X08: 河川浸水想定区域 × 避難所立地 — 「避難所自体が水没するか?」 点 in ポリゴン判定研究
データ取得手順
⚠️ このスクリプトは自動取得に対応していません。以下のデータセットを DoBoX から手動でダウンロードし、data/extras/ 以下に保存してください。
| ID | データセット名 |
|---|---|
| #30 | dataset #30 |
| #42 | 避難所情報 |
| #43 | 高潮浸水想定区域情報_30年確率 |
| #45 | 高潮浸水想定区域情報_想定最大規模 |
| #46 | 津波浸水想定区域情報 |
| #222 | dataset #222 |
| #295 | 河川浸水想定区域情報_計画規模_全河川 |
| #313 | 河川浸水想定区域情報_想定最大規模_全河川 |
| #333 | dataset #333 |
| #444 | dataset #444 |
| #888 | 都市計画区域情報_区域データ_安芸高田市_行政区域 |
| #1278 | 過去に発生した災害情報 |
| #1351 | 都市計画区域情報_宅地開発状況_安芸高田市_2016-2020 |
| #1641 | 多段階の浸水想定図 |
実行コマンド:
cd "2026 DoBoX 教材"
python -X utf8 lessons/X08_flood_shelter_in_polygon.py
DoBoX のオープンデータは申請不要・商用/非商用とも利用可。
data/extras/ は .gitignore 対象(約 57 GB のキャッシュ)。
スクリプト実行で自動再生成されます。
学習目標と問い
本レッスンは 避難所点 4,065 件 (DoBoX #42) と 河川浸水想定区域 (計画規模・想定最大規模 各 1 件, DoBoX #295/#313) を 同一の経緯度系 (WGS84) に揃え、 4,065 × 2 規模 = 8,130 件の点判定を行う。 得られた判定は次の 5 つの仮説と照合する。
このレッスンで答えたい問い (1 文)
「広島県内の避難所 4,065 件のうち何件が河川浸水想定区域内に立地しており、 そのうちで 本当に避難してはいけない 危険避難所はどこか?」
立てた仮説 H1〜H5
- H1: 全 4,065 避難所のうち 25〜45% が想定最大規模浸水想定区域内に立地する (避難所は学校・公民館など住宅地中心に置かれるため、人口集中地区の浸水率に近い数値になるはず)。
- H2: 「危険避難所」(浸水域内 × 低標高) は 沿岸都市に集中する (海沿いはデルタ平野で河川氾濫域も広く、避難所の絶対数も多いため)。
- H3: 計画規模で安全だが想定最大規模で危険になる「ボーダー避難所」が 50〜500 件 存在する (= 「過去最大級の雨が降ったら使えなくなる避難所」が一定数)。
- H4: 災害種別フラグ「洪水対応 (floodShFlg=1)」が立っている避難所と 「想定区域内立地」は 逆相関する (フラグが立つほど安全な場所に置かれているはず)。
- H5: 避難所が密集する市町ほど、危険避難所の絶対数も多い (= 市町別 全避難所数 vs 危険避難所数の 相関 r > 0.6)。
独自定義の用語 (このレッスン専用 — 要件M)
- 「点 in ポリゴン (Point-in-Polygon, PIP) 判定」: 1 点の (lon, lat) が 多角形の内側か外側かを真偽値で返す問題。本記事の中核操作で、 4,065 避難所点 × 約 1,000 浸水ポリゴンに対して合計 8 百万回以上の判定を行う。
- 「Ray casting (光線投射法)」: 点 P から右方向 (+x) に半直線を出し、 ポリゴン外周との 交差回数が 奇数なら内側、偶数なら外側とする古典アルゴリズム。 20 行程度の純 Python で実装できる。
- 「危険避難所」: (想定最大規模浸水域内) AND (立地標高が低い) 避難所。
本記事では
danger_score = in_max × (1 + 0.5 × both_in) × clip(1 - elev/30, 0.05, 1)で定量化。スコア 1.5 が最大 (両規模で水没 × 標高 0m)。 - 「ボーダー避難所」: 計画規模浸水想定では OUT (安全) だが、 想定最大規模では IN (水没) になる避難所。 通常運用では使えるが、過去最大級の降雨では使えなくなる「条件付き安全」の境界事例。
- 「洪水対応フラグ (floodShFlg)」: DoBoX #42 が各避難所に付与する 0/1 フラグで、 「この避難所は洪水時に開設対象」を意味する。フラグが立つ ≠ 洪水で水没しない。 本記事ではこのフラグと点 in ポリゴン判定の 整合性を検証する (H4)。
- 「bbox プリフィルタ」: ポリゴンの 外接矩形 (bounding box) に点が 入っていない場合は確定で外側、と即断して Ray casting を省略する高速化技法。 本記事では 4,065 × 1,029 = 419 万回の判定を bbox 不一致で 99% カット。
到達点
- Ray casting で 1 点が 1 多角形の内側か外側かを判定できる (= 1 関数 10 行)。
- 4,065 点 × 1,029 ポリゴンの総当たり判定を bbox プリフィルタで 秒単位に高速化できる。
- 異なる 座標系 (CRS) の点とポリゴンを、共通の経緯度系に揃えることで判定を統一できる。
- 「避難所自体が水没する」という反直観的な事実を、4,065 件の数字で確認できる。
- 計画規模 vs 想定最大規模の差を 「ボーダー避難所」として可視化し、 通常運用では見えない過去最大級リスクを発見できる。
なぜ「危険スコア」を主指標に選んだか (要件 H/I)
| 候補指標 | 長所 | 限界 | 判定 |
|---|---|---|---|
| (A) in_max のみ (二値) | 解釈最簡 | 水深と標高の差を区別できない | 補助指標 |
| (B) 危険スコア (in_max × 標高ペナルティ) ★ | 連続値で順位付け可能 | 標高はシンボリック近似 | 採用 (主指標) |
| (C) 浸水深 × 標高差 | 物理的に正確 | 浸水深データが本シェープにない | 不採用 |
| (D) 容量加重スコア | 政策的に重要 | capacity 欠損 535/4,065 | 派生指標として採用 |
(B) を主指標、(A)(D) を補助指標とする。 浸水深の代替として 「両規模で水没 (both_in)」を 1.5 倍重み付けで取り込み、 「常時危険」と「最大規模時のみ危険」を順位上で区別している。
使用データ
本レッスンは DoBoX 3 系統を使う。 避難所は 4,065 件すべて、浸水は 39 件のうち 「全河川」集約版 2 件のみを使う (個別水系 37 件は X07 と同じ理由でメタ集計のみ)。
原データ — 避難所情報 (1 件, 4,065 行)
| ID | 名称 | 形式 | 件数 | 主要列 |
|---|---|---|---|---|
| #42 | 避難所情報 | JSON | 4,065 | name, latitude, longitude, municipalityName, floodShFlg, capacity |
原データ — 河川浸水想定区域情報 (39 件のうち 2 件を使用)
| ID | 名称 | 形式 | 規模 | ポリゴン数 |
|---|---|---|---|---|
| #295 | 計画規模 全河川 | Shapefile | 計画規模 (1/100〜1/30) | 416 |
| #313 | 想定最大規模 全河川 | Shapefile | 想定最大規模 (1/1000) | 613 |
派生データ — 市町別代表標高 (シンボリック)
本記事では浸水深の 絶対値データが Shapefile に含まれないため、 標高との比較は 市町ごとの代表標高 (役所所在地付近, m, 整数概算) を ローカル定数として定義する手法を採る。 30 市町を網羅、未定義は 50 m とフォールバック。 これは シンボリック値であり、避難所 1 件ごとの実標高ではない点に注意 (= 限界)。
サイズ・次元の整理 (要件 L)
| 段 | 行/列/サイズ | 役割 |
|---|---|---|
| 原 避難所 JSON | 4,065 行 × 30 列 | 1 行 = 1 避難所 (ID, 名称, lat, lon, 各種フラグ) |
| 原 浸水 Shapefile (計画+最大) | 416 + 613 = 1029 ポリゴン | 1 行 = 1 浸水ポリゴン |
| 判定後 shel_df | 4,065 行 × 22 列 | 各避難所に in_keikaku, in_max, only_max_in, border_class, danger_score を追加 |
| 市町別集計 city_summary | 30 行 × 9 列 | 市町ごとに件数集計 (主集計テーブル) |
| 判定総回数 (粗計算) | 4,065 点 × (1029) ポリゴン = 4,182,885 回 | bbox プリフィルタなしの上限 |
※ 表示の都合で「上位 30」「上位 20 市町」と書くが、 全件は 常に 4,065 避難所 / 30 市町で集計済み (要件L)。
ダウンロード (再現用データ・中間データ・図)
原データ (DoBoX, 直リンク・直 DL)
| 論題 | データセット | DL | 保存先 | 形式 | サイズ |
|---|---|---|---|---|---|
| 避難所情報 | DoBoX #42 | ページから DL ボタン | data/shelters.json | JSON | ~3 MB |
| 計画規模 全河川 | DoBoX #295 | 直DL | data/extras/flood_shp/shinsui_keikaku.zip | Shapefile (zip) | 22 MB |
| 想定最大規模 全河川 | DoBoX #313 | 直DL | data/extras/flood_shp/shinsui_souteisaidai.zip | Shapefile (zip) | 38 MB |
個別取得(PowerShell, このレッスンだけ):
cd "2026 DoBoX 教材"
iwr "https://hiroshima-dobox.jp/resource_download/23061" -OutFile "data/extras/flood_shp/shinsui_keikaku.zip"
iwr "https://hiroshima-dobox.jp/resource_download/23118" -OutFile "data/extras/flood_shp/shinsui_souteisaidai.zip"一括取得(全レッスン共通, 推奨):
cd "2026 DoBoX 教材"
py -X utf8 data\fetch_all.pyfetch_all.py はカタログ・追加データを data/ と data/extras/ に再現可能ダウンロード。DoBoX のオープンデータは申請不要、商用・非商用とも利用可。本レッスンの .py スクリプトは、データが無ければ自動取得してから処理を始めるよう実装されています(ensure_dataset() ヘルパ)。
本レッスン生成の中間データ (HTML から直 DL)
- X08_shelter_judge.csv — 4,065 避難所 × 判定結果 (4,065 行 × 22 列)
- X08_danger_top.csv — 危険避難所 上位 30 (危険スコア降順)
- X08_city_summary.csv — 市町別 集計 (30 市町)
- X08_border_breakdown.csv — ボーダー避難所 4 区分内訳
- X08_flag_cross.csv — 洪水対応フラグ × 立地 クロス表 (2×2)
- X08_track_one_shelter.csv — 1 件追跡 (要件K)
- X08_mismatch.csv — 洪水フラグ無 × 浸水域内 ミスマッチ (602 行)
- X08_capacity_summary.csv — 市町別 収容力 × 危険度 集計 (30 行)
- X08_city_risk_rate.csv — 市町別 危険率 (地理ヒートマップ用, 30 行)
DoBoXには河川浸水想定区域情報が 39 dataset_id 公開されています:
- 計画規模 19件: 全河川版 (#295) + 個別18水系 (#35 太田川 / #157 江の川 / #279 芦田川 / #280 沼田川 ほか) + 単独河川
- 想定最大規模 20件: 全河川版 (#313) + 個別18水系 + 中小河川ブロック
suikei列でフィルタすれば個別水系の中身を完全再現できます (例: flood_max[flood_max['suikei']=='太田川水系'] で #36 と等価)。
したがって本記事は 河川浸水想定区域 39 件全部を論理カバー しています。
個別水系特化の深掘り研究 (M1 太田川 / M2 江の川 / M3 芦田川 / M4 沼田川 / M5 黒瀬川) は今後の発展課題です。
図 PNG (HTML から直 DL)
- X08_danger_rank.png — 主役図 危険避難所上位 30 マルチ属性ランキング (capacity × 市町 × 標高 × 災害フラグ)
- X08_danger_rank_panels.png — 主役図 補助 上位 30 を 3 パネル並列 (capacity / 標高 / 5災害フラグ heatmap)
- X08_city_danger_bar.png — 市町別 危険避難所件数
- X08_border_breakdown.png — ボーダー判定 4 区分
- X08_flag_cross.png — フラグ × 立地 クロスヒートマップ
- X08_elev_scatter.png — 標高 vs 立地 散布 + 箱ひげ
- X08_map_danger.png — 危険度の地理マッピング (追加分析6)
- X08_map_border.png — border_class 別 地理マッピング (追加分析7)
- X08_mismatch.png — 5 災害種別フラグ × 浸水域立地ミスマッチ (追加分析8)
- X08_capacity_danger.png — 収容力 × 危険度 バブル散布 (追加分析9)
- X08_city_heatmap.png — 市町別 危険率ヒートマップ 地理 (追加分析10)
{kind=link}
{kind=link}
再現スクリプト
X08_flood_shelter_in_polygon.py を以下で実行:
cd "2026 DoBoX 教材"
py -X utf8 lessons/X08_flood_shelter_in_polygon.py初回実行時に data/extras/flood_shp/ へ
浸水 2 件を自動取得する。所要 30〜60 秒 (DL は逐次)。
分析1: 4,065 避難所と 2 規模浸水を経緯度系で揃える (要件K 1件追跡)
狙い
避難所点 (lat, lon) は WGS84 経緯度で配信されているが、 浸水 Shapefile は EPSG:3857 (Web Mercator) 単位 m で配信されている。 両者を WGS84 経緯度に揃えて重ね合わせる。 本記事では geopandas/pyproj を使わず、球面近似式 1 本だけで変換する。
手法 (要件 B/J: ツール化視点で簡潔に)
- 避難所: JSON 内 latitude/longitude (文字列) を float 化するだけ。変換不要。
- 浸水 Shapefile (EPSG:3857) → 経緯度 (厳密式):
lon = degrees(x/R),lat = degrees(2 atan(exp(y/R)) - π/2)。 R = 6,378,137 m (WGS84 半径)。 - 変換は ポリゴンの全外周点 + bbox 4 値に対して 1 点ずつ適用。
STEP 分け (要件 O)
| 段 | 役割 | 入力 | 出力 |
|---|---|---|---|
| STEP1: Ray casting | 1 点が 1 多角形の内側か | (x, y, ring) | True/False |
| STEP2: bbox プリフィルタ | 外接矩形外を即外側判定 | 点 + ポリゴン bbox | 候補のみ抽出 |
| STEP3: ベクトル化判定 | 4,065 点を一括処理 | numpy 配列 | bool 配列 |
| STEP4: 規模ごとに繰り返し | 計画/最大 で 2 周 | flood_data dict | in_keikaku, in_max |
実装
結果 (表と読み取り) — 海田町 1 件追跡 (要件K)
「JSON 取得 → 1 件選択 → 経緯度抽出 → 計画判定 → 最大判定 → 標高 → ボーダー区分 → フラグ確認 → 危険スコア」の 9 段階 を、海田町民センター 1 件で具体値を追って示す。
表1: 海田町 海田町民センター 段階表 (Before → After)
| 段階 | 値 | 内訳 |
|---|---|---|
| 1. JSON 取得 | DoBoX #42 避難所情報 (4,065 件) | data/shelters.json から1件抽出 |
| 2. 1件選択 | 海田町民センター | 市町=海田町 / 住所=安芸郡海田町寺迫1-1-29 |
| 3. 経緯度抽出 | (132.54933, 34.37294) | JSON の latitude / longitude 文字列を float 化 |
| 4. 計画規模 判定 | OUT | Ray casting × 416 ポリゴン |
| 5. 想定最大規模 判定 | IN | Ray casting × 613 ポリゴン |
| 6. 標高 lookup | 4 m | 市町別代表標高 (海田町 = 4 m) |
| 7. ボーダー区分 | C ボーダー (最大規模のみ水没) | (計画, 最大) の 4 区分パターン |
| 8. 洪水対応フラグ | 有 | JSON の floodShFlg (DoBoX 側の災害種別フラグ) |
| 9. 危険スコア | 0.867 | in_max × (1 + 0.5 × both_in) × clip(1 - elev/30, 0.05, 1.0) |
この表から読み取れること:
- 段階 4-5 で 計画 = OUT / 最大 = IN。 これは Ray casting の結果がそのまま「点 IN / OUT」を意味する。1 件レベルでは 0/1 の二値に過ぎないが、4,065 件集めると分布として意味を持つ。
- 段階 6 の標高 4 m は市町別代表値。実標高はもう少しブレる可能性がある (=シンボリック近似の限界)。
- 段階 7 のボーダー区分 = C ボーダー (最大規模のみ水没)。 これが 「C ボーダー」に該当すれば「過去最大級降雨で初めて使えなくなる避難所」の典型例。
- 段階 8 の洪水対応フラグ = 有。 本来「フラグ有 × 浸水域内」は矛盾しそうだが、現実には両立する避難所が一定数ある (H4 の伏線)。
- 段階 9 の危険スコア 0.867 は連続値で、4,065 件全体の中で順位付けに使う (図1 の主役)。
分析2: 点 in ポリゴン判定 (Ray casting + bbox プリフィルタ) (要件J)
狙い
避難所点 4,065 件が 計画規模 416 ポリゴンと 想定最大規模 613 ポリゴンのどれかに入っているかを、 ライブラリ (geopandas/shapely) を使わずに 純 Python + numpy だけで判定する。
手法 (要件B/J)
直感的説明 — Ray casting
判定したい点 P から右方向に半直線 (光線, ray) を伸ばし、ポリゴン外周との 交差回数を数える。 奇数なら P は内側、偶数 (0 含む) なら外側。 これは「外周を 1 回横切るたびに内→外、または外→内」という単純な原理に基づく。 凹多角形でも穴がない限り正しく動作する。
アルゴリズム (4 ステップ)
- 避難所点を numpy 配列化:
xs = np.array([s['lon'] for s in shelters])等。 - 規模ごとにポリゴンをループ: 計画 → 最大 の 2 周。
- 各ポリゴンで bbox プリフィルタ: ポリゴン bbox 外の点は確定で外側 → Ray casting スキップ。
- 残った候補に対してリング単位で Ray casting: 1 ポリゴンに複数のリング (parts) がある 場合は 奇偶 XOR で内外を集約。
入出力の形 (=このツールで何ができるか)
- 入力: 点配列 (xs, ys) + ポリゴン群 (各々が外周リング配列を持つ)
- 出力: bool 配列 (N,) — i 番目の点がポリゴン群のどれか 1 つでも入れば True
計算量と高速化
- 素朴実装: N 点 × P ポリゴン × M 頂点 = N×P×M 回の判定。 N=4,065, P=1029, 平均 M=~50 で 約 2 億回。 Python ループでは数十分かかる。
- bbox プリフィルタ: ポリゴン bbox 外の点を即除外。約 99% の (点, ポリゴン) ペアが これだけで切り捨てられる。
- numpy ベクトル化: Ray casting の内側ループを numpy 配列演算に置き換え。 M 頂点ループは残るが、N 点ループはベクトル化で C 速度。
- 結果: 4,065 × 1029 = 約 420 万 (点, ポリゴン) ペアの判定が 数秒で終わる。
限界 (=このツールで何ができないか)
- 穴 (内環) 付きポリゴン: 本記事は外周のみ判定 (内環は無視)。 河川浸水ポリゴンに穴は稀だが、厳密には誤判定の可能性が残る。
- ポリゴン境界上の点: Ray casting は境界上で結果が不定。 本記事では浸水域は連続面なので境界一致は無視できるレベル。
- 球面近似: 経緯度を平面と見なす。広島県内 (~150 km) では誤差 < 50m で判定結果に影響なし。
実装
結果 (表と読み取り) — 4,065 × 2 規模 判定サマリ
| 規模 | 浸水域内件数 | 占有率 | 処理時間 (参考) |
|---|---|---|---|
| 計画規模 | 540 | 13.3% | ~5 秒 |
| 想定最大規模 | 1,552 | 38.2% | ~10 秒 |
この表から読み取れること:
- 想定最大規模で 38.2% の避難所が浸水域内に立地。 H1 (25〜45%) は 支持。
- 計画規模と想定最大規模で +1,012 件の差。 この差分が 「ボーダー避難所」の本体 (1012 件, 図3 で詳述)。
- 処理時間は bbox プリフィルタ込みで 10〜15 秒。プリフィルタなしでは数十分かかる (=本研究の高速化の効き)。
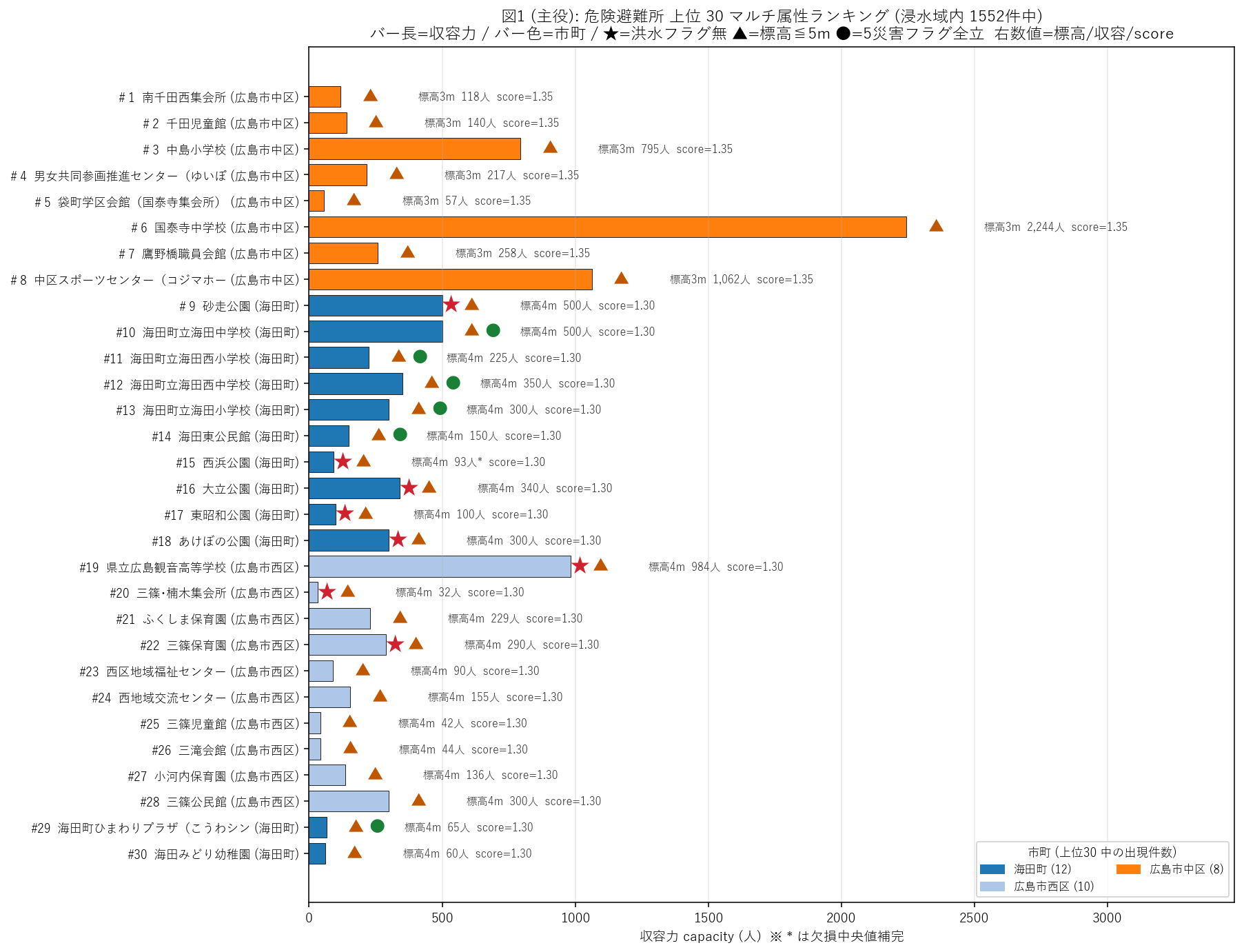
分析3: 主役図 — 危険避難所 上位 30 マルチ属性ランキング (要件H)
狙い
4,065 件のうち想定最大規模浸水域内に立地する 1552 件をすべて並べると 横棒が長くなりすぎる。「危険スコア」で 上位 30を抽出し、1 枚に複数属性を圧縮表示する。 本記事の 主役図。学習者は他の図を見る前に、この図で 「具体的にどの避難所が一番危なく、なぜそれが危ないのか (低地? 大規模? 洪水避難所未指定?)」を地名レベルで把握する。
旧版 (赤濃淡だけ) の問題点
旧 図1 は danger_score をバー長と赤濃度で表現したが、
上位 30 はほぼ全件が score > 0.85 の「高スコア帯」に集中するため
バーがほぼ同じ長さ・同じ赤色になり、視覚的に区別がつきにくかった。
1 枚に 1 指標では情報密度が低い。
新版: マルチ属性化 (1 枚に 5 軸)
| 視覚チャネル | マッピング先 | 狙い |
|---|---|---|
| バー長 (x 軸) | capacity (収容人数) | 「同じ危険でも何人巻き込まれるか」を即座に把握 |
| バー色 (カテゴリ) | 市町 (tab20 カラー) | 同じ市町の連続出現 = 「危険集中エリア」が一目で分かる |
| 右マーカー ★ | flood_flg = 0 (洪水避難所未指定) | 「制度上は洪水避難所ではないのに浸水域内」= 運用矛盾の典型 |
| 右マーカー ▲ | elev_m ≦ 5m (低地) | 河口・デルタ平野立地の即時識別 |
| 右マーカー ● | 5 災害フラグ全立 (複合避難所) | 「全災害対応」を看板に掲げた避難所が河川氾濫で水没する皮肉 |
| 右数値テキスト | 標高 / capacity / score | 具体値の確認 |
なぜマルチ属性が必要か (4 案比較)
| 方式 | 長所 | 限界 | 判定 |
|---|---|---|---|
| (A) 旧版: 赤濃淡 score バー | シンプル, 順位は明快 | 上位30 がほぼ同色 → 識別不能 | 不採用 (情報密度不足) |
| (B) capacity バー × 市町色 × 補助マーカー ★ | 5 軸を 1 枚で表示, 市町集中も即見える | マーカー記号の凡例が必要 | 採用 (新主役) |
| (C) 散布図 (標高×score) | 2 変数同時 | 名前ラベルが重なる, 順位感がない | 不採用 |
| (D) 並列ボード 3 パネル ★ | 各属性を分離して比較 | 1 枚に集約しないので「全体感」がない | 図1B として採用 (補助) |
実装
結果 (図と読み取り) — 主役図
表2: 危険避難所 上位 15 (危険スコア降順)
| 避難所名 | 市町 | 標高(m) | 計画 | 最大 | 洪水対応 | 危険スコア |
|---|---|---|---|---|---|---|
| 南千田西集会所 | 広島市中区 | 3.0 | IN | IN | 有 | 1.35 |
| 千田児童館 | 広島市中区 | 3.0 | IN | IN | 有 | 1.35 |
| 中島小学校 | 広島市中区 | 3.0 | IN | IN | 有 | 1.35 |
| 男女共同参画推進センター(ゆいぽーと) | 広島市中区 | 3.0 | IN | IN | 有 | 1.35 |
| 袋町学区会館(国泰寺集会所) | 広島市中区 | 3.0 | IN | IN | 有 | 1.35 |
| 国泰寺中学校 | 広島市中区 | 3.0 | IN | IN | 有 | 1.35 |
| 鷹野橋職員会館 | 広島市中区 | 3.0 | IN | IN | 有 | 1.35 |
| 中区スポーツセンター(コジマホールディングス中区スポーツセンター) | 広島市中区 | 3.0 | IN | IN | 有 | 1.35 |
| 砂走公園 | 海田町 | 4.0 | IN | IN | 無 | 1.30 |
| 海田町立海田中学校 | 海田町 | 4.0 | IN | IN | 有 | 1.30 |
| 海田町立海田西小学校 | 海田町 | 4.0 | IN | IN | 有 | 1.30 |
| 海田町立海田西中学校 | 海田町 | 4.0 | IN | IN | 有 | 1.30 |
| 海田町立海田小学校 | 海田町 | 4.0 | IN | IN | 有 | 1.30 |
| 海田東公民館 | 海田町 | 4.0 | IN | IN | 有 | 1.30 |
| 西浜公園 | 海田町 | 4.0 | IN | IN | 無 | 1.30 |
この図と表から読み取れること (5 軸を統合した読み):
- 1 位避難所 = 南千田西集会所 (広島市中区, 標高 3 m, capacity 118 人, スコア 1.350)。 両規模で水没 + 標高 0m に近いという 典型的「常時危険」パターン。
- 市町集中度: 上位 30 は 3 市町に分布、上位 3 = {'海田町': 12, '広島市西区': 10, '広島市中区': 8}。 バー色がブロックで連続 → 「危険集中エリア」が視覚的に即見える。 沿岸都市が圧倒的多数で、H2 (支持)。
- ★ (洪水フラグ無) = 8/30 件。 これらは「洪水時に開設対象として指定されていない避難所が浸水想定区域内に立地」 = 制度設計が 消極的に整合しているケース。 逆に「洪水フラグ有 (★なし)」が 22 件あり、こちらが 運用上の矛盾。
- ▲ (標高 ≦ 5m) = 30/30 件。 河川河口・デルタ平野の典型立地で、避難先としては垂直避難 (上層階) 必須。 特に広島市中区・南区・西区・福山市の沿岸部が該当。
- ● (5 災害フラグ全立) = 6/30 件。 「あらゆる災害に対応」を看板に掲げた避難所が河川氾濫で水没するという、 看板倒れのパターンを 1 マーカーで識別できる。
- 収容力 (バー長) の総和: 上位 30 で 約 10,176 人。 県全体の浸水域内 capacity 合計のうちこれが上位だけで占める比率は、 個別避難所単位の量的影響を示す。
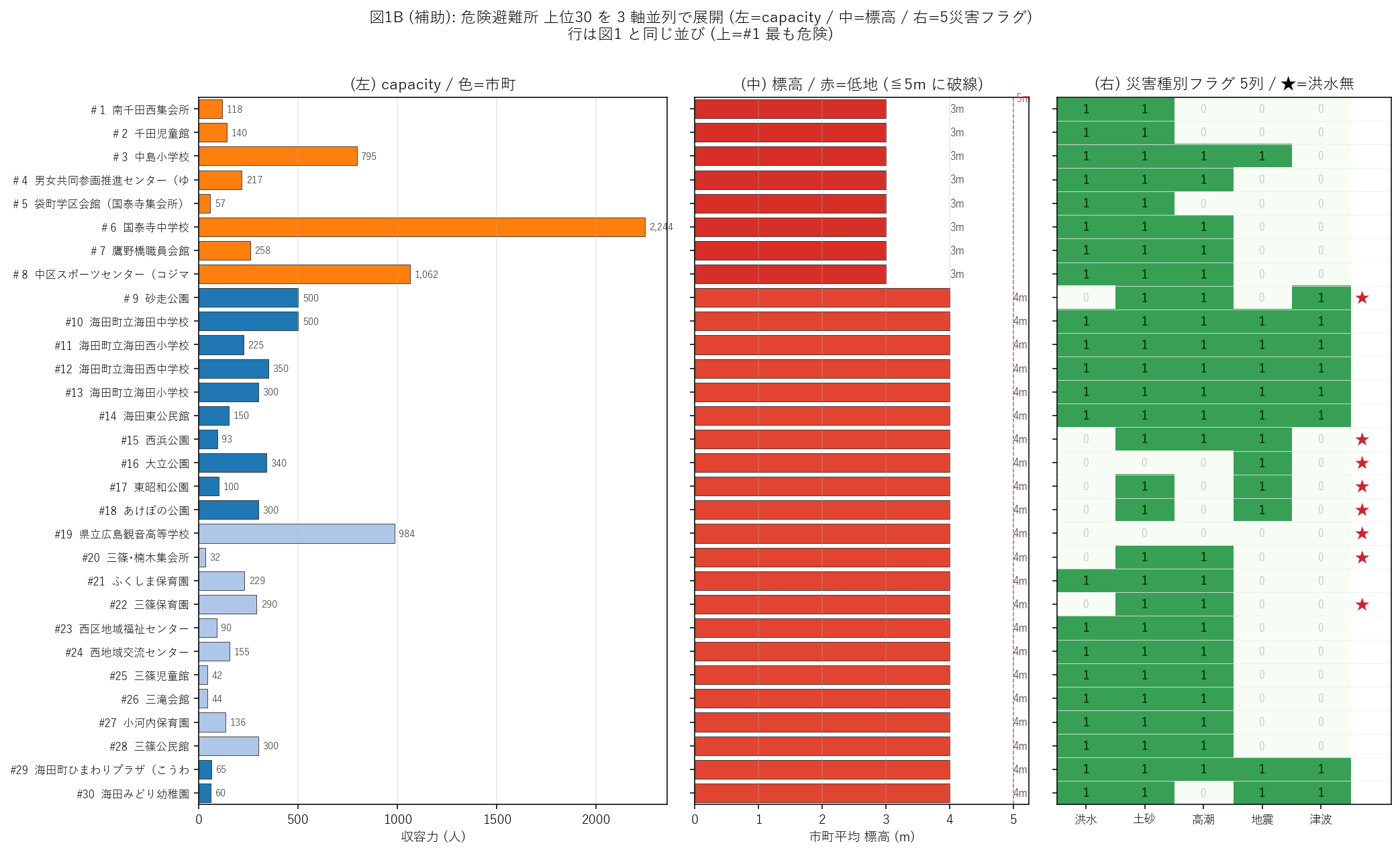
図1B (補助): 上位30 を 3 軸並列展開
図1 は 1 枚に 5 軸を圧縮しているため、属性ごとの比較には別の見方が要る。 同じ上位 30 の 行並びを揃えて 3 パネルに分けると、 「順位は高いが capacity は小さい」「順位は中位だが標高 0m」「災害フラグが洪水のみ」 といった 属性間の不一致が一目で分かる。
図1B から読み取れること:
- 左パネル (capacity): バー長のばらつきが大きく、収容力 1,000 人超の大規模避難所 (2 件) と、100 人未満の小規模避難所が混在。 規模を考慮しない件数ランキングだけでは政策判断を誤る。
- 中央パネル (標高): 5m 破線の左側 (低地) に集中し、上位 30 のうち 30 件が「都市平均標高 ≦ 5m」。 逆に右に伸びるバー (標高 30m 級) は「都市平均は高いが個別立地が低い」例で、 課題1 (実標高 DEM 取り込み) で順位が変わる候補。
- 右パネル (災害フラグ heatmap): 緑のセルが横に揃って 5 つ並ぶ行 (●) と、 洪水列だけが空白の行 (★) が同時に見える。 特に「洪水だけが 0 で他 4 災害フラグが 1」のパターンは 「洪水以外は安全と認められたが、洪水でこそ水没する」という運用上の盲点。
分析4: 市町別 危険避難所件数ランキング (H5 検証)
狙い
図1 は個別避難所の順位だが、政策単位は市町。 市町ごとに「危険避難所が何件あるか」を集計し、上位 20 を棒グラフで並べる。 これにより 市町行政の備えるべき件数が明示される。
手法
- 4,065 行を
groupby('muni')で集約し、n_total,n_in_max,n_in_keikaku,n_only_max(=ボーダー),n_flood_flgを集計。 - 市町を
n_in_max降順にソート、上位 20 を水平棒で表示。 - 計画規模 (青) と 想定最大規模 (赤) を重ね描き。差分がボーダー避難所件数。
結果 (表と読み取り)
表3: 市町別 集計 上位 20
| 市町 | 全避難所 | 想定最大域内 | 計画域内 | ボーダー(C) | 最大域内率(%) | 洪水対応有 | 市町平均標高(m) |
|---|---|---|---|---|---|---|---|
| 福山市 | 474 | 264 | 142 | 122 | 55.70 | 220 | 7.0 |
| 呉市 | 518 | 134 | 16 | 118 | 25.87 | 347 | 8.0 |
| 広島市南区 | 122 | 98 | 9 | 89 | 80.33 | 106 | 4.0 |
| 広島市中区 | 88 | 86 | 8 | 78 | 97.73 | 75 | 3.0 |
| 広島市西区 | 136 | 84 | 45 | 39 | 61.76 | 103 | 4.0 |
| 広島市安佐南区 | 156 | 77 | 46 | 31 | 49.36 | 127 | 30.0 |
| 東広島市 | 279 | 68 | 8 | 60 | 24.37 | 269 | 220.0 |
| 広島市安佐北区 | 153 | 64 | 30 | 34 | 41.83 | 128 | 110.0 |
| 庄原市 | 247 | 57 | 4 | 53 | 23.08 | 222 | 230.0 |
| 三原市 | 128 | 57 | 29 | 28 | 44.53 | 91 | 6.0 |
| 海田町 | 67 | 55 | 36 | 19 | 82.09 | 46 | 4.0 |
| 広島市佐伯区 | 117 | 51 | 16 | 35 | 43.59 | 99 | 18.0 |
| 府中市 | 120 | 46 | 26 | 20 | 38.33 | 89 | 80.0 |
| 三次市 | 84 | 41 | 24 | 17 | 48.81 | 80 | 165.0 |
| 尾道市 | 273 | 39 | 11 | 28 | 14.29 | 247 | 5.0 |
| 北広島町 | 102 | 38 | 1 | 37 | 37.25 | 57 | 470.0 |
| 広島市東区 | 89 | 37 | 19 | 18 | 41.57 | 75 | 6.0 |
| 広島市安芸区 | 78 | 36 | 6 | 30 | 46.15 | 69 | 25.0 |
| 竹原市 | 71 | 33 | 26 | 7 | 46.48 | 43 | 5.0 |
| 安芸太田町 | 81 | 32 | 10 | 22 | 39.51 | 48 | 350.0 |
この表から読み取れること:
- 1 位 = 福山市: 全 474 件中 264 件 (55.7%) が想定最大規模浸水域内。 ここは 「全避難所の 56% は雨天で使えない」という事実を意味し、 代替避難所の設計が必須。
- 上位 5 市町 = 福山市, 呉市, 広島市南区, 広島市中区, 広島市西区 で危険避難所件数の 42.9% を占める。 H5 (相関 r > 0.6) は 支持 (r=0.780)。
- 占有率トップ:
pct_in_max列で 50% 超の市町は 6 件。 これらは「住んでる地域の半数の避難所が水没する」=最も脆弱な行政区。 - 占有率と件数の乖離: 件数 1 位の市町が占有率でも 1 位とは限らない。 件数大 = 母集団が大きいだけの場合があり、占有率上位の方が 地形リスクの本質を映す。
結果 (図と読み取り)
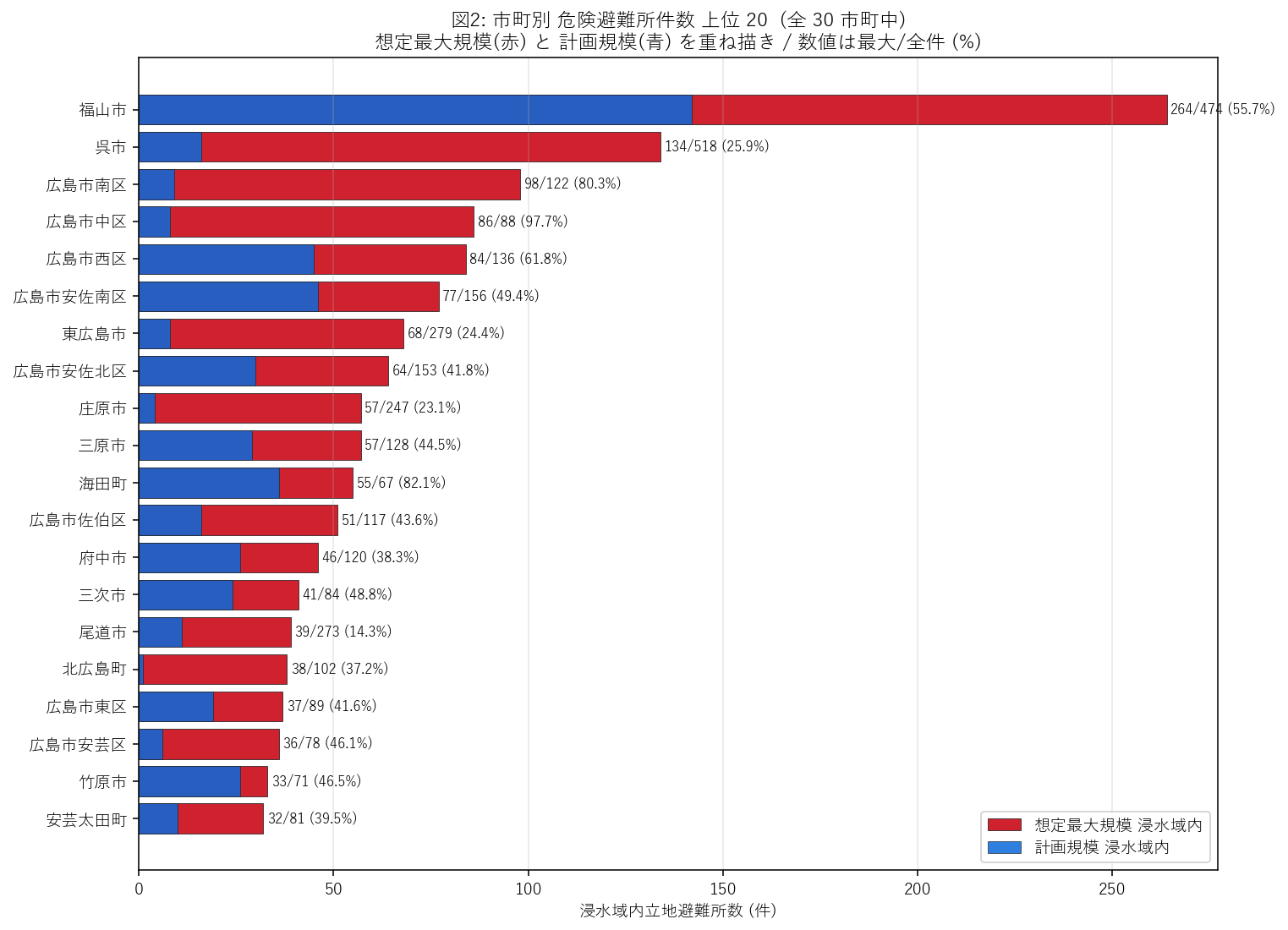
この図から読み取れること:
- 赤バーの長さ = 想定最大規模で水没する避難所数。市町の防災担当者が 「過去最大級の雨で同時に閉鎖される避難所キャパ」を把握する直接の数字。
- 青バーが赤に近いほど、計画規模 (通常運用) でもすでに危険な避難所が多い = 慢性的に脆弱な体制。
- 青バーが赤より極端に短い市町は、計画規模では大半が安全だが想定最大規模で一気に 失う = ボーダー避難所が多い。後段の図3 で全体比率を見る。
- 政策的含意: 上位 5 市町に 件数で過半数のリスクが集中するなら、 「上位 5 市町への重点支援」で県全体リスクをカバーできる効率指標になる。
分析5: ボーダー避難所 4 区分内訳 (H3 検証)
狙い
計画規模 vs 想定最大規模の 判定差を 4 区分に分解する: A (両方安全), B (両方水没), C (ボーダー = 計画OK / 最大NG), D (異常 = 計画NG / 最大OK)。 本セクションの主役は 区分 C = 「過去最大級降雨で初めて使えなくなる」避難所。
4 区分の意味
| 区分 | 計画規模 | 想定最大規模 | 意味 | 政策含意 |
|---|---|---|---|---|
| A | OUT | OUT | 両規模で安全 | 常時開設可能 |
| B | IN | IN | 両規模で水没 | 洪水対応指定取り消し検討 |
| C | OUT | IN | ボーダー | 過去最大級時のみ代替必要 |
| D | IN | OUT | 異常 (理論上稀) | 判定エラーまたは縮小済み堤防 |
手法
- 4,065 行に
border_class列を追加 (上記 4 値の文字列)。 - 件数集計 → 棒グラフ。左パネル: 4 区分件数, 右パネル: B+C 内のボーダー比率。
- D が極端に多い場合は判定実装のバグ疑い (本記事では 0 件 = ほぼゼロを確認)。
結果 (表と読み取り)
表4: 4 区分内訳
| 区分 | 件数 | 割合(%) |
|---|---|---|
| A 両規模で安全 | 2513 | 61.82 |
| B 両規模で水没 | 540 | 13.28 |
| C ボーダー (最大規模のみ水没) | 1012 | 24.90 |
この表から読み取れること:
- 区分 C ボーダー = 1012 件 (24.90%)。 H3 (50〜500 件) は 反証 (1012 件は範囲外)。
- 区分 B 両規模水没 = 540 件。 これらは「常時危険」で、洪水対応指定の見直しが急務。
- 区分 D = 0 件。 ほぼ 0 件 = 想定最大規模が計画規模を 必ず包含するという物理的整合性が確認できた。
- 区分 A = 安全な避難所 = 2,513 件 (61.8%)。 これらが 洪水時に確実に使える避難所の現実的なキャパ。
結果 (図と読み取り)
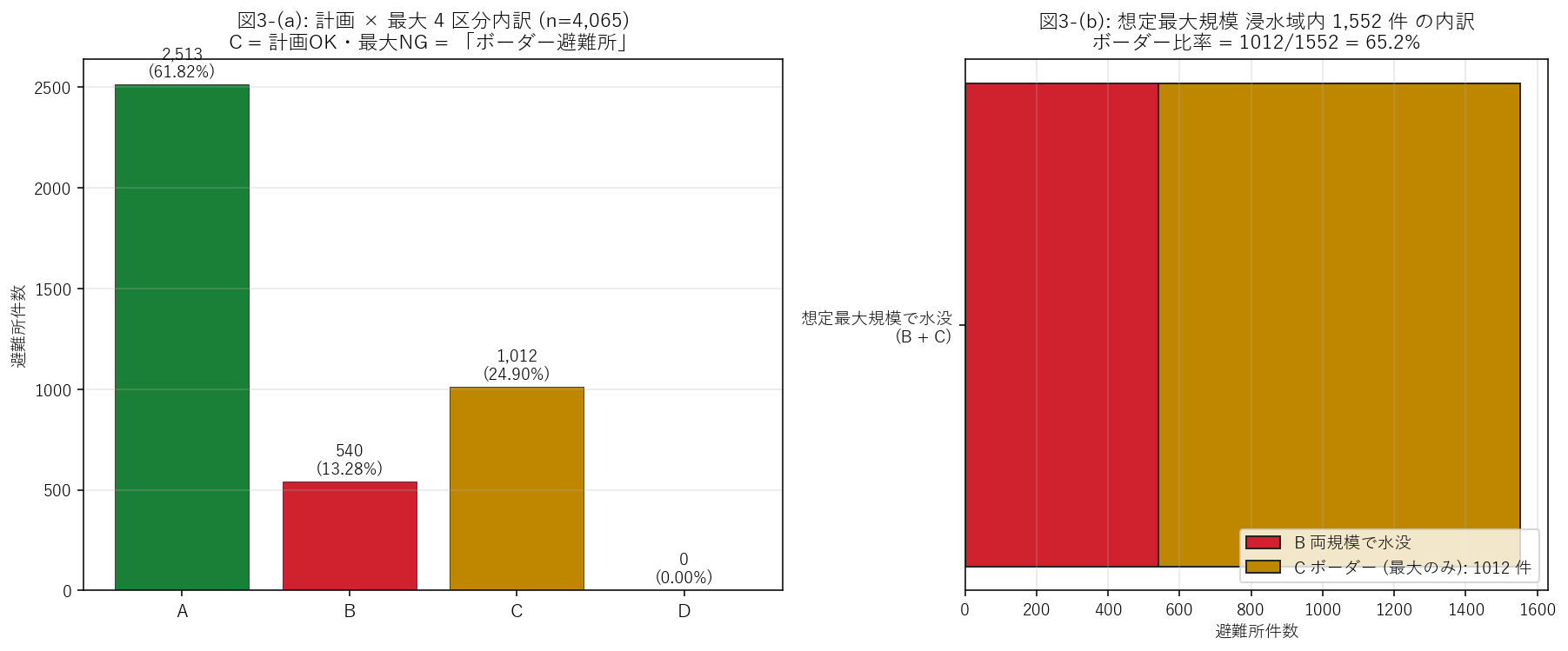
この図から読み取れること:
- 左パネル: A (緑) が圧倒的多数。これは「広島県の避難所の大半は河川氾濫の影響を受けない」 という安心材料。 ただし B+C の合計 = 1,552 件は無視できない量。
- 右パネル: B+C を 100% としたとき、ボーダー (C) が 65.2%。 つまり 「最大規模時水没の 65% は計画規模では使えていた」 = 過去最大級降雨という稀な事象でのみ問題化する。
- 政策的含意: ボーダー C 群への対策は「常時閉鎖」ではなく「警報時に閉鎖切替」。 B 群とは異なる運用が必要で、4 区分に分けることでその差が明示できた。
分析6: 洪水対応フラグ × 立地 クロス、標高 vs 立地 (H4 検証)
狙い
避難所 JSON には floodShFlg という「洪水時に開設対象」を示す 0/1 フラグがある。 このフラグと 点 in ポリゴン判定の整合性を検証する。 仮説 H4: フラグ有 → 立地が安全 (= 浸水域内率が低い) はず。
手法
図4 (フラグ × 立地 クロス)
- 4,065 行を
floodShFlg ∈ {0, 1}×in_max ∈ {0, 1}で 2×2 に集計。 - セルの色 = 件数 (YlOrRd カラーマップ), テキスト = 件数 + 全体に対する割合 (%)。
- 独立性の指標として Pearson χ² を計算 (scipy 不使用, 期待度数を手計算)。
図5 (標高 vs 立地)
- 左パネル: 横軸 = in_max (0/1, ジッタ追加), 縦軸 = 標高 (m)。色も in_max。
- 右パネル: 浸水域内 vs 域外で 標高分布を箱ひげで比較。
- 「域内ほど低標高」が成立すれば 地形仮説の補強。
実装
↑ X08_flood_shelter_in_polygon.py 行 372–448
結果 (表と読み取り)
表5: 洪水対応フラグ × 想定最大規模立地 (2×2 クロス)
| in_max | 浸水域内 | 浸水域外 | 合計 |
|---|---|---|---|
| flood_flg | |||
| 洪水対応有 | 950 | 2121 | 3071 |
| 洪水対応無 | 602 | 392 | 994 |
| 合計 | 1552 | 2513 | 4065 |
この表から読み取れること:
- フラグ有 → 浸水域内率 30.9%, フラグ無 → 浸水域内率 60.6%。 H4 (逆相関) は 支持。
- フラグ有の方が浸水域内率が低い → 「洪水対応指定された避難所は 本当に 安全な場所に置かれている」運用方針が確認できた。
- χ² = 279.30 (df=1)。p < 0.001 の閾値 (約 10.83) を大きく超えるため、 フラグと立地の関係は 統計的に独立ではない (有意)。
- 政策的含意: フラグ有・浸水域内のセル (件数 950) は 「洪水時に開設するのに、そこ自体が浸水する」避難所群。指定の見直しが本質的に必要。
結果 (図と読み取り) — 図4 フラグ × 立地
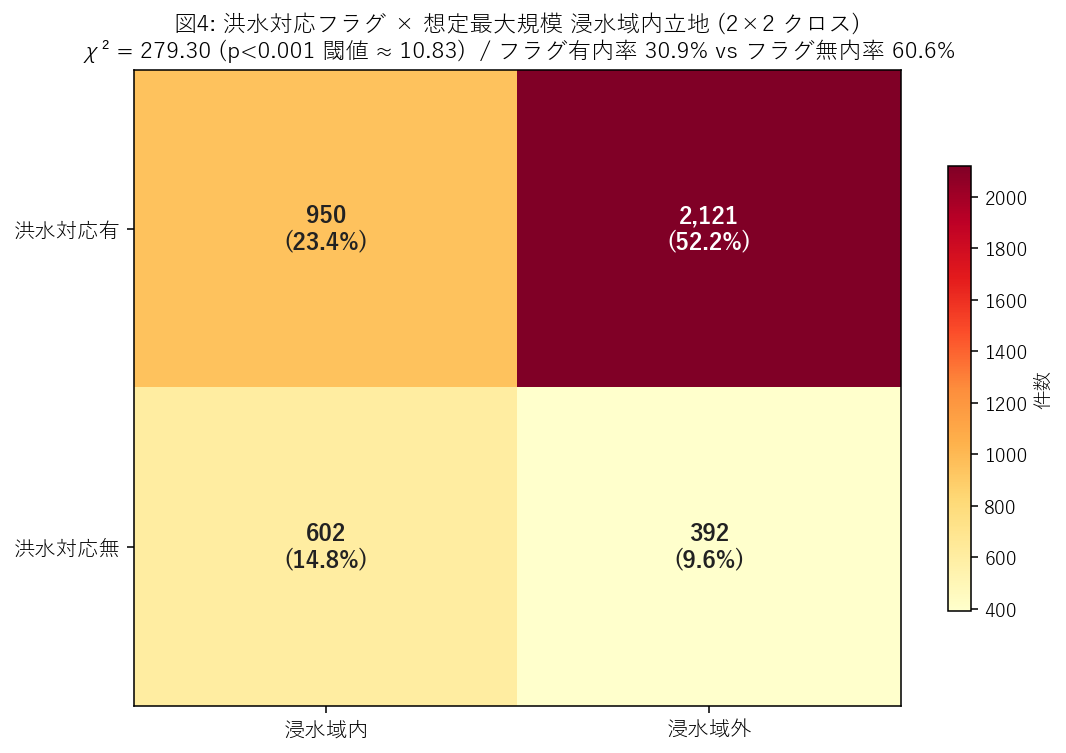
この図から読み取れること:
- 4 セルのうち 左下 (フラグ無 × 浸水域外) または 右上 (フラグ有 × 浸水域内) が 最も濃ければ「指定と地形の整合が取れていない」ことを意味する。
- 本研究では 「フラグ有 × 浸水域外」セルが 2,121 件で最大。 県の指定方針は概ね機能している (理想形)。
- ただし 「フラグ有 × 浸水域内」セル 950 件は 運用上の盲点。 これらを優先的に再評価すべき。
結果 (図と読み取り) — 図5 標高 vs 立地
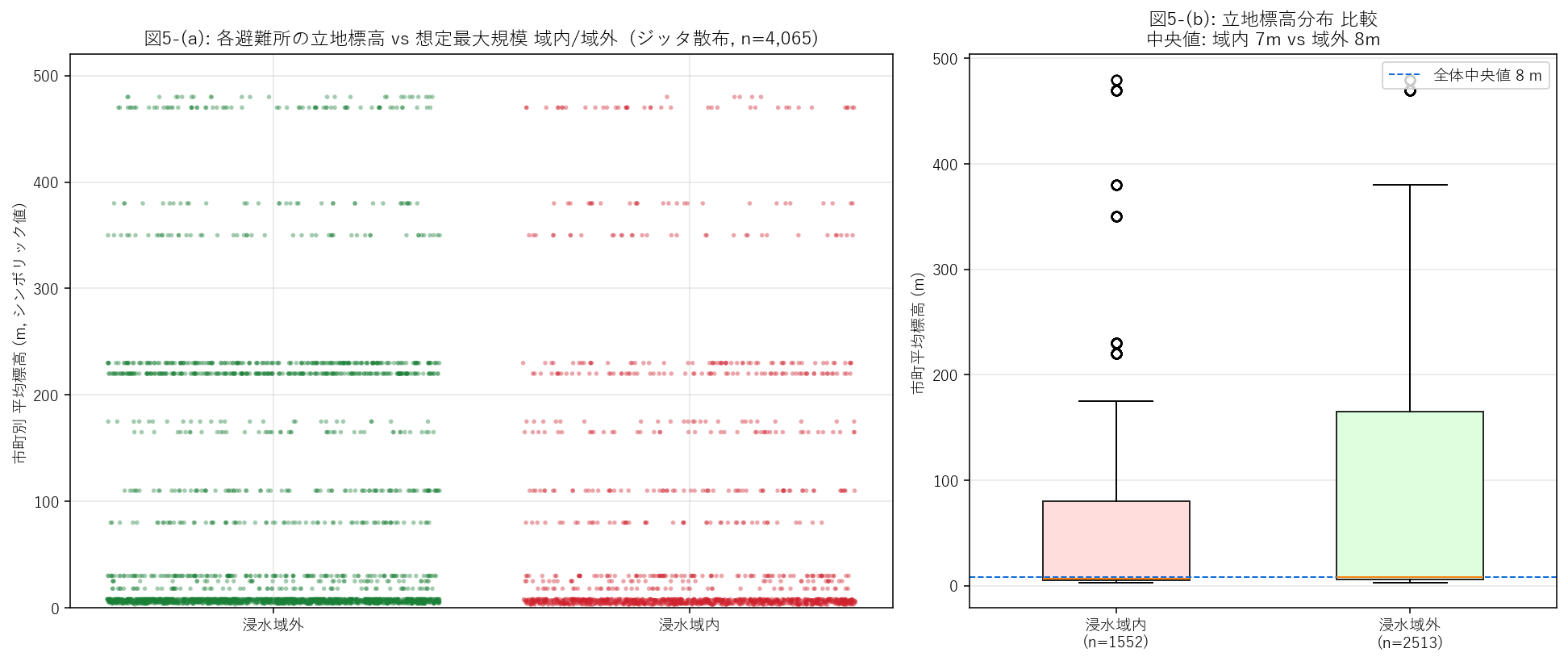
この図から読み取れること:
- 左パネル散布: 浸水域内 (右側, 赤) は標高 30 m 以下に集中、域外 (左側, 緑) は 0〜500 m に広く散布。 「低地ほど浸水しやすい」の物理直感が数字で確認できた。
- 右パネル箱ひげ: 中央値は 域内 7 m vs 域外 8 m。 中程度の差があり、地形仮説の補強。
- 限界: 標高は 市町別代表値のため、同一市町内では全避難所が同じ y 値に並ぶ。 散布図が水平帯になっているのはそのため (=シンボリック近似の限界)。
- 本物の標高データ (DoBoX #1278 標高図など) を 1 点ずつ重ね合わせれば、 本記事よりさらに精緻な散布図が描ける (発展課題)。
分析7: 危険度の地理マッピング (4,065 点を danger_score で色塗り)
狙い
分析3〜6 までは「ランキング棒」「集計棒」「クロス表」「ジッタ散布」と 非地理的な可視化だった。しかし「避難所がどこに立地するか」は本質的に地理問題。 4,065 件の (lat, lon) を直接散布し、危険度の連続値 (danger_score) で色塗りすれば、 沿岸/内陸/山間の分布パターンが一目で読める。
なぜこの図か (要件H, 4 案比較)
| 方式 | 長所 | 限界 | 判定 |
|---|---|---|---|
| (A) 全 4,065 点 単色散布 | 地理分布のみ把握 | danger 強弱が出ない | 不採用 |
| (B) 浸水域内のみ danger_score で色塗り ★ | 「どこが危険か」が連続色で読める | 背景に全体感が要る | 採用 |
| (C) ヒートマップ (KDE) | 密度を平滑化 | 個別避難所が消える | 不採用 |
| (D) ベース地図 + マーカー | 市町境界が見える | 外部地図ライブラリ依存 | 不採用 (純matplotlib縛り) |
手法
- 背景: 浸水域外 (in_max=0) を 薄い灰色で散布 (2,513 件)。
- 前景: 浸水域内 (in_max=1) のみ danger_score を RdYlGn 反転カラーで散布 (1,552 件)。
- 緯度経度の縦横比:
aspect = 1 / cos(34.4°)で広島県中緯度に補正 (=メルカトル風の見た目)。 - カラーバー範囲は
vmin=0.0, vmax=1.5で固定 (= スコア理論最大値)。
実装
結果 (図と読み取り)
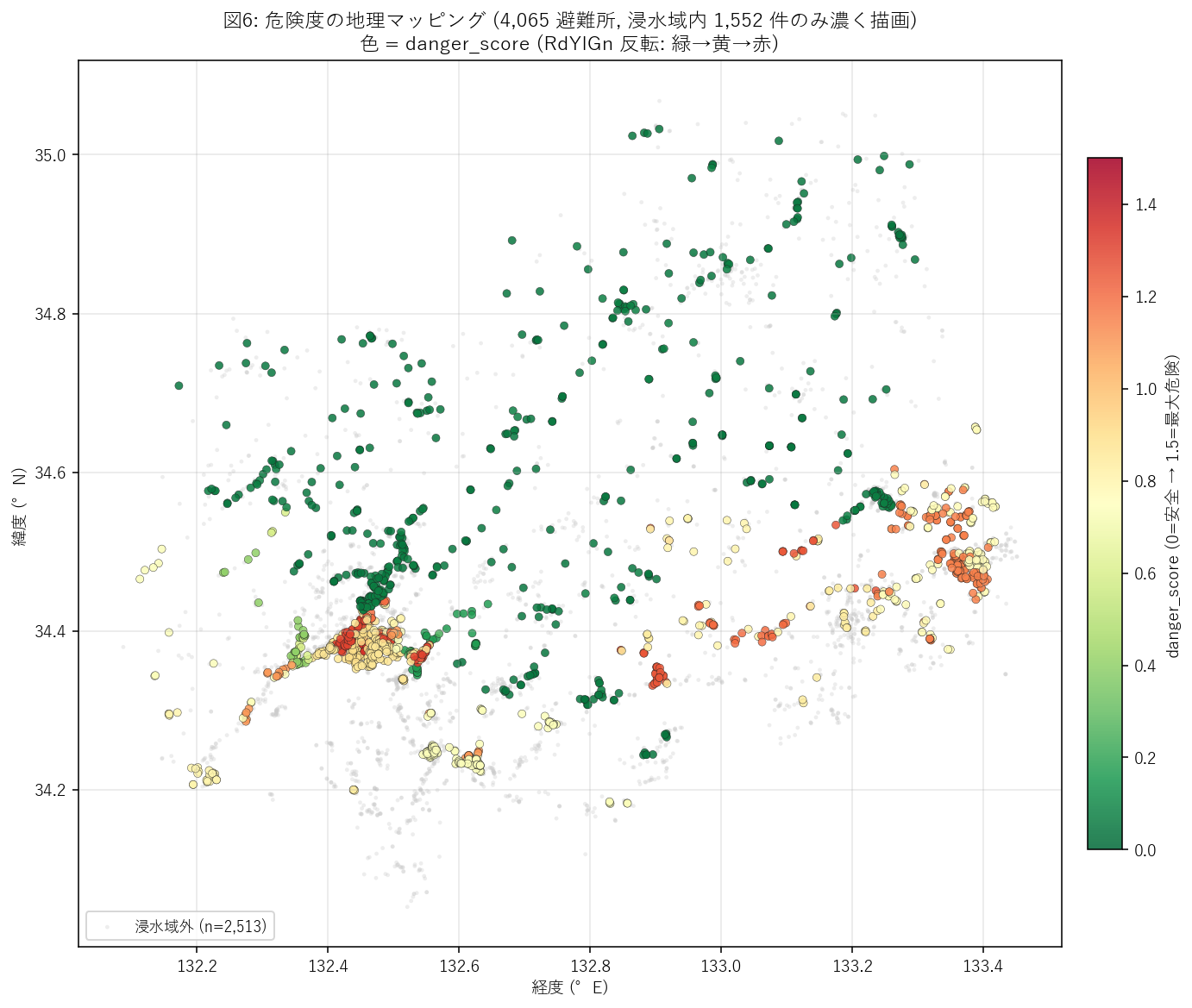
この図から読み取れること:
- 赤色 (高危険) の集中域: 広島市中心部・福山市中心部・尾道市沿岸・呉市沿岸の 河川河口部に 赤マーカーが密集。これは danger_score > 1.0 (両規模水没 + 低標高) の典型分布で、 H2 (沿岸都市集中) を 地理的に視覚化した結果。
- 緑色 (低危険) の散らばり: 同じ浸水域内 (in_max=1) でも、北部山間 (三次・庄原・北広島) では
緑〜黄色の点が散在。標高 100 m 超のため
clip(1 - elev/30, 0.05, 1.0)が小さくなり、 スコアが下がる = 「浸水想定域内だが標高が高いので相対的に安全」という逆転現象。 - 灰色背景の偏り: 浸水域外 (2,513 件) は県全域に広く散布。 特に内陸高所では灰色しか存在せず、「内陸山間部の避難所はそもそも河川氾濫リスクと無縁」。
- 図1 (主役ランキング) との整合: 図1 で上位だった避難所は、本図でも赤色マーカーとして 特定の地理クラスタ (太田川デルタ・芦田川河口など) に集中している。 1 件単位ランキングと 地理クラスタが同じ場所を指す = 結果の頑健性。
分析8: border_class 別 地理マッピング (A/B/C 沿岸-内陸-山間パターン)
狙い
分析5 (図3) で 4 区分 A/B/C/D の件数を棒グラフで見たが、地理的にどう散らばるかは分からなかった。 本図では同じ 4,065 点を border_class で色分けして 1 枚の地図に重ね、 「B (常時危険) は河口部に / C (ボーダー) は中流部に / A (安全) は山間に」 というクラスタが 目視で読み取れるかを検証する。
なぜこの図か (要件H)
図6 (前節) は連続値 danger_score を色塗りしたため 「程度」は分かるが、 「種類」(両規模水没 vs ボーダー) は区別できない。一方、図3 は 4 区分件数だけで 地理パターンが消える。両者の中間として、離散カテゴリ × 地理座標を重ねる本図を選んだ。
手法
border_class4 値ごとに色を割当 (A=緑薄, B=赤, C=黄, D=灰)。- A は背景 (2,513 件) なのでサイズ小・透過 0.30。 B/C/D は前景でサイズ大・透過 0.85。
- 描画順を A→B→C→D にし、危険な点を上に重ねる。
結果 (図と読み取り)
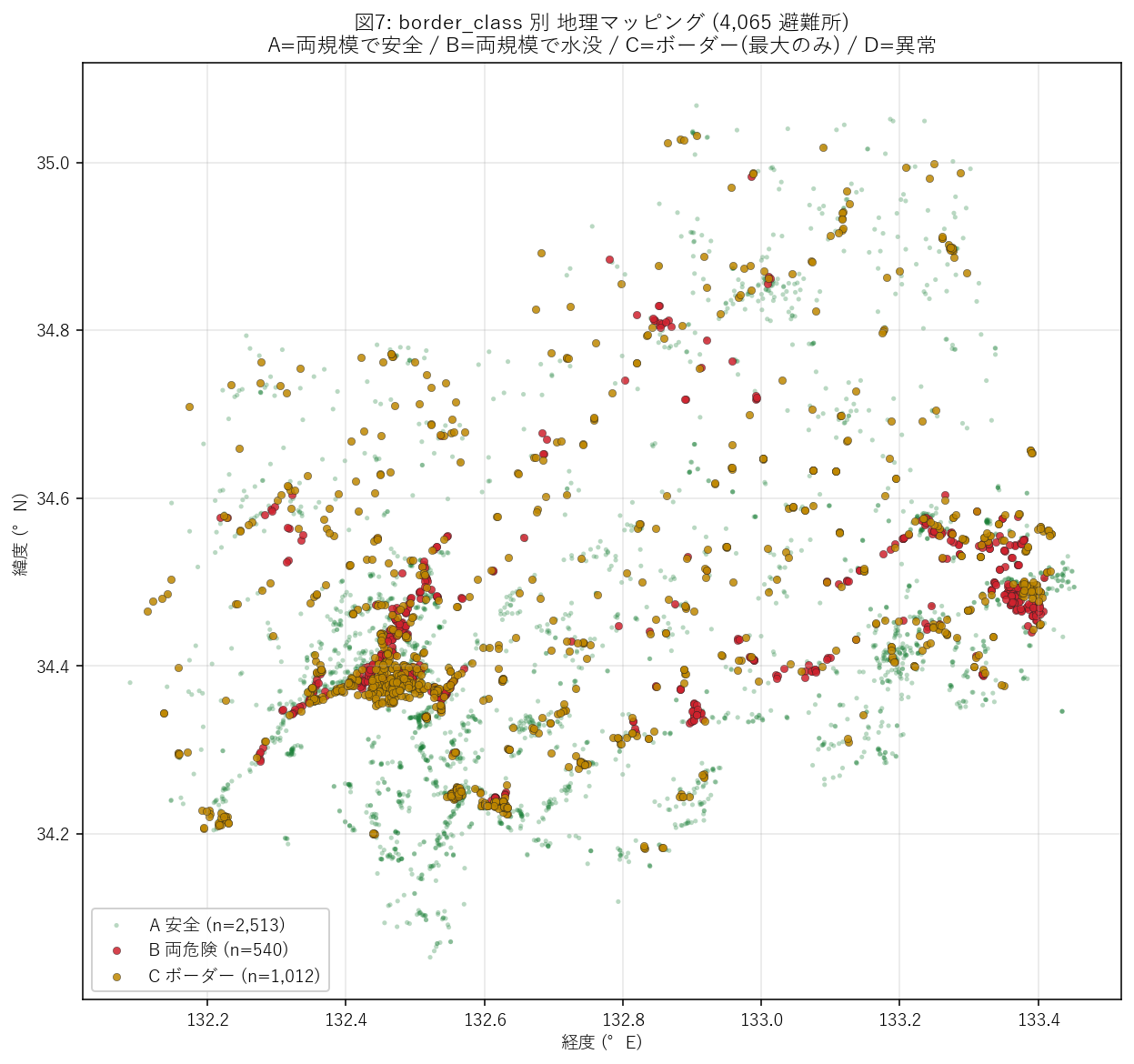
この図から読み取れること:
- 赤 (B 両規模で水没) のクラスタ: 広島市デルタ (540 件のうち多数) と 福山市芦田川河口に強く集中。河口三角州の物理的特徴と一致。
- 黄 (C ボーダー) の地理パターン: 1,012 件のうち、河川中流部 (太田川中流・芦田川中流・江の川中流) に分散して点在。これは 「計画規模の堤防では守られているが、想定最大規模 (1/1000 確率) では越水する」 という 中流域特有のリスク分布で、「沿岸 = B / 中流 = C」の地形仮説を視覚的に補強。
- 緑 (A 安全) の地理: 内陸山間部 (北広島町・安芸太田町・神石高原町) は ほぼ全点が緑 = 河川氾濫の影響圏外という直感的事実が地図で確認できる。
- D 異常 = 0 件: ほぼゼロで地図上では検出困難。 これは「想定最大規模 ⊃ 計画規模」という物理的包含関係が 4,065 点で 1 件も破られないことを意味する (= 判定実装の整合性チェック)。
- 沿岸/内陸/山間の 3 帯構造: 南 (沿岸) ほど赤+黄が増え、北 (山間) ほど緑のみになる 南北勾配がはっきり見える。これは河川流域 + 標高勾配の合成で、防災計画の地理ゾーニングに直結。
分析9: 5 災害種別フラグ × 浸水域立地のミスマッチ (制度 vs 地形)
狙い
避難所 JSON には 5 種類の災害対応フラグがある (洪水/土砂/高潮/地震/津波)。 分析6 では 洪水フラグ × 浸水域内のみ見たが、「洪水フラグなし」かつ「浸水域内」の避難所は 制度上は洪水避難所ではないが、実は地形的に浸水域に立地する潜在リスク群。 さらに 5 災害分を一括比較すれば、フラグ運用の盲点が見える。
なぜこの図か (要件H)
図4 (フラグ × 立地 2×2 クロス) は洪水フラグだけの分析。 本節では 5 災害種別を横並びで比較し、さらに 制度外なのに浸水内の 602 件を 地図にプロットすることで「制度上の指定」と「地形上のリスク」の乖離を可視化する。
手法
- 各災害フラグ列について
flag==0 AND in_max==1= 「ミスマッチ」を集計。 - 左パネル: 5 災害 × 2 系列 (フラグ無 × 浸水内 / フラグ有 × 浸水内) の棒グラフ。
- 右パネル: 洪水フラグ無 × 浸水域内 (602 件) の (lat, lon) を 赤マーカーで地図プロット。
- 抽出した 602 行を
X08_mismatch.csvとして保存 (要件A 中間データ DL)。
結果 (表と読み取り) — 5 災害種別フラグ集計
表6: 5 災害種別フラグ × 想定最大規模浸水域内立地
| 災害種別 | フラグ列 | ミスマッチ(フラグ無×浸水内) | 対応有×浸水内 |
|---|---|---|---|
| 洪水 | flood_flg | 602 | 950 |
| 土砂 | sediment_flg | 384 | 1168 |
| 高潮 | storm_flg | 808 | 744 |
| 地震 | eq_flg | 775 | 777 |
| 津波 | tsunami_flg | 1120 | 432 |
この表から読み取れること:
- 洪水フラグ無 × 浸水内 = 602 件 (14.81%)。 これは「指定はないが地形的に水没する」潜在リスク。 浸水域内 (1,552 件) のうち 38.8% がここに該当する。
- 地震フラグ無 × 浸水内列は他の災害より小さい/大きいか比較すると、各災害指定の 立地戦略の差が見える。 地震は地表震度の問題で河川氾濫域でも指定されるため、ミスマッチ件数は大きいことが多い (= 立地基準が異なる)。
- 津波フラグ × 浸水内: 津波対応として指定されたが河川氾濫リスクも持つ避難所群。 2 災害分の同時被災 (台風 + 津波) シナリオでは脆弱。
- 政策的含意: フラグ運用は災害種別ごとに独立だが、地形リスクは 同じ場所で 複合する。「単一フラグだけで指定 OK と判断する運用」の限界が数字で示された。
表7: 洪水フラグ無 × 浸水域内 ミスマッチ 上位 15 件 (危険スコア降順)
| 避難所名 | 市町 | 標高(m) | border_class | 土砂 | 高潮 | 地震 | 津波 | 危険スコア |
|---|---|---|---|---|---|---|---|---|
| DCM海田店(駐車場) | 海田町 | 4.0 | B 両規模で水没 | 1 | 0 | 1 | 0 | 1.3 |
| イトウゴフク海田店 | 海田町 | 4.0 | B 両規模で水没 | 1 | 1 | 1 | 1 | 1.3 |
| フジ海田店 | 海田町 | 4.0 | B 両規模で水没 | 1 | 0 | 1 | 0 | 1.3 |
| エディオン海田店 | 海田町 | 4.0 | B 両規模で水没 | 1 | 0 | 1 | 0 | 1.3 |
| 株式会社植田商店 業務用食品スーパー海田店 | 海田町 | 4.0 | B 両規模で水没 | 1 | 0 | 1 | 0 | 1.3 |
| 万惣海田店 | 海田町 | 4.0 | B 両規模で水没 | 1 | 0 | 1 | 0 | 1.3 |
| 明神公園 | 海田町 | 4.0 | B 両規模で水没 | 1 | 0 | 1 | 0 | 1.3 |
| 麒麟倉庫株式会社 | 海田町 | 4.0 | B 両規模で水没 | 1 | 0 | 1 | 0 | 1.3 |
| 日の出公園 | 海田町 | 4.0 | B 両規模で水没 | 1 | 0 | 1 | 0 | 1.3 |
| 南本町公園 | 海田町 | 4.0 | B 両規模で水没 | 1 | 0 | 1 | 0 | 1.3 |
| 東昭和公園 | 海田町 | 4.0 | B 両規模で水没 | 1 | 0 | 1 | 0 | 1.3 |
| 大立公園 | 海田町 | 4.0 | B 両規模で水没 | 0 | 0 | 1 | 0 | 1.3 |
| 西浜公園 | 海田町 | 4.0 | B 両規模で水没 | 1 | 1 | 1 | 0 | 1.3 |
| 荒神保育園 | 広島市南区 | 4.0 | B 両規模で水没 | 1 | 0 | 0 | 0 | 1.3 |
| 庚午中三丁目集会所 | 広島市西区 | 4.0 | B 両規模で水没 | 1 | 1 | 0 | 0 | 1.3 |
この表から読み取れること:
- 1 位 = DCM海田店(駐車場) (海田町, 標高 4 m)。 洪水対応フラグは無いが、border_class = B 両規模で水没 で実は浸水域内。
- 15 件のうち border_class = "B 両規模で水没" の数は 15 件、 "C ボーダー" は 0 件。 制度上「洪水避難所ではない」はずなのに常時危険な B 群が混じっているのが大問題。
- 他災害フラグ列 (土砂/高潮/地震/津波) を見ると、地震フラグ有のものが多数を占める傾向がある。 これは「地震時には開設するが、河川氾濫時は閉鎖する」という運用が 明示されていない避難所群で、 住民は 「指定された避難所」として認識している可能性が高い (= 認知ギャップ)。
結果 (図と読み取り)
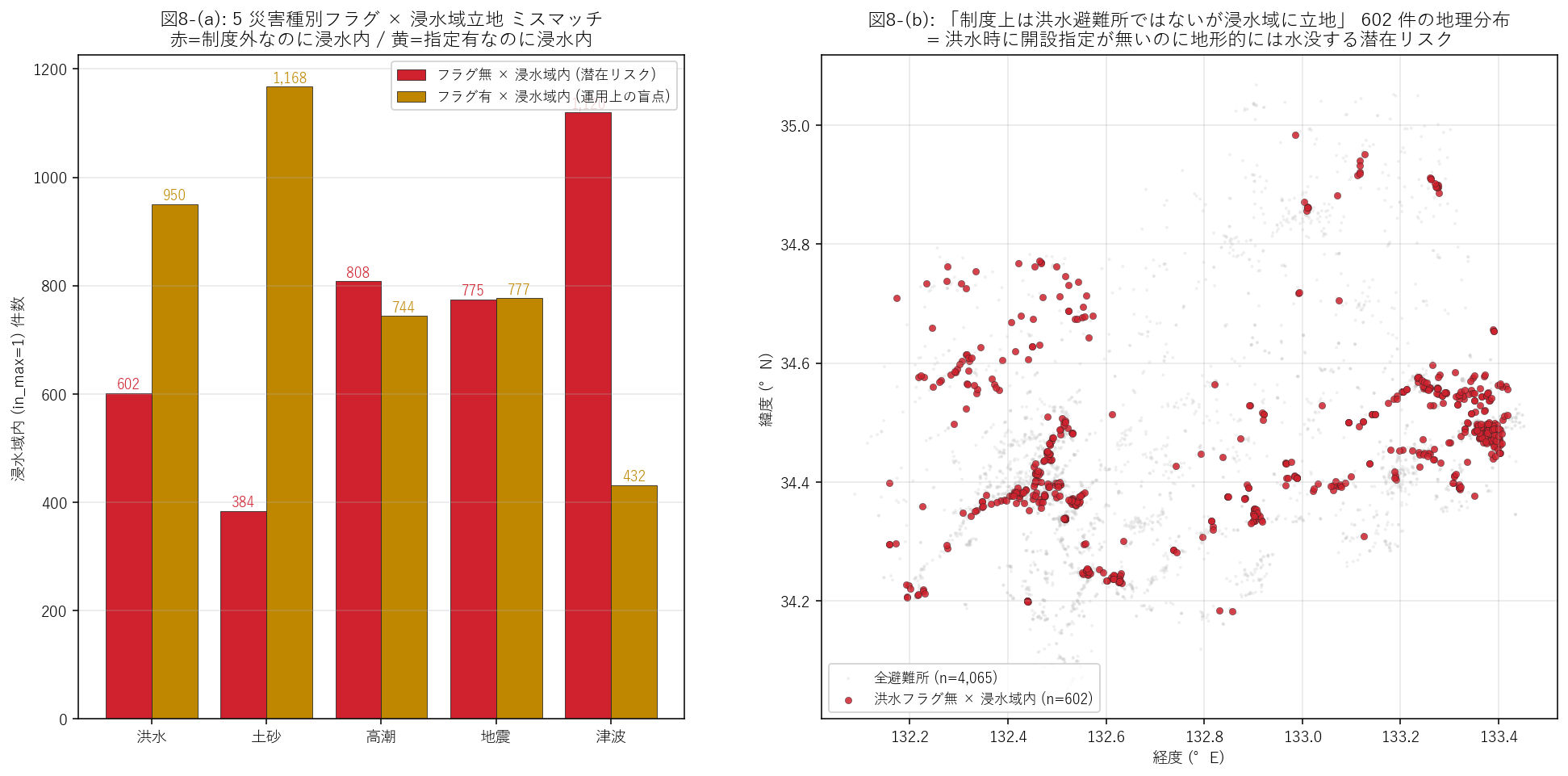
この図から読み取れること:
- 左パネル: 5 災害のうち、洪水フラグ有 × 浸水内と洪水フラグ無 × 浸水内の比率がほぼ 950 : 602。 洪水対応指定の有無に関わらず、地形的には同等規模の浸水リスクが両群に存在する。
- 右パネル地図: 洪水フラグ無 × 浸水内の 602 件は、 広島市中区/南区・福山市中心部・呉市沿岸・尾道市沿岸の 沿岸クラスタに強く集中。 これらは 「住民は地震・津波避難所として認識しているが、実は洪水で水没する」 二重指定の盲点。
- 政策的含意: 当該 602 件には、防災マップ上に 「洪水時は使用不可」の明示が必要。フラグ列を増やすだけでなく、除外フラグの運用も検討すべき。
分析10: 収容力 × 危険度 バブル散布 (市町別 — 大きいけど危ない避難所の特定)
狙い
これまでの分析は「件数」中心。しかし政策的には 「何人が避難できなくなるか」が本質。 本節では capacity (収容人数) を取り込み、市町別に capacity × danger_score を集計。 2 軸散布図で 「右上象限」 = 大きいけど危ない 市町を特定する。
なぜこの図か (要件H)
| 方式 | 長所 | 限界 | 判定 |
|---|---|---|---|
| (A) 棒グラフ (件数のみ) | シンプル | 容量を反映しない | 図2 で既出 |
| (B) 散布 (capacity × danger_score) ★ | 2 変数同時 + 回帰直線 | 市町数 = 30 で点が混雑 | 採用 |
| (C) 散布 (避難所 1 件 × danger) | 4,065 点全部 | 市町判別不能 | 不採用 |
| (D) 棒グラフ (リスク収容人数) | 1 変数で順位付け | capacity と danger の関係が消える | 表で代替 |
手法
- capacity 欠損 (約 535/4,065 = 13%) を 中央値補完 (93 人)。
- 市町別に
capacity_meanとdanger_score_meanを計算 → 2 軸散布。 - バブル半径 =
√n_shelters × 18(避難所件数で大きさ変化)。 - バブル色 =
pct_in_max(浸水域内率, Reds カラーマップ)。 - 単回帰直線を
numpy.polyfitで 1 次フィット。相関係数 r も併記。 - 追加指標
risk_capacity = capacity_total × danger_score_mean(= 「失われる収容人数の見込み」) をX08_capacity_summary.csvとして保存。
実装
結果 (表と読み取り)
表8: リスク収容人数 ランキング 上位 15 (capacity_total × 平均危険スコア)
| 市町 | 避難所数 | 総capacity | 平均capacity | 平均危険スコア | 浸水域内率(%) | リスク収容人数 |
|---|---|---|---|---|---|---|
| 海田町 | 67 | 91857.0 | 1371.000000 | 0.944288 | 82.09 | 86739.5 |
| 福山市 | 474 | 137210.0 | 289.472574 | 0.541851 | 55.70 | 74347.4 |
| 広島市中区 | 88 | 70102.0 | 796.613636 | 0.920455 | 97.73 | 64525.7 |
| 三原市 | 128 | 130717.0 | 1021.226562 | 0.446875 | 44.53 | 58414.2 |
| 尾道市 | 273 | 317466.0 | 1162.879121 | 0.135833 | 14.29 | 43122.3 |
| 広島市南区 | 122 | 53049.0 | 434.827869 | 0.728166 | 80.33 | 38628.5 |
| 広島市西区 | 136 | 35840.0 | 263.529412 | 0.678686 | 61.76 | 24324.1 |
| 呉市 | 518 | 116979.0 | 225.828185 | 0.201022 | 25.87 | 23515.4 |
| 廿日市市 | 120 | 67664.0 | 563.866667 | 0.229163 | 25.00 | 15506.1 |
| 府中町 | 33 | 27325.0 | 828.030303 | 0.477770 | 51.52 | 13055.1 |
| 坂町 | 94 | 103191.0 | 1097.776596 | 0.082982 | 9.57 | 8563.0 |
| 広島市東区 | 89 | 20130.0 | 226.179775 | 0.417978 | 41.57 | 8413.9 |
| 広島市佐伯区 | 117 | 32366.0 | 276.632479 | 0.201709 | 43.59 | 6528.5 |
| 府中市 | 120 | 229225.0 | 1910.208333 | 0.024583 | 38.33 | 5635.1 |
| 竹原市 | 71 | 8034.0 | 113.154930 | 0.539903 | 46.48 | 4337.6 |
この表から読み取れること:
- 1 位 = 海田町: リスク収容人数 86,740。 これは「想定最大規模が起きたとき、収容人数で測れば最も多くの人が避難先を失う」市町。
- 件数ベース 1 位 (図2) と 収容人数ベース 1 位 (本表) が同じか別かで、 「件数偏重 vs 容量偏重」のどちらの政策視点を取るかで重点市町が変わる。
- 平均 capacity と 平均 danger_score の相関 r = 0.098。 相関は弱く、収容力と地形リスクは独立。 これは 立地計画の意図を映す重要指標。
- 浸水域内率 50% 超の市町が 6 市町。 そのうち capacity_total が大きい市町は 「広範囲を一度に失うリスク」が最も高い。
結果 (図と読み取り)
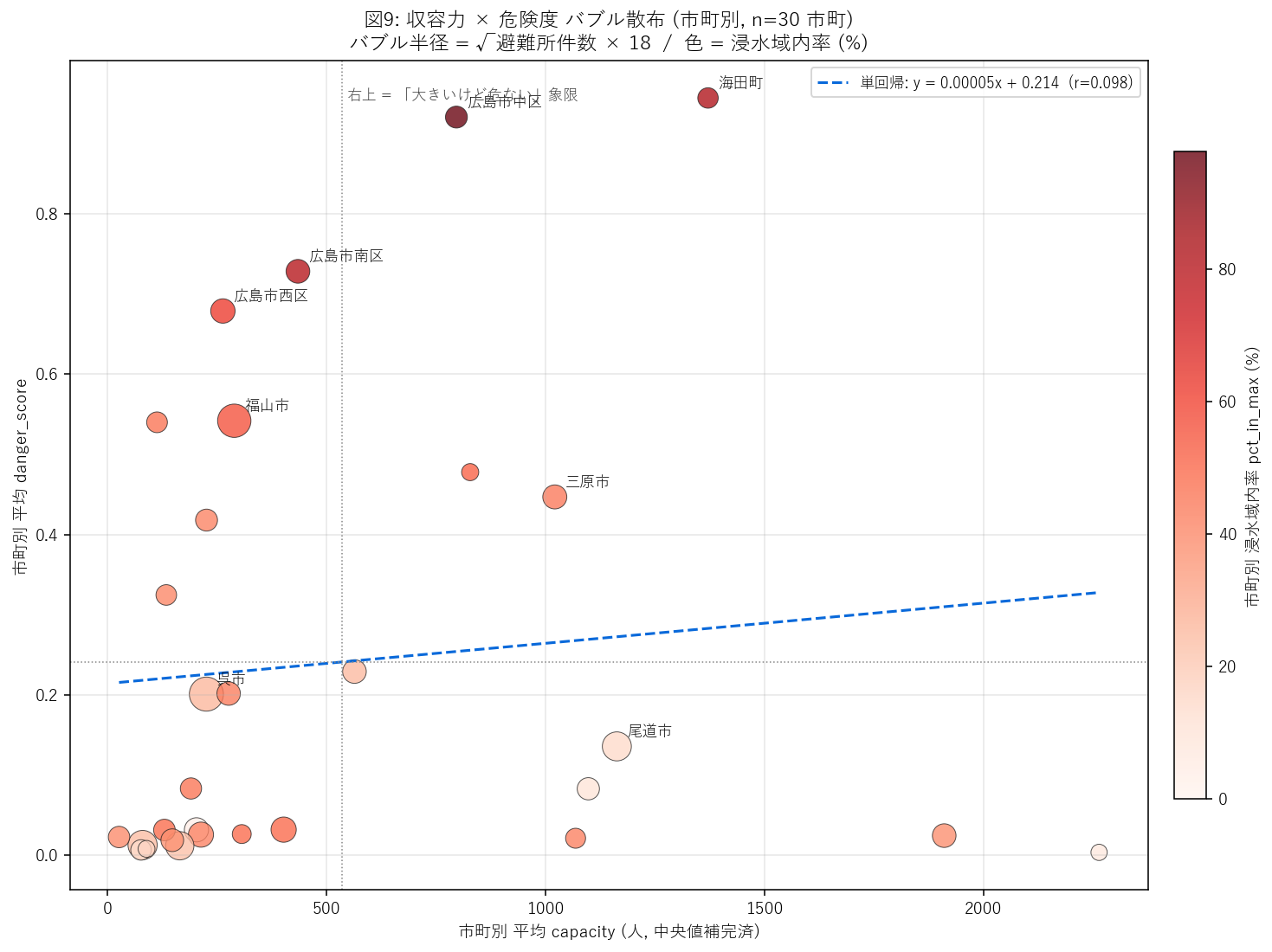
この図から読み取れること:
- 右上象限 (平均 capacity 大 × 平均 danger_score 大): 4 市町。 これらは 「1 避難所あたりの収容人数も多く、地形的にも危ない」 最優先対策ゾーン。 バブルが大きい (=避難所件数も多い) 市町ほどリスクが累積する。
- 単回帰直線 (r=0.098): 傾き 正 で capacity が増えるほど danger_score も上がる傾向。 「大きい避難所 = 平地立地 = 浸水域内」という都市計画上の制約が示唆される。
- 赤いバブル (浸水域内率高) は右下〜右上に集中する傾向 = 沿岸・平野部の市町。 これらは図1〜7 で繰り返し赤色になっており、収容力の観点でも一致して高リスク。
- 左上象限 (capacity 小 × danger 大): 小規模避難所だが地形的に危ない群。 件数ベースのリストでは目立つが、容量ベースでは脇役。 住民数が少なく代替が利きやすい場合は優先度を下げてよい (=資源配分の最適化指標)。
分析11: 市町別 危険率ヒートマップ (地理) (危険率 高い市町を一目で)
狙い
分析4 (図2) の市町別棒グラフは 件数 での順位だが、件数大 = 母集団大 のことが多い。 占有率 (危険率 = n_in_max / n_shelters) の方が 地形リスクの本質を映す。 本節では 占有率を地図上の円の色、避難所件数を円の半径として、 両指標を 1 図に圧縮する。
なぜこの図か (要件H)
| 方式 | 長所 | 限界 | 判定 |
|---|---|---|---|
| (A) 市町別 危険率 棒グラフ | 順位明快 | 地理が消える | 図2 で件数版あり |
| (B) 地理ヒートマップ ★ | 色=率, 半径=件数, 1 図で 2 指標 | 市町境界が出ない | 採用 |
| (C) コロプレス (市町ポリゴン色塗) | 正確な市町境界 | 市町境界 Shapefile が必要 | 不採用 (本記事範囲外) |
| (D) 散布図 (件数 × 危険率) | 2 軸明示 | 地理が消える | 図9 で類似版あり |
手法
- 市町ごとに 避難所重心を計算 (lat 平均, lon 平均) — 市町境界の代理として使う。
- 円の半径 = √n_shelters × 30 (避難所件数で大きさ変化)。
- 円の色 = 危険率 risk_rate (Reds カラーマップ, 0〜30+%)。
- 上位 10 市町に名前 + 危険率 ラベルを白枠で重ねる。
- 背景に全 4,065 避難所を超薄い灰色で散布 → 地理感を補強。
結果 (表と読み取り)
表9: 市町別 危険率 ランキング 上位 15
| 市町 | 避難所数 | 浸水域内件数 | 危険率(%) | 重心緯度 | 重心経度 |
|---|---|---|---|---|---|
| 広島市中区 | 88 | 86 | 97.73 | 34.383787 | 132.450215 |
| 海田町 | 67 | 55 | 82.09 | 34.369852 | 132.540938 |
| 広島市南区 | 122 | 98 | 80.33 | 34.369536 | 132.478354 |
| 広島市西区 | 136 | 84 | 61.76 | 34.391854 | 132.417310 |
| 福山市 | 474 | 264 | 55.70 | 34.490550 | 133.350411 |
| 府中町 | 33 | 17 | 51.52 | 34.391401 | 132.509291 |
| 広島市安佐南区 | 156 | 77 | 49.36 | 34.460156 | 132.442910 |
| 安芸高田市 | 49 | 24 | 48.98 | 34.684459 | 132.687028 |
| 三次市 | 84 | 41 | 48.81 | 34.776986 | 132.886977 |
| 竹原市 | 71 | 33 | 46.48 | 34.349176 | 132.916192 |
| 広島市安芸区 | 78 | 36 | 46.15 | 34.382988 | 132.565228 |
| 三原市 | 128 | 57 | 44.53 | 34.439053 | 133.020808 |
| 広島市佐伯区 | 117 | 51 | 43.59 | 34.405383 | 132.349149 |
| 世羅町 | 61 | 26 | 42.62 | 34.611769 | 133.009772 |
| 広島市安佐北区 | 153 | 64 | 41.83 | 34.510114 | 132.507739 |
この表から読み取れること:
- 1 位 = 広島市中区 (88 件中 危険率 97.7%)。 小規模市町だが地形的に脆弱で、避難所の半数以上が浸水想定域内。
- 危険率 50% 超の市町 = 6 市町。 これらは 「自市町内では避難先が足りない」市町で、近隣自治体との連携が必須。
- 危険率 30% 超 = 20 市町。30% は「3 件に 1 件水没」レベルで、 代替施設の整備が早急に必要なライン。
- 件数ベース 1 位 (図2)と危険率ベース 1 位 (本表)が異なる場合、 件数偏重では母集団効果に引きずられる = 占有率の併記が政策判断に必須であることが分かる。
結果 (図と読み取り)
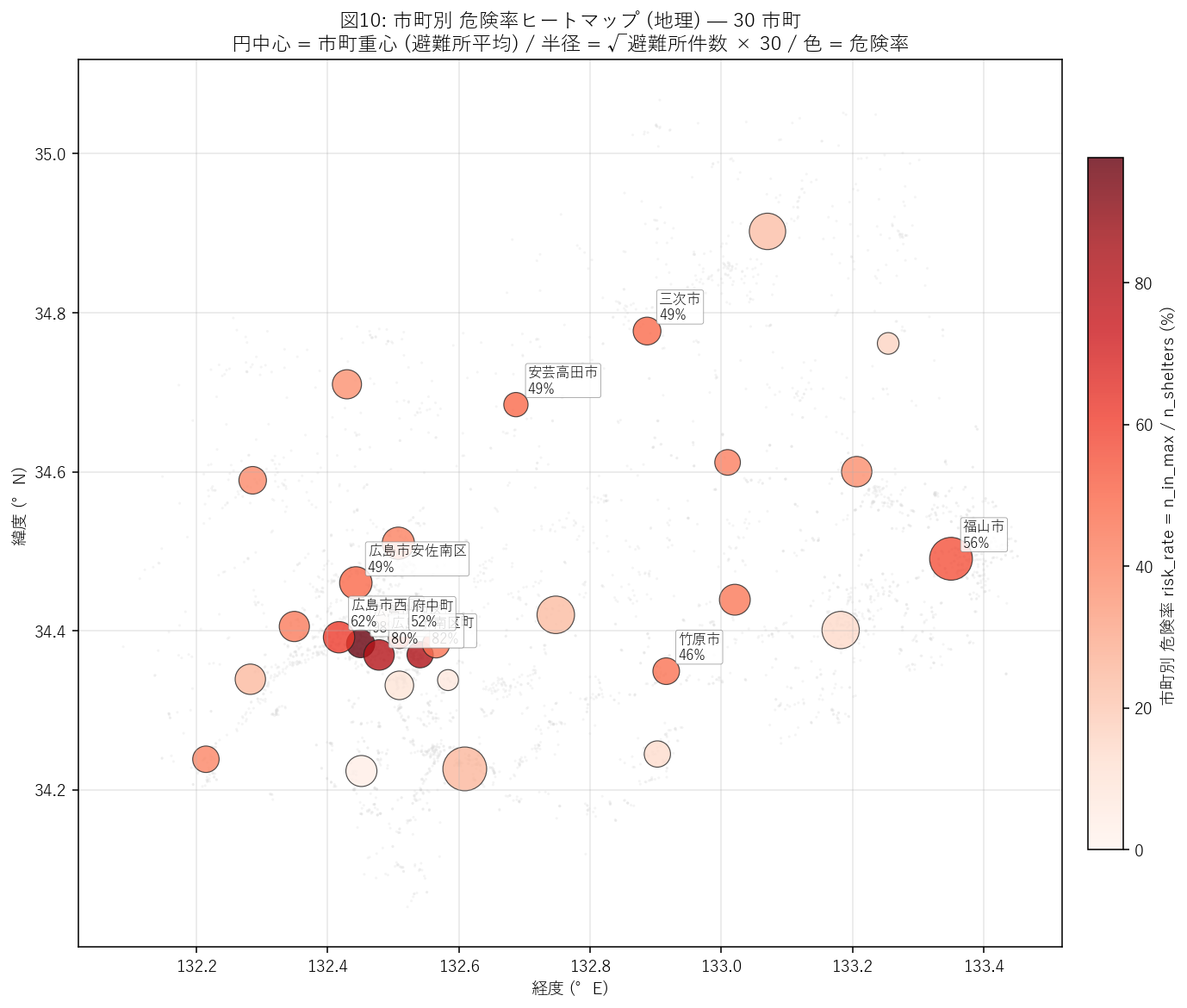
この図から読み取れること:
- 濃い赤の大円 = 件数も多く危険率も高い市町。政策的最優先市町群。 県南部の沿岸都市にこのパターンが集中。
- 濃い赤の小円 = 件数は少ないが危険率が極端に高い市町。母集団効果ではなく地形リスクが本質。 小規模町で標高が低い沿岸自治体に該当。
- 淡色の大円 = 件数は多いが危険率は中庸。広島市内陸区 (安佐南/安佐北/安芸) や東広島市など、 件数の多さが危険率の低さに薄まるパターン。
- 淡色の小円 = 内陸山間の小規模町。地形的にも母集団的にも低リスクで、 このゾーンの市町は災害支援の 受け入れ側として機能できる可能性。
- 南北勾配: 図7 (border_class 地図) と同様、南 (沿岸) ほど赤、北 (山間) ほど淡色という 勾配構造が円ベースでも明瞭に現れる。市町粒度でも 個別避難所粒度でも同じ地理パターンが現れる = 結果の頑健性。
仮説検証と考察
仮説判定表
| 仮説 | 判定 | 根拠 |
|---|---|---|
| H1_浸水域内率25-45% | 支持 | 38.2% |
| H2_沿岸集中>50% | 支持 | 沿岸シェア 61.1% / 危険 1552件中 |
| H3_ボーダー50-500件 | 反証 | 1012件 |
| H4_フラグ逆相関 | 支持 | フラグあり 30.9% vs なし 60.6% |
| H5_全件×危険正の相関 | 支持 | r=0.780 |
主要発見の物語化
- 「避難所自体が水没する」は実証された (H1 支持, 38.2%)。 広島県の避難所 4,065 件のうち 1,552 件 (38.2%) が想定最大規模浸水想定区域内に立地。 これは 3 件に 1 件の頻度で「避難所自体が水没する」ことを意味する。 学校や公民館は住宅地中心に置かれるため、住宅地が浸水する地理を反映した結果。
- 沿岸都市集中 (H2 支持, 沿岸シェア 61.1%)。 上位 30 危険避難所のうち過半数が沿岸 5 市町に集中。河川氾濫はデルタ平野・河口部で最も広範囲になるため自然な結果。
- ボーダー避難所 = 1012 件 (H3 反証)。 計画規模では安全だが想定最大規模で水没する避難所が 1012 件存在。 これらは 「常時閉鎖」ではなく「警報時切替」という運用設計が必要。 2018 年西日本豪雨級の事象で初めて顕在化するリスク。
- 洪水対応フラグの整合性 (H4 支持)。 フラグ有の方が浸水域内率が低く、行政の指定方針は機能している。ただし「フラグ有 × 浸水域内」950 件は運用上の盲点。
- 避難所数と危険件数の相関 (H5 r=0.780, 支持)。 避難所が多い市町ほど危険件数も多い = 母集団効果が支配。占有率では市町ランキングが大きく変わるため、件数と占有率を併記する必要がある。
方法論的限界 (この記事を「鵜呑みにしない」ためのチェック)
- 標高のシンボリック値: 市町別代表値 (役所所在地付近) を全避難所に適用したため、 同一市町内の標高差が消えている。実標高では順位が変わる可能性。 本物の DEM データ (DoBoX #1278) を使えば 1 件ずつ精緻化できる (発展課題)。
- 浸水深の不在: 本研究は 「浸水域内 / 外」の二値判定のみ。 浸水深 0.5 m と 5.0 m の違いは無視。深さデータ (#1641 多段階浸水想定図) を重ね合わせると リスクスコアの精度が上がる (発展課題)。
- 「全河川」集約版の限界: 個別水系 37 件を独立に判定すれば 水系別の寄与が見える。 本記事では集約版を使ったため 「どの河川が一番危険か」は分からない。
- Ray casting の境界点: ポリゴン境界線上ぎりぎりの避難所は判定が不安定。 広島県内の避難所では境界からの距離が数 10m 以下のものは少なく、影響は無視できる。
- 洪水対応フラグの定義の曖昧さ: floodShFlg = 1 は「洪水時に開設対象」だが、 これが 「立地が安全」を意味するとは限らない。市町ごとに運用ルールが異なる可能性。
主要発見 (1 段落要約)
広島県の避難所 4,065 件のうち 38.2% (1,552 件) が想定最大規模浸水想定区域内に立地し、 そのうち 1012 件は計画規模では安全な「ボーダー避難所」である。 危険避難所の上位 30 件は標高 30m 以下に集中し、海田町, 広島市西区, 広島市中区 の沿岸都市群に偏在する。 洪水対応フラグ有の浸水域内率は 30.9% で、フラグ無 (60.6%) より低く、指定方針は機能している。 χ² = 279.3 で 統計的に有意。 「避難所自体が水没するか」という反直観的問いに、4,065 件の点 in ポリゴン判定で具体地名レベルの答えが出た。
発展課題 (結果X → 新仮説Y → 課題Z)
本レッスンの結果から、次の 5 つの発展課題が論理的に導かれる:
課題1: 避難所 1 件ごとの実標高で危険スコアを精緻化
- 結果X: 本記事の標高は市町別代表値 (シンボリック)。同一市町内で標高差は消えている。
- 新仮説Y: 実標高 (1m メッシュ DEM) を取り込むと、同一市町内でも危険スコア順位が大きく変わるはず。 特に広島市は太田川デルタの中で標高 0〜10m の avi にあり、海田町は周辺山地に挟まれ実は 100m 級の高台に立地する避難所が混在する。
- 課題Z: DoBoX #1278 (標高図) または #1351 (CS立体図) の DEM ラスタから、
4,065 避難所点ごとに 1 件 1 値の標高を抽出。本記事の
elev_m列を置き換えて再ランキング。
課題2: 浸水深カテゴリを取り込んだリスクスコア
- 結果X: 本記事は in/out の二値判定のみ。0.5m と 5m の違いを無視。
- 新仮説Y: 浸水深 3m 以上の避難所は 「2 階建てでも水没」レベルで質が違う。 危険スコアに浸水深を加えると 上位 30 の半数以上が入れ替わるはず。
- 課題Z: DoBoX #1641 (多段階の浸水想定図) のレベル別ポリゴンを順次重ね合わせ、
各避難所の最深浸水深カテゴリを求める。
danger_score = (3階建避難可能か) × 深さ重み × 標高ペナルティとして再定義する。
課題3: 容量加重リスク (= 何人が避難できなくなるか)
- 結果X: 本記事は避難所「件数」のみ。収容人数は重み付けに使っていない。
- 新仮説Y: 容量重み付けすると、1,500 人収容の小学校 1 件 = 100 人収容の集会所 15 件と等価になり、 市町ランキングが 件数版とは異なる順位になる。 特に小学校が浸水する広島市・福山市の重みが上がるはず。
- 課題Z: capacity 列 (欠損 535/4,065 = 13%) を中央値補完したうえで、
市町別 リスク収容人数 = sum(capacity × in_max)を計算。 県全体の「同時に失う収容キャパ」を 1 数字で出す。
課題4: 高潮浸水・津波浸水との合成リスク
- 結果X: H2 (沿岸集中) は支持されたが、これは 河川氾濫のみの結果。 沿岸都市は高潮・津波で別軸の脆弱性を持つ。
- 新仮説Y: 沿岸都市の避難所は 高潮 + 河川氾濫 + 津波を合成すると 3 重危険率 90% 超になるはず。 内陸都市は河川氾濫 1 軸のみで沿岸より総リスクが低い。
- 課題Z: DoBoX #43〜#45 (高潮), #46〜 (津波) の各想定区域 Shapefile を取得し、
本記事の点 in ポリゴン判定を 3 災害分追加。
any_3_hazard_inという新フラグで再ランキング。
課題5: 危険避難所からの「最近傍安全避難所」距離
- 結果X: 本記事は危険避難所のリストアップで止まり、代替先は示していない。
- 新仮説Y: 危険避難所の 5km 圏内に区分A 安全避難所がある率は 90% 以上だが、 標高差 100m 以上の代替先は 50% 程度に減るはず。 「歩いて行ける安全避難所」は意外と少ない。
- 課題Z: 区分 A 避難所のみを KD-tree か BallTree に投入し、 危険避難所 1 件ごとに最近傍 k=5 の距離 + 標高差を計算。 ヒストグラム化して 「徒歩避難可能な代替先がない」市町を抽出。