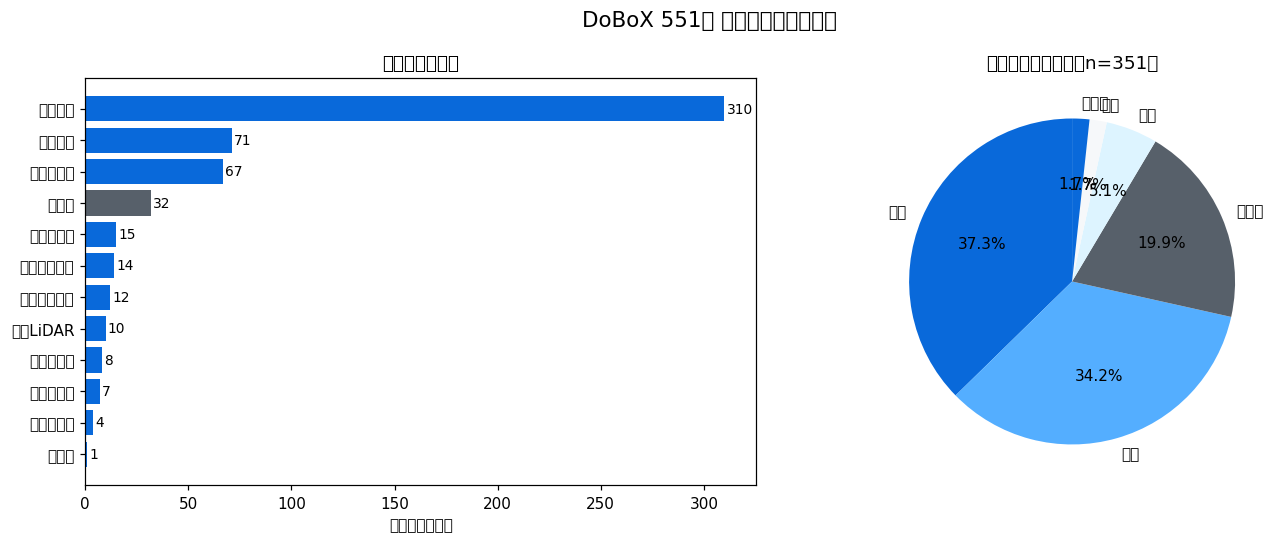
DoBoX に登録された {len(CAT)} 件のデータセットを 13 カテゴリに分類した。
H3 検証: ハザード系(洪水・土砂・津波)は {hazard_n} 件({hazard_pct:.1f}%) ― {("仮説支持 ✓" if hazard_pct >= 33 else "仮説棄却 ✗")}(閾値 33%)。 防災県・広島の特性がデータ構成に表れている。
全 {len(CAT)} 件は 広島県オープンデータ利用規約 に準拠する。 CC BY 4.0 に相当する規約で、商用・非商用ともに申請不要。ただし:
| 要件 | 内容 | 注意点 |
|---|---|---|
| 出典表記 | 「広島県」または提供組織名を明示 | 図のキャプションや論文の参考文献に必須 |
| 改変・加工 | 可(原データとの区別表示が必要) | 分析結果を「DoBoX 原データ」と混同させない |
| 商用利用 | 可・申請不要 | 二次配布時も同規約を継承 |
| AI 学習利用 | 可(規約に明示なし・黙示可) | モデルの出典表記ルールは今後整備予定 |
| LiDAR 派生データ | 国土地理院基盤地図情報を含む場合あり | 測量法第29条の複製許可が必要な場合がある |
LiDAR 点群(dataset #65, #1434)は国土地理院の基盤地図情報を含む可能性がある。 この場合、DoBoX 規約のみでは不十分で 測量法に基づく複製・刊行の許可申請が別途必要になることがある。 派生データを公開・配布する前には出典の法的地位を必ず確認すること。
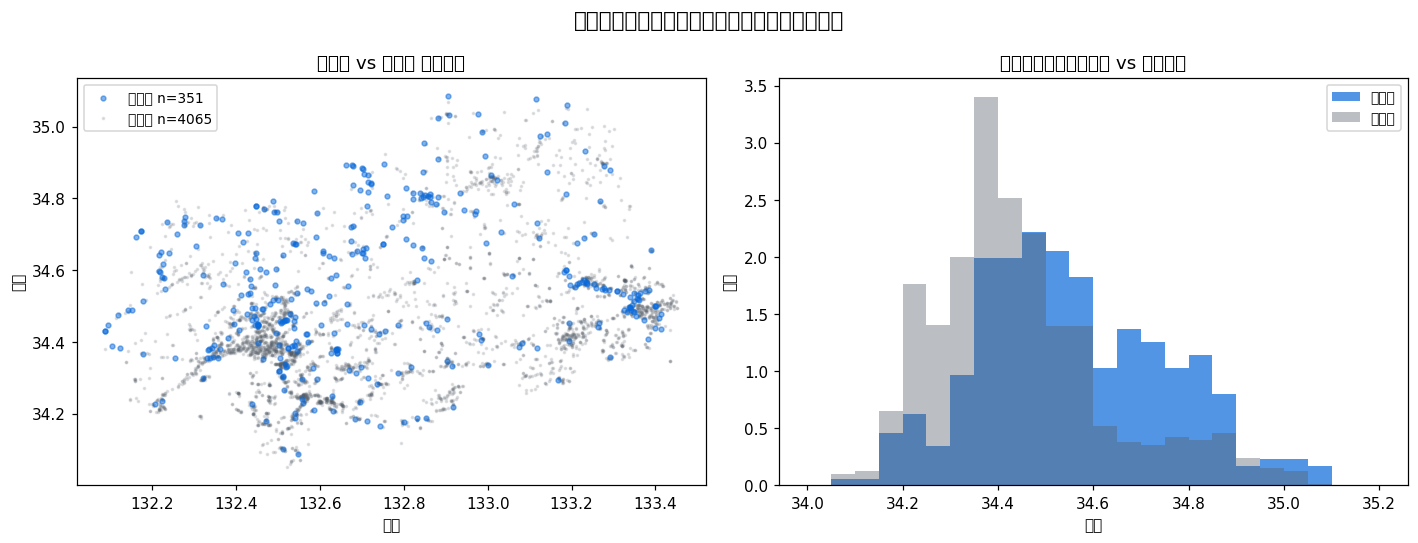
""" return "DoBoX カタログ分析とライセンス規約", body # ───────────────────────────────────────────── # Section 2: センサーの空間偏在性(観測バイアス) # ───────────────────────────────────────────── def sec_spatial_bias() -> tuple[str, str]: print("[2] 空間偏在性分析 ...") fig, axes = plt.subplots(1, 2, figsize=(13, 5)) fig.suptitle("センサーデータの空間偏在性(観測バイアス)", fontsize=14) # 左: カメラ vs 避難所の緯度・経度散布図 ax = axes[0] valid_cam = CAM.dropna(subset=["緯度", "経度"]) ax.scatter(valid_cam["経度"], valid_cam["緯度"], s=10, alpha=0.5, color=ACCENT, label=f"カメラ n={len(valid_cam)}", zorder=3) valid_shel = SHEL.dropna(subset=["latitude", "longitude"]) ax.scatter(valid_shel["longitude"], valid_shel["latitude"], s=2, alpha=0.15, color=MUTED, label=f"避難所 n={len(valid_shel)}", zorder=2) ax.set_xlabel("経度") ax.set_ylabel("緯度") ax.set_title("カメラ vs 避難所 空間分布") ax.legend(fontsize=9) # 右: 管理区分別緯度分布(ヴァイオリン or ヒストグラム) ax2 = axes[1] bins = np.linspace(34.0, 35.2, 25) ax2.hist(valid_cam["緯度"], bins=bins, alpha=0.7, color=ACCENT, label="カメラ", density=True) ax2.hist(valid_shel["latitude"], bins=bins, alpha=0.4, color=MUTED, label="避難所", density=True) ax2.set_xlabel("緯度") ax2.set_ylabel("密度") ax2.set_title("緯度分布比較(カメラ vs 避難所)") ax2.legend(fontsize=9) plt.tight_layout() fig.savefig(ASSETS / "X16_spatial_bias.png", dpi=110, bbox_inches="tight") plt.close(fig) # H1 検証: カメラの管理区分で「道路」系の割合 road_n = CAM["管理区分"].str.contains("道路", na=False).sum() road_pct = 100 * road_n / len(CAM) # カメラ数ゼロ市町を特定(大まかに緯度帯で分割) low_lat = valid_cam[valid_cam["緯度"] < 34.5] high_lat = valid_cam[valid_cam["緯度"] >= 34.8] body = f"""H1 検証: カメラ {len(CAM)} 台のうち「道路」管理区分は {road_n} 台({road_pct:.1f}%) ― {("仮説支持 ✓" if road_pct >= 70 else "仮説棄却 ✗(ただし道路系が主体)")}。 河川・砂防管理カメラも相当数含まれる。
| バイアス種別 | このデータでの例 | AI への影響 | 緩和策 |
|---|---|---|---|
| 収集バイアス | カメラは幹線国道・主要河川沿いに集中 山間部・離島に空白域 |
空白域の交通状況・水位を AI が推論できない | 衛星・気象レーダーで補完 |
| ラベルバイアス | カメラなし地点は「異常なし」と誤認されやすい | 過去の被害記録が少ない地域でモデル精度が低下 | 欠損を「不明」として明示 |
| フィードバックバイアス | 監視密度が高い地点の事故データが訓練に過剰使用 | 都市部偏重モデルが農村部で失敗 | サンプリング重み付け |
AI モデルの予測精度は訓練データの空間範囲に依存する。 広島県北部(三次市・庄原市)や島嶼部(江田島市・大崎上島)では センサー密度が沿岸都市部の 1/5 以下であり、これらの地域向け AI モデルには 別途の精度検証と不確実性の開示が必要である。
""" return "観測センサーの空間偏在性と AI バイアス", body # ───────────────────────────────────────────── # Section 3: 位置情報集約と再識別リスク # ───────────────────────────────────────────── def sec_reidentification() -> tuple[str, str]: print("[3] 再識別リスク分析 ...") valid = CAM.dropna(subset=["緯度", "経度"]).copy() valid = valid.rename(columns={"緯度": "lat", "経度": "lng"}) # グリッド解像度変化 → ユニークセル数 resolutions = [0.001, 0.005, 0.01, 0.02, 0.05, 0.1] approx_m = [111, 555, 1110, 2220, 5550, 11100] unique_cells = [] k1_fractions = [] for res in resolutions: grid_lat = (valid["lat"] // res).astype(int) grid_lng = (valid["lng"] // res).astype(int) cell_key = grid_lat.astype(str) + "_" + grid_lng.astype(str) vc = cell_key.value_counts() unique_cells.append(len(vc)) k1_fractions.append((vc == 1).sum() / len(vc)) fig, axes = plt.subplots(1, 2, figsize=(13, 5)) fig.suptitle("位置情報の集約粒度と再識別リスク", fontsize=14) ax = axes[0] ax.plot(approx_m, unique_cells, "o-", color=ACCENT, lw=2) ax.set_xscale("log") ax.set_xlabel("グリッドサイズ (m)") ax.set_ylabel("ユニークグリッド数") ax.set_title("解像度 vs 識別可能セル数") for x, y in zip(approx_m, unique_cells): ax.annotate(str(y), (x, y), textcoords="offset points", xytext=(5, 3), fontsize=9) ax2 = axes[1] ax2.plot(approx_m, [v * 100 for v in k1_fractions], "s-", color="#cf222e", lw=2) ax2.axhline(30, ls="--", color=MUTED, lw=1, label="閾値 30%") ax2.set_xscale("log") ax2.set_xlabel("グリッドサイズ (m)") ax2.set_ylabel("k=1 セル割合 (%)") ax2.set_title("グリッド内カメラ 1 台のみのセル割合") ax2.legend(fontsize=9) plt.tight_layout() fig.savefig(ASSETS / "X16_reidentification.png", dpi=110, bbox_inches="tight") plt.close(fig) # H2 検証: 1 km グリッドで k=1 セル割合 res_1km = 0.01 cell_1km = ((valid["lat"] // res_1km).astype(str) + "_" + (valid["lng"] // res_1km).astype(str)) vc_1km = cell_1km.value_counts() k1_1km_pct = 100 * (vc_1km == 1).sum() / len(vc_1km) body = f"""再識別リスク(Re-identification Risk)とは、 匿名化されたデータから特定の個人・物体を特定できてしまうリスク。 位置情報は氏名を削除しても「自宅付近 → 職場付近」の移動パターンで個人が特定される。
H2 検証: 1 km グリッドで集約した際に k=1(グリッド内カメラ 1 台のみ)のセルは {k1_1km_pct:.1f}% ― {("仮説支持 ✓" if k1_1km_pct >= 30 else "仮説棄却 ✗(集約で十分匿名化)")}。 単独セルでは集約後も位置と ID が 1 対 1 対応するため、カメラ個体が特定可能。
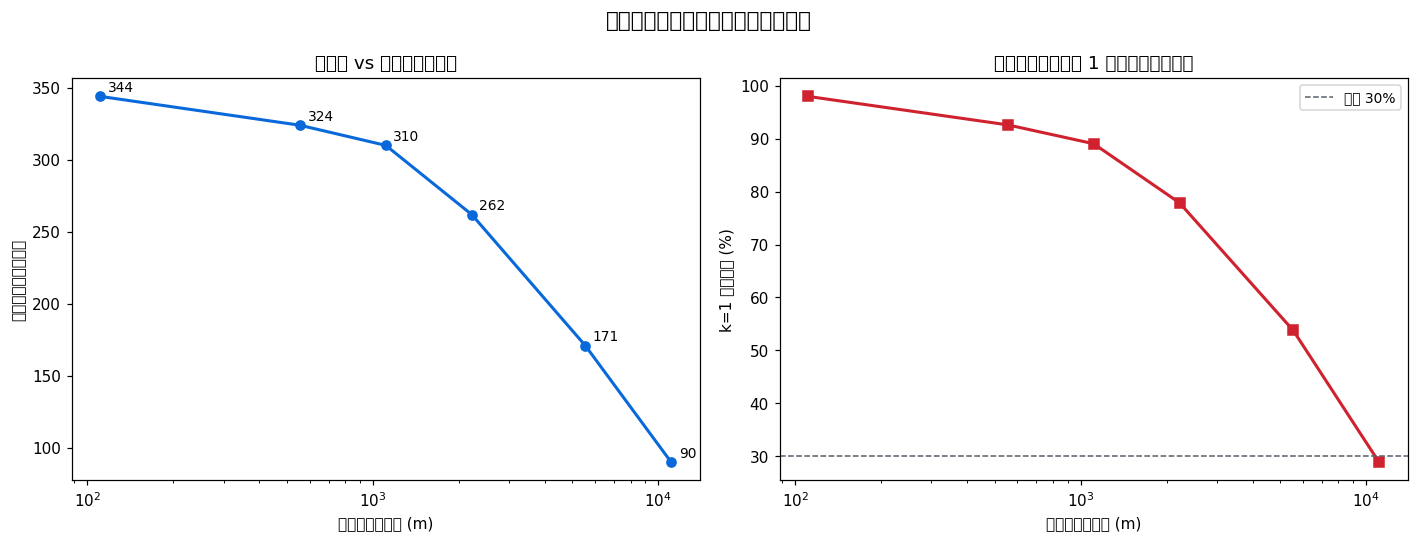
k-匿名性モデルでは、あるレコードが少なくとも k 件の他レコードと 区別できない状態を「k 匿名」とする。 最低でも k≥3 を確保するため、約 330 m グリッドへの集約が必要であることがわかる。
| 手法 | 概要 | DoBoX での適用例 | 限界 |
|---|---|---|---|
| グリッド集計 | 500 m〜1 km 格子に集約 | L10 プライバシーグリッド | 単独セルには効果なし |
| k-匿名化 | k≥3 以上に強制統合 | 要援護者情報(非公開) | 均質性攻撃に脆弱 |
| 差分プライバシー | 統計値にノイズ付加 | 人口密度マップ(応用) | 精度とのトレードオフ |
| トークン化 | 位置を「○○エリア」名に変換 | 避難所の地区名表記 | 地名から逆引き可能 |
{fp.name}{sha[:32]}...データ真正性(Data Integrity)とは、データが改ざんされていないことを保証する性質。 分析を再現する際、ダウンロードしたファイルが公式版と一致するかを確認することで 「分析条件の完全な記録」が可能になる。
| ファイル | サイズ | SHA-256(先頭 32 桁) |
|---|
ファイルが 1 バイトでも変更されると完全に異なるハッシュになる。
DoBoX の各データセットページには「更新日時」フィールドがある。 前回分析時のハッシュ値と比較することで、データが更新されたタイミングで 分析を再実行するワークフロー(CI/CD)を構築できる。
位置情報・センサーデータを公開・AI 学習に使う際は、 どの法制度が適用されるかを把握する必要がある。 DoBoX は広島県の公的機関が公開したオープンデータのため「個人情報」には 直接該当しないが、二次利用で個人を特定できる加工データを作成した場合は注意が必要。
| 法制度 | 適用地域 | 位置情報規制 | AI・自動処理 | 違反時制裁 |
|---|---|---|---|---|
| GDPR EU 一般データ保護規則 |
EU/EEA + EU 市民データを扱う全組織 | 高リスクデータに準拠 同意または正当利益が必要 |
自動的決定・プロファイリングへの異議権(22 条) | 最大 2,000 万 EUR または年間売上 4% |
| PIPL 中国個人情報保護法 |
中国国内 + 中国人データを扱う全組織 | 「機微個人情報」 明示的同意必須 |
AI 推薦への対抗権あり | 最大 5,000 万人民元または年間売上 5% |
| 個人情報保護法 日本 |
日本国内 | 単独位置情報は個人情報に非該当 (本人識別可能なら該当) |
自動処理への明示規制は限定的 | 1 億円以下の罰金(法人) |
| 文書 | 発行 | 要点 |
|---|---|---|
| 人間中心の AI 社会原則 | 内閣府 2019 | プライバシー確保・公平性・透明性・説明責任 |
| AI 利活用ガイドライン | 総務省 2019 | 利用者への説明・透明性・安全確保 |
| EU AI 法(参考) | EU 2024 施行 | リスク分類(禁止 / 高リスク / 低リスク) |
エラー: {e}
{traceback.format_exc()}"))
html_out = render_lesson(
num=16,
title="X16: データ倫理・AI ガバナンス実習",
tags=["X系", "横断研究", "データ倫理", "プライバシー", "ライセンス", "AI倫理", "GDPR", "再識別リスク"],
time="60分",
level="リテラシ基礎〜心得",
data_label=(
'カメラ情報(#1279) × '
'避難所情報(#42) × '
'カタログ 551件'
),
sections=sections,
script_filename="lessons/X16_data_ethics_governance.py",
)
html_out = html_out.replace("", '', 1)
out_path = LESSONS / "X16_data_ethics_governance.html"
out_path.write_text(html_out, encoding="utf-8")
print(f"\n[HTML] {out_path.name} ({len(html_out):,} bytes)")
print(f"=== DONE in {_time.time() - t0:.1f}s ===")