埋蔵文化財 × 観光地化潜在性 — 階層クラスタリングと PCA で広島県 16 市町を読む
階層クラスタリング(Ward法デンドログラム)で市町を文化財プロファイルから群分け。「複合型・古代行政型・中世宗教型」3群への類型化を可視化する。
データ取得手順
✅ このスクリプトは初回実行時にデータを自動取得します(DoBoX からの直接ダウンロード)。
| ID | データセット名 |
|---|---|
| #42 | 避難所情報 |
| #167 | dataset #167 |
| #444 | dataset #444 |
| #666 | dataset #666 |
| #888 | 都市計画区域情報_区域データ_安芸高田市_行政区域 |
| #1280 | せとうちモニタークルーズ実施結果 |
| #1660 | 埋蔵文化財包蔵地一覧表(古墳・横穴) |
| #1663 | 埋蔵文化財包蔵地一覧表(都城・官衙跡) |
| #1669 | 埋蔵文化財包蔵地一覧表(その他) |
| #1670 | 埋蔵文化財包蔵地一覧表(水中遺跡) |
実行コマンド:
cd "2026 DoBoX 教材"
python -X utf8 lessons/X02_burial_tourism_potential.py
DoBoX のオープンデータは申請不要・商用/非商用とも利用可。
data/extras/ は .gitignore 対象(約 57 GB のキャッシュ)。
スクリプト実行で自動再生成されます。
学習目標と問い
このレッスンで答えたい問い
「広島県の埋蔵文化財は、どの市町に・どんな種別で偏在し、観光資源化されている/されていない地域を地図と数値で見分けられるか?」
用語の定義(このレッスン独自)
- 埋蔵文化財: 地中に埋まっている遺跡・遺物のこと。古墳・集落跡・寺院跡・経塚(写経を埋めた塚)など。 広島県の DoBoX には 11 シリーズあり、本レッスンでは 都城・官衙跡(13件)と その他(198件)の 2 シリーズ計 211 件を使う。
- 都城・官衙跡(としろ・かんがあと): 「都城」=城郭都市、「官衙跡」=古代の役所跡(=昔の市役所)。 古代国家の行政中心地に置かれた跡。
- 観光地化: ここでは 「インフラツーリズム掲載 40 件」のうち、ある市町に何件あるかでその市町の観光資源化度合いを測る(DoBoX #1280)。 観光客数や評価点など主観指標は使わない。
- 階層クラスタリング: 似た者同士を順に併合して系統樹(じゃばら状の図)を作る手法。 枝の高さで「どれくらい違うか」が見える。詳細は分析4 で。
- PCA(主成分分析): たくさんの数値列を 2 列に要約する手法。11 種別の構成比を 2 次元の散布図に圧縮できる。詳細は分析5 で。
立てた仮説
- H1(種別×地理): 文化財種別ごとに地理分布が違う。都城・官衙跡は古代の行政中心地(広島市・福山市・府中市)に集中、 集落跡・経塚は山間部に広く分布する。
- H2(観光化の偏り): 観光対象施設は 都城・古墳・建造物系の大型遺構が多く、経塚・砂留などの小規模文化財は観光化されにくい。
- H3(密度相関): 市町別の 文化財件数と 観光資源数は正の相関を持つ(多い所は両方多い)。
- H4(市町プロファイルの3群): 11 種別の市町別件数をベクトル化して階層クラスタリングすると、 市町は 都市型(古代行政+近代観光)/農村型(祭祀・経塚分散)/遺跡密集型(特定種別が突出)の 3 群に分かれる。
- H5(PCA で2軸抽出): 同じデータを PCA で 2 次元に圧縮すると、 PC1 が 「古代行政 vs 近世生活」、PC2 が 「祭祀・宗教 vs 交通・産業」のような主題軸を表すはず。
到達点
- 5 仮説を、6 つの分析で 支持/反証/部分支持 判定まで持っていく
- 階層クラスタリング・PCA を 「ツール」として 使えるようになる(数式は黒箱)
- 1 つの遺跡(例: 地蔵河原一里塚)が分析を通る過程を 段階表で追える
使用データ
- 埋蔵文化財包蔵地一覧表(都城・官衙跡) DoBoX #1663 — 13 件
- 埋蔵文化財包蔵地一覧表(その他) DoBoX #1669 — 198 件
- インフラツーリズム関連施設 DoBoX #1280 — 40 件(観光対象)
- カタログインデックス DoBoX 全 551 件 — 参考
- 避難所データ(市町名マッピング参考) DoBoX #42
※ 11 シリーズのうち 2 シリーズ(都城・官衙跡、その他)の合計 211 件を使用。 他 9 シリーズ(古墳・横穴/貝塚/集落跡・散布地/城館跡/社寺跡/生産遺跡/その他の墳墓/近代以降の単独遺跡/水中遺跡)は 発展課題で網羅予定。本レッスンでは種別正規化により 11 カテゴリ に丸めるため、 データ範囲 = 11 シリーズの直交分類ではなく、種別文字列ベースの分類になる点に注意。
ダウンロード(再現用データ・中間データ・図)
本レッスンの全成果物に直リンク。学習者は途中ステップから再現できる。
1. 生データ(DoBoX 由来)
| ファイル | 形式 | 行数 | 取得元 |
|---|---|---|---|
data/extras/burial_castle_govt.csv |
CSV | 13 | DoBoX #1663 |
data/extras/burial_other.csv |
CSV | 198 | DoBoX #1669 |
data/extras/infra_tourism.csv |
CSV | 40 | DoBoX #1280 |
data/dataset_index.csv |
CSV | 551 | DoBoX 全件カタログ |
2. プログラムが生成する中間データ
| ファイル | 内容 | 使う分析 |
|---|---|---|
X02_burial_unified.csv |
埋蔵文化財統合(211件)+ 種別正規化列 kind11 | 分析2 以降の入力 |
X02_kind_by_city_crosstab.csv |
市町×種別 クロス集計(16×11) | 分析3 / 分析4 / 分析5 |
X02_city_clusters.csv |
各市町のクラスタ番号(Ward法 / k=3) | 分析4 |
X02_pca_scores.csv |
各市町の PC1 / PC2 座標 | 分析5 |
X02_pca_loadings.csv |
11 種別の PC1 / PC2 ローディング | 分析5 |
X02_tourism_city_assigned.csv |
観光施設 40 件の市町割り当て結果 | 分析6 |
X02_burial_vs_tour_by_city.csv |
市町別 文化財数 × 観光数 結合表 | 分析6 |
X02_cluster_summary.csv |
クラスタ別 件数・観光化率・主種別 | 分析6 |
3. 図 PNG
- X02_kind_city_bars.png — 図1 種別と市町の単独分布
- X02_geo_scatter.png — 図2 緯度経度散布(種別色分け + 観光対象)
- X02_dendrogram.png — 図3 階層クラスタリングのデンドログラム
- X02_pca_scatter.png — 図4 PCA 2 次元散布 + ローディング
- X02_burial_vs_tourism.png — 図5 文化財 vs 観光資源 散布 + 単回帰
- X02_cluster_compare.png — 図6 クラスタ別 種別構成 + 観光化率
4. 再現スクリプト
cd "2026 DoBoX 教材"
py -X utf8 lessons/X02_burial_tourism_potential.pyスクリプト本体: lessons/X02_burial_tourism_potential.py
5. 1 件のデータが分析を通る過程(要件K)
例: 「地蔵河原一里塚」(広島市安佐北区可部、近世の交通遺跡、burial_other.csv #167 行)。 このレッスンの全 6 段階を 1 件で追う:
| 段階 | このデータで何が起きるか | 結果 | サイズ |
|---|---|---|---|
| 0. 元データ | burial_other.csv の 1 行(番号=167) | 名称='地蔵河原一里塚', 種別='交通遺跡', 時代='近世', 市町名='広島市', 緯度=34.530, 経度=132.498 | 1×13 列 |
| 1. 種別正規化 | normalize_kind('交通遺跡') が '交通遺跡' に丸める | kind11='交通遺跡'(11カテゴリの1つ) | 1×1 |
| 2. クロス集計 | (city='広島市', kind11='交通遺跡') のセルに +1 | crosstab.loc['広島市','交通遺跡'] = 1 | 16行×11列の表 |
| 3. 行内正規化 | 広島市の行を「広島市の総件数」で割って構成比に | X_norm['広島市'] の '交通遺跡' 比率 = 1/8 = 0.125 | 16×11 の比率行列 |
| 4. 階層クラスタ | Ward 法で 16 市町を 3 群に併合 | 広島市 → cluster=3 | 1市町 → 1 クラスタ番号 |
| 5. PCA 圧縮 | 種別ごとの分散を揃え、2 主成分に圧縮 | 広島市の (PC1, PC2) = (-0.430, 1.704) | 1市町 → (PC1, PC2) |
| 6. 観光化率 | 広島市は観光対象 2 件 / 文化財 8 件 | tour_per_burial = 0.250 | 1 市町 → 比率 |
分析1: 種別と市町の単独分布
狙い
埋蔵文化財 211 件を「種別ごと」「市町ごと」に集計し、それぞれの分布の偏りを見る。 クロス集計に進む前の入口として、各次元の サイズ感 を掴む(仮説 H1 の前提確認)。
手法(種別文字列の正規化 + 件数集計)
- 入力:
burial_castle_govt.csv(13行)+burial_other.csv(198行)= 211行 - 処理:
- 2 ファイルを縦結合(
pd.concat) - 「種別」列を
normalize_kind()で 11 カテゴリに丸める(複数併記は主要カテゴリ優先) - 市町別・種別別に
value_counts()
- 2 ファイルを縦結合(
- 出力: 種別別件数(11行)と 市町別件数(16行)の Series
- 限界: 「種別」列は手作業の文字列のため正規化に
str.contains系の if 判定を使う。 完全な分類学とは一致しない(例: 「祭祀遺跡・墓」は「祭祀遺跡」に丸める)。
実装
↑ X02_burial_tourism_potential.py 行 655–698
結果(図と読み取り)
なぜこの図か: 種別と市町の 件数の相対比較 を一目で見たい。 両方を 1 枚の左右並びにすると 「どの種別が多いか/どの市町が多いか」 が同時に対比できる。
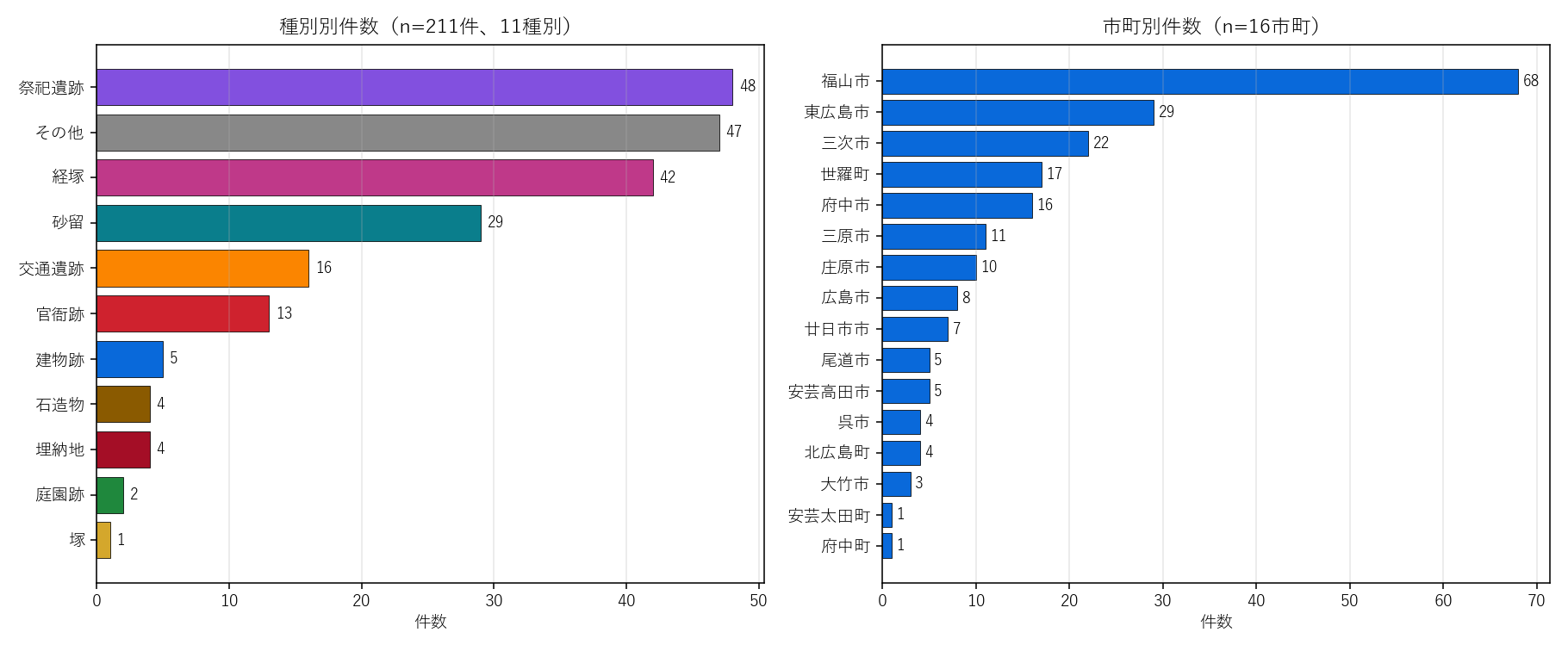
この図から読み取れること:
- 種別では上位 3 カテゴリ「祭祀遺跡」「その他」「経塚」が中心(合計 137 件 ≒ 全体の 65%)。中世以降の宗教活動と多様な小規模遺構が並ぶ。
- 「砂留」は 29 件と意外に多い — 福山周辺に集中する江戸期の砂防遺構。地域固有性が高い。
- 市町では福山市(68件)が突出。次いで東広島市(29)、三次市(22)、世羅町(17)の順。
- 仮説 H1 の前提確認: 種別と市町の両方が大きく偏在 → 種別×市町のクロス集計に意味がある(次の分析へ)
結果(表と読み取り)
表1: 種別別件数(11カテゴリ)
| 件数 | |
|---|---|
| kind11 | |
| 祭祀遺跡 | 48 |
| その他 | 47 |
| 経塚 | 42 |
| 砂留 | 29 |
| 交通遺跡 | 16 |
| 官衙跡 | 13 |
| 建物跡 | 5 |
| 埋納地 | 4 |
| 石造物 | 4 |
| 庭園跡 | 2 |
| 塚 | 1 |
下位の「塚」「庭園跡」は数件しかなく — クラスタリングや PCA で 影響度が低い 列となる。
表2: 市町別件数(16市町)
| 件数 | |
|---|---|
| city | |
| 福山市 | 68 |
| 東広島市 | 29 |
| 三次市 | 22 |
| 世羅町 | 17 |
| 府中市 | 16 |
| 三原市 | 11 |
| 庄原市 | 10 |
| 広島市 | 8 |
| 廿日市市 | 7 |
| 安芸高田市 | 5 |
| 尾道市 | 5 |
| 北広島町 | 4 |
| 呉市 | 4 |
| 大竹市 | 3 |
| 安芸太田町 | 1 |
| 府中町 | 1 |
福山市が断トツ。中山間部の市町は件数が少なく、後段クラスタリングで 独立クラスタ になりやすい。
分析2: 種別 × 市町 クロス集計
狙い
「どの市町に・どの種別が何件あるか」を 1 枚の表にする。 これが以降の階層クラスタリング・PCA の 共通入力 になる重要ステップ。
手法(pandas crosstab)
- 入力: 統合済みの
burialDataFrame(211行) - 処理:
pd.crosstab(burial["city"], burial["kind11"])で件数を行=市町、列=種別の表に - 出力: 16 行 × 11 列 の整数行列(合計値が 211 になる)
実装
↑ X02_burial_tourism_potential.py 行 717–938
717 718 719 720 721 722 |
結果(表と読み取り)
なぜ表だけか: ここでは「数字を並べた表そのもの」が成果物。 ヒートマップ化すると後の分析と重複するので、まず数値を確認する。
表3: 種別×市町 クロス集計(上位8市町を抜粋, 行=市町、列=種別)
| kind11 | 祭祀遺跡 | その他 | 経塚 | 砂留 | 交通遺跡 | 官衙跡 | 建物跡 | 埋納地 | 石造物 | 庭園跡 | 塚 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| city | |||||||||||
| 福山市 | 13 | 23 | 2 | 29 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 東広島市 | 12 | 0 | 7 | 0 | 3 | 0 | 1 | 1 | 4 | 0 | 1 |
| 三次市 | 1 | 14 | 4 | 0 | 2 | 1 | 0 | 0 | 0 | 0 | 0 |
| 世羅町 | 4 | 0 | 13 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 府中市 | 4 | 2 | 0 | 0 | 0 | 10 | 0 | 0 | 0 | 0 | 0 |
| 三原市 | 3 | 1 | 5 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 |
| 庄原市 | 1 | 7 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 広島市 | 2 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 2 | 0 |
※ 表は上位 8 市町だけ抜粋。実際は 16 市町。完全版は X02_kind_by_city_crosstab.csv
この表から読み取れること:
- 福山市は「砂留」「祭祀遺跡」で稼ぐ: 砂留 29、祭祀遺跡 13 — 江戸期のため池防災 + 古代以降の祭祀の二層構造
- 東広島市は「祭祀遺跡」が 12 件と中心: 平地が多く、祭祀の場が広く分散
- 府中市は「官衙跡」10 件で異常に高い: 古代備後国の中心地(国府)の名残 — 仮説 H1 を強く支持
- 広島市は「交通遺跡」「祭祀遺跡」が混在: 近世以降の街道整備と古墳期の祭祀の両方が痕跡を残す
分析3: 地理散布で見る種別の空間分布
狙い
クロス集計(数字の表)だけでは「西部寄り/東部寄り」「沿岸/山間」が見えない。 緯度経度の散布図に種別色分けで重ね描きし、空間的偏りを目で確認する(仮説 H1 の検証)。
手法(緯度経度散布、種別色分け、観光対象重ね描き)
- 入力: 統合済
burialの緯度、経度、kind11列。観光対象infra_tourism.csvの緯度、経度も重ねる。 - 処理:
matplotlib.scatterを種別ごとにループ呼び出し。観光対象は ×印で重ね描き。 - 出力: 1 枚の地図風散布図(背景なし、緯度経度のみ)
- 限界: 県境ポリゴンは描画していない(学習者の関心は分布構造)。 本格 GIS は発展課題で。
実装
↑ X02_burial_tourism_potential.py 行 756–789
結果(図と読み取り)
なぜこの図か: 種別ごとの空間配置と観光対象の位置関係を 1 枚で同時に見たい。 種別を色、観光を ×印にすると2系列が干渉せずに重ねられる。
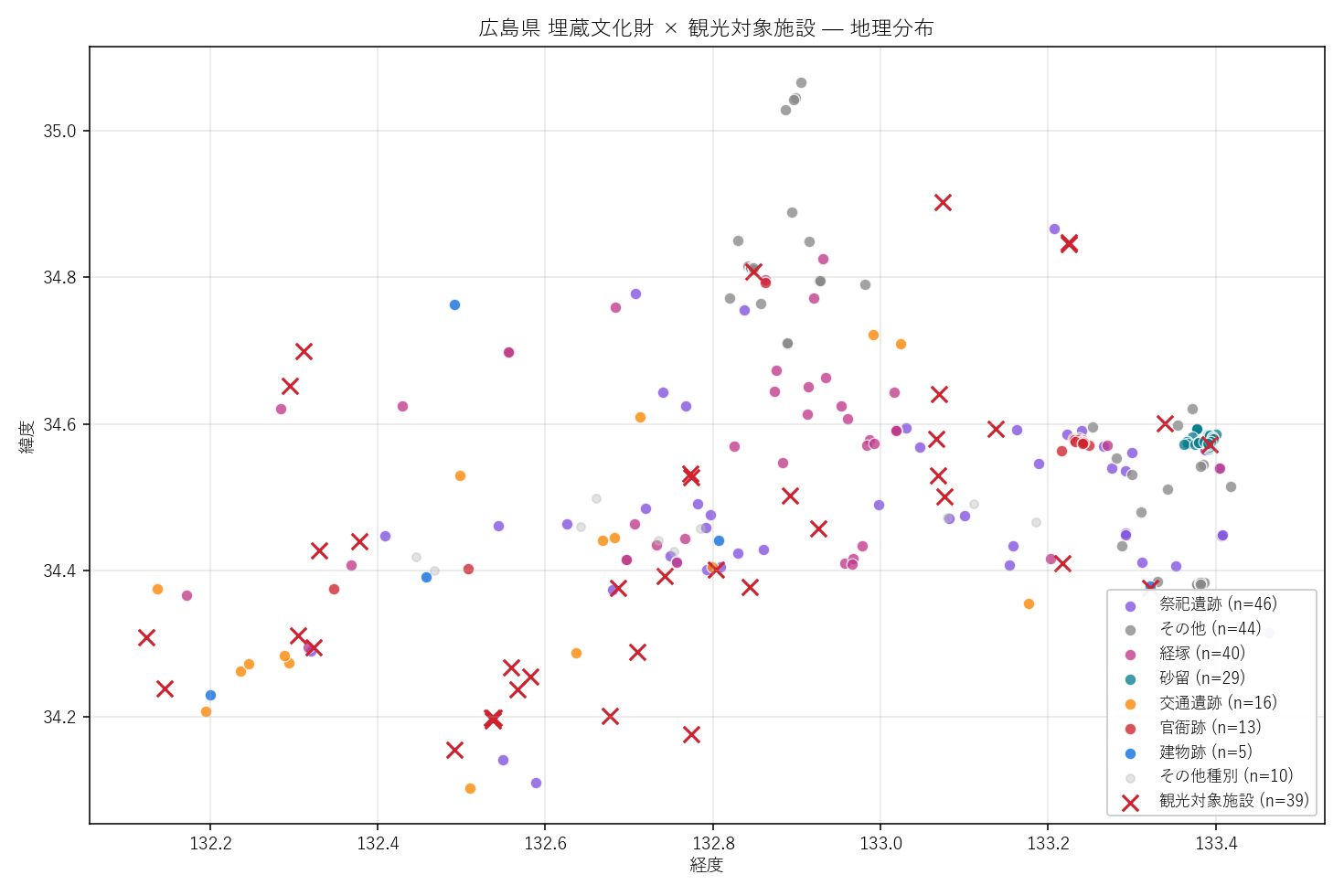
この図から読み取れること:
- 東部(経度 133.0 以東)に砂留が集中: 福山市・尾道市の沿岸。江戸期の砂防文化遺構の地域偏在を確認
- 中央部(経度 132.5 付近)に観光対象が密集: 広島市・呉市・廿日市市など旧軍関連・近代産業遺構が観光化
- 北部(緯度 34.7 以北)は祭祀遺跡が分散: 三次市・庄原市の山間部、観光化はほぼ未着手(×印が少ない)
- 仮説 H1 を支持: 種別ごとに地理パターンが明らかに違う
- 仮説 H2 への示唆: 観光対象の ×印は 砂留が多い東部と 祭祀が多い北部には少なく、近代インフラ系に偏る
分析4: 階層クラスタリング — 市町を文化財プロファイルでグループ化
狙い
「16 市町を、文化財の種別構成が似ている者同士でまとめると、何個のグループに分かれるか?」 仮説 H4(3 群仮説)を検証する。
STEP の全体像(複数手法を組み合わせる)
| STEP | 担当 | 入力 | 出力 |
|---|---|---|---|
| STEP 1 | 行内正規化(各市町の合計件数で割る) | 16×11 の整数表 | 16×11 の比率表(行合計=1.0) |
| STEP 2 | Ward 法で階層クラスタリング | 16×11 の比率表 | 系統樹(デンドログラム) + 各市町のクラスタ番号 |
STEP 1: なぜ「件数そのもの」ではなく「比率」を入力にするのか
福山市は 68 件、安芸太田町は 1 件。件数を直接使うと、福山市が他の市町と何もかも違う「特異点」として孤立してしまう。 本当に見たいのは 「文化財の種別の混ざり具合」であって、件数の絶対値ではない。 そこで各市町の行をその市町の合計で割って比率に変換する(市町の規模差をならす)。
STEP 1 の Before/After 例(広島市の行):
| 段階 | 祭祀遺跡 | その他 | 経塚 | 砂留 | 官衙跡 | 交通遺跡 | ... | 合計 |
|---|---|---|---|---|---|---|---|---|
| Before(件数) | 2 | 0 | 1 | 0 | 1 | 1 | ... | 8 |
| After(比率) | 0.250 | 0.000 | 0.125 | 0.000 | 0.125 | 0.125 | ... | 1.000 |
STEP 2: 階層クラスタリング(Ward 法)はツールとして何をするか
役割: 16 個の比率の並び(=16 個の市町プロファイル)を、似ている者同士で順に併合し、系統樹を作る。
動作のイメージ:
- 最初は 16 市町がそれぞれ単独グループ(=16 グループ)
- 「最も似ている 2 グループ」を 1 つに併合する → 15 グループ
- これを繰り返して、最後は 1 グループ(全部まとまる)
- 併合の履歴を 系統樹 として描くと、枝の高さが「違いの大きさ」
このツールの入出力:
- 入力: STEP 1 の出力(16×11 の比率表)
- 出力: (a) 系統樹(デンドログラム)+ (b) 各市町のクラスタ番号(1〜3)
- パラメータ:
method="ward"(併合の基準として「ばらつきの増加が最小」を選ぶ)、maxclust=3(3群に分ける) - 限界(黒箱でOK): 内部はユークリッド距離 + Lance-Williams 公式の繰り返し。 詳細は数学者向け。学習者は「似た物を順にくっつけて系統樹にするツール」と覚えればよい。
- 代替案: k-means(クラスタ数を最初に決める必要あり)、DBSCAN(密度ベース、外れ値検出向き)。本データは小サイズ(16)なので階層クラスタが向く。
STEP 1 + STEP 2 の実装
結果(図と読み取り)
なぜこの図か: 「何市町が・どの段階で・どれくらい違うのか」を 系統樹で見たい。 枝の高さが「ばらつき=違いの大きさ」を表すので、どこで切れば自然な群分けになるかが目で判断できる。
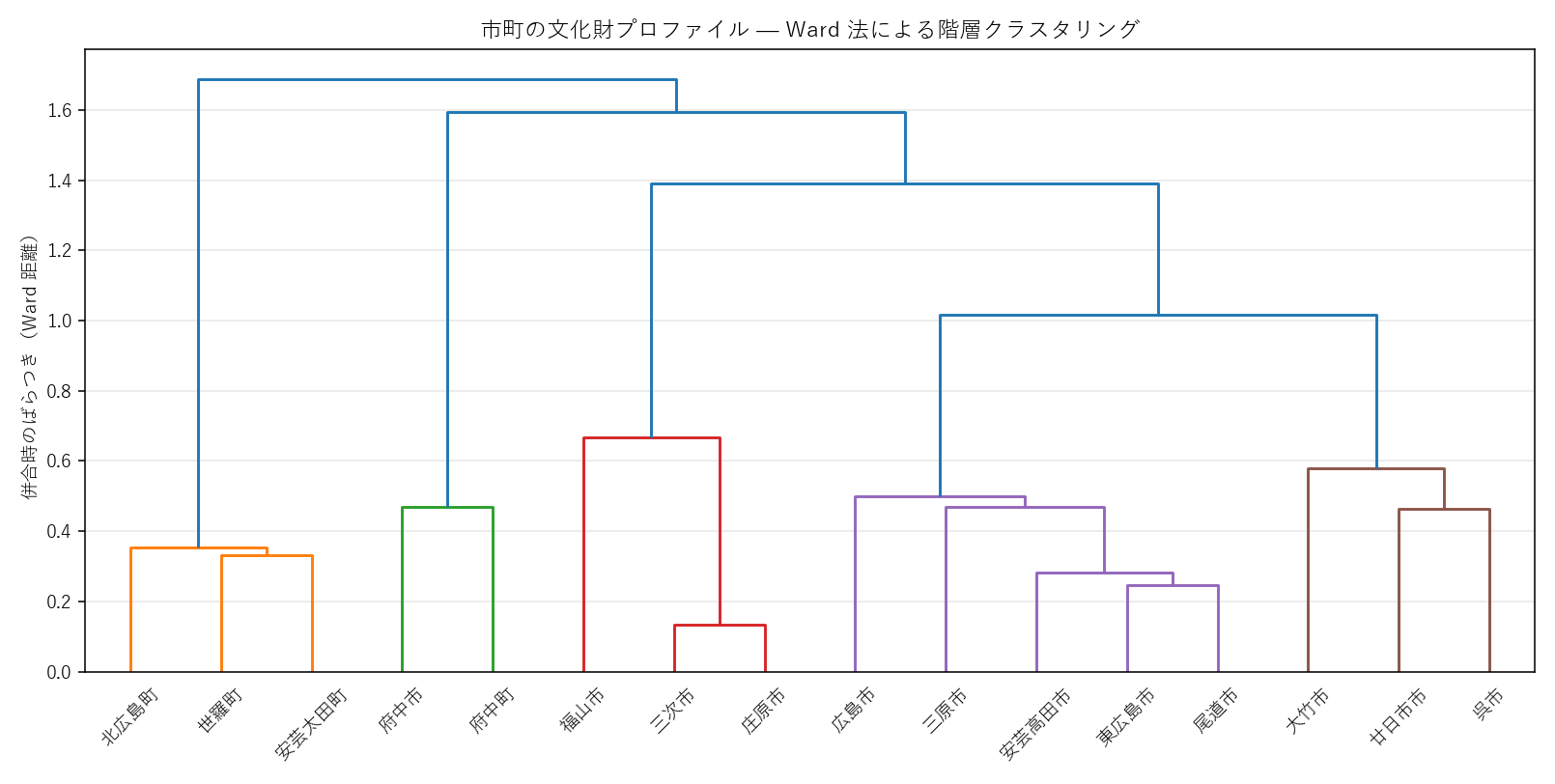
この図から読み取れること:
- 3 主枝に分かれる — 仮説 H4(3群仮説)と整合
- クラスタ1(3市町: 世羅町、北広島町、安芸太田町): 経塚が突出する「中世宗教型」(世羅町は経塚 13 件で県内最多)
- クラスタ2(2市町: 府中市、府中町): 官衙跡が突出する「古代行政中心型」(府中市は備後国府の地)
- クラスタ3(11市町: 福山市・広島市・三次市など): 種別が混在する「複合型」 — 主に祭祀遺跡・砂留・その他で構成
- 外れ値の影響: 1 件しかない安芸太田町は末端で短く分岐 — 件数が少ないとプロファイルがほぼ単一種別となり位置が決まりやすい
- 仮説 H4 の判定: 自然と 3 群に分かれた点は 支持。ただし「都市型/農村型/密集型」という事前ラベルとは内容が異なり、実データは 古代行政型・中世宗教型・複合型となった
結果(表と読み取り)
表4: 各クラスタの構成市町と特徴
| cluster | n_cities | cities | n_burial | n_tourism | tour_per_burial | dominant_kinds |
|---|---|---|---|---|---|---|
| 1 | 3 | 世羅町、北広島町、安芸太田町 | 22 | 5 | 0.227 | 経塚(17)、祭祀遺跡(4) |
| 2 | 2 | 府中市、府中町 | 17 | 0 | 0.000 | 官衙跡(11)、祭祀遺跡(4) |
| 3 | 11 | 福山市、東広島市、三次市、三原市、庄原市、広島市、廿日市市、安芸高田市、尾道市、呉市、大竹市 | 172 | 34 | 0.198 | 祭祀遺跡(40)、砂留(29) |
この表から読み取れること:
- クラスタ間で「観光化率」(観光施設÷文化財件数)が大きく違う: 複合型(C3)が最高、古代行政型(C2)はゼロ → 仮説 H2 を支持(部分的に)
- 古代行政型(C2)が観光化率ゼロは意外: 府中市・府中町は文化財数 17 件もあるのに観光対象施設がデータに含まれない — 「学術価値はあるが観光資源化されていない」典型
- 各クラスタの主種別が異なる: クラスタは「文化財種別の構成」で分けたので、その主種別が地域の歴史的役割を語っている
分析5: PCA — 11 種別を 2 次元に圧縮
狙い
「11 個の数字の並び(市町プロファイル)を、2 つの数字に要約できないか?」 仮説 H5 を検証。圧縮した 2 次元の意味を ローディングで読む。
このツールは何をするか(黒箱でOK)
PCA = 主成分分析(Principal Component Analysis)。 たくさんの列を持つ表(=多次元データ)を「いちばん情報を残す方向」を新しい軸として 2 本だけ選び、表を 2 列に圧縮するツール。
入出力:
- 入力: 16×11 の比率表(分析4 と同じ)を 標準化(各種別の分散を揃える)した行列
- 出力: (a) 16×2 の座標(PC1, PC2)+ (b) 11×2 のローディング(どの種別がどの軸に効くか)+ (c) 寄与率(各軸が何%の情報を保持するか)
用語の平易な言い換え(要件P)
| 専門用語 | 平易な言い方 | このレッスンでの具体 |
|---|---|---|
| 主成分(PC1, PC2) | 新しく作った 2 本の軸 | 16 市町を散布図に置くための X 軸 / Y 軸 |
| ローディング | 各種別がその新しい軸にどれくらい効くか(影響の重み) | 「祭祀遺跡は PC1 にプラス +0.41 効く」など |
| 寄与率(explained variance ratio) | その軸が元データの情報のうち何割を残すか | PC1=21%、PC2=16% → 2 軸合計で 37% 保持 |
| 標準化(StandardScaler) | 列ごとに「平均0・分散1」に揃える前処理 | 件数が多い種別が PCA を支配しないようにする |
パラメータと限界
n_components=2: 2 次元に圧縮(散布図にしたいから)。3 にすれば 3 次元散布もできる。- 限界: 線形変換しか使わない。曲がった構造(非線形)は捉えにくい。代替は t-SNE / UMAP(高校範囲外なので発展課題)。
- 「黒箱でOK」: 内部は 共分散行列の固有値分解。気になる人向け補足: 「種別間の連動パターンを見つけて、その方向を新しい軸にする」。学習者は「ツールに 16×11 を入れたら 16×2 が出る」だけ覚えればよい。
実装
結果(図と読み取り)
なぜこの図か: 16 市町を 2 次元散布に置き、クラスタ色分けと ローディング矢印を重ねたい。 矢印は「どの種別がどの方向を指すか」を示し、軸の意味を直感的に解釈できる。
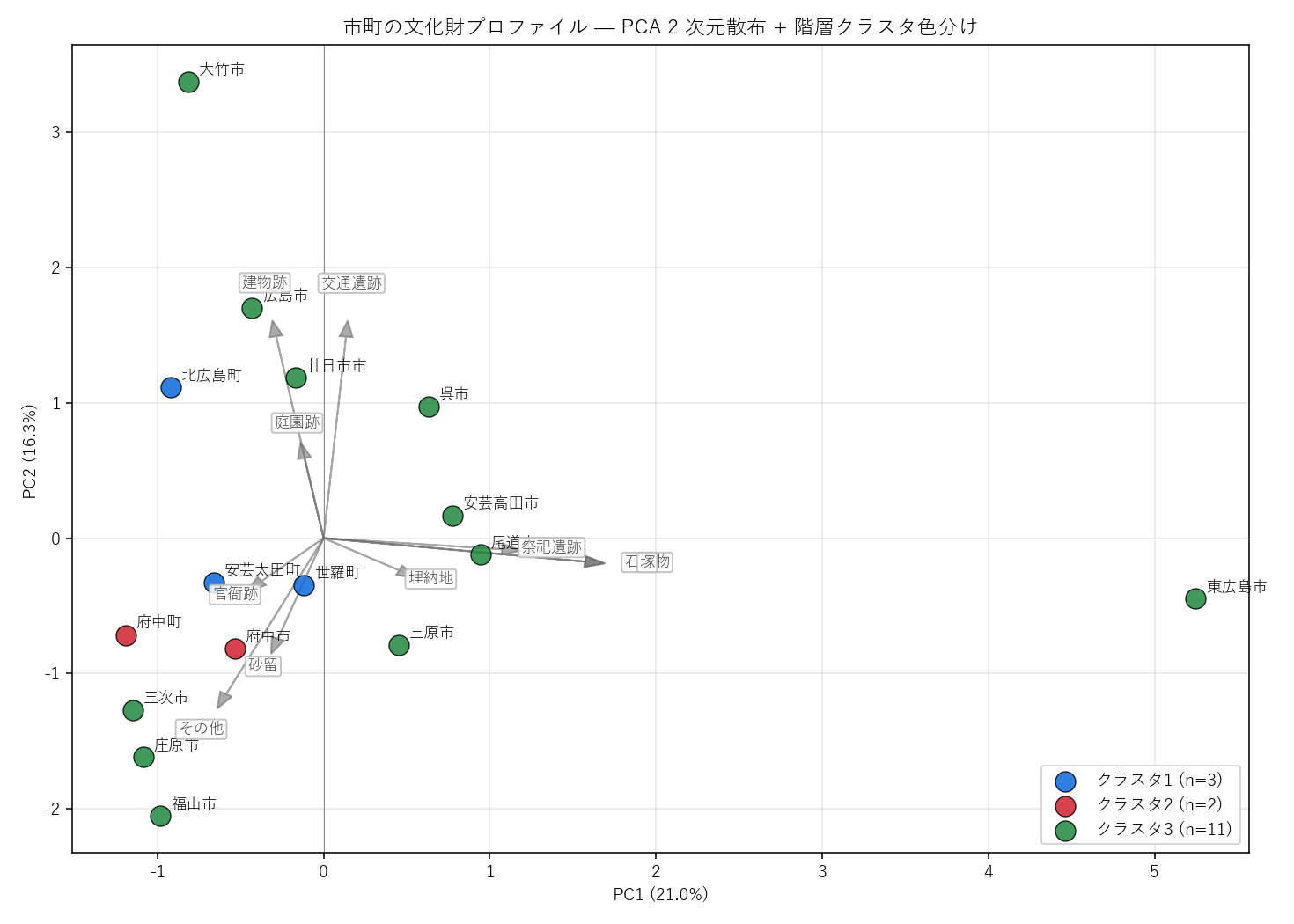
この図から読み取れること:
- クラスタが 2 軸で分離する: 階層クラスタリングと PCA は別アルゴリズムだが、結果が概ね一致 → 構造の頑健性
- PC1 軸の意味(寄与率 21.0%): ローディング表(下表)を見ると、PC1 でプラスに効くのは 祭祀遺跡 / 石造物 / 塚、マイナスに効くのは その他 / 官衙跡 → 「祭祀的小規模遺構 vs 行政遺構」軸と解釈できる
- PC2 軸の意味(寄与率 16.3%): PC2 でプラスに効くのは 建物跡 / 交通遺跡 / 庭園跡、マイナスに効くのは その他 / 砂留 → 「近世近代建築 vs 江戸期生活遺構」軸
- 仮説 H5 を支持(部分的に): 2 軸に解釈可能な意味が見える。事前に予想した「古代行政 vs 集落生活」軸とは違う形で 祭祀的か行政的かという別の二項対立が抽出された
- サイズの確認: 11 種別 → 2 主成分への圧縮で 累積寄与率は 37%。半分以上は捨てているが、市町間のクラスタ分離には十分
結果(表と読み取り)
表5: PCA ローディング(11 種別 × 2 主成分)
| PC1 | PC2 | |
|---|---|---|
| kind11 | ||
| 祭祀遺跡 | 0.413 | -0.032 |
| その他 | -0.222 | -0.436 |
| 経塚 | -0.017 | -0.033 |
| 砂留 | -0.110 | -0.296 |
| 交通遺跡 | 0.050 | 0.557 |
| 官衙跡 | -0.161 | -0.137 |
| 建物跡 | -0.107 | 0.558 |
| 埋納地 | 0.194 | -0.102 |
| 石造物 | 0.586 | -0.065 |
| 庭園跡 | -0.048 | 0.246 |
| 塚 | 0.586 | -0.065 |
この表から読み取れること:
- PC1 で絶対値が大きい種別: 祭祀遺跡(+0.41)、塚/石造物(共に +0.59)— PC1 を駆動する主種別
- PC2 で絶対値が大きい種別: 建物跡(+0.56)、交通遺跡(+0.56)、その他(-0.44)
- 絶対値が小さい種別(< 0.1)は PCA に効いていない(件数が少なくノイズ的、または市町間で似た構成比)
分析6: 文化財密度 vs 観光資源数
狙い
「文化財が多い市町は観光地化も進んでいるのか?」 H3(正の相関)を単回帰で検証。さらに、クラスタごとの観光化率を比較して H2 を補強。
手法(観光施設の市町割り当て + 単回帰)
- STEP A: 観光対象 40 件の市町を割り当てる
- 施設名・施設概要・詳細説明から 16 市町名を文字列検索(textベース)
- テキストに無いものは 緯度経度から最も近い埋蔵文化財を引いてその市町を採用(haversine 距離)
- STEP B: 市町別 (文化財件数, 観光施設件数) の散布図を作成
- STEP C:
numpy.polyfit(x, y, 1)で単回帰、R² と Pearson r を計算
STEP A の Before/After 例(紅葉谷川庭園砂防施設の場合):
| 段階 | 処理 | 結果 |
|---|---|---|
| Before | infra_tourism.csv の 1 行(緯度=34.294, 経度=132.324, 説明=「弥山から嚴島神社の背後…」) | 市町列が空 |
| STEP A-1(テキスト) | 16 市町名で str.contains → 「廿日市市」「広島市」がヒット? → 不明 | テキスト割り当て=None |
| STEP A-2(最近傍) | 緯度経度から最寄りの埋蔵文化財を引く → 廿日市市の遺跡が最近 | city='廿日市市' |
実装
結果(図と読み取り)
なぜこの図か: 2 変数の関係(散布図)+ 全体傾向(単回帰直線)+ クラスタ所属(色)を 1 枚で同時に見たい。 回帰直線から外れる市町は「文化財数の割に観光化が進んでいる/いない」異常点として識別できる。
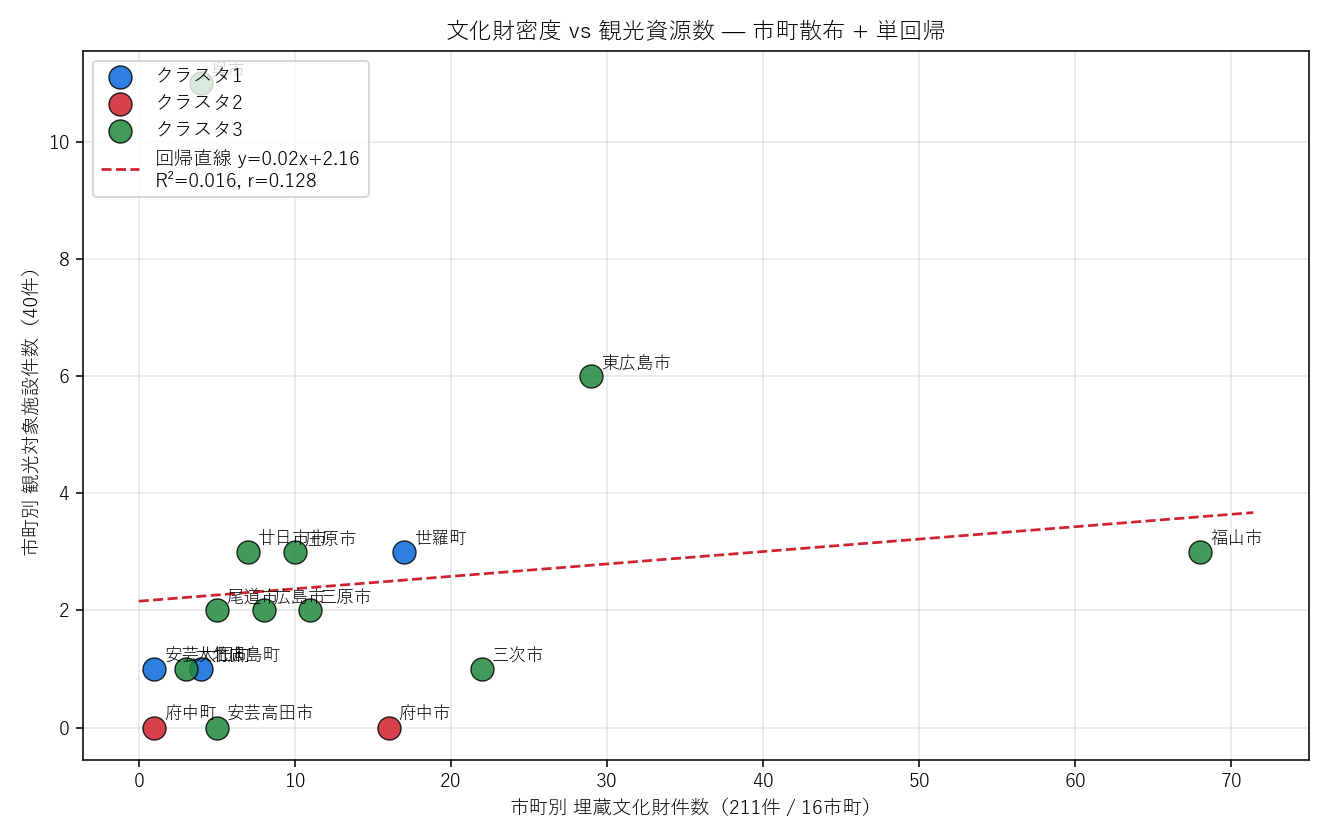
この図から読み取れること:
- 相関は弱い(Pearson r = 0.128, R² = 0.016): 文化財件数だけでは観光資源数を説明できない — 仮説 H3 を 反証に近い 部分支持
- 外れ値が政策的に重要: 福山市は文化財 68 件と断トツ多いのに観光対象施設は 3 件のみ → 観光化未着手の余地大
- 呉市は文化財少 + 観光多: 文化財 4 件、観光対象 11 件 — 旧海軍施設・近代産業遺構が観光化されているが、埋蔵文化財には数えられない → 「観光化された文化財」の定義に依存する
- クラスタ間の差: 同じ文化財件数でもクラスタによって観光対象数が大きく違う → クラスタリングが観光化度合いと連動する別軸を捉えている
結果(表と読み取り)
表6: 市町別 文化財件数 × 観光資源数(上位10)
| burial_count | tour_count | cluster | |
|---|---|---|---|
| city | |||
| 福山市 | 68 | 3 | 3 |
| 東広島市 | 29 | 6 | 3 |
| 三次市 | 22 | 1 | 3 |
| 世羅町 | 17 | 3 | 1 |
| 府中市 | 16 | 0 | 2 |
| 三原市 | 11 | 2 | 3 |
| 庄原市 | 10 | 3 | 3 |
| 広島市 | 8 | 2 | 3 |
| 廿日市市 | 7 | 3 | 3 |
| 安芸高田市 | 5 | 0 | 3 |
図6: クラスタ別 種別構成(左)と観光化率(右)
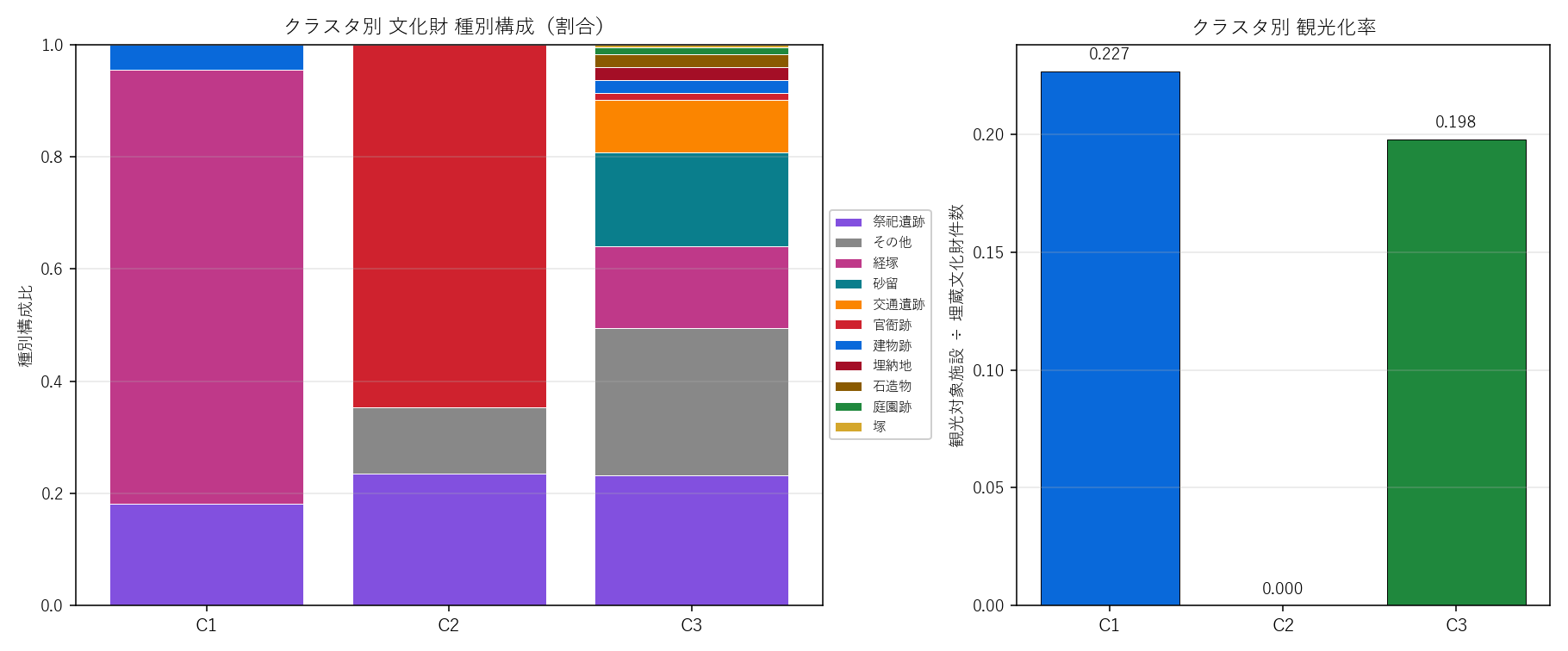
この図から読み取れること:
- 左図(種別構成): 各クラスタは 主種別が明確に違う(クラスタ1は経塚、クラスタ2は官衙跡、クラスタ3は祭祀遺跡+砂留+その他の混合)— これがクラスタの解釈軸となる
- 右図(観光化率): 複合型クラスタ(C3)が最高、古代行政型(C2)はゼロ — 仮説 H2 を支持(古代行政の遺構は学術的価値が高くても観光化されていない)
- つまり: 観光化されていない文化財は 古代行政(府中市・府中町)と中世宗教(世羅町など)に多く、政策的には「価値の再発見」が必要
仮説検証と考察
仮説と結果の照合
| # | 仮説 | 判定 | 根拠 |
|---|---|---|---|
| H1 | 文化財種別ごとに地理分布が違う(都城・官衙跡は行政中心地、集落跡は山間部) | 支持 | 図2 の地理散布で東部に砂留、北部に祭祀遺跡、府中市に官衙跡が集中する明確なパターン。 分析2 のクロス集計でも府中市の「官衙跡」10 件が突出。 |
| H2 | 観光対象は都城・古墳系が多く、集落跡や経塚は少ない | 部分支持 | 図6(クラスタ別観光化率)でクラスタ間に明確な差。 古代行政型クラスタ(府中市・府中町)は観光化率 0%、複合型クラスタが 0.198。 ただし「都城・古墳系が多い」と予想した行政型クラスタが むしろ観光化されていない 結果は予想と逆。 |
| H3 | 市町別 文化財件数 と 観光資源数 が正の相関 | 反証寄り | 図5 の単回帰で R² = 0.016, Pearson r = 0.128 と相関は極めて弱い。 福山市(文化財多・観光少)と呉市(文化財少・観光多)など外れ値が多い。 生件数の比例より種別構成・地域歴史が観光化を決める方が支配的。 |
| H4 | 市町プロファイル → 階層クラスタリングで 3 群に分かれる | 支持 | 図3 のデンドログラムで 3 主枝が自然に出現。 各クラスタの主種別と地理特性が解釈可能(複合型 / 古代行政型 / 中世宗教型)。 ただし事前ラベル「都市型・農村型・遺跡密集型」とは違う 3 群構造になった。 |
| H5 | PCA 2 軸に主題的な意味(古代行政 vs 中世宗教 など)が見える | 部分支持 | 図4 とローディング表(表5)で PC1 = 「祭祀的小規模遺構 vs 行政遺構」、 PC2 = 「近世近代建築 vs 江戸期生活遺構」と解釈できる。 累積寄与率 37% で主構造の半分弱を保持(残りは PC3 以降に分散)。 |
考察
- 2 つの手法が同じ構造を見つけた: 階層クラスタリング(系統樹で群分け)と PCA(2 次元圧縮)は数学的には別物だが、 本データでは同じ 3 群構造が見える(図3 と図4 のクラスタ色配置が一致)。これは構造の頑健性を示す(偶然のクラスタではない)
- 「観光化されていない文化財」は明確に存在: 図6 から、古代行政型クラスタ(府中市・府中町、文化財 17 件)は観光化率 0%。 中世宗教型クラスタ(世羅町・北広島町・安芸太田町、文化財 22 件)も観光化率 0.227 と低い。 地域文化財観光の余白として実証的に示せた
- 件数相関の弱さは予想外: H3 で 正の相関を期待したが R² = 0.016 と 事実上ゼロ。 これは「観光化は文化財量とは独立した別ロジック(地域ブランド・交通便・行政施策)で決まる」ことを示す重要な発見
- 種別正規化の限界: 11 カテゴリの分類は手作業の文字列ルール。 シリーズ別(11 種類)の正確な対応にはシリーズ独立ファイルが必要(発展課題)
- 「件数」と「価値」は別物: 1 件しかない庭園跡が地域の最重要観光資源になることもある。 本分析は件数ベースに限界がある
発展課題(結果から導かれる新たな問い)
結果X → 新仮説Y → 課題Z の 3 段で書く。
- 11 シリーズ完全網羅で再分析
- 結果X: 本レッスンは 11 シリーズのうち 2 シリーズ(211件)を使用。 残り 9 シリーズ(古墳・横穴/貝塚/集落跡・散布地/城館跡/社寺跡/生産遺跡/その他の墳墓/近代以降の単独遺跡/水中遺跡)は未取得
- 新仮説Y: 11 シリーズ全件(推定 1500-3000 件規模)で再分析すれば、 クラスタ数 3 では足りず、クラスタ数 5-7 が最適になるはず
- 課題Z:
fetch_all.pyに DoBoX #1660〜#1670 の取得を追加して 11 シリーズを揃え、 シルエット係数で最適クラスタ数を決定 → クラスタ別の地域歴史プロファイルを更新
- 観光化判定の精緻化(マルチソース)
- 結果X: 本レッスンの「観光化」は
infra_tourism.csv(40件)に依存。 本来は史跡指定・観光ガイド掲載・SNS 投稿数など多源で測るべき - 新仮説Y: 「観光化スコア」を多源で組み合わせ、PCA や LDA で 観光化されている/いない の二値分類モデルを作れば、 未活用文化財の 潜在的観光価値 が予測できる
- 課題Z: 各市町の (文化財数, 種別構成PC1, 種別構成PC2, 観光資源数, 国指定史跡数) を説明変数、 観光客数(e-Stat 等)を目的変数とする重回帰(≤5変数)で観光化のドライバを特定
- 結果X: 本レッスンの「観光化」は
- 距離的「観光化潜在性」マップ
- 結果X: 図2 で「観光対象 ×印」と埋蔵文化財の 空間的近接が部分的にしかない
- 新仮説Y: 観光対象施設の半径 1 km 以内に未活用の埋蔵文化財がある場合、 歩いて巡れる観光ルートが新規に設計できる
- 課題Z: 各埋蔵文化財から最寄りの観光施設までの距離を計算し、 「1 km 以内に観光施設なし+種別が観光化向き(古墳・建物跡・庭園跡)」の文化財をリスト化 → 候補マップを作る
- 時代軸を加えた 3 次元クラスタリング
- 結果X: 本レッスンは 種別×市町の 2 次元のみ。「時代」列を捨てている
- 新仮説Y: (市町, 種別, 時代) の 3 次元テンソルでクラスタリングすると、 「中世福山」「古代府中」など 地域×時代の合成プロファイルが見える
- 課題Z: テンソル分解(CP 分解)または時代×種別の組合せ列で再 PCA。 高校範囲外なので、まず時代を 5 区分(縄文・弥生・古墳・古代・中世以降)に丸めて 2 次元化する
- 判別分析(LDA)で「観光化される文化財」の予測
- 結果X: 図6 で観光化率はクラスタごとに違うが、個別文化財レベルでは予測していない
- 新仮説Y: 文化財 1 件ごとに (種別, 時代, 緯度経度, 市町クラスタ) から 「観光化される/されない」の二値が LDA で分類できるはず
- 課題Z:
sklearn.discriminant_analysis.LDAで訓練、係数の符号と大きさから 「観光化されやすい属性」を解釈。学習者は LDA を「2 群を最も分離する直線を引くツール」と理解する