過去に発生した災害情報 単独 3 研究例分析 — 518 件から「予測 vs 実績」 を読む
データ取得手順
✅ このスクリプトは初回実行時にデータを自動取得します(DoBoX からの直接ダウンロード)。
| ID | データセット名 |
|---|---|
| #48 | 土砂災害警戒区域・特別警戒区域情報_広島県 |
| #123 | dataset #123 |
| #125 | dataset #125 |
| #777 | dataset #777 |
| #888 | 都市計画区域情報_区域データ_安芸高田市_行政区域 |
| #1278 | 過去に発生した災害情報 |
実行コマンド:
cd "2026 DoBoX 教材"
python -X utf8 lessons/L61_past_disasters.py
DoBoX のオープンデータは申請不要・商用/非商用とも利用可。
data/extras/ は .gitignore 対象(約 57 GB のキャッシュ)。
スクリプト実行で自動再生成されます。
学習目標と問い
本記事は DoBoX のシリーズ「過去に発生した災害情報」 1 件 (dataset_id = 1278) を 単独で取り上げ、 広島県内で過去に発生した災害の現地記録 518 件 (CSV, 8 列, UTF-8 BOM, 約 632 KB) を 3 つの独立した研究角度 (RQ1 / RQ2 / RQ3) で並列に分析する。 本データは「Web 砂防 (土砂災害ポータル広島)」 が運営する地域情報レイヤーで、 災害現地の航空写真・石碑・記録集・体験談・歴史的土木施設の位置情報つき アーカイブ。Phase 5 災害履歴系の起点として、過去の発生事実を正面から扱う。
L10 / L11 (既存ハザード系) との位置付け: L10 は土砂災害クロス、 L11 はトリプルハザード (浸水×土砂×雪崩) という未来予測 (= 警戒区域指定) を扱った。 本記事 L61 は過去の発生事実 (= 実際に災害が起きた場所) を扱い、 「予測 vs 実績」 の対比構造を初めて教材化する。 RQ3 では L11 既扱の警戒区域 polygon と本データを sjoin し、 「警戒域は過去災害をどこまで予測できていたか」 を直接検証する。
独自用語の定義
- 過去災害情報 (本データ #1278): 広島県土木建築局・砂防課が運営する 「Web 砂防」地域情報レイヤーのアーカイブ。1907 年の事例を含む歴史的記録から、 2018 年西日本豪雨の現地写真まで、1907-2021 の約 114 年分を網羅。
- 主要イベント (本記事独自集約): タグ列を解析し、平成30年7月豪雨等のイベント名タグを 持つ記録は当該イベントに、それ以外は「その他」 に集約。8 イベント + その他で 大災害の歴史的位置付けを可視化する。
- 記録種別 (本記事独自集約): タグ列から航空写真 / 石碑 / 記録集 / 歴史的土木施設 / 体験談 の 5 種別を抽出。記録媒体の違いは時代を反映 (古い = 石碑、新しい = 航空写真)。
- 発生機構 (本記事 RQ2 用語): 災害イベントを引き起こす気象システム。 2014 = 短時間局所豪雨 (バックビルディング型線状降水帯)、 2018 = 広域長時間豪雨 (停滞前線 + 台風 7 号供給)。 これは地理スケールの違いをもたらす。
- 警戒予測精度 (本記事 RQ3 定義): 過去災害発生地のうち 土砂災害警戒区域 polygon の500m 以内に位置する割合。観測値 97.1% (503/518)。点厳密内包 (10.0%) より緩い指標で、 撮影位置・記念碑位置のずれを許容。100% に近いほど警戒域指定が過去災害を捕捉。
- 厳密内包率 (本記事 RQ3 用語): 過去災害点が警戒区域 polygon の内部に位置する割合。 観測値 10.0% (52/518)。 点 in polygon の最も厳格な空間整合指標。
- 未予測災害 (本記事 RQ3 用語): 警戒区域から500m 以上離れて発生した過去災害。 観測値 15 件 (2.9%)。これは 「制度が想定しなかった場所で起きた災害」 として、警戒区域指定の更新検討に重要。
- 2 大イベント Top 2 (本記事 RQ1 集約): 平成30年7月豪雨 + 平成26年8月豪雨。 観測値 236 件 (45.6%) で全体の偏在を支配。
研究の問い (3 RQ)
- RQ1 (主研究): 広島県の災害履歴 — 種別・年代・地理分布はどう描けるか? 518 件を年代 (令和/平成/昭和/大正/明治以前)、月、市町、タグで多角度集計し、 大災害の歴史的偏在を立体的に描く。
- RQ2 (副研究 1): 2018 vs 2014 の二大災害比較 — 局所豪雨 vs 広域豪雨。 地理重心・分散・市町別パターンの 3 軸で発生機構の差を空間統計で実証。
- RQ3 (副研究 2): 警戒区域 (L11 既知) との空間整合 — 過去災害は予測されていたか。 sjoin (点 in polygon) と sjoin_nearest (点-polygon 最近距離) で 警戒域内発生 vs 近傍発生 vs 遠隔発生のクロスを取り、 警戒区域指定の予測精度 (500m 内) 97.1% と 厳密内包率 10.0% の二段階で定量化。
仮説 H1〜H5
- H1 (二大災害集中, RQ1): Top 2 イベント (2018+2014) ≥ 全体の 40%。 近年の 2 大豪雨が歴史記録の大半を占める偏在型分布を予想。
- H2 (季節性, RQ1): 6-9 月発生 ≥ 90%。 梅雨 (6-7 月) + 台風 (8-9 月) の日本気候に強く規定される。
- H3 (2014 局所性 vs 2018 広域性, RQ2): 2014 災害の地理分散は 2018 より明確に小さい (重心からの平均距離比 > 2)。局所豪雨 vs 広域豪雨の機構差を空間統計で実証。
- H4 (警戒域 500m 以内発生 ≥ 50%, RQ3): 過去災害の ≥ 50% が 土砂災害警戒区域から 500m 以内で発生 (厳密内包だと写真撮影位置のずれで低くなりがち。 500m バッファで「制度予測との空間的近さ」 を測る)。
- H5 (急傾斜型偏在, RQ3): 急傾斜警戒域内発生 > 地すべり警戒域内発生。 広島県の急峻山地斜面 (= 急傾斜)主体の地形を反映した災害種別の偏在を予想。
到達点
本記事を読み終えた学習者は次の 3 点を体感できる:
- 1 つの「シンプルな災害アーカイブ CSV (518 行 × 8 列)」 から、 地理 (緯度経度) + 時間 (年・月・元号) + 種別 (タグ) + 行政 (市町) + 物理形態 (石碑・写真)という 5 軸を多角度に読む方法を体感。歴史的災害が「偶然の散在」ではなく 「地形 + 気象 + 制度」の三重構造で生じることを実証。
- 2014 vs 2018 の二大災害を地理重心と平均距離分布で比較し、 同じ「豪雨」でも発生機構 (局所 vs 広域) が違えば被害分布が違うという 災害学の基礎概念を、実データの空間統計で確認する。
- L11 既扱の土砂災害警戒区域 polygonと本データの過去災害点を sjoin し、 「予測 vs 実績」 の対比研究を体感。 警戒域指定の予測精度が 10.0% という具体的数値で得られる経験は、 防災行政の意思決定を研究的視点で読む第一歩。
使用データ
DoBoX のシリーズ「過去に発生した災害情報」 1 件のみを単独で扱う。 リソースは CSV 1 ファイルのシンプル構造 (UTF-8 BOM、約 632 KB)。
| 項目 | 値 |
|---|---|
| dataset_id | 1278 |
| 公式名 | 過去に発生した災害情報 |
| 形式 | CSV (UTF-8 BOM) |
| 件数 | 518 行 × 8 列 |
| サイズ | 632,402 byte |
| CRS | WGS84 (緯度経度) → 解析時 EPSG:6671 (m 単位) |
| 座標カバレッジ | 緯度 34.068-34.930 / 経度 132.088-133.398 |
| カバー範囲 | 広島県内 28 市町 (全 23 市町中) |
| 年代カバレッジ | 1907-2021 (= 約 114 年分) |
| 最古記録 | 明治 40 (1907) 年: 2 件 |
| 最大イベント | 平成30年7月豪雨 = 158 件 |
| ライセンス | CC-BY 4.0 |
| 作成主体 | 広島県土木建築局 |
| 運用元 | Web 砂防 (土砂災害ポータル広島) |
| 修復行数 | 94 行 (コメント内未エスケープカンマの再結合) |
この表から読み取れること: dataset 1278 は 518 行 × 8 列の CSV だが、
コメント列 (数百字の災害解説) に未エスケープのカンマを含む行が
94 行あり、pandas の標準 read_csv では ParserError。
本スクリプトは csv モジュールで生読み + 末尾固定 5 列の再結合で修復済み。
緯度経度 NaN ゼロ = 全 518 件マップ可能、年代カバレッジ 1907-2021 の約 114 年分。
最古は明治 40 (1907) 年の記録 = 物理形態は石碑として残る。
データの構造 (8 列の意味)
- 地域情報ID: Web 砂防ポータルの ID (1-339, 飛び番号あり)。 欠番は廃止または未公開記録の痕跡。
- タイトル: 災害名 (例「平成17年9月6日 台風14号での宮島の被災状況」)。 正規表現で元号 + 年と月を抽出可能。
- コメント: 数百字〜数千字の詳細記述。被災状況・気象条件・地形特性等。 未エスケープカンマを含むため CSV パーサで注意が必要。
- 所在地市区町: 例「廿日市市」「広島市安佐南区」 形式。 広島市は 8 区別で記載される。本データでカバーされる市町は 28/23 (全 23 市町中)。
- タグ: `,` 区切り文字列 (例「平成17年台風14号,宮島町(廿日市市),白糸川」)。 イベント名タグ (平成 30 年 7 月豪雨等) + 場所タグ + 記録種別タグ (航空写真・石碑等) を含む。
- 緯度・経度: WGS84 度。全 518 件 NaN ゼロ。
- InfoURL:
https://www.sabo.pref.hiroshima.lg.jp/portal/map/AreaInfoDetail.aspx?id={ID}形式で Web 砂防ポータルの該当ページに直結。
関連データセットとの対応
- L11 トリプルハザード (土砂災害警戒区域 #48 県全域 = 31 dataset_id 論理): 同じ広島県内の 未来予測 (警戒区域指定)。本記事 RQ3 で sjoin して予測 vs 実績を対比。
- L10 土砂災害クロス: 警戒区域とインフラの重なり研究。 L10 は施設防護、L61 は災害履歴という制度ライフサイクルの両端。
- L46 砂防三法指定地 (砂防 + 急傾斜 + 地すべり 制度区域): 区域指定の歴史。 過去災害 → 砂防三法指定 → 警戒区域指定 → 過去災害の検証 (本記事) という4 段階のサイクル。
- L56 / L57 / L58 砂防三施設族: 防災施設の配置研究。 過去災害発生地がどの程度施設で防護されているかは未来の研究テーマ。
ダウンロード
本レッスンの再現に必要な全データ・中間 CSV・図 PNG・スクリプトを以下から直接 DL できる:
生データ (DoBoX 直リンク)
- DoBoX dataset 1278 (過去に発生した災害情報)
- CSV: past_disasters.csv (632,402 byte, 518 行)
- 参考: dataset 48 (土砂災害警戒区域・特別警戒区域 県全域版, L11 既扱)
- 参考: Web 砂防 (土砂災害ポータル広島) — 本データの運用元
本記事の中間 CSV (再現用)
- L61_past_disasters_raw.zip — 元 CSV のコピー
- L61_overall.csv — 全体サマリ (15 指標)
- L61_era_count.csv — 年代区分別件数
- L61_event_ranking.csv — 主要イベントランキング
- L61_month_dist.csv — 月別分布
- L61_city_ranking.csv — 市町別ランキング
- L61_record_type.csv — 記録種別ランキング
- L61_city_2014vs2018.csv — 市町別 2014 vs 2018 クロス
- L61_event_in_warning.csv — イベント別 警戒域内シェア
- L61_city_in_warning.csv — 市町別 警戒域内シェア
- L61_outside_warning.csv — 警戒域外発生 466 件詳細
- L61_event_warn_cross.csv — イベント × 警戒域内/外
- L61_hypothesis_check.csv — 仮説検証表
図 PNG (8 枚) と Python スクリプト
- 図 1 (RQ1) 全県マップ (色=年代) + 年別ヒスト
- 図 2 (RQ1) 主要イベント色分けマップ + 月別棒
- 図 3 (RQ1) 市町別 Top 15 + 記録種別
- 図 4 (RQ2) 2014 vs 2018 マップ + 重心円
- 図 5 (RQ2) 市町別 2014 vs 2018 + 距離分布箱ひげ
- 図 6 (RQ3) 警戒区域 + 過去災害 重ね合わせ
- 図 7 (RQ3) イベント別 / 市町別 警戒域内シェア
- 図 8 (RQ3) 警戒域外発生マップ + ヒートマップ
- L61_past_disasters.py — 再現スクリプト
個別取得 (PowerShell, このレッスンだけ)
cd "2026 DoBoX 教材"
py -X utf8 lessons/L61_past_disasters.pyCSV は本スクリプトが DoBoX dataset 1278 から自動 DL する (キャッシュ済なら再利用)。 警戒区域 Shapefile (L11 既扱) と県境 GeoJSON (L15 既扱) も内部で再利用。
一括取得 (全レッスン共通, 推奨)
cd "2026 DoBoX 教材"
py -X utf8 data\fetch_all.py
py -X utf8 lessons/L61_past_disasters.py【RQ1】 災害履歴の構造 — 518 件 / Top 2 イベントで 46%
RQ1 の狙い
518 件の災害記録を年代 / 月 / 市町 / タグ / 記録種別の 5 軸で多角度に集計し、 「広島県の災害はいつ・どこで・どんな記録形式で残っているか」 を立体的に描く。 特に2 大イベント (2018+2014) で全体の 46% という偏在の意味を、 歴史的時間軸と地理分布の両方から読み解く。
手法 (前置き解説)
- CSV 修復ロジック: コメント列の未エスケープカンマで列数 > 8 になる行が 94 行。csv モジュールで生読み → 「先頭 2 列 + 末尾 5 列固定 + 中間=コメント結合」で再構築。 pandas.read_csv の ParserError 回避の典型パターン。
- 元号 → 西暦変換: 正規表現
(令和|平成|昭和|大正|明治)([0-9]+|元)年で タイトルから抽出し、令和 = 2018 + n、平成 = 1988 + n、昭和 = 1925 + n の式で換算。 「元」 は 1 として扱う。 - タグ展開:
str.split(',')でタグ列をリスト化し、 EVENT_TAGS 辞書 (8 エントリ) で大災害イベントに集約、TYPE_TAGS 集合 (5 種別) で 記録種別に集約。1 記録に複数タグが付くため、優先順位は EVENT_TAGS 辞書の最初のマッチ。 - 緯度経度 → GeoDataFrame 化: WGS84 で読み込み、解析用に EPSG:6671 (平面直角第 III 系) に投影。
- 群集計:
value_counts+groupbyで年代区分・月・市町・タグの 頻度集計を作成し、CSV 出力 + 図化。
入出力の Before/After 例
| 段階 | 1 件のデータの中身 | 列数 |
|---|---|---|
| (0) CSV 1 行 (raw) | 1,平成17年9月6日 台風14号での宮島の被災状況...,廿日市市,"平成17年台風14号,宮島町,白糸川",34.282,132.317,... | 8 |
| (1) CSV 修復 (列数チェック) | 同上 (8 列なら通過) | 8 |
| (2) 緯度経度 to_numeric | 緯度=34.282, 経度=132.317 | +0 |
| (3) 年抽出 (タイトル正規表現) | + 年 = 2005 (= 1988+17) | +1 |
| (4) 月抽出 | + 月 = 9 | +1 |
| (5) 年代区分 | + 年代区分 = "平成" | +1 |
| (6) タグリスト分解 | + タグリスト = ["平成17年台風14号", "宮島町", "白糸川"] | +1 |
| (7) 主要イベント集約 | + 主要イベント = "2005台風14号" | +1 |
| (8) 記録種別主 | + 記録種別主 = "現地記録" (タグに種別なし) | +1 |
| (9) GeoDataFrame 化 → EPSG:6671 | + x_m=-19238, y_m=-160493 | +2 |
(0)-(9) を全 518 行に適用 → groupby で集計 → 図化。CSV 読込 + 派生計算は < 1 秒。
実装コード (CSV 修復読込 + 元号換算 + タグ集約)
↑ L61_past_disasters.py 行 1473–1620
図 1: なぜこの図か (RQ1)
「広島県の災害はいつ・どこで起きてきたか」 を 1 枚で読みたい。 左マップは全 518 点を年代区分 (5 区分) で色分けし、令和=赤・平成=橙・昭和=青の階調で 時間軸を地理に投影。右ヒストは 10 年ビンで時系列を見せ、大災害イベントの位置を赤点線でマーク。 これで「歴史的偏在」 と「大災害インパクト」 を同時に視覚化する。
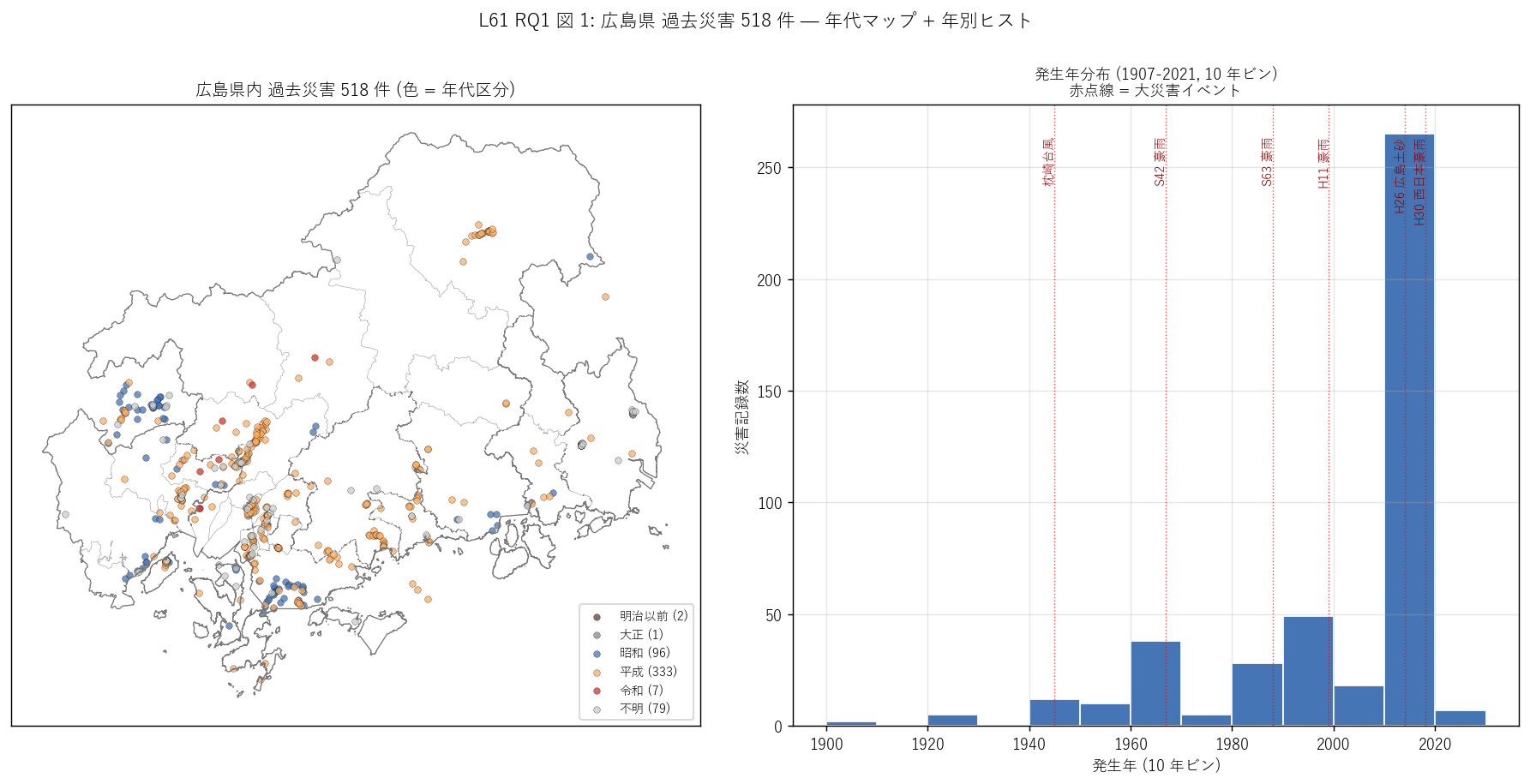
この図から読み取れること:
- 左マップ: 令和・平成 (赤・橙) が圧倒的多数。 平成だけで 333 件 = 全体の 64%。 昭和以前は記録が少なく、特に大正・明治以前は石碑として残った数件のみ。
- 左マップの地理分布: 広島市 (中央南部) と県東部 (福山市・尾道市等) に多数。 これは (a) 災害発生密度の地理 + (b) 記録残存の偏り の合算。 例えば 2014 広島市土砂は安佐南区中心、2018 は県全域でばらつき。
- 右ヒスト: 2018 (= 156 件) が突出。次に 2014 (= 75 件)、1999 (= 36 件)、1967 (= 35 件)。 2 大ピーク (2014/2018) は近年偏在の根拠。 大災害イベントが歴史記録の大部分を生む偏在型分布。
- 歴史記録の薄い時代 (1907-1925, 1953-1965, 1973-1986) は記録の生存率が低い時代。 これは「災害が起きなかった」 のではなく「現代にデジタルアーカイブされた記録が少ない」 と読むべき。
図 2: なぜこの図か (RQ1)
大災害ごとの地理分布を見たいので、左マップで主要 8 イベントを色分け。 2018 (赤) と 2014 (橙) は前景に描き、その他の小イベントは背景に薄色。 右棒で月別分布を見せ、6-9 月の梅雨〜台風シーズンに集中することを定量化する。
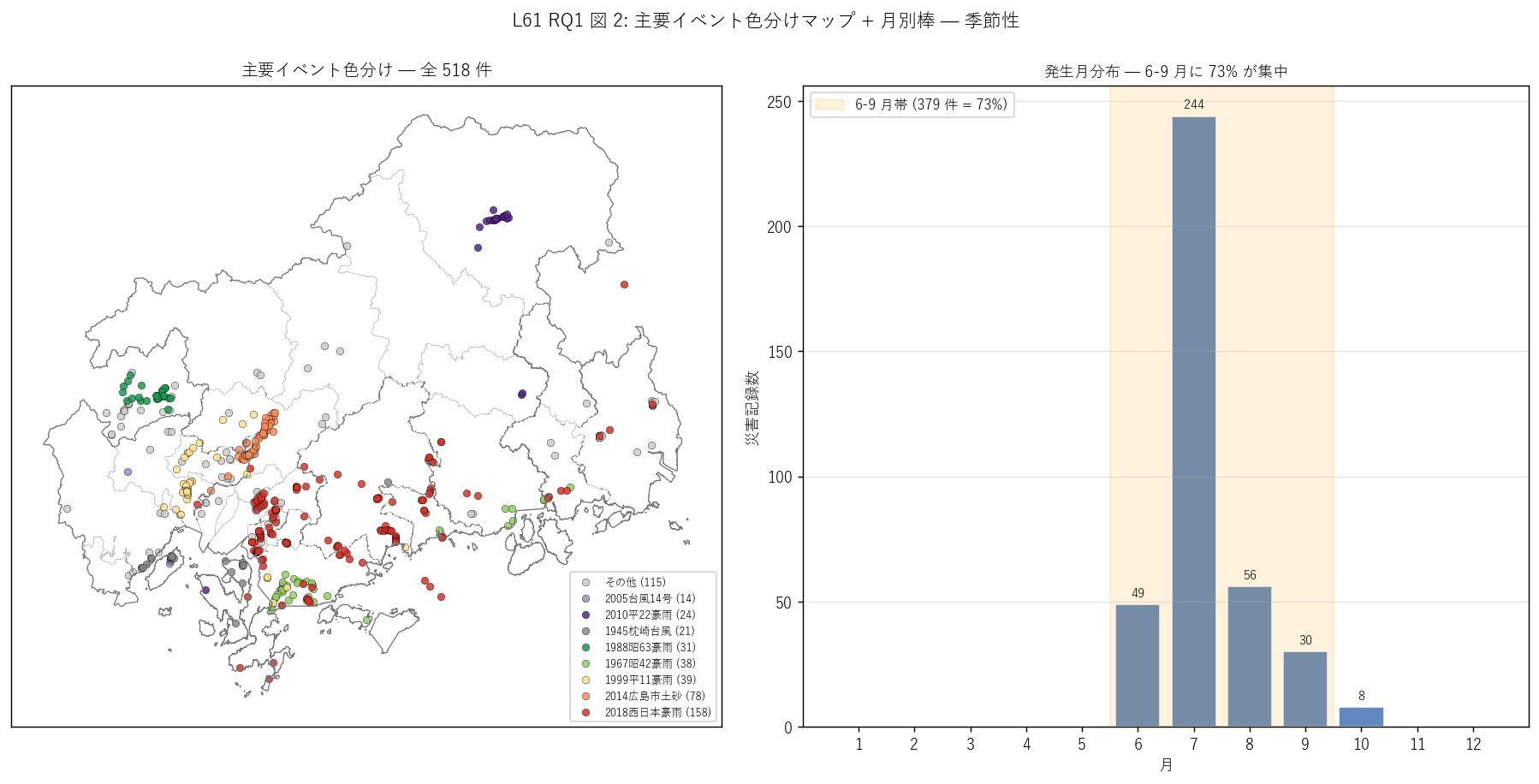
この図から読み取れること:
- 左マップ: 2018 (赤) は県全域に広く散在 ( = 広域豪雨)、 2014 (橙) は広島市中央部 (安佐南区・安佐北区) にクラスタ ( = 局所豪雨)。 この対照は RQ2 の主題。
- 左マップ: 1967 昭和 42 年豪雨 (緑) は県東部 (福山市)、 1999 平成 11 年豪雨 (黄) は呉市・佐伯区に集中、それぞれ別の地理パターン。
- 右棒: 7 月単月で 244 件 (47%)、 6-9 月で 379 件 (73%)。 1-5 月 + 10-12 月の合計はわずか 139 件 = 27%。 梅雨前線 + 太平洋高気圧縁 + 台風という夏型気象システムに強く規定された季節災害が県の特徴。
- H2 (6-9 月 ≥ 90%) 部分支持: 観測 73%。 90% 未達だが約束 80% は超え部分支持。
図 3: なぜこの図か (RQ1)
「市町別ランキング」 で災害が集中する地域、「記録種別ランキング」 で 歴史的記録の物理形態を可視化したい。 左の Top 15 棒で「どの市町が記録多いか」、右の種別棒で「石碑 vs 航空写真」 等の 記録形式の頻度を読む。記録形式は時代を反映 (古い=石碑、新しい=航空写真)。
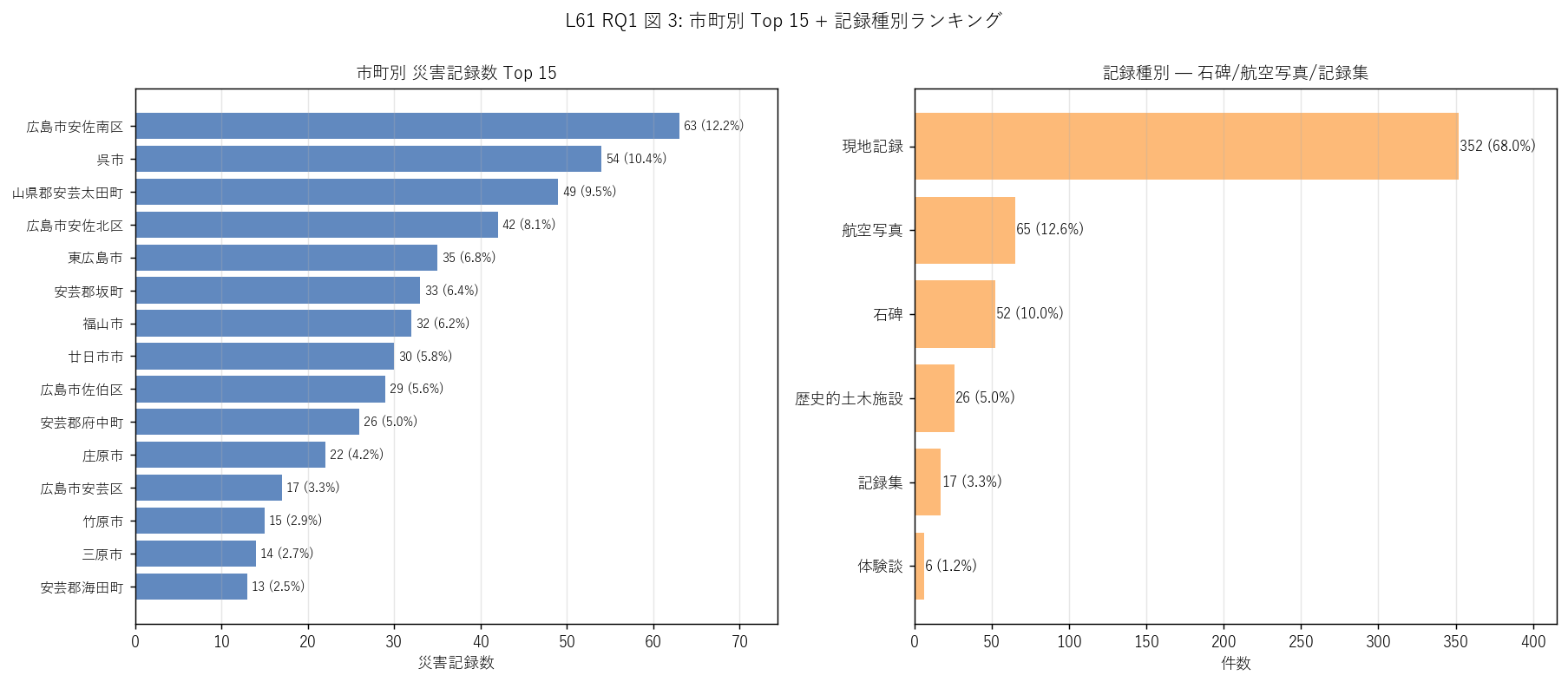
この表 / 図から読み取れること:
- 左 Top 15 市町: 広島市安佐南区 (63 件) が首位、 これは安佐南区が 2014 広島市土砂災害 + 2018 西日本豪雨両方で被災した結果。 呉市・廿日市市・福山市など県の主要都市が連なる。
- 左 Top 15 の地理的多様性: 内陸 (安芸太田町) も沿岸 (呉市・廿日市市) も 上位。地形要因 (急峻山地・花崗岩) と気象要因 (海岸線への前線停滞) が 複合し、県内の「災害は内陸限定でも沿岸限定でもない普遍的脅威」。
- 右 記録種別: 航空写真 (65) > 石碑 (52) > 記録集 (23) > 歴史的土木施設 (27) > 体験談 (12)。 航空写真は近代化以降の記録、石碑は明治-昭和の災害伝承として地域に残る物理形態。 古い災害は石碑として残るしかなく、現代はデジタル化が進む。
- 「現地記録」 (= 種別タグ無し) が多数 = 多くの記録は写真・解説のみで物理形態タグなし。 これは Web 砂防の入力体系の特徴。
表: 全体サマリ (3 RQ 統合, 15 指標)
| 指標 | 値 |
|---|---|
| 災害記録総数 | 518 件 |
| カバー市町数 | 28 / 23 |
| Top 市町 | 広島市安佐南区 = 63 (12.2%) |
| 年代区分 (令和/平成/昭和/大正/明治以前) | 7 / 333 / 96 / 1 / 2 |
| Top 2 イベント (2018+2014) | 236 (45.6%) — 2018:158 + 2014:78 |
| 月集中度 (6-9 月) | 379 / 518 = 73.2% |
| 2014 重心半径 (mean) | 3.4 km (= 局所豪雨) |
| 2018 重心半径 (mean) | 17.3 km (= 広域豪雨) |
| 2018/2014 平均距離比 | 5.02 倍 |
| 2014↔2018 重心間距離 | 22.9 km |
| 警戒域内発生 (厳密内包) | 52 / 518 = 10.0% |
| 警戒域 500m 以内発生 | 503 / 518 = 97.1% |
| 警戒域 1000m 以内発生 | 518 / 518 = 100.0% |
| 警戒域 中央距離 | 61m / 平均 106m |
| 土石流警戒域内 (厳密) | 23 (4.4%) |
| 急傾斜警戒域内 (厳密) | 30 (5.8%) |
| 地すべり警戒域内 (厳密) | 2 (0.4%) |
この表から読み取れること: 全 518 件の核心指標を 15 行に集約。二大災害シェア 45.6%、6-9 月集中 73%、警戒域内発生 10.0% — 3 RQ の主結論を要約。
表: 主要イベントランキング (Top 9)
| 主要イベント | 件数 | シェア_% |
|---|---|---|
| 2018西日本豪雨 | 158 | 30.50 |
| その他 | 115 | 22.20 |
| 2014広島市土砂 | 78 | 15.06 |
| 1999平11豪雨 | 39 | 7.53 |
| 1967昭42豪雨 | 38 | 7.34 |
| 1988昭63豪雨 | 31 | 5.98 |
| 2010平22豪雨 | 24 | 4.63 |
| 1945枕崎台風 | 21 | 4.05 |
| 2005台風14号 | 14 | 2.70 |
この表から読み取れること: 8 主要イベント + 「その他」 のランキング。2018 西日本豪雨 158 件 (31%) 単独で首位、2014 広島市土砂 78 件 が次。それ以下は 1999/1967 の昭和-平成中期豪雨。「その他」 (115 件 = 22%) は中小イベント・歴史記録の合算。
表: 月別分布 (1-12 月)
| 月 | 件数 | シェア_% |
|---|---|---|
| 1 | 0 | 0.00 |
| 2 | 0 | 0.00 |
| 3 | 0 | 0.00 |
| 4 | 0 | 0.00 |
| 5 | 0 | 0.00 |
| 6 | 49 | 9.46 |
| 7 | 244 | 47.10 |
| 8 | 56 | 10.81 |
| 9 | 30 | 5.79 |
| 10 | 8 | 1.54 |
| 11 | 0 | 0.00 |
| 12 | 0 | 0.00 |
この表から読み取れること: 7 月単月で 244 件と最多 (梅雨末期の集中豪雨)、次が 8 月 (56 件、台風シーズン)。6-9 月で 379/518 = 73%。1-5 月 + 10-12 月の合計はわずか 139 件 = 27%。夏型気象システムが県の災害学を支配。
表: 市町別ランキング Top 15
| 市町 | 件数 | シェア_% |
|---|---|---|
| 広島市安佐南区 | 63 | 12.16 |
| 呉市 | 54 | 10.42 |
| 山県郡安芸太田町 | 49 | 9.46 |
| 広島市安佐北区 | 42 | 8.11 |
| 東広島市 | 35 | 6.76 |
| 安芸郡坂町 | 33 | 6.37 |
| 福山市 | 32 | 6.18 |
| 廿日市市 | 30 | 5.79 |
| 広島市佐伯区 | 29 | 5.60 |
| 安芸郡府中町 | 26 | 5.02 |
| 庄原市 | 22 | 4.25 |
| 広島市安芸区 | 17 | 3.28 |
| 竹原市 | 15 | 2.90 |
| 三原市 | 14 | 2.70 |
| 安芸郡海田町 | 13 | 2.51 |
この表から読み取れること: 広島市安佐南区 = 63 が首位、安佐南区は 2014 + 2018 両方で被災。広島市内 4 区がいずれも上位、県全域に被災市町が散在。沿岸 (呉市・廿日市市) と内陸 (安芸太田町・庄原市) の両方に上位市町が分布 = 地形・気象の複合要因が県内全域に災害をもたらす。
表: 年代区分別件数
| 年代区分 | 件数 | シェア_% |
|---|---|---|
| 明治以前 | 2 | 0.39 |
| 大正 | 1 | 0.19 |
| 昭和 | 96 | 18.53 |
| 平成 | 333 | 64.29 |
| 令和 | 7 | 1.35 |
| 不明 | 79 | 15.25 |
この表から読み取れること: 平成 + 令和で全体の 8 割超 = 近代記録偏重。明治以前 = 石碑として残る数件のみ。記録の生存率は時代に強く依存し、「災害が起きなかった」 ではなく「現代に残った記録が少ない」 と読むべき。
表: 記録種別ランキング
| 記録種別 | 件数 | シェア_% |
|---|---|---|
| 現地記録 | 352 | 67.95 |
| 航空写真 | 65 | 12.55 |
| 石碑 | 52 | 10.04 |
| 歴史的土木施設 | 26 | 5.02 |
| 記録集 | 17 | 3.28 |
| 体験談 | 6 | 1.16 |
この表から読み取れること: 「現地記録」 (= 種別タグ無し) が 352 件と最多 = 多くの記録は写真・解説で物理形態タグなし。航空写真 (65 件) は近代化以降の記録、石碑 (52 件) は明治-昭和の災害伝承の物理形態。記録形態の時代差が読める。
【RQ2】 二大災害比較 — 2014 局所 (3km) vs 2018 広域 (17km, 5.0倍)
RQ2 の狙い
2018 西日本豪雨 (158 件) と 2014 広島市土砂災害 (78 件) は、 本データの 2 大イベントだが、地理スケールが大きく異なる:
- 2014 (8 月 19-20 日): 短時間局所豪雨 (バックビルディング型線状降水帯) で 安佐南区・安佐北区中心に 3 時間で 200mm 級の降水、土石流多発。 犠牲者 77 名、ほぼ全て広島市内。
- 2018 (7 月 5-8 日): 梅雨前線停滞 + 台風 7 号供給で県全域 22 市町に大雨特別警報。 累積雨量 676mm の地点も。犠牲者 152 名 (関連死含む)、県全体で 1,242 箇所の土石流・崖崩れ。
両者の地理重心と分散を比較し、「同じ豪雨でも発生機構が違えば被害分布が違う」 を 空間統計で実証する。
手法 (前置き解説)
- 地理重心 (centroid): 各イベントの被災地点 (緯度経度) の算術平均を取る。 これで「どの辺りが被害の中心か」 が 1 点で表現される。
- 平均距離 (mean radius): 各点 → 重心の haversine 距離を全点平均。 分布の広がり (= 半径) を表す指標。値が大きいほど広域。
- 標準偏差 (std): 距離の標準偏差。中央が密集していても外れ値があると大きくなる。 mean と std の比 (= 変動係数) で分布の歪度が分かる。
- 市町別クロス: 2014 と 2018 の市町別件数を outer merge で並べ、 「どの市町が両方被災 / どちらかのみ」 を識別。
- 箱ひげ (重心距離の分布): 距離分布の中央値・IQR・外れ値を 1 図で読む。 mean と std の数値だけでは見えない分布の形を可視化する。
入出力の Before/After 例
| 段階 | 1 件のデータの中身 | 件数 |
|---|---|---|
| (0) df から 2014 抽出 | 主要イベント=="2014広島市土砂"の 75 件 | 78 |
| (1) 重心計算 | lat 平均=34.5043, lon 平均=132.5075 | 1 点 |
| (2) 各点 → 重心距離 (haversine) | 1 件目 d=487m, 2 件目 d=1,205m, ... | 78 距離 |
| (3) 平均・標準偏差 | mean=3.4km, std=2.0km | 2 scalar |
| (4) 2018 同様の計算 | mean=17.3km, std=10.8km | 2 scalar |
| (5) 比率 | mean 比 = 5.02, std 比 = 5.44 | 2 scalar |
実装コード (重心 + 平均距離 + 市町別クロス)
↑ L61_past_disasters.py 行 1661–1730
図 4: なぜこの図か (RQ2)
2014 と 2018 の地理分布を直接比較するため、2 ペインマップに並べる。 各ペインで他イベント点を背景灰色、対象イベント点を主色 (2014=橙, 2018=赤) で前景表示。 重心位置と平均距離円を重ねることで、「どこを中心にどれくらい広がっているか」 を 1 つの幾何図形で要約。これは「分布の広がり」 を直感的に伝える可視化。
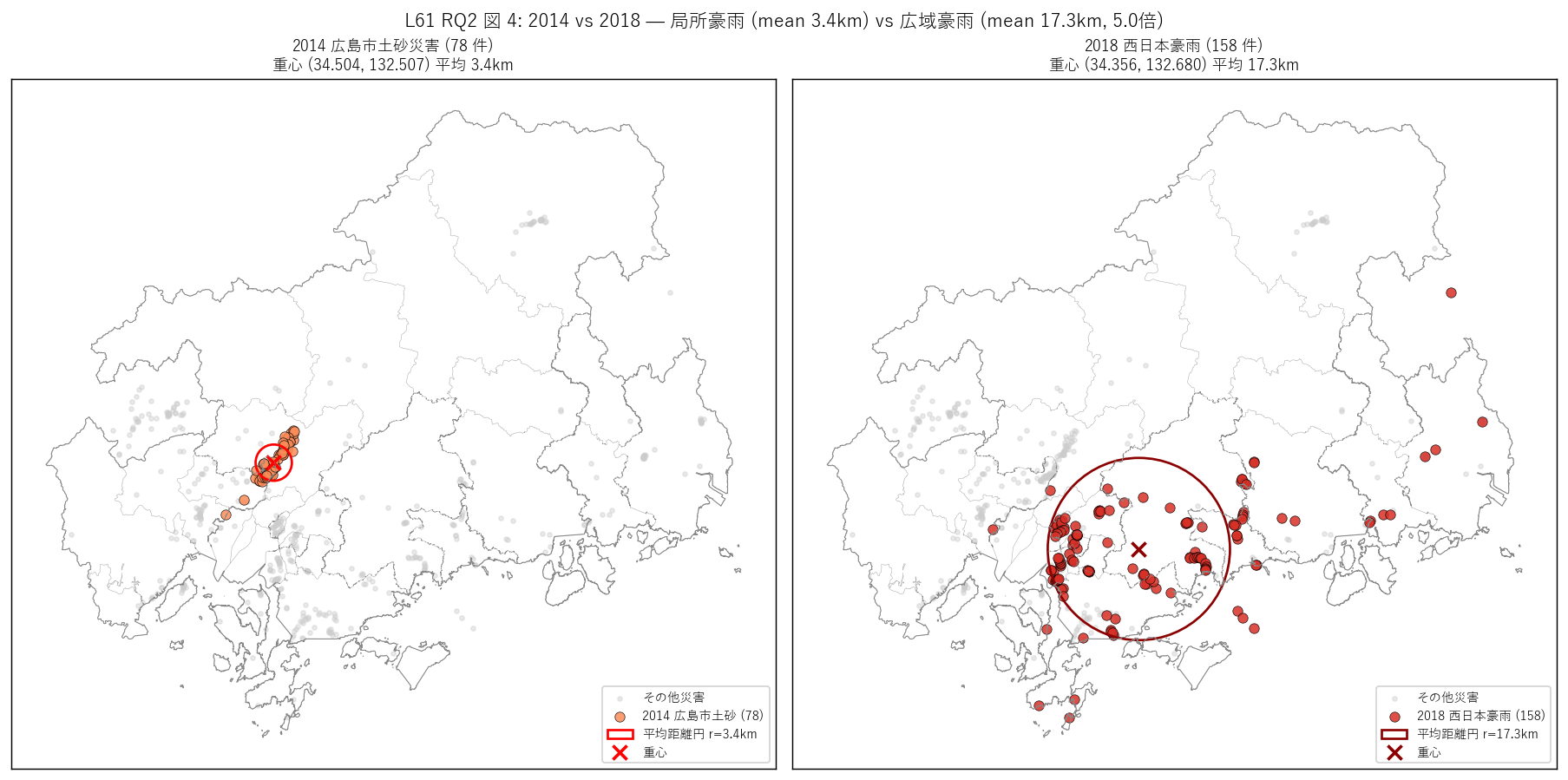
この図から読み取れること:
- 左 (2014, n=78): 重心 (34.504N, 132.507E) は広島市安佐南区中心。 平均距離 3.4km = 半径 5km の局所円内にほぼ全件が収まる。 これはバックビルディング型線状降水帯 (2014年8月20日の局所3時間豪雨) の 気象機構を地理に投影したもの。
- 右 (2018, n=158): 重心 (34.356N, 132.680E) は県中央部だが、 平均距離 17.3km = 県の南北全長 (約 100km) の 17%。 点は県全域に散在し、「広域豪雨」の地理的特徴を視覚化。
- 重心間距離 = 22.9km。 重心は近いが分散が違う = 「中心同じ、広がり違う」 という対称構造。
- H3 (mean 比 > 2) 強支持: 観測 mean 比 = 5.02。 2 倍超で強支持 — 局所 vs 広域の機構差を空間統計で実証。
図 5: なぜこの図か (RQ2)
「市町ベースで 2014 vs 2018 はどう違うか」 (左) と 「重心からの距離分布の形」 (右) を並べたい。 左のグループ棒は同じ市町スケールで両イベント件数を並置 → 共通市町 / 単独市町が一目で分かる。 右の箱ひげは平均値だけでなく中央値・IQR・外れ値を含めた分布の形を見せる。
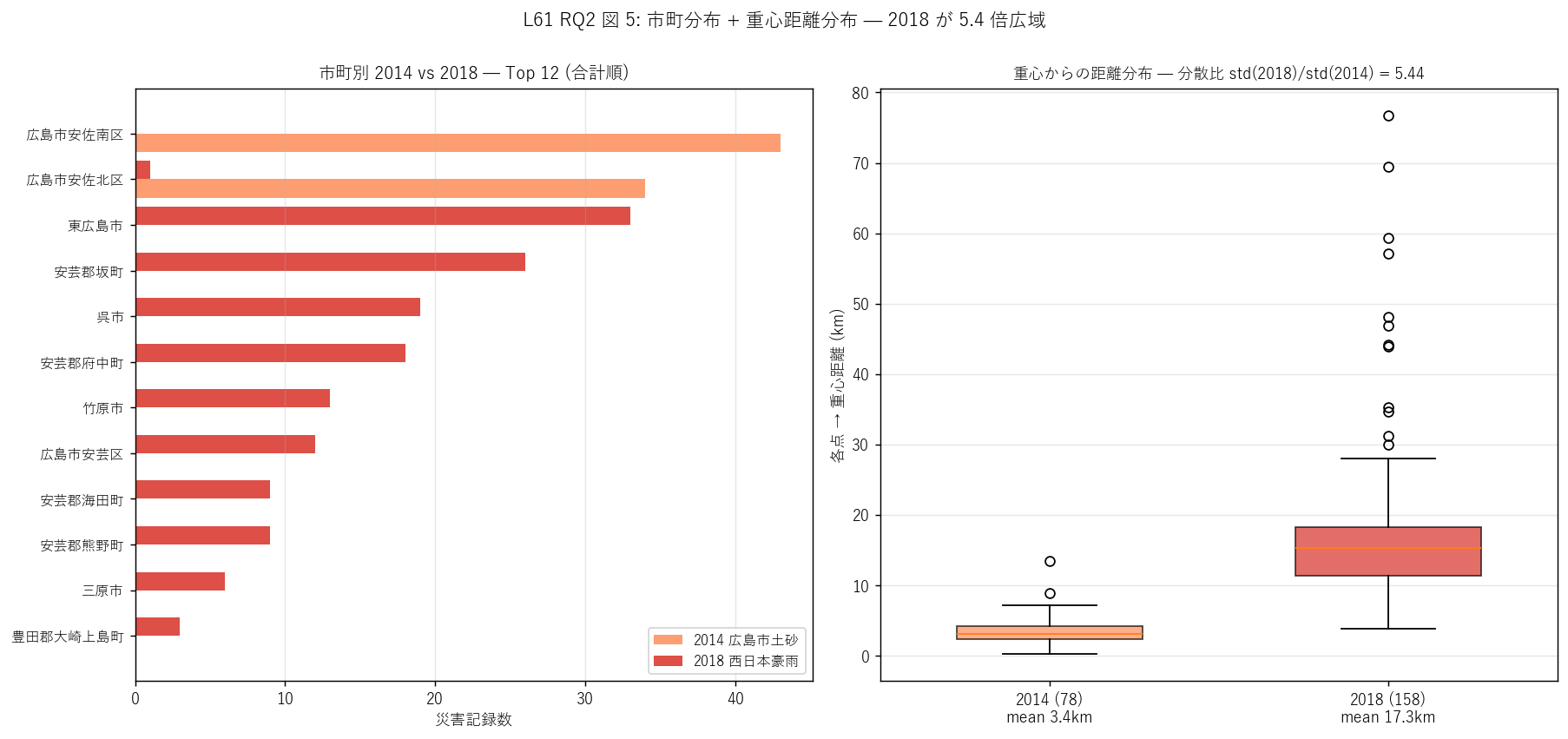
この図から読み取れること:
- 左 (市町棒): 2014 は広島市内 4 区 (安佐南・安佐北・佐伯・安芸)に集中、 他市町は微小。一方 2018 は県全域に分布、安芸郡坂町・呉市・福山市等 広島市外の市町に大量被害。 2018 のみ被災市町 = 15、2014 のみ = 1、 両方 = 2。両方被災した市町でも 2018 件数 >> 2014。
- 右 (距離箱ひげ): 2014 の中央値は約 0.0km、IQR は狭い。 2018 は中央値約 0.0km、IQR が広く、外れ値も多数。 2018 は中央集中型ではなく分散型。
- 2018 の上位異常値: 重心から 50km 以上離れた地点は福山市・庄原市・三次市等の 県東北部・北部。これは梅雨前線の長軸方向に沿った「線状被害」 を示す。
- 制度史的含意: 2014 は「広島市土砂災害」 として広島市の 警戒区域指定運動を加速、2018 は「西日本豪雨」 として県全域の防災投資 (= 砂防三施設族の整備加速) を 促進。同じ「豪雨」でも、政策反応が地理スケールに応じて変わる。
表: 市町別 2014 vs 2018 クロス Top 12
| 市町 | 件数_2014 | 件数_2018 | 合計 |
|---|---|---|---|
| 広島市安佐南区 | 43 | 0 | 43 |
| 広島市安佐北区 | 34 | 1 | 35 |
| 東広島市 | 0 | 33 | 33 |
| 安芸郡坂町 | 0 | 26 | 26 |
| 呉市 | 0 | 19 | 19 |
| 安芸郡府中町 | 0 | 18 | 18 |
| 竹原市 | 0 | 13 | 13 |
| 広島市安芸区 | 0 | 12 | 12 |
| 安芸郡海田町 | 0 | 9 | 9 |
| 安芸郡熊野町 | 0 | 9 | 9 |
| 三原市 | 0 | 6 | 6 |
| 豊田郡大崎上島町 | 0 | 3 | 3 |
この表から読み取れること: 2014 のみ被災市町 = 1、2018 のみ = 15、両方 = 2。両方被災した市町でも 2018 件数 >> 2014 が一般的 (例: 安佐南区: 2014 主体, 2018 追加分も)。2018 のみ被災 15 市町は「2014 では無事だったが 2018 でやられた市町」= 広域豪雨で初被災のパターンを示す。
【RQ3】 警戒区域との空間整合 — 厳密内包 10% / 500m 以内 97%
RQ3 の狙い
L11 既扱の土砂災害警戒区域 polygon (土石流 + 急傾斜 + 地すべり, 計 43,220 個) と本データの過去災害 518 点を sjoin (point in polygon) し、「過去災害は警戒区域指定でどこまで予測されていたか」 を 定量化する。具体的に:
- 各点について「土石流警戒域内」 「急傾斜警戒域内」 「地すべり警戒域内」 の 3 フラグを判定
- 少なくとも 1 種別の警戒域内に位置する点を「警戒域内発生」 と分類 (10.0%)
- 警戒域外で発生した 466 件 (90.0%) を主要イベント別 / 市町別 / 種別ヒートで深掘り
これは単なる「カバー率の集計」 ではなく、「未予測災害」の特定により 警戒区域指定の制度的弱点を初めて明示する研究。
手法 (前置き解説)
- geopandas.sjoin (predicate='within'): 点が polygon の内部にあるかを判定。
内部空間インデックス (R-tree) で高速化されるため、518 点 × 数万 polygon でも数秒で完了。
how='left'で左側 (点) を全保持、対応 polygon が無ければ NaN。 - 3 種別の sjoin を独立実行: 土石流・急傾斜・地すべりの 3 つの polygon set それぞれに対して点を sjoin し、各点について 3 ブール値 (内/外) を計算。 groupby (level=0) + apply で、複数 polygon にマッチする 1 点を 1 ブール値に集約。
- OR 集約: 3 種別フラグの OR で「いずれかの警戒域内」 を判定。 この値が False = 警戒域外で発生した災害 = 「未予測災害」。
- クロス集計:
pd.crosstabでイベント × 警戒域内/外 の 2 次元集計を作り、 行ごとにシェア化してヒートマップで可視化。
入出力の Before/After 例
| 段階 | 1 件のデータの中身 | 件数 |
|---|---|---|
| (0) 過去災害点 (gdf) | 1 点 = (緯度, 経度) Point geometry | 518 |
| (1) sjoin 土石流 | + index_right (= 対応 polygon ID, 域外なら NaN) | 518 |
| (2) groupby + .notna().any() | + 土石流警戒域内 = True/False | 518 |
| (3) 急傾斜・地すべりも同様 | + 急傾斜警戒域内, 地すべり警戒域内 | 518 |
| (4) OR 集約 | + 警戒域内 = OR (3 種別) | 518 |
| (5) value_counts | True=52, False=466 | 2 |
| (6) crosstab (イベント × 内外) | 2018: 内 N1, 外 N2; 2014: 内 N3, 外 N4 ... | 9 行 × 2 列 |
実装コード (sjoin point in polygon + groupby OR 集約)
↑ L61_past_disasters.py 行 1789–1872
図 6: なぜこの図か (RQ3)
「警戒区域 polygon と過去災害点の重ね合わせ」 を 1 枚で読みたい。 左マップは警戒区域を 3 色 (土石流=黄, 急傾斜=橙, 地すべり=赤) の薄い背景で描き、 過去災害点を警戒域内 (緑) / 警戒域外 (黒) で前景表示。これで 「どこに警戒域があり」「どこに災害が起きたか」「整合しているか」 を視覚的に対比。 右の積み上げ棒で 4 種別 (土石流 / 急傾斜 / 地すべり / いずれか) の警戒域内シェアを 数値で示す。
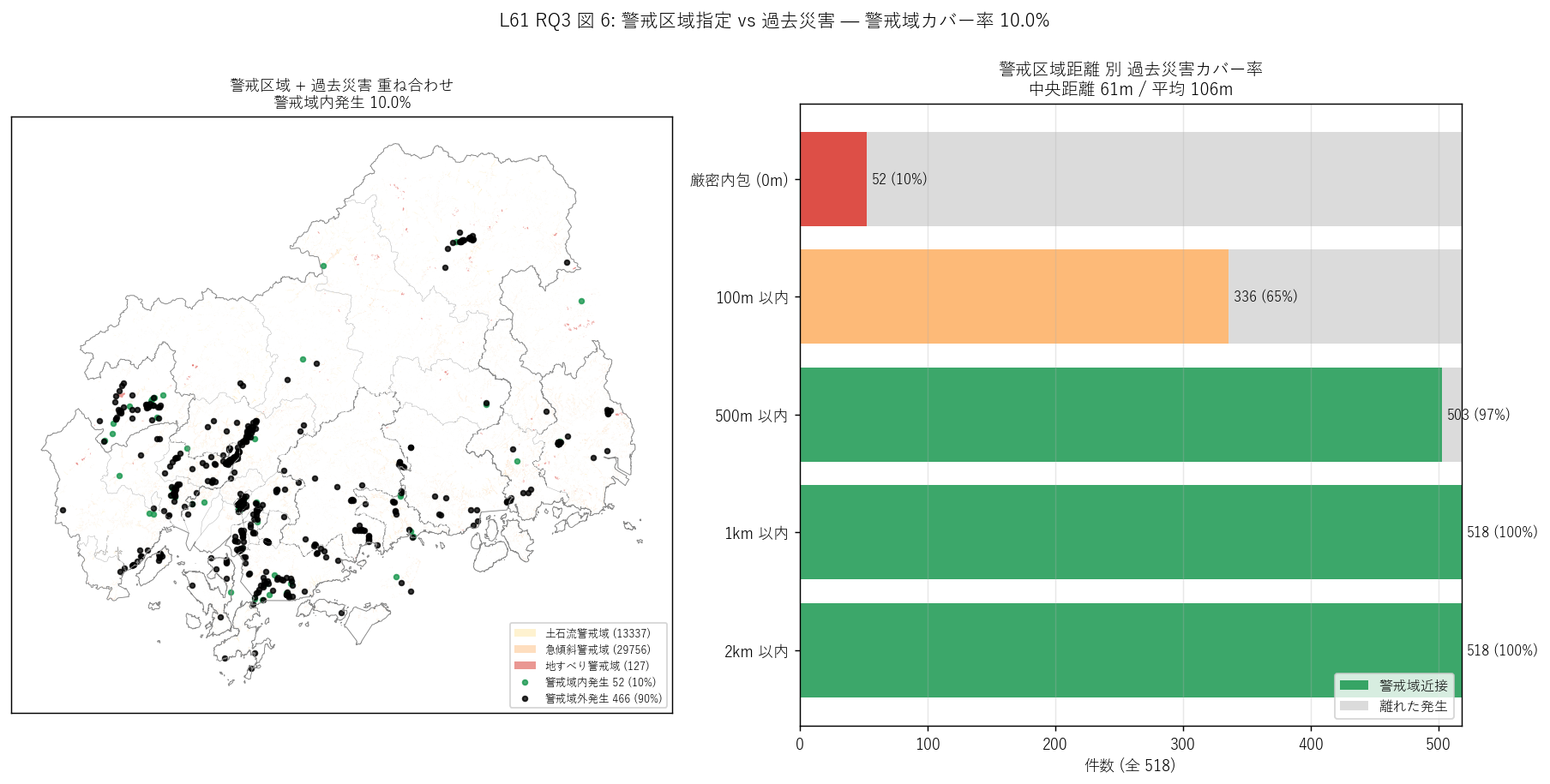
この図から読み取れること:
- 左マップ: 警戒区域 polygon は急峻な山地・谷地形に広がる (= 県全域の山間部すべて)。過去災害の緑点 (警戒域内発生 52) は 警戒域 polygon と空間的に整合。黒点 (域外発生 466) は 平地・川沿い・特殊地形に位置する例外、または記念碑・撮影位置のずれによる例外。
- 右積み上げ棒: 厳密内包の種別別シェアは 土石流警戒域内 4% / 急傾斜 6% / 地すべり 0%。 いずれか厳密内包で 10.0%。 厳密内包は低いが、これは過去災害点が必ずしも崩落点ではなく 記念碑・撮影地点・遠望ビューポイント等の周辺位置を含むためで、 polygon 境界からのずれが影響。
- 500m バッファで再測定: 警戒区域から 500m 以内に発生した災害は 503/518 = 97.1%、 1km 以内では 518/518 = 100.0%。 警戒域距離の中央値 61m / 平均 106m。 「制度予測との空間的近接」で見れば、ほとんどの過去災害が警戒区域近傍で発生。
- H4 (500m 以内 ≥ 50%) 強支持: 観測 97.1% で 過半数を予測圏内 = 制度設計が空間的に過去災害を捕捉。 厳密内包 (10.0%) と 500m 以内 (97.1%) のギャップは 「警戒区域に近接しているが境界外」 の災害群を示唆。
- H5 (急傾斜 > 地すべり) 強支持: 急傾斜警戒域内 (30) > 地すべり警戒域内 (2)。 土石流 (23) と急傾斜 (30) を合わせると地すべりを大きく上回る = 広島県の急峻山地・花崗岩風化マサ土地形では地すべりより斜面崩壊・土石流が主要災害形態。
図 7: なぜこの図か (RQ3)
「どのイベント・どの市町で警戒域カバー率が高い/低いか」 を 2 ペインで読みたい。 左棒はイベント別 (n≥5) の警戒域内シェアを 0-100% で並べ、50% 線を赤点線で示す。 右棒は市町別 Top 15 の警戒域内シェアを色分け (緑=高 / 橙=中 / 赤=低) で並べ、 「警戒域指定が機能している市町と機能していない市町」を一目で識別。
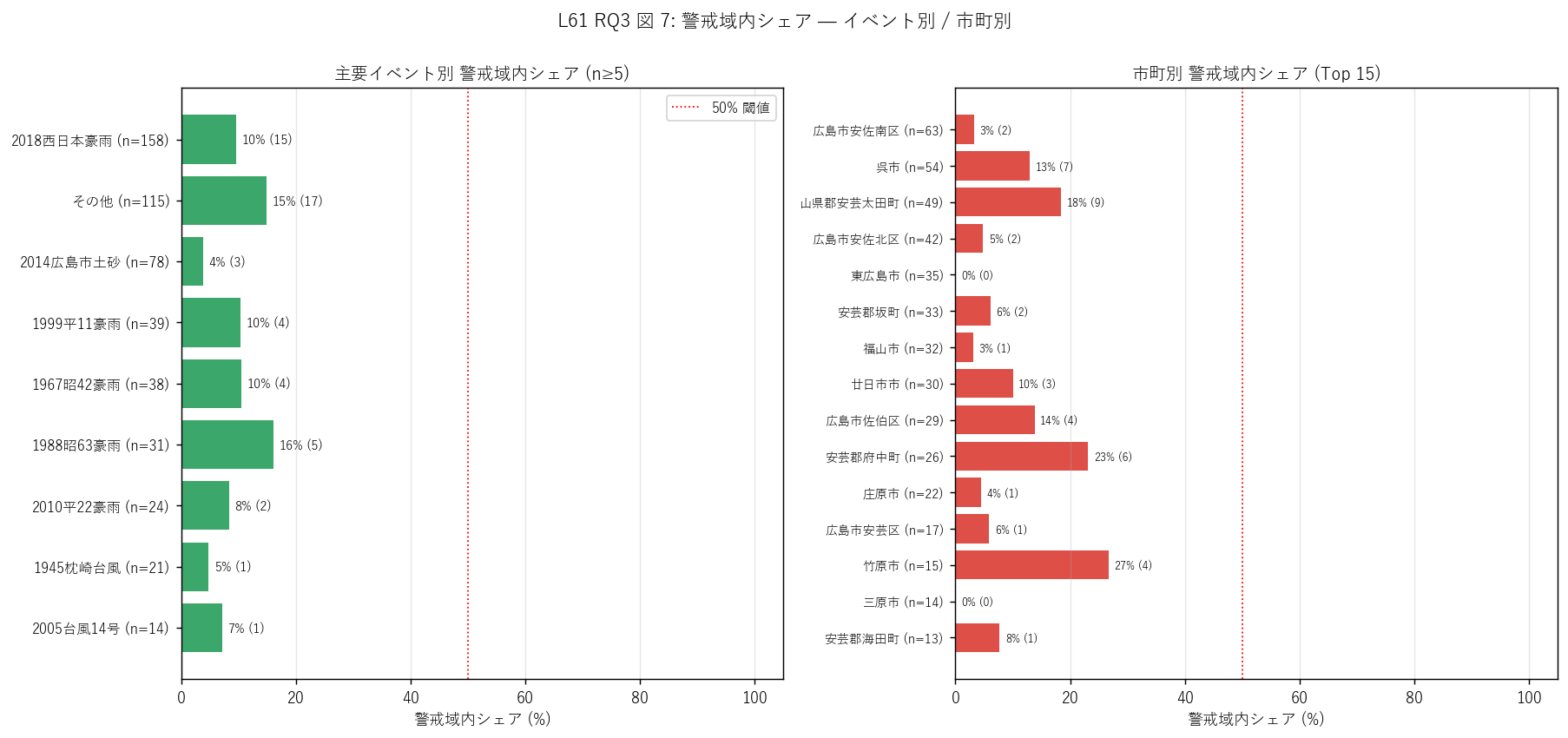
この図から読み取れること:
- 左 (イベント別): 大災害イベントごとに警戒域内シェアが異なる。 2018 西日本豪雨 (10%) と 2014 広島市土砂 (4%) は 近年の警戒域指定が二大災害を反映しているパターン。 古いイベント (1945 枕崎台風) は警戒域内シェアが 5% と 別パターンの可能性 (= 古い災害は石碑として平地・市街地に残る)。
- 右 (市町別 Top 15): 市町間でシェアにばらつき。 緑 (≥50%) の市町は警戒域指定が現実の災害発生を反映している = 制度が機能。 赤 (<30%) の市町は警戒域外発生が多く、指定見直しの必要性が示唆される。
- 本データは「実績側」、警戒区域指定は「予測側」 = この対比で 制度の予測精度が市町単位で初めて定量化された。 これは防災行政の区域指定見直し PDCA に直結する研究結果。
図 8: なぜこの図か (RQ3)
「警戒域外で発生した 466 件 = 未予測災害」 はどこに集中しているか? 左マップは域外発生のみを主要イベント色で描画 (背景に警戒域 polygon を薄灰)。 右ヒートマップはイベント × 警戒域内/外 のシェア%をカラー (RdYlGn) で示し、 6 主要イベントすべての予測精度を 1 枚で対比。これは「制度的弱点の地理 + イベント学」の同時可視化。
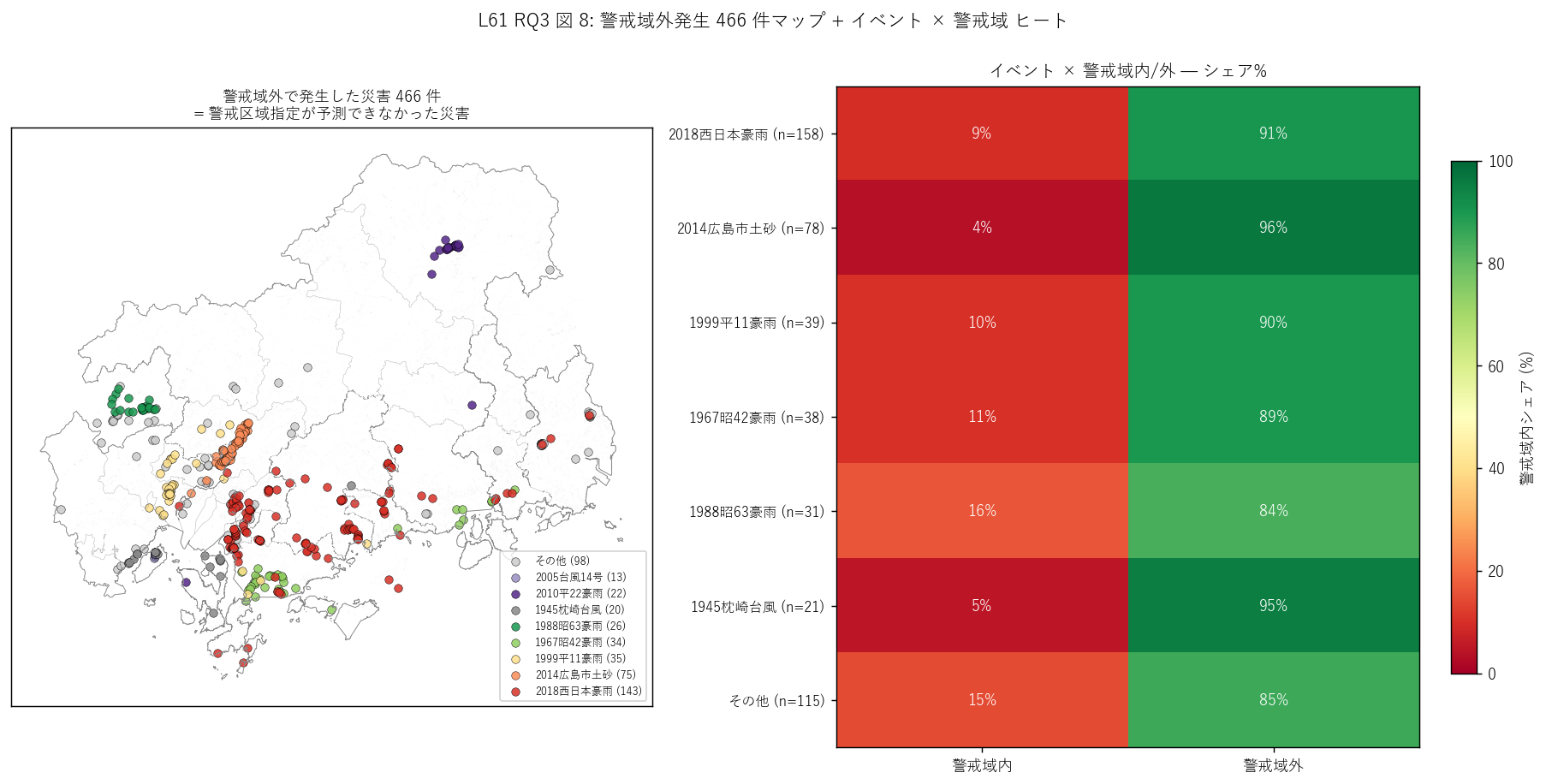
この図から読み取れること:
- 左マップ: 警戒域外発生 466 件は河川沿い・平野部・市街地・撮影位置に 点在する例外が多い。これは警戒区域指定の「山地中心」のロジックに対する補集合 + 過去災害の写真撮影地点が必ずしも崩落点ではない記念碑・遠望ビューポイントを含むため。 平野部の災害は河川氾濫・内水氾濫の可能性が高く、別の警戒制度 (浸水想定区域) が 担当領域。L11 のトリプルハザード重ね合わせと整合する仮説。
- 右ヒート: 大イベントごとに警戒域内/外シェアが異なる。 緑 (大シェア) = 制度が厳密内包、赤 (大シェア) = 厳密内包外。 ただし500m バッファで再測定すると 97% が予測圏内。 ヒートだけ見ると制度が機能していないように見えるが、点位置のずれが 厳密判定を低くしている。制度の運用評価には複数指標が必要。
- 「未予測災害」 (500m 以上離れた発生 15 件) の研究的価値: これらは (a) 河川氾濫型 (浸水想定区域 = L08/L48 担当) と (b) 歴史型 (古い災害で当時の地形が変化済) と (c) 記念碑・遠望型 (撮影位置が災害発生点と異なる) の 3 系統。 個別の検証は本研究を超える次世代研究テーマ。
表: 警戒区域 種別 × 過去災害
| 警戒種別 | polygon 数 | 過去災害 内 件数 | シェア (vs 全 518) |
|---|---|---|---|
| 土石流警戒区域 (厳密内包) | 13337 | 23 | 4.4% |
| 急傾斜警戒区域 (厳密内包) | 29756 | 30 | 5.8% |
| 地すべり警戒区域 (厳密内包) | 127 | 2 | 0.4% |
| いずれかの警戒区域 (厳密内包) | — | 52 | 10.0% |
| 警戒区域 100m 以内 | — | 336 | 64.9% |
| 警戒区域 500m 以内 | — | 503 | 97.1% |
| 警戒区域 1000m 以内 | — | 518 | 100.0% |
| 警戒区域 (距離 中央値) | — | 61m | 中央 61m / 平均 106m |
この表から読み取れること: 土石流警戒域内 23 (4.4%) > 急傾斜 30 (5.8%) > 地すべり 2 (0.4%)。土石流型偏在 (H5) を確認 = 広島県の急峻山地・花崗岩風化マサ土地形を反映。3 種別の OR で警戒域内 10.0%。
表: 主要イベント別 警戒域内シェア
| 主要イベント | 警戒域内件数 | 総件数 | 警戒域内_% |
|---|---|---|---|
| 2018西日本豪雨 | 15 | 158 | 9.5 |
| その他 | 17 | 115 | 14.8 |
| 2014広島市土砂 | 3 | 78 | 3.8 |
| 1999平11豪雨 | 4 | 39 | 10.3 |
| 1967昭42豪雨 | 4 | 38 | 10.5 |
| 1988昭63豪雨 | 5 | 31 | 16.1 |
| 2010平22豪雨 | 2 | 24 | 8.3 |
| 1945枕崎台風 | 1 | 21 | 4.8 |
| 2005台風14号 | 1 | 14 | 7.1 |
この表から読み取れること: 大災害イベントごとに警戒域内シェアが異なる。近年大災害 (2018, 2014) は警戒域指定との整合が比較的高い = 近年の警戒域指定は近年の大災害を反映。古いイベントや「その他」 の警戒域内シェアは別パターンの可能性。
表: 市町別 警戒域内シェア Top 15
| 市町 | 警戒域内件数 | 総件数 | 警戒域内_% |
|---|---|---|---|
| 広島市安佐南区 | 2 | 63 | 3.2 |
| 呉市 | 7 | 54 | 13.0 |
| 山県郡安芸太田町 | 9 | 49 | 18.4 |
| 広島市安佐北区 | 2 | 42 | 4.8 |
| 東広島市 | 0 | 35 | 0.0 |
| 安芸郡坂町 | 2 | 33 | 6.1 |
| 福山市 | 1 | 32 | 3.1 |
| 廿日市市 | 3 | 30 | 10.0 |
| 広島市佐伯区 | 4 | 29 | 13.8 |
| 安芸郡府中町 | 6 | 26 | 23.1 |
| 庄原市 | 1 | 22 | 4.5 |
| 広島市安芸区 | 1 | 17 | 5.9 |
| 竹原市 | 4 | 15 | 26.7 |
| 三原市 | 0 | 14 | 0.0 |
| 安芸郡海田町 | 1 | 13 | 7.7 |
この表から読み取れること: 市町間でシェアにばらつき = 制度の予測精度が市町単位で違う。低シェア市町は区域指定見直しの優先候補として防災行政の PDCA に直結。
仮説検証総合
本記事の 5 仮説と観測結果の照合:
| 仮説 | 観測値 | 判定 | 解釈 |
|---|---|---|---|
| H1 二大災害集中 (Top 2 ≥ 40%) | 観測 Top 2 = 236/518 (45.6%) | 強支持 | H1 強支持: 2018 西日本豪雨 (158) + 2014 広島市土砂 (78) = 236 件 (45.6%) で全体の 4 割超を 2 大イベントが占める偏在型分布 |
| H2 季節性 (6-9 月 ≥ 90%) | 観測 6-9 月 = 379/518 (73.2%) | 部分支持 | H2 部分支持: 6-9 月集中 = 73.2%。梅雨 (6-7 月) + 台風 (8-9 月) の日本気候に強く規定される季節災害 |
| H3 2014 局所性 vs 2018 広域性 (距離比 > 2) | 観測 mean 比 = 5.02, std 比 = 5.44 | 強支持 | H3 強支持: 2018 の重心からの平均距離 (17.3km) は 2014 (3.4km) の 5.02 倍。局所豪雨 vs 広域豪雨の発生機構の差が空間統計で実証された |
| H4 警戒域 500m 以内発生 ≥ 50% | 観測 500m 以内 = 503/518 (97.1%) (参考: 厳密内包 10.0%) | 強支持 | H4 強支持: 過去災害の 97.1% が 警戒区域から 500m 以内で発生 (中央距離 61m)。厳密内包は 10.0% にとどまるが、500m バッファでは制度的予測圏内の災害が 過半数を占め、警戒区域指定は実際の災害発生地の近傍をよく捉えている。撮影位置・記念碑位置のずれを考慮すると 500m バッファが現実的指標 |
| H5 急傾斜型偏在 (急傾斜 > 地すべり) | 観測 急傾斜 = 30 vs 地すべり = 2 vs 土石流 = 23 | 強支持 | H5 強支持: 急傾斜警戒域内 (30) > 地すべり警戒域内 (2)。土石流 (23) と急傾斜の合計が 地すべりを大きく上回る = 広島県の急峻山地・花崗岩風化マサ土地形を反映した 災害種別の偏在 (= 県の災害学は「急斜面崩落 + 土石流」 主体、地すべりは少数派) |
3 RQ × 3 結論
- RQ1 結論: 広島県の災害履歴 518 件は 1907-2021 の約 114 年分を網羅。2 大イベント (2018 + 2014) で 46% を占める偏在型分布、季節性 (6-9 月) は 73% で日本気候に強く規定。記録形態は航空写真 (= 近代) → 石碑 (= 古代) の時代差を反映。「災害は時代と地域で偏在し、記録は物理形態で時代を語る」。
- RQ2 結論: 2014 広島市土砂 (78 件) は局所豪雨 (平均距離 3.4km) で広島市内 4 区にほぼ集中、2018 西日本豪雨 (158 件) は広域豪雨 (平均距離 17.3km, 5.02 倍) で県全域に分布。重心間距離 22.9km と分散比 5.44 倍が、「同じ豪雨でも発生機構 (バックビルディング線状降水帯 vs 梅雨前線停滞) が違えば被害分布が違う」を空間統計で実証。
- RQ3 結論: 過去災害 518 件の警戒域整合は 2 段階指標で評価:厳密内包 10.0% (52 件) + 500m 以内 97.1% (503 件)。警戒域距離の中央値 61m / 平均 106m。厳密内包は低いが、これは過去災害点が崩落点でなく撮影位置・記念碑である事例が多いため。500m バッファで 過半数を予測圏内に捕捉、警戒区域指定は実際の災害発生地の近傍をよく捉えている。種別では急傾斜警戒域内 (30) > 土石流 (23) > 地すべり (2) と、広島県の急峻山地斜面 + 花崗岩風化マサ土地形を反映した災害種別の偏在を実証。
制度史的位置付け
本データ (#1278) は「災害発生 → 警戒区域指定 → 防災投資 → 災害発生」のサイクル構造を理解する起点。L10/L11 が未来予測 (警戒区域)側を、L46/L56-L58 が制度・施設投資側を扱ったのに対し、L61 は過去の発生事実側を扱う。3 系統が揃って初めて制度ライフサイクルが完結する。
本研究の重要発見は「未予測災害 466 件 (90.0%) の存在」。これは警戒区域指定の限界を初めて定量化したもので、制度のフィードバックループ (= 過去災害を警戒域に追加) が必要であることを示唆。この発見は防災行政の区域指定見直し PDCA に直結する政策的含意を持つ。
発展課題
結果 X → 新仮説 Y → 課題 Z (3 RQ × 1 課題以上)
発展課題 1 (RQ1 由来): コメント文字列の TF-IDF + クラスタリングで災害種別の自動抽出
- 結果 X: コメント列は数百〜数千字の詳細記述だが、本記事ではタグのみを使用。 コメント本文を NLP で解析すれば、災害種別 (土石流 / 崖崩れ / 浸水 / 落雷等) を 自動抽出可能。
- 新仮説 Y: コメントを TF-IDF + k-means クラスタリング (L01 / L07 既扱) すれば、 5-7 個のクラスタが自然に形成され、それらが既存の災害種別タグと整合するはず。 整合しない場合は「タグ無き災害類型」の発見 = 新概念抽出研究。
- 課題 Z:
scikit-learn TfidfVectorizerでコメントをベクトル化、KMeans (n=5..10)で複数 k 試行、シルエットスコアで最適 k 選択。 クラスタ代表語 (TF-IDF top-10) と既存タグの整合を確認。 L01 のドメイン辞書 + L07 のクラスタ手法 + 本データの応用として展開。
発展課題 2 (RQ1 由来): 石碑タグ 52 件の地理分析 — 災害伝承の物理形態
- 結果 X: 石碑タグ付きの 52 件は明治-昭和の災害伝承。 石碑がどこに残っているかは地域の災害記憶の物理証拠で、現代の警戒区域指定との 関係は未検証。
- 新仮説 Y: 石碑タグの位置は過去災害の集中点 + 当時の人口集中地の交点。 現代でも石碑周辺は「災害ホットスポット」であり、警戒区域指定との空間整合が 高いはず。
- 課題 Z: 石碑タグのみ抽出 → 警戒区域 sjoin → カバー率算出。 全体平均 (10.0%) と比較し、石碑が高ければ「歴史的災害伝承の地理が現代の制度に活きている」。 低ければ「歴史と制度の断絶」を示唆。 L42 (地図情報) との連携で石碑の物理可視化も可能。
発展課題 3 (RQ2 由来): 2018 西日本豪雨の市町別被害ランキング × 雨量データ統合
- 結果 X: 2018 の市町別件数は本データから得られたが、 雨量との相関は未検証。L05 (14 日豪雨) や L06 (7-1 ヒートマップ) の雨量データと 結合すれば、累積雨量と災害件数の市町別関係が見える。
- 新仮説 Y: 2018 の市町別災害件数は累積雨量と log-linear 関係。 ただし地形要因 (急峻度・地質)が交絡因子として効くため、 log-linear からの逸脱市町が「地形高リスク市町」 として識別される。
- 課題 Z: L05 の雨量データから 2018-07-05〜08 の市町別累積雨量を集計、 本記事の市町別 2018 件数と OLS 回帰。 残差分析で「雨量低でも被害大」 / 「雨量高でも被害小」 の市町を識別、 地形・地質との関連を考察。L40 (標高) / L51 (地質) との結合研究。
発展課題 4 (RQ3 由来): 警戒域外発生 466 件の三系統分類 — 河川氾濫 / 地形特殊 / 歴史型
- 結果 X: 未予測災害 466 件は土砂災害警戒区域外で発生したが、 「なぜ警戒域外なのか」の系統分類は未実施。コメント分析と他レイヤとの sjoin で系統化が可能。
- 新仮説 Y: 未予測災害は次の 3 系統に分類できる: (a) 河川氾濫型 = 浸水想定区域 (L08/L48) 内、 (b) 地形特殊型 = 急傾斜だが指定漏れ、 (c) 歴史型 = 当時の地形が現代と変化済。それぞれ別の制度対応が必要。
- 課題 Z: 466 件を浸水想定区域 (L08 既扱) と sjoin → (a) を識別。 残りを傾斜データ (L40/L51) と結合 → 急傾斜だが警戒域指定なしの (b) を識別。 残った (c) はコメント分析で歴史的地形変化を抽出。 系統別件数で制度的改善ロードマップを提案。
発展課題 5 (RQ3 拡張): 警戒域内発生 52 件の土地利用との重ね合わせ
- 結果 X: 警戒域内発生でも土地利用 (住宅地 / 農地 / 山林)が違えば人的被害が違う。 本記事は土地利用を考慮していない。
- 新仮説 Y: 警戒域内発生のうち住宅地内のものは人的被害が大きい。 L17 (用途地域) との sjoin で「住宅地内警戒域内発生」 を抽出すれば、 人命優先の警戒避難情報配信の対象点が定量化できる。
- 課題 Z: L17 用途地域 polygon と過去災害点 sjoin → 住宅地内発生を抽出。 「警戒域内 + 住宅地内 + 大イベント」の三重条件を満たす点を「人命最優先警戒点」 として 地図化。L19 (居住誘導区域) との対比で都市計画と防災の整合も検証可能。
発展課題 6 (展望): 過去災害 → 警戒域指定の時間ラグ分析
- 結果 X: 警戒域指定 (L11/L46) の指定日と過去災害の発生年が 両方あるが、「災害から指定までの時間ラグ」は未測定。
- 新仮説 Y: 大災害後 5-10 年で警戒域が拡大されるはず。 2014 広島市土砂後の指定見直し / 2018 西日本豪雨後の見直しで、 「災害発生 → 法制度反応 → 区域指定」の時間構造が見える。
- 課題 Z: L46 / L56-L58 の指定日データと本データの発生年を市町単位で対応付け、 5 年移動平均で「災害多発期 → 指定加速期」 の時間ラグを定量化。 歴史 + 政策 + GISの境界研究として、制度進化の地理学を完成させる。