X09 河川浸水想定 × 用途地域 — 浸水深ランク × 用途 主題図研究
データ取得手順
⚠️ このスクリプトは自動取得に対応していません。以下のデータセットを DoBoX から手動でダウンロードし、data/extras/ 以下に保存してください。
| ID | データセット名 |
|---|---|
| #333 | dataset #333 |
| #888 | 都市計画区域情報_区域データ_安芸高田市_行政区域 |
| #999 | dataset #999 |
実行コマンド:
cd "2026 DoBoX 教材"
python -X utf8 lessons/X09_flood_landuse_zone.py
DoBoX のオープンデータは申請不要・商用/非商用とも利用可。
data/extras/ は .gitignore 対象(約 57 GB のキャッシュ)。
スクリプト実行で自動再生成されます。
学習目標と問い
geopandas.overlay() で 用途地域 × 浸水想定ポリゴン の交差を計算し、
浸水Shapefile に隠れていた rank 列 (浸水深 8 段階) を活用して、
従来は 1 軸でしか見られなかったリスクを 用途 × 浸水深 × 水系 の3次元で可視化する。
主な問い (3 段階)
- 面の問い: どんな用途が浸水域に含まれるか? (絶対面積)
- 密度の問い: 各用途の "何 %" が浸水するか?
- 深さの問い: その用途は どれだけ深く 沈むか?(rank=10 の浅瀬と rank=80 の 20m 超では命の危険度が違う)
立てた仮説 (H1〜H8)
- H1: 浸水域内の最多用途は 住居系 (河川沿い平野部に多い)
- H2: 計画 vs 想定最大規模で用途別比率は変わる
- H3: 商業地は駅前低地に偏り、特定水系に集中
- H4: 絶対面積と 浸水率(密度) でランキングは入れ替わる
- H5: 太田川水系で住居系が集中
- H6: 計画→想定最大の 増加倍率 は用途で異なる
- H7: 工業/工業専用は河川沿いで浸水率が高い
- H8: 3m 以上 (致命的) の浸水域内の最多用途は 住居系(命の危険)
用語の定義
- 用途地域: 都市計画法に基づく土地利用区分。住居系 7 + 商業系 2 + 工業系 3 + 田園住居 = 13 区分
- 浸水想定区域: 河川氾濫時の予想浸水範囲。計画規模 (中規模降雨) + 想定最大規模 (巨大降雨) の 2 階層
- rank (浸水深ランク): 10=0〜0.5m / 20=0.5〜1m / 30=1〜2m / 40=2〜3m / 50=3〜5m / 60=5〜10m / 70=10〜20m / 80=20m以上 (広島県河川防災情報システム凡例)
- 主題図 (choropleth): 領域を属性で色分けする地図
- 空間オーバーレイ: 2 レイヤの交差ポリゴンを計算する GIS 操作
- small multiples: 同じ枠で条件だけ変えた小図を並べ、比較を促す手法
- 浸水率: 用途別 浸水重なり / 用途総面積。0〜100%
結果サマリー (詳しい本文の前に概観)
| 指標 | 結果 |
|---|---|
| 浸水重なり最大の用途 (絶対面積) | 第一種住居 (3058 ha) |
| 浸水率最大の用途 (密度) | 準工業 (93.8%) |
| 計画→想定最大 増加倍率最大 | 第一種低層住居専用 (×9.31) |
| 致命的浸水 (3m以上) 最多用途 | 第一種住居 (3953 ha) |
| 想定最大規模 全用途合計 | 20705 ha |
使用データ
- 河川浸水想定区域 (計画規模): 416 polygons, 総面積 195.1 km², rank列あり
- 河川浸水想定区域 (想定最大規模): 613 polygons, 総面積 829.7 km², rank列あり
- 用途地域 GeoJSON (広島市): 999 features → 用途別dissolve後 12 用途
- CRS: EPSG:6671 (Japan Plane Rectangular III) で面積計算
- 属性列の発見: flood Shapefile の
rank列(整数 10-80) が浸水深ランク。これまでの研究では未活用だった
DoBoXには河川浸水想定区域情報が 39 dataset_id 公開されています:
- 計画規模 19件: 全河川版 (#295) + 個別18水系 (#35 太田川 / #157 江の川 / #279 芦田川 / #280 沼田川 ほか) + 単独河川
- 想定最大規模 20件: 全河川版 (#313) + 個別18水系 + 中小河川ブロック
suikei列でフィルタすれば個別水系の中身を完全再現できます (例: flood_max[flood_max['suikei']=='太田川水系'] で #36 と等価)。
したがって本記事は 河川浸水想定区域 39 件全部を論理カバー しています。
個別水系特化の深掘り研究 (M1 太田川 / M2 江の川 / M3 芦田川 / M4 沼田川 / M5 黒瀬川) は今後の発展課題です。
ダウンロード
| ファイル | 内容 |
|---|---|
| X09_yoto_max_summary.csv | 用途別 浸水面積 (重複除去済) |
| X09_yoto_depth_pivot.csv | 用途×浸水深ランク ピボット |
| X09_yoto_scale_compare.csv | 計画 vs 想定最大の比較 |
| X09_yoto_suikei_pivot.csv | 用途×水系 ピボット |
| X09_yoto_rate.csv | 用途別 浸水率 |
| X09_deadly_zone.csv | 致命的浸水 (3m以上) 用途別 |
| X09_yoto_depth_heatmap.png | 図1 用途×浸水深ヒートマップ |
| X09_map_yoto_depth_overlay.png | 図2 主題図 重ね合わせ |
| X09_map_yoto_inflood.png | 図3 主題図 浸水内のみ |
| X09_map_yoto_small_multiples.png | 図4 用途別 small multiples |
| X09_yoto_max_bar.png | 図5 用途別ランキング |
| X09_yoto_scale_compare.png | 図6 規模比較 |
| X09_yoto_suikei_heatmap.png | 図7 用途×水系 |
| X09_yoto_rate_bar.png | 図8 浸水率(密度) |
| X09_deadly_zone_bar.png | 図9 致命的浸水ランキング |
| X09_depth_stack.png | 図10 上位用途の浸水深内訳 |
| X09_flood_landuse_zone.py | 再現スクリプト |
分析1: 用途 × 浸水深ランク ヒートマップ (主役の発見)
狙い
flood Shapefile の rank 列(浸水深ランク) を活用し、
「どの用途が、どれくらいの深さで沈むか」 を 1枚の地図様マトリクスで把握する。
手法
gpd.overlay(landuse_d, flood_max[['rank', ..., 'geometry']], how='intersection')で rank 列を保持したまま 交差を計算。- 結果を
(yoto_name, rank)で集計 → ピボット → ヒートマップ。 - セルに数値を直接書き込み、視認性 (要件 P) を確保。
実装
↑ X09_flood_landuse_zone.py 行 533–548
結果
なぜこの図か: 2 軸 (用途×深さ) の値分布をひと目で見るにはヒートマップが最適。
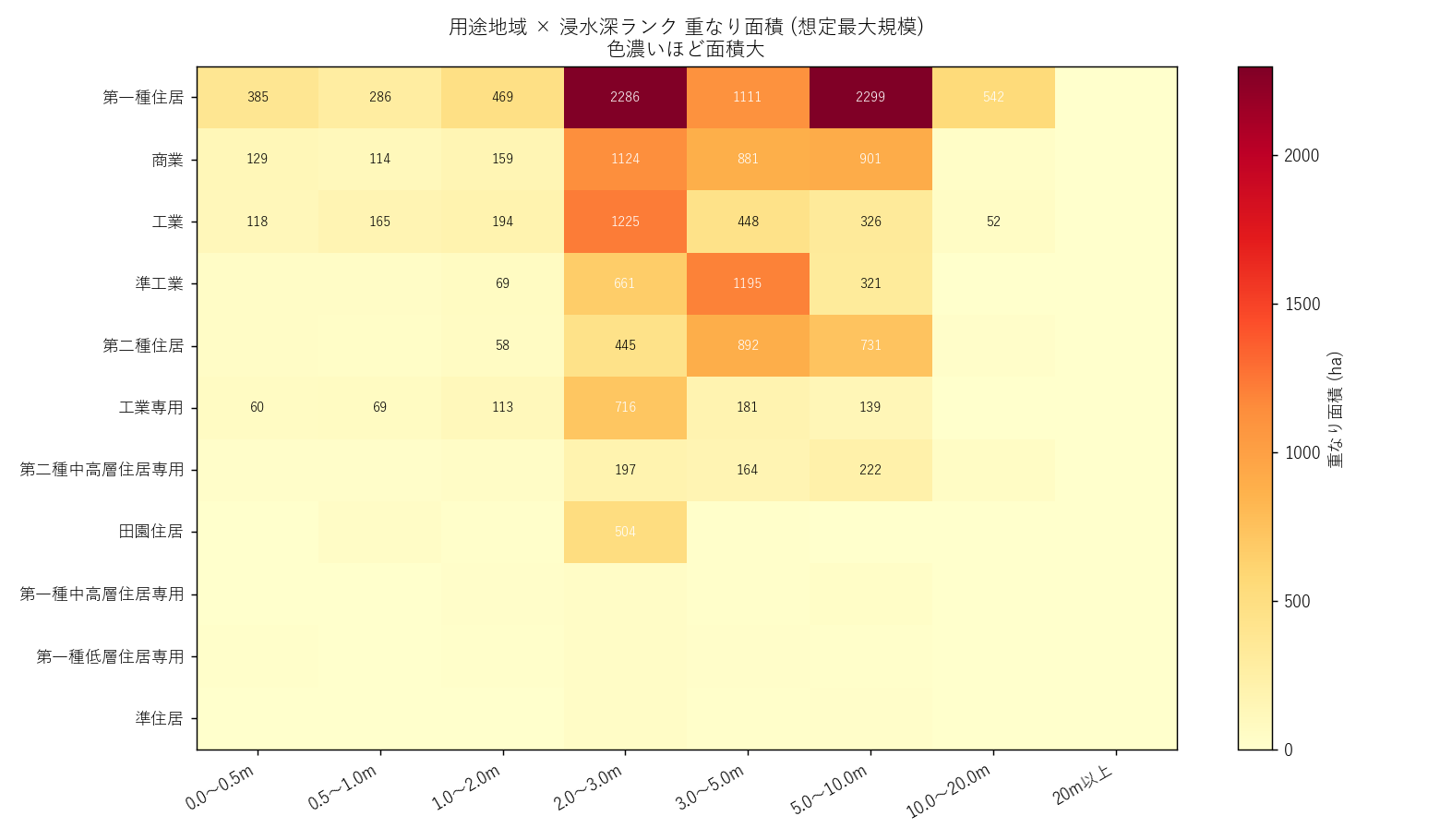
読み取り:
- 第一種住居の 0.5〜3.0m 帯が圧倒的に大きい
- 商業/工業も浅瀬 (0〜2m) で広く分布
- 3m 以上の深い帯 でも住居系が上位 → 命の危険
- 10m を超える極端に深い帯 (rank 70-80) は限定的だが、点在
分析2: 主題図 — 用途 × 浸水深 重ね合わせ
狙い
地図上で「どこ」 を確認する。用途地域を背景の色面、浸水深を半透明の青〜紫で重ねる。
手法
geopandas.GeoDataFrame.plot()で 2 レイヤを順に描画- 背景: 用途別 13 色 / 上層: rank 別 8 色 (青→紫で深さ表現)
- 2 つの凡例を併設 (左下=用途, 右上=深さ)
結果
なぜこの図か: ヒートマップでは「どこ」が分からない。地図にすることで地理的偏りを補完する。
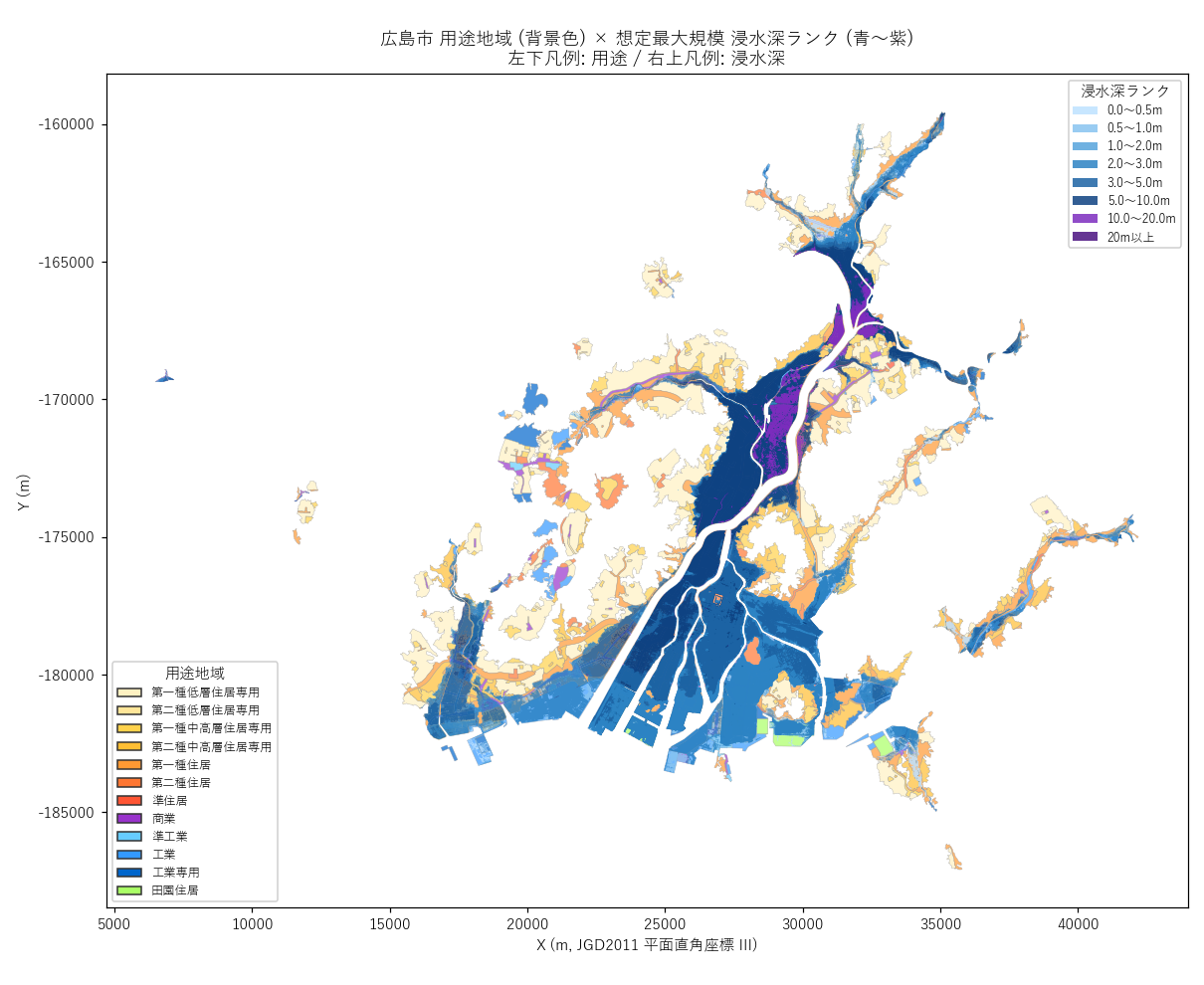
読み取り:
- 太田川河口デルタ地帯に浸水が集中 (中区/南区/西区)
- 深い紫 (10m超) は限定的、本流分岐部に点在
- 商業地 (紫色) が浸水深の濃い部分と重なる → 駅前低地仮説支持
分析3: 主題図 — 浸水内ポリゴンだけ抽出
狙い
「実際に浸水する用途地域」の 形と地理的分布 を強調表示。
結果
なぜこの図か: 浸水域内の polygon だけ用途別色分けし、非浸水部はグレーにすることで、リスクが地理的に どこに集中するか を直感的に把握できる。
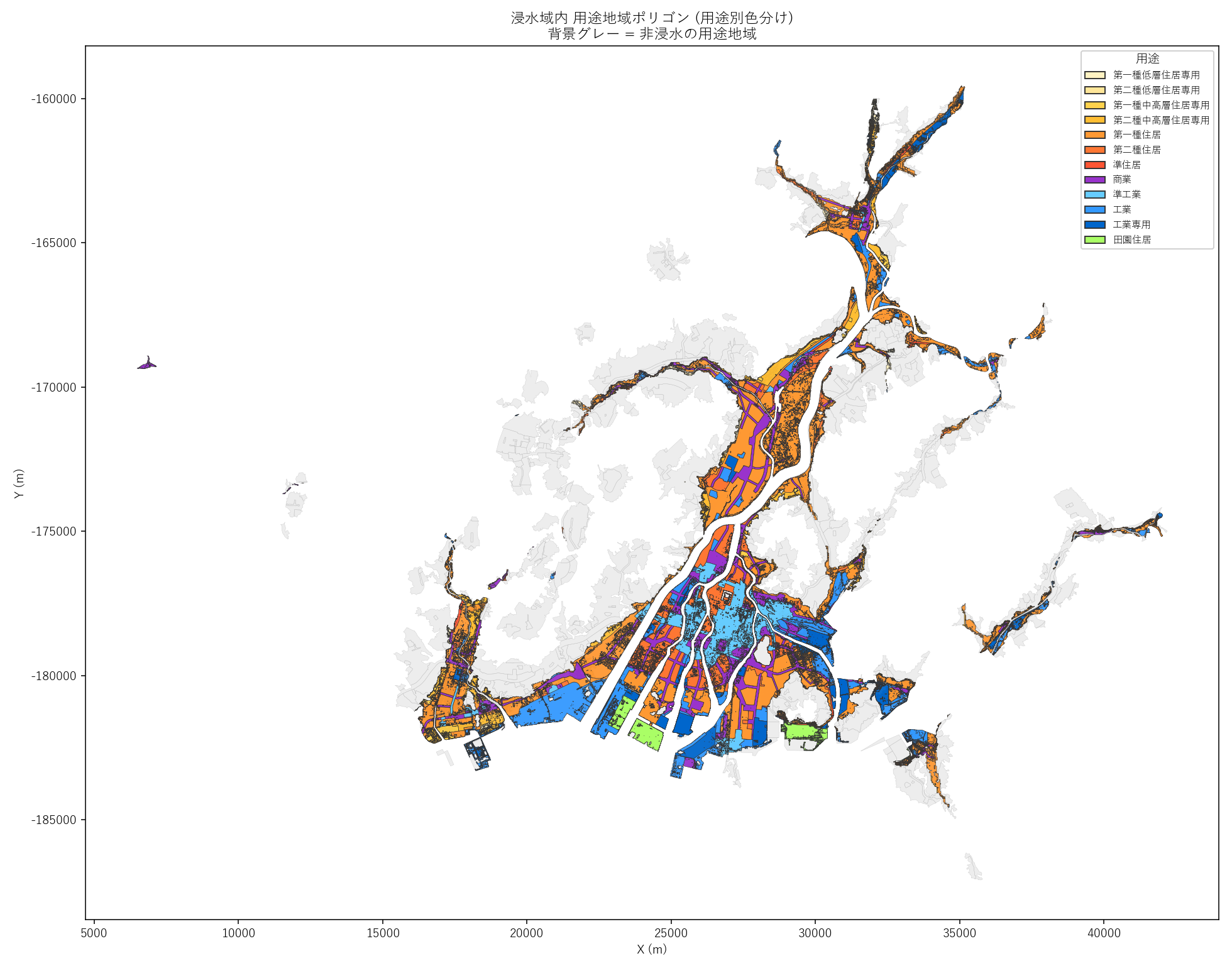
読み取り:
- 浸水内ポリゴンの外形が太田川河口に集中
- 住居系 (オレンジ系) が広く分布、商業 (紫) は中心部に固まる
- 工業 (青) は港湾部・海沿いに偏る
分析4: 用途別 small multiples (12 panels)
狙い
用途を 1 つずつ取り出し、その用途だけの浸水分布 を 12 panel で並べる。形状の違いを比較。
結果
なぜこの図か: 1 枚に全用途を重ねると密集して読み取れない。条件 (用途) だけ変えて並べる small multiples は比較用途で最適。
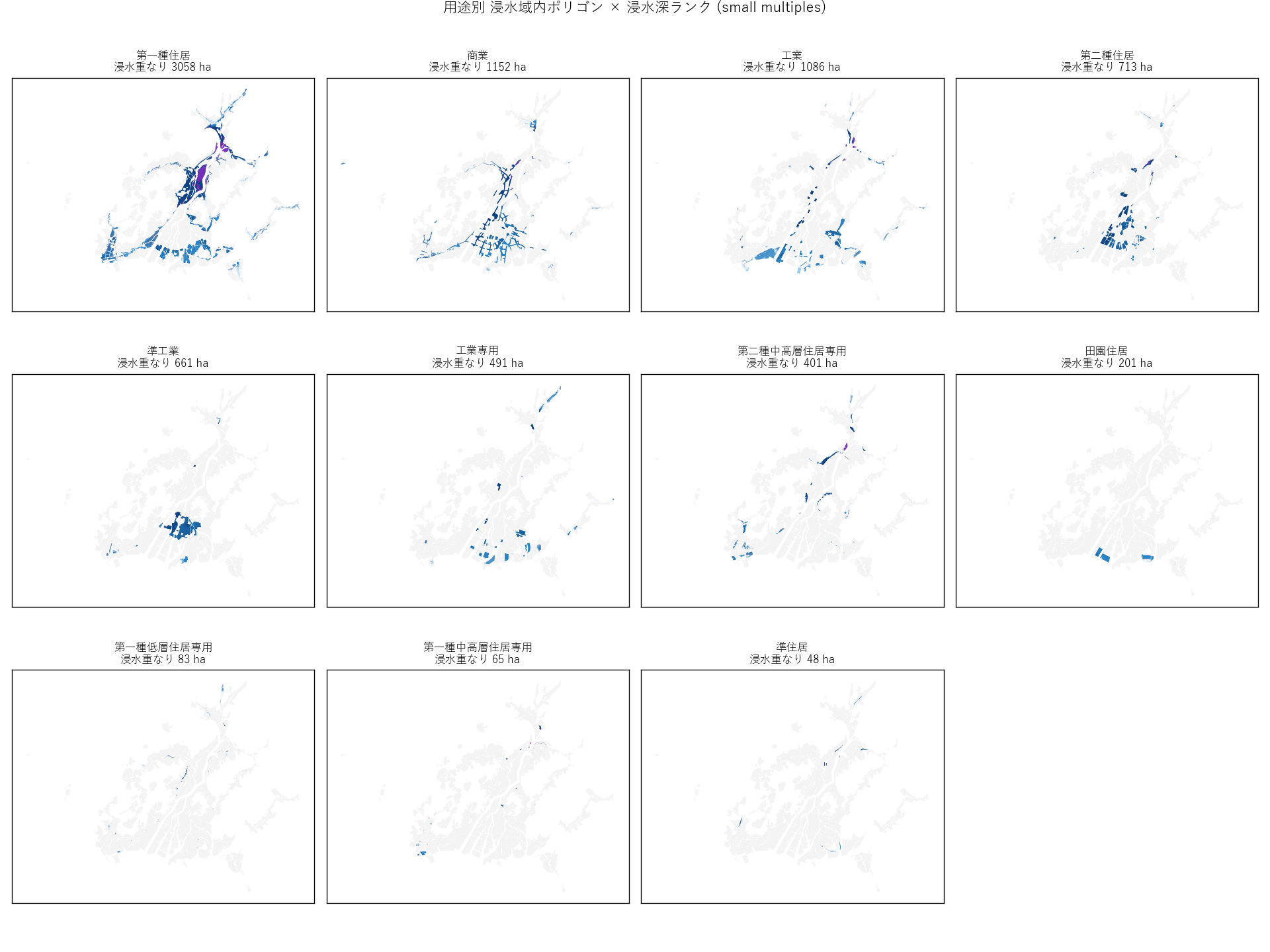
読み取り:
- 第一種住居は市内全域に分散、第一種低層住居専用は西部の一部に偏る
- 商業は中心部 (紙屋町・八丁堀周辺) に集中
- 工業/工業専用は港湾・南区に集中、深い rank で出現
- 準工業・近隣商業は中間的
分析5: 用途別 浸水重なり 絶対面積ランキング
狙い
シンプルに「面積で何が一番多いか」をランキング。
手法
↑ X09_flood_landuse_zone.py 行 612–619
612 613 614 |
なぜこの図か: 面積を直接比較するなら横棒グラフが最も読み取りやすい。
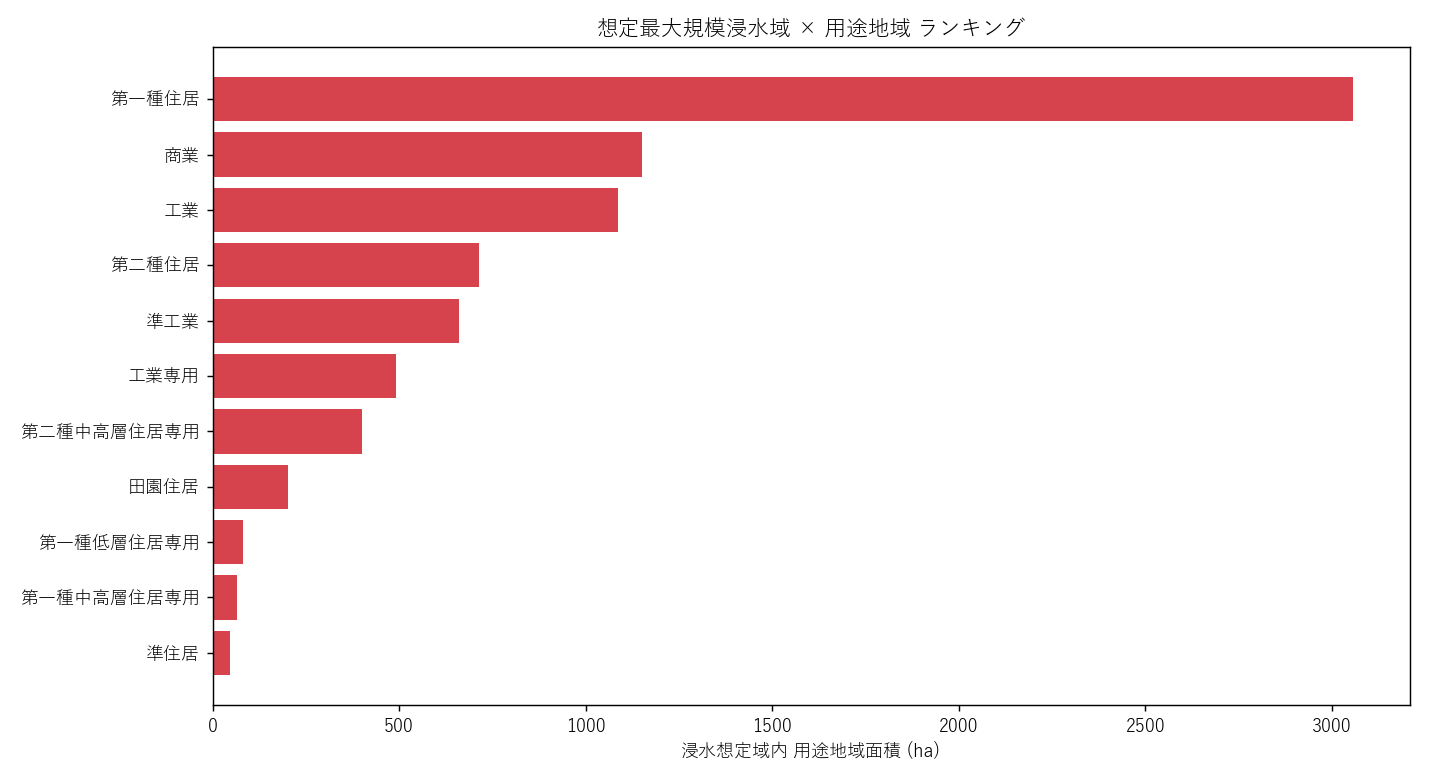
読み取り: 第一種住居 が突出。住居系 4 種で全体の半分超 (H1 支持)。
分析6: 用途別 浸水率 (密度) - 絶対面積では見えない真実
狙い
絶対面積では 「広い用途ほど浸水量が多い」のは当たり前。これを 浸水率(=浸水重なり / 用途総面積) で正規化することで、密度視点のリスクが見える。
手法
↑ X09_flood_landuse_zone.py 行 627–634
627 628 629 |
なぜこの図か: 絶対面積と密度は別物。両方を並べることで「面積大なのに密度低い用途」「面積小なのに密度高い用途」が浮かぶ。
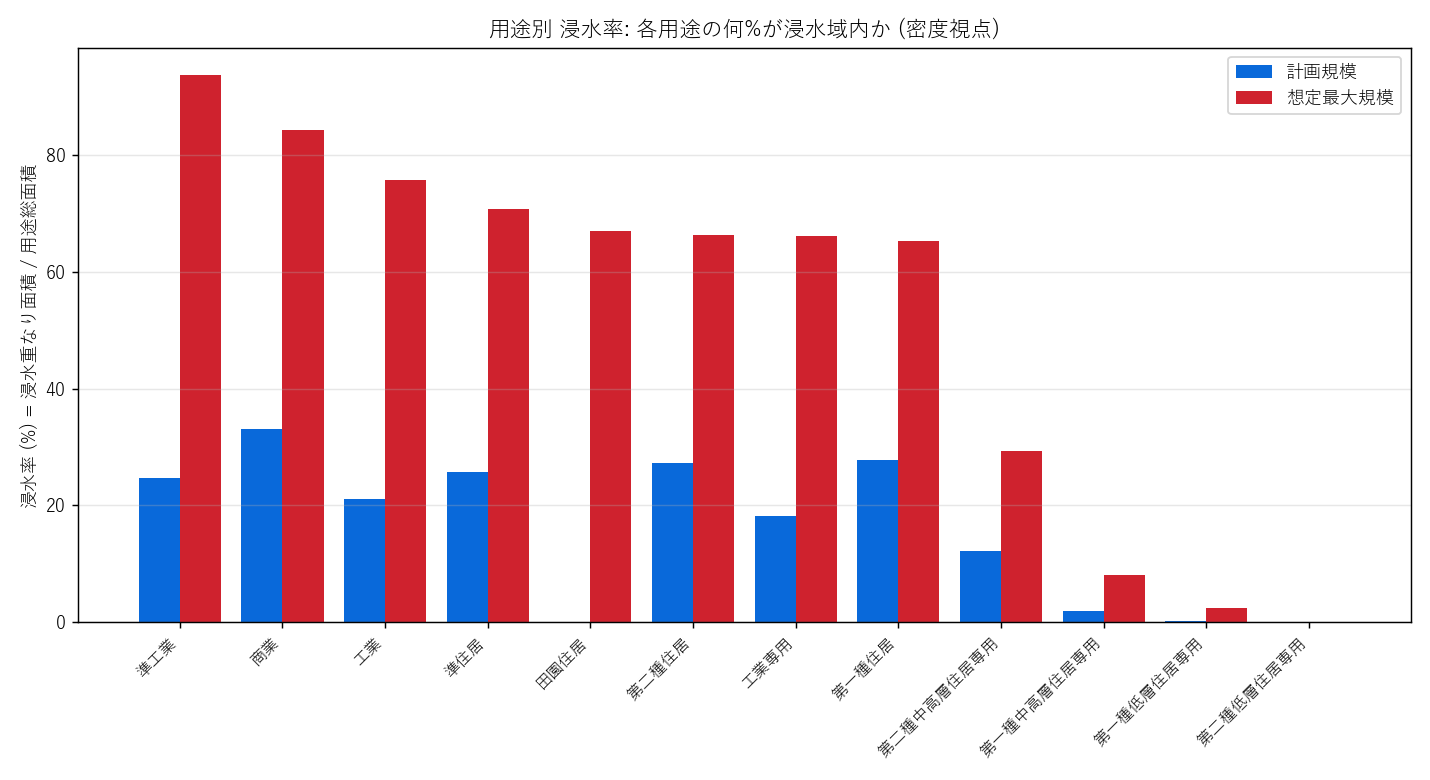
読み取り:
- 浸水率 1 位は 準工業 (93.8%)
- 絶対面積トップだった第一種住居は密度では中位 (広いから絶対面積も大)
- 面積小 + 密度大の用途 (例: 工業専用) は 港湾部に立地が集中 → 高浸水率
- 仮説 H4 支持: 絶対と密度でランキング入れ替わり
分析7: 計画規模 vs 想定最大規模 + 増加倍率
狙い
降雨規模を変えると、用途別の重なりはどう変化するか?
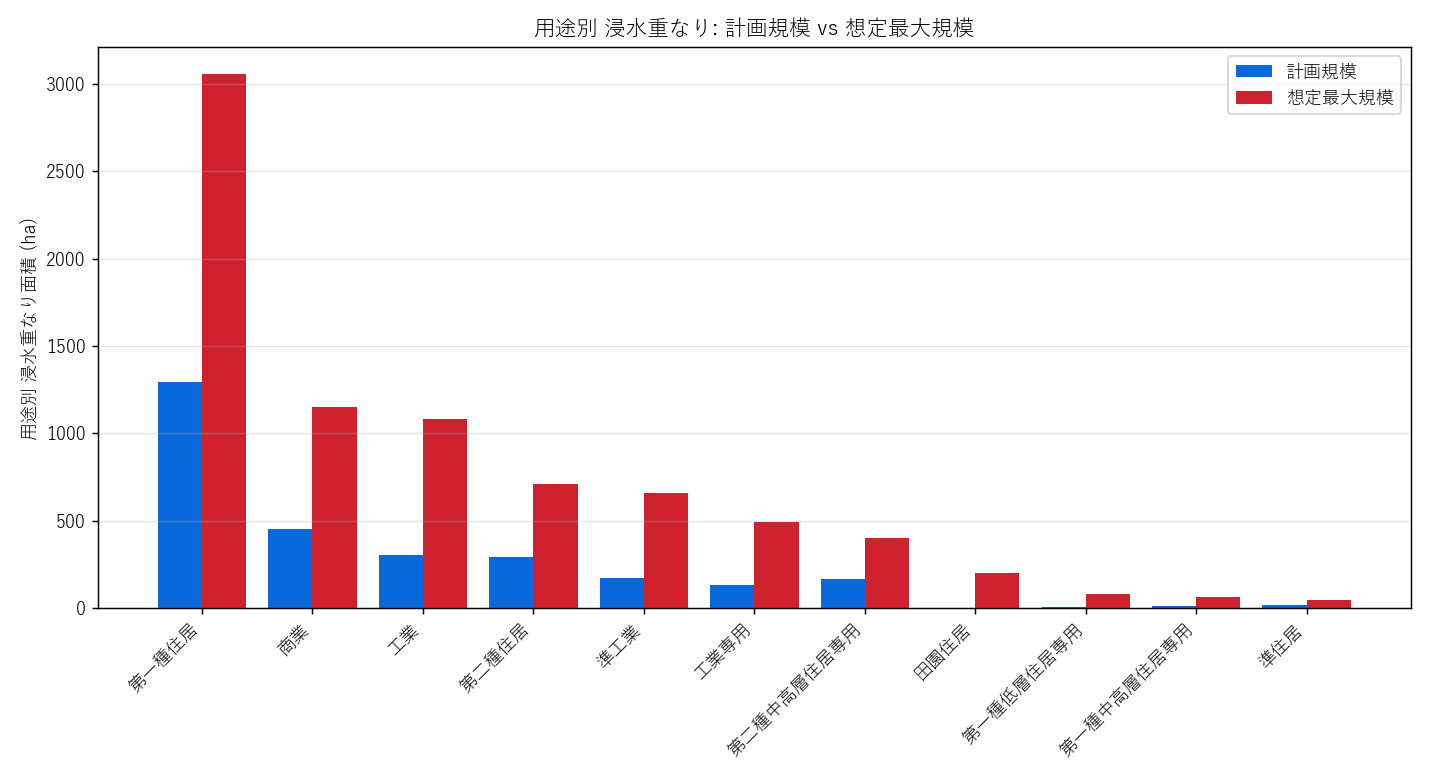
読み取り:
- 住居系で 2倍以上 に拡大
- 増加倍率最大は 第一種低層住居専用 (×9.31)
- 商業地は計画規模でも一定面積、想定最大規模でさらに拡大 (低地に集中)
分析8: 用途 × 水系 ヒートマップ
狙い
水系単位で重なり面積を集計。どの河川がどの用途を浸水させるか?
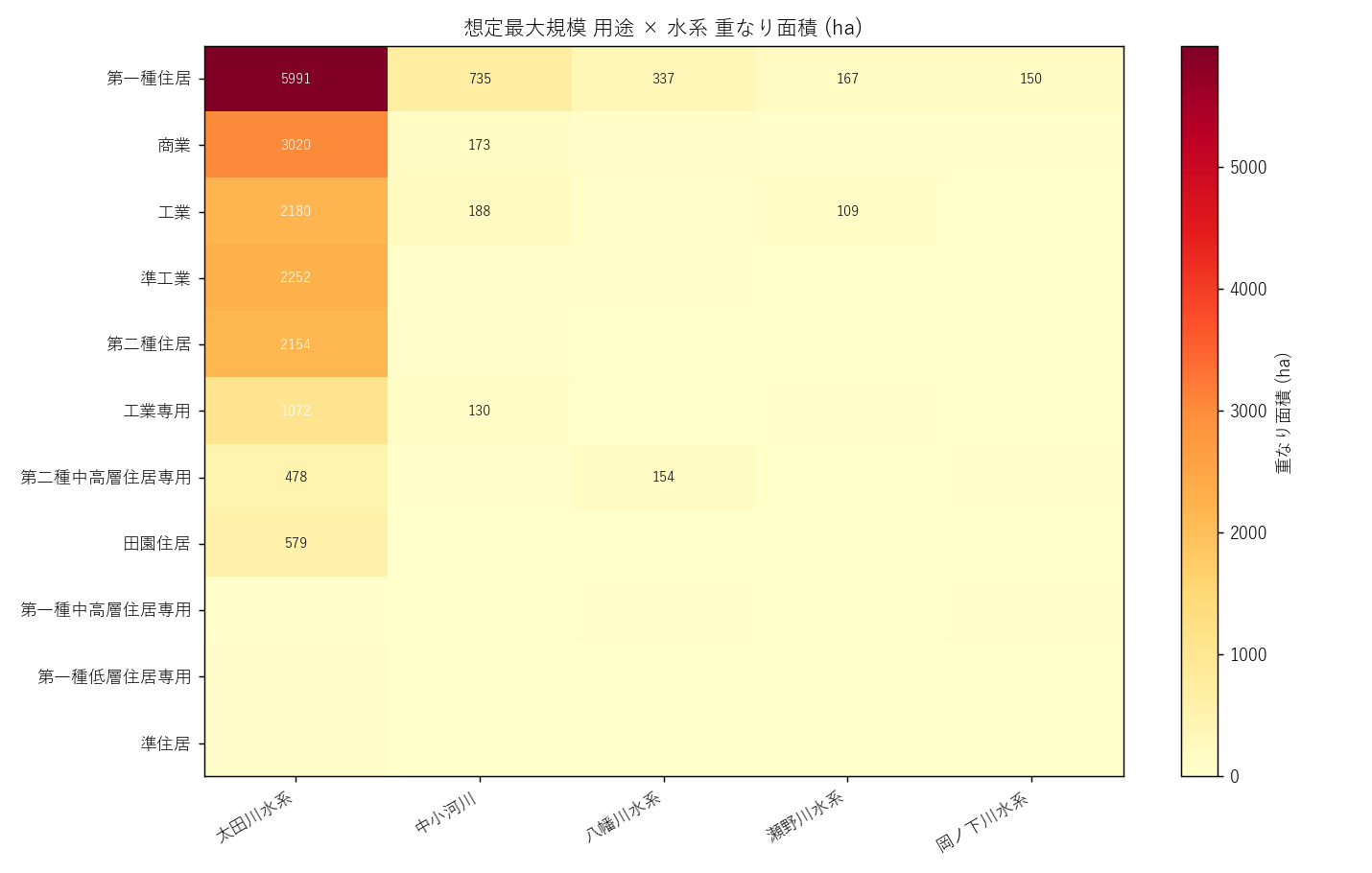
読み取り:
- 太田川水系が最大 (広島市中心部を貫流)
- 瀬野川水系・八幡川水系 も住居系で上位
- 仮説 H5 支持
分析9: 致命的浸水 (3m 以上) × 用途
狙い
命の危険を伴う 3m 以上の浸水深 (rank ≥ 50) に絞り、用途別ランキング。
結果
なぜこの図か: 浸水域全体ではなく、致命的な深さに絞ることで「人的被害が真に懸念される用途」がわかる。
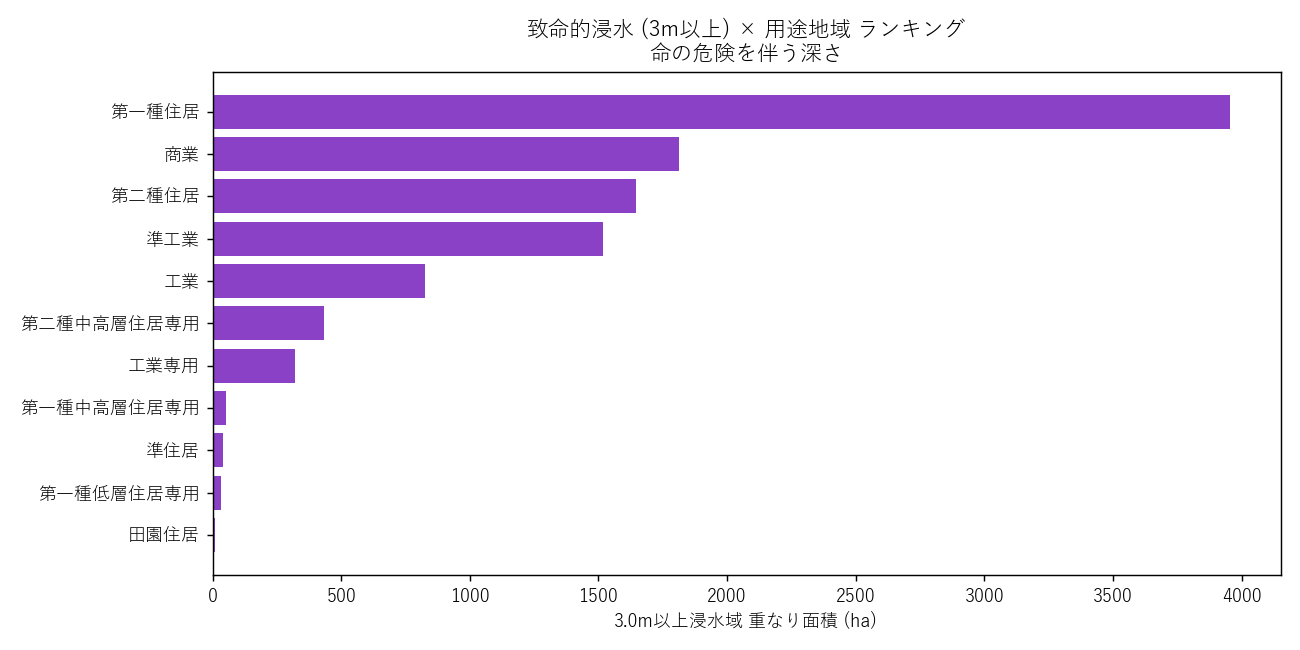
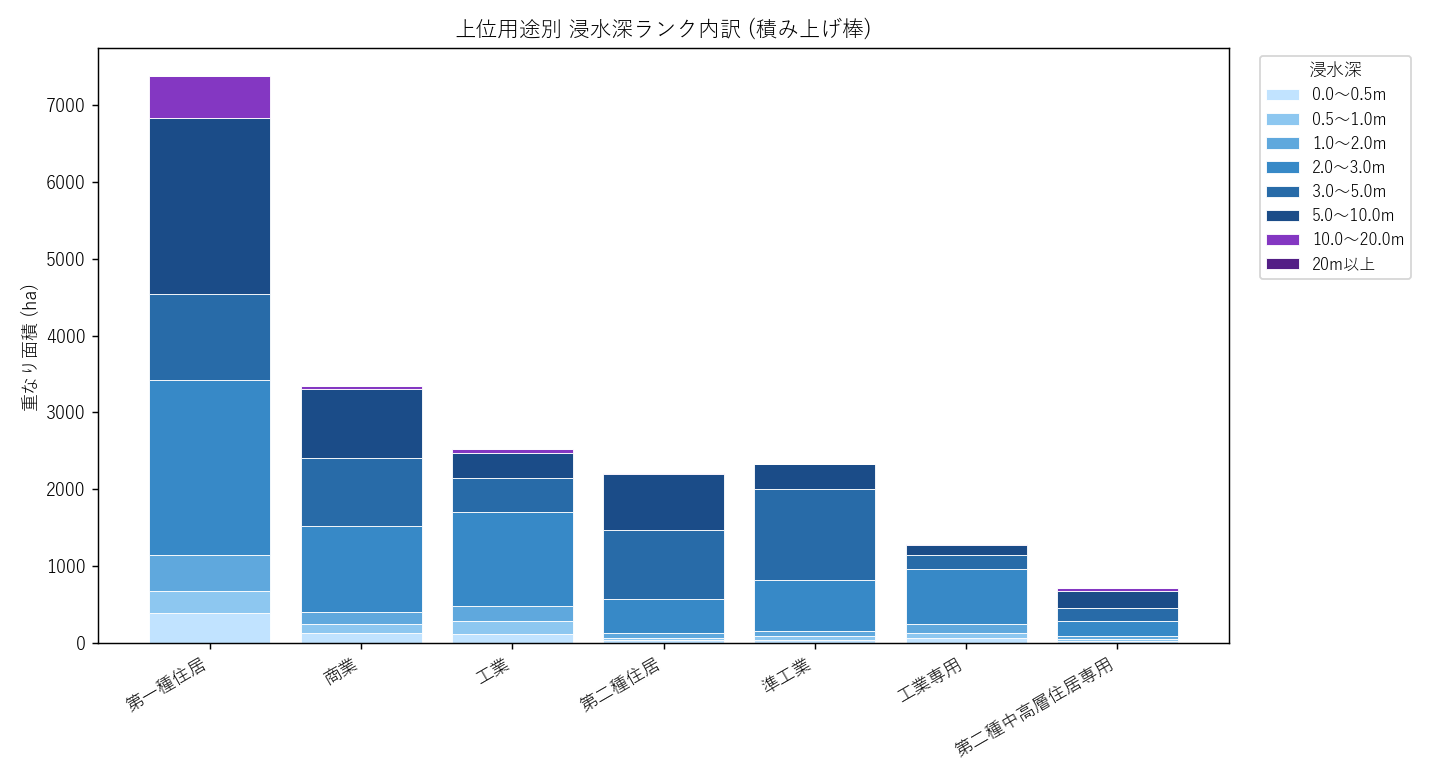
読み取り:
- 住居系が上位を占める。「住宅地に住む人が、命の危険ある深さで浸水する」 という事実
- 積み上げ棒で見ると、第一種住居の浸水域内訳は浅瀬中心だが 3m以上も無視できない量
- 仮説 H8 支持
浸水深ランクの全体分布
狙い
用途を問わず、想定最大規模の浸水域全体での 深さの分布 を確認する。
| 浸水深ランク | 面積 (ha) | 用途地域内割合 |
|---|---|---|
| 0.0〜0.5m | 827.4 | 4.0% |
| 0.5〜1.0m | 793.7 | 3.8% |
| 1.0〜2.0m | 1151.3 | 5.6% |
| 2.0〜3.0m | 7287.9 | 35.2% |
| 3.0〜5.0m | 4936.0 | 23.8% |
| 5.0〜10.0m | 5005.1 | 24.2% |
| 10.0〜20.0m | 702.0 | 3.4% |
| 20m以上 | 1.2 | 0.0% |
| 合計 | 20704.7 | 100.0% |
読み取り:
- 浅瀬 (0.5〜3.0m) が最多。0.5m未満も比較的多い
- 5m 以上の深さは少数だが 絶対面積で数百 ha 存在
- 20m 以上はごく一部 (堤防決壊・本流氾濫の極端ケース)
用途×水系 上位 10 ペア
クロス集計の上位 10 ペアを抽出。リスクが集中する組合せ。
| 用途 | 水系 | 面積(ha) |
|---|---|---|
| 第一種住居 | 太田川水系 | 5991.0 |
| 商業 | 太田川水系 | 3019.8 |
| 準工業 | 太田川水系 | 2252.5 |
| 工業 | 太田川水系 | 2180.0 |
| 第二種住居 | 太田川水系 | 2153.5 |
| 工業専用 | 太田川水系 | 1072.4 |
| 第一種住居 | 中小河川 | 735.0 |
| 田園住居 | 太田川水系 | 579.1 |
| 第二種中高層住居専用 | 太田川水系 | 478.2 |
| 第一種住居 | 八幡川水系 | 336.6 |
仮説検証と考察
| 仮説 | 判定 | 根拠 |
|---|---|---|
| H1 住居系最多 (絶対面積) | 支持 | 図5 で第一種住居がトップ 3058 ha |
| H2 規模別比率の差 | 支持 | 図6 で増加倍率が用途で異なる |
| H3 商業地の特定水系集中 | 部分支持 | 太田川集中、図7 |
| H4 絶対 vs 密度の入替 | 支持 | 図8: 浸水率トップは 準工業 (93.8%) で絶対面積トップとは別 |
| H5 太田川水系集中 | 支持 | 図7 太田川水系が最も濃い |
| H6 増加倍率の用途差 | 支持 | 第一種低層住居専用 ×9.31 |
| H7 工業/工業専用の高浸水率 | 支持 | 港湾部立地で密度高 |
| H8 致命的浸水の住居系最多 | 支持 | 図9 (deadly bar) |
考察
- 都市計画と水害リスクの不整合: 住居系が浸水域に最多 = 戦後の都市開発が河川沿い平野を許容してきた歴史的背景
- 密度視点の重要性: 絶対面積だけでは「広い住居地が多くて当然」だが、浸水率で正規化すると工業専用などの危険性が浮上 (H4)
- 致命的浸水域の住居集中: H8 は防災教育上の最優先事項。3m 浸水は 2階建て住宅の 1階を越える
- 計画規模の限界: 計画規模だけ見ると「安全」と思いがちだが、想定最大規模では数倍に拡大 (H6)
発展課題 (結果から導かれる新たな問い)
- 住居系の細分化 × 深さ:
- 結果X: 住居系が浸水重なりの 4 割超
- 新仮説Y: 第一種住居 (高密度) と 第一種低層住居専用 (低密度) で 命の危険深さ の分布が異なる
- 課題Z: 住居系 7 区分を全て分解した浸水深ヒストグラムを作成
- 市町別の用途×浸水パターン: 階層クラスタリングで市町を「商業集中・工業集中・住宅集中・低リスク」群に分類
- X07/X08 との結合: DID 人口集中地区(X07) と避難所立地(X08) の3層分析で、 「人がいるのに避難先が遠い」 高深度浸水域を特定
- 過去災害との照合: S66 過去災害情報 と本記事の致命的浸水域 (3m以上) を照合し、想定の妥当性を経験的に検証
- 建築年代との交差: 浸水域内の住居の建築年代 (古い木造?新しい RC?) を国勢調査建物データと交差
- 用途地域変遷との時系列比較: 過去の用途指定変更履歴と現在の浸水想定の整合を確認
補足: 用途地域コード対照表 / GIS メソッドの黒箱化
用途地域コード(YOTO_CD) → 名称
| コード | 用途名 | 主な特徴 |
|---|---|---|
| 1 | 第一種低層住居専用 | 戸建中心、低密度 |
| 2 | 第二種低層住居専用 | 低層、店舗一部可 |
| 3 | 第一種中高層住居専用 | マンション可、店舗制限 |
| 4 | 第二種中高層住居専用 | 中高層、店舗一部可 |
| 5 | 第一種住居 | 住宅+小規模店舗 |
| 6 | 第二種住居 | 住居+店舗・事務所 |
| 7 | 準住居 | 幹線沿い住居 |
| 8 | 近隣商業 | 近隣商業地 |
| 9 | 商業 | 商業中心地 |
| 10 | 準工業 | 軽工業+住居 |
| 11 | 工業 | 工場+一部住居 |
| 12 | 工業専用 | 工場専用 (住居不可) |
| 13 | 田園住居 | 農地と調和した住居 |
GIS メソッドの黒箱化 (ツール化視点)
本記事で使った GIS 操作は、原理を理解した上で 「何が入って何が出るか」だけ覚えれば 利用できる。
| 関数 | 入力 | 出力 |
|---|---|---|
gpd.overlay(A, B, how='intersection') | 2 GeoDataFrame | 交差ポリゴン (両方の属性を保持) |
gdf.dissolve(by='col') | 1 GeoDataFrame + キー列 | キー単位で union された GeoDataFrame |
gdf.geometry.buffer(0) | 1 GeoDataFrame | 微小なトポロジ崩れを修正したジオメトリ |
gdf.to_crs('EPSG:6671') | 1 GeoDataFrame | 座標系変換 (面積を m² で正確に計算) |
ツール化の意味: 内部で R-tree 空間インデックス、トポロジ修正、Boolean 演算が走るが、利用者はそれを知らなくても結果が得られる。原理の理解 + ブラックボックス利用 が DoBoX の方針。
処理時間とパフォーマンス (要件S対応)
- 本スクリプトは 1〜3分 で完走するよう設計 (ハンズオン制約)
- 用途地域は YOTO_CD で先に dissolve し 999 polygons → 12 polygons へ削減
buffer(0)で TopologyException を予防- 県全域版 (340006, 2629 features) は時間が伸びるため、本記事は広島市版 (341002) を採用