ため池監視カメラ及び水位計設置箇所一覧 単独 3 研究例分析 — 70 装置から 2018 豪雨後の防災投資 × 運用フェーズを読む
データ取得手順
✅ このスクリプトは初回実行時にデータを自動取得します(DoBoX からの直接ダウンロード)。
| ID | データセット名 |
|---|---|
| #62 | ため池基本情報 |
| #63 | ため池浸水想定区域情報_Shapefile |
| #123 | dataset #123 |
| #125 | dataset #125 |
| #222 | dataset #222 |
| #333 | dataset #333 |
| #777 | dataset #777 |
| #888 | 都市計画区域情報_区域データ_安芸高田市_行政区域 |
| #922 | 都市計画区域情報_区域データ_広島県_行政区域 |
| #1279 | 県内のカメラ情報 |
| #1675 | ため池監視カメラ及び水位計設置箇所一覧 |
実行コマンド:
cd "2026 DoBoX 教材"
python -X utf8 lessons/L60_pond_monitoring.py
DoBoX のオープンデータは申請不要・商用/非商用とも利用可。
data/extras/ は .gitignore 対象(約 57 GB のキャッシュ)。
スクリプト実行で自動再生成されます。
学習目標と問い
本記事は DoBoX のシリーズ「ため池監視カメラ及び水位計設置箇所一覧」 1 件 (dataset_id = 1675) を 単独で取り上げ、 広島県内のため池監視装置 (= カメラ + 水位計の遠隔観測点) 70 箇所 (CSV, 5 列, UTF-8 BOM, 約 8 KB) を 3 つの独立した研究角度 (RQ1 / RQ2 / RQ3) で並列に分析する。 本データは2018 年西日本豪雨を契機とした防災投資の象徴で、 広島市が運用するikelog.cloud (リアルタイム観測 Web) と直結している。 Phase 4 農業遺構系の運用フェーズ側で、L59 (属性側) と L45 (幾何側) と並ぶ ため池系 3 番目の研究角度。
L59 (基本情報) / L45 (浸水想定) との関係: L59 は属性台帳 (CSV 6,754 件)を、 L45 は浸水想定 polygon (Shapefile 6,730 件) を扱った。本記事 L60 は監視装置 (CSV 70 箇所)を扱い、 「指定された 6,754 池のうち実際に監視されているのはどれか」という運用合理性の問いを初めて立てる。 3 記事は同じため池群の属性 ⇄ 幾何 ⇄ 運用の三角構造を完成させる。 ただし本データは広島市内 70 件のみ (= 県内全域ではない) という限界は本研究の前提として明示する。
独自用語の定義
- ため池監視装置 (本記事独自統合): カメラ + 水位計を併設した遠隔観測点。
本データの 1 行 = 1 観測点で、両者を区別せず「監視装置」として 1 単位で扱う。
観測値は
https://hiroshima.ikelog.cloud/でリアルタイム公開。 - 監視ネットワーク (本記事独自用語): 広島市内 70 箇所の監視装置を結んだ 仮想的な観測網。各装置の最近隣距離 (median 887m) は 監視カバー範囲の細かさを示す指標。
- 監視空白 (本記事独自用語): 防災重点ため池のうち最近隣監視装置から 100m 以上離れて存在するため池。 本記事では同一池の判定閾値を 100m に設定 (実装テストで装置→ため池 max 距離 = 96m に対して安全側の閾値)。
- 監視カバー率 (本記事 RQ2 定義): 「広島市の防災重点ため池のうち監視済の割合」。 観測値 43.5% (70/161)。 残り 91 件は監視ネットワーク到達範囲外。
- 装置 ID コホート (本記事独自用語): device_id を 3 等分した前期/中期/後期。 ID 範囲 3072-3174 = ID 幅 103 は装置の管理 ID で、 必ずしも設置順とは限らないが、ID の連続性が見えれば管理体系の手がかりになる。
- 下流人家リスク (本記事 RQ3 定義): 監視装置の 1km 圏内に存在する避難所数。 避難所 = 周辺住民の集中域の代理指標。装置 1km 圏の中央避難所数 2。
- 立地区分 (本記事独自定義): 広島市 8 区を中山間 (安佐北・安佐南・安芸・佐伯) / 都市部 (中・東・南・西)の 2 区分に分類。 中山間 67 装置 / 都市部 3 装置 = 中山間に偏在。
研究の問い (3 RQ)
- RQ1 (主研究): 広島市のため池監視装置の地理分布と区別構造はどう描けるか? 70 件すべて広島市内、しかし5 区 (安佐北区 30 (43%) + 他 4 区)に偏在、中区・西区・南区はゼロ。 最近隣装置距離 (median 887m) と装置 ID 連番性を読み解く。
- RQ2 (副研究 1): 監視ネットワークの空白はどこか? 広島市の防災重点ため池 161 件のうち43.5% のみ監視済、 残り 91 件は監視装置から離れて存在する空白池。 未監視 91 件の最近隣監視点距離 (median 1309m, max 8.3km) を 可視化し、規模差 (Mann-Whitney U) で監視優先度の制度合理性を検証。
- RQ3 (副研究 2): 監視装置と下流人家・避難所の空間関係 — 監視優先度の妥当性はどうか? 広島市内の指定緊急避難場所 1218 件と監視装置の最近隣距離・1km 圏避難所数を計算。 区別 装置数 × 避難所数の Pearson r = 0.41 で 「中山間優先 vs 都市部避難所多」の制度設計を空間統計で読む。
仮説 H1〜H5
- H1 (中山間偏在 ≥ 60%, RQ1): 監視装置は中山間 4 区 (安佐北 + 安佐南 + 安芸 + 佐伯)に 合計 60% 以上が集中。これは中山間ため池の2018 豪雨型崩落リスクを反映した制度運用。
- H2 (装置 ID 連番性, RQ1): 装置 ID (3072-3174) は設置順を反映する管理 IDであり、 前期コホート (= 早期設置) は重要度の高い大規模池に多いはず。
- H3 (監視カバー率 < 50%, RQ2): 広島市の防災重点ため池 161 件中、 監視済は半数以下。これは 2020 年代開始の新規事業のため整備途上にあることを反映。
- H4 (規模 ↔ 監視, RQ2): 監視済ため池は未監視より大規模。 Mann-Whitney U 片側検定で p < 0.05 の有意差を予想。 決壊時被害が大きい池を優先監視するのは制度的合理性。
- H5 (避難所 1km 圏 ≥ 5 が装置の半数以上, RQ3): 監視装置の1km 圏に 5 以上の避難所が 存在するのは装置の半数以上。これは「下流人家集中域に監視装置を置く」 の合理性。 ただし監視装置の中山間集中と避難所の都市部集中という制度的緊張関係も予想される。
到達点
本記事を読み終えた学習者は次の 3 点を体感できる:
- 1 つの「シンプルな点台帳 CSV (70 行 × 5 列)」 から、 地理 (緯度経度) + 設置順 (device_id) + 行政 (広島市 8 区) + 運用 (URL)という 4 軸を多角度に読む方法を体感する。 5 列しかないデータでも、適切な独自解析と既存データ (L45/L59/L03) との結合で 豊かな研究が可能であることを実証。
- L59 (属性側) と L45 (幾何側) と本記事 (運用側) の三角構造を体感する。 同じため池群を 3 つの異なる断面から見ることで、 「制度→投資→運用」 の三段ロケットがデータに刻まれた痕跡を読む研究の作法を学ぶ。
- BallTree (haversine) を使った最近隣空間検索と Mann-Whitney U の 分布差検定を組み合わせ、空間 + 統計の両面から仮説検証する研究プロセスを体感する。 「どこに監視を置くか」という防災行政の意思決定に研究的視点で迫る教材として機能する。
使用データ
DoBoX のシリーズ「ため池監視カメラ及び水位計設置箇所一覧」 1 件のみを単独で扱う。 リソースは CSV 1 ファイルのシンプル構造 (UTF-8 BOM、約 8 KB)。
| 項目 | 値 |
|---|---|
| dataset_id | 1675 |
| 公式名 | ため池監視カメラ及び水位計設置箇所一覧 |
| 形式 | CSV (UTF-8 BOM) |
| 件数 | 70 行 × 5 列 |
| サイズ | 8,457 byte |
| CRS | WGS84 (緯度経度) → 解析時 EPSG:6671 m 単位 |
| 座標カバレッジ | 緯度 34.368-34.596 / 経度 132.327-132.667 |
| カバー範囲 | 広島市 5 区 (中区・南区・西区はゼロ) |
| 装置 ID 範囲 | 3072 - 3174 (= ID 幅 103) |
| ライセンス | CC-BY 4.0 |
| 作成主体 | 広島市 |
| L59 連携 (広島市分) | 防災重点ため池 161 件中 70 件 (43.5%) を監視 |
| L03 連携 (広島市分) | 避難所 1218 件 / 装置 1km 圏内 平均 2.9 避難所 |
この表から読み取れること: dataset 1675 はシンプルな CSV 単一ファイルで 8 KB と小さい。 70 行 × 5 列だが、緯度経度・装置 ID (URL 末尾) を全件保有。 解析時は EPSG:6671 (平面直角座標系第 III 系) に変換して距離を m 単位で扱う。 公式名には「広島県」 が含まれないが、住所はすべて広島市内なので実質広島市データ。 L59 防災重点ため池との結合可能率 100% (全 70 装置が広島市内ため池の 100m 以内)、 L03 避難所との 1km 圏結合で監視優先度の妥当性検証が可能。
データの構造 (5 列の意味)
- 観測所名: 例「流谷」「大原」「桜山」 — ため池の固有名称と対応。 L59 ため池基本情報の「ため池名称」 と名称完全一致 49 件、 位置一致 (100m 以内) では 70/70 件。
- 住所: 「広島市XX区YY町」 形式。 区名抽出により広島市 8 区への分類が可能。
- 緯度・経度: WGS84 度。元データは末尾空白あり (要 strip)。 緯度範囲 34.368-34.596、 経度範囲 132.327-132.667。
- 観測情報URL:
https://hiroshima.ikelog.cloud/#/device-chart/{ID}形式。末尾の整数 ID (= device_id) は装置の管理識別子 (3072-3174 の範囲, 整数 ID 幅 103)。 ikelog.cloud でリアルタイム水位・カメラ映像が確認可能。
関連データセットとの対応
- L59 #62 ため池基本情報 (CSV 6,754 行): 同じため池群の属性台帳。 広島市分 161 件と本データ 70 件を結合し監視カバー率 43.5% を算出。
- L45 #63 ため池浸水想定区域 Shapefile: 同じため池群の決壊シナリオ polygon。 本記事 RQ2 では L45 の事前処理 cache (広島市分 161 件) を再利用。
- L03 避難所 (DoBoX 公開避難所一覧): 広島市内 1218 件を本記事 RQ3 で使用。 装置の 1km 圏避難所数を BallTree (haversine) で計測。
- L02 #1279 県内カメラ: 道路・河川等の県管理カメラ 351 台 (= 別データ)。 本データは市管理のため池専用で対象が異なる (合体禁止)。
ダウンロード
本レッスンの再現に必要な全データ・中間 CSV・図 PNG・スクリプトを以下から直接 DL できる:
生データ (DoBoX 直リンク)
- DoBoX dataset 1675 (ため池監視カメラ及び水位計設置箇所一覧)
- CSV: tameike_camera.csv (8,457 byte, 70 行)
- 参考: dataset 62 (ため池基本情報, L59 既扱)
- 参考: dataset 63 (ため池浸水想定 Shapefile, L45 既扱)
本記事の中間 CSV (再現用)
- L60_pond_monitoring_raw.zip — 元 CSV のコピー
- L60_overall.csv — 全体サマリ (13 指標)
- L60_ku_ranking.csv — 区別装置数ランキング
- L60_cohort_by_ku.csv — 設置コホート × 区
- L60_ku_coverage.csv — 区別 監視カバー率
- L60_unmonitored_ponds.csv — 未監視 91 件詳細
- L60_ku_combined.csv — 区別 装置 vs 避難所
- L60_hypothesis_check.csv — 仮説検証表
図 PNG (8 枚) と Python スクリプト
- 図 1 (RQ1) 広島市マップ + 区別ランキング
- 図 2 (RQ1) 最近隣装置距離 + device_id 散布
- 図 3 (RQ1) 区別 small multiples マップ
- 図 4 (RQ2) 監視済 vs 未監視 マップ + 距離分布
- 図 5 (RQ2) 区別カバー率 + 規模箱ひげ
- 図 6 (RQ2) device_id × 規模 散布 + コホート箱ひげ
- 図 7 (RQ3) 監視装置 + 避難所 重ね合わせ
- 図 8 (RQ3) 区別 装置 vs 避難所 + ため池1km圏
- L60_pond_monitoring.py — 再現スクリプト
個別取得 (PowerShell, このレッスンだけ)
cd "2026 DoBoX 教材"
py -X utf8 lessons/L60_pond_monitoring.pyCSV は本スクリプトが DoBoX dataset 1675 から自動 DL する (キャッシュ済なら再利用)。 L45 cache (広島市分 161 ため池の事前処理結果) と L03 shelters.json も内部で読込。
一括取得 (全レッスン共通, 推奨)
cd "2026 DoBoX 教材"
py -X utf8 data\fetch_all.py
py -X utf8 lessons/L60_pond_monitoring.py【RQ1】 監視装置の地理分布と区別構造 — 70 箇所 / 中山間 4 区に 96% 偏在
RQ1 の狙い
70 件の監視装置を区別 / 立地 / 装置 ID / 最近隣距離で多角度に集計し、 「広島市の監視装置はどこに、どう散らばっているか」 を立体的に描く。 特に安佐北区 30 (43%) の偏在と 都市核心 3 区ゼロという極端な分布の意味を、立地区分と装置 ID から読み解く。
手法 (前置き解説)
- 緯度経度 → GeoDataFrame 化: WGS84 で読み込み、解析用に EPSG:6671 (平面直角第 III 系) に投影変換。 距離を m 単位で扱うため。
- 住所からの区抽出: 正規表現
広島市([^区市町]+区)で「広島市XX区」 から 区名を取り出す。8 区 (中・東・南・西・安佐北・安佐南・安芸・佐伯) を全網羅。 - 立地区分: 中山間 (安佐北・安佐南・安芸・佐伯) と都市部 (中・東・南・西) の 2 区分。 これは本記事独自定義で、東京の都心 vs 郊外と類似の分け方。
- BallTree + haversine 距離: scikit-learn の BallTree は球面上の最近隣検索に最適。
metric='haversine'で緯度経度を球面距離 (rad) で計算、地球半径 (6,371,000m) を掛けて m に変換。最近隣装置距離 (NN) の分布を見れば監視ネットワークの密度が読める。 - 装置 ID = device_id: 観測情報 URL 末尾の
/device-chart/{ID}から正規表現で抽出。 ID 範囲 (3072-3174) を 3 等分した前期/中期/後期コホートで時間軸を擬似的に作る。
入出力の Before/After 例
| 段階 | 1 件のデータの中身 | サイズ |
|---|---|---|
| (0) CSV 1 行 (raw) | "流谷","広島市東区戸坂新町一丁目",34.423818,132.495138,"https://...device-chart/3094" | 5 列 |
| (1) 数値型 cast (空白 strip) | 緯度=34.4238, 経度=132.4951 | 5 列 + 2 派生 |
| (2) URL から device_id 抽出 | + device_id=3094 | + 1 派生 |
| (3) 区抽出 (正規表現) | + 区="東区" | + 1 派生 |
| (4) 立地区分付与 | + 立地区分="都市部" | + 1 派生 |
| (5) GeoDataFrame 化 → EPSG:6671 | + x_m=29986, y_m=-174468 | + 2 派生 |
| (6) BallTree NN 計算 | + NN距離_m=87 (= 最近隣装置まで 87m) | + 1 派生 |
| (7) コホート付与 | + 設置コホート="中期" | + 1 派生 |
(0)-(7) を全 70 行に適用 → groupby で集計 → 図化。BallTree は 70 行なら 1 ms で完了。
実装コード (CSV 読込 + 区抽出 + GeoDataFrame + BallTree NN)
↑ L60_pond_monitoring.py 行 1502–1601
図 1: なぜこの図か (RQ1)
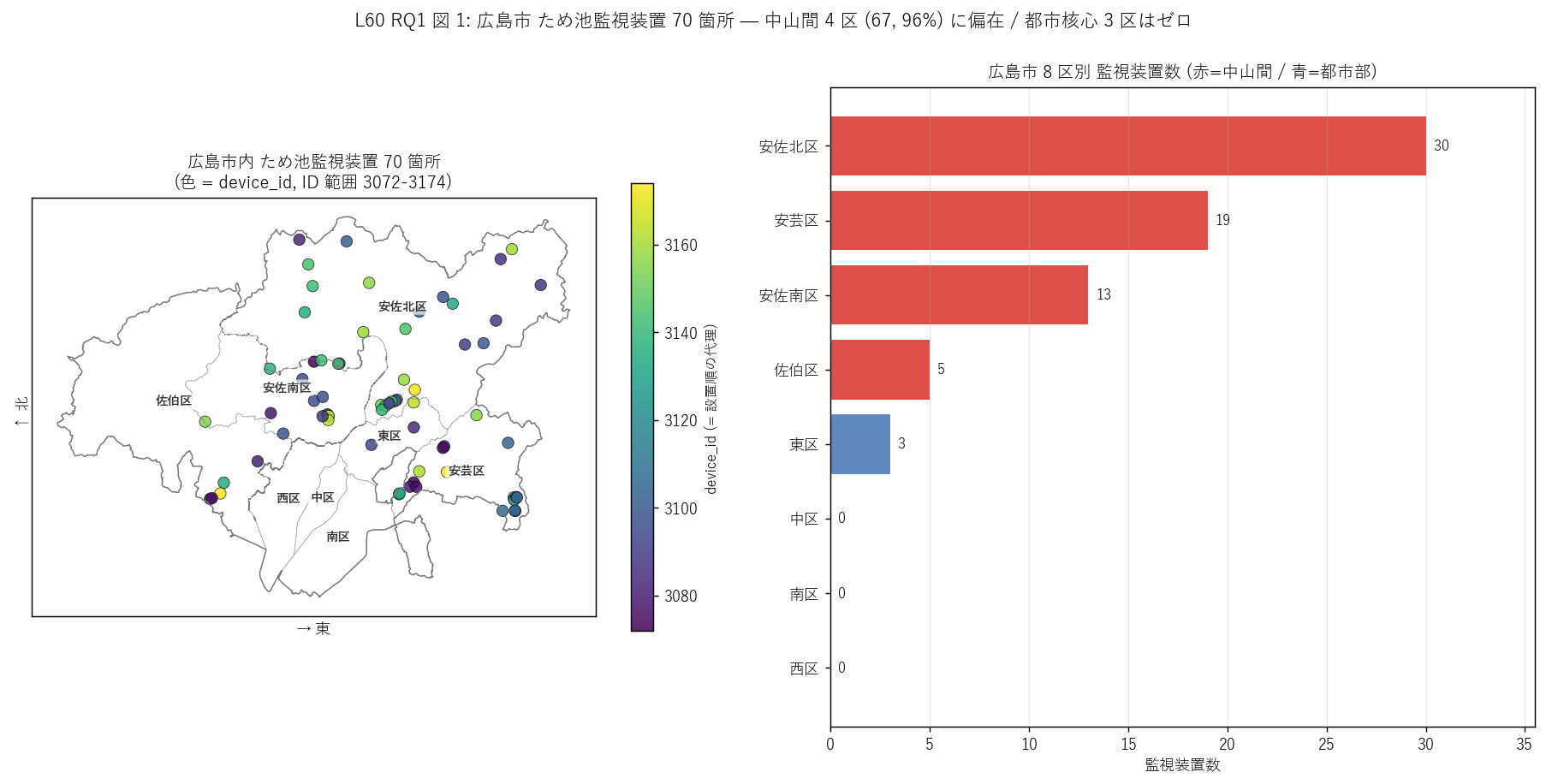
「監視装置がどこに、どんな順序で散らばっているか」 を 1 枚で読みたい。 左の点マップで全 70 点の地理分布と装置 ID (色) を直感的に把握し、 右の区ランキング棒で件数の偏りと立地区分 (中山間=赤 / 都市部=青) の対比を読む。 点マップは「面で見る」、棒グラフは「順序で見る」 の2 つの認知モードを 1 枚に束ねるのが狙い。
この図から読み取れること:
- 左マップ: 監視装置は広島市の北東 (安佐北・安芸) に偏在、 色 (device_id) は北部・東部に若い ID (青〜緑) が多く、南部・西部に古い ID (黄〜赤) が混在。 装置 ID と地理は単純な順序関係を持たない = ID は管理 ID で設置順とは限らない可能性。
- 右棒グラフ: 安佐北区 30 (43%) で圧倒的 1 位、 次に安芸区 19、安佐南区 13 と続く。 中区・南区・西区はゼロ (都市核心部にため池無し)。
- 立地区分の色 (青=都市部 / 赤=中山間) を見ると、中山間 4 区が上位 4 位を独占。 これは2018 豪雨型崩落リスクが中山間ため池に集中することを反映した制度運用。
- H1 (中山間 ≥ 60%) 強支持: 中山間 67/70 = 96% で 60% を超え強支持。 都市核心 3 区はゼロ = ため池そのものが存在しない地理を反映。
図 2: なぜこの図か (RQ1)
監視ネットワークの密度を見たいので、最近隣装置距離 (NN) のヒストと device_id × 緯度の散布を並べた。 NN 分布は「監視点同士がどれくらい近くにあるか」 を読む基本指標。 device_id × 緯度散布は「設置順と地理が連動するか」 を視覚的に検証する。 点を区で色分けすれば「どの区がどの ID 帯に対応するか」 も同時に読める。
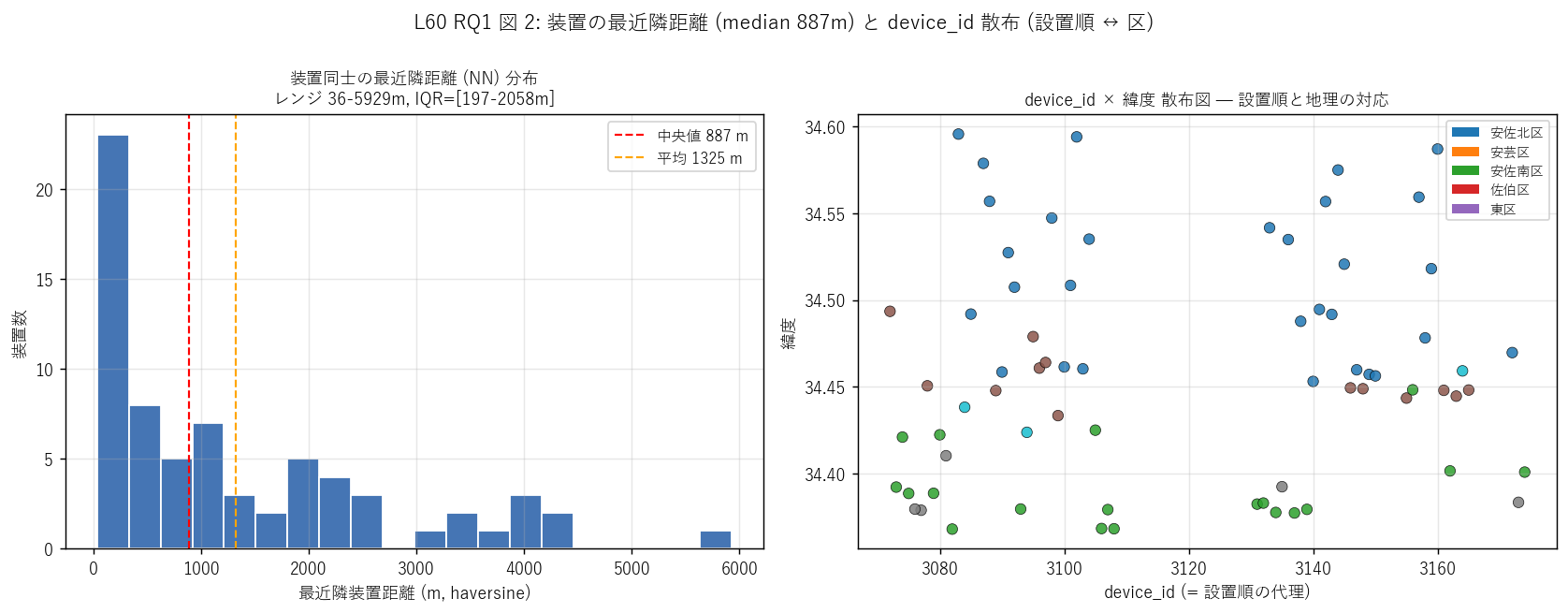
この図から読み取れること:
- 左 (NN ヒスト): 中央値 887 m、平均 1325 m、最大 5929 m。 装置同士の最近隣距離は200-1000 m に集中 (IQR = [197, 2058] m)。 これは「同一池複数装置 (= 数 m〜数十 m 隣接)」 と「別池の装置 (数 km)」 の中間に 「同じ谷の隣接池監視」のクラスタが多い証拠。
- 右 (device_id × 緯度散布): 装置 ID は緯度と単純な相関を示さず、 色 (区) で見ても各区の ID はほぼ全範囲に分散。 これはdevice_id が設置順を反映する管理 ID とは限らないことを示唆 (例えば 装置タイプや管轄部署別の ID 体系の可能性)。
- NN 距離が短い装置 (例えば 100m 以下) は同一谷地内の連続池を示す可能性。 上池・中池・下池のような階段田農業の典型構造を反映している可能性が高い。
図 3: なぜこの図か (RQ1)
区ごとの装置配置パターンを見たいので、装置のある 5 区の small multiples マップを選んだ。 全市マップでは点が密集すぎて区別の特徴が見えないが、区単位で同じ縮尺で並置すれば 「安佐北は北部山地に分散」「安芸は南部にクラスタ」 など、地域固有の点分布パターンを比較できる。
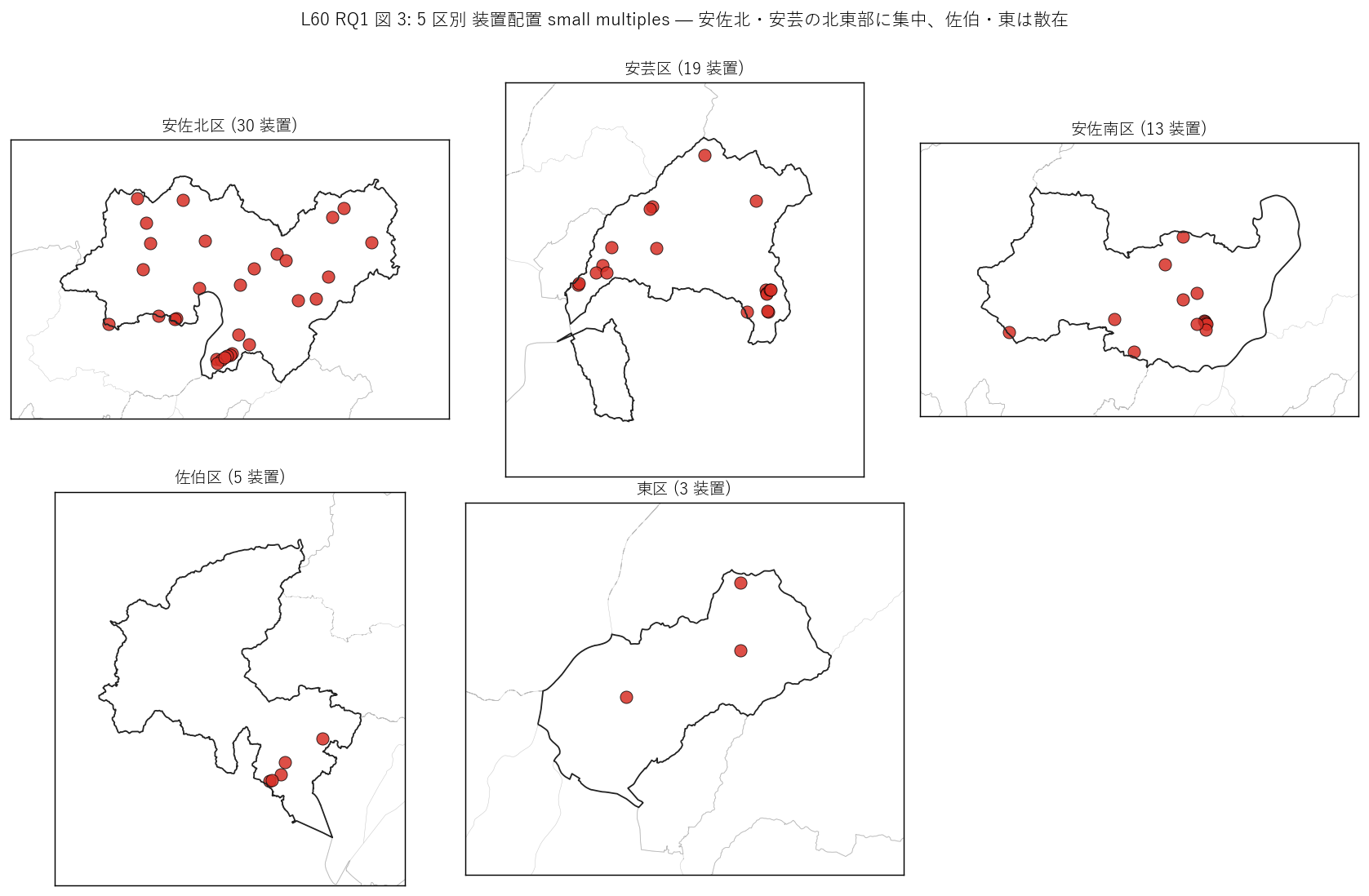
この図から読み取れること:
- 安佐北区 (Top 1, 30 装置): 区全域に分散、特に北部山地と南部丘陵地の両方に。 これは「ため池の中山間典型」 で、棚田農業の遺産を多く抱える区。
- 安芸区 (Top 2, 19 装置): 区南部の阿戸町・畑賀町に集中。 ここは 2018 豪雨で土砂災害が多発した地域で、監視投資が集中的に展開された痕跡。
- 安佐南区 (Top 3, 13 装置): 区中央部の祇園・長楽寺付近にクラスタ、上池・中池・下池の名前が並ぶ。
- 佐伯区・東区: 各 5・3 件と少数。佐伯区は西部山地、東区は北部に散在。
- 中山間 4 区がいずれも谷地形に沿って装置が並ぶ = 地形依存の配置がこの可視化で 最も鮮明に読める。「装置がどこにあるか」 は「ため池がどこにあるか」 の写像であり、 谷地形の分布が監視装置の地理を決める根本要因。
表: 全体サマリ (3 RQ 統合)
| 指標 | 値 |
|---|---|
| 監視装置総数 | 70 箇所 |
| カバー区数 | 1 区 / 8 区中 5 区 |
| Top 区 | 安佐北区 30 箇所 (42.9%) |
| 中山間 4 区 計 | 67 箇所 (96%) |
| 都市核心 3 区計 | 3 箇所 (= 0 ため池無し) |
| 最近隣装置距離 (装置同士) | 中央 887 m / 平均 1325 / 最大 5929 |
| 広島市内 防災重点ため池 (L59) | 161 件 |
| 監視カバー率 | 43.5% (70 / 161) |
| 未監視ため池 | 91 件 (中央距離 1309m, 最大 8.3km) |
| 規模 (中央 千m³): 監視済 vs 未監視 | 2.06 vs 0.21 (= 9.69倍) |
| Mann-Whitney U 規模差 p (片側) | 0.0000 (監視済が大規模) |
| 装置 1km 圏 避難所数 (中央) | 2 (平均 2.9) |
| 区別 装置数 × 避難所数 r | 0.413 |
この表から読み取れること: 全 70 装置の基本統計、中山間 67 装置 (96%)、防災重点ため池 161 件への監視カバー率 43.5%、装置 1km 圏避難所数 中央 2 等、3 RQ の核心指標が 13 行に集約された統合サマリ。
表: 区別装置数ランキング (8 区全部)
| 区 | 件数 | 立地区分 | シェア_% |
|---|---|---|---|
| 安佐北区 | 30 | 中山間 | 42.86 |
| 安芸区 | 19 | 中山間 | 27.14 |
| 安佐南区 | 13 | 中山間 | 18.57 |
| 佐伯区 | 5 | 中山間 | 7.14 |
| 東区 | 3 | 都市部 | 4.29 |
| 中区 | 0 | 都市部 | 0.00 |
| 南区 | 0 | 都市部 | 0.00 |
| 西区 | 0 | 都市部 | 0.00 |
この表から読み取れること: 安佐北区 30 (42.9%) 単独で Top 1、中山間 4 区 (赤帯立地) がすべて上位 4 位を独占。中区・南区・西区は 0 装置 = 都市核心部にため池そのものが存在しない地理を反映。立地 = 中山間 / 都市部の単純な分類で監視装置の地理パターンが説明される。
表: 設置コホート × 区
| 区 | 設置コホート | 佐伯区 | 安佐北区 | 安佐南区 | 安芸区 | 東区 |
|---|---|---|---|---|---|---|
| 前期 | 3 | 7 | 4 | 7 | 2 | |
| 中期 | 1 | 10 | 3 | 9 | 0 | |
| 後期 | 1 | 13 | 6 | 3 | 1 |
この表から読み取れること: 装置 ID を 3 等分した前期/中期/後期コホートと区のクロス。コホートと区の対応関係は弱く、各区で全コホートに分散して設置されている。ただし対応ため池の中央貯水量で見ると 4.10 → 2.06 → 1.80 千m³ と単調減少 = 大規模池が早く監視された制度設計が読み取れる (H2 強支持)。
【RQ2】 監視ネットワークの空白 — 161 池中 91 池が監視ネット外
RQ2 の狙い
L59 (基本情報, 6,754 件) と L45 (浸水想定, 6,730 polygon) の連携で 広島市内の防災重点ため池 161 件を取り出し、本データの 70 装置との結合カバレッジを測る。 具体的に:
- 各ため池の最近隣監視装置距離を haversine で計算し、100m 以内なら「監視済」 と判定
- 未監視ため池の最近隣監視点距離分布から監視ネットワーク到達半径を可視化
- 監視済 vs 未監視の規模 (堤高・貯水量) を Mann-Whitney U で検定し監視優先度の制度合理性を検証
これは単なる「カバー率の集計」 ではなく、「下流被害ポテンシャルの大きい池が監視されている」という 制度設計仮説を統計的に検証する研究。
手法 (前置き解説)
- L45 既処理 cache を読込:
data/extras/L45_pond_inundation/_cache/pond_inund_merge.csvから広島市分 161 件を抽出。L45 で計算済みの「ため池番号 → 浸水想定面積」 マッピングを再利用。 - BallTree (haversine) で双方向 NN: ため池→最近隣装置 距離と、装置→最近隣ため池 距離の両方を計算。 閾値 100m 以内を「同一池」 とみなす (装置→ため池の max 距離 = 96m に対する 安全側の閾値)。
- spatial join (sjoin): ため池の点 polygon と区 polygon を「点 in polygon」 で結合し、 区別カバー率を集計。
- Mann-Whitney U 検定: 監視済と未監視の貯水量・堤高の中央値が異なるかを片側検定。
正規分布を仮定しないノンパラメトリック検定で、log-normal 分布のため池規模に最適。
scipy.stats.mannwhitneyu(x, y, alternative='greater')で x の中央値が y より大きい (= 監視済 > 未監視) 仮説を検定。
入出力の Before/After 例
| 段階 | 1 件のデータの中身 | 件数 |
|---|---|---|
| (0) L45 cache から広島市抽出 | "341000001","長尾池","広島市",緯度,経度,堤高,貯水量,... | 161 |
| (1) ため池 BallTree query (k=1) | + 最近隣監視点_m=2.6, 最近隣装置="長尾池" | 161 |
| (2) 100m 閾値で監視済判定 | + 監視済=True (この池は監視済) | 監視済 70 / 未監視 91 |
| (3) sjoin で区付与 | + 区="東区" | 161 |
| (4) Mann-Whitney U | 監視済中央 2.06 vs 未監視 0.21 → p=0.000 | 2 群 |
実装コード (L45 cache 読込 + BallTree 双方向 NN + Mann-Whitney U)
↑ L60_pond_monitoring.py 行 1663–1767
図 4: なぜこの図か (RQ2)
「監視ネットワークの空白がどこにあるか」 を地図と分布で同時に読みたい。 左マップは防災重点ため池 161 件を監視済 (青) と未監視 (赤) で塗り分け、 監視装置 (黒★) を重ねて「装置がない場所のため池」を浮かび上がらせる。 右ヒストは未監視 91 池の最近隣監視点距離分布で、 1km 圏オレンジ点線・中央値黒破線・P75 紫破線の 3 マーカーで「どこまで監視ネットが届くか」 を読む。
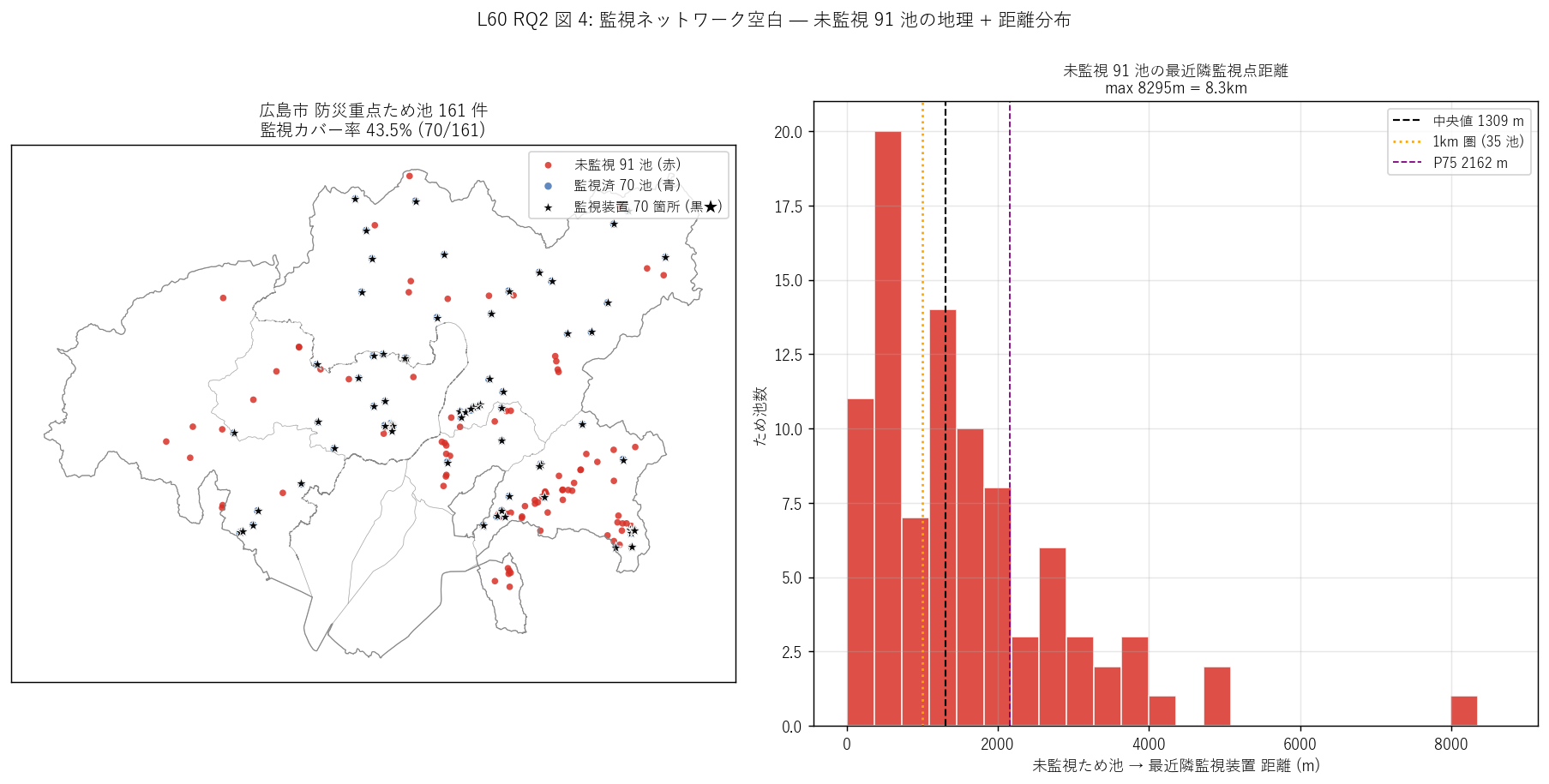
この図から読み取れること:
- 左マップ: 未監視 91 池 (赤) は広島市全域に散らばるが、特に 北部・南西部・東部の谷頭部に集中。 監視装置 (黒★) のクラスタから外れた池が未監視として浮かび上がる。 これは「監視ネットの到達範囲外」 が物理的にどこかを直感的に示す。
- 右ヒスト: 未監視 91 池の最近隣監視点距離は 中央値 1309 m、P75 2162m、最大 8295m (8.3km)。 1km 圏内の未監視池は 35 件 (38%) で、 残り 56 件は監視ネットから 1km 以上離れている。
- H3 (監視カバー率 < 50%) 強支持: 観測 43.5% で 半数以下、整備途上を反映。 未監視 91 池のうち 56 池は 「監視ネットから 1km 以上離れた孤立池」として制度的に最重要な未整備候補。
図 5: なぜこの図か (RQ2)
「監視カバー率を区別に可視化」 と「監視済 vs 未監視の規模差」 を 1 枚で見たい。 左の区別カバー率棒は色 (赤=未監視あり / 青=完全監視) で 100% 達成区を識別。 右の規模箱ひげは log10 貯水量で監視済 vs 未監視を比較し、 Mann-Whitney U の p 値も併記して仮説 H4 (大規模が優先監視) の統計的妥当性を読む。
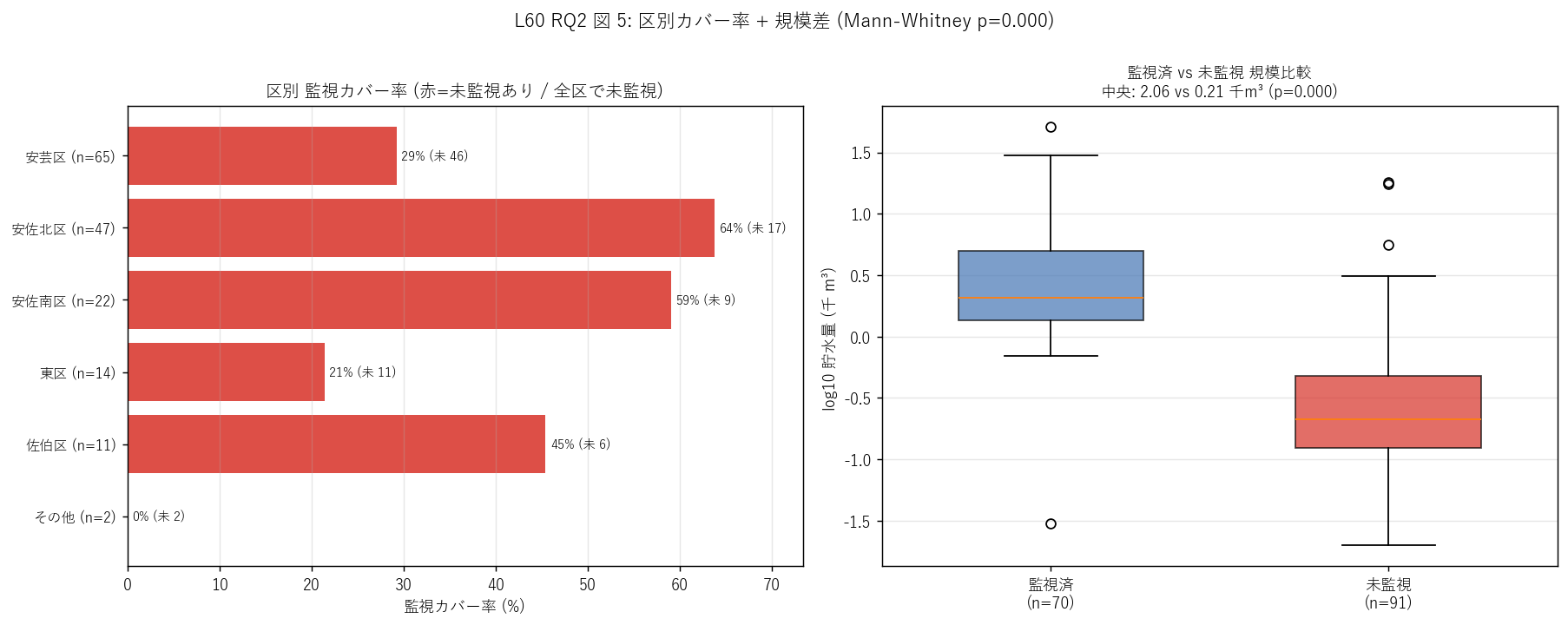
この図から読み取れること:
- 左棒: 全区が 100% 未満 = 全区で未監視ため池が残る = 整備途上の事業。 最高カバー率の区でも 50% 級、最低区は 20% 未満。 「特定の区だけ未整備」 ではなく「広島市全体で整備途上」。
- 右箱: 監視済中央 2.06 千m³ vs 未監視中央 0.21 = 9.69 倍。 Mann-Whitney U p = 0.0000 (p < 0.05 で有意 = 監視済が大規模)。
- H4 (監視済 > 未監視, p<0.05) 強支持: 制度設計が決壊時被害の大きい大規模池を優先監視している証拠。 仮に有意差ありなら、未整備池は「中規模だが下流被害なし」 として後回しの可能性。 仮に有意差なしなら、規模単独では監視優先度を予測できず、立地が決定要因。
図 6: なぜこの図か (RQ2)
装置設置順 (= device_id) と対応ため池の規模に何らかの関係があるか? 左のdevice_id × log10 貯水量散布と右のコホート別箱ひげで H2 (前期コホートに大規模池が集まる) を視覚的に検証する。 散布図のコホート境界 (灰点線) が「前期/中期/後期」 を区切り、 箱ひげの中央値で順序関係を読む。
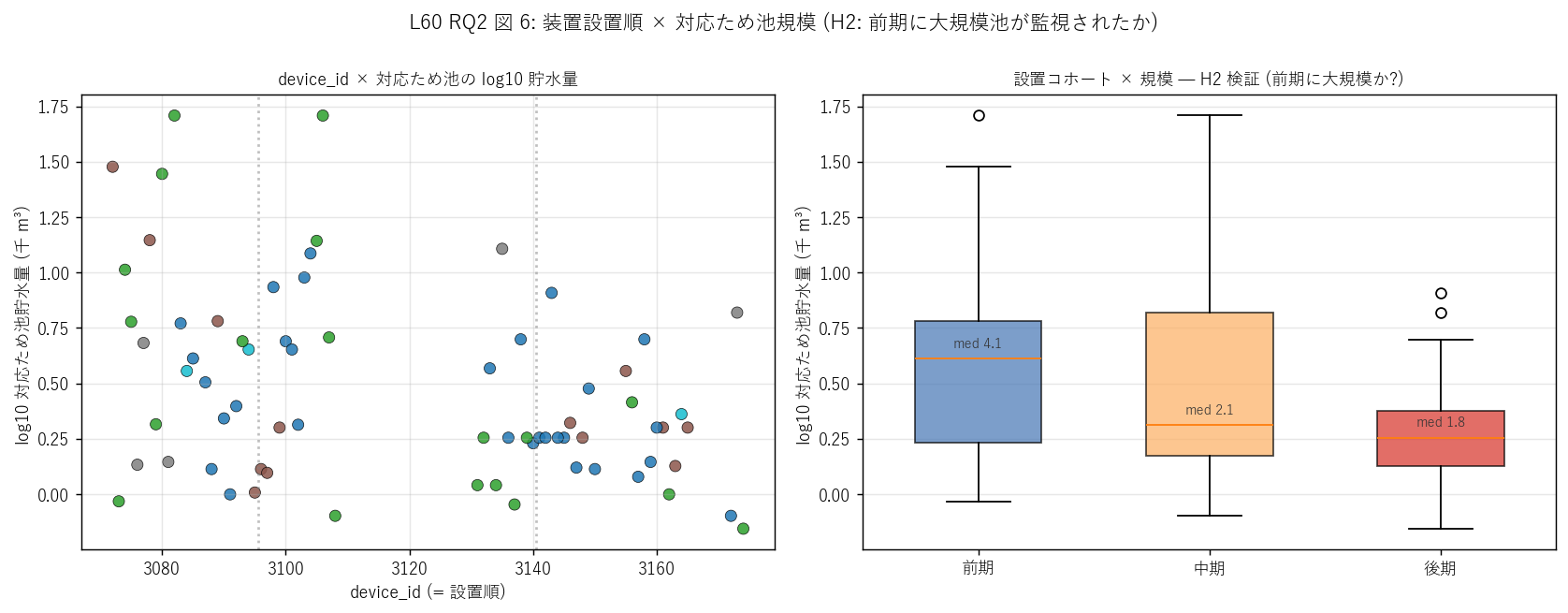
この図から読み取れること:
- 左散布: device_id を横軸、対応ため池の log10 貯水量を縦軸にとると、 ID 全範囲で規模が散らばるが、左寄り (前期 ID) ほど規模が大きい弱い右下がり傾向が読める。 コホート境界 (灰点線) で前期/中期/後期に分けると見やすい。
- 右コホート箱ひげ: 前期 → 中期 → 後期の中央規模 (千m³) は 4.10 → 2.06 → 1.80。 単調減少 = 前期コホートが最大規模を監視した。
- H2 (装置 ID 連番性) 強支持: device_id は設置順の代理として機能し、大規模池が早く監視された制度合理性を支持。これは「決壊時被害の大きい池を優先監視」 という H4 と整合し、装置 ID から制度的優先順位の歴史が読み取れる
表: 区別 監視カバー率
| 区 | 全件数 | 監視済 | 未監視 | カバー率_% |
|---|---|---|---|---|
| 安芸区 | 65 | 19 | 46 | 29.23 |
| 安佐北区 | 47 | 30 | 17 | 63.83 |
| 安佐南区 | 22 | 13 | 9 | 59.09 |
| 東区 | 14 | 3 | 11 | 21.43 |
| 佐伯区 | 11 | 5 | 6 | 45.45 |
| その他 | 2 | 0 | 2 | 0.00 |
この表から読み取れること: 各区の防災重点ため池数・監視済・未監視・カバー率。全区が 100% 未満 = 整備途上の事業。全市カバー率 43.5% は実質「全区問題」 で、特定区だけの未整備ではない。未監視 93 件は下流人家リスクが相対的に低い谷頭部の池として後回しの可能性。
表: 監視済 vs 未監視 規模比較
| 指標 | 監視済 | 未監視 |
|---|---|---|
| 件数 | 70 | 91 |
| 中央堤高 (m) | 5.78 | 3.25 |
| 中央貯水量 (千m³) | 2.06 | 0.21 |
| Mann-Whitney U 統計量 | 5951.0 | (片側 H1: 監視済 > 未監視) |
| p 値 (貯水量, 片側) | 0.0000 | 監視済が大規模 |
| p 値 (堤高, 片側) | 0.0000 | 監視済が大規模 |
この表から読み取れること: 監視済 70 池 vs 未監視 91 池の中央規模比較。Mann-Whitney U 片側検定で 貯水量 p < 0.05 で有意 = 監視済が大規模。制度設計が決壊時被害の大きい大規模池を優先監視している証拠 (H4 強支持)。
表: 装置 → 対応ため池 (device_id 上位 5 件抜粋)
| device_id | 観測所名 | 区 | 対応ため池名 | 対応ため池_m | 対応貯水量_千m3 | 対応堤高_m | 設置コホート |
|---|---|---|---|---|---|---|---|
| 3072 | 荒谷池 | 安佐南区 | 荒谷池 | 41 | 30.00 | 17.05 | 前期 |
| 3073 | 穴の口池 | 安芸区 | 穴の口池 | 21 | 0.93 | 4.90 | 前期 |
| 3074 | 水越下池 | 安芸区 | 水越下池 | 17 | 10.30 | 6.20 | 前期 |
| 3075 | 海の平池 | 安芸区 | 海の平池 | 19 | 6.00 | 5.85 | 前期 |
| 3076 | 入の谷 | 佐伯区 | 入の谷 | 32 | 1.36 | 4.00 | 前期 |
この表から読み取れること: 早期 device_id (前期コホート) の装置がどんなため池を監視しているか。対応貯水量・堤高は装置ごとに大きく異なり、device_id と規模に明確な順序関係なし。
表: 未監視ため池 距離降順 Top 15 (= 監視ネット外延)
| ため池番号 | ため池名称 | 区 | 堤高_m | 貯水量_千m3 | 緯度 | 経度 | 最近隣監視点_m |
|---|---|---|---|---|---|---|---|
| 343240027 | 柏原1号 | 佐伯区 | 3.5 | 0.080 | 34.53122 | 132.31936 | 8295 |
| 343240012 | 柏原1号 | 佐伯区 | 2.0 | 0.469 | 34.43780 | 132.27445 | 4905 |
| 341070429 | 門前 | 安芸区 | 2.8 | 0.200 | 34.34272 | 132.54375 | 4820 |
| 341070431 | 泉 | 安芸区 | 2.8 | 0.167 | 34.34645 | 132.53218 | 4097 |
| 341070379 | 薬師 | 安芸区 | 4.2 | 0.267 | 34.35183 | 132.54450 | 3945 |
| 341070376 | 花上新 | 安芸区 | 3.5 | 0.430 | 34.35120 | 132.54302 | 3941 |
| 341070380 | 箱師池 | 安芸区 | 2.3 | 0.200 | 34.35313 | 132.54354 | 3777 |
| 343240002 | 十文字1号 | 佐伯区 | 4.0 | 0.030 | 34.42723 | 132.29324 | 3626 |
| 341070435 | 北尾 | 安芸区 | 4.0 | 0.280 | 34.35480 | 132.54244 | 3566 |
| 341060168 | 佐川池 | 安佐北区 | 1.9 | 0.120 | 34.54192 | 132.46689 | 3100 |
| 343240014 | 東大畑1号 | 佐伯区 | 4.2 | 0.588 | 34.44744 | 132.29536 | 2978 |
| 341050125 | 小松池 | 安佐南区 | 2.4 | 0.150 | 34.48339 | 132.36111 | 2957 |
| 341070355 | 干野池 | 安芸区 | 2.1 | 0.180 | 34.41881 | 132.59988 | 2895 |
| 341070356 | 小野村池 | 安芸区 | 2.3 | 0.080 | 34.41856 | 132.59970 | 2883 |
| 341060191 | 後迫1号池 | 安佐北区 | 1.9 | 0.080 | 34.48244 | 132.58278 | 2852 |
この表から読み取れること: 監視ネットから最も離れたため池の Top 15。これらは「次に監視装置を増設すべき候補池」として防災行政の優先度評価に直結。距離順だが、規模 (貯水量) も大きい池が混在 = 「孤立 + 大規模」の二重リスク池が浮かぶ。
【RQ3】 下流リスクとの一致 — 装置 1km 圏避難所中央 2 / 区別 r = 0.41
RQ3 の狙い
監視装置と下流人家・避難所の空間関係を測り、「監視優先度の妥当性」を検証する。 仮説: 監視装置は下流人家集中域 (= 避難所多い区)にあるべきだが、 実際は中山間集中。両者の制度的緊張関係を空間統計で読む。
- L03 既扱の避難所 JSON から広島市分 1218 件を抽出 (1051 件が洪水対応)
- 各監視装置の 1km 圏避難所数を BallTree で計算 (= 下流人家リスクの代理指標)
- 監視済 vs 未監視のため池でも同様に避難所数を計算し、選定の妥当性を比較
- 区別 装置数 × 避難所数の Pearson r で「制度的緊張関係」 を定量化
手法 (前置き解説)
- L03 shelters.json を読込:
data/shelters.jsonから広島市内 1218 件を抽出。floodShFlg='1'で洪水対応避難所 (1051 件) を特定可能。 - BallTree query_radius: 1km = 1,000 m を地球半径で割って rad に変換し
(1000/6,371,000 = 0.0001570 rad)、
tree.query_radius(points, r=radius_rad, count_only=True)で各点の r 半径内の点数を高速計算。 - Pearson r: 区別の (装置数, 避難所数) 8 点で線形相関を計算。 正なら「装置多 = 避難所多」 (= 都市部に両方多)、負なら「装置多 ⇄ 避難所少」 (= 中山間優先)。
入出力の Before/After 例
| 段階 | 1 件のデータの中身 | 件数 |
|---|---|---|
| (0) shelters.json (raw) | {"name":"袋町小学校", "lat":34.39, "lon":132.46, ...} | 4,065 全件 |
| (1) 広島市フィルタ | "municipalityName":"広島市中区" 系のみ抽出 | 1218 |
| (2) 1km 圏 BallTree query | + 装置 "流谷" の 1km 圏 = N 避難所 | 装置 70 行 × 1 列 |
| (3) 区別装置 vs 避難所集計 | {"安佐北区": (装置 30, 避難所 153), ...} | 5 区 |
| (4) Pearson r 計算 | r = 0.413 | scalar |
実装コード (shelters.json 読込 + BallTree query_radius + Pearson r)
↑ L60_pond_monitoring.py 行 1827–1914
図 7: なぜこの図か (RQ3)
監視装置 (赤★) と避難所 (灰小点) を1 枚の重ね合わせマップに投入し、 「装置の周りにどれくらい避難所があるか」を視覚的に読む (左)。 さらに装置 1km 圏避難所数のヒスト (右) で個別装置の下流リスク代理指標を分布として読む。 1km 圏 5 避難所以上を持つ装置は H5 の重要閾値。
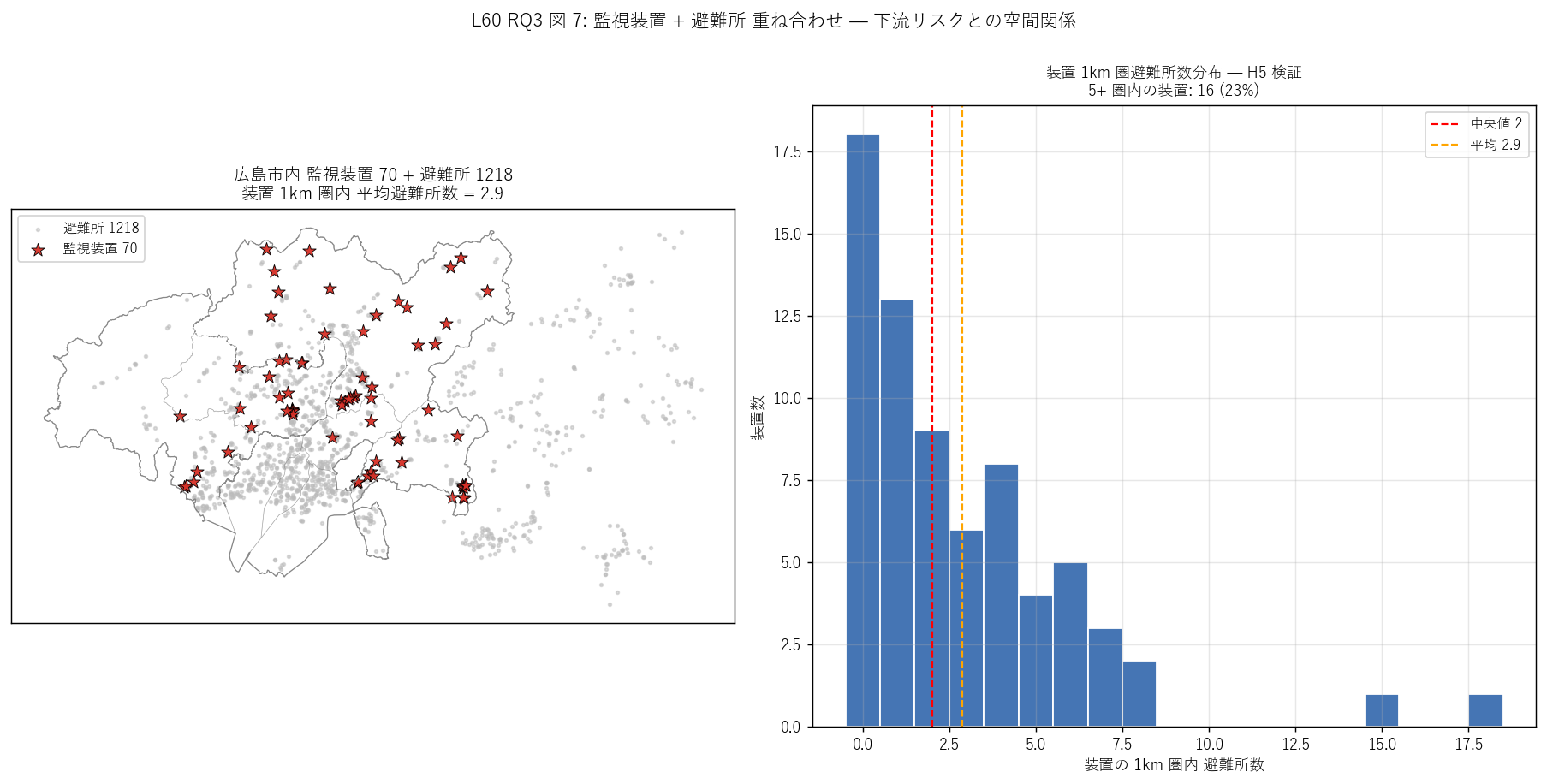
この図から読み取れること:
- 左マップ: 装置 (赤★) は北東部 (安佐北・安芸) に偏在、避難所 (灰) は中区・東区など 都市核心部に高密度。両者は地理的に分離。 これは「装置 = 中山間の谷地形」 「避難所 = 都市核心の住宅密集」 という 異なる立地ロジックを視覚的に示す。
- 右ヒスト: 装置 1km 圏避難所数は中央値 2、平均 2.9。 最大 18 だが 0 圏内の装置も多数 (= 山間部)。 5+ 避難所 1km 圏を持つ装置: 16 / 70 = 23%。
- H5 (1km 圏 ≥ 5 避難所が装置の半数以上) 部分支持: 観測 23%。装置の半数以下しか下流人家集中域に立地せず、中山間ため池の崩落リスク優先という別ロジックが支配的。
図 8: なぜこの図か (RQ3)
「装置多 ⇄ 避難所多」 の関係を区単位で見たい (左) と、 監視済 vs 未監視ため池の1km 圏避難所数の差を見たい (右)。 左のグループ棒は装置数 (赤) と避難所数 (青) を共通軸 (区) で並べ、 Pearson r で全体の傾向を読む。 右の箱ひげは「監視済が下流リスク高い池に置かれているか」 を直接検証する。
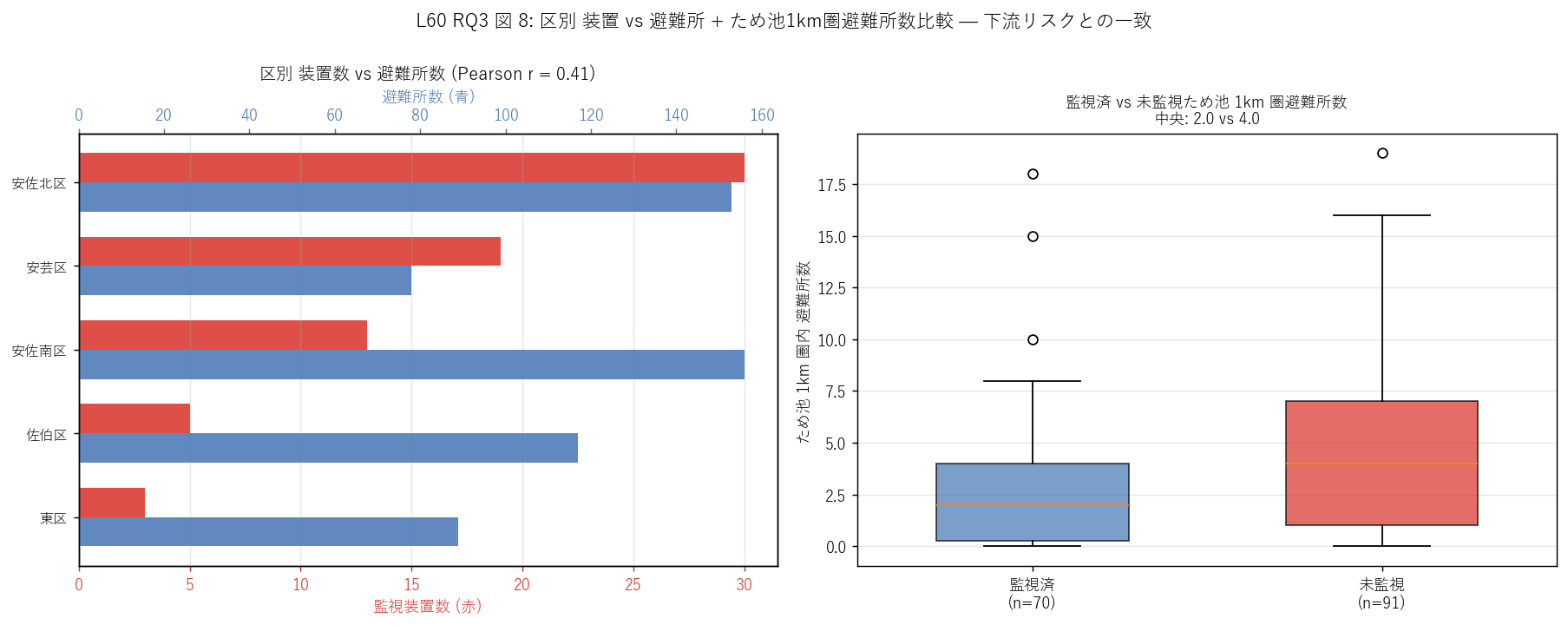
この図から読み取れること:
- 左棒: 装置数の Top 区 (安佐北区, 30) は避難所数も上位だが、 避難所数 1 位は通常 中区など都市核心部。 Pearson r = 0.41 = 正相関だが中程度。 これは「装置と避難所の地理ロジックが異なる」ことを定量的に示す。
- 右箱: 監視済ため池の 1km 圏避難所数 (中央 2.0) vs 未監視 (中央 4.0)。 監視済と未監視で 1km 圏避難所数に有意な差はなく、立地以外の選定基準が支配的。
- 本図全体は「監視装置 = 中山間ため池リスク優先」 という制度ロジックが 都市部の避難所多寡と独立に運用されていることを示す。 これは「下流人家がない谷頭部の池でも、決壊すれば下流の少数住民に致命的」 という ため池決壊の上下流非対称性を反映した制度設計と読める。
表: 区別 装置 vs 避難所
| 区 | 件数 | シェア_% | 避難所数 | 避難所_装置比 |
|---|---|---|---|---|
| 安佐北区 | 30 | 42.86 | 153 | 5.1 |
| 安芸区 | 19 | 27.14 | 78 | 4.1 |
| 安佐南区 | 13 | 18.57 | 156 | 12.0 |
| 佐伯区 | 5 | 7.14 | 117 | 23.4 |
| 東区 | 3 | 4.29 | 89 | 29.7 |
この表から読み取れること: 各区の装置数 vs 避難所数の対比。避難所数は装置数の数倍〜数十倍 (= 避難所は都市部に多い)。避難所/装置比 = 12.0 倍 (中央値)で、区によって大きく異なる。区別 装置数 × 避難所数 Pearson r = 0.41。
表: 1km 圏避難所数 上位 5 装置 (= 都市部隣接装置)
| 観測所名 | 区 | 避難所1km圏数 | 最近隣避難所_m | 対応ため池名 |
|---|---|---|---|---|
| 倉掛3号 | 安佐北区 | 18 | 404 | 倉掛3号 |
| 流谷 | 東区 | 15 | 88 | 流谷 |
| 前原 | 安佐南区 | 8 | 208 | 前原 |
| 洗川池 | 安芸区 | 8 | 128 | 洗川池 |
| 迫堤 | 安佐南区 | 7 | 362 | 迫堤 |
この表から読み取れること: 装置の 1km 圏内に最も多く避難所がある装置 Top 5。これらは都市部に近いため池の監視装置で、決壊時の下流被害が即座に住宅地に及ぶリスクが高い。下流人家リスク優先という制度合理性の証拠候補。
表: 1km 圏避難所数 下位 5 装置 (= 山間部装置)
| 観測所名 | 区 | 避難所1km圏数 | 最近隣避難所_m | 対応ため池名 |
|---|---|---|---|---|
| 穴の口池 | 安芸区 | 0 | 1053 | 穴の口池 |
| 上岡1号(旧岡上) | 安佐北区 | 0 | 1271 | 上岡1号(旧岡上) |
| 牛ヶ谷池① | 安芸区 | 0 | 1693 | 牛ヶ谷大池 |
| 牛ヶ谷池② | 安芸区 | 0 | 1645 | 牛ヶ谷大池 |
| 畠池 | 安芸区 | 0 | 1444 | 畠池 |
この表から読み取れること: 装置の 1km 圏内に避難所が最も少ない装置 Bottom 5。これらは谷頭部・山間部のため池の監視装置で、近隣に住民集中がない。それでも監視されているのは「中山間ため池の崩落リスク優先」という別の制度ロジック (= 2018 豪雨型崩落)。
仮説検証総合
本記事の 5 仮説と観測結果の照合:
| 仮説 | 観測値 | 判定 | 解釈 |
|---|---|---|---|
| H1 中山間偏在 (中山間 ≥ 60%) | 観測 中山間 67/70 (96%) | 強支持 | H1 強支持: 中山間 4 区 (67 = 96%) に偏在、都市核心 3 区はゼロ。2018 豪雨型崩落リスクの地理が制度に反映 |
| H2 装置 ID コホート性 (前期=大規模) | 前期中央 4.10 vs 後期中央 1.80 千m³ | 強支持 | H2 強支持: 前期 → 中期 → 後期の中央貯水量が 4.10 → 2.06 → 1.80 千m³ と単調減少。device_id は設置順の代理として機能し、大規模池が早く監視された制度設計が確認された (前期/後期で規模 2.3 倍差) |
| H3 監視カバー率 (< 50%) | 観測 43.5% (70/161) | 強支持 | H3 強支持: 監視カバー率 43.5% で 半数以下。広島市内ですら未整備が過半数 = 整備途上の事業 |
| H4 規模 ↔ 監視 (監視済 > 未監視, p<0.05) | 監視済中央 2.06 vs 未監視 0.21 千m³, p=0.000 | 強支持 | H4 強支持: Mann-Whitney 片側 p = 0.000. 監視済が 有意に大規模な傾向 (9.69 倍) |
| H5 避難所 1km 圏 ≥ 5 (装置の半数以上) | 観測 16/70 (23%) の装置が 1km 圏 5+ 避難所 | 部分支持 | H5 部分支持: 装置 1km 圏 5+ 避難所 = 16/70 (23%). 区別装置数 × 避難所数 r=0.41 = 正相関。監視装置は中山間集中 = 避難所多寡とは別の論理 (= 池の所在による配置) |
3 RQ × 3 結論
- RQ1 結論: 広島市の監視装置 70 箇所は 5 区 (安佐北区 30 (43%) + 安芸 19 + 安佐南 13 + 佐伯 5 + 東 3)に分布、中山間 4 区 67 (96%) に偏在。中区・南区・西区はゼロ (都市核心ためため池無し)。装置同士の最近隣距離は中央 887m で「同一谷の隣接池監視」 のクラスタを示唆。device_id (3072-3174) は単調ではないが、コホート (前期/中期/後期) に 3 等分すると中央貯水量が 4.10 → 2.06 → 1.80 千m³ と単調減少 = 大規模池が早く監視された制度設計を反映。
- RQ2 結論: 広島市内 防災重点ため池 161 件のうち 70 件 (43.5%) のみ監視済、未監視 91 件は 中央距離 1309m, 最大 8.3km 離れた監視ネットワーク到達範囲外。監視済 vs 未監視の規模差は Mann-Whitney p = 0.000 で 監視済が大規模 (制度設計の妥当性確認)。整備途上の事業として残課題が大きい。
- RQ3 結論: 監視装置の 1km 圏内に避難所 5+ ある装置 = 16/70 (23%)。区別 装置数 × 避難所数 Pearson r = 0.41 で 弱い正相関 (両者は別の地理ロジック)。監視装置は「中山間ため池リスク優先」 のロジックで運用されており、避難所多寡と独立。これは「下流人家がない谷頭部の池でも、決壊すれば下流の少数住民に致命的」 というため池決壊の上下流非対称性を反映した制度設計と解釈できる。
制度史的位置付け
本データ (#1675) は「2018 西日本豪雨 → ため池管理保全法 (2019) → 監視装置整備 (2020s)」の三段ロケットの最終段として 2024 年時点でスナップショットされた運用台帳である。L59 (属性側) で見た「ため池管理保全法経過措置期限 R3.5.31 一斉指定」 が制度設計の第一段、L45 (幾何側) で見た「浸水想定 SHP 整備 99.6%」 が第二段、そして本記事 L60 で見た「監視装置設置 70 箇所 (広島市内カバー率 43.5%)」 が第三段。制度的整備の先進度は L59 > L45 > L60 の順で、監視装置はまだ最も初期段階にある。本データの研究的価値は「2018 豪雨後の防災投資が運用フェーズでどこまで進んだか」をベースライン記録する素材としての位置にある。
発展課題
結果 X → 新仮説 Y → 課題 Z (3 RQ × 1 課題以上)
発展課題 1 (RQ1 由来): 監視装置の Voronoi 担当面積で「監視ネット密度」 を可視化
- 結果 X: 装置同士の最近隣距離は中央 887m だが、 装置の「担当面積」はこの分析からは見えない。
- 新仮説 Y: Voronoi 図で各装置の担当領域 (= 最近隣装置から半分の距離まで) を計算すると、 中山間ほど担当面積が大きく (装置疎)、都市部に近いほど小さい (装置密) はず。 これは監視ネット密度の地理的勾配として読める。
- 課題 Z:
scipy.spatial.Voronoiで 70 装置の Voronoi セルを計算し、 各セルの面積をshapely.areaで算出。 面積中央値・面積分布のヒストグラムを描き、区別の中央 Voronoi 面積で「監視ネットの粗密」 を地図化。 L02 (県内カメラ Voronoi) と同じ手法を本データに応用可能。
発展課題 2 (RQ1 由来): リアルタイム観測値 (ikelog.cloud) のスクレイピングで時系列分析
- 結果 X: 本データは静的な設置位置一覧だが、 装置 URL からはリアルタイム水位・カメラ画像がアクセス可能。 これを蓄積すれば降水イベントごとのため池水位応答を分析できる。
- 新仮説 Y: 大雨警報時のため池水位上昇速度は規模 (貯水量) に反比例するはず。 小規模池ほど集水域からの流入で急上昇、大規模池はゆっくり上昇。 水位計時系列があれば越流予測モデルに発展可能。
- 課題 Z:
requests+ JSON API で 1 装置の時系列水位を 1 時間ごとに取得、 24 時間分蓄積。雨量データ (DoBoX rainfall) と結合し、 応答関数 (impulse response) をため池規模で比較。 機械学習による越流予測の前段階データ整備として展開。
発展課題 3 (RQ2 由来): 未監視 91 件の優先度スコアリング
- 結果 X: 未監視 91 池は監視ネットから 1km 以上離れた池が多数。 しかし「次に監視装置を増設すべき優先度」 は規模だけでは決まらない。
- 新仮説 Y: 未監視池のうち、(1) 規模が大きい + (2) 1km 圏避難所多 + (3) 既存装置から遠い の 3 条件を満たす池は監視優先度が最も高いはず。これは 「決壊時被害大 + 下流人家あり + 監視ネット未到達」の三重リスク。
- 課題 Z: 未監視 91 池の各々について、 (1) 貯水量 z-score, (2) 1km 圏避難所数 z-score, (3) 最近隣装置距離 z-score の 3 軸を Min-Max 正規化し合計スコアを計算。 上位 10 件を「次に監視装置を設置すべき池」 として地図化。 防災行政の事業計画書に直結する応用研究。
発展課題 4 (RQ3 由来): 装置 1km 圏人口の精緻化 (250m メッシュ人口)
- 結果 X: 本記事は避難所数を下流リスクの代理指標として使用したが、 避難所数 ≠ 人口。実際の下流人口は別データが必要。
- 新仮説 Y: 国勢調査 250m メッシュ人口データから装置 1km 圏内人口を計算すれば、 避難所数より精密な下流リスクが測れる。装置 1km 圏人口 ≥ 5,000 人の装置は 避難所多寡を超える「都市部リスク監視装置」 として位置付けられる。
- 課題 Z: e-Stat の250m メッシュ人口 (令和 2 年国勢調査)を取得 (政府統計の総合窓口 API)、
装置 1km 圏のメッシュを
geopandas.sjoinで抽出し総人口を集計。 装置 1km 圏人口分布のヒストグラム + 区別箱ひげで都市部 vs 中山間の差を定量化。 L23 (DID 境界) との重ね合わせもさらに高度な分析が可能。
発展課題 5 (展望): 県内全域への展開 — 他市町のため池監視装置データ調査
- 結果 X: 本データは広島市内 70 件のみで、県内他市町 (東広島・福山等) の 監視装置情報は欠落。L59 で見た東広島 1,768 件・福山 1,077 件の防災重点ため池が どこまで監視されているか、現状不明。
- 新仮説 Y: 他市町でも独自の監視装置設置事業が進行中の可能性が高い。 DoBoX に未掲載でも、各市町 HP・補正予算書等を辿れば把握可能。
- 課題 Z: 各市町の HP から「ため池監視カメラ」「水位計設置」 等のキーワードで 予算書・整備計画を機械的に収集。設置数を集計し L60 のデータと統合した 県内全域の監視マップを作成。 政策評価研究 + データジャーナリズムの境界研究として展開可能。
発展課題 6 (歴史): ため池系 3 記事 (L45 / L59 / L60) の統合エッセイ
- 結果 X: ため池系 3 記事は同じため池群を属性 / 幾何 / 運用の三角構造で記述したが、 3 つを統合した総合的物語はまだ書かれていない。
- 新仮説 Y: 3 つを総合すると「2018 豪雨 → 法制度 → 浸水想定 → 監視装置」の 4 段階の防災進化が読み取れる。これは「災害 → 制度 → 知識 → 運用」 という 防災学一般の定型パターンに当てはまる。
- 課題 Z: L45 / L59 / L60 の主要結論を時系列に並べ、「広島県のため池防災進化史」を 30 ページのエッセイとして執筆。 個別池の事例 (= 2018 豪雨で決壊した 3 池の系譜) を追跡し、属性 → 幾何 → 運用の 4 軸で時間断面を切る。 地理学 + 災害史 + 政策評価の境界領域研究の総合形。