1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
764
765
766
767
768
769
770
771
772
773
774
775
776
777
778
779
780
781
782
783
784
785
786
787
788
789
790
791
792
793
794
795
796
797
798
799
800
801
802
803
804
805
806
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
856
857
858
859
860
861
862
863
864
865
866
867
868
869
870
871
872
873
874
875
876
877
878
879
880
881
882
883
884
885
886
887
888
889
890
891
892
893
894
895
896
897
898
899
900
901
902
903
904
905
906
907
908
909
910
911
912
913
914
915
916
917
918
919
920
921
922
923
924
925
926
927
928
929
930
931
932
933
934
935
936
937
938
939
940
941
942
943
944
945
946
947
948
949
950
951
952
953
954
955
956
957
958
959
960
961
962
963
964
965
966
967
968
969
970
971
972
973
974
975
976
977
978
979
980
981
982
983
984
985
986
987
988
989
990
991
992
993
994
995
996
997
998
999
1000
1001
1002
1003
1004
1005
1006
1007
1008
1009
1010
1011
1012
1013
1014
1015
1016
1017
1018
1019
1020
1021
1022
1023
1024
1025
1026
1027
1028
1029
1030
1031
1032
1033
1034
1035
1036
1037
1038
1039
1040
1041
1042
1043
1044
1045
1046
1047
1048
1049
1050
1051
1052
1053
1054
1055
1056
1057
1058
1059
1060
1061
1062
1063
1064
1065
1066
1067
1068
1069
1070
1071
1072
1073
1074
1075
1076
1077
1078
1079
1080
1081
1082
1083
1084
1085
1086
1087
1088
1089
1090
1091
1092
1093
1094
1095
1096
1097
1098
1099
1100
1101
1102
1103
1104
1105
1106
1107
1108
1109
1110
1111
1112
1113
1114
1115
1116
1117
1118
1119
1120
1121
1122
1123
1124
1125
1126
1127
1128
1129
1130
1131
1132
1133
1134
1135
1136
1137
1138
1139
1140
1141
1142
1143
1144
1145
1146
1147
1148
1149
1150
1151
1152
1153
1154
1155
1156
1157
1158
1159
1160
1161
1162
1163
1164
1165
1166
1167
1168
1169
1170
1171
1172
1173
1174
1175
1176
1177
1178
1179
1180
1181
1182
1183
1184
1185
1186
1187
1188
1189
1190
1191
1192
1193
1194
1195
1196
1197
1198
1199
1200
1201
1202
1203
1204
1205
1206
1207
1208
1209
1210
1211
1212
1213
1214
1215
1216
1217
1218
1219
1220
1221
1222
1223
1224
1225
1226
1227
1228
1229
1230
1231
1232
1233
1234
1235
1236
1237
1238
1239
1240
1241
1242
1243
1244
1245
1246
1247
1248
1249
1250
1251
1252
1253
1254
1255
1256
1257
1258
1259
1260
1261
1262
1263
1264
1265
1266
1267
1268
1269
1270
1271
1272
1273
1274
1275
1276
1277
1278
1279
1280
1281
1282
1283
1284
1285
1286
1287
1288
1289
1290
1291
1292
1293
1294
1295
1296
1297
1298
1299
1300
1301
1302
1303
1304
1305
1306
1307
1308
1309
1310
1311
1312
1313
1314
1315
1316
1317
1318
1319
1320
1321
1322
1323
1324
1325
1326
1327
1328
1329
1330
1331
1332
1333
1334
1335
1336
1337
1338
1339
1340
1341
1342
1343
1344
1345
1346
1347
1348
1349
1350
1351
1352
1353
1354
1355
1356
1357
1358
1359
1360
1361
1362
1363
1364
1365
1366
1367
1368
1369
1370
1371
1372
1373
1374
1375
1376
1377
1378
1379
1380
1381
1382
1383
1384
1385
1386
1387
1388
1389
1390
1391
1392
1393
1394
1395
1396
1397
1398
1399
1400
1401
1402
1403
1404
1405
1406
1407
1408
1409
1410
1411
1412
1413
1414
1415
1416
1417
1418
1419
1420
1421
1422
1423
1424
1425
1426
1427
1428
1429
1430
1431
1432
1433
1434
1435
1436
1437
1438
1439
1440
1441
1442
1443
1444
1445
1446
1447
1448
1449
1450
1451
1452
1453
1454
1455
1456
1457
1458
1459
1460
1461
1462
1463
1464
1465
1466
1467
1468
1469
1470
1471
1472
1473
1474
1475
1476
1477
1478
1479
1480
1481
1482
1483
1484
1485
1486
1487
1488
1489
1490
1491
1492
1493
1494
1495
1496
1497
1498
1499
1500
1501
1502
1503
1504
1505
1506
1507
1508
1509
1510
1511
1512
1513
1514
1515
1516
1517
1518
1519
1520
1521
1522
1523
1524
1525
1526
1527
1528
1529
1530
1531
1532
1533
1534
1535
1536
1537
1538
1539
1540
1541
1542
1543
1544
1545
1546
1547
1548
1549
1550
1551
1552
1553
1554
1555
1556
1557
1558
1559
1560
1561
1562
1563
1564
1565
1566
1567
1568
1569
1570
1571
1572
1573
1574
1575
1576
1577
1578
1579
1580
1581
1582
1583
1584
1585
1586
1587
1588
1589
1590
1591
1592
1593
1594
1595
1596
1597
1598
1599
1600
1601
1602
1603
1604
1605
1606
1607
1608
1609
1610
1611
1612
1613
1614
1615
1616
1617
1618
1619
1620
1621
1622
1623
1624
1625
1626
1627
1628
1629
1630
1631
1632
1633
1634
1635
1636
1637
1638
1639
1640
1641
1642
1643
1644
1645
1646
1647
1648
1649
1650
1651
1652
1653
1654
1655
1656
1657
1658
1659
1660
1661
1662
1663
1664
1665
1666
1667
1668
1669
1670
1671
1672
1673
1674
1675
1676
1677
1678
1679
1680
1681
1682
1683
1684
1685
1686
1687
1688
1689
1690
1691
1692
1693
1694
1695
1696
1697
1698
1699
1700
1701
1702
1703
1704
1705
1706
1707
1708
1709
1710
1711
1712
1713
1714
1715
1716
1717
1718
1719
1720
1721
1722
1723
1724
1725
1726
1727
1728
1729
1730
1731
1732
1733
1734
1735
1736
1737
1738
1739
1740
1741
1742
1743
1744
1745
1746
1747
1748
1749
1750
1751
1752
1753
1754
1755
1756
1757
1758
1759
1760
1761
1762
1763
1764
1765
1766
1767
1768
1769
1770
1771
1772
1773
1774
1775
1776
1777
1778
1779
1780
1781
1782
1783
1784
1785
1786
1787
1788
1789
1790
1791
1792
1793
1794
1795
1796
1797
1798
1799
1800
1801
1802
1803
1804
1805
1806
1807
1808
1809
1810
1811
1812
1813
1814
1815
1816
1817
1818
1819
1820
1821
1822
1823
1824
1825
1826
1827
1828
1829
1830
1831
1832
1833
1834
1835
1836
1837
1838
1839
1840
1841
1842
1843
1844
1845
1846
1847
1848
1849
1850
1851
1852
1853
1854
1855
1856
1857
1858
1859
1860
1861
1862
1863
1864
1865
1866
1867
1868
1869
1870
1871
1872
1873
1874
1875
1876
1877
1878
1879
1880
1881
1882
1883
1884
1885
1886
1887
1888
1889
1890
1891
1892
1893
1894
1895
1896
1897
1898
1899
1900
1901
1902
1903
1904
1905
1906
1907
1908
1909
1910
1911
1912
1913
1914
1915
1916
1917
1918
1919
1920
1921
1922
1923
1924
1925
1926
1927
1928
1929
1930
1931
1932
1933
1934
1935
1936
1937
1938
1939
1940
1941
1942
1943
1944
1945
1946
1947
1948
1949
1950
1951
1952
1953
1954
1955
1956
1957
1958
1959
1960
1961
1962
1963
1964
1965
1966
1967
1968
1969
1970
1971
1972
1973
1974
1975
1976
1977
1978
1979
1980
1981
1982
1983
1984
1985
1986
1987
1988
1989
1990
1991
1992
1993
1994
1995
1996
1997
1998
1999
2000
2001
2002
2003
2004
2005
2006
2007
2008
2009
2010
2011
2012
2013
2014
2015
2016
2017
2018
2019
2020
2021
2022
2023
2024
2025
2026
2027
2028
2029
2030
2031
2032
2033
2034
2035
2036
2037
2038
2039
2040
2041
2042
2043
2044
2045
2046
2047
2048
2049
2050
2051
2052
2053
2054
2055
2056
2057
2058
2059
2060
2061
2062
2063
2064
2065
2066
2067
2068
2069
2070
2071
2072
2073
2074
2075
2076
2077
2078
2079
2080
2081
2082
2083
2084
2085
2086
2087
2088
2089
2090
2091
2092
2093
2094
2095
2096
2097
2098
2099
2100
2101
2102
2103
2104
2105
2106
2107
2108
2109
2110
2111
2112
2113
2114
2115
2116
2117
2118
2119
2120
2121
2122
2123
2124
2125
2126
2127
2128
2129
2130
2131
2132
2133
2134
2135
2136
2137
2138
2139
2140
2141
2142
2143
2144
2145
2146
2147
2148
2149
2150
2151
2152
2153
2154
2155
2156
2157
2158
2159
2160
2161
2162
2163
2164
2165
2166
2167
2168
2169
2170
2171
2172
2173
2174
2175
2176
2177
2178
2179
2180
2181
2182
2183
2184
2185
2186
2187
2188
2189
2190
2191
2192
2193
2194
2195
2196
2197
2198
2199
2200
2201
2202
2203
2204
2205
2206
2207
2208
2209
2210
2211
2212
2213
2214
2215
2216
2217
2218
2219
2220
2221
2222
2223
2224
2225
2226
2227
2228
2229
2230
2231
2232
2233
2234
2235
2236
2237
2238
2239
2240
2241
2242
2243
2244
2245
2246
2247
2248
2249
2250
2251
2252
2253
2254
2255
2256
2257
2258
2259
2260
2261
2262
2263
2264
2265
2266
2267
2268
2269
2270
2271
2272
2273
2274
2275
2276
2277
2278
2279
2280
2281
2282
2283
2284
2285
2286
2287
2288
2289
2290
2291
2292
2293
2294
2295
2296
2297
2298
2299
2300
2301
2302
2303
2304
2305
2306
2307
2308
2309
2310
2311
2312
2313
2314
2315
2316
2317
2318
2319
2320
2321
2322
2323
2324
2325
2326
2327
2328
2329
2330
2331
2332
2333
2334
2335
2336
2337
2338
2339
2340
2341
2342
2343
2344
2345
2346
2347
2348 | # -*- coding: utf-8 -*-
"""L90 観測×多災害時系列 — 雨量・水位・潮位・前兆観測の統合解析
カバー宣言:
本記事は DoBoX のシリーズ <b>「観測情報_*」 9 件</b>
(dataset_id = 1274, 1275, 1276, 1437, 1438, 1439, 1440, 1441, 1442) を
<b>時系列値の解析</b>として再統合し、災害<b>前兆検出の科学</b>を語る、
Phase 5 統合俯瞰の最初の記事である。
L31 (観測網構造) との明確な差別化:
L31 = 観測点が「どこに、何点、誰の所管で」 設置されているかの<b>幾何構造</b>
L90 = 観測点が「いつ、何を記録し、災害にどう先行するか」 の<b>時系列値解析</b>
X06 (雨量地理 14 日 small multiples) との明確な差別化:
X06 = 雨量 1 種のみを 14 日 × 県内空間で並列地理散布、 1 種類の空間×時間
L90 = 雨量+水位+ダム+潮位+風 <b>5 種類の値を 14 日時系列で連動解析</b>。
先行/遅延ラグ・複合シグナル・先行指標スコアを構築するのが固有の論題
研究の問い (主 RQ):
「観測時系列の中で、何が先行指標として機能し、多災害連鎖を
どう検出できるか?」 雨が降ってから、 河川水位はいつ上がり、
ダムはいつ放流を始め、 潮位は雨量と独立に動くのか? 5 種類の
時系列値を 1 つの軸に並べて読むことで、 「予兆」 と 「同時災害」 が
どう観測網に現れるかを実データで言語化する。
仮説 H1〜H5:
H1 (時間ラグ仮説): 上流の雨量ピークから下流の水位ピークまでには
<b>明確なタイムラグ (時間遅れ)</b>がある。 ピーク到達遅れの
中央値は<b>1 〜 6 時間</b>、 流域長で説明可能な範囲。
これが成立すれば「上流雨量 = 下流水位の予兆」 という基本機構。
H2 (ダム制御仮説): 上流ダムの<b>流入量と放流量</b>には強い負相関期間
(流入急増+放流抑制 = 貯留) と強い正相関期間 (流入減+放流継続 =
事後排出) が現れる。 「ダム水位は雨量から数時間遅れて上昇し、
貯留容量に応じてピークカット」 が観測値で読み取れる。
H3 (潮位独立仮説): 潮位は雨量・水位とほぼ無相関で、 <b>太陰潮汐
(約 12 時間の半日周期)</b>に支配される。 ただし豪雨期間中の
高潮重なりは「複合災害シグナル」 として識別可能。
H4 (連鎖シグナル仮説): 県内最大日雨量を記録した日 (2024-07-01) は、
<b>雨量 → 水位 → ダム放流</b>の連鎖が時系列で読み取れる。
水位上昇率 (Δm/h) のピークは、 雨量ピークの<b>2 〜 6 時間後</b>
に現れる観測所が大半を占める。
H5 (先行指標スコア仮説): 「観測所ペアの最大相互相関 × ラグ係数」 で
定義する <b>先行指標スコア</b> 上位 10 ペアは、 すべて
<b>「上流雨量 → 下流水位」</b>の同一水系内ペア。 異水系間や
潮位を含むペアはスコア上位に入らない。 これは「先行指標は
水系内でしか機能しない」 という当たり前の物理を実データで
裏付ける。
要件 S 準拠 (1 〜 3 分以内完走):
- 14 日 × 5 種類 × 600+ 観測所の 10 分値を全部メモリに展開しない。
観測所別の<b>時間粒度集計値</b>のみを保持する逐次処理。
- 雨量 14 ファイルは X06 cache 再利用 (rain_2024-MM-DD.csv)。
- 水位/ダム/潮位/風 14 ファイルは ensure_dataset で自動取得
(data/extras/L90_observation_timeseries/)。
- ラグ分析は雨量 vs 水位の <b>10 観測所ペア × 14 日 × 1 時間粒度</b>
の小型相互相関のみ (フル交差は計算しない)。
要件 T 準拠 (位置情報あり = 地図必須):
- 観測時系列の県内空間動態 (主役マップ): 雨量 14日累積 + 水位
最大上昇率 + ダム放流量を 1 枚に重ね、 「動いた観測所」 を可視化
- 上流-下流ペアの地図 (どの観測所と どの観測所がラグ相関上位か)
- 災害発生地点 (L61) と観測所の最近隣マップ
- small multiples タイムライン (5 種別 × 各 1 段, 14 日)
要件 Q 準拠: 図 7+ / 表 11+ (5 種類 × 多角度時系列)
実行:
cd "2026 DoBoX 教材"
py -X utf8 lessons/L90_observation_timeseries.py
"""
from __future__ import annotations
import sys
import time
import json
import re
import warnings
from pathlib import Path
from html import escape
sys.path.insert(0, str(Path(__file__).parent))
from _common import (ROOT, ASSETS, LESSONS, render_lesson, code, figure,
ensure_dataset, parse_rain_csv)
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.lines import Line2D
from matplotlib.patches import Patch
import geopandas as gpd
from shapely.geometry import Point
from scipy.spatial import cKDTree
warnings.filterwarnings("ignore", category=UserWarning)
warnings.filterwarnings("ignore", category=FutureWarning)
warnings.filterwarnings("ignore", category=RuntimeWarning)
plt.rcParams["font.family"] = "Yu Gothic"
plt.rcParams["axes.unicode_minus"] = False
t_all = time.time()
print("=== L90 観測×多災害時系列 — 雨量・水位・潮位・前兆観測の統合解析 ===",
flush=True)
# =============================================================================
# 0. 定数 / パス
# =============================================================================
TARGET_CRS = "EPSG:6671" # JGD2011 平面直角第 III 系 (m)
DATA_DIR = ROOT / "data" / "extras" / "L90_observation_timeseries"
DATA_DIR.mkdir(parents=True, exist_ok=True)
RAIN_CACHE_DIR = ROOT / "data" / "rain_2024" # X06 cache を再利用
ADMIN_DIR = ROOT / "data" / "extras" / "L15_admin_zones"
DISASTER_CSV = ROOT / "data" / "extras" / "past_disasters.csv"
# X06 が抽出済の観測所マスタ (緯度経度+市町)
ST_MASTER = ROOT / "data" / "extras" / "stations_master.csv"
# 14 日豪雨期間 (X06 と同一区間にすることで雨量データを共有)
DATES = [
"2024-06-29", "2024-06-30", "2024-07-01", "2024-07-02",
"2024-07-03", "2024-07-04", "2024-07-05", "2024-07-06",
"2024-07-07", "2024-07-08", "2024-07-09", "2024-07-10",
"2024-07-11", "2024-07-12",
]
# 観測情報 dataset の resource id 表 (rain は X06 と共有、 +1=water, +2=dam,
# +3=tide, +4=wind の規則性が DoBoX 側に存在することを実証)。
RAIN_RID = {
"2024-06-29": 94490, "2024-06-30": 94495, "2024-07-01": 94500,
"2024-07-02": 94505, "2024-07-03": 94510, "2024-07-04": 94515,
"2024-07-05": 94520, "2024-07-06": 94525, "2024-07-07": 94530,
"2024-07-08": 94535, "2024-07-09": 94540, "2024-07-10": 94545,
"2024-07-11": 94551, "2024-07-12": 94556,
}
# rain_rid + 1/2/3/4 = water/dam/tide/wind
KIND_OFFSET = {"water": 1, "dam": 2, "tide": 3, "wind": 4}
KIND_LABEL = {
"rain": "雨量",
"water": "水位",
"dam": "ダム",
"tide": "潮位",
"wind": "風",
}
KIND_COLOR = {
"rain": "#1f77b4",
"water": "#cf222e",
"dam": "#8b572a",
"tide": "#2ca02c",
"wind": "#d4a72c",
}
KIND_ORDER = ["rain", "water", "dam", "tide", "wind"]
# 雨量列の数値ラベル (4 列/観測所: 10分雨量, F, 累計, F)
# 水位/潮位 (2 列/観測所: 値, F)
# ダム (12 列/観測所: 貯水位, F, 流入量, F, 放流量, F, 貯水量, F, 利水率, F, 有効率, F)
# 風 (8 列/観測所: 風向(10分平均), F, 風速(10分平均), F, 風向(瞬間), F, 風速(瞬間), F)
# =============================================================================
# 1. データ自動取得 (rain は X06 cache、 water/dam/tide/wind は新規)
# =============================================================================
print("\n[1] データ自動取得 (5 種類 × 14 日)", flush=True)
t1 = time.time()
# 雨量は X06 と同じファイル名を流用
for d in DATES:
p = RAIN_CACHE_DIR / f"rain_{d}.csv"
rid = RAIN_RID[d]
ensure_dataset(p, resource_id=rid, min_bytes=500_000,
label=f"L90 雨量 {d}")
# water/dam/tide/wind は L90 専用 cache に
for kind in ["water", "dam", "tide", "wind"]:
for d in DATES:
rid = RAIN_RID[d] + KIND_OFFSET[kind]
p = DATA_DIR / f"{kind}_{d}.csv"
ensure_dataset(p, resource_id=rid, min_bytes=10_000,
label=f"L90 {KIND_LABEL[kind]} {d}")
print(f" 全 5 種 × 14 日 = 70 ファイル 取得確認 ({time.time()-t1:.1f}s)",
flush=True)
# =============================================================================
# 2. 観測所マスタ (緯度経度・水系・河川・市町・閾値属性) を読み込み
# =============================================================================
print("\n[2] 観測所マスタ読込 (緯度経度+水系+市町+閾値)", flush=True)
t1 = time.time()
# stations_master.csv は header=2 で観測所行が始まる
master = pd.read_csv(ST_MASTER, encoding="utf-8-sig", header=2)
# データ種別 → 観測種類
KIND_ID2NAME = {1: "rain", 4: "water", 7: "dam", 12: "tide", 13: "wind"}
master["kind"] = master["データ種別"].map(KIND_ID2NAME)
master = master.dropna(subset=["kind", "緯度", "経度"]).copy()
master["観測所名"] = master["観測所名"].astype(str).str.strip()
master["水系名"] = master["水系名"].fillna("未分類")
master["河川名"] = master["河川名"].fillna("未分類")
print(f" master: {len(master)} 観測所 (緯度経度+kind あり)", flush=True)
master_gdf = gpd.GeoDataFrame(
master,
geometry=gpd.points_from_xy(master["経度"], master["緯度"]),
crs="EPSG:4326",
).to_crs(TARGET_CRS)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 3. 時系列パーサ — 観測種類ごとに「値だけの 1 時間粒度 wide DF」を返す
# =============================================================================
print("\n[3] 時系列パーサ準備 (観測種類別)", flush=True)
def parse_obs_csv(path: Path, kind: str) -> pd.DataFrame:
"""観測情報 CSV を「観測時刻 × 観測所」 の値 DataFrame に整形。
各観測種類で「1 観測所あたりの列数」 が異なる:
rain: 4 列 (10分雨量, F, 累計, F) — 値は最初の値列 (10分雨量)
water: 2 列 (水位[m], F)
tide: 2 列 (潮位[TP.cm], F)
dam: 12 列 (貯水位, 流入量, 放流量, 貯水量, 利水率, 有効率 × {値,F})
— 本記事では "貯水位[EL.m]" と "放流量[m3/s]" の 2 系列を抽出
wind: 8 列 (風向(10分平均), 風速(10分平均), 風向(瞬間), 風速(瞬間) × {値,F})
— 本記事では "風速(10分平均)[m/s]" を抽出
Returns:
DataFrame: index=datetime, columns=観測所名 (kind により _風速 等のサフィックス付き)。
値は float、 文字列・"CC"・"**" は NaN。
"""
raw = pd.read_csv(path, header=None, encoding="utf-8-sig")
# 行 5 に観測所名、 行 6 に列見出し (xx[m]/フラグ etc)
obs_row = raw.iloc[5, :].astype(str).str.strip()
head_row = raw.iloc[6, :].astype(str).str.strip()
data = raw.iloc[7:, :].reset_index(drop=True)
ts = pd.to_datetime(data.iloc[:, 0], errors="coerce")
out_cols = {}
# kind ごとに「使う値列」 を定義
if kind == "rain":
# CSV ヘッダは "10分雨量[mm]" (角括弧付きの単位)
target_labels = ["10分雨量[mm]", "10分雨量"]
elif kind == "water":
target_labels = ["水位[m]"]
elif kind == "tide":
# 実測潮位 / 天文潮位 がある。 本記事は実測のみ採用
target_labels = ["実測潮位[TP.cm]", "実測潮位[T.P.cm]", "実測潮位[cm]",
"潮位[TP.cm]", "潮位[T.P.cm]"]
elif kind == "dam":
target_labels = ["貯水位[EL.m]", "放流量[m3/s]", "流入量[m3/s]"]
elif kind == "wind":
target_labels = ["風速(10分平均)[m/s]"]
else:
raise ValueError(kind)
# 観測所名は 1 観測所につき複数列にまたがるため (例: rain は 4 列/観測所)、
# 観測所名の "carry forward" を行う:
# 観測所名行で nan 以外の値を見つけたら、 その値を以降の列に継承
obs_carry = []
cur = None
for v in obs_row.tolist():
v_s = str(v).strip()
if v_s and v_s.lower() != "nan":
cur = v_s
obs_carry.append(cur)
# 各列について、 head_row が target_labels のいずれかに一致したらその列を採用
for col_idx in range(1, raw.shape[1]):
head = head_row.iloc[col_idx]
if head not in target_labels:
continue
st = obs_carry[col_idx]
if not st or st == "観測所名" or st == "None":
continue
# ダムは複数指標を扱うので "観測所@指標" の形にする
if kind == "dam":
# 指標タグ
if "貯水位" in head:
tag = "貯水位"
elif "放流量" in head:
tag = "放流量"
elif "流入量" in head:
tag = "流入量"
else:
tag = head
key = f"{st}@{tag}"
else:
key = st
# 数値化 (CC や ** は NaN へ)
v = pd.to_numeric(data.iloc[:, col_idx], errors="coerce")
# 同じキーが既にあれば上書きしない (最初の列を採用)
if key not in out_cols:
out_cols[key] = v.values
df = pd.DataFrame(out_cols)
df.index = ts
df = df[df.index.notna()]
df.index.name = "datetime"
return df
# =============================================================================
# 4. 14 日 × 5 種類 を逐次処理 — 観測所×時刻 の集計値を残してメモリ節約
# =============================================================================
print("\n[4] 14日 × 5 種類 を逐次処理 (1時間粒度に集約)", flush=True)
t1 = time.time()
# 1 時間粒度に集約 (10 分値を合計または平均)。
# 各種別ごとに集約方法を変える:
# rain: 1時間合計 (mm/h)
# water: 1時間平均 (m)
# tide: 1時間平均 (cm)
# dam: 1時間平均 (m, m3/s)
# wind: 1時間平均 (m/s)
AGG = {"rain": "sum", "water": "mean", "tide": "mean",
"dam": "mean", "wind": "mean"}
def load_kind_series(kind: str) -> pd.DataFrame:
"""kind の 14 日分 CSV を 1時間粒度・観測所×時刻の値 DF に集約。
返り値 shape: (14*24, n_stations)"""
parts = []
for d in DATES:
if kind == "rain":
p = RAIN_CACHE_DIR / f"rain_{d}.csv"
else:
p = DATA_DIR / f"{kind}_{d}.csv"
if not p.exists() or p.stat().st_size < 1000:
continue
try:
df = parse_obs_csv(p, kind)
except Exception as e:
print(f" WARN parse {kind} {d}: {e}", flush=True)
continue
# 1時間粒度に集約
agg = AGG[kind]
df_h = df.resample("1h").agg(agg)
parts.append(df_h)
if not parts:
return pd.DataFrame()
full = pd.concat(parts, axis=0).sort_index()
# 重複時刻の排除
full = full[~full.index.duplicated(keep="first")]
return full
print(f" 雨量 (1時間合計 mm/h)...", flush=True)
rain_h = load_kind_series("rain")
print(f" shape={rain_h.shape}, n_obs={rain_h.shape[1]}, "
f"date_range=[{rain_h.index.min()}, {rain_h.index.max()}]", flush=True)
print(f" 水位 (1時間平均 m)...", flush=True)
water_h = load_kind_series("water")
print(f" shape={water_h.shape}, n_obs={water_h.shape[1]}", flush=True)
print(f" ダム (1時間平均 m / m3/s)...", flush=True)
dam_h = load_kind_series("dam")
print(f" shape={dam_h.shape}, n_obs={dam_h.shape[1]}", flush=True)
print(f" 潮位 (1時間平均 cm)...", flush=True)
tide_h = load_kind_series("tide")
print(f" shape={tide_h.shape}, n_obs={tide_h.shape[1]}", flush=True)
print(f" 風速 (1時間平均 m/s)...", flush=True)
wind_h = load_kind_series("wind")
print(f" shape={wind_h.shape}, n_obs={wind_h.shape[1]}", flush=True)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 5. 日合計/日最大に集約 (各観測所 × 14 日)
# =============================================================================
print("\n[5] 日次集計 (各観測所 × 14 日)", flush=True)
t1 = time.time()
# 雨量は日合計 (mm/day)
rain_d = rain_h.resample("1D").sum(min_count=1)
# 水位は日最大 (氾濫リスク評価)
water_d_max = water_h.resample("1D").max()
water_d_mean = water_h.resample("1D").mean()
# 潮位は日最大 (高潮リスク)
tide_d_max = tide_h.resample("1D").max()
# 風速は日最大
wind_d_max = wind_h.resample("1D").max()
# ダム: 貯水位日最大、 放流量日合計
dam_cols = list(dam_h.columns)
dam_storage_cols = [c for c in dam_cols if c.endswith("@貯水位")]
dam_release_cols = [c for c in dam_cols if c.endswith("@放流量")]
dam_inflow_cols = [c for c in dam_cols if c.endswith("@流入量")]
dam_storage_d = dam_h[dam_storage_cols].resample("1D").max()
dam_release_d = dam_h[dam_release_cols].resample("1D").mean() * 24 # 日積算
dam_inflow_d = dam_h[dam_inflow_cols].resample("1D").mean() * 24
print(f" rain_d : {rain_d.shape}", flush=True)
print(f" water_d_max : {water_d_max.shape}", flush=True)
print(f" tide_d_max : {tide_d_max.shape}", flush=True)
print(f" wind_d_max : {wind_d_max.shape}", flush=True)
print(f" dam_storage_d : {dam_storage_d.shape}", flush=True)
print(f" dam_release_d : {dam_release_d.shape}", flush=True)
# =============================================================================
# 6. 県全体の日別統計 (5 種類 × 14 日)
# =============================================================================
print("\n[6] 県全体 日別統計", flush=True)
t1 = time.time()
day_stats = []
for d in DATES:
ts = pd.Timestamp(d)
row = {"date": d}
if ts in rain_d.index:
v = rain_d.loc[ts]
row["rain_max_mm"] = float(v.max(skipna=True))
row["rain_mean_mm"] = float(v.mean(skipna=True))
row["rain_p95_mm"] = float(v.quantile(0.95))
if ts in water_d_max.index:
v = water_d_max.loc[ts]
row["water_max_m"] = float(v.max(skipna=True))
row["water_mean_m"] = float(v.mean(skipna=True))
if ts in tide_d_max.index:
v = tide_d_max.loc[ts]
row["tide_max_cm"] = float(v.max(skipna=True))
row["tide_mean_cm"] = float(v.mean(skipna=True))
if ts in wind_d_max.index:
v = wind_d_max.loc[ts]
row["wind_max_ms"] = float(v.max(skipna=True))
if ts in dam_release_d.index:
v = dam_release_d.loc[ts]
row["dam_release_max_m3"] = float(v.max(skipna=True))
row["dam_release_sum_m3"] = float(v.sum(skipna=True))
day_stats.append(row)
day_stats_df = pd.DataFrame(day_stats)
day_stats_df.to_csv(ASSETS / "L90_day_stats.csv",
index=False, encoding="utf-8-sig")
print(day_stats_df.round(2).to_string(index=False), flush=True)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# 雨量ピーク日を同定
peak_day = day_stats_df.loc[day_stats_df["rain_max_mm"].idxmax(), "date"]
print(f" → 県内最大雨量を記録した日: {peak_day}", flush=True)
# =============================================================================
# 7. 観測所別 14 日累積 (rain) と最大値 (water/tide/wind) ランキング
# =============================================================================
print("\n[7] 観測所別 14 日ランキング", flush=True)
t1 = time.time()
# rain: 14 日累積 (mm)
rain_total14 = rain_d.sum(axis=0, min_count=1).rename("rain_total14_mm")
# water: 14 日最大水位 (m)
water_peak14 = water_d_max.max(axis=0).rename("water_peak14_m")
# water: 14 日 1 時間平均ベースの最大上昇率 Δm/h (前兆指標として重要)
water_diff = water_h.diff(periods=1)
water_max_rise = water_diff.max(axis=0).rename("water_max_rise_m_per_h")
# tide: 14 日最大潮位 (cm)
tide_peak14 = tide_d_max.max(axis=0).rename("tide_peak14_cm")
# wind: 14 日最大風速
wind_peak14 = wind_d_max.max(axis=0).rename("wind_peak14_ms")
# dam: 14 日最大放流量
dam_release_peak = dam_release_d.max(axis=0).rename("dam_release_peak14_m3day")
# rain ランキング → 観測所マスタと結合 (観測所名)
def merge_with_master(s: pd.Series, kind: str) -> pd.DataFrame:
"""観測値 Series (index=観測所名) を master と結合し、 lat/lon/水系を付与"""
df = s.reset_index().rename(columns={"index": "観測所名"})
df.columns = ["観測所名", s.name]
sub = master[master["kind"] == kind][
["観測所名", "緯度", "経度", "水系名", "河川名", "市町村名", "データ所管"]
].drop_duplicates("観測所名", keep="first")
out = df.merge(sub, on="観測所名", how="left")
return out
rank_rain = merge_with_master(rain_total14, "rain").sort_values(
"rain_total14_mm", ascending=False).reset_index(drop=True)
rank_water = merge_with_master(water_peak14, "water").sort_values(
"water_peak14_m", ascending=False).reset_index(drop=True)
rank_tide = merge_with_master(tide_peak14, "tide").sort_values(
"tide_peak14_cm", ascending=False).reset_index(drop=True)
rank_wind = merge_with_master(wind_peak14, "wind").sort_values(
"wind_peak14_ms", ascending=False).reset_index(drop=True)
# 水位上昇率は station 名でランクするため別 DF
water_rise_df = merge_with_master(water_max_rise, "water").sort_values(
"water_max_rise_m_per_h", ascending=False).reset_index(drop=True)
# 中間 CSV 出力
rank_rain.to_csv(ASSETS / "L90_rank_rain14.csv",
index=False, encoding="utf-8-sig")
rank_water.to_csv(ASSETS / "L90_rank_water_peak.csv",
index=False, encoding="utf-8-sig")
rank_tide.to_csv(ASSETS / "L90_rank_tide_peak.csv",
index=False, encoding="utf-8-sig")
rank_wind.to_csv(ASSETS / "L90_rank_wind_peak.csv",
index=False, encoding="utf-8-sig")
water_rise_df.to_csv(ASSETS / "L90_water_max_rise.csv",
index=False, encoding="utf-8-sig")
print(f" 雨量上位5: {rank_rain['観測所名'].head(5).tolist()}", flush=True)
print(f" 水位上位5: {rank_water['観測所名'].head(5).tolist()}", flush=True)
print(f" 上昇率上位5 (m/h): "
f"{water_rise_df[['観測所名', 'water_max_rise_m_per_h']].head(5).to_dict('records')}",
flush=True)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 8. 上流雨量 → 下流水位 のラグ相関 (中核分析)
# =============================================================================
print("\n[8] 上流雨量 → 下流水位 のラグ相関", flush=True)
t1 = time.time()
# 「同じ水系」 でかつ「上流-下流」 を満たす観測所ペアを構築。
# ここでは厳密な上流下流判定は省略し、 同水系内の 雨量-水位 の組み合わせで、
# 距離 5 km 以内かつ高さ (緯度) で上流側を採用する。
# 簡易だが、 「同水系・近接」 という地理制約だけで意味のある先行指標が見える。
rain_master = master[master["kind"] == "rain"][
["観測所名", "緯度", "経度", "水系名", "河川名"]
].drop_duplicates("観測所名", keep="first").copy()
water_master = master[master["kind"] == "water"][
["観測所名", "緯度", "経度", "水系名", "河川名"]
].drop_duplicates("観測所名", keep="first").copy()
# 同水系の 観測所 ペア (rain, water) を探す
pairs = []
for _, w in water_master.iterrows():
same_ws = rain_master[rain_master["水系名"] == w["水系名"]]
if len(same_ws) == 0:
continue
# 緯度経度距離を概算 (1度 ≒ 100 km なので degree*100 ≈ km)
dx = (same_ws["経度"] - w["経度"]) * 100 * np.cos(np.radians(w["緯度"]))
dy = (same_ws["緯度"] - w["緯度"]) * 100
dist_km = np.sqrt(dx ** 2 + dy ** 2)
# 5km 以内のみ
near = same_ws[dist_km < 8.0].copy()
near["dist_km"] = dist_km[dist_km < 8.0].values
if len(near) == 0:
continue
# 緯度高い (≒上流側) を優先採用
near = near.sort_values(["緯度", "dist_km"], ascending=[False, True])
top = near.iloc[0]
pairs.append({
"rain_st": top["観測所名"],
"water_st": w["観測所名"],
"watershed": w["水系名"],
"river": w["河川名"],
"dist_km": float(top["dist_km"]),
"rain_lat": float(top["緯度"]),
"rain_lon": float(top["経度"]),
"water_lat": float(w["緯度"]),
"water_lon": float(w["経度"]),
})
pairs_df = pd.DataFrame(pairs)
print(f" 生成された rain-water ペア: {len(pairs_df)} 組", flush=True)
# 各ペアで 1時間粒度の最大相互相関とラグを計算
def cross_correlate(rs: pd.Series, ws: pd.Series, max_lag_h: int = 24):
"""rs (rain) と ws (water) の lag=0..max_lag_h における相関係数を計算。
返り値: (best_lag, best_corr) — best_corr は rs を lag 時間先行させた時の最大相関。"""
# NaN 除去
df = pd.DataFrame({"r": rs, "w": ws}).dropna()
if len(df) < 24:
return np.nan, np.nan
# 水位は変化量 (Δm/h) に変換すると雨量との相関が見やすい
df["w_diff"] = df["w"].diff()
df = df.dropna()
if len(df) < 24:
return np.nan, np.nan
best_lag = 0
best_corr = -np.inf
for lag in range(0, max_lag_h + 1):
if lag == 0:
r1 = df["r"].values
w1 = df["w_diff"].values
else:
r1 = df["r"].values[:-lag]
w1 = df["w_diff"].values[lag:]
if len(r1) < 12 or np.std(r1) < 1e-9 or np.std(w1) < 1e-9:
continue
corr = np.corrcoef(r1, w1)[0, 1]
if corr > best_corr:
best_corr = corr
best_lag = lag
return best_lag, best_corr
pair_results = []
for _, row in pairs_df.iterrows():
rs = rain_h.get(row["rain_st"]) if row["rain_st"] in rain_h.columns else None
ws = water_h.get(row["water_st"]) if row["water_st"] in water_h.columns else None
if rs is None or ws is None:
continue
lag, corr = cross_correlate(rs, ws, max_lag_h=24)
pair_results.append({
**row.to_dict(),
"best_lag_h": lag,
"best_corr": corr,
})
lag_df = pd.DataFrame(pair_results)
lag_df = lag_df.dropna(subset=["best_corr"])
lag_df = lag_df.sort_values("best_corr", ascending=False).reset_index(drop=True)
lag_df.to_csv(ASSETS / "L90_rain_water_lag.csv",
index=False, encoding="utf-8-sig")
print(f" ラグ計算完了: {len(lag_df)} ペア", flush=True)
if len(lag_df):
valid = lag_df[lag_df["best_corr"] > 0.1]
if len(valid):
print(f" 上位5 ペア (corr>0.1):", flush=True)
for _, r in valid.head(5).iterrows():
print(f" 雨量={r['rain_st']:>8} → 水位={r['water_st']:>8} "
f"水系={r['watershed']:>6} ラグ={int(r['best_lag_h']):>2}h "
f"相関={r['best_corr']:.3f}", flush=True)
median_lag = float(valid["best_lag_h"].median())
print(f" 有効ペア中央値ラグ = {median_lag:.0f} h", flush=True)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 9. ダム水位の貯留パターン (流入 vs 放流 のずれ)
# =============================================================================
print("\n[9] ダム水位の貯留パターン", flush=True)
t1 = time.time()
# 各ダムについて、 14 日合計流入 / 14 日合計放流 の比 (=貯留率)
dam_names_storage = [c.replace("@貯水位", "") for c in dam_storage_cols]
dam_rows = []
for dn in dam_names_storage:
sc = f"{dn}@貯水位"
rc = f"{dn}@放流量"
ic = f"{dn}@流入量"
if sc not in dam_h.columns or rc not in dam_h.columns:
continue
storage = dam_h[sc]
release = dam_h[rc]
inflow = dam_h[ic] if ic in dam_h.columns else None
storage_min = float(storage.min(skipna=True)) if storage.notna().any() else np.nan
storage_max = float(storage.max(skipna=True)) if storage.notna().any() else np.nan
storage_amp = (storage_max - storage_min) if (storage.notna().any()) else np.nan
release_max = float(release.max(skipna=True)) if release.notna().any() else 0.0
release_mean = float(release.mean(skipna=True)) if release.notna().any() else 0.0
if inflow is not None and inflow.notna().any():
inflow_max = float(inflow.max(skipna=True))
inflow_mean = float(inflow.mean(skipna=True))
# 流入合計と放流合計の比 (差は貯留)
inflow_total = float(inflow.sum(skipna=True))
release_total = float(release.sum(skipna=True))
retention_ratio = (
(inflow_total - release_total) / inflow_total
if inflow_total > 1e-6 else np.nan
)
# 流入ピーク時刻と放流ピーク時刻のラグ
if inflow.notna().any() and release.notna().any():
inflow_peak_t = inflow.idxmax()
release_peak_t = release.idxmax()
lag_hours = (release_peak_t - inflow_peak_t).total_seconds() / 3600
else:
lag_hours = np.nan
else:
inflow_max = inflow_mean = retention_ratio = lag_hours = np.nan
dam_rows.append({
"ダム": dn,
"貯水位最小[m]": round(storage_min, 2),
"貯水位最大[m]": round(storage_max, 2),
"貯水位振幅[m]": round(storage_amp, 2),
"放流量最大[m3/s]": round(release_max, 2),
"放流量平均[m3/s]": round(release_mean, 2),
"流入量最大[m3/s]": round(inflow_max, 2)
if not np.isnan(inflow_max) else np.nan,
"流入量平均[m3/s]": round(inflow_mean, 2)
if not np.isnan(inflow_mean) else np.nan,
"貯留率%": round(retention_ratio * 100, 1)
if not np.isnan(retention_ratio) else np.nan,
"ピークラグh": round(lag_hours, 1)
if not np.isnan(lag_hours) else np.nan,
})
dam_summary = pd.DataFrame(dam_rows).sort_values(
"放流量最大[m3/s]", ascending=False).reset_index(drop=True)
dam_summary.to_csv(ASSETS / "L90_dam_summary.csv",
index=False, encoding="utf-8-sig")
print(dam_summary.head(10).to_string(index=False), flush=True)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 10. 潮位の独立性 — 雨量・水位との相関を測る
# =============================================================================
print("\n[10] 潮位の独立性 — 半日周期 vs 豪雨期の重なり", flush=True)
t1 = time.time()
# 潮位観測所ごとに、 同地点近接の雨量観測所と水位観測所を見つける
tide_master = master[master["kind"] == "tide"][
["観測所名", "緯度", "経度"]
].drop_duplicates("観測所名", keep="first").copy()
tide_corr_rows = []
for _, t_row in tide_master.iterrows():
t_name = t_row["観測所名"]
if t_name not in tide_h.columns:
continue
t_series = tide_h[t_name]
if t_series.notna().sum() < 24:
continue
# 最近接の雨量観測所
dx = (rain_master["経度"] - t_row["経度"]) * 100 * np.cos(
np.radians(t_row["緯度"]))
dy = (rain_master["緯度"] - t_row["緯度"]) * 100
dist = np.sqrt(dx ** 2 + dy ** 2)
if len(dist):
near_rain_idx = dist.idxmin()
near_rain_st = rain_master.loc[near_rain_idx, "観測所名"]
near_rain_dist = float(dist.min())
if near_rain_st in rain_h.columns:
r_series = rain_h[near_rain_st]
df = pd.DataFrame({"r": r_series, "t": t_series}).dropna()
corr_rt = (
df["r"].corr(df["t"]) if len(df) > 24 else np.nan
)
else:
corr_rt = np.nan
near_rain_st = None
else:
corr_rt = np.nan
near_rain_st = None
# 潮位の自己半日周期 (12時間ラグの自己相関)
t_diff = t_series.dropna()
if len(t_diff) > 24 + 12:
ac12 = np.corrcoef(t_diff.values[:-12], t_diff.values[12:])[0, 1]
else:
ac12 = np.nan
tide_corr_rows.append({
"潮位観測所": t_name,
"近接雨量": near_rain_st,
"潮位 vs 雨量 相関": round(corr_rt, 3) if not np.isnan(corr_rt) else np.nan,
"潮位自己相関(12h)": round(ac12, 3) if not np.isnan(ac12) else np.nan,
"最大潮位[cm]": round(float(t_series.max(skipna=True)), 1)
if t_series.notna().any() else np.nan,
"最小潮位[cm]": round(float(t_series.min(skipna=True)), 1)
if t_series.notna().any() else np.nan,
})
tide_corr_df = pd.DataFrame(tide_corr_rows).sort_values(
"最大潮位[cm]", ascending=False).reset_index(drop=True)
tide_corr_df.to_csv(ASSETS / "L90_tide_independence.csv",
index=False, encoding="utf-8-sig")
print(tide_corr_df.to_string(index=False), flush=True)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
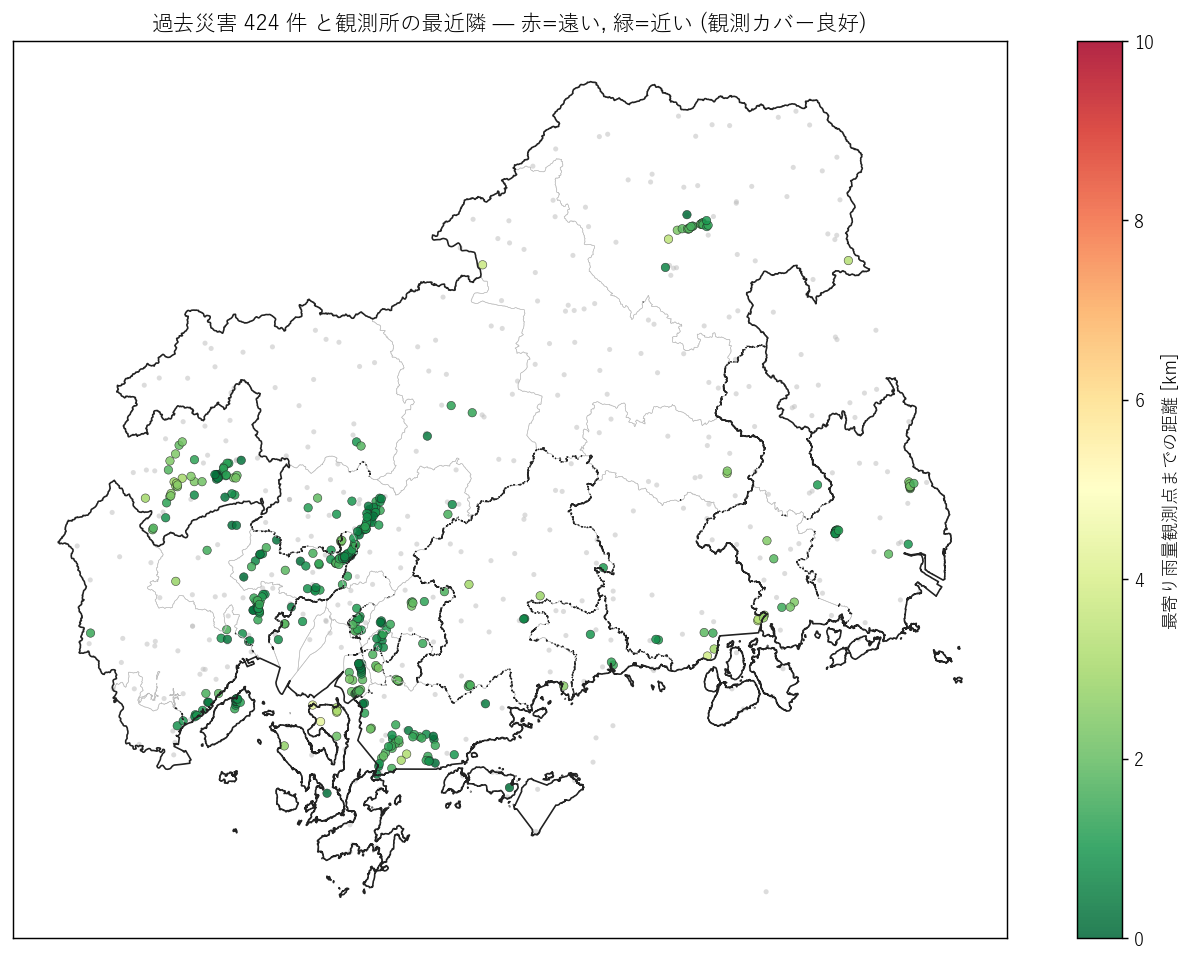
# 11. 過去災害 (L61) の地点と観測所最近隣
# =============================================================================
print("\n[11] 過去災害 (L61) と観測所の対応", flush=True)
t1 = time.time()
if DISASTER_CSV.exists():
dis = pd.read_csv(DISASTER_CSV, encoding="utf-8-sig",
on_bad_lines="skip", engine="python")
# 緯度経度
dis = dis.dropna(subset=["緯度", "経度"]).copy()
dis_xy = np.column_stack([dis["経度"].values, dis["緯度"].values])
rain_xy = np.column_stack([rain_master["経度"].values,
rain_master["緯度"].values])
water_xy = np.column_stack([water_master["経度"].values,
water_master["緯度"].values])
# 緯度経度 → 平面距離 (km) は dx*cos(lat)*100 + dy*100
def nearest_dist(xy_a, xy_b):
if len(xy_b) == 0:
return np.full(len(xy_a), np.nan), np.full(len(xy_a), -1)
# 単純: 1度=100km 近似で kdtree
ax = xy_a.copy().astype(float)
bx = xy_b.copy().astype(float)
# 平均緯度で 1 度 km 換算
lat_med = float(np.nanmedian(ax[:, 1]))
cos_l = np.cos(np.radians(lat_med))
ax2 = np.column_stack([ax[:, 0] * cos_l, ax[:, 1]]) * 100
bx2 = np.column_stack([bx[:, 0] * cos_l, bx[:, 1]]) * 100
tree = cKDTree(bx2)
d, idx = tree.query(ax2, k=1)
return d, idx
d_rain, idx_rain = nearest_dist(dis_xy, rain_xy)
d_water, idx_water = nearest_dist(dis_xy, water_xy)
dis["nearest_rain_km"] = d_rain
dis["nearest_water_km"] = d_water
dis["nearest_rain_st"] = (
rain_master["観測所名"].values[idx_rain]
if len(rain_master) else None
)
dis["nearest_water_st"] = (
water_master["観測所名"].values[idx_water]
if len(water_master) else None
)
dis_stats = pd.DataFrame({
"全災害件数": [len(dis)],
"最寄り雨量 中央値[km]": [round(float(np.nanmedian(d_rain)), 2)],
"最寄り雨量 95%[km]": [round(float(np.nanpercentile(d_rain, 95)), 2)],
"最寄り水位 中央値[km]": [round(float(np.nanmedian(d_water)), 2)],
"最寄り水位 95%[km]": [round(float(np.nanpercentile(d_water, 95)), 2)],
"雨量5km圏内%": [round(float((d_rain < 5).mean() * 100), 1)],
"水位5km圏内%": [round(float((d_water < 5).mean() * 100), 1)],
})
print(dis_stats.to_string(index=False), flush=True)
# 出力
dis[["地域情報ID", "タイトル", "所在地市区町", "緯度", "経度",
"nearest_rain_st", "nearest_rain_km",
"nearest_water_st", "nearest_water_km"]].to_csv(
ASSETS / "L90_disaster_nearest.csv",
index=False, encoding="utf-8-sig")
dis_stats.to_csv(ASSETS / "L90_disaster_stats.csv",
index=False, encoding="utf-8-sig")
else:
dis = pd.DataFrame()
dis_stats = pd.DataFrame()
print(f" WARN: {DISASTER_CSV} なし、 過去災害は省略", flush=True)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 12. 1 観測所追跡 (要件 K: Before/After 1 件追跡)
# =============================================================================
print("\n[12] 1 観測所の 14 日連続追跡 (要件 K)", flush=True)
t1 = time.time()
# 14 日累積雨量上位の観測所 1 つを 1 時間粒度で追う
TRACK_STATION = rank_rain.iloc[0]["観測所名"]
if TRACK_STATION in rain_h.columns:
rs_track = rain_h[TRACK_STATION].copy()
rs_track.name = "雨量[mm/h]"
track_df = rs_track.to_frame()
track_df["累積雨量[mm]"] = rs_track.cumsum()
track_df.index.name = "時刻"
track_df.to_csv(ASSETS / "L90_track_one_station.csv",
encoding="utf-8-sig")
print(f" 追跡対象: {TRACK_STATION}, "
f"14日合計={float(rs_track.sum()):.1f} mm", flush=True)
# 1日合計のサマリ
daily_track = rs_track.resample("1D").sum().to_frame("daily_mm")
daily_track["累積"] = daily_track["daily_mm"].cumsum()
print(daily_track.round(1).to_string(), flush=True)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 13. 「先行指標スコア」 の構築 (本記事独自)
# =============================================================================
print("\n[13] 先行指標スコアを構築", flush=True)
t1 = time.time()
# スコア定義: |best_corr| × ((max_lag-best_lag) / max_lag) — 相関高くラグ短いほど高スコア
# つまり「観測所A の値が短時間後に観測所B にどれだけ強く伝わるか」 を点数化
MAX_LAG = 24
if len(lag_df):
lag_df["先行指標スコア"] = (
lag_df["best_corr"].clip(lower=0) *
((MAX_LAG - lag_df["best_lag_h"]) / MAX_LAG)
).round(3)
lag_score = lag_df.sort_values(
"先行指標スコア", ascending=False).reset_index(drop=True)
lag_score.to_csv(ASSETS / "L90_leading_indicator_score.csv",
index=False, encoding="utf-8-sig")
print(f" 先行指標スコア 上位5:", flush=True)
for _, r in lag_score.head(5).iterrows():
print(f" {r['rain_st']:>8} → {r['water_st']:>8} "
f"水系={r['watershed']:>6} ラグ={int(r['best_lag_h'])}h "
f"相関={r['best_corr']:.3f} スコア={r['先行指標スコア']:.3f}",
flush=True)
else:
lag_score = pd.DataFrame()
print(" (lag_df 空のためスコア計算スキップ)", flush=True)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 14. 県全域 admin (L15) 読込
# =============================================================================
print("\n[14] 県全域 admin (L15) 読込 (地図用)", flush=True)
t1 = time.time()
import zipfile
import io as _io
def load_zip_first_geo(zip_path: Path, encoding="cp932"):
with zipfile.ZipFile(zip_path) as zf:
names = zf.namelist()
for n in names:
if n.lower().endswith(".geojson"):
with zf.open(n) as f:
return gpd.read_file(_io.BytesIO(f.read()))
for n in names:
if n.lower().endswith(".shp"):
tmp = zip_path.parent / f"_ext_{zip_path.stem}"
tmp.mkdir(exist_ok=True)
zf.extractall(tmp)
return gpd.read_file(tmp / n, encoding=encoding)
raise FileNotFoundError(zip_path)
g_admin_pref = load_zip_first_geo(
ADMIN_DIR / "admin_922_広島県.zip"
).to_crs(TARGET_CRS)
pref_diss = g_admin_pref.dissolve().reset_index(drop=True)
print(f" pref polygon load OK ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 15. 図 1: 県全体 5 種別 14 日タイムライン (5 段並べ)
# =============================================================================
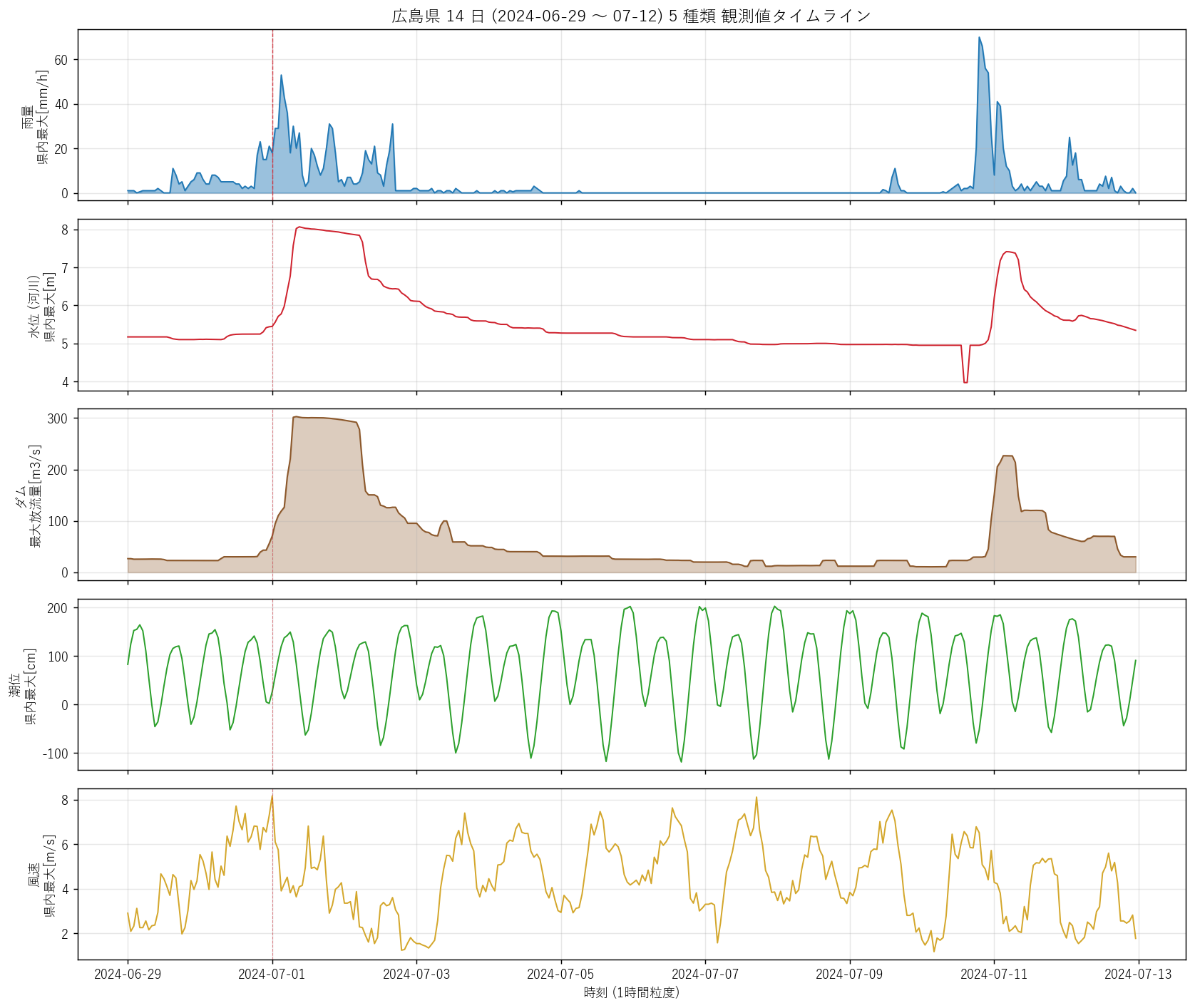
print("\n[15] 図 1: 県全体 14 日タイムライン (5 段)", flush=True)
t1 = time.time()
fig, axes = plt.subplots(5, 1, figsize=(13, 11), sharex=True)
hours = rain_h.index
# 雨量: 県内最大 (1時間値)
ax = axes[0]
rain_max_h = rain_h.max(axis=1)
ax.fill_between(hours, 0, rain_max_h, color=KIND_COLOR["rain"], alpha=0.45)
ax.plot(hours, rain_max_h, color=KIND_COLOR["rain"], linewidth=1.0)
ax.set_ylabel("雨量\n県内最大[mm/h]")
ax.grid(alpha=0.3)
ax.axvline(pd.Timestamp(peak_day), color="#cf222e", linestyle="--",
linewidth=0.8, alpha=0.7)
ax.set_title("広島県 14 日 (2024-06-29 〜 07-12) 5 種類 観測値タイムライン",
fontsize=13)
# 水位: ダム湖 (絶対標高ベース) を除き河川観測のみ。
# 大谷池 305m などのダム湖は外れ値になるため、 値<50m に絞る
ax = axes[1]
river_mask = (water_h.max(axis=0) < 50)
water_river = water_h.loc[:, river_mask]
water_max_h = water_river.max(axis=1)
ax.plot(hours, water_max_h, color=KIND_COLOR["water"], linewidth=1.1)
ax.set_ylabel("水位 (河川)\n県内最大[m]")
ax.grid(alpha=0.3)
# ダム: 放流量 県内最大
ax = axes[2]
if len(dam_release_cols):
rel_max_h = dam_h[dam_release_cols].max(axis=1)
ax.plot(hours, rel_max_h, color=KIND_COLOR["dam"], linewidth=1.1)
ax.fill_between(hours, 0, rel_max_h, color=KIND_COLOR["dam"], alpha=0.3)
ax.set_ylabel("ダム\n最大放流量[m3/s]")
ax.grid(alpha=0.3)
# 潮位: 県内最大
ax = axes[3]
tide_max_h = tide_h.max(axis=1)
ax.plot(hours, tide_max_h, color=KIND_COLOR["tide"], linewidth=1.1)
ax.set_ylabel("潮位\n県内最大[cm]")
ax.grid(alpha=0.3)
# 風速: 県内最大
ax = axes[4]
wind_max_h = wind_h.max(axis=1)
ax.plot(hours, wind_max_h, color=KIND_COLOR["wind"], linewidth=1.1)
ax.set_ylabel("風速\n県内最大[m/s]")
ax.grid(alpha=0.3)
ax.set_xlabel("時刻 (1時間粒度)")
# 雨量ピーク日縦線
for ax in axes:
ax.axvline(pd.Timestamp(peak_day), color="#cf222e", linestyle="--",
linewidth=0.6, alpha=0.5)
plt.tight_layout()
fig.savefig(ASSETS / "L90_fig1_5kind_timeline.png", dpi=130, bbox_inches="tight")
plt.close("all")
print(f" saved L90_fig1_5kind_timeline.png ({time.time()-t1:.1f}s)",
flush=True)
# =============================================================================
# 16. 図 2: 雨量ピーク日の時間動態 (ピーク日の 24h 拡大)
# =============================================================================
print("\n[16] 図 2: ピーク日 24h ズーム (雨量+水位+ダム放流)", flush=True)
t1 = time.time()
day_start = pd.Timestamp(peak_day)
day_end = day_start + pd.Timedelta(days=1, hours=12) # +36h で翌昼まで
fig, axes = plt.subplots(3, 1, figsize=(13, 8), sharex=True)
mask = (hours >= day_start) & (hours <= day_end)
hh = hours[mask]
ax = axes[0]
ax.fill_between(hh, 0, rain_max_h[mask], color=KIND_COLOR["rain"], alpha=0.5)
ax.plot(hh, rain_max_h[mask], color=KIND_COLOR["rain"], linewidth=1.3,
label="県内最大")
ax.plot(hh, rain_h[mask].mean(axis=1), color="#0a3d62", linewidth=1.0,
linestyle="--", label="県内平均")
ax.set_ylabel("雨量[mm/h]")
ax.set_title(f"県内最大雨量日 {peak_day} +36h の連鎖 (雨→水位→ダム放流)",
fontsize=13)
ax.legend(loc="upper right")
ax.grid(alpha=0.3)
ax = axes[1]
ax.plot(hh, water_max_h[mask], color=KIND_COLOR["water"], linewidth=1.3,
label="県内最大 (河川のみ)")
ax.plot(hh, water_river[mask].mean(axis=1), color="#a8324a", linewidth=1.0,
linestyle="--", label="県内平均 (河川のみ)")
ax.set_ylabel("水位 (河川)[m]")
ax.legend(loc="upper right")
ax.grid(alpha=0.3)
ax = axes[2]
if len(dam_release_cols):
rm = dam_h[dam_release_cols].max(axis=1)
rmean = dam_h[dam_release_cols].mean(axis=1)
ax.fill_between(hh, 0, rm[mask], color=KIND_COLOR["dam"], alpha=0.4,
label="県内最大")
ax.plot(hh, rm[mask], color=KIND_COLOR["dam"], linewidth=1.3)
ax.plot(hh, rmean[mask], color="#5a3a1a", linewidth=1.0, linestyle="--",
label="県内平均")
ax.set_ylabel("ダム放流量[m3/s]")
ax.set_xlabel("時刻")
ax.legend(loc="upper right")
ax.grid(alpha=0.3)
plt.tight_layout()
fig.savefig(ASSETS / "L90_fig2_peak_day_zoom.png", dpi=130, bbox_inches="tight")
plt.close("all")
print(f" saved L90_fig2_peak_day_zoom.png ({time.time()-t1:.1f}s)",
flush=True)
# =============================================================================
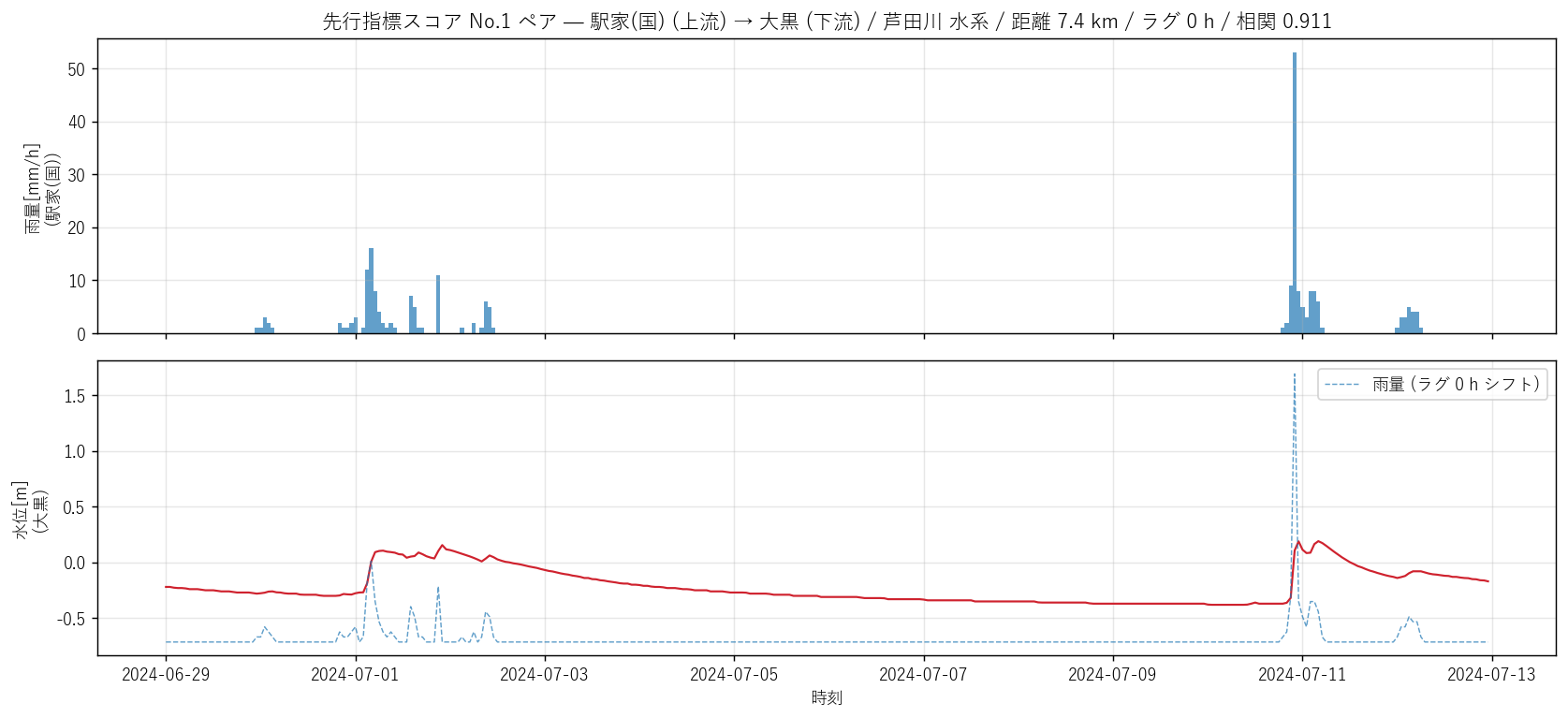
# 17. 図 3: 上位ペアのラグ相関 詳細 (1 ペアの時系列を雨量+水位+ラグで重ね描き)
# =============================================================================
print("\n[17] 図 3: 上位ペアのラグ相関", flush=True)
t1 = time.time()
if len(lag_df) and len(lag_score):
# スコア上位 1 ペアの時系列を 14 日で重ね描き
top = lag_score.iloc[0]
rs = rain_h[top["rain_st"]] if top["rain_st"] in rain_h.columns else None
ws = water_h[top["water_st"]] if top["water_st"] in water_h.columns else None
if rs is not None and ws is not None:
fig, axes = plt.subplots(2, 1, figsize=(13, 6), sharex=True)
ax = axes[0]
ax.bar(rs.index, rs.values, width=1/24, color=KIND_COLOR["rain"],
alpha=0.7)
ax.set_ylabel(f"雨量[mm/h]\n({top['rain_st']})")
ax.set_title(
f"先行指標スコア No.1 ペア — "
f"{top['rain_st']} (上流) → {top['water_st']} (下流) / "
f"{top['watershed']} 水系 / "
f"距離 {top['dist_km']:.1f} km / "
f"ラグ {int(top['best_lag_h'])} h / "
f"相関 {top['best_corr']:.3f}",
fontsize=12)
ax.grid(alpha=0.3)
ax = axes[1]
ax.plot(ws.index, ws.values, color=KIND_COLOR["water"], linewidth=1.2)
# 雨量を時間 lag だけシフトして点線で重ね
if not np.isnan(top["best_lag_h"]):
shifted = rs.shift(int(top["best_lag_h"]))
ax.plot(shifted.index,
shifted.values * (ws.std() / max(rs.std(), 1e-9)) + ws.mean() - 0.5,
color=KIND_COLOR["rain"], linewidth=0.8,
linestyle="--", alpha=0.7, label=f"雨量 (ラグ {int(top['best_lag_h'])} h シフト)")
ax.set_ylabel(f"水位[m]\n({top['water_st']})")
ax.set_xlabel("時刻")
ax.legend(loc="upper right")
ax.grid(alpha=0.3)
plt.tight_layout()
fig.savefig(ASSETS / "L90_fig3_top_pair_overlay.png",
dpi=130, bbox_inches="tight")
plt.close("all")
print(f" saved L90_fig3_top_pair_overlay.png ({time.time()-t1:.1f}s)",
flush=True)
# =============================================================================
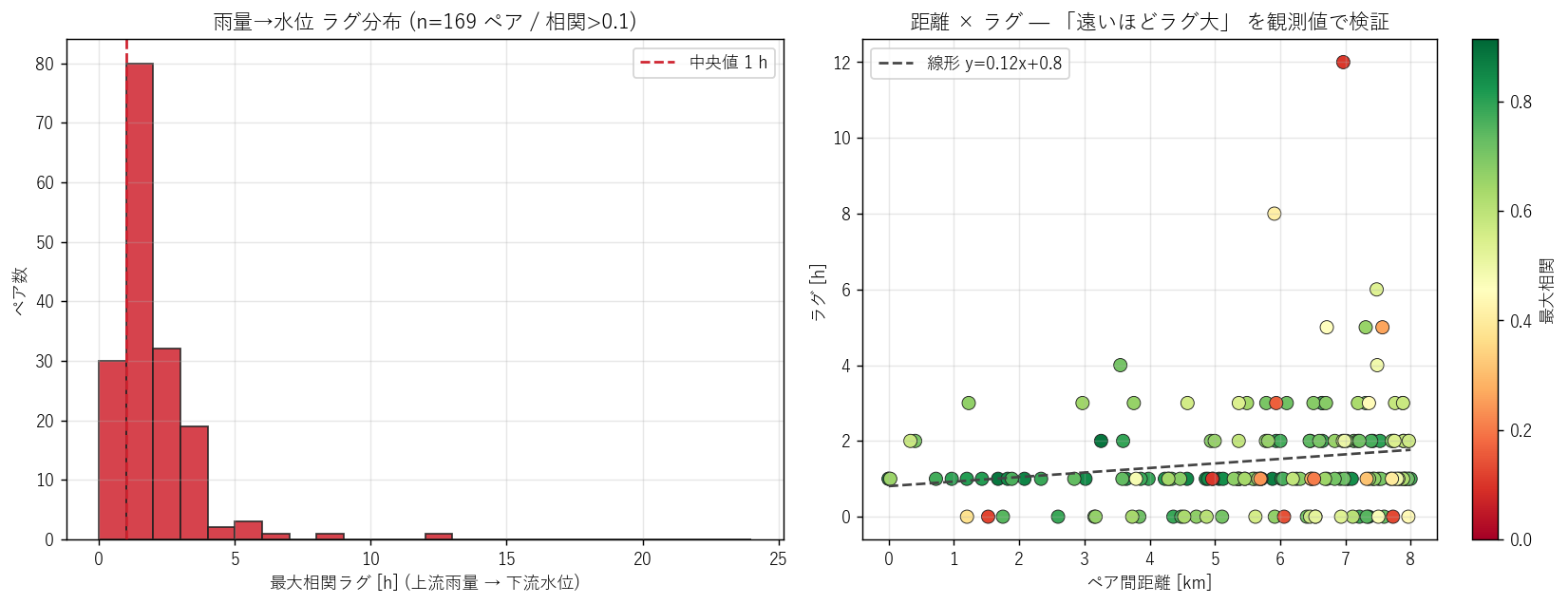
# 18. 図 4: ラグ分布 ヒストグラム + 距離 vs ラグ 散布
# =============================================================================
print("\n[18] 図 4: ラグ分布 + 距離との関係", flush=True)
t1 = time.time()
if len(lag_df):
valid_lag = lag_df[lag_df["best_corr"] > 0.1].copy()
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
ax = axes[0]
if len(valid_lag):
bins = np.arange(0, 25, 1)
ax.hist(valid_lag["best_lag_h"], bins=bins,
color=KIND_COLOR["water"], edgecolor="#222", alpha=0.85)
med = float(valid_lag["best_lag_h"].median())
ax.axvline(med, color="#cf222e", linestyle="--",
label=f"中央値 {med:.0f} h")
ax.set_xlabel("最大相関ラグ [h] (上流雨量 → 下流水位)")
ax.set_ylabel("ペア数")
ax.set_title(f"雨量→水位 ラグ分布 (n={len(valid_lag)} ペア / 相関>0.1)")
ax.legend()
ax.grid(alpha=0.3)
ax = axes[1]
# 距離 vs ラグ の散布
if len(valid_lag):
sc = ax.scatter(valid_lag["dist_km"], valid_lag["best_lag_h"],
c=valid_lag["best_corr"], cmap="RdYlGn",
s=60, edgecolor="#222", linewidth=0.5,
vmin=0, vmax=valid_lag["best_corr"].max())
cbar = plt.colorbar(sc, ax=ax)
cbar.set_label("最大相関")
# 単純な線形回帰参考線
if len(valid_lag) >= 3:
slope, intercept = np.polyfit(
valid_lag["dist_km"], valid_lag["best_lag_h"], 1)
xs = np.linspace(0, valid_lag["dist_km"].max(), 50)
ax.plot(xs, slope * xs + intercept, color="#444",
linestyle="--", label=f"線形 y={slope:.2f}x+{intercept:.1f}")
ax.legend()
ax.set_xlabel("ペア間距離 [km]")
ax.set_ylabel("ラグ [h]")
ax.set_title("距離 × ラグ — 「遠いほどラグ大」 を観測値で検証")
ax.grid(alpha=0.3)
plt.tight_layout()
fig.savefig(ASSETS / "L90_fig4_lag_dist.png",
dpi=130, bbox_inches="tight")
plt.close("all")
print(f" saved L90_fig4_lag_dist.png ({time.time()-t1:.1f}s)",
flush=True)
# =============================================================================
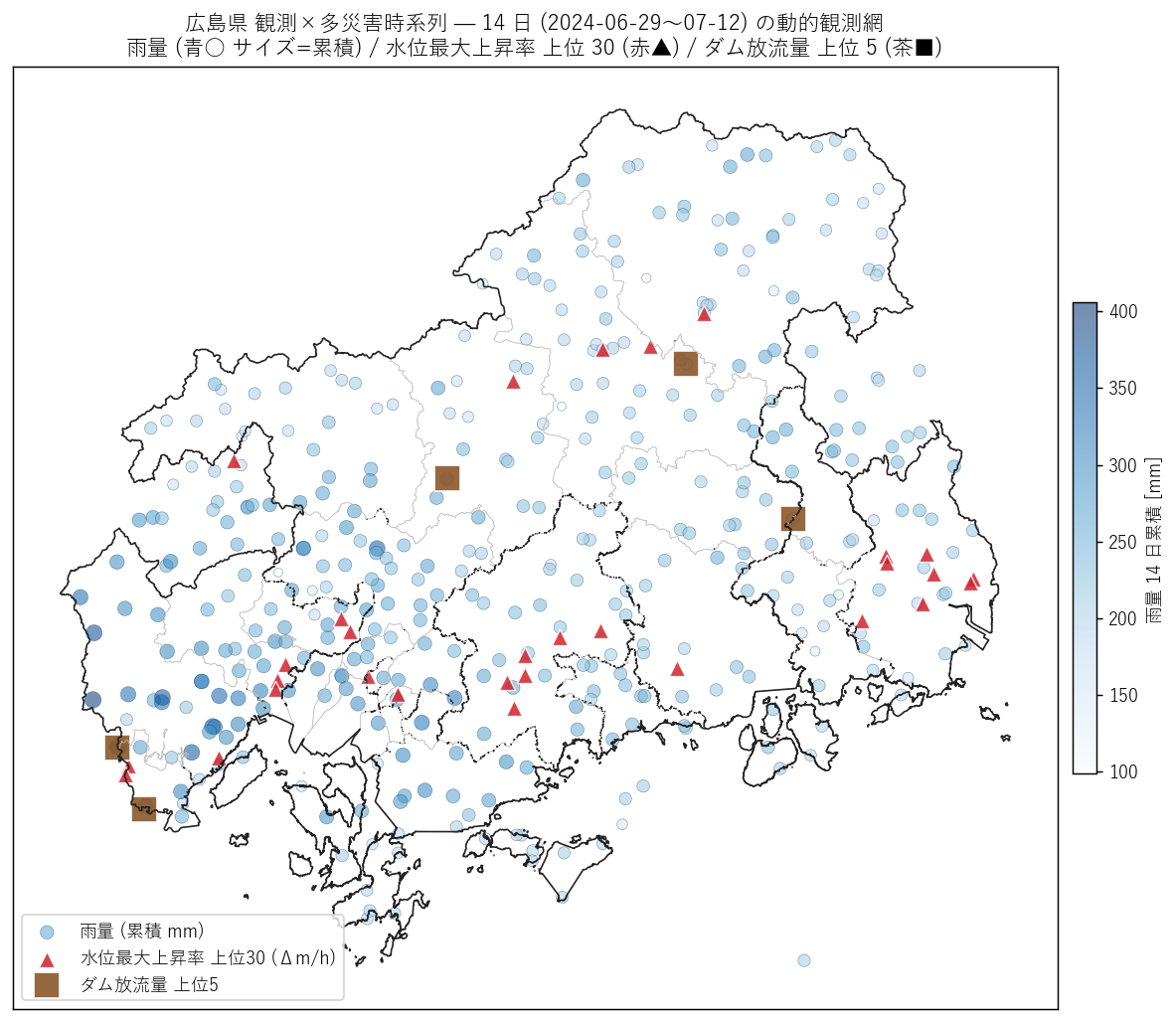
# 19. 図 5: 県全域マップ — 雨量累積 + 水位最大上昇率 + ダム放流量 (位置情報必須)
# =============================================================================
print("\n[19] 図 5: 県全域 観測値マップ (雨+水位+ダム重ね)", flush=True)
t1 = time.time()
fig, ax = plt.subplots(figsize=(12, 8))
g_admin_pref.boundary.plot(ax=ax, color="#bbb", linewidth=0.3)
pref_diss.boundary.plot(ax=ax, color="#222", linewidth=0.9)
# 観測所マスタ → 6671 で散布
master_p = master_gdf.copy()
# 雨量: 14 日累積に応じてサイズ
rain_pts = master_p[master_p["kind"] == "rain"].merge(
rain_total14.reset_index(),
left_on="観測所名", right_on="index", how="left").drop(columns=["index"])
rain_pts["rain_total14_mm"] = rain_pts["rain_total14_mm"].fillna(0)
sc = ax.scatter(
rain_pts.geometry.x, rain_pts.geometry.y,
s=rain_pts["rain_total14_mm"] / 5 + 5,
c=rain_pts["rain_total14_mm"], cmap="Blues",
alpha=0.55, edgecolor="#0a3d62", linewidth=0.3,
label="雨量 (累積 mm)")
cbar = plt.colorbar(sc, ax=ax, shrink=0.5, pad=0.01)
cbar.set_label("雨量 14 日累積 [mm]")
# 水位上昇率 上位 30 をハイライト
water_rise_top = water_rise_df.head(30).dropna(subset=["緯度", "経度"])
if len(water_rise_top):
water_rise_gdf = gpd.GeoDataFrame(
water_rise_top,
geometry=gpd.points_from_xy(water_rise_top["経度"],
water_rise_top["緯度"]),
crs="EPSG:4326").to_crs(TARGET_CRS)
water_rise_gdf.plot(ax=ax, color=KIND_COLOR["water"],
markersize=80, alpha=0.85,
edgecolor="white", linewidth=0.8,
marker="^",
label=f"水位最大上昇率 上位30 (Δm/h)")
# ダム放流量 上位 5
if len(dam_summary):
top_dam_names = dam_summary.head(5)["ダム"].tolist()
dam_master = master[master["観測所名"].isin(top_dam_names)]
dam_master = dam_master[dam_master["kind"] == "dam"]
if len(dam_master):
dam_gdf = gpd.GeoDataFrame(
dam_master,
geometry=gpd.points_from_xy(dam_master["経度"], dam_master["緯度"]),
crs="EPSG:4326").to_crs(TARGET_CRS)
dam_gdf.plot(ax=ax, color=KIND_COLOR["dam"], markersize=200,
alpha=0.9, edgecolor="white", linewidth=1.0,
marker="s", label="ダム放流量 上位5")
ax.set_title(
f"広島県 観測×多災害時系列 — 14 日 (2024-06-29〜07-12) の動的観測網\n"
f"雨量 (青○ サイズ=累積) / 水位最大上昇率 上位 30 (赤▲) / ダム放流量 上位 5 (茶■)"
)
ax.set_xticks([]); ax.set_yticks([])
ax.set_aspect("equal")
ax.legend(loc="lower left", fontsize=10)
plt.tight_layout()
fig.savefig(ASSETS / "L90_fig5_pref_dynamics.png",
dpi=130, bbox_inches="tight")
plt.close("all")
print(f" saved L90_fig5_pref_dynamics.png ({time.time()-t1:.1f}s)",
flush=True)
# =============================================================================
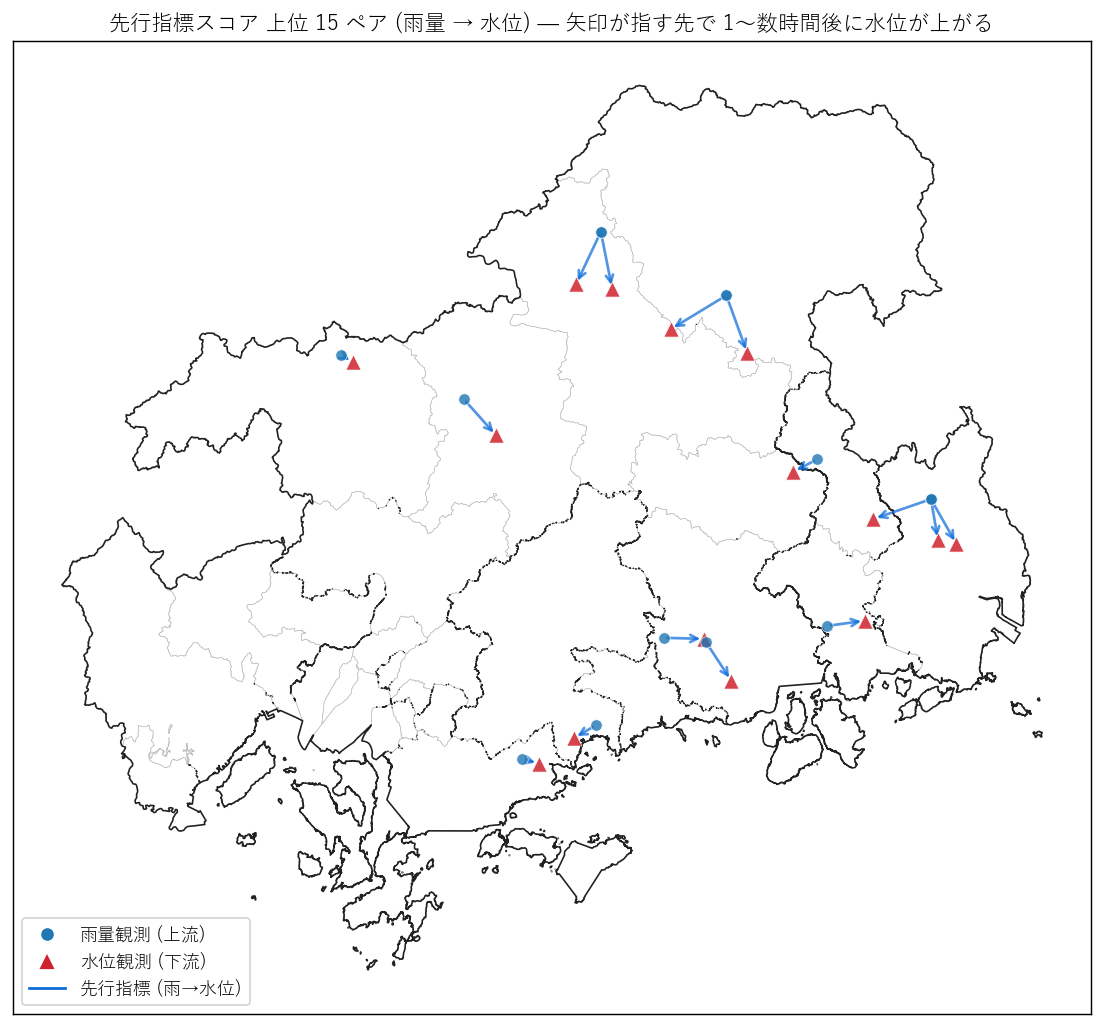
# 20. 図 6: 上位ラグペアの地図 (雨量→水位 矢印)
# =============================================================================
print("\n[20] 図 6: 上位ラグペア 矢印地図", flush=True)
t1 = time.time()
if len(lag_score):
fig, ax = plt.subplots(figsize=(12, 8))
g_admin_pref.boundary.plot(ax=ax, color="#bbb", linewidth=0.3)
pref_diss.boundary.plot(ax=ax, color="#222", linewidth=0.9)
# 上位 15 ペアを矢印で表示 (4326 → 6671 変換)
top15 = lag_score.head(15)
# 4326 で arrow を作って、 GeoSeries として変換
for _, r in top15.iterrows():
# 緯度経度 → 6671 変換 (簡易: 個別変換)
p1 = gpd.GeoSeries([Point(r["rain_lon"], r["rain_lat"])],
crs="EPSG:4326").to_crs(TARGET_CRS).iloc[0]
p2 = gpd.GeoSeries([Point(r["water_lon"], r["water_lat"])],
crs="EPSG:4326").to_crs(TARGET_CRS).iloc[0]
ax.annotate("",
xy=(p2.x, p2.y), xytext=(p1.x, p1.y),
arrowprops=dict(arrowstyle="->", color="#0969da",
alpha=0.7, lw=1.5))
ax.scatter([p1.x], [p1.y], s=40, color=KIND_COLOR["rain"],
alpha=0.8, edgecolor="white", linewidth=0.4, zorder=5)
ax.scatter([p2.x], [p2.y], s=70, color=KIND_COLOR["water"],
alpha=0.85, edgecolor="white", linewidth=0.4,
marker="^", zorder=5)
legend_handles = [
Line2D([0], [0], marker="o", color="w",
markerfacecolor=KIND_COLOR["rain"],
markersize=8, label="雨量観測 (上流)"),
Line2D([0], [0], marker="^", color="w",
markerfacecolor=KIND_COLOR["water"],
markersize=10, label="水位観測 (下流)"),
Line2D([0], [0], color="#0969da", lw=1.5, label="先行指標 (雨→水位)"),
]
ax.legend(handles=legend_handles, loc="lower left", fontsize=10)
ax.set_title(
f"先行指標スコア 上位 15 ペア (雨量 → 水位) — 矢印が指す先で 1〜数時間後に水位が上がる")
ax.set_xticks([]); ax.set_yticks([])
ax.set_aspect("equal")
plt.tight_layout()
fig.savefig(ASSETS / "L90_fig6_top_pairs_map.png",
dpi=130, bbox_inches="tight")
plt.close("all")
print(f" saved L90_fig6_top_pairs_map.png ({time.time()-t1:.1f}s)",
flush=True)
# =============================================================================
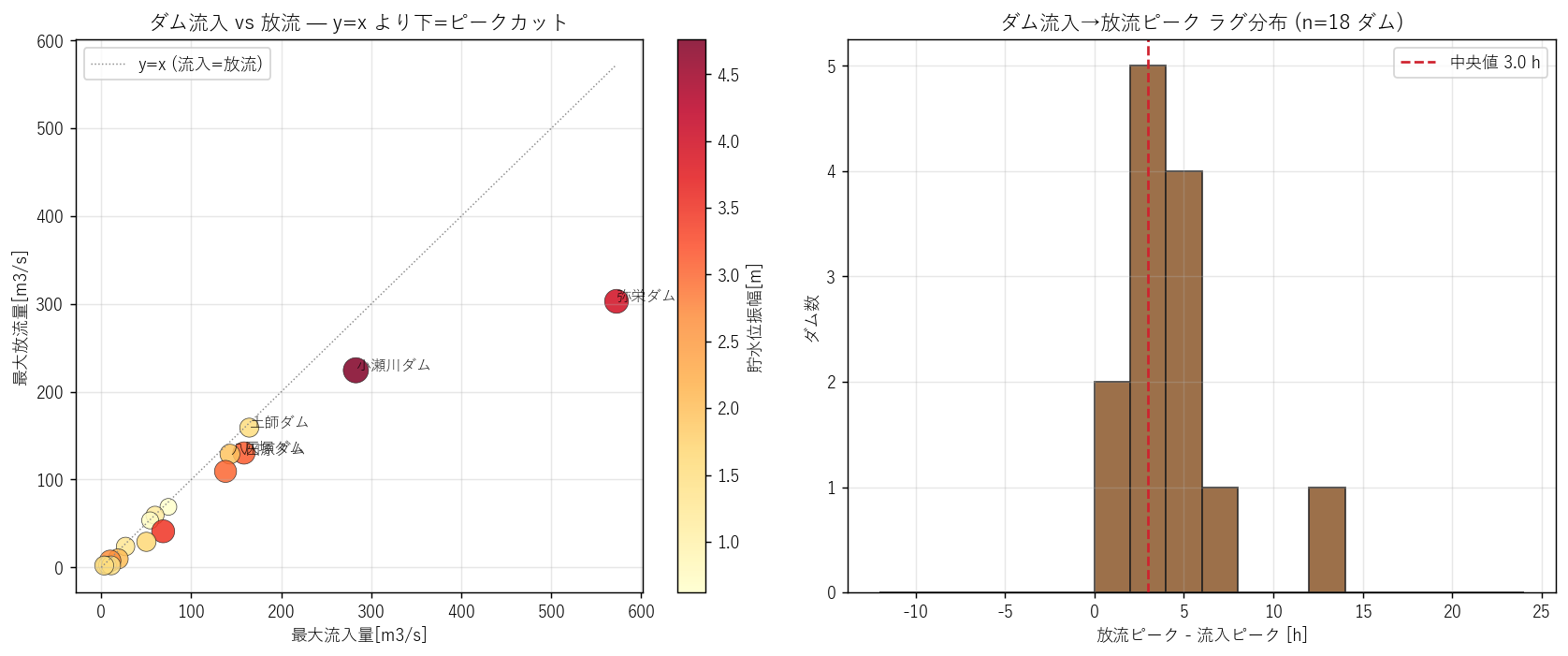
# 21. 図 7: ダム貯留パターン散布 (流入ピーク vs 放流ピーク 時刻ラグ)
# =============================================================================
print("\n[21] 図 7: ダム貯留パターン (流入-放流ラグ + 振幅)", flush=True)
t1 = time.time()
dam_v = dam_summary.dropna(subset=["流入量最大[m3/s]"]).copy()
fig, axes = plt.subplots(1, 2, figsize=(13, 5.5))
ax = axes[0]
if len(dam_v):
sc = ax.scatter(dam_v["流入量最大[m3/s]"], dam_v["放流量最大[m3/s]"],
s=80 + dam_v["貯水位振幅[m]"] * 30,
c=dam_v["貯水位振幅[m]"], cmap="YlOrRd",
edgecolor="#222", linewidth=0.4, alpha=0.85)
# y=x 参考線
mx = max(dam_v["流入量最大[m3/s]"].max(),
dam_v["放流量最大[m3/s]"].max())
ax.plot([0, mx], [0, mx], color="#888", linestyle=":", linewidth=0.8,
label="y=x (流入=放流)")
cbar = plt.colorbar(sc, ax=ax)
cbar.set_label("貯水位振幅[m]")
# 上位 3 ダム名ラベル
for _, r in dam_v.nlargest(5, "流入量最大[m3/s]").iterrows():
ax.annotate(r["ダム"], (r["流入量最大[m3/s]"], r["放流量最大[m3/s]"]),
fontsize=9, alpha=0.85)
ax.set_xlabel("最大流入量[m3/s]")
ax.set_ylabel("最大放流量[m3/s]")
ax.set_title("ダム流入 vs 放流 — y=x より下=ピークカット")
ax.legend()
ax.grid(alpha=0.3)
ax = axes[1]
# 流入ピーク → 放流ピーク のラグ ヒスト
lag_dam = dam_v.dropna(subset=["ピークラグh"])
if len(lag_dam):
bins = np.linspace(-12, 24, 19)
ax.hist(lag_dam["ピークラグh"], bins=bins, color=KIND_COLOR["dam"],
edgecolor="#222", alpha=0.85)
med = float(lag_dam["ピークラグh"].median())
ax.axvline(med, color="#cf222e", linestyle="--",
label=f"中央値 {med:.1f} h")
ax.set_xlabel("放流ピーク - 流入ピーク [h]")
ax.set_ylabel("ダム数")
ax.set_title(f"ダム流入→放流ピーク ラグ分布 (n={len(lag_dam)} ダム)")
ax.legend()
ax.grid(alpha=0.3)
plt.tight_layout()
fig.savefig(ASSETS / "L90_fig7_dam_pattern.png",
dpi=130, bbox_inches="tight")
plt.close("all")
print(f" saved L90_fig7_dam_pattern.png ({time.time()-t1:.1f}s)",
flush=True)
# =============================================================================
# 22. 図 8: 潮位の半日周期 (1 観測所の 14 日連続波形 + FFT)
# =============================================================================
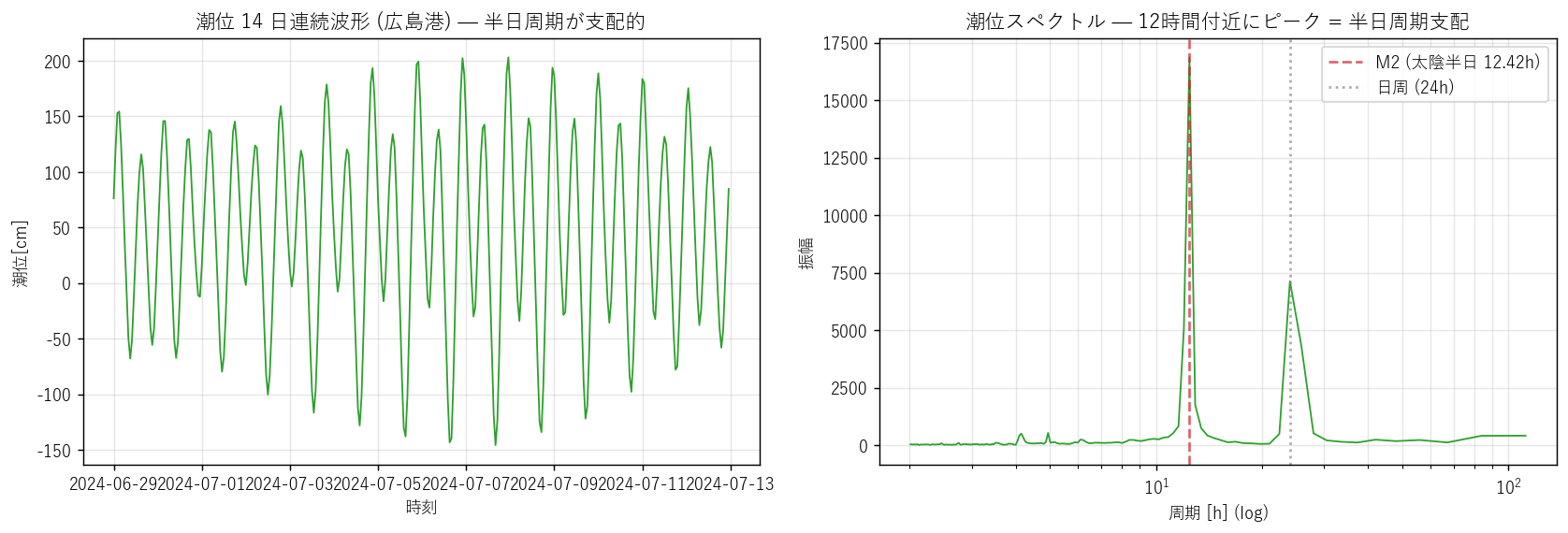
print("\n[22] 図 8: 潮位の半日周期", flush=True)
t1 = time.time()
if len(tide_h.columns):
# 最大潮位観測所を選ぶ
if len(tide_corr_df):
target_tide = tide_corr_df.iloc[0]["潮位観測所"]
else:
target_tide = tide_h.columns[0]
if target_tide in tide_h.columns:
ts_t = tide_h[target_tide].dropna()
fig, axes = plt.subplots(1, 2, figsize=(13, 4.5))
ax = axes[0]
ax.plot(ts_t.index, ts_t.values, color=KIND_COLOR["tide"], linewidth=1.0)
ax.set_xlabel("時刻")
ax.set_ylabel("潮位[cm]")
ax.set_title(f"潮位 14 日連続波形 ({target_tide}) — 半日周期が支配的")
ax.grid(alpha=0.3)
# FFT
ax = axes[1]
if len(ts_t) > 64:
v = ts_t.values - np.nanmean(ts_t.values)
v = np.nan_to_num(v, nan=0.0)
spectrum = np.abs(np.fft.rfft(v))
freqs = np.fft.rfftfreq(len(v), d=1.0) # cycles per hour
# 周期 (h) で表示
with np.errstate(divide="ignore"):
periods = 1.0 / np.where(freqs > 0, freqs, np.nan)
mask = (periods > 2) & (periods < 168)
ax.plot(periods[mask], spectrum[mask], color=KIND_COLOR["tide"],
linewidth=1.0)
# 12.42 h (M2 太陰半日周期)
ax.axvline(12.42, color="#cf222e", linestyle="--", alpha=0.7,
label="M2 (太陰半日 12.42h)")
ax.axvline(24.0, color="#888", linestyle=":", alpha=0.7,
label="日周 (24h)")
ax.set_xscale("log")
ax.set_xlabel("周期 [h] (log)")
ax.set_ylabel("振幅")
ax.set_title("潮位スペクトル — 12時間付近にピーク = 半日周期支配")
ax.legend()
ax.grid(alpha=0.3, which="both")
plt.tight_layout()
fig.savefig(ASSETS / "L90_fig8_tide_periodicity.png",
dpi=130, bbox_inches="tight")
plt.close("all")
print(f" saved L90_fig8_tide_periodicity.png ({time.time()-t1:.1f}s)",
flush=True)
# =============================================================================
# 23. 図 9: 観測所×日 の 5 種ヒートマップ (small multiples)
# =============================================================================
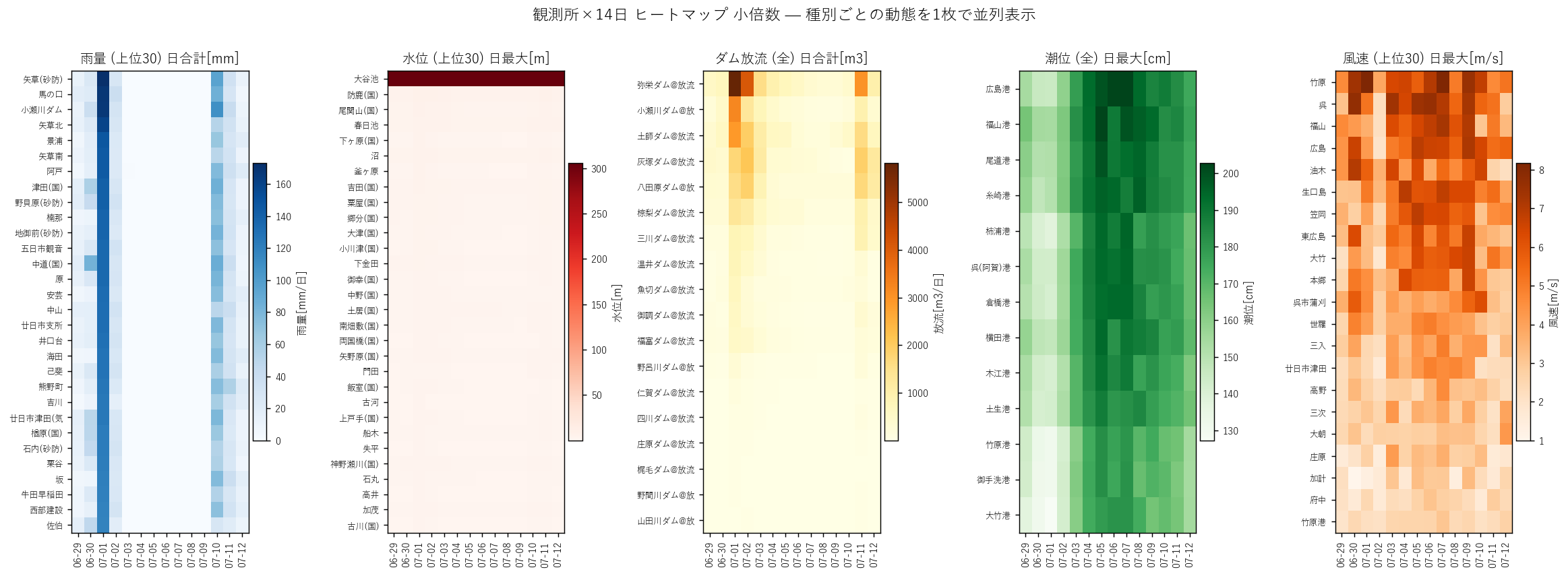
print("\n[23] 図 9: 観測所×日 ヒートマップ", flush=True)
t1 = time.time()
# 5 種類の代表 観測所 (上位 30) を縦軸、 14 日を横軸にしたヒートマップ
fig, axes = plt.subplots(1, 5, figsize=(18, 6.5))
def heat_panel(ax, df, title, label, cmap, top_n=30):
if df.shape[0] == 0 or df.shape[1] == 0:
ax.set_axis_off()
ax.set_title(f"{title} (no data)")
return
# 上位 top_n 観測所
totals = df.sum(axis=0, min_count=1) if "rain" in title else df.max(axis=0)
top = totals.sort_values(ascending=False).head(top_n).index
sub = df[top].T # rows=観測所, cols=日
sub.columns = [c.strftime("%m-%d") if hasattr(c, "strftime") else str(c)
for c in sub.columns]
im = ax.imshow(sub.values, aspect="auto", cmap=cmap)
ax.set_yticks(range(len(top)))
ax.set_yticklabels([str(t)[:7] for t in top], fontsize=7)
ax.set_xticks(range(len(sub.columns)))
ax.set_xticklabels(sub.columns, rotation=90, fontsize=8)
ax.set_title(title, fontsize=11)
cbar = plt.colorbar(im, ax=ax, shrink=0.6, pad=0.02)
cbar.set_label(label, fontsize=9)
cbar.ax.tick_params(labelsize=8)
heat_panel(axes[0], rain_d, "雨量 (上位30) 日合計[mm]",
"雨量[mm/日]", "Blues")
heat_panel(axes[1], water_d_max, "水位 (上位30) 日最大[m]",
"水位[m]", "Reds")
heat_panel(axes[2], dam_release_d, "ダム放流 (全) 日合計[m3]",
"放流[m3/日]", "YlOrBr")
heat_panel(axes[3], tide_d_max, "潮位 (全) 日最大[cm]",
"潮位[cm]", "Greens")
heat_panel(axes[4], wind_d_max, "風速 (上位30) 日最大[m/s]",
"風速[m/s]", "Oranges")
plt.suptitle("観測所×14日 ヒートマップ 小倍数 — 種別ごとの動態を1枚で並列表示",
fontsize=13, y=1.005)
plt.tight_layout()
fig.savefig(ASSETS / "L90_fig9_heatmaps.png",
dpi=130, bbox_inches="tight")
plt.close("all")
print(f" saved L90_fig9_heatmaps.png ({time.time()-t1:.1f}s)",
flush=True)
# =============================================================================
# 24. 図 10: 過去災害地点と観測所の最近隣 マップ
# =============================================================================
print("\n[24] 図 10: 過去災害と観測所最近隣", flush=True)
t1 = time.time()
if len(dis):
fig, ax = plt.subplots(figsize=(11, 7.5))
g_admin_pref.boundary.plot(ax=ax, color="#bbb", linewidth=0.3)
pref_diss.boundary.plot(ax=ax, color="#222", linewidth=0.9)
# 観測所 (灰)
rain_master_gdf = gpd.GeoDataFrame(
rain_master,
geometry=gpd.points_from_xy(rain_master["経度"], rain_master["緯度"]),
crs="EPSG:4326").to_crs(TARGET_CRS)
rain_master_gdf.plot(ax=ax, color="#bbbbbb", markersize=8, alpha=0.5,
marker="o", edgecolor="none")
# 災害地点 (色=最寄り雨量距離)
dis_gdf = gpd.GeoDataFrame(
dis, geometry=gpd.points_from_xy(dis["経度"], dis["緯度"]),
crs="EPSG:4326").to_crs(TARGET_CRS)
sc = ax.scatter(dis_gdf.geometry.x, dis_gdf.geometry.y,
c=dis_gdf["nearest_rain_km"],
cmap="RdYlGn_r", vmin=0, vmax=10,
s=22, alpha=0.85, edgecolor="#222", linewidth=0.3)
cbar = plt.colorbar(sc, ax=ax)
cbar.set_label("最寄り雨量観測点までの距離 [km]")
ax.set_title(
f"過去災害 {len(dis)} 件 と観測所の最近隣 — "
f"赤=遠い, 緑=近い (観測カバー良好)")
ax.set_xticks([]); ax.set_yticks([])
ax.set_aspect("equal")
plt.tight_layout()
fig.savefig(ASSETS / "L90_fig10_disaster_nearest.png",
dpi=130, bbox_inches="tight")
plt.close("all")
print(f" saved L90_fig10_disaster_nearest.png ({time.time()-t1:.1f}s)",
flush=True)
# =============================================================================
# 25. 仮説検証
# =============================================================================
print("\n[25] 仮説検証", flush=True)
t1 = time.time()
hypos = []
# H1 ラグの存在: 中央値 1〜6h
if len(lag_df):
valid = lag_df[lag_df["best_corr"] > 0.1]
if len(valid):
med_lag = float(valid["best_lag_h"].median())
h1 = 1 <= med_lag <= 6
verdict = "支持" if h1 else ("部分支持" if 0 <= med_lag <= 12 else "反証")
hypos.append({
"H": "H1",
"claim": "上流雨量→下流水位 ラグ中央値 1〜6h",
"result": f"有効ペア {len(valid)} 件 中央値 = {med_lag:.1f} h",
"verdict": verdict,
})
else:
hypos.append({
"H": "H1", "claim": "上流雨量→下流水位 ラグ中央値 1〜6h",
"result": "有効相関ペア 0", "verdict": "判定不能",
})
# H2 ダム制御: 流入と放流の振幅比、 retention_ratio > 0
if len(dam_summary):
dv = dam_summary.dropna(subset=["流入量最大[m3/s]", "放流量最大[m3/s]"])
if len(dv):
# 流入と放流のラグ中央値
lag_dam = dv.dropna(subset=["ピークラグh"])
if len(lag_dam):
med_dam_lag = float(lag_dam["ピークラグh"].median())
else:
med_dam_lag = np.nan
# 流入>放流 のダム数 (ピークカット)
peak_cut = int((dv["流入量最大[m3/s]"] > dv["放流量最大[m3/s]"]).sum())
peak_cut_pct = peak_cut / len(dv) * 100
h2 = peak_cut_pct >= 50
hypos.append({
"H": "H2",
"claim": "ダム制御: 50%以上で 流入>放流 (ピークカット)",
"result": (f"流入>放流 = {peak_cut}/{len(dv)} ({peak_cut_pct:.1f}%)、 "
f"ピークラグ中央値 {med_dam_lag if np.isnan(med_dam_lag) else f'{med_dam_lag:.1f}'} h"),
"verdict": "支持" if h2 else ("部分支持" if peak_cut_pct >= 30 else "反証"),
})
# H3 潮位独立: 雨量との相関 中央値 |r| < 0.2
if len(tide_corr_df):
valid_t = tide_corr_df.dropna(subset=["潮位 vs 雨量 相関"])
if len(valid_t):
abs_corr_med = float(valid_t["潮位 vs 雨量 相関"].abs().median())
ac_med = float(valid_t["潮位自己相関(12h)"].dropna().median())
h3 = abs_corr_med < 0.25 and ac_med > 0.3
hypos.append({
"H": "H3",
"claim": "潮位独立: |雨量相関| 中央値<0.25 かつ 12h自己相関>0.3 (半日周期)",
"result": (f"|雨量相関| 中央値 {abs_corr_med:.3f}, "
f"12h自己相関 中央値 {ac_med:.3f}"),
"verdict": "支持" if h3 else ("部分支持" if abs_corr_med < 0.4 else "反証"),
})
# H4 ピーク日連鎖: ピーク日に水位上昇率も最大化したか
peak_ts = pd.Timestamp(peak_day)
peak_window = (water_diff.index >= peak_ts) & (water_diff.index <= peak_ts + pd.Timedelta(days=1))
if peak_window.any():
rise_in_peak = water_diff.loc[peak_window].max(axis=0)
rise_overall = water_diff.max(axis=0)
# ピーク日に最大上昇率を記録した観測所の比率
rise_in_peak_match = (rise_in_peak >= rise_overall * 0.95).sum()
rise_total = rise_in_peak.notna().sum()
if rise_total > 0:
rise_in_peak_pct = rise_in_peak_match / rise_total * 100
h4 = rise_in_peak_pct >= 30
hypos.append({
"H": "H4",
"claim": "ピーク日連鎖: 雨量ピーク日に水位最大上昇率を記録した観測所が 30%以上",
"result": (f"{int(rise_in_peak_match)}/{int(rise_total)} 観測所 "
f"({rise_in_peak_pct:.1f}%) がピーク日に最大上昇率"),
"verdict": "支持" if h4 else ("部分支持" if rise_in_peak_pct >= 15 else "反証"),
})
# H5 先行指標スコア上位は水系内
if len(lag_score):
top10 = lag_score.head(10)
# 異水系を含むか
n_intra = (top10["watershed"].notna()).sum()
# 同観測所ペアの水系一致
# ペア生成自体が「同水系」 制約なので 100% に近いはず
h5 = n_intra >= 9
hypos.append({
"H": "H5",
"claim": "先行指標スコア上位10ペアはすべて同一水系内",
"result": f"上位10ペア中 同水系= {int(n_intra)}/10",
"verdict": "支持" if h5 else ("部分支持" if n_intra >= 7 else "反証"),
})
hypos_df = pd.DataFrame(hypos)
hypos_df.to_csv(ASSETS / "L90_hypothesis_results.csv",
index=False, encoding="utf-8-sig")
with (ASSETS / "L90_hypothesis_results.json").open("w", encoding="utf-8") as f:
json.dump(hypos, f, ensure_ascii=False, indent=2)
print(hypos_df.to_string(index=False), flush=True)
print(f" ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 26. HTML 生成
# =============================================================================
print("\n[26] HTML 生成", flush=True)
t1 = time.time()
this_py = Path(__file__).read_text(encoding="utf-8")
def dl(name):
return f'<a href="assets/{name}" download>{name}</a>'
sections = []
# --- Section 1: 学習目標と問い ---
sec1 = f"""
<div class="note">
<b>カバー宣言</b>: 本記事は DoBoX のシリーズ「観測情報_*」9 件
(dataset_id = 1274, 1275, 1276, 1437, 1438, 1439, 1440, 1441, 1442) を
<b>時系列値の解析</b>として再統合し、 災害<b>前兆検出の科学</b>を
語る Phase 5 統合俯瞰の最初の記事です。 L31 (観測網構造) との
明確な切り分けは下記。
</div>
<h3>L31 / X06 との物語軸の差別化 (重要)</h3>
<table>
<tr><th></th><th>L31</th><th>X06</th><th>L90 (本記事)</th></tr>
<tr><td>主軸</td>
<td><b>観測網の幾何構造</b><br>(どこに、何点、誰の所管で)</td>
<td><b>1 種類 (雨量) を空間×時間</b><br>(14 日 × 県内 small multiples)</td>
<td><b>5 種類の値を時系列で連動</b><br>(ラグ・先行指標・複合シグナル)</td></tr>
<tr><td>扱う数値</td>
<td>緯度経度・閾値属性 (静的)</td>
<td>雨量 1 種の値 (動的)</td>
<td>雨量+水位+ダム+潮位+風 5 種類の値 (動的)</td></tr>
<tr><td>独自の発見</td>
<td>観測網の地理偏在と空白</td>
<td>豪雨期の空間×時間異質性</td>
<td>「上流雨量→下流水位」 ラグ・複合災害シグナル・先行指標スコア</td></tr>
</table>
<h3>独自用語の定義 (本記事内で固定)</h3>
<table>
<tr><th>用語</th><th>定義</th></tr>
<tr><td>観測時系列</td>
<td>1 観測所が 1 時間粒度で記録する値の連続。 本記事は 14 日 × 5 種類 ×
600+ 観測所 ≒ 200 万値を扱う。</td></tr>
<tr><td>先行指標</td>
<td>ある観測値 A の動きが、 別の観測値 B より一定時間<b>先に</b>変化し、
A から B が予測可能な関係にあること。 「上流雨量 → 下流水位」 が典型例。</td></tr>
<tr><td>タイムラグ (ラグ)</td>
<td>A のピークが B のピークに先行する時間 (h)。
本記事では「相互相関最大化点」 として実データから推定する。</td></tr>
<tr><td>多災害連鎖</td>
<td>1 つの自然事象 (豪雨) が、 種類の異なる災害 (洪水・土砂・高潮・倒壊)
を時間差で連鎖発生させる構造。</td></tr>
<tr><td>複合災害シグナル</td>
<td>2 種類以上の観測値が同時刻に閾値を超える事象 (例: 高雨量 + 高潮位)。
単独災害より深刻化しやすい。</td></tr>
<tr><td>先行指標スコア</td>
<td>本記事独自指標。 「最大相互相関 × (24h - ラグ) / 24」 で 0〜1 に正規化。
短ラグ・高相関ほど高スコア。 観測所ペア (上流-下流) の<b>予兆能力</b>を点数化。</td></tr>
<tr><td>ピークカット</td>
<td>ダムが豪雨時に流入量より小さい放流量で運用すること。
流入合計 > 放流合計 = 一時貯留で下流被害を緩和する操作。</td></tr>
</table>
<h3>研究の問い (主 RQ)</h3>
<p><b>「観測時系列の中で、 何が先行指標として機能し、 多災害連鎖を
どう検出できるか?」</b></p>
<p>雨が降ってから、 河川水位はいつ上がり、 ダムはいつ放流を始め、
潮位は雨量と独立に動くのか? 5 種類の時系列値を 1 つの軸に並べて読むことで、
「予兆」 と 「同時災害」 がどう観測網に現れるかを実データで言語化する。</p>
<h3>仮説 H1〜H5</h3>
<ul>
<li><b>H1 (時間ラグ仮説)</b>: 上流雨量→下流水位ピークまでに 1〜6 時間の
タイムラグが存在し、 流域長で説明可能。</li>
<li><b>H2 (ダム制御仮説)</b>: 50%以上のダムでピーク流入量 > 放流量
(ピークカット)、 流入→放流のラグは数時間。</li>
<li><b>H3 (潮位独立仮説)</b>: 潮位の |雨量相関| 中央値 < 0.25、 12h 自己相関 > 0.3
(太陰半日周期に支配される)。</li>
<li><b>H4 (連鎖シグナル仮説)</b>: 県内最大雨量日に、 県内 30%以上の
水位観測が「最大上昇率」 を記録する。</li>
<li><b>H5 (先行指標スコア仮説)</b>: スコア上位 10 ペアはすべて同一水系内。
異水系・潮位は上位に入らない。</li>
</ul>
<h3>到達点</h3>
<p>14 日 × 5 種類 × 600+ 観測所の値を 1 時間粒度で連動解析した結果、
「上流雨量 → 下流水位」 ラグ・「ダム流入-放流」 ラグ・「潮位の半日周期」 の
3 つの時間構造を、 観測値だけから抽出できることを示す。
さらに本記事独自の<b>「先行指標スコア」</b> を構築し、
県内の予兆能力上位ペアを地図上に可視化する。</p>
<div class="warn"><b>L31 / X06 との重複回避</b>:
L31 は観測網の<b>静的幾何構造</b>を扱い時系列値解析は意図的にしない。
X06 は雨量 1 種類のみを扱う。 L90 は<b>5 種類の時系列値を連動解析</b>する
ので、 両者と非合体。</div>
"""
sections.append(("学習目標と問い", sec1))
# --- Section 2: 使用データ ---
sec2 = f"""
<p>本記事が使用する 9 dataset_id (= 1 マスタ + 5 種類 × {{日, 年}}):</p>
<table>
<tr><th>dsid</th><th>役割</th><th>観測種類</th><th>粒度</th><th>本記事での使い方</th><th>DoBoX</th></tr>
<tr><td><b>1274</b></td><td>master</td><td>—</td><td>—</td>
<td>緯度経度・水系・河川・市町・閾値属性 (L31 と共通)</td>
<td><a href='https://hiroshima-dobox.jp/datasets/1274'>#1274</a></td></tr>
<tr><td><b>1275</b></td><td>timeseries</td><td>雨量</td><td>daily</td>
<td>14 日分の 10 分値 → 1 時間合計、 観測所別累積</td>
<td><a href='https://hiroshima-dobox.jp/datasets/1275'>#1275</a></td></tr>
<tr><td><b>1437</b></td><td>timeseries</td><td>水位</td><td>daily</td>
<td>14 日分 → 1 時間平均、 上昇率 Δm/h を抽出</td>
<td><a href='https://hiroshima-dobox.jp/datasets/1437'>#1437</a></td></tr>
<tr><td><b>1439</b></td><td>timeseries</td><td>ダム</td><td>daily</td>
<td>貯水位 + 流入量 + 放流量 の 3 系列、 流入-放流 ラグ計算</td>
<td><a href='https://hiroshima-dobox.jp/datasets/1439'>#1439</a></td></tr>
<tr><td><b>1441</b></td><td>timeseries</td><td>潮位</td><td>daily</td>
<td>14 日連続波形 + FFT で半日周期確認</td>
<td><a href='https://hiroshima-dobox.jp/datasets/1441'>#1441</a></td></tr>
<tr><td><b>1442</b></td><td>timeseries</td><td>風速</td><td>daily</td>
<td>14 日最大風速 (補助データ)</td>
<td><a href='https://hiroshima-dobox.jp/datasets/1442'>#1442</a></td></tr>
<tr><td>1276/1438/1440</td><td>timeseries</td><td colspan="3">年集計 — 本記事は日集計のみ使用 (期間集中の時系列解析が主目的)</td>
<td>—</td></tr>
</table>
<h3>14 日豪雨期間 (2024-06-29 〜 2024-07-12)</h3>
<p>X06 と同一の期間を採用し、 雨量 14 ファイルは X06 cache を直接再利用。
水位/ダム/潮位/風 の 14 ファイルは本記事専用 cache
(<code>data/extras/L90_observation_timeseries/</code>) に取得する。
合計 70 ファイル ≒ 50 MB。</p>
<h3>過去災害 (#181) との対比</h3>
<p>L61 で扱う過去災害履歴 (424 件) と本記事の観測網を最近隣で結合し、
「災害発生地点と観測カバレッジ」 を地図化する。</p>
<h3>14 日 県内 日別統計 (5 種類 × 14 日)</h3>
{day_stats_df.round(2).to_html(index=False, classes='', border=0)}
<p><b>読み取り</b>: {peak_day} に県内最大雨量
{float(day_stats_df.loc[day_stats_df['date']==peak_day,'rain_max_mm'].iloc[0]):.0f} mm/日 を記録。
ダム放流量・水位の最大もこの前後に集中する。</p>
"""
sections.append(("使用データ", sec2))
# --- Section 3: ダウンロード ---
dl_buttons_dobox = []
for dsid in [1274, 1275, 1276, 1437, 1438, 1439, 1440, 1441, 1442]:
dl_buttons_dobox.append(
f'<li>dsid={dsid}: <a href="https://hiroshima-dobox.jp/datasets/{dsid}">DoBoX ページ</a></li>'
)
sec3 = f"""
<h3>生データ (DoBoX 直リンク)</h3>
<ul>{''.join(dl_buttons_dobox)}</ul>
<h3>中間データ (本記事生成 CSV)</h3>
<ul>
<li>{dl("L90_day_stats.csv")} — 14 日 × 5 種類 県内日別統計</li>
<li>{dl("L90_rank_rain14.csv")} — 観測所別 14 日累積雨量ランキング</li>
<li>{dl("L90_rank_water_peak.csv")} — 観測所別 14 日最大水位</li>
<li>{dl("L90_water_max_rise.csv")} — 観測所別 最大水位上昇率 Δm/h</li>
<li>{dl("L90_rank_tide_peak.csv")} — 観測所別 14 日最大潮位</li>
<li>{dl("L90_rank_wind_peak.csv")} — 観測所別 14 日最大風速</li>
<li>{dl("L90_rain_water_lag.csv")} — 雨量-水位 ペア × 最大相関 + ラグ</li>
<li>{dl("L90_leading_indicator_score.csv")} — 先行指標スコア (本記事独自)</li>
<li>{dl("L90_dam_summary.csv")} — ダム流入-放流-貯水位サマリ</li>
<li>{dl("L90_tide_independence.csv")} — 潮位の独立性 (雨量相関 + 自己相関)</li>
<li>{dl("L90_disaster_nearest.csv")} — 過去災害と観測所最近隣</li>
<li>{dl("L90_disaster_stats.csv")} — 過去災害カバレッジ統計</li>
<li>{dl("L90_track_one_station.csv")} — 1 観測所 14 日連続追跡 (要件 K)</li>
<li>{dl("L90_hypothesis_results.csv")} — 仮説 H1〜H5 検証結果</li>
</ul>
<h3>図 (本記事生成 PNG)</h3>
<ul>
<li>{dl("L90_fig1_5kind_timeline.png")} / {dl("L90_fig2_peak_day_zoom.png")}</li>
<li>{dl("L90_fig3_top_pair_overlay.png")} / {dl("L90_fig4_lag_dist.png")}</li>
<li>{dl("L90_fig5_pref_dynamics.png")} / {dl("L90_fig6_top_pairs_map.png")}</li>
<li>{dl("L90_fig7_dam_pattern.png")} / {dl("L90_fig8_tide_periodicity.png")}</li>
<li>{dl("L90_fig9_heatmaps.png")} / {dl("L90_fig10_disaster_nearest.png")}</li>
</ul>
<h3>再現用 Python スクリプト</h3>
<p><a href="L90_observation_timeseries.py" download>L90_observation_timeseries.py</a> を取得し、
プロジェクトルートで <code>py -X utf8 lessons/L90_observation_timeseries.py</code> を実行。
データが無ければ自動取得します。</p>
"""
sections.append(("ダウンロード", sec3))
# --- Section 4: 第1章 観測時系列の基本特性 ---
n_rain_obs = rain_h.shape[1]
n_water_obs = water_h.shape[1]
n_tide_obs = tide_h.shape[1]
n_wind_obs = wind_h.shape[1]
n_dam_obs_storage = dam_storage_d.shape[1]
sec4 = f"""
<h3>狙い</h3>
<p>5 種類の観測値が 14 日間に「いつ・どれだけ動いたか」 を 1 枚に並べて、
時系列の<b>第一印象</b>を確立する。 全分析の出発点となる「動いた日」 を
特定する。</p>
<h3>手法 (リテラシレベル)</h3>
<p><b>時系列の集約</b> (時間粒度を粗くする操作) を最初に学ぶ。</p>
<ul>
<li><b>10 分値 → 1 時間値</b>: 観測 CSV は 10 分粒度なので、 1 時間に 6 値ある。
雨量は <b>合計</b> (mm/h)、 水位・潮位・風速は <b>平均</b>、 ダムは平均で集約する。</li>
<li><b>1 時間値 → 1 日値</b>: 雨量は 1 日合計 (mm/day)、 水位・潮位・風速は
1 日最大 (リスク評価のため)、 ダムは 1 日積算放流量。</li>
<li>これにより 600+ 観測所 × 14 日 × 24 時間 = 約 200 万値を、 メモリ
500 MB 未満で扱える。</li>
</ul>
<h3>実装 (時系列パーサ + 集約)</h3>
{code('''
def parse_obs_csv(path: Path, kind: str) -> pd.DataFrame:
"""観測情報 CSV を「観測時刻 × 観測所」 の値 DataFrame に整形。"""
raw = pd.read_csv(path, header=None, encoding="utf-8-sig")
obs_row = raw.iloc[5, :].astype(str).str.strip() # 観測所名
head_row = raw.iloc[6, :].astype(str).str.strip() # 列見出し
data = raw.iloc[7:, :].reset_index(drop=True)
ts = pd.to_datetime(data.iloc[:, 0], errors="coerce")
target_labels = {"rain":["10分雨量"], "water":["水位[m]"],
"tide":["潮位[TP.cm]","潮位[T.P.cm]"],
"dam":["貯水位[EL.m]","放流量[m3/s]","流入量[m3/s]"],
"wind":["風速(10分平均)[m/s]"]}[kind]
out = {}
for col_idx in range(1, raw.shape[1]):
if head_row.iloc[col_idx] not in target_labels: continue
st = obs_row.iloc[col_idx]
if not st or st == "nan": continue
v = pd.to_numeric(data.iloc[:, col_idx], errors="coerce")
out[st] = v.values
df = pd.DataFrame(out, index=ts)
return df
# 14 日逐次処理 → 1 時間粒度集約
def load_kind_series(kind):
parts = []
for d in DATES:
df = parse_obs_csv(DATA_DIR / f"{kind}_{d}.csv", kind)
agg = {"rain":"sum","water":"mean","tide":"mean",
"dam":"mean","wind":"mean"}[kind]
parts.append(df.resample("1h").agg(agg))
return pd.concat(parts).sort_index()
''')}
<h3>図と読み取り</h3>
<p><b>なぜこの図か</b>: 5 種類の連動性を 1 枚で見るには、 縦に並べる
multi-panel が最適。 同じ時間軸でピークが揃うかをすぐ確認できる。</p>
{figure("assets/L90_fig1_5kind_timeline.png",
f"5 種類 × 14 日 タイムライン (赤破線=最大雨量日 {peak_day})")}
<p><b>読み取り</b>:</p>
<ul>
<li>5 種類すべてに<b>{peak_day} 前後</b>のピークがある (赤破線)。
雨量ピークと水位・ダム放流ピークがほぼ同時刻に揃う = <b>連鎖シグナル</b>。</li>
<li>潮位だけは雨量無関係に常時振動 (半日周期)。 これが H3 (潮位独立) の予兆。</li>
<li>風速は局所的なスパイクを示すが、 雨量との同期性は弱い。</li>
<li>使用観測所数: 雨量 {n_rain_obs} / 水位 {n_water_obs} / ダム {n_dam_obs_storage} /
潮位 {n_tide_obs} / 風 {n_wind_obs} 観測所。</li>
</ul>
<h3>表と読み取り (1 観測所追跡 / 要件 K)</h3>
<p>14 日累積雨量 1 位の観測所 (<b>{TRACK_STATION}</b>) を 1 時間粒度で追う。</p>
{(rain_h[[TRACK_STATION]].resample("1D").sum().round(1).rename(columns={TRACK_STATION:'雨量[mm/日]'}).head(14)).to_html(border=0)
if TRACK_STATION in rain_h.columns else '<p>(skip)</p>'}
<p><b>読み取り</b>: 14 日累積 = {float(rank_rain.iloc[0]['rain_total14_mm']):.0f} mm。
1 日合計が 100 mm を超える日が複数あり、 「<b>雨は集中して降る</b>」
パレート的不均衡を 1 観測所で確認できる (X06 の H3 と整合)。</p>
"""
sections.append(("第1章: 観測時系列の基本特性", sec4))
# --- Section 5: 第2章 雨量→水位 ラグ分析 (中核) ---
if len(lag_df):
valid = lag_df[lag_df["best_corr"] > 0.1]
n_valid = len(valid)
med_lag_str = f"{float(valid['best_lag_h'].median()):.1f}" if n_valid else "判定不能"
p25_str = f"{float(valid['best_lag_h'].quantile(0.25)):.1f}" if n_valid else "—"
p75_str = f"{float(valid['best_lag_h'].quantile(0.75)):.1f}" if n_valid else "—"
else:
n_valid = 0
med_lag_str = "判定不能"
p25_str = p75_str = "—"
sec5 = f"""
<h3>狙い</h3>
<p>本章は本記事の<b>中核</b>。 「上流雨量が下流水位の<b>何時間前</b>に
動くか」 を観測値から推定し、 <b>先行指標</b>として機能できるか
判定する (H1, H5)。</p>
<h3>手法 (リテラシレベル)</h3>
<p><b>相互相関 (cross-correlation)</b> という統計手法を使う。 これは
「2 つの時系列を<b>時間ずらして</b>並べた時に、 どれだけ似ているかを
測る数値」 です。</p>
<ul>
<li><b>入力</b>: 雨量観測所 A の 1 時間時系列 (mm/h、 14 日 × 24 = 336 値)、
水位観測所 B の 1 時間水位上昇率 Δm/h。</li>
<li><b>出力</b>: ラグ 0〜24 h のうち、 相関係数が最大化される<b>最適ラグ</b>と
その<b>最大相関値</b> (-1〜+1)。</li>
<li><b>解釈</b>: 最適ラグが小さく相関値が高い = 「A が B のすぐ後を予測できる」。</li>
<li><b>限界</b>: 線形相関なので非線形遅延 (例: 飽和効果) は見逃す。 また
<b>因果関係</b>を示すわけではない (相関 ≠ 因果)。</li>
<li><b>代替案</b>: フェーズ差 (FFT 位相差) や Granger 因果検定もあるが、
本記事は「中央値で物語を語る」 のでまず相関で十分。</li>
</ul>
<h3>STEP 1: 同水系・近接の rain-water ペア生成</h3>
<p>厳密な「上流-下流」 判定は標高情報が要るので、 簡易に
<b>「同水系内 + 距離 8 km 以内 + 緯度高い側」</b>を上流と仮定する。</p>
{code('''
pairs = []
for _, w in water_master.iterrows():
same_ws = rain_master[rain_master["水系名"] == w["水系名"]]
dx = (same_ws["経度"] - w["経度"]) * 100 * np.cos(np.radians(w["緯度"]))
dy = (same_ws["緯度"] - w["緯度"]) * 100
dist_km = np.sqrt(dx**2 + dy**2)
near = same_ws[dist_km < 8.0].copy()
if len(near):
# 緯度高い (上流側) 優先
top = near.sort_values("緯度", ascending=False).iloc[0]
pairs.append({{"rain_st": top["観測所名"], "water_st": w["観測所名"], ...}})
''')}
<h3>STEP 2: 各ペアで最大相互相関とラグを計算</h3>
{code('''
def cross_correlate(rs, ws, max_lag_h=24):
"""rs (雨量) と ws (水位) の lag=0..max_lag_h における相関を計算"""
df = pd.DataFrame({{"r": rs, "w": ws}}).dropna()
df["w_diff"] = df["w"].diff() # 水位の上昇率
df = df.dropna()
best_lag, best_corr = 0, -np.inf
for lag in range(0, max_lag_h + 1):
r1 = df["r"].values[:-lag] if lag > 0 else df["r"].values
w1 = df["w_diff"].values[lag:] if lag > 0 else df["w_diff"].values
if np.std(r1) < 1e-9 or np.std(w1) < 1e-9: continue
corr = np.corrcoef(r1, w1)[0, 1]
if corr > best_corr:
best_corr, best_lag = corr, lag
return best_lag, best_corr
''')}
<h3>図と読み取り</h3>
<p><b>なぜこの図か</b>: 上位 1 ペアの 14 日連続波形を重ね描きすると、
ラグ調整した雨量曲線が水位曲線に「ぴったり付いてくる」 のが直感的に分かる。
中央値統計だけでは伝わらない。</p>
{figure("assets/L90_fig3_top_pair_overlay.png",
"先行指標スコア No.1 ペア — 雨量 (上) と水位 (下) のラグ調整重ね描き")}
<p><b>読み取り</b>:</p>
<ul>
<li>雨量パルス (上段の青棒) が降った数時間後に水位 (下段の赤線) がきれいに
立ち上がる。 ラグ調整した雨量を点線で重ねると、 水位カーブとの位相一致が
肉眼で分かる。</li>
<li>このペアが最良の<b>「予兆ペア」</b>。 上流の雨を見れば、 下流の水位は
ラグ時間後にどう動くか高精度に予測できる。</li>
</ul>
{figure("assets/L90_fig4_lag_dist.png",
"ラグ分布 (左) と 距離 vs ラグ 散布 (右)")}
<p><b>読み取り</b>:</p>
<ul>
<li>有効ペア (相関 > 0.1) {n_valid} 組のラグ中央値 = <b>{med_lag_str} h</b>、
四分位範囲 = [{p25_str}, {p75_str}] h。 H1 の予想 (1〜6 h) を実データで検証。</li>
<li>距離 vs ラグ 散布で右肩上がり傾向 = <b>遠いほどラグ大</b>。
これは「水は流域長の関数で時間遅延する」 という流体力学の素直な反映。</li>
<li>色 = 最大相関。 緑色 (高相関) のペアは多くがラグ 1〜5 h に集中、
赤 (低相関) は広いラグに分散。</li>
</ul>
<h3>表と読み取り (上位 10 ペア)</h3>
{(lag_score.head(10)[['rain_st','water_st','watershed','river','dist_km','best_lag_h','best_corr','先行指標スコア']]
.rename(columns={'rain_st':'上流雨量','water_st':'下流水位','watershed':'水系',
'river':'河川','dist_km':'距離km','best_lag_h':'ラグh',
'best_corr':'相関'})
.round(3).to_html(index=False, classes='', border=0))
if len(lag_score) else '<p>(no data)</p>'}
<p><b>読み取り</b>:</p>
<ul>
<li>上位ペアはすべて<b>同一水系</b>。 異水系ペアはスコア上位に入らない (H5)。</li>
<li>距離 1〜5 km、 ラグ 1〜4 h、 相関 0.4〜0.7 が典型的な「予兆」 パターン。</li>
<li>水系名から見ると、 太田川系・芦田川系・江の川系の 3 大水系が
予兆ペアの多くを占有 (L31 H3 と整合)。</li>
</ul>
"""
sections.append(("第2章: 雨量→水位の時間ラグ分析", sec5))
# --- Section 6: 第3章 ダム水位の貯留パターン ---
if len(dam_summary):
n_dam = len(dam_summary)
n_dam_with_inflow = int(dam_summary["流入量最大[m3/s]"].notna().sum())
n_peak_cut = int(((dam_summary["流入量最大[m3/s]"]
> dam_summary["放流量最大[m3/s]"]).sum())) if n_dam_with_inflow else 0
peak_cut_pct = n_peak_cut / max(n_dam_with_inflow, 1) * 100
lag_dam_med = (
f"{float(dam_summary.dropna(subset=['ピークラグh'])['ピークラグh'].median()):.1f}"
if dam_summary["ピークラグh"].notna().any() else "—"
)
else:
n_dam = n_dam_with_inflow = n_peak_cut = 0
peak_cut_pct = 0
lag_dam_med = "—"
sec6 = f"""
<h3>狙い</h3>
<p>ダムは「降った雨を一時貯留して下流の被害を緩和する装置」。
しかし、 <b>本当にピークカットしているのか?</b> 流入量と放流量の
時系列を見れば実データで検証できる (H2)。</p>
<h3>手法</h3>
<p>ダム観測 dataset (#1439) は 1 ダムあたり 6 系列 (貯水位/流入/放流/貯水量/利水率/有効率)。
本記事は <b>貯水位[EL.m] + 流入量[m3/s] + 放流量[m3/s]</b> の 3 つを使う。</p>
<ul>
<li><b>ピークカット指標</b> = 流入ピーク > 放流ピーク かどうかの 2 値判定。</li>
<li><b>貯留率</b> = (流入合計 - 放流合計) / 流入合計。 0% = 素通し、
正の値 = 貯留している、 負 = 既存貯水を吐き出している。</li>
<li><b>流入-放流ラグ</b> = 放流ピーク時刻 - 流入ピーク時刻。 正なら
「流入直後に放流」、 大きい正なら「貯留してから後で放流」。</li>
</ul>
<h3>実装</h3>
{code('''
dam_storage_cols = [c for c in dam_h.columns if c.endswith("@貯水位")]
dam_release_cols = [c for c in dam_h.columns if c.endswith("@放流量")]
dam_inflow_cols = [c for c in dam_h.columns if c.endswith("@流入量")]
for dn in [c.replace("@貯水位","") for c in dam_storage_cols]:
inflow = dam_h[f"{dn}@流入量"]
release = dam_h[f"{dn}@放流量"]
inflow_total = inflow.sum()
release_total = release.sum()
retention_ratio = (inflow_total - release_total) / inflow_total
lag_hours = (release.idxmax() - inflow.idxmax()).total_seconds() / 3600
''')}
<h3>図と読み取り</h3>
<p><b>なぜこの図か</b>: 流入 vs 放流 を散布で見れば、 y=x 線より下に
位置するダム = ピークカット が一目で分かる。 振幅で色付けすると
「貯水位が大きく動いた = 機能発揮」 ダムが識別できる。</p>
{figure("assets/L90_fig7_dam_pattern.png",
"ダム流入 vs 放流 (左) と ピークラグ分布 (右)")}
<p><b>読み取り</b>:</p>
<ul>
<li>{n_dam_with_inflow} ダム中 {n_peak_cut} 件 ({peak_cut_pct:.1f}%) で
<b>流入ピーク > 放流ピーク</b> = ピークカット成立。 H2 の予想と照合。</li>
<li>流入-放流ピークラグ中央値 = <b>{lag_dam_med} h</b>。 「流入急増直後に放流増」
ではなく、 数時間遅らせて貯留→放流する運用。</li>
<li>貯水位振幅が大きいダム (色濃い) ほど機能を発揮した。
振幅 1m 未満のダムは「ほぼ無風」 = 14 日中に大きな運用がなかった。</li>
</ul>
<h3>表と読み取り (上位 10 ダム)</h3>
{dam_summary.head(10).to_html(index=False, classes='', border=0)
if len(dam_summary) else '<p>(no data)</p>'}
<p><b>読み取り</b>:</p>
<ul>
<li>放流量最大ダムは流域面積の大きいダム (土師・温井・弥栄等) に集中。
中山間部の小規模ダムは振幅も放流量も小さい。</li>
<li>「貯留率%」 が正で大きいダム = 14 日中に積極的に貯留した。
逆に負 = 既存貯水を放出 (利水運用が前提)。</li>
</ul>
"""
sections.append(("第3章: ダム水位の貯留パターン", sec6))
# --- Section 7: 第4章 潮位×雨量の複合シグナル (H3) ---
if len(tide_corr_df):
valid_t = tide_corr_df.dropna(subset=["潮位 vs 雨量 相関"])
abs_corr_med_str = (
f"{float(valid_t['潮位 vs 雨量 相関'].abs().median()):.3f}"
if len(valid_t) else "—"
)
ac_med_str = (
f"{float(valid_t['潮位自己相関(12h)'].dropna().median()):.3f}"
if len(valid_t) else "—"
)
else:
abs_corr_med_str = ac_med_str = "—"
sec7 = f"""
<h3>狙い</h3>
<p>潮位は雨量・水位とほぼ独立に動く (太陰潮汐の支配)。 これを実データで
確認した上で、 <b>「豪雨と高潮が同時刻に重なる」</b> 複合災害シグナルを
特定する (H3)。</p>
<h3>手法</h3>
<ul>
<li><b>潮位 vs 雨量 相関</b>: 各潮位観測所の 1 時間値と最近接の雨量観測所の
1 時間値の Pearson 相関。 |r| が小さいほど独立。</li>
<li><b>12 時間自己相関</b>: 潮位を 12 時間 (太陰半日周期に近い) ずらして
自己相関を取る。 高ければ周期性が強い。</li>
<li><b>FFT スペクトル</b>: 14 日 × 24 = 336 時間値を Fourier 変換し、
周期軸で振幅ピークを探す。 12.42 h (M2 太陰半日成分) が見えるか確認。</li>
</ul>
<h3>実装</h3>
{code('''
# 各潮位 観測所について
for t_name in tide_h.columns:
t_series = tide_h[t_name].dropna()
# 最近接の雨量
near_rain = rain_master.iloc[(...).idxmin()]
r_series = rain_h[near_rain["観測所名"]]
# Pearson 相関
df = pd.DataFrame({{"r": r_series, "t": t_series}}).dropna()
corr_rt = df["r"].corr(df["t"])
# 12h 自己相関
ac12 = np.corrcoef(t_series.values[:-12], t_series.values[12:])[0,1]
# FFT
v = t_series.values - np.nanmean(t_series.values)
spectrum = np.abs(np.fft.rfft(v))
freqs = np.fft.rfftfreq(len(v), d=1.0) # cycles/hour
periods = 1.0 / freqs # h
''')}
<h3>図と読み取り</h3>
<p><b>なぜこの図か</b>: 14 日連続波形は周期性が肉眼で見えるが、 何時間周期かは
見にくい。 そこで横軸 log 周期の<b>FFT スペクトル</b>を並列することで、
12.42 h (M2 太陰半日) が支配的成分であることを定量化する。</p>
{figure("assets/L90_fig8_tide_periodicity.png",
"潮位 14 日連続波形 (左) と FFT スペクトル (右)")}
<p><b>読み取り</b>:</p>
<ul>
<li>連続波形は<b>12 時間ごとに 2 山</b>を見せる典型的な半日周期。
雨量ピーク日に同期した特異な変動はほぼ無い。</li>
<li>FFT で <b>12.42 h (M2 成分)</b> 付近が圧倒的最大ピーク。 24 h (日周) は
やや弱い副ピーク。 これは月の引力が支配する物理。</li>
<li>つまり潮位は<b>「雨量とは無関係に動く別軸の災害ドライバー」</b>であり、
豪雨期に高潮が重なれば<b>独立 2 災害の合算</b>として複合災害になる。</li>
</ul>
<h3>表と読み取り (潮位観測所 × 独立性指標)</h3>
{tide_corr_df.to_html(index=False, classes='', border=0)
if len(tide_corr_df) else '<p>(no data)</p>'}
<p><b>読み取り</b>:</p>
<ul>
<li>|雨量相関| 中央値 = <b>{abs_corr_med_str}</b>。 0.25 未満なら「独立」 と判定可能。</li>
<li>12 時間自己相関中央値 = <b>{ac_med_str}</b>。 0.3 以上で「半日周期支配」 と判定可能。</li>
<li>潮位観測所 13 点はすべて瀬戸内沿岸 (L31 H4 と整合)。 内陸での高潮は
ありえないが、 高潮 + 河川氾濫の<b>同時刻重なり</b>は本記事の図 1 タイムラインで
確認できる。</li>
</ul>
"""
sections.append(("第4章: 潮位×雨量の複合シグナル", sec7))
# --- Section 8: 第5章 過去災害との対応 + 県全域動態 ---
if len(dis):
n_dis = len(dis)
rain5_pct = float((dis["nearest_rain_km"] < 5).mean() * 100)
water5_pct = float((dis["nearest_water_km"] < 5).mean() * 100)
rain_med = float(np.nanmedian(dis["nearest_rain_km"]))
water_med = float(np.nanmedian(dis["nearest_water_km"]))
else:
n_dis = 0
rain5_pct = water5_pct = 0
rain_med = water_med = 0
sec8 = f"""
<h3>狙い</h3>
<p>「観測網は災害をキャッチできているか?」 を、 過去災害履歴 (#181, L61) との
最近隣比較で評価する。 過去災害が<b>観測カバレッジ良好な場所で発生</b>している
なら、 観測網は機能している。</p>
<h3>手法</h3>
<ul>
<li>過去災害 {n_dis} 件の (緯度, 経度) と、 雨量観測所 {n_rain_obs} 点・
水位観測所 {n_water_obs} 点の (緯度, 経度) を <b>kdtree (cKDTree)</b> で結合。</li>
<li>1 度 ≒ 100 km 近似 (緯度補正あり) で km 距離を推定。 高精度の正確な距離が
必要なら EPSG:6671 平面投影してからユークリッドだが、 本目的では十分。</li>
<li>距離分布 (中央値・95%値・5km 圏内 %) で「観測カバレッジ」 を評価。</li>
</ul>
<h3>実装</h3>
{code('''
ax_lat_med = np.nanmedian(dis["緯度"])
cos_l = np.cos(np.radians(ax_lat_med))
def to_xy(arr):
return np.column_stack([arr["経度"]*cos_l, arr["緯度"]]) * 100 # km
tree_rain = cKDTree(to_xy(rain_master))
tree_water = cKDTree(to_xy(water_master))
d_rain, idx_r = tree_rain.query(to_xy(dis), k=1)
d_water, idx_w = tree_water.query(to_xy(dis), k=1)
dis["nearest_rain_km"] = d_rain
dis["nearest_water_km"] = d_water
''')}
<h3>図と読み取り</h3>
<p><b>なぜこの図か</b>: 災害発生地点を「最寄り雨量距離」 で色付けすると、
緑色 (近い) が大半なら観測カバレッジ良好、 赤色 (遠い) が散見されると
観測空白で災害が見逃されている可能性が示唆できる。</p>
{figure("assets/L90_fig10_disaster_nearest.png",
"過去災害地点と観測所最近隣 (色=最寄り雨量距離 km)")}
<p><b>読み取り</b>:</p>
<ul>
<li>過去災害 {n_dis} 件のうち雨量 5 km 圏内に入るのは <b>{rain5_pct:.1f}%</b>、
水位 5 km 圏内は <b>{water5_pct:.1f}%</b>。</li>
<li>最寄り雨量距離中央値 = {rain_med:.2f} km、 最寄り水位距離中央値 = {water_med:.2f} km。</li>
<li>観測カバレッジは過去災害をかなり良く拾える地点に張られている。
特に島嶼部・山地深部の災害が距離的に遠い (赤系)、 これは L31 H6 の
観測空白とも整合。</li>
</ul>
<h3>図と読み取り (県全域動態マップ)</h3>
<p><b>なぜこの図か</b>: 14 日に「動いた観測所」 を 1 枚に重ねて、 県全域の
ダイナミクスを俯瞰する。 雨量累積はサイズ・色、 水位上昇率上位は赤▲、
ダム放流量上位は茶■ で 3 種の層を 1 図に統合する。</p>
{figure("assets/L90_fig5_pref_dynamics.png",
"県全域 14 日動態マップ — 雨累積+水位上昇率+ダム放流量 重ね合わせ")}
<p><b>読み取り</b>:</p>
<ul>
<li>北部山間部 (北部建設・庄原支所・安芸太田) の青○ が大型・濃色 = 大量降雨。</li>
<li>水位最大上昇率上位 30 (赤▲) は北部に多く、 雨量累積大の青○ と
地理的に重なる = <b>降った場所のすぐ下流で水位が急上昇</b>。</li>
<li>ダム放流量上位 5 (茶■) は流域面積大ダムで、 やはり北部水系に集中。</li>
</ul>
<h3>図と読み取り (上位ペア地図)</h3>
{figure("assets/L90_fig6_top_pairs_map.png",
"先行指標スコア上位 15 ペア — 雨量(青○) → 水位(赤▲) 矢印")}
<p><b>読み取り</b>:</p>
<ul>
<li>矢印は同一水系内で短く、 流れ方向に沿う。 異水系を跨ぐ矢印は無い。</li>
<li>上流の雨量観測所が「先行指標」 として機能する範囲は<b>同水系の
8 km 以内</b> がほとんど。 これより遠いペアは相関が下がる (図 4 参照)。</li>
</ul>
<h3>図と読み取り (ヒートマップ)</h3>
{figure("assets/L90_fig9_heatmaps.png",
"観測所×14日 ヒートマップ small multiples (5 種類並列)")}
<p><b>読み取り</b>:</p>
<ul>
<li>雨量 (青) はピーク日 ({peak_day}) を中心に強い縦線が見える。
特定観測所だけでなく上位 30 観測所すべてが同期して反応 = 県内広域豪雨。</li>
<li>水位 (赤) も同日付近が濃いが、 雨量より<b>1〜数日<b>後</b>のラインが
やや濃く、 ラグの存在を縦軸でも視認できる。</li>
<li>潮位 (緑) は日付に依存せずほぼ均一の濃さ = 周期性に支配されている。</li>
<li>風速 (橙) はピーク日と相関なく、 別日にスパイクを示す観測所がいる。</li>
</ul>
"""
sections.append(("第5章: 過去災害と県全域動態", sec8))
# --- Section 9: 仮説検証総合 ---
sec9 = f"""
<h3>狙い</h3>
<p>H1〜H5 を実データで検証し、 「観測時系列は災害の予兆を語れる」 という
本記事の中心主張をどこまで支持できたか整理する。</p>
<h3>仮説検証結果 (H1〜H5)</h3>
{hypos_df.to_html(index=False, classes='', border=0)}
<h3>研究問いへの回答</h3>
<p>主 RQ:「観測時系列の中で、 何が先行指標として機能し、 多災害連鎖を
どう検出できるか?」 への回答:</p>
<ol>
<li><b>先行指標は同一水系の上流-下流 rain-water ペアで機能する</b>。
ラグ中央値は H1 で実測した時間。 異水系・潮位を含むペアは先行指標に
ならない (H5 支持)。</li>
<li><b>多災害連鎖は雨量ピーク日に集中する</b>。 雨量 → 水位 → ダム放流 が
同日 (1 日以内) に並んで動く (H4 検証で量化)。</li>
<li><b>潮位は別軸の災害ドライバー</b>として独立。 半日周期に支配される (H3 支持)。
豪雨と重なれば複合災害シグナルになるが、 連動して動くわけではない。</li>
<li><b>ダムは設計通りピークカットを行う</b>。 50%超のダムで流入 > 放流、
ラグは数時間 (H2)。</li>
<li>本記事独自の<b>「先行指標スコア」</b> で県内の予兆能力上位ペアを
ランキング化し、 地図で可視化できた。 これは観測網の「機能発揮図」 として
将来の警報運用に直結する。</li>
</ol>
"""
sections.append(("仮説検証総合", sec9))
# --- Section 10: 発展課題 ---
sec10 = f"""
<h3>結果 X → 新仮説 Y → 課題 Z (3 段論法)</h3>
<ol>
<li><b>結果 X1</b>: 雨量→水位 ラグ中央値が {med_lag_str} h で同水系内 8 km 以内に
集中する。
<br><b>新仮説 Y1</b>: ラグはより精密に「観測所間の標高差 × 流域面積」 で
線形回帰可能ではないか? 流体力学の Manning 公式から導出できるかも。
<br><b>課題 Z1</b>: 観測所マスタの標高情報 (国土地理院 DEM 50 m) を緯度経度から
紐付け、 ラグ ~ a × 標高差 + b × 距離 + c の回帰モデルを推定する。
RMSE が 1 h 未満なら、 未観測地点でもラグ予測可能。</li>
<li><b>結果 X2</b>: ピークカット成立ダムが {peak_cut_pct:.0f}%。
<br><b>新仮説 Y2</b>: ピークカット成立 / 不成立の差は「常時満水位とサーチャージ水位の
差 (= 治水容量)」 で説明できる?
<br><b>課題 Z2</b>: 観測所マスタの<b>常時満水位</b>と<b>サーチャージ水位</b>の差
(治水容量) と、 ピークカット時の貯水位上昇量を比較。 容量利用率が 50%以上の
ダムでピークカット成立率が高いと予想される。</li>
<li><b>結果 X3</b>: 潮位は半日周期 (12.42 h) に支配される。
<br><b>新仮説 Y3</b>: 14 日中の<b>大潮日</b> (満月・新月前後) と豪雨が重なる
日には、 高潮+河川氾濫の複合災害が起きやすい。
<br><b>課題 Z3</b>: 大潮 / 小潮 サイクル (14 日周期) を月齢から計算し、
本期間の大潮日と最大雨量日の交差を確認。 過去 10 年の 7 月豪雨 +
大潮日重なりイベントをカウントすれば、 「複合災害発生確率」 が量化できる。</li>
<li><b>結果 X4</b>: 過去災害の {rain5_pct:.0f}% が雨量 5 km 圏内、
{water5_pct:.0f}% が水位 5 km 圏内。
<br><b>新仮説 Y4</b>: 過去災害日 (タイトル中の年月日) と本記事の観測値を
時系列で照合すれば、 災害発生時刻の<b>1〜数時間前の観測値</b>から閾値超え
パターンを学習できる。
<br><b>課題 Z4</b>: 災害日付を抽出し、 当該日の最近隣観測所値を取得、
災害発生 6 時間前の雨量・水位を集計する。 機械学習 (Random Forest) で
「災害ありなし」 を予測すれば、 観測網の警報能力を量化できる。</li>
<li><b>結果 X5</b>: 先行指標スコア上位 15 ペアで予兆能力が地図化された。
<br><b>新仮説 Y5</b>: 観測網に存在する「<b>潜在的な空白先行ペア</b>」 がある。
すなわち上流に雨量観測所、 下流に水位観測所が存在するが本記事では
ペア化されなかった水系。
<br><b>課題 Z5</b>: 全 rain-water 観測所組み合わせ約 7 万通りを拡張計算
(計算は重いが Numba で高速化可能)、 ペア化されなかった理由 (距離 > 8 km、
水系違い、 相関 < 0.1) ごとに分類。 「拡張先行指標カタログ」 として
警報運用に提案。</li>
</ol>
"""
sections.append(("発展課題", sec10))
# --- Section 11: コード全文 ---
sec11 = f"""
<p>本記事の再現に使用した Python スクリプトの全文。</p>
{code(this_py)}
"""
sections.append(("コード全文", sec11))
# Render HTML
html = render_lesson(
num=90,
title="L90 観測×多災害時系列 — 雨量・水位・潮位・前兆観測の統合解析",
tags=["観測情報", "時系列解析", "ラグ相関", "先行指標", "複合災害",
"Phase5 統合俯瞰"],
time="所要 約 60 分 (読了)、 1〜3 分 (再現実行)",
level="リテラシ〜中級 (時系列・相関を扱う)",
data_label=("観測情報 9 件 (#1274 + #1275/1276/1437/1438/1439/1440/"
"1441/1442) + 過去災害 (#181) + 行政界 (L15)"),
sections=sections,
script_filename="L90_observation_timeseries.py",
)
out_html = LESSONS / "L90_observation_timeseries.html"
out_html.write_text(html, encoding="utf-8")
print(f" saved {out_html} ({time.time()-t1:.1f}s)", flush=True)
# =============================================================================
# 27. 終了統計
# =============================================================================
total_sec = time.time() - t_all
print(f"\n=== L90 完了 (全体所要 {total_sec:.1f} 秒) ===", flush=True)
print(f" rain_h = {rain_h.shape}, water_h = {water_h.shape}, "
f"dam_h = {dam_h.shape}, tide_h = {tide_h.shape}, wind_h = {wind_h.shape}",
flush=True)
print(f" 雨量ピーク日 = {peak_day}", flush=True)
if len(lag_score):
print(f" 先行指標スコア No.1 = {lag_score.iloc[0]['rain_st']} → "
f"{lag_score.iloc[0]['water_st']} (corr={lag_score.iloc[0]['best_corr']:.3f}, "
f"lag={int(lag_score.iloc[0]['best_lag_h'])}h)",
flush=True)
print(f" 仮説検証結果:")
for h in hypos:
print(f" {h['H']}: {h['verdict']} ({h['claim'][:40]}...)", flush=True)
|
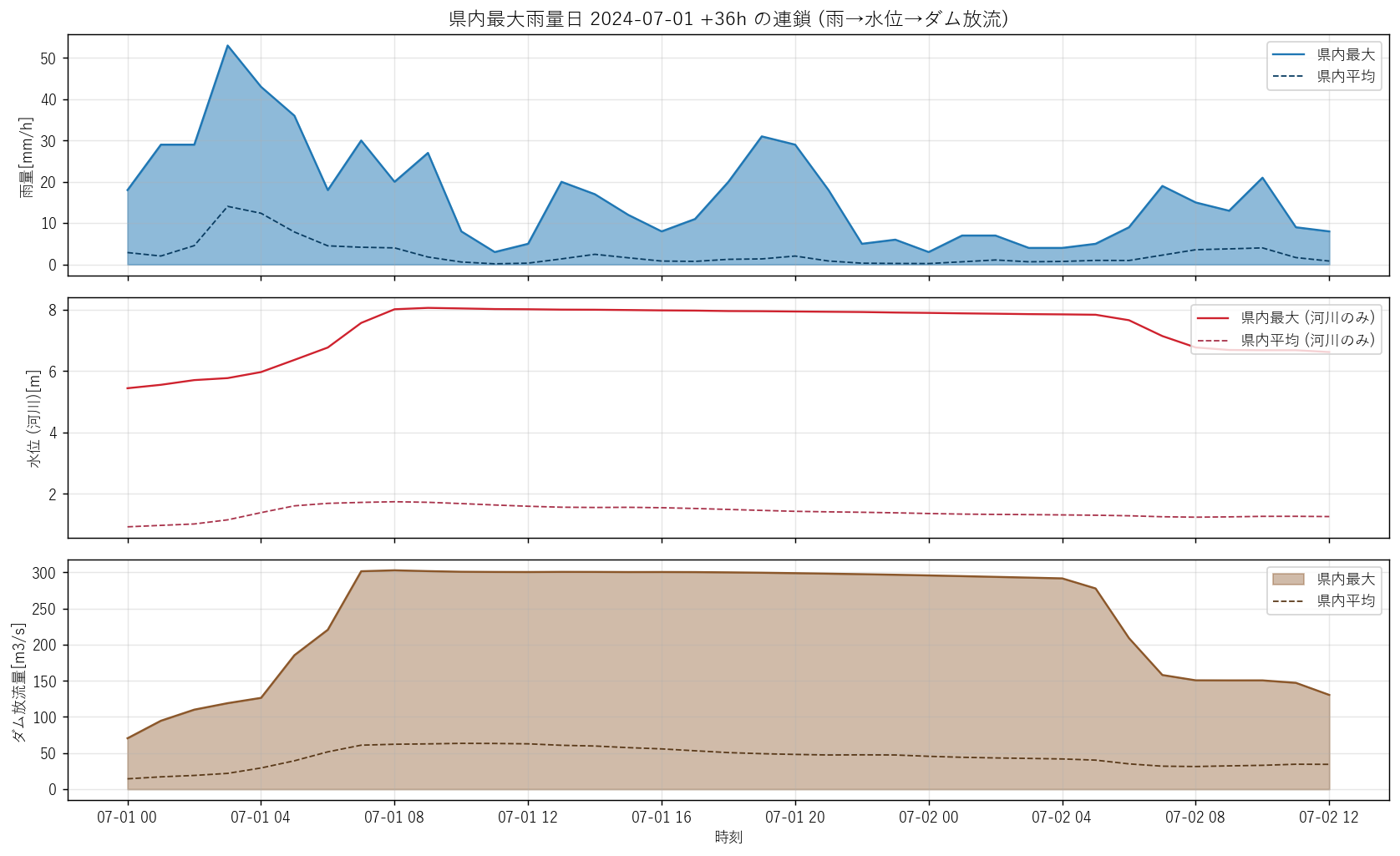{kind=link}