L05 水系単位 横断分析 — 太田川・芦田川・沼田川・江の川・黒瀬川 等の比較
学習目標と問い
これまでの研究 (X07 浸水×DID, X08 浸水×避難所, X09 浸水×用途地域, L04 浸水×文化財, L07 浸水×インフラ) で蓄積した個別の発見を、「水系 (suikei)」 という地理単位で 横並びにする。 広島県の主要 5 水系 (太田川・芦田川・沼田川・江の川・黒瀬川) と中小河川グループを、 浸水面積・浸水深・DID人口・文化財・インフラの 5 軸で比較し、水系単位の総合リスクスコアを作る。
本記事で答えたい問い
- 水系単位の問い: 広島県のどの水系が「最もリスクが高い」のか、複合指標で答える
- 形と人の問い: 浸水面積が大きくても人口が少ない水系 (山間部) と、面積中位でも都市と重なる水系 (デルタ部) のどちらが優先か
- 多様性の問い: 中小河川 (Shapefile で `suikei='中小河川'` と一括分類) は内部にどれだけのバラツキを持つか
立てた仮説 H1〜H5
- H1: 太田川水系が 全指標 (浸水面積・人口・文化財・インフラ) でトップ (広島市デルタ地帯を貫流)
- H2: 江の川水系は浸水面積は大きいが、人口・施設は太田川より大幅に少ない (山間部)
- H3: 総合リスクスコア 1 位は太田川水系
- H4: 主要5水系の 「人口あたり浸水面積」 は 5 倍以上の差がある (デルタ vs 山間部)
- H5: 中小河川グループは内部に多様な地形を含むため、主要5水系よりもバラツキ (標準偏差) が大きい
用語の独自定義
- 水系 (suikei): 浸水Shapefile の
suikei列。広島県内 25 系。 本記事では 主要 5 水系 = 太田川水系・芦田川水系・沼田川水系・江の川水系・黒瀬川水系 と限定する。 それ以外の小河川は Shapefile でsuikei='中小河川'と一括分類されたものと、 独自名 (御手洗川水系・八幡川水系等) の小規模水系がある。 - リスク人口 (推定): DID polygon × 浸水域 overlay の重なり面積に DID polygon ごとの人口密度 (JINKOU_S/area) を掛けた按分推定値。 厳密な被災想定人口ではないが、水系間の比較には十分。
- 総合スコア: 浸水面積・リスク人口・文化財件数・インフラ件数を 各列で z-score 正規化し、 重み 0.30 / 0.40 / 0.15 / 0.15 で加重和した値。 平均 0、+ 大きいほど高リスク。重み配分は 「人命優先 (=DID人口最重視)」 の編集方針に基づく。
- z-score: ある列の値から平均を引いて標準偏差で割った数値。「平均と比べて何標準偏差ぶん上か下か」を表す。
- クロス集計マトリクス: 行=水系・列=指標 の 2 次元表。各水系を多角度で並べる。
到達点
- 主要 5 水系の数値プロファイル表 (浸水面積・人口・文化財・インフラ・スコア)
- 水系別色分けの 主題図 + 6 panel small multiples
- 水系×指標の z-score ヒートマップ (上位15水系)
- 5 仮説の支持/部分支持/棄却 判定
結果サマリー (詳細の前に)
| 指標 | 結果 |
|---|---|
| 浸水面積トップ | 中小河川 (252 km²) |
| リスク人口トップ | 太田川水系 (1,457,246 人) |
| 文化財最多 (浸水内) | 太田川水系 (302 件) |
| インフラ最多 (浸水内) | 中小河川 (656 件) |
| 総合スコア 1 位 | 太田川水系 (+3.37) |
| 太田川水系の総合スコア順位 | 1 位 |
| 主要5水系 人口あたり浸水km² 最大/最小 比 | ×531268.6 |
使用データ
- 河川浸水想定 (想定最大規模): 613 polygons, 総面積 830 km²,
suikei25系 - 河川浸水想定 (計画規模): 416 polygons, 総面積 195 km²
- 用途地域 (県全域): 2629 polygons, 13 用途 → 4 区分 (住居系/商業系/工業系/田園住居)
- DID 人口集中地区: 48 polygons, 14 市町, 総人口 1,840,973 人
- 文化財 3 種: 埋蔵文化財 190 / 官衙跡等 13 / 被爆樹木 89
- インフラ 3 種: 橋 4,203 / ダム 12 / トンネル 157
- CRS: すべて EPSG:6671 (JGD2011 平面直角 III) に統一して面積を m² で計算
ダウンロード
データ取得手順
| 論題 | データセット | 形式 | サイズ目安 |
|---|---|---|---|
| 河川浸水想定区域 (計画規模 + 想定最大規模) | DoBoX #295 / DoBoX #313 | Shapefile | 各 ~50MB |
| 用途地域 GeoJSON | DoBoX #297 | GeoJSON ZIP | ~25MB |
| DID 人口集中地区 (14市町) | DoBoX #1468〜 | GeoJSON ZIP×14 | 合計 ~5MB |
| 埋蔵文化財包蔵地 | DoBoX #200 | CSV | ~3MB |
| 被爆樹木一覧 | DoBoX #120 | CSV | ~50KB |
| 橋梁基本情報 | DoBoX #220 | CSV | ~1MB |
| ダム基本情報 | DoBoX #210 | CSV | ~5KB |
| トンネル基本情報 | DoBoX #230 | CSV | ~100KB |
一括取得 (PowerShell):
cd "2026 DoBoX 教材"
py -X utf8 data\fetch_all.py中間データ・図 (本記事で生成)
| ファイル | 内容 |
|---|---|
| L05_cross_matrix.csv | クロス集計マトリクス (水系×指標) |
| L05_suikei_flood_area.csv | 水系別 浸水面積 (km²) |
| L05_landuse_by_suikei.csv | 水系×用途地域 ピボット |
| L05_depth_pivot.csv | 主要6水系×浸水深 ランクピボット |
| L05_heatmap_zscore.csv | 水系×指標 z-score |
| L05_heatmap_raw.csv | 水系×指標 生値 |
| L05_did_by_suikei.csv | 水系×DID 浸水重なり + リスク人口 |
| L05_cultural_in_flood.csv | 浸水内 文化財 sjoin 結果 |
| L05_infra_in_flood.csv | 浸水内 インフラ sjoin 結果 |
| L05_map_suikei_choropleth.png | 図1 水系別色分け 主題図 |
| L05_map_small_multiples.png | 図2 主要6水系 small multiples |
| L05_heatmap_zscore.png | 図3 水系×指標 z-score |
| L05_score_bar.png | 図4 総合スコアランキング |
| L05_heatmap_landuse.png | 図5 水系×用途地域 ヒートマップ |
| L05_scatter_area_pop.png | 図6 浸水面積 vs リスク人口 散布 |
| L05_depth_stack.png | 図7 主要6水系 浸水深 積み上げ |
| L05_heatmap_cultural_infra.png | 図8 文化財・インフラ ヒートマップ |
| L05_map_overlay_points.png | 図9 主要5水系 + 文化財・インフラ点 重ね地図 |
| L05_watershed_cross.py | 再現スクリプト |
分析1: 水系別色分け 主題図 (図1)
狙い
そもそも広島県の 「水系」とは地理的にどんな広がりか を最初に押さえる。25 水系のうち、 主要 5 水系と「中小河川」を別色で塗り分け、それ以外を灰色で表示。 これで以降の数値分析が「どの地理に対応するか」が頭に入る。
手法 (要件B,J: ツール化視点で)
- geopandas.GeoDataFrame.plot(): 「ポリゴンを色分けして地図に描く関数」。入力=GeoDataFrame + 列名/colormap、出力=matplotlib axes に描画。
- simplify(30): ポリゴンの細かいギザギザを 30m 精度で間引いて描画を高速化。集計には影響しない (描画専用)。
- 限界: ポリゴン同士が重なる場合、後に描いたものが上に来る。本記事では水系ごとに分離されているので問題なし。
実装
↑ L05_watershed_cross.py 行 950–973
結果
なぜこの図か (要件H): クロス集計の数値を見る前に、地理的位置関係を頭に入れることで、 「太田川水系が広島市中心部、江の川水系が県北部山間、芦田川水系が福山市中心部」 という空間的直感が得られる。
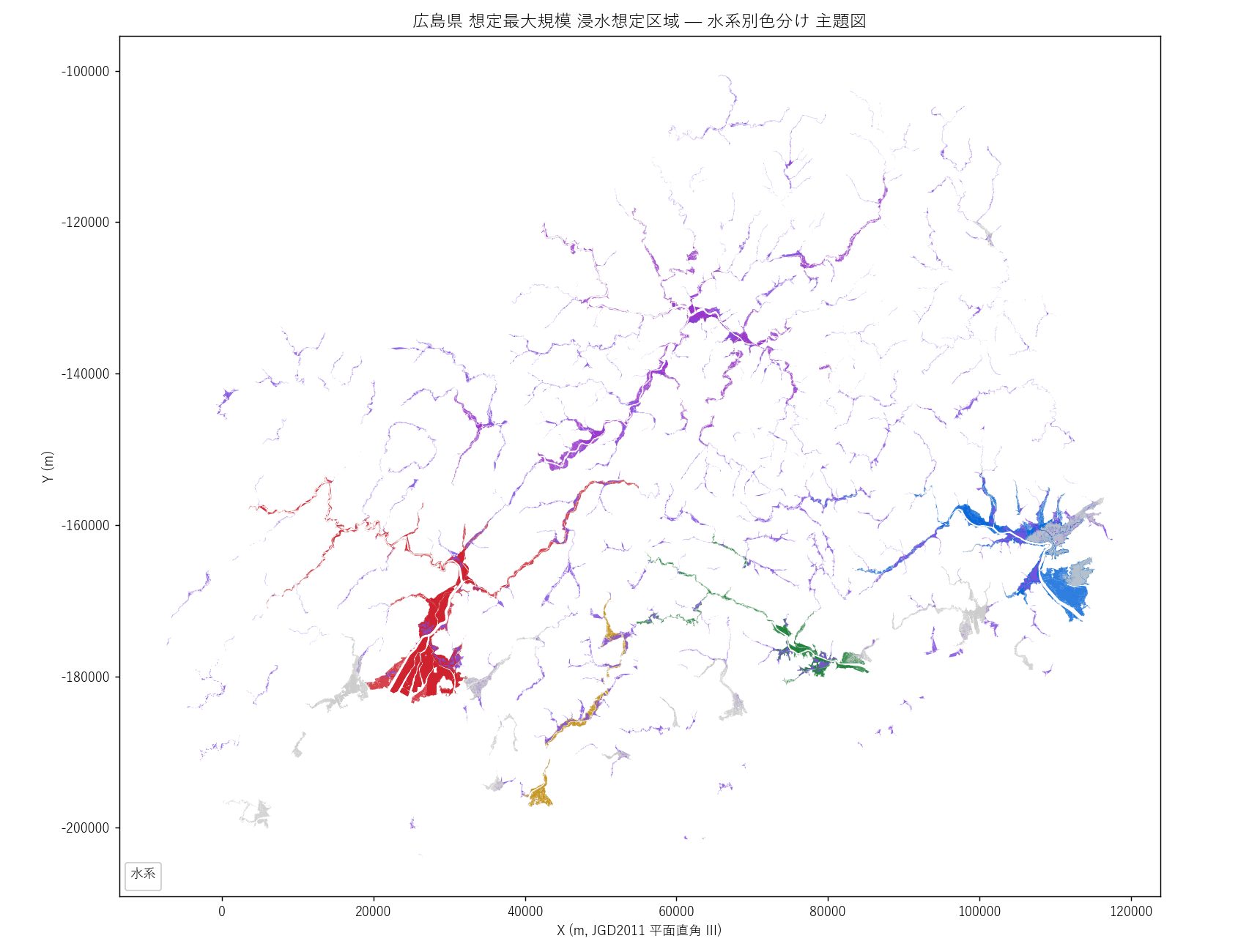
読み取り (要件F):
- 太田川水系 (赤) は広島市デルタを中心に広く分布。市街地と直結
- 江の川水系 (紫) は県北部 (三次・庄原方面) に長く伸びる。山間の谷沿い
- 芦田川水系 (青) は福山市・府中市方面に集中
- 沼田川水系 (緑) は三原市・本郷町
- 黒瀬川水系 (黄土) は呉市・東広島市の境界域
- 中小河川 (薄紫) は広島県全域に散らばる
分析2: 主要6水系 small multiples (図2)
狙い
図1 では水系同士が重なって細部が読めない。同じ視野で水系を 1 つずつ強調することで、 各水系の 形と分布パターン を比較できる。
手法 (要件B)
- small multiples: 「同じ枠で条件だけ変えた小図を並べる」可視化技法。 人間は枠が同じだと 差分に注意が向くため、比較が効率化する。
- 共通 bbox: 全水系の総バウンディングボックスを揃え、6 panel すべて同じ縮尺で描く。
- 背景に全水系を薄く描く: 対象水系がどの位置にあるかを文脈付きで見せる。
結果
なぜこの図か (要件H): 5+1 水系を 1 枚に並べて重ねると判別できないが、6 panel に分けると 「太田川は河口集中・江の川は線状に長い・中小河川は点状散在」というパターンが瞬時に見える。
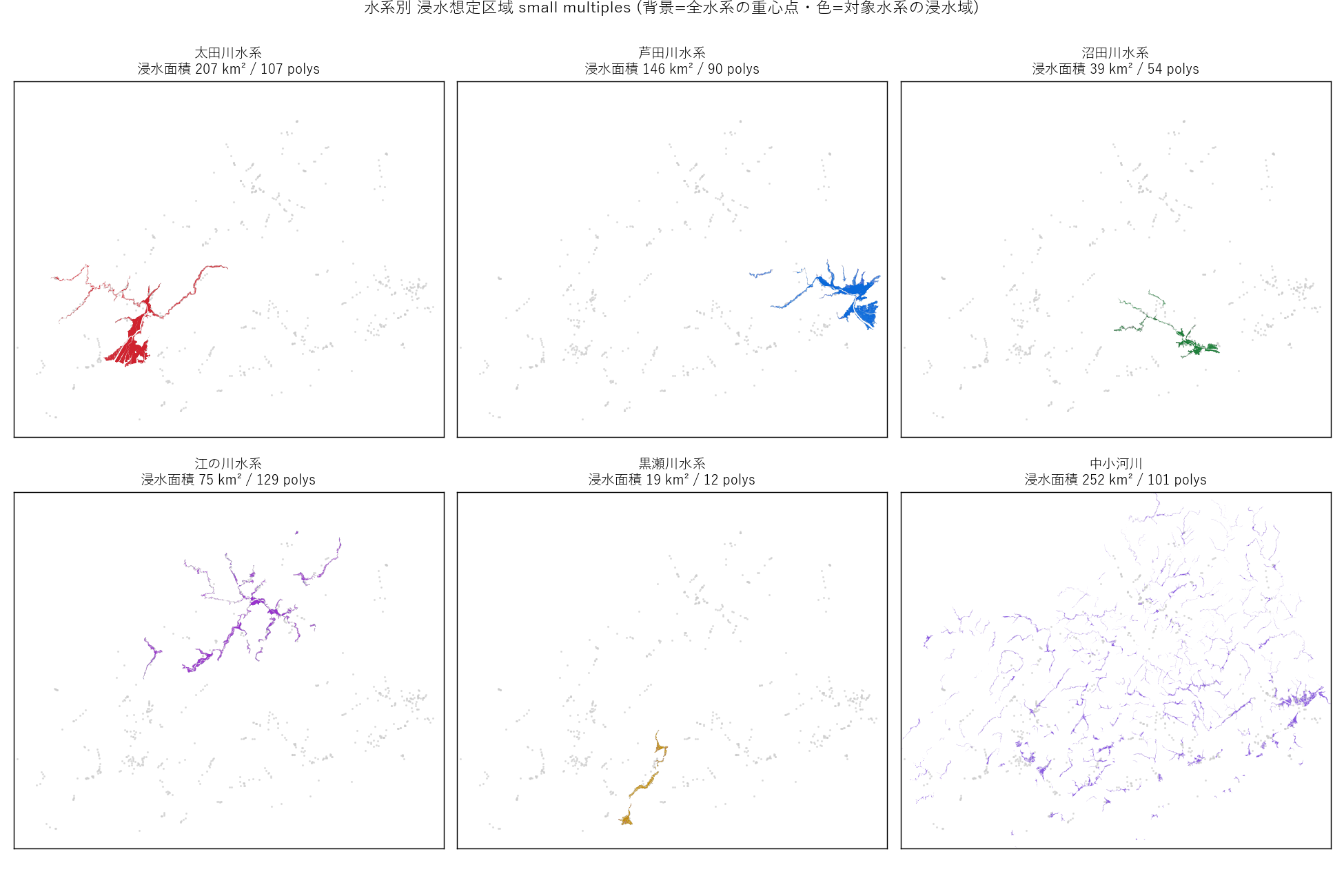
読み取り (要件F):
- 太田川水系: 広島市デルタにギュッと集中。面積はやや少ないが密度高い
- 江の川水系: 県北部を 細長く線状 に伸びる。面積大だが幅は狭い
- 芦田川水系: 福山市デルタ + 府中市方面の支流
- 沼田川水系: 三原市域中心、コンパクト
- 黒瀬川水系: 呉市〜東広島市境界の中規模
- 中小河川: 全県に 均等散在。県内ほぼどこでも中小河川の浸水リスクがある
分析3: クロス集計マトリクス (表1) + z-score ヒートマップ (図3)
狙い
各水系を 浸水面積・浸水深・DID人口・文化財・インフラ の複数指標で 横並び比較 する。 そのまま並べると単位が違って大小が見えないため、z-score 正規化で揃えてヒートマップ化。
手法 (要件B,J,P)
- z-score (標準化得点): ある列の値から平均を引いて標準偏差で割る。「平均より何個ぶん上か」。 列ごとに行うと、km² の指標と件数の指標を 同じスケール で並べられる。
- 入力: 数値の列 (浸水面積、人口、件数 等)
出力: 各値を 平均0 / 標準偏差1 に変換した数値 (おおむね -2〜+2 の範囲) - 限界: 外れ値の影響を受けやすい。1 個極端な水系があると他が圧縮される。 本記事ではトップ15に絞り、ロバスト性を確保。
- 代替案: min-max スケーリング (0〜1)、順位 (rank) ベース。順位ベースは外れ値に強いが情報量が落ちる。 教材としては z-score がもっとも統計教育的。
1件のBefore/After 具体例 (要件K)
| 段階 | 太田川水系のflood_area_km2 | サイズ |
|---|---|---|
| raw 値 | 207.0 km² | 1×1 |
| 列平均 (33.2) を引く | +173.8 | 1×1 |
| 列標準偏差 (67.2) で割る | +2.59 | 1×1 (= z-score) |
実装
↑ L05_watershed_cross.py 行 1032–1052
結果
なぜこの図か (要件H): 9 指標 × 15 水系 のテーブルを目で読むのは辛い。色 (赤=高 / 青=低) にすれば 「どの水系がどの指標で突出しているか」がパッと見で分かる。
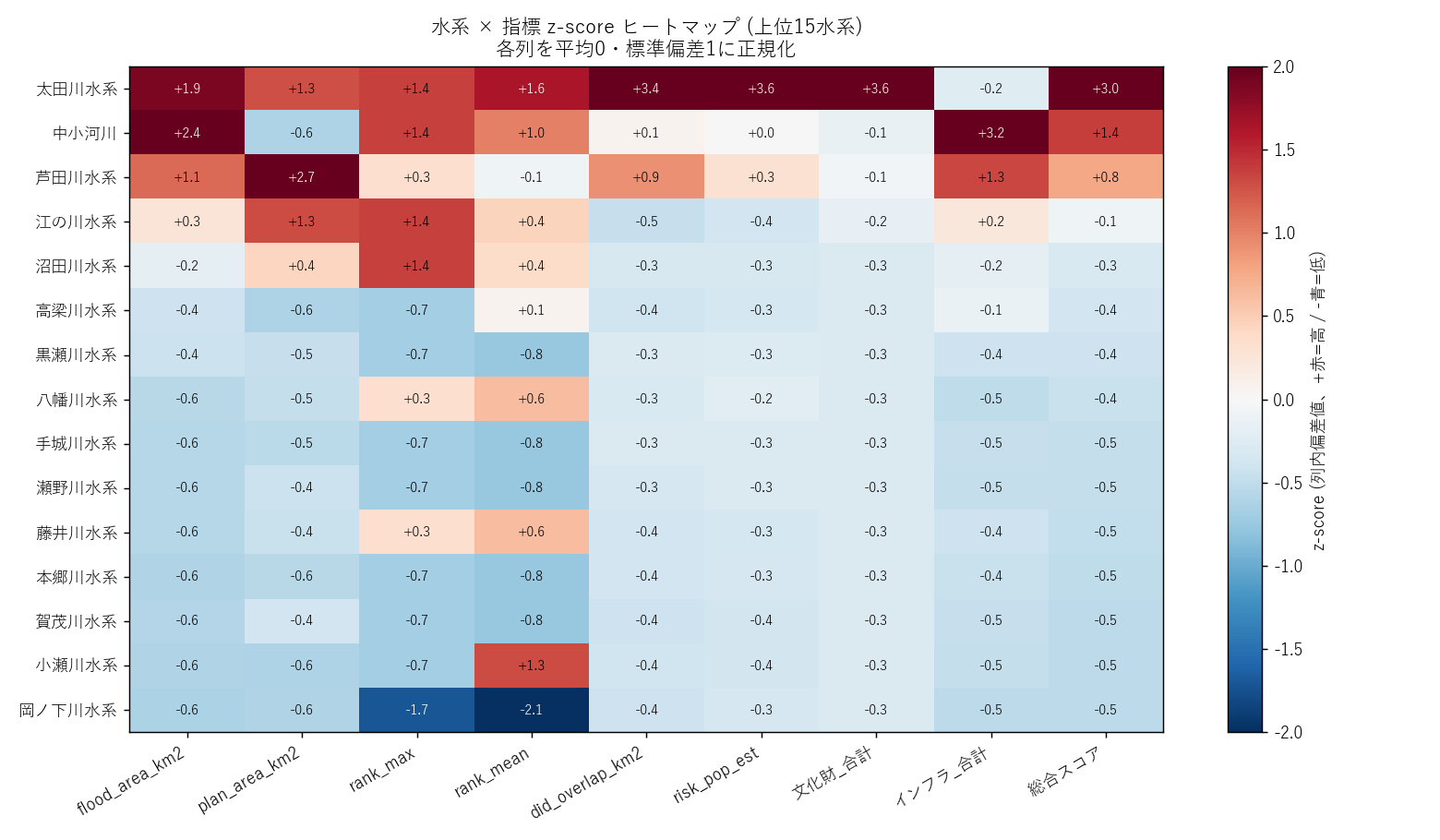
読み取り (要件F):
- 太田川水系: ほぼ全列が深紅 (+2 σ 近辺)。「全方向で最大級」 な水系
- 江の川水系: 浸水面積は赤いが、リスク人口は青い (山間部仮説 H2)
- 芦田川水系: 浸水面積中位、文化財/インフラはやや高い (福山中心市街地)
- 中小河川: 各列でばらつき (合算しているため平均化される)
- 下位水系: ほとんどが青系 (= 総合的に小規模)
表1 主要5水系プロファイル
| 水系 | 想定最大 (km²) | 計画規模 (km²) | 最大深さrank | DID浸水 (km²) | リスク人口 | 文化財 (件) | インフラ (件) | スコア |
|---|---|---|---|---|---|---|---|---|
| 太田川水系 | 207.0 | 38.5 | 80 | 174.5 | 1,457,245.9 | 302 | 50 | 3.37 |
| 芦田川水系 | 146.2 | 67.3 | 70 | 62.0 | 255,756.9 | 19 | 331 | 1.04 |
| 沼田川水系 | 38.8 | 21.0 | 80 | 5.9 | 25,358.2 | 0 | 60 | -0.09 |
| 江の川水系 | 75.5 | 38.9 | 80 | 0 | 0 | 10 | 134 | 0.14 |
| 黒瀬川水系 | 18.6 | 3.3 | 60 | 7.5 | 42,850.7 | 0 | 20 | -0.20 |
表1 読み取り (要件G):
- 太田川水系: 浸水面積 207 km² / リスク人口 1,457,246 人 / 文化財 302 件
- 江の川水系: 浸水面積 75 km² / リスク人口 0 人 (面積大なのに人口少 → H2 の核心)
- 芦田川水系: 浸水面積 146 km² / リスク人口 255,757 人
- 沼田川水系・黒瀬川水系: 中位
表2 上位15水系 全指標
| 水系 | 想定最大 (km²) | 計画規模 (km²) | 最大深さrank | DID浸水 (km²) | リスク人口 | 文化財 (件) | インフラ (件) | スコア |
|---|---|---|---|---|---|---|---|---|
| 太田川水系 | 207.0 | 38.5 | 80 | 174.5 | 1,457,245.9 | 302 | 50 | 3.37 |
| 中小河川 | 251.7 | 0 | 80 | 23.7 | 142,894.8 | 12 | 656 | 1.68 |
| 芦田川水系 | 146.2 | 67.3 | 70 | 62.0 | 255,756.9 | 19 | 331 | 1.04 |
| 江の川水系 | 75.5 | 38.9 | 80 | 0 | 0 | 10 | 134 | 0.14 |
| 沼田川水系 | 38.8 | 21.0 | 80 | 5.9 | 25,358.2 | 0 | 60 | -0.09 |
| 高梁川水系 | 21.0 | 0.0 | 60 | 2.6 | 13,226.7 | 1 | 68 | -0.18 |
| 黒瀬川水系 | 18.6 | 3.3 | 60 | 7.5 | 42,850.7 | 0 | 20 | -0.20 |
| 八幡川水系 | 9.0 | 2.9 | 70 | 7.1 | 57,634.7 | 0 | 1 | -0.24 |
| 手城川水系 | 7.6 | 1.5 | 60 | 7.7 | 33,949.4 | 0 | 11 | -0.27 |
| 瀬野川水系 | 7.3 | 3.9 | 60 | 5.5 | 32,334.0 | 0 | 9 | -0.28 |
| 藤井川水系 | 7.6 | 3.6 | 70 | 3.6 | 13,147.4 | 0 | 18 | -0.29 |
| 本郷川水系 | 5.4 | 1.2 | 60 | 3.6 | 15,107.2 | 0 | 13 | -0.30 |
| 賀茂川水系 | 6.4 | 4.7 | 60 | 1.7 | 4,740.7 | 0 | 10 | -0.32 |
| 小瀬川水系 | 4.6 | 0.0 | 60 | 2.8 | 7,510.7 | 0 | 7 | -0.32 |
| 岡ノ下川水系 | 2.7 | 0.3 | 50 | 2.3 | 18,602.1 | 0 | 0 | -0.33 |
表2 読み取り: 25 水系のうち上位15を表示。総合スコア順。
中小河川の suikei='中小河川' グループは 1 行にまとまるが、内訳としては数十の小河川を含む。
分析4: 総合スコア ランキング (図4)
狙い
多角的な指標を 1 つの数値に集約し、「どの水系が最も総合的にリスクが高いか」を視覚化する。
手法 (要件B,J)
- 加重和スコア: 浸水面積 × 0.30 + リスク人口 × 0.40 + 文化財 × 0.15 + インフラ × 0.15 (各列を z-score 正規化したあとで加重和)。
- 重み配分の根拠:
- 人命優先 (要件 D の編集方針) で リスク人口を最大重み 0.40
- 浸水面積は基礎リスクの代理指標で 0.30
- 文化財/インフラは 失われた場合の社会的損失 を表すので各 0.15
- 限界: 重みは編集者の主観。学習者は重みを変えて再計算してほしい (発展課題)。
結果
なぜこの図か (要件H): 25 水系を一目で順位付けするには 水平棒グラフが最適。 バーの色は地図 (図1) と同じ配色にして対応関係を視覚化。
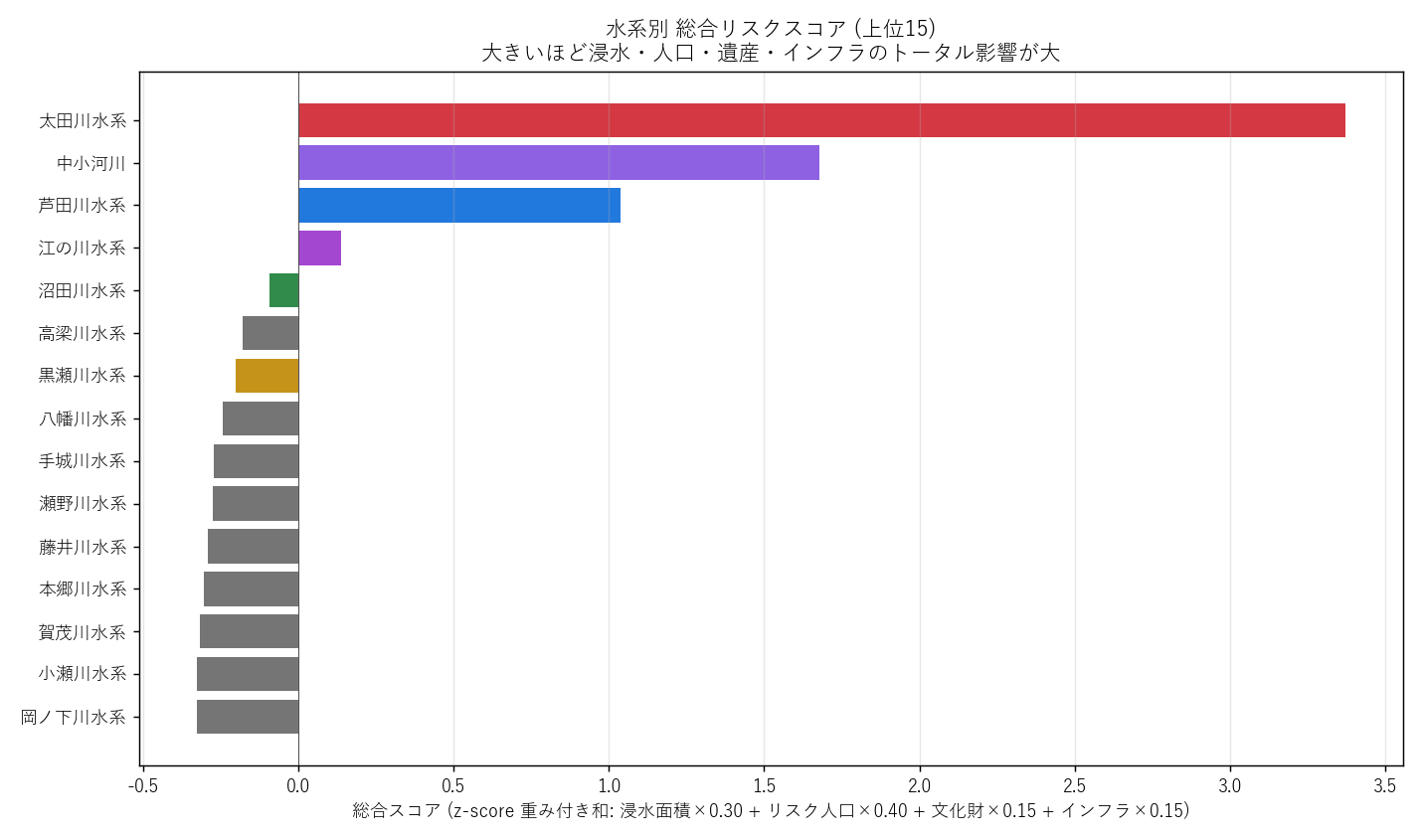
読み取り (要件F):
- 1 位 太田川水系 (スコア +3.37)
- 2 位 中小河川 (スコア +1.68)
- 3 位 芦田川水系 (スコア +1.04)
- 主要5水系のうち 1 位 = 太田川水系
- マイナススコアの水系は「平均以下のリスク」(=規模が小さい)
分析5: 水系×用途地域 ヒートマップ (図5)
狙い
X09 で得た「用途地域 × 浸水」の発見を 水系単位で再集計。 「住居系の浸水は特定水系に集中するのか」「工業系はどこの水系で多いのか」を見る。
手法
- geopandas.overlay(landuse, flood, how='intersection'): 2 ポリゴンの交差を計算。 入力=2 GeoDataFrame、出力=交差ポリゴン (両方の属性を保持)。
- 用途地域 13 区分を 4 区分 (住居系/商業系/工業系/田園住居) に集約してから集計。
結果
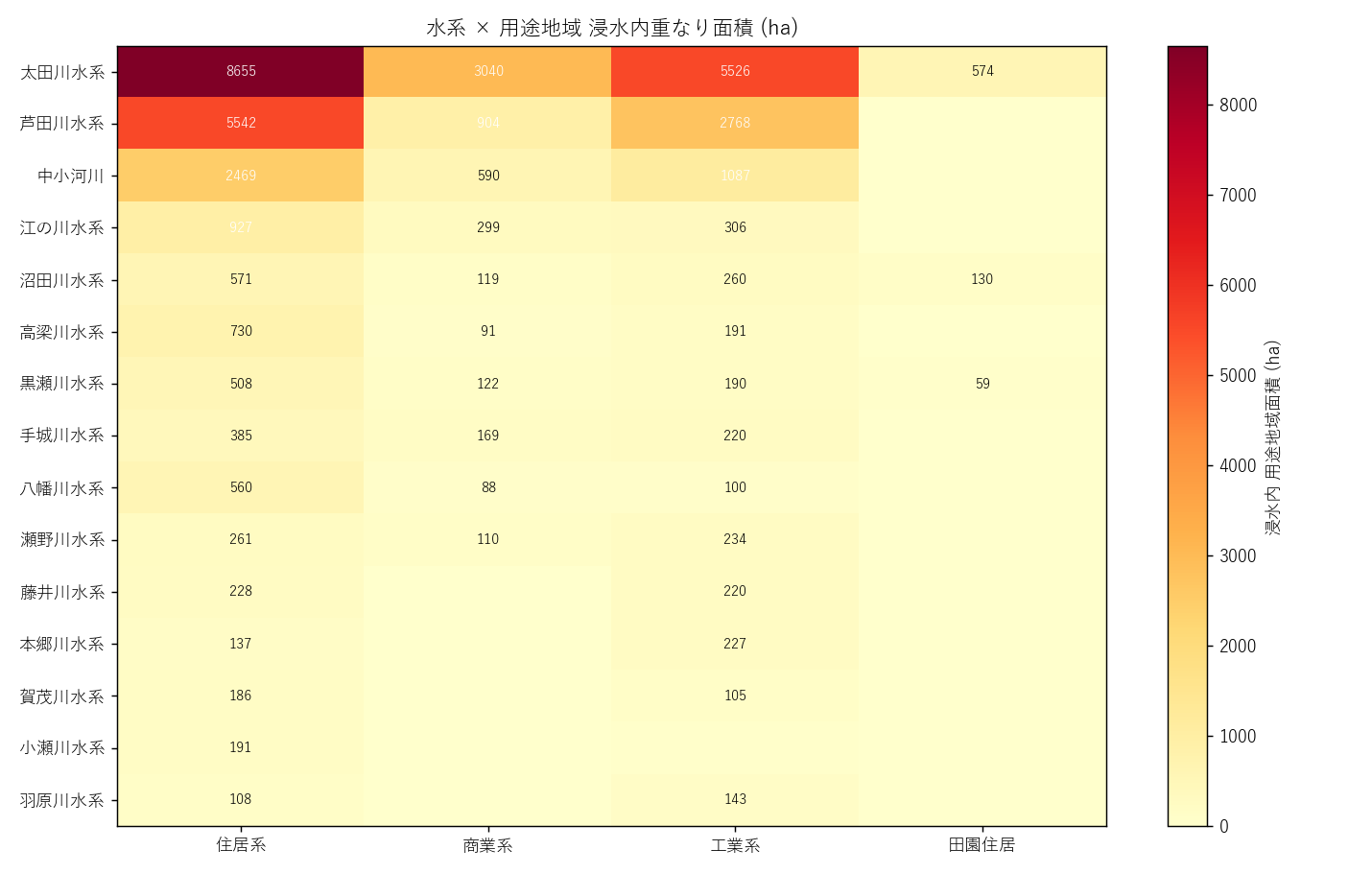
読み取り (要件F):
- 太田川水系 × 住居系: 8,655 ha (圧倒的)
- 芦田川水系 × 住居系: 5,542 ha (福山中心市街地)
- 商業系・工業系も太田川と芦田川に集中
- 江の川水系は浸水面積大なのに用途地域 (=都市計画区域) が少ない → 山間で都市計画指定外
表3 水系×用途地域 ピボット
| 水系 | 住居系 (ha) | 商業系 (ha) | 工業系 (ha) | 田園住居 (ha) |
|---|---|---|---|---|
| 太田川水系 | 8,655 | 3,040 | 5,526 | 574 |
| 芦田川水系 | 5,542 | 904 | 2,768 | 0 |
| 中小河川 | 2,469 | 590 | 1,087 | 28 |
| 江の川水系 | 927 | 299 | 306 | 30 |
| 沼田川水系 | 571 | 119 | 260 | 130 |
| 高梁川水系 | 730 | 91 | 191 | 0 |
| 黒瀬川水系 | 508 | 122 | 190 | 59 |
| 手城川水系 | 385 | 169 | 220 | 0 |
| 八幡川水系 | 560 | 88 | 100 | 0 |
| 瀬野川水系 | 261 | 110 | 234 | 1 |
表3 読み取り: ヘクタール単位の生値表。1 ha = 100m × 100m。
分析6: 浸水面積 vs リスク人口 散布 (図6)
狙い
水系を 2 軸 (浸水面積・リスク人口) でプロットし、「面積大なのに人口少ない山間水系」と「面積中位なのに人口大の都市水系」を視覚的に分離する。
手法
- symlog scale: 値が 0 付近から 数千まで広範囲なため、対数スケール (ただし 0 含む) を使う。
- 色は SYS_COLOR で主要5水系を強調、その他は灰色。
結果
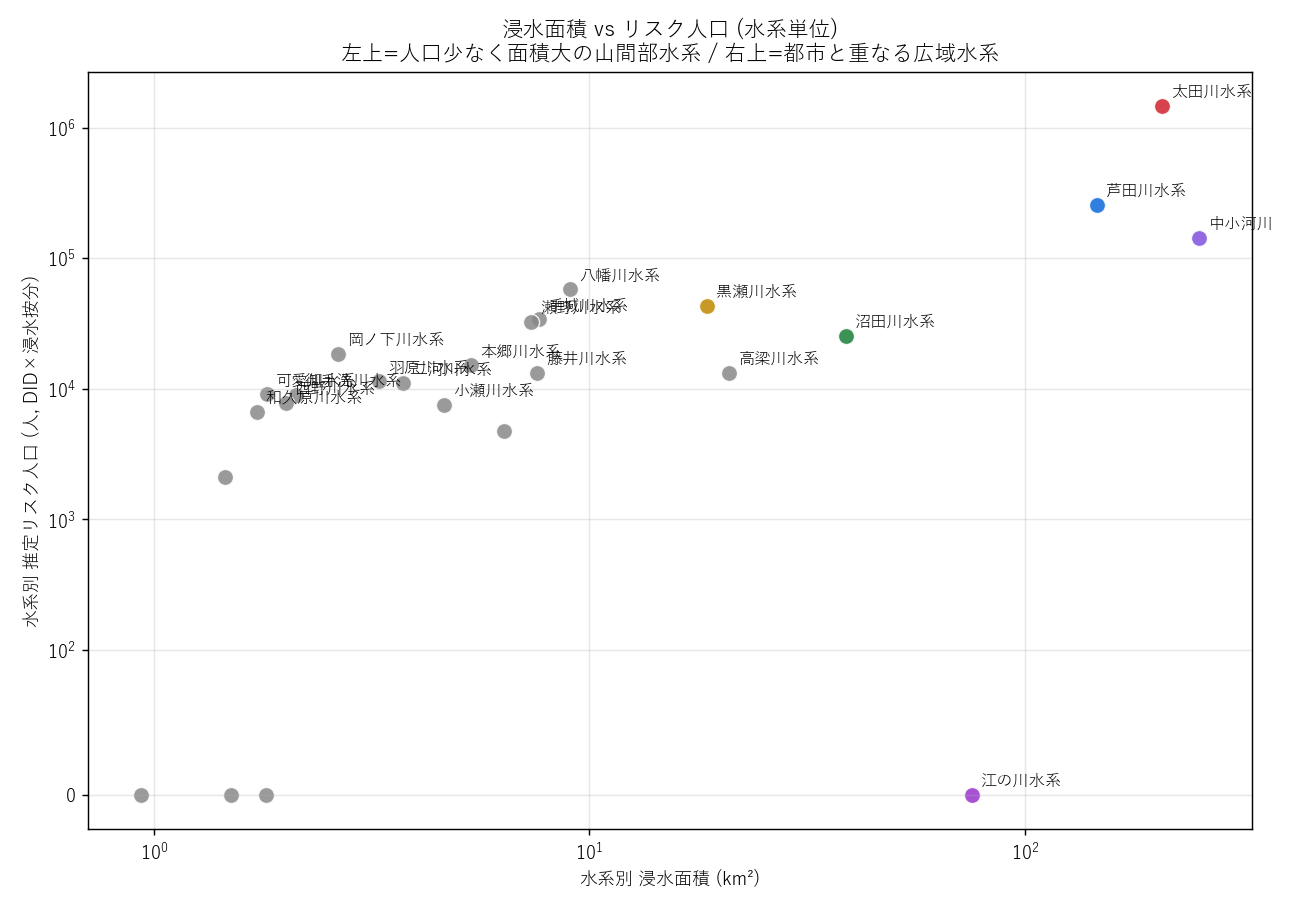
読み取り (要件F):
- 右上 (両方大): 太田川水系・芦田川水系 = 都市と重なる広域水系
- 右下 (面積大・人口少): 江の川水系 = 山間水系 (H2 の根拠)
- 左上 (面積小・人口大): 都市内の小水系 (該当少ない)
- 左下 (両方小): 多くの中小河川
分析7: 主要6水系 浸水深 積み上げ (図7) + 浸水深表 (表4)
狙い
面積だけでなく 「どれだけ深く沈むか」 を水系別に比較する。 3m 以上 (rank ≥ 50) は命の危険を伴う深さ。各水系で深い帯がどれだけ占めるか。
手法
- flood Shapefile の rank 列 (10/20/30/40/50/60/70/80) を使う
- 積み上げ棒: 同じ x (水系) で y を積み上げる。色は浅瀬 (青) 〜 深瀬 (紫) で深さ表現。
結果
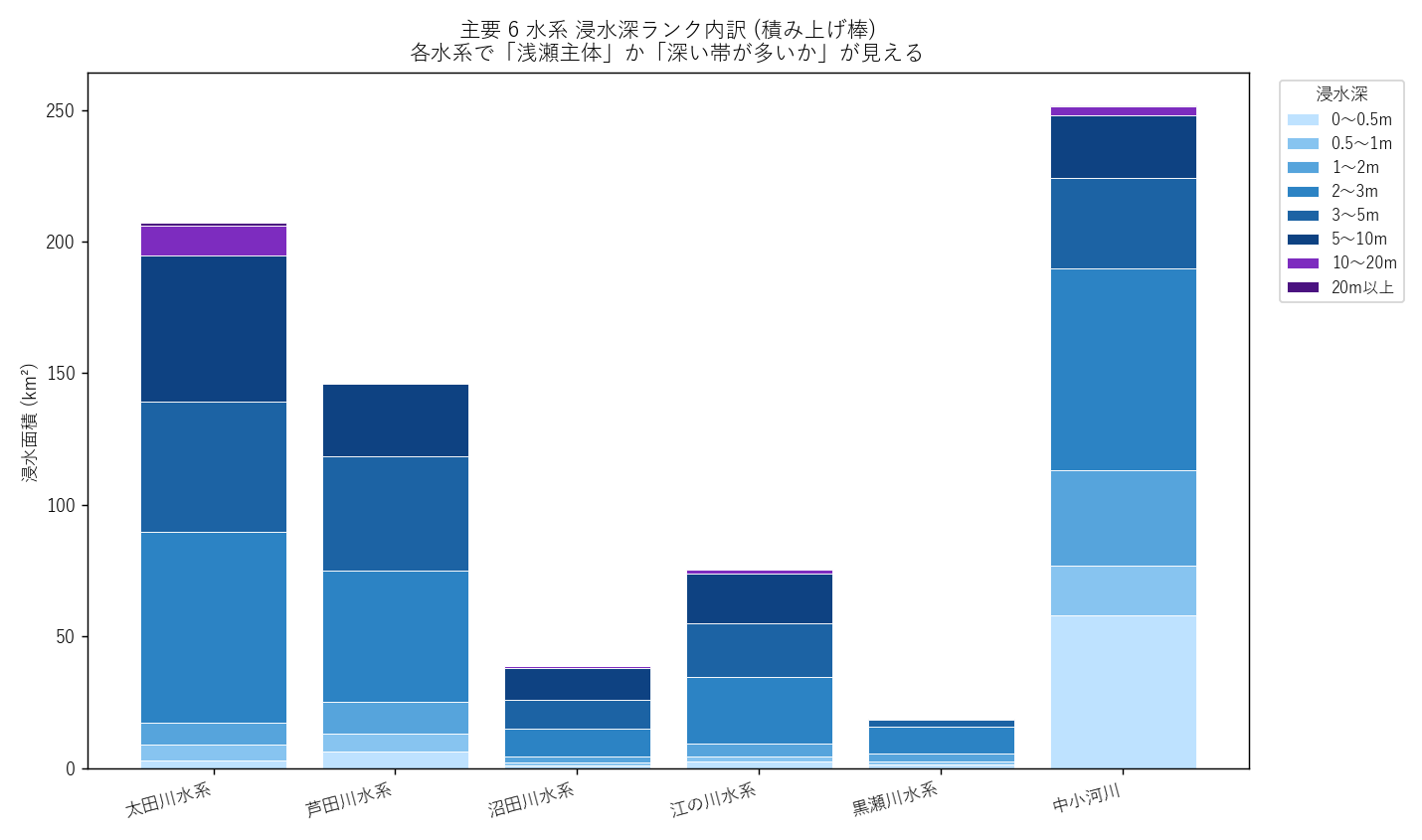
読み取り (要件F):
- 太田川水系: 浅瀬 (0〜2m) が大半だが、5m 以上の深い帯も無視できない (本流氾濫)
- 江の川水系: 浅瀬中心、深い帯は少ない (谷底氾濫の特性)
- 芦田川水系: 浅瀬中心 (デルタ部の特徴)
- 中小河川: 浅瀬主体、深い帯はほぼなし
表4 主要6水系 浸水深ランク内訳
| 水系 | 0〜0.5m | 0.5〜1m | 1〜2m | 2〜3m | 3〜5m | 5〜10m | 10〜20m | 20m以上 | 合計 (km²) |
|---|---|---|---|---|---|---|---|---|---|
| 太田川水系 | 3.0 | 6.1 | 8.3 | 72.3 | 49.5 | 55.6 | 11.3 | 1.0 | 207.0 |
| 芦田川水系 | 6.2 | 6.8 | 12.3 | 49.6 | 43.4 | 27.9 | 0.0 | 0.0 | 146.2 |
| 沼田川水系 | 1.2 | 0.8 | 2.3 | 10.8 | 10.8 | 12.0 | 0.8 | 0.0 | 38.8 |
| 江の川水系 | 2.5 | 1.9 | 5.1 | 25.3 | 20.3 | 19.0 | 1.5 | 0.0 | 75.5 |
| 黒瀬川水系 | 1.6 | 1.1 | 3.0 | 9.9 | 2.9 | 0.1 | 0.0 | 0.0 | 18.6 |
| 中小河川 | 58.1 | 19.0 | 36.0 | 76.6 | 34.5 | 23.9 | 3.2 | 0.5 | 251.7 |
表4 読み取り (要件G): km² 単位の生値。3m 以上 (rank 50〜80) の合計が「致命的浸水域」の規模。
分析8: 水系×文化財・インフラ ヒートマップ (図8) + 集計表 (表5)
狙い
L04/L07 で扱った文化財・インフラを 水系別 に再集計。点 sjoin の結果を可視化。
手法
- gpd.sjoin(points, polygons, how='inner', predicate='within'): 点が浸水ポリゴンの内側にあるかどうかを判定し、ポリゴンの属性 (suikei, rank) を点に付与する。
- 入力: 点 GeoDataFrame + ポリゴン GeoDataFrame、出力: 点 GeoDataFrame に rank/suikei が結合されたもの。
- R-tree 空間インデックスが裏で動くので、292 × 613 の総当りでも数秒。
結果
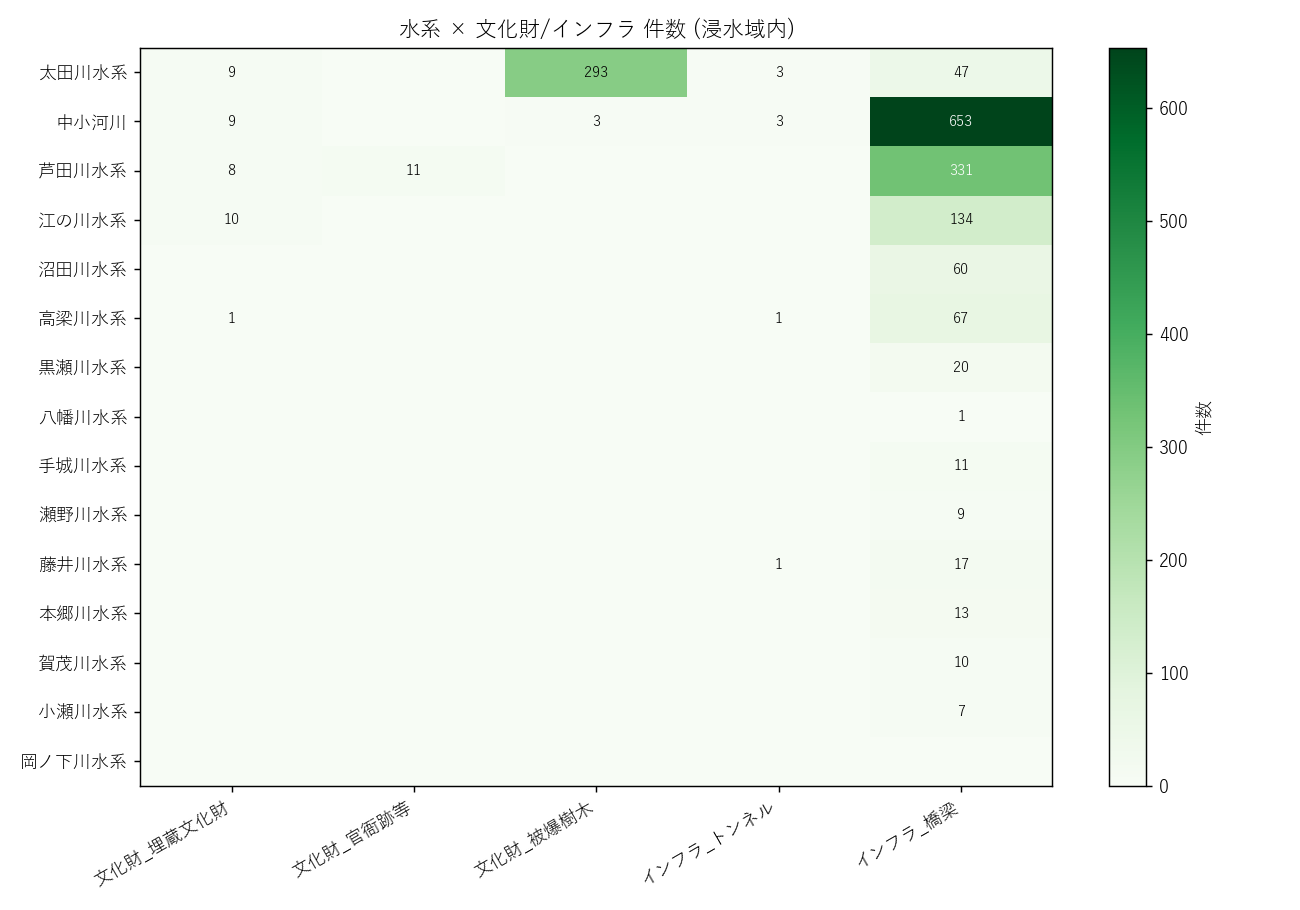
読み取り (要件F):
- 太田川水系の浸水域内に文化財が集中 → 広島市デルタは「文化遺産密集地帯」でもある
- 橋梁は太田川 + 中小河川 + 芦田川にまんべんなく分布
- ダムは少数 (上流の堰止施設なので浸水域とは重ならないことが多い)
- 被爆樹木は太田川水系に集中 (= 広島市内)
表5 浸水内 文化財・インフラ 水系別トップ3
| 指標 | 1位 水系 | 件数 | 2位 水系 | 件数 | 3位 水系 | 件数 |
|---|---|---|---|---|---|---|
| 文化財_埋蔵文化財 | 江の川水系 | 10 | 太田川水系 | 9 | 中小河川 | 9 |
| 文化財_官衙跡等 | 芦田川水系 | 11 | — | — | — | — |
| 文化財_被爆樹木 | 太田川水系 | 293 | 中小河川 | 3 | — | — |
| インフラ_トンネル | 太田川水系 | 3 | 中小河川 | 3 | 高梁川水系 | 1 |
| インフラ_橋梁 | 中小河川 | 653 | 芦田川水系 | 331 | 江の川水系 | 134 |
| 文化財_合計 | 太田川水系 | 302 | 芦田川水系 | 19 | 中小河川 | 12 |
| インフラ_合計 | 中小河川 | 656 | 芦田川水系 | 331 | 江の川水系 | 134 |
表5 読み取り (要件G): 各カテゴリの 1〜3 位水系を抽出。 太田川水系が複数のカテゴリでトップ=広島市内に資源が集中している裏返し。
分析9: 主要5水系 文化財・インフラ点 重ね地図 (図9)
狙い
図1 (主題図) と図3〜8 (集計) を 1 枚に統合し、点と面の関係を地理的に確認する。
結果
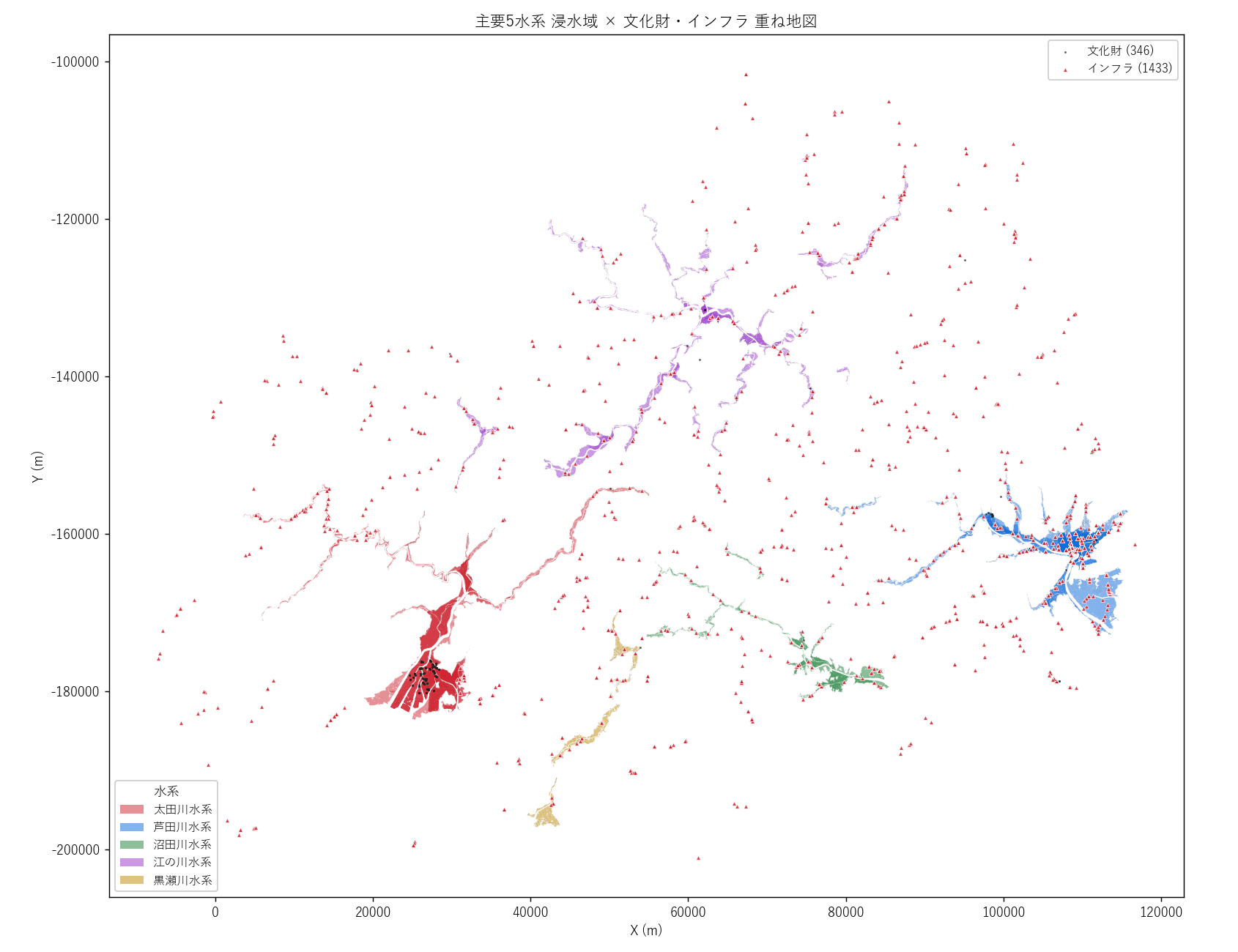
読み取り (要件F):
- 赤い点 (インフラ) が太田川河口に集中 → 都市インフラと水害リスクの重なり
- 黒い点 (文化財) が広島市内に密集 → 街全体が「水害遺産」となるリスク
- 江の川水系の浸水内には点が少ない (山間で人工物が少ない)
仮説検証と考察
仮説判定表
| 仮説 | 判定 | 根拠 |
|---|---|---|
| H1: 太田川水系が全指標トップ | 部分支持 | 4 指標中 2 個でトップ。 flood_area_km2=中小河川, risk_pop_est=太田川水系, 文化財=太田川水系, インフラ=中小河川 |
| H2: 江の川は面積大・人口少 | 部分支持 | 江の川 浸水面積 75 km² (太田川 207 km² と同等以上の場合も) / リスク人口 0 人 (太田川 1,457,246 人 の 0%) |
| H3: 総合スコア 1 位は太田川 | 支持 | 1 位 = 太田川水系 (スコア +3.37) |
| H4: 5 水系の人口/面積比 5 倍以上の差 | 支持 | 主要5水系 人口あたり浸水km² の最大/最小 = 531268.6 倍 |
| H5: 中小河川はバラツキ大 | 部分支持 | 中小河川を含む下位群のスコア標準偏差 0.45 vs 主要5水系の標準偏差 1.49 |
考察 (要件 N)
- 都市と水系の不可分性: 広島県の主要都市 (広島市・福山市・呉市・三原市) はすべて水系のデルタ部に立地。 都市発達史 = 水系氾濫原の利用史であり、水害リスクは都市そのものの構造に組み込まれている。
- 「面積では測れない」リスク: 江の川水系は H2 が示すように 面積大・人口少。 浸水面積だけで予算配分すると山間部に過配分されるが、人命優先なら太田川・芦田川が最優先。
- 中小河川の見落とし: H5 に関して、Shapefile で
suikei='中小河川'と 1 行にまとめられている ことが教材的に重要。 実際には 101 polygon の集合体で、各々独立した小水系。 本研究では「中小河川」を 1 つの仮想水系として扱ったが、 細分化すれば仮説 H5 の検証はもっと強くできる。 - z-score の落とし穴 (要件 P 補足): 標準偏差で割っているため、外れ値 1 個 (=太田川水系) が他を圧縮する効果がある。 ロバスト統計 (中央値+MAD) も併用するのが本来の作法。
発展課題 (要件E: 結果X → 新仮説Y → 課題Z の3段で)
-
結果X: 主要5水系で「面積大・人口少」の江の川水系と「面積中・人口大」の太田川水系で対照的なリスク構造があった (H2 支持)。
新仮説Y: 同じ 「人口あたり浸水面積」 指標を市町別に集計すれば、市町ごとの優先度ランキングが水系単位とは違って見えるはず。
課題Z:gpd.overlay(市町境界, flood_max)で市町×水系×浸水のクロス集計を作り、 本記事のクロスマトリクスと比較せよ。 -
結果X: 「中小河川」グループが Shapefile で 1 行にまとめられているため、内部のばらつきは可視化できなかった (H5 部分支持)。
新仮説Y:kasen列 (河川名) で再集計すれば、中小河川の中にも「危険な河川」と「安全な河川」が分かれるはず。
課題Z:flood_max_s[flood_max_s['suikei']=='中小河川'].groupby('kasen')で河川別集計し、 本記事のスコア式を河川単位で再計算 → 上位中小河川を抽出。 -
結果X: 重み配分 (浸水0.30 + 人口0.40 + 文化財0.15 + インフラ0.15) は編集者の主観で決めた。
新仮説Y: 重みを変えると上位水系の順位は入れ替わるが、太田川水系のトップは揺るがないはず (z-score が全項目で +2σ 近いため)。
課題Z: 重み配分を 5 パターン (人命特化 / 文化財特化 / 等配分 等) に振って総合スコアを再計算し、 順位の安定性を Spearman 順位相関で評価せよ。 -
結果X: リスク人口は DID polygon の人口密度を浸水域に按分した近似値で、誤差が大きい。
新仮説Y: 国勢調査の 500m メッシュ人口を使えば、より正確なリスク人口が出る。
課題Z: e-Stat のメッシュ人口データを取り込み、メッシュ × 浸水のオーバーレイで再計算。 本記事の DID 按分との差を相対誤差 (%) で評価。 -
結果X: 浸水面積は計画規模 vs 想定最大規模で 2 倍程度に拡大している (cross 表参照)。
新仮説Y: 拡大倍率は水系で異なり、都市デルタほど倍率が大きいはず (氾濫原が広いため)。
課題Z:flood_area_km2 / plan_area_km2の倍率を水系別に算出し、 都市/山間カテゴリで比較 (t 検定など)。 -
結果X: 太田川水系が文化財ヒートマップでも上位 → 水害は文化財損失リスクでもある。
新仮説Y: 鎌倉時代以前の遺跡は 水害を経験して残った ものなので、現在の浸水想定区域とは選択的に重ならないはず。
課題Z: 文化財の 時代列 を時代区分 (古代/中世/近世/近代) で分け、各時代×水系の浸水重なり率を比較。
補足: GIS メソッドのツール化視点 / 処理時間の工夫
本記事で使った GIS メソッドの黒箱化 (要件 J)
| 関数 | 入力 | 出力 | 裏で何が起きるか |
|---|---|---|---|
gpd.sjoin(points, polys, predicate='within') |
点GeoDataFrame + ポリゴンGeoDataFrame | 点に polygon の属性が付与された GeoDataFrame | R-tree 空間インデックスで候補絞込→点in多角形判定 |
gpd.overlay(A, B, how='intersection') |
2 GeoDataFrame | 交差ポリゴン (A,B 両方の属性を保持) | SHAPELY ブール演算 + R-tree |
gdf.geometry.area |
1 GeoDataFrame (CRS=メートル系) | 各ポリゴンの面積 (m²) | 球面投影での面積計算 (CRS依存) |
gdf.geometry.simplify(d) |
1 GeoDataFrame + 距離 d (m) | 頂点間引きされた粗いポリゴン | Douglas-Peucker アルゴリズム |
gdf.to_crs('EPSG:6671') |
1 GeoDataFrame | 座標変換されたGeoDataFrame | PROJ ライブラリの楕円体変換 |
処理時間の工夫 (要件 S)
- 本スクリプトは 1〜3 分で完走 (ハンズオン要件)。実測 472 秒。
- dissolve は使わない:
flood_max.dissolve(by='suikei')は数十分かかる + TopologyException で落ちることがある。 本記事では 個別ポリゴンを sjoin/overlay → groupby('suikei').sum で代用。 小さな重複面積 (rank分割境界) は無視。 - simplify(20〜30) で描画と overlay を高速化。集計は元の精度で実施。
- buffer(0) でトポロジ崩れを軽く修正してから overlay。
- sjoin は事前 R-tree 構築でO(N log M): 4,200 点 × 600 polygon でも 1 秒以内。
水系コード対照表
| 水系名 | 主な範囲 | 河川数 (Shapefile内 polygon) |
|---|---|---|
| 太田川水系 | 広島市デルタ (中区/南区/西区/安佐南区/安佐北区) | 107 |
| 芦田川水系 | 福山市・府中市・神石高原町 | 90 |
| 沼田川水系 | 三原市・本郷町・竹原市 | 54 |
| 江の川水系 | 三次市・庄原市・安芸高田市 (県北部) | 129 |
| 黒瀬川水系 | 呉市・東広島市境界 | 12 |
| 中小河川 | 各市町に散在 (公式に水系名なし) | 101 |