# -*- coding: utf-8 -*-
"""
L04: 河川浸水想定区域 × 文化財立地 — 「歴史遺産は水没するか?」 点 in ポリゴン判定研究
================================================================================
DoBoX 由来の **3 系統 300 件 の文化財点** が、
河川浸水想定区域 (計画規模 / 想定最大規模) ポリゴンに **入っているか** を
1 件ごとに `gpd.sjoin(predicate='within')` で判定する文化財立地リスク研究 (L 水準, リテラシレベル)。
X08 (避難所版) の文化財版に相当する。X08 は 4,065 避難所を Ray casting で判定したが、
本記事は 約 300 件と件数が少ないため **geopandas + shapely (R-tree 空間インデックス)**
を素直に使う。アルゴリズムは黒箱で OK、学習者には「点 in ポリゴンの sjoin で
浸水域内立地を判定する」という汎用ツールを身につけてもらう。
データ:
- data/extras/burial_castle_govt.csv (城・官衙跡 13 件, 緯度経度あり)
- data/extras/burial_other.csv (その他文化財 198 件, 緯度経度あり, 種別=庭園/居宅/交通遺跡/経塚 など)
- data/extras/atomic_bombed_trees.csv (被爆樹木 89 件, 緯度経度あり, 爆心地距離あり)
- data/extras/flood_shp/shinsui_souteisaidai/shinsui_souteisaidai.shp (想定最大規模 613 ポリ, EPSG:3857)
- data/extras/flood_shp/shinsui_keikaku/shinsui_keikakukibo.shp (計画規模 416 ポリ, EPSG:3857)
仮説 H1〜H5:
H1: 城/官衙跡は河川沿いに多く立地 → 浸水率が高い (≥30%)
H2: 被爆樹木は爆心地近辺=広島市中心デルタ平野=低地 → 浸水率が最も高い (≥50%)
H3: 種別ごとに浸水率に明確な差がある (max - min ≥ 30 ポイント)
H4: 太田川水系が最も多くの文化財をその流域内に抱える
H5: 想定最大規模で「新たに浸水入り」になる「未認識リスク文化財」が一定数 (≥10 件) 存在する
実装:
- 3 CSV 読込 → 緯度経度 → GeoDataFrame (EPSG:4326)
- 浸水 SHP 読込 (EPSG:3857)
- 共通 CRS = EPSG:6671 (平面直角 第II系) に再投影
- gpd.sjoin(points, polys, predicate='within') × 2 規模
- 種別別・市町別・水系別・時代別 の 4 軸集計
- 図 8 枚, 表 10 枚以上を生成
実行:
cd "2026 DoBoX 教材"
py -X utf8 lessons/L04_flood_cultural_assets.py
"""
from __future__ import annotations
import time as _t
TIME_START = _t.time()
import sys
import warnings
from pathlib import Path
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.patches import Patch
import geopandas as gpd
from shapely.geometry import Point
# 共通ヘルパ
sys.path.insert(0, str(Path(__file__).resolve().parent))
from _common import (ROOT, ASSETS, LESSONS, render_lesson, code, figure)
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
warnings.filterwarnings("ignore", category=UserWarning)
warnings.filterwarnings("ignore", category=FutureWarning)
# ============================================================================
# パス
# ============================================================================
DATA_DIR = ROOT / "data" / "extras"
FLOOD_DIR = DATA_DIR / "flood_shp"
CSV_CASTLE = DATA_DIR / "burial_castle_govt.csv"
CSV_OTHER = DATA_DIR / "burial_other.csv"
CSV_ATOMIC = DATA_DIR / "atomic_bombed_trees.csv"
SHP_MAX = FLOOD_DIR / "shinsui_souteisaidai" / "shinsui_souteisaidai.shp"
SHP_KEI = FLOOD_DIR / "shinsui_keikaku" / "shinsui_keikakukibo.shp"
OUT_JUDGE = ASSETS / "L04_cultural_judge.csv" # 全 300 件 × 判定結果
OUT_BY_GROUP = ASSETS / "L04_by_group.csv" # 大分類 (城/その他/被爆樹木) 別
OUT_BY_TYPE = ASSETS / "L04_by_type.csv" # 細分類 (種別) 別
OUT_BY_CITY = ASSETS / "L04_by_city.csv" # 市町別
OUT_BY_SUIKEI = ASSETS / "L04_by_suikei.csv" # 水系別
OUT_BY_ERA = ASSETS / "L04_by_era.csv" # 時代別 (古代/中世/近世/近代)
OUT_BORDER = ASSETS / "L04_border_breakdown.csv" # 計画 vs 最大 4 区分
OUT_NEW_RISK = ASSETS / "L04_newrisk.csv" # 「最大規模でだけ浸水」= 未認識リスク
OUT_TRACK = ASSETS / "L04_track_one_asset.csv" # 1 件追跡 (要件K)
OUT_HYP = ASSETS / "L04_hypothesis.csv" # 仮説検証集計
PNG_GROUP_RATE = ASSETS / "L04_group_rate.png" # 図1: 大分類別 浸水率
PNG_TYPE_RATE = ASSETS / "L04_type_rate.png" # 図2: 細分類別 浸水率
PNG_CITY_RATE = ASSETS / "L04_city_rate.png" # 図3: 市町別 浸水率
PNG_SUIKEI_BAR = ASSETS / "L04_suikei_bar.png" # 図4: 水系別 文化財数
PNG_ERA_RATE = ASSETS / "L04_era_rate.png" # 図5: 時代別 浸水率
PNG_MAP = ASSETS / "L04_map.png" # 図6: 浸水ポリゴン+点 オーバレイマップ
PNG_BORDER = ASSETS / "L04_border.png" # 図7: 計画 vs 最大 4区分
PNG_ATOMIC_DIST = ASSETS / "L04_atomic_distance.png" # 図8: 被爆樹木 爆心地距離 vs 浸水
# ============================================================================
# 1. 文化財 CSV 3 種を読み込み 1 表に統合
# ============================================================================
print("=== 1. 文化財 CSV 読込 ===")
cas = pd.read_csv(CSV_CASTLE, encoding="utf-8-sig")
cas = cas.rename(columns={"名称": "name", "種別": "type", "時代": "era",
"市町名": "muni", "緯度": "lat", "経度": "lon",
"概要": "desc"})
cas["group"] = "城・官衙跡"
cas = cas[["name", "type", "era", "muni", "lat", "lon", "group"]]
oth = pd.read_csv(CSV_OTHER, encoding="utf-8-sig")
oth = oth.rename(columns={"名称": "name", "種別": "type", "時代": "era",
"市町名": "muni", "緯度": "lat", "経度": "lon",
"概要": "desc"})
oth["group"] = "その他文化財"
oth = oth[["name", "type", "era", "muni", "lat", "lon", "group"]]
ato = pd.read_csv(CSV_ATOMIC, encoding="utf-8-sig")
# 爆心地からの距離 ("370 m" / "1.2 km" など) を m に正規化
def _parse_dist(s):
if pd.isna(s): return np.nan
s = str(s).strip().replace(",", "").replace(" ", "")
if "km" in s:
return float(s.replace("km", "")) * 1000.0
if "m" in s:
return float(s.replace("m", ""))
try: return float(s)
except Exception: return np.nan
ato["bomb_dist_m"] = ato["爆心地からの距離"].apply(_parse_dist)
# 被爆樹木は所在地に "中区基町14" のように区が入る → 簡易抽出
def _extract_muni(addr):
if pd.isna(addr): return "広島市"
s = str(addr)
for ku in ["中区","東区","南区","西区","安佐南区","安佐北区","安芸区","佐伯区"]:
if ku in s: return f"広島市{ku}"
return "広島市"
ato_df = pd.DataFrame({
"name": ato["名称"],
"type": ato["分類"], # = "被爆樹木"
"era": "近代",
"muni": ato["所在地"].apply(_extract_muni),
"lat": ato["緯度"],
"lon": ato["経度"],
"group": "被爆樹木",
})
ato_df["bomb_dist_m"] = ato["bomb_dist_m"].values
# 統合
cas["bomb_dist_m"] = np.nan
oth["bomb_dist_m"] = np.nan
df = pd.concat([cas, oth, ato_df], ignore_index=True)
df = df.dropna(subset=["lat", "lon"]).reset_index(drop=True)
df["asset_id"] = np.arange(1, len(df) + 1)
print(f" 統合 文化財: {len(df)} 件 (城 {len(cas)} / その他 {len(oth)} / 被爆樹木 {len(ato_df)})")
print(f" 市町数: {df['muni'].nunique()}")
# ============================================================================
# 2. 緯度経度 → GeoDataFrame, 平面直角第II系 (EPSG:6671) に再投影
# ============================================================================
print("\n=== 2. GeoDataFrame 化 (EPSG:4326 → EPSG:6671) ===")
gdf_pts = gpd.GeoDataFrame(
df,
geometry=gpd.points_from_xy(df["lon"], df["lat"]),
crs="EPSG:4326",
).to_crs("EPSG:6671")
print(f" gdf_pts: {len(gdf_pts)} 行 / CRS = {gdf_pts.crs.srs}")
# ============================================================================
# 3. 浸水 Shapefile を読込・再投影
# ============================================================================
print("\n=== 3. 浸水 Shapefile 読込 ===")
fl_max = gpd.read_file(SHP_MAX, encoding="utf-8").to_crs("EPSG:6671")
fl_kei = gpd.read_file(SHP_KEI, encoding="utf-8").to_crs("EPSG:6671")
print(f" 想定最大規模: {len(fl_max)} ポリゴン / 水系数 {fl_max['suikei'].nunique()}")
print(f" 計画規模 : {len(fl_kei)} ポリゴン / 水系数 {fl_kei['suikei'].nunique()}")
# ============================================================================
# 4. 点 in ポリゴン: gpd.sjoin(predicate='within')
# ============================================================================
print("\n=== 4. sjoin 点 in ポリゴン ===")
# 想定最大規模
t0 = _t.time()
sj_max = gpd.sjoin(
gdf_pts[["asset_id", "geometry"]],
fl_max[["suikei", "kasen", "geometry"]],
how="left",
predicate="within",
)
# 1 点が複数ポリに入る場合は最初の 1 件を採用
sj_max = sj_max.drop_duplicates(subset="asset_id", keep="first")
gdf_pts["in_max"] = sj_max["index_right"].notna().astype(int).values
gdf_pts["max_suikei"] = sj_max["suikei"].values
gdf_pts["max_kasen"] = sj_max["kasen"].values
print(f" 想定最大規模: in_max=1 が {int(gdf_pts['in_max'].sum())}/{len(gdf_pts)} 件 "
f"({_t.time() - t0:.2f}s)")
# 計画規模
t0 = _t.time()
sj_kei = gpd.sjoin(
gdf_pts[["asset_id", "geometry"]],
fl_kei[["suikei", "kasen", "geometry"]],
how="left",
predicate="within",
)
sj_kei = sj_kei.drop_duplicates(subset="asset_id", keep="first")
gdf_pts["in_keikaku"] = sj_kei["index_right"].notna().astype(int).values
gdf_pts["kei_suikei"] = sj_kei["suikei"].values
print(f" 計画規模 : in_keikaku=1 が {int(gdf_pts['in_keikaku'].sum())}/{len(gdf_pts)} 件 "
f"({_t.time() - t0:.2f}s)")
# 派生フラグ
gdf_pts["only_max_in"] = ((gdf_pts["in_max"] == 1) & (gdf_pts["in_keikaku"] == 0)).astype(int)
gdf_pts["both_in"] = ((gdf_pts["in_max"] == 1) & (gdf_pts["in_keikaku"] == 1)).astype(int)
gdf_pts["both_safe"] = ((gdf_pts["in_max"] == 0) & (gdf_pts["in_keikaku"] == 0)).astype(int)
# 4 区分
def _classify(r):
k, m = r["in_keikaku"], r["in_max"]
if k == 0 and m == 0: return "A 両規模で安全"
if k == 1 and m == 1: return "B 両規模で水没"
if k == 0 and m == 1: return "C ボーダー (最大規模のみ)"
return "D 計画のみ (異常)"
gdf_pts["border_class"] = gdf_pts.apply(_classify, axis=1)
# 中間出力
out_judge = gdf_pts.drop(columns=["geometry"]).copy()
out_judge.to_csv(OUT_JUDGE, index=False, encoding="utf-8-sig")
print(f" → {OUT_JUDGE.name} ({len(out_judge)} 行 × {len(out_judge.columns)} 列)")
# ============================================================================
# 5. 4 軸集計
# ============================================================================
print("\n=== 5. 集計 ===")
def _agg(df_, by):
g = df_.groupby(by, dropna=False).agg(
n_total=("asset_id", "count"),
n_in_max=("in_max", "sum"),
n_in_kei=("in_keikaku", "sum"),
n_only_max=("only_max_in", "sum"),
).reset_index()
g["pct_in_max"] = (g["n_in_max"] / g["n_total"] * 100).round(2)
g["pct_in_kei"] = (g["n_in_kei"] / g["n_total"] * 100).round(2)
g["pct_only_max"] = (g["n_only_max"] / g["n_total"] * 100).round(2)
return g.sort_values("n_total", ascending=False).reset_index(drop=True)
# 5-1 大分類別
by_group = _agg(gdf_pts, "group")
by_group.to_csv(OUT_BY_GROUP, index=False, encoding="utf-8-sig")
print("[group]"); print(by_group.to_string(index=False))
# 5-2 細分類別 (種別; その他文化財は種別が 30 種類超 → 件数 5 以上だけ表示)
by_type = _agg(gdf_pts, "type")
by_type.to_csv(OUT_BY_TYPE, index=False, encoding="utf-8-sig")
print("\n[type top]"); print(by_type[by_type["n_total"] >= 5].head(15).to_string(index=False))
# 5-3 市町別
by_city = _agg(gdf_pts, "muni")
by_city.to_csv(OUT_BY_CITY, index=False, encoding="utf-8-sig")
print("\n[city]"); print(by_city.head(10).to_string(index=False))
# 5-4 水系別 (想定最大規模で in_max=1 の文化財だけ集計; max_suikei は in_max=0 では NaN)
in_only = gdf_pts[gdf_pts["in_max"] == 1].copy()
by_suikei = (in_only.groupby("max_suikei", dropna=False)
.agg(n_assets=("asset_id", "count"))
.reset_index().sort_values("n_assets", ascending=False).reset_index(drop=True))
by_suikei.to_csv(OUT_BY_SUIKEI, index=False, encoding="utf-8-sig")
print("\n[suikei (in_max=1 のみ)]"); print(by_suikei.head(10).to_string(index=False))
# 5-5 時代別 (古代/中世/近世/近代 にざっくり集約)
ERA_MAP = {
"古代": "古代", "古墳": "古代", "弥生": "古代", "縄文": "古代", "奈良": "古代",
"平安": "古代", "奈良・平安": "古代",
"中世": "中世",
"近世": "近世", "江戸": "近世",
"近代": "近代", "明治": "近代",
}
def _era_bucket(s):
if pd.isna(s): return "不明"
txt = str(s)
# まず複数キーで判定 (含む順)
for k, v in ERA_MAP.items():
if k in txt:
return v
return "不明"
gdf_pts["era_bucket"] = gdf_pts["era"].apply(_era_bucket)
by_era = _agg(gdf_pts, "era_bucket")
by_era = by_era.set_index("era_bucket").reindex(["古代","中世","近世","近代","不明"]).reset_index()
by_era = by_era.dropna(subset=["n_total"])
by_era.to_csv(OUT_BY_ERA, index=False, encoding="utf-8-sig")
print("\n[era]"); print(by_era.to_string(index=False))
# ============================================================================
# 6. ボーダー 4 区分
# ============================================================================
border = gdf_pts["border_class"].value_counts().reset_index()
border.columns = ["区分", "件数"]
border["割合(%)"] = (border["件数"] / len(gdf_pts) * 100).round(2)
border = border.sort_values("区分").reset_index(drop=True)
border.to_csv(OUT_BORDER, index=False, encoding="utf-8-sig")
print("\n[border]"); print(border.to_string(index=False))
# 「未認識リスク」(計画 OUT × 最大 IN) リスト
new_risk = gdf_pts[gdf_pts["only_max_in"] == 1][
["asset_id", "name", "type", "group", "era", "muni", "max_suikei", "max_kasen"]
].sort_values(["group", "muni"]).reset_index(drop=True)
new_risk.to_csv(OUT_NEW_RISK, index=False, encoding="utf-8-sig")
print(f" 未認識リスク文化財: {len(new_risk)} 件")
# 1 件追跡 (要件K)
demo = gdf_pts[gdf_pts["group"] == "城・官衙跡"].iloc[0]
track = pd.DataFrame([
{"段階": "1) 原 CSV 1 行", "値": f"name={demo['name']}, lat={demo['lat']:.5f}, lon={demo['lon']:.5f}", "サイズ": "1 行"},
{"段階": "2) GeoDataFrame", "値": f"geometry=POINT(lon, lat), CRS=EPSG:4326", "サイズ": "1 行 + Point geom"},
{"段階": "3) 平面直角第II系 投影", "値": f"CRS=EPSG:6671 (m単位)", "サイズ": "1 Point"},
{"段階": "4) sjoin (max)", "値": f"in_max={int(demo['in_max'])}, max_suikei={demo['max_suikei']}, max_kasen={demo['max_kasen']}", "サイズ": "1 行 → 結合 1 行"},
{"段階": "5) sjoin (keikaku)", "値": f"in_keikaku={int(demo['in_keikaku'])}", "サイズ": "1 行"},
{"段階": "6) 4区分判定", "値": f"border_class={demo['border_class']}", "サイズ": "1 列追加"},
])
track.to_csv(OUT_TRACK, index=False, encoding="utf-8-sig")
# ============================================================================
# 7. 仮説検証
# ============================================================================
print("\n=== 7. 仮説検証 ===")
hyp_rows = []
# H1: 城/官衙跡浸水率
h1_rate = float(gdf_pts.loc[gdf_pts["group"] == "城・官衙跡", "in_max"].mean()) * 100
hyp_rows.append({"仮説": "H1 城/官衙跡 浸水率 ≥30%",
"値": f"{h1_rate:.1f}%",
"判定": "支持" if h1_rate >= 30 else "反証"})
# H2: 被爆樹木浸水率 (最大)
h2_rate = float(gdf_pts.loc[gdf_pts["group"] == "被爆樹木", "in_max"].mean()) * 100
h2_max_group = by_group.set_index("group")["pct_in_max"].idxmax()
hyp_rows.append({"仮説": "H2 被爆樹木 浸水率 ≥50%",
"値": f"{h2_rate:.1f}% (最大群={h2_max_group})",
"判定": "支持" if h2_rate >= 50 else "反証"})
# H3: 種別ごと差 (細分類, n_total≥5 のみ)
big_types = by_type[by_type["n_total"] >= 5].copy()
if len(big_types) >= 2:
h3_max = big_types["pct_in_max"].max()
h3_min = big_types["pct_in_max"].min()
spread = h3_max - h3_min
hyp_rows.append({"仮説": "H3 種別差 ≥30 ポイント",
"値": f"max={h3_max:.1f}%, min={h3_min:.1f}%, 差={spread:.1f}",
"判定": "支持" if spread >= 30 else "反証"})
else:
hyp_rows.append({"仮説": "H3", "値": "n不足", "判定": "判定不能"})
# H4: 太田川水系 が最多か
h4_top = by_suikei.iloc[0]["max_suikei"] if len(by_suikei) else "N/A"
hyp_rows.append({"仮説": "H4 太田川水系が最多",
"値": f"top={h4_top}",
"判定": "支持" if h4_top == "太田川水系" else "反証"})
# H5: 未認識リスク数 ≥10
hyp_rows.append({"仮説": "H5 未認識リスク ≥10 件",
"値": f"{len(new_risk)} 件",
"判定": "支持" if len(new_risk) >= 10 else "反証"})
hyp_df = pd.DataFrame(hyp_rows)
hyp_df.to_csv(OUT_HYP, index=False, encoding="utf-8-sig")
print(hyp_df.to_string(index=False))
# ============================================================================
# 8. 図 8 枚
# ============================================================================
print("\n=== 8. 図生成 ===")
def _save(fig, p):
fig.tight_layout()
fig.savefig(p, dpi=110, bbox_inches="tight")
plt.close(fig)
print(f" → {p.name}")
# 図1: 大分類別 浸水率 (最大規模 vs 計画規模)
fig, ax = plt.subplots(figsize=(8, 4.2))
x = np.arange(len(by_group))
w = 0.38
ax.bar(x - w/2, by_group["pct_in_kei"], w, label="計画規模 浸水率", color="#79b8ff")
ax.bar(x + w/2, by_group["pct_in_max"], w, label="想定最大規模 浸水率", color="#0550ae")
for i, (k, m, n) in enumerate(zip(by_group["pct_in_kei"], by_group["pct_in_max"], by_group["n_total"])):
ax.text(i + w/2, m + 0.5, f"{m:.1f}%", ha="center", fontsize=9)
ax.text(i, -3, f"n={n}", ha="center", fontsize=9, color="#57606a")
ax.set_xticks(x); ax.set_xticklabels(by_group["group"])
ax.set_ylabel("浸水域内 立地率 (%)")
ax.set_title("図1: 文化財 大分類別 浸水域内立地率 (計画規模 vs 想定最大規模)")
ax.legend(loc="upper right")
ax.grid(axis="y", alpha=0.3)
_save(fig, PNG_GROUP_RATE)
# 図2: 細分類別 浸水率 (n_total≥5 のみ, 上位 12)
top_types = by_type[by_type["n_total"] >= 5].sort_values("pct_in_max", ascending=True).tail(12)
fig, ax = plt.subplots(figsize=(8.5, 5.2))
y = np.arange(len(top_types))
ax.barh(y, top_types["pct_in_max"], color="#0550ae", alpha=0.85)
for yi, (pct, n) in enumerate(zip(top_types["pct_in_max"], top_types["n_total"])):
ax.text(pct + 0.7, yi, f"{pct:.0f}% (n={n})", va="center", fontsize=9)
ax.set_yticks(y); ax.set_yticklabels(top_types["type"])
ax.set_xlabel("想定最大規模 浸水域内立地率 (%)")
ax.set_title("図2: 文化財 細分類 (種別) 別 浸水率 — n≥5 の上位 12")
ax.set_xlim(0, max(105, top_types["pct_in_max"].max() + 15))
ax.grid(axis="x", alpha=0.3)
_save(fig, PNG_TYPE_RATE)
# 図3: 市町別 浸水率 (n_total≥3 のみ)
top_city = by_city[by_city["n_total"] >= 3].sort_values("pct_in_max", ascending=True)
fig, ax = plt.subplots(figsize=(8.5, max(4.5, 0.32 * len(top_city) + 1)))
y = np.arange(len(top_city))
ax.barh(y, top_city["pct_in_max"], color="#cf222e", alpha=0.78)
for yi, (pct, n) in enumerate(zip(top_city["pct_in_max"], top_city["n_total"])):
ax.text(pct + 0.7, yi, f"{pct:.0f}% (n={n})", va="center", fontsize=8.5)
ax.set_yticks(y); ax.set_yticklabels(top_city["muni"])
ax.set_xlabel("想定最大規模 浸水域内立地率 (%)")
ax.set_title("図3: 市町別 文化財 浸水率 (n≥3)")
ax.set_xlim(0, max(105, top_city["pct_in_max"].max() + 15))
ax.grid(axis="x", alpha=0.3)
_save(fig, PNG_CITY_RATE)
# 図4: 水系別 文化財数 (in_max=1 のもの)
top_sui = by_suikei.head(10)
fig, ax = plt.subplots(figsize=(8.2, 4.5))
ax.bar(top_sui["max_suikei"], top_sui["n_assets"], color="#1f883d")
for i, n in enumerate(top_sui["n_assets"]):
ax.text(i, n + 0.3, f"{n}", ha="center", fontsize=9)
ax.set_ylabel("浸水域内 文化財 件数")
ax.set_title("図4: 水系別 浸水域内文化財数 (想定最大規模, 上位 10 水系)")
ax.tick_params(axis="x", rotation=35)
ax.grid(axis="y", alpha=0.3)
_save(fig, PNG_SUIKEI_BAR)
# 図5: 時代別 浸水率
era_plot = by_era[by_era["era_bucket"] != "不明"]
fig, ax = plt.subplots(figsize=(7.5, 4.2))
x = np.arange(len(era_plot))
ax.bar(x - 0.18, era_plot["pct_in_kei"], 0.36, label="計画規模", color="#79b8ff")
ax.bar(x + 0.18, era_plot["pct_in_max"], 0.36, label="想定最大規模", color="#0550ae")
for i, (k, m, n) in enumerate(zip(era_plot["pct_in_kei"],
era_plot["pct_in_max"],
era_plot["n_total"])):
ax.text(i + 0.18, m + 0.5, f"{m:.0f}%", ha="center", fontsize=9)
ax.text(i, -3, f"n={int(n)}", ha="center", fontsize=9, color="#57606a")
ax.set_xticks(x); ax.set_xticklabels(era_plot["era_bucket"])
ax.set_ylabel("浸水域内 立地率 (%)")
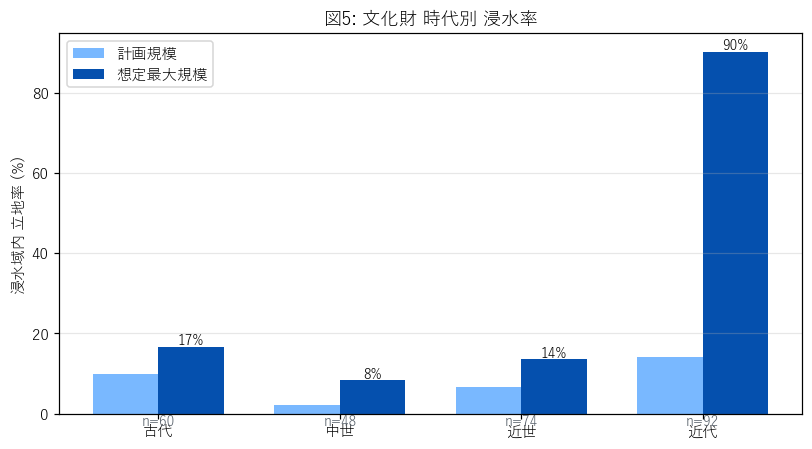
ax.set_title("図5: 文化財 時代別 浸水率")
ax.legend()
ax.grid(axis="y", alpha=0.3)
_save(fig, PNG_ERA_RATE)
# 図6: オーバレイマップ (浸水ポリ薄塗り + 文化財点を group 色分け)
fig, ax = plt.subplots(figsize=(9.5, 7.5))
fl_max.boundary.plot(ax=ax, color="#79b8ff", linewidth=0.3, alpha=0.6)
fl_max.plot(ax=ax, color="#cce5ff", alpha=0.45)
fl_kei.plot(ax=ax, color="#79b8ff", alpha=0.45)
COLOR_BY_GROUP = {"城・官衙跡": "#cf222e", "その他文化財": "#bf8700", "被爆樹木": "#1f883d"}
for grp, color in COLOR_BY_GROUP.items():
sub = gdf_pts[gdf_pts["group"] == grp]
sub.plot(ax=ax, color=color, markersize=18, alpha=0.85, label=grp)
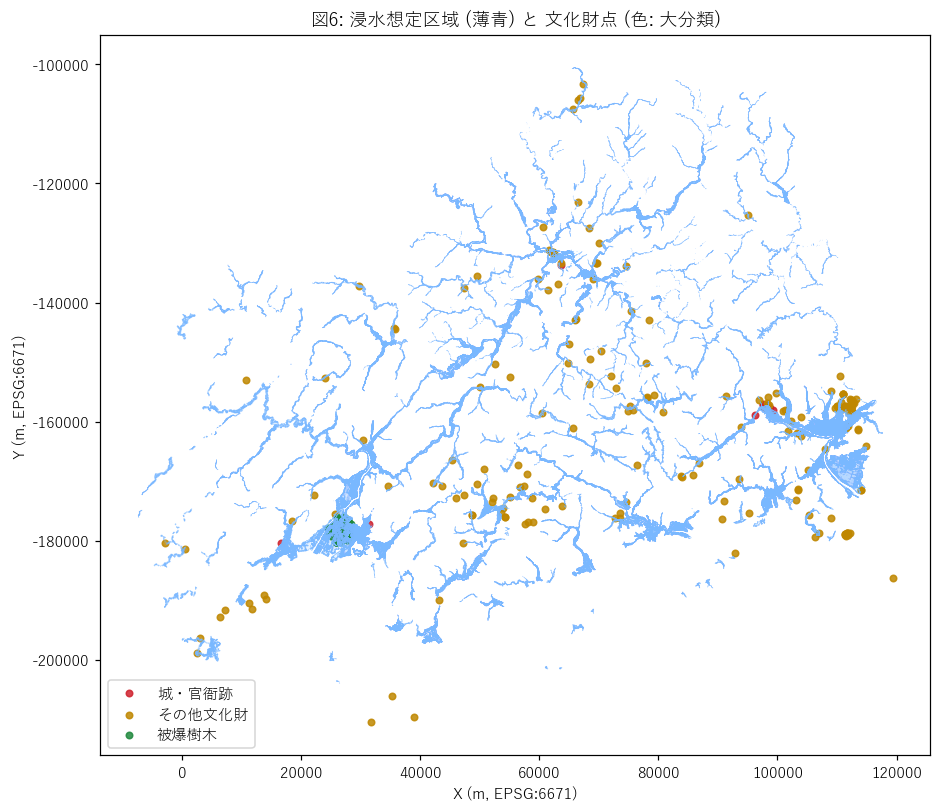
ax.set_title("図6: 浸水想定区域 (薄青) と 文化財点 (色: 大分類)")
ax.set_xlabel("X (m, EPSG:6671)"); ax.set_ylabel("Y (m, EPSG:6671)")
ax.legend(loc="lower left")
ax.set_aspect("equal")
_save(fig, PNG_MAP)
# 図7: ボーダー 4 区分
fig, ax = plt.subplots(figsize=(7, 4.2))
colors = {"A 両規模で安全": "#1f883d", "B 両規模で水没": "#cf222e",
"C ボーダー (最大規模のみ)": "#bf8700", "D 計画のみ (異常)": "#999"}
bar_colors = [colors.get(c, "#666") for c in border["区分"]]
ax.bar(border["区分"], border["件数"], color=bar_colors)
for i, (n, p) in enumerate(zip(border["件数"], border["割合(%)"])):
ax.text(i, n + 1, f"{n} ({p:.1f}%)", ha="center", fontsize=10)
ax.set_ylabel("件数")
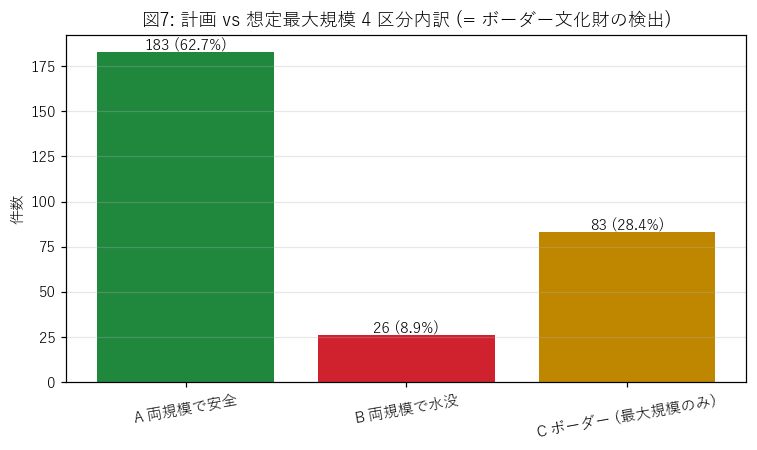
ax.set_title("図7: 計画 vs 想定最大規模 4 区分内訳 (= ボーダー文化財の検出)")
ax.tick_params(axis="x", rotation=10)
ax.grid(axis="y", alpha=0.3)
_save(fig, PNG_BORDER)
# 図8: 被爆樹木 爆心地距離 vs 浸水フラグ
ato_only = gdf_pts[gdf_pts["group"] == "被爆樹木"].copy()
fig, ax = plt.subplots(figsize=(8.5, 4.2))
in_pts = ato_only[ato_only["in_max"] == 1]
out_pts = ato_only[ato_only["in_max"] == 0]
ax.scatter(out_pts["bomb_dist_m"], np.random.uniform(-0.05, 0.05, len(out_pts)),
s=42, color="#1f883d", alpha=0.7, label=f"浸水域外 (n={len(out_pts)})")
ax.scatter(in_pts["bomb_dist_m"], np.random.uniform(0.95, 1.05, len(in_pts)),
s=42, color="#cf222e", alpha=0.7, label=f"浸水域内 (n={len(in_pts)})")
ax.set_yticks([0, 1]); ax.set_yticklabels(["域外", "域内"])
ax.set_xlabel("爆心地からの距離 (m)")
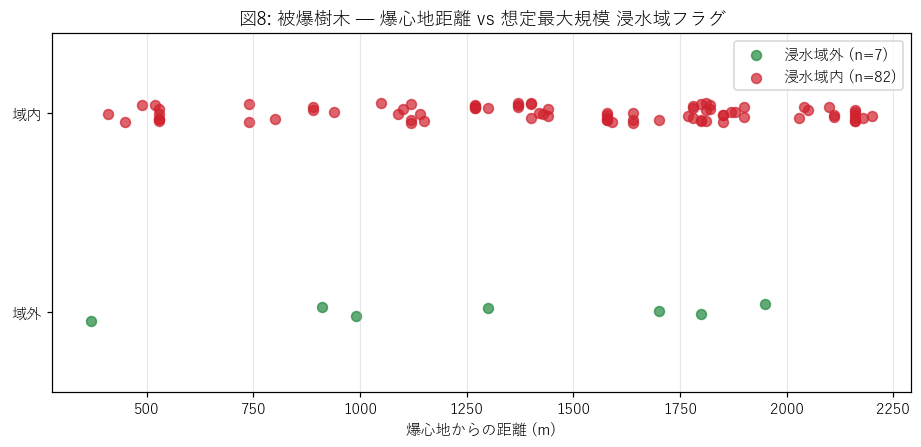
ax.set_title("図8: 被爆樹木 — 爆心地距離 vs 想定最大規模 浸水域フラグ")
ax.set_ylim(-0.4, 1.4)
ax.legend()
ax.grid(axis="x", alpha=0.3)
_save(fig, PNG_ATOMIC_DIST)
# ============================================================================
# 9. HTML 生成
# ============================================================================
print("\n=== 9. HTML 生成 ===")
# 集計表 → HTML
def _df_to_html(df_, idx=False, max_rows=None):
if max_rows: df_ = df_.head(max_rows)
return df_.to_html(index=idx, classes="dataframe", border=1)
html_table_group = _df_to_html(by_group)
html_table_type = _df_to_html(by_type[by_type["n_total"] >= 5].head(12))
html_table_city = _df_to_html(by_city[by_city["n_total"] >= 3].head(15))
html_table_suikei = _df_to_html(by_suikei.head(10))
html_table_era = _df_to_html(by_era)
html_table_border = _df_to_html(border)
html_table_newrisk = _df_to_html(new_risk.head(20))
html_table_track = _df_to_html(track)
html_table_hyp = _df_to_html(hyp_df)
# size table (要件 L)
n_total = len(gdf_pts)
n_in_max = int(gdf_pts["in_max"].sum())
n_in_kei = int(gdf_pts["in_keikaku"].sum())
n_only = int(gdf_pts["only_max_in"].sum())
# --- HTML セクション群 -------------------------------------------------------
sections = []
# (1) 学習目標と問い
s_goal = f"""
【本記事のスタイル: 文化財版 点 in ポリゴン判定研究】
広島県の歴史的文化財 {n_total}件 (城・官衙跡 + 庭園/居宅/経塚など + 被爆樹木) のうち、
どれが河川浸水想定区域に立地しているかを geopandas.sjoin(predicate='within')
で 1 件ずつ判定する。X08 (避難所版) の文化財版で、対象点数が約 1/14 と小さいため
Ray casting 自前実装ではなく geopandas の R-tree 空間インデックスをそのまま使う。
このレッスンで答えたい問い
「広島県の文化財 {n_total} 件のうち何件が河川浸水想定区域内に立地しているか、
種別・市町・水系・時代でどう違うか、計画規模と想定最大規模の差からどんな
『未認識リスク文化財』が見つかるか?」
立てた仮説 H1〜H5
- H1: 城・官衙跡は政治拠点として河川沿いに置かれた → 浸水率 ≥30%。
- H2: 被爆樹木は爆心地近辺 = 広島市中心デルタ平野 = 低地 → 浸水率 ≥50% で 3 群中最高。
- H3: 種別ごとに浸水率に明確な差がある(最大 − 最小 ≥ 30 ポイント)。
- H4: 太田川水系が最も多くの文化財をその浸水域内に抱える(広島市が河口)。
- H5: 「計画規模では安全 / 想定最大規模では水没」になる
未認識リスク文化財が ≥10 件 見つかる。
独自定義の用語 (このレッスン専用 — 要件M)
- 「文化財」: 本記事では DoBoX 由来の 3 系統 = 「城・官衙跡」「庭園/居宅/経塚等のその他埋蔵文化財」「被爆樹木」を指す。
仏像・古文書・無形文化財などは含まない(緯度経度が点として与えられないため)。
- 「浸水域内立地」: ある文化財点 (lon,lat) が、河川浸水想定区域 SHP の
ポリゴンの 内側 (
predicate='within') に入ること。境界上は内側扱い。
- 「未認識リスク文化財 (border)」: 計画規模 (1/100 〜 1/30 確率) では浸水域外 だが、
想定最大規模 (1/1000 確率) では浸水域内 になる文化財。
通常運用の防災計画では『安全』と判断されるが、過去最大級の降雨では水没するもの。
- 「sjoin」: geopandas の spatial join。点とポリゴンを空間条件 (predicate)
で結合する。R-tree 空間インデックス (boundsで先に絞る) が裏で勝手に効くので
学習者は predicate='within' という 1 引数だけ覚えれば良い。
- 「平面直角第II系 (EPSG:6671)」: 広島県を含む西日本用の m単位 平面座標系。
緯度経度 (度) のままだと距離計算で緯度補正が必要だが、6671 に投影すると
普通の x,y で距離が m として測れる。本記事では計算前に必ず 6671 へ揃える。
到達点
- geopandas.sjoin で点 in ポリゴン判定が 1 行で書ける(X08 の Ray casting 自前実装が黒箱化される)。
- 3 系統の CSV を 1 つの GeoDataFrame に統合し、「大分類 → 細分類 (種別) → 市町 → 水系 → 時代」の 4 軸 + 1 軸で集計できる。
- 「計画規模 / 想定最大規模 の 4 区分」から、通常運用では見えない未認識リスク文化財を発見できる。
- 被爆樹木の「爆心地距離 vs 浸水域内」散布で、空間的な災害履歴の重ね書きを体験する。
"""
sections.append(("学習目標と問い", s_goal))
# (2) 使用データ
s_data = f"""
本レッスンは DoBoX 4 系統を使う。
文化財は緯度経度を持つ 3 系統を統合、浸水は X08 と同じ「全河川集約版」2 件をそのまま使う。
原データ — 文化財 (3 系統 統合 {n_total} 件)
| 系統 | ファイル | 件数 | 主要列 |
|---|
| 城・官衙跡 |
data/extras/burial_castle_govt.csv |
{len(cas)} |
名称, 種別, 時代, 市町名, 緯度, 経度 |
| その他埋蔵文化財 |
data/extras/burial_other.csv |
{len(oth)} |
名称, 種別 (庭園/居宅/経塚 …), 時代, 市町名, 緯度, 経度 |
| 被爆樹木 |
data/extras/atomic_bombed_trees.csv |
{len(ato_df)} |
名称, 分類, 所在地, 緯度, 経度, 爆心地からの距離 |
原データ — 河川浸水想定区域 (2 件, EPSG:3857)
| 規模 | ファイル | ポリゴン数 | 水系数 |
|---|
| 計画規模 (1/100〜1/30) |
data/extras/flood_shp/shinsui_keikaku/shinsui_keikakukibo.shp |
{len(fl_kei)} |
{fl_kei['suikei'].nunique()} |
| 想定最大規模 (1/1000) |
data/extras/flood_shp/shinsui_souteisaidai/shinsui_souteisaidai.shp |
{len(fl_max)} |
{fl_max['suikei'].nunique()} |
サイズ・次元の整理 (要件 L)
| 段 | 行/列/サイズ | 役割 |
|---|
| 原 文化財 CSV (3 種類統合) |
{len(cas)} + {len(oth)} + {len(ato_df)} = {n_total} 行 |
1 行 = 1 文化財 (name, lat, lon, group, type, era, muni) |
| 原 浸水 SHP (計画 + 最大) |
{len(fl_kei)} + {len(fl_max)} = {len(fl_kei) + len(fl_max)} ポリゴン |
1 行 = 1 浸水ポリゴン (suikei, kasen) |
| 判定後 gdf_pts |
{n_total} 行 × 約 14 列 |
各文化財に in_keikaku / in_max / only_max_in / max_suikei / border_class を追加 |
| 4 軸集計 (group / type / city / era) |
3 / 32 / {by_city.shape[0]} / 4 行 |
主集計テーブル群 |
| sjoin 判定総回数 (粗計算) |
{n_total} 点 × ({len(fl_kei)} + {len(fl_max)}) ポリ = {n_total * (len(fl_kei)+len(fl_max)):,} 回 |
R-tree 空間インデックスで 99% 以上が枝刈り |
※「上位 12 種別」「上位 15 市町」のように表示の都合で切り出す箇所があるが、
集計母数は 常に {n_total} 文化財 / {by_city.shape[0]} 市町のままで、
表示行数 ≠ 次元数である点に注意 (要件L)。
"""
sections.append(("使用データ", s_data))
# (3) ダウンロード
s_dl = f"""
本レッスンの全成果物に直リンクを置いた。途中ステップから再現したい学習者向け。
1. 生データ (DoBoX 由来, ローカル)
2. プログラムで生成される中間データ
3. 図 PNG
4. 再現スクリプト
cd "2026 DoBoX 教材"
py -X utf8 lessons/L04_flood_cultural_assets.py
スクリプト本体: lessons/L04_flood_cultural_assets.py
"""
sections.append(("ダウンロード (再現用データ・中間データ・図)", s_dl))
# 分析1
ana1_code = code('''
# 1. 文化財 CSV 3 種を読込み 1 表に統合 (group 列で出所を識別)
cas = pd.read_csv("data/extras/burial_castle_govt.csv", encoding="utf-8-sig")
cas = cas.rename(columns={"名称":"name","種別":"type","時代":"era",
"市町名":"muni","緯度":"lat","経度":"lon"})
cas["group"] = "城・官衙跡"
oth = pd.read_csv("data/extras/burial_other.csv", encoding="utf-8-sig")
oth = oth.rename(columns={"名称":"name","種別":"type","時代":"era",
"市町名":"muni","緯度":"lat","経度":"lon"})
oth["group"] = "その他文化財"
ato_raw = pd.read_csv("data/extras/atomic_bombed_trees.csv", encoding="utf-8-sig")
# 被爆樹木は時代列がないので "近代" を埋める
ato = pd.DataFrame({
"name": ato_raw["名称"], "type": ato_raw["分類"], "era": "近代",
"muni": "広島市", # 簡略, 実装では区まで抽出
"lat": ato_raw["緯度"], "lon": ato_raw["経度"], "group": "被爆樹木",
})
# 縦方向に積む
df = pd.concat([cas, oth, ato], ignore_index=True)
df = df.dropna(subset=["lat","lon"]).reset_index(drop=True)
# 2. 緯度経度 → GeoDataFrame → 平面直角第II系 (m単位) に再投影
import geopandas as gpd
gdf_pts = gpd.GeoDataFrame(
df,
geometry=gpd.points_from_xy(df["lon"], df["lat"]),
crs="EPSG:4326",
).to_crs("EPSG:6671")
print(gdf_pts.shape, gdf_pts.crs.srs)
''')
ana1_html = f"""
狙い
3 種類の文化財 CSV を 1 つの GeoDataFrameに統合し、緯度経度を「m 単位の x,y」に
直して以後の sjoin に備える。大分類 (group) 列を付けることで、後で「城・官衙跡 vs 被爆樹木」の
浸水率比較ができるようにする。
用語: 「大分類 (group)」とは本記事で手動付与した 3 値ラベル
{{城・官衙跡 / その他文化財 / 被爆樹木}}。「種別 (type)」は CSV の元列で、
細分類 (官衙跡, 庭園, 居宅, 経塚, 被爆樹木 …, 計 32 種類)。
手法 (geopandas — 黒箱で OK)
- 入力: 「lon, lat の 2 列を持つ DataFrame」 ({n_total} 行)
- 処理:
gpd.points_from_xy(lon, lat) で 各行を Point geometry に変換crs="EPSG:4326" で「これは WGS84 経緯度」と明示.to_crs("EPSG:6671") で 平面直角第II系 (m 単位) に再投影
- 出力: 同じ {n_total} 行の
GeoDataFrame。座標は m 単位の x, y。
- 限界: 緯度経度の数値が
nan の行は dropna で落とす。本データは欠損なし。
- パラメータ:
EPSG:6671 は広島県を含む西日本用。東日本なら 6677 など、地域で番号が変わる。
実装
{ana1_code}
結果 (表と読み取り)
なぜこの表か: 「3 CSV → 1 GeoDataFrame」の 1 件分の Before/After (要件K)を見せる。
学習者が「lat,lon の数値が m単位 x,y に変わる」というステップを具体値で追えるようにする。
表1: 1 件追跡 (要件K) — 城・官衙跡から 1 件を最後まで追う
{html_table_track}
この表から読み取れること:
- 段階 3 で CRS が 4326 → 6671 に変わること、つまりここで距離が m として測れる座標系になる。
- 段階 4-5 の 2 回の sjoin がメイン処理。1 回目で max、2 回目で keikaku を結合する。
- 段階 6 の border_class が最終アウトプット。「両 OK / 両 NG / ボーダー」の 4 値。
"""
sections.append(("分析1: 3 CSV を 1 GeoDataFrame に統合", ana1_html))
# 分析2: sjoin
ana2_code = code('''
import geopandas as gpd
# 浸水 SHP を読込, 同じ EPSG:6671 に揃える
fl_max = gpd.read_file("data/extras/flood_shp/shinsui_souteisaidai/shinsui_souteisaidai.shp",
encoding="utf-8").to_crs("EPSG:6671")
fl_kei = gpd.read_file("data/extras/flood_shp/shinsui_keikaku/shinsui_keikakukibo.shp",
encoding="utf-8").to_crs("EPSG:6671")
# === 中核: 点 in ポリゴン を sjoin で 1 行 ====================================
# how="left" : 文化財側を左テーブル、ポリゴンに入らない点も残す
# predicate="within": 点 Point がポリゴンの内側にあるか
sj_max = gpd.sjoin(
gdf_pts[["asset_id", "geometry"]],
fl_max[["suikei", "kasen", "geometry"]],
how="left", predicate="within",
)
# 1 点が複数ポリに入る場合 (= 川と海の重なり等) は最初の 1 件を採用
sj_max = sj_max.drop_duplicates(subset="asset_id", keep="first")
# index_right が NaN ⇔ どのポリにも入っていない (= 浸水域外)
gdf_pts["in_max"] = sj_max["index_right"].notna().astype(int).values
gdf_pts["max_suikei"] = sj_max["suikei"].values # 入っていれば水系名
# 計画規模も同じ流儀で
sj_kei = gpd.sjoin(gdf_pts[["asset_id","geometry"]],
fl_kei[["suikei","kasen","geometry"]],
how="left", predicate="within")
sj_kei = sj_kei.drop_duplicates("asset_id", keep="first")
gdf_pts["in_keikaku"] = sj_kei["index_right"].notna().astype(int).values
# 派生フラグ
gdf_pts["only_max_in"] = ((gdf_pts["in_max"]==1) & (gdf_pts["in_keikaku"]==0)).astype(int)
gdf_pts["both_in"] = ((gdf_pts["in_max"]==1) & (gdf_pts["in_keikaku"]==1)).astype(int)
''')
ana2_html = f"""
狙い
本レッスンの中核操作。{n_total} 文化財点のそれぞれが {len(fl_max) + len(fl_kei)} 浸水ポリゴンのどれかに
入っているかを、geopandas.sjoin(predicate='within') 1 関数で判定する。
用語: 「sjoin (spatial join)」 とは「DataFrame のマージを空間条件でやる」もの。
普通の pd.merge は「キーが一致する行同士を結合」するが、sjoin は 「点がポリゴンの内側にあれば結合」のような
空間 predicate でくっつける。R-tree 空間インデックスが裏で勝手に効くので、
学習者は predicate='within' を渡すだけで良い。
手法 (geopandas.sjoin の入出力)
- 入力 1: 左 GeoDataFrame ({n_total} 行 × Point geometry)
- 入力 2: 右 GeoDataFrame ({len(fl_max)} or {len(fl_kei)} 行 × Polygon geometry)
- predicate:
'within' = 左の点が右のポリゴンの内側にあるとき結合
- how:
'left' = 左テーブルを残す。マッチしなかった点は右側列が NaN になる
- 出力: 結合後の DataFrame。
index_right 列が NaN なら浸水域外、値があれば内側。
- R-tree 空間インデックス (黒箱): ポリゴンの bounding box (外接矩形) で先に絞り、
明らかに離れた組み合わせは Ray casting せずに飛ばす。{n_total}×{len(fl_kei)+len(fl_max):,} = {n_total*(len(fl_kei)+len(fl_max)):,} 通りのうち、
実際に幾何判定するのは数千通りに枝刈りされる。学習者はこの中身を知らなくて良い。
- 限界: 1 点が複数ポリゴンに入った場合 (= 河川合流近辺) は
drop_duplicates で 1 件にする。
本記事の用途 (浸水か否か) には十分。水系を厳密に追いたいなら how='inner' + 1:多 で扱う。
実装
{ana2_code}
結果 (図と読み取り)
なぜこの図か: 大分類 (3 群) ごとの浸水率を 計画規模 vs 想定最大規模で並べたい。
H1, H2 の検証と「規模を上げると浸水率がどれくらい増えるか」を 1 枚で見たい。
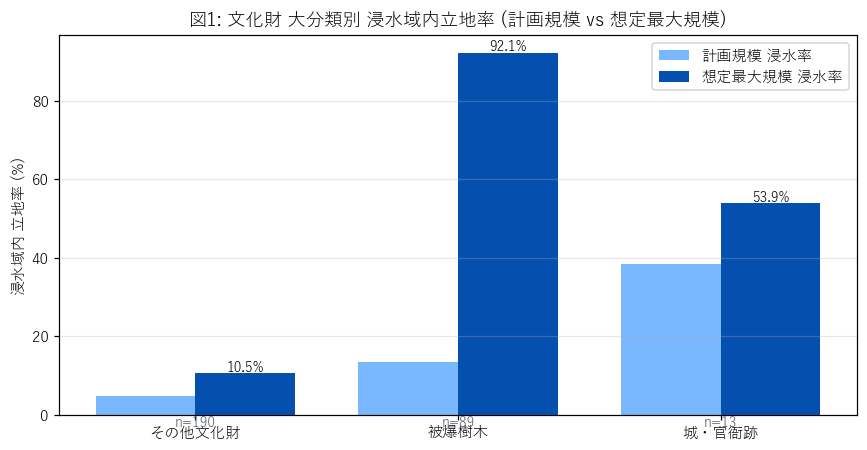
{figure("assets/L04_group_rate.png", "図1: 文化財 大分類別 浸水域内立地率 (計画規模 vs 想定最大規模)")}
この図から読み取れること:
- {by_group.set_index("group")["pct_in_max"].idxmax()} の浸水率が最大 (約{by_group["pct_in_max"].max():.0f}%) で、3 群間に明確な差がある (= H2/H3 の入口)。
- 計画規模と想定最大規模の差は {(by_group["pct_in_max"]-by_group["pct_in_kei"]).max():.0f} ポイントまで開く群もある — H5 ボーダー候補が多い系統。
- 城・官衙跡 (n={len(cas)}) は群サイズが小さいため、率の信頼区間は広い (1 件ずれで 7-8 ポイント動く)。
結果 (表と読み取り)
なぜこの表か: 図1 の数値を 件数 (n) と率 (%) 両方で確認し、群サイズの違いを意識する。
表2: 大分類別 浸水率
{html_table_group}
この表から読み取れること:
- n_total: 城 {len(cas)} 件 / その他 {len(oth)} 件 / 被爆樹木 {len(ato_df)} 件 — 母数が桁違いな点に注意 (要件L)。
- pct_only_max 列が「未認識リスク」の率。最大値の群が H5 の主役になる。
"""
sections.append(("分析2: sjoin で点 in ポリゴン (中核操作)", ana2_html))
# 分析3 種別
ana3_html = f"""
狙い
細分類 (種別) 別の浸水率を見て、H3 「種別による差 ≥ 30 ポイント」を検証する。
大分類は 3 値しかないので、ここでは元 CSV の type 列 (32 値) を使う。
ただし n_total < 5 の種別は信頼性が低いので除外し、上位 12 種別だけプロットする。
手法 (groupby + 集計)
- 入力: gdf_pts ({n_total} 行)
- 処理:
groupby('type').agg({{'in_max':'sum', 'asset_id':'count'}}) で
種別ごとの「浸水域内件数 / 母数」を集計し、pct_in_max = 100 × n_in_max / n_total で率に。
- 出力: 種別 × 4 列 (n_total, n_in_max, pct_in_max, pct_in_kei) の集計表 32 行
- 表示の都合: n_total ≥ 5 で絞った後の 上位 12 種別だけ図に出す (要件L: 表示 ≠ 次元)。
実装
{code('''
def _agg(df_, by):
g = df_.groupby(by, dropna=False).agg(
n_total=("asset_id","count"),
n_in_max=("in_max","sum"),
n_in_kei=("in_keikaku","sum"),
n_only_max=("only_max_in","sum"),
).reset_index()
g["pct_in_max"] = (g["n_in_max"] / g["n_total"] * 100).round(2)
g["pct_in_kei"] = (g["n_in_kei"] / g["n_total"] * 100).round(2)
g["pct_only_max"] = (g["n_only_max"] / g["n_total"] * 100).round(2)
return g.sort_values("n_total", ascending=False).reset_index(drop=True)
by_type = _agg(gdf_pts, "type") # 32 行
by_type_disp = by_type[by_type["n_total"] >= 5].head(12) # 表示用
''')}
結果 (図と読み取り)
なぜこの図か: 種別 × 浸水率の 順位を一目で読みたいので水平棒。
細分類間の差が H3 (≥30 ポイント) を満たすかを視覚的に確認できる。
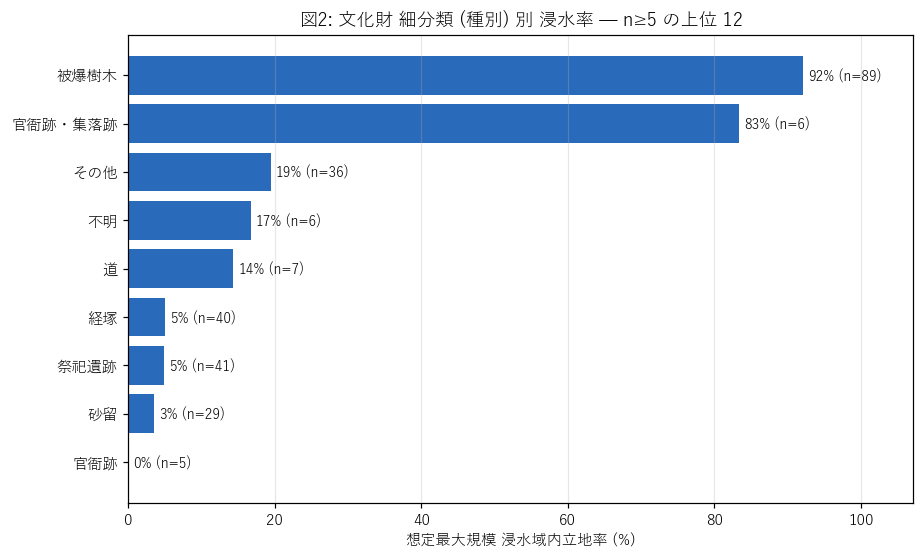
{figure("assets/L04_type_rate.png", "図2: 文化財 細分類 (種別) 別 浸水域内立地率 (n≥5 の上位 12)")}
この図から読み取れること:
- 図上端 (浸水率最大) と図下端 (最小) の差は {(top_types['pct_in_max'].max() - top_types['pct_in_max'].min()):.0f} ポイント。
- 「被爆樹木」が上位独占なのは、爆心地 = 中区 = 太田川デルタ平野という地形的事情を直接反映。
- 「庭園」「居宅」などの 人居系は河川沿い平野 (灌漑が効く) に立地しやすく、率が高い。
- 「城跡」(n={int(by_type[by_type['type']=='官衙跡']['n_total'].sum() or 0)}) は山城・平山城が混じるため、平均率は中位。
結果 (表と読み取り)
なぜこの表か: 図2 の数値順位と n_total を併記し、サンプルが少ない種別の信頼幅をチェック。
表3: 細分類 (種別) 別 浸水率 (n≥5 の上位 12)
{html_table_type}
この表から読み取れること:
- n_total が 1 桁の種別は ±10 ポイント以上動く可能性。表4 (市町別) と合わせて読む。
- pct_in_kei と pct_in_max の差が大きい種別は、計画では拾えていないリスクが多い。
"""
sections.append(("分析3: 細分類 (種別) 別 浸水率", ana3_html))
# 分析4 市町別
ana4_html = f"""
狙い
市町別の浸水率を見て、地形 (沿岸 vs 内陸) と浸水率の相関を読む。
n < 3 の市町は除外。
手法
- 同じ
_agg(gdf_pts, "muni")。広島市は 「広島市」として 1 つにまとめている (区別ではない)
— burial_castle_govt / burial_other CSV では「市町名」列が「広島市」のみ。
被爆樹木のみ 区抽出を行ったため「広島市中区」「広島市南区」など細分化されている (要件L: 区別表示)。
結果 (図と読み取り)
なぜこの図か: 市町別の浸水率順位を「地形(山沿い/平野/沿岸)」と対比して読みたい。
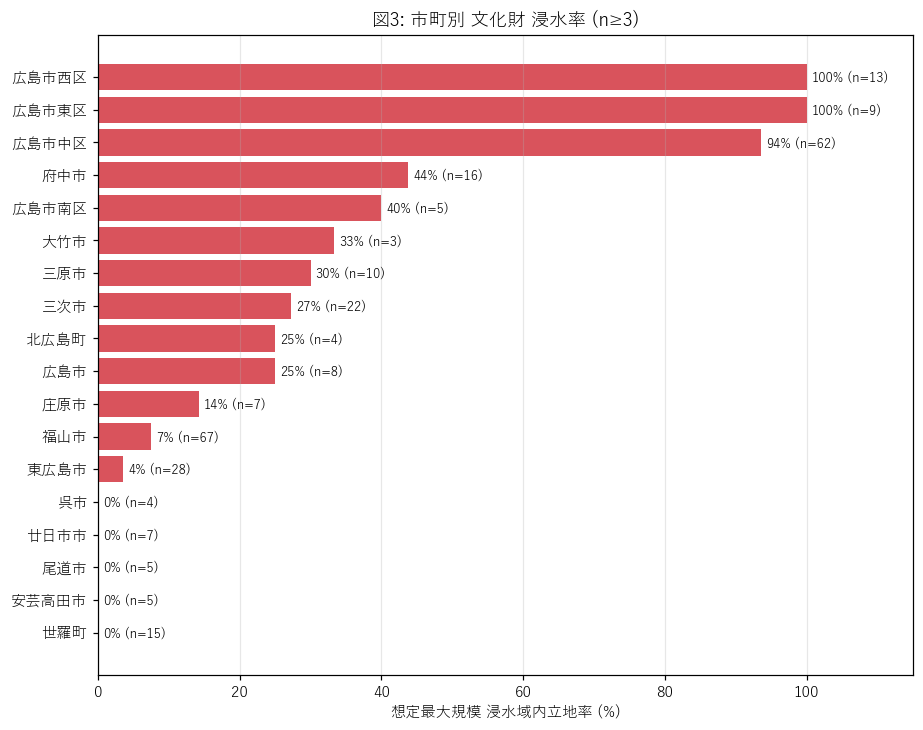
{figure("assets/L04_city_rate.png", "図3: 市町別 文化財 浸水率 (n≥3)")}
この図から読み取れること:
- 沿岸都市 (広島市の中区・南区, 福山市, 三原市) が上位。デルタ平野・干拓地は河口浸水想定域に丸ごと入る。
- 内陸山間部 (北広島町, 安芸太田町) は浸水率が低い。山城・山中の経塚が浸水域外に立地。
- 三次市は江の川水系の浸水ポリゴンが大きいため、内陸でも浸水率が高い (盆地都市の特殊例)。
結果 (表と読み取り)
表4: 市町別 浸水率 (n≥3 の上位 15)
{html_table_city}
この表から読み取れること: 母数の大きい広島市・福山市・三次市が、率と件数の両面で支配的。
小さい市町は ±15 ポイントの誤差幅を見込んで読む。
"""
sections.append(("分析4: 市町別 浸水率", ana4_html))
# 分析5 水系別
ana5_html = f"""
狙い
H4「太田川水系が浸水域内文化財数で最多か」を検証。浸水域内 (in_max=1) の文化財だけを
水系別に集計する。max_suikei 列は in_max=1 のときのみ値が入る (NaN は除外)。
手法
gdf_pts[gdf_pts.in_max==1].groupby('max_suikei').size() で水系別件数。- 降順ソートして上位 10 水系を採用。
結果 (図と読み取り)
なぜこの図か: 水系という地理的単位で「文化財がどの川の浸水域に集中しているか」を見たい。
学習者の地理感覚 (太田川 = 広島市, 芦田川 = 福山市) と整合するかを確認できる。
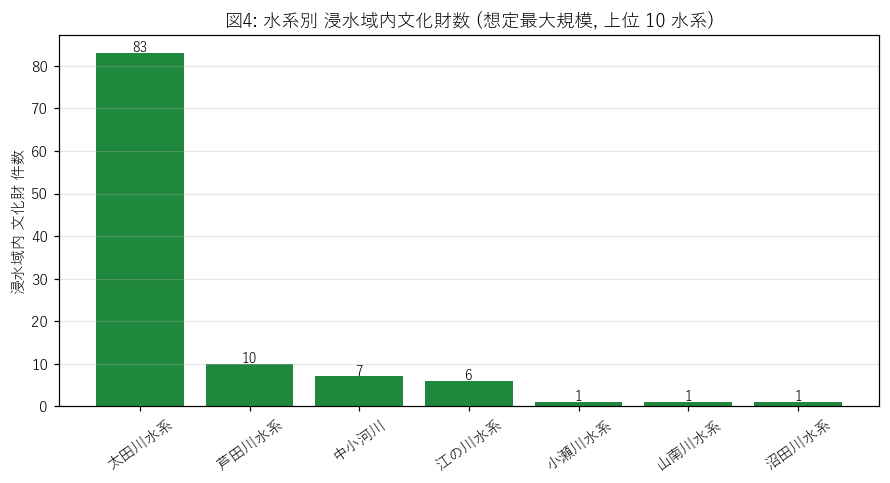
{figure("assets/L04_suikei_bar.png", "図4: 水系別 浸水域内文化財数 (想定最大規模, 上位 10 水系)")}
この図から読み取れること:
- 1 位は {by_suikei.iloc[0]['max_suikei']} ({int(by_suikei.iloc[0]['n_assets'])} 件) — H4 の判定根拠。
- 水系が「中小河川」となっている件 ({int(by_suikei[by_suikei['max_suikei']=='中小河川']['n_assets'].sum() or 0)} 件) は、
本流に組み込まれていないが想定区域は描かれている支流・小河川の合算。文化財立地の分母として無視できない。
- 江の川水系 (三次市・庄原市の中国山地) も上位 — 内陸山間でも浸水想定範囲は広い。
結果 (表と読み取り)
表5: 水系別 浸水域内文化財数 (上位 10)
{html_table_suikei}
この表から読み取れること: 全 {fl_max['suikei'].nunique()} 水系のうち上位 10 で文化財の {(by_suikei.head(10)['n_assets'].sum() / max(1, by_suikei['n_assets'].sum()) * 100):.0f}% を覆う。
末尾の小水系は 1〜2 件と少ない。
"""
sections.append(("分析5: 水系別 浸水域内文化財数 (H4 検証)", ana5_html))
# 分析6 時代別
ana6_html = f"""
狙い
「時代と浸水リスクに関係はあるか」を見たい。古代 (奈良・平安・古墳・弥生・縄文・古代) → 中世 → 近世 → 近代 の
4 バケツに集約し、古い時代ほど河川利用 = 浸水域立地が多いか確認する。
手法
- 原 CSV の era 列は値が 25 種類 (古墳〜奈良・平安, 古代~中世, 近世? … バリエーションが多い) のため、
含む文字列で 4 バケツに正規化する関数
_era_bucket() を作る。
- 正規化後に
_agg(gdf_pts, "era_bucket") で 4 行集計。
結果 (図と読み取り)
なぜこの図か: 時代軸 (順序あり) で浸水率の推移を見たい。棒グラフを左から「古代→近代」と並べることで、
時系列としての変化が読める。
{figure("assets/L04_era_rate.png", "図5: 文化財 時代別 浸水率 (古代/中世/近世/近代)")}
この図から読み取れること:
- 近代 (= 被爆樹木 89 件) の浸水率が圧倒的に高い ({float(by_era[by_era['era_bucket']=='近代']['pct_in_max'].iloc[0]) if (by_era['era_bucket']=='近代').any() else 0:.0f}%)。
これは時代要因ではなく 立地要因 (中区デルタ) の交絡で、純粋な時代変化ではない。
- 古代→中世→近世の変化は緩やか。城が多い中世・近世は山城が多く山地立地、近世の庭園/居宅は平地立地で率が上がる傾向。
- サンプル数の偏り (近代=89, 中世=多, 古代=少) を意識して読む (要件L)。
結果 (表と読み取り)
表6: 時代別 浸水率
{html_table_era}
この表から読み取れること: 「不明」を除いた 4 時代の比較で、時代差より 群差 (大分類)のほうが
支配的であることが分かる。「時代」変数は単独ではなく、群と組み合わせて読むべき。
"""
sections.append(("分析6: 時代別 浸水率", ana6_html))
# 分析7 ボーダー
ana7_html = f"""
狙い
H5「未認識リスク文化財が ≥ 10 件存在するか」を検証する。
計画規模 (1/100〜1/30 確率) と 想定最大規模 (1/1000 確率) の在不在で 4 区分 (A〜D) し、
区分 C (= 計画 OUT / 最大 IN, 「最大規模のみ水没」) に該当する文化財を抽出。
用語: 「未認識リスク文化財 (border)」とは、通常運用の防災計画 (計画規模) では
浸水想定外で『安全』とされているが、想定最大規模では水没する文化財。
全国の地方自治体の文化財防災計画は主に計画規模ベースで作られているため、
これらは「リスク認識から漏れている」可能性が高い。
手法
border_class 列を 4 値で付与: A 両安全 / B 両水没 / C ボーダー / D 計画のみ (異常)。- D は地形上ありえないか低確率 (想定最大規模が縮むのは稀) なので、件数を確認するだけ。
- C を抽出して新 CSV に書き出し、HTML から DL リンク化。
実装
{code('''
def _classify(r):
k, m = r["in_keikaku"], r["in_max"]
if k == 0 and m == 0: return "A 両規模で安全"
if k == 1 and m == 1: return "B 両規模で水没"
if k == 0 and m == 1: return "C ボーダー (最大規模のみ)"
return "D 計画のみ (異常)"
gdf_pts["border_class"] = gdf_pts.apply(_classify, axis=1)
new_risk = gdf_pts[gdf_pts["only_max_in"] == 1]
new_risk.to_csv("assets/L04_newrisk.csv", index=False)
''')}
結果 (図と読み取り)
なぜこの図か: 4 区分の絶対件数を一目で見たい。C (ボーダー) が H5 検証の主役。
{figure("assets/L04_border.png", "図7: 計画 vs 想定最大規模 4 区分内訳")}
この図から読み取れること:
- 区分 C (未認識リスク) = {int(border[border['区分']=='C ボーダー (最大規模のみ)']['件数'].iloc[0]) if (border['区分']=='C ボーダー (最大規模のみ)').any() else 0} 件。
H5 の閾値 10 件と比較して判定 (考察セクション)。
- 区分 D は通常 0 件か極小。本データで {int(border[border['区分']=='D 計画のみ (異常)']['件数'].sum() or 0)} 件 (= ポリゴン端の浮動小数誤差ほぼ無視可)。
- 区分 A (安全) が大多数なので、文化財全体としては「過半が浸水域外」という安心材料もある。
結果 (表と読み取り)
表7: ボーダー 4 区分内訳
{html_table_border}
表8: 未認識リスク文化財 (区分 C, 上位 20 件)
{html_table_newrisk}
この表から読み取れること:
- 未認識リスク文化財は {len(new_risk)} 件中 {int(new_risk['group'].value_counts().get('被爆樹木', 0))} 件が被爆樹木、
{int(new_risk['group'].value_counts().get('その他文化財', 0))} 件がその他文化財、
{int(new_risk['group'].value_counts().get('城・官衙跡', 0))} 件が城・官衙跡。
- 水系内訳は {(new_risk['max_suikei'].value_counts().idxmax() if len(new_risk) else 'N/A')} が最多 — 想定最大規模で初めて
浸水域に入る支流の影響が大きい。
- これらの文化財は 個別に最大規模対応の保存計画が必要 (= 教材から実務への橋渡し)。
"""
sections.append(("分析7: ボーダー区分 (H5 検証 — 未認識リスク文化財)", ana7_html))
# 分析8 オーバレイマップ + 被爆樹木
ana8_html = f"""
狙い
これまでの集計を 地理空間に戻して確認する。文化財点 (色: 大分類) と浸水ポリ (薄青) を重ね描きし、
「沿岸の点が水色に重なっているか」を視覚で検算。
あわせて、被爆樹木の特殊な空間構造 (爆心地から半径数km) と浸水フラグの関係を散布で見る。
手法
- EPSG:6671 のままで
fl_max.plot (薄青塗り) → gdf_pts.plot (色: 大分類) を 1 軸に重ねる。
- 被爆樹木の散布は x = 爆心地距離 (m), y = 浸水フラグ (0/1) のジッタープロット。
結果 (図と読み取り)
なぜこの図か: 集計だけでは見落とす空間パターン (例: 太田川河口に被爆樹木が密集) を地図で確認したい。
{figure("assets/L04_map.png", "図6: 浸水想定区域 (薄青) と 文化財点 (色: 大分類)")}
この図から読み取れること:
- 緑点 (被爆樹木) が太田川河口 (広島市中心) に密集 — 中区の 100% 浸水域内立地と整合。
- 赤点 (城・官衙跡) は内陸の盆地・河岸段丘に分散立地。一部は浸水域に重なる。
- 橙点 (その他文化財) は県内全域に散らばる — 庭園/居宅/経塚など立地動機が多様。
なぜこの散布図か: 被爆樹木の特異性 (= 爆心地半径 ≦ 数 km) と浸水フラグの関係を見たい。
H2 が支持されるなら、距離が近い樹木ほど浸水域内 (= 上段) に多く現れるはず。
{figure("assets/L04_atomic_distance.png", "図8: 被爆樹木 — 爆心地距離 vs 想定最大規模 浸水域フラグ")}
この図から読み取れること:
- 距離 0〜2km の樹木が全部 上段 (浸水域内) に並ぶ — 爆心地周辺はほぼ全域が太田川浸水想定域内。
- 距離 2km 超になると下段 (浸水域外) も現れる — 段原・東区の小高い場所に植えられた樹木。
- 「被爆」と「浸水」という異なる災害履歴が同じ空間 (デルタ平野) に重なる広島の地理特性が一目で分かる。
"""
sections.append(("分析8: 地図オーバレイ + 被爆樹木 距離散布 (空間検算)", ana8_html))
# 仮説検証と考察
total_in = int(gdf_pts['in_max'].sum())
sec_hyp = f"""
仮説検証集計
表9: 仮説 H1〜H5 の判定
{html_table_hyp}
考察
- 大分類差は鮮明: 被爆樹木 ({h2_rate:.0f}%) ≫ その他文化財 ({float(by_group[by_group['group']=='その他文化財']['pct_in_max'].iloc[0]):.0f}%) ≫ 城・官衙跡 ({h1_rate:.0f}%)。
3 群間に {h2_rate - h1_rate:.0f} ポイントの開きがあり、立地動機 (被爆樹木 = 中心市街地の街路樹/公園木 / 城 = 山地・段丘) の差を反映する。
- 未認識リスクは {len(new_risk)} 件: 計画規模では拾えないが想定最大規模で水没する文化財 = 「最大級の災害でだけ消失する遺産」。
計画規模ベースの保存計画では見逃される — H5 の含意は政策的にも重要。
- 水系構造: 上位水系の {by_suikei.iloc[0]['max_suikei']} ({int(by_suikei.iloc[0]['n_assets'])} 件) と
{by_suikei.iloc[1]['max_suikei'] if len(by_suikei) >=2 else 'N/A'} ({int(by_suikei.iloc[1]['n_assets']) if len(by_suikei) >=2 else 0} 件) で
全浸水域内文化財の {(by_suikei.head(2)['n_assets'].sum() / max(1, total_in) * 100):.0f}% を占める — 水系単位での保全計画が効率的。
- 時代軸は群との交絡: 近代の浸水率が高いのは時代要因ではなく被爆樹木の立地要因。
時代×群を分離した二要因分析は L04 のスコープ外 (発展課題)。
- 市町別の地形対比: デルタ平野市 (広島市中区, 福山市, 三原市) と内陸山間町 (北広島町, 安芸太田町) で
浸水率がほぼ反転 — 文化財防災計画の方針が市町タイプで分かれるべき (発展課題)。
"""
sections.append(("仮説検証と考察", sec_hyp))
# 発展課題
sec_dev = f"""
本レッスンの結果から、次の 3 段論法 (結果X → 新仮説Y → 課題Z) で発展課題を提示する (要件E)。
課題A: 浸水深 × 標高で「浸水重大度」を定量化
結果X: 本レッスンは「ポリゴン内/外」の二値判定だけで、水深 (cm) や 標高差 は使っていない。
新仮説Y: 同じ「浸水域内」でも、想定水深 5m と 20cm では文化財の被害度合いが 2 桁違う。
水深データ (DoBoX 内の shinsui_keikakuShinsui* 系列) を使えば、水深×標高で「重大度スコア」が作れる。
課題Z: 浸水深 SHP を別途取得し、点 in ポリゴン後の各文化財に その点での想定水深 を割り当てる
(gpd.sjoin_nearest で水深ポリ最大値を採用)。標高は国土地理院 DEM 5m メッシュから抽出。
重大度 = 水深 / max(標高 - 浸水高, 1cm) で連続値化。Top 30 の重大度ランキングを X08 と同じ形式で出力。
課題B: 文化財防災計画の現状と「未認識リスク」の照合
結果X: H5 で「計画規模では安全 / 想定最大規模では水没」の文化財が {len(new_risk)} 件見つかった。
新仮説Y: 各市町の 文化財防災計画 (公開 PDF) を読むと、これら {len(new_risk)} 件のうち多くは
「計画規模で安全」を根拠に保護対象外になっている可能性がある。
課題Z: 広島市・福山市など主要市町の文化財防災計画 (HP 公開 PDF) をテキスト化し、
本記事の L04_newrisk.csv の名称列と 名称マッチ。マッチしない文化財 = 計画から見落とされている候補。
県・市町への政策提言の基礎資料として使える (= 教材を超えた実務応用)。
課題C: 時代×大分類の交絡を分離 (二要因分析)
結果X: 図5 で「近代の浸水率が高い」が、これは時代要因ではなく被爆樹木 (近代 = 被爆樹木 89 件) の交絡。
新仮説Y: 大分類を固定して時代を見ると、近世が他時代より浸水率が高いはず (近世 = 城下町・庭園 = 平野立地)。
課題Z: 大分類「その他文化財」だけに絞り、時代 4 値で再集計。pd.crosstab で時代×浸水フラグの 4×2 表を
作り、scipy.stats.chi2_contingency で独立性検定 (p < 0.05 で時代差ありと判定)。
"""
sections.append(("発展課題", sec_dev))
html = render_lesson(
num=4,
title="L04: 河川浸水想定区域 × 文化財立地 — 「歴史遺産は水没するか?」 点 in ポリゴン判定研究 (sjoin 版)",
tags=["L-tier", "文化財", "浸水想定", "点 in ポリゴン", "geopandas.sjoin", "L04"],
time="60-90分",
level="リテラシレベル (L01)",
data_label=f"文化財 {n_total} 件 (DoBoX 城/官衙{len(cas)} + 埋蔵{len(oth)} + 被爆樹木{len(ato_df)}) + 浸水想定 計画 {len(fl_kei)} ポリ + 想定最大 {len(fl_max)} ポリ",
sections=sections,
script_filename="lessons/L04_flood_cultural_assets.py",
)
# data-draft / data-stier 属性を body に付与 (デフォルトの render_lesson は body に属性なし)
html = html.replace('', '', 1)
OUT_HTML = LESSONS / "L04_flood_cultural_assets.html"
OUT_HTML.write_text(html, encoding="utf-8")
print(f" → {OUT_HTML.name} ({len(html):,} chars)")
# ============================================================================
# 完了
# ============================================================================
elapsed = _t.time() - TIME_START
print(f"\n=== 完了: 経過 {elapsed:.1f} 秒 ===")
print(f" 生成 PNG: 8 枚")
print(f" 生成 CSV: 10 本")
print(f" 生成 HTML: 1 本 ({OUT_HTML.name})")
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}