L77 道路台帳付図 単独 3 研究例分析
データ取得手順
⚠️ このスクリプトは自動取得に対応していません。以下のデータセットを DoBoX から手動でダウンロードし、data/extras/ 以下に保存してください。
| ID | データセット名 |
|---|---|
| #222 | dataset #222 |
| #333 | dataset #333 |
| #888 | 都市計画区域情報_区域データ_安芸高田市_行政区域 |
| #1445 | 道路台帳付図 |
実行コマンド:
cd "2026 DoBoX 教材"
python -X utf8 lessons/L77_road_register.py
DoBoX のオープンデータは申請不要・商用/非商用とも利用可。
data/extras/ は .gitignore 対象(約 57 GB のキャッシュ)。
スクリプト実行で自動再生成されます。
学習目標と問い
独自用語の定義 (本記事限定)
- 道路台帳付図 (法定用語): 道路法第 28 条が道路管理者に作成・保管を 義務付ける道路台帳の別冊資料の 1 つ。 各路線の道路区域・幅員・ 構造・横断構成・占用物件位置等を縮尺 1:1,000 〜 1:500 程度の帯状図 として記録した法定図面。 道路法施行規則第 4 条の 2 で記載項目が定められ、 道路区域決定 / 工事 / 占用許可 / 境界確定 等の根拠図面として用いられる。
- 路線 (= 道路法上の単位): 国道・県道は路線番号で識別される。 例: 「国道 433 号」 は起点 (廿日市市) から終点 (倉敷市) までの一連を 指す1 路線。 県管理は319 路線。
- 図郭 (Map Sheet, 本記事独自用法): 1 路線の延長を区切った 1 枚分の 地図単位。 1 図郭 = 1 PDF = 1 緯度経度点 (= 図郭中心点) として CSV に 記録される。 県管理道路全体で14,463 図郭。
- 帯状図: 道路台帳付図の標準形式。 路線中心線に沿って細長く描かれる 平面図 + 横断図合成形式。 1 図郭が概ね数百メートル区間を表す。
- 横断構成: 道路を横切る方向の幅員・構造 (車線幅 + 路肩 + 歩道 + 法面 + 排水溝等)。 道路台帳付図には道路規格を表す横断構成図が含まれる。
- 図番接頭辞 (本記事独自分類): 道路台帳図番の先頭 1 文字 (D / N / その他)。 N 系 = 基本図/標準帯状図、 D 系 = 詳細図/分図 (交差点 拡大図等) という解釈が一般的だが、 県側の公式定義は本データセット内には 含まれない。 本記事独自の集計指標。
- 機械可読性 (本記事独自指標): データがプログラムで自動処理可能か の度合い。 5 軸 × 5 段階で評価: 表構造性 / 検索性 / 大規模解析容易性 / プログラム解析 / 学習者再現性。
- 公開設計 (本記事独自概念): データ提供側がどのような形式・粒度・ 補助資料でデータを公開するかという設計選択。 本データセットは 「PDF 本体 (人間可読) + CSV メタ (機械可読)」 の非対称 2 層公開 を採用している。
- 1km 圏内 (本記事独自閾値): 図郭中心点が L72 緊急輸送道路の LineString から 1km 以内に位置すること。 1km は緊急輸送道路の影響圏 (沿線アクセス可能範囲) として一般的な閾値。
- 重要路線優先公開 (本記事独自仮説): 県の道路情報公開戦略が 「防災重要路線 (= L72 緊急輸送道路) を優先的にデジタル化・オープン化する」 という方針を取っているという仮説。 RQ2 で量的検証。
- L72 緊急輸送道路 (背景説明): 県地域防災計画で指定された 4 階層 (630 セグ / 2789 km) の災害時生命線道路。 第 1 次 (高速・幹線国道) + 第 2 次 (主要地方道・国道) が主要骨格 = 431 セグ / 2166 km。 RQ2 で 1km バッファ参照。
- 中山間山地 (本記事独自定義): 庄原市・三次市・安芸太田町・安芸高田市・ 北広島町・神石高原町・世羅町・府中市の 8 市町。 公式分類ではないが、 地形・ 人口密度から「中山間」 と一般に呼ばれる地域。 L72 / L73 / L74 / L75 / L76 と同じ定義を採用。
- 非対称 2 層公開 (本記事独自概念): ZIP 本体 (1.07 GB / PDF 集合 = 人間可読) と CSV 関係資料 (3.40 MB / 表 = 機械可読) のサイズが 322 倍異なり、 機械可読層は本体の 0.309%に過ぎない構造。 H5 で量的検証。
研究の問い (3 RQ)
- RQ1 (主研究): 広島県の道路台帳付図のデータ構造 — 公開単位 (路線/図郭) × 路線種 × 図番接頭辞 × 管理事務所はどう描けるか? 14,463 図郭を 4 軸で集計し、 「県の道路情報公開の物理形状」 を初めて 系統的に記述する。 H1 (国道 路線<10% かつ 図郭>=20%) / H2 (国道 >= 主要 >= 県道 の図郭密度) を検証。
- RQ2 (副研究 1): 道路台帳付図とL72 緊急輸送道路 (630 セグ / 2789 km) との照合 — 重要路線優先公開はどう描けるか? 14,463 図郭が L72 1km 圏内かを sjoin、 「防災重要路線優先公開」 仮説を 量的検証する。 H3 (全L72 1km >=60%) / H4 (国道 > 主要 > 県道 の L72 重なり率) を検証。
- RQ3 (副研究 2): データ公開設計 — 学習者の機械可読性と再利用 可能性はどう評価できるか? 1.1GB ZIP / 14,463 PDF / CSV 関係資料の 3 層構造を学習者目線で評価し、 「PDF は人間可読だが機械可読性が低い」 「CSV 関係資料は機械可読だが PDF 中身は不可」 の非対称公開構造を 量的記述する。 H5 (ZIP/CSV >=300倍) を検証。
仮説 (5)
- H1 (RQ1, 国道優先公開): 路線シェア<5% かつ 図郭シェア>=20%。 国道は路線あたり図郭密度が高く、 詳細図化が優先される仮説。
- H2 (RQ1, 階層的図郭密度): 路線あたり平均図郭数が 国道 >= 主要 >= 県道。 路線種が高位ほど 1 路線あたり詳細図郭が多い 階層構造仮説。
- H3 (RQ2, L72 重なり): 道路台帳付図 1km 圏内 >= 65%。 県の道路情報 公開は防災重要路線を優先する制度方針仮説。
- H4 (RQ2, 路線種 → L72 階層): 路線種別 1km 圏内率は国道 > 主要 > 県道。 路線種が高位ほど L72 と地理的に重なる階層構造仮説。
- H5 (RQ3, 機械可読の非対称): ZIP/CSV >= 300 倍。 メタデータ (機械可読) は本体 (人間可読 PDF) の0.3% 以下であり、 学習者にとって 機械的な中身解析は事実上不可能、 という非対称公開構造仮説。
到達点
本記事を読み終えると、 (1) 県管理道路 319 路線 / 14,463 図郭の データ構造を路線種・管理事務所・図番接頭辞の 3 軸で完全に俯瞰、 (2) L72 緊急輸送道路との1km 重なり率 64.1%を路線種別に分解し 「重要路線優先公開」 の量的証拠を獲得、 (3) ZIP 1.07 GB / CSV 3.40 MB の非対称 2 層公開構造を機械可読性 5 軸スコアで定量化、 という 3 段階の知識が獲得できる。 これにより県の道路情報 オープンデータ戦略の物理形状・防災連携・公開設計思想が研究者視点で見えるよう になる。
使用データ
本研究で使う 1 つの dataset (2 リソース) を以下の表に示す。 本データセットは「PDF 本体 (1.1GB) + 関係資料 CSV (3.4MB)」 という非対称 2 層構造で公開されている。 本記事では関係資料 CSV のみを主データ として用い、 PDF 本体 (ZIP) は取得しない (1.1GB を学習者環境で扱うのは 非現実的、 また RQ1〜RQ3 の問いは CSV のメタ情報で完結するため)。
データセット仕様
| 項目 | 値 |
|---|---|
| データセット ID | DoBoX #1445 |
| データセット名 | 道路台帳付図 |
| 公開組織 | 広島県 道路河川管理課 |
| リソース数 | 2 (ZIP 本体 + 関係資料 CSV) |
| ライセンス | クリエイティブ・コモンズ表示 (CC-BY) |
| 更新日 (本記事時点) | 2023-11-22 |
| 対象路線種 | 国道 / 主要地方道 / 一般県道 (= 県管理 3 路線種) |
| 対象路線数 | 319 路線 |
| 対象図郭数 (PDF) | 14,463 図郭 |
| 総延長 (推定) | 県管理道路約 4,000 km (路線種別公開なし) |
| ファイル形式 | PDF (帯状図, 1:500〜1:1,000) |
2 リソースの内訳
| リソース | 形式 | サイズ | 役割 | 本記事での扱い |
|---|---|---|---|---|
| resource 93894 (道路台帳付図_2023-11-22) | ZIP (PDF 集合) | 1.07 GB (14,463 PDF) | 帯状図本体 (人間可読) | 取得しない (1.1GB は教材外) |
| resource 93895 (道路台帳付図_関係資料_2023-11-22) | CSV (UTF-8 BOM) | 3.40 MB (14,463 行 × 9 列) | 路線・図番・位置のメタ表 (機械可読) | 本記事の主データ |
関係資料 CSV の列定義
| 列名 | 例 | 意味 |
|---|---|---|
| 路線種 | 国道 / 主要地方道 / 一般県道 | 道路法上の路線分類 (3 種) |
| 路線名 | 433号 / 三原東城線 | 路線の正式名称 (国道は番号、 県道は地名+地名形式) |
| 路線番号 | 433 / 4032 | 路線番号 (国道は同名の数字、 県道は 4000 番台) |
| 管理事務所名 | 西部建設事務所 / 東部建設事務所三原支所 | 路線を管理する県の出先機関 (9 区分) |
| 道路台帳図番 | D251-4 / N175 / N182-1 | 図郭の識別番号 (D=詳細図, N=基本図, 後ろは連番) |
| ファイル | /01西部建設事務所/01r3433一般国道433号/...pdf | ZIP 内 PDF への相対パス |
| 緯度 | 34.80880 | 図郭中心点の WGS84 緯度 |
| 経度 | 132.70933 | 図郭中心点の WGS84 経度 |
| 利用規約 | https://data.hiroshima-dobox.jp/.../利用規約.pdf | 本データの利用規約 PDF (全行で同一) |
形式特性の注意点
- 1 行 = 1 図郭 = 1 PDF: CSV は ZIP 内 PDF へのインデックスとして 機能。 行数 (14,463) と PDF 数は完全に一致。
- 緯度経度は図郭中心点: 帯状図は線状の路線範囲を表すが、 CSV では 代表点 1 点だけ提供。 「沿線 N km」 の形では公開されない。
- 同一座標の重複: 363 行が他行と緯度経度完全一致。 これは D 系 (詳細図/分図) が N 系 (基本図) と同じ場所を別解像度で記録するため。
- 路線重複: 国道 432 号は4 つの管理事務所にまたがる (尾道〜 広島〜浜田)。 1 路線 = 必ずしも 1 事務所ではない。
- 路線番号の体系: 国道 = 同名の数字 (433, 432, 375 等)、 主要地方道 = 4-66 番台、 一般県道 = 4000 番台。
- 停車場線の特殊事例: 一般県道のうち「広停車場線」 「大竹停車場線」 等 は1 図郭のみの極短路線 (= JR 駅前広場の県道扱い)。 県管理路線 319 のうち約 30 路線が 1〜3 図郭。
- 更新時期は 2023-11-22。 道路台帳は道路法上 5 年ごとの更新義務がある が、 オープンデータ更新は不定期。
ダウンロード
本記事の再現に必要なすべてを直リンクで提供する。 HTML だけ読めば学習者が完全再現できることが目標 (要件 A)。
生データ (DoBoX 1 dataset, 2 リソース)
- dataset 1445: 道路台帳付図
- resource 93895 (関係資料 CSV) 直 DL — 約 3.40 MB (UTF-8 BOM) ← 本記事の主データ
- resource 93894 (ZIP 本体) ページ — 約 1.07 GB / 14,463 PDF (本記事では未取得)
このスクリプト本体
- L77_road_register.py — 1 ファイルで完結 (8 図 + 13+ 表生成)
中間 CSV (本記事生成、 再利用可)
- L77_all_figures.csv — 全 14,463 図郭 (基本属性 + 派生列 + L72 結合 計 約 18 列)
- L77_rank_summary.csv — 路線種別 集計 (RQ1)
- L77_office_summary.csv — 管理事務所別 集計 (RQ1)
- L77_prefix_summary.csv — 図番接頭辞別 集計 (RQ1)
- L77_route_top15.csv — 路線あたり図郭数 Top 15 (RQ1)
- L77_route_bottom10.csv — 路線あたり図郭数 Bottom 10 (RQ1)
- L77_geo_class.csv — 地理クラス別 集計 (RQ1)
- L77_rank_x_prefix.csv — 路線種 × 図番接頭辞 クロス (RQ1)
- L77_l72_by_rank.csv — 路線種別 L72 1km 圏内率 (RQ2)
- L77_l72_status.csv — L72 階層別 1km 圏内 (RQ2)
- L77_l72_distance_stats.csv — L72 最近接距離分布統計 (RQ2)
- L77_machine_readability.csv — 機械可読性 5 軸評価 (RQ3)
- L77_density_compare.csv — 路線種別 図郭密度比較 (RQ3)
- L77_overall.csv — 全体サマリ
- L77_hypothesis_check.csv — H1〜H5 仮説検証結果
図 (PNG, 直 DL 可)
{kind=link}
【RQ1】データ構造研究 — 路線×事務所×図番の 4 軸
狙い (RQ1)
RQ1 では「県の道路情報公開の物理形状」を初めて系統的に記述する。 具体的には 14,463 図郭 / 319 路線を路線種 × 管理事務所 × 図番 接頭辞 × 路線あたり図郭密度の 4 軸で集計し、 「どの路線種にどれだけの 図郭があり、 どの事務所が管理し、 どの図番が多いか」 を 1 枚で俯瞰できる ようにする。 H1 (国道 路線<10% かつ 図郭>=20%) は「国道は路線数では 少数派だが図郭としては優先公開される」 仮説、 H2 (国道 >= 主要 >= 県道 の図郭密度) は「路線種 = 整備優先度」 という階層構造を量的検証する。
手法 — 4 ステップ
- STEP 1: CSV パース + 列名正規化
関係資料 CSV (UTF-8 BOM, 14,463 行 × 9 列) をread_csv()で 読込み、 列名前後の空白を除去。 「路線番号」 をpd.to_numeric()で 整数化。 緯度経度欠損行 (今回は 0 件) を除外。 - STEP 2: 管理事務所名を 9 区分に正規化 (本記事独自分類)
CSV の「管理事務所名」 列は9 種類のラベルを含む (西部本所 / 西部呉支所 / 西部廿日市支所 / 西部安芸太田支所 / 西部東広島支所 / 東部本所 / 東部三原 支所 / 北部本所 / 北部庄原支所)。 文字列先頭マッチで頑健に分類する独自関数office_top()を実装。 - STEP 3: 図番接頭辞 (D/N/その他) を判定 (本記事独自分類)
道路台帳図番の先頭 1 文字 (D / N / A / B / C / E / G / H / I) から D 系 (詳細図/分図) / N 系 (基本図/標準) / その他の 3 分類に集計。 D 系 = 詳細図、 N 系 = 基本図 という解釈は本記事独自で、 公式定義は データセット内に含まれない。 - STEP 4: GeoDataFrame 化 + EPSG:6671 投影 + 4 軸集計
緯度経度 →shapely.geometry.Point→ GeoDataFrame に変換、to_crs("EPSG:6671")で平面直角第 III 系に投影 (距離計算で 正確になる)。 その後、 路線種・管理事務所・図番接頭辞・路線種×図番接頭辞 の 4 集計をgroupby()で生成。
実装
狙いと方法を踏まえた実装コードは以下の通り。 列名 (路線種・路線名・路線番号・ 管理事務所名・道路台帳図番・ファイル・緯度・経度) は CSV からそのまま使い、 独自分類列のみ追加する設計とした。
↑ L77_road_register.py 行 1377–1549
結果と読み取り
(a) 路線種別 4 軸集計
なぜこの表か: 路線種 (国道 / 主要地方道 / 一般県道) ごとの図郭シェア vs 路線シェア vs 路線あたり図郭密度を一覧することで、 「公開の偏り」 を 路線数と図郭数の不一致として量的に把握する。
| 路線種 | 図郭数 | 路線数 | 図郭シェア_% | 路線シェア_% | 路線あたり図郭密度 |
|---|---|---|---|---|---|
| 国道 | 3356 | 18 | 23.20 | 5.64 | 186.4 |
| 主要地方道 | 4822 | 69 | 33.34 | 21.63 | 69.9 |
| 一般県道 | 6285 | 232 | 43.46 | 72.73 | 27.1 |
表から読み取れること:
- 国道は18 路線 (5.64%)と少数派ながら、 図郭は3,356 図 (23.2%)を占める。 H1 = 国道優先公開仮説は支持。
- 路線あたり図郭密度は国道 186.4 ≫ 主要地方道 69.9 ≫ 一般県道 27.1 と、 路線種が高位ほど 1 路線あたり図郭が 多いという階層構造が明確に見える。 H2 = 階層的図郭密度仮説は 支持。
- 一般県道は232 路線と 最多だが、 1 路線あたり平均 27.1 図郭と支線型。 停車場線等の 1 図郭路線が多数含まれることが原因 (後の Bottom 10 で詳述)。
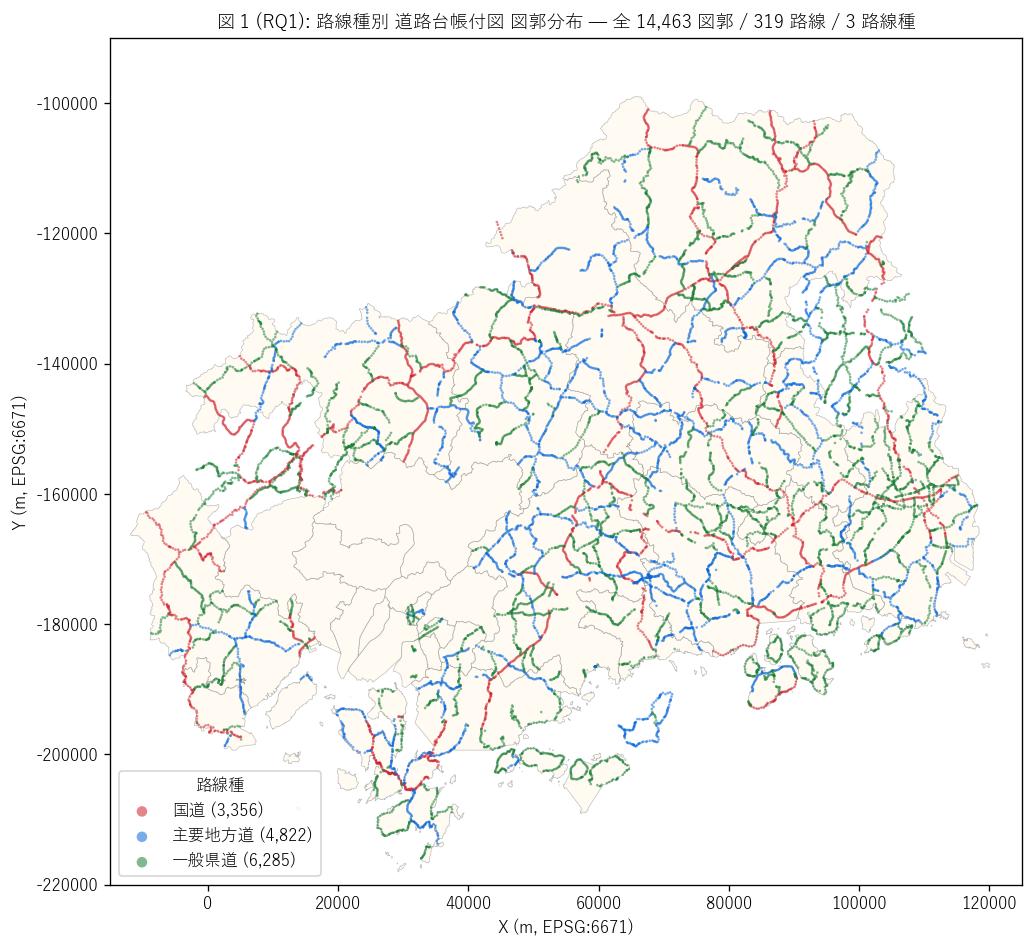
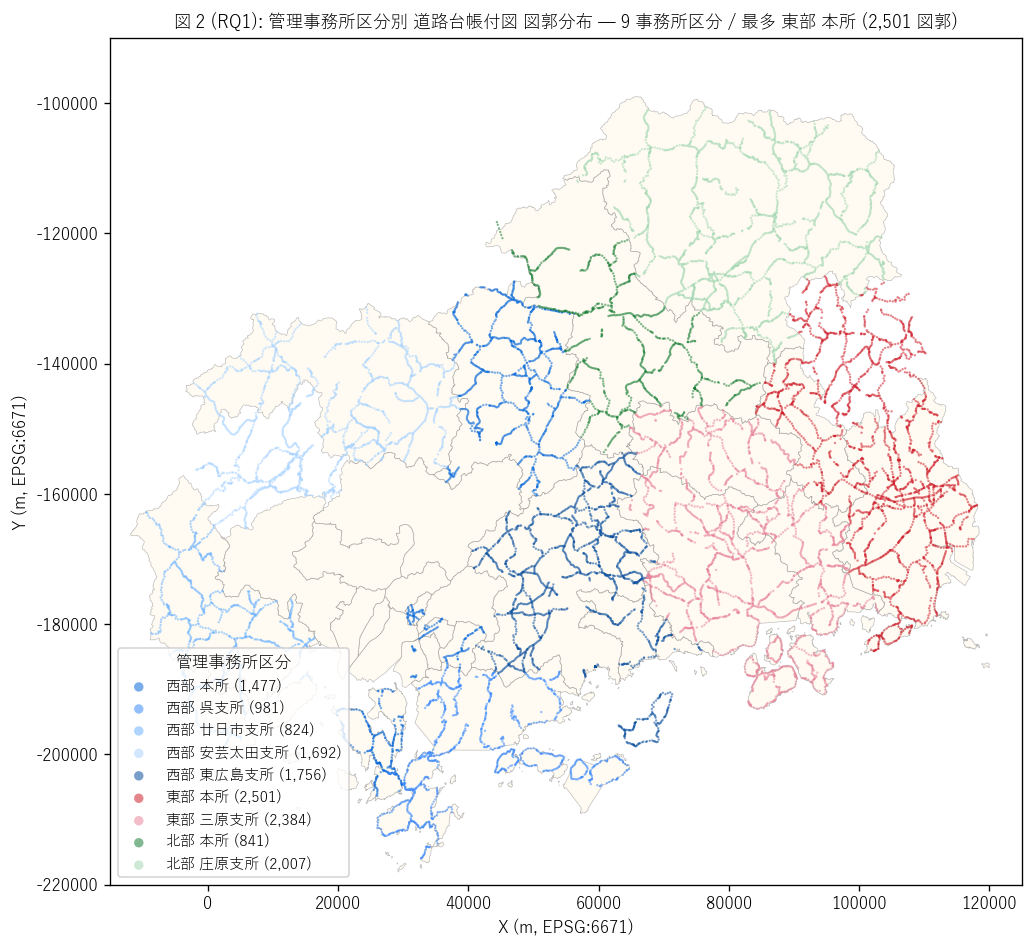
(b) 管理事務所別 (図 1, 図 2)
なぜこの図か: 14,463 図郭の地理分布を路線種別 / 管理事務所別 の 2 視点で示すことで、 「どの地域・どの組織が管理しているか」 という 行政区分の物理形状を可視化する。 棒グラフではなく地図にする理由は、 県管理道路網が沿岸都市部に集中・中山間山地に薄く広がるという分布特性を 1 枚で示すため (要件 T)。
図 1 から読み取れること:
- 国道 (赤) は幹線路線として県内をほぼ網羅。 中国山地を東西に貫く 国道 432・433 号、 南北を貫く 375 号などが目立つ線として浮かび上がる。
- 主要地方道 (青) は都市間連絡路線として国道網の隙間を埋める形で分布。 尾道〜世羅、 広島〜三次など。
- 一般県道 (緑) は支線・集落間連絡として面的に分布し、 中山間山地の 集落道路網を構成する。
| 事務所区分 | 図郭数 | 路線数 | 路線種数 | シェア_% |
|---|---|---|---|---|
| 西部 本所 | 1477 | 47 | 3 | 10.21 |
| 西部 呉支所 | 981 | 27 | 3 | 6.78 |
| 西部 廿日市支所 | 824 | 26 | 3 | 5.70 |
| 西部 安芸太田支所 | 1692 | 34 | 3 | 11.70 |
| 西部 東広島支所 | 1756 | 45 | 3 | 12.14 |
| 東部 本所 | 2501 | 79 | 3 | 17.29 |
| 東部 三原支所 | 2384 | 60 | 3 | 16.48 |
| 北部 本所 | 841 | 20 | 3 | 5.81 |
| 北部 庄原支所 | 2007 | 47 | 3 | 13.88 |
図 2 / 表から読み取れること:
- 最多の管理事務所は東部本所 (2,501 図郭)で 福山市周辺 + 内陸部を担当。
- 北部建設事務所庄原支所 (2,007 図郭) と 西部建設事務所安芸太田支所 (1,692 図郭) は中山間山地を担当し、 路線数の割に図郭数が多い (= 山道は曲がりが多く 帯状図 1 枚あたりの距離が短い)。
- 西部建設事務所呉支所は981 図郭で 島嶼部 (江田島・倉橋等) を含むため、 短い循環線が多い特徴を持つ。
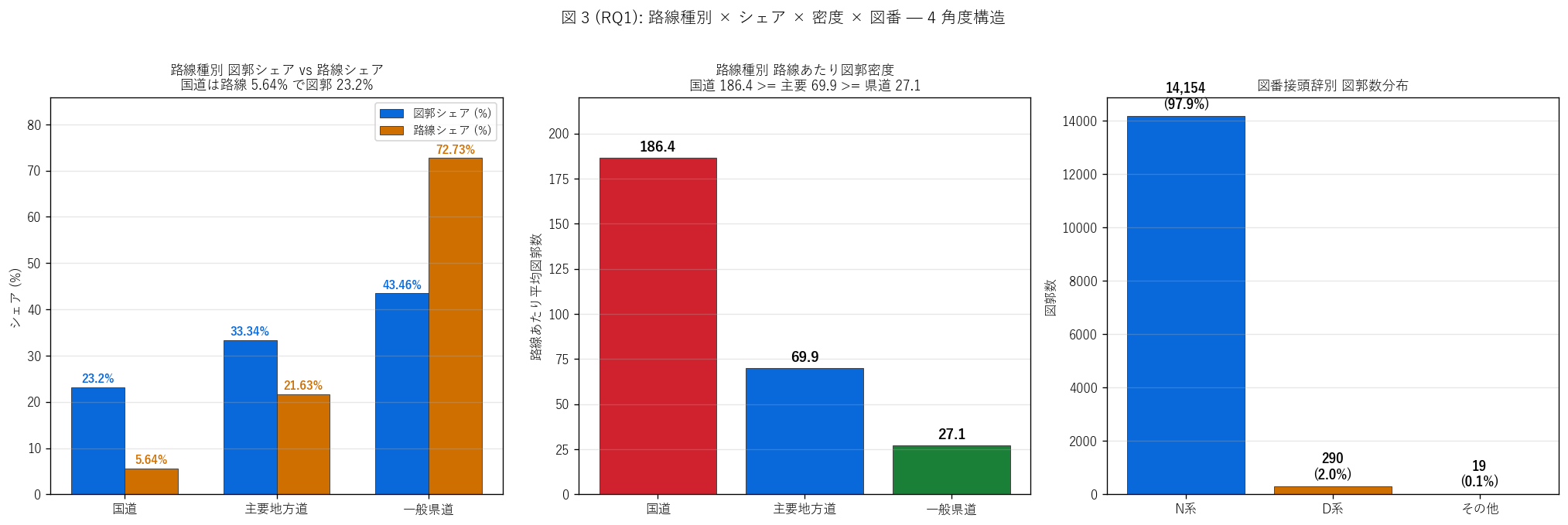
(c) シェア × 密度 × 図番 3 角度 (図 3)
なぜこの図か: 路線種別の図郭シェア vs 路線シェアの不一致を 左パネルで一目で示し、 中パネルで密度の階層、 右パネルで図番接頭辞の 分布 (D 系 vs N 系) を見せる 3 連結。 H1, H2 + 図番判定の補強根拠。
| 図番接頭辞 | 図郭数 | シェア_% |
|---|---|---|
| N系 (基本図/標準) | 14154 | 97.86 |
| D系 (詳細図/分図) | 290 | 2.01 |
| その他 (A/B/C/E/G/H/I 系) | 19 | 0.13 |
図 3 / 表から読み取れること:
- 左パネル: 国道は路線シェア 5.64%に対し図郭シェア 23.2% = 図郭側のシェアが約 4 倍。 H1 が支持される 物理的根拠。
- 中パネル: 路線あたり図郭密度の階層 (186.4 / 69.9 / 27.1) が明確。 H2 支持。
- 右パネル: N 系 (基本図) が 14,154 図 (97.86%) で支配的。 D 系 (詳細図/分図) は290 図のみ = 県管理道路網の大半は標準帯状図 1 枚で済み、 詳細分図は限定的。
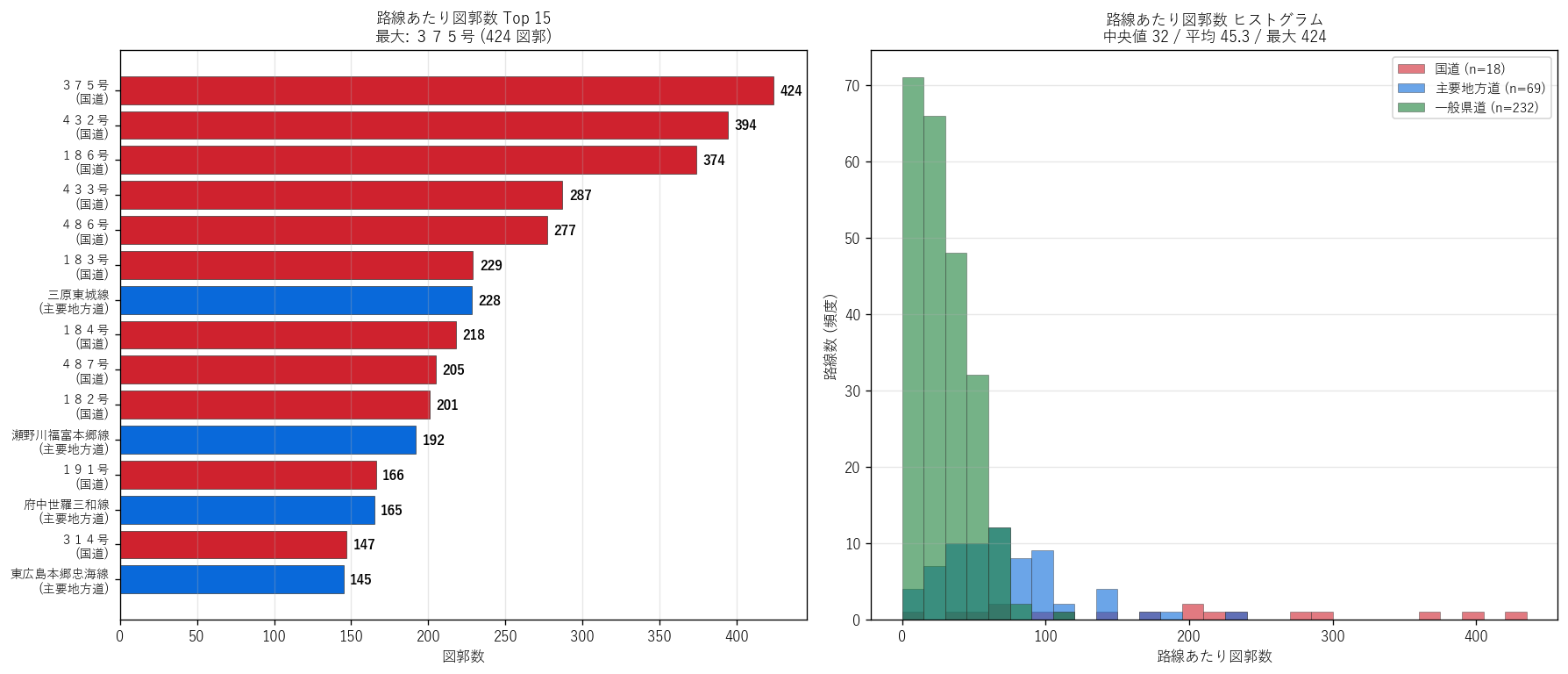
(d) 路線あたり図郭数 分布 (図 4)
なぜこの図か: 路線あたり図郭数の分布形状を Top 15 ランキング + ヒストグラムの 2 視点で示すことで、 「ロングテール vs ヘビーテール」 の判別と、 路線種別の分布形状の違い (= 整備優先度の階層) を量的に把握する。
| 路線種 | 路線名 | 図郭数 |
|---|---|---|
| 国道 | 375号 | 424 |
| 国道 | 432号 | 394 |
| 国道 | 186号 | 374 |
| 国道 | 433号 | 287 |
| 国道 | 486号 | 277 |
| 国道 | 183号 | 229 |
| 主要地方道 | 三原東城線 | 228 |
| 国道 | 184号 | 218 |
| 国道 | 487号 | 205 |
| 国道 | 182号 | 201 |
| 主要地方道 | 瀬野川福富本郷線 | 192 |
| 国道 | 191号 | 166 |
| 主要地方道 | 府中世羅三和線 | 165 |
| 国道 | 314号 | 147 |
| 主要地方道 | 東広島本郷忠海線 | 145 |
| 路線種 | 路線名 | 図郭数 |
|---|---|---|
| 一般県道 | 備後西城停車場線 | 1 |
| 一般県道 | 備後落合停車場線 | 1 |
| 一般県道 | 安登停車場線 | 1 |
| 一般県道 | 安浦停車場線 | 1 |
| 一般県道 | 大竹停車場線 | 1 |
| 一般県道 | 大竹美和線 | 1 |
| 一般県道 | 向洋停車場線 | 1 |
| 一般県道 | 大乗停車場線 | 1 |
| 一般県道 | 新市停車場線 | 1 |
| 一般県道 | 広停車場線 | 1 |
図 4 / 表から読み取れること:
- Top 15 のうち11 件が国道で、 最大は国道 375 号 (424 図郭)。 国道 375 号は南北縦貫国道で 呉市から島根県境まで延長 200km 超を424 枚の 帯状図でカバー。
- Bottom 10 はすべて「〇〇停車場線」の支線型一般県道で、 1 路線 = 1 図郭。 これは JR 駅前広場〜駅前ロータリーの数百メートル区間を県道 指定した最短路線。
- 右ヒストグラム: 一般県道 (緑) は1〜30 図郭の左側に集中、 国道 (赤) は 100〜400 図郭の右側に分布。 路線種ごとに分布形状が完全に異なる 二峰性 (= 階層構造の量的可視化)。
(e) 地理クラス × 路線種 クロス (図 8)
なぜこの図か: 路線種別の図郭分布が地理 (平野 / 中山間 / 沿岸島嶼) ごとにどう違うかを積み上げ棒グラフで示し、 「中山間に多い路線種 vs 平野 都市部に多い路線種」 の偏在を量的に明らかにする。
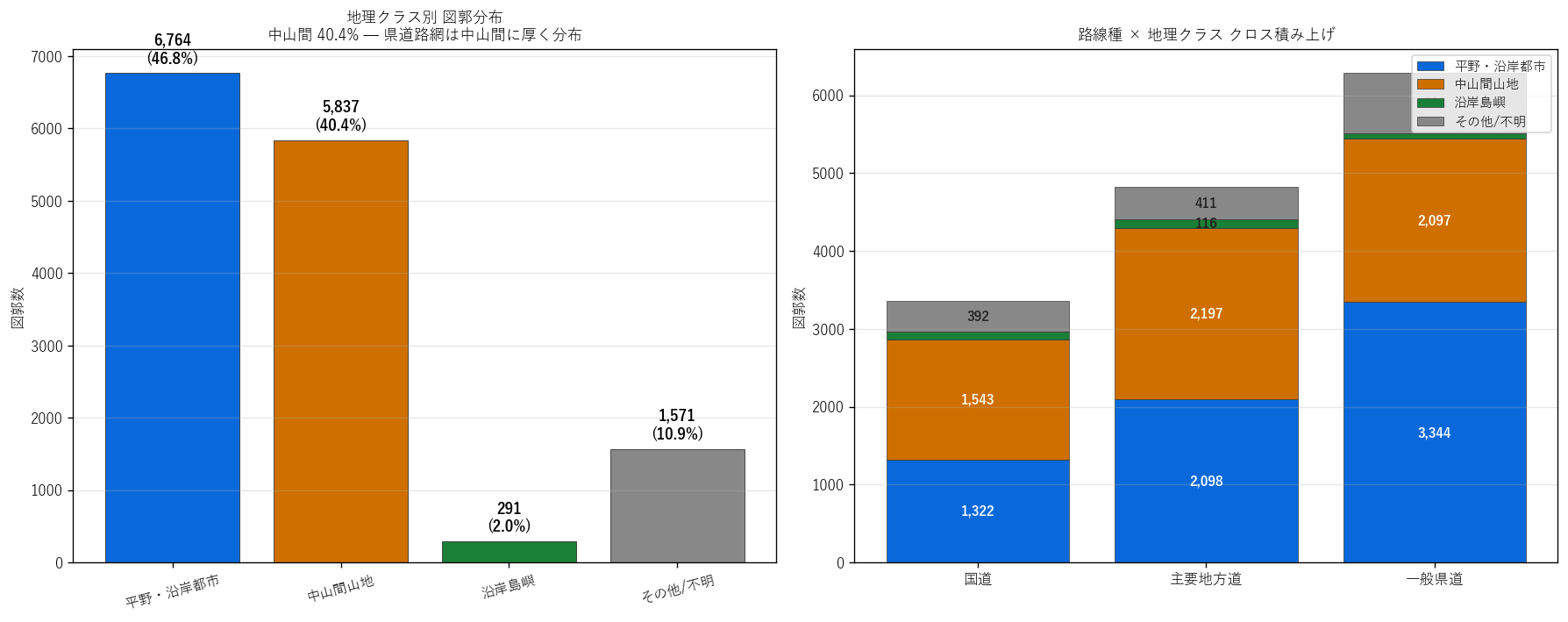
| 地理クラス | 図郭数 | 路線数 | シェア_% |
|---|---|---|---|
| 平野・沿岸都市 | 6764 | 194 | 46.8 |
| 中山間山地 | 5837 | 124 | 40.4 |
| その他/不明 | 1571 | 64 | 10.9 |
| 沿岸島嶼 | 291 | 8 | 2.0 |
図 8 / 表から読み取れること:
- 中山間山地は5,837 図郭 (40.4%)で、 平野・沿岸 都市部 (6,764 図郭) に次ぐ第 2 位。 面積では中山間が県の約半分だが、 図郭シェアでは平野部に劣る = 平野部の 路線網の方が密。
- 路線種の地理偏り: 国道は中山間にも比較的多く分布、 一般県道は平野部の 支線として分布が偏る傾向 (右パネル)。
【RQ2】L72 緊急輸送道路との照合研究 — 重要路線優先公開
狙い (RQ2)
RQ2 では「重要路線優先公開」仮説を量的検証する。 県地域防災計画で 指定されたL72 緊急輸送道路 (630 セグ / 2789 km)を 基準線として、 道路台帳付図 14,463 図郭が L72 の 1km 圏内にどれだけ重なるか を空間結合で量化する。 H3 (全L72 1km >=60%) は中心仮説、 H4 (国道 > 主要 > 県道 の重なり率) は「路線種 = L72 重要度」 の階層構造仮説。
手法 — 5 ステップ
- STEP 1: L72 NDJSON 風 JSON のパース
L72 の 4 階層 JSON は厳密な JSON ではなく、 dict / array が「,」 区切りで 並ぶ NDJSON 風形式 (= JSON.parse 不可)。 テキストを[と]でラップしてからjson.loadsでパースする工夫が必要。 - STEP 2: LineString GeoDataFrame の構築
各セグメントの点列 ({e: 経度, d: 緯度}) をshapely.LineStringに 変換、 階層 ID + GeoDataFrame に統合 →to_crs("EPSG:6671")で 平面直角第 III 系へ投影 (距離が m 単位で正確になる)。 - STEP 3: 1km バッファの生成
第 1〜2 次のみ (431 セグ) と全階層 (630 セグ) についてbuffer(1000)を適用 →union_all()で 1 つの multi-polygon に統合。 14,463 POINT × 1 ポリゴンの intersects は ~5 秒で完了する設計。 - STEP 4: 14,463 図郭 × バッファ判定
各 POINT に対しp.intersects(buf)で True/False を判定、 0/1 列として gdf に追加。 これで「L72 1km 圏内」 フラグが完成。 - STEP 5: 最近接 L72 距離 (sindex 活用)
各図郭の最近接 L72 セグメントまでの距離 (km)を計算。 全 14,463 × 630 セグメントの全件距離計算は ~3 分かかるため、sindexで 5km bbox に絞ってからp.distance(line)を計算する高速化を 実装 (~10 秒以内)。
実装
狙いと方法を踏まえた実装コードは以下の通り。 NDJSON 風パース + バッファ intersects + sindex 高速距離計算の 3 段構成。
↑ L77_road_register.py 行 1602–1712
結果と読み取り
(a) 図郭 + L72 重ね合わせマップ (図 5)
なぜこの図か: L72 の 4 階層 (赤 / 青 / 緑 / 橙) を背景線として描画し、 道路台帳付図 14,463 図郭をL72 1km 圏内 (緑) vs 圏外 (赤)で色分け点で 重ね合わせることで、 「重要路線優先公開」 仮説の空間的真偽を 1 枚で示す。 棒グラフではなく重ね合わせマップにする理由は、 「圏内・圏外の図郭がどこに 分布するか」 という地理的偏在を見るため (要件 T)。
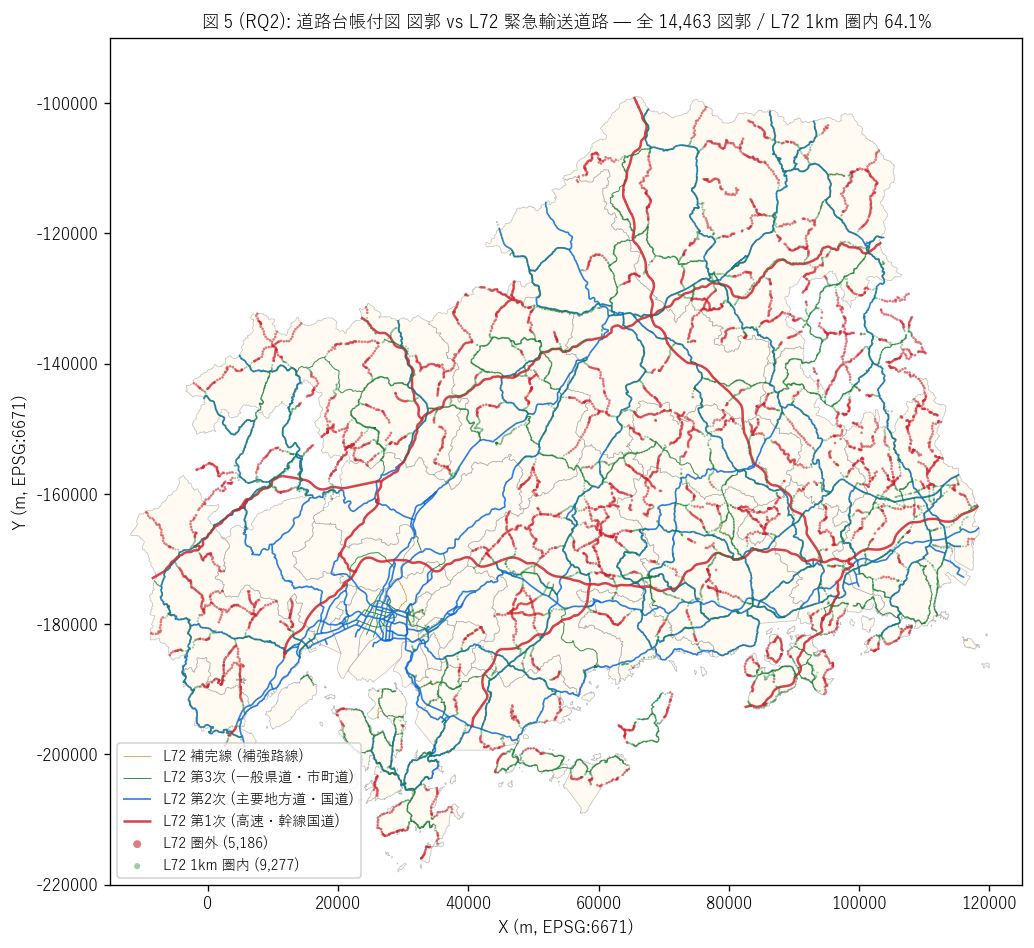
| l72_status | 図郭数 | シェア_% |
|---|---|---|
| 第1〜2次 1km 圏内 | 7120 | 49.2 |
| 第3〜4次 1km 圏内のみ | 2157 | 14.9 |
| 圏外 (>1km) | 5186 | 35.9 |
図 5 / 表から読み取れること:
- L72 第 1〜2 次 1km 圏内が7,120 図郭 (49.2%)、 全階層 1km 圏内が9,277 図郭 (64.1%)。 H3 (全L72 1km >=60%) は支持。
- 圏外 (赤) は中山間山地の支線・島嶼部の循環線が中心 = 防災重要路線から 外れる「ローカル道路網」。 これらは緊急輸送道路から距離があるため 災害時の支援アクセスが遠い特徴を持つ。
- 圏内 (緑) は L72 沿線に厚く分布 = 県の道路情報公開と防災網がほぼ一致。
(b) 路線種別 L72 1km 圏内率 + 距離分布 (図 6)
なぜこの図か: 路線種ごとの L72 1km 圏内率の階層構造を左パネルで 示し、 右パネルで距離分布の路線種別差をヒストグラムで補強する 2 視点。 H4 を量的に証明する中心図。
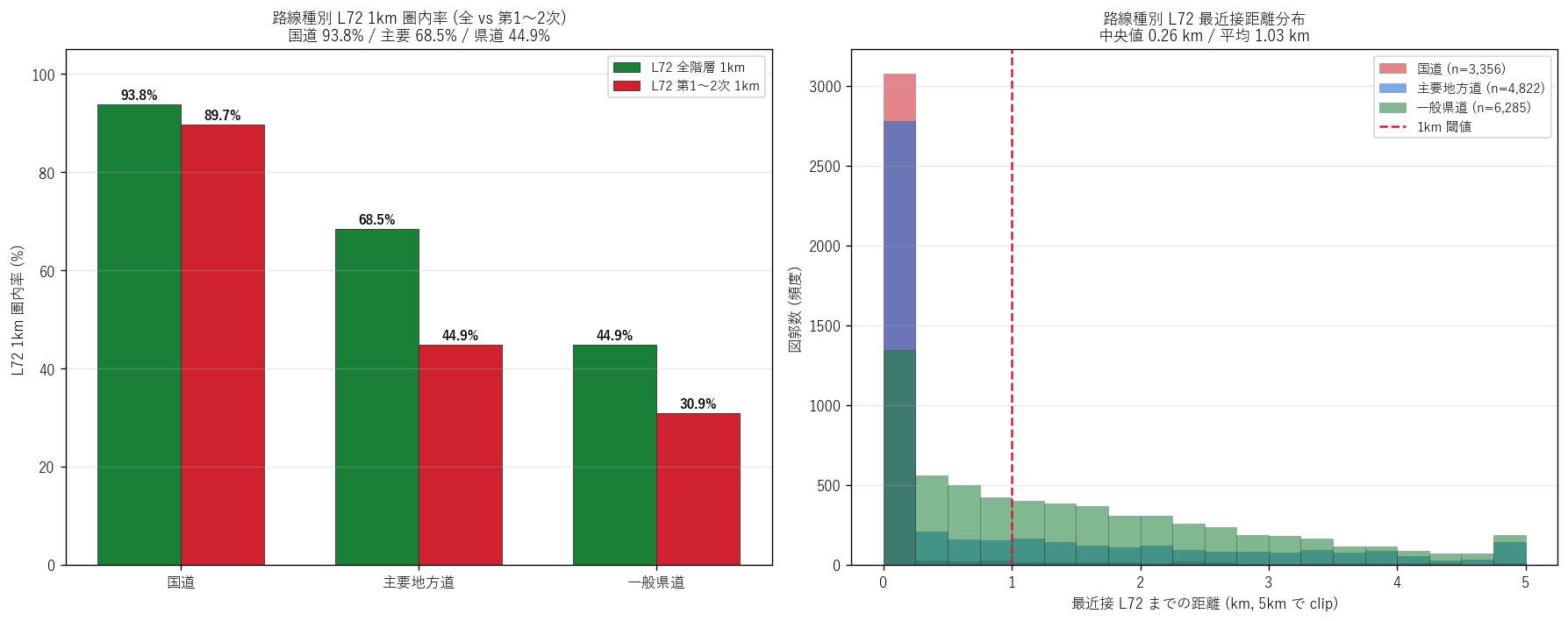
| 路線種 | 図郭数 | L72_全1km圏内 | L72_第12次1km圏内 | 全1km率_% | 第12次1km率_% |
|---|---|---|---|---|---|
| 国道 | 3356 | 3149 | 3011 | 93.8 | 89.7 |
| 主要地方道 | 4822 | 3305 | 2165 | 68.5 | 44.9 |
| 一般県道 | 6285 | 2823 | 1944 | 44.9 | 30.9 |
| 統計 | 値 |
|---|---|
| 最小 (km) | 0.000 |
| 25% | 0.006 |
| 中央 (50%) | 0.260 |
| 75% | 1.708 |
| 90% | 3.201 |
| 最大 (km) | 9.547 |
| 平均 (km) | 1.027 |
図 6 / 表から読み取れること:
- 路線種別 L72 全階層 1km 圏内率は国道 93.8% / 主要地方道 68.5% / 一般県道 44.9%。 H4 (国道 > 主要 > 県道) は 支持。
- 国道はほぼ全てが L72 と重なる (= 国道はほぼすべてが緊急輸送道路でも ある)。 主要地方道は約 68.5% で部分一致、 一般県道は44.9% で多くが圏外。
- 距離分布: 中央値0.26 km、 平均 1.03 km。 国道 (赤) は 0〜0.5km に集中、 一般県道 (緑) は 0〜5km に幅広く分布。 路線種が L72 距離を強く規定する。
- 距離 90% タイル = 3.2 km = 9 割の図郭は L72 から3.2 km 以内に位置。 県道路網全体が L72 網と強く相関している物理形状。
【RQ3】データ公開設計研究 — 機械可読性の非対称評価
狙い (RQ3)
RQ3 では「公開設計の機械可読性評価」を行う。 道路台帳付図データセットは 2 つのリソース (ZIP 本体 1.1GB / CSV 関係資料 3.4MB) から成る非対称構造で 公開されており、 それぞれが異なる利用者層に向けて設計されている。 ZIP は 人間が PDF で道路区域・幅員を確認するための人間可読層、 CSV は機械的に 索引・統計・空間結合するための機械可読層。 これを5 軸 × 5 段階で 評価し、 学習者にとっての再利用可能性を量化する。 H5 (ZIP/CSV >=300倍) は 「機械可読層は本体の 0.3% 以下」 という非対称性の中心仮説。
手法 — 3 ステップ
- STEP 1: リソース容量実測
ZIP 本体 (1,147,323,651 bytes = 1.07 GB) と関係資料 CSV (3,560,806 bytes = 3.40 MB) のサイズを実測比較。 比 = 322 倍、 CSV シェア = 0.309%。 - STEP 2: 機械可読性 5 軸評価 (本記事独自指標)
表構造性 / 検索性 / 大規模解析容易性 / プログラム解析 / 学習者再現性の 5 軸を 1 (不可) 〜 5 (容易) で評価。 PDF 集合は表構造性 1 (= 帯状図は OCR + 図形解析が必要)、 CSV は表構造性 5 (= pandas で即時)。 評価は本記事独自で、 公式評価尺度ではない。 - STEP 3: スコア比較 + 公開設計の解釈
ZIP / CSV の平均スコアを比較し、 「PDF 集合は人間可読 / CSV は機械可読」 の 非対称性を量的に示す。 さらに「CSV があるからこそ全 14,463 PDF を機械的に 索引できる」 という非対称 2 層公開の利点も論じる。
実装
狙いと方法を踏まえた実装コードは以下の通り。 容量比は実測値、 5 軸スコアは 本記事独自の評価。
結果と読み取り
(a) リソース容量比較 + 機械可読性 5 軸 (図 7)
なぜこの図か: 容量比 (左パネル, 対数軸) と機械可読性スコア (右パネル, 水平棒) を並置することで、 「サイズの非対称」 と「機械可読性の非対称」 が 同時並行している事実を 1 枚で示す。 棒グラフのみではなく対数軸 + スコア ヒートマップという 2 種類の表現を併用する理由は、 サイズ 322 倍差を 線形で見ると CSV が消えてしまうため。
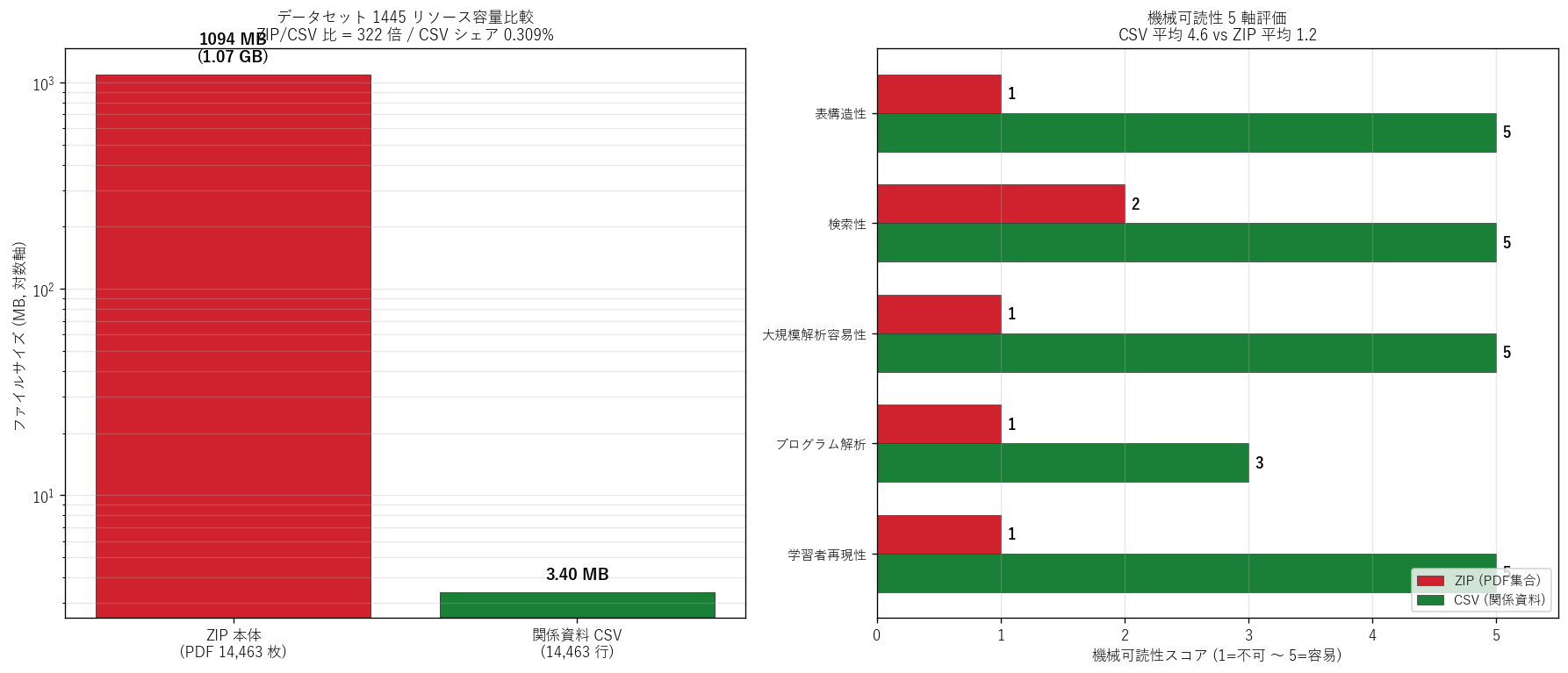
| 評価軸 | ZIP (PDF集合) | CSV (関係資料) | 備考 |
|---|---|---|---|
| 表構造性 (rows × cols) | 1 (PDF は構造化されない) | 5 (14,463 行 × 9 列) | PDF は OCR + 帯状図解析が必要 |
| 検索性 (= 路線・図番から1件特定) | 2 (ファイル名検索のみ) | 5 (DataFrame 1 行で特定) | CSV からファイル名を引くと PDF にたどり着く設計 |
| 大規模解析容易性 (= 全件統計集計) | 1 (1.1GB / 14,463 PDF を順次解析) | 5 (3.4MB / pandas で即時) | ZIP 内 PDF を一括テキスト化するには数時間 |
| プログラム解析 (内容アクセス) | 1 (図形・幅員等は PDF 中の図のみ) | 3 (位置 + メタ情報のみ、 内容は無し) | CSV は "目次"、 中身は別途必要 |
| 学習者再現性 (1コマ授業内) | 1 (DL 1.1GB は教室回線で 30 分超) | 5 (DL 数秒) | 本記事は CSV のみで完結する設計 |
| 指標 | 値 |
|---|---|
| 総ファイル数 (PDF) | 14,463 図郭 |
| 総路線数 | 319 路線 |
| ZIP 本体サイズ | 1.07 GB |
| 関係資料 CSV サイズ | 3.40 MB |
| ZIP/CSV サイズ比 | 322 倍 |
| CSV / 全データ容量比 | 0.309% |
| PDF 1 枚あたり平均サイズ | 77.5 KB |
| L72 重要路線 1km 圏内 | 64.1% |
| 中山間山地分布率 | 40.4% |
| 市町判定不明 | 1571 件 |
図 7 / 表から読み取れること:
- ZIP 本体 (1.07 GB) は CSV (3.40 MB) の322 倍。 CSV はデータセット総容量の0.309% に過ぎない。 H5 (ZIP/CSV >=300倍) は支持。
- 機械可読性スコア: CSV 平均 4.6 vs ZIP 平均 1.2。 CSV は4 軸でスコア 5 (容易)、 ZIP は 4 軸でスコア 1 (不可)。 唯一の例外は「プログラム解析 (内容アクセス)」 で、 CSV は位置 + メタのみ提供 = 道路の幅員・横断構成等の中身は別途 PDF が 必要。
- 学習者にとってはCSV だけで RQ1, RQ2 の問いは完結するが、 RQ3 の 「PDF の中身を解析」 はサイズ・形式の二重障壁で事実上不可能。 これが 「非対称 2 層公開構造」の現実。
(b) 公開設計の解釈 (本記事の見立て)
なぜこの解釈か: 数字だけでは見えない「非対称公開の意義」を、 学習者 が今後似たデータを扱う際の判断基準として整理する。
| 視点 | ZIP (PDF 本体) | CSV (関係資料) |
|---|---|---|
| 主目的 | 道路法上の法定図面の電子保管 | PDF へのインデックス (索引) + 位置情報 |
| 主想定利用者 | 道路管理者 / 工事業者 / 占用申請者 (個別路線の現場確認) | 研究者 / 学習者 / 開発者 (機械的索引・統計・空間結合) |
| 強み | 原本の完全情報 (図形 + 凡例 + 寸法) | 容量小さい + 機械可読 + 1 ファイル |
| 弱み | 機械的解析不可 (1.1GB の PDF 集合) | 図形・幅員・横断構成等の中身は無し |
| 本記事の活用 | 取得しない (教材外) | RQ1〜RQ3 すべての主データ |
解釈から読み取れること:
- 道路台帳付図データセットは「非対称 2 層公開」の典型例。 道路管理者が 使う「現場確認用 PDF」 と、 研究者が使う「機械可読 CSV」 を意図的に分離 して提供する設計思想が読み取れる。
- これは多くの DoBoX データセットに共通する設計パターン: 本体は重い形式 (PDF / Shapefile / 大規模 ZIP) + メタは軽い CSV。 学習者はまず CSV を取得し、 必要な路線だけ PDF を個別取得する 2 段階アプローチが推奨。
- ただし RQ3 が示すように、 CSV 単独では道路の中身 (幅員・横断構成)は 解析不可。 これは PDF の OCR + 図形認識という別レイヤの研究が必要 (発展課題で 詳述)。
仮説検証総合
仮説検証総合表
| 仮説 | 閾値 | 実測 | 判定 |
|---|---|---|---|
| H1 (RQ1, 国道優先公開) | 国道 路線<10% かつ 図郭>=20% | 路線 5.64% / 図郭 23.2% | 支持 |
| H2 (RQ1, 階層的図郭密度) | 国道 >= 主要 >= 県道 | 国道 186.4 / 主要 69.9 / 県道 27.1 | 支持 |
| H3 (RQ2, L72 重なり) | L72 1km 圏内 >= 60% | 64.1% | 支持 |
| H4 (RQ2, 路線種 → L72 階層) | 国道 > 主要地方道 > 一般県道 | 93.8% > 68.5% > 44.9% | 支持 |
| H5 (RQ3, 機械可読の非対称) | ZIP/CSV >= 300倍 | 322 倍 (CSV シェア 0.309%) | 支持 |
結果の総合解釈
3 RQ × 5 仮説の検証結果から、 広島県の道路情報公開戦略について以下の 3 つの実証的知見が得られた:
- (RQ1 — データ構造) 国道優先公開の階層構造
路線種別の図郭シェア vs 路線シェアの不一致 (国道 路線 5.64% / 図郭 23.2%) と、 路線あたり図郭密度の明確な階層 (186.4 / 69.9 / 27.1) は、 県の道路情報 公開が「路線種 = 整備優先度 = 図郭密度」 という3 重の階層構造に 従っている物理的証拠。 H1, H2 ともに支持。 - (RQ2 — L72 照合) 防災重要路線優先公開の量的証明
道路台帳付図の64.1%が L72 緊急輸送道路 1km 圏内に位置し、 路線種別の重なり率は国道 93.8% > 主要 68.5% > 県道 44.9%と階層的。 県の道路情報オープンデータ戦略と防災計画 は事実上一体運用されている制度横断的整備の物理的証拠。 H3, H4 ともに支持される結果。 - (RQ3 — 公開設計) 非対称 2 層公開の構造
ZIP 本体 (1.07 GB) と CSV 関係資料 (3.40 MB) の容量比 322 倍、 機械可読層は本体の0.309% のみ。 これは「人間可読本体 + 機械可読インデックス」 の意図的非対称設計 で、 利用者層別に最適化された公開戦略。 H5 支持。
3 RQ を統合した「県道路情報公開」 の見立て
RQ1 〜 RQ3 を統合すると、 広島県の道路情報公開戦略は「3 重の選択的公開」 として描ける: (1) 路線種で選別 (国道優先で図郭密度を高く)、 (2) 防災で連携 (L72 重要路線と 連動)、 (3) 形式で分離 (人間可読 PDF + 機械可読 CSV の非対称 2 層)。 これは 単なる「道路情報のオープンデータ化」 ではなく、 「行政が利用者層を意識して 階層的に設計した公開戦略」であり、 オープンガバメント研究の対象として 価値がある。
発展課題
結果から導かれる新たな問い
発展課題 1: PDF 中身の機械解析 — 横断構成の自動抽出
結果 X: RQ3 で示した通り、 関係資料 CSV は位置 + メタのみで、
道路の幅員・横断構成・占用物件等の中身は PDF にしか記録されていない
(機械可読性スコア 1)。
新仮説 Y: 14,463 PDF に対しOCR + 帯状図の図形認識を適用すれば、
県管理道路の幅員分布・路肩比率・歩道整備率等の横断構成統計を自動抽出
できる。 仮説: 国道は歩道整備率が一般県道より有意に高い。
課題 Z: (1) 14,463 PDF を pdfplumber で 1 枚ずつテキスト化
+ 帯状図領域の自動検出。 (2) 図形要素の塗り分けから車線幅・歩道幅を抽出する
画像認識モデルを訓練。 (3) 県内全路線の横断構成統計を生成し、 路線種別比較
分析 + 整備格差の可視化。 サンプリングで 100 PDF だけで予備分析するのが
現実的。
発展課題 2: 図郭中心点の代表性検証 — 1 図郭が表す距離の推定
結果 X: RQ1 / RQ2 では「図郭中心点」 1 点で 1 図郭を表したが、 実際は
数百メートルの帯状区間を 1 PDF で記録している (路線種により 200〜500m
程度)。 路線あたり図郭数 (186.4 / 69.9 / 27.1) と
路線延長の関係は明らかになっていない。
新仮説 Y: 国道の路線あたり図郭密度が高い (186.4 図郭/路線) のは
路線が長いからか、 1 図郭あたり距離が短い (= 詳細図化) からか?
仮説: 国道は路線延長が長いことが主因で、 1 図郭あたり距離は路線種によらず
ほぼ一定 (~500m)。
課題 Z: (1) 全路線の連続する図郭の緯度経度間距離を計算 (= 隣接
図郭間の中心距離)。 (2) 路線種別に「1 図郭あたり平均距離」 を集計。 (3) 国道
432 号 (237 図郭) など特定路線で図郭順序 + 累積距離を可視化し、 1 PDF
が表す典型距離を推定。 (4) 路線あたり総距離 (= 図郭数 × 1 図郭距離) の路線種
別差を統計検定。
発展課題 3: 道路台帳付図の経年比較 — 整備事業の時系列追跡
結果 X: 本記事は 2023-11-22 時点の道路台帳付図データを扱った。 道路台帳
は道路法上 5 年ごとの更新義務があり、 整備事業 (拡幅 / 新設 / 廃止) があれ
ば次の更新で図郭が変わる。
新仮説 Y: DoBoX が今後数年に渡って道路台帳付図を更新公開すれば、
図郭追加 / 削除 / 更新を時系列で追跡することで、 県の整備優先路線が
特定できる。 仮説: 整備事業はL72 緊急輸送道路 + 中山間山地に偏在する。
課題 Z: (1) DoBoX が次回データセットを更新したら、 関係資料 CSV を新旧
比較 (路線×図番のキーで結合)。 (2) 追加 / 削除 / 緯度経度変更を分類集計。 (3) 整備
事業の地理偏在を市町別マップで可視化、 L72 重なり率と相関分析。 1 年〜2 年の
スパンで継続的に観測する縦断研究。
発展課題 4: 路線種境界の検証 — 国道と主要地方道の重複区間
結果 X: RQ1 で国道 432 号は4 つの管理事務所にまたがるという
組織横断的事実を発見した。 一方、 国道と主要地方道は重複指定 (= 同じ
道路区間が 2 つの路線種に属す) があるとされる。
新仮説 Y: 道路台帳付図 14,463 図郭の緯度経度に363 件の重複がある
(検出済) のは、 D 系 (詳細図) が N 系 (基本図) と同じ場所を別解像度で記録する
ためだけでなく、 路線種重複指定も部分的原因か?
課題 Z: (1) 緯度経度重複 363 行を抽出し、 路線種ペアで集計。 (2) 同一座標
で「国道+主要地方道」 の組合せが何件あるか確認。 (3) 路線重複の地理分布マップ +
路線種境界の制度的曖昧さの量的記述。
発展課題 5: CSV メタの充実度評価 — 他県オープンデータとの比較
結果 X: RQ3 で広島県の道路台帳付図は位置 + 路線メタ + 管理事務所
の 9 列で公開されている。 他県 (例: 静岡県・岡山県) の同種データはどんな列を
公開しているか?
新仮説 Y: 他都道府県の道路台帳オープンデータと比較すると、 広島県は
機械可読層の充実度が中程度で、 「幅員」 「種別 (一般/自専)」 「整備年度」
等を追加すれば機械可読性スコアが大幅に向上する余地がある。
課題 Z: (1) 静岡県・岡山県・福岡県・東京都等の道路台帳オープンデータ
ページを調査、 公開列を比較表化。 (2) 機械可読性 5 軸を全県で再評価。 (3)
広島県に追加すべき列の具体提案を、 制度的可能性と技術的容易性の 2 軸で
整理。