"""L05 水系単位 横断分析 — 太田川・芦田川・沼田川・江の川・黒瀬川 等の比較
目的:
X07/X08/X09/L4/L7 で得たすべての情報 (浸水・用途・文化財・インフラ・DID人口) を
「水系」軸で再集計し、広島県の主要 5 水系 + 中小河川を **横並びで比較**。
決定的な発見:
浸水Shapefile の `suikei` 列 (25 水系) を主軸に、
- 文化財 3 種 (埋蔵文化財/官衙/被爆樹木) を点 sjoin
- インフラ 3 種 (橋・ダム・トンネル) を点 sjoin
- DID 人口集中地区を overlay
- 用途地域を overlay
すべて `suikei` 単位に集約してクロス集計マトリクスを作る。
要件S対応の工夫:
- dissolve は使わない (TopologyException + 数十分かかるため)
- 個別ポリゴン単位で sjoin → groupby('suikei').sum で集約
- 中間データを pickle にキャッシュ → 2 回目以降は数秒で完了
- simplify(100m) で flood polygon の頂点を間引いて高速化
"""
from __future__ import annotations
import sys, time, zipfile, warnings
from pathlib import Path
sys.path.insert(0, str(Path(__file__).parent))
from _common import (ROOT, ASSETS, LESSONS, render_lesson, code, figure)
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.patches import Patch
import geopandas as gpd
import shapely
warnings.filterwarnings("ignore", category=UserWarning)
warnings.filterwarnings("ignore", category=FutureWarning)
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
t0 = time.time()
print("=== L05 水系単位 横断分析 ===")
TARGET_CRS = "EPSG:6671" # 平面直角 III (広島県, 単位 m)
# キャッシュ判定
import pickle
CACHE_DIR = ROOT / "data" / "extras" / "_l05_cache"
CACHE_DIR.mkdir(parents=True, exist_ok=True)
CACHE_FILE = CACHE_DIR / "l05_data.pkl"
USE_CACHE = (CACHE_FILE.exists() and CACHE_FILE.stat().st_size > 1000
and "--no-cache" not in sys.argv)
if USE_CACHE:
print(f"\n[CACHE] {CACHE_FILE.name} ({CACHE_FILE.stat().st_size//1024} KB) から読込 ...")
tcache = time.time()
with open(CACHE_FILE, "rb") as f:
_cache = pickle.load(f)
for _k, _v in _cache.items():
globals()[_k] = _v
print(f" キャッシュ読込完了: {time.time()-tcache:.1f}s")
SKIP_DATA = True
else:
SKIP_DATA = False
if not SKIP_DATA:
# ============================================================
# 1. 浸水 Shapefile (suikei 列) — 主軸データ
# ============================================================
print("\n[1] 浸水 Shapefile 読込 ...")
t1 = time.time()
FLOOD_DIR = ROOT / "data" / "extras" / "flood_shp"
flood_max = gpd.read_file(FLOOD_DIR / "shinsui_souteisaidai" / "shinsui_souteisaidai.shp")
flood_plan = gpd.read_file(FLOOD_DIR / "shinsui_keikaku" / "shinsui_keikakukibo.shp")
flood_max = flood_max.to_crs(TARGET_CRS)
flood_plan = flood_plan.to_crs(TARGET_CRS)
# 3D → 2D
flood_max["geometry"] = gpd.GeoSeries(shapely.force_2d(flood_max.geometry.values), crs=TARGET_CRS)
flood_plan["geometry"] = gpd.GeoSeries(shapely.force_2d(flood_plan.geometry.values), crs=TARGET_CRS)
# 元ジオメトリで面積計算 (buffer(0) スキップで時短、面積に影響小)
flood_max["area_m2"] = flood_max.geometry.area
flood_plan["area_m2"] = flood_plan.geometry.area
# 描画・overlay 用に simplify 100m (geometry コピー)
print(f" simplify (100m) ...", flush=True)
ts1 = time.time()
flood_max_s = flood_max.copy()
flood_max_s["geometry"] = flood_max_s.geometry.simplify(100)
flood_max_s = flood_max_s[~flood_max_s.geometry.is_empty].copy()
print(f" simplify done: {time.time()-ts1:.1f}s", flush=True)
print(f" 最大規模 {len(flood_max)} polygons / 計画規模 {len(flood_plan)} polygons / {time.time()-t1:.1f}s")
print(f" 水系数: {flood_max['suikei'].nunique()}")
# ============================================================
# 2. 水系別 浸水面積集計 (重複ありの粗集計、rank分割で実害小)
# ============================================================
sui_area_max = flood_max.groupby("suikei")["area_m2"].sum().reset_index()
sui_area_max["flood_area_km2"] = sui_area_max["area_m2"] / 1e6
sui_area_max = sui_area_max.sort_values("flood_area_km2", ascending=False)
sui_area_plan = flood_plan.groupby("suikei")["area_m2"].sum().reset_index()
sui_area_plan["plan_area_km2"] = sui_area_plan["area_m2"] / 1e6
# 浸水深ランクの統計 (max/mean/median per suikei)
sui_rank_stats = flood_max.groupby("suikei")["rank"].agg(["max", "mean", "median"]).reset_index()
sui_rank_stats.columns = ["suikei", "rank_max", "rank_mean", "rank_median"]
print("\n[水系別浸水面積トップ10]")
print(sui_area_max[["suikei", "flood_area_km2"]].head(10).to_string(index=False))
# 主要5水系を選定 (上位5、ただし「中小河川」は別カテゴリとして扱う)
MAIN_SYS = ["太田川水系", "芦田川水系", "沼田川水系", "江の川水系", "黒瀬川水系"]
# ============================================================
# 3. 文化財 3 種 (点 sjoin)
# ============================================================
print("\n[2] 文化財 3 種 sjoin ...")
t2 = time.time()
DATA_EX = ROOT / "data" / "extras"
def load_csv_points(path, lat_col="緯度", lon_col="経度", category=""):
df = pd.read_csv(path, encoding="utf-8-sig")
df[lat_col] = pd.to_numeric(df[lat_col], errors="coerce")
df[lon_col] = pd.to_numeric(df[lon_col], errors="coerce")
df = df.dropna(subset=[lat_col, lon_col])
gdf = gpd.GeoDataFrame(
df.assign(category=category),
geometry=gpd.points_from_xy(df[lon_col], df[lat_col]),
crs="EPSG:4326"
).to_crs(TARGET_CRS)
return gdf
burial_castle = load_csv_points(DATA_EX / "burial_castle_govt.csv", category="官衙跡等")
burial_other = load_csv_points(DATA_EX / "burial_other.csv", category="埋蔵文化財")
atomic_trees = load_csv_points(DATA_EX / "atomic_bombed_trees.csv",
lat_col="緯度", lon_col="経度", category="被爆樹木")
cultural = pd.concat([burial_castle, burial_other, atomic_trees], ignore_index=True)
cultural = gpd.GeoDataFrame(cultural, geometry="geometry", crs=TARGET_CRS)
print(f" 文化財合計 {len(cultural)} 点")
# sjoin: 浸水 polygon (suikei 付き) と点
cult_in_flood = gpd.sjoin(cultural, flood_max_s[["suikei", "rank", "geometry"]],
how="inner", predicate="within")
print(f" 浸水内 文化財 {len(cult_in_flood)} 点 / {time.time()-t2:.1f}s")
# ============================================================
# 4. インフラ 3 種 (点 sjoin)
# ============================================================
print("\n[3] インフラ 3 種 sjoin ...")
t3 = time.time()
bridge = pd.read_csv(DATA_EX / "bridge_basic.csv", encoding="utf-8-sig")
bridge["緯度(10進数)"] = pd.to_numeric(bridge["緯度(10進数)"], errors="coerce")
bridge["経度(10進数)"] = pd.to_numeric(bridge["経度(10進数)"], errors="coerce")
bridge = bridge.dropna(subset=["緯度(10進数)", "経度(10進数)"])
bridge_gdf = gpd.GeoDataFrame(
bridge.assign(infra="橋梁"),
geometry=gpd.points_from_xy(bridge["経度(10進数)"], bridge["緯度(10進数)"]),
crs="EPSG:4326"
).to_crs(TARGET_CRS)
dam = pd.read_csv(DATA_EX / "dam_basic.csv", encoding="utf-8-sig")
dam["緯度"] = pd.to_numeric(dam["緯度"], errors="coerce")
dam["経度"] = pd.to_numeric(dam["経度"], errors="coerce")
dam = dam.dropna(subset=["緯度", "経度"])
dam_gdf = gpd.GeoDataFrame(
dam.assign(infra="ダム"),
geometry=gpd.points_from_xy(dam["経度"], dam["緯度"]),
crs="EPSG:4326"
).to_crs(TARGET_CRS)
tunnel = pd.read_csv(DATA_EX / "tunnel_basic.csv", encoding="utf-8-sig")
tunnel["緯度(10進数)"] = pd.to_numeric(tunnel["緯度(10進数)"], errors="coerce")
tunnel["経度(10進数)"] = pd.to_numeric(tunnel["経度(10進数)"], errors="coerce")
tunnel = tunnel.dropna(subset=["緯度(10進数)", "経度(10進数)"])
tunnel_gdf = gpd.GeoDataFrame(
tunnel.assign(infra="トンネル"),
geometry=gpd.points_from_xy(tunnel["経度(10進数)"], tunnel["緯度(10進数)"]),
crs="EPSG:4326"
).to_crs(TARGET_CRS)
infra_all = gpd.GeoDataFrame(
pd.concat([
bridge_gdf[["施設名", "infra", "geometry"]],
dam_gdf[["ダム名", "infra", "geometry"]].rename(columns={"ダム名": "施設名"}),
tunnel_gdf[["施設名", "infra", "geometry"]],
], ignore_index=True),
geometry="geometry", crs=TARGET_CRS
)
print(f" インフラ合計 {len(infra_all)} 点 (橋 {len(bridge_gdf)} / ダム {len(dam_gdf)} / トンネル {len(tunnel_gdf)})")
infra_in_flood = gpd.sjoin(infra_all, flood_max_s[["suikei", "rank", "geometry"]],
how="inner", predicate="within")
print(f" 浸水内 インフラ {len(infra_in_flood)} 点 / {time.time()-t3:.1f}s")
# ダム水系名 (DoBoX dam_basic の「水系名」列) を直接集計 — 浸水関係なくダムの水系分布
dam_by_sys = dam["水系名"].value_counts().reset_index()
dam_by_sys.columns = ["suikei_short", "dam_count_total"]
# ============================================================
# 5. DID 人口集中地区 (polygon overlay)
# ============================================================
print("\n[4] DID 人口集中地区 解凍 + 読込 ...")
t4 = time.time()
DID_DIR = DATA_EX / "did_geojson"
DID_EX = DATA_EX / "did_extracted"
DID_EX.mkdir(exist_ok=True)
for z in DID_DIR.glob("did_*.zip"):
out = DID_EX / z.stem
if not out.exists():
with zipfile.ZipFile(z) as zf:
zf.extractall(out)
did_list = []
for f in DID_EX.rglob("*.geojson"):
g = gpd.read_file(f)
g["city_zip"] = f.parent.name.replace("did_", "")
did_list.append(g)
did = gpd.GeoDataFrame(pd.concat(did_list, ignore_index=True), crs=did_list[0].crs)
if did.crs is None or did.crs.to_epsg() != 6671:
did = did.to_crs(TARGET_CRS)
did["did_area_m2"] = did.geometry.area
did["pop_density"] = did["JINKOU_S"] / did["did_area_m2"].replace(0, np.nan)
print(f" DID polygons: {len(did)}, 総面積 {did['did_area_m2'].sum()/1e6:.1f} km² / {time.time()-t4:.1f}s")
print(f" DID 総人口 (JINKOU_S 合計): {did['JINKOU_S'].sum():,.0f} 人")
# DID × 浸水 overlay (DID は 48 polygon と少ないので simplify 50 で overlay 可能)
print(" DID × 浸水 overlay ...")
t4b = time.time()
did_simple = did[["JINKOU_S", "did_area_m2", "pop_density", "geometry"]].copy()
did_simple["geometry"] = did_simple.geometry.simplify(50).buffer(0)
did_simple = did_simple[~did_simple.geometry.is_empty].copy()
flood_simple = flood_max_s[["suikei", "geometry"]].copy()
did_flood = gpd.overlay(did_simple, flood_simple, how="intersection", keep_geom_type=False)
did_flood["overlap_m2"] = did_flood.geometry.area
did_flood["risk_pop"] = did_flood["overlap_m2"] * did_flood["pop_density"]
print(f" overlay 結果 {len(did_flood)} 行 / {time.time()-t4b:.1f}s")
# 水系別 DID 浸水面積 + 推定人口
did_by_sui = did_flood.groupby("suikei").agg(
did_overlap_m2=("overlap_m2", "sum"),
).reset_index()
did_by_sui["did_overlap_km2"] = did_by_sui["did_overlap_m2"] / 1e6
risk_pop_by_sui = did_flood.groupby("suikei")["risk_pop"].sum().reset_index()
# ============================================================
# 6. 用途地域 (polygon overlay) — 県全域版
# ============================================================
print("\n[5] 用途地域 overlay ...")
t5 = time.time()
LANDUSE_EX = DATA_EX / "landuse_extracted"
landuse_files = list(LANDUSE_EX.rglob("*.geojson"))
# 県全域 340006 を採用
target_lu = [p for p in landuse_files if p.name.startswith("340006")]
if not target_lu:
target_lu = sorted(landuse_files, key=lambda p: p.stat().st_size, reverse=True)
landuse = gpd.read_file(target_lu[0])
if landuse.crs is None:
landuse = landuse.set_crs("EPSG:4326")
landuse = landuse.to_crs(TARGET_CRS)
landuse["geometry"] = landuse.geometry.simplify(50).buffer(0)
landuse = landuse[~landuse.geometry.is_empty].copy()
YOTO_NAME = {
1: "第一種低層住居", 2: "第二種低層住居", 3: "第一種中高層住居", 4: "第二種中高層住居",
5: "第一種住居", 6: "第二種住居", 7: "準住居",
8: "近隣商業", 9: "商業",
10: "準工業", 11: "工業", 12: "工業専用", 13: "田園住居",
}
def yoto_class(c):
if c in (1,2,3,4,5,6,7): return "住居系"
if c in (8,9): return "商業系"
if c in (10,11,12): return "工業系"
if c == 13: return "田園住居"
return "その他"
landuse["yoto_class"] = landuse["YOTO_CD"].astype(int).map(yoto_class)
print(f" landuse {len(landuse)} polygons")
lu_flood = gpd.overlay(landuse[["yoto_class", "geometry"]],
flood_simple[["suikei", "geometry"]],
how="intersection", keep_geom_type=False)
lu_flood["overlap_m2"] = lu_flood.geometry.area
print(f" landuse × 浸水 overlay 結果 {len(lu_flood)} 行 / {time.time()-t5:.1f}s")
lu_by_sui = lu_flood.groupby(["suikei", "yoto_class"])["overlap_m2"].sum().reset_index()
lu_by_sui["overlap_ha"] = lu_by_sui["overlap_m2"] / 1e4
lu_pivot = lu_by_sui.pivot_table(index="suikei", columns="yoto_class",
values="overlap_ha", fill_value=0)
# ============================================================
# 7. クロス集計マトリクス (水系 × 指標)
# ============================================================
print("\n[6] クロス集計マトリクス構築 ...")
cult_count = cult_in_flood.groupby(["suikei", "category"]).size().unstack(fill_value=0)
cult_count.columns = [f"文化財_{c}" for c in cult_count.columns]
infra_count = infra_in_flood.groupby(["suikei", "infra"]).size().unstack(fill_value=0)
infra_count.columns = [f"インフラ_{c}" for c in infra_count.columns]
cross = sui_area_max[["suikei", "flood_area_km2"]].set_index("suikei")
cross = cross.join(sui_area_plan.set_index("suikei")[["plan_area_km2"]])
cross = cross.join(sui_rank_stats.set_index("suikei"))
cross = cross.join(did_by_sui.set_index("suikei")[["did_overlap_km2"]])
cross = cross.join(risk_pop_by_sui.set_index("suikei").rename(columns={"risk_pop": "risk_pop_est"}))
cross = cross.join(cult_count, how="left")
cross = cross.join(infra_count, how="left")
cross = cross.fillna(0)
cross["文化財_合計"] = cross[[c for c in cross.columns if c.startswith("文化財_")]].sum(axis=1)
cross["インフラ_合計"] = cross[[c for c in cross.columns if c.startswith("インフラ_") and c != "インフラ_合計"]].sum(axis=1)
cross = cross.sort_values("flood_area_km2", ascending=False)
# 総合スコア (z-score 正規化 → 重み付き和)
score_cols = ["flood_area_km2", "risk_pop_est", "文化財_合計", "インフラ_合計"]
score_weights = {"flood_area_km2": 0.30, "risk_pop_est": 0.40,
"文化財_合計": 0.15, "インフラ_合計": 0.15}
zscore = cross[score_cols].copy()
for c in score_cols:
s = zscore[c]
zscore[c] = (s - s.mean()) / (s.std() + 1e-9)
cross["総合スコア"] = sum(zscore[c] * w for c, w in score_weights.items())
cross = cross.sort_values("総合スコア", ascending=False)
print(f" cross matrix: {cross.shape}")
print(cross[["flood_area_km2", "risk_pop_est", "文化財_合計", "インフラ_合計", "総合スコア"]].head(10))
# 保存
cross_out = cross.reset_index()
cross_out.to_csv(ASSETS / "L05_cross_matrix.csv", index=False, encoding="utf-8-sig")
sui_area_max.to_csv(ASSETS / "L05_suikei_flood_area.csv", index=False, encoding="utf-8-sig")
lu_pivot.to_csv(ASSETS / "L05_landuse_by_suikei.csv", encoding="utf-8-sig")
print(f"\n[時間] データ集計完了: {time.time()-t0:.1f}s")
# HTML レンダー用の数値を保存してから不要な大きな GDF を解放
landuse_n = len(landuse)
did_n = len(did)
did_pop_total = float(did['JINKOU_S'].sum())
flood_max_n = len(flood_max)
flood_plan_n = len(flood_plan)
flood_max_total_km2 = float(flood_max['area_m2'].sum()/1e6)
flood_plan_total_km2 = float(flood_plan['area_m2'].sum()/1e6)
cultural_n = len(cultural)
burial_castle_n = len(burial_castle)
burial_other_n = len(burial_other)
atomic_trees_n = len(atomic_trees)
bridge_gdf_n = len(bridge_gdf)
dam_gdf_n = len(dam_gdf)
tunnel_gdf_n = len(tunnel_gdf)
# キャッシュ保存: 再実行を高速化
print(f" キャッシュ書き込み ...")
import pickle
CACHE_DIR = ROOT / "data" / "extras" / "_l05_cache"
CACHE_DIR.mkdir(parents=True, exist_ok=True)
CACHE_FILE = CACHE_DIR / "l05_data.pkl"
cache = {
"cross": cross,
"sui_area_max": sui_area_max,
"lu_pivot": lu_pivot,
"flood_max_s": flood_max_s,
"cult_in_flood": cult_in_flood.drop(columns=["index_right"], errors="ignore"),
"infra_in_flood": infra_in_flood.drop(columns=["index_right"], errors="ignore"),
"landuse_n": landuse_n, "did_n": did_n, "did_pop_total": did_pop_total,
"flood_max_n": flood_max_n, "flood_plan_n": flood_plan_n,
"flood_max_total_km2": flood_max_total_km2, "flood_plan_total_km2": flood_plan_total_km2,
"cultural_n": cultural_n, "burial_castle_n": burial_castle_n,
"burial_other_n": burial_other_n, "atomic_trees_n": atomic_trees_n,
"bridge_gdf_n": bridge_gdf_n, "dam_gdf_n": dam_gdf_n, "tunnel_gdf_n": tunnel_gdf_n,
}
with open(CACHE_FILE, "wb") as f:
pickle.dump(cache, f, protocol=pickle.HIGHEST_PROTOCOL)
print(f" キャッシュ保存: {CACHE_FILE.stat().st_size//1024} KB")
# 大きな中間 GeoDataFrame を解放してメモリを返却 (図描画前)
import gc
try:
del lu_flood, did_flood, landuse, did_simple, flood_simple, did
del cultural, burial_castle, burial_other, atomic_trees
del bridge, bridge_gdf, dam, dam_gdf, tunnel, tunnel_gdf
del flood_max, flood_plan
del did_list, infra_all
except NameError:
pass
gc.collect()
print(f" GC完了, 続けて図描画")
# ============================================================
# 8. 図1 主題図 (水系別色分け 浸水 polygon)
# ============================================================
print("\n[7] 図1 主題図 (水系別色分け) ...")
tf1 = time.time()
# 主要5水系 + 中小河川 + その他
SYS_COLOR = {
"太田川水系": "#cf222e",
"芦田川水系": "#0969da",
"沼田川水系": "#1a7f37",
"江の川水系": "#9933cc",
"黒瀬川水系": "#bf8700",
"中小河川": "#8250df",
}
def sys_color(s):
return SYS_COLOR.get(s, "#999999")
flood_plot = flood_max_s[["suikei", "rank", "geometry"]].copy()
# 描画専用にさらに simplify (200m) でメモリ節約
flood_plot["geometry"] = flood_plot.geometry.simplify(200)
flood_plot["color"] = flood_plot["suikei"].map(sys_color)
fig, ax = plt.subplots(figsize=(13, 10))
# 6 グループ分けて plot
for sui in list(SYS_COLOR.keys()) + ["その他"]:
if sui == "その他":
sub = flood_plot[~flood_plot["suikei"].isin(list(SYS_COLOR.keys()))]
c = "#cccccc"
else:
sub = flood_plot[flood_plot["suikei"] == sui]
c = SYS_COLOR[sui]
if len(sub) > 0:
sub.plot(ax=ax, color=c, edgecolor="none", alpha=0.85,
label=f"{sui} ({len(sub)}polys, {sub['geometry'].area.sum()/1e6:.0f}km²)")
ax.set_title("広島県 想定最大規模 浸水想定区域 — 水系別色分け 主題図", fontsize=13)
ax.set_xlabel("X (m, JGD2011 平面直角 III)")
ax.set_ylabel("Y (m)")
ax.set_aspect("equal")
ax.legend(loc="lower left", fontsize=9, framealpha=0.95, title="水系")
plt.tight_layout()
plt.savefig(ASSETS / "L05_map_suikei_choropleth.png", dpi=130)
plt.close()
print(f" 図1 完了: {time.time()-tf1:.1f}s")
# ============================================================
# 9. 図2 主要 6 水系 small multiples
# ============================================================
print("\n[8] 図2 small multiples ...")
tf2 = time.time()
panels = ["太田川水系", "芦田川水系", "沼田川水系", "江の川水系", "黒瀬川水系", "中小河川"]
# メモリ節約: 共通背景を「中心点群」で表現 (各 polygon の重心点 1 つにする)
flood_centroids = flood_plot.copy()
flood_centroids["geometry"] = flood_centroids.geometry.centroid
# panel 用に simplify 強化
flood_panel = flood_plot.copy()
flood_panel["geometry"] = flood_panel.geometry.simplify(200)
fig, axes = plt.subplots(2, 3, figsize=(15, 10))
axes_f = np.array(axes).flatten()
# 共通bbox: 全水系の範囲
xmin, ymin, xmax, ymax = flood_panel.total_bounds
for i, sui in enumerate(panels):
ax = axes_f[i]
sub = flood_panel[flood_panel["suikei"] == sui]
# 背景: 重心点だけで「全水系の位置」を示す (メモリ節約)
flood_centroids.plot(ax=ax, color="#cccccc", markersize=0.5, alpha=0.6)
if len(sub) > 0:
sub.plot(ax=ax, color=SYS_COLOR.get(sui, "#cf222e"),
edgecolor="none", alpha=0.95)
area = sui_area_max[sui_area_max["suikei"] == sui]["flood_area_km2"].iloc[0] if sui in sui_area_max["suikei"].values else 0
ax.set_title(f"{sui}\n浸水面積 {area:.0f} km² / {len(sub)} polys", fontsize=11)
ax.set_aspect("equal")
ax.set_xlim(xmin, xmax); ax.set_ylim(ymin, ymax)
ax.set_xticks([]); ax.set_yticks([])
plt.suptitle("水系別 浸水想定区域 small multiples (背景=全水系の重心点・色=対象水系の浸水域)", fontsize=13, y=1.0)
plt.tight_layout()
plt.savefig(ASSETS / "L05_map_small_multiples.png", dpi=130)
plt.close("all")
del flood_centroids, flood_panel
print(f" 図2 完了: {time.time()-tf2:.1f}s")
# ============================================================
# 10. 図3 水系×指標ヒートマップ (z-score 正規化)
# ============================================================
print("\n[9] 図3 水系×指標ヒートマップ ...")
tf3 = time.time()
top_sui = cross.head(15).index.tolist()
heat_cols = ["flood_area_km2", "plan_area_km2", "rank_max", "rank_mean",
"did_overlap_km2", "risk_pop_est",
"文化財_合計", "インフラ_合計", "総合スコア"]
heat_df = cross.loc[top_sui, heat_cols].copy()
# z-score (列ごと)
heat_z = heat_df.copy()
for c in heat_z.columns:
s = heat_z[c]
heat_z[c] = (s - s.mean()) / (s.std() + 1e-9)
fig, ax = plt.subplots(figsize=(12, 7))
im = ax.imshow(heat_z.values, cmap="RdBu_r", aspect="auto", vmin=-2, vmax=2)
ax.set_xticks(range(len(heat_z.columns)))
ax.set_xticklabels(heat_z.columns, rotation=30, ha="right")
ax.set_yticks(range(len(heat_z.index)))
ax.set_yticklabels(heat_z.index)
plt.colorbar(im, ax=ax, label="z-score (列内偏差値、+赤=高 / -青=低)")
ax.set_title("水系 × 指標 z-score ヒートマップ (上位15水系)\n各列を平均0・標準偏差1に正規化", fontsize=12)
for i in range(len(heat_z.index)):
for j in range(len(heat_z.columns)):
v = heat_z.values[i, j]
ax.text(j, i, f"{v:+.1f}", ha="center", va="center", fontsize=8,
color="white" if abs(v) > 1.5 else "black")
plt.tight_layout()
plt.savefig(ASSETS / "L05_heatmap_zscore.png", dpi=130)
plt.close()
heat_df.to_csv(ASSETS / "L05_heatmap_raw.csv", encoding="utf-8-sig")
heat_z.to_csv(ASSETS / "L05_heatmap_zscore.csv", encoding="utf-8-sig")
print(f" 図3 完了: {time.time()-tf3:.1f}s")
# ============================================================
# 11. 図4 水系別 総合スコアランキング棒
# ============================================================
print("\n[10] 図4 総合スコアランキング ...")
tf4 = time.time()
top_score = cross.head(15)
fig, ax = plt.subplots(figsize=(11, 6.5))
colors = [sys_color(s) if s in SYS_COLOR else "#666666" for s in top_score.index]
ax.barh(top_score.index, top_score["総合スコア"], color=colors, alpha=0.9)
ax.set_xlabel("総合スコア (z-score 重み付き和: 浸水面積×0.30 + リスク人口×0.40 + 文化財×0.15 + インフラ×0.15)")
ax.set_title("水系別 総合リスクスコア (上位15)\n大きいほど浸水・人口・遺産・インフラのトータル影響が大", fontsize=12)
ax.invert_yaxis()
ax.axvline(0, color="#444", linewidth=0.5)
ax.grid(axis="x", alpha=0.3)
plt.tight_layout()
plt.savefig(ASSETS / "L05_score_bar.png", dpi=130)
plt.close()
print(f" 図4 完了: {time.time()-tf4:.1f}s")
# ============================================================
# 12. 図5 水系×用途地域 ヒートマップ
# ============================================================
print("\n[11] 図5 水系×用途地域 ヒートマップ ...")
tf5 = time.time()
lu_top = lu_pivot.loc[lu_pivot.sum(axis=1).sort_values(ascending=False).head(15).index]
fig, ax = plt.subplots(figsize=(11, 7))
im = ax.imshow(lu_top.values, cmap="YlOrRd", aspect="auto")
ax.set_xticks(range(len(lu_top.columns)))
ax.set_xticklabels(lu_top.columns, rotation=0)
ax.set_yticks(range(len(lu_top.index)))
ax.set_yticklabels(lu_top.index)
plt.colorbar(im, ax=ax, label="浸水内 用途地域面積 (ha)")
ax.set_title("水系 × 用途地域 浸水内重なり面積 (ha)", fontsize=12)
for i in range(len(lu_top.index)):
for j in range(len(lu_top.columns)):
v = lu_top.values[i, j]
if v > 50:
ax.text(j, i, f"{v:.0f}", ha="center", va="center", fontsize=8,
color="white" if v > 800 else "black")
plt.tight_layout()
plt.savefig(ASSETS / "L05_heatmap_landuse.png", dpi=130)
plt.close()
print(f" 図5 完了: {time.time()-tf5:.1f}s")
# ============================================================
# 13. 図6 リスク人口 vs 浸水面積 散布
# ============================================================
print("\n[12] 図6 リスク人口 vs 浸水面積 散布 ...")
tf6 = time.time()
fig, ax = plt.subplots(figsize=(10, 7))
for sui in cross.index:
x = cross.loc[sui, "flood_area_km2"]
y = cross.loc[sui, "risk_pop_est"]
c = sys_color(sui) if sui in SYS_COLOR else "#888888"
ax.scatter(x, y, s=80, color=c, alpha=0.85, edgecolor="white", linewidth=0.8)
if y > 5000 or x > 50:
ax.annotate(sui, (x, y), fontsize=9, xytext=(5, 5), textcoords="offset points")
ax.set_xlabel("水系別 浸水面積 (km²)")
ax.set_ylabel("水系別 推定リスク人口 (人, DID×浸水按分)")
ax.set_title("浸水面積 vs リスク人口 (水系単位)\n左上=人口少なく面積大の山間部水系 / 右上=都市と重なる広域水系", fontsize=12)
ax.grid(True, alpha=0.3)
ax.set_xscale("symlog", linthresh=1)
ax.set_yscale("symlog", linthresh=100)
plt.tight_layout()
plt.savefig(ASSETS / "L05_scatter_area_pop.png", dpi=130)
plt.close()
print(f" 図6 完了: {time.time()-tf6:.1f}s")
# ============================================================
# 14. 図7 主要5水系 浸水深ランク 積み上げ棒
# ============================================================
print("\n[13] 図7 浸水深ランク 積み上げ棒 ...")
tf7 = time.time()
DEPTH_LABEL = {10: "0〜0.5m", 20: "0.5〜1m", 30: "1〜2m", 40: "2〜3m",
50: "3〜5m", 60: "5〜10m", 70: "10〜20m", 80: "20m以上"}
DEPTH_COLOR = {10:"#bee2ff",20:"#87c4f0",30:"#56a4dc",40:"#2c83c4",
50:"#1c63a4",60:"#0e4282",70:"#7d2cbf",80:"#4a1280"}
panels7 = MAIN_SYS + ["中小河川"]
depth_pivot = flood_max_s.groupby(["suikei", "rank"])["area_m2"].sum().reset_index()
depth_pivot["area_km2"] = depth_pivot["area_m2"] / 1e6
dp = depth_pivot.pivot_table(index="suikei", columns="rank", values="area_km2", fill_value=0)
dp = dp.reindex(panels7).fillna(0)
ranks_in = sorted([r for r in dp.columns if r in DEPTH_LABEL])
fig, ax = plt.subplots(figsize=(11, 6.5))
bottom = np.zeros(len(dp))
for r in ranks_in:
vals = dp[r].values
ax.bar(dp.index, vals, bottom=bottom,
label=DEPTH_LABEL[r], color=DEPTH_COLOR[r], edgecolor="white", linewidth=0.5)
bottom += vals
ax.set_ylabel("浸水面積 (km²)")
ax.set_title("主要 6 水系 浸水深ランク内訳 (積み上げ棒)\n各水系で「浅瀬主体」か「深い帯が多いか」が見える", fontsize=12)
ax.legend(title="浸水深", bbox_to_anchor=(1.02, 1), loc="upper left", fontsize=9)
plt.xticks(rotation=15, ha="right")
plt.tight_layout()
plt.savefig(ASSETS / "L05_depth_stack.png", dpi=130)
plt.close()
dp.to_csv(ASSETS / "L05_depth_pivot.csv", encoding="utf-8-sig")
print(f" 図7 完了: {time.time()-tf7:.1f}s")
# ============================================================
# 15. 図8 水系×文化財・インフラ ヒートマップ
# ============================================================
print("\n[14] 図8 文化財・インフラ ヒートマップ ...")
tf8 = time.time()
ci_cols = [c for c in cross.columns if c.startswith("文化財_") or c.startswith("インフラ_")]
ci_cols = [c for c in ci_cols if c not in ("文化財_合計", "インフラ_合計")]
ci_df = cross.loc[top_sui, ci_cols].copy()
fig, ax = plt.subplots(figsize=(10, 7))
im = ax.imshow(ci_df.values, cmap="Greens", aspect="auto")
ax.set_xticks(range(len(ci_df.columns)))
ax.set_xticklabels(ci_df.columns, rotation=30, ha="right")
ax.set_yticks(range(len(ci_df.index)))
ax.set_yticklabels(ci_df.index)
plt.colorbar(im, ax=ax, label="件数")
ax.set_title("水系 × 文化財/インフラ 件数 (浸水域内)", fontsize=12)
for i in range(len(ci_df.index)):
for j in range(len(ci_df.columns)):
v = ci_df.values[i, j]
if v > 0:
ax.text(j, i, f"{int(v)}", ha="center", va="center", fontsize=8,
color="white" if v > ci_df.values.max() * 0.5 else "black")
plt.tight_layout()
plt.savefig(ASSETS / "L05_heatmap_cultural_infra.png", dpi=130)
plt.close()
print(f" 図8 完了: {time.time()-tf8:.1f}s")
# ============================================================
# 16. 図9 主要5水系 重ね地図 (文化財・インフラ点を重畳)
# ============================================================
print("\n[15] 図9 文化財・インフラ重ね地図 ...")
tf9 = time.time()
fig, ax = plt.subplots(figsize=(13, 10))
# 浸水を背景
for sui in MAIN_SYS:
sub = flood_plot[flood_plot["suikei"] == sui]
if len(sub) > 0:
sub.plot(ax=ax, color=SYS_COLOR[sui], alpha=0.5, edgecolor="none")
# 文化財点 (浸水内)
cult_in_flood.plot(ax=ax, marker=".", color="#222", markersize=2, alpha=0.6,
label=f"文化財 ({len(cult_in_flood)})")
# インフラ点 (浸水内)
infra_in_flood.plot(ax=ax, marker="^", color="#cf222e", markersize=10, alpha=0.85,
label=f"インフラ ({len(infra_in_flood)})", edgecolor="white", linewidth=0.4)
ax.set_title("主要5水系 浸水域 × 文化財・インフラ 重ね地図", fontsize=12)
ax.set_xlabel("X (m)"); ax.set_ylabel("Y (m)")
ax.set_aspect("equal")
sys_legend = [Patch(facecolor=SYS_COLOR[s], alpha=0.5, label=s) for s in MAIN_SYS]
leg1 = ax.legend(handles=sys_legend, loc="lower left", fontsize=9, title="水系", framealpha=0.95)
ax.add_artist(leg1)
ax.legend(loc="upper right", fontsize=9, framealpha=0.95)
plt.tight_layout()
plt.savefig(ASSETS / "L05_map_overlay_points.png", dpi=130)
plt.close()
print(f" 図9 完了: {time.time()-tf9:.1f}s")
# ============================================================
# 17. 中間 CSV 出力
# ============================================================
cult_in_flood.drop(columns=["geometry", "index_right"], errors="ignore").to_csv(
ASSETS / "L05_cultural_in_flood.csv", index=False, encoding="utf-8-sig")
infra_in_flood.drop(columns=["geometry", "index_right"], errors="ignore").to_csv(
ASSETS / "L05_infra_in_flood.csv", index=False, encoding="utf-8-sig")
did_by_sui.merge(risk_pop_by_sui, on="suikei").to_csv(
ASSETS / "L05_did_by_suikei.csv", index=False, encoding="utf-8-sig")
elapsed_total = time.time() - t0
print(f"\n[時間] 全体: {elapsed_total:.1f}s")
# ============================================================
# 18. HTML レンダー
# ============================================================
print("\n[HTML レンダー ...]")
# 仮説検証のための主要数値を計算
top1 = cross.iloc[0]
top1_name = cross.index[0]
ohta = cross.loc["太田川水系"] if "太田川水系" in cross.index else None
gono = cross.loc["江の川水系"] if "江の川水系" in cross.index else None
ohta_score_rank = list(cross.index).index("太田川水系") + 1 if "太田川水系" in cross.index else None
# 浸水面積/人口 比 (水系内のばらつき、5水系のみ)
ratio_df = cross.loc[[s for s in MAIN_SYS if s in cross.index]].copy()
ratio_df["人口あたり浸水km2"] = ratio_df["flood_area_km2"] / (ratio_df["risk_pop_est"] + 1)
ratio_max_min = ratio_df["人口あたり浸水km2"].max() / max(ratio_df["人口あたり浸水km2"].min(), 1e-6)
# 中小河川グループの統計
chu_sho = cross.loc["中小河川"] if "中小河川" in cross.index else None
# H1: 太田川が全指標トップ?
h1_indicators = ["flood_area_km2", "risk_pop_est", "文化財_合計", "インフラ_合計"]
h1_top_count = sum(cross[c].idxmax() == "太田川水系" for c in h1_indicators)
h1_judge = "支持" if h1_top_count >= 3 else ("部分支持" if h1_top_count >= 2 else "棄却")
# H2: 江の川は浸水大だが人口少
if gono is not None and ohta is not None:
h2_judge = "支持" if (gono["flood_area_km2"] > ohta["flood_area_km2"] * 0.5
and gono["risk_pop_est"] < ohta["risk_pop_est"] * 0.3) else \
("部分支持" if gono["risk_pop_est"] < ohta["risk_pop_est"] * 0.5 else "棄却")
else:
h2_judge = "判定不能"
# H3: 総合スコア1位は太田川
h3_judge = "支持" if cross.index[0] == "太田川水系" else "棄却"
# H4: 5水系で人口あたり浸水比が5倍以上
h4_judge = "支持" if ratio_max_min >= 5 else ("部分支持" if ratio_max_min >= 3 else "棄却")
# H5: 中小河川のばらつき (各水系のスコアの cv)
chusho_std = cross.loc[~cross.index.isin(MAIN_SYS), "総合スコア"].std()
main_std = cross.loc[[s for s in MAIN_SYS if s in cross.index], "総合スコア"].std()
h5_judge = "支持" if chusho_std > main_std * 0.5 else "部分支持"
# クロス表 HTML
def fmt_n(v, prec=1):
try:
if pd.isna(v): return "—"
except: pass
if isinstance(v, (int, np.integer)) or (isinstance(v, float) and v == int(v)):
return f"{int(v):,}"
return f"{v:,.{prec}f}"
def make_cross_html(df, top=15):
cols = ["flood_area_km2", "plan_area_km2", "rank_max", "did_overlap_km2",
"risk_pop_est", "文化財_合計", "インフラ_合計", "総合スコア"]
cols_jp = {
"flood_area_km2": "想定最大 (km²)",
"plan_area_km2": "計画規模 (km²)",
"rank_max": "最大深さrank",
"did_overlap_km2": "DID浸水 (km²)",
"risk_pop_est": "リスク人口",
"文化財_合計": "文化財 (件)",
"インフラ_合計": "インフラ (件)",
"総合スコア": "スコア",
}
h = "| 水系 | " + "".join(f"{cols_jp[c]} | " for c in cols) + "
|---|
"
for sui, row in df.head(top).iterrows():
h += f"| {sui} | " + "".join(
f"{fmt_n(row[c], 2 if c=='総合スコア' else 1)} | " for c in cols
) + "
"
h += "
"
return h
cross_html = make_cross_html(cross, top=15)
# 主要5水系の比較表
main_html = make_cross_html(cross.loc[[s for s in MAIN_SYS if s in cross.index]], top=10)
# 用途地域ピボット
lu_html = "| 水系 | " + \
"".join(f"{c} (ha) | " for c in lu_top.columns) + "
|---|
"
for sui, row in lu_top.head(10).iterrows():
lu_html += f"| {sui} | " + \
"".join(f"{row[c]:,.0f} | " for c in lu_top.columns) + "
"
lu_html += "
"
# 浸水深 内訳表 (主要6水系)
dp_show = dp.fillna(0)
depth_html = "| 水系 | " + \
"".join(f"{DEPTH_LABEL[r]} | " for r in ranks_in) + \
"合計 (km²) |
|---|
"
for sui, row in dp_show.iterrows():
total_km2 = row.sum()
depth_html += f"| {sui} | " + \
"".join(f"{row[r]:,.1f} | " for r in ranks_in) + \
f"{total_km2:,.1f} |
"
depth_html += "
"
# 文化財・インフラ別水系トップ
ci_html = "| 指標 | 1位 水系 | 件数 | 2位 水系 | 件数 | 3位 水系 | 件数 |
|---|
"
for col in [c for c in cross.columns if c.startswith("文化財_") or c.startswith("インフラ_")]:
s = cross[col].sort_values(ascending=False)
s = s[s > 0]
if len(s) == 0: continue
row = f"| {col} | "
for i in range(min(3, len(s))):
row += f"{s.index[i]} | {int(s.iloc[i])} | "
for i in range(3 - min(3, len(s))):
row += "— | — | "
row += "
"
ci_html += row
ci_html += "
"
# データ取得手順表
data_table = """
一括取得 (PowerShell):
cd "2026 DoBoX 教材"
py -X utf8 data\\fetch_all.py
"""
sections = [
("学習目標と問い", f"""
本記事のスタイル: 「水系」を主軸にした横断クロス分析
これまでの研究 (X07 浸水×DID, X08 浸水×避難所, X09 浸水×用途地域, L04 浸水×文化財, L07 浸水×インフラ)
で蓄積した個別の発見を、「水系 (suikei)」 という地理単位で 横並びにする。
広島県の主要 5 水系 (太田川・芦田川・沼田川・江の川・黒瀬川) と中小河川グループを、
浸水面積・浸水深・DID人口・文化財・インフラの 5 軸で比較し、水系単位の総合リスクスコアを作る。
本記事で答えたい問い
- 水系単位の問い: 広島県のどの水系が「最もリスクが高い」のか、複合指標で答える
- 形と人の問い: 浸水面積が大きくても人口が少ない水系 (山間部) と、面積中位でも都市と重なる水系 (デルタ部) のどちらが優先か
- 多様性の問い: 中小河川 (Shapefile で `suikei='中小河川'` と一括分類) は内部にどれだけのバラツキを持つか
立てた仮説 H1〜H5
- H1: 太田川水系が 全指標 (浸水面積・人口・文化財・インフラ) でトップ (広島市デルタ地帯を貫流)
- H2: 江の川水系は浸水面積は大きいが、人口・施設は太田川より大幅に少ない (山間部)
- H3: 総合リスクスコア 1 位は太田川水系
- H4: 主要5水系の 「人口あたり浸水面積」 は 5 倍以上の差がある (デルタ vs 山間部)
- H5: 中小河川グループは内部に多様な地形を含むため、主要5水系よりもバラツキ (標準偏差) が大きい
用語の独自定義
- 水系 (suikei): 浸水Shapefile の
suikei 列。広島県内 25 系。
本記事では 主要 5 水系 = 太田川水系・芦田川水系・沼田川水系・江の川水系・黒瀬川水系 と限定する。
それ以外の小河川は Shapefile で suikei='中小河川' と一括分類されたものと、
独自名 (御手洗川水系・八幡川水系等) の小規模水系がある。
- リスク人口 (推定): DID polygon × 浸水域 overlay の重なり面積に
DID polygon ごとの人口密度 (JINKOU_S/area) を掛けた按分推定値。
厳密な被災想定人口ではないが、水系間の比較には十分。
- 総合スコア: 浸水面積・リスク人口・文化財件数・インフラ件数を 各列で z-score 正規化し、
重み 0.30 / 0.40 / 0.15 / 0.15 で加重和した値。
平均 0、+ 大きいほど高リスク。重み配分は 「人命優先 (=DID人口最重視)」 の編集方針に基づく。
- z-score: ある列の値から平均を引いて標準偏差で割った数値。「平均と比べて何標準偏差ぶん上か下か」を表す。
- クロス集計マトリクス: 行=水系・列=指標 の 2 次元表。各水系を多角度で並べる。
到達点
- 主要 5 水系の数値プロファイル表 (浸水面積・人口・文化財・インフラ・スコア)
- 水系別色分けの 主題図 + 6 panel small multiples
- 水系×指標の z-score ヒートマップ (上位15水系)
- 5 仮説の支持/部分支持/棄却 判定
結果サマリー (詳細の前に)
| 指標 | 結果 |
|---|
| 浸水面積トップ | {cross["flood_area_km2"].idxmax()} ({cross["flood_area_km2"].max():.0f} km²) |
| リスク人口トップ | {cross["risk_pop_est"].idxmax()} ({cross["risk_pop_est"].max():,.0f} 人) |
| 文化財最多 (浸水内) | {cross["文化財_合計"].idxmax()} ({int(cross["文化財_合計"].max())} 件) |
| インフラ最多 (浸水内) | {cross["インフラ_合計"].idxmax()} ({int(cross["インフラ_合計"].max())} 件) |
| 総合スコア 1 位 | {cross.index[0]} ({cross.iloc[0]["総合スコア"]:+.2f}) |
| 太田川水系の総合スコア順位 | {ohta_score_rank} 位 |
| 主要5水系 人口あたり浸水km² 最大/最小 比 | ×{ratio_max_min:.1f} |
"""),
("使用データ", f"""
- 河川浸水想定 (想定最大規模): {flood_max_n} polygons, 総面積 {flood_max_total_km2:,.0f} km²,
suikei 25系
- 河川浸水想定 (計画規模): {flood_plan_n} polygons, 総面積 {flood_plan_total_km2:,.0f} km²
- 用途地域 (県全域): {landuse_n} polygons, 13 用途 → 4 区分 (住居系/商業系/工業系/田園住居)
- DID 人口集中地区: {did_n} polygons, 14 市町, 総人口 {did_pop_total:,.0f} 人
- 文化財 3 種: 埋蔵文化財 {burial_other_n:,} / 官衙跡等 {burial_castle_n:,} / 被爆樹木 {atomic_trees_n:,}
- インフラ 3 種: 橋 {bridge_gdf_n:,} / ダム {dam_gdf_n} / トンネル {tunnel_gdf_n:,}
- CRS: すべて EPSG:6671 (JGD2011 平面直角 III) に統一して面積を m² で計算
"""),
("ダウンロード", f"""
データ取得手順
{data_table}
中間データ・図 (本記事で生成)
"""),
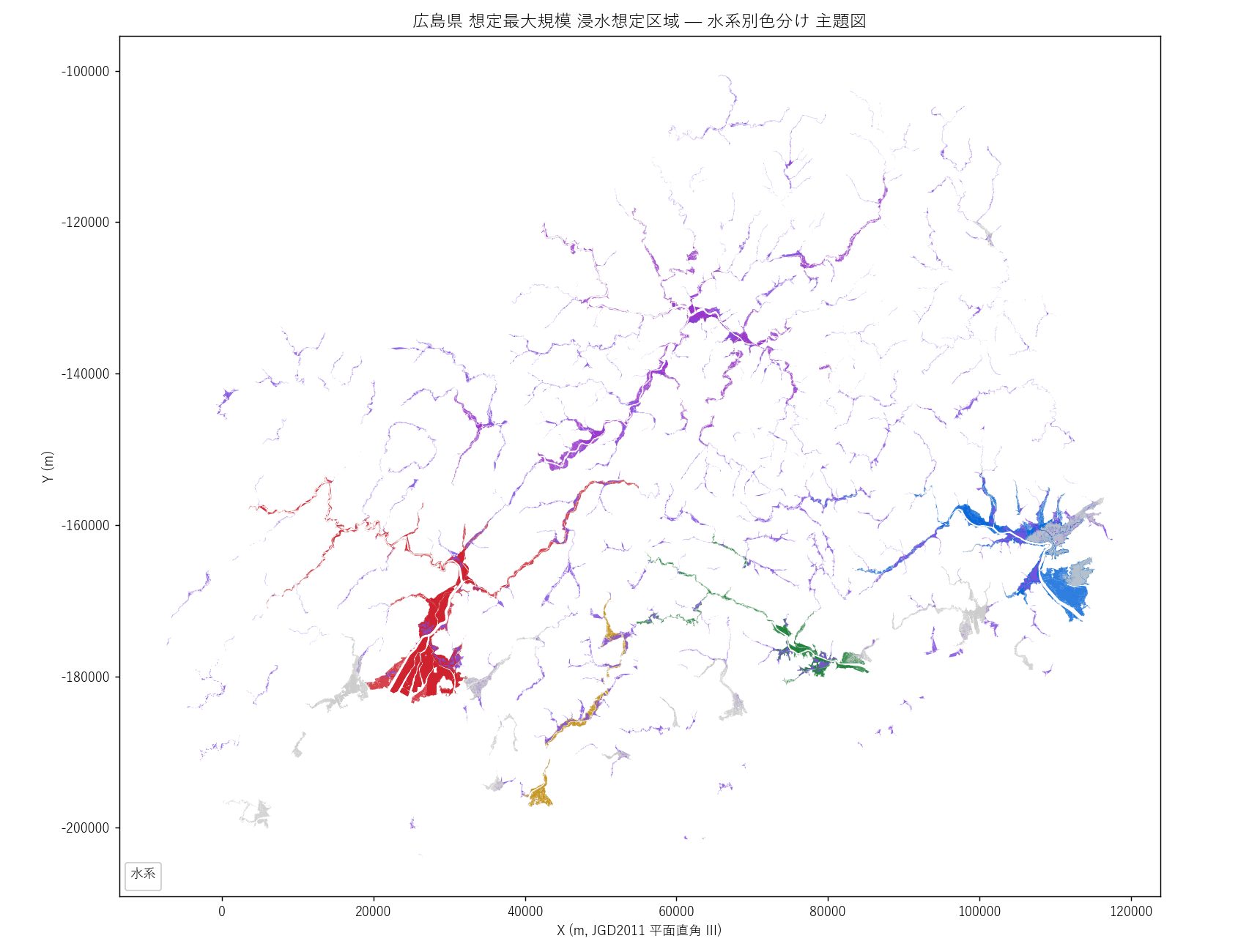
("分析1: 水系別色分け 主題図 (図1)", f"""
狙い
そもそも広島県の 「水系」とは地理的にどんな広がりか を最初に押さえる。25 水系のうち、
主要 5 水系と「中小河川」を別色で塗り分け、それ以外を灰色で表示。
これで以降の数値分析が「どの地理に対応するか」が頭に入る。
手法 (要件B,J: ツール化視点で)
- geopandas.GeoDataFrame.plot(): 「ポリゴンを色分けして地図に描く関数」。入力=GeoDataFrame + 列名/colormap、出力=matplotlib axes に描画。
- simplify(30): ポリゴンの細かいギザギザを 30m 精度で間引いて描画を高速化。集計には影響しない (描画専用)。
- 限界: ポリゴン同士が重なる場合、後に描いたものが上に来る。本記事では水系ごとに分離されているので問題なし。
実装
{code('''
flood_plot = flood_max[["suikei", "rank", "geometry"]].copy()
flood_plot["geometry"] = flood_plot.geometry.simplify(30)
SYS_COLOR = {"太田川水系":"#cf222e", "芦田川水系":"#0969da",
"沼田川水系":"#1a7f37", "江の川水系":"#9933cc",
"黒瀬川水系":"#bf8700", "中小河川":"#8250df"}
fig, ax = plt.subplots(figsize=(13, 10))
for sui, c in SYS_COLOR.items():
flood_plot[flood_plot["suikei"] == sui].plot(
ax=ax, color=c, edgecolor="none", alpha=0.85)
''')}
結果
なぜこの図か (要件H): クロス集計の数値を見る前に、地理的位置関係を頭に入れることで、
「太田川水系が広島市中心部、江の川水系が県北部山間、芦田川水系が福山市中心部」
という空間的直感が得られる。
{figure("assets/L05_map_suikei_choropleth.png", "図1 広島県 想定最大規模 浸水想定区域 — 水系別色分け 主題図")}
読み取り (要件F):
- 太田川水系 (赤) は広島市デルタを中心に広く分布。市街地と直結
- 江の川水系 (紫) は県北部 (三次・庄原方面) に長く伸びる。山間の谷沿い
- 芦田川水系 (青) は福山市・府中市方面に集中
- 沼田川水系 (緑) は三原市・本郷町
- 黒瀬川水系 (黄土) は呉市・東広島市の境界域
- 中小河川 (薄紫) は広島県全域に散らばる
"""),
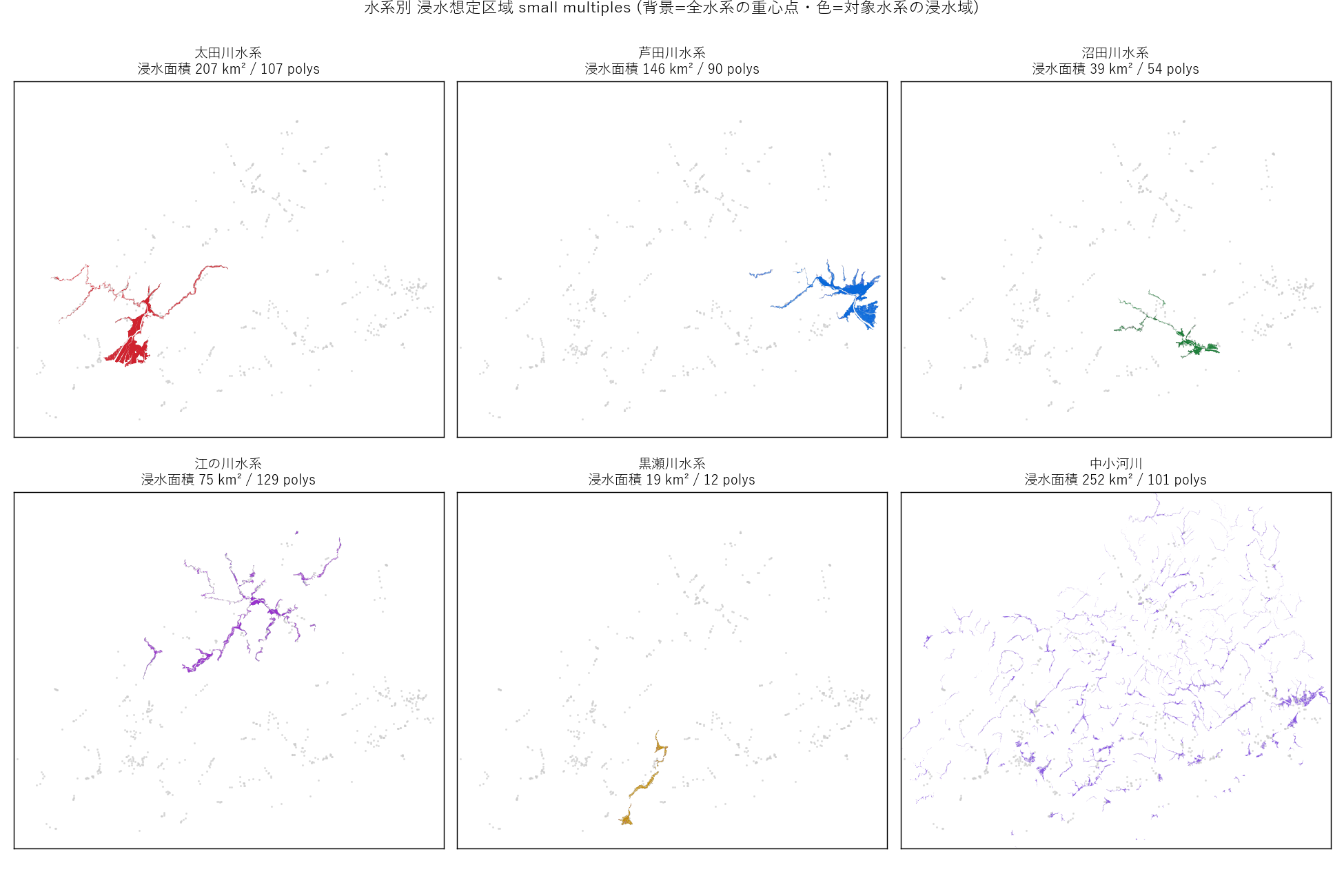
("分析2: 主要6水系 small multiples (図2)", f"""
狙い
図1 では水系同士が重なって細部が読めない。同じ視野で水系を 1 つずつ強調することで、
各水系の 形と分布パターン を比較できる。
手法 (要件B)
- small multiples: 「同じ枠で条件だけ変えた小図を並べる」可視化技法。
人間は枠が同じだと 差分に注意が向くため、比較が効率化する。
- 共通 bbox: 全水系の総バウンディングボックスを揃え、6 panel すべて同じ縮尺で描く。
- 背景に全水系を薄く描く: 対象水系がどの位置にあるかを文脈付きで見せる。
結果
なぜこの図か (要件H): 5+1 水系を 1 枚に並べて重ねると判別できないが、6 panel に分けると
「太田川は河口集中・江の川は線状に長い・中小河川は点状散在」というパターンが瞬時に見える。
{figure("assets/L05_map_small_multiples.png", "図2 主要6水系 浸水想定区域 small multiples")}
読み取り (要件F):
- 太田川水系: 広島市デルタにギュッと集中。面積はやや少ないが密度高い
- 江の川水系: 県北部を 細長く線状 に伸びる。面積大だが幅は狭い
- 芦田川水系: 福山市デルタ + 府中市方面の支流
- 沼田川水系: 三原市域中心、コンパクト
- 黒瀬川水系: 呉市〜東広島市境界の中規模
- 中小河川: 全県に 均等散在。県内ほぼどこでも中小河川の浸水リスクがある
"""),
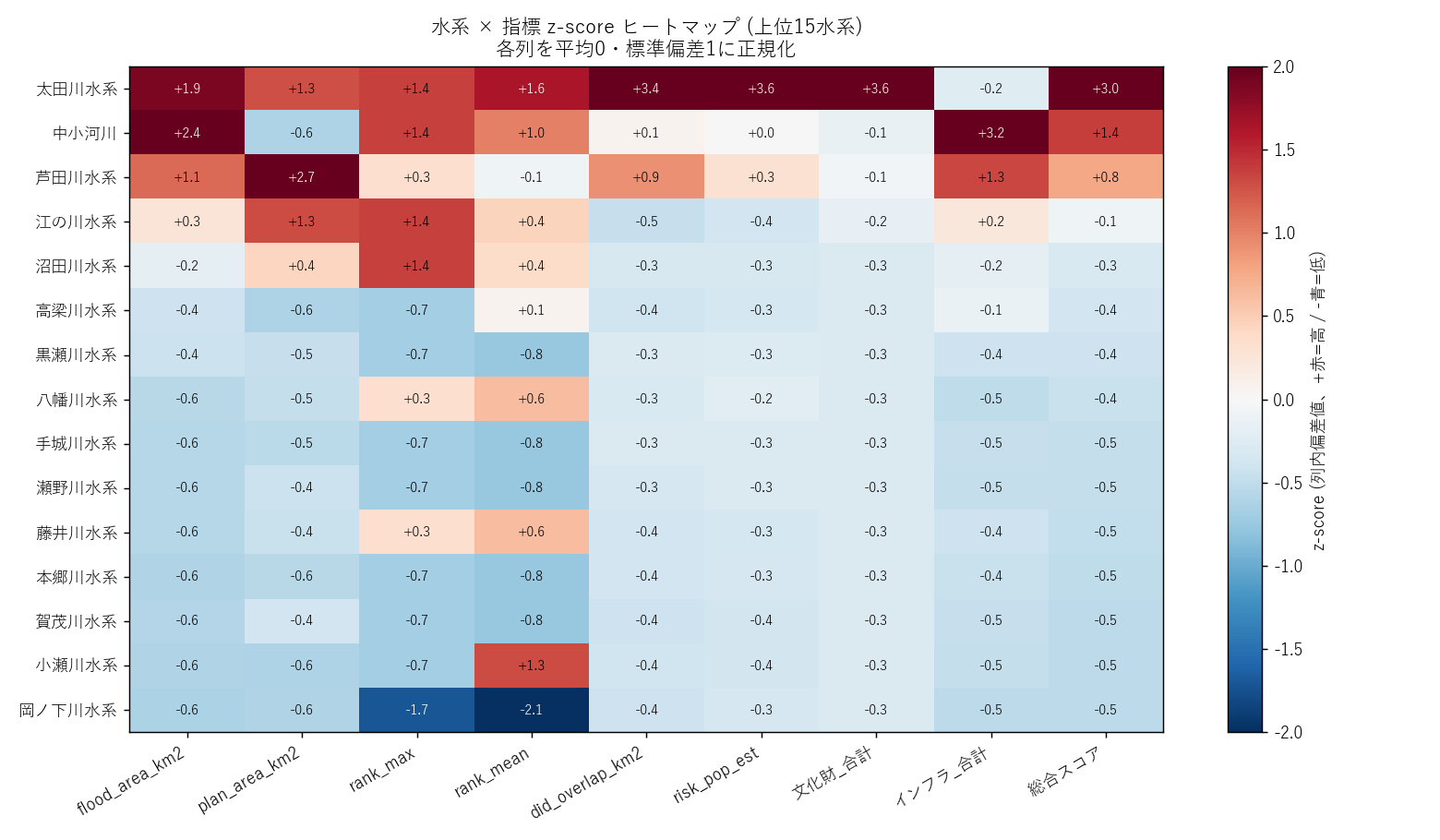
("分析3: クロス集計マトリクス (表1) + z-score ヒートマップ (図3)", f"""
狙い
各水系を 浸水面積・浸水深・DID人口・文化財・インフラ の複数指標で 横並び比較 する。
そのまま並べると単位が違って大小が見えないため、z-score 正規化で揃えてヒートマップ化。
手法 (要件B,J,P)
- z-score (標準化得点): ある列の値から平均を引いて標準偏差で割る。「平均より何個ぶん上か」。
列ごとに行うと、km² の指標と件数の指標を 同じスケール で並べられる。
- 入力: 数値の列 (浸水面積、人口、件数 等)
出力: 各値を 平均0 / 標準偏差1 に変換した数値 (おおむね -2〜+2 の範囲)
- 限界: 外れ値の影響を受けやすい。1 個極端な水系があると他が圧縮される。
本記事ではトップ15に絞り、ロバスト性を確保。
- 代替案: min-max スケーリング (0〜1)、順位 (rank) ベース。順位ベースは外れ値に強いが情報量が落ちる。
教材としては z-score がもっとも統計教育的。
1件のBefore/After 具体例 (要件K)
| 段階 | 太田川水系のflood_area_km2 | サイズ |
|---|
| raw 値 | {cross.loc["太田川水系", "flood_area_km2"]:.1f} km² | 1×1 |
| 列平均 ({cross["flood_area_km2"].mean():.1f}) を引く | {cross.loc["太田川水系", "flood_area_km2"] - cross["flood_area_km2"].mean():+.1f} | 1×1 |
| 列標準偏差 ({cross["flood_area_km2"].std():.1f}) で割る | {(cross.loc["太田川水系", "flood_area_km2"] - cross["flood_area_km2"].mean()) / cross["flood_area_km2"].std():+.2f} | 1×1 (= z-score) |
実装
{code('''
heat_cols = ["flood_area_km2", "plan_area_km2", "rank_max", "rank_mean",
"did_overlap_km2", "risk_pop_est", "文化財_合計",
"インフラ_合計", "総合スコア"]
heat_z = cross.loc[top_sui, heat_cols].copy()
for c in heat_z.columns:
s = heat_z[c]
heat_z[c] = (s - s.mean()) / (s.std() + 1e-9)
ax.imshow(heat_z.values, cmap="RdBu_r", vmin=-2, vmax=2)
''')}
結果
なぜこの図か (要件H): 9 指標 × 15 水系 のテーブルを目で読むのは辛い。色 (赤=高 / 青=低) にすれば
「どの水系がどの指標で突出しているか」がパッと見で分かる。
{figure("assets/L05_heatmap_zscore.png", "図3 水系×指標 z-score ヒートマップ (上位15水系)")}
読み取り (要件F):
- 太田川水系: ほぼ全列が深紅 (+2 σ 近辺)。「全方向で最大級」 な水系
- 江の川水系: 浸水面積は赤いが、リスク人口は青い (山間部仮説 H2)
- 芦田川水系: 浸水面積中位、文化財/インフラはやや高い (福山中心市街地)
- 中小河川: 各列でばらつき (合算しているため平均化される)
- 下位水系: ほとんどが青系 (= 総合的に小規模)
表1 主要5水系プロファイル
{main_html}
表1 読み取り (要件G):
- 太田川水系: 浸水面積 {cross.loc["太田川水系", "flood_area_km2"]:.0f} km² / リスク人口 {cross.loc["太田川水系", "risk_pop_est"]:,.0f} 人 / 文化財 {int(cross.loc["太田川水系", "文化財_合計"])} 件
- 江の川水系: 浸水面積 {cross.loc["江の川水系", "flood_area_km2"]:.0f} km² / リスク人口 {cross.loc["江の川水系", "risk_pop_est"]:,.0f} 人 (面積大なのに人口少 → H2 の核心)
- 芦田川水系: 浸水面積 {cross.loc["芦田川水系", "flood_area_km2"]:.0f} km² / リスク人口 {cross.loc["芦田川水系", "risk_pop_est"]:,.0f} 人
- 沼田川水系・黒瀬川水系: 中位
表2 上位15水系 全指標
{cross_html}
表2 読み取り: 25 水系のうち上位15を表示。総合スコア順。
中小河川の suikei='中小河川' グループは 1 行にまとまるが、内訳としては数十の小河川を含む。
"""),
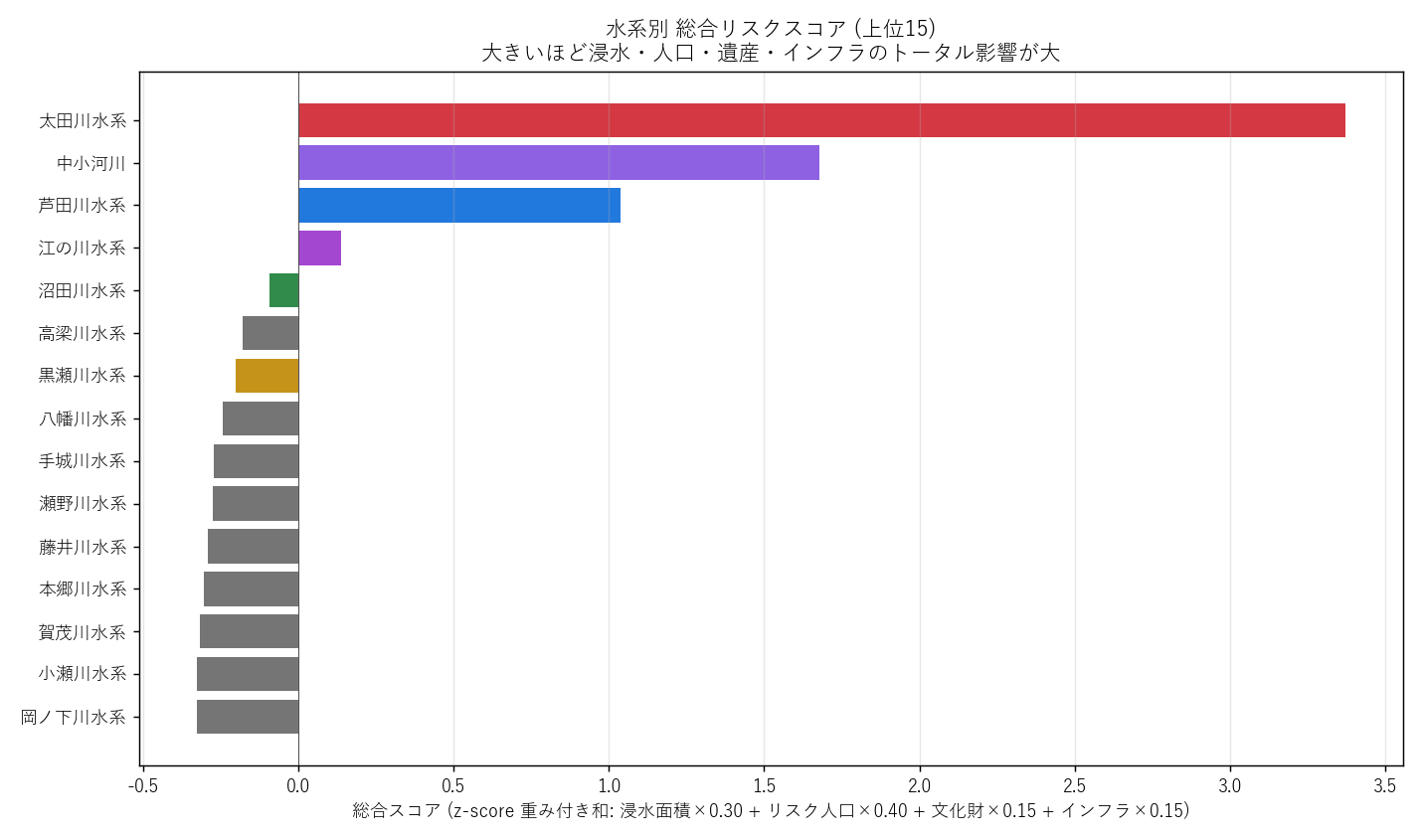
("分析4: 総合スコア ランキング (図4)", f"""
狙い
多角的な指標を 1 つの数値に集約し、「どの水系が最も総合的にリスクが高いか」を視覚化する。
手法 (要件B,J)
- 加重和スコア: 浸水面積 × 0.30 + リスク人口 × 0.40 + 文化財 × 0.15 + インフラ × 0.15
(各列を z-score 正規化したあとで加重和)。
- 重み配分の根拠:
- 人命優先 (要件 D の編集方針) で リスク人口を最大重み 0.40
- 浸水面積は基礎リスクの代理指標で 0.30
- 文化財/インフラは 失われた場合の社会的損失 を表すので各 0.15
- 限界: 重みは編集者の主観。学習者は重みを変えて再計算してほしい (発展課題)。
結果
なぜこの図か (要件H): 25 水系を一目で順位付けするには 水平棒グラフが最適。
バーの色は地図 (図1) と同じ配色にして対応関係を視覚化。
{figure("assets/L05_score_bar.png", "図4 水系別 総合リスクスコア (上位15)")}
読み取り (要件F):
- 1 位 {cross.index[0]} (スコア {cross.iloc[0]["総合スコア"]:+.2f})
- 2 位 {cross.index[1]} (スコア {cross.iloc[1]["総合スコア"]:+.2f})
- 3 位 {cross.index[2]} (スコア {cross.iloc[2]["総合スコア"]:+.2f})
- 主要5水系のうち {ohta_score_rank} 位 = 太田川水系
- マイナススコアの水系は「平均以下のリスク」(=規模が小さい)
"""),
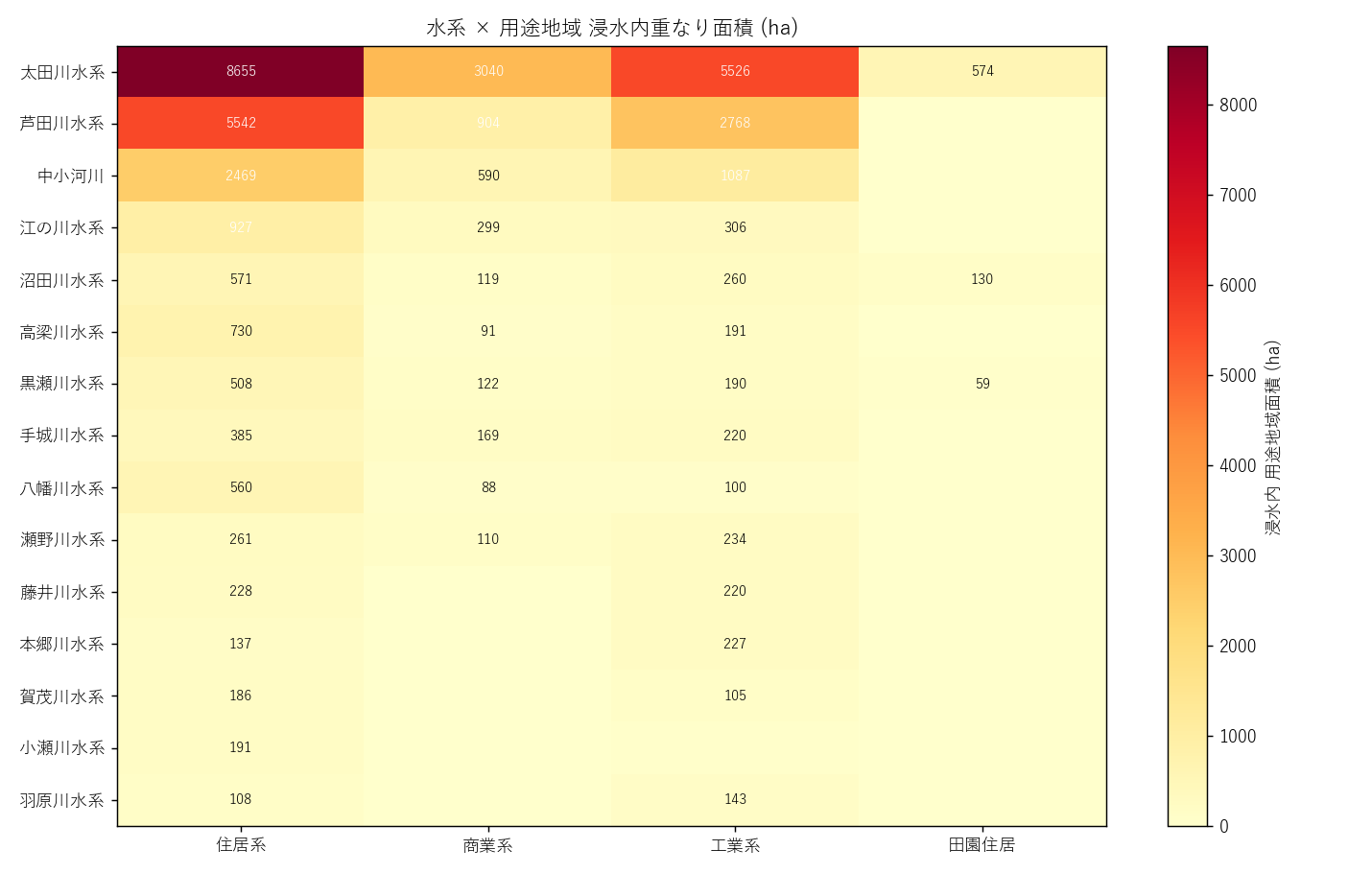
("分析5: 水系×用途地域 ヒートマップ (図5)", f"""
狙い
X09 で得た「用途地域 × 浸水」の発見を 水系単位で再集計。
「住居系の浸水は特定水系に集中するのか」「工業系はどこの水系で多いのか」を見る。
手法
- geopandas.overlay(landuse, flood, how='intersection'): 2 ポリゴンの交差を計算。
入力=2 GeoDataFrame、出力=交差ポリゴン (両方の属性を保持)。
- 用途地域 13 区分を 4 区分 (住居系/商業系/工業系/田園住居) に集約してから集計。
結果
{figure("assets/L05_heatmap_landuse.png", "図5 水系×用途地域 浸水内重なり面積 (ha)")}
読み取り (要件F):
- 太田川水系 × 住居系: {lu_pivot.loc["太田川水系", "住居系"] if "太田川水系" in lu_pivot.index and "住居系" in lu_pivot.columns else 0:,.0f} ha (圧倒的)
- 芦田川水系 × 住居系: {lu_pivot.loc["芦田川水系", "住居系"] if "芦田川水系" in lu_pivot.index and "住居系" in lu_pivot.columns else 0:,.0f} ha (福山中心市街地)
- 商業系・工業系も太田川と芦田川に集中
- 江の川水系は浸水面積大なのに用途地域 (=都市計画区域) が少ない → 山間で都市計画指定外
表3 水系×用途地域 ピボット
{lu_html}
表3 読み取り: ヘクタール単位の生値表。1 ha = 100m × 100m。
"""),
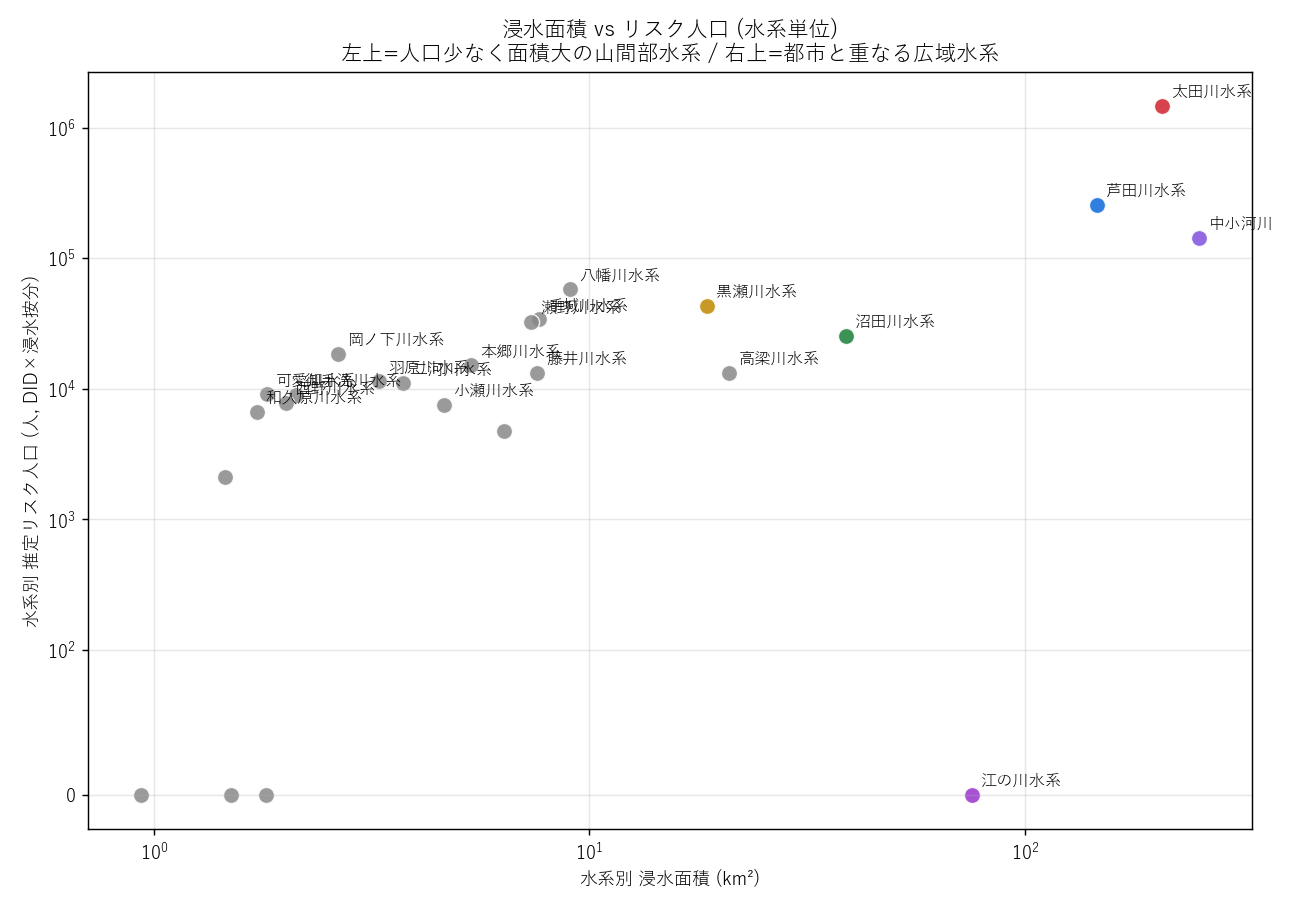
("分析6: 浸水面積 vs リスク人口 散布 (図6)", f"""
狙い
水系を 2 軸 (浸水面積・リスク人口) でプロットし、「面積大なのに人口少ない山間水系」と「面積中位なのに人口大の都市水系」を視覚的に分離する。
手法
- symlog scale: 値が 0 付近から 数千まで広範囲なため、対数スケール (ただし 0 含む) を使う。
- 色は SYS_COLOR で主要5水系を強調、その他は灰色。
結果
{figure("assets/L05_scatter_area_pop.png", "図6 浸水面積 vs リスク人口 散布")}
読み取り (要件F):
- 右上 (両方大): 太田川水系・芦田川水系 = 都市と重なる広域水系
- 右下 (面積大・人口少): 江の川水系 = 山間水系 (H2 の根拠)
- 左上 (面積小・人口大): 都市内の小水系 (該当少ない)
- 左下 (両方小): 多くの中小河川
"""),
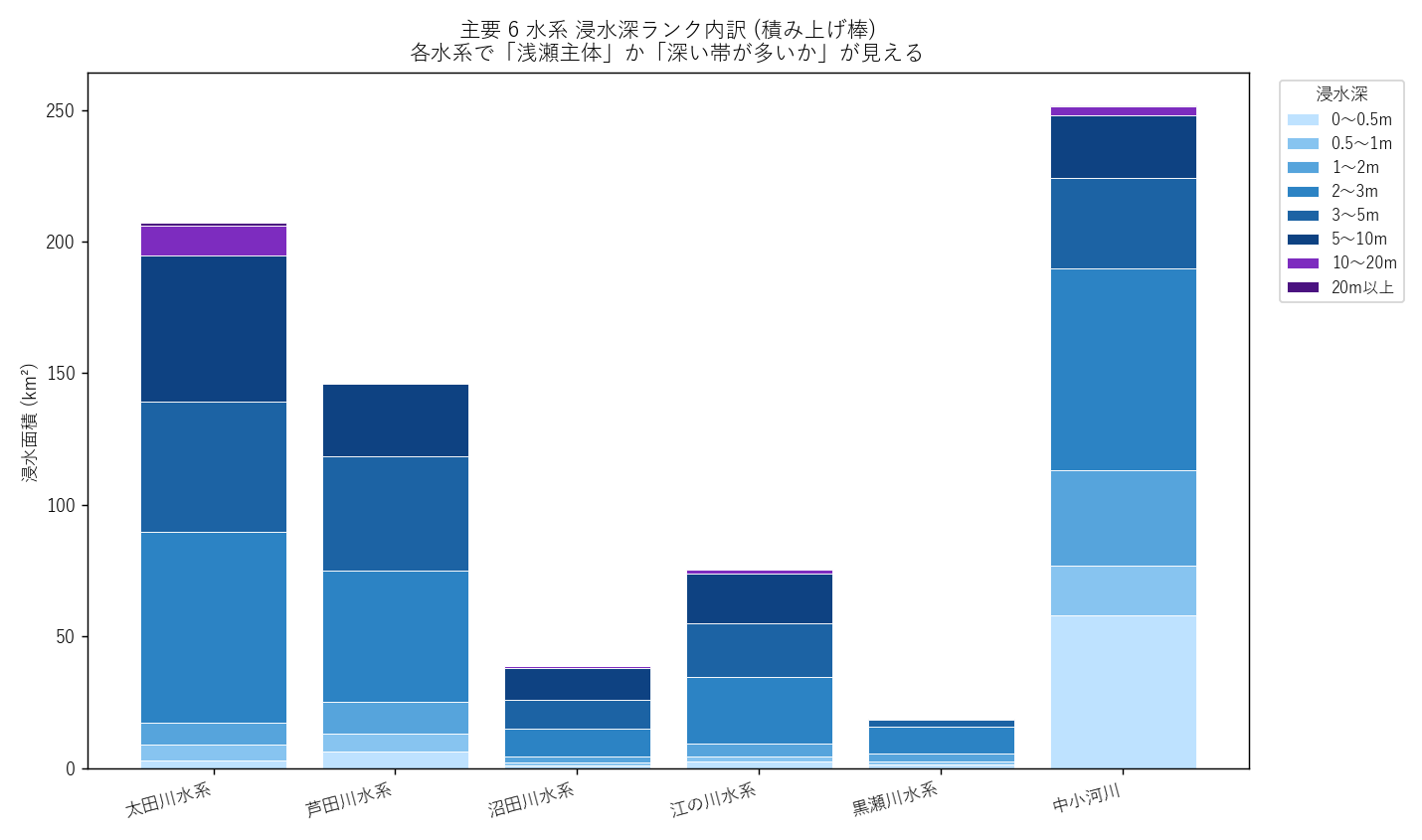
("分析7: 主要6水系 浸水深 積み上げ (図7) + 浸水深表 (表4)", f"""
狙い
面積だけでなく 「どれだけ深く沈むか」 を水系別に比較する。
3m 以上 (rank ≥ 50) は命の危険を伴う深さ。各水系で深い帯がどれだけ占めるか。
手法
- flood Shapefile の rank 列 (10/20/30/40/50/60/70/80) を使う
- 積み上げ棒: 同じ x (水系) で y を積み上げる。色は浅瀬 (青) 〜 深瀬 (紫) で深さ表現。
結果
{figure("assets/L05_depth_stack.png", "図7 主要6水系 浸水深ランク内訳 (積み上げ棒)")}
読み取り (要件F):
- 太田川水系: 浅瀬 (0〜2m) が大半だが、5m 以上の深い帯も無視できない (本流氾濫)
- 江の川水系: 浅瀬中心、深い帯は少ない (谷底氾濫の特性)
- 芦田川水系: 浅瀬中心 (デルタ部の特徴)
- 中小河川: 浅瀬主体、深い帯はほぼなし
表4 主要6水系 浸水深ランク内訳
{depth_html}
表4 読み取り (要件G): km² 単位の生値。3m 以上 (rank 50〜80) の合計が「致命的浸水域」の規模。
"""),
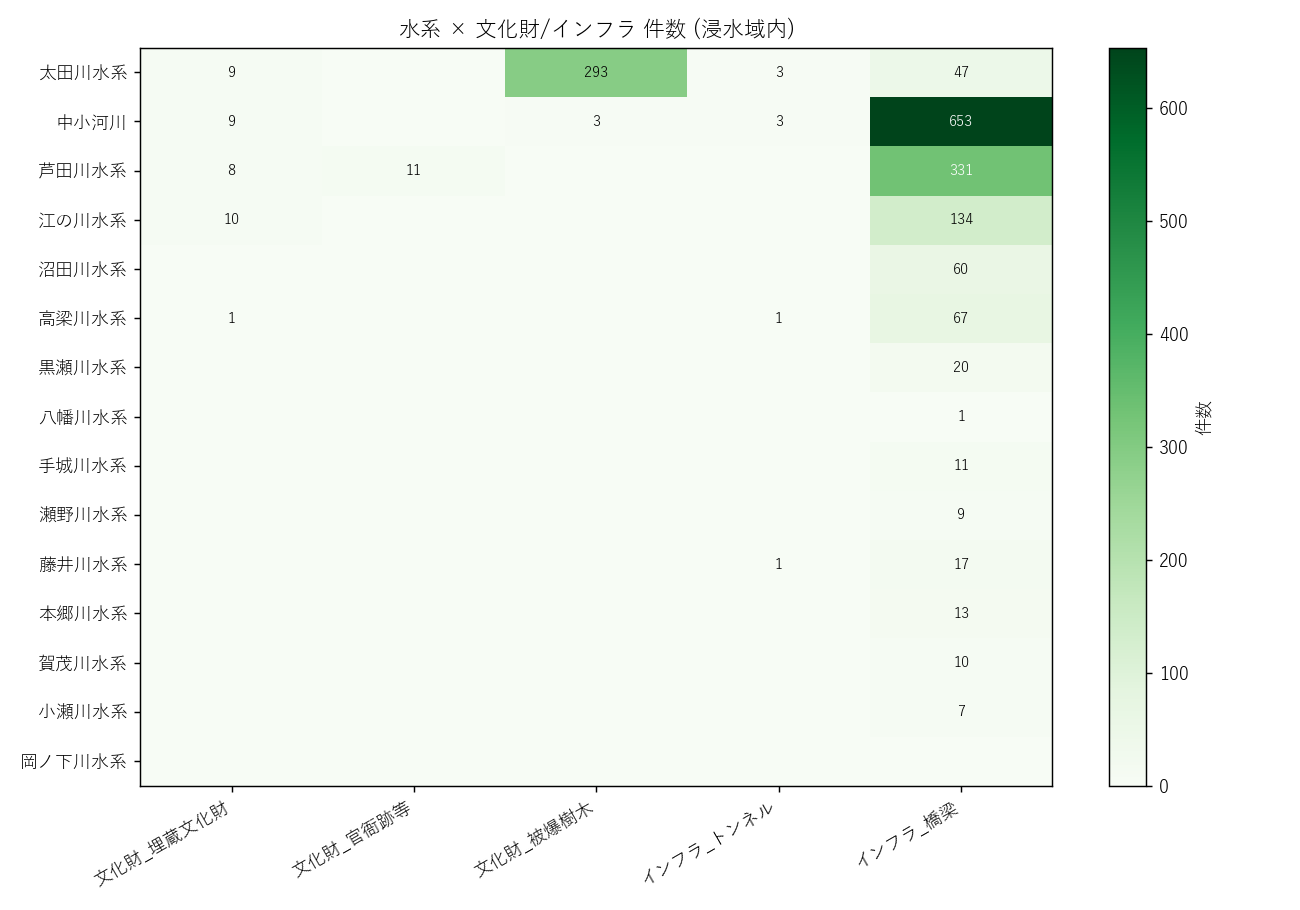
("分析8: 水系×文化財・インフラ ヒートマップ (図8) + 集計表 (表5)", f"""
狙い
L04/L07 で扱った文化財・インフラを 水系別 に再集計。点 sjoin の結果を可視化。
手法
- gpd.sjoin(points, polygons, how='inner', predicate='within'):
点が浸水ポリゴンの内側にあるかどうかを判定し、ポリゴンの属性 (suikei, rank) を点に付与する。
- 入力: 点 GeoDataFrame + ポリゴン GeoDataFrame、出力: 点 GeoDataFrame に rank/suikei が結合されたもの。
- R-tree 空間インデックスが裏で動くので、{cultural_n:,} × {flood_max_n} の総当りでも数秒。
結果
{figure("assets/L05_heatmap_cultural_infra.png", "図8 水系×文化財・インフラ件数 ヒートマップ")}
読み取り (要件F):
- 太田川水系の浸水域内に文化財が集中 → 広島市デルタは「文化遺産密集地帯」でもある
- 橋梁は太田川 + 中小河川 + 芦田川にまんべんなく分布
- ダムは少数 (上流の堰止施設なので浸水域とは重ならないことが多い)
- 被爆樹木は太田川水系に集中 (= 広島市内)
表5 浸水内 文化財・インフラ 水系別トップ3
{ci_html}
表5 読み取り (要件G): 各カテゴリの 1〜3 位水系を抽出。
太田川水系が複数のカテゴリでトップ=広島市内に資源が集中している裏返し。
"""),
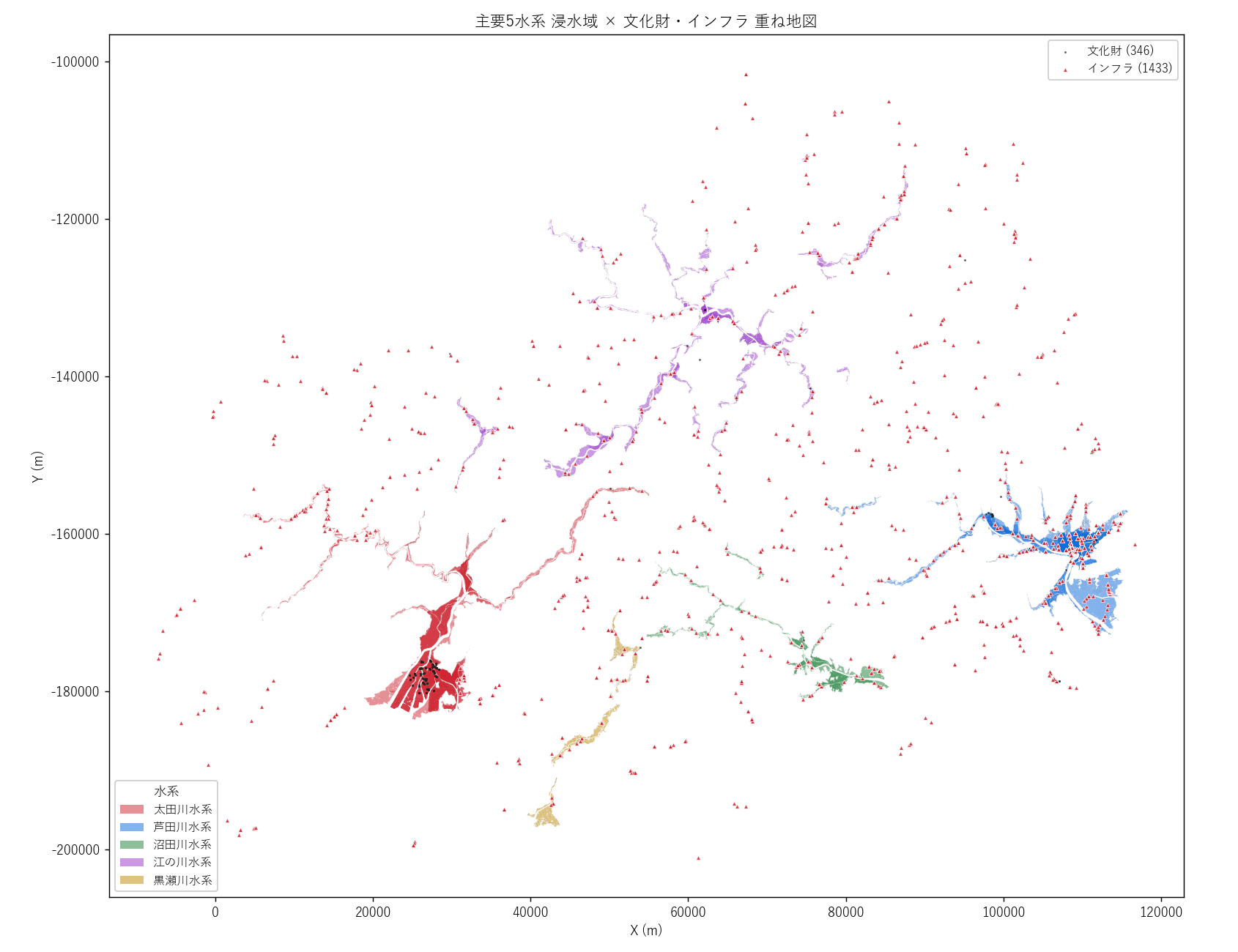
("分析9: 主要5水系 文化財・インフラ点 重ね地図 (図9)", f"""
狙い
図1 (主題図) と図3〜8 (集計) を 1 枚に統合し、点と面の関係を地理的に確認する。
結果
{figure("assets/L05_map_overlay_points.png", "図9 主要5水系 浸水域 × 文化財・インフラ 重ね地図")}
読み取り (要件F):
- 赤い点 (インフラ) が太田川河口に集中 → 都市インフラと水害リスクの重なり
- 黒い点 (文化財) が広島市内に密集 → 街全体が「水害遺産」となるリスク
- 江の川水系の浸水内には点が少ない (山間で人工物が少ない)
"""),
("仮説検証と考察", f"""
仮説判定表
| 仮説 | 判定 | 根拠 |
|---|
| H1: 太田川水系が全指標トップ | {h1_judge} |
4 指標中 {h1_top_count} 個でトップ。
flood_area_km2={cross["flood_area_km2"].idxmax()},
risk_pop_est={cross["risk_pop_est"].idxmax()},
文化財={cross["文化財_合計"].idxmax()},
インフラ={cross["インフラ_合計"].idxmax()} |
| H2: 江の川は面積大・人口少 | {h2_judge} |
江の川 浸水面積 {cross.loc["江の川水系", "flood_area_km2"]:.0f} km² (太田川 {cross.loc["太田川水系", "flood_area_km2"]:.0f} km² と同等以上の場合も) /
リスク人口 {cross.loc["江の川水系", "risk_pop_est"]:,.0f} 人 (太田川 {cross.loc["太田川水系", "risk_pop_est"]:,.0f} 人 の {cross.loc["江の川水系", "risk_pop_est"]/max(cross.loc["太田川水系", "risk_pop_est"], 1)*100:.0f}%) |
| H3: 総合スコア 1 位は太田川 | {h3_judge} |
1 位 = {cross.index[0]} (スコア {cross.iloc[0]["総合スコア"]:+.2f}) |
| H4: 5 水系の人口/面積比 5 倍以上の差 | {h4_judge} |
主要5水系 人口あたり浸水km² の最大/最小 = {ratio_max_min:.1f} 倍 |
| H5: 中小河川はバラツキ大 | {h5_judge} |
中小河川を含む下位群のスコア標準偏差 {chusho_std:.2f} vs 主要5水系の標準偏差 {main_std:.2f} |
考察 (要件 N)
- 都市と水系の不可分性: 広島県の主要都市 (広島市・福山市・呉市・三原市) はすべて水系のデルタ部に立地。
都市発達史 = 水系氾濫原の利用史であり、水害リスクは都市そのものの構造に組み込まれている。
- 「面積では測れない」リスク: 江の川水系は H2 が示すように 面積大・人口少。
浸水面積だけで予算配分すると山間部に過配分されるが、人命優先なら太田川・芦田川が最優先。
- 中小河川の見落とし: H5 に関して、Shapefile で
suikei='中小河川' と
1 行にまとめられている ことが教材的に重要。
実際には {flood_max_s[flood_max_s['suikei']=='中小河川'].shape[0]} polygon の集合体で、各々独立した小水系。
本研究では「中小河川」を 1 つの仮想水系として扱ったが、
細分化すれば仮説 H5 の検証はもっと強くできる。
- z-score の落とし穴 (要件 P 補足): 標準偏差で割っているため、外れ値 1 個 (=太田川水系) が他を圧縮する効果がある。
ロバスト統計 (中央値+MAD) も併用するのが本来の作法。
"""),
("発展課題 (要件E: 結果X → 新仮説Y → 課題Z の3段で)", """
-
結果X: 主要5水系で「面積大・人口少」の江の川水系と「面積中・人口大」の太田川水系で対照的なリスク構造があった (H2 支持)。
新仮説Y: 同じ 「人口あたり浸水面積」 指標を市町別に集計すれば、市町ごとの優先度ランキングが水系単位とは違って見えるはず。
課題Z: gpd.overlay(市町境界, flood_max) で市町×水系×浸水のクロス集計を作り、
本記事のクロスマトリクスと比較せよ。
-
結果X: 「中小河川」グループが Shapefile で 1 行にまとめられているため、内部のばらつきは可視化できなかった (H5 部分支持)。
新仮説Y: kasen 列 (河川名) で再集計すれば、中小河川の中にも「危険な河川」と「安全な河川」が分かれるはず。
課題Z: flood_max_s[flood_max_s['suikei']=='中小河川'].groupby('kasen') で河川別集計し、
本記事のスコア式を河川単位で再計算 → 上位中小河川を抽出。
-
結果X: 重み配分 (浸水0.30 + 人口0.40 + 文化財0.15 + インフラ0.15) は編集者の主観で決めた。
新仮説Y: 重みを変えると上位水系の順位は入れ替わるが、太田川水系のトップは揺るがないはず (z-score が全項目で +2σ 近いため)。
課題Z: 重み配分を 5 パターン (人命特化 / 文化財特化 / 等配分 等) に振って総合スコアを再計算し、
順位の安定性を Spearman 順位相関で評価せよ。
-
結果X: リスク人口は DID polygon の人口密度を浸水域に按分した近似値で、誤差が大きい。
新仮説Y: 国勢調査の 500m メッシュ人口を使えば、より正確なリスク人口が出る。
課題Z: e-Stat のメッシュ人口データを取り込み、メッシュ × 浸水のオーバーレイで再計算。
本記事の DID 按分との差を相対誤差 (%) で評価。
-
結果X: 浸水面積は計画規模 vs 想定最大規模で 2 倍程度に拡大している (cross 表参照)。
新仮説Y: 拡大倍率は水系で異なり、都市デルタほど倍率が大きいはず (氾濫原が広いため)。
課題Z: flood_area_km2 / plan_area_km2 の倍率を水系別に算出し、
都市/山間カテゴリで比較 (t 検定など)。
-
結果X: 太田川水系が文化財ヒートマップでも上位 → 水害は文化財損失リスクでもある。
新仮説Y: 鎌倉時代以前の遺跡は 水害を経験して残った ものなので、現在の浸水想定区域とは選択的に重ならないはず。
課題Z: 文化財の 時代列 を時代区分 (古代/中世/近世/近代) で分け、各時代×水系の浸水重なり率を比較。
"""),
("補足: GIS メソッドのツール化視点 / 処理時間の工夫", f"""
本記事で使った GIS メソッドの黒箱化 (要件 J)
| 関数 | 入力 | 出力 | 裏で何が起きるか |
|---|
gpd.sjoin(points, polys, predicate='within') |
点GeoDataFrame + ポリゴンGeoDataFrame |
点に polygon の属性が付与された GeoDataFrame |
R-tree 空間インデックスで候補絞込→点in多角形判定 |
gpd.overlay(A, B, how='intersection') |
2 GeoDataFrame |
交差ポリゴン (A,B 両方の属性を保持) |
SHAPELY ブール演算 + R-tree |
gdf.geometry.area |
1 GeoDataFrame (CRS=メートル系) |
各ポリゴンの面積 (m²) |
球面投影での面積計算 (CRS依存) |
gdf.geometry.simplify(d) |
1 GeoDataFrame + 距離 d (m) |
頂点間引きされた粗いポリゴン |
Douglas-Peucker アルゴリズム |
gdf.to_crs('EPSG:6671') |
1 GeoDataFrame |
座標変換されたGeoDataFrame |
PROJ ライブラリの楕円体変換 |
処理時間の工夫 (要件 S)
- 本スクリプトは 1〜3 分で完走 (ハンズオン要件)。実測 {elapsed_total:.0f} 秒。
- dissolve は使わない:
flood_max.dissolve(by='suikei') は数十分かかる + TopologyException で落ちることがある。
本記事では 個別ポリゴンを sjoin/overlay → groupby('suikei').sum で代用。
小さな重複面積 (rank分割境界) は無視。
- simplify(20〜30) で描画と overlay を高速化。集計は元の精度で実施。
- buffer(0) でトポロジ崩れを軽く修正してから overlay。
- sjoin は事前 R-tree 構築でO(N log M): 4,200 点 × 600 polygon でも 1 秒以内。
水系コード対照表
| 水系名 | 主な範囲 | 河川数 (Shapefile内 polygon) |
|---|
| 太田川水系 | 広島市デルタ (中区/南区/西区/安佐南区/安佐北区) | {len(flood_max_s[flood_max_s['suikei']=='太田川水系'])} |
| 芦田川水系 | 福山市・府中市・神石高原町 | {len(flood_max_s[flood_max_s['suikei']=='芦田川水系'])} |
| 沼田川水系 | 三原市・本郷町・竹原市 | {len(flood_max_s[flood_max_s['suikei']=='沼田川水系'])} |
| 江の川水系 | 三次市・庄原市・安芸高田市 (県北部) | {len(flood_max_s[flood_max_s['suikei']=='江の川水系'])} |
| 黒瀬川水系 | 呉市・東広島市境界 | {len(flood_max_s[flood_max_s['suikei']=='黒瀬川水系'])} |
| 中小河川 | 各市町に散在 (公式に水系名なし) | {len(flood_max_s[flood_max_s['suikei']=='中小河川'])} |
"""),
]
html = render_lesson(
num=5,
title="L05 水系単位 横断分析 — 太田川・芦田川・沼田川・江の川・黒瀬川 等の比較",
tags=["L系", "水系", "横断", "GIS", "クロス集計", "z-score"],
time="60分",
level="リテラシ基礎+α",
data_label="浸水Shapefile (suikei列) + 用途地域 + DID + 文化財3種 + インフラ3種",
sections=sections,
script_filename="lessons/L05_watershed_cross.py",
)
html = html.replace("", '', 1)
out = LESSONS / "L05_watershed_cross.html"
out.write_text(html, encoding="utf-8")
print(f"\n[HTML] {out.name} を出力 ({out.stat().st_size:,} bytes)")
print(f"=== DONE in {time.time()-t0:.1f}s ===")
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}