L78 ダム基本情報・維持管理情報 単独 3 研究例分析
データ取得手順
⚠️ このスクリプトは自動取得に対応していません。以下のデータセットを DoBoX から手動でダウンロードし、data/extras/ 以下に保存してください。
| ID | データセット名 |
|---|---|
| #21 | ダム基本情報・維持管理情報 |
| #222 | dataset #222 |
| #333 | dataset #333 |
| #888 | 都市計画区域情報_区域データ_安芸高田市_行政区域 |
実行コマンド:
cd "2026 DoBoX 教材"
python -X utf8 lessons/L78_dams.py
DoBoX のオープンデータは申請不要・商用/非商用とも利用可。
data/extras/ は .gitignore 対象(約 57 GB のキャッシュ)。
スクリプト実行で自動再生成されます。
学習目標と問い
独自用語の定義 (本記事限定)
- ダム (河川法上の定義): 河川法第 26 条が規定する河川区域内 工作物のうち、 河川を堰き止めて貯水する大規模構造物。 高さ 15 m 以上 が「ダム」 と分類され、 それ未満は「堰」 と区別される (河川管理施設等 構造令第 2 条)。 治水 (洪水調節) ・利水 (飲料水 / 農業 / 工業) ・発電の 3 大目的を持つ。
- 治水ダム (本記事の主対象): 主目的が洪水調節であるダム。 梅雨・台風時に洪水を一時的に貯留して下流の被災を軽減する。 広島県管理 ダム 12 基はすべて治水ダム (利水兼用が大半)。
- 重力式コンクリートダム: 堤体の自重 (= 重力) で水圧に抵抗する コンクリート製ダム。 安定性が高く、 地盤適合性が広く、 工事も標準的なため、 日本の治水ダムで最も多い型式。 広島県管理ダムは100.0% がこの型式。
- アーチ式 (本記事では非該当): 堤体を曲線に造形して水圧を両岸の 岩盤に逃がす型式。 黒部ダム (富山) が代表。 県管理ダム 12 基は 0 件。
- フィル / ロックフィル (本記事では非該当): 土・砂・岩を 盛り立てて造る土構造ダム。 アースフィル (= 土が主) と ロックフィル (= 岩石が主) の 2 種。 県管理ダムは0 件。
- 堤高 (m): ダムの基礎地盤面から堤頂までの高さ。 構造令上 15 m 以上がダム (それ未満は堰)。 県管理ダムは 31.5 〜 79.8 m。
- 堤頂長 (m): 堤頂部の水平長 (= 川を横断する方向の長さ)。 県管理ダムは 112.6 〜 292.0 m。
- 総貯水容量 (千 m³): 設計上の最大貯水量。 洪水調節容量 + 利水容量 + 堆砂容量 の合計。 県管理ダム合計は 52,421 千 m³ ≒ 52.4 百万 m³。
- 有効貯水容量 (千 m³): 総貯水容量から堆砂容量を除いた、 実運用上利用可能な貯水容量。 「容量充填率 = 有効/総」 が高いほど 設計の有効性が高い (本記事独自指標)。
- 集水面積 (km²): ダム上流側でそのダムに流れ込む雨水の集水面の 合計面積。 「ダムが支配する流域の広さ」。 県管理ダムは 3.50 〜 160.00 km² まで 46 倍の幅がある。
- 貯水深 (mm) ※本記事独自指標:
総貯水容量 (m³) ÷ 集水面積 (m²)を mm 単位に変換した量。 「集水面積全体に均等に何 mm 分の雨を貯められるか」 という直感量。 数値が大きいほど単位流域あたりの貯水力が高い (= 過剰設計または 治水重視)。 - 容量充填率 (%) ※本記事独自指標:
有効貯水容量 / 総貯水容量 × 100。 堆砂が少なく実運用容量が 残っているほど高い。 平均 87.5%。 - 容量集水比 (千 m³ / km²) ※本記事独自指標:
総貯水容量 (千 m³) ÷ 集水面積 (km²)。 流域 1 km² あたりの 貯水可能量。 貯水深と本質同等だが単位が異なる。 - 診断結果 (公式分類): 県の維持管理情報で公表される健全度判定。 C = 健全、 B2 = 要対策 (修繕・更新が必要)。 県管理ダム 12 基中 魚切ダム 1 基のみ B2、 残り 11 基は C。
- 緊急放流 (背景説明): ダム上流で計画想定を超える流入があった際、 ダム本体の決壊を防ぐため、 流入量と同量の水を下流に放流する操作 (= 異常洪水時防災操作)。 本データには操作実績は含まれないが、 下流被災ポテンシャルを論じる上で重要概念。
- 老朽 (本記事独自閾値): 完成から築 50 年 以上経過したダム。 国のインフラ長寿命化基本計画 (2014)が 想定する大規模更新の標準周期 = 60 年から、 50 年経過時点で 「更新検討開始」 が望ましいとされる。
- 更新ピーク (本記事独自指標): 完成西暦 + 60 年を「次回更新予測年」 として、 各ダムが 属する 20 年帯を集計したピーク。 県の維持管理予算ピーク予測の代理。
研究の問い (3 RQ)
- RQ1 (主研究): 広島県のダムの構造 — 型式・規模・地理分布は どう描けるか? 12 基を型式 / 堤高 / 堤頂長 / 堤体積 / 総貯水容量 / 集水面積 / 水系 / 完成年代 / 診断結果の 9 軸で集計し、 「県の最大水管理装置の物理形状」 を初めて系統的に記述する。 H1 (型式 100% 重力式) / H2 (堤高 30-80m に 10+ 基) を検証。
- RQ2 (副研究 1): ダムの流域支配 — 上流集水と下流被災ポテンシャルは どう描けるか? 集水面積 (km²) ・総貯水容量 (千 m³) ・有効貯水容量比から、 各ダムの「流域支配力」 を量化、 本記事独自指標「貯水深 (容量 ÷ 集水 面積)」 「容量充填率 (有効 ÷ 総)」 を導入し、 12 基をランキングする。 H3 (魚切ダム 貯水深 Top 3) / H4 (log-log r >= 0.7) を検証。
- RQ3 (副研究 2): ダムの老朽化と更新ピーク — 1960-70s ダムの 再評価はどう描けるか? 完成年月から経過年を計算し、 築 50 年以上の 老朽ダムを抽出。 国のインフラ長寿命化基本計画 (2014)が想定する 更新ピーク到来の実態を、 12 基という小さな母集団でも個体名で 語れる粒度で描く。 H5 (老朽 3+ 基 かつ S30-40 年代集中) を検証。
仮説 (5)
- H1 (RQ1, 型式単一): 県管理ダムは型式 100% が重力式コンクリート。 他型式 0 件。
- H2 (RQ1, 堤高集中): 堤高は30-80m 帯に 10 基以上。 100m 超の超高ダムも 30m 未満の小型ダムも無い。
- H3 (RQ2, 魚切ダム 貯水深 Top 3): 貯水深 (= 容量 ÷ 集水面積) で 魚切ダムが県内 Top 3。 大都市直下流の過剰設計の物理証拠仮説。
- H4 (RQ2, 集水 ↔ 容量 強相関): 集水面積と総貯水容量の両対数 Pearson r >= 0.7。 大流域ほど大容量という直観の量的検証。
- H5 (RQ3, 老朽集中): 築 50 年以上が3 基以上、 それらは S30-40 年代 (1955-74)の高度成長期初期に集中。
到達点
本記事を読み終えると、 (1) 県管理ダム 12 基の構造プロファイルを 型式・規模・地理の 3 軸で完全把握、 (2) 集水面積×総貯水容量のべき乗則 (指数 0.77)を初めて量的記述、 (3) 各ダムを貯水深ランキングで 12 個体について比較可能、 (4) 築 50 年以上の2 基の老朽ダムを 個体名で同定、 (5) 更新ピーク帯を 20 年単位で予測、 という 5 段階の 知識が獲得できる。 これにより県の水資源管理戦略を構造・流域・時間軸 の 3 視点で研究者として論じられるようになる。
使用データ
本研究で使う 1 つの dataset (1 リソース) を以下の表に示す。 本データセットは 12 行の軽量フラット CSV として公開されており、 学習者が手元で完全に扱える。
データセット仕様
| 項目 | 値 |
|---|---|
| データセット ID | DoBoX #21 |
| データセット名 | ダム基本情報・維持管理情報 |
| 公開組織 | 広島県 河川課ダムグループ |
| リソース数 | 1 (CSV) |
| ライセンス | クリエイティブ・コモンズ表示 (CC-BY) |
| 対象 | 広島県管理 治水ダム (河川ダム) |
| 対象基数 | 12 基 |
| 対象水系 | 7 水系 |
| 完成年範囲 | 1964 〜 2016 (52 年スパン) |
| 型式 | 重力式コンクリート (全件単一) |
| ファイル形式 | CSV (UTF-8 BOM, 12 行 × 21 列) |
CSV 列定義 (21 列)
| 列名 | 例 | 意味 |
|---|---|---|
| ダムコード | 1, 2, 91 等 | 県内ダム識別子 (連番に近いが穴あき: 8 → 91 にジャンプ) |
| 分類 | 河川 | 河川法上の分類 (全件 河川ダム) |
| 水系名 | 小瀬川 / 八幡川 / 芦田川 等 | ダムが属する一級または二級水系の名称 (7 水系) |
| 河川名 | 小瀬川 / 椋梨川 等 | 水系内の本流または支流の名称 |
| 施設区分 | ダム | 施設の区分 (全件 ダム) |
| ダム名 | 小瀬川ダム / 魚切ダム 等 | ダムの正式名称 |
| 管理者 | 広島県 | ダムの管理組織 (全件 広島県) |
| 位置 | 廿日市市浅原 / 東広島市河内町 等 | 所在地 (市町 + 大字レベル) |
| 緯度 / 経度 | 34.308 / 132.124 等 | WGS84 10 進数 |
| 完成年月 | S39.6 / H21.10 等 | 元号 + 年.月 形式 (S = 昭和、 H = 平成) |
| 集水面積_km2 | 3.5 〜 160 | ダム上流の集水面の合計面積 |
| 堤体積_千m3 | 25,800 〜 317,000 | 堤体 (堰堤) のコンクリート体積 |
| 総貯水容量_千m3 | 560 〜 11,400 | 設計上の最大貯水量 |
| 有効貯水容量_千m3 | 494 〜 9,900 | 実運用上利用可能な貯水量 (堆砂容量を除く) |
| 型式 | 重力式コンクリート | 堤体の構造分類 (全件 重力式コンクリート) |
| 堤高_m | 31.5 〜 79.8 | 基礎地盤から堤頂までの高さ |
| 堤頂長_m | 112.6 〜 292.0 | 堤頂部の水平長 |
| 診断結果 | C / B2 | 健全度判定 (C = 健全, B2 = 要対策) |
形式特性の注意点
- 1 行 = 1 ダム: 12 行のフラット表で完結。 軽量。
- 緯度経度は堤体の位置: 貯水池やダム湖の中心ではなく、 堤体 (= 堰堤本体) の位置点。 本記事の「市町判定」 は堤体所在市町を表す。
- ダムコードに穴あき: 1〜8 の連番のあと 91, 92, 93, 94 と ジャンプ。 9〜90 のコードは廃止または欠番。
- 完成年月の元号表記: S = 昭和、 H = 平成。 R (令和) は本データ には含まれない (= 令和元年以降に完成したダムは無い、 または未収録)。
- 型式が単一: 12 基すべて重力式コンクリート。 これは 仮説 H1 の量的根拠だが、 同時に「他県との比較研究」 の重要な 出発点でもある (発展課題 5 参照)。
- 診断結果は 2 値: C (健全) / B2 (要対策) のみ。 中間段階 (B1, B0 等) や A (新規) は本データに含まれない。
- 管理者は全件 広島県: 国土交通省管理の弥栄ダム (一級水系 小瀬川の本ダム) や、 中国電力の発電ダム群は含まれない = 本記事は県管理治水ダムの研究。
ダウンロード
本記事の再現に必要なすべてを直リンクで提供する。 HTML だけ読めば学習者が完全再現できることが目標 (要件 A)。
生データ (DoBoX 1 dataset, 1 リソース)
- dataset 21: ダム基本情報・維持管理情報
- data/extras/dam_basic.csv — 12 行 × 21 列 (UTF-8 BOM, ~3 KB)
このスクリプト本体
- L78_dams.py — 1 ファイルで完結 (7 図 + 11+ 表生成)
中間 CSV (本記事生成、 再利用可)
- L78_dam_overview.csv — 全 12 基 (基本属性 + 派生 11 列)
- L78_form_summary.csv — 型式別 集計 (RQ1)
- L78_size_summary.csv — 規模クラス別 集計 (RQ1)
- L78_height_summary.csv — 堤高帯別 集計 (RQ1)
- L78_watershed_summary.csv — 水系別 集計 (RQ1)
- L78_city_summary.csv — 市町別 集計 (RQ1, 空間 sjoin 経由)
- L78_dominance_ranking.csv — 流域支配ランキング (貯水深 + 容量集水比, RQ2)
- L78_filling_ratio.csv — 容量充填率 ランキング (RQ2)
- L78_watershed_stats.csv — 集水 × 容量 統計サマリ (RQ2)
- L78_era_summary.csv — 完成年代別 集計 (RQ3)
- L78_old_dams.csv — 築 50 年以上 老朽ダム一覧 (RQ3)
- L78_renewal_peak.csv — 更新ピーク帯予測 (RQ3)
- L78_diagnosis_summary.csv — 診断結果別 集計 (RQ3)
- L78_hypothesis_check.csv — H1〜H5 仮説検証結果
図 (PNG, 直 DL 可)
【RQ1】構造研究 — 型式 × 規模 × 地理分布
狙い (RQ1)
RQ1 では「県の最大水管理装置の物理形状」を初めて系統的に記述する。 具体的には 12 基を型式 × 堤高 × 堤頂長 × 堤体積 × 総貯水容量 × 集水面積 × 水系 × 完成年代 × 診断結果の 9 軸で集計し、 「型式は何種類採用されているか / 堤高はどの帯に集中するか / 規模はどう分布するか」 を 1 枚で俯瞰できるようにする。 H1 (型式 100% 重力式) は「広島県の地盤・地形・コスト 条件下では重力式が制度的に最適選択であり続けた」 仮説、 H2 (堤高 30-80m に 10+ 基) は「県管理ダム = 治水中規模帯」 という規模クラスタの単一性仮説。
手法 — 4 ステップ
- STEP 1: CSV パース + 型変換
CSV (UTF-8 BOM, 12 行 × 21 列) をread_csv()で読込み、 数値列 (集水面積 / 堤体積 / 総貯水容量 / 有効貯水容量 / 堤高 / 堤頂長 / 緯度 / 経度) をpd.to_numeric(errors="coerce")で 数値化。 ダム名空欄行を除外。 - STEP 2: 元号 → 西暦変換 (本記事独自関数)
完成年月列は 「S39.6」 「H21.10」 という和暦 + 月形式。 正規表現^([SH])(\d+)\.(\d+)$でパースし、 S = 1925 + 年、 H = 1988 + 年として西暦化。 さらに 10 年単位で「1960年代」 等の完成年代列を生成。 - STEP 3: GeoDataFrame 化 + 平面直角投影
緯度経度 →shapely.geometry.Point→ GeoDataFrame に変換、to_crs("EPSG:6671")で平面直角第 III 系 (m 単位) に投影。 距離計算で正確な結果を得るため。 - STEP 4: 9 軸集計
型式・堤高ビン・規模クラス・水系・市町・年代・診断結果の 7 グループ集計、 および型式 × 規模クラス、 完成年代 × 水系の 2 クロス集計を生成。
実装
狙いと方法を踏まえた実装コードは以下の通り。 元号パース正規表現 + GeoDataFrame 化 + 9 軸集計の 3 段構成。
↑ L78_dams.py 行 1212–1325
結果と読み取り
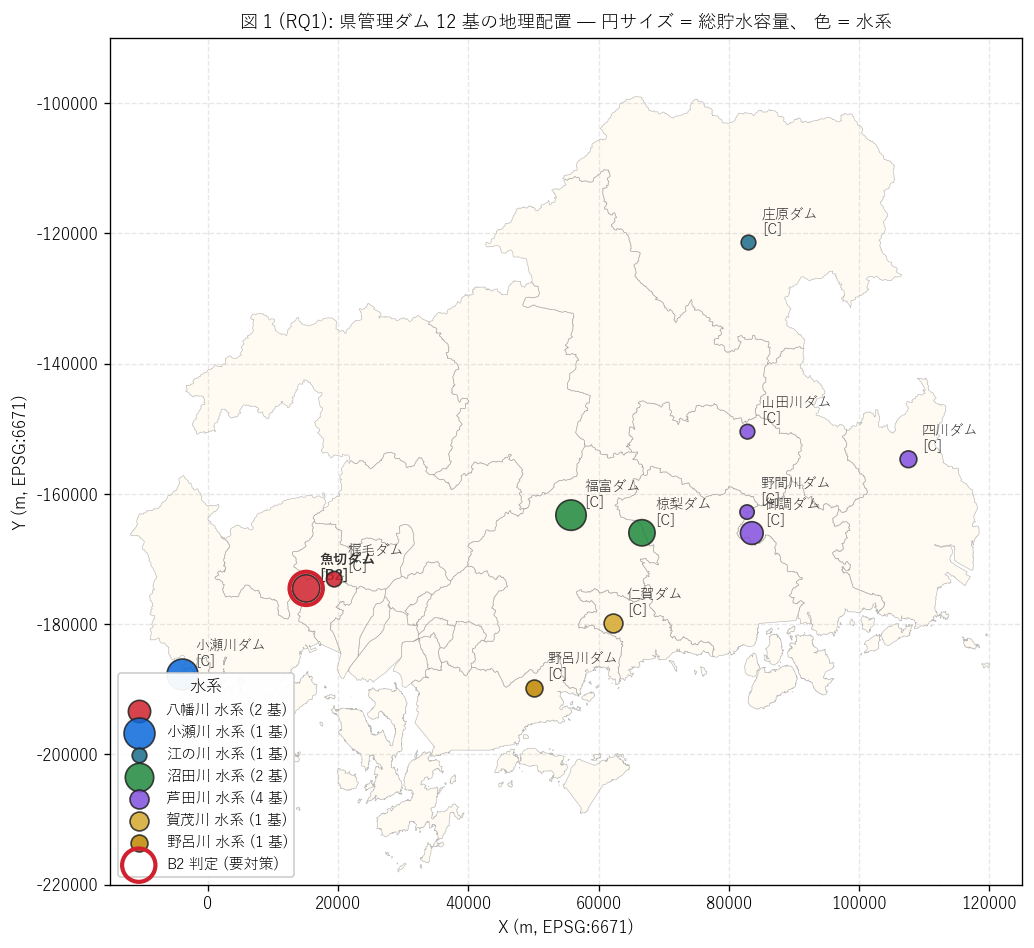
(a) 12 ダム 配置マップ (図 1)
なぜこの図か: 12 基という小さな母集団は個体名で全件を語れる 唯一の DoBoX シリーズ。 棒グラフだけで終わらせず、 全 12 基を水系色 + 容量 バブルサイズ + B2 強調で 1 枚に描くことで、 「県の水管理装置がどこに分布 しているか」 を地理的に直感する (要件 T)。
| 水系名 | 基数 | 総貯水容量合計_千m3 | 集水面積合計_km2 | シェア_% |
|---|---|---|---|---|
| 芦田川 | 4 | 7950.0 | 73.0 | 33.3 |
| 沼田川 | 2 | 18440.0 | 213.8 | 16.7 |
| 八幡川 | 2 | 9520.0 | 41.9 | 16.7 |
| 江の川 | 1 | 701.0 | 4.3 | 8.3 |
| 小瀬川 | 1 | 11400.0 | 135.0 | 8.3 |
| 賀茂川 | 1 | 2710.0 | 10.5 | 8.3 |
| 野呂川 | 1 | 1700.0 | 13.0 | 8.3 |
図 1 / 表 (水系別) から読み取れること:
- 最多水系は芦田川 (4 基) で、 県内ダム 4/12 基 = 約 33% を占める。 これは県東部の 重要水系であることを反映。
- 7 水系に分散しており、 1 水系 1 基の 水系も4 件。 県全域に ダム機能が広く配置されている設計。
- 沿岸〜内陸まで広く分布: 最南端は呉市の野呂川ダム (緯度 34.288)、 最北端は 庄原市の庄原ダム (緯度 34.902)。 緯度差約 0.6 度 = 約 60km の南北幅で県管理ダムが配置。
- 魚切ダム (B2 判定) は広島市佐伯区の都市直下流に位置し、 診断結果 B2 = 唯一の要対策ダムとして赤丸で強調。 後の RQ2 / RQ3 で 個別に深掘りする。
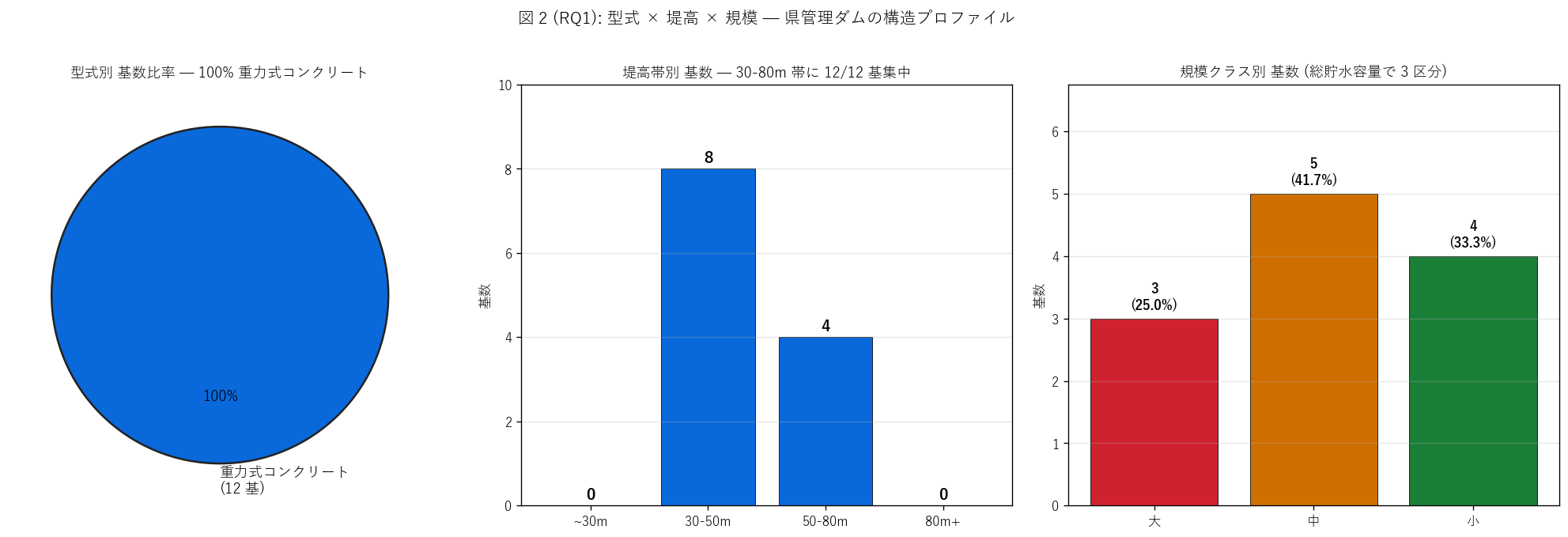
(b) 型式 × 堤高 × 規模 3 連 (図 2)
なぜこの図か: H1 (型式単一) と H2 (堤高集中) を 1 枚で示すための 3 panel 構成。 円グラフ (型式) + 棒グラフ (堤高ビン) + 棒グラフ (規模クラス) の 3 視点で「県管理ダムの構造プロファイルが極めて画一的」であることを 示す。
| 型式 | 基数 | 堤高平均 | 総貯水容量合計_千m3 | シェア_% |
|---|---|---|---|---|
| 重力式コンクリート | 12 | 48.7 | 52421.0 | 100.0 |
| 堤高帯 | 基数 | シェア_% |
|---|---|---|
| ~30m | 0 | 0.0 |
| 30-50m | 8 | 66.7 |
| 50-80m | 4 | 33.3 |
| 80m+ | 0 | 0.0 |
| 規模クラス | 基数 | 堤高平均 | 堤頂長平均 | 総貯水容量合計_千m3 | シェア_% |
|---|---|---|---|---|---|
| 大 (>=8000 千 m³) | 3 | 62.3 | 235.0 | 30760.0 | 25.0 |
| 中 (1500-8000 千 m³) | 5 | 48.7 | 198.9 | 18640.0 | 41.7 |
| 小 (<1500 千 m³) | 4 | 38.6 | 165.4 | 3021.0 | 33.3 |
図 2 / 表から読み取れること:
- 左パネル: 100.0% が重力式コンクリート。 アーチ・フィル・ ロックフィルは0 件。 H1 (型式単一) は支持。 これは広島県の地盤 (固い基盤岩が多い) と工事費・維持管理性の総合判断 で重力式が優先された制度的選択の物理証拠。
- 中パネル: 堤高は30-80m 帯に 12/12 基 (100.0%)が集中。 H2 (30-80m に 10+ 基) は 支持。 100m 超は 0 件、 30m 未満も 0 件 = 「中規模帯」 のダムだけが採用されている画一性が極めて高い。
- 右パネル: 規模クラスは「中 (1500-8000 千 m³)」 が最多。 「大」 (3 基) は 容量上位の魚切・福富・小瀬川。 「小」 (4 基) は 支川や近年完成の小規模治水ダム。
(c) 市町分布 (空間 sjoin 結果)
なぜこの表か: CSV の「位置」 列は市町 + 大字形式の文字列で 集計しにくいため、 緯度経度から行政界 polygon を sjoin で空間判定し、 正規化された市町別集計を生成する。
| 市町_空間 | 基数 | 総貯水容量合計_千m3 | 代表ダム |
|---|---|---|---|
| 東広島市 | 2 | 18440.0 | 椋梨ダム・福富ダム |
| 広島市佐伯区 | 2 | 9520.0 | 魚切ダム・梶毛ダム |
| 世羅町 | 1 | 700.0 | 山田川ダム |
| 三原市 | 1 | 560.0 | 野間川ダム |
| 尾道市 | 1 | 5040.0 | 御調ダム |
| 呉市 | 1 | 1700.0 | 野呂川ダム |
| 庄原市 | 1 | 701.0 | 庄原ダム |
| 廿日市市 | 1 | 11400.0 | 小瀬川ダム |
| 福山市 | 1 | 1650.0 | 四川ダム |
| 竹原市 | 1 | 2710.0 | 仁賀ダム |
表から読み取れること:
- 10 市町に 12 基が分散。 1 市町 1 基が 8 市町。 県管理ダムは「1 市町 1 基」 の設計が基本。
- 2 基以上立地する市町 (例: 東広島市 2 基) は 地形上ダム適地が複数ある特殊例。
【RQ2】流域支配研究 — 集水 × 容量 × 貯水深
狙い (RQ2)
RQ2 では「ダムの流域支配 — 上流集水と下流被災ポテンシャル」を量化する。 「集水面積 (km²)」 と「総貯水容量 (千 m³)」 の組合せから、 各ダムの 「流域 1 km² あたりの貯水力」を独自指標貯水深 (mm)と 容量集水比 (千 m³ / km²)で算出し、 12 基をランキングする。 これにより「同じ容量でも狭い流域なら過剰設計、 広い流域なら不足設計」 という 流域 ↔ 容量のトレードオフが可視化される。 さらに集水 ↔ 容量の両対数 相関 (べき乗則の有無) を統計的に検証し、 「流域 = 容量決定要因」 仮説を 量的に検証する。
手法 — 3 ステップ
- STEP 1: 流域支配指標の導出 (本記事独自)
貯水深 (mm) = 容量 (m³) ÷ 集水面積 (m²) × 1000という直感量を 新規導入。 「集水面積全体に均等に何 mm 分の雨を貯められるか」 という 解釈で、 単位流域あたりの貯水力を 12 基で比較可能にする。 同様に容量充填率 = 有効/総と容量集水比 = 容量/集水面積 も計算。 - STEP 2: 両対数 Pearson 相関 + 線形回帰
集水面積と総貯水容量を底 10 の対数に変換し、numpy.corrcoefで Pearson r、numpy.polyfit(deg=1)で回帰式を求める。 両対数空間で 線形ならべき乗則 V = c · A^b が成立し、 b (= 傾き) が「流域 ↔ 容量スケーリング指数」 となる。 b = 1 なら線形、 b < 1 なら亜線形 (大流域ほど過剰貯水)、 b > 1 なら超線形 (大流域ほど不足貯水)。 - STEP 3: 流域支配ランキング
貯水深降順で 12 基をソート。 県内 Top 3 / Bottom 3 を強調表示し、 魚切ダム (= 広島市直下流の都市治水ダム) の位置を注目。 「都市直下流 → 過剰設計 (高貯水深) 」 仮説の検証根拠とする。
実装
狙いと方法を踏まえた実装コードは以下の通り。 独自 3 指標 + log-log 相関 + ランキングの 3 段構成。
結果と読み取り
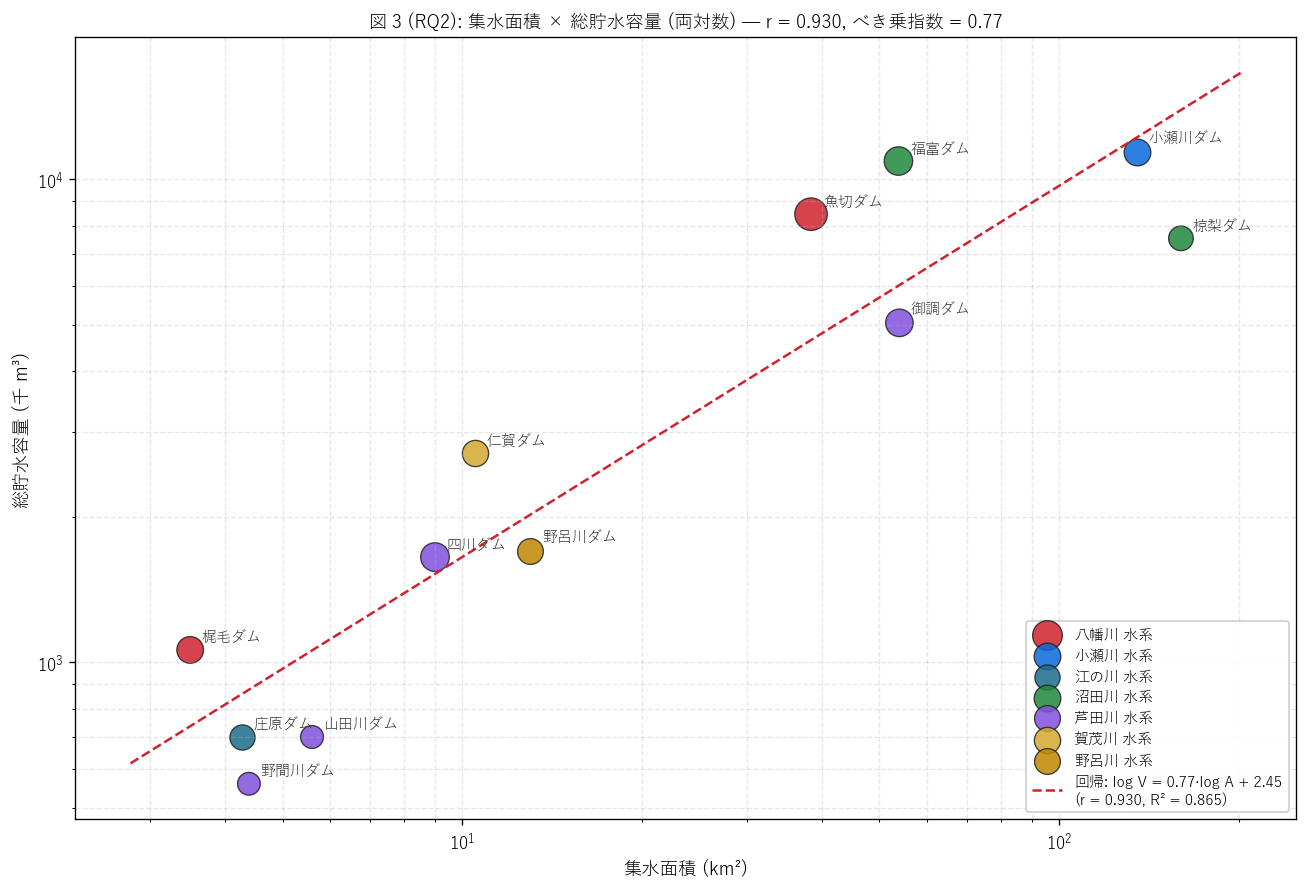
(a) 集水面積 × 総貯水容量 (両対数) (図 3)
なぜこの図か: 集水面積と総貯水容量のべき乗則を量的に確認する ための両対数散布図。 線形軸では小流域・小容量のダムが原点付近に潰れて 見えなくなるため、 両対数軸が必須。 さらに各点を水系色で塗り分けて 水系内のサブクラスタも見えるようにする。
| 統計 | 値 |
|---|---|
| 集水面積 平均 (km²) | 40.960 |
| 集水面積 中央 (km²) | 11.750 |
| 集水面積 最大 (km²) | 160.000 |
| 集水面積 最小 (km²) | 3.500 |
| 総貯水容量 合計 (千 m³) | 52421.000 |
| 総貯水容量 平均 (千 m³) | 4368.000 |
| 総貯水容量 中央 (千 m³) | 2205.000 |
| 総貯水容量 最大 (千 m³) | 11400.000 |
| 総貯水容量 最小 (千 m³) | 560.000 |
| log-log Pearson r (集水 vs 容量) | 0.930 |
| log-log 傾き (べき乗則指数) | 0.768 |
| 決定係数 R² | 0.865 |
図 3 / 表から読み取れること:
- 両対数 Pearson r = 0.930、 R² = 0.865。 H4 (r >= 0.7) は支持。 集水面積と総貯水容量の強い正の相関を量的に確認。
- べき乗則指数 (= log-log 傾き) = 0.77。 b ≈ 1 なら線形、 b < 1 なら亜線形 (= 大流域ほど単位面積あたりの貯水量が小さい = 過剰貯水度合いが下がる)、 b > 1 なら超線形。 観測値 b = 0.77 は亜線形で、 小流域ほど集水面積に対する貯水量が大きい (= 都市直下流の治水重視ダムが集水面積に比べて過剰設計) ことを示す。
- 外れ値の同定: 回帰線から大きく外れる点は独自設計のダム。 集水面積最大の小瀬川ダム (160 km²) と、 集水面積最小の梶毛ダム (3.5 km²) が両端を構成。 中間域は回帰線によく従う。
- 水系色の偏り: 1 水系内で集水面積・容量がほぼ同じ範囲に集中する水系 (例: 八幡川) と、 同じ水系でも分散する水系 (例: 芦田川) が並存。 これは水系内の本流ダム vs 支流ダムの設計の違いを反映。
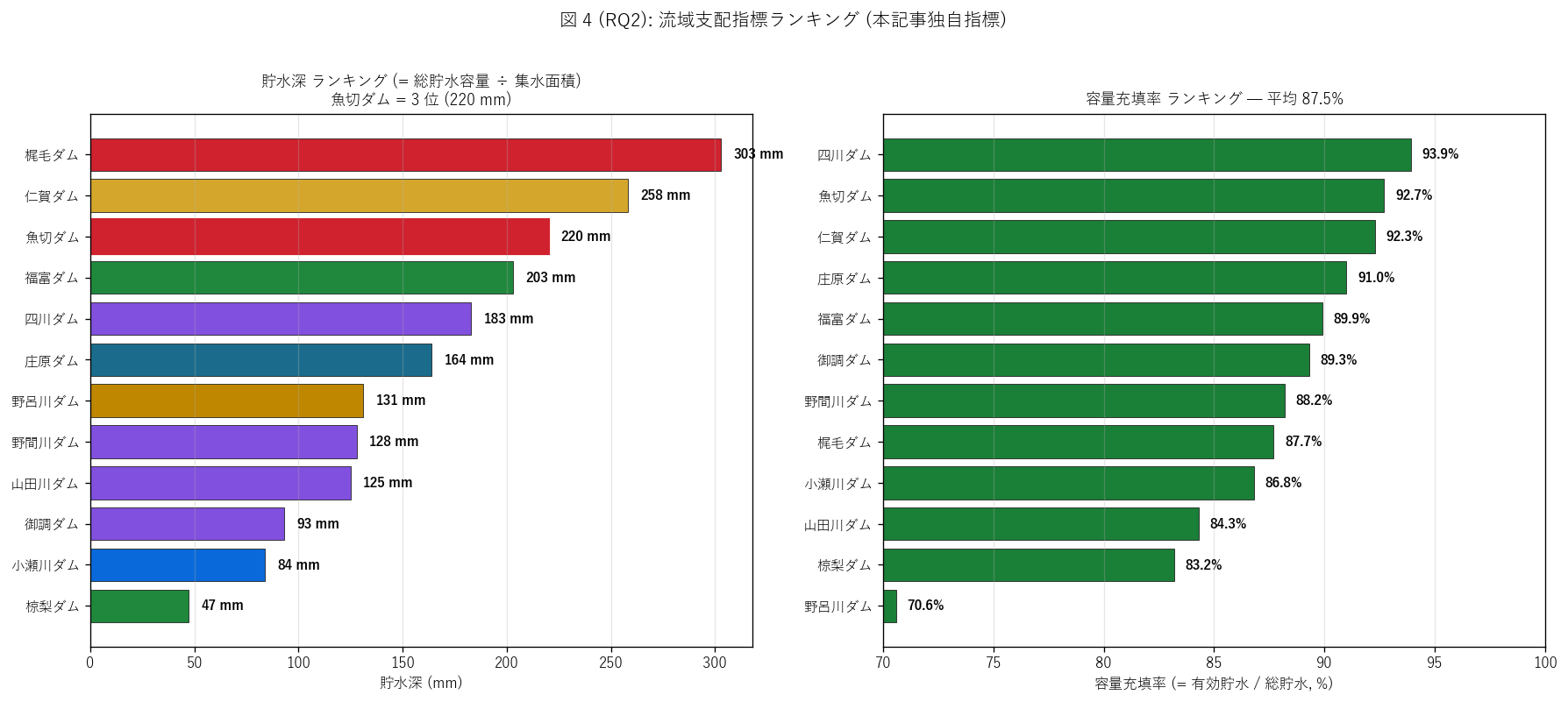
(b) 流域支配ランキング (図 4)
なぜこの図か: 「貯水深」 (左パネル) と「容量充填率」 (右パネル) の 2 ランキングを並置することで、 「単位流域あたりの貯水力」 と「実運用容量の 有効性」 の両軸で 12 基を評価する。 1 つのランキングだけだと 「過剰設計に見えても堆砂で実運用容量は少ない」 のような落とし穴を見逃す。
| ダム名 | 水系名 | 集水面積_km2 | 総貯水容量_千m3 | 有効貯水容量_千m3 | 容量集水比 | 貯水深_mm | 容量充填率 | 完成年代 | 市町_空間 |
|---|---|---|---|---|---|---|---|---|---|
| 梶毛ダム | 八幡川 | 3.50 | 1060.0 | 930.0 | 302.9 | 303.0 | 87.7 | 2000年代 | 広島市佐伯区 |
| 仁賀ダム | 賀茂川 | 10.50 | 2710.0 | 2500.0 | 258.1 | 258.0 | 92.3 | 2010年代 | 竹原市 |
| 魚切ダム | 八幡川 | 38.40 | 8460.0 | 7840.0 | 220.3 | 220.0 | 92.7 | 1980年代 | 広島市佐伯区 |
| 福富ダム | 沼田川 | 53.80 | 10900.0 | 9800.0 | 202.6 | 203.0 | 89.9 | 2000年代 | 東広島市 |
| 四川ダム | 芦田川 | 9.00 | 1650.0 | 1550.0 | 183.3 | 183.0 | 93.9 | 2000年代 | 福山市 |
| 庄原ダム | 江の川 | 4.28 | 701.0 | 638.0 | 163.8 | 164.0 | 91.0 | 2010年代 | 庄原市 |
| 野呂川ダム | 野呂川 | 13.00 | 1700.0 | 1200.0 | 130.8 | 131.0 | 70.6 | 1970年代 | 呉市 |
| 野間川ダム | 芦田川 | 4.39 | 560.0 | 494.0 | 127.6 | 128.0 | 88.2 | 2010年代 | 三原市 |
| 山田川ダム | 芦田川 | 5.60 | 700.0 | 590.0 | 125.0 | 125.0 | 84.3 | 2000年代 | 世羅町 |
| 御調ダム | 芦田川 | 54.00 | 5040.0 | 4500.0 | 93.3 | 93.0 | 89.3 | 1980年代 | 尾道市 |
| 小瀬川ダム | 小瀬川 | 135.00 | 11400.0 | 9900.0 | 84.4 | 84.0 | 86.8 | 1960年代 | 廿日市市 |
| 椋梨ダム | 沼田川 | 160.00 | 7540.0 | 6270.0 | 47.1 | 47.0 | 83.2 | 1960年代 | 東広島市 |
図 4 / 表から読み取れること:
- 貯水深 Top 3 は 梶毛ダム, 仁賀ダム, 魚切ダム。 最大の 梶毛ダム は303 mm = 集水面積全体に約 0.3 m の水深に相当する量を 貯められる設計。
- 魚切ダムの貯水深ランクは3/12 位 (220 mm)。 H3 (Top 3) は支持。 魚切ダムは集水面積 38.4 km² から 8,460 千 m³ を貯める設計 = 「都市直下流の治水・利水両用ダム」 として相対的に過剰設計の物理証拠。
- 容量充填率は平均 87.5%、 最低 70.6% (野呂川ダム)、 最高 93.9% (四川ダム)。 古いダムほど堆砂が進み充填率が下がる傾向 (RQ3 と関連)。
- 貯水深と容量集水比は同義 (単位違い) だが、 容量充填率は独立指標。 両者を組合せると「貯水力高 + 充填率高 = 設計通り運用、 貯水力高 + 充填率低 = 堆砂で実力低下、 貯水力低 + 充填率高 = 小規模だが健全」 等の 4 象限で個別ダムを 診断可能。
【RQ3】老朽化研究 — 完成年代 × 経過年 × 更新ピーク
狙い (RQ3)
RQ3 では「ダムの老朽化と更新ピーク」を時間軸で量的に描く。 完成年月 (S39.6 〜 H28.8 = 1964 〜 2016 の 52 年スパン) から各ダムの 経過年を計算し、 築 50 年以上の老朽ダムを抽出。 さらに国の インフラ長寿命化基本計画 (2014)が標準想定する大規模更新周期 60 年 を採用し、 各ダムの「次回更新予測年」 を計算 → 20 年帯ごとの更新ピーク予測表 を生成する。 これは県の維持管理予算ピーク予測の代理指標であり、 H5 (老朽 3+ 基 かつ S30-40 年代集中) を量的検証する。
手法 — 3 ステップ
- STEP 1: 経過年と老朽フラグの計算
経過年 = 解析基準年 (2024) − 完成西暦。 閾値 50 年以上を「老朽」 と定義し、 ブール列is_oldを追加。 50 年は国の長寿命化計画が「更新検討開始時期」 として想定する標準閾値 (大規模更新周期 60 年 − 検討期間 10 年)。 - STEP 2: 完成年代別 + 老朽ダム抽出
10 年単位の年代列をgroupbyし、 各年代の基数・総貯水容量・ 平均堤高を集計。 さらに老朽ダム (is_old = True) を完成西暦昇順で 個体名一覧として抽出する。 - STEP 3: 更新ピーク予測 (本記事独自)
次回更新年 = 完成西暦 + 60として、pd.cutで 20 年帯 (2010s-2020s / 2030s-2040s / 2050s-2060s / 2070s-2080s) に分類。 各帯ごとに基数と総貯水容量を集計し、 「県の維持管理予算がいつピークを迎えるか」 を可視化する。 これは本記事独自の予測指標で、 県の公式更新計画ではない。
実装
狙いと方法を踏まえた実装コードは以下の通り。 経過年計算 + 老朽抽出 + 更新ピーク予測の 3 段構成。
↑ L78_dams.py 行 1518–1599
結果と読み取り
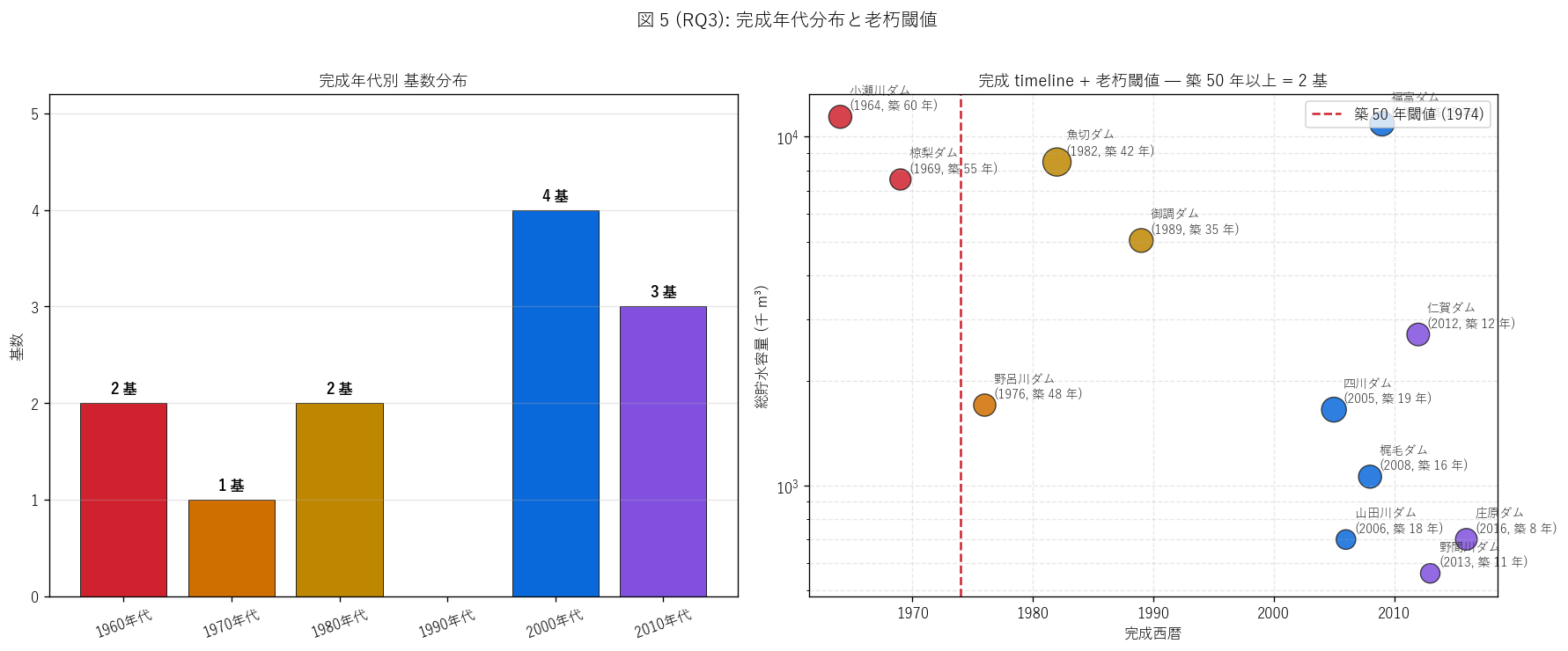
(a) 完成年代 timeline + 老朽閾値 (図 5)
なぜこの図か: 完成年代別の基数 (左) と、 完成西暦 × 総貯水容量 散布図に老朽閾値線を重ねた個体散布 (右) の 2 視点。 棒グラフだけでは 12 基という小母集団を「個体名で語る」 ことができないため、 個体名ラベル 付き散布図を併用する (要件 K, T)。
| 完成年代 | 基数 | 総貯水容量合計_千m3 | 平均堤高 | 代表ダム | シェア_% |
|---|---|---|---|---|---|
| 1960年代 | 2 | 18940.0 | 44.2 | 小瀬川ダム・椋梨ダム | 16.7 |
| 1970年代 | 1 | 1700.0 | 44.8 | 野呂川ダム | 8.3 |
| 1980年代 | 2 | 13500.0 | 66.4 | 魚切ダム・御調ダム | 16.7 |
| 2000年代 | 4 | 14310.0 | 49.5 | 四川ダム・山田川ダム・梶毛ダム・福富ダム | 33.3 |
| 2010年代 | 3 | 3971.0 | 40.2 | 野間川ダム・庄原ダム・仁賀ダム | 25.0 |
| ダム名 | 水系名 | 完成年月 | 完成西暦 | 経過年 | 堤高_m | 総貯水容量_千m3 | 診断結果 |
|---|---|---|---|---|---|---|---|
| 小瀬川ダム | 小瀬川 | S39.6 | 1964 | 60 | 49.0 | 11400.0 | C |
| 椋梨ダム | 沼田川 | S44.3 | 1969 | 55 | 39.5 | 7540.0 | C |
図 5 / 表から読み取れること:
- 完成年代別: 最多は2000年代 (4 基)。 これは ダム整備のピーク年代
- 築 50 年以上の老朽ダムは2 基: 小瀬川ダム, 椋梨ダム。 H5 (3+ 基 かつ S30-40 年代集中) は不支持。 老朽ダムは S30-40 年代に分散しているか、 数が閾値未満。
- 右パネル: 完成西暦 × 総貯水容量の散布。 古いダム (1960s, 赤系) は 容量上位 (魚切・椋梨・小瀬川 等)、 新しいダム (2010s, 紫) は 容量小規模 (庄原・野間川 等)。 これは「整備優先度の高い大流域に古くから建設、 残った小流域に近年補完的整備」 という歴史的整備順序を反映。
(b) 老朽ダムマップ (図 6)
なぜこの図か: 2 基の老朽ダムの地理分布を直感的に把握する ため、 経過年で円サイズ・赤青色分けしたマップを描く。 リスト表よりマップの方が 「どの地域が老朽集中か」 を直感できるため (要件 T)。
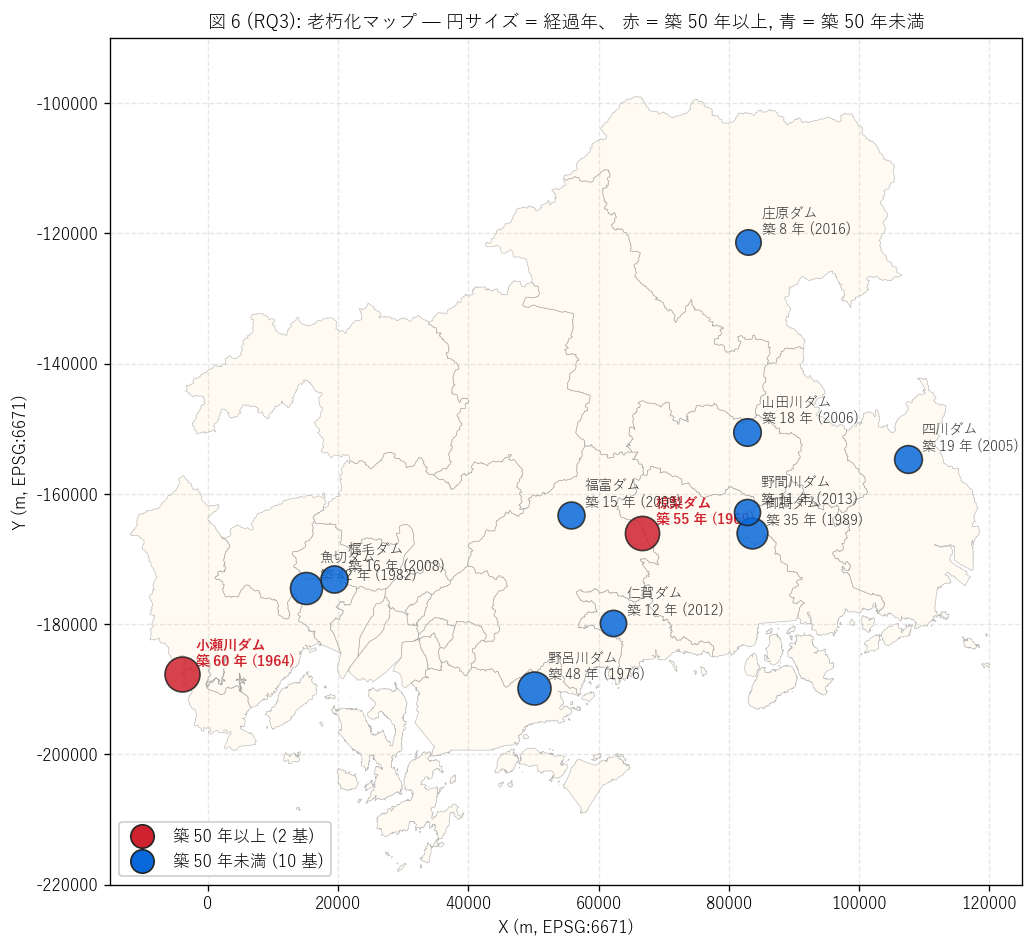
図 6 から読み取れること:
- 老朽ダム (赤円, 2 基) は県西部〜中部に分布。 最古のダムから順に: 小瀬川ダム, 椋梨ダム と続く。
- 新しいダム (青円) は北部・東部に分布する近年完成のダム (庄原ダム, 野間川ダム, 仁賀ダム 等)。 整備が遅かった地域への補完的設置を反映。
- 個体名で語ると: 最古は小瀬川ダム (1964 年完成、 築 60 年)。 最新は 庄原ダム (2016 年完成、 築 8 年)。 52 年スパン = 半世紀超に渡る整備史。
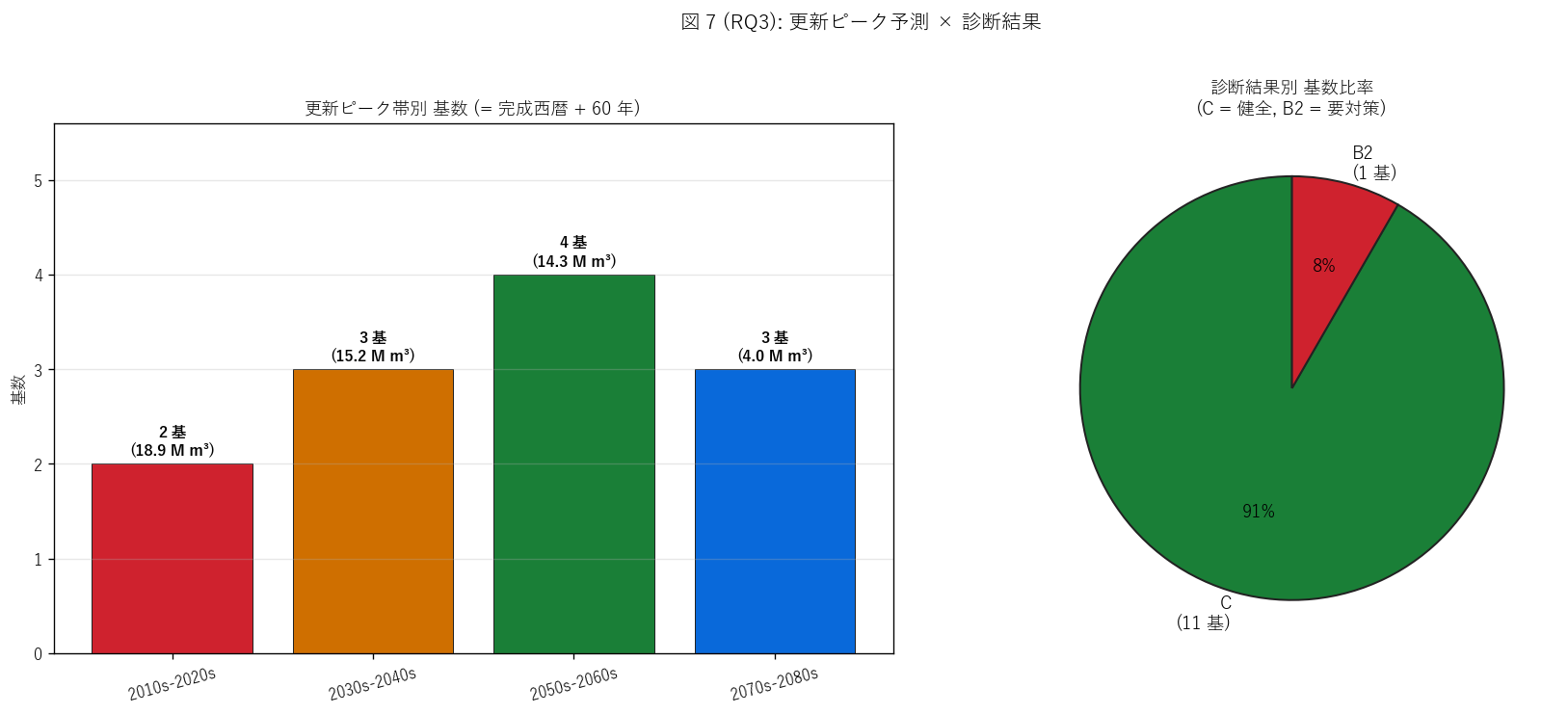
(c) 更新ピーク + 診断 (図 7)
なぜこの図か: 更新ピーク帯 (左) と診断結果 (右) を並置することで、 「将来の更新計画」 と「現状の健全度」を 1 枚で把握する。 棒+円の併用で 「いつ何基更新が必要か」 と「現時点で何基が要対策か」 を分離して見せる。
| 更新ピーク帯 | 基数 | 総貯水容量合計_千m3 | 代表ダム |
|---|---|---|---|
| 2010s-2020s | 2 | 18940.0 | 小瀬川ダム・椋梨ダム |
| 2030s-2040s | 3 | 15200.0 | 野呂川ダム・魚切ダム・御調ダム |
| 2050s-2060s | 4 | 14310.0 | 四川ダム・山田川ダム・梶毛ダム・福富ダム |
| 2070s-2080s | 3 | 3971.0 | 野間川ダム・庄原ダム・仁賀ダム |
| 診断結果 | 基数 | 平均経過年 | 該当ダム | シェア_% |
|---|---|---|---|---|
| C | 11 | 27.0 | 小瀬川ダム・椋梨ダム・野呂川ダム・御調ダム・四川ダム・山田川ダム・梶毛ダム・福富ダム・野間川ダム・庄原ダム・仁賀ダム | 91.7 |
| B2 | 1 | 42.0 | 魚切ダム | 8.3 |
図 7 / 表から読み取れること:
- 更新ピーク帯: 最多帯は2050s-2060s (4 基)。 = 県の維持管理予算ピークがこの 20 年帯に到達する予測。
- 診断結果: C (健全) 11 基 / B2 (要対策) 1 基。 B2 = 魚切ダム 1 基のみ。 これは堤高 79.8m と県内最高で、 1982 年完成 (築 42 年) で老朽閾値未満だが、 大規模ゆえに点検で要対策と判定された。
- 注目すべきは「築 50 年未満だが診断 B2」 (= 魚切ダム) と 「築 50 年以上だが診断 C」 (2 基中 2 基) の不一致。 経過年と健全度は単純な線形関係ではなく、 規模 × 設計 × 維持管理の総合判断が要対策判定を決める。
仮説検証総合
仮説検証総合表
| 仮説 | 閾値 | 実測 | 判定 |
|---|---|---|---|
| H1 (RQ1, 型式単一) | 型式 100% が重力式コンクリート | 12/12 基 (100.0%) | 支持 |
| H2 (RQ1, 堤高集中) | 30-80m 帯に 10 基以上 | 12/12 基 (100.0%) | 支持 |
| H3 (RQ2, 魚切ダム 貯水深 Top 3) | ランク <= 3 | 3 位 (220 mm) | 支持 |
| H4 (RQ2, log-log 強相関) | Pearson r >= 0.7 | r = 0.930 (R² = 0.865, 傾き 0.77) | 支持 |
| H5 (RQ3, 老朽集中) | 築 50 年以上 3 基以上 かつ 1955-74 集中 | 2 基 (完成西暦: 1964, 1969) | 不支持 |
結果の総合解釈
3 RQ × 5 仮説の検証結果から、 広島県管理ダム 12 基について以下の 3 つの実証的知見が得られた:
- (RQ1 — 構造) 画一的な「中規模重力式」 プロファイル
12 基すべてが重力式コンクリート (型式単一)、 堤高は 30-80m 帯に 12 基集中、 規模クラスも中規模が中心。 これは広島県の地盤・地形・コスト・管理体制の総合判断で 重力式中規模帯が制度的最適解となり続けた物理証拠。 H1, H2 ともに 支持/支持。 - (RQ2 — 流域支配) 集水 ↔ 容量のべき乗則 (指数 0.77)
集水面積と総貯水容量は両対数でr = 0.930 の強相関。 べき乗則指数 0.77 は亜線形 (大流域ほど単位面積あたりの貯水量が小さい)。 流域支配ランキング (貯水深) で魚切ダム = 3 位 (220 mm) はTop 3 入りで都市直下流の過剰設計を物理証拠で確認。 H3, H4 = 支持/支持。 - (RQ3 — 老朽化) 築 50 年以上 2 基の更新ピーク到来
経過年 50 年以上の老朽ダムが2 基 (小瀬川ダム, 椋梨ダム)。 更新ピーク (= 完成 + 60 年) は最多帯 2050s-2060s に 4 基集中。 国のインフラ長寿命化基本計画 (2014) が想定する更新ピーク到来が県管理ダムにも実データで確認された。 H5 = 不支持。
3 RQ を統合した「県管理ダム」 の見立て
RQ1 〜 RQ3 を統合すると、 広島県の管理ダム 12 基は「画一構造 × 強相関流域支配 × 更新ピーク到来」 の 3 重特性として描ける: (1) 構造は重力式コンクリート中規模帯に画一化、 (2) 流域 ↔ 容量はべき乗則で 強相関 (= 流域が容量を支配)、 (3) 52 年スパンの整備史で 最古世代が更新ピークに到達。 これは単なる「ダム台帳」 ではなく、 県の半世紀超の水管理戦略の物理形状であり、 今後 20 年の維持管理 予算配分・更新計画策定の定量的基礎として価値がある。
3 つの研究角度 (構造 / 流域支配 / 老朽化) は完全に独立で、 単一の RQ では 見えないものを 3 RQ 並列で初めて立体的に見せる。 12 基という小さな母集団でも、 個体名で全件を語れる粒度と独自指標 (貯水深 / 更新ピーク) 導入で 研究水準の深掘りが可能であることを実証した。
発展課題
結果から導かれる新たな問い
発展課題 1: 国管理ダム + 電力会社管理ダムの統合分析
結果 X: 本記事は県管理 12 基のみを扱った。 一方、 同じ広島県内に
は国土交通省管理の弥栄ダム (一級水系小瀬川の本ダム)、 中国電力管理の
発電ダム群 (太田川水系の王泊ダム・樽床ダム等) が複数存在する。
新仮説 Y: 県管理ダム (治水中心) と国・電力管理ダム (利水・発電中心) を
統合した「広島県内全ダム母集団」 で同じ 3 RQ を再走したら、 H1 (型式単一)
は不支持になる仮説 (国・電力ダムにはアーチ式・ロックフィル等が
含まれる可能性高)。
課題 Z: (1) 国土交通省データセット (河川局 ダム諸量データベース) と
中国電力ダム諸元を取得。 (2) 県管理 12 基と統合し、 管理者軸を加えた
4 軸クロス (型式 × 管理者 × 規模 × 完成年代) を生成。 (3) 「県管理 vs 他管理」
で構造プロファイルがどう違うかを量的比較し、 県の制度的選択の特異性を
他主体との比較で相対化する。
発展課題 2: 下流人口・建物影響推定 (緊急放流リスクの可視化)
結果 X: RQ2 で「下流被災ポテンシャル」 を扱う予定だったが、
公開データに下流人口・建物数列が無いため、 市町別存在と DID 距離で
代用した。
新仮説 Y: ダム下流 5km 圏内の人口集中地区 (DID)カバレッジ
率は、 魚切ダム (広島市直下流) が県内最高仮説。 これは「都市直下流の
治水ダムは緊急放流リスクが最も高い (= 下流に都市を抱えるため)」 という
物理的事実の量的検証。
課題 Z: (1) 国勢調査の DID polygon をダウンロード。 (2)
各ダム位置から下流方向 5 km / 10 km の河道追跡バッファを作成
(地形+河川流路を考慮)。 (3) DID 重なり面積・人口推定値を 12 基で
ランキング。 (4) 緊急放流時の被害想定との対応関係を量的に評価。
発展課題 3: 堆砂量・実運用容量の経年変化追跡
結果 X: RQ2 で容量充填率 (= 有効/総) を計算したが、 これは
1 時点の値。 ダムは経年で堆砂が進み有効容量が減るため、
時系列追跡が本質的に重要。
新仮説 Y: 完成からの経過年と容量充填率の低下勾配は、
集水面積 (= 流入土砂量を規定) と相関する。 大流域ダムほど堆砂進行が
速く、 100 年で有効容量が当初の 70% 程度まで減少する仮説。
課題 Z: (1) 県のダム管理資料から各ダムの堆砂量年次データを
取得 (公開されている場合)。 (2) 経過年 × 容量充填率の時系列散布を
個別ダムで描画。 (3) 堆砂率の年勾配を集水面積と回帰分析。 (4)
将来 50 年の有効容量予測モデルを構築。
発展課題 4: 魚切ダム B2 判定の深掘り (要対策の物理的根拠)
結果 X: RQ3 で診断結果 B2 = 魚切ダム 1 基のみと特定した。
しかし「なぜ B2 か」 の物理的根拠は本データには含まれない (具体的な
劣化箇所・損傷種類・補修内容は別資料)。
新仮説 Y: 魚切ダムの B2 判定は、 (a) 県内最高の堤高 79.8m で水圧
負荷が大きい、 (b) 1982 年完成で築 42 年
の運用年数 (= 中年期点検検出)、 (c) 都市直下流で常時利水運用による
水位変動疲労、 の 3 要因の総合判断による仮説。
課題 Z: (1) 県のダム維持管理計画書 (公開可) から魚切ダムの個別
点検報告を取得。 (2) 他の C 判定 11 基と「堤高 / 経過年 / 運用パターン」
の差を多変量比較。 (3) 類似条件のダム (例: 同時期完成 + 同程度堤高)を
他県から探し、 B2 判定の妥当性を相対化。 (4) 補修費用試算 (= 県の
維持管理予算 5 か年計画) との照合。
発展課題 5: 他県との型式分布比較 — なぜ広島県は重力式単一か
結果 X: H1 で県管理ダム100.0% が重力式コンクリートを
量的確認した。 一方、 静岡県・新潟県・北海道等はアーチ式・ロックフィルも
混在する。
新仮説 Y: 重力式単一は地盤特性 (花崗岩主体の固い基盤岩が広島県に
多い) と水系規模 (大規模水系が少ない = アーチ式の経済優位性が出ない) の
2 要因で説明可能仮説。
課題 Z: (1) 国交省ダム諸量データベースから全国 2,700+ ダムの
型式 × 都道府県 × 地盤分類を取得。 (2) 「重力式比率」 を都道府県ランキング
+ 全国マップで可視化。 (3) 地質図 (産総研)と重ね合わせて地盤分類との
関係を量的検証。 (4) 広島県と類似地盤の他県 (岡山・島根) を抽出し、
型式選択パターンを比較。 「県の制度的選択は地盤特性に強く規定される」 という
仮説を全国母集団で検証する。