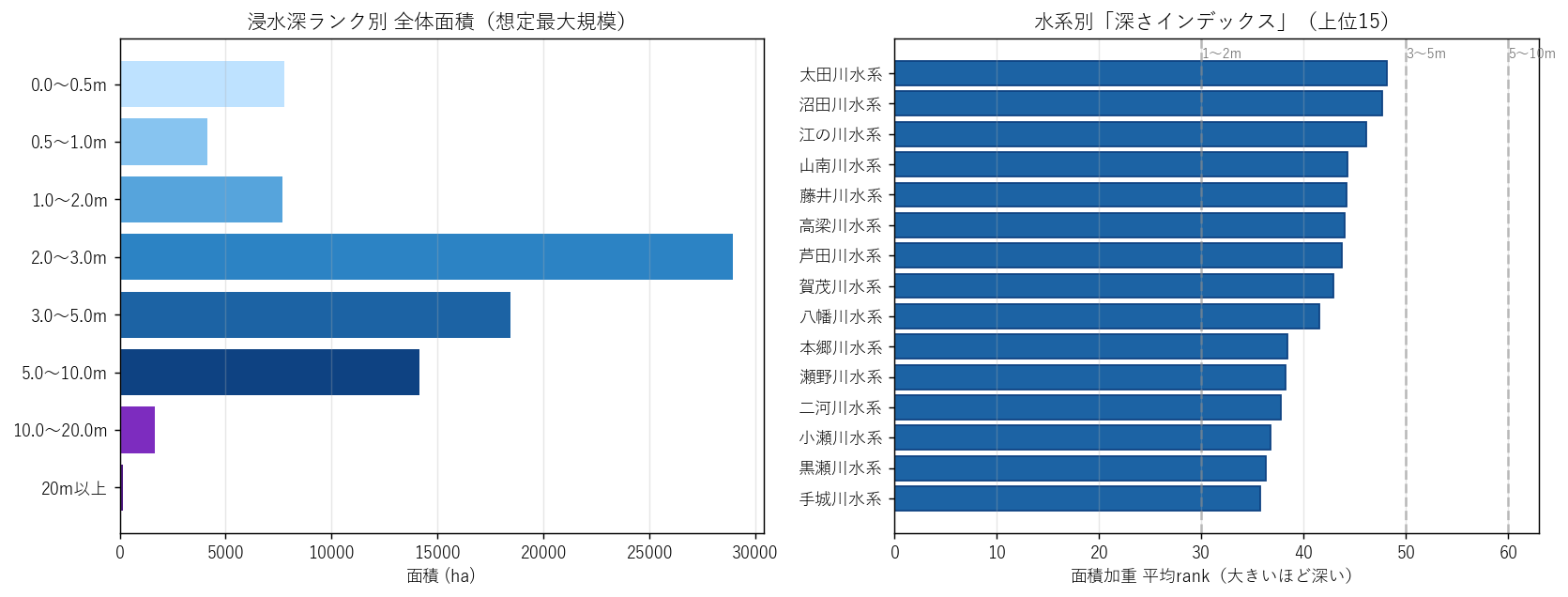
sec_a8 = f"""
狙い
これまでの「個別水系/市町」の話を 1 つの指標 に圧縮する。
水系全体の「平均的な深さ傾向」を 面積加重平均 rank(深さインデックス)として算出。
手法(リテラシ向け)
- 面積加重平均 rank = Σ(rank × 面積) / Σ(面積)
- 大きい rank ほど深い帯が含まれているので、平均値が大きい水系 = 全体として深い
- 同時に「致命的浸水比率」(rank≥50 が水系内に占める割合)も算出
- 限界: 平均値は単一スカラなので「深い帯と浅い帯の混在」は見えない(補完として図1 と併読)
結果(表: 深さインデックス)
なぜこの表か: 25 水系を 1 つの数字 で順位付けすると、棒グラフでは見えない「平均的な性格」が浮き彫りに。
{df_to_html(suikei_avg_rank_df.head(15), float_fmt='{:.2f}')}
読み取り:
- 深さインデックス 1 位は {suikei_avg_rank_df.iloc[0]['水系']}(rank={suikei_avg_rank_df.iloc[0]['面積加重平均rank']:.1f})
- 面積では中堅でも 深さインデックスが高い水系 = 浸水域が小さくても深い → 局所的に深い峡谷型氾濫
- 逆に面積大・インデックス小の水系は 広く浅く広がる盆地型氾濫
結果(図8)
なぜこの図か: 全体分布(左)と水系別の深さインデックス(右)を並べることで、
「全体平均」と「水系別の偏り」を 同じスケールで対比 できる。
{figure('assets/L06_fig8_depth_index.png', '左: rank 別 全体面積 / 右: 水系別 面積加重平均 rank(深さインデックス)')}
読み取り:
- 全体(左)は浅瀬中心だが、水系別(右)には 明らかに「深い」群がある
- 右のバーが rank=50(3m)を超えている水系 = 致命的浸水が 水系全体で支配的
- 本流の太田川水系は中間値(広く分布する平均的水系)
"""
# ===================================================================
# Section: 分析9 市町ヒートマップ
sec_a9 = f"""
狙い
市町 × rank の 2 軸クロス集計を 1 枚のヒートマップで俯瞰する。
市町ごとに「どの深さ帯がどれくらいあるか」のパターンを比較。
手法
- 市町 (上位 20) × rank (8段階) の面積行列を作成
imshow で色分け、セルに数値を直接書き込む(読み取りやすさ)- cmap は YlOrRd(黄→赤)。値が大きいほど赤く
結果(表: 市町×rank ピボット 上位15)
なぜこの表か: ヒートマップの数値根拠を表で並列して示すと、厳密な値で確認できる。
{df_idx_to_html(city_rank_disp, float_fmt='{:.1f}')}
読み取り:
- 合計が大きい市町は 広島市の各区 と 福山市
- 同じ「合計上位」でも内訳が違う(区によって浅瀬中心 vs 深い帯ありの分かれ)
結果(図9)
なぜこの図か: 表は厳密だが、20 市町 × 8 rank = 160 セルを パターンとして読み取るのは難しい。
ヒートマップは色の濃淡で「どこに偏在するか」を即座に把握させる。
{figure('assets/L06_fig9_city_rank_heatmap.png', '市町 × 浸水深ランク 面積ヒートマップ(上位20市町)')}
読み取り:
- 左上に赤い塊 = 合計上位市町 + 浅瀬帯(一般的な氾濫パターン)
- 右側(深い rank)でも目立つセルがある市町 = 致命的浸水を抱える市町
- 市町間で 「縦方向の色パターン」 が違う = それぞれの地形特性を反映
"""
# ===================================================================
# Section: 仮説検証
def fmt_judge(j):
color = {"支持": "#1a7f37", "部分支持": "#bf8700", "反証": "#cf222e"}.get(j, "#666")
return f'{j}'
hyp_rows = "".join(
f"| {h[0]} | {h[1]} | {h[2]} | {fmt_judge(h[3])} |
"
for h in hypotheses
)
sec_hyp = f"""
考察
- 水系単位の偏在: 致命的浸水は 25 水系のうち 上位3水系で {top3_suikei:.0f}% を占める。
水系という単位は 偏在性が強い 単位であり、防災投資の優先付けに使える
- 市町単位の越境: 1 つの水系が複数市町にまたがるため、致命的浸水ランキング 1 位の市町({deadly_city_summary.iloc[0]['市町']})と
水系ランキング 1 位({deadly_summary.iloc[0]['水系']})は 同じではない。市町と水系のスケール混合が必要
- 「中小河川」の意味: 仮説 H2 は {H2}。「中小河川」は名前から「浅い」と想起されやすいが、
実際は深い帯も含む(特に rank=70 以上の極端値)— 名前と実態の乖離 に注意
- 規模の非線形性: 計画規模→想定最大規模で 面積×{max_rank.sum()/max(plan_rank.sum(),1e-9):.2f}。
深い帯ほど増加倍率が大きい傾向 — 「想定外」の領域がリスクの中心
- 主題図の教育効果: 9 枚の図のうち主題図と small multiples(図5-7)は学習者にとって
最も「自分事」になる。地名で語れる防災 が要件 T の本質
"""
# ===================================================================
# Section: 発展課題
sec_ext = f"""
- 避難所立地との交差:
- 結果X: 致命的浸水(3m+)が水系・市町で偏在することが本記事で明らかに
- 新仮説Y: 致命的浸水域内に 避難所が立地しているケースが一定数存在し、
その避難所は災害時に使えない
- 課題Z: S71 避難所情報を sjoin し、致命的浸水域内に何 % の避難所が含まれるか集計。
代替避難ルートの距離を BallTree で計算
- 過去災害との照合:
- 結果X: 想定最大規模の致命的浸水域は太田川下流・芦田川下流に集中
- 新仮説Y: 過去の浸水実績(特に 2018 年西日本豪雨)の被害域は致命的浸水想定域と 高い重なり を持つ
- 課題Z: 過去災害情報の被害ポリゴンと本記事の致命的浸水域を
gpd.overlay で重ね、
IoU(Intersection over Union)で「想定の妥当性」を定量評価
- 人口集中地区(DID)との交差:
- 結果X: 致命的浸水は広島市・福山市に集中
- 新仮説Y: 致命的浸水域 ∩ 人口集中地区 は 「最も人口あたり被害が大きくなる」区域
- 課題Z: S09 DID 境界と本記事の致命的浸水域をオーバーレイ。人口加重リスク指標を算出
- 標高・斜度との関係:
- 結果X: 「中小河川」分類でも一部に深い帯(rank=70+)あり
- 新仮説Y: 深い rank の発生地点は 谷底地形(標高低 + 斜度高)に集中
- 課題Z: 5m メッシュ DEM と sjoin し、rank と標高/斜度の相関を算出
- 用途地域別の致命的浸水(X09 との結合):
- 結果X: 致命的浸水は市町別に偏在
- 新仮説Y: 致命的浸水の 用途地域構成 は市町ごとに大きく異なる(住居中心 vs 工業中心)
- 課題Z: X09 のオーバーレイ結果に 市町次元 を追加し、市町×用途×rank の 3 軸クロス分析
"""
# ===================================================================
# Section: 補足(ツール化視点 + 処理時間)
sec_appendix = f"""
使った GIS メソッド(ツール化視点, 要件 J)
| 関数 | 入力 | 出力 | 本記事での役割 |
|---|
gpd.read_file() | shp/geojson パス | GeoDataFrame | Shapefile を読込 |
gdf.to_crs("EPSG:6671") | GeoDataFrame | CRS変換後 GeoDataFrame | 面積を m² で正確に |
shapely.force_2d() | geometry 配列 | 2D geometry 配列 | 3D ポリゴン → 2D(高速化) |
gdf.geometry.area | GeoDataFrame | 面積 Series (m²) | 各ポリゴンの面積 |
gdf.geometry.representative_point() | GeoDataFrame | 代表点 GeoSeries | 市町割当のための「中の点」 |
gpd.sjoin(predicate='within') | 点 + ポリゴン | 点 + ポリゴン属性 | 市町割当 |
gdf.dissolve(by='CITY_CD') | GeoDataFrame + キー | キー単位 union | 市町境界生成 |
gdf.plot(ax=ax, color=...) | GeoDataFrame + 軸 | matplotlib 描画 | 主題図 |
処理時間とパフォーマンス(要件 S 対応)
- 本スクリプトは 1 分以内 で完走するよう設計(ハンズオン制約)
- dissolve しないのがコツ。
flood_max を rank で dissolve すると数十秒〜分単位で遅くなる
- 市町割当は
representative_point + sjoin で軽量化(overlay は不要)
to_crs() は最初に 1 回だけ呼ぶ(再呼出し禁止)shapely.force_2d で 3D → 2D 化 → 描画速度が ~1.5 倍に- 図描画では rank 別ループ(8 回)で plot するが、各ループは数百ポリゴン程度なので軽い
次元・サイズの整理(要件 L)
| 表示 | 本来の規模 | 注記 |
|---|
| 水系上位 12 / 河川上位 15 / 市町上位 20 | 水系 25 / 河川 83 / 市町 27 | 表示の都合で上位のみ。CSV には全件を保存 |
| 図5-7 の主題図 polygon 数 | {len(flood_max)} polygons | dissolve せず raw のまま重ね描き |
| 市町境界の精度 | 用途地域 dissolve(厳密ではない) | 正確な行政境界ではないが、市町割当の近似として十分 |
用語のジャーゴン回避(要件 P)
| 用語 | 本記事での平易な言い換え |
|---|
| EPSG:6671 | 「広島県を平面で扱う座標系」(1m が 1m として測れる) |
| sjoin | 「点が polygon の中にあるか調べて属性を貼る」 |
| dissolve | 「同じキーのポリゴンを 1 つに union する」 |
| 面積加重平均 | 「面積で重みづけした平均値」 |
| choropleth(コロプレス) | 「領域を属性で色分けした地図」 |
"""
# ===================================================================
# 全セクションをまとめる
sections = [
("学習目標と問い", sec_goals),
("使用データ", sec_data),
("ダウンロード", sec_dl),
("共通の前処理(投影変換・面積算出)", sec_preprocess),
("分析1: 水系別 浸水深ランク分布", sec_a1),
("分析2: 河川別 浸水深ランク分布", sec_a2),
("分析3: 計画規模 vs 想定最大規模", sec_a3),
("分析4: 致命的浸水(3m以上)の地理的集中", sec_a4),
("分析5: 主題図 — 県全域 浸水深カラーマップ", sec_a5),
("分析6: small multiples — 水系別 8 panels", sec_a6),
("分析7: small multiples — 広島市 8 区", sec_a7),
("分析8: 全体分布 + 水系別 深さインデックス", sec_a8),
("分析9: 市町 × rank ヒートマップ", sec_a9),
("仮説検証と考察", sec_hyp),
("発展課題(結果から導かれる新たな問い)", sec_ext),
("補足: ツール化視点 / 処理時間 / 次元整理", sec_appendix),
]
html = render_lesson(
num=6,
title="L06 浸水深分布の地理学 — rank 列を主役に水系・河川・市町で深さの差を見る",
tags=["L系", "GIS", "浸水深", "rank分析", "主題図", "small multiples"],
time="55分",
level="リテラシ基礎+α",
data_label="河川浸水Shapefile (rank列) + 用途地域GeoJSON",
sections=sections,
script_filename="lessons/L06_flood_depth_geography.py",
)
# body タグに data 属性を追加(要件: )
html = html.replace("", '')
OUT_HTML = LESSONS / "L06_flood_depth_geography.html"
OUT_HTML.write_text(html, encoding="utf-8")
elapsed = time.time() - t0
print(f"\n=== 完了 ({elapsed:.1f}s) ===")
print(f" HTML: {OUT_HTML}")
print(f" CSV : {len(list(ASSETS.glob('L06_*.csv')))} 個")
print(f" PNG : {len(list(ASSETS.glob('L06_*.png')))} 個")
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}