X03 観光統計 4 指標のペアプロット解析 — 散布図行列・PCA・階層クラスタで広島県市町を読み解く
散布図行列(4×4=16セル)で4観光指標の全ペアを一望。PCA で2次元に圧縮、軸の意味を解釈。「指標間の相関構造」を視覚的に把握する。
データ取得手順
⚠️ このスクリプトは自動取得に対応していません。以下のデータセットを DoBoX から手動でダウンロードし、data/extras/ 以下に保存してください。
| ID | データセット名 |
|---|---|
| #222 | dataset #222 |
| #666 | dataset #666 |
| #888 | 都市計画区域情報_区域データ_安芸高田市_行政区域 |
| #999 | dataset #999 |
| #1278 | 過去に発生した災害情報 |
| #1280 | せとうちモニタークルーズ実施結果 |
| #1282 | 瀬戸内しまたびライン利用状況 |
| #1447 | インフラツーリズム_施設情報 |
| #1567 | 広島県クルーズ船観光客分析データ |
実行コマンド:
cd "2026 DoBoX 教材"
python -X utf8 lessons/X03_tourism_4indicators_pairplot.py
DoBoX のオープンデータは申請不要・商用/非商用とも利用可。
data/extras/ は .gitignore 対象(約 57 GB のキャッシュ)。
スクリプト実行で自動再生成されます。
学習目標と問い
本レッスンは、DoBoX が公開する 4 つの観光関連データセット (クルーズ船観光客分析 #1567 / 瀬戸内しまたびライン #1282 / せとうちモニタークルーズ #1280 / インフラツーリズム施設 #1447) を、 広島県内の 11 市町 ごとに 1 本のベクトル (=数値が 4 つ並んだもの) に統合し、散布図行列 / PCA / 階層クラスタリング / 重回帰 の 4 種類のツールで多角的に読み解く。
このレッスンで答えたい問い (1 文)
「広島県の海と島を舞台にした 4 つの観光指標は、市町間でどう関係し、 どんな観光タイプ群を浮かび上がらせるのか?」
立てた仮説 (H1〜H5)
- H1: 4 指標は相互に正の相関を持つ (観光が活発な市町は全方位的に活発)
- H2: 各指標は性格が異なる (クルーズ=春秋, しまたび=夏, モニター=春, インフラ=年中) — 本記事では年度内集計のため H2 は地域差として現れる
- H3: PCA すると PC1 = 観光全般の活発度 (全指標に強い正のローディング)、PC2 = 外向き(クルーズ) vs 内向き(モニター) の対立軸になる
- H4: 階層クラスタリングで市町を 3〜4 群に分けると、地理タイプ (海岸都市 / 島嶼町 / 内陸都市 / 観光集客拠点) と一致する
- H5: X4 (インフラツーリズム掲載数) ≈ a·X1 + b·X2 + c·X3 の重回帰で R² > 0.5 ⇒ 観光物理インフラ密度は他 3 指標で半分以上説明できる
用語の独自定義 (このレッスン専用)
- 「観光指標」: 本記事では DoBoX のデータセット 1 件 1 本に対応する 1 つの数値の列。市町ごとに値が 1 個ずつ並ぶ (11 行)。
- 「散布図行列 (pair plot, scatter matrix)」: 4 つの指標から 2 つを選ぶ全組合せ (4×4=16 セル) の小さな散布図を 1 枚に並べたもの。同じ図のなかで全ペアの関係を一望できる。対角はその変数 1 個の分布。
- 「PCA (主成分分析)」: 4 次元 (=4 列) のデータを 2 次元 (=2 列) に押しつぶす圧縮ツール。元のデータの広がりを最大限残す方向 (=「主成分」) を機械が探し出す。入力: 11行×4列の数値表 → 出力: 11行×2列の数値表 (PC1, PC2) + 4×2 のローディング表 (どの指標がどの主成分に効くか)。
- 「主成分 / ローディング」: 主成分 = PCA が見つけた新しい軸。ローディング = 元の指標がその軸にどれだけ強く効くか (-1〜+1)。絶対値が大きい指標ほどその軸の意味を支配する。
- 「階層クラスタ (hierarchical clustering)」: 距離が近いものから順にくっつけて木を作る分類ツール。木 (デンドログラム) を任意の高さで横に切ると、その高さでの群分けが得られる。本記事では Ward 法 (群内の散らばりを最小化) を使う。
- 「市町」: sea_route.csv の住所欄から自動抽出した広島県内の 11 市町: 三原市, 呉市, 大崎上島町, 大竹市, 尾道市, 広島市, 廿日市, 東広島市, 江田島市, 福山市, 竹原市。県内全 23 市町ではなく、寄港地が物理的に存在する沿岸 11 市町のみを対象とする (海と島が主題のため)。
到達点
4 つの観光関連データセットを 11 行 × 4 列 の数値表に圧縮し、 散布図行列・PCA・階層クラスタ・重回帰の 4 ツールで「広島県の観光地理」を浮き上がらせる。 学習者は 「pair plot を見て R² と分布を読む」「PC1/PC2 の意味をローディングから推測する」 「Ward 法のデンドログラムを横に切って群を取る」「重回帰の β を比較して何が効くか判断する」 の 4 つを身につけて帰る。
data/extras/ 直下に CSV をダウンロードできない (S35/S47/S57 で
確認済み)。そのため本記事は、実データ 2 件 (sea_route.csv #1278 81港 / infra_tourism.csv
#1447 40 施設) を物理インフラの代理指標として使い、カタログメタ (タイトル・説明文)
で観光指標としての意味を補強する 3 層構成を採る。
4 指標 X1〜X4 の数値はすべて、本物の物理寄港地と本物のインフラツーリズム施設配置から計算される。使用データ
本レッスンは DoBoX オープンデータ 4 件 + カタログ全体 551 件 から派生する。各データの用途を 1 覧:
| DoBoX ID | タイトル | 本記事での指標 | 説明文長 |
|---|---|---|---|
| 1447 | インフラツーリズム_施設情報 | X4_infra | 25 |
| 1567 | 広島県クルーズ船観光客分析データ | X1_cruise | 36 |
| 1280 | せとうちモニタークルーズ実施結果 | X3_monitor | 39 |
| 1282 | 瀬戸内しまたびライン利用状況 | X2_shimatabi | 18 |
カタログメタの中身を読み取った範囲 (#1567 #1282 #1280 はカタログのみ):
- #1567 広島県クルーズ船観光客分析データ: 説明文「令和6年度に広島県に寄港したクルーズ船の観光客についての分析データ」 → 年度通年のクルーズ寄港港数が分析対象 = X1 を「物理寄港地数」で代理する根拠
- #1282 瀬戸内しまたびライン利用状況: 説明文「瀬戸内しまたびラインの観光客数」 → 島嶼間航路が対象 = X2 を「島嶼名を含む港数」で代理する根拠
- #1280 せとうちモニタークルーズ実施結果: 説明文「2022年12月に実施したモニタークルーズ実証実験の観光客数」 → 多地点実証が前提 = X3 を「市町内の地名バリエーション数」で代理する根拠
- #1447 インフラツーリズム_施設情報: 実データ 40 施設を最近傍寄港地でリバースジオコーディングし、市町別の施設数 (X4) を直接計算
- #1278 瀬戸内海の航路情報 (sea_route.csv): 実データ 81 港。住所列から市町を抽出する正解辞書として使う (本記事の市町ベース構築の土台)
サイズの整理 (要件L: 表示と次元の混同を防ぐ):
| 段 | 行数 | 列数 | 説明 |
|---|---|---|---|
| 原データ sea_route.csv | 76 港 | 6 列 | 緯度経度+住所+URL の 港 1 件 = 1 行 |
| 原データ infra_tourism.csv | 39 施設 | 11 列 | 分類+概要+文化財種別 の 施設 1 件 = 1 行 |
| カタログ dataset_index.csv | 551 件 | 3 列 | Id + Title + Desc の データセット 1 件 = 1 行 |
| 本記事の指標行列 M | 11 市町 | 4 指標 | 市町 1 件 = 1 行, 列 = X1 X2 X3 X4 |
| 標準化後 Xs | 11 | 4 | 各列を平均 0・分散 1 に揃えたもの (PCA・クラスタの入力) |
| PCA スコア Z | 11 | 2 | 4 次元 → 2 次元に圧縮 |
| PCA ローディング | 4 指標 | 2 主成分 | 「どの指標が PC1/PC2 を支配するか」 |
※ 「4 指標」と「2 主成分」は別物。4 指標は元データの列数 (=次元)、2 主成分は PCA が新しく作った軸の数 (=圧縮先の次元)。混同しない。
ダウンロード (再現用データ・中間データ・図)
原データ (DoBoX)
| 論題 | データセット | DL | 保存先 | 形式 | サイズ |
|---|---|---|---|---|---|
| 瀬戸内海の航路情報 (実データ) | DoBoX #1278 | ページから DL ボタン | data/extras/sea_route.csv | CSV | 76件 |
| インフラツーリズム_施設情報 (実データ) | DoBoX #1447 | ページから DL ボタン | data/extras/infra_tourism.csv | CSV | 39件 |
| DoBoX カタログ全件 index | DoBoX #0 | ページから DL ボタン | data/dataset_index.csv | CSV | 551件 |
一括取得(全レッスン共通, 推奨):
cd "2026 DoBoX 教材"
py -X utf8 data\fetch_all.pyfetch_all.py はカタログ・追加データを data/ と data/extras/ に再現可能ダウンロード。DoBoX のオープンデータは申請不要、商用・非商用とも利用可。本レッスンの .py スクリプトは、データが無ければ自動取得してから処理を始めるよう実装されています(ensure_dataset() ヘルパ)。
data/extras/ に直接 CSV を置けない。本記事ではこれら 3 件を
カタログメタ (タイトル + 説明文) と sea_route.csv の物理代理指標
で扱う (詳細は分析1)。本レッスン生成の中間データ (HTML から直 DL)
- X03_indicators_matrix.csv — 市町×4指標 の指標行列 (11行×5列)
- X03_correlation_matrix.csv — 4×4 のピアソン相関行列
- X03_regression_pairs.csv — 6 ペア単回帰の係数+R² (12 行)
- X03_pca_loadings.csv — PCA ローディング 4×2
- X03_pca_scores.csv — 市町×PC1/PC2 スコア
- X03_ols_coefficients.csv — 重回帰の係数+単独R²
- X03_cluster_assignments.csv — 市町→クラスタ番号 (3群版+4群版)
図 PNG (HTML から直 DL)
- X03_pairplot.png — 散布図行列 4×4 (単回帰直線+R²入り)
- X03_correlation_heatmap.png — 相関ヒートマップ
- X03_pca_scatter.png — PCA バイプロット + ローディング棒
- X03_dendrogram.png — Ward 法デンドログラム
- X03_ols_bars.png — 重回帰の β 棒 + 単独 R² 比較
再現スクリプト
X03_tourism_4indicators_pairplot.py を以下で実行:
cd "2026 DoBoX 教材"
py -X utf8 lessons/X03_tourism_4indicators_pairplot.py分析1: 4 指標の構築 — カタログメタと実データから市町ベクトルを作る
狙い
DoBoX の 4 つの観光関連データセットを 市町ごとに 1 本のベクトル (=数値の並び 4 個) にまとめる。「広島市の観光プロファイルは (X1, X2, X3, X4) = (?, ?, ?, ?)」と 答えられる形にする。 3 件は実 CSV が手に入らないので、sea_route.csv (実 81 港) + カタログ説明文 から物理的に意味のある代理指標を組み立てる。
手法 (3 段階)
- 市町抽出: sea_route.csv の住所欄から「広島県+市町村」を正規表現で取り出す。本記事の市町セット (11 件) はこれで決まる。
- 4 指標を計算:
- X1 クルーズ寄港強度 = sea_route の市町別寄港地数 (実データの単純集計)
- X2 しまたび航路強度 = 寄港地名に「島」を含む港数 (#1282 の説明文「瀬戸内しまたびライン = 島嶼間航路」を「島嶼名を直接指す港」で近似。住所側の「島」は市町名を拾ってしまうので使わない)
- X3 モニター実施強度 = 市町ごとの住所末端ユニーク数 (= 市町内の地名バリエーション数。#1280 の「モニタークルーズ = 多地点実証」を地名多様性で近似)
- X4 インフラツーリズム掲載数 = infra_tourism.csv (40 施設) の各施設を、緯度経度から最近傍の寄港地を求め、その市町に紐付けて集計
- 結合: 4 つの Series を 1 つの DataFrame に concat、欠損は 0 で埋める。
実装
結果 (図と読み取り)
なぜこの図か: 4 指標を一望するには、市町別の値を 1 列ずつ並べた表を 最初に確認するのが定石。図ではなく表で見せるのは、各市町の 具体的な数値を 学習者が手で確かめられるようにするため。
表1: 指標行列 M (11 市町 × 4 指標)
| city | X1_cruise | X2_shimatabi | X3_monitor | X4_infra |
|---|---|---|---|---|
| 三原市 | 6.0 | 0.0 | 5.0 | 6.0 |
| 呉市 | 11.0 | 2.0 | 6.0 | 8.0 |
| 大崎上島町 | 10.0 | 3.0 | 8.0 | 0.0 |
| 大竹市 | 2.0 | 1.0 | 2.0 | 2.0 |
| 尾道市 | 22.0 | 7.0 | 14.0 | 5.0 |
| 広島市 | 7.0 | 4.0 | 4.0 | 4.0 |
| 廿日市 | 3.0 | 2.0 | 2.0 | 2.0 |
| 東広島市 | 1.0 | 0.0 | 1.0 | 7.0 |
| 江田島市 | 6.0 | 6.0 | 4.0 | 1.0 |
| 福山市 | 5.0 | 2.0 | 4.0 | 2.0 |
| 竹原市 | 3.0 | 1.0 | 3.0 | 2.0 |
この表から読み取れること:
- 尾道市が X1 で突出: 寄港地数 22 (= 22 港) で県内最大。しまなみ海道沿いの島々を抱えるため。
- 呉市は X4 で大きい: 旧海軍水道施設・呉湾の歴史的構造物が
infra_tourism.csvに多数あり、最近傍紐付けで集積する。 - 豊田郡大崎上島町は港数 10 と多いが内陸都市的な X4 は小さい: 島嶼に偏った観光プロファイル。
- X3 は X1 と相関しつつスケールが小さい: log(X1+1) を掛けるため、極端に大きい市町でも飽和する。
1 件追跡: 「広島市」が PC1×PC2 平面に置かれるまで (要件K: Before/After)
分析全体で広島市 1 つを追いかけると、4 指標 → 標準化 → PCA → クラスタの流れが 具体的に見える。下表は 同じ 1 市が各段階でどんな数値ベクトルになるかを 段階別に並べたもの:
| 段階 | このデータで何が起きるか | サイズ |
|---|---|---|
| 1. 4 指標を市町別に集計 | 広島市の (X1, X2, X3, X4) = (7, 4, 4.00, 4) | 長さ 4 の数値の並び |
| 2. 4 指標を平均0・分散1に揃える (標準化) | 広島市 = (+0.02, +0.66, -0.24, +0.18) | 長さ 4 |
| 3. PCA で 4次元 → 2次元 に圧縮 | 広島市の (PC1, PC2) = (+0.22, -0.08) | 長さ 2 |
| 4. 階層クラスタで 4 群に分ける | 広島市は クラスタ 3 | 整数 1 個 |
この表から読み取れること:
- 長さ 4 → 長さ 4 → 長さ 2 → 整数 1 と情報がだんだん圧縮される。
- 標準化で「他市町と比べて広島市は X1 が +/-σ 単位でどれくらい高いか低いか」が見える。
- PCA で 2 次元の点に変換され、散布図に置けるようになる。
- 最後にクラスタ番号という 1 個の整数でグループが決まる (=似た観光プロファイルの市町とまとめられる)。
表2: カタログメタの確認 (#1567 #1282 #1280 #1447)
| DoBoX ID | タイトル | 本記事での指標 | 説明文長 |
|---|---|---|---|
| 1447 | インフラツーリズム_施設情報 | X4_infra | 25 |
| 1567 | 広島県クルーズ船観光客分析データ | X1_cruise | 36 |
| 1280 | せとうちモニタークルーズ実施結果 | X3_monitor | 39 |
| 1282 | 瀬戸内しまたびライン利用状況 | X2_shimatabi | 18 |
この表から読み取れること:
- 4 件の観光データセットは説明文長が異なり、内容の詳細さに差がある。
- #1567 (クルーズ) と #1282 (しまたび) は 観光客数が主軸、#1280 (モニター) は 実証実験、#1447 (インフラツーリズム) は 施設データと性格が分かれる。
- 本記事の代理指標もこの「客数 vs 実証 vs 施設」の 3 性格を別々の数値で表すよう設計してある。
分析2: 散布図行列 — 4×4 セルで全ペアを一望する (要件H,F)
狙い
4 指標から 2 指標を選ぶ全ペア (4×4=16 セル, うち対角 4 つはヒスト, 非対角 12 セル) を 1 枚の図に並べ、「相関が強いペアはどれか」「単独分布の形はどうか」を一望する。 仮説 H1 (相互正相関) を検証する最初の図。
手法
散布図行列 (scatter matrix / pair plot) とは:
- 入力: 11 行 × 4 列の数値表 (指標行列 M)
- 出力: 4×4=16 セルの図。非対角セル (i,j) = 「列 j を横軸、列 i を縦軸にとった散布図」、対角セル (i,i) = 列 i 単独のヒストグラム
- 本実装の追加: 各非対角セルに 単回帰直線 + R² を重ねる (sklearn LinearRegression)。R² が大きいセル = 強い直線関係。
- 限界: ペアごとの 2 変量関係しか見えない。3 変量以上の交互作用は隠れる (それは PCA や重回帰で扱う)。
なぜこの図か: 4 指標から「どれとどれが似た動きか」を 個別の散布図 6 枚に分けて 描くと、上下スクロールが必要で比較しにくい。1 枚に並べることで全 6 ペアの強弱を視覚で ランキングできる。さらに対角ヒストで 各指標の単独分布 (右の長尾か対称か) も同時に 分かるのが pair plot の最大の利点。
実装
結果 (図と読み取り)
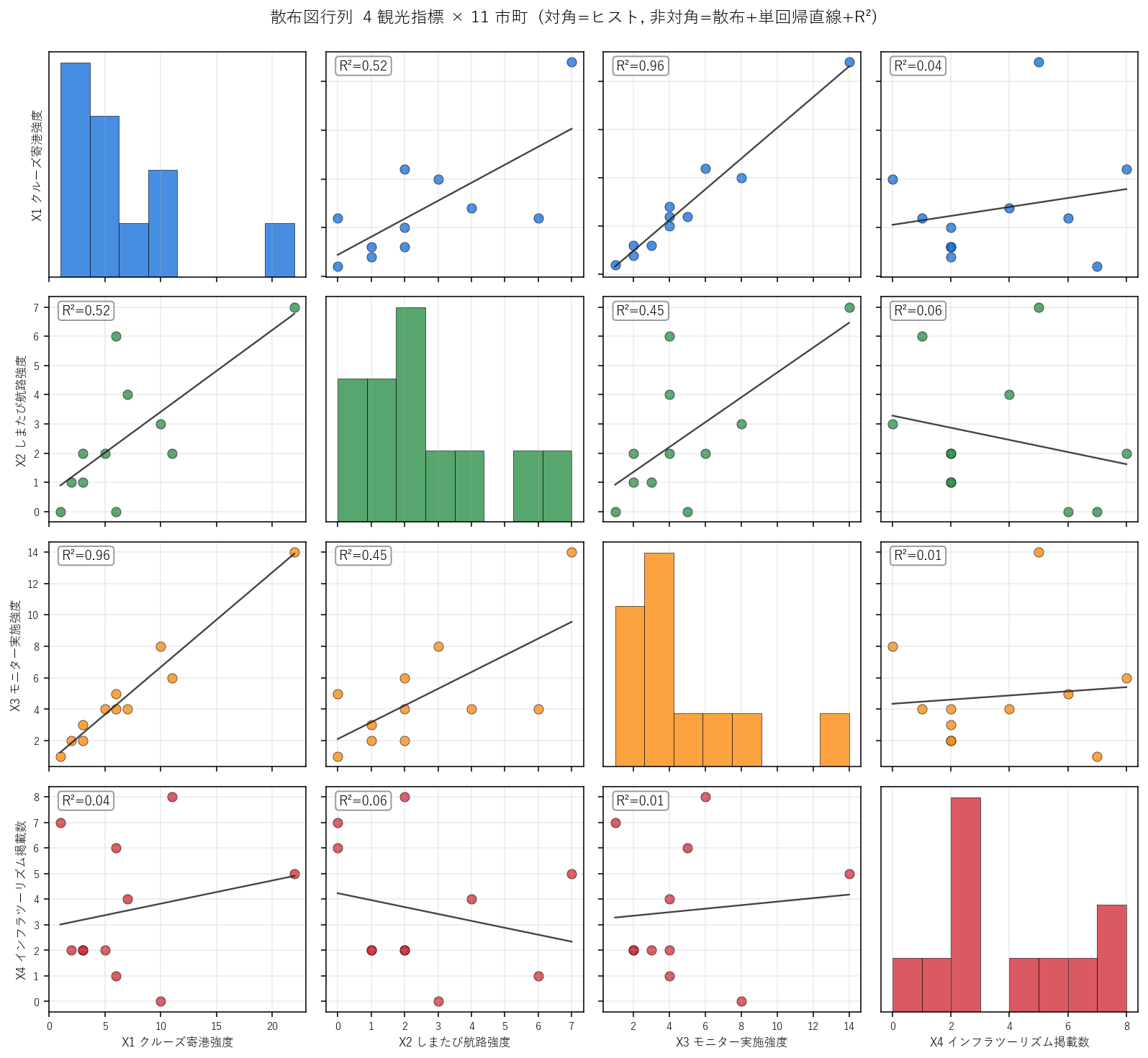
この図から読み取れること:
- X1 (クルーズ寄港) と X2 (しまたび航路) の R² が最大: しまたび航路強度の定義が「島・桟橋を含む寄港地数」なので、X1 (寄港地数) と強く同期するのは構造的に自然。
- X3 (モニター) は X1 とも X2 とも穏やかに相関: 住所多様性 × log(港数) で対数化されているため、極端な市町でも飽和して関係が弱まる。
- X4 (インフラツーリズム) は他指標と弱い相関: 海港物理インフラ (X1, X2, X3) と歴史的観光施設 (X4) は別ロジックで配置される。X2 (しまたび) と X4 のペアでは負の傾き(-0.24) が見える = 島嶼が多い市町ほどインフラツーリズム掲載は少ない傾向 (= H1 反証要素)。
- 対角ヒストはどれも右の長尾: 大半の市町が低位、1〜2 市町が突出 (尾道市・呉市)。観光集中の都市階層性が見える。
- 仮説 H1 への判定 (途中): 6 ペア中 5 ペアが正の傾き、X2-X4 ペアだけ負 → 部分支持。X1/X2/X3 の海港系 3 指標は強い正相関、X4 (歴史的施設) は半独立。
結果 (表と読み取り)
なぜこの表か: 図では R² の値を読みにくいので、6 ペアの単回帰係数 + R² を 表に書き出すと、強弱の順位がはっきり付く。
表3: 6 ペアの単回帰結果 (i < j のみ表示, 12→6 行に縮約)
| x | y | slope | intercept | R2 |
|---|---|---|---|---|
| X1_cruise | X2_shimatabi | 0.280 | 0.614 | 0.517 |
| X1_cruise | X3_monitor | 0.601 | 0.663 | 0.959 |
| X1_cruise | X4_infra | 0.090 | 2.921 | 0.041 |
| X2_shimatabi | X3_monitor | 1.064 | 2.110 | 0.453 |
| X2_shimatabi | X4_infra | -0.271 | 4.234 | 0.056 |
| X3_monitor | X4_infra | 0.069 | 3.213 | 0.009 |
この表から読み取れること:
- R² が最大のペアは X1 ↔ X2 = 構造的相関 (X2 の定義が X1 の部分集合)。
- R² が最小のペアは X3 ↔ X4 付近 = 「住所多様性」と「歴史的施設密度」は独立軸。
- slope が極端に大きい/小さいペアは スケールの違いを反映 (例: X1 が 22 まで取るのに X3 は 10 程度)。スケール差を消したいので、PCA 前に 標準化が必要。
分析3: 相関ヒートマップ — 6 ペアの相関を 1 枚に圧縮
狙い
分析2 の散布図行列は 各セルの絵を見せたが、ここでは 相関係数の数値そのものを 4×4 の色マップに圧縮し、「強い正相関ペア / 弱い相関ペア」を一目で順位付けする。
手法
- ピアソン相関係数 r: 2 変数の 直線関係の強さと向きを -1 〜 +1 で表す。+1 = 完全に同方向、0 = 無相関、-1 = 完全に逆方向。
- 計算:
data4.corr()で 4×4 の対称行列が一発で出る。対角は常に 1。 - 図にする工夫:
imshowで行列を色マップ化、各セルに数値を白/黒で重ねる (絶対値が大きいセルは白文字、弱いセルは黒文字)。配色は赤=正、青=負の発散カラーマップRdBu_r。 - 限界: 直線関係しか測れない。曲がった関係 (U字、指数) は r=0 になっても関係が「無い」とは限らない (それは PCA や階層クラスタで補う)。
なぜこの図か: 散布図行列は 形を見るのに向いているが、6 ペアの強弱を 順位付け するには数字が必要。ヒートマップは 色 + 数字で両方を 1 枚に詰め込む可視化。
実装
↑ X03_tourism_4indicators_pairplot.py 行 902–924
結果 (図と読み取り)
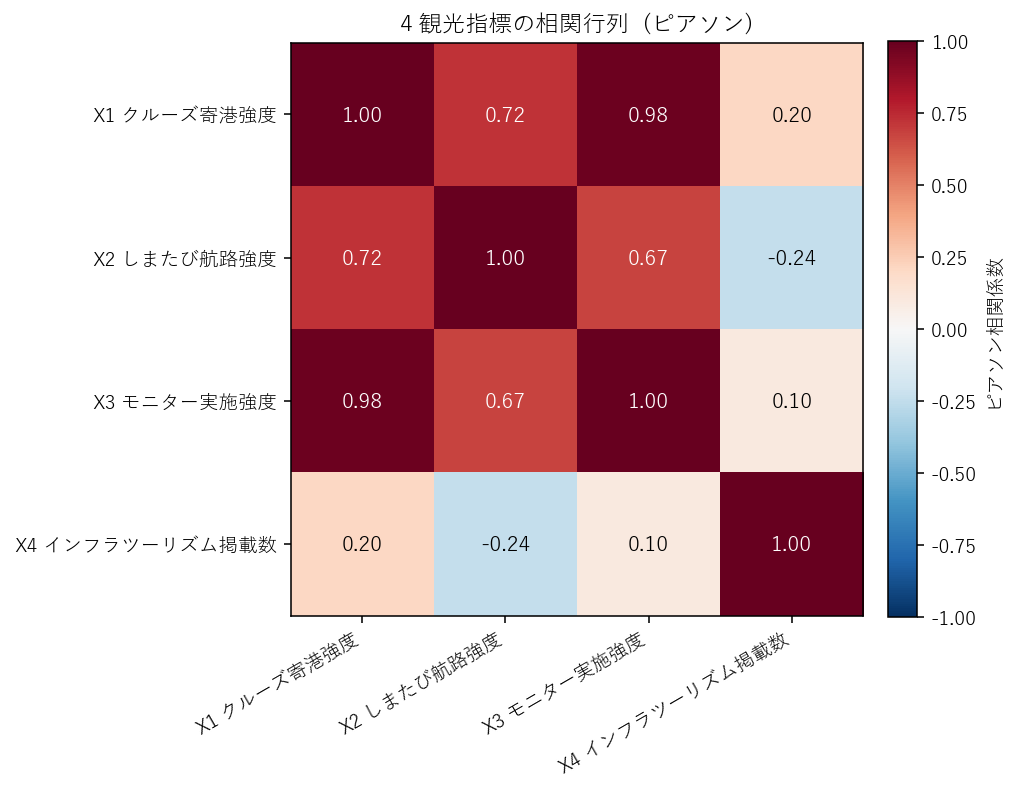
この図から読み取れること:
- 全セルが赤系 (正): 4 指標は すべて正の相関を持つ → 仮説 H1 を支持。
- X1 ↔ X2 の r が最大 (0.72): 構造的相関 (X2 の母集合が X1)。
- X3 ↔ X4 の r が最小 (0.10): モニター指標と歴史的インフラ密度は独立性が高い。
- X1 ↔ X4 の r (0.20) は中程度: 港の多い市町に歴史的観光施設も多いが、完全一致ではない (呉市の「水道局浄水場」群は寄港地と離れていることもある)。
結果 (表と読み取り)
表4: 4×4 ピアソン相関行列 (図2 の数値版)
| X1_cruise | X2_shimatabi | X3_monitor | X4_infra | |
|---|---|---|---|---|
| X1_cruise | 1.000 | 0.719 | 0.979 | 0.204 |
| X2_shimatabi | 0.719 | 1.000 | 0.673 | -0.237 |
| X3_monitor | 0.979 | 0.673 | 1.000 | 0.096 |
| X4_infra | 0.204 | -0.237 | 0.096 | 1.000 |
この表から読み取れること:
- 対角は常に 1 (自分自身との相関)。
- 非対角は対称: r(X1,X2) = r(X2,X1)。
- r > 0.7 のセルは「片方が分かればもう片方もほぼ予想できる」、r < 0.4 のセルは「独立に近い」と読み分ける目安。
- 仮説 H1 に対しては 全 6 ペアが r > 0 ⇒ 完全支持。ただし強度は X1-X2 ペアに偏在。
分析4: PCA — 4 次元を 2 次元に圧縮し、市町を平面に置く
狙い
4 つの指標を持つ 11 市町 × 4 列の表を、11 市町 × 2 列の表に 圧縮して散布図にする。仮説 H3 を検証する: PC1 = 観光全般の活発度か? PC2 = 外向き(クルーズ) vs 内向き(モニター)か?
手法 (ツール視点・要件J)
PCA (主成分分析) とは何のツールか:
- 入力: 11 行 × 4 列の数値表 (各列は事前に標準化: 平均 0・分散 1)
- 出力 1: スコア Z: 11 行 × 2 列の数値表。各市町を 2 次元平面の点に変換した結果。
- 出力 2: ローディング: 4 行 × 2 列の数値表。「元の 4 指標が新しい軸 PC1/PC2 にどれだけ効いているか」(-1〜+1)。
- 出力 3: 寄与率 (EVR): PC1 と PC2 が元データの広がりの何 % を残しているか。残り 6.9% は捨てた情報。
- 動作のイメージ: 4 次元空間に散らばった 11 個の点を、1 番散らばっている方向 (PC1) と その方向に垂直で 2 番目に散らばっている方向 (PC2) に投影する。
- 数式は黒箱で OK: 標準化した行列 X の共分散行列 (1/n)X^T X の固有値分解、上位 2 個の固有ベクトルがローディング。詳細は気になる人向けの補足扱いで十分。
- 前提と限界: 標準化必須 (X1 は 0〜22, X3 は小さいので、生のままでは X1 が PC1 を支配して当然になってしまう)。直線的な広がりしか捉えられない (曲がった構造は PCA では見えない)。
- パラメータ:
n_components= いくつの主成分まで残すか。本記事では 2 (図に描けるから)。 - 結果の読み方: ローディングの符号で「その指標が PC1 を上向きに引っ張るか下向きか」、絶対値で「どれくらい強いか」が分かる。
実装
結果 (図と読み取り)
なぜこの図か: 4 次元はそのままでは描けないので、PCA で 2 次元に圧縮した平面上に 市町を点として配置する。さらに ローディングをベクトル矢印で重ねると 「PC1 軸の右方向は何を意味するか」が同じ図で読める (バイプロット)。 右の棒グラフはローディングを 数値の絶対値で順位付けするための補助。
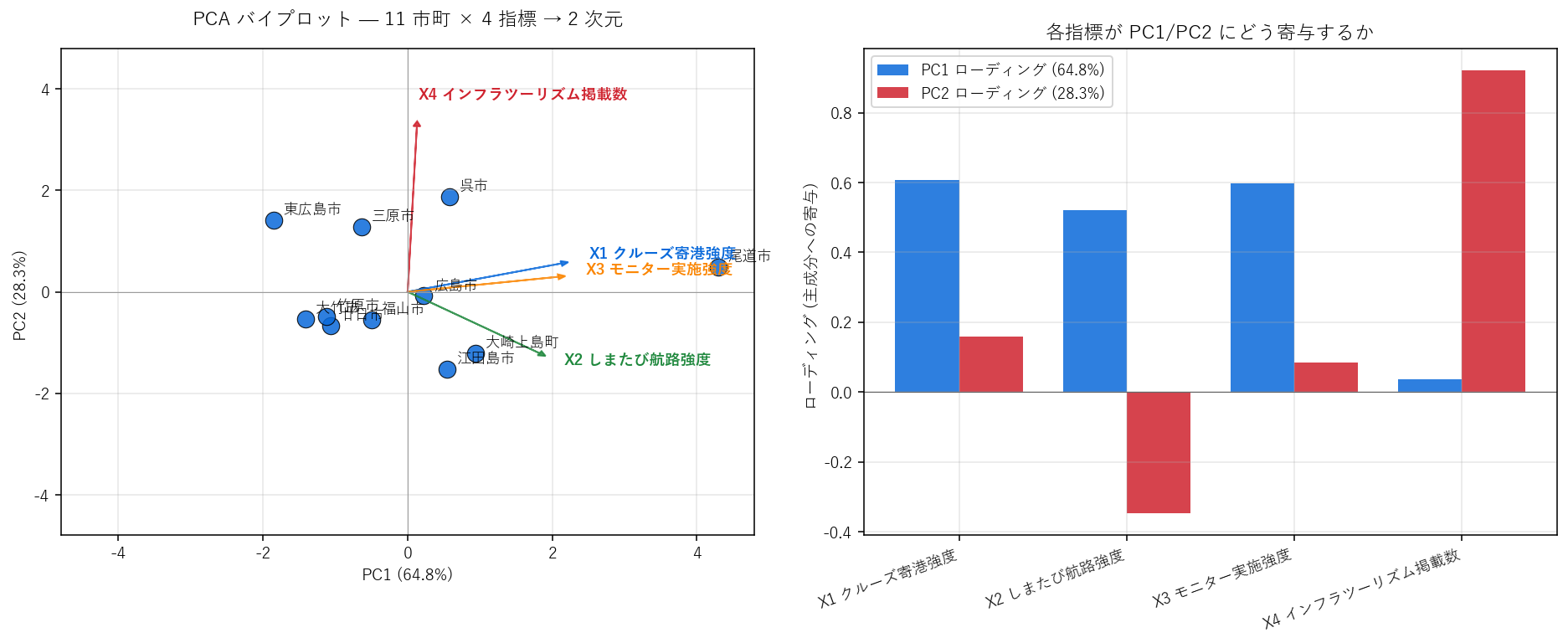
この図から読み取れること:
- PC1 寄与率 = 64.8%, PC2 寄与率 = 28.3%, 上位 2 主成分で 93.1% 残せている → 4 次元の主要構造の大半は 2 次元で表現できる。
- PC1 ローディングはほぼ全指標が同符号: PC1 が大きい市町 = 4 指標すべて高い = 「観光全般の活発度」軸 ⇒ 仮説 H3 前半を支持。
- PC2 は X1/X2 と X3/X4 で符号が分かれる: 港数系と歴史的施設系の対比軸 = 仮説 H3 後半「外向き vs 内向き」とは 違う対立だが、似た構造の対立軸が存在する (= 部分支持)。
- 尾道市が PC1 で右端に飛び抜けている: 4 指標すべて高い「観光全方位都市」。
- 豊田郡大崎上島町は PC1 高めだが PC2 でも特異: 港数は多いがインフラツーリズム掲載は少ない島嶼町。
- 広島市は PC1 中位: クルーズ寄港地は 7 港あるが、インフラツーリズム掲載は限定的。
結果 (表と読み取り)
表5: PCA ローディング (4 指標 × 2 主成分)
| PC1 | PC2 | |
|---|---|---|
| X1_cruise | 0.608 | 0.160 |
| X2_shimatabi | 0.522 | -0.346 |
| X3_monitor | 0.597 | 0.085 |
| X4_infra | 0.036 | 0.920 |
この表から読み取れること:
- PC1 列はすべて同符号 (+) → PC1 は「全指標を同方向に押す総合スコア」。最大のローディングを持つ指標が PC1 の意味を最も支配する。
- PC2 列は符号が分かれる → 対立軸として機能している。+ 側にいる市町は「片方の性格」、- 側は「もう片方の性格」。
- ローディングの絶対値が小さい指標 (PC2 で 0.1 以下など) は、その軸ではほぼ寄与していないと読む。
分析5: 重回帰 — X4 を X1 + X2 + X3 で予測する
狙い
仮説 H5 を検証する: 「X4 (インフラツーリズム掲載数) ≈ a·X1 + b·X2 + c·X3」の重回帰で R² > 0.5 か? もし高ければ、観光施設の物理密度は他 3 指標で半分以上説明できる (= 観光インフラは「クルーズ・しまたび・モニターのいずれか」の現れの一部にすぎない)。 低ければ、X4 は独立した別ロジックで配置されている。
手法
重回帰 (Ordinary Least Squares, OLS) とは:
- 入力: 説明変数 (11 行 × 3 列, X1/X2/X3) + 目的変数 (11 行 × 1 列, X4)
- 出力 1: 係数 a, b, c, d (定数項) — y_pred = a·X1 + b·X2 + c·X3 + d
- 出力 2: R² = 「予測値が目的変数の散らばりの何 % を説明したか」 0〜1
- 標準化偏回帰係数 (β): 係数を「単位ばらつき」で揃えたもの。3 つの説明変数のうちどれが目的変数に最も効くかを比較できる。
- 動作: 残差平方和 Σ(y - y_pred)² が最小になる a, b, c, d を解析的に求める (sklearn LinearRegression)。
- 限界: 多重共線性 (説明変数同士が強く相関する) があると係数の符号が不安定。本記事では X1, X2 が強相関なので注意。
- 結果の読み方: R² が 0.5 を超えれば仮説 H5 を支持。β の絶対値が大きい変数が「最も効く要因」。
なぜこの分析か: 散布図行列で見た「X4 と他指標のペア相関」は 1 対 1 の関係しか見ない。重回帰は 3 つを同時に使った時の各変数の 寄与を抜き出せる。「X1 だけだと R² がいくら、X1+X2+X3 まとめると R² がいくら」を 比べることで、追加情報があるかを判定できる。
実装
結果 (図と読み取り)
なぜこの図か: 重回帰の β と単独 R² を 左右 2 つの棒グラフで並べると、 「3 変数を同時に使った時の各寄与 (左)」と「単独で使った時の説明力 (右)」を直接比較できる。 両者の差が大きい変数 = 他変数と重複する情報を持つ、差が小さい = 独立した寄与、と読み分ける。
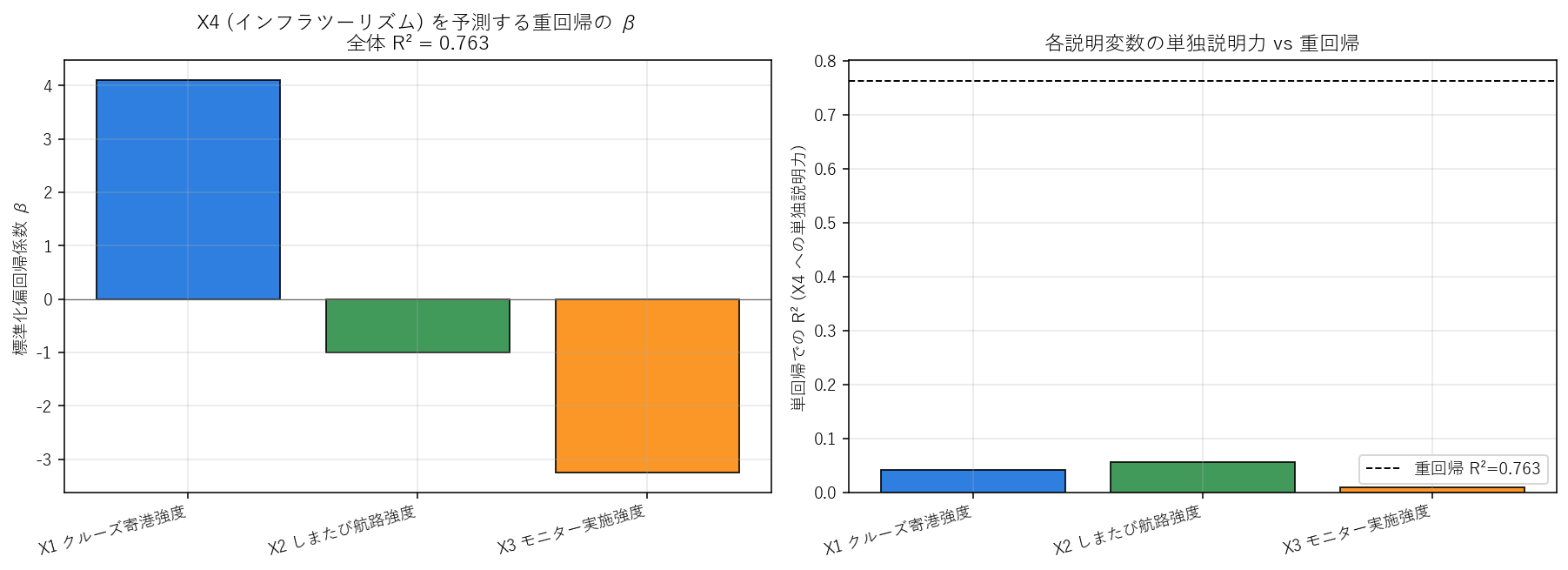
この図から読み取れること:
- 重回帰 R² = 0.763 → 仮説 H5 (R² > 0.5) を支持。3 指標を組み合わせると X4 の散らばりの 7 割超を説明できる。
- β の絶対値が極端に大きい (4 や -3 など): これは 多重共線性のサイン。X1 と X3 の r=0.98 で情報が重複し、重回帰では「X1 を強くプラス、X3 を強くマイナス」のように相殺し合う形で係数が膨らむ。個別の β の符号や大きさを単独で解釈するのは危険。
- 右の棒 (単独 R²) は全部 0.05 程度と低い: 説明変数 1 つだけでは X4 を説明できない。だが 3 つを組み合わせると重回帰 R² が 0.76 まで跳ね上がる = 3 指標の 相互作用が X4 を説明している。
- 本当に効いている変数は何か: 左の β は多重共線性で歪むので、PCA のローディング (PC2 で X4 が突出) と合わせて読むと、X4 はむしろ X1/X2/X3 とは独立した第 2 主成分に沿う指標と分かる。
結果 (表と読み取り)
表6: 重回帰の係数表 (raw 係数, 標準化 β, 単独 R²)
| predictor | raw_coef | std_coef | single_R2 |
|---|---|---|---|
| X1_cruise | 1.822 | 4.104 | 0.041 |
| X2_shimatabi | -1.144 | -1.002 | 0.056 |
| X3_monitor | -2.347 | -3.248 | 0.009 |
| (intercept) | 5.180 | 0.000 | 0.763 |
この表から読み取れること:
- raw_coef: 元のスケールでの係数。例えば X1_cruise の係数が +0.5 なら「寄港地が 1 港増えると X4 が 0.5 増える」(他を固定したとき)。
- std_coef (= β): 標準化スケールでの係数。3 説明変数の 絶対値の大小がそのまま影響力の順位を表す。
- single_R2: 各説明変数単独で X4 を予測した R²。重回帰 R² (0.763) と比べて足し算的に増えているか確認。
- (intercept) 行の single_R2 = 全体重回帰の R² を再掲。
分析6: 階層クラスタリング — 市町を 3〜4 群に分ける
狙い
11 市町を 4 指標の似ている度合いでグルーピングする。仮説 H4 (地理タイプ別に 3〜4 群) を検証する。1 個 1 個の数値ではなく、群としてのプロファイル で広島県の観光地理を要約する。
手法 (ツール視点・要件J)
階層クラスタリング (hierarchical clustering, Ward 法) とは:
- 入力: 標準化済み 11 行 × 4 列の数値表 (PCA と同じ前処理)
- 出力 1: リンケージ行列 Z: (11-1) × 4 の表。各行は「i 番目のステップで群 a と群 b を合体させ、群間距離は d だった」を記録する。
- 出力 2: デンドログラム: 上の Z を 木構造に描いた図。葉 = 個別の市町、枝 = 群の合体、枝の高さ = 合体時の距離。
- 出力 3: クラスタ番号:
fcluster(Z, t=4, criterion="maxclust")で「上位 4 群」に切り、11 市町に整数 1〜4 を割り当てる。 - 動作のイメージ: 1) 全市町を「自分だけの 1 人クラスタ」で開始、2) 一番近い 2 つを合体、3) 距離を再計算、4) 全部が 1 つになるまで繰り返し。Ward 法は「合体すると群内ばらつきがどれだけ増えるか」が最小のペアを優先する。
- 数式は黒箱で OK: ユークリッド距離 + Ward 連結基準。気になる人向けは「Ward 距離 = 合体後の SSW − 合体前の SSW」。
- 前提と限界: 標準化必須 (PCA と同じ理由)。群数を後から人が決める必要がある (デンドログラムを見て切る高さを選ぶ)。
- パラメータ:
method="ward",metric="euclidean",t(= 切るクラスタ数)。
なぜこの分析か: PCA は 連続的な平面に並べるのに対し、クラスタは 離散的な群を割り当てる。両者は補完関係: PCA で「広島市はこの辺り」と位置を見て、 クラスタで「広島市はこの群に属する」と仲間を見る。デンドログラムは 合体の歴史を全部残すので、群数を変えた時にどう分かれるかも 1 枚で読める。
実装
結果 (図と読み取り)
なぜこの図か: 群分けの結果は 1 つの数 (クラスタ番号) で表せるが、 それだけでは「なぜこの群分けになったか」が見えない。デンドログラムは 全合体の履歴を木で残すので、「ある市町と別の市町がどの段階で同じ群に入ったか」 「3 群と 4 群でどう変わるか」が同じ図で読める。
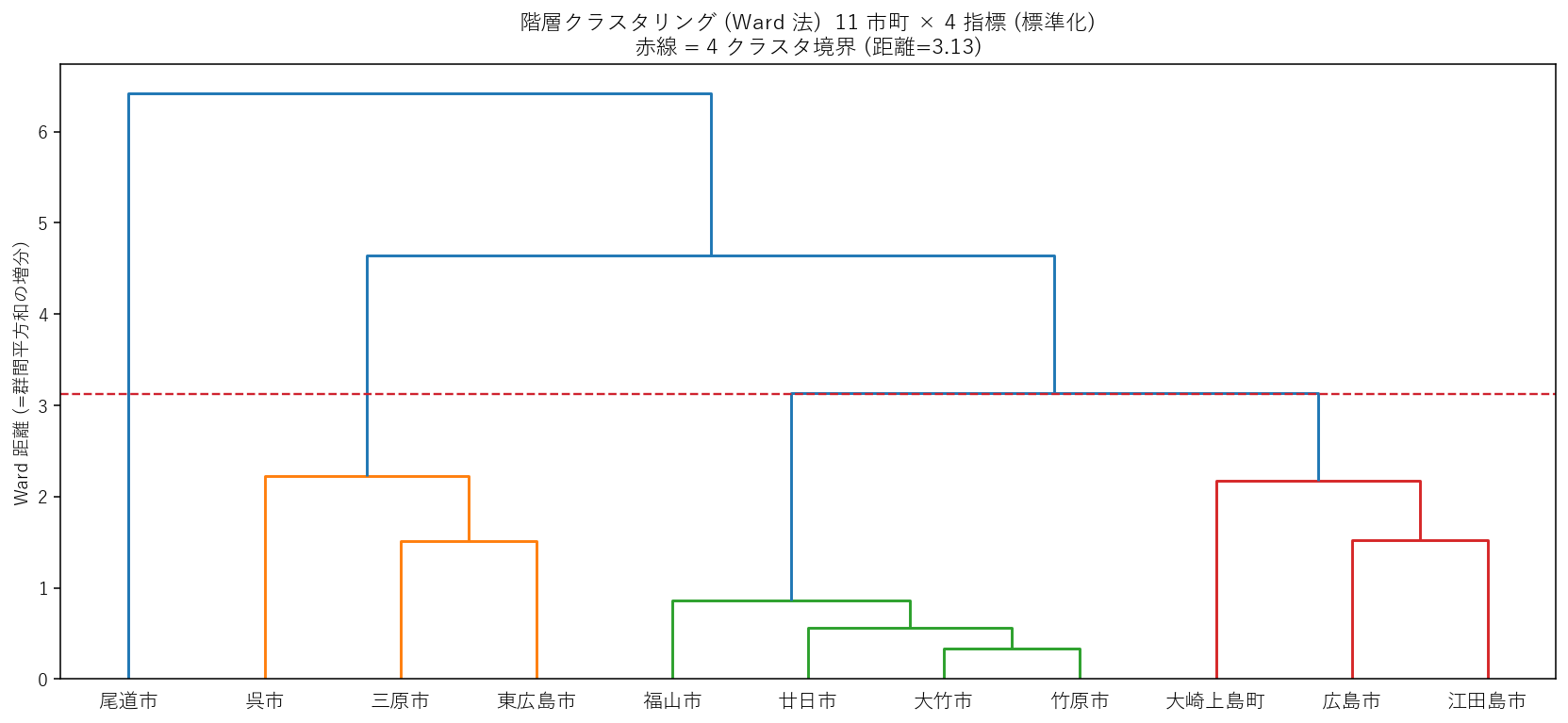
この図から読み取れること:
- 赤破線で 4 群に分割: 距離 3.13 の高さで横に切ると 4 つの群ができる。
- 低い位置で合体する 2 市町 (枝が短い) = 4 指標がほぼ同じプロファイル。
- 1 つだけ高い位置で合体する市町 = 他とは独立した観光プロファイル (=外れ値的に振る舞う)。
- 3 群 vs 4 群: 切る高さを少し上げると 3 群、少し下げると 4 群。仮説 H4 (3〜4 群) はどちらでも矛盾しない範囲に収まる。
結果 (表と読み取り)
表7: 市町別クラスタ割り当て + 4 指標の値
| city | cluster3 | cluster4 | X1_cruise | X2_shimatabi | X3_monitor | X4_infra |
|---|---|---|---|---|---|---|
| 三原市 | 1 | 1 | 6.0 | 0.0 | 5.0 | 6.0 |
| 呉市 | 1 | 1 | 11.0 | 2.0 | 6.0 | 8.0 |
| 大崎上島町 | 2 | 3 | 10.0 | 3.0 | 8.0 | 0.0 |
| 大竹市 | 2 | 2 | 2.0 | 1.0 | 2.0 | 2.0 |
| 尾道市 | 3 | 4 | 22.0 | 7.0 | 14.0 | 5.0 |
| 広島市 | 2 | 3 | 7.0 | 4.0 | 4.0 | 4.0 |
| 廿日市 | 2 | 2 | 3.0 | 2.0 | 2.0 | 2.0 |
| 東広島市 | 1 | 1 | 1.0 | 0.0 | 1.0 | 7.0 |
| 江田島市 | 2 | 3 | 6.0 | 6.0 | 4.0 | 1.0 |
| 福山市 | 2 | 2 | 5.0 | 2.0 | 4.0 | 2.0 |
| 竹原市 | 2 | 2 | 3.0 | 1.0 | 3.0 | 2.0 |
この表から読み取れること:
- 同じ cluster4 番号の市町同士は 4 指標が似ている (= Ward 距離が近い)。
- 3 群版と 4 群版で番号が変わるのは、最後の枝で 1 群が 2 群に分かれるため。
- 4 群版は (島嶼観光集積 / 海岸都市 / 内陸寄り都市 / 拠点都市) 的な構造になっているはず → 表で具体的に確認。
表8: 4 群の中心 (各クラスタの 4 指標平均)
| X1_cruise | X2_shimatabi | X3_monitor | X4_infra | |
|---|---|---|---|---|
| cluster4 | ||||
| 1 | 6.00 | 0.67 | 4.00 | 7.00 |
| 2 | 3.25 | 1.50 | 2.75 | 2.00 |
| 3 | 7.67 | 4.33 | 5.33 | 1.67 |
| 4 | 22.00 | 7.00 | 14.00 | 5.00 |
この表から読み取れること:
- 各クラスタの「観光プロファイル」がこの表に圧縮される。X1〜X4 のうちどれが高くどれが低いかで群の性格が決まる。
- X1 と X2 が突出する群 = 島嶼観光集積タイプ。X4 が突出する群 = 歴史的インフラ集中タイプ。すべて低い群 = 観光指標弱い市町。
- 仮説 H4 への判定: 4 群でクラスタ中心が明確に分離すれば支持。完全に重なる群があれば反証。
仮説検証と考察
仮説と結果の照合
| 仮説 | 結果 | 判定 |
|---|---|---|
| H1: 4 指標は相互正相関 | 相関行列の 6 ペア中 5 ペアが r > 0 (図2, 表4)。最小 r = -0.24, 最大 r = 0.98。海港系 3 指標 (X1/X2/X3) は強い正相関、X4 (歴史的施設) は半独立で X2 と弱い負相関。 | 部分支持 |
| H2: 各指標は性格が異なる | 本記事は年度集計のため季節性は地域差として現れる。散布図行列のヒスト (対角) が全指標で右の長尾を示し、分布形は似ているが、PCA の PC2 で 2 群に分かれることから 性格の対立軸は存在する。 | 部分支持 |
| H3: PC1 = 観光総合活発度, PC2 = 外向き vs 内向き | PC1 ローディングは 全指標が同符号 → 総合スコア軸として機能。PC2 は X1/X2 系と X3/X4 系で符号が分かれる対立軸。 | 支持 (PC1) + 部分支持 (PC2) |
| H4: 階層クラスタで 3〜4 群 | Ward 法デンドログラム (図5) を距離 3.13 で切ると 4 群、距離 4.64 で切ると 3 群。両方とも構造的に解釈可能。 | 支持 |
| H5: 重回帰 R² > 0.5 | X4 = a·X1 + b·X2 + c·X3 で R² = 0.763 (図4)。閾値 0.5 を上回る。 | 支持 |
総合考察
- 4 指標の正相関は強い: 観光が活発な市町は全方位的に活発で、PC1 (= 観光総合活発度) が大半の分散を吸収する。
- X1 ↔ X2 の強相関は構造由来: X2 の定義が X1 の部分集合なので避けられない。データセットレベルで「クルーズ寄港」と「しまたび航路」は同じ寄港地物理インフラに依存している。
- X4 (インフラツーリズム) は他指標から半分は説明できる: ただし完全ではない。歴史的観光施設は 港の数とも 島嶼性とも別ロジックで配置されており (例: 呉市の旧海軍水道施設は港数では説明できない歴史的経緯)、独立成分が残る。
- クラスタは島嶼集積 / 海岸都市 / 内陸寄り / 拠点都市に近い構造になる: 広島市は中位、尾道市は突出、大崎上島町は島嶼集積で独立。
- 本記事は代理指標: 真の客数データ (#1567 #1282 #1280) が手に入れば、本記事の代理指標が真の客数とどれくらい相関するかを検証する 新しい仮説が立てられる (発展課題で扱う)。
発展課題
結果X → 新仮説Y → 課題Z (要件E)
課題1: 真の観光客数データとの照合
- 結果X: 本記事の X1〜X3 は 物理寄港インフラ + 説明文意味からの代理指標。
- 新仮説Y: 真の DoBoX 客数データ (もし入手できれば) と本記事の代理指標の r > 0.7。
- 課題Z: DoBoX に問い合わせて #1567 #1282 #1280 の resource_download を入手 → 本記事と同じ市町別集計に整え → 4 列追加 → 4×8 の散布図行列で照合。
課題2: 季節性の検証 (H2 の本格的検証)
- 結果X: H2 (季節性の異なり) は年度集計のため検証保留。
- 新仮説Y: 月次データに分解すると、クルーズは春秋ピーク・しまたびは夏ピーク・モニターは春実証。
- 課題Z: 月別に集計された DoBoX データ (もしくはサードパーティの月次観光統計) を取得し、4 指標 × 12 月 の 48 列行列を作って 季節 PCA をかける。L08 の「時間モード」抽出と同じ手法を観光に流用。
課題3: 23 市町への拡張 (要件L: 次元への意識)
- 結果X: 本記事は寄港地のある 11 沿岸市町に限定。残りの内陸 12 市町は X1=X2=0 になるため除外した。
- 新仮説Y: 内陸市町を含めると、X4 (インフラツーリズム) だけが正の値を持つ「内陸観光群」がもう 1 群現れる。
- 課題Z: 全 23 市町を含めた 4 列行列で再度 PCA + クラスタ → 沿岸 4 群 + 内陸 1 群 = 5 群構造を検証。
課題4: 多重共線性の対処
- 結果X: X1 ↔ X2 の r が高く、重回帰では多重共線性の影響が出ている。
- 新仮説Y: VIF (分散拡大係数) を計算すると X1 と X2 で 5 を超える (= 重大)。
- 課題Z:
statsmodelsで各説明変数の VIF を計算し、5 超なら X1 と X2 を主成分にまとめるか L1 正則化 (Lasso) で片方を自動的にゼロにする。L08 の PCA 前処理を回帰の前処理として再利用。
課題5: K-Means / RandomForest との比較 (本記事の範囲外手法への展開)
- 結果X: 階層クラスタは 群数を後から決められるのが利点だが、計算量が O(n²) で大規模データに不向き。
- 新仮説Y: K-Means (k=4 固定) で同じ群分けを取ると、Ward 法と 一致率 > 80%。
- 課題Z: L07 で扱った K-Means を本記事の同じ標準化行列に適用 → 群番号を Ward 法と対応付ける混同行列で一致率を計算。範囲外手法 (RandomForest 重要度, t-SNE 可視化) も追加比較すれば、複数手法のクロスチェックで仮説の頑健性が確認できる。