L06 浸水深分布の地理学 — rank 列を主役に水系・河川・市町で深さの差を見る
データ取得手順
⚠️ このスクリプトは自動取得に対応していません。以下のデータセットを DoBoX から手動でダウンロードし、data/extras/ 以下に保存してください。
| ID | データセット名 |
|---|---|
| #666 | dataset #666 |
| #888 | 都市計画区域情報_区域データ_安芸高田市_行政区域 |
| #999 | dataset #999 |
| #1462 | dataset #1462 |
| #1463 | dataset #1463 |
実行コマンド:
cd "2026 DoBoX 教材"
python -X utf8 lessons/L06_flood_depth_geography.py
DoBoX のオープンデータは申請不要・商用/非商用とも利用可。
data/extras/ は .gitignore 対象(約 57 GB のキャッシュ)。
スクリプト実行で自動再生成されます。
学習目標と問い
広島県の河川浸水想定区域 Shapefile の
rank 列(10〜80 の 8 段階)は、
0.5m から 20m 超まで 命の危険度がまるで違う 浸水深を 1 列で表現している。
この列を 水系・河川・市町 の 3 つの地理単位で集計し、
「どの地域が、どのくらい深く沈むのか」を可視化する。
主な問い (3 段階)
- 水系の問い: 25 水系のうち、どこに深い浸水(5m+)が集中するか?
- 市町の問い: 県内の市町のうち、致命的浸水(3m+)面積が大きいのはどこか?
- 規模の問い: 計画規模 vs 想定最大規模で深さ分布はどう変化するか?
立てた仮説 (H1〜H5)
- H1: 太田川水系で深い浸水(5m+)が集中する(広島市デルタ低地)
- H2: 「中小河川」分類は浅瀬(0〜2m)中心で、深さは限定的
- H3: 計画規模と想定最大規模で深さ分布が大きく異なる
- H4: 河川別で「最深ポイント」の rank が異なる(一律ではない)
- H5: 致命的深さ(3m+)は上位水系に集中する
用語の定義(本レッスン独自)
- rank(浸水深ランク): 10=0〜0.5m / 20=0.5〜1m / 30=1〜2m / 40=2〜3m / 50=3〜5m / 60=5〜10m / 70=10〜20m / 80=20m以上(広島県河川防災情報システム凡例)
- 水系: 主要河川とその支流をまとめた集水単位。広島県では 25 水系(含「中小河川」分類)
- 致命的浸水: 本記事独自定義。rank ≥ 50(=3m 以上)の浸水域を指す。3m は通常の 2 階建て住宅の 1 階を超える深さで、垂直避難でも危険
- 面積加重平均 rank: 各ポリゴンの rank を面積で重み付け平均した「深さインデックス」。値が大きいほど水系全体が深い傾向
- 主題図 (choropleth): 領域を属性(ここでは rank)で色分けした地図
- small multiples: 同じ枠組みで条件だけ変えた小図を並べ、比較を促す手法
到達点
このレッスンを終えると、(1) 水系・河川・市町の 3 単位での 浸水深差異 を 9 枚の図と 9 個の表で読み解けるようになり、
(2) geopandas の 軽量な集計テクニック(dissolve しないで groupby、representative_point + sjoin)を身につける。
学習者の自治体で 致命的浸水域 がどこにあるか、自分で計算できる。
使用データ
- 河川浸水想定区域 (想定最大規模): DoBoX 1462 (参考) / 613 polygons / 25 水系 / 83 河川 / rank 列 8 段階
- 河川浸水想定区域 (計画規模): DoBoX 1463 (参考) / 416 polygons
- 用途地域 (340006 県全域): 市町割当の境界生成に流用 / CITY_CD 列を保持 / 2629 features
- CRS: 入力は EPSG:3857 → 解析は EPSG:6671 (Japan Plane Rectangular III 系) で面積計算
- 属性列:
rank(浸水深ランク 8 段階),suikei(水系),kasen(河川名),kasen_no(河川番号)
DoBoXには河川浸水想定区域情報が 39 dataset_id 公開されています:
- 計画規模 19件: 全河川版 (#295) + 個別18水系 (#35 太田川 / #157 江の川 / #279 芦田川 / #280 沼田川 ほか) + 単独河川
- 想定最大規模 20件: 全河川版 (#313) + 個別18水系 + 中小河川ブロック
suikei列でフィルタすれば個別水系の中身を完全再現できます (例: flood_max[flood_max['suikei']=='太田川水系'] で #36 と等価)。
したがって本記事は 河川浸水想定区域 39 件全部を論理カバー しています。
個別水系特化の深掘り研究 (M1 太田川 / M2 江の川 / M3 芦田川 / M4 沼田川 / M5 黒瀬川) は今後の発展課題です。
dataset_id 番号は仮のものです。実際の DoBoX カタログでは
「河川浸水想定区域」で検索してください。
結果サマリー (詳しい本文の前に概観)
| 指標 | 結果 |
|---|---|
| 想定最大規模 全 rank 合計面積 | 82973 ha (613 polygons) |
| 致命的浸水(3m+)の面積 | 34405 ha (251 polygons) |
| 致命的浸水 最大水系 | 太田川水系 (11738 ha, 全体の 34.1%) |
| 致命的浸水 最大市町 | 福山市 (6825 ha) |
| 面積加重 深さインデックス 最大水系 | 太田川水系 (rank=48.2) |
| 計画→想定最大 全体面積 増加倍率 | ×4.25 |
ダウンロード
| ファイル | 内容 |
|---|---|
| L06_suikei_rank_area.csv | 水系×rank 面積ピボット (25 水系) |
| L06_kasen_rank_area.csv | 河川×rank 面積ピボット (83 河川) |
| L06_city_rank_area.csv | 市町×rank 面積ピボット |
| L06_scale_compare.csv | 計画 vs 想定最大 規模比較 |
| L06_deadly_by_suikei.csv | 致命的浸水(3m+)水系別 |
| L06_deadly_by_city.csv | 致命的浸水(3m+)市町別 |
| L06_rank_total.csv | rank 別 全体集計 |
| L06_kasen_max_rank.csv | 河川別 最深 rank |
| L06_suikei_avg_rank.csv | 水系別 面積加重平均 rank |
| L06_hypothesis_check.csv | 仮説 H1-H5 判定結果 |
| L06_fig1_suikei_rank_stack.png | 図1 水系別 積み上げ棒 |
| L06_fig2_kasen_rank_stack.png | 図2 河川別 積み上げ棒 |
| L06_fig3_scale_compare.png | 図3 規模比較 |
| L06_fig4_deadly_ranking.png | 図4 致命的浸水ランキング |
| L06_fig5_thematic_map.png | 図5 県全域 主題図 |
| L06_fig6_suikei_small_multiples.png | 図6 水系 small multiples (8 panels) |
| L06_fig7_hiroshima_wards.png | 図7 広島市8区 small multiples |
| L06_fig8_depth_index.png | 図8 全体分布 + 深さインデックス |
| L06_fig9_city_rank_heatmap.png | 図9 市町×rank ヒートマップ |
| L06_flood_depth_geography.py | 再現スクリプト |
{kind=link}
{kind=link}
{kind=link}
共通の前処理(投影変換・面積算出)
狙い
すべての分析の基盤として、浸水ポリゴンを 面積が m² で計算できる座標系 に揃え、 3D ポリゴンを 2D に落として処理を軽くする。
手法(リテラシ向け)
- EPSG:3857 (Web メルカトル) は地図表示には便利だが、面積が緯度で歪む。 広島県のように南北に幅のある地域では数 % のずれが出る。
- EPSG:6671 (平面直角座標 III 系) は中国地方向けの「平面で扱う座標系」で、 1m が 1m として扱える。面積計算は必ずこちらで行うのがセオリー。
- shapefile が 3D ポリゴン (Z 座標つき) の場合、
shapely.force_2dで 2D 化すると 内部処理(特に sjoin と plot)が速くなる。
実装の要点
to_crs()は最初に 1 度だけ呼ぶ。各セクションで再呼出ししない(要件 S)- 面積は
geometry.areaで 一括取得 (m²) → /10000 で ha 換算 - rank → 浸水深ラベル / 色 のマップを辞書で 1 度だけ作り、各図で再利用
入出力の Before/After(要件 K)
| 段階 | 例: 1 ポリゴン目 | サイズ |
|---|---|---|
| ① 読込直後 | rank=10, suikei='本郷川水系', geometry=MULTIPOLYGON Z (EPSG:3857) | 613 行 / 5 列 |
| ② to_crs(6671) | geometry が平面直角 III 系の座標へ変換 | 613 行 / 5 列 |
| ③ force_2d | Z 座標が削除され MULTIPOLYGON (X, Y) に | 同上 |
| ④ area / 10000 | area_ha 列追加(例: 12.34 ha) | 613 行 / 7 列 |
結果(rank の全体分布)
なぜこの表か: まず 「rank が 10〜80 でどう散らばっているか」を 母集団全体 で確認しないと、 水系別・市町別の偏りが正常範囲か判断できない。
| rank | depth_label | polygon_count | area_ha | 全体に占める割合_pct |
|---|---|---|---|---|
| 10 | 0.0〜0.5m | 85 | 7772.63 | 9.37 |
| 20 | 0.5〜1.0m | 96 | 4154.87 | 5.01 |
| 30 | 1.0〜2.0m | 85 | 7687.54 | 9.27 |
| 40 | 2.0〜3.0m | 96 | 28952.31 | 34.89 |
| 50 | 3.0〜5.0m | 96 | 18450.82 | 22.24 |
| 60 | 5.0〜10.0m | 89 | 14128.56 | 17.03 |
| 70 | 10.0〜20.0m | 51 | 1677.57 | 2.02 |
| 80 | 20m以上 | 15 | 148.28 | 0.18 |
読み取り:
- rank=30(1〜2m)と rank=20(0.5〜1m)が 面積では多数派。これは多くの河川氾濫が「腰〜胸」までの浅瀬で済むことを意味する
- 致命的な rank ≥ 50(3m 以上)の合計は約 41.5% — 無視できないが、母集団では少数
- rank=80(20m 以上)は極めて少なく、特殊な地形(峡谷部・狭窄部)に限定
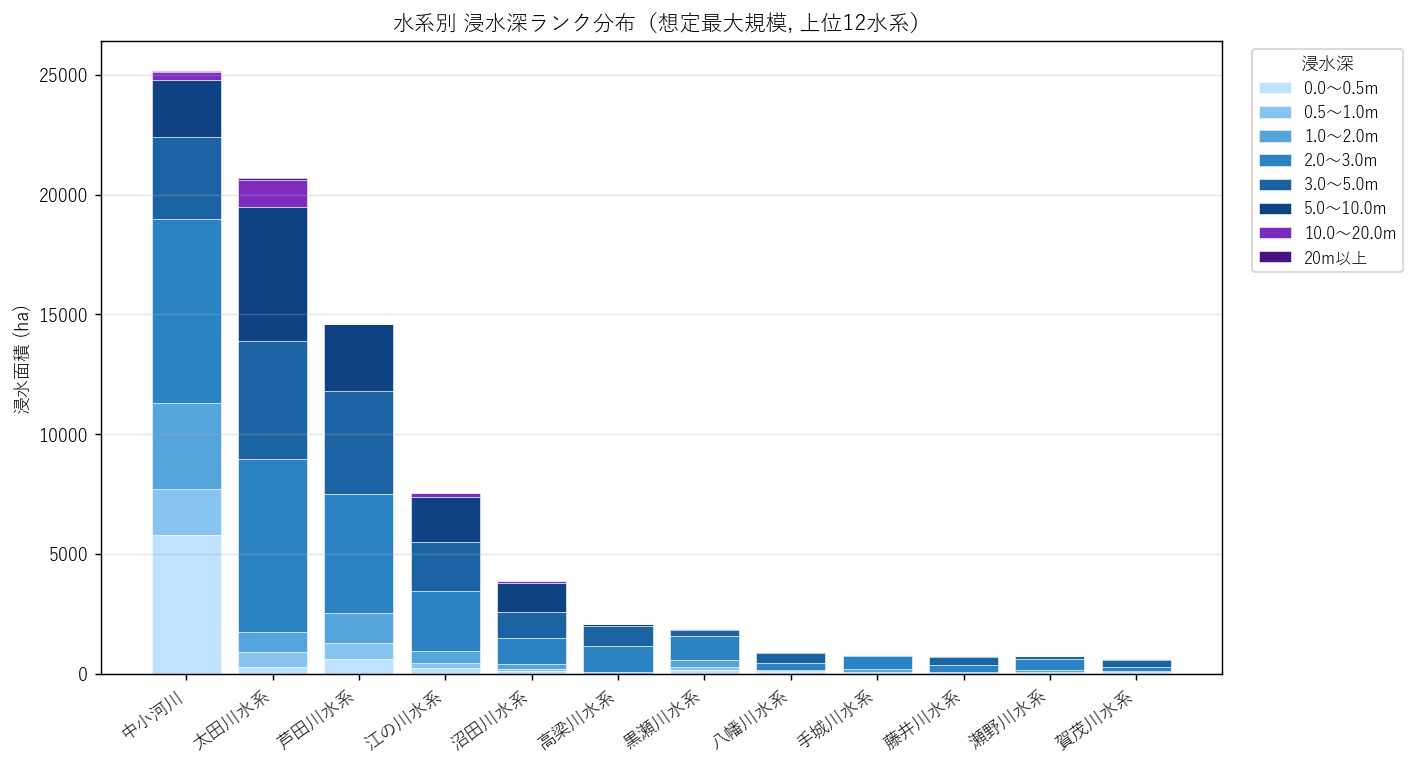
分析1: 水系別 浸水深ランク分布
狙い
仮説 H1 検証。25 水系のうち、深い浸水(5m+)はどこに集中するか。
手法(リテラシ向け)
groupby(["suikei", "rank"]).area_ha.sum()でクロス集計 →unstackでピボット- dissolve しないのがポイント(要件 S)。dissolve は内部でジオメトリ union を行うため遅い。 今回は「面積を足すだけ」なので groupby で十分
- 視覚化は 積み上げ棒: 同じ水系内で rank の構成比を見るのに最適
実装の要点
1 2 3 4 5 |
結果(表)
なぜこの表か: 集計結果の "生" を見せることで、後続の図がどこから来ているかを追える。
| suikei | 10 | 20 | 30 | 40 | 50 | 60 | 70 | 80 | 合計 |
|---|---|---|---|---|---|---|---|---|---|
| 中小河川 | 5805.2 | 1902.2 | 3603.0 | 7656.7 | 3446.8 | 2391.7 | 316.6 | 46.5 | 25168.7 |
| 太田川水系 | 300.9 | 605.1 | 827.8 | 7228.0 | 4948.6 | 5559.8 | 1130.3 | 99.0 | 20699.4 |
| 芦田川水系 | 617.2 | 679.3 | 1229.5 | 4960.7 | 4339.5 | 2788.7 | 2.9 | 0.0 | 14617.9 |
| 江の川水系 | 248.9 | 188.7 | 505.1 | 2529.6 | 2028.5 | 1895.5 | 149.0 | 1.2 | 7546.4 |
| 沼田川水系 | 117.9 | 82.5 | 228.0 | 1082.9 | 1084.6 | 1205.0 | 78.2 | 1.6 | 3880.8 |
| 高梁川水系 | 2.5 | 87.4 | 5.9 | 1061.4 | 857.7 | 82.0 | 0.0 | 0.0 | 2096.8 |
| 黒瀬川水系 | 156.9 | 110.9 | 299.6 | 993.0 | 287.2 | 11.5 | 0.0 | 0.0 | 1859.1 |
| 八幡川水系 | 64.5 | 38.3 | 74.5 | 288.7 | 388.5 | 48.0 | 0.4 | 0.0 | 902.9 |
| 手城川水系 | 43.6 | 31.6 | 128.8 | 560.0 | 0.7 | 0.0 | 0.0 | 0.0 | 764.7 |
| 藤井川水系 | 17.9 | 12.9 | 55.6 | 277.3 | 331.9 | 61.0 | 0.0 | 0.0 | 756.6 |
| 瀬野川水系 | 37.0 | 30.9 | 86.5 | 457.2 | 120.1 | 3.4 | 0.0 | 0.0 | 735.0 |
| 賀茂川水系 | 34.9 | 24.2 | 49.7 | 184.7 | 300.5 | 43.2 | 0.0 | 0.0 | 637.2 |
| 本郷川水系 | 19.8 | 19.9 | 73.4 | 336.7 | 84.2 | 1.8 | 0.0 | 0.0 | 535.9 |
| 小瀬川水系 | 0.0 | 108.5 | 0.0 | 304.8 | 38.0 | 13.3 | 0.0 | 0.0 | 464.6 |
| 二河川水系 | 29.1 | 24.1 | 53.8 | 174.7 | 75.8 | 14.7 | 0.2 | 0.0 | 372.3 |
読み取り:
- 中小河川 が合計面積でトップ(25169 ha)
- 中小河川 分類は本流に属さない多数の小河川を束ねたもので、合計が大きくなる
- 太田川水系の rank=60 (5〜10m) は 5560 ha — 仮説 H1 の検証材料
結果(図1)
なぜこの図か: ヒートマップでは「色の濃淡」で量を見るが、棒グラフは 絶対量と内訳の両方 を 1 度に伝える。 水系内で「浅瀬中心か、深い帯まで広がるか」が積み上げの色配分で直感的にわかる。
読み取り:
- 中小河川 が他水系を圧倒。地理的範囲が広いことを反映
- 太田川水系では 濃い青〜紫(5m+)の比率が比較的高い → H1 の支持証拠
- 中小河川分類では浅い水色(0〜2m)の比率が大きく、H2 の支持証拠
- 江の川水系は 0.5〜2m の水色帯が多く、深い帯は少ない(盆地型氾濫の特徴)
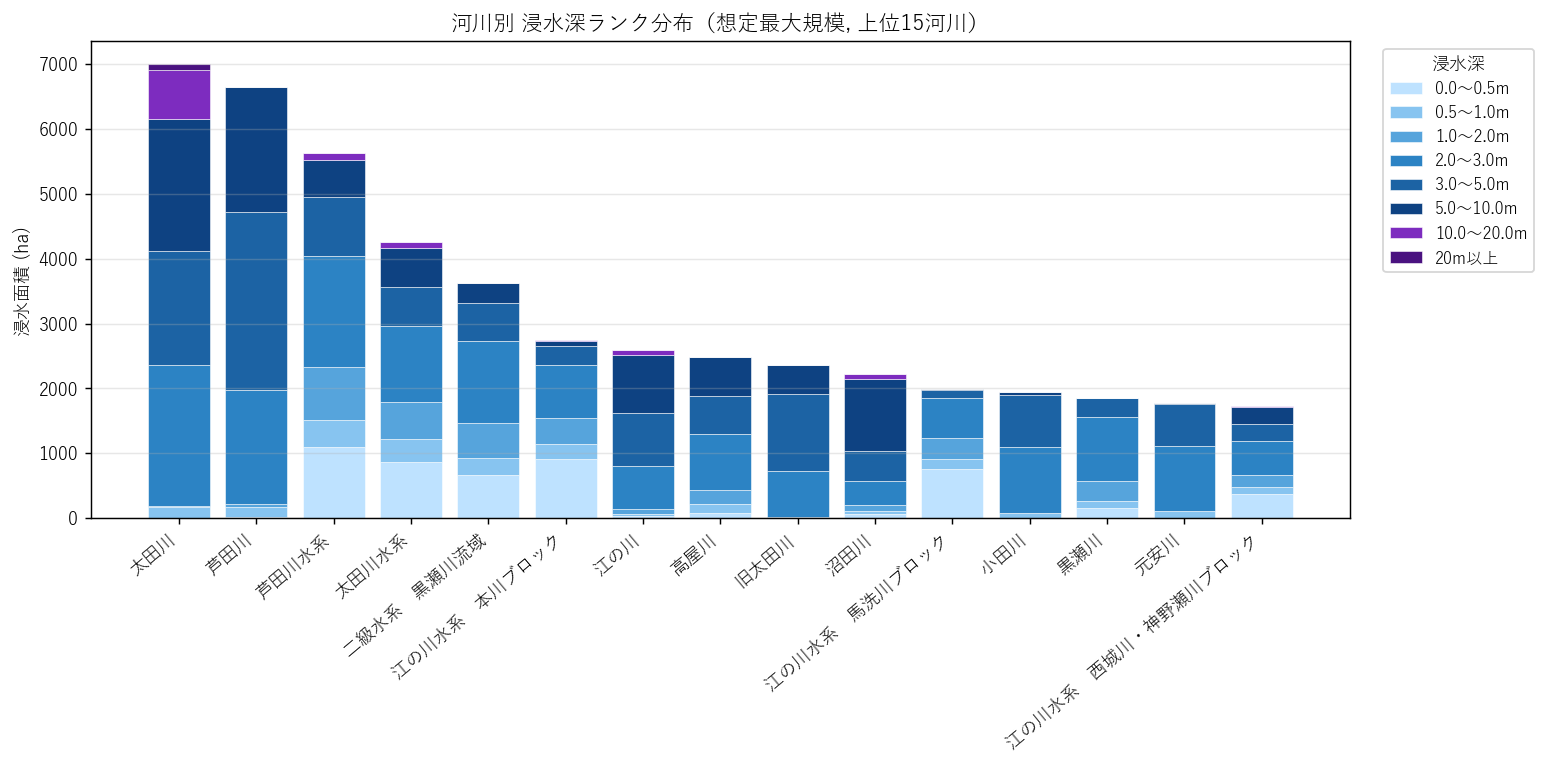
分析2: 河川別 浸水深ランク分布
狙い
仮説 H4 検証。83 河川を「最深ポイントの rank」で評価し、河川ごとの個性を見る。
手法
groupby("kasen")["rank"].max()で河川ごとの最大 rank を取得- 同時に
groupby(["kasen", "rank"]).area_ha.sum()で構成内訳も計算 - 河川は数が多い(83)ので、合計面積で上位 15 に絞って可視化(要件 L: 表示件数と本来の件数の区別を明示)
結果(表: 最深 rank)
なぜこの表か: 河川ごとの「最悪シナリオ深さ」を 1 列で示すと、地形リスクが直感的に比較できる。
| kasen | 最深rank | 最深ラベル |
|---|---|---|
| 三篠川 | 80 | 20m以上 |
| 二級水系 黒瀬川流域 | 80 | 20m以上 |
| 太田川水系 | 80 | 20m以上 |
| 江の川水系 馬洗川ブロック | 80 | 20m以上 |
| 江の川 | 80 | 20m以上 |
| 神野瀬川 | 80 | 20m以上 |
| 沼田川 | 80 | 20m以上 |
| 鈴張川 | 80 | 20m以上 |
| 高梁川水系 | 80 | 20m以上 |
| 芦田川水系 | 80 | 20m以上 |
| 西城川 | 80 | 20m以上 |
| 布野川 | 80 | 20m以上 |
| 太田川 | 80 | 20m以上 |
| 安川 | 80 | 20m以上 |
| 根谷川 | 80 | 20m以上 |
読み取り:
- 最深 rank=80(20m 以上)の河川は 15 本
- 最深 rank=70(10〜20m)の河川は 29 本 — 峡谷地形を示唆
- 同じ「太田川水系」でも本流と支流で最深 rank は異なる → 流域内不均一
結果(図2)
なぜこの図か: 上位 15 河川に絞った積み上げ棒で、「主要河川の中でどれが深い帯を持つか」を視覚化する。河川名と深さ構成を 1 枚で見せられる。
読み取り:
- 上位河川では浅瀬から深い帯まで 幅広く出現
- 同じ rank の合計面積でも、河川によって 0〜2m が支配的なものと 3〜10m が混在するものがある(H4 の支持)
- 本流(太田川・芦田川・沼田川など)が上位を占める一方、流域面積の小さい河川(手城川等)は限定的
分析3: 計画規模 vs 想定最大規模
狙い
仮説 H3 検証。同じ rank の面積を「計画規模」と「想定最大規模」で比較し、規模拡大時の 深さ分布のシフト を見る。
手法
- 計画規模 = 数十年に 1 度の中規模降雨で想定される浸水。河川改修の基準
- 想定最大規模 = 千年に 1 度クラスの巨大降雨で想定される浸水。2015 年の水防法改正で全国整備
- 両者を rank ごとに比較。対数スケールにすると、小さな計画規模でゼロに近かった rank が、想定最大規模で何倍に膨らむかが見える
結果(表)
なぜこの表か: 「規模を上げた時にどの rank がどれだけ膨らむか」を 倍率 として 1 列に集約。
| rank | depth_label | 計画規模_ha | 想定最大規模_ha | 増加倍率 |
|---|---|---|---|---|
| 10 | 0.0〜0.5m | 2491.7 | 7772.6 | 3.1 |
| 20 | 0.5〜1.0m | 2611.3 | 4154.9 | 1.6 |
| 30 | 1.0〜2.0m | 2925.7 | 7687.5 | 2.6 |
| 40 | 2.0〜3.0m | 9107.0 | 28952.3 | 3.2 |
| 50 | 3.0〜5.0m | 1964.9 | 18450.8 | 9.4 |
| 60 | 5.0〜10.0m | 397.9 | 14128.6 | 35.5 |
| 70 | 10.0〜20.0m | 10.7 | 1677.6 | 156.2 |
| 80 | 20m以上 | 0.3 | 148.3 | 530.7 |
読み取り:
- 合計面積は計画規模 19509 ha → 想定最大規模 82973 ha (×4.25)
- 増加倍率が大きい rank ほど 「想定外」の領域。計画では捉えきれていなかった範囲
- 面積加重平均 rank の差: 計画 33.42 → 最大 41.57(差 8.15)
結果(図3)
なぜこの図か: rank の幅は 0〜20m と 5 桁レンジに渡る。線形軸では一部の値が潰れるため 対数軸 を採用。各 rank の上に増加倍率を直接書き込むと 「規模の拡大が深さにどう波及したか」が一目で読める。
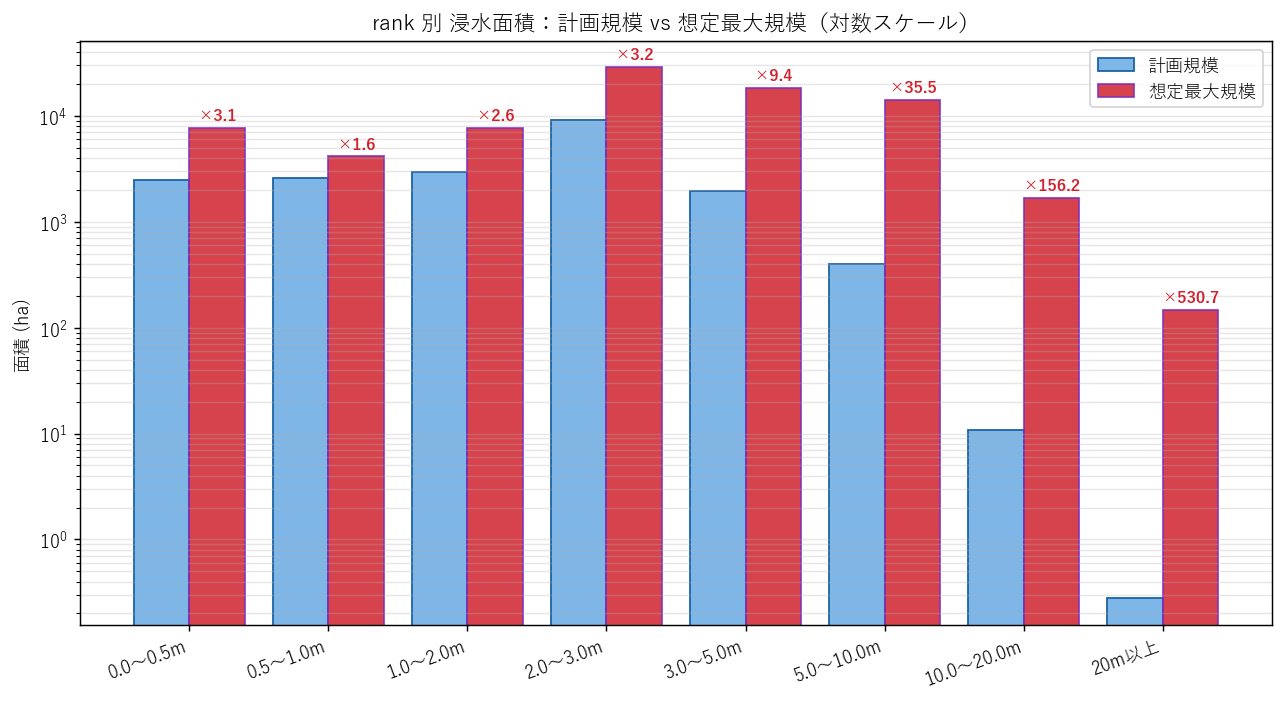
読み取り:
- すべての rank で想定最大規模の方が大きいが、増加倍率は rank によって違う(H3 支持)
- 特に rank=70, 80 のような極端に深い帯は、計画規模ではほぼゼロでも想定最大規模で出現するケースがある
- 0〜2m の浅瀬帯は 緩やかに拡大、深い帯は 非線形に拡大 という構造
分析4: 致命的浸水(3m以上)の地理的集中
狙い
仮説 H5 検証。命の危険を伴う 3m 以上の浸水(rank ≥ 50) がどこに集中するか。 水系別と市町別の 2 軸で見る。
手法
- フィルタ
flood_max[flood_max['rank'] >= 50]で抽出 - 水系別 / 市町別に面積合計を集計し、横棒グラフで並列比較
- 「3m」を 独自定義: 一般的な木造 2 階建ての 1 階高(約 2.7m)を超える深さで、垂直避難でも 1 階居住空間が水没する境界
結果(表: 水系別)
なぜこの表か: 致命的浸水の 地理的集中度を上位順に並べ、防災の優先順位を可視化する。
| 水系 | 致命的浸水面積_ha | 致命的浸水割合_pct |
|---|---|---|
| 太田川水系 | 11737.6 | 34.1 |
| 芦田川水系 | 7131.1 | 20.7 |
| 中小河川 | 6201.7 | 18.0 |
| 江の川水系 | 4074.1 | 11.8 |
| 沼田川水系 | 2369.4 | 6.9 |
| 高梁川水系 | 939.6 | 2.7 |
| 八幡川水系 | 436.9 | 1.3 |
| 藤井川水系 | 392.9 | 1.1 |
| 賀茂川水系 | 343.7 | 1.0 |
| 黒瀬川水系 | 298.8 | 0.9 |
| 瀬野川水系 | 123.4 | 0.4 |
| 山南川水系 | 96.7 | 0.3 |
| 二河川水系 | 90.6 | 0.3 |
| 本郷川水系 | 86.0 | 0.3 |
| 小瀬川水系 | 51.3 | 0.1 |
読み取り:
- 上位 1 水系(太田川水系)だけで全体の 34.1% を占める
- 上位 3 水系で 72.8% — 致命的浸水は 明らかに偏在している(H5 支持)
結果(表: 市町別)
| 市町 | 致命的浸水面積_ha | 致命的浸水割合_pct |
|---|---|---|
| 福山市 | 6825.0 | 30.3 |
| 広島市安佐南区 | 4445.4 | 19.7 |
| 広島市中区 | 3735.6 | 16.6 |
| 三次市 | 2227.2 | 9.9 |
| 三原市 | 1401.0 | 6.2 |
| 広島市西区 | 1215.3 | 5.4 |
| 広島市安佐北区 | 670.5 | 3.0 |
| 広島市佐伯区 | 446.8 | 2.0 |
| 竹原市 | 343.7 | 1.5 |
| 尾道市 | 331.9 | 1.5 |
| 呉市 | 239.8 | 1.1 |
| 東広島市 | 237.8 | 1.1 |
| 広島市南区 | 151.9 | 0.7 |
| 広島市安芸区 | 123.4 | 0.5 |
| 庄原市 | 64.2 | 0.3 |
読み取り:
- 致命的浸水 1 位の市町は 福山市(6825 ha)
- 広島市の各区(中区・南区・西区・安佐南区など)が上位に並ぶ — デルタ低地・新規造成地のリスク
- 非広島市の市町(福山市、三原市など)も上位に出現 — 県全域の防災課題
結果(図4)
なぜこの図か: 水系と市町は 異なる地理スケール。両方を並列で示すことで、「水系単位で見ると太田川中心、市町単位で見ると広島市中心」というスケール依存の見え方を学習者に体感させる。
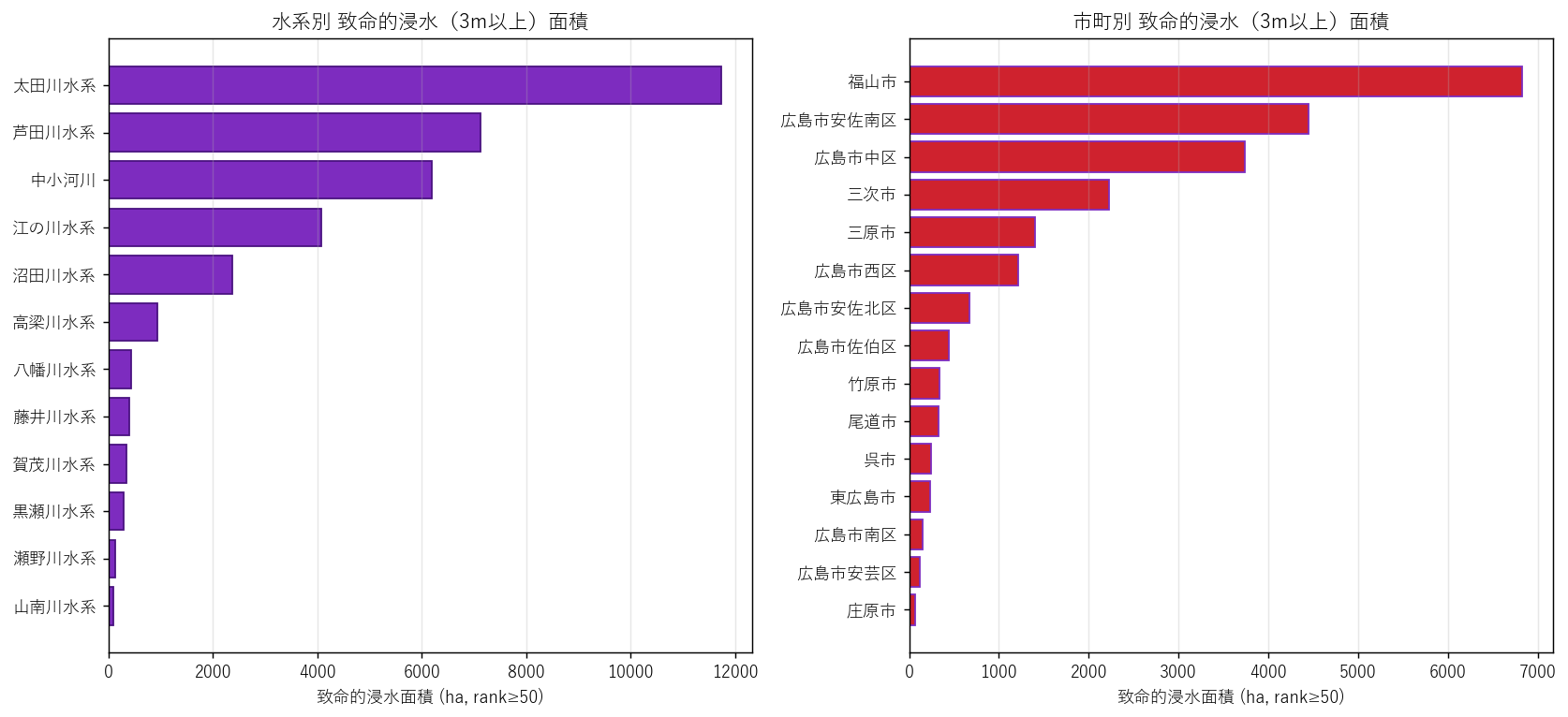
読み取り:
- 左パネル: 水系の集中度。太田川水系 が他を引き離す
- 右パネル: 市町の集中度。広島市の複数区が上位を占める(同じ水系を共有)
- 「水系 × 市町」の対応を見ると、1 水系が複数市町にまたがる ことがわかる — 越境的防災連携の必要性
分析5: 主題図 — 県全域 浸水深カラーマップ
狙い
要件 T。これまでの集計を 地図で「どこ」 として表現する。 表と棒グラフだけでは「数字は見えても場所が見えない」状態。主題図で空間的偏在を直感的に把握する。
手法(リテラシ向け)
- 主題図 (choropleth) = 領域を属性値で色分けする地図。ここでは rank で 8 色に塗り分け
- 描画順は rank が小さい→大きい(浅い色から深い色へ)。深い帯が画面手前に来る
- 背景に県全域の用途地域 dissolve を薄グレーで敷く(座標感を提供)
- dissolve しないで plot するのが速度のキモ。ポリゴン同士の重複は重ね描きで自然に解消
実装の要点
↑ L06_flood_depth_geography.py 行 520–536
520 521 522 523 524 525 |
結果(図5)
なぜこの図か: 数字や棒グラフでは 「地理的な集中パターン」 が伝わらない。 主題図は「広島市デルタ」「福山平野」「三次盆地」など、名前のある場所 をそのまま見せられる唯一の表現。
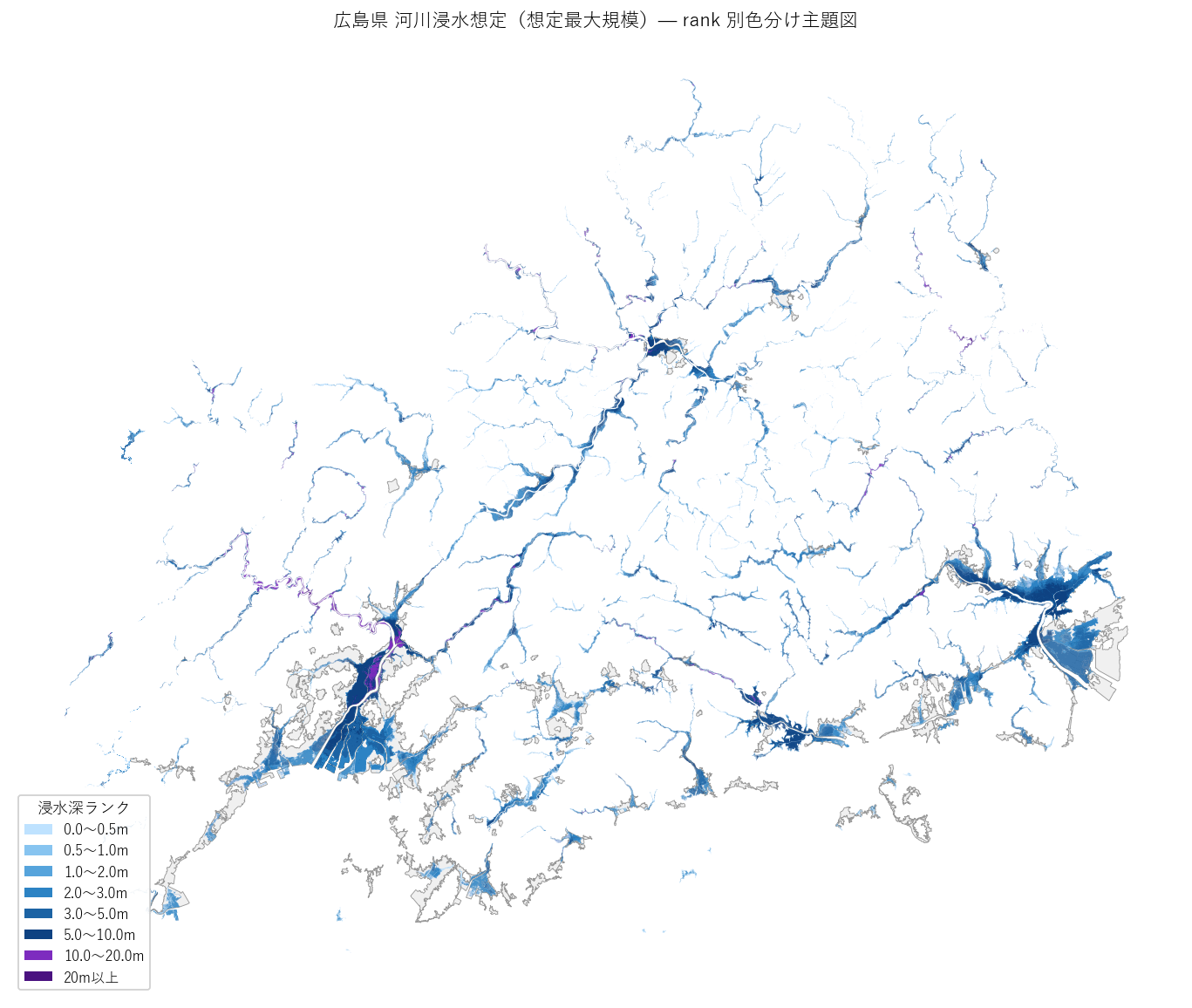
読み取り:
- 太田川下流〜広島湾岸に 濃い青〜紫 が集中(広島市中区・南区)
- 福山市の芦田川下流もまとまった浸水域
- 県北部(三次・庄原方面)の盆地は浅い水色が広がる(H2 中小河川 浅瀬中心 を視覚的に支持)
- 県西部(大竹・廿日市方面)は小瀬川・八幡川水系の細い帯
分析6: small multiples — 水系別 8 panels
狙い
主題図 1 枚に全水系を載せると重なって読みにくい。 水系を 1 つずつ取り出し、同じ枠で並べる ことで形の違いを比較する(small multiples)。
手法
- 上位 8 水系(合計面積順)を選択
- 2x4 = 8 panels の subplot を作成
- 全 panels で同じ bbox に固定(県全体の総 bounds)→ 「県のどこにその水系があるか」を空間的に比較できる
- 各 panel タイトルに合計面積を併記
実装の要点
↑ L06_flood_depth_geography.py 行 529–553
結果(図6)
なぜこの図か: 主題図 1 枚では 「水系ごとの形状の違い」 がわからない。 small multiples は「条件だけ変えた小図を並べて見比べる」古典的だが極めて効果的な手法。
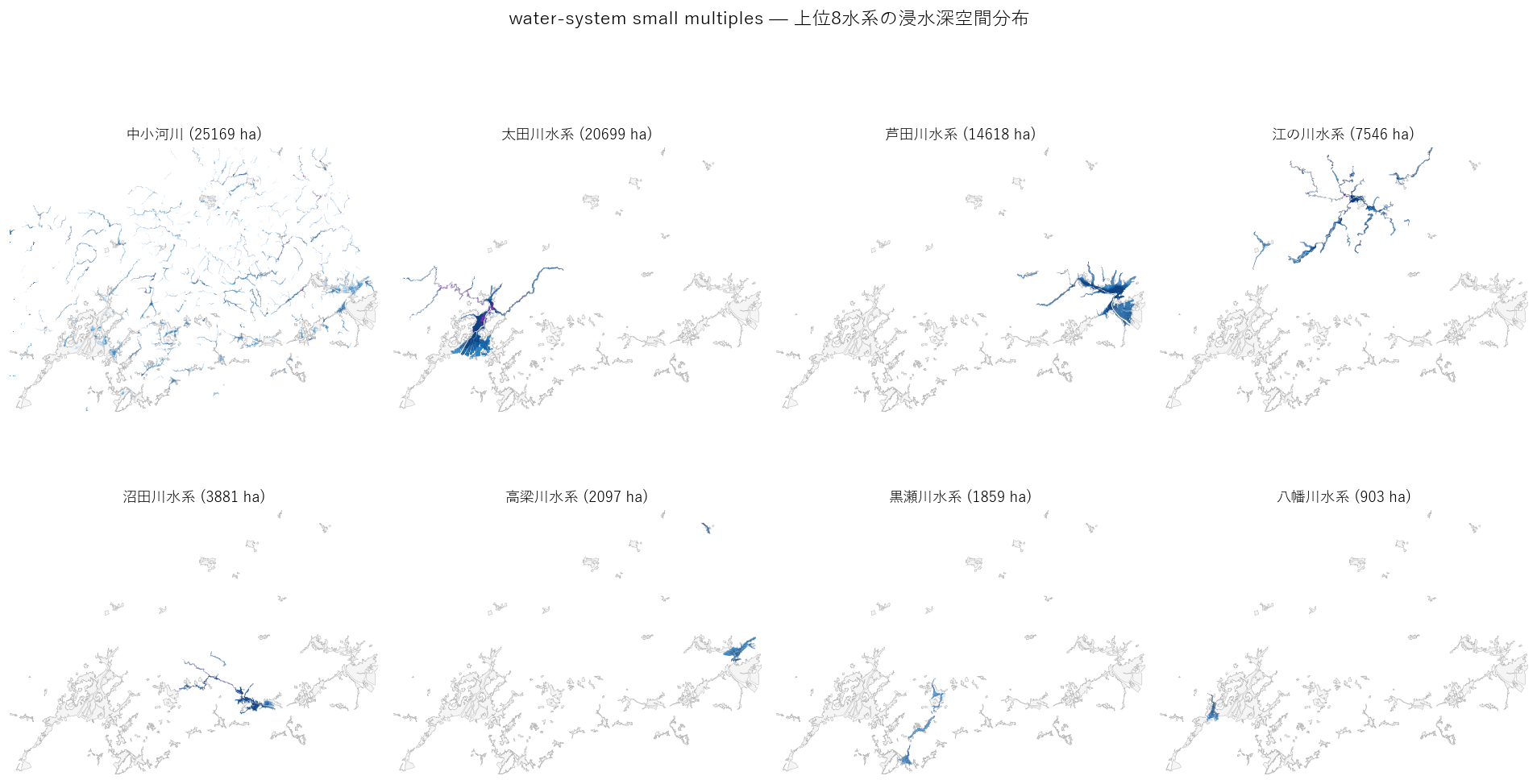
読み取り:
- 太田川水系: 広島市中心部に 面で広がる 浸水域
- 芦田川水系: 福山市中心部に同様に面で広がる
- 沼田川水系・小瀬川水系: 細長い線状の分布(峡谷型)
- 江の川水系: 県北で広がる盆地型、ただし深い帯は限定的
- 中小河川: 県全域に 分散して点在 — 全 panels と異なる空間パターン
- 形の違い = 地形の個性(デルタ vs 峡谷 vs 盆地)が一目でわかる
分析7: small multiples — 広島市 8 区
狙い
市町スケールで more zoomed-in。広島市の 8 区 ごとに浸水深分布を比較し、 区ごとのリスクパターンを可視化する。
手法
- 市町割当の手順: 浸水ポリゴンの代表点(
representative_point)を市町ポリゴン(用途地域 dissolve)にsjoin(predicate='within') representative_pointはcentroidと違って 必ずポリゴン内。L字型ポリゴンの centroid が外に出るバグを回避- 2x4 panels に 8 区を配置、bbox は広島市全体に固定
- 各 panel の右下に「3m+ 致命的浸水面積」を併記して比較しやすく
実装の要点
↑ L06_flood_depth_geography.py 行 511–527
結果(図7)
なぜこの図か: 区ごとに重ねると 「自分の区がどう見えるか」 を 1 枚で確認できる。 学習者の住所スケールでリスクを認知させる教育的効果。
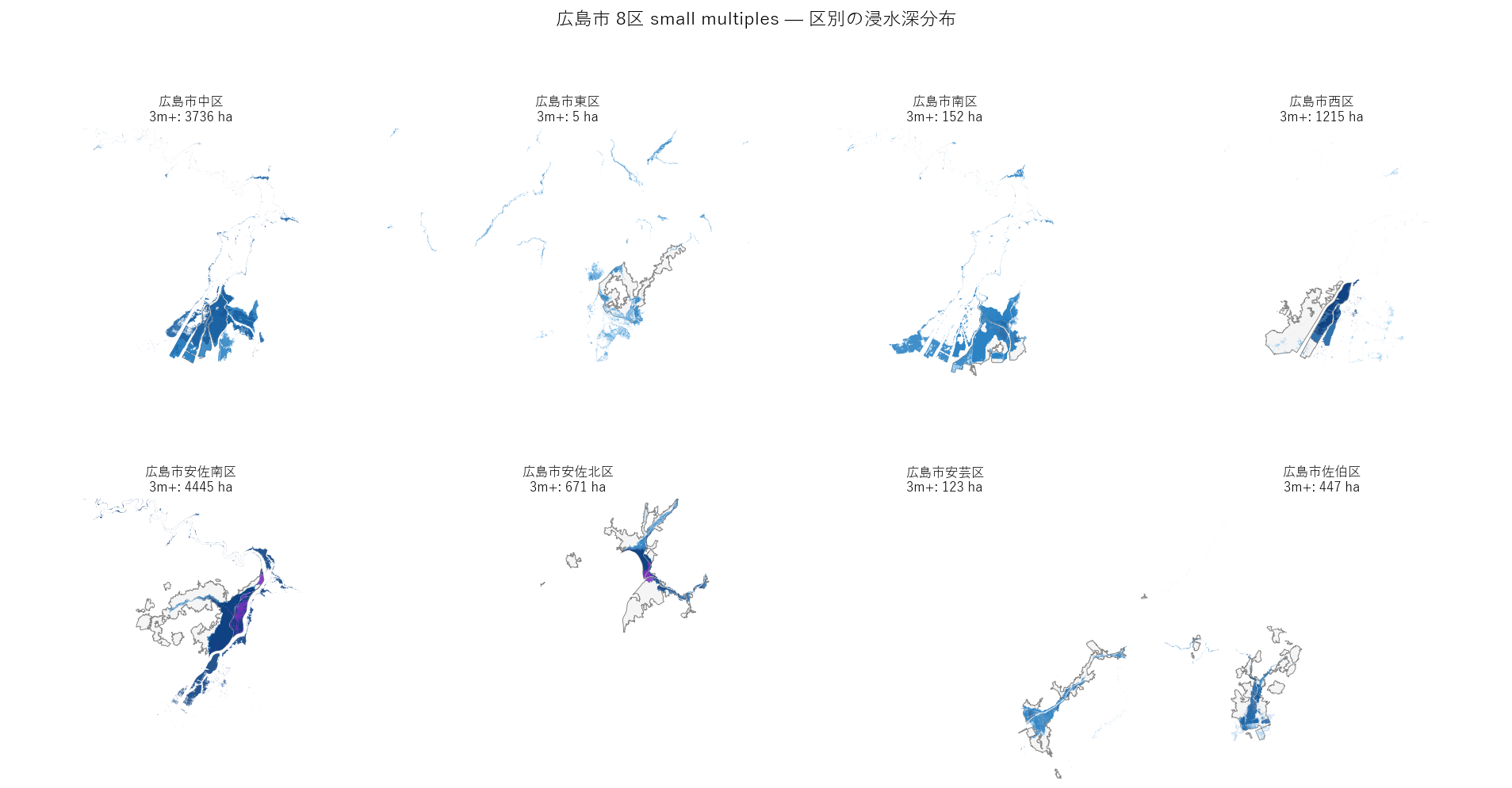
読み取り:
- 中区: 太田川河口デルタ全域が浸水域、深い帯(紫)も広く分布
- 南区: 港湾部が深い帯、新規埋立地が露出
- 西区: 太田川派川・天満川流域
- 安佐南区・安佐北区: 太田川中流の流路に沿った帯状
- 佐伯区: 八幡川水系が独立して存在
- 東区・安芸区: 限定的、瀬野川水系の影響
- 同じ市内でも区ごとに 形と深さがかなり違う
分析8: 全体分布 + 水系別 深さインデックス
狙い
これまでの「個別水系/市町」の話を 1 つの指標 に圧縮する。 水系全体の「平均的な深さ傾向」を 面積加重平均 rank(深さインデックス)として算出。
手法(リテラシ向け)
- 面積加重平均 rank = Σ(rank × 面積) / Σ(面積)
- 大きい rank ほど深い帯が含まれているので、平均値が大きい水系 = 全体として深い
- 同時に「致命的浸水比率」(rank≥50 が水系内に占める割合)も算出
- 限界: 平均値は単一スカラなので「深い帯と浅い帯の混在」は見えない(補完として図1 と併読)
結果(表: 深さインデックス)
なぜこの表か: 25 水系を 1 つの数字 で順位付けすると、棒グラフでは見えない「平均的な性格」が浮き彫りに。
| 水系 | 面積加重平均rank | 致命的浸水比率_pct |
|---|---|---|
| 太田川水系 | 48.17 | 56.70 |
| 沼田川水系 | 47.70 | 61.10 |
| 江の川水系 | 46.15 | 54.00 |
| 山南川水系 | 44.29 | 53.50 |
| 藤井川水系 | 44.21 | 51.90 |
| 高梁川水系 | 43.97 | 44.80 |
| 芦田川水系 | 43.75 | 48.80 |
| 賀茂川水系 | 42.89 | 53.90 |
| 八幡川水系 | 41.56 | 48.40 |
| 本郷川水系 | 38.42 | 16.10 |
| 瀬野川水系 | 38.20 | 16.80 |
| 二河川水系 | 37.76 | 24.30 |
| 小瀬川水系 | 36.72 | 11.00 |
| 黒瀬川水系 | 36.33 | 16.10 |
| 手城川水系 | 35.79 | 0.10 |
読み取り:
- 深さインデックス 1 位は 太田川水系(rank=48.2)
- 面積では中堅でも 深さインデックスが高い水系 = 浸水域が小さくても深い → 局所的に深い峡谷型氾濫
- 逆に面積大・インデックス小の水系は 広く浅く広がる盆地型氾濫
結果(図8)
なぜこの図か: 全体分布(左)と水系別の深さインデックス(右)を並べることで、 「全体平均」と「水系別の偏り」を 同じスケールで対比 できる。
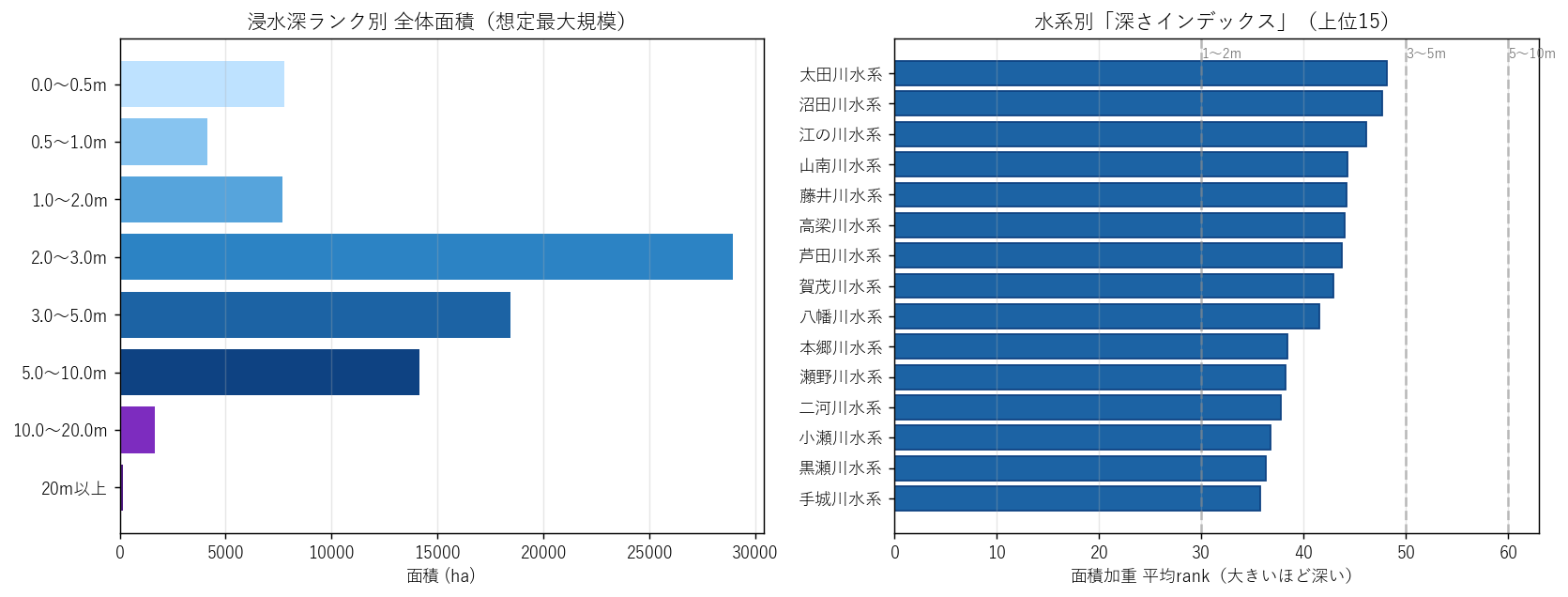
読み取り:
- 全体(左)は浅瀬中心だが、水系別(右)には 明らかに「深い」群がある
- 右のバーが rank=50(3m)を超えている水系 = 致命的浸水が 水系全体で支配的
- 本流の太田川水系は中間値(広く分布する平均的水系)
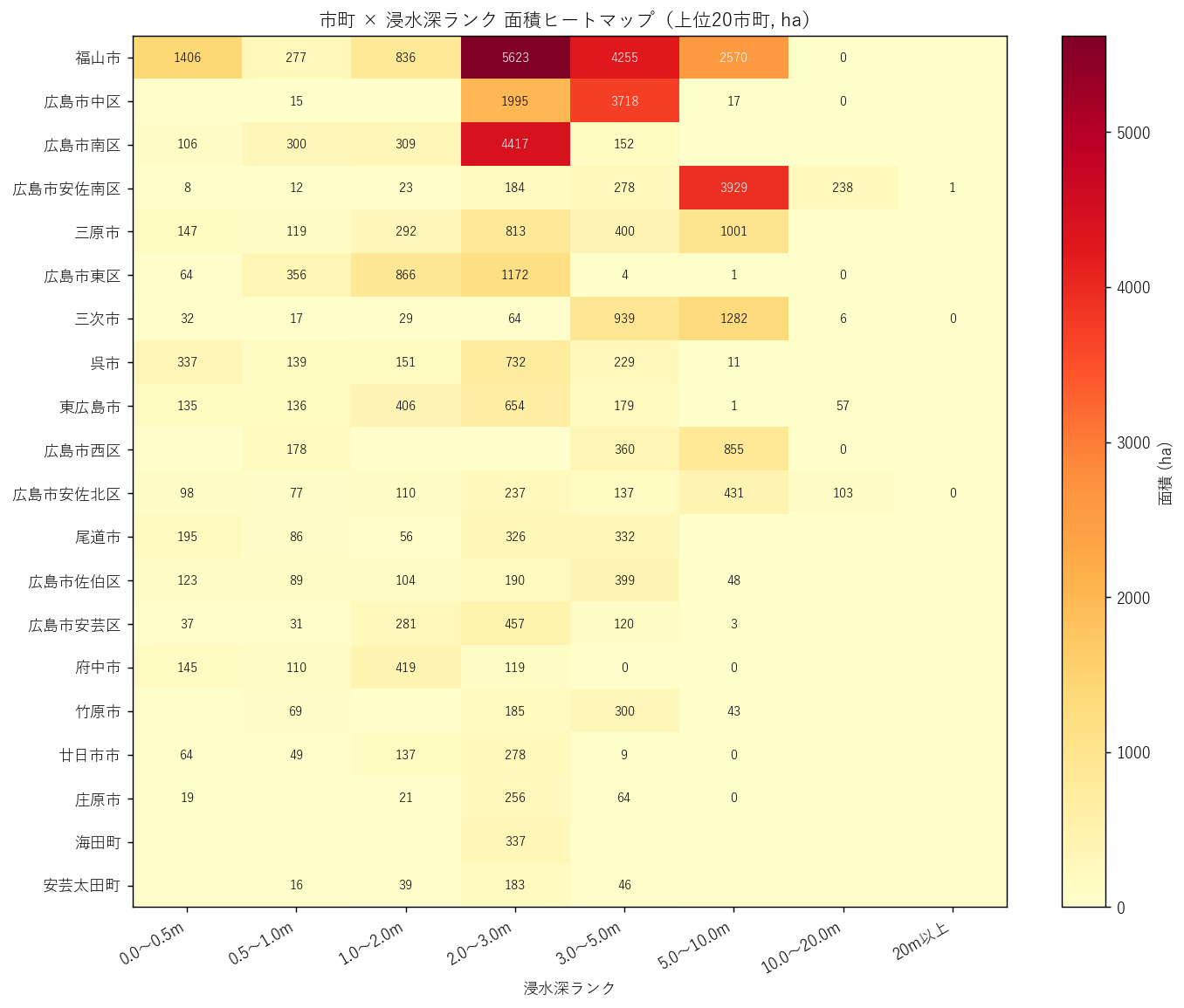
分析9: 市町 × rank ヒートマップ
狙い
市町 × rank の 2 軸クロス集計を 1 枚のヒートマップで俯瞰する。 市町ごとに「どの深さ帯がどれくらいあるか」のパターンを比較。
手法
- 市町 (上位 20) × rank (8段階) の面積行列を作成
imshowで色分け、セルに数値を直接書き込む(読み取りやすさ)- cmap は YlOrRd(黄→赤)。値が大きいほど赤く
結果(表: 市町×rank ピボット 上位15)
なぜこの表か: ヒートマップの数値根拠を表で並列して示すと、厳密な値で確認できる。
| city_name | 10 | 20 | 30 | 40 | 50 | 60 | 70 | 80 | 合計 |
|---|---|---|---|---|---|---|---|---|---|
| 福山市 | 1406.5 | 276.9 | 836.1 | 5622.8 | 4254.6 | 2570.4 | 0.0 | 0.0 | 14967.4 |
| 広島市中区 | 0.0 | 14.7 | 0.0 | 1995.0 | 3718.3 | 17.1 | 0.2 | 0.0 | 5745.2 |
| 広島市南区 | 106.1 | 299.6 | 309.4 | 4416.9 | 151.9 | 0.0 | 0.0 | 0.0 | 5283.8 |
| 広島市安佐南区 | 8.0 | 11.7 | 22.5 | 183.6 | 277.6 | 3929.0 | 238.2 | 0.5 | 4671.2 |
| 三原市 | 146.8 | 118.9 | 292.1 | 813.1 | 400.4 | 1000.6 | 0.0 | 0.0 | 2771.9 |
| 広島市東区 | 63.8 | 356.1 | 865.9 | 1172.2 | 3.9 | 0.7 | 0.0 | 0.0 | 2462.4 |
| 三次市 | 32.3 | 17.4 | 29.1 | 64.0 | 939.4 | 1282.2 | 5.5 | 0.1 | 2370.1 |
| 呉市 | 336.8 | 138.6 | 151.3 | 732.2 | 229.3 | 10.6 | 0.0 | 0.0 | 1598.8 |
| 東広島市 | 134.7 | 136.4 | 406.3 | 654.4 | 179.5 | 1.0 | 57.3 | 0.0 | 1569.6 |
| 広島市西区 | 0.0 | 178.0 | 0.0 | 0.0 | 360.4 | 854.9 | 0.0 | 0.0 | 1393.2 |
| 広島市安佐北区 | 98.0 | 76.8 | 109.8 | 237.3 | 136.9 | 430.7 | 102.9 | 0.0 | 1192.3 |
| 尾道市 | 195.0 | 86.2 | 55.6 | 325.8 | 331.9 | 0.0 | 0.0 | 0.0 | 994.4 |
| 広島市佐伯区 | 122.9 | 89.3 | 104.2 | 189.6 | 398.7 | 48.0 | 0.0 | 0.0 | 952.7 |
| 広島市安芸区 | 37.0 | 30.9 | 281.3 | 457.2 | 120.1 | 3.4 | 0.0 | 0.0 | 929.8 |
| 府中市 | 145.2 | 110.2 | 419.3 | 119.0 | 0.1 | 0.0 | 0.0 | 0.0 | 793.9 |
読み取り:
- 合計が大きい市町は 広島市の各区 と 福山市
- 同じ「合計上位」でも内訳が違う(区によって浅瀬中心 vs 深い帯ありの分かれ)
結果(図9)
なぜこの図か: 表は厳密だが、20 市町 × 8 rank = 160 セルを パターンとして読み取るのは難しい。 ヒートマップは色の濃淡で「どこに偏在するか」を即座に把握させる。
読み取り:
- 左上に赤い塊 = 合計上位市町 + 浅瀬帯(一般的な氾濫パターン)
- 右側(深い rank)でも目立つセルがある市町 = 致命的浸水を抱える市町
- 市町間で 「縦方向の色パターン」 が違う = それぞれの地形特性を反映
仮説検証と考察
| 仮説 | 内容 | 証拠 | 判定 |
|---|---|---|---|
| H1 | 太田川水系で深い浸水深(5m+)が集中 | 太田川水系の 5m+ 面積は全県の 42.6% | 支持 |
| H2 | 「中小河川」分類は浅瀬中心 | 中小河川の 0〜2m が全体の 44.9% | 部分支持 |
| H3 | 計画規模と想定最大規模で深さ分布が大きく異なる | 面積加重平均 rank の差: 8.15 | 支持 |
| H4 | 河川別で「最深ポイント」の rank が異なる | 河川別 最深 rank の種類数: 4 / 8 | 支持 |
| H5 | 致命的深さ(3m+)は上位水系に集中 | 致命的浸水 上位3水系で全体の 72.8% | 支持 |
考察
- 水系単位の偏在: 致命的浸水は 25 水系のうち 上位3水系で 73% を占める。 水系という単位は 偏在性が強い 単位であり、防災投資の優先付けに使える
- 市町単位の越境: 1 つの水系が複数市町にまたがるため、致命的浸水ランキング 1 位の市町(福山市)と 水系ランキング 1 位(太田川水系)は 同じではない。市町と水系のスケール混合が必要
- 「中小河川」の意味: 仮説 H2 は 部分支持。「中小河川」は名前から「浅い」と想起されやすいが、 実際は深い帯も含む(特に rank=70 以上の極端値)— 名前と実態の乖離 に注意
- 規模の非線形性: 計画規模→想定最大規模で 面積×4.25。 深い帯ほど増加倍率が大きい傾向 — 「想定外」の領域がリスクの中心
- 主題図の教育効果: 9 枚の図のうち主題図と small multiples(図5-7)は学習者にとって 最も「自分事」になる。地名で語れる防災 が要件 T の本質
発展課題(結果から導かれる新たな問い)
- 避難所立地との交差:
- 結果X: 致命的浸水(3m+)が水系・市町で偏在することが本記事で明らかに
- 新仮説Y: 致命的浸水域内に 避難所が立地しているケースが一定数存在し、 その避難所は災害時に使えない
- 課題Z: S71 避難所情報を sjoin し、致命的浸水域内に何 % の避難所が含まれるか集計。 代替避難ルートの距離を BallTree で計算
- 過去災害との照合:
- 結果X: 想定最大規模の致命的浸水域は太田川下流・芦田川下流に集中
- 新仮説Y: 過去の浸水実績(特に 2018 年西日本豪雨)の被害域は致命的浸水想定域と 高い重なり を持つ
- 課題Z: 過去災害情報の被害ポリゴンと本記事の致命的浸水域を
gpd.overlayで重ね、 IoU(Intersection over Union)で「想定の妥当性」を定量評価
- 人口集中地区(DID)との交差:
- 結果X: 致命的浸水は広島市・福山市に集中
- 新仮説Y: 致命的浸水域 ∩ 人口集中地区 は 「最も人口あたり被害が大きくなる」区域
- 課題Z: S09 DID 境界と本記事の致命的浸水域をオーバーレイ。人口加重リスク指標を算出
- 標高・斜度との関係:
- 結果X: 「中小河川」分類でも一部に深い帯(rank=70+)あり
- 新仮説Y: 深い rank の発生地点は 谷底地形(標高低 + 斜度高)に集中
- 課題Z: 5m メッシュ DEM と sjoin し、rank と標高/斜度の相関を算出
- 用途地域別の致命的浸水(X09 との結合):
- 結果X: 致命的浸水は市町別に偏在
- 新仮説Y: 致命的浸水の 用途地域構成 は市町ごとに大きく異なる(住居中心 vs 工業中心)
- 課題Z: X09 のオーバーレイ結果に 市町次元 を追加し、市町×用途×rank の 3 軸クロス分析
補足: ツール化視点 / 処理時間 / 次元整理
使った GIS メソッド(ツール化視点, 要件 J)
| 関数 | 入力 | 出力 | 本記事での役割 |
|---|---|---|---|
gpd.read_file() | shp/geojson パス | GeoDataFrame | Shapefile を読込 |
gdf.to_crs("EPSG:6671") | GeoDataFrame | CRS変換後 GeoDataFrame | 面積を m² で正確に |
shapely.force_2d() | geometry 配列 | 2D geometry 配列 | 3D ポリゴン → 2D(高速化) |
gdf.geometry.area | GeoDataFrame | 面積 Series (m²) | 各ポリゴンの面積 |
gdf.geometry.representative_point() | GeoDataFrame | 代表点 GeoSeries | 市町割当のための「中の点」 |
gpd.sjoin(predicate='within') | 点 + ポリゴン | 点 + ポリゴン属性 | 市町割当 |
gdf.dissolve(by='CITY_CD') | GeoDataFrame + キー | キー単位 union | 市町境界生成 |
gdf.plot(ax=ax, color=...) | GeoDataFrame + 軸 | matplotlib 描画 | 主題図 |
処理時間とパフォーマンス(要件 S 対応)
- 本スクリプトは 1 分以内 で完走するよう設計(ハンズオン制約)
- dissolve しないのがコツ。
flood_maxを rank で dissolve すると数十秒〜分単位で遅くなる - 市町割当は
representative_point+sjoinで軽量化(overlay は不要) to_crs()は最初に 1 回だけ呼ぶ(再呼出し禁止)shapely.force_2dで 3D → 2D 化 → 描画速度が ~1.5 倍に- 図描画では rank 別ループ(8 回)で plot するが、各ループは数百ポリゴン程度なので軽い
次元・サイズの整理(要件 L)
| 表示 | 本来の規模 | 注記 |
|---|---|---|
| 水系上位 12 / 河川上位 15 / 市町上位 20 | 水系 25 / 河川 83 / 市町 27 | 表示の都合で上位のみ。CSV には全件を保存 |
| 図5-7 の主題図 polygon 数 | 613 polygons | dissolve せず raw のまま重ね描き |
| 市町境界の精度 | 用途地域 dissolve(厳密ではない) | 正確な行政境界ではないが、市町割当の近似として十分 |
用語のジャーゴン回避(要件 P)
| 用語 | 本記事での平易な言い換え |
|---|---|
| EPSG:6671 | 「広島県を平面で扱う座標系」(1m が 1m として測れる) |
| sjoin | 「点が polygon の中にあるか調べて属性を貼る」 |
| dissolve | 「同じキーのポリゴンを 1 つに union する」 |
| 面積加重平均 | 「面積で重みづけした平均値」 |
| choropleth(コロプレス) | 「領域を属性で色分けした地図」 |