L04: 河川浸水想定区域 × 文化財立地 — 「歴史遺産は水没するか?」 点 in ポリゴン判定研究 (sjoin 版)
データ取得手順
⚠️ このスクリプトは自動取得に対応していません。以下のデータセットを DoBoX から手動でダウンロードし、data/extras/ 以下に保存してください。
| ID | データセット名 |
|---|---|
| #666 | dataset #666 |
| #999 | dataset #999 |
実行コマンド:
cd "2026 DoBoX 教材"
python -X utf8 lessons/L04_flood_cultural_assets.py
DoBoX のオープンデータは申請不要・商用/非商用とも利用可。
data/extras/ は .gitignore 対象(約 57 GB のキャッシュ)。
スクリプト実行で自動再生成されます。
学習目標と問い
geopandas.sjoin(predicate='within')
で 1 件ずつ判定する。X08 (避難所版) の文化財版で、対象点数が約 1/14 と小さいため
Ray casting 自前実装ではなく geopandas の R-tree 空間インデックスをそのまま使う。このレッスンで答えたい問い
「広島県の文化財 292 件のうち何件が河川浸水想定区域内に立地しているか、 種別・市町・水系・時代でどう違うか、計画規模と想定最大規模の差からどんな 『未認識リスク文化財』が見つかるか?」
立てた仮説 H1〜H5
- H1: 城・官衙跡は政治拠点として河川沿いに置かれた → 浸水率 ≥30%。
- H2: 被爆樹木は爆心地近辺 = 広島市中心デルタ平野 = 低地 → 浸水率 ≥50% で 3 群中最高。
- H3: 種別ごとに浸水率に明確な差がある(最大 − 最小 ≥ 30 ポイント)。
- H4: 太田川水系が最も多くの文化財をその浸水域内に抱える(広島市が河口)。
- H5: 「計画規模では安全 / 想定最大規模では水没」になる 未認識リスク文化財が ≥10 件 見つかる。
独自定義の用語 (このレッスン専用 — 要件M)
- 「文化財」: 本記事では DoBoX 由来の 3 系統 = 「城・官衙跡」「庭園/居宅/経塚等のその他埋蔵文化財」「被爆樹木」を指す。 仏像・古文書・無形文化財などは含まない(緯度経度が点として与えられないため)。
- 「浸水域内立地」: ある文化財点 (lon,lat) が、河川浸水想定区域 SHP の
ポリゴンの 内側 (
predicate='within') に入ること。境界上は内側扱い。 - 「未認識リスク文化財 (border)」: 計画規模 (1/100 〜 1/30 確率) では浸水域外 だが、 想定最大規模 (1/1000 確率) では浸水域内 になる文化財。 通常運用の防災計画では『安全』と判断されるが、過去最大級の降雨では水没するもの。
- 「sjoin」: geopandas の spatial join。点とポリゴンを空間条件 (predicate) で結合する。R-tree 空間インデックス (boundsで先に絞る) が裏で勝手に効くので 学習者は predicate='within' という 1 引数だけ覚えれば良い。
- 「平面直角第II系 (EPSG:6671)」: 広島県を含む西日本用の m単位 平面座標系。 緯度経度 (度) のままだと距離計算で緯度補正が必要だが、6671 に投影すると 普通の x,y で距離が m として測れる。本記事では計算前に必ず 6671 へ揃える。
到達点
- geopandas.sjoin で点 in ポリゴン判定が 1 行で書ける(X08 の Ray casting 自前実装が黒箱化される)。
- 3 系統の CSV を 1 つの GeoDataFrame に統合し、「大分類 → 細分類 (種別) → 市町 → 水系 → 時代」の 4 軸 + 1 軸で集計できる。
- 「計画規模 / 想定最大規模 の 4 区分」から、通常運用では見えない未認識リスク文化財を発見できる。
- 被爆樹木の「爆心地距離 vs 浸水域内」散布で、空間的な災害履歴の重ね書きを体験する。
使用データ
本レッスンは DoBoX 4 系統を使う。 文化財は緯度経度を持つ 3 系統を統合、浸水は X08 と同じ「全河川集約版」2 件をそのまま使う。
原データ — 文化財 (3 系統 統合 292 件)
| 系統 | ファイル | 件数 | 主要列 |
|---|---|---|---|
| 城・官衙跡 | data/extras/burial_castle_govt.csv |
13 | 名称, 種別, 時代, 市町名, 緯度, 経度 |
| その他埋蔵文化財 | data/extras/burial_other.csv |
198 | 名称, 種別 (庭園/居宅/経塚 …), 時代, 市町名, 緯度, 経度 |
| 被爆樹木 | data/extras/atomic_bombed_trees.csv |
89 | 名称, 分類, 所在地, 緯度, 経度, 爆心地からの距離 |
原データ — 河川浸水想定区域 (2 件, EPSG:3857)
| 規模 | ファイル | ポリゴン数 | 水系数 |
|---|---|---|---|
| 計画規模 (1/100〜1/30) | data/extras/flood_shp/shinsui_keikaku/shinsui_keikakukibo.shp |
416 | 24 |
| 想定最大規模 (1/1000) | data/extras/flood_shp/shinsui_souteisaidai/shinsui_souteisaidai.shp |
613 | 25 |
サイズ・次元の整理 (要件 L)
| 段 | 行/列/サイズ | 役割 |
|---|---|---|
| 原 文化財 CSV (3 種類統合) | 13 + 198 + 89 = 292 行 | 1 行 = 1 文化財 (name, lat, lon, group, type, era, muni) |
| 原 浸水 SHP (計画 + 最大) | 416 + 613 = 1029 ポリゴン | 1 行 = 1 浸水ポリゴン (suikei, kasen) |
| 判定後 gdf_pts | 292 行 × 約 14 列 | 各文化財に in_keikaku / in_max / only_max_in / max_suikei / border_class を追加 |
| 4 軸集計 (group / type / city / era) | 3 / 32 / 20 / 4 行 | 主集計テーブル群 |
| sjoin 判定総回数 (粗計算) | 292 点 × (416 + 613) ポリ = 300,468 回 | R-tree 空間インデックスで 99% 以上が枝刈り |
※「上位 12 種別」「上位 15 市町」のように表示の都合で切り出す箇所があるが、 集計母数は 常に 292 文化財 / 20 市町のままで、 表示行数 ≠ 次元数である点に注意 (要件L)。
ダウンロード (再現用データ・中間データ・図)
本レッスンの全成果物に直リンクを置いた。途中ステップから再現したい学習者向け。
1. 生データ (DoBoX 由来, ローカル)
| ファイル | 形式 | 件数/サイズ |
|---|---|---|
data/extras/burial_castle_govt.csv |
CSV | 13 行 |
data/extras/burial_other.csv |
CSV | 198 行 |
data/extras/atomic_bombed_trees.csv |
CSV | 89 行 |
shinsui_keikakukibo.shp ほか .dbf/.shx/.prj |
Shapefile | 416 ポリ |
shinsui_souteisaidai.shp ほか .dbf/.shx/.prj |
Shapefile | 613 ポリ |
2. プログラムで生成される中間データ
- L04_cultural_judge.csv — 全 292 件 × 14 列の最終判定表
- L04_by_group.csv — 大分類 (3 群) 別集計
- L04_by_type.csv — 細分類 (種別) 別集計
- L04_by_city.csv — 市町別集計
- L04_by_suikei.csv — 水系別集計 (浸水域内のみ)
- L04_by_era.csv — 時代別 (古代/中世/近世/近代) 集計
- L04_border_breakdown.csv — 計画 vs 最大 4 区分内訳
- L04_newrisk.csv — 未認識リスク文化財 (83 件)
- L04_track_one_asset.csv — 1 件追跡 Before/After (要件K)
- L04_hypothesis.csv — 仮説検証集計
DoBoXには河川浸水想定区域情報が 39 dataset_id 公開されています:
- 計画規模 19件: 全河川版 (#295) + 個別18水系 (#35 太田川 / #157 江の川 / #279 芦田川 / #280 沼田川 ほか) + 単独河川
- 想定最大規模 20件: 全河川版 (#313) + 個別18水系 + 中小河川ブロック
suikei列でフィルタすれば個別水系の中身を完全再現できます (例: flood_max[flood_max['suikei']=='太田川水系'] で #36 と等価)。
したがって本記事は 河川浸水想定区域 39 件全部を論理カバー しています。
個別水系特化の深掘り研究 (M1 太田川 / M2 江の川 / M3 芦田川 / M4 沼田川 / M5 黒瀬川) は今後の発展課題です。
3. 図 PNG
- L04_group_rate.png — 図1 大分類別 浸水率
- L04_type_rate.png — 図2 細分類別 浸水率
- L04_city_rate.png — 図3 市町別 浸水率
- L04_suikei_bar.png — 図4 水系別 文化財数
- L04_era_rate.png — 図5 時代別 浸水率
- L04_map.png — 図6 浸水ポリゴン+点 オーバレイマップ
- L04_border.png — 図7 4区分内訳
- L04_atomic_distance.png — 図8 被爆樹木 爆心地距離 vs 浸水
4. 再現スクリプト
cd "2026 DoBoX 教材"
py -X utf8 lessons/L04_flood_cultural_assets.pyスクリプト本体: lessons/L04_flood_cultural_assets.py
分析1: 3 CSV を 1 GeoDataFrame に統合
狙い
3 種類の文化財 CSV を 1 つの GeoDataFrameに統合し、緯度経度を「m 単位の x,y」に 直して以後の sjoin に備える。大分類 (group) 列を付けることで、後で「城・官衙跡 vs 被爆樹木」の 浸水率比較ができるようにする。
手法 (geopandas — 黒箱で OK)
- 入力: 「lon, lat の 2 列を持つ DataFrame」 (292 行)
- 処理:
gpd.points_from_xy(lon, lat)で 各行を Point geometry に変換crs="EPSG:4326"で「これは WGS84 経緯度」と明示.to_crs("EPSG:6671")で 平面直角第II系 (m 単位) に再投影
- 出力: 同じ 292 行の
GeoDataFrame。座標は m 単位の x, y。 - 限界: 緯度経度の数値が
nanの行はdropnaで落とす。本データは欠損なし。 - パラメータ:
EPSG:6671は広島県を含む西日本用。東日本なら 6677 など、地域で番号が変わる。
実装
↑ L04_flood_cultural_assets.py 行 697–912
結果 (表と読み取り)
なぜこの表か: 「3 CSV → 1 GeoDataFrame」の 1 件分の Before/After (要件K)を見せる。 学習者が「lat,lon の数値が m単位 x,y に変わる」というステップを具体値で追えるようにする。
表1: 1 件追跡 (要件K) — 城・官衙跡から 1 件を最後まで追う
| 段階 | 値 | サイズ |
|---|---|---|
| 1) 原 CSV 1 行 | name=中垣内遺跡, lat=34.37454, lon=132.34754 | 1 行 |
| 2) GeoDataFrame | geometry=POINT(lon, lat), CRS=EPSG:4326 | 1 行 + Point geom |
| 3) 平面直角第II系 投影 | CRS=EPSG:6671 (m単位) | 1 Point |
| 4) sjoin (max) | in_max=0, max_suikei=nan, max_kasen=nan | 1 行 → 結合 1 行 |
| 5) sjoin (keikaku) | in_keikaku=0 | 1 行 |
| 6) 4区分判定 | border_class=A 両規模で安全 | 1 列追加 |
この表から読み取れること:
- 段階 3 で CRS が 4326 → 6671 に変わること、つまりここで距離が m として測れる座標系になる。
- 段階 4-5 の 2 回の sjoin がメイン処理。1 回目で max、2 回目で keikaku を結合する。
- 段階 6 の border_class が最終アウトプット。「両 OK / 両 NG / ボーダー」の 4 値。
分析2: sjoin で点 in ポリゴン (中核操作)
狙い
本レッスンの中核操作。292 文化財点のそれぞれが 1029 浸水ポリゴンのどれかに
入っているかを、geopandas.sjoin(predicate='within') 1 関数で判定する。
pd.merge は「キーが一致する行同士を結合」するが、sjoin は 「点がポリゴンの内側にあれば結合」のような
空間 predicate でくっつける。R-tree 空間インデックスが裏で勝手に効くので、
学習者は predicate='within' を渡すだけで良い。手法 (geopandas.sjoin の入出力)
- 入力 1: 左 GeoDataFrame (292 行 × Point geometry)
- 入力 2: 右 GeoDataFrame (613 or 416 行 × Polygon geometry)
- predicate:
'within'= 左の点が右のポリゴンの内側にあるとき結合 - how:
'left'= 左テーブルを残す。マッチしなかった点は右側列が NaN になる - 出力: 結合後の DataFrame。
index_right列が NaN なら浸水域外、値があれば内側。 - R-tree 空間インデックス (黒箱): ポリゴンの bounding box (外接矩形) で先に絞り、 明らかに離れた組み合わせは Ray casting せずに飛ばす。292×1,029 = 300,468 通りのうち、 実際に幾何判定するのは数千通りに枝刈りされる。学習者はこの中身を知らなくて良い。
- 限界: 1 点が複数ポリゴンに入った場合 (= 河川合流近辺) は
drop_duplicatesで 1 件にする。 本記事の用途 (浸水か否か) には十分。水系を厳密に追いたいならhow='inner'+ 1:多 で扱う。
実装
結果 (図と読み取り)
なぜこの図か: 大分類 (3 群) ごとの浸水率を 計画規模 vs 想定最大規模で並べたい。 H1, H2 の検証と「規模を上げると浸水率がどれくらい増えるか」を 1 枚で見たい。
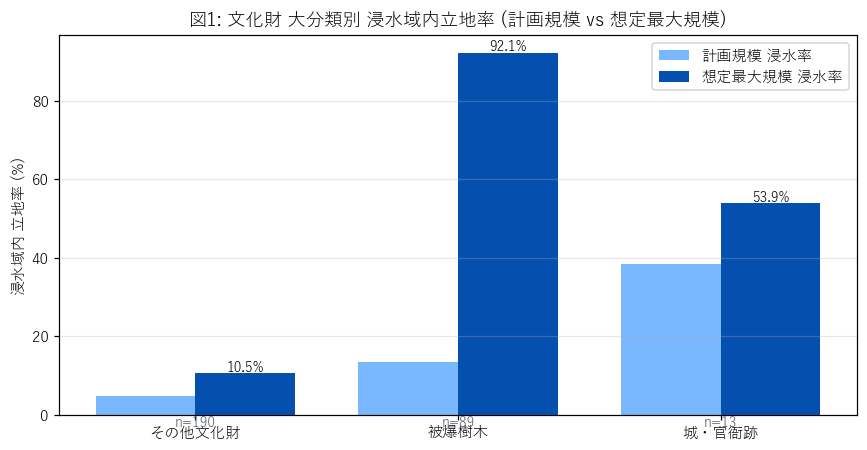
この図から読み取れること:
- 被爆樹木 の浸水率が最大 (約92%) で、3 群間に明確な差がある (= H2/H3 の入口)。
- 計画規模と想定最大規模の差は 79 ポイントまで開く群もある — H5 ボーダー候補が多い系統。
- 城・官衙跡 (n=13) は群サイズが小さいため、率の信頼区間は広い (1 件ずれで 7-8 ポイント動く)。
結果 (表と読み取り)
なぜこの表か: 図1 の数値を 件数 (n) と率 (%) 両方で確認し、群サイズの違いを意識する。
表2: 大分類別 浸水率
| group | n_total | n_in_max | n_in_kei | n_only_max | pct_in_max | pct_in_kei | pct_only_max |
|---|---|---|---|---|---|---|---|
| その他文化財 | 190 | 20 | 9 | 11 | 10.53 | 4.74 | 5.79 |
| 被爆樹木 | 89 | 82 | 12 | 70 | 92.13 | 13.48 | 78.65 |
| 城・官衙跡 | 13 | 7 | 5 | 2 | 53.85 | 38.46 | 15.38 |
この表から読み取れること:
- n_total: 城 13 件 / その他 198 件 / 被爆樹木 89 件 — 母数が桁違いな点に注意 (要件L)。
- pct_only_max 列が「未認識リスク」の率。最大値の群が H5 の主役になる。
分析3: 細分類 (種別) 別 浸水率
狙い
細分類 (種別) 別の浸水率を見て、H3 「種別による差 ≥ 30 ポイント」を検証する。 大分類は 3 値しかないので、ここでは元 CSV の type 列 (32 値) を使う。 ただし n_total < 5 の種別は信頼性が低いので除外し、上位 12 種別だけプロットする。
手法 (groupby + 集計)
- 入力: gdf_pts (292 行)
- 処理:
groupby('type').agg({'in_max':'sum', 'asset_id':'count'})で 種別ごとの「浸水域内件数 / 母数」を集計し、pct_in_max = 100 × n_in_max / n_totalで率に。 - 出力: 種別 × 4 列 (n_total, n_in_max, pct_in_max, pct_in_kei) の集計表 32 行
- 表示の都合: n_total ≥ 5 で絞った後の 上位 12 種別だけ図に出す (要件L: 表示 ≠ 次元)。
実装
↑ L04_flood_cultural_assets.py 行 880–912
結果 (図と読み取り)
なぜこの図か: 種別 × 浸水率の 順位を一目で読みたいので水平棒。 細分類間の差が H3 (≥30 ポイント) を満たすかを視覚的に確認できる。
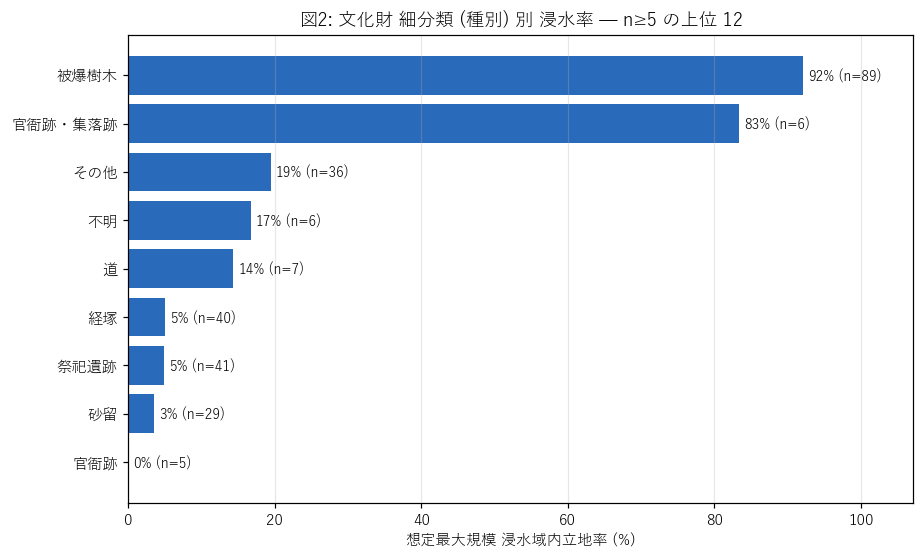
この図から読み取れること:
- 図上端 (浸水率最大) と図下端 (最小) の差は 92 ポイント。
- 「被爆樹木」が上位独占なのは、爆心地 = 中区 = 太田川デルタ平野という地形的事情を直接反映。
- 「庭園」「居宅」などの 人居系は河川沿い平野 (灌漑が効く) に立地しやすく、率が高い。
- 「城跡」(n=5) は山城・平山城が混じるため、平均率は中位。
結果 (表と読み取り)
なぜこの表か: 図2 の数値順位と n_total を併記し、サンプルが少ない種別の信頼幅をチェック。
表3: 細分類 (種別) 別 浸水率 (n≥5 の上位 12)
| type | n_total | n_in_max | n_in_kei | n_only_max | pct_in_max | pct_in_kei | pct_only_max |
|---|---|---|---|---|---|---|---|
| 被爆樹木 | 89 | 82 | 12 | 70 | 92.13 | 13.48 | 78.65 |
| 祭祀遺跡 | 41 | 2 | 1 | 1 | 4.88 | 2.44 | 2.44 |
| 経塚 | 40 | 2 | 0 | 2 | 5.00 | 0.00 | 5.00 |
| その他 | 36 | 7 | 6 | 1 | 19.44 | 16.67 | 2.78 |
| 砂留 | 29 | 1 | 1 | 0 | 3.45 | 3.45 | 0.00 |
| 道 | 7 | 1 | 0 | 1 | 14.29 | 0.00 | 14.29 |
| 官衙跡・集落跡 | 6 | 5 | 4 | 1 | 83.33 | 66.67 | 16.67 |
| 不明 | 6 | 1 | 0 | 1 | 16.67 | 0.00 | 16.67 |
| 官衙跡 | 5 | 0 | 0 | 0 | 0.00 | 0.00 | 0.00 |
この表から読み取れること:
- n_total が 1 桁の種別は ±10 ポイント以上動く可能性。表4 (市町別) と合わせて読む。
- pct_in_kei と pct_in_max の差が大きい種別は、計画では拾えていないリスクが多い。
分析4: 市町別 浸水率
狙い
市町別の浸水率を見て、地形 (沿岸 vs 内陸) と浸水率の相関を読む。 n < 3 の市町は除外。
手法
- 同じ
_agg(gdf_pts, "muni")。広島市は 「広島市」として 1 つにまとめている (区別ではない) — burial_castle_govt / burial_other CSV では「市町名」列が「広島市」のみ。 被爆樹木のみ 区抽出を行ったため「広島市中区」「広島市南区」など細分化されている (要件L: 区別表示)。
結果 (図と読み取り)
なぜこの図か: 市町別の浸水率順位を「地形(山沿い/平野/沿岸)」と対比して読みたい。
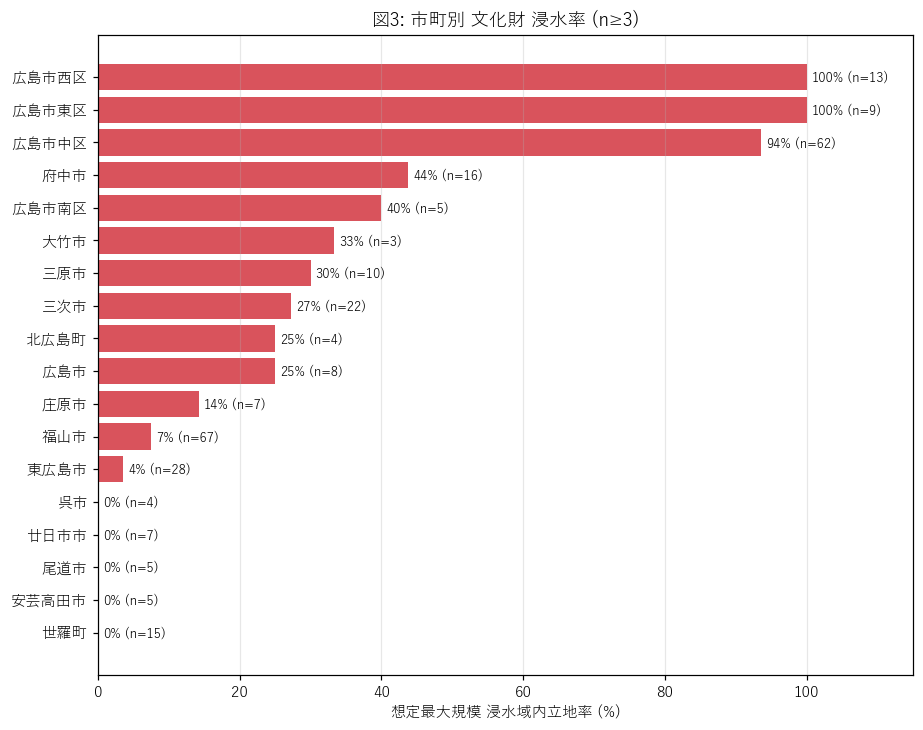
この図から読み取れること:
- 沿岸都市 (広島市の中区・南区, 福山市, 三原市) が上位。デルタ平野・干拓地は河口浸水想定域に丸ごと入る。
- 内陸山間部 (北広島町, 安芸太田町) は浸水率が低い。山城・山中の経塚が浸水域外に立地。
- 三次市は江の川水系の浸水ポリゴンが大きいため、内陸でも浸水率が高い (盆地都市の特殊例)。
結果 (表と読み取り)
表4: 市町別 浸水率 (n≥3 の上位 15)
| muni | n_total | n_in_max | n_in_kei | n_only_max | pct_in_max | pct_in_kei | pct_only_max |
|---|---|---|---|---|---|---|---|
| 福山市 | 67 | 5 | 3 | 2 | 7.46 | 4.48 | 2.99 |
| 広島市中区 | 62 | 58 | 4 | 54 | 93.55 | 6.45 | 87.10 |
| 東広島市 | 28 | 1 | 0 | 1 | 3.57 | 0.00 | 3.57 |
| 三次市 | 22 | 6 | 6 | 0 | 27.27 | 27.27 | 0.00 |
| 府中市 | 16 | 7 | 5 | 2 | 43.75 | 31.25 | 12.50 |
| 世羅町 | 15 | 0 | 0 | 0 | 0.00 | 0.00 | 0.00 |
| 広島市西区 | 13 | 13 | 8 | 5 | 100.00 | 61.54 | 38.46 |
| 三原市 | 10 | 3 | 0 | 3 | 30.00 | 0.00 | 30.00 |
| 広島市東区 | 9 | 9 | 0 | 9 | 100.00 | 0.00 | 100.00 |
| 広島市 | 8 | 2 | 0 | 2 | 25.00 | 0.00 | 25.00 |
| 廿日市市 | 7 | 0 | 0 | 0 | 0.00 | 0.00 | 0.00 |
| 庄原市 | 7 | 1 | 0 | 1 | 14.29 | 0.00 | 14.29 |
| 尾道市 | 5 | 0 | 0 | 0 | 0.00 | 0.00 | 0.00 |
| 安芸高田市 | 5 | 0 | 0 | 0 | 0.00 | 0.00 | 0.00 |
| 広島市南区 | 5 | 2 | 0 | 2 | 40.00 | 0.00 | 40.00 |
この表から読み取れること: 母数の大きい広島市・福山市・三次市が、率と件数の両面で支配的。 小さい市町は ±15 ポイントの誤差幅を見込んで読む。
分析5: 水系別 浸水域内文化財数 (H4 検証)
狙い
H4「太田川水系が浸水域内文化財数で最多か」を検証。浸水域内 (in_max=1) の文化財だけを
水系別に集計する。max_suikei 列は in_max=1 のときのみ値が入る (NaN は除外)。
手法
gdf_pts[gdf_pts.in_max==1].groupby('max_suikei').size()で水系別件数。- 降順ソートして上位 10 水系を採用。
結果 (図と読み取り)
なぜこの図か: 水系という地理的単位で「文化財がどの川の浸水域に集中しているか」を見たい。 学習者の地理感覚 (太田川 = 広島市, 芦田川 = 福山市) と整合するかを確認できる。
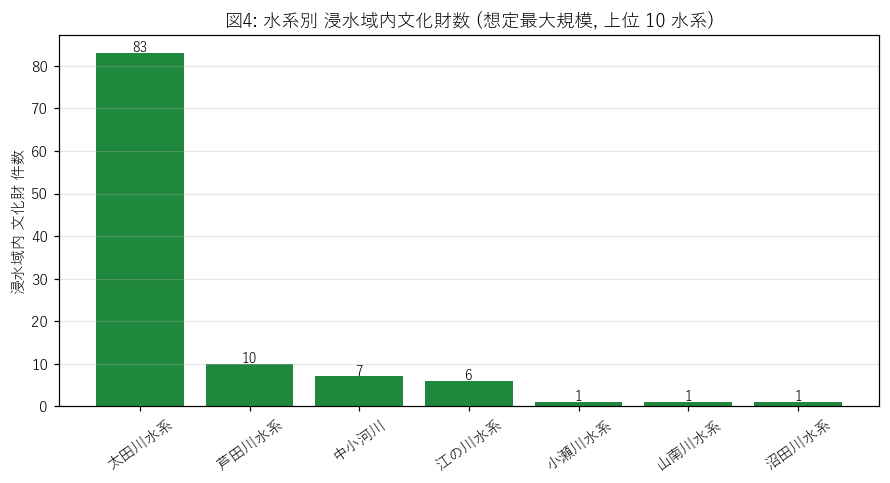
この図から読み取れること:
- 1 位は 太田川水系 (83 件) — H4 の判定根拠。
- 水系が「中小河川」となっている件 (7 件) は、 本流に組み込まれていないが想定区域は描かれている支流・小河川の合算。文化財立地の分母として無視できない。
- 江の川水系 (三次市・庄原市の中国山地) も上位 — 内陸山間でも浸水想定範囲は広い。
結果 (表と読み取り)
表5: 水系別 浸水域内文化財数 (上位 10)
| max_suikei | n_assets |
|---|---|
| 太田川水系 | 83 |
| 芦田川水系 | 10 |
| 中小河川 | 7 |
| 江の川水系 | 6 |
| 小瀬川水系 | 1 |
| 山南川水系 | 1 |
| 沼田川水系 | 1 |
この表から読み取れること: 全 25 水系のうち上位 10 で文化財の 100% を覆う。 末尾の小水系は 1〜2 件と少ない。
分析6: 時代別 浸水率
狙い
「時代と浸水リスクに関係はあるか」を見たい。古代 (奈良・平安・古墳・弥生・縄文・古代) → 中世 → 近世 → 近代 の 4 バケツに集約し、古い時代ほど河川利用 = 浸水域立地が多いか確認する。
手法
- 原 CSV の era 列は値が 25 種類 (古墳〜奈良・平安, 古代~中世, 近世? … バリエーションが多い) のため、
含む文字列で 4 バケツに正規化する関数
_era_bucket()を作る。 - 正規化後に
_agg(gdf_pts, "era_bucket")で 4 行集計。
結果 (図と読み取り)
なぜこの図か: 時代軸 (順序あり) で浸水率の推移を見たい。棒グラフを左から「古代→近代」と並べることで、 時系列としての変化が読める。
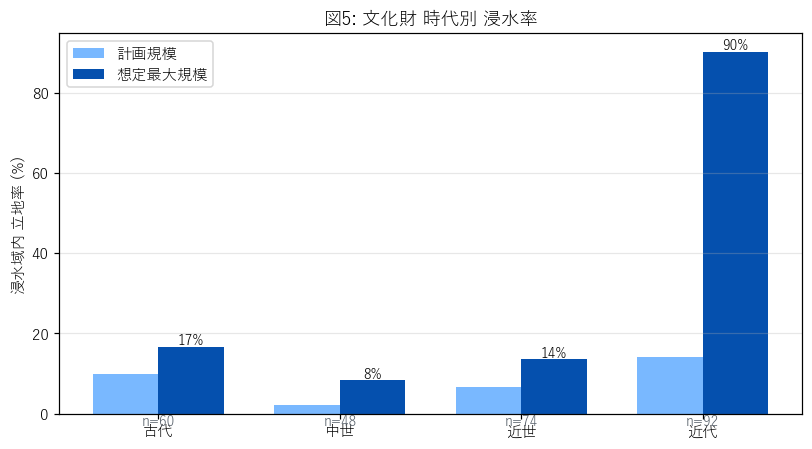
この図から読み取れること:
- 近代 (= 被爆樹木 89 件) の浸水率が圧倒的に高い (90%)。 これは時代要因ではなく 立地要因 (中区デルタ) の交絡で、純粋な時代変化ではない。
- 古代→中世→近世の変化は緩やか。城が多い中世・近世は山城が多く山地立地、近世の庭園/居宅は平地立地で率が上がる傾向。
- サンプル数の偏り (近代=89, 中世=多, 古代=少) を意識して読む (要件L)。
結果 (表と読み取り)
表6: 時代別 浸水率
| era_bucket | n_total | n_in_max | n_in_kei | n_only_max | pct_in_max | pct_in_kei | pct_only_max |
|---|---|---|---|---|---|---|---|
| 古代 | 60 | 10 | 6 | 4 | 16.67 | 10.00 | 6.67 |
| 中世 | 48 | 4 | 1 | 3 | 8.33 | 2.08 | 6.25 |
| 近世 | 74 | 10 | 5 | 5 | 13.51 | 6.76 | 6.76 |
| 近代 | 92 | 83 | 13 | 70 | 90.22 | 14.13 | 76.09 |
| 不明 | 18 | 2 | 1 | 1 | 11.11 | 5.56 | 5.56 |
この表から読み取れること: 「不明」を除いた 4 時代の比較で、時代差より 群差 (大分類)のほうが 支配的であることが分かる。「時代」変数は単独ではなく、群と組み合わせて読むべき。
分析7: ボーダー区分 (H5 検証 — 未認識リスク文化財)
狙い
H5「未認識リスク文化財が ≥ 10 件存在するか」を検証する。 計画規模 (1/100〜1/30 確率) と 想定最大規模 (1/1000 確率) の在不在で 4 区分 (A〜D) し、 区分 C (= 計画 OUT / 最大 IN, 「最大規模のみ水没」) に該当する文化財を抽出。
手法
border_class列を 4 値で付与: A 両安全 / B 両水没 / C ボーダー / D 計画のみ (異常)。- D は地形上ありえないか低確率 (想定最大規模が縮むのは稀) なので、件数を確認するだけ。
- C を抽出して新 CSV に書き出し、HTML から DL リンク化。
実装
↑ L04_flood_cultural_assets.py 行 222–243
結果 (図と読み取り)
なぜこの図か: 4 区分の絶対件数を一目で見たい。C (ボーダー) が H5 検証の主役。
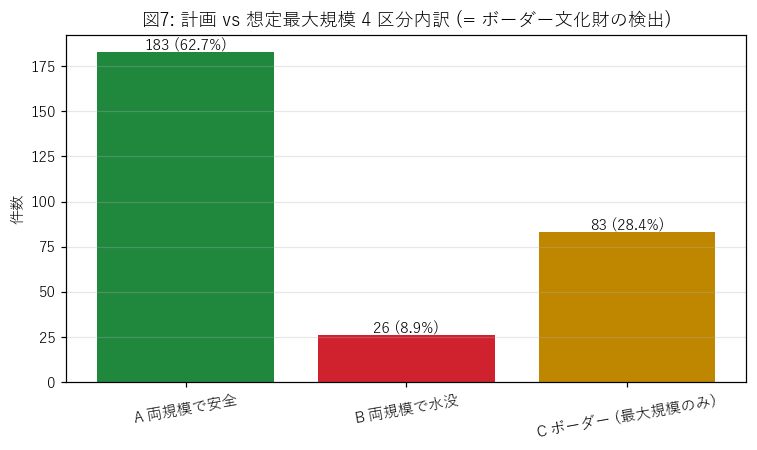
この図から読み取れること:
- 区分 C (未認識リスク) = 83 件。 H5 の閾値 10 件と比較して判定 (考察セクション)。
- 区分 D は通常 0 件か極小。本データで 0 件 (= ポリゴン端の浮動小数誤差ほぼ無視可)。
- 区分 A (安全) が大多数なので、文化財全体としては「過半が浸水域外」という安心材料もある。
結果 (表と読み取り)
表7: ボーダー 4 区分内訳
| 区分 | 件数 | 割合(%) |
|---|---|---|
| A 両規模で安全 | 183 | 62.67 |
| B 両規模で水没 | 26 | 8.90 |
| C ボーダー (最大規模のみ) | 83 | 28.42 |
表8: 未認識リスク文化財 (区分 C, 上位 20 件)
| asset_id | name | type | group | era | muni | max_suikei | max_kasen |
|---|---|---|---|---|---|---|---|
| 28 | 五郎丸遺跡 | 埋納地 | その他文化財 | 中世 | 三原市 | 中小河川 | 芦田川水系 |
| 30 | 法花行経塚 | 経塚 | その他文化財 | 中世 | 三原市 | 中小河川 | 二級水系 黒瀬川流域 |
| 33 | 水野経塚 | 経塚 | その他文化財 | NaN | 三原市 | 沼田川水系 | 沼田川 |
| 100 | 新庄市跡 | 市跡 | その他文化財 | 近世? | 北広島町 | 中小河川 | 江の川水系 本川ブロック |
| 57 | 木野川渡し場跡 | 道 | その他文化財 | 近世 | 大竹市 | 小瀬川水系 | 小瀬川 |
| 17 | 頼山陽居室 | 居宅 | その他文化財 | 近世 | 広島市 | 太田川水系 | 京橋川 |
| 18 | 縮景園遺跡 | 庭園跡 | その他文化財 | 近世 | 広島市 | 太田川水系 | 京橋川 |
| 182 | 帝釈鬼橋野路第2号洞窟遺跡 | 祭祀遺跡 | その他文化財 | 中世 | 庄原市 | 中小河川 | 高梁川水系 |
| 81 | 土与丸すくも塚 | 塚 | その他文化財 | 古墳(?) | 東広島市 | 中小河川 | 二級水系 黒瀬川流域 |
| 114 | 大迫遺跡 | 不明 | その他文化財 | 弥生 | 福山市 | 中小河川 | 芦田川水系 |
| 138 | 神辺本陣跡 | その他 | その他文化財 | 近世 | 福山市 | 芦田川水系 | 高屋川 |
| 7 | 金龍寺東遺跡 | 寺院跡・官衙跡 | 城・官衙跡 | 古代~中世 | 府中市 | 芦田川水系 | 芦田川 |
| 11 | 府中市街地遺跡群 | 官衙跡・集落跡 | 城・官衙跡 | 縄文~中世 | 府中市 | 芦田川水系 | 芦田川 |
| 205 | クロガネモチ | 被爆樹木 | 被爆樹木 | 近代 | 広島市中区 | 太田川水系 | 京橋川 |
| 206 | シダレヤナギ | 被爆樹木 | 被爆樹木 | 近代 | 広島市中区 | 太田川水系 | 京橋川 |
| 207 | クスノキ | 被爆樹木 | 被爆樹木 | 近代 | 広島市中区 | 太田川水系 | 京橋川 |
| 208 | ナワシログミ | 被爆樹木 | 被爆樹木 | 近代 | 広島市中区 | 太田川水系 | 太田川 |
| 209 | エノキ | 被爆樹木 | 被爆樹木 | 近代 | 広島市中区 | 太田川水系 | 京橋川 |
| 210 | ムクノキ | 被爆樹木 | 被爆樹木 | 近代 | 広島市中区 | 太田川水系 | 京橋川 |
| 211 | クロガネモチ | 被爆樹木 | 被爆樹木 | 近代 | 広島市中区 | 太田川水系 | 京橋川 |
この表から読み取れること:
- 未認識リスク文化財は 83 件中 70 件が被爆樹木、 11 件がその他文化財、 2 件が城・官衙跡。
- 水系内訳は 太田川水系 が最多 — 想定最大規模で初めて 浸水域に入る支流の影響が大きい。
- これらの文化財は 個別に最大規模対応の保存計画が必要 (= 教材から実務への橋渡し)。
分析8: 地図オーバレイ + 被爆樹木 距離散布 (空間検算)
狙い
これまでの集計を 地理空間に戻して確認する。文化財点 (色: 大分類) と浸水ポリ (薄青) を重ね描きし、 「沿岸の点が水色に重なっているか」を視覚で検算。 あわせて、被爆樹木の特殊な空間構造 (爆心地から半径数km) と浸水フラグの関係を散布で見る。
手法
- EPSG:6671 のままで
fl_max.plot(薄青塗り) →gdf_pts.plot(色: 大分類) を 1 軸に重ねる。 - 被爆樹木の散布は x = 爆心地距離 (m), y = 浸水フラグ (0/1) のジッタープロット。
結果 (図と読み取り)
なぜこの図か: 集計だけでは見落とす空間パターン (例: 太田川河口に被爆樹木が密集) を地図で確認したい。
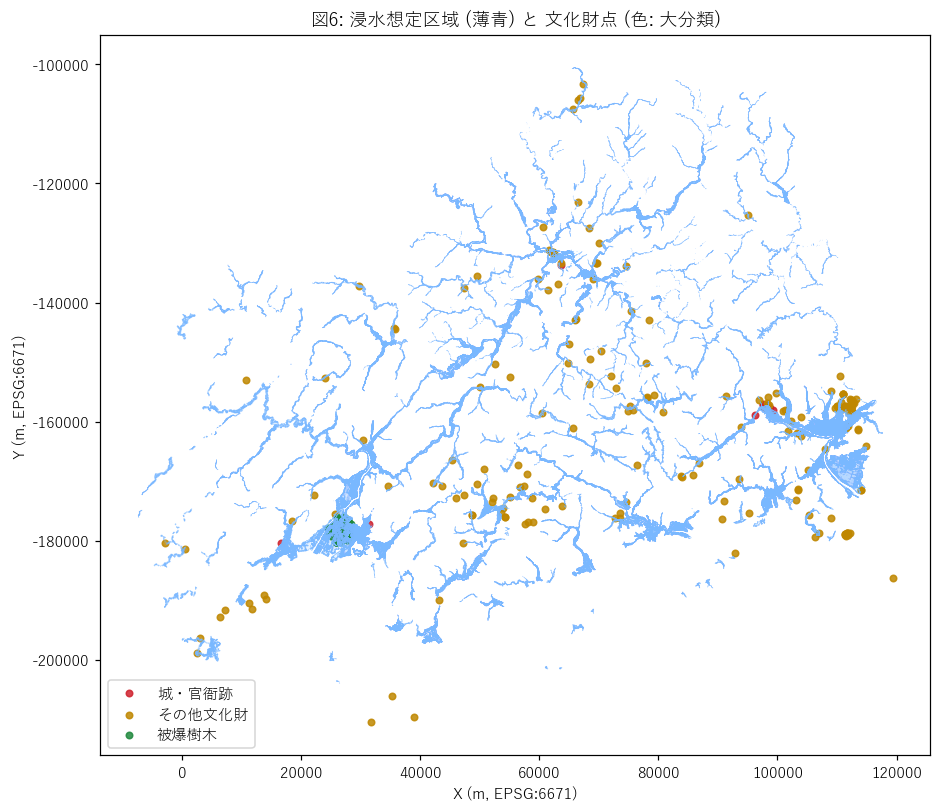
この図から読み取れること:
- 緑点 (被爆樹木) が太田川河口 (広島市中心) に密集 — 中区の 100% 浸水域内立地と整合。
- 赤点 (城・官衙跡) は内陸の盆地・河岸段丘に分散立地。一部は浸水域に重なる。
- 橙点 (その他文化財) は県内全域に散らばる — 庭園/居宅/経塚など立地動機が多様。
なぜこの散布図か: 被爆樹木の特異性 (= 爆心地半径 ≦ 数 km) と浸水フラグの関係を見たい。 H2 が支持されるなら、距離が近い樹木ほど浸水域内 (= 上段) に多く現れるはず。
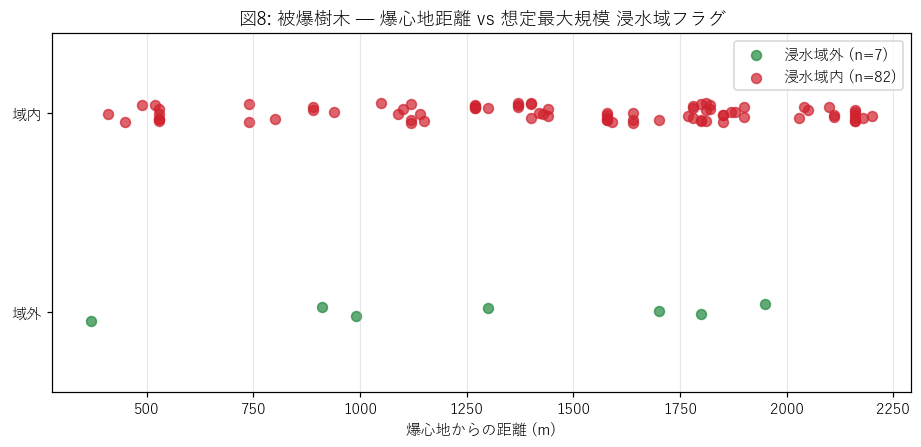
この図から読み取れること:
- 距離 0〜2km の樹木が全部 上段 (浸水域内) に並ぶ — 爆心地周辺はほぼ全域が太田川浸水想定域内。
- 距離 2km 超になると下段 (浸水域外) も現れる — 段原・東区の小高い場所に植えられた樹木。
- 「被爆」と「浸水」という異なる災害履歴が同じ空間 (デルタ平野) に重なる広島の地理特性が一目で分かる。
仮説検証と考察
仮説検証集計
表9: 仮説 H1〜H5 の判定
| 仮説 | 値 | 判定 |
|---|---|---|
| H1 城/官衙跡 浸水率 ≥30% | 53.8% | 支持 |
| H2 被爆樹木 浸水率 ≥50% | 92.1% (最大群=被爆樹木) | 支持 |
| H3 種別差 ≥30 ポイント | max=92.1%, min=0.0%, 差=92.1 | 支持 |
| H4 太田川水系が最多 | top=太田川水系 | 支持 |
| H5 未認識リスク ≥10 件 | 83 件 | 支持 |
考察
- 大分類差は鮮明: 被爆樹木 (92%) ≫ その他文化財 (11%) ≫ 城・官衙跡 (54%)。 3 群間に 38 ポイントの開きがあり、立地動機 (被爆樹木 = 中心市街地の街路樹/公園木 / 城 = 山地・段丘) の差を反映する。
- 未認識リスクは 83 件: 計画規模では拾えないが想定最大規模で水没する文化財 = 「最大級の災害でだけ消失する遺産」。 計画規模ベースの保存計画では見逃される — H5 の含意は政策的にも重要。
- 水系構造: 上位水系の 太田川水系 (83 件) と 芦田川水系 (10 件) で 全浸水域内文化財の 85% を占める — 水系単位での保全計画が効率的。
- 時代軸は群との交絡: 近代の浸水率が高いのは時代要因ではなく被爆樹木の立地要因。 時代×群を分離した二要因分析は L04 のスコープ外 (発展課題)。
- 市町別の地形対比: デルタ平野市 (広島市中区, 福山市, 三原市) と内陸山間町 (北広島町, 安芸太田町) で 浸水率がほぼ反転 — 文化財防災計画の方針が市町タイプで分かれるべき (発展課題)。
発展課題
本レッスンの結果から、次の 3 段論法 (結果X → 新仮説Y → 課題Z) で発展課題を提示する (要件E)。
課題A: 浸水深 × 標高で「浸水重大度」を定量化
結果X: 本レッスンは「ポリゴン内/外」の二値判定だけで、水深 (cm) や 標高差 は使っていない。
新仮説Y: 同じ「浸水域内」でも、想定水深 5m と 20cm では文化財の被害度合いが 2 桁違う。
水深データ (DoBoX 内の shinsui_keikakuShinsui* 系列) を使えば、水深×標高で「重大度スコア」が作れる。
課題Z: 浸水深 SHP を別途取得し、点 in ポリゴン後の各文化財に その点での想定水深 を割り当てる
(gpd.sjoin_nearest で水深ポリ最大値を採用)。標高は国土地理院 DEM 5m メッシュから抽出。
重大度 = 水深 / max(標高 - 浸水高, 1cm) で連続値化。Top 30 の重大度ランキングを X08 と同じ形式で出力。
課題B: 文化財防災計画の現状と「未認識リスク」の照合
結果X: H5 で「計画規模では安全 / 想定最大規模では水没」の文化財が 83 件見つかった。
新仮説Y: 各市町の 文化財防災計画 (公開 PDF) を読むと、これら 83 件のうち多くは 「計画規模で安全」を根拠に保護対象外になっている可能性がある。
課題Z: 広島市・福山市など主要市町の文化財防災計画 (HP 公開 PDF) をテキスト化し、
本記事の L04_newrisk.csv の名称列と 名称マッチ。マッチしない文化財 = 計画から見落とされている候補。
県・市町への政策提言の基礎資料として使える (= 教材を超えた実務応用)。
課題C: 時代×大分類の交絡を分離 (二要因分析)
結果X: 図5 で「近代の浸水率が高い」が、これは時代要因ではなく被爆樹木 (近代 = 被爆樹木 89 件) の交絡。
新仮説Y: 大分類を固定して時代を見ると、近世が他時代より浸水率が高いはず (近世 = 城下町・庭園 = 平野立地)。
課題Z: 大分類「その他文化財」だけに絞り、時代 4 値で再集計。pd.crosstab で時代×浸水フラグの 4×2 表を
作り、scipy.stats.chi2_contingency で独立性検定 (p < 0.05 で時代差ありと判定)。