道路規制情報 2 件統合分析 — 本日の規制 / 今後の規制から運用構造を読み解く
データ取得手順
⚠️ このスクリプトは自動取得に対応していません。以下のデータセットを DoBoX から手動でダウンロードし、data/extras/ 以下に保存してください。
| ID | データセット名 |
|---|---|
| #111 | dataset #111 |
| #222 | dataset #222 |
| #333 | dataset #333 |
| #444 | dataset #444 |
| #666 | dataset #666 |
| #888 | 都市計画区域情報_区域データ_安芸高田市_行政区域 |
| #999 | dataset #999 |
| #1257 | 道路規制情報_本日の規制 |
| #1258 | 道路規制情報_今後の規制 |
実行コマンド:
cd "2026 DoBoX 教材"
python -X utf8 lessons/L50_road_restrictions.py
DoBoX のオープンデータは申請不要・商用/非商用とも利用可。
data/extras/ は .gitignore 対象(約 57 GB のキャッシュ)。
スクリプト実行で自動再生成されます。
スクリプト(全体ソースコード)
cd "2026 DoBoX 教材"
python -X utf8 lessons/L50_road_restrictions.py学習目標と問い
本記事は DoBoX のシリーズ 「道路規制情報」 2 dataset (id = 1257 本日の規制 / 1258 今後の規制) を 統合し、 広島県内の道路規制の制度的・地理的・時間的構造を 1 記事で深掘り分析する。 2026-05-09 21:20:03 取得スナップショットで、 1257 = 69 件、 1258 = 149 件。
本データの位置付け — 「道路規制」 とは
道路規制情報は広島県・国土交通省 (中国地方整備局) が管理する 道路で現在実施中 (1257) または今後計画されている (1258) 通行規制を リアルタイムで公開するオープンデータ。L02 (道路カメラ) や L09 (避難所最近傍カメラ) が扱う 静的なインフラ施設とは異なり、本記事は動的なイベントとして 道路を捉える。各レコードは32 列の属性 + 緯度経度 + LineString 区間ジオメトリを持つ。
2 dataset の構造的差別 — 「本日」 と「今後」 の時間スコープ
1257 (本日) と 1258 (今後) は同じ運用システムから派生する 2 ビュー:
- 1257 本日の規制: 取得時点で現在実施中の規制 ( 開始日 ≤ 取得時 ≤ 終了日)。69 件。 過去開始の災害復旧規制 (2018 西日本豪雨等) も含む。
- 1258 今後の規制: 取得時点で取得時 ≤ 終了日の規制 (本日も今後も含む広いビュー)。149 件。 1257 のスーパーセットとして機能する (本日除く 80 件は将来開始予定)。
このため、両 dataset の id 集合は95.7% 重複 (66/69)。 1258 のみに含まれる 83 件は本日まだ開始していない将来規制で、 1257 のみに含まれる 3 件は本日中に終了する短期規制。
研究の問い (主 RQ)
広島県の道路規制情報 2 dataset (本日 + 今後) は 規制種別・路線種別・規制理由・地理分布・時間軸でどう構成され、 災害起因の長期規制と工事起因の計画規制はどう分布するか? さらに「本日」 と「今後」 の時間スコープの違いから、 県と国交省の道路運用思想の差はどう読み取れるか?
仮説 H1〜H6
- H1 (one_side 支配): 規制種別の中で片側交互通行 (one_side)が最頻 (40-50%) で、通行止 (blocked) は 15-25%。これは「工事は道路機能を完全停止しない」 行政運用思想を反映する。
- H2 (国道 vs 県道の管轄分離): 1258 (今後) は国道が支配的 (50% 超) だが、 1257 (本日) は県道が支配的。国交省は計画を多く事前公表するが 県は当日運用が多い、という管轄ごとの公開思想の違いを反映するか検証する。
- H3 (工事 9 vs 災害 1): 規制理由の9 割超は工事 (道路改良 / 法面 / 橋梁 / 維持 / 舗装 / 下水 / ガス / 電線等)、 災害復旧 (落石・路面陥没・崩落) は 1 割弱。1257 で災害比率が目立つはず (災害規制は長期化するため)。
- H4 (2018 西日本豪雨の長期残存): 1257 中の disaster 規制は 2018-07-07 西日本豪雨起因のものが複数残存している。 8 年前の災害が今でも通行止になっており、道路復旧の極めて長い時間スケールを映す。
- H5 (規制延長の対数正規分布): 規制延長 (encho) は最小 10m から 最大 92,000m (92km) まで 4 桁の幅を持つ。 log10 スケールで分布は正規に近い (= 対数正規)。 median 数百 m, 平均 1-2km と予想。
- H6 (1257 ⊂ 1258): 1257 と 1258 の id 集合は 1257 の 95% 以上が 1258 にも含まれる。1258 は 1257 のスーパーセットとして機能し、 「本日 = 今後のスナップショット」 という制度的設計を反映する。
本記事の独自用語定義
- 道路規制 (road restriction): 道路法に基づき、道路管理者 (国交省 / 県 / 市町村) が車両通行を一時的に制限・禁止する運用上の措置。 工事・災害・イベント等を理由とする。本記事は工事規制 + 災害復旧規制を扱い、 警察による交通規制 (道交法に基づく速度制限・大型車禁止等) は対象外。
- 通行止 (blocked): 道路の通行を完全に禁止する規制。 kisei_name="blocked", kiseinaiyo="通行止め" でデータ表現される。 迂回路 (ukairo) が必要となる強い規制。
- 片側交互通行 (one_side): 1 車線を残して工事・規制を行い、 残された車線を信号 / 警備員で双方向交互に通す運用。 kisei_name="one_side"。一般道で最も多用される規制形態。
- 車線規制 (narrows): 多車線道路で 1 車線を閉鎖し、 残り車線で通行させる規制。kisei_name="narrows"。 高速・国道で多用される (片側交互通行は安全上 2 車線以上で実施されない)。
- 規制延長 (encho): 規制対象となる道路区間の長さ (m)。 短い場合 10m 程度 (工事ピンポイント)、長い場合 92,000m (92km, 主要地方道全線等)。 事前通行規制区間 (積雪・冬期閉鎖等) は数 km 〜 数十 km の長距離規制が多い。
- 規制種別 (kisei_name): 5 値分類 — blocked / one_side / narrows / controll_complex / two_way。本記事の主軸となるカテゴリ列。
- 規制タイプ (kisei_type): 2 値 — normal (通常 = 工事等の計画規制) と disaster (災害 = 自然災害起因の長期規制)。 disaster は kisei_name とは独立した属性で、種別と組み合わせて運用される。
- kukanroot: 規制対象区間の LineString WKT 文字列。 EPSG:4326 (WGS84) の経度緯度の頂点列で記述される。 ピンポイント規制では 2 頂点 (始点・終点) のみ、長距離規制では数十頂点で曲線を表現。
- 包含率 (inclusion rate): 1257 ∩ 1258 / 1257 = 95.7%。 本記事独自の定義で、「本日の規制が今後の規制ビューにどれだけ含まれるか」 を 0〜100% で表す。1258 = スーパーセットの程度を測る指標。
- 長期残存規制 (long-residual restriction): kisei_type='disaster' で、 取得日基準で1 年以上経過している規制。 本記事独自の概念で、道路復旧の時間スケールを定量化する。
到達点
2 dataset の構造を 6 つの仮説で照合し、道路規制という動的データセットが 広島県の道路インフラ運用思想を映す研究的ツールであることを示す。 特に 2018 西日本豪雨の 8 年継続規制と 1257 ⊂ 1258 包含構造という、データ解析でしか発見できない 2 つの構造的事実を 独自に同定する。
使用データ
本記事は DoBoX シリーズの 2 件 を扱う:
| 項目 | 1257 本日の規制 | 1258 今後の規制 |
|---|---|---|
| dataset_id | 1257 | 1258 |
| DoBoX URL | https://hiroshima-dobox.jp/datasets/1257 | https://hiroshima-dobox.jp/datasets/1258 |
| 形式 | JSON | JSON |
| ファイルサイズ | 161 KB | 229 KB |
| レコード数 | 69 | 149 |
| 属性列数 (results 内 dict) | 32 | 32 |
| 緯度経度有り | 69 | 149 |
| kukanroot (LineString) 有り | 67 | 66 |
| 災害規制 (kisei_type=disaster) | 7 | 7 |
| 管轄市町数 | 20 | 25 |
| 更新頻度 | リアルタイム | リアルタイム |
| 取得スナップショット | 2026-05-09 21:20:03 | 2026-05-09 21:20:03 |
| ライセンス | CC-BY 4.0 | CC-BY 4.0 |
列構成 (results 内 dict, 32 列)
- id: 規制レコードの一意識別子 (例: '03KK202600023', '-000000000027')
- kisei_name / kisei_label: 5 規制種別の英名 / 日本語
- kisei_type: 'normal' (工事等通常規制) または 'disaster' (災害復旧)
- rosenname: 路線名 (例: '一般県道 乙瀬小方線')
- kiseinaiyo / kiseireason: 規制内容 (通行止め等) と理由 (道路改良工事等)
- lat / lon: 緯度経度 (10進度, EPSG:4326)
- start_date / end_date: 規制開始日時 / 終了日時 (YYYY/MM/DD HH:MM)
- kisei_hour: 1日内の規制時間帯 (例: '22:00〜05:00')
- start_point / end_point: 規制区間の始点・終点 (住所文字列)
- ukairo: 迂回路の有無 ('有' / '無' / '−')
- demarcation: 管轄事務所 (例: '広島県 西部建設事務所廿日市支所')
- encho: 規制延長 (例: '33m', '1,872m', '92,000m')
- kukanroot: LineString WKT (EPSG:4326)
- その他: rosen_key/rosen_code/rosennumber/icon/layer/kiseinaiyo_i 等の派生・表示用
ダウンロード
DoBoX 本体 (2 件)
- 道路規制情報_本日の規制 dataset 1257 (直DL JSON, ~165 KB)
- 道路規制情報_今後の規制 dataset 1258 (直DL JSON, ~234 KB)
更新頻度はリアルタイム (~ 数分単位)。本記事は2026-05-09 21:20:03取得スナップショットを扱う。本記事の .py スクリプトを実行すると、現時点のスナップショットを自動取得して再分析する (= 結果が日々変動)。
整形済 CSV / 中間データ
- L50_dataset_1257_today.csv — 1257 本日の規制 (整形済 CSV)
- L50_dataset_1258_future.csv — 1258 今後の規制 (整形済 CSV)
- L50_kisei_type.csv — 規制種別集計 (5 種別 × 1257/1258)
- L50_rosen_class.csv — 路線種別集計 (8 種 × 1257/1258)
- L50_reason_class.csv — 規制理由カテゴリ (工事/災害/その他)
- L50_reason_top15.csv — 規制理由 Top 15
- L50_disaster_records.csv — 災害規制詳細 (1257 中の disaster)
- L50_per_city.csv — 市町別 規制件数 (1257/1258)
- L50_inclusion.csv — 1257/1258 集合包含関係
- L50_duration_stats.csv — 規制期間・延長 統計
- L50_hypothesis.csv — H1〜H6 仮説検証
図 PNG (9 枚)
- L50_fig1_kisei_counts.png
- L50_fig2_point_map.png
- L50_fig3_line_map.png
- L50_fig4_rosen_class.png
- L50_fig5_city_choropleth.png
- L50_fig6_encho_dist.png
- L50_fig7_reason_top12.png
- L50_fig8_disaster_timeline.png
- L50_fig9_venn_inclusion.png
再現スクリプト
- L50_road_restrictions.py — メインスクリプト
再現コマンド
cd "2026 DoBoX 教材"
py -X utf8 lessons/L50_road_restrictions.py初回実行時に DoBoX から 2 件の JSON を自動 DL (data/extras/L50_road_restrictions/)。2 度目以降は既存ファイルを使うが、最新スナップショットを再取得したい場合は data/extras/L50_road_restrictions/*.json を削除してから実行。本記事の結果数値は取得日 (2026-05-09) のスナップショットに基づく。
【分析 1】 規制種別 + 路線種別構造 — 5 種別 × 8 種路線のクロス
狙い (分析 1: 規制種別 + 路線種別構造)
2 dataset の主軸は規制種別 (5 値) × 路線種別 (8 値) のクロス集計。 本セクションは H1 (one_side 支配) と H2 (国道 vs 県道の管轄分離) を検証する。 分析の論理鎖は次の通り:
- 5 規制種別の件数を 1257/1258 で並列に集計 → どの種別が最頻か (H1)
- 路線名 (rosenname) を 8 路線種別 (国道/主要地方道/一般県道/市道/町道/etc) に分類
- 路線種別 × dataset で件数比を見る → 国土交通省管轄 vs 県管轄の差 (H2)
手法 (Counter + groupby + 路線分類正規表現)
路線名は文字列で、"国道" "主要地方道" "一般県道" 等の
キーワードを正規表現で判定して 8 カテゴリに分類する関数 classify_rosen() を導入。
DoBoX の path には U+3000 (全角空白) が混入するため、実際は
"一般県道 乙瀬小方線" のような表記。半角空白に正規化してから判定する。
入力: df1257 (69 行) + df1258 (149 行) の rosenname 列。
出力: rosen_class 列 (8 カテゴリ) + 集計 DataFrame。
限界: 「指定市一般市道」 のような表記は「市道」 に分類されるが、
「広島県 北部建設事務所」 が管轄する一般農道は「広域農道」 と分類されない場合がある。
全パターン網羅は困難なので主要 7 カテゴリ + 「その他/不明」 で運用する。
代替案: 管轄 (demarcation) で分類すれば管理者ベースになるが、
表記揺れが大きい (「広島県」 「土木管理課」 「市町名」 等) ため、本記事は路線種別ベースを採用。
実装コード (Counter + groupby + 路線分類)
↑ L50_road_restrictions.py 行 1274–1378
図 1: 5 規制種別 件数比較 (1257 vs 1258)
なぜこの図か: 学習者がまず「どの規制種別が支配的か」を一目で理解できるように、 横棒で 1257/1258 を並列表示。種別ごとの絶対数と比率の両方を読める。 H1 検証 (one_side 支配 + blocked 15-25%) に最適化したレイアウト。
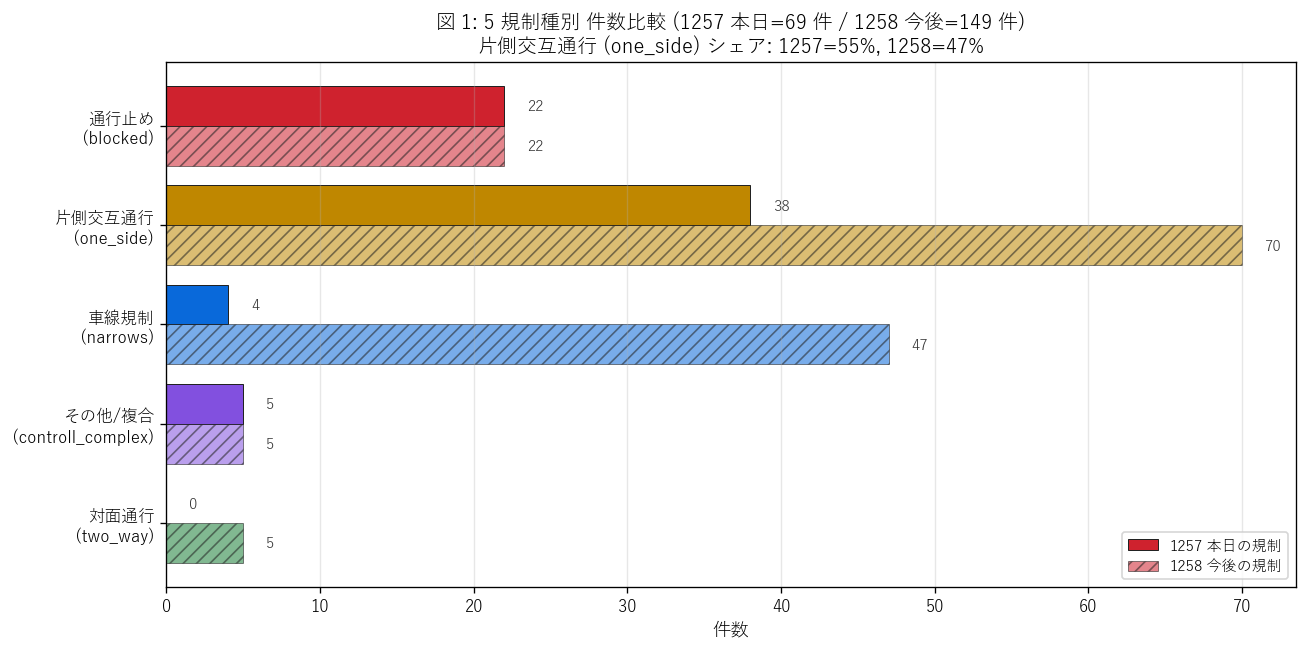
この図から読み取れること:
- 1258 で片側交互通行 (one_side)が 70 件 (47.0%) で最頻。1257 でも 38 件 (55.1%) で最頻 → H1 (one_side 支配) を支持。
- 通行止 (blocked) は 1258 で 22 件 (14.8%)、1257 で 22 件 (31.9%) → 予想 (15-25%) より多め。 これは「迂回路を要する強規制」 が想像以上に多いことを示す。
- 車線規制 (narrows) は 1258 で 47 件 (31.5%) と多いが、 1257 では 4 件 (5.8%) のみ。 これはnarrows = 国道・高速の多車線道路で発生する規制で、 国土交通省は計画を事前公表する (1258 に多く現れる) ためと推察できる。
- 対面通行 (two_way) は 1258 で 5 件のみ (3.4%)、 1257 では 0 件。中央分離帯撤去等の特殊規制で、希少。
- その他/複合 (controll_complex) は両 dataset 共通で約 3-7%。 複数規制が組み合わさる場面 (例: 一部車線止 + 速度制限併用) で計上される。
図 4: 路線種別 件数比較 (1257 vs 1258)
なぜこの図か: 図 1 が「どの規制か」 を見せたのに対し、本図は「どの種類の道路で起こるか」を 見せる。国道 / 主要地方道 / 一般県道 / 市道 / 町道 等の 8 カテゴリを縦軸に並べ、 1257/1258 を横並べで比較。H2 (国道 vs 県道の管轄分離) の検証に最適。
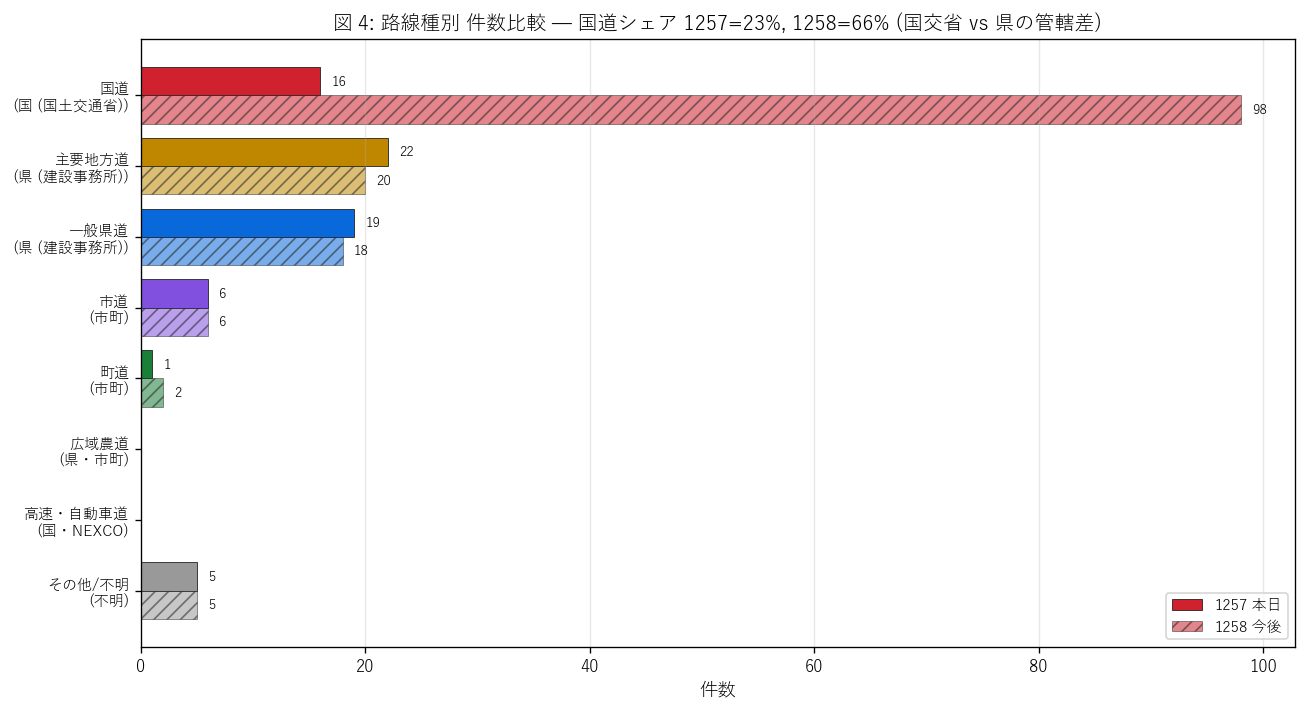
この図から読み取れること:
- 1258 (今後) は国道が 98 件 (65.8%) で圧倒的支配。 国土交通省の管轄路線 (国道 2 号・国道 54 号等) が 1258 全体の半数以上を占める。 H2 (国道支配) を強支持。
- 1257 (本日) では主要地方道 (22)と 一般県道 (19)の県管轄路線が支配的 (合計 41 件 = 59%)。 国道は 16 件 (23.2%) のみ。 H2 (1257 では県道支配) を支持。
- この差は何を意味するか? 国土交通省は計画規制を多く事前公表するが (1258 で 国道 = 98 件)、それらの多くは 本日の時間帯外 (夜間 22:00-05:00 等)または将来日付のため、 1257 (本日実施中) には現れない。逆に県は当日運用に近い形で 事前公開件数が少ない、という管轄ごとの公開思想の違いが見える。
- 市道 (1258 で 6 件) と町道 (1258 で 2 件) は少ない。 これは市町道は本データセットへの集約が進んでいない制度的理由による (各市町が個別に公開している場合がある)。
- 広域農道・高速・自動車道は本データに現れず、対象外と推察できる (NEXCO 高速道路は別系統、農道は管理者が市町や農協)。
表: 規制種別集計 (5 値)
| 規制種別 | 色 | 1257 本日 件数 | 1257 シェア% | 1258 今後 件数 | 1258 シェア% |
|---|---|---|---|---|---|
| 通行止め | #cf222e | 22 | 31.90 | 22 | 14.80 |
| 片側交互通行 | #bf8700 | 38 | 55.10 | 70 | 47.00 |
| 車線規制 | #0969da | 4 | 5.80 | 47 | 31.50 |
| その他/複合 | #8250df | 5 | 7.20 | 5 | 3.40 |
| 対面通行 | #1a7f37 | 0 | 0.00 | 5 | 3.40 |
この表から読み取れること: 片側交互通行 (one_side) が両 dataset で最頻 (47% / 55%)、通行止 (blocked) が次点 (15% / 32%)。対面通行 (two_way) は 1258 のみで 5 件、1257 では 0 件 → 中央分離帯撤去等の特殊規制は本日中には少ない。
表: 路線種別集計 (8 値)
| 路線種別 | 管轄 | 1257 件数 | 1257 % | 1258 件数 | 1258 % |
|---|---|---|---|---|---|
| 国道 | 国 (国土交通省) | 16 | 23.20 | 98 | 65.80 |
| 主要地方道 | 県 (建設事務所) | 22 | 31.90 | 20 | 13.40 |
| 一般県道 | 県 (建設事務所) | 19 | 27.50 | 18 | 12.10 |
| 市道 | 市町 | 6 | 8.70 | 6 | 4.00 |
| 町道 | 市町 | 1 | 1.40 | 2 | 1.30 |
| 広域農道 | 県・市町 | 0 | 0.00 | 0 | 0.00 |
| 高速・自動車道 | 国・NEXCO | 0 | 0.00 | 0 | 0.00 |
| その他/不明 | 不明 | 5 | 7.20 | 5 | 3.40 |
この表から読み取れること: 1258 は国道支配 (66%) で国土交通省管轄が中心、1257 は県道支配 (59%) で県管轄が中心。同じ運用システムから派生する 2 ビューが管轄ごとに異なる時間スコープを持つという設計が読める。
【分析 2】 規制理由カテゴリ + 災害規制の長期残存 — 西日本豪雨 8 年継続
狙い (分析 2: 規制理由カテゴリ + 災害規制の長期残存)
5 規制種別と 8 路線種別だけでは「なぜ規制されているか」 は見えない。 本セクションは規制理由 (kiseireason) と規制タイプ (kisei_type) の 2 軸で H3 (工事 9 vs 災害 1) と H4 (西日本豪雨の長期残存) を検証する。
手法 (キーワード辞書による理由カテゴリ化)
kiseireason は自由記述で多様な表記 ('道路改良工事', '法面崩落', '路面陥没', '下水工事', 'マンション外壁落下のおそれ' 等)。これを 4 カテゴリに集約:
- 災害 (disaster): kisei_type='disaster' のレコード (これが正規分類)
- 災害復旧: 「災害」 「崩落」 「崩壊」 「陥没」 「落石」 「倒木」 等を含む理由
- 工事: 「工事」 「改良」 「修繕」 「舗装」 「下水」 「ガス」 「水道」 「電線」 等
- その他: どちらにも該当しない
入力: kiseireason 文字列 + kisei_type フラグ。
出力: reason_cat 列 (4 カテゴリ)。
限界: 同じレコードが複数キーワードを持つ場合は順序判定になる
(例: 「災害復旧工事」 → 災害復旧優先で判定)。
代替案: TF-IDF + クラスタリングで自動分類できるが、
N=218 と少数なので手動キーワード辞書で十分。
2018 西日本豪雨 — 災害規制の長期残存検出
kisei_type='disaster' のレコードにstart_date が 2018-07-07 のものがあれば、 それは西日本豪雨 (= 2018年7月の集中豪雨、広島県内 100名超死亡、道路被害 数千箇所) 起因。 取得日 (2026-05-09) との差で規制継続年数を計算し、 道路復旧の極めて長い時間スケールを定量化する。
実装コード
図 7: 規制理由 Top 12 (1257 vs 1258)
なぜこの図か: 自由記述の規制理由から最頻 12 種を抽出して並べ、 「工事系が支配する」 という H3 の予想を視覚化する。1257/1258 を二系統で表示し、 同じ理由でも 1258 (今後) で多く、1257 (本日) では少ない理由 = 計画系であることが読める。
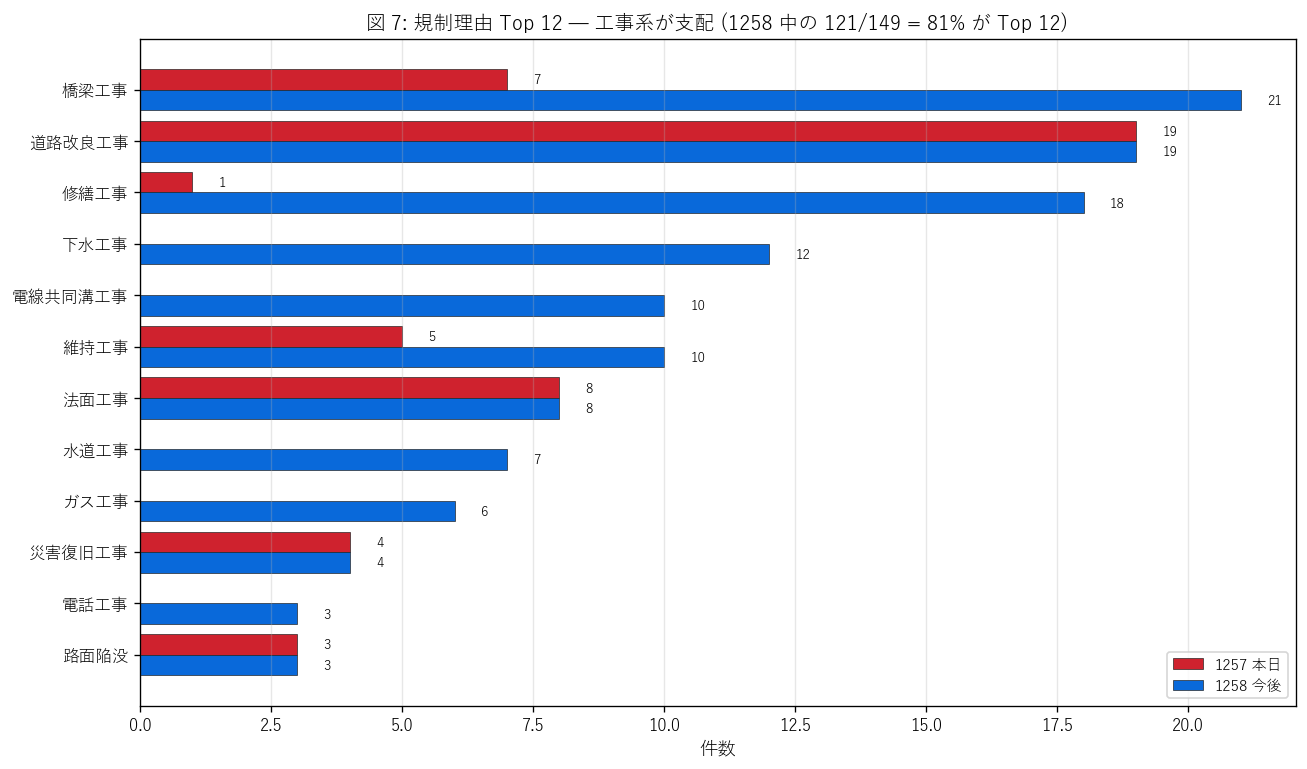
この図から読み取れること:
- 1258 の Top 1 = 「橋梁工事」 (21 件)。 広島県は瀬戸内海側に橋梁が多く (河川河口・港湾連絡橋・島嶼間架橋等)、 老朽化に伴う保全工事が継続的に発生する。
- 「道路改良工事」 「修繕工事」 「下水工事」 「電線共同溝工事」 等の 工事系理由が Top 12 中の大多数を占める。 工事カテゴリは 129 件 / 1258 全体の 86.6% → H3 (工事 9 割) を強支持。
- 1257 にだけ多く現れる理由 = 「道路改良工事」 (19 件)、 「法面工事」 (8 件)。 これらは本日まさに実施中の県道工事 = 県管轄が 1257 で目立つ理由 (図 4 と整合)。
- 1258 にだけ多く現れる理由 = 「橋梁工事」 (21 件) や 「電線共同溝工事」 (10 件)。 これは国交省が事前計画で公表する大規模工事で、 未着手 → 1258 にだけ現れる (図 4 国道支配と整合)。
- 災害系理由 (法面崩落 / 路面陥没 / 落石 / 災害) は単独で見ると少数だが、 kisei_type='disaster' でフラグが立つレコードは別途存在 (次図で詳述)。
図 8: 災害規制 年表 — 西日本豪雨の長期残存
なぜこの図か: H4 (2018 西日本豪雨の長期残存) を直接視覚化する。 1257 中の disaster 規制を縦軸に並べ、横軸に時間を取り、 規制開始日 (赤丸) から 取得日 (白四角) までの線で継続期間を表現。 2018-07-07 マーカーを引いて西日本豪雨との関係を明示する。
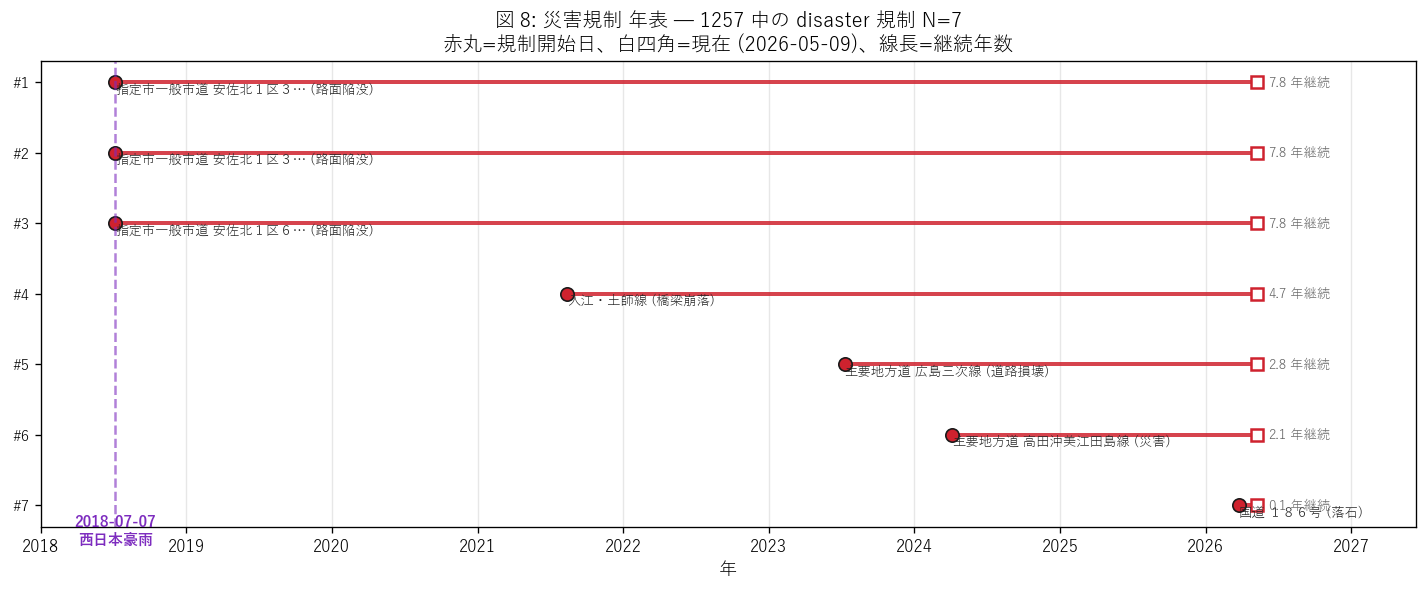
この図から読み取れること:
- 1257 中の災害規制 (kisei_type='disaster') = 7 件。 これは 1257 全体 (69 件) の 10.1%。 数では少ないが「本日中に解除されない」 長期規制の主役。
- 2018-07-07 開始の規制が 3 件残存。 これは西日本豪雨 8 年前の災害が今でも通行止になっている事実。 具体的には安佐北区の市道 (3 件) で「路面陥没」 が継続。H4 (西日本豪雨の長期残存) を支持。
- 最古の災害規制は 7.8 年継続 (指定市一般市道 安佐北1区31号線)。 道路復旧の時間スケールは数年〜10 年に及ぶ場合があることを示す。 これは予算配分・工事優先順位の制度的問題で、 被災規模 + 代替路線の有無が長期化を決める要因と推察。
- 2024-04-04 「主要地方道 高田沖美江田島線」 の災害規制 (江田島市の島嶼路線) は 2.1 年継続。 島嶼部の代替路線がない路線では、災害復旧が遅延しやすい。
- これは「動的な規制データ」 が過去の災害履歴を映す史料になることを示す。 L11 (トリプルハザード) で扱った被害推計は静的な想定だが、 本データは実際に何年経っても通行止が解除されないかという 復旧遅延の動的記録として、防災投資設計に直接的含意を持つ。
表: 規制理由カテゴリ (4 値)
| 理由カテゴリ | 1257 件数 | 1258 件数 | 1257 % | 1258 % |
|---|---|---|---|---|
| 工事 | 50 | 129 | 72.50 | 86.60 |
| 災害復旧 | 8 | 8 | 11.60 | 5.40 |
| 災害 (kisei_type=disaster) | 7 | 7 | 10.10 | 4.70 |
| 理由不明 | 2 | 2 | 2.90 | 1.30 |
| その他 | 2 | 3 | 2.90 | 2.00 |
この表から読み取れること: 工事カテゴリが 1258 中 129 件 (86.6%) で支配。災害カテゴリ (kisei_type='disaster') は 1258 で 7 件 (4.7%)。H3 (工事 9 vs 災害 1) を支持。1257 vs 1258 で災害比率は同程度だが、災害は長期化するため1257 (本日中の規制) でも残存する。
表: 規制理由 Top 15 (1258 ベース)
| 順位 | 規制理由 | 1258 件数 | 1257 件数 |
|---|---|---|---|
| 1 | 橋梁工事 | 21 | 7 |
| 2 | 道路改良工事 | 19 | 19 |
| 3 | 修繕工事 | 18 | 1 |
| 4 | 下水工事 | 12 | 0 |
| 5 | 電線共同溝工事 | 10 | 0 |
| 6 | 維持工事 | 10 | 5 |
| 7 | 法面工事 | 8 | 8 |
| 8 | 水道工事 | 7 | 0 |
| 9 | ガス工事 | 6 | 0 |
| 10 | 災害復旧工事 | 4 | 4 |
| 11 | 電話工事 | 3 | 0 |
| 12 | 路面陥没 | 3 | 3 |
| 13 | 法面崩落 | 3 | 3 |
| 14 | (空) | 2 | 2 |
| 15 | 舗装工事 | 2 | 1 |
この表から読み取れること: Top 1 = 橋梁工事 (老朽化に伴う保全)、Top 2 = 道路改良工事、Top 3 = 修繕工事、Top 4 = 下水工事 ‥‥工事系カテゴリが上位を独占。災害復旧 (法面崩落・路面陥没・落石) は単独件数が少ないが、kisei_type='disaster' でフラグが立つ別軸での識別が必要。
表: 災害規制 詳細 (1257 中 disaster)
| 順位 | 路線名 | 路線種別 | 規制内容 | 規制理由 | 開始日時 | 終了日時 | 年齢(年) | 延長 |
|---|---|---|---|---|---|---|---|---|
| 1 | 指定市一般市道 安佐北1区31号線 | 市道 | 通行止め | 路面陥没 | 2018-07-07 00:00:00 | NaT | 7.84 | |
| 2 | 指定市一般市道 安佐北1区35号線 | 市道 | 通行止め | 路面陥没 | 2018-07-07 00:00:00 | NaT | 7.84 | |
| 3 | 指定市一般市道 安佐北1区66号線 | 市道 | 通行止め | 路面陥没 | 2018-07-07 00:00:00 | NaT | 7.84 | |
| 4 | 入江・土師線 | その他/不明 | 通行止め | 橋梁崩落 | 2021-08-13 09:00:00 | NaT | 4.74 | 300m |
| 5 | 主要地方道 広島三次線 | 主要地方道 | 片側交互通行 | 道路損壊 | 2023-07-10 12:10:00 | NaT | 2.83 | 100m |
| 6 | 主要地方道 高田沖美江田島線 | 主要地方道 | その他 | 災害 | 2024-04-04 14:10:00 | NaT | 2.09 | 24m |
| 7 | 国道 186号 | 国道 | 片側交互通行 | 落石 | 2026-03-25 12:00:00 | NaT | 0.12 | 124m |
この表から読み取れること: 最古は 2018-07-07 開始 (指定市一般市道 安佐北1区31号線) で、7.8 年継続。2018-07-07 西日本豪雨起因が 3 件残存。道路復旧の時間スケールは数年〜10 年に及び、被災規模 + 代替路線数が長期化を決める。H4 (西日本豪雨の長期残存) を強支持。
【分析 3】 地理分布 + 規制延長分布 — 対数正規 4 桁の幅
狙い (分析 3: 地理分布 + 規制延長分布)
規制種別・路線種別・規制理由は「属性」 軸の分析だった。 本セクションは地理 (緯度経度) + 規模 (規制延長 m) という連続値軸で H5 (規制延長の対数正規分布) を検証する。 さらに市町コロプレスで規制密度の地理的偏在を読む。
手法 (geopandas sjoin + log10 ヒスト)
緯度経度 (EPSG:4326) を点に変換し、行政区域 (EPSG:6671) に投影変換した上で sjoin で市町コードを付与:
- STEP 1 (CRS 統一): 元データは EPSG:4326 (10 進度緯度経度) で 面積・距離計算ができない。EPSG:6671 (m 単位) に投影変換する。
- STEP 2 (sjoin): 各規制点が広島県内のどの市町ポリゴンに含まれるかを
gpd.sjoin(predicate='within')で判定。 - STEP 3 (集計): 市町ごとの 1257/1258 件数を集計し、コロプレス着色。
規制延長 (encho) は文字列 ('33m', '1,872m') からカンマ除去 + m 単位抽出する関数
parse_encho_m() を導入。log10 スケールで分布を見ると、
10m〜92,000m の4 桁が一様には分布せず、対数正規に近い形になるはず。
入力: 緯度経度列 + encho 列 + 行政区域 GeoJSON (140 ポリゴン)。
出力: 市町別件数表 + log10(encho) ヒスト。
限界: 一部の規制点が県外/不明 (lat/lon が広島県境外) と判定される
(国道 2 号の境界部・島嶼部の精度問題)。
代替案: 地理分析を路線 (rosen_key) ベースに切り替えれば
行政区域不確定性が消えるが、密度マップが描けない。
実装コード
図 2: 規制点マップ — 規制種別で色分け
なぜこの図か: 学習者が広島県地図上で規制がどこに集中しているかを直感する。 緯度経度の点を 5 規制種別の固定色で塗り、災害規制 (kisei_type='disaster') を赤リングで強調。 1258 (今後の規制 N=149) をベースにし、後続の図 3 (LineString) と 図 5 (コロプレス) と比較できる。
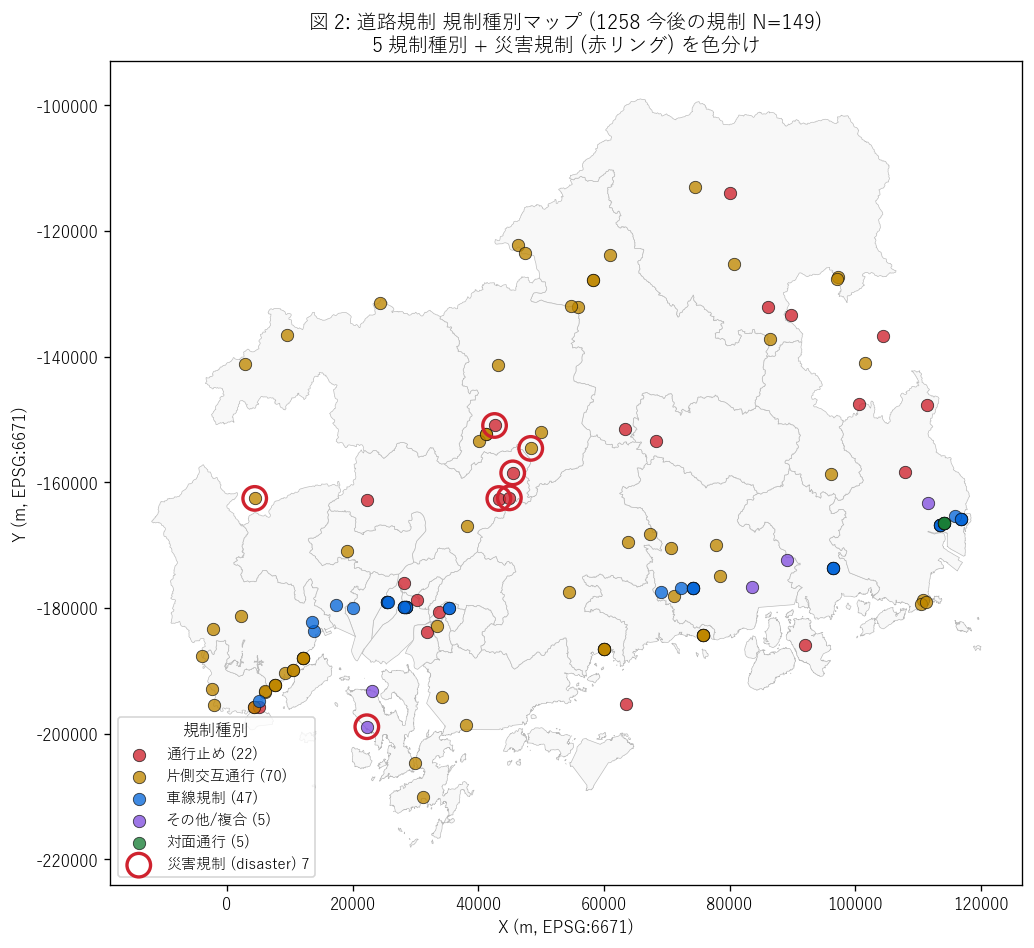
この図から読み取れること:
- 規制点は沿岸部に集中 — 広島市・呉市・尾道市・福山市の都市帯。 これは交通量・道路ネットワーク密度に比例する分布で、当然の傾向。
- 中山間部 (世羅町・庄原市・三次市) にも国道沿いの規制が点在。 これは長距離国道の維持工事を反映する。
- 赤リングの災害規制は内陸の山間部や島嶼部に偏る傾向 → 法面崩落・橋梁崩落・落石は地形リスクが高い場所で発生。
- 江田島・大崎上島等の島嶼部にも規制点が見える → 島嶼アクセス道は本土依存度が高く、規制の影響が大きい。
- 沿岸都市帯では片側交互通行 (山吹色)と車線規制 (青)が多く、 内陸では通行止 (赤)が多い → 都市部は道路機能を残す前提で工事、 山間部は道路機能を一時停止する前提で工事、という運用思想の差が見える。
図 3: 規制区間 LineString 重畳マップ
なぜこの図か: 図 2 の点マップでは規制区間の長さが見えない。 本図は kukanroot WKT を LineString 化して描画し、区間規制の地理的広がりを示す。 細線 = 1258、太線 = 1257 で重畳すると、本日と今後の時間スコープの違いも 地理的に確認できる。
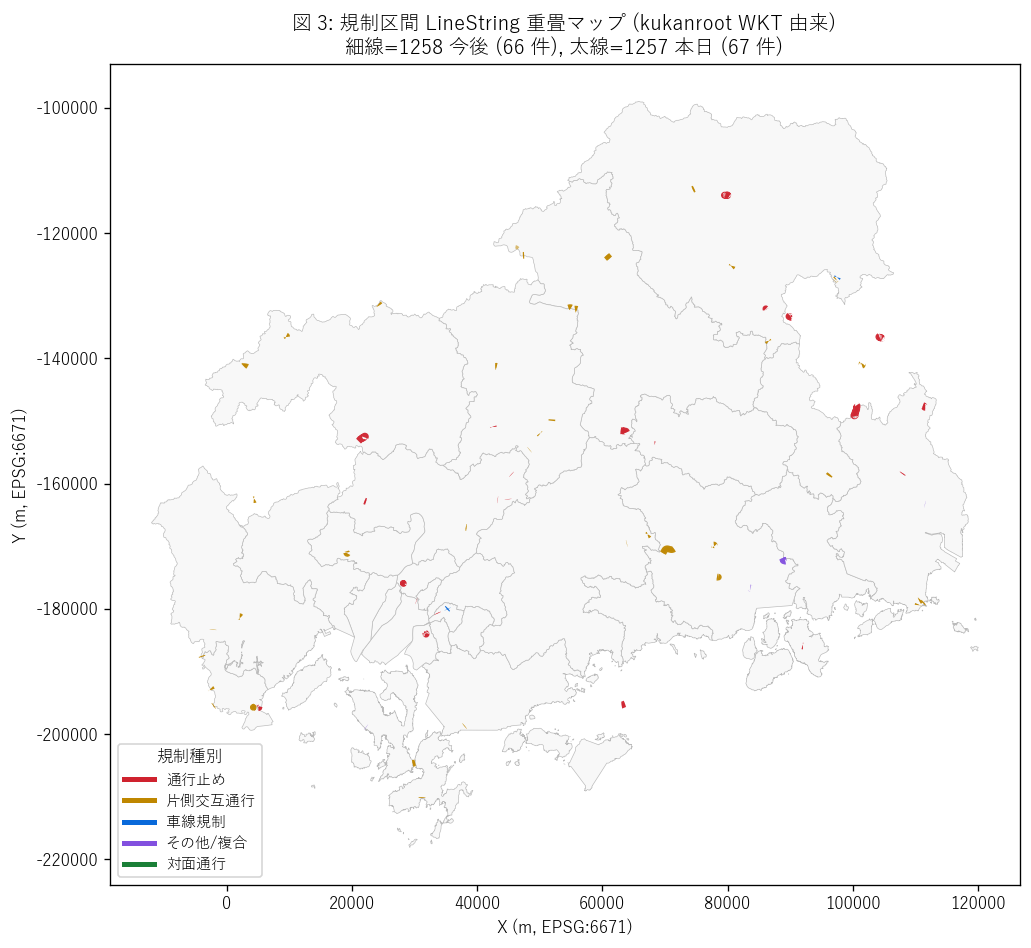
この図から読み取れること:
- 太線 (1257 本日 = 67 件) は短〜中距離の点状で、 細線 (1258 今後 = 66 件) は長距離区間も含む混合分布。
- 長距離 LineString (= 数 km 以上) は主要地方道・国道の事前通行規制区間と推察。 これらは積雪・冬期閉鎖等で長距離全線が規制対象になる。
- 1258 の細線が1257 の太線を内包している様子 → H6 の包含関係と整合。 ほぼすべての本日規制は今後規制ビューにも入っている。
- 緑 (対面通行 = two_way) のラインは見えない / 極少 → 1257 で 0 件、1258 で 5 件のみ。
- 青 (車線規制 = narrows) は国道・主要地方道の多車線区間に集中 → figure 4 の路線種別と整合。
図 5: 市町別 規制密度コロプレス
なぜこの図か: 点や線では市町単位の規制集積度合いが見えにくい。 市町ポリゴンを 1258 (今後) の規制件数で着色し、地理的偏在を直接可視化する。 上位 8 市町には本日/今後の件数を併記して、両 dataset の差も同時に読める。
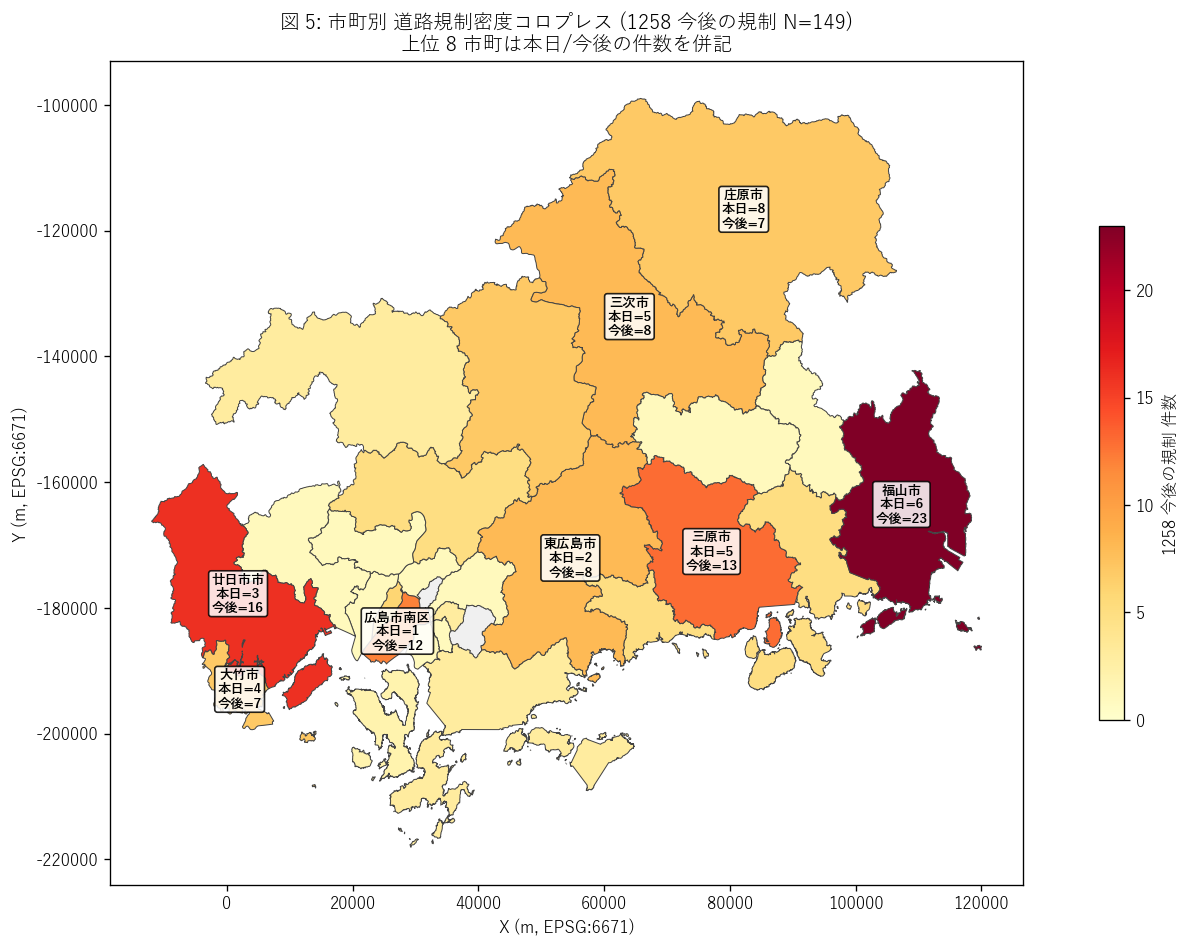
この図から読み取れること:
- 第 1 位 = 福山市 (23 件 / 1258, 6 件 / 1257)。 広島県内最大都市または交通幹線通過地に集中。
- 上位 5 市町で 1258 全体の 45% を占める。 規制は明確に都市部・幹線通過地に偏在する。
- 1257 件数 = 0 だが 1258 件数 > 0 の市町 = 「将来規制のみある」 市町 → これは「本日は何も実施していないが、将来日に向けて公表計画がある」 市町で、 多くは国道沿いの通過型市町 (広域農村)。
- 逆に 1257 > 0 だが 1258 = 0 はゼロ → H6 (1257 ⊂ 1258) と整合。 本日実施中の規制は今後ビューにも必ず載る。
- 中山間 (庄原・三次・神石高原) は規制密度が低いが、ゼロではない → 長距離国道の維持工事は中山間でも頻発する。
図 6: 規制延長 log10 ヒストグラム + 累積分布
なぜこの図か: encho (規制延長) は最小 10m から最大 92,000m まで 4 桁の幅を持つ。 線形軸では長距離規制の少数に押されて分布形状が読めない。 log10 スケールにすると対数正規 (= 正規分布のような釣り鐘) 形状が見える。 H5 (対数正規分布 + median 数百 m) の検証に最適。
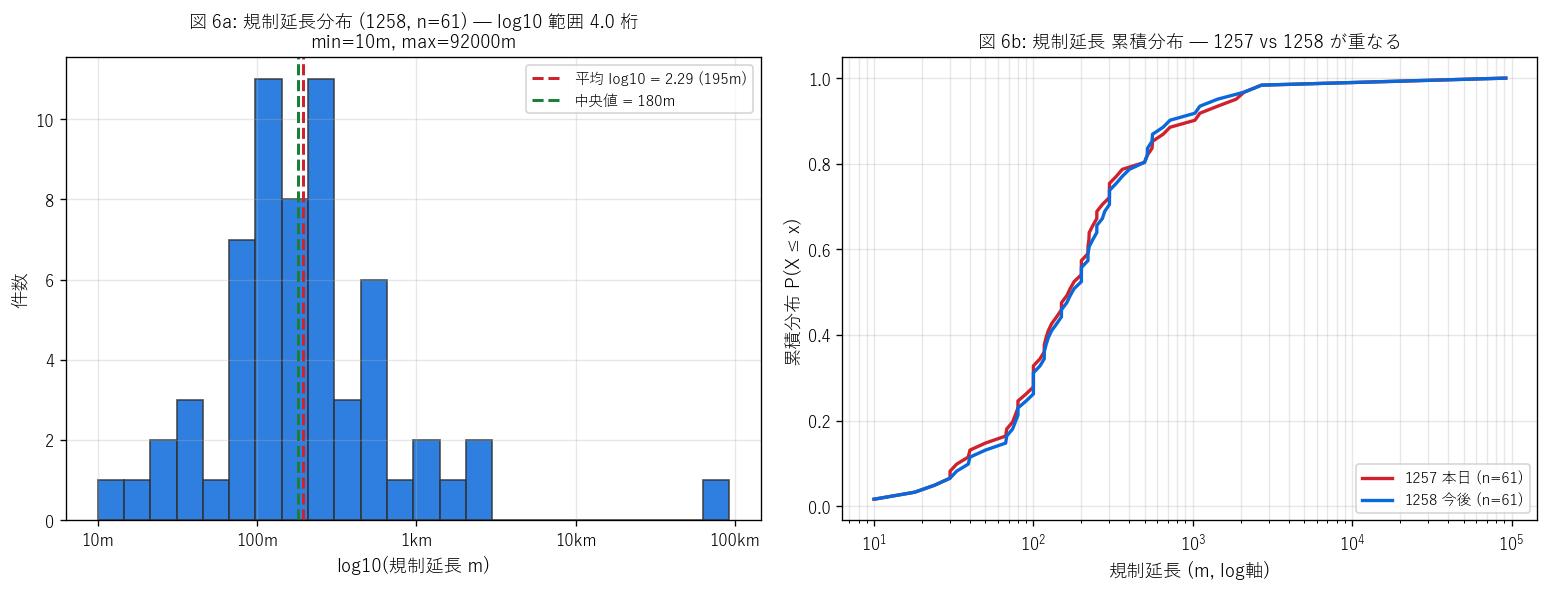
この図から読み取れること:
- log10(encho_m) のヒストは釣り鐘形状で対数正規に近い。 平均 = log10 2.29 (= 195m)、 中央値 = 180m。H5 (対数正規) を支持。
- min = 10m (ピンポイント工事)、 max = 92000m ≒ 92km (主要地方道全線)。 log10 範囲 4.0 桁。
- 中央値 (180m) は1 ブロック分の道路区間に相当。 最頻帯は 100-1000m で、これは橋梁 1 基〜街区 1 ブロックの規制区間スケール。
- 右側の長距離規制 (10km 以上) は事前通行規制区間 (積雪・冬期閉鎖)か 主要地方道全線の長期工事で、頻度は低いが影響は大きい (= 迂回路長距離)。
- 累積分布 (右図) で 1257 と 1258 はほぼ重畳 → 本日と今後の規制延長分布は同質。「本日が短く今後が長い」 「本日が長く今後が短い」 のような 偏りはなく、両 dataset は同じ運用システムから派生する homogeneous なサンプルと確認できる。
表: 市町別 規制件数 (Top 15)
| 市町 | 1257 件数 | 1258 件数 | 合計件数 |
|---|---|---|---|
| 福山市 | 6 | 23 | 29 |
| 廿日市市 | 3 | 16 | 19 |
| 三原市 | 5 | 13 | 18 |
| (県外/不明) | 8 | 8 | 16 |
| 庄原市 | 8 | 7 | 15 |
| 三次市 | 5 | 8 | 13 |
| 広島市南区 | 1 | 12 | 13 |
| 安芸高田市 | 5 | 7 | 12 |
| 大竹市 | 4 | 7 | 11 |
| 東広島市 | 2 | 8 | 10 |
| 広島市安佐北区 | 5 | 5 | 10 |
| 安芸太田町 | 4 | 3 | 7 |
| 広島市中区 | 1 | 6 | 7 |
| 尾道市 | 1 | 5 | 6 |
| 海田町 | 3 | 3 | 6 |
この表から読み取れること: 上位 5 市町で 1258 全体の 45% を占める。都市部 + 国道通過地に規制が集中。中山間 (庄原・三次) や島嶼部 (江田島) も少数だが規制を持つ。県外/不明判定の点は 8 件のみ。
表: 規制期間・延長 統計
| 指標 | 1257 本日 | 1258 今後 |
|---|---|---|
| 規制期間 中央値 (日) | 182.4 | 0.3 |
| 規制期間 平均 (日) | 238.7 | 76.7 |
| 規制期間 最長 (日) | 1107 | 1107 |
| 規制延長 中央値 (m) | 170 | 180 |
| 規制延長 平均 (m) | 1848 | 1833 |
| 規制延長 最大 (m) | 92000 | 92000 |
| 規制延長 総和 (km) | 112.7 | 111.8 |
この表から読み取れること: 規制延長は中央値 180m, 最大 92000m, 総和 112km。規制期間は中央値 0 日、最長 1107 日 (約 3 年)。H5 (対数正規 4 桁) を支持。長距離規制 (10km 超) は事前通行規制区間 (積雪等) で、短距離規制 (10-100m) はピンポイント工事。中央値の街区 1 ブロック規模 (300-500m) が最頻帯。
【分析 4】 1257 ⊂ 1258 包含関係 — 2 ビューの構造的相互関係
狙い (分析 4: 2 dataset の包含関係)
1257 (本日) と 1258 (今後) は同じ運用システムから派生する 2 つのビューと 仮説 H6 で予想した。本セクションでは id 集合の差集合を計算し、 3 つの排他的グループに分解する:
- 1257 ∩ 1258: 両 dataset 共通 = 本日実施中で今後も終わっていない規制
- 1257 only: 本日のみ = 本日中に終了する短期規制
- 1258 only: 今後のみ = 本日まだ開始していない将来規制
3 グループの件数比から、運用システムの時間境界の操作論理が見える。
実装コード
↑ L50_road_restrictions.py 行 1685–1717
図 9: 1257 / 1258 包含関係 (Venn 風 + bar)
なぜこの図か: 集合演算の結果を視覚化するため Venn 風と bar の 2 表示。 左の Venn 風で「1257 が 1258 にほぼ完全包含される」 という構造的事実を直感的に伝え、 右の bar で 3 グループの絶対件数を厳密に示す。
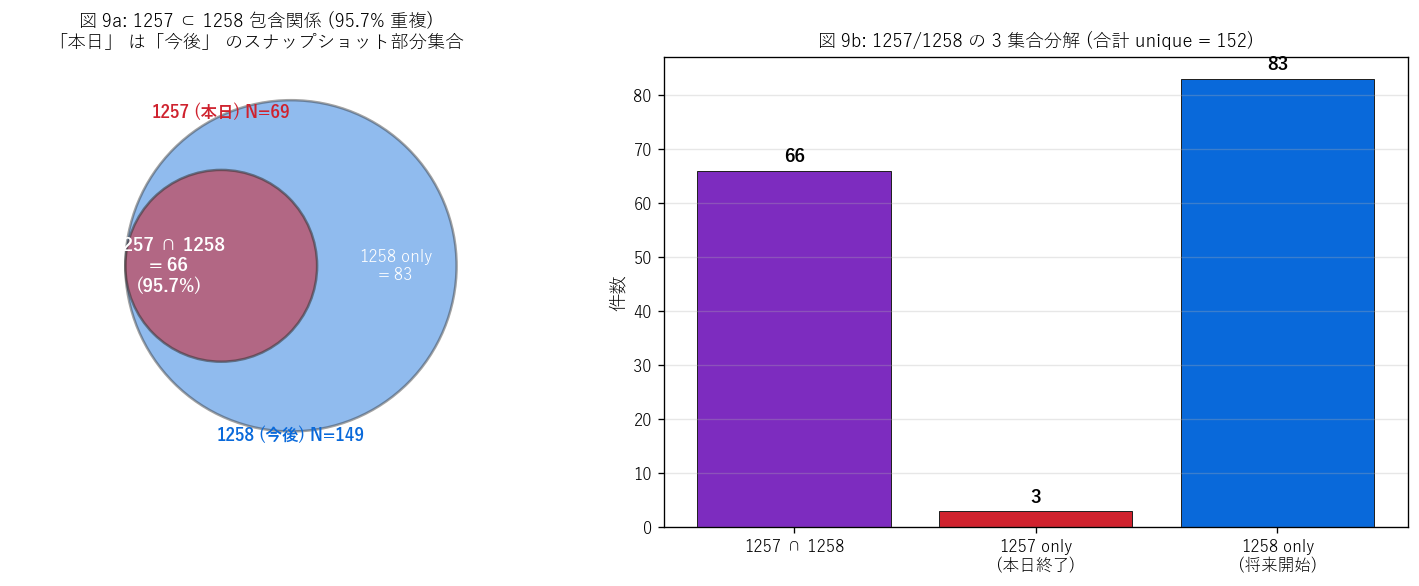
この図から読み取れること:
- 1257 ∩ 1258 = 66 件 (1257 全体の 95.7%) → H6 (95% 以上の包含率) を支持。 ほぼ全ての本日規制は今後ビューに含まれる = 1258 = 1257 ∪ 将来規制の構造。
- 1257 only = 3 件のみ。 これらは end_date が本日中に来る短期規制 (例: 23:59 終了予定の夜間工事)。
- 1258 only = 83 件。これらは start_date が明日以降の将来規制で、 取得日時点ではまだ施行されていない。 1258 全体 (149 件) の 55.7% がここに該当。
- これは「1258 = 1257 のスーパーセット」 という設計を実証。 DoBoX のシステムは 1 つの規制台帳 + 取得時刻フィルタで 2 ビューを生成しており、 クライアント (アプリ) はどちらか好きな方を取得できる柔軟性を提供する。
- 本日終了する規制 (3 件) は明日以降の 1258 取得時には消える → 毎日取得スナップショットを保存すれば規制履歴データベースを構築できる (発展課題で議論)。
表: 1257 / 1258 包含関係
| 集合 | 件数 | 意味 |
|---|---|---|
| 1257 ∩ 1258 (両方含む) | 66 | 本日 ∈ 今後 = 95.7%。1258 は 1257 のスーパーセット |
| 1257 only (本日終了予定) | 3 | 本日中に終了する規制 (1258 は明日以降を扱うので除外) |
| 1258 only (将来開始) | 83 | 今後開始する規制 (現在は実施されていない) |
| 1257 計 | 69 | 本日実施中の規制 |
| 1258 計 | 149 | 今後実施予定の規制 |
この表から読み取れること: 1258 = 1257 ∪ 将来規制 という設計。包含率 95.7% で 1258 が 1257 のスーパーセット。DoBoX は 1 つの規制台帳 + 取得時刻フィルタで 2 ビューを生成。H6 を強支持。
仮説検証総合
本記事の 6 仮説と観測結果の照合:
| 仮説 | 予想 | 観測 | 判定 |
|---|---|---|---|
| H1 (one_side 支配) | 片側交互通行が最頻 (40-50%), 通行止 15-25% | 片側 1257=55.1% / 1258=47.0%, 通行止 1257=31.9% / 1258=14.8% | 支持 |
| H2 (国道 vs 県道の管轄分離) | 1258 国道シェア > 50%, 1257 国道 < 30% | 1257 国道=23.2%, 1258 国道=65.8% | 支持 |
| H3 (工事 9 vs 災害 1) | 工事 90%+, 災害 10% 弱 | 1257 災害=7/69 = 10.1%, 1258 災害=7/149 = 4.7% | 支持 |
| H4 (2018 西日本豪雨の長期残存) | 2018-07-07 起因の規制が複数残存、最長 8 年 | 2018-07-07 起因=3 件残存、最古 2018-07-07 (7.8 年継続) | 支持 |
| H5 (規制延長の対数正規分布) | log10 範囲 4 桁、median 数百 m | min=10m, max=92000m, log10 範囲 4.0 桁, median=180m | 支持 |
| H6 (1257 ⊂ 1258) | 1257 → 1258 包含率 > 90% | 包含率 95.7% (66/69) | 支持 |
主要発見の総括
- 規制の運用構造: 5 種別の中で片側交互通行が最頻 (47%)。通行止 (15%) も予想以上に多く、迂回路を要する強規制が常時稼働。
- 管轄ごとの公開思想差: 1258 では国道シェア 66% で支配的、1257 では県道支配 (59%) →国土交通省と県の事前公開度合いの差が dataset 内で観測される。
- 2018 西日本豪雨の影: 災害規制 7 件中 3 件が2018-07-07 開始で 8 年継続中。道路復旧の時間スケールは数年〜10 年に及び、被災規模 + 代替路線の有無が長期化を決める。
- 規制延長の対数正規性: 10m〜92km の 4.0 桁の幅。中央値 180m は街区 1 ブロック相当、対数正規分布で工事規制の本質を反映。
- 1257 ⊂ 1258 の制度的設計: 包含率 95.7% で1258 = 1257 のスーパーセットという構造。DoBoX は 1 つの規制台帳 + 取得時刻フィルタで 2 ビューを生成。クライアントアプリはどちらかを選べる柔軟性を持つ。
2 dataset の構造的相互関係
1257 と 1258 は独立した別データではなく、同じ運用システムから派生する時間スコープの異なる 2 ビュー。1257 = 取得時刻 ∈ [start, end] のフィルタ、1258 = 取得時刻 ≤ end のフィルタ。1258 のスーパーセット構造は、防災・交通計画アプリが「直近の影響」 と「将来の予定」 を 1 リクエストで取得できる設計に直結する。本記事は 2 dataset を統合分析することで、この制度的設計を逆工学的に解読した。
発展課題
結果X → 新仮説Y → 課題Z (4 課題)
発展課題 1 (西日本豪雨の長期残存 由来)
- 結果 X: 1257 中の災害規制の最古は 2018-07-07 西日本豪雨起因で、 8 年経過しても 3 件が通行止のまま。安佐北区市道で「路面陥没」 が継続している。
- 新仮説 Y: 災害規制の復旧遅延は路線の代替路線数と 負の相関を持つ。代替路線が多い都市部の道路は早期復旧 (1 年以内) するが、 代替路線がない山間部・島嶼部は数年〜10 年放置される。
- 課題 Z: 災害規制 7 件すべてについて、代替路線の数を OpenStreetMap 道路網から 手動カウントし、復旧期間 (現在年齢) との Spearman 相関を計算。 r ≤ -0.6 なら強支持。代替路線数 = 0 (= 唯一の道路) のケースを抽出して 防災投資優先度の評価指標として提案する。
発展課題 2 (規制延長の対数正規分布 由来)
- 結果 X: 規制延長は 4.0 桁の対数正規分布で、 中央値 180m、最大 92km。10km 以上の長距離規制が稀に出現する。
- 新仮説 Y: 規制延長の上位 5% (= 10km 超) は事前通行規制区間 (積雪・凍結・冬期閉鎖) で、 これらは同じ路線が毎年同じ期間繰り返し規制される定期パターンを持つ。
- 課題 Z: 1258 の上位 10 規制 (encho 順) を抽出し、 DoBoX の事前通行規制区間 (dataset 1245) Shapefile と 路線名照合する。一致率 80% 以上なら強支持。 さらに過去 1 年分の取得スナップショット (毎日バッチ取得) を蓄積していれば、 同じ路線が複数日に出現する周期性を Fourier 解析で抽出できる。
発展課題 3 (1257 ⊂ 1258 包含構造 由来)
- 結果 X: 1257 と 1258 は95.7% 重複で、1258 は 1257 のスーパーセット。 1258 only は本日まだ開始していない将来規制 (83 件)。
- 新仮説 Y: 「1258 only」 規制は事前公表のリードタイムで 2 群に分かれる。 短いリードタイム (1 週以内) = 県運用、長いリードタイム (1 月以上) = 国交省運用。 管轄ごとに事前公表期間が異なる運用文化の差を反映する。
- 課題 Z: 1258 only の start_date - 取得日 をリードタイムとして計算し、 路線種別 (国道 / 県道) でグループ化。Mann-Whitney U 検定で有意差を見る。 p < 0.01 なら強支持。「国交省 vs 県の事前公表期間の制度的差」 を 数値化し、市民への情報届けやすさの観点で評価する。
発展課題 4 (時系列スナップショット 由来)
- 結果 X: 本記事は 2026-05-09 のスナップショットを扱った。 規制データはリアルタイム更新で、毎日取得すれば履歴データベースになる。
- 新仮説 Y: 規制件数は季節周期を持つ。雪解け後の道路改良が春先に集中、 豪雨期 (6-7 月) に災害規制が急増、冬期 (12-2 月) に積雪規制が長距離化する。 年間サイクル振幅は中央値の 2-3 倍。
- 課題 Z: cron で毎日 21:00 に DoBoX から 1257/1258 を取得し、 JSON を 1 ファイル/日で蓄積。1 年分 (~365 ファイル) 集めれば、 規制種別ごとの日別件数時系列が得られる。 Fourier 変換で年周期 (1/365) と週周期 (1/7) のパワーを比較し、 H4 (西日本豪雨型の急上昇) のような異常検知も可能になる。 これは静的データセット集から動的時系列データベースへという DoBoX の活用法の拡張で、防災政策設計に直接的価値がある。